
@ Counter Narrative
2023-11-22 03:58:28
Coming off of my original blog post about the theoretical set up of storage “relays” for the purposes of decentralized storage, I wanted to introduce my new project, Derby. Derby aims to be an open, decentralized, data transfer protocol that can be used for publishing and sharing files on the Internet.
It was written with Nostr integration in mind and is not limited to that protocol.
I aim to provide an overview of how the protocol works and go a little into the building blocks and the layers that Derby builds out for hopefully being a useful project for both the Nostr ecosystem and the greater freedom technology software stack.
## Note on name
Derby is not an acronym or back-ronym for anything. The project is named after someone close to me and I think it sounds nice. I think the important thing is that it’s not called dump-str.
## Nodes not relays
In my original post, I used the word “relays” to reference the server side storage for this network and I am revising that to nodes. The architecture, cryptographic backed pointers, and protocol already borrow heavily from Nostr and using the work relay may cause confusion with Nostr relays.
The Derby protocol is not compatible with Nostr and a Nostr client won’t know what to do with a Nostr relay and vice verse. The integration happens at a higher layer (will get into layers later) that complements each protocol.
## Architecture of Derby
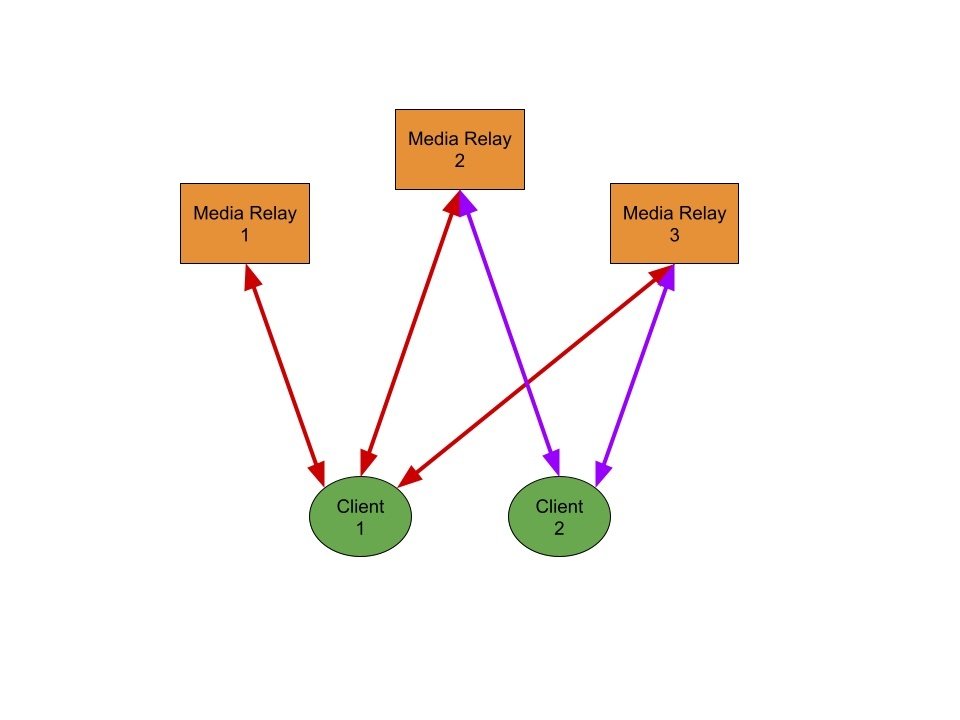
Derby uses the same architecture as Nostr with a client that may connect to multiple servers to grab requested data. The graphic from my original post is relevant here (see below) and with one of the the aim being decentralization.
## Storage nodes
Storage nodes are the backbone of Derby, storing, managing, and sending various pieces of data. As with Nostr, a storage node is a “dumb” server that maintains a database of pointers and the data blobs it references.
Data blobs are also capped at a certain size and multiple blobs can be added to make up a coherent file.
Storage nodes use web sockets to communicate, which make it “web friendly” and uses a very simple protocol for communication.
There are currently 5 actions that can be taken toward a storage node:
* Publish pointer w/ data
* Publish pointer w/o data (References existing data)
* Update pointer
* Delete pointer
* Retrieve Data
## Building blocks on the storage node
Storage nodes only have context on storing a piece of binary data on its system and the pointer objects that is used to cryptographically reference them. Let’s get into pointers.
Pointers
Pointers act as the messaging for storage nodes. They are used to associate a user with a piece of data.
Here is what a pointer looks like
```
{
id:"c868b2defabe0683b5426fd66318db1beac1c6af7143f75f389926ac28a827f7",
pubkey:"1a305a7ae5d63329fc3597155521638ff1c5d989285b5a7be275e38826f12885",
timestamp:1699213847,
pointerhash":"f323fe7ecdacc0bba46a8bd70ea61f2622297b40b0a93ab2beabd3a03a2a7bbd",
size:5000000,
nonce:513029,
signature:"37e721ad91c2323f4b73ccc4e2c006632b348c6b99b5f372b796daab3b75d1062e727687a41ac579d088d1db2121015a7df6cf2e049024d199de880d894e81ac"
}
```
The above looks very much like a Nostr event, for anyone familiar with Nostr events and development. It is a very simple way of managing associations with uploaded data.
The components are broken down into the following:
**ID **- Sha256 hash of the pointer object. This hashes the string of the pointer with the following field order:
1. id
2. pubkey
3. timestamp
4. pointerhash
5. size
6. nonce
**pubkey** - The 256-bit public key of the pointer owner.
**timestamp** - Unix Time in seconds.
**pointerhash** - sha256 hash of the raw binary data being pointed to. This will be used to reference the raw binary data.
**size** - Size of the raw binary data being pointed to in bytes.
**nonce** - Random integer. Can be used for future POW and is required for pointer deletion
**signature** - Schnorr signature of the id. Used to verify the pubkey’s ownership of the pointer
I will post a protocol guide on how to interact with the storage nodes on github.
The gist of the usage is:
* To upload data, a pointer will need to be created and sent to the storage node with the Base64 representation of the data
* The pointer will be verified and data will be validated against the pointer
* Upon success, the pointer will be stored on the relay
Retrieval of the data uses the pointer’s ID as reference, instead of the raw data’s hash.
A public key can be associated with a pointerhash at a time. For deduplication purposes (i.e. another user uploading the same data), another pointer with another public key can be published and associated with the data.
Lastly, any data without a pointer, will be deleted as orphaned. All data needs to have at least one pointer associated with it
# Client side
The building blocks of using pointers and data blobs are useless without context.
While storage nodes are dumb and have no intrinsic knowledge of the data being stored, a client has the ability to contextualize the data by associating all published pointers and data into a coherent file.
Data descriptors are how client’s make sense of any uploaded data.
## Data Descriptors
A data descriptor is a map of how multiple pointers and data come together to form a file.
When a client uploads a file, it will chop it up into multiple data chunks (as required by the storage node) and create multiple pointers. The client will keep track of the pointers, the hashes, the sequence, and the storage nodes that were used.
Any other user would be able to use the data descriptor to download and combine the file back up into its original form.
The current Derby libraries use JSON for the metadata and data map fields. The data descriptor can be transposed into any format necessary as long as a client can use it to piece together the original uploaded data.
Here is an example of a data descriptor:
```
{
"merkelroot": "0b19cda5f68c7769a2bbb1c96f070f8d3cc6aa54d360383297effadceebe21b5",
"metadata": {
"size": 184292,
"streamable": false,
"filename": "bitcoin_whitepaper.pdf",
"mimetype": ""
},
"datamap": [
[
"fab50aa24cb8259e630324039b7faf2fde57614c3a4e572f0e0151183ce86ce6",
"b1674191a88ec5cdd733e4240a81803105dc412d6c6708d53ab94fc248f4f553",
[
"ws://localhost:8080",
"ws://nostr.messagepush.io:8081"
],
184292
]
]
}
```
## And here enters Nostr
While users can share data descriptor files with each other via email or other means, Nostr provides a real opportunity to storage and retrieve Derby stored files using Nostr based addresses.
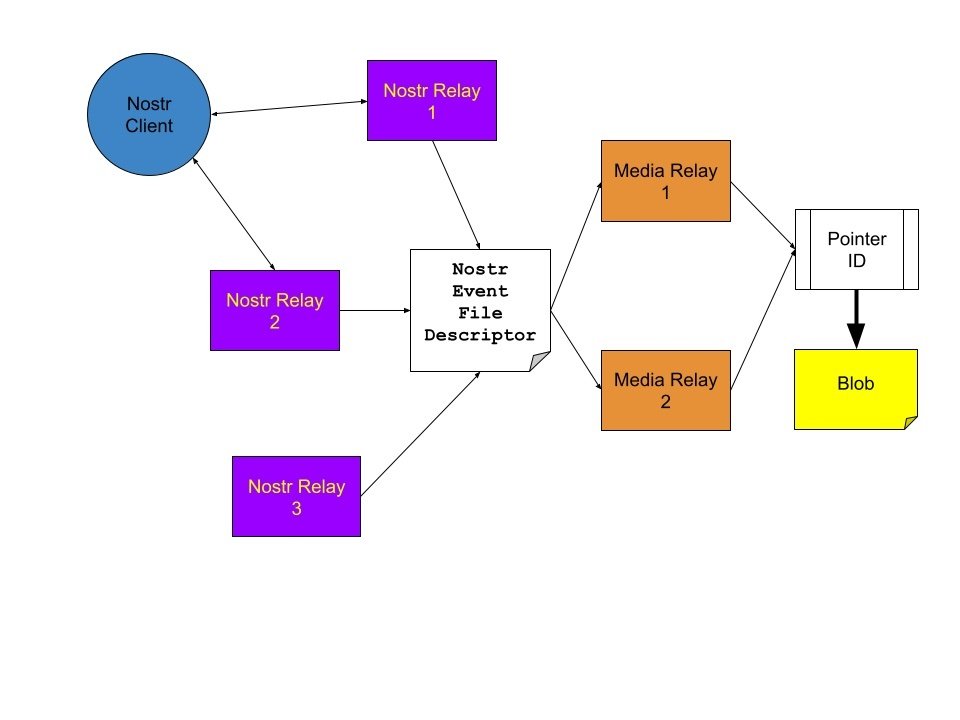
Currently, a data descriptor can be converted to a Nostr event of Kind 37337.
Here is an example of an data descriptor Nostr event:
```
{
"kind": 37337,
"pubkey": "3656bee87d4edcc676f94d4959d0af5351410348d0af3a6fd777d9ccabfcc689",
"created_at": 1700622074,
"content": "[[\"fab50aa24cb8259e630324039b7faf2fde57614c3a4e572f0e0151183ce86ce6\",\"b1674191a88ec5cdd733e4240a81803105dc412d6c6708d53ab94fc248f4f553\",[\"ws://localhost:8080\",\"ws://nostr.messagepush.io:8081\"],184292]]",
"tags": [
[
"d",
"0b19cda5f68c7769a2bbb1c96f070f8d3cc6aa54d360383297effadceebe21b5"
],
[
"m",
""
],
[
"streamable",
"false"
],
[
"l",
"bitcoin_whitepaper.pdf"
],
[
"size",
"184292"
]
],
"id": "10f5b1dc997406f89775d0e4d37339d716f69d5be71b224c1673289737483e3a",
"sig": "0830376a2f345c3f70f3a95d250ef62445c3b44b1a012b502a0d19965b191fe11becc140d0250c2535162c10274fc314a880bafdcf556e39753185eb40f6d20d"
}
```
In the above, we can see this is a parameterized replaceable event. The “d” tag is used for the merkel root and allows for easy searching per nostr pubkey.
The event is addressable using the naddr1 bech-32 format parameters:
**Pubkey** - The pubkey of the event author
**Kind** - 37337
**Relays** - List of relays being published to. Clients can just use these relays
**Identifier** - Will reference the d tag (also used as the merkel root) of the event.
A data descriptor then becomes something more addressable as `naddr1qpqrqc33893kgcf4vcmrscehxumrjcfjvf3xyvtr8ymxvvphxpnrsepnvd3nvctpx56xgvekxqensvej8ymk2enxv9jxxet9vfjnyvtzx5q3gamnwvaz7tmjv4kxz7fwv3sk6atn9e5k7qg5waehxw309amkycewdehhxarjxyhxxmmdqgsrv447ap75ahxxwmu56j2e6zh4x52pqdydpte6dlth0kwv407vdzgrqsqqpywearwqq5`
Using an shareable naddress have the following benefits:
* Inline addressing to files on nostr posts (Nostr clients would need to pull in the event and know how to use a data descriptor)
* Addressable links from a website or app (front end library could execute the download)
* Preventable content rug pull. I.e. Puppies.jpeg couldn’t turn into something distasteful without a change in the merkel root value.
# Development Roadmap and Code availability
Currently there are 3 projects being built for Derby:
* Derby storage node - [https://github.com/StevenDay83/derby-storage-relay](https://github.com/StevenDay83/derby-storage-relay)
* Derby Tools NodeJS library - [https://github.com/StevenDay83/derby-tools](https://github.com/StevenDay83/derby-tools)
* Derby CLI Utility - [https://github.com/StevenDay83/derby-cli-client](https://github.com/StevenDay83/derby-cli-client)