-
 @ 3bf0c63f:aefa459d
2024-01-14 13:55:28
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28IPFS-dropzone
Instead of uploading the dropped files to an URL, this subclass of Dropzone.js publishes them to IPFS with js-ipfs (no running local nodes needed).
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Parallel Chains
We want merged-mined blockchains. We want them because it is possible to do things in them that aren't doable in the normal Bitcoin blockchain because it is rightfully too expensive, but there are other things beside the world money that could benefit from a "distributed ledger" -- just like people believed in 2013 --, like issued assets and domain names (just the most obvious examples).
On the other hand we can't have -- like people believed in 2013 -- a copy of Bitcoin for every little idea with its own native token that is mined by proof-of-work and must get off the ground from being completely valueless into having some value by way of a miracle that operated only once with Bitcoin.
It's also not a good idea to have blockchains with custom merged-mining protocol (like Namecoin and Rootstock) that require Bitcoin miners to run their software and be an active participant and miner for that other network besides Bitcoin, because it's too cumbersome for everybody.
Luckily Ruben Somsen invented this protocol for blind merged-mining that solves the issue above. Although it doesn't solve the fact that each parallel chain still needs some form of "native" token to pay miners -- or it must use another method that doesn't use a native token, such as trusted payments outside the chain.
How does it work
With the
SIGHASH_NOINPUT/SIGHASH_ANYPREVOUTsoft-fork[^eltoo] it becomes possible to create presigned transactions that aren't related to any previous UTXO.Then you create a long sequence of transactions (sufficient to last for many many years), each with an
nLockTimeof 1 and each spending the next (you create them from the last to the first). Since theirscriptSig(the unlocking script) will useSIGHASH_ANYPREVOUTyou can obtain a transaction id/hash that doesn't include the previous TXO, you can, for example, in a sequence of transactionsA0-->B(B spends output 0 from A), include the signature for "spending A0 on B" inside thescriptPubKey(the locking script) of "A0".With the contraption described above it is possible to make that long string of transactions everybody will know (and know how to generate) but each transaction can only be spent by the next previously decided transaction, no matter what anyone does, and there always must be at least one block of difference between them.
Then you combine it with
RBF,SIGHASH_SINGLEandSIGHASH_ANYONECANPAYso parallel chain miners can add inputs and outputs to be able to compete on fees by including their own outputs and getting change back while at the same time writing a hash of the parallel block in the change output and you get everything working perfectly: everybody trying to spend the same output from the long string, each with a different parallel block hash, only the highest bidder will get the transaction included on the Bitcoin chain and thus only one parallel block will be mined.See also
[^eltoo]: The same thing used in Eltoo.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
litepub
A Go library that abstracts all the burdensome ActivityPub things and provides just the right amount of helpers necessary to integrate an existing website into the "fediverse" (what an odious name). Made for the gravity integration.
See also
-
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Replacing the web with something saner
This is a simplification, but let's say that basically there are just 3 kinds of websites:
- Websites with content: text, images, videos;
- Websites that run full apps that do a ton of interactive stuff;
- Websites with some interactive content that uses JavaScript, or "mini-apps";
In a saner world we would have 3 different ways of serving and using these. 1 would be "the web" (and it was for a while, although I'm not claiming here that the past is always better and wanting to get back to the glorious old days).
1 would stay as "the web", just static sites, styled with CSS, no JavaScript whatsoever, but designers can still thrive and make they look pretty. Or it could also be something like Gemini. Maybe the two protocols could coexist.
2 would be downloadable native apps, much easier to write and maintain for developers (considering that multi-platform and cross-compilation is easy today and getting easier), faster, more polished experience for users, more powerful, integrates better with the computer.
(Remember that since no one would be striving to make the same app run both on browsers and natively no one would have any need for Electron or other inefficient bloated solutions, just pure native UI, like the Telegram app, have you seen that? It's fast.)
But 2 is mostly for apps that people use every day, something like Google Docs, email (although email is also broken technology), Netflix, Twitter, Trello and so on, and all those hundreds of niche SaaS that people pay monthly fees to use, each tailored to a different industry (although most of functions they all implement are the same everywhere). What do we do with dynamic open websites like StackOverflow, for example, where one needs to not only read, but also search and interact in multiple ways? What about that website that asks you a bunch of questions and then discovers the name of the person you're thinking about? What about that mini-app that calculates the hash of your provided content or shrinks your video, or that one that hosts your image without asking any questions?
All these and tons of others would fall into category 3, that of instantly loaded apps that you don't have to install, and yet they run in a sandbox.
The key for making category 3 worth investing time into is coming up with some solid grounds, simple enough that anyone can implement in multiple different ways, but not giving the app too much choices.
Telegram or Discord bots are super powerful platforms that can accomodate most kinds of app in them. They can't beat a native app specifically made with one purpose, but they allow anyone to provide instantly usable apps with very low overhead, and since the experience is so simple, intuitive and fast, users tend to like it and sometimes even pay for their services. There could exist a protocol that brings apps like that to the open world of (I won't say "web") domains and the websockets protocol -- with multiple different clients, each making their own decisions on how to display the content sent by the servers that are powering these apps.
Another idea is that of Alan Kay: to design a nice little OS/virtual machine that can load these apps and run them. Kinda like browsers are today, but providing a more well-thought, native-like experience and framework, but still sandboxed. And I add: abstracting away details about design, content disposition and so on.
These 3 kinds of programs could coexist peacefully. 2 are just standalone programs, they can do anything and each will be its own thing. 1 and 3, however, are still similar to browsers of today in the sense that you need clients to interact with servers and show to the user what they are asking. But by simplifying everything and separating the scopes properly these clients would be easy to write, efficient, small, the environment would be open and the internet would be saved.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Soft-fork activation through
bitcoindcompetitionOr: how to activate Drivechain.
Imagine a world in which there are 10 different
bitcoindflavors, as described inbitcoinddecentralization.Now how do you enable a soft-fork?
Flavor 1 enables it. Seeing that nothing bad happened, flavor 2 enables it. Then flavor 3 enables it.
And so on.
When what is perceived by miners to be a big chunk of support for the proposal, a miner can try to mine a block that contains the new feature.
No need for a flag day or a centralized decision making process that depends on one or two courageous leaders to enable a timer.
This probably sounds silly, and maybe is.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
LessPass remoteStorage
LessPass is a nice idea: a password manager without any state. Just remember one master password and you can generate a different one for every site using the power of hashes.
But it has a very bad issue: some sites require just numbers, others have a minimum or maximum character limits, some require non-letter characters, uppercase characters, others forbid these and so on.
The solution: to allow you to specify parameters when generating the password so you can fit a generated password on every service.
The problem with the solution: it creates state. Now you must remember what parameters you used when generating a password for each site.
This was a way to store these settings on a remoteStorage bucket. Since it isn't confidential information in any way, that wasn't a problem, and I thought it was a good fit for remoteStorage.
Some time later I realized it maybe would be better to have a centralized repository hosting all weird requirements for passwords each domain forced on its users, and let LessPass use data from that central place when generating a password. Still stateful, not ideal, not very far from a centralized password manager, but still requiring less trust and less cryptographic assumptions.
- https://github.com/fiatjaf/lesspass-remotestorage
- https://addons.mozilla.org/firefox/addon/lesspass-remotestorage/
- https://chrome.google.com/webstore/detail/lesspass-remotestorage/aogdpopejodechblppdkpiimchbmdcmc
- https://lesspass.alhur.es/
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: Rumple
a payments network based on trust channels
This is the description of a Lightning-like network that will work only with credit or trust-based channels and exist alongside the normal Lightning Network. I imagine some people will think this is undesirable and at the same time very easy to do (such that if it doesn't exist yet it must be because no one cares), but in fact it is a very desirable thing -- which I hope I can establish below -- and at the same time a very non-trivial problem to solve, as the history of Ryan Fugger's Ripple project and posterior copies of it show.
Read these first to get the full context:
- Ryan Fugger's Ripple
- Ripple and the problem of the decentralized commit
- The Lightning Network solves the problem of the decentralized commit
- Parallel Chains
Explanation about the name
Since we're copying the fundamental Ripple idea from Ryan Fugger and since the name "Ripple" is now associated with a scam coin called XRP, and since Ryan Fugger has changed the name of his old website "Ripplepay" to "Rumplepay", we will follow his lead here. If "Ripplepay" was the name of a centralized prototype to the open peer-to-peer network "Ripple", now that the centralized version is called "Rumplepay" the peer-to-peer version must be called "Rumple".
Now the idea
Basically we copy the Lightning Network, but without HTLCs or channels being opened and closed with funds committed to them on multisig Bitcoin transactions published to the blockchain. Instead we use pure trust relationships like the original Ripple concept.
And we use the blockchain commit method, but instead of spending an absurd amount of money to use the actual Bitcoin blockchain instead we use a parallel chain.
How exactly -- a protocol proposal attempt
It could work like this:
The parallel chain, or "Rumple Chain"
- We define a parallel chain with a genesis block;
- Following blocks must contain
a. the ID of the previous block; b. a list of up to 32768 entries of arbitrary 32-byte values; c. an ID constituted by sha256(the previous block ID + the merkle root of all the entries) - To be mined, each parallel block must be included in the Bitcoin chain according as explained above.
Now that we have a structure for a simple "blockchain" that is completely useless, just blocks over blocks of meaningless values, we proceed to the next step of assigning meaning to these values.
The off-chain payments network, or "Rumple Network"
- We create a network of nodes that can talk to each other via TCP messages (all details are the same as the Lightning Network, except where mentioned otherwise);
- These nodes can create trust channels to each other. These channels are backed by nothing except the willingness of one peer to pay the other what is owed.
- When Alice creates a trust channel with Bob (
Alice trusts Bob), contrary to what happens in the Lightning Network, it's A that can immediately receive payments through that channel, and everything A receives will be an IOU from Bob to Alice. So Alice should never open a channel to Bob unless Alice trusts Bob. But also Alice can choose the amount of trust it has in Bob, she can, for example, open a very small channel with Bob, which means she will only lose a few satoshis if Bob decides to exit scam her. (in the original Ripple examples these channels were always depicted as friend relationships, and they can continue being that, but it's expected -- given the experience of the Lightning Network -- that the bulk of the channels will exist between users and wallet provider nodes that will act as hubs). - As Alice receive a payment through her channel with Bob, she becomes a creditor and Bob a debtor, i.e., the balance of the channel moves a little to her side. Now she can use these funds to make payments over that channel (or make a payment that combines funds from multiple channels using MPP).
- If at any time Alice decides to close her channel with Bob, she can send all the funds she has standing there to somewhere else (for example, another channel she has with someone else, another wallet somewhere else, a shop that is selling some good or service, or a service that will aggregate all funds from all her channels and send a transaction to the Bitcoin chain on her behalf).
- If at any time Bob leaves the network Alice is entitled by Bob's cryptographic signatures to knock on his door and demand payment, or go to a judge and ask him to force Bob to pay, or share the signatures and commitments online and hurt Bob's reputation with the rest of the network (but yes, none of these things is good enough and if Bob is a very dishonest person none of these things is likely to save Alice's funds).
The payment flow
- Suppose there exists a route
Alice->Bob->Caroland Alice wants to send a payment to Carol. - First Alice reads an invoice she received from Carol. The invoice (which can be pretty similar or maybe even the same as BOLT11) contains a payment hash
hand information about how to reach Carol's node, optionally an amount. Let's say it's 100 satoshis. - Using the routing information she gathered, Alice builds an onion and sends it to Bob, at the same time she offers to Bob a "conditional IOU". That stands for a signed commitment that Alice will owe Bob an 100 satoshis if in the next 50 blocks of the Rumple Chain there appears a block containing the preimage
psuch thatsha256(p) == h. - Bob peels the onion and discovers that he must forward that payment to Carol, so he forwards the peeled onion and offers a conditional IOU to Carol with the same
h. Bob doesn't know Carol is the final recipient of the payment, it could potentially go on and on. - When Carol gets the conditional IOU from Bob, she makes a list of all the nodes who have announced themselves as miners (which is not something I have mentioned before, but nodes that are acting as miners will must announce themselves somehow) and are online and bidding for the next Rumple block. Each of these miners will have previously published a random 32-byte value
vthey they intend to include in their next block. - Carol sends payments through routes to all (or a big number) of these miners, but this time the conditional IOU contains two conditions (values that must appear in a block for the IOU to be valid):
psuch thatsha256(p) == h(the same that featured in the invoice) andv(which must be unique and constant for each miner, something that is easily verifiable by Carol beforehand). Also, instead of these conditions being valid for the next 50 blocks they are valid only for the single next block. - Now Carol broadcasts
pto the mempool and hopes one of the miners to which she sent conditional payments sees it and, allured by the possibility of cashing in Carol's payment, includespin the next block. If that does not happen, Carol can try again in the next block.
Why bother with this at all?
-
The biggest advantage of Lightning is its openness
It has been said multiple times that if trust is involved then we don't need Lightning, we can use Coinbase, or worse, Paypal. This is very wrong. Lightning is good specially because it serves as a bridge between Coinbase, Paypal, other custodial provider and someone running their own node. All these can transact freely across the network and pay each other without worrying about who is in which provider or setup.
Rumple inherits that openness. In a Rumple Network anyone is free to open new trust channels and immediately route payments to anyone else.
Also, since Rumple payments are also based on the reveal of a preimage it can do swaps with Lightning inside a payment route from day one (by which I mean one can pay from Rumple to Lightning and vice-versa).
-
Rumple fixes Lightning's fragility
Lightning is too fragile.
It's known that Lightning is vulnerable to multiple attacks -- like the flood-and-loot attack, for example, although not an attack that's easy to execute, it's still dangerous even if failed. Given the existence of these attacks, it's important to not ever open channels with random anonymous people. Some degree of trust must exist between peers.
But one does not even have to consider attacks. The creation of HTLCs is a liability that every node has to do multiple times during its life. Every initiated, received or forwarded payment require adding one HTLC then removing it from the commitment transaction.
Another issue that makes trust needed between peers is the fact that channels can be closed unilaterally. Although this is a feature, it is also a bug when considering high-fee environments. Imagine you pay $2 in fees to open a channel, your peer may close that unilaterally in the next second and then you have to pay another $15 to close the channel. The opener pays (this is also a feature that can double as a bug by itself). Even if it's not you opening the channel, a peer can open a channel with you, make a payment, then clone the channel, and now you're left with, say, an output of 800 satoshis, which is equal to zero if network fees are high.
So you should only open channels with people you know and know aren't going to actively try to hack you and people who are not going to close channels and impose unnecessary costs on you. But even considering a fully trusted Lightning Network, even if -- to be extreme -- you only opened channels with yourself, these channels would still be fragile. If some HTLC gets stuck for any reason (peer offline or some weird small incompatibility between node softwares) and you're forced to close the channel because of that, there are the extra costs of sweeping these UTXO outputs plus the total costs of closing and reopening a channel that shouldn't have been closed in the first place. Even if HTLCs don't get stuck, a fee renegotiation event during a mempool spike may cause channels to force-close, become valueless or settle for very high closing fee.
Some of these issues are mitigated by Eltoo, others by only having channels with people you trust. Others referenced above, plus the the griefing attack and in general the ability of anyone to spam the network for free with payments that can be pending forever or a lot of payments fail repeatedly makes it very fragile.
Rumple solves most of these problems by not having to touch the blockchain at all. Fee negotiation makes no sense. Opening and closing channels is free. Flood-and-loot is a non-issue. The griefing attack can be still attempted as funds in trust channels must be reserved like on Lightning, but since there should be no theoretical limit to the number of prepared payments a channel can have, the griefing must rely on actual amounts being committed, which prevents large attacks from being performed easily.
-
Rumple fixes Lightning's unsolvable reputation issues
In the Lightning Conference 2019, Rusty Russell promised there would be pre-payments on Lightning someday, since everybody was aware of potential spam issues and pre-payments would be the way to solve that. Fast-forward to November 2020 and these pre-payments have become an apparently unsolvable problem[^thread-402]: no one knows how to implement them reliably without destroying privacy completely or introducing worse problems.
Replacing these payments with tables of reputation between peers is also an unsolved problem[^reputation-lightning], for the same reasons explained in the thread above.
-
Rumple solves the hot wallet problem
Since you don't have to use Bitcoin keys or sign transactions with a Rumple node, only your channel trust is at risk at any time.
-
Rumple ends custodianship
Since no one is storing other people's funds, a big hub or wallet provider can be used in multiple payment routes, but it cannot be immediately classified as a "custodian". At best, it will be a big debtor.
-
Rumple is fun
Opening channels with strangers is boring. Opening channels with friends and people you trust even a little makes that relationship grow stronger and the trust be reinforced. (But of course, like it happens in the Lightning Network today, if Rumple is successful the bulk of trust will be from isolated users to big reliable hubs.)
Questions or potential issues
-
So many advantages, yes, but trusted? Custodial? That's easy and stupid!
Well, an enormous part of the current Lightning Network (and also onchain Bitcoin wallets) already rests on trust, mainly trust between users and custodial wallet providers like ZEBEDEE, Alby, Wallet-of-Satoshi and others. Worse: on the current Lightning Network users not only trust, they also expose their entire transaction history to these providers[^hosted-channels].
Besides that, as detailed in point 3 of the previous section, there are many unsolvable issues on the Lightning protocol that make each sovereign node dependent on some level of trust in its peers (and the network in general dependent on trusting that no one else will spam it to death).
So, given the current state of the Lightning Network, to trust peers like Rumple requires is not a giant change -- but it is still a significant change: in Rumple you shouldn't open a large trust channel with someone just because it looks trustworthy, you must personally know that person and only put in what you're willing to lose. In known brands that have reputation to lose you can probably deposit more trust, same for long-term friends, and that's all. Still it is probably good enough, given the existence of MPP payments and the fact that the purpose of Rumple is to be a payments network for day-to-day purchases and not a way to buy real estate.
-
Why would anyone run a node in this parallel chain?
I don't know. Ideally every server running a Rumple Network node will be running a Bitcoin node and a Rumple chain node. Besides using it to confirm and publish your own Rumple Network transactions it can be set to do BMM mining automatically and maybe earn some small fees comparable to running a Lightning routing node or a JoinMarket yield generator.
Also it will probably be very lightweight, as pruning is completely free and no verification-since-the-genesis-block will take place.
-
What is the maturity of the debt that exists in the Rumple Network or its legal status?
By default it is to be understood as being payable on demand for payments occurring inside the network (as credit can be used to forward or initiate payments by the creditor using that channel). But details of settlement outside the network or what happens if one of the peers disappears cannot be enforced or specified by the network.
Perhaps some standard optional settlement methods (like a Bitcoin address) can be announced and negotiated upon channel creation inside the protocol, but nothing more than that.
[^thread-402]: Read at least the first 10 messages of the thread to see how naïve proposals like you and me could have thought about are brought up and then dismantled very carefully by the group of people most committed to getting Lightning to work properly. [^reputation-lightning]: See also the footnote at Ripple and the problem of the decentralized commit. [^hosted-channels]: Although that second part can be solved by hosted channels.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Thafne venceu o Soletrando 2008.
As palavras que Thafne teve que soletrar: "ocioso", "hermético", "glossário", "argênteo", "morfossintaxe", "infra-hepático", "hagiológio". Enquanto isso Eder recebia: "intramuscular", "destilação", "inabitável", "subcutâneo", "homogeneidade", "predecessor", "displicência", "subconsciência", "psicroestesia" (isto segundo o site da folha, donde certamente faltam algumas palavras de Thafne). Sério, "argênteo"? Não é errado dizer que a Globo tentou promover o menino pobre da escola pública do sertão contra a riquinha de Curitiba.
O mais espetacular disto é que deu errado e o Brasil inteiro torceu pela Thafne, o que se verifica com uma simples busca no Google. Eis aqui alguns exemplos:
- O problema de Thafne traz comentários tentando incriminar o governo do Estado de Minas Gerais com a vitória forçada de Eder.
- este vídeo mostrando os erros do programa e a vitória triunfal, embora parcial, de Thafne, traz a brilhante descrição "globo de puleira quis complicar a vida da menina!!!!!!!!!!!!!!!!!!!!!!"
- este vídeo, com o mesmo conteúdo,, porém chamado "Thafne versus Luciano Huck, o confronto do século", tem, além disto, vários comentários de francos torcedores de Thafne:
- "Nossa isso é burrice porq o doutor falou duas vezes como o luciano não prestou atenção logo thafine deu duas patadas no luciano... Proxima luciano presta atenção na pronuncia"
- "ele nao pronunciou errado porque é burro, isso foi pra manipular o resultado"
- "Gabriel o Bostador ficou pianinho. Babaca do krl"
- "Pena que ela perdeu :("
- "verdade... ela que ganhou, o outro só ficou com o título :S"
- "A menina deu um banho nesse que além de idiota é BURRO."
- e muitos, muitos outros.
- Globo Erra e Luciano Huck dá Vexame, um breve artigo descrevendo alguns dos pontos em que Eder foi favorecido.
- esta comunidade do Orkut, apenas a maior dentre várias que foram criadas.
O movimento de apoio a Thafne é um exemplo entre poucos de união total da nação em prol de uma causa.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Just malinvestiment
Traditionally the Austrian Theory of Business Cycles has been explained and reworked in many ways, but the most widely accepted version (or the closest to the Mises or Hayek views) view is that banks (or the central bank) cause the general interest rate to decline by creation of new money and that prompts entrepreneurs to invest in projects of longer duration. This can be confusing because sometimes entrepreneurs embark in very short-time projects during one of these bubbles and still contribute to the overall cycle.
The solution is to think about the "longer term" problem is to think of the entire economy going long-term, not individual entrepreneurs. So if one entrepreneur makes an investiment in a thing that looks simple he may actually, knowingly or not, be inserting himself in a bigger machine that is actually involved in producing longer-term things. Incidentally this thinking also solves the biggest criticism of the Austrian Business Cycle Theory: that of the rational expectations people who say: "oh but can't the entrepreneurs know that the interest rate is artificially low and decide to not make long-term investiments?" ("and if they don't know they should lose money and be replaced like in a normal economy flow blablabla?"). Well, the answer is that they are not really relying on the interest rate, they are only looking for profit opportunities, and this is the key to another confusion that has always followed my thinkings about this topic.
If a guy opens a bar in an area of a town where many new buildings are being built during a "housing bubble" he may not know, but he is inserting himself right into the eye of that business cycle. He expects all these building projects to continue, and all the people involved in that to be getting paid more and be able to spend more at his bar and so on. That is a bet that may or may not end up paying.
Now what does that bar investiment has to do with the interest rate? Nothing. It is just a guy who saw a business opportunity in a place where hungry people with money had no bar to buy things in, so he opened a bar. Additionally the guy has made some calculations about all the ending, starting and future building projects in the area, and then the people that would live or work in that area afterwards (after all the buildings were being built with the expectation of being used) and so on, there is no interest rate calculations involved. And yet that may be a malinvestiment because some building projects will end up being canceled and the expected usage of the finished ones will turn out to be smaller than predicted.
This bubble may have been caused by a decline in interest rates that prompted some people to start buying houses that they wouldn't otherwise, but this is just a small detail. The bubble can only be kept going by a constant influx of new money into the economy, but the focus on the interest rate is wrong. If new money is printed and used by the government to buy ships then there will be a boom and a bubble in the ship market, and that involves all the parts of production process of ships and also bars that will be opened near areas of the town where ships are built and new people are being hired with higher salaries to do things that will eventually contribute to the production of ships that will then be sold to the government.
It's not interest rates or the length of the production process that matters, it's just printed money and malinvestiment.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Profits, not wages, as the originary factor
Adam Smith says that there were first workers earning wages, but then came the capitalists and extracted profits from those wages.
But in fact if that primitive state ever existed there were no workers, but entrepreneursearning profit. And since they were not capitalists ("capitalist" defined as someone that buys with the intent of selling) they were earning an infinite rate of profit.
When capitalists came they were responsible for introducing costs (investment) reducing thus the rate of profit -- and the more capitalistic the society the smaller the rate of profits.
-- George Reisman in https://www.bobmurphyshow.com/139
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
nostr - Notes and Other Stuff Transmitted by Relays
The simplest open protocol that is able to create a censorship-resistant global "social" network once and for all.
It doesn't rely on any trusted central server, hence it is resilient; it is based on cryptographic keys and signatures, so it is tamperproof; it does not rely on P2P techniques, therefore it works.
Very short summary of how it works, if you don't plan to read anything else:
Everybody runs a client. It can be a native client, a web client, etc. To publish something, you write a post, sign it with your key and send it to multiple relays (servers hosted by someone else, or yourself). To get updates from other people, you ask multiple relays if they know anything about these other people. Anyone can run a relay. A relay is very simple and dumb. It does nothing besides accepting posts from some people and forwarding to others. Relays don't have to be trusted. Signatures are verified on the client side.
This is needed because other solutions are broken:
The problem with Twitter
- Twitter has ads;
- Twitter uses bizarre techniques to keep you addicted;
- Twitter doesn't show an actual historical feed from people you follow;
- Twitter bans people;
- Twitter shadowbans people.
- Twitter has a lot of spam.
The problem with Mastodon and similar programs
- User identities are attached to domain names controlled by third-parties;
- Server owners can ban you, just like Twitter; Server owners can also block other servers;
- Migration between servers is an afterthought and can only be accomplished if servers cooperate. It doesn't work in an adversarial environment (all followers are lost);
- There are no clear incentives to run servers, therefore they tend to be run by enthusiasts and people who want to have their name attached to a cool domain. Then, users are subject to the despotism of a single person, which is often worse than that of a big company like Twitter, and they can't migrate out;
- Since servers tend to be run amateurishly, they are often abandoned after a while — which is effectively the same as banning everybody;
- It doesn't make sense to have a ton of servers if updates from every server will have to be painfully pushed (and saved!) to a ton of other servers. This point is exacerbated by the fact that servers tend to exist in huge numbers, therefore more data has to be passed to more places more often;
- For the specific example of video sharing, ActivityPub enthusiasts realized it would be completely impossible to transmit video from server to server the way text notes are, so they decided to keep the video hosted only from the single instance where it was posted to, which is similar to the Nostr approach.
The problem with SSB (Secure Scuttlebutt)
- It doesn't have many problems. I think it's great. In fact, I was going to use it as a basis for this, but
- its protocol is too complicated because it wasn't thought about being an open protocol at all. It was just written in JavaScript in probably a quick way to solve a specific problem and grew from that, therefore it has weird and unnecessary quirks like signing a JSON string which must strictly follow the rules of ECMA-262 6th Edition;
- It insists on having a chain of updates from a single user, which feels unnecessary to me and something that adds bloat and rigidity to the thing — each server/user needs to store all the chain of posts to be sure the new one is valid. Why? (Maybe they have a good reason);
- It is not as simple as Nostr, as it was primarily made for P2P syncing, with "pubs" being an afterthought;
- Still, it may be worth considering using SSB instead of this custom protocol and just adapting it to the client-relay server model, because reusing a standard is always better than trying to get people in a new one.
The problem with other solutions that require everybody to run their own server
- They require everybody to run their own server;
- Sometimes people can still be censored in these because domain names can be censored.
How does Nostr work?
- There are two components: clients and relays. Each user runs a client. Anyone can run a relay.
- Every user is identified by a public key. Every post is signed. Every client validates these signatures.
- Clients fetch data from relays of their choice and publish data to other relays of their choice. A relay doesn't talk to another relay, only directly to users.
- For example, to "follow" someone a user just instructs their client to query the relays it knows for posts from that public key.
- On startup, a client queries data from all relays it knows for all users it follows (for example, all updates from the last day), then displays that data to the user chronologically.
- A "post" can contain any kind of structured data, but the most used ones are going to find their way into the standard so all clients and relays can handle them seamlessly.
How does it solve the problems the networks above can't?
- Users getting banned and servers being closed
- A relay can block a user from publishing anything there, but that has no effect on them as they can still publish to other relays. Since users are identified by a public key, they don't lose their identities and their follower base when they get banned.
- Instead of requiring users to manually type new relay addresses (although this should also be supported), whenever someone you're following posts a server recommendation, the client should automatically add that to the list of relays it will query.
- If someone is using a relay to publish their data but wants to migrate to another one, they can publish a server recommendation to that previous relay and go;
- If someone gets banned from many relays such that they can't get their server recommendations broadcasted, they may still let some close friends know through other means with which relay they are publishing now. Then, these close friends can publish server recommendations to that new server, and slowly, the old follower base of the banned user will begin finding their posts again from the new relay.
-
All of the above is valid too for when a relay ceases its operations.
-
Censorship-resistance
- Each user can publish their updates to any number of relays.
-
A relay can charge a fee (the negotiation of that fee is outside of the protocol for now) from users to publish there, which ensures censorship-resistance (there will always be some Russian server willing to take your money in exchange for serving your posts).
-
Spam
-
If spam is a concern for a relay, it can require payment for publication or some other form of authentication, such as an email address or phone, and associate these internally with a pubkey that then gets to publish to that relay — or other anti-spam techniques, like hashcash or captchas. If a relay is being used as a spam vector, it can easily be unlisted by clients, which can continue to fetch updates from other relays.
-
Data storage
- For the network to stay healthy, there is no need for hundreds of active relays. In fact, it can work just fine with just a handful, given the fact that new relays can be created and spread through the network easily in case the existing relays start misbehaving. Therefore, the amount of data storage required, in general, is relatively less than Mastodon or similar software.
-
Or considering a different outcome: one in which there exist hundreds of niche relays run by amateurs, each relaying updates from a small group of users. The architecture scales just as well: data is sent from users to a single server, and from that server directly to the users who will consume that. It doesn't have to be stored by anyone else. In this situation, it is not a big burden for any single server to process updates from others, and having amateur servers is not a problem.
-
Video and other heavy content
-
It's easy for a relay to reject large content, or to charge for accepting and hosting large content. When information and incentives are clear, it's easy for the market forces to solve the problem.
-
Techniques to trick the user
- Each client can decide how to best show posts to users, so there is always the option of just consuming what you want in the manner you want — from using an AI to decide the order of the updates you'll see to just reading them in chronological order.
FAQ
- This is very simple. Why hasn't anyone done it before?
I don't know, but I imagine it has to do with the fact that people making social networks are either companies wanting to make money or P2P activists who want to make a thing completely without servers. They both fail to see the specific mix of both worlds that Nostr uses.
- How do I find people to follow?
First, you must know them and get their public key somehow, either by asking or by seeing it referenced somewhere. Once you're inside a Nostr social network you'll be able to see them interacting with other people and then you can also start following and interacting with these others.
- How do I find relays? What happens if I'm not connected to the same relays someone else is?
You won't be able to communicate with that person. But there are hints on events that can be used so that your client software (or you, manually) knows how to connect to the other person's relay and interact with them. There are other ideas on how to solve this too in the future but we can't ever promise perfect reachability, no protocol can.
- Can I know how many people are following me?
No, but you can get some estimates if relays cooperate in an extra-protocol way.
- What incentive is there for people to run relays?
The question is misleading. It assumes that relays are free dumb pipes that exist such that people can move data around through them. In this case yes, the incentives would not exist. This in fact could be said of DHT nodes in all other p2p network stacks: what incentive is there for people to run DHT nodes?
- Nostr enables you to move between server relays or use multiple relays but if these relays are just on AWS or Azure what’s the difference?
There are literally thousands of VPS providers scattered all around the globe today, there is not only AWS or Azure. AWS or Azure are exactly the providers used by single centralized service providers that need a lot of scale, and even then not just these two. For smaller relay servers any VPS will do the job very well.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Alternatives to Drivechain
If Drivechain doesn't get soft-forked into Bitcoin, the alternatives people are left with are:
- Altcoins. People who want super-powers (privacy, smart contracts, cheap transactions) move their stake to shitcoins. This doesn't make much sense because even if altcoins had the necessary technology they wouldn't have the base money with which to use the technology, but still this remains an option.
- Fully-custodial and trusted systems. Instead of moving their money to a sidechain secured by Drivechain people can use a centralized service with much less safety and subject to all kinds of regulations, hacks and government takedowns.
- Federated sidechains, which are the same as custodial systems, but with distributed trust and maybe less, maybe more government involvement.
- Less secure sidechain-like constructions, like sidechains secured by a multisig of a fixed set of entities with names, or BTC tokens in other blockchains guaranteed by a collateral denominated in shitcoins which tends to zero.
- Corporate takeover. Big banks and giant corporations start buying all the coins and exposing part of them through their closed systems to normal people. Instead of an open network and free market as everybody expected, all meaningful activity now happens inside these legacy evil entities that are already sold to governments from the start.
Every time one person goes against Drivechain without proposing something else better, they're condemning bitcoiners to one or many of the above forever.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On Bitcoin Bounties
The HRF has awarded two bounties yesterday. The episode exposes some of the problems of the bounties and grants culture that exists on Bitcoin.
First, when the bounties were announced, almost an year ago, I felt they were very hard to achieve (and also very useless, but let's set that aside).
The first, "a wallet that integrates bolt12 so it can receive tips noncustodially", could be understood as a bounty for mobile wallets only, in which case the implementation would be hacky, hard and take a lot of time; or it could be understood as being valid for any wallet, in which case it was already implemented in CLN (at the time called "c-lightning"), so the bounty didn't make sense.
The second, a wallet with a noncustodial US dollar balance, is arguably impossible, since there is no way to achieve it without trusted oracles, therefore it is probably invalid. If one assumed that trust was fine, then it was already implemented by StandardSats at the time. It felt it was designed to use some weird construct like DLCs -- and Chris Steward did publish a guide on how to implement a wallet that would be eligible for the bounty using DLCs, therefore the path seemed to be set there, but this would be a very hard and time-intensive thing.
The third, a noncustodial wallet with optional custodial ecash functionality, seemed to be targeting Fedimint directly, which already existed at the time and was about to release exactly these features.
Time passed and apparently no one tried to claim any of these bounties. My explanation is that, at least for 1 and 2, it was so hard to get it done that no one would risk trying and getting rejected. It is better for a programmer to work on something that interests them directly if they're working for free.
For 3 I believe no one even tried anything because the bounty was already set to be given to Fedimint.
Fast-forward to today and bounties 1 and 3 were awarded to two projects that were created by the sole interest of the developers with no attempt to actually claim these bounties -- and indeed, the two winners strictly do not qualify according to the descriptions from last year.
What if someone was working for months on trying to actually fulfill the criteria? That person would be in a very bad shape now, having thrown away all the work. Considering this it was a very good choice for everyone involved to not try to claim any of the bounties.
The winners have merit only in having pursued their own interests and in creating useful programs as the result. I'm sure the bounties do not feel to them like a deserved payment for the specific work they did, but more like a token of recognition for having worked on Bitcoin-related stuff at all, and an incentive to continue to work.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Splitpages
The simplest possible service: it splitted PDF pages in half.
Created specially to solve the problem of those scanned books that come with two pages side-by-side as if they were a single page and are much harder to read on Kindle because of that.

It required me to learn about Heroku Buildpacks though, and fork or contribute to a Heroku Buildpack that embedded a mupdf binary.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Gerador de tabelas de todos contra todos
I don't remember exactly when I did this, but I think a friend wanted to do software that would give him money over the internet without having to work. He didn't know how to program. He mentioned this idea he had which was some kind of football championship manager solution, but I heard it like this: a website that generated a round-robin championship table for people to print.
It is actually not obvious to anyone how to do it, it requires an algorithm that people will not reach casually while thinking, and there was no website doing it in Portuguese at the time, so I made this and it worked and it had a couple hundred daily visitors, and it even generated money from Google Ads (not much)!
First it was a Python web app running on Heroku, then Heroku started charging or limiting the amount of free time I could have on their platform, so I migrated it to a static site that ran everything on the client. Since I didn't want to waste my Python code that actually generated the tables I used Brython to run Python on JavaScript, which was an interesting experience.
In hindsight I could have just taken one of the many
round-robinJavaScript libraries that exist on NPM, so eventually after a couple of more years I did that.I also removed Google Ads when Google decided it had so many requirements to send me the money it was impossible, and then the money started to vanished.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
How being "flexible" can bloat a protocol
(A somewhat absurd example, but you'll get the idea)
Iimagine some client decides to add support for a variant of nip05 that checks for values at /.well-known/nostr.yaml besides /.well-known/nostr.json. "Why not?", they think, "I like YAML more than JSON, this can't hurt anyone".
Then some user makes a nip05 file in YAML and it will work on that client, they will think their file is good since it works on that client. When the user sees that other clients are not recognizing their YAML file, they will complain to the other client developers: "Hey, your client is broken, it is not supporting my YAML file!".
The developer of the other client, astonished, replies: "Oh, I am sorry, I didn't know that was part of the nip05 spec!"
The user, thinking it is doing a good thing, replies: "I don't know, but it works on this other client here, see?"
Now the other client adds support. The cycle repeats now with more users making YAML files, more and more clients adding YAML support, for fear of providing a client that is incomplete or provides bad user experience.
The end result of this is that now nip05 extra-officially requires support for both JSON and YAML files. Every client must now check for /.well-known/nostr.yaml too besides just /.well-known/nostr.json, because a user's key could be in either of these. A lot of work was wasted for nothing. And now, going forward, any new clients will require the double of work than before to implement.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
tempreites
My first library to get stars on GitHub, was a very stupid templating library that used just HTML and HTML attributes ("DSL-free"). I was inspired by http://microjs.com/ at the time and ended up not using the library. Probably no one ever did.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
OP_CHECKTEMPLATEVERIFYand the "covenants" dramaThere are many ideas for "covenants" (I don't think this concept helps in the specific case of examining proposals, but fine). Some people think "we" (it's not obvious who is included in this group) should somehow examine them and come up with the perfect synthesis.
It is not clear what form this magic gathering of ideas will take and who (or which ideas) will be allowed to speak, but suppose it happens and there is intense research and conversations and people (ideas) really enjoy themselves in the process.
What are we left with at the end? Someone has to actually commit the time and put the effort and come up with a concrete proposal to be implemented on Bitcoin, and whatever the result is it will have trade-offs. Some great features will not make into this proposal, others will make in a worsened form, and some will be contemplated very nicely, there will be some extra costs related to maintenance or code complexity that will have to be taken. Someone, a concreate person, will decide upon these things using their own personal preferences and biases, and many people will not be pleased with their choices.
That has already happened. Jeremy Rubin has already conjured all the covenant ideas in a magic gathering that lasted more than 3 years and came up with a synthesis that has the best trade-offs he could find. CTV is the result of that operation.
The fate of CTV in the popular opinion illustrated by the thoughtless responses it has evoked such as "can we do better?" and "we need more review and research and more consideration of other ideas for covenants" is a preview of what would probably happen if these suggestions were followed again and someone spent the next 3 years again considering ideas, talking to other researchers and came up with a new synthesis. Again, that person would be faced with "can we do better?" responses from people that were not happy enough with the choices.
And unless some famous Bitcoin Core or retired Bitcoin Core developers were personally attracted by this synthesis then they would take some time to review and give their blessing to this new synthesis.
To summarize the argument of this article, the actual question in the current CTV drama is that there exists hidden criteria for proposals to be accepted by the general community into Bitcoin, and no one has these criteria clear in their minds. It is not as simple not as straightforward as "do research" nor it is as humanly impossible as "get consensus", it has a much bigger social element into it, but I also do not know what is the exact form of these hidden criteria.
This is said not to blame anyone -- except the ignorant people who are not aware of the existence of these things and just keep repeating completely false and unhelpful advice for Jeremy Rubin and are not self-conscious enough to ever realize what they're doing.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: Custom multi-use database app
Since 2015 I have this idea of making one app that could be repurposed into a full-fledged app for all kinds of uses, like powering small businesses accounts and so on. Hackable and open as an Excel file, but more efficient, without the hassle of making tables and also using ids and indexes under the hood so different kinds of things can be related together in various ways.
It is not a concrete thing, just a generic idea that has taken multiple forms along the years and may take others in the future. I've made quite a few attempts at implementing it, but never finished any.
I used to refer to it as a "multidimensional spreadsheet".
Can also be related to DabbleDB.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: a website for feedback exchange
I thought a community of people sharing feedback on mutual interests would be a good thing, so as always I broadened and generalized the idea and mixed with my old criticue-inspired idea-feedback project and turned it into a "token". You give feedback on other people's things, they give you a "point". You can then use that point to request feedback from others.
This could be made as an Etleneum contract so these points were exchanged for satoshis using the shitswap contract (yet to be written).
In this case all the Bitcoin/Lightning side of the website must be hidden until the user has properly gone through the usage flow and earned points.
If it was to be built on Etleneum then it needs to emphasize the login/password login method instead of the lnurl-auth method. And then maybe it could be used to push lnurl-auth to normal people, but with a different name.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
bolt12 problems
- clients can't programatically build new offers by changing a path or query params (services like zbd.gg or lnurl-pay.me won't work)
- impossible to use in a load-balanced custodian way -- since offers would have to be pregenerated and tied to a specific lightning node.
- the existence of fiat currency fields makes it so wallets have to fetch exchange rates from somewhere on the internet (or offer a bad user experience), using HTTP which hurts user privacy.
- the vendor field is misleading, can be phished very easily, not as safe as a domain name.
- onion messages are an improvement over fake HTLC-based payments as a way of transmitting data, for sure. but we must decide if they are (i) suitable for transmitting all kinds of data over the internet, a replacement for tor; or (ii) not something that will scale well or on which we can count on for the future. if there was proper incentivization for data transmission it could end up being (i), the holy grail of p2p communication over the internet, but that is a very hard problem to solve and not guaranteed to yield the desired scalability results. since not even hints of attempting to solve that are being made, it's safer to conclude it is (ii).
bolt12 limitations
- not flexible enough. there are some interesting fields defined in the spec, but who gets to add more fields later if necessary? very unclear.
- services can't return any actionable data to the users who paid for something. it's unclear how business can be conducted without an extra communication channel.
bolt12 illusions
- recurring payments is not really solved, it is just a spec that defines intervals. the actual implementation must still be done by each wallet and service. the recurring payment cannot be enforced, the wallet must still initiate the payment. even if the wallet is evil and is willing to initiate a payment without the user knowing it still needs to have funds, channels, be online, connected etc., so it's not as if the services could rely on the payments being delivered in time.
- people seem to think it will enable pushing payments to mobile wallets, which it does not and cannot.
- there is a confusion of contexts: it looks like offers are superior to lnurl-pay, for example, because they don't require domain names. domain names, though, are common and well-established among internet services and stores, because these services have websites, so this is not really an issue. it is an issue, though, for people that want to receive payments in their homes. for these, indeed, bolt12 offers a superior solution -- but at the same time bolt12 seems to be selling itself as a tool for merchants and service providers when it includes and highlights features as recurring payments and refunds.
- the privacy gains for the receiver that are promoted as being part of bolt12 in fact come from a separate proposal, blinded paths, which should work for all normal lightning payments and indeed are a very nice solution. they are (or at least were, and should be) independent from the bolt12 proposal. a separate proposal, which can be (and already is being) used right now, also improves privacy for the receiver very much anway, it's called trampoline routing.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Thoughts on Nostr key management
On Why I don't like NIP-26 as a solution for key management I talked about multiple techniques that could be used to tackle the problem of key management on Nostr.
Here are some ideas that work in tandem:
- NIP-41 (stateless key invalidation)
- NIP-46 (Nostr Connect)
- NIP-07 (signer browser extension)
- Connected hardware signing devices
- other things like musig or frostr keys used in conjunction with a semi-trusted server; or other kinds of trusted software, like a dedicated signer on a mobile device that can sign on behalf of other apps; or even a separate protocol that some people decide to use as the source of truth for their keys, and some clients might decide to use that automatically
- there are probably many other ideas
Some premises I have in my mind (that may be flawed) that base my thoughts on these matters (and cause me to not worry too much) are that
- For the vast majority of people, Nostr keys aren't a target as valuable as Bitcoin keys, so they will probably be ok even without any solution;
- Even when you lose everything, identity can be recovered -- slowly and painfully, but still --, unlike money;
- Nostr is not trying to replace all other forms of online communication (even though when I think about this I can't imagine one thing that wouldn't be nice to replace with Nostr) or of offline communication, so there will always be ways.
- For the vast majority of people, losing keys and starting fresh isn't a big deal. It is a big deal when you have followers and an online persona and your life depends on that, but how many people are like that? In the real world I see people deleting social media accounts all the time and creating new ones, people losing their phone numbers or other accounts associated with their phone numbers, and not caring very much -- they just find a way to notify friends and family and move on.
We can probably come up with some specs to ease the "manual" recovery process, like social attestation and explicit signaling -- i.e., Alice, Bob and Carol are friends; Alice loses her key; Bob sends a new Nostr event kind to the network saying what is Alice's new key; depending on how much Carol trusts Bob, she can automatically start following that and remove the old key -- or something like that.
One nice thing about some of these proposals, like NIP-41, or the social-recovery method, or the external-source-of-truth-method, is that they don't have to be implemented in any client, they can live in standalone single-purpose microapps that users open or visit only every now and then, and these can then automatically update their follow lists with the latest news from keys that have changed according to multiple methods.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A response to Achim Warner's "Drivechain brings politics to miners" article
I mean this article: https://achimwarner.medium.com/thoughts-on-drivechain-i-miners-can-do-things-about-which-we-will-argue-whether-it-is-actually-a5c3c022dbd2
There are basically two claims here:
1. Some corporate interests might want to secure sidechains for themselves and thus they will bribe miners to have these activated
First, it's hard to imagine why they would want such a thing. Are they going to make a proprietary KYC chain only for their users? They could do that in a corporate way, or with a federation, like Facebook tried to do, and that would provide more value to their users than a cumbersome pseudo-decentralized system in which they don't even have powers to issue currency. Also, if Facebook couldn't get away with their federated shitcoin because the government was mad, what says the government won't be mad with a sidechain? And finally, why would Facebook want to give custody of their proprietary closed-garden Bitcoin-backed ecosystem coins to a random, open and always-changing set of miners?
But even if they do succeed in making their sidechain and it is very popular such that it pays miners fees and people love it. Well, then why not? Let them have it. It's not going to hurt anyone more than a proprietary shitcoin would anyway. If Facebook really wants a closed ecosystem backed by Bitcoin that probably means we are winning big.
2. Miners will be required to vote on the validity of debatable things
He cites the example of a PoS sidechain, an assassination market, a sidechain full of nazists, a sidechain deemed illegal by the US government and so on.
There is a simple solution to all of this: just kill these sidechains. Either miners can take the money from these to themselves, or they can just refuse to engage and freeze the coins there forever, or they can even give the coins to governments, if they want. It is an entirely good thing that evil sidechains or sidechains that use horrible technology that doesn't even let us know who owns each coin get annihilated. And it was the responsibility of people who put money in there to evaluate beforehand and know that PoS is not deterministic, for example.
About government censoring and wanting to steal money, or criminals using sidechains, I think the argument is very weak because these same things can happen today and may even be happening already: i.e., governments ordering mining pools to not mine such and such transactions from such and such people, or forcing them to reorg to steal money from criminals and whatnot. All this is expected to happen in normal Bitcoin. But both in normal Bitcoin and in Drivechain decentralization fixes that problem by making it so governments cannot catch all miners required to control the chain like that -- and in fact fixing that problem is the only reason we need decentralization.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Things a coalition of evil miners can do on Bitcoin
If a miner coalition has 75% of hashrate for 6 months they can steal coins from a Drivechain without any risk, that's what the drivechain haters say.
What other evil things can a coalition of 75% hashrate do in 6 months?
- steal money from all open Lightning nodes on the network by opening channels to them, mining 3 blocks, spending the funds out on Lightning instantly, then rolling back the 3 blocks and canceling the channel.
- the above would eventually -- but not instantly and only after many steals have happened (even if they're not all perfectly coordinated and instant) -- cause Lightning to shrink in size a lot and become more of a closed friends network than truly open.
- only mine empty blocks and cause the mempool to be enormously clogged.
- refuse to use the mempool, force a proprietary API for transaction propagation with zero transparency and force other miners to use that same infrastructure too and extract a fee from them.
- censor anything and force other miners to censor too, at the threat of orphaning their blocks.
- easily cause so much confusion in the mining process that Bitcoin is deemed unusable and price falls drastically, miners can then buy at low price.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Sol e Terra
A Terra não gira em torno do Sol. Tudo depende do ponto de referência e não existe um ponto de referência absoluto. Só é melhor dizer que a Terra gira em torno do Sol porque há outros planetas fazendo movimentos análogos e aí fica mais fácil para todo mundo entender os movimentos tomando o Sol como ponto de referência.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Using Spacechains and Fedimint to solve scaling
What if instead of trying to create complicated "layer 2" setups involving noveau cryptographic techniques we just did the following:
- we take that Fedimint source code and remove the "mint" stuff, and just use their federation stuff secure coins with multisig;
- then we make a spacechain;
- and we make the federations issue multisig-btc tokens on it;
- and then we put some uniswap-like thing in there to allow these tokens to be exchanged freely.
Why?
The recent spike in fees caused by Ordinals and BRC-20 shitcoinery has shown that Lightning isn't a silver bullet. Channels are too fragile, it costs a lot to open a channel under a high fee environment, to run a routing node and so on.
People who want to keep using Lightning are instead flocking to the big Lightning custodial providers: WalletofSatoshi, ZEBEDEE, OpenNode and so on. We could leverage that trust people have in these companies (and individuals) operating shadow Lightning providers and turn each of these into a btc-token issuer. Each issue their own token, transactions flow freely. Each person can hold only assets from the issuers they trust more.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On HTLCs and arbiters
This is another attempt and conveying the same information that should be in Lightning and its fake HTLCs. It assumes you know everything about Lightning and will just highlight a point. This is also valid for PTLCs.
The protocol says HTLCs are trimmed (i.e., not actually added to the commitment transaction) when the cost of redeeming them in fees would be greater than their actual value.
Although this is often dismissed as a non-important fact (often people will say "it's trusted for small payments, no big deal"), but I think it is indeed very important for 3 reasons:
- Lightning absolutely relies on HTLCs actually existing because the payment proof requires them. The entire security of each payment comes from the fact that the payer has a preimage that comes from the payee. Without that, the state of the payment becomes an unsolvable mystery. The inexistence of an HTLC breaks the atomicity between the payment going through and the payer receiving a proof.
- Bitcoin fees are expected to grow with time (arguably the reason Lightning exists in the first place).
- MPP makes payment sizes shrink, therefore more and more of Lightning payments are to be trimmed. As I write this, the mempool is clear and still payments smaller than about 5000sat are being trimmed. Two weeks ago the limit was at 18000sat, which is already below the minimum most MPP splitting algorithms will allow.
Therefore I think it is important that we come up with a different way of ensuring payment proofs are being passed around in the case HTLCs are trimmed.
Channel closures
Worse than not having HTLCs that can be redeemed is the fact that in the current Lightning implementations channels will be closed by the peer once an HTLC timeout is reached, either to fulfill an HTLC for which that peer has a preimage or to redeem back that expired HTLCs the other party hasn't fulfilled.
For the surprise of everybody, nodes will do this even when the HTLCs in question were trimmed and therefore cannot be redeemed at all. It's very important that nodes stop doing that, because it makes no economic sense at all.
However, that is not so simple, because once you decide you're not going to close the channel, what is the next step? Do you wait until the other peer tries to fulfill an expired HTLC and tell them you won't agree and that you must cancel that instead? That could work sometimes if they're honest (and they have no incentive to not be, in this case). What if they say they tried to fulfill it before but you were offline? Now you're confused, you don't know if you were offline or they were offline, or if they are trying to trick you. Then unsolvable issues start to emerge.
Arbiters
One simple idea is to use trusted arbiters for all trimmed HTLC issues.
This idea solves both the protocol issue of getting the preimage to the payer once it is released by the payee -- and what to do with the channels once a trimmed HTLC expires.
A simple design would be to have each node hardcode a set of trusted other nodes that can serve as arbiters. Once a channel is opened between two nodes they choose one node from both lists to serve as their mutual arbiter for that channel.
Then whenever one node tries to fulfill an HTLC but the other peer is unresponsive, they can send the preimage to the arbiter instead. The arbiter will then try to contact the unresponsive peer. If it succeeds, then done, the HTLC was fulfilled offchain. If it fails then it can keep trying until the HTLC timeout. And then if the other node comes back later they can eat the loss. The arbiter will ensure they know they are the ones who must eat the loss in this case. If they don't agree to eat the loss, the first peer may then close the channel and blacklist the other peer. If the other peer believes that both the first peer and the arbiter are dishonest they can remove that arbiter from their list of trusted arbiters.
The same happens in the opposite case: if a peer doesn't get a preimage they can notify the arbiter they hadn't received anything. The arbiter may try to ask the other peer for the preimage and, if that fails, settle the dispute for the side of that first peer, which can proceed to fail the HTLC is has with someone else on that route.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On the state of programs and browsers
Basically, there are basically (not exhaustively) 2 kinds of programs one can run in a computer nowadays:
1.1. A program that is installed, permanent, has direct access to the Operating System, can draw whatever it wants, modify files, interact with other programs and so on; 1.2. A program that is transient, fetched from someone else's server at run time, interpreted, rendered and executed by another program that bridges the access of that transient program to the OS and other things.
Meanwhile, web browsers have basically (not exhaustively) two use cases:
2.1. Display text, pictures, videos hosted on someone else's computer; 2.2. Execute incredibly complex programs that are fetched at run time, executed and so on -- you get it, it's the same 1.2.
These two use cases for browsers are at big odds with one another. While stretching itsel f to become more and more a platform for programs that can do basically anything (in the 1.1 sense) they are still restricted to being an 1.2 platform. At the same time, websites that were supposed to be on 2.1 sometimes get confused and start acting as if they were 2.2 -- and other confusing mixed up stuff.
I could go hours in philosophical inquiries on the nature of browsers, how rewriting everything in JavaScript is not healthy or where everything went wrong, but I think other people have done this already.
One thing that bothers me a lot, though, is that computers can do a lot of things, and with the internet and in the current state of the technology it's fairly easy to implement tools that would help in many aspects of human existence and provide high-quality, useful programs, with the help of a server to coordinate access, store data, authenticate users and so on many things are possible. However, due to the nature of UI in the browser, it's very hard to get any useful tool to users.
Writing a UI, even the most basic UI imaginable (some text input boxes and some buttons, or a table) can take a long time, always more than the time necessary to code the actual core features of whatever program is being developed -- and that is considering that the person capable of writing interesting programs that do the functionality in the backend are also capable of interacting with JavaScript and the giant amount of frameworks, transpilers, styling stuff, CSS, the fact that all this is built on top of HTML and so on.
This is not good.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
IPFS problems: Community
I was an avid IPFS user until yesterday. Many many times I asked simple questions for which I couldn't find an answer on the internet in the #ipfs IRC channel on Freenode. Most of the times I didn't get an answer, and even when I got it was rarely by someone who knew IPFS deeply. I've had issues go unanswered on js-ipfs repositories for year – one of these was raising awareness of a problem that then got fixed some months later by a complete rewrite, I closed my own issue after realizing that by myself some couple of months later, I don't think the people responsible for the rewrite were ever acknowledge that he had fixed my issue.
Some days ago I asked some questions about how the IPFS protocol worked internally, sincerely trying to understand the inefficiencies in finding and fetching content over IPFS. I pointed it would be a good idea to have a drawing showing that so people would understand the difficulties (which I didn't) and wouldn't be pissed off by the slowness. I was told to read the whitepaper. I had already the whitepaper, but read again the relevant parts. The whitepaper doesn't explain anything about the DHT and how IPFS finds content. I said that in the room, was told to read again.
Before anyone misread this section, I want to say I understand it's a pain to keep answering people on IRC if you're busy developing stuff of interplanetary importance, and that I'm not paying anyone nor I have the right to be answered. On the other hand, if you're developing a super-important protocol, financed by many millions of dollars and a lot of people are hitting their heads against your software and there's no one to help them; you're always busy but never delivers anything that brings joy to your users, something is very wrong. I sincerely don't know what IPFS developers are working on, I wouldn't doubt they're working on important things if they said that, but what I see – and what many other users see (take a look at the IPFS Discourse forum) is bugs, bugs all over the place, confusing UX, and almost no help.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A list of things artificial intelligence is not doing
If AI is so good why can't it:
- write good glue code that wraps a documented HTTP API?
- make good translations using available books and respective published translations?
- extract meaningful and relevant numbers from news articles?
- write mathematical models that fit perfectly to available data better than any human?
- play videogames without cheating (i.e. simulating human vision, attention and click speed)?
- turn pure HTML pages into pretty designs by generating CSS
- predict the weather
- calculate building foundations
- determine stock values of companies from publicly available numbers
- smartly and automatically test software to uncover bugs before releases
- predict sports matches from the ball and the players' movement on the screen
- continuously improve niche/local search indexes based on user input and and reaction to results
- control traffic lights
- predict sports matches from news articles, and teams and players' history
This was posted first on Twitter.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
ijq
An interactive REPL for
jqwith smart helpers (for example, it automatically assigns each line of input to a variable so you can reference it later, it also always referenced the previous line automatically).See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Trelew
A CLI tool for navigating Trello boards. It used vorpal for an "immersive" experience and was pretty good.

-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The unit test bubble
Look at the following piece of Go code:
func NewQuery(query []rune) *Query { q := &Query{ query: &[]rune{}, complete: &[]rune{}, } _ = q.Set(query) return q } func NewQueryWithString(query string) *Query { return NewQuery([]rune(query)) }It is taken from a GitHub project with over 2000 stars.
Now take a look at these unit tests for the same package:
``` func TestNewQuery(t *testing.T) { var assert = assert.New(t)
v := []rune(".name") q := NewQuery(v) assert.Equal(*q.query, []rune(".name")) assert.Equal(*q.complete, []rune(""))}
func TestNewQueryWithString(t *testing.T) { var assert = assert.New(t)
q := NewQueryWithString(".name") assert.Equal(*q.query, []rune(".name")) assert.Equal(*q.complete, []rune(""))} ```
Now be honest: what are these for? Is this part of an attack to eat all GitHub storage and head them to bankruptcy?
Also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A estrutura lógica do livro didático
Todos os livros didáticos e cursos expõem seus conteúdos a partir de uma organização lógica prévia, um esquema de todo o conteúdo que julgam relevante, tudo muito organizadinho em tópicos e subtópicos segundo a ordem lógica que mais se aproxima da ordem natural das coisas. Imagine um sumário de um manual ou livro didático.
A minha experiência é a de que esse método serve muito bem para ninguém entender nada. A organização lógica perfeita de um campo de conhecimento é o resultado final de um estudo, não o seu início. As pessoas que escrevem esses manuais e dão esses cursos, mesmo quando sabem do que estão falando (um acontecimento aparentemente raro), o fazem a partir do seu próprio ponto de vista, atingido após uma vida de dedicação ao assunto (ou então copiando outros manuais e livros didáticos, o que eu chutaria que é o método mais comum).
Para o neófito, a melhor maneira de entender algo é através de imersões em micro-tópicos, sem muita noção da posição daquele tópico na hierarquia geral da ciência.
- Revista Educativa, um exemplo de como não ensinar nada às crianças.
- Zettelkasten, a ordem surgindo do caos, ao invés de temas se encaixando numa ordem preexistentes.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: clarity.fm on Lightning
Getting money from clients very easily, dispatching that money to "world class experts" (what a silly way to market things, but I guess it works) very easily are the job for Bitcoin and the Lightning Network.
EDIT 2020-09-04
My idea was that people would advertise themselves, so you would book an hour with people you know already, but it seems that clarify.fm has gone through the route of offering a "catalog of experts" to potential clients, all full of verification processes probably and marketing. So I guess this is not a thing I can do.
Actually I did https://s4a.etleneum.com/ (on Etleneum) that is somewhat similar, but of course doesn't have the glamour and network effect and marketing -- also it's just text, when in Clarity is fancy calls.
Thinking about it, this is just a simple and obvious idea: just copy things from the fiat world and make them on Lightning, but maybe it is still worth pointing these out as there are hundreds of developers out there trying to make yet another lottery game with Lightning.
It may also be a good idea to not just copy fiat-businesses models, but also change them experimenting with new paradigms, like idea: Patreon, but simple, and without subscription.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
O voto negativo
É simples: Você pode escolher entre votar em um candidato qualquer, como todos fazemos normalmente, ou tirar um voto de um político que não quer que seja eleito de jeito nenhum. A possibilidade de votarmos negativamente duas vezes é muito interessante também.
Outro motivo para implementar essa inovação na democracia: é muito mais divertido que o voto nulo.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Channels without HTLCs
HTLCs below the dust limit are not possible, because they're uneconomical.
So currently whenever a payment below the dust limit is to be made Lightning peers adjust their commitment transactions to pay that amount as fees in case the channel is closed. That's a form of reserving that amount and incentivizing peers to resolve the payment, either successfully (in case it goes to the receiving node's balance) or not (it then goes back to the sender's balance).
SOLUTION
I didn't think too much about if it is possible to do what I think can be done in the current implementation on Lightning channels, but in the context of Eltoo it seems possible.
Eltoo channels have UPDATE transactions that can be published to the blockchain and SETTLEMENT transactions that spend them (after a relative time) to each peer. The barebones script for UPDATE transactions is something like (copied from the paper, because I don't understand these things):
OP_IF # to spend from a settlement transaction (presigned) 10 OP_CSV 2 As,i Bs,i 2 OP_CHECKMULTISIGVERIFY OP_ELSE # to spend from a future update transaction <Si+1> OP_CHECKLOCKTIMEVERIFY 2 Au Bu 2 OP_CHECKMULTISIGVERIFY OP_ENDIFDuring a payment of 1 satoshi it could be updated to something like (I'll probably get this thing completely wrong):
OP_HASH256 <payment_hash> OP_EQUAL OP_IF # for B to spend from settlement transaction 1 in case the payment went through # and they have a preimage 10 OP_CSV 2 As,i1 Bs,i1 2 OP_CHECKMULTISIGVERIFY OP_ELSE OP_IF # for A to spend from settlement transaction 2 in case the payment didn't went through # and the other peer is uncooperative <now + 1day> OP_CHECKLOCKTIMEVERIFY 2 As,i2 Bs,i2 2 OP_CHECKMULTISIGVERIFY OP_ELSE # to spend from a future update transaction <Si+1> OP_CHECKLOCKTIMEVERIFY 2 Au Bu 2 OP_CHECKMULTISIGVERIFY OP_ENDIF OP_ENDIFThen peers would have two presigned SETTLEMENT transactions, 1 and 2 (with different signature pairs, as badly shown in the script). On SETTLEMENT 1, funds are, say, 999sat for A and 1001sat for B, while on SETTLEMENT 2 funds are 1000sat for A and 1000sat for B.
As soon as B gets the preimage from the next peer in the route it can give it to A and them can sign a new UPDATE transaction that replaces the above gimmick with something simpler without hashes involved.
If the preimage doesn't come in viable time, peers can agree to make a new UPDATE transaction anyway. Otherwise A will have to close the channel, which may be bad, but B wasn't a good peer anyway.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Drivechain comparison with Ethereum
Ethereum and other "smart contract platforms" capable of running turing-complete code and "developer-friendly" mindset and community have been running for years and they were able to produce a very low number of potentially useful "contracts".
What are these contracts, actually? (Considering Ethereum, but others are similar:) they are sidechains that run inside the Ethereum blockchain (and thus their verification and data storage are forced upon all Ethereum nodes). Users can peg-in to a contract by depositing money on it and peg-out by making a contract operation that sends money to a normal Ethereum address.
Now be generous and imagine these platforms are able to produce 3 really cool, useful ideas (out of many thousands of attempts): Bitcoin can copy these, turn them into 3 different sidechains, each running fixed, specific, optimized code. Bitcoin users can now opt to use these platforms by transferring coins to it – all that without damaging the nodes or the consensus protocol that has been running for years, and without forcing anyone to be aware of these chains.
The process of turning a useful idea into a sidechain doesn't come spontaneously, and can't be done by a single company (like often happens in Ethereum-land), it must be acknowledge by a rough consensus in the Bitcoin community that that specific sidechain with that specific design is a desirable thing, and ultimately approved by miners, as they're the ones that are going to be in charge of that.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Software
2013
2014
2015
- Gerador de tabelas de todos contra todos
- questo.email
- jekmentions
- Websites For Trello
- Temperos
- Trello Attachment Editor
- WelcomeBot
- Classless Templates
2016
- Module Linker
- Boardthreads
- Batch for Trello
- Custom spreadsheets
- SummaDB
- Flowi.es
- Trelew
- Washer
- hyperscript-go
- jiq
- busca múltipla na estante virtual
- Splitpages
- requesthub.xyz
2017
2018
- ijq
- sitios.xyz
- hledger-web
- LessPass remoteStorage
- TiddlyWiki remoteStorage
- fieldbook-to-sql
- jq-finder
- jiq-web
- superform.xyz
- piln
- gravity
- howoldis
- litepub
2019
2020
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
ZBD Social
If you have a closed system, a platform with users inside that login with name and password, it's not hard to introduce "social network" features into it. It was always the plan at ZEBEDEE to introduce such a thing, but much better than a closed social network just for ZBD users is if one such a thing can plug into the outer world of Nostr. Therefore ZBD Social is both an internal social network and a network that is open to the external world through Nostr.
The ZBD app already includes a custodial Bitcoin Lightning wallet and the target userbase doesn't want to care about keys and prefers email and password as the login mechanism to a trusted platform, therefore the ZBD Social is a custodial Nostr client. ZBD users also may be running their app on low-spec phones and low bandwidth, and since the key is already custodial it makes more sense to have all the Nostr logic for each ZBD user to be done on a ZEBEDEE server, instead of in the device itself, therefore the Social section on the ZBD app is just a thin client to an internal API.
Doing the correct thing given the constraints
In order for Nostr to scale, people must be able to host their notes in whatever relay they want and their followers must still be able to find these.
With that goal in mind, the ZBD Social server keeps track of all associations it can find -- in event hints, kind 3 and kind 10002 events,
nprofileandneventcodes and the bare fact that a given event from someone was found in a given relay -- and uses that information to estimate the best possible set of relays to be used to fetch notes for each Nostr user, along with some variance to account for the fact that these sets are dynamic.Whenever a ZBD user wants to read notes from any external Nostr user -- either because they've opened on that user's profile or because they follow that user and are browsing their classic "home feed" with notes from everybody they follow -- the ZBD Social backend will gather the best relays for that given user and open new subscriptions -- if there isn't already a subscription open -- for that user. If there are already other subscriptions open for other users in that same relay, the subscriptions will be merged in order to not spam external relays.
As they come in, notes from external users are cached in a way that they are automatically evicted as soon as memory is low and they haven't been accessed for a while. Browsing through old notes is done through paging these cached notes, indexed by author.
The
wss://nostr.zbd.ggrelayThe ZBD relay stores all events emitted by ZBD users. It runs strfry with a plugin that makes it interact with the rest of the backend. It is replicated accross multiple instances using strfry's native syncing capabilities and serves both as a normal relay interface to which external Nostr clients can talk normally and as a database that can be queried by the internal backend (turns out strfry is not only a Nostr relay, it is also a mechanism to turn LMDB into a cloud-native datastore).
This makes it easy to have a dedicated tab on the app with the feed of all the other ZBD users, which is effectively the same as browsing just
wss://nostr.zbd.ggfrom any other Nostr client -- see, for example, Coracle, nostrrr, nostr.com or using the CLI:nak req -l 10 --stream wss://nostr.zbd.gg | jq.It also contributes to the future world of Nostr in which niche relays can be browsed individually to enhance the experience of normal social interactions. For any given note, for example, you should be able to see "what are the ZBD users commenting about this" or "what are the gold enthusiasts saying" and so on.
Ideas for the future
Being a Nostr custodian in a platform that offers Lightning payment services and other third-party integrations for its existing userbase, it's easy to see how ZEBEDEE can start bridging Nostr into more things inside its domain.
For example, in the future ZEBEDEE could offer a way for game vendors to plug in a social networking layer into their games and that wouldn't be just an API to a proprietary platform, but a bridge to the real Nostr world that integrates seamlessly with the ZBD app for ZBD users, but works in Nostr-native mode for any Nostr user. Another use case could be powering social features for music and entertainment apps. Another very obvious use case is a NIP-58 badges system that games and other "gamified" services and apps can use.
In a not distant future, I imagine we'll see also integrations with the ZBD browser extension and NIP-07, Nostr features with the Telegram and Discord bots, and NIP-53 integration with ZBD Streamer (but I am not officially announcing anything).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A entrevista da Flávia Tavares com o Olavo de Carvalho
Não li todas as reclamações que o Olavo fez, mas li algumas. Também não li toda a matéria que saiu na Época, porque não tive paciência, mas assisti aos dois vídeos da entrevista que o Olavo publicou.
Tendo lido primeiro as muitas reclamações do Olavo, esperei encontrar no vídeo uma pessoa falsa, que fingiu-se de amigável para obter informações que usaria depois para destruir a imagem do Olavo, mas não vi nada disso.
Claro que ela poderia ter me enganado também, se enganou ao Olavo. Mas na matéria em si, também não vi nada além de sinceridade -- talvez não excelência jornalística, mas nada que eu não esperasse de qualquer matéria de qualquer revista. Flavia Tavares não entendeu muitas coisas, mas não fingiu que não entendeu nada, foi simples e honestamente Flavia Tavares, como ela mesma declarou no final do vídeo da entrevista: "olha, eu não fingi nada aqui, viu?".
O mais importante de tudo isso, porém, são as partes da matéria que apresentam idéias difíceis de conceber, como as que Olavo tem sobre o governo mundial ou a disseminação da pedofilia. Em toda discussão pública ou privada, essas idéias são proibidas. Muita gente pode concordar que a esquerda não presta, mas ninguém em sã consciência admitirá a possibilidade de que haja qualquer intenção significativa de implantação de um governo mundial ou da disseminação da pedofilia. A mesma carinha de deboche que seu amigo esquerdista faria à simples menção desses assuntos é a que Flavia Tavares usa no seu texto quando quer mostrar que Olavo é meio tantã. A carinha de deboche vem desacompanhada de qualquer reflexão séria ou tentativa de refutação, sempre.
Link da tal matéria: http://epoca.globo.com/sociedade/noticia/2017/10/olavo-de-carvalho-o-guru-da-direita-que-rejeita-o-que-dizem-seus-fas.html?utm_source=twitter&utm_medium=social&utm_campaign=post Vídeos: https://www.youtube.com/watch?v=C0TUsKluhok, https://www.youtube.com/watch?v=yR0F1haQ07Y&t=5s
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Reisman on opportunity cost
If I bought things for 10 and sold them for 20 did I earn a profit of 10?
-- Yes, says common sense. -- No, says the economist, because you could have bought a bond that yielded you some return with those initial 10 then spent your time working for someone else instead of working in your sales business. If that yielded more money than 10 then you actually had a loss.
That is crazy, because it produces an economy in which everybody is always losing all the time, except one ideal person who makes all the correct investment decisions and thus has no opportunity cost. That person has a profit of zero.
-- George Reisman in https://www.bobmurphyshow.com/139
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Viva o mata-mata
outro dia o comentarista Falcão, da Globo, disse, sobre o título do São Paulo: [i]"um jogo se ganha com um bom ataque, um campeonato se ganha com uma boa defesa"[/i], e foi deveras assustador pensar no que se transformou o futebol com o sistema de disputa do campeonato brasileiro por pontos corridos. um esporte em que vencia quem fazia mais gols está se transformando num esporte em que vence quem leva menos gols. é o sistema de pontos corridos - que premia a constância, o time que perde menos, mesmo que isso signifique empatar todos os jogos fora de casa em 0x0 e vencer todos em casa por 1x0. o sistema de pontos corridos premia o futebol feio, covarde, ou - como também é conhecido o futebol retranqueiro - o "equilíbrio".
eis que o futebol brasileiro, resolvendo seguir a linha européia, institui a disputa por pontos corridos e se transforma numa cópia malfeita e pobre do chato futebol europeu. e perde-se tudo que tínhamos de aqui que eles não tinham lá (é claro, os europeus têm mais estrutura, mais dinheiro, mais tudo), a ousadia, os brios, a coragem, a categoria e o escambau.
daí falam que o sistema de pontos corridos é mais justo. é mais justo porque dá o título aos times que jogaram melhor durante o campeonato, os mais regulares. mas ninguém disse por que não é justo premiar os times que conseguem vencer na semifinal e na final, o time que consegue ser pior o campeonato inteiro e no final tirar forças não sei de onde pra vencer aquele que era (ou parecia ser) bem melhor do que ele, o time que dá a volta por cima, o time que - mesmo não sendo regular - sabe jogar em decisões, sabe se segurar em um estádio com 80 mil torcendo contra e sabe aproveitar quando há 80 mil torcendo a favor e matar o adversário. o melhor time é o que vai ganhando pontinhos em jogos bobos e no final junta tudo e a soma dá mais do que os pontinhos do adversário ou é o time que consegue entrar num estádio numa final e derrotar, cara a cara, o adversário?
e quem disse que futebol é regularidade? repare que não se ouve mais a expressão desde o início dos pontos corridos, mas futebol é uma caixinha de surpresas. dos esportes que eu conheço, futebol é o único em que o último colocado pode vencer o primeiro e ninguém considerar isso um absurdo. com os pontos corridos, morrem metade dos componentes do futebol: o amor pelo ataque - conforme explicitado na supracitada afirmação de Falcão - a coragem, os brios e a emoção.
ao premiar a regularidade no futebol, pode-se estar chamando de “campeão” um time que facilmente tremeria numa final. e não é justo que um time covarde seja campeão. duvido que o São Paulo de 2007 jogaria bem numa final contra o Flamengo. e dificilmente o Corinthians de 2005 venceria uma final contra o Internacional (aliás, perdeu, moralmente, aquele jogo que foi quase uma final entre os dois).
mas se todo mundo gosta tanto assim desse campeonato de pseudo-futebol, vem aí a Copa do Mundo por pontos corridos.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A big Ethereum problem that is fixed by Drivechain
While reading the following paragraphs, assume Drivechain itself will be a "smart contract platform", like Ethereum. And that it won't be used to launch an Ethereum blockchain copy, but instead each different Ethereum contract could be turned into a different sidechain under BIP300 rules.
A big Ethereum problem
Anyone can publish any "contract" to Ethereum. Often people will come up with somewhat interesting ideas and publish them. Since they want money they will add an unnecessary token and use that to bring revenue to themselves, gamify the usage of their contract somehow, and keep some control over the supposedly open protocol they've created by keeping a majority of the tokens. They will use the profits on marketing and branding, have a visual identity, a central website and a forum with support personnel and so on: their somewhat interesting idea have become a full-fledged company.
If they have success then another company will appear in the space and copy the idea, launch it using exactly the same strategy with a tweak, then try to capture the customers of the first company and new people. And then another, and another, and another. Very often these contracts require some network effect to work, i.e., they require people to be using it so others will use it. The fact that the market is now split into multiple companies offering roughly the same product hurts that, such that none of these protocols get ever enough usage to become really useful in the way they were first conceived. At this point it doesn't matter though, they get some usage, and they use that in their marketing material. It becomes a race to pump the value of the tokens and the current usage is just another point used for that purpose. The company will even start giving out money to attract new users and other weird moves that have no relationship with the initial somewhat intereting idea.
Once in a lifetime it happens that the first implementer of these things is not a company seeking profits, but some altruistic developer or company that believes in Ethereum and wants to see it grow -- or more likely someone financed by the Ethereum Foundation, which allegedly doesn't like these token schemes and would prefer everybody to use the token they issued first, the ETH --, but that's a fruitless enterprise because someone else will copy that idea anyway and turn it into a company as described above.
How Drivechain fixes it
In the Drivechain world, if someone had an idea, they would -- as it happens all the time with Bitcoin things -- publish it in a public forum. Other members of the community would evaluate that idea, add or remove things, all interested parties would contribute to make it the best possible incarnation of that idea. Once the design was settled, someone would volunteer to start writing the code to turn that idea into a sidechain. Maybe some company would fund those efforts and then more people would join. It's not a perfect process and one that often involves altruism, but Bitcoin inspires people to do these things.
Slowly, the thing would get built, tested, activated as a sidechain on testnet, tested more, and at this point luckily the entire community of interested Bitcoin users and miners would have grown to like that idea and see its benefits. It could then be proposed to be activated according to BIP300 rules.
Once it was activated, the entire pool of interested users would join it. And it would be impossible for someone else to create a copy of that because everybody would instantly notice it was a copy. There would be no token, no one profiting directly from the operations of that "smart contract". And everybody would be incentivized to join and tell others to join that same sidechain since the network effect was already the biggest there, they will know more network effect would only be good for everybody involved, and there would be no competing marketing and free token giveaways from competing entities.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The monolithic approach to CouchDB views
Imagine you have an app that created one document for each day. The docs ids are easily "2015-02-05", "2015-02-06" and so on. Nothing could be more simple. Let's say each day you record "sales", "expenses" and "events", so this a document for a typical day for the retail management Couchapp for an orchid shop:
{ "_id": "2015-02-04", "sales": [{ "what": "A blue orchid", "price": 50000 }, { "what": "A red orchid", "price": 3500 }, { "what": "A yellow orchid", "price": 11500 }], "expenses": [{ "what": "A new bucket", "how much": 300 },{ "what": "The afternoon snack", "how much": "1200" }], "events": [ "Bob opened the store", "Lisa arrived", "Bob went home", "Lisa closed the store" ] }Now when you want to know what happened in a specific day, you know where to look at.
But you don't want only that, you want profit reports, cash flows, day profitability, a complete log of the events et cetera. Then you create one view to turn this mess into something more useful:
``` function (doc) { var spldate = doc._id.split("-") var year = parseInt(spldate[0]) var month = parseInt(spldate[1]) var day = parseInt(spldate[2])
doc.sales.forEach(function (sale, i) { emit(["sale", sale.what], sale.price) emit(["cashflow", year, month, day, i], sale.price) }) doc.expenses.forEach(function (exp, i) { emit(["expense", exp.what], exp.price) emit(["cashflow", year, month, day, i], -exp.price) }) doc.events.forEach(function (ev, i) { emit(["log", year, month, day, i], ev) }) } ```
Then you add a reduce function with the value of
_sumand you get a bunch of useful query endpoints. For example, you can request/_design/orchids/_view/main?startkey=["cashflow", "2014", "12"]&endkey=["cashflow", "2014", "12", {}] -
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
contratos.alhur.es
A website that allowed people to fill a form and get a standard Contrato de Locação.
Better than all the other "templates" that float around the internet, which are badly formatted
.docfiles.It was fully programmable so other templates could be added later, but I never did. This website made maybe one dollar in Google Ads (and Google has probably stolen these like so many other dollars they did with their bizarre requirements).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The illusion of note-taking
Most ideas come to me while I'm nowhere near a computer, so it's impossible to note them all down.
Even this one -- the realization of the illusion that many people have, including me, that it's possible to note down all our ideas in a ["zettelkasten"][797984e3] that will contain the history of all our insights -- is only noted later, with great distress since I forgot the other thoughts that lead to it and now am wasting time mentioning these unknowns forever lost.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
@lntxbot
A Telegram bot I made just because I was bored and no one had done yet. I didn't have any experience with Telegram bots or running a Lightning Network node, but it turned out to be quite well-received and successful.
As I slowly included things in it, lnurl stuff, custom integrations to other apps and social features, It has a large number of commands and arcane functionality hidden in it. This opaque output of the
/helpcommand is a hint:/start [<tutorial>] /lnurl <lnurl> /receive (lnurl | (any | <satoshis>) [<description>...]) /pay (lnurl <satoshis> | [now] [<invoice>] [<satoshis>]) /send [anonymously] <satoshis> [<receiver>...] [--anonymous] /balance [apps] /apps /tx <hash> /log <hash> /transactions [<tag>] [--in] [--out] /giveaway <satoshis> /coinflip <satoshis> [<num_participants>] /giveflip <satoshis> [<num_participants>] /fundraise <satoshis> <num_participants> <receiver>... /hide <satoshis> [<message>...] [--revealers=<num_revealers>] [--crowdfund=<num_participants>] [--public] [--private] /reveal <hidden_message_id> /etleneum [history | withdraw | (apps | contracts) | call <id> | <contract> [state [<jqfilter>] | subscribe | unsubscribe | <method> [<satoshis>] [<params>...]]] /satellite <satoshis> [<message>...] /bitclouds [create | status [<host>] | topup <satoshis> [<host>] | adopt <host> | abandon <host>] /rub <service> <account> [<rub>] /skype <username> [<usd>] /bitrefill (country <country_code> | <query> [<phone_number>]) /gifts (list | [<satoshis>]) /sats4ads (on [<msat_per_character>] | off | rate | rates | broadcast <satoshis> [<text>...] [--max-rate=<maxrate>] [--skip=<offset>] | preview) /api [full | invoice | readonly | url | refresh] /lightningatm /bluewallet [refresh] /rename <name> /toggle (ticket [<price>] | renamable [<price>] | spammy | language [<lang>] | coinflips) /dollar <satoshis> /moon /help [<command>] /stop -
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Uma boa margem
- No primeiro semestre da faculdade de Economia nós, os alunos, fomos guiados por um livro imbecil chamado "Introdução à Economia". O livro listava lá trocentas coisas que economistas supostamente faziam como parte da sua natureza de economistas. Uma delas era, lembro-me desta frase, "economistas pensam na margem".
- De início eu não entendi onde era essa margem, mas a professora passou quase uma aula inteira explicando (isto é, lendo o capítulo) que "pensar na margem" era considerar que pequenas mudanças nas condições de qualquer coisa causariam mudanças em pequenos grupos de pessoas: as pessoas que estavam na margem da mudança.
- Por exemplo, se um limão custa 5 reais e 100.000 pessoas compram limão todo dia, se aumentamos o preço para 5,05 pode ser que, sei lá, só 99.873 continuem comprando. Faz sentido, não faz? Isto era tão óbvio para mim no primeiro período de faculdade que não imaginei que alguém precisasse explicar, por isso não percebi qual era a da margem.
- Até hoje, porém, vejo pessoas o tempo todo afirmarem categoricamente que o "cinco centavos não vão fazer diferença nenhuma, as pessoas vão continuar comprando o limão como sempre compraram" e invocando em defesa desta tese argumentos perfeitamente lógicos como "até parece que você ia deixar de comprar seu limão por causa de 5 centavos", "eu nem olho o preço das coisas no supermercado" e "as pessoas precisam do limão, então elas vão ter que comprar, não importa o preço".
- Muitas destas pessoas entenderão a explicação sobre a margem, mas na próxima oportunidade que tiverem falharão em perceber a analogia ou em se lembrarem da margem e novamente evocarão os seus chavões. Para outras pessoas, porém, o pensamento na margem faz parte do bom senso habitual.
- Tirando fora a inútil conclusão de que a maior parte das pessoas é burra, sobra-nos um problema.
- Discussão
- Estaria o autor do livro, contra sua própria vontade, enunciando uma verdade acerca dos tipos de pessoas que povoam a sociedade, "os economistas", que são economistas desde o berço, e que "pensam na margem" por natureza, contra "o resto", os não-economistas, que não pensam na margem, não importa o que se faça?
- Esta é uma solução bem mixuruca. Nem é uma solução, na verdade, além disto ela deixa escapar um outro problema: por que diabos um sujeito que não consegue entender o problema do limão se candidata a um diploma de economista?
- Bom, talvez aqui a hipótese da burrice generalizada explique bem as coisas: aparentemente a burrice que há nas universidades, no valor dos diplomas, na natureza da escola e em sua relação com as universidades faça com que jovens sejam despejados em qualquer curso sem terem noção nenhuma do que eles mesmos esperam que se dê lá. Ei-lo.
- Há algum outro mistério aqui? O bom senso (enquanto um conhecimento apreendido dos meus vizinhos de sociedade) me ensinou a pensar na margem, ou não? Onde eu aprendi isso? Por que eu penso assim e o meu vizinho não?
- Imagino que Bernard Lonergan responderia dizendo que os economistas são pessoas que tiveram esse insight e as outras pessoas não. Para as que tiveram o insight ele aparece já como uma obviedade, para os que não tiveram ele não é nem percebido como possibilidade (do contrário ele se efetuaria automaticamente como insight).
- Neste caso, o que explica que pessoas entendam o caso do limão, caso se lhas explique com calma, mas falhem em aplicá-lo, minutos depois, a laranjas?
- Há casos de economistas famosos e premiados que não conseguem conceber, por exemplo, que o aumento do salário mínimo possa fazer com que menos pessoas contratem funcionários -- na margem. Estes mesmos economistas passariam facilmente no teste do limão. Paul Krugman é um exemplo clássico de pessoa definitivamente "economista" (pelo critério do limão), mas que falha na aplicação do mesmo princípio a situações em que ele tem interesse político.
- Aqui caímos num outro problema totalmente diferente, mas talvez a dissonância cognitiva explique.
- Falha na aplicação de analogias não é um defeito, segundo me parece. Afinal de contas cada nova aplicação de uma analogia ou de relação previamente conhecida é, em si, um novo insight. O insight pode não ocorrer facilmente em certas condições. Mas, nestes casos, imagino que com algum auxílio (alguém que te lembre da analogia correta a ser aplicada ali, fazendo com que você a teste por si mesmo) o insight ocorra.
- Também posso considerar que eu estou errado e que é ilógico pensar que cinco centavos farão com que menos pessoas comprem o limão. Há centenas de estudos "empíricos" que mostram como "pensar na margem" é correto, mas estes estudos são todos inconclusivos, ou afetados por dissonância cognitiva por parte dos autores, economistas, que já começaram a fazer o estudo sabendo da conclusão. Tudo isto parece razoável. Tenho para mim, no entando, que não é nada razoável, mas um absurdo louco.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On "zk-rollups" applied to Bitcoin
ZK rollups make no sense in bitcoin because there is no "cheap calldata". all data is already ~~cheap~~ expensive calldata.
There could be an onchain zk verification that allows succinct signatures maybe, but never a rollup.
What happens is: you can have one UTXO that contains multiple balances on it and in each transaction you can recreate that UTXOs but alter its state using a zk to compress all internal transactions that took place.
The blockchain must be aware of all these new things, so it is in no way "L2".
And you must have an entity responsible for that UTXO and for conjuring the state changes and zk proofs.
But on bitcoin you also must keep the data necessary to rebuild the proofs somewhere else, I'm not sure how can the third party responsible for that UTXO ensure that happens.
I think such a construct is similar to a credit card corporation: one central party upon which everybody depends, zero interoperability with external entities, every vendor must have an account on each credit card company to be able to charge customers, therefore it is not clear that such a thing is more desirable than solutions that are truly open and interoperable like Lightning, which may have its defects but at least fosters a much better environment, bringing together different conflicting parties, custodians, anyone.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The problem with ION
ION is a DID method based on a thing called "Sidetree".
I can't say for sure what is the problem with ION, because I don't understand the design, even though I have read all I could and asked everybody I knew. All available information only touches on the high-level aspects of it (and of course its amazing wonders) and no one has ever bothered to explain the details. I've also asked the main designer of the protocol, Daniel Buchner, but he may have thought I was trolling him on Twitter and refused to answer, instead pointing me to an incomplete spec on the Decentralized Identity Foundation website that I had already read before. I even tried to join the DIF as a member so I could join their closed community calls and hear what they say, maybe eventually ask a question, so I could understand it, but my entrance was ignored, then after many months and a nudge from another member I was told I had to do a KYC process to be admitted, which I refused.
One thing I know is:
- ION is supposed to provide a way to rotate keys seamlessly and automatically without losing the main identity (and the ION proponents also claim there are no "master" keys because these can also be rotated).
- ION is also not a blockchain, i.e. it doesn't have a deterministic consensus mechanism and it is decentralized, i.e. anyone can publish data to it, doesn't have to be a single central server, there may be holes in the available data and the protocol doesn't treat that as a problem.
- From all we know about years of attempts to scale Bitcoins and develop offchain protocols it is clear that you can't solve the double-spend problem without a central authority or a kind of blockchain (i.e. a decentralized system with deterministic consensus).
- Rotating keys also suffer from the double-spend problem: whenever you rotate a key it is as if it was "spent", you aren't supposed to be able to use it again.
The logic conclusion of the 4 assumptions above is that ION is flawed: it can't provide the key rotation it says it can if it is not a blockchain.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Why IPFS cannot work, again
Imagine someone comes up with a solution for P2P content-addressed data-sharing that involves storing all the files' contents in all computers of the network. That wouldn't work, right? Too much data, if you think this can work then you're a BSV enthusiast.
Then someone comes up with the idea of not storing everything in all computers, but only some things on some computers, based on some algorithm to determine what data a node would store given its pubkey or something like that. Still wouldn't work, right? Still too much data no matter how much you spread it, but mostly incentives not aligned, would implode in the first day.
Now imagine someone says they will do the same thing, but instead of storing the full contents each node would only store a pointer to where each data is actually available. Does that make it better? Hardly so. Still, you're just moving the problem.
This is IPFS.
Now you have less data on each computer, but on a global scale that is still a lot of data.
No incentives.
And now you have the problem of finding the data. First if you have some data you want the world to access you have to broadcast information about that, flooding the network -- and everybody has to keep doing this continuously for every single file (or shard of file) that is available.
And then whenever someone wants some data they must find the people who know about that, which means they will flood the network with requests that get passed from peer to peer until they get to the correct peer.
The more you force each peer to store the worse it becomes to run a node and to store data on behalf of others -- but the less your force each peer to store the more flooding you'll have on the global network, and the slower will be for anyone to actually get any file.
But if everybody just saves everything to Infura or Cloudflare then it works, magic decentralized technology.
Related
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Multi-service Graph Reputation protocol
The problem
- Users inside centralized services need to know reputations of other users they're interacting with;
- Building reputation with ratings imposes a big burden on the user and still accomplishes nothing, can be faked, no one cares about these ratings etc.
The ideal solution
Subjective reputation: reputation based on how you rated that person previously, and how other people you trust rated that person, and how other people trusted by people you trust rated that person and so on, in a web-of-trust that actually can give you some insight on the trustworthiness of someone you never met or interacted with.
The problem with the ideal solution
- Most of the times the service that wants to implement this is not as big as Facebook, so it won't have enough people in it for such graphs of reputation to be constructed.
- It is not trivial to build.
My proposed solution:
I've drafted a protocol for an open system based on services publishing their internal reputation records and indexers using these to build graphs, and then serving the graphs back to the services so they can show them to users when it is needed (as HTTP APIs that can be called directly from the user client app or browser).
Crucially, these indexers will gather data from multiple services and cross-link users from these services so the graph is better.
https://github.com/fiatjaf/multi-service-reputation-rfc
The first and single actionable and useful feedback I got, from @bootstrapbandit was that services shouldn't share email addresses in plain text (email addresses and other external relationships users of a service may have are necessary to establish links from users accross services), but I think it is ok if services publish hashes of these email addresses instead. At some point I will update the spec draft and that may have been before the time you're reading this.
Another issue is that services may lie about their reputation records and that will hurt other services and users in these other services that are relying on that data. Maybe indexers will have to do some investigative job here to assert service honesty. Or maybe this entire protocol is just failed and we will actually need a system in which users themselves will publish their own records.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
IPFS problems: Dynamic links
Content-addressability is cool and we all like it, but we all also know we can't live in a world without readable and memorizeable names. IPFS has proposed IPNS, the Interplanetary Name System (the names are very cool indeed), since its beggining (or maybe it was some months after the first IPFS idea, which would indicate this problem arrived as an afterthought).
It has been said IPNS would work in a manner similar to Git heads and branches (this was probably part of Juan Benet's marketing pitches that were immensely repeated in the first years, that IPFS was a mix between Torrents, Git and some other cool technology). This remains a distant promise, however. IPNS has been, for the last years, a very slow, unrecommended by their own developers and unusable way of addressing content that is basically just a pointer from a public key to an object hash.
Recommendations fall on using a domain and dnslink, the way to tell IPFS nodes you own a domain and that can be used to identify an object hash. That works, but it is not the wonder of decentralization that was promised, and still, it's just a pointer. Any key-value store, database of filesystem can do pointers.
Here I'm not saying, like tons of stupid people have on the internet, that IPFS should support dynamic links so we can build web apps on it. No, I would be pretty fine with just static links for static content, and continue to use the other internet protocols for things that needed to be dynamic.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
fieldbook-to-sql
This used to turn books from the late multi-things-manager (or tridimensional spreadsheets provider) fieldbook.com into complete SQLite3 databases.
It was referenced in their official shutdown message and helped people move data off (it would have been better if they had open-sourced the entire site, I don't understand why they haven't).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Estórias
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Bluesky is a scam
Bluesky advertises itself as an open network, they say people won't lose followers or their identity, they advertise themselves as a protocol ("atproto") and because of that they are tricking a lot of people into using them. These three claims are false.
protocolness
Bluesky is a company. "atproto" is the protocol. Supposedly they are two different things, right? Bluesky just releases software that implements the protocol, but others can also do that, it's open!
And yet, the protocol has an official webpage with a waitlist and a private beta? Why is the protocol advertised as a company product? Because it is. The "protocol" is just a description of whatever the Bluesky app and servers do, it can and does change anytime the Bluesky developers decide they want to change it, and it will keep changing for as long as Bluesky apps and servers control the biggest part of the network.
Oh, so there is the possibility of other players stepping in and then it becomes an actual interoperable open protocol? Yes, but what is the likelihood of that happening? It is very low. No serious competitor is likely to step in and build serious apps using a protocol that is directly controlled by Bluesky. All we will ever see are small "community" apps made by users and small satellite small businesses -- not unlike the people and companies that write plugins, addons and alternative clients for popular third-party centralized platforms.
And last, even if it happens that someone makes an app so good that it displaces the canonical official Bluesky app, then that company may overtake the protocol itself -- not because they're evil, but because there is no way it cannot be like this.
identity
According to their own documentation, the Bluesky people were looking for an identity system that provided global ids, key rotation and human-readable names.
They must have realized that such properties are not possible in an open and decentralized system, but instead of accepting a tradeoff they decided they wanted all their desired features and threw away the "decentralized" part, quite literally and explicitly (although they make sure to hide that piece in the middle of a bunch of code and text that very few will read).
The "DID Placeholder" method they decided to use for their global identities is nothing more than a normal old boring trusted server controlled by Bluesky that keeps track of who is who and can, at all times, decide to ban a person and deprive them from their identity (they dismissively call a "denial of service attack").
They decided to adopt this method as a placeholder until someone else doesn't invent the impossible alternative that would provide all their desired properties in a decentralized manner -- which is nothing more than a very good excuse: "yes, it's not great now, but it will improve!".
openness
Months after launching their product with an aura of decentralization and openness and getting a bunch of people inside that believed, falsely, they were joining an actually open network, Bluesky has decided to publish a part of their idea of how other people will be able to join their open network.
When I first saw their app and how they were very prominently things like follower counts, like counts and other things that are typical of centralized networks and can't be reliable or exact on truly open networks (like Nostr), I asked myself how were they going to do that once they became and open "federated" network as they were expected to be.
Turns out their decentralization plan is to just allow you, as a writer, to host your own posts on "personal data stores", but not really have any control over the distribution of the posts. All posts go through the Bluesky central server, called BGS, and they decide what to do with it. And you, as a reader, doesn't have any control of what you're reading from either, all you can do is connect to the BGS and ask for posts. If the BGS decides to ban, shadow ban, reorder, miscount, hide, deprioritize, trick or maybe even to serve ads, then you are out of luck.
Oh, but anyone can run their own BGS!, they will say. Even in their own blog post announcing the architecture they assert that "it’s a fairly resource-demanding service" and "there may be a few large full-network providers". But I fail to see why even more than one network provider will exist, if Bluesky is already doing that job, and considering the fact there are very little incentives for anyone to switch providers -- because the app does not seem to be at all made to talk to multiple providers, one would have to stop using the reliable, fast and beefy official BGS and start using some half-baked alternative and risk losing access to things.
When asked about the possibility of switching, one of Bluesky overlords said: "it would look something like this: bluesky has gone evil. there's a new alternative called freesky that people are rushing to. I'm switching to freesky".
The quote is very naïve and sounds like something that could be said about Twitter itself: "if Twitter is evil you can just run your own social network". Both are fallacies because they ignore the network-effect and the fact that people will never fully agree that something is "evil". In fact these two are the fundamental reasons why -- for social networks specifically (and not for other things like commerce) -- we need truly open protocols with no owners and no committees.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
An argument according to which fractional-reserve banking is merely theft and nothing else
Fractional-reserve banking isn't anything else besides transfer of money from the people at large to bankers.
It has been argued that fractional-reserve banking serves a purpose in making new funds available out of no one's pocket for lending and thus directing resources to productive borrowers. This financing method is preferrable to the more conservative way of borrowing funds directly from a saver and then using that to lend to others because it uses new money, money not tied to anyone else before, and thus it's cheaper and involves less friction.
Instead, what happens is that someone must at all times be the owner of each money. So when banks use their power of generating fractional-reserve funds, they are creating new money and they are the owners – at this point, a theft occurs from the public at large to them – and then they proceed to lend their own money. From this description it is clear that the fact that bank customers have previously deposited their own funds in the banks' vaults have no direct relation with the fact that banks created money afterwards, there's only a legal relation and the fact that banks may need cash deposited by its customers to redeem borrowers claims, but even that wouldn't be necessary if banks were allowed to print their own cash.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Carl R. Rogers sobre a ciência
Creio que o objetivo primário da ciência é fornecer uma hipótese, uma convicção e uma fé mais seguras e que satisfaçam melhor o próprio investigador. Na medida em que o cientista procura provar qualquer coisa a alguém -- um erro em que incorri mais de uma vez --, creio que ele está se servindo da ciência para remediar uma insegurança pessoal, desviando-a do seu verdadeiro papel criativo a serviço do indivíduo.
Tornar-se Pessoa, página aleatória
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A list of things artificial intelligence is not doing
If AI is so good why can't it:
- write good glue code that wraps a documented HTTP API?
- make good translations using available books and respective published translations?
- extract meaningful and relevant numbers from news articles?
- write mathematical models that fit perfectly to available data better than any human?
- play videogames without cheating (i.e. simulating human vision, attention and click speed)?
- turn pure HTML pages into pretty designs by generating CSS
- predict the weather
- calculate building foundations
- determine stock values of companies from publicly available numbers
- smartly and automatically test software to uncover bugs before releases
- predict sports matches from the ball and the players' movement on the screen
- continuously improve niche/local search indexes based on user input and and reaction to results
- control traffic lights
- predict sports matches from news articles, and teams and players' history
This was posted first on Twitter.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Who will build the roads?
Who will build the roads? Em Lagoa Santa, as mais novas e melhores ruas -- que na verdade acabam por formar enormes teias de bairros que se interligam -- são construídas pelos loteadores que querem as ruas para que seus lotes valham mais -- e querem que outras pessoas usem as ruas também. Também são esses mesmos loteadores que colocam os postes de luz e os encanamentos de água, não sem antes terem que se submeter a extorsões de praxe praticadas por COPASA e CEMIG.
Se ao abrir um loteamento, condomínio, prédio um indivíduo ou uma empresa consegue sem muito problema passar rua, eletricidade, água e esgoto, por que não seria possível existir livre-concorrência nesses mercados? Mesmo aquela velha estória de que é ineficiente passar cabos de luz duplicados para que companhias elétricas possam competir já me parece bobagem.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
IPFS problems: General confusion
Most IPFS open-source projects, libraries and apps (excluding Ethereum stuff) are things that rely heavily on dynamic data and temporary links. The most common projects you'll see when following the IPFS communities are chat rooms and similar things. I've seen dozens of these chat-rooms. There's also a famous IPFS-powered database. How can you do these things with content-addressing is a mistery. Of course they probably rely on IPNS or other external address system.
There's also a bunch of "file-sharing" on IPFS. The kind of thing people use for temporary making a file available for a third-party. There's image sharing on IPFS, pastebins on IPFS and so on. People don't seem to share the preoccupation with broken links here.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
O caso da Grêmio TV
enquanto vinha se conduzindo pela plataforma superior daquela arena que se pensava totalmente preenchida por adeptos da famosa equipe do Grêmio de Porto Alegre, viu-se, como por obra de algum nigromante - dos muitos que existem e estão a todo momento a fazer más obras e a colocar-se no caminhos dos que procuram, se não fazer o bem acima de todas as coisas, a pelo menos não fazer o mal no curso da realização dos seus interesses -, o discretíssimo jornalista a ser xingado e moído em palavras por uma horda de malandrinos a cinco ou seis passos dele surgida que cantavam e moviam seus braços em movimentos que não se pode classificar senão como bárbaros, e assim cantavam:
Grêmio TV pior que o SBT !
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Castas hindus em nova chave
Shudras buscam o máximo bem para os seus próprios corpos; vaishyas o máximo bem para a sua própria vida terrena e a da sua família; kshatriyas o máximo bem para a sociedade e este mundo terreno; brâmanes buscam o máximo bem.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Lightning and its fake HTLCs
Lightning is terrible but can be very good with two tweaks.
How Lightning would work without HTLCs
In a world in which HTLCs didn't exist, Lightning channels would consist only of balances. Each commitment transaction would have two outputs: one for peer
A, the other for peerB, according to the current state of the channel.When a payment was being attempted to go through the channel, peers would just trust each other to update the state when necessary. For example:
- Channel
AB's balances areA[10:10]B(in sats); Asends a 3sat payment throughBtoC;AasksBto route the payment. ChannelABdoesn't change at all;Bsends the payment toC,Caccepts it;- Channel
BCchanges fromB[20:5]CtoB[17:8]C; BnotifiesAthe payment was successful,Aacknowledges that;- Channel
ABchanges fromA[10:10]BtoA[7:13]B.
This in the case of a success, everything is fine, no glitches, no dishonesty.
But notice that
Acould have refused to acknowledge that the payment went through, either because of a bug, or because it went offline forever, or because it is malicious. Then the channelABwould stay asA[10:10]BandBwould have lost 3 satoshis.How Lightning would work with HTLCs
HTLCs are introduced to remedy that situation. Now instead of commitment transactions having always only two outputs, one to each peer, now they can have HTLC outputs too. These HTLC outputs could go to either side dependending on the circumstance.
Specifically, the peer that is sending the payment can redeem the HTLC after a number of blocks have passed. The peer that is receiving the payment can redeem the HTLC if they are able to provide the preimage to the hash specified in the HTLC.
Now the flow is something like this:
- Channel
AB's balances areA[10:10]B; Asends a 3sat payment throughBtoC:AasksBto route the payment. Their channel changes toA[7:3:10]B(the middle number is the HTLC).Boffers a payment toC. Their channel changes fromB[20:5]CtoB[17:3:5]C.CtellsBthe preimage for that HTLC. Their channel changes fromB[17:3:5]CtoB[17:8]C.BtellsAthe preimage for that HTLC. Their channel changes fromA[7:3:10]BtoA[7:13]B.
Now if
Awants to trickBand stop respondingBdoesn't lose money, becauseBknows the preimage,Bjust needs to publish the commitment transactionA[7:3:10]B, which gives him 10sat and then redeem the HTLC using the preimage he got fromC, which gives him 3 sats more.Bis fine now.In the same way, if
Bstops responding for any reason,Awon't lose the money it put in that HTLC, it can publish the commitment transaction, get 7 back, then redeem the HTLC after the certain number of blocks have passed and get the other 3 sats back.How Lightning doesn't really work
The example above about how the HTLCs work is very elegant but has a fatal flaw on it: transaction fees. Each new HTLC added increases the size of the commitment transaction and it requires yet another transaction to be redeemed. If we consider fees of 10000 satoshis that means any HTLC below that is as if it didn't existed because we can't ever redeem it anyway. In fact the Lightning protocol explicitly dictates that if HTLC output amounts are below the fee necessary to redeem them they shouldn't be created.
What happens in these cases then? Nothing, the amounts that should be in HTLCs are moved to the commitment transaction miner fee instead.
So considering a transaction fee of 10000sat for these HTLCs if one is sending Lightning payments below 10000sat that means they operate according to the unsafe protocol described in the first section above.
It is actually worse, because consider what happens in the case a channel in the middle of a route has a glitch or one of the peers is unresponsive. The other node, thinking they are operating in the trustless protocol, will proceed to publish the commitment transaction, i.e. close the channel, so they can redeem the HTLC -- only then they find out they are actually in the unsafe protocol realm and there is no HTLC to be redeemed at all and they lose not only the money, but also the channel (which costed a lot of money to open and close, in overall transaction fees).
One of the biggest features of the trustless protocol are the payment proofs. Every payment is identified by a hash and whenever the payee releases the preimage relative to that hash that means the payment was complete. The incentives are in place so all nodes in the path pass the preimage back until it reaches the payer, which can then use it as the proof he has sent the payment and the payee has received it. This feature is also lost in the unsafe protocol: if a glitch happens or someone goes offline on the preimage's way back then there is no way the preimage will reach the payer because no HTLCs are published and redeemed on the chain. The payee may have received the money but the payer will not know -- but the payee will lose the money sent anyway.
The end of HTLCs
So considering the points above you may be sad because in some cases Lightning doesn't use these magic HTLCs that give meaning to it all. But the fact is that no matter what anyone thinks, HTLCs are destined to be used less and less as time passes.
The fact that over time Bitcoin transaction fees tend to rise, and also the fact that multipart payment (MPP) are increasedly being used on Lightning for good, we can expect that soon no HTLC will ever be big enough to be actually worth redeeming and we will be at a point in which not a single HTLC is real and they're all fake.
Another thing to note is that the current unsafe protocol kicks out whenever the HTLC amount is below the Bitcoin transaction fee would be to redeem it, but this is not a reasonable algorithm. It is not reasonable to lose a channel and then pay 10000sat in fees to redeem a 10001sat HTLC. At which point does it become reasonable to do it? Probably in an amount many times above that, so it would be reasonable to even increase the threshold above which real HTLCs are made -- thus making their existence more and more rare.
These are good things, because we don't actually need HTLCs to make a functional Lightning Network.
We must embrace the unsafe protocol and make it better
So the unsafe protocol is not necessarily very bad, but the way it is being done now is, because it suffers from two big problems:
- Channels are lost all the time for no reason;
- No guarantees of the proof-of-payment ever reaching the payer exist.
The first problem we fix by just stopping the current practice of closing channels when there are no real HTLCs in them.
That, however, creates a new problem -- or actually it exarcebates the second: now that we're not closing channels, what do we do with the expired payments in them? These payments should have either been canceled or fulfilled before some block x, now we're in block x+1, our peer has returned from its offline period and one of us will have to lose the money from that payment.
That's fine because it's only 3sat and it's better to just lose 3sat than to lose both the 3sat and the channel anyway, so either one would be happy to eat the loss. Maybe we'll even split it 50/50! No, that doesn't work, because it creates an attack vector with peers becoming unresponsive on purpose on one side of the route and actually failing/fulfilling the payment on the other side and making a profit with that.
So we actually need to know who is to blame on these payments, even if we are not going to act on that imediatelly: we need some kind of arbiter that both peers can trust, such that if one peer is trying to send the preimage or the cancellation to the other and the other is unresponsive, when the unresponsive peer comes back, the arbiter can tell them they are to blame, so they can willfully eat the loss and the channel can continue. Both peers are happy this way.
If the unresponsive peer doesn't accept what the arbiter says then the peer that was operating correctly can assume the unresponsive peer is malicious and close the channel, and then blacklist it and never again open a channel with a peer they know is malicious.
Again, the differences between this scheme and the current Lightning Network are that:
a. In the current Lightning we always close channels, in this scheme we only close channels in case someone is malicious or in other worst case scenarios (the arbiter is unresponsive, for example). b. In the current Lightning we close the channels without having any clue on who is to blame for that, then we just proceed to reopen a channel with that same peer even in the case they were actively trying to harm us before.
What is missing? An arbiter.
The Bitcoin blockchain is the ideal arbiter, it works in the best possible way if we follow the trustless protocol, but as we've seen we can't use the Bitcoin blockchain because it is expensive.
Therefore we need a new arbiter. That is the hard part, but not unsolvable. Notice that we don't need an absolutely perfect arbiter, anything is better than nothing, really, even an unreliable arbiter that is offline half of the day is better than what we have today, or an arbiter that lies, an arbiter that charges some satoshis for each resolution, anything.
Here are some suggestions:
- random nodes from the network selected by an algorithm that both peers agree to, so they can't cheat by selecting themselves. The only thing these nodes have to do is to store data from one peer, try to retransmit it to the other peer and record the results for some time.
- a set of nodes preselected by the two peers when the channel is being opened -- same as above, but with more handpicked-trust involved.
- some third-party cloud storage or notification provider with guarantees of having open data in it and some public log-keeping, like Twitter, GitHub or a Nostr relay;
- peers that get paid to do the job, selected by the fact that they own some token (I know this is stepping too close to the shitcoin territory, but could be an idea) issued in a Spacechain;
- a Spacechain itself, serving only as the storage for a bunch of
OP_RETURNs that are published and tracked by these Lightning peers whenever there is an issue (this looks wrong, but could work).
Key points
- Lightning with HTLC-based routing was a cool idea, but it wasn't ever really feasible.
- HTLCs are going to be abandoned and that's the natural course of things.
- It is actually good that HTLCs are being abandoned, but
- We must change the protocol to account for the existence of fake HTLCs and thus make the bulk of the Lightning Network usage viable again.
See also
- Channel
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Trelew
A CLI tool for navigating Trello boards. It used vorpal for an "immersive" experience and was pretty good.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Liquidificador
A fragilidade da comunicação humana fica clara quando alguém liga o liquidificador.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
jq-finder
Made with jq-web, a tool to explore JSON using
jqqueries that build intermediate results so you can inspect each step of the process.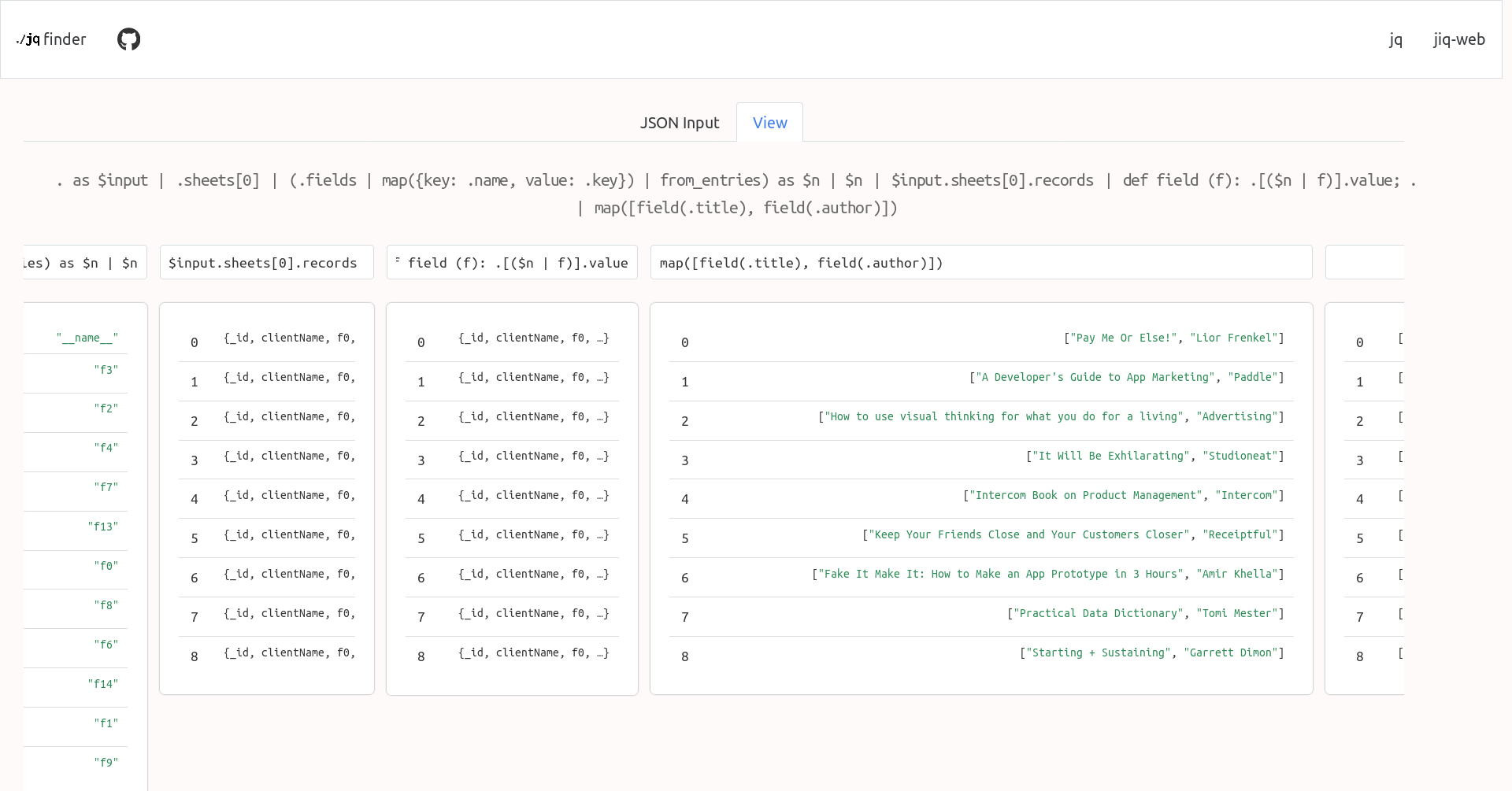
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Músicas que você já conhece
É bom escutar as mesmas músicas que você já conhece um pouco. cada nova escuta te deixa mais familiarizado e faz com que aquela música se torne parte do seu cabedal interno de melodias.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
superform.xyz
This was an app that allowed people to create micro apps powered by forms. Actually just one form I believe. The idea was for the micro apps to be really micro.
For example, you want a list of people, but you can only have at most 10 people in the list. Your app could keep a state with list of people already added and reject any other submissions above the specified limit. This would be done with 3 lines of code and provide an automatic form for people to fill with expected data.
Another example, you wanted to create a list of people that would go to an event and each would have to bring one item from a list: you created an initial state of a list of the items that should be brought, then specified a form where people could write their names and select the item they would bring, then code that for each submitted form added the name of the person plus the item they would bring to the state while also removing the selected item from the available items. Also 3 or 4 lines of data.
Something like this can't be done anywhere else. But also of course it would be arcane and frighten normal people and so on (although I do believe some "normal" people would be able to use such a thing if they needed it, just like they learn to write complex Excel formulas and still don't call themselves programmers).
See also
- Etleneum, as it is basically the same core idea of a mutable state that is affected by calls, but Etleneum introduces (and actually forces the usage of) money, both in the sense that it acts as an escrow for contract results and that it mandates the payment of a small amount with each call, so it ends up not serving the same purposes.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Classless Templates
There are way too many hours being wasted in making themes for blogs. And then comes a new blog framework, it requires new themes. Old themes can't be used because they relied on different ways of rendering the website. Everything is a mess.
Classless was an attempt at solving it. It probably didn't work because I wasn't the best person to make themes and showcase the thing.
Basically everybody would agree on a simple HTML template that could fit blogs and simple websites very easily. Then other people would make pure-CSS themes expecting that template to be in place.
No classes were needed, only a fixed structure of
header.main,articleetc.With flexbox and grid CSS was enough to make this happen.
The templates that were available were all ported by me from other templates I saw on the web, and there was a simple one I created for my old website.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
neuron.vim
I started using this neuron thing to create an update this same zettelkasten, but the existing vim plugin had too many problems, so I forked it and ended up changing almost everything.
Since the upstream repository was somewhat abandoned, most users and people who were trying to contribute upstream migrate to my fork too.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Timeu
Os quatro elementos, a esfera como a forma mais perfeita, os cinco sentidos, a dor como perturbação e o prazer como retorno, o demiurgo que cria da melhor maneira possível com a matéria que tem, o conceito de duro e mole, todas essas coisas que ensinam nas escolas e nos desenhos animados ou sei lá como entram na nossa consciência como se fossem uma verdade, mas sempre uma verdade provisória, infantil -- como os nomes infantis dos dedos (mata-piolho, fura-bolo etc.) --, que mesmo as crianças sabem que não é verdade mesmo.
Parece que todas essas coisas estão nesse livro. Talvez até mesmo a classificação dos cinco dedos como mata-piolho e tal, mas talvez eu tenha dormido nessa parte.
Me pergunto se essas coisas não eram ensinadas tradicionalmente na idade média como sendo verdade absoluta (pois afinal estava lá o Platão dizendo, em sua única obra) e persistiram até hoje numa tradição que se mantém aos trancos e barrancos, contra tudo e contra todos, sem ninguém saber como, um conhecimento em que ninguém acredita mas acha bonito mesmo assim, harmonioso, e vem despida de suas origens e fontes primárias e de todo o seu contexto perturbar o entendimento do mundo pelas crianças.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
IPFS problems: Conceit
IPFS is trying to do many things. The IPFS leaders are revolutionaries who think they're smarter than the rest of the entire industry.
The fact that they've first proposed a protocol for peer-to-peer distribution of immutable, content-addressed objects, then later tried to fix that same problem using their own half-baked solution (IPNS) is one example.
Other examples are their odd appeal to decentralization in a very non-specific way, their excessive flirtation with Ethereum and their never-to-be-finished can-never-work-as-advertised Filecoin project.
They could have focused on just making the infrastructure for distribution of objects through hashes (not saying this would actually be a good idea, but it had some potential) over a peer-to-peer network, but in trying to reinvent the entire internet they screwed everything up.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Democracy as a failed open-network protocol
In the context of protocols for peer-to-peer open computer networks -- those in which new actors can freely enter and immediately start participating in the protocol --, without any central entity, specially without any central human mind judging things from the top --, it's common for decisions about the protocol to be thought taking in consideration all the possible ways a rogue peer can disrupt the entire network, abuse it, make the experience terrible for others. The protocol design must account for all incentives in play and how they will affect each participant, always having in mind that each participant may be acting in a purely egoistical self-interested manner, not caring at all about the health of the network (even though most participants won't be like that). So a protocol, to be successful, must have incentives aligned such that self-interested actors cannot profit by hurting others and will gain most by cooperating (whatever that means in the envisaged context), or there must be a way for other peers to detect attacks and other kinds of harm or attempted harm and neutralize these.
Since computers are very fast, protocols can be designed to be executed many times per day by peers involved, and since the internet is a very open place to which people of various natures are connected, many open-network protocols with varied goals have been tried in large scale and most of them failed and were shut down (or kept existing, but offering a bad experience and in a much more limited scope than they were expected to be). Often the failure of a protocol leads to knowledge about its shortcomings being more-or-less widespread and agreed upon, and these lead to the development of a better protocol the next time something with similar goals is tried.
Ideally democracies are supposed to be an open-entry network in the same sense as these computer networks, and although that is a noble goal, it's one full of shortcomings. Democracies are supposed to the governing protocol of States that have the power to do basically anything with the lives of millions of citizens.
One simple inference we may take from the history of computer peer-to-peer protocols is that the ones that work better are those that are simple and small in scope (Bitcoin, for example, is very simple; BitTorrent is also very simple and very limited in what it tries to do and the number of participants that get involved in each run of the protocol).
Democracies, as we said above, are the opposite of that. Besides being in a very hard position to achieve success as an open protocol, democracies also suffer from the fact that they take a long time to run, so it's hard to see where it is failing every time.
The fundamental incentives of democracy, i.e. the rules of the protocol, posed by the separation of powers and checks-and-balances are basically the same in every place and in every epoch since the XIII century, and even today most people who dedicate their lives to the subject still don't see how they're completely flawed.
The system of checks and balances was thought from the armchair of a couple of political theorists who had never done anything like that in their lives, didn't have any experience dealing with very adversarial environments like the internet -- and probably couldn't even imagine that the future users of their network were going to be creatures completely different than themselves and their fellow philosophers and aristocrats who all shared the same worldview (and how fast that future would come!).
Also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
lnurl-auth explained
You may have seen the lnurl-auth spec or heard about it, but might not know how it works or what is its relationship with other lnurl protocols. This document attempts to solve that.
Relationship between lnurl-auth and other lnurl protocols
First, what is the relationship of lnurl-auth with other lnurl protocols? The answer is none, except the fact that they all share the lnurl format for specifying
httpsURLs.In fact, lnurl-auth is very unique in the sense that it doesn't even need a Lightning wallet to work, it is a standalone authentication protocol that can work anywhere.
How does it work
Now, how does it work? The basic idea is that each wallet has a seed, which is a random value (you may think of the BIP39 seed words, for example). Usually from that seed different keys are derived, each of these yielding a Bitcoin address, and also from that same seed may come the keys used to generate and manage Lightning channels.
What lnurl-auth does is to generate a new key from that seed, and from that a new key for each service (identified by its domain) you try to authenticate with.

That way, you effectively have a new identity for each website. Two different services cannot associate your identities.
The flow goes like this: When you visit a website, the website presents you with a QR code containing a callback URL and a challenge. The challenge should be a random value.

When your wallet scans or opens that QR code it uses the domain in the callback URL plus the main lnurl-auth key to derive a key specific for that website, uses that key to sign the challenge and then sends both the public key specific for that for that website plus the signed challenge to the specified URL.

When the service receives the public key it checks it against the challenge signature and start a session for that user. The user is then identified only by its public key. If the service wants it can, of course, request more details from the user, associate it with an internal id or username, it is free to do anything. lnurl-auth's goals end here: no passwords, maximum possible privacy.
FAQ
-
What is the advantage of tying this to Bitcoin and Lightning?
One big advantage is that your wallet is already keeping track of one seed, it is already a precious thing. If you had to keep track of a separate auth seed it would be arguably worse, more difficult to bootstrap the protocol, and arguably one of the reasons similar protocols, past and present, weren't successful.
-
Just signing in to websites? What else is this good for?
No, it can be used for authenticating to installable apps and physical places, as long as there is a service running an HTTP server somewhere to read the signature sent from the wallet. But yes, signing in to websites is the main problem to solve here.
-
Phishing attack! Can a malicious website proxy the QR from a third website and show it to the user to it will steal the signature and be able to login on the third website?
No, because the wallet will only talk to the the callback URL, and it will either be controlled by the third website, so the malicious won't see anything; or it will have a different domain, so the wallet will derive a different key and frustrate the malicious website's plan.
-
I heard SQRL had that same idea and it went nowhere.
Indeed. SQRL in its first version was basically the same thing as lnurl-auth, with one big difference: it was vulnerable to phishing attacks (see above). That was basically the only criticism it got everywhere, so the protocol creators decided to solve that by introducing complexity to the protocol. While they were at it they decided to add more complexity for managing accounts and so many more crap that in the the spec which initially was a single page ended up becoming 136 pages of highly technical gibberish. Then all the initial network effect it had, libraries and apps were trashed and nowadays no one can do anything with it (but, see, there are still people who love the protocol writing in a 90's forum with no clue of anything besides their own Java).
-
We don't need this, we need WebAuthn!
WebAuthn is essentially the same thing as lnurl-auth, but instead of being simple it is complex, instead of being open and decentralized it is centralized in big corporations, and instead of relying on a key generated by your own device it requires an expensive hardware HSM you must buy and trust the manufacturer. If you like WebAuthn and you like Bitcoin you should like lnurl-auth much more.
-
What about BitID?
This is another one that is very similar to lnurl-auth, but without the anti-phishing prevention and extra privacy given by making one different key for each service.
-
What about LSAT?
It doesn't compete with lnurl-auth. LSAT, as far as I understand it, is for when you're buying individual resources from a server, not authenticating as a user. Of course, LSAT can be repurposed as a general authentication tool, but then it will lack features that lnurl-auth has, like the property of having keys generated independently by the user from a common seed and a standard way of passing authentication info from one medium to another (like signing in to a website at the desktop from the mobile phone, for example).
-
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Reasons why Lightning is not that great
Some Bitcoiners, me included, were fooled by hyperbolic discourse that presented Lightning as some magical scaling solution with no flaws. This is an attempt to list some of the actual flaws uncovered after 5 years of experience. The point of this article is not to say Lightning is a complete worthless piece of crap, but only to highlight the fact that Bitcoin needs to put more focus on developing and thinking about other scaling solutions (such as Drivechain, less crappy and more decentralized trusted channels networks and statechains).
Unbearable experience
Maintaining a node is cumbersome, you have to deal with closed channels, allocating funds, paying fees unpredictably, choosing new channels to open, storing channel state backups -- or you'll have to delegate all these decisions to some weird AI or third-party services, it's not feasible for normal people.
Channels fail for no good reason all the time
Every time nodes disagree on anything they close channels, there have been dozens, maybe hundreds, of bugs that lead to channels being closed in the past, and implementors have been fixing these bugs, but since these node implementations continue to be worked on and new features continue to be added we can be quite sure that new bugs continue to be introduced.
Trimmed (fake) HTLCs are not sound protocol design
What would you tell me if I presented a protocol that allowed for transfers of users' funds across a network of channels and that these channels would pledge to send the money to miners while the payment was in flight, and that these payments could never be recovered if a node in the middle of the hop had a bug or decided to stop responding? Or that the receiver could receive your payment, but still claim he didn't, and you couldn't prove that at all?
These are the properties of "trimmed HTLCs", HTLCs that are uneconomical to have their own UTXO in the channel presigned transaction bundles, therefore are just assumed to be there while they are not (and their amounts are instead added to the fees of the presigned transaction).
Trimmed HTLCs, like any other HTLC, have timelocks, preimages and hashes associated with them -- which are properties relevant to the redemption of actual HTLCs onchain --, but unlike actual HTLCs these things have no actual onchain meaning since there is no onchain UTXO associated with them. This is a game of make-believe that only "works" because (1) payment proofs aren't worth anything anyway, so it makes no sense to steal these; (2) channels are too expensive to setup; (3) all Lightning Network users are honest; (4) there are so many bugs and confusion in a Lightning Network node's life that events related to trimmed HTLCs do not get noticed by users.
Also, so far these trimmed HTLCs have only been used for very small payments (although very small payments probably account for 99% of the total payments), so it is supposedly "fine" to have them. But, as fees rise, more and more HTLCs tend to become fake, which may make people question the sanity of the design.
Tadge Dryja, one of the creators of the Lightning Network proposal, has been critical of the fact that these things were allowed to creep into the BOLT protocol.
Routing
Routing is already very bad today even though most nodes have a basically 100% view of the public network, the reasons being that some nodes are offline, others are on Tor and unreachable or too slow, channels have the balance shifted in the wrong direction, so payments fail a lot -- which leads to the (bad) solution invented by professional node runners and large businesses of probing the network constantly in order to discard bad paths, this creates unnecessary load and increases the risk of channels being dropped for no good reason.
As the network grows -- if it indeed grow and not centralize in a few hubs -- routing tends to become harder and harder.
While each implementation team makes their own decisions with regard to how to best way to route payments and these decisions may change at anytime, it's worth noting, for example, that CLN will use MPP to split up any payment in any number of chunks of 10k satoshis, supposedly to improve routing success rates. While this often backfires and causes payments to fail when they should have succeeded, it also contributes to making it so there are proportionally more fake HTLCs than there should be, as long as the threshold for fake HTLCs is above 10k.
Payment proofs are somewhat useless
Even though payment proofs were seen by many (including me) as one of the great things about Lightning, the sad fact is that they do not work as proofs if people are not aware of the fact that they are proofs. Wallets do all they can to hide these details from users because it is considered "bad UX" and low-level implementors do not care very much to talk about them at all. There have been attempts from Lightning Labs to get rid of the payment proofs entirely (which at the time to me sounded like a terrible idea, but now I realize they were not wrong).
Here's a piece of anecdote: I've personally witnessed multiple episodes in which Phoenix wallet released the preimage without having actually received the payment (they did receive a minor part of the payment, but the payment was split in many parts). That caused my service, @lntxbot, to mark the outgoing payment as complete, only then to have to endure complaints from the users because the receiver side, Phoenix, had not received the full amount. In these cases, if the protocol and the idea of preimages as payment proofs be respected, should I have been the one in charge of manually fixing user balances?
Another important detail: when an HTLC is sent and then something goes wrong with the payment the channel has to be closed in order to redeem that payment. When the redeemer is on the receiver side, the very act of redeeming should cause the preimage to be revealed and a proof of payment to be made available for the sender, who can then send that back to the previous hop and the payment is proven without any doubt. But when this happens for fake HTLCs (which is the vast majority of payments, as noted above) there is no place in the world for a preimage and therefore there are no proofs available. A channel is just closed, the payer loses money but can't prove a payment. It also can't send that proof back to the previous hop so he is forced to say the payment failed -- even if it wasn't him the one who declared that hop a failure and closed the channel, which should be a prerequisite. I wonder if this isn't the source of multiple bugs in implementations that cause channels to be closed unnecessarily. The point is: preimages and payment proofs are mostly a fiction.
Another important fact is that the proofs do not really prove anything if the keypair that signs the invoice can't be provably attached to a real world entity.
LSP-centric design
The first Lightning wallets to show up in the market, LND as a desktop daemon (then later with some GUIs on top of it like Zap and Joule) and Anton's BLW and Eclair wallets for mobile devices, then later LND-based mobile wallets like Blixt and RawTX, were all standalone wallets that were self-sufficient and meant to be run directly by consumers. Eventually, though, came Breez and Phoenix and introduced the "LSP" model, in which a server would be trusted in various forms -- not directly with users' funds, but with their privacy, fees and other details -- but most importantly that LSP would be the primary source of channels for all users of that given wallet software. This was all fine, but as time passed new features were designed and implemented that assumed users would be running software connected to LSPs. The very idea of a user having a standalone mobile wallet was put out of question. The entire argument for implementation of the bolt12 standard, for example, hinged on the assumption that mobile wallets would have LSPs capable of connecting to Google messaging services and being able to "wake up" mobile wallets in order for them to receive payments. Other ideas, like a complicated standard for allowing mobile wallets to receive payments without having to be online all the time, just assume LSPs always exist; and changes to the expected BOLT spec behavior with regards to, for example, probing of mobile wallets.
Ark is another example of a kind of LSP that got so enshrined that it become a new protocol that depends on it entirely.
Protocol complexity
Even though the general idea of how Lightning is supposed to work can be understood by many people (as long as these people know how Bitcoin works) the Lightning protocol is not really easy: it will take a long time of big dedication for anyone to understand the details about the BOLTs -- this is a bad thing if we want a world of users that have at least an idea of what they are doing. Moreover, with each new cool idea someone has that gets adopted by the protocol leaders, it increases in complexity and some of the implementors are kicked out of the circle, therefore making it easier for the remaining ones to proceed with more and more complexity. It's the same process by which Chrome won the browser wars, kicked out all competitors and proceeded to make a supposedly open protocol, but one that no one can implement as it gets new and more complex features every day, all envisioned by the Chrome team.
Liquidity issues?
I don't believe these are a real problem if all the other things worked, but still the old criticism that Lightning requires parking liquidity and that has a cost is not a complete non-issue, specially given the LSP-centric model.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A Lightning penalty transaction
It was a cold day and I remembered that this
lightningdnode I was running on my local desktop to work on poncho actually had mainnet channels in it. Two channels, both private, bought on https://lnbig.com/ a while ago when I was trying to conduct an anonymous griefing attack on big nodes of the network just to prove it was possible (the attempts proved unsuccessful after some hours and I gave up).It is always painful to close channels because paying fees hurts me psychologically, and then it hurts even more to be left with a new small UTXO that will had to be spent to somewhere but that can barely pay for itself, but it also didn't make sense to just leave the channels there and risk forgetting them and losing them forever, so I had to do something.
One of the channels had 0 satoshis on my side, so that was easy. Mutually closed and I don't have to think anymore about it.
The other one had 10145 satoshis on my side -- out of a total of 100000 satoshis. Why can't I take my part all over over Lightning and leave the full channel UTXO to LNBIG? I wish I could do that, I don't want a small UTXO. I was not sure about it, but if the penalty reserve was 1% maybe I could take out abou 9000 satoshis and then close it with 1000 on my side? But then what would I do with this 1000 sat UTXO that would remain? Can't I donate it to miners or something?
I was in the middle of this thoughts stream when it came to me the idea of causing a penalty transaction to give those abundant 1000 sat to Mr. LNBIG as a donation for his excellent services to the network and the cause of Bitcoin, and for having supported the development of https://sbw.app/ and the hosted channels protocol.
Unfortunately
lightningddoesn't have a commandtriggerpenaltytransactionortrytostealusingoldstate, so what I did was:First I stopped
lightningdthen copied the database to elsewhere:cp ~/.lightningd/bitcoin/lightningd.sqlite3 ~/.lightning/bitcoin/lightningd.sqlite3.bakthen I restartedlightningdand fighted against the way-too-aggressive MPP splitting algorithm thepaycommand uses to pay invoices, but finally managed to pull about 9000 satoshis to my Z Bot that lives on the terrible (but still infinitely better than Twitter DMs) "webk" flavor of the Telegram web application and which is linked to my against-bitcoin-ethos-country-censoring ZEBEDEE Wallet. The operation wasn't smooth but it didn't take more than 10 invoices andpaycommands.
With the money out and safe elsewhere, I stopped the node again, moved the database back with a reckless
mv ~/.lightning/bitcoin/lightningd.sqlite3.bak ~/.lightningd/bitcoin/lightningd.sqlite3and restarted it, but to prevent mylightningdfrom being super naïve and telling LNBIG that it had an old state (I don't know if this would happen) which would cause LNBIG to close the channel in a boring way, I used the--offlineflag which apparently causes the node to not do any external connections.Finally I checked my balance using
lightning-cli listfundsand there it was, again, the 10145 satoshis I had at the start! A fantastic money creation trick, comparable to the ones central banks execute daily.
I was ready to close the channel now, but the
lightning-cli closecommand had an option for specifying how many seconds I would wait for a mutual close before proceeding to a unilateral close. There is noforceclosecommand like Éclair hasor anything like that. I was afraid that even if I gave LNBIG one second it would try to do boring things, so I paused to consider how could I just broadcast the commitment transaction manually, looked inside the SQLite database and thechannelstable with its millions of columns with cryptic names in the unbearable.schemaoutput, imagined thatlightningdmaybe wouldn't know how to proceed to take the money from theto-localoutput if I managed to broadcast it manually (and in the unlikely event that LNBIG wouldn't broadcast the penalty transaction), so I decided to just accept the risk and calllightning-cli close 706327x1588x0 1But it went well. The
--offlineflag apparently really works, as it just considered LNBIG to be offline and 1 second later I got the desired result.
My happiness was complete when I saw the commitment transaction with my output for 10145 satoshis published on the central database of Bitcoin, blockstream.info.
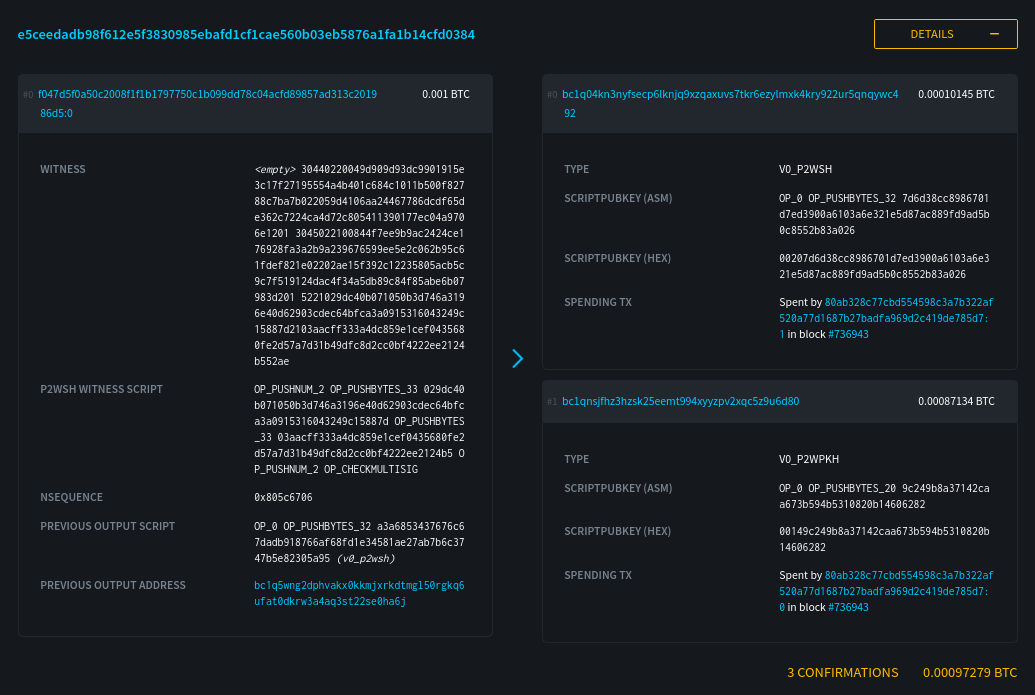
Then I went to eat something and it seems LNBIG wasn't offline or sleeping, he was certainly looking at all the logs from his 274 nodes in a big room full of monitors, very alert and eating an apple while drinking coffee, ready to take action, for when I came back, minutes later, I could see it, again on the single source of truth for the Bitcoin blockchain, the Blockstream explorer. I've refreshed the page and there it was, a small blue link right inside the little box that showed my
to-localoutput, a notice saying it had been spent -- not by mylightningdsince that would have to wait 9000 blocks, but by the same transaction that spent the other output, from which I could be very sure it was it, the glorious, mighty, unforgiving penalty transaction, splitting the earth, showing itself in all its power, and taking my 10145 satoshis to their rightful owner.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
doulas.club
A full catalog of all Brazilian doulas with data carefully scrapped from many websites that contained partial catalogs and some data manually included. All this packaged as a Couchapp and served directly from Cloudant.
This was done because the idea of doulas was good, but I spotted an issue: pregnant womwn should know many doulas before choosing one that would match well, therefore a full catalog with a lot of information was necessary.
This was a huge amount of work mostly wasted.
Many doulas who knew about this didn't like it and sent angry and offensive emails telling me to remove them. This was information one should know before choosing a doula.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Trello Attachment Editor
A static JS app that allowed you to authorize with your Trello account, fetch the board structure, find attachments, edit them in the browser then replace them in the cards.
Quite a nice thing. I believe it was done to help with Websites For Trello attached scripts and CSS files.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
localchat
A server that creates instant chat rooms with Server-Sent Events and normal HTTP
POSTrequests (instead of WebSockets which are an overkill most of the times).It defaults to a room named as your public IP, so if two machines in the same LAN connect they'll be in the same chat automatically -- but then you can also join someone else's LAN if you need.
This is supposed to be useful.
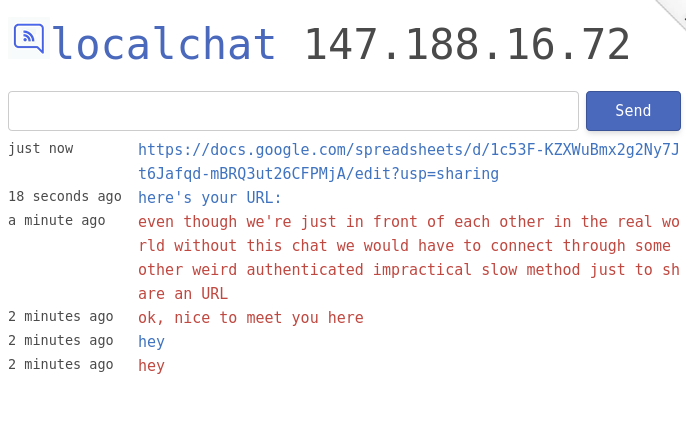
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A biblioteca infinita
Agora esqueci o nome do conto de Jorge Luis Borges em que a tal biblioteca é descrita, ou seus detalhes específicos. Eu tinha lido o conto e nunca havia percebido que ele matava a questão da aleatoriedade ser capaz de produzir coisas valiosas. Precisei mesmo da Wikipédia me dizer isso.
Alguns anos atrás levantei essa questão para um grupo de amigos sem saber que era uma questão tão batida e baixa. No meu exemplo era um cachorro andando sobre letras desenhadas e não um macaco numa máquina de escrever. A minha conclusão da discussão foi que não importa o que o cachorro escrevesse, sem uma inteligência capaz de compreender aquilo nada passaria de letras aleatórias.
Borges resolve tudo imaginando uma biblioteca que contém tudo o que o cachorro havia escrito durante todo o infinito em que fez o experimento, e portanto contém todo o conhecimento sobre tudo e todas as obras literárias possíveis -- mas entre cada página ou frase muito boa ou pelo menos legívei há toneladas de livros completamente aleatórios e uma pessoa pode passar a vida dentro dessa biblioteca que contém tanto conhecimento importante e mesmo assim não aprender nada porque nunca vai achar os livros certos.
Everything would be in its blind volumes. Everything: the detailed history of the future, Aeschylus' The Egyptians, the exact number of times that the waters of the Ganges have reflected the flight of a falcon, the secret and true nature of Rome, the encyclopedia Novalis would have constructed, my dreams and half-dreams at dawn on August 14, 1934, the proof of Pierre Fermat's theorem, the unwritten chapters of Edwin Drood, those same chapters translated into the language spoken by the Garamantes, the paradoxes Berkeley invented concerning Time but didn't publish, Urizen's books of iron, the premature epiphanies of Stephen Dedalus, which would be meaningless before a cycle of a thousand years, the Gnostic Gospel of Basilides, the song the sirens sang, the complete catalog of the Library, the proof of the inaccuracy of that catalog. Everything: but for every sensible line or accurate fact there would be millions of meaningless cacophonies, verbal farragoes, and babblings. Everything: but all the generations of mankind could pass before the dizzying shelves – shelves that obliterate the day and on which chaos lies – ever reward them with a tolerable page.
Tenho a impressão de que a publicação gigantesca de artigos, posts, livros e tudo o mais está transformando o mundo nessa biblioteca. Há tanta coisa pra ler que é difícil achar o que presta. As pessoas precisam parar de escrever.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: Patreon, but simple, and without subscription
Basically instead of a subscription and becoming member of something, you just get a forum for your inner circle and people get lnurl-pay codes they can use to donate. Some amount of donations is required to remain in the group (like x per month), but if you donate more than that on the beginning you can stay until your credits expire.
Every time someone donates a notice is posted in the group page.
Perhaps that could be an @lntxbot feature.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
sitio
A static site generator that works with imperative code instead of declarative templates and directory structures. It assumes nothing and can be used to transform anything into HTML pages.
It uses React so it can be used to generate single-page apps too if you want -- and normal sites that work like single-page apps.
It also provides helpers for reading Markdown files, like all static site generator does.
A long time after creating this and breaking it while trying to add too many features at once I realized Gatsby also had an imperative engine underlying the default declarative interface that could be used and it was pretty similar to
sitio. That both made me happy to have arrived at the same results of such an acclaimed tool and sad for the same reason, as Gatsby is the worse static site generator ever created considering user experience. -
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
My stupid introduction to Haskell
While I was writing my first small program on Haskell (really simple, but functional webapp) in December 2017 I only knew vaguely what was the style of things, some basic notions about functions, pure functions and so on (I've read about a third of LYAH).
An enourmous amount of questions began to appear in my head while I read tutorials and documentation. Here I present some of the questions and the insights I got that solved them. Technically, they may be wrong, but they helped me advance in the matter, so I'm writing them down while I still can -- If I keep working with Haskell I'll probably get to know more and so my new insights will replace the previous ones, and the new ones won't be useful for total begginers anymore.
Here we go:
- Why do modules have odd names?
- modules are the things you import, like
Data.Time.ClockorWeb.Scotty. - packages are the things you install, like 'time' or 'scotty'
- packages can contain any number of modules they like
- a module is just a collection of functions
- a package is just a collection of modules
- a package is just name you choose to associate your collection of modules with when you're publishing it to Hackage or whatever
- the module names you choose when you're writing a package can be anything, and these are the names people will have to
importwhen they want to use you functions- if you're from Javascript, Python or anything similar, you'll expect to be importing/writing the name of the package directly in your code, but in Haskell you'll actually be writing the name of the module, which may have nothing to do with the name of the package
- people choose things that make sense, like for
aesoninstead ofimport Aesonyou'll be doingimport Data.Aeson,import Data.Aeson.Typesetc. why theData? because they thought it would be nice. dealing with JSON is a form of dealing with data, so be it. - you just have to check the package documentation to see which modules it exposes.
- What is
data User = User { name :: Text }? - a data type definition. means you'll have a function
Userthat will take a Text parameter and output aUserrecord or something like that. - you can also have
Animal = Giraffe { color :: Text } | Human { name :: Text }, so you'll have two functions, Giraffe and Human, each can take a different set of parameters, but they will both yield an Animal.- then, in the functions that take an Animal parameter you must typematch to see if the animal is a giraffe or a human.
- What is a monad?
- a monad is a context, an environment.
- when you're in the context of a monad you can write imperative code.
- you do that when you use the keyword
do. - in the context of a monad, all values are prefixed by the monad type,
- thus, in the
IOmonad allTextisIO Textand so on. - some monads have a relationship with others, so values from that monad can be turned into values from another monad and passed between context easily.
- for exampĺe, scotty's
ActionMandIO.ActionMis just a subtype ofIOor something like that. - when you write imperative code inside a monad you can do assignments like
varname <- func x y - in these situations some transformation is done by the
<-, I believe it is that the pure value returned byfuncis being transformed into a monad value. so iffuncreturnsText, now varname is of typeIO Text(if we're in the IO monad).- so it will not work (and it can be confusing) if you try to concatenate functions like
varname <- transform $ func x y, but you can somehow do varname <- func x yothervarname <- transform varname- or you can do other fancy things you'll get familiar with later, like
varname <- fmap transform $ func x y - why? I don't know.
- so it will not work (and it can be confusing) if you try to concatenate functions like
- How do I deal with Maybe, Either or other crazy stuff? "ok, I understand what is a Maybe: it is a value that could be something or nothing. but how do I use that in my program?"
- you don't! you turn it into other thing. for example, you use fromMaybe, a function that takes a default value and that's it. if your
MaybeisJust xyou getx, if it isNothingyou get the default value.- using only that function you can already do whatever there is to be done with Maybes.
- you can also manipulate the values inside the
Maybe, for example: - if you have a
Maybe PersonandPersonhas anamewhich isText, you can apply a function that turnsMaybe PersonintoMaybe TextAND ONLY THEN you apply the default value (which would be something like the"unnamed") and take the name from inside theMaybe.
- basically these things (
Maybe,Either,IOalso!) are just tags. they tag the value, and you can do things with the values inside them, or you can remove the values.- besides the example above with Maybes and the
fromMaybefunction, you can also remove the values by usingcase-- for example: case x ofLeft error -> errorRight success -> success
case y ofNothing -> "nothing!"Just value -> value
- (in some cases I believe you can't remove the values, but in these cases you'll also don't need to)
- for example, for values tagged with the IO, you can't remove the IO and turn these values into pure values, but you don't need that, you can just take the value from the outside world, so it's a IO Text, apply functions that modify that value inside IO, then output the result to the user -- this is enough to make a complete program, any complete program.
- besides the example above with Maybes and the
- JSON and interfaces (or instances?)
- using Aeson is easy, you just have to implement the
ToJSONandFromJSONinterfaces. - "interface" is not the correct name, but I don't care.
ToJSON, for example, requires a function namedtoJSON, so you doinstance ToJSON YourType wheretoJSON (YourType your type values) = object []... etc.
- I believe lots of things require interface implementation like this and it can be confusing, but once you know the mystery of implementing functions for interfaces everything is solved.
FromJSONis a little less intuitive at the beggining, and I don't know if I did it correctly, but it is working here. Anyway, if you're trying to do that, I can only tell you to follow the types, copy examples from other places on the internet and don't care about the meaning of symbols.
See also
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Reasons for miners to not steal
See Drivechain for an introduction. Here we'll just have a list of reasons why miners would not steal:
- they will lose future fees from that specific drivechain: you can discount all future fees and condense them into a single present number in order to do some mathematical calculation.
- they may lose future fees from all other Drivechains, if the users assume they will steal from those too.
- Bitcoin will be devalued if they steal, because:
- Bitcoin is worth more if it has Drivechains working, because it is more useful, has more use-cases, more users. Without Drivechains it necessarily has to be worth less.
- Bitcoin has more fee revenue if has Drivechains working, which means it has a bigger chance of surviving going forward and being more censorship-resistant and resistant to State attacks, therefore it has to worth more if Drivechains work and less if they don't.
- Bitcoin is worth more if the public perception is that Bitcoin miners are friendly and doing their work peacefully instead of being a band of revolted peons that are constantly threating to use their 75% hashrate to do evil things such as:
- double-spending attacks;
- censoring of transactions for a certain group of people;
- selfish mining.
- if Bitcoin is devalued its price is bound to fall, meaning that miners will lose on
- their future mining rewards;
- their ASIC investiment;
- the same coins they are trying to steal from the drivechain.
- if a mining pool tries to steal, they will risk losing their individual miners to other pools that don't.
- whenever a steal attempt begins, the coins in the drivechain will lose value (if the steal attempt is credible their price will drop quite substantially), which means that if a coalition of miners really try to steal, there is an incentive for another coalition of miners to buy some devalued coins and then stop the steal.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A podridão
É razoável dizer que há três tipos de reações à menção do nome O que é Bitcoin? no Brasil:
- A reação das pessoas velhas
Muito sabiamente, as pessoas velhas que já ouviram falar de Bitcoin o encaram ou como uma coisa muito distante e reservada ao conhecimento dos seus sobrinhos que entendem de computador ou como um golpe que se deve temer e do qual o afastamento é imperativo, e de qualquer modo isso não as deve afetar mesmo então para que perder o seu tempo. Essas pessoas estão erradas: nem o sobrinho que entende de computador sabe nada sobre Bitcoin, nem o Bitcoin é um golpe, e nem é o Bitcoin uma coisa totalmente irrelevante para elas.
É razoável ter cautela diante do desconhecido, no que as pessoas velhas fazem bem, mas creio eu que também muito do medo que essas pessoas têm vem da ignorância que foi criada e difundida durante os primeiros 10 anos de Bitcoin por jornalistas analfabetos e desinformados em torno do assunto.
- A reação das pessoas pragmáticas
"Já tenho um banco e já posso enviar dinheiro, pra que Bitcoin? O quê, eu ainda tenho que pagar para transferir bitcoins? Isso não é vantagem nenhuma!"
Enquanto querem parecer muito pragmáticas e racionais, essas pessoas ignoram vários aspectos das suas próprias vidas, a começar pelo fato de que o uso dos bancos comuns não é gratuito, e depois que a existência desse sistema financeiro no qual elas se crêem muito incluídas e confortáveis é baseada num grande esquema chamado Banco Central, que tem como um dos seus fundamentos a possibilidade da inflação ilimitada da moeda, que torna todas as pessoas mais pobres, incluindo essas mesmas, tão pragmáticas e racionais.
Mais importante é notar que essas pessoas tão racionais foram também ludibriadas pela difusão da ignorância sobre Bitcoin como sendo um sistema de transferência de dinheiro. O Bitcoin não é e não pode ser um sistema de transferência de dinheiro porque ele só pode transferir-se a si mesmo, não pode transferir "dinheiro" no sentido comum dessa palavra (tenho em mente o dinheiro comum no Brasil, os reais). O fato de que haja hoje pessoas que conseguem "transferir dinheiro" usando o Bitcoin é uma coisa totalmente inesperada: a existência de pessoas que trocam bitcoins por reais (e outros dinheiros de outros lugares) e vice-versa. Não era necessário que fosse assim, não estava determinado em lugar nenhum, 10 anos atrás, que haveria demanda por um bem digital sem utilidade imediata nenhuma, foi assim por um milagre.
Porém, o milagre só estará completo quando esses bitcoins se tornarem eles mesmo o dinheiro comum. E aí assim será possível usar o sistema Bitcoin para transferir dinheiro de fato. Antes disso, chamar o Bitcoin de sistema de pagamentos ou qualquer coisa que o valha é perverter-lhe o sentido, é confundir um acidente com a essência da coisa.
- A reação dos jovens analfabetos
Os jovens analfabetos são as pessoas que usam a expressão "criptos" e freqüentam sítios que dão notícias totalmente irrelevantes sobre "criptomoedas" o dia inteiro. Não sei muito bem como eles vivem porque não lhes suporto a presença, mas são pessoas que estão muito empolgadas com toda a "onda das criptomoedas" e acham tudo muito incrível, tão incrível que acabam se interessando e então comprando todos os tokens vagabundos que inventam. Usam a palavra "decentralizado", um anglicismo muito feio que deveria significar que não existe um centro controlador da moeda x ou y e que o seu protocolo continuaria funcionando mesmo que vários operadores saíssem do ar, mas como o aplicam aos tokens que são literalmente emitidos por um centro controlador com uma figura humana no centro que toma todas as decisões sobre tudo -- como o Ethereum e conseqüentemente todos os milhares de tokens ERC20 criados dentro do sistema Ethereum -- essa palavra não faz mais sentido.
Na sua empolgação e completo desconhecimento sobre como um ente nocivo poderia destruir cadauma das suas criptomoedas tão decentralizadas, ou como mesmo sem ninguém querer uma falha fundamental no protocolo e no sistema de incentivos poderia pôr tudo abaixo, sem imaginar que toda a valorização do token XYZ pode ter sido fabricada de caso pensado pelos seus próprios emissores ou só ser mesmo uma bolha, acabam esses jovens por igualar o token XYZ, ou ETH, BCH ou o que for, ao Bitcoin, ignorando todas as diferenças qualitativas e apenas mencionando de leve as quantitativas.
Misturada à sua empolgação, e como um bônus, surge a perspectiva de ficar rico. Se um desses por algum golpe de sorte surfou em alguma bolha como a de 2017 e conseguiu multiplicar um dinheiro por 10 comprando e vendendo EOS, já começa logo a usar como argumento para convencer os outros de que "criptomoedas são o futuro" o fato de que ele ficou rico. Não subestime a burrice humana.
Há jovens no grupo das pessoas velhas, velhas no grupo das pessoas jovens, pessoas que não estão em nenhum dos grupos e pessoas que estão em mais de um grupo, isso não importa.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Ripple and the problem of the decentralized commit
This is about Ryan Fugger's Ripple.
The summary is: unless everybody is good and well-connected at all times a transaction can always be left in a half-committed state, which creates confusion, erodes trust and benefits no one.
If you're unconvinced consider the following protocol flow:
- A finds a route (A--B--C--D) between her and D somehow;
- A "prepares" a payment to B, tells B to do the same with C and so on (to prepare means to give B a conditional IOU that will be valid as long as the full payment completes);
- When the chain of prepared messages reaches D, D somehow "commits" the payment.
- After the commit, A now really does owe B and so on, and D really knows it has been effectively paid by A (in the form of debt from C) so it can ship goods to A.
The most obvious (but wrong) way of structuring this would be for the entire payment chain to be dependent on the reveal of some secret. For example, the "prepare" messages could contain something like "I will pay you as long as you know
psuch thatsha256(p) == h".The payment flow then starts with D presenting A with an invoice that contains
h, so D knowsp, but no one else knows. A can then send the "prepare" message to B and B do the same until it reaches D.When it reaches D, D can be sure that C will pay him because he knows
psuch thatsha256(p) == h. He then revealspto C, C now reveals it to B and B to A. When A gets it it has a proof that D has received his payment, therefore it is happy to settle it later with B and can prove to an external arbitrator that he has indeed paid D in case D doesn't deliver his products.Issues with the naïve flow above
What if D never reveals
pto C?Then no one knows what happened. And then 10 years later he arrives at C's house (remember they are friends or have a trust relationship somehow) and demands his payment, and shows
pto her in a piece of paper. Or worse: go directly to the court and shows C's message that says "I will pay you as long as you knowpsuch thatsha256(p) == h" (but with an actual number instead of "h") and the correspondingp. Now the judge has to decide in favor of D.Now C was supposed to do the same with B, but C is not playing with this anymore, has lost all contact with B after they did their final settlement many years ago, no one was expecting this.
This clearly can't work. There must be a timeout for these payments.
What if we have a timeout?
Now what if we say the payment expires in one hour. D cannot hold the payment hostage and reveal
pafter 10 years. It must either reveal it before the timeout or conditional IOU will be void. Solves everything!Except no, now it's the time we reach the most dark void of the protocol, the flaw that sucks its life into the abyss: subjectivity and ambiguity.
The big issue is that we don't have an independent judge to assert, for example, that D has indeed "revealed"
pto C in time. C must acknowledge that voluntarily. C could do it using messages over the internet, but these messages are not reliable. C is not reliable. Clocks are not synchronized. Also if we now require C to confirm it has receivedpfrom D then the "prepare" message means nothing, as for D now just knowingpis not enough to claim before an arbitrator that C owes her -- because, again, D also must prove it has shownpto C before the timeout, therefore it needs a new signed acknowledgement from C, or from some other party.Let's see a few examples.
Subjectivity and perverse incentives
D could send
pto C, and C acknowledge it, but then when C goes to B and send it B will not acknowledge it, and claim it's past the time. Now C loses money.Maybe C can not acknowledge it received anything from D before checking first with B? But B will have to check with A too! And it subverts the entire flow of the thing. And now A has a "proof of payment" (knowledge of
p) without even having to acknowledge anything! In this case knowingpor not becomes meaningless as everybody knowspwithout acknowleding it to anyone else.But even if A is honest and sends an "acknowledge" message to B, now B can just sit quiet and enjoy the credit it has just earned from A without ever acknowleding anything to C. It's perverted incentives in every step.
Ambiguity
But isn't this a protocol based on trust?, you ask, isn't C trusting that B will behave honestly already? Therefore if B is dishonest C just has to acknowledge his loss and break his chain of trust with B.
No, because C will not know what happened. B can say "I could have sent you an acknowledgement, but was waiting for A, and A didn't send anything" and C won't ever know if that was true. Or B could say "what? You didn't send me
pat all", and that could be true. B could have been offline when A sent it, there could have been a broken connection or many other things, and B continues: "I was waiting for you to present me withp, but you didn't, therefore the payment timed out, you can't come here withpnow, because now A won't accept it anymore from me". That could be true or could be false, who knows?Therefore it is impossible for trust relationships and reputations to be maintained in such a system without "good fences".[^ln-solution][^ln-issue]
[^ln-solution]: The Lightning Network has a solution for the problem of the decentralized commit. [^ln-issue]: Ironically this same ambiguity problem is being faced by the Lightning Network community when trying to create a reputation/payment system to prevent routing abuses. It seems simple when you first think about it: "let each node manage its own trust", but in fact it is somewhat impossible.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A crappy course on torrents
In 8 points[^twitterlink]:
- You start seeding a file -- that means you split the file in a certain way, hash the pieces and wait.
- If anyone connects to you (either by TCP or UDP -- and now there's the webRTC transport) and ask for a piece you'll send it.
- Before downloading anything leechers must understand how many pieces exist and what are they -- and other things. For that exists the .torrent file, it contains the final hash of the file, metadata about all files, the list of pieces and hash of each.
- To know where you are so people can connect to you[^nathole], there exists an HTTP (or UDP) server called "tracker". A list of trackers is also contained in the .torrent file.
- When you add a torrent to your client, it gets a list of peers from the trackers. Then you try to connect to them (and you keep getting peers from the trackers while simultaneously sending data to the tracker like "I'm downloading, I have x bytes already" or "I'm seeding").
- Magnet links contain a tracker URL and a hash of the metadata contained in the .torrent file -- with that you can safely download the same data that should be inside a .torrent file -- but now you ask it from a peer before requesting any actual file piece.
- DHTs are an afterthought and I don't know how important they are for the torrent ecosystem (trackers work just fine). They intend to replace the centralized trackers with message passing between DHT peers (DHT peers are different and independent from file-download peers).
- All these things (.torrent files, tracker messages, messages passed between peers) are done in a peculiar encoding format called "bencode" that is just a slightly less verbose, less readable JSON.
[^twitterlink]: Posted first as this Twitter thread. [^nathole]: Also your torrent client must be accessible from the external internet, NAT hole-punching is almost a myth.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
"Você só aprendeu mesmo uma coisa quando consegue explicar para os outros"
Mentira. Tá certo que existe um ponto em que você acha que sabe algo mas não consegue explicar, mas não necessariamente isso significa não saber. Conseguir explicar não depende de saber, mas de verbalizar. Podemos saber muitas coisas sem as conseguir verbalizar. Aliás, para a maior parte das experiências humanas verbalizar é que é a parte difícil. Por último, é importante dizer que a verbalização é uma abstração e portanto quando alguém tenta explicar algo e se força a fazer uma abstração está arriscando substituir a experiência concreta ou mesmo o conhecimento difuso de algo por aquela abstração e com isso ficar mais burro -- me parece que esse é risco é maior quanto mais prematura for a tentativa de explicação e quando mais sucesso a abstração improvisada fizer.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The problem with DIDs
Decentralized Identifiers are supposedly a standard that will allow anyone (or anything) to have an online identity. The DID is a URI like
did:<method>:<data>in which<method>determines how to interpret the<data>. The data is generally a public key in some cryptographic system or shitcoin blockchain, or a naked key, or a DNS-backed web address.Some of the DID proponents argue that this is for maximum interoperability, since any new system can be supported under the same standard, i.e. supposedly an application could "support DIDs" (as some would say) and that would allow anyone to just paste their DID string there and that would refer to something.
There are a gazillion of different DID "methods", most of them are probably barely used. What does it mean for an application to "support" DIDs, then? For the interoperability argument to make any sense that must mean that the application must understand all the "methods" -- which involves understanding all cryptographic protocols and reading and interpreting data from a gazillion different blockchains and also understanding the specifics of each method, since the data of each blockchain or website and so on must also be interpreted according to the rules of the method.
It must be clear from the paragraph above that the DID goal is is unimplementable and therefore will either fail horribly by lack of adoption; or it will have to be changed to something else (for example everybody will start accepting just
did:keyand ignore others and that will be the standard); or it will become a centralized thing with all supporting applications using a single set of libraries that have built-in support for all methods by calling centralized servers that return the final product of processing the DID data for each method.See also:
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
UBI calculations
The United States population (counting only people more than 25 years old) is
222098080 people, the United States GDP is20807000000000 USD. The Federal government has received5845968000000in taxes in 2019.The standard UBI plan (from Andrew Yang) is to give $1000 to each person every month, which means a total annual expenditure of
2665176960000 USD, or12.81%of the GDP and45.59%of all tax money received from the federal government.Mandatory spending (which includes healthcare and social security) corresponds to $2.7 trillion, or
46.18%of annual receipts. Discretionary spending (which includes education and military stuff) corresponds to $1.3 trillion, or22.23%of annual receipts.Does it fit?
If you are capable of cutting more-or-less all spending in social security (
17.10%of federal receipts), all military (11.56%), all education, transportation, housing, veterans benefits and most other things the federal government does (11.30%) and parts of Medicare and Medicaid (26.17%) then it will be possible to fit UBI.Welcome to the leftist paradise, one in which the government budget has to be drastically cut in every possible (cruel?) way.
Data sources
- https://en.wikipedia.org/wiki/United_States
- https://en.wikipedia.org/wiki/Demographics_of_the_United_States#Structure
- https://en.wikipedia.org/wiki/Government_spending_in_the_United_States
- https://www.bea.gov/tools/
- https://www.pbs.org/newshour/politics/how-would-andrew-yang-give-americans-1000-per-month-with-this-tax
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
WelcomeBot
The first bot ever created for Trello.
It invited to a public board automatically anyone who commented on a card he was added to.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28

A command line utility to create and manage personal graphs, then write them to dot and make images with graphviz.
It manages a bunch of YAML files, one for each entity in the graph. Each file lists the incoming and outgoing links it has (could have listen only the outgoing, now that I'm tihnking about it).
Each run of the tool lets you select from existing nodes or add new ones to generate a single link type from one to one, one to many, many to one or many to many -- then updates the YAML files accordingly.
It also includes a command that generates graphs with graphviz, and it can accept a template file that lets you customize the
dotthat is generated and thus the graphviz graph.rel
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
As valas comuns de Manaus
https://www.terra.com.br/noticias/brasil/cidades/manaus-comeca-a-enterrar-em-valas-coletivas,e7da8b2579e7f032629cf65fa27a11956wd2qblx.html

Todo o Estado do Amazonas tem 193 mortos por Coronavirus, mas essa foto de "valas coletivas" sendo abertas em Manaus tem aproximadamente 500 túmulos. As notícias de "calamidade total" já estão acontecendo pelo menos desde o dia 11 (https://www.oantagonista.com/brasil/manaus-sao-paulo-e-rio-de-janeiro-nao-podem-relaxar-com-as-medidas-de-distanciamento/).
O comércio está fechado por decreto desde o final de março (embora a matéria diga que as pessoas não estão respeitando).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Idéia de um sistema jurídico centralizado, mas com um pouco de lógica
um processo, é, essencialmente, imagino eu na minha ingenuidade leiga, um apelo que se faz ao juiz para que este reconheça certos fatos como probantes de um certo fenômeno tipificado por uma certa lei.
imagino então o seguinte:
uma petição não é mais um enorme documento escrito numa linguagem nojenta com referências a leis e a evidências factuais espalhadas segundo a (in) capacidade ensaística do advogado, mas apenas um esquema lógico - talvez até um diagrama desenhado (ou talvez quem sabe uma série de instruções compreensíveis por um computador?) - mostrando a ligação entre a lei e os fatos e os pedidos, por exemplo:
- a lei tal diz que ninguém pode vender
- fulano vendeu cigarros
- é prova de que fulano vendeu cigarros ia foto tirada na rua tal no dia tal que mostra fulano vendendo cigarros
- a mesma lei pede que fulano pague uma multa
este exemplo está ainda muito verborrágico, mas é só um exemplo simples. coisas mais complicadas precisariam de outras formas de expressão caso queiramos evitar as longas dissertações jurídicas em voga.
a idéia é que o esquema acima vale por si. um proto-juiz pode julgá-lo como válido ou inválido apenas pela sua lógica interna.
a outra parte do julgamento seria a ligação desse esquema com a realidade externa: anexados à petição viriam as evidências. no caso, anexada ao ponto 3 viria uma foto do fulano. ao ponto 1 também precisa ser anexado o texto da lei referida, mas isto pode ser feito automaticamente pelo número da lei.
uma vez que tenhamos um esquema lógico válido um outro proto-juiz, ou vários outros, pode julgar individualmente cada evidência: ver se o texto da lei confere com a interpretação feita no ponto 1, e se a foto anexada ao ponto 3 é mesmo a foto do réu vendendo cigarro e não a de um urso comendo laranjas.
cada um desses julgamentos pode ser feito sem que o proto-juiz tenha conhecimento do resto das coisas do processo: o primeiro proto-juiz não precisa ver a foto ou a lei, o segundo não precisa ver o esquema lógico ou a foto, o terceiro não precisa ver a lei nem o esquema lógico, e mesmo assim teríamos um julgamento de procedência ou não da petição ao final, o mais impessoal e provavelmente o mais justo possível.
a defesa consistiria em apontar erros no esquema lógico ou falhas no nexo entre a realidade é o esquema. por exemplo:
- uma foto assim não é uma prova de que fulano vendeu, ele podia estar só passando lá perto.
- ele estava de fato só passando lá perto. do que é prova este documento mostrando seu comparecimento a uma aula do curso de direito da UFMG no mesmo horário.
perdoem-me se estiver falando besteira, mas são 5h e estou ainda dormindo. obviamente há vários pontos problemáticos aí, e quero entendê-los, mas a forma geral me parece bem razoável.
o que descrevi acima é uma proposta, digamos, de sistema jurídico que não se diferencia em nada do nosso sistema jurídico atual, exceto na forma (não no sentido escolástico). é também uma tentativa de compreender sua essência.
as vantagens desse formato ao atual são muitas:
- menos papel, coisas pra ler, repetição infinita de citações legais e longuíssimas dissertações escritas por advogados analfabetos que destroem a língua e a inteligência de todos
- diminuição drástica do tempo gasto por cada juiz em cada processo
- diminuição do poder de cada juiz (se cada ato de julgamento humano necessário em cada processo pode ser feito por qualquer juiz, sem conhecimento dos outros aspectos do mesmo processo, tudo é muito mais rápido, e cada julgamento desses pode ser feito por vários juízes diferentes, escolhidos aleatoriamente)
- diminuição da pomposidade de casa juiz: com menos poder e obrigações maus simples, um juiz não precisa ser mais uma pessoa especial que ganha milhões, pode ser uma pessoa comum, um proto-juiz, ganhando menos (o que possibilitaria até ter mais desses e aumentar a confiabilidade de cada julgamento)
- os juízes podem trabalhar da casa deles e a qualquer momento
- passa a ter sentido a existência de um sistema digital de processos (porque é ridículo que o sistema digital atual seja só uma forma de passar documentos do Word de um lado para o outro)
- o fim das audiências de conciliação, que são uma monstruosidade criada apenas pela necessidade de diminuir a quantidade de processos em tramitação e acabam retirandobo sentido da justiça (as partes são levemente pressionadas a ignorar a validade ou não das suas posições e fazer um acordo, sob pena de o juiz ficar com raiva delas depois)
milhares de precauções devem ser tomadas caso um sistema desses vá ser implantado (ahahah), talvez manter uma forma de julgamento tradicional, de corpo presente e com um juiz ou júri que tem conhecimento de toda situação, mas apenas para processos que chegarem até certo ponto, e assim por diante.
Ver também
- P2P reputation thing para um fundamento de um sistema jurídico anárquico.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
How IPFS is broken
I once fell for this talk about "content-addressing". It sounds very nice. You know a certain file exists, you know there are probably people who have it, but you don't know where or if it is hosted on a domain somewhere. With content-addressing you can just say "start" and the download will start. You don't have to care.
Other magic properties that address common frustrations: webpages don't go offline, links don't break, valuable content always finds its way, other people will distribute your website for you, any content can be transmitted easily to people near you without anyone having to rely on third-party centralized servers.
But you know what? Saying a thing is good doesn't automatically make it possible and working. For example: saying stuff is addressed by their content doesn't change the fact that the internet is "location-addressed" and you still have to know where peers that have the data you want are and connect to them.
And what is the solution for that? A DHT!
DHT?
Turns out DHTs have terrible incentive structure (as you would expect, no one wants to hold and serve data they don't care about to others for free) and the IPFS experience proves it doesn't work even in a small network like the IPFS of today.
If you have run an IPFS client you'll notice how much it clogs your computer. Or maybe you don't, if you are very rich and have a really powerful computer, but still, it's not something suitable to be run on the entire world, and on web pages, and servers, and mobile devices. I imagine there may be a lot of unoptimized code and technical debt responsible for these and other problems, but the DHT is certainly the biggest part of it. IPFS can open up to 1000 connections by default and suck up all your bandwidth -- and that's just for exchanging keys with other DHT peers.
Even if you're in the "client" mode and limit your connections you'll still get overwhelmed by connections that do stuff I don't understand -- and it makes no sense to run an IPFS node as a client, that defeats the entire purpose of making every person host files they have and content-addressability in general, centralizes the network and brings back the dichotomy client/server that IPFS was created to replace.
Connections?
So, DHTs are a fatal flaw for a network that plans to be big and interplanetary. But that's not the only problem.
Finding content on IPFS is the most slow experience ever and for some reason I don't understand downloading is even slower. Even if you are in the same LAN of another machine that has the content you need it will still take hours to download some small file you would do in seconds with
scp-- that's considering that IPFS managed to find the other machine, otherwise your command will just be stuck for days.Now even if you ignore that IPFS objects should be content-addressable and not location-addressable and, knowing which peer has the content you want, you go there and explicitly tell IPFS to connect to the peer directly, maybe you can get some seconds of (slow) download, but then IPFS will drop the connection and the download will stop. Sometimes -- but not always -- it helps to add the peer address to your bootstrap nodes list (but notice this isn't something you should be doing at all).
IPFS Apps?
Now consider the kind of marketing IPFS does: it tells people to build "apps" on IPFS. It sponsors "databases" on top of IPFS. It basically advertises itself as a place where developers can just connect their apps to and all users will automatically be connected to each other, data will be saved somewhere between them all and immediately available, everything will work in a peer-to-peer manner.
Except it doesn't work that way at all. "libp2p", the IPFS library for connecting people, is broken and is rewritten every 6 months, but they keep their beautiful landing pages that say everything works magically and you can just plug it in. I'm not saying they should have everything perfect, but at least they should be honest about what they truly have in place.
It's impossible to connect to other people, after years there's no js-ipfs and go-ipfs interoperability (and yet they advertise there will be python-ipfs, haskell-ipfs, whoknowswhat-ipfs), connections get dropped and many other problems.
So basically all IPFS "apps" out there are just apps that want to connect two peers but can't do it manually because browsers and the IPv4/NAT network don't provide easy ways to do it and WebRTC is hard and requires servers. They have nothing to do with "content-addressing" anything, they are not trying to build "a forest of merkle trees" nor to distribute or archive content so it can be accessed by all. I don't understand why IPFS has changed its core message to this "full-stack p2p network" thing instead of the basic content-addressable idea.
IPNS?
And what about the database stuff? How can you "content-address" a database with values that are supposed to change? Their approach is to just save all values, past and present, and then use new DHT entries to communicate what are the newest value. This is the IPNS thing.
Apparently just after coming up with the idea of content-addressability IPFS folks realized this would never be able to replace the normal internet as no one would even know what kinds of content existed or when some content was updated -- and they didn't want to coexist with the normal internet, they wanted to replace it all because this message is more bold and gets more funding, maybe?
So they invented IPNS, the name system that introduces location-addressability back into the system that was supposed to be only content-addressable.
And how do they manage to do it? Again, DHTs. And does it work? Not really. It's limited, slow, much slower than normal content-addressing fetches, most of the times it doesn't even work after hours. But still although developers will tell it is not working yet the IPFS marketing will talk about it as if it was a thing.
Archiving content?
The main use case I had for IPFS was to store content that I personally cared about and that other people might care too, like old articles from dead websites, and videos, sometimes entire websites before they're taken down.
So I did that. Over many months I've archived stuff on IPFS. The IPFS API and CLI don't make it easy to track where stuff are. The
pincommand doesn't help as it just throws your pinned hash in a sea of hashes and subhashes and you're never able to find again what you have pinned.The IPFS daemon has a fake filesystem that is half-baked in functionality but allows you to locally address things by names in a tree structure. Very hard to update or add new things to it, but still doable. It allows you to give names to hashes, basically. I even began to write a wrapper for it, but suddenly after many weeks of careful content curation and distribution all my entries in the fake filesystem were gone.
Despite not having lost any of the files I did lose everything, as I couldn't find them in the sea of hashes I had in my own computer. After some digging and help from IPFS developers I managed to recover a part of it, but it involved hacks. My things vanished because of a bug at the fake filesystem. The bug was fixed, but soon after I experienced a similar (new) bug. After that I even tried to build a service for hash archival and discovery, but as all the problems listed above began to pile up I eventually gave up. There were also problems of content canonicalization, the code the IPFS daemon use to serve default HTML content over HTTP, problems with the IPFS browser extension and others.
Future-proof?
One of the core advertised features of IPFS was that it made content future-proof. I'm not sure they used this expression, but basically you have content, you hash that, you get an address that never expires for that content, now everybody can refer to the same thing by the same name. Actually, it's better: content is split and hashed in a merkle-tree, so there's fine-grained deduplication, people can store only chunks of files and when a file is to be downloaded lots of people can serve it at the same time, like torrents.
But then come the protocol upgrades. IPFS has used different kinds of hashing algorithms, different ways to format the hashes, and will change the default algorithm for building the merkle-trees, so basically the same content now has a gigantic number of possible names/addresses, which defeats the entire purpose, and yes, files hashed using different strategies aren't automagically compatible.
Actually, the merkle algorithm could have been changed by each person on a file-by-file basis since the beginning (you could for example split a book file by chapter or page instead of by chunks of bytes) -- although probably no one ever did that. I know it's not easy to come up with the perfect hashing strategy in the first go, but the way these matters are being approached make me wonder that IPFS promoters aren't really worried about future-proof, or maybe we're just in Beta phase forever.
Ethereum?
This is also a big problem. IPFS is built by Ethereum enthusiasts. I can't read the mind of people behind IPFS, but I would imagine they have a poor understanding of incentives like the Ethereum people, and they tend towards scammer-like behavior like getting a ton of funds for investors in exchange for promises they don't know they can fulfill (like Filecoin and IPFS itself) based on half-truths, changing stuff in the middle of the road because some top-managers decided they wanted to change (move fast and break things) and squatting fancy names like "distributed web".
The way they market IPFS (which is not the main thing IPFS was initially designed to do) as a "peer-to-peer cloud" is very seductive for Ethereum developers just like Ethereum itself is: as a place somewhere that will run your code for you so you don't have to host a server or have any responsibility, and then Infura will serve the content to everybody. In the same vein, Infura is also hosting and serving IPFS content for Ethereum developers these days for free. Ironically, just like the Ethereum hoax peer-to-peer money, IPFS peer-to-peer network may begin to work better for end users as things get more and more centralized.
More about IPFS problems:
- IPFS problems: Too much immutability
- IPFS problems: General confusion
- IPFS problems: Shitcoinery
- IPFS problems: Community
- IPFS problems: Pinning
- IPFS problems: Conceit
- IPFS problems: Inefficiency
- IPFS problems: Dynamic links
See also
- A crappy course on torrents, on the protocol that has done most things right
- The Tragedy of IPFS in a series of links, an ongoing Twitter thread.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
O que é Bitcoin?
Todo guia infeliz sobre Bitcoin começa com esta pergunta manjada, e normalmente já vai respondendo que é uma "moeda virtual"[^moeda_virtual], um conceito estúpido que não esclarece nada.
Esqueça esse papo. Bitcoin não é uma moeda. Bitcoin é um protocolo[^protocolo].
Por que então dizem que é uma moeda? Porque essas pessoas muito apressadinhas gostam de dizer que tudo que é facilmente divisível e transferível, e cujas várias unidades são idênticas umas às outras, é uma moeda. Então, nesse sentido, Bitcoin é uma moeda, mas ignore esse papo de moeda.
O protocolo Bitcoin diz que existem "créditos" (ou "pontos", ou "unidades") que podem ser transferidas entre os participantes, e vários computadores, cada um operando independentemente do outro, desde que sigam o protocolo (ou seja: que estejam todos rodando o mesmo programa, ou programas compatíveis), estarão sempre em acordo a respeito de quem gastou cada crédito e como gastou.
É basicamente essa a idéia: um monte de "pontos virtuais" que são transferidos de uns para outros, sem que exista uma entidade organizadora, "o dono do Bitcoin", "o chefe supremo do Bitcoin", que controle nada, coordene nada, ou tenha poder sobre essas transferências.
Como funciona
Imagine vários computadores rodando o mesmo programa (ou programas compatíveis). Agora imagine que esses programas se comunicam entre si através da internet: eles enviam mensagens uns para os outros e esperam respostas. De vez em quando a resposta não vem, ou vem num formato que o programa não entende, isso significa que o outro computador saiu do ar, ou está rodando uma versão incompatível do programa, e aí todos os outros vão ignorá-lo. Mas em geral a resposta vem certinha e todos conseguem falar com todos.
Agora que você imaginou isso, fica fácil imaginar, por exemplo, que cada um desses computadores mantém uma lista de todos os bitcoins existentes e quem tem cada um. Eles pegam a lista dos outros computadores na rede e depois a vão atualizando à medida que novas transações vão sendo feitas. Toda vez que alguém quer fazer alguma transação, ele deve fazê-la por meio de um desses computadores, a pessoa chega no computador que está rodando o programa e diz: "sou fulano, tenho x bitcoins, e quero enviá-los para tal lugar", o programa vai lá e envia essa mensagem para os outros computadores, que atualizam a sua lista. Fim.
Essa seria uma versão ingênua do protocolo, que funcionaria se todos os participantes fossem muito honestos e ninguém jamais tentasse gastar os bitcoins que não têm.
Pra uma coisa dessas funcionar no mundo real teve de entrar a grande invenção do Bitcoin, o insight genial do Satoshi Nakamoto, que é a tal cadeia de blocos, conhecida por aí como blockchain.
Funciona assim: ao invés de cada computador manter uma lista de onde está cada bitcoin, cada computador mantém a tal cadeia de blocos. Um "bloco" é só um nome bonitinho para um conjunto de dados. Cada bloco é composto por uma referência ao bloco anterior e uma lista de transações. Como eles contém uma referência ao anterior, existe uma seqüência, uma fila indiana, e o computador pode ficar tranqüilo sabendo a ordem das transações (as transações que aconteceram no terceiro bloco são posteriores às que aconteceram no segundo bloco, por exemplo) e saber que os mesmos bitcoins não foram gastos duas vezes seguidas pela mesma pessoa, o que seria inválido. Quando aparece um novo bloco, é só todos os computadores conferirem se não existe nenhuma transação inválida ali e, caso exista, rejeitarem aquele bloco por inteiro e esperarem que o próximo descarte aquela transação inválida e venha certinho.
Quem faz os blocos
Em tese, qualquer um dos computadores pode fazer o próximo bloco. A idéia é que cada pessoa que queira fazer uma transação vai lá e usa um computador da rede para enviar a sua proposta de transação ("quero transferir bitcoins para tal lugar e tal") para todos os demais, e que, quando alguém for fazer um bloco, pegue todas essas propostas de transação que forem válidas e as coloque no bloco que então será aceito por todos os outros computadores e incluído na cadeia global de blocos. Essa cadeia global tem que ser exatamente igual em todos os computadores.
Na prática, existe uma regra que faz com que nem todos consigam fazer blocos: é que o hash dos dados do bloco + um número mágico deve ser menor do que um valor muito pequeno
x. O número mágico é um número qualquer que o computador que está tentando fazer o bloco pode ajustar, por tentativa e erro, para que o hash saia de um jeito que ele queira. Oxpode ser maior ou menor de acordo com a freqüência dos últimos blocos produzidos. Quanto menor forx, mais estatisticamente difícil é encontrar um número mágico que, junto com os dados do bloco, tenha um hash menor do quex.Ou seja: para fazer um bloco, muitos números mágicos diferentes devem ser tentados até que seja encontrado algum que satisfaça as condições.
O que é um hash? Um hash é uma função matemática que é fácil fazer para um lado e difícil de fazer para o outro. A multiplicação, por exemplo, é fácil de fazer e fácil de fazer, e sua operação contrária, a divisão, também (tanto é que qualquer um com papel e caneta consegue, tem aquela coisa de ir passando os números pra baixo e subtraindo e tal). Já uma operação de exponenciação -- um número elevado a 1000, por exemplo -- é fácil de fazer, mas pra desfazer só com tentativa e erro (e é por tentativa e erro que o computador ou a calculadora fazem).
No caso do Bitcoin, o computador que está tentando produzir um bloco tem que achar um número tal que
(esse número mágico + fatores predeterminados do bloco) elevados a 50resultem num valor menor do quefator de dificuldade, um outro fator predeterminado pelo estado geral da cadeia de blocos.Suponha que um computador acha um número
1798465042647412146620280340569649349251249, por exemplo, e ele é menor do que ofator de dificuldade. Ele então diz para os outros: "aqui está meu bloco, o hash do meu bloco é1798465042647412146620280340569649349251249, os fatorespredeterminados do blocosão4(esses fatores todo mundo pode conferir), e meu número mágico é3.(4 + 3) elevado a 50é1798465042647412146620280340569649349251249, como todos podem conferir, então meu bloco é válido". Então todos aceitam aquele bloco como válido e começam a tentar achar o número mágico para o próximo bloco (e desta vez os fatores do bloco são diferentes, já que um novo bloco foi adicionado à cadeia e fez com que tudo mudasse).As regras para a definição de
xfazem com que na média cada novo bloco fique pronto em 10 minutos. Logo, se há apenas um computador tentando produzir blocos, o protocolo dirá quexseja relativamente alto, de modo que esse computador conseguirá, em 10 minutos, na média, encontrar um número mágico. Se, porém, milhares de computadores superpotentes estiverem tentando produzir blocos,xserá ajustado para um valor muito mais baixo, de modo que o esforço de todos esses computadores fazendo milhares de tentativas-e-erros por segundo só conseguirá encontrar um número mágico a cada 10 minutos.Hoje existem computadores feitos especialmente para procurar números mágicos que conseguem calcular hashes muito mais rápido do que o seu computador caseiro, o que torna inviável que qualquer pessoa não especializada tente produzir blocos, veja este gráfico da evolução da quantidade de hashes que são tentados a cada segundo.
Por algum motivo convencionou-se chamar os computadores que se empenham em fazer novos blocos de "mineradores".
Se dois computadores da rede fizerem blocos ao mesmo tempo, qual dos dois vale?
Se você já sabe quem faz os blocos fica fácil imaginar que isso é um pouco improvável. Mas mesmo assim pode acontecer. Mesmo que os blocos não fiquem prontos exatamente no mesmo instante, problemas podem acontecer porque os outros computadores da rede receberão os dois novos blocos em ordens diferentes, e aí não vai dar pra determinar qual vale ou qual deixa de valer assim, pela ordem.
Os computadores então ficam num estado de indeterminação acerca das duas cadeias de blocos possíveis, A e B, digamos, ambas idênticas até o bloco de número 723, mas diferentes no que diz respeito ao bloco 724, para o qual há duas alternativas. O protocolo determina que a cadeia que tenha mais trabalho realizado é a que vale, mas durante algum tempo podemos ter um estado em que alguns computadores da rede só sabem da existência do bloco A, enquanto outros só sabem da existência do bloco B, o que é uma grande confusão que só pode ser resolvida pelo advento do próximo bloco, o 725.
Como cada bloco se refere a um bloco anterior, é necessário que um desses dois blocos 724 seja escolhido pelos mineradores para ser o "pai" do bloco 725 quando o número mágico for encontrado e ele for feito. Mesmo que cada minerador escolha um pai diferente, desse processo sairá provavelmente apenas um bloco 725, e quando ele for espalhado ele determinará, pela sua ascendência, qual foi o bloco 724 que ficou valendo. Caso dois ou mais blocos 725 sejam produzidos ao mesmo tempo, o sistema continua nesse estado de indecisão até o 726, e assim por diante.
Por este motivo não se deve confiar que uma transação está concretizada pra valer mesmo só porque ela foi incluída num bloco. Você não tem como saber se existe um outro bloco alternativo que será preferido ao seu até que pelo menos mais alguns blocos tenham sido adicionados.
Transações
Muitas pessoas acreditam que existem endereços e que esses endereços têm um dono e ele é o dono dos bitcoins. Esta crença errônea é resultado de uma analogia com bancos tradicionais e contas bancárias (as contas são endereços que têm um dono e guardam dinheiro).
Na verdade assim que as transações são incluídas num bloco elas não "ficam em um endereço", mas vagando num grande limbo de transações. Deste limbo elas podem ser retiradas por qualquer pessoa que cumpra as condições que foram previamente especificadas pelo criador da transação.
Uma analogia mais útil do que a analogia das contas bancárias é a analogia do dinheiro: imagine que você tem uma nota de 20 dinheiros e você quer usá-la pra pagar 10 dinheiros a outrem. Você precisa quebrar aquela nota de 20 em duas de 10 e aí uma fica com você e a outra com a outra pessoa, ou, se você tiver duas notas de 5, você pode juntar as duas e dar para a outra pessoa. Todas essas notas que você está gastando têm uma história prévia: elas vieram de algum lugar em algum momento para o seu controle.
Transações com Bitcoin também são assim: você precisa mencionar especificamente uma transação anterior.
Por exemplo,
- Carlos paga 10 bitcoins a Dandara, Dandara agora tem uma transação no valor de 10
- Elisa paga 17 bitcoins a Dandara, Dandara tem uma transação no valor de 10 e uma no valor de 17
- Dandara paga 23 bitcoins a Felipe, ela junta suas duas transações e faz duas novas, uma no valor de 23, que vai para o controle de Felipe, e outra no valor de 4, que volta para o seu controle, Dandara agora tem uma transação no valor de 4, Felipe tem uma transação no valor de 23
- Felipe paga 14 bitcoins a Geraldo, ele divide sua transação em duas, uma no valor de 14 e outra no valor de 9, e assim por diante
Uma diferença, porém, é que no Bitcoin ninguém sabe quem é o dono da nota, você apenas sabe que pode gastá-la, caso você realmente possa (se uma transação prévia especifica uma condição que você pode cumprir, você deve cumprir aquela condição no momento em que estiver mencionando a transação prévia). Por isso uma carteira Bitcoin pode dizer que você "tem" um número x de bitcoins: a carteira sabe quais chaves privadas você controla e quais transações, dentre todas as transações não-gastas de toda a blockchain, podem ser gastas usando aquela chave.
Uma forma comum de transação é que especifica a condição
qualquer pessoa que tiver a chave privada capaz de assinar a chave pública cujo hash vai aqui dito pode gastar esta transação. Outras condições comuns são as que especificamnchaves, das quaismprecisam assinar a transação para que ela seja gasta (por exemplo, entre Fulano, Beltrano e Ciclano, quaisquer dois deles precisam concordar, mas não um só), o famoso multisig.Canal de pagamento
Um payment channel, ou via de pagamento, ou canal de pagamento é uma seqüência de promessas de pagamento feitas entre dois usuários de Bitcoin que não precisam ser publicados na blockchain e por isso são instantâneas e grátis.
Antes que você se pergunte o que acontece se alguém descumprir a promessa, devo dizer que "promessa" é um termo ruim, porque promessas de verdade podem ser quebradas, mas estas promessas são auto-cumpríveis, elas são transações assinadas que podem ser resgatadas a qualquer momento pelo destinatário bastando que ele as publique na blockchain.
A idéia é que na maioria das vezes você não vai precisar disso, e pode continuar fazendo transações novas que invalidam as antigas até que você decida publicar a última transação válida. Deste modo seu dinheiro está seguro numa via de pagamento
O grande problema é que caso a outra parte decida roubar e publicar uma transação antiga, você precisa aparecer num espaço de tempo razoável (isto depende do combinado entre os dois usuários, mas acho que o padrão é 24 horas) e publicar a última transação. Existem incentivos para impedir que alguém tente roubar (por exemplo, quem tentar roubar e for pego perde todo o dinheiro que estava naquela via) e outros mecanismos, como as atalaias que vigiam as vias de pagamentos dos outros pra ver se ninguém está roubando.
Exemplo:
- Ângela e Bóris decidem criar uma via de pagamento, pois esperam realizar muitos pagamentos de pequeno valor entre eles, tanto de ida quanto de volta, ao longo de vários meses
- Ângela cria uma transação para um endereço compartilhado entre ela e Bóris, no valor de 1000 satoshis, e desse endereço ela e Bóris criam uma transação devolvendo os 1000 para Ângela
- Ao resolver pagar 200 satoshis para Bóris, eles criam uma nova transação que transfere 800 para Ângela e 200 para Bóris
- Agora Bóris quer pagar 17 satoshis para Ângela, eles criam uma nova transação que transfere 817 para Ângela e 173 para Bóris
- E assim por diante eles vão criando novas transações que invalidam as anteriores e vão alterando o "saldo" da via de pagamento. Quando qualquer um dos dois quiser sacar o dinheiro que tem no saldo é só publicar a última transação e pronto.
A rede Relâmpago é uma grande rede de canais de pagamento que permite que pessoas façam pagamentos para pessoas não diretamente ligadas a elas por canais diretos, mas através de uma rota que percorre vários canais de outrem e ajusta seus saldos.
Existem outras criptomoedas além do Bitcoin?
Pra começar, jamais use essa palavra de novo. "criptomoeda" é ainda pior do que "moeda virtual"[^moeda_virtual].
Agora, respondendo: sim, de certo modo existem, são chamadas as "altcoins" ou "shitcoins" ("moedas de cocô", tradução amigável), porque elas são, de fato, grandes porcarias.
De outro modo, pode-se dizer que elas não são comparáveis ao Bitcoin, porque só pode haver uma moeda num livre mercado de moedas, e esse posto já é do Bitcoin, e também porque o Bitcoin é livre, sem donos, sem grandes poderes que o controlam, o que não se pode dizer de nenhuma altcoin.
Depois que o Bitcoin foi inventado e seu insight genial foi assimilado pela comunidade interessada, milhares de pessoas copiaram o protocolo, com pequenas modificações, para criar suas próprias moedas.
Assim surgiram Litecoin, Ethereum e muitas outras. No fundo são apenas cópias do Bitcoin que tentam melhorá-lo de algum modo ou adicionar outras funções.
Veja também:
- Aos poucos, e aí tudo de uma vez, Parker Lewis
- Não tem solução
- A podridão
- O Bitcoin como um sistema social humano
- Rede Relâmpago
[^protocolo]: Neste contexto, um protocolo é um conjunto de regras (inventadas arbitrariamente ou surgidas dos usos e costumes ao longo do tempo) que permitem que dois computadores diferentes se entendam e saibam que tipo de mensagens e comportamentos esperar dos demais. [^moeda_virtual]: Virtual? Virtual era pra significar uma coisa que não é ainda "atual", ou seja, que ainda não se concretizou na realidade. Mas como nossos amigos falantes da língüa portuguesa quiseram que isso passasse também a significar qualquer coisa que aconteça em um computador, "moeda virtual" ficou sendo uma moeda que existe no computador. O Bitcoin claramente é uma moeda que existe no computador, mas mesmo assim esse conceito é confuso. Uma transferência bancária tradicional também não é "dinheiro virtual"? Ela acontece no computador, mas você ainda não pegou as notas de papel ali na sua mão, então é virtual. Chamar só o Bitcoin de moeda virtual pode talvez criar a impressão de que é o Bitcoin é um brinquedinho, como por exemplo as moedas virtuais que existem dentro do universo de jogos de simulação, como, sei lá, World of Warcraft.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Personagens de jogos e símbolos
A sensação de "ser" um personagem em um jogo ou uma brincadeira talvez seja o mais próximo que eu tenha conseguido chegar do entendimento de um símbolo religioso.
A hóstia consagrada é, segundo a religião, o corpo de Cristo, mas nossa mente moderna só consegue concebê-la como sendo uma representação do corpo de Cristo. Da mesma forma outras culturas e outras religiões têm símbolos parecidos, inclusive nos quais o próprio participante do ritual faz o papel de um deus ou de qualquer coisa parecida.
"Faz o papel" é de novo a interpretação da mente moderna. O sujeito ali é a coisa, mas ele ao mesmo tempo que é também sabe que não é, que continua sendo ele mesmo.
Nos jogos de videogame e brincadeiras infantis em que se encarna um personagem o jogador é o personagem. não se diz, entre os jogadores, que alguém está "encenando", mas que ele é e pronto. nem há outra denominação ou outro verbo. No máximo "encarnando", mas já aí já é vocabulário jornalístico feito para facilitar a compreensão de quem está de fora do jogo.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
jiq
When someone created
jiqclaiming it had "jq queries" I went to inspect and realized it didn't, it just had a poor simple JSON query language that implemented 1% of alljqfeatures, so I forked it and pluggedjqdirectly into it, and renamed tojiq.After some comments on issues in the original repository from people complaining about lack of
jqcompatibility it got a ton of unexpected users, was even packaged to ArchLinux.