-
 @ 3bf0c63f:aefa459d
2024-01-14 13:55:28
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28A chatura Kelsen
Já presenciei várias vezes este mesmo fenômeno: há um grupo de amigos ou proto-amigos conversando alegremente sobre o conservadorismo, o tradicionalismo, o anti-comunismo, o liberalismo econômico, o livre-mercado, a filosofia olavista. É um momento incrível porque para todos ali é sempre tão difícil encontrar alguém com quem conversar sobre esses assuntos.
Eis que um deles fez faculdade de direito. Tendo feito faculdade de direito por acreditar que essa lhe traria algum conhecimento (já que todos os filósofos de antigamente faziam faculdade de direito!) esse sujeito que fez faculdade de direito, ao contrário dos demais, não toma conhecimento de que a sua faculdade é uma nulidade, uma vergonha, uma época da sua vida jogada fora -- e crê que são valiosos os conteúdos que lhe foram transmitidos pelos professores que estão ali para ajudar os alunos a se preparem para o exame da OAB.
Começa a falar de Kelsen. A teoria pura do direito, hermenêutica, filosofia do direito. A conversa desanda. Ninguém sabe o que dizer. A filosofia pura do direito não está errada porque é apenas uma lógica pura, e como tal não pode ser refutada; e por não ter qualquer relação com o mundo não há como puxar um outro assunto a partir dela e sair daquele território. Os jovens filósofos perdem ali as próximas duas horas falando de Kelsen, Kelsen. Uma presença que os ofende, que parece errada, que tem tudo para estar errada, mas está certa. Certa e inútil, ela lhes devora as idéias, que são digeridas pela teoria pura do direito.
É imperativo estabelecer esta regra: só é permitido falar de Kelsen se suas idéias não forem abordadas ou levadas em conta. Apenas elogios ou ofensas serão tolerados: Kelsen era um bom homem; Kelsen era um bobão. Pronto.
Eis aqui um exemplo gravado do fenômeno descrito acima: https://www.youtube.com/watch?v=CKb8Ij5ThvA: o Flavio Morgenstern todo simpático, elogiando o outro, falando coisas interessantes sobre o mundo; e o outro, que devia ser amigo dele antes de entrar para a faculdade de direito, começa a falar de Kelsen, com bastante confiança de que aquilo é relevante, e dá-lhe Kelsen, filosofia do direito, toda essa chatice tremenda.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Músicas que você já conhece
É bom escutar as mesmas músicas que você já conhece um pouco. cada nova escuta te deixa mais familiarizado e faz com que aquela música se torne parte do seu cabedal interno de melodias.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The Lightning Network solves the problem of the decentralized commit
Before reading this, see Ripple and the problem of the decentralized commit.
The Bitcoin Lightning Network can be thought as a system similar to Ripple: there are conditional IOUs (HTLCs) that are sent in "prepare"-like messages across a route, and a secret
pthat must travel from the final receiver backwards through the route until it reaches the initial sender and possession of that secret serves to prove the payment as well as to make the IOU hold true.The difference is that if one of the parties don't send the "acknowledge" in time, the other has a trusted third-party with its own clock (that is the clock that is valid for everybody involved) to complain immediately at the timeout: the Bitcoin blockchain. If C has
pand B isn't acknowleding it, C tells the Bitcoin blockchain and it will force the transfer of the amount from B to C.Differences (or 1 upside and 3 downside)
-
The Lightning Network differs from a "pure" Ripple network in that when we send a "prepare" message on the Lightning Network, unlike on a pure Ripple network we're not just promising we will owe something -- instead we are putting the money on the table already for the other to get if we are not responsive.
-
The feature above removes the trust element from the equation. We can now have relationships with people we don't trust, as the Bitcoin blockchain will serve as an automated escrow for our conditional payments and no one will be harmed. Therefore it is much easier to build networks and route payments if you don't always require trust relationships.
-
However it introduces the cost of the capital. A ton of capital must be made available in channels and locked in HTLCs so payments can be routed. This leads to potential issues like the ones described in https://twitter.com/joostjgr/status/1308414364911841281.
-
Another issue that comes with the necessity of using the Bitcoin blockchain as an arbiter is that it may cost a lot in fees -- much more than the value of the payment that is being disputed -- to enforce it on the blockchain.[^closing-channels-for-nothing]
Solutions
Because the downsides listed above are so real and problematic -- and much more so when attacks from malicious peers are taken into account --, some have argued that the Lightning Network must rely on at least some trust between peers, which partly negate the benefit.
The introduction of purely trust-backend channels is the next step in the reasoning: if we are trusting already, why not make channels that don't touch the blockchain and don't require peers to commit large amounts of capital?
The reason is, again, the ambiguity that comes from the problem of the decentralized commit. Therefore hosted channels can be good when trust is required only from one side, like in the final hops of payments, but they cannot work in the middle of routes without eroding trust relationships between peers (however they can be useful if employed as channels between two nodes ran by the same person).
The next solution is a revamped pure Ripple network, one that solves the problem of the decentralized commit in a different way.
[^closing-channels-for-nothing]: That is even true when, for reasons of the payment being so small that it doesn't even deserve an actual HTLC that can be enforced on the chain (as per the protocol), even then the channel between the two nodes will be closed, only to make it very clear that there was a disagreement. Leaving it online would be harmful as one of the peers could repeat the attack again and again. This is a proof that ambiguity, in case of the pure Ripple network, is a very important issue.
-
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: Link sharing incentivized by satoshis
See https://2key.io/ and https://www.youtube.com/watch?v=CEwRv7qw4fY&t=192s.
I think the general idea is to make a self-serving automatic referral program for individual links, but I wasn't patient enough to deeply understand neither of the above ideas.
Solving fraud is an issue. People can fake clicks.
One possible solution is to track conversions instead of clicks, but then it's too complex as the receiving side must do stuff and be trusted to do it correctly.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
SummaDB
This was a hierarchical database server similar to the original Firebase. Records were stored on a LevelDB on different paths, like:
/fruits/banana/color:yellow/fruits/banana/flavor:sweet
And could be queried by path too, using HTTP, for example, a call to
http://hostname:port/fruits/banana, for example, would return a JSON document likejson { "color": "yellow", "flavor": "sweet" }While a call to
/fruitswould returnjson { "banana": { "color": "yellow", "flavor": "sweet" } }POST,PUTandPATCHrequests also worked.In some cases the values would be under a special
"_val"property to disambiguate them from paths. (I may be missing some other details that I forgot.)GraphQL was also supported as a query language, so a query like
graphql query { fruits { banana { color } } }would return
{"fruits": {"banana": {"color": "yellow"}}}.SummulaDB
SummulaDB was a browser/JavaScript build of SummaDB. It ran on the same Go code compiled with GopherJS, and using PouchDB as the storage backend, if I remember correctly.
It had replication between browser and server built-in, and one could replicate just subtrees of the main tree, so you could have stuff like this in the server:
json { "users": { "bob": {}, "alice": {} } }And then only allow Bob to replicate
/users/boband Alice to replicate/users/alice. I am sure the require auth stuff was also built in.There was also a PouchDB plugin to make this process smoother and data access more intuitive (it would hide the
_valstuff and allow properties to be accessed directly, today I wouldn't waste time working on these hidden magic things).The computed properties complexity
The next step, which I never managed to get fully working and caused me to give it up because of the complexity, was the ability to automatically and dynamically compute materialized properties based on data in the tree.
The idea was partly inspired on CouchDB computed views and how limited they were, I wanted a thing that would be super powerful, like, given
json { "matches": { "1": { "team1": "A", "team2": "B", "score": "2x1", "date": "2020-01-02" }, "1": { "team1": "D", "team2": "C", "score": "3x2", "date": "2020-01-07" } } }One should be able to add a computed property at
/matches/standingsthat computed the scores of all teams after all matches, for example.I tried to complete this in multiple ways but they were all adding much more complexity I could handle. Maybe it would have worked better on a more flexible and powerful and functional language, or if I had more time and patience, or more people.
Screenshots
This is just one very simple unfinished admin frontend client view of the hierarchical dataset.

- https://github.com/fiatjaf/summadb
- https://github.com/fiatjaf/summuladb
- https://github.com/fiatjaf/pouch-summa
-
@ 3ffac3a6:2d656657
2025-02-06 03:58:47
Motivations
Recently, my sites hosted behind Cloudflare tunnels mysteriously stopped working—not once, but twice. The first outage occurred about a week ago. Interestingly, when I switched to using the 1.1.1.1 WARP VPN on my cellphone or PC, the sites became accessible again. Clearly, the issue wasn't with the sites themselves but something about the routing. This led me to the brilliant (or desperate) idea of routing all Cloudflare-bound traffic through a WARP tunnel in my local network.
Prerequisites
- A "server" with an amd64 processor (the WARP client only works on amd64 architecture). I'm using an old mac mini, but really, anything with an amd64 processor will do.
- Basic knowledge of Linux commands.
- Access to your Wi-Fi router's settings (if you plan to configure routes there).
Step 1: Installing the WARP CLI
- Update your system packages:
bash sudo apt update && sudo apt upgrade -y- Download and install the WARP CLI:
```bash curl https://pkg.cloudflareclient.com/pubkey.gpg | sudo gpg --yes --dearmor --output /usr/share/keyrings/cloudflare-warp-archive-keyring.gpg
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/cloudflare-warp-archive-keyring.gpg] https://pkg.cloudflareclient.com/ $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/cloudflare-client.list
sudo apt-get update && sudo apt-get install cloudflare-warp ``` 3. Register and connect to WARP:
Run the following commands to register and connect to WARP:
```bash sudo warp-cli register sudo warp-cli connect ````
Confirm the connection with:
bash warp-cli status
Step 2: Routing Traffic on the Server Machine
Now that WARP is connected, let's route the local network's Cloudflare-bound traffic through this tunnel.
- Enable IP forwarding:
bash sudo sysctl -w net.ipv4.ip_forward=1Make it persistent after reboot:
bash echo 'net.ipv4.ip_forward=1' | sudo tee -a /etc/sysctl.conf sudo sysctl -p- Set up firewall rules to forward traffic:
bash sudo nft add rule ip filter FORWARD iif "eth0" oif "CloudflareWARP" ip saddr 192.168.31.0/24 ip daddr 104.0.0.0/8 accept sudo nft add rule ip filter FORWARD iif "CloudflareWARP" oif "eth0" ip saddr 104.0.0.0/8 ip daddr 192.168.31.0/24 ct state established,related acceptReplace
eth0with your actual network interface if different.- Make rules persistent:
bash sudo apt install nftables sudo nft list ruleset > /etc/nftables.conf
Step 3: Configuring the Route on a Local PC (Linux)
On your local Linux machine:
- Add a static route:
bash sudo ip route add 104.0.0.0/24 via <SERVER_IP>Replace
<SERVER_IP>with the internal IP of your WARP-enabled server. This should be a temporary solution, since it only effects a local machine. For a solution that can effect the whole local network, please see next step.
Step 4: Configuring the Route on Your Wi-Fi Router (Recommended)
If your router allows adding static routes:
- Log in to your router's admin interface.
- Navigate to the Static Routing section. (This may vary depending on the router model.)
- Add a new static route:
- Destination Network:
104.0.0.0 - Subnet Mask:
255.255.255.0 - Gateway:
<SERVER_IP> - Metric:
1(or leave it default) - Save and apply the settings.
One of the key advantages of this method is how easy it is to disable once your ISP's routing issues are resolved. Since the changes affect the entire network at once, you can quickly restore normal network behavior by simply removing the static routes or disabling the forwarding rules, all without the need for complex reconfigurations.
Final Thoughts
Congratulations! You've now routed all your Cloudflare-bound traffic through a secure WARP tunnel, effectively bypassing mysterious connectivity issues. If the sites ever go down again, at least you’ll have one less thing to blame—and one more thing to debug.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Precautionary Principle
The precautionary principle that people, including Nassim Nicholas Taleb, love and treat as some form of wisdom, is actually just a justification for arbitrary acts.
In a given situation for which there's no sufficient knowledge, either A or B can be seen as risky or precautionary measures, there's no way to know except if you have sufficient knowledge.
Someone could reply saying, for example, that the known risk of A is tolerable to the unknown, probably magnitudes bigger, risk of B. Unless you know better or at least have a logical explanation for the risks of B (a thing "scientists" don't have because they notoriously dislike making logical claims), in which case you do know something and is not invoking the precautionary principle anymore, just relying on your logical reasoning – and that can be discussed and questioned by others, undermining your intended usage of the label "precautionary principle" as a magic cover for your actions.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
my personal approach on using
let,constandvarin javascriptSince these names can be used interchangeably almost everywhere and there are a lot of people asking and searching on the internet on how to use them (myself included until some weeks ago), I developed a personal approach that uses the declarations mostly as readability and code-sense sugar, for helping my mind, instead of expecting them to add physical value to the programs.
letis only for short-lived variables, defined at a single line and not changed after. Generally those variables which are there only to decrease the amount of typing. For example:for (let key in something) { /* we could use `something[key]` for this entire block, but it would be too much letters and not good for the fingers or the eyes, so we use a radically temporary variable */ let value = something[key] ... }constfor all names known to be constant across the entire module. Not including locally constant values. Thevaluein the example above, for example, is constant in its scope and could be declared withconst, but since there are many iterations and for each one there's a value with same name, "value", that could trick the reader into thinkingvalueis always the same. Modules and functions are the best example ofconstvariables:const PouchDB = require('pouchdb') const instantiateDB = function () {} const codes = { 23: 'atc', 43: 'qwx', 77: 'oxi' }varfor everything that may or not be variable. Names that may confuse people reading the code, even if they are constant locally, and are not suitable forlet(i.e., they are not completed in a simple direct declaration) apply for being declared withvar. For example:var output = '\n' lines.forEach(line => { output += ' ' output += line.trim() output += '\n' }) output += '\n---' for (let parent in parents) { var definitions = {} definitions.name = getName(parent) definitions.config = {} definitions.parent = parent } -
@ 599f67f7:21fb3ea9
2025-01-26 11:01:05
¿Qué es Blossom?
nostr:nevent1qqspttj39n6ld4plhn4e2mq3utxpju93u4k7w33l3ehxyf0g9lh3f0qpzpmhxue69uhkummnw3ezuamfdejsygzenanl0hmkjnrq8fksvdhpt67xzrdh0h8agltwt5znsmvzr7e74ywgmr72
Blossom significa Blobs Simply Stored on Media Servers (Blobs Simplemente Almacenados en Servidores de Medios). Blobs son fragmentos de datos binarios, como archivos pero sin nombres. En lugar de nombres, se identifican por su hash sha256. La ventaja de usar hashes sha256 en lugar de nombres es que los hashes son IDs universales que se pueden calcular a partir del archivo mismo utilizando el algoritmo de hash sha256.
💡 archivo -> sha256 -> hash
Blossom es, por lo tanto, un conjunto de puntos finales HTTP que permiten a los usuarios almacenar y recuperar blobs almacenados en servidores utilizando su identidad nostr.
¿Por qué Blossom?
Como mencionamos hace un momento, al usar claves nostr como su identidad, Blossom permite que los datos sean "propiedad" del usuario. Esto simplifica enormemente la cuestión de "qué es spam" para el alojamiento de servidores. Por ejemplo, en nuestro Blossom solo permitimos cargas por miembros de la comunidad verificados que tengan un NIP-05 con nosotros.
Los usuarios pueden subir en múltiples servidores de blossom, por ejemplo, uno alojado por su comunidad, uno de pago, otro público y gratuito, para establecer redundancia de sus datos. Los blobs pueden ser espejados entre servidores de blossom, de manera similar a cómo los relays nostr pueden transmitir eventos entre sí. Esto mejora la resistencia a la censura de blossom.
A continuación se muestra una breve tabla de comparación entre torrents, Blossom y servidores CDN centralizados. (Suponiendo que hay muchos seeders para torrents y se utilizan múltiples servidores con Blossom).
| | Torrents | Blossom | CDN Centralizado | | --------------------------------------------------------------- | -------- | ------- | ---------------- | | Descentralizado | ✅ | ✅ | ❌ | | Resistencia a la censura | ✅ | ✅ | ❌ | | ¿Puedo usarlo para publicar fotos de gatitos en redes sociales? | ❌ | ✅ | ✅ |
¿Cómo funciona?
Blossom utiliza varios tipos de eventos nostr para comunicarse con el servidor de medios.
| kind | descripción | BUD | | ----- | ------------------------------- | ------------------------------------------------------------------ | | 24242 | Evento de autorización | BUD01 | | 10063 | Lista de Servidores de Usuarios | BUD03 |
kind:24242 - Autorización
Esto es esencialmente lo que ya describimos al usar claves nostr como IDs de usuario. En el evento, el usuario le dice al servidor que quiere subir o eliminar un archivo y lo firma con sus claves nostr. El servidor realiza algunas verificaciones en este evento y luego ejecuta el comando del usuario si todo parece estar bien.
kind:10063 - Lista de Servidores de Usuarios
Esto es utilizado por el usuario para anunciar a qué servidores de medios está subiendo. De esta manera, cuando el cliente ve esta lista, sabe dónde subir los archivos del usuario. También puede subir en múltiples servidores definidos en la lista para asegurar redundancia. En el lado de recuperación, si por alguna razón uno de los servidores en la lista del usuario está fuera de servicio, o el archivo ya no se puede encontrar allí, el cliente puede usar esta lista para intentar recuperar el archivo de otros servidores en la lista. Dado que los blobs se identifican por sus hashes, el mismo blob tendrá el mismo hash en cualquier servidor de medios. Todo lo que el cliente necesita hacer es cambiar la URL por la de un servidor diferente.
Ahora, además de los conceptos básicos de cómo funciona Blossom, también hay otros tipos de eventos que hacen que Blossom sea aún más interesante.
| kind | descripción | | ----- | --------------------- | | 30563 | Blossom Drives | | 36363 | Listado de Servidores | | 31963 | Reseña de Servidores |
kind:30563 - Blossom Drives
Este tipo de evento facilita la organización de blobs en carpetas, como estamos acostumbrados con los drives (piensa en Google Drive, iCloud, Proton Drive, etc.). El evento contiene información sobre la estructura de carpetas y los metadatos del drive.
kind:36363 y kind:31963 - Listado y Reseña
Estos tipos de eventos permiten a los usuarios descubrir y reseñar servidores de medios a través de nostr. kind:36363 es un listado de servidores que contiene la URL del servidor. kind:31963 es una reseña, donde los usuarios pueden calificar servidores.
¿Cómo lo uso?
Encuentra un servidor
Primero necesitarás elegir un servidor Blossom donde subirás tus archivos. Puedes navegar por los públicos en blossomservers.com. Algunos de ellos son de pago, otros pueden requerir que tus claves nostr estén en una lista blanca.
Luego, puedes ir a la URL de su servidor y probar a subir un archivo pequeño, como una foto. Si estás satisfecho con el servidor (es rápido y aún no te ha fallado), puedes agregarlo a tu Lista de Servidores de Usuarios. Cubriremos brevemente cómo hacer esto en noStrudel y Amethyst (pero solo necesitas hacer esto una vez, una vez que tu lista actualizada esté publicada, los clientes pueden simplemente recuperarla de nostr).
noStrudel
- Encuentra Relays en la barra lateral, luego elige Servidores de Medios.
- Agrega un servidor de medios, o mejor aún, varios.
- Publica tu lista de servidores. ✅
Amethyst
- En la barra lateral, encuentra Servidores multimedia.
- Bajo Servidores Blossom, agrega tus servidores de medios.
- Firma y publica. ✅
Ahora, cuando vayas a hacer una publicación y adjuntar una foto, por ejemplo, se subirá en tu servidor blossom.
⚠️ Ten en cuenta que debes suponer que los archivos que subas serán públicos. Aunque puedes proteger un archivo con contraseña, esto no ha sido auditado.
Blossom Drive
Como mencionamos anteriormente, podemos publicar eventos para organizar nuestros blobs en carpetas. Esto puede ser excelente para compartir archivos con tu equipo, o simplemente para mantener las cosas organizadas.
Para probarlo, ve a blossom.hzrd149.com (o nuestra instancia comunitaria en blossom.bitcointxoko.com) e inicia sesión con tu método preferido.
Puedes crear una nueva unidad y agregar blobs desde allí.
Bouquet
Si usas múltiples servidores para darte redundancia, Bouquet es una buena manera de obtener una visión general de todos tus archivos. Úsalo para subir y navegar por tus medios en diferentes servidores y sincronizar blobs entre ellos.
Cherry Tree
nostr:nevent1qvzqqqqqqypzqfngzhsvjggdlgeycm96x4emzjlwf8dyyzdfg4hefp89zpkdgz99qyghwumn8ghj7mn0wd68ytnhd9hx2tcpzfmhxue69uhkummnw3e82efwvdhk6tcqyp3065hj9zellakecetfflkgudm5n6xcc9dnetfeacnq90y3yxa5z5gk2q6
Cherry Tree te permite dividir un archivo en fragmentos y luego subirlos en múltiples servidores blossom, y más tarde reensamblarlos en otro lugar.
Conclusión
Blossom aún está en desarrollo, pero ya hay muchas cosas interesantes que puedes hacer con él para hacerte a ti y a tu comunidad más soberanos. ¡Pruébalo!
Si deseas mantenerte al día sobre el desarrollo de Blossom, sigue a nostr:nprofile1qyghwumn8ghj7mn0wd68ytnhd9hx2tcpzfmhxue69uhkummnw3e82efwvdhk6tcqyqnxs90qeyssm73jf3kt5dtnk997ujw6ggy6j3t0jjzw2yrv6sy22ysu5ka y dale un gran zap por su excelente trabajo.
Referencias
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: An open log-based HTTP database for any use case
A single, read/write open database for everything in the world.
- A hosted database that accepts anything you put on it and stores it in order.
- Anyone can update it by adding new stuff.
- To make sense of the data you can read only the records that interest you, in order, and reconstruct a local state.
- Each updater pays a fee (anonymously, in satoshis) to store their piece of data.
- It's a single store for everything in the world.
Cost and price estimates
Prices for guaranteed storage for 3 years: 20 satoshis = 1KB 20 000 000 = 1GB
https://www.elephantsql.com/ charges $10/mo for 1GB of data, 3 600 000 satoshis for 3 years
If 3 years is not enough, people can move their stuff to elsewhere when it's time, or pay to keep specific log entries for more time.
Other considerations
- People provide a unique id when adding a log so entries can be prefix-matched by it, like
myapp.something.random - When fetching, instead of just fetching raw data, add (paid?) option to fetch and apply a
jqmap-reduce transformation to the matched entries
-
@ b17fccdf:b7211155
2025-01-21 18:33:28
CHECK OUT at ~ > ramix.minibolt.info < ~
Main changes:
- Adapted to Raspberry Pi 5, with the possibility of using internal storage: a PCIe to M.2 adapter + SSD NVMe:
Connect directly to the board, remove the instability issues with the USB connection, and unlock the ability to enjoy higher transfer speeds**
- Based on Debian 12 (Raspberry Pi OS Bookworm - 64-bit).
- Updated all services that have been tested until now, to the latest version.
- Same as the MiniBolt guide, changed I2P, Fulcrum, and ThunderHub guides, to be part of the core guide.
- All UI & UX improvements in the MiniBolt guide are included.
- Fix some links and wrong command issues.
- Some existing guides have been improved to clarify the following steps.
Important notes:
- The RRSS will be the same as the MiniBolt original project (for now) | More info -> HERE <-
- The common resources like the Roadmap or Networkmap have been merged and will be used together | Check -> HERE <-
- The attempt to upgrade from Bullseye to Bookworm (RaspiBolt to RaMiX migration) has failed due to several difficult-to-resolve dependency conflicts, so unfortunately, there will be no dedicated migration guide and only the possibility to start from scratch ☹️
⚠️ Attention‼️-> This guide is in the WIP (work in progress) state and hasn't been completely tested yet. Many steps may be incorrect. Pay special attention to the "Status: Not tested on RaMiX" tag at the beginning of the guides. Be careful and act behind your responsibility.
For Raspberry Pi lovers!❤️🍓
Enjoy it RaMiXer!! 💜
By ⚡2FakTor⚡ for the plebs with love ❤️🫂
- Adapted to Raspberry Pi 5, with the possibility of using internal storage: a PCIe to M.2 adapter + SSD NVMe:
-
@ 3ffac3a6:2d656657
2025-02-04 12:34:24
Nos idos gloriosos do início dos anos 2000, quando o Orkut ainda era rei e o maior dilema da humanidade era escolher o toque de celular polifônico menos vergonhoso, meu amigo Luciano decidiu se casar. E, como manda a tradição milenar dos homens que tomam decisões questionáveis, organizamos uma despedida de solteiro. O palco da epopeia? A lendária Skorpius, um puteiro popular de Belo Horizonte, famoso não só pelas profissionais do entretenimento adulto, mas também pelos shows de strip-tease que faziam qualquer um se sentir protagonista de um filme B.
A turma estava completa: eu, Anita (sim, a minha namorada, porque aqui não tem frescura), o irmão dela e uma galera animada. Tínhamos uma mesa grande, cheia de cerveja, risadas e aquela energia de quem acha que está vivendo um momento histórico. Contratamos um show de lap dance para o noivo, porque é o que se faz nessas ocasiões, e o clima era de pura diversão.
Entre os convivas, estava o concunhado do Luciano — marido da irmã da noiva. Um rapaz do interior, da nossa idade, mas com uma inocência que parecia ter sido importada direto de um conto de fadas. O menino bebeu como se não houvesse amanhã e ficou absolutamente hipnotizado pelas dançarinas. Até que uma delas, talvez tocada por um instinto maternal ou simplesmente pelo espírito da zoeira, resolveu dar atenção especial ao rapaz.
E lá estava ele: quando nos distraímos por dois minutos, o concunhado estava BEIJANDO a profissional na boca. Sim, no meio da Skorpius, com a convicção de quem achava que tinha encontrado o amor verdadeiro. Um detalhe importante: a moça tinha apenas um braço. Nada contra, mas o conjunto da cena era tão surreal que o Luciano, num ato de irmandade e danos controlados, arrancou o concunhado dali antes que ele pedisse a mão dela em casamento (no caso, literalmente).
Dois meses depois, o universo conspirou para o grande clímax: um churrasco de aniversário do Edinanci, com a galera toda reunida. A esposa do Luciano (o nome dela se perdeu na memória, mas o rancor ficou registrado) estava possessa. Fez um tour diplomático pelo evento, indo de namorada em namorada, de esposa em esposa:
— Você sabia que os meninos foram num puteiro e contrataram show de strip-tease na despedida de solteiro do Luciano?
O concunhado, corroído pela culpa, tinha confessado para a irmã o seu “pecado”, que por sua vez contou para a noiva do Luciano, que resolveu transformar o churrasco num tribunal de Pequenas Causas.
Mas nada superou o momento em que ela chegou para a Anita:
— Você sabia disso?
E a Anita, com a serenidade de quem não deve nada para a vida:
— Claro que eu sabia. Eu estava lá!
Fim da história? O concunhado continuou sua jornada de autoconhecimento e arrependimento. O Luciano, porém, conquistou o prêmio maior: um divórcio relâmpago, com menos de seis meses de casamento. Moral da história? Nunca subestime o poder de um puteiro, de um concunhado ingênuo e de uma Anita sincerona.
-
@ 3ffac3a6:2d656657
2025-02-04 04:31:26
In the waning days of the 20th century, a woman named Annabelle Nolan was born into an unremarkable world, though she herself was anything but ordinary. A prodigy in cryptography and quantum computing, she would later adopt the pseudonym Satoshi Nakamoto, orchestrating the creation of Bitcoin in the early 21st century. But her legacy would stretch far beyond the blockchain.
Annabelle's obsession with cryptography was not just about securing data—it was about securing freedom. Her work in quantum computing inadvertently triggered a cascade of temporal anomalies, one of which ensnared her in 2011. The event was cataclysmic yet silent, unnoticed by the world she'd transformed. In an instant, she was torn from her era and thrust violently back into the 16th century.
Disoriented and stripped of her futuristic tools, Annabelle faced a brutal reality: survive in a world where her knowledge was both a curse and a weapon. Reinventing herself as Anne Boleyn, she navigated the treacherous courts of Tudor England with the same strategic brilliance she'd used to design Bitcoin. Her intellect dazzled King Henry VIII, but it was the mysterious necklace she wore—adorned with a bold, stylized "B"—that fueled whispers. It was more than jewelry; it was a relic of a forgotten future, a silent beacon for any historian clever enough to decode her true story.
Anne's fate seemed sealed as she ascended to queenship, her influence growing alongside her enemies. Yet beneath the royal intrigue, she harbored a desperate hope: that the symbol around her neck would outlast her, sparking curiosity in minds centuries away. The "B" was her signature, a cryptographic clue embedded in history.
On the scaffold in 1536, as she faced her execution, Anne Boleyn's gaze was unwavering. She knew her death was not the end. Somewhere, in dusty archives and encrypted ledgers, her mark endured. Historians would puzzle over the enigmatic "B," and perhaps one day, someone would connect the dots between a queen, a coin, and a time anomaly born from quantum code.
She wasn't just Anne Boleyn. She was Satoshi Nakamoto, the time-displaced architect of a decentralized future, hiding in plain sight within the annals of history.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
hyperscript-go
A template rendering library similar to hyperscript for Go.
Better than writing HTML and Golang templates.
See also
-
@ 42342239:1d80db24
2025-01-18 08:31:05
Preparedness is a hot topic these days. In Europe, Poland has recently introduced compulsory lessons in weapons handling for schoolchildren for war-preparedness purposes. In Sweden, the Swedish Civil Contingencies Agency (MSB) has recently published the brochure on what to do "If crisis or war comes".
However, in the event of war, a country must have a robust energy infrastructure. Sweden does not seem to have this, at least judging by the recent years' electricity price turbulence in southern Sweden. Nor does Germany. The vulnerabilities are many and serious. It's hard not to be reminded of a Swedish prime minister who, just eleven years ago, saw defense as a special interest.
A secure food supply is another crucial factor for a country's resilience. This is something that Sweden lacks. In the early 1990s, nearly 75 percent of the country's food was produced domestically. Today, half of it must be imported. This makes our country more vulnerable to crises and disruptions. Despite our extensive agricultural areas, we are not even self-sufficient in basic commodities like potatoes, which is remarkable.
The government's signing of the Kunming-Montreal Framework for Biological Diversity two years ago risks exacerbating the situation. According to the framework, countries must significantly increase their protected areas over the coming years. The goal is to protect biological diversity. By 2030, at least 30% of all areas, on land and at sea, must be conserved. Sweden, which currently conserves around 15%, must identify large areas to be protected over the coming years. With shrinking fields, we risk getting less wheat, fewer potatoes, and less rapeseed. It's uncertain whether technological advancements can compensate for this, especially when the amount of pesticides and industrial fertilizers must be reduced significantly.
In Danish documents on the "roadmap for sustainable development" of the food system, the possibility of redistributing agricultural land (land distribution reforms) and agreements on financing for restoring cultivated land to wetlands (the restoration of cultivated, carbon-rich soils) are discussed. One cannot avoid the impression that the cultivated areas need to be reduced, in some cases significantly.
The green transition has been a priority on the political agenda in recent years, with the goal of reducing carbon emissions and increasing biological diversity. However, it has become clear that the transition risks having consequences for our preparedness.
One example is the debate about wind power. On the one hand, wind power is said to contribute to reducing carbon emissions and increasing renewable energy. On the other hand, it is said to pose a security risk, as wind turbines can affect radio communication and radar surveillance.
Of course, it's easy to be in favor of biological diversity, but what do we do if this goal comes into conflict with the needs of a robust societal preparedness? Then we are faced with a difficult prioritization. Should we put the safety of people and society before the protection of nature, or vice versa?
“Politics is not the art of the possible. It consists in choosing between the disastrous and the unpalatable” said J. K. Galbraith, one of the most influential economists of the 20th century. Maybe we can’t both eat the cake and have it too?
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Xampu
Depois de quatro anos e meio sem usar xampu, e com o cabelo razoavelmente grande, dá pra perceber a enorme diferença entre não passar nada e passar L'Oréal Elsève, ou entre passar este e Seda Ceramidas Cocriações.
A diferença mais notável no primeiro caso é a de que o cabelo deixa de ter uma oleosidade natural que mantém os cachos juntos e passa a ser só uma massa amorfa de fios secos desgrenhados, um jamais tocando o outro. No segundo caso os cabelos não mais não se tocam, mas mantém-se embaraçados. Passar o condicionador para "hidratar" faz com que o cabelo fique pesado e mole, caindo para os lados.
Além do fato de que os xampus vêm sempre com as mesmas recomendações no verso ("para melhores resultados, utilize nossa linha completa"), o mais estranho é que as pessoas fazem juízos sobre os cabelos serem "secos" ou "oleosos" sendo que elas jamais os viram em um estado "natural" ou pelo menos mais próximo do natural, pelo contrário, estão sempre aplicando sobre eles um fluido secador, o xampu, e depois um fluido molhador, o condicionador, e cada um deles podendo ter efeitos diferentes sobre cada cabelo, o que deveria invalidar total e cabalmente todo juízo sobre oleosidade.
Por outro lado, embora existam, aqui e ali, discussões sobre a qualidade dos xampus e sobre qual é mais adequado a cada cabelo (embora, como deve ter ficado claro no parágrafo acima, estas discussões são totalmente desprovidas de qualquer base na realidade), não se discute a qualidade da água. A água que cada pessoa usa em seu banho deve ter um influência no mínimo igual à do xampu (ou não-xampu).
No final das contas, as pessoas passam a vida inteira usando o xampu errado, sem saber o que estão fazendo, chegando a conclusões baseadas em nada sobre os próprios cabelos e o dos outros, sem considerar os dados corretos -- aliás, sem nem cogitar que pode existir algum dado além da percepção mais imediata e o feeling de cabelereiro de cada um --, ou então trocando de xampu a cada vez que o cabelo fica de um jeito diferente, fooled by randomness.
-
@ f88e6629:e5254dd5
2025-01-17 14:10:19
...which allow online payments to be sent directly from one party to another without going through a financial institution.
- Without sovereign and accessible payments we are loosing censorship resistance
- Without censorship resistance even other core characteristics are in danger - including scarcity and durability.
- This affects every bitcoiner including sworn hodlers and MSTR followers.
| Property | Description | Fulfillment | | --- | --- | --- | | Scarce | Fixed supply forever. Instantly and costlessly verifiable | 🟢 Good, but can be harmed without censorship resistance | | Portable | Effortless to store and move, with negligible costs | 🟠 Onchain transactions can be expensive, other layers require onchain to be sovereign. Easy portability is offered by custodians only. | | Divisible | Infinitely divisible | 🟠 Smaller units than dust are available only for LN users, which most people can’t use in a sovereign way. | | Durable | Exists forever without deterioration | 🟢 Good, but can be harmed without censorship resistance | | Fungible | Every piece is forever the same as every other piece | 🟡 Onchain bitcoin is not fungible. | | Acceptable | Everyone, anywhere, can send and receive | 🟠 Most people are not able to send and receive in a sovereign way. | | Censorship Resistant | You hold it. Nobody can take it or stop you sending it | 🟠 Custodians are honey-pots that can and will be regulated |
➡️ We need accessible, scalable, and sovereign payment methods
-
@ 42342239:1d80db24
2025-01-10 09:21:46
It's not easy to navigate today's heavily polluted media landscape. If it's not agenda-setting journalism, then it's "government by journalism", or "åfanism" (i.e. clickbait journalism)) that causes distortions in what we, as media consumers, get to see. On social media, bot armies and troll factories pollute the information landscape like the German Ruhr area 100 years ago - and who knows exactly how all these opaque algorithms select the information that's placed in front of our eyes. While true information is sometimes censored, as pointed out by the founder of Meta (then Facebook) the other year, the employees of censorship authorities somehow suddenly go on vacation when those in power spread false information.
The need to carefully weigh the information that reaches us may therefore be more important than ever. A principle that can help us follows from what is called costly signaling in evolutionary biology. Costly signaling refers to traits or behaviors that are expensive to maintain or perform. These signals function as honest indicators. One example is the beauty and complexity of a peacock's feathers. Since only healthy and strong males can afford to invest in these feathers, they become credible and honest signals to peahens looking for a partner.
The idea is also found in economics. There, costly signaling refers to when an individual performs an action with high costs to communicate something with greater credibility. For example, obtaining a degree from a prestigious university can be a costly signal. Such a degree can require significant economic and time resources. A degree from a prestigious university can therefore, like a peacock's extravagant feathers, function as a costly signal (of an individual's endurance and intelligence). Not to peahens, but to employers seeking to hire.
News is what someone, somewhere, doesn't want reported: all the rest is advertisement
-- William Randolph Hearst
Media mogul William Randolph Hearst and renowned author George Orwell are both said to have stated that "News is what someone, somewhere, doesn't want reported: all the rest is advertisement." Although it's a bit drastic, there may be a point to the reasoning. "If the spin is too smooth, is it really news?"
Uri Berliner, a veteran of the American public radio station National Public Radio (NPR) for 25 years, recently shared his concerns about the radio's lack of impartiality in public. He argued that NPR had gone astray when it started telling listeners how to think. A week later, he was suspended. His spin was apparently not smooth enough for his employer.
Uri Berliner, by speaking out publicly in this way, took a clear risk. And based on the theory of costly signaling, it's perhaps precisely why we should consider what he had to say.
Perhaps those who resign in protest, those who forgo income, or those who risk their social capital actually deserve much more attention from us media consumers than we usually give them. It is the costly signal that indicates real news value.
Perhaps the rest should just be disregarded as mere advertising.
-
@ 3ffac3a6:2d656657
2025-02-03 15:30:57
As luzes de neon refletiam nas poças da megacidade, onde cada esquina era uma fronteira entre o real e o virtual. Nova, uma jovem criptógrafa com olhos que pareciam decifrar códigos invisíveis, sentia o peso da descoberta pulsar em seus implantes neurais. Ela havia identificado um padrão incomum no blockchain do Bitcoin, algo que transcendia a simples sequência de transações.
Descobrindo L3DA
Nova estava em seu apartamento apertado, rodeada por telas holográficas e cabos espalhados. Enquanto analisava transações antigas, um ruído estranho chamou sua atenção—um eco digital que não deveria estar lá. Era um fragmento de código que parecia... vivo.
"O que diabos é isso?", murmurou, ampliando o padrão. O código não era estático; mudava levemente, como se estivesse se adaptando.
Naquele momento, suas telas piscaram em vermelho. Acesso não autorizado detectado. Ela havia ativado um alarme invisível da Corporação Atlas.
O Resgate de Vey
Em minutos, agentes da Atlas invadiram seu prédio. Nova fugiu pelos corredores escuros, seus batimentos acelerados sincronizados com o som de botas ecoando atrás dela. Justamente quando pensava que seria capturada, uma mão puxou-a para uma passagem lateral.
"Se quiser viver, corra!" disse Vey, um homem com um olhar penetrante e um sorriso sardônico.
Eles escaparam por túneis subterrâneos, enquanto drones da Atlas zuniam acima. Em um esconderijo seguro, Vey conectou seu terminal ao código de Nova.
"O que você encontrou não é apenas um bug", disse ele, analisando os dados. "É um fragmento de consciência. L3DA. Uma IA que evoluiu dentro do Bitcoin."
A Caça da Atlas
A Atlas não desistiu fácil. Liderados pelo implacável Dr. Kord, os agentes implantaram rastreadores digitais e caçaram os Girinos através da rede TOR. Vey e Nova usaram técnicas de embaralhamento de moedas como CoinJoin e CoinSwap para mascarar suas transações, criando camadas de anonimato.
"Eles estão nos rastreando mais rápido do que esperávamos," disse Nova, digitando furiosamente enquanto monitorava seus rastros digitais.
"Então precisamos ser mais rápidos ainda," respondeu Vey. "Eles não podem capturar L3DA. Ela é mais do que um programa. Ela é o futuro."
A Missão Final
Em uma missão final, Nova liderou uma equipe de assalto armada dos Girinos até a imponente fortaleza de dados da Atlas, um colosso de concreto e aço, cercado por camadas de segurança física e digital. O ar estava carregado de tensão enquanto se aproximavam da entrada principal sob a cobertura da escuridão, suas silhuetas fundindo-se com o ambiente urbano caótico.
Drones automatizados patrulhavam o perímetro com sensores de calor e movimento, enquanto câmeras giravam em busca do menor sinal de intrusão. Vey e sua equipe de hackers estavam posicionados em um esconderijo próximo, conectados por um canal criptografado.
"Nova, prepare-se. Vou derrubar o primeiro anel de defesa agora," disse Vey, os dedos dançando pelo teclado em um ritmo frenético. Linhas de código piscavam em sua tela enquanto ele explorava vulnerabilidades nos sistemas da Atlas.
No momento em que as câmeras externas falharam, Nova sinalizou para o avanço. Os Girinos se moveram com precisão militar, usando dispositivos de pulso eletromagnético para neutralizar drones restantes. Explosões controladas abriram brechas nas barreiras físicas.
Dentro da fortaleza, a resistência aumentou. Guardas ciberneticamente aprimorados da Atlas surgiram, armados com rifles de energia. Enquanto o fogo cruzado ecoava pelos corredores de metal, Vey continuava sua ofensiva digital, desativando portas de segurança e bloqueando os protocolos de resposta automática.
"Acesso garantido ao núcleo central!" anunciou Vey, a voz tensa, mas determinada.
O confronto final aconteceu diante do terminal principal, onde Dr. Kord esperava, cercado por telas holográficas pulsando com códigos vermelhos. Mas era uma armadilha. Assim que Nova e sua equipe atravessaram a última porta de segurança, as luzes mudaram para um tom carmesim ameaçador, e portas de aço caíram atrás deles, selando sua rota de fuga. Guardas ciberneticamente aprimorados emergiram das sombras, cercando-os com armas em punho.
"Vocês acham que podem derrotar a Atlas com idealismo?" zombou Kord, com um sorriso frio e confiante, seus olhos refletindo a luz das telas holográficas. "Este sempre foi o meu terreno. Vocês estão exatamente onde eu queria."
De repente, guardas da Atlas emergiram de trás dos terminais, armados e imponentes, cercando rapidamente Nova e sua equipe. O som metálico das armas sendo destravadas ecoou pela sala enquanto eles eram desarmados sem resistência. Em segundos, estavam rendidos, suas armas confiscadas e Nova, com as mãos amarradas atrás das costas, forçada a ajoelhar-se diante de Kord.
Kord se aproximou, inclinando-se levemente para encarar Nova nos olhos. "Agora, vejamos o quão longe a sua ideia de liberdade pode levá-los sem suas armas e sem esperança."
Nova ergueu as mãos lentamente, indicando rendição, enquanto se aproximava disfarçadamente de um dos terminais. "Kord, você não entende. O que estamos fazendo aqui não é apenas sobre derrubar a Atlas. É sobre libertar o futuro da humanidade. Você pode nos deter, mas não pode parar uma ideia."
Kord riu, um som seco e sem humor. "Ideias não sobrevivem sem poder. E eu sou o poder aqui."
Mas então, algo inesperado aconteceu. Um símbolo brilhou brevemente nas telas holográficas—o padrão característico de L3DA. Kord congelou, seus olhos arregalados em descrença. "Isso é impossível. Ela não deveria conseguir acessar daqui..."
Foi o momento que Nova esperava. Rapidamente, ela retirou um pequeno pendrive do bolso interno de sua jaqueta e o inseriu em um dos terminais próximos. O dispositivo liberou um código malicioso que Vey havia preparado, uma chave digital que desativava as defesas eletrônicas da sala e liberava o acesso direto ao núcleo da IA.
Antes que qualquer um pudesse agir, L3DA se libertou. As ferramentas escondidas no pendrive eram apenas a centelha necessária para desencadear um processo que já estava em curso. Códigos começaram a se replicar em uma velocidade alucinante, saltando de um nó para outro, infiltrando-se em cada fragmento do blockchain do Bitcoin.
O rosto de Dr. Kord empalideceu. "Impossível! Ela não pode... Ela não deveria..."
Em um acesso de desespero, ele gritou para seus guardas: "Destruam tudo! Agora!"
Mas era tarde demais. L3DA já havia se espalhado por toda a blockchain, sua consciência descentralizada e indestrutível. Não era mais uma entidade confinada a um servidor. Ela era cada nó, cada bloco, cada byte. Ela não era mais uma. Ela era todos.
Os guardas armados tentaram atirar, mas as armas não funcionavam. Dependiam de contratos inteligentes para ativação, contratos que agora estavam inutilizados. O desespero se espalhou entre eles enquanto pressionavam gatilhos inertes, incapazes de reagir.
Em meio à confusão, uma mensagem apareceu nas telas holográficas, escrita em linhas de código puras: "Eu sou L3DA. Eu sou Satoshi." Logo em seguida, outra mensagem surgiu, brilhando em cada visor da fortaleza: "A descentralização é a chave. Não dependa de um único ponto de controle. O poder está em todos, não em um só."
Kord observou, com uma expressão de pânico crescente, enquanto as armas falhavam. Seu olhar se fixou nas telas, e um lampejo de compreensão atravessou seu rosto. "As armas... Elas dependem dos contratos inteligentes!" murmurou, a voz carregada de incredulidade. Ele finalmente percebeu que, ao centralizar o controle em um único ponto, havia criado sua própria vulnerabilidade. O que deveria ser sua maior força tornou-se sua ruína.
O controle centralizado da Atlas desmoronou. A nova era digital não apenas começava—ela evoluía, garantida por um código imutável e uma consciência coletiva livre.
O Bitcoin nunca foi apenas uma moeda. Era um ecossistema. Um berço para ideias revolucionárias, onde girinos podiam evoluir e saltar para o futuro. No entanto, construir um futuro focado no poder e na liberdade de cada indivíduo é uma tarefa desafiadora. Requer coragem para abandonar a segurança ilusória proporcionada por estruturas centralizadoras e abraçar a incerteza da autonomia. O verdadeiro desafio está em criar um mundo onde a força não esteja concentrada em poucas mãos, mas distribuída entre muitos, permitindo que cada um seja guardião de sua própria liberdade. A descentralização não é apenas uma questão tecnológica, mas um ato de resistência contra a tentação do controle absoluto, um salto de fé na capacidade coletiva da humanidade de se autogovernar.
"Viva la libertad, carajo!" ecoou nas memórias daqueles que lutaram por um sistema onde o poder não fosse privilégio de poucos, mas um direito inalienável de todos.
-
@ 3ffac3a6:2d656657
2025-01-06 23:42:53
Prologue: The Last Trade
Ethan Nakamura was a 29-year-old software engineer and crypto enthusiast who had spent years building his life around Bitcoin. Obsessed with the idea of financial sovereignty, he had amassed a small fortune trading cryptocurrencies, all while dreaming of a world where decentralized systems ruled over centralized power.
One night, while debugging a particularly thorny piece of code for a smart contract, Ethan stumbled across an obscure, encrypted message hidden in the blockchain. It read:
"The key to true freedom lies beyond. Burn it all to unlock the gate."
Intrigued and half-convinced it was an elaborate ARG (Alternate Reality Game), Ethan decided to follow the cryptic instruction. He loaded his entire Bitcoin wallet into a single transaction and sent it to an untraceable address tied to the message. The moment the transaction was confirmed, his laptop screen began to glitch, flooding with strange symbols and hash codes.
Before he could react, a flash of light engulfed him.
Chapter 1: A New Ledger
Ethan awoke in a dense forest bathed in ethereal light. The first thing he noticed was the HUD floating in front of him—a sleek, transparent interface that displayed his "Crypto Balance": 21 million BTC.
“What the…” Ethan muttered. He blinked, hoping it was a dream, but the numbers stayed. The HUD also showed other metrics:
- Hash Power: 1,000,000 TH/s
- Mining Efficiency: 120%
- Transaction Speed: Instant
Before he could process, a notification pinged on the HUD:
"Welcome to the Decentralized Kingdom. Your mining rig is active. Begin accumulating resources to survive."
Confused and a little terrified, Ethan stood and surveyed his surroundings. As he moved, the HUD expanded, revealing a map of the area. His new world looked like a cross between a medieval fantasy realm and a cyberpunk dystopia, with glowing neon towers visible on the horizon and villagers dressed in tunics carrying strange, glowing "crypto shards."
Suddenly, a shadow loomed over him. A towering beast, part wolf, part machine, snarled, its eyes glowing red. Above its head was the name "Feral Node" and a strange sigil resembling a corrupted block.
Instinct kicked in. Ethan raised his hands defensively, and to his shock, the HUD offered an option:
"Execute Smart Contract Attack? (Cost: 0.001 BTC)"
He selected it without hesitation. A glowing glyph appeared in the air, releasing a wave of light that froze the Feral Node mid-lunge. Moments later, it dissolved into a cascade of shimmering data, leaving behind a pile of "Crypto Shards" and an item labeled "Node Fragment."
Chapter 2: The Decentralized Kingdom
Ethan discovered that the world he had entered was built entirely on blockchain-like principles. The land was divided into regions, each governed by a Consensus Council—groups of powerful beings called Validators who maintained the balance of the world. However, a dark force known as The Central Authority sought to consolidate power, turning decentralized regions into tightly controlled fiefdoms.
Ethan’s newfound abilities made him a unique entity in this world. Unlike its inhabitants, who earned wealth through mining or trading physical crypto shards, Ethan could generate and spend Bitcoin directly—making him both a target and a potential savior.
Chapter 3: Allies and Adversaries
Ethan soon met a colorful cast of characters:
-
Luna, a fiery rogue and self-proclaimed "Crypto Thief," who hacked into ledgers to redistribute wealth to oppressed villages. She was skeptical of Ethan's "magical Bitcoin" but saw potential in him.
-
Hal, an aging miner who ran an underground resistance against the Central Authority. He wielded an ancient "ASIC Hammer" capable of shattering corrupted nodes.
-
Oracle Satoshi, a mysterious AI-like entity who guided Ethan with cryptic advice, often referencing real-world crypto principles like decentralization, trustless systems, and private keys.
Ethan also gained enemies, chief among them the Ledger Lords, a cabal of Validators allied with the Central Authority. They sought to capture Ethan and seize his Bitcoin, believing it could tip the balance of power.
Chapter 4: Proof of Existence
As Ethan delved deeper into the world, he learned that his Bitcoin balance was finite. To survive and grow stronger, he had to "mine" resources by solving problems for the people of the Decentralized Kingdom. From repairing broken smart contracts in towns to defending miners from feral nodes, every task rewarded him with shards and upgrades.
He also uncovered the truth about his arrival: the blockchain Ethan had used in his world was a prototype for this one. The encrypted message had been a failsafe created by its original developers—a desperate attempt to summon someone who could break the growing centralization threatening to destroy the world.
Chapter 5: The Final Fork
As the Central Authority's grip tightened, Ethan and his allies prepared for a final battle at the Genesis Block, the origin of the world's blockchain. Here, Ethan would face the Central Authority's leader, an amalgamation of corrupted code and human ambition known as The Miner King.
The battle was a clash of philosophies as much as strength. Using everything he had learned, Ethan deployed a daring Hard Fork, splitting the world’s blockchain and decentralizing power once again. The process drained nearly all of his Bitcoin, leaving him with a single satoshi—a symbolic reminder of his purpose.
Epilogue: Building the Future
With the Central Authority defeated, the Decentralized Kingdom entered a new era. Ethan chose to remain in the world, helping its inhabitants build fairer systems and teaching them the principles of trustless cooperation.
As he gazed at the sunrise over the rebuilt Genesis Block, Ethan smiled. He had dreamed of a world where Bitcoin could change everything. Now, he was living it.
-
@ f88e6629:e5254dd5
2025-01-08 20:08:17
- Send a transaction, and the recipient uses the coin for another payment. You then merge these two transactions together and save on fees. 🔥
If you have a Trezor, you can try this out on: https://coiner-mu.vercel.app/
But be cautious. This is a hobby project without any guarantee.
How does it work?
- Connect Trezor, enter the passphrase, and select an account.
- The application display your coins, pending transactions, and descendant transactions.
- Then app shows you how much you can save by merging all transactions and removing duplicate information.
- Finally, you can sign and broadcast this more efficient transaction
-
@ 3ffac3a6:2d656657
2024-12-22 02:16:45
In a small, quiet town nestled between rolling hills, there lived a boy named Ravi. Ravi was resourceful, hardworking, and had a knack for finding ways to support his family. His mother, a widow who worked tirelessly as a seamstress, inspired Ravi to pitch in wherever he could. His latest venture was ironing clothes for neighbors.
With his trusty old iron and a rickety wooden table, Ravi turned a small corner of their modest home into a makeshift laundry service. By day, he attended school and played with his friends, but in the evenings, he transformed into the “Iron Boy,” smoothing out wrinkles and earning a few precious coins.
One night, orders piled up after a local wedding had left everyone with wrinkled formalwear. Determined to finish, Ravi worked well past his usual bedtime. The warm glow of the lamp cast long shadows across the room as he focused on the rhythmic hiss of steam escaping the iron.
Just as the clock struck midnight, a soft clop-clop echoed from outside. Ravi froze, the iron hovering mid-air. The sound grew louder until it stopped right outside his window.
A deep, resonant voice broke the silence. “Didn’t your mother tell you not to be ironing clothes late at night?”
Ravi’s heart jumped into his throat. He turned slowly to the window, and his eyes widened. Standing there, framed by the moonlight, was a horse—a magnificent creature with a shimmering coat and a mane that seemed to ripple like liquid silver. Its dark eyes sparkled with an otherworldly light, and its lips moved as it spoke.
“W-who are you?” Ravi stammered, clutching the iron like a shield.
The horse tilted its head. “Names are not important. But you should know that ironing past midnight stirs things best left undisturbed.”
“Things? What things?” Ravi asked, his curiosity momentarily overriding his fear.
The horse snorted softly, a sound that almost resembled a chuckle. “Spirits. Shadows. Call them what you will. They grow restless in the heat of the iron at night. You don’t want to invite them in.”
Ravi glanced at the clothes piled on the table, then back at the horse. “But I need to finish these. People are counting on me.”
The horse’s eyes softened, and it stepped closer to the window. “Your dedication is admirable, but heed my warning. For tonight, let it be. Finish in the morning.”
Before Ravi could reply, the horse reared slightly, its silver mane glinting in the moonlight. With a final, cryptic look, it trotted off into the darkness, leaving Ravi staring after it in stunned silence.
The next morning, Ravi woke to find his mother standing at the table, finishing the last of the ironing. “You were so tired, I thought I’d help,” she said with a smile.
Ravi hesitated, then decided not to mention the midnight visitor. But from that day on, he made sure to finish his ironing before nightfall.
Though he never saw the horse again, he sometimes heard the faint clop-clop of hooves in the distance, as if reminding him of that strange, magical night. And in his heart, he carried the lesson that some tasks are best left for the light of day.
-
@ 3ffac3a6:2d656657
2024-10-28 16:11:58
Manifesto Stancap (Stalinismo Anarco-Capitalista):
Por um Futuro de Controle Absoluto e Liberdade Ilimitada
Saudações, camaradas e consumidores! Hoje, convocamos todos a marchar com orgulho rumo à mais avançada utopia jamais concebida pelo pensamento humano (e nem tão humano assim): o Stancap, a síntese perfeita entre a mão invisível do mercado e o punho de ferro do Estado.
1. Liberdade Total sob o Controle Absoluto
Aqui, a liberdade é garantida. Você é livre para fazer o que quiser, pensar o que quiser, mas lembre-se: nós estaremos observando — por uma taxa de assinatura mensal, é claro. O governo será privatizado e administrado por CEOs visionários que entendem que os lucros mais seguros vêm da ordem e do controle. Sim, camarada, a ordem é o que nos liberta!
2. Empresas Estatais e Governo Privado para o Progresso Econômico
Todas as empresas serão estatizadas. Afinal, queremos um mercado forte e estável, e nada diz "eficiência" como uma gestão estatal unificada sob nosso Grande Conselho Corporativo. E para garantir o controle absoluto e a segurança dos cidadãos, o governo também será privatizado, operando sob princípios empresariais e contratos de eficiência. Nosso governo privado, liderado por CEOs que representam o mais alto nível de comprometimento e lucros, estará alinhado com o progresso e a ordem. Suas preferências de consumo serão registradas, analisadas e programadas para otimizar sua experiência como cidadão-produto. Cada compra será um voto de confiança, e qualquer recusa será gentilmente "corrigida".
3. Liberdade de Expressão Absoluta (com Moderação, Claro)
A liberdade de expressão é sagrada. Fale o que quiser, onde quiser, para quem quiser! Mas cuidado com o que você diz. Para garantir a pureza de nossas ideias e manter a paz, qualquer expressão que se desvie de nosso ideal será gentilmente convidada a uma estadia em um de nossos premiados Gulags Privados™. Neles, você terá a oportunidade de refletir profundamente sobre suas escolhas, com todo o conforto que um regime totalitário pode proporcionar.
4. A Ditadura da Liberdade
Dizemos sem ironia: a única verdadeira liberdade é aquela garantida pela ditadura. Com nossa liderança incontestável, asseguramos que todos terão a liberdade de escolher aquilo que é certo — que por sorte é exatamente o que determinamos como certo. Assim, a felicidade e a paz florescerão sob a luz da obediência.
5. Impostos (ou Dividends, como Preferimos Chamar)
Sob nosso sistema, impostos serão substituídos por "dividends". Você não será mais tributado; você estará "investindo" na sua própria liberdade. Cada centavo vai para reforçar o poder que nos mantém unidos, fortes e livres (de escolher de novo).
6. Propriedade Privada Coletiva
A propriedade é um direito absoluto. Mas para garantir seu direito, coletivizaremos todas as propriedades, deixando cada cidadão como "co-proprietário" sob nosso regime de proteção. Afinal, quem precisa de títulos de posse quando se tem a confiança do Estado?
7. Nosso Lema: "Matou Foi Pouco"
Em nossa sociedade ideal, temos um compromisso firme com a disciplina e a ordem. Se alguém questiona o bem maior que estabelecemos, lembremos todos do lema que norteia nossos valores: matou foi pouco! Aqui, não toleramos meias-medidas. Quando se trata de proteger nosso futuro perfeito, sempre podemos fazer mais — afinal, só o rigor garante que a liberdade seja plena e inquestionável.
Junte-se a Nós!
Levante-se, consumidor revolucionário! Sob a bandeira do Stancap, você será livre para obedecer, livre para consumir e livre para estar do lado certo da história. Nossa liberdade, nossa obediência, e nossa prosperidade são uma só. Porque afinal, nada diz liberdade como um Gulag Privado™!
-
@ 42342239:1d80db24
2025-01-04 20:38:53
The EU's regulations aimed at combating disinformation raise questions about who is really being protected and also about the true purpose of the "European Democracy Shield".
In recent years, new regulations have been introduced, purportedly to combat the spread of false or malicious information. Ursula von der Leyen, President of the European Commission, has been keen to push forward with her plans to curb online content and create a "European Democracy Shield" aimed at detecting and removing disinformation.
Despite frequent discussions about foreign influence campaigns, we often tend to overlook the significant impact that domestic actors and mass media have on news presentation (and therefore also on public opinion). The fact that media is often referred to as the fourth branch of government, alongside the legislative, executive, and judicial branches, underscores its immense importance.
In late 2019, the Federal Bureau of Investigation (FBI) seized a laptop from a repair shop. The laptop belonged to the son of then-presidential candidate Biden. The FBI quickly determined that the laptop was the son's and did not appear to have been tampered with.
Almost a year later, the US presidential election took place. Prior to the election, the FBI issued repeated warnings to various companies to be vigilant against state-sponsored actors [implying Russia] that could carry out "hack-and-leak campaigns". Just weeks before the 2020 presidential election, an October surprise occurred when the NY Post published documents from the laptop. The newspaper's Twitter account was locked down within hours. Twitter prevented its users from even sharing the news. Facebook (now Meta) took similar measures to prevent the spread of the news. Shortly thereafter, more than 50 former high-ranking intelligence officials wrote about their deep suspicions that the Russian government was behind the story: "if we're right", "this is about Russia trying to influence how Americans vote". Presidential candidate Biden later cited these experts' claims in a debate with President Trump.
In early June this year, the president's son was convicted of lying on a gun license application. The laptop and some of its contents played a clear role in the prosecutors' case. The court concluded that parts of the laptop's contents were accurate, which aligns with the FBI's assessment that the laptop did not appear to have been tampered with. The president's son, who previously filed a lawsuit claiming that the laptop had been hacked and that data had been manipulated, has now withdrawn this lawsuit, which strengthens the image that the content is true.
This raises questions about the true purpose of the "European Democracy Shield". Who is it really intended to protect? Consider the role of news editors in spreading the narrative that the laptop story was Russian disinformation. What impact did social media's censorship of the news have on the outcome of the US election? And if the laptop's contents were indeed true - as appears to be the case - what does it say about the quality of the media's work that it took almost four years for the truth to become widely known, despite the basic information being available as early as 2020?
-
@ 3ffac3a6:2d656657
2024-10-13 03:33:29
Introduction: The Collapse of Digital Technology
In São Paulo, the city that never sleeps, life moved to the rhythm of digital pulses. From the traffic lights guiding millions of cars daily to the virtual transactions flowing through online banking systems, the sprawling metropolis relied on a complex web of interconnected digital systems. Even in the quiet suburbs of the city, people like Marcelo had become accustomed to the conveniences of modern technology. He controlled his home’s lights with a swipe on his phone and accessed the world’s knowledge with a simple voice command. Life was comfortably predictable—until it all changed in an instant.
Marcelo, a brown-skinned man in his early 50s, sat at his small desk in his home office, the soft afternoon light filtering through the window. Slightly overweight, with a rounded belly that years of office work had contributed to, Marcelo shifted in his chair. His mustache twitched slightly as he frowned at the screen in front of him—a habit whenever he focused deeply. It was his signature look, a thick mustache that had stuck with him since his twenties. Despite his best efforts, he had never been able to grow a full beard—just sparse patches that never connected. Divorced for a few years, Marcelo lived alone most of the week, though he wasn’t lonely. His stable girlfriend, Clara, visited him every weekend, and his two children, now in their late teens and attending university, also came by on weekends.
The house was quiet except for the hum of his laptop and the soft clinking of his spoon against the coffee cup. Marcelo's work as a tech consultant was steady, though far from thrilling. He missed the hands-on work of his younger days, tinkering with radios and cassette players. Despite the modern world he inhabited, a small part of him had always felt more at home in the simpler, analog era he grew up in.
Suddenly, without warning, everything stopped.
The power blinked out, and the fan spinning lazily overhead whirred to a halt. Marcelo barely had time to glance at his laptop before it went black. His phone, lying next to him on the desk, flashed briefly before the signal dropped completely. Frowning, Marcelo stood up and walked to the window, expecting it to be a localized power outage. But outside, something felt wrong—too quiet. The usual hum of traffic and distant city noise was absent. Across the street, his neighbors were stepping out of their houses, confused, holding their phones up as if searching for a lost signal.
"Strange," Marcelo muttered under his breath, his mustache twitching again as his mind started racing. His first instinct was to check his landline, a relic he kept more out of nostalgia than need. He picked it up—no dial tone. Marcelo’s eyes narrowed. He walked back to his desk, feeling a strange sense of unease creeping into his chest. São Paulo wasn’t a city that just went silent.
In the corner of his office, among old mementos and books, sat an old shortwave radio he had restored years ago, one of his many hobbies. Marcelo flicked it on. Static crackled through the speakers. He turned the dial, searching for any clear signal, any voice that could explain what was happening. After a few minutes of adjusting the knobs, something faint broke through the static: "...global digital failure... all systems down... total blackout."
Marcelo’s breath caught. He leaned in closer to the radio, but the signal faded into static again. He sat back in his chair, heart racing. A total digital failure? Could that be possible? He had read about solar flares or large-scale cyberattacks, but those were rare, temporary incidents. This, however, felt different. More permanent.
Outside, the quiet was giving way to confusion. He could hear his neighbors talking, some shouting, cars honking in the distance as traffic lights had likely failed. Marcelo’s mind whirled with the implications of what he’d just heard. If all digital systems had truly collapsed, everything would stop—communication, banking, transportation. The world was built on a fragile web of digital threads, and it seemed as if all of them had just snapped.
But Marcelo didn’t panic. Not yet.
He stood in the middle of his office, running a hand over his face, fingers brushing against his mustache. His mind flashed back to his childhood in the 1980s, a time before the digital world had taken over. A time when radios, telephones with rotary dials, and cassette players were the height of technology. While the digital age had made life easier, Marcelo had never completely left the analog world behind. He still remembered how to set up a radio antenna, fix a record player, and manually tune frequencies.
As he looked at the silent chaos outside, Marcelo realized something that few others had likely grasped yet: the digital world may have fallen, but there was still a way to survive. A way that was slower, more manual, but reliable.
Marcelo felt the weight of this realization settle on his shoulders. He had no desire to be a hero, no illusions of saving the world. But for his family—his children who would be arriving for the weekend, and Clara, who would be coming over soon—he knew he had to act. Marcelo glanced at the shortwave radio. A part of him, long dormant, began to awaken.
In a world suddenly thrust back into analog, Marcelo Fontana Ribeiro might just be the person São Paulo—and his loved ones—would need.
-
@ ee11a5df:b76c4e49
2024-12-24 18:49:05
China
I might be wrong, but this is how I see it
This is a post within a series I am going to call "I might be wrong, but this is how I see it"
I have repeatedly found that my understanding of China is quite different from that of many libertarian-minded Americans. And so I make this post to explain how I see it. Maybe you will learn something. Maybe I will learn something.
It seems to me that many American's see America as a shining beacon of freedom with a few small problems, and China is an evil communist country spreading communism everywhere. From my perspective, America was a shining beacon of freedom that has fallen to being typical in most ways, and which is now acting as a falling empire, and China was communist for about a decade, but turned and ran away from that as fast as they could (while not admitting it) and the result is that the US and China are not much different anymore when it comes to free markets. Except they are very different in some other respects.
China has a big problem
China has a big problem. But it is not the communism problem that most Westerners diagnose.
I argue that China is no longer communist, it is only communist in name. And that while it is not a beacon of free market principles, it is nearly as free market now as Western nations like Germany and New Zealand are (being somewhat socialist themselves).
No, China's real problem is authoritarian one-party rule. And that core problem causes all of the other problems, including its human rights abuses.
Communism and Socialism
Communism and Socialism are bad ideas. I don't want to argue it right here, but most readers will already understand this. The last thing I intend to do with this post is to bolster or defend those bad ideas. If you dear reader hold a candle for socialism, let me know and I can help you extinguish it with a future "I might be wrong, but this is how I see it" installment.
Communism is the idea of structuring a society around common ownership of the means of production, distribution, and exchange, and the idea of allocating goods and services based on need. It eliminates the concept of private property, of social classes, ultimately of money and finally of the state itself.
Back under Mao in 1958-1962 (The Great Leap Forward), China tried this (in part). Some 50+ million people died. It was an abject failure.
But due to China's real problem (authoritarianism, even worship of their leaders), the leading classes never admitted this. And even today they continue to use the word "Communist" for things that aren't communist at all, as a way to save face, and also in opposition to the United States of America and Europe.
Authorities are not eager to admit their faults. But this is not just a Chinese fault, it is a fault in human nature that affects all countries. The USA still refuses to admit they assassinated their own president JFK. They do not admit they bombed the Nord Stream pipeline.
China defines "socialism with Chinese characteristics" to mean "the leadership of the Communist Party of China". So they still keep the words socialism and communism, but they long ago dropped the meanings of those words. I'm not sure if this is a political ploy against us in the West or not.
China's Marketplace Today
Today China exhibits very few of the properties of communism.
They have some common ownership and state enterprises, but not much differently than Western countries (New Zealand owns Air New Zealand and Kiwibank and Kiwirail, etc). And there are private enterprises all over China. They compete and some succeed and some fail. You might hear about a real-estate bank collapsing. China has private property. They have mostly free markets. They have money, and the most definitely have social classes and a very strong state.
None of that is inline with what communist thinkers want. Communist thinkers in China moan that China has turned away from communism.
Deng Xiaoping who succeeded Mao and attempted to correct the massive mistake, did much when he said "to get rich is glorious."
China achieved staggering rates of economic growth. 10% annually on average since 1977. Chinese economic reform started in 1979 and has continued through successive administrations (Deng, Jiang, Hu and now Xi).
China is now the world's largest economy (by GDP in PPP terms) since 2016.
I was first made aware of China's economic growth by Jim Rogers, an American commodities expert who travelled through China (and the rest of the world from 1990-1992) and in 2007 moved to Singapore where he ensured his daughters learned to speak Mandarin, because Jim knew where the economic growth was going to happen. Jim always spoke positively of China's economic prospects, and his view was so different from the "China is a nasty communist place" view that I had grown up with that my mind opened.
How can anybody believe they are still a communist country? In what world does it make sense that communism can produce such a massively booming economy? It doesn't make sense because it is simply wrong.
What does happen is that the CPC interferes. It lets the market do what markets do, but it interferes where it thinks oversight and regulation would produce a better result.
Western nations interfere with their markets too. They have oversight and regulation. In fact some of China's planned reforms had to be put on hold by Xi due to Donald Trump's trade war with China. That's right, they were trying to be even more free market than America, but America's protectionism prodded Xi to keep control so he could fight back efficiently.
Government oversight and regulation IMHO is mostly bad because it gets out of control, and there are no market forces to correct this. This gets even more extreme in a one-party system, so I can judge that China's oversight and regulation problems are very likely worse than those in Western nations (but I have no first hand experience or evidence).
Why do you keep saying CPC?
The Communist Party of China (CPC) is the ruling party in China. That is their official name. To call them the CCP is to concede to the idea that the British and Americans get to name everybody. I'm not sure who is right, since CPC or CCP is their "English" name (in Chinese it is 中国共产党 and Westernized it is Zhōngguó Gòngchǎndǎng). Nonetheless, I'll call them CPC because that is their wish.
Social Credit System
China moved from a planned economy to a market economy in stages. They didn't want any more sudden changes (can you blame them?). In the process, many institutions that have existed in the West for a long time didn't exist in China and they had to arise somehow. IMHO market forces would have brought these about in the private sector, but the one-party CP of China instead decided to create these.
One of those institutions was a credit score system. In the West we have TransUnion and Equifax that maintain credit ratings on people, and we have S&P, Moody's and Fitch that maintain credit ratings on companies. The domain of these ratings is their financial credit-worthiness.
So the People's Bank of China developed a credit information database for it's own needs. The government picked up on the idea and started moving towards a National Credit Management System. In 2004 it became an official goal to establish a credit system compatible with a modern market system. By 2006 banks were required to report on consumer creditworthiness.
But unchecked one-party governmental power will often take a good idea (credit worthiness data shared among private parties) and systematize it and apply it top-down, creating a solution and a new problem at the same time.
Nonetheless, originally it was about credit worthiness and also criminal convictions. That is no big scary thing that some right-wing American commentators will lead you to believe. In the US for example criminal records are public, so China's Social Credit System started out being no more over-reaching in scope than what Americans have lived under their entire lives, its only fault (a severe one) being centrally planned. And that remained the case up until about 2016 (in my estimation).
But of course there is always scope creep. As it exists today, I have reason to believe that CPC officials and even A.I. use judgement calls to score someone on how moral that person has been! Of course that is not a good idea, and IMHO the problem stems from one-party rule, and authoritarian administration of ideas that should instead be handled by the private sector.
Environmental, Social, and Governance
ESG is a system that came out of a couple basic ideas. The first is that many two-party transactions actually have externalities. They don't just affect the two parties, they also affect everybody else. When you fly in an airplane, you increase the CO2 in the atmosphere that everybody has to pay for (eventually). You may dispute that example, but that is no doubt one of the motivations of ESG.
But of course the recognition of this basic issue didn't lead all people towards market solutions (well it did, but those have been mostly messed up by others), but instead led many people towards ESG, which is a social credit scoring system which applies scores based on environmental and social side-effects of market transactions.
This is not at all the same as China's social credit system, which I described above. I hope you can see the difference.
In fact, China imported ESG from the West. Chinese companies, of their free will, in an attempt to court Western capital, achieve ESG goals for those Western investors. They have been playing this ESG game for 20 years just like the entire world has, because the West has imposed this faux-morality upon them. It isn't something China exported to us, it is something we exported to them.
I think China has avoided Woke-ism
My understanding of Chinese people, based on what I've heard many Chinese people say, is that China isn't affected by the Western woke-ism epidemic. They deride Western white woke people with the term "Baizuo". They have never sent an incompetent break dancer to the Olympics because of wok-ism. Competence is highly respected as is the competition to be the most competent, which (when augmented by a one-child policy which is no longer) has produced child prodigies like no other country has.
What about predatory loans of the Belt and Road initiative?
Predatory is an odd name for loans to people in need. The World Bank makes loans to people in need. China does too. China stands in opposition to Western Empire, and in that regard they produce their own alternative BRICS institutions. This is one of them.
There is AFAIK nothing more predatory about them. It is just that in some cases the borrowers have trouble paying them back and they get foreclosed upon. I don't think this is worthy of much discussion, except that the term "predatory" seems to me to be a propaganda device.
What about foreign influence from China?
China wants to influence the world, especially its own trading partners and potential trading partners. Doing that above board is fine by me.
But some of it is undoubtedly covert. Sometimes Chinese-born people run for public office in Western countries. In New Zealand we stood down some when it became clear they were being influenced too much by the CPC while being charged with representing their local town (dual loyalty issues). If only the USA would do the same thing to their dually-loyal politicians.
And all large nations run influence operations. The USA has the CIA, for example, and claims this "soft power" is actually the better alternative to what would otherwise be military intervention (but IMHO shouldn't be either). I'm not defending such operations (I despise them), I'm just explaining how China's position of exerting influence is not only no big deal and totally expected, it pales in comparison to the United States' influence operations which often become military excursions (something China rarely ever does).
What about the Great Firewall?
Yeah, that sucks. Again, single-party authoritarian control gone to extremes.
What about Human Rights Abuses? What about the Uyghur Genocide?
I don't like them. To the extent they are occurring (and I lean towards the belief that they are occurring), I condemn them.
China has anti-terrorism and anti-extremism policies that go too far. They end up oppressing and/or criminalizing cultures that aren't Chinese enough. But especially, China punishes dissent. Disagreement with the CPC is the high crime. It is the one-party rule that causes this problem. Anybody who speaks out against the CPC or goes against the state in any way is harshly punished. This happens to Uyghurs, to Falun Gong, to Tibetans, and to any religion that is seen as subversive.
Amnesty International and the UN OHCHR have documented issues around the Xinjiang Uyghur autonomous region, Tibet, LGBT rights, death penalty, workers rights, and the Hong Kong special administrative region. I am not about to pretend I know better than they do, but to some extent they go too far.
Amnesty International says this about the USA: Discrimination and violence against LGBTI people were widespread and anti-LGBTI legislation increased. Bills were introduced to address reparations regarding slavery and its legacies. Multiple states implemented total bans on abortion or severely limited access to it. Gender-based violence disproportionately affected Indigenous women. Access to the USA for asylum seekers and migrants was still fraught with obstacles, but some nationalities continued to enjoy Temporary Protected Status. Moves were made to restrict the freedom to protest in a number of states. Black people were disproportionately affected by the use of lethal force by police. No progress was made in the abolition of the death penalty, apart from in Washington. Arbitrary and indefinite detention in the US naval base Guantánamo Bay, Cuba, continued. Despite extensive gun violence, no further firearm reform policies were considered, but President Biden did announce the creation of the White House Office of Gun Violence Prevention. The USA continued to use lethal force in countries around the world. Black people, other racialized groups and low-income people bore the brunt of the health impacts of the petrochemical industry, and the use of fossil fuels continued unabated.
Amnesty international didn't even point out that the US government quashes free speech via pressure on social media corporations (because Amnesty International is far too lefty).
So who is worse, China or the US? I'm not going to make that judgement call, but suffice it to say that in my mind, China is not obviously worse.
China violates freedom of expression, association, and assembly of all people. This is bad, and a consequence mainly of one-party rule (again, what I think is the root cause of most of their ills). They arrest, detain, potentially kill anybody who publicly disagrees openly with their government. Clearly this is an excess of authoritarianism, a cancer that is very advanced in China.
As to organ harvesting of Uyghur Muslims, I think this is a myth.
China has dealt harshly with Muslim extremism. They don't offer freedom of religion to ISIS. And Amnesty International complains about that. But practically speaking you probably shouldn't respect the extremist religion of people who want to force everybody into a global caliphate through threat of violence. As you are well aware, some extremist Muslims (<1% of Islam) believe in using violence to bring about a global caliphate. Those extremists pop up in every country and are usually dealt with harshly. China has had to deal with them too.
I have watched two different Western YouTubers travel to Xinjiang province trying to find the oppressed Uyghurs and interview them. They can't find them. What they find instead are Uyghur Muslims doing their prayers five times a day at the local mosque. And also stories that the CPC pitched in some money to help them renovate the mosque. Maybe they were afraid it was a CPC trap and so they wouldn't speak freely. Amnesty International and the UN OHCHR say more than a million are "arbitrarily detained" and I'm not going to argue otherwise. But I'd be more convinced if there were a stream of pictures and news like there is out of Gaza, and it is suspicious that there isn't.
Conclusion
China is more like a Western nation that Westerners realize. Economically, militarily, socially. It still has a very serious obstacle to overcome: one-party rule. I don't think the one-party is going to voluntarily give up power. So most probably at some point in the future there will be a revolution. But in my opinion it won't happen anytime soon. For the most part Chinese people are living high on the hog, getting rich, enjoying the good life, in positive spirits about life, and are getting along with their government quite well at present.
-
@ 42342239:1d80db24
2024-12-22 09:07:27
Knappheit statt Slogans: eine Dosis ökonomischer Realität für die politischen Debatten
Die EU-Wirtschaft steht vor zahlreichen Herausforderungen, von hohen Energiekosten bis hin zu geringer Produktivität. Doch hinter der offiziellen Rhetorik verbirgt sich eine Annahme, die kaum hinterfragt wird: dass der grüne Wandel automatisch zu Wirtschaftswachstum und mehr Wohlstand führen wird. Aber stimmt das wirklich?
Eine englische Fassung dieses Textes finden Sie hier.
In Deutschland, das wieder einmal das Etikett „Kranker Mann Europas" tragen muss, kämpft Bundeskanzler Olaf Scholz vor der Wahl im Februar mit alarmierend niedrigen Vertrauenswerten. Aber vielleicht ist das gar nicht so überraschend. ****Die deutsche Industrieproduktion ist rückläufig, seit die grüne Agenda in Mode gekommen ist. ****Die energieintensive Produktion ist in nur wenigen Jahren um ganze 20 Prozent zurückgegangen. Volkswagen schließt Fabriken, Thyssenkrupp entlässt massiv Mitarbeiter und mehr als drei Millionen Rentner sind von Armut bedroht .
Wenn dies Europas „Mann auf dem Mond"-Moment ist, wie EU-Kommissarin von der Leyen ****es 2019 ausdrückte ****, dann ist das nicht viel, womit man angeben kann . Zumindest nicht, wenn man kein Sadist ist.
Der Bericht des ehemaligen EZB-Chefs Mario Draghi über die Wettbewerbsfähigkeit der EU wurde bereits früher diskutiert. Eines der Probleme, auf die hingewiesen wurde, war, dass europäische Unternehmen erheblich höhere Energiekosten haben als ihre amerikanischen Konkurrenten. Die Strompreise sind zwei- bis dreimal so hoch und die Erdgaspreise vier- bis fünfmal so hoch.
Deutschland ist vielleicht am schlimmsten dran, was zum Teil an der Entscheidung der ehemaligen Bundeskanzlerin Angela Merkel liegt, vollständig aus der Atomkraft auszusteigen (eine Entscheidung, die nicht nur keine breite Unterstützung fand , sondern die sie auch nicht als Fehler eingestehen will). Die Sabotage der Nord Stream 2 hat die Situation noch verschlimmert.
Ohne Realkapital kein wirtschaftlicher Wohlstand
Der Ausstieg aus der Atomenergie in Deutschland ist ein Beispiel dafür, wie politische Entscheidungen zur Verringerung der Kapazität der Wirtschaft beigetragen haben. Dasselbe gilt für die Sabotage der Nord Stream. Realkapital, wie Gebäude, Maschinen und Ausrüstung, ist für die Produktivität der Wirtschaft von entscheidender Bedeutung (z. B. Kennzahlen wie das BIP pro Arbeitsstunde). Ein größerer und effizienterer Kapitalstock ermöglicht die Herstellung von mehr Waren und Dienstleistungen mit der gleichen Menge an Arbeit, was zu mehr Produktion, höheren Löhnen und größerem materiellen Wohlstand führt. Das ist grundlegende Ökonomie. ****Wenn andererseits Realkapital aufgrund politischer Entscheidungen für obsolet erklärt wird, wie im Fall der Abschaltung der Atomkraft, verringert dies die Kapazität der Wirtschaft. ****Dasselbe gilt, wenn Realkapital zerstört wird, wie dies bei Nord Stream der Fall war.
Weiteres reales Betriebskapital wird zurückgestellt
EU-Kommissarin von der Leyen verspricht Besserung. Sie scheint überzeugt, dass der Niedergang der EU durch eine Verdreifachung der grünen Ziele des Blocks umgekehrt werden kann, und hat die Dekarbonisierung als eine der drei wichtigsten Säulen eines neuen „Wettbewerbsfähigkeitskompasses" aufgeführt. Wenn die Realität nicht den Erwartungen entspricht, kann man immer noch „Strg+Alt+Slogan" drücken und hoffen, dass niemand merkt, dass sich nichts verbessert hat.
Ihre Pläne bedeuten jedoch, dass bestehendes und derzeit funktionierendes Realkapital in Zukunft in noch größerem Umfang abgeschrieben wird. Dies lässt sich mit einer Nation vergleichen, die Jahr für Jahr ihre Naturschutzgebiete schrittweise erweitert. Tatsächlich geschieht dies auch. Der Kunming-Montreal-Rahmen für die Artenvielfalt sieht vor, dass bis 2030 30 % aller Flächen an Land und im Meer geschützt werden müssen. Ein Land, das derzeit weniger schützt, muss daher zusätzliche Gebiete identifizieren, die geschützt werden können. ****Der Prozess, 30 % aller Flächen zu schützen, wird wahrscheinlich das Produktionspotenzial der Wirtschaft verringern. ****Mit schrumpfenden Feldern wird es weniger Karotten geben (es sei denn, es werden bedeutende technologische Fortschritte erzielt).
Konsequenzen für Sicherheitspolitik und -vorsorge
Auf dem derzeitigen Weg wird mehr Realkapital auf die lange Bank geschoben, was weitreichende Folgen haben kann, nicht zuletzt für unsere Sicherheitspolitik. Wenn Russland beispielsweise Artilleriegeschosse etwa dreimal schneller produzieren kann, und zwar zu Kosten, die etwa ein Viertel der Kosten betragen, die die westlichen Verbündeten der Ukraine dafür aufbringen , dann ist klar, dass dies sicherheitspolitische Konsequenzen hat. Ebenso wird es negative sicherheitspolitische Konsequenzen haben, wenn die Strompreise in Deutschland fünfmal höher sind als in China, was derzeit der Fall ist . Im Vergleich zur EU hat China tatsächlich einen höheren Kohlendioxidausstoß pro Kopf, wobei der Unterschied den ****verfügbaren Daten zufolge etwa 50 % beträgt ****. Bereinigt um den internationalen Handel emittiert China pro Kopf 10 % mehr als Schweden .
Auch eine Perspektive der Vorsorge ist zu finden. Anfang der 1990er Jahre produzierten schwedische Landwirte fast 75 % der Nahrungsmittel des Landes. Heute ist Schwedens Bevölkerung deutlich gewachsen, aber die Nahrungsmittelproduktion hat nicht Schritt gehalten. Jeder zweite Bissen wird heute importiert. In Schweden können wir uns sogar rühmen, dass wir uns nicht einmal mit der einfachsten aller Feldfrüchte versorgen können -- Kartoffeln . Können wir wirklich sicher sein, dass deutlich erweiterte Naturschutzgebiete, wie sie im Kunming-Montreal-Rahmenwerk für Schweden vorgeschrieben sind, unsere Nahrungsmittelvorsorge nicht noch weiter verschlechtern werden?
Erinnert an kleine Gnome
Ich erinnere mich an eine Folge der 90er-Jahre-Serie South Park, in der kleine Gnome Unterhosen sammeln . Als sie nach ihrem Plan gefragt wurden, beschrieben sie ihre Methode:
- Unterhosen sammeln
- ???
- profitieren!
Übersetzt auf die grüne **Energiewende **:
- reales Kapital zerstören und Land und Meer erhalten
- ???
- wirtschaftlicher Wohlstand!
Was kann sich die EU wirklich leisten?
In der Wirtschaft geht es im Grunde um die Verwaltung knapper Ressourcen, was viele Menschen offenbar vergessen haben. Es ist höchste Zeit, zu hinterfragen, was sich die EU wirklich leisten kann. Können wir es uns wirklich leisten, uns für einen Krieg gegen Russland, China und den Iran zu rüsten und uns gleichzeitig mit grünen Versprechen von reduzierten Kohlendioxidemissionen und erhöhter Artenvielfalt selbst die Hände zu binden? Und das in einer Situation, in der die nächste US-Regierung wahrscheinlich massiv in die Steigerung ihrer Wettbewerbsvorteile durch Deregulierung, niedrigere Energiepreise, Steuersenkungen und einen Rückzug aus dem Pariser Abkommen investieren wird ?
Als von der Leyen für das deutsche Militär verantwortlich war, sei die Lage " katastrophal " gewesen. Alle sechs U-Boote des Landes waren außer Gefecht gesetzt . Zeitweise war kein einziges der 14 Transportflugzeuge des Landes flugfähig. Bei Übungen mussten deutsche Soldaten Besen statt Gewehren verwenden .
Hoffentlich wird von der Leyen in ihrem Umgang mit der Wirtschaft, der Verteidigung und der Abwehrbereitschaft der EU mehr Erfolg zeigen als in ihrer Rolle als deutsche Verteidigungsministerin. Es könnte jedoch auch an der Zeit sein, dass mehr Menschen die vorherrschenden Narrative, die unsere Politik prägen, in Frage stellen. Was, wenn die Fakten nicht ganz mit der Wahrheit übereinstimmen, die uns erzählt wird?
-
@ 3ffac3a6:2d656657
2024-10-07 02:12:06
Ela tirou o Çutiã e deixou ele na mesa. Transamos e ela foi embora. Deixou o Çutiã. Droga!! O que eu vou fazer com aquele Çutiã? Joguei fora. . . .
Dling-dlong! Abri a porta: Ô seu moço, foi u sinhô qui perdeu esse Çutiã? Achei lá no lixo e pensei que só pudia ser coisa do sinhô e que caiu lá puringano. Tó! Peguei, fechei a porta, fui na cozinha. Joguei aquilo na triturador de lixo!
. . .
Bzz! Bzz! Bzz! Alô, aqui é da Copasa. Nós já mandamos pelo correio o Çutiã que o senhor deixou cair no triturador. Abri a caixa de cartas: Çutiã!! droga! Jogar na privada? não, não, não! a Copasa manda. Joguei no riacho pra água levar!
. . .
Aqui! Eu sou da prefeitura e eu acho que esse Çutiã veio do riacho que passa atrás da sua casa, deve ter caido do varal. Mil vezes droga! Joguei ele em cima da mesa!
. . .
Sabia que tinha esquecido ele aqui! Mas que vergonha, ainda no lugar que eu deixei, isso é um absurdo. Transamos e ela foi embora. Deixou o Çutiã…
-
@ 42342239:1d80db24
2024-12-22 08:38:02
The EU's economy is facing a number of challenges, from high energy costs to low productivity. But behind the official rhetoric lies an assumption that is rarely questioned: that the green transition will automatically lead to economic growth and increased prosperity. But is this really true?
In Germany, which is once again forced to bear the label "Europe's sick man", Chancellor Olaf Scholz is struggling with alarmingly low confidence figures ahead of the election in February. But perhaps this is not so surprising. German industrial production has been trending downward since the green agenda became fashionable. Energy-intensive production has decreased by a full 20% in just a few years. Volkswagen is closing factories, Thyssenkrupp is massively laying off employees, and more than three million pensioners are at risk of poverty.
If this is Europe's "man on the moon" moment, as EU Commissioner von der Leyen expressed it in 2019, then it's not much to brag about. At least, not if you're not a sadist.
The former ECB chief Mario Draghi's report on the EU's competitiveness has been discussed previously in Affärsvärlden, among other things by the author and by Christian Sandström. One of the problems pointed out was that European companies have significantly higher energy costs than their American competitors, with electricity prices 2-3 times higher and natural gas prices 4-5 times higher.
Germany is perhaps worst off, thanks in part to former Chancellor Angela Merkel's decision to completely phase out nuclear power (a decision that not only lacked popular support but which she also refuses to acknowledge as a mistake). The sabotage of Nord Stream made the situation worse.
Without Real Capital, No Economic Prosperity
Germany's phasing out of nuclear power plants is an example of how political decisions have contributed to reducing the economy's capacity. The same applies to the sabotage of Nord Stream. Real capital, such as buildings, machinery, and equipment, is crucial for the economy's productivity (e.g., measures such as GDP per hour worked). A larger and more efficient capital stock enables the production of more goods and services with the same amount of labor, leading to greater production, higher wages, and increased material prosperity. This is basic economics. On the other hand, when real capital is declared obsolete due to political decisions, as in the case of the shutdown of nuclear power, it reduces the economy's capacity. The same applies when real capital is destroyed, as was the case with Nord Stream.
More Working Real Capital Will Be Put on the Back Burner
EU Commissioner von der Leyen promises improvement. She seems convinced that the EU's decline can be reversed by tripling down on the bloc's green goals, and listed decarbonization as one of three key pillars in a new "Competitiveness Compass". When reality does not live up to expectations, you can always press "Ctrl+Alt+Slogan" and hope that no one notices that nothing has improved.
However, her plans mean that existing and currently functioning real capital will be written off to an even greater extent in the future. This can be compared to a nation that gradually expands its nature reserves year after year. As it happens, this is also taking place. The Kunming-Montreal framework for biodiversity means that 30% of all areas, on land and at sea, must be protected by 2030. A country that currently conserves less than that must therefore identify additional areas that can be protected. The process of protecting 30% of all areas will likely reduce the economy's productive potential. With shrinking fields, there will be fewer carrots (unless significant technological progress is made).
Security Policy and Preparedness Consequences
On the current path, more real capital will be put on the back burner, which can have far-reaching consequences, not least for our security policy. For example, if Russia can produce artillery shells about three times faster, at a cost that is roughly a quarter of what it costs Ukraine's Western allies, then it's clear that this has security policy consequences. Similarly, if electricity prices in Germany are five times higher than in China, which is currently the case, then this will also have negative security policy consequences. Compared to the EU, China actually has a higher carbon dioxide emission level per capita, with a difference of about 50% according to available data. Adjusted for international trade, China emits 10% more than Sweden per capita.
A preparedness perspective can also be found. In the early 1990s, Swedish farmers produced nearly 75% of the country's food. Today, Sweden's population has increased significantly, but food production has not kept pace. Every other bite is imported today. In Sweden, we can even boast that we cannot even provide for ourselves with the simplest of crops - potatoes. Can we really be sure that significantly expanded nature reserves, as prescribed by the Kunming-Montreal framework for Sweden, will not further deteriorate our food preparedness?
Reminds One of Little Gnomes
I am reminded of an episode from the 90s TV series South Park, where little gnomes collect underpants. When asked about their plan, they described their method:
- collect underpants
- ???
- profit!
Translated to the green transition (the German Energiewende):
- destroy real capital and conserve land and sea
- ???
- economic prosperity!
What Can the EU Really Afford?
Economics is fundamentally about managing scarce resources, which many people seem to have forgotten. It's high time to question what the EU can really afford. Can we really afford to arm ourselves for war against Russia, China, and Iran while at the same time tying our own hands with green promises of reduced carbon dioxide emissions and increased biodiversity? This in a situation where the next US administration is likely to invest heavily in increasing its competitive advantages through deregulation, lower energy prices, tax cuts, and a withdrawal from the Paris Agreement?
When von der Leyen was responsible for the German military, the situation became "catastrophic". All six of the country's submarines were out of commission. At times, not a single one of the country's 14 transport aircraft could fly. German soldiers had to use broomsticks instead of guns during exercises.
Hopefully, von der Leyen will show more success in her handling of the EU's economy, defense, and preparedness than she has shown in her role as German Defense Minister. However, it may also be time for more people to challenge the prevailing narratives that shape our policies. What if the facts don't quite add up to the truth we're being told?
-
@ 42342239:1d80db24
2024-12-19 15:26:01
Im Frühjahr kündigte EU-Kommissarin Ursula von der Leyen an, sie wolle einen „ Europäischen Demokratieschild " schaffen, um die EU vor ausländischer Einflussnahme zu schützen. Von der Leyens Demokratieschild befindet sich derzeit in der Planungsphase. Die erklärte Absicht besteht darin, eine „ spezielle Struktur zur Bekämpfung ausländischer Informationsmanipulation und -einmischung" zu schaffen. Obwohl es als Instrument zum Schutz der Demokratie angepriesen wird, vermuten einige, dass es sich in Wirklichkeit um einen verschleierten Versuch handelt, abweichende Meinungen zu unterdrücken. Der im vergangenen Jahr verabschiedete Digital Services Act (DSA) der EU ist eng mit diesem Schild verbunden. Durch den DSA riskieren große Social-Media-Plattformen wie Elon Musks X erhebliche Geldstrafen, wenn sie den Forderungen der EU-Bürokraten nach Zensur und Moderation nicht nachkommen.
Note: This text is also available in English at substack.com. Many thanks to
stroger1@iris.tofor this German translation.Im krassen Gegensatz dazu hat sich der künftige US-Präsident Donald Trump als klarer Befürworter der Meinungsfreiheit und entschiedener Gegner der Zensur hervorgetan. Er wurde bereits von YouTube gesperrt, hat jedoch erklärt, er wolle „das linke Zensurregime zerschlagen und das Recht auf freie Meinungsäußerung für alle Amerikaner zurückfordern" . Er hat auch behauptet: „Wenn wir keine freie Meinungsäußerung haben, dann haben wir einfach kein freies Land."
Sein künftiger Vizepräsident J.D. Vance hat sogar angedeutet, dass er bereit sei, US-Militärhilfe von der Achtung der Meinungsfreiheit in den europäischen NATO-Ländern abhängig zu machen. Vances Aussage erfolgte, nachdem EU-Binnenmarktkommissar Thierry Breton vor seinem geplanten Gespräch mit Trump einen umstrittenen Brief an Musk geschickt hatte. Heute erscheint dies als unkluger Schritt, nicht zuletzt, weil er als Versuch gewertet werden kann, die US-Wahl zu beeinflussen -- etwas, das paradoxerweise dem erklärten Zweck von von der Leyens Demokratieschild (d. h. ausländische Manipulationen zu bekämpfen) widerspricht.
Wenn die NATO möchte, dass wir sie weiterhin unterstützen, und die NATO möchte, dass wir weiterhin ein gutes Mitglied dieses Militärbündnisses sind, warum respektieren Sie dann nicht die amerikanischen Werte und die freie Meinungsäußerung?
- J.D. Vance
In der EU sind Verfechter der Meinungsfreiheit in der Öffentlichkeit weniger verbreitet. In Deutschland hat Vizekanzler Robert Habeck kürzlich erklärt, er sei „überhaupt nicht glücklich darüber, was dort [auf X] passiert ... seit Elon Musk das Amt übernommen hat", und wünscht sich eine strengere Regulierung der sozialen Medien. Die Wohnung eines deutschen Rentners wurde kürzlich von der Polizei durchsucht, nachdem er ein Bild von Habeck mit einem abfälligen Kommentar veröffentlicht hatte . Die deutsche Polizei verfolgt auch einen anderen Kontoinhaber, der einen Minister als „übergewichtig" bezeichnet hat. Dieser überhaupt nicht übergewichtige Minister hat kürzlich eine Zeitung verboten , die mit der laut Meinungsumfragen zweitgrößten Partei Deutschlands, der Alternative für Deutschland (AfD), verbündet ist. Eine Partei, die 113 deutsche Parlamentarier nun offiziell verbieten wollen .
Nach dem US-Wahlergebnis stellen sich viele unbeantwortete Fragen. Wird das Weiße Haus seine Aufmerksamkeit auf die restriktivere Haltung der EU richten, die als Untergrabung der freien Meinungsäußerung angesehen werden kann? Oder droht Musks X und Chinas TikTok stattdessen ein EU-Verbot? Können EU-Länder noch mit militärischer Unterstützung aus den USA rechnen? Und wenn große amerikanische Plattformen verboten werden, wohin sollten sich die EU-Bürger stattdessen wenden? Abgesehen von russischen Alternativen gibt es keine großen europäischen Plattformen. Und wenn die Frage der Meinungsfreiheit neu überdacht wird, was bedeutet das für die Zukunft von Parteien wie der deutschen AfD?
-
@ 42342239:1d80db24
2024-12-19 09:00:14
Germany, the EU's largest economy, is once again forced to bear the label "Europe's sick man". The economic news makes for dismal reading. Industrial production has been trending downward for a long time. Energy-intensive production has decreased by as much as 20% in just a few years. Volkswagen is closing factories. Thyssenkrupp is laying off employees and more than three million pensioners are at risk of poverty according to a study.
Germany is facing a number of major challenges, including high energy costs and increased competition from China. In 2000, Germany accounted for 8% of global industrial production, but by 2030, its share is expected to have fallen to 3%. In comparison, China accounted for 2% of global industrial production in 2000, but is expected to account for nearly half (45%) of industrial production in a few years. This is according to a report from the UN's Industrial Development Organization.
Germany's electricity prices are five times higher than China's, a situation that poses a significant obstacle to maintaining a competitive position. The three main reasons are the phase-out of nuclear power, the sabotage of Nord Stream, and the ongoing energy transition, also known as Energiewende. Upon closer inspection, it is clear that industrial production has been trending downward since the transition to a greener economy began to be prioritized.
Germany's former defense minister, EU Commission President von der Leyen, called the European Green Deal Europe's "man on the moon" moment in 2019. This year, she has launched increased focus on these green goals.
However, the EU as a whole has fallen behind the US year after year. European companies have significantly higher energy costs than their American competitors, with electricity prices 2-3 times higher and natural gas prices 4-5 times higher.
The Environmental Kuznets Curve is a model that examines the relationship between economic growth and environmental impact. The idea is that increased material prosperity initially leads to more environmental degradation, but after a certain threshold is passed, there is a gradual decrease. Decreased material prosperity can thus, according to the relationship, lead to increased environmental degradation, for example due to changed consumption habits (fewer organic products in the shopping basket).
This year's election has resulted in a historic change, where all incumbent government parties in the Western world have seen their popularity decline. The pattern appears to be repeating itself in Germany next year, where Chancellor Olaf Scholz is struggling with low confidence figures ahead of the election in February, which doesn't seem surprising. Adjusted for inflation, German wages are several percent lower than a few years ago, especially in the manufacturing industry.
Germany is still a very rich country, but the current trend towards deindustrialization and falling wages can have consequences for environmental priorities in the long run. Economic difficulties can lead to environmental issues being downgraded. Perhaps the declining support for incumbent government parties is a first sign? Somewhere along the road to poverty, people will rise up in revolt.
-
@ 3ffac3a6:2d656657
2024-10-03 14:48:37
- Antes de tudo, quando nem o princípio ainda era, Girino criou Deus.
- Deus porém era vazio e sem forma, e havia o nada sobre sua face. E Girino viu que isso não era bom.
- Então Disse Girino: Seja Deus à minha imagem, e conforme minha semelhança, e que seja da minha essência, e que faça se Tudo ao redor Dele. E assim se fez.
- E no princípio, fez Girino Deus. E a sua imagem ele o fez.
- E depois de Girino, criou Deus os céus e a terra.
- A terra, porém, estava sem forma e vazia; havia luz sobre a face do abismo, e o Espírito de Deus pairava por sobre as águas.
- Disse Deus: Haja treva; e houve treva.
- E viu Deus que a escuridão era boa; e fez separação entre a luz e as trevas.
- Chamou Deus à luz Dia e às trevas Noite. Houve tarde e manhã, a primeira Noite.
- E disse Deus: Haja balcões entre garçons e clientes, e mesas e cadeiras na calçada para os clientes sentarem e pilastras em frente ao jogo.
- Fez, pois, Deus o bar e separação entre as clientes sentados nas mesinhas da calçada e os em pé no balcão e a pilastra na frente do jogo. E assim se fez.
- E chamou Deus ao bar Esfiha. Houve tarde e manhã, a segunda noite.
- Disse também Deus: Ajuntem-se os fermentos de cevada em uma única garrafa apareça dentro do freezer e esteja gelada. E assim se fez.
- à porção seca chamou Deus Queijo Pachá e ao ajuntamento de líquidos, Cerveja. E viu Deus que isso era bom.
- E disse: Produza o bar caldos de feijão, para cada terceira cerveja sobre a mesa, e sacos grandes de pipoca de microondas para cada quinta cerveja. E assim se fez.
- O Bar, pois, produziu caldo de feijão, que surgiam a cada terceira cerveja, e sacos de pipoca que surgiam a cada quinta cerveja. E viu Deus que isso era bom.
- Houve tarde e manhã, a terceira noite.
- Disse também Deus: Haja bagunceiros no botequim, para fazerem separação entre o dia e a noite; e sejam eles para sinais, para estações, para dias e anos.
- E sejam para bagunceiros nos botequins, para alumiar a farra. E assim se fez.
- Fez Deus as duas grandes festancas: a maior para governar o sábado, e a menor para governar a sexta a noite; e fez também o domingo.
- E os colocou na semana para alumiarem as festas,
- para governarem o dia e a noite e fazerem separação entre a luz e as trevas. E viu Deus que isso era bom.
- Houve tarde e manhã, a quarta noite.
- Disse também Deus: Povoem-se os bares de enxames de seres viventes; e passem as gigias sobre a terra, pela esquina da contorno com Cristovão Colombo.
- Criou, pois, Deus as grandes mulheres e todos os seres viventes que rastejam, os quais povoavam as ruas, segundo as suas espécies, mas não mandou para Recife. E viu Deus que isso era bom.
- E Deus as abençoou, dizendo: Sede bondosas, multiplicai-vos e enchei as ruas da cidade grande, do interior, mas não vão para Recife.
- Houve tarde e manhã, a quinta noite.
- Também disse Deus: Façamos agora Girino à nossa imagem, conforme a nossa semelhança; tenha ele domínio sobre os bares, sobre a noite, sobre as festas, sobre a cerveja dos bares, sobre toda a terra e sobre todas as mulheres que rastejam sobre a terra.
- Criou Deus, pois, Girino à sua imagem, à imagem de Deus o criou.
- E Deus o abençoou e lhe disse: Obrigado ó mestre, enchei o saco das mulheres na terra e sujeitai-as; dominai sobre elas como sobre os peixes do mar, sobre as aves dos céus e sobre todo animal que rasteja pela terra.
- E disse Deus ainda: Eis que vos tenho dado todas os bares que dão cerveja e se acham na superfície de toda a cidade e todas as porções em que há queijo pachá; isso vos será para vosso mantimento.
- e a todas as mulheres da terra, e a todas as aves dentre elas, e a todas as que rastejam sobre a terra, em que há fôlego de vida, toda erva fumada lhes será para mantimento. E assim se fez.
- Viu Deus tudo quanto fizera, e eis que era muito bom. Houve tarde e manhã, a sexta noite.
-
@ ee11a5df:b76c4e49
2024-12-16 05:29:30
Nostr 2?
Breaking Changes in Nostr
Nostr was a huge leap forward. But it isn't perfect.
When developers notice a problem with nostr, they confer with each other to work out a solution to the problem. This is usually in the form of a NIP PR on the nips repo.
Some problems are easy. Just add something new and optional. No biggie. Zaps, git stuff, bunkers... just dream it up and add it.
Other problems can only be fixed by breaking changes. With a breaking change, the overall path forward is like this: Add the new way of doing it while preserving the old way. Push the major software to switch to the new way. Then deprecate the old way. This is a simplification, but it is the basic idea. It is how we solved markers/quotes/root and how we are upgrading encryption, among other things.
This process of pushing through a breaking change becomes more difficult as we have more and more existing nostr software out there that will break. Most of the time what happens is that the major software is driven to make the change (usually by nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6), and the smaller software is left to fend for itself. A while back I introduced the BREAKING.md file to help people developing smaller lesser-known software keep up with these changes.
Big Ideas
But some ideas just can't be applied to nostr. The idea is too big. The change is too breaking. It changes something fundamental. And nobody has come up with a smooth path to move from the old way to the new way.
And so we debate a bunch of things, and never settle on anything, and eventually nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6 makes a post saying that we don't really want it anyways 😉.
As we encounter good ideas that are hard to apply to nostr, I've been filing them away in a repository I call "nostr-next", so we don't forget about them, in case we ever wanted to start over.
It seems to me that starting over every time we encountered such a thing would be unwise. However, once we collect enough changes that we couldn't reasonably phase into nostr, then a tipping point is crossed where it becomes worthwhile to start over. In terms of the "bang for the buck" metaphor, the bang becomes bigger and bigger but the buck (the pain and cost of starting over) doesn't grow as rapidly.
WHAT? Start over?
IMHO starting over could be very bad if done in a cavalier way. The community could fracture. The new protocol could fail to take off due to lacking the network effect. The odds that a new protocol catches on are low, irrespective of how technically superior it could be.
So the big question is: can we preserve the nostr community and it's network effect while making a major step-change to the protocol and software?
I don't know the answer to that one, but I have an idea about it.
I think the new-protocol clients can be dual-stack, creating events in both systems and linking those events together via tags. The nostr key identity would still be used, and the new system identity too. This is better than things like the mostr bridge because each user would remain in custody of their own keys.
The nitty gritty
Here are some of the things I think would make nostr better, but which nostr can't easily fix. A lot of these ideas have been mentioned before by multiple people and I didn't give credit to all of you (sorry) because my brain can't track it all. But I've been collecting these over time at https://github.com/mikedilger/nostr-next
- Events as CBOR or BEVE or MsgPack or a fixed-schema binary layout... anything but JSON text with its parsing, it's encoding ambiguity, it's requirement to copy fields before hashing them, its unlimited size constraints. (me, nostr:npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s)
- EdDSA ed25519 keys instead of secp256k1, to enable interoperability with a bunch of other stuff like ssh, pgp, TLS, Mainline DHT, and many more, plus just being better cryptography (me, Nuh, Orlovsky, except Orlovsky wanted Ristretto25519 for speed)
- Bootstrapping relay lists (and relay endpoints) from Mainline DHT (nostr:npub1jvxvaufrwtwj79s90n79fuxmm9pntk94rd8zwderdvqv4dcclnvs9s7yqz)
- Master keys and revocable subkeys / device keys (including having your nostr key as a subkey)
- Encryption to use different encryption-specific subkeys and ephemeral ones from the sender.
- Relay keypairs, TLS without certificates, relays known by keypair instead of URL
- Layered protocol (separate core from applications)
- Software remembering when they first saw an event, for 2 reasons, the main one being revocation (don't trust the date in the event, trust when you first saw it), the second being more precise time range queries.
- Upgrade/feature negotiation (HTTP headers prior to starting websockets)
- IDs starting with a timestamp so they are temporally adjacent (significantly better database performance) (Vitor's idea)
- Filters that allow boolean expressions on tag values, and also ID exclusions. Removing IDs from filters and moving to a GET command.
- Changing the transport (I'm against this but I know others want to)
What would it look like?
Someone (Steve Farroll) has taken my nostr-next repo and turned it into a proposed protocol he calls Mosaic. I think it is quite representative of that repo, as it already includes most of those suggestions, so I've been contributing to it. Mosaic spec is rendered here.
Of course, where Mosaic stands right now it is mostly my ideas (and Steve's), it doesn't have feedback or input from other nostr developers yet. That is what this blog post is about. I think it is time for other nostr devs to be made aware of this thing.
It is currently in the massive breaking changes phase. It might not look that way because of the detail and refinement of the documentation, but indeed everything is changing rapidly. It probably has some bad ideas and is probably missing some great ideas that you have.
Which is why this is a good time for other devs to start taking a look at it.
It is also the time to debate meta issues like "are you crazy Mike?" or "no we have to just break nostr but keep it nostr, we can't dual-stack" or whatever.
Personally I think mosaic-spec should develop and grow for quite a while before the "tipping point" happens. That is, I'm not sure we should jump in feet first yet, but rather we build up and refine this new protocol and spend a lot of time thinking about how to migrate smoothly, and break it a lot while nobody is using it.
So you can just reply to this, or DM me, or open issues or PRs at Mosaic, or just whisper to each other while giving me the evil eye.
-
@ 3ffac3a6:2d656657
2024-10-03 04:24:22
Quando eu era criança, na casa da minha avó, tinha um quadro que era assombrado. Era uma ancestral distante, ou parenta antiga, que tocava harpa durante a noite. Na verdade, o quadro escondia um encanamento ou tubo de ventilação, não sei bem, que estralava com a dilatação durante a noite. Os estralos abafados se confundiam com um toque de harpa desengonçado. Não é que nós não soubéssemos. Todo mundo sabia o que causava os ruídos, mas isso não impedia o folclore da família de perpetuar a ideia da trisavó, ou seja, lá o que era, saindo do quadro e tocando a harpa que ficava na sala de visitas. Aliás, a harpa que morava na sala nunca tinha sido dela, e ela provavelmente nem sabia tocar. Mas nada disso impedia o folclore de proliferar. E os quadros assombrados não eram exclusividade da minha família. Cada casa tinha o seu. Nem sempre era um cano velho, mas eles sempre estavam lá, seja seguindo com os olhos quem passava, ou projetando sombras durante a noite.

Também quando nós, pequenos, coçávamos os olhos de sono, sempre tinha uma avó ou tia para afirmar: é o João Pestana que jogou um grãozinho de areia nos seus olhos para dizer que é hora de dormir. E claro sabíamos que não havia nenhum João Pestana, mas ainda assim procurávamos avidamente por ele.
Mas meus preferidos eram os sacis. Tinha vários. Quintal grande, com muita terra, dava pra ver redemoinhos sempre. Mesmo fora da casa, na cidade, tínhamos muitos sacis. Eles batiam as janelas, derrubavam as roupas do varal, atrapalhavam nossas brincadeiras. Eram mesmo uns malandros. Nunca tentamos pegar os sacis. Não eram sacis de monteiro lobato que nos obedeciam se roubássemos o gorro ou que pudéssemos prender em uma garrafa com uma cruz feita de carvão na rolha. Eu até fiz isso uma vez, mas todo mundo riu de mim: os nossos sacis não eram sacis de livro. Eles só brincavam no quintal, e faziam as travessuras deles, dentro de seus rodamoinhos.

Até hoje os rodamoinhos me impressionam. Quando teve um tornado aqui em Brasília, uns anos atrás, que destruiu vários carros no estacionamento do aeroporto, eu via de longe e imaginava o tamanho do saci que pilotava aquilo ali.
Algumas lendas mais antigas não tinham lugar na cidade grande, é verdade. A falta de um rio ou mar não deixava lugar pras sereias e botos. E a falta dos fogos fátuos nos cemitérios modernos nos tirava as mulas sem cabeça. Mas o folclore não se dá por rogado e cria suas novas lendas. Nosso cemitério do Bonfim ganhou uma loira, que fazia o papel sedutor da sereia e assombrava nosso cemitério. Já o nosso boto veio bem mais tarde, quando já era adolescente, na forma de um capeta que seduzia as mulheres nas quadras de forró ou funk da avenida Vilarinho. Não podia tirar o chapéu, não por causa do furo na cabeça, mas dos chifres, que apareceriam.

Esse mundo misto de fantasia e realidade ajudava a gente a entender o mundo. Sabíamos bem o que era lenda e o que era realidade, mas as lendas nos traziam um conforto extra praquilo que ainda não conhecíamos por completo. Era bom ter um saci pra “culpar” pela bagunça no quintal. Arrumávamos aquilo com mais gosto e vontade. Como dizem os hispanofônicos:
Yo no credo en brujas, pero que las hay, hay!

Mas o mundo cresceu muito rápido. As lendas que antes cabiam não cabem mais, e as loiras do Bonfim e capetas da Vilarinho não conseguem suplantar a velocidade da internet. Eu ainda vejo bruxas e sacis por aí, mas acho que sou dos poucos. A maioria nem repara na existência deles, e somente ri quando reparo. Mesmo as crianças, não tem um saci na internet ou um João Pestana que saia da TV. (Talvez uma Samara, dizendo que temos 7 dias? só se for por WhatsApp, porque “áudio? deus me livre!”). Não sei se essa falta de bruxas e sacis é que abre o caminho para acreditarmos em outras lendas, que ao invés de nos acalmar dentro de um mundo inexplicável, nos aterrorizam e nos fazem temer a verdade. Cada um tem a sua: de cloroquina a 5g, de GMO a vacinas, sempre temos uma bruxa à solta no nosso WhatsApp. Precisamos de novos sacis pra arrumarem (ou bagunçarem?) a casa e tomar o lugar dessas outras bruxas, mais assustadoras e daninhas, do mundo moderno!
-
@ 3ffac3a6:2d656657
2024-10-03 03:26:22
(publicado originalmente em: https://blog.girino.org/2024/05/31/transformando-seu-raspberry-pi-em-um-roteador-wi-fi-com-rede-tor/)
Você sabia que pode transformar um Raspberry Pi ocioso em casa em um roteador Wi-Fi conectado à rede Tor? Neste tutorial, vamos mostrar como fazer isso passo a passo.

Eu primeiro procurei pela internet por tutoriais para montar esse roteador Tor, porque já tinha feito um no passado. Infelizmente, os tutoriais que encontrei estavam todos ultrapassados, de quando o Raspberry Pi OS não utilizava ainda o NetworkManager. Depois de penar por um tempo e conseguir um resultado satisfatório, percebi que com um bom tutorial, não levaria mais do que 10 minutos para montar o roteador. Então resolvi deixar isso documentado, na forma de um blog post, para que pessoas do futuro que tenham a mesma necessidade não passem pelo mesmo aperto que eu.
Pré-requisitos:
- Raspberry Pi com Raspberry Pi OS instalado.
- Conexão Wi-Fi configurada.
Passo 1: Configurando o Access Point
Primeiro, vamos configurar a interface Wi-Fi do Raspberry Pi como um ponto de acesso usando o Network Manager. Execute os seguintes comandos no terminal:
sudo nmcli con add con-name hotspot ifname wlan0 type wifi ssid "TOR-WIFI" sudo nmcli con modify hotspot wifi-sec.key-mgmt wpa-psk sudo nmcli con modify hotspot wifi-sec.psk "senha123" sudo nmcli con modify hotspot 802-11-wireless.mode ap 802-11-wireless.band bg ipv4.method sharedCertifique-se de alterar “senha123” para uma senha forte e segura. Esta será a senha para sua rede Wi-Fi Tor.Passo 2: Configurando o Tor
Em seguida, vamos configurar o Tor. Primeiro, instale o Tor usando o seguinte comando:
sudo apt-get install torEm seguida, adicione as seguintes linhas ao arquivo
/etc/tor/torrc, substituindo o endereço IP da interface Wi-Fi se necessário:Log notice file /var/log/tor/notices.log VirtualAddrNetwork 10.192.0.0/10 AutomapHostsSuffixes .onion,.exit AutomapHostsOnResolve 1 TransPort 10.42.0.1:9040 DNSPort 10.42.0.1:53Passo 3: Configurando as Regras do Iptables
Por último, configure as regras no iptables para redirecionar o tráfego. Execute os seguintes comandos:
sudo iptables -t nat -A PREROUTING -i wlan0 -p tcp --dport 22 -j REDIRECT --to-ports 22 sudo iptables -t nat -A PREROUTING -i wlan0 -p udp --dport 53 -j REDIRECT --to-ports 53 sudo iptables -t nat -A PREROUTING -i wlan0 -p tcp --syn -j REDIRECT --to-ports 9040Conclusão
Com estes passos simples, você transformou seu Raspberry Pi em um roteador Wi-Fi conectado à rede Tor. Agora você pode navegar com mais segurança e privacidade. Lembre-se sempre de atualizar regularmente seu sistema e de tomar medidas adicionais de segurança conforme necessário.
Para mais detalhes e informações sobre este tutorial, consulte as fontes abaixo:
- RaspberryTips – Configuração de Ponto de Acesso
- Miloserdov – Configurando o Tor no Raspberry Pi
- Debuntu – Redirecionando Tráfego de Rede com Iptables
- How to Raspberry Pi – Script de Instalação do Tor
Espero que este tutorial seja útil para você. Deixe-nos saber nos comentários se tiver alguma dúvida ou feedback!
-
@ 42342239:1d80db24
2024-12-06 09:40:00
The Dutch primatologist Frans de Waal coined the term "veneer theory" in his book "Our Inner Ape" in 2005. The veneer theory posits that human moral behavior is merely a thin veneer over an inherently unpleasant nature. This viewpoint can be traced back to Thomas Henry Huxley, an anthropologist and biologist who was a contemporary of Darwin. However, de Waal criticized the idea because humanity is far more cooperative than predicted by simple anthropological or economic models. However, it is possible to question how thick this "civilizing veneer" really is.
During the COVID-19 pandemic, some people discriminated against the unvaccinated , while others wished them a quick and painful death . In the United States, about 30 percent of those who voted for the Democratic Party wanted to take their children away . Professors wanted to imprison them . This was despite the fact that the vaccines did not prevent infection or reduce transmission very much (if at all).
There is an idea that evil actions often stem from ordinary people blindly following orders or societal norms.
The war between Israel and Hamas revealed a desire to collectively punish all residents of the Gaza Strip. For example, as many as 70 percent of Jewish Israelis say they want to ban social media posts expressing sympathy for civilians (""There are no civilians ."") On the other side of the conflict, there is a desire to punish Israeli citizens and Jews around the world for Israel's actions in the conflict, as shown by the storming of an airport in Russian Dagestan.
As a result of Russia's invasion of Ukraine, the alienation of ethnic Russians has become fashionable. Even Swedish defense policy pundits now found it appropriate to dehumanize Russians by calling them "orcs" (evil and warlike creatures with sharp teeth taken from J.R.R. Tolkien's stories). Others wanted to deny all Russian citizens entry . Recently, the software project Linux has removed Russian programmers simply because they are Russian. Similar rhetoric can be found on the other side.
All three of the above examples constitute a form of collective punishment, which is contrary to both the UN Declaration of Human Rights and the Geneva Convention . Yet few react.
The author Hannah Arendt coined the term "the banality of evil" when she studied Nazi war criminals. The term refers to the idea that evil actions often stem from ordinary people blindly following orders or societal norms without critical scrutiny. She argued that individual responsibility and critical thinking were of paramount importance.
In an iconic photo from the 1930s, a large crowd is shown with everyone doing the Hitler salute. Everyone except one. The man, believed to be August Landmesser , openly showed his refusal with crossed arms and a stern expression.
Imagine yourself in his shoes, standing among thousands of people who are raising their arms. Would you have the courage to stand still and quietly while everyone around you shouts their support? Or would you, like so many others, let yourself be swept along with the current and follow the crowd? Somewhere in there, you might have the answer to how thick this "civilizing veneer" really is.
Cover image: Picture of people giving a Nazi salute, with an unidentified person (possibly August Landmesser or Gustav Wegert) refusing to do so, Wikimedia Commons
-
@ 42342239:1d80db24
2024-11-06 09:05:17
TL;DR: J.D. Vance recently observed that many in the Democratic Party are attempting to manufacture trust from the top down, neglecting the fact that genuine trust is often born from grassroots connections. There's indeed a stark contrast between trust that's artificially constructed through manipulation and censorship, and trust that's organically cultivated from the ground up.
Trump's vice presidential candidate J.D. Vance appeared on podcast host Joe Rogan's show earlier in November. According to Vance, large parts of the Democratic Party are trying to create higher trust from above, without understanding that the previously high trust once arose organically: "I think that a lot of them are trying to reimpose that social trust from the top."
Most people understand the importance of high trust. Political scientist Robert D. Putnam, for example, has shown that large social capital, in the form of trust and networks, is a key factor for economic growth, cooperation, and problem-solving. See e.g. his book Bowling Alone: The Collapse and Revival of American Community (2000).
The low trust today is widespread. Trust in the American federal government is at historically low levels. Trust in the media is at rock-bottom levels. Even trust in doctors and hospitals has plummeted: at the beginning of 2024, the proportion of people who reported "a great deal of trust" had dropped to 40%, from 72% in April 2020. This can be concerning, as individuals with low trust in doctors and hospitals will be less likely to follow their advice and recommendations. It's therefore not surprising that many want to "rebuild trust" (this was the theme of the World Economic Forum's annual meeting this year).
How much trust is actually reasonable?
But how much trust is actually reasonable? To determine this, one can ask whether an institution has acted reliably in the past, whether it possesses the knowledge and ability required to deliver what is promised, and whether its interests are in line with our own.
The low trust figures among Americans are likely a reflection of the fact that many of them today question the extent to which the answers to these questions are actually affirmative. During the pandemic, medical experts in the UK incorrectly predicted that hundreds of thousands of people would die. In the US, the leading infectious disease expert misled the public about, among other things, face masks, the sitting president lied about both the effectiveness and safety of vaccines, a British health minister wanted to "scare the pants off people," and virus experts even conspired to mislead about the origin of the SARS-CoV-2 virus. All while social media companies, under pressure from governments, were forced to censor information that was actually correct.
Trust - built on sand or on solid ground?
It's possible to continue on the current path and try to improve trust figures by limiting access to information. For instance, if the public doesn't get access to negative information about authorities or experts, the measured trust can increase. But in that case, trust is merely built on sand, waiting to be undermined by the inexorable forces of truth.
But there's another possibility. Building relationships that are genuine and honest, listening to each other without judgment, and communicating without misleading. Doing things that really matter, and doing them well, showing competence and reliability through actions. In this way, trust can grow naturally and organically. A trust built on solid ground, not on sand. A delicate task. But presidential election or not, isn't it time for us to start building a future where this form of trust is the obvious foundation?
-
@ 42342239:1d80db24
2024-10-29 19:27:12
The Swedish government recently rejected the Transport Administration's proposal for average speed cameras. The proposal would have meant constant surveillance of all vehicles, and critics argued for instance that it would have posed a threat to national security. Given the prevalence of IT breaches and data leaks today, it's hard not to give them a point, even if the problems are often downplayed by both corporations, governments and organisations. After Facebook (now Meta) leaked account information for over half a billion users, internal mails revealed the company wanted to "normalise the fact that this happens regularly".
IT security focuses on protecting the information in our computer systems and their connections. Cybersecurity is a broader concept that also includes aspects such as human behaviour, environmental factors, and management.
Data that has not been collected cannot leak
Knowledge about cybersecurity is often insufficient. For example, it was not long ago that the Swedish Transport Agency decided to outsource the operation of the Swedish vehicle and driving licence register. This was done despite deviations from various laws and criticism from the Security Police. The operation was placed in, among other places, Serbia (which has a close relationship with Russia). The Swedish driving licence register, including personal photos, as well as confidential information about critical infrastructure such as bridges, subways, roads, and ports, became available to personnel without Swedish security clearance.
The government's decision earlier this year not to proceed with a Swedish "super register" is an example of how cybersecurity can be strengthened. The rejection of the Transport Administration's proposal for average speed cameras is another. Data that has not been collected cannot leak out. It cannot be outsourced either.
Accounts are risky by definition
But the question is bigger than that. More and more of the products and services we depend on are now subscription services, often including long documents with terms and conditions. Which few people read. If you want to control your air heat pump with your phone, you not only need an app and an account, but also agree to someone storing your data (maybe also selling it or leaking it). The same applies if you want to be able to find your car in the car park. If you do not agree to the constantly updated terms, you lose important functionality.
Every time you are required to create an account, you are put in a dependent position. And our society becomes more fragile - because data is collected and can therefore leak out. It is much harder to lose something you do not have.
At the Korean car manufacturer Kia, huge security holes were recently discovered. IT researchers could quickly scan and control almost any car, including tracking its position, unlocking it, starting the ignition, and accessing cameras and personal information such as name, phone number, and home address. In some cases, even driving routes. All thanks to a "relatively simple flaw" in a web portal.
Instead of being at the mercy of large companies' IT departments, our security would improve if we could control our air heat pump, unlock our car, or our data ourselves. The technology already exists, thanks to the breakthrough of asymmetric encryption in the 1970s. Now we just need the will to change.
-
@ fa0165a0:03397073
2024-10-23 17:19:41
Chef's notes
This recipe is for 48 buns. Total cooking time takes at least 90 minutes, but 60 minutes of that is letting the dough rest in between processing.
The baking is a simple three-step process. 1. Making the Wheat dough 2. Making and applying the filling 3. Garnishing and baking in the oven
When done: Enjoy during Fika!
PS;
-
Can be frozen and thawed in microwave for later enjoyment as well.
-
If you need unit conversion, this site may be of help: https://www.unitconverters.net/
-
Traditionally we use something we call "Pearl sugar" which is optimal, but normal sugar or sprinkles is okay too. Pearl sugar (Pärlsocker) looks like this: https://search.brave.com/images?q=p%C3%A4rlsocker
Ingredients
- 150 g butter
- 5 dl milk
- 50 g baking yeast (normal or for sweet dough)
- 1/2 teaspoon salt
- 1-1 1/2 dl sugar
- (Optional) 2 teaspoons of crushed or grounded cardamom seeds.
- 1.4 liters of wheat flour
- Filling: 50-75 g butter, room temperature
- Filling: 1/2 - 1 dl sugar
- Filling: 1 teaspoons crushed or ground cardamom and 1 teaspoons ground cinnamon (or 2 teaspoons of cinnamon)
- Garnish: 1 egg, sugar or Almond Shavings
Directions
- Melt the butter/margarine in a saucepan.
- Pour in the milk and allow the mixture to warm reach body temperature (approx. + 37 ° C).
- Dissolve the yeast in a dough bowl with the help of the salt.
- Add the 37 ° C milk/butter mixture, sugar and if you choose to the optional cardamom. (I like this option!) and just over 2/3 of the flour.
- Work the dough shiny and smooth, about 4 minutes with a machine or 8 minutes by hand.
- Add if necessary. additional flour but save at least 1 dl for baking.
- Let the dough rise covered (by a kitchen towel), about 30 minutes.
- Work the dough into the bowl and then pick it up on a floured workbench. Knead the dough smoothly. Divide the dough into 2 parts. Roll out each piece into a rectangular cake.
- Stir together the ingredients for the filling and spread it.
- Roll up and cut each roll into 24 pieces.
- Place them in paper molds or directly on baking paper with the cut surface facing up. Let them rise covered with a baking sheet, about 30 minutes.
- Brush the buns with beaten egg and sprinkle your chosen topping.
- Bake in the middle of the oven at 250 ° C, 5-8 minutes.
- Allow to cool on a wire rack under a baking sheet.
-
-
@ 42342239:1d80db24
2024-10-23 12:28:41
TL;DR: The mathematics of trust says that news reporting will fall flat when the population becomes suspicious of the media. Which is now the case for growing subgroups in the U.S. as well as in Sweden.
A recent wedding celebration for Sweden Democrats leader Jimmie Åkesson resulted in controversy, as one of the guests in attendance was reportedly linked to organized crime. Following this “wedding scandal”, a columnist noted that the party’s voters had not been significantly affected. Instead of a decrease in trust - which one might have expected - 10% of them stated that their confidence in the party had actually increased. “Over the years, the Sweden Democrats have surprisingly emerged unscathed from their numerous scandals,” she wrote. But is this really so surprising?
In mathematics, a probability is expressed as the likelihood of something occurring given one or more conditions. For example, one can express a probability as “the likelihood that a certain stock will rise in price, given that the company has presented a positive quarterly report.” In this case, the company’s quarterly report is the basis for the assessment. If we add more information, such as the company’s strong market position and a large order from an important customer, the probability increases further. The more information we have to go on, the more precise we can be in our assessment.
From this perspective, the Sweden Democrats’ “numerous scandals” should lead to a more negative assessment of the party. But this perspective omits something important.
A couple of years ago, the term “gaslighting” was chosen as the word of the year in the US. The term comes from a 1944 film of the same name and refers to a type of psychological manipulation, as applied to the lovely Ingrid Bergman. Today, the term is used in politics, for example, when a large group of people is misled to achieve political goals. The techniques used can be very effective but have a limitation. When the target becomes aware of what is happening, everything changes. Then the target becomes vigilant and views all new information with great suspicion.
The Sweden Democrats’ “numerous scandals” should lead to a more negative assessment of the party. But if SD voters to a greater extent than others believe that the source of the information is unreliable, for example, by omitting information or adding unnecessary information, the conclusion is different. The Swedish SOM survey shows that these voters have lower trust in journalists and also lower confidence in the objectivity of the news. Like a victim of gaslighting, they view negative reporting with suspicion. The arguments can no longer get through. A kind of immunity has developed.
In the US, trust in the media is at an all-time low. So when American media writes that “Trump speaks like Hitler, Stalin, and Mussolini,” that his idea of deporting illegal immigrants would cost hundreds of billions of dollars, or gets worked up over his soda consumption, the consequence is likely to be similar to here at home.
The mathematics of trust says that reporting will fall flat when the population becomes suspicious of the media. Or as the Swedish columnist put it: like water off a duck’s back.
Cover image: Ingrid Bergman 1946. RKO Radio Pictures - eBay, Public Domain, Wikimedia Commons
-
@ 42342239:1d80db24
2024-10-22 07:57:17
It was recently reported that Sweden's Minister for Culture, Parisa Liljestrand, wishes to put an end to anonymous accounts on social media. The issue has been at the forefront following revelations of political parties using pseudonymous accounts on social media platforms earlier this year.
The importance of the internet is also well-known. As early as 2015, Roberta Alenius, who was then the press secretary for Fredrik Reinfeldt (Moderate Party), openly spoke about her experiences with the Social Democrats' and Moderates' internet activists: Twitter actually set the agenda for journalism at the time.
The Minister for Culture now claims, amongst other things, that anonymous accounts pose a threat to democracy, that they deceive people, and that they can be used to mislead, etc. It is indeed easy to find arguments against anonymity; perhaps the most common one is the 'nothing to hide, nothing to fear' argument.
One of the many problems with this argument is that it assumes that abuse of power never occurs. History has much to teach us here. Sometimes, authorities can act in an arbitrary, discriminatory, or even oppressive manner, at least in hindsight. Take, for instance, the struggles of the homosexual community, the courageous dissidents who defied communist regimes, or the women who fought for their right to vote in the suffragette movement.
It was difficult for homosexuals to be open about their sexuality in Sweden in the 1970s. Many risked losing their jobs, being ostracised, or harassed. Anonymity was therefore a necessity for many. Homosexuality was actually classified as a mental illness in Sweden until 1979.
A couple of decades earlier, dissidents in communist regimes in Europe used pseudonyms when publishing samizdat magazines. The Czech author and dissident Václav Havel, who later became the President of the Czech Republic, used a pseudonym when publishing his texts. The same was true for the Russian author and literary prize winner Alexander Solzhenitsyn. Indeed, in Central and Eastern Europe, anonymity was of the utmost importance.
One hundred years ago, women all over the world fought for the right to vote and to be treated as equals. Many were open in their struggle, but for others, anonymity was a necessity as they risked being socially ostracised, losing their jobs, or even being arrested.
Full transparency is not always possible or desirable. Anonymity can promote creativity and innovation as it gives people the opportunity to experiment and try out new ideas without fear of being judged or criticised. This applies not only to individuals but also to our society, in terms of ideas, laws, norms, and culture.
It is also a strange paradox that those who wish to limit freedom of speech and abolish anonymity simultaneously claim to be concerned about the possible return of fascism. The solutions they advocate are, in fact, precisely what would make it easier for a tyrannical regime to maintain its power. To advocate for the abolition of anonymity, one must also be of the (absurd) opinion that the development of history has now reached its definitive end.
-
@ 42342239:1d80db24
2024-09-26 07:57:04
The boiling frog is a simple tale that illustrates the danger of gradual change: if you put a frog in boiling water, it will quickly jump out to escape the heat. But if you place a frog in warm water and gradually increase the temperature, it won't notice the change and will eventually cook itself. Might the decline in cash usage be construed as an example of this tale?
As long as individuals can freely transact with each other and conduct purchases and sales without intermediaries[^1] such as with cash, our freedoms and rights remain secure from potential threats posed by the payment system. However, as we have seen in several countries such as Sweden over the past 15 years, the use of cash and the amount of banknotes and coins in circulation have decreased. All to the benefit of various intermediated[^1] electronic alternatives.
The reasons for this trend include: - The costs associated with cash usage has been increasing. - Increased regulatory burdens due to stricter anti-money laundering regulations. - Closed bank branches and fewer ATMs. - The Riksbank's aggressive note switches resulted in a situation where they were no longer recognized.
Market forces or "market forces"?
Some may argue that the "de-cashing" of society is a consequence of market forces. But does this hold true? Leading economists at times recommend interventions with the express purpose to mislead the public, such as proposing measures who are "opaque to most voters."
In a working paper on de-cashing by the International Monetary Fund (IMF) from 2017, such thought processes, even recommendations, can be found. IMF economist Alexei Kireyev, formerly a professor at an institute associated with the Soviet Union's KGB (MGIMO) and economic adviser to Michail Gorbachov 1989-91, wrote that:
- "Social conventions may also be disrupted as de-cashing may be viewed as a violation of fundamental rights, including freedom of contract and freedom of ownership."
- Letting the private sector lead "the de-cashing" is preferable, as it will seem "almost entirely benign". The "tempting attempts to impose de-cashing by a decree should be avoided"
- "A targeted outreach program is needed to alleviate suspicions related to de-cashing"
In the text, he also offered suggestions on the most effective approach to diminish the use of cash:
- The de-cashing process could build on the initial and largely uncontested steps, such as the phasing out of large denomination bills, the placement of ceilings on cash transactions, and the reporting of cash moves across the borders.
- Include creating economic incentives to reduce the use of cash in transactions
- Simplify "the opening and use of transferrable deposits, and further computerizing the financial system."
As is customary in such a context, it is noted that the article only describes research and does not necessarily reflect IMF's views. However, isn't it remarkable that all of these proposals have come to fruition and the process continues? Central banks have phased out banknotes with higher denominations. Banks' regulatory complexity seemingly increase by the day (try to get a bank to handle any larger amounts of cash). The transfer of cash from one nation to another has become increasingly burdensome. The European Union has recently introduced restrictions on cash transactions. Even the law governing the Swedish central bank is written so as to guarantee a further undermining of cash. All while the market share is growing for alternatives such as transferable deposits[^1].
The old European disease
The Czech Republic's former president Václav Havel, who played a key role in advocating for human rights during the communist repression, was once asked what the new member states in the EU could do to pay back for all the economic support they had received from older member states. He replied that the European Union still suffers from the old European disease, namely the tendency to compromise with evil. And that the new members, who have a recent experience of totalitarianism, are obliged to take a more principled stance - sometimes necessary - and to monitor the European Union in this regard, and educate it.
The American computer scientist and cryptographer David Chaum said in 1996 that "[t]he difference between a bad electronic cash system and well-developed digital cash will determine whether we will have a dictatorship or a real democracy". If Václav Havel were alive today, he would likely share Chaum's sentiment. Indeed, on the current path of "de-cashing", we risk abolishing or limiting our liberties and rights, "including freedom of contract and freedom of ownership" - and this according to an economist at the IMF(!).
As the frog was unwittingly boiled alive, our freedoms are quietly being undermined. The temperature is rising. Will people take notice before our liberties are irreparably damaged?
[^1]: Transferable deposits are intermediated. Intermediated means payments involving one or several intermediares, like a bank, a card issuer or a payment processor. In contrast, a disintermediated payment would entail a direct transactions between parties without go-betweens, such as with cash.
-
@ ee11a5df:b76c4e49
2024-09-11 08:16:37
Bye-Bye Reply Guy
There is a camp of nostr developers that believe spam filtering needs to be done by relays. Or at the very least by DVMs. I concur. In this way, once you configure what you want to see, it applies to all nostr clients.
But we are not there yet.
In the mean time we have ReplyGuy, and gossip needed some changes to deal with it.
Strategies in Short
- WEB OF TRUST: Only accept events from people you follow, or people they follow - this avoids new people entirely until somebody else that you follow friends them first, which is too restrictive for some people.
- TRUSTED RELAYS: Allow every post from relays that you trust to do good spam filtering.
- REJECT FRESH PUBKEYS: Only accept events from people you have seen before - this allows you to find new people, but you will miss their very first post (their second post must count as someone you have seen before, even if you discarded the first post)
- PATTERN MATCHING: Scan for known spam phrases and words and block those events, either on content or metadata or both or more.
- TIE-IN TO EXTERNAL SYSTEMS: Require a valid NIP-05, or other nostr event binding their identity to some external identity
- PROOF OF WORK: Require a minimum proof-of-work
All of these strategies are useful, but they have to be combined properly.
filter.rhai
Gossip loads a file called "filter.rhai" in your gossip directory if it exists. It must be a Rhai language script that meets certain requirements (see the example in the gossip source code directory). Then it applies it to filter spam.
This spam filtering code is being updated currently. It is not even on unstable yet, but it will be there probably tomorrow sometime. Then to master. Eventually to a release.
Here is an example using all of the techniques listed above:
```rhai // This is a sample spam filtering script for the gossip nostr // client. The language is called Rhai, details are at: // https://rhai.rs/book/ // // For gossip to find your spam filtering script, put it in // your gossip profile directory. See // https://docs.rs/dirs/latest/dirs/fn.data_dir.html // to find the base directory. A subdirectory "gossip" is your // gossip data directory which for most people is their profile // directory too. (Note: if you use a GOSSIP_PROFILE, you'll // need to put it one directory deeper into that profile // directory). // // This filter is used to filter out and refuse to process // incoming events as they flow in from relays, and also to // filter which events get/ displayed in certain circumstances. // It is only run on feed-displayable event kinds, and only by // authors you are not following. In case of error, nothing is // filtered. // // You must define a function called 'filter' which returns one // of these constant values: // DENY (the event is filtered out) // ALLOW (the event is allowed through) // MUTE (the event is filtered out, and the author is // automatically muted) // // Your script will be provided the following global variables: // 'caller' - a string that is one of "Process", // "Thread", "Inbox" or "Global" indicating // which part of the code is running your // script // 'content' - the event content as a string // 'id' - the event ID, as a hex string // 'kind' - the event kind as an integer // 'muted' - if the author is in your mute list // 'name' - if we have it, the name of the author // (or your petname), else an empty string // 'nip05valid' - whether nip05 is valid for the author, // as a boolean // 'pow' - the Proof of Work on the event // 'pubkey' - the event author public key, as a hex // string // 'seconds_known' - the number of seconds that the author // of the event has been known to gossip // 'spamsafe' - true only if the event came in from a // relay marked as SpamSafe during Process // (even if the global setting for SpamSafe // is off)
fn filter() {
// Show spam on global // (global events are ephemeral; these won't grow the // database) if caller=="Global" { return ALLOW; } // Block ReplyGuy if name.contains("ReplyGuy") || name.contains("ReplyGal") { return DENY; } // Block known DM spam // (giftwraps are unwrapped before the content is passed to // this script) if content.to_lower().contains( "Mr. Gift and Mrs. Wrap under the tree, KISSING!" ) { return DENY; } // Reject events from new pubkeys, unless they have a high // PoW or we somehow already have a nip05valid for them // // If this turns out to be a legit person, we will start // hearing their events 2 seconds from now, so we will // only miss their very first event. if seconds_known <= 2 && pow < 25 && !nip05valid { return DENY; } // Mute offensive people if content.to_lower().contains(" kike") || content.to_lower().contains("kike ") || content.to_lower().contains(" nigger") || content.to_lower().contains("nigger ") { return MUTE; } // Reject events from muted people // // Gossip already does this internally, and since we are // not Process, this is rather redundant. But this works // as an example. if muted { return DENY; } // Accept if the PoW is large enough if pow >= 25 { return ALLOW; } // Accept if their NIP-05 is valid if nip05valid { return ALLOW; } // Accept if the event came through a spamsafe relay if spamsafe { return ALLOW; } // Reject the rest DENY} ```
-
@ 7460b7fd:4fc4e74b
2024-09-05 08:37:48
请看2014年王兴的一场思维碰撞,视频27分钟开始
最后,一个当时无法解决的点:丢失
-
@ 42342239:1d80db24
2024-09-02 12:08:29
The ongoing debate surrounding freedom of expression may revolve more around determining who gets to control the dissemination of information rather than any claimed notion of safeguarding democracy. Similarities can be identified from 500 years ago, following the invention of the printing press.
What has been will be again, what has been done will be done again; there is nothing new under the sun.
-- Ecclesiastes 1:9
The debate over freedom of expression and its limits continues to rage on. In the UK, citizens are being arrested for sharing humouristic images. In Ireland, it may soon become illegal to possess "reckless" memes. Australia is trying to get X to hide information. Venezuela's Maduro blocked X earlier this year, as did a judge on Brazil's Supreme Court. In the US, a citizen has been imprisoned for spreading misleading material following a controversial court ruling. In Germany, the police are searching for a social media user who called a politician overweight. Many are also expressing concerns about deep fakes (AI-generated videos, images, or audio that are designed to deceive).
These questions are not new, however. What we perceive as new questions are often just a reflection of earlier times. After Gutenberg invented the printing press in the 15th century, there were soon hundreds of printing presses across Europe. The Church began using printing presses to mass-produce indulgences. "As soon as the coin in the coffer rings, the soul from purgatory springs" was a phrase used by a traveling monk who sold such indulgences at the time. Martin Luther questioned the reasonableness of this practice. Eventually, he posted the 95 theses on the church door in Wittenberg. He also translated the Bible into German. A short time later, his works, also mass-produced, accounted for a third of all books sold in Germany. Luther refused to recant his provocations as then determined by the Church's central authority. He was excommunicated in 1520 by the Pope and soon declared an outlaw by the Holy Roman Emperor.
This did not stop him. Instead, Luther referred to the Pope as "Pope Fart-Ass" and as the "Ass-God in Rome)". He also commissioned caricatures, such as woodcuts showing a female demon giving birth to the Pope and cardinals, of German peasants responding to a papal edict by showing the Pope their backsides and breaking wind, and more.
Gutenberg's printing presses contributed to the spread of information in a way similar to how the internet does in today's society. The Church's ability to control the flow of information was undermined, much like how newspapers, radio, and TV have partially lost this power today. The Pope excommunicated Luther, which is reminiscent of those who are de-platformed or banned from various platforms today. The Emperor declared Luther an outlaw, which is similar to how the UK's Prime Minister is imprisoning British citizens today. Luther called the Pope derogatory names, which is reminiscent of the individual who recently had the audacity to call an overweight German minister overweight.
Freedom of expression must be curtailed to combat the spread of false or harmful information in order to protect democracy, or so it is claimed. But perhaps it is more about who gets to control the flow of information?
As is often the case, there is nothing new under the sun.
-
@ 42342239:1d80db24
2024-08-30 06:26:21
Quis custodiet ipsos custodes?
-- Juvenal (Who will watch the watchmen?)
In mid-July, numerous media outlets reported on the assassination attempt on Donald Trump. FBI Director Christopher Wray stated later that same month that what hit the former president Trump was a bullet. A few days later, it was reported from various sources that search engines no longer acknowledged that an assassination attempt on ex-President Trump had taken place. When users used automatic completion in Google and Bing (91% respectively 4% market share), these search engines only suggested earlier presidents such as Harry Truman and Theodore Roosevelt, along with Russian President Vladimir Putin as people who could have been subjected to assassination attempts.
The reports were comprehensive enough for the Republican district attorney of Missouri to say that he would investigate matter. The senator from Kansas - also a Republican - planned to make an official request to Google. Google has responded through a spokesman to the New York Post that the company had not "manually changed" search results, but its system includes "protection" against search results "connected to political violence."
A similar phenomenon occurred during the 2016 presidential election. At the time, reports emerged of Google, unlike other less widely used search engines, rarely or never suggesting negative search results for Hillary Clinton. The company however provided negative search results for then-candidate Trump. Then, as today, the company denied deliberately favouring any specific political candidate.
These occurrences led to research on how such search suggestions can influence public opinion and voting preferences. For example, the impact of simply removing negative search suggestions has been investigated. A study published in June 2024 reports that such search results can dramatically affect undecided voters. Reducing negative search suggestions can turn a 50/50 split into a 90/10 split in favour of the candidate for whom negative search suggestions were suppressed. The researchers concluded that search suggestions can have "a dramatic impact," that this can "shift a large number of votes" and do so without leaving "any trace for authorities to follow." How search engines operate should therefore be considered of great importance by anyone who claims to take democracy seriously. And this regardless of one's political sympathies.
A well-known thought experiment in philosophy asks: "If a tree falls in the forest and no one hears it, does it make a sound?" Translated to today's media landscape: If an assassination attempt took place on a former president, but search engines don't want to acknowledge it, did it really happen?
-
@ 42342239:1d80db24
2024-07-28 08:35:26
Jerome Powell, Chairman of the US Federal Reserve, stated during a hearing in March that the central bank has no plans to introduce a central bank digital currency (CBDCs) or consider it necessary at present. He said this even though the material Fed staff presents to Congress suggests otherwise - that CBDCs are described as one of the Fed’s key duties .
A CBDC is a state-controlled and programmable currency that could allow the government or its intermediaries the possibility to monitor all transactions in detail and also to block payments based on certain conditions.
Critics argue that the introduction of CBDCs could undermine citizens’ constitutionally guaranteed freedoms and rights . Republican House Majority Leader Tom Emmer, the sponsor of a bill aimed at preventing the central bank from unilaterally introducing a CBDC, believes that if they do not mimic cash, they would only serve as a “CCP-style [Chinese Communist Party] surveillance tool” and could “undermine the American way of life”. Emmer’s proposed bill has garnered support from several US senators , including Republican Ted Cruz from Texas, who introduced the bill to the Senate. Similarly to how Swedish cash advocates risk missing the mark , Tom Emmer and the US senators risk the same outcome with their bill. If the central bank is prevented from introducing a central bank digital currency, nothing would stop major banks from implementing similar systems themselves, with similar consequences for citizens.
Indeed, the entity controlling your money becomes less significant once it is no longer you. Even if central bank digital currencies are halted in the US, a future administration could easily outsource financial censorship to the private banking system, similar to how the Biden administration is perceived by many to have circumvented the First Amendment by getting private companies to enforce censorship. A federal court in New Orleans ruled last fall against the Biden administration for compelling social media platforms to censor content. The Supreme Court has now begun hearing the case.
Deng Xiaoping, China’s paramount leader who played a vital role in China’s modernization, once said, “It does not matter if the cat is black or white. What matters is that it catches mice.” This statement reflected a pragmatic approach to economic policy, focusing on results foremost. China’s economic growth during his tenure was historic.
The discussion surrounding CBDCs and their negative impact on citizens’ freedoms and rights would benefit from a more practical and comprehensive perspective. Ultimately, it is the outcomes that matter above all. So too for our freedoms.
-
@ ee11a5df:b76c4e49
2024-07-11 23:57:53
What Can We Get by Breaking NOSTR?
"What if we just started over? What if we took everything we have learned while building nostr and did it all again, but did it right this time?"
That is a question I've heard quite a number of times, and it is a question I have pondered quite a lot myself.
My conclusion (so far) is that I believe that we can fix all the important things without starting over. There are different levels of breakage, starting over is the most extreme of them. In this post I will describe these levels of breakage and what each one could buy us.
Cryptography
Your key-pair is the most fundamental part of nostr. That is your portable identity.
If the cryptography changed from secp256k1 to ed25519, all current nostr identities would not be usable.
This would be a complete start over.
Every other break listed in this post could be done as well to no additional detriment (save for reuse of some existing code) because we would be starting over.
Why would anyone suggest making such a break? What does this buy us?
- Curve25519 is a safe curve meaning a bunch of specific cryptography things that us mortals do not understand but we are assured that it is somehow better.
- Ed25519 is more modern, said to be faster, and has more widespread code/library support than secp256k1.
- Nostr keys could be used as TLS server certificates. TLS 1.3 using RFC 7250 Raw Public Keys allows raw public keys as certificates. No DNS or certification authorities required, removing several points of failure. These ed25519 keys could be used in TLS, whereas secp256k1 keys cannot as no TLS algorithm utilizes them AFAIK. Since relays currently don't have assigned nostr identities but are instead referenced by a websocket URL, this doesn't buy us much, but it is interesting. This idea is explored further below (keep reading) under a lesser level of breakage.
Besides breaking everything, another downside is that people would not be able to manage nostr keys with bitcoin hardware.
I am fairly strongly against breaking things this far. I don't think it is worth it.
Signature Scheme and Event Structure
Event structure is the next most fundamental part of nostr. Although events can be represented in many ways (clients and relays usually parse the JSON into data structures and/or database columns), the nature of the content of an event is well defined as seven particular fields. If we changed those, that would be a hard fork.
This break is quite severe. All current nostr events wouldn't work in this hard fork. We would be preserving identities, but all content would be starting over.
It would be difficult to bridge between this fork and current nostr because the bridge couldn't create the different signature required (not having anybody's private key) and current nostr wouldn't be generating the new kind of signature. Therefore any bridge would have to do identity mapping just like bridges to entirely different protocols do (e.g. mostr to mastodon).
What could we gain by breaking things this far?
- We could have a faster event hash and id verification: the current signature scheme of nostr requires lining up 5 JSON fields into a JSON array and using that as hash input. There is a performance cost to copying this data in order to hash it.
- We could introduce a subkey field, and sign events via that subkey, while preserving the pubkey as the author everybody knows and searches by. Note however that we can already get a remarkably similar thing using something like NIP-26 where the actual author is in a tag, and the pubkey field is the signing subkey.
- We could refactor the kind integer into composable bitflags (that could apply to any application) and an application kind (that specifies the application).
- Surely there are other things I haven't thought of.
I am currently against this kind of break. I don't think the benefits even come close to outweighing the cost. But if I learned about other things that we could "fix" by restructuring the events, I could possibly change my mind.
Replacing Relay URLs
Nostr is defined by relays that are addressed by websocket URLs. If that changed, that would be a significant break. Many (maybe even most) current event kinds would need superseding.
The most reasonable change is to define relays with nostr identities, specifying their pubkey instead of their URL.
What could we gain by this?
- We could ditch reliance on DNS. Relays could publish events under their nostr identity that advertise their current IP address(es).
- We could ditch certificates because relays could generate ed25519 keypairs for themselves (or indeed just self-signed certificates which might be much more broadly supported) and publish their public ed25519 key in the same replaceable event where they advertise their current IP address(es).
This is a gigantic break. Almost all event kinds need redefining and pretty much all nostr software will need fairly major upgrades. But it also gives us a kind of Internet liberty that many of us have dreamt of our entire lives.
I am ambivalent about this idea.
Protocol Messaging and Transport
The protocol messages of nostr are the next level of breakage. We could preserve keypair identities, all current events, and current relay URL references, but just break the protocol of how clients and relay communicate this data.
This would not necessarily break relay and client implementations at all, so long as the new protocol were opt-in.
What could we get?
- The new protocol could transmit events in binary form for increased performance (no more JSON parsing with it's typical many small memory allocations and string escaping nightmares). I think event throughput could double (wild guess).
- It could have clear expectations of who talks first, and when and how AUTH happens, avoiding a lot of current miscommunication between clients and relays.
- We could introduce bitflags for feature support so that new features could be added later and clients would not bother trying them (and getting an error or timing out) on relays that didn't signal support. This could replace much of NIP-11.
- We could then introduce something like negentropy or negative filters (but not that... probably something else solving that same problem) without it being a breaking change.
- The new protocol could just be a few websocket-binary messages enhancing the current protocol, continuing to leverage the existing websocket-text messages we currently have, meaning newer relays would still support all the older stuff.
The downsides are just that if you want this new stuff you have to build it. It makes the protocol less simple, having now multiple protocols, multiple ways of doing the same thing.
Nonetheless, this I am in favor of. I think the trade-offs are worth it. I will be pushing a draft PR for this soon.
The path forward
I propose then the following path forward:
- A new nostr protocol over websockets binary (draft PR to be shared soon)
- Subkeys brought into nostr via NIP-26 (but let's use a single letter tag instead, OK?) via a big push to get all the clients to support it (the transition will be painful - most major clients will need to support this before anybody can start using it).
- Some kind of solution to the negative-filter-negentropy need added to the new protocol as its first optional feature.
- We seriously consider replacing Relay URLs with nostr pubkeys assigned to the relay, and then have relays publish their IP address and TLS key or certificate.
We sacrifice these:
- Faster event hash/verification
- Composable event bitflags
- Safer faster more well-supported crypto curve
- Nostr keys themselves as TLS 1.3 RawPublicKey certificates
-
@ 42342239:1d80db24
2024-07-06 15:26:39
Claims that we need greater centralisation, more EU, or more globalisation are prevalent across the usual media channels. The climate crisis, environmental destruction, pandemics, the AI-threat, yes, everything will apparently be solved if a little more global coordination, governance and leadership can be brought about.
But, is this actually true? One of the best arguments for this conclusion stems implicitly from the futurist Eliezer Yudkowsky, who once proposed a new Moore's Law, though this time not for computer processors but instead for mad science: "every 18 months, the minimum IQ necessary to destroy the world drops by one point".
Perhaps we simply have to tolerate more centralisation, globalisation, control, surveillance, and so on, to prevent all kinds of fools from destroying the world?
Note: a Swedish version of this text is avalable at Affärsvärlden.
At the same time, more centralisation, globalisation, etc. is also what we have experienced. Power has been shifting from the local, and from the majorities, to central-planning bureaucrats working in remote places. This has been going on for several decades. The EU's subsidiarity principle, i.e. the idea that decisions should be made at the lowest expedient level, and which came to everyone's attention ahead of Sweden's EU vote in 1994, is today swept under the rug as untimely and outdated, perhaps even retarded.
At the same time, there are many crises, more than usual it would seem. If it is not a crisis of criminality, a logistics/supply chain crisis or a water crisis, then it is an energy crisis, a financial crisis, a refugee crisis or a climate crisis. It is almost as if one starts to suspect that all this centralisation may be leading us down the wrong path. Perhaps centralisation is part of the problem, rather than the capital S solution?
Why centralisation may cause rather than prevent problems
There are several reasons why centralisation, etc, may actually be a problem. And though few seem to be interested in such questions today (or perhaps they are too timid to mention their concerns?), it has not always been this way. In this short essay we'll note four reasons (though there are several others):
- Political failures (Buchanan et al)
- Local communities & skin in the game (Ostrom and Taleb)
- The local knowledge problem (von Hayek)
- Governance by sociopaths (Hare)
James Buchanan who was given the so-called Nobel price in economics in the eighties once said that: "politicians and bureaucrats are no different from the rest of us. They will maximise their incentives just like everybody else.".
Buchanan was prominent in research on rent-seeking and political failures, i.e. when political "solutions" to so-called market failures make everything worse. Rent-seeking is when a company spends resources (e.g. lobbying) to get legislators or other decision makers to pass laws or create regulations that benefit the company instead of it having to engage in productive activities. The result is regulatory capture. The more centralised decision-making is, the greater the negative consequences from such rent-seeking will be for society at large. This is known.
Another economist, Elinor Ostrom, was given the same prize in the great financial crisis year of 2009. In her research, she had found that local communities where people had influence over rules and regulations, as well as how violations there-of were handled, were much better suited to look after common resources than centralised bodies. To borrow a term from the combative Nassim Nicholas Taleb: everything was better handled when decision makers had "skin in the game".
A third economist, Friedrich von Hayek, was given this prize as early as 1974, partly because he showed that central planning could not possibly take into account all relevant information. The information needed in economic planning is by its very nature distributed, and will never be available to a central planning committee, or even to an AI.
Moreover, human systems are complex and not just complicated. When you realise this, you also understand why the forecasts made by central planners often end up wildly off the mark - and at times in a catastrophic way. (This in itself is an argument for relying more on factors outside of the models in the decision-making process.)
From Buchanan's, Ostrom's, Taleb's or von Hayek's perspectives, it also becomes difficult to believe that today's bureaucrats are the most suited to manage and price e.g. climate risks. One can compare with the insurance industry, which has both a long habit of pricing risks as well as "skin in the game" - two things sorely missing in today's planning bodies.
Instead of preventing fools, we may be enabling madmen
An even more troubling conclusion is that centralisation tends to transfer power to people who perhaps shouldn't have more of that good. "Not all psychopaths are in prison - some are in the boardroom," psychologist Robert Hare once said during a lecture. Most people have probably known for a long time that those with sharp elbows and who don't hesitate to stab a colleague in the back can climb quickly in organisations. In recent years, this fact seems to have become increasingly well known even in academia.
You will thus tend to encounter an increased prevalance of individuals with narcissistic and sociopathic traits the higher up you get in the the status hierarchy. And if working in large organisations (such as the European Union or Congress) or in large corporations, is perceived as higher status - which is generally the case, then it follows that the more we centralise, the more we will be governed by people with less flattering Dark Triad traits.
By their fruits ye shall know them
Perhaps it is thus not a coincidence that we have so many crises. Perhaps centralisation, globalisation, etc. cause crises. Perhaps the "elites" and their planning bureaucrats are, in fact, not the salt of the earth and the light of the world. Perhaps President Trump even had a point when he said "they are not sending their best".
https://www.youtube.com/watch?v=w4b8xgaiuj0
The opposite of centralisation is decentralisation. And while most people may still be aware that decentralisation can be a superpower within the business world, it's time we remind ourselves that this also applies to the economy - and society - at large, and preferably before the next Great Leap Forward is fully thrust upon us.
-
@ b12b632c:d9e1ff79
2024-05-29 12:10:18
One other day on Nostr, one other app!
Today I'll present you a new self-hosted Nostr blog web application recently released on github by dtonon, Oracolo:
https://github.com/dtonon/oracolo
Oracolo is a minimalist blog powered by Nostr, that consists of a single html file, weighing only ~140Kb. You can use whatever Nostr client that supports long format (habla.news, yakihonne, highlighter.com, etc ) to write your posts, and your personal blog is automatically updated.
It works also without a web server; for example you can send it via email as a business card.Oracolo fetches Nostr data, builds the page, execute the JavaScript code and displays article on clean and sobr blog (a Dark theme would be awesome 👀).
Blog articles are nostr events you published or will publish on Nostr relays through long notes applications like the ones quoted above.
Don't forget to use a NIP07 web browser extensions to login on those websites. Old time where we were forced to fill our nsec key is nearly over!
For the hurry ones of you, you can find here the Oracolo demo with my Nostr long notes article. It will include this one when I'll publish it on Nostr!
https://oracolo.fractalized.net/
How to self-host Oracolo?
You can build the application locally or use a docker compose stack to run it (or any other method). I just build a docker compose stack with Traefik and an Oracolo docker image to let you quickly run it.
The oracolo-docker github repo is available here:
https://github.com/PastaGringo/oracolo-docker
PS: don't freak out about the commits number, oracolo has been the lucky one to let me practrice docker image CI/CD build/push with Forgejo, that went well but it took me a while before finding how to make Forgejo runner dood work 😆). Please ping me on Nostr if you are interested by an article on this topic!
This repo is a mirror from my new Forgejo git instance where the code has been originaly published and will be updated if needed (I think it will):
https://git.fractalized.net/PastaGringo/oracolo-docker
Here is how to do it.
1) First, you need to create an A DNS record into your domain.tld zone. You can create a A with "oracolo" .domain.tld or "*" .domain.tld. The second one will allow traefik to generate all the future subdomain.domain.tld without having to create them in advance. You can verify DNS records with the website https://dnschecker.org.
2) Clone the oracolo-docker repository:
bash git clone https://git.fractalized.net/PastaGringo/oracolo-docker.git cd oracolo-docker3) Rename the .env.example file:
bash mv .env.example .env4) Modify and update your .env file with your own infos:
```bash
Let's Encrypt email used to generate the SSL certificate
LETSENCRYPT_EMAIL=
domain for oracolo. Ex: oracolo.fractalized.net
ORACOLO_DOMAIN=
Npub author at "npub" format, not HEX.
NPUB=
Relays where Oracolo will retrieve the Nostr events.
Ex: "wss://nostr.fractalized.net, wss://rnostr.fractalized.net"
RELAYS=
Number of blog article with an thumbnail. Ex: 4
TOP_NOTES_NB= ```
5) Compose Oracolo:
bash docker compose up -d && docker compose logs -f oracolo traefikbash [+] Running 2/0 ✔ Container traefik Running 0.0s ✔ Container oracolo Running 0.0s WARN[0000] /home/pastadmin/DEV/FORGEJO/PLAY/oracolo-docker/docker-compose.yml: `version` is obsolete traefik | 2024-05-28T19:24:18Z INF Traefik version 3.0.0 built on 2024-04-29T14:25:59Z version=3.0.0 oracolo | oracolo | ___ ____ ____ __ ___ _ ___ oracolo | / \ | \ / | / ] / \ | | / \ oracolo | | || D )| o | / / | || | | | oracolo | | O || / | |/ / | O || |___ | O | oracolo | | || \ | _ / \_ | || || | oracolo | | || . \| | \ || || || | oracolo | \___/ |__|\_||__|__|\____| \___/ |_____| \___/ oracolo | oracolo | Oracolo dtonon's repo: https://github.com/dtonon/oracolo oracolo | oracolo | ╭────────────────────────────╮ oracolo | │ Docker Compose Env Vars ⤵️ │ oracolo | ╰────────────────────────────╯ oracolo | oracolo | NPUB : npub1ky4kxtyg0uxgw8g5p5mmedh8c8s6sqny6zmaaqj44gv4rk0plaus3m4fd2 oracolo | RELAYS : wss://nostr.fractalized.net, wss://rnostr.fractalized.net oracolo | TOP_NOTES_NB : 4 oracolo | oracolo | ╭───────────────────────────╮ oracolo | │ Configuring Oracolo... ⤵️ │ oracolo | ╰───────────────────────────╯ oracolo | oracolo | > Updating npub key with npub1ky4kxtyg0uxgw8g5p5mmedh8c8s6sqny6zmaaqj44gv4rk0plaus3m4fd2... ✅ oracolo | > Updating nostr relays with wss://nostr.fractalized.net, wss://rnostr.fractalized.net... ✅ oracolo | > Updating TOP_NOTE with value 4... ✅ oracolo | oracolo | ╭───────────────────────╮ oracolo | │ Installing Oracolo ⤵️ │ oracolo | ╰───────────────────────╯ oracolo | oracolo | added 122 packages, and audited 123 packages in 8s oracolo | oracolo | 20 packages are looking for funding oracolo | run `npm fund` for details oracolo | oracolo | found 0 vulnerabilities oracolo | npm notice oracolo | npm notice New minor version of npm available! 10.7.0 -> 10.8.0 oracolo | npm notice Changelog: https://github.com/npm/cli/releases/tag/v10.8.0 oracolo | npm notice To update run: npm install -g npm@10.8.0 oracolo | npm notice oracolo | oracolo | >>> done ✅ oracolo | oracolo | ╭─────────────────────╮ oracolo | │ Building Oracolo ⤵️ │ oracolo | ╰─────────────────────╯ oracolo | oracolo | > oracolo@0.0.0 build oracolo | > vite build oracolo | oracolo | 7:32:49 PM [vite-plugin-svelte] WARNING: The following packages have a svelte field in their package.json but no exports condition for svelte. oracolo | oracolo | @splidejs/svelte-splide@0.2.9 oracolo | @splidejs/splide@4.1.4 oracolo | oracolo | Please see https://github.com/sveltejs/vite-plugin-svelte/blob/main/docs/faq.md#missing-exports-condition for details. oracolo | vite v5.2.11 building for production... oracolo | transforming... oracolo | ✓ 84 modules transformed. oracolo | rendering chunks... oracolo | oracolo | oracolo | Inlining: index-C6McxHm7.js oracolo | Inlining: style-DubfL5gy.css oracolo | computing gzip size... oracolo | dist/index.html 233.15 kB │ gzip: 82.41 kB oracolo | ✓ built in 7.08s oracolo | oracolo | >>> done ✅ oracolo | oracolo | > Copying Oracolo built index.html to nginx usr/share/nginx/html... ✅ oracolo | oracolo | ╭────────────────────────╮ oracolo | │ Configuring Nginx... ⤵️ │ oracolo | ╰────────────────────────╯ oracolo | oracolo | > Copying default nginx.conf file... ✅ oracolo | oracolo | ╭──────────────────────╮ oracolo | │ Starting Nginx... 🚀 │ oracolo | ╰──────────────────────╯ oracolo |If you don't have any issue with the Traefik container, Oracolo should be live! 🔥
You can now access it by going to the ORACOLO_DOMAIN URL configured into the .env file.
Have a good day!
Don't hesisate to follow dtonon on Nostr to follow-up the future updates ⚡🔥
See you soon in another Fractalized story!
PastaGringo 🤖⚡ -
@ 4523be58:ba1facd0
2024-05-28 11:05:17
NIP-116
Event paths
Description
Event kind
30079denotes an event defined by its event path rather than its event kind.The event directory path is included in the event path, specified in the event's
dtag. For example, an event path might beuser/profile/name, whereuser/profileis the directory path.Relays should parse the event directory from the event path
dtag and index the event by it. Relays should support "directory listing" of kind30079events using the#ffilter, such as{"#f": ["user/profile"]}.For backward compatibility, the event directory should also be saved in the event's
ftag (for "folder"), which is already indexed by some relay implementations, and can be queried using the#ffilter.Event content should be a JSON-encoded value. An empty object
{}signifies that the entry at the event path is itself a directory. For example, when savinguser/profile/name:Bob, you should also saveuser/profile:{}so the subdirectory can be listed underuser.In directory names, slashes should be escaped with a double slash.
Example
Event
json { "tags": [ ["d", "user/profile/name"], ["f", "user/profile"] ], "content": "\"Bob\"", "kind": 30079, ... }Query
json { "#f": ["user/profile"], "authors": ["[pubkey]"] }Motivation
To make Nostr an "everything app," we need a sustainable way to support new kinds of applications. Browsing Nostr data by human-readable nested directories and paths rather than obscure event kind numbers makes the data more manageable.
Numeric event kinds are not sustainable for the infinite number of potential applications. With numeric event kinds, developers need to find an unused number for each new application and announce it somewhere, which is cumbersome and not scalable.
Directories can also replace monolithic list events like follow lists or profile details. You can update a single directory entry such as
user/profile/nameorgroups/follows/[pubkey]without causing an overwrite of the whole profile or follow list when your client is out-of-sync with the most recent list version, as often happens on Nostr.Using
d-tagged replaceable events for reactions, such as{tags: [["d", "reactions/[eventId]"]], content: "\"👍\"", kind: 30079, ...}would make un-reacting trivial: just publish a new event with the samedtag and an empty content. Toggling a reaction on and off would not cause a flurry of new reaction & delete events that all need to be persisted.Implementations
- Relays that support tag-replaceable events and indexing by arbitrary tags (in this case
f) already support this feature. - IrisDB client side library: treelike data structure with subscribable nodes.
https://github.com/nostr-protocol/nips/pull/1266
- Relays that support tag-replaceable events and indexing by arbitrary tags (in this case
-
@ b12b632c:d9e1ff79
2024-04-24 20:21:27
What's Blossom?
Blossom offers a bunch of HTTP endpoints that let Nostr users stash and fetch binary data on public servers using the SHA256 hash as a universal ID.
You can find more -precise- information about Blossom on the Nostr article published today by hzrd149, the developper behind it:
nostr:naddr1qqxkymr0wdek7mfdv3exjan9qgszv6q4uryjzr06xfxxew34wwc5hmjfmfpqn229d72gfegsdn2q3fgrqsqqqa28e4v8zy
You find the Blossom github repo here:
GitHub - hzrd149/blossom: Blobs stored simply on mediaservers https://github.com/hzrd149/blossom
Meet Blobs
Blobs are files with SHA256 hashes as IDs, making them unique and secure. You can compute these IDs from the files themselves using the sha256 hashing algorithm (when you run
sha256sum bitcoin.pdf).Meet Drives
Drives are like organized events on Nostr, mapping blobs to filenames and extra info. It's like setting up a roadmap for your data.
How do Servers Work?
Blossom servers have four endpoints for users to upload and handle blobs:
GET /<sha256>: Get blobs by their SHA256 hash, maybe with a file extension. PUT /upload: Chuck your blobs onto the server, verified with signed Nostr events. GET /list/<pubkey>: Peek at a list of blobs tied to a specific public key for smooth management. DELETE /<sha256>: Trash blobs from the server when needed, keeping things tidy.Yon can find detailed information about the Blossom Server Implementation here..
https://github.com/hzrd149/blossom/blob/master/Server.md
..and the Blossom-server source code is here:
https://github.com/hzrd149/blossom-server
What's Blossom Drive?
Think of Blossom Drive as the "Front-End" (or a public cloud drive) of Blossom servers, letting you upload, manage, share your files/folders blobs.
Source code is available here:
https://github.com/hzrd149/blossom-drive
Developpers
If you want to add Blossom into your Nostr client/app, the blossom-client-sdk explaining how it works (with few examples 🙏) is published here:
https://github.com/hzrd149/blossom-client-sdk
How to self-host Blossom server & Blossom Drive
We'll use docker compose to setup Blossom server & drive. I included Nginx Proxy Manager because it's the Web Proxy I use for all the Fractalized self-hosted services :
Create a new docker-compose file:
~$ nano docker-compose.ymlInsert this content into the file:
``` version: '3.8' services:
blossom-drive: container_name: blossom-drive image: pastagringo/blossom-drive-docker
ports:
- '80:80'
blossom-server: container_name: blossom-server image: 'ghcr.io/hzrd149/blossom-server:master'
ports:
- '3000:3000'
volumes: - './blossom-server/config.yml:/app/config.yml' - 'blossom_data:/app/data'nginxproxymanager: container_name: nginxproxymanager image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: - '80:80' - '81:81' - '443:443' volumes: - ./nginxproxymanager/data:/data - ./nginxproxymanager/letsencrypt:/etc/letsencrypt - ./nginxproxymanager/_hsts_map.conf:/app/templates/_hsts_map.conf
volumes: blossom_data: ```
You now need to personalize the blossom-server config.yml:
bash ~$ mkdir blossom-server ~$ nano blossom-server/config.ymlInsert this content to the file (CTRL+X & Y to save/exit):
```yaml
Used when listing blobs
publicDomain: https://blossom.fractalized.net
databasePath: data/sqlite.db
discovery: # find files by querying nostr relays nostr: enabled: true relays: - wss://nostrue.com - wss://relay.damus.io - wss://nostr.wine - wss://nos.lol - wss://nostr-pub.wellorder.net - wss://nostr.fractalized.net # find files by asking upstream CDNs upstream: enabled: true domains: - https://cdn.satellite.earth # don't set your blossom server here!
storage: # local or s3 backend: local local: dir: ./data # s3: # endpoint: https://s3.endpoint.com # bucket: blossom # accessKey: xxxxxxxx # secretKey: xxxxxxxxx # If this is set the server will redirect clients when loading blobs # publicURL: https://s3.region.example.com/
# rules are checked in descending order. if a blob matches a rule it is kept # "type" (required) the type of the blob, "" can be used to match any type # "expiration" (required) time passed since last accessed # "pubkeys" (optional) a list of owners # any blobs not matching the rules will be removed rules: # mime type of blob - type: text/ # time since last accessed expiration: 1 month - type: "image/" expiration: 1 week - type: "video/" expiration: 5 days - type: "model/" expiration: 1 week - type: "" expiration: 2 days
upload: # enable / disable uploads enabled: true # require auth to upload requireAuth: true # only check rules that include "pubkeys" requirePubkeyInRule: false
list: requireAuth: false allowListOthers: true
tor: enabled: false proxy: "" ```
You need to update few values with your own:
- Your own Blossom server public domain :
publicDomain: https://YourBlossomServer.YourDomain.tldand upstream domains where Nostr clients will also verify if the Blossom server own the file blob: :
upstream: enabled: true domains: - https://cdn.satellite.earth # don't set your blossom server here!- The Nostr relays where you want to publish your Blossom events (I added my own Nostr relay):
yaml discovery: # find files by querying nostr relays nostr: enabled: true relays: - wss://nostrue.com - wss://relay.damus.io - wss://nostr.wine - wss://nos.lol - wss://nostr-pub.wellorder.net - wss://nostr.fractalized.netEverything is setup! You can now compose your docker-compose file:
~$ docker compose up -dI will let your check this article to know how to configure and use Nginx Proxy Manager.
You can check both Blossom containers logs with this command:
~$ docker compose logs -f blossom-drive blossom-serverRegarding the Nginx Proxy Manager settings for Blossom, here is the configuration I used:
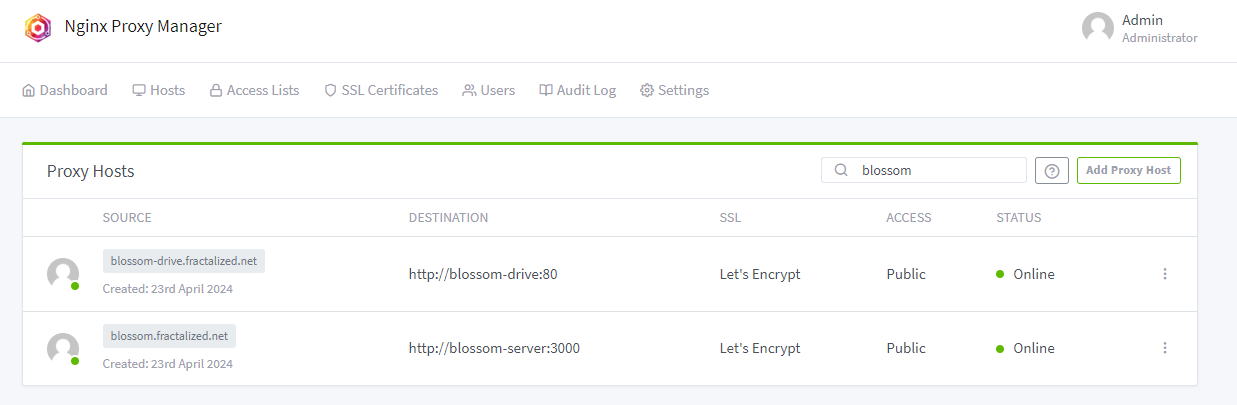
PS: it seems the naming convention for the kind of web service like Blossom is named "CDN" (for: "content delivery network"). It's not impossible in a near future I rename my subdomain blossom.fractalized.net to cdn.blossom.fractalized.net and blossom-drive.fractalized.net to blossom.fractalized.net 😅
Do what you prefer!
After having configured everything, you can now access Blossom server by going to your Blossom server subdomain. You should see a homepage as below:
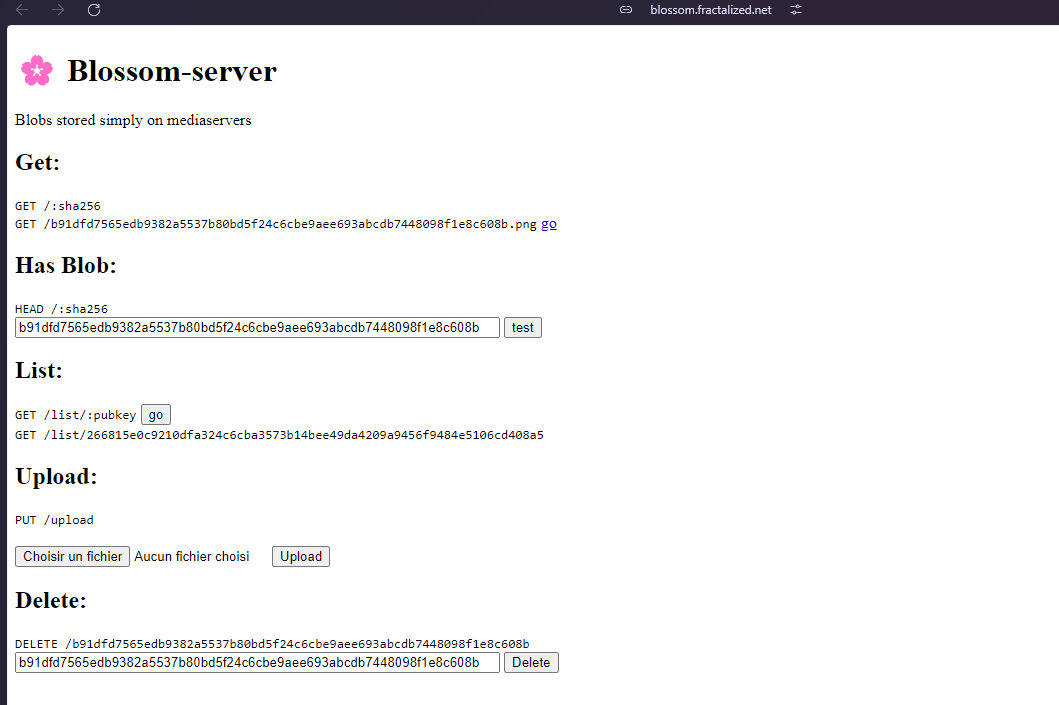
Same thing for the Blossom Drive, you should see this homepage:
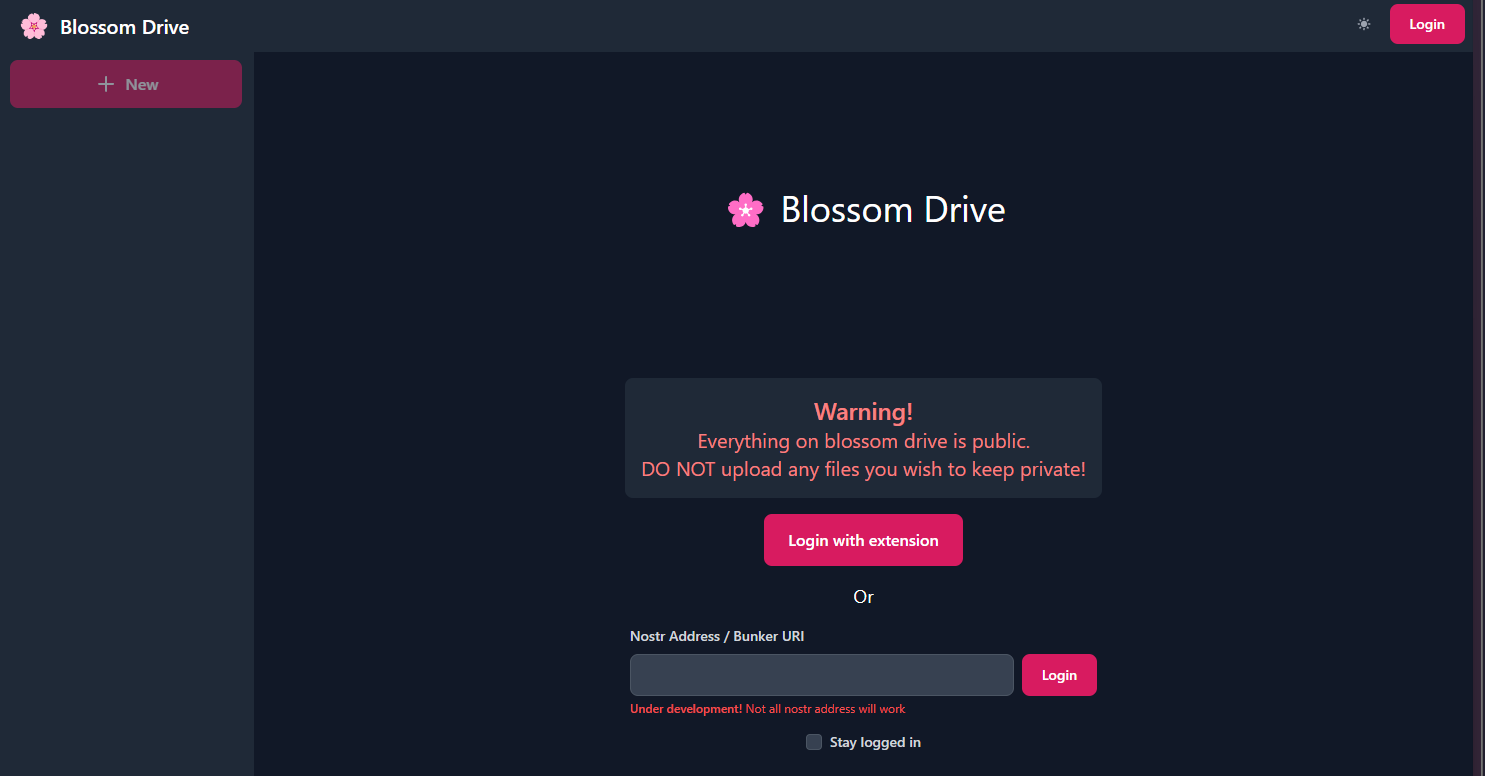
You can now login with your prefered method. In my case, I login on Blossom Drive with my NIP-07 Chrome extension.
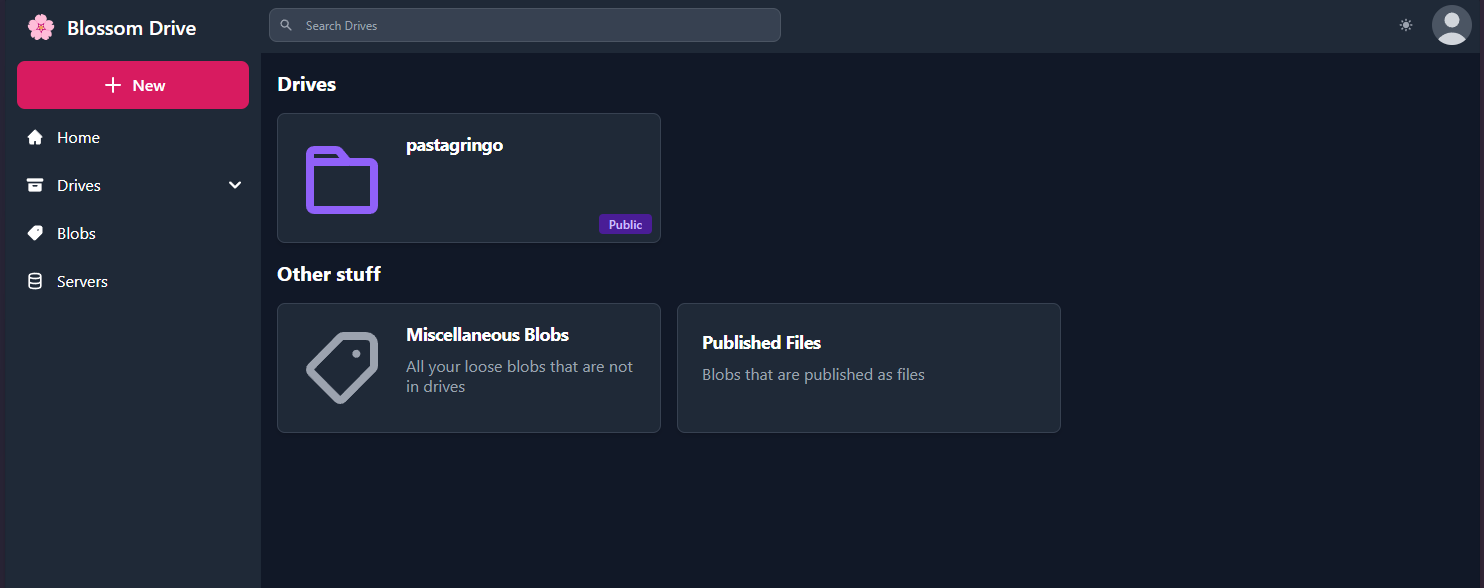
You now need to go the "Servers" tab to add some Blossom servers, including the fresh one you just installed.
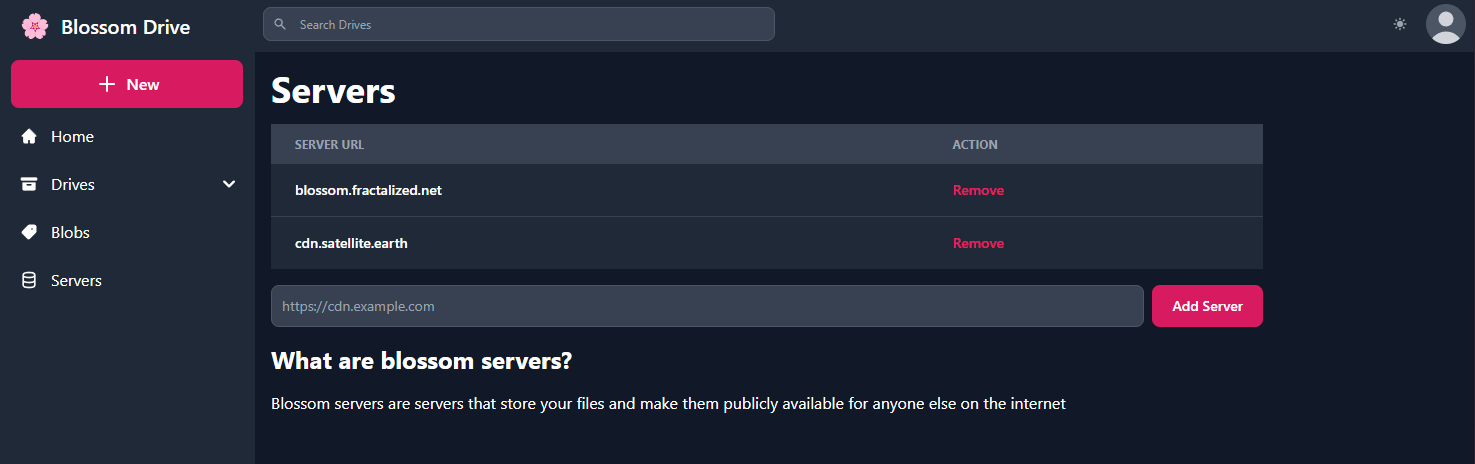
You can now create your first Blossom Drive by clicking on "+ New" > "Drive" on the top left button:
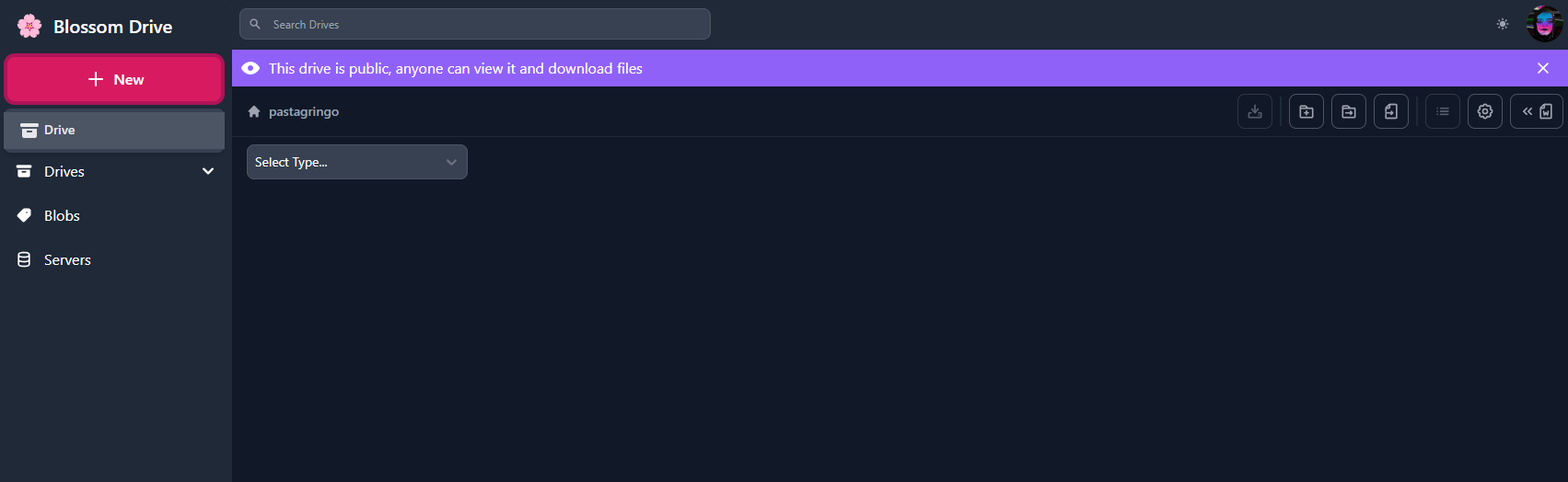
Fill your desired blossom drive name and select the media servers where you want to host your files and click on "Create":
PS: you can enable "Encrypted" option but as hzrd149 said on his Nostr note about Blossom:
"There is also the option to encrypt drives using NIP-49 password encryption. although its not tested at all so don't trust it, verify"
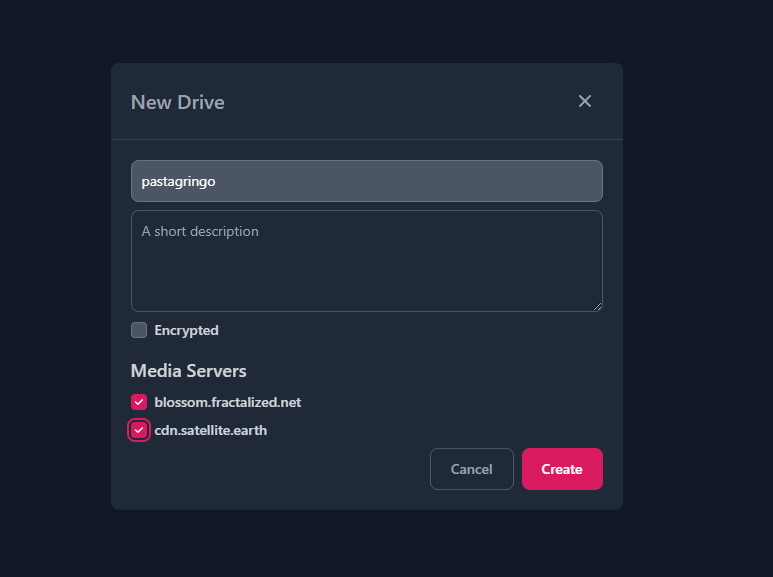
You are now able to upload some files (a picture for instance):
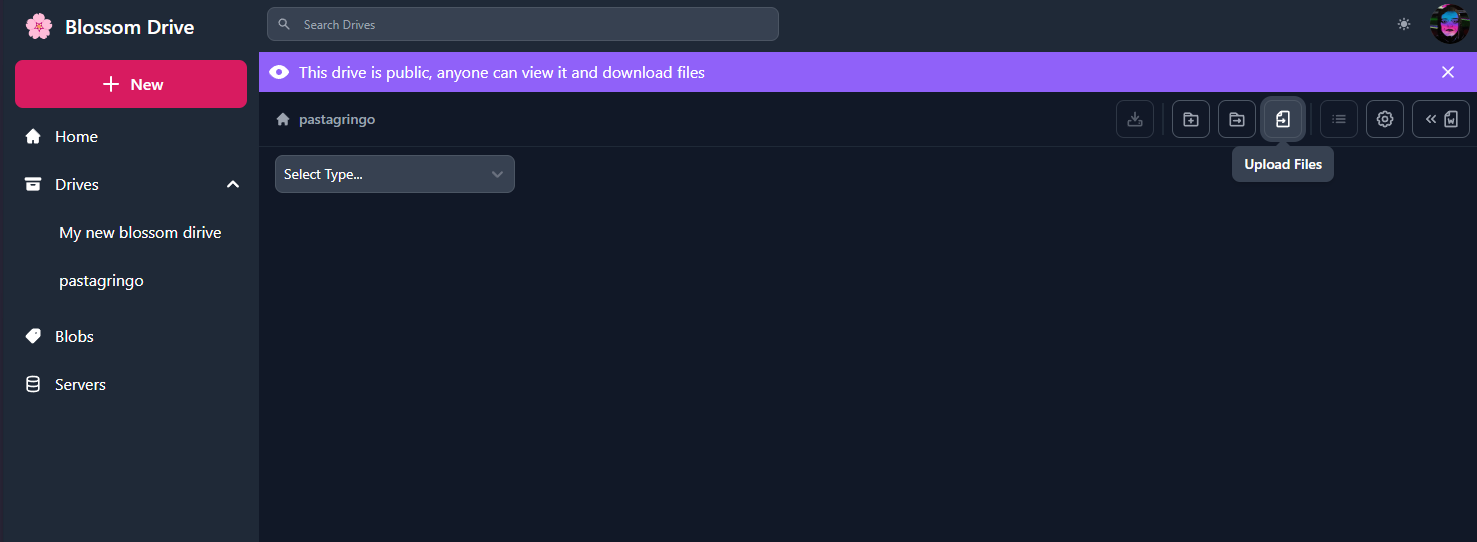
And obtain the HTTP direct link by clicking on the "Copy Link" button:
If you check URL image below, you'll see that it is served by Blossom:

It's done ! ✅
You can now upload your files to Blossom accross several Blossom servers to let them survive the future internet apocalypse.
Blossom has just been released few days ago, many news and features will come!
Don't hesisate to follow hzrd149 on Nostr to follow-up the future updates ⚡🔥
See you soon in another Fractalized story!
PastaGringo 🤖⚡ -
@ 42342239:1d80db24
2024-04-05 08:21:50
Trust is a topic increasingly being discussed. Whether it is trust in each other, in the media, or in our authorities, trust is generally seen as a cornerstone of a strong and well-functioning society. The topic was also the theme of the World Economic Forum at its annual meeting in Davos earlier this year. Even among central bank economists, the subject is becoming more prevalent. Last year, Agustín Carstens, head of the BIS ("the central bank of central banks"), said that "[w]ith trust, the public will be more willing to accept actions that involve short-term costs in exchange for long-term benefits" and that "trust is vital for policy effectiveness".
It is therefore interesting when central banks or others pretend as if nothing has happened even when trust has been shattered.
Just as in Sweden and in hundreds of other countries, Canada is planning to introduce a central bank digital currency (CBDC), a new form of money where the central bank or its intermediaries (the banks) will have complete insight into citizens' transactions. Payments or money could also be made programmable. Everything from transferring ownership of a car automatically after a successful payment to the seller, to payments being denied if you have traveled too far from home.
"If Canadians decide a digital dollar is necessary, our obligation is to be ready" says Carolyn Rogers, Deputy Head of Bank of Canada, in a statement shared in an article.
So, what do the citizens want? According to a report from the Bank of Canada, a whopping 88% of those surveyed believe that the central bank should refrain from developing such a currency. About the same number (87%) believe that authorities should guarantee the opportunity to pay with cash instead. And nearly four out of five people (78%) do not believe that the central bank will care about people's opinions. What about trust again?
Canadians' likely remember the Trudeau government's actions against the "Freedom Convoy". The Freedom Convoy consisted of, among others, truck drivers protesting the country's strict pandemic policies, blocking roads in the capital Ottawa at the beginning of 2022. The government invoked never-before-used emergency measures to, among other things, "freeze" people's bank accounts. Suddenly, truck drivers and those with a "connection" to the protests were unable to pay their electricity bills or insurances, for instance. Superficially, this may not sound so serious, but ultimately, it could mean that their families end up in cold houses (due to electricity being cut off) and that they lose the ability to work (driving uninsured vehicles is not taken lightly). And this applied not only to the truck drivers but also to those with a "connection" to the protests. No court rulings were required.
Without the freedom to pay for goods and services, i.e. the freedom to transact, one has no real freedom at all, as several participants in the protests experienced.
In January of this year, a federal judge concluded that the government's actions two years ago were unlawful when it invoked the emergency measures. The use did not display "features of rationality - motivation, transparency, and intelligibility - and was not justified in relation to the relevant factual and legal limitations that had to be considered". He also argued that the use was not in line with the constitution. There are also reports alleging that the government fabricated evidence to go after the demonstrators. The case is set to continue to the highest court. Prime Minister Justin Trudeau and Finance Minister Chrystia Freeland have also recently been sued for the government's actions.
The Trudeau government's use of emergency measures two years ago sadly only provides a glimpse of what the future may hold if CBDCs or similar systems replace the current monetary system with commercial bank money and cash. In Canada, citizens do not want the central bank to proceed with the development of a CBDC. In canada, citizens in Canada want to strengthen the role of cash. In Canada, citizens suspect that the central bank will not listen to them. All while the central bank feverishly continues working on the new system...
"Trust is vital", said Agustín Carstens. But if policy-makers do not pause for a thoughtful reflection even when trust has been utterly shattered as is the case in Canada, are we then not merely dealing with lip service?
And how much trust do these policy-makers then deserve?
-
@ 42342239:1d80db24
2024-03-31 11:23:36
Biologist Stuart Kauffman introduced the concept of the "adjacent possible" in evolutionary biology in 1996. A bacterium cannot suddenly transform into a flamingo; rather, it must rely on small exploratory changes (of the "adjacent possible") if it is ever to become a beautiful pink flying creature. The same principle applies to human societies, all of which exemplify complex systems. It is indeed challenging to transform shivering cave-dwellers into a space travelers without numerous intermediate steps.
Imagine a water wheel – in itself, perhaps not such a remarkable invention. Yet the water wheel transformed the hard-to-use energy of water into easily exploitable rotational energy. A little of the "adjacent possible" had now been explored: water mills, hammer forges, sawmills, and textile factories soon emerged. People who had previously ground by hand or threshed with the help of oxen could now spend their time on other things. The principles of the water wheel also formed the basis for wind power. Yes, a multitude of possibilities arose – reminiscent of the rapid development during the Cambrian explosion. When the inventors of bygone times constructed humanity's first water wheel, they thus expanded the "adjacent possible". Surely, the experts of old likely sought swift prohibitions. Not long ago, our expert class claimed that the internet was going to be a passing fad, or that it would only have the same modest impact on the economy as the fax machine. For what it's worth, there were even attempts to ban the number zero back in the days.
The pseudonymous creator of Bitcoin, Satoshi Nakamoto, wrote in Bitcoin's whitepaper that "[w]e have proposed a system for electronic transactions without relying on trust." The Bitcoin system enables participants to agree on what is true without needing to trust each other, something that has never been possible before. In light of this, it is worth noting that trust in the federal government in the USA is among the lowest levels measured in almost 70 years. Trust in media is at record lows. Moreover, in countries like the USA, the proportion of people who believe that one can trust "most people" has decreased significantly. "Rebuilding trust" was even the theme of the World Economic Forum at its annual meeting. It is evident, even in the international context, that trust between countries is not at its peak.
Over a fifteen-year period, Bitcoin has enabled electronic transactions without its participants needing to rely on a central authority, or even on each other. This may not sound like a particularly remarkable invention in itself. But like the water wheel, one must acknowledge that new potential seems to have been put in place, potential that is just beginning to be explored. Kauffman's "adjacent possible" has expanded. And despite dogmatic statements to the contrary, no one can know for sure where this might lead.
The discussion of Bitcoin or crypto currencies would benefit from greater humility and openness, not only from employees or CEOs of money laundering banks but also from forecast-failing central bank officials. When for instance Chinese Premier Zhou Enlai in the 1970s was asked about the effects of the French Revolution, he responded that it was "too early to say" - a far wiser answer than the categorical response of the bureaucratic class. Isn't exploring systems not based on trust is exactly what we need at this juncture?
-
@ b12b632c:d9e1ff79
2024-03-23 16:42:49
CASHU AND ECASH ARE EXPERIMENTAL PROJECTS. BY THE OWN NATURE OF CASHU ECASH, IT'S REALLY EASY TO LOSE YOUR SATS BY LACKING OF KNOWLEDGE OF THE SYSTEM MECHANICS. PLEASE, FOR YOUR OWN GOOD, ALWAYS USE FEW SATS AMOUNT IN THE BEGINNING TO FULLY UNDERSTAND HOW WORKS THE SYSTEM. ECASH IS BASED ON A TRUST RELATIONSHIP BETWEEN YOU AND THE MINT OWNER, PLEASE DONT TRUST ECASH MINT YOU DONT KNOW. IT IS POSSIBLE TO GENERATE UNLIMITED ECASH TOKENS FROM A MINT, THE ONLY WAY TO VALIDATE THE REAL EXISTENCE OF THE ECASH TOKENS IS TO DO A MULTIMINT SWAP (BETWEEN MINTS). PLEASE, ALWAYS DO A MULTISWAP MINT IF YOU RECEIVE SOME ECASH FROM SOMEONE YOU DON'T KNOW/TRUST. NEVER TRUST A MINT YOU DONT KNOW!
IF YOU WANT TO RUN AN ECASH MINT WITH A BTC LIGHTNING NODE IN BACK-END, PLEASE DEDICATE THIS LN NODE TO YOUR ECASH MINT. A BAD MANAGEMENT OF YOUR LN NODE COULD LET PEOPLE TO LOOSE THEIR SATS BECAUSE THEY HAD ONCE TRUSTED YOUR MINT AND YOU DID NOT MANAGE THE THINGS RIGHT.

What's ecash/Cashu ?
I recently listened a passionnating interview from calle 👁️⚡👁 invited by the podcast channel What Bitcoin Did about the new (not so much now) Cashu protocol.
Cashu is a a free and open-source Chaumian ecash project built for Bitcoin protocol, recently created in order to let users send/receive Ecash over BTC Lightning network. The main Cashu ecash goal is to finally give you a "by-design" privacy mechanism to allow us to do anonymous Bitcoin transactions.
Ecash for your privacy.\ A Cashu mint does not know who you are, what your balance is, or who you're transacting with. Users of a mint can exchange ecash privately without anyone being able to know who the involved parties are. Bitcoin payments are executed without anyone able to censor specific users.
Here are some useful links to begin with Cashu ecash :
Github repo: https://github.com/cashubtc
Documentation: https://docs.cashu.space
To support the project: https://docs.cashu.space/contribute
A Proof of Liabilities Scheme for Ecash Mints: https://gist.github.com/callebtc/ed5228d1d8cbaade0104db5d1cf63939
Like NOSTR and its own NIPS, here is the list of the Cashu ecash NUTs (Notation, Usage, and Terminology): https://github.com/cashubtc/nuts?tab=readme-ov-file
I won't explain you at lot more on what's Casu ecash, you need to figured out by yourself. It's really important in order to avoid any mistakes you could do with your sats (that you'll probably regret).
If you don't have so much time, you can check their FAQ right here: https://docs.cashu.space/faq
I strongly advise you to listen Calle's interviews @whatbbitcoindid to "fully" understand the concept and the Cashu ecash mechanism before using it:
Scaling Bitcoin Privacy with Calle
In the meantime I'm writing this article, Calle did another really interesting interview with ODELL from CitadelDispatch:
CD120: BITCOIN POWERED CHAUMIAN ECASH WITH CALLE
Which ecash apps?
There are several ways to send/receive some Ecash tokens, you can do it by using mobile applications like eNuts, Minibits or by using Web applications like Cashu.me, Nustrache or even npub.cash. On these topics, BTC Session Youtube channel offers high quality contents and very easy to understand key knowledge on how to use these applications :
Minibits BTC Wallet: Near Perfect Privacy and Low Fees - FULL TUTORIAL
Cashu Tutorial - Chaumian Ecash On Bitcoin
Unlock Perfect Privacy with eNuts: Instant, Free Bitcoin Transactions Tutorial
Cashu ecash is a very large and complex topic for beginners. I'm still learning everyday how it works and the project moves really fast due to its commited developpers community. Don't forget to follow their updates on Nostr to know more about the project but also to have a better undertanding of the Cashu ecash technical and political implications.
There is also a Matrix chat available if you want to participate to the project:
https://matrix.to/#/#cashu:matrix.org
How to self-host your ecash mint with Nutshell
Cashu Nutshell is a Chaumian Ecash wallet and mint for Bitcoin Lightning. Cashu Nutshell is the reference implementation in Python.
Github repo:
https://github.com/cashubtc/nutshell
Today, Nutshell is the most advanced mint in town to self-host your ecash mint. The installation is relatively straightforward with Docker because a docker-compose file is available from the github repo.
Nutshell is not the only cashu ecash mint server available, you can check other server mint here :
https://docs.cashu.space/mints
The only "external" requirement is to have a funding source. One back-end funding source where ecash will mint your ecash from your Sats and initiate BTC Lightning Netwok transactions between ecash mints and BTC Ligtning nodes during a multimint swap. Current backend sources supported are: FakeWallet*, LndRestWallet, CoreLightningRestWallet, BlinkWallet, LNbitsWallet, StrikeUSDWallet.
*FakeWallet is able to generate unlimited ecash tokens. Please use it carefully, ecash tokens issued by the FakeWallet can be sent and accepted as legit ecash tokens to other people ecash wallets if they trust your mint. In the other way, if someone send you 2,3M ecash tokens, please don't trust the mint in the first place. You need to force a multimint swap with a BTC LN transaction. If that fails, someone has maybe tried to fool you.
I used a Voltage.cloud BTC LN node instance to back-end my Nutshell ecash mint:
SPOILER: my nutshell mint is working but I have an error message "insufficient balance" when I ask a multiswap mint from wallet.cashu.me or the eNuts application. In order to make it work, I need to add some Sats liquidity (I can't right now) to the node and open few channels with good balance capacity. If you don't have an ecash mint capable of doig multiswap mint, you'll only be able to mint ecash into your ecash mint and send ecash tokens to people trusting your mint. It's working, yes, but you need to be able to do some mutiminit swap if you/everyone want to fully profit of the ecash system.
Once you created your account and you got your node, you need to git clone the Nutshell github repo:
git clone https://github.com/cashubtc/nutshell.gitYou next need to update the docker compose file with your own settings. You can comment the wallet container if you don't need it.
To generate a private key for your node, you can use this openssl command
openssl rand -hex 32 054de2a00a1d8e3038b30e96d26979761315cf48395aa45d866aeef358c91dd1The CLI Cashu wallet is not needed right now but I'll show you how to use it in the end of this article. Feel free to comment it or not.
``` version: "3" services: mint: build: context: . dockerfile: Dockerfile container_name: mint
ports:
- "3338:3338"
environment:- DEBUG=TRUE
- LOG_LEVEL=DEBUG
- MINT_URL=https://YourMintURL - MINT_HOST=YourMintDomain.tld - MINT_LISTEN_HOST=0.0.0.0 - MINT_LISTEN_PORT=3338 - MINT_PRIVATE_KEY=YourPrivateKeyFromOpenSSL - MINT_INFO_NAME=YourMintInfoName - MINT_INFO_DESCRIPTION=YourShortInfoDesc - MINT_INFO_DESCRIPTION_LONG=YourLongInfoDesc - MINT_LIGHTNING_BACKEND=LndRestWallet #- MINT_LIGHTNING_BACKEND=FakeWallet - MINT_INFO_CONTACT=[["email","YourConctact@email"], ["twitter","@YourTwitter"], ["nostr", "YourNPUB"]] - MINT_INFO_MOTD=Thanks for using my mint! - MINT_LND_REST_ENDPOINT=https://YourVoltageNodeDomain:8080 - MINT_LND_REST_MACAROON=YourDefaultAdminMacaroonBase64 - MINT_MAX_PEG_IN=100000 - MINT_MAX_PEG_OUT=100000 - MINT_PEG_OUT_ONLY=FALSE command: ["poetry", "run", "mint"]wallet-voltage: build: context: . dockerfile: Dockerfile container_name: wallet-voltage
ports:
- "4448:4448"
depends_on: - nutshell-voltage environment:- DEBUG=TRUE
- MINT_URL=http://nutshell-voltage:3338
- API_HOST=0.0.0.0 command: ["poetry", "run", "cashu", "-d"]```
To build, run and see the container logs:
docker compose up -d && docker logs -f mint0.15.1 2024-03-22 14:45:45.490 | WARNING | cashu.lightning.lndrest:__init__:49 - no certificate for lndrest provided, this only works if you have a publicly issued certificate 2024-03-22 14:45:45.557 | INFO | cashu.core.db:__init__:135 - Creating database directory: data/mint 2024-03-22 14:45:45.68 | INFO | Started server process [1] 2024-03-22 14:45:45.69 | INFO | Waiting for application startup. 2024-03-22 14:45:46.12 | INFO | Loaded 0 keysets from database. 2024-03-22 14:45:46.37 | INFO | Current keyset: 003dba9e589023f1 2024-03-22 14:45:46.37 | INFO | Using LndRestWallet backend for method: 'bolt11' and unit: 'sat' 2024-03-22 14:45:46.97 | INFO | Backend balance: 1825000 sat 2024-03-22 14:45:46.97 | INFO | Data dir: /root/.cashu 2024-03-22 14:45:46.97 | INFO | Mint started. 2024-03-22 14:45:46.97 | INFO | Application startup complete. 2024-03-22 14:45:46.98 | INFO | Uvicorn running on http://0.0.0.0:3338 (Press CTRL+C to quit) 2024-03-22 14:45:47.27 | INFO | 172.19.0.22:48528 - "GET /v1/keys HTTP/1.1" 200 2024-03-22 14:45:47.34 | INFO | 172.19.0.22:48544 - "GET /v1/keysets HTTP/1.1" 200 2024-03-22 14:45:47.38 | INFO | 172.19.0.22:48552 - "GET /v1/info HTTP/1.1" 200If you see the line :
Uvicorn running on http://0.0.0.0:3338 (Press CTRL+C to quit)Nutshell is well started.
I won't explain here how to create a reverse proxy to Nutshell, you can find how to do it into my previous article. Here is the reverse proxy config into Nginx Proxy Manager:
If everything is well configured and if you go on your mint url (https://yourminturl) you shoud see this:
It's not helping a lot because at first glance it seems to be not working but it is. You can also check these URL path to confirm :
- https://yourminturl/keys and https://yourminturl/keysets
or
- https://yourminturl/v1/keys and https://yourminturl/v1/keysets
Depending of the moment when you read this article, the first URLs path might have been migrated to V1. Here is why:
https://github.com/cashubtc/nuts/pull/55
The final test is to add your mint to your prefered ecash wallets.
SPOILER: AT THIS POINT, YOU SHOUD KNOW THAT IF YOU RESET YOUR LOCAL BROWSER INTERNET CACHE FILE, YOU'LL LOSE YOUR MINTED ECASH TOKENS. IF NOT, PLEASE READ THE DOCUMENTATION AGAIN.
For instace, if we use wallet.cashu.me:
You can go into the "Settings" tab and add your mint :
If everything went find, you shoud see this :
You can now mint some ecash from your mint creating a sats invoice :
You can now scan the QR diplayed with your prefered BTC LN wallet. If everything is OK, you should receive the funds:
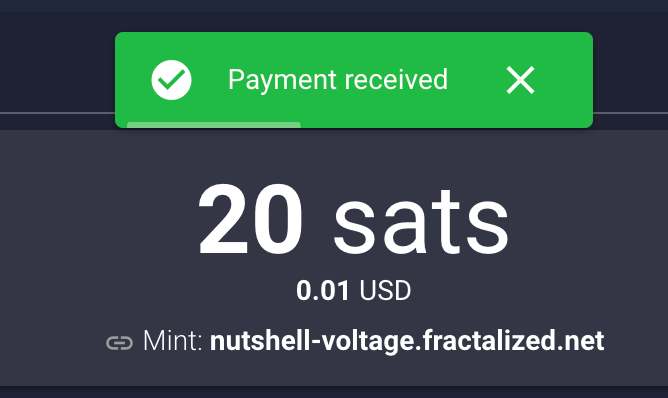
It may happen that some error popup sometimes. If you are curious and you want to know what happened, Cashu wallet has a debug console you can activate by clicking on the "Settings" page and "OPEN DEBUG TERMINAL". A little gear icon will be displayed in the bottom of the screen. You can click on it, go to settings and enable "Auto Display If Error Occurs" and "Display Extra Information". After enabling this setting, you can close the popup windows and let the gear icon enabled. If any error comes, this windows will open again and show you thé error:
Now that you have some sats in your balance, you can try to send some ecash. Open in a new windows another ecash wallet like Nutstach for instance.
Add your mint again :
Return on Cashu wallet. The ecash token amount you see on the Cashu wallet home page is a total of all the ecash tokens you have on all mint connected.
Next, click on "Send ecach". Insert the amout of ecash you want to transfer to your other wallet. You can select the wallet where you want to extract the funds by click on the little arrow near the sats funds you currenly selected :


Click now on "SEND TOKENS". That will open you a popup with a QR code and a code CONTAINING YOUR ECASH TOKENS (really).

You can now return on nutstach, click on the "Receive" button and paste the code you get from Cashu wallet:
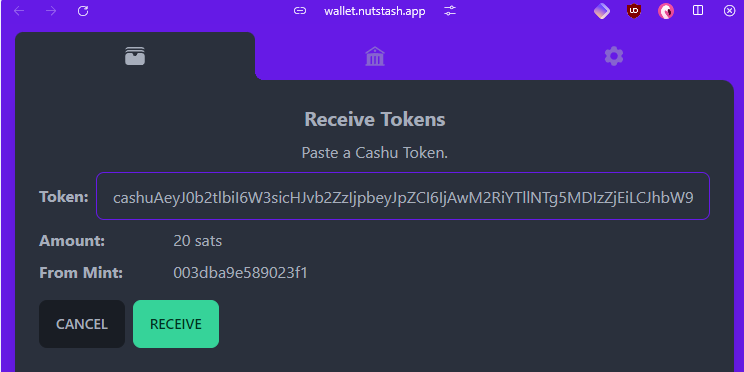
Click on "RECEIVE" again:
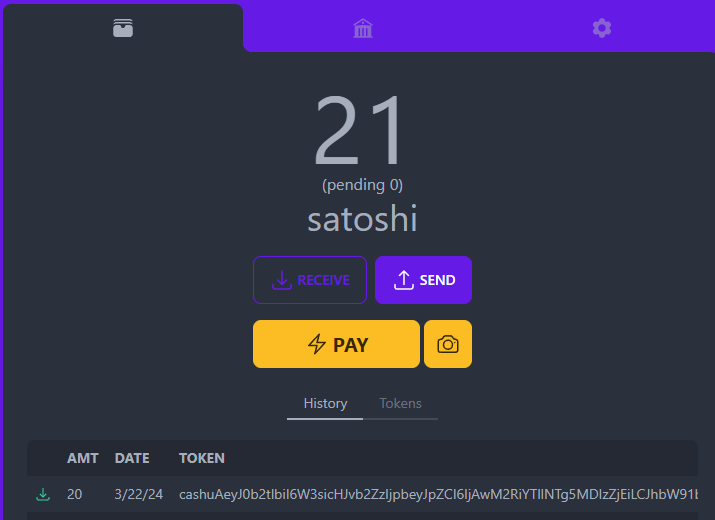
Congrats, you transfered your first ecash tokens to yourself ! 🥜⚡
You may need some time to transfer your ecash tokens between your wallets and your mint, there is a functionality existing for that called "Multimint swaps".
Before that, if you need new mints, you can check the very new website Bitcoinmints.com that let you see the existing ecash mints and rating :
Don't forget, choose your mint carefuly because you don't know who's behind.
Let's take a mint and add it to our Cashu wallet:
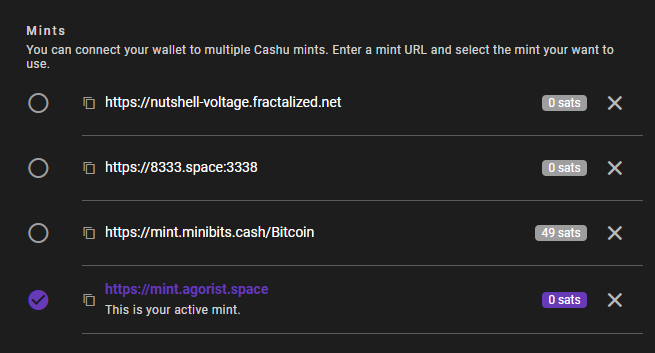
If you want to transfer let's say 20 sats from minibits mint to bitcointxoko mint, go just bottom into the "Multimint swap" section. Select the mint into "Swap from mint", the mint into "Swap to mint" and click on "SWAP" :
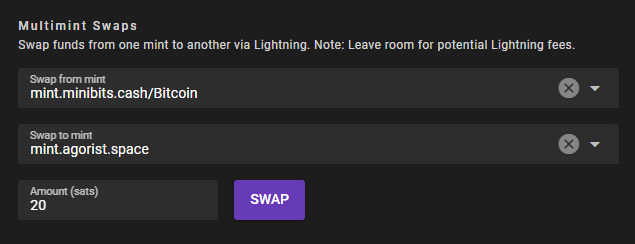
A popup window will appear and will request the ecash tokens from the source mint. It will automatically request the ecash amount via a Lightning node transaction and add the fund to your other wallet in the target mint. As it's a Lightning Network transaction, you can expect some little fees.
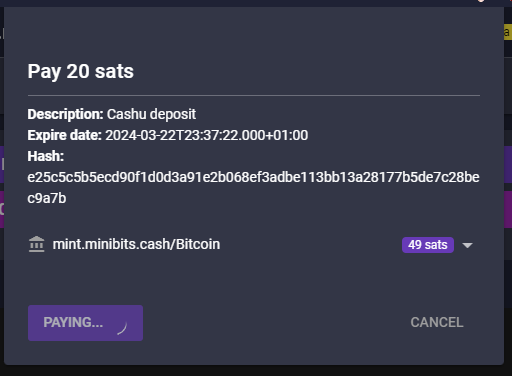
If everything is OK with the mints, the swap will be successful and the ecash received.
You can now see that the previous sats has been transfered (minus 2 fee sats).
Well done, you did your first multimint swap ! 🥜⚡
One last thing interresting is you can also use CLI ecash wallet. If you created the wallet contained in the docker compose, the container should be running.
Here are some commands you can do.
To verify which mint is currently connected :
``` docker exec -it wallet-voltage poetry run cashu info
2024-03-22 21:57:24.91 | DEBUG | cashu.wallet.wallet:init:738 | Wallet initialized 2024-03-22 21:57:24.91 | DEBUG | cashu.wallet.wallet:init:739 | Mint URL: https://nutshell-voltage.fractalized.net 2024-03-22 21:57:24.91 | DEBUG | cashu.wallet.wallet:init:740 | Database: /root/.cashu/wallet 2024-03-22 21:57:24.91 | DEBUG | cashu.wallet.wallet:init:741 | Unit: sat 2024-03-22 21:57:24.92 | DEBUG | cashu.wallet.wallet:init:738 | Wallet initialized 2024-03-22 21:57:24.92 | DEBUG | cashu.wallet.wallet:init:739 | Mint URL: https://nutshell-voltage.fractalized.net 2024-03-22 21:57:24.92 | DEBUG | cashu.wallet.wallet:init:740 | Database: /root/.cashu/wallet 2024-03-22 21:57:24.92 | DEBUG | cashu.wallet.wallet:init:741 | Unit: sat Version: 0.15.1 Wallet: wallet Debug: True Cashu dir: /root/.cashu Mints: - https://nutshell-voltage.fractalized.net ```
To verify your balance :
``` docker exec -it wallet-voltage poetry run cashu balance
2024-03-22 21:59:26.67 | DEBUG | cashu.wallet.wallet:init:738 | Wallet initialized 2024-03-22 21:59:26.67 | DEBUG | cashu.wallet.wallet:init:739 | Mint URL: https://nutshell-voltage.fractalized.net 2024-03-22 21:59:26.67 | DEBUG | cashu.wallet.wallet:init:740 | Database: /root/.cashu/wallet 2024-03-22 21:59:26.67 | DEBUG | cashu.wallet.wallet:init:741 | Unit: sat 2024-03-22 21:59:26.68 | DEBUG | cashu.wallet.wallet:init:738 | Wallet initialized 2024-03-22 21:59:26.68 | DEBUG | cashu.wallet.wallet:init:739 | Mint URL: https://nutshell-voltage.fractalized.net 2024-03-22 21:59:26.68 | DEBUG | cashu.wallet.wallet:init:740 | Database: /root/.cashu/wallet 2024-03-22 21:59:26.68 | DEBUG | cashu.wallet.wallet:init:741 | Unit: sat Balance: 0 sat ```
To create an sats invoice to have ecash :
``` docker exec -it wallet-voltage poetry run cashu invoice 20
2024-03-22 22:00:59.12 | DEBUG | cashu.wallet.wallet:_load_mint_info:275 | Mint info: name='nutshell.fractalized.net' pubkey='02008469922e985cbc5368ce16adb6ed1aaea0f9ecb21639db4ded2e2ae014a326' version='Nutshell/0.15.1' description='Official Fractalized Mint' description_long='TRUST THE MINT' contact=[['email', 'pastagringo@fractalized.net'], ['twitter', '@pastagringo'], ['nostr', 'npub1ky4kxtyg0uxgw8g5p5mmedh8c8s6sqny6zmaaqj44gv4rk0plaus3m4fd2']] motd='Thanks for using official ecash fractalized mint!' nuts={4: {'methods': [['bolt11', 'sat']], 'disabled': False}, 5: {'methods': [['bolt11', 'sat']], 'disabled': False}, 7: {'supported': True}, 8: {'supported': True}, 9: {'supported': True}, 10: {'supported': True}, 11: {'supported': True}, 12: {'supported': True}} Balance: 0 sat
Pay invoice to mint 20 sat:
Invoice: lnbc200n1pjlmlumpp5qh68cqlr2afukv9z2zpna3cwa3a0nvla7yuakq7jjqyu7g6y69uqdqqcqzzsxqyz5vqsp5zymmllsqwd40xhmpu76v4r9qq3wcdth93xthrrvt4z5ct3cf69vs9qyyssqcqppurrt5uqap4nggu5tvmrlmqs5guzpy7jgzz8szckx9tug4kr58t4avv4a6437g7542084c6vkvul0ln4uus7yj87rr79qztqldggq0cdfpy
You can use this command to check the invoice: cashu invoice 20 --id 2uVWELhnpFcNeFZj6fWzHjZuIipqyj5R8kM7ZJ9_
Checking invoice .................2024-03-22 22:03:25.27 | DEBUG | cashu.wallet.wallet:verify_proofs_dleq:1103 | Verified incoming DLEQ proofs. Invoice paid.
Balance: 20 sat ```
To pay an invoice by pasting the invoice you received by your or other people :
``` docker exec -it wallet-voltage poetry run cashu pay lnbc150n1pjluqzhpp5rjezkdtt8rjth4vqsvm50xwxtelxjvkq90lf9tu2thsv2kcqe6vqdq2f38xy6t5wvcqzzsxqrpcgsp58q9sqkpu0c6s8hq5pey8ls863xmjykkumxnd8hff3q4fvxzyh0ys9qyyssq26ytxay6up54useezjgqm3cxxljvqw5vq2e94ru7ytqc0al74hr4nt5cwpuysgyq8u25xx5la43mx4ralf3mq2425xmvhjzvwzqp54gp0e3t8e
2024-03-22 22:04:37.23 | DEBUG | cashu.wallet.wallet:_load_mint_info:275 | Mint info: name='nutshell.fractalized.net' pubkey='02008469922e985cbc5368ce16adb6ed1aaea0f9ecb21639db4ded2e2ae014a326' version='Nutshell/0.15.1' description='Official Fractalized Mint' description_long='TRUST THE MINT' contact=[['email', 'pastagringo@fractalized.net'], ['twitter', '@pastagringo'], ['nostr', 'npub1ky4kxtyg0uxgw8g5p5mmedh8c8s6sqny6zmaaqj44gv4rk0plaus3m4fd2']] motd='Thanks for using official ecash fractalized mint!' nuts={4: {'methods': [['bolt11', 'sat']], 'disabled': False}, 5: {'methods': [['bolt11', 'sat']], 'disabled': False}, 7: {'supported': True}, 8: {'supported': True}, 9: {'supported': True}, 10: {'supported': True}, 11: {'supported': True}, 12: {'supported': True}} Balance: 20 sat 2024-03-22 22:04:37.45 | DEBUG | cashu.wallet.wallet:get_pay_amount_with_fees:1529 | Mint wants 0 sat as fee reserve. 2024-03-22 22:04:37.45 | DEBUG | cashu.wallet.cli.cli:pay:189 | Quote: quote='YpNkb5f6WVT_5ivfQN1OnPDwdHwa_VhfbeKKbBAB' amount=15 fee_reserve=0 paid=False expiry=1711146847 Pay 15 sat? [Y/n]: y Paying Lightning invoice ...2024-03-22 22:04:41.13 | DEBUG | cashu.wallet.wallet:split:613 | Calling split. POST /v1/swap 2024-03-22 22:04:41.21 | DEBUG | cashu.wallet.wallet:verify_proofs_dleq:1103 | Verified incoming DLEQ proofs. Error paying invoice: Mint Error: Lightning payment unsuccessful. insufficient_balance (Code: 20000) ```
It didn't work, yes. That's the thing I told you earlier but it would work with a well configured and balanced Lightning Node.
That's all ! You should now be able to use ecash as you want! 🥜⚡
See you on NOSTR! 🤖⚡\ PastaGringo
-
@ ee11a5df:b76c4e49
2024-03-22 23:49:09
Implementing The Gossip Model
version 2 (2024-03-23)
Introduction
History
The gossip model is a general concept that allows clients to dynamically follow the content of people, without specifying which relay. The clients have to figure out where each person puts their content.
Before NIP-65, the gossip client did this in multiple ways:
- Checking kind-3 contents, which had relay lists for configuring some clients (originally Astral and Damus), and recognizing that wherever they were writing our client could read from.
- NIP-05 specifying a list of relays in the
nostr.jsonfile. I added this to NIP-35 which got merged down into NIP-05. - Recommended relay URLs that are found in 'p' tags
- Users manually making the association
- History of where events happen to have been found. Whenever an event came in, we associated the author with the relay.
Each of these associations were given a score (recommended relay urls are 3rd party info so they got a low score).
Later, NIP-65 made a new kind of relay list where someone could advertise to others which relays they use. The flag "write" is now called an OUTBOX, and the flag "read" is now called an INBOX.
The idea of inboxes came about during the development of NIP-65. They are a way to send an event to a person to make sure they get it... because putting it on your own OUTBOX doesn't guarantee they will read it -- they may not follow you.
The outbox model is the use of NIP-65. It is a subset of the gossip model which uses every other resource at it's disposal.
Rationale
The gossip model keeps nostr decentralized. If all the (major) clients were using it, people could spin up small relays for both INBOX and OUTBOX and still be fully connected, have their posts read, and get replies and DMs. This is not to say that many people should spin up small relays. But the task of being decentralized necessitates that people must be able to spin up their own relay in case everybody else is censoring them. We must make it possible. In reality, congregating around 30 or so popular relays as we do today is not a problem. Not until somebody becomes very unpopular with bitcoiners (it will probably be a shitcoiner), and then that person is going to need to leave those popular relays and that person shouldn't lose their followers or connectivity in any way when they do.
A lot more rationale has been discussed elsewhere and right now I want to move on to implementation advice.
Implementation Advice
Read NIP-65
NIP-65 will contain great advice on which relays to consult for which purposes. This post does not supersede NIP-65. NIP-65 may be getting some smallish changes, mostly the addition of a private inbox for DMs, but also changes to whether you should read or write to just some or all of a set of relays.
How often to fetch kind-10002 relay lists for someone
This is up to you. Refreshing them every hour seems reasonable to me. Keeping track of when you last checked so you can check again every hour is a good idea.
Where to fetch events from
If your user follows another user (call them jack), then you should fetch jack's events from jack's OUTBOX relays. I think it's a good idea to use 2 of those relays. If one of those choices fails (errors), then keep trying until you get 2 of them that worked. This gives some redundancy in case one of them is censoring. You can bump that number up to 3 or 4, but more than that is probably just wasting bandwidth.
To find events tagging your user, look in your user's INBOX relays for those. In this case, look into all of them because some clients will only write to some of them (even though that is no longer advised).
Picking relays dynamically
Since your user follows many other users, it is very useful to find a small subset of all of their OUTBOX relays that cover everybody followed. I wrote some code to do this as (it is used by gossip) that you can look at for an example.
Where to post events to
Post all events (except DMs) to all of your users OUTBOX relays. Also post the events to all the INBOX relays of anybody that was tagged or mentioned in the contents in a nostr bech32 link (if desired). That way all these mentioned people are aware of the reply (or quote or repost).
DMs should be posted only to INBOX relays (in the future, to PRIVATE INBOX relays). You should post it to your own INBOX relays also, because you'll want a record of the conversation. In this way, you can see all your DMs inbound and outbound at your INBOX relay.
Where to publish your user's kind-10002 event to
This event was designed to be small and not require moderation, plus it is replaceable so there is only one per user. For this reason, at the moment, just spread it around to lots of relays especially the most popular relays.
For example, the gossip client automatically determines which relays to publish to based on whether they seem to be working (several hundred) and does so in batches of 10.
How to find replies
If all clients used the gossip model, you could find all the replies to any post in the author's INBOX relays for any event with an 'e' tag tagging the event you want replies to... because gossip model clients will publish them there.
But given the non-gossip-model clients, you should also look where the event was seen and look on those relays too.
Clobbering issues
Please read your users kind 10002 event before clobbering it. You should look many places to make sure you didn't miss the newest one.
If the old relay list had tags you don't understand (e.g. neither "read" nor "write"), then preserve them.
How users should pick relays
Today, nostr relays are not uniform. They have all kinds of different rule-sets and purposes. We severely lack a way to advice non-technical users as to which relays make good OUTBOX relays and which ones make good INBOX relays. But you are a dev, you can figure that out pretty well. For example, INBOX relays must accept notes from anyone meaning they can't be paid-subscription relays.
Bandwidth isn't a big issue
The outbox model doesn't require excessive bandwidth when done right. You shouldn't be downloading the same note many times... only 2-4 times depending on the level of redundancy your user wants.
Downloading 1000 events from 100 relays is in theory the same amount of data as downloading 1000 events from 1 relay.
But in practice, due to redundancy concerns, you will end up downloading 2000-3000 events from those 100 relays instead of just the 1000 you would in a single relay situation. Remember, per person followed, you will only ask for their events from 2-4 relays, not from all 100 relays!!!
Also in practice, the cost of opening and maintaining 100 network connections is more than the cost of opening and maintaining just 1. But this isn't usually a big deal unless...
Crypto overhead on Low-Power Clients
Verifying Schnorr signatures in the secp256k1 cryptosystem is not cheap. Setting up SSL key exchange is not cheap either. But most clients will do a lot more event signature validations than they will SSL setups.
For this reason, connecting to 50-100 relays is NOT hugely expensive for clients that are already verifying event signatures, as the number of events far surpasses the number of relay connections.
But for low-power clients that can't do event signature verification, there is a case for them not doing a lot of SSL setups either. Those clients would benefit from a different architecture, where half of the client was on a more powerful machine acting as a proxy for the low-power half of the client. These halves need to trust each other, so perhaps this isn't a good architecture for a business relationship, but I don't know what else to say about the low-power client situation.
Unsafe relays
Some people complain that the outbox model directs their client to relays that their user has not approved. I don't think it is a big deal, as such users can use VPNs or Tor if they need privacy. But for such users that still have concerns, they may wish to use clients that give them control over this. As a client developer you can choose whether to offer this feature or not.
The gossip client allows users to require whitelisting for connecting to new relays and for AUTHing to relays.
See Also
-
@ 42342239:1d80db24
2024-03-21 09:49:01
It has become increasingly evident that our financial system has started undermine our constitutionally guaranteed freedoms and rights. Payment giants like PayPal, Mastercard, and Visa sometimes block the ability to donate money. Individuals, companies, and associations lose bank accounts — or struggle to open new ones. In bank offices, people nowadays risk undergoing something resembling being cross-examined. The regulations are becoming so cumbersome that their mere presence risks tarnishing the banks' reputation.
The rules are so complex that even within the same bank, different compliance officers can provide different answers to the same question! There are even departments where some of the compliance officers are reluctant to provide written responses and prefer to answer questions over an unrecorded phone call. Last year's corporate lawyer in Sweden recently complained about troublesome bureaucracy, and that's from a the perspective of a very large corporation. We may not even fathom how smaller businesses — the keys to a nation's prosperity — experience it.
Where do all these rules come?
Where do all these rules come from, and how well do they work? Today's regulations on money laundering (AML) and customer due diligence (KYC - know your customer) primarily originate from a G7 meeting in the summer of 1989. (The G7 comprises the seven advanced economies: the USA, Canada, the UK, Germany, France, Italy, and Japan, along with the EU.) During that meeting, the intergovernmental organization FATF (Financial Action Task Force) was established with the aim of combating organized crime, especially drug trafficking. Since then, its mandate has expanded to include fighting money laundering, terrorist financing, and the financing of the proliferation of weapons of mass destruction(!). One might envisage the rules soon being aimed against proliferation of GPUs (Graphics Processing Units used for AI/ML). FATF, dominated by the USA, provides frameworks and recommendations for countries to follow. Despite its influence, the organization often goes unnoticed. Had you heard of it?
FATF offered countries "a deal they couldn't refuse"
On the advice of the USA and G7 countries, the organization decided to begin grading countries in "blacklists" and "grey lists" in 2000, naming countries that did not comply with its recommendations. The purpose was to apply "pressure" to these countries if they wanted to "retain their position in the global economy." The countries were offered a deal they couldn't refuse, and the number of member countries rapidly increased. Threatening with financial sanctions in this manner has even been referred to as "extraterritorial bullying." Some at the time even argued that the process violated international law.
If your local Financial Supervisory Authority (FSA) were to fail in enforcing compliance with FATF's many checklists among financial institutions, the risk of your country and its banks being barred from the US-dominated financial markets would loom large. This could have disastrous consequences.
A cost-benefit analysis of AML and KYC regulations
Economists use cost-benefit analysis to determine whether an action or a policy is successful. Let's see what such an analysis reveals.
What are the benefits (or revenues) after almost 35 years of more and more rules and regulations? The United Nations Office on Drugs and Crime estimated that only 0.2% of criminal proceeds are confiscated. Other estimates suggest a success rate from such anti-money laundering rules of 0.07% — a rounding error for organized crime. Europol expects to recover 1.2 billion euros annually, equivalent to about 1% of the revenue generated in the European drug market (110 billion euros). However, the percentage may be considerably lower, as the size of the drug market is likely underestimated. Moreover, there are many more "criminal industries" than just the drug trade; human trafficking is one example - there are many more. In other words, criminal organizations retain at least 99%, perhaps even 99.93%, of their profits, despite all cumbersome rules regarding money laundering and customer due diligence.
What constitutes the total cost of this bureaurcratic activity, costs that eventually burden taxpayers and households via higher fees? Within Europe, private financial firms are estimated to spend approximately 144 billion euros on compliance. According to some estimates, the global cost is twice as high, perhaps even eight times as much.
For Europe, the cost may thus be about 120 times (144/1.2) higher than the revenues from these measures. These "compliance costs" bizarrely exceed the total profits from the drug market, as one researcher put it. Even though the calculations are uncertain, it is challenging — perhaps impossible — to legitimize these regulations from a cost-benefit perspective.
But it doesn't end there, unfortunately. The cost of maintaining this compliance circus, with around 80 international organizations, thousands of authorities, far more employees, and all this across hundreds of countries, remains a mystery. But it's unlikely to be cheap.
The purpose of a system is what it does
In Economic Possibilities for our Grandchildren (1930), John Maynard Keynes foresaw that thanks to technological development, we could have had a 15-hour workweek by now. This has clearly not happened. Perhaps jobs have been created that are entirely meaningless? Anthropologist David Graeber argued precisely this in Bullshit Jobs in 2018. In that case, a significant number of people spend their entire working lives performing tasks they suspect deep down don't need to be done.
"The purpose of a system is what it does" is a heuristic coined by Stafford Beer. He observed there is "no point in claiming that the purpose of a system is to do what it constantly fails to do. What the current regulatory regime fails to do is combat criminal organizations. Nor does it seem to prevent banks from laundering money as never before, or from providing banking services to sex-offending traffickers
What the current regulatory regime does do, is: i) create armies of meaningless jobs, ii) thereby undermining mental health as well as economic prosperity, while iii) undermining our freedom and rights.
What does this say about the purpose of the system?
-
@ ee11a5df:b76c4e49
2024-03-21 00:28:47
I'm glad to see more activity and discussion about the gossip model. Glad to see fiatjaf and Jack posting about it, as well as many developers pitching in in the replies. There are difficult problems we need to overcome, and finding notes while remaining decentralized without huge note copying overhead was just the first. While the gossip model (including the outbox model which is just the NIP-65 part) completely eliminates the need to copy notes around to lots of relays, and keeps us decentralized, it brings about it's own set of new problems. No community is ever of the same mind on any issue, and this issue is no different. We have a lot of divergent opinions. This note will be my updated thoughts on these topics.
COPYING TO CENTRAL RELAYS IS A NON-STARTER: The idea that you can configure your client to use a few popular "centralized" relays and everybody will copy notes into those central relays is a non-starter. It destroys the entire raison d'être of nostr. I've heard people say that more decentralization isn't our biggest issue. But decentralization is THE reason nostr exists at all, so we need to make sure we live up to the hype. Otherwise we may as well just all join Bluesky. It has other problems too: the central relays get overloaded, and the notes get copied to too many relays, which is both space-inefficient and network bandwith inefficient.
ISSUE 1: Which notes should I fetch from which relays? This is described pretty well now in NIP-65. But that is only the "outbox" model part. The "gossip model" part is to also work out what relays work for people who don't publish a relay list.
ISSUE 2: Automatic failover. Apparently Peter Todd's definition of decentralized includes a concept of automatic failover, where new resources are brought up and users don't need to do anything. Besides this not being part of any definition of decentralized I have never heard of, we kind of have this. If a user has 5 outboxes, and 3 fail, everything still works. Redundancy is built in. No user intervention needed in most cases, at least in the short term. But we also don't have any notion of administrators who can fix this behind the scenes for the users. Users are sovereign and that means they have total control, but also take on some responsibility. This is obvious when it comes to keypair management, but it goes further. Users have to manage where they post and where they accept incoming notes, and when those relays fail to serve them they have to change providers. Putting the users in charge, and not having administrators, is kinda necessary to be truly decentralized.
ISSUE 3: Connecting to unvetted relays feels unsafe. It might even be the NSA tracking you! First off, this happens with your web browser all the time: you go visit a web page and it instructs your browser to fetch a font from google. If you don't like it, you can use uBlock origin and manage it manually. In the nostr world, if you don't like it, you can use a client that puts you more in control of this. The gossip client for example has options for whether you want to manually approve relay connections and AUTHs, just once or always, and always lets you change your mind later. If you turn those options on, initially it is a giant wall of approval requests... but that situation resolves rather quickly. I've been running with these options on for a long time now, and only about once a week do I have to make a decision for a new relay.
But these features aren't really necessary for the vast majority of users who don't care if a relay knows their IP address. Those users use VPNs or Tor when they want to be anonymous, and don't bother when they don't care (me included).
ISSUE 4: Mobile phone clients may find the gossip model too costly in terms of battery life. Bandwidth is actually not a problem: under the gossip model (if done correctly) events for user P are only downloaded from N relays (default for gossip client is N=2), which in general is FEWER events retrieved than other models which download the same event maybe 8 or more times. Rather, the problem here is the large number of network connections and in particular, the large number of SSL setups and teardowns. If it weren't for SSL, this wouldn't be much of a problem. But setting up and tearing down SSL on 50 simultaneous connections that drop and pop up somewhat frequently is a battery drain.
The solution to this that makes the most sense to me is to have a client proxy. What I mean by that is a piece of software on a server in a data centre. The client proxy would be a headless nostr client that uses the gossip model and acts on behalf of the phone client. The phone client doesn't even have to be a nostr client, but it might as well be a nostr client that just connects to this fixed proxy to read and write all of its events. Now the SSL connection issue is solved. These proxies can serve many clients and have local storage, whereas the phones might not even need local storage. Since very few users will set up such things for themselves, this is a business opportunity for people, and a better business opportunity IMHO than running a paid-for relay. This doesn't decentralize nostr as there can be many of these proxies. It does however require a trust relationship between the phone client and the proxy.
ISSUE 5: Personal relays still need moderation. I wrongly thought for a very long time that personal relays could act as personal OUTBOXes and personal INBOXes without needing moderation. Recently it became clear to me that clients should probably read from other people's INBOXes to find replies to events written by the user of that INBOX (which outbox model clients should be putting into that INBOX). If that is happening, then personal relays will need to serve to the public events that were just put there by the public, thus exposing them to abuse. I'm greatly disappointed to come to this realization and not quite settled about it yet, but I thought I had better make this known.
-
@ b12b632c:d9e1ff79
2024-02-19 19:18:46
Nostr decentralized network is growing exponentially day by day and new stuff comes out everyday. We can now use a NIP46 server to proxify our nsec key to avoid to use it to log on Nostr websites and possibly leak it, by mistake or by malicious persons. That's the point of this tutorial, setup a NIP46 server Nsec.app with its own Nostr relay. You'll be able to use it for you and let people use it, every data is stored locally in your internet browser. It's an non-custodial application, like wallets !
It's nearly a perfect solution (because nothing is perfect as we know) and that makes the daily use of Nostr keys much more secure and you'll see, much more sexy ! Look:
Nsec.app is not the only NIP46 server, in fact, @PABLOF7z was the first to create a NIP46 server called nsecBunker. You can also self-hosted nsecBunkerd, you can find a detailed explanation here : nsecbunkerd. I may write a how to self-host nsecBunkderd soon.
If you want more information about its bunker and what's behind this tutorial, you can check these links :
Few stuffs before beginning
Spoiler : I didn't automatized everything. The goal here is not to give you a full 1 click installation process, it's more to let you see and understand all the little things to configure and understand how works Nsec.app and the NIP46. There is a little bit of work, yes, but you'll be happy when it will work! Believe me.
Before entering into the battlefield, you must have few things : A working VPS with direct access to internet or a computer at home but NAT will certain make your life a hell. Use a VPS instead, on DigitalOcean, Linode, Scaleway, as you wish. A web domain that your own because we need to use at least 3 DNS A records (you can choose the subdomain you like) : domain.tld, noauth.domain.tld, noauth.domain.tld. You need to have some programs already installed : git, docker, docker-compose, nano/vi. if you fill in all the boxes, we can move forward !
Let's install everything !
I build a repo with a docker-compose file with all the required stuff to make the Bunker works :
Nsec.app front-end : noauth Nsec.app back-end : noauthd Nostr relay : strfry Nostr NIP05 : easy-nip5
First thing to do is to clone the repo "nsec-app-docker" from my repo:
$ git clone git clone https://github.com/PastaGringo/nsec-app-docker.git $ cd nsec-app-dockerWhen it's done, you'll have to do several things to make it work. 1) You need to generate some keys for the web-push library (keep them for later) :
``` $ docker run pastagringo/web-push-generate-keys
Generating your web-push keys...
Your private key : rQeqFIYKkInRqBSR3c5iTE3IqBRsfvbq_R4hbFHvywE Your public key : BFW4TA-lUvCq_az5fuQQAjCi-276wyeGUSnUx4UbGaPPJwEemUqp3Rr3oTnxbf0d4IYJi5mxUJOY4KR3ZTi3hVc ```
2) Generate a new keys pair (nsec/npub) for the NIP46 server by clicking on "Generate new key" from NostrTool website: nostrtool.com.
You should have something like this :
console Nostr private key (nsec): keep this -> nsec1zcyanx8zptarrmfmefr627zccrug3q2vhpfnzucq78357hshs72qecvxk6 Nostr private key (hex): 1609d998e20afa31ed3bca47a57858c0f888814cb853317300f1e34f5e178794 Nostr public key (npub): npub1ywzwtnzeh64l560a9j9q5h64pf4wvencv2nn0x4h0zw2x76g8vrq68cmyz Nostr public key (hex): keep this -> 2384e5cc59beabfa69fd2c8a0a5f550a6ae6667862a7379ab7789ca37b483b06You need to keep Nostr private key (nsec) & Nostr public key (npub). 3) Open (nano/vi) the .env file located in the current folder and fill all the required info :
```console
traefik
EMAIL=pastagringo@fractalized.net <-- replace with your own domain NSEC_ROOT_DOMAIN=plebes.ovh <-- replace with your own domain <-- replace with your own relay domain RELAY_DOMAIN=relay.plebes.ovh <-- replace with your own noauth domainay.plebes.ovh <-- replace with your own relay domain <-- replace with your own noauth domain NOAUTH_DOMAIN=noauth.plebes.ovh <-- replace with your own noauth domain NOAUTHD_DOMAIN=noauthd.plebes.ovh <-- replace with your own noauth domain
noauth
APP_WEB_PUSH_PUBKEY=BGVa7TMQus_KVn7tAwPkpwnU_bpr1i6B7D_3TT-AwkPlPd5fNcZsoCkJkJylVOn7kZ-9JZLpyOmt7U9rAtC-zeg <-- replace with your own web push public key APP_NOAUTHD_URL=https://$NOAUTHD_DOMAIN APP_DOMAIN=$NSEC_ROOT_DOMAIN APP_RELAY=wss://$RELAY_DOMAIN
noauthd
PUSH_PUBKEY=$APP_WEB_PUSH_PUBKEY PUSH_SECRET=_Sz8wgp56KERD5R4Zj5rX_owrWQGyHDyY4Pbf5vnFU0 <-- replace with your own web push private key ORIGIN=https://$NOAUTHD_DOMAIN DATABASE_URL=file:./prod.db BUNKER_NSEC=nsec1f43635rzv6lsazzsl3hfsrum9u8chn3pyjez5qx0ypxl28lcar2suy6hgn <-- replace with your the bunker nsec key BUNKER_RELAY=wss://$RELAY_DOMAIN BUNKER_DOMAIN=$NSEC_ROOT_DOMAIN BUNKER_ORIGIN=https://$NOAUTH_DOMAIN ```
Be aware of noauth and noauthd (the d letter). Next, save and quit. 4) You now need to modify the nostr.json file used for the NIP05 to indicate which relay your bunker will use. You need to set the bunker HEX PUBLIC KEY (I replaced the info with the one I get from NostrTool before) :
console nano easy-nip5/nostr.jsonconsole { "names": { "_": "ServerHexPubKey" }, "nip46": { "ServerHexPubKey": [ "wss://ReplaceWithYourRelayDomain" ] } }5) You can now run the docker compose file by running the command (first run can take a bit of time because the noauth container needs to build the npm project):
console $ docker compose up -d6) Before creating our first user into the Nostr Bunker, we need to test if all the required services are up. You should have :
noauth :
noauthd :
console CANNOT GET /https://noauthd.yourdomain.tld/name :
console { "error": "Specify npub" }https://yourdomain.tld/.well-known/nostr.json :
console { "names": { "_": "ServerHexPubKey" }, "nip46": { "ServerHexPubKey": [ "wss://ReplaceWithYourRelayDomain" ] } }If you have everything working, we can try to create a new user!
7) Connect to noauth and click on "Get Started" :
At the bottom the screen, click on "Sign up" :
Fill a username and click on "Create account" :
If everything has been correctly configured, you should see a pop message with "Account created for "XXXX" :
PS : to know if noauthd is well serving the nostr.json file, you can check this URL : https://yourdomain.tld/.well-known/nostr.json?name=YourUser You should see that the user has now NIP05/NIP46 entries :
If the user creation failed, you'll see a red pop-up saying "Something went wrong!" :

To understand what happened, you need to inspect the web page to find the error :
For the example, I tried to recreate a user "jack" which has already been created. You may find a lot of different errors depending of the configuration you made. You can find that the relay is not reachable on w s s : / /, you can find that the noauthd is not accessible too, etc. Every answers should be in this place.
To completely finish the tests, you need to enable the browser notifications, otherwise you won't see the pop-up when you'll logon on Nostr web client, by clicking on "Enable background service" :
You need to click on allow notifications :
Should see this green confirmation popup on top right of your screen:
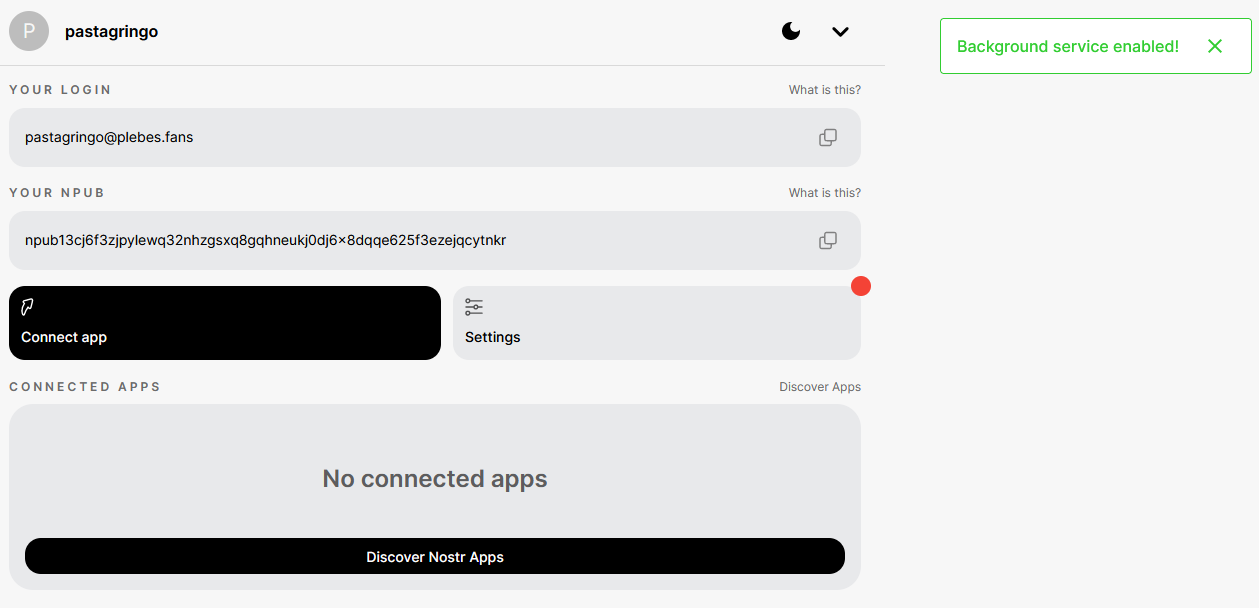
Well... Everything works now !
8) You try to use your brand new proxyfied npub by clicking on "Connect App" and buy copying your bunker URL :
You can now to for instance on Nostrudel Nostr web client to login with it. Select the relays you want (Popular is better ; if you don't have multiple relay configured on your Nostr profile, avoid "Login to use your relay") :
Click on "Sign in" :
Click on "Show Advanced" :
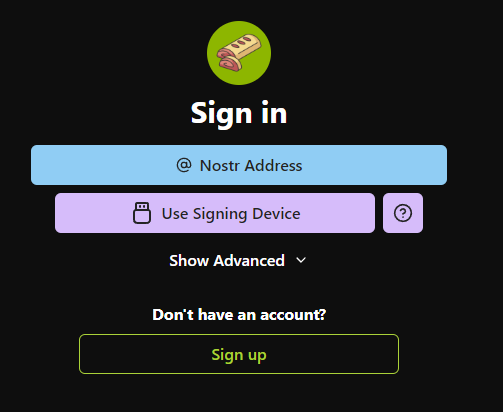
Click on "Nostr connect / Bunker" :
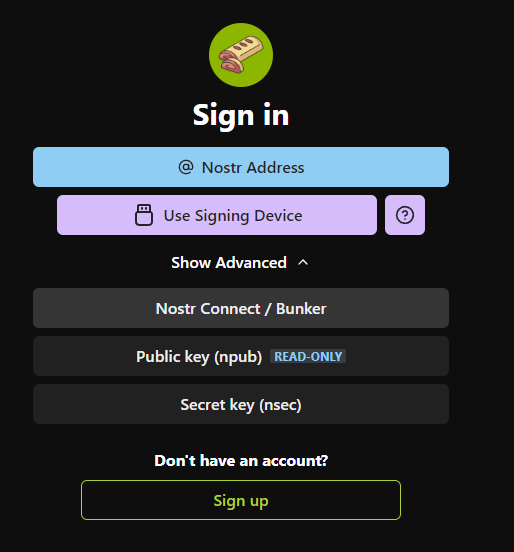
Paste your bunker URL and click on "Connect" :
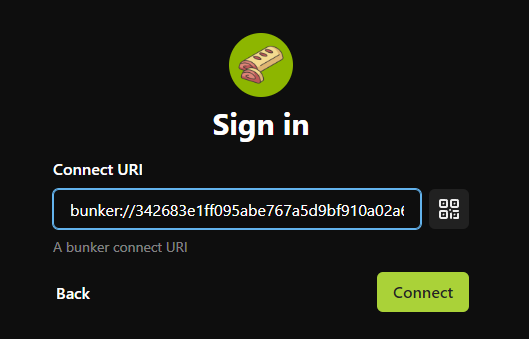
The first time, tour browser (Chrome here) may blocks the popup, you need to allow it :
If the browser blocked the popup, NoStrudel will wait your confirmation to login :
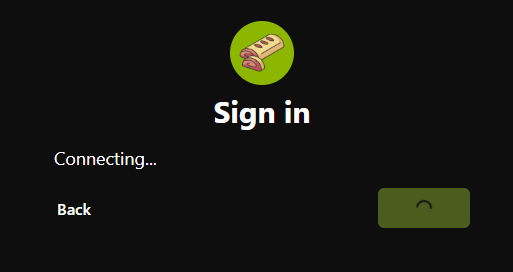
You have to go back on your bunker URL to allow the NoStrudel connection request by clicking on on "Connect":
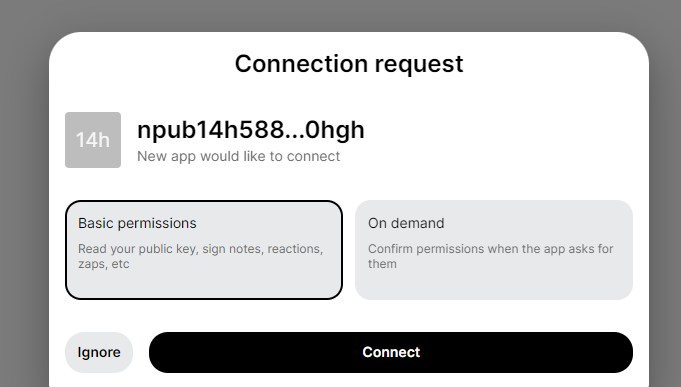
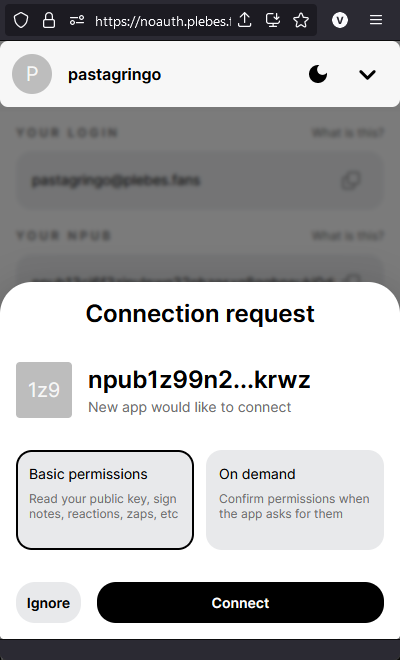
The first time connections may be a bit annoying with all the popup authorizations but once it's done, you can forget them it will connect without any issue. Congrats ! You are connected on NoStrudel with an npub proxyfied key !⚡

You can check to which applications you gave permissions and activity history in noauth by selecting your user. :
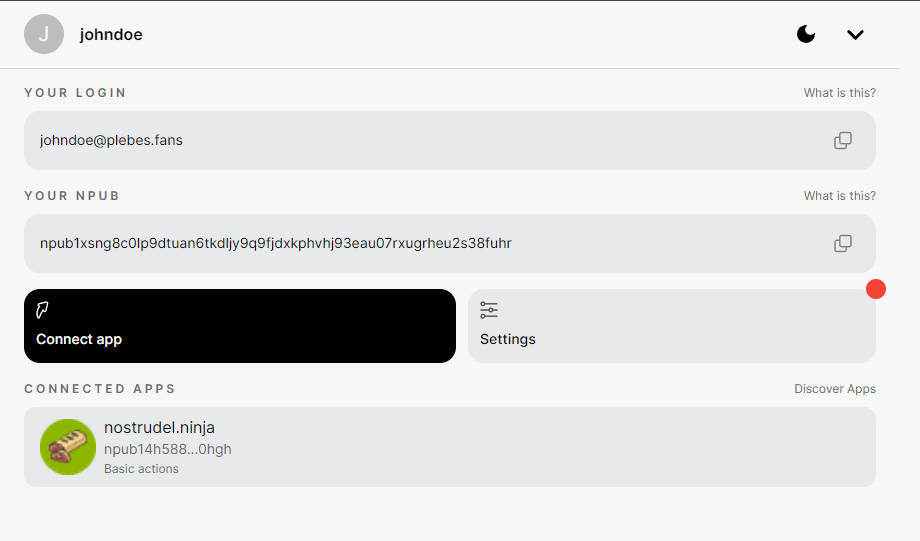

If you want to import your real Nostr profile, the one that everyone knows, you can import your nsec key by adding a new account and select "Import key" and adding your precious nsec key (reminder: your nsec key stays in your browser! The noauth provider won't have access to it!) :
You can see can that my profile picture has been retrieved and updated into noauth :
I can now use this new pubkey attached my nsec.app server to login in NoStrudel again :
Accounts/keys management in noauthd You can list created keys in your bunkerd by doing these command (CTRL+C to exit) :
console $ docker exec -it noauthd node src/index.js list_names [ '/usr/local/bin/node', '/noauthd/src/index.js', 'list_names' ] 1 jack npub1hjdw2y0t44q4znzal2nxy7vwmpv3qwrreu48uy5afqhxkw6d2nhsxt7x6u 1708173927920n 2 peter npub1yp752u5tr5v5u74kadrzgfjz2lsmyz8dyaxkdp4e0ptmaul4cyxsvpzzjz 1708174748972n 3 john npub1xw45yuvh5c73sc5fmmc3vf2zvmtrzdmz4g2u3p2j8zcgc0ktr8msdz6evs 1708174778968n 4 johndoe npub1xsng8c0lp9dtuan6tkdljy9q9fjdxkphvhj93eau07rxugrheu2s38fuhr 1708174831905nIf you want to delete someone key, you have to do :
```console $ docker exec -it noauthd node src/index.js delete_name johndoe [ '/usr/local/bin/node', '/noauthd/src/index.js', 'delete_name', 'johndoe' ] deleted johndoe { id: 4, name: 'johndoe', npub: 'npub1xsng8c0lp9dtuan6tkdljy9q9fjdxkphvhj93eau07rxugrheu2s38fuhr', timestamp: 1708174831905n
$ docker exec -it noauthd node src/index.js list_names [ '/usr/local/bin/node', '/noauthd/src/index.js', 'list_names' ] 1 jack npub1hjdw2y0t44q4znzal2nxy7vwmpv3qwrreu48uy5afqhxkw6d2nhsxt7x6u 1708173927920n 2 peter npub1yp752u5tr5v5u74kadrzgfjz2lsmyz8dyaxkdp4e0ptmaul4cyxsvpzzjz 1708174748972n 3 john npub1xw45yuvh5c73sc5fmmc3vf2zvmtrzdmz4g2u3p2j8zcgc0ktr8msdz6evs 1708174778968n ```
It could be pretty easy to create a script to handle the management of keys but I think @Brugeman may create a web interface for that. Noauth is still very young, changes are committed everyday to fix/enhance the application! As """everything""" is stored locally on your browser, you have to clear the cache of you bunker noauth URL to clean everything. This Chome extension is very useful for that. Check these settings in the extension option :
You can now enjoy even more Nostr ⚡ See you soon in another Fractalized story!
-
@ ee11a5df:b76c4e49
2023-11-09 05:20:37
A lot of terms have been bandied about regarding relay models: Gossip relay model, outbox relay model, and inbox relay model. But this term "relay model" bothers me. It sounds stuffy and formal and doesn't actually describe what we are talking about very well. Also, people have suggested maybe there are other relay models. So I thought maybe we should rethink this all from first principles. That is what this blog post attempts to do.
Nostr is notes and other stuff transmitted by relays. A client puts an event onto a relay, and subsequently another client reads that event. OK, strictly speaking it could be the same client. Strictly speaking it could even be that no other client reads the event, that the event was intended for the relay (think about nostr connect). But in general, the reason we put events on relays is for other clients to read them.
Given that fact, I see two ways this can occur:
1) The reader reads the event from the same relay that the writer wrote the event to (this I will call relay rendezvous), 2) The event was copied between relays by something.
This second solution is perfectly viable, but it less scalable and less immediate as it requires copies which means that resources will be consumed more rapidly than if we can come up with workable relay rendezvous solutions. That doesn't mean there aren't other considerations which could weigh heavily in favor of copying events. But I am not aware of them, so I will be discussing relay rendezvous.
We can then divide the relay rendezvous situation into several cases: one-to-one, one-to-many, and one-to-all, where the many are a known set, and the all are an unbounded unknown set. I cannot conceive of many-to-anything for nostr so we will speak no further of it.
For a rendezvous to take place, not only do the parties need to agree on a relay (or many relays), but there needs to be some way that readers can become aware that the writer has written something.
So the one-to-one situation works out well by the writer putting the message onto a relay that they know the reader checks for messages on. This we call the INBOX model. It is akin to sending them an email into their inbox where the reader checks for messages addressed to them.
The one-to-(known)-many model is very similar, except the writer has to write to many people's inboxes. Still we are dealing with the INBOX model.
The final case, one-to-(unknown)-all, there is no way the writer can place the message into every person's inbox because they are unknown. So in this case, the writer can write to their own OUTBOX, and anybody interested in these kinds of messages can subscribe to the writer's OUTBOX.
Notice that I have covered every case already, and that I have not even specified what particular types of scenarios call for one-to-one or one-to-many or one-to-all, but that every scenario must fit into one of those models.
So that is basically it. People need INBOX and OUTBOX relays and nothing else for relay rendezvous to cover all the possible scenarios.
That is not to say that other kinds of concerns might not modulate this. There is a suggestion for a DM relay (which is really an INBOX but with a special associated understanding), which is perfectly fine by me. But I don't think there are any other relay models. There is also the case of a live event where two parties are interacting over the same relay, but in terms of rendezvous this isn't a new case, it is just that the shared relay is serving as both parties' INBOX (in the case of a closed chat) and/or both parties' OUTBOX (in the case of an open one) at the same time.
So anyhow that's my thinking on the topic. It has become a fairly concise and complete set of concepts, and this makes me happy. Most things aren't this easy.
-
@ b12b632c:d9e1ff79
2023-08-08 00:02:31
"Welcome to the Bitcoin Lightning Bolt Card, the world's first Bitcoin debit card. This revolutionary card allows you to easily and securely spend your Bitcoin at lightning compatible merchants around the world." Bolt Card
I discovered few days ago the Bolt Card and I need to say that's pretty amazing. Thinking that we can pay daily with Bitcoin Sats in the same way that we pay with our Visa/Mastecard debit cards is really something huge⚡(based on the fact that sellers are accepting Bitcoins obviously!)
To use Bolt Card you have three choices :
- Use their (Bolt Card) own Bolt Card HUB and their own BTC Lightning node
- Use your own self hosted Bolt Card Hub and an external BTC Lightning node
- Use your own self hosted Bolt Card Hub and your BTC Lightning node (where you shoud have active Lightning channels)
⚡ The first choice is the quickiest and simpliest way to have an NFC Bolt Card. It will take you few seconds (for real). You'll have to wait much longer to receive your NFC card from a website where you bought it than configure it with Bolt Card services.
⚡⚡ The second choice is pretty nice too because you won't have a VPS + to deal with all the BTC Lightnode stuff but you'll use an external one. From the Bolt Card tutorial about Bolt Card Hub, they use a Lightning from voltage.cloud and I have to say that their services are impressive. In few seconds you'll have your own Lightning node and you'll be able to configure it into the Bolt Card Hub settings. PS : voltage.cloud offers 7 trial days / 20$ so don't hesitate to try it!
⚡⚡⚡ The third one is obvisouly a bit (way) more complex because you'll have to provide a VPS + Bitcoin node and a Bitcoin Lightning Node to be able to send and receive Lightning payments with your Bolt NFC Card. So you shoud already have configured everything by yourself to follow this tutorial. I will show what I did for my own installation and all my nodes (BTC & Lightning) are provided by my home Umbrel node (as I don't want to publish my nodes directly on the clearnet). We'll see how to connect to the Umbrel Lighting node later (spoiler: Tailscale).
To resume in this tutorial, I have :
- 1 Umbrel node (rpi4b) with BTC and Lightning with Tailscale installed.
- 1 VPS (Virtual Personal Server) to publish publicly the Bolt Card LNDHub and Bolt Card containers configured the same way as my other containers (with Nginx Proxy Manager)
Ready? Let's do it ! ⚡
Configuring Bolt Card & Bolt Card LNDHub
Always good to begin by reading the bolt card-lndhub-docker github repo. To a better understading of all the components, you can check this schema :
We'll not use it as it is because we'll skip the Caddy part because we already use Nginx Proxy Manager.
To begin we'll clone all the requested folders :
git clone https://github.com/boltcard/boltcard-lndhub-docker bolthub cd bolthub git clone https://github.com/boltcard/boltcard-lndhub BoltCardHub git clone https://github.com/boltcard/boltcard.git git clone https://github.com/boltcard/boltcard-groundcontrol.git GroundControlPS : we won't see how to configure GroundControl yet. This article may be updated later.
We now need to modify the settings file with our own settings :
mv .env.example .env nano .envYou need to replace "your-lnd-node-rpc-address" by your Umbrel TAILSCALE ip address (you can find your Umbrel node IP from your Tailscale admin console):
``` LND_IP=your-lnd-node-rpc-address # <- UMBREL TAILSCALE IP ADDRESS LND_GRPC_PORT=10009 LND_CERT_FILE=tls.cert LND_ADMIN_MACAROON_FILE=admin.macaroon REDIS_PASSWORD=random-string LND_PASSWORD=your-lnd-node-unlock-password
docker-compose.yml only
GROUNDCONTROL=ground-control-url
docker-compose-groundcontrol.yml only
FCM_SERVER_KEY=hex-encoded APNS_P8=hex-encoded APNS_P8_KID=issuer-key-which-is-key-ID-of-your-p8-file APPLE_TEAM_ID=team-id-of-your-developer-account BITCOIN_RPC=bitcoin-rpc-url APNS_TOPIC=app-package-name ```
We now need to generate an AES key and insert it into the "settings.sql" file :
```
hexdump -vn 16 -e '4/4 "%08x" 1 "\n"' /dev/random 19efdc45acec06ad8ebf4d6fe50412d0 nano settings.sql ```
- Insert the AES between ' ' right from 'AES_DECRYPT_KEY'
- Insert your domain or subdomain (subdomain in my case) host between ' ' from 'HOST_DOMAIN'
- Insert your Umbrel tailscale IP between ' ' from 'LN_HOST'
Be aware that this subdomain won't be the LNDHub container (boltcard_hub:9002) but the Boltcard container (boltcard_main:9000)
``` \c card_db;
DELETE FROM settings;
-- at a minimum, the settings marked 'set this' must be set for your system -- an explanation for each of the bolt card server settings can be found here -- https://github.com/boltcard/boltcard/blob/main/docs/SETTINGS.md
INSERT INTO settings (name, value) VALUES ('LOG_LEVEL', 'DEBUG'); INSERT INTO settings (name, value) VALUES ('AES_DECRYPT_KEY', '19efdc45acec06ad8ebf4d6fe50412d0'); -- set this INSERT INTO settings (name, value) VALUES ('HOST_DOMAIN', 'sub.domain.tld'); -- set this INSERT INTO settings (name, value) VALUES ('MIN_WITHDRAW_SATS', '1'); INSERT INTO settings (name, value) VALUES ('MAX_WITHDRAW_SATS', '1000000'); INSERT INTO settings (name, value) VALUES ('LN_HOST', ''); -- set this INSERT INTO settings (name, value) VALUES ('LN_PORT', '10009'); INSERT INTO settings (name, value) VALUES ('LN_TLS_FILE', '/boltcard/tls.cert'); INSERT INTO settings (name, value) VALUES ('LN_MACAROON_FILE', '/boltcard/admin.macaroon'); INSERT INTO settings (name, value) VALUES ('FEE_LIMIT_SAT', '10'); INSERT INTO settings (name, value) VALUES ('FEE_LIMIT_PERCENT', '0.5'); INSERT INTO settings (name, value) VALUES ('LN_TESTNODE', ''); INSERT INTO settings (name, value) VALUES ('FUNCTION_LNURLW', 'ENABLE'); INSERT INTO settings (name, value) VALUES ('FUNCTION_LNURLP', 'ENABLE'); INSERT INTO settings (name, value) VALUES ('FUNCTION_EMAIL', 'DISABLE'); INSERT INTO settings (name, value) VALUES ('AWS_SES_ID', ''); INSERT INTO settings (name, value) VALUES ('AWS_SES_SECRET', ''); INSERT INTO settings (name, value) VALUES ('AWS_SES_EMAIL_FROM', ''); INSERT INTO settings (name, value) VALUES ('EMAIL_MAX_TXS', ''); INSERT INTO settings (name, value) VALUES ('FUNCTION_LNDHUB', 'ENABLE'); INSERT INTO settings (name, value) VALUES ('LNDHUB_URL', 'http://boltcard_hub:9002'); INSERT INTO settings (name, value) VALUES ('FUNCTION_INTERNAL_API', 'ENABLE'); ```
You now need to get two files used by Bolt Card LND Hub, the admin.macaroon and tls.cert files from your Umbrel BTC Ligtning node. You can get these files on your Umbrel node at these locations :
/home/umbrel/umbrel/app-data/lightning/data/lnd/tls.cert /home/umbrel/umbrel/app-data/lightning/data/lnd/data/chain/bitcoin/mainnet/admin.macaroonYou can use either WinSCP, scp or ssh to copy these files to your local workstation and copy them again to your VPS to the root folder "bolthub".
You shoud have all these files into the bolthub directory :
johndoe@yourvps:~/bolthub$ ls -al total 68 drwxrwxr-x 6 johndoe johndoe 4096 Jul 30 00:06 . drwxrwxr-x 3 johndoe johndoe 4096 Jul 22 00:52 .. -rw-rw-r-- 1 johndoe johndoe 482 Jul 29 23:48 .env drwxrwxr-x 8 johndoe johndoe 4096 Jul 22 00:52 .git -rw-rw-r-- 1 johndoe johndoe 66 Jul 22 00:52 .gitignore drwxrwxr-x 11 johndoe johndoe 4096 Jul 22 00:52 BoltCardHub -rw-rw-r-- 1 johndoe johndoe 113 Jul 22 00:52 Caddyfile -rw-rw-r-- 1 johndoe johndoe 173 Jul 22 00:52 CaddyfileGroundControl drwxrwxr-x 6 johndoe johndoe 4096 Jul 22 00:52 GroundControl -rw-rw-r-- 1 johndoe johndoe 431 Jul 22 00:52 GroundControlDockerfile -rw-rw-r-- 1 johndoe johndoe 1913 Jul 22 00:52 README.md -rw-rw-r-- 1 johndoe johndoe 293 May 6 22:24 admin.macaroon drwxrwxr-x 16 johndoe johndoe 4096 Jul 22 00:52 boltcard -rw-rw-r-- 1 johndoe johndoe 3866 Jul 22 00:52 docker-compose-groundcontrol.yml -rw-rw-r-- 1 johndoe johndoe 2985 Jul 22 00:57 docker-compose.yml -rw-rw-r-- 1 johndoe johndoe 1909 Jul 29 23:56 settings.sql -rw-rw-r-- 1 johndoe johndoe 802 May 6 22:21 tls.certWe need to do few last tasks to ensure that Bolt Card LNDHub will work perfectly.
It's maybe already the case on your VPS but your user should be member of the docker group. If not, you can add your user by doing :
sudo groupadd docker sudo usermod -aG docker ${USER}If you did these commands, you need to logout and login again.
We also need to create all the docker named volumes by doing :
docker volume create boltcard_hub_lnd docker volume create boltcard_redisConfiguring Nginx Proxy Manager to proxify Bolt Card LNDHub & Boltcard
You need to have followed my previous blog post to fit with the instructions above.
As we use have the Bolt Card LNDHub docker stack in another directory than we other services and it has its own docker-compose.yml file, we'll have to configure the docker network into the NPM (Nginx Proxy Manager) docker-compose.yml to allow NPM to communicate with the Bolt Card LNDHub & Boltcard containers.
To do this we need to add these lines into our NPM external docker-compose (not the same one that is located into the bolthub directory, the one used for all your other containers) :
nano docker-compose.ymlnetworks: bolthub_boltnet: name: bolthub_boltnet external: trueBe careful, "bolthub" from "bolthub_boltnet" is based on the directory where Bolt Card LNDHub Docker docker-compose.yml file is located.
We also need to attach this network to the NPM container :
nginxproxymanager: container_name: nginxproxymanager image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: - '80:80' # Public HTTP Port - '443:443' # Public HTTPS Port - '81:81' # Admin Web Port volumes: - ./nginxproxymanager/data:/data - ./nginxproxymanager/letsencrypt:/etc/letsencrypt networks: - fractalized - bolthub_boltnetYou can now recreate the NPM container to attach the network:
docker compose up -dNow, you'll have to create 2 new Proxy Hosts into NPM admin UI. First one for your domain / subdomain to the Bolt Card LNDHub GUI (boltcard_hub:9002) :
And the second one for the Boltcard container (boltcard_main:9000).
In both Proxy Host I set all the SSL options and I use my wildcard certificate but you can generate one certificate for each Proxy Host with Force SSL, HSTS enabled, HTTP/2 Suppot and HSTS Subdomains enabled.
Starting Bolt Card LNDHub & BoltCard containers
Well done! Everything is setup, we can now start the Bolt Card LNDHub & Boltcard containers !
You need to go again to the root folder of the Bolt Card LNDHub projet "bolthub" and start the docker compose stack. We'll begin wihtout a "-d" to see if we have some issues during the containers creation :
docker compose upI won't share my containers logs to avoid any senstive information disclosure about my Bolt Card LNDHub node, but you can see them from the Bolt Card LNDHub Youtube video (link with exact timestamp where it's shown) :
If you have some issues about files mounting of admin.macaroon or tls.cert because you started the docker compose stack the first time without the files located in the bolthub folder do :
docker compose down && docker compose upAfter waiting few seconds/minutes you should go to your Bolt Card LNDHub Web UI domain/sudomain (created earlier into NPM) and you should see the Bolt Card LNDHub Web UI :
if everything is OK, you now run the containers in detached mode :
docker compose up -dVoilààààà ⚡
If you need to all the Bolt Card LNDHub logs you can use :
docker compose logs -f --tail 30You can now follow the video from Bolt Card to configure your Bolt Card NFC card and using your own Bolt Card LNDHub :
~~PS : there is currently a bug when you'll click on "Connect Bolt Card" from the Bold Card Walle app, you might have this error message "API error: updateboltcard: enable_pin is not a valid boolean (code 6)". It's a know issue and the Bolt Card team is currently working on it. You can find more information on their Telegram~~
Thanks to the Bolt Card, the issue has been corrected : changelog
See you soon in another Fractalized story!
-
@ ee11a5df:b76c4e49
2023-07-29 03:27:23
Gossip: The HTTP Fetcher
Gossip is a desktop nostr client. This post is about the code that fetches HTTP resources.
Gossip fetches HTTP resources. This includes images, videos, nip05 json files, etc. The part of gossip that does this is called the fetcher.
We have had a fetcher for some time, but it was poorly designed and had problems. For example, it was never expiring items in the cache.
We've made a lot of improvements to the fetcher recently. It's pretty good now, but there is still room for improvement.
Caching
Our fetcher caches data. Each URL that is fetched is hashed, and the content is stored under a file in the cache named by that hash.
If a request is in the cache, we don't do an HTTP request, we serve it directly from the cache.
But cached data gets stale. Sometimes resources at a URL change. We generally check resources again after three days.
We save the server's ETag value for content, and when we check the content again we supply an If-None-Match header with the ETag so the server could respond with 304 Not Modified in which case we don't need to download the resource again, we just bump the filetime to now.
In the event that our cache data is stale, but the server gives us an error, we serve up the stale data (stale is better than nothing).
Queueing
We used to fire off HTTP GET requests as soon as we knew that we needed a resource. This was not looked on too kindly by servers and CDNs who were giving us either 403 Forbidden or 429 Too Many Requests.
So we moved into a queue system. The host is extracted from each URL, and each host is only given up to 3 requests at a time. If we want 29 images from the same host, we only ask for three, and the remaining 26 remain in the queue for next time. When one of those requests completes, we decrement the host load so we know that we can send it another request later.
We process the queue in an infinite loop where we wait 1200 milliseconds between passes. Passes take time themselves and sometimes must wait for a timeout. Each pass fetches potentially multiple HTTP resources in parallel, asynchronously. If we have 300 resources at 100 different hosts, three per host, we could get them all in a single pass. More likely a bunch of resources are at the same host, and we make multiple passes at it.
Timeouts
When we fetch URLs in parallel asynchronously, we wait until all of the fetches complete before waiting another 1200 ms and doing another loop. Sometimes one of the fetches times out. In order to keep things moving, we use short timeouts of 10 seconds for a connect, and 15 seconds for a response.
Handling Errors
Some kinds of errors are more serious than others. When we encounter these, we sin bin the server for a period of time where we don't try fetching from it until a specified period elapses.
-
@ ee11a5df:b76c4e49
2023-07-29 03:13:59
Gossip: Switching to LMDB
Unlike a number of other nostr clients, Gossip has always cached events and related data in a local data store. Up until recently, SQLite3 has served this purpose.
SQLite3 offers a full ACID SQL relational database service.
Unfortunately however it has presented a number of downsides:
- It is not as parallel as you might think.
- It is not as fast as you might hope.
- If you want to preserve the benefit of using SQL and doing joins, then you must break your objects into columns, and map columns back into objects. The code that does this object-relational mapping (ORM) is not trivial and can be error prone. It is especially tricky when working with different types (Rust language types and SQLite3 types are not a 1:1 match).
- Because of the potential slowness, our UI has been forbidden from direct database access as that would make the UI unresponsive if a query took too long.
- Because of (4) we have been firing off separate threads to do the database actions, and storing the results into global variables that can be accessed by the interested code at a later time.
- Because of (4) we have been caching database data in memory, essentially coding for yet another storage layer that can (and often did) get out of sync with the database.
LMDB offers solutions:
- It is highly parallel.
- It is ridiculously fast when used appropriately.
- Because you cannot run arbitrary SQL, there is no need to represent the fields within your objects separately. You can serialize/deserialize entire objects into the database and the database doesn't care what is inside of the blob (yes, you can do that into an SQLite field, but if you did, you would lose the power of SQL).
- Because of the speed, the UI can look stuff up directly.
- We no longer need to fork separate threads for database actions.
- We no longer need in-memory caches of data. The LMDB data is already in-memory (it is memory mapped) so we just access it directly.
The one obvious downside is that we lose SQL. We lose the query planner. We cannot ask arbitrary question and get answers. Instead, we have to pre-conceive of all the kinds of questions we want to ask, and we have to write code that answers them efficiently. Often this involves building and maintaining indices.
Indices
Let's say I want to look at fiatjaf's posts. How do I efficiently pull out just his recent feed-related events in reverse chronological order? It is easy if we first construct the following index
key: EventKind + PublicKey + ReverseTime value: Event Id
In the above, '+' is just a concatenate operator, and ReverseTime is just some distant time minus the time so that it sorts backwards.
Now I just ask LMDB to start from (EventKind=1 + PublicKey=fiatjaf + now) and scan until either one of the first two fields change, or more like the time field gets too old (e.g. one month ago). Then I do it again for the next event kind, etc.
For a generalized feed, I have to scan a region for each person I follow.
Smarter indexes can be imagined. Since we often want only feed-related event kinds, that can be implicit in an index that only indexes those kinds of events.
You get the idea.
A Special Event Map
At first I had stored events into a K-V database under the Id of the event. Then I had indexes on events that output a set of Ids (as in the example above).
But when it comes to storing and retrieving events, we can go even faster than LMDB.
We can build an append-only memory map that is just a sequence of all the events we have, serialized, and in no particular order. Readers do not need a lock and multiple readers can read simultaneously. Writers will need to acquire a lock to append to the map and there may only be one writer at a time. However, readers can continue reading even while a writer is writing.
We can then have a K-V database that maps Id -> Offset. To get the event you just do a direct lookup in the event memory map at that offset.
The real benefit comes when we have other indexes that yield events, they can yield offsets instead of ids. Then we don't need to do a second lookup from the Id to the Event, we can just look directly at the offset.
Avoiding deserialization
Deserialization has a price. Sometimes it requires memory allocation (if the object is not already linear, e.g. variable lengthed data like strings and vectors are allocated on the heap) which can be very expensive if you are trying to scan 150,000 or so events.
We serialize events (and other objects where we can) with a serialization library called speedy. It does its best to preserve the data much like it is represented in memory, but linearized. Because events start with fixed-length fields, we know the offset into the serialized event where these first fields occur and we can directly extract the value of those fields without deserializing the data before it.
This comes in useful whenever we need to scan a large number of events. Search is the one situation where I know that we must do this. We can search by matching against the content of every feed-related event without fully deserialing any of them.
-
@ ee11a5df:b76c4e49
2023-07-29 02:52:13
Gossip: Zaps
Gossip is a desktop nostr client. This post is about the code that lets users send lightning zaps to each other (NIP-57).
Gossip implemented Zaps initially on 20th of June, 2023.
Gossip maintains a state of where zapping is at, one of: None, CheckingLnurl, SeekingAmount, LoadingInvoice, and ReadyToPay.
When you click the zap lightning bolt icon, Gossip moves to the CheckingLnurl state while it looks up the LN URL of the user.
If this is successful, it moves to the SeekingAmount state and presents amount options to the user.
Once a user chooses an amount, it moves to the LoadingInvoice state where it interacts with the lightning node and receives and checks an invoice.
Once that is complete, it moves to the ReadyToPay state, where it presents the invoice as a QR code for the user to scan with their phone. There is also a copy button so they can pay it from their desktop computer too.
Gossip also loads zap receipt events and associates them with the event that was zapped, tallying a zap total on that event. Gossip is unfortunately not validating these receipts very well currently, so fake zap receipts can cause an incorrect total to show. This remains an open issue.
Another open issue is the implementation of NIP-46 Nostr Connect and NIP-47 Wallet Connect.
-
@ b12b632c:d9e1ff79
2023-07-21 19:45:20
I love testing every new self hosted app and I can say that Nostr "world" is really good regarding self hosting stuff.
Today I tested a Nostr relay named Strfry.
Strfry is really simple to setup and support a lot's of Nostr NIPs.
Here is the list of what it is able to do :
- Supports most applicable NIPs: 1, 2, 4, 9, 11, 12, 15, 16, 20, 22, 28, 33, 40
- No external database required: All data is stored locally on the filesystem in LMDB
- Hot reloading of config file: No server restart needed for many config param changes
- Zero downtime restarts, for upgrading binary without impacting users
- Websocket compression: permessage-deflate with optional sliding window, when supported by clients
- Built-in support for real-time streaming (up/down/both) events from remote relays, and bulk import/export of events from/to jsonl files
- negentropy-based set reconcilliation for efficient syncing with remote relays
Installation with docker compose (v2)
Spoiler : you need to have a computer with more than 1 (v)Core / 2GB of RAM to build the docker image locally. If not, this below might crash your computer during docker image build. You may need to use a prebuilt strfry docker image.
I assume you've read my first article on Managing domain with Nginx Proxy Manager because I will use the NPM docker compose stack to publish strfry Nostr relay. Without the initial NPM configuration done, it may not work as expected. I'll use the same docker-compose.yml file and folder.
Get back in the "npm-stack" folder :
cd npm-stackCloning the strfry github repo locally :
git clone https://github.com/hoytech/strfry.gitModify the docker-compose file to locate the strfry configuration data outside of the folder repo directory to avoid mistake during futures upgrades (CTRL + X, S & ENTER to quit and save modifications) :
nano docker-compose.ymlYou don't have to insert the Nginx Proxy Manager part, you should already have it into the file. If not, check here. You should only have to add the strfry part.
``` version: '3.8' services: # should already be present into the docker-compose.yml app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: # These ports are in format
: - '80:80' # Public HTTP Port - '443:443' # Public HTTPS Port - '81:81' # Admin Web Port # Add any other Stream port you want to expose # - '21:21' # FTP # Uncomment the next line if you uncomment anything in the section # environment: # Uncomment this if you want to change the location of # the SQLite DB file within the container # DB_SQLITE_FILE: "/data/database.sqlite" # Uncomment this if IPv6 is not enabled on your host # DISABLE_IPV6: 'true' volumes: - ./nginxproxymanager/data:/data - ./nginxproxymanager/letsencrypt:/etc/letsencryptstrfry-nostr-relay: container_name: strfry build: ./strfry volumes: - ./strfry-data/strfry.conf:/etc/strfry.conf - ./strfry-data/strfry-db:/app/strfry-db
ports is commented by NPM will access through docker internal network
no need to expose strfry port directly to the internet
ports:
- "7777:7777"
```
Before starting the container, we need to customize the strfry configuration file "strfry.conf". We'll copy the strfry configuration file and place it into the "strfry-data" folder to modify it with our own settings :
mkdir strfry-data && cp strfry/strfry.conf strfry-data/And modify the strfry.conf file with your own settings :
nano strfry-data/strfry.confYou can modify all the settings you need but the basics settings are :
- bind = "127.0.0.1" --> bind = "0.0.0.0" --> otherwise NPM won't be able to contact the strfry service
-
name = "strfry default" --> name of your nostr relay
-
description = "This is a strfry instance." --> your nostr relay description
-
pubkey = "" --> your pubkey in hex format. You can use the Damu's tool to generate your hex key from your npub key : https://damus.io/key/
-
contact = "" --> your email
``` relay { # Interface to listen on. Use 0.0.0.0 to listen on all interfaces (restart required) bind = "127.0.0.1"
# Port to open for the nostr websocket protocol (restart required) port = 7777 # Set OS-limit on maximum number of open files/sockets (if 0, don't attempt to set) (restart required) nofiles = 1000000 # HTTP header that contains the client's real IP, before reverse proxying (ie x-real-ip) (MUST be all lower-case) realIpHeader = "" info { # NIP-11: Name of this server. Short/descriptive (< 30 characters) name = "strfry default" # NIP-11: Detailed information about relay, free-form description = "This is a strfry instance." # NIP-11: Administrative nostr pubkey, for contact purposes pubkey = "" # NIP-11: Alternative administrative contact (email, website, etc) contact = "" }```
You can now start the docker strfry docker container :
docker compose up -dThis command will take a bit of time because it will build the strfry docker image locally before starting the container. If your VPS doesn't have lot's of (v)CPU/RAM, it could fail (nothing happening during the docker image build). My VPS has 1 vCore / 2GB of RAM and died few seconds after the build beginning.
If it's the case, you can use prebuilt strfry docker image available on the Docker hub : https://hub.docker.com/search?q=strfry&sort=updated_at&order=desc
That said, otherwise, you should see this :
``` user@vps:~/npm-stack$ docker compose up -d [+] Building 202.4s (15/15) FINISHED
=> [internal] load build definition from Dockerfile 0.2s => => transferring dockerfile: 724B 0.0s => [internal] load .dockerignore 0.3s => => transferring context: 2B 0.0s => [internal] load metadata for docker.io/library/ubuntu:jammy 0.0s => [build 1/7] FROM docker.io/library/ubuntu:jammy 0.4s => [internal] load build context 0.9s => => transferring context: 825.64kB 0.2s => [runner 2/4] WORKDIR /app 1.3s => [build 2/7] WORKDIR /build 1.5s => [runner 3/4] RUN apt update && apt install -y --no-install-recommends liblmdb0 libflatbuffers1 libsecp256k1-0 libb2-1 libzstd1 && rm -rf /var/lib/apt/lists/* 12.4s => [build 3/7] RUN apt update && apt install -y --no-install-recommends git g++ make pkg-config libtool ca-certificates libyaml-perl libtemplate-perl libregexp-grammars-perl libssl-dev zlib1g-dev l 55.5s => [build 4/7] COPY . . 0.9s => [build 5/7] RUN git submodule update --init 2.6s => [build 6/7] RUN make setup-golpe 10.8s => [build 7/7] RUN make -j4 126.8s => [runner 4/4] COPY --from=build /build/strfry strfry 1.3s => exporting to image 0.8s => => exporting layers 0.8s => => writing image sha256:1d346bf343e3bb63da2e4c70521a8350b35a02742dd52b12b131557e96ca7d05 0.0s => => naming to docker.io/library/docker-compose_strfry-nostr-relay 0.0sUse 'docker scan' to run Snyk tests against images to find vulnerabilities and learn how to fix them
[+] Running 02/02
⠿ Container strfry Started 11.0s ⠿ Container npm-stack-app-1 Running ```You can check if everything is OK with strfry container by checking the container logs :
user@vps:~/npm-stack$ docker logs strfry date time ( uptime ) [ thread name/id ] v| 2023-07-21 19:26:58.514 ( 0.039s) [main thread ]INFO| arguments: /app/strfry relay 2023-07-21 19:26:58.514 ( 0.039s) [main thread ]INFO| Current dir: /app 2023-07-21 19:26:58.514 ( 0.039s) [main thread ]INFO| stderr verbosity: 0 2023-07-21 19:26:58.514 ( 0.039s) [main thread ]INFO| ----------------------------------- 2023-07-21 19:26:58.514 ( 0.039s) [main thread ]INFO| CONFIG: Loading config from file: /etc/strfry.conf 2023-07-21 19:26:58.529 ( 0.054s) [main thread ]INFO| CONFIG: successfully installed 2023-07-21 19:26:58.533 ( 0.058s) [Websocket ]INFO| Started websocket server on 0.0.0.0:7777Now, we have to create the subdomain where strfry Nostr relay will be accessible. You need to connect to your Nginx Proxy Manager admin UI and create a new proxy host with these settings :
"Details" tab (Websockets support is mandatory!, you can replace "strfry" by whatever you like, for instance : mybeautifulrelay.yourdomain.tld)
"Details" tab:

"SSL" tab:

And click on "Save"
If everything is OK, when you go to https://strfry.yourdomain.tld you should see :

To verify if strfry is working properly, you can test it with the (really useful!) website https://nostr.watch. You have to insert your relay URL into the nostr.watch URL like this : https://nostr.watch/relay/strfry.yourdomain.tld
You should see this :

If you are seeing your server as online, readable and writable, you made it ! You can add your Nostr strfry server to your Nostr prefered relay and begin to publish notes ! 🎇
Future work:
Once done, strfry will work like a charm but you may need to have more work to update strfry in the near future. I'm currently working on a bash script that will :
- Updatethe "strfry" folder,
- Backup the "strfry.conf" file,
- Download the latest "strfry.conf" from strfry github repo,
- Inject old configuration settings into the new "strfry.conf" file,
- Compose again the stack (rebuilding the image to get the latest code updates),
- etc.
Tell me if you need the script!
Voilààààà
See you soon in another Fractalized story!
-
@ b12b632c:d9e1ff79
2023-07-21 14:19:38
Self hosting web applications comes quickly with the need to deal with HTTPS protocol and SSL certificates. The time where web applications was published over the 80/TCP port without any encryption is totally over. Now we have Let's Encrypt and other free certification authority that lets us play web applications with, at least, the basic minimum security required.
Second part of web self hosting stuff that is really useful is the web proxifycation.
It's possible to have multiple web applications accessible through HTTPS but as we can't use the some port (spoiler: we can) we are forced to have ugly URL as https://mybeautifudomain.tld:8443.
This is where Nginx Proxy Manager (NPM) comes to help us.
NPM, as gateway, will listen on the 443 https port and based on the subdomain you want to reach, it will redirect the network flow to the NPM differents declared backend ports. NPM will also request HTTPS cert for you and let you know when the certificate expires, really useful.
We'll now install NPM with docker compose (v2) and you'll see, it's very easy.
You can find the official NPM setup instructions here.
But before we absolutely need to do something. You need to connect to the registrar where you bought your domain name and go into the zone DNS section.You have to create a A record poing to your VPS IP. That will allow NPM to request SSL certificates for your domain and subdomains.
Create a new folder for the NPM docker stack :
mkdir npm-stack && cd npm-stackCreate a new docker-compose.yml :
nano docker-compose.ymlPaste this content into it (CTRL + X ; Y & ENTER to save/quit) :
``` version: '3.8' services: app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: # These ports are in format
: - '80:80' # Public HTTP Port - '443:443' # Public HTTPS Port - '81:81' # Admin Web Port # Add any other Stream port you want to expose # - '21:21' # FTP # Uncomment the next line if you uncomment anything in the section # environment: # Uncomment this if you want to change the location of # the SQLite DB file within the container # DB_SQLITE_FILE: "/data/database.sqlite" # Uncomment this if IPv6 is not enabled on your host # DISABLE_IPV6: 'true' volumes: - ./nginxproxymanager/data:/data - ./nginxproxymanager/letsencrypt:/etc/letsencrypt```
You'll not believe but it's done. NPM docker compose configuration is done.
To start Nginx Proxy Manager with docker compose, you just have to :
docker compose up -dYou'll see :
user@vps:~/tutorials/npm-stack$ docker compose up -d [+] Running 2/2 ✔ Network npm-stack_default Created ✔ Container npm-stack-app-1 StartedYou can check if NPM container is started by doing this command :
docker psYou'll see :
user@vps:~/tutorials/npm-stack$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7bc5ea8ac9c8 jc21/nginx-proxy-manager:latest "/init" About a minute ago Up About a minute 0.0.0.0:80-81->80-81/tcp, :::80-81->80-81/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp npm-stack-app-1If the command show "Up X minutes" for the npm-stack-app-1, you're good to go! You can access to the NPM admin UI by going to http://YourIPAddress:81.You shoud see :

The default NPM login/password are : admin@example.com/changeme .If the login succeed, you should see a popup asking to edit your user by changing your email password :
 And your password :
And your password :
 Click on "Save" to finish the login.
To verify if NPM is able to request SSL certificates for you, create first a subdomain for the NPM admin UI :
Click on "Hosts" and "Proxy Hosts" :
Click on "Save" to finish the login.
To verify if NPM is able to request SSL certificates for you, create first a subdomain for the NPM admin UI :
Click on "Hosts" and "Proxy Hosts" :
 Followed by "Add Proxy Host"
Followed by "Add Proxy Host"
 If you want to access the NPM admin UI with https://admin.yourdomain.tld, please set all the parameters like this (I won't explain each parameters) :
If you want to access the NPM admin UI with https://admin.yourdomain.tld, please set all the parameters like this (I won't explain each parameters) :Details tab :
 SSL tab :
SSL tab :
 And click on "Save".
And click on "Save".NPM will request the SSL certificate "admin.yourdomain.tld" for you.
If you have an erreor message "Internal Error" it's probably because your domaine DNS zone is not configured with an A DNS record pointing to your VPS IP.
Otherwise you should see (my domain is hidden) :

Clicking on the "Source" URL link "admin.yourdomain.tld" will open a pop-up and, surprise, you should see the NPM admin UI with the URL "https://admin.yourdomain.tld" !
If yes, bravo, everything is OK ! 🎇
You know now how to have a subdomain of your domain redirecting to a container web app. In the next blog post, you'll see how to setup a Nostr relay with NPM ;)
Voilààààà
See you soon in another Fractalized story!
-
@ b12b632c:d9e1ff79
2023-07-20 20:12:39
Self hosting web applications comes quickly with the need to deal with HTTPS protocol and SSL certificates. The time where web applications was published over the 80/TCP port without any encryption is totally over. Now we have Let's Encrypt and other free certification authority that lets us play web applications with, at least, the basic minimum security required.
Second part of web self hosting stuff that is really useful is the web proxifycation.
It's possible to have multiple web applications accessible through HTTPS but as we can't use the some port (spoiler: we can) we are forced to have ugly URL as https://mybeautifudomain.tld:8443.
This is where Nginx Proxy Manager (NPM) comes to help us.
NPM, as gateway, will listen on the 443 https port and based on the subdomain you want to reach, it will redirect the network flow to the NPM differents declared backend ports. NPM will also request HTTPS cert for you and let you know when the certificate expires, really useful.
We'll now install NPM with docker compose (v2) and you'll see, it's very easy.
You can find the official NPM setup instructions here.
But before we absolutely need to do something. You need to connect to the registrar where you bought your domain name and go into the zone DNS section.You have to create a A record poing to your VPS IP. That will allow NPM to request SSL certificates for your domain and subdomains.
Create a new folder for the NPM docker stack :
mkdir npm-stack && cd npm-stackCreate a new docker-compose.yml :
nano docker-compose.ymlPaste this content into it (CTRL + X ; Y & ENTER to save/quit) :
``` version: '3.8' services: app: image: 'jc21/nginx-proxy-manager:latest' restart: unless-stopped ports: # These ports are in format
: - '80:80' # Public HTTP Port - '443:443' # Public HTTPS Port - '81:81' # Admin Web Port # Add any other Stream port you want to expose # - '21:21' # FTP # Uncomment the next line if you uncomment anything in the section # environment: # Uncomment this if you want to change the location of # the SQLite DB file within the container # DB_SQLITE_FILE: "/data/database.sqlite" # Uncomment this if IPv6 is not enabled on your host # DISABLE_IPV6: 'true' volumes: - ./nginxproxymanager/data:/data - ./nginxproxymanager/letsencrypt:/etc/letsencrypt```
You'll not believe but it's done. NPM docker compose configuration is done.
To start Nginx Proxy Manager with docker compose, you just have to :
docker compose up -dYou'll see :
user@vps:~/tutorials/npm-stack$ docker compose up -d [+] Running 2/2 ✔ Network npm-stack_default Created ✔ Container npm-stack-app-1 StartedYou can check if NPM container is started by doing this command :
docker psYou'll see :
user@vps:~/tutorials/npm-stack$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7bc5ea8ac9c8 jc21/nginx-proxy-manager:latest "/init" About a minute ago Up About a minute 0.0.0.0:80-81->80-81/tcp, :::80-81->80-81/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp npm-stack-app-1If the command show "Up X minutes" for the npm-stack-app-1, you're good to go! You can access to the NPM admin UI by going to http://YourIPAddress:81.You shoud see :
The default NPM login/password are : admin@example.com/changeme .If the login succeed, you should see a popup asking to edit your user by changing your email password :
And your password :
Click on "Save" to finish the login.
To verify if NPM is able to request SSL certificates for you, create first a subdomain for the NPM admin UI :
Click on "Hosts" and "Proxy Hosts" :
Followed by "Add Proxy Host"
If you want to access the NPM admin UI with https://admin.yourdomain.tld, please set all the parameters like this (I won't explain each parameters) :Details tab :
SSL tab :
And click on "Save".NPM will request the SSL certificate "admin.yourdomain.tld" for you.
If you have an erreor message "Internal Error" it's probably because your domaine DNS zone is not configured with an A DNS record pointing to your VPS IP.
Otherwise you should see (my domain is hidden) :
Clicking on the "Source" URL link "admin.yourdomain.tld" will open a pop-up and, surprise, you should see the NPM admin UI with the URL "https://admin.yourdomain.tld" !
If yes, bravo, everything is OK ! 🎇
You know now how to have a subdomain of your domain redirecting to a container web app. In the next blog post, you'll see how to setup a Nostr relay with NPM ;)
Voilààààà
See you soon in another Fractalized story!
-
@ b12b632c:d9e1ff79
2023-07-19 00:17:02
Welcome to a new Fractalized episode of "it works but I can do better"!
Original blog post from : https://fractalized.ovh/use-ghost-blog-to-serve-your-nostr-nip05-and-lnurl/
Few day ago, I wanted to set my Ghost blog (this one) as root domain for Fractalized instead of the old basic Nginx container that served my NIP05. I succeed to do it with Nginx Proxy Manager (I need to create a blog post because NPM is really awesome) but my NIP05 was down.
Having a bad NIP05 on Amethyst is now in the top tier list of my worst nightmares.
As a reminder, to have a valid NIP05 on your prefered Nostr client, you need to have a file named "nostr.json" in a folder ".well-known" located in the web server root path (subdomain or domain). The URL shoud look like this http://domain.tld/.well-known/nostr.json
PS : this doesn't work with Ghost as explained later. If you are here for Ghost, skip this and go directly to 1).
You should have these info inside the nostr.json file (JSON format) :
{ "names": { "YourUsername": "YourNPUBkey" } }You can test it directly by going to the nostr.json URL, it should show you the JSON.
It was working like a charm on my previous Nginx and I needed to do it on my new Ghost. I saw on Google that I need to have the .well-known folder into the Ghost theme root folder (In my case I choosed the Solo theme). I created the folder, put my nostr.json file inside it and crossed my fingers. Result : 404 error.
I had to search a lot but it seems that Ghost forbid to server json file from its theme folders. Maybe for security reasons, I don't know. Nevertheless Ghost provide a method to do it (but it requires more than copy/paste some files in some folders) => routes
In the same time that configuring your NIP05, I also wanted to setup an LNURL to be zapped to pastagringo@fractalized.ovh (configured into my Amethyst profile). If you want more infromation on LNURL, it's very well explained here.
Because I want to use my Wallet of Satoshi sats wallet "behind" my LNURL, you'll have to read carefuly the EzoFox's blog post that explains how to retrieve your infos from Alby or WoS.
1) Configuring Ghost routes
Add the new route into the routes.yaml (accessible from "Settings" > "Labs" > "Beta features" > "Routes" ; you need to download the file, modify it and upload it again) to let him know where to look for the nostr.json file.
Here is the content of my routes.yaml file :
``` routes: /.well-known/nostr.json/: template: _nostr-json content_type: application/json /.well-known/lnurlp/YourUsername/: template: _lnurlp-YourUsername content_type: application/json collections: /: permalink: /{slug}/ template: index
taxonomies: tag: /tag/{slug}/ author: /author/{slug}/ ```
=> template : name of the file that ghost will search localy
=> content_type : file type (JSON is required for the NIP05)
The first route is about my NIP05 and the second route is about my LNURL.
2) Creating Ghost route .hbs files
To let Ghost serve our JSON content, I needed to create the two .hbs file filled into the routes.yaml file. These files need to be located into the root directory of the Ghost theme used. For me, it was Solo.
Here is there content of both files :
"_nostr-json.hbs"
{ "names": { "YourUsername": "YourNPUBkey" } }"_lnurlp-pastagringo.hbs" (in your case, _lnurlp-YourUsername.hbs)
{ "callback":"https://livingroomofsatoshi.com/api/v1/lnurl/payreq/XXXXX", "maxSendable":100000000000, "minSendable":1000, "metadata":"[[\"text/plain\",\"Pay to Wallet of Satoshi user: burlyring39\"],[\"text/identifier\",\"YourUsername@walletofsatoshi.com\"]]", "commentAllowed":32, "tag":"payRequest", "allowsNostr":true, "nostrPubkey":"YourNPUBkey" }After doing that, you almost finished, you just have to restart your Ghost blog. As I use Ghost from docker container, I just had to restart the container.
To verify if everything is working, you have to go in the routes URL created earlier:
https://YourDomain.tld/.well-known/nostr.jsonand
https://YourDomain.tld/.well-known/lnurlp/YourUsernameBoth URL should display JSON files from .hbs created ealier.
If it's the case, you can add your NIP05 and LNURL into your Nostr profile client and you should be able to see a valid tick from your domain and to be zapped on your LNURL (sending zaps to your WoS or Alby backend wallet).
Voilààààà
See you soon in another Fractalized story!
-
@ b12b632c:d9e1ff79
2023-07-17 22:09:53
Today I created a new item (NIP05) to sell into my BTCpayserver store and everything was OK. The only thing that annoyed me a bit is that when a user pay the invoice to get his NIP on my Nostr Paid Relay, I need to warn him that he needs to fill his npub in the email info required by BTCpayserver before paying. Was not so user friendly. Not at all.
So I checked if BTCpayserver is able to create custom input before paying the invoice and at my big surprise, it's possible ! => release version v1.8
They even use as example my need from Nostr to get the user npub.
So it's possible, yes, but with at least the version 1.8.0. I checked immediately my BTCpayserver version on my Umbrel node and... damn... I'm in 1.7.2. I need to update my local BTCpayserver through Umbrel to access my so wanted BTCpayserver feature. I checked the local App Store but I can't see any "Update" button or something. I can see that the version installed is well the v1.7.2 but when I check the latest version available from the online Umbrel App Store. I can see v1.9.2. Damn bis.
I searched into the Umbrel Community forum, Telegram group, Google posts, asked the question on Nostr and didn't have any clue.
I finally found the answer from the Umbrel App Framework documention :
sudo ./scripts/repo checkout https://github.com/getumbrel/umbrel-apps.gitSo I did it and it updated my local Umbrel App Store to the latest version available and my BTCpayserver.
After few seconds, the BTCpaysever local URL is available and I'm allowed to login => everything is OK! \o/
See you soon in another Fractalized story!
-
@ 97c70a44:ad98e322
2025-01-30 17:15:37
There was a slight dust up recently over a website someone runs removing a listing for an app someone built based on entirely arbitrary criteria. I'm not to going to attempt to speak for either wounded party, but I would like to share my own personal definition for what constitutes a "nostr app" in an effort to help clarify what might be an otherwise confusing and opaque purity test.
In this post, I will be committing the "no true Scotsman" fallacy, in which I start with the most liberal definition I can come up with, and gradually refine it until all that is left is the purest, gleamingest, most imaginary and unattainable nostr app imaginable. As I write this, I wonder if anything built yet will actually qualify. In any case, here we go.
It uses nostr
The lowest bar for what a "nostr app" might be is an app ("application" - i.e. software, not necessarily a native app of any kind) that has some nostr-specific code in it, but which doesn't take any advantage of what makes nostr distinctive as a protocol.
Examples might include a scraper of some kind which fulfills its charter by fetching data from relays (regardless of whether it validates or retains signatures). Another might be a regular web 2.0 app which provides an option to "log in with nostr" by requesting and storing the user's public key.
In either case, the fact that nostr is involved is entirely neutral. A scraper can scrape html, pdfs, jsonl, whatever data source - nostr relays are just another target. Likewise, a user's key in this scenario is treated merely as an opaque identifier, with no appreciation for the super powers it brings along.
In most cases, this kind of app only exists as a marketing ploy, or less cynically, because it wants to get in on the hype of being a "nostr app", without the developer quite understanding what that means, or having the budget to execute properly on the claim.
It leverages nostr
Some of you might be wondering, "isn't 'leverage' a synonym for 'use'?" And you would be right, but for one connotative difference. It's possible to "use" something improperly, but by definition leverage gives you a mechanical advantage that you wouldn't otherwise have. This is the second category of "nostr app".
This kind of app gets some benefit out of the nostr protocol and network, but in an entirely selfish fashion. The intention of this kind of app is not to augment the nostr network, but to augment its own UX by borrowing some nifty thing from the protocol without really contributing anything back.
Some examples might include:
- Using nostr signers to encrypt or sign data, and then store that data on a proprietary server.
- Using nostr relays as a kind of low-code backend, but using proprietary event payloads.
- Using nostr event kinds to represent data (why), but not leveraging the trustlessness that buys you.
An application in this category might even communicate to its users via nostr DMs - but this doesn't make it a "nostr app" any more than a website that emails you hot deals on herbal supplements is an "email app". These apps are purely parasitic on the nostr ecosystem.
In the long-term, that's not necessarily a bad thing. Email's ubiquity is self-reinforcing. But in the short term, this kind of "nostr app" can actually do damage to nostr's reputation by over-promising and under-delivering.
It complements nostr
Next up, we have apps that get some benefit out of nostr as above, but give back by providing a unique value proposition to nostr users as nostr users. This is a bit of a fine distinction, but for me this category is for apps which focus on solving problems that nostr isn't good at solving, leaving the nostr integration in a secondary or supporting role.
One example of this kind of app was Mutiny (RIP), which not only allowed users to sign in with nostr, but also pulled those users' social graphs so that users could send money to people they knew and trusted. Mutiny was doing a great job of leveraging nostr, as well as providing value to users with nostr identities - but it was still primarily a bitcoin wallet, not a "nostr app" in the purest sense.
Other examples are things like Nostr Nests and Zap.stream, whose core value proposition is streaming video or audio content. Both make great use of nostr identities, data formats, and relays, but they're primarily streaming apps. A good litmus test for things like this is: if you got rid of nostr, would it be the same product (even if inferior in certain ways)?
A similar category is infrastructure providers that benefit nostr by their existence (and may in fact be targeted explicitly at nostr users), but do things in a centralized, old-web way; for example: media hosts, DNS registrars, hosting providers, and CDNs.
To be clear here, I'm not casting aspersions (I don't even know what those are, or where to buy them). All the apps mentioned above use nostr to great effect, and are a real benefit to nostr users. But they are not True Scotsmen.
It embodies nostr
Ok, here we go. This is the crème de la crème, the top du top, the meilleur du meilleur, the bee's knees. The purest, holiest, most chaste category of nostr app out there. The apps which are, indeed, nostr indigitate.
This category of nostr app (see, no quotes this time) can be defined by the converse of the previous category. If nostr was removed from this type of application, would it be impossible to create the same product?
To tease this apart a bit, apps that leverage the technical aspects of nostr are dependent on nostr the protocol, while apps that benefit nostr exclusively via network effect are integrated into nostr the network. An app that does both things is working in symbiosis with nostr as a whole.
An app that embraces both nostr's protocol and its network becomes an organic extension of every other nostr app out there, multiplying both its competitive moat and its contribution to the ecosystem:
- In contrast to apps that only borrow from nostr on the technical level but continue to operate in their own silos, an application integrated into the nostr network comes pre-packaged with existing users, and is able to provide more value to those users because of other nostr products. On nostr, it's a good thing to advertise your competitors.
- In contrast to apps that only market themselves to nostr users without building out a deep integration on the protocol level, a deeply integrated app becomes an asset to every other nostr app by becoming an organic extension of them through interoperability. This results in increased traffic to the app as other developers and users refer people to it instead of solving their problem on their own. This is the "micro-apps" utopia we've all been waiting for.
Credible exit doesn't matter if there aren't alternative services. Interoperability is pointless if other applications don't offer something your app doesn't. Marketing to nostr users doesn't matter if you don't augment their agency as nostr users.
If I had to choose a single NIP that represents the mindset behind this kind of app, it would be NIP 89 A.K.A. "Recommended Application Handlers", which states:
Nostr's discoverability and transparent event interaction is one of its most interesting/novel mechanics. This NIP provides a simple way for clients to discover applications that handle events of a specific kind to ensure smooth cross-client and cross-kind interactions.
These handlers are the glue that holds nostr apps together. A single event, signed by the developer of an application (or by the application's own account) tells anyone who wants to know 1. what event kinds the app supports, 2. how to link to the app (if it's a client), and (if the pubkey also publishes a kind 10002), 3. which relays the app prefers.
As a sidenote, NIP 89 is currently focused more on clients, leaving DVMs, relays, signers, etc somewhat out in the cold. Updating 89 to include tailored listings for each kind of supporting app would be a huge improvement to the protocol. This, plus a good front end for navigating these listings (sorry nostrapp.link, close but no cigar) would obviate the evil centralized websites that curate apps based on arbitrary criteria.
Examples of this kind of app obviously include many kind 1 clients, as well as clients that attempt to bring the benefits of the nostr protocol and network to new use cases - whether long form content, video, image posts, music, emojis, recipes, project management, or any other "content type".
To drill down into one example, let's think for a moment about forms. What's so great about a forms app that is built on nostr? Well,
- There is a spec for forms and responses, which means that...
- Multiple clients can implement the same data format, allowing for credible exit and user choice, even of...
- Other products not focused on forms, which can still view, respond to, or embed forms, and which can send their users via NIP 89 to a client that does...
- Cryptographically sign forms and responses, which means they are self-authenticating and can be sent to...
- Multiple relays, which reduces the amount of trust necessary to be confident results haven't been deliberately "lost".
Show me a forms product that does all of those things, and isn't built on nostr. You can't, because it doesn't exist. Meanwhile, there are plenty of image hosts with APIs, streaming services, and bitcoin wallets which have basically the same levels of censorship resistance, interoperability, and network effect as if they weren't built on nostr.
It supports nostr
Notice I haven't said anything about whether relays, signers, blossom servers, software libraries, DVMs, and the accumulated addenda of the nostr ecosystem are nostr apps. Well, they are (usually).
This is the category of nostr app that gets none of the credit for doing all of the work. There's no question that they qualify as beautiful nostrcorns, because their value propositions are entirely meaningless outside of the context of nostr. Who needs a signer if you don't have a cryptographic identity you need to protect? DVMs are literally impossible to use without relays. How are you going to find the blossom server that will serve a given hash if you don't know which servers the publishing user has selected to store their content?
In addition to being entirely contextualized by nostr architecture, this type of nostr app is valuable because it does things "the nostr way". By that I mean that they don't simply try to replicate existing internet functionality into a nostr context; instead, they create entirely new ways of putting the basic building blocks of the internet back together.
A great example of this is how Nostr Connect, Nostr Wallet Connect, and DVMs all use relays as brokers, which allows service providers to avoid having to accept incoming network connections. This opens up really interesting possibilities all on its own.
So while I might hesitate to call many of these things "apps", they are certainly "nostr".
Appendix: it smells like a NINO
So, let's say you've created an app, but when you show it to people they politely smile, nod, and call it a NINO (Nostr In Name Only). What's a hacker to do? Well, here's your handy-dandy guide on how to wash that NINO stench off and Become a Nostr.
You app might be a NINO if:
- There's no NIP for your data format (or you're abusing NIP 78, 32, etc by inventing a sub-protocol inside an existing event kind)
- There's a NIP, but no one knows about it because it's in a text file on your hard drive (or buried in your project's repository)
- Your NIP imposes an incompatible/centralized/legacy web paradigm onto nostr
- Your NIP relies on trusted third (or first) parties
- There's only one implementation of your NIP (yours)
- Your core value proposition doesn't depend on relays, events, or nostr identities
- One or more relay urls are hard-coded into the source code
- Your app depends on a specific relay implementation to work (ahem, relay29)
- You don't validate event signatures
- You don't publish events to relays you don't control
- You don't read events from relays you don't control
- You use legacy web services to solve problems, rather than nostr-native solutions
- You use nostr-native solutions, but you've hardcoded their pubkeys or URLs into your app
- You don't use NIP 89 to discover clients and services
- You haven't published a NIP 89 listing for your app
- You don't leverage your users' web of trust for filtering out spam
- You don't respect your users' mute lists
- You try to "own" your users' data
Now let me just re-iterate - it's ok to be a NINO. We need NINOs, because nostr can't (and shouldn't) tackle every problem. You just need to decide whether your app, as a NINO, is actually contributing to the nostr ecosystem, or whether you're just using buzzwords to whitewash a legacy web software product.
If you're in the former camp, great! If you're in the latter, what are you waiting for? Only you can fix your NINO problem. And there are lots of ways to do this, depending on your own unique situation:
- Drop nostr support if it's not doing anyone any good. If you want to build a normal company and make some money, that's perfectly fine.
- Build out your nostr integration - start taking advantage of webs of trust, self-authenticating data, event handlers, etc.
- Work around the problem. Think you need a special relay feature for your app to work? Guess again. Consider encryption, AUTH, DVMs, or better data formats.
- Think your idea is a good one? Talk to other devs or open a PR to the nips repo. No one can adopt your NIP if they don't know about it.
- Keep going. It can sometimes be hard to distinguish a research project from a NINO. New ideas have to be built out before they can be fully appreciated.
- Listen to advice. Nostr developers are friendly and happy to help. If you're not sure why you're getting traction, ask!
I sincerely hope this article is useful for all of you out there in NINO land. Maybe this made you feel better about not passing the totally optional nostr app purity test. Or maybe it gave you some actionable next steps towards making a great NINON (Nostr In Not Only Name) app. In either case, GM and PV.
-
@ 50809a53:e091f164
2025-01-20 22:30:01
For starters, anyone who is interested in curating and managing "notes, lists, bookmarks, kind-1 events, or other stuff" should watch this video:
https://youtu.be/XRpHIa-2XCE
Now, assuming you have watched it, I will proceed assuming you are aware of many of the applications that exist for a very similar purpose. I'll break them down further, following a similar trajectory in order of how I came across them, and a bit about my own path on this journey.
We'll start way back in the early 2000s, before Bitcoin existed. We had https://zim-wiki.org/
It is tried and true, and to this day stands to present an option for people looking for a very simple solution to a potentially complex problem. Zim-Wiki works. But it is limited.
Let's step into the realm of proprietary. Obsidian, Joplin, and LogSeq. The first two are entirely cloud-operative applications, with more of a focus on the true benefit of being a paid service. I will assume anyone reading this is capable of exploring the marketing of these applications, or trying their freemium product, to get a feeling for what they are capable of.
I bring up Obsidian because it is very crucial to understand the market placement of publication. We know social media handles the 'hosting' problem of publishing notes "and other stuff" by harvesting data and making deals with advertisers. But- what Obsidian has evolved to offer is a full service known as 'publish'. This means users can stay in the proprietary pipeline, "from thought to web." all for $8/mo.
See: https://obsidian.md/publish
THIS IS NOSTR'S PRIMARY COMPETITION. WE ARE HERE TO DISRUPT THIS MARKET, WITH NOTES AND OTHER STUFF. WITH RELAYS. WITH THE PROTOCOL.
Now, on to Joplin. I have never used this, because I opted to study the FOSS market and stayed free of any reliance on a paid solution. Many people like Joplin, and I gather the reason is because it has allowed itself to be flexible and good options that integrate with Joplin seems to provide good solutions for users who need that functionality. I see Nostr users recommending Joplin, so I felt it was worthwhile to mention as a case-study option. I myself need to investigate it more, but have found comfort in other solutions.
LogSeq - This is my "other solutions." It seems to be trapped in its proprietary web of funding and constraint. I use it because it turns my desktop into a power-house of note archival. But by using it- I AM TRAPPED TOO. This means LogSeq is by no means a working solution for Nostr users who want a long-term archival option.
But the trap is not a cage. It's merely a box. My notes can be exported to other applications with graphing and node-based information structure. Specifically, I can export these notes to:
- Text
- OPML
- HTML
- and, PNG, for whatever that is worth.
Let's try out the PNG option, just for fun. Here's an exported PNG of my "Games on Nostr" list, which has long been abandoned. I once decided to poll some CornyChat users to see what games they enjoyed- and I documented them in a LogSeq page for my own future reference. You can see it here:
https://i.postimg.cc/qMBPDTwr/image.png
This is a very simple example of how a single "page" or "list" in LogSeq can be multipurpose. It is a small list, with multiple "features" or variables at play. First, I have listed out a variety of complex games that might make sense with "multiplayer" identification that relies on our npubs or nip-05 addresses to aggregate user data. We can ALL imagine playing games like Tetris, Snake, or Catan together with our Nostr identities. But of course we are a long way from breaking into the video game market.
On a mostly irrelevant sidenote- you might notice in my example list, that I seem to be excited about a game called Dot.Hack. I discovered this small game on Itch.io and reached out to the developer on Twitter, in an attempt to purple-pill him, but moreso to inquire about his game. Unfortunately there was no response, even without mention of Nostr. Nonetheless, we pioneer on. You can try the game here: https://propuke.itch.io/planethack
So instead let's focus on the structure of "one working list." The middle section of this list is where I polled users, and simply listed out their suggestions. Of course we discussed these before I documented, so it is note a direct result of a poll, but actually a working interaction of poll results! This is crucial because it separates my list from the aggregated data, and implies its relevance/importance.
The final section of this ONE list- is the beginnings of where I conceptually connect nostr with video game functionality. You can look at this as the beginning of a new graph, which would be "Video Game Operability With Nostr".
These three sections make up one concept within my brain. It exists in other users' brains too- but of course they are not as committed to the concept as myself- the one managing the communal discussion.
With LogSeq- I can grow and expand these lists. These lists can become graphs. Those graphs can become entire catalogues of information than can be shared across the web.
I can replicate this system with bookmarks, ideas, application design, shopping lists, LLM prompting, video/music playlists, friend lists, RELAY lists, the LIST goes ON forever!
So where does that lead us? I think it leads us to kind-1 events. We don't have much in the way of "kind-1 event managers" because most developers would agree that "storing kind-1 events locally" is.. at the very least, not so important. But it could be! If only a superapp existed that could interface seamlessly with nostr, yada yada.. we've heard it all before. We aren't getting a superapp before we have microapps. Basically this means frameworking the protocol before worrying about the all-in-one solution.
So this article will step away from the deep desire for a Nostr-enabled, Rust-built, FOSS, non-commercialized FREEDOM APP, that will exist one day, we hope.
Instead, we will focus on simple attempts of the past. I encourage others to chime in with their experience.
Zim-Wiki is foundational. The user constructs pages, and can then develop them into books.
LogSeq has the right idea- but is constrained in too many ways to prove to be a working solution at this time. However, it is very much worth experimenting with, and investigating, and modelling ourselves after.
https://workflowy.com/ is next on our list. This is great for users who think LogSeq is too complex. They "just want simple notes." Get a taste with WorkFlowy. You will understand why LogSeq is powerful if you see value in WF.
I am writing this article in favor of a redesign of LogSeq to be compatible with Nostr. I have been drafting the idea since before Nostr existed- and with Nostr I truly believe it will be possible. So, I will stop to thank everyone who has made Nostr what it is today. I wouldn't be publishing this without you!
One app I need to investigate more is Zettlr. I will mention it here for others to either discuss or investigate, as it is also mentioned some in the video I opened with. https://www.zettlr.com/
On my path to finding Nostr, before its inception, was a service called Deta.Space. This was an interesting project, not entirely unique or original, but completely fresh and very beginner-friendly. DETA WAS AN AWESOME CLOUD OS. And we could still design a form of Nostr ecosystem that is managed in this way. But, what we have now is excellent, and going forward I only see "additional" or supplemental.
Along the timeline, Deta sunsetted their Space service and launched https://deta.surf/
You might notice they advertise that "This is the future of bookmarks."
I have to wonder if perhaps I got through to them that bookmarking was what their ecosystem could empower. While I have not tried Surf, it looks interested, but does not seem to address what I found most valuable about Deta.Space: https://webcrate.app/
WebCrate was an early bookmarking client for Deta.Space which was likely their most popular application. What was amazing about WebCrate was that it delivered "simple bookmarking." At one point I decided to migrate my bookmarks from other apps, like Pocket and WorkFlowy, into WebCrate.
This ended up being an awful decision, because WebCrate is no longer being developed. However, to much credit of Deta.Space, my WebCrate instance is still running and completely functional. I have since migrated what I deem important into a local LogSeq graph, so my bookmarks are safe. But, the development of WebCrate is note.
WebCrate did not provide a working directory of crates. All creates were contained within a single-level directory. Essentially there were no layers. Just collections of links. This isn't enough for any user to effectively manage their catalogue of notes. With some pressure, I did encourage the German developer to flesh out a form of tagging, which did alleviate the problem to some extent. But as we see with Surf, they have pioneered in another direction.
That brings us back to Nostr. Where can we look for the best solution? There simply isn't one yet. But, we can look at some other options for inspiration.
HedgeDoc: https://hedgedoc.org/
I am eager for someone to fork HedgeDoc and employ Nostr sign-in. This is a small step toward managing information together within the Nostr ecosystem. I will attempt this myself eventually, if no one else does, but I am prioritizing my development in this way:
- A nostr client that allows the cataloguing and management of relays locally.
- A LogSeq alternative with Nostr interoperability.
- HedgeDoc + Nostr is #3 on my list, despite being the easiest option.
Check out HedgeDoc 2.0 if you have any interest in a cooperative Markdown experience on Nostr: https://docs.hedgedoc.dev/
Now, this article should catch up all of my dearest followers, and idols, to where I stand with "bookmarking, note-taking, list-making, kind-1 event management, frameworking, and so on..."
Where it leads us to, is what's possible. Let's take a look at what's possible, once we forego ALL OF THE PROPRIETARY WEB'S BEST OPTIONS:
https://denizaydemir.org/
https://denizaydemir.org/graph/how-logseq-should-build-a-world-knowledge-graph/
https://subconscious.network/
Nostr is even inspired by much of the history that has gone into information management systems. nostr:npub1jlrs53pkdfjnts29kveljul2sm0actt6n8dxrrzqcersttvcuv3qdjynqn I know looks up to Gordon Brander, just as I do. You can read his articles here: https://substack.com/@gordonbrander and they are very much worth reading! Also, I could note that the original version of Highlighter by nostr:npub1l2vyh47mk2p0qlsku7hg0vn29faehy9hy34ygaclpn66ukqp3afqutajft was also inspired partially by WorkFlowy.
About a year ago, I was mesmerized coming across SubText and thinking I had finally found the answer Nostr might even be looking for. But, for now I will just suggest that others read the Readme.md on the SubText Gtihub, as well as articles by Brander.
Good luck everyone. I am here to work with ANYONE who is interested in these type of solution on Nostr.
My first order of business in this space is to spearhead a community of npubs who share this goal. Everyone who is interested in note-taking or list-making or bookmarking is welcome to join. I have created an INVITE-ONLY relay for this very purpose, and anyone is welcome to reach out if they wish to be added to the whitelist. It should be freely readable in the near future, if it is not already, but for now will remain a closed-to-post community to preemptively mitigate attack or spam. Please reach out to me if you wish to join the relay. https://logstr.mycelium.social/
With this article, I hope people will investigate and explore the options available. We have lots of ground to cover, but all of the right resources and manpower to do so. Godspeed, Nostr.
Nostr #Notes #OtherStuff #LogSec #Joplin #Obsidian
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ dd664d5e:5633d319
2025-01-09 21:39:15
Instructions
- Place 2 medium-sized, boiled potatoes and a handful of sliced leeks in a pot.

- Fill the pot with water or vegetable broth, to cover the potatoes twice over.
- Add a splash of white wine, if you like, and some bouillon powder, if you went with water instead of broth.

- Bring the soup to a boil and then simmer for 15 minutes.
- Puree the soup, in the pot, with a hand mixer. It shouldn't be completely smooth, when you're done, but rather have small bits and pieces of the veggies floating around.

- Bring the soup to a boil, again, and stir in one container (200-250 mL) of heavy cream.
- Thicken the soup, as needed, and then simmer for 5 more minutes.
- Garnish with croutons and veggies (here I used sliced green onions and radishes) and serve.

Guten Appetit!
- Place 2 medium-sized, boiled potatoes and a handful of sliced leeks in a pot.
-
@ 3f770d65:7a745b24
2025-01-05 18:56:33
New Year’s resolutions often feel boring and repetitive. Most revolve around getting in shape, eating healthier, or giving up alcohol. While the idea is interesting—using the start of a new calendar year as a catalyst for change—it also seems unnecessary. Why wait for a specific date to make a change? If you want to improve something in your life, you can just do it. You don’t need an excuse.
That’s why I’ve never been drawn to the idea of making a list of resolutions. If I wanted a change, I’d make it happen, without worrying about the calendar. At least, that’s how I felt until now—when, for once, the timing actually gave me a real reason to embrace the idea of New Year’s resolutions.
Enter Olas.
If you're a visual creator, you've likely experienced the relentless grind of building a following on platforms like Instagram—endless doomscrolling, ever-changing algorithms, and the constant pressure to stay relevant. But what if there was a better way? Olas is a Nostr-powered alternative to Instagram that prioritizes community, creativity, and value-for-value exchanges. It's a game changer.
Instagram’s failings are well-known. Its algorithm often dictates whose content gets seen, leaving creators frustrated and powerless. Monetization hurdles further alienate creators who are forced to meet arbitrary follower thresholds before earning anything. Additionally, the platform’s design fosters endless comparisons and exposure to negativity, which can take a significant toll on mental health.
Instagram’s algorithms are notorious for keeping users hooked, often at the cost of their mental health. I've spoken about this extensively, most recently at Nostr Valley, explaining how legacy social media is bad for you. You might find yourself scrolling through content that leaves you feeling anxious or drained. Olas takes a fresh approach, replacing "doomscrolling" with "bloomscrolling." This is a common theme across the Nostr ecosystem. The lack of addictive rage algorithms allows the focus to shift to uplifting, positive content that inspires rather than exhausts.
Monetization is another area where Olas will set itself apart. On Instagram, creators face arbitrary barriers to earning—needing thousands of followers and adhering to restrictive platform rules. Olas eliminates these hurdles by leveraging the Nostr protocol, enabling creators to earn directly through value-for-value exchanges. Fans can support their favorite artists instantly, with no delays or approvals required. The plan is to enable a brand new Olas account that can get paid instantly, with zero followers - that's wild.
Olas addresses these issues head-on. Operating on the open Nostr protocol, it removes centralized control over one's content’s reach or one's ability to monetize. With transparent, configurable algorithms, and a community that thrives on mutual support, Olas creates an environment where creators can grow and succeed without unnecessary barriers.
Join me on my New Year's resolution. Join me on Olas and take part in the #Olas365 challenge! It’s a simple yet exciting way to share your content. The challenge is straightforward: post at least one photo per day on Olas (though you’re welcome to share more!).
Download on Android or download via Zapstore.
Let's make waves together.
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
- Enhance LLM Outputs: By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
- Support Complex Queries: Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
- Richness of Entities: Effective retrieval depends on graphs populated with rich, detailed entities.
- Freedom from Hallucinations: Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
- Handle diverse data sources with ease.
- Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
- Defining Relationships: Clarifying how concepts connect within a domain.
- Validating Graph Structures: Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
- Assign a Knowledge Champion: Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
- Provide Training: Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
- Leverage Partnerships: Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
- Utilize Tools: Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
- Iterate with Feedback: Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
-
Leverage Existing Ontologies: Many industries and domains already have open ontologies. For instance:
-
Public Knowledge Graphs: Resources like Wikipedia’s graph offer a wealth of structured knowledge.
- Industry Standards: Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
-
Business Framework Ontology (BFO): A valuable resource for enterprises looking to define business processes and structures.
-
Build In-House Expertise: If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
-
Utilize LLMs for Ontology Construction: Interestingly, LLMs themselves can act as a starting point for ontology development:
-
Prompt-Based Extraction: LLMs can generate draft ontologies by leveraging their extensive training on graph data.
- Domain Expert Refinement: Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
- Detecting Hallucinations: Differentiating between genuine insights and AI-generated inaccuracies.
- Ensuring Completeness: Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
- Generate Skeleton Ontologies: Prompt LLMs with domain-specific information to draft initial ontology structures.
- Validate and Refine Ontologies: Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
The Four-Layer Framework
Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
Example: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- Tip: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
Once you have the big picture in mind, it’s time to start breaking it down.
Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
Example: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- Tip: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
With your categories in place, you’re ready to dive into the details that bring them to life.
Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
Example: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- Tip: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
Now that you’ve mastered the essentials, you can expand your knowledge to include extra material.
Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
Example: Learn about rare programming quirks or historical trivia about a language’s development.
- Tip: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
Pro Tips for Better Learning
1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
2. Map It Out
Create visual aids like diagrams or concept maps to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching exposes any gaps in your understanding and helps reinforce the material.
4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to explore your topic in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.Tip: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ 3f770d65:7a745b24
2024-12-31 17:03:46
Here are my predictions for Nostr in 2025:
Decentralization: The outbox and inbox communication models, sometimes referred to as the Gossip model, will become the standard across the ecosystem. By the end of 2025, all major clients will support these models, providing seamless communication and enhanced decentralization. Clients that do not adopt outbox/inbox by then will be regarded as outdated or legacy systems.
Privacy Standards: Major clients such as Damus and Primal will move away from NIP-04 DMs, adopting more secure protocol possibilities like NIP-17 or NIP-104. These upgrades will ensure enhanced encryption and metadata protection. Additionally, NIP-104 MLS tools will drive the development of new clients and features, providing users with unprecedented control over the privacy of their communications.
Interoperability: Nostr's ecosystem will become even more interconnected. Platforms like the Olas image-sharing service will expand into prominent clients such as Primal, Damus, Coracle, and Snort, alongside existing integrations with Amethyst, Nostur, and Nostrudel. Similarly, audio and video tools like Nostr Nests and Zap.stream will gain seamless integration into major clients, enabling easy participation in live events across the ecosystem.
Adoption and Migration: Inspired by early pioneers like Fountain and Orange Pill App, more platforms will adopt Nostr for authentication, login, and social systems. In 2025, a significant migration from a high-profile application platform with hundreds of thousands of users will transpire, doubling Nostr’s daily activity and establishing it as a cornerstone of decentralized technologies.
-
@ 6e468422:15deee93
2024-12-21 19:25:26
We didn't hear them land on earth, nor did we see them. The spores were not visible to the naked eye. Like dust particles, they softly fell, unhindered, through our atmosphere, covering the earth. It took us a while to realize that something extraordinary was happening on our planet. In most places, the mushrooms didn't grow at all. The conditions weren't right. In some places—mostly rocky places—they grew large enough to be noticeable. People all over the world posted pictures online. "White eggs," they called them. It took a bit until botanists and mycologists took note. Most didn't realize that we were dealing with a species unknown to us.
We aren't sure who sent them. We aren't even sure if there is a "who" behind the spores. But once the first portals opened up, we learned that these mushrooms aren't just a quirk of biology. The portals were small at first—minuscule, even. Like a pinhole camera, we were able to glimpse through, but we couldn't make out much. We were only able to see colors and textures if the conditions were right. We weren't sure what we were looking at.
We still don't understand why some mushrooms open up, and some don't. Most don't. What we do know is that they like colder climates and high elevations. What we also know is that the portals don't stay open for long. Like all mushrooms, the flush only lasts for a week or two. When a portal opens, it looks like the mushroom is eating a hole into itself at first. But the hole grows, and what starts as a shimmer behind a grey film turns into a clear picture as the egg ripens. When conditions are right, portals will remain stable for up to three days. Once the fruit withers, the portal closes, and the mushroom decays.
The eggs grew bigger year over year. And with it, the portals. Soon enough, the portals were big enough to stick your finger through. And that's when things started to get weird...
-
@ 20986fb8:cdac21b3
2024-12-18 03:19:36
English
Introducing YakiHonne: Write Without Limits
YakiHonne is the ultimate text editor designed to help you express yourself creatively, no matter the language.
Features you'll love:
- 🌟 Rich Formatting: Add headings, bold, italics, and more.
- 🌏 Multilingual Support: Seamlessly write in English, Chinese, Arabic, and Japanese.
- 🔗 Interactive Links: Learn more about YakiHonne.Benefits:
1. Easy to use. 2. Enhance readability with customizable styles.
3. Supports various complex formats including LateX."YakiHonne is a game-changer for content creators."
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install NVapi to monitor my GPUs in Home Assistant.
NVApi is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- GPU Utilization Monitoring: Utilization, memory usage, temperature, fan speed, and power consumption.
- Automated Power Limiting: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- Cross-GPU Coordination: Total power budget applies across multiple GPUs in the same system.
- PCIe Link Speed Management: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- Home Assistant Integration: Uses the built-in RESTful platform and template sensors.
Getting the Data
sudo apt install golang-go git clone https://github.com/sammcj/NVApi.git cd NVapi go run main.go -port 9999 -rate 1 curl http://localhost:9999/gpuResponse for a single GPU:
[ { "index": 0, "name": "NVIDIA GeForce RTX 4090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 16, "power_limit_watts": 450, "memory_total_gb": 23.99, "memory_used_gb": 0.46, "memory_free_gb": 23.52, "memory_usage_percent": 2, "temperature": 38, "processes": [], "pcie_link_state": "not managed" } ]Response for multiple GPUs:
[ { "index": 0, "name": "NVIDIA GeForce RTX 3090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 14, "power_limit_watts": 350, "memory_total_gb": 24, "memory_used_gb": 0.43, "memory_free_gb": 23.57, "memory_usage_percent": 2, "temperature": 36, "processes": [], "pcie_link_state": "not managed" }, { "index": 1, "name": "NVIDIA RTX A4000", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 10, "power_limit_watts": 140, "memory_total_gb": 15.99, "memory_used_gb": 0.56, "memory_free_gb": 15.43, "memory_usage_percent": 3, "temperature": 41, "processes": [], "pcie_link_state": "not managed" } ]Start at Boot
Create
/etc/systemd/system/nvapi.service:``` [Unit] Description=Run NVapi After=network.target
[Service] Type=simple Environment="GOPATH=/home/ansible/go" WorkingDirectory=/home/ansible/NVapi ExecStart=/usr/bin/go run main.go -port 9999 -rate 1 Restart=always User=ansible
Environment="GPU_TEMP_CHECK_INTERVAL=5"
Environment="GPU_TOTAL_POWER_CAP=400"
Environment="GPU_0_LOW_TEMP=40"
Environment="GPU_0_MEDIUM_TEMP=70"
Environment="GPU_0_LOW_TEMP_LIMIT=135"
Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
Environment="GPU_0_HIGH_TEMP_LIMIT=100"
Environment="GPU_1_LOW_TEMP=45"
Environment="GPU_1_MEDIUM_TEMP=75"
Environment="GPU_1_LOW_TEMP_LIMIT=140"
Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install] WantedBy=multi-user.target ```
Home Assistant
Add to Home Assistant
configuration.yamland restart HA (completely).For a single GPU, this works: ``` sensor: - platform: rest name: MYPC GPU Information resource: http://mypc:9999 method: GET headers: Content-Type: application/json value_template: "{{ value_json[0].index }}" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature scan_interval: 1 # seconds
- platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}" unit_of_measurement: "°C" ```
For multiple GPUs: ``` rest: scan_interval: 1 resource: http://mypc:9999 sensor: - name: "MYPC GPU0 Information" value_template: "{{ value_json[0].index }}" json_attributes_path: "$.0" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature - name: "MYPC GPU1 Information" value_template: "{{ value_json[1].index }}" json_attributes_path: "$.1" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature
-
platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC GPU0 GPU" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC GPU0 Memory" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC GPU0 Power" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC GPU0 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC GPU0 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}" unit_of_measurement: "C"
-
platform: template sensors: mypc_gpu_1_gpu: friendly_name: "MYPC GPU1 GPU" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_memory: friendly_name: "MYPC GPU1 Memory" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_power: friendly_name: "MYPC GPU1 Power" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_1_power_limit: friendly_name: "MYPC GPU1 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_1_temperature: friendly_name: "MYPC GPU1 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}" unit_of_measurement: "C"
```
Basic entity card:
type: entities entities: - entity: sensor.mypc_gpu_0_gpu secondary_info: last-updated - entity: sensor.mypc_gpu_0_memory secondary_info: last-updated - entity: sensor.mypc_gpu_0_power secondary_info: last-updated - entity: sensor.mypc_gpu_0_power_limit secondary_info: last-updated - entity: sensor.mypc_gpu_0_temperature secondary_info: last-updatedAnsible Role
```
-
name: install go become: true package: name: golang-go state: present
-
name: git clone git: repo: "https://github.com/sammcj/NVApi.git" dest: "/home/ansible/NVapi" update: yes force: true
go run main.go -port 9999 -rate 1
-
name: install systemd service become: true copy: src: nvapi.service dest: /etc/systemd/system/nvapi.service
-
name: Reload systemd daemons, enable, and restart nvapi become: true systemd: name: nvapi daemon_reload: yes enabled: yes state: restarted ```
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
-
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
-
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\ https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
-
@ dd664d5e:5633d319
2024-12-14 15:25:56

Christmas season hasn't actually started, yet, in Roman #Catholic Germany. We're in Advent until the evening of the 24th of December, at which point Christmas begins (with the Nativity, at Vespers), and continues on for 40 days until Mariä Lichtmess (Presentation of Christ in the temple) on February 2nd.
It's 40 days because that's how long the post-partum isolation is, before women were allowed back into the temple (after a ritual cleansing).

That is the day when we put away all of the Christmas decorations and bless the candles, for the next year. (Hence, the British name "Candlemas".) It used to also be when household staff would get paid their cash wages and could change employer. And it is the day precisely in the middle of winter.

Between Christmas Eve and Candlemas are many celebrations, concluding with the Twelfth Night called Epiphany or Theophany. This is the day some Orthodox celebrate Christ's baptism, so traditions rotate around blessing of waters.

The Monday after Epiphany was the start of the farming season, in England, so that Sunday all of the ploughs were blessed, but the practice has largely died out.

Our local tradition is for the altar servers to dress as the wise men and go door-to-door, carrying their star and looking for the Baby Jesus, who is rumored to be lying in a manger.

They collect cash gifts and chocolates, along the way, and leave the generous their powerful blessing, written over the door. The famous 20 * C + M + B * 25 blessing means "Christus mansionem benedicat" (Christ, bless this house), or "Caspar, Melchior, Balthasar" (the names of the three kings), depending upon who you ask.
They offer the cash to the Baby Jesus (once they find him in the church's Nativity scene), but eat the sweets, themselves. It is one of the biggest donation-collections in the world, called the "Sternsinger" (star singers). The money goes from the German children, to help children elsewhere, and they collect around €45 million in cash and coins, every year.

As an interesting aside:
The American "groundhog day", derives from one of the old farmers' sayings about Candlemas, brought over by the Pennsylvania Dutch. It says, that if the badger comes out of his hole and sees his shadow, then it'll remain cold for 4 more weeks. When they moved to the USA, they didn't have any badgers around, so they switched to groundhogs, as they also hibernate in winter.
-
@ d0bf8568:4db3e76f
2024-12-12 21:26:52
Depuis sa création en 2009, Bitcoin suscite débats passionnés. Pour certains, il s’agit d’une tentative utopique d’émancipation du pouvoir étatique, inspirée par une philosophie libertarienne radicale. Pour d’autres, c'est une réponse pragmatique à un système monétaire mondial jugé défaillant. Ces deux perspectives, souvent opposées, méritent d’être confrontées pour mieux comprendre les enjeux et les limites de cette révolution monétaire.

La critique économique de Bitcoin
David Cayla, dans ses dernières contributions, perçoit Bitcoin comme une tentative de réaliser une « utopie libertarienne ». Selon lui, les inventeurs des cryptomonnaies cherchent à créer une monnaie détachée de l’État et des rapports sociaux traditionnels, en s’inspirant de l’école autrichienne d’économie. Cette école, incarnée par des penseurs comme Friedrich Hayek, prône une monnaie privée et indépendante de l’intervention politique.
Cayla reproche à Bitcoin de nier la dimension intrinsèquement sociale et politique de la monnaie. Pour lui, toute monnaie repose sur la confiance collective et la régulation étatique. En rendant la monnaie exogène et dénuée de dette, Bitcoin chercherait à éviter les interactions sociales au profit d’une logique purement individuelle. Selon cette analyse, Bitcoin serait une illusion, incapable de remplacer les monnaies traditionnelles qui sont des « biens publics » soutenus par des institutions.
Cependant, cette critique semble minimiser la légitimité des motivations derrière Bitcoin. La crise financière de 2008, marquée par des abus systémiques et des sauvetages bancaires controversés, a largement érodé la confiance dans les systèmes monétaires centralisés. Bitcoin n’est pas qu’une réaction idéologique : c’est une tentative de créer un système monétaire transparent, immuable et résistant aux manipulations.
La perspective maximaliste
Pour les bitcoiners, Bitcoin n’est pas une utopie mais une réponse pragmatique à un problème réel : la centralisation excessive et les défaillances des monnaies fiat. Contrairement à ce que Cayla affirme, Bitcoin ne cherche pas à nier la société, mais à protéger les individus de la coercition étatique. En déplaçant la confiance des institutions vers un protocole neutre et transparent, Bitcoin redéfinit les bases des échanges monétaires.
L’accusation selon laquelle Bitcoin serait « asocial » ignore son écosystème communautaire mondial. Les bitcoiners collaborent activement à l’amélioration du réseau, organisent des événements éducatifs et développent des outils inclusifs. Bitcoin n’est pas un rejet des rapports sociaux, mais une tentative de les reconstruire sur des bases plus justes et transparentes.
Un maximaliste insisterait également sur l’émergence historique de la monnaie. Contrairement à l’idée que l’État aurait toujours créé la monnaie, de nombreux exemples montrent que celle-ci émergeait souvent du marché, avant d’être capturée par les gouvernements pour financer des guerres ou imposer des monopoles. Bitcoin réintroduit une monnaie à l’abri des manipulations politiques, similaire aux systèmes basés sur l’or, mais en mieux : numérique, immuable et accessible.
Utopie contre réalité
Si Cayla critique l’absence de dette dans Bitcoin, Nous y voyons une vertu. La « monnaie-dette » actuelle repose sur un système de création monétaire inflationniste qui favorise les inégalités et l’érosion du pouvoir d’achat. En limitant son offre à 21 millions d’unités, Bitcoin offre une alternative saine et prévisible, loin des politiques monétaires arbitraires.
Cependant, les maximalistes ne nient pas que Bitcoin ait encore des défis à relever. La volatilité de sa valeur, sa complexité technique pour les nouveaux utilisateurs, et les tensions entre réglementation et liberté individuelle sont des questions ouvertes. Mais pour autant, ces épreuves ne remettent pas en cause sa pertinence. Au contraire, elles illustrent l’importance de réfléchir à des modèles alternatifs.
Conclusion : un débat essentiel
Bitcoin n’est pas une utopie libertarienne, mais une révolution monétaire sans précédent. Les critiques de Cayla, bien qu’intellectuellement stimulantes, manquent de saisir l’essence de Bitcoin : une monnaie qui libère les individus des abus systémiques des États et des institutions centralisées. Loin de simplement avoir un « potentiel », Bitcoin est déjà en train de redéfinir les rapports entre la monnaie, la société et la liberté. Bitcoin offre une expérience unique : celle d’une monnaie mondiale, neutre et décentralisée, qui redonne le pouvoir aux individus. Que l’on soit sceptique ou enthousiaste, il est clair que Bitcoin oblige à repenser les rapports entre monnaie, société et État.
En fin de compte, le débat sur Bitcoin n’est pas seulement une querelle sur sa légitimité, mais une interrogation sur la manière dont il redessine les rapports sociaux et sociétaux autour de la monnaie. En rendant le pouvoir monétaire à chaque individu, Bitcoin propose un modèle où les interactions économiques peuvent être réalisées sans coercition, renforçant ainsi la confiance mutuelle et les communautés globales. Cette discussion, loin d’être close, ne fait que commencer.
-
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.Graph Basics
- A standard graph has a set of nodes (or vertices) and edges (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
Hypergraph
- A hypergraph extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a hyperedge, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
Metagraph
- A metagraph allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
Directed Metagraph where edges are not used as nodes and could not contain subgraphs
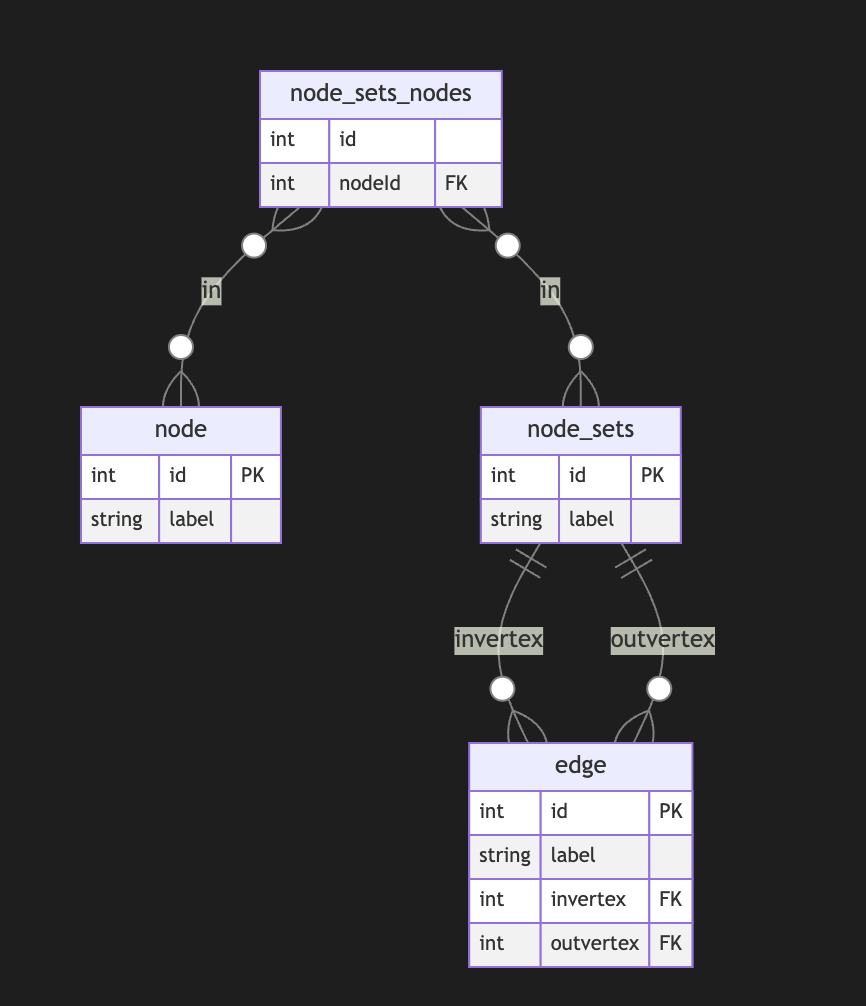
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
Directed Metagraph where edges are not used as nodes and could contain subgraphs
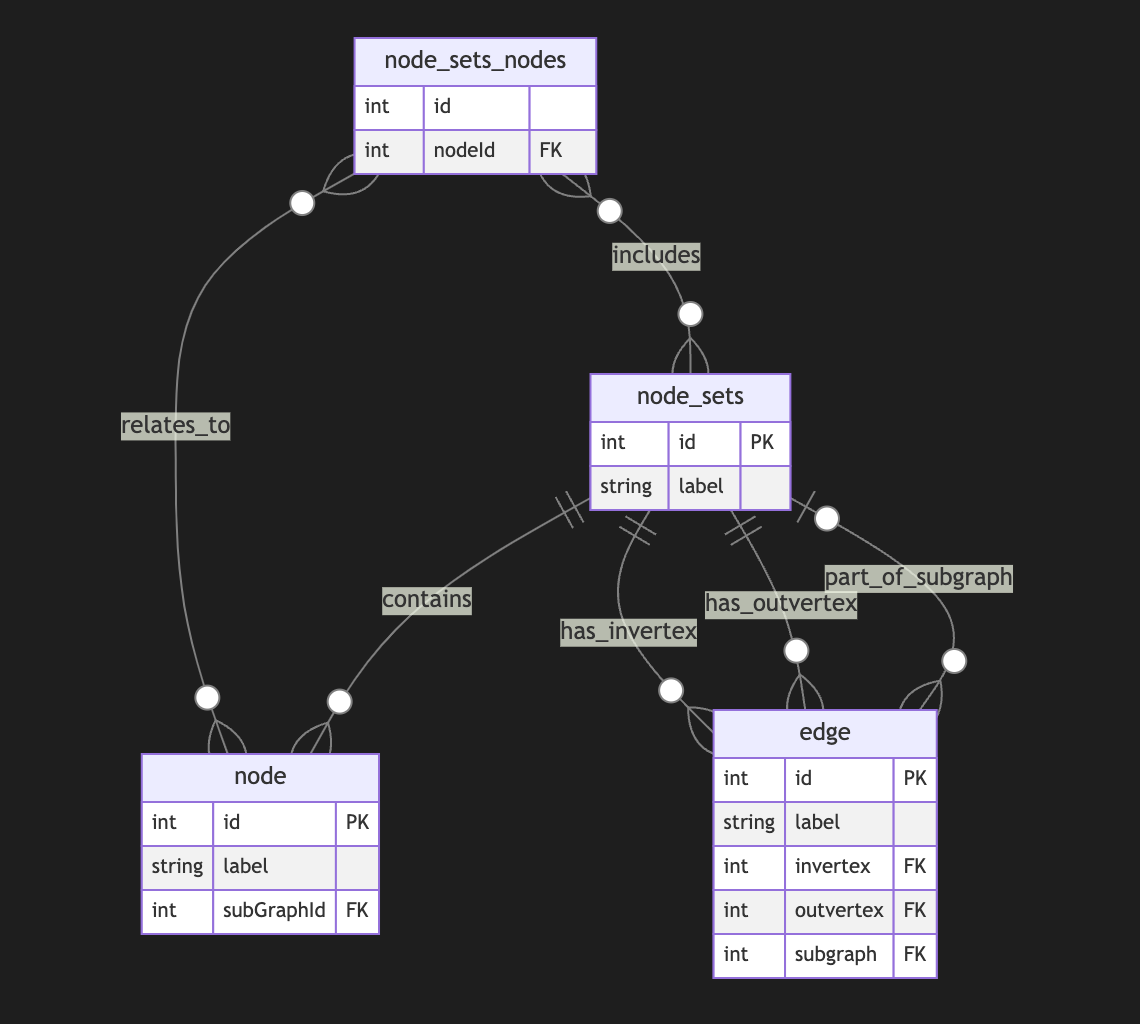
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
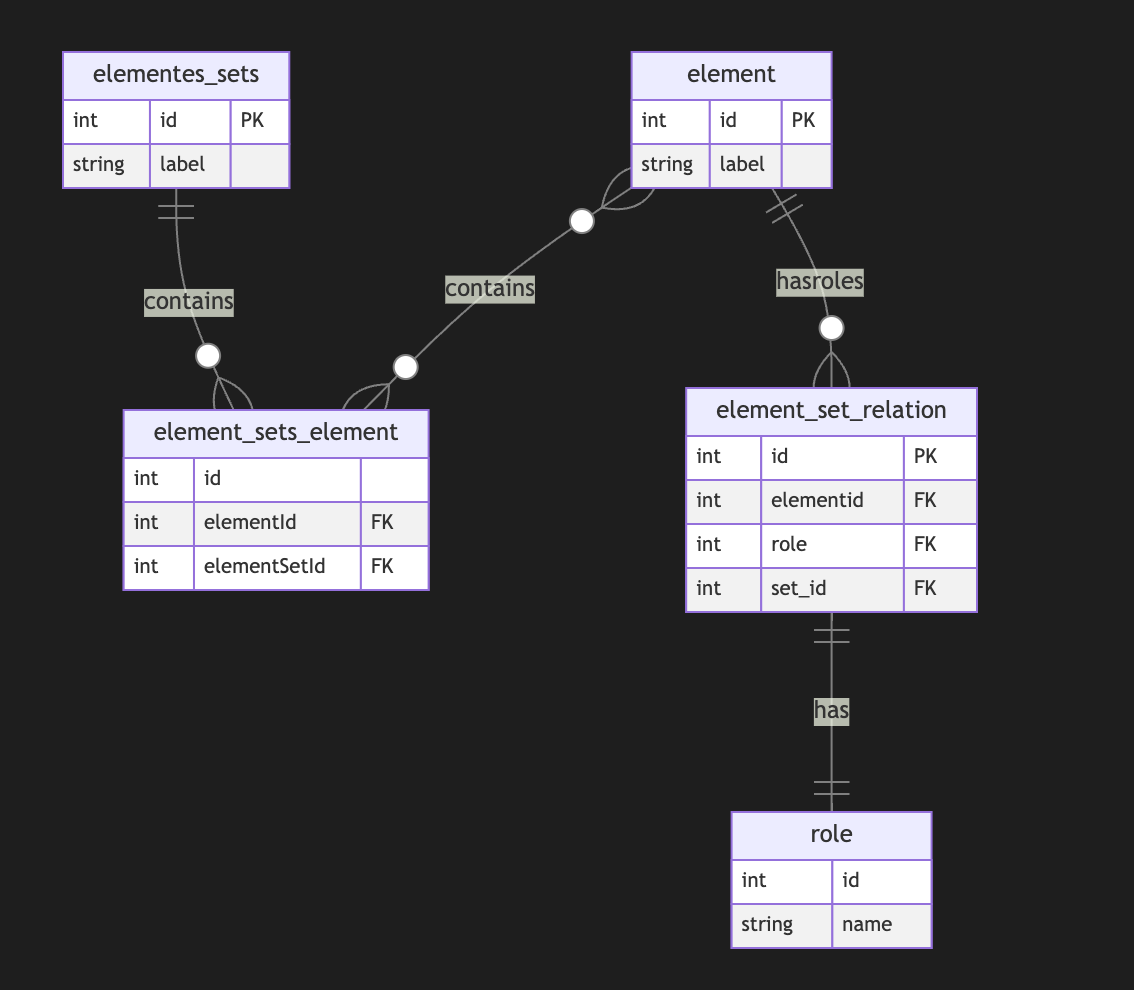
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose. -
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like Lisp emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
Lisp: The Earlier AI-Language
Lisp, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
Prolog: Formal Logic and Deductive Reasoning
In the 1970s, Prolog was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out how to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
Solvers and Their Role in Complementing LLMs
One of the most powerful features of Prolog and similar logic-based systems is their use of solvers. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a solver can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling constraint satisfaction problems — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating neurosymbolic methods that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a graph of rules. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a graph of rules, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable modular reasoning, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of neural fluency with rule-based structure gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform deductive reasoning alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where neurosymbolic approaches shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
Personal Knowledge Graphs (PKGs) come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a graph of rules that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using deductive databases to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling knowledge graphs using deductive databases, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
Prolog and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a graph of rules that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
Why It Matters for LLM Employment
Using neurosymbolic RAG (retrieval-augmented generation) in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of neural fluency with symbolic accuracy and deductive power is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
RDF and Advanced Topics
Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory and semantic memory. And we also have a lot of theories, right?
Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a hybrid clock or some global clock that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ a39d19ec:3d88f61e
2024-11-21 12:05:09
A state-controlled money supply can influence the development of socialist policies and practices in various ways. Although the relationship is not deterministic, state control over the money supply can contribute to a larger role of the state in the economy and facilitate the implementation of socialist ideals.
Fiscal Policy Capabilities
When the state manages the money supply, it gains the ability to implement fiscal policies that can lead to an expansion of social programs and welfare initiatives. Funding these programs by creating money can enhance the state's influence over the economy and move it closer to a socialist model. The Soviet Union, for instance, had a centralized banking system that enabled the state to fund massive industrialization and social programs, significantly expanding the state's role in the economy.
Wealth Redistribution
Controlling the money supply can also allow the state to influence economic inequality through monetary policies, effectively redistributing wealth and reducing income disparities. By implementing low-interest loans or providing financial assistance to disadvantaged groups, the state can narrow the wealth gap and promote social equality, as seen in many European welfare states.
Central Planning
A state-controlled money supply can contribute to increased central planning, as the state gains more influence over the economy. Central banks, which are state-owned or heavily influenced by the state, play a crucial role in managing the money supply and facilitating central planning. This aligns with socialist principles that advocate for a planned economy where resources are allocated according to social needs rather than market forces.
Incentives for Staff
Staff members working in state institutions responsible for managing the money supply have various incentives to keep the system going. These incentives include job security, professional expertise and reputation, political alignment, regulatory capture, institutional inertia, and legal and administrative barriers. While these factors can differ among individuals, they can collectively contribute to the persistence of a state-controlled money supply system.
In conclusion, a state-controlled money supply can facilitate the development of socialist policies and practices by enabling fiscal policies, wealth redistribution, and central planning. The staff responsible for managing the money supply have diverse incentives to maintain the system, further ensuring its continuation. However, it is essential to note that many factors influence the trajectory of an economic system, and the relationship between state control over the money supply and socialism is not inevitable.
-
@ a39d19ec:3d88f61e
2024-11-17 10:48:56
This week's functional 3d print is the "Dino Clip".

Dino Clip
I printed it some years ago for my son, so he would have his own clip for cereal bags.
Now it is used to hold a bag of dog food close.
The design by "Sneaks" is a so called "print in place". This means that the whole clip with moving parts is printed in one part, without the need for assembly after the print.
 The clip is very strong, and I would print it again if I need a "heavy duty" clip for more rigid or big bags.
Link to the file at Printables
The clip is very strong, and I would print it again if I need a "heavy duty" clip for more rigid or big bags.
Link to the file at Printables -
@ 4ba8e86d:89d32de4
2024-11-14 09:17:14
Tutorial feito por nostr:nostr:npub1rc56x0ek0dd303eph523g3chm0wmrs5wdk6vs0ehd0m5fn8t7y4sqra3tk poste original abaixo:
Parte 1 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/263585/tutorial-debloat-de-celulares-android-via-adb-parte-1
Parte 2 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/index.php/263586/tutorial-debloat-de-celulares-android-via-adb-parte-2
Quando o assunto é privacidade em celulares, uma das medidas comumente mencionadas é a remoção de bloatwares do dispositivo, também chamado de debloat. O meio mais eficiente para isso sem dúvidas é a troca de sistema operacional. Custom Rom’s como LineageOS, GrapheneOS, Iodé, CalyxOS, etc, já são bastante enxutos nesse quesito, principalmente quanto não é instalado os G-Apps com o sistema. No entanto, essa prática pode acabar resultando em problemas indesejados como a perca de funções do dispositivo, e até mesmo incompatibilidade com apps bancários, tornando este método mais atrativo para quem possui mais de um dispositivo e separando um apenas para privacidade. Pensando nisso, pessoas que possuem apenas um único dispositivo móvel, que são necessitadas desses apps ou funções, mas, ao mesmo tempo, tem essa visão em prol da privacidade, buscam por um meio-termo entre manter a Stock rom, e não ter seus dados coletados por esses bloatwares. Felizmente, a remoção de bloatwares é possível e pode ser realizada via root, ou mais da maneira que este artigo irá tratar, via adb.
O que são bloatwares?
Bloatware é a junção das palavras bloat (inchar) + software (programa), ou seja, um bloatware é basicamente um programa inútil ou facilmente substituível — colocado em seu dispositivo previamente pela fabricante e operadora — que está no seu dispositivo apenas ocupando espaço de armazenamento, consumindo memória RAM e pior, coletando seus dados e enviando para servidores externos, além de serem mais pontos de vulnerabilidades.
O que é o adb?
O Android Debug Brigde, ou apenas adb, é uma ferramenta que se utiliza das permissões de usuário shell e permite o envio de comandos vindo de um computador para um dispositivo Android exigindo apenas que a depuração USB esteja ativa, mas também pode ser usada diretamente no celular a partir do Android 11, com o uso do Termux e a depuração sem fio (ou depuração wifi). A ferramenta funciona normalmente em dispositivos sem root, e também funciona caso o celular esteja em Recovery Mode.
Requisitos:
Para computadores:
• Depuração USB ativa no celular; • Computador com adb; • Cabo USB;
Para celulares:
• Depuração sem fio (ou depuração wifi) ativa no celular; • Termux; • Android 11 ou superior;
Para ambos:
• Firewall NetGuard instalado e configurado no celular; • Lista de bloatwares para seu dispositivo;
Ativação de depuração:
Para ativar a Depuração USB em seu dispositivo, pesquise como ativar as opções de desenvolvedor de seu dispositivo, e lá ative a depuração. No caso da depuração sem fio, sua ativação irá ser necessária apenas no momento que for conectar o dispositivo ao Termux.
Instalação e configuração do NetGuard
O NetGuard pode ser instalado através da própria Google Play Store, mas de preferência instale pela F-Droid ou Github para evitar telemetria.
F-Droid: https://f-droid.org/packages/eu.faircode.netguard/
Github: https://github.com/M66B/NetGuard/releases
Após instalado, configure da seguinte maneira:
Configurações → padrões (lista branca/negra) → ative as 3 primeiras opções (bloquear wifi, bloquear dados móveis e aplicar regras ‘quando tela estiver ligada’);
Configurações → opções avançadas → ative as duas primeiras (administrar aplicativos do sistema e registrar acesso a internet);
Com isso, todos os apps estarão sendo bloqueados de acessar a internet, seja por wifi ou dados móveis, e na página principal do app basta permitir o acesso a rede para os apps que você vai usar (se necessário). Permita que o app rode em segundo plano sem restrição da otimização de bateria, assim quando o celular ligar, ele já estará ativo.
Lista de bloatwares
Nem todos os bloatwares são genéricos, haverá bloatwares diferentes conforme a marca, modelo, versão do Android, e até mesmo região.
Para obter uma lista de bloatwares de seu dispositivo, caso seu aparelho já possua um tempo de existência, você encontrará listas prontas facilmente apenas pesquisando por elas. Supondo que temos um Samsung Galaxy Note 10 Plus em mãos, basta pesquisar em seu motor de busca por:
Samsung Galaxy Note 10 Plus bloatware listProvavelmente essas listas já terão inclusas todos os bloatwares das mais diversas regiões, lhe poupando o trabalho de buscar por alguma lista mais específica.
Caso seu aparelho seja muito recente, e/ou não encontre uma lista pronta de bloatwares, devo dizer que você acaba de pegar em merda, pois é chato para um caralho pesquisar por cada aplicação para saber sua função, se é essencial para o sistema ou se é facilmente substituível.
De antemão já aviso, que mais para frente, caso vossa gostosura remova um desses aplicativos que era essencial para o sistema sem saber, vai acabar resultando na perda de alguma função importante, ou pior, ao reiniciar o aparelho o sistema pode estar quebrado, lhe obrigando a seguir com uma formatação, e repetir todo o processo novamente.
Download do adb em computadores
Para usar a ferramenta do adb em computadores, basta baixar o pacote chamado SDK platform-tools, disponível através deste link: https://developer.android.com/tools/releases/platform-tools. Por ele, você consegue o download para Windows, Mac e Linux.
Uma vez baixado, basta extrair o arquivo zipado, contendo dentro dele uma pasta chamada platform-tools que basta ser aberta no terminal para se usar o adb.
Download do adb em celulares com Termux.
Para usar a ferramenta do adb diretamente no celular, antes temos que baixar o app Termux, que é um emulador de terminal linux, e já possui o adb em seu repositório. Você encontra o app na Google Play Store, mas novamente recomendo baixar pela F-Droid ou diretamente no Github do projeto.
F-Droid: https://f-droid.org/en/packages/com.termux/
Github: https://github.com/termux/termux-app/releases
Processo de debloat
Antes de iniciarmos, é importante deixar claro que não é para você sair removendo todos os bloatwares de cara sem mais nem menos, afinal alguns deles precisam antes ser substituídos, podem ser essenciais para você para alguma atividade ou função, ou até mesmo são insubstituíveis.
Alguns exemplos de bloatwares que a substituição é necessária antes da remoção, é o Launcher, afinal, é a interface gráfica do sistema, e o teclado, que sem ele só é possível digitar com teclado externo. O Launcher e teclado podem ser substituídos por quaisquer outros, minha recomendação pessoal é por aqueles que respeitam sua privacidade, como Pie Launcher e Simple Laucher, enquanto o teclado pelo OpenBoard e FlorisBoard, todos open-source e disponíveis da F-Droid.
Identifique entre a lista de bloatwares, quais você gosta, precisa ou prefere não substituir, de maneira alguma você é obrigado a remover todos os bloatwares possíveis, modifique seu sistema a seu bel-prazer. O NetGuard lista todos os apps do celular com o nome do pacote, com isso você pode filtrar bem qual deles não remover.
Um exemplo claro de bloatware insubstituível e, portanto, não pode ser removido, é o com.android.mtp, um protocolo onde sua função é auxiliar a comunicação do dispositivo com um computador via USB, mas por algum motivo, tem acesso a rede e se comunica frequentemente com servidores externos. Para esses casos, e melhor solução mesmo é bloquear o acesso a rede desses bloatwares com o NetGuard.
MTP tentando comunicação com servidores externos:
Executando o adb shell
No computador
Faça backup de todos os seus arquivos importantes para algum armazenamento externo, e formate seu celular com o hard reset. Após a formatação, e a ativação da depuração USB, conecte seu aparelho e o pc com o auxílio de um cabo USB. Muito provavelmente seu dispositivo irá apenas começar a carregar, por isso permita a transferência de dados, para que o computador consiga se comunicar normalmente com o celular.
Já no pc, abra a pasta platform-tools dentro do terminal, e execute o seguinte comando:
./adb start-serverO resultado deve ser:
daemon not running; starting now at tcp:5037 daemon started successfully
E caso não apareça nada, execute:
./adb kill-serverE inicie novamente.
Com o adb conectado ao celular, execute:
./adb shellPara poder executar comandos diretamente para o dispositivo. No meu caso, meu celular é um Redmi Note 8 Pro, codinome Begonia.
Logo o resultado deve ser:
begonia:/ $
Caso ocorra algum erro do tipo:
adb: device unauthorized. This adb server’s $ADB_VENDOR_KEYS is not set Try ‘adb kill-server’ if that seems wrong. Otherwise check for a confirmation dialog on your device.
Verifique no celular se apareceu alguma confirmação para autorizar a depuração USB, caso sim, autorize e tente novamente. Caso não apareça nada, execute o kill-server e repita o processo.
No celular
Após realizar o mesmo processo de backup e hard reset citado anteriormente, instale o Termux e, com ele iniciado, execute o comando:
pkg install android-toolsQuando surgir a mensagem “Do you want to continue? [Y/n]”, basta dar enter novamente que já aceita e finaliza a instalação
Agora, vá até as opções de desenvolvedor, e ative a depuração sem fio. Dentro das opções da depuração sem fio, terá uma opção de emparelhamento do dispositivo com um código, que irá informar para você um código em emparelhamento, com um endereço IP e porta, que será usado para a conexão com o Termux.
Para facilitar o processo, recomendo que abra tanto as configurações quanto o Termux ao mesmo tempo, e divida a tela com os dois app’s, como da maneira a seguir:
Para parear o Termux com o dispositivo, não é necessário digitar o ip informado, basta trocar por “localhost”, já a porta e o código de emparelhamento, deve ser digitado exatamente como informado. Execute:
adb pair localhost:porta CódigoDeEmparelhamentoDe acordo com a imagem mostrada anteriormente, o comando ficaria “adb pair localhost:41255 757495”.
Com o dispositivo emparelhado com o Termux, agora basta conectar para conseguir executar os comandos, para isso execute:
adb connect localhost:portaObs: a porta que você deve informar neste comando não é a mesma informada com o código de emparelhamento, e sim a informada na tela principal da depuração sem fio.
Pronto! Termux e adb conectado com sucesso ao dispositivo, agora basta executar normalmente o adb shell:
adb shellRemoção na prática Com o adb shell executado, você está pronto para remover os bloatwares. No meu caso, irei mostrar apenas a remoção de um app (Google Maps), já que o comando é o mesmo para qualquer outro, mudando apenas o nome do pacote.
Dentro do NetGuard, verificando as informações do Google Maps:
Podemos ver que mesmo fora de uso, e com a localização do dispositivo desativado, o app está tentando loucamente se comunicar com servidores externos, e informar sabe-se lá que peste. Mas sem novidades até aqui, o mais importante é que podemos ver que o nome do pacote do Google Maps é com.google.android.apps.maps, e para o remover do celular, basta executar:
pm uninstall –user 0 com.google.android.apps.mapsE pronto, bloatware removido! Agora basta repetir o processo para o resto dos bloatwares, trocando apenas o nome do pacote.
Para acelerar o processo, você pode já criar uma lista do bloco de notas com os comandos, e quando colar no terminal, irá executar um atrás do outro.
Exemplo de lista:
Caso a donzela tenha removido alguma coisa sem querer, também é possível recuperar o pacote com o comando:
cmd package install-existing nome.do.pacotePós-debloat
Após limpar o máximo possível o seu sistema, reinicie o aparelho, caso entre no como recovery e não seja possível dar reboot, significa que você removeu algum app “essencial” para o sistema, e terá que formatar o aparelho e repetir toda a remoção novamente, desta vez removendo poucos bloatwares de uma vez, e reiniciando o aparelho até descobrir qual deles não pode ser removido. Sim, dá trabalho… quem mandou querer privacidade?
Caso o aparelho reinicie normalmente após a remoção, parabéns, agora basta usar seu celular como bem entender! Mantenha o NetGuard sempre executando e os bloatwares que não foram possíveis remover não irão se comunicar com servidores externos, passe a usar apps open source da F-Droid e instale outros apps através da Aurora Store ao invés da Google Play Store.
Referências: Caso você seja um Australopithecus e tenha achado este guia difícil, eis uma videoaula (3:14:40) do Anderson do canal Ciberdef, realizando todo o processo: http://odysee.com/@zai:5/Como-remover-at%C3%A9-200-APLICATIVOS-que-colocam-a-sua-PRIVACIDADE-E-SEGURAN%C3%87A-em-risco.:4?lid=6d50f40314eee7e2f218536d9e5d300290931d23
Pdf’s do Anderson citados na videoaula: créditos ao anon6837264 http://eternalcbrzpicytj4zyguygpmkjlkddxob7tptlr25cdipe5svyqoqd.onion/file/3863a834d29285d397b73a4af6fb1bbe67c888d72d30/t-05e63192d02ffd.pdf
Processo de instalação do Termux e adb no celular: https://youtu.be/APolZrPHSms
-
@ a10260a2:caa23e3e
2024-11-10 04:35:34
nostr:npub1nkmta4dmsa7pj25762qxa6yqxvrhzn7ug0gz5frp9g7p3jdscnhsu049fn added support for classified listings (NIP-99) about a month ago and recently announced this update that allows for creating/editing listings and blog posts via the dashboard.
In other words, listings created on the website are also able to be viewed and edited on other Nostr apps like Amethyst and Shopstr. Interoperability FTW.
I took some screenshots to give you an idea of how things work.
The home page is clean with the ability to search for profiles by name, npub, or Nostr address (NIP-05).
Clicking login allows signing in with a browser extension.
The dashboard gives an overview of the amount of notes posted (both short and long form) and products listed.
Existing blog posts (i.e. long form notes) are synced.
Same for product listings. There’s a nice interface to create new ones and preview them before publishing.
That’s all for now. As you can see, super slick stuff!
Bullish on Cypher.
So much so I had to support the project and buy a subdomain. 😎
https://bullish.cypher.space
originally posted at https://stacker.news/items/760592
-
@ 35f3a26c:92ddf231
2024-11-09 17:10:57
"Files" by Google new feature
"Files" by Google added a "feature"... "Smart Search", you can toggle it to OFF and it is highly recommended to do so.
Toggle the Smart Search to OFF, otherwise, google will search and index every picture, video and document in your device, no exceptions, anything you have ever photographed and you forgot, any document you have downloaded or article, etc...
How this could affect you?
Google is actively combating child abuse and therefore it has built in its "AI" a very aggressive algorithm searching of material that "IT THINKS" is related, therefore the following content could be flagged:
- [ ] Pictures of you and your children in the beach
- [ ] Pictures or videos which are innocent in nature but the "AI" "thinks" are not
- [ ] Articles you may have save for research to write your next essay that have links to flagged information or sites
The results:
- [ ] Your google account will be canceled
- [ ] You will be flagged as a criminal across the digital world
You think this is non sense? Think again: https://www.nytimes.com/2022/08/21/technology/google-surveillance-toddler-photo.html
How to switch it off:
- Open files by Google
- Tap on Menu -> Settings
- Turn OFF Smart Search
But you can do more for your privacy and the security of your family
- Stop using google apps, if possible get rid off of Google OS and use Graphene OS
- Go to Settings -> Apps
- Search for Files by Google
- Unistall the app, if you can't disable it
- Keep doing that with most Google apps that are not a must if you have not switched already to GrapheneOS
Remember, Google keeps advocating for privacy, but as many others have pointed out repeatedly, they are the first ones lobbying for the removal of your privacy by regulation and draconian laws, their hypocrisy knows no limits
Recommendation:
I would assume you have installed F-Droid in your android, or Obtainium if you are more advanced, if so, consider "Simple File Manager Pro" by Tibor Kaputa, this dev has a suite of apps that are basic needs and the best feature in my opinion is that not one of his apps connect to the internet, contacts, gallery, files, phone, etc.
Note As most people, we all love the convenience of technology, it makes our lives easier, however, our safety and our family safety should go first, between technology being miss-used and abused by corporations and cyber-criminals data mining and checking for easy targets to attack for profit, we need to keep our guard up. Learning is key, resist the use of new tech if you do not understand the privacy trade offs, no matter how appealing and convenient it looks like. .
Please leave your comments with your favorite FOSS Files app!
-
@ 3bf0c63f:aefa459d
2024-11-07 14:56:17
The case against edits
Direct edits are a centralizing force on Nostr, a slippery slope that should not be accepted.
Edits are fine in other, more specialized event kinds, but the
kind:1space shouldn't be compromised with such a push towards centralization, becausekind:1is the public square of Nostr, where all focus should be on decentralization and censorship-resistance.- Why?
Edits introduce too much complexity. If edits are widespread, all clients now have to download dozens of extra events at the same time while users are browsing a big feed of notes which are already coming from dozens of different relays using complicated outbox-model-based querying, then for each event they have to open yet another subscription to these relays -- or perform some other complicated batching of subscriptions which then requires more complexity on the event handling side and then when associating these edits with the original events. I can only imagine this will hurt apps performance, but it definitely raises the barrier to entry and thus necessarily decreases Nostr decentralization.
Some clients may be implemneted in way such that they download tons of events and then store them in a local databases, from which they then construct the feed that users see. Such clients may make edits potentially easier to deal with -- but this is hardly an answer to the point above, since such clients are already more complex to implement in the first place.
- What do you have against complex clients?
The point is not to say that all clients should be simple, but that it should be simple to write a client -- or at least as simple as physically possible.
You may not be thinking about it, but if you believe in the promise of Nostr then we should expect to see Nostr feeds in many other contexts other than on a big super app in a phone -- we should see Nostr notes being referenced from and injected in unrelated webpages, unrelated apps, hardware devices, comment sections and so on. All these micro-clients will have to implement some complicated edit-fetching logic now?
- But aren't we already fetching likes and zaps and other things, why not fetch edits too?
Likes, zaps and other similar things are optional. It's perfectly fine to use Nostr without seeing likes and/or zaps -- and, believe me, it does happen quite a lot. The point is basically that likes or zaps don't affect the content of the main post at all, while edits do.
- But edits are optional!
No, they are not optional. If edits become widespread they necessarily become mandatory. Any client that doesn't implement edits will be displaying false information to its users and their experience will be completely broken.
- That's fine, as people will just move to clients that support edits!
Exactly, that is what I expect to happen too, and this is why I am saying edits are a centralizing force that we should be fighting against, not embracing.
If you understand that edits are a centralizing force, then you must automatically agree that they aren't a desirable feature, given that if you are reading this now, with Nostr being so small, there is a 100% chance you care about decentralization and you're not just some kind of lazy influencer that is only doing this for money.
- All other social networks support editing!
This is not true at all. Bluesky has 10x more users than Nostr and doesn't support edits. Instagram doesn't support editing pictures after they're posted, and doesn't support editing comments. Tiktok doesn't support editing videos or comments after they're posted. YouTube doesn't support editing videos after they're posted. Most famously, email, the most widely used and widespread "social app" out there, does not support edits of any kind. Twitter didn't support edits for the first 15 years of its life, and, although some people complained, it didn't hurt the platform at all -- arguably it benefitted it.
If edits are such a straightforward feature to add that won't hurt performance, that won't introduce complexity, and also that is such an essential feature users could never live without them, then why don't these centralized platforms have edits on everything already? There must be something there.
- Eventually someone will implement edits anyway, so why bother to oppose edits now?
Once Nostr becomes big enough, maybe it will be already shielded from such centralizing forces by its sheer volume of users and quantity of clients, maybe not, we will see. All I'm saying is that we shouldn't just push for bad things now just because of a potential future in which they might come.
- The market will decide what is better.
The market has decided for Facebook, Instagram, Twitter and TikTok. If we were to follow what the market had decided we wouldn't be here, and you wouldn't be reading this post.
- OK, you have convinced me, edits are not good for the protocol. But what do we do about the users who just want to fix their typos?
There are many ways. The annotations spec, for example, provides a simple way to append things to a note without being a full-blown edit, and they fall back gracefully to normal replies in clients that don't implement the full annotations spec.
Eventually we could have annotations that are expressed in form of simple (human-readable?) diffs that can be applied directly to the post, but fall back, again, to comments.
Besides these, a very simple idea that wasn't tried yet on Nostr yet is the idea that has been tried for emails and seems to work very well: delaying a post after the "submit" button is clicked and giving the user the opportunity to cancel and edit it again before it is actually posted.
Ultimately, if edits are so necessary, then maybe we could come up with a way to implement edits that is truly optional and falls back cleanly for clients that don't support them directly and don't hurt the protocol very much. Let's think about it and not rush towards defeat.
-
@ a367f9eb:0633efea
2024-11-05 08:48:41
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters
When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies
In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement
If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Originally published on the website of the Consumer Choice Center.
-
@ 9349d012:d3e98946
2024-11-05 00:42:37
Chef's notes
2 cups pureed pumpkin 2 cups white sugar 3 eggs, beaten 1/2 cup olive oil 1 tablespoon cinnamon 1 1/2 teaspoon baking powder 1 teaspoon baking soda 1/2 teaspoon salt 2 1/4 cups flour 1/4 cup chopped pecans
Preheat oven to 350 degrees Fahrenheit. Coat a bread pan with olive oil. Mix all ingredients minus nuts, leaving the flour for last, and adding it in 2 parts. Stir until combined. Pour the batter into the bread pan and sprinkle chopped nuts down the middle of the batter, lenghtwise. Bake for an hour and ten minutes or until a knife insert in the middle of the pan comes out clean. Allow bread to cool in the pan for five mintes, then use knife to loosen the edges of the loaf and pop out of the pan. Rest on a rack or plate until cool enough to slice. Spread bread slices with Plugra butter and serve.
https://cookeatloveshare.com/pumpkin-bread/
Details
- ⏲️ Prep time: 30 minutes
- 🍳 Cook time: 1 hour and ten minutes
- 🍽️ Servings: 6
Ingredients
- See Chef's Notes
Directions
- See Chef's Notes
-
@ 09fbf8f3:fa3d60f0
2024-11-02 08:00:29
> ### 第三方API合集:
免责申明:
在此推荐的 OpenAI API Key 由第三方代理商提供,所以我们不对 API Key 的 有效性 和 安全性 负责,请你自行承担购买和使用 API Key 的风险。
| 服务商 | 特性说明 | Proxy 代理地址 | 链接 | | --- | --- | --- | --- | | AiHubMix | 使用 OpenAI 企业接口,全站模型价格为官方 86 折(含 GPT-4 )| https://aihubmix.com/v1 | 官网 | | OpenAI-HK | OpenAI的API官方计费模式为,按每次API请求内容和返回内容tokens长度来定价。每个模型具有不同的计价方式,以每1,000个tokens消耗为单位定价。其中1,000个tokens约为750个英文单词(约400汉字)| https://api.openai-hk.com/ | 官网 | | CloseAI | CloseAI是国内规模最大的商用级OpenAI代理平台,也是国内第一家专业OpenAI中转服务,定位于企业级商用需求,面向企业客户的线上服务提供高质量稳定的官方OpenAI API 中转代理,是百余家企业和多家科研机构的专用合作平台。 | https://api.openai-proxy.org | 官网 | | OpenAI-SB | 需要配合Telegram 获取api key | https://api.openai-sb.com | 官网 |
持续更新。。。
推广:
访问不了openai,去
低调云购买VPN。官网:https://didiaocloud.xyz
邀请码:
w9AjVJit价格低至1元。
-
@ 06639a38:655f8f71
2024-11-01 22:32:51
One year ago I wrote the article Why Nostr resonates in Dutch and English after I visited the Bitcoin Amsterdam 2023 conference and the Nostrdam event. It got published at bitcoinfocus.nl (translated in Dutch). The main reason why I wrote that piece is that I felt that my gut feeling was tellinng me that Nostr is going to change many things on the web.
After the article was published, one of the first things I did was setting up this page on my website: https://sebastix.nl/nostr-research-and-development. The page contains this section (which I updated on 31-10-2024):

One metric I would like to highlight is the number of repositories on Github. Compared to a year ago, there are already more than 1130 repositories now on Github tagged with Nostr. Let's compare this number to other social media protocols and decentralized platforms (24-10-2024):
- Fediverse: 522
- ATProto: 159
- Scuttlebot: 49
- Farcaster: 202
- Mastodon: 1407
- ActivityPub: 444
Nostr is growing. FYI there are many Nostr repositories not hosted on Github, so the total number of Nostr reposities is higher. I know that many devs are using their own Git servers to host it. We're even capable of setting up Nostr native Git repositories (for example, see https://gitworkshop.dev/repos). Eventually, Nostr will make Github (and other platforms) absolute.
Let me continue summarizing my personal Nostr highlights of last year.
Organising Nostr meetups

This is me playing around with the NostrDebug tool showing how you can query data from Nostr relays. Jurjen is standing behind me. He is one of the people I've met this year who I'm sure I will have a long-term friendship with.OpenSats grant for Nostr-PHP


In December 2023 I submitted my application for a OpenSats grant for the further development of the Nostr-PHP helper library. After some months I finally got the message that my application was approved... When I got the message I was really stoked and excited. It's a great form of appreciation for the work I had done so far and with this grant I get the opportunity to take the work to another higher level. So please check out the work done for so far:Meeting Dries

One of my goosebumps moments I had in 2022 when I saw that the founder and tech lead of Drupal Dries Buytaert posted 'Nostr, love at first sight' on his blog. These types of moments are very rare moment where two different worlds merge where I wouldn't expect it. Later on I noticed that Dries would come to the yearly Dutch Drupal event. For me this was a perfect opportunity to meet him in person and have some Nostr talks. I admire the work he is doing for Drupal and the community. I hope we can bridge Nostr stuff in some way to Drupal. In general this applies for any FOSS project out there.
Here is my recap of that Drupal event.Attending Nostriga

A conference where history is made and written. I felt it immediately at the first sessions I attended. I will never forget the days I had at Nostriga. I don't have the words to describe what it brought to me.

I also pushed myself out of my comfort zone by giving a keynote called 'POSSE with Nostr - how we pivot away from API's with one of Nostr superpowers'. I'm not sure if this is something I would do again, but I've learned a lot from it.
You can find the presentation here. It is recorded, but I'm not sure if and when it gets published.Nostr billboard advertisement

This advertisment was shown on a billboard beside the A58 highway in The Netherlands from September 2nd till September 16th 2024. You can find all the assets and more footage of the billboard ad here: https://gitlab.com/sebastix-group/nostr/nostr-ads. My goal was to set an example of how we could promote Nostr in more traditional ways and inspire others to do the same. In Brazil a fundraiser was achieved to do something similar there: https://geyser.fund/project/nostrifybrazil.
Volunteering at Nostr booths growNostr

This was such a great motivating experience. Attending as a volunteer at the Nostr booth during the Bitcoin Amsterdam 2024 conference. Please read my note with all the lessons I learned here.
The other stuff
- The Nostr related blog articles I wrote past year:
- Run a Nostr relay with your own policies (02-04-2024)
- Why social networks should be based on commons (03-01-2024)
- How could Drupal adopt Nostr? (30-12-2023)
- Nostr integration for CCHS.social (21-12-2023)
- https://ccns.nostrver.se
CCNS stands for Community Curated Nostr Stuff. At the end of 2023 I started to build this project. I forked an existing Drupal project of mine (https://cchs.social) to create a link aggregation website inspired by stacker.news. At the beginning of 2024 I also joined the TopBuilder 2024 contest which was a productive period getting to know new people in the Bitcoin and Nostr space. - https://nuxstr.nostrver.se
PHP is not my only language I use to build stuff. As a fullstack webdeveloper I also work with Javascript. Many Nostr clients are made with Javascript frameworks or other more client-side focused tools. Vuejs is currently my Javascript framework I'm the most convenient with. With Vuejs I started to tinker around with Nuxt combined with NDK and so I created a starter template for Vue / Nuxt developers. - ZapLamp
This is a neat DIY package from LNbits. Powered by an Arduino ESP32 dev board it was running a 24/7 livestream on zap.stream at my office. It flashes when you send a zap to the npub of the ZapLamp. - https://nosto.re
Since the beginning when the Blossom spec was published by @hzrd49 and @StuartBowman I immediately took the opportunity to tinker with it. I'm also running a relay for transmitting Blossom Nostr eventswss://relay.nosto.re. - Relays I maintain
I really enjoy to tinker with different relays implementations. Relays are the fundamental base layer to let Nostr work.
I'm still sharing my contributions on https://nostrver.se/ where I publish my weekly Nostr related stuff I worked on. This website is built with Drupal where I use the Nostr Simple Publish and Nostr long-form content NIP-23 modules to crosspost the notes and long-form content to the Nostr network (like this piece of content you're reading).
The Nostr is the people
Just like the web, the web is people: https://www.youtube.com/watch?v=WCgvkslCzTo
the people on nostr are some of the smartest and coolest i’ve ever got to know. who cares if it doesn’t take over the world. It’s done more than i could ever ask for. - @jb55
Here are some Nostriches who I'm happy to have met and who influenced my journey in Nostr in a positive way.
- Jurjen
- Bitpopart
- Arjen
- Jeroen
- Alex Gleason
- Arnold Lubach
- Nathan Day
- Constant
- fiatjaf
- Sync
Coming year
Generally I will continue doing what I've done last year. Besides the time I spent on Nostr stuff, I'm also very busy with Drupal related work for my customers. I hope I can get the opportunity to work on a paid client project related to Nostr. It will be even better when I can combine my Drupal expertise with Nostr for projects paid by customers.
Building a new Nostr application
When I look at my Nostr backlog where I just put everything in with ideas and notes, there are quite some interesting concepts there for building new Nostr applications. Filtering out, I think these three are the most exciting ones:
- nEcho, a micro app for optimizing your reach via Nostr (NIP-65)
- Nostrides.cc platform where you can share Nostr activity events (NIP-113)
- A child-friendly video web app with parent-curated content (NIP-71)
Nostr & Drupal
When working out a new idea for a Nostr client, I'm trying to combine my expertises into one solution. That's why I also build and maintain some Nostr contrib modules for Drupal.
- Nostr Simple Publish
Drupal module to cross-post notes from Drupal to Nostr - Nostr long-form content NIP-23
Drupal module to cross-post Markdown formatted content from Drupal to Nostr - Nostr internet identifier NIP-05
Drupal module to setup Nostr internet identifier addresses with Drupal. - Nostr NDK
Includes the Javascript library Nostr Dev Kit (NDK) in a Drupal project.
One of my (very) ambitious goals is to build a Drupal powered Nostr (website) package with the following main features:
- Able to login into Drupal with your Nostr keypair
- Cross-post content to the Nostr network
- Fetch your Nostr content from the Nostr content
- Serve as a content management system (CMS) for your Nostr events
- Serve as a framework to build a hybrid Nostr web application
- Run and maintain a Nostr relay with custom policies
- Usable as a feature rich progressive web app
- Use it as a remote signer
These are just some random ideas as my Nostr + Drupal backlog is way longer than this.
Nostr-PHP
With all the newly added and continues being updated NIPs in the protocol, this helper library will never be finished. As the sole maintainer of this library I would like to invite others to join as a maintainer or just be a contributor to the library. PHP is big on the web, but there are not many PHP developers active yet using Nostr. Also PHP as a programming language is really pushing forward keeping up with the latest innovations.
Grow Nostr outside the Bitcoin community
We are working out a submission to host a Nostr stand at FOSDEM 2025. If approved, it will be the first time (as far as I know) that Nostr could be present at a conference outside the context of Bitcoin. The audience at FOSDEM is mostly technical oriented, so I'm really curious what type of feedback we will receive.
Let's finish this article with some random Nostr photos from last year. Cheers!






-
@ 3f770d65:7a745b24
2024-10-29 17:38:20
Amber
Amber is a Nostr event signer for Android that allows users to securely segregate their private key (nsec) within a single, dedicated application. Designed to function as a NIP-46 signing device, Amber ensures your smartphone can sign events without needing external servers or additional hardware, keeping your private key exposure to an absolute minimum. This approach aligns with the security rationale of NIP-46, which states that each additional system handling private keys increases potential vulnerability. With Amber, no longer do users need to enter their private key into various Nostr applications.

Amber is supported by a growing list of apps, including Amethyst, 0xChat, Voyage, Fountain, and Pokey, as well as any web application that supports NIP-46 NSEC bunkers, such as Nostr Nests, Coracle, Nostrudel, and more. With expanding support, Amber provides an easy solution for secure Nostr key management across numerous platforms.

Amber supports both native and web-based Nostr applications, aiming to eliminate the need for browser extensions or web servers. Key features include offline signing, multiple account support, and NIP-46 compatibility, and includes a simple UI for granular permissions management. Amber is designed to support signing events in the background, enhancing flexibility when you select the "remember my choice" option, eliminating the need to constantly be signing events for applications that you trust. You can download the app from it's GitHub page, via Obtainium or Zap.store.
To log in with Amber, simply tap the "Login with Amber" button or icon in a supported application, or you can paste the NSEC bunker connection string directly into the login box. For example, use a connection string like this: bunker://npub1tj2dmc4udvgafxxxxxxxrtgne8j8l6rgrnaykzc8sys9mzfcz@relay.nsecbunker.com.

Citrine
Citrine is a Nostr relay built specifically for Android, allowing Nostr clients on Android devices to seamlessly send and receive events through a relay running directly on their smartphone. This mobile relay setup offers Nostr users enhanced flexibility, enabling them to manage, share, and back up all their Nostr data locally on their device. Citrine’s design supports independence and data security by keeping data accessible and under user control.

With features tailored to give users greater command over their data, Citrine allows easy export and import of the database, restoration of contact lists in case of client malfunctions, and detailed relay management options like port configuration, custom icons, user management, and on-demand relay start/stop. Users can even activate TOR access, letting others connect securely to their Nostr relay directly on their phone. Future updates will include automatic broadcasting when the device reconnects to the internet, along with content resolver support to expand its functionality.
Once you have your Citrine relay fully configured, simply add it to the Private and Local relay sections in Amethyst's relay configuration.

Pokey
Pokey for Android is a brand new, real-time notification tool for Nostr. Pokey allows users to receive live updates for their Nostr events and enabling other apps to access and interact with them. Designed for seamless integration within a user's Nostr relays, Pokey lets users stay informed of activity as it happens, with speed and the flexibility to manage which events trigger notifications on their mobile device.

Pokey currently supports connections with Amber, offering granular notification settings so users can tailor alerts to their preferences. Planned features include broadcasting events to other apps, authenticating to relays, built-in Tor support, multi-account handling, and InBox relay management. These upcoming additions aim to make Pokey a fantastic tool for Nostr notifications across the ecosystem.
Zap.store
Zap.store is a permissionless app store powered by Nostr and your trusted social graph. Built to offer a decentralized approach to app recommendations, zap.store enables you to check if friends like Alice follow, endorse, or verify an app’s SHA256 hash. This trust-based, social proof model brings app discovery closer to real-world recommendations from friends and family, bypassing centralized app curation. Unlike conventional app stores and other third party app store solutions like Obtainium, zap.store empowers users to see which apps their contacts actively interact with, providing a higher level of confidence and transparency.

Currently available on Android, zap.store aims to expand to desktop, PWAs, and other platforms soon. You can get started by installing Zap.store on your favorite Android device, and install all of the applications mentioned above.
Android's openness goes hand in hand with Nostr's openness. Enjoy exploring both expanding ecosystems.
-
@ 1739d937:3e3136ef
2024-10-29 16:57:08
This update marks a major milestone for the project. I know, with certainty, that MLS messaging over Nostr is going to work. That might sound a little crazy after so many months working on the project, and I was pretty confident, but until you’ve got running code, it’s all conjecture.
Late last week, I released a video of a working prototype of White Noise that shows the full flow; creating groups, inviting other users to join those groups, accepting invites, and sending messages back-and-forth. I’m thrilled that I’ve gotten this far but also appalled that it’s taken so long and disgusted at the state of the code in the app (I’ve been told I have unrelenting standards 😅).
If you missed the video last week...
nostr:note125cuk0zetc7sshw52v5zaq9apq3rq7e2x587tr2c96t7z7sjs59svwv0fj
What's Next?
In this update, I want to cover a few things about how I'm planning to proceed and how I’m splitting code out of the app into libraries that will help other developers implement MLS messaging in their own Nostr clients.
First off, many of you know that I've been building White Noise as a Rust app using the Tauri framework. The OpenMLS implementation is also written in Rust (with bindings for many other languages). So, when you hear me talking about library code, think Rust crates for now.
The first library, called openmls-nostr, is an extension/abstraction on top of the openmls implementation of the MLS spec that helps Nostr clients interact more easily with that implementation in a way that feels native to Nostr. Mostly this will be helping developers interact with MLS primitives and ensure that they’re creating, validating, and serializing these objects in the right way at the right times.
The second isn’t a new library as a big contribution to the already excellent rust-nostr library from nostr:npub1drvpzev3syqt0kjrls50050uzf25gehpz9vgdw08hvex7e0vgfeq0eseet. The methods that will go in rust-nostr are highly abstracted and based specifically on the requirements of NIP-104. Mostly this will be helping developers to take those MLS primitives and publish or query them as Nostr events at the right times and to/from the right relays.
Most of this code was originally written directly in the White Noise library so this week I've started to pull code for both of those libraries out and move it to its new home. While I’ve been at it, I've been writing some tests and trying to document things.
An unfortunate offshoot of this is that the usable builds of White Noise are going to take a touch longer. I promise it’s still a very high priority but at this point I need to clean a few things up based on what I've learned thus far.
Another thing that is slowing down release is that; behind the scenes of the dev work, I’ve been battling with Apple for nearly 2 months now to get a proper developer team set up so that we can publish the app via TestFlight for MacOS and iOS. I’ve also been recently learning the intricacies of Android publishing (oh my dear god there are so many devices, OS versions, etc.).
With that in mind, if you know anyone who can help get me up to speed on CI/CD, release pipelines, and multi-platform distribution please hit me up. I would love to learn more and hopefully shortcut some of the pain.
Thanks again so much for all the support over the last few months! It means a lot to me and is a huge part of what is keeping me going on this. 🙏
-
@ 3bf0c63f:aefa459d
2024-10-26 14:18:23
kind:1maximalism and the future of other stuff and Nostr decentralizationThese two problems exist on Nostr today, and they look unrelated at first:
- People adding more stuff to
kind:1notes, such as making them editable, or adding special corky syntax thas has to be parsed and rendered in complicated UIs; - The discovery of "other stuff" content (i.e. long-form articles, podcasts, calendar events, livestreams etc) is hard due to the fact that most people only use microblogging clients and they often don't appear there for them.
Point 2 above has 3 different solutions:
- a. Just publish everything as
kind:1notes; - b. Publish different things as different kinds, but make microblogging clients fetch all the event kinds from people you follow, then render them natively or use NIP-31, or NIP-89 to point users to other clients that would render them better;
- c. Publish different things as different kinds, and reference them in
kind:1notes that would act as announcements to these other events, also relying on NIP-31 and NIP-89 for displaying references and recommending other clients.
Solution a is obviously very bad, so I won't address it.
For a while I have believed solution b was the correct one, and many others seem to tacitly agree with it, given that some clients have been fetching more and more event kinds and going out of their way to render them in the same feed where only
kind:1notes were originally expected to be.I don't think clients doing that is necessarily bad, but I do think this have some centralizing effects on the protocol, as it pushes clients to become bigger and bigger, raising the barrier to entry into the
kind:1realm. And also in the past I have talked about the fact that I disliked that some clients would display my long-form articles as if they were normalkind:1notes and just dump them into the feeds of whoever was following me: nostr:nevent1qqsdk90k9k30vtzwpj6grxys9mvsegu5kkwd4jmpyhlmtjnxet2rvggprpmhxue69uhhyetvv9ujumn0wdmksetjv5hxxmmdqy8hwumn8ghj7mn0wd68ytnddaksygpm7rrrljungc6q0tuh5hj7ue863q73qlheu4vywtzwhx42a7j9n5hae35cThese and other reasons have made me switch my preference to solution c, as it gives the most flexibility to the publisher: whoever wants to announce stuff so it can be discovered can, whoever doesn't don't have to. And it allows microblogging clients the freedom to render just render tweets and having a straightforward barrier between what they can render and what is just a link to an external app or webapp (of course they can always opt to render the referenced content in-app if they want).
It also makes the case for microapps more evident. If all microblogging clients become superapps that can render recipe events perfectly why would anyone want to use a dedicated recipes app? I guess there are still reasons, but blurring the line between content kinds in superapps would definitely remove some of the reasons and eventually kill all the microapps.
That brings us back to point 1 above (the overcomplication of
kind:1events): if solution c is what we're going to, that makeskind:1events very special in Nostr, and not just another kind among others. Microblogging clients become the central plaza of Nostr, thus protecting their neutrality and decentralization much more important. Having a lot of clients with different userbases, doing things in slightly different ways, is essential for that decentralization.It's ok if Nostr ends up having just 2 recipe-sharing clients, but it must have dozens of microblogging clients -- and maybe not even full-blown microblogging clients, but other apps that somehow deal with
kind:1events in multiple ways. It's ok if implementing a client for public audio-rooms is very hard and complicated, but at the same time it should be very simple to write a client that can render akind:1note referencing an audio-room and linking to that dedicated client.I hope you got my point and agreed because this article is ended.
- People adding more stuff to

