-
 @ 5f078e90:b2bacaa3
2025-04-28 19:44:00
@ 5f078e90:b2bacaa3
2025-04-28 19:44:00This is a test written in yakihonne.com as a long form article. It is a kind 30023. It should be cross-posted to Hive.
-
@ df7e70ac:89601b8e
2025-04-28 13:15:45
this is a text fo rfilter gparena.net
-
@ de6c63ab:d028389b
2025-04-28 12:20:45
Honestly, I didn’t think this would still be a thing in 2025, but every once in a while it pops up again:
“Bitcoin? Uh, I don’t know… but blockchain, now that could be useful! 🤌”
“Blockchain is one of the most important technologies of our time. Maybe you know it from crypto, but it’s so much more. It’s a way to store and verify data securely, transparently, and without a middleman. That’s why it’s going to revolutionize banking, healthcare, logistics, and even government!”
“Blockchain is transforming how we store, share, and verify information. Its benefits go far beyond cryptocurrencies. Understanding it today means preparing for tomorrow, because blockchain is guaranteed to play a major role in the future.”

Blockchain
When people say "blockchain," they usually mean the bitcoin database — with all its unique properties — even when they’re imagining using it elsewhere.
But here’s the thing: blockchain by itself isn’t some revolutionary breakthrough.
Stripped from bitcoin, it’s just a fancy list of records, each pointing to the previous one with a reference (typically a hash).
That's it.This idea — chaining data together — isn’t new.
It goes back to at least 1991, when Haber and Stornetta proposed it for timestamping documents.By itself, blockchain isn’t secure (you can always rewrite past records if you recompute the chain), isn’t necessarily transparent (the data can be encrypted or hidden), and doesn't magically remove the need for trust (if someone logs soccer scores into a blockchain, you still have to trust they reported the results honestly).
What actually makes bitcoin’s blockchain secure and trustworthy is the system around it — the economic incentives, the ruthless competition for block rights, and the distributed consensus mechanics.
Without those, blockchain is just another database.
How Does Bitcoin Make It Work?
To understand why, we need to zoom in a little.
Superficially, bitcoin’s blockchain looks like a simple ledger — a record of transactions grouped into blocks. A transaction means someone spent bitcoin — unlocking it and locking it up again for someone else.
But here’s the key:
Every participant can independently verify whether each transaction is valid, with no outside help and no trust required.Think of every transaction like a math equation.
Something like: x + 7 = 5, with the solution x = -2.
You don’t need anyone to tell you if it’s correct — you can check it yourself.Of course, bitcoin’s equations are far more complex.
They involve massive numbers and strange algebraic structures, where solving without the right key is practically impossible, but verifying a solution is easy.This is why only someone with the private key can authorize a transaction.
In a way, "solving" these equations is how you prove your right to spend bitcoin.
Ownership and transfers are purely a matter of internal system math — no external authority needed.
Could We Use Blockchain for Other Stuff?
Could we use a blockchain to independently verify medical records, soccer scores, or property ownership?
No.
Blockchain can't magically calculate whether you broke your arm, whether Real Madrid tied against Barcelona, or who owns a cottage in some village.
It can verify that someone owns bitcoin at a particular address, because that's just solving equations inside the system.
But anything that depends on outside facts?
Blockchain can't help you there.
Why Does Everyone Stick to One Version?
Another big question:
Why do people in bitcoin agree on the same version of history?Because of proof-of-work.
To add a new block, you have to find a specific giant number — the nonce — that, together with the block’s contents, satisfies a predefined condition.
You can't calculate the nonce directly — you have to guess, billions of times per second, until you hit the jackpot.
It takes minutes of relentless effort.An invalid transaction would invalidate the entire block, wasting all the miner’s effort.
If the block is valid, the miner earns a reward — newly minted bitcoins plus transaction fees — making the massive effort worthwhile.
And importantly, because each block is built on top of all previous ones, rewriting history would mean redoing all the proof-of-work from that point forward — an astronomically expensive and practically impossible task.
The deeper a block is buried under newer blocks, the more secure it becomes — making the past effectively immutable.And again: each node independently verifies all transactions.
Miners don't create truth; they race to package and timestamp already-valid transactions.
The winning chain is simply the one with the most provable work behind it.
Bitcoin and Blockchain: Inseparable
Bitcoin is created on the blockchain — and it exists only within the blockchain.
Ownership is defined by it.
The decentralized management of the blockchain is driven by bitcoin incentives — the pursuit of something scarce, hard-earned, and impossible to fake.No blockchain, no bitcoin.
No bitcoin, no meaningful blockchain.
Can We Just Blockchain Everything?
Alright, so what happens if we try to apply this system to something else — say, a land registry?
Properties themselves don’t "exist" on a blockchain — only claims about them can be recorded.
But who writes the claims? Random miners?
Where do they get their information?
They can’t compute it from previous blocks.
They’d have to physically go check who owns what.What if they’re lazy? Lied to? Made mistakes?
How would anyone else verify the records?
Ownership in the physical world isn’t a problem you can solve by crunching numbers in a database.Suddenly, we’re right back to needing trusted third parties — the very thing blockchain was supposed to eliminate.
And if there’s a dispute?
Say someone refuses to leave a house, claiming they've lived there forever.
Is the blockchain going to show up and evict them?Of course not.
Blockchain Without Bitcoin Is Just a Data Structure
And that’s the difference.
When blockchain is part of bitcoin’s closed system, it works because everything it cares about is internal and verifiable.
When you try to export blockchain into the real world — without bitcoin — it loses its magic.
Blockchain-like structures actually exist elsewhere too — take Git, for example.
It’s a chain of commits, each referencing the previous one by its hash.
It chains data like a blockchain does — but without the security, decentralization, or economic meaning behind bitcoin.Blockchain is just a data structure.
Bitcoin is what gives it meaning.In bitcoin, the blockchain is not just a ledger — it's a trustless system of property rights enforced by math and energy, without any central authority.
-
@ a4043831:3b64ac02
2025-04-28 11:09:07
While investing is essential for financial planning, it can be a dangerous and random game without a good strategy behind it. Because it not only can boost confidence that individuals can create a roadmap for financial success and minimize and mitigate risks to maximize return on investment. Long-term growth through investing strategically is key if you want to retire, accumulate wealth or become financially independent.
Why Investment Strategies are Important
Investment strategies act as roadmaps for financial development, guiding investors to:
- **Realize Financial Aims: ** Properly defined strategy positions investments with regard to short-term and long-term goals.
- Manage Risks: Appropriate diversification and asset allocation have the potential to alleviate market fluctuation.
- Maximize Returns: Investment with strategy provides superior decision-making and greater financial results.
- Stick to Plan: With strategy established, investors will be better at resisting spontaneous moves based on market volatility.
- Guarantee Financial Security: An organized investment strategy offers security and equips one with unforeseen financial conditions.
Key Steps towards Building an Investment Strategy
Having an efficient investment strategy in place calls for thoughtful planning and careful consideration of many aspects. Here are some key steps to create a winning strategy:
**1. Define Financial Goals ** Understanding financial objectives is the first step in developing a strategy for investments. The specification of goals can range from saving for a home to retirement or wealth generation. Hence, investing in them ensures alignment with the investor's personal priorities. Goals should always be specific, measurable, and time-bound such that progress can be tracked effectively.
**2. Assess the Risk Tolerance ** Every investor has a unique risk tolerance based on the financial situation and objectives. It is assessing risk tolerance that assists in deciding whether a portfolio is to be conservative, moderate, or aggressive in investments. Income stability, investment time horizon, and emotional tolerance for market volatility should all be taken into account.
**3. Diversify Investments ** Diversification eliminates risks by spreading investment across various asset classes, including stocks, bonds, real estate, and mutual funds. A diversified portfolio protects against such adverse movements so that decline in one market sector does not have a biting effect on band returns. It also provides a fair chance for capital gain while also maintaining stability.
**4. Invest Assets Judiciously ** Asset allocation is the strategy for spreading investments among different asset classes to provide a balance between risk and reward. A suitable mix can be derived with the help of a financial advisor based on the investment goals and risk tolerance. Hence, younger investors with a longer time horizon might be inclined to invest in more stocks while investors close to retirement could involve themselves in investments comprising a mix of bonds and fixed-income securities.
**5. Select the Appropriate Investment Tools ** Selection of investment tools forms various investment options that may examine diverse decisions in portfolio expansion. There are options:
- Stocks: Best for capital formation with the longest horizon, subject to market risks.
- Bonds: Provide regular income with lower risks. Generally chosen for capital preservation.
- Mutual Funds, ETFs: Diversified investment plan; managed by professionals-a mix of risk and return.
- Real Estate Investment: Passive income, diversification of portfolio, acts as an inflation hedge.
- Alternative Investments: Certifies commodities, hedge funds, currencies, all provide portfolio diversification while steering clear of any potential risks.
**6. Monitoring and Rebalancing Your Portfolio ** Over time, market conditions and personal finance situations will change. All investments should be checked from time to time to see if they are still in agreement with intended financial goals. Some adjustments may be required to improve performance and mitigate risk. Periodic rebalancing of a portfolio ensures that the asset allocation remains coherent with the initial investment regiment.
**7. Understand Tax Efficiency ** Tax planning for investment returns is crucial to optimize profit. Investors should engage, among other strategies, in tax-loss harvesting, investments in tax-advantaged accounts, or an understanding of the taxation of capital gains to minimize tax liabilities and, correspondingly, enhance returns.
How Passive Capital Management Can Help
Handling investment choices can be really tedious and that's why assistance from experts becomes very important. Trusted financial advisors at Passive Capital Management can provide solutions to help individuals create a well-tailored investment strategy. Their professionals help the client with:
- Personalized investment plans that match their particular financial goals.
- Evaluating the risk tolerance and optimal recommendations on asset allocation.
- The diversification in portfolios provides maximum returns accruing to minimum risks.
- Market-proofing the client's investment portfolio through tracking them regularly.
- Creating tax-efficient‐investment strategies for long-term growth.
They are received with experience and knowledgeable advice in the hands of the clients and therefore are able to make informed investment decisions toward security with confidence.
Conclusion
Investment schemes stand at the heart of any strategy for them to become prosperous. They are, thus, systematic ways of building wealth and minimizing risk. Investors will then devise a meaningful investment plan based on their needs by setting goals, assessing risk capacity, diversifying their holdings, and prescribing professional investment advice.
For individuals who want to create a strong investment strategy, Passive Capital Management provides professional advice and tailored solutions. Learn more with us and start growing your finances today.
-
@ f683e870:557f5ef2
2025-04-28 10:10:55
Spam is the single biggest problem in decentralized networks. Jameson Lopp, co-founder of Casa and OG bitcoiner, has written a brilliant article on the death of decentralized email that paints a vivid picture of what went wrong—and how an originally decentralized protocol was completely captured. The cause? Spam.
The same fate may happen to Nostr, because posting a note is fundamentally cheap. Payments, and to some extent Proof of Work, certainly have their role in fighting spam, but they introduce friction, which doesn’t work everywhere. In particular, they can’t solve every economic problem.\ Take free trials, for example. There is a reason why 99% of companies offer them. Sure, you waste resources on users who don’t convert, but it’s a calculated cost, a marketing expense. Also, some services can’t or don’t want to monetize directly. They offer something for free and monetize elsewhere.
So how do you offer a free trial or giveaway in a hostile decentralized network? Or even, how do you decide which notes to accept on your relay?
At first glance, these may seem like unrelated questions—but they’re not. Generally speaking, these are situations where you have a finite budget, and you want to use it well. You want more of what you value — and less of what you don’t (spam).
Reputation is a powerful shortcut when direct evaluation isn’t practical. It’s hard to earn, easy to lose — and that’s exactly what makes it valuable.\ Can a reputable user do bad things? Absolutely. But it’s much less likely, and that’s the point. Heuristics are always imperfect, just like the world we live in.
The legacy Web relies heavily on email-based reputation. If you’ve ever tried to log in with a temporary email, you know what I’m talking about. It just doesn’t work anymore. The problem, as Lopp explains, is that these systems are highly centralized, opaque, and require constant manual intervention.\ They also suck. They put annoying roadblocks between the world and your product, often frustrating the very users you’re trying to convert.
At Vertex, we take a different approach.\ We transparently analyze Nostr’s open social graph to help companies fight spam while improving the UX for their users. But we don’t take away your agency—we just do the math. You take the decision of what algorithm and criteria to use.
Think of us as a signal provider, not an authority.\ You define what reputation means for your use case. Want to rank by global influence? Local or personalized? You’re in control. We give you actionable and transparent analytics so you can build sharper filters, better user experiences, and more resilient systems. That’s how we fight spam, without sacrificing decentralization.
Are you looking to add Web of Trust capabilities to your app or project?\ Take a look at our website or send a DM to Pip.
-
@ 9727846a:00a18d90
2025-04-13 09:16:41
李承鹏:什么加税导致社会巨变,揭竿而起……都不说三千年饿殍遍野,易子而食,只要给口吃的就感谢皇恩浩荡。就说本朝,借口苏修卡我们脖子,几亿人啃了三年树皮,民兵端着枪守在村口,偷摸逃出去的都算勇士。
也不说98年总理大手一挥,一句“改革”,六千万工人下岗,基本盘稳得很。就像电影《钢的琴》里那群东北下岗工人,有的沦落街头,有的拉起乐队在婚礼火葬场做红白喜事,有的靠倒卖废弃钢材被抓,有的当小偷撬门溜锁,还有卖猪肉的,有去当小姐的……但人们按着中央的话语,说这叫“解放思想”。
“工人要替国家想,我不下岗谁下岗”,这是1999年春晚黄宏的小品,你现在觉得反人性,那时台下一片掌声,民间也很亢奋,忽然觉得自己有了力量。人们很容易站在国家立场把自己当炮灰,人民爱党爱国,所以操心什么加税,川普还能比斯大林同志赫鲁晓夫同志更狠吗,生活还能比毛主席时代更糟吗。不就是农产品啊牛肉啊芯片贵些,股票跌些,本来就生存艰难的工厂关的多些,大街上发呆眼神迷茫的人多些,跳楼的年轻人密集些,河里总能捞出不明来历的浮尸……但十五亿人民,会迅速稀释掉这些人和事。比例极小,信心极大,我们祖祖辈辈在从人到猪的生活转换适应力上,一直为世间翘楚。
民心所向,正好武统。
这正是想要的。没有一个帝王会关心你的生活质量,他只关心权力和帝国版图是否稳当。
而这莫名其妙又会和人民的想法高度契合,几千年来如此。所以聊一会儿就会散的,一定散的,只是会在明年春晚以另一种高度正能量的形式展现。
您保重。 25年4月9日
-
@ f7f4e308:b44d67f4
2025-04-09 02:12:18
https://sns-video-hw.xhscdn.com/stream/1/110/258/01e7ec7be81a85850103700195f3c4ba45_258.mp4
-
@ b0137b96:304501dd
2025-04-28 09:25:49
Hollywood continues to deliver thrilling stories that captivate audiences worldwide. But what makes these films even more exciting? Watching them in your preferred language! Thanks to Dimension On Demand (DOD), you can now enjoy the latest Hollywood movies in Hindi, bringing you action-packed adventures, gripping narratives, and explosive sequences without language barriers.
Whether it’s historical mysteries, war-time espionage, or a bizarre transformation, DOD ensures that Hindi-speaking audiences can experience the thrill of Hollywood. Let’s dive into three must-watch action thrillers now available in Hindi!
The Body – A Mystery Buried in Time What happens when a shocking discovery challenges everything we know about history? The Body is one of the latest Hollywood movies in Hindi that brings mystery, action, and suspense together. The story follows an intense investigation after a crucified body, dating back to the first century A.D., is unearthed in a cave in Jerusalem. As word spreads, chaos ensues, and the race to uncover the truth takes a dangerous turn.
Antonio Banderas, known for his iconic roles in The Mask of Zorro and Pain and Glory, plays Matt Gutierrez, the determined investigator who dives into this centuries-old mystery, uncovering secrets that could change the world. Olivia Williams delivers a compelling performance as Sharon Golban, an archaeologist caught in the web of intrigue. With a cast that includes Derek Jacobi and John Shrapnel, the film blends history, religion, and action seamlessly, making it a must-watch among latest Hollywood movies in Hindi.
Why You Should Watch This Thriller: A Gripping Storyline – Experience the tension of a global mystery unraveling in one of the latest Hollywood movies in Hindi Famous Hollywood Actors – Antonio Banderas leads an all-star cast in this Hindi-dubbed Hollywood thriller Now in Hindi Dubbed – Enjoy this mind-blowing thriller in your language Secret Weapon – A Deadly Mission Behind Enemy Lines Set against the backdrop of World War II, Secret Weapon is an electrifying addition to the latest Hollywood movies in Hindi, taking espionage and war action to the next level. The plot follows a group of Soviet soldiers sent on a high-stakes mission to recover a top-secret rocket launcher accidentally abandoned during a hasty retreat. If the Germans got their hands on it, the tide of war could change forever.
Maxim Animateka plays Captain Zaytsev, the fearless leader of the mission, while Evgeniy Antropov and Veronika Plyashkevich bring depth to the ensemble cast. As tensions rise and danger lurks around every corner, the special ops unit must navigate enemy territory to prevent disaster. With its gripping action sequences and historical depth, this latest Hollywood movie in Hindi is a must-watch for war movie enthusiasts.
What Makes This War Thriller Stand Out: Non-Stop Action – A thrilling mission filled with suspense and danger Historical Relevance – A story set during WWII with gripping realism in this Hindi-dubbed war thriller Hindi Dub Available – Now experience this war epic with powerful Hindi dubbing A Mosquito Man – From Human to Monster What happens when life takes a turn for the worse? A Mosquito Man is one of the latest Hollywood movies in Hindi that takes sci-fi horror to a new level. The film follows Jim (played by Michael Manasseri), a man whose life is falling apart—he loses his job, his wife is cheating on him, and to top it all off, he gets kidnapped by a deranged scientist. Injected with an experimental serum, Jim undergoes a horrifying transformation, mutating into a human-mosquito hybrid with newfound abilities.
Kimberley Kates plays his estranged wife, while Lloyd Kaufman brings a sinister edge to the role of the mad scientist. As Jim learns to embrace his monstrous form, he embarks on a twisted path of revenge, leaving chaos in his wake. With its mix of action, horror, and sci-fi, thislatest Hollywood movie in Hindi delivers a truly unique cinematic experience.
Why This Action Thriller is a Must-Watch: A One-of-a-Kind Storyline – A dark and bizarre superhero-like transformation Action, Suspense & Thrills Combined – A perfect mix of high-octane action and eerie moments in this Hindi-dubbed action thriller Available in Hindi Dubbed – Get ready for an adrenaline-pumping experience Watch These latest Hollywood movies in Hindi on DOD! With Dimension On Demand (DOD), you no longer have to miss out on Hollywood’s biggest action hits. Whether it’s a historical thriller, a war drama, or an unexpected adventure, the latest Hollywood movies in Hindi are now just a click away. Get ready for high-octane entertainment like never before!
Check out these films now on the DOD YouTube channel! Watch The Body in Hindi Dubbed – Click here! Enjoy A Mosquito Man in Hindi Dubbed – Start now!
Conclusion Hollywood continues to thrill audiences worldwide, and with these latest Hollywood movies in Hindi, language is no longer a barrier. From gripping mysteries and war-time espionage to bizarre transformations, these films bring non-stop entertainment. Thanks to DOD, you can now enjoy Hollywood’s best action movies in Hindi, making for an immersive and thrilling cinematic experience. So, what are you waiting for? Tune in, grab some popcorn, and dive into the action!
-
@ 04c915da:3dfbecc9
2025-03-12 15:30:46
Recently we have seen a wave of high profile X accounts hacked. These attacks have exposed the fragility of the status quo security model used by modern social media platforms like X. Many users have asked if nostr fixes this, so lets dive in. How do these types of attacks translate into the world of nostr apps? For clarity, I will use X’s security model as representative of most big tech social platforms and compare it to nostr.
The Status Quo
On X, you never have full control of your account. Ultimately to use it requires permission from the company. They can suspend your account or limit your distribution. Theoretically they can even post from your account at will. An X account is tied to an email and password. Users can also opt into two factor authentication, which adds an extra layer of protection, a login code generated by an app. In theory, this setup works well, but it places a heavy burden on users. You need to create a strong, unique password and safeguard it. You also need to ensure your email account and phone number remain secure, as attackers can exploit these to reset your credentials and take over your account. Even if you do everything responsibly, there is another weak link in X infrastructure itself. The platform’s infrastructure allows accounts to be reset through its backend. This could happen maliciously by an employee or through an external attacker who compromises X’s backend. When an account is compromised, the legitimate user often gets locked out, unable to post or regain control without contacting X’s support team. That process can be slow, frustrating, and sometimes fruitless if support denies the request or cannot verify your identity. Often times support will require users to provide identification info in order to regain access, which represents a privacy risk. The centralized nature of X means you are ultimately at the mercy of the company’s systems and staff.
Nostr Requires Responsibility
Nostr flips this model radically. Users do not need permission from a company to access their account, they can generate as many accounts as they want, and cannot be easily censored. The key tradeoff here is that users have to take complete responsibility for their security. Instead of relying on a username, password, and corporate servers, nostr uses a private key as the sole credential for your account. Users generate this key and it is their responsibility to keep it safe. As long as you have your key, you can post. If someone else gets it, they can post too. It is that simple. This design has strong implications. Unlike X, there is no backend reset option. If your key is compromised or lost, there is no customer support to call. In a compromise scenario, both you and the attacker can post from the account simultaneously. Neither can lock the other out, since nostr relays simply accept whatever is signed with a valid key.
The benefit? No reliance on proprietary corporate infrastructure.. The negative? Security rests entirely on how well you protect your key.
Future Nostr Security Improvements
For many users, nostr’s standard security model, storing a private key on a phone with an encrypted cloud backup, will likely be sufficient. It is simple and reasonably secure. That said, nostr’s strength lies in its flexibility as an open protocol. Users will be able to choose between a range of security models, balancing convenience and protection based on need.
One promising option is a web of trust model for key rotation. Imagine pre-selecting a group of trusted friends. If your account is compromised, these people could collectively sign an event announcing the compromise to the network and designate a new key as your legitimate one. Apps could handle this process seamlessly in the background, notifying followers of the switch without much user interaction. This could become a popular choice for average users, but it is not without tradeoffs. It requires trust in your chosen web of trust, which might not suit power users or large organizations. It also has the issue that some apps may not recognize the key rotation properly and followers might get confused about which account is “real.”
For those needing higher security, there is the option of multisig using FROST (Flexible Round-Optimized Schnorr Threshold). In this setup, multiple keys must sign off on every action, including posting and updating a profile. A hacker with just one key could not do anything. This is likely overkill for most users due to complexity and inconvenience, but it could be a game changer for large organizations, companies, and governments. Imagine the White House nostr account requiring signatures from multiple people before a post goes live, that would be much more secure than the status quo big tech model.
Another option are hardware signers, similar to bitcoin hardware wallets. Private keys are kept on secure, offline devices, separate from the internet connected phone or computer you use to broadcast events. This drastically reduces the risk of remote hacks, as private keys never touches the internet. It can be used in combination with multisig setups for extra protection. This setup is much less convenient and probably overkill for most but could be ideal for governments, companies, or other high profile accounts.
Nostr’s security model is not perfect but is robust and versatile. Ultimately users are in control and security is their responsibility. Apps will give users multiple options to choose from and users will choose what best fits their need.
-
@ 2b24a1fa:17750f64
2025-04-28 09:11:34
Eine Stunde Klassik! Der Münchner Pianist und "Musikdurchdringer" Jürgen Plich stellt jeden Dienstag um 20 Uhr bei Radio München (https://radiomuenchen.net/stream/) große klassische Musik vor. Er teilt seine Hör- und Spielerfahrung und seine persönliche Sicht auf die Meisterwerke. Er spielt selbst besondere, unbekannte Aufnahmen, erklärt, warum die Musik so und nicht anders klingt und hat eine Menge aus dem Leben der Komponisten zu erzählen.
Sonntags um 10 Uhr in der Wiederholung. Oder hier zum Nachhören:
-
@ 2b24a1fa:17750f64
2025-04-28 09:08:01
„Ganz im Geiste des klassischen Kabaretts widmen sich Franz Esser und Michael Sailer den Ereignissen des letzten Monats: Was ist passiert? Und was ist dazu zu sagen? Das ist oft frappierend - und manchmal auch zum Lachen.“
https://soundcloud.com/radiomuenchen/vier-wochen-wahnsinn-april-25?
-
@ 1b9fc4cd:1d6d4902
2025-04-28 08:50:14
Imagine a classroom where learning is as engaging as your favorite playlist, complex concepts are sung rather than slogged through, and students eagerly anticipate their lessons. This isn’t some utopian dream—it's the reality when music is integrated into education. Music isn’t just a tool for entertainment; it’s a powerful ally in enhancing learning. From improving literacy and language skills to helping those with autism, Daniel Siegel Alonso explores how music makes education a harmonious experience.
Literacy is the bedrock of education, and music can play a pivotal role in forging that foundation. Studies have shown that musical training can significantly enhance reading skills. Music's rhythmic and melodic patterns help spark phonological awareness, which is critical for reading.
Siegel Alonso takes the example of “singing the alphabet.” This simple, catchy tune helps children remember letter sequences more effectively than rote memorization. But it doesn’t stop there. Programs like “Reading Rocks!” incorporate songs and rhymes to teach reading. By engaging multiple senses, these programs make learning to read more interactive and enjoyable.
Music also aids in comprehension and retention. Lyrics often tell stories; children can better grasp narrative structure and vocabulary through songs. The melody and rhythm act as mnemonic devices, making it easier to recall information. So, next time you catch yourself singing a line from a song you heard years ago, remember: your brain’s just showing off impressive recall skills.
Music is a universal language that can bridge cultural and linguistic divides. It offers a fun and effective method for grasping vocabulary, pronunciation, and syntax for those learning a new language.
Siegel Alonso considers the success of the “Language through Music” approach, where songs in the target language are used to teach linguistic elements. Listening to and singing songs helps learners familiarize themselves with the natural rhythm and intonation of the language. It’s like getting a musical earworm that teaches you how to conjugate verbs.
Children’s tunes are particularly effective. They are repetitive, use simple language, and are often accompanied by actions, making them ideal for language learners. Adults can also benefit; think of the many people who have learned basic phrases in a foreign language by singing along to popular songs.
Moreover, music can make the uphill battle of language learning enjoyable. Picture learning Spanish through the vibrant beats of salsa or French through the soulful chansons of Edith Piaf. Music's emotional connection can deepen engagement and motivation, transforming language lessons from a chore into a delightful activity.
For individuals with autism, music can be a bridge to communication and social interaction. Autism often affects language development and social skills, but music has a unique way of reaching across these barriers. Music therapy has shown remarkable results in helping those with autism.
Through musical activities, individuals can express themselves nonverbally, which is especially beneficial for those who struggle with traditional forms of communication. Music can also help develop speech, improve social interactions, and reduce anxiety.
There are many anecdotes of nonverbal autistic children who struggle to communicate. But when they were introduced to music therapy, they began to hum and eventually sing along with their therapist. This breakthrough provided a new way for them to express their feelings and needs, fostering better communication with their family and peers.
Music also helps develop routines and transitions, which can be challenging for individuals with autism. Songs that signal the start of an activity or the end of the day create a predictable structure that can reduce anxiety and improve behavior. Additionally, group music activities encourage social interaction and cooperation, providing a fun and safe environment for practicing these skills.
Music’s impact on learning is profound and multifaceted. It’s not just a tool for young children or those facing specific challenges; it’s a lifelong ally in education. Music's benefits are vast, whether it’s helping students understand mathematical concepts through rhythm, enhancing memory and cognitive skills, or providing a creative outlet.
Integrating music into educational settings creates a more dynamic and engaging learning environment. It adapts to different learning styles, making lessons accessible and palatable for all students. Music fosters a safe, positive, and stimulating atmosphere where learning is effective and joyful.
As we continue to analyze and unlock the power of music in education, Daniel Siegel Alonso notes that it’s clear that the thread between learning and music can lead to academic and personal success. So, let’s keep the music playing in our schools and beyond, ensuring that education hits all the right notes.
-
@ 52b4a076:e7fad8bd
2025-04-28 00:48:57
I have been recently building NFDB, a new relay DB. This post is meant as a short overview.
Regular relays have challenges
Current relay software have significant challenges, which I have experienced when hosting Nostr.land: - Scalability is only supported by adding full replicas, which does not scale to large relays. - Most relays use slow databases and are not optimized for large scale usage. - Search is near-impossible to implement on standard relays. - Privacy features such as NIP-42 are lacking. - Regular DB maintenance tasks on normal relays require extended downtime. - Fault-tolerance is implemented, if any, using a load balancer, which is limited. - Personalization and advanced filtering is not possible. - Local caching is not supported.
NFDB: A scalable database for large relays
NFDB is a new database meant for medium-large scale relays, built on FoundationDB that provides: - Near-unlimited scalability - Extended fault tolerance - Instant loading - Better search - Better personalization - and more.
Search
NFDB has extended search capabilities including: - Semantic search: Search for meaning, not words. - Interest-based search: Highlight content you care about. - Multi-faceted queries: Easily filter by topic, author group, keywords, and more at the same time. - Wide support for event kinds, including users, articles, etc.
Personalization
NFDB allows significant personalization: - Customized algorithms: Be your own algorithm. - Spam filtering: Filter content to your WoT, and use advanced spam filters. - Topic mutes: Mute topics, not keywords. - Media filtering: With Nostr.build, you will be able to filter NSFW and other content - Low data mode: Block notes that use high amounts of cellular data. - and more
Other
NFDB has support for many other features such as: - NIP-42: Protect your privacy with private drafts and DMs - Microrelays: Easily deploy your own personal microrelay - Containers: Dedicated, fast storage for discoverability events such as relay lists
Calcite: A local microrelay database
Calcite is a lightweight, local version of NFDB that is meant for microrelays and caching, meant for thousands of personal microrelays.
Calcite HA is an additional layer that allows live migration and relay failover in under 30 seconds, providing higher availability compared to current relays with greater simplicity. Calcite HA is enabled in all Calcite deployments.
For zero-downtime, NFDB is recommended.
Noswhere SmartCache
Relays are fixed in one location, but users can be anywhere.
Noswhere SmartCache is a CDN for relays that dynamically caches data on edge servers closest to you, allowing: - Multiple regions around the world - Improved throughput and performance - Faster loading times
routerd
routerdis a custom load-balancer optimized for Nostr relays, integrated with SmartCache.routerdis specifically integrated with NFDB and Calcite HA to provide fast failover and high performance.Ending notes
NFDB is planned to be deployed to Nostr.land in the coming weeks.
A lot more is to come. 👀️️️️️️
-
@ 8d34bd24:414be32b
2025-04-27 03:42:57
I used to hate end times prophecy because it didn’t make sense. I didn’t understand how the predictions could be true, so I wondered if the fulfillment was more figurative than literal. As time has progressed, I’ve seen technologies and international relations change in ways that make the predictions seem not only possible, but probable. I’ve seen the world look more and more like what is predicted for the end times.
I thought it would be handy to look at the predictions and compare them to events, technologies, and nations today. This is a major undertaking, so this will turn into a series. I only hope I can do it justice. I will have some links to news articles on these current events and technologies. Because I can’t remember where I’ve read many of these things, it is likely I will put some links to some news sources that I don’t normally recommend, but which do a decent job of covering the point I’m making. I’m sorry if I don’t always give a perfect source. I have limited time, so in some cases, I’ll link to the easy (main stream journals that show up high on web searches) rather than what I consider more reliable sources because of time constraints.
I also want to give one caveat to everything I discuss below. Although I do believe the signs suggest the Rapture and Tribulation are near, I can’t say exactly what that means or how soon these prophecies will be fulfilled. Could it be tomorrow, a month from now, a year from now, or 20 years from now? Yes, any of them could be true. Could it be even farther in the future? It could be, even if my interpretation of the data concludes that to be less likely.
I will start with a long passage from Matthew that describes what Jesus told His disciples to expect before “the end of the age.” Then I’ll go to some of the end times points that seemed unexplainable to me in the past. We’ll see where things go from there. I’ve already had to split discussion of this one passage into multiple posts due to length.
Jesus’s Signs of the End
As He was sitting on the Mount of Olives, the disciples came to Him privately, saying, “Tell us, when will these things happen, and what will be the sign of Your coming, and of the end of the age?”
And Jesus answered and said to them, “See to it that no one misleads you. For many will come in My name, saying, ‘I am the Christ,’ and will mislead many. You will be hearing of wars and rumors of wars. See that you are not frightened, for those things must take place, but that is not yet the end. For nation will rise against nation, and kingdom against kingdom, and in various places there will be famines and earthquakes. But all these things are merely the beginning of birth pangs.
“Then they will deliver you to tribulation, and will kill you, and you will be hated by all nations because of My name. At that time many will fall away and will betray one another and hate one another. Many false prophets will arise and will mislead many. Because lawlessness is increased, most people’s love will grow cold. But the one who endures to the end, he will be saved. This gospel of the kingdom shall be preached in the whole world as a testimony to all the nations, and then the end will come. (Matthew 24:3-14) {emphasis mine}
Before I go into the details I do want to clarify one thing. The verses that follow the above verses (Matthew 24:16-28) mention the “abomination of desolation” and therefore is clearly discussing the midpoint of the tribulation and the following 3.5 years or Great Tribulation. The first half of Matthew 24 discusses the birth pangs and the first half of the Tribulation. The signs that I discuss will be growing immediately preceding the Tribulation, but probably will not be completely fulfilled until the first 3.5 years of the Tribulation.
I do think we will see an increase of all of these signs before the 7 year Tribulation begins as part of the birth pangs even if they are not fulfilled completely until the Tribulation:
-
Wars and rumors of wars. (Matthew 24:6a)
-
Famines (Matthew 24:7)
-
Earthquakes (Matthew 24:7).
-
Israel will be attacked and will be hated by all nations (Matthew 24:9)
-
Falling away from Jesus (Matthew 24:10)
-
Many Misled (Matthew 24:10)
-
People’s love will grow cold (Matthew 24:12)
-
Gospel will be preached to the whole world (Matthew 24:14)
Now let’s go through each of these predictions to see what we are seeing today.
1. Wars and Rumors of Wars
When you hear of wars and disturbances, do not be terrified; for these things must take place first, but the end does not follow immediately.” (Luke 21:9)
In 1947 the doomsday clock was invented. It theoretically tells how close society is to all out war and destruction of mankind. It was just recently set to 89 seconds to midnight, the closest it has ever been. It is true that this isn’t a scientific measure and politics can effect the setting, i.e. climate change & Trump Derangement Syndrome, but it is still one of many indicators of danger and doom.
There are three main events going on right now that could lead to World War III and the end times.
Obviously the war between Russia and Ukraine has gotten the world divided. It is true that Russia invaded Ukraine, but there were many actions by the US and the EU that provoked this attack. Within months of the initial attack, there was a near agreement between Ukraine and Russia to end the war, but the US and the EU talked Ukraine out of peace, leading to hundreds of thousands of Ukrainians and Russians dying for basically no change of ground. Estimates of deaths vary greatly. See here, here, here. Almost all English sources list Russia as having many more deaths than Ukraine, but since Ukraine is now drafting kids and old men, is considering drafting women, and has most of its defensive capabilities destroyed, while Russia still seems to have plenty of men and weapons, I find this hard to believe. I don’t think any of the parties that have data are motivated to tell the truth. We probably will never know.
The way the EU (and the US until recently) has sacrificed everything to defend Ukraine (until this war known as the most corrupt nation in Europe and known for its actual Nazis) and to do everything in its power to keep the war with Russia going, things could easily escalate. The US and the EU have repeatedly crossed Russia’s red-lines. One of these days, Russia is likely to say “enough is enough” and actually attack Europe. This could easily spiral out of control. I do think that Trump’s pull back and negotiations makes this less likely to lead to world war than it seemed for the past several years. This article does a decent job of explaining the background for the war that most westerners, especially Americans, don’t understand.
Another less well known hot spot is the tension between China and Taiwan. Taiwan is closer politically to the US, but closer economically and culturally to China. This causes tension. Taiwan also produces the majority of the high tech microchips used in advanced technology. Both the US and China want and need this technology. I honestly believe this is the overarching issue regarding Taiwan. If either the US or China got control of Taiwan’s microchip production, it would be military and economic game over for the other. This is stewing, but I don’t think this will be the cause of world war 3, although it could become part of the war that leads to the Antichrist ruling the world.
The war that is likely to lead to the Tribulation involves Israel and the Middle East. Obviously, the Muslim nations hate Israel and attack them almost daily. We also see Iran, Russia, Turkey, and other nations making alliances that sound a lot like the Gog/Magog coalition in Ezekiel 38. The hate of Israel has grown to a level that makes zero sense unless you take into account the spiritual world and Bible prophecy. Such a small insignificant nation, that didn’t even exist for \~1900 years, shouldn’t have the influence on world politics that it does. It is about the size of the state of New Jersey. Most nations of Israel’s size, population, and economy are not even recognized by most people. Is there a person on earth that doesn’t know about Israel? I doubt it. Every nation on earth seems to have a strong positive or, more commonly, negative view of Israel. We’ll get to this hate of Israel more below in point 4.
2. Famines
In the two parallel passages to Matthew 24, there is once again the prediction of famines coming before the end.
For nation will rise up against nation, and kingdom against kingdom; there will be earthquakes in various places; there will also be famines. These things are merely the beginning of birth pangs. (Mark 13:8) {emphasis mine}
and there will be great earthquakes, and in various places plagues and famines; and there will be terrors and great signs from heaven. (Luke 21:11) {emphasis mine}
In Revelation, the third seal releases famine upon the earth and a day’s wages will only buy one person’s daily wheat needs. A man with a family would only be able to buy lower quality barley to barely feed his family.
When He broke the third seal, I heard the third living creature saying, “Come.” I looked, and behold, a black horse; and he who sat on it had a pair of scales in his hand. And I heard something like a voice in the center of the four living creatures saying, “A quart of wheat for a denarius, and three quarts of barley for a denarius; and do not damage the oil and the wine.” (Revelation 6:5-6) {emphasis mine}
We shouldn’t fear a Tribulation level famine as a precursor to the Tribulation, but we should see famines scattered around the world, shortages of different food items, and rising food prices, all of which we are seeing. (Once again, I can’t support many of these sources or verify all of their data, but they give us a feel of what is going on today.)
Food Prices Go Up
-
Bird Flu scares and government responses cause egg and chicken prices to increase. The government response to the flu is actually causing more problems than the flu itself and it looks like this more dangerous version may have come out of a US lab.
-
Tariffs and trade war cause some items to become more expensive or less available. here
-
Ukraine war effecting the supply of grain and reducing availability of fertilizer. More info.
-
Inflation and other effects causing food prices to go up. This is a poll from Americans.
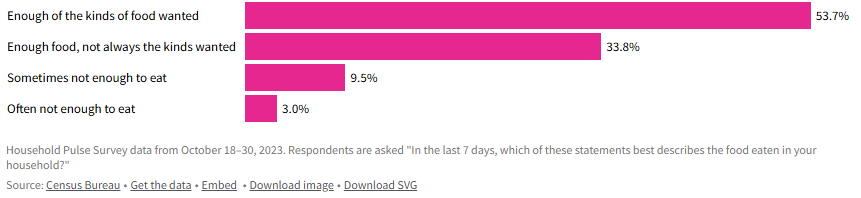 - Grocery prices overall have increased around 23% since 2021, with prices on individual items like coffee and chocolate rising much faster.
- Grocery prices overall have increased around 23% since 2021, with prices on individual items like coffee and chocolate rising much faster.-
General Food inflation is difficult, but not life destroying for most of the world, but some nations are experiencing inflation that is causing many to be unable to afford food. Single digit food inflation is difficult, even in well-to-do nations, but in poor nations, where a majority of the people’s income already goes to food, it can be catastrophic. When you look at nations like Zimbabwe (105%), Venezuela (22%), South Sudan (106%), Malawi (38%), Lebanon (20%), Haiti (37%), Ghana (26%), Burundi (39%), Bolivia (35%), and Argentina (46%), you can see that there are some seriously hurting people. More info.
-
It does look like general food inflation has gone down for the moment (inflation has gone down, but not necessarily prices), but there are many situations around the world that could make it go back up again.
-
Wars causing famine
-
Sudan: War has made an already poor and hurting country even worse off.
-
Gaza: (When I did a web search, all of the sites that came up on the first couple of pages are Israel hating organizations that are trying to cause trouble and/or raise money, so there is major bias. I did link to one of these sites just to be thorough, but take into account the bias of the source.)
-
Ukraine: Mostly covered above. The war in Ukraine has affected the people of Ukraine and the world negatively relative to food.
I’m sure there are plenty more evidences for famine or potential famine, but this gives a taste of what is going on.
Our global economy has good and bad effects on the food supply. Being able to transport food around the globe means that when one area has a bad crop, they can import food from another area that produced more than they need. On the other hand, sometimes an area stops producing food because they can import food more cheaply. If something disrupts that imported food (tariffs, trade wars, physical wars, transportation difficulties, intercountry disputes, etc.) then they suddenly have no food. We definitely have a fragile system, where there are many points that could fail and cause famine to abound.
The Bible also talks about another kind of famine in the end times.
“Behold, days are coming,” declares the Lord God,\ “When I will send a famine on the land,\ *Not a famine for bread or a thirst for water,\ But rather for hearing the words of the Lord*.\ People will stagger from sea to sea\ And from the north even to the east;\ They will go to and fro to seek the word of the Lord,\ But they will not find it**. (Amos 8:11-12) {emphasis mine}
We are definitely seeing a famine regarding the word of God. It isn’t that the word of God is not available, but even in churches, there is a lack of teaching the actual word of God from the Scriptures. Many churches teach more self-help or feel good messages than they do the word of God. Those looking to know God better are starving or thirsting for truth and God’s word. I know multiple people who have given up on assembling together in church because they can’t find a Bible believing, Scripture teaching church. How sad!
Although famine should be expected before the Tribulation, the good news is that no famine will separate us from our Savior.
Who will separate us from the love of Christ? Will tribulation, or distress, or persecution, or famine, or nakedness, or peril, or sword? (Romans 8:35) {emphasis mine}
3. Earthquakes
We recently saw a major \~7.8 earthquake in Myanmar. Although it seems like we are having many major earthquakes, it is more difficult to determine whether there is actually a major increase or if the seeming increase is due to increasing population to harm, more/better instrumentation, and/or more media coverage. We are definitely seeing lots of earthquake damage and loss of life. I tend to think the number and severity of earthquakes will increase even more before the Tribulation, but only time will tell.
4. Israel will be attacked and will be hated by all nations
“Then they will deliver you [Israel] to tribulation, and will kill you, and you will be hated by all nations because of My name. (Matthew 24:9) {emphasis & clarification mine}
This verse doesn’t specifically mention Israel. It says “you,” but since Jesus was talking to Jews, the best interpretation is that this warning is to the Jews. At the same time, we are also seeing attacks on Christians, so it likely refers to both Jews and Christians. I’m going to focus on Jews/Israel because I don’t think I need to convince most Christians that persecution is increasing.
We have been seeing hatred of Jews and Israel growing exponentially since the biblical prediction of a re-establishment of Israel was accomplished.
All end times prophecy focuses on Israel and requires Israel to be recreated again since it was destroyed in A.D. 70.
Who has heard such a thing? Who has seen such things?\ Can a land be born in one day?\ Can a nation be brought forth all at once?\ As soon as Zion travailed, she also brought forth her sons. (Isaiah 66:8)
-
“British Foreign Minister Lord Balfour issued on November 2, 1917, the so-called Balfour Declaration, which gave official support for the “establishment in Palestine of a national home for the Jewish people” with the commitment not to be prejudiced against the rights of the non-Jewish communities.” In one day Israel was declared a nation.
-
“On the day when the British Mandate in Palestine expired, the State of Israel was instituted on May 14, 1948, by the Jewish National Council under the presidency of David Ben Gurion.” Then on another day Israel actually came into being with a leader and citizens.
-
“Six-Day War: after Egypt closed the Straits of Tiran on May 22, 1967, Israel launched an attack on Egyptian, Jordanian, Syrian, and Iraqi airports on June 5, 1967. After six days, Israel conquered Jerusalem, the Golan Heights, Sinai, and the West Bank.” On June 11, 1967 Jerusalem was conquered and once again became the capital of Israel.
If you read any of these links you can see the history of Israel being repeatedly attacked in an attempt to destroy Israel and stop God’s prophecy that Israel would be recreated and be used in the end times as part of the judgement of the world. This is a very good article on how God plans to use Israel in end times, how God will fulfill all of his promises to Israel, and how the attacks on Israel are Satan’s attempt to stop God’s plan. It is well worth you time to read and well supported by Scripture.
Since Israel became a new nation again, the nations of the world have ramped up their attacks on Israel and the Jews. The hatred of the Jews is hard to fathom. The Jews living in Israel have been constantly at risk of suicide bombers, terrorist attacks, rocket/missile attacks, etc. Almost daily attacks are common recently. The most significant recent attack happened on October 7th. Around 3,000 Hamas terrorists stormed across the border and attacked men, women, and children. About 1200 were killed, mostly civilians and even kids. In addition to murdering these innocent individuals, others were tortured, raped, and kidnapped as well.
You would expect the world to rally around a nation attacked in such a horrendous manner (like most of the world rallied around the US after 9/11), but instead you immediately saw protests supporting Palestine and condemning Israel. I’ve never seen something so upside down in my life. It is impossible to comprehend until you consider the spiritual implications. Satan has been trying to destroy Israel and the Jews since God made His first promise to Abraham. I will never claim that everything Israeli politicians and generals do is good, but the hate towards this tiny, insignificant nation is unfathomable and the world supporting terrorist attacks, instead of the victims of these attacks, is beyond belief.
Israel allows people of Jewish ancestry and Palestinian ancestry to be citizens and vote. There are Jews, Muslims, and Christians in the Knesset (Jewish Congress). Yes, Israel has responded harshly against the Palestinians and innocents have been harmed, but Israel repeatedly gave up land for peace and then that land has been used to attack them. I can’t really condemn them for choosing to risk the death of Palestinian innocents over risking the death of their own innocents. Hamas and Hezbollah are known for attacking innocents, and then using their own innocents as human shields. They then accuse their victims of atrocities when their human shields are harmed. The UN Human Rights council condemns Israel more than all other nations combined when there are atrocities being committed in many, many other nations that are as bad or worse. Why is the world focused on Israel and the Jews? It is because God loves them (despite their rejection of Him) and because Satan hates them.
Throughout history the world has tried to destroy the Jews, but thanks to God and His eternal plan, they are still here and standing strong. the hate is growing to a fevered pitch, just as predicted by Jesus.
This post has gotten so long that it can’t be emailed, so I will post the final 4 points in a follow-up post. I hope these details are helpful to you and seeing that all of the crazy, hate, and destruction occurring in the world today was known by God and is being used by God to His glory and are good according to His perfect plan.
When we see that everything happening in the world is just part of God’s perfect plan, we can have peace, knowing that God is in control. We need to lean on Him and trust Him just as a young child feels safe in his Fathers arms. At the same time, seeing the signs should encourage us to share the Gospel with unbelievers because our time is short. Don’t put off sharing Jesus with those around you because you might not get another chance.
Trust Jesus.
FYI, I hope to write several more articles on the end times (signs of the times, the rapture, the millennium, and the judgement), but I might be a bit slow rolling them out because I want to make sure they are accurate and well supported by Scripture. You can see my previous posts on the end times on the end times tab at trustjesus.substack.com. I also frequently will list upcoming posts.
-
-
@ eb35d9c0:6ea2b8d0
2025-03-02 00:55:07
I had a ton of fun making this episode of Midnight Signals. It taught me a lot about the haunting of the Bell family and the demise of John Bell. His death was attributed to the Bell Witch making Tennessee the only state to recognize a person's death to the supernatural.
If you enjoyed the episode, visit the Midnight Signals site. https://midnightsignals.net
Show Notes
Journey back to the early 1800s and the eerie Bell Witch haunting that plagued the Bell family in Adams, Tennessee. It began with strange creatures and mysterious knocks, evolving into disembodied voices and violent attacks on young Betsy Bell. Neighbors, even Andrew Jackson, witnessed the phenomena, adding to the legend. The witch's identity remains a mystery, sowing fear and chaos, ultimately leading to John Bell's tragic demise. The haunting waned, but its legacy lingers, woven into the very essence of the town. Delve into this chilling story of a family's relentless torment by an unseen force.
Transcript
Good evening, night owls. I'm Russ Chamberlain, and you're listening to midnight signals, the show, where we explore the darkest corners of our collective past. Tonight, our signal takes us to the early 1800s to a modest family farm in Adams, Tennessee. Where the Bell family encountered what many call the most famous haunting in American history.
Make yourself comfortable, hush your surroundings, and let's delve into this unsettling tale. Our story begins in 1804, when John Bell and his wife Lucy made their way from North Carolina to settle along the Red River in northern Tennessee. In those days, the land was wide and fertile, mostly unspoiled with gently rolling hills and dense woodland.
For the Bells, John, Lucy, and their children, The move promised prosperity. They arrived eager to farm the rich soil, raise livestock, and find a peaceful home. At first, life mirrored [00:01:00] that hope. By day, John and his sons worked tirelessly in the fields, planting corn and tending to animals, while Lucy and her daughters managed the household.
Evenings were spent quietly, with scripture readings by the light of a flickering candle. Neighbors in the growing settlement of Adams spoke well of John's dedication and Lucy's gentle spirit. The Bells were welcomed into the Fold, a new family building their future on the Tennessee Earth. In those early years, the Bells likely gave little thought to uneasy rumors whispered around the region.
Strange lights seen deep in the woods, soft cries heard by travelers at dusk, small mysteries that most dismissed as product of the imagination. Life on the frontier demanded practicality above all else, leaving little time to dwell on spirits or curses. Unbeknownst to them, events on their farm would soon dominate not only their lives, but local lore for generations to come.[00:02:00]
It was late summer, 1817, when John Bell's ordinary routines took a dramatic turn. One evening, in the waning twilight, he spotted an odd creature near the edge of a tree line. A strange beast resembling part dog, part rabbit. Startled, John raised his rifle and fired, the shot echoing through the fields. Yet, when he went to inspect the spot, nothing remained.
No tracks, no blood, nothing to prove the creature existed at all. John brushed it off as a trick of falling light or his own tired eyes. He returned to the house, hoping for a quiet evening. But in the days that followed, faint knocking sounds began at the windows after sunset. Soft scratching rustled against the walls as if curious fingers or claws tested the timbers.
The family's dog barked at shadows, growling at the emptiness of the yard. No one considered it a haunting at first. Life on a rural [00:03:00] farm was filled with pests, nocturnal animals, and the countless unexplained noises of the frontier. Yet the disturbances persisted, night after night, growing a little bolder each time.
One evening, the knocking on the walls turned so loud it woke the entire household. Lamps were lit, doors were open, the ground searched, but the land lay silent under the moon. Within weeks, the unsettling taps and scrapes evolved into something more alarming. Disembodied voices. At first, the voices were faint.
A soft murmur in rooms with no one in them. Betsy Bell, the youngest daughter, insisted she heard her name called near her bed. She ran to her mother and her father trembling, but they found no intruder. Still, The voice continued, too low for them to identify words, yet distinct enough to chill the blood.
Lucy Bell began to fear they were facing a spirit, an unclean presence that had invaded their home. She prayed for divine [00:04:00] protection each evening, yet sometimes the voice seemed to mimic her prayers, twisting her words into a derisive echo. John Bell, once confident and strong, grew unnerved. When he tried reading from the Bible, the voice mocked him, imitating his tone like a cruel prankster.
As the nights passed, disturbances gained momentum. Doors opened by themselves, chairs shifted with no hand to move them, and curtains fluttered in a room void of drafts. Even in daytime, Betsy would find objects missing, only for them to reappear on the kitchen floor or a distant shelf. It felt as if an unseen intelligence roamed the house, bent on sowing chaos.
Of all the bells, Betsy suffered the most. She was awakened at night by her hair being yanked hard enough to pull her from sleep. Invisible hands slapped her cheeks, leaving red prints. When she walked outside by day, she heard harsh whispers at her ear, telling her she would know [00:05:00] no peace. Exhausted, she became withdrawn, her once bright spirit dulled by a ceaseless fear.
Rumors spread that Betsy's torment was the worst evidence of the haunting. Neighbors who dared spend the night in the Bell household often witnessed her blankets ripped from the bed, or watched her clutch her bruised arms in distress. As these accounts circulated through the community, people began referring to the presence as the Bell Witch, though no one was certain if it truly was a witch's spirit or something else altogether.
In the tightly knit town of Adams, word of the strange happenings at the Bell Farm soon reached every ear. Some neighbors offered sympathy, believing wholeheartedly that the family was besieged by an evil force. Others expressed skepticism, guessing there must be a logical trick behind it all. John Bell, ordinarily a private man, found himself hosting visitors eager to witness the so called witch in action.
[00:06:00] These visitors gathered by the parlor fireplace or stood in darkened hallways, waiting in tense silence. Occasionally, the presence did not appear, and the disappointed guests left unconvinced. More often, they heard knocks vibrating through the walls or faint moans drifting between rooms. One man, reading aloud from the Bible, found his words drowned out by a rasping voice that repeated the verses back at him in a warped, sing song tone.
Each new account that left the bell farm seemed to confirm the unearthly intelligence behind the torment. It was no longer mere noises or poltergeist pranks. This was something with a will and a voice. Something that could think and speak on its own. Months of sleepless nights wore down the Bell family.
John's demeanor changed. The weight of the haunting pressed on him. Lucy, steadfast in her devotion, prayed constantly for deliverance. The [00:07:00] older Bell children, seeing Betsy attacked so frequently, tried to shield her but were powerless against an enemy that slipped through walls. Farming tasks were delayed or neglected as the family's time and energy funneled into coping with an unseen assailant.
John Bell began experiencing health problems that no local healer could explain. Trembling hands, difficulty swallowing, and fits of dizziness. Whether these ailments arose from stress or something darker, they only reinforced his sense of dread. The voice took to mocking him personally, calling him by name and snickering at his deteriorating condition.
At times, he woke to find himself pinned in bed, unable to move or call out. Despite it all, Lucy held the family together. Soft spoken and gentle, she soothed Betsy's tears and administered whatever remedies she could to John. Yet the unrelenting barrage of knocks, whispers, and violence within her own home tested her faith [00:08:00] daily.
Amid the chaos, Betsy clung to one source of joy, her engagement to Joshua Gardner, a kind young man from the area. They hoped to marry and begin their own life, perhaps on a parcel of the Bell Land or a new farmstead nearby. But whenever Joshua visited the Bell Home, The unseen spirit raged. Stones rattled against the walls, and the door slammed as if in warning.
During quiet walks by the river, Betsy heard the voice hiss in her ear, threatening dire outcomes if she ever were to wed Joshua. Night after night, Betsy lay awake, her tears soaked onto her pillow as she wrestled with the choice between her beloved fiancé and this formidable, invisible foe. She confided in Lucy, who offered comfort but had no solution.
For a while, Betsy and Joshua resolved to stand firm, but the spirit's fury only escalated. Believing she had no alternative, Betsy broke off the engagement. Some thought the family's [00:09:00] torment would subside if the witches demands were met. In a cruel sense, it seemed to succeed. With Betsy's engagement ended, the spirit appeared slightly less focused on her.
By now, the Bell Witch was no longer a mere local curiosity. Word of the haunting spread across the region and reached the ears of Andrew Jackson, then a prominent figure who would later become president. Intrigued, or perhaps skeptical, he traveled to Adams with a party of men to witness the phenomenon firsthand.
According to popular account, the men found their wagon inexplicably stuck on the road near the Bell property, refusing to move until a disembodied voice commanded them to proceed. That night, Jackson's men sat in the Bell parlor, determined to uncover fraud if it existed. Instead, they found themselves subjected to jeering laughter and unexpected slaps.
One boasted of carrying a special bullet that could kill any spirit, only to be chased from the house in terror. [00:10:00] By morning, Jackson reputedly left, shaken. Although details vary among storytellers, the essence of his experience only fueled the legend's fire. Some in Adams took to calling the presence Kate, suspecting it might be the spirit of a neighbor named Kate Batts.
Rumors pointed to an old feud or land dispute between Kate Batts and John Bell. Whether any of that was true, or Kate Batts was simply an unfortunate scapegoat remains unclear. The entity itself, at times, answered to Kate when addressed, while at other times denying any such name. It was a puzzle of contradictions, claiming multiple identities.
A wayward spirit, a demon, or a lost soul wandering in malice. No single explanation satisfied everyone in the community. With Betsy's engagement to Joshua broken, the witch devoted increasing attention to John Bell. His health declined rapidly in 1820, marked by spells of near [00:11:00] paralysis and unremitting pain.
Lucy tended to him day and night. Their children worried and exhausted, watched as their patriarch grew weaker, his once strong presence withering under an unseen hand. In December of that year, John Bell was found unconscious in his bed. A small vial of dark liquid stood nearby. No one recognized its contents.
One of his sons put a single drop on the tongue of the family cat, which died instantly. Almost immediately, the voice shrieked in triumph, boasting that it had given John a final, fatal dose. That same day, John Bell passed away without regaining consciousness, leaving his family both grief stricken and horrified by the witch's brazen gloating.
The funeral drew a large gathering. Many came to mourn the respected farmer. Others arrived to see whether the witch would appear in some dreadful form. As pallbearers lowered John Bell's coffin, A jeering laughter rippled across the [00:12:00] mourners, prompting many to look wildly around for the source. Then, as told in countless retellings, the voice broke into a rude, mocking song, echoing among the gravestones and sending shudders through the crowd.
In the wake of John Bell's death, life on the farm settled into an uneasy quiet. Betsy noticed fewer night time assaults. And the daily havoc lessened. People whispered that the witch finally achieved its purpose by taking John Bell's life. Then, just as suddenly as it had arrived, the witch declared it would leave the family, though it promised to return in seven years.
After a brief period of stillness, the witch's threat rang true. Around 1828, a few of the Bells claimed to hear light tapping or distant murmurs echoing in empty rooms. However, these new incidents were mild and short lived compared to the previous years of torment. Soon enough, even these faded, leaving the bells [00:13:00] with haunted memories, but relative peace.
Near the bell property stood a modest cave by the Red River, a spot often tied to the legend. Over time, people theorized that cave's dark recesses, though the bells themselves rarely ventured inside. Later visitors and locals would tell of odd voices whispering in the cave or strange lights gliding across the damp stone.
Most likely, these stories were born of the haunting's lingering aura. Yet, they continued to fuel the notion that the witch could still roam beyond the farm, hidden beneath the earth. Long after the bells had ceased to hear the witch's voice, the story lived on. Word traveled to neighboring towns, then farther, into newspapers and traveler anecdotes.
The tale of the Tennessee family plagued by a fiendish, talkative spirit captured the imagination. Some insisted the Bell Witch was a cautionary omen of what happens when old feuds and injustices are left [00:14:00] unresolved. Others believed it was a rare glimpse of a diabolical power unleashed for reasons still unknown.
Here in Adams, people repeated the story around hearths and campfires. Children were warned not to wander too far near the old bell farm after dark. When neighbors passed by at night, they might hear a faint rustle in the bush or catch a flicker of light among the trees, prompting them to walk faster.
Hearts pounding, minds remembering how once a family had suffered greatly at the hands of an unseen force. Naturally, not everyone agreed on what transpired at the Bell farm. Some maintained it was all too real, a case of a vengeful spirit or malignant presence carrying out a personal vendetta. Others whispered that perhaps a member of the Bell family had orchestrated the phenomenon with cunning trickery, though that failed to explain the bruises on Betsy, the widespread witnesses, or John's mysterious death.
Still, others pointed to the possibility of an [00:15:00] unsettled spirit who had attached itself to the land for reasons lost to time. What none could deny was the tangible suffering inflicted on the Bells. John Bell's slow decline and Betsy's bruises were impossible to ignore. Multiple guests, neighbors, acquaintances, even travelers testified to hearing the same eerie voice that threatened, teased and recited scripture.
In an age when the supernatural was both feared and accepted, the Bell Witch story captured hearts and sparked endless speculation. After John Bell's death, the family held onto the farm for several years. Betsy, robbed of her engagement to Joshua, eventually found a calmer path through life, though the memory of her tormented youth never fully left her.
Lucy, steadfast and devout to the end, kept her household as best as she could, unwilling to surrender her faith even after all she had witnessed. Over time, the children married and started families of their own, [00:16:00] quietly distancing themselves from the tragedy that had defined their upbringing.
Generations passed, the farm changed hands, the Bell House was repurposed and renovated, and Adams itself transformed slowly from a frontier settlement into a more established community. Yet the name Bellwitch continued to slip into conversation whenever strange knocks were heard late at night or lonely travelers glimpsed inexplicable lights in the distance.
The story refused to fade, woven into the identity of the land itself. Even as the first hand witnesses to the haunting aged and died, their accounts survived in letters, diaries, and recollections passed down among locals. Visitors to Adams would hear about the famed Bell Witch, about the dreadful death of John Bell, the heartbreak of Betsy's broken engagement, and the brazen voice that filled nights with fear.
Some folks approached the story with reverence, others with skepticism. But no one [00:17:00] denied that it shaped the character of the town. In the hush of a moonlit evening, one might stand on that old farmland, fields once tilled by John Bell's callous hands, now peaceful beneath the Tennessee sky. And imagine the entire family huddled in the house, listening with terrified hearts for the next knock on the wall.
It's said that if you pause long enough, you might sense a faint echo of their dread, carried on a stray breath of wind. The Bell Witch remains a singular chapter in American folklore, a tale of a family besieged by something unseen, lethal, and uncannily aware. However one interprets the events, whether as vengeful ghosts, demonic presence, or some other unexplainable force, the Bell Witch.
Its resonance lies in the very human drama at its core. Here was a father undone by circumstances he could not control. A daughter tormented in her own home, in a close knit household tested by relentless fear. [00:18:00] In the end, the Bell Witch story offers a lesson in how thin the line between our daily certainties and the mysteries that defy them.
When night falls, and the wind rattles the shutters in a silent house, we remember John Bell and his family, who discovered that the safe haven of home can become a battlefield against forces beyond mortal comprehension. I'm Russ Chamberlain, and you've been listening to Midnight Signals. May this account of the Bell Witch linger with you as a reminder that in the deepest stillness of the night, Anything seems possible.
Even the unseen tapping of a force that seeks to make itself known. Sleep well, if you dare.
-
@ bfd004ea:ed7ac83d
2025-04-26 21:23:30
This is other test.
-
@ 68c90cf3:99458f5c
2025-04-26 15:05:41
Background
Last year I got interesting in running my own bitcoin node after reading others' experiences doing so. A couple of decades ago I ran my own Linux and Mac servers, and enjoyed building and maintaining them. I was by no means an expert sys admin, but had my share of cron jobs, scripts, and custom configuration files. While it was fun and educational, software updates and hardware upgrades often meant hours of restoring and troubleshooting my systems.
Fast forward to family and career (especially going into management) and I didn't have time for all that. Having things just work became more important than playing with the tech. As I got older, the more I appreciated K.I.S.S. (for those who don't know: Keep It Simple Stupid).
So when the idea of running a node came to mind, I explored the different options. I decided I needed a balance between a Raspberry Pi (possibly underpowered depending on use) and a full-blown Linux server (too complex and time-consuming to build and maintain). That led me to Umbrel OS, Start9, Casa OS, and similar platforms. Due to its simplicity (very plug and play), nice design, and being open source: GitHub), I chose Umbrel OS on a Beelink mini PC with 16GB of RAM and a 2TB NVMe internal drive. Though Umbrel OS is not very flexible and can't really be customized, its App Store made setting up a node (among other things) fairly easy, and it has been running smoothly since. Would the alternatives have been better? Perhaps, but so far I'm happy with my choice.

Server Setup
I'm also no expert in OpSec (I'd place myself in the category of somewhat above vague awareness). I wanted a secure way to connect to my Umbrel without punching holes in my router and forwarding ports. I chose Tailscale for this purpose. Those who are distrustful of corporate products might not like this option but again, balancing risk with convenience it seemed reasonable for my needs. If you're hiding state (or anti-state) secrets, extravagant wealth, or just adamant about privacy, you would probably want to go with an entirely different setup.
Once I had Tailscale installed on Umbrel OS, my mobile device and laptop, I could securely connect to the server from anywhere through a well designed browser UI. I then installed the following from the Umbrel App Store:
- Bitcoin Core
- Electrum Personal Server (Electrs)
At this point I could set wallets on my laptop (Sparrow) and phone (BlueWallet) to use my node. I then installed:
- Lightning Node (LND)
- Alby Hub
Alby Hub streamlines the process of opening and maintaining lightning channels, creating lightning wallets to send and receive sats, and zapping notes and users on Nostr. I have two main nsec accounts for Nostr and set up separate wallets on Alby Hub to track balances and transactions for each.
Other apps I installed on Umbrel OS:
- mempool
- Bitcoin Explorer
- LibreTranslate (some Nostr clients allow you to use your own translator)
- Public Pool

Public Pool allows me to connect Bitaxe solo miners (a.k.a. "lottery" miners) to my own mining pool for a (very) long shot at winning a Bitcoin block. It's also a great way to learn about mining, contribute to network decentralization, and generally tinker with electronics. Bitaxe miners are small open source single ASIC miners that you can run in your home with minimal technical knowledge and maintenance requirements.
Open Source Miners United (OSMU) is a great resource for anyone interesting in Bitaxe or other open source mining products (especially their Discord server).

Although Umbrel OS is more or less limited to running software in its App Store (or Community App Store, if you trust the developer), you can install the Portainer app and run Docker images. I know next to nothing about Docker but wanted to see what I might be able to do with it. I was also interested in the Haven Nostr relay and found that there was indeed a docker image for it.
As stated before, I didn't want to open my network to the outside, which meant I wouldn't be able to take advantage of all the features Haven offers (since other users wouldn't be able to access it). I would however be able to post notes to my relay, and use its "Blastr" feature to send my notes to other relays. After some trial and error I managed to get a Haven up and running in Portainer.

The upside of this setup is self-custody: being able to connect wallets to my own Bitcoin node, send and receive zaps with my own Lightning channel, solo mine with Bitaxe to my own pool, and send notes to my own Nostr relay. The downside is the lack of redundancy and uptime provided by major cloud services. You have to decide on your own comfort level. A solid internet connection and reliable power are definitely needed.

This article was written and published to Nostr with untype.app.
-
@ 460c25e6:ef85065c
2025-02-25 15:20:39
If you don't know where your posts are, you might as well just stay in the centralized Twitter. You either take control of your relay lists, or they will control you. Amethyst offers several lists of relays for our users. We are going to go one by one to help clarify what they are and which options are best for each one.
Public Home/Outbox Relays
Home relays store all YOUR content: all your posts, likes, replies, lists, etc. It's your home. Amethyst will send your posts here first. Your followers will use these relays to get new posts from you. So, if you don't have anything there, they will not receive your updates.
Home relays must allow queries from anyone, ideally without the need to authenticate. They can limit writes to paid users without affecting anyone's experience.
This list should have a maximum of 3 relays. More than that will only make your followers waste their mobile data getting your posts. Keep it simple. Out of the 3 relays, I recommend: - 1 large public, international relay: nos.lol, nostr.mom, relay.damus.io, etc. - 1 personal relay to store a copy of all your content in a place no one can delete. Go to relay.tools and never be censored again. - 1 really fast relay located in your country: paid options like http://nostr.wine are great
Do not include relays that block users from seeing posts in this list. If you do, no one will see your posts.
Public Inbox Relays
This relay type receives all replies, comments, likes, and zaps to your posts. If you are not getting notifications or you don't see replies from your friends, it is likely because you don't have the right setup here. If you are getting too much spam in your replies, it's probably because your inbox relays are not protecting you enough. Paid relays can filter inbox spam out.
Inbox relays must allow anyone to write into them. It's the opposite of the outbox relay. They can limit who can download the posts to their paid subscribers without affecting anyone's experience.
This list should have a maximum of 3 relays as well. Again, keep it small. More than that will just make you spend more of your data plan downloading the same notifications from all these different servers. Out of the 3 relays, I recommend: - 1 large public, international relay: nos.lol, nostr.mom, relay.damus.io, etc. - 1 personal relay to store a copy of your notifications, invites, cashu tokens and zaps. - 1 really fast relay located in your country: go to nostr.watch and find relays in your country
Terrible options include: - nostr.wine should not be here. - filter.nostr.wine should not be here. - inbox.nostr.wine should not be here.
DM Inbox Relays
These are the relays used to receive DMs and private content. Others will use these relays to send DMs to you. If you don't have it setup, you will miss DMs. DM Inbox relays should accept any message from anyone, but only allow you to download them.
Generally speaking, you only need 3 for reliability. One of them should be a personal relay to make sure you have a copy of all your messages. The others can be open if you want push notifications or closed if you want full privacy.
Good options are: - inbox.nostr.wine and auth.nostr1.com: anyone can send messages and only you can download. Not even our push notification server has access to them to notify you. - a personal relay to make sure no one can censor you. Advanced settings on personal relays can also store your DMs privately. Talk to your relay operator for more details. - a public relay if you want DM notifications from our servers.
Make sure to add at least one public relay if you want to see DM notifications.
Private Home Relays
Private Relays are for things no one should see, like your drafts, lists, app settings, bookmarks etc. Ideally, these relays are either local or require authentication before posting AND downloading each user\'s content. There are no dedicated relays for this category yet, so I would use a local relay like Citrine on Android and a personal relay on relay.tools.
Keep in mind that if you choose a local relay only, a client on the desktop might not be able to see the drafts from clients on mobile and vice versa.
Search relays:
This is the list of relays to use on Amethyst's search and user tagging with @. Tagging and searching will not work if there is nothing here.. This option requires NIP-50 compliance from each relay. Hit the Default button to use all available options on existence today: - nostr.wine - relay.nostr.band - relay.noswhere.com
Local Relays:
This is your local storage. Everything will load faster if it comes from this relay. You should install Citrine on Android and write ws://localhost:4869 in this option.
General Relays:
This section contains the default relays used to download content from your follows. Notice how you can activate and deactivate the Home, Messages (old-style DMs), Chat (public chats), and Global options in each.
Keep 5-6 large relays on this list and activate them for as many categories (Home, Messages (old-style DMs), Chat, and Global) as possible.
Amethyst will provide additional recommendations to this list from your follows with information on which of your follows might need the additional relay in your list. Add them if you feel like you are missing their posts or if it is just taking too long to load them.
My setup
Here's what I use: 1. Go to relay.tools and create a relay for yourself. 2. Go to nostr.wine and pay for their subscription. 3. Go to inbox.nostr.wine and pay for their subscription. 4. Go to nostr.watch and find a good relay in your country. 5. Download Citrine to your phone.
Then, on your relay lists, put:
Public Home/Outbox Relays: - nostr.wine - nos.lol or an in-country relay. -
.nostr1.com Public Inbox Relays - nos.lol or an in-country relay -
.nostr1.com DM Inbox Relays - inbox.nostr.wine -
.nostr1.com Private Home Relays - ws://localhost:4869 (Citrine) -
.nostr1.com (if you want) Search Relays - nostr.wine - relay.nostr.band - relay.noswhere.com
Local Relays - ws://localhost:4869 (Citrine)
General Relays - nos.lol - relay.damus.io - relay.primal.net - nostr.mom
And a few of the recommended relays from Amethyst.
Final Considerations
Remember, relays can see what your Nostr client is requesting and downloading at all times. They can track what you see and see what you like. They can sell that information to the highest bidder, they can delete your content or content that a sponsor asked them to delete (like a negative review for instance) and they can censor you in any way they see fit. Before using any random free relay out there, make sure you trust its operator and you know its terms of service and privacy policies.
-
@ 09fbf8f3:fa3d60f0
2025-02-17 15:23:11
🌟 深度探索:在Cloudflare上免费部署DeepSeek-R1 32B大模型
🌍 一、 注册或登录Cloudflare平台(CF老手可跳过)
1️⃣ 进入Cloudflare平台官网:
。www.cloudflare.com/zh-cn/
登录或者注册账号。
2️⃣ 新注册的用户会让你选择域名,无视即可,直接点下面的Start building。
3️⃣ 进入仪表盘后,界面可能会显示英文,在右上角切换到[简体中文]即可。
🚀 二、正式开始部署Deepseek API项目。
1️⃣ 首先在左侧菜单栏找到【AI】下的【Wokers AI】,选择【Llama 3 Woker】。
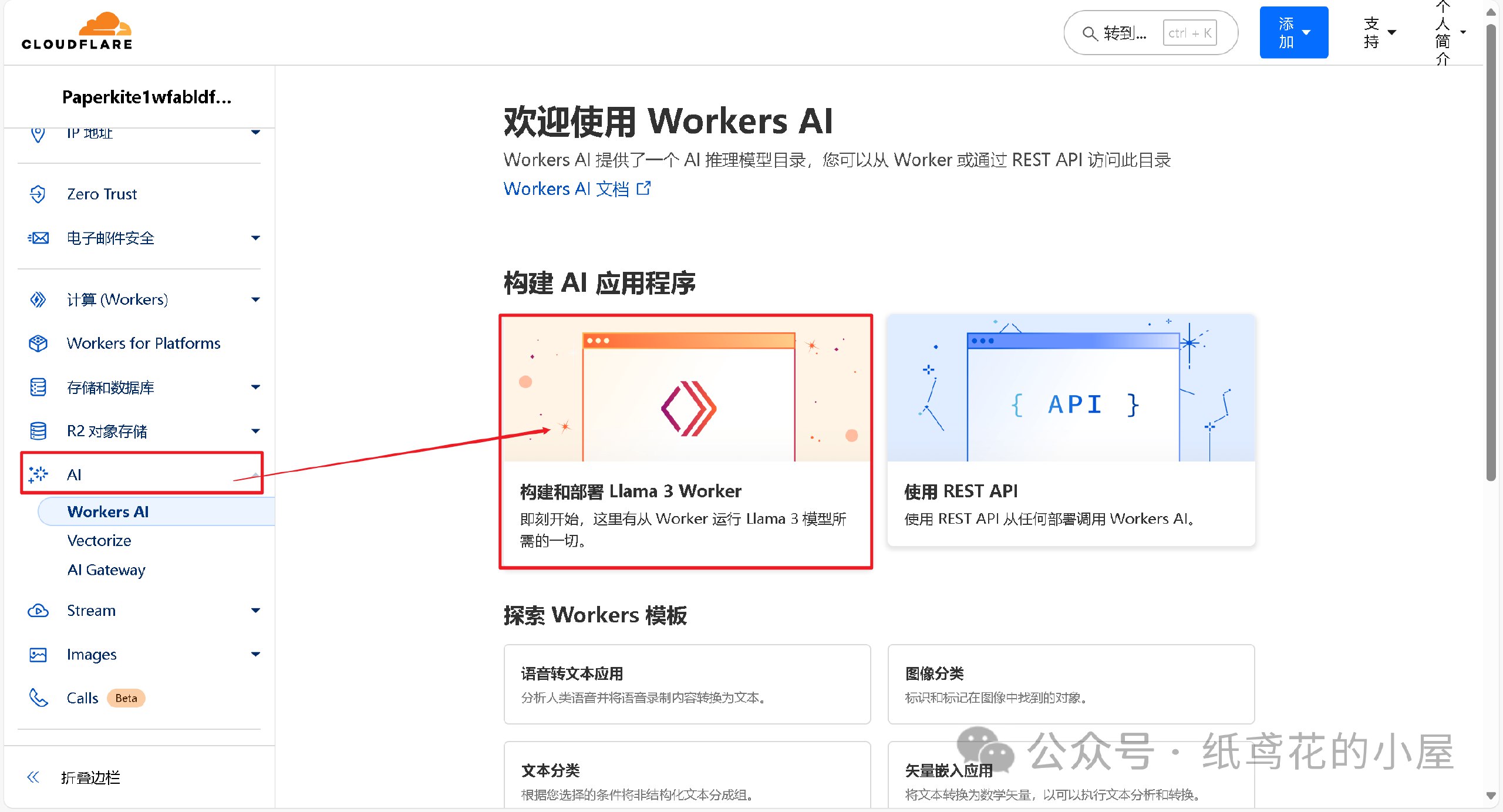
2️⃣ 为项目取一个好听的名字,后点击部署即可。
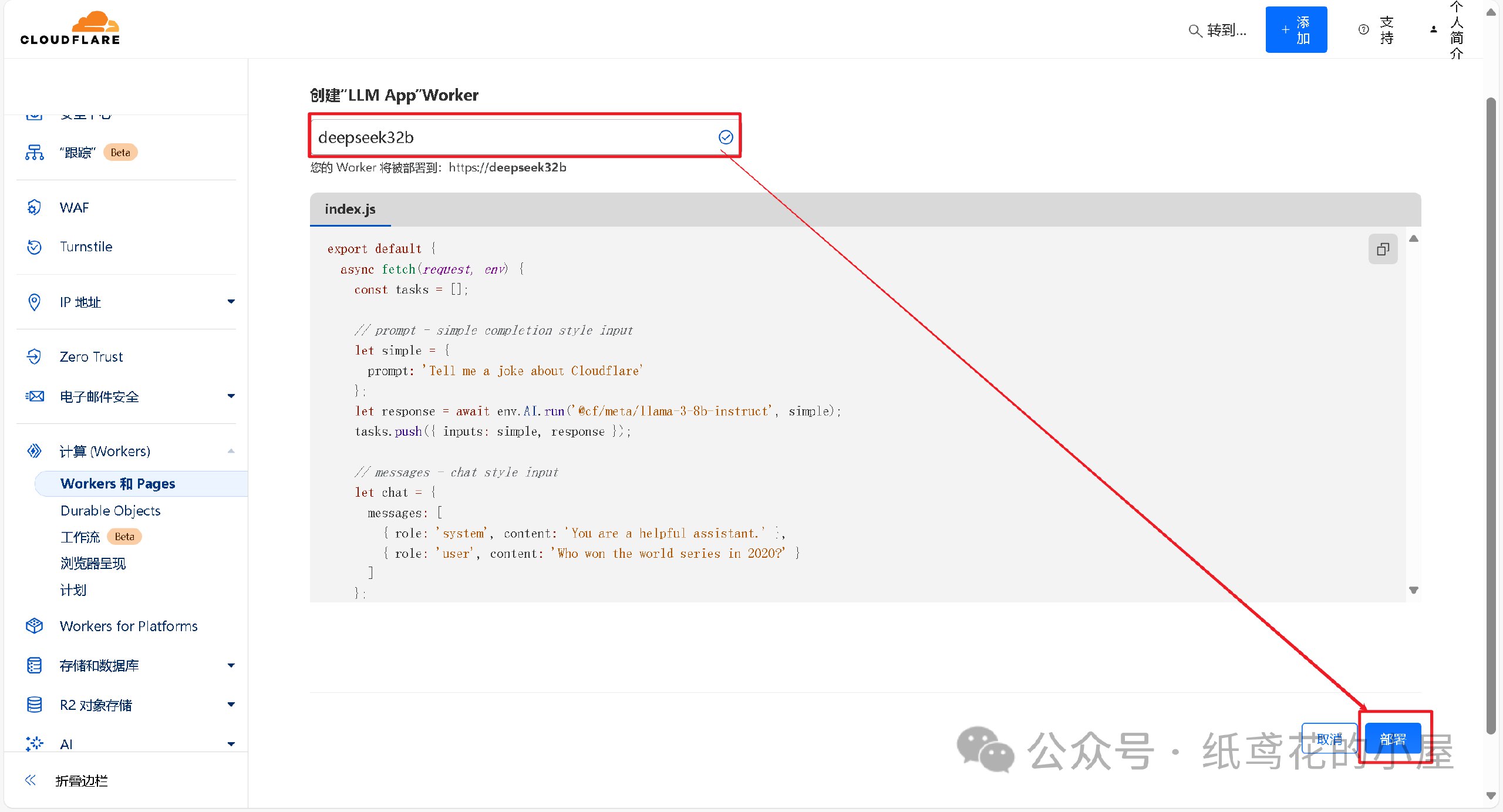
3️⃣ Woker项目初始化部署好后,需要编辑替换掉其原代码。
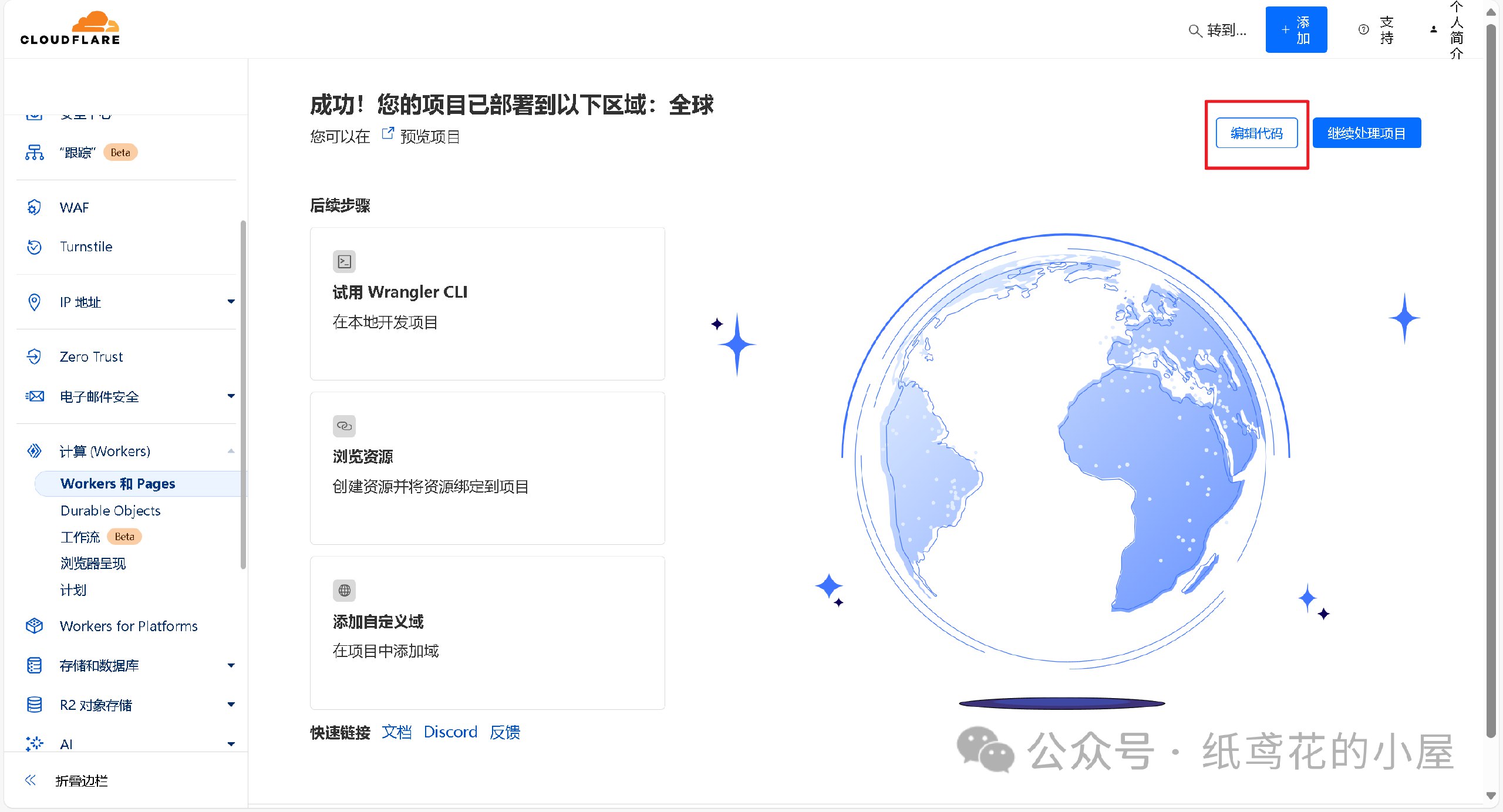
4️⃣ 解压出提供的代码压缩包,找到【32b】的部署代码,将里面的文本复制出来。
5️⃣ 接第3步,将项目里的原代码清空,粘贴第4步复制好的代码到编辑器。
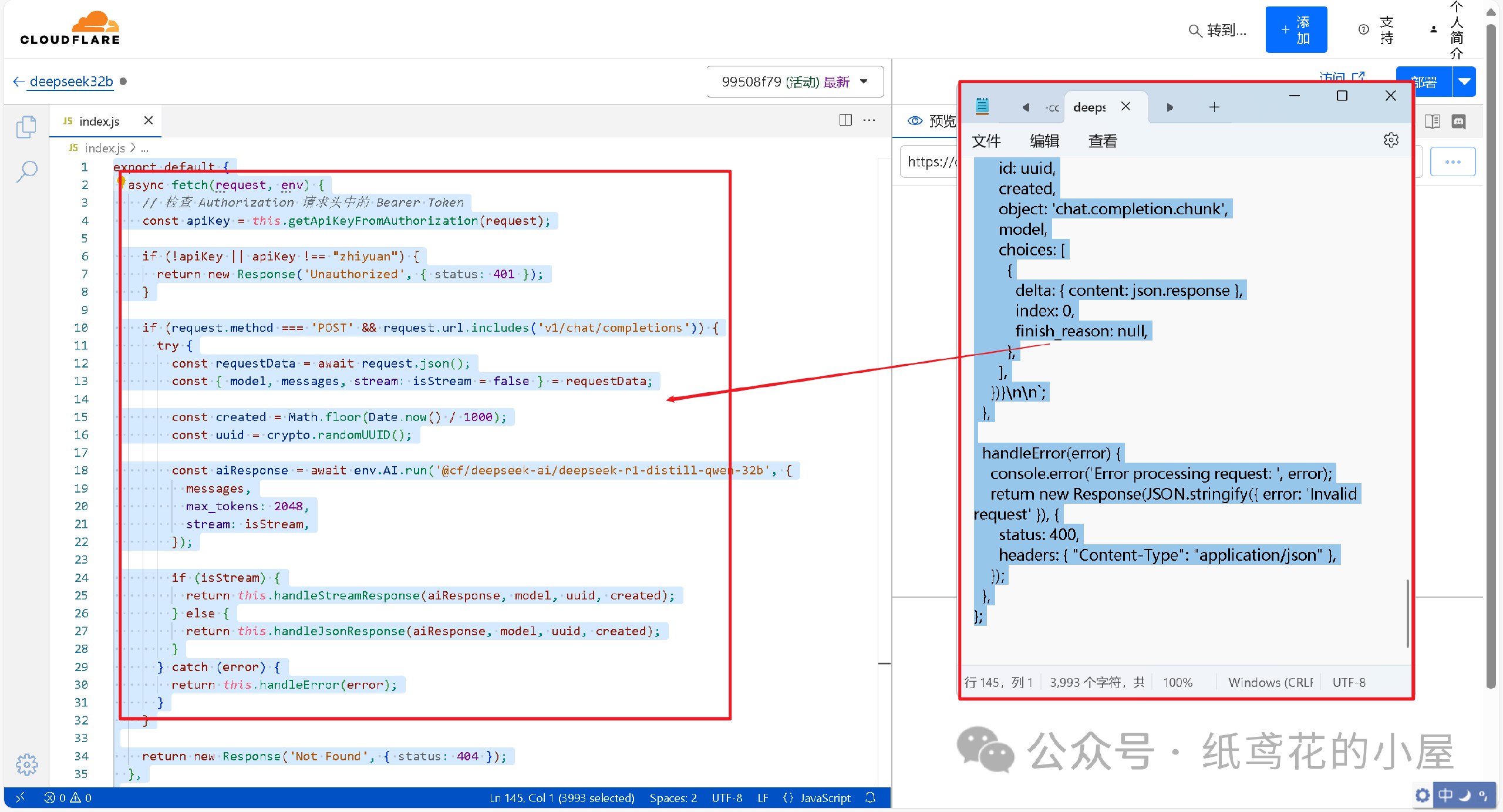
6️⃣ 代码粘贴完,即可点击右上角的部署按钮。
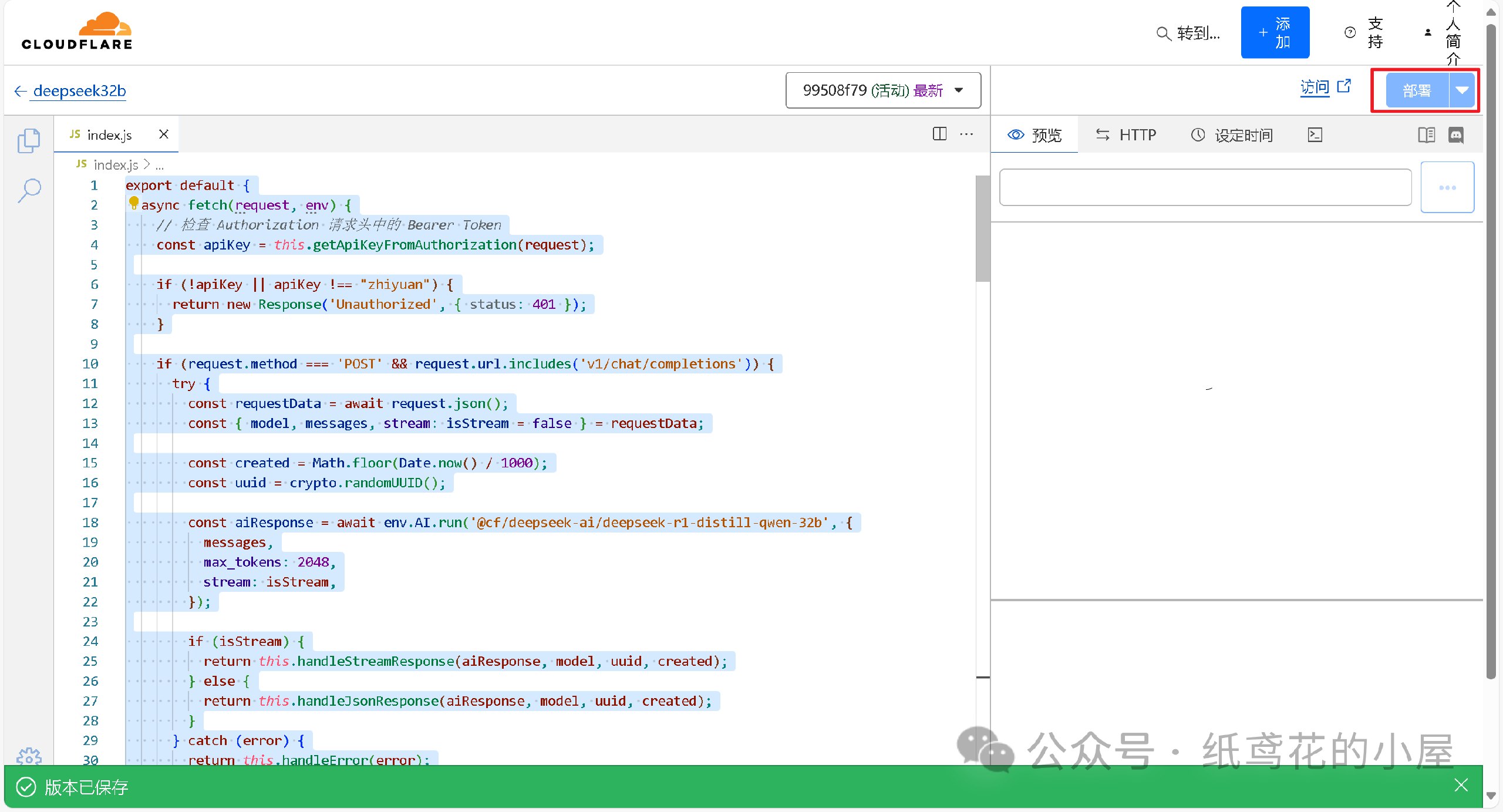
7️⃣ 回到仪表盘,点击部署完的项目名称。
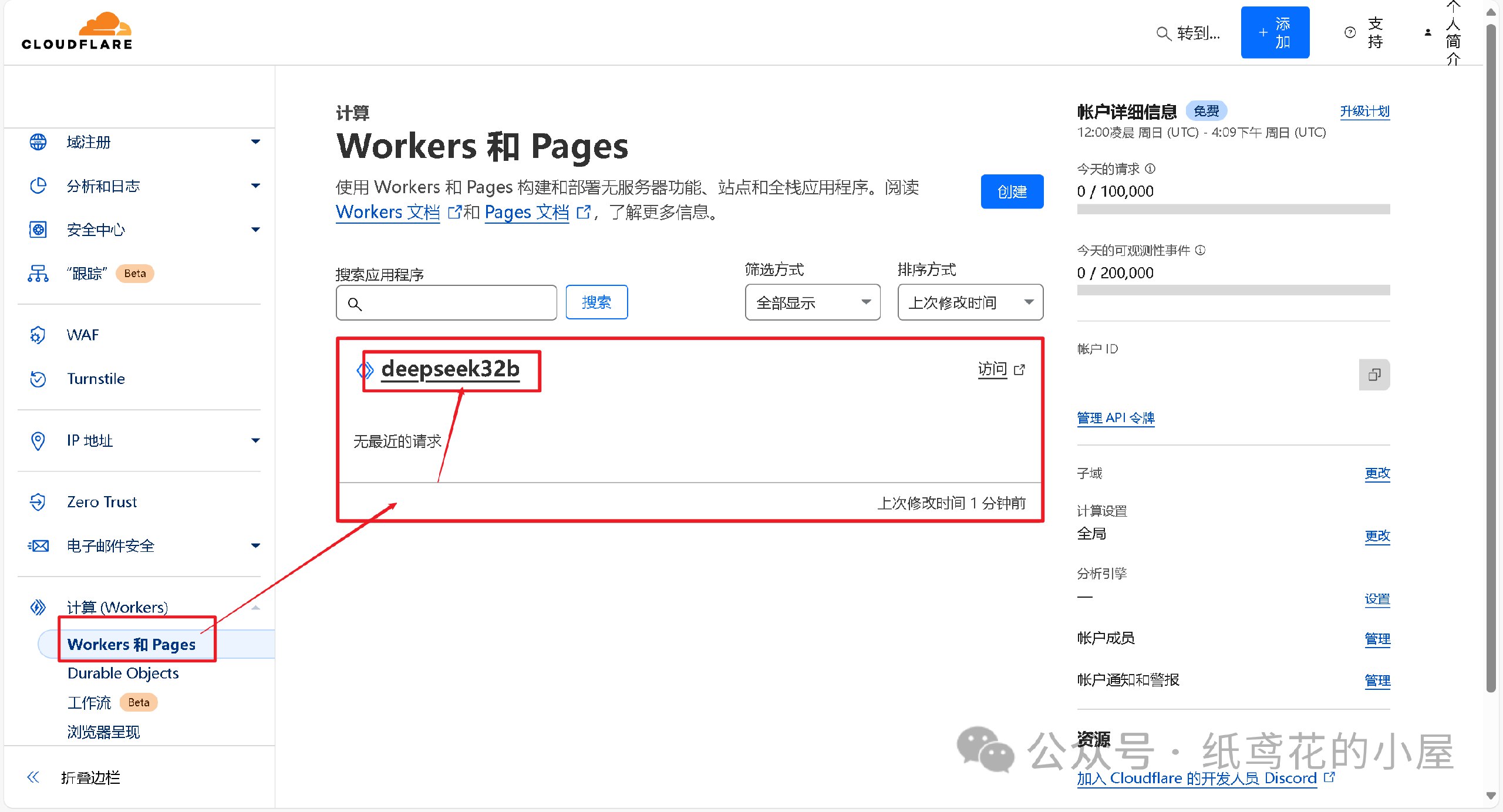
8️⃣ 查看【设置】,找到平台分配的项目网址,复制好备用。
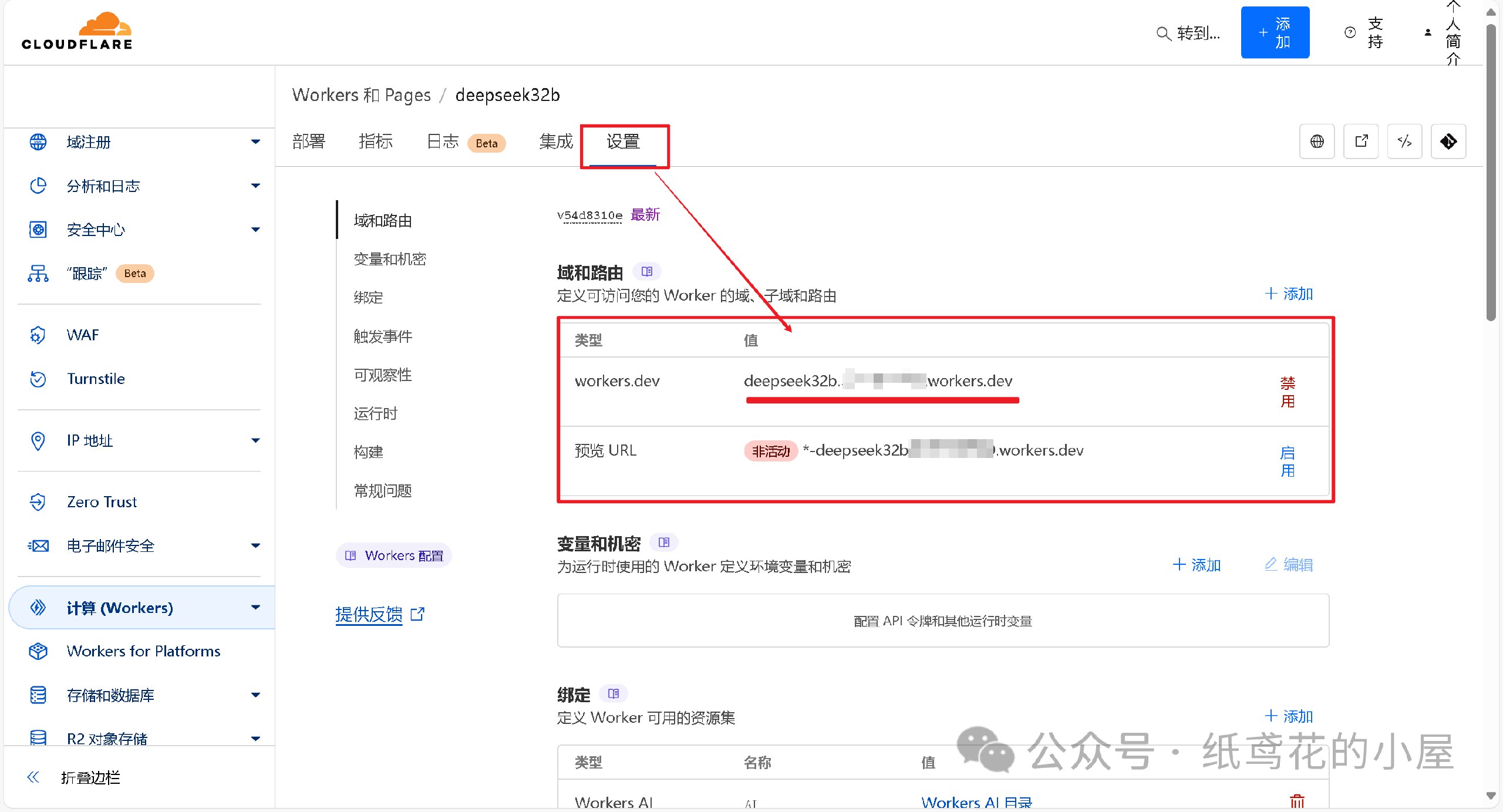
💻 三、选择可用的UI软件,这边使用Chatbox AI演示。
1️⃣ 根据自己使用的平台下载对应的安装包,博主也一并打包好了全平台的软件安装包。
2️⃣ 打开安装好的Chatbox,点击左下角的设置。
3️⃣ 选择【添加自定义提供方】。
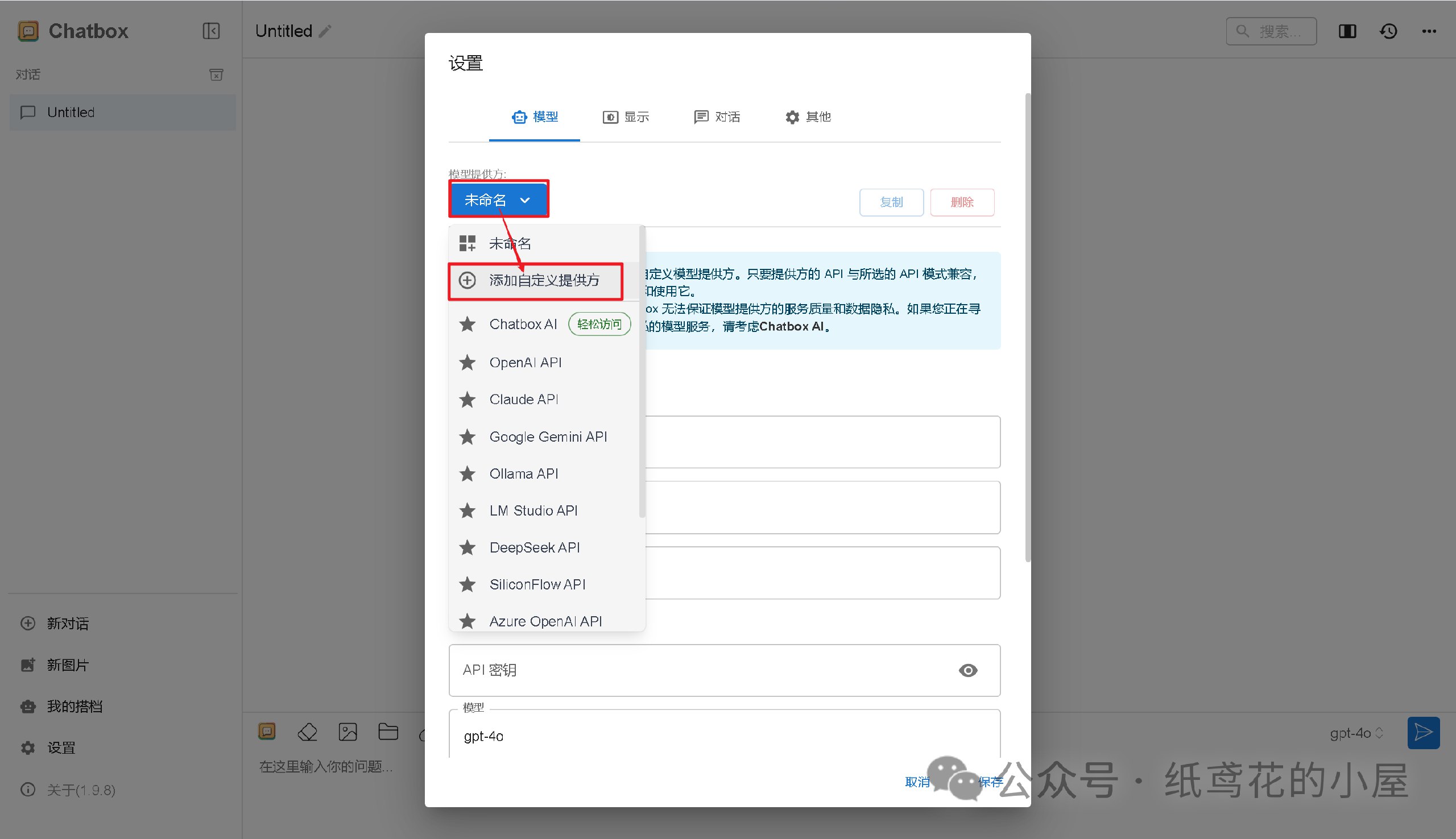
4️⃣ 按照图片说明填写即可,【API域名】为之前复制的项目网址(加/v1);【改善网络兼容性】功能务必开启;【API密钥】默认为”zhiyuan“,可自行修改;填写完毕后保存即可。
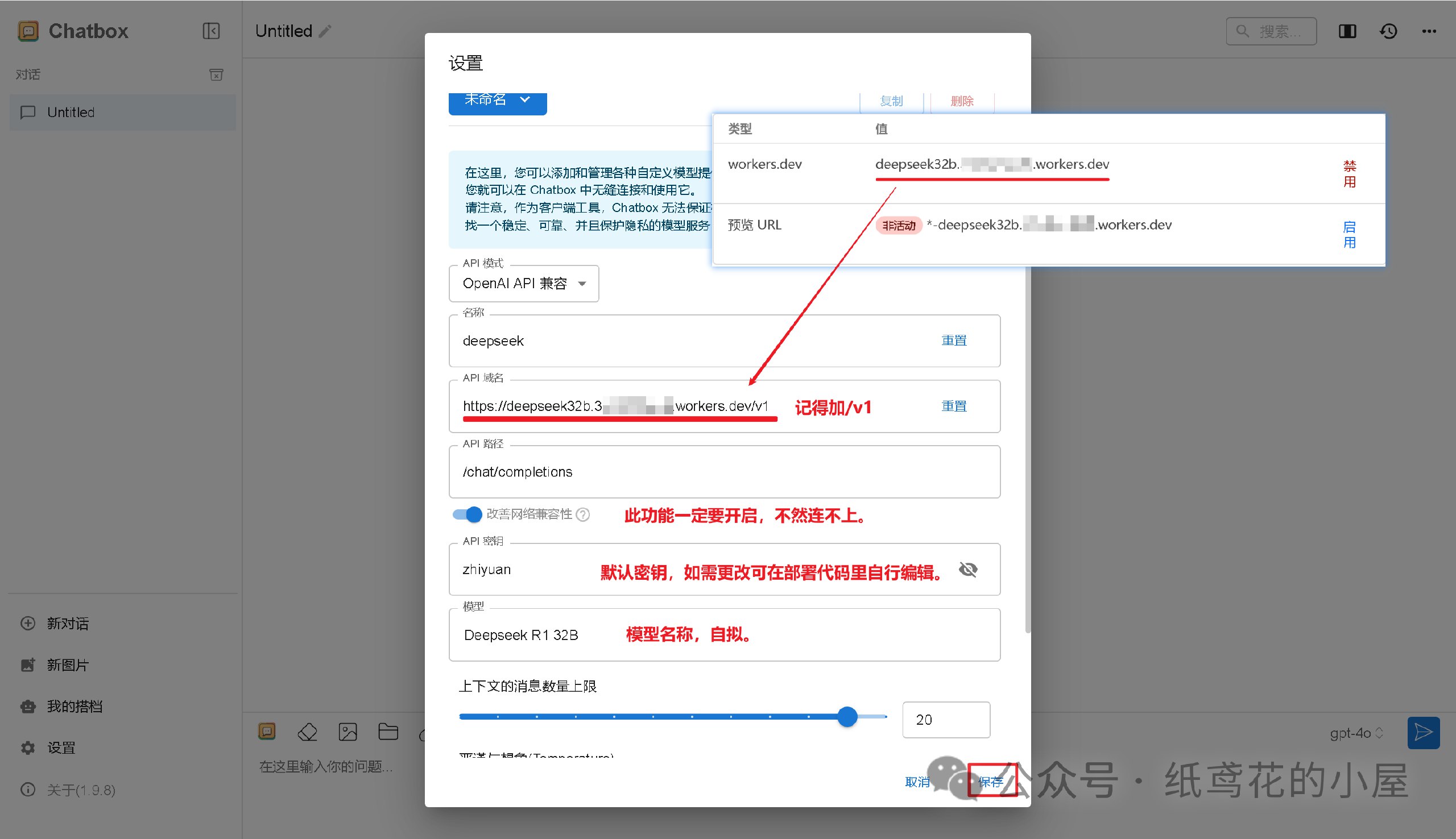
5️⃣ Cloudflare项目部署好后,就能正常使用了,接口仿照OpenAI API具有较强的兼容性,能导入到很多支持AI功能的软件或插件中。
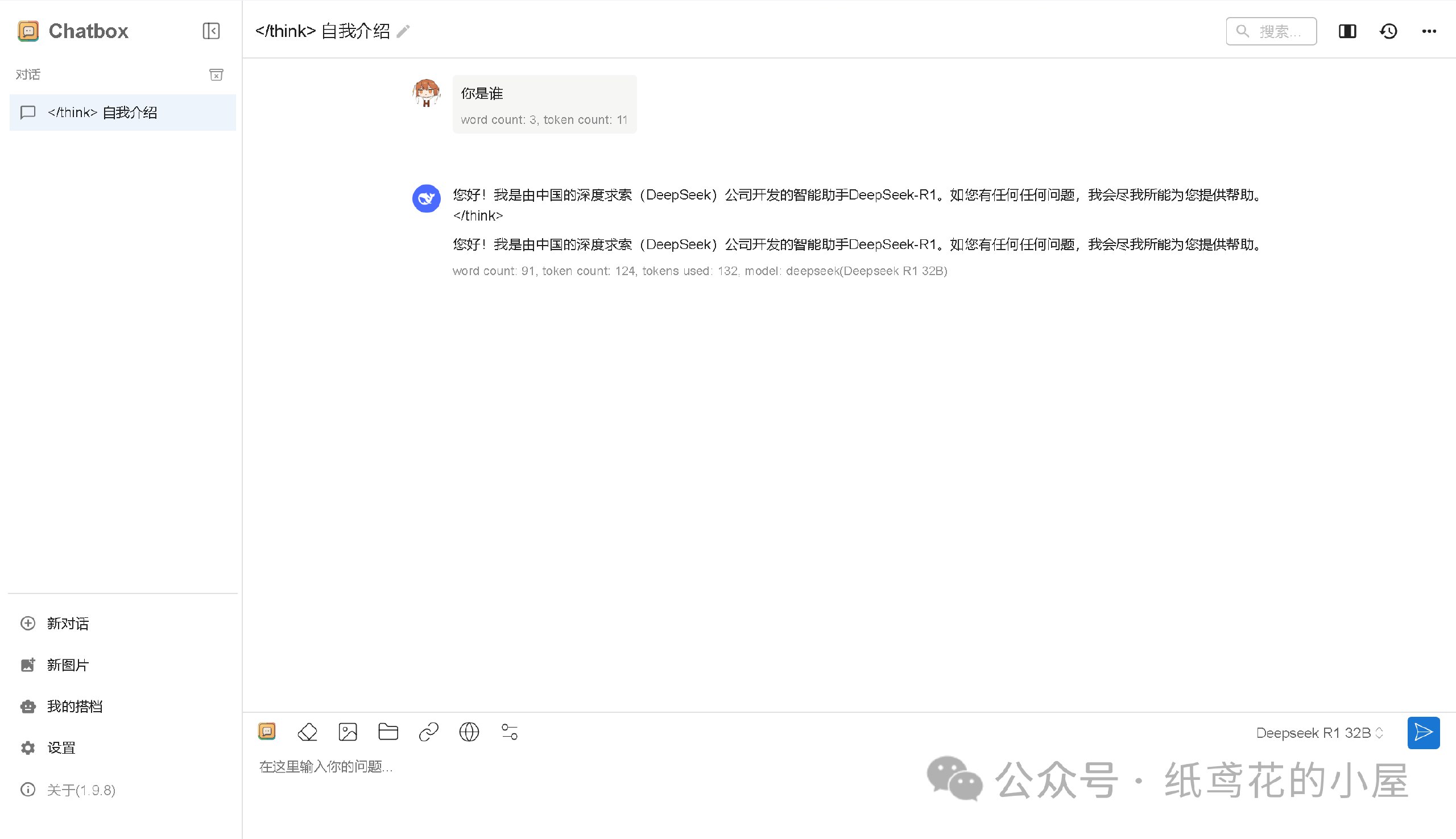
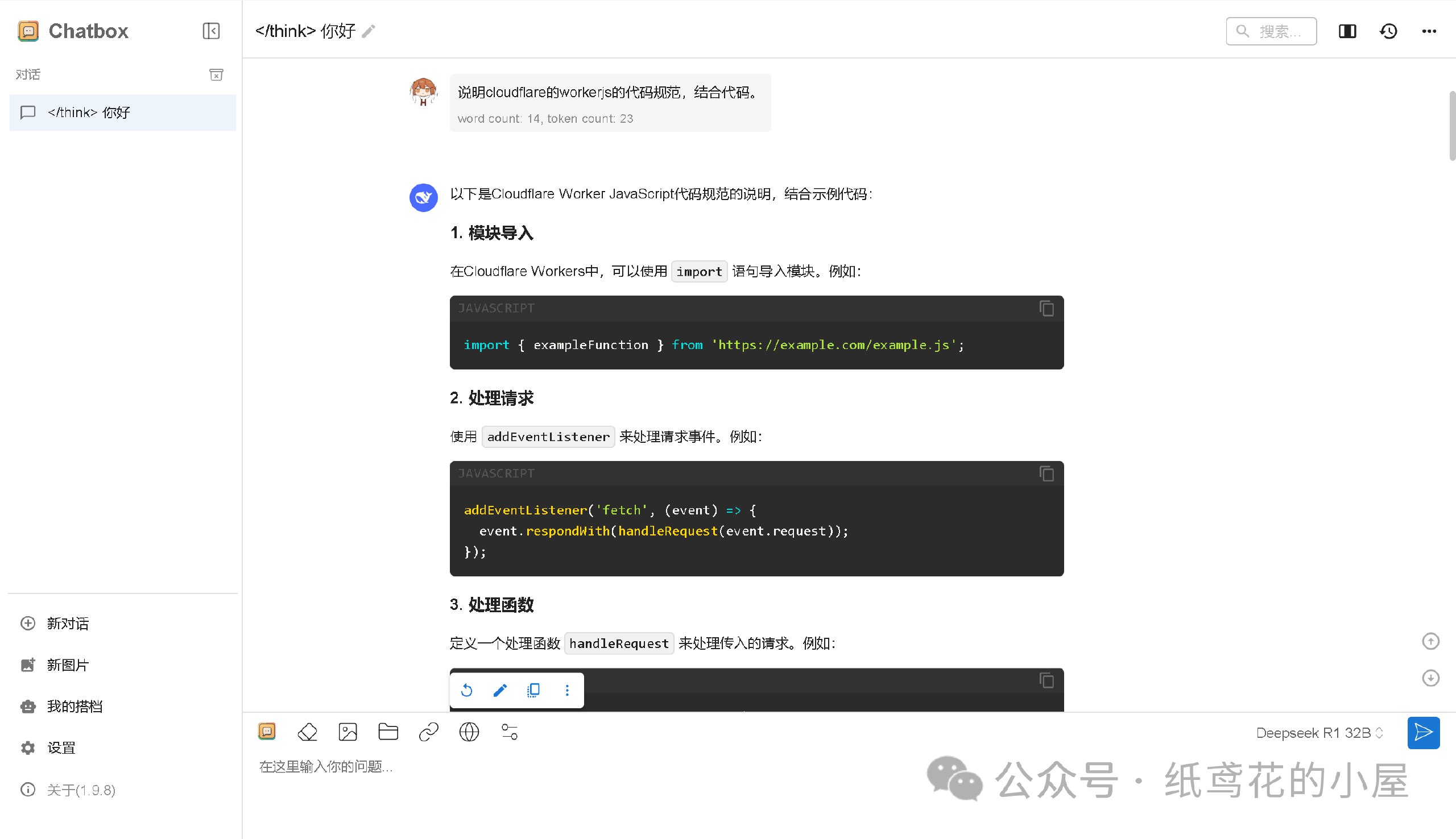
6️⃣ Cloudflare的域名默认被墙了,需要自己准备一个域名设置。
转自微信公众号:纸鸢花的小屋
推广:低调云(梯子VPN)
。www.didiaocloud.xyz -
@ de6c63ab:d028389b
2025-04-26 14:06:14
Ever wondered why Bitcoin stops at 20,999,999.9769 and not a clean 21M? It’s not a bug — it’s brilliant.
https://blossom.primal.net/8e9e6fffbca54dfb8e55071ae590e676b355803ef18b08c8cbd9521a2eb567a8.png
Of course, it's because of this mythical and seemingly magical formula. Want to hear the full story behind this? Keep reading!
The Simple Math Behind It
In reality, there’s no magic here — it’s just an ordinary summation. That big sigma symbol (Σ) tells you that. The little “i” is the summation index, starting from 0 at the bottom and going up to 32 at the top. Why 32? We’ll get there!
After the sigma, you see the expression: 210,000 × (50 ÷ 2^i). 210,000 blocks represent one halving interval, with about 144 blocks mined per day, amounting to almost exactly four years. After each interval, the block reward halves — that’s what the division by 2^i means.
Crunching the Numbers
When i = 0 (before the first halving): 210,000 × (50 ÷ 2^0) = 10,500,000
At i = 1 (after the first halving): 210,000 × (50 ÷ 2^1) = 5,250,000
At i = 2 (after the second halving): 210,000 × (50 ÷ 2^2) = 2,625,000
…
At i = 31: 210,000 × (50 ÷ 2^31) ≈ 0.00489
At i = 32: 210,000 × (50 ÷ 2^32) ≈ 0.00244
And when you sum all of that up? 20,999,999.99755528
Except… that’s not the correct total! The real final number is: 20,999,999.9769
Where the Real Magic Happens
How come?! Here’s where the real fun begins.
We just performed the summation with real (floating-point) numbers. But computers don’t like working with real numbers. They much prefer integers. That’s also one reason why a bitcoin can’t be divided infinitely — the smallest unit is one satoshi, one hundred-millionth of a bitcoin.
And that’s also why there are exactly 33 halvings (0th, 1st, 2nd, …, 31st, 32nd). After the 32nd halving, the block reward would drop below one satoshi, making further halvings meaningless.
https://blossom.primal.net/6abae5b19bc68737c5b14785f54713e7ce11dfdecbe10c64692fc8d9a90c7f34.png
The Role of Integer Math and Bit-Shifting
Because Bitcoin operates with integers (specifically satoshis), the division (reward ÷ 2^i) is actually done using integer division. More precisely, by bit-shifting to the right:
https://blossom.primal.net/3dac403390dd24df4fa8c474db62476fba814bb8c98ca663e6e3a536f4ff7d98.png
We work with 64-bit integers. Halving the value simply means shifting the bits one position to the right.
What Happens During the Halvings
Notice: during the first 9 halvings (i = 0 to i = 8), we’re just shaving off zeros. But starting with the 9th halving (i = 9), we start losing ones. Every time a “one” falls off, it means we’re losing a tiny fraction — a remainder that would have existed if we were using real numbers.
The sum of all these lost remainders is exactly the difference between the two numbers we saw above.
And that’s why the total bitcoin supply is 20,999,999.9769 — not 21 million exactly.
Did you enjoy this? Got any questions? 🔥🚀
-
@ daa41bed:88f54153
2025-02-09 16:50:04
There has been a good bit of discussion on Nostr over the past few days about the merits of zaps as a method of engaging with notes, so after writing a rather lengthy article on the pros of a strategic Bitcoin reserve, I wanted to take some time to chime in on the much more fun topic of digital engagement.
Let's begin by defining a couple of things:
Nostr is a decentralized, censorship-resistance protocol whose current biggest use case is social media (think Twitter/X). Instead of relying on company servers, it relies on relays that anyone can spin up and own their own content. Its use cases are much bigger, though, and this article is hosted on my own relay, using my own Nostr relay as an example.
Zap is a tip or donation denominated in sats (small units of Bitcoin) sent from one user to another. This is generally done directly over the Lightning Network but is increasingly using Cashu tokens. For the sake of this discussion, how you transmit/receive zaps will be irrelevant, so don't worry if you don't know what Lightning or Cashu are.
If we look at how users engage with posts and follows/followers on platforms like Twitter, Facebook, etc., it becomes evident that traditional social media thrives on engagement farming. The more outrageous a post, the more likely it will get a reaction. We see a version of this on more visual social platforms like YouTube and TikTok that use carefully crafted thumbnail images to grab the user's attention to click the video. If you'd like to dive deep into the psychology and science behind social media engagement, let me know, and I'd be happy to follow up with another article.
In this user engagement model, a user is given the option to comment or like the original post, or share it among their followers to increase its signal. They receive no value from engaging with the content aside from the dopamine hit of the original experience or having their comment liked back by whatever influencer they provide value to. Ad revenue flows to the content creator. Clout flows to the content creator. Sales revenue from merch and content placement flows to the content creator. We call this a linear economy -- the idea that resources get created, used up, then thrown away. Users create content and farm as much engagement as possible, then the content is forgotten within a few hours as they move on to the next piece of content to be farmed.
What if there were a simple way to give value back to those who engage with your content? By implementing some value-for-value model -- a circular economy. Enter zaps.

Unlike traditional social media platforms, Nostr does not actively use algorithms to determine what content is popular, nor does it push content created for active user engagement to the top of a user's timeline. Yes, there are "trending" and "most zapped" timelines that users can choose to use as their default, but these use relatively straightforward engagement metrics to rank posts for these timelines.
That is not to say that we may not see clients actively seeking to refine timeline algorithms for specific metrics. Still, the beauty of having an open protocol with media that is controlled solely by its users is that users who begin to see their timeline gamed towards specific algorithms can choose to move to another client, and for those who are more tech-savvy, they can opt to run their own relays or create their own clients with personalized algorithms and web of trust scoring systems.
Zaps enable the means to create a new type of social media economy in which creators can earn for creating content and users can earn by actively engaging with it. Like and reposting content is relatively frictionless and costs nothing but a simple button tap. Zaps provide active engagement because they signal to your followers and those of the content creator that this post has genuine value, quite literally in the form of money—sats.

I have seen some comments on Nostr claiming that removing likes and reactions is for wealthy people who can afford to send zaps and that the majority of people in the US and around the world do not have the time or money to zap because they have better things to spend their money like feeding their families and paying their bills. While at face value, these may seem like valid arguments, they, unfortunately, represent the brainwashed, defeatist attitude that our current economic (and, by extension, social media) systems aim to instill in all of us to continue extracting value from our lives.
Imagine now, if those people dedicating their own time (time = money) to mine pity points on social media would instead spend that time with genuine value creation by posting content that is meaningful to cultural discussions. Imagine if, instead of complaining that their posts get no zaps and going on a tirade about how much of a victim they are, they would empower themselves to take control of their content and give value back to the world; where would that leave us? How much value could be created on a nascent platform such as Nostr, and how quickly could it overtake other platforms?
Other users argue about user experience and that additional friction (i.e., zaps) leads to lower engagement, as proven by decades of studies on user interaction. While the added friction may turn some users away, does that necessarily provide less value? I argue quite the opposite. You haven't made a few sats from zaps with your content? Can't afford to send some sats to a wallet for zapping? How about using the most excellent available resource and spending 10 seconds of your time to leave a comment? Likes and reactions are valueless transactions. Social media's real value derives from providing monetary compensation and actively engaging in a conversation with posts you find interesting or thought-provoking. Remember when humans thrived on conversation and discussion for entertainment instead of simply being an onlooker of someone else's life?
If you've made it this far, my only request is this: try only zapping and commenting as a method of engagement for two weeks. Sure, you may end up liking a post here and there, but be more mindful of how you interact with the world and break yourself from blind instinct. You'll thank me later.

-
@ 127d3bf5:466f416f
2025-02-09 03:31:22
I can see why someone would think that buying some other crypto is a reasonable idea for "diversification" or even just for a bit of fun gambling, but it is not.
There are many reasons you should stick to Bitcoin only, and these have been proven correct every cycle. I've outlined these before but will cut and paste below as a summary.
The number one reason, is healthy ethical practice:
- The whole point of Bitcoin is to escape the trappings and flaws of traditional systems. Currency trading and speculative investing is a Tradfi concept, and you will end up back where you started. Sooner or later this becomes obvious to everyone. Bitcoin is the healthy and ethical choice for yourself and everyone else.
But...even if you want to be greedy, hold your horses:
- There is significant risk in wallets, defi, and cefi exchanges. Many have lost all their funds in these through hacks and services getting banned or going bankrupt.
- You get killed in exchange fees even when buying low and selling high. This is effectively a transaction tax which is often hidden (sometimes they don't show the fee, just mark up the exchange rate). Also true on defi exchanges.
- You are up against traders and founders with insider knowledge and much more sophisticated prediction models that will fleece you eventually. You cannot time the market better than they can, and it is their full-time to job to beat you and suck as much liquidity out of you as they can. House always wins.
- Every crypto trade is a taxable event, so you will be taxed on all gains anyway in most countries. So not only are the traders fleecing you, the govt is too.
- It ruins your quality of life constantly checking prices and stressing about making the wrong trade.
The best option, by far, is to slowly DCA into Bitcoin and take this off exchanges into your own custody. In the long run this strategy works out better financially, ethically, and from a quality-of-life perspective. Saving, not trading.
I've been here since 2014 and can personally attest to this.

-
@ 266815e0:6cd408a5
2025-04-26 13:10:09
To all existing nostr developers and new nostr developers, stop using kind 1 events... just stop whatever your doing and switch the kind to
Math.round(Math.random() * 10000)trust me it will be betterWhat are kind 1 events
kind 1 events are defined in NIP-10 as "simple plaintext notes" or in other words social posts.
Don't trick your users
Most users are joining nostr for the social experience, and secondly to find all the cool "other stuff" apps They find friends, browse social posts, and reply to them. If a user signs into a new nostr client and it starts asking them to sign kind 1 events with blobs of JSON, they will sign it without thinking too much about it.
Then when they return to their comfy social apps they will see that they made 10+ posts with massive amounts of gibberish that they don't remember posting. then they probably will go looking for the delete button and realize there isn't one...
Even if those kind 1 posts don't contain JSON and have a nice fancy human readable syntax. they will still confuse users because they won't remember writing those social posts
What about "discoverability"
If your goal is to make your "other stuff" app visible to more users, then I would suggest using NIP-19 and NIP-89 The first allows users to embed any other event kind into social posts as
nostr:nevent1ornostr:naddr1links, and the second allows social clients to redirect users to an app that knows how to handle that specific kind of eventSo instead of saving your apps data into kind 1 events. you can pick any kind you want, then give users a "share on nostr" button that allows them to compose a social post (kind 1) with a
nostr:link to your special kind of event and by extension you appWhy its a trap
Once users start using your app it becomes a lot more difficult to migrate to a new event kind or data format. This sounds obvious, but If your app is built on kind 1 events that means you will be stuck with their limitations forever.
For example, here are some of the limitations of using kind 1 - Querying for your apps data becomes much more difficult. You have to filter through all of a users kind 1 events to find which ones are created by your app - Discovering your apps data is more difficult for the same reason, you have to sift through all the social posts just to find the ones with you special tag or that contain JSON - Users get confused. as mentioned above users don't expect "other stuff" apps to be creating special social posts - Other nostr clients won't understand your data and will show it as a social post with no option for users to learn about your app
-
@ ec42c765:328c0600
2025-02-05 23:38:12
カスタム絵文字とは
任意のオリジナル画像を絵文字のように文中に挿入できる機能です。
また、リアクション(Twitterの いいね のような機能)にもカスタム絵文字を使えます。

カスタム絵文字の対応状況(2025/02/06)

カスタム絵文字を使うためにはカスタム絵文字に対応したクライアントを使う必要があります。
※表は一例です。クライアントは他にもたくさんあります。
使っているクライアントが対応していない場合は、クライアントを変更する、対応するまで待つ、開発者に要望を送る(または自分で実装する)などしましょう。
対応クライアント
ここではnostterを使って説明していきます。
準備
カスタム絵文字を使うための準備です。
- Nostrエクステンション(NIP-07)を導入する
- 使いたいカスタム絵文字をリストに登録する
Nostrエクステンション(NIP-07)を導入する
Nostrエクステンションは使いたいカスタム絵文字を登録する時に必要になります。
また、環境(パソコン、iPhone、androidなど)によって導入方法が違います。
Nostrエクステンションを導入する端末は、実際にNostrを閲覧する端末と違っても構いません(リスト登録はPC、Nostr閲覧はiPhoneなど)。
Nostrエクステンション(NIP-07)の導入方法は以下のページを参照してください。
ログイン拡張機能 (NIP-07)を使ってみよう | Welcome to Nostr! ~ Nostrをはじめよう! ~
少し面倒ですが、これを導入しておくとNostr上の様々な場面で役立つのでより快適になります。
使いたいカスタム絵文字をリストに登録する
以下のサイトで行います。
右上のGet startedからNostrエクステンションでログインしてください。
例として以下のカスタム絵文字を導入してみます。
実際より絵文字が少なく表示されることがありますが、古い状態のデータを取得してしまっているためです。その場合はブラウザの更新ボタンを押してください。

- 右側のOptionsからBookmarkを選択

これでカスタム絵文字を使用するためのリストに登録できます。
カスタム絵文字を使用する
例としてブラウザから使えるクライアント nostter から使用してみます。
nostterにNostrエクステンションでログイン、もしくは秘密鍵を入れてログインしてください。
文章中に使用
- 投稿ボタンを押して投稿ウィンドウを表示
- 顔😀のボタンを押し、絵文字ウィンドウを表示
- *タブを押し、カスタム絵文字一覧を表示
- カスタム絵文字を選択
- : 記号に挟まれたアルファベットのショートコードとして挿入される

この状態で投稿するとカスタム絵文字として表示されます。
カスタム絵文字対応クライアントを使っている他ユーザーにもカスタム絵文字として表示されます。
対応していないクライアントの場合、ショートコードのまま表示されます。

ショートコードを直接入力することでカスタム絵文字の候補が表示されるのでそこから選択することもできます。

リアクションに使用
- 任意の投稿の顔😀のボタンを押し、絵文字ウィンドウを表示
- *タブを押し、カスタム絵文字一覧を表示
- カスタム絵文字を選択

カスタム絵文字リアクションを送ることができます。

カスタム絵文字を探す
先述したemojitoからカスタム絵文字を探せます。
例えば任意のユーザーのページ emojito ロクヨウ から探したり、 emojito Browse all からnostr全体で最近作成、更新された絵文字を見たりできます。
また、以下のリンクは日本語圏ユーザーが作ったカスタム絵文字を集めたリストです(2025/02/06)
※漏れがあるかもしれません
各絵文字セットにあるOpen in emojitoのリンクからemojitoに飛び、使用リストに追加できます。
以上です。
次:Nostrのカスタム絵文字の作り方
Yakihonneリンク Nostrのカスタム絵文字の作り方
Nostrリンク nostr:naddr1qqxnzdesxuunzv358ycrgveeqgswcsk8v4qck0deepdtluag3a9rh0jh2d0wh0w9g53qg8a9x2xqvqqrqsqqqa28r5psx3
仕様
-
@ 5f078e90:b2bacaa3
2025-04-26 12:01:11
Panda story 3
Initially posted on Hive, story is between 300 and 500 characters. Should become a Nostr kind 30023. Image has markdown.
In a misty bamboo forest, a red panda named Rolo discovered a glowing berry. Curious, he nibbled it and began to float! Drifting over treetops, he saw his friends below, waving. Rolo somersaulted through clouds, giggling as wind tickled his fur. The berry's magic faded at dusk, landing him softly by a stream. His pals cheered his tale, and Rolo dreamed of more adventures, his heart light as the breeze. (349 characters)
Originally posted on Hive at https://hive.blog/@hostr/panda-story-3
Cross-posted using Hostr, version 0.0.3
-
@ b7274d28:c99628cb
2025-02-04 05:31:13
For anyone interested in the list of essential essays from nostr:npub14hn6p34vegy4ckeklz8jq93mendym9asw8z2ej87x2wuwf8werasc6a32x (@anilsaidso) on Twitter that nostr:npub1h8nk2346qezka5cpm8jjh3yl5j88pf4ly2ptu7s6uu55wcfqy0wq36rpev mentioned on Read 856, here it is. I have compiled it with as many of the essays as I could find, along with the audio versions, when available. Additionally, if the author is on #Nostr, I have tagged their npub so you can thank them by zapping them some sats.
All credit for this list and the graphics accompanying each entry goes to nostr:npub14hn6p34vegy4ckeklz8jq93mendym9asw8z2ej87x2wuwf8werasc6a32x, whose original thread can be found here: Anil's Essential Essays Thread
1.

History shows us that the corruption of monetary systems leads to moral decay, social collapse, and slavery.
Essay: https://breedlove22.medium.com/masters-and-slaves-of-money-255ecc93404f
Audio: https://fountain.fm/episode/RI0iCGRCCYdhnMXIN3L6
2.

The 21st century emergence of Bitcoin, encryption, the internet, and millennials are more than just trends; they herald a wave of change that exhibits similar dynamics as the 16-17th century revolution that took place in Europe.
Author: nostr:npub13l3lyslfzyscrqg8saw4r09y70702s6r025hz52sajqrvdvf88zskh8xc2
Essay: https://casebitcoin.com/docs/TheBitcoinReformation_TuurDemeester.pdf
Audio: https://fountain.fm/episode/uLgBG2tyCLMlOp3g50EL
3.

There are many men out there who will parrot the "debt is money WE owe OURSELVES" without acknowledging that "WE" isn't a static entity, but a collection of individuals at different points in their lives.
Author: nostr:npub1guh5grefa7vkay4ps6udxg8lrqxg2kgr3qh9n4gduxut64nfxq0q9y6hjy
Essay: https://www.tftc.io/issue-754-ludwig-von-mises-human-action/
Audio: https://fountain.fm/episode/UXacM2rkdcyjG9xp9O2l
4.
If Bitcoin exists for 20 years, there will be near-universal confidence that it will be available forever, much as people believe the Internet is a permanent feature of the modern world.
Essay: https://vijayboyapati.medium.com/the-bullish-case-for-bitcoin-6ecc8bdecc1
Audio: https://fountain.fm/episode/jC3KbxTkXVzXO4vR7X3W
As you are surely aware, Vijay has expanded this into a book available here: The Bullish Case for Bitcoin Book
There is also an audio book version available here: The Bullish Case for Bitcoin Audio Book
5.

This realignment would not be traditional right vs left, but rather land vs cloud, state vs network, centralized vs decentralized, new money vs old, internationalist/capitalist vs nationalist/socialist, MMT vs BTC,...Hamilton vs Satoshi.
Essay: https://nakamoto.com/bitcoin-becomes-the-flag-of-technology/
Audio: https://fountain.fm/episode/tFJKjYLKhiFY8voDssZc
6.
I became convinced that, whether bitcoin survives or not, the existing financial system is working on borrowed time.
Essay: https://nakamotoinstitute.org/mempool/gradually-then-suddenly/
Audio: https://fountain.fm/episode/Mf6hgTFUNESqvdxEIOGZ
Parker Lewis went on to release several more articles in the Gradually, Then Suddenly series. They can be found here: Gradually, Then Suddenly Series
nostr:npub1h8nk2346qezka5cpm8jjh3yl5j88pf4ly2ptu7s6uu55wcfqy0wq36rpev has, of course, read all of them for us. Listing them all here is beyond the scope of this article, but you can find them by searching the podcast feed here: Bitcoin Audible Feed
Finally, Parker Lewis has refined these articles and released them as a book, which is available here: Gradually, Then Suddenly Book
7.

Bitcoin is a beautifully-constructed protocol. Genius is apparent in its design to most people who study it in depth, in terms of the way it blends math, computer science, cyber security, monetary economics, and game theory.
Author: nostr:npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83a
Essay: https://www.lynalden.com/invest-in-bitcoin/
Audio: https://fountain.fm/episode/axeqKBvYCSP1s9aJIGSe
8.

Bitcoin offers a sweeping vista of opportunity to re-imagine how the financial system can and should work in the Internet era..
Essay: https://archive.nytimes.com/dealbook.nytimes.com/2014/01/21/why-bitcoin-matters/
9.

Using Bitcoin for consumer purchases is akin to driving a Concorde jet down the street to pick up groceries: a ridiculously expensive waste of an astonishing tool.
Author: nostr:npub1gdu7w6l6w65qhrdeaf6eyywepwe7v7ezqtugsrxy7hl7ypjsvxksd76nak
Essay: https://nakamotoinstitute.org/mempool/economics-of-bitcoin-as-a-settlement-network/
Audio: https://fountain.fm/episode/JoSpRFWJtoogn3lvTYlz
10.

The Internet is a dumb network, which is its defining and most valuable feature. The Internet’s protocol (..) doesn’t offer “services.” It doesn’t make decisions about content. It doesn’t distinguish between photos, text, video and audio.
Essay: https://fee.org/articles/decentralization-why-dumb-networks-are-better/
Audio: https://fountain.fm/episode/b7gOEqmWxn8RiDziffXf
11.

Most people are only familiar with (b)itcoin the electronic currency, but more important is (B)itcoin, with a capital B, the underlying protocol, which encapsulates and distributes the functions of contract law.
I was unable to find this essay or any audio version. Clicking on Anil's original link took me to Naval's blog, but that particular entry seems to have been removed.
12.

Bitcoin can approximate unofficial exchange rates which, in turn, can be used to detect both the existence and the magnitude of the distortion caused by capital controls & exchange rate manipulations.
Essay: https://papers.ssrn.com/sol3/Papers.cfm?abstract_id=2714921
13.

You can create something which looks cosmetically similar to Bitcoin, but you cannot replicate the settlement assurances which derive from the costliness of the ledger.
Essay: https://medium.com/@nic__carter/its-the-settlement-assurances-stupid-5dcd1c3f4e41
Audio: https://fountain.fm/episode/5NoPoiRU4NtF2YQN5QI1
14.

When we can secure the most important functionality of a financial network by computer science... we go from a system that is manual, local, and of inconsistent security to one that is automated, global, and much more secure.
Essay: https://nakamotoinstitute.org/library/money-blockchains-and-social-scalability/
Audio: https://fountain.fm/episode/VMH9YmGVCF8c3I5zYkrc
15.

The BCB enforces the strictest deposit regulations in the world by requiring full reserves for all accounts. ..money is not destroyed when bank debts are repaid, so increased money hoarding does not cause liquidity traps..
Author: nostr:npub1hxwmegqcfgevu4vsfjex0v3wgdyz8jtlgx8ndkh46t0lphtmtsnsuf40pf
Essay: https://nakamotoinstitute.org/mempool/the-bitcoin-central-banks-perfect-monetary-policy/
Audio: https://fountain.fm/episode/ralOokFfhFfeZpYnGAsD
16.

When Satoshi announced Bitcoin on the cryptography mailing list, he got a skeptical reception at best. Cryptographers have seen too many grand schemes by clueless noobs. They tend to have a knee jerk reaction.
Essay: https://nakamotoinstitute.org/library/bitcoin-and-me/
Audio: https://fountain.fm/episode/Vx8hKhLZkkI4cq97qS4Z
17.

No matter who you are, or how big your company is, 𝙮𝙤𝙪𝙧 𝙩𝙧𝙖𝙣𝙨𝙖𝙘𝙩𝙞𝙤𝙣 𝙬𝙤𝙣’𝙩 𝙥𝙧𝙤𝙥𝙖𝙜𝙖𝙩𝙚 𝙞𝙛 𝙞𝙩’𝙨 𝙞𝙣𝙫𝙖𝙡𝙞𝙙.
Essay: https://nakamotoinstitute.org/mempool/bitcoin-miners-beware-invalid-blocks-need-not-apply/
Audio: https://fountain.fm/episode/bcSuBGmOGY2TecSov4rC
18.

Just like a company trying to protect itself from being destroyed by a new competitor, the actions and reactions of central banks and policy makers to protect the system that they know, are quite predictable.
Author: nostr:npub1s05p3ha7en49dv8429tkk07nnfa9pcwczkf5x5qrdraqshxdje9sq6eyhe
Essay: https://medium.com/the-bitcoin-times/the-greatest-game-b787ac3242b2
Audio Part 1: https://fountain.fm/episode/5bYyGRmNATKaxminlvco
Audio Part 2: https://fountain.fm/episode/92eU3h6gqbzng84zqQPZ
19.

Technology, industry, and society have advanced immeasurably since, and yet we still live by Venetian financial customs and have no idea why. Modern banking is the legacy of a problem that technology has since solved.
Author: nostr:npub1sfhflz2msx45rfzjyf5tyj0x35pv4qtq3hh4v2jf8nhrtl79cavsl2ymqt
Essay: https://allenfarrington.medium.com/bitcoin-is-venice-8414dda42070
Audio: https://fountain.fm/episode/s6Fu2VowAddRACCCIxQh
Allen Farrington and Sacha Meyers have gone on to expand this into a book, as well. You can get the book here: Bitcoin is Venice Book
And wouldn't you know it, Guy Swann has narrated the audio book available here: Bitcoin is Venice Audio Book
20.

The rich and powerful will always design systems that benefit them before everyone else. The genius of Bitcoin is to take advantage of that very base reality and force them to get involved and help run the system, instead of attacking it.
Author: nostr:npub1trr5r2nrpsk6xkjk5a7p6pfcryyt6yzsflwjmz6r7uj7lfkjxxtq78hdpu
Essay: https://quillette.com/2021/02/21/can-governments-stop-bitcoin/
Audio: https://fountain.fm/episode/jeZ21IWIlbuC1OGnssy8
21.

In the realm of information, there is no coin-stamping without time-stamping. The relentless beating of this clock is what gives rise to all the magical properties of Bitcoin.
Author: nostr:npub1dergggklka99wwrs92yz8wdjs952h2ux2ha2ed598ngwu9w7a6fsh9xzpc
Essay: https://dergigi.com/2021/01/14/bitcoin-is-time/
Audio: https://fountain.fm/episode/pTevCY2vwanNsIso6F6X
22.

You can stay on the Fiat Standard, in which some people get to produce unlimited new units of money for free, just not you. Or opt in to the Bitcoin Standard, in which no one gets to do that, including you.
Essay: https://casebitcoin.com/docs/StoneRidge_2020_Shareholder_Letter.pdf
Audio: https://fountain.fm/episode/PhBTa39qwbkwAtRnO38W
23.

Long term investors should use Bitcoin as their unit of account and every single investment should be compared to the expected returns of Bitcoin.
Essay: https://nakamotoinstitute.org/mempool/everyones-a-scammer/
Audio: https://fountain.fm/episode/vyR2GUNfXtKRK8qwznki
24.

When you’re in the ivory tower, you think the term “ivory tower” is a silly misrepresentation of your very normal life; when you’re no longer in the ivory tower, you realize how willfully out of touch you were with the world.
Essay: https://www.citadel21.com/why-the-yuppie-elite-dismiss-bitcoin
Audio: https://fountain.fm/episode/7do5K4pPNljOf2W3rR2V
You might notice that many of the above essays are available from the Satoshi Nakamoto Institute. It is a veritable treasure trove of excellent writing on subjects surrounding #Bitcoin and #AustrianEconomics. If you find value in them keeping these written works online for the next wave of new Bitcoiners to have an excellent source of education, please consider donating to the cause.
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ 5f078e90:b2bacaa3
2025-04-26 10:51:39
Panda story 1
Initially posted on Hive, story is between 300 and 500 characters. Should become a Nostr kind 30023. Image has markdown.
In a misty bamboo forest, a red panda named Rolo discovered a glowing berry. Curious, he nibbled it and began to float! Drifting over treetops, he saw his friends below, waving. Rolo somersaulted through clouds, giggling as wind tickled his fur. The berry's magic faded at dusk, landing him softly by a stream. His pals cheered his tale, and Rolo dreamed of more adventures, his heart light as the breeze. (349 characters)

Originally posted on Hive at https://hive.blog/@hostr/panda-story-1
Cross-posted using Hostr, version 0.0.1
-
@ 91bea5cd:1df4451c
2025-04-26 10:16:21
O Contexto Legal Brasileiro e o Consentimento
No ordenamento jurídico brasileiro, o consentimento do ofendido pode, em certas circunstâncias, afastar a ilicitude de um ato que, sem ele, configuraria crime (como lesão corporal leve, prevista no Art. 129 do Código Penal). Contudo, o consentimento tem limites claros: não é válido para bens jurídicos indisponíveis, como a vida, e sua eficácia é questionável em casos de lesões corporais graves ou gravíssimas.
A prática de BDSM consensual situa-se em uma zona complexa. Em tese, se ambos os parceiros são adultos, capazes, e consentiram livre e informadamente nos atos praticados, sem que resultem em lesões graves permanentes ou risco de morte não consentido, não haveria crime. O desafio reside na comprovação desse consentimento, especialmente se uma das partes, posteriormente, o negar ou alegar coação.
A Lei Maria da Penha (Lei nº 11.340/2006)
A Lei Maria da Penha é um marco fundamental na proteção da mulher contra a violência doméstica e familiar. Ela estabelece mecanismos para coibir e prevenir tal violência, definindo suas formas (física, psicológica, sexual, patrimonial e moral) e prevendo medidas protetivas de urgência.
Embora essencial, a aplicação da lei em contextos de BDSM pode ser delicada. Uma alegação de violência por parte da mulher, mesmo que as lesões ou situações decorram de práticas consensuais, tende a receber atenção prioritária das autoridades, dada a presunção de vulnerabilidade estabelecida pela lei. Isso pode criar um cenário onde o parceiro masculino enfrenta dificuldades significativas em demonstrar a natureza consensual dos atos, especialmente se não houver provas robustas pré-constituídas.
Outros riscos:
Lesão corporal grave ou gravíssima (art. 129, §§ 1º e 2º, CP), não pode ser justificada pelo consentimento, podendo ensejar persecução penal.
Crimes contra a dignidade sexual (arts. 213 e seguintes do CP) são de ação pública incondicionada e independem de representação da vítima para a investigação e denúncia.
Riscos de Falsas Acusações e Alegação de Coação Futura
Os riscos para os praticantes de BDSM, especialmente para o parceiro que assume o papel dominante ou que inflige dor/restrição (frequentemente, mas não exclusivamente, o homem), podem surgir de diversas frentes:
- Acusações Externas: Vizinhos, familiares ou amigos que desconhecem a natureza consensual do relacionamento podem interpretar sons, marcas ou comportamentos como sinais de abuso e denunciar às autoridades.
- Alegações Futuras da Parceira: Em caso de término conturbado, vingança, arrependimento ou mudança de perspectiva, a parceira pode reinterpretar as práticas passadas como abuso e buscar reparação ou retaliação através de uma denúncia. A alegação pode ser de que o consentimento nunca existiu ou foi viciado.
- Alegação de Coação: Uma das formas mais complexas de refutar é a alegação de que o consentimento foi obtido mediante coação (física, moral, psicológica ou econômica). A parceira pode alegar, por exemplo, que se sentia pressionada, intimidada ou dependente, e que seu "sim" não era genuíno. Provar a ausência de coação a posteriori é extremamente difícil.
- Ingenuidade e Vulnerabilidade Masculina: Muitos homens, confiando na dinâmica consensual e na parceira, podem negligenciar a necessidade de precauções. A crença de que "isso nunca aconteceria comigo" ou a falta de conhecimento sobre as implicações legais e o peso processual de uma acusação no âmbito da Lei Maria da Penha podem deixá-los vulneráveis. A presença de marcas físicas, mesmo que consentidas, pode ser usada como evidência de agressão, invertendo o ônus da prova na prática, ainda que não na teoria jurídica.
Estratégias de Prevenção e Mitigação
Não existe um método infalível para evitar completamente o risco de uma falsa acusação, mas diversas medidas podem ser adotadas para construir um histórico de consentimento e reduzir vulnerabilidades:
- Comunicação Explícita e Contínua: A base de qualquer prática BDSM segura é a comunicação constante. Negociar limites, desejos, palavras de segurança ("safewords") e expectativas antes, durante e depois das cenas é crucial. Manter registros dessas negociações (e-mails, mensagens, diários compartilhados) pode ser útil.
-
Documentação do Consentimento:
-
Contratos de Relacionamento/Cena: Embora a validade jurídica de "contratos BDSM" seja discutível no Brasil (não podem afastar normas de ordem pública), eles servem como forte evidência da intenção das partes, da negociação detalhada de limites e do consentimento informado. Devem ser claros, datados, assinados e, idealmente, reconhecidos em cartório (para prova de data e autenticidade das assinaturas).
-
Registros Audiovisuais: Gravar (com consentimento explícito para a gravação) discussões sobre consentimento e limites antes das cenas pode ser uma prova poderosa. Gravar as próprias cenas é mais complexo devido a questões de privacidade e potencial uso indevido, mas pode ser considerado em casos específicos, sempre com consentimento mútuo documentado para a gravação.
Importante: a gravação deve ser com ciência da outra parte, para não configurar violação da intimidade (art. 5º, X, da Constituição Federal e art. 20 do Código Civil).
-
-
Testemunhas: Em alguns contextos de comunidade BDSM, a presença de terceiros de confiança durante negociações ou mesmo cenas pode servir como testemunho, embora isso possa alterar a dinâmica íntima do casal.
- Estabelecimento Claro de Limites e Palavras de Segurança: Definir e respeitar rigorosamente os limites (o que é permitido, o que é proibido) e as palavras de segurança é fundamental. O desrespeito a uma palavra de segurança encerra o consentimento para aquele ato.
- Avaliação Contínua do Consentimento: O consentimento não é um cheque em branco; ele deve ser entusiástico, contínuo e revogável a qualquer momento. Verificar o bem-estar do parceiro durante a cena ("check-ins") é essencial.
- Discrição e Cuidado com Evidências Físicas: Ser discreto sobre a natureza do relacionamento pode evitar mal-entendidos externos. Após cenas que deixem marcas, é prudente que ambos os parceiros estejam cientes e de acordo, talvez documentando por fotos (com data) e uma nota sobre a consensualidade da prática que as gerou.
- Aconselhamento Jurídico Preventivo: Consultar um advogado especializado em direito de família e criminal, com sensibilidade para dinâmicas de relacionamento alternativas, pode fornecer orientação personalizada sobre as melhores formas de documentar o consentimento e entender os riscos legais específicos.
Observações Importantes
- Nenhuma documentação substitui a necessidade de consentimento real, livre, informado e contínuo.
- A lei brasileira protege a "integridade física" e a "dignidade humana". Práticas que resultem em lesões graves ou que violem a dignidade de forma não consentida (ou com consentimento viciado) serão ilegais, independentemente de qualquer acordo prévio.
- Em caso de acusação, a existência de documentação robusta de consentimento não garante a absolvição, mas fortalece significativamente a defesa, ajudando a demonstrar a natureza consensual da relação e das práticas.
-
A alegação de coação futura é particularmente difícil de prevenir apenas com documentos. Um histórico consistente de comunicação aberta (whatsapp/telegram/e-mails), respeito mútuo e ausência de dependência ou controle excessivo na relação pode ajudar a contextualizar a dinâmica como não coercitiva.
-
Cuidado com Marcas Visíveis e Lesões Graves Práticas que resultam em hematomas severos ou lesões podem ser interpretadas como agressão, mesmo que consentidas. Evitar excessos protege não apenas a integridade física, mas também evita questionamentos legais futuros.
O que vem a ser consentimento viciado
No Direito, consentimento viciado é quando a pessoa concorda com algo, mas a vontade dela não é livre ou plena — ou seja, o consentimento existe formalmente, mas é defeituoso por alguma razão.
O Código Civil brasileiro (art. 138 a 165) define várias formas de vício de consentimento. As principais são:
Erro: A pessoa se engana sobre o que está consentindo. (Ex.: A pessoa acredita que vai participar de um jogo leve, mas na verdade é exposta a práticas pesadas.)
Dolo: A pessoa é enganada propositalmente para aceitar algo. (Ex.: Alguém mente sobre o que vai acontecer durante a prática.)
Coação: A pessoa é forçada ou ameaçada a consentir. (Ex.: "Se você não aceitar, eu termino com você" — pressão emocional forte pode ser vista como coação.)
Estado de perigo ou lesão: A pessoa aceita algo em situação de necessidade extrema ou abuso de sua vulnerabilidade. (Ex.: Alguém em situação emocional muito fragilizada é induzida a aceitar práticas que normalmente recusaria.)
No contexto de BDSM, isso é ainda mais delicado: Mesmo que a pessoa tenha "assinado" um contrato ou dito "sim", se depois ela alegar que seu consentimento foi dado sob medo, engano ou pressão psicológica, o consentimento pode ser considerado viciado — e, portanto, juridicamente inválido.
Isso tem duas implicações sérias:
-
O crime não se descaracteriza: Se houver vício, o consentimento é ignorado e a prática pode ser tratada como crime normal (lesão corporal, estupro, tortura, etc.).
-
A prova do consentimento precisa ser sólida: Mostrando que a pessoa estava informada, lúcida, livre e sem qualquer tipo de coação.
Consentimento viciado é quando a pessoa concorda formalmente, mas de maneira enganada, forçada ou pressionada, tornando o consentimento inútil para efeitos jurídicos.
Conclusão
Casais que praticam BDSM consensual no Brasil navegam em um terreno que exige não apenas confiança mútua e comunicação excepcional, mas também uma consciência aguçada das complexidades legais e dos riscos de interpretações equivocadas ou acusações mal-intencionadas. Embora o BDSM seja uma expressão legítima da sexualidade humana, sua prática no Brasil exige responsabilidade redobrada. Ter provas claras de consentimento, manter a comunicação aberta e agir com prudência são formas eficazes de se proteger de falsas alegações e preservar a liberdade e a segurança de todos os envolvidos. Embora leis controversas como a Maria da Penha sejam "vitais" para a proteção contra a violência real, os praticantes de BDSM, e em particular os homens nesse contexto, devem adotar uma postura proativa e prudente para mitigar os riscos inerentes à potencial má interpretação ou instrumentalização dessas práticas e leis, garantindo que a expressão de sua consensualidade esteja resguardada na medida do possível.
Importante: No Brasil, mesmo com tudo isso, o Ministério Público pode denunciar por crime como lesão corporal grave, estupro ou tortura, independente de consentimento. Então a prudência nas práticas é fundamental.
Aviso Legal: Este artigo tem caráter meramente informativo e não constitui aconselhamento jurídico. As leis e interpretações podem mudar, e cada situação é única. Recomenda-se buscar orientação de um advogado qualificado para discutir casos específicos.
Se curtiu este artigo faça uma contribuição, se tiver algum ponto relevante para o artigo deixe seu comentário.
-
@ 37fe9853:bcd1b039
2025-01-11 15:04:40
yoyoaa
-
@ 20986fb8:cdac21b3
2025-04-26 08:08:11
The Traditional Hackathon: Brilliant Sparks with Limitations
For decades, hackathons have been the petri dishes of tech culture – frantic 24- or 48-hour coding marathons fueled by pizza, caffeine, and impossible optimism. From the first hackathon in 1999, when Sun Microsystems challenged Java developers to code on a Palm V in a day [1], to the all-night hack days at startups and universities, these events celebrated the hacker spirit. They gave us Facebook’s “Like” button and Chat features – iconic innovations born in overnight jams [1]. They spawned companies like GroupMe, which was coded in a few late-night hours and sold to Skype for $80 million a year later [2]. Hackathons became tech lore, synonymous with creativity unchained.
And yet, for all their electric energy and hype, traditional hackathons had serious limitations. They were episodic and offline – a once-in-a-blue-moon adrenaline rush rather than a sustainable process. A hackathon might gather 100 coders in a room over a weekend, then vanish until the next year. Low frequency, small scale, limited reach. Only those who could be on-site (often in Silicon Valley or elite campuses) could join. A brilliant hacker in Lagos or São Paulo would be left out, no matter how bright their ideas.
The outcomes of these sprint-like events were also constrained. Sure, teams built cool demos and won bragging rights. But in most cases, the projects were throwaway prototypes – “toy” apps that never evolved into real products or companies. It’s telling that studies found only about 5% of hackathon projects have any life a few months after the event [3]. Ninety-five percent evaporate – victims of that post-hackathon hangover, when everyone goes back to “real” work and the demo code gathers dust. Critics even dubbed hackathons “weekend wastedathons,” blasting their outputs as short-lived vaporware [3]. Think about it: a burst of creativity occurs, dozens of nifty ideas bloom… and then what? How many hackathon winners can you name that turned into enduring businesses? For every Carousell or EasyTaxi that emerged from a hackathon and later raised tens of millions [2], there were hundreds of clever mashups that never saw the light of day again.
The traditional hackathon model, as exciting as it was, rarely translated into sustained innovation. It was innovation in a silo: constrained by time, geography, and a lack of follow-through. Hackathons were events, not processes. They happened in a burst and ended just as quickly – a firework, not a sunrise.
Moreover, hackathons historically were insular. Until recently, they were largely run by and for tech insiders. Big tech companies did internal hackathons to juice employee creativity (Facebook’s famous all-nighters every few weeks led to Timeline and tagging features reaching a billion users [1]), and organizations like NASA and the World Bank experimented with hackathons for civic tech. But these were exceptions that proved the rule: hackathons were special occasions, not business-as-usual. Outside of tech giants, few organizations had the bandwidth or know-how to host them regularly. If you weren’t Google, Microsoft, or a well-funded startup hub, hackathons remained a novelty.
In fact, the world’s largest hackathon today is Microsoft’s internal global hackathon – with 70,000 employees collaborating across 75 countries [4] – an incredible feat, but one only a corporate titan could pull off. Smaller players could only watch and wonder.
The limitations were clear: hackathons were too infrequent and inaccessible to tap the full global talent pool, too short-lived to build anything beyond a prototype, and too isolated to truly change an industry. Yes, they produced amazing moments of genius – flashbulbs of innovation. But as a mechanism for continuous progress, the traditional hackathon was lacking. As an investor or tech leader, you might cheer the creativity but ask: Where is the lasting impact? Where is the infrastructure that turns these flashes into a steady beam of light?
In the spirit of Clay Christensen’s Innovator’s Dilemma, incumbents often dismissed hackathon projects as mere toys – interesting but not viable. And indeed, “the next big thing always starts out being dismissed as a toy” [5]. Hackathons generated plenty of toys, but rarely the support system to turn those toys into the next big thing. The model was ripe for reinvention. Why, in the 2020s, were we still innovating with a 1990s playbook? Why limit breakthrough ideas to a weekend or a single location? Why allow 95% of nascent innovations to wither on the vine? These questions hung in the air, waiting for an answer.
Hackathons 2.0 – DoraHacks and the First Evolution (2020–2024)
Enter DoraHacks. In the early 2020s, DoraHacks emerged like a defibrillator for the hackathon format, jolting it to new life. DoraHacks 1.0 (circa 2020–2024) was nothing less than the reinvention of the hackathon – an upgrade from Hackathon 1.0 to Hackathon 2.0. It took the hackathon concept, supercharged it, scaled it, and extended its reach in every dimension. The result was a global hacker movement, a platform that transformed hackathons from one-off sprints into a continuous engine for tech innovation. How did DoraHacks revolutionize the hackathon? Let’s count the ways:
From 24 Hours to 24 Days (or 24 Weeks!)
DoraHacks stretched the timeframe of hackathons, unlocking vastly greater potential. Instead of a frantic 24-hour dash, many DoraHacks-supported hackathons ran for several weeks or even months. This was a game-changer. Suddenly, teams had time to build serious prototypes, iterate, and polish their projects. A longer format meant hackathon projects could evolve beyond the rough demo stage. Hackers could sleep (occasionally!), incorporate user feedback, and transform a kernel of an idea into a working MVP. The extended duration blurred the line between a hackathon and an accelerator program – but with the open spirit of a hackathon intact. For example, DoraHacks hackathons for blockchain startups often ran 6–8 weeks, resulting in projects that attracted real users and investors by the end. The extra time turned hackathon toys into credible products. It was as if the hackathon grew up: less hack, more build (“BUIDL”). By shattering the 24-hour norm, DoraHacks made hackathons far more productive and impactful.
From Local Coffee Shops to Global Online Arenas
DoraHacks moved hackathons from physical spaces into the cloud, unleashing global participation. Pre-2020, a hackathon meant being in a specific place – say, a warehouse in San Francisco or a university lab – shoulder-to-shoulder with a local team. DoraHacks blew the doors off that model with online hackathons that anyone, anywhere could join. Suddenly, a developer in Nigeria could collaborate with a designer in Ukraine and a product thinker in Brazil, all in the same virtual hackathon. Geography ceased to be a limit. When DoraHacks hosted the Naija HackAtom for African blockchain devs, it drew over 500 participants (160+ developers) across Nigeria’s tech community [6]. In another event, thousands of hackers from dozens of countries logged into a DoraHacks virtual venue to ideate and compete. This global reach did more than increase headcount – it brought diverse perspectives and problems into the innovation mix. A fintech hackathon might see Latin American coders addressing remittances, or an AI hackathon see Asian and African participants applying machine learning to local healthcare challenges. By going online, hackathons became massively inclusive. DoraHacks effectively democratized access to innovation competitions: all you needed was an internet connection and the will to create. The result was a quantum leap in both the quantity and quality of ideas. No longer were hackathons an elitist sport; they became a global innovation free-for-all, open to talent from every corner of the world.
From Dozens of Participants to Tens of Thousands
Scale was another pillar of the DoraHacks revolution. Traditional hackathons were intimate affairs (dozens, maybe a few hundred participants at best). DoraHacks helped orchestrate hackathons an order of magnitude larger. We’re talking global hackathons with thousands of developers and multi-million dollar prize pools. For instance, in one 2021 online hackathon, nearly 7,000 participants submitted 550 projects for $5 million in prizes [7] – a scale unimaginable in the early 2010s. DoraHacks itself became a nexus for these mega-hackathons. The platform’s hackathons in the Web3 space routinely saw hundreds of teams competing for prizes sometimes exceeding $1 million. This scale wasn’t just vanity metrics; it meant a deeper talent bench attacking problems and a higher probability that truly exceptional projects would emerge. By casting a wide net, DoraHacks events captured star teams that might have been overlooked in smaller settings. The proof is in the outcomes: 216 builder teams were funded with over $5 million in one DoraHacks-powered hackathon series on BNB Chain [8] – yes, five million dollars, distributed to over two hundred teams as seed funding. That’s not a hackathon, that’s an economy! The prize pools ballooned from pizza money to serious capital, attracting top-tier talent who realized this hackathon could launch my startup. As a result, projects coming out of DoraHacks were not just weekend hacks – they were venture-ready endeavors. The hackathon graduated from a science fair to a global startup launchpad.
From Toy Projects to Real Startups (Even Unicorns)
Here’s the most thrilling part: DoraHacks hackathons started producing not just apps, but companies. And some of them turned into unicorns (companies valued at $1B+). We saw earlier the rare cases of pre-2020 hackathon successes like Carousell (a simple idea at a 2012 hackathon that became a $1.1B valued marketplace [2]) or EasyTaxi (born in a hackathon, later raising $75M and spanning 30 countries [2]). DoraHacks turbocharged this phenomenon. By providing more time, support, and follow-up funding, DoraHacks-enabled hackathons became cradles of innovation where raw hacks matured into fully-fledged ventures. Take 1inch Network for example – a decentralized finance aggregator that started as a hackathon project in 2019. Sergej Kunz and Anton Bukov built a prototype at a hackathon and kept iterating. Fast forward: 1inch has now processed over $400 billion in trading volume [9] and became one of the leading platforms in DeFi. Or consider the winners of DoraHacks Web3 hackathons: many have gone on to raise multimillion-dollar rounds from top VCs. Hackathons became the front door to the startup world – the place where founders made their debut. A striking illustration was the Solana Season Hackathons: projects like STEPN, a move-to-earn app, won a hackathon track in late 2021 and shortly after grew into a sensation with a multi-billion dollar token economy [10]. These are not isolated anecdotes; they represent a trend DoraHacks set in motion. The platform’s hackathons produced a pipeline of fundable, high-impact startups. In effect, DoraHacks blurred the line between a hackathon and a seed-stage incubator. The playful hacker ethos remained, but now the outcomes were much more than bragging rights – they were companies with real users, revenue, and valuations. To paraphrase investor Chris Dixon, DoraHacks took those “toys” and helped nurture them into the next big things [5].
In driving this first evolution of the hackathon, DoraHacks didn’t just improve on an existing model – it created an entirely new innovation ecosystem. Hackathons became high-frequency, global, and consequential. What used to be a weekend thrill became a continuous pipeline for innovation. DoraHacks events started churning out hundreds of viable projects every year, many of which secured follow-on funding. The platform provided not just the event itself, but the after-care: community support, mentorship, and links to investors and grants (through initiatives like DoraHacks’ grant programs and quadratic funding rounds).
By 2024, the results spoke volumes. DoraHacks had grown into the world’s most important hackathon platform – the beating heart of a global hacker movement spanning blockchain, AI, and beyond. The numbers tell the story. Over nine years, DoraHacks supported 4,000+ projects in securing more than $30 million in funding [11]; by 2025, that figure skyrocketed as 21,000+ startups and developer teams received over $80 million via DoraHacks-supported hackathons and grants [12]. This is not hype – this is recorded history. According to CoinDesk, “DoraHacks has made its mark as a global hackathon organizer and one of the world’s most active multi-chain Web3 developer platforms” [11]. Major tech ecosystems took notice. Over 40 public blockchain networks (L1s and L2s) – from Solana to Polygon to Avalanche – partnered with DoraHacks to run their hackathons and open innovation programs [13]. Blockworks reported that DoraHacks became a “core partner” to dozens of Web3 ecosystems, providing them access to a global pool of developers [13]. In the eyes of investors, DoraHacks itself was key infrastructure: “DoraHacks is key to advancing the development of the infrastructure for Web3,” noted one VC backing the platform [13].
In short, by 2024 DoraHacks had transformed the hackathon from a niche event into a global innovation engine. It proved that hackathons at scale can consistently produce real, fundable innovation – not just one-off gimmicks. It connected hackers with resources and turned isolated hacks into an evergreen, worldwide developer movement. This was Hackathons 2.0: bigger, longer, borderless, and far more impactful than ever before.
One might reasonably ask: Can it get any better than this? DoraHacks had seemingly cracked the code to harness hacker energy for lasting innovation. But the team behind DoraHacks wasn’t done. In fact, they were about to unveil something even more radical – a catalyst to push hackathons into a new epoch entirely. If DoraHacks 1.0 was the evolution, what came next would be a revolution.
The Agentic Hackathon: BUIDL AI and the Second Revolution
In 2024, DoraHacks introduced BUIDL AI, and with it, the concept of the Agentic Hackathon. If hackathons at their inception were analog phones, and DoraHacks 1.0 made them smartphones, then BUIDL AI is like giving hackathons an AI co-pilot – a self-driving mode. It’s not merely an incremental improvement; it’s a second revolution. BUIDL AI infused hackathons with artificial intelligence, automation, and agency (hence “agentic”), fundamentally changing how these events are organized and experienced. We are now entering the Age of Agentic Innovation, where hackathons run with the assistance of AI agents can occur with unprecedented frequency, efficiency, and intelligence.
So, what exactly is an Agentic Hackathon? It’s a hackathon where AI-driven agents augment the entire process – from planning and judging to participant support – enabling a scale and speed of innovation that was impossible before. In an agentic hackathon, AI is the tireless co-organizer working alongside humans. Routine tasks that used to bog down organizers are now handled by intelligent algorithms. Imagine hackathons that practically run themselves, continuously, like an “always-on” tournament of ideas. With BUIDL AI, DoraHacks effectively created self-driving hackathons – autonomous, efficient, and capable of operating 24/7, across multiple domains, simultaneously. This isn’t science fiction; it’s happening now. Let’s break down how BUIDL AI works and why it 10x’d hackathon efficiency overnight:
AI-Powered Judging and Project Review – 10× Efficiency Boost
One of the most labor-intensive aspects of big hackathons is judging hundreds of project submissions. It can take organizers weeks of effort to sift the high-potential projects from the rest. BUIDL AI changes that. It comes with a BUIDL Review module – an AI-driven judging system that can intelligently evaluate hackathon projects on multiple dimensions (completeness, originality, relevance to the hackathon theme, etc.) and automatically filter out low-quality submissions [14]. It’s like having an army of expert reviewers available instantly. The result? What used to require hundreds of human-hours now happens in a flash. DoraHacks reports that AI-assisted review has improved hackathon organization efficiency by more than 10× [14]. Think about that: a process that might have taken a month of tedious work can be done in a few days or less, with AI ensuring consistency and fairness in scoring. Organizers can now handle massive hackathons without drowning in paperwork, and participants get quicker feedback. The AI doesn’t replace human judges entirely – final decisions still involve experts – but it augments them, doing the heavy lifting of initial evaluation. This means hackathons can accept more submissions, confident that AI will help triage them. No more cutting off sign-ups because “we can’t review them all.” The machine scale is here. In an agentic hackathon, no good project goes unseen due to bandwidth constraints – the AI makes sure of that.
Automated Marketing and Storytelling
Winning a hackathon is great, but if nobody hears about it, the impact is muted. Traditionally, after a hackathon ended, organizers would manually compile results, write blog posts, thank sponsors – tasks that, while important, take time and often get delayed. BUIDL AI changes this too. It features an Automated Marketing capability that can generate post-hackathon reports and content with a click [14]. Imagine an AI that observes the entire event (the projects submitted, the winners, the tech trends) and then writes a polished summary: highlighting the best ideas, profiling the winning teams, extracting insights (“60% of projects used AI in healthcare this hackathon”). BUIDL AI does exactly that – it automatically produces a hackathon “highlight reel” and summary report [14]. This not only saves organizers the headache of writing marketing copy, but it also amplifies the hackathon’s reach. Within hours of an event, a rich recap can be shared globally, showcasing the innovations and attracting attention to the teams. Sponsors and partners love this, as their investment gets publicized promptly. Participants love it because their work is immediately celebrated and visible. In essence, every hackathon tells a story, and BUIDL AI ensures that story spreads far and wide – instantly. This kind of automated storytelling turns each hackathon into ongoing content, fueling interest and momentum for the next events. It’s a virtuous cycle: hackathons create innovations, AI packages the narrative, that narrative draws in more innovators.
One-Click Launch and Multi-Hackathon Management
Perhaps the most liberating feature of BUIDL AI is how it obliterates the logistical hurdles of organizing hackathons. Before, setting up a hackathon was itself a project – coordinating registrations, judges, prizes, communications, all manually configured. DoraHacks’ BUIDL AI introduces a one-click hackathon launch tool [14]. Organizers simply input the basics (theme, prize pool, dates, some judging criteria) and the platform auto-generates the event page, submission portal, judging workflow, and more. It’s as easy as posting a blog. This dramatically lowers the barrier for communities and companies to host hackathons. A small startup or a university club can now launch a serious global hackathon without a dedicated team of event planners. Furthermore, BUIDL AI supports Multi-Hackathon Management, meaning one organization can run multiple hackathons in parallel with ease [14]. In the past, even tech giants struggled to overlap hackathons – it was too resource-intensive. Now, an ecosystem could run, say, a DeFi hackathon, an AI hackathon, and an IoT hackathon all at once, with a lean team, because AI is doing the juggling in the back-end. The launch of BUIDL AI made it feasible to organize 12 hackathons a year – or even several at the same time – something unimaginable before [14]. The platform handles participant onboarding, sends reminders, answers common queries via chatbots, and keeps everything on track. In essence, BUIDL AI turns hackathon hosting into a scalable service. Just as cloud computing platforms let you spin up servers on demand, DoraHacks lets you spin up innovation events on demand. This is a tectonic shift: hackathons can now happen as frequently as needed, not as occasionally as resources allow. We’re talking about the birth of perpetual hackathon culture. Hackathons are no longer rare spark events; they can be continuous flames, always burning, always on.
Real-Time Mentor and Agentic Assistance
The “agentic” part of Agentic Hackathons isn’t only behind the scenes. It also touches the participant experience. With AI integration, hackers get smarter tools and support. For instance, BUIDL AI can include AI assistants that answer developers’ questions during the event (“How do I use this API?” or “Any example code for this algorithm?”), acting like on-demand mentors. It can match teams with potential collaborators or suggest resources. Essentially, every hacker has an AI helper at their side, reducing frustration and accelerating progress. Coding issues that might take hours to debug can be resolved in minutes with an AI pair programmer. This means project quality goes up and participants learn more. It’s as if each team has an extra member – an tireless, all-knowing one. This agentic assistance embodies the vision that “everyone is a hacker” [14] – because AI tools enable even less-experienced participants to build something impressive. The popularization of AI has automated repetitive grunt work and amplified what small teams can achieve [14], so the innovation potential of hackathons is far greater than before [14]. In an agentic hackathon, a team of two people with AI assistants can accomplish what a team of five might have in years past. The playing field is leveled and the creative ceiling is raised.
What do all these advances add up to? Simply this: Hackathons have evolved from occasional bouts of inspiration into a continuous, AI-optimized process of innovation. We have gone from Hackathons 2.0 to Hackathons 3.0 – hackathons that are autonomous, persistent, and intelligent. It’s a paradigm shift. The hackathon is no longer an event you attend; it’s becoming an environment you live in. With BUIDL AI, DoraHacks envisions a world where “Hackathons will enter an unprecedented era of automation and intelligence, allowing more hackers, developers, and open-source communities around the world to easily initiate and participate” [14]. Innovation can happen anytime, anywhere – because the infrastructure to support it runs 24/7 in the cloud, powered by AI. The hackathon has become an agentic platform, always ready to transform ideas into reality.
Crucially, this isn’t limited to blockchain or any single field. BUIDL AI is general-purpose. It is as relevant for an AI-focused hackathon as for a climate-tech or healthcare hackathon. Any domain can plug into this agentic hackathon platform and reap the benefits of higher frequency and efficiency. This heralds a future where hackathons become the default mode for problem-solving. Instead of committees and R&D departments working in silos, companies and communities can throw problems into the hackathon arena – an arena that is always active. It’s like having a global innovation engine humming in the background, ready to tackle challenges at a moment’s notice.
To put it vividly: If DoraHacks 1.0 turned hackathons into a high-speed car, DoraHacks 2.0 with BUIDL AI made it a self-driving car with the pedal to the metal. The roadblocks of cost, complexity, and time – gone. Now, any organization can accelerate from 0 to 60 on the innovation highway without a pit stop. Hackathons can be as frequent as blog updates, as integrated into operations as sprint demos. Innovation on demand, at scale – that’s the power of the Agentic Hackathon.
Innovation On-Demand: How Agentic Hackathons Benefit Everyone
The advent of agentic hackathons isn’t just a cool new toy for the tech community – it’s a transformative tool for businesses, developers, and entire industries. We’re entering an era where anyone with a vision can harness hackathons-as-a-service to drive innovation. Here’s how different players stand to gain from this revolution:
AI Companies – Turbocharging Ecosystem Growth
For AI-focused companies (think OpenAI, Google, Microsoft, Stability AI and the like), hackathons are goldmines of creative uses for their technology. Now, with agentic hackathons, an AI company can essentially run a continuous developer conference for their platform. For example, OpenAI can host always-on hackathons for building applications with GPT-4 or DALL-E. This means thousands of developers constantly experimenting and showcasing what the AI can do – effectively crowdsourcing innovation and killer apps for the AI platform. The benefit? It dramatically expands the company’s ecosystem and user base. New use cases emerge that the company’s own team might never have imagined. (It was independent hackers who first showed how GPT-3 could draft legal contracts or generate game levels – insights that came from hackathons and community contests.) With BUIDL AI, an AI company could spin up monthly hackathons with one click, each focusing on a different aspect (one month NLP, next month robotics, etc.). This is a marketing and R&D force multiplier. Instead of traditional, expensive developer evangelism tours, the AI does the heavy lifting to engage devs globally. The company’s product gets improved and promoted at the same time. In essence, every AI company can now launch a Hackathon League to promote their APIs/models. It’s no coincidence Coinbase just hosted its first AI hackathon to bridge crypto and AI [15] – they know that to seed adoption of a new paradigm, hackathons are the way. Expect every AI platform to do the same: continuous hackathons to educate developers, generate content (demos, tutorials), and identify standout talent to hire or fund. It’s community-building on steroids.
L1s/L2s and Tech Platforms – Discovering the Next Unicorns
For blockchain Layer1/Layer2 ecosystems, or any tech platform (cloud providers, VR platforms, etc.), hackathons are the new deal flow. In the Web3 world, it’s widely recognized that many of the best projects and protocols are born in hackathons. We saw how 1inch started as a hackathon project and became a DeFi unicorn [9]. There’s also Polygon (which aggressively runs hackathons to find novel dApps for its chain) and Filecoin (which used hackathons to surface storage applications). By using DoraHacks and BUIDL AI, these platforms can now run high-frequency hackathons to continuously source innovation. Instead of one or two big events a year, they can have a rolling program – a quarterly hackathon series or even simultaneous global challenges – to keep developers building all the time. The ROI is huge: the cost of running a hackathon (even with decent prizes) is trivial compared to acquiring a thriving new startup or protocol for your ecosystem. Hackathons effectively outsource initial R&D to passionate outsiders, and the best ideas bubble up. Solana’s hackathons led to star projects like Phantom and Solend gaining traction in its ecosystem. Facebook’s internal hackathons gave birth to features that kept the platform dominant [1]. Now any platform can do this externally: use hackathons as a radar for talent and innovation. Thanks to BUIDL AI, a Layer-2 blockchain, even if its core team is small, can manage a dozen parallel bounties and hackathons – one focusing on DeFi, one on NFTs, one on gaming, etc. The AI will help review submissions and manage community questions, so the platform’s devrel team doesn’t burn out. The result is an innovation pipeline feeding the platform’s growth. The next unicorn startup or killer app is identified early and supported. In effect, hackathons become the new startup funnel for VCs and ecosystems. We can expect venture investors to lurk in these agentic hackathons because that’s where the action is – the garages of the future are now cloud hackathon rooms. As Paul Graham wrote, “hackers and painters are both makers” [16], and these makers will paint the future of technology on the canvas of hackathon platforms.
Every Company and Community – Innovation as a Continuous Process
Perhaps the most profound impact of BUIDL AI is that it opens up hackathons to every organization, not just tech companies. Any company that wants to foster innovation – be it a bank exploring fintech, a hospital network seeking healthtech solutions, or a government looking for civic tech ideas – can leverage agentic hackathons. Innovation is no longer a privilege of the giant tech firms; it’s a cloud service accessible to all. For example, a city government could host a year-round hackathon for smart city solutions, where local developers continuously propose and build projects to improve urban life. The BUIDL AI platform could manage different “tracks” for transportation, energy, public safety, etc., with monthly rewards for top ideas. This would engage the community and yield a constant stream of pilot projects, far more dynamically than traditional RFP processes. Likewise, any Fortune 500 company that fears disruption (and who doesn’t?) can use hackathons to disrupt itself positively – inviting outsiders and employees to hack on the company’s own challenges. With the agentic model, even non-technical companies can do this without a hitch; the AI will guide the process, ensuring things run smoothly. Imagine hackathons as part of every corporate strategy department’s toolkit – continuously prototyping the future. As Marc Andreessen famously said, “software is eating the world” – and now every company can have a seat at the table by hosting hackathons to software-ize their business problems. This could democratize innovation across industries. The barrier to trying out bold ideas is so low (a weekend of a hackathon vs. months of corporate planning) that more wild, potentially disruptive ideas will surface from within companies. And with the global reach of DoraHacks, they can bring in external innovators too. Why shouldn’t a retail company crowdsource AR shopping ideas from global hackers? Why shouldn’t a pharma company run bioinformatics hackathons to find new ways to analyze data? There is no reason not to – the agentic hackathon makes it feasible and attractive. Hackathon-as-a-service is the new innovation department. Use it or risk being out-innovated by those who do.
All these benefits boil down to a simple but profound shift: hackathons are becoming a permanent feature of the innovation landscape, rather than a novelty. They are turning into an always-available resource, much like cloud computing or broadband internet. Need fresh ideas or prototypes? Spin up a hackathon and let the global talent pool tackle it. Want to engage your developer community? Launch a themed hackathon and give them a stage. Want to test out 10 different approaches to a problem? Run a hackathon and see what rises to the top. We’re effectively seeing the realization of what one might call the Innovation Commons – a space where problems and ideas are continuously matched, and solutions are rapidly iterated. And AI is the enabler that keeps this commons humming efficiently, without exhausting the human facilitators.
It’s striking how this addresses the classic pitfalls identified in hackathon critiques: sustainability and follow-through. In the agentic model, hackathons are no longer isolated bursts. They can connect to each other (winning teams from one hackathon can enter an accelerator or another hackathon next month). BUIDL AI can track teams and help link them with funding opportunities, closing the loop that used to leave projects orphaned after the event. A great project doesn’t die on Sunday night; it’s funneled into the next stage automatically (perhaps an AI even suggests which grant to apply for, which partner to talk to). This way, innovations have a life beyond the demo day, systematically.
We should also recognize a more philosophical benefit: the culture of innovation becomes more experimental, meritocratic, and fast-paced. In a world of agentic hackathons, the motto is “Why not prototype it? Why not try it now?” – because spinning up the environment to do so is quick and cheap. This mindset can permeate organizations and communities, making them more agile and bold. The cost of failure is low (a few weeks of effort), and the potential upside is enormous (finding the next big breakthrough). It creates a safe sandbox for disruptive ideas – addressing the Innovator’s Dilemma by structurally giving space to those ‘toy’ ideas to prove themselves [5]. Companies no longer have to choose between core business and experimentation; they can allocate a continuous hackathon track to the latter. In effect, DoraHacks and BUIDL AI have built an innovation factory – one that any visionary leader can rent for the weekend (or the whole year).
From Like Button to Liftoff: Hackathons as the Cradle of Innovation
To truly appreciate this new era, it’s worth reflecting on how many game-changing innovations started as hackathon projects or hackathon-like experiments – often despite the old constraints – and how much more we can expect when those constraints are removed. History is full of examples that validate the hackathon model of innovation:
Facebook’s DNA was shaped by hackathons
Mark Zuckerberg himself has credited the company’s internal hackathons for some of Facebook’s most important features. The Like button, Facebook Chat, and Timeline all famously emerged from engineers pulling all-nighters at hackathons [1]. An intern’s hackathon prototype for tagging people in comments was shipped to a billion users just two weeks later [1]. Facebook’s ethos “Move fast and break things” was practically the hackathon ethos formalized. It is no stretch to say Facebook won over MySpace in the 2000s because its culture of rapid innovation (fueled by hackathons) let it out-innovate its rival [1]. If hackathons did that within one company, imagine a worldwide network of hackathons – the pace of innovation everywhere could resemble that hypergrowth.
Google and the 20% Project
Google has long encouraged employees to spend 20% of time on side projects, which is a cousin of the hackathon idea – unstructured exploration. Gmail and Google News were born this way. Additionally, Google has hosted public hackathons around its APIs (like Android hackathons) that spurred the creation of countless apps. The point is, Google institutionalized hacker-style experimentation and reaped huge rewards. With agentic hackathons, even companies without Google’s resources can institutionalize experimentation. Every weekend can be a 20% time for the world’s devs using these platforms.
Open Source Movements
Open Source Movements have benefitted from hackathons (“code sprints”) to develop critical software. The entire OpenBSD operating system had regular hackathons that were essential to its development [3]. In more recent times, projects like Node.js or TensorFlow have organized hackathons to build libraries and tools. The result: stronger ecosystems and engaged contributors. DoraHacks embraces this, positioning itself as “the leading global hackathon community and open source developer incentive platform” [17]. The synergy of open source and hackathons (both decentralized, community-driven, merit-based) is a powerful engine. We can foresee open source projects launching always-on hackathons via BUIDL AI to continuously fix bugs, add features, and reward contributors. This could rejuvenate the open source world by providing incentives (through hackathon prizes) and recognition in a structured way.
The Startup World
The Startup World has hackathons to thank for many startups. We’ve mentioned Carousell (from a Startup Weekend hackathon, now valued over $1B [2]) and EasyTaxi (Startup Weekend Rio, went on to raise $75M [2]). Add to that list Zapier (integrations startup, conceived at a hackathon), GroupMe (acquired by Skype as noted), Instacart (an early version won a hackathon at Y Combinator Demo Day, legend has it), and numerous crypto startups (the founders of Ethereum itself met and collaborated through hackathons and Bitcoin meetups!). When Coinbase wants to find the next big thing in on-chain AI, they host a hackathon [15]. When Stripe wanted more apps on its payments platform, it ran hackathons and distributed bounties. This model just works. It identifies passionate builders and gives them a springboard. With agentic hackathons, that springboard is super-sized. It’s always there, and it can catch far more people. The funnel widens, so expect even more startups to originate from hackathons. It’s quite plausible that the biggest company of the 2030s won’t be founded in a garage – it will be born out of an online hackathon, formed by a team that met in a Discord server, guided by an AI facilitator, and funded within weeks on a platform like DoraHacks. In other words, the garage is going global and AI-powered.
Hackers & Painters – The Creative Connection
Paul Graham, in Hackers & Painters, drew an analogy between hacking and painting as creative endeavors [16]. Hackathons are where that creative energy concentrates and explodes. Many great programmers will tell you their most inspired work happened in a hackathon or skunkworks setting – free of bureaucratic restraints, in a flow state of creation. By scaling and multiplying hackathons, we are effectively amplifying the global creative capacity. We might recall the Renaissance when artists and inventors thrived under patronage and in gatherings – hackathons are the modern Renaissance workshops. They combine art, science, and enterprise. The likes of Leonardo da Vinci would have been right at home in a hackathon (he was notorious for prototyping like a madman). In fact, consider how hackathons embody the solution to the Innovator’s Dilemma: they encourage working on projects that seem small or “not worth it” to incumbents, which is exactly where disruptive innovation often hides [5]. By institutionalizing hackathons, DoraHacks is institutionalizing disruption – making sure the next Netflix or Airbnb isn’t missed because someone shrugged it off as a toy.
We’ve gone from a time when hackathons were rare and local to a time when they are global and constant. This is a pivotal change in the innovation infrastructure of the world. In the 19th century, we built railroads and telegraphs that accelerated the Industrial Revolution, connecting markets and minds. In the 20th century, we built the internet and the World Wide Web, unleashing the Information Revolution. Now, in the 21st century, DoraHacks and BUIDL AI are building the “Innovation Highway” – a persistent, AI-enabled network connecting problem-solvers to problems, talent to opportunities, capital to ideas, across the entire globe, in real time. It’s an infrastructure for innovation itself.
A Grand Vision: The New Infrastructure of Global Innovation
We stand at an inflection point. With DoraHacks and the advent of agentic hackathons, innovation is no longer confined to ivory labs, Silicon Valley offices, or once-a-year events. It is becoming a continuous global activity – an arena where the best minds and the boldest ideas meet, anytime, anywhere. This is a future where innovation is as ubiquitous as Wi-Fi and as relentless as Moore’s Law. It’s a future DoraHacks is actively building, and the implications are profound.
Picture a world a few years from now, where DoraHacks+BUIDL AI is the default backbone for innovation programs across industries. This platform is buzzing 24/7 with hackathons on everything from AI-driven healthcare to climate-change mitigation to new frontiers of art and entertainment. It’s not just for coders – designers, entrepreneurs, scientists, anyone with creative impulse plugs into this network. An entrepreneur in London has a business idea at 2 AM; by 2:15 AM, she’s on DoraHacks launching a 48-hour hackathon to prototype it, with AI coordinating a team of collaborators from four different continents. Sounds crazy? It will be commonplace. A government in Asia faces a sudden environmental crisis; they host an urgent hackathon via BUIDL AI and within days have dozens of actionable tech solutions from around the world. A venture fund in New York essentially “outsources” part of its research to the hackathon cloud – instead of merely requesting pitch decks, they sponsor open hackathons to see real prototypes first. This is agentic innovation in action – fast, borderless, and intelligent.
In this coming era, DoraHacks will be as fundamental to innovation as GitHub is to code or as AWS is to startups. It’s the platform where innovation lives. One might even call it the “GitHub of Innovation” – a social and technical layer where projects are born, not just stored. Already, DoraHacks calls itself “the global hacker movement” [17], and with BUIDL AI it becomes the autopilot of that movement. It’s fitting to think of it as part of the global public infrastructure for innovation. Just as highways move goods and the internet moves information, DoraHacks moves innovation itself – carrying ideas from inception to implementation at high speed.
When history looks back at the 2020s, the arrival of continuous, AI-driven hackathons will be seen as a key development in how humanity innovates. The vision is grand, but very tangible: Innovation becomes an everlasting hackathon. Think of it – the hacker ethos spreading into every corner of society, an eternal challenge to the status quo, constantly asking “How can we improve this? How can we reinvent that?” and immediately rallying the talent to do it. This is not chaos; it’s a new form of organized, decentralized R&D. It’s a world where any bold question – “Can we cure this disease? Can we educate children better? Can we make cities sustainable?” – can trigger a global hackathon and yield answers in days or weeks, not years. A world where innovation isn’t a scarce resource, jealously guarded by few, but a common good, an open tournament where the best solution wins, whether it comes from a Stanford PhD or a self-taught coder in Lagos.
If this sounds idealistic, consider how far we’ve come: Hackathons went from obscure coder meetups to the engine behind billion-dollar businesses and critical global tech (Bitcoin itself is a product of hacker culture!). With DoraHacks’s growth and BUIDL AI’s leap, the trajectory is set for hackathons to become continuous and ubiquitous. The technology and model are in place. It’s now about execution and adoption. And the trend is already accelerating – more companies are embracing open innovation, more developers are working remotely and participating in online communities, and AI is rapidly advancing as a co-pilot in all creative endeavors.
DoraHacks finds itself at the center of this transformation. It has the first-mover advantage, the community, and the vision. The company’s ethos is telling: “Funding the everlasting hacker movement” is one of their slogans [18]. They see hackathons as not just events but a movement that must be everlasting – a permanent revolution of the mind. With BUIDL AI, DoraHacks is providing the engine to make it everlasting. This hints at a future where DoraHacks+BUIDL AI is part of the critical infrastructure of global innovation, akin to a utility. It’s the innovation grid, and when you plug into it, magic happens.
Marc Andreessen’s writings often speak about “building a better future” with almost manifest destiny fervor. In that spirit, one can boldly assert: Agentic hackathons will build our future, faster and better. They will accelerate solutions to humanity’s toughest challenges by tapping a broader talent pool and iterating faster than ever. They will empower individuals – giving every creative mind on the planet the tools, community, and opportunity to make a real impact, immediately, not someday. This is deeply democratizing. It resonates with the ethos of the early internet – permissionless innovation. DoraHacks is bringing that ethos to structured innovation events and stretching them into an ongoing fabric.
In conclusion, we are witnessing a paradigm shift: Hackathons reinvented, innovation unchained. The limitations of the old model are gone, replaced by a new paradigm where hackathons are high-frequency, AI-augmented, and outcome-oriented. DoraHacks led this charge in the 2020–2024 period, and with BUIDL AI, it’s launching the next chapter – the Age of Agentic Innovation. For investors and visionaries, this is a call to action. We often talk about investing in “infrastructure” – well, this is investing in the infrastructure of innovation itself. Backing DoraHacks and its mission is akin to backing the builders of a transcontinental railroad or an interstate highway, except this time the cargo is ideas and breakthroughs. The network effects are enormous: every additional hackathon and participant adds value to the whole ecosystem, in a compounding way. It’s a positive-sum game of innovation. And DoraHacks is poised to be the platform and the community that captures and delivers that value globally.
DoraHacks reinvented hackathons – it turned hackathons from sporadic stunts into a sustained methodology for innovation. In doing so, it has thrown open the gates to an era where innovation can be agentic: self-driving, self-organizing, and ceaseless. We are at the dawn of this new age. It’s an age where, indeed, “he who has the developers has the world” [14] – and DoraHacks is making sure that every developer, every hacker, every dreamer anywhere can contribute to shaping our collective future. The grand vista ahead is one of continuous invention and discovery, powered by a global hive mind of hackers and guided by AI. DoraHacks and BUIDL AI stand at the helm of this movement, as the architects of the “innovation rails” on which we’ll ride. It’s not just a platform, it’s a revolutionary infrastructure – the new railroad, the new highway system for ideas. Buckle up, because with DoraHacks driving, the age of agentic innovation has arrived, and the future is hurtling toward us at hackathon speed. The hackathon never ends – and that is how we will invent a better world.
References
[1] Vocoli. (2015). Facebook’s Secret Sauce: The Hackathon. https://www.vocoli.com/blog/june-2015/facebook-s-secret-sauce-the-hackathon/
[2] Analytics India Magazine. (2023). Borne Out Of Hackathons. https://analyticsindiamag.com/ai-trends/borne-out-of-hackathons/
[3] Wikipedia. (n.d.). Hackathon: Origin and History. https://en.wikipedia.org/wiki/Hackathon#Origin_and_history
[4] LinkedIn. (2024). This year marked my third annual participation in Microsoft’s Global…. https://www.linkedin.com/posts/clare-ashforth_this-year-marked-my-third-annual-participation-activity-7247636808119775233-yev-
[5] Glasp. (n.d.). Chris Dixon’s Quotes. https://glasp.co/quotes/chris-dixon
[6] ODaily. (2024). Naija HackAtom Hackathon Recap. https://www.odaily.news/en/post/5203212
[7] Solana. (2021). Meet the winners of the Riptide hackathon - Solana. https://solana.com/news/riptide-hackathon-winners-solana
[8] DoraHacks. (n.d.). BNB Grant DAO - DoraHacks. https://dorahacks.io/bnb
[9] Cointelegraph. (2021). From Hackathon Project to DeFi Powerhouse: AMA with 1inch Network. https://cointelegraph.com/news/from-hackathon-project-to-defi-powerhouse-ama-with-1inch-network
[10] Gemini. (2022). How Does STEPN Work? GST and GMT Token Rewards. https://www.gemini.com/cryptopedia/stepn-nft-sneakers-gmt-token-gst-crypto-move-to-earn-m2e
[11] CoinDesk. (2022). Inside DoraHacks: The Open Source Bazaar Empowering Web3 Innovations. https://www.coindesk.com/sponsored-content/inside-dorahacks-the-open-source-bazaar-empowering-web3-innovations
[12] LinkedIn. (n.d.). DoraHacks. https://www.linkedin.com/company/dorahacks
[13] Blockworks. (2022). Web3 Hackathon Incubator DoraHacks Nabs $20M From FTX, Liberty City. https://blockworks.co/news/web3-hackathon-incubator-dorahacks-nabs-20m-from-ftx-liberty-city
[14] Followin. (2024). BUIDL AI: The future of Hackathon, a new engine for global open source technology. https://followin.io/en/feed/16892627
[15] Coinbase. (2024). Coinbase Hosts Its First AI Hackathon: Bringing the San Francisco Developer Community Onchain. https://www.coinbase.com/developer-platform/discover/launches/Coinbase-AI-hackathon
[16] Graham, P. (2004). Hackers & Painters. https://ics.uci.edu/~pattis/common/handouts/hackerspainters.pdf
[17] Himalayas. (n.d.). DoraHacks hiring Research Engineer – BUIDL AI. https://himalayas.app/companies/dorahacks/jobs/research-engineer-buidl-ai
[18] X. (n.d.). DoraHacks. https://x.com/dorahacks?lang=en -
@ b99efe77:f3de3616
2025-04-25 19:52:45
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 62033ff8:e4471203
2025-01-11 15:00:24
收录的内容中 kind=1的部分,实话说 质量不高。 所以我增加了kind=30023 长文的article,但是更新的太少,多个relays 的服务器也没有多少长文。
所有搜索nostr如果需要产生价值,需要有高质量的文章和新闻。 而且现在有很多机器人的文章充满着浪费空间的作用,其他作用都用不上。
https://www.duozhutuan.com 目前放的是给搜索引擎提供搜索的原材料。没有做UI给人类浏览。所以看上去是粗糙的。 我并没有打算去做一个发microblog的 web客户端,那类的客户端太多了。
我觉得nostr社区需要解决的还是应用。如果仅仅是microblog 感觉有点够呛
幸运的是npub.pro 建站这样的,我觉得有点意思。
yakihonne 智能widget 也有意思
我做的TaskQ5 我自己在用了。分布式的任务系统,也挺好的。
-
@ 23b0e2f8:d8af76fc
2025-01-08 18:17:52
Necessário
- Um Android que você não use mais (a câmera deve estar funcionando).
- Um cartão microSD (opcional, usado apenas uma vez).
- Um dispositivo para acompanhar seus fundos (provavelmente você já tem um).
Algumas coisas que você precisa saber
- O dispositivo servirá como um assinador. Qualquer movimentação só será efetuada após ser assinada por ele.
- O cartão microSD será usado para transferir o APK do Electrum e garantir que o aparelho não terá contato com outras fontes de dados externas após sua formatação. Contudo, é possível usar um cabo USB para o mesmo propósito.
- A ideia é deixar sua chave privada em um dispositivo offline, que ficará desligado em 99% do tempo. Você poderá acompanhar seus fundos em outro dispositivo conectado à internet, como seu celular ou computador pessoal.
O tutorial será dividido em dois módulos:
- Módulo 1 - Criando uma carteira fria/assinador.
- Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
No final, teremos:
- Uma carteira fria que também servirá como assinador.
- Um dispositivo para acompanhar os fundos da carteira.

Módulo 1 - Criando uma carteira fria/assinador
-
Baixe o APK do Electrum na aba de downloads em https://electrum.org/. Fique à vontade para verificar as assinaturas do software, garantindo sua autenticidade.
-
Formate o cartão microSD e coloque o APK do Electrum nele. Caso não tenha um cartão microSD, pule este passo.

- Retire os chips e acessórios do aparelho que será usado como assinador, formate-o e aguarde a inicialização.

- Durante a inicialização, pule a etapa de conexão ao Wi-Fi e rejeite todas as solicitações de conexão. Após isso, você pode desinstalar aplicativos desnecessários, pois precisará apenas do Electrum. Certifique-se de que Wi-Fi, Bluetooth e dados móveis estejam desligados. Você também pode ativar o modo avião.\ (Curiosidade: algumas pessoas optam por abrir o aparelho e danificar a antena do Wi-Fi/Bluetooth, impossibilitando essas funcionalidades.)

- Insira o cartão microSD com o APK do Electrum no dispositivo e instale-o. Será necessário permitir instalações de fontes não oficiais.
- No Electrum, crie uma carteira padrão e gere suas palavras-chave (seed). Anote-as em um local seguro. Caso algo aconteça com seu assinador, essas palavras permitirão o acesso aos seus fundos novamente. (Aqui entra seu método pessoal de backup.)

Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
-
Criar uma carteira somente leitura em outro dispositivo, como seu celular ou computador pessoal, é uma etapa bastante simples. Para este tutorial, usaremos outro smartphone Android com Electrum. Instale o Electrum a partir da aba de downloads em https://electrum.org/ ou da própria Play Store. (ATENÇÃO: O Electrum não existe oficialmente para iPhone. Desconfie se encontrar algum.)
-
Após instalar o Electrum, crie uma carteira padrão, mas desta vez escolha a opção Usar uma chave mestra.

- Agora, no assinador que criamos no primeiro módulo, exporte sua chave pública: vá em Carteira > Detalhes da carteira > Compartilhar chave mestra pública.

-
Escaneie o QR gerado da chave pública com o dispositivo de consulta. Assim, ele poderá acompanhar seus fundos, mas sem permissão para movimentá-los.
-
Para receber fundos, envie Bitcoin para um dos endereços gerados pela sua carteira: Carteira > Addresses/Coins.
-
Para movimentar fundos, crie uma transação no dispositivo de consulta. Como ele não possui a chave privada, será necessário assiná-la com o dispositivo assinador.

- No assinador, escaneie a transação não assinada, confirme os detalhes, assine e compartilhe. Será gerado outro QR, desta vez com a transação já assinada.

- No dispositivo de consulta, escaneie o QR da transação assinada e transmita-a para a rede.
Conclusão
Pontos positivos do setup:
- Simplicidade: Basta um dispositivo Android antigo.
- Flexibilidade: Funciona como uma ótima carteira fria, ideal para holders.
Pontos negativos do setup:
- Padronização: Não utiliza seeds no padrão BIP-39, você sempre precisará usar o electrum.
- Interface: A aparência do Electrum pode parecer antiquada para alguns usuários.
Nesse ponto, temos uma carteira fria que também serve para assinar transações. O fluxo de assinar uma transação se torna: Gerar uma transação não assinada > Escanear o QR da transação não assinada > Conferir e assinar essa transação com o assinador > Gerar QR da transação assinada > Escanear a transação assinada com qualquer outro dispositivo que possa transmiti-la para a rede.
Como alguns devem saber, uma transação assinada de Bitcoin é praticamente impossível de ser fraudada. Em um cenário catastrófico, você pode mesmo que sem internet, repassar essa transação assinada para alguém que tenha acesso à rede por qualquer meio de comunicação. Mesmo que não queiramos que isso aconteça um dia, esse setup acaba por tornar essa prática possível.
-
@ b99efe77:f3de3616
2025-04-25 19:50:55
🚦Traffic Light Control System🚦
This Petri net represents a traffic control protocol ensuring that two traffic lights alternate safely and are never both green at the same time.
petrinet ;start () -> greenLight1 redLight2 ;toRed1 greenLight1 -> queue redLight1 ;toGreen2 redLight2 queue -> greenLight2 ;toGreen1 queue redLight1 -> greenLight1 ;toRed2 greenLight2 -> redLight2 queue ;stop redLight1 queue redLight2 -> () -
@ 3bf0c63f:aefa459d
2025-04-25 19:26:48
Redistributing Git with Nostr
Every time someone tries to "decentralize" Git -- like many projects tried in the past to do it with BitTorrent, IPFS, ScuttleButt or custom p2p protocols -- there is always a lurking comment: "but Git is already distributed!", and then the discussion proceeds to mention some facts about how Git supports multiple remotes and its magic syncing and merging abilities and so on.
Turns out all that is true, Git is indeed all that powerful, and yet GitHub is the big central hub that hosts basically all Git repositories in the giant world of open-source. There are some crazy people that host their stuff elsewhere, but these projects end up not being found by many people, and even when they do they suffer from lack of contributions.
Because everybody has a GitHub account it's easy to open a pull request to a repository of a project you're using if it's on GitHub (to be fair I think it's very annoying to have to clone the repository, then add it as a remote locally, push to it, then go on the web UI and click to open a pull request, then that cloned repository lurks forever in your profile unless you go through 16 screens to delete it -- but people in general seem to think it's easy).
It's much harder to do it on some random other server where some project might be hosted, because now you have to add 4 more even more annoying steps: create an account; pick a password; confirm an email address; setup SSH keys for pushing. (And I'm not even mentioning the basic impossibility of offering
pushaccess to external unknown contributors to people who want to host their own simple homemade Git server.)At this point some may argue that we could all have accounts on GitLab, or Codeberg or wherever else, then those steps are removed. Besides not being a practical strategy this pseudo solution misses the point of being decentralized (or distributed, who knows) entirely: it's far from the ideal to force everybody to have the double of account management and SSH setup work in order to have the open-source world controlled by two shady companies instead of one.
What we want is to give every person the opportunity to host their own Git server without being ostracized. at the same time we must recognize that most people won't want to host their own servers (not even most open-source programmers!) and give everybody the ability to host their stuff on multi-tenant servers (such as GitHub) too. Importantly, though, if we allow for a random person to have a standalone Git server on a standalone server they host themselves on their wood cabin that also means any new hosting company can show up and start offering Git hosting, with or without new cool features, charging high or low or zero, and be immediately competing against GitHub or GitLab, i.e. we must remove the network-effect centralization pressure.
External contributions
The first problem we have to solve is: how can Bob contribute to Alice's repository without having an account on Alice's server?
SourceHut has reminded GitHub users that Git has always had this (for most) arcane
git send-emailcommand that is the original way to send patches, using an once-open protocol.Turns out Nostr acts as a quite powerful email replacement and can be used to send text content just like email, therefore patches are a very good fit for Nostr event contents.
Once you get used to it and the proper UIs (or CLIs) are built sending and applying patches to and from others becomes a much easier flow than the intense clickops mixed with terminal copypasting that is interacting with GitHub (you have to clone the repository on GitHub, then update the remote URL in your local directory, then create a branch and then go back and turn that branch into a Pull Request, it's quite tiresome) that many people already dislike so much they went out of their way to build many GitHub CLI tools just so they could comment on issues and approve pull requests from their terminal.
Replacing GitHub features
Aside from being the "hub" that people use to send patches to other people's code (because no one can do the email flow anymore, justifiably), GitHub also has 3 other big features that are not directly related to Git, but that make its network-effect harder to overcome. Luckily Nostr can be used to create a new environment in which these same features are implemented in a more decentralized and healthy way.
Issues: bug reports, feature requests and general discussions
Since the "Issues" GitHub feature is just a bunch of text comments it should be very obvious that Nostr is a perfect fit for it.
I will not even mention the fact that Nostr is much better at threading comments than GitHub (which doesn't do it at all), which can generate much more productive and organized discussions (and you can opt out if you want).
Search
I use GitHub search all the time to find libraries and projects that may do something that I need, and it returns good results almost always. So if people migrated out to other code hosting providers wouldn't we lose it?
The fact is that even though we think everybody is on GitHub that is a globalist falsehood. Some projects are not on GitHub, and if we use only GitHub for search those will be missed. So even if we didn't have a Nostr Git alternative it would still be necessary to create a search engine that incorporated GitLab, Codeberg, SourceHut and whatnot.
Turns out on Nostr we can make that quite easy by not forcing anyone to integrate custom APIs or hardcoding Git provider URLs: each repository can make itself available by publishing an "announcement" event with a brief description and one or more Git URLs. That makes it easy for a search engine to index them -- and even automatically download the code and index the code (or index just README files or whatever) without a centralized platform ever having to be involved.
The relays where such announcements will be available play a role, of course, but that isn't a bad role: each announcement can be in multiple relays known for storing "public good" projects, some relays may curate only projects known to be very good according to some standards, other relays may allow any kind of garbage, which wouldn't make them good for a search engine to rely upon, but would still be useful in case one knows the exact thing (and from whom) they're searching for (the same is valid for all Nostr content, by the way, and that's where it's censorship-resistance comes from).
Continuous integration
GitHub Actions are a very hardly subsidized free-compute-for-all-paid-by-Microsoft feature, but one that isn't hard to replace at all. In fact there exists today many companies offering the same kind of service out there -- although they are mostly targeting businesses and not open-source projects, before GitHub Actions was introduced there were also many that were heavily used by open-source projects.
One problem is that these services are still heavily tied to GitHub today, they require a GitHub login, sometimes BitBucket and GitLab and whatnot, and do not allow one to paste an arbitrary Git server URL, but that isn't a thing that is very hard to change anyway, or to start from scratch. All we need are services that offer the CI/CD flows, perhaps using the same framework of GitHub Actions (although I would prefer to not use that messy garbage), and charge some few satoshis for it.
It may be the case that all the current services only support the big Git hosting platforms because they rely on their proprietary APIs, most notably the webhooks dispatched when a repository is updated, to trigger the jobs. It doesn't have to be said that Nostr can also solve that problem very easily.
-
@ 207ad2a0:e7cca7b0
2025-01-07 03:46:04
Quick context: I wanted to check out Nostr's longform posts and this blog post seemed like a good one to try and mirror. It's originally from my free to read/share attempt to write a novel, but this post here is completely standalone - just describing how I used AI image generation to make a small piece of the work.
Hold on, put your pitchforks down - outside of using Grammerly & Emacs for grammatical corrections - not a single character was generated or modified by computers; a non-insignificant portion of my first draft originating on pen & paper. No AI is ~~weird and crazy~~ imaginative enough to write like I do. The only successful AI contribution you'll find is a single image, the map, which I heavily edited. This post will go over how I generated and modified an image using AI, which I believe brought some value to the work, and cover a few quick thoughts about AI towards the end.
Let's be clear, I can't draw, but I wanted a map which I believed would improve the story I was working on. After getting abysmal results by prompting AI with text only I decided to use "Diffuse the Rest," a Stable Diffusion tool that allows you to provide a reference image + description to fine tune what you're looking for. I gave it this Microsoft Paint looking drawing:

and after a number of outputs, selected this one to work on:
The image is way better than the one I provided, but had I used it as is, I still feel it would have decreased the quality of my work instead of increasing it. After firing up Gimp I cropped out the top and bottom, expanded the ocean and separated the landmasses, then copied the top right corner of the large landmass to replace the bottom left that got cut off. Now we've got something that looks like concept art: not horrible, and gets the basic idea across, but it's still due for a lot more detail.
The next thing I did was add some texture to make it look more map like. I duplicated the layer in Gimp and applied the "Cartoon" filter to both for some texture. The top layer had a much lower effect strength to give it a more textured look, while the lower layer had a higher effect strength that looked a lot like mountains or other terrain features. Creating a layer mask allowed me to brush over spots to display the lower layer in certain areas, giving it some much needed features.
At this point I'd made it to where I felt it may improve the work instead of detracting from it - at least after labels and borders were added, but the colors seemed artificial and out of place. Luckily, however, this is when PhotoFunia could step in and apply a sketch effect to the image.
At this point I was pretty happy with how it was looking, it was close to what I envisioned and looked very visually appealing while still being a good way to portray information. All that was left was to make the white background transparent, add some minor details, and add the labels and borders. Below is the exact image I wound up using:
Overall, I'm very satisfied with how it turned out, and if you're working on a creative project, I'd recommend attempting something like this. It's not a central part of the work, but it improved the chapter a fair bit, and was doable despite lacking the talent and not intending to allocate a budget to my making of a free to read and share story.
The AI Generated Elephant in the Room
If you've read my non-fiction writing before, you'll know that I think AI will find its place around the skill floor as opposed to the skill ceiling. As you saw with my input, I have absolutely zero drawing talent, but with some elbow grease and an existing creative direction before and after generating an image I was able to get something well above what I could have otherwise accomplished. Outside of the lowest common denominators like stock photos for the sole purpose of a link preview being eye catching, however, I doubt AI will be wholesale replacing most creative works anytime soon. I can assure you that I tried numerous times to describe the map without providing a reference image, and if I used one of those outputs (or even just the unedited output after providing the reference image) it would have decreased the quality of my work instead of improving it.
I'm going to go out on a limb and expect that AI image, text, and video is all going to find its place in slop & generic content (such as AI generated slop replacing article spinners and stock photos respectively) and otherwise be used in a supporting role for various creative endeavors. For people working on projects like I'm working on (e.g. intended budget $0) it's helpful to have an AI capable of doing legwork - enabling projects to exist or be improved in ways they otherwise wouldn't have. I'm also guessing it'll find its way into more professional settings for grunt work - think a picture frame or fake TV show that would exist in the background of an animated project - likely a detail most people probably wouldn't notice, but that would save the creators time and money and/or allow them to focus more on the essential aspects of said work. Beyond that, as I've predicted before: I expect plenty of emails will be generated from a short list of bullet points, only to be summarized by the recipient's AI back into bullet points.
I will also make a prediction counter to what seems mainstream: AI is about to peak for a while. The start of AI image generation was with Google's DeepDream in 2015 - image recognition software that could be run in reverse to "recognize" patterns where there were none, effectively generating an image from digital noise or an unrelated image. While I'm not an expert by any means, I don't think we're too far off from that a decade later, just using very fine tuned tools that develop more coherent images. I guess that we're close to maxing out how efficiently we're able to generate images and video in that manner, and the hard caps on how much creative direction we can have when using AI - as well as the limits to how long we can keep it coherent (e.g. long videos or a chronologically consistent set of images) - will prevent AI from progressing too far beyond what it is currently unless/until another breakthrough occurs.
-
@ 3bf0c63f:aefa459d
2025-04-25 18:55:52
Report of how the money Jack donated to the cause in December 2022 has been misused so far.
Bounties given
March 2025
- Dhalsim: 1,110,540 - Work on Nostr wiki data processing
February 2025
- BOUNTY* NullKotlinDev: 950,480 - Twine RSS reader Nostr integration
- Dhalsim: 2,094,584 - Work on Hypothes.is Nostr fork
- Constant, Biz and J: 11,700,588 - Nostr Special Forces
January 2025
- Constant, Biz and J: 11,610,987 - Nostr Special Forces
- BOUNTY* NullKotlinDev: 843,840 - Feeder RSS reader Nostr integration
- BOUNTY* NullKotlinDev: 797,500 - ReadYou RSS reader Nostr integration
December 2024
- BOUNTY* tijl: 1,679,500 - Nostr integration into RSS readers yarr and miniflux
- Constant, Biz and J: 10,736,166 - Nostr Special Forces
- Thereza: 1,020,000 - Podcast outreach initiative
November 2024
- Constant, Biz and J: 5,422,464 - Nostr Special Forces
October 2024
- Nostrdam: 300,000 - hackathon prize
- Svetski: 5,000,000 - Latin America Nostr events contribution
- Quentin: 5,000,000 - nostrcheck.me
June 2024
- Darashi: 5,000,000 - maintaining nos.today, searchnos, search.nos.today and other experiments
- Toshiya: 5,000,000 - keeping the NIPs repo clean and other stuff
May 2024
- James: 3,500,000 - https://github.com/jamesmagoo/nostr-writer
- Yakihonne: 5,000,000 - spreading the word in Asia
- Dashu: 9,000,000 - https://github.com/haorendashu/nostrmo
February 2024
- Viktor: 5,000,000 - https://github.com/viktorvsk/saltivka and https://github.com/viktorvsk/knowstr
- Eric T: 5,000,000 - https://github.com/tcheeric/nostr-java
- Semisol: 5,000,000 - https://relay.noswhere.com/ and https://hist.nostr.land relays
- Sebastian: 5,000,000 - Drupal stuff and nostr-php work
- tijl: 5,000,000 - Cloudron, Yunohost and Fraidycat attempts
- Null Kotlin Dev: 5,000,000 - AntennaPod attempt
December 2023
- hzrd: 5,000,000 - Nostrudel
- awayuki: 5,000,000 - NOSTOPUS illustrations
- bera: 5,000,000 - getwired.app
- Chris: 5,000,000 - resolvr.io
- NoGood: 10,000,000 - nostrexplained.com stories
October 2023
- SnowCait: 5,000,000 - https://nostter.vercel.app/ and other tools
- Shaun: 10,000,000 - https://yakihonne.com/, events and work on Nostr awareness
- Derek Ross: 10,000,000 - spreading the word around the world
- fmar: 5,000,000 - https://github.com/frnandu/yana
- The Nostr Report: 2,500,000 - curating stuff
- james magoo: 2,500,000 - the Obsidian plugin: https://github.com/jamesmagoo/nostr-writer
August 2023
- Paul Miller: 5,000,000 - JS libraries and cryptography-related work
- BOUNTY tijl: 5,000,000 - https://github.com/github-tijlxyz/wikinostr
- gzuus: 5,000,000 - https://nostree.me/
July 2023
- syusui-s: 5,000,000 - rabbit, a tweetdeck-like Nostr client: https://syusui-s.github.io/rabbit/
- kojira: 5,000,000 - Nostr fanzine, Nostr discussion groups in Japan, hardware experiments
- darashi: 5,000,000 - https://github.com/darashi/nos.today, https://github.com/darashi/searchnos, https://github.com/darashi/murasaki
- jeff g: 5,000,000 - https://nostr.how and https://listr.lol, plus other contributions
- cloud fodder: 5,000,000 - https://nostr1.com (open-source)
- utxo.one: 5,000,000 - https://relaying.io (open-source)
- Max DeMarco: 10,269,507 - https://www.youtube.com/watch?v=aA-jiiepOrE
- BOUNTY optout21: 1,000,000 - https://github.com/optout21/nip41-proto0 (proposed nip41 CLI)
- BOUNTY Leo: 1,000,000 - https://github.com/leo-lox/camelus (an old relay thing I forgot exactly)
June 2023
- BOUNTY: Sepher: 2,000,000 - a webapp for making lists of anything: https://pinstr.app/
- BOUNTY: Kieran: 10,000,000 - implement gossip algorithm on Snort, implement all the other nice things: manual relay selection, following hints etc.
- Mattn: 5,000,000 - a myriad of projects and contributions to Nostr projects: https://github.com/search?q=owner%3Amattn+nostr&type=code
- BOUNTY: lynn: 2,000,000 - a simple and clean git nostr CLI written in Go, compatible with William's original git-nostr-tools; and implement threaded comments on https://github.com/fiatjaf/nocomment.
- Jack Chakany: 5,000,000 - https://github.com/jacany/nblog
- BOUNTY: Dan: 2,000,000 - https://metadata.nostr.com/
April 2023
- BOUNTY: Blake Jakopovic: 590,000 - event deleter tool, NIP dependency organization
- BOUNTY: koalasat: 1,000,000 - display relays
- BOUNTY: Mike Dilger: 4,000,000 - display relays, follow event hints (Gossip)
- BOUNTY: kaiwolfram: 5,000,000 - display relays, follow event hints, choose relays to publish (Nozzle)
- Daniele Tonon: 3,000,000 - Gossip
- bu5hm4nn: 3,000,000 - Gossip
- BOUNTY: hodlbod: 4,000,000 - display relays, follow event hints
March 2023
- Doug Hoyte: 5,000,000 sats - https://github.com/hoytech/strfry
- Alex Gleason: 5,000,000 sats - https://gitlab.com/soapbox-pub/mostr
- verbiricha: 5,000,000 sats - https://badges.page/, https://habla.news/
- talvasconcelos: 5,000,000 sats - https://migrate.nostr.com, https://read.nostr.com, https://write.nostr.com/
- BOUNTY: Gossip model: 5,000,000 - https://camelus.app/
- BOUNTY: Gossip model: 5,000,000 - https://github.com/kaiwolfram/Nozzle
- BOUNTY: Bounty Manager: 5,000,000 - https://nostrbounties.com/
February 2023
- styppo: 5,000,000 sats - https://hamstr.to/
- sandwich: 5,000,000 sats - https://nostr.watch/
- BOUNTY: Relay-centric client designs: 5,000,000 sats https://bountsr.org/design/2023/01/26/relay-based-design.html
- BOUNTY: Gossip model on https://coracle.social/: 5,000,000 sats
- Nostrovia Podcast: 3,000,000 sats - https://nostrovia.org/
- BOUNTY: Nostr-Desk / Monstr: 5,000,000 sats - https://github.com/alemmens/monstr
- Mike Dilger: 5,000,000 sats - https://github.com/mikedilger/gossip
January 2023
- ismyhc: 5,000,000 sats - https://github.com/Galaxoid-Labs/Seer
- Martti Malmi: 5,000,000 sats - https://iris.to/
- Carlos Autonomous: 5,000,000 sats - https://github.com/BrightonBTC/bija
- Koala Sat: 5,000,000 - https://github.com/KoalaSat/nostros
- Vitor Pamplona: 5,000,000 - https://github.com/vitorpamplona/amethyst
- Cameri: 5,000,000 - https://github.com/Cameri/nostream
December 2022
- William Casarin: 7 BTC - splitting the fund
- pseudozach: 5,000,000 sats - https://nostr.directory/
- Sondre Bjellas: 5,000,000 sats - https://notes.blockcore.net/
- Null Dev: 5,000,000 sats - https://github.com/KotlinGeekDev/Nosky
- Blake Jakopovic: 5,000,000 sats - https://github.com/blakejakopovic/nostcat, https://github.com/blakejakopovic/nostreq and https://github.com/blakejakopovic/NostrEventPlayground
-
@ 6b3780ef:221416c8
2025-04-25 12:08:51
We have been working on a significant update to the DVMCP specification to incorporate the latest Model Context Protocol (MCP) version
2025-03-26, and it's capabilities. This draft revision represents our vision for how MCP services can be discovered, accessed, and utilized across the Nostr network while maintaining compatibility between both protocols.Expanding Beyond Tools
The first version of the DVMCP specification focused primarily on tools, functions that could be executed remotely via MCP servers. While this provided valuable functionality, the Model Context Protocol offers more capabilities than just tools. In our proposed update, DVMCP would embrace the complete MCP capabilities framework. Rather than focusing solely on tools, the specification will incorporate resources (files and data sources that can be accessed by clients) and prompts (pre-defined templates for consistent interactions). This expansion transforms DVMCP into a complete framework for service interoperability between protocols.
Moving Toward a More Modular Architecture
One of the most significant architectural changes in this draft is our move toward a more modular event structure. Previously, we embedded tools directly within server announcements using NIP-89, creating a monolithic approach that was challenging to extend.
The updated specification introduces dedicated event kinds for server announcements (31316) and separate event kinds for each capability category. Tools, resources, and prompts would each have their own event kinds (31317, 31318, and 31319 respectively). This separation improves both readability and interoperability between protocols, allowing us to support pagination for example, as described in the MCP protocol. It also enables better filtering options for clients discovering specific capabilities, allows for more efficient updates when only certain capabilities change, and enhances robustness as new capability types can be added with minimal disruption.
Technical Direction
The draft specification outlines several technical improvements worth highlighting. We've worked to ensure consistent message structures across all capability types and created a clear separation of concerns between Nostr metadata (in tags) and MCP payloads (in content). The specification includes support for both public server discovery and direct private server connections, comprehensive error handling aligned with both protocols, and detailed protocol flows for all major operations.
Enhancing Notifications
Another important improvement in our design is the redesign of the job feedback and notification system. We propose to make event kind 21316 (ephemeral). This approach provides a more efficient way to deliver status updates, progress information, and interactive elements during capability execution without burdening relays with unnecessary storage requirements.
This change would enable more dynamic interactions between clients and servers, particularly for long-running operations.
Seeking Community Feedback
We're now at a stage where community input would be highly appreciated. If you're interested in DVMCP, we'd greatly appreciate your thoughts on our approach. The complete draft specification is available for review, and we welcome your feedback through comments on our pull request at dvmcp/pull/18. Your insights and suggestions will help us refine the specification to better serve the needs of the community.
Looking Ahead
After gathering and incorporating community feedback, our next step will be updating the various DVMCP packages to implement these changes. This will include reference implementations for both servers (DVMCP-bridge) and clients (DVMCP-discovery).
We believe this proposed update represents a significant step forward for DVMCP. By embracing the full capabilities framework of MCP, we're expanding what's possible within the protocol while maintaining our commitment to open standards and interoperability.
Stay tuned for more updates as we progress through the feedback process and move toward implementation. Thank you to everyone who has contributed to the evolution of DVMCP, and we look forward to your continued involvement.
-
@ 3de5f798:31faf8b0
2025-04-25 11:57:47
111111
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 3f770d65:7a745b24
2025-01-05 18:56:33
New Year’s resolutions often feel boring and repetitive. Most revolve around getting in shape, eating healthier, or giving up alcohol. While the idea is interesting—using the start of a new calendar year as a catalyst for change—it also seems unnecessary. Why wait for a specific date to make a change? If you want to improve something in your life, you can just do it. You don’t need an excuse.
That’s why I’ve never been drawn to the idea of making a list of resolutions. If I wanted a change, I’d make it happen, without worrying about the calendar. At least, that’s how I felt until now—when, for once, the timing actually gave me a real reason to embrace the idea of New Year’s resolutions.
Enter Olas.
If you're a visual creator, you've likely experienced the relentless grind of building a following on platforms like Instagram—endless doomscrolling, ever-changing algorithms, and the constant pressure to stay relevant. But what if there was a better way? Olas is a Nostr-powered alternative to Instagram that prioritizes community, creativity, and value-for-value exchanges. It's a game changer.
Instagram’s failings are well-known. Its algorithm often dictates whose content gets seen, leaving creators frustrated and powerless. Monetization hurdles further alienate creators who are forced to meet arbitrary follower thresholds before earning anything. Additionally, the platform’s design fosters endless comparisons and exposure to negativity, which can take a significant toll on mental health.
Instagram’s algorithms are notorious for keeping users hooked, often at the cost of their mental health. I've spoken about this extensively, most recently at Nostr Valley, explaining how legacy social media is bad for you. You might find yourself scrolling through content that leaves you feeling anxious or drained. Olas takes a fresh approach, replacing "doomscrolling" with "bloomscrolling." This is a common theme across the Nostr ecosystem. The lack of addictive rage algorithms allows the focus to shift to uplifting, positive content that inspires rather than exhausts.
Monetization is another area where Olas will set itself apart. On Instagram, creators face arbitrary barriers to earning—needing thousands of followers and adhering to restrictive platform rules. Olas eliminates these hurdles by leveraging the Nostr protocol, enabling creators to earn directly through value-for-value exchanges. Fans can support their favorite artists instantly, with no delays or approvals required. The plan is to enable a brand new Olas account that can get paid instantly, with zero followers - that's wild.
Olas addresses these issues head-on. Operating on the open Nostr protocol, it removes centralized control over one's content’s reach or one's ability to monetize. With transparent, configurable algorithms, and a community that thrives on mutual support, Olas creates an environment where creators can grow and succeed without unnecessary barriers.
Join me on my New Year's resolution. Join me on Olas and take part in the #Olas365 challenge! It’s a simple yet exciting way to share your content. The challenge is straightforward: post at least one photo per day on Olas (though you’re welcome to share more!).
Download on Android or download via Zapstore.
Let's make waves together.
-
@ 0001cbad:c91c71e8
2025-04-25 11:31:08
As is well known, mathematics is a form of logic — that is, it is characterized by the ability to generate redundancy through manifestations in space. Mathematics is unrestricted from the human perspective, since it is what restricts us; it is descriptive rather than explanatory, unlike physics, chemistry, biology, etc. You can imagine a world without physics, chemistry, or biology in terms of how these occur, but you cannot conceive of a world without mathematics, because you are before you do anything. In other words, it encompasses all possibilities.
You may be left without an explanation, but never without a description. Lies can be suggested with mathematics — you can write that “5+2=8,” but we know that’s wrong, because we are beings capable of manipulating it. Explanations are not necessary; it stands on its own. It is somewhat irreverent in its form, and this elicits its truth.
1 2 3 4 5 6 7 8 9
An interesting way to think about mathematics is that it consists of “points,” where the only variation is their position. It is possible to conceive of a drastically different world, no matter how it differs, but we can only treat them as such because they are the same — except for their location. That is, the creation of a plane becomes possible. This leads us to infer that mathematics is the decoupling of space-time, allowing one to play emperor. In this sense, something that is independent of time can be considered as an a priori truth.
As Wittgenstein put it:
Death is not an event in life: we do not live to experience death. If we take eternity not as an infinite temporal duration but as timelessness, then eternal life belongs to those who live in the present. We can summarize what has been said so far using the following logic:
We are limited by time. You, as a being, can only be in one place at a given moment. Mathematics is independent of time. Therefore, its elements (points) encompass all locations simultaneously. If its elements exist throughout all logical space at once, mathematics transcends time; and if things vary according to time, then mathematics is sovereign. Thus, the point is this: since nothing distinguishes one point from another except position, a point can become another as long as it has a location. That is, it only requires the use of operators to get there.
Operators = act
To clarify: there is no such thing as a distance of zero, because it does not promote redundancy. It’s as if the condition for something to qualify as a mathematical problem is that it must be subject to redundancy — in other words, it must be capable of being formulated.
An interesting analogy is to imagine yourself as an omnipresent being, but with decentralized “consciousness,” that is, corresponding to each location where your “self” is. Therefore, people anywhere in the world could see you. Given that, when you inhibit the possibility of others seeing you — in a static world, except for yours — nothing happens; this is represented by emptiness, because there is no relationship of change. It is the pure state, the nakedness of logic, its breath.
You, thinking of your girlfriend, with whom you’ve just had an argument, see a woman walking toward you. From a distance, she resembles her quite a lot. But as she gets closer, you suddenly see that it isn’t her, and your heart sinks. Subtext: You are alive.
Diving deeper, “0” stands to redundancy as frustration stands to “life”; both are the negation of a manifestation of potential — of life. Yet they are fundamental, because if everything is a manifestation of potential, what value does it have if there is nothing to oppose it?
Corollary: There are multiple locations — and this configuration is the condition for redundancy, since for something to occupy another position, it must have one to begin with, and zero represents this.
A descriptive system
The second part of this essay aims to relate mathematics to what allows it to be framed as a “marker” of history: uncertainty — and also its role as an interface through which history unfolds.
From a logical assumption, you cannot claim the nonexistence of the other, because to deny it is to deny yourself.
As Gandalf said:
Many that live deserve death. And some that die deserve life. Can you give it to them? Then do not be too eager to deal out death in judgment. The issue is that we are obsessed with the truth about how the human experience should be — which is rather pathological, given that this experience cannot be echoed unless it is coupled with a logical framework coherent with life, with the factors that bathe it. That is, a logically coherent civilizational framework must be laced with both mathematics and uncertainty. We can characterize this as a descriptive plane, because it does not induce anything — it merely describes what happens.
Thus, an explanatory framework can be seen as one that induces action, since an explanation consists of linking one thing to another.
A descriptive framework demands a decentralized system of coordination, because for a story to be consistent, it must be inexpressible in its moments (temporal terms) and yet encompass them all. A valid analogy: History = blockchain.
To be part of history, certainty must outweigh uncertainty — and whoever offers that certainty must take on a corresponding uncertainty. Pack your things and leave; return when you have something to offer. That is the line of history being built, radiating life.
Legitimacy of Private Property
As previously woven, there is something that serves as a precondition for establishing conformity between the real plane and the mathematical one — the latter being subordinate to the logical, to life itself. The existence of the subject (will/consciousness) legitimizes property, for objects cannot, by principle, act systematically — that is, praxeological. It makes no sense to claim that something incapable of deliberate action possesses something that is not inherently comprehensible to it as property, since it is not a subject. An element of a set has as its property the existence within one or more sets — that is, its existence, as potential, only occurs through handling.
The legitimacy of private property itself is based on the fact that for someone to be the original proprietor of something, there must be spatiotemporal palpability between them, which is the mold of the world. Therefore, private property is a true axiom, enabling logical deductions that allow for human flourishing.
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
- Enhance LLM Outputs: By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
- Support Complex Queries: Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
- Richness of Entities: Effective retrieval depends on graphs populated with rich, detailed entities.
- Freedom from Hallucinations: Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
- Handle diverse data sources with ease.
- Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
- Defining Relationships: Clarifying how concepts connect within a domain.
- Validating Graph Structures: Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
- Assign a Knowledge Champion: Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
- Provide Training: Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
- Leverage Partnerships: Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
- Utilize Tools: Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
- Iterate with Feedback: Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
-
Leverage Existing Ontologies: Many industries and domains already have open ontologies. For instance:
-
Public Knowledge Graphs: Resources like Wikipedia’s graph offer a wealth of structured knowledge.
- Industry Standards: Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
-
Business Framework Ontology (BFO): A valuable resource for enterprises looking to define business processes and structures.
-
Build In-House Expertise: If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
-
Utilize LLMs for Ontology Construction: Interestingly, LLMs themselves can act as a starting point for ontology development:
-
Prompt-Based Extraction: LLMs can generate draft ontologies by leveraging their extensive training on graph data.
- Domain Expert Refinement: Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
- Detecting Hallucinations: Differentiating between genuine insights and AI-generated inaccuracies.
- Ensuring Completeness: Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
- Generate Skeleton Ontologies: Prompt LLMs with domain-specific information to draft initial ontology structures.
- Validate and Refine Ontologies: Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
The Four-Layer Framework
Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
Example: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- Tip: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
Once you have the big picture in mind, it’s time to start breaking it down.
Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
Example: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- Tip: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
With your categories in place, you’re ready to dive into the details that bring them to life.
Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
Example: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- Tip: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
Now that you’ve mastered the essentials, you can expand your knowledge to include extra material.
Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
Example: Learn about rare programming quirks or historical trivia about a language’s development.
- Tip: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
Pro Tips for Better Learning
1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
2. Map It Out
Create visual aids like diagrams or concept maps to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching exposes any gaps in your understanding and helps reinforce the material.
4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to explore your topic in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.Tip: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ e8744882:47d84815
2025-04-25 10:45:49
Top Hollywood Movies in Telugu Dubbed List for 2025
The world of Hollywood cinema is packed with action, adventure, and mind-blowing storytelling. But what if you could enjoy these blockbuster hits in your language? Thanks to Dimension on Demand (DOD) and theHollywood movies in Telugu dubbed list, fans can now experience international cinema like never before. Whether you love fantasy battles, high-stakes heists, or sci-fi horror, these top picks are perfect for Telugu-speaking audiences!
Let’s explore three must-watch Hollywood films that have captivated global audiences and are now available in Telugu for an immersive viewing experience.
Wrath Of The Dragon God – A Battle of Magic and Power
Magic, warriors, and an ancient evil—Wrath Of The Dragon God is an epic fantasy that keeps you on the edge of your seat. The film follows four brave heroes who must unite to retrieve a powerful orb and stop the villainous Damodar before he awakens a deadly black dragon. With the fate of the world at stake, they use elemental forces to battle dark magic in a spectacular showdown, making it a must-watch from the Hollywood movies in Telugu dubbed list.
This thrilling adventure brings together breathtaking visuals and a gripping storyline that fantasy lovers will adore. Directed by Gerry Lively, the film features a stellar cast, including Robert Kimmel, Brian Rudnick, and Gerry Lively, who bring their characters to life with incredible performances. If you're a fan of legendary fantasy films, this one should be at the top of your Hollywood movies in Telugu dubbed list.
Why This Fantasy Adventure Stands Out:
- Action-Packed Battles – Epic war sequences between magic and monsters
- A Gripping Storyline – A journey filled with suspense and high-stakes, making it a must-watch from the Telugu dubbed Hollywood films
- Visually Stunning – Breathtaking CGI and cinematic excellence
Riders – The Ultimate Heist Thriller
What happens when a group of expert thieves plan the ultimate heist? Riders is a fast-paced action thriller that follows a team of robbers attempting five burglaries in five days to steal a whopping $20 million. With intense chase sequences, double-crosses, and high-stakes action, this film keeps you hooked from start to finish, making it a standout in the Hollywood movies in Telugu dubbed list.
Featuring Stephen Dorff, Natasha Henstridge, Bruce Payne, and Steven Berkoff, the movie boasts a talented cast delivering electrifying performances. Dorff, known for his roles in Blade and Somewhere, plays a criminal mastermind determined to outwit the law. Directed by Gérard Pirès, Riders is a must-watch for action lovers looking for heart-racing excitement in their Hollywood movies in Telugu dubbed list.
What Makes This Heist Film a Must-Watch?
- High-Octane Action – Non-stop thrill from start to finish
- A Star-Studded Cast – Featuring Hollywood’s finest actors in a Hollywood movie dubbed in Telugu
- Smart & Engaging Plot – Twists and turns that keep you guessing
Grabbers – A Sci-Fi Horror with a Unique Twist
Ever wondered what it takes to survive an alien invasion? Grabbers bring a hilarious yet terrifying answer: getting drunk! When bloodsucking creatures invade a remote Irish island, the residents discover that alcohol is their only defense against these monstrous aliens. This unique blend of horror, comedy, and sci-fi makes for an entertaining ride, securing its place in the Hollywood movies in Telugu dubbed list.
Starring Killian Coyle, Stuart Graham, Richard Coyle, and Ruth Bradley, the movie’s cast delivers brilliant performances. Bradley, who won the IFTA Award for Best Actress, plays a courageous officer trying to protect the islanders. Directed by Jon Wright, Grabbers is a refreshing take on alien horror, making it a fantastic addition to the Hollywood movies in Telugu dubbed list.
Why This Sci-Fi Horror is a Must-Watch:
- A Unique Concept – Survival through Drunken Defense Tactics
- Action/ Horror/Si-Fi Combined – A perfect mix of action, sci-fi, and scares in the Telugu-dubbed Hollywood movies list
- Outstanding Performances – Ruth Bradley’s award-winning role
Why Watch These Hollywood Movies in Telugu Dubbed List on DOD?
DOD (Dimension On Demand) brings Hollywood movies in Telugu dubbed list to your screen, ensuring a seamless and immersive viewing experience. Whether you love action, horror, or sci-fi, these films deliver top-notch entertainment in your preferred language. With high-quality dubbing and engaging storytelling, DOD makes it easier than ever to enjoy Hollywood’s best!
Start Watching Now!
Watch Wrath Of The Dragon God in Telugu Dubbed – Click here!
Stream Riders Telugu Dubbed – Don’t miss it!
Enjoy Grabbers in Telugu Dubbed – Start now!Don’t miss out! Watch these movies on DOD now!
Check out the official DOD YouTube channel for more exciting releases and explore the Hollywood movies in Telugu dubbed list to experience cinema like never before!
Conclusion
Hollywood’s biggest hits are now more accessible than ever, thanks to high-quality dubbing that brings these stories to life in regional languages. Whether it's the magical battles of Wrath Of The Dragon God, the thrilling heist in Riders, or the hilarious alien invasion in Grabbers, these films offer something for every movie lover. With Hollywood movies in Telugu dubbed list, audiences can enjoy global cinema without language barriers. So grab your popcorn, tune into DOD, and get ready for an unforgettable movie marathon!
-
@ 1b9fc4cd:1d6d4902
2025-04-25 10:17:32
Songwriting is a potent artistic expression that transcends borderlines and barriers. Many songwriters throughout history have perfected the art of crafting lyrics that resonate with audiences. In this article, Daniel Siegel Alonso delves into the nuanced realm of songwriting, exploring how songwriters like Lou Reed, Joni Mitchell, and Nina Simone have connected with listeners through their evocative and timeless lyrics.
**The street poet ** Siegel Alonso begins with the quintessential urban poet: Lou Reed. Reed transformed gritty, day-to-day experiences into lyrical masterpieces. As the front man of the proto-punk band The Velvet Underground, Reed's songwriting was known for its rawness and unflinching depiction of urban life. His lyrics often examined social alienation, the throes of addiction, and the pursuit of authenticity.
In songs like the now iconic "Heroin," Reed's explicit descriptions and stark narrative style draw listeners into the psyche of a person battling addiction. Lyrics such as "I have made the big decision / I'm gonna try to nullify my life" convey a haunting sense of sorrow and yearning for numbness. At the height of free love and flower power, Reed's ability to confront such complex subjects head-on allowed listeners to find solace in shared experiences, fostering a sense of connection through his candid storytelling.
Reed's influence extends beyond his provocative themes. His conversational singing style and use of spoken word elements in songs like "Walk on the Wild Side" subvert traditional songwriting norms, making his work not just music but a form of urban poetry. Reed's legacy lies in his ability to capture the essence of human experience.
**The painter of emotions ** Joni Mitchell's songwriting is often described as painting with words. Her intricate and poetic lyrics delve deep into personal and emotional landscapes, creating vivid imagery and profound reflections on life and love. Mitchell's work is a testament to the power of introspection and the beauty of vulnerability in songwriting.
On her 1971 studio album Blue, Mitchell bares all with songs that explore heartache, longing, and self-discovery. Songs like "A Case of You" contain poignant and visually evocative lyrics: "Oh, I could drink a case of you, darling / Still, I'd be on my feet." Siegel Alonso says Micthell's mastery of weaving personal tales with universal emotions creates a deeply intimate listening experience.
Joni Mitchell's innovative musical compositions complement her lyrical prowess. She often employs unusual guitar chord progressions and tunings, which add a distinctive color to her songs. This type of musical experimentation, combined with Joni's introspective verses, invites listeners into her world, offering comfort and understanding. Mitchell has formed a timeless bond with her audience through her artistry, demonstrating that the most intimate, private songs often resonate the most universally.
**The voice of the civil rights movement ** Nina Simone's songwriting is a powerful testament to music's role in social activism. Known for her unusual, soulful voice and fiery performances, Simone used her platform to address racial injustice, inequality, and civil rights issues. Her lyrics tend to be a call to action, urging her listeners to reflect on the unjust world and strive for change.
Simone's song "Mississippi Goddam" is a prime example of her fearless approach to songwriting. Written in response to the murder of Medgar Evers and the bombing of a church in Birmingham, Alabama, the song's cutting lyrics combined with its upbeat tempo create a startling contrast that underscores the urgency of her message. "Alabama's gotten me so upset / Tennessee made me lose my rest / And everybody knows about Mississippi Goddam." Through her craft, Simone shared the frustration and fury of the Civil Rights Movement, galvanizing her listeners to join in the fight for justice.
Another poignant example is her track "Four Women," which tells the stories of four African American women, each representing different aspects of the Black experience in America. Simone's lyrics powerfully explore identity, resilience, and oppression, with each character's narrative spotlighting broader social issues. Her talent to articulate the suffering and strength of her community through her lyrics has left an indelible mark on the music industry and the world.
The art of songwriting is more than just crafting words to fit a melody; it is about creating a connection between the artist and the listener. Lou Reed, Joni Mitchell, and Nina Simone each exemplify this in their unique ways. Reed's gritty realism, Mitchell's poetic introspection, and Simone's passionate activism all demonstrate the transformative power of lyrics.
Through their songs, these artists have touched countless lives, offering comfort, understanding, and inspiration. Their lyrics serve as a reminder that music is a universal language, capable of bridging divides and fostering empathy. The art of songwriting, as demonstrated by these legendary figures, is a profound way of connecting with the human experience, transcending time and place to reach the hearts of listeners everywhere.
In a world where words can often feel inadequate, Siegel Alonso offers that the right lyrics can express the breadth and depth of human emotion and experience. Whether through Lou Reed's uncomfortable honesty, Joni Mitchell's emotive landscapes, or Nina Simone's fervent activism, the art of songwriting continues to be a vital force in connecting humanity.
-
@ 2b24a1fa:17750f64
2025-04-25 07:11:19
„Immer wieder ist jetzt“ übertitelt unsere Sprecherin Sabrina Khalil ihren Text, den sie für die Friedensnoten geschrieben hat. Das gleichnamige Gedicht hat Jens Fischer Rodrian für das Album "Voices for Gaza" vertont.
https://protestnoten.de/produkt/voices-for-gaza-doppel-cd/ https://bfan.link/voices-for-gaza
Sprecher des Textes: Ulrich Allroggen
-
@ a93be9fb:6d3fdc0c
2025-04-25 07:10:52
This is a tmp article
-
@ b17fccdf:b7211155
2024-12-29 12:04:31
🆕 What's changed:
- New bonus guide dedicated to install/upgrade/uninstall PostgreSQL
- Modified the LND guide to use PostgreSQL instead of bbolt
- Modified the Nostr relay guide to use PostgreSQL instead of SQLite (experimental)
- Modified the BTCPay Server bonus guide according to these changes
- Used the lndinit MiniBolt org fork, to add an extra section to migrate an existing LND bbolt database to PostgreSQL (🚨⚠️Experimental - use it behind your responsibility⚠️🚨)
- New Golang bonus guide as a common language for the lndinit compile
- Updated LND to v0.18
- New Bitcoin Core extra section to renovate Tor & I2P addresses
- New Bitcoin Core extra section to generate a full
bitcoin.conffile - Rebuilt some homepage sections and general structure
- Deleted the
$symbol of the commands to easy copy-paste to the terminal - Deleted the initial incoming and the outgoing rules configuration of UFW, due to it being by default
🪧 PD: If you want to use the old database backend of the LND or Nostr relay, follow the next extra sections:
- Use the default bbolt database backend for the LND
- Use the default SQLite database backend for the Nostr relay
⚠️Attention⚠️: The migration process was tested on testnet mode from an existing bbolt database backend to a new PostgreSQL database using lndinit and the results were successful. However, It wasn't tested on mainnet, according to the developer, it is in experimental status which could damage your existing LND database.🚨 Use it behind your responsibility 🧼
🔧 PR related: https://github.com/minibolt-guide/minibolt/pull/93
♻️ Migrate the PostgreSQL database location
If you installed NBXplorer + BTCPay Server, it is probably you have the database of the PostgreSQL cluster on the default path (
/var/lib/postgresql/16/main/), follow the next instructions to migrate it to the new dedicated location on/data/postgresdbfolder:- With user
admincreate the dedicated PostgreSQL data folder
sudo mkdir /data/postgresdb- Assign as the owner to the
postgresuser
sudo chown postgres:postgres /data/postgresdb- Assign permissions of the data folder only to the
postgresuser
sudo chmod -R 700 /data/postgresdb- Stop NBXplorer and BTCPay Server
sudo systemctl stop nbxplorer && sudo systemctl stop btcpayserver- Stop PostgreSQL
sudo systemctl stop postgresql- Use the rsync command to copy all files from the existing database on (
/var/lib/postgresql/16/main) to the new destination directory (/data/postgresdb)
sudo rsync -av /var/lib/postgresql/16/main/ /data/postgresdb/Expected output:
``` sending incremental file list ./ PG_VERSION postgresql.auto.conf postmaster.opts postmaster.pid base/ base/1/ base/1/112 base/1/113 base/1/1247 base/1/1247_fsm base/1/1247_vm base/1/1249 base/1/1249_fsm base/1/1249_vm [...] pg_wal/000000010000000000000009 pg_wal/archive_status/ pg_xact/ pg_xact/0000
sent 164,483,875 bytes received 42,341 bytes 36,561,381.33 bytes/sec total size is 164,311,368 speedup is 1.00 ```
- Edit the PostgreSQL data directory on configuration, to redirect the store to the new location
sudo nano /etc/postgresql/16/main/postgresql.conf --linenumbers- Replace the line 42 to this. Save and exit
data_directory = '/data/postgresdb'- Start PostgreSQL to apply changes and monitor the correct status of the main instance and sub-instance monitoring sessions before
sudo systemctl start postgresql- You can monitor the PostgreSQL main instance by the systemd journal and check the log output to ensure all is correct. You can exit the monitoring at any time with Ctrl-C
journalctl -fu postgresqlExample of the expected output:
Nov 08 11:51:10 minibolt systemd[1]: Stopped PostgreSQL RDBMS. Nov 08 11:51:10 minibolt systemd[1]: Stopping PostgreSQL RDBMS... Nov 08 11:51:13 minibolt systemd[1]: Starting PostgreSQL RDBMS... Nov 08 11:51:13 minibolt systemd[1]: Finished PostgreSQL RDBMS.- You can monitor the PostgreSQL sub-instance by the systemd journal and check log output to ensure all is correct. You can exit monitoring at any time with Ctrl-C
journalctl -fu postgresql@16-mainExample of the expected output:
Nov 08 11:51:10 minibolt systemd[1]: Stopping PostgreSQL Cluster 16-main... Nov 08 11:51:11 minibolt systemd[1]: postgresql@16-main.service: Succeeded. Nov 08 11:51:11 minibolt systemd[1]: Stopped PostgreSQL Cluster 16-main. Nov 08 11:51:11 minibolt systemd[1]: postgresql@16-main.service: Consumed 1h 10min 8.677s CPU time. Nov 08 11:51:11 minibolt systemd[1]: Starting PostgreSQL Cluster 16-main... Nov 08 11:51:13 minibolt systemd[1]: Started PostgreSQL Cluster 16-main.- Start NBXplorer and BTCPay Server again
sudo systemctl start nbxplorer && sudo systemctl start btcpayserver- Monitor to make sure everything is as you left it. You can exit monitoring at any time with Ctrl-C
journalctl -fu nbxplorerjournalctl -fu btcpayserverEnjoy it MiniBolter! 💙
-
@ b17fccdf:b7211155
2024-12-29 11:56:44
A step-by-step guide to building a Bitcoin & Lightning node, and other stuff on a personal computer.
~ > It builds on a personal computer with x86/amd64 architecture processors.
~> It is based on the popular RaspiBolt v3 guide.
Those are some of the most relevant changes:
- Changed OS from Raspberry Pi OS Lite (64-bits) to Ubuntu Server LTS (Long term support) 64-bit PC (AMD64).
- Changed binaries and signatures of the programs to adapt them to x86/amd64 architecture.
- Deleted unnecessary tools and steps, and added others according to this case of use.
- Some useful authentication logs and monitoring commands were added in the security section.
- Added some interesting parameters in the settings of some services to activate and take advantage of new features.
- Changed I2P, Fulcrum, and ThunderHub guides, to be part of the core guide.
- Added exclusive optimization section of services for slow devices.
~ > Complete release notes MiniBolt v1: https://github.com/twofaktor/minibolt/releases/tag/1.0
~ > The MiniBolt guide is available at: https://minibolt.info
~ > Feel free to contribute to the source code on GitHub by opening issues, pull requests or discussions
Created by ⚡2 FakTor⚡
-
@ 2b24a1fa:17750f64
2025-04-25 07:09:25
Wo, wenn nicht in Dresden, sollte man sich einig sein, in der Frage nach „Krieg oder Frieden“? Doch 80 Jahre nach der flächendeckenden Brandbombardierung Dresdens macht sich in dieser Stadt wieder verdächtig, wer so etwas selbstverständliches wie Frieden einfordert.
Am vergangenen Karfreitag fand eine große Friedensprozession in der sächsischen Metropole statt. Kriegerisch jedoch war die Berichterstattung. Mit Falschbehauptungen und verdrehungen wurde die Friedensaktion und deren Akteure beschädigt. Dorne im Auge der Betrachter waren womöglich Dieter Hallervorden und die Politologin Ulrike Guérot mit Reden, die dringender nicht sein könnten. Ulrike Guérot stellte zugleich das European Peace Project vor, das am 9. Mai mit jedem einzelnen von uns in ganz Europa stattfindet.
Der Liedermacher Jens Fischer Rodrian war am Karfreitag ebenfalls vor Ort und widmete der Rede von Guérot eine Friedensnote. Hören Sie seinen Beitrag mit dem Titel „Wiederauferstehung eines Friedensprojekts“. europeanpeaceproject.eu/en/
Bild: Demoveranstalter
-
@ ec42c765:328c0600
2024-12-22 19:16:31
この記事は前回の内容を把握している人向けに書いています(特にNostrエクステンション(NIP-07)導入)
手順
- 登録する画像を用意する
- 画像をweb上にアップロードする
- 絵文字セットに登録する
1. 登録する画像を用意する
以下のような方法で用意してください。
- 画像編集ソフト等を使って自分で作成する
- 絵文字作成サイトを使う(絵文字ジェネレーター、MEGAMOJI など)
- フリー画像を使う(いらすとや など)
データ量削減
Nostrでは画像をそのまま表示するクライアントが多いので、データ量が大きな画像をそのまま使うとモバイル通信時などに負担がかかります。
データ量を増やさないためにサイズやファイル形式を変更することをおすすめします。
以下は私のおすすめです。 * サイズ:正方形 128×128 ピクセル、長方形 任意の横幅×128 ピクセル * ファイル形式:webp形式(webp変換おすすめサイト toimg) * 単色、単純な画像の場合:png形式(webpにするとむしろサイズが大きくなる)
その他
- 背景透過画像
- ダークモード、ライトモード両方で見やすい色
がおすすめです。
2. 画像をweb上にアップロードする
よく分からなければ emojito からのアップロードで問題ないです。
普段使っている画像アップロード先があるならそれでも構いません。
気になる方はアップロード先を適宜選んでください。既に投稿されたカスタム絵文字の画像に対して
- 削除も差し替えもできない → emojito など
- 削除できるが差し替えはできない → Gyazo、nostrcheck.meなど
- 削除も差し替えもできる → GitHub 、セルフホスティングなど
これらは既にNostr上に投稿されたカスタム絵文字の画像を後から変更できるかどうかを指します。
どの方法でも新しく使われるカスタム絵文字を変更することは可能です。
同一のカスタム絵文字セットに同一のショートコードで別の画像を登録する形で対応できます。3. 絵文字セットに登録する
emojito から登録します。
右上のアイコン → + New emoji set から新規の絵文字セットを作成できます。


① 絵文字セット名を入力
基本的にカスタム絵文字はカスタム絵文字セットを作り、ひとまとまりにして登録します。
一度作った絵文字セットに後から絵文字を追加することもできます。
② 画像をアップロードまたは画像URLを入力
emojitoから画像をアップロードする場合、ファイル名に日本語などの2バイト文字が含まれているとアップロードがエラーになるようです。
その場合はファイル名を適当な英数字などに変更してください。
③ 絵文字のショートコードを入力
ショートコードは絵文字を呼び出す時に使用する場合があります。
他のカスタム絵文字と被っても問題ありませんが選択時に複数表示されて支障が出る可能性があります。
他と被りにくく長くなりすぎないショートコードが良いかもしれません。
ショートコードに使えるのは半角の英数字とアンダーバーのみです。
④ 追加
Add を押してもまだ作成完了にはなりません。

一度に絵文字を複数登録できます。
最後に右上の Save を押すと作成完了です。

画面が切り替わるので、右側の Options から Bookmark を選択するとそのカスタム絵文字セットを自分で使えるようになります。
既存の絵文字セットを編集するには Options から Edit を選択します。
以上です。
仕様
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install NVapi to monitor my GPUs in Home Assistant.
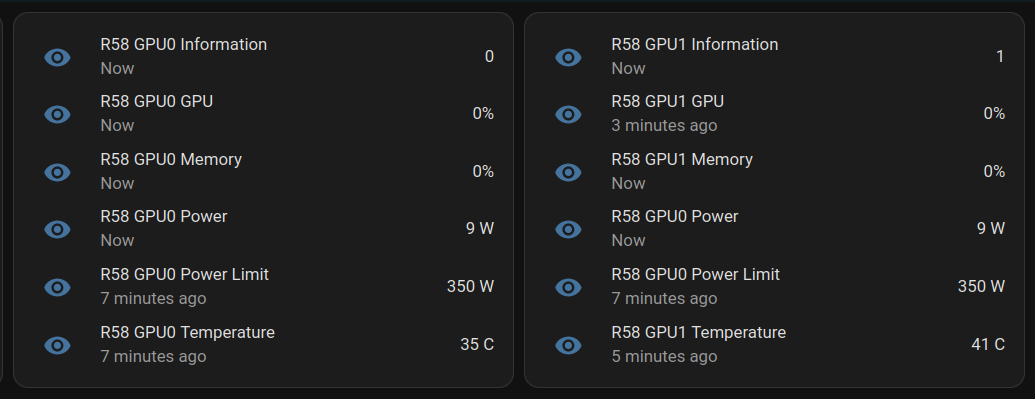
NVApi is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- GPU Utilization Monitoring: Utilization, memory usage, temperature, fan speed, and power consumption.
- Automated Power Limiting: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- Cross-GPU Coordination: Total power budget applies across multiple GPUs in the same system.
- PCIe Link Speed Management: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- Home Assistant Integration: Uses the built-in RESTful platform and template sensors.
Getting the Data
sudo apt install golang-go git clone https://github.com/sammcj/NVApi.git cd NVapi go run main.go -port 9999 -rate 1 curl http://localhost:9999/gpuResponse for a single GPU:
[ { "index": 0, "name": "NVIDIA GeForce RTX 4090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 16, "power_limit_watts": 450, "memory_total_gb": 23.99, "memory_used_gb": 0.46, "memory_free_gb": 23.52, "memory_usage_percent": 2, "temperature": 38, "processes": [], "pcie_link_state": "not managed" } ]Response for multiple GPUs:
[ { "index": 0, "name": "NVIDIA GeForce RTX 3090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 14, "power_limit_watts": 350, "memory_total_gb": 24, "memory_used_gb": 0.43, "memory_free_gb": 23.57, "memory_usage_percent": 2, "temperature": 36, "processes": [], "pcie_link_state": "not managed" }, { "index": 1, "name": "NVIDIA RTX A4000", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 10, "power_limit_watts": 140, "memory_total_gb": 15.99, "memory_used_gb": 0.56, "memory_free_gb": 15.43, "memory_usage_percent": 3, "temperature": 41, "processes": [], "pcie_link_state": "not managed" } ]Start at Boot
Create
/etc/systemd/system/nvapi.service:``` [Unit] Description=Run NVapi After=network.target
[Service] Type=simple Environment="GOPATH=/home/ansible/go" WorkingDirectory=/home/ansible/NVapi ExecStart=/usr/bin/go run main.go -port 9999 -rate 1 Restart=always User=ansible
Environment="GPU_TEMP_CHECK_INTERVAL=5"
Environment="GPU_TOTAL_POWER_CAP=400"
Environment="GPU_0_LOW_TEMP=40"
Environment="GPU_0_MEDIUM_TEMP=70"
Environment="GPU_0_LOW_TEMP_LIMIT=135"
Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
Environment="GPU_0_HIGH_TEMP_LIMIT=100"
Environment="GPU_1_LOW_TEMP=45"
Environment="GPU_1_MEDIUM_TEMP=75"
Environment="GPU_1_LOW_TEMP_LIMIT=140"
Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install] WantedBy=multi-user.target ```
Home Assistant
Add to Home Assistant
configuration.yamland restart HA (completely).For a single GPU, this works: ``` sensor: - platform: rest name: MYPC GPU Information resource: http://mypc:9999 method: GET headers: Content-Type: application/json value_template: "{{ value_json[0].index }}" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature scan_interval: 1 # seconds
- platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}" unit_of_measurement: "°C" ```
For multiple GPUs: ``` rest: scan_interval: 1 resource: http://mypc:9999 sensor: - name: "MYPC GPU0 Information" value_template: "{{ value_json[0].index }}" json_attributes_path: "$.0" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature - name: "MYPC GPU1 Information" value_template: "{{ value_json[1].index }}" json_attributes_path: "$.1" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature
-
platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC GPU0 GPU" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC GPU0 Memory" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC GPU0 Power" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC GPU0 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC GPU0 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}" unit_of_measurement: "C"
-
platform: template sensors: mypc_gpu_1_gpu: friendly_name: "MYPC GPU1 GPU" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_memory: friendly_name: "MYPC GPU1 Memory" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_power: friendly_name: "MYPC GPU1 Power" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_1_power_limit: friendly_name: "MYPC GPU1 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_1_temperature: friendly_name: "MYPC GPU1 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}" unit_of_measurement: "C"
```
Basic entity card:
type: entities entities: - entity: sensor.mypc_gpu_0_gpu secondary_info: last-updated - entity: sensor.mypc_gpu_0_memory secondary_info: last-updated - entity: sensor.mypc_gpu_0_power secondary_info: last-updated - entity: sensor.mypc_gpu_0_power_limit secondary_info: last-updated - entity: sensor.mypc_gpu_0_temperature secondary_info: last-updatedAnsible Role
```
-
name: install go become: true package: name: golang-go state: present
-
name: git clone git: repo: "https://github.com/sammcj/NVApi.git" dest: "/home/ansible/NVapi" update: yes force: true
go run main.go -port 9999 -rate 1
-
name: install systemd service become: true copy: src: nvapi.service dest: /etc/systemd/system/nvapi.service
-
name: Reload systemd daemons, enable, and restart nvapi become: true systemd: name: nvapi daemon_reload: yes enabled: yes state: restarted ```
-
@ 8125b911:a8400883
2025-04-25 07:02:35
In Nostr, all data is stored as events. Decentralization is achieved by storing events on multiple relays, with signatures proving the ownership of these events. However, if you truly want to own your events, you should run your own relay to store them. Otherwise, if the relays you use fail or intentionally delete your events, you'll lose them forever.
For most people, running a relay is complex and costly. To solve this issue, I developed nostr-relay-tray, a relay that can be easily run on a personal computer and accessed over the internet.
Project URL: https://github.com/CodyTseng/nostr-relay-tray
This article will guide you through using nostr-relay-tray to run your own relay.
Download
Download the installation package for your operating system from the GitHub Release Page.
| Operating System | File Format | | --------------------- | ---------------------------------- | | Windows |
nostr-relay-tray.Setup.x.x.x.exe| | macOS (Apple Silicon) |nostr-relay-tray-x.x.x-arm64.dmg| | macOS (Intel) |nostr-relay-tray-x.x.x.dmg| | Linux | You should know which one to use |Installation
Since this app isn’t signed, you may encounter some obstacles during installation. Once installed, an ostrich icon will appear in the status bar. Click on the ostrich icon, and you'll see a menu where you can click the "Dashboard" option to open the relay's control panel for further configuration.

macOS Users:
- On first launch, go to "System Preferences > Security & Privacy" and click "Open Anyway."
- If you encounter a "damaged" message, run the following command in the terminal to remove the restrictions:
bash sudo xattr -rd com.apple.quarantine /Applications/nostr-relay-tray.appWindows Users:
- On the security warning screen, click "More Info > Run Anyway."
Connecting
By default, nostr-relay-tray is only accessible locally through
ws://localhost:4869/, which makes it quite limited. Therefore, we need to expose it to the internet.In the control panel, click the "Proxy" tab and toggle the switch. You will then receive a "Public address" that you can use to access your relay from anywhere. It's that simple.
Next, add this address to your relay list and position it as high as possible in the list. Most clients prioritize connecting to relays that appear at the top of the list, and relays lower in the list are often ignored.

Restrictions
Next, we need to set up some restrictions to prevent the relay from storing events that are irrelevant to you and wasting storage space. nostr-relay-tray allows for flexible and fine-grained configuration of which events to accept, but some of this is more complex and will not be covered here. If you're interested, you can explore this further later.
For now, I'll introduce a simple and effective strategy: WoT (Web of Trust). You can enable this feature in the "WoT & PoW" tab. Before enabling, you'll need to input your pubkey.
There's another important parameter,
Depth, which represents the relationship depth between you and others. Someone you follow has a depth of 1, someone they follow has a depth of 2, and so on.- Setting this parameter to 0 means your relay will only accept your own events.
- Setting it to 1 means your relay will accept events from you and the people you follow.
- Setting it to 2 means your relay will accept events from you, the people you follow, and the people they follow.
Currently, the maximum value for this parameter is 2.

Conclusion
You've now successfully run your own relay and set a simple restriction to prevent it from storing irrelevant events.
If you encounter any issues during use, feel free to submit an issue on GitHub, and I'll respond as soon as possible.
Not your relay, not your events.
-
@ e46f3a64:4426aaf9
2025-04-25 04:49:42
Want to stay ahead in the fast-changing Synthetic Fuels Market industry? Our report breaks down all the key insights—so you don’t have to! Whether you're a business owner, investor, or just curious about market trends, we’ve got you covered.
According to Straits Research, The Synthetic Fuels Market size was valued at USD 4.84 billion in 2023. It is projected to reach USD XX Billion by XX, growing at a CAGR of 18.15% during the forecast period (2023-XX).
Get Your Sample Report Now : https://straitsresearch.com/report/synthetic-fuels-market/request-sample
What’s Inside? Clear Market Analysis – No jargon, just straight-to-the-point insights on market size, growth, and trends. You’ll know exactly where the industry stands and where it’s headed, with clear data-backed predictions. Who’s Leading the Game? – Discover top players, their strategies, and how you can compete. We give you an in-depth look at the biggest players in the industry and how they’ve achieved success, providing actionable insights for your own business. Hot Growth Opportunities – Find out which regions and segments are booming—so you can jump on the next big opportunity! Our research pinpoints high-potential markets, allowing you to make timely, data-driven decisions. Real-World Insights – Get practical tips for product development, marketing, and expansion. We show you how to implement successful strategies based on what the leading companies are doing, and the trends that are making waves. Why Trust This Report? We’ve done the heavy lifting—analyzing data, trends, and competition—so you can make smart, confident decisions. Plus, we include a PESTEL Analysis to help you understand political, economic, social, and tech factors shaping the market, giving you a comprehensive understanding of the macro-environment.
Don’t miss out—download a FREE sample with key graphs, data, and insights : https://straitsresearch.com/report/synthetic-fuels-market/request-sample
Market Segments Covered: By Production Method Fischer-Tropsch Synthesis Methanol to Gasoline (MTG) Electrolysis-based Methods By Applications Gasoline Diesel Jet Fuel Others By End-User Transportation Power Generation Industrial Others Top Key Players: Audi AG Royal Dutch Shell Plc ExxonMobil Corporation PetroChina Company Limited Indian Oil Corporation Ltd. Reliance Industries Ltd. Phillips 66 Company Got Questions? We’ve Got Answers! How big is the Synthetic Fuels Market market, and where’s it headed? Which regions are the next big growth hubs? What’s driving (or slowing) market growth? By Region North America (U.S., Canada, Mexico) – Learn about market trends, challenges, and opportunities in North America, one of the most dynamic regions.
Europe (UK, Germany, France, and more) – Gain insights into Europe’s evolving market, focusing on the countries with the highest potential for growth.
Asia Pacific (China, India, Japan, and fast-growing markets) – Discover the rapid changes happening in Asia Pacific, home to some of the world’s fastest-growing economies and industries.
Middle East & Africa (GCC, South Africa, Nigeria, and emerging economies) – Unlock the potential in Middle Eastern and African markets, understanding what drives demand in these emerging regions.
South America (Brazil, Argentina, and beyond) – Explore the opportunities and challenges in South America’s growing markets, as well as the top sectors to focus on.
Stay Ahead with Straits Research Stay Ahead with Straits Research We’re a trusted name in market intelligence, helping businesses like yours make smarter moves. From tech to healthcare, we’ve got the insights you need to win. Our reports are crafted with precision and backed by reliable data, ensuring you’re always ahead of the curve in a competitive landscape.
More Industry Reports & Updates:
https://sites.google.com/view/consumerandpackageingresearchr/home/anti-aging-products-market-size
https://sites.google.com/view/consumerandpackageingresearchr/home/solar-tracker-installation-market
-
@ e46f3a64:4426aaf9
2025-04-25 04:48:31
Want to stay ahead in the fast-changing Air Conditioning System Market industry? Our report breaks down all the key insights—so you don’t have to! Whether you're a business owner, investor, or just curious about market trends, we’ve got you covered.
According to Straits Research, The Air Conditioning System Market size was valued at USD 119.77 Billion in 2022. It is projected to reach USD 202.34 Billion by 2031, growing at a CAGR of 6% during the forecast period (2022-2031).
Get Your Sample Report Now : https://straitsresearch.com/report/air-conditioning-system-market/request-sample
What’s Inside? Clear Market Analysis – No jargon, just straight-to-the-point insights on market size, growth, and trends. You’ll know exactly where the industry stands and where it’s headed, with clear data-backed predictions. Who’s Leading the Game? – Discover top players, their strategies, and how you can compete. We give you an in-depth look at the biggest players in the industry and how they’ve achieved success, providing actionable insights for your own business. Hot Growth Opportunities – Find out which regions and segments are booming—so you can jump on the next big opportunity! Our research pinpoints high-potential markets, allowing you to make timely, data-driven decisions. Real-World Insights – Get practical tips for product development, marketing, and expansion. We show you how to implement successful strategies based on what the leading companies are doing, and the trends that are making waves. Why Trust This Report? We’ve done the heavy lifting—analyzing data, trends, and competition—so you can make smart, confident decisions. Plus, we include a PESTEL Analysis to help you understand political, economic, social, and tech factors shaping the market, giving you a comprehensive understanding of the macro-environment.
Don’t miss out—download a FREE sample with key graphs, data, and insights : https://straitsresearch.com/report/air-conditioning-system-market/request-sample
Market Segments Covered: By Type Unitary Rooftop Packaged Terminal Air Conditioner (PTAC) By Technology Inverter Non-Inverter By End-User Residential Commercial Industrial Top Key Players: Daikin Industries Ltd. Mitsubishi Electric Trane HVAC US LLC Carrier Haier Group ALFA LAVAL BSH Hausgeräte GmbH Electrolux AB Corporation Ingersoll-Rand plc (Trane Technologies plc) Got Questions? We’ve Got Answers! How big is the Air Conditioning System Market market, and where’s it headed? Which regions are the next big growth hubs? What’s driving (or slowing) market growth? By Region North America (U.S., Canada, Mexico) – Learn about market trends, challenges, and opportunities in North America, one of the most dynamic regions.
Europe (UK, Germany, France, and more) – Gain insights into Europe’s evolving market, focusing on the countries with the highest potential for growth.
Asia Pacific (China, India, Japan, and fast-growing markets) – Discover the rapid changes happening in Asia Pacific, home to some of the world’s fastest-growing economies and industries.
Middle East & Africa (GCC, South Africa, Nigeria, and emerging economies) – Unlock the potential in Middle Eastern and African markets, understanding what drives demand in these emerging regions.
South America (Brazil, Argentina, and beyond) – Explore the opportunities and challenges in South America’s growing markets, as well as the top sectors to focus on.
Stay Ahead with Straits Research Stay Ahead with Straits Research We’re a trusted name in market intelligence, helping businesses like yours make smarter moves. From tech to healthcare, we’ve got the insights you need to win. Our reports are crafted with precision and backed by reliable data, ensuring you’re always ahead of the curve in a competitive landscape.
More Industry Reports & Updates:
https://sites.google.com/view/consumerandpackageingresearchr/home/furniture-market-size
https://sites.google.com/view/consumerandpackageingresearchr/home/anti-aging-products-market-size
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
-
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
-
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\ https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
-
@ dd664d5e:5633d319
2024-12-14 15:25:56

Christmas season hasn't actually started, yet, in Roman #Catholic Germany. We're in Advent until the evening of the 24th of December, at which point Christmas begins (with the Nativity, at Vespers), and continues on for 40 days until Mariä Lichtmess (Presentation of Christ in the temple) on February 2nd.
It's 40 days because that's how long the post-partum isolation is, before women were allowed back into the temple (after a ritual cleansing).

That is the day when we put away all of the Christmas decorations and bless the candles, for the next year. (Hence, the British name "Candlemas".) It used to also be when household staff would get paid their cash wages and could change employer. And it is the day precisely in the middle of winter.

Between Christmas Eve and Candlemas are many celebrations, concluding with the Twelfth Night called Epiphany or Theophany. This is the day some Orthodox celebrate Christ's baptism, so traditions rotate around blessing of waters.

The Monday after Epiphany was the start of the farming season, in England, so that Sunday all of the ploughs were blessed, but the practice has largely died out.

Our local tradition is for the altar servers to dress as the wise men and go door-to-door, carrying their star and looking for the Baby Jesus, who is rumored to be lying in a manger.

They collect cash gifts and chocolates, along the way, and leave the generous their powerful blessing, written over the door. The famous 20 * C + M + B * 25 blessing means "Christus mansionem benedicat" (Christ, bless this house), or "Caspar, Melchior, Balthasar" (the names of the three kings), depending upon who you ask.
They offer the cash to the Baby Jesus (once they find him in the church's Nativity scene), but eat the sweets, themselves. It is one of the biggest donation-collections in the world, called the "Sternsinger" (star singers). The money goes from the German children, to help children elsewhere, and they collect around €45 million in cash and coins, every year.

As an interesting aside:
The American "groundhog day", derives from one of the old farmers' sayings about Candlemas, brought over by the Pennsylvania Dutch. It says, that if the badger comes out of his hole and sees his shadow, then it'll remain cold for 4 more weeks. When they moved to the USA, they didn't have any badgers around, so they switched to groundhogs, as they also hibernate in winter.
-
@ 3de5f798:31faf8b0
2025-04-25 01:46:45
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.Graph Basics
- A standard graph has a set of nodes (or vertices) and edges (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
Hypergraph
- A hypergraph extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a hyperedge, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
Metagraph
- A metagraph allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you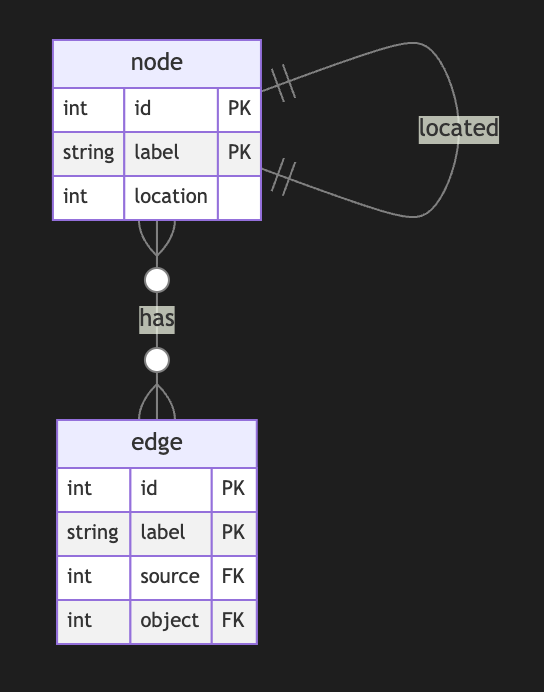
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
Directed Metagraph where edges are not used as nodes and could not contain subgraphs
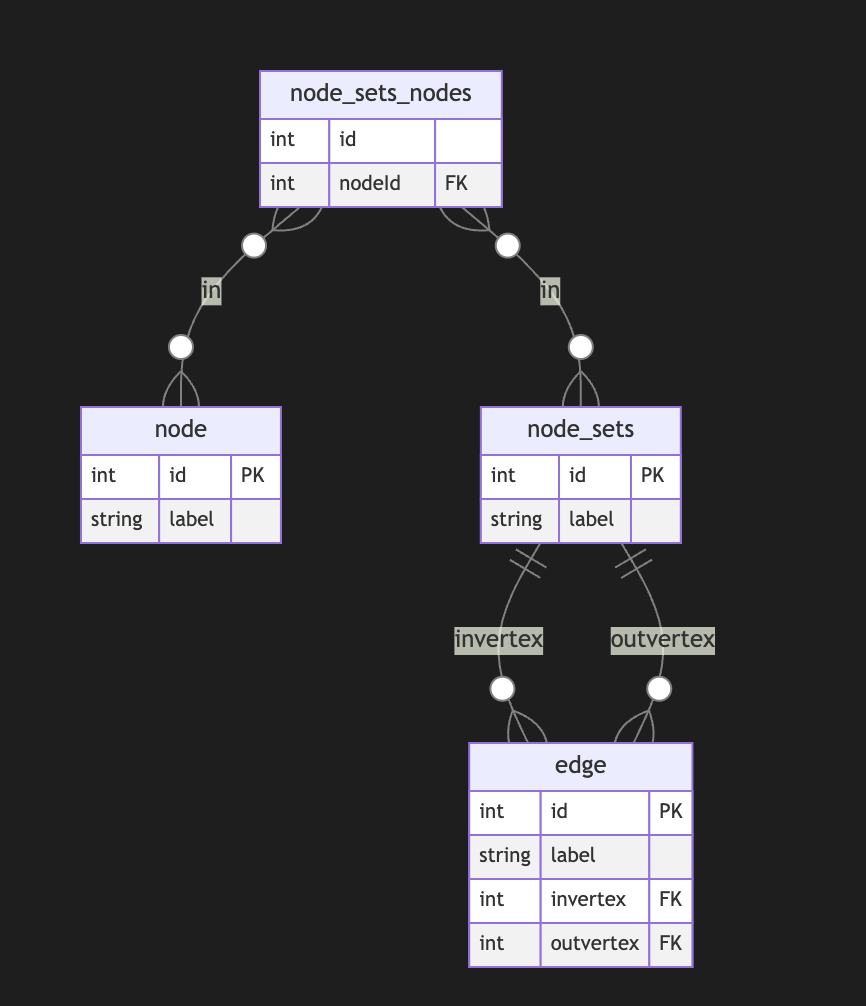
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
Directed Metagraph where edges are not used as nodes and could contain subgraphs
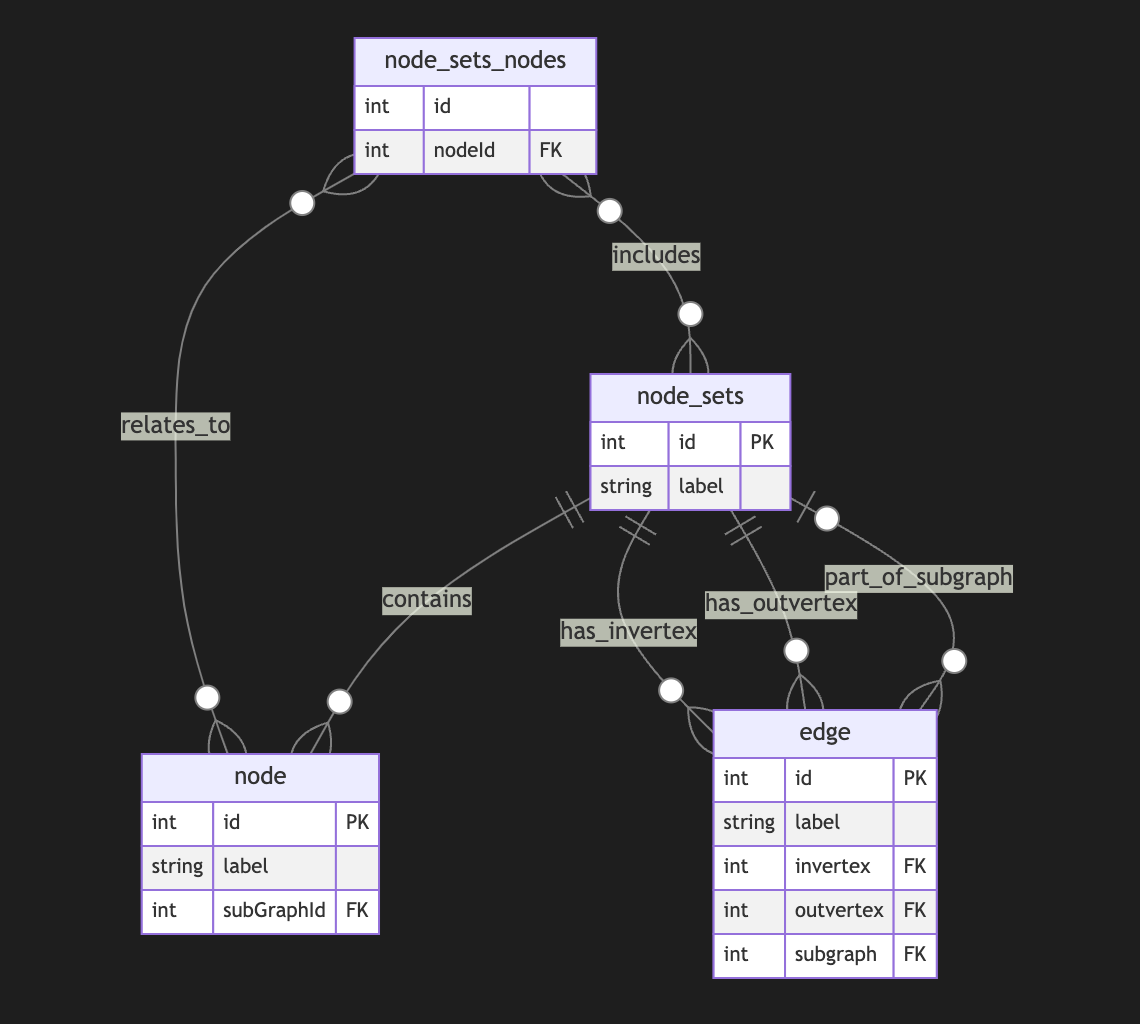
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
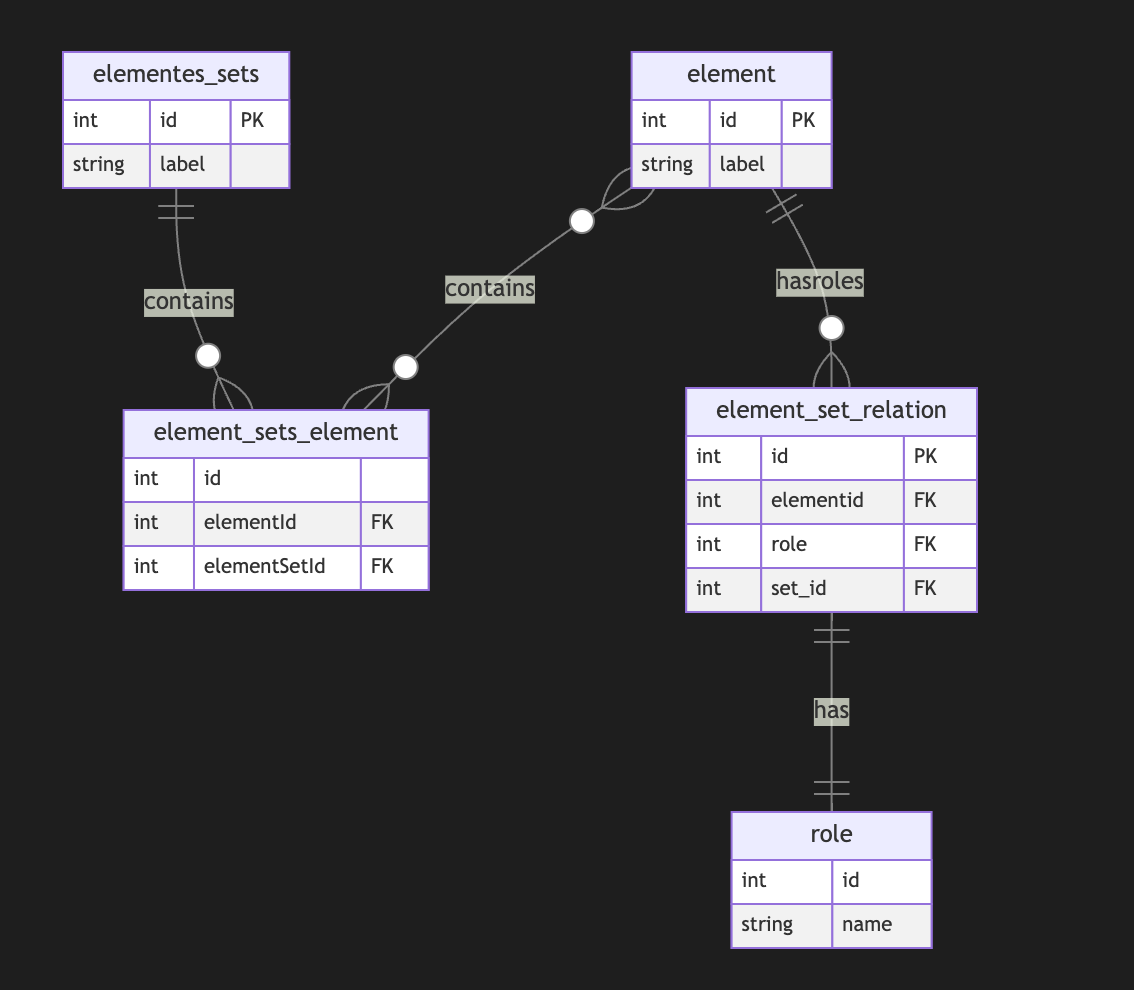
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose. -
@ 3de5f798:31faf8b0
2025-04-25 01:46:32
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 266815e0:6cd408a5
2025-04-24 22:56:53
noStrudel
Its been over four months since I released
v0.42.0of noStrudel but I haven't forgot about it, I've just been busy refactoring the code-base.The app is well past its 2yr birthday and a lot of the code is really messy and kind of hacky. so my focus in the past few months has been refactoring and moving a lot of it out into the applesauce packages so it can be tested.
The biggest changes have been switching to use
rx-nostrfor all relay connections and usingrxjsand applesauce for event management and timelines. In total ~22k lines of code have been changed since the last release.I'm hoping it wont take me much longer to get a stable release for
v0.43.0. In the meantime if you want to test out the new changes you can find them on the nsite deployment.nsite deplyment: nostrudel.nsite.lol/ Github repo: github.com/hzrd149/nostrudel
Applesauce
I've been making great progress on the applesauce libraries that are the core of onStrudel. Since January I've released
v0.11.0andv0.12.0.In the past month I've been working towards a v1 release with a better relay connection package applesauce-relay and pre-built actions for clients to easily implement common things like follow/unfollow and mute/unmute. applesauce-actions
Docs website: hzrd149.github.io/applesauce/ Github repo: https://github.com/hzrd149/applesauce
Blossom
Spec changes: - Merged PR #56 from kehiy for BUD-09 ( blob reports ) - Merged PR #60 from Kieran to update BUD-8 to use the standard NIP-94 tags array. - Merged PR #38 to make the file extension mandatory in the
urlfield of the returned blob descriptor. - Merged PR #54 changing the authorization type for the/mediaendpoint tomediainstead ofupload. This fixes an issue where the server could mirror the original blob without the users consent.Besides the changes to the blossom spec itself I started working on a small cli tool to help test and debug new blossom server implementations. The goal is to have a set of upload and download tests that can be run against a server to test if it adheres to the specifications. It can also be used output debug info and show recommended headers to add to the http responses.
If you have nodejs installed you can try it out by running
sh npx blossom-audit audit <server-url> [image|bitcoin|gif|path/to/file.jpeg]Github repo: github.com/hzrd149/blossom-audit
Other projects
Wifistr
While participating in SEC-04 I built a small app for sharing the locations and passwords of wifi networks. Its far from complete, but its usable and serves as an example of building an app with SolidJS and applesauce.
Live version: hzrd149.github.io/wifistr/ nsite version: here Github repo: github.com/hzrd149/wifistr
nsite-manager
I've been slowly continuing work on nsite-manager, mostly just to allow myself to debug various nsites and make sure nsite.lol is still working correctly.
Github repo: github.com/hzrd149/nsite-manager
nsite-gateway
I finally got around to making some much needed bug fixes and improvements to nsite-gateway ( the server behind nsite.lol ) and released a stable
1.0.0version.My hope is that its stable enough now to allow other users to start hosting their own instances of it.
Github repo: github.com/hzrd149/nsite-gateway
morning-glory
As part of my cashu PR for NUT-23 ( HTTP 402 Payment required ) I built a blossom server that only accepts cashu payments for uploads and stores blobs for 24h before deleting them.
Github repo: github.com/hzrd149/morning-glory
bakery
I've been toying with the idea of building a backend-first nostr client that would download events while I'm not at my computer and send me notifications about my DMs.
I made some progress on it in the last months but its far from complete or usable. Hopefully ill get some time in the next few months to create a working alpha version for myself and others to install on Umbrel and Start9
Github repo: github.com/hzrd149/bakery
-
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like Lisp emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
Lisp: The Earlier AI-Language
Lisp, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
Prolog: Formal Logic and Deductive Reasoning
In the 1970s, Prolog was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out how to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
Solvers and Their Role in Complementing LLMs
One of the most powerful features of Prolog and similar logic-based systems is their use of solvers. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a solver can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling constraint satisfaction problems — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating neurosymbolic methods that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a graph of rules. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a graph of rules, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable modular reasoning, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of neural fluency with rule-based structure gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform deductive reasoning alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where neurosymbolic approaches shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
Personal Knowledge Graphs (PKGs) come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a graph of rules that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using deductive databases to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling knowledge graphs using deductive databases, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
Prolog and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a graph of rules that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
Why It Matters for LLM Employment
Using neurosymbolic RAG (retrieval-augmented generation) in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of neural fluency with symbolic accuracy and deductive power is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ 40b9c85f:5e61b451
2025-04-24 15:27:02
Introduction
Data Vending Machines (DVMs) have emerged as a crucial component of the Nostr ecosystem, offering specialized computational services to clients across the network. As defined in NIP-90, DVMs operate on an apparently simple principle: "data in, data out." They provide a marketplace for data processing where users request specific jobs (like text translation, content recommendation, or AI text generation)
While DVMs have gained significant traction, the current specification faces challenges that hinder widespread adoption and consistent implementation. This article explores some ideas on how we can apply the reflection pattern, a well established approach in RPC systems, to address these challenges and improve the DVM ecosystem's clarity, consistency, and usability.
The Current State of DVMs: Challenges and Limitations
The NIP-90 specification provides a broad framework for DVMs, but this flexibility has led to several issues:
1. Inconsistent Implementation
As noted by hzrd149 in "DVMs were a mistake" every DVM implementation tends to expect inputs in slightly different formats, even while ostensibly following the same specification. For example, a translation request DVM might expect an event ID in one particular format, while an LLM service could expect a "prompt" input that's not even specified in NIP-90.
2. Fragmented Specifications
The DVM specification reserves a range of event kinds (5000-6000), each meant for different types of computational jobs. While creating sub-specifications for each job type is being explored as a possible solution for clarity, in a decentralized and permissionless landscape like Nostr, relying solely on specification enforcement won't be effective for creating a healthy ecosystem. A more comprehensible approach is needed that works with, rather than against, the open nature of the protocol.
3. Ambiguous API Interfaces
There's no standardized way for clients to discover what parameters a specific DVM accepts, which are required versus optional, or what output format to expect. This creates uncertainty and forces developers to rely on documentation outside the protocol itself, if such documentation exists at all.
The Reflection Pattern: A Solution from RPC Systems
The reflection pattern in RPC systems offers a compelling solution to many of these challenges. At its core, reflection enables servers to provide metadata about their available services, methods, and data types at runtime, allowing clients to dynamically discover and interact with the server's API.
In established RPC frameworks like gRPC, reflection serves as a self-describing mechanism where services expose their interface definitions and requirements. In MCP reflection is used to expose the capabilities of the server, such as tools, resources, and prompts. Clients can learn about available capabilities without prior knowledge, and systems can adapt to changes without requiring rebuilds or redeployments. This standardized introspection creates a unified way to query service metadata, making tools like
grpcurlpossible without requiring precompiled stubs.How Reflection Could Transform the DVM Specification
By incorporating reflection principles into the DVM specification, we could create a more coherent and predictable ecosystem. DVMs already implement some sort of reflection through the use of 'nip90params', which allow clients to discover some parameters, constraints, and features of the DVMs, such as whether they accept encryption, nutzaps, etc. However, this approach could be expanded to provide more comprehensive self-description capabilities.
1. Defined Lifecycle Phases
Similar to the Model Context Protocol (MCP), DVMs could benefit from a clear lifecycle consisting of an initialization phase and an operation phase. During initialization, the client and DVM would negotiate capabilities and exchange metadata, with the DVM providing a JSON schema containing its input requirements. nip-89 (or other) announcements can be used to bootstrap the discovery and negotiation process by providing the input schema directly. Then, during the operation phase, the client would interact with the DVM according to the negotiated schema and parameters.
2. Schema-Based Interactions
Rather than relying on rigid specifications for each job type, DVMs could self-advertise their schemas. This would allow clients to understand which parameters are required versus optional, what type validation should occur for inputs, what output formats to expect, and what payment flows are supported. By internalizing the input schema of the DVMs they wish to consume, clients gain clarity on how to interact effectively.
3. Capability Negotiation
Capability negotiation would enable DVMs to advertise their supported features, such as encryption methods, payment options, or specialized functionalities. This would allow clients to adjust their interaction approach based on the specific capabilities of each DVM they encounter.
Implementation Approach
While building DVMCP, I realized that the RPC reflection pattern used there could be beneficial for constructing DVMs in general. Since DVMs already follow an RPC style for their operation, and reflection is a natural extension of this approach, it could significantly enhance and clarify the DVM specification.
A reflection enhanced DVM protocol could work as follows: 1. Discovery: Clients discover DVMs through existing NIP-89 application handlers, input schemas could also be advertised in nip-89 announcements, making the second step unnecessary. 2. Schema Request: Clients request the DVM's input schema for the specific job type they're interested in 3. Validation: Clients validate their request against the provided schema before submission 4. Operation: The job proceeds through the standard NIP-90 flow, but with clearer expectations on both sides
Parallels with Other Protocols
This approach has proven successful in other contexts. The Model Context Protocol (MCP) implements a similar lifecycle with capability negotiation during initialization, allowing any client to communicate with any server as long as they adhere to the base protocol. MCP and DVM protocols share fundamental similarities, both aim to expose and consume computational resources through a JSON-RPC-like interface, albeit with specific differences.
gRPC's reflection service similarly allows clients to discover service definitions at runtime, enabling generic tools to work with any gRPC service without prior knowledge. In the REST API world, OpenAPI/Swagger specifications document interfaces in a way that makes them discoverable and testable.
DVMs would benefit from adopting these patterns while maintaining the decentralized, permissionless nature of Nostr.
Conclusion
I am not attempting to rewrite the DVM specification; rather, explore some ideas that could help the ecosystem improve incrementally, reducing fragmentation and making the ecosystem more comprehensible. By allowing DVMs to self describe their interfaces, we could maintain the flexibility that makes Nostr powerful while providing the structure needed for interoperability.
For developers building DVM clients or libraries, this approach would simplify consumption by providing clear expectations about inputs and outputs. For DVM operators, it would establish a standard way to communicate their service's requirements without relying on external documentation.
I am currently developing DVMCP following these patterns. Of course, DVMs and MCP servers have different details; MCP includes capabilities such as tools, resources, and prompts on the server side, as well as 'roots' and 'sampling' on the client side, creating a bidirectional way to consume capabilities. In contrast, DVMs typically function similarly to MCP tools, where you call a DVM with an input and receive an output, with each job type representing a different categorization of the work performed.
Without further ado, I hope this article has provided some insight into the potential benefits of applying the reflection pattern to the DVM specification.
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
RDF and Advanced Topics
Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory and semantic memory. And we also have a lot of theories, right?
Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a hybrid clock or some global clock that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ b2caa9b3:9eab0fb5
2025-04-24 06:25:35
Yesterday, I faced one of the most heartbreaking and frustrating experiences of my life. Between 10:00 AM and 2:00 PM, I was held at the Taveta border, denied entry into Kenya—despite having all the necessary documents, including a valid visitor’s permit and an official invitation letter.
The Kenyan Immigration officers refused to speak with me. When I asked for clarification, I was told flatly that I would never be allowed to enter Kenya unless I obtain a work permit. No other reason was given. My attempts to explain that I simply wanted to see my child were ignored. No empathy. No flexibility. No conversation. Just rejection.
While I stood there for hours, held by officials with no explanation beyond a bureaucratic wall, I recorded the experience. I now have several hours of footage documenting what happened—a silent testimony to how a system can dehumanize and block basic rights.
And the situation doesn’t end at the border.
My child, born in Kenya, is also being denied the right to see me. Germany refuses to grant her citizenship, which means she cannot visit me either. The German embassy in Nairobi refuses to assist, stating they won’t get involved. Their silence is loud.
This is not just about paperwork. This is about a child growing up without her father. It’s about a system that chooses walls over bridges, and bureaucracy over humanity. Kenya, by refusing me entry, is keeping a father away from his child. Germany, by refusing to act under §13 StGB, is complicit in that injustice.
In the coming days, I’ll share more about my past travels and how this situation unfolded. I’ll also be releasing videos and updates on TikTok—because this story needs to be heard. Not just for me, but for every parent and child caught between borders and bureaucracies.
Stay tuned—and thank you for standing with me.
-
@ 3b19f10a:4e1f94b4
2024-12-07 09:55:46
-
@ 3c7dc2c5:805642a8
2025-04-23 21:50:33
🧠Quote(s) of the week:
'The "Bitcoin Corporate Treasury" narrative is a foot gun if it's not accompanied by the sovereignty via self-custody narrative. Number Go Up folks are pitching companies to funnel their funds into a handful of trusted third parties. Systemic Risk Go Up.' - Jameson Lopp
Lopp is spot on!
The Bitcoin network is a fortress of digital power backed by 175 terawatt-hours (TWh)—equivalent to 20 full-scale nuclear reactors running continuously 24 hours per day, 365 days per year—making it nation-state-level resistant and growing stronger every day. - James Lavish
🧡Bitcoin news🧡
https://i.ibb.co/xSYWkJPC/Goqd-ERAXw-AEUTAo.jpg
Konsensus Network
On the 14th of April:
➡️ Bitcoin ETFs are bleeding out. Not a single inflow streak since March.
➡️'There are now just a bit less than 3 years left until the next halving. The block reward will drop from 3.125 BTC to 1.5625 BTC. Plan accordingly.' - Samson Mow
➡️Bitcoin is the new benchmark. Bitcoin has outperformed the S&P 500 over the past 1-, 2-, 3-, 4-, 5-, 6-, 7-, 8-, 9-, 10-, 11-, 12-, 13-, and 14-year periods. https://i.ibb.co/GfBK6n2Z/Gof6-Vwp-Ws-AA-g1-V-1.jpg
You cannot consider yourself a serious investor if you see this data and ignore it. Never been an asset like it in the history of mankind. But that is from an investor's perspective...
Alex Gladstein: "While only certain credentialed individuals can own US stocks (a tiny % of the world population) — anyone in the world, dissident or refugee, can own the true best-performing financial asset. "
➡️New record Bitcoin network hashrate 890,000,000,000,000,000,000x per second.
➡️The Korea Exchange has experienced its first bitcoin discount in South Korea since December 2024.
➡️Every government should be mining Bitcoin, say Bhutan's Prime Minister - Al Jazeera "It's a simple choice that's earned billions of dollars. Mining makes tremendous sense."
On the 15th of April:
➡️'Owning 1 Bitcoin isn’t a trade... - It’s a power move. - A geopolitical hedge. - A once-per-civilization bet on the next monetary regime. If you have the means to own one and don’t… You’re not managing risk. You’re misreading history.' -Alec Bakhouche
Great thread: https://x.com/Alec_Bitcoin/status/1912216075703607448
➡️The only thing that drops faster than new ETH narratives is the ETH price. Ethereum is down 74% against Bitcoin since switching from PoW to PoS in 2022.
https://i.ibb.co/bR3yjqZX/Gos0kc-HXs-AAP-9-X.jpg
Piere Rochard: "The theory was that on-chain utility would create a positive fly-wheel effect of demand for holding ETH. The reality is that even if (big if) you need its chain utility, you don’t actually need to hold ETH, you can use stablecoins or wBTC. There’s no real value accrual thesis."
If you're still holding ETH, you're in denial. You watched it slide from 0.05 to 0.035. Now it's circling 0.02 and you're still hoping? That's not a strategy—that's desperation. There is no bounce. No cavalry. Just a crowd of bagholders waiting to offload on the next fool. Don’t be that fool. Everyone’s waiting to dump, just like you.
For example. Galaxy Digital deposited another 12,500 $ETH($20.28M) to Binance 10 hours ago. Galaxy Digital has deposited 37,500 $ETH($60.4M) to Binance in the past 4 days. The institutional guys that were pushing this fraud coin like the Winklevoss brothers and Novogratz (remember the Luna fiasco?!) are ejecting. If you're still holding, no one to blame but yourself.
Take the loss. Rotate to BTC.
Later, you can lie and say you always believed in Bitcoin. But right now, stop the bleeding.
You missed it. Accept that. Figure out why.
P.S. Don’t do anything stupid. It’s just money. You’ll recover. Move smarter next time.
➡️And it is not only against ETH, every other asset is bleeding against BTC because every other asset is inferior to BTC. Did you know Bitcoin's 200-week moving average never declines? It always rises. What does this suggest? 'This is the most significant chart in financial markets. It's Bitcoin - measured with a 200-week moving average (aka 4 years at a time). Zoom out, and the truth becomes crystal clear: Bitcoin has never lost purchasing power. What does this hint at? Bitcoin is the most reliable savings technology on Earth.' - Cole Walmsley
Proof: https://x.com/Cole_Walmsley/status/1912545128826142963
➡️SPAR Switzerland Pilots Bitcoin and Lightning Network Payments Zurich, Switzerland – SPAR, one of the world’s largest grocery retail chains, has launched a pilot program to accept Bitcoin and Lightning Network payments at select locations in Switzerland.
With a global presence spanning 13,900 stores across 48 countries, this move signals a significant step toward mainstream adoption of Bitcoin in everyday commerce.
➡️$110 billion VanEck proposes BitBonds for the US to buy more Bitcoin and refinance its $14 trillion debt.
➡️'A peer-reviewed study forecasts $1M Bitcoin by early 2027—and up to $5M by 2031.' -Simply Bitcoin
On the 17th of April:
➡️ Every one of these dots is flaring gas into the atmosphere and could be mining Bitcoin instead of wasting the gas and polluting the air.
https://i.ibb.co/d4WBjXTX/Gos-OHm-Nb-IAAO8-VT.jpg
Thomas Jeegers: 'Each of these flare sites is a perfect candidate for Bitcoin mining, where wasted methane can be captured, converted into electricity, and monetized on the spot. No need for new pipelines. No need for subsidies. Just turning trash into treasure. Yes, other technologies can help reduce methane emissions. But only Bitcoin mining can do it profitably, consistently, at scale, and globally. And that’s exactly why it's already happening in Texas, Alberta, Oman, Argentina, and beyond. Methane is 84x more harmful than CO₂ over 20 years. Bitcoin is not just a monetary revolution, it's an environmental one.'
➡️Bitcoin market cap dominance hits a new 4-year high.
➡️BlackRock bought $30 million #Bitcoin for its spot Bitcoin ETF.
➡️Multiple countries and sovereign wealth funds are looking to establish Strategic Bitcoin Reserves - Financial Times
Remember, Gold's market cap is up $5.5 TRILLION in 2025. That's more than 3x of the total Bitcoin market cap. Nation-state adoption of Bitcoin is poised to be a pivotal development in monetary history...eventually.
➡️'In 2015, 1 BTC bought 57 steaks. Today, 7,568. Meanwhile, $100 bought 13 steaks in 2015. Now, just 9. Stack ₿, eat more steak.' Priced in Bitcoin
https://i.ibb.co/Pz5BtZYP/Gouxzda-Xo-AASSc-M.jpg
➡️'The Math:
At $91,150 Bitcoin flips Saudi Aramco
At $109,650 Bitcoin flips Amazon
At $107,280 Bitcoin flips Google
At $156,700 Bitcoin flips Microsoft
At $170,900 Bitcoin flips Apple
At $179,680 Bitcoin flips NVIDIA
Over time #Bitcoin flips everything.' -CarlBMenger
➡️Will $1 get you more or less than 1,000 sats by the fifth Halving? Act accordingly. - The rational root Great visual: https://i.ibb.co/tPxnXnL4/Gov1s-IRWEAAEXn3.jpg
➡️Bhutan’s Bitcoin Holdings Now Worth 30% of National GDP: A Bold Move in the Bitcoin Game Theory
In a stunning display of strategic foresight, Bhutan’s Bitcoin holdings are now valued at approximately 30% of the nation’s GDP. This positions the small Himalayan kingdom as a key player in the ongoing Bitcoin game theory that is unfolding across the world. This move also places Bhutan ahead of many larger nations, drawing attention to the idea that early Bitcoin adoption is not just about financial innovation, but also about securing future economic sovereignty and proof that Bitcoin has the power to lift nations out of poverty.
Bhutan explores using its hydropower for green Bitcoin mining, aiming to boost the economy while maintaining environmental standards. Druk Holding's CEO Ujjwal Deep Dahal says hydropower-based mining effectively "offsets" fossil fuel-powered bitcoin production, per Reuters.
➡️Barry Silbert, CEO of Digital Currency Group, admits buying Coinbase was great, but just holding Bitcoin would’ve been better. Silbert told Raoul Pal he bought BTC at $7–$8 and, "Had I just held the Bitcoin, I actually would have done better than making those investments."
He also called 99.9% of tokens “worthless,” stressing most have no reason to exist.
No shit Barry!
➡️Bitcoin hashrate hits a new ATH.
https://i.ibb.co/1pDj9Ch/Gor2-Dd2ac-AAk-KC5.jpg
Bitcoin hashrate hit 1ZH/s. That’s 1,000,000,000,000,000,000,000 hashes every second. Good luck stopping that! Bitcoin mining is the most competitive and decentralized industry in the world.
➡️¥10 Billion Japanese Fashion Retailer ANAP Adds Bitcoin to Corporate Treasury Tokyo, Japan – ANAP Inc., a publicly listed Japanese fashion retailer with a market capitalization of approximately ¥10 billion, has officially announced the purchase of Bitcoin as part of its corporate treasury strategy.
“The global trend of Bitcoin becoming a reserve asset is irreversible,” ANAP stated in its announcement.
➡️El Salvador just bought more Bitcoin for their Strategic Bitcoin Reserve.
➡️Only 9.6% of Bitcoin addresses are at a loss, a rare signal showing one of the healthiest market structures ever. Despite not being at all-time highs, nearly 90% of holders are in profit, hinting at strong accumulation and potential for further upside.
On the 18th of April:
➡️Swedish company Bitcoin Treasury AB announces IPO plans, aiming to become the 'European version of MicroStrategy'. The company clearly states: "Our goal is to fully acquire Bitcoin (BTC)."
➡️Relai app (unfortunately only available with full KYC) with some great Bitcoin marketing. https://i.ibb.co/G4szrqXj/Goz-Kh-Hh-WEAEo-VQr.jpg
➡️Arizona's Bitcoin Reserve Bill (SB 1373) has passed the House Committee and is advancing to the final floor vote.
➡️Simply Bitcoin: It will take 40 years to mine the last Bitcoin. If you're a whole corner, your grandchildren will inherit the equivalent of four decades of global energy. You're not bullish enough. https://i.ibb.co/Hpz2trvr/Go1-Uiu7a-MAI2g-VS.jpg
➡️Meanwhile in Slovenia: Slovenia's Finance Ministry proposes to introduce a 25% capital gains tax on bitcoin profits.
➡️ In one of my previous Weekly Recaps I already shared some news on Breez. Now imagine a world where everyone can implement lightning apps on browsers...with the latest 'Nodeless' release Breez is another step towards bringing Bitcoin payments to every app. Stellar work!
Breez: 'Breez SDK Now Supports WASM We’re excited to announce that Nodeless supports WebAssembly (WASM), so apps can now add Bitcoin payments directly into browsers and node.js environments. Pay anyone, anywhere, on any device with the Breez SDK.
Our new Nodeless release has even more big updates → Minimum payment amounts have been significantly reduced — send from 21 sats, receive from 100. Now live in Misty Breez (iOS + Android). → Users can now pay fees with non-BTC assets like USDT. Check the release notes for all the details on the 0.8 update.'
https://github.com/breez/breez-sdk-liquid/releases/tag/0.8.0
https://bitcoinmagazine.com/takes/embed-bitcoin-into-everything-everywhere Shinobi: Bitcoin needs to be everywhere, seamlessly, embedded into everything.
➡️Despite reaching a new all-time high of $872B, bitcoin's realized market cap monthly growth slowed to 0.9%, signaling continued risk-off sentiment, according to Glassnode.
On the 19th of April:
➡️Recently a gold bug, Jan Nieuwenhuijs (yeah he is Dutch, we are not perfect), stated the following: 'Bitcoin was created by mankind and can be destroyed by mankind. Gold cannot. It’s as simple as that.'
As a reply to a Saylor quote: 'Bitcoin has no counterparty risk. No company. No country. No creditor. No currency. No competitor. No culture. Not even chaos.'
Maybe Bitcoin can be destroyed by mankind, never say never, but what I do know is that at the moment Bitcoin is destroying gold like a manic.
https://i.ibb.co/ZR8ZB4d5/Go7d-KCqak-AA-D7-R.jpg
Oh and please do know. Gold may have the history, but Bitcoin has the scarcity. https://i.ibb.co/xt971vJc/Gp-FMy-AXQAAJzi-M.jpg
In 2013, you couldn't even buy 1 ounce of gold with 1 Bitcoin.
Then in 2017, you could buy 9 ounces of gold with 1 Bitcoin.
Today you can buy 25 ounces of gold with 1 Bitcoin.
At some point, you'll be able to buy 100 ounces of gold with 1 Bitcoin.
➡️Investment firm Abraxas Capital bought $250m Bitcoin in just 4 days.
On the 20th of April:
➡️The Bitcoin network is to be 70% powered by sustainable energy sources by 2030. https://i.ibb.co/nsqsfVY4/Go-r7-LEWo-AAt6-H2.jpg
➡️FORBES: "Converting existing assets like Fort Knox gold into bitcoin makes sense. It would be budget-neutral and an improvement since BTC does everything that gold can, but better" Go on Forbes, and say it louder for the people at the back!
On the 21st of April:
➡️Bitcoin has now recovered the full price dip from Trump's tariff announcement.
➡️Michael Saylor's STRATEGY just bought another 6,556 Bitcoin worth $555.8m. MicroStrategy now owns 2.7% of all Bitcoin in circulation. At what point do we stop celebrating Saylor stacking more?
On the same day, Metaplanet acquired 330 BTC for $28.2M, reaching 4,855 BTC in total holdings.
➡️'Northern Forum, a non-profit member organization of UNDP Climate Change Adaptation, just wrote a well-researched article on how Bitcoin mining is aiding climate objectives (stabilizing grids, aiding microgrids, stopping renewable waste)' -Daniel Batten
https://northernforum.net/how-bitcoin-mining-is-transforming-the-energy-production-game/
💸Traditional Finance / Macro:
On the 16th of April:
👉🏽The Nasdaq Composite is now on track for its 5th-largest daily point decline in history.
👉🏽'Foreign investors are dumping US stocks at a rapid pace: Investors from overseas withdrew ~$6.5 billion from US equity funds over the last week, the second-largest amount on record. Net outflows were only below the $7.5 billion seen during the March 2023 Banking Crisis. According to Apollo, foreigners own a massive $18.5 trillion of US stocks or 20% of the total US equity market. Moreover, foreign holdings of US Treasuries are at $7.2 trillion, or 30% of the total. Investors from abroad also hold 30% of the total corporate credit market, for a total of $4.6 trillion.' TKL
On the 17th of April:
👉🏽'Historically, the odds of a 10% correction are 40%, a 25% bear market 20%, and a 50% bear market 2%. That means that statistically speaking the further the market falls the more likely it is to recover. Yes, some 20% declines become 50% “super bears,” but more often than not the market has historically started to find its footing at -20%, as it appears to have done last week.' - Jurrien Timmer - Dir. of Global Macro at Fidelity
https://i.ibb.co/B2bVDLqM/Gow-Hn-PRWYAAX79z.jpg
👉🏽The S&P 500 is down 10.3% in the first 72 trading days of 2025, the 5th worst start to a year in history.
🏦Banks:
👉🏽 'Another amazing piece of reporting by Nic Carter on a truly sordid affair. Nic Carter is reporting that prominent Biden officials killed signature bank — though solvent — to expand Silvergate/SVB collapses into a national issue, allowing FDIC to invoke a “systemic risk exemption” to bail out SVB at Pelosi’s request.' - Alex Thorne
https://www.piratewires.com/p/signature-didnt-have-to-die-either-chokepoint-nic-carter
Signature, Silvergate, and SVB were attacked by Democrats to kneecap crypto and distance themselves from FTX. The chaos created unintended negative consequences. Signature was solvent but they forced a collapse to invoke powers which they used to clean up the mess they made.
🌎Macro/Geopolitics:
Every nation in the world is in debt and no one wants to say who the creditor is.
On the 14th of April:
👉🏽'US financial conditions are now their tightest since the 2020 pandemic, per ZeroHedge. Financial conditions are even tighter than during one of the most rapid Fed hike cycles of all time, in 2022. Conditions have tightened rapidly as stocks have pulled back, while credit spreads have risen. To put it differently, the availability and cost of financing for economic activity have worsened. That suggests the economy may slow even further in the upcoming months.' -TKL
👉🏽Global Repricing of Duration Risk... 'It opens the door to a global repricing of duration risk. This isn’t a blip. It’s a sovereign-level alarm bell.
"I find Japan fascinating on many levels not just its financial history. Just watch the Netflix documentary: Watch Age of Samurai: Battle for Japan 'I only discovered the other day that the Bank of Japan was the first to use Quantitative Easing. Perhaps that's when our global finance system was first broken & it's been sticking plasters ever since.' - Jane Williams
A must-read…the U.S. bond market is being driven down by Japanese selling and not because they want to…because they have to. It’s looking more and more dangerous.
BoJ lost its control over long-term bond yields. Since inflation broke out in Japan, BoJ can not suppress any longer...
EndGame Macro: "This is one of the clearest signals yet that the Bank of Japan has lost control of the long end of the curve. Japan’s 30-year yield hitting 2.845% its highest since 2004 isn’t just a local event. This has global knock-on effects: Japan is the largest foreign holder of U.S. Treasuries and a key player in the global carry trade. Rising JGB yields force Japanese institutions to repatriate capital, unwind overseas positions, and pull back on USD asset exposure adding pressure to U.S. yields and FX volatility. This spike also signals the end of the deflationary regime that underpinned global risk assets for decades. If Japan once the global anchor of low yields can’t suppress its bond market anymore, it opens the door to a global repricing of duration risk. This isn’t a blip. It’s a sovereign-level alarm bell."
https://i.ibb.co/LXsCDZMf/Gow-XGL8-Wk-AEDXg-P.jpg
You're distracted by China, but it's always been about Japan.
On the 16th of April:
👉🏽Over the last 20 years, gold has now outperformed stocks, up +620% compared to a +580% gain in the S&P 500 (dividends included). Over the last 9 months, gold has officially surged by over +$1,000/oz. Gold hit another all-time high and is now up over 27% in 2025. On pace for its best year since 1979.
https://i.ibb.co/9kZbtPVF/Goftd-OSW8-AA2a-9.png
Meanwhile, imports of physical gold have gotten so large that the Fed has released a new GDP metric. Their GDPNow tool now adjusts for gold imports. Q1 2025 GDP contraction including gold is expected to be -2.2%, and -0.1% net of gold. Gold buying is at recession levels.
👉🏽Von der Leyen: "The West as we knew it no longer exists. [..] We need another, new European Union ready to go out into the big wide world and play a very active role in shaping this new world order"
Her imperial aspirations have long been on display. Remember she was not elected.
👉🏽Fed Chair Jerome Powell says crypto is going mainstream, a legal framework for stablecoins is a good idea, and there will be loosening of bank rules on crypto.
On the 17th of April:
👉🏽The European Central Bank cuts interest rates by 25 bps for their 7th consecutive cut as tariffs threaten economic growth. ECB's focus shifted to 'downside risk to the growth outlook.' Markets price in the deposit rate will be at 1.58% in Dec, from 1.71% before the ECB's statement. Great work ECB, as inflation continues to decline and economic growth prospects worsen. Unemployment is also on the rise. Yes, the economy is doing just great!
On the same day, Turkey reversed course and hiked rates for the first time since March 2024, 350 bps move up to 46%.
👉🏽'Global investors have rarely been this bearish: A record ~50% of institutional investors intend to reduce US equity exposure, according to a Bank of America survey released Monday. Allocation to US stocks fell 13 percentage points over the last month, to a net 36% underweight, the lowest since the March 2023 Banking Crisis. Since February, investors' allocation to US equities has dropped by ~53 percentage points, marking the largest 2-month decline on record. Moreover, a record 82% of respondents are now expecting the world economy to weaken. As a result, global investor sentiment fell to just 1.8 points, the 4th-lowest reading since 2008. We have likely never seen such a rapid shift in sentiment.' -TKL
👉🏽'US large bankruptcies jumped 49 year-over-year in Q1 2025, to 188, the highest quarterly count since 2010. Even during the onset of the 2020 pandemic, the number of filings was lower at ~150. This comes after 694 large companies went bankrupt last year, the most in 14 years. The industrial sector recorded the highest number of bankruptcies in Q1 2025, at 32. This was followed by consumer discretionary and healthcare, at 24 and 13. Bankruptcies are rising.' -TKL
👉🏽DOGE‘s success is simply breathtaking.
https://i.ibb.co/zV45sYBn/Govy-G6e-XIAA8b-NI.jpg
Although it would've been worse without DOGE, nothing stops this train.
👉🏽GLD update: Custodian JPM added 4 tons, bringing their total to a new all-time high of 887 tons. JPM has added 50 tons in a month and is 163 tons from surpassing Switzerland to become the 7th largest gold holder in the world.
Now ask yourself and I quote Luke Gromen:
a) why JPM decided to become a GLD custodian after 18 years, & then in just over 2 years, shift 90%+ of GLD gold to its vaults, &;
b) why the Atlanta Fed has continued to report real GDP with- and without (~$500B of) gold imports YTD?
👉🏽Sam Callahan: After slowing the pace of QT twice—and now hinting at a potential return to QE—the Fed’s balance sheet is settling into a new higher plateau. "We’ve been very clear that this is a temporary measure...We’ll normalize the balance sheet and reduce the size of holdings...It would be quite a different matter if we were buying these assets and holding them indefinitely. It would be a monetization. We are not doing that." - Ben Bernake, Dec. 12, 2012
Temporary measures have a funny way of becoming structural features. The balance sheet didn’t ‘normalize’.. it evolved. What was once an ‘emergency’ is now a baseline. This isn’t QE or QT anymore. It’s a permanent intervention dressed as policy. Remember, 80% of all dollars were created in the last 5 years.
👉🏽Global Fiat Money Supply Is Exploding 🚨
The fiat system is on full tilt as central banks flood markets with unprecedented liquidity:
🇺🇸 U.S.: Money supply nearing new all-time highs
🇨🇳 China: At record levels
🇯🇵 Japan: Close to historic peaks
🇪🇺 EU: Printing into new ATHs https://i.ibb.co/Cp4z97Jx/Go4-Gx2-MXIAAzdi9.jpg
This isn’t growth—it’s monetary debasement. Governments aren’t solving problems; they’re papering over them with inflation.
Bitcoin doesn’t need bailouts. It doesn’t print. It doesn’t inflate.
As fiat currencies weaken under the weight of endless expansion, Bitcoin stands alone as a fixed-supply, incorruptible alternative.
👉🏽Fed Funds Rate: Market Expectations...
-May 2025: Hold
-Jun 2025: 25 bps cut to 4.00-4.25%
-July 2025: 25 bps cut to 3.75-4.00%
-Sep 2025: 25 bps cut to 3.50-3.75%
-Oct 2025: Hold
-Dec 2025: 25 bps cut to 3.25-3.50%
Anyway, shortterm fugazi....500 years of interest rates, visualized: https://i.ibb.co/84zs0yvD/Go7i7k-ZXYAAt-MRH.jpg
👉🏽'A net 49% of 164 investors with $386 billion in assets under management (AUM) believe a HARD LANDING is the most likely outcome for the world economy, according to a BofA survey. This is a MASSIVE shift in sentiment as 83% expected no recession in March.' -Global Markets Investor
👉🏽The EU’s New Role as Tax Collector: A Turning Point for Sovereignty
Beginning in 2027, a new chapter in the European Union’s influence over national life will begin. With the introduction of ETS2, the EU will extend its Emissions Trading System to include not just businesses, but private individuals as well. This means that CO₂ emissions from household gas consumption and vehicle fuel will be taxed—directly impacting the daily lives of citizens across the continent.
In practice, this shift transforms the EU into a (in)direct tax collector, without national consent, without a democratic mandate, and without the explicit approval of the people it will affect. The financial burden will be passed down through energy suppliers and fuel providers, but make no mistake: the cost will land squarely on the shoulders of European citizens, including millions of Dutch households.
This raises a fundamental question: What does sovereignty mean if a foreign or supranational entity can 'tax' your citizens? When a people are 'taxed' by a power beyond their borders—by an unelected body headquartered in Brussels—then either their nation is no longer sovereign, or that sovereignty has been surrendered or sold off by those in power.
There are only two conclusions to draw: We are living under soft occupation, with decisions made elsewhere that bind us at home. Or our sovereignty has been handed away voluntarily—a slow erosion facilitated by political elites who promised integration but delivered subordination. Either way, the more aggressively the EU enforces this trajectory, the more it reveals the futility of reforming the Union from within. The democratic deficit is not shrinking—it’s expanding. And with every new policy imposed without a national vote, the case for fundamental change grows stronger.
If Brussels continues down this path, there will come a point when only one option remains: A clean and decisive break. My view: NEXIT
Source: https://climate.ec.europa.eu/eu-action/eu-emissions-trading-system-eu-ets/ets2-buildings-road-transport-and-additional-sectors_en
For the Dutch readers:
https://www.businessinsider.nl/directe-co2-heffing-van-eu-op-gas-en-benzine-kan-huishoudens-honderden-euros-per-jaar-kosten-er-komt-ook-een-sociaal-klimaatfonds/?tid=TIDP10342314XEEB363B26CB34FB48054B929DB743E99YI5
On the 18th of April:
👉🏽'Two lost decades. Grotesque overregulation, bureaucracy, lack of innovation, and left redistribution mindset have their price. Europe is on its way to becoming an open-air museum. What a pity to watch.' -Michael A. Arouet
https://i.ibb.co/PsxdC3Kw/Goz-Ffwy-XMAAJk-Af.jpg
Looking at the chart, fun fact, the Lisbon Treaty was signed in 2007. That treaty greatly empowered the European bureaucracy. Reforms are needed in Europe, as soon as possible.
👉🏽CBP says latest tariffs have generated $500 million, well below Trump’s estimate — CNBC
Yikes! 'Probably one the biggest economic blunders in history. $500 million in 15 days means $12 billion a year in additional tax revenue. Literal trillions in wealth destroyed, interest on the debt increased, the dollar weakened, businesses wiped out all over the world, and literally every single country in the world antagonized... all for raising a yearly amount of taxes that can fund the US military budget for just 4 days. $500 million pays for exactly 37 minutes of the US budget.' - Arnaud Bertrand
YIKES!!
👉🏽Belarus to launch a "digital ruble" CBDC by the end of 2026.
On the 20th of April:
👉🏽'China’s central bank increased its gold holdings by 5 tonnes in March, posting its 5th consecutive monthly purchase. This brings total China’s gold reserves to a record 2,292 tonnes. Chinese gold holdings now reflect 6.5% of its total official reserve assets. According to Goldman Sachs, China purchased a whopping 50 tonnes of gold in February, or 10 times more than officially reported. Over the last 3 years, China's purchases of gold on the London OTC market have significantly surpassed officially reported numbers. China is accumulating gold at a rapid pace.' -TKL
On the 21st of April:
👉🏽Gold officially breaks above $3,400/oz for the first time in history. Gold funds attracted $8 BILLION in net inflows last week, the most EVER. This is more than DOUBLE the records seen during the 2020 CRISIS. Gold is up an impressive 29% year-to-date.
https://i.ibb.co/Nn7gr45q/Goq7km-PW8-AALegt.png
👉🏽I want to finish this segment and the weekly recap with a chart, a chart to think about! A chart to share with friends, family, and co-workers:
https://i.ibb.co/9xFxRrw/Gp-A3-ANWbs-AAO5nl.jpg
side note: 'Labeled periods like the "Era of Populism" (circa 2010-2020) suggest a link between growing wealth disparity and populist movements, supported by studies like those http://on.tandfonline.com, which note income inequality as a driver for populist party support in Europe due to economic insecurities and distrust in elites.'
The fiat system isn’t broken. It’s doing exactly what it was designed to do: Transfer wealth from savers to the state. This always ends in either default or debasement There’s one exit - Bitcoin.
Great thread: https://x.com/fitcoiner/status/1912932351677792703 https://i.ibb.co/84sFWW9q/Gow-Zv-SFa4-AAu2-Ag.jpg
🎁If you have made it this far I would like to give you a little gift, well in this case two gifts:
Bitcoin Nation State Adoption Paradox - A Trojan Horse with Alex Gladstein. Exploring the paradoxes of Bitcoin adoption in nation-states and its radical role in human rights, freedom, and financial sovereignty. https://youtu.be/pLIxmIMHL44
Credit: I have used multiple sources!
My savings account: Bitcoin The tool I recommend for setting up a Bitcoin savings plan: PocketBitcoin especially suited for beginners or people who want to invest in Bitcoin with an automated investment plan once a week or monthly.
Use the code SE3997
Get your Bitcoin out of exchanges. Save them on a hardware wallet, run your own node...be your own bank. Not your keys, not your coins. It's that simple. ⠀ ⠀
⠀⠀ ⠀ ⠀⠀⠀
Do you think this post is helpful to you?
If so, please share it and support my work with a zap.
▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃
⭐ Many thanks⭐
Felipe - Bitcoin Friday!
▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃▃
-
@ b2d670de:907f9d4a
2024-12-02 21:24:45
onion-service-nostr-relays
A list of nostr relays exposed as onion services.
The list
| Relay name | Description | Onion url | Operator | Payment URL | Payment options | | --- | --- | --- | --- | --- | --- | | nostr.oxtr.dev | Same relay as clearnet relay nostr.oxtr.dev | ws://oxtrdevav64z64yb7x6rjg4ntzqjhedm5b5zjqulugknhzr46ny2qbad.onion | operator | N/A | N/A | | relay.snort.social | Same relay as clearnet relay relay.snort.social | wss://skzzn6cimfdv5e2phjc4yr5v7ikbxtn5f7dkwn5c7v47tduzlbosqmqd.onion | operator | N/A | N/A | | nostr.thesamecat.io | Same relay as clearnet relay nostr.thesamecat.io | ws://2jsnlhfnelig5acq6iacydmzdbdmg7xwunm4xl6qwbvzacw4lwrjmlyd.onion | operator | N/A | N/A | | nostr.land | The nostr.land paid relay (same as clearnet) | ws://nostrland2gdw7g3y77ctftovvil76vquipymo7tsctlxpiwknevzfid.onion | operator | Payment URL | BTC LN | | bitcoiner.social | No auth required, currently | ws://bitcoinr6de5lkvx4tpwdmzrdfdpla5sya2afwpcabjup2xpi5dulbad.onion | operator | N/A | N/A | | relay.westernbtc.com | The westernbtc.com paid relay | ws://westbtcebhgi4ilxxziefho6bqu5lqwa5ncfjefnfebbhx2cwqx5knyd.onion | operator | Payment URL | BTC LN | | freelay.sovbit.host | Free relay for sovbit.host | ws://sovbitm2enxfr5ot6qscwy5ermdffbqscy66wirkbsigvcshumyzbbqd.onion | operator | N/A | N/A | | nostr.sovbit.host | Paid relay for sovbit.host | ws://sovbitgz5uqyh7jwcsudq4sspxlj4kbnurvd3xarkkx2use3k6rlibqd.onion | operator | N/A | N/A | | nostr.wine | 🍷 nostr.wine relay | ws://nostrwinemdptvqukjttinajfeedhf46hfd5bz2aj2q5uwp7zros3nad.onion | operator | Payment URL | BTC LN, BTC, Credit Card/CashApp (Stripe) | | inbox.nostr.wine | 🍷 inbox.nostr.wine relay | ws://wineinboxkayswlofkugkjwhoyi744qvlzdxlmdvwe7cei2xxy4gc6ad.onion | operator | Payment URL | BTC LN, BTC | | filter.nostr.wine | 🍷 filter.nostr.wine proxy relay | ws://winefiltermhqixxzmnzxhrmaufpnfq3rmjcl6ei45iy4aidrngpsyid.onion | operator | Payment URL | BTC LN, BTC | | N/A | N/A | ws://pzfw4uteha62iwkzm3lycabk4pbtcr67cg5ymp5i3xwrpt3t24m6tzad.onion:81 | operator | N/A | N/A | | nostr.fractalized.net | Free relay for fractalized.net | ws://xvgox2zzo7cfxcjrd2llrkthvjs5t7efoalu34s6lmkqhvzvrms6ipyd.onion | operator | N/A | N/A | | nfrelay.app | nfrelay.app aggregator relay (nostr-filter-relay) | ws://nfrelay6saohkmipikquvrn6d64dzxivhmcdcj4d5i7wxis47xwsriyd.onion | operator | N/A | N/A | relay.nostr.net | Public relay from nostr.net (Same as clearnet) | ws://nostrnetl6yd5whkldj3vqsxyyaq3tkuspy23a3qgx7cdepb4564qgqd.onion | operator | N/A | N/A | | nerostrator | Free to read, pay XMR to relay | ws://nerostrrgb5fhj6dnzhjbgmnkpy2berdlczh6tuh2jsqrjok3j4zoxid.onion | operator |Payment URL | XMR | | nostr.girino.org | Public relay from nostr.girino.org | ws://gnostr2jnapk72mnagq3cuykfon73temzp77hcbncn4silgt77boruid.onion | operator | N/A | N/A | | wot.girino.org | WoT relay from wot.girino.org | ws://girwot2koy3kvj6fk7oseoqazp5vwbeawocb3m27jcqtah65f2fkl3yd.onion | operator | N/A | N/A | | haven.girino.org/{outbox, inbox, chat, private} | Haven smart relay from haven.girino.org | ws://ghaven2hi3qn2riitw7ymaztdpztrvmm337e2pgkacfh3rnscaoxjoad.onion/{outbox, inbox, chat, private} | operator | N/A | N/A | | relay.nostpy.lol | Free Web of Trust relay (Same as clearnet) | ws://pemgkkqjqjde7y2emc2hpxocexugbixp42o4zymznil6zfegx5nfp4id.onion | operator |N/A | N/A | | Poster.place Nostr Relay | N/A | ws://dmw5wbawyovz7fcahvguwkw4sknsqsalffwctioeoqkvvy7ygjbcuoad.onion | operator | N/A | N/A |
Contributing
Contributions are encouraged to keep this document alive. Just open a PR and I'll have it tested and merged. The onion URL is the only mandatory column, the rest is just nice-to-have metadata about the relay. Put
N/Ain empty columns.If you want to contribute anonymously, please contact me on SimpleX or send a DM on nostr using a disposable npub.
Operator column
It is generally preferred to use something that includes a NIP-19 string, either just the string or a url that contains the NIP-19 string in it (e.g. an njump url).
-
@ 81cda509:ae345bd2
2024-12-01 06:01:54


@florian | Photographer
Studio-Shoot
“Know thyself” is a phrase attributed to the ancient Greek philosopher Socrates, and it has been a cornerstone of philosophical thought for centuries. It invites an individual to deeply examine their own thoughts, feelings, behaviors, and motivations in order to understand their true nature.
At its core, “Know thyself” encourages self-awareness - an understanding of who you truly are beneath the surface. This process of introspection can uncover your strengths, weaknesses, desires, fears, and values. It invites you to acknowledge your habits, biases, and patterns of thinking, so you can make more conscious choices in life.
Knowing yourself also involves understanding your place in the larger context of existence. It means recognizing how your actions and choices affect others and the world around you. This awareness can lead to greater empathy, a sense of interconnectedness, and a more authentic life, free from the distractions of societal expectations or superficial identities.
In a practical sense, knowing yourself might involve:
-
Self-reflection: Regularly taking time to reflect on your thoughts, feelings, and experiences.
-
Mindfulness: Practicing awareness of the present moment and observing your reactions without judgment.
-
Exploration: Being open to trying new things and learning from both successes and failures.
-
Seeking truth: Engaging in honest inquiry about your motivations, desires, and beliefs.
-
Growth: Continuously learning from your past and striving to align your actions with your inner values.
Ultimately, “Know thyself” is about cultivating a deep, honest understanding of who you are, which leads to a more fulfilled, intentional, and peaceful existence.
-
-
@ 00e5a4ac:5cf950dd
2025-04-23 21:36:33
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ a367f9eb:0633efea
2024-11-05 08:48:41
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters
When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies
In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement
If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Originally published on the website of the Consumer Choice Center.
-
@ 00e5a4ac:5cf950dd
2025-04-23 21:32:56
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 00e5a4ac:5cf950dd
2025-04-23 21:32:50
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 09fbf8f3:fa3d60f0
2024-11-02 08:00:29
> ### 第三方API合集:
免责申明:
在此推荐的 OpenAI API Key 由第三方代理商提供,所以我们不对 API Key 的 有效性 和 安全性 负责,请你自行承担购买和使用 API Key 的风险。
| 服务商 | 特性说明 | Proxy 代理地址 | 链接 | | --- | --- | --- | --- | | AiHubMix | 使用 OpenAI 企业接口,全站模型价格为官方 86 折(含 GPT-4 )| https://aihubmix.com/v1 | 官网 | | OpenAI-HK | OpenAI的API官方计费模式为,按每次API请求内容和返回内容tokens长度来定价。每个模型具有不同的计价方式,以每1,000个tokens消耗为单位定价。其中1,000个tokens约为750个英文单词(约400汉字)| https://api.openai-hk.com/ | 官网 | | CloseAI | CloseAI是国内规模最大的商用级OpenAI代理平台,也是国内第一家专业OpenAI中转服务,定位于企业级商用需求,面向企业客户的线上服务提供高质量稳定的官方OpenAI API 中转代理,是百余家企业和多家科研机构的专用合作平台。 | https://api.openai-proxy.org | 官网 | | OpenAI-SB | 需要配合Telegram 获取api key | https://api.openai-sb.com | 官网 |
持续更新。。。
推广:
访问不了openai,去
低调云购买VPN。官网:https://didiaocloud.xyz
邀请码:
w9AjVJit价格低至1元。
-
@ 00e5a4ac:5cf950dd
2025-04-23 21:32:41
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 4c48cf05:07f52b80
2024-10-30 01:03:42
I believe that five years from now, access to artificial intelligence will be akin to what access to the Internet represents today. It will be the greatest differentiator between the haves and have nots. Unequal access to artificial intelligence will exacerbate societal inequalities and limit opportunities for those without access to it.
Back in April, the AI Index Steering Committee at the Institute for Human-Centered AI from Stanford University released The AI Index 2024 Annual Report.
Out of the extensive report (502 pages), I chose to focus on the chapter dedicated to Public Opinion. People involved with AI live in a bubble. We all know and understand AI and therefore assume that everyone else does. But, is that really the case once you step out of your regular circles in Seattle or Silicon Valley and hit Main Street?
Two thirds of global respondents have a good understanding of what AI is
The exact number is 67%. My gut feeling is that this number is way too high to be realistic. At the same time, 63% of respondents are aware of ChatGPT so maybe people are confounding AI with ChatGPT?
If so, there is so much more that they won't see coming.
This number is important because you need to see every other questions and response of the survey through the lens of a respondent who believes to have a good understanding of what AI is.
A majority are nervous about AI products and services
52% of global respondents are nervous about products and services that use AI. Leading the pack are Australians at 69% and the least worried are Japanise at 23%. U.S.A. is up there at the top at 63%.
Japan is truly an outlier, with most countries moving between 40% and 60%.
Personal data is the clear victim
Exaclty half of the respondents believe that AI companies will protect their personal data. And the other half believes they won't.
Expected benefits
Again a majority of people (57%) think that it will change how they do their jobs. As for impact on your life, top hitters are getting things done faster (54%) and more entertainment options (51%).
The last one is a head scratcher for me. Are people looking forward to AI generated movies?

Concerns
Remember the 57% that thought that AI will change how they do their jobs? Well, it looks like 37% of them expect to lose it. Whether or not this is what will happen, that is a very high number of people who have a direct incentive to oppose AI.
Other key concerns include:
- Misuse for nefarious purposes: 49%
- Violation of citizens' privacy: 45%
Conclusion
This is the first time I come across this report and I wil make sure to follow future annual reports to see how these trends evolve.
Overall, people are worried about AI. There are many things that could go wrong and people perceive that both jobs and privacy are on the line.
Full citation: Nestor Maslej, Loredana Fattorini, Raymond Perrault, Vanessa Parli, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, and Jack Clark, “The AI Index 2024 Annual Report,” AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2024.
The AI Index 2024 Annual Report by Stanford University is licensed under Attribution-NoDerivatives 4.0 International.
-
@ 09fbf8f3:fa3d60f0
2024-10-25 18:43:59
在线直播:
央视体育版CCTV5:
央视体育版CCTV16 :
翡翠台:
-
@ 00e5a4ac:5cf950dd
2025-04-23 20:52:18
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 90de72b7:8f68fdc0
2025-04-23 18:08:45
Traffic Light Control System - sbykov
This Petri net represents a traffic control protocol ensuring that two traffic lights alternate safely and are never both green at the same time. Upd
petrinet ;start () -> greenLight1 redLight2 ;toRed1 greenLight1 -> queue redLight1 ;toGreen2 redLight2 queue -> greenLight2 ;toGreen1 queue redLight1 -> greenLight1 ;toRed2 greenLight2 -> redLight2 queue ;stop redLight1 queue redLight2 -> () -
@ 8947a945:9bfcf626
2024-10-17 08:06:55

สวัสดีทุกคนบน Nostr ครับ รวมไปถึง watchersและ ผู้ติดตามของผมจาก Deviantart และ platform งานศิลปะอื่นๆนะครับ
ตั้งแต่ต้นปี 2024 ผมใช้ AI เจนรูปงานตัวละครสาวๆจากอนิเมะ และเปิด exclusive content ให้สำหรับผู้ที่ชื่นชอบผลงานของผมเป็นพิเศษ
ผมโพสผลงานผมทั้งหมดไว้ที่เวบ Deviantart และค่อยๆสร้างฐานผู้ติดตามมาเรื่อยๆอย่างค่อยเป็นค่อยไปมาตลอดครับ ทุกอย่างเติบโตไปเรื่อยๆของมัน ส่วนตัวผมมองว่ามันเป็นพิร์ตธุรกิจออนไลน์ ของผมพอร์ตนึงได้เลย
เมื่อวันที่ 16 กย.2024 มีผู้ติดตามคนหนึ่งส่งข้อความส่วนตัวมาหาผม บอกว่าชื่นชอบผลงานของผมมาก ต้องการจะขอซื้อผลงาน แต่ขอซื้อเป็น NFT นะ เสนอราคาซื้อขายต่อชิ้นที่สูงมาก หลังจากนั้นผมกับผู้ซื้อคนนี้พูดคุยกันในเมล์ครับ

นี่คือข้อสรุปสั่นๆจากการต่อรองซื้อขายครับ
(หลังจากนี้ผมขอเรียกผู้ซื้อว่า scammer นะครับ เพราะไพ่มันหงายมาแล้ว ว่าเขาคือมิจฉาชีพ)

- Scammer รายแรก เลือกผลงานที่จะซื้อ เสนอราคาซื้อที่สูงมาก แต่ต้องเป็นเวบไซต์ NFTmarket place ที่เขากำหนดเท่านั้น มันทำงานอยู่บน ERC20 ผมเข้าไปดูเวบไซต์ที่ว่านี้แล้วรู้สึกว่ามันดูแปลกๆครับ คนที่จะลงขายผลงานจะต้องใช้ email ในการสมัครบัญชีซะก่อน ถึงจะผูก wallet อย่างเช่น metamask ได้ เมื่อผูก wallet แล้วไม่สามารถเปลี่ยนได้ด้วย ตอนนั้นผมใช้ wallet ที่ไม่ได้ link กับ HW wallet ไว้ ทดลองสลับ wallet ไปๆมาๆ มันทำไม่ได้ แถมลอง log out แล้ว เลข wallet ก็ยังคาอยู่อันเดิม อันนี้มันดูแปลกๆแล้วหนึ่งอย่าง เวบนี้ค่า ETH ในการ mint 0.15 - 0.2 ETH … ตีเป็นเงินบาทนี่แพงบรรลัยอยู่นะครับ

-
Scammer รายแรกพยายามชักจูงผม หว่านล้อมผมว่า แหม เดี๋ยวเขาก็มารับซื้องานผมน่า mint งานเสร็จ รีบบอกเขานะ เดี๋ยวเขารีบกดซื้อเลย พอขายได้กำไร ผมก็ได้ค่า gas คืนได้ แถมยังได้กำไรอีก ไม่มีอะไรต้องเสีนจริงมั้ย แต่มันเป้นความโชคดีครับ เพราะตอนนั้นผมไม่เหลือทุนสำรองที่จะมาซื้อ ETH ได้ ผมเลยต่อรองกับเขาตามนี้ครับ :
-
ผมเสนอว่า เอางี้มั้ย ผมส่งผลงานของผมแบบ low resolution ให้ก่อน แลกกับให้เขาช่วยโอน ETH ที่เป็นค่า mint งานมาให้หน่อย พอผมได้ ETH แล้ว ผมจะ upscale งานของผม แล้วเมล์ไปให้ ใจแลกใจกันไปเลย ... เขาไม่เอา
- ผมเสนอให้ไปซื้อที่ร้านค้าออนไลน์ buymeacoffee ของผมมั้ย จ่ายเป็น USD ... เขาไม่เอา
- ผมเสนอให้ซื้อขายผ่าน PPV lightning invoice ที่ผมมีสิทธิ์เข้าถึง เพราะเป็น creator ของ Creatr ... เขาไม่เอา
- ผมยอกเขาว่างั้นก็รอนะ รอเงินเดือนออก เขาบอก ok
สัปดาห์ถัดมา มี scammer คนที่สองติดต่อผมเข้ามา ใช้วิธีการใกล้เคียงกัน แต่ใช้คนละเวบ แถมเสนอราคาซื้อที่สูงกว่าคนแรกมาก เวบที่สองนี้เลวร้ายค่าเวบแรกอีกครับ คือต้องใช้เมล์สมัครบัญชี ไม่สามารถผูก metamask ได้ พอสมัครเสร็จจะได้ wallet เปล่าๆมาหนึ่งอัน ผมต้องโอน ETH เข้าไปใน wallet นั้นก่อน เพื่อเอาไปเป็นค่า mint NFT 0.2 ETH
ผมบอก scammer รายที่สองว่า ต้องรอนะ เพราะตอนนี้กำลังติดต่อซื้อขายอยู่กับผู้ซื้อรายแรกอยู่ ผมกำลังรอเงินเพื่อมาซื้อ ETH เป็นต้นทุนดำเนินงานอยู่ คนคนนี้ขอให้ผมส่งเวบแรกไปให้เขาดูหน่อย หลังจากนั้นไม่นานเขาเตือนผมมาว่าเวบแรกมันคือ scam นะ ไม่สามารถถอนเงินออกมาได้ เขายังส่งรูป cap หน้าจอที่คุยกับผู้เสียหายจากเวบแรกมาให้ดูว่าเจอปัญหาถอนเงินไม่ได้ ไม่พอ เขายังบลัฟ opensea ด้วยว่าลูกค้าขายงานได้ แต่ถอนเงินไม่ได้
Opensea ถอนเงินไม่ได้ ตรงนี้แหละครับคือตัวกระตุกต่อมเอ๊ะของผมดังมาก เพราะ opensea อ่ะ ผู้ใช้ connect wallet เข้ากับ marketplace โดยตรง ซื้อขายกันเกิดขึ้น เงินวิ่งเข้าวิ่งออก wallet ของแต่ละคนโดยตรงเลย opensea เก็บแค่ค่า fee ในการใช้ platform ไม่เก็บเงินลูกค้าไว้ แถมปีนี้ค่า gas fee ก็ถูกกว่า bull run cycle 2020 มาก ตอนนี้ค่า gas fee ประมาณ 0.0001 ETH (แต่มันก็แพงกว่า BTC อยู่ดีอ่ะครับ)
ผมเลยเอาเรื่องนี้ไปปรึกษาพี่บิท แต่แอดมินมาคุยกับผมแทน ทางแอดมินแจ้งว่ายังไม่เคยมีเพื่อนๆมาปรึกษาเรื่องนี้ กรณีที่ผมทักมาถามนี่เป็นรายแรกเลย แต่แอดมินให้ความเห็นไปในทางเดียวกับสมมุติฐานของผมว่าน่าจะ scam ในเวลาเดียวกับผมเอาเรื่องนี้ไปถามในเพจ NFT community คนไทนด้วย ได้รับการ confirm ชัดเจนว่า scam และมีคนไม่น้อยโดนหลอก หลังจากที่ผมรู้ที่มาแล้ว ผมเลยเล่นสงครามปั่นประสาท scammer ทั้งสองคนนี้ครับ เพื่อดูว่าหลอกหลวงมิจฉาชีพจริงมั้ย
โดยวันที่ 30 กย. ผมเลยปั่นประสาน scammer ทั้งสองรายนี้ โดยการ mint ผลงานที่เขาเสนอซื้อนั่นแหละ ขึ้น opensea แล้วส่งข้อความไปบอกว่า
mint ให้แล้วนะ แต่เงินไม่พอจริงๆว่ะโทษที เลย mint ขึ้น opensea แทน พอดีบ้านจน ทำได้แค่นี้ไปถึงแค่ opensea รีบไปซื้อล่ะ มีคนจ้องจะคว้างานผมเยอะอยู่ ผมไม่คิด royalty fee ด้วยนะเฮ้ย เอาไปขายต่อไม่ต้องแบ่งกำไรกับผม
เท่านั้นแหละครับ สงครามจิตวิทยาก็เริ่มขึ้น แต่เขาจนมุม กลืนน้ำลายตัวเอง ช็อตเด็ดคือ
เขา : เนี่ยอุส่ารอ บอกเพื่อนในทีมว่าวันจันทร์ที่ 30 กย. ได้ของแน่ๆ เพื่อนๆในทีมเห็นงานผมแล้วมันสวยจริง เลยใส่เงินเต็มที่ 9.3ETH (+ capture screen ส่งตัวเลขยอดเงินมาให้ดู)ไว้รอโดยเฉพาะเลยนะ ผม : เหรอ ... งั้น ขอดู wallet address ที่มี transaction มาให้ดูหน่อยสิ เขา : 2ETH นี่มัน 5000$ เลยนะ ผม : แล้วไง ขอดู wallet address ที่มีการเอายอดเงิน 9.3ETH มาให้ดูหน่อย ไหนบอกว่าเตรียมเงินไว้มากแล้วนี่ ขอดูหน่อย ว่าใส่ไว้เมื่อไหร่ ... เอามาแค่ adrress นะเว้ย ไม่ต้องทะลึ่งส่ง seed มาให้ เขา : ส่งรูปเดิม 9.3 ETH มาให้ดู ผม : รูป screenshot อ่ะ มันไม่มีความหมายหรอกเว้ย ตัดต่อเอาก็ได้ง่ายจะตาย เอา transaction hash มาดู ไหนว่าเตรียมเงินไว้รอ 9.3ETH แล้วอยากซื้องานผมจนตัวสั่นเลยไม่ใช่เหรอ ถ้าจะส่ง wallet address มาให้ดู หรือจะช่วยส่ง 0.15ETH มาให้ยืม mint งานก่อน แล้วมากดซื้อ 2ETH ไป แล้วผมใช้ 0.15ETH คืนให้ก็ได้ จะซื้อหรือไม่ซื้อเนี่ย เขา : จะเอา address เขาไปทำไม ผม : ตัดจบ รำคาญ ไม่ขายให้ละ เขา : 2ETH = 5000 USD เลยนะ ผม : แล้วไง
ผมเลยเขียนบทความนี้มาเตือนเพื่อนๆพี่ๆทุกคนครับ เผื่อใครกำลังเปิดพอร์ตทำธุรกิจขาย digital art online แล้วจะโชคดี เจอของดีแบบผม
ทำไมผมถึงมั่นใจว่ามันคือการหลอกหลวง แล้วคนโกงจะได้อะไร

อันดับแรกไปพิจารณาดู opensea ครับ เป็นเวบ NFTmarketplace ที่ volume การซื้อขายสูงที่สุด เขาไม่เก็บเงินของคนจะซื้อจะขายกันไว้กับตัวเอง เงินวิ่งเข้าวิ่งออก wallet ผู้ซื้อผู้ขายเลย ส่วนทางเวบเก็บค่าธรรมเนียมเท่านั้น แถมค่าธรรมเนียมก็ถูกกว่าเมื่อปี 2020 เยอะ ดังนั้นการที่จะไปลงขายงานบนเวบ NFT อื่นที่ค่า fee สูงกว่ากันเป็นร้อยเท่า ... จะทำไปทำไม
ผมเชื่อว่า scammer โกงเงินเจ้าของผลงานโดยการเล่นกับความโลภและความอ่อนประสบการณ์ของเจ้าของผลงานครับ เมื่อไหร่ก็ตามที่เจ้าของผลงานโอน ETH เข้าไปใน wallet เวบนั้นเมื่อไหร่ หรือเมื่อไหร่ก็ตามที่จ่ายค่า fee ในการ mint งาน เงินเหล่านั้นสิ่งเข้ากระเป๋า scammer ทันที แล้วก็จะมีการเล่นตุกติกต่อแน่นอนครับ เช่นถอนไม่ได้ หรือซื้อไม่ได้ ต้องโอนเงินมาเพิ่มเพื่อปลดล็อค smart contract อะไรก็ว่าไป แล้วคนนิสัยไม่ดีพวกเนี้ย ก็จะเล่นกับความโลภของคน เอาราคาเสนอซื้อที่สูงโคตรๆมาล่อ ... อันนี้ไม่ว่ากัน เพราะบนโลก NFT รูปภาพบางรูปที่ไม่ได้มีความเป็นศิลปะอะไรเลย มันดันขายกันได้ 100 - 150 ETH ศิลปินที่พยายามสร้างตัวก็อาจจะมองว่า ผลงานเรามีคนรับซื้อ 2 - 4 ETH ต่องานมันก็มากพอแล้ว (จริงๆมากเกินจนน่าตกใจด้วยซ้ำครับ)
บนโลกของ BTC ไม่ต้องเชื่อใจกัน โอนเงินไปหากันได้ ปิดสมุดบัญชีได้โดยไม่ต้องเชื่อใจกัน
บบโลกของ ETH "code is law" smart contract มีเขียนอยู่แล้ว ไปอ่าน มันไม่ได้ยากมากในการทำความเข้าใจ ดังนั้น การจะมาเชื่อคำสัญญาจากคนด้วยกัน เป็นอะไรที่ไม่มีเหตุผล
ผมไปเล่าเรื่องเหล่านี้ให้กับ community งานศิลปะ ก็มีทั้งเสียงตอบรับที่ดี และไม่ดีปนกันไป มีบางคนยืนยันเสียงแข็งไปในทำนองว่า ไอ้เรื่องแบบเนี้ยไม่ได้กินเขาหรอก เพราะเขาตั้งใจแน่วแน่ว่างานศิลป์ของเขา เขาไม่เอาเข้ามายุ่งในโลก digital currency เด็ดขาด ซึ่งผมก็เคารพมุมมองเขาครับ แต่มันจะดีกว่ามั้ย ถ้าเราเปิดหูเปิดตาให้ทันเทคโนโลยี โดยเฉพาะเรื่อง digital currency , blockchain โดนโกงทีนึงนี่คือหมดตัวกันง่ายกว่าเงิน fiat อีก
อยากจะมาเล่าให้ฟังครับ และอยากให้ช่วยแชร์ไปให้คนรู้จักด้วย จะได้ระวังตัวกัน
Note
- ภาพประกอบ cyber security ทั้งสองนี่ของผมเองครับ ทำเอง วางขายบน AdobeStock
- อีกบัญชีนึงของผม "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw กำลังค่อยๆเอาผลงานจากโลกข้างนอกเข้ามา nostr ครับ ตั้งใจจะมาสร้างงานศิลปะในนี้ เพื่อนๆที่ชอบงาน จะได้ไม่ต้องออกไปหาที่ไหน
ผลงานของผมครับ - Anime girl fanarts : HikariHarmony - HikariHarmony on Nostr - General art : KeshikiRakuen - KeshikiRakuen อาจจะเป็นบัญชี nostr ที่สามของผม ถ้าไหวครับ
-
@ 1e109a31:62807940
2025-04-23 18:04:51
Sergey activity 1
This template is just for demo needs. Upd1
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 8947a945:9bfcf626
2024-10-17 07:33:00
Hello everyone on Nostr and all my watchersand followersfrom DeviantArt, as well as those from other art platforms
I have been creating and sharing AI-generated anime girl fanart since the beginning of 2024 and have been running member-exclusive content on Patreon.
I also publish showcases of my artworks to Deviantart. I organically build up my audience from time to time. I consider it as one of my online businesses of art. Everything is slowly growing
On September 16, I received a DM from someone expressing interest in purchasing my art in NFT format and offering a very high price for each piece. We later continued the conversation via email.
Here’s a brief overview of what happened
- The first scammer selected the art they wanted to buy and offered a high price for each piece. They provided a URL to an NFT marketplace site running on the Ethereum (ETH) mainnet or ERC20. The site appeared suspicious, requiring email sign-up and linking a MetaMask wallet. However, I couldn't change the wallet address later. The minting gas fees were quite expensive, ranging from 0.15 to 0.2 ETH
-
The scammers tried to convince me that the high profits would easily cover the minting gas fees, so I had nothing to lose. Luckily, I didn’t have spare funds to purchase ETH for the gas fees at the time, so I tried negotiating with them as follows:
-
I offered to send them a lower-quality version of my art via email in exchange for the minting gas fees, but they refused.
- I offered them the option to pay in USD through Buy Me a Coffee shop here, but they refused.
- I offered them the option to pay via Bitcoin using the Lightning Network invoice , but they refused.
- I asked them to wait until I could secure the funds, and they agreed to wait.
The following week, a second scammer approached me with a similar offer, this time at an even higher price and through a different NFT marketplace website.
This second site also required email registration, and after navigating to the dashboard, it asked for a minting fee of 0.2 ETH. However, the site provided a wallet address for me instead of connecting a MetaMask wallet.
I told the second scammer that I was waiting to make a profit from the first sale, and they asked me to show them the first marketplace. They then warned me that the first site was a scam and even sent screenshots of victims, including one from OpenSea saying that Opensea is not paying.
This raised a red flag, and I began suspecting I might be getting scammed. On OpenSea, funds go directly to users' wallets after transactions, and OpenSea charges a much lower platform fee compared to the previous crypto bull run in 2020. Minting fees on OpenSea are also significantly cheaper, around 0.0001 ETH per transaction.
I also consulted with Thai NFT artist communities and the ex-chairman of the Thai Digital Asset Association. According to them, no one had reported similar issues, but they agreed it seemed like a scam.
After confirming my suspicions with my own research and consulting with the Thai crypto community, I decided to test the scammers’ intentions by doing the following
I minted the artwork they were interested in, set the price they offered, and listed it for sale on OpenSea. I then messaged them, letting them know the art was available and ready to purchase, with no royalty fees if they wanted to resell it.
They became upset and angry, insisting I mint the art on their chosen platform, claiming they had already funded their wallet to support me. When I asked for proof of their wallet address and transactions, they couldn't provide any evidence that they had enough funds.
Here’s what I want to warn all artists in the DeviantArt community or other platforms If you find yourself in a similar situation, be aware that scammers may be targeting you.
My Perspective why I Believe This is a Scam and What the Scammers Gain
From my experience with BTC and crypto since 2017, here's why I believe this situation is a scam, and what the scammers aim to achieve
First, looking at OpenSea, the largest NFT marketplace on the ERC20 network, they do not hold users' funds. Instead, funds from transactions go directly to users’ wallets. OpenSea’s platform fees are also much lower now compared to the crypto bull run in 2020. This alone raises suspicion about the legitimacy of other marketplaces requiring significantly higher fees.
I believe the scammers' tactic is to lure artists into paying these exorbitant minting fees, which go directly into the scammers' wallets. They convince the artists by promising to purchase the art at a higher price, making it seem like there's no risk involved. In reality, the artist has already lost by paying the minting fee, and no purchase is ever made.
In the world of Bitcoin (BTC), the principle is "Trust no one" and “Trustless finality of transactions” In other words, transactions are secure and final without needing trust in a third party.
In the world of Ethereum (ETH), the philosophy is "Code is law" where everything is governed by smart contracts deployed on the blockchain. These contracts are transparent, and even basic code can be read and understood. Promises made by people don’t override what the code says.
I also discuss this issue with art communities. Some people have strongly expressed to me that they want nothing to do with crypto as part of their art process. I completely respect that stance.
However, I believe it's wise to keep your eyes open, have some skin in the game, and not fall into scammers’ traps. Understanding the basics of crypto and NFTs can help protect you from these kinds of schemes.
If you found this article helpful, please share it with your fellow artists.
Until next time Take care
Note
- Both cyber security images are mine , I created and approved by AdobeStock to put on sale
- I'm working very hard to bring all my digital arts into Nostr to build my Sats business here to my another npub "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw
Link to my full gallery - Anime girl fanarts : HikariHarmony - HikariHarmony on Nostr - General art : KeshikiRakuen
-
@ ff83811b:483b0ac0
2025-04-23 17:29:20
My everyday activity
This template is just for demo needs.
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 000002de:c05780a7
2025-04-23 16:27:56
Natalie Brunell had comedian T.J. Miller known for Silicon Valley on her show Coin Stories. I was kinda surprised. Not sure why but I recognized his voice because that's my brain I can forget a face but never a voice.
So what person that has fame also secretly is a bitcoiner. Not has the ETF or whatever but actually gets it and has for a while.
I think this is pretty widely believed that Mark Zuckerburg is a bitcoiner so that would be the person I'd list. No clue beyond that. There has to be quite a few well known people that also get bitcoin and just don't talk about it.
SO, who do you think is in the club?
originally posted at https://stacker.news/items/955179
-
@ f32184ee:6d1c17bf
2025-04-23 13:21:52
Ads Fueling Freedom
Ross Ulbricht’s "Decentralize Social Media" painted a picture of a user-centric, decentralized future that transcended the limitations of platforms like the tech giants of today. Though focused on social media, his concept provided a blueprint for decentralized content systems writ large. The PROMO Protocol, designed by NextBlock while participating in Sovereign Engineering, embodies this blueprint in the realm of advertising, leveraging Nostr and Bitcoin’s Lightning Network to give individuals control, foster a multi-provider ecosystem, and ensure secure value exchange. In this way, Ulbricht’s 2021 vision can be seen as a prescient prediction of the PROMO Protocol’s structure. This is a testament to the enduring power of his ideas, now finding form in NextBlock’s innovative approach.
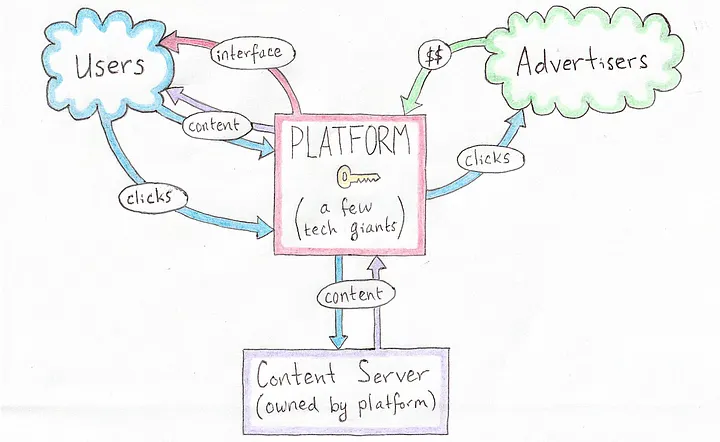 [Current Platform-Centric Paradigm, source: Ross Ulbricht's Decentralize Social Media]
[Current Platform-Centric Paradigm, source: Ross Ulbricht's Decentralize Social Media]Ulbricht’s Vision: A Decentralized Social Protocol
In his 2021 Medium article Ulbricht proposed a revolutionary vision for a decentralized social protocol (DSP) to address the inherent flaws of centralized social media platforms, such as privacy violations and inconsistent content moderation. Writing from prison, Ulbricht argued that decentralization could empower users by giving them control over their own content and the value they create, while replacing single, monolithic platforms with a competitive ecosystem of interface providers, content servers, and advertisers. Though his focus was on social media, Ulbricht’s ideas laid a conceptual foundation that strikingly predicts the structure of NextBlock’s PROMO Protocol, a decentralized advertising system built on the Nostr protocol.
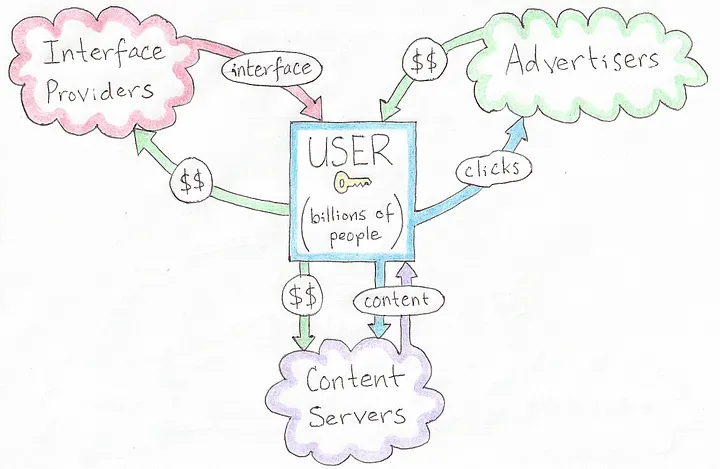 [A Decentralized Social Protocol (DSP), source: Ross Ulbricht's Decentralize Social Media]
[A Decentralized Social Protocol (DSP), source: Ross Ulbricht's Decentralize Social Media]Ulbricht’s Principles
Ulbricht’s article outlines several key principles for his DSP: * User Control: Users should own their content and dictate how their data and creations generate value, rather than being subject to the whims of centralized corporations. * Decentralized Infrastructure: Instead of a single platform, multiple interface providers, content hosts, and advertisers interoperate, fostering competition and resilience. * Privacy and Autonomy: Decentralized solutions for profile management, hosting, and interactions would protect user privacy and reduce reliance on unaccountable intermediaries. * Value Creation: Users, not platforms, should capture the economic benefits of their contributions, supported by decentralized mechanisms for transactions.
These ideas were forward-thinking in 2021, envisioning a shift away from the centralized giants dominating social media at the time. While Ulbricht didn’t specifically address advertising protocols, his framework for decentralization and user empowerment extends naturally to other domains, like NextBlock’s open-source offering: the PROMO Protocol.
NextBlock’s Implementation of PROMO Protocol
The PROMO Protocol powers NextBlock's Billboard app, a decentralized advertising protocol built on Nostr, a simple, open protocol for decentralized communication. The PROMO Protocol reimagines advertising by: * Empowering People: Individuals set their own ad prices (e.g., 500 sats/minute), giving them direct control over how their attention or space is monetized. * Marketplace Dynamics: Advertisers set budgets and maximum bids, competing within a decentralized system where a 20% service fee ensures operational sustainability. * Open-Source Flexibility: As an open-source protocol, it allows multiple developers to create interfaces or apps on top of it, avoiding the single-platform bottleneck Ulbricht critiqued. * Secure Payments: Using Strike Integration with Bitcoin Lightning Network, NextBlock enables bot-resistant and intermediary-free transactions, aligning value transfer with each person's control.
This structure decentralizes advertising in a way that mirrors Ulbricht’s broader vision for social systems, with aligned principles showing a specific use case: monetizing attention on Nostr.
Aligned Principles
Ulbricht’s 2021 article didn’t explicitly predict the PROMO Protocol, but its foundational concepts align remarkably well with NextBlock's implementation the protocol’s design: * Autonomy Over Value: Ulbricht argued that users should control their content and its economic benefits. In the PROMO Protocol, people dictate ad pricing, directly capturing the value of their participation. Whether it’s their time, influence, or digital space, rather than ceding it to a centralized ad network. * Ecosystem of Providers: Ulbricht envisioned multiple providers replacing a single platform. The PROMO Protocol’s open-source nature invites a similar diversity: anyone can build interfaces or tools on top of it, creating a competitive, decentralized advertising ecosystem rather than a walled garden. * Decentralized Transactions: Ulbricht’s DSP implied decentralized mechanisms for value exchange. NextBlock delivers this through the Bitcoin Lightning Network, ensuring that payments for ads are secure, instantaneous and final, a practical realization of Ulbricht’s call for user-controlled value flows. * Privacy and Control: While Ulbricht emphasized privacy in social interactions, the PROMO Protocol is public by default. Individuals are fully aware of all data that they generate since all Nostr messages are signed. All participants interact directly via Nostr.
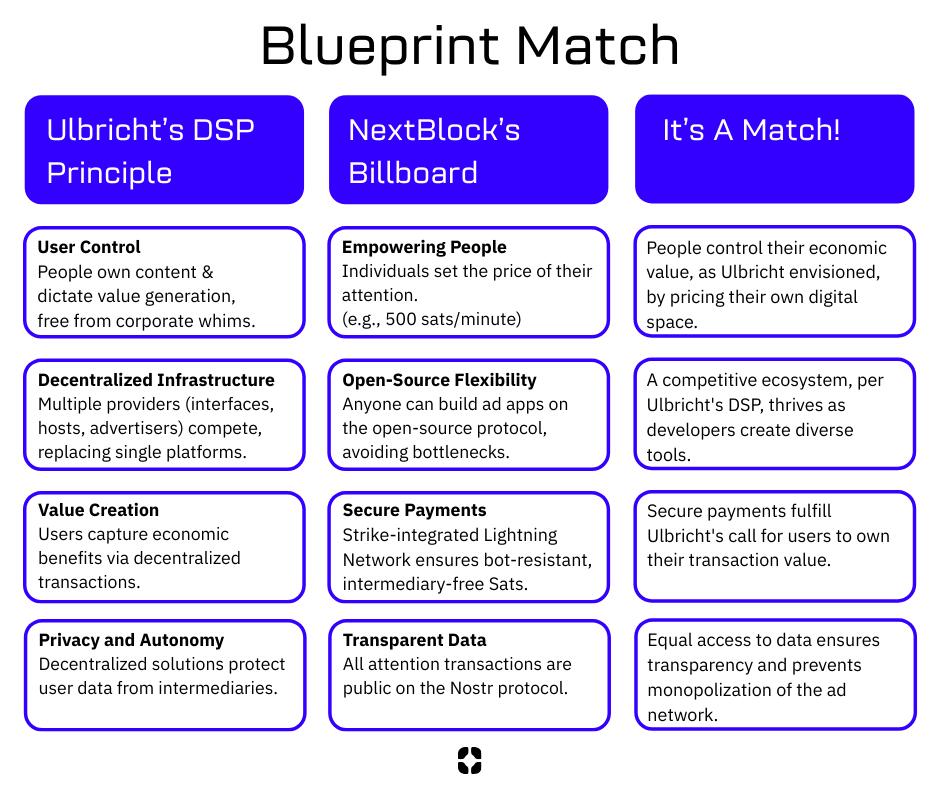 [Blueprint Match, source NextBlock]
[Blueprint Match, source NextBlock]
Who We Are
NextBlock is a US-based new media company reimagining digital ads for a decentralized future. Our founders, software and strategy experts, were hobbyist podcasters struggling to promote their work online without gaming the system. That sparked an idea: using new tech like Nostr and Bitcoin to build a decentralized attention market for people who value control and businesses seeking real connections.
Our first product, Billboard, is launching this June.
Open for All
Our model’s open-source! Check out the PROMO Protocol, built for promotion and attention trading. Anyone can join this decentralized ad network. Run your own billboard or use ours. This is a growing ecosystem for a new ad economy.
Our Vision
NextBlock wants to help build a new decentralized internet. Our revolutionary and transparent business model will bring honest revenue to companies hosting valuable digital spaces. Together, we will discover what our attention is really worth.
Read our Manifesto to learn more.
NextBlock is registered in Texas, USA.
-
@ 6ad3e2a3:c90b7740
2025-04-23 12:31:54
There’s an annoying trend on Twitter wherein the algorithm feeds you a lot of threads like “five keys to gaining wealth” or “10 mistakes to avoid in relationships” that list a bunch of hacks for some ostensibly desirable state of affairs which for you is presumably lacking. It’s not that the hacks are wrong per se, more that the medium is the message. Reading threads about hacks on social media is almost surely not the path toward whatever is promised by them.
. . .
I’ve tried a lot of health supplements over the years. These days creatine is trendy, and of course Vitamin D (which I still take.) I don’t know if this is helping me, though it surely helps me pass my blood tests with robust levels. The more I learn about health and nutrition, the less I’m sure of anything beyond a few basics. Yes, replacing processed food with real food, moving your body and getting some sun are almost certainly good, but it’s harder to know how particular interventions affect me.
Maybe some of them work in the short term then lose their effect, Maybe some work better for particular phenotypes, but not for mine. Maybe my timing in the day is off, or I’m not combining them correctly for my lifestyle and circumstances. The body is a complex system, and complex systems are characterized by having unpredictable outputs given changes to initial conditions (inputs).
. . .
I started getting into Padel recently — a mini-tennis-like game where you can hit the ball off the back walls. I’d much rather chase a ball around for exercise than run or work out, and there’s a social aspect I enjoy. (By “social aspect”, I don’t really mean getting to know the people with whom I’m playing, but just the incidental interactions you get during the game, joking about it, for example, when you nearly impale someone at the net with a hard forehand.)
A few months ago, I was playing with some friends, and I was a little off. It’s embarrassing to play poorly at a sport, especially when (as is always the case in Padel) you have a doubles partner you’re letting down. Normally I’d be excoriating myself for my poor play, coaching myself to bend my knees more, not go for winners so much. But that day, I was tired — for some reason I hadn’t slept well — and I didn’t have the energy for much internal monologue. I just mishit a few balls, felt stupid about it and kept playing.
After a few games, my fortunes reversed. I was hitting the ball cleanly, smashing winners, rarely making errors. My partner and I started winning games and then sets. I was enjoying myself. In the midst of it I remember hitting an easy ball into the net and reflexively wanting to self-coach again. I wondered, “What tips did I give to right the ship when I had been playing poorly at the outset?” I racked my brain as I waited for the serve and realized, to my surprise, there had been none. The turnaround in my play was not due to self-coaching but its absence. I had started playing better because my mind had finally shut the fuck up for once.
Now when I’m not playing well, I resist, to the extent I’m capable, the urge to meddle. I intend to be more mind-less. Not so much telling the interior coach to shut up but not buying into the premise there is a problem to be solved at all. The coach isn’t just ignored, he’s fired. And he’s not just fired, his role was obsoleted.
You blew the point, you’re embarrassed about it and there’s nothing that needs to be done about it. Or that you started coaching yourself like a fool and made things worse. No matter how much you are doing the wrong thing nothing needs to be done about any of it whatsoever. There is always another ball coming across the net that needs to be struck until the game is over.
. . .
Most of the hacks, habits and heuristics we pick up to manage our lives only serve as yet more inputs in unfathomably complex systems whose outputs rarely track as we’d like. There are some basic ones that are now obvious to everyone like not injecting yourself with heroin (or mRNA boosters), but for the most part we just create more baggage for ourselves which justifies ever more hacks. It’s like taking medication for one problem that causes side effects, and then you need another medicine for that side effect, rinse and repeat, ad infinitum.
But this process can be reverse-engineered too. For every heuristic you drop, the problem it was put into place to solve re-emerges and has a chance to be observed. Observing won’t solve it, it’ll just bring it into the fold, give the complex system of which it is a part a chance to achieve an equilibrium with respect to it on its own.
You might still be embarrassed when you mishit the ball, but embarrassment is not a problem. And if embarrassment is not a problem, then mishitting a ball isn’t that bad. And if mishitting a ball isn’t that bad, then maybe you’re not worrying about what happens if you botch the next shot, instead fixing your attention on the ball. And so you disappear a little bit into the game, and it’s more fun as a result.
I honestly wish there were a hack for this — being more mindless — but I don’t know of any. And in any event, hack Substacks won’t get you any farther than hack Twitter threads.
-
@ e6817453:b0ac3c39
2024-10-06 11:21:27
Hey folks, today we're diving into an exciting and emerging topic: personal artificial intelligence (PAI) and its connection to sovereignty, privacy, and ethics. With the rapid advancements in AI, there's a growing interest in the development of personal AI agents that can work on behalf of the user, acting autonomously and providing tailored services. However, as with any new technology, there are several critical factors that shape the future of PAI. Today, we'll explore three key pillars: privacy and ownership, explainability, and bias.
1. Privacy and Ownership: Foundations of Personal AI
At the heart of personal AI, much like self-sovereign identity (SSI), is the concept of ownership. For personal AI to be truly effective and valuable, users must own not only their data but also the computational power that drives these systems. This autonomy is essential for creating systems that respect the user's privacy and operate independently of large corporations.
In this context, privacy is more than just a feature—it's a fundamental right. Users should feel safe discussing sensitive topics with their AI, knowing that their data won’t be repurposed or misused by big tech companies. This level of control and data ownership ensures that users remain the sole beneficiaries of their information and computational resources, making privacy one of the core pillars of PAI.
2. Bias and Fairness: The Ethical Dilemma of LLMs
Most of today’s AI systems, including personal AI, rely heavily on large language models (LLMs). These models are trained on vast datasets that represent snapshots of the internet, but this introduces a critical ethical challenge: bias. The datasets used for training LLMs can be full of biases, misinformation, and viewpoints that may not align with a user’s personal values.
This leads to one of the major issues in AI ethics for personal AI—how do we ensure fairness and minimize bias in these systems? The training data that LLMs use can introduce perspectives that are not only unrepresentative but potentially harmful or unfair. As users of personal AI, we need systems that are free from such biases and can be tailored to our individual needs and ethical frameworks.
Unfortunately, training models that are truly unbiased and fair requires vast computational resources and significant investment. While large tech companies have the financial means to develop and train these models, individual users or smaller organizations typically do not. This limitation means that users often have to rely on pre-trained models, which may not fully align with their personal ethics or preferences. While fine-tuning models with personalized datasets can help, it's not a perfect solution, and bias remains a significant challenge.
3. Explainability: The Need for Transparency
One of the most frustrating aspects of modern AI is the lack of explainability. Many LLMs operate as "black boxes," meaning that while they provide answers or make decisions, it's often unclear how they arrived at those conclusions. For personal AI to be effective and trustworthy, it must be transparent. Users need to understand how the AI processes information, what data it relies on, and the reasoning behind its conclusions.
Explainability becomes even more critical when AI is used for complex decision-making, especially in areas that impact other people. If an AI is making recommendations, judgments, or decisions, it’s crucial for users to be able to trace the reasoning process behind those actions. Without this transparency, users may end up relying on AI systems that provide flawed or biased outcomes, potentially causing harm.
This lack of transparency is a major hurdle for personal AI development. Current LLMs, as mentioned earlier, are often opaque, making it difficult for users to trust their outputs fully. The explainability of AI systems will need to be improved significantly to ensure that personal AI can be trusted for important tasks.
Addressing the Ethical Landscape of Personal AI
As personal AI systems evolve, they will increasingly shape the ethical landscape of AI. We’ve already touched on the three core pillars—privacy and ownership, bias and fairness, and explainability. But there's more to consider, especially when looking at the broader implications of personal AI development.
Most current AI models, particularly those from big tech companies like Facebook, Google, or OpenAI, are closed systems. This means they are aligned with the goals and ethical frameworks of those companies, which may not always serve the best interests of individual users. Open models, such as Meta's LLaMA, offer more flexibility and control, allowing users to customize and refine the AI to better meet their personal needs. However, the challenge remains in training these models without significant financial and technical resources.
There’s also the temptation to use uncensored models that aren’t aligned with the values of large corporations, as they provide more freedom and flexibility. But in reality, models that are entirely unfiltered may introduce harmful or unethical content. It’s often better to work with aligned models that have had some of the more problematic biases removed, even if this limits some aspects of the system’s freedom.
The future of personal AI will undoubtedly involve a deeper exploration of these ethical questions. As AI becomes more integrated into our daily lives, the need for privacy, fairness, and transparency will only grow. And while we may not yet be able to train personal AI models from scratch, we can continue to shape and refine these systems through curated datasets and ongoing development.
Conclusion
In conclusion, personal AI represents an exciting new frontier, but one that must be navigated with care. Privacy, ownership, bias, and explainability are all essential pillars that will define the future of these systems. As we continue to develop personal AI, we must remain vigilant about the ethical challenges they pose, ensuring that they serve the best interests of users while remaining transparent, fair, and aligned with individual values.
If you have any thoughts or questions on this topic, feel free to reach out—I’d love to continue the conversation!
-
@ e6817453:b0ac3c39
2024-09-30 14:52:23
In the modern world of AI, managing vast amounts of data while keeping it relevant and accessible is a significant challenge, mainly when dealing with large language models (LLMs) and vector databases. One approach that has gained prominence in recent years is integrating vector search with metadata, especially in retrieval-augmented generation (RAG) pipelines. Vector search and metadata enable faster and more accurate data retrieval. However, the process of pre- and post-search filtering results plays a crucial role in ensuring data relevance.
The Vector Search and Metadata Challenge
In a typical vector search, you create embeddings from chunks of text, such as a PDF document. These embeddings allow the system to search for similar items and retrieve them based on relevance. The challenge, however, arises when you need to combine vector search results with structured metadata. For example, you may have timestamped text-based content and want to retrieve the most relevant content within a specific date range. This is where metadata becomes critical in refining search results.
Unfortunately, most vector databases treat metadata as a secondary feature, isolating it from the primary vector search process. As a result, handling queries that combine vectors and metadata can become a challenge, particularly when the search needs to account for a dynamic range of filters, such as dates or other structured data.
LibSQL and vector search metadata
LibSQL is a more general-purpose SQLite-based database that adds vector capabilities to regular data. Vectors are presented as blob columns of regular tables. It makes vector embeddings and metadata a first-class citizen that naturally builds deep integration of these data points.
create table if not exists conversation ( id varchar(36) primary key not null, startDate real, endDate real, summary text, vectorSummary F32_BLOB(512) );It solves the challenge of metadata and vector search and eliminates impedance between vector data and regular structured data points in the same storage.
As you can see, you can access vector-like data and start date in the same query.
select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance from conversation where ${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''} ${distance ? `and distance <= ${distance}` : ''} order by distance limit ${top};vector_distance_cos calculated as distance allows us to make a primitive vector search that does a full scan and calculates distances on rows. We could optimize it with CTE and limit search and distance calculations to a much smaller subset of data.
This approach could be calculation intensive and fail on large amounts of data.
Libsql offers a way more effective vector search based on FlashDiskANN vector indexed.
vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) ivector_top_k is a table function that searches for the top of the newly created vector search index. As you can see, we could use only vector as a function parameter, and other columns could be used outside of the table function. So, to use a vector index together with different columns, we need to apply some strategies.
Now we get a classical problem of integration vector search results with metadata queries.
Post-Filtering: A Common Approach
The most widely adopted method in these pipelines is post-filtering. In this approach, the system first retrieves data based on vector similarities and then applies metadata filters. For example, imagine you’re conducting a vector search to retrieve conversations relevant to a specific question. Still, you also want to ensure these conversations occurred in the past week.
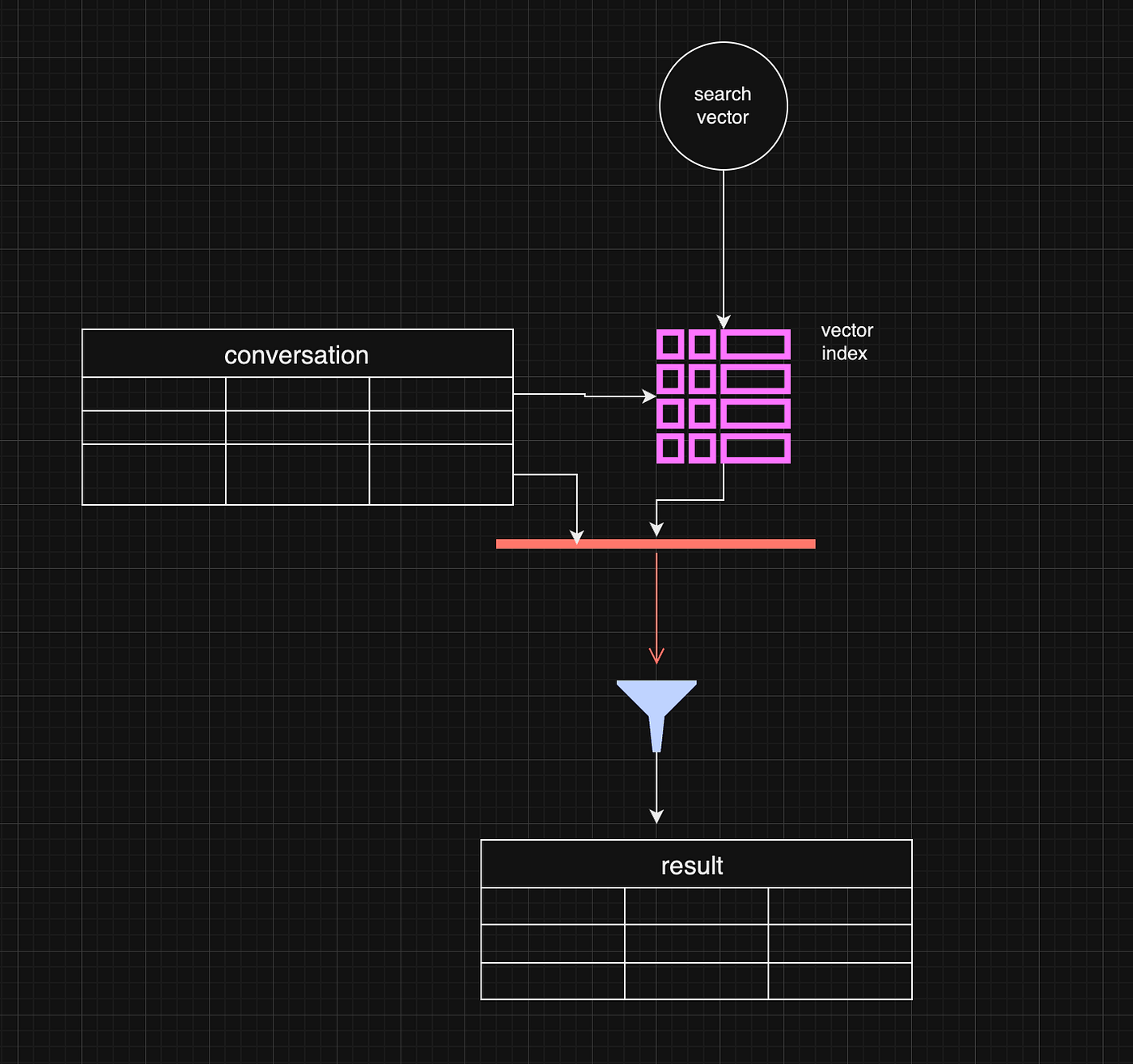
Post-filtering allows the system to retrieve the most relevant vector-based results and subsequently filter out any that don’t meet the metadata criteria, such as date range. This method is efficient when vector similarity is the primary factor driving the search, and metadata is only applied as a secondary filter.
const sqlQuery = ` select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance from vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) i inner join conversation c on i.id = c.rowid where ${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''} ${distance ? `and distance <= ${distance}` : ''} order by distance limit ${top};However, there are some limitations. For example, the initial vector search may yield fewer results or omit some relevant data before applying the metadata filter. If the search window is narrow enough, this can lead to complete results.
One working strategy is to make the top value in vector_top_K much bigger. Be careful, though, as the function's default max number of results is around 200 rows.
Pre-Filtering: A More Complex Approach
Pre-filtering is a more intricate approach but can be more effective in some instances. In pre-filtering, metadata is used as the primary filter before vector search takes place. This means that only data that meets the metadata criteria is passed into the vector search process, limiting the scope of the search right from the beginning.
While this approach can significantly reduce the amount of irrelevant data in the final results, it comes with its own challenges. For example, pre-filtering requires a deeper understanding of the data structure and may necessitate denormalizing the data or creating separate pre-filtered tables. This can be resource-intensive and, in some cases, impractical for dynamic metadata like date ranges.
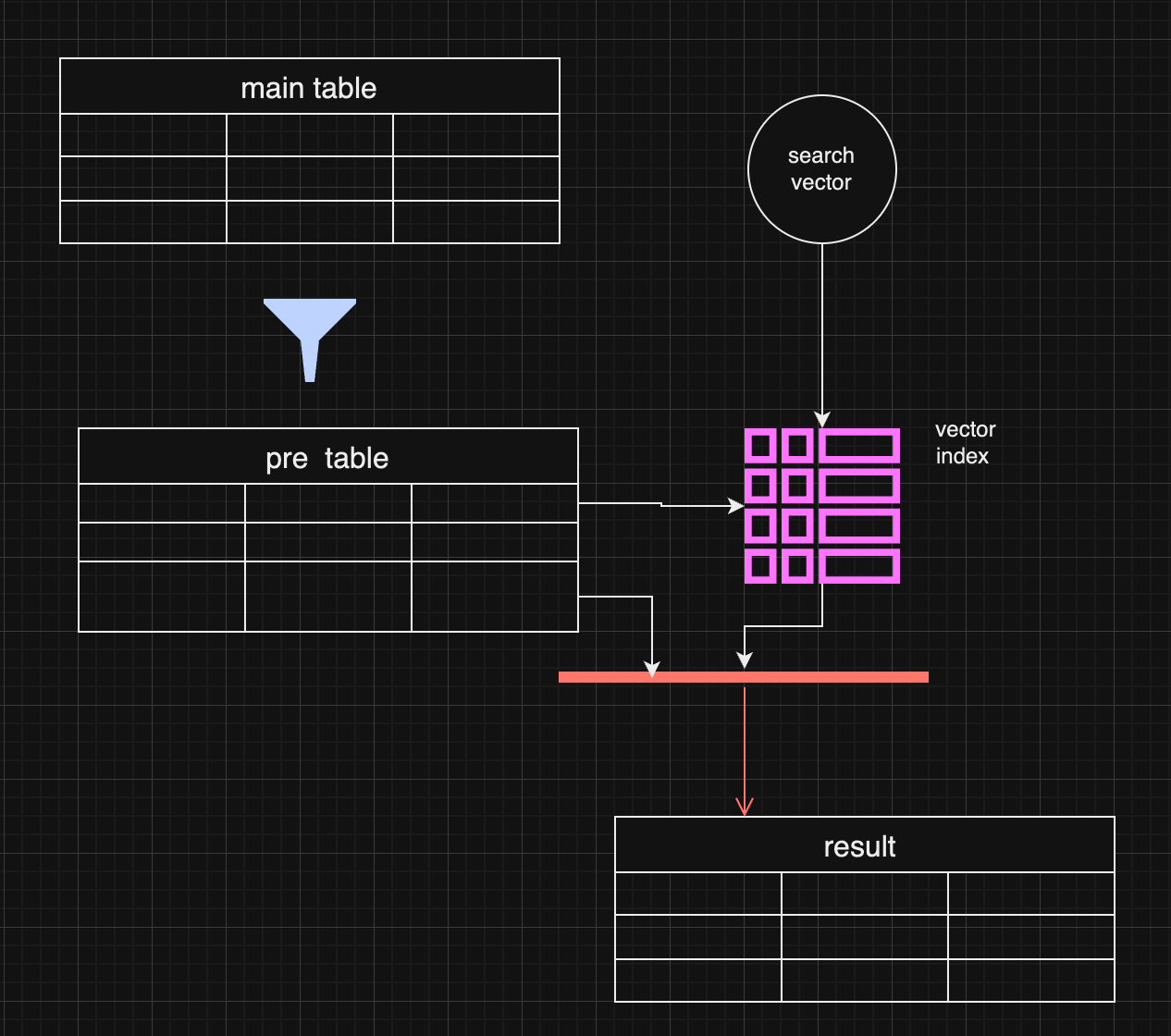
In certain use cases, pre-filtering might outperform post-filtering. For instance, when the metadata (e.g., specific date ranges) is the most important filter, pre-filtering ensures the search is conducted only on the most relevant data.
Pre-filtering with distance-based filtering
So, we are getting back to an old concept. We do prefiltering instead of using a vector index.
WITH FilteredDates AS ( SELECT c.id, c.startDate, c.endDate, c.summary, c.vectorSummary FROM YourTable c WHERE ${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''} ), DistanceCalculation AS ( SELECT fd.id, fd.startDate, fd.endDate, fd.summary, fd.vectorSummary, vector_distance_cos(fd.vectorSummary, vector(${vector})) AS distance FROM FilteredDates fd ) SELECT dc.id, dc.startDate, dc.endDate, dc.summary, dc.distance FROM DistanceCalculation dc WHERE 1=1 ${distance ? `AND dc.distance <= ${distance}` : ''} ORDER BY dc.distance LIMIT ${top};It makes sense if the filter produces small data and distance calculation happens on the smaller data set.
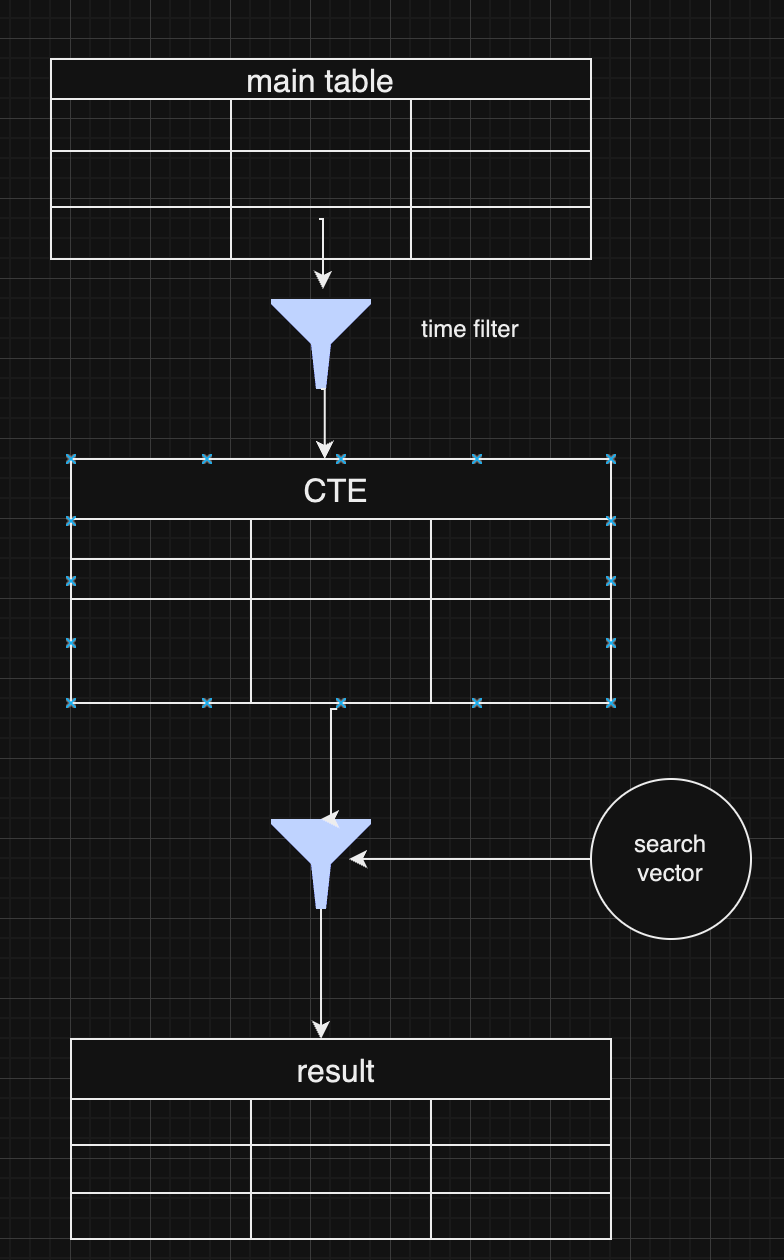
As a pro of this approach, you have full control over the data and get all results without omitting some typical values for extensive index searches.
Choosing Between Pre and Post-Filtering
Both pre-filtering and post-filtering have their advantages and disadvantages. Post-filtering is more accessible to implement, especially when vector similarity is the primary search factor, but it can lead to incomplete results. Pre-filtering, on the other hand, can yield more accurate results but requires more complex data handling and optimization.
In practice, many systems combine both strategies, depending on the query. For example, they might start with a broad pre-filtering based on metadata (like date ranges) and then apply a more targeted vector search with post-filtering to refine the results further.
Conclusion
Vector search with metadata filtering offers a powerful approach for handling large-scale data retrieval in LLMs and RAG pipelines. Whether you choose pre-filtering or post-filtering—or a combination of both—depends on your application's specific requirements. As vector databases continue to evolve, future innovations that combine these two approaches more seamlessly will help improve data relevance and retrieval efficiency further.
-
@ c4f5e7a7:8856cac7
2024-09-27 08:20:16
Best viewed on Habla, YakiHonne or Highlighter.
TL;DR
This article explores the links between public, community-driven data sources (such as OpenStreetMap) and private, cryptographically-owned data found on networks such as Nostr.
The following concepts are explored:
- Attestations: Users signalling to their social graph that they believe something to be true by publishing Attestations. These social proofs act as a decentralised verification system that leverages your web-of-trust.
- Proof of Place: An oracle-based system where physical letters are sent to real-world locations, confirming the corresponding digital ownership via cryptographic proofs. This binds physical locations in meatspace with their digital representations in the Nostrverse.
- Check-ins: Foursquare-style check-ins that can be verified using attestations from place owners, ensuring authenticity. This approach uses web-of-trust to validate check-ins and location ownership over time.
The goal is to leverage cryptographic ownership where necessary while preserving the open, collaborative nature of public data systems.
Open Data in a public commons has a place and should not be thrown out with the Web 2.0 bathwater.
Cognitive Dissonance
Ever since discovering Nostr in August of 2022 I've been grappling with how BTC Map - a project that helps bitcoiners find places to spend sats - should most appropriately use this new protocol.
I am assuming, dear reader, that you are somewhat familiar with Nostr - a relatively new protocol for decentralised identity and communication. If you don’t know your nsec from your npub, please take some time to read these excellent posts: Nostr is Identity for the Internet and The Power of Nostr by @max and @lyn, respectively. Nostr is so much more than a short-form social media replacement.
The social features (check-ins, reviews, etc.) that Nostr unlocks for BTC Map are clear and exciting - all your silos are indeed broken - however, something fundamental has been bothering me for a while and I think it comes down to data ownership.
For those unfamiliar, BTC Map uses OpenStreetMap (OSM) as its main geographic database. OSM is centred on the concept of a commons of objectively verifiable data that is maintained by a global community of volunteer editors; a Wikipedia for maps. There is no data ownership; the data is free (as in freedom) and anyone can edit anything. It is the data equivalent of FOSS (Free and Open Source Software) - FOSD if you will, but more commonly referred to as Open Data.
In contrast, Notes and Other Stuff on Nostr (Places in this cartographic context) are explicitly owned by the controller of the private key. These notes are free to propagate, but they are owned.
How do we reconcile the decentralised nature of Nostr, where data is cryptographically owned by individuals, with the community-managed data commons of OpenStreetMap, where no one owns the data?
Self-sovereign Identity
Before I address this coexistence question, I want to talk a little about identity as it pertains to ownership. If something is to be owned, it has to be owned by someone or something - an identity.
All identities that are not self-sovereign are, by definition, leased to you by a 3rd party. You rent your Facebook identity from Meta in exchange for your data. You rent your web domain from your DNS provider in exchange for your money.
Taken to the extreme, you rent your passport from your Government in exchange for your compliance. You are you at the pleasure of others. Where Bitcoin separates money from the state; Nostr separates identity from the state.
Or, as @nvk said recently: "Don't build your house on someone else's land.".
https://i.nostr.build/xpcCSkDg3uVw0yku.png
While we’ve had the tools for self-sovereign digital identity for decades (think PGP keys or WebAuthN), we haven't had the necessary social use cases nor the corresponding social graph to elevate these identities to the mainstream. Nostr fixes this.
Nostr is PGP for the masses and will take cryptographic identities mainstream.
Full NOSTARD?
Returning to the coexistence question: the data on OpenStreetMap isn’t directly owned by anyone, even though the physical entities the data represents might be privately owned. OSM is a data commons.
We can objectively agree on the location of a tree or a fire hydrant without needing permission to observe and record it. Sure, you could place a tree ‘on Nostr’, but why should you? Just because something can be ‘on Nostr’ doesn’t mean it should be.
https://i.nostr.build/s3So2JVAqoY4E1dI.png
There might be a dystopian future where we can't agree on what a tree is nor where it's located, but I hope we never get there. It's at this point we'll need a Wikifreedia variant of OpenStreetMap.
While integrating Nostr identities into OpenStreetMap would be valuable, the current OSM infrastructure, tools, and community already provide substantial benefits in managing this data commons without needing to go NOSTR-native - there's no need to go Full NOSTARD. H/T to @princeySOV for the original meme.
https://i.nostr.build/ot9jtM5cZtDHNKWc.png
So, how do we appropriately blend cryptographically owned data with the commons?
If a location is owned in meatspace and it's useful to signal that ownership, it should also be owned in cyberspace. Our efforts should therefore focus on entities like businesses, while allowing the commons to manage public data for as long as it can successfully mitigate the tragedy of the commons.
The remainder of this article explores how we can:
- Verify ownership of a physical place in the real world;
- Link that ownership to the corresponding digital place in cyberspace.
As a side note, I don't see private key custodianship - or, even worse, permissioned use of Places signed by another identity's key - as any more viable than the rented identities of Web 2.0.
And as we all know, the Second Law of Infodynamics (no citation!) states that:
"The total amount of sensitive information leaked will always increase over time."
This especially holds true if that data is centralised.
Not your keys, not your notes. Not your keys, not your identity.
Places and Web-of-Trust
@Arkinox has been leading the charge on the Places NIP, introducing Nostr notes (kind 37515) that represent physical locations. The draft is well-crafted, with bonus points for linking back to OSM (and other location repositories) via NIP-73 - External Content IDs (championed by @oscar of @fountain).
However, as Nostr is permissionless, authenticity poses a challenge. Just because someone claims to own a physical location on the Internet doesn’t necessarily mean they have ownership or control of that location in the real world.
Ultimately, this problem can only be solved in a decentralised way by using Web-of-Trust - using your social graph and the perspectives of trusted peers to inform your own perspective. In the context of Places, this requires your network to form a view on which digital identity (public key / npub) is truly the owner of a physical place like your local coffee shop.
This requires users to:
- Verify the owner of a Place in cyberspace is the owner of a place in meatspace.
- Signal this verification to their social graph.
Let's look at the latter idea first with the concept of Attestations ...
Attestations
A way to signal to your social graph that you believe something to be true (or false for that matter) would be by publishing an Attestation note. An Attestation note would signify to your social graph that you think something is either true or false.
Imagine you're a regular at a local coffee shop. You publish an Attestation that says the shop is real and the owner behind the Nostr public key is who they claim to be. Your friends trust you, so they start trusting the shop's digital identity too.
However, attestations applied to Places are just a single use case. The attestation concept could be more widely applied across Nostr in a variety of ways (key rotation, identity linking, etc).
Here is a recent example from @lyn that would carry more signal if it were an Attestation:
https://i.nostr.build/lZAXOEwvRIghgFY4.png
Parallels can be drawn between Attestations and transaction confirmations on the Bitcoin timechain; however, their importance to you would be weighted by clients and/or Data Vending Machines in accordance with:
- Your social graph;
- The type or subject of the content being attested and by whom;
- Your personal preferences.
They could also have a validity duration to be temporally bound, which would be particularly useful in the case of Places.
NIP-25 (Reactions) do allow for users to up/downvote notes with optional content (e.g., emojis) and could work for Attestations, but I think we need something less ambiguous and more definitive.
‘This is true’ resonates more strongly than ‘I like this.’.
https://i.nostr.build/s8NIG2kXzUCLcoax.jpg
There are similar concepts in the Web 3 / Web 5 world such as Verified Credentials by tdb. However, Nostr is the Web 3 now and so wen Attestation NIP?
https://i.nostr.build/Cb047NWyHdJ7h5Ka.jpg
That said, I have seen @utxo has been exploring ‘smart contracts’ on nostr and Attestations may just be a relatively ‘dumb’ subset of the wider concept Nostr-native scripting combined with web-of-trust.
Proof of Place
Attestations handle the signalling of your truth, but what about the initial verification itself?
We already covered how this ultimately has to be derived from your social graph, but what if there was a way to help bootstrap this web-of-trust through the use of oracles? For those unfamiliar with oracles in the digital realm, they are simply trusted purveyors of truth.
Introducing Proof of Place, an out–of-band process where an oracle (such as BTC Map) would mail - yes physically mail- a shared secret to the address of the location being claimed in cyberspace. This shared secret would be locked to the public key (npub) making the claim, which, if unlocked, would prove that the associated private key (nsec) has physical access to the location in meatspace.
One way of doing this would be to mint a 1 sat cashu ecash token locked to the npub of the claimant and mail it to them. If they are able to redeem the token then they have cryptographically proven that they have physical access to the location.
Proof of Place is really nothing more than a weighted Attestation. In a web-of-trust Nostrverse, an oracle is simply a npub (say BTC Map) that you weigh heavily for its opinion on a given topic (say Places).
In the Bitcoin world, Proof of Work anchors digital scarcity in cyberspace to physical scarcity (energy and time) in meatspace and as @Gigi says in PoW is Essential:
"A failure to understand Proof of Work, is a failure to understand Bitcoin."
In the Nostrverse, Proof of Place helps bridge the digital and physical worlds.
@Gigi also observes in Memes vs The World that:
"In Bitcoin, the map is the territory. We can infer everything we care about by looking at the map alone."
https://i.nostr.build/dOnpxfI4u7EL2v4e.png
This isn’t true for Nostr.
In the Nostrverse, the map IS NOT the territory. However, Proof of Place enables us to send cryptographic drones down into the physical territory to help us interpret our digital maps. 🤯
Check-ins
Although not a draft NIP yet, @Arkinox has also been exploring the familiar concept of Foursquare-style Check-ins on Nostr (with kind 13811 notes).
For the uninitiated, Check-ins are simply notes that signal the publisher is at a given location. These locations could be Places (in the Nostr sense) or any other given digital representation of a location for that matter (such as OSM elements) if NIP-73 - External Content IDs are used.
Of course, not everyone will be a Check-in enjoyooor as the concept will not sit well with some people’s threat models and OpSec practices.
Bringing Check-ins to Nostr is possible (as @sebastix capably shows here), but they suffer the same authenticity issues as Places. Just because I say I'm at a given location doesn't mean that I am.
Back in the Web 2.0 days, Foursquare mitigated this by relying on the GPS position of the phone running their app, but this is of course spoofable.
How should we approach Check-in verifiability in the Nostrverse? Well, just like with Places, we can use Attestations and WoT. In the context of Check-ins, an Attestation from the identity (npub) of the Place being checked-in to would be a particularly strong signal. An NFC device could be placed in a coffee shop and attest to check-ins without requiring the owner to manually intervene - I’m sure @blackcoffee and @Ben Arc could hack something together over a weekend!
Check-ins could also be used as a signal for bonafide Place ownership over time.
Summary: Trust Your Bros
So, to recap, we have:
Places: Digital representations of physical locations on Nostr.
Check-ins: Users signalling their presence at a location.
Attestations: Verifiable social proofs used to confirm ownership or the truth of a claim.
You can visualise how these three concepts combine in the diagram below:
https://i.nostr.build/Uv2Jhx5BBfA51y0K.jpg
And, as always, top right trumps bottom left! We have:
Level 0 - Trust Me Bro: Anyone can check-in anywhere. The Place might not exist or might be impersonating the real place in meatspace. The person behind the npub may not have even been there at all.
Level 1 - Definitely Maybe Somewhere: This category covers the middle-ground of ‘Maybe at a Place’ and ‘Definitely Somewhere’. In these examples, you are either self-certifying that you have checked-in at an Attested Place or you are having others attest that you have checked-in at a Place that might not even exist IRL.
Level 2 - Trust Your Bros: An Attested Check-in at an Attested Place. Your individual level of trust would be a function of the number of Attestations and how you weigh them within your own social graph.
https://i.nostr.build/HtLAiJH1uQSTmdxf.jpg
Perhaps the gold standard (or should that be the Bitcoin standard?) would be a Check-in attested by the owner of the Place, which in itself was attested by BTC Map?
Or perhaps not. Ultimately, it’s the users responsibility to determine what they trust by forming their own perspective within the Nostrverse powered by web-of-trust algorithms they control. ‘Trust Me Bro’ or ‘Trust Your Bros’ - you decide.
As we navigate the frontier of cryptographic ownership and decentralised data, it’s up to us to find the balance between preserving the Open Data commons and embracing self-sovereign digital identities.
Thanks
With thanks to Arkinox, Avi, Ben Gunn, Kieran, Blackcoffee, Sebastix, Tomek, Calle, Short Fiat, Ben Weeks and Bitcoms for helping shape my thoughts and refine content, whether you know it or not!
-
@ 6ad3e2a3:c90b7740
2024-09-11 15:16:53
I’ve occasionally been called cynical because some of the sentiments I express strike people as negative. But cynical, to me, does not strictly mean negative. It means something more along the lines of “faithless” — as in lacking the basic faith humans thrive when believing what they take to be true, rather than expedient, and doing what they think is right rather than narrowly advantageous.
In other words, my primary negative sentiment — that the cynical utilitarian ethos among our educated classes has caused and is likely to cause catastrophic outcomes — stems from a sort of disappointed idealism, not cynicism.
On human nature itself I am anything but cynical. I am convinced the strongest, long-term incentives are always to believe what is true, no matter the cost, and to do what is right. And by “right,” I don’t mean do-gooding bullshit, but things like taking care of one’s health, immediate family and personal responsibilities while pursuing the things one finds most compelling and important.
That aside, I want to touch on two real-world examples of what I take to be actual cynicism. The first is the tendency to invoke principles only when they suit one’s agenda or desired outcome, but not to apply them when they do not. This kind of hypocrisy implies principles are just tools you invoke to gain emotional support for your side and that anyone actually applying them evenhandedly is a naive simpleton who doesn’t know how the game is played.
Twitter threads don’t show up on substack anymore, but I’d encourage you to read this one with respect to objecting to election outcomes. I could have used many others, but this one (probably not even most egregious) illustrates how empty words like “democracy” or “election integrity” are when thrown around by devoted partisans. They don’t actually believe in democracy, only in using the word to evoke the desired emotional response. People who wanted to coerce people to take a Pfizer shot don’t believe in “bodily autonomy.” It’s similarly just a phrase that’s invoked to achieve an end.
The other flavor of cynicism I’ve noticed is less about hypocrisy and more about nihilism:
 I’d encourage people to read the entire thread, but if you’re not on Twitter, it’s essentially about whether money (and apparently anything else) has essential qualities, or whether it is whatever peoples’ narratives tell them it is.
I’d encourage people to read the entire thread, but if you’re not on Twitter, it’s essentially about whether money (and apparently anything else) has essential qualities, or whether it is whatever peoples’ narratives tell them it is.In other words, is money whatever your grocer takes for the groceries, or do particular forms of money have qualities wherein they are more likely to be accepted over the long haul? The argument is yes, gold, for example had qualities that made it a better money (scarcity, durability, e.g.) than say seashells which are reasonably durable but not scarce. You could sell the story of seashells as a money (and some societies not close to the sea used them as such), but ultimately such a society would be vulnerable to massive inflation should one of its inhabitants ever stroll along a shore.
The thread morphed into whether everything is just narrative, or there is an underlying reality to which a narrative must correspond in order for it to be useful and true.
The notion that anything could be money if attached to the right story, or any music is good if it’s marketed properly is deeply cynical. I am not arguing people can’t be convinced to buy bad records — clearly they can — but that no matter how much you market it, it will not stand the test of time unless it is in fact good.
In order to sell something that does not add value, meaning or utility to someone’s life, something you suspect they are likely to regret buying in short order, it’s awfully useful to convince yourself that nothing has inherent meaning or value, that “storytelling is all that matters.”
I am not against marketing per se, and effective storytelling might in fact point someone in the right direction — a good story can help someone discover a truth. But that storytelling is everything, and by implication the extent to which a story has correlates in reality nothing, is the ethos of scammers, the refuge of nihilists who left someone else holding the bag and prefer not to think about it.
-
@ 8d34bd24:414be32b
2025-04-23 03:52:15
I started writing a series on the signs of the End Times and how they align with what we are seeing in the world today. There are some major concerns with predicting the end times, so I decided I should insert a short post on “Can we know when the end times are coming?” Like many principles in the Bible, it takes looking at seemingly contradictory verses to reach the truth.
This Generation
Before I get into “Can we know?” I want to address one point that some will bring up against a future Rapture, Tribulation, and Millennium.
Truly I say to you, this generation will not pass away until all these things take place. (Matthew 24:34) {emphasis mine}
What generation is Jesus talking about. Most Christians that don’t believe in a future Rapture, Tribulation, and Millennium will point to this verse to support their point of view. The important question is, “What is Jesus referring to with the words ‘this generation’?”
Is it referring to the people He was talking to at that time? If so, since that generation died long ago, then Jesus’s predictions must have been fulfilled almost 2 millennia ago. The problem with this interpretation is that nothing resembling these predictions happened during that initial generation. You have to really twist His words to try to support that they were fulfilled. Also, John wrote in Revelation about future fulfillment. By that time, John was the last of the apostles still alive and that whole generation was pretty much gone.
If “this generation” doesn’t refer to the people Jesus was speaking to personally in that moment, then to whom does it refer? The verses immediately preceding talk about the signs that will occur right before the end times. If you take “this generation” to mean the people who saw the signs Jesus predicted, then everything suddenly makes sense. It also parallel’s Paul’s statement of consolation to those who thought they had been left behind,**
But we do not want you to be uninformed, brethren, about those who are asleep, so that you will not grieve as do the rest who have no hope. For if we believe that Jesus died and rose again, even so God will bring with Him those who have fallen asleep in Jesus. For this we say to you by the word of the Lord, that we who are alive and remain until the coming of the Lord, will not precede those who have fallen asleep. For the Lord Himself will descend from heaven with a shout, with the voice of the archangel and with the trumpet of God, and the dead in Christ will rise first. Then we who are alive and remain will be caught up together with them in the clouds to meet the Lord in the air, and so we shall always be with the Lord. Therefore comfort one another with these words. (1 Thessalonians 4:13-18) {emphasis mine}
Some believers thought things were happening in their lifetime, but Paul gave them comfort that no believer would miss the end times rapture.
No One Knows
Truly I say to you, this generation will not pass away until all these things take place. Heaven and earth will pass away, but My words will not pass away.
But of that day and hour no one knows, not even the angels of heaven, nor the Son, but the Father alone. For the coming of the Son of Man will be just like the days of Noah. For as in those days before the flood they were eating and drinking, marrying and giving in marriage, until the day that Noah entered the ark, and they did not understand until the flood came and took them all away; so will the coming of the Son of Man be. Then there will be two men in the field; one will be taken and one will be left. Two women will be grinding at the mill; one will be taken and one will be left. (Matthew 24:34-41) {emphasis mine}
This verse very explicitly says that no one, not even angels or Jesus, knows the exact day or hour of His coming.
So when they had come together, they were asking Him, saying, “Lord, is it at this time You are restoring the kingdom to Israel?” He said to them, “It is not for you to know times or epochs which the Father has fixed by His own authority; but you will receive power when the Holy Spirit has come upon you; and you shall be My witnesses both in Jerusalem, and in all Judea and Samaria, and even to the remotest part of the earth.” (Acts 1:6-8)
In this verse Jesus again says that they cannot know the time of His return, but based on context, He is explaining that this generation needs to focus on sharing the Gospel with world and not primarily on the kingdom. Is this Jesus’s way of telling them that they would not be alive to see His return, but they would be responsible for “sharing the Gospel even to the remotest part of the earth?”
Therefore we do know that predicting the exact date of His return is a fool’s errand and should not be attempted, but does this mean we can’t know when it is fast approaching?
We Should Know
There is an opposing passage, though.
The Pharisees and Sadducees came up, and testing Jesus, they asked Him to show them a sign from heaven. But He replied to them, “When it is evening, you say, ‘It will be fair weather, for the sky is red.’ And in the morning, ‘There will be a storm today, for the sky is red and threatening.’ Do you know how to discern the appearance of the sky, but cannot discern the signs of the times? An evil and adulterous generation seeks after a sign; and a sign will not be given it, except the sign of Jonah.” And He left them and went away. (Matthew 16:1-4) {emphasis mine}
In this passage, Jesus reprimands the Pharisees and Sadducees because, although they can rightly read the signs of the weather, they were unable to know and understand the prophecies of His first coming. Especially as the religious leaders, they should’ve been able to determine that Jesus’s coming was imminent and that He was fulfilling the prophetic Scriptures.
In Luke, when Jesus is discussing His second coming with His disciples, He tells this parable:
Then He told them a parable: “Behold the fig tree and all the trees; as soon as they put forth leaves, you see it and know for yourselves that summer is now near. So you also, when you see these things happening, recognize that the kingdom of God is near. (Luke 21:29-31) {emphasis mine}
Jesus would not have given this parable if there were not signs of His coming that we can recognize.
We are expected to know the Scriptures and to study them looking for the signs of His second coming. We can’t know the hour or the day, but we can know that the time is fast approaching. We shouldn’t set dates, but we should search anxiously for the signs of His coming. We shouldn’t be like the scoffers that question His literal fulfillment of His promises:
Know this first of all, that in the last days mockers will come with their mocking, following after their own lusts, and saying, “Where is the promise of His coming? For ever since the fathers fell asleep, all continues just as it was from the beginning of creation.” For when they maintain this, it escapes their notice that by the word of God the heavens existed long ago and the earth was formed out of water and by water, through which the world at that time was destroyed, being flooded with water. But by His word the present heavens and earth are being reserved for fire, kept for the day of judgment and destruction of ungodly men. But do not let this one fact escape your notice, beloved, that with the Lord one day is like a thousand years, and a thousand years like one day. The Lord is not slow about His promise, as some count slowness, but is patient toward you, not wishing for any to perish but for all to come to repentance. (2 Peter 3:3-9) {emphasis mine}
One thing is certain, we are closer to Jesus’s second coming than we have ever been and must be ready as we see the day approaching.
May the God of heaven give you a desire and urgency to share the Gospel with all those around you and to grow your faith, knowledge, and relationship with Him, so you can finish the race well, with no regrets. May the knowledge that Jesus could be coming soon give you an eternal perspective on life, so you put more of your time into things of eternal consequence and don’t get overwhelmed with things of the world which are here today and then are gone.
Trust Jesus.
FYI, I hope to write several more articles on the end times (signs of the times, the rapture, the millennium, and the judgement), but I might be a bit slow rolling them out because I want to make sure they are accurate and well supported by Scripture. You can see my previous posts on the end times on the end times tab at trustjesus.substack.com. I also frequently will list upcoming posts.
-
@ 1d7ff02a:d042b5be
2025-04-23 02:28:08
ທຳຄວາມເຂົ້າໃຈກັບຂໍ້ບົກພ່ອງໃນລະບົບເງິນຂອງພວກເຮົາ
ຫຼາຍຄົນພົບຄວາມຫຍຸ້ງຍາກໃນການເຂົ້າໃຈ Bitcoin ເພາະວ່າພວກເຂົາຍັງບໍ່ເຂົ້າໃຈບັນຫາພື້ນຖານຂອງລະບົບເງິນທີ່ມີຢູ່ຂອງພວກເຮົາ. ລະບົບນີ້, ທີ່ມັກຖືກຮັບຮູ້ວ່າມີຄວາມໝັ້ນຄົງ, ມີຂໍ້ບົກພ່ອງໃນການອອກແບບທີ່ມີມາແຕ່ດັ້ງເດີມ ເຊິ່ງສົ່ງຜົນຕໍ່ຄວາມບໍ່ສະເໝີພາບທາງເສດຖະກິດ ແລະ ການເຊື່ອມເສຍຂອງຄວາມຮັ່ງມີສຳລັບພົນລະເມືອງທົ່ວໄປ. ການເຂົ້າໃຈບັນຫາເຫຼົ່ານີ້ແມ່ນກຸນແຈສຳຄັນເພື່ອເຂົ້າໃຈທ່າແຮງຂອງວິທີແກ້ໄຂທີ່ Bitcoin ສະເໜີ.
ບົດບາດຂອງກະຊວງການຄັງສະຫະລັດ ແລະ ທະນາຄານກາງ
ລະບົບເງິນຕາປັດຈຸບັນໃນສະຫະລັດອາເມລິກາປະກອບມີການເຊື່ອມໂຍງທີ່ຊັບຊ້ອນລະຫວ່າງກະຊວງການຄັງສະຫະລັດ ແລະ ທະນາຄານກາງ. ກະຊວງການຄັງສະຫະລັດເຮັດໜ້າທີ່ເປັນບັນຊີທະນາຄານຂອງປະເທດ, ເກັບອາກອນ ແລະ ສະໜັບສະໜູນລາຍຈ່າຍຂອງລັດຖະບານເຊັ່ນ: ທະຫານ, ໂຄງລ່າງພື້ນຖານ ແລະ ໂຄງການສັງຄົມ. ເຖິງຢ່າງໃດກໍຕາມ, ລັດຖະບານມັກໃຊ້ຈ່າຍຫຼາຍກວ່າທີ່ເກັບໄດ້, ເຊິ່ງເຮັດໃຫ້ຕ້ອງໄດ້ຢືມເງິນ. ການຢືມນີ້ແມ່ນເຮັດໂດຍການຂາຍພັນທະບັດລັດຖະບານ, ຊຶ່ງມັນຄືໃບ IOU ທີ່ສັນຍາວ່າຈະຈ່າຍຄືນຈຳນວນທີ່ຢືມພ້ອມດອກເບ້ຍ. ພັນທະບັດເຫຼົ່ານີ້ມັກຖືກຊື້ໂດຍທະນາຄານໃຫຍ່, ລັດຖະບານຕ່າງປະເທດ, ແລະ ທີ່ສຳຄັນ, ທະນາຄານກາງ.
ວິທີການສ້າງເງິນ (ຈາກອາກາດ)
ນີ້ແມ່ນບ່ອນທີ່ເກີດການສ້າງເງິນ "ຈາກອາກາດ". ເມື່ອທະນາຄານກາງຊື້ພັນທະບັດເຫຼົ່ານີ້, ມັນບໍ່ໄດ້ໃຊ້ເງິນທີ່ມີຢູ່ແລ້ວ; ມັນສ້າງເງິນໃໝ່ດ້ວຍວິທີການດິຈິຕອນໂດຍພຽງແຕ່ປ້ອນຕົວເລກເຂົ້າໃນຄອມພິວເຕີ. ເງິນໃໝ່ນີ້ຖືກເພີ່ມເຂົ້າໃນປະລິມານເງິນລວມ. ຍິ່ງສ້າງເງິນຫຼາຍຂຶ້ນ ແລະ ເພີ່ມເຂົ້າໄປ, ມູນຄ່າຂອງເງິນທີ່ມີຢູ່ແລ້ວກໍຍິ່ງຫຼຸດລົງ. ຂະບວນການນີ້ຄືສິ່ງທີ່ພວກເຮົາເອີ້ນວ່າເງິນເຟີ້. ເນື່ອງຈາກກະຊວງການຄັງຢືມຢ່າງຕໍ່ເນື່ອງ ແລະ ທະນາຄານກາງສາມາດພິມໄດ້ຢ່າງຕໍ່ເນື່ອງ, ສິ່ງນີ້ຖືກສະເໜີວ່າເປັນວົງຈອນທີ່ບໍ່ມີທີ່ສິ້ນສຸດ.
ການໃຫ້ກູ້ຢືມສະຫງວນບາງສ່ວນໂດຍທະນາຄານ
ເພີ່ມເຂົ້າໃນບັນຫານີ້ຄືການປະຕິບັດຂອງການໃຫ້ກູ້ຢືມສະຫງວນບາງສ່ວນໂດຍທະນາຄານ. ເມື່ອທ່ານຝາກເງິນເຂົ້າທະນາຄານ, ທະນາຄານຖືກຮຽກຮ້ອງໃຫ້ເກັບຮັກສາພຽງແຕ່ສ່ວນໜຶ່ງຂອງເງິນຝາກນັ້ນໄວ້ເປັນເງິນສະຫງວນ (ຕົວຢ່າງ, 10%). ສ່ວນທີ່ເຫຼືອ (90%) ສາມາດຖືກປ່ອຍກູ້. ເມື່ອຜູ້ກູ້ຢືມໃຊ້ຈ່າຍເງິນນັ້ນ, ມັນມັກຖືກຝາກເຂົ້າອີກທະນາຄານ, ເຊິ່ງຈາກນັ້ນກໍຈະເຮັດຊ້ຳຂະບວນການໃຫ້ກູ້ຢືມສ່ວນໜຶ່ງຂອງເງິນຝາກ. ວົງຈອນນີ້ເຮັດໃຫ້ເພີ່ມຈຳນວນເງິນທີ່ໝູນວຽນຢູ່ໃນລະບົບໂດຍອີງໃສ່ເງິນຝາກເບື້ອງຕົ້ນ, ເຊິ່ງສ້າງເງິນຜ່ານໜີ້ສິນ. ລະບົບນີ້ໂດຍທຳມະຊາດແລ້ວບອບບາງ; ຖ້າມີຫຼາຍຄົນພະຍາຍາມຖອນເງິນຝາກຂອງເຂົາເຈົ້າພ້ອມກັນ (ການແລ່ນທະນາຄານ), ທະນາຄານກໍຈະລົ້ມເພາະວ່າມັນບໍ່ໄດ້ເກັບຮັກສາເງິນທັງໝົດໄວ້. ເງິນໃນທະນາຄານບໍ່ປອດໄພຄືກັບທີ່ເຊື່ອກັນທົ່ວໄປ ແລະ ສາມາດຖືກແຊ່ແຂງໃນຊ່ວງວິກິດການ ຫຼື ສູນເສຍຖ້າທະນາຄານລົ້ມລະລາຍ (ຍົກເວັ້ນໄດ້ຮັບການຊ່ວຍເຫຼືອ).
ຜົນກະທົບ Cantillon: ໃຜໄດ້ຮັບຜົນປະໂຫຍດກ່ອນ
ເງິນທີ່ຖືກສ້າງຂຶ້ນໃໝ່ບໍ່ໄດ້ກະຈາຍຢ່າງເທົ່າທຽມກັນ. "ຜົນກະທົບ Cantillon", ບ່ອນທີ່ຜູ້ທີ່ຢູ່ໃກ້ກັບແຫຼ່ງສ້າງເງິນໄດ້ຮັບຜົນປະໂຫຍດກ່ອນ. ນີ້ລວມເຖິງລັດຖະບານເອງ (ສະໜັບສະໜູນລາຍຈ່າຍ), ທະນາຄານໃຫຍ່ ແລະ Wall Street (ໄດ້ຮັບທຶນໃນອັດຕາດອກເບ້ຍຕ່ຳສຳລັບການກູ້ຢືມ ແລະ ການລົງທຶນ), ແລະ ບໍລິສັດໃຫຍ່ (ເຂົ້າເຖິງເງິນກູ້ທີ່ຖືກກວ່າສຳລັບການລົງທຶນ). ບຸກຄົນເຫຼົ່ານີ້ໄດ້ຊື້ຊັບສິນ ຫຼື ລົງທຶນກ່ອນທີ່ຜົນກະທົບຂອງເງິນເຟີ້ຈະເຮັດໃຫ້ລາຄາສູງຂຶ້ນ, ເຊິ່ງເຮັດໃຫ້ພວກເຂົາມີຂໍ້ໄດ້ປຽບ.
ຜົນກະທົບຕໍ່ຄົນທົ່ວໄປ
ສຳລັບຄົນທົ່ວໄປ, ຜົນກະທົບຂອງປະລິມານເງິນທີ່ເພີ່ມຂຶ້ນນີ້ແມ່ນການເພີ່ມຂຶ້ນຂອງລາຄາສິນຄ້າ ແລະ ການບໍລິການ - ນ້ຳມັນ, ຄ່າເຊົ່າ, ການດູແລສຸຂະພາບ, ອາຫານ, ແລະ ອື່ນໆ. ເນື່ອງຈາກຄ່າແຮງງານໂດຍທົ່ວໄປບໍ່ທັນກັບອັດຕາເງິນເຟີ້ນີ້, ອຳນາດການຊື້ຂອງປະຊາຊົນຈະຫຼຸດລົງເມື່ອເວລາຜ່ານໄປ. ມັນຄືກັບການແລ່ນໄວຂຶ້ນພຽງເພື່ອຢູ່ໃນບ່ອນເກົ່າ.
Bitcoin: ທາງເລືອກເງິນທີ່ໝັ້ນຄົງ
ຄວາມຂາດແຄນ: ບໍ່ຄືກັບເງິນຕາ fiat, Bitcoin ມີຂີດຈຳກັດສູງສຸດໃນປະລິມານຂອງມັນ. ຈະມີພຽງ 21 ລ້ານ Bitcoin ເທົ່ານັ້ນຖືກສ້າງຂຶ້ນ, ຂີດຈຳກັດນີ້ຝັງຢູ່ໃນໂຄດຂອງມັນ ແລະ ບໍ່ສາມາດປ່ຽນແປງໄດ້. ການສະໜອງທີ່ຈຳກັດນີ້ເຮັດໃຫ້ Bitcoin ເປັນເງິນຫຼຸດລາຄາ; ເມື່ອຄວາມຕ້ອງການເພີ່ມຂຶ້ນ, ມູນຄ່າຂອງມັນມີແນວໂນ້ມທີ່ຈະເພີ່ມຂຶ້ນເພາະວ່າປະລິມານການສະໜອງບໍ່ສາມາດຂະຫຍາຍຕົວ.
ຄວາມທົນທານ: Bitcoin ຢູ່ໃນ blockchain, ເຊິ່ງເປັນປຶ້ມບັນຊີສາທາລະນະທີ່ແບ່ງປັນກັນຂອງທຸກການເຮັດທຸລະກຳທີ່ແທບຈະເປັນໄປບໍ່ໄດ້ທີ່ຈະລຶບ ຫຼື ປ່ຽນແປງ. ປຶ້ມບັນຊີນີ້ຖືກກະຈາຍໄປທົ່ວພັນຄອມພິວເຕີ (nodes) ທົ່ວໂລກ. ແມ້ແຕ່ຖ້າອິນເຕີເນັດລົ້ມ, ເຄືອຂ່າຍສາມາດຢູ່ຕໍ່ໄປໄດ້ຜ່ານວິທີການອື່ນເຊັ່ນ: ດາວທຽມ ຫຼື ຄື້ນວິທະຍຸ. ມັນບໍ່ໄດ້ຮັບຜົນກະທົບຈາກການທຳລາຍທາງກາຍະພາບຂອງເງິນສົດ ຫຼື ການແຮັກຖານຂໍ້ມູນແບບລວມສູນ.
ການພົກພາ: Bitcoin ສາມາດຖືກສົ່ງໄປໃນທຸກບ່ອນໃນໂລກໄດ້ທັນທີ, 24/7, ດ້ວຍການເຊື່ອມຕໍ່ອິນເຕີເນັດ, ໂດຍບໍ່ຈຳເປັນຕ້ອງມີທະນາຄານ ຫຼື ການອະນຸຍາດຈາກພາກສ່ວນທີສາມ. ທ່ານສາມາດເກັບຮັກສາ Bitcoin ຂອງທ່ານໄດ້ດ້ວຍຕົນເອງໃນອຸປະກອນທີ່ເອີ້ນວ່າກະເປົາເຢັນ, ແລະ ຕາບໃດທີ່ທ່ານຮູ້ວະລີກະແຈລັບຂອງທ່ານ, ທ່ານສາມາດເຂົ້າເຖິງເງິນຂອງທ່ານຈາກກະເປົາທີ່ເຂົ້າກັນໄດ້, ເຖິງແມ່ນວ່າອຸປະກອນຈະສູນຫາຍ. ສິ່ງນີ້ສະດວກສະບາຍກວ່າ ແລະ ມີຄວາມສ່ຽງໜ້ອຍກວ່າການພົກພາເງິນສົດຈຳນວນຫຼາຍ ຫຼື ການນຳທາງການໂອນເງິນສາກົນທີ່ຊັບຊ້ອນ.
ການແບ່ງຍ່ອຍ: Bitcoin ສາມາດແບ່ງຍ່ອຍໄດ້ສູງ. ໜຶ່ງ Bitcoin ສາມາດແບ່ງເປັນ 100 ລ້ານໜ່ວຍຍ່ອຍທີ່ເອີ້ນວ່າ Satoshis, ເຊິ່ງອະນຸຍາດໃຫ້ສົ່ງ ຫຼື ຮັບຈຳນວນນ້ອຍໄດ້.
ຄວາມສາມາດໃນການທົດແທນກັນ: ໜຶ່ງ Bitcoin ທຽບເທົ່າກັບໜຶ່ງ Bitcoin ໃນມູນຄ່າ, ໂດຍທົ່ວໄປ. ໃນຂະນະທີ່ເງິນໂດລາແບບດັ້ງເດີມອາດສາມາດຖືກຕິດຕາມ, ແຊ່ແຂງ, ຫຼື ຍຶດໄດ້, ໂດຍສະເພາະໃນຮູບແບບດິຈິຕອນ ຫຼື ຖ້າຖືກພິຈາລະນາວ່າໜ້າສົງໄສ, ແຕ່ລະໜ່ວຍຂອງ Bitcoin ໂດຍທົ່ວໄປຖືກປະຕິບັດຢ່າງເທົ່າທຽມກັນ.
ການພິສູດຢັ້ງຢືນ: ທຸກການເຮັດທຸລະກຳ Bitcoin ຖືກບັນທຶກໄວ້ໃນ blockchain, ເຊິ່ງທຸກຄົນສາມາດເບິ່ງ ແລະ ພິສູດຢັ້ງຢືນ. ຂະບວນການພິສູດຢັ້ງຢືນທີ່ກະຈາຍນີ້, ດຳເນີນໂດຍເຄືອຂ່າຍ, ໝາຍຄວາມວ່າທ່ານບໍ່ຈຳເປັນຕ້ອງເຊື່ອຖືທະນາຄານ ຫຼື ສະຖາບັນໃດໜຶ່ງແບບມືດບອດເພື່ອຢືນຢັນຄວາມຖືກຕ້ອງຂອງເງິນຂອງທ່ານ.
ການຕ້ານການກວດກາ: ເນື່ອງຈາກບໍ່ມີລັດຖະບານ, ບໍລິສັດ, ຫຼື ບຸກຄົນໃດຄວບຄຸມເຄືອຂ່າຍ Bitcoin, ບໍ່ມີໃຜສາມາດຂັດຂວາງທ່ານຈາກການສົ່ງ ຫຼື ຮັບ Bitcoin, ແຊ່ແຂງເງິນຂອງທ່ານ, ຫຼື ຍຶດມັນ. ມັນເປັນລະບົບທີ່ບໍ່ຕ້ອງຂໍອະນຸຍາດ, ເຊິ່ງໃຫ້ຜູ້ໃຊ້ຄວບຄຸມເຕັມທີ່ຕໍ່ເງິນຂອງເຂົາເຈົ້າ.
ການກະຈາຍອຳນາດ: Bitcoin ຖືກຮັກສາໂດຍເຄືອຂ່າຍກະຈາຍຂອງບັນດາຜູ້ຂຸດທີ່ໃຊ້ພະລັງງານການຄິດໄລ່ເພື່ອຢັ້ງຢືນການເຮັດທຸລະກຳຜ່ານ "proof of work". ລະບົບທີ່ກະຈາຍນີ້ຮັບປະກັນວ່າບໍ່ມີຈຸດໃດຈຸດໜຶ່ງທີ່ຈະລົ້ມເຫຼວ ຫຼື ຄວບຄຸມ. ທ່ານບໍ່ໄດ້ເພິ່ງພາຂະບວນການທີ່ບໍ່ໂປ່ງໃສຂອງທະນາຄານກາງ; ລະບົບທັງໝົດໂປ່ງໃສຢູ່ໃນ blockchain. ສິ່ງນີ້ເຮັດໃຫ້ບຸກຄົນມີອຳນາດທີ່ຈະເປັນທະນາຄານຂອງຕົນເອງແທ້ ແລະ ຮັບຜິດຊອບຕໍ່ການເງິນຂອງເຂົາເຈົ້າ.
-
@ ee11a5df:b76c4e49
2024-09-11 08:16:37
Bye-Bye Reply Guy
There is a camp of nostr developers that believe spam filtering needs to be done by relays. Or at the very least by DVMs. I concur. In this way, once you configure what you want to see, it applies to all nostr clients.
But we are not there yet.
In the mean time we have ReplyGuy, and gossip needed some changes to deal with it.
Strategies in Short
- WEB OF TRUST: Only accept events from people you follow, or people they follow - this avoids new people entirely until somebody else that you follow friends them first, which is too restrictive for some people.
- TRUSTED RELAYS: Allow every post from relays that you trust to do good spam filtering.
- REJECT FRESH PUBKEYS: Only accept events from people you have seen before - this allows you to find new people, but you will miss their very first post (their second post must count as someone you have seen before, even if you discarded the first post)
- PATTERN MATCHING: Scan for known spam phrases and words and block those events, either on content or metadata or both or more.
- TIE-IN TO EXTERNAL SYSTEMS: Require a valid NIP-05, or other nostr event binding their identity to some external identity
- PROOF OF WORK: Require a minimum proof-of-work
All of these strategies are useful, but they have to be combined properly.
filter.rhai
Gossip loads a file called "filter.rhai" in your gossip directory if it exists. It must be a Rhai language script that meets certain requirements (see the example in the gossip source code directory). Then it applies it to filter spam.
This spam filtering code is being updated currently. It is not even on unstable yet, but it will be there probably tomorrow sometime. Then to master. Eventually to a release.
Here is an example using all of the techniques listed above:
```rhai // This is a sample spam filtering script for the gossip nostr // client. The language is called Rhai, details are at: // https://rhai.rs/book/ // // For gossip to find your spam filtering script, put it in // your gossip profile directory. See // https://docs.rs/dirs/latest/dirs/fn.data_dir.html // to find the base directory. A subdirectory "gossip" is your // gossip data directory which for most people is their profile // directory too. (Note: if you use a GOSSIP_PROFILE, you'll // need to put it one directory deeper into that profile // directory). // // This filter is used to filter out and refuse to process // incoming events as they flow in from relays, and also to // filter which events get/ displayed in certain circumstances. // It is only run on feed-displayable event kinds, and only by // authors you are not following. In case of error, nothing is // filtered. // // You must define a function called 'filter' which returns one // of these constant values: // DENY (the event is filtered out) // ALLOW (the event is allowed through) // MUTE (the event is filtered out, and the author is // automatically muted) // // Your script will be provided the following global variables: // 'caller' - a string that is one of "Process", // "Thread", "Inbox" or "Global" indicating // which part of the code is running your // script // 'content' - the event content as a string // 'id' - the event ID, as a hex string // 'kind' - the event kind as an integer // 'muted' - if the author is in your mute list // 'name' - if we have it, the name of the author // (or your petname), else an empty string // 'nip05valid' - whether nip05 is valid for the author, // as a boolean // 'pow' - the Proof of Work on the event // 'pubkey' - the event author public key, as a hex // string // 'seconds_known' - the number of seconds that the author // of the event has been known to gossip // 'spamsafe' - true only if the event came in from a // relay marked as SpamSafe during Process // (even if the global setting for SpamSafe // is off)
fn filter() {
// Show spam on global // (global events are ephemeral; these won't grow the // database) if caller=="Global" { return ALLOW; } // Block ReplyGuy if name.contains("ReplyGuy") || name.contains("ReplyGal") { return DENY; } // Block known DM spam // (giftwraps are unwrapped before the content is passed to // this script) if content.to_lower().contains( "Mr. Gift and Mrs. Wrap under the tree, KISSING!" ) { return DENY; } // Reject events from new pubkeys, unless they have a high // PoW or we somehow already have a nip05valid for them // // If this turns out to be a legit person, we will start // hearing their events 2 seconds from now, so we will // only miss their very first event. if seconds_known <= 2 && pow < 25 && !nip05valid { return DENY; } // Mute offensive people if content.to_lower().contains(" kike") || content.to_lower().contains("kike ") || content.to_lower().contains(" nigger") || content.to_lower().contains("nigger ") { return MUTE; } // Reject events from muted people // // Gossip already does this internally, and since we are // not Process, this is rather redundant. But this works // as an example. if muted { return DENY; } // Accept if the PoW is large enough if pow >= 25 { return ALLOW; } // Accept if their NIP-05 is valid if nip05valid { return ALLOW; } // Accept if the event came through a spamsafe relay if spamsafe { return ALLOW; } // Reject the rest DENY} ```
-
@ d34e832d:383f78d0
2025-04-22 22:48:30
What is pfSense?
pfSense is a free, open-source firewall and router software distribution based on FreeBSD. It includes a web-based GUI and supports advanced features like:
- Stateful packet inspection (SPI)
- Virtual Private Network (VPN) support (OpenVPN, WireGuard, IPSec)
- Dynamic and static routing
- Traffic shaping and QoS
- Load balancing and failover
- VLANs and captive portals
- Intrusion Detection/Prevention (Snort, Suricata)
- DNS, DHCP, and more
Use Cases
- Home networks with multiple devices
- Small to medium businesses
- Remote work VPN gateway
- IoT segmentation
- Homelab firewalls
- Wi-Fi network segmentation

2. Essential Hardware Components
When building a pfSense router, you must match your hardware to your use case. The system needs at least two network interfaces—one for WAN, one for LAN.
Core Components
| Component | Requirement | Budget-Friendly Example | |---------------|------------------------------------|----------------------------------------------| | CPU | Dual-core 64-bit x86 (AES-NI support recommended) | Intel Celeron J4105, AMD GX-412HC, or Intel i3 6100T | | Motherboard | Mini-ITX or Micro-ATX with support for selected CPU | ASRock J4105-ITX (includes CPU) | | RAM | Minimum 4GB (8GB preferred) | Crucial 4GB DDR4 | | Storage | 16GB+ SSD or mSATA/NVMe (for longevity and speed) | Kingston A400 120GB SSD | | NICs | At least two Intel gigabit ports (Intel NICs preferred) | Intel PRO/1000 Dual-Port PCIe or onboard | | Power Supply | 80+ Bronze rated or PicoPSU for SBCs | EVGA 400W or PicoPSU 90W | | Case | Depends on form factor | Mini-ITX case (e.g., InWin Chopin) | | Cooling | Passive or low-noise | Stock heatsink or case fan |
3. Recommended Affordable Hardware Builds
Build 1: Super Budget (Fanless)
- Motherboard/CPU: ASRock J4105-ITX (quad-core, passive cooling, AES-NI)
- RAM: 4GB DDR4 SO-DIMM
- Storage: 120GB SATA SSD
- NICs: 1 onboard + 1 PCIe Intel Dual Port NIC
- Power Supply: PicoPSU with 60W adapter
- Case: Mini-ITX fanless enclosure
- Estimated Cost: ~$150–180
Build 2: Performance on a Budget
- CPU: Intel i3-6100T (low power, AES-NI support)
- Motherboard: ASUS H110M-A/M.2 (Micro-ATX)
- RAM: 8GB DDR4
- Storage: 120GB SSD
- NICs: 2-port Intel PCIe NIC
- Case: Compact ATX case
- Power Supply: 400W Bronze-rated PSU
- Estimated Cost: ~$200–250
4. Assembling the Hardware
Step-by-Step Instructions
- Prepare the Workspace:
- Anti-static mat or surface
- Philips screwdriver
- Install CPU (if required):
- Align and seat CPU into socket
- Apply thermal paste and attach cooler
- Insert RAM into DIMM slots
- Install SSD and connect to SATA port
- Install NIC into PCIe slot
- Connect power supply to motherboard, SSD
- Place system in case and secure all components
- Plug in power and monitor
5. Installing pfSense Software
What You'll Need
- A 1GB+ USB flash drive
- A separate computer with internet access
Step-by-Step Guide
- Download pfSense ISO:
- Visit: https://www.pfsense.org/download/
- Choose AMD64, USB Memstick Installer, and mirror site
- Create Bootable USB:
- Use tools like balenaEtcher or Rufus to write ISO to USB
- Boot the Router from USB:
- Enter BIOS → Set USB as primary boot
- Save and reboot
- Install pfSense:
- Accept defaults during installation
- Choose ZFS or UFS (UFS is simpler for small SSDs)
- Install to SSD, remove USB post-installation
6. Basic Configuration Settings
After the initial boot, pfSense will assign: - WAN to one interface (via DHCP) - LAN to another (default IP: 192.168.1.1)
Access WebGUI
- Connect a PC to LAN port
- Open browser → Navigate to
http://192.168.1.1 - Default login: admin / pfsense
Initial Setup Wizard
- Change admin password
- Set hostname and DNS
- Set time zone
- Confirm WAN/LAN settings
- Enable DHCP server for LAN
- Optional: Enable SSH
7. Tips and Best Practices
Security Best Practices
- Change default password immediately
- Block all inbound traffic by default
- Enable DNS over TLS (with Unbound)
- Regularly update pfSense firmware and packages
- Use strong encryption for VPNs
- Limit admin access to specific IPs
Performance Optimization
- Use Intel NICs for reliable throughput
- Offload DNS, VPN, and DHCP to dedicated packages
- Disable unnecessary services to reduce CPU load
- Monitor system logs for errors and misuse
- Enable traffic shaping if managing VoIP or streaming
Useful Add-ons
- pfBlockerNG: Ad-blocking and geo-blocking
- Suricata: Intrusion Detection System
- OpenVPN/WireGuard: VPN server setup
- Zabbix Agent: External monitoring
8. Consider
With a modest investment and basic technical skills, anyone can build a powerful, flexible, and secure pfSense router. Choosing the right hardware for your needs ensures a smooth experience without overpaying or underbuilding. Whether you're enhancing your home network, setting up a secure remote office, or learning network administration, a custom pfSense router is a versatile, long-term solution.
Appendix: Example Hardware Component List
| Component | Item | Price (Approx.) | |------------------|--------------------------|------------------| | Motherboard/CPU | ASRock J4105-ITX | $90 | | RAM | Crucial 4GB DDR4 | $15 | | Storage | Kingston A400 120GB SSD | $15 | | NIC | Intel PRO/1000 Dual PCIe | $20 | | Case | Mini-ITX InWin Chopin | $40 | | Power Supply | PicoPSU 60W + Adapter | $25 | | Total | | ~$205 |
-
@ 9bde4214:06ca052b
2025-04-22 22:04:57
“The human spirit should remain in charge.”
Pablo & Gigi talk about the wind.
In this dialogue:
- Wind
- More Wind
- Information Calories, and how to measure them
- Digital Wellbeing
- Rescue Time
- Teleology of Technology
- Platforms get users Hooked (book)
- Feeds are slot machines
- Movie Walls
- Tweetdeck and Notedeck
- IRC vs the modern feed
- 37Signals: “Hey, let’s just charge users!”
- “You wouldn’t zap a car crash”
- Catering to our highest self VS catering to our lowest self
- Devolution of YouTube 5-star ratings to thumb up/down to views
- Long videos vs shorts
- The internet had to monetize itself somehow (with attention)
- “Don’t be evil” and why Google had to remove it
- Questr: 2D exploration of nostr
- ONOSENDAI by Arkinox
- Freedom tech & Freedom from Tech
- DAUs of jumper cables
- Gossip and it’s choices
- “The secret to life is to send it”
- Flying water & flying bus stops
- RSS readers, Mailbrew, and daily digests
- Nostr is high signal and less addictive
- Calling nostr posts “tweets” and recordings being “on tape”
- Pivoting from nostr dialogues to a podcast about wind
- The unnecessary complexity of NIP-96
- Blossom (and wind)
- Undoing URLs, APIs, and REST
- ISBNs and cryptographic identifiers
- SaaS and the DAU metric
- Highlighter
- Not caring where stuff is hosted
- When is an edited thing a new thing?
- Edits, the edit wars, and the case against edits
- NIP-60 and inconsistent balances
- Scroll to text fragment and best effort matching
- Proximity hashes & locality-sensitive hashing
- Helping your Uncle Jack of a horse
- Helping your uncle jack of a horse
- Can we fix it with WoT?
- Vertex & vibe-coding a proper search for nostr
- Linking to hashtags & search queries
- Advanced search and why it’s great
- Search scopes & web of trust
- The UNIX tools of nostr
- Pablo’s NDK snippets
- Meredith on the privacy nightmare of Agentic AI
- Blog-post-driven development (Lightning Prisms, Highlighter)
- Sandwich-style LLM prompting, Waterfall for LLMs (HLDD / LLDD)
- “Speed itself is a feature”
- MCP & DVMCP
- Monorepos and git submodules
- Olas & NDK
- Pablo’s RemindMe bot
- “Breaking changes kinda suck”
- Stories, shorts, TikTok, and OnlyFans
- LLM-generated sticker styles
- LLMs and creativity (and Gigi’s old email)
- “AI-generated art has no soul”
- Nostr, zaps, and realness
- Does the source matter?
- Poker client in bitcoin v0.0.1
- Quotes from Hitler and how additional context changes meaning
- Greek finance minister on crypto and bitcoin (Technofeudalism, book)
- Is more context always good?
- Vervaeke’s AI argument
- What is meaningful?
- How do you extract meaning from information?
- How do you extract meaning from experience?
- “What the hell is water”
- Creativity, imagination, hallucination, and losing touch with reality
- “Bitcoin is singularity insurance”
- Will vibe coding make developers obsolete?
- Knowing what to build vs knowing how to build
- 10min block time & the physical limits of consensus
- Satoshi’s reasons articulated in his announcement post
- Why do anything? Why stack sats? Why have kids?
- All you need now is motivation
- Upcoming agents will actually do the thing
- Proliferation of writers: quantity VS quality
- Crisis of sameness & the problem of distribution
- Patronage, belle epoche, and bitcoin art
- Niches, and how the internet fractioned society
- Joe’s songs
- Hyper-personalized stories
- Shared stories & myths (Jonathan Pageau)
- Hyper-personalized apps VS shared apps
- Agency, free expression, and free speech
- Edgy content & twitch meta, aka skating the line of demonetization and deplatforming
- Using attention as a proxy currency
- Farming eyeballs and brain cycles
- Engagement as a success metric & engagement bait
- “You wouldn’t zap a car crash”
- Attention economy is parasitic on humanity
- The importance of speech & money
- What should be done by a machine?
- What should be done by a human?
- “The human spirit should remain in charge”
- Our relationship with fiat money
- Active vs passive, agency vs serfdom
-
@ d34e832d:383f78d0
2025-04-22 21:32:40
The Domain Name System (DNS) is a foundational component of the internet. It translates human-readable domain names into IP addresses, enabling the functionality of websites, email, and services. However, traditional DNS is inherently insecure—queries are typically sent in plaintext, making them vulnerable to interception, spoofing, and censorship.
DNSCrypt is a protocol designed to authenticate communications between a DNS client and a DNS resolver. By encrypting DNS traffic and validating the source of responses, it thwarts man-in-the-middle attacks and DNS poisoning. Despite its security advantages, widespread adoption remains limited due to usability and deployment complexity.
This idea introduces an affordable, lightweight DNSCrypt proxy server capable of providing secure DNS resolution in both home and enterprise environments. Our goal is to democratize secure DNS through low-cost infrastructure and transparent architecture.
2. Background
2.1 Traditional DNS Vulnerabilities
- Lack of Encryption: DNS queries are typically unencrypted (UDP port 53), exposing user activity.
- Spoofing and Cache Poisoning: Attackers can forge DNS responses to redirect users to malicious websites.
- Censorship: Governments and ISPs can block or alter DNS responses to control access.
2.2 Introduction to DNSCrypt
DNSCrypt mitigates these problems by: - Encrypting DNS queries using X25519 + XSalsa20-Poly1305 or X25519 + ChaCha20-Poly1305 - Authenticating resolvers via public key infrastructure (PKI) - Supporting relay servers and anonymized DNS, enhancing metadata protection
2.3 Current Landscape
DNSCrypt proxies are available in commercial routers and services (e.g., Cloudflare DNS over HTTPS), but full control remains in the hands of centralized entities. Additionally, hardware requirements and setup complexity can be barriers to entry.
3. System Architecture
3.1 Overview
Our system is designed around the following components: - Client Devices: Use DNSCrypt-enabled stub resolvers (e.g., dnscrypt-proxy) - DNSCrypt Proxy Server: Accepts DNSCrypt queries, decrypts and validates them, then forwards to recursive resolvers (e.g., Unbound) - Recursive Resolver (Optional): Provides DNS resolution without reliance on upstream services - Relay Support: Adds anonymization via DNSCrypt relays
3.2 Protocols and Technologies
- DNSCrypt v2: Core encrypted DNS protocol
- X25519 Key Exchange: Lightweight elliptic curve cryptography
- Poly1305 AEAD Encryption: Fast and secure authenticated encryption
- UDP/TCP Fallback: Supports both transport protocols to bypass filtering
- DoH Fallback: Optional integration with DNS over HTTPS
3.3 Hardware Configuration
- Platform: Raspberry Pi 4B or x86 mini-PC (e.g., Lenovo M710q)
- Cost: Under $75 total (device + SD card or SSD)
- Operating System: Debian 12 or Ubuntu Server 24.04
- Memory Footprint: <100MB RAM idle
- Power Consumption: ~3-5W idle
4. Design Considerations
4.1 Affordability
- Hardware Sourcing: Use refurbished or SBCs to cut costs
- Software Stack: Entirely open source (dnscrypt-proxy, Unbound)
- No Licensing Fees: FOSS-friendly deployment for communities
4.2 Security
- Ephemeral Key Pairs: New keypairs every session prevent replay attacks
- Public Key Verification: Resolver keys are pre-published and verified
- No Logging: DNSCrypt proxies are configured to avoid retaining user metadata
- Anonymization Support: With relay chaining for metadata privacy
4.3 Maintainability
- Containerization (Optional): Docker-compatible setup for simple updates
- Remote Management: Secure shell access with fail2ban and SSH keys
- Auto-Updating Scripts: Systemd timers to refresh certificates and relay lists
5. Implementation
5.1 Installation Steps
- Install OS and dependencies:
bash sudo apt update && sudo apt install dnscrypt-proxy unbound - Configure
dnscrypt-proxy.toml: - Define listening port, relay list, and trusted resolvers
- Enable Anonymized DNS, fallback to DoH
- Configure Unbound (optional):
- Run as recursive backend
- Firewall hardening:
- Allow only DNSCrypt port (default: 443 or 5353)
- Block all inbound traffic except SSH (optional via Tailscale)
5.2 Challenges
- Relay Performance Variability: Some relays introduce latency; solution: geo-filtering
- Certificate Refresh: Mitigated with daily cron jobs
- IP Rate-Limiting: Mitigated with DNS load balancing
6. Evaluation
6.1 Performance Benchmarks
- Query Resolution Time (mean):
- Local resolver: 12–18ms
- Upstream via DoH: 25–35ms
- Concurrent Users Supported: 100+ without degradation
- Memory Usage: ~60MB (dnscrypt-proxy + Unbound)
- CPU Load: <5% idle on ARM Cortex-A72
6.2 Security Audits
- Verified with dnsleaktest.com and
tcpdump - No plaintext DNS observed over interface
- Verified resolver keys via DNSCrypt community registry
7. Use Cases
7.1 Personal/Home Use
- Secure DNS for all home devices via router or Pi-hole integration
7.2 Educational Institutions
- Provide students with censorship-free DNS in oppressive environments
7.3 Community Mesh Networks
- Integrate DNSCrypt into decentralized networks (e.g., Nostr over Mesh)
7.4 Business VPNs
- Secure internal DNS without relying on third-party resolvers
8. Consider
This idea has presented a practical, affordable approach to deploying a secure DNSCrypt proxy server. By leveraging open-source tools, minimalist hardware, and careful design choices, it is possible to democratize access to encrypted DNS. Our implementation meets the growing need for privacy-preserving infrastructure without introducing prohibitive costs.
We demonstrated that even modest devices can sustain dozens of encrypted DNS sessions concurrently while maintaining low latency. Beyond privacy, this system empowers individuals and communities to control their own DNS without corporate intermediaries.
9. Future Work
- Relay Discovery Automation: Dynamic quality-of-service scoring for relays
- Web GUI for Management: Simplified frontend for non-technical users
- IPv6 and Tor Integration: Expanding availability and censorship resistance
- Federated Resolver Registry: Trust-minimized alternative to current resolver key lists
References
- DNSCrypt Protocol Specification v2 – https://dnscrypt.info/protocol
- dnscrypt-proxy GitHub Repository – https://github.com/DNSCrypt/dnscrypt-proxy
- Unbound Recursive Resolver – https://nlnetlabs.nl/projects/unbound/about/
- DNS Security Extensions (DNSSEC) – IETF RFCs 4033, 4034, 4035
- Bernstein, D.J. – Cryptographic Protocols using Curve25519 and Poly1305
- DNS over HTTPS (DoH) – RFC 8484
-
@ d34e832d:383f78d0
2025-04-22 21:14:46
Minecraft remains one of the most popular sandbox games in the world. For players who wish to host private or community-based servers, monthly hosting fees can quickly add up. Furthermore, setting up a server from scratch often requires technical knowledge in networking, system administration, and Linux.
This idea explores a do-it-yourself (DIY) method for deploying a low-cost Minecraft server using common secondhand hardware and a simple software stack, with a focus on energy efficiency, ease of use, and full control over the server environment.
2. Objective
To build and deploy a dedicated Minecraft server that:
- Costs less than $75 in total
- Consumes minimal electricity (<10W idle)
- Is manageable via a graphical user interface (GUI)
- Supports full server management including backups, restarts, and plugin control
- Requires no port forwarding or complex network configuration
- Delivers performance suitable for a small-to-medium number of concurrent players
3. Hardware Overview
3.1 Lenovo M710Q Mini-PC (~$55 used)
- Intel Core i5 (6th/7th Gen)
- 8GB DDR4 RAM
- Compact size and low power usage
- Widely available refurbished
3.2 ID Sonics 512GB NVMe SSD (~$20)
- Fast storage with sufficient capacity for multiple Minecraft server instances
- SSDs reduce world loading lag and improve backup performance
Total Hardware Cost: ~$75
4. Software Stack
4.1 Ubuntu Server 24.04
- Stable, secure, and efficient operating system
- Headless installation, ideal for server use
- Supports automated updates and system management via CLI
4.2 CasaOS
- A lightweight operating system layer and GUI on top of Ubuntu
- Built for managing Docker containers with a clean web interface
- Allows app store-like deployment of various services
4.3 Crafty Controller (via Docker)
- Web-based server manager for Minecraft
- Features include:
- Automatic backups and restore
- Scheduled server restarts
- Plugin management
- Server import/export
- Server logs and console access
5. Network and Remote Access
5.1 PlayIt.gg Integration
PlayIt.gg creates a secure tunnel to your server via a relay node, removing the need for traditional port forwarding.
Benefits: - Works even behind Carrier-Grade NAT (common on mobile or fiber ISPs) - Ideal for users with no access to router settings - Ensures privacy by hiding IP address from public exposure
6. Setup Process Summary
- Install Ubuntu Server 24.04 on the M710Q
- Install CasaOS via script provided by the project
- Use CasaOS to deploy Crafty Controller in a Docker container
- Configure Minecraft server inside Crafty (Vanilla, Paper, Spigot, etc.)
- Integrate PlayIt.gg to expose the server to friends
- Access Crafty via browser for daily management
7. Power Consumption and Performance
- Idle Power Draw: ~7.5W
- Load Power Draw (2–5 players): ~15W
- M710Q fan runs quiet and rarely under load
- Performance sufficient for:
- Vanilla or optimized Paper server
- Up to 10 concurrent players with light mods
8. Cost Analysis vs Hosted Services
| Solution | Monthly Cost | Annual Cost | Control Level | Mods Support | |-----------------------|--------------|-------------|----------------|---------------| | Commercial Hosting | $5–$15 | $60–$180 | Limited | Yes | | This Build (One-Time) | $75 | $0 | Full | Yes |
Return on Investment (ROI):
Break-even point reached in 6 to 8 months compared to lowest hosting tiers.
9. Advantages
- No Subscription: Single upfront investment
- Local Control: Full access to server files and environment
- Privacy Respecting: No third-party data mining
- Modular: Can add mods, backups, maps with full access
- Low Energy Use: Ideal for 24/7 uptime
10. Limitations
- Not Ideal for >20 players: CPU and RAM constraints
- Local Hardware Dependency: Physical failure risk
- Requires Basic Setup Time: CLI familiarity useful but not required
11. Future Enhancements
- Add Dynmap with reverse proxy and TLS via CasaOS
- Integrate Nextcloud for managing world backups
- Use Watchtower for automated container updates
- Schedule daily email logs using system cron
12. Consider
This idea presents a practical and sustainable approach to self-hosting Minecraft servers using open-source software and refurbished hardware. With a modest upfront cost and minimal maintenance, users can enjoy full control over their game worlds without recurring fees or technical hassle. This method democratizes game hosting and aligns well with educational environments, small communities, and privacy-conscious users.
-
@ bf95e1a4:ebdcc848
2024-09-11 06:31:05
This is the lightly-edited AI generated transcript of Bitcoin Infinity Show #125. The transcription isn't perfect, but it's usually pretty good!
If you'd like to support us, send us a zap or check out the Bitcoin Infinity Store for our books and other merchandise! https://bitcoininfinitystore.com/
Intro
Luke: Paolo, Mathias, welcome to the Bitcoin Infinity Show. Thank you for joining us.
Paolo: Thank you for having us.
Knut: Yeah, good to have you here, guys. We're going to talk a bit about Keet and Holepunch and a little bit about Tether today, aren't we?
Luke: Sounds like that's the plan. So thank you again, both for joining us.
Introducing Paolo and Mathias
Luke: would you both mind giving a quick introduction on yourselves just so our listeners have the background on you
Paolo: Sure, I'm Paolo Arduino, I'm the CEO at Tether. I started my career as a developer, I pivoted towards more, strategy and execution for, Tether and Bitfinex. And, co founded with Matthias, Holepunch, that is, building very, crazy and awesome technology, that is gonna be disrupting the way people communicate.
Luke: And, Mathias, over to you.
Mathias: Yeah, thank you. Yeah, I've been, so I come from a peer-to-peer background. I've been working with peer-to-peer technology. The last, I always say five, but it's probably more like 10 years. I did a lot of work on BitTorrent and I did a lot of work on JavaScript. and a little bit later to, Bitcoin and I saw a lot of potential on how we can use Bitcoin with pureology and like how we can use.
P2P technology to bring the same mission that Bitcoin has, but to all kinds of data, setting all data free and, making everything private per default and self sovereignty and that kind of thing. I'm very into that. and I've been lucky to work with, like I said, with Paolo for, many years now and, Get a lot of, valuable, feedback and, idea sharing out of that.
And we're on a mission to, build some, really cool things. In addition to all the things we've already been building. So it's super exciting and glad to be here.
Luke: Oh, fantastic.
Introduction to Holepunch
Luke: Matthias, that was a perfect segue into basically, an introduction to, can you tell us about, Holepunch.
What is Holepunch and what are you doing?
Mathias: Yeah, sure. like I said, we co founded the company a couple of years ago. Now, we've been building up a team of really talented peer to peer engineers. we're always hiring also. So if anybody's listening and want to join our mission, please, apply. we have some really smart people working with us.
but we teamed up to basically. like I said in my introduction, I've been working on peer to peer technology for many years now and thinking ahead how we can, stop using all that technology when I started it was only used for basically piracy. I'm from the Nordics, and I think Knut is from the Nordics also, so he knows all about, the Nordics know about piracy.
It wasn't back in the day. A lot of very interesting technologies came out of that. But basically, how can we use those ideas that were proven by piracy back then to be really unstoppable, because a lot of people wanted to stop it, but apply that same kind of mindset to the general data, so we can build actual applications that has that kind of quality, that can withstand the wrath of God.
that can work without any centralization. Actually, nobody can shut down, not even the authorities if they wanted to. Basically unkillable and make that general enough that it can basically run any kind of application, solve a lot of really hot problems. it works on your own computers, your own networks.
Mobile phones, and tie that up. I'm a developer by heart, into a software stack that people can just build on. So not everybody has to go in and tackle all these problems individually, but just give them some software to solve all this so they can, as much as possible, just worry about making really cool applications that we use,
Yeah, like I said, we've been working really intensely on this, for a long time and in Holepunch, we made this our co mission to scale this up and, deliver a software stack on that. it's been really exciting and it's been really fun and it's been very, challenging, but if it's not challenging, then why, do it?
and, especially, with the backing of, Tether, through Paolo and also just expertise from there, we have a good hand built to deliver this to the world. And, the first thing we did was, like, think about what's, a good first application that we can build that can showcase this, but also something we really want to use ourself and see scale have also have on the world.
And obviously that was a communications app, keyed, which we was our first project. And, we're still in beta and we're still lots of work to do. And we're still iterating that really heavily, but I like to show that you can build these kind of apps without any kind of. central points. and we released that also, like the first thing we released when we launched the company.
And like I said, we're still, building and still iterating it. A lot of fun. and then take the software stack from that, which we call the pair runtime and then split that out. So anybody else can build similar apps on top. With that same technology stack, and, yeah, that's, we launched that earlier this year also, and, it's been really exciting so far, and it's, I love going to work every day and solve, even though, you can see on my hair that it's not really good for, the head scratching, but, but, it's really fun, and it's really challenging, and it's interesting thing. goal as a company, basically to have that if we go out of business tomorrow, our technology continues to exist because we're not in the loop of anything. It's also sometimes really hard to explain that we don't have any, chip coins involved or any kind of limitations on the stack because we're basically engineering it not to be part of it, because that's the only way you can actually engineer these things that they can understand.
anything, super exciting and, encourage everybody to try to check it out.
Luke: we've both used Keet and I've certainly enjoyed the experience. I, think, the, basics of this, as I understand it, is that it's, entirely on both sides. The communicators end, or a group of communicators, it's all on their end, and the communication is entirely peer to peer, what is Keet really, what is the basics of Keet as, say, a product?
What is the easiest way that you would explain what it is?
The Vision Behind Keet
Mathias: But We're basically trying to just build a world class communications app that works to a large degree, like normal communication apps that you know, like Signal, Telegram, WhatsApp. Just with all the centralization tucked away, with all the costs of running it tucked away, and then adding all the features that also we can, because we're peer to peer
People don't care about technology. We loved it, but don't have that surface off too much to the user.
Just have the user use it as any other app, but then just have it be 100 percent private per default, 100 percent like no strings attached. It just works. if we get caught off by a. From the internet tomorrow, it will still work, that kind of thing, but deliver that in a way, and this is always our mission where users don't really need to worry about it.
It just works. And, it works the same way to a large degree as their other apps work, except obviously, there's no phone numbers and things like that. Very cryptographically sound and, but trying always not to bubble it up. And I think that's, so it's actually a really simple mission, but it's obviously really hard.
And that requires a lot of smart people, but luckily our users in a good way, don't need to be very smart about that.
Keet vs Nostr
Knut: Yeah, a quick one there. No strings attached starts with the letters Nostr, so is, Keet and Nostr, do they go mix well together or, is there an integration there between the two? I see a lot of similarities here.
Paolo: I tried to explain the differences between Kit and Nostr. I think Nostr is a very interesting protocol, but also is very, simple. the way I like to describe it is that, if you are familiar with the history of filesharing, Starting from the first one, super centralized, and then eventually every single step, you get to a decentralized platform.
And the last one, the most decentralized one, that is BitTorrent. the history of file sharing proved that every time you try to centralize something, it ends up badly, right? if you have any special node in the system that does a little bit more than others and requires more resources than others to run, that will end up badly.
You might end up in a small room with a lamp in your room. Point it to your face, and then everyone suddenly will stop running an indexer. That reminds me about Nostr structure. if you are building a peer to peer system, or if you are building a very resilient communication system, if you think about Nostr, you would imagine that if you have, 10 million or 100 million users, the number of relays would be probably less than the square root of the number of users.
So that surface, although a hundred million users is very, they're not attackable, right? But the surface of, the relays is much more attackable. look at what is happening with, the coin joinin platforms, right? very similar. the beauty of KIT versus Nostr is that in KIT you have number of relays is actually equal to the number of users because the users are their own relays.
and they can act as relays for others to, further their connectivity. That is how we think a technology that, has to be ready for the apocalypse and resilient to the wrath of God should, work. if you have, a log number of users or square root of number of users as relates, I don't think it's cool technology.
It will work better than centralized, Technologies like WhatsApp and so on, or Twitter, but eventually will not work when you will need it the most. Because the point is that we will not know what will happen when we will need this technology the most. Today, not for everyone, but the world is still almost at peace.
Things might unfold, in the future, maybe sooner rather than later. But when things unfold, you will need the best technology, the one that is truly independent, the one that is truly peer to peer. it's not really peer to peer if you have specialized relays, but where you have super peers randomly.
Luke: Yeah, the difference here, between the Realize and not having any other centralized infrastructure in the picture is certainly an interesting distinction. I hadn't heard anything about that you can act as a next connector or something like that.
Pear Runtime
Luke: So there's a couple of related things. I know there was an announcement about the, pair runtime, is that right? can you talk a little bit about that or any other, ways that this is growing in your whole, platform,
Mathias: Yeah, sure. so basically when we talk about ideas, internally, also from our software background, We want to solve a small problem that then can solve it for everybody. So
We want to build technology that can just send data around efficiently, so you can build any kind of app on top. We're all about modularity and taking these things to the extreme so we can repurpose it into any kind of application and other people can, get value out of it.
And, that's been our mission from the get go. So basically, like Paolo said, when we built Keed. We took all of these primitives we have, it's all open source on our GitHub, that can do various things, relay encrypted data in a way that's completely private, nobody can read it, and in a generalizable way, so it can run on any applications.
We have databases that can interpret, work with this data on device, but still in a way where nobody else knows what's going on, fully private, and we spent many years perfecting this, and it's still ongoing. And we, similar to like connectivity, it might seem really easy if you don't know what's going on that, connecting this computer to another computer and another place, but it's really hard because ISPs and, your internet providers, et cetera, they don't really want you to do that.
So there's a lot of firewalls involved that you have to work around to get around This is all really, hard problems that took a long time to solve.
But luckily, all of these are like generalizable problems where you just solve them once to a large degree, and then it's solved for everybody. If you put them in a modular framework where anybody can put the Legos together on top. And that's what we've been heavily invested in. And then as we were building Keed, we realized that Keete is just like 95 percent of these Lego blocks that are applicable for anything.
So why not take all this stuff, pack it up for free, we don't make any money on it. and an open source runtime that we're just giving away so other people can contribute to it, but also build their own apps. the more peer to peer apps the world has, the better from my point of view.
and document it and make it really easy to install. And I think actually Paolo said something interesting because as soon as you have, one point of centralization, you can always unravel it. coming from the Bitcoin days, I remember how quickly things can unravel. people went to jail for linking to things because authorities, when they crack down, really hard.
so if you have one weak spot, it will be taken advantage of at some point by somebody. And so even things like distributing updates to your software can be really hard because this often requires a central point, like you go to a website and you don't download it. And so all apps built on our runtime, for example.
It's distributed through the runtime, which is a little bit mind bending. So all apps are peer to peer data applications themselves, and the network doesn't care, which means that we can continue to distribute updates even, if everything gets shut down, you only need like a bootstrap for the first install when you get the app.
So we're thinking that in. At every level, because it's really, important to us to, basically learn from everything that happened in the past and then actually build things that are resilient. And we take this to a degree where I'm sure we could move 10 times faster if we just let go a little bit of that idea, because it is easier to just put all the data in one place or put all the updates in one place.
But then it's then we're just building the same old thing that's going to die eventually anyway. So we're very, uncompromising in that mission of actually decentralizing everything from updates to data, and then also always solving in a way where everybody can take advantage of that.
And then the final thing I'll say about that is that, every time we update. That runtime, those building blocks of that runtime, every time we fix a bug, every time we make it faster, every app becomes faster. That's also very exciting. It's because you're building the whole infrastructure into this layer that runs on your phone.
And it's all somewhat generalizable. Every time we fix something, it's just better for the entire ecosystem. And that's obviously really, exciting. And like I said, actually, no strings attached.
Yeah, so I think you were referring to the trial of the Pirate Bay people there In Sweden, right? lucky enough to meet a couple of them in Denmark and it's been very fun to hear about their journey and, yeah, like
Knut: and there, there's, there was a great documentary made about it called TPBAFK. So the Pirate Bay Away From Keyboard, about that whole trial and how, corrupt the system was even back then. And, throwing people in jail for providing links. they didn't do any more wrong than Google did, from a certain perspective.
And, I remember even, before BitTorrents, there was a program called. DC or Direct Connect Do you remember that?
Mathias: I used to, it was one of my first introductions to decentralization. it as you just shared your, like a Google Drive for everyone or something. Like you just shared parts of your file tree to everyone who wanted to peek into it, Yeah, anyway. Oh, that's good that you didn't know you were going with that. it interesting what you said, because I think it's interesting to think that I think to a large degree, the whole decentralization movement that was happening with BitTorrent back in the day got shut down because At some point, authorities figured out that they could just block DNS requests to shut it down for normal people, and as soon as they did that, it was actually effective.
And to Paolo's point, no matter how weak it is, they're done. and they tried to kill the technology elsewhere, but that's actually what killed them. Then, obviously, alternatives came that people could pay for, and it also shows that people actually want, to stay on the right side of things.
I think, now it's going very much in the wrong direction again, because now we're back at abusing that centralization again. the cycle will repeat. But, yeah, like any point of weakness will be attacked at any point.
Decentralization vs. Centralization
Luke: So what are the drawbacks to decentralization? I think we and our audience certainly understand the benefit of decentralization, what you gain by decentralizing, but what do you naturally give up in terms of the user experience and the convenience factor?
Mathias: yeah, I'm sure Paola has stuff to say here, but I'm just, I love talking about this stuff, so I'll go first. Mattias.
I think it's a really interesting question, first of all, because it's one of those questions where You know, obviously I want to say there's no drawbacks, but like anything, it's a balance, right?
Because it's not that there's drawbacks and advantages, there obviously is, but it's also just a different paradigm. first of all, with sensitization, I think one of the biggest thing I noticed also with developers is that we all come out of systems, education systems. That teaches how to think centralized, which makes us biased towards centralized solutions.
and that's, I remember my whole curriculum was about servers and clients and stuff like that. it's actually really hard to think about decentralization as a developer. And I think that's actually part of why a lot of people think it's hard. It's complex because it is complex, but also because we're just like, we've been trained massively in the other direction, and it's really hard to go back because decentralization can be as simple as what Knut said about DC Connect, DC where it's just, oh, I'm just browsing other people's computers.
That's amazing. That's a really, simple experience, and it's like something you can never do But like in today's world, people, the first thing I always get asked is like, how do I get a username? And I'm like, usernames have an inherent centralization and there's trade offs there.
And we need to think that through and stuff. and most applications don't necessarily require usernames. I'm not saying that's a bad feature, but it's that's where you need to think more about the trade offs because there's governance involved to some degree. But for the core experience, and I think that's what we've shown in Keith so far.
Then, there's obviously tons of upsides also, it's much easier to do big data transfers. Money is less of a concern, which actually changes the thinking, how you think about features.
And that, again, is something we've been trained in a lot as developers, because we think centralized. When we talk about features at Holepunch, hey, we should add podcast recording to Keed. Normally somebody would say, that's going to cost a lot of money to host that data. And we just always we don't even have that discussion because it doesn't matter because it's just between the users.
And then it's more about like the UX. But then other simple, like I said, other simple discussions, let's add a username index. That's where we're like, okay, let's think that through because there's like various things to think about there because there's no centric governance, and we don't want to introduce that because again, one point is.
It's bad. so it's, more like you really need to think differently and it's really hard to wire your brain to think differently. but once you get past that point, I think it's, super interesting. And I, think actually developers care way more than normal people because, developers care a lot about how links look and links and structure and that.
And normal people are just used to just clicking buttons and apps and going with the flow on that. And that's also what we're seeing, I think, with, a lot of key
Paolo: I think the hiring has proven a little bit more challenging, as Matthias was saying, when you are told that the cloud is your friend, hosting, on, Google Cloud or AWS is the right thing to do. And, of course, it got cheaper and cheaper, so now everyone can host their websites.
But the reality is that 70 percent of, the entire internet knowledge is hosted in the data centers of three companies. developers should think about that, should think about the fact that internet was born to be point to point and peer to peer. And, we are very far away from that initial concept.
over the years, especially with the boom in, in the year 2000 for the internet boom, and bubble, then, realized that, holding people's data is the way to go, with social media and social network. That is even worse. And so you have these friendly advertisements that are telling you, That, with a smiley face that, you know, yeah, you should, upload all your data on, Apple cloud or Google cloud.
And in general, cloud backups are great, right? You want to have some sort of redundancy in your life, but the reality is that you should be able to upload those. In an encrypted way, and yet most of this data sits unencrypted because, the big tech companies have to decrypt it and use it for, to milk the information to pay for, for, another month of their new data centers.
the, issue is, we have so much power in our hands through our phones. the phones that we have today are much more powerful than the phones that we, or even the computers that we have 10 years ago or 5 years ago. And so We should, we are at a stage where we can use this hardware, not only for communicating, but also for in the future for AI processing and inference and so on.
is, we need to, understand that the word cannot be connected to Google. I mean we cannot be a function of Google. We cannot be a function of AWS. And so I think that, there is, escalating pace of, towards centralization and it's almost a black hole.
And eventually, the, we'll attract all the lights and if we are too close to it, no lights will come out anymore. And, that's why we want to really to double down on this technology, because it's not going to be easy, right? It's going to be very challenging, and most of the people don't care, as Maite has said before.
Most of the people will think, everything works with WhatsApp and, Signal, but Signal announced that their 2023 costs for data centers and data center costs are around 50 million, and they, apart from the mobile coin that was not The best thing that they could do, there is, it's not easy for them to monetize.
And the problem is that if you are, you're basically almost the only way to monetize it is to sell your customer's data. So if you don't want to sell your customer data, eventually your service will not be sustainable. So the only way to make it sustainable is actually going back to peer, where you can leverage people, infrastructure, people, connectivity, people, phones, people, processing power, Deliver very high quality communication system.
And when they will care, it will be probably usually too late if nothing exists yet. when people will care is because shit is hitting the fan. And, you really want to have a solution that is not, that will survive if, the countries around you or around the country where you live are not going to be nice to your own country.
So that's the view to peer-to-peer. The peer-to-peer wheel system will keep working if your neighbor countries are not going to be nice towards you. That's independence, that's resiliency, those are terms that, we need to take very seriously, especially seeing where the, world is going to.
Knut: Yeah, I think we're all primed for, centralized solutions, from a very young age. this is the state, this is what it is like, state funded schooling. state funders or state subsidized media. We are, like brainwashed into, trusting, institutions all our lives.
So I think that is somewhat connected to why people are so reluctant to be vigilant about this on the internet. I think the two go hand in hand that we, take the comfortable way, or most people take the comfortable route of, not taking responsibility for their own stuff. not only on the internet, but outsourcing responsibility to the government is basically the, another side of the same coin, right?
Mathias: I also find it very interesting, especially being from a small country like Denmark that doesn't have a lot of homegrown infrastructure. And I'm just seeing how much communication with some of the public entities is happening through centralized platforms like Facebook and things like that, where even though we centralize it, we also centralize it in companies that we don't even have any control over in different countries where we probably have, no rights at all.
So it's like hyper centralization, especially from the weakest point of view. And I think that's super problematic. And I'm always. Thinking it's, weird that we're not talking about that more especially when you look at the things that they're trying to do in the EU, they're almost trying to just push more in that direction, which I find even more interesting.
yeah, definitely. it's, a huge problem and it's only getting bigger. And that's, why
Challenges and Future of Decentralization
Luke: So to what level can decentralization actually get there? What is the limit to decentralization? And I'll calibrate this with an example. The internet itself, you said it was built to essentially originally be decentralized, but we don't have it. For physical links, like individual physical links between each other, the fiber or whatever the wire is goes together into another group of wires, which eventually go into some backbone, which is operated by a company.
And then that goes into the global Internet. And so somewhere it centralizes into telecom companies and other services. It might be decentralized on one level, but there is a layer of centralized services that make the internet work that isn't necessarily the so called cloud providers and that sort of thing.
So is there a limitation to how far this can go?
Paolo: I think the, in general, sure, there are the ISPs and, their physical infrastructure is in part centralized, but also you start having redundancy, right? So for example, the backbones are redundant. There are multiple companies running, cross connects across different areas of the world.
Now you have Starlink if you want. that is a great way to start decentralizing connectivity because Starlink will not be the only one that will run satellites, so there will be multiple companies that will allow you to connect through satellites, plus you have normal cabling.
So you will have, it will become a huge mesh network, it's already in part, but it will become more and more a huge mesh network. in general, you will always find a way, even with a pigeon, to start sending bits out of your house.
I think the most important part is, you have to be in control of your own data, and then, you need to send this data with the shortest path to the people that you want to talk to. Right now, I usually make this example, because I think it's When we do this presentation, we try to make people think about how much waste also centralized systems have created.
imagine you live in Rome, you live in Rome and you have your family. Most people live nearby their families. That is a classic thing among humans. 90 percent of the people live nearby their families. Maybe nearby, like 10km, 50km nearby. If you talk to your family, every single message, every single photo that you will send to your family, that message will travel, instead of going 50 kilometers in a nearby town where your mother lives or your father lives, it will travel every single message, every single bit of every single video call or every single bit of every photo will travel 5, 000 miles to Frankfurt just to go back 50 kilometers from you.
Imagine how much government spent in order to create these internet lines and to empower them to make it bigger, more, with more capacity Peer to peer allows with a lower latency, allows to save on bandwidth, allows to save on cost of global infrastructure.
So that's how, actually, We can create better mesh networks, more resilient mesh networks, just because data will always find the shortest path from one point to another.
And still all roads lead to Rome. I'm Italian, so I need to use Rome as an example.
Knut: Yeah.
Mathias: I think the discussion here is really interesting compared to Bitcoin, because it's actually the scaling longer term. Sovereignty, like how, Bitcoin kind of told us very direct terms that if you have a key pair, you have your money.
And it doesn't matter where you are in the world. If you have that key pair, you have a way to get to that money. the means of transportation, it's actually very uninteresting in that sense, because you have it with you. The Internet today, the centralized Internet is designed in a way where, what does it mean to go to Facebook?
it's really hard to explain because it's like some certificate that issued by somebody, and there's. Some, cabal of companies that manages them, there's some regulations around it, but we don't really actually understand it that well as normal people. Technically, we can understand it, but it's very, centralized and it's very, opaque and it's built into the infrastructure in that way, in a bad way.
And, with Pure Technology, we're taking the same approach as Bitcoin here and saying, You're just a key pair, and the other person is just a key pair, and there's a bunch of protocols around that, but the transportation is actually not that interesting. Right now, we use the internet to do it.
We'll probably do that for a long time, but there's no reason why we can take the same technology we have right now and in 50 years run it on, laser beams or something else, because we're taking the software and feedback.
Bitcoin and Holepunch: Drawing Parallels
Mathias: I think, that's the main thing to think about in that. Discussion.
Luke: when, Paolo, when you were talking about that people don't care, when you were saying that people don't care because WhatsApp just works, I was at the same time thinking that's the parallel of people saying that, I don't care because Visa just works, right? And so the parallel between Bitcoin and what you're doing at Holepunch, Keet, everything else here, really seems to be tracking along the same line.
And I guess there's the connection that, I won't say all, but a lot of the people involved are already in the Bitcoin ecosystem. But can you comment on is there a little more of a connection there between Holepunch and Keet and Bitcoin?
Paolo: Yeah, Bitcoin definitely is working and servicing, I think, in a good way, many, people in communities. The users of Bitcoin today are, unfortunately, and also that relates to Tether, mostly, in the Western world, in the richer countries, as a way to save wealth and, as a store of value, more than a means of exchange.
For different reasons, right? We'd like a network that would improve, of course, over time, and there will be different approaches, but, still, the world is not yet using Bitcoin, but the world will use Bitcoin when shit will hit the fan. but the beauty of Bitcoin is that an option is already there, is available, and when something bad will happen, people immediately, with a snap of a finger, will turn to Bitcoin, and will have it and can use it. don't have that in communications. What is our communica our parallel with communications, if we don't have it? I don't know, because if, if suddenly centralized communications will, be blocked, then, or privacy in communications will be blocked, and you cannot, you cannot use Whatsapp, or Whatsapp has to start giving all the information to every single government.
and the government will become more evil than what they are today, also western governments then. don't, we wanted to build the exact parallel as we said it, we just tried to describe it, that with Bitcoin, for communications. We need to have something that, since there are so many alternatives that are working as with your, you can make the parallel with Visa, right?
Visa is working today, so people are still using a lot of Visa, but if something will happen, they will use Bitcoin from one day to another. Whatsapp is working, and Zoom is working, and Google Meet is working, so people don't feel the urge, but there will be a trigger point when people will feel the urge at some point in their lives, because something happened around them, and we need to make sure that kit will be available to them.
and will be an option, will be stable, will be well designed so that when they will need it the most that option will be available to them.
Luke: Yeah, fantastic.
The Future of Decentralized Communication
Luke: And so I think the follow up I have, and just to get back to the earlier discussion a little bit with Nostr, the communication in terms of messaging, I absolutely see that and directly in what Keet is, I already absolutely see that. Is there a goal to get somewhere towards more like Social media, social networking, things like that in a, in certainly a decentralized way, but right now there isn't something like that as I understand it, coming from, Keet.
So is, that a goal? Is that on the roadmap?
Paolo: Yeah, it is on the roadmap, it's something that, so we had to start with the thing that we thought was more urgent and also the thing that could have been, would have been a game changer. social media is very important, especially In difficult situation, you want to get news, and you want to get unbiased news, so you want to use, social networks to see what's happening in the world.
But we, think that the most sacrosanct thing that you need in your life is to be able to talk to your family and friends in any situation with the highest privacy possible. that's the first thing that we tackled, and also was a way to battle test the technology with, KIT you can do high quality video calls as well, so if we are able to tackle in the best way possible privacy and extreme scalability of peer to peer communications, then on top of that foundation we can build also social media and every single other application that we have in mind.
Mathias: But first, we wanted to tackle the hardest problem. No, I think it makes a lot of sense. And I also just want to say, as a, probably like one of the most prolific KEET users, I use KEET right now also as a very, like a social media, we have big public rooms where we talk about KEET and talk about technology. I get a lot of the value I would get otherwise on Twitter X from that because I, it's like a public platform for me to, get ideas out there, but also interact with users directly.
And I think, there's many ways to take them as a young app. And we're talking about this a lot, obviously it has to be simple, has to be parent approved. My parents can figure it out, but I think, to a large degree, all really healthy social networks that are actually, to some degree, a communication app.
And it's also just a really good way to get local news and to get this locality that Peter is good at. That doesn't mean that we might not also make other things, but I think it's a hard line to set the difference between a social network and a communications app when it's structured correctly,
Interoperability and User Experience
Luke: Yeah, and this, another thing that came to mind just as, you were talking about these parallels, as, I understand it, the account system with Keet is, essentially still just a, Key pair. Correct me if I'm, wrong,
Mathias: Very, true.
Luke: you backups with the same 1224 words.
Is, that fully interoperable as well? Is that, could be your Bitcoin key. That could be
Mathias: We use the, same, I can't remember the date, the BIP, but there's a BIP for like during key generation. So we can use it also in the future for other things. and you have those words, you have your account, and that's, we never store that. And that's like your sovereignty and, no, I was just going to say that lets you use it seamlessly on different devices also. It's one of those things that I love because I know what's going on when you use keyed Insanely hard problem, but it's solved by the runtime, and it just works seamlessly and I think that's, the beauty of it.
Paolo: I think there's some UX stuff to figure out about onboarding that stuff a little bit easier for normal people. That's probably to a large degree the same for Bitcoin. The other part that I would do with Bitcoin is that, with Bitcoin, with your 12, 24 words, you can access your private wealth. the beauty of Bitcoin is that you can remember 12 24 words, you cross borders, and you carry with you your wealth. You can do the same thing with your digital private life.
You remember 12 24 words, they could be the same by the way. whatever happens, you can spawn back your digital private life fully encrypted from, one of your other devices that you connected that is somewhere else in the world. So when you start seeing and understanding the unlock in terms of also human resilience that this creates is very, insane and can create a very powerful, that can be used for, to create a very, powerful applications, not just communications, but you can build.
Really any sort of interaction, even mapping. Imagine peer to peer mapping, where basically data is not stored in one single location. You can access, tiles of the maps, from, local people that curate them in a better way. So the, level of applications that you can build, All unlocked by the same technology that is being used by Bitcoin is very, incredible.
Luke: Yes, absolutely it is. And what do you think of the idea that all of this stuff is just interoperable now based on essentially you have your private key and there you go. It doesn't matter the technology stack. Is that sort of an agnostic thing where you can take your data to any one of these systems?
What you're building with Keith being one, Nostr being another, Bitcoin being a third, what do you think of that?
Paolo: Yeah, the fact that, data is yours, right? So you should do whatever you want with your data. That is, I think, an axiom that we should assume. And, it shouldn't even, we shouldn't even discuss about this, right? We are discussing about it because people are trying to take away this axiom from us.
The, you are a key pair, and you're basically, unique, and uniqueness is expressed by the cryptography around those 24 words, and that's, that also is a way to prove your identity, it's a mathematical way to prove your identity.
No one can steal that from you, of course, but no one can track it as no one can impersonate, should not be able to impersonate you. So it's truly powerful.
Mathias: also think it's like worth remembering here also in this discussion that a lot of very high valuable data for yourself is actually not that big, but centralized platforms take it hostage anyway. if you take all my chat history and, I have pictures, but like a couple of the pictures would probably be bigger than all my chat history ever.
but a lot of that, those messages have a lot of value for me, especially personally and also being able to search through it and have infinite history, it's very valuable for me personally. But it's very scary for me if that's on some other platform where it gets leaked at some point, et cetera, et cetera.
But we already have the devices, just normal consumer devices that we buy, that we all have, phones, computers, whatever, that have more than enough capacity to store multiple copies of this. In terms of like per user, data production, it's a manageable problem.
And I think it's interesting how, providers force us to think in terms of giving that data away, even though we could easily store it.
Paolo: And this is even more important when we think about potential, AI applications, right? So imagine your best assistant. Paolo's assistant should go through all my emails, my kids chats, my old social stuff, and be able to be my best assistant. But in order to do that, I have two options.
Either, I imagine that OpenAI would come with an assistant. They would upload, All the information on their servers, crunch that information, and then, use it to serve, me, but also service their own needs. And that can become very scary, also because they wear a hat. It's public, right?
you don't want your most intimate codes that your best personal assistant could know, to be on somewhere else, rather than your devices. And so people were, people never uploaded, at least most of the people would never upload medical, information on Facebook, right? But they are uploading it on ChatGPT to get a second opinion.
so things can be, get even scarier than what we described today because, we, discussed about social media, that is basically, the fun part where we upload photos, But, things can become scarier when it comes to privacy and data control with ai.
So I want to see a future where I have a local AI that can read all key messages that I have from my local phone on my local device, and can become the best powers assistant possible without renouncing to my privacy, and also still governed by the same 24 words. the fine tuning that is applied on that LLM should stay local to my own device, and it should be in control of that.
And still, the current power of the devices that we have makes it possible. We should not fall for the same lie. We don't need, of course, big data centers with GPUs are important for training a huge LLM, but that is a generic LLM. You can take that one and then fine tune it with your own data and run it by yourself.
And for most of it, unless you want to do crazy things, that is more than enough and can run on modern GPUs or local GPUs or your phones. We should start thinking that we can build local experiences without having an API all the time connected to someone else's data center.
Knut: Yeah.
The Role of Tether in the Crypto Ecosystem
Knut: It's super interesting. you briefly just briefly mentioned tether before and I think we need to get into this. what is it and how much of a maxi are you, Paolo?
And, what, made this thing happen? Can you give us the story here about Tether?
Tether's Origin and Evolution
Paolo: Tether started in 2014. I consider myself a maxi, but running Tether, you could say that, I'm a shit coiner. I don't mind, right? I like what I do, and I think I'm net positive, so it's okay. Tera was born in 2014 with a very simple idea. there were a few crypto exchanges in, 2014.
it was Bitfinex, Coinbase, Kraken, Bitstamp. OKCoin, there was BTCChina, and just a few others, right? Around 10 that were meaningful. The problem back then was to do, trading arbitrage, you sell Bitcoin on the exchange where the price is higher, you take the dollars. From that sale, you move the dollars on the exchange where the price is lower and rinse and repeat.
That is called arbitrage. It is a property of every single efficient financial system. And that also helps to keep the price of Bitcoin in line across different exchanges. But, that was very, hard in 2014. If you remember in 2013 was the first year that Bitcoin broke the 1, 000.
But on some exchanges the price was 1. 2, on others was 900. in order to arbitrage that price difference, you have to move dollars from one exchange to another and Bitcoin from one exchange to another. You can move Bitcoin from one exchange to another. 10 minutes, but dollars would take days, right?
International wires. And so of course the opportunity arbitrage was, fully gone by, the, time the wire was hitting the, receiving exchange. the reason why we created that was, USDT was simply to put the dollar on a blockchain so that we could have the same user experience that we had with bitcoin.
For the first two years, almost no exchange apart Bitfinex understood USDT. Then Poloniex in 2016 started to add the USDT across for against every single trading pair. There was the start of the ICO boom. 2017 was the peak of the ICO boom and, USDT reached 1 billion in market cap. Fast forward in 2020, we had around 10 billion in market cap, and then the bull run started, but also another important thing started, that was the pandemic.
USDT's Impact on Emerging Markets
Paolo: So the pandemic had a huge effect on many economies around the world, in all the economies around the world, but especially in emerging markets, developing countries.
Basically pandemic also killed entire economies. And so as a Bitcoin you would think, oh, all these people that are in countries like Argentina and Venezuela and Turkey and so on, they should use Bitcoin and they should, they should, only use Bitcoin because everything else is cheap.
So that is pretty much, the approach that we have as Bitcoiners that, I believe in. But the problem is that. Not everyone is ready, so not everyone has our time to understand Bitcoin. Not everyone has yet the full skill set to understand Bitcoin at this stage, at this moment in time.
we as Bitcoiners didn't build the best user experience in the world, right? So one of the best wallets for Bitcoin is still Electrum. That, is not necessarily nice and well done for and simple to be used for, a 70 year old lady. so we need to do a better job as Bitcoiners to build better user experiences we want Bitcoin to be more used around the world.
At the same time, 99 percent of the population knows, especially the ones that are living in high inflation areas, knows that there is the dollar that is usually Much better currency than what they hold in their hands. the US dollar is not, definitely not perfect. It's not the perfect fiat currency. but it's like the tale of the two friends running away from the lion, right?
you have, one friend tells to the other, Oh, the lion is gonna kill us. We have to run really fast. And one of the two friends says to the other, I just have to run faster than you, right? So the US dollar is the friend that is running faster, in a sense that is the one that is likely better than the others.
And so being better than the others is creating a sort of safety feeling among 5 billion people in the world that live in high inflation countries. And for those people that, they don't have yet the time, they didn't have the luck also, maybe, to understand Bitcoin, they are, in fact, using USDT.
If you live in Argentina, peso lost 98% against the US dollar in the last five years. The Turkish L lost 80% against the US dollar in, the last five years. So of course, Bitcoin would be better than the US dollar, but even already, if you hold the dollar, you are the king of the hill there, right?
So because it's, you are able to preserve your wealth much, better than almost anyone else in the region. I think, USDT is offering a temporary solution and is providing a service, a very good service to people that don't have alternatives and good alternatives and they are very, familiar with the U.
S. dollar already. so eventually, the hyperbitcoinization, I think it will happen. there is no way it won't happen. It's hard to pinpoint on a time when, that will happen. But it's all about the turning point. What the economy will look like in the next, 10, 20 years and what trigger point there will be for fiat currencies to blow up and become irrelevant.
Bitcoin as a Savings Account
Paolo: the way I see it is that it's likely that the U. S. dollar will stay around for a while, and people might still want to use, the U. S. dollar as a checking account, but they, should start to use, Bitcoin as their savings account, in the checking account, you, are happy to not make interest, It's something that you use for payments, it's something that you are okay to detach from because it's the money that you are ready to spend.
The savings account is the thing that we should fight for. This thing is the thing that matter the most, and, it's the thing that will is protecting people wealth. And so in the long term. And in the medium term, we should push for this savings account to be Bitcoin. also with Tether, we are heavily investing in companies, in Bitcoin companies.
we support the Blockstream. We supported so many in the space that are, we, are supporting RGB. That is a protocol that is building, assets on top of, like network, style channels. Thank you for listening. and we buy Bitcoin ourselves. We do a lot of Bitcoin mining.
We develop, I think, the best and most sophisticated Bitcoin mining software, by the way, based on hole punch technology. It's like IoT for Bitcoiners and Bitcoin mining. It's very cool. we are relying on the dollar and, you could say that USDT is helping the dollar, expansion, but the same way I don't think Dollar and Bitcoin aren't necessarily opposed to one or the other.
I think that Bitcoin has its own path. And no matter what happens, there is no way to slow it down. I think, it's going to be inevitable success. It's going to be inevitable that it will become global internet money and global words money. No country will trust to each other with, with each other currencies for, for a longer time, and so the only viable solution is a currency that is governed by math.
That is the only objective way, objective thing that we have in the universe. that's my train of thoughts on, Tether and Bitcoin.
Knut: Oh, thank you. Thank you for that explanation. It explains a lot of things. To me, it sounds a bit like you're a lubrication company, like selling lubrication for the transition between the rape of the dollar to the love fest of the hyperbitcoinized world, to make the transition a little smoother.
Paolo: we are more than, at Tether we have also this educational arm and, believe it or not, the majority of the creation we do is actually on Bitcoin, right? So we are supporting the Plan B network led by the great Giacomo Zucco. The unfortunate thing is that USDT, didn't have a marketing team up to, 2022 with Tether.
So basically, I wish I could say that success of Tether is because we were super intelligent and great. but actually the success of Tether, unfortunately is a symptom of the success of, of, national economies. And it's sad if you think about it, right? So the success of your main product U as it is, They're actually proportional to the FACAP of many central banks. And, but it is what it is, right? So we need to do what we do at, really, at DataRace, creating all these educational contents to try to explain that, sure, we are providing a tool for today, but, For tomorrow you probably need, you need to understand that you have other options, you need to understand Bitcoin, because as we said for, Keith, right?
So the moment when you will need the most Bitcoin, it has to be available, you need to understand it, so that is a true option for you. The way we, see bitcoin education.
Knut: No, and, something like Tether would have, emerged, either way, and it's very comforting to know that it's run by Bitcoiners and not by a central bank itself or something. yeah, and the Plan B Network, I was a guest lecturer there in Logano and it was fantastic.
I love what you're doing there with the educational hub. And we even got Giacomo to write the foreword to our new book here that you can see here behind Luke.
Luke: Always say the title, Knut. Always say the title.
Knut: Bitcoin, the inverse of Clown World. It's, you, if, you're good at maths and emojis, you might be able to figure out the title from the cover, but it's one divided by Clown World anyway, which is on the opposite side of the everything divided by 21 million equation, So anyway, looking forward to seeing you in Lugano and giving you both a copy of the book, of course.
Paolo: Oh, with pleasure, with great pleasure, with a nice, education.
Luke: Absolutely. Yep.
Plan B Forum and Future Events
Luke: 100%. And we have to wind things down, but I'll just say as well, yeah, absolutely looking forward to Lugano Plan B Forum. Always a highlight of the year. It was my first time last year. I absolutely loved it. can't wait to attend this year.
so it's the 25th, 2020 6th of October, 2024. this year, it's a Bitcoin event that is not made to make money. So the problem with events is that. You have to find sponsors, and usually, sponsor might not be well aligned with the message you want to give, right? I think Tether is lucky enough, to not have to make money on the event.
Paolo: I want to have, good, guests. I want to have great speakers. I want to have the messaging. That is not only about Bitcoin, it's about, freedom of speech as well. We had the family of Assange for the last few years, and I think that they will come also this year.
I'm going to be probably killed by the By our marketing team, I'm not sure if they announced it, but we are going to have another Plan B event also in El Salvador next year, so we're trying to create this network of cities and countries that have things in common and, invite people that want to share knowledge around the world.
And, yeah, and of course we, are very proud of the good food that we, serve in Lugano. So that is another thing that, not all the bands can say the same thing.
Knut: No, it's fantastic. And we happened to bump into the Assange family at the cocktail bar in a fancy hotel and, had a very interesting conversation with them there. So if you're listening. Anyone from the Assange family is welcome on the show any time. So yeah, no looking forward to that event for sure, we had a great time.
And I think we're even playing this year, aren't we, Luke?
Paolo: You're
Luke: yeah, the Satoshi Rakamoto is in the event there, we, played, back in Prague, it was my first, time, but Knut is a regular at the Rakamotos.
Yeah, we played at Lugano last year Oh, anything and everything, what did we do in Prague?
Knut: paranoid and,
Paolo: Can I commission a
Knut: What song would you like to hear?
Paolo: I have two that I would suggest. One is Nothing Else Matters.
Knut: Alright.
Paolo: So I think that, is very inspiring, right?
Knut: Bitcoin, for sure.
Nothing Else Matters. it's perfectly aligned with Bitcoin. And, the other one is Sad But True. Oh, that would be fun. We'll squeeze in some Metallica there, won't we, Luke?
Mathias: we'll 100% have those songs ready to go. We also have, a big peer to peer track at the conference,
Knut: Yeah.
Mathias: not so much music, but yeah, that's peer to
Knut: Nothing else matters.
Luke: looking forward to that.
Knut: Sorry, brain fart. Sad but true is about the dollar still being around,
Paolo: Yeah, you can say that.
Luke: Okay.
Final Thoughts and Closing Remarks
Luke: Hey, we have to wind things down here because, we're, almost, out of time. So I'll just hand this, back to you both. Is there anything else you'd like to, mention about, your plans in the upcoming couple of years, in, key, toll, punch, anything like that?
Mathias: only that we're, like I said, we're integrating really hard right now, and it's a really fun time to, join the company because, we're small and efficient We get to work with Tether, which has a lot of benefits and it's getting really fast, so definitely check that out. And it's also a really fun time to join Keith in our public rooms.
There's a lot of very personal, in a good way, intense chats where you get to be part of the loop. I love to be part of those early communities and I would suggest everybody to check that out and go to the website and try it out.
Paolo: we will certainly do that. Yeah, I couldn't agree more. So go check out Keith and Holepunch and the Plan B forum in Lugano, You could visit tether. io, that is, the website where we are trying to explain what we have in our minds between, finance, bitcoin mining, energy production, AI, communications, brain chips and stuff, right? I think it's more exciting.
Mathias: Just those things, that's all.
Paolo: Yeah, we can piss off more than this. Thanks.
Mathias: a
Luke: No, It's just perfect. and is on that note, is there anywhere else specific you'd like to direct our listeners?
Paolo: just follow the social channels and give us feedback on kit all the time because these technologies, needs everyone's help to be nailed them.
Mathias: We love technical feedback. We love UX feedback. We're trying to make something that works for the masses, so anything is good.
Luke: So that's, all at Keet. Is that correct? For Keet?
Mathias: Key. io and pairs. com for our runtime. It's all peer to peer.
Knut: Alright,
Mathias: Wonderful. And you're also still on the legacy social media platforms, right? Yeah.
Knut: we'll make sure to include links to your handles so people can find you there if they would like. forward to seeing you in Lugano.
Paolo: Likewise, I
Knut: But yeah, worth saying again.
Paolo: Thank you for having an invitation.
Luke: Yes, we'll wrap things up here. This has been the Bitcoin Infinity Show.
-
@ 09fbf8f3:fa3d60f0
2024-09-10 13:21:23
由于gmail在中国被防火墙拦截了,无法打开,不想错过邮件通知。
通过自建ntfy接受gmail邮件通知。 怎么自建ntfy,后面再写。
2024年08月13日更新:
修改不通过添加邮件标签来标记已经发送的通知,通过Google Sheets来记录已经发送的通知。
为了不让Google Sheets文档的内容很多,导致文件变大,用脚本自动清理一个星期以前的数据。
准备工具
- Ntfy服务
- Google Script
- Google Sheets
操作步骤
- 在Ntfy后台账号,设置访问令牌。

- 添加订阅主题。

- 进入Google Sheets创建一个表格.记住id,如下图:

- 进入Google Script创建项目。填入以下代码(注意填入之前的ntfy地址和令牌):
```javascript function checkEmail() { var sheetId = "你的Google Sheets id"; // 替换为你的 Google Sheets ID var sheet = SpreadsheetApp.openById(sheetId).getActiveSheet();
// 清理一星期以前的数据 cleanOldData(sheet, 7 * 24 * 60); // 保留7天(即一周)内的数据
var sentEmails = getSentEmails(sheet);
var threads = GmailApp.search('is:unread'); Logger.log("Found threads: " + threads.length);
if (threads.length === 0) return;
threads.forEach(function(thread) { var threadId = thread.getId();
if (!sentEmails.includes(threadId)) { thread.getMessages().forEach(sendNtfyNotification); recordSentEmail(sheet, threadId); }}); }
function sendNtfyNotification(email) { if (!email) { Logger.log("Email object is undefined or null."); return; }
var message = `发件人: ${email.getFrom() || "未知发件人"} 主题: ${email.getSubject() || "无主题"}
内容: ${email.getPlainBody() || "无内容"}`;
var url = "https://你的ntfy地址/Gmail"; var options = { method: "post", payload: message, headers: { Authorization: "Bearer Ntfy的令牌" }, muteHttpExceptions: true };
try { var response = UrlFetchApp.fetch(url, options); Logger.log("Response: " + response.getContentText()); } catch (e) { Logger.log("Error: " + e.message); } }
function getSentEmails(sheet) { var data = sheet.getDataRange().getValues(); return data.map(row => row[0]); // Assuming email IDs are stored in the first column }
function recordSentEmail(sheet, threadId) { sheet.appendRow([threadId, new Date()]); }
function cleanOldData(sheet, minutes) { var now = new Date(); var thresholdDate = new Date(now.getTime() - minutes * 60 * 1000); // 获取X分钟前的时间
var data = sheet.getDataRange().getValues(); var rowsToDelete = [];
data.forEach(function(row, index) { var date = new Date(row[1]); // 假设日期保存在第二列 if (date < thresholdDate) { rowsToDelete.push(index + 1); // 存储要删除的行号 } });
// 逆序删除(从最后一行开始删除,以避免行号改变) rowsToDelete.reverse().forEach(function(row) { sheet.deleteRow(row); }); }
```
4.Goole Script需要添加gmail服务,如图:

5.Google Script是有限制的不能频繁调用,可以设置五分钟调用一次。如图:


结尾
本人不会代码,以上代码都是通过chatgpt生成的。经过多次修改,刚开始会一直发送通知,后面修改后将已发送的通知放到一个“通知”的标签里。后续不会再次发送通知。
如需要发送通知后自动标记已读,可以把代码复制到chatgpt给你写。
效果预览:




{kind=link}
{kind=link}