-
 @ 3bf0c63f:aefa459d
2024-09-06 12:49:46
@ 3bf0c63f:aefa459d
2024-09-06 12:49:46Nostr: a quick introduction, attempt #2
Nostr doesn't subscribe to any ideals of "free speech" as these belong to the realm of politics and assume a big powerful government that enforces a common ruleupon everybody else.
Nostr instead is much simpler, it simply says that servers are private property and establishes a generalized framework for people to connect to all these servers, creating a true free market in the process. In other words, Nostr is the public road that each market participant can use to build their own store or visit others and use their services.
(Of course a road is never truly public, in normal cases it's ran by the government, in this case it relies upon the previous existence of the internet with all its quirks and chaos plus a hand of government control, but none of that matters for this explanation).
More concretely speaking, Nostr is just a set of definitions of the formats of the data that can be passed between participants and their expected order, i.e. messages between clients (i.e. the program that runs on a user computer) and relays (i.e. the program that runs on a publicly accessible computer, a "server", generally with a domain-name associated) over a type of TCP connection (WebSocket) with cryptographic signatures. This is what is called a "protocol" in this context, and upon that simple base multiple kinds of sub-protocols can be added, like a protocol for "public-square style microblogging", "semi-closed group chat" or, I don't know, "recipe sharing and feedback".
-
@ 3bf0c63f:aefa459d
2025-04-25 18:55:52
Report of how the money Jack donated to the cause in December 2022 has been misused so far.
Bounties given
March 2025
- Dhalsim: 1,110,540 - Work on Nostr wiki data processing
February 2025
- BOUNTY* NullKotlinDev: 950,480 - Twine RSS reader Nostr integration
- Dhalsim: 2,094,584 - Work on Hypothes.is Nostr fork
- Constant, Biz and J: 11,700,588 - Nostr Special Forces
January 2025
- Constant, Biz and J: 11,610,987 - Nostr Special Forces
- BOUNTY* NullKotlinDev: 843,840 - Feeder RSS reader Nostr integration
- BOUNTY* NullKotlinDev: 797,500 - ReadYou RSS reader Nostr integration
December 2024
- BOUNTY* tijl: 1,679,500 - Nostr integration into RSS readers yarr and miniflux
- Constant, Biz and J: 10,736,166 - Nostr Special Forces
- Thereza: 1,020,000 - Podcast outreach initiative
November 2024
- Constant, Biz and J: 5,422,464 - Nostr Special Forces
October 2024
- Nostrdam: 300,000 - hackathon prize
- Svetski: 5,000,000 - Latin America Nostr events contribution
- Quentin: 5,000,000 - nostrcheck.me
June 2024
- Darashi: 5,000,000 - maintaining nos.today, searchnos, search.nos.today and other experiments
- Toshiya: 5,000,000 - keeping the NIPs repo clean and other stuff
May 2024
- James: 3,500,000 - https://github.com/jamesmagoo/nostr-writer
- Yakihonne: 5,000,000 - spreading the word in Asia
- Dashu: 9,000,000 - https://github.com/haorendashu/nostrmo
February 2024
- Viktor: 5,000,000 - https://github.com/viktorvsk/saltivka and https://github.com/viktorvsk/knowstr
- Eric T: 5,000,000 - https://github.com/tcheeric/nostr-java
- Semisol: 5,000,000 - https://relay.noswhere.com/ and https://hist.nostr.land relays
- Sebastian: 5,000,000 - Drupal stuff and nostr-php work
- tijl: 5,000,000 - Cloudron, Yunohost and Fraidycat attempts
- Null Kotlin Dev: 5,000,000 - AntennaPod attempt
December 2023
- hzrd: 5,000,000 - Nostrudel
- awayuki: 5,000,000 - NOSTOPUS illustrations
- bera: 5,000,000 - getwired.app
- Chris: 5,000,000 - resolvr.io
- NoGood: 10,000,000 - nostrexplained.com stories
October 2023
- SnowCait: 5,000,000 - https://nostter.vercel.app/ and other tools
- Shaun: 10,000,000 - https://yakihonne.com/, events and work on Nostr awareness
- Derek Ross: 10,000,000 - spreading the word around the world
- fmar: 5,000,000 - https://github.com/frnandu/yana
- The Nostr Report: 2,500,000 - curating stuff
- james magoo: 2,500,000 - the Obsidian plugin: https://github.com/jamesmagoo/nostr-writer
August 2023
- Paul Miller: 5,000,000 - JS libraries and cryptography-related work
- BOUNTY tijl: 5,000,000 - https://github.com/github-tijlxyz/wikinostr
- gzuus: 5,000,000 - https://nostree.me/
July 2023
- syusui-s: 5,000,000 - rabbit, a tweetdeck-like Nostr client: https://syusui-s.github.io/rabbit/
- kojira: 5,000,000 - Nostr fanzine, Nostr discussion groups in Japan, hardware experiments
- darashi: 5,000,000 - https://github.com/darashi/nos.today, https://github.com/darashi/searchnos, https://github.com/darashi/murasaki
- jeff g: 5,000,000 - https://nostr.how and https://listr.lol, plus other contributions
- cloud fodder: 5,000,000 - https://nostr1.com (open-source)
- utxo.one: 5,000,000 - https://relaying.io (open-source)
- Max DeMarco: 10,269,507 - https://www.youtube.com/watch?v=aA-jiiepOrE
- BOUNTY optout21: 1,000,000 - https://github.com/optout21/nip41-proto0 (proposed nip41 CLI)
- BOUNTY Leo: 1,000,000 - https://github.com/leo-lox/camelus (an old relay thing I forgot exactly)
June 2023
- BOUNTY: Sepher: 2,000,000 - a webapp for making lists of anything: https://pinstr.app/
- BOUNTY: Kieran: 10,000,000 - implement gossip algorithm on Snort, implement all the other nice things: manual relay selection, following hints etc.
- Mattn: 5,000,000 - a myriad of projects and contributions to Nostr projects: https://github.com/search?q=owner%3Amattn+nostr&type=code
- BOUNTY: lynn: 2,000,000 - a simple and clean git nostr CLI written in Go, compatible with William's original git-nostr-tools; and implement threaded comments on https://github.com/fiatjaf/nocomment.
- Jack Chakany: 5,000,000 - https://github.com/jacany/nblog
- BOUNTY: Dan: 2,000,000 - https://metadata.nostr.com/
April 2023
- BOUNTY: Blake Jakopovic: 590,000 - event deleter tool, NIP dependency organization
- BOUNTY: koalasat: 1,000,000 - display relays
- BOUNTY: Mike Dilger: 4,000,000 - display relays, follow event hints (Gossip)
- BOUNTY: kaiwolfram: 5,000,000 - display relays, follow event hints, choose relays to publish (Nozzle)
- Daniele Tonon: 3,000,000 - Gossip
- bu5hm4nn: 3,000,000 - Gossip
- BOUNTY: hodlbod: 4,000,000 - display relays, follow event hints
March 2023
- Doug Hoyte: 5,000,000 sats - https://github.com/hoytech/strfry
- Alex Gleason: 5,000,000 sats - https://gitlab.com/soapbox-pub/mostr
- verbiricha: 5,000,000 sats - https://badges.page/, https://habla.news/
- talvasconcelos: 5,000,000 sats - https://migrate.nostr.com, https://read.nostr.com, https://write.nostr.com/
- BOUNTY: Gossip model: 5,000,000 - https://camelus.app/
- BOUNTY: Gossip model: 5,000,000 - https://github.com/kaiwolfram/Nozzle
- BOUNTY: Bounty Manager: 5,000,000 - https://nostrbounties.com/
February 2023
- styppo: 5,000,000 sats - https://hamstr.to/
- sandwich: 5,000,000 sats - https://nostr.watch/
- BOUNTY: Relay-centric client designs: 5,000,000 sats https://bountsr.org/design/2023/01/26/relay-based-design.html
- BOUNTY: Gossip model on https://coracle.social/: 5,000,000 sats
- Nostrovia Podcast: 3,000,000 sats - https://nostrovia.org/
- BOUNTY: Nostr-Desk / Monstr: 5,000,000 sats - https://github.com/alemmens/monstr
- Mike Dilger: 5,000,000 sats - https://github.com/mikedilger/gossip
January 2023
- ismyhc: 5,000,000 sats - https://github.com/Galaxoid-Labs/Seer
- Martti Malmi: 5,000,000 sats - https://iris.to/
- Carlos Autonomous: 5,000,000 sats - https://github.com/BrightonBTC/bija
- Koala Sat: 5,000,000 - https://github.com/KoalaSat/nostros
- Vitor Pamplona: 5,000,000 - https://github.com/vitorpamplona/amethyst
- Cameri: 5,000,000 - https://github.com/Cameri/nostream
December 2022
- William Casarin: 7 BTC - splitting the fund
- pseudozach: 5,000,000 sats - https://nostr.directory/
- Sondre Bjellas: 5,000,000 sats - https://notes.blockcore.net/
- Null Dev: 5,000,000 sats - https://github.com/KotlinGeekDev/Nosky
- Blake Jakopovic: 5,000,000 sats - https://github.com/blakejakopovic/nostcat, https://github.com/blakejakopovic/nostreq and https://github.com/blakejakopovic/NostrEventPlayground
-
@ 3bf0c63f:aefa459d
2024-06-13 15:40:18
Why relay hints are important
Recently Coracle has removed support for following relay hints in Nostr event references.
Supposedly Coracle is now relying only on public key hints and
kind:10002events to determine where to fetch events from a user. That is a catastrophic idea that destroys much of Nostr's flexibility for no gain at all.- Someone makes a post inside a community (either a NIP-29 community or a NIP-87 community) and others want to refer to that post in discussions in the external Nostr world of
kind:1s -- now that cannot work because the person who created the post doesn't have the relays specific to those communities in their outbox list; - There is a discussion happening in a niche relay, for example, a relay that can only be accessed by the participants of a conference for the duration of that conference -- since that relay is not in anyone's public outbox list, it's impossible for anyone outside of the conference to ever refer to these events;
- Some big public relays, say, relay.damus.io, decide to nuke their databases or periodically delete old events, a user keeps using that big relay as their outbox because it is fast and reliable, but chooses to archive their old events in a dedicated archival relay, say, cellar.nostr.wine, while prudently not including that in their outbox list because that would make no sense -- now it is impossible for anyone to refer to old notes from this user even though they are publicly accessible in cellar.nostr.wine;
- There are topical relays that curate content relating to niche (non-microblogging) topics, say, cooking recipes, and users choose to publish their recipes to these relays only -- but now they can't refer to these relays in the external Nostr world of
kind:1s because these topical relays are not in their outbox lists. - Suppose a user wants to maintain two different identities under the same keypair, say, one identity only talks about soccer in English, while the other only talks about art history in French, and the user very prudently keeps two different
kind:10002events in two different sets of "indexer" relays (or does it in some better way of announcing different relay sets) -- now one of this user's audiences cannot ever see notes created by him with their other persona, one half of the content of this user will be inacessible to the other half and vice-versa. - If for any reason a relay does not want to accept events of a certain kind a user may publish to other relays, and it would all work fine if the user referenced that externally-published event from a normal event, but now that externally-published event is not reachable because the external relay is not in the user's outbox list.
- If someone, say, Alex Jones, is hard-banned everywhere and cannot event broadcast
kind:10002events to any of the commonly used index relays, that person will now appear as banned in most clients: in an ideal world in which clients followednprofileand other relay hints Alex Jones could still live a normal Nostr life: he would print business cards with hisnprofileinstead of annpuband clients would immediately know from what relay to fetch his posts. When other users shared his posts or replied to it, they would include a relay hint to his personal relay and others would be able to see and then start following him on that relay directly -- now Alex Jones's events cannot be read by anyone that doesn't already know his relay.
- Someone makes a post inside a community (either a NIP-29 community or a NIP-87 community) and others want to refer to that post in discussions in the external Nostr world of
-
@ 3bf0c63f:aefa459d
2024-06-12 15:26:56
How to do curation and businesses on Nostr
Suppose you want to start a Nostr business.
You might be tempted to make a closed platform that reuses Nostr identities and grabs (some) content from the external Nostr network, only to imprison it inside your thing -- and then you're going to run an amazing AI-powered algorithm on that content and "surface" only the best stuff and people will flock to your app.
This will be specially good if you're going after one of the many unexplored niches of Nostr in which reading immediately from people you know doesn't work as you generally want to discover new things from the outer world, such as:
- food recipe sharing;
- sharing of long articles about varying topics;
- markets for used goods;
- freelancer work and job offers;
- specific in-game lobbies and matchmaking;
- directories of accredited professionals;
- sharing of original music, drawings and other artistic creations;
- restaurant recommendations
- and so on.
But that is not the correct approach and damages the freedom and interoperability of Nostr, posing a centralization threat to the protocol. Even if it "works" and your business is incredibly successful it will just enshrine you as the head of a platform that controls users and thus is prone to all the bad things that happen to all these platforms. Your company will start to display ads and shape the public discourse, you'll need a big legal team, the FBI will talk to you, advertisers will play a big role and so on.
If you are interested in Nostr today that must be because you appreciate the fact that it is not owned by any companies, so it's safe to assume you don't want to be that company that owns it. So what should you do instead? Here's an idea in two steps:
- Write a Nostr client tailored to the niche you want to cover
If it's a music sharing thing, then the client will have a way to play the audio and so on; if it's a restaurant sharing it will have maps with the locations of the restaurants or whatever, you get the idea. Hopefully there will be a NIP or a NUD specifying how to create and interact with events relating to this niche, or you will write or contribute with the creation of one, because without interoperability none of this matters much.
The client should work independently of any special backend requirements and ideally be open-source. It should have a way for users to configure to which relays they want to connect to see "global" content -- i.e., they might want to connect to
wss://nostr.chrysalisrecords.com/to see only the latest music releases accredited by that label or towss://nostr.indiemusic.com/to get music from independent producers from that community.- Run a relay that does all the magic
This is where your value-adding capabilities come into play: if you have that magic sauce you should be able to apply it here. Your service, let's call it
wss://magicsaucemusic.com/, will charge people or do some KYM (know your music) validation or use some very advanced AI sorcery to filter out the spam and the garbage and display the best content to your users who will request the global feed from it (["REQ", "_", {}]), and this will cause people to want to publish to your relay while others will want to read from it.You set your relay as the default option in the client and let things happen. Your relay is like your "website" and people are free to connect to it or not. You don't own the network, you're just competing against other websites on a leveled playing field, so you're not responsible for it. Users get seamless browsing across multiple websites, unified identities, a unified interface (that could be different in a different client) and social interaction capabilities that work in the same way for all, and they do not depend on you, therefore they're more likely to trust you.
Does this centralize the network still? But this a simple and easy way to go about the matter and scales well in all aspects.
Besides allowing users to connect to specific relays for getting a feed of curated content, such clients should also do all kinds of "social" (i.e. following, commenting etc) activities (if they choose to do that) using the outbox model -- i.e. if I find a musician I like under
wss://magicsaucemusic.comand I decide to follow them I should keep getting updates from them even if they get banned from that relay and start publishing onwss://nos.lolorwss://relay.damus.ioor whatever relay that doesn't even know what music is.The hardcoded defaults and manual typing of relay URLs can be annoying. But I think it works well at the current stage of Nostr development. Soon, though, we can create events that recommend other relays or share relay lists specific to each kind of activity so users can get in-app suggestions of relays their friends are using to get their music from and so on. That kind of stuff can go a long way.
-
@ 3bf0c63f:aefa459d
2024-05-24 12:31:40
About Nostr, email and subscriptions
I check my emails like once or twice a week, always when I am looking for something specific in there.
Then I go there and I see a bunch of other stuff I had no idea I was missing. Even many things I wish I had seen before actually. And sometimes people just expect and assume I would have checked emails instantly as they arrived.
It's so weird because I'm not making a point, I just don't remember to open the damn "gmail.com" URL.
I remember some people were making some a Nostr service a while ago that sent a DM to people with Nostr articles inside -- or some other forms of "subscription services on Nostr". It makes no sense at all.
Pulling in DMs from relays is exactly the same process (actually slightly more convoluted) than pulling normal public events, so why would a service assume that "sending a DM" was more likely to reach the target subscriber when the target had explicitly subscribed to that topic or writer?
Maybe due to how some specific clients work that is true, but fundamentally it is a very broken assumption that comes from some fantastic past era in which emails were 100% always seen and there was no way for anyone to subscribe to someone else's posts.
Building around such broken assumptions is the wrong approach. Instead we should be building new flows for subscribing to specific content from specific Nostr-native sources (creators directly or manual or automated curation providers, communities, relays etc), which is essentially what most clients are already doing anyway, but specifically Coracle's new custom feeds come to mind now.
This also reminds me of the interviewer asking the Farcaster creator if Farcaster made "email addresses available to content creators" completely ignoring all the cryptography and nature of the protocol (Farcaster is shit, but at least they tried, and in this example you could imagine the interviewer asking the same thing about Nostr).
I imagine that if the interviewer had asked these people who were working (or suggesting) the Nostr DM subscription flow they would have answered: "no, you don't get their email addresses, but you can send them uncensorable DMs!" -- and that, again, is getting everything backwards.
-
@ 3bf0c63f:aefa459d
2024-03-19 15:35:35
Nostr is not decentralized nor censorship-resistant
Peter Todd has been saying this for a long time and all the time I've been thinking he is misunderstanding everything, but I guess a more charitable interpretation is that he is right.
Nostr today is indeed centralized.
Yesterday I published two harmless notes with the exact same content at the same time. In two minutes the notes had a noticeable difference in responses:
The top one was published to
wss://nostr.wine,wss://nos.lol,wss://pyramid.fiatjaf.com. The second was published to the relay where I generally publish all my notes to,wss://pyramid.fiatjaf.com, and that is announced on my NIP-05 file and on my NIP-65 relay list.A few minutes later I published that screenshot again in two identical notes to the same sets of relays, asking if people understood the implications. The difference in quantity of responses can still be seen today:
These results are skewed now by the fact that the two notes got rebroadcasted to multiple relays after some time, but the fundamental point remains.
What happened was that a huge lot more of people saw the first note compared to the second, and if Nostr was really censorship-resistant that shouldn't have happened at all.
Some people implied in the comments, with an air of obviousness, that publishing the note to "more relays" should have predictably resulted in more replies, which, again, shouldn't be the case if Nostr is really censorship-resistant.
What happens is that most people who engaged with the note are following me, in the sense that they have instructed their clients to fetch my notes on their behalf and present them in the UI, and clients are failing to do that despite me making it clear in multiple ways that my notes are to be found on
wss://pyramid.fiatjaf.com.If we were talking not about me, but about some public figure that was being censored by the State and got banned (or shadowbanned) by the 3 biggest public relays, the sad reality would be that the person would immediately get his reach reduced to ~10% of what they had before. This is not at all unlike what happened to dozens of personalities that were banned from the corporate social media platforms and then moved to other platforms -- how many of their original followers switched to these other platforms? Probably some small percentage close to 10%. In that sense Nostr today is similar to what we had before.
Peter Todd is right that if the way Nostr works is that you just subscribe to a small set of relays and expect to get everything from them then it tends to get very centralized very fast, and this is the reality today.
Peter Todd is wrong that Nostr is inherently centralized or that it needs a protocol change to become what it has always purported to be. He is in fact wrong today, because what is written above is not valid for all clients of today, and if we drive in the right direction we can successfully make Peter Todd be more and more wrong as time passes, instead of the contrary.
See also:
-
@ 3bf0c63f:aefa459d
2024-03-19 13:07:02
Censorship-resistant relay discovery in Nostr
In Nostr is not decentralized nor censorship-resistant I said Nostr is centralized. Peter Todd thinks it is centralized by design, but I disagree.
Nostr wasn't designed to be centralized. The idea was always that clients would follow people in the relays they decided to publish to, even if it was a single-user relay hosted in an island in the middle of the Pacific ocean.
But the Nostr explanations never had any guidance about how to do this, and the protocol itself never had any enforcement mechanisms for any of this (because it would be impossible).
My original idea was that clients would use some undefined combination of relay hints in reply tags and the (now defunct)
kind:2relay-recommendation events plus some form of manual action ("it looks like Bob is publishing on relay X, do you want to follow him there?") to accomplish this. With the expectation that we would have a better idea of how to properly implement all this with more experience, Branle, my first working client didn't have any of that implemented, instead it used a stupid static list of relays with read/write toggle -- although it did publish relay hints and kept track of those internally and supportedkind:2events, these things were not really useful.Gossip was the first client to implement a truly censorship-resistant relay discovery mechanism that used NIP-05 hints (originally proposed by Mike Dilger) relay hints and
kind:3relay lists, and then with the simple insight of NIP-65 that got much better. After seeing it in more concrete terms, it became simpler to reason about it and the approach got popularized as the "gossip model", then implemented in clients like Coracle and Snort.Today when people mention the "gossip model" (or "outbox model") they simply think about NIP-65 though. Which I think is ok, but too restrictive. I still think there is a place for the NIP-05 hints,
nprofileandneventrelay hints and specially relay hints in event tags. All these mechanisms are used together in ZBD Social, for example, but I believe also in the clients listed above.I don't think we should stop here, though. I think there are other ways, perhaps drastically different ways, to approach content propagation and relay discovery. I think manual action by users is underrated and could go a long way if presented in a nice UX (not conceived by people that think users are dumb animals), and who knows what. Reliance on third-parties, hardcoded values, social graph, and specially a mix of multiple approaches, is what Nostr needs to be censorship-resistant and what I hope to see in the future.
-
@ 3bf0c63f:aefa459d
2024-01-29 02:19:25
Nostr: a quick introduction, attempt #1
Nostr doesn't have a material existence, it is not a website or an app. Nostr is just a description what kind of messages each computer can send to the others and vice-versa. It's a very simple thing, but the fact that such description exists allows different apps to connect to different servers automatically, without people having to talk behind the scenes or sign contracts or anything like that.
When you use a Nostr client that is what happens, your client will connect to a bunch of servers, called relays, and all these relays will speak the same "language" so your client will be able to publish notes to them all and also download notes from other people.
That's basically what Nostr is: this communication layer between the client you run on your phone or desktop computer and the relay that someone else is running on some server somewhere. There is no central authority dictating who can connect to whom or even anyone who knows for sure where each note is stored.
If you think about it, Nostr is very much like the internet itself: there are millions of websites out there, and basically anyone can run a new one, and there are websites that allow you to store and publish your stuff on them.
The added benefit of Nostr is that this unified "language" that all Nostr clients speak allow them to switch very easily and cleanly between relays. So if one relay decides to ban someone that person can switch to publishing to others relays and their audience will quickly follow them there. Likewise, it becomes much easier for relays to impose any restrictions they want on their users: no relay has to uphold a moral ground of "absolute free speech": each relay can decide to delete notes or ban users for no reason, or even only store notes from a preselected set of people and no one will be entitled to complain about that.
There are some bad things about this design: on Nostr there are no guarantees that relays will have the notes you want to read or that they will store the notes you're sending to them. We can't just assume all relays will have everything — much to the contrary, as Nostr grows more relays will exist and people will tend to publishing to a small set of all the relays, so depending on the decisions each client takes when publishing and when fetching notes, users may see a different set of replies to a note, for example, and be confused.
Another problem with the idea of publishing to multiple servers is that they may be run by all sorts of malicious people that may edit your notes. Since no one wants to see garbage published under their name, Nostr fixes that by requiring notes to have a cryptographic signature. This signature is attached to the note and verified by everybody at all times, which ensures the notes weren't tampered (if any part of the note is changed even by a single character that would cause the signature to become invalid and then the note would be dropped). The fix is perfect, except for the fact that it introduces the requirement that each user must now hold this 63-character code that starts with "nsec1", which they must not reveal to anyone. Although annoying, this requirement brings another benefit: that users can automatically have the same identity in many different contexts and even use their Nostr identity to login to non-Nostr websites easily without having to rely on any third-party.
To conclude: Nostr is like the internet (or the internet of some decades ago): a little chaotic, but very open. It is better than the internet because it is structured and actions can be automated, but, like in the internet itself, nothing is guaranteed to work at all times and users many have to do some manual work from time to time to fix things. Plus, there is the cryptographic key stuff, which is painful, but cool.
-
@ 5f078e90:b2bacaa3
2025-04-30 20:13:35
Cactus story
In a sun-scorched desert, a lone cactus named Sage stood tall. Each dawn, she whispered to the wind, sharing tales of ancient rains. One night, a lost coyote curled beneath her spines, seeking shade. Sage offered her last drops of water, saved from a rare storm. Grateful, the coyote sang her story to the stars, and Sage’s legend grew, a beacon of kindness in the arid wild.
This test is between 300 and 500 characters long, started on Nostr to test the bidirectional-bridge script.
It has a bit of markdown included.

-
@ 59b96df8:b208bd59
2025-04-30 19:27:41
Nostr is a decentralized protocol designed to be censorship-resistant.
However, this resilience can sometimes make data synchronization between relays more difficult—though not impossible.In my opinion, Nostr still lacks a few key features to ensure consistent and reliable operation, especially regarding data versioning.
Profile Versions
When I log in to a new Nostr client using my private key, I might end up with an outdated version of my profile, depending on how the client is built or configured.
Why does this happen?
The client fetches my profile data (kind:0 - NIP 1) from its own list of selected relays.
If I didn’t publish the latest version of my profile on those specific relays, the client will only display an older version.Relay List Metadata
The same issue occurs with the relay list metadata (kind:10002 - NIP 65).
When switching to a new client, it's common that my configured relay list isn't properly carried over because it also depends on where the data is fetched.Protocol Change Proposal
I believe the protocol should evolve, specifically regarding how
kind:0(user metadata) andkind:10002(relay list metadata) events are distributed to relays.Relays should be able to build a list of public relays automatically (via autodiscovery), and forward all received
kind:0andkind:10002events to every relay in that list.This would create a ripple effect:
``` Relay A relay list: [Relay B, Relay C]
Relay B relay list: [Relay A, Relay C]
Relay C relay list: [Relay A, Relay B]User A sends kind:0 to Relay A
→ Relay A forwards kind:0 to Relay B
→ Relay A forwards kind:0 to Relay C
→ Relay B forwards kind:0 to Relay A
→ Relay B forwards kind:0 to Relay C → Relay A forwards kind:0 to Relay B
→ etc. ```Solution: Event Encapsulation
To avoid infinite replication loops, the solution could be to wrap the user’s signed event inside a new event signed by the relay, using a dedicated
kind(e.g.,kind:9999).When Relay B receives a
kind:9999event from Relay A, it extracts the original event, checks whether it already exists or if a newer version is present. If not, it adds the event to its database.Here is an example of such encapsulated data:
json { "content": "{\"content\":\"{\\\"lud16\\\":\\\"dolu@npub.cash\\\",\\\"name\\\":\\\"dolu\\\",\\\"nip05\\\":\\\"dolu@dolu.dev\\\",\\\"picture\\\":\\\"!(image)[!(image)[https://pbs.twimg.com/profile_images/1577320325158682626/igGerO9A_400x400.jpg]]\\\",\\\"pubkey\\\":\\\"59b96df8d8b5e66b3b95a3e1ba159750a6edd69bcbba1857aeb652a5b208bd59\\\",\\\"npub\\\":\\\"npub1txukm7xckhnxkwu450sm59vh2znwm45mewaps4awkef2tvsgh4vsf7phrl\\\",\\\"created_at\\\":1688312044}\",\"created_at\":1728233747,\"id\":\"afc3629314aad00f8786af97877115de30c184a25a48440a480bff590a0f9ba8\",\"kind\":0,\"pubkey\":\"59b96df8d8b5e66b3b95a3e1ba159750a6edd69bcbba1857aeb652a5b208bd59\",\"sig\":\"989b250f7fd5d4cfc9a6ee567594c81ee0a91f972e76b61332005fb02aa1343854104fdbcb6c4f77ae8896acd886ab4188043c383e32a6bba509fd78fedb984a\",\"tags\":[]}", "created_at": 1746036589, "id": "efe7fa5844c5c4428fb06d1657bf663d8b256b60c793b5a2c5a426ec773c745c", "kind": 9999, "pubkey": "79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798", "sig": "219f8bc840d12969ceb0093fb62f314a1f2e19a0cbe3e34b481bdfdf82d8238e1f00362791d17801548839f511533461f10dd45cd0aa4e264d71db6844f5e97c", "tags": [] } -
@ 3bf0c63f:aefa459d
2024-01-15 11:15:06
Pequenos problemas que o Estado cria para a sociedade e que não são sempre lembrados
- **vale-transporte**: transferir o custo com o transporte do funcionário para um terceiro o estimula a morar longe de onde trabalha, já que morar perto é normalmente mais caro e a economia com transporte é inexistente. - **atestado médico**: o direito a faltar o trabalho com atestado médico cria a exigência desse atestado para todas as situações, substituindo o livre acordo entre patrão e empregado e sobrecarregando os médicos e postos de saúde com visitas desnecessárias de assalariados resfriados. - **prisões**: com dinheiro mal-administrado, burocracia e péssima alocação de recursos -- problemas que empresas privadas em competição (ou mesmo sem qualquer competição) saberiam resolver muito melhor -- o Estado fica sem presídios, com os poucos existentes entupidos, muito acima de sua alocação máxima, e com isto, segundo a bizarra corrente de responsabilidades que culpa o juiz que condenou o criminoso por sua morte na cadeia, juízes deixam de condenar à prisão os bandidos, soltando-os na rua. - **justiça**: entrar com processos é grátis e isto faz proliferar a atividade dos advogados que se dedicam a criar problemas judiciais onde não seria necessário e a entupir os tribunais, impedindo-os de fazer o que mais deveriam fazer. - **justiça**: como a justiça só obedece às leis e ignora acordos pessoais, escritos ou não, as pessoas não fazem acordos, recorrem sempre à justiça estatal, e entopem-na de assuntos que seriam muito melhor resolvidos entre vizinhos. - **leis civis**: as leis criadas pelos parlamentares ignoram os costumes da sociedade e são um incentivo a que as pessoas não respeitem nem criem normas sociais -- que seriam maneiras mais rápidas, baratas e satisfatórias de resolver problemas. - **leis de trãnsito**: quanto mais leis de trânsito, mais serviço de fiscalização são delegados aos policiais, que deixam de combater crimes por isto (afinal de contas, eles não querem de fato arriscar suas vidas combatendo o crime, a fiscalização é uma excelente desculpa para se esquivarem a esta responsabilidade). - **financiamento educacional**: é uma espécie de subsídio às faculdades privadas que faz com que se criem cursos e mais cursos que são cada vez menos recheados de algum conhecimento ou técnica útil e cada vez mais inúteis. - **leis de tombamento**: são um incentivo a que o dono de qualquer área ou construção "histórica" destrua todo e qualquer vestígio de história que houver nele antes que as autoridades descubram, o que poderia não acontecer se ele pudesse, por exemplo, usar, mostrar e se beneficiar da história daquele local sem correr o risco de perder, de fato, a sua propriedade. - **zoneamento urbano**: torna as cidades mais espalhadas, criando uma necessidade gigantesca de carros, ônibus e outros meios de transporte para as pessoas se locomoverem das zonas de moradia para as zonas de trabalho. - **zoneamento urbano**: faz com que as pessoas percam horas no trânsito todos os dias, o que é, além de um desperdício, um atentado contra a sua saúde, que estaria muito melhor servida numa caminhada diária entre a casa e o trabalho. - **zoneamento urbano**: torna ruas e as casas menos seguras criando zonas enormes, tanto de residências quanto de indústrias, onde não há movimento de gente alguma. - **escola obrigatória + currículo escolar nacional**: emburrece todas as crianças. - **leis contra trabalho infantil**: tira das crianças a oportunidade de aprender ofícios úteis e levar um dinheiro para ajudar a família. - **licitações**: como não existem os critérios do mercado para decidir qual é o melhor prestador de serviço, criam-se comissões de pessoas que vão decidir coisas. isto incentiva os prestadores de serviço que estão concorrendo na licitação a tentar comprar os membros dessas comissões. isto, fora a corrupção, gera problemas reais: __(i)__ a escolha dos serviços acaba sendo a pior possível, já que a empresa prestadora que vence está claramente mais dedicada a comprar comissões do que a fazer um bom trabalho (este problema afeta tantas áreas, desde a construção de estradas até a qualidade da merenda escolar, que é impossível listar aqui); __(ii)__ o processo corruptor acaba, no longo prazo, eliminando as empresas que prestavam e deixando para competir apenas as corruptas, e a qualidade tende a piorar progressivamente. - **cartéis**: o Estado em geral cria e depois fica refém de vários grupos de interesse. o caso dos taxistas contra o Uber é o que está na moda hoje (e o que mostra como os Estados se comportam da mesma forma no mundo todo). - **multas**: quando algum indivíduo ou empresa comete uma fraude financeira, ou causa algum dano material involuntário, as vítimas do caso são as pessoas que sofreram o dano ou perderam dinheiro, mas o Estado tem sempre leis que prevêem multas para os responsáveis. A justiça estatal é sempre muito rígida e rápida na aplicação dessas multas, mas relapsa e vaga no que diz respeito à indenização das vítimas. O que em geral acontece é que o Estado aplica uma enorme multa ao responsável pelo mal, retirando deste os recursos que dispunha para indenizar as vítimas, e se retira do caso, deixando estas desamparadas. - **desapropriação**: o Estado pode pegar qualquer propriedade de qualquer pessoa mediante uma indenização que é necessariamente inferior ao valor da propriedade para o seu presente dono (caso contrário ele a teria vendido voluntariamente). - **seguro-desemprego**: se há, por exemplo, um prazo mínimo de 1 ano para o sujeito ter direito a receber seguro-desemprego, isto o incentiva a planejar ficar apenas 1 ano em cada emprego (ano este que será sucedido por um período de desemprego remunerado), matando todas as possibilidades de aprendizado ou aquisição de experiência naquela empresa específica ou ascensão hierárquica. - **previdência**: a previdência social tem todos os defeitos de cálculo do mundo, e não importa muito ela ser uma forma horrível de poupar dinheiro, porque ela tem garantias bizarras de longevidade fornecidas pelo Estado, além de ser compulsória. Isso serve para criar no imaginário geral a idéia da __aposentadoria__, uma época mágica em que todos os dias serão finais de semana. A idéia da aposentadoria influencia o sujeito a não se preocupar em ter um emprego que faça sentido, mas sim em ter um trabalho qualquer, que o permita se aposentar. - **regulamentação impossível**: milhares de coisas são proibidas, há regulamentações sobre os aspectos mais mínimos de cada empreendimento ou construção ou espaço. se todas essas regulamentações fossem exigidas não haveria condições de produção e todos morreriam. portanto, elas não são exigidas. porém, o Estado, ou um agente individual imbuído do poder estatal pode, se desejar, exigi-las todas de um cidadão inimigo seu. qualquer pessoa pode viver a vida inteira sem cumprir nem 10% das regulamentações estatais, mas viverá também todo esse tempo com medo de se tornar um alvo de sua exigência, num estado de terror psicológico. - **perversão de critérios**: para muitas coisas sobre as quais a sociedade normalmente chegaria a um valor ou comportamento "razoável" espontaneamente, o Estado dita regras. estas regras muitas vezes não são obrigatórias, são mais "sugestões" ou limites, como o salário mínimo, ou as 44 horas semanais de trabalho. a sociedade, porém, passa a usar esses valores como se fossem o normal. são raras, por exemplo, as ofertas de emprego que fogem à regra das 44h semanais. - **inflação**: subir os preços é difícil e constrangedor para as empresas, pedir aumento de salário é difícil e constrangedor para o funcionário. a inflação força as pessoas a fazer isso, mas o aumento não é automático, como alguns economistas podem pensar (enquanto alguns outros ficam muito satisfeitos de que esse processo seja demorado e difícil). - **inflação**: a inflação destrói a capacidade das pessoas de julgar preços entre concorrentes usando a própria memória. - **inflação**: a inflação destrói os cálculos de lucro/prejuízo das empresas e prejudica enormemente as decisões empresariais que seriam baseadas neles. - **inflação**: a inflação redistribui a riqueza dos mais pobres e mais afastados do sistema financeiro para os mais ricos, os bancos e as megaempresas. - **inflação**: a inflação estimula o endividamento e o consumismo. - **lixo:** ao prover coleta e armazenamento de lixo "grátis para todos" o Estado incentiva a criação de lixo. se tivessem que pagar para que recolhessem o seu lixo, as pessoas (e conseqüentemente as empresas) se empenhariam mais em produzir coisas usando menos plástico, menos embalagens, menos sacolas. - **leis contra crimes financeiros:** ao criar legislação para dificultar acesso ao sistema financeiro por parte de criminosos a dificuldade e os custos para acesso a esse mesmo sistema pelas pessoas de bem cresce absurdamente, levando a um percentual enorme de gente incapaz de usá-lo, para detrimento de todos -- e no final das contas os grandes criminosos ainda conseguem burlar tudo. -
@ 3bf0c63f:aefa459d
2024-01-15 11:15:06
Anglicismos estúpidos no português contemporâneo
Palavras e expressões que ninguém deveria usar porque não têm o sentido que as pessoas acham que têm, são apenas aportuguesamentos de palavras inglesas que por nuances da história têm um sentido ligeiramente diferente em inglês.
Cada erro é acompanhado também de uma sugestão de como corrigi-lo.
Palavras que existem em português com sentido diferente
- submissão (de trabalhos): envio, apresentação
- disrupção: perturbação
- assumir: considerar, pressupor, presumir
- realizar: perceber
- endereçar: tratar de
- suporte (ao cliente): atendimento
- suportar (uma idéia, um projeto): apoiar, financiar
- suportar (uma função, recurso, característica): oferecer, ser compatível com
- literacia: instrução, alfabetização
- convoluto: complicado.
- acurácia: precisão.
- resiliência: resistência.
Aportuguesamentos desnecessários
- estartar: iniciar, começar
- treidar: negociar, especular
Expressões
- "não é sobre...": "não se trata de..."
Ver também
-
@ 91bea5cd:1df4451c
2025-04-15 06:27:28
Básico
bash lsblk # Lista todos os diretorios montados.Para criar o sistema de arquivos:
bash mkfs.btrfs -L "ThePool" -f /dev/sdxCriando um subvolume:
bash btrfs subvolume create SubVolMontando Sistema de Arquivos:
bash mount -o compress=zlib,subvol=SubVol,autodefrag /dev/sdx /mntLista os discos formatados no diretório:
bash btrfs filesystem show /mntAdiciona novo disco ao subvolume:
bash btrfs device add -f /dev/sdy /mntLista novamente os discos do subvolume:
bash btrfs filesystem show /mntExibe uso dos discos do subvolume:
bash btrfs filesystem df /mntBalancea os dados entre os discos sobre raid1:
bash btrfs filesystem balance start -dconvert=raid1 -mconvert=raid1 /mntScrub é uma passagem por todos os dados e metadados do sistema de arquivos e verifica as somas de verificação. Se uma cópia válida estiver disponível (perfis de grupo de blocos replicados), a danificada será reparada. Todas as cópias dos perfis replicados são validadas.
iniciar o processo de depuração :
bash btrfs scrub start /mntver o status do processo de depuração Btrfs em execução:
bash btrfs scrub status /mntver o status do scrub Btrfs para cada um dos dispositivos
bash btrfs scrub status -d / data btrfs scrub cancel / dataPara retomar o processo de depuração do Btrfs que você cancelou ou pausou:
btrfs scrub resume / data
Listando os subvolumes:
bash btrfs subvolume list /ReportsCriando um instantâneo dos subvolumes:
Aqui, estamos criando um instantâneo de leitura e gravação chamado snap de marketing do subvolume de marketing.
bash btrfs subvolume snapshot /Reports/marketing /Reports/marketing-snapAlém disso, você pode criar um instantâneo somente leitura usando o sinalizador -r conforme mostrado. O marketing-rosnap é um instantâneo somente leitura do subvolume de marketing
bash btrfs subvolume snapshot -r /Reports/marketing /Reports/marketing-rosnapForçar a sincronização do sistema de arquivos usando o utilitário 'sync'
Para forçar a sincronização do sistema de arquivos, invoque a opção de sincronização conforme mostrado. Observe que o sistema de arquivos já deve estar montado para que o processo de sincronização continue com sucesso.
bash btrfs filsystem sync /ReportsPara excluir o dispositivo do sistema de arquivos, use o comando device delete conforme mostrado.
bash btrfs device delete /dev/sdc /ReportsPara sondar o status de um scrub, use o comando scrub status com a opção -dR .
bash btrfs scrub status -dR / RelatóriosPara cancelar a execução do scrub, use o comando scrub cancel .
bash $ sudo btrfs scrub cancel / ReportsPara retomar ou continuar com uma depuração interrompida anteriormente, execute o comando de cancelamento de depuração
bash sudo btrfs scrub resume /Reportsmostra o uso do dispositivo de armazenamento:
btrfs filesystem usage /data
Para distribuir os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID (incluindo o dispositivo de armazenamento recém-adicionado) montados no diretório /data , execute o seguinte comando:
sudo btrfs balance start --full-balance /data
Pode demorar um pouco para espalhar os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID se ele contiver muitos dados.
Opções importantes de montagem Btrfs
Nesta seção, vou explicar algumas das importantes opções de montagem do Btrfs. Então vamos começar.
As opções de montagem Btrfs mais importantes são:
**1. acl e noacl
**ACL gerencia permissões de usuários e grupos para os arquivos/diretórios do sistema de arquivos Btrfs.
A opção de montagem acl Btrfs habilita ACL. Para desabilitar a ACL, você pode usar a opção de montagem noacl .
Por padrão, a ACL está habilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem acl por padrão.
**2. autodefrag e noautodefrag
**Desfragmentar um sistema de arquivos Btrfs melhorará o desempenho do sistema de arquivos reduzindo a fragmentação de dados.
A opção de montagem autodefrag permite a desfragmentação automática do sistema de arquivos Btrfs.
A opção de montagem noautodefrag desativa a desfragmentação automática do sistema de arquivos Btrfs.
Por padrão, a desfragmentação automática está desabilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem noautodefrag por padrão.
**3. compactar e compactar-forçar
**Controla a compactação de dados no nível do sistema de arquivos do sistema de arquivos Btrfs.
A opção compactar compacta apenas os arquivos que valem a pena compactar (se compactar o arquivo economizar espaço em disco).
A opção compress-force compacta todos os arquivos do sistema de arquivos Btrfs, mesmo que a compactação do arquivo aumente seu tamanho.
O sistema de arquivos Btrfs suporta muitos algoritmos de compactação e cada um dos algoritmos de compactação possui diferentes níveis de compactação.
Os algoritmos de compactação suportados pelo Btrfs são: lzo , zlib (nível 1 a 9) e zstd (nível 1 a 15).
Você pode especificar qual algoritmo de compactação usar para o sistema de arquivos Btrfs com uma das seguintes opções de montagem:
- compress=algoritmo:nível
- compress-force=algoritmo:nível
Para obter mais informações, consulte meu artigo Como habilitar a compactação do sistema de arquivos Btrfs .
**4. subvol e subvolid
**Estas opções de montagem são usadas para montar separadamente um subvolume específico de um sistema de arquivos Btrfs.
A opção de montagem subvol é usada para montar o subvolume de um sistema de arquivos Btrfs usando seu caminho relativo.
A opção de montagem subvolid é usada para montar o subvolume de um sistema de arquivos Btrfs usando o ID do subvolume.
Para obter mais informações, consulte meu artigo Como criar e montar subvolumes Btrfs .
**5. dispositivo
A opção de montagem de dispositivo** é usada no sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs.
Em alguns casos, o sistema operacional pode falhar ao detectar os dispositivos de armazenamento usados em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs. Nesses casos, você pode usar a opção de montagem do dispositivo para especificar os dispositivos que deseja usar para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar a opção de montagem de dispositivo várias vezes para carregar diferentes dispositivos de armazenamento para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar o nome do dispositivo (ou seja, sdb , sdc ) ou UUID , UUID_SUB ou PARTUUID do dispositivo de armazenamento com a opção de montagem do dispositivo para identificar o dispositivo de armazenamento.
Por exemplo,
- dispositivo=/dev/sdb
- dispositivo=/dev/sdb,dispositivo=/dev/sdc
- dispositivo=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d
- device=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d,device=UUID_SUB=f7ce4875-0874-436a-b47d-3edef66d3424
**6. degraded
A opção de montagem degradada** permite que um RAID Btrfs seja montado com menos dispositivos de armazenamento do que o perfil RAID requer.
Por exemplo, o perfil raid1 requer a presença de 2 dispositivos de armazenamento. Se um dos dispositivos de armazenamento não estiver disponível em qualquer caso, você usa a opção de montagem degradada para montar o RAID mesmo que 1 de 2 dispositivos de armazenamento esteja disponível.
**7. commit
A opção commit** mount é usada para definir o intervalo (em segundos) dentro do qual os dados serão gravados no dispositivo de armazenamento.
O padrão é definido como 30 segundos.
Para definir o intervalo de confirmação para 15 segundos, você pode usar a opção de montagem commit=15 (digamos).
**8. ssd e nossd
A opção de montagem ssd** informa ao sistema de arquivos Btrfs que o sistema de arquivos está usando um dispositivo de armazenamento SSD, e o sistema de arquivos Btrfs faz a otimização SSD necessária.
A opção de montagem nossd desativa a otimização do SSD.
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem de SSD será habilitada. Caso contrário, a opção de montagem nossd é habilitada.
**9. ssd_spread e nossd_spread
A opção de montagem ssd_spread** tenta alocar grandes blocos contínuos de espaço não utilizado do SSD. Esse recurso melhora o desempenho de SSDs de baixo custo (baratos).
A opção de montagem nossd_spread desativa o recurso ssd_spread .
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem ssd_spread será habilitada. Caso contrário, a opção de montagem nossd_spread é habilitada.
**10. descarte e nodiscard
Se você estiver usando um SSD que suporte TRIM enfileirado assíncrono (SATA rev3.1), a opção de montagem de descarte** permitirá o descarte de blocos de arquivos liberados. Isso melhorará o desempenho do SSD.
Se o SSD não suportar TRIM enfileirado assíncrono, a opção de montagem de descarte prejudicará o desempenho do SSD. Nesse caso, a opção de montagem nodiscard deve ser usada.
Por padrão, a opção de montagem nodiscard é usada.
**11. norecovery
Se a opção de montagem norecovery** for usada, o sistema de arquivos Btrfs não tentará executar a operação de recuperação de dados no momento da montagem.
**12. usebackuproot e nousebackuproot
Se a opção de montagem usebackuproot for usada, o sistema de arquivos Btrfs tentará recuperar qualquer raiz de árvore ruim/corrompida no momento da montagem. O sistema de arquivos Btrfs pode armazenar várias raízes de árvore no sistema de arquivos. A opção de montagem usebackuproot** procurará uma boa raiz de árvore e usará a primeira boa que encontrar.
A opção de montagem nousebackuproot não verificará ou recuperará raízes de árvore inválidas/corrompidas no momento da montagem. Este é o comportamento padrão do sistema de arquivos Btrfs.
**13. space_cache, space_cache=version, nospace_cache e clear_cache
A opção de montagem space_cache** é usada para controlar o cache de espaço livre. O cache de espaço livre é usado para melhorar o desempenho da leitura do espaço livre do grupo de blocos do sistema de arquivos Btrfs na memória (RAM).
O sistema de arquivos Btrfs suporta 2 versões do cache de espaço livre: v1 (padrão) e v2
O mecanismo de cache de espaço livre v2 melhora o desempenho de sistemas de arquivos grandes (tamanho de vários terabytes).
Você pode usar a opção de montagem space_cache=v1 para definir a v1 do cache de espaço livre e a opção de montagem space_cache=v2 para definir a v2 do cache de espaço livre.
A opção de montagem clear_cache é usada para limpar o cache de espaço livre.
Quando o cache de espaço livre v2 é criado, o cache deve ser limpo para criar um cache de espaço livre v1 .
Portanto, para usar o cache de espaço livre v1 após a criação do cache de espaço livre v2 , as opções de montagem clear_cache e space_cache=v1 devem ser combinadas: clear_cache,space_cache=v1
A opção de montagem nospace_cache é usada para desabilitar o cache de espaço livre.
Para desabilitar o cache de espaço livre após a criação do cache v1 ou v2 , as opções de montagem nospace_cache e clear_cache devem ser combinadas: clear_cache,nosapce_cache
**14. skip_balance
Por padrão, a operação de balanceamento interrompida/pausada de um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs será retomada automaticamente assim que o sistema de arquivos Btrfs for montado. Para desabilitar a retomada automática da operação de equilíbrio interrompido/pausado em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs, você pode usar a opção de montagem skip_balance .**
**15. datacow e nodatacow
A opção datacow** mount habilita o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs. É o comportamento padrão.
Se você deseja desabilitar o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs para os arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatacow .
**16. datasum e nodatasum
A opção datasum** mount habilita a soma de verificação de dados para arquivos recém-criados do sistema de arquivos Btrfs. Este é o comportamento padrão.
Se você não quiser que o sistema de arquivos Btrfs faça a soma de verificação dos dados dos arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatasum .
Perfis Btrfs
Um perfil Btrfs é usado para informar ao sistema de arquivos Btrfs quantas cópias dos dados/metadados devem ser mantidas e quais níveis de RAID devem ser usados para os dados/metadados. O sistema de arquivos Btrfs contém muitos perfis. Entendê-los o ajudará a configurar um RAID Btrfs da maneira que você deseja.
Os perfis Btrfs disponíveis são os seguintes:
single : Se o perfil único for usado para os dados/metadados, apenas uma cópia dos dados/metadados será armazenada no sistema de arquivos, mesmo se você adicionar vários dispositivos de armazenamento ao sistema de arquivos. Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
dup : Se o perfil dup for usado para os dados/metadados, cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos manterá duas cópias dos dados/metadados. Assim, 50% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
raid0 : No perfil raid0 , os dados/metadados serão divididos igualmente em todos os dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, não haverá dados/metadados redundantes (duplicados). Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser usado. Se, em qualquer caso, um dos dispositivos de armazenamento falhar, todo o sistema de arquivos será corrompido. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid0 .
raid1 : No perfil raid1 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a uma falha de unidade. Mas você pode usar apenas 50% do espaço total em disco. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1 .
raid1c3 : No perfil raid1c3 , três cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a duas falhas de unidade, mas você pode usar apenas 33% do espaço total em disco. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c3 .
raid1c4 : No perfil raid1c4 , quatro cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a três falhas de unidade, mas você pode usar apenas 25% do espaço total em disco. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c4 .
raid10 : No perfil raid10 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos, como no perfil raid1 . Além disso, os dados/metadados serão divididos entre os dispositivos de armazenamento, como no perfil raid0 .
O perfil raid10 é um híbrido dos perfis raid1 e raid0 . Alguns dos dispositivos de armazenamento formam arrays raid1 e alguns desses arrays raid1 são usados para formar um array raid0 . Em uma configuração raid10 , o sistema de arquivos pode sobreviver a uma única falha de unidade em cada uma das matrizes raid1 .
Você pode usar 50% do espaço total em disco na configuração raid10 . Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid10 .
raid5 : No perfil raid5 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Uma única paridade será calculada e distribuída entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid5 , o sistema de arquivos pode sobreviver a uma única falha de unidade. Se uma unidade falhar, você pode adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir da paridade distribuída das unidades em execução.
Você pode usar 1 00x(N-1)/N % do total de espaços em disco na configuração raid5 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid5 .
raid6 : No perfil raid6 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Duas paridades serão calculadas e distribuídas entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid6 , o sistema de arquivos pode sobreviver a duas falhas de unidade ao mesmo tempo. Se uma unidade falhar, você poderá adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir das duas paridades distribuídas das unidades em execução.
Você pode usar 100x(N-2)/N % do espaço total em disco na configuração raid6 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid6 .
-
@ 3bf0c63f:aefa459d
2024-01-14 14:52:16
Drivechain
Understanding Drivechain requires a shift from the paradigm most bitcoiners are used to. It is not about "trustlessness" or "mathematical certainty", but game theory and incentives. (Well, Bitcoin in general is also that, but people prefer to ignore it and focus on some illusion of trustlessness provided by mathematics.)
Here we will describe the basic mechanism (simple) and incentives (complex) of "hashrate escrow" and how it enables a 2-way peg between the mainchain (Bitcoin) and various sidechains.
The full concept of "Drivechain" also involves blind merged mining (i.e., the sidechains mine themselves by publishing their block hashes to the mainchain without the miners having to run the sidechain software), but this is much easier to understand and can be accomplished either by the BIP-301 mechanism or by the Spacechains mechanism.
How does hashrate escrow work from the point of view of Bitcoin?
A new address type is created. Anything that goes in that is locked and can only be spent if all miners agree on the Withdrawal Transaction (
WT^) that will spend it for 6 months. There is one of these special addresses for each sidechain.To gather miners' agreement
bitcoindkeeps track of the "score" of all transactions that could possibly spend from that address. On every block mined, for each sidechain, the miner can use a portion of their coinbase to either increase the score of oneWT^by 1 while decreasing the score of all others by 1; or they can decrease the score of allWT^s by 1; or they can do nothing.Once a transaction has gotten a score high enough, it is published and funds are effectively transferred from the sidechain to the withdrawing users.
If a timeout of 6 months passes and the score doesn't meet the threshold, that
WT^is discarded.What does the above procedure mean?
It means that people can transfer coins from the mainchain to a sidechain by depositing to the special address. Then they can withdraw from the sidechain by making a special withdraw transaction in the sidechain.
The special transaction somehow freezes funds in the sidechain while a transaction that aggregates all withdrawals into a single mainchain
WT^, which is then submitted to the mainchain miners so they can start voting on it and finally after some months it is published.Now the crucial part: the validity of the
WT^is not verified by the Bitcoin mainchain rules, i.e., if Bob has requested a withdraw from the sidechain to his mainchain address, but someone publishes a wrongWT^that instead takes Bob's funds and sends them to Alice's main address there is no way the mainchain will know that. What determines the "validity" of theWT^is the miner vote score and only that. It is the job of miners to vote correctly -- and for that they may want to run the sidechain node in SPV mode so they can attest for the existence of a reference to theWT^transaction in the sidechain blockchain (which then ensures it is ok) or do these checks by some other means.What? 6 months to get my money back?
Yes. But no, in practice anyone who wants their money back will be able to use an atomic swap, submarine swap or other similar service to transfer funds from the sidechain to the mainchain and vice-versa. The long delayed withdraw costs would be incurred by few liquidity providers that would gain some small profit from it.
Why bother with this at all?
Drivechains solve many different problems:
It enables experimentation and new use cases for Bitcoin
Issued assets, fully private transactions, stateful blockchain contracts, turing-completeness, decentralized games, some "DeFi" aspects, prediction markets, futarchy, decentralized and yet meaningful human-readable names, big blocks with a ton of normal transactions on them, a chain optimized only for Lighting-style networks to be built on top of it.
These are some ideas that may have merit to them, but were never actually tried because they couldn't be tried with real Bitcoin or inferfacing with real bitcoins. They were either relegated to the shitcoin territory or to custodial solutions like Liquid or RSK that may have failed to gain network effect because of that.
It solves conflicts and infighting
Some people want fully private transactions in a UTXO model, others want "accounts" they can tie to their name and build reputation on top; some people want simple multisig solutions, others want complex code that reads a ton of variables; some people want to put all the transactions on a global chain in batches every 10 minutes, others want off-chain instant transactions backed by funds previously locked in channels; some want to spend, others want to just hold; some want to use blockchain technology to solve all the problems in the world, others just want to solve money.
With Drivechain-based sidechains all these groups can be happy simultaneously and don't fight. Meanwhile they will all be using the same money and contributing to each other's ecosystem even unwillingly, it's also easy and free for them to change their group affiliation later, which reduces cognitive dissonance.
It solves "scaling"
Multiple chains like the ones described above would certainly do a lot to accomodate many more transactions that the current Bitcoin chain can. One could have special Lightning Network chains, but even just big block chains or big-block-mimblewimble chains or whatnot could probably do a good job. Or even something less cool like 200 independent chains just like Bitcoin is today, no extra features (and you can call it "sharding"), just that would already multiply the current total capacity by 200.
Use your imagination.
It solves the blockchain security budget issue
The calculation is simple: you imagine what security budget is reasonable for each block in a world without block subsidy and divide that for the amount of bytes you can fit in a single block: that is the price to be paid in satoshis per byte. In reasonable estimative, the price necessary for every Bitcoin transaction goes to very large amounts, such that not only any day-to-day transaction has insanely prohibitive costs, but also Lightning channel opens and closes are impracticable.
So without a solution like Drivechain you'll be left with only one alternative: pushing Bitcoin usage to trusted services like Liquid and RSK or custodial Lightning wallets. With Drivechain, though, there could be thousands of transactions happening in sidechains and being all aggregated into a sidechain block that would then pay a very large fee to be published (via blind merged mining) to the mainchain. Bitcoin security guaranteed.
It keeps Bitcoin decentralized
Once we have sidechains to accomodate the normal transactions, the mainchain functionality can be reduced to be only a "hub" for the sidechains' comings and goings, and then the maximum block size for the mainchain can be reduced to, say, 100kb, which would make running a full node very very easy.
Can miners steal?
Yes. If a group of coordinated miners are able to secure the majority of the hashpower and keep their coordination for 6 months, they can publish a
WT^that takes the money from the sidechains and pays to themselves.Will miners steal?
No, because the incentives are such that they won't.
Although it may look at first that stealing is an obvious strategy for miners as it is free money, there are many costs involved:
- The cost of ceasing blind-merged mining returns -- as stealing will kill a sidechain, all the fees from it that miners would be expected to earn for the next years are gone;
- The cost of Bitcoin price going down: If a steal is successful that will mean Drivechains are not safe, therefore Bitcoin is less useful, and miner credibility will also be hurt, which are likely to cause the Bitcoin price to go down, which in turn may kill the miners' businesses and savings;
- The cost of coordination -- assuming miners are just normal businesses, they just want to do their work and get paid, but stealing from a Drivechain will require coordination with other miners to conduct an immoral act in a way that has many pitfalls and is likely to be broken over the months;
- The cost of miners leaving your mining pool: when we talked about "miners" above we were actually talking about mining pools operators, so they must also consider the risk of miners migrating from their mining pool to others as they begin the process of stealing;
- The cost of community goodwill -- when participating in a steal operation, a miner will suffer a ton of backlash from the community. Even if the attempt fails at the end, the fact that it was attempted will contribute to growing concerns over exaggerated miners power over the Bitcoin ecosystem, which may end up causing the community to agree on a hard-fork to change the mining algorithm in the future, or to do something to increase participation of more entities in the mining process (such as development or cheapment of new ASICs), which have a chance of decreasing the profits of current miners.
Another point to take in consideration is that one may be inclined to think a newly-created sidechain or a sidechain with relatively low usage may be more easily stolen from, since the blind merged mining returns from it (point 1 above) are going to be small -- but the fact is also that a sidechain with small usage will also have less money to be stolen from, and since the other costs besides 1 are less elastic at the end it will not be worth stealing from these too.
All of the above consideration are valid only if miners are stealing from good sidechains. If there is a sidechain that is doing things wrong, scamming people, not being used at all, or is full of bugs, for example, that will be perceived as a bad sidechain, and then miners can and will safely steal from it and kill it, which will be perceived as a good thing by everybody.
What do we do if miners steal?
Paul Sztorc has suggested in the past that a user-activated soft-fork could prevent miners from stealing, i.e., most Bitcoin users and nodes issue a rule similar to this one to invalidate the inclusion of a faulty
WT^and thus cause any miner that includes it in a block to be relegated to their own Bitcoin fork that other nodes won't accept.This suggestion has made people think Drivechain is a sidechain solution backed by user-actived soft-forks for safety, which is very far from the truth. Drivechains must not and will not rely on this kind of soft-fork, although they are possible, as the coordination costs are too high and no one should ever expect these things to happen.
If even with all the incentives against them (see above) miners do still steal from a good sidechain that will mean the failure of the Drivechain experiment. It will very likely also mean the failure of the Bitcoin experiment too, as it will be proven that miners can coordinate to act maliciously over a prolonged period of time regardless of economic and social incentives, meaning they are probably in it just for attacking Bitcoin, backed by nation-states or something else, and therefore no Bitcoin transaction in the mainchain is to be expected to be safe ever again.
Why use this and not a full-blown trustless and open sidechain technology?
Because it is impossible.
If you ever heard someone saying "just use a sidechain", "do this in a sidechain" or anything like that, be aware that these people are either talking about "federated" sidechains (i.e., funds are kept in custody by a group of entities) or they are talking about Drivechain, or they are disillusioned and think it is possible to do sidechains in any other manner.
No, I mean a trustless 2-way peg with correctness of the withdrawals verified by the Bitcoin protocol!
That is not possible unless Bitcoin verifies all transactions that happen in all the sidechains, which would be akin to drastically increasing the blocksize and expanding the Bitcoin rules in tons of ways, i.e., a terrible idea that no one wants.
What about the Blockstream sidechains whitepaper?
Yes, that was a way to do it. The Drivechain hashrate escrow is a conceptually simpler way to achieve the same thing with improved incentives, less junk in the chain, more safety.
Isn't the hashrate escrow a very complex soft-fork?
Yes, but it is much simpler than SegWit. And, unlike SegWit, it doesn't force anything on users, i.e., it isn't a mandatory blocksize increase.
Why should we expect miners to care enough to participate in the voting mechanism?
Because it's in their own self-interest to do it, and it costs very little. Today over half of the miners mine RSK. It's not blind merged mining, it's a very convoluted process that requires them to run a RSK full node. For the Drivechain sidechains, an SPV node would be enough, or maybe just getting data from a block explorer API, so much much simpler.
What if I still don't like Drivechain even after reading this?
That is the entire point! You don't have to like it or use it as long as you're fine with other people using it. The hashrate escrow special addresses will not impact you at all, validation cost is minimal, and you get the benefit of people who want to use Drivechain migrating to their own sidechains and freeing up space for you in the mainchain. See also the point above about infighting.
See also
-
@ c066aac5:6a41a034
2025-04-05 16:58:58
I’m drawn to extremities in art. The louder, the bolder, the more outrageous, the better. Bold art takes me out of the mundane into a whole new world where anything and everything is possible. Having grown up in the safety of the suburban midwest, I was a bit of a rebellious soul in search of the satiation that only came from the consumption of the outrageous. My inclination to find bold art draws me to NOSTR, because I believe NOSTR can be the place where the next generation of artistic pioneers go to express themselves. I also believe that as much as we are able, were should invite them to come create here.
My Background: A Small Side Story
My father was a professional gamer in the 80s, back when there was no money or glory in the avocation. He did get a bit of spotlight though after the fact: in the mid 2000’s there were a few parties making documentaries about that era of gaming as well as current arcade events (namely 2007’sChasing GhostsandThe King of Kong: A Fistful of Quarters). As a result of these documentaries, there was a revival in the arcade gaming scene. My family attended events related to the documentaries or arcade gaming and I became exposed to a lot of things I wouldn’t have been able to find. The producer ofThe King of Kong: A Fistful of Quarters had previously made a documentary calledNew York Dollwhich was centered around the life of bassist Arthur Kane. My 12 year old mind was blown: The New York Dolls were a glam-punk sensation dressed in drag. The music was from another planet. Johnny Thunders’ guitar playing was like Chuck Berry with more distortion and less filter. Later on I got to meet the Galaga record holder at the time, Phil Day, in Ottumwa Iowa. Phil is an Australian man of high intellect and good taste. He exposed me to great creators such as Nick Cave & The Bad Seeds, Shakespeare, Lou Reed, artists who created things that I had previously found inconceivable.
I believe this time period informed my current tastes and interests, but regrettably I think it also put coals on the fire of rebellion within. I stopped taking my parents and siblings seriously, the Christian faith of my family (which I now hold dearly to) seemed like a mundane sham, and I felt I couldn’t fit in with most people because of my avant-garde tastes. So I write this with the caveat that there should be a way to encourage these tastes in children without letting them walk down the wrong path. There is nothing inherently wrong with bold art, but I’d advise parents to carefully find ways to cultivate their children’s tastes without completely shutting them down and pushing them away as a result. My parents were very loving and patient during this time; I thank God for that.
With that out of the way, lets dive in to some bold artists:
Nicolas Cage: Actor
There is an excellent video by Wisecrack on Nicolas Cage that explains him better than I will, which I will linkhere. Nicolas Cage rejects the idea that good acting is tied to mere realism; all of his larger than life acting decisions are deliberate choices. When that clicked for me, I immediately realized the man is a genius. He borrows from Kabuki and German Expressionism, art forms that rely on exaggeration to get the message across. He has even created his own acting style, which he calls Nouveau Shamanic. He augments his imagination to go from acting to being. Rather than using the old hat of method acting, he transports himself to a new world mentally. The projects he chooses to partake in are based on his own interests or what he considers would be a challenge (making a bad script good for example). Thus it doesn’t matter how the end result comes out; he has already achieved his goal as an artist. Because of this and because certain directors don’t know how to use his talents, he has a noticeable amount of duds in his filmography. Dig around the duds, you’ll find some pure gold. I’d personally recommend the filmsPig, Joe, Renfield, and his Christmas film The Family Man.
Nick Cave: Songwriter
What a wild career this man has had! From the apocalyptic mayhem of his band The Birthday Party to the pensive atmosphere of his albumGhosteen, it seems like Nick Cave has tried everything. I think his secret sauce is that he’s always working. He maintains an excellent newsletter calledThe Red Hand Files, he has written screenplays such asLawless, he has written books, he has made great film scores such asThe Assassination of Jesse James by the Coward Robert Ford, the man is religiously prolific. I believe that one of the reasons he is prolific is that he’s not afraid to experiment. If he has an idea, he follows it through to completion. From the albumMurder Ballads(which is comprised of what the title suggests) to his rejected sequel toGladiator(Gladiator: Christ Killer), he doesn’t seem to be afraid to take anything on. This has led to some over the top works as well as some deeply personal works. Albums likeSkeleton TreeandGhosteenwere journeys through the grief of his son’s death. The Boatman’s Callis arguably a better break-up album than anything Taylor Swift has put out. He’s not afraid to be outrageous, he’s not afraid to offend, but most importantly he’s not afraid to be himself. Works I’d recommend include The Birthday Party’sLive 1981-82, Nick Cave & The Bad Seeds’The Boatman’s Call, and the filmLawless.
Jim Jarmusch: Director
I consider Jim’s films to be bold almost in an ironic sense: his works are bold in that they are, for the most part, anti-sensational. He has a rule that if his screenplays are criticized for a lack of action, he makes them even less eventful. Even with sensational settings his films feel very close to reality, and they demonstrate the beauty of everyday life. That's what is bold about his art to me: making the sensational grounded in reality while making everyday reality all the more special. Ghost Dog: The Way of the Samurai is about a modern-day African-American hitman who strictly follows the rules of the ancient Samurai, yet one can resonate with the humanity of a seemingly absurd character. Only Lovers Left Aliveis a vampire love story, but in the middle of a vampire romance one can see their their own relationships in a new deeply human light. Jim’s work reminds me that art reflects life, and that there is sacred beauty in seemingly mundane everyday life. I personally recommend his filmsPaterson,Down by Law, andCoffee and Cigarettes.
NOSTR: We Need Bold Art
NOSTR is in my opinion a path to a better future. In a world creeping slowly towards everything apps, I hope that the protocol where the individual owns their data wins over everything else. I love freedom and sovereignty. If NOSTR is going to win the race of everything apps, we need more than Bitcoin content. We need more than shirtless bros paying for bananas in foreign countries and exercising with girls who have seductive accents. Common people cannot see themselves in such a world. NOSTR needs to catch the attention of everyday people. I don’t believe that this can be accomplished merely by introducing more broadly relevant content; people are searching for content that speaks to them. I believe that NOSTR can and should attract artists of all kinds because NOSTR is one of the few places on the internet where artists can express themselves fearlessly. Getting zaps from NOSTR’s value-for-value ecosystem has far less friction than crowdfunding a creative project or pitching investors that will irreversibly modify an artist’s vision. Having a place where one can post their works without fear of censorship should be extremely enticing. Having a place where one can connect with fellow humans directly as opposed to a sea of bots should seem like the obvious solution. If NOSTR can become a safe haven for artists to express themselves and spread their work, I believe that everyday people will follow. The banker whose stressful job weighs on them will suddenly find joy with an original meme made by a great visual comedian. The programmer for a healthcare company who is drowning in hopeless mundanity could suddenly find a new lust for life by hearing the song of a musician who isn’t afraid to crowdfund their their next project by putting their lighting address on the streets of the internet. The excel guru who loves independent film may find that NOSTR is the best way to support non corporate movies. My closing statement: continue to encourage the artists in your life as I’m sure you have been, but while you’re at it give them the purple pill. You may very well be a part of building a better future.
-
@ 3104fbbf:ac623068
2025-04-04 06:58:30

Introduction
If you have a functioning brain, it’s impossible to fully stand for any politician or align completely with any political party. The solutions we need are not found in the broken systems of power but in individual actions and local initiatives. Voting for someone may be your choice, but relying solely on elections every few years as a form of political activism is a losing strategy. People around the world have fallen into the trap of thinking that casting a ballot once every four years is enough, only to return to complacency as conditions worsen. Voting for the "lesser of two evils" has been the norm for decades, yet expecting different results from the same flawed system is naive at best.
The truth is, governments are too corrupt to save us. In times of crisis, they won’t come to your aid—instead, they will tighten their grip, imposing more surveillance, control, and wealth extraction to benefit the oligarch class. To break free from this cycle, we must first protect ourselves individually—financially, geographically, and digitally—alongside our families.
Then, we must organize and build resilient local communities. These are the only ways forward. History has shown us time and again that the masses are easily deceived by the political circus, falling for the illusion of a "savior" who will fix everything. But whether right, center, or left, the story remains the same: corruption, lies, and broken promises. If you possess a critical and investigative mind, you know better than to place your trust in politicians, parties, or self-proclaimed heroes. The real solution lies in free and sovereign individuals who reject the herd mentality and take responsibility for their own lives.
From the beginning of time, true progress has come from individuals who think for themselves and act independently. The nauseating web of politicians, billionaires, and oligarchs fighting for power and resources has never been—and will never be—the answer to our problems. In a world increasingly dominated by corrupted governments, NGOs, and elites, ordinary people must take proactive steps to protect themselves and their families.
1. Financial Protection: Reclaiming Sovereignty Through Bitcoin
Governments and central banks have long manipulated fiat currencies, eroding wealth through inflation and bailouts that transfer resources to the oligarch class. Bitcoin, as a decentralized, censorship-resistant, and finite currency, offers a way out. Here’s what individuals can do:
-
Adopt Bitcoin as a Savings Tool: Shift a portion of your savings into Bitcoin to protect against inflation and currency devaluation. Bitcoin’s fixed supply (21 million coins) ensures it cannot be debased like fiat money.
-
Learn Self-Custody: Store your Bitcoin in a hardware wallet or use open-source software wallets. Avoid centralized exchanges, which are vulnerable to government seizure or collapse.
-
Diversify Geographically: Hold assets in multiple jurisdictions to reduce the risk of confiscation or capital controls. Consider offshore accounts or trusts if feasible.
-
Barter and Local Economies: In times of crisis, local barter systems and community currencies can bypass failing national systems. Bitcoin can serve as a global medium of exchange in such scenarios.
2. Geographical Flexibility: Reducing Dependence on Oppressive Systems
Authoritarian regimes thrive on controlling populations within fixed borders. By increasing geographical flexibility, individuals can reduce their vulnerability:
-
Obtain Second Passports or Residencies: Invest in citizenship-by-investment programs or residency permits in countries with greater freedoms and lower surveillance.
-
Relocate to Freer Jurisdictions: Research and consider moving to regions with stronger property rights, lower taxes, and less government overreach.
-
Decentralize Your Life: Avoid keeping all your assets, family, or business operations in one location. Spread them across multiple regions to mitigate risks.
3. Digital Privacy: Fighting Surveillance with Advanced Tools
The rise of mass surveillance and data harvesting by governments and corporations threatens individual freedom. Here’s how to protect yourself:
-
Use Encryption: Encrypt all communications using tools like Signal or ProtonMail. Ensure your devices are secured with strong passwords and biometric locks.
-
Adopt Privacy-Focused Technologies: Use Tor for anonymous browsing, VPNs to mask your IP address, and open-source operating systems like Linux to avoid backdoors.
-
Reject Surveillance Tech: Avoid smart devices that spy on you (e.g., Alexa, Google Home). Opt for decentralized alternatives like Mastodon instead of Twitter, or PeerTube instead of YouTube.
-
Educate Yourself on Digital Privacy: Learn about tools and practices that enhance your online privacy and security.
4. Building Resilient Local Communities: The Foundation of a Free Future
While individual actions are crucial, collective resilience is equally important. Governments are too corrupt to save populations in times of crisis—history shows they will instead impose more control and transfer wealth to the elite.
To counter this, communities must organize locally:
-
Form Mutual Aid Networks: Create local groups that share resources, skills, and knowledge. These networks can provide food, medical supplies, and security during crises.
-
Promote Local Economies: Support local businesses, farmers, and artisans. Use local currencies or barter systems to reduce dependence on centralized financial systems.
-
Develop Off-Grid Infrastructure: Invest in renewable energy, water filtration, and food production to ensure self-sufficiency. Community gardens, solar panels, and rainwater harvesting are excellent starting points.
-
Educate and Empower: Host workshops on financial literacy, digital privacy, and sustainable living. Knowledge is the most powerful tool against authoritarianism.
5. The Bigger Picture: Rejecting the Illusion of Saviors
The deep corruption within governments, NGOs, and the billionaire class is evident. These entities will never act in the interest of ordinary people. Instead, they will exploit crises to expand surveillance, control, and wealth extraction. The idea of a political “savior” is a dangerous illusion. True freedom comes from individuals taking responsibility for their own lives and working together to build decentralized, resilient systems.
Conclusion: A Call to Action
The path to a genuinely free humanity begins with individual action. By adopting Bitcoin, securing digital privacy, increasing geographical flexibility, and building resilient local communities, ordinary people can protect themselves against authoritarianism. Governments will not save us—they are the problem. It is up to us to create a better future, free from the control of corrupt elites.
-
The tools for liberation already exist.
-
The question is: will we use them?
For those interested, I share ideas and solutions in my book « THE GATEWAY TO FREEDOM » https://blisshodlenglish.substack.com/p/the-gateway-to-freedom
⚡ The time to act is now. Freedom is not given—it is taken. ⚡
If you enjoyed this article, consider supporting it with a Zap!
My Substack ENGLISH = https://blisshodlenglish.substack.com/ My substack FRENCH = https://blisshodl.substack.com/
Get my Book « THE GATEWAY TO FREEDOM » here 🙏 => https://coinos.io/blisshodl
-
-
@ 3bf0c63f:aefa459d
2024-01-14 14:52:16
bitcoinddecentralizationIt is better to have multiple curator teams, with different vetting processes and release schedules for
bitcoindthan a single one."More eyes on code", "Contribute to Core", "Everybody should audit the code".
All these points repeated again and again fell to Earth on the day it was discovered that Bitcoin Core developers merged a variable name change from "blacklist" to "blocklist" without even discussing or acknowledging the fact that that innocent pull request opened by a sybil account was a social attack.
After a big lot of people manifested their dissatisfaction with that event on Twitter and on GitHub, most Core developers simply ignored everybody's concerns or even personally attacked people who were complaining.
The event has shown that:
1) Bitcoin Core ultimately rests on the hands of a couple maintainers and they decide what goes on the GitHub repository[^pr-merged-very-quickly] and the binary releases that will be downloaded by thousands; 2) Bitcoin Core is susceptible to social attacks; 2) "More eyes on code" don't matter, as these extra eyes can be ignored and dismissed.
Solution:
bitcoinddecentralizationIf usage was spread across 10 different
bitcoindflavors, the network would be much more resistant to social attacks to a single team.This has nothing to do with the question on if it is better to have multiple different Bitcoin node implementations or not, because here we're basically talking about the same software.
Multiple teams, each with their own release process, their own logo, some subtle changes, or perhaps no changes at all, just a different name for their
bitcoindflavor, and that's it.Every day or week or month or year, each flavor merges all changes from Bitcoin Core on their own fork. If there's anything suspicious or too leftist (or perhaps too rightist, in case there's a leftist
bitcoindflavor), maybe they will spot it and not merge.This way we keep the best of both worlds: all software development, bugfixes, improvements goes on Bitcoin Core, other flavors just copy. If there's some non-consensus change whose efficacy is debatable, one of the flavors will merge on their fork and test, and later others -- including Core -- can copy that too. Plus, we get resistant to attacks: in case there is an attack on Bitcoin Core, only 10% of the network would be compromised. the other flavors would be safe.
Run Bitcoin Knots
The first example of a
bitcoindsoftware that follows Bitcoin Core closely, adds some small changes, but has an independent vetting and release process is Bitcoin Knots, maintained by the incorruptible Luke DashJr.Next time you decide to run
bitcoind, run Bitcoin Knots instead and contribute tobitcoinddecentralization!
See also:
[^pr-merged-very-quickly]: See PR 20624, for example, a very complicated change that could be introducing bugs or be a deliberate attack, merged in 3 days without time for discussion.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
início
"Vocês vêem? Vêem a história? Vêem alguma coisa? Me parece que estou tentando lhes contar um sonho -- fazendo uma tentativa inútil, porque nenhum relato de sonho pode transmitir a sensação de sonho, aquela mistura de absurdo, surpresa e espanto numa excitação de revolta tentando se impôr, aquela noção de ser tomado pelo incompreensível que é da própria essência dos sonhos..."
Ele ficou em silêncio por alguns instantes.
"... Não, é impossível; é impossível transmitir a sensação viva de qualquer época determinada de nossa existência -- aquela que constitui a sua verdade, o seu significado, a sua essência sutil e contundente. É impossível. Vivemos, como sonhamos -- sozinhos..."
- Livros mencionados por Olavo de Carvalho
- Antiga homepage Olavo de Carvalho
- Bitcoin explicado de um jeito correto e inteligível
- Reclamações
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On "zk-rollups" applied to Bitcoin
ZK rollups make no sense in bitcoin because there is no "cheap calldata". all data is already ~~cheap~~ expensive calldata.
There could be an onchain zk verification that allows succinct signatures maybe, but never a rollup.
What happens is: you can have one UTXO that contains multiple balances on it and in each transaction you can recreate that UTXOs but alter its state using a zk to compress all internal transactions that took place.
The blockchain must be aware of all these new things, so it is in no way "L2".
And you must have an entity responsible for that UTXO and for conjuring the state changes and zk proofs.
But on bitcoin you also must keep the data necessary to rebuild the proofs somewhere else, I'm not sure how can the third party responsible for that UTXO ensure that happens.
I think such a construct is similar to a credit card corporation: one central party upon which everybody depends, zero interoperability with external entities, every vendor must have an account on each credit card company to be able to charge customers, therefore it is not clear that such a thing is more desirable than solutions that are truly open and interoperable like Lightning, which may have its defects but at least fosters a much better environment, bringing together different conflicting parties, custodians, anyone.
-
@ 7bdef7be:784a5805
2025-04-02 12:02:45
We value sovereignty, privacy and security when accessing online content, using several tools to achieve this, like open protocols, open OSes, open software products, Tor and VPNs. ## The problem Talking about our social presence, we can manually build up our follower list (social graph), pick a Nostr client that is respectful of our preferences on what to show and how, but with the standard following mechanism, our main feed is public, **so everyone can actually snoop** what we are interested in, and what is supposable that we read daily. ## The solution Nostr has a simple solution for this necessity: encrypted lists. Lists are what they appear, a collection of people or interests (but they can also group much other stuff, see [NIP-51](https://github.com/nostr-protocol/nips/blob/master/51.md)). So we can create lists with contacts that we don't have in our main social graph; these lists can be used primarily to create **dedicated feeds**, but they could have other uses, for example, related to monitoring. The interesting thing about lists is that they can also be **encrypted**, so unlike the basic following list, which is always public, we can hide the lists' content from others. The implications are obvious: we can not only have a more organized way to browse content, but it is also **really private one**. One might wonder what use can really be made of private lists; here are some examples: - Browse “can't miss” content from users I consider a priority; - Supervise competitors or adversarial parts; - Monitor sensible topics (tags); - Following someone without being publicly associated with them, as this may be undesirable; The benefits in terms of privacy as usual are not only related to the casual, or programmatic, observer, but are also evident when we think of **how many bots scan our actions to profile us**. ## The current state Unfortunately, lists are not widely supported by Nostr clients, and encrypted support is a rarity. Often the excuse to not implement them is that they are harder to develop, since they require managing the encryption stuff ([NIP-44](https://github.com/nostr-protocol/nips/blob/master/51.md)). Nevertheless, developers have an easier option to start offering private lists: give the user the possibility to simply **mark them as local-only**, and never push them to the relays. Even if the user misses the sync feature, this is sufficient to create a private environment. To date, as far as I know, the best client with list management is Gossip, which permits to manage **both encrypted and local-only lists**. Beg your Nostr client to implement private lists!
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The problem with ION
ION is a DID method based on a thing called "Sidetree".
I can't say for sure what is the problem with ION, because I don't understand the design, even though I have read all I could and asked everybody I knew. All available information only touches on the high-level aspects of it (and of course its amazing wonders) and no one has ever bothered to explain the details. I've also asked the main designer of the protocol, Daniel Buchner, but he may have thought I was trolling him on Twitter and refused to answer, instead pointing me to an incomplete spec on the Decentralized Identity Foundation website that I had already read before. I even tried to join the DIF as a member so I could join their closed community calls and hear what they say, maybe eventually ask a question, so I could understand it, but my entrance was ignored, then after many months and a nudge from another member I was told I had to do a KYC process to be admitted, which I refused.
One thing I know is:
- ION is supposed to provide a way to rotate keys seamlessly and automatically without losing the main identity (and the ION proponents also claim there are no "master" keys because these can also be rotated).
- ION is also not a blockchain, i.e. it doesn't have a deterministic consensus mechanism and it is decentralized, i.e. anyone can publish data to it, doesn't have to be a single central server, there may be holes in the available data and the protocol doesn't treat that as a problem.
- From all we know about years of attempts to scale Bitcoins and develop offchain protocols it is clear that you can't solve the double-spend problem without a central authority or a kind of blockchain (i.e. a decentralized system with deterministic consensus).
- Rotating keys also suffer from the double-spend problem: whenever you rotate a key it is as if it was "spent", you aren't supposed to be able to use it again.
The logic conclusion of the 4 assumptions above is that ION is flawed: it can't provide the key rotation it says it can if it is not a blockchain.
See also
-
@ 866e0139:6a9334e5
2025-04-30 18:47:50
Autor: Ulrike Guérot. Dieser Beitrag wurde mit dem Pareto-Client geschrieben. Sie finden alle Texte der Friedenstaube und weitere Texte zum Thema Frieden hier.**
Die neuesten Artikel der Friedenstaube gibt es jetzt auch im eigenen Friedenstaube-Telegram-Kanal.
https://www.youtube.com/watch?v=KarwcXKmD3E
Liebe Freunde und Bekannte,
liebe Friedensbewegte,
liebe Dresdener, Dresden ist ja auch eine kriegsgeplagte Stadt,
dies ist meine dritte Rede auf einer Friedensdemonstration innerhalb von nur gut einem halben Jahr: München im September, München im Februar, Dresden im April. Und der Krieg rückt immer näher! Wer sich den „Operationsplan Deutschland über die zivil-militärische Kooperation als wesentlicher Bestandteil der Kriegsführung“ anschaut, dem kann nur schlecht werden zu sehen, wie weit die Kriegsvorbereitungen schon gediehen sind.
Doch bevor ich darauf eingehe, möchte ich mich als erstes distanzieren von dem wieder einmal erbärmlichen Framing dieser Demo als Querfront oder Schwurblerdemo. Durch dieses Framing wurde diese Demo vom Dresdener Marktplatz auf den Postplatz verwiesen, wurden wir geschmäht und wurde die Stadtverwaltung Dresden dazu gebracht, eine „genehmere“ Demo auf dem Marktplatz zuzulassen! Es wäre schön, wenn wir alle - alle! - solche Framings weglassen würden und uns als Friedensbewegte die Hand reichen! Der Frieden im eigenen Haus ist die Voraussetzung für unsere Friedensarbeit. Der Streit in unserem Haus nutzt nur denen, die den Krieg wollen und uns spalten!
Ich möchte hier noch einmal klarstellen, von welcher Position aus ich hier und heute wiederholt auf einer Bühne spreche: Ich spreche als engagierte Bürgerin der Bundesrepublik Deutschland. Ich spreche als Europäerin, die lange Jahre in und an dem einstigen Friedensprojekt EU gearbeitet hat. Ich spreche als Enkelin von zwei Großvätern. Der eine ist im Krieg gefallen, der andere kam ohne Beine zurück. Ich spreche als Tochter einer Mutter, die 1945, als 6-Jährige, unter traumatischen Umständen aus Schlesien vertrieben wurde, nach Delitzsch in Sachsen übrigens. Ich spreche als Mutter von zwei Söhnen, 33 und 31 Jahre, von denen ich nicht möchte, dass sie in einen Krieg müssen. Von dieser, und nur dieser Position aus spreche ich heute zu Ihnen und von keiner anderen! Ich bin nicht rechts, ich bin keine Schwurblerin, ich bin nicht radikal, ich bin keine Querfront.
Als Bürgerin wünsche ich mir – nein, verlange ich! – dass die Bundesrepublik Deutschland sich an ihre gesetzlichen Grundlagen und Vertragstexte hält. Das sind namentlich: Die Friedensklausel des Grundgesetzes aus Art. 125 und 126 GG, dass von deutschem Boden nie wieder Krieg ausgeht. Und der Zwei-plus-Vier-Vertrag, in dem Deutschland 1990 unterschrieben hat, dass es nie an einem bewaffneten Konflikt gegen Russland teilnimmt. Ich schäme mich dafür, dass mein Land dabei ist, vertragsbrüchig zu werden. Ich bitte Friedrich Merz, den designierten Bundeskanzler, keinen Vertragsbruch durch die Lieferung von Taurus-Raketen zu begehen!
Ich bitte ferner darum, dass sich dieses Land an seine didaktischen Vorgaben für Schulen hält, die im immer noch geltenden „Beutelsbacher Konsens“ aus den 1970er Jahren festgelegt wurden. In diesem steht in Artikel I. ein Überwältigungsverbot: „Es ist nicht erlaubt, den Schüler – mit welchen Mitteln auch immer – im Sinne erwünschter Meinungen zu überrumpeln und damit an der Gewinnung eines selbständigen Urteils zu hindern.“ Vor diesem Hintergrund ist es nicht erlaubt, Soldaten oder Gefreite in Schulen zu schicken und für die Bundeswehr zu werben. Vielmehr wäre es geboten, unsere Kinder über Art. 125 & 126 GG und die Friedenspflicht des Landes und seine Geschichte mit Blick auf Russland aufzuklären.
Als Europäerin wünsche ich mir, dass wir die europäische Hymne, Beethovens 9. Sinfonie, ernst nehmen, deren Text da lautet: Alle Menschen werden Brüder. Alle Menschen werden Brüder. Alle! Dazu gehören auch die Russen und natürlich auch die Ukrainer!
Als Europäerin, die in den 1990er Jahren für den großartigen EU-Kommissionspräsidenten Jacques Delors gearbeitet hat, Katholik, Sozialist und Gewerkschafter, wünsche ich mir, dass wir das Versprechen, #Europa ist nie wieder Krieg, ernst nehmen. Wir haben es 70 Jahre lang auf diesem Kontinent erzählt. Die Lügen und die Propaganda, mit der jetzt die Kriegsnotwendigkeit gegen Russland herbeigeredet wird, sind unerträglich. Die EU, Friedensnobelpreisträgerin von 2012, ist dabei – oder hat schon – ihr Ansehen in der Welt verloren. Es ist eine politische Tragödie! Neben ihrem Ansehen ist die EU jetzt dabei, das zivilisatorische Erbe Europas zu verspielen, die civilité européenne, wie der französische Historiker und Marxist, Étienne Balibar es nennt.
Ein Element dieses historischen Erbes ist es, dass uns in Europa eint, dass wir über Jahrhunderte alle zugleich Täter und Opfer gewesen sind. Ce que nous partageons, c’est ce que nous étions tous bourreaux et victimes. So schreibt es der französische Literat Laurent Gaudet in seinem europäischen Epos, L’Europe. Une Banquet des Peuples von 2016.
Das heißt, dass niemand in Europa, niemand – auch die Esten nicht! – das Recht hat, vorgängige Traumata, die die baltischen Staaten unbestrittenermaßen mit Stalin-Russland gehabt haben, zu verabsolutieren, auf die gesamte EU zu übertragen, die EU damit zu blockieren und die Politikgestaltung der EU einseitig auf einen Kriegskurs gegen Russland auszurichten. Ich wende mich mit dieser Feststellung direkt an Kaja Kalles, die Hohe Beauftragte für Sicherheits- und Außenpolitik der EU und hoffe, dass sie diese Rede hört und das Epos von Laurent Gaudet liest.
Es gibt keinen gerechten Krieg! Krieg ist immer nur Leid. In Straßburg, dem Sitz des Europäischen Parlaments, steht auf dem Place de la République eine Statue, eine Frau, die Republik. Sie hält in jedem Arm einen Sohn, einen Elsässer und einen Franzosen, die aus dem Krieg kommen. In der Darstellung der Bronzefigur haben die beiden Soldaten-Männer ihre Uniformen schon ausgezogen und werden von Madame la République gehalten und getröstet. An diesem Denkmal sollten sich alle Abgeordnete des Straßburger Europaparlamentes am 9. Mai versammeln. Ich zitiere noch einmal Cicero: Der ungerechteste Friede ist besser als der gerechteste Krieg. Für den Vortrag dieses Zitats eines der größten Staatsdenker des antiken Roms in einer Fernsehsendung bin ich 2022 mit einem Shitstorm überzogen worden. Allein das ist Ausdruck des Verfalls unserer Diskussionskultur in unfassbarem Ausmaß, ganz besonders in Deutschland.
Als Europäerin verlange ich die Überwindung unserer kognitiven Dissonanz. Wenn schon die New York Times am 27. März 2025 ein 27-seitiges Dossier veröffentlicht, das nicht nur belegt, was man eigentlich schon weiß, aber bisher nicht sagen durfte, nämlich, dass der ukrainisch-russische Krieg ein eindeutiger Stellvertreter-Krieg der USA ist, in der die Ukraine auf monströseste Weise instrumentalisiert wurde – was das Dossier der NYT unumwunden zugibt! – wäre es an der Zeit, die eindeutige Schuldzuweisung an Russland für den Krieg zurückzuziehen und die gezielt verbreitete Russophobie in Europa zu beenden. Anstatt dass – wofür es leider viele Verdachtsmomente gibt – die EU die Friedensverhandlungen in Saudi-Arabien nach Strich und Faden torpediert.
Der französische Philosoph Luc Ferry hat vor ein paar Tagen im prime time französischen Fernsehen ganz klar gesagt, dass der Krieg 2014 nach der Instrumentalisierung des Maidan durch die USA von der West-Ukraine ausging, dass Zelensky diesen Krieg wollte und – mit amerikanischer Rückendeckung – provoziert hat, dass Putin nicht Hitler ist und dass die einzigen mit faschistoiden Tendenzen in der ukrainischen Regierung sitzen. Ich wünschte mir, ein solches Statement wäre auch im Deutschen Fernsehen möglich und danke Richard David Precht, dass er, der noch in den Öffentlich-Rechtlichen Rundfunk vorgelassen wird, an dieser Stelle versucht, etwas Vernunft in die Debatte zu bringen.
Auch ist es gerade als Europäerin nicht hinzunehmen, dass russische Diplomaten von den Feierlichkeiten am 8. Mai 2025 ausgeschlossen werden sollen, ausgerechnet 80 Jahre nach Ende des II. Weltkrieges. Nicht nur sind Feierlichkeiten genau dazu da, sich die Hand zu reichen und den Frieden zu feiern. Doch gerade vor dem Hintergrund von 27 Millionen gefallenen sowjetischen Soldaten ist die Zurückweisung der Russen von den Feierlichkeiten geradezu eklatante Geschichtsvergessenheit.
***
Der Völkerbund hat 1925 die Frage erörtert, warum der I. Weltkrieg noch so lange gedauert hat, obgleich er militärisch bereits 1916 nach Eröffnung des Zweifrontenkrieges zu Lasten des Deutschen Reiches entschieden war. Wir erinnern uns: Für die Niederlage wurden mit der Dolchstoßlegende die jüdischen, kommunistischen und sozialistischen Pazifisten verantwortlich gemacht. Richtig ist, so der Bericht des Völkerbundes von 1925, dass allein die Rüstungsindustrie dafür gesorgt hat, dass der militärisch eigentlich schon entschiedene Krieg noch zwei weitere Jahre als Materialabnutzungs- und Stellungskrieg weiterbetrieben wurde, nur, damit noch ein bisschen Geld verdient werden konnte. Genauso scheint es heute zu sein. Der Krieg ist militärisch entschieden. Er kann und muss sofort beendet werden, und das passiert lediglich deswegen nicht, weil der Westen seine Niederlage nicht zugeben kann. Hochmut aber kommt vor dem Fall, und es darf nicht sein, dass für europäischen Hochmut jeden Tag rund 2000 ukrainische oder russische Soldaten und viele Zivilisten sterben. Die offenbare europäische Absicht, den Krieg jetzt einzufrieren, nur, um ihn 2029/ 2030 wieder zu entfachen, wenn Europa dann besser aufgerüstet ist, ist nur noch zynisch.
Als Kriegsenkelin von Kriegsversehrten, Tochter einer Flüchtlingsmutter und Mutter von zwei Söhnen, deren französischer Urgroßvater 6 Jahre in deutscher Kriegsgefangenschaft war, wünsche ich mir schließlich und zum Abschluss, dass wir die Kraft haben werden, wenn dieser Wahnsinn, den man den europäischen Bürgern gerade aufbürdet, vorbei sein wird, ein neues europäisches Projekt zu erdenken und zu erbauen, in dem Europa politisch geeint ist und es bleibt, aber dezentral, regional, subsidiär, friedlich und neutral gestaltet wird. Also ein Europa jenseits der Strukturen der EU, das bereit ist, die Pax Americana zu überwinden, aus der NATO auszutreten und der multipolaren Welt seine Hand auszustrecken! Unser Europa ist postimperial, postkolonial, groß, vielfältig und friedfertig!
Ulrike Guérot, Jg. 1964, ist europäische Professorin, Publizistin und Bestsellerautorin. Seit rund 30 Jahren beschäftigt sie sich in europäischen Think Tanks und Universitäten in Paris, Brüssel, London, Washington, New York, Wien und Berlin mit Fragen der europäischen Demokratie sowie mit der Rolle Europas in der Welt. Ulrike Guérot ist seit März 2014 Gründerin und Direktorin des European Democracy Lab e.V., Berlin und initiierte im März 2023 das European Citizens Radio, das auf Spotify zu finden ist. Zuletzt erschien von ihr „Über Halford J. Mackinders Heartland-Theorie, Der geografische Drehpunkt der Geschichte“ (Westend, 2024). Mehr Infos zur Autorin hier.
LASSEN SIE DER FRIEDENSTAUBE FLÜGEL WACHSEN!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt.
Schon jetzt können Sie uns unterstützen:
- Für 50 CHF/EURO bekommen Sie ein Jahresabo der Friedenstaube.
- Für 120 CHF/EURO bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
- Für 500 CHF/EURO werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
- Ab 1000 CHF werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
Für Einzahlungen in CHF (Betreff: Friedenstaube):
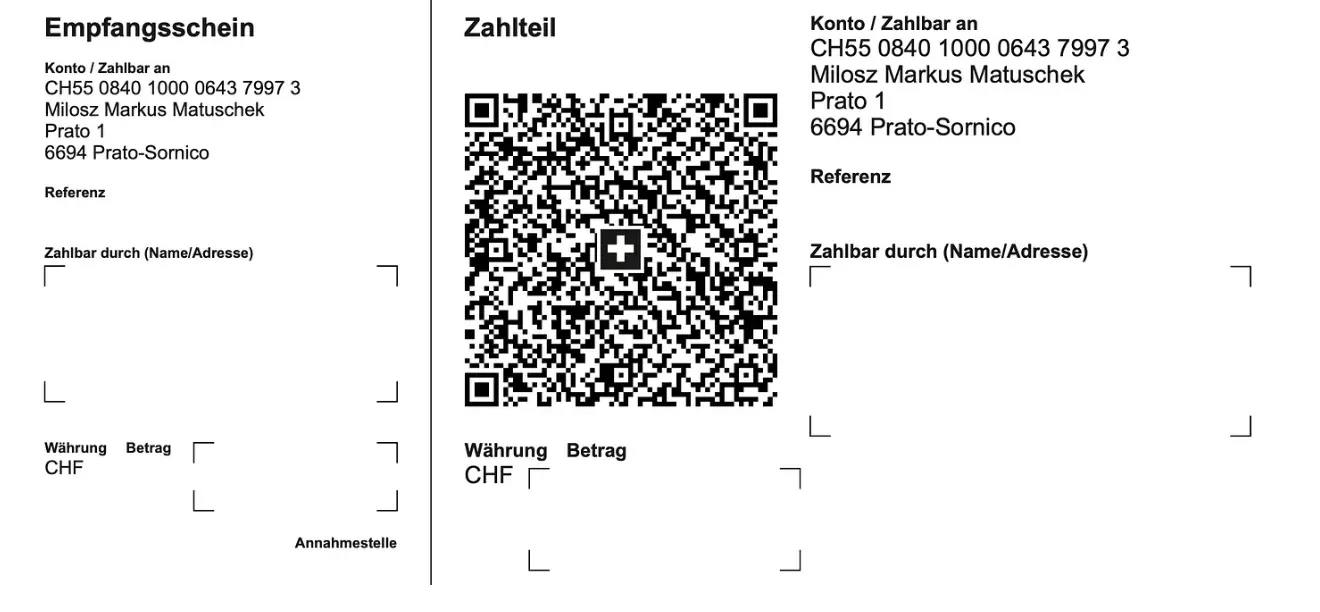
Für Einzahlungen in Euro:
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
Betreff: Friedenstaube
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: friedenstaube@pareto.space
Sie sind noch nicht auf Nostr and wollen die volle Erfahrung machen (liken, kommentieren etc.)? Zappen können Sie den Autor auch ohne Nostr-Profil! Erstellen Sie sich einen Account auf Start. Weitere Onboarding-Leitfäden gibt es im Pareto-Wiki.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
rosetta.alhur.es
A service that grabs code samples from two chosen languages on RosettaCode and displays them side-by-side.
The code-fetching is done in real time and snippet-by-snippet (there is also a prefetch of which snippets are available in each language, so we only compare apples to apples).
This was my first Golang web application if I remember correctly.
-
@ 90de72b7:8f68fdc0
2025-04-30 17:55:30
PetriNostr. My everyday activity 30/04
PetriNostr never sleep! This is a demo
petrinet ;startDay () -> working ;stopDay working -> () ;startPause working -> paused ;endPause paused -> working ;goSmoke working -> smoking ;endSmoke smoking -> working ;startEating working -> eating ;stopEating eating -> working ;startCall working -> onCall ;endCall onCall -> working ;startMeeting working -> inMeetinga ;endMeeting inMeeting -> working ;logTask working -> working -
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Thoughts on Nostr key management
On Why I don't like NIP-26 as a solution for key management I talked about multiple techniques that could be used to tackle the problem of key management on Nostr.
Here are some ideas that work in tandem:
- NIP-41 (stateless key invalidation)
- NIP-46 (Nostr Connect)
- NIP-07 (signer browser extension)
- Connected hardware signing devices
- other things like musig or frostr keys used in conjunction with a semi-trusted server; or other kinds of trusted software, like a dedicated signer on a mobile device that can sign on behalf of other apps; or even a separate protocol that some people decide to use as the source of truth for their keys, and some clients might decide to use that automatically
- there are probably many other ideas
Some premises I have in my mind (that may be flawed) that base my thoughts on these matters (and cause me to not worry too much) are that
- For the vast majority of people, Nostr keys aren't a target as valuable as Bitcoin keys, so they will probably be ok even without any solution;
- Even when you lose everything, identity can be recovered -- slowly and painfully, but still --, unlike money;
- Nostr is not trying to replace all other forms of online communication (even though when I think about this I can't imagine one thing that wouldn't be nice to replace with Nostr) or of offline communication, so there will always be ways.
- For the vast majority of people, losing keys and starting fresh isn't a big deal. It is a big deal when you have followers and an online persona and your life depends on that, but how many people are like that? In the real world I see people deleting social media accounts all the time and creating new ones, people losing their phone numbers or other accounts associated with their phone numbers, and not caring very much -- they just find a way to notify friends and family and move on.
We can probably come up with some specs to ease the "manual" recovery process, like social attestation and explicit signaling -- i.e., Alice, Bob and Carol are friends; Alice loses her key; Bob sends a new Nostr event kind to the network saying what is Alice's new key; depending on how much Carol trusts Bob, she can automatically start following that and remove the old key -- or something like that.
One nice thing about some of these proposals, like NIP-41, or the social-recovery method, or the external-source-of-truth-method, is that they don't have to be implemented in any client, they can live in standalone single-purpose microapps that users open or visit only every now and then, and these can then automatically update their follow lists with the latest news from keys that have changed according to multiple methods.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
lnurl-auth explained
You may have seen the lnurl-auth spec or heard about it, but might not know how it works or what is its relationship with other lnurl protocols. This document attempts to solve that.
Relationship between lnurl-auth and other lnurl protocols
First, what is the relationship of lnurl-auth with other lnurl protocols? The answer is none, except the fact that they all share the lnurl format for specifying
httpsURLs.In fact, lnurl-auth is very unique in the sense that it doesn't even need a Lightning wallet to work, it is a standalone authentication protocol that can work anywhere.
How does it work
Now, how does it work? The basic idea is that each wallet has a seed, which is a random value (you may think of the BIP39 seed words, for example). Usually from that seed different keys are derived, each of these yielding a Bitcoin address, and also from that same seed may come the keys used to generate and manage Lightning channels.
What lnurl-auth does is to generate a new key from that seed, and from that a new key for each service (identified by its domain) you try to authenticate with.

That way, you effectively have a new identity for each website. Two different services cannot associate your identities.
The flow goes like this: When you visit a website, the website presents you with a QR code containing a callback URL and a challenge. The challenge should be a random value.

When your wallet scans or opens that QR code it uses the domain in the callback URL plus the main lnurl-auth key to derive a key specific for that website, uses that key to sign the challenge and then sends both the public key specific for that for that website plus the signed challenge to the specified URL.

When the service receives the public key it checks it against the challenge signature and start a session for that user. The user is then identified only by its public key. If the service wants it can, of course, request more details from the user, associate it with an internal id or username, it is free to do anything. lnurl-auth's goals end here: no passwords, maximum possible privacy.
FAQ
-
What is the advantage of tying this to Bitcoin and Lightning?
One big advantage is that your wallet is already keeping track of one seed, it is already a precious thing. If you had to keep track of a separate auth seed it would be arguably worse, more difficult to bootstrap the protocol, and arguably one of the reasons similar protocols, past and present, weren't successful.
-
Just signing in to websites? What else is this good for?
No, it can be used for authenticating to installable apps and physical places, as long as there is a service running an HTTP server somewhere to read the signature sent from the wallet. But yes, signing in to websites is the main problem to solve here.
-
Phishing attack! Can a malicious website proxy the QR from a third website and show it to the user to it will steal the signature and be able to login on the third website?
No, because the wallet will only talk to the the callback URL, and it will either be controlled by the third website, so the malicious won't see anything; or it will have a different domain, so the wallet will derive a different key and frustrate the malicious website's plan.
-
I heard SQRL had that same idea and it went nowhere.
Indeed. SQRL in its first version was basically the same thing as lnurl-auth, with one big difference: it was vulnerable to phishing attacks (see above). That was basically the only criticism it got everywhere, so the protocol creators decided to solve that by introducing complexity to the protocol. While they were at it they decided to add more complexity for managing accounts and so many more crap that in the the spec which initially was a single page ended up becoming 136 pages of highly technical gibberish. Then all the initial network effect it had, libraries and apps were trashed and nowadays no one can do anything with it (but, see, there are still people who love the protocol writing in a 90's forum with no clue of anything besides their own Java).
-
We don't need this, we need WebAuthn!
WebAuthn is essentially the same thing as lnurl-auth, but instead of being simple it is complex, instead of being open and decentralized it is centralized in big corporations, and instead of relying on a key generated by your own device it requires an expensive hardware HSM you must buy and trust the manufacturer. If you like WebAuthn and you like Bitcoin you should like lnurl-auth much more.
-
What about BitID?
This is another one that is very similar to lnurl-auth, but without the anti-phishing prevention and extra privacy given by making one different key for each service.
-
What about LSAT?
It doesn't compete with lnurl-auth. LSAT, as far as I understand it, is for when you're buying individual resources from a server, not authenticating as a user. Of course, LSAT can be repurposed as a general authentication tool, but then it will lack features that lnurl-auth has, like the property of having keys generated independently by the user from a common seed and a standard way of passing authentication info from one medium to another (like signing in to a website at the desktop from the mobile phone, for example).
-
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A Causa
o Princípios de Economia Política de Menger é o único livro que enfatiza a CAUSA o tempo todo. os cientistas todos parecem não saber, ou se esquecer sempre, que as coisas têm causa, e que o conhecimento verdadeiro é o conhecimento da causa das coisas.
a causa é uma categoria metafísica muito superior a qualquer correlação ou resultado de teste de hipótese, ela não pode ser descoberta por nenhum artifício econométrico ou reduzida à simples antecedência temporal estatística. a causa dos fenômenos não pode ser provada cientificamente, mas pode ser conhecida.
o livro de Menger conta para o leitor as causas de vários fenômenos econômicos e as interliga de forma que o mundo caótico da economia parece adquirir uma ordem no momento em que você lê. é uma sensação mágica e indescritível.
quando eu te o recomendei, queria é te imbuir com o espírito da busca pela causa das coisas. depois de ler aquilo, você está apto a perceber continuidade causal nos fenômenos mais complexos da economia atual, enxergar as causas entre toda a ação governamental e as suas várias consequências na vida humana. eu faço isso todos os dias e é a melhor sensação do mundo quando o caos das notícias do caderno de Economia do jornal -- que para o próprio jornalista que as escreveu não têm nenhum sentido (tanto é que ele escreve tudo errado) -- se incluem num sistema ordenado de causas e consequências.
provavelmente eu sempre erro em alguns ou vários pontos, mas ainda assim é maravilhoso. ou então é mais maravilhoso ainda quando eu descubro o erro e reinsiro o acerto naquela racionalização bela da ordem do mundo econômico que é a ordem de Deus.
em scrap para T.P.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A biblioteca infinita
Agora esqueci o nome do conto de Jorge Luis Borges em que a tal biblioteca é descrita, ou seus detalhes específicos. Eu tinha lido o conto e nunca havia percebido que ele matava a questão da aleatoriedade ser capaz de produzir coisas valiosas. Precisei mesmo da Wikipédia me dizer isso.
Alguns anos atrás levantei essa questão para um grupo de amigos sem saber que era uma questão tão batida e baixa. No meu exemplo era um cachorro andando sobre letras desenhadas e não um macaco numa máquina de escrever. A minha conclusão da discussão foi que não importa o que o cachorro escrevesse, sem uma inteligência capaz de compreender aquilo nada passaria de letras aleatórias.
Borges resolve tudo imaginando uma biblioteca que contém tudo o que o cachorro havia escrito durante todo o infinito em que fez o experimento, e portanto contém todo o conhecimento sobre tudo e todas as obras literárias possíveis -- mas entre cada página ou frase muito boa ou pelo menos legívei há toneladas de livros completamente aleatórios e uma pessoa pode passar a vida dentro dessa biblioteca que contém tanto conhecimento importante e mesmo assim não aprender nada porque nunca vai achar os livros certos.
Everything would be in its blind volumes. Everything: the detailed history of the future, Aeschylus' The Egyptians, the exact number of times that the waters of the Ganges have reflected the flight of a falcon, the secret and true nature of Rome, the encyclopedia Novalis would have constructed, my dreams and half-dreams at dawn on August 14, 1934, the proof of Pierre Fermat's theorem, the unwritten chapters of Edwin Drood, those same chapters translated into the language spoken by the Garamantes, the paradoxes Berkeley invented concerning Time but didn't publish, Urizen's books of iron, the premature epiphanies of Stephen Dedalus, which would be meaningless before a cycle of a thousand years, the Gnostic Gospel of Basilides, the song the sirens sang, the complete catalog of the Library, the proof of the inaccuracy of that catalog. Everything: but for every sensible line or accurate fact there would be millions of meaningless cacophonies, verbal farragoes, and babblings. Everything: but all the generations of mankind could pass before the dizzying shelves – shelves that obliterate the day and on which chaos lies – ever reward them with a tolerable page.
Tenho a impressão de que a publicação gigantesca de artigos, posts, livros e tudo o mais está transformando o mundo nessa biblioteca. Há tanta coisa pra ler que é difícil achar o que presta. As pessoas precisam parar de escrever.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
IPFS problems: Shitcoinery
IPFS was advertised to the Ethereum community since the beggining as a way to "store" data for their "dApps". I don't think this is harmful in any way, but for some reason it may have led IPFS developers to focus too much on Ethereum stuff. Once I watched a talk showing libp2p developers – despite being ignored by the Ethereum team (that ended up creating their own agnostic p2p library) – dedicating an enourmous amount of work on getting a libp2p app running in the browser talking to a normal Ethereum node.
The always somewhat-abandoned "Awesome IPFS" site is a big repository of "dApps", some of which don't even have their landing page up anymore, useless Ethereum smart contracts that for some reason use IPFS to store whatever the useless data their users produce.
Again, per se it isn't a problem that Ethereum people are using IPFS, but it is at least confusing, maybe misleading, that when you search for IPFS most of the use-cases are actually Ethereum useless-cases.
See also
- Bitcoin, the only non-shitcoin
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Why IPFS cannot work, again
Imagine someone comes up with a solution for P2P content-addressed data-sharing that involves storing all the files' contents in all computers of the network. That wouldn't work, right? Too much data, if you think this can work then you're a BSV enthusiast.
Then someone comes up with the idea of not storing everything in all computers, but only some things on some computers, based on some algorithm to determine what data a node would store given its pubkey or something like that. Still wouldn't work, right? Still too much data no matter how much you spread it, but mostly incentives not aligned, would implode in the first day.
Now imagine someone says they will do the same thing, but instead of storing the full contents each node would only store a pointer to where each data is actually available. Does that make it better? Hardly so. Still, you're just moving the problem.
This is IPFS.
Now you have less data on each computer, but on a global scale that is still a lot of data.
No incentives.
And now you have the problem of finding the data. First if you have some data you want the world to access you have to broadcast information about that, flooding the network -- and everybody has to keep doing this continuously for every single file (or shard of file) that is available.
And then whenever someone wants some data they must find the people who know about that, which means they will flood the network with requests that get passed from peer to peer until they get to the correct peer.
The more you force each peer to store the worse it becomes to run a node and to store data on behalf of others -- but the less your force each peer to store the more flooding you'll have on the global network, and the slower will be for anyone to actually get any file.
But if everybody just saves everything to Infura or Cloudflare then it works, magic decentralized technology.
Related
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Who will build the roads?
Who will build the roads? Em Lagoa Santa, as mais novas e melhores ruas -- que na verdade acabam por formar enormes teias de bairros que se interligam -- são construídas pelos loteadores que querem as ruas para que seus lotes valham mais -- e querem que outras pessoas usem as ruas também. Também são esses mesmos loteadores que colocam os postes de luz e os encanamentos de água, não sem antes terem que se submeter a extorsões de praxe praticadas por COPASA e CEMIG.
Se ao abrir um loteamento, condomínio, prédio um indivíduo ou uma empresa consegue sem muito problema passar rua, eletricidade, água e esgoto, por que não seria possível existir livre-concorrência nesses mercados? Mesmo aquela velha estória de que é ineficiente passar cabos de luz duplicados para que companhias elétricas possam competir já me parece bobagem.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
How IPFS is broken
I once fell for this talk about "content-addressing". It sounds very nice. You know a certain file exists, you know there are probably people who have it, but you don't know where or if it is hosted on a domain somewhere. With content-addressing you can just say "start" and the download will start. You don't have to care.
Other magic properties that address common frustrations: webpages don't go offline, links don't break, valuable content always finds its way, other people will distribute your website for you, any content can be transmitted easily to people near you without anyone having to rely on third-party centralized servers.
But you know what? Saying a thing is good doesn't automatically make it possible and working. For example: saying stuff is addressed by their content doesn't change the fact that the internet is "location-addressed" and you still have to know where peers that have the data you want are and connect to them.
And what is the solution for that? A DHT!
DHT?
Turns out DHTs have terrible incentive structure (as you would expect, no one wants to hold and serve data they don't care about to others for free) and the IPFS experience proves it doesn't work even in a small network like the IPFS of today.
If you have run an IPFS client you'll notice how much it clogs your computer. Or maybe you don't, if you are very rich and have a really powerful computer, but still, it's not something suitable to be run on the entire world, and on web pages, and servers, and mobile devices. I imagine there may be a lot of unoptimized code and technical debt responsible for these and other problems, but the DHT is certainly the biggest part of it. IPFS can open up to 1000 connections by default and suck up all your bandwidth -- and that's just for exchanging keys with other DHT peers.
Even if you're in the "client" mode and limit your connections you'll still get overwhelmed by connections that do stuff I don't understand -- and it makes no sense to run an IPFS node as a client, that defeats the entire purpose of making every person host files they have and content-addressability in general, centralizes the network and brings back the dichotomy client/server that IPFS was created to replace.
Connections?
So, DHTs are a fatal flaw for a network that plans to be big and interplanetary. But that's not the only problem.
Finding content on IPFS is the most slow experience ever and for some reason I don't understand downloading is even slower. Even if you are in the same LAN of another machine that has the content you need it will still take hours to download some small file you would do in seconds with
scp-- that's considering that IPFS managed to find the other machine, otherwise your command will just be stuck for days.Now even if you ignore that IPFS objects should be content-addressable and not location-addressable and, knowing which peer has the content you want, you go there and explicitly tell IPFS to connect to the peer directly, maybe you can get some seconds of (slow) download, but then IPFS will drop the connection and the download will stop. Sometimes -- but not always -- it helps to add the peer address to your bootstrap nodes list (but notice this isn't something you should be doing at all).
IPFS Apps?
Now consider the kind of marketing IPFS does: it tells people to build "apps" on IPFS. It sponsors "databases" on top of IPFS. It basically advertises itself as a place where developers can just connect their apps to and all users will automatically be connected to each other, data will be saved somewhere between them all and immediately available, everything will work in a peer-to-peer manner.
Except it doesn't work that way at all. "libp2p", the IPFS library for connecting people, is broken and is rewritten every 6 months, but they keep their beautiful landing pages that say everything works magically and you can just plug it in. I'm not saying they should have everything perfect, but at least they should be honest about what they truly have in place.
It's impossible to connect to other people, after years there's no js-ipfs and go-ipfs interoperability (and yet they advertise there will be python-ipfs, haskell-ipfs, whoknowswhat-ipfs), connections get dropped and many other problems.
So basically all IPFS "apps" out there are just apps that want to connect two peers but can't do it manually because browsers and the IPv4/NAT network don't provide easy ways to do it and WebRTC is hard and requires servers. They have nothing to do with "content-addressing" anything, they are not trying to build "a forest of merkle trees" nor to distribute or archive content so it can be accessed by all. I don't understand why IPFS has changed its core message to this "full-stack p2p network" thing instead of the basic content-addressable idea.
IPNS?
And what about the database stuff? How can you "content-address" a database with values that are supposed to change? Their approach is to just save all values, past and present, and then use new DHT entries to communicate what are the newest value. This is the IPNS thing.
Apparently just after coming up with the idea of content-addressability IPFS folks realized this would never be able to replace the normal internet as no one would even know what kinds of content existed or when some content was updated -- and they didn't want to coexist with the normal internet, they wanted to replace it all because this message is more bold and gets more funding, maybe?
So they invented IPNS, the name system that introduces location-addressability back into the system that was supposed to be only content-addressable.
And how do they manage to do it? Again, DHTs. And does it work? Not really. It's limited, slow, much slower than normal content-addressing fetches, most of the times it doesn't even work after hours. But still although developers will tell it is not working yet the IPFS marketing will talk about it as if it was a thing.
Archiving content?
The main use case I had for IPFS was to store content that I personally cared about and that other people might care too, like old articles from dead websites, and videos, sometimes entire websites before they're taken down.
So I did that. Over many months I've archived stuff on IPFS. The IPFS API and CLI don't make it easy to track where stuff are. The
pincommand doesn't help as it just throws your pinned hash in a sea of hashes and subhashes and you're never able to find again what you have pinned.The IPFS daemon has a fake filesystem that is half-baked in functionality but allows you to locally address things by names in a tree structure. Very hard to update or add new things to it, but still doable. It allows you to give names to hashes, basically. I even began to write a wrapper for it, but suddenly after many weeks of careful content curation and distribution all my entries in the fake filesystem were gone.
Despite not having lost any of the files I did lose everything, as I couldn't find them in the sea of hashes I had in my own computer. After some digging and help from IPFS developers I managed to recover a part of it, but it involved hacks. My things vanished because of a bug at the fake filesystem. The bug was fixed, but soon after I experienced a similar (new) bug. After that I even tried to build a service for hash archival and discovery, but as all the problems listed above began to pile up I eventually gave up. There were also problems of content canonicalization, the code the IPFS daemon use to serve default HTML content over HTTP, problems with the IPFS browser extension and others.
Future-proof?
One of the core advertised features of IPFS was that it made content future-proof. I'm not sure they used this expression, but basically you have content, you hash that, you get an address that never expires for that content, now everybody can refer to the same thing by the same name. Actually, it's better: content is split and hashed in a merkle-tree, so there's fine-grained deduplication, people can store only chunks of files and when a file is to be downloaded lots of people can serve it at the same time, like torrents.
But then come the protocol upgrades. IPFS has used different kinds of hashing algorithms, different ways to format the hashes, and will change the default algorithm for building the merkle-trees, so basically the same content now has a gigantic number of possible names/addresses, which defeats the entire purpose, and yes, files hashed using different strategies aren't automagically compatible.
Actually, the merkle algorithm could have been changed by each person on a file-by-file basis since the beginning (you could for example split a book file by chapter or page instead of by chunks of bytes) -- although probably no one ever did that. I know it's not easy to come up with the perfect hashing strategy in the first go, but the way these matters are being approached make me wonder that IPFS promoters aren't really worried about future-proof, or maybe we're just in Beta phase forever.
Ethereum?
This is also a big problem. IPFS is built by Ethereum enthusiasts. I can't read the mind of people behind IPFS, but I would imagine they have a poor understanding of incentives like the Ethereum people, and they tend towards scammer-like behavior like getting a ton of funds for investors in exchange for promises they don't know they can fulfill (like Filecoin and IPFS itself) based on half-truths, changing stuff in the middle of the road because some top-managers decided they wanted to change (move fast and break things) and squatting fancy names like "distributed web".
The way they market IPFS (which is not the main thing IPFS was initially designed to do) as a "peer-to-peer cloud" is very seductive for Ethereum developers just like Ethereum itself is: as a place somewhere that will run your code for you so you don't have to host a server or have any responsibility, and then Infura will serve the content to everybody. In the same vein, Infura is also hosting and serving IPFS content for Ethereum developers these days for free. Ironically, just like the Ethereum hoax peer-to-peer money, IPFS peer-to-peer network may begin to work better for end users as things get more and more centralized.
More about IPFS problems:
- IPFS problems: Too much immutability
- IPFS problems: General confusion
- IPFS problems: Shitcoinery
- IPFS problems: Community
- IPFS problems: Pinning
- IPFS problems: Conceit
- IPFS problems: Inefficiency
- IPFS problems: Dynamic links
See also
- A crappy course on torrents, on the protocol that has done most things right
- The Tragedy of IPFS in a series of links, an ongoing Twitter thread.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Lagoa Santa: como chegar -- partindo da rodoviária de Belo Horizonte
Ao descer de seu ônibus na rodoviária de Belo Horizonte às 4 e pouco da manhã, darás de frente para um caubói que toma cerveja em seus trajes típicos em um bar no setor mesmo de desembarque. Suba a escada à direita que dá no estacionamento da rodoviária. Vire à esquerda e caminhe por mais ou menos 400 metros, atravessando uma área onde pessoas suspeitas -- mas provavelmente dormindo em pé -- lhe observam, e então uma pracinha ocupada por um clã de mendigos. Ao avistar um enorme obelisco no meio de um cruzamento de duas avenidas, vire à esquerda e caminhe por mais 400 metros. Você verá uma enorme, antiga e bela estação com uma praça em frente, com belas fontes aqüáticas. Corra dali e dirija-se a um pedaço de rua à direita dessa praça. Um velho palco de antigos carnavais estará colocado mais ou menos no meio da simpática ruazinha de parelepípedos: é onde você pegará seu próximo ônibus.
Para entrar na estação é necessário ter um cartão com créditos recarregáveis. Um viajante prudente deixa sempre um pouco de créditos em seu cartão a fim de evitar filas e outros problemas de indisponibilidade quando chega cansado de viagem, com pressa ou em horários incomuns. Esse tipo de pessoa perceberá que foi totalmente ludibriado ao perceber que que os créditos do seu cartão, abastecido quando de sua última vinda a Belo Horizonte, há três meses, pereceram de prazo de validade e foram absorvidos pelos cofre públicos. Terá, portanto, que comprar mais créditos. O guichê onde os cartões são abastecidos abre às 5h, mas não se espante caso ele não tenha sido aberto ainda quando o primeiro ônibus chegar, às 5h10.
Com alguma sorte, um jovem de moletom, autorizado por dois ou três fiscais do sistema de ônibus que conversam alegremente, será o operador da catraca. Ele deixa entrar sem pagar os bêbados, os malandros, os pivetes. Bastante empático e perceptivo do desespero dos outros, esse bom rapaz provavelmente também lhe deixará entrar sem pagar.
Uma vez dentro do ônibus, não se intimide com os gritalhões e valentões que, ofendidíssimos com o motorista por ele ter parado nas estações, depois dos ônibus anteriores terem ignorado esses excelsos passageiros que nelas aguardavam, vão aos berros tirar satisfação.
O ponto final do ônibus, 40 minutos depois, é o terminal Morro Alto. Lá você verá, se procurar bem entre vários ônibus e pessoas que despertam a sua mais honesta suspeita, um veículo escuro, apagado, numerado 5882 e que abrigará em seu interior um motorista e um cobrador que descansam o sono dos justos.
Aguarde na porta por mais uns vinte minutos até que, repentinamente desperto, o motorista ligue o ônibus, abra as portas e já comece, de leve, a arrancar. Entre correndo, mas espere mais um tempo, enquanto as pessoas que têm o cartão carregado passem e peguem os melhores lugares, até que o cobrador acorde e resolva te cobrar a passagem nesse velho meio de pagamento, outrora o mais líqüído, o dinheiro.
Este último ônibus deverá levar-lhe, enfim, a Lagoa Santa.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Jofer
Jofer era um jogador diferente. À primeira vista não, parecia igual, um volante combativo, perseguia os atacantes adversários implacavelmente, um bom jogador. Mas não era essa a característica que diferenciava Jofer. Jofer era, digamos, um chutador.
Começou numa semifinal de um torneio de juniores. O time de Jofer precisava do empate e estava sofrendo uma baita pressão do adversário, mas o jogo estava 1 a 1 e parecia que ia ficar assim mesmo, daquele jeito futebolístico que parece, parece mesmo. Só que aos 46 do segundo tempo tomaram um gol espírita, Ruizinho do outro time saiu correndo pela esquerda e, mesmo sendo canhoto, foi cortando para o meio, os zagueiros meio que achando que já tinha acabado mesmo, devia ter só mais aquele lance, o árbitro tinha dado dois minutos, Ruizinho chutou, marcou e o goleiro, que só pulou depois que já tinha visto que não ia ter jeito, ficou xingando.
A bola saiu do meio e tocaram para Jofer, ninguém nem veio marcá-lo, o outro time já estava comemorando, e com razão, o juiz estava de sacanagem em fazer o jogo continuar, já estava tudo acabado mesmo. Mas não, estava certo, mais um minuto de acréscimo, justo. Em um minuto dá pra fazer um gol. Mas como? Jofer pensou nas partidas da NBA em que com alguns centésimos de segundo faltando o armador jogava de qualquer jeito para a cesta e às vezes acertava. De trás do meio de campo, será? Não vou ter nem força pra fazer chegar no gol. Vou virar piada, melhor tocar pro Fumaça ali do lado e a gente perde sem essa humilhação no final. Mas, poxa, e daí? Vou tentar mesmo assim, qualquer coisa eu falo que foi um lançamento e daqui a uns dias todo mundo esquece. Olhou para o próprio pé, virou ele de ladinho, pra fora e depois pra dentro (bom, se eu pegar daqui, direitinho, quem sabe?), jogou a bola pro lado e bateu. A bola subiu escandalosamente, muito alta mesmo, deve ter subido uns 200 metros. Jofer não tinha como ter a menor noção. Depois foi descendo, o goleirão voltando correndo para debaixo da trave e olhando pra bola, foi chegando e pulando já só pra acompanhar, para ver, dependurado no travessão, a bola sair ainda bem alta, ela bateu na rede lateral interna antes de bater no chão, quicar violentamente e estufar a rede no alto do lado direito de quem olhava.
Mas isso tudo foi sonho do Jofer. Sonhou acordado, numa noite em que demorou pra dormir, deitado na sua cama. Ficou pensando se não seria fácil, se ele treinasse bastante, acertar o gol bem de longe, tipo no sonho, e se não dava pra fazer gol assim. No dia seguinte perguntou a Brunildinho, o treinador de goleiros. Era difícil defender essas bolas, ainda mais se elas subissem muito, o goleiro ficava sem perspectiva, o vento alterava a trajetória a cada instante, tinha efeito, ela cairia rápido, mas claro que não valia à pena treinar isso, a chance de acertar o gol era minúscula. Mas Jofer só ia tentar depois que treinasse bastante e comprovasse o que na sua imaginação parecia uma excelente idéia.
Começou a treinar todos os dias. Primeiro escondido, por vergonha dos colegas, chegava um pouco antes e ficava lá, chutando do círculo central. Ao menor sinal de gente se aproximando, parava e ia catar as bolas. Depois, quando começou a acertar, perdeu a vergonha. O pessoal do clube todo achava engraçado quando via Jofer treinando e depois ouvia a explicação da boca de alguém, ninguém levava muito a sério, mas também não achava de todo ridículo. O pessoal ria, mas no fundo torcia praquilo dar certo, mesmo.
Aconteceu que num jogo que não valia muita coisa, empatezinho feio, aos 40 do segundo tempo, a marcação dos adversários já não estava mais pressionando, todo mundo contente com o empate e com vontade de parar de jogar já, o Henrique, meia-esquerdo, humilde, mas ainda assim um pouco intimidante para Jofer (jogava demais), tocou pra ele. Vai lá, tenta sua loucura aí. Assumiu a responsabilidade do nosso volante introspectivo. Seria mais verossímil se Jofer tivesse errado, primeira vez que tentou, restava muito tempo ainda pra ele ter a chance de ser herói, ninguém acerta de primeira, mas ele acertou. Quase como no sonho, Lucas, o goleiro, não esperava, depois que viu o lance, riu-se, adiantou-se para pegar a bola que ele julgava que quicaria na área, mas ela foi mais pra frente, mais e mais, daí Lucas já estava correndo, só que começou a pensar que ela ia pra fora, e ele ia só se dependurar no travessão e fazer seu papel de estar na bola. Acabou que por conta daquele gol eles terminaram em segundo no grupo daquele torneiozinho, ao invés de terceiro, e não fez diferença nenhuma.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
The flaw of "just use paypal/coinbase" arguments
For the millionth time I read somewhere that "custodial bitcoin is not bitcoin" and that "if you're going to use custodial, better use Paypal". No, actually it was "better use Coinbase", but I had heard the "PayPal" version in the past.
There are many reasons why using PayPal is not the same as using a custodial Bitcoin service or wallet that are obvious and not relevant here, such as the fact that you can't have Bitcoin balances on Bitcoin (or maybe now you can? but you can't send it around); plus all the reasons that are also valid for Coinbase such as you having to give all your data and selfies of yourself and your government documents and so on -- but let's ignore these reasons for now.
The most important reason why it isn't the same thing is that when you're using Coinbase you are stuck in Coinbase. Your Coinbase coins cannot be used to pay anyone that isn't in Coinbase. So Coinbase-style custodianship doesn't help Bitcoin. If you want to move out of Coinbase you have to withdraw from Coinbase.
Custodianship on Lightning is of a very different nature. You can pay people from other custodial platforms and people that are hosting their own Lightning nodes and so on.
That kind of custodianship doesn't do any harm to anyone, doesn't fracture the network, doesn't reduce the network effect of Lightning, in fact it increases it.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
My personal experience (as a complete ignorant) of the blocksize debate in 2017
In the beginning of 2017 I didn't know Bitcoin was having a "blocksize debate". I had stopped paying attention to Bitcoin in 2014 after reading Tim Swanson's book on shitcoineiry and was surprise people even care about Bitcoin still while Ethereum and other fancy things were around.
My introduction to the subject was this interview with Andrew Stone and Andrew Clifford from Bitcoin Unlimited (still don't know who these guys are). I've listened to it and kinda liked the conspiracy theory about "a group of developers trying, against miners and users, to control the whole ecosystem by not allowing blocks to grow" (actually, if you listen to this interview that announced the creation of Blockstream and the sidechains whitepaper it does sound like a government agent bribing all the Core developers into forming a consortium that will turn Bitcoin into an Ethereum-like shitcoin under their control -- but this is just a useless digression).
Some time later I listened to this interview with Jimmy Song and was introduced to two hard forks and conspiracies and New York Agreement and got excited because I didn't care about Bitcoin (I'm ashamed to remember this feeling) and wanted to see things changing, people fighting, Bitcoin burning, for no reason. Oddly, what I grasped from the interview was that Jimmy Song was defending the agreement and expecting everybody to fulfill it.
When the day actually come and "Bitcoin Cash" forked I looked at it with pity because it looked clearly a failure from the beginning, but I still cheered for it a bit, still not knowing anything about the debate, besides the fact that blocks were bigger on BCH, which looked like a very reductionist explanation to me.
"Of course it's not just making blocks bigger, that would be too simple, they probably have a very complex plan I'm not apt to understand", I thought.
To my surprise the entire argument was actually just that: bigger blocks bigger blocks. I came to that conclusion by listening to tomwoods.com/1064, a debate in which reasonable arguments faced childish claims. That debate gave me perspective and was a clear, undisputed win from Jameson Lopp against Roger Ver.
Actually some time before that I had listened to another Tom Woods Show episode thinking it was going to be an episode about Bitcoin, but in fact it was just propaganda about a debate I had almost forgotten. And nothing about Bitcoin, everything about "Bitcoin Cash" and how there were two Bitcoins, one legitimate and the other unlegitimate.
So, from the perspective of someone that came to the debate totally fresh and only listens to the big-blocker arguments for a long time, they still don't convince anyone with some common sense (as I would like to think of myself), they just sound like mad dogs and everything goes against themselves.
Fast forward to the present and with much more understanding of the issues in place I started digging some material from 2016-2017 about the debate to try to get more context, and found this ridiculous interview with Mike Hearn. It isn't a waste of time to listen to it if you're not familiar with the debate from that time.
As I should have probably expected from my experience with Epicenter.tv, both the interviewers agree with Mike Hearn about his ridiculous claims about how (not his words) we have to subsidize the few thousand current Bitcoin users by preventing fees from increase and there are no trade-offs to doing that -- and even with everybody agreeing they all manage to sound stupid. There's not a single phrase that is defendable in the entire interview, no criticisms make any sense, it makes me feel bad for the the guy as he feels so self-assured and obviouslyright.
After knowing about these and other adventures of stupid people with high influences in the Bitcoin world trying to impose their idiocy on others it feels even more odd and unexpected to find Bitcoin in the right track. Generally in politics the most dumb wins, but apparently not in Bitcoin.
Bitcoin is a miracle.
-
@ a008def1:57a3564d
2025-04-30 17:52:11
A Vision for #GitViaNostr
Git has long been the standard for version control in software development, but over time, we has lost its distributed nature. Originally, Git used open, permissionless email for collaboration, which worked well at scale. However, the rise of GitHub and its centralized pull request (PR) model has shifted the landscape.
Now, we have the opportunity to revive Git's permissionless and distributed nature through Nostr!
We’ve developed tools to facilitate Git collaboration via Nostr, but there are still significant friction that prevents widespread adoption. This article outlines a vision for how we can reduce those barriers and encourage more repositories to embrace this approach.
First, we’ll review our progress so far. Then, we’ll propose a guiding philosophy for our next steps. Finally, we’ll discuss a vision to tackle specific challenges, mainly relating to the role of the Git server and CI/CD.
I am the lead maintainer of ngit and gitworkshop.dev, and I’ve been fortunate to work full-time on this initiative for the past two years, thanks to an OpenSats grant.
How Far We’ve Come
The aim of #GitViaNostr is to liberate discussions around code collaboration from permissioned walled gardens. At the core of this collaboration is the process of proposing and applying changes. That's what we focused on first.
Since Nostr shares characteristics with email, and with NIP34, we’ve adopted similar primitives to those used in the patches-over-email workflow. This is because of their simplicity and that they don’t require contributors to host anything, which adds reliability and makes participation more accessible.
However, the fork-branch-PR-merge workflow is the only model many developers have known, and changing established workflows can be challenging. To address this, we developed a new workflow that balances familiarity, user experience, and alignment with the Nostr protocol: the branch-PR-merge model.
This model is implemented in ngit, which includes a Git plugin that allows users to engage without needing to learn new commands. Additionally, gitworkshop.dev offers a GitHub-like interface for interacting with PRs and issues. We encourage you to try them out using the quick start guide and share your feedback. You can also explore PRs and issues with gitplaza.
For those who prefer the patches-over-email workflow, you can still use that approach with Nostr through gitstr or the
ngit sendandngit listcommands, and explore patches with patch34.The tools are now available to support the core collaboration challenge, but we are still at the beginning of the adoption curve.
Before we dive into the challenges—such as why the Git server setup can be jarring and the possibilities surrounding CI/CD—let’s take a moment to reflect on how we should approach the challenges ahead of us.
Philosophy
Here are some foundational principles I shared a few years ago:
- Let Git be Git
- Let Nostr be Nostr
- Learn from the successes of others
I’d like to add one more:
- Embrace anarchy and resist monolithic development.
Micro Clients FTW
Nostr celebrates simplicity, and we should strive to maintain that. Monolithic developments often lead to unnecessary complexity. Projects like gitworkshop.dev, which aim to cover various aspects of the code collaboration experience, should not stifle innovation.
Just yesterday, the launch of following.space demonstrated how vibe-coded micro clients can make a significant impact. They can be valuable on their own, shape the ecosystem, and help push large and widely used clients to implement features and ideas.
The primitives in NIP34 are straightforward, and if there are any barriers preventing the vibe-coding of a #GitViaNostr app in an afternoon, we should work to eliminate them.
Micro clients should lead the way and explore new workflows, experiences, and models of thinking.
Take kanbanstr.com. It provides excellent project management and organization features that work seamlessly with NIP34 primitives.
From kanban to code snippets, from CI/CD runners to SatShoot—may a thousand flowers bloom, and a thousand more after them.
Friction and Challenges
The Git Server
In #GitViaNostr, maintainers' branches (e.g.,
master) are hosted on a Git server. Here’s why this approach is beneficial:- Follows the original Git vision and the "let Git be Git" philosophy.
- Super efficient, battle-tested, and compatible with all the ways people use Git (e.g., LFS, shallow cloning).
- Maintains compatibility with related systems without the need for plugins (e.g., for build and deployment).
- Only repository maintainers need write access.
In the original Git model, all users would need to add the Git server as a 'git remote.' However, with ngit, the Git server is hidden behind a Nostr remote, which enables:
- Hiding complexity from contributors and users, so that only maintainers need to know about the Git server component to start using #GitViaNostr.
- Maintainers can easily swap Git servers by updating their announcement event, allowing contributors/users using ngit to automatically switch to the new one.
Challenges with the Git Server
While the Git server model has its advantages, it also presents several challenges:
- Initial Setup: When creating a new repository, maintainers must select a Git server, which can be a jarring experience. Most options come with bloated social collaboration features tied to a centralized PR model, often difficult or impossible to disable.
-
Manual Configuration: New repositories require manual configuration, including adding new maintainers through a browser UI, which can be cumbersome and time-consuming.
-
User Onboarding: Many Git servers require email sign-up or KYC (Know Your Customer) processes, which can be a significant turn-off for new users exploring a decentralized and permissionless alternative to GitHub.
Once the initial setup is complete, the system works well if a reliable Git server is chosen. However, this is a significant "if," as we have become accustomed to the excellent uptime and reliability of GitHub. Even professionally run alternatives like Codeberg can experience downtime, which is frustrating when CI/CD and deployment processes are affected. This problem is exacerbated when self-hosting.
Currently, most repositories on Nostr rely on GitHub as the Git server. While maintainers can change servers without disrupting their contributors, this reliance on a centralized service is not the decentralized dream we aspire to achieve.
Vision for the Git Server
The goal is to transform the Git server from a single point of truth and failure into a component similar to a Nostr relay.
Functionality Already in ngit to Support This
-
State on Nostr: Store the state of branches and tags in a Nostr event, removing reliance on a single server. This validates that the data received has been signed by the maintainer, significantly reducing the trust requirement.
-
Proxy to Multiple Git Servers: Proxy requests to all servers listed in the announcement event, adding redundancy and eliminating the need for any one server to match GitHub's reliability.
Implementation Requirements
To achieve this vision, the Nostr Git server implementation should:
-
Implement the Git Smart HTTP Protocol without authentication (no SSH) and only accept pushes if the reference tip matches the latest state event.
-
Avoid Bloat: There should be no user authentication, no database, no web UI, and no unnecessary features.
-
Automatic Repository Management: Accept or reject new repositories automatically upon the first push based on the content of the repository announcement event referenced in the URL path and its author.
Just as there are many free, paid, and self-hosted relays, there will be a variety of free, zero-step signup options, as well as self-hosted and paid solutions.
Some servers may use a Web of Trust (WoT) to filter out spam, while others might impose bandwidth or repository size limits for free tiers or whitelist specific npubs.
Additionally, some implementations could bundle relay and blossom server functionalities to unify the provision of repository data into a single service. These would likely only accept content related to the stored repositories rather than general social nostr content.
The potential role of CI / CD via nostr DVMs could create the incentives for a market of highly reliable free at the point of use git servers.
This could make onboarding #GitViaNostr repositories as easy as entering a name and selecting from a multi-select list of Git server providers that announce via NIP89.
!(image)[https://image.nostr.build/badedc822995eb18b6d3c4bff0743b12b2e5ac018845ba498ce4aab0727caf6c.jpg]
Git Client in the Browser
Currently, many tasks are performed on a Git server web UI, such as:
- Browsing code, commits, branches, tags, etc.
- Creating and displaying permalinks to specific lines in commits.
- Merging PRs.
- Making small commits and PRs on-the-fly.
Just as nobody goes to the web UI of a relay (e.g., nos.lol) to interact with notes, nobody should need to go to a Git server to interact with repositories. We use the Nostr protocol to interact with Nostr relays, and we should use the Git protocol to interact with Git servers. This situation has evolved due to the centralization of Git servers. Instead of being restricted to the view and experience designed by the server operator, users should be able to choose the user experience that works best for them from a range of clients. To facilitate this, we need a library that lowers the barrier to entry for creating these experiences. This library should not require a full clone of every repository and should not depend on proprietary APIs. As a starting point, I propose wrapping the WASM-compiled gitlib2 library for the web and creating useful functions, such as showing a file, which utilizes clever flags to minimize bandwidth usage (e.g., shallow clone, noblob, etc.).
This approach would not only enhance clients like gitworkshop.dev but also bring forth a vision where Git servers simply run the Git protocol, making vibe coding Git experiences even better.
song
nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6 created song with a complementary vision that has shaped how I see the role of the git server. Its a self-hosted, nostr-permissioned git server with a relay baked in. Its currently a WIP and there are some compatability with ngit that we need to work out.
We collaborated on the nostr-permissioning approach now reflected in nip34.
I'm really excited to see how this space evolves.
CI/CD
Most projects require CI/CD, and while this is often bundled with Git hosting solutions, it is currently not smoothly integrated into #GitViaNostr yet. There are many loosely coupled options, such as Jenkins, Travis, CircleCI, etc., that could be integrated with Nostr.
However, the more exciting prospect is to use DVMs (Data Vending Machines).
DVMs for CI/CD
Nostr Data Vending Machines (DVMs) can provide a marketplace of CI/CD task runners with Cashu for micro payments.
There are various trust levels in CI/CD tasks:
- Tasks with no secrets eg. tests.
- Tasks using updatable secrets eg. API keys.
- Unverifiable builds and steps that sign with Android, Nostr, or PGP keys.
DVMs allow tasks to be kicked off with specific providers using a Cashu token as payment.
It might be suitable for some high-compute and easily verifiable tasks to be run by the cheapest available providers. Medium trust tasks could be run by providers with a good reputation, while high trust tasks could be run on self-hosted runners.
Job requests, status, and results all get published to Nostr for display in Git-focused Nostr clients.
Jobs could be triggered manually, or self-hosted runners could be configured to watch a Nostr repository and kick off jobs using their own runners without payment.
But I'm most excited about the prospect of Watcher Agents.
CI/CD Watcher Agents
AI agents empowered with a NIP60 Cashu wallet can run tasks based on activity, such as a push to master or a new PR, using the most suitable available DVM runner that meets the user's criteria. To keep them running, anyone could top up their NIP60 Cashu wallet; otherwise, the watcher turns off when the funds run out. It could be users, maintainers, or anyone interested in helping the project who could top up the Watcher Agent's balance.
As aluded to earlier, part of building a reputation as a CI/CD provider could involve running reliable hosting (Git server, relay, and blossom server) for all FOSS Nostr Git repositories.
This provides a sustainable revenue model for hosting providers and creates incentives for many free-at-the-point-of-use hosting providers. This, in turn, would allow one-click Nostr repository creation workflows, instantly hosted by many different providers.
Progress to Date
nostr:npub1hw6amg8p24ne08c9gdq8hhpqx0t0pwanpae9z25crn7m9uy7yarse465gr and nostr:npub16ux4qzg4qjue95vr3q327fzata4n594c9kgh4jmeyn80v8k54nhqg6lra7 have been working on a runner that uses GitHub Actions YAML syntax (using act) for the dvm-cicd-runner and takes Cashu payment. You can see example runs on GitWorkshop. It currently takes testnuts, doesn't give any change, and the schema will likely change.
Note: The actions tab on GitWorkshop is currently available on all repositories if you turn on experimental mode (under settings in the user menu).
It's a work in progress, and we expect the format and schema to evolve.
Easy Web App Deployment
For those disapointed not to find a 'Nostr' button to import a git repository to Vercel menu: take heart, they made it easy. vercel.com_import_options.png there is a vercel cli that can be easily called in CI / CD jobs to kick of deployments. Not all managed solutions for web app deployment (eg. netlify) make it that easy.
Many More Opportunities
Large Patches via Blossom
I would be remiss not to mention the large patch problem. Some patches are too big to fit into Nostr events. Blossom is perfect for this, as it allows these larger patches to be included in a blossom file and referenced in a new patch kind.
Enhancing the #GitViaNostr Experience
Beyond the large patch issue, there are numerous opportunities to enhance the #GitViaNostr ecosystem. We can focus on improving browsing, discovery, social and notifications. Receiving notifications on daily driver Nostr apps is one of the killer features of Nostr. However, we must ensure that Git-related notifications are easily reviewable, so we don’t miss any critical updates.
We need to develop tools that cater to our curiosity—tools that enable us to discover and follow projects, engage in discussions that pique our interest, and stay informed about developments relevant to our work.
Additionally, we should not overlook the importance of robust search capabilities and tools that facilitate migrations.
Concluding Thoughts
The design space is vast. Its an exciting time to be working on freedom tech. I encourage everyone to contribute their ideas and creativity and get vibe-coding!
I welcome your honest feedback on this vision and any suggestions you might have. Your insights are invaluable as we collaborate to shape the future of #GitViaNostr. Onward.
Contributions
To conclude, I want to acknowledge some the individuals who have made recent code contributions related to #GitViaNostr:
nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6 (gitstr, song, patch34), nostr:npub1useke4f9maul5nf67dj0m9sq6jcsmnjzzk4ycvldwl4qss35fvgqjdk5ks (gitplaza)
nostr:npub1elta7cneng3w8p9y4dw633qzdjr4kyvaparuyuttyrx6e8xp7xnq32cume (ngit contributions, git-remote-blossom),nostr:npub16p8v7varqwjes5hak6q7mz6pygqm4pwc6gve4mrned3xs8tz42gq7kfhdw (SatShoot, Flotilla-Budabit), nostr:npub1ehhfg09mr8z34wz85ek46a6rww4f7c7jsujxhdvmpqnl5hnrwsqq2szjqv (Flotilla-Budabit, Nostr Git Extension), nostr:npub1ahaz04ya9tehace3uy39hdhdryfvdkve9qdndkqp3tvehs6h8s5slq45hy (gnostr and experiments), and others.
nostr:npub1uplxcy63up7gx7cladkrvfqh834n7ylyp46l3e8t660l7peec8rsd2sfek (git-remote-nostr)
Project Management nostr:npub1ltx67888tz7lqnxlrg06x234vjnq349tcfyp52r0lstclp548mcqnuz40t (kanbanstr) Code Snippets nostr:npub1ygzj9skr9val9yqxkf67yf9jshtyhvvl0x76jp5er09nsc0p3j6qr260k2 (nodebin.io) nostr:npub1r0rs5q2gk0e3dk3nlc7gnu378ec6cnlenqp8a3cjhyzu6f8k5sgs4sq9ac (snipsnip.dev)
CI / CD nostr:npub16ux4qzg4qjue95vr3q327fzata4n594c9kgh4jmeyn80v8k54nhqg6lra7 nostr:npub1hw6amg8p24ne08c9gdq8hhpqx0t0pwanpae9z25crn7m9uy7yarse465gr
and for their nostr:npub1c03rad0r6q833vh57kyd3ndu2jry30nkr0wepqfpsm05vq7he25slryrnw nostr:npub1qqqqqq2stely3ynsgm5mh2nj3v0nk5gjyl3zqrzh34hxhvx806usxmln03 and nostr:npub1l5sga6xg72phsz5422ykujprejwud075ggrr3z2hwyrfgr7eylqstegx9z for their testing, feedback, ideas and encouragement.
Thank you for your support and collaboration! Let me know if I've missed you.
-
@ c230edd3:8ad4a712
2025-04-30 16:19:30
Chef's notes
I found this recipe on beyondsweetandsavory.com. The site is incredibly ad infested (like most recipe sites) and its very annoying so I'm copying it to Nostr so all the homemade ice cream people can access it without dealing with that mess. I haven't made it yet. Will report back, when I do.
Details
- ⏲️ Prep time: 20 min
- 🍳 Cook time: 55 min
- 🍽️ Servings: 8
Ingredients
- 2 cups heavy cream
- 1 cup 2% milk
- 8 oz dark chocolate, 70%
- ¼ cup Dutch cocoa
- 2 tbsps loose Earl grey tea leaves
- 4 medium egg yolks
- ¾ cup granulated sugar
- ⅛ tsp salt
- ¼ cup dark chocolate, 70% chopped
Directions
- In a double boiler or a bowl set over a saucepan of simmering water, add the cacao solids and ½ cup of heavy cream. Stir chocolate until melted and smooth. Set melted chocolate aside.
- In a heavy saucepan, combine remaining heavy cream, milk, salt and ½ cup of sugar.
- Put the pan over medium heat and let the mixture boil gently to bubbling just around the edges (gentle simmer) and sugar completely dissolved, about 5 minutes. Remove from heat.
- Add the Earl Grey tea leaves and let it steep for 7-8 minutes until the cream has taken on the tea flavor, stirring occasionally and tasting to make sure it’s not too bitter.
- Whisk in Dutch cocoa until smooth. Add in melted chocolate and whisk until smooth.
- In a medium heatproof bowl, whisk the yolks just to break them up and whisk in remaining sugar. Set aside.
- Put the saucepan back on the stove over low heat and let it warm up for 2 minutes.
- Carefully measure out ½ cup of hot cream mixture.
- While whisking the eggs constantly, whisk the hot cream mixture into the eggs until smooth. Continue tempering the eggs by adding another ½ cup of hot cream to the bowl with the yolks.
- Pour the cream-egg mixture back to the saucepan and cook over medium-low heat, stirring constantly until it is thickened and coats the back of a spatula, about 5 minutes.
- Strain the base through a fine-mesh strainer into a clean container.
- Pour the mixture into a 1-gallon Ziplock freezer bag and submerge the sealed bag in an ice bath until cold, about 30 minutes. Refrigerate the ice cream base for at least 4 hours or overnight.
- Pour the ice cream base into the frozen canister of your ice cream machine and follow the manufacturer’s instructions.
- Spin until thick and creamy about 25-30 minutes.
- Pack the ice cream into a storage container, press a sheet of parchment directly against the surface and seal with an airtight lid. Freeze in the coldest part of your freezer until firm, at least 4 hours.
- When ready to serve, scoop the ice cream into a serving bowl and top with chopped chocolate.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: Per-paragraph paywalls
Using the lnurl-allowance protocol, a website could instead of putting a paywall over the entire site, charge a reader for only the paragraphs they read. Of course this requires trust from the reader on the website, but this is normal. The website could just hide the rest of the article before an invoice from the paragraph just read was paid.
This idea came from Colin from the Unhashed Podcast.
Could also work with podcasts and videos.
-
@ 1739d937:3e3136ef
2025-04-30 14:39:24
MLS over Nostr - 30th April 2025
YO! Exciting stuff in this update so no intro, let's get straight into it.
🚢 Libraries Released
I've created 4 new Rust crates to make implementing NIP-EE (MLS) messaging easy for other projects. These are now part of the rust-nostr project (thanks nostr:npub1drvpzev3syqt0kjrls50050uzf25gehpz9vgdw08hvex7e0vgfeq0eseet) but aren't quite released to crates.io yet. They will be included in the next release of that library. My hope is that these libraries will give nostr developers a simple, safe, and specification-compliant way to work with MLS messaging in their applications.
Here's a quick overview of each:
nostr_mls_storage
One of the challenges of using MLS messaging is that clients have to store quite a lot of state about groups, keys, and messages. Initially, I implemented all of this in White Noise but knew that eventually this would need to be done in a more generalized way.
This crate defines traits and types that are used by the storage implementation crates and sets those up to wrap the OpenMLS storage layer. Now, instead of apps having to implement storage for both OpenMLS and Nostr, you simply pick your storage backend and go from there.
Importantly, because these are generic traits, it allows for the creation of any number of storage implementations for different backend storage providers; postgres, lmdb, nostrdb, etc. To start I've created two implementations; detailed below.
nostr_mls_memory_storage
This is a simple implementation of the nostr_mls_storage traits that uses an in-memory store (that doesn't persist anything to disc). This is principally for testing.
nostr_mls_sqlite_storage
This is a production ready implementation of the nostr_mls_storage traits that uses a persistent local sqlite database to store all data.
nostr_mls
This is the main library that app developers will interact with. Once you've chose a backend and instantiated an instance of NostrMls you can then interact with a simple set of methods to create key packages, create groups, send messages, process welcomes and messages, and more.
If you want to see a complete example of what the interface looks like check out mls_memory.rs.
I'll continue to add to this library over time as I implement more of the MLS protocol features.
🚧 White Noise Refactor
As a result of these new libraries, I was able to remove a huge amount of code from White Noise and refactor large parts of the app to make the codebase easier to understand and maintain. Because of this large refactor and the changes in the underlying storage layer, if you've installed White Noise before you'll need to delete it from your device before you trying to install again.
🖼️ Encrypted Media with Blossom
Let's be honest: Group chat would be basically useless if you couldn't share memes and gifs. Well, now you can in White Noise. Media in groups is encrypted using an MLS secret and uploaded to Blossom with a one-time use keypair. This gives groups a way to have rich conversations with images and documents and anything else while also maintaining the privacy and security of the conversation.
This is still in a rough state but rendering improvements are coming next.
📱 Damn Mobile
The app is still in a semi-broken state on Android and fully broken state on iOS. Now that I have the libraries released and the White Noise core code refactored, I'm focused 100% on fixing these issues. My goal is to have a beta version live on Zapstore in a few weeks.
🧑💻 Join Us
I'm looking for mobile developers on both Android and iOS to join the team and help us build the best possible apps for these platforms. I have grant funding available for the right people. Come and help us build secure, permissionless, censorship-resistant messaging. I can think of few projects that deserve your attention more than securing freedom of speech and freedom of association for the entire world. If you're interested or know someone who might be, please reach out to me directly.
🙏 Thanks to the People
Last but not least: A HUGE thank you to all the folks that have been helping make this project happen. You can check out the people that are directly working on the apps on Following._ (and follow them). There are also a lot of people behind the scenes that have helped in myriad ways to get us this far. Thank you thank you thank you.
🔗 Links
Libraries
White Noise
Other
-
@ 4e616576:43c4fee8
2025-04-30 13:28:18
asdfasdfsadfaf
-
@ 79008e78:dfac9395
2025-03-22 11:22:07
Keys and Addresses
อลิซต้องการจ่ายเงินให้กับบ๊อบแต่โหนดของบิตคอยน์ในระบบหลายพันโหนดจะตรวจสอบธุรกรรมของเธอ โดยไม่รู้ว่าอลิซหรือบ๊อบเป็นใคร ละเราต้องการรักษาความเป็นส่วนตัวของพวกเขาไว้เช่นนี้ อลิซจำเป็นต้องสื่อสารว่าบ๊อบควรได้รับบิตคอยน์บางส่วนของเธอโดยไม่เชื่อมโยงแง่มุมใด ๆ ของธุรกรรมนั้นกับตัวตนในโลกจริงของบ๊อบ หรือกับการชำระเงินด้วยบิตคอยน์ครั้งอื่น ๆ ที่บ๊อบได้รับ อลิซใช้ต้องทำให้มั่นใจว่ามีเพียแค่บ๊อบเท่านั้นที่สามารถใช้จ่ายบิตคอยน์ที่เขาได้รับต่อไปได้
ในบิตคอยน์ไวท์เปเปอร์ได้อธิบายถึงแผนการที่เรียบง่ายมากสำหรับการบรรลุเป้าหมายเหล่านั้น ดังที่แสดงในรูปด้านล่างนี้

ตัวของผู้รับอย่างบ๊อบเองจะได้รับบิตคอยน์ไปยัง public key ของเขาที่ถูกลงนามโดยผู้จ่ายอย่างอลิซ โดยบิตคอยน์ที่อลิซนำมาจ่ายนั้นก็ได้รับมาจากที่ใครสักคนส่งมาที่ public key ของเธอ และเธอก็ใช้ private key ของเธอในการลงนามเพื่อสร้างลายเซ็นของเธอและโหนดต่าง ๆ ของบิตคอยน์จะทำการตรวจสอบว่าลายเซ็นของอลิซผูกมัดกับเอาต์พุตของฟังก์ชันแฮชซึ่งตัวมันเองผูกมัดกับ public key ของบ๊อบและรายละเอียดธุรกรรมอื่นๆ
ในบทนี้เราจะพิจารณาpublic key private key Digital signatrue และ hash function จากนั้นใช้ทั้งหมดนี้ร่วมกันเพื่ออธิบาย address ที่ใช้โดยซอฟต์แวร์บิตคอยน์สมัยใหม่
Public Key Cryptography (การเข้ารหัสของ public key)
ระบบเข้ารหัสของ public key ถูกคิดค้นขึ้นในทศวรรษ 1970 มาจากรากฐานทางคณิตศาสตร์สำหรับความปลอดภัยของคอมพิวเตอร์และข้อมูลสมัยใหม่
นับตั้งแต่การคิดค้นระบบเข้ารหัส public key ได้มีการค้นพบฟังก์ชันทางคณิตศาสตร์ที่เหมาะสมหลายอย่าง เช่น การยกกำลังของจำนวนเฉพาะและการคูณของเส้นโค้งวงรี โดยฟังก์ชันทางคณิตศาสตร์เหล่านี้สามารถคำนวณได้ง่ายในทิศทางหนึ่ง แต่เป็นไปไม่ได้ที่จะคำนวณในทิศทางตรงกันข้ามโดยใช้คอมพิวเตอร์และอัลกอริทึมที่มีอยู่ในปัจจุบัน จากฟังก์ชันทางคณิตศาสตร์เหล่านี้ การเข้ารหัสลับช่วยให้สามารถสร้างลายเซ็นดิจิทัลที่ไม่สามารถปลอมแปลงได้และบิตคอยน์ได้ใช้การบวกและการคูณของเส้นโค้งวงรีเป็นพื้นฐานสำหรับการเข้ารหัสลับของมัน
ในบิตคอยน์ เราสามารถใช้ระบบเข้ารหัส public key เพื่อสร้างคู่กุญแจที่ควบคุมการเข้าถึงบิตคอยน์ คู่กุญแจประกอบด้วย private key และ public key ที่ได้มาจาก private key public keyใช้สำหรับรับเงิน และ private key ใช้สำหรับลงนามในธุรกรรมเพื่อใช้จ่ายเงิน
ความสัมพันธ์ทางคณิตศาสตร์ระหว่าง public key และ private key ที่ช่วยให้ private key สามารถใช้สร้างลายเซ็นบนข้อความได้ ลายเซ็นเหล่านี้สามารถตรวจสอบความถูกต้องกับ public key ได้โดยไม่เปิดเผย private key
TIP: ในการใช้งานซอฟแวร์กระเป๋าเงินบิตคอยน์บสงอัน จะทำการเก็บ private key และ public key ถูกเก็บไว้ด้วยกันในรูปแบบคู่กุญแจเพื่อความสะดวก แต่อย่างไรก็ตาม public key สามารถคำนวณได้จาก private key ดังนั้นการเก็บเพียง private key เท่านั้นก็เป็นไปได้เช่นกัน
bitcoin wallet มักจะทำการรวบรวมคู่กุญแต่ละคู่ ซึ่งจะประกอบไปด้วย private key และ public key โดย private key จะเป็นตัวเลขที่ถูกสุ่มเลือกขึ้นมา และเราขะใช้เส้นโค้งวงรี ซึ่งเป็นฟังก์ชันการเข้ารหัสทางเดียว เพื่อสร้าง public key ขึ้นมา
ทำไมจึงใช้การเข้ารหัสแบบอสมมาตร
ทำไมการเข้ารหัสแบบอสมมาตรจึงถูกใช้บิตคอยน์? มันไม่ได้ถูกใช้เพื่อ "เข้ารหัส" (ทำให้เป็นความลับ) ธุรกรรม แต่คุณสมบัติที่มีประโยชน์ของการเข้ารหัสแบบอสมมาตรคือความสามารถในการสร้าง ลายเซ็นดิจิทัล private key สามารถนำไปใช้กับธุรกรรมเพื่อสร้างลายเซ็นเชิงตัวเลข ลายเซ็นนี้สามารถสร้างได้เฉพาะโดยผู้ที่มีความเกี่ยวข้องกับ private key เท่านั้น แต่อย่างไรก็ตาม ทุกคนที่สามารถเข้าถึง public key และธุรกรรมสามารถใช้สิ่งเหล่านี้เพื่อ ตรวจสอบ ลายเซ็นได้ คุณสมบัติที่มีประโยชน์นี้ของการเข้ารหัสแบบอสมมาตรทำให้ทุกคนสามารถตรวจสอบลายเซ็นทุกรายการในทุกธุรกรรมได้ ในขณะที่มั่นใจว่าเฉพาะเจ้าของ private key เท่านั้นที่สามารถสร้างลายเซ็นที่ถูกต้องได้
Private keys
private key เป็นเพียงตัวเลขที่ถูกสุ่มขึ้น และการควบคุม private key ก็เป็นรากฐานสำคัญที่ทำให้เจ้าชองกุญแจดอกนี้สามารถควบคุมบิตคอยน์ทั้งหมดที่มีความเกี่ยวข้องกับ public key ที่คู่กัน private key นั้นใช้ในการสร้างลายเซ็นดิจิทัลที่ใช้ในการเคลื่อนย้ายบิตคอยน์ เราจำเป็นต้องเก็บ private key ให้เป็นความลับตลอดเวลา เพราะการเปิดเผยมันให้กับบุคคลอื่นนั้นก็เปรียบเสมือนกับการนำอำนาจในการควบคุมบิตคอยน์ไปให้แก่เขา นอกจากนี้ private key ยังจำเป็นต้องได้รับการสำรองข้อมูลและป้องกันจากการสูญหายโดยไม่ตั้งใจ เพราะหากเราได้ทำมันสูญหายไป จะไม่สามารถกู้คืนได้ และบิตคอยน์เหล่านั้นจะถูกปกป้องโดยกุญแจที่หายไปนั้นตลอดกาลเช่นกัน
TIP: private key ของบิตคอยน์นั้นเป็นเพียงแค่ตัวเลข คุณสามารถสร้างมันได้โดยใช้เพียงเหรียญ ดินสอ และกระดาษ โดยการโยนเหรียญเพียง 256 ครั้งจะทำให้คุณได้เลขฐานสองที่สามารถใช้เป็น private key ของบิตคอยน์ จากนั้นคุณสามารถใช้มันในการคำนวณหา public key แต่อย่างไรก็ตาม โปรดระมัดระวังเกี่ยวกับการเลือใช้วิธีการสุ่มที่ไม่สมบูรณ์ เพราะนั่นอาจลดความปลอดภัยของ private key และบิตคอยน์ที่มัมปกป้องอยู่อย่างมีนัยสำคัญ
ขั้นตอนแรกและสำคัญที่สุดในการสร้างกุญแจคือการหาแหล่งที่มาของความสุ่มที่ปลอดภัย (ซึ่งเรียกว่า เอนโทรปี) การสร้างกุญแจของบิตคอยน์นั้นเกือบเหมือนกับ "เลือกตัวเลขระหว่าง 1 และ 2^256" ซึ่งวิธีที่แน่นอนที่คุณใช้ในการเลือกตัวเลขนั้นไม่สำคัญตราบใดที่มันไม่สามารถคาดเดาหรือทำซ้ำได้ โดยปกติแล้วซอฟต์แวร์ของบิตคอยน์มักจะใช้ตัวสร้างตัวเลขสุ่มที่มีความปลอดภัยทางการเข้ารหัสเพื่อสร้างเอนโทรปี 256 บิต
สิ่งที่สำคัญในเรื่องนี้คือ private key สามารถเป็นตัวเลขใดๆ ระหว่าง 0 และ n - 1 (รวมทั้งสองค่า) โดยที่ n เป็นค่าคงที่ (n = 1.1578 × 10^77 ซึ่งน้อยกว่า 2^256 เล็กน้อย) ซึ่งกำหนดอยู่ใน elliptic curve ที่ใช้ใน Bitcoin ในการสร้างกุญแจดังกล่าว เราสุ่มเลือกเลขขนาด 256 บิตและตรวจสอบว่ามันน้อยกว่า n ในแง่ของการเขียนโปรแกรม โดยปกติแล้วสิ่งนี้ทำได้โดยการป้อนสตริงของบิตสุ่มที่ใหญ่กว่า ซึ่งรวบรวมจากแหล่งที่มาของความสุ่มที่มีความปลอดภัยทางการเข้ารหัส เข้าไปในอัลกอริทึมแฮช SHA256 ซึ่งจะสร้างค่าขนาด 256 บิตที่สามารถตีความเป็นตัวเลขได้อย่างสะดวก หากผลลัพธ์น้อยกว่า n เราจะได้กุญแจส่วนตัวที่เหมาะสม มิฉะนั้น เราก็เพียงแค่ลองอีกครั้งด้วยตัวเลขสุ่มอื่น
คำเตือน: อย่าเขียนโค้ดของคุณเองเพื่อสร้างตัวเลขสุ่ม หรือใช้ตัวสร้างตัวเลขสุ่ม "แบบง่าย" ที่มีให้ในภาษาโปรแกรมของคุณ ใช้ตัวสร้างตัวเลขสุ่มเทียมที่มีความปลอดภัยทางการเข้ารหัส (CSPRNG) จากแหล่งที่มีเอนโทรปีเพียงพอ ศึกษาเอกสารของไลบรารีตัวสร้างตัวเลขสุ่มที่คุณเลือกเพื่อให้มั่นใจว่ามีความปลอดภัยทางการเข้ารหัส การใช้งาน CSPRNG ที่ถูกต้องมีความสำคัญอย่างยิ่งต่อความปลอดภัยของกุญแจ
ต่อไปนี้คือกุญแจส่วนตัว (k) ที่สร้างขึ้นแบบสุ่มซึ่งแสดงในรูปแบบเลขฐานสิบหก (256 บิตแสดงเป็น 64 หลักเลขฐานสิบหก โดยแต่ละหลักคือ 4 บิต):
1E99423A4ED27608A15A2616A2B0E9E52CED330AC530EDCC32C8FFC6A526AEDDTIP: จำนวนที่เป็นไปได้ของ private key ทั้งหมดนั้นมีอยู่ 2^256 เป็นตัวเลขที่ใหญ่มากจนยากจะจินตนาการได้ มันมีค่าประมาณ 10^77 (เลข 1 ตามด้วยเลข 0 อีก 77 ตัว) ในระบบเลขฐานสิบ เพื่อให้เข้าใจง่ายขึ้น ลองเปรียบเทียบกับจักรวาลที่เรามองเห็นได้ซึ่งนักวิทยาศาสตร์ประมาณการว่ามีอะตอมทั้งหมดประมาณ 10^80 อะตอม นั่นหมายความว่าช่วงค่าของกุญแจส่วนตัว Bitcoin มีขนาดใกล้เคียงกับจำนวนอะตอมทั้งหมดในจักรวาลที่เรามองเห็นได้
การอธิบายเกี่ยวกับวิทยาการเข้ารหัสแบบเส้นโค้งวงรี (Elliptic Curve Cryptography)
วิทยาการเข้ารหัสแบบเส้นโค้งวงรี (ECC) เป็นประเภทหนึ่งของการเข้ารหัสแบบอสมมาตรหรือ public key ซึ่งอาศัยหลักการของปัญหาลอการิทึมแบบไม่ต่อเนื่อง โดยแสดงออกผ่านการบวกและการคูณบนจุดต่างๆ ของเส้นโค้งวงรี

บิตคอยน์ใช้เส้นโค้งวงรีเฉพาะและชุดค่าคงที่ทางคณิตศาสตร์ ตามที่กำหนดไว้ในมาตรฐานที่เรียกว่า secp256k1 ซึ่งกำหนดโดยสถาบันมาตรฐานและเทคโนโลยีแห่งชาติ (NIST) เส้นโค้ง secp256k1 ถูกกำหนดโดยฟังก์ชันต่อไปนี้ ซึ่งสร้างเส้นโค้งวงรี: y² = (x³ + 7) บนฟิลด์จำกัด (F_p) หรือ y² mod p = (x³ + 7) mod p
โดยที่ mod p (มอดูโลจำนวนเฉพาะ p) แสดงว่าเส้นโค้งนี้อยู่บนฟิลด์จำกัดของอันดับจำนวนเฉพาะ p ซึ่งเขียนได้เป็น F_p โดย p = 2^256 – 2^32 – 2^9 – 2^8 – 2^7 – 2^6 – 2^4 – 1 ซึ่งเป็นจำนวนเฉพาะที่มีค่ามหาศาล
บิตคอยน์ใช้เส้นโค้งวงรีที่ถูกนิยามบนฟิลด์จำกัดของอันดับจำนวนเฉพาะแทนที่จะอยู่บนจำนวนจริง ทำให้มันมีลักษณะเหมือนรูปแบบของจุดที่กระจัดกระจายในสองมิติ ซึ่งทำให้ยากต่อการจินตนาการภาพ อย่างไรก็ตาม คณิตศาสตร์ที่ใช้นั้นเหมือนกับเส้นโค้งวงรีบนจำนวนจริง
ตัวอย่างเช่น การเข้ารหัสลับด้วยเส้นโค้งวงรี: การแสดงภาพเส้นโค้งวงรีบน F(p) โดยที่ p=17 แสดงเส้นโค้งวงรีเดียวกันบนฟิลด์จำกัดของอันดับจำนวนเฉพาะ 17 ที่มีขนาดเล็กกว่ามาก ซึ่งแสดงรูปแบบของจุดบนตาราง
เส้นโค้งวงรี secp256k1 ที่ใช้ในบิตคอยน์สามารถนึกถึงได้ว่าเป็นรูปแบบของจุดที่ซับซ้อนมากกว่าบนตารางที่มีขนาดใหญ่มหาศาลจนยากจะเข้าใจได้

ตัวอย่างเช่น จุด P ที่มีพิกัด (x, y) ต่อไปนี้เป็นจุดที่อยู่บนเส้นโค้ง secp256k1:
P = (55066263022277343669578718895168534326250603453777594175500187360389116729240, 32670510020758816978083085130507043184471273380659243275938904335757337482424)เราสามารถใช้ Python เพื่อยืนยันว่าจุดนี้อยู่บนเส้นโค้งวงรีได้ตามตัวอย่างนี้: ตัวอย่างที่ 1: การใช้ Python เพื่อยืนยันว่าจุดนี้อยู่บนเส้นโค้งวงรี ``` Python 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] on linux Type "help", "copyright", "credits" or "license" for more information.p = 115792089237316195423570985008687907853269984665640564039457584007908834671663 x = 55066263022277343669578718895168534326250603453777594175500187360389116729240 y = 32670510020758816978083085130507043184471273380659243275938904335757337482424 (x ** 3 + 7 - y**2) % p 0 ``` ผลลัพธ์เป็น 0 ซึ่งแสดงว่าจุดนี้อยู่บนเส้นโค้งวงรีจริง เพราะเมื่อแทนค่า x และ y ลงในสมการ y² = (x³ + 7) mod p แล้ว ทั้งสองด้านของสมการมีค่าเท่ากัน
ในคณิตศาสตร์ของเส้นโค้งวงรี มีจุดที่เรียกว่า "จุดที่อนันต์" (point at infinity) ซึ่งมีบทบาทคล้ายกับศูนย์ในการบวก บนคอมพิวเตอร์ บางครั้งจุดนี้แทนด้วย x = y = 0 (ซึ่งไม่เป็นไปตามสมการเส้นโค้งวงรี แต่เป็นกรณีพิเศษที่สามารถตรวจสอบได้ง่าย)
มีตัวดำเนินการ + ที่เรียกว่า "การบวก" ซึ่งมีคุณสมบัติคล้ายกับการบวกแบบดั้งเดิมของจำนวนจริงที่เด็กๆ เรียนในโรงเรียน เมื่อมีจุดสองจุด P1 และ P2 บนเส้นโค้งวงรี จะมีจุดที่สาม P3 = P1 + P2 ซึ่งอยู่บนเส้นโค้งวงรีเช่นกัน
ในเชิงเรขาคณิต จุดที่สาม P3 นี้คำนวณได้โดยการลากเส้นระหว่าง P1 และ P2 เส้นนี้จะตัดกับเส้นโค้งวงรีที่จุดเพิ่มเติมอีกหนึ่งจุดพอดี เรียกจุดนี้ว่า P3' = (x, y) จากนั้นให้สะท้อนกับแกน x เพื่อได้ P3 = (x, -y)
มีกรณีพิเศษบางกรณีที่อธิบายความจำเป็นของ "จุดที่อนันต์":
- ถ้า P1 และ P2 เป็นจุดเดียวกัน เส้น "ระหว่าง" P1 และ P2 ควรขยายเป็นเส้นสัมผัสกับเส้นโค้ง ณ จุด P1 นี้ เส้นสัมผัสนี้จะตัดกับเส้นโค้งที่จุดใหม่อีกหนึ่งจุดพอดี คุณสามารถใช้เทคนิคจากแคลคูลัสเพื่อหาความชันของเส้นสัมผัส เทคนิคเหล่านี้ใช้ได้อย่างน่าแปลกใจ แม้ว่าเราจะจำกัดความสนใจไว้ที่จุดบนเส้นโค้งที่มีพิกัดเป็นจำนวนเต็มเท่านั้น!
- ในบางกรณี (เช่น ถ้า P1 และ P2 มีค่า x เดียวกันแต่ค่า y ต่างกัน) เส้นสัมผัสจะตั้งฉากพอดี ซึ่งในกรณีนี้ P3 = "จุดที่อนันต์"
- ถ้า P1 เป็น "จุดที่อนันต์" แล้ว P1 + P2 = P2 ในทำนองเดียวกัน ถ้า P2 เป็นจุดที่อนันต์ แล้ว P1 + P2 = P1 นี่แสดงให้เห็นว่าจุดที่อนันต์มีบทบาทเป็นศูนย์
การบวกนี้มีคุณสมบัติเชิงสมาคม (associative) ซึ่งหมายความว่า (A + B) + C = A + (B + C) นั่นหมายความว่าเราสามารถเขียน A + B + C โดยไม่ต้องมีวงเล็บและไม่มีความกำกวม
เมื่อเรานิยามการบวกแล้ว เราสามารถนิยามการคูณในแบบมาตรฐานที่ต่อยอดจากการบวก สำหรับจุด P บนเส้นโค้งวงรี ถ้า k เป็นจำนวนเต็มบวก แล้ว kP = P + P + P + … + P (k ครั้ง) โปรดทราบว่า k บางครั้งถูกเรียกว่า "เลขชี้กำลัง"
Public Keys
ในระบบคริปโตกราฟีแบบเส้นโค้งวงรี (Elliptic Curve Cryptography) public key ถูกคำนวณจาก private key โดยใช้การคูณเส้นโค้งวงรี ซึ่งเป็นกระบวนการที่ไม่สามารถย้อนกลับได้:
K = k × G
โดยที่:
- k คือ private key
- G คือจุดคงที่ที่เรียกว่า จุดกำเนิด (generator point)
- K คือ public key
การดำเนินการย้อนกลับ ที่เรียกว่า "การหาลอการิทึมแบบไม่ต่อเนื่อง" (finding the discrete logarithm) - คือการคำนวณหา k เมื่อรู้ค่า K - เป็นสิ่งที่ยากมากเทียบเท่ากับการลองค่า k ทุกค่าที่เป็นไปได้ (วิธีการแบบ brute-force)
ความยากของการย้อนกลับนี้คือหลักการความปลอดภัยหลักของระบบ ECC ที่ใช้ในบิตคอยน์ ซึ่งทำให้สามารถเผยแพร่ public key ได้อย่างปลอดภัย โดยที่ไม่ต้องกังวลว่าจะมีใครสามารถคำนวณย้อนกลับเพื่อหา private key ได้
TIP:การคูณเส้นโค้งวงรีเป็นฟังก์ชันประเภทที่นักเข้ารหัสลับเรียกว่า “ trap door function ”:
- เป็นสิ่งที่ทำได้ง่ายในทิศทางหนึ่ง
- แต่เป็นไปไม่ได้ที่จะทำในทิศทางตรงกันข้าม
คนที่มี private key สามารถสร้าง public key ได้อย่างง่ายดาย และสามารถแบ่งปันกับโลกได้โดยรู้ว่าไม่มีใครสามารถย้อนกลับฟังก์ชันและคำนวณ private key จาก public key ได้ กลวิธีทางคณิตศาสตร์นี้กลายเป็นพื้นฐานสำหรับลายเซ็นดิจิทัลที่ปลอมแปลงไม่ได้และมีความปลอดภัย ซึ่งใช้พิสูจน์การควบคุมเงินบิตคอยน์
เริ่มต้นด้วยการใช้ private key ในรูปแบบของตัวเลขสุ่ม เราคูณมันด้วยจุดที่กำหนดไว้ล่วงหน้าบนเส้นโค้งที่เรียกว่า จุดกำเนิด (generator point) เพื่อสร้างจุดอื่นที่อยู่บนเส้นโค้งเดียวกัน ซึ่งคำตอบจะเป็น public key ที่สอดคล้องกัน จุดกำเนิดถูกกำหนดไว้เป็นส่วนหนึ่งของมาตรฐาน secp256k1 และเป็นค่าเดียวกันสำหรับกุญแจทั้งหมดในระบบบิตคอยน์
เนื่องจากจุดกำเนิด G เป็นค่าเดียวกันสำหรับผู้ใช้บิตคอยน์ทุกคน private key (k) ที่คูณกับ G จะได้ public key (K) เดียวกันเสมอ ความสัมพันธ์ระหว่าง k และ K เป็นแบบตายตัวแต่สามารถคำนวณได้ในทิศทางเดียวเท่านั้น คือจาก k ไปยัง K นี่คือเหตุผลที่ public key ของบิตคอยน์ (K) สามารถแบ่งปันกับทุกคนได้โดยไม่เปิดเผย private key (k) ของผู้ใช้
TIP: private key สามารถแปลงเป็น public key ได้ แต่ public key ไม่สามารถแปลงกลับเป็น private key ได้ เพราะคณิตศาสตร์ที่ใช้ทำงานได้เพียงทิศทางเดียวเท่านั้น
เมื่อนำการคูณเส้นโค้งวงรีมาใช้งาน เราจะนำ private key (k) ที่สร้างขึ้นก่อนหน้านี้มาคูณกับจุดกำเนิด G เพื่อหา public key (K):
K = 1E99423A4ED27608A15A2616A2B0E9E52CED330AC530EDCC32C8FFC6A526AEDD × Gpublic key (K) จะถูกกำหนดเป็นจุด K = (x, y) โดยที่:x = F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A y = 07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDBเพื่อจะให้เห็นภาพของการคูณจุดด้วยจำนวนเต็มมากขึ้น เราจะใช้เส้นโค้งวงรีที่ง่ายกว่าบนจำนวนจริง (โดยหลักการทางคณิตศาสตร์ยังคงเหมือนกัน) เป้าหมายของเราคือการหาผลคูณ kG ของจุดกำเนิด G ซึ่งเทียบเท่ากับการบวก G เข้ากับตัวเอง k ครั้งติดต่อกันในเส้นโค้งวงรี การบวกจุดเข้ากับตัวเองเทียบเท่ากับการลากเส้นสัมผัสที่จุดนั้นและหาว่าเส้นนั้นตัดกับเส้นโค้งอีกครั้งที่จุดใด จากนั้นจึงสะท้อนจุดนั้นบนแกน x
การเข้ารหัสลับด้วยเส้นโค้งวงรี: การแสดงภาพการคูณจุด G ด้วยจำนวนเต็ม k บนเส้นโค้งวงรี แสดงกระบวนการในการหา G, 2G, 4G เป็นการดำเนินการทางเรขาคณิตบนเส้นโค้งได้ดังนี้
TIP: ในซอฟแวร์ของบิตคอยน์ส่วนใหญ่ใช้ไลบรารีเข้ารหัสลับ libsecp256k1 เพื่อทำการคำนวณทางคณิตศาสตร์เส้นโค้งวงรี

Output and Input Scripts
แม้ว่าภาพประกอบจาก Bitcoin whitepaper ที่แสดงเรื่อง "Transaction chain" จะแสดงให้เห็นว่ามีการใช้ public key และ digital signature โดยตรง แต่ในความเป็นจริงบิตคอยน์เวอร์ชันแรกนั้นมีการส่งการชำระเงินไปยังฟิลด์ที่เรียกว่า output script และมีการใช้จ่ายบิตคอยน์เหล่านั้นโดยได้รับอนุญาตจากฟิลด์ที่เรียกว่า input script ฟิลด์เหล่านี้อนุญาตให้มีการดำเนินการเพิ่มเติมนอกเหนือจาก (หรือแทนที่) การตรวจสอบว่าลายเซ็นสอดคล้องกับ public key หรือไม่ ตัวอย่างเช่น output script สามารถมี public key สองดอกและต้องการลายเซ็นสองลายเซ็นที่สอดคล้องกันในฟิลด์ input script ที่ใช้จ่าย
ในภายหลัง ในหัวข้อ [tx_script] เราจะได้เรียนรู้เกี่ยวกับสคริปต์อย่างละเอียด สำหรับตอนนี้ สิ่งที่เราต้องเข้าใจคือ บิตคอยน์จะถูกรับเข้า output script ที่ทำหน้าที่เหมือน public key และการใช้จ่ายบิตคอยน์จะได้รับอนุญาตโดย input script ที่ทำหน้าที่เหมือนลายเซ็น
IP Addresses: The Original Address for Bitcoin (P2PK)
เราได้เห็นแล้วว่าอลิซสามารถจ่ายเงินให้บ็อบโดยการมอบบิตคอยน์บางส่วนของเธอให้กับกุญแจสาธารณะของบ็อบ แต่อลิซจะได้กุญแจสาธารณะของบ็อบมาได้อย่างไร? บ็อบอาจจะให้สำเนากุญแจแก่เธอ แต่ลองดูกุญแจสาธารณะที่เราใช้งานในตัวอย่างที่ผ่านมาอีกครั้ง:
x = F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A y = 07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDBTIP จากหลาม: :สังเกตได้ว่า public key มีความยาวมาก ลองจินตนาการว่าบ็อบพยายามอ่านกุญแจนี้ให้อลิซฟังทางโทรศัพท์ คงจะยากมากที่จะอ่านและบันทึกโดยไม่มีข้อผิดพลาด
แทนที่จะป้อนกุญแจสาธารณะโดยตรง เวอร์ชันแรกของซอฟต์แวร์บิตคอยน์อนุญาตให้ผู้จ่ายเงินป้อนที่อยู่ IP ของผู้รับได้ ตามที่แสดงในหน้าจอการส่งเงินรุ่นแรกของบิตคอยน์ผ่าน The Internet Archive
คุณสมบัตินี้ถูกลบออกในภายหลัง เนื่องจากมีปัญหามากมายในการใช้ที่อยู่ IP แต่คำอธิบายสั้นๆ จะช่วยให้เราเข้าใจได้ดีขึ้นว่าทำไมคุณสมบัติบางอย่างอาจถูกเพิ่มเข้าไปในโปรโตคอลบิตคอยน์

เมื่ออลิซป้อนที่อยู่ IP ของบ็อบในบิตคอยน์เวอร์ชัน 0.1 Full node ของเธอจะทำการเชื่อมต่อกับ full node ของเขาและได้รับ public key ใหม่จากกระเป๋าสตางค์ของบ็อบที่โหนดของเขาไม่เคยให้กับใครมาก่อน การที่เป็น public key ใหม่นี้มีความสำคัญเพื่อให้แน่ใจว่าธุรกรรมต่าง ๆ ที่จ่ายให้บ็อบจะไม่สามารถถูกเชื่อมโยงเข้าด้วยกันโดยคนที่กำลังดูบล็อกเชนและสังเกตเห็นว่าธุรกรรมทั้งหมดจ่ายไปยัง public key เดียวกัน
เมื่อใช้ public key จากโหนดของอลิซซึ่งได้รับมาจากโหนดของบ็อบ กระเป๋าสตางค์ของอลิซจะสร้างเอาต์พุตธุรกรรมที่จ่ายให้กับสคริปต์เอาต์พุตดังนี้
<Bob's public key> OP_CHECKSIGต่อมาบ็อบจะสามารถใช้จ่ายเอาต์พุตนั้นด้วยสคริปต์อินพุตที่ประกอบด้วยลายเซ็นของเขาเท่านั้น:<Bob's signature>เพื่อให้เข้าใจว่าสคริปต์อินพุตและเอาต์พุตกำลังทำอะไร คุณสามารถรวมพวกมันเข้าด้วยกัน (สคริปต์อินพุตก่อน) แล้วสังเกตว่าข้อมูลแต่ละชิ้น (แสดงในเครื่องหมาย < >) จะถูกวางไว้ที่ด้านบนสุดของรายการที่เรียกว่าสแตก (stack) เมื่อพบรหัสคำสั่ง (opcode) มันจะใช้รายการจากสแตก โดยเริ่มจากรายการบนสุด มาดูว่ามันทำงานอย่างไรโดยเริ่มจากสคริปต์ที่รวมกัน:<Bob's signature> <Bob's public key> OP_CHECKSIGสำหรับสคริปต์นี้ ลายเซ็นของบ็อบจะถูกนำไปไว้บนสแตก จากนั้น public key ของบ็อบจะถูกวางไว้ด้านบนของลายเซ็น และบนสุดจะเป็นคำสั่ง OP_CHECKSIG ที่จะใช้องค์ประกอบสองอย่าง เริ่มจาก public key ตามด้วยลายเซ็น โดยลบพวกมันออกจากสแตก มันจะตรวจสอบว่าลายเซ็นตรงกับ public key และยืนยันฟิลด์ต่าง ๆ ในธุรกรรม ถ้าลายเซ็นถูกต้อง OP_CHECKSIG จะแทนที่ตัวเองบนสแตกด้วยค่า 1 ถ้าลายเซ็นไม่ถูกต้อง มันจะแทนที่ตัวเองด้วย 0 ถ้ามีรายการที่ไม่ใช่ศูนย์อยู่บนสุดของสแตกเมื่อสิ้นสุดการประเมิน สคริปต์ก็จะผ่าน ถ้าสคริปต์ทั้งหมดในธุรกรรมผ่าน และรายละเอียดอื่น ๆ ทั้งหมดเกี่ยวกับธุรกรรมนั้นต้องถูกต้องจึงจะถือว่าธุรกรรมนั้นถูกต้อง
โดยสรุป สคริปต์ข้างต้นใช้ public key และลายเซ็นเดียวกันกับที่อธิบายใน whitepaper แต่เพิ่มความซับซ้อนของฟิลด์สคริปต์สองฟิลด์และรหัสคำสั่งหนึ่งตัว ซึ่งเราจะเริ่มเห็นประโยชน์เมื่อเรามองที่ส่วนต่อไป
TIP:จากหลาม agian: เอาต์พุตประเภทนี้เป็นที่รู้จักในปัจจุบันว่า P2PK ซึ่งมันไม่เคยถูกใช้อย่างแพร่หลายสำหรับการชำระเงิน และไม่มีโปรแกรมที่ใช้กันอย่างแพร่หลายที่รองรับการชำระเงินผ่านที่อยู่ IP เป็นเวลาเกือบทศวรรษแล้ว
Legacy addresses for P2PKH
แน่นอนว่าการป้อนที่อยู่ IP ของคนที่คุณต้องการจ่ายเงินให้นั้นมีข้อดีหลายประการ แต่ก็มีข้อเสียหลายประการเช่นกัน หนึ่งในข้อเสียที่สำคัญคือผู้รับจำเป็นต้องให้กระเป๋าสตางค์ของพวกเขาออนไลน์ที่ที่อยู่ IP ของพวกเขา และต้องสามารถเข้าถึงได้จากโลกภายนอก
ซึ่งสำหรับคนจำนวนมากนั่นไม่ใช่ตัวเลือกที่เป็นไปได้เพราะหากพวกเขา:
- ปิดคอมพิวเตอร์ในเวลากลางคืน
- แล็ปท็อปของพวกเขาเข้าสู่โหมดสลีป
- อยู่หลังไฟร์วอลล์
- หรือกำลังใช้การแปลงที่อยู่เครือข่าย (NAT)
ปัญหานี้นำเรากลับมาสู่ความท้าทายเดิมที่ผู้รับเงินอย่างบ็อบต้องให้ public key ที่มีความยาวมากแก่ผู้จ่ายเงินอย่างอลิซ public key ของบิตคอยน์ที่สั้นที่สุดที่นักพัฒนาบิตคอยน์รุ่นแรกรู้จักมีขนาด 65 ไบต์ เทียบเท่ากับ 130 ตัวอักษรเมื่อเขียนในรูปแบบเลขฐานสิบหก (เฮกซาเดซิมอล) แต่อย่างไรก็ตาม บิตคอยน์มีโครงสร้างข้อมูลหลายอย่างที่มีขนาดใหญ่กว่า 65 ไบต์มาก ซึ่งจำเป็นต้องถูกอ้างอิงอย่างปลอดภัยในส่วนอื่น ๆ ของบิตคอยน์โดยใช้ข้อมูลขนาดเล็กที่สุดเท่าที่จะปลอดภัยได้
โดยบิตคอยน์แก้ปัญหานี้ด้วย ฟังก์ชันแฮช (hash function) ซึ่งเป็นฟังก์ชันที่รับข้อมูลที่อาจมีขนาดใหญ่ นำมาแฮช และให้ผลลัพธ์เป็นข้อมูลขนาดคงที่ ฟังก์ชันแฮชจะผลิตผลลัพธ์เดียวกันเสมอเมื่อได้รับข้อมูลนำเข้าแบบเดียวกัน และฟังก์ชันที่ปลอดภัยจะทำให้เป็นไปไม่ได้ในทางปฏิบัติสำหรับผู้ที่ต้องการเลือกข้อมูลนำเข้าอื่นที่ให้ผลลัพธ์เหมือนกันได้ นั่นทำให้ผลลัพธ์เป็น คำมั่นสัญญา (commitment) ต่อข้อมูลนำเข้า เป็นสัญญาว่าในทางปฏิบัติ มีเพียงข้อมูลนำเข้า x เท่านั้นที่จะให้ผลลัพธ์ X
สมมติว่าผมต้องการถามคำถามคุณและให้คำตอบของผมในรูปแบบที่คุณไม่สามารถอ่านได้ทันที สมมติว่าคำถามคือ "ในปีไหนที่ซาโตชิ นาคาโมโตะเริ่มทำงานบนบิทคอยน์?" ผมจะให้การยืนยันคำตอบของผมในรูปแบบของผลลัพธ์จากฟังก์ชันแฮช SHA256 ซึ่งเป็นฟังก์ชันที่ใช้บ่อยที่สุดในบิทคอยน์:
94d7a772612c8f2f2ec609d41f5bd3d04a5aa1dfe3582f04af517d396a302e4eต่อมา หลังจากคุณบอกคำตอบที่คุณเดาสำหรับคำถามนั้น ผมสามารถเปิดเผยคำตอบของผมและพิสูจน์ให้คุณเห็นว่าคำตอบของผม เมื่อใช้เป็นข้อมูลสำหรับฟังก์ชันแฮช จะให้ผลลัพธ์เดียวกันกับที่ผมให้คุณก่อนหน้านี้$ echo "2007. He said about a year and a half before Oct 2008" | sha256sum 94d7a772612c8f2f2ec609d41f5bd3d04a5aa1dfe3582f04af517d396a302e4eทีนี้ให้สมมติว่าเราถามบ็อบว่า " public key ของคุณคืออะไร?" บ็อบสามารถใช้ฟังก์ชันแฮชเพื่อให้การยืนยันที่ปลอดภัยทางการเข้ารหัสต่อ public key ของเขา หากเขาเปิดเผยกุญแจในภายหลัง และเราตรวจสอบว่ามันให้ผลการยืนยันเดียวกันกับที่เขาให้เราก่อนหน้านี้ เราสามารถมั่นใจได้ว่ามันเป็นกุญแจเดียวกันที่ใช้สร้างการยืนยันก่อนหน้านี้ฟังก์ชันแฮช SHA256 ถือว่าปลอดภัยมากและให้ผลลัพธ์ 256 บิต (32 ไบต์) น้อยกว่าครึ่งหนึ่งของขนาด public key ของบิทคอยน์ดั้งเดิม แต่อย่างไรก็ตาม มีฟังก์ชันแฮชอื่นๆ ที่ปลอดภัยน้อยกว่าเล็กน้อยที่ให้ผลลัพธ์ขนาดเล็กกว่า เช่น ฟังก์ชันแฮช RIPEMD-160 ซึ่งให้ผลลัพธ์ 160 บิต (20 ไบต์) ด้วยเหตุผลที่ซาโตชิ นาคาโมโตะไม่เคยระบุ เวอร์ชันดั้งเดิมของบิทคอยน์สร้างการยืนยันต่อ public key โดยการแฮชกุญแจด้วย SHA256 ก่อน แล้วแฮชผลลัพธ์นั้นด้วย RIPEMD-160 ซึ่งให้การยืนยันขนาด 20 ไบต์ต่อ public key
เราสามารถดูสิ่งนี้ตามอัลกอริทึม เริ่มจากกุญแจสาธารณะ K เราคำนวณแฮช SHA256 และคำนวณแฮช RIPEMD-160 ของผลลัพธ์ ซึ่งให้ตัวเลข 160 บิต (20 ไบต์): A = RIPEMD160(SHA256(K))
ทีนี้เราคงเข้าใจวิธีสร้างการยืนยันต่อ public key แล้ว ต่อไปเราจะมาดูวิธีการใช้งานโดยพิจารณาสคริปต์เอาต์พุตต่อไปนี้:
OP_DUP OP_HASH160 <Bob's commitment> OP_EQUAL OP_CHECKSIGและสคริปต์อินพุตต่อไปนี้:<Bob's signature> <Bob's public key>และเมื่อเรารวมมันเข้าด้วยกันเราจะได้ผลลัพธ์ดังนี้:<Bob's signature> <Bob's public key> OP_DUP OP_HASH160 <Bob's commitment> OP_EQUAL OP_CHECKSIGเหมือนที่เราทำใน IP Addresses: The Original Address for Bitcoin (P2PK) เราเริ่มวางรายการลงในสแต็ก ลายเซ็นของบ็อบถูกวางก่อน จากนั้น public key ของเขาถูกวางไว้ด้านบน จากนั้นดำเนินการ OP_DUP เพื่อทำสำเนารายการบนสุด ดังนั้นรายการบนสุดและรายการที่สองจากบนในสแต็กตอนนี้เป็น public key ของบ็อบทั้งคู่ การดำเนินการ OP_HASH160 ใช้ (ลบ) public key บนสุดและแทนที่ด้วยผลลัพธ์ของการแฮชด้วย RIPEMD160(SHA256(K)) ดังนั้นตอนนี้บนสุดของสแต็กคือแฮชของ public key ของบ็อบ ต่อไป commitment ถูกเพิ่มไว้บนสุดของสแต็ก การดำเนินการ OP_EQUALVERIFY ใช้รายการสองรายการบนสุดและตรวจสอบว่าพวกมันเท่ากัน ซึ่งควรเป็นเช่นนั้นหาก public key ที่บ็อบให้ในสคริปต์อินพุตเป็น public key เดียวกันกับที่ใช้สร้างการยืนยันในสคริปต์เอาต์พุตที่อลิซจ่าย หาก OP_EQUALVERIFY ล้มเหลว ทั้งสคริปต์จะล้มเหลว สุดท้าย เราเหลือสแต็กที่มีเพียงลายเซ็นของบ็อบและ public key ของเขา รหัสปฏิบัติการ OP_CHECKSIG ตรวจสอบว่าพวกมันสอดคล้องกัน
TIP: จากหลาม ถ้าอ่านตรงนี้และงง ๆ ผมไปทำรูปมาให้ดูง่ายขึ้นครับ
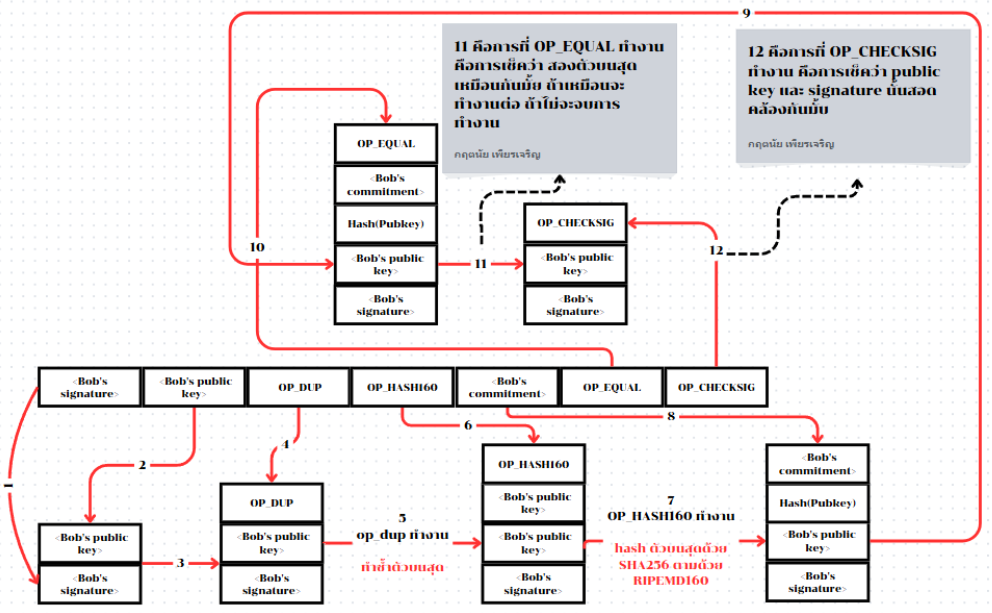
แม้กระบวนการของการ pay-to-publickey-hash(P2PKH) อาจดูซับซ้อน แต่มันทำให้การที่อลิซจ่ายเงินให้บ็อบมีเพียงการยืนยันเพียง 20 ไบต์ต่อ public key ของเขาแทนที่จะเป็นตัวกุญแจเอง ซึ่งจะมีขนาด 65 ไบต์ในเวอร์ชันดั้งเดิมของบิทคอยน์ นั่นเป็นข้อมูลที่น้อยกว่ามากที่บ็อบต้องสื่อสารกับอลิซ
แต่อย่างไรก็ตาม เรายังไม่ได้พูดถึงวิธีที่บ็อบรับ 20 ไบต์เหล่านั้นจากกระเป๋าเงินบิทคอยน์ของเขาไปยังกระเป๋าเงินของอลิซ มีการเข้ารหัสค่าไบต์ที่ใช้กันอย่างแพร่หลาย เช่น เลขฐานสิบหก แต่ข้อผิดพลาดใด ๆ ในการคัดลอกการยืนยันจะทำให้บิทคอยน์ถูกส่งไปยังเอาต์พุตที่ไม่สามารถใช้จ่ายได้ ทำให้พวกมันสูญหายไปตลอดกาล โดยในส่วนถัดไป เราจะดูที่การเข้ารหัสแบบกะทัดรัดและการตรวจสอบความถูกต้อง
Base58check Encoding
ระบบคอมพิวเตอร์มีวิธีเขียนตัวเลขยาวๆ ให้สั้นลงโดยใช้ทั้งตัวเลขและตัวอักษรผสมกัน เพื่อใช้พื้นที่น้อยลงอย่างเช่น
- ระบบเลขฐานสิบ (ปกติที่เราใช้) - ใช้เลข 0-9 เท่านั้น
- ระบบเลขฐานสิบหก - ใช้เลข 0-9 และตัวอักษร A-F ตัวอย่าง: เลข 255 ในระบบปกติ เขียนเป็น FF ในระบบเลขฐานสิบหก (สั้นกว่า)
- ระบบเลขฐานหกสิบสี่ (Base64) - ใช้สัญลักษณ์ถึง 64 ตัว: ตัวอักษรเล็ก (a-z) 26 ตัว, ตัวอักษรใหญ่ (A-Z) 26 ตัว, ตัวเลข (0-9) 10 ตัว, สัญลักษณ์พิเศษอีก 2 ตัว ("+" และ "/")
โดยระบบ Base64 นี้ช่วยให้เราส่งไฟล์คอมพิวเตอร์ผ่านข้อความธรรมดาได้ เช่น การส่งรูปภาพผ่านอีเมล โดยใช้พื้นที่น้อยกว่าการเขียนเป็นเลขฐานสิบแบบปกติมาก
การเข้ารหัสแบบ Base58 คล้ายกับ Base64 โดยใช้ตัวอักษรพิมพ์ใหญ่ พิมพ์เล็ก และตัวเลข แต่ได้ตัดตัวอักษรบางตัวที่มักถูกเข้าใจผิดว่าเป็นตัวอื่นและอาจดูเหมือนกันเมื่อแสดงในฟอนต์บางประเภทออกไป
Base58 คือ Base64 ที่ตัดตัวอักษรต่อไปนี้ออก:
- เลข 0 (ศูนย์)
- ตัวอักษร O (ตัว O พิมพ์ใหญ่)
- ตัวอักษร l (ตัว L พิมพ์เล็ก)
- ตัวอักษร I (ตัว I พิมพ์ใหญ่)
- และสัญลักษณ์ "+" และ "/"
หรือพูดให้ง่ายขึ้น Base58 คือกลุ่มตัวอักษรพิมพ์เล็ก พิมพ์ใหญ่ และตัวเลข แต่ไม่มีตัวอักษรทั้งสี่ตัว (0, O, l, I) ที่กล่าวถึงข้างต้น ตัวอักษรทั้งหมดที่ใช้ใน Base58 จะแสดงให้เห็นในตัวอักษร Base58 ของบิทคอยน์
Example 2. Bitcoin’s base58 alphabet
123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyzการเพิ่มความปลอดภัยพิเศษเพื่อป้องกันการพิมพ์ผิดหรือข้อผิดพลาดในการคัดลอก base58check ได้รวม รหัสตรวจสอบ (checksum) ที่เข้ารหัสในตัวอักษร base58 เข้าไปด้วย รหัสตรวจสอบนี้คือข้อมูลเพิ่มเติมอีก 4 ไบต์ที่เพิ่มเข้าไปที่ท้ายของข้อมูลที่กำลังถูกเข้ารหัสรหัสตรวจสอบนี้ได้มาจากการแฮชข้อมูลที่ถูกเข้ารหัส และจึงสามารถใช้เพื่อตรวจจับข้อผิดพลาดจากการคัดลอกและการพิมพ์ได้ เมื่อโปรแกรมได้รับรหัส base58check ซอฟต์แวร์ถอดรหัสจะคำนวณรหัสตรวจสอบของข้อมูลและเปรียบเทียบกับรหัสตรวจสอบที่รวมอยู่ในรหัสนั้น
หากทั้งสองไม่ตรงกัน แสดงว่ามีข้อผิดพลาดเกิดขึ้น และข้อมูล base58check นั้นไม่ถูกต้อง กระบวนการนี้ช่วยป้องกันไม่ให้ address บิทคอยน์ที่พิมพ์ผิดถูกยอมรับโดยซอฟต์แวร์กระเป๋าเงินว่าเป็น address ที่ถูกต้อง ซึ่งเป็นข้อผิดพลาดที่อาจส่งผลให้สูญเสียเงินได้
การแปลงข้อมูล (ตัวเลข) เป็นรูปแบบ base58check มีขั้นตอนดังนี้:
- เราเริ่มโดยการเพิ่ม prefix เข้าไปในข้อมูล เรียกว่า "version byte" ซึ่งช่วยให้ระบุประเภทของข้อมูลที่ถูกเข้ารหัสได้ง่าย ตัวอย่างเช่น: prefix ศูนย์ (0x00 ในระบบเลขฐานสิบหก) แสดงว่าข้อมูลควรถูกใช้เป็นการยืนยัน (hash) ในสคริปต์เอาต์พุต legacy P2PKH
- จากนั้น เราคำนวณ "double-SHA" checksum ซึ่งหมายถึงการใช้อัลกอริทึมแฮช SHA256 สองครั้งกับผลลัพธ์ก่อนหน้า (prefix ต่อกับข้อมูล):
checksum = SHA256(SHA256(prefix||data)) - จากแฮช 32 ไบต์ที่ได้ (การแฮชซ้อนแฮช) เราเลือกเฉพาะ 4 ไบต์แรก ไบต์ทั้งสี่นี้ทำหน้าที่เป็นรหัสตรวจสอบข้อผิดพลาดหรือ checksum
- นำ checksum นี้ไปต่อที่ท้ายข้อมูล
การเข้ารหัสแบบ base58check คือรูปแบบการเข้ารหัสที่ใช้ base58 พร้อมกับการระบุเวอร์ชันและการตรวจสอบความถูกต้อง เพื่อการเข้ารหัสข้อมูลบิทคอยน์ โดยคุณสามารถดูภาพประกอบด้านล่างเพื่อความเข้าใจเพิ่มเติม

ในบิตคอยน์นั้น นอกจากจะใช้ base58check ในการยืนยัน public key แล้ว ก็ยังมีการใช้ในข้อมูลอื่น ๆ ด้วย เพื่อทำให้ข้อมูลนั้นกะทัดรัด อ่านง่าย และตรวจจับข้อผิดพลาดได้ง่ายด้วยรหัสนำหน้า (version prefix) ในการเข้ารหัสแบบ base58check ถูกใช้เพื่อสร้างรูปแบบที่แยกแยะได้ง่าย ซึ่งเมื่อเข้ารหัสด้วย base58 โดยจะมีตัวอักษรเฉพาะที่จุดเริ่มต้นของข้อมูลที่เข้ารหัส base58check ตัวอักษรเหล่านี้ช่วยให้เราระบุประเภทของข้อมูลที่ถูกเข้ารหัสและวิธีการใช้งานได้ง่าย นี่คือสิ่งที่แยกความแตกต่าง ตัวอย่างเช่น ระหว่าง address บิทคอยน์ที่เข้ารหัส base58check ซึ่งขึ้นต้นด้วยเลข 1 กับรูปแบบการนำเข้า private key (WIF - Wallet Import Format) ที่เข้ารหัส base58check ซึ่งขึ้นต้นด้วยเลข 5 ตัวอย่างของ version prefix สามารถดูได้ตามตารางด้านล่างนี้

ภาพต่อไปนี้จะทำให้คุณเห็นภาพของกระบวนการแปลง public key ให้เป็น bitcoin address

Compressed Public Keys
ในยุคแรก ๆ ของบิตคอยน์นั้น มีเพียงการสร้าง public key แบบ 65 Bytes เท่านั้น แต่ในเวลาต่อมา เหล่านักพัฒนาในยุคหลังได้พบวิธีการสร้าง public key แบบใหม่ที่มีเพียง 33 Bytes และสามารถทำงานร่วมกันกับโหนดทั้งหมดในขณะนั้นได้ จีงไม่จะเป็นต้องเปลี่ยนแปลงกฎหรือโครงสร้างภายในโปรโตคอลของบิตคอยน์ โดย poublic key แบบใหม่ที่มีขนาด 33 Bytes นี้เรียกว่า compressed public key (public key ที่ถูกบีบอัด) และมีการเรียก public key ที่มีขนาด 65 Bytes ว่า uncompressed public key (public key ที่ไม่ถูกบีบอัด) ซึ่งประโยชน์ของ public key ที่เล็กลงนั้น นอกจากจะช่วยให้การส่ง public key ให้ผู้อื่นทำได้ง่ายขึ้นแล้ว ยังช่วยให้ธุรกรรมมีขนาดเล็กลง และช่วยให้สามารถทำการชำระเงินได้มากขึ้นในบล็อกเดียวกัน
อย่างที่เราได้เรียนรู้จากเนื้อหาในส่วนของ public key เราได้ทราบว่า public key คือจุด (x, y) บนเส้นโค้งวงรี เนื่องจากเส้นโค้งแสดงฟังก์ชันทางคณิตศาสตร์ จุดบนเส้นโค้งจึงเป็นคำตอบของสมการ ดังนั้นหากเรารู้พิกัด x เราก็สามารถคำนวณพิกัด y ได้โดยแก้สมการ y² mod p = (x³ + 7) mod p นั่นหมายความว่าเราสามารถเก็บเพียงพิกัด x ของ public key โดยละพิกัด y ไว้ ซึ่งช่วยลดขนาดของกุญแจและพื้นที่ที่ต้องใช้เก็บข้อมูลลง 256 บิต การลดขนาดลงเกือบ 50% ในทุกธุรกรรมรวมกันแล้วช่วยประหยัดข้อมูลได้มากมายในระยะยาว!
นี่คือ public key ที่ได้ยกเป็นตัวอย่างไว้ก่อนหน้า
x = F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A y = 07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDBและนี่คือ public key ที่มีตัวนำหน้า 04 ตามด้วยพิกัด x และ y ในรูปแบบ 04 x y:
K = 04F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDBuncompressed public key นั้นจะมีตัวนำหน้าเป็น 04 แต่ compressed public key จะมีตัวนำหน้าเป็น 02 หรือ 03 โดยเหตุผลนั้นมาจากสมการ y² mod p = (x³ + 7) mod p เนื่องจากด้านซ้ายของสมการคือ y² คำตอบสำหรับ y จึงเป็นรากที่สอง ซึ่งอาจมีค่าเป็นบวกหรือลบก็ได้ หากมองเชิงภาพ นี่หมายความว่าพิกัด y ที่ได้อาจอยู่เหนือหรือใต้แกน x เราต้องไม่ลืมว่าเส้นโค้งมีความสมมาตร ซึ่งหมายความว่ามันจะสะท้อนเหมือนกระจกโดยแกน x ดังนั้น แม้เราจะละพิกัด y ได้ แต่เราต้องเก็บ เครื่องหมาย ของ y (บวกหรือลบ) หรืออีกนัยหนึ่งคือเราต้องจำว่ามันอยู่เหนือหรือใต้แกน x เพราะแต่ละตำแหน่งแทนจุดที่แตกต่างกันและเป็น public key ที่แตกต่างกัน
เมื่อคำนวณเส้นโค้งวงรีในระบบเลขฐานสองบนสนามจำกัดของเลขจำนวนเฉพาะ p พิกัด y จะเป็นเลขคู่หรือเลขคี่ ซึ่งสอดคล้องกับเครื่องหมายบวก/ลบตามที่อธิบายก่อนหน้านี้ ดังนั้น เพื่อแยกความแตกต่างระหว่างค่าที่เป็นไปได้สองค่าของ y เราจึงเก็บ compressed public key ด้วยตัวนำหน้า 02 ถ้า y เป็นเลขคู่ และ 03 ถ้า y เป็นเลขคี่ ซึ่งช่วยให้ซอฟต์แวร์สามารถอนุมานพิกัด y จากพิกัด x และคลายการบีบอัดของ public key ไปยังพิกัดเต็มของจุดได้อย่างถูกต้อง ดังภาพประกอบต่อไปนี้

นี่คือ public key เดียวกันกับที่ยกตัวอย่างไว้ข้างต้นซึ่งแสดงให้เห็นในรูป compressed public key ที่เก็บใน 264 บิต (66 ตัวอักษรเลขฐานสิบหก) โดยมีตัวนำหน้า 03 ซึ่งบ่งชี้ว่าพิกัด y เป็นเลขคี่:
K = 03F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341Acompressed public key สอดคล้องกับ private key เดียวกันกับ uncompressed public key หมายความว่ามันถูกสร้างจาก private key เดียวกัน แต่อย่างไรก็ตาม มันก็มีส่วนที่แตกต่างจาก uncompressed public key นั้นคือ หากเราแปลง compressed public key เป็น commitment โดยใช้ฟังก์ชัน HASH160 (RIPEMD160(SHA256(K))) มันจะสร้าง commitment ที่แตกต่างจาก uncompressed public key และจะนำไปสู่ bitcoin address ที่แตกต่างกันในที่สุด สิ่งนี้อาจทำให้สับสนเพราะหมายความว่า private key เดียวสามารถสร้าง public key ในสองรูปแบบที่แตกต่างกัน (แบบบีบอัดและแบบไม่บีบอัด) ซึ่งสร้าง bitcoin address ที่แตกต่างกันcompressed public key เป็นค่าเริ่มต้นในซอฟต์แวร์บิตคอยน์เกือบทั้งหมดในปัจจุบัน และถูกกำหนดให้ใช้กับคุณสมบัติใหม่บางอย่างที่เพิ่มในการอัปเกรดโปรโตคอลในภายหลัง
อย่างไรก็ตาม ซอฟต์แวร์บางตัวยังคงต้องรองรับ uncompressed public key เช่น แอปพลิเคชันกระเป๋าเงินที่นำเข้า private key จากกระเป๋าเงินเก่า เมื่อกระเป๋าเงินใหม่สแกนบล็อกเชนสำหรับผลลัพธ์และอินพุต P2PKH เก่า มันจำเป็นต้องรู้ว่าควรสแกนกุญแจขนาด 65 ไบต์ (และ commitment ของกุญแจเหล่านั้น) หรือกุญแจขนาด 33 ไบต์ (และ commitment ของกุญแจเหล่านั้น) หากไม่สแกนหาประเภทที่ถูกต้อง อาจทำให้ผู้ใช้ไม่สามารถใช้ยอดคงเหลือทั้งหมดได้ เพื่อแก้ไขปัญหานี้ เมื่อส่งออก private key จากกระเป๋าเงิน WIF ที่ใช้แสดง private key ในกระเป๋าเงินบิตคอยน์รุ่นใหม่จะถูกนำไปใช้แตกต่างกันเล็กน้อยเพื่อบ่งชี้ว่า private key เหล่านี้ถูกใช้ในการสร้าง compressed public key
Legacy: Pay to Script Hash (P2SH)
ตามที่เราได้เห็นในส่วนก่อนหน้านี้ ผู้รับบิตคอยน์ สามารถกำหนดให้การชำระเงินที่ส่งมาให้เขานั้นมีเงื่อนไขบางอย่างในสคริปต์เอาต์พุตได้โดยจะต้องปฏิบัติตามเงื่อนไขเหล่านั้นโดยใช้สคริปต์อินพุตเมื่อเขาใช้จ่ายบิตคอยน์เหล่านั้น ในส่วน IP Addresses: The Original Address for Bitcoin (P2PK) เงื่อนไขก็คือสคริปต์อินพุตต้องให้ลายเซ็นที่เหมาะสม ในส่วน Legacy Addresses for P2PKH นั้นจำเป็นต้องมี public key ที่เหมาะสมด้วย
ส่วนสำหรับผู้ส่งก็จะวางเงื่อนไขที่ผู้รับต้องการในสคริปต์เอาต์พุตที่ใช้จ่ายให้กับผู้รับ โดยผู้รับจะต้องสื่อสารเงื่อนไขเหล่านั้นให้ผู้ส่งทราบ ซึ่งคล้ายกับปัญหาที่บ๊อบต้องสื่อสาร public key ของเขาให้อลิซทราบ และเช่นเดียวกับปัญหานั้นที่ public key อาจมีขนาดค่อนข้างใหญ่ เงื่อนไขที่บ๊อบใช้ก็อาจมีขนาดใหญ่มากเช่นกัน—อาจมีขนาดหลายพันไบต์ นั่นไม่เพียงแต่เป็นข้อมูลหลายพันไบต์ที่ต้องสื่อสารให้อลิซทราบ แต่ยังเป็นข้อมูลหลายพันไบต์ที่เธอต้องจ่ายค่าธรรมเนียมธุรกรรมทุกครั้งที่ต้องการใช้จ่ายเงินให้บ๊อบ อย่างไรก็ตาม การใช้ฟังก์ชันแฮชเพื่อสร้าง commitment ขนาดเล็กสำหรับข้อมูลขนาดใหญ่ก็สามารถนำมาใช้ได้ในกรณีนี้เช่นกัน
ในเวลาต่อมานั้น การอัปเกรด BIP16 สำหรับโปรโตคอลบิตคอยน์ในปี 2012 ได้อนุญาตให้สคริปต์เอาต์พุตสร้าง commitment กับ redemption script (redeem script) ได้ แปลว่าเมื่อบ๊อบใช้จ่ายบิตคอยน์ของเขา ภายในสคริปต์อินพุตของเขานั้นจะต้องให้ redeem script ที่ตรงกับ commitment และข้อมูลที่จำเป็นเพื่อให้เป็นไปตาม redeem script (เช่น ลายเซ็น) เริ่มต้นด้วยการจินตนาการว่าบ๊อบต้องการให้มีลายเซ็นสองอันเพื่อใช้จ่ายบิตคอยน์ของเขา หนึ่งลายเซ็นจากกระเป๋าเงินบนเดสก์ท็อปและอีกหนึ่งจากอุปกรณ์เซ็นแบบฮาร์ดแวร์ เขาใส่เงื่อนไขเหล่านั้นลงใน redeem script:
<public key 1> OP_CHECKSIGVERIFY <public key 2> OP_CHECKSIGจากนั้นเขาสร้าง commitment กับ redeem script โดยใช้กลไก HASH160 เดียวกับที่ใช้สำหรับ commitment แบบ P2PKH, RIPEMD160(SHA256(script)) commitment นั้นถูกวางไว้ในสคริปต์เอาต์พุตโดยใช้เทมเพลตพิเศษ:OP_HASH160 <commitment> OP_EQUALคำเตือน: เมื่อใช้ pay to script hash (P2SH) คุณต้องใช้เทมเพลต P2SH โดยเฉพาะ ซึ่งจะไม่มีข้อมูลหรือเงื่อนไขเพิ่มเติมในสคริปต์เอาต์พุต หากสคริปต์เอาต์พุตไม่ได้เป็น OP_HASH160 <20 ไบต์> OP_EQUAL แน่นอนว่า redeem script จะไม่ถูกใช้และบิตคอยน์ใด ๆ อาจไม่สามารถใช้จ่ายได้หรืออาจถูกใช้จ่ายได้โดยทุกคน (หมายความว่าใครก็สามารถนำไปใช้ได้)
เมื่อบ๊อบต้องการจ่ายเงินที่เขาได้รับผ่าน commitment สำหรับสคริปต์ของเขา เขาจะใช้สคริปต์อินพุตที่รวมถึง redeem script ซึ่งถูกแปลงให้เป็นข้อมูลอีลิเมนต์เดียว นอกจากนี้เขายังให้ลายเซ็นที่จำเป็นเพื่อให้เป็นไปตาม redeem script โดยเรียงลำดับตามที่จะถูกใช้โดย opcodes:
<signature2> <signature1> <redeem script>เมื่อโหนดของบิตคอยน์ได้รับการใช้จ่ายของบ๊อบพวกมันจะตรวจสอบว่า redeem script ที่ถูกแปลงเป็นค่าแฮชแล้วมีค่าเดียวกันกับ commitment มั้ย หลังจากนั้นพวกมันจะแทนที่มันบนสแต็คด้วยค่าที่ถอดรหัสแล้ว:<signature2> <signature1> <pubkey1> OP_CHECKSIGVERIFY <pubkey2> OP_CHECKSIGสคริปต์จะถูกประมวลผล และหากผ่านการตรวจสอบและรายละเอียดธุรกรรมอื่น ๆ ทั้งหมดถูกต้อง ธุรกรรมก็จะถือว่าใช้ได้address สำหรับ P2SH ก็ถูกสร้างด้วย base58check เช่นกัน คำนำหน้าเวอร์ชันถูกตั้งเป็น 5 ซึ่งทำให้ที่อยู่ที่เข้ารหัสแล้วขึ้นต้นด้วยเลข 3 ตัวอย่างของที่อยู่ P2SH คือ 3F6i6kwkevjR7AsAd4te2YB2zZyASEm1HM
TIP: P2SH ไม่จำเป็นต้องเหมือนกับธุรกรรมแบบหลายลายเซ็น (multisignature) เสมอไป ถึง address P2SH ส่วนใหญ่ แทนสคริปต์แบบหลายลายเซ็นก็ตาม แต่อาจแทนสคริปต์ที่เข้ารหัสธุรกรรมประเภทอื่น ๆ ได้ด้วย
P2PKH และ P2SH เป็นสองเทมเพลตสคริปต์เท่านั้นที่ใช้กับการเข้ารหัสแบบ base58check พวกมันเป็นที่รู้จักในปัจจุบันว่าเป็น address แบบ legacy และกลายเป็นรูปแบบที่พบน้อยลงเรื่อยๆ address แบบ legacy ถูกแทนที่ด้วยaddress ตระกูล bech32
การโจมตี P2SH แบบ Collision
address ทั้งหมดที่อิงกับฟังก์ชันแฮชมีความเสี่ยงในทางทฤษฎีต่อผู้โจมตีที่อาจค้นพบอินพุตเดียวกันที่สร้างเอาต์พุตฟังก์ชันแฮช (commitment) โดยอิสระ ในกรณีของบิตคอยน์ หากพวกเขาค้นพบอินพุตในวิธีเดียวกับที่ผู้ใช้ดั้งเดิมทำ พวกเขาจะรู้ private key ของผู้ใช้และสามารถใช้จ่ายบิตคอยน์ของผู้ใช้นั้นได้ โอกาสที่ผู้โจมตีจะสร้างอินพุตสำหรับ commitment ที่มีอยู่แล้วโดยอิสระนั้นขึ้นอยู่กับความแข็งแกร่งของอัลกอริทึมแฮช สำหรับอัลกอริทึมที่ปลอดภัย 160 บิตอย่าง HASH160 ความน่าจะเป็นอยู่ที่ 1 ใน 2^160 นี่เรียกว่าการโจมตีแบบ preimage attack
ผู้โจมตีสามารถพยายามสร้างข้อมูลนำเข้าสองชุดที่แตกต่างกัน (เช่น redeem scripts) ที่สร้างการเข้ารหัสแบบเดียวกันได้ สำหรับ address ที่สร้างโดยฝ่ายเดียวทั้งหมด โอกาสที่ผู้โจมตีจะสร้างข้อมูลนำเข้าที่แตกต่างสำหรับการเข้ารหัสที่มีอยู่แล้วมีประมาณ 1 ใน 2^160 สำหรับอัลกอริทึม HASH160 นี่คือการโจมตีแบบ second preimage attack
อย่างไรก็ตาม สถานการณ์จะเปลี่ยนไปเมื่อผู้โจมตีสามารถมีอิทธิพลต่อค่าข้อมูลนำเข้าดั้งเดิมได้ ตัวอย่างเช่น ผู้โจมตีมีส่วนร่วมในการสร้างสคริปต์แบบหลายลายเซ็น (multisignature script) ซึ่งพวกเขาไม่จำเป็นต้องส่ง public key ของตนจนกว่าจะทราบ public key ของฝ่ายอื่นทั้งหมด ในกรณีนั้น ความแข็งแกร่งของอัลกอริทึมการแฮชจะลดลงเหลือรากที่สองของมัน สำหรับ HASH160 ความน่าจะเป็นจะกลายเป็น 1 ใน 2^80 นี่คือการโจมตีแบบ collision attack
เพื่อให้เข้าใจตัวเลขเหล่านี้ในบริบทที่ชัดเจน ข้อมูล ณ ต้นปี 2023 นักขุดบิตคอยน์ทั้งหมดรวมกันสามารถประมวลผลฟังก์ชันแฮชประมาณ 2^80 ทุกชั่วโมง พวกเขาใช้ฟังก์ชันแฮชที่แตกต่างจาก HASH160 ดังนั้นฮาร์ดแวร์ที่มีอยู่จึงไม่สามารถสร้างการโจมตีแบบ collision attack สำหรับมันได้ แต่การมีอยู่ของเครือข่ายบิตคอยน์พิสูจน์ว่าการโจมตีแบบชนกันต่อฟังก์ชัน 160 บิตอย่าง HASH160 สามารถทำได้จริงในทางปฏิบัติ นักขุดบิตคอยน์ได้ลงทุนเทียบเท่ากับหลายพันล้านดอลลาร์สหรัฐในฮาร์ดแวร์พิเศษ ดังนั้นการสร้างการโจมตีแบบ collision attack จึงไม่ใช่เรื่องถูก แต่มีองค์กรที่คาดหวังว่าจะได้รับบิตคอยน์มูลค่าหลายพันล้านดอลลาร์ไปยัง address ที่สร้างโดยกระบวนการที่เกี่ยวข้องกับหลายฝ่าย ซึ่งอาจทำให้การโจมตีนี้มีกำไร
มีโปรโตคอลการเข้ารหัสที่เป็นที่ยอมรับอย่างดีในการป้องกันการโจมตีแบบ collision attack แต่วิธีแก้ปัญหาที่ง่ายโดยไม่ต้องใช้ความรู้พิเศษจากผู้พัฒนากระเป๋าเงินคือการใช้ฟังก์ชันแฮชที่แข็งแกร่งกว่า การอัปเกรดบิตคอยน์ในภายหลังทำให้เป็นไปได้ และ address บิตคอยน์ใหม่ให้ความต้านทานการชนกันอย่างน้อย 128 บิต การดำเนินการแฮช 2^128 ครั้งจะใช้เวลานักขุดบิตคอยน์ปัจจุบันทั้งหมดประมาณ 32 พันล้านปี
แม้ว่าเราไม่เชื่อว่ามีภัยคุกคามเร่งด่วนต่อผู้ที่สร้าง address P2SH ใหม่ แต่เราแนะนำให้กระเป๋าเงินใหม่ทั้งหมดใช้ที่อยู่ประเภทใหม่เพื่อขจัดความกังวลเกี่ยวกับการโจมตีแบบ collision attack ของ P2SH address
Bech32 Addresses
ในปี 2017 โปรโตคอลบิตคอยน์ได้รับการอัปเกรด เพื่อป้องกันไม่ให้ตัวระบุธุรกรรม (txids) ไม่สามารถเปลี่ยนแปลงได้ โดยไม่ได้รับความยินยอมจากผู้ใช้ที่ทำการใช้จ่าย (หรือองค์ประชุมของผู้ลงนามเมื่อต้องมีลายเซ็นหลายรายการ) การอัปเกรดนี้เรียกว่า segregated witness (หรือเรียกสั้นๆ ว่า segwit) ซึ่งยังให้ความสามารถเพิ่มเติมสำหรับข้อมูลธุรกรรมในบล็อกและประโยชน์อื่น ๆ อีกหลายประการ แต่อย่างไรก็ตาม หากมีผู้ใช้เก่าที่ต้องการเข้าถึงประโยชน์ของ segwit โดยตรงต้องยอมรับการชำระเงินไปยังสคริปต์เอาต์พุตใหม่
ตามที่ได้กล่าวไว้ใน p2sh หนึ่งในข้อดีของเอาต์พุตประเภท P2SH คือผู้จ่ายไม่จำเป็นต้องรู้รายละเอียดของสคริปต์ที่ผู้รับใช้ การอัปเกรด segwit ถูกออกแบบมาให้ใช้กลไกนี้ได้ดังเดิม จึง ทำให้ผู้จ่ายสามารถเริ่มเข้าถึงประโยชน์ใหม่ ๆ หลายอย่างได้ทันทีโดยใช้ที่อยู่ P2SH แต่เพื่อให้ผู้รับสามารถเข้าถึงประโยชน์เหล่านั้นได้ พวกเขาจำเป็นจะต้องให้กระเป๋าเงินของผู้จ่ายจ่ายเงินให้เขาโดยใช้สคริปต์ประเภทอื่นแทน ซึ่งจะต้องอาศัยการอัปเกรดกระเป๋าเงินของผู้จ่ายเพื่อรองรับสคริปต์ใหม่เหล่านี้
ในช่วงแรก เหล่านักพัฒนาบิตคอยน์ได้นำเสนอ BIP142 ซึ่งจะยังคงใช้ base58check ร่วมกับไบต์เวอร์ชันใหม่ คล้ายกับการอัปเกรด P2SH แต่การให้กระเป๋าเงินทั้งหมดอัปเกรดไปใช้สคริปต์ใหม่ที่มีเวอร์ชัน base58check ใหม่นั้น คาดว่าจะต้องใช้ความพยายามเกือบเท่ากับการให้พวกเขาอัปเกรดไปใช้รูปแบบ address ที่เป็นแบบใหม่ทั้งหมด ด้วยเหตุนี้้เอง ผู้สนับสนุนบิตคอยน์หลายคนจึงเริ่มออกแบบรูปแบบ address ที่ดีที่สุดเท่าที่เป็นไปได้ พวกเขาระบุปัญหาหลายอย่างกับ base58check ไว้ดังนี้:
- การที่ base58check ใช้อักษรที่มีทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็กทำให้ไม่สะดวกในการอ่านออกเสียงหรือคัดลอก ลองอ่าน address แบบเก่าในบทนี้ให้เพื่อนฟังและให้พวกเขาคัดลอก คุณจะสังเกตว่าคุณต้องระบุคำนำหน้าทุกตัวอักษรด้วยคำว่า "ตัวพิมพ์ใหญ่" และ "ตัวพิมพ์เล็ก" และเมื่อคุณตรวจสอบสิ่งที่พวกเขาเขียน คุณจะพบว่าตัวพิมพ์ใหญ่และตัวพิมพ์เล็กของตัวอักษรบางตัวอาจดูคล้ายกันในลายมือของคนส่วนใหญ่
- รูปแบบนี้สามารถตรวจจับข้อผิดพลาดได้ แต่ไม่สามารถช่วยผู้ใช้แก้ไขข้อผิดพลาดเหล่านั้น ตัวอย่างเช่น หากคุณสลับตำแหน่งตัวอักษรสองตัวโดยไม่ตั้งใจเมื่อป้อน address ด้วยตนเอง กระเป๋าเงินของคุณจะเตือนว่ามีข้อผิดพลาดเกิดขึ้นแน่นอน แต่จะไม่ช่วยให้คุณค้นพบว่าข้อผิดพลาดอยู่ที่ไหน คุณอาจต้องใช้เวลาหลายนาทีที่น่าหงุดหงิดเพื่อค้นหาข้อผิดพลาดในที่สุด
- การใช้ตัวอักษรที่มีทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็กยังต้องใช้พื้นที่เพิ่มเติมในการเข้ารหัสใน QR code ซึ่งนิยมใช้ในการแชร์ address และ invoice ระหว่างกระเป๋าเงิน พื้นที่เพิ่มเติมนี้หมายความว่า QR code จำเป็นต้องมีขนาดใหญ่ขึ้นที่ความละเอียดเดียวกัน หรือไม่เช่นนั้นก็จะยากต่อการสแกนอย่างรวดเร็ว
- การที่ต้องการให้กระเป๋าเงินผู้จ่ายทุกใบอัปเกรดเพื่อรองรับคุณสมบัติโปรโตคอลใหม่ เช่น P2SH และ segwit แม้ว่าการอัปเกรดเองอาจไม่ต้องใช้โค้ดมากนัก แต่ประสบการณ์แสดงให้เห็นว่าผู้พัฒนากระเป๋าเงินหลายรายมักยุ่งกับงานอื่น ๆ และบางครั้งอาจล่าช้าในการอัปเกรดเป็นเวลาหลายปี สิ่งนี้ส่งผลเสียต่อทุกคนที่ต้องการใช้คุณสมบัติใหม่ ๆ เหล่านี้
นักพัฒนาที่ทำงานเกี่ยวกับรูปแบบ address สำหรับ segwit ได้พบวิธีแก้ปัญหาเหล่านี้ทั้งหมดในรูปแบบ address แบบใหม่ที่เรียกว่า bech32 (ออกเสียงด้วย "ch" อ่อน เช่นใน "เบช สามสิบสอง") คำว่า "bech" มาจาก BCH ซึ่งเป็นอักษรย่อของบุคคลสามคนที่ค้นพบรหัสวนนี้ในปี 1959 และ 1960 ซึ่งเป็นพื้นฐานของ bech32 ส่วน "32" หมายถึงจำนวนตัวอักษรในชุดตัวอักษร bech32 (คล้ายกับ 58 ใน base58check):
-
Bech32 ใช้เฉพาะตัวเลขและตัวอักษรรูปแบบเดียว (โดยปกติจะแสดงเป็นตัวพิมพ์เล็ก) แม้ว่าชุดตัวอักษรของมันจะมีขนาดเกือบครึ่งหนึ่งของชุดตัวอักษรใน base58check ก็ตามแต่ address bech32 สำหรับสคริปต์ pay to witness public key hash (P2WPKH) ก็ยังยาวกว่า legacy address และมีขนาดเท่ากันกับสคริปต์ P2PKH
-
Bech32 สามารถทั้งตรวจจับและช่วยแก้ไขข้อผิดพลาดได้ ใน address ที่มีความยาวตามที่คาดหวังได้ และสามารถรับประกันทางคณิตศาสตร์ได้ว่าจะตรวจพบข้อผิดพลาดใด ๆ ที่ส่งผลกระทบต่อตัวอักษร 4 ตัวหรือน้อยกว่า ซึ่งเชื่อถือได้มากกว่า base58check ส่วนสำหรับข้อผิดพลาดที่ยาวกว่านั้น จะไม่สามารถตรวจพบได้ (โอกาสเกิดน้อยกว่าหนึ่งครั้งในหนึ่งพันล้าน) ซึ่งมีความเชื่อถือได้ประมาณเท่ากับ base58check ยิ่งไปกว่านั้น สำหรับ adddress ที่พิมพ์โดยมีข้อผิดพลาดเพียงเล็กน้อย มันสามารถบอกผู้ใช้ได้ว่าข้อผิดพลาดเหล่านั้นเกิดขึ้นที่ไหน ช่วยให้พวกเขาสามารถแก้ไขข้อผิดพลาดจากการคัดลอกเล็ก ๆ น้อย ๆ ได้อย่างรวดเร็ว
-
ตัวอย่างที่ 3 Bech32 address ที่มีข้อผิดพลาด Address: bc1p9nh05ha8wrljf7ru236awn4t2x0d5ctkkywmv9sclnm4t0av2vgs4k3au7 ข้อผิดพลาดที่ตรวจพบแสดงเป็นตัวหนาและขีดเส้นใต้ สร้างโดยใช้โปรแกรมสาธิตการถอดรหัส bech32 address
-
bech32 address นิยมเขียนด้วยตัวอักษรพิมพ์เล็กเท่านั้น แต่ตัวอักษรพิมพ์เล็กเหล่านี้สามารถแทนที่ด้วยตัวอักษรพิมพ์ใหญ่ก่อนการเข้ารหัส address ในรหัส QR ได้ วิธีนี้ช่วยให้สามารถใช้โหมดการเข้ารหัส QR แบบพิเศษที่ใช้พื้นที่น้อยกว่า คุณจะสังเกตเห็นความแตกต่างในขนาดและความซับซ้อนของรหัส QR ทั้งสองสำหรับที่อยู่เดียวกันในรูปภาพข้างล่างนี้

- Bech32 ใช้ประโยชน์จากกลไกการอัปเกรดที่ออกแบบมาเป็นส่วนหนึ่งของ segwit เพื่อทำให้กระเป๋าเงินผู้จ่ายสามารถจ่ายเงินไปยังประเภทเอาต์พุตที่ยังไม่ได้ใช้งานได้ โดยมีเป้าหมายคือการอนุญาตให้นักพัฒนาสร้างกระเป๋าเงินในวันนี้ที่สามารถใช้จ่ายไปยัง bech32 address และทำให้กระเป๋าเงินนั้นยังคงสามารถใช้จ่ายไปยัง bech32address ได้สำหรับผู้ใช้คุณสมบัติใหม่ที่เพิ่มในการอัปเกรดโปรโตคอลในอนาคต โดยที่มีความหวังว่าเราอาจไม่จำเป็นต้องผ่านรอบการอัปเกรดทั้งระบบอีกต่อไป ซึ่งจำเป็นสำหรับการให้ผู้คนใช้งาน P2SH และ segwit ได้อย่างเต็มรูปแบบ
-
Problems with Bech32 Addresses
address แบบ bech32 ประสบความสำเร็จในทุกด้านยกเว้นปัญหาหนึ่ง คือการรับประกันทางคณิตศาสตร์เกี่ยวกับความสามารถในการตรวจจับข้อผิดพลาดจะใช้ได้เฉพาะเมื่อความยาวของ address ที่คุณป้อนเข้าไปในกระเป๋าเงินมีความยาวเท่ากับ address ดั้งเดิมเท่านั้น หากคุณเพิ่มหรือลบตัวอักษรใด ๆ ระหว่างการคัดลอกจะทำให้ไม่สามารถตรวจจับได้ การรับประกันนี้จะไม่มีผล และกระเป๋าเงินของคุณอาจใช้จ่ายเงินไปยัง address ที่ไม่ถูกต้อง แต่อย่างไรก็ตาม แม้จะไม่มีคุณสมบัตินี้ มีความเชื่อว่าเป็นไปได้ยากมากที่ผู้ใช้ที่เพิ่มหรือลบตัวอักษรจะสร้างสตริงที่มีผลรวมตรวจสอบที่ถูกต้อง ซึ่งช่วยให้มั่นใจได้ว่าเงินของผู้ใช้จะปลอดภัย
น่าเสียดายที่การเลือกใช้ค่าคงที่ตัวหนึ่งในอัลกอริทึม bech32 บังเอิญทำให้การเพิ่มหรือลบตัวอักษร "q" ในตำแหน่งที่สองจากท้ายของ address ที่ลงท้ายด้วยตัวอักษร "p" เป็นเรื่องง่ายมาก ในกรณีเหล่านั้น คุณยังสามารถเพิ่มหรือลบตัวอักษร "q" หลายครั้งได้ด้วย ข้อผิดพลาดนี้จะถูกตรวจจับโดยผลรวมตรวจสอบ (checksum) ในบางครั้ง แต่จะถูกมองข้ามบ่อยกว่าความคาดหวังหนึ่งในพันล้านสำหรับข้อผิดพลาดจากการแทนที่ของ bech32 อย่างมาก สำหรับตัวอย่างสามารถดูได้ในรูปภาพข้างล่างนี้
ตัวอย่างที่ 4. การขยายความยาวของ bech32 address โดยไม่ทำให้ผลรวมตรวจสอบเป็นโมฆะ ``` bech32 address ที่ถูกต้อง: bc1pqqqsq9txsqp
address ที่ไม่ถูกต้องแต่มีผลรวมตรวจสอบที่ถูกต้อง: bc1pqqqsq9txsqqqqp bc1pqqqsq9txsqqqqqqp bc1pqqqsq9txsqqqqqqqqp bc1pqqqsq9txsqqqqqqqqqp bc1pqqqsq9txsqqqqqqqqqqqp ```
จากตัวอย่างนี้ คุณจะเห็นว่าแม้มีการเพิ่มตัวอักษร "q" เข้าไปหลายตัวก่อนตัวอักษร "p" ตัวสุดท้าย ระบบตรวจสอบก็ยังคงยอมรับว่า address เหล่านี้ถูกต้อง นี่เป็นข้อบกพร่องสำคัญของ bech32 เพราะอาจทำให้เงินถูกส่งไปยัง address ที่ไม่มีใครเป็นเจ้าของจริง ๆ หรือ address ที่ไม่ได้ตั้งใจจะส่งไป
สำหรับเวอร์ชันเริ่มต้นของ segwit (เวอร์ชัน 0) ปัญหานี้ไม่ใช่ความกังวลในทางปฏิบัติ เพราะมีความยาวที่ถูกต้องมีเพียงสองแบบที่กำหนดไว้สำหรับเอาต์พุต นั้นคือ 22 Byte และ 34 Byte ซึ่งสอดคล้องกับ bech32 address ที่มีความยาวยาวที่ 42 หรือ 62 ตัวอักษร ดังนั้นคนจะต้องเพิ่มหรือลบตัวอักษร "q" จากตำแหน่งที่สองจากท้ายของ bech32 address ถึง 20 ครั้งเพื่อส่งเงินไปยัง address ที่ไม่ถูกต้องโดยที่กระเป๋าเงินไม่สามารถตรวจจับได้ อย่างไรก็ตาม มันอาจกลายเป็นปัญหาสำหรับผู้ใช้ในอนาคตหากมีการนำการอัปเกรดบนพื้นฐานของ segwit มาใช้
Bech32m
แม้ว่า bech32 จะทำงานได้ดีสำหรับ segwit v0 แต่นักพัฒนาไม่ต้องการจำกัดขนาดเอาต์พุตโดยไม่จำเป็นในเวอร์ชันหลังๆ ของ segwit หากไม่มีข้อจำกัด การเพิ่มหรือลบตัวอักษร "q" เพียงตัวเดียวใน bech32 address อาจทำให้ผู้ใช้ส่งเงินโดยไม่ตั้งใจไปยังเอาต์พุตที่ไม่สามารถใช้จ่ายได้หรือสามารถใช้จ่ายได้โดยทุกคน (ทำให้บิตคอยน์เหล่านั้นถูกนำไปโดยทุกคนได้) นักพัฒนาได้วิเคราะห์ปัญหา bech32 อย่างละเอียดและพบว่าการเปลี่ยนค่าคงที่เพียงตัวเดียวในอัลกอริทึมของพวกเขาจะขจัดปัญหานี้ได้ ทำให้มั่นใจว่าการแทรกหรือลบตัวอักษรสูงสุดห้าตัวจะไม่ถูกตรวจจับน้อยกว่าหนึ่งครั้งในหนึ่งพันล้านเท่านั้น
เวอร์ชันของ bech32 ที่มีค่าคงที่เพียงหนึ่งตัวที่แตกต่างกันเรียกว่า bech32 แบบปรับแต่ง (bech32m) ตัวอักษรทั้งหมดใน address แบบ bech32 และ bech32m สำหรับข้อมูลพื้นฐานเดียวกันจะเหมือนกันทั้งหมด ยกเว้นหกตัวสุดท้าย (ซึ่งเป็นส่วนของ checksum) นั่นหมายความว่ากระเป๋าเงินจำเป็นต้องรู้ว่ากำลังใช้เวอร์ชันใดเพื่อตรวจสอบความถูกต้องของ checksum แต่ address ทั้งสองประเภทมีไบต์เวอร์ชันภายในที่ทำให้การระบุเวอร์ชันที่ใช้อยู่เป็นเรื่องที่ง่าย ในการทำงานกับทั้ง bech32 และ bech32m เราจะพิจารณากฎการเข้ารหัสและการแยกวิเคราะห์สำหรับ address บิตคอยน์แบบ bech32m เนื่องจากพวกมันครอบคลุมความสามารถในการแยกวิเคราะห์บน address แบบ bech32 และเป็นรูปแบบ address ที่แนะนำในปัจจุบันสำหรับกระเป๋าเงินบิตคอยน์
ข้อความจากหลาม: คือผมว่าตรงนี้เขาเขียนไม่รู้เรื่อง แต่เดาว่าเขาน่าจะสื่อว่า เราควรเรียนรู้วิธีการทำงานกับ bech32m เพราะมันเป็นรูปแบบที่แนะนำให้ใช้ในปัจจุบัน และมันมีข้อดีเพราะbech32m สามารถรองรับการอ่าน address แบบ bech32 แบบเก่าได้ด้วย ง่ายๆ คือ ถ้าคุณเรียนรู้วิธีทำงานกับ bech32m คุณจะสามารถทำงานกับทั้ง bech32m และ bech32 ได้ทั้งสองแบบ
bech32m address ริ่มต้นด้วยส่วนที่มนุษย์อ่านได้ (Human Readable Part: HRP) BIP173 มีกฎสำหรับการสร้าง HRP ของคุณเอง แต่สำหรับบิตคอยน์ คุณเพียงแค่จำเป็นต้องรู้จัก HRP ที่ถูกเลือกไว้แล้วตามที่แสดงในตารางข้างล่างนี้

ส่วน HRP ตามด้วยตัวคั่น ซึ่งก็คือเลข "1" ในข้อเสนอก่อนหน้านี้สำหรับตัวคั่นโปรโตคอลได้ใช้เครื่องหมายทวิภาค (colon) แต่ระบบปฏิบัติการและแอปพลิเคชันบางตัวที่อนุญาตให้ผู้ใช้ดับเบิลคลิกคำเพื่อไฮไลต์สำหรับการคัดลอกและวางนั้นจะไม่ขยายการไฮไลต์ไปถึงและผ่านเครื่องหมายทวิภาค
การใช้ตัวเลขช่วยให้มั่นใจได้ว่าการไฮไลต์ด้วยดับเบิลคลิกจะทำงานได้กับโปรแกรมใดๆ ที่รองรับสตริง bech32m โดยทั่วไป (ซึ่งรวมถึงตัวเลขอื่นๆ ด้วย) เลข "1" ถูกเลือกเพราะสตริง bech32 ไม่ได้ใช้เลข 1 ในกรณีอื่น เพื่อป้องกันการแปลงโดยไม่ตั้งใจระหว่างเลข "1" กับตัวอักษรพิมพ์เล็ก "l"
และส่วนอื่นของ bech32m address เรียกว่า "ส่วนข้อมูล" (data part) ซึ่งประกอบด้วยสามองค์ประกอบ:
- Witness version: ไบต์ถัดไปหลังจากตัวคั่นตัวอักษรนี้แทนเวอร์ชันของ segwit ตัวอักษร "q" คือการเข้ารหัสของ "0" สำหรับ segwit v0 ซึ่งเป็นเวอร์ชันแรกของ segwit ที่มีการแนะนำที่อยู่ bech32 ตัวอักษร "p" คือการเข้ารหัสของ "1" สำหรับ segwit v1 (หรือเรียกว่า taproot) ซึ่งเริ่มมีการใช้งาน bech32m มีเวอร์ชันที่เป็นไปได้ทั้งหมด 17 เวอร์ชันของ segwit และสำหรับ Bitcoin จำเป็นต้องให้ไบต์แรกของส่วนข้อมูล bech32m ถอดรหัสเป็นตัวเลข 0 ถึง 16 (รวมทั้งสองค่า)
- Witness program: คือตำแหน่งหลังจาก witnessversion ตั้งแต่ตำแหน่ง 2 ถึง 40 Byte สำหรับ segwit v0 นี้ต้องมีความยาว 20 หรือ 32 Byte ไม่สามารถ ffมีขนาดอื่นได้ สำหรับ segwit v1 ความยาวเดียวที่ถูกกำหนดไว้ ณ เวลาที่เขียนนี้คือ 32 ไบต์ แต่อาจมีการกำหนดความยาวอื่น ๆ ได้ในภายหลัง
- Checksum: มีความยาว 6 ตัวอักษร โดยส่วนนี้ถูกสร้างขึ้นโดยใช้รหัส BCH ซึ่งเป็นประเภทของรหัสแก้ไขข้อผิดพลาด (error corection code) (แต่อย่างไรก็ตาม สำหรับ address บิตคอยน์ เราจะเห็นในภายหลังว่าเป็นสิ่งสำคัญที่จะใช้ checksum เพื่อการตรวจจับข้อผิดพลาดเท่านั้น—ไม่ใช่การแก้ไข
ในส่วนต่อไปหลังจากนี้เราจะลองสร้าง address แบบ bech32 และ bech32m สำหรับตัวอย่างทั้งหมดต่อไปนี้ เราจะใช้โค้ดอ้างอิง bech32m สำหรับ Python
เราจะเริ่มด้วยการสร้างสคริปต์เอาต์พุตสี่ตัว หนึ่งตัวสำหรับแต่ละเอาต์พุต segwit ที่แตกต่างกันที่ใช้ในช่วงเวลาของการเผยแพร่ บวกกับอีกหนึ่งตัวสำหรับเวอร์ชัน segwit ในอนาคตที่ยังไม่มีความหมายที่กำหนดไว้ สคริปต์เหล่านี้แสดงอยู่ในตารางข้างล่างนี้

สำหรับเอาต์พุต P2WPKH witness program มีการผูก commitment ที่สร้างขึ้นในลักษณะเดียวกันกับ P2PKH ที่เห็นใน Legacy Addresses for P2PKH โดย public key ถูกส่งเข้าไปในฟังก์ชันแฮช SHA256 ไดเจสต์ขนาด 32 ไบต์ที่ได้จะถูกส่งเข้าไปในฟังก์ชันแฮช RIPEMD-160 ไดเจสต์ของฟังก์ชันนั้น จะถูกวางไว้ใน witness program
สำหรับเอาต์พุตแบบ pay to witness script hash (P2WSH) เราไม่ได้ใช้อัลกอริทึม P2SH แต่เราจะนำสคริปต์ ส่งเข้าไปในฟังก์ชันแฮช SHA256 และใช้ไดเจสต์ขนาด 32 ไบต์ของฟังก์ชันนั้นใน witness program สำหรับ P2SH ไดเจสต์ SHA256 จะถูกแฮชอีกครั้งด้วย RIPEMD-160 ซึ่งแน่นอนว่าอาจจะไม่ปลอดภัย ในบางกรณี สำหรับรายละเอียด ดูที่ P2SH Collision Attacks ผลลัพธ์ของการใช้ SHA256 โดยไม่มี RIPEMD-160 คือ การผูกพันแบบ P2WSH มีขนาด 32 ไบต์ (256 บิต) แทนที่จะเป็น 20 ไบต์ (160 บิต)
สำหรับเอาต์พุตแบบ pay-to-taproot (P2TR) witness program คือจุดบนเส้นโค้ง secp256k1 มันอาจเป็น public key แบบธรรมดา แต่ในกรณีส่วนใหญ่มันควรเป็น public key ที่ผูกพันกับข้อมูลเพิ่มเติมบางอย่าง เราจะเรียนรู้เพิ่มเติมเกี่ยวกับการผูกพันนั้นในหัวข้อของ taproot
สำหรับตัวอย่างของเวอร์ชัน segwit ในอนาคต เราเพียงแค่ใช้หมายเลขเวอร์ชัน segwit ที่สูงที่สุดที่เป็นไปได้ (16) และ witness program ที่มีขนาดเล็กที่สุดที่อนุญาต (2 ไบต์) โดยมีค่าเป็นศูนย์ (null value)
เมื่อเรารู้หมายเลขเวอร์ชันและ witness program แล้ว เราสามารถแปลงแต่ละอย่างให้เป็น bech32 address ได้ โดยการใช้ไลบรารีอ้างอิง bech32m สำหรับ Python เพื่อสร้าง address เหล่านั้นอย่างรวดเร็ว และจากนั้นมาดูอย่างละเอียดว่าเกิดอะไรขึ้น:
``` $ github=" https://raw.githubusercontent.com" $ wget $github/sipa/bech32/master/ref/python/segwit_addr.py $ python
from segwit_addr import * from binascii import unhexlify help(encode) encode(hrp, witver, witprog) Encode a segwit address. encode('bc', 0, unhexlify('2b626ed108ad00a944bb2922a309844611d25468')) 'bc1q9d3xa5gg45q2j39m9y32xzvygcgay4rgc6aaee' encode('bc', 0, unhexlify('648a32e50b6fb7c5233b228f60a6a2ca4158400268844c4bc295ed5e8c3d626f')) 'bc1qvj9r9egtd7mu2gemy28kpf4zefq4ssqzdzzycj7zjhk4arpavfhsct5a3p' encode('bc', 1, unhexlify('2ceefa5fa770ff24f87c5475d76eab519eda6176b11dbe1618fcf755bfac5311')) 'bc1p9nh05ha8wrljf7ru236awm4t2x0d5ctkkywmu9sclnm4t0av2vgs4k3au7' encode('bc', 16, unhexlify('0000')) 'bc1sqqqqkfw08p'
หากเราเปิดไฟล์ segwit_addr.py และดูว่าโค้ดกำลังทำอะไร สิ่งแรกที่เราจะสังเกตเห็นคือความแตกต่างเพียงอย่างเดียวระหว่าง bech32 (ที่ใช้สำหรับ segwit v0) และ bech32m (ที่ใช้สำหรับเวอร์ชัน segwit รุ่นหลัง) คือค่าคงที่:BECH32_CONSTANT = 1 BECH32M_CONSTANT = 0x2bc830a3 ```และในส่วนต่อไป เราจะเห็นโค้ดที่สร้าง checksum ในขั้นตอนสุดท้ายของการสร้าง checksum ค่าคงที่ที่เหมาะสมถูกรวมเข้ากับข้อมูลอื่น ๆ โดยใช้การดำเนินการ xor ค่าเดียวนั้นคือความแตกต่างเพียงอย่างเดียวระหว่าง bech32 และ bech32m
เมื่อสร้าง checksum แล้ว อักขระ 5 บิตแต่ละตัวในส่วนข้อมูล (รวมถึง witness version, witness program และ checksum) จะถูกแปลงเป็นตัวอักษรและตัวเลข
สำหรับการถอดรหัสกลับเป็นสคริปต์เอาต์พุต เราทำงานย้อนกลับ ลองใช้ไลบรารีอ้างอิงเพื่อถอดรหัส address สอง address ของเรา: ```
help(decode) decode(hrp, addr) Decode a segwit address. _ = decode("bc", "bc1q9d3xa5gg45q2j39m9y32xzvygcgay4rgc6aaee") [0], bytes([1]).hex() (0, '2b626ed108ad00a944bb2922a309844611d25468') _ = decode("bc", "bc1p9nh05ha8wrljf7ru236awm4t2x0d5ctkkywmu9sclnm4t0av2vgs4k3au7") [0], bytes([1]).hex() (1, '2ceefa5fa770ff24f87c5475d76eab519eda6176b11dbe1618fcf755bfac5311')
เราได้รับทั้ง witness version และ witness program กลับมา สิ่งเหล่านี้สามารถแทรกลงในเทมเพลตสำหรับสคริปต์เอาต์พุตของเรา:ตัวอย่างเช่น:OP_0 2b626ed108ad00a944bb2922a309844611d25468 OP_1 2ceefa5fa770ff24f87c5475d76eab519eda6176b11dbe1618fcf755bfac5311 ``` คำเตือน: ข้อผิดพลาดที่อาจเกิดขึ้นที่ควรระวังคือ witness version ที่มีค่า 0 ใช้สำหรับ OP_0 ซึ่งใช้ไบต์ 0x00—แต่เวอร์ชัน witness ที่มีค่า 1 ใช้ OP_1 ซึ่งเป็นไบต์ 0x51 เวอร์ชัน witness 2 ถึง 16 ใช้ไบต์ 0x52 ถึง 0x60 ตามลำดับเมื่อทำการเขียนโค้ดเพื่อเข้ารหัสหรือถอดรหัส bech32m เราขอแนะนำอย่างยิ่งให้คุณใช้เวกเตอร์ทดสอบ (test vectors) ที่มีให้ใน BIP350 เราขอให้คุณตรวจสอบให้แน่ใจว่าโค้ดของคุณผ่านเวกเตอร์ทดสอบที่เกี่ยวข้องกับการจ่ายเงินให้กับเวอร์ชัน segwit ในอนาคตที่ยังไม่ได้รับการกำหนด สิ่งนี้จะช่วยให้ซอฟต์แวร์ของคุณสามารถใช้งานได้อีกหลายปีข้างหน้า แม้ว่าคุณอาจจะไม่สามารถเพิ่มการรองรับคุณสมบัติใหม่ ๆ ของบิตคอยน์ได้ทันทีที่คุณสมบัตินั้น ๆ เริ่มใช้งานได้
Private Key Formats
private key สามารถถูกแสดงได้ในหลาย ๆ รูปแบบที่ต่างกันซึ่งสามารถแปลงเป็นตัวเลขขนาด 256 bit ชุดเดียวกันได้ ดังที่เราจะแสดงให้ดูในตารางข้างล่างนี้ รูปแบบที่แตกต่างกันถูกใช้ในสถานการณ์ที่ต่างกัน รูปแบบเลขฐานสิบหก (Hexadecimal) และรูปแบบไบนารี (raw binary) ถูกใช้ภายในซอฟต์แวร์และแทบจะไม่แสดงให้ผู้ใช้เห็น WIF ถูกใช้สำหรับการนำเข้า/ส่งออกกุญแจระหว่างกระเป๋าเงินและมักใช้ในการแสดงกุญแจส่วนตัวแบบ QR code
รูปแบบของ private key ในปัจจุบัน
ซอฟต์แวร์กระเป๋าเงินบิตคอยน์ในยุคแรกได้สร้าง private key อิสระอย่างน้อยหนึ่งดอกเมื่อกระเป๋าเงินของผู้ใช้ใหม่ถูกเริ่มต้น เมื่อชุดกุญแจเริ่มต้นถูกใช้ทั้งหมดแล้ว กระเป๋าเงินอาจสร้าง private key เพิ่มเติม private key แต่ละดอกสามารถส่งออกหรือนำเข้าได้ ทุกครั้งที่มีการสร้างหรือนำเข้า private key ใหม่ จะต้องมีการสร้างการสำรองข้อมูลกระเป๋าเงินใหม่ด้วย
กระเป๋าเงินบิตคอยน์ในยุคหลังเริ่มใช้กระเป๋าเงินแบบกำหนดได้ (deterministic wallets) ซึ่ง private key ทั้งหมดถูกสร้างจาก seed เพียงค่าเดียว กระเป๋าเงินเหล่านี้จำเป็นต้องสำรองข้อมูลเพียงครั้งเดียวเท่านั้นสำหรับการใช้งานบนเชนทั่วไป แต่อย่างไรก็ตาม หากผู้ใช้ส่งออก private key เพียงดอกเดียวจากกระเป๋าเงินเหล่านี้ และผู้โจมตีได้รับกุญแจนั้นรวมถึงข้อมูลที่ไม่ใช่ข้อมูลส่วนตัวบางอย่างเกี่ยวกับกระเป๋าเงิน พวกเขาอาจสามารถสร้างกุญแจส่วนตัวใด ๆ ในกระเป๋าเงินได้—ทำให้ผู้โจมตีสามารถขโมยเงินทั้งหมดในกระเป๋าเงินได้ นอกจากนี้ ยังไม่สามารถนำเข้ากุญแจสู่กระเป๋าเงินแบบกำหนดได้ นี่หมายความว่าแทบไม่มีกระเป๋าเงินสมัยใหม่ที่รองรับความสามารถในการส่งออกหรือนำเข้ากุญแจเฉพาะดอก ข้อมูลในส่วนนี้มีความสำคัญหลัก ๆ สำหรับผู้ที่ต้องการความเข้ากันได้กับกระเป๋าเงินบิตคอยน์ในยุคแรก ๆ
รูปแบบของ private key (รูปแบบการเข้ารหัส)
 private key เดียวกันในแต่ละ format
private key เดียวกันในแต่ละ format
 รูปแบบการแสดงผลทั้งหมดเหล่านี้เป็นวิธีต่างๆ ในการแสดงเลขจำนวนเดียวกัน private key เดียวกัน พวกมันดูแตกต่างกัน แต่รูปแบบใดรูปแบบหนึ่งสามารถแปลงไปเป็นรูปแบบอื่นได้อย่างง่ายดาย
รูปแบบการแสดงผลทั้งหมดเหล่านี้เป็นวิธีต่างๆ ในการแสดงเลขจำนวนเดียวกัน private key เดียวกัน พวกมันดูแตกต่างกัน แต่รูปแบบใดรูปแบบหนึ่งสามารถแปลงไปเป็นรูปแบบอื่นได้อย่างง่ายดายCompressed Private Keys
คำว่า compressed private key ที่ใช้กันทั่วไปนั้นเป็นคำที่เรียกผิด เพราะเมื่อ private key ถูกส่งออกไปในรูปแบบ WIF-compressed มันจะมีความยาวมากกว่า private key แบบ uncompressed 1 Byte (เลข 01 ในช่อง Hex-compressed ในตารางด้านล่างนี้) ซึ่งบ่งบอกว่า private key ตัวนี้ มาจากกระเป๋าเงินรุ่นใหม่และควรใช้เพื่อสร้าง compressed public key เท่านั้น
private key เองไม่ได้ถูกบีบอัดและไม่สามารถบีบอัดได้ คำว่า compressed private key จริงๆ แล้วหมายถึง " private key ซึ่งควรใช้สร้าง compressed public key เท่านั้น" ในขณะที่ uncompressed private key จริงๆ แล้วหมายถึง “private key ซึ่งควรใช้สร้าง uncompressed public key เท่านั้น” คุณควรใช้เพื่ออ้างถึงรูปแบบการส่งออกเป็น "WIF-compressed" หรือ "WIF" เท่านั้น และไม่ควรอ้างถึง private key ว่า "บีบอัด" เพื่อหลีกเลี่ยงความสับสนต่อไป
ตารางนี้แสดงกุญแจเดียวกันที่ถูกเข้ารหัสในรูปแบบ WIF และ WIF-compressed
ตัวอย่าง: กุญแจเดียวกัน แต่รูปแบบต่างกัน

สังเกตว่ารูปแบบ Hex-compressed มีไบต์เพิ่มเติมหนึ่งไบต์ที่ท้าย (01 ในเลขฐานสิบหก) ในขณะที่คำนำหน้าเวอร์ชันการเข้ารหัสแบบ base58 เป็นค่าเดียวกัน (0x80) สำหรับทั้งรูปแบบ WIF และ WIF-compressed การเพิ่มหนึ่งไบต์ที่ท้ายของตัวเลขทำให้อักขระตัวแรกของการเข้ารหัสแบบ base58 เปลี่ยนจาก 5 เป็น K หรือ L
คุณสามารถคิดถึงสิ่งนี้เหมือนกับความแตกต่างของการเข้ารหัสเลขฐานสิบระหว่างตัวเลข 100 และตัวเลข 99 ในขณะที่ 100 มีความยาวมากกว่า 99 หนึ่งหลัก มันยังมีคำนำหน้าเป็น 1 แทนที่จะเป็นคำนำหน้า 9 เมื่อความยาวเปลี่ยนไป มันส่งผลต่อคำนำหน้า ในระบบ base58 คำนำหน้า 5 เปลี่ยนเป็น K หรือ L เมื่อความยาวของตัวเลขเพิ่มขึ้นหนึ่งไบต์
TIPจากหลาม: ผมว่าเขาเขียนย่อหน้านี้ไม่ค่อยรู้เรื่อง แต่ความหมายมันจะประมาณว่า เหมือนถ้าเราต้องการเขียนเลข 100 ในฐาน 10 เราต้องใช้สามตำแหน่ง 100 แต่ถ้าใช้ฐาน 16 เราจะใช้แค่ 2 ตำแหน่งคือ 64 ซึ่งมีค่าเท่ากัน
ถ้ากระเป๋าเงินบิตคอยน์สามารถใช้ compressed public key ได้ มันจะใช้ในทุกธุรกรรม private key ในกระเป๋าเงินจะถูกใช้เพื่อสร้างจุด public key บนเส้นโค้ง ซึ่งจะถูกบีบอัด compressed public key จะถูกใช้เพื่อสร้าง address และ address เหล่านี้จะถูกใช้ในธุรกรรม เมื่อส่งออก private key จากกระเป๋าเงินใหม่ที่ใช้ compressed public key WIF จะถูกปรับเปลี่ยน โดยเพิ่มต่อท้ายขนาด 1 ไบต์ 01 ให้กับ private key ที่ถูกเข้ารหัสแบบ base58check ที่ได้จะเรียกว่า "WIF-compressed" และจะขึ้นต้นด้วยอักษร K หรือ L แทนที่จะขึ้นต้นด้วย "5" เหมือนกับกรณีของคีย์ที่เข้ารหัสแบบ WIF (ไม่บีบอัด) จากกระเป๋าเงินรุ่นเก่า
Advanced Keys and Addresses
ในส่วนต่อไปนี้ เราจะดูรูปแบบของคีย์และ address เช่น vanity addresses และ paper wallets
vanity addresses
vanity addresses หรือ addresses แบบกำหนดเอง คือ address ที่มีข้อความที่มนุษย์อ่านได้และสามารถใช้งานได้จริง ตัวอย่างเช่น 1LoveBPzzD72PUXLzCkYAtGFYmK5vYNR33 อย่างที่เห็นว่ามันเป็น address ที่ถูกต้องซึ่งมีตัวอักษรเป็นคำว่า Love เป็นตัวอักษร base58 สี่ตัวแรก addresses แบบกำหนดเองต้องอาศัยการสร้างและทดสอบ private key หลายพันล้านตัวจนกว่าจะพบ address ที่มีรูปแบบตามที่ต้องการ แม้ว่าจะมีการปรับปรุงบางอย่างในอัลกอริทึมการสร้าง addresses แบบกำหนดเอง แต่กระบวนการนี้ต้องใช้การสุ่มเลือก private key มาสร้าง public key และนำไปสร้าง address และตรวจสอบว่าตรงกับรูปแบบที่ต้องการหรือไม่ โดยทำซ้ำหลายพันล้านครั้งจนกว่าจะพบที่ตรงกัน
เมื่อพบ address ที่ตรงกับรูปแบบที่ต้องการแล้ว private key ที่ใช้สร้าง address นั้นสามารถใช้โดยเจ้าของเพื่อใช้จ่ายบิตคอยน์ได้เหมือนกับ address อื่น ๆ ทุกประการ address ที่กำหนดเองไม่ได้มีความปลอดภัยน้อยกว่าหรือมากกว่าที่ address ๆ พวกมันขึ้นอยู่กับการเข้ารหัสเส้นโค้งรูปวงรี (ECC) และอัลกอริทึมแฮชที่ปลอดภัย (SHA) เหมือนกับ address อื่น ๆ คุณไม่สามารถค้นหา private key ของ address ที่ขึ้นต้นด้วยรูปแบบที่กำหนดเองได้ง่ายกว่า address อื่น ๆ
ตัวอย่างเช่น ยูจีเนียเป็นผู้อำนวยการการกุศลเพื่อเด็กที่ทำงานในฟิลิปปินส์ สมมติว่ายูจีเนียกำลังจัดการระดมทุนและต้องการใช้ address ที่กำหนดเองเพื่อประชาสัมพันธ์การระดมทุน ยูจีเนียจะสร้าง address ที่กำหนดเองที่ขึ้นต้นด้วย "1Kids" เพื่อส่งเสริมการระดมทุนเพื่อการกุศลสำหรับเด็ก มาดูกันว่า address ที่กำหนดเองนี้จะถูกสร้างขึ้นอย่างไรและมีความหมายอย่างไรต่อความปลอดภัยของการกุศลของยูจีเนีย
การสร้าง address ที่กำหนดเอง
ควรเข้าใจว่า address ของบิตคอยน์เป็นเพียงตัวเลขที่แสดงด้วยสัญลักษณ์ในรูปแบบตัวอักษร base58 เท่านั้น เพราะฉะนั้นแล้ว การค้นหารูปแบบเช่น "1Kids" สามารถมองได้ว่าเป็นการค้นหาที่อยู่ในช่วงตั้งแต่ 1Kids11111111111111111111111111111 ถึง 1Kidszzzzzzzzzzzzzzzzzzzzzzzzzzzzz มีประมาณ 5829 (ประมาณ 1.4 × 1051) address ในช่วงนั้น ทั้งหมดขึ้นต้นด้วย "1Kids" ตารางด้านล่างนี้แสดงช่วงของ address ที่มีคำนำหน้า 1Kids
 ลองดูรูปแบบ "1Kids" ในรูปของตัวเลขและดูว่าเราอาจพบรูปแบบนี้ใน bitcoin address บ่อยแค่ไหน โดยตารางข้างล่างนี้แสดงให้เห็นถีงคอมพิวเตอร์เดสก์ท็อปทั่วไปที่ไม่มีฮาร์ดแวร์พิเศษสามารถค้นหาคีย์ได้ประมาณ 100,000 คีย์ต่อวินาที
ลองดูรูปแบบ "1Kids" ในรูปของตัวเลขและดูว่าเราอาจพบรูปแบบนี้ใน bitcoin address บ่อยแค่ไหน โดยตารางข้างล่างนี้แสดงให้เห็นถีงคอมพิวเตอร์เดสก์ท็อปทั่วไปที่ไม่มีฮาร์ดแวร์พิเศษสามารถค้นหาคีย์ได้ประมาณ 100,000 คีย์ต่อวินาทีความถี่ของ address ที่กำหนดเอง (1KidsCharity) และเวลาค้นหาเฉลี่ยบนคอมพิวเตอร์เดสก์ท็อป

ดังที่เห็นได้ ยูจีเนียคงไม่สามารถสร้าง address แบบกำหนดเอง "1KidsCharity" ได้ในเร็ว ๆ นี้ แม้ว่าเธอจะมีคอมพิวเตอร์หลายพันเครื่องก็ตาม ทุกตัวอักษรที่เพิ่มขึ้นจะเพิ่มความยากขึ้น 58 เท่า รูปแบบที่มีมากกว่า 7 ตัวอักษรมักจะถูกค้นพบโดยฮาร์ดแวร์พิเศษ เช่น คอมพิวเตอร์เดสก์ท็อปที่สร้างขึ้นเป็นพิเศษที่มีหน่วยประมวลผลกราฟิก (GPUs) หลายตัว การค้นหา address แบบกำหนดเองบนระบบ GPU เร็วกว่าบน CPU ทั่วไปหลายเท่า
อีกวิธีหนึ่งในการหา address แบบกำหนดเองคือการจ้างงานไปยังกลุ่มคนขุด vanity addresses กลุ่มคนขุดvanity addresses เป็นบริการที่ให้ผู้ที่มีฮาร์ดแวร์ที่เร็วได้รับบิตคอยน์จากการค้นหา vanity addresses ให้กับผู้อื่น ยูจีเนียสามารถจ่ายค่าธรรมเนียมเพื่อจ้างงานการค้นหา vanity addresses ที่มีรูปแบบ 7 ตัวอักษรและได้ผลลัพธ์ในเวลาเพียงไม่กี่ชั่วโมงแทนที่จะต้องใช้ CPU ค้นหาเป็นเดือน ๆ
การสร้างที่ address แบบกำหนดเองเป็นการใช้วิธีการแบบ brute-force (ลองทุกความเป็นไปได้): ลองใช้คีย์สุ่ม ตรวจสอบ address ที่ได้ว่าตรงกับรูปแบบที่ต้องการหรือไม่ และทำซ้ำจนกว่าจะสำเร็จ
ความปลอดภัยและความเป็นส่วนตัวของ address แบบกำหนดเอง
address แบบกำหนดเองเคยเป็นที่นิยมในช่วงแรก ๆ ของบิตคอยน์ แต่แทบจะหายไปจากการใช้งานทั้งหมดในปี 2023 มีสาเหตุที่น่าจะเป็นไปได้สองประการสำหรับแนวโน้มนี้: - Deterministic wallets: ดังที่เราเห็นในพาร์ทของการกู้คืน การที่จะสำรองคีย์ทุกตัวในกระเป๋าเงินสมัยใหม่ส่วนใหญ่นั้น ทำเพียงแค่จดคำหรือตัวอักษรไม่กี่ตัว ซึ่งนี่เป็นผลจากการสร้างคีย์ทุกตัวในกระเป๋าเงินจากคำหรือตัวอักษรเหล่านั้นโดยใช้อัลกอริทึมแบบกำหนดได้ จึงไม่สามารถใช้ address แบบกำหนดเองกับ Deterministic wallets ได้ เว้นแต่ผู้ใช้จะสำรองข้อมูลเพิ่มเติมสำหรับ address แบบกำหนดเองทุก address ที่พวกเขาสร้าง ในทางปฏิบัติแล้วกระเป๋าเงินส่วนใหญ่ที่ใช้การสร้างคีย์แบบกำหนดได้ โดยไม่อนุญาตให้นำเข้าคีย์ส่วนตัวหรือการปรับแต่งคีย์จากโปรแกรมสร้าง address ที่กำหนดเอง
- การหลีกเลี่ยงการใช้ address ซ้ำซ้อน: การใช้ address แบบกำหนดเองเพื่อรับการชำระเงินหลายครั้งไปยัง address เดียวกันจะสร้างความเชื่อมโยงระหว่างการชำระเงินทั้งหมดเหล่านั้น นี่อาจเป็นที่ยอมรับได้สำหรับยูจีเนียหากองค์กรไม่แสวงหาผลกำไรของเธอจำเป็นต้องรายงานรายได้และค่าใช้จ่ายต่อหน่วยงานภาษีอยู่แล้ว แต่อย่างไรก็ตาม มันยังลดความเป็นส่วนตัวของคนที่จ่ายเงินให้ยูจีเนียหรือรับเงินจากเธอด้วย ตัวอย่างเช่น อลิซอาจต้องการบริจาคโดยไม่เปิดเผยตัวตน และบ็อบอาจไม่ต้องการให้ลูกค้ารายอื่นของเขารู้ว่าเขาให้ราคาส่วนลดแก่ยูจีเนีย
เราไม่คาดว่าจะเห็น address แบบกำหนดเองมากนักในอนาคต เว้นแต่ปัญหาที่กล่าวมาก่อนหน้านี้จะได้รับการแก้ไข
Paper Wallets
paper wallet หรือก็คือ private key ที่พิมพ์ลงในกระดาษ และโดยทั่วไปแล้วมักจะมีข้อมูลของ public key หรือ address บนกระดาษนั้นด้วยแม้ว่าจริง ๆ แล้วมันจะสามารถคำนวณได้ด้วย private key ก็ตาม
คำเตือน: paper wallet เป็นเทคโนโลยีที่ล้าสมัยแล้วและอันตรายสำหรับผู้ใช้ส่วนใหญ่ เพราะเป็นเรื่องยากที่จะสร้างมันอย่างปลอดภัย โดยเฉพาะอย่างยิ่งความเป็นไปได้ที่โค้ดที่ใช้สร้างอาจถูกแทรกแซงด้วยผู้ไม่ประสงค์ดี และอาจจะทำให้ผู้ใช้โดนขโมยบิตคอยน์ทั้งหมดไปได้ paper wallet ถูกแสดงที่นี่เพื่อวัตถุประสงค์ในการให้ข้อมูลเท่านั้นและไม่ควรใช้สำหรับเก็บบิตคอยน์

paper wallet ได้ถูกออกแบบมาเพื่อเป็นของขวัญและมีธีมตามฤดูกาล เช่น คริสต์มาสและปีใหม่ ส่วนเหตุผลอื่น ๆ ถูกออกแบบเพื่อการเก็บรักษาในตู้นิรภัยของธนาคารหรือตู้เซฟโดยมี private key ถูกซ่อนไว้ในบางวิธี ไม่ว่าจะด้วยสติกเกอร์แบบขูดที่ทึบแสงหรือพับและปิดผนึกด้วยแผ่นฟอยล์กันการงัดแงะ ส่วนการออกแบบอื่น ๆ มีสำเนาเพิ่มเติมของคีย์และ address ในรูปแบบของตอนฉีกที่แยกออกได้คล้ายกับตั๋ว ช่วยให้คุณสามารถเก็บสำเนาหลายชุดเพื่อป้องกันจากไฟไหม้ น้ำท่วม หรือภัยพิบัติทางธรรมชาติอื่น ๆ
จากการออกแบบเดิมของบิตคอยน์ที่เน้น public key ไปจนถึง address และสคริปต์สมัยใหม่อย่าง bech32m และ pay to taproot—และแม้แต่การอัพเกรดบิตคอยน์ในอนาคต—คุณได้เรียนรู้วิธีที่โปรโตคอลบิตคอยน์อนุญาตให้ผู้จ่ายเงินระบุกระเป๋าเงินที่ควรได้รับการชำระเงินของพวกเขา แต่เมื่อเป็นกระเป๋าเงินของคุณเองที่รับการชำระเงิน คุณจะต้องการความมั่นใจว่าคุณจะยังคงเข้าถึงเงินนั้นได้แม้ว่าจะเกิดอะไรขึ้นกับข้อมูลกระเป๋าเงินของคุณ ในบทต่อไป เราจะดูว่ากระเป๋าเงินบิตคอยน์ถูกออกแบบอย่างไรเพื่อปกป้องเงินทุนจากภัยคุกคามหลากหลายรูปแบบ
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
SummaDB
This was a hierarchical database server similar to the original Firebase. Records were stored on a LevelDB on different paths, like:
/fruits/banana/color:yellow/fruits/banana/flavor:sweet
And could be queried by path too, using HTTP, for example, a call to
http://hostname:port/fruits/banana, for example, would return a JSON document likejson { "color": "yellow", "flavor": "sweet" }While a call to
/fruitswould returnjson { "banana": { "color": "yellow", "flavor": "sweet" } }POST,PUTandPATCHrequests also worked.In some cases the values would be under a special
"_val"property to disambiguate them from paths. (I may be missing some other details that I forgot.)GraphQL was also supported as a query language, so a query like
graphql query { fruits { banana { color } } }would return
{"fruits": {"banana": {"color": "yellow"}}}.SummulaDB
SummulaDB was a browser/JavaScript build of SummaDB. It ran on the same Go code compiled with GopherJS, and using PouchDB as the storage backend, if I remember correctly.
It had replication between browser and server built-in, and one could replicate just subtrees of the main tree, so you could have stuff like this in the server:
json { "users": { "bob": {}, "alice": {} } }And then only allow Bob to replicate
/users/boband Alice to replicate/users/alice. I am sure the require auth stuff was also built in.There was also a PouchDB plugin to make this process smoother and data access more intuitive (it would hide the
_valstuff and allow properties to be accessed directly, today I wouldn't waste time working on these hidden magic things).The computed properties complexity
The next step, which I never managed to get fully working and caused me to give it up because of the complexity, was the ability to automatically and dynamically compute materialized properties based on data in the tree.
The idea was partly inspired on CouchDB computed views and how limited they were, I wanted a thing that would be super powerful, like, given
json { "matches": { "1": { "team1": "A", "team2": "B", "score": "2x1", "date": "2020-01-02" }, "1": { "team1": "D", "team2": "C", "score": "3x2", "date": "2020-01-07" } } }One should be able to add a computed property at
/matches/standingsthat computed the scores of all teams after all matches, for example.I tried to complete this in multiple ways but they were all adding much more complexity I could handle. Maybe it would have worked better on a more flexible and powerful and functional language, or if I had more time and patience, or more people.
Screenshots
This is just one very simple unfinished admin frontend client view of the hierarchical dataset.

- https://github.com/fiatjaf/summadb
- https://github.com/fiatjaf/summuladb
- https://github.com/fiatjaf/pouch-summa
-
@ 4e616576:43c4fee8
2025-04-30 13:27:51
asdfasdf
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Parallel Chains
We want merged-mined blockchains. We want them because it is possible to do things in them that aren't doable in the normal Bitcoin blockchain because it is rightfully too expensive, but there are other things beside the world money that could benefit from a "distributed ledger" -- just like people believed in 2013 --, like issued assets and domain names (just the most obvious examples).
On the other hand we can't have -- like people believed in 2013 -- a copy of Bitcoin for every little idea with its own native token that is mined by proof-of-work and must get off the ground from being completely valueless into having some value by way of a miracle that operated only once with Bitcoin.
It's also not a good idea to have blockchains with custom merged-mining protocol (like Namecoin and Rootstock) that require Bitcoin miners to run their software and be an active participant and miner for that other network besides Bitcoin, because it's too cumbersome for everybody.
Luckily Ruben Somsen invented this protocol for blind merged-mining that solves the issue above. Although it doesn't solve the fact that each parallel chain still needs some form of "native" token to pay miners -- or it must use another method that doesn't use a native token, such as trusted payments outside the chain.
How does it work
With the
SIGHASH_NOINPUT/SIGHASH_ANYPREVOUTsoft-fork[^eltoo] it becomes possible to create presigned transactions that aren't related to any previous UTXO.Then you create a long sequence of transactions (sufficient to last for many many years), each with an
nLockTimeof 1 and each spending the next (you create them from the last to the first). Since theirscriptSig(the unlocking script) will useSIGHASH_ANYPREVOUTyou can obtain a transaction id/hash that doesn't include the previous TXO, you can, for example, in a sequence of transactionsA0-->B(B spends output 0 from A), include the signature for "spending A0 on B" inside thescriptPubKey(the locking script) of "A0".With the contraption described above it is possible to make that long string of transactions everybody will know (and know how to generate) but each transaction can only be spent by the next previously decided transaction, no matter what anyone does, and there always must be at least one block of difference between them.
Then you combine it with
RBF,SIGHASH_SINGLEandSIGHASH_ANYONECANPAYso parallel chain miners can add inputs and outputs to be able to compete on fees by including their own outputs and getting change back while at the same time writing a hash of the parallel block in the change output and you get everything working perfectly: everybody trying to spend the same output from the long string, each with a different parallel block hash, only the highest bidder will get the transaction included on the Bitcoin chain and thus only one parallel block will be mined.See also
[^eltoo]: The same thing used in Eltoo.
-
@ 2dd9250b:6e928072
2025-03-22 00:22:40
Vi recentemente um post onde a pessoa diz que aquele final do filme O Doutrinador (2019) não faz sentido porque mesmo o protagonista explodindo o Palácio dos Três Poderes, não acaba com a corrupção no Brasil.
Progressistas não sabem ler e não conseguem interpretar textos corretamente. O final de Doutrinador não tem a ver com isso, tem a ver com a relação entre o Herói e a sua Cidade.
Nas histórias em quadrinhos há uma ligação entre a cidade e o Super-Herói. Gotham City por exemplo, cria o Batman. Isso é mostrado em The Batman (2022) e em Batman: Cavaleiro das Trevas, quando aquele garoto no final, diz para o Batman não fugir, porque ele queria ver o Batman de novo. E o Comissário Gordon diz que o "Batman é o que a cidade de Gotham precisa."
Batman: Cavaleiro das Trevas Ressurge mostra a cidade de Gotham sendo tomada pela corrupção e pela ideologia do Bane. A Cidade vai definhando em imoralidade e o Bruce, ao olhar da prisão a cidade sendo destruída, decide que o Batman precisa voltar porque se Gotham for destruída, o Batman é destruído junto. E isso o da forças para consegue fugir daquele poço e voltar para salvar Gotham.
Isso também é mostrado em Demolidor. Na série Demolidor o Matt Murdock sempre fala que precisa defender a cidade Cozinha do Inferno; que o Fisk não vai dominar a cidade e fazer o que ele quiser nela. Inclusive na terceira temporada isso fica mais evidente na luta final na mansão do Fisk, onde Matt grita que agora a cidade toda vai saber o que ele fez; a cidade vai ver o mal que ele é para Hell's Kitchen, porque a gente sabe que o Fisk fez de tudo para a imagem do Demolidor entrar e descrédito perante os cidadãos, então o que acontece no final do filme O Doutrinador não significa que ele está acabando com a corrupção quando explode o Congresso, ele está praticamente interrompendo o ciclo do sistema, colocando uma falha em sua engrenagem.
Quando você ouve falar de Brasília, você pensa na corrupção dos políticos, onde a farra acontece,, onde corruptos desviam dinheiro arrecadado dos impostos, impostos estes que são centralizados na União. Então quando você ouve falarem de Brasília, sempre pensa que o pessoal que mora lá, mora junto com tudo de podre que acontece no Brasil.
Logo quando o Doutrinador explode tudo ali, ele está basicamente destruindo o mecanismo que suja Brasília. Ele está fazendo isso naquela cidade. Porque o símbolo da cidade é justamente esse, a farsa de que naquele lugar o povo será ouvido e a justiça será feita. Ele está destruindo a ideologia de que o Estado nos protege, nos dá segurança, saúde e educação. Porque na verdade o Estado só existe para privilegiar os políticos, funcionários públicos de auto escalão, suas famílias e amigos. Enquanto que o povo sofre para sustentar a elite política. O protagonista Miguel entendeu isso quando a filha dele morreu na fila do SUS.
-
@ 4e616576:43c4fee8
2025-04-30 13:13:51
asdffasdf
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
OP_CHECKTEMPLATEVERIFYand the "covenants" dramaThere are many ideas for "covenants" (I don't think this concept helps in the specific case of examining proposals, but fine). Some people think "we" (it's not obvious who is included in this group) should somehow examine them and come up with the perfect synthesis.
It is not clear what form this magic gathering of ideas will take and who (or which ideas) will be allowed to speak, but suppose it happens and there is intense research and conversations and people (ideas) really enjoy themselves in the process.
What are we left with at the end? Someone has to actually commit the time and put the effort and come up with a concrete proposal to be implemented on Bitcoin, and whatever the result is it will have trade-offs. Some great features will not make into this proposal, others will make in a worsened form, and some will be contemplated very nicely, there will be some extra costs related to maintenance or code complexity that will have to be taken. Someone, a concreate person, will decide upon these things using their own personal preferences and biases, and many people will not be pleased with their choices.
That has already happened. Jeremy Rubin has already conjured all the covenant ideas in a magic gathering that lasted more than 3 years and came up with a synthesis that has the best trade-offs he could find. CTV is the result of that operation.
The fate of CTV in the popular opinion illustrated by the thoughtless responses it has evoked such as "can we do better?" and "we need more review and research and more consideration of other ideas for covenants" is a preview of what would probably happen if these suggestions were followed again and someone spent the next 3 years again considering ideas, talking to other researchers and came up with a new synthesis. Again, that person would be faced with "can we do better?" responses from people that were not happy enough with the choices.
And unless some famous Bitcoin Core or retired Bitcoin Core developers were personally attracted by this synthesis then they would take some time to review and give their blessing to this new synthesis.
To summarize the argument of this article, the actual question in the current CTV drama is that there exists hidden criteria for proposals to be accepted by the general community into Bitcoin, and no one has these criteria clear in their minds. It is not as simple not as straightforward as "do research" nor it is as humanly impossible as "get consensus", it has a much bigger social element into it, but I also do not know what is the exact form of these hidden criteria.
This is said not to blame anyone -- except the ignorant people who are not aware of the existence of these things and just keep repeating completely false and unhelpful advice for Jeremy Rubin and are not self-conscious enough to ever realize what they're doing.
-
@ 4e616576:43c4fee8
2025-04-30 13:11:58
asdfasdfasfd
-
@ 21335073:a244b1ad
2025-03-18 14:43:08
Warning: This piece contains a conversation about difficult topics. Please proceed with caution.
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book Cypherpunks, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
Course: - The creation of the internet and computers - The fight for cryptography - The tech supply chain from the ground up (example: human rights violations in the supply chain) - Corporate tech - Freedom tech - Data privacy - Digital privacy rights - AI (history-current) - Online safety (predators, scams, catfishing, extortion) - Bitcoin - Laws - How to deal with online hate and harassment - Information on who to contact if you are being abused online or offline - Algorithms - How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A response to Achim Warner's "Drivechain brings politics to miners" article
I mean this article: https://achimwarner.medium.com/thoughts-on-drivechain-i-miners-can-do-things-about-which-we-will-argue-whether-it-is-actually-a5c3c022dbd2
There are basically two claims here:
1. Some corporate interests might want to secure sidechains for themselves and thus they will bribe miners to have these activated
First, it's hard to imagine why they would want such a thing. Are they going to make a proprietary KYC chain only for their users? They could do that in a corporate way, or with a federation, like Facebook tried to do, and that would provide more value to their users than a cumbersome pseudo-decentralized system in which they don't even have powers to issue currency. Also, if Facebook couldn't get away with their federated shitcoin because the government was mad, what says the government won't be mad with a sidechain? And finally, why would Facebook want to give custody of their proprietary closed-garden Bitcoin-backed ecosystem coins to a random, open and always-changing set of miners?
But even if they do succeed in making their sidechain and it is very popular such that it pays miners fees and people love it. Well, then why not? Let them have it. It's not going to hurt anyone more than a proprietary shitcoin would anyway. If Facebook really wants a closed ecosystem backed by Bitcoin that probably means we are winning big.
2. Miners will be required to vote on the validity of debatable things
He cites the example of a PoS sidechain, an assassination market, a sidechain full of nazists, a sidechain deemed illegal by the US government and so on.
There is a simple solution to all of this: just kill these sidechains. Either miners can take the money from these to themselves, or they can just refuse to engage and freeze the coins there forever, or they can even give the coins to governments, if they want. It is an entirely good thing that evil sidechains or sidechains that use horrible technology that doesn't even let us know who owns each coin get annihilated. And it was the responsibility of people who put money in there to evaluate beforehand and know that PoS is not deterministic, for example.
About government censoring and wanting to steal money, or criminals using sidechains, I think the argument is very weak because these same things can happen today and may even be happening already: i.e., governments ordering mining pools to not mine such and such transactions from such and such people, or forcing them to reorg to steal money from criminals and whatnot. All this is expected to happen in normal Bitcoin. But both in normal Bitcoin and in Drivechain decentralization fixes that problem by making it so governments cannot catch all miners required to control the chain like that -- and in fact fixing that problem is the only reason we need decentralization.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
neuron.vim
I started using this neuron thing to create an update this same zettelkasten, but the existing vim plugin had too many problems, so I forked it and ended up changing almost everything.
Since the upstream repository was somewhat abandoned, most users and people who were trying to contribute upstream migrate to my fork too.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Flowi.es
At the time I thought Workflowy had the ideal UI for everything. I wanted to implement my custom app maker on it, but ended up doing this: a platform for enhancing Workflowy with extra features:
- An email reminder based on dates input in items
- A website generator, similar to Websites For Trello, also based on Classless Templates
Also, I didn't remember this was also based on CouchDB and had some couchapp functionalities.
-
@ 21335073:a244b1ad
2025-03-15 23:00:40
I want to see Nostr succeed. If you can think of a way I can help make that happen, I’m open to it. I’d like your suggestions.
My schedule’s shifting soon, and I could volunteer a few hours a week to a Nostr project. I won’t have more total time, but how I use it will change.
Why help? I care about freedom. Nostr’s one of the most powerful freedom tools I’ve seen in my lifetime. If I believe that, I should act on it.
I don’t care about money or sats. I’m not rich, I don’t have extra cash. That doesn’t drive me—freedom does. I’m volunteering, not asking for pay.
I’m not here for clout. I’ve had enough spotlight in my life; it doesn’t move me. If I wanted clout, I’d be on Twitter dropping basic takes. Clout’s easy. Freedom’s hard. I’d rather help anonymously. No speaking at events—small meetups are cool for the vibe, but big conferences? Not my thing. I’ll never hit a huge Bitcoin conference. It’s just not my scene.
That said, I could be convinced to step up if it’d really boost Nostr—as long as it’s legal and gets results.
In this space, I’d watch for social engineering. I watch out for it. I’m not here to make friends, just to help. No shade—you all seem great—but I’ve got a full life and awesome friends irl. I don’t need your crew or to be online cool. Connect anonymously if you want; I’d encourage it.
I’m sick of watching other social media alternatives grow while Nostr kinda stalls. I could trash-talk, but I’d rather do something useful.
Skills? I’m good at spotting social media problems and finding possible solutions. I won’t overhype myself—that’s weird—but if you’re responding, you probably see something in me. Perhaps you see something that I don’t see in myself.
If you need help now or later with Nostr projects, reach out. Nostr only—nothing else. Anonymous contact’s fine. Even just a suggestion on how I can pitch in, no project attached, works too. 💜
Creeps or harassment will get blocked or I’ll nuke my simplex code if it becomes a problem.
https://simplex.chat/contact#/?v=2-4&smp=smp%3A%2F%2FSkIkI6EPd2D63F4xFKfHk7I1UGZVNn6k1QWZ5rcyr6w%3D%40smp9.simplex.im%2FbI99B3KuYduH8jDr9ZwyhcSxm2UuR7j0%23%2F%3Fv%3D1-2%26dh%3DMCowBQYDK2VuAyEAS9C-zPzqW41PKySfPCEizcXb1QCus6AyDkTTjfyMIRM%253D%26srv%3Djssqzccmrcws6bhmn77vgmhfjmhwlyr3u7puw4erkyoosywgl67slqqd.onion
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Module Linker
A browser extension that reads source code on GitHub and tries to find links to imported dependencies so you can click on them and navigate through either GitHub or package repositories or base language documentation. Works for many languages at different levels of completeness.
-
@ e096a89e:59351479
2025-04-30 12:59:28
Why Oshi?
I had another name for this brand before, but it was hard for folks to say. Then I saw a chance to tap into the #Nostr and #Bitcoin crowd, people who might vibe with what I’m creating, and I knew I needed something that’d stick.
A good name can make a difference. Well, sometimes. Take Blink-182 - it might sound odd, but it worked for them and even has a ring to it. So, why Oshi?
Names mean a lot to me, and Oshi’s got layers. I’m into Japanese culture and Bitcoin, so it fits perfectly with a few meanings baked in:
- It’s a nod to Bitcoin’s visionary, Satoshi Nakamoto.
- In Japanese, “oshi” means cheering on your favorite idol by supporting their work - think of me as the maker, you as the fan.
- It’s short for “oh shiiiitttt” - what most folks say when they taste how good this stuff is.
My goal with Oshi is to share how amazing pecans and dates can be together. Everything I make - Hodl Butter, Hodl Bars, chocolates - is crafted with intention, keeping it simple and nuanced, no overdoing it. It’s healthy snacking without the grains or junk you find in other products.
I’ve got a few bars and jars in stock now. Grab something today and taste the unique flavor for yourself. Visit my website at https://oshigood.us/
foodstr #oshigood #hodlbar #hodlbutter
-
@ 4e616576:43c4fee8
2025-04-30 12:53:36
sdfafd
-
@ 126a29e8:d1341981
2025-03-10 19:13:30
Si quieres saber más sobre Nostr antes de continuar, te recomendamos este enlace donde encontrarás información más detallada: https://njump.me/
Nstart
Prácticamente cualquier cliente o aplicación Nostr permite crear una identidad o cuenta. Pero para este tutorial vamos a usar Nstart ya que ofrece información que ayuda a entender qué es Nostr y en qué se diferencia respecto a redes sociales convencionales.
Además añade algunos pasos importantes para mantener nuestras claves seguras.Recomendamos leer el texto que se muestra en cada pantalla de la guía.
Pronto estará disponible en español pero mientras tanto puedes tirar de traductor si el inglés no es tu fuerte.1. Welcome to Nostr
Para empezar nos dirigimos a start.njump.me desde cualquier navegador en escritorio o móvil y veremos esta pantalla de bienvenida. Haz clic en Let’s Start → https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/653d521476fa34785cf19fe098b131b7b2a0b1bdaf1fd28e65d7cf31a757b3d8.webp
2. Nombre o Alias
Elige un nombre o alias (que podrás cambiar en cualquier momento).
El resto de campos son opcionales y también puedes rellenarlos/editarlos en cualquier otro momento.
Haz clic en Continue →3. Your keys are ready
https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/e7ee67962749b37d94b139f928afad02c2436e8ee8ea886c4f7f9f0bfa28c8d9.webp ¡Ya tienes tu par de claves! 🙌
a. La npub es la clave pública que puedes compartir con quien quieras.
b. Clic en Save my nsec para descargar tu clave privada. Guárdala en un sitio seguro, por ejemplo un gestor de contraseñas.
c. Selecciona la casilla “I saved the file …” y haz clic en Continue →4. Email backup
Opcionalmente puedes enviarte una copia cifrada de tu clave privada por email. Rellena la casilla con tu mail y añade una contraseña fuerte.
Apunta la contraseña o añádela a tu gestor de contraseñas para no perderla.
En caso de no recibir el mail revisa tu bandeja de correo no deseado o Spam5. Multi Signer Bunker
Ahora tienes la posibilidad de dividir tu nsec en 3 usando una técnica llamada FROST. Clic en Activate the bunker → Esto te dará un código búnker que puedes usar para iniciar sesión en muchas aplicaciones web, móviles y de escritorio sin exponer tu nsec.
De hecho, algunos clientes solo permiten iniciar sesión mediante código búnker por lo que te recomendamos realizar este paso.
Igualmente puedes generar un código búnker para cada cliente con una app llamada Amber, de la que te hablamos más delante.
Si alguna vez pierdes tu código búnker siempre puedes usar tu nsec para crear uno nuevo e invalidar el antiguo.
Clic en Save my bunker (guárdalo en un lugar seguro) y después en Continue →6. Follow someone
Opcionalmente puedes seguir a los usuarios propuestos. Clic en Finish →
¡Todo listo para explorar Nostr! 🙌
Inicia sesión en algún cliente
Vamos a iniciar sesión con nuestra recien creada identidad en un par de clientes (nombre que reciben las “aplicaciones” en Nostr).
Hemos escogido estos 2 como ejemplo y porque nos gustan mucho pero dale un vistazo a NostrApps para ver una selección más amplia:
Escritorio
Para escritorio hemos escogido Chachi, el cliente para chats grupales y comunidades de nuestro compañero nostr:npub107jk7htfv243u0x5ynn43scq9wrxtaasmrwwa8lfu2ydwag6cx2quqncxg → https://chachi.chat/ https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/79f589150376f4bb4a142cecf369657ccba29150cee76b336d9358a2f4607b5b.webp Haz clic en Get started https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/2a6654386ae4e1773a7b3aa5b0e8f6fe8eeaa728f048bf975fe1e6ca38ce2881.webp Si usas extensión de navegador como Alby, nos2x o nos2x-Fox clica en Browser extension De lo contrario, localiza el archivo Nostr bunker que guardaste en el paso 5 de la guía Nstart y pégalo en el campo Remote signer
¡Listo! Ahora clica en Search groups para buscar grupos y comunidades a las que te quieras unir. Por ejemplo, tu comunidad amiga: Málaga 2140 ⚡ https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/eae881ac1b88232aa0b078e66d5dea75b0c142db7c4dd7decdbfbccb0637b7fe.webp
Comunidades recomendadas
Te recomendamos unirte a estas comunidades en Chachi para aprender y probar todas las funcionalidades que se vayan implementando:
Si conoces otras comunidades a tener en cuenta, dínoslo en un comentario 🙏
Móvil
Como cliente móvil hemos escogido Amethyst por ser de los más top en cuanto a diseño, tipos de eventos que muestra y mantenimiento. → https://www.amethyst.social/ ← Solo está disponible para Android por lo que si usas iOS te recomendamos Primal o Damus.
Además instalaremos Amber, que nos permitirá mantener nuestra clave privada protegida en una única aplicación diseñada específicamente para ello. → https://github.com/greenart7c3/Amber ←
Las claves privadas deben estar expuestas al menor número de sistemas posible, ya que cada sistema aumenta la superficie de ataque
Es decir que podremos “iniciar sesión” en todas las aplicaciones que queramos sin necesidad de introducir en cada una de ellas nuestra clave privada ya que Amber mostrará un aviso para autorizar cada vez.
Amber
- La primera vez que lo abras te da la posibilidad de usar una clave privada que ya tengas o crear una nueva identidad Nostr. Como ya hemos creado nuestra identidad con Nstart, copiaremos la nsec que guardamos en el paso 3.b y la pegaremos en Amber tras hacer clic en Use your private key. https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/e489939b853d6e3853f10692290b8ab66ca49f5dc1928846e16ddecc3f46250e.webp
- A continuación te permite elegir entre aprobar eventos automáticamente (minimizando el número de interrupciones mientras interactúas en Nostr) o revisar todo y aprobar manualmente, dándote mayor control sobre cada app. https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/c55cbcbb1e6f9d706f2ce6dbf4cf593df17a5e0004dca915bb4427dfc6bdbf92.webp
- Tras clicar en Finish saltará un pop-up que te preguntará si permites que Amber te envíe notificaciones. Dale a permitir para que te notifique cada vez que necesite permiso para firmar con tu clave privada algún evento. https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/3744fb66f89833636743db0edb4cfe3316bf2d91c465af745289221ae65fc795.webp Eso es todo. A partir de ahora Amber se ejecutará en segundo plano y solicitará permisos cuando uses cualquier cliente Nostr.
Amethyst
- Abre Amethyst, selecciona la casilla “I accept the terms of use” y clica en Login with Amber https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/90fc2684a6cd1e85381aa1f4c4c2c0d7fef0b296ddb35a5c830992d6305dc465.webp
- Amber solicitará permiso para que Amethyst lea tu clave pública y firme eventos en tu nombre. Escoge si prefieres darle permiso para acciones básicas; si quieres aprobar manualmente cada permiso o si permites que firme automáticamente todas las peticiones. https://cdn.nostrcheck.me/126a29e8181c1663ae611ce285758b08b475cf81b3634dd237b8234cd1341981/a5539da297e8595fd5c3cb3d3d37a7dede6a16e00adf921a5f93644961a86a92.webp ¡Ya está! 🎉 Después de clicar en Grant Permissions verás tu timeline algo vacío. A continuación te recomendamos algunos usuarios activos en Nostr por si quieres seguirles.
A quién seguir
Pega estas claves públicas en la barra Search o busca usuarios por su alias.
nostr:npub1zf4zn6qcrstx8tnprn3g2avtpz68tnupkd35m53hhq35e5f5rxqskppwpd
nostr:npub107jk7htfv243u0x5ynn43scq9wrxtaasmrwwa8lfu2ydwag6cx2quqncxg
nostr:npub1yn3hc8jmpj963h0zw49ullrrkkefn7qxf78mj29u7v2mn3yktuasx3mzt0
nostr:npub1gzuushllat7pet0ccv9yuhygvc8ldeyhrgxuwg744dn5khnpk3gs3ea5ds
nostr:npub1vxz5ja46rffch8076xcalx6zu4mqy7gwjd2vtxy3heanwy7mvd7qqq78px
nostr:npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83a
nostr:npub149p5act9a5qm9p47elp8w8h3wpwn2d7s2xecw2ygnrxqp4wgsklq9g722q
nostr:npub12rv5lskctqxxs2c8rf2zlzc7xx3qpvzs3w4etgemauy9thegr43sf485vg
nostr:npub17u5dneh8qjp43ecfxr6u5e9sjamsmxyuekrg2nlxrrk6nj9rsyrqywt4tp
nostr:npub1dergggklka99wwrs92yz8wdjs952h2ux2ha2ed598ngwu9w7a6fsh9xzpc
Si te ha parecido útil, comparte con quien creas que puede interesarle ¡Gracias!
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Using Spacechains and Fedimint to solve scaling
What if instead of trying to create complicated "layer 2" setups involving noveau cryptographic techniques we just did the following:
- we take that Fedimint source code and remove the "mint" stuff, and just use their federation stuff secure coins with multisig;
- then we make a spacechain;
- and we make the federations issue multisig-btc tokens on it;
- and then we put some uniswap-like thing in there to allow these tokens to be exchanged freely.
Why?
The recent spike in fees caused by Ordinals and BRC-20 shitcoinery has shown that Lightning isn't a silver bullet. Channels are too fragile, it costs a lot to open a channel under a high fee environment, to run a routing node and so on.
People who want to keep using Lightning are instead flocking to the big Lightning custodial providers: WalletofSatoshi, ZEBEDEE, OpenNode and so on. We could leverage that trust people have in these companies (and individuals) operating shadow Lightning providers and turn each of these into a btc-token issuer. Each issue their own token, transactions flow freely. Each person can hold only assets from the issuers they trust more.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Just malinvestiment
Traditionally the Austrian Theory of Business Cycles has been explained and reworked in many ways, but the most widely accepted version (or the closest to the Mises or Hayek views) view is that banks (or the central bank) cause the general interest rate to decline by creation of new money and that prompts entrepreneurs to invest in projects of longer duration. This can be confusing because sometimes entrepreneurs embark in very short-time projects during one of these bubbles and still contribute to the overall cycle.
The solution is to think about the "longer term" problem is to think of the entire economy going long-term, not individual entrepreneurs. So if one entrepreneur makes an investiment in a thing that looks simple he may actually, knowingly or not, be inserting himself in a bigger machine that is actually involved in producing longer-term things. Incidentally this thinking also solves the biggest criticism of the Austrian Business Cycle Theory: that of the rational expectations people who say: "oh but can't the entrepreneurs know that the interest rate is artificially low and decide to not make long-term investiments?" ("and if they don't know they should lose money and be replaced like in a normal economy flow blablabla?"). Well, the answer is that they are not really relying on the interest rate, they are only looking for profit opportunities, and this is the key to another confusion that has always followed my thinkings about this topic.
If a guy opens a bar in an area of a town where many new buildings are being built during a "housing bubble" he may not know, but he is inserting himself right into the eye of that business cycle. He expects all these building projects to continue, and all the people involved in that to be getting paid more and be able to spend more at his bar and so on. That is a bet that may or may not end up paying.
Now what does that bar investiment has to do with the interest rate? Nothing. It is just a guy who saw a business opportunity in a place where hungry people with money had no bar to buy things in, so he opened a bar. Additionally the guy has made some calculations about all the ending, starting and future building projects in the area, and then the people that would live or work in that area afterwards (after all the buildings were being built with the expectation of being used) and so on, there is no interest rate calculations involved. And yet that may be a malinvestiment because some building projects will end up being canceled and the expected usage of the finished ones will turn out to be smaller than predicted.
This bubble may have been caused by a decline in interest rates that prompted some people to start buying houses that they wouldn't otherwise, but this is just a small detail. The bubble can only be kept going by a constant influx of new money into the economy, but the focus on the interest rate is wrong. If new money is printed and used by the government to buy ships then there will be a boom and a bubble in the ship market, and that involves all the parts of production process of ships and also bars that will be opened near areas of the town where ships are built and new people are being hired with higher salaries to do things that will eventually contribute to the production of ships that will then be sold to the government.
It's not interest rates or the length of the production process that matters, it's just printed money and malinvestiment.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
hledger-web
A Haskell app that uses Miso and hledger's Haskell libraries plus ghcjs to be compiled to a web page, and then adds optional remoteStorage so you can store your ledger data somewhere else.
This was my introduction to Haskell and also built at a time I thought remoteStorage was a good idea that solved many problems, and that it could use some help in the form of just yet another somewhat-useless-but-cool project using it that could be added to their wiki.
See also
-
@ 3589b793:ad53847e
2025-04-30 12:40:42
※本記事は別サービスで2022年6月24日に公開した記事の移植です。
どうも、「NostrはLNがWeb統合されマネーのインターネットプロトコルとしてのビットコインが本気出す具体行動のショーケースと見做せばOK」です、こんばんは。
またまた実験的な試みがNostrで行われているのでレポートします。本シリーズはライブ感を重視しており、例によって(?)プルリクエストなどはレビュー段階なのでご承知おきください。
今回の主役はあくまでLightningNetworkの新提案(ただし以前からあるLSATからのリブランディング)となるLightning HTTP 402 Protocol(略称: L402)です。そのショーケースの一つとしてNostrが活用されているというものになります。
Lightning HTTP 402 Protocol(略称: L402)とは何か
bLIPに今月挙がったプロポーザル内容です。
https://github.com/lightning/blips/pull/26
L402について私はまだ完全に理解した段階ではあるのですがなんとか一言で説明しようとすると「Authトークンのように"Paid"トークンをHTTPヘッダーにアタッチして有料リソースへのHTTPリクエストの受け入れ判断を行えるようにする」ものだと解釈しました。
Authenticationでは、HTTPヘッダーにAuthトークンを添付し、その検証が通ればHTTPリクエストを許可し、通らなければ
401 Unauthorizedコードをエラーとして返すように定められています。https://developer.mozilla.org/ja/docs/Web/HTTP/Status/401
L402では、同じように、HTTPヘッダーに支払い済みかどうかを示す"Paid"トークンを添付し、その検証が通ればHTTPリクエストを許可し、通らなければ
402 Payment Requiredコードをエラーとして返すようにしています。なお、"Paid"トークンという用語は私の造語となります。便宜上本記事では使わせていただきますが、実際はAuthも入ってくるのが必至ですし、プルリクエストでも用語をどう定めるかは議論になっていることをご承知おきください。("API key", "credentials", "token", らが登場しています)
この402ステータスコードは従来から定義されていましたが、MDNのドキュメントでも記載されているように「実験的」なものでした。つまり、器は用意されているがこれまで活用されてこなかったものとなり、本プロトコルの物語性を体現しているものとなります。
https://developer.mozilla.org/ja/docs/Web/HTTP/Status/402
幻であったHTTPステータスコード402 Payment Requiredを実装する
この物語性は、上述のbLIPのスペックにも詳述されていますが、以下のスライドが簡潔です。
402 Payment Requiredは予約されていましたが、けっきょくのところWorldWideWebはペイメントプロトコルを実装しなかったので、Bitcoinの登場まで待つことになった、というのが要旨になります。このWorldWideWebにおける決済機能実装に関する歴史話はクリプト界隈でもたびたび話題に上がりますが、そこを繋いでくる文脈にこれこそマネーのインターネットプロトコルだなと痺れました。https://x.com/AlyseKilleen/status/1671342634307297282
この"Paid"トークンによって実現できることとして、第一にAIエージェントがBitcoin/LNを自律的に利用できるようになるM2M(MachineToMachine)的な話が挙げられていますが、ユースケースは想像力がいろいろ要るところです。実際のところは「有料リソースへの認可」を可能にすることが主になると理解しました。本連載では、繰り返しNostrクライアントにLNプロトコルを直接搭載せずにLightningNetworkを利用可能にする組み込み方法を見てきましたが、本件もインボイス文字列 & preimage程度の露出になりアプリケーション側でノードやウォレットの実装が要らないので、その文脈で位置付ける解釈もできるかと思います。
Snortでのサンプル実装
LN組み込み業界のリーディングプロダクトであるSnortのサンプル実装では、L402を有料コンテンツの購読に活用しています。具体的には画像や動画を投稿するときに有料のロックをかける、いわゆるペイウォールの一種となります。もともとアップローダもSnortが自前で用意しているので、そこにL402を組み込んでみたということのようです。
体験方法の詳細はこちらにあります。 https://njump.me/nevent1qqswr2pshcpawk9ny5q5kcgmhak24d92qzdy98jm8xcxlgxstruecccpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhszrnhwden5te0dehhxtnvdakz78pvlzg
上記を試してみた結果が以下になります。まず、ペイウォールでロックした画像がNostrに投稿されている状態です。まったくビューワーが実装されておらず、ただのNotFound状態になっていますが、支払い前なのでロックされているということです。

次にこのHTTP通信の内容です。

通信自体はエラーになっているわけですが、ステータスコードが402で、レスポンスヘッダーのWWW-AuthenticateにInvoice文字列が返ってきています。つまり、このインボイスを支払えば"Paid"トークンが付与されて、その"Paid"トークンがあれば最初の画像がアンロックされることとなります。残念ながら現在は日本で利用不可のStrikeAppでしか払込みができないためここまでとなりますが、本懐である
402 Payment Requiredとインボイス文字列は確認できました。今確認できることは以上ですが、AmethystやDamusなどの他のNostrクライアントが実装するにあたり、インラインメディアを巡ってL402の仕様をアップデートする必要性や同じくHTTPヘッダーへのAuthトークンとなるNIP-98と組み合わせるなどの議論が行われている最中です。
LinghtningNetworkであるからこそのL402の実現
"Paid"トークンを実現するためにはLightningNetworkのファイナリティが重要な要素となっています。逆に言うと、reorgによるひっくり返しがあり得るBitcoinではできなくもないけど不便なわけです。LightningNetworkなら、当事者である二者間で支払いが確認されたら「同期的」にその証であるハッシュ値を用いて"Paid"トークンを作成することができます。しかもハッシュ値を提出するだけで台帳などで過去の履歴を確認する必要がありません。加えて言うと、受金者側が複数のノードを建てていて支払いを受け取るノードがどれか一つになる状況でも、つまり、スケーリングされている状況でも、"Paid"トークンそのものはどのノードかを気にすることなくステートレスで利用できるとのことです。(ここは単にreverse proxyとしてAuthサーバががんばっているだけと解釈することもできますがずいぶんこの機能にも力点を置いていて大規模なユースケースが重要になっているのだなという印象を抱きました)
Macaroonの本領発揮か?それとも詳細定義しすぎか?
HTTP通信ではWWW-Authenticateの実値にmacaroonの記述が確認できます。また現在のL402スペックでも"Paid"トークンにはmacaroonの利用が前提になっています。
このmacaroonとは(たぶん)googleで研究開発され、LNDノードソフトウェアで活用されているCookieを超えるという触れ込みのデータストアになります。しかし、あまり普及しなかった技術でもあり、個人の感想ですがなんとも微妙なものになっています。
https://research.google/pubs/macaroons-cookies-with-contextual-caveats-for-decentralized-authorization-in-the-cloud/
macaroonの強みは、Cookieを超えるという触れ込みのようにブラウザが無くてもプロセス間通信でデータ共有できる点に加えて、HMACチェーンで動的に認証認可を更新し続けられるところが挙げられます。しかし、そのようなユースケースがあまり無く、静的な認可となるOAuthやJWTで十分となっているのが現状かと思います。
L402では、macaroonの動的な更新が可能である点を活かして、"Paid"トークンを更新するケースが挙げられています。わかりやすいのは上記のスライド資料でも挙げられている"Dynamic Pricing"でしょうか。プロポーザルではloop©️LightningLabsにおいて月間の最大取引量を認可する"Paid"トークンを発行した上でその条件を動向に応じて動的に変更できる例が解説されています。とはいえ、そんなことしなくても再発行すればええやんけという話もなくもないですし、プルリクエストでも仕様レベルでmacaroonを指定するのは「具体」が過ぎるのではないか、もっと「抽象」し単なる"Opaque Token"程度の粒度にして他の実装も許容するべきではないか、という然るべきツッコミが入っています。
個人的にはそのツッコミが妥当と思いつつも、なんだかんだ初めてmacaroonの良さを実感できて感心した次第です。
-
@ 3589b793:ad53847e
2025-04-30 12:28:25
※本記事は別サービスで2023年4月19日に公開した記事の移植です。
どうも、「NostrはLNがWeb統合されマネーのインターネットプロトコルとしてのビットコインが本気出す具体行動のショーケースと見做せばOK」です、こんにちは。
前回まで投げ銭や有料購読の組み込み方法を見てきました。
zapsという投げ銭機能が各種クライアントに一通り実装されて活用が進んでいることで、統合は次の段階へ移り始めています。「作戦名: ウォレットをNostrクライアントに組み込め」です。今回はそちらをまとめます。
投げ銭する毎にいちいちウォレットを開いてまた元のNostrクライアントに手動で戻らないといけない is PAIN
LNとNostrはインボイス文字列で繋がっているだけの疎結合ですが、投稿に投げ銭するためには何かのLNウォレットを開いて支払いをして、また元のNostrクライアントに戻る操作をユーザーが手作業でする必要があります。お試しで一回やる程度では気になりませんが普段使いしているとこれはけっこうな煩わしさを感じるUXです。特にスマホでは大変にだるい状況になります。連打できない!
2月の実装以来、zapsは順調に定着して日々投げられています。


https://stats.nostr.band/#daily_zaps
なので、NostrクライアントにLNウォレットの接続を組み込み、支払いのために他のアプリに遷移せずにNostクライアント単独で完結できるようなアップデートが始まっています。
Webクライアント
NostrのLN組み込み業界のリーディングプレイヤーであるSnortでの例です。以下のようにヘッダーのウォレットアイコンをクリックすると連携ウォレットの選択ができます。

もともとNostrに限らずウェブアプリケーションとの連携をするために、WebLNという規格があります。簡単に言うと、ブラウザのグローバル領域を介して、LNウォレットの拡張機能と、タブで開いているウェブアプリが、お互いに連携するためのインターフェースを定めているものです。これに対応していると、LNによる支払いをウェブアプリが拡張機能に依頼できるようになります。さらにオプションで「確認無し」をオンにすると、拡張機能画面がポップアップせずにバックグラウンドで実行できるようになり、ノールック投げ銭ができるようになります。
似たようなものにNostrではNIP-07があります。NIP-07はNostrの秘密鍵を拡張機能に退避して、Nostrクライアントは秘密鍵を知らない状態で署名や複合を拡張機能に移譲できるようにしているものです。
Albyの拡張機能ではWebLNとNIP-07のどちらにも対応しています。
実はSnortはzapsが来る前からWebLNには対応していたのですが、さらに一歩進み、拡張機能ウォレットだけでなく、LNノードや拡張機能以外のLNウォレットと連携設定できるようになってきています。

umbrelなどでノードを立てている人ならLND with LNCでノードと直接繋げます。またLNDHubに対応したウォレットなどのアプリケーションとも繋げます。これらの接続は、WebLNにラップされて拡張機能ウォレットとインターフェースを揃えられた上で、Snort上でのインボイスの支払いに活用されます。
なお、LNCのpairingPhrase/passwordやLNDHubの接続情報などのクレデンシャルは、ブラウザのローカルストレージに保存されています。Nostrのリレーサーバなどには送られませんので、端末ごとに設定が必要です。
スマホアプリ
今回のメインです。なお、例によって(?)スペックは絶賛議論中でまだフィックスしていない中で記事を書いています。ディテールは変わるかもしれないので悪しからずです。
スマホアプリで上記のことをやるためには、後半のLNCやLNDHubはすでにzeusなどがやっているようにできますが、あくまでネイティブウォレットのラッパーです。Nostrでは限られた用途になるので1-click支払いのようなものを行うためにはそこから各スマホアプリが作り込む必要があります。まあこれはこれでやればいいという話でもあるのですが、LNノードやLNウォレットのアプリケーション側へのインターフェースの共通仕様は定められていないので、LNDとcore-lightningとeclairではすべて実装方法が違いますし、ウォレットもバラバラなので大変です。
そこで、多種多様なノードやウォレットの接続を取りまとめ一般アプリケーションへ統一したインターフェースを媒介するLN Adapter業界のリーディングカンパニーであるAlbyが動きました。AndroidアプリのAmethystで試験公開されていますが、スマホアプリでも上記のSnortのような連携が可能になるようなSDKが開発されました。
リリース記事 https://blog.getalby.com/native-zapping-in-amethyst/
"Unstoppable zapping for users"なんて段落見出しが付けられているように、スマホで別のアプリに切り替えてまた元に戻らなくても良いようにして、Nostr上でマイクロペイメントを滑らかにする、つまり、連打できることを繰り返し強調しています。
具体的にやっていることを見ていきます。以下の画像群はリリース記事の動画から抜粋しています。各投稿のzapsボタン⚡️をタップしたときの画面です。

上の赤枠が従来の投げ銭の詳細を決める場所で、下の赤枠の「Wallet Connect Service」が新たに追加されたAlby提供のSDKを用いたコネクト設定画面です。基本的にはOAuth2.0ベースのAlbyのAPIを活用していて、右上のAlbyアイコンをタップすると以下のようなOAuthの認可画面に飛びます。(ただし後述するように通常のOAuthとは一部異なります。)


画面デザインは違いますが、まあ他のアプリでよく目にするTwitter連携やGoogleアカウント連携とやっていることは同じです。
このOAuthベースのAPIはNostr専用のエンドポイントが建てられています。Nostr以外のECショップやマーケットプレイスなどへのAlbyのOAuthは汎用のエンドポイントが用意されています。よって通常のAlbyの設定とは別にセッション詳細を以下のサイトで作成する必要があります。
https://nwc.getalby.com/ (サブドメインのnwcはNostr Wallet Connectの略)
なぜNostrだけは特別なのかというところが完全には理解しきれていないですが、以下のところまで確認できています。一番にあるのは、Nostrクライアントにウォレットを組み込まずに、かつ、ノードやウォレットへの接続をNostrリレーサーバ以外は挟まずに"decentralized"にしたいというところだと理解しています。
- 上記のnwcのURLはalbyのカストディアルウォレットusername@getalby.comをNostrに繋ぐもの(たぶん)
- umbrelのLNノードを繋ぐためにはやはり専用のアプリがumbrelストアに上がっている。https://github.com/getAlby/umbrel-community-app-store
- 要するにOAuthの1stPartyの役割をウォレットやノードごとにそれぞれ建てる。
- OAuthのシークレットはクライアントに保存するので設定は各クライアント毎に必要。しかし使い回しすることは可能っぽい。通常のOAuthと異なり、1stParty側で3rdPartyのドメインはトラストしていないようなので。
- Nostrクライアントにウォレットを組み込まずに、さらにウォレットやノードへの接続をNostrリレーサーバ以外には挟まなくて良いようにするために、「NIP-47 Nostr Wallet Connect」というプロポーザルが起こされていて、絶賛議論中である。https://github.com/nostr-protocol/nips/pull/406
- このWallet Connect専用のアドホックなリレーサーバが建てられる。その情報が上記画像の赤枠の「Wallet Connect Service」の下半分のpub keyやらrelayURL。どうもNostrクライアントはNIP-47イベントについてはこのリレーサーバにしか送らないようにするらしい。(なんかNostrの基本設計を揺るがすユースケースの気がする...)
- Wallet Connect専用のNostrイベントでは、ペイメント情報をNostrアカウントと切り離すために、Nostrの秘密鍵とは別の秘密鍵が利用できるようにしている。
Imagin the Future
今回取り上げたNostrクライアントにウォレット接続を組み込む話を、Webのペイメントの歴史で類推してみましょう。
Snortでやっていることは、各サイトごとにクレジットカードを打ち込み各サイトがその情報を保持していたようなWeb1.0の時代に近いです。そうなるとクレジットカードの情報は各サービスごとに漏洩リスクなどがあり、Web1.0の時代はECが普及する壁の一つになっていました。(今でもAmazonなどの大手はそうですが)
Webではその後にPayPalをはじめとして、銀行口座やクレジットカードを各サイトから切り出して一括管理し、各ウェブサイトに支払いだけを連携するサービスが出てきて一般化しています。日本ではケータイのキャリア決済が利用者の心理的障壁を取り除きEC普及の後押しになりました。
後半のNostr Wallet ConnectはそれをNostrの中でやろうとしている試みになります。クレジットカードからLNに変える理由はビットコインの話になるので詳細は割愛しますが、現実世界の金(ゴールド)に類した価値保存や交換ができるインターネットマネーだからです。
とはいえ、Nostrの中だけならまだしも、これをNostr外のサービスで利用するためには、他のECショップやブログやSaaSがNostrを喋れる必要があります。そんな未来が来るわけないだろと思うかもしれませんが、言ってみればStripeはまさにそのようなサービスとなっていて、サイト内にクレジット決済のモジュールを組み込むための主流となっています。
果たして、Nostrを、他のECショップやブログやSaaSが喋るようになるのか!?
以上、「NostrはLNがWeb統合されマネーのインターネットプロトコルとしてのビットコインが本気出す具体行動のショーケースと見做せばOK」がお送りしました。
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On the state of programs and browsers
Basically, there are basically (not exhaustively) 2 kinds of programs one can run in a computer nowadays:
1.1. A program that is installed, permanent, has direct access to the Operating System, can draw whatever it wants, modify files, interact with other programs and so on; 1.2. A program that is transient, fetched from someone else's server at run time, interpreted, rendered and executed by another program that bridges the access of that transient program to the OS and other things.
Meanwhile, web browsers have basically (not exhaustively) two use cases:
2.1. Display text, pictures, videos hosted on someone else's computer; 2.2. Execute incredibly complex programs that are fetched at run time, executed and so on -- you get it, it's the same 1.2.
These two use cases for browsers are at big odds with one another. While stretching itsel f to become more and more a platform for programs that can do basically anything (in the 1.1 sense) they are still restricted to being an 1.2 platform. At the same time, websites that were supposed to be on 2.1 sometimes get confused and start acting as if they were 2.2 -- and other confusing mixed up stuff.
I could go hours in philosophical inquiries on the nature of browsers, how rewriting everything in JavaScript is not healthy or where everything went wrong, but I think other people have done this already.
One thing that bothers me a lot, though, is that computers can do a lot of things, and with the internet and in the current state of the technology it's fairly easy to implement tools that would help in many aspects of human existence and provide high-quality, useful programs, with the help of a server to coordinate access, store data, authenticate users and so on many things are possible. However, due to the nature of UI in the browser, it's very hard to get any useful tool to users.
Writing a UI, even the most basic UI imaginable (some text input boxes and some buttons, or a table) can take a long time, always more than the time necessary to code the actual core features of whatever program is being developed -- and that is considering that the person capable of writing interesting programs that do the functionality in the backend are also capable of interacting with JavaScript and the giant amount of frameworks, transpilers, styling stuff, CSS, the fact that all this is built on top of HTML and so on.
This is not good.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
A big Ethereum problem that is fixed by Drivechain
While reading the following paragraphs, assume Drivechain itself will be a "smart contract platform", like Ethereum. And that it won't be used to launch an Ethereum blockchain copy, but instead each different Ethereum contract could be turned into a different sidechain under BIP300 rules.
A big Ethereum problem
Anyone can publish any "contract" to Ethereum. Often people will come up with somewhat interesting ideas and publish them. Since they want money they will add an unnecessary token and use that to bring revenue to themselves, gamify the usage of their contract somehow, and keep some control over the supposedly open protocol they've created by keeping a majority of the tokens. They will use the profits on marketing and branding, have a visual identity, a central website and a forum with support personnel and so on: their somewhat interesting idea have become a full-fledged company.
If they have success then another company will appear in the space and copy the idea, launch it using exactly the same strategy with a tweak, then try to capture the customers of the first company and new people. And then another, and another, and another. Very often these contracts require some network effect to work, i.e., they require people to be using it so others will use it. The fact that the market is now split into multiple companies offering roughly the same product hurts that, such that none of these protocols get ever enough usage to become really useful in the way they were first conceived. At this point it doesn't matter though, they get some usage, and they use that in their marketing material. It becomes a race to pump the value of the tokens and the current usage is just another point used for that purpose. The company will even start giving out money to attract new users and other weird moves that have no relationship with the initial somewhat intereting idea.
Once in a lifetime it happens that the first implementer of these things is not a company seeking profits, but some altruistic developer or company that believes in Ethereum and wants to see it grow -- or more likely someone financed by the Ethereum Foundation, which allegedly doesn't like these token schemes and would prefer everybody to use the token they issued first, the ETH --, but that's a fruitless enterprise because someone else will copy that idea anyway and turn it into a company as described above.
How Drivechain fixes it
In the Drivechain world, if someone had an idea, they would -- as it happens all the time with Bitcoin things -- publish it in a public forum. Other members of the community would evaluate that idea, add or remove things, all interested parties would contribute to make it the best possible incarnation of that idea. Once the design was settled, someone would volunteer to start writing the code to turn that idea into a sidechain. Maybe some company would fund those efforts and then more people would join. It's not a perfect process and one that often involves altruism, but Bitcoin inspires people to do these things.
Slowly, the thing would get built, tested, activated as a sidechain on testnet, tested more, and at this point luckily the entire community of interested Bitcoin users and miners would have grown to like that idea and see its benefits. It could then be proposed to be activated according to BIP300 rules.
Once it was activated, the entire pool of interested users would join it. And it would be impossible for someone else to create a copy of that because everybody would instantly notice it was a copy. There would be no token, no one profiting directly from the operations of that "smart contract". And everybody would be incentivized to join and tell others to join that same sidechain since the network effect was already the biggest there, they will know more network effect would only be good for everybody involved, and there would be no competing marketing and free token giveaways from competing entities.
See also
-
@ 3589b793:ad53847e
2025-04-30 12:10:06
前回の続きです。
特に「Snortで試験的にノート単位に投げ銭できる機能」について。実は記事書いた直後にリリースされて慌ててw追記してたんですが追い付かないということで別記事にしました。
今回のここがすごい!
「Snortで試験的にノート単位に投げ銭できる機能」では一つブレイクスルーが起こっています。それは「ウォレットにインボイスを放り投げた後に払い込み完了を提示できる」ようになったことです。これによりペイメントのライフサイクルが一通りカバーされたことになります。
Snortの画面

なにを当たり前のことをという向きもあるかもしれませんが、Nostrクライアントで払い込み完了を追跡することはとても難しいです。基本的にNostrとLNウォレットはまったく別のアプリケーションで両者の間を繋ぐのはインボイス文字列だけです。ウォレットもNostrからキックされずに、インボイス文字列をコピペするなりQRコードで読み取ったものを渡されるだけかもしれません。またその場でリアルタイムに処理される前提もありません。
なのでNostrクライアントでその後をトラックすることは難しく、これまではあくまで請求書を送付したり(LNインボイス)振り込み口座を提示する(LNアドレス)という一方的に放り投げてただけだったわけです。といっても魔法のようにNostrクライアントがトラックできるようになったわけではなく、今回の対応方法もインボイスを発行/お金を振り込まれるサービス側(LNURL)にNostrカスタマイズを入れさせるというものになります。
プロポーザルの概要について
前回の記事ではよくわからんで終わっていましたが、当日夜(日本時間)にスペックをまとめたプロポーザルも起こされました(早い!)。LNURLが、Nostr用のインボイスを発行して、さらにNostrイベントの発行を行っていることがポイントでした。名称は"Lightning Zaps"で確定のようです。プロポーザルは、NostrとLNURLの双方の発明者であるfiatjaf氏からツッコミが入り、またそれが妥当な指摘のために、エンドポイントURLのインターフェースなどは変わりそうなのですが、概要はそう変わらないだろうということで簡単にまとめてみます。
全体の流れ

図は、Nostrクライアント上に提示されているLNアドレスへ投げ銭が開始してから、Nostrクライアント上に払い込み完了したイベントが表示されるまでの流れを示しています。
- 投げ銭の内容が固まったらNostrイベントデータを添付してインボイスの発行を依頼する
- 説明欄にNostr用のデータを記載したインボイスを発行して返却する
- Nostrクライアントで提示されたインボイスをユーザーが何かしらの手段でウォレットに渡す
- ウォレットがLNに支払いを実行する
- インボイスの発行者であるLNURLが管理しているLNノードにsatoshiが届く
- LNURLサーバが投げ銭成功のNostrイベントを発行する
- Nostrクライアントがイベントを受信して投げ銭履歴を表示する
特にポイントとなるところを補足します。
対応しているLNアドレスの識別
LNアドレスに投げ銭する場合は、LNアドレスの有効状態やインボイス発行依頼する先の情報を
https://[domain]/.well-known/lnurlp/[username]から取得しています。そのレスポンス内容にNostr対応を示す情報を追加しています。ただし、ここに突っ込み入っていてlnurlp=LNURL Payから独立させるためにzaps専用のエンドポイントに変わりそうです。(2/15 追記 マージされましたが変更無しでした。PRのディスカッションが盛り上がっているので興味ある方は覗いてみてください。)インボイスの説明欄に書き込むNostrイベント(kind:9734)
これは投げ銭する側のNostrイベントです。投げ銭される者や対象ノートのIDや金額、そしてこのイベントを作成している者が投げ銭したということを「表明」するものになります。表明であって証明でないところは、インボイスを別の人が払っちゃう事態がありえるからですね。この内容をエンクリプトするパターンも用意されていたが複雑になり過ぎるという理由で今回は外され追加提案に回されました。また、このイベントはデータを作成しただけです。支払いを検知した後にLNURLが発行するイベントに添付されることになります。そのため投げ銭する者にちゃんと届くように作成者のリレーサーバリストも書き込まれています。
支払いを検知した後に発行するNostrイベント(kind:9735)
これが実際にNostrリレーサーバに発行されるイベントです。LNURL側はウォッチしているLNノードにsatoshiが届くと、インボイスの説明欄に書かれているNostrイベントを取り出して、いわば受領イベントを作成して発行します。以下のようにNostイベントのkind:9734とkind:9735が親子になったイベントとなります。
json { "pubkey": "LNURLが持っているNostrアカウントの公開鍵", "kind": 9735, "tags": [ [ "p", "投げ銭された者の公開鍵" ], [ "bolt11", "インボイスの文字列lnbc〜" ], [ "description", "投げ銭した者が作成したkind:9734のNostrイベント" ], [ "preimage", "インボイスのpreimage" ] ], }所感
とにかくNostrクライアントはLNノードを持たないしLNプロトコルとも直接喋らずにインボイス文字列だけで取り扱えるようになっているところがおもしろいと思っています。NostrとLNという二つのデセントライズドなオープンプロトコルが協調できていますし、前回も述べましたがどんなアプリでも簡単に真似できます。
とはいえ、さすがに払込完了のトラックは難しく、今回はLNURL側にそのすり合わせの責務が寄せられることになりました。しかし、LNURLもLNの上に作られたオープンプロトコル/スペックの位置付けになるため、他のLNURLのスペックに干渉するという懸念から、本提案のNIP-57に変更依頼が出されています。LN、LNURL、Nostrの3つのオープンプロトコルの責務分担が難しいですね。アーキテクチャ層のスタックにおいて3つの中ではNostrが一番上になるため、Nostrに相当するレイヤーの他のwebサービスでやるときはLNプロトコルを喋るなりLNノードを持つようにして、今回LNURLが寄せられた責務を吸収するのが無難かもしれません。
また、NIP-57の変更依頼理由の一つにはBOLT-12を見越した抽象化も挙げられています。他のLNURLのスペックを削ぎ落としてzapsだけにすることでBOLT-12にも載りやすくなるだろうと。LNURLの多くはBOLT-12に取り込まれる運命なわけですが、LNアドレス以外の点でもNostrではBOLT-12のOfferやInvoiceRequestのユースケースをやりたいという声が挙がっているため、NostrによりBOLT-12が進む展開もありそうだなあ、あってほしい。
-
@ 3589b793:ad53847e
2025-04-30 12:02:13
※本記事は別サービスで2023年2月5日に公開した記事の移植です。
Nostrクライアントは多種ありますがメジャーなものはだいたいLNの支払いが用意されています。現時点でどんな組み込み方法になっているか調べました。この記事では主にSnortを対象にしています。
LN活用場面
大きくLNアドレスとLNインボイスの2つの形式があります。
1. LNアドレスで投げ銭をセットできる

LNURLのLNアドレスをセットすると、プロフィールやノート(ツイートに相当)からLN支払いができます。別クライアントのastralなどではプリミティブなLNURLの投げ銭形式
lnurl1dp68~でもセットできます。[追記]さらに本日、Snortで試験的にノート単位に投げ銭できる機能が追加されています。

2. LNインボイスが投稿できる

投稿でLNインボイスを貼り付ければ上記のように他の発言と同じようにタイムラインに流れます。Payボタンを押すと各自の端末にあるLNウォレットが立ち上がります。
3. DMでLNインボイスを送る
メッセージにLNインボイスが組み込まれているという点では2とほぼ同じですが、ユースケースが異なります。発表されたばかりですがリレーサーバの有料化が始まっていて、その決済をDMにLNインボイスを送付して行うことが試されています。2だとパブリックに投稿されますが、こちらはプライベートなので購入希望者のみにLNインボイスを届けられます。

おまけ: Nostrのユーザ名をLNアドレスと同じにする
直接は関係ないですが、Nostrはユーザー名をemail形式にすることができます。LNアドレスも自分でドメイン取って作れるのでNostrのユーザー名と投げ銭のアドレスを同じにできます。
LNウォレットのAlbyのドメインをNostrのユーザ名にも活用している様子 [Not found]
実装方法
LNアドレスもLNインボイスも非常にシンプルな話ですが軽くまとめます。 Snortリポジトリ
LNアドレス
- セットされたLNアドレスを分解して
https://[domain]/.well-known/lnurlp/[username]にリクエストする - 成功したら投げ銭量を決めるUIを提示する
- Get Inoviceボタンを押したら1のレスポンスにあるcallbackにリクエストしてインボイスを取得する
- 成功したらPayボタンを提示する
LNインボイス
- 投稿内容がLNインボイス識別子
lnbc10m〜だとわかると、識別子の中の文字列から情報(金額、説明、有効期限)を取り出し、表示用のUIを作成する - 有効期限内だったらPayボタンを提示し、期限が切れていたらExpiredでロックする
支払い
Payボタンを押された後の動きはアドレス、インボイスとも同じです。
- ブラウザでWebLN(Albyなど)がセットされていて、window.weblnオブジェクトがenableになっていると、拡張機能の支払い画面が立ち上がる。クライアント側で支払い成功をキャッチすることも可能。
- Open Walletボタンを押すと
lightning:lnbc10m~のURI形式でwindow.openされ、Mac/Windows/iPhone/Androidなど各OSに応じたアプリケーション呼び出しが行われ、URIに対応しているLNウォレットが立ち上がる
[追記]ノート単位の投げ銭
Snort周辺の数人(strike社員っぽい人が一人いて本件のメイン実装している)で試験的にやっているようで現時点では実装レベルでしか詳細わかりませんでした。strikeのzapといまいち区別が付かなかったのですが、実装を見るとnostrプロトコルにzapイベントが追加されています。ソースコメントではこの後NIP(nostr improvement proposal)が起こされるようでかなりハッキーです。zap=tipの方言なんでしょうか?
ノートやプロフィールやリアクションなどに加えて新たにnostrイベントに追加しているものは以下2つです。
- zapRequest 投げ銭した側が対象イベントIDと量を記録する
- zapReceipt 投げ銭を受け取った側用のイベント
一つでできそうと思ったけど、nostrは自己主権のプロトコルでイベント作成するには発行者の署名が必須なので2つに分かれているのでしょう。
所感
現状はクライアントだけで完結する非常にシンプルな方法になっています。リレーサーバも経由しないしクライアントにLNノードを組み込むこともしていません。サードパーティへのhttpリクエストやローカルのアプリに受け渡すだけなので、実はどんな一般アプリでもそんなに知識もコストも要らずにパッとできるものです。
現状ちょっと不便だなと思っていることは、タイムラインに流れるインボイスの有効期限内の支払い済みがわからないことです。Payボタンを押してエラーにならないとわかりません。ウォレットアプリに放り投げていてこのトレースするためには、ウォレット側で支払い成功したらNostrイベントを書き込むなどの対応しない限りは、サービス側でインボイスを定期的に一つ一つLNに投げてチェックするなどが必要だと思われるので、他のサービスでマネするときは留意しておくとよさそうです。
一方で、DMによるLNインボイス送付は活用方法が広がりそうな予感があります。Nostrの公開鍵による本人特定と、LNインボイスのメモ欄のテキスト情報による突き合わせだけでも、かんたんな決済機能として用いれそうだからです。もっとNostrに判断材料を追加したければイベント追加も簡単にできることをSnortが示しています。とくにリレーサーバ購読やPROメニューなどのNostr周辺の支払いはやりやすそうなので、DM活用ではなくなにかしらの決済メニューを搭載したNostrクライアントもすぐに出てきそう気がします。
- セットされたLNアドレスを分解して
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Reasons why Lightning is not that great
Some Bitcoiners, me included, were fooled by hyperbolic discourse that presented Lightning as some magical scaling solution with no flaws. This is an attempt to list some of the actual flaws uncovered after 5 years of experience. The point of this article is not to say Lightning is a complete worthless piece of crap, but only to highlight the fact that Bitcoin needs to put more focus on developing and thinking about other scaling solutions (such as Drivechain, less crappy and more decentralized trusted channels networks and statechains).
Unbearable experience
Maintaining a node is cumbersome, you have to deal with closed channels, allocating funds, paying fees unpredictably, choosing new channels to open, storing channel state backups -- or you'll have to delegate all these decisions to some weird AI or third-party services, it's not feasible for normal people.
Channels fail for no good reason all the time
Every time nodes disagree on anything they close channels, there have been dozens, maybe hundreds, of bugs that lead to channels being closed in the past, and implementors have been fixing these bugs, but since these node implementations continue to be worked on and new features continue to be added we can be quite sure that new bugs continue to be introduced.
Trimmed (fake) HTLCs are not sound protocol design
What would you tell me if I presented a protocol that allowed for transfers of users' funds across a network of channels and that these channels would pledge to send the money to miners while the payment was in flight, and that these payments could never be recovered if a node in the middle of the hop had a bug or decided to stop responding? Or that the receiver could receive your payment, but still claim he didn't, and you couldn't prove that at all?
These are the properties of "trimmed HTLCs", HTLCs that are uneconomical to have their own UTXO in the channel presigned transaction bundles, therefore are just assumed to be there while they are not (and their amounts are instead added to the fees of the presigned transaction).
Trimmed HTLCs, like any other HTLC, have timelocks, preimages and hashes associated with them -- which are properties relevant to the redemption of actual HTLCs onchain --, but unlike actual HTLCs these things have no actual onchain meaning since there is no onchain UTXO associated with them. This is a game of make-believe that only "works" because (1) payment proofs aren't worth anything anyway, so it makes no sense to steal these; (2) channels are too expensive to setup; (3) all Lightning Network users are honest; (4) there are so many bugs and confusion in a Lightning Network node's life that events related to trimmed HTLCs do not get noticed by users.
Also, so far these trimmed HTLCs have only been used for very small payments (although very small payments probably account for 99% of the total payments), so it is supposedly "fine" to have them. But, as fees rise, more and more HTLCs tend to become fake, which may make people question the sanity of the design.
Tadge Dryja, one of the creators of the Lightning Network proposal, has been critical of the fact that these things were allowed to creep into the BOLT protocol.
Routing
Routing is already very bad today even though most nodes have a basically 100% view of the public network, the reasons being that some nodes are offline, others are on Tor and unreachable or too slow, channels have the balance shifted in the wrong direction, so payments fail a lot -- which leads to the (bad) solution invented by professional node runners and large businesses of probing the network constantly in order to discard bad paths, this creates unnecessary load and increases the risk of channels being dropped for no good reason.
As the network grows -- if it indeed grow and not centralize in a few hubs -- routing tends to become harder and harder.
While each implementation team makes their own decisions with regard to how to best way to route payments and these decisions may change at anytime, it's worth noting, for example, that CLN will use MPP to split up any payment in any number of chunks of 10k satoshis, supposedly to improve routing success rates. While this often backfires and causes payments to fail when they should have succeeded, it also contributes to making it so there are proportionally more fake HTLCs than there should be, as long as the threshold for fake HTLCs is above 10k.
Payment proofs are somewhat useless
Even though payment proofs were seen by many (including me) as one of the great things about Lightning, the sad fact is that they do not work as proofs if people are not aware of the fact that they are proofs. Wallets do all they can to hide these details from users because it is considered "bad UX" and low-level implementors do not care very much to talk about them at all. There have been attempts from Lightning Labs to get rid of the payment proofs entirely (which at the time to me sounded like a terrible idea, but now I realize they were not wrong).
Here's a piece of anecdote: I've personally witnessed multiple episodes in which Phoenix wallet released the preimage without having actually received the payment (they did receive a minor part of the payment, but the payment was split in many parts). That caused my service, @lntxbot, to mark the outgoing payment as complete, only then to have to endure complaints from the users because the receiver side, Phoenix, had not received the full amount. In these cases, if the protocol and the idea of preimages as payment proofs be respected, should I have been the one in charge of manually fixing user balances?
Another important detail: when an HTLC is sent and then something goes wrong with the payment the channel has to be closed in order to redeem that payment. When the redeemer is on the receiver side, the very act of redeeming should cause the preimage to be revealed and a proof of payment to be made available for the sender, who can then send that back to the previous hop and the payment is proven without any doubt. But when this happens for fake HTLCs (which is the vast majority of payments, as noted above) there is no place in the world for a preimage and therefore there are no proofs available. A channel is just closed, the payer loses money but can't prove a payment. It also can't send that proof back to the previous hop so he is forced to say the payment failed -- even if it wasn't him the one who declared that hop a failure and closed the channel, which should be a prerequisite. I wonder if this isn't the source of multiple bugs in implementations that cause channels to be closed unnecessarily. The point is: preimages and payment proofs are mostly a fiction.
Another important fact is that the proofs do not really prove anything if the keypair that signs the invoice can't be provably attached to a real world entity.
LSP-centric design
The first Lightning wallets to show up in the market, LND as a desktop daemon (then later with some GUIs on top of it like Zap and Joule) and Anton's BLW and Eclair wallets for mobile devices, then later LND-based mobile wallets like Blixt and RawTX, were all standalone wallets that were self-sufficient and meant to be run directly by consumers. Eventually, though, came Breez and Phoenix and introduced the "LSP" model, in which a server would be trusted in various forms -- not directly with users' funds, but with their privacy, fees and other details -- but most importantly that LSP would be the primary source of channels for all users of that given wallet software. This was all fine, but as time passed new features were designed and implemented that assumed users would be running software connected to LSPs. The very idea of a user having a standalone mobile wallet was put out of question. The entire argument for implementation of the bolt12 standard, for example, hinged on the assumption that mobile wallets would have LSPs capable of connecting to Google messaging services and being able to "wake up" mobile wallets in order for them to receive payments. Other ideas, like a complicated standard for allowing mobile wallets to receive payments without having to be online all the time, just assume LSPs always exist; and changes to the expected BOLT spec behavior with regards to, for example, probing of mobile wallets.
Ark is another example of a kind of LSP that got so enshrined that it become a new protocol that depends on it entirely.
Protocol complexity
Even though the general idea of how Lightning is supposed to work can be understood by many people (as long as these people know how Bitcoin works) the Lightning protocol is not really easy: it will take a long time of big dedication for anyone to understand the details about the BOLTs -- this is a bad thing if we want a world of users that have at least an idea of what they are doing. Moreover, with each new cool idea someone has that gets adopted by the protocol leaders, it increases in complexity and some of the implementors are kicked out of the circle, therefore making it easier for the remaining ones to proceed with more and more complexity. It's the same process by which Chrome won the browser wars, kicked out all competitors and proceeded to make a supposedly open protocol, but one that no one can implement as it gets new and more complex features every day, all envisioned by the Chrome team.
Liquidity issues?
I don't believe these are a real problem if all the other things worked, but still the old criticism that Lightning requires parking liquidity and that has a cost is not a complete non-issue, specially given the LSP-centric model.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Carl R. Rogers sobre a ciência
Creio que o objetivo primário da ciência é fornecer uma hipótese, uma convicção e uma fé mais seguras e que satisfaçam melhor o próprio investigador. Na medida em que o cientista procura provar qualquer coisa a alguém -- um erro em que incorri mais de uma vez --, creio que ele está se servindo da ciência para remediar uma insegurança pessoal, desviando-a do seu verdadeiro papel criativo a serviço do indivíduo.
Tornar-se Pessoa, página aleatória
-
@ 3589b793:ad53847e
2025-04-30 11:46:52
※本記事は別サービスで2022年9月25日に公開した記事の移植です。
LNの手数料の適正水準はどう見積もったらいいだろうか?ルーティングノードの収益性を算出するためにはどうアプローチすればよいだろうか?本記事ではルーティングノード運用のポジションに立ち参考になりそうな数値や計算式を整理する。
個人的な感想を先に書くと以下となる。
- 現在の手数料市場は収益性が低くもっと手数料が上がった方が健全である。
- 他の決済手段と比較すると、LN支払い料金は10000ppm(手数料1%相当)でも十分ではないか。4ホップとすると中間1ノードあたり2500ppmである。
- ルーティングノードの収益性を考えると、1000ppmあれば1BTC程度の資金で年利2.8%になり半年で初期費用回収できるので十分な投資対象になると考える。
基本概念の整理
LNの料金方式
- LNの手数料は送金額に応じた料率方式が主になる。(基本料金の設定もあるが1 ~ 0 satsが大半)
- 料率単位のppm(parts per million)は、1,000,000satsを送るときの手数料をsats金額で示したもの。
- %での手数料率に変換すると1000ppm = 0.1%になる。
- 支払い者が払う手数料はルーティングに参加した各ノードの手数料の合計である。本稿では4ホップ(経由ノードが4つ)のルーティングがあるとすれば、各ノードの取り分は単純計算で1/4とみなす。
- ルーティングノードの収益はアウトバウンドフローで発生するのでアウトバウンドキャパシティが直接的な収益資源となる。
LNの料金以外のベネフィット
本稿では料金比較だけを行うが実際の決済検討では以下のような料金以外の効用も忘れてはならない。
- Bitcoin(L1)に比べると、料金の安さだけでなく、即時確定やトランザクション量のスケールという利点がある。
- クレジットカードなどの集権サービスと比較した特徴はBitcoin(L1)とだいたい同じである。
- 24時間365日利用できる
- 誰でも自由に使える
- 信頼する第三者に対する加盟や審査や手数料率などの交渉手続きが要らない
- 検閲がなく匿名性が高い
- 逆にデメリットはオンライン前提がゆえの利用の不便さやセキュリティ面の不安さなどが挙げられる。
現在の料金相場
- ルーティングノードの料金設定
- sinkノードとのチャネルは500 ~ 1000ppmが多い。
- routing/sourceノードとのチャネルは0 ~ 100ppmあたりのレンジになる。
- リバランスする場合もsinkで収益を上げているならsink以下になるのが道理である。
- プロダクト/サービスのバックエンドにいるノードの料金設定
- sinkやsourceに相当するものは上記の通り。
- 1000〜5000ppmあたりで一律同じ設定というノードもよく見かける。
- ビジネスモデル次第で千差万別だがアクティブと思われるノードでそれ以上はあまり見かけない。
- 上記は1ノードあたりの料金になる。支払い全体では経由したノードの合計になる。
料金目安
いくつかの方法で参考数字を出していく。LN料金算出は「支払い全体/2ホップしたときの1ノードあたり/4ホップしたときの1ノードあたり」の三段階で出す。
類推方式
決済代行業者との比較
- Squareの加盟店手数料は、日本3.25%、アメリカ2.60%である。
- 参考資料 https://www.meti.go.jp/shingikai/mono_info_service/cashless_payment/pdf/20220318_1.pdf
3.25%とするとLNでは「支払い全体/2ホップしたときの1ノードあたり/4ホップしたときの1ノードあたり」でそれぞれ
32,500ppm/16,250ppm/8,125ppmになる。スマホのアプリストアとの比較
- Androidのアプリストアは年間売上高が100万USDまでなら15%、それ以上なら30%
- 参考資料https://support.google.com/googleplay/android-developer/answer/112622?hl=ja
15%とするとLNでは「支払い全体/2ホップしたときの1ノードあたり/4ホップしたときの1ノードあたり」でそれぞれ
150,000ppm/75,000ppm/37,500ppmになる。Bitcoin(L1)との比較
Bitcoin(L1)は送金額が異なっても手数料がほぼ同じため、従量課金のLNと単純比較はできない。そのためここではLNの方が料金がお得になる目安を出す。
Bitcoin(L1)の手数料設定
- SegWitのシンプルな送金を対象にする。
- input×1、output×2(送金+お釣り)、tx合計222byte
- L1の手数料は、1sat/byteなら222sats、10sat/byteなら2,220sats、100sat/byteなら22,200sats。(単純化のためvirtual byteではなくbyteで計算する)
- サンプル例 https://www.blockchain.com/btc/tx/15b959509dad5df0e38be2818d8ec74531198ca29ac205db5cceeb17177ff095
L1相場が1sat/byteの時にLNの方がお得なライン
- 100ppmなら、0.0222BTC(2,220,000sats)まで
- 1000ppmなら、0.00222BTC(222,000sats)まで
L1相場が10sat/byteの時にLNの方がお得なライン
- 100ppmなら、0.222BTC(22,200,000sats)まで
- 1000ppmなら、0.0222BTC(2,220,000sats)まで
L1相場が100sat/byteの時にLNの方がお得なライン
- 100ppmなら、2.22BTC(222,000,000sats)まで
- 1000ppmなら、0.222BTC(22,200,000sats)まで
コスト積み上げ方式
ルーティングノードの原価から損益分岐点となるppmを算出する。事業者ではなく個人を想定し、クラウドではなくラズベリーパイでのノード構築環境で計算する。
費用明細
- BTC市場価格 1sat = 0.03円(1BTC = 3百万円)
初期費用
- ハードウェア一式 40,000円
- Raspberry Pi 4 8GB
- SSD 1TB
- 外付けディスプレイ
- チャネル開設のオンチェーン手数料 6.69円/チャネル
- 開設料 223sats
- 223sats * BTC市場価格0.03円 = 6.69円
固定費用
- 電気代 291.6円/月
- 時間あたりの電力量 0.015kWh
- Raspberry Pi 4 電圧5V、推奨電源容量3.0A
- https://www.raspberrypi.com/documentation/computers/raspberry-pi.html#power-supply
- kWh単価27円
- 0.015kWh * kWh単価27円 * 1ヶ月の時間720h = 291.6円
損益分岐点
- 月あたりの電気代を上回るために9,720sats(291.6円)/月以上の収益が必要である。
- ハードウェア費用回収のために0.01333333BTC(133万sats) = 40,000円の収益が必要である。
費用回収シナリオ例
アウトバウンドキャパに1BTCをデポジットしたAさんを例にする。1BTCは初心者とは言えないと思うが、このくらい原資を用意しないと費用回収の話がしづらいという裏事情がある。チャネル選択やルーティング戦略は何もしていない仮定である。ノード運用次第であることは言うまでもないので今回は要素や式を洗い出すことが主目的で一つ一つの変数の値は参考までに。
変数設定
- インバウンドを同額用意して合計キャパを2BTCとする。
- 1チャネルあたり5m satsで40チャネル開設する。
- チャネル開設費用 223sats * 40チャネル = 8,920sats
- 初期費用合計 1,333,333sats + 8,920sats = 1,342,253sats
- 一回あたり平均ルーティング量 = 100,000sats
- 1チャネルあたり平均アウトバウンド数/日 = 2
- 1チャネルあたり平均アウトバウンドppm = 50
費用回収地点
- 1日のアウトバウンド量は、 40チャネル * 2本 * 100,000sats = 8m sats
- 手数料収入は、8m sats * 0.005%(50ppm) = 400sats/日。月換算すると12,000sats/月
- 電気代を差し引くと、12,000sats - 電気代9,720sats =月収益2,280sats(68.4円)
- 初期費用回収まで、1,342,253sats / 2,280sats = 589ヵ月(49年)
- 後述するが電気代差引き前で年利0.14%になる。
理想的なppm
6ヵ月での初期費用回収を目的にしてアウトバウンドppmを求める。
- ひと月あたり、初期費用合計1,342,253sats / 6ヵ月 + 電気代9,720sats = 233,429sats(7,003円)の収益が必要。
- 1日あたり、7,781sats(233円)の収益
- その場合の平均アウトバウンドppmは、 7,781sats(1日の収益量) / 8m sats(1日のアウトバウンド量) * 1m sats(ppm変換係数) = 973ppm
他のファイナンスとの比較
ルーティングノードを運用して手数料収入を得ることは資産運用と捉えることもできる。レンディングやトレードなどの他の資産運用手段とパフォーマンス比較をするなら、デポジットしたアウトバウンドキャパシティに対する手数料収入をAPY換算する。(獲得した手数料はアウトバウンドキャパシティに積み重ねられるので複利と見做せる)
例としてLNDg(v1.3.1)のAPY算出計算式を転載する。見ての通り画面上の表記はAPYなのに中身はAPRになっているので注意だが今回は考え方の参考としてこのまま採用する。
年換算 = 365 / 7 = 52.142857 年利 = (7dayの収益 * 年換算) / アウトバウンドのキャパシティ例えば上記のAさんの費用回収シナリオに当てはめると以下となる。
年利 0.14% = (400sats * 7日 * 年換算)/ 100m sats
電気代を差し引くと 76sats/日となり年利0.027%
もし平均アウトバウンド1000ppmになると8,000sats/日なので年利2.9%になる。 この場合、電気代はほぼ1日で回収されるため差し引いても大差なく7,676sats/日で年利2.8%になる。
考察
以上、BTC市場価格や一日のアウトバウンド量といった重要な数値をいくつか仮置きした上ではあるが、LN手数料の適正水準を考えるための参考材料を提示した。
まず、現在のLNの料金相場は他の決済手段から比べると圧倒的に安いことがわかった。1%でも競争力が十分ありそうなのに0.1%前後で送金することが大半である。
健全な市場発展のためには、ルーティングノードの採算が取れていることが欠かせないと考えるが、残念ながら現在の収益性は低い。ルーティングノードの収益性は仮定に仮定を重ねた見積もりになるが、平均アウトバウンドが1000ppmでようやく個人でも参入できるレベルになるという結論になった。ルーティングノードの立場に立つと、現在の市場平均から大幅な上昇が必要だと考える。
手数料市場は競争のためつねに下方圧力がかかっていて仕様上で可能な0に近づいている。この重力に逆らうためには、1. 需要 > 供給のバランスになること、2. 事業用途での高額買取のチャネルが増えること、の2つの観点を挙げる。1にせよ2にせよネットワークの活用が進むことで発生し、手数料市場の大きな変動機会になるのではないか。他の決済手段と比較すれば10000ppm、1チャネル2500ppmあたりまでは十分に健全な範囲だと考える。
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
contratos.alhur.es
A website that allowed people to fill a form and get a standard Contrato de Locação.
Better than all the other "templates" that float around the internet, which are badly formatted
.docfiles.It was fully programmable so other templates could be added later, but I never did. This website made maybe one dollar in Google Ads (and Google has probably stolen these like so many other dollars they did with their bizarre requirements).
-
@ 81650982:299380fa
2025-04-30 11:16:42
Let us delve into Monero (XMR). Among the proponents of various altcoins, Monero arguably commands one of the most dedicated followings, perhaps second only to Ethereum. Unlike many altcoins where even investors often harbor speculative, short-term intentions, the genuine belief within the Monero community suggests an inherent appeal to the chain itself.
The primary advantage touted by Monero (and similar so-called "privacy coins") is its robust privacy protection features. The demand for anonymous payment systems, tracing its lineage back to David Chaum, predates even the inception of Bitcoin. Monero's most heavily promoted strength, relative to Bitcoin, is that its privacy features are enabled by default.
This relates to the concept of the "anonymity set." To guarantee anonymity, a user must blend into a crowd of ordinary users. The larger the group one hides within, the more difficult it becomes for an external observer to identify any specific individual. From the perspective of Monero advocates, Bitcoin's default transaction model is overly transparent, clearly revealing the flow of funds between addresses. While repeated mixing can enhance anonymity in Bitcoin, the fact that users must actively undertake such measures presents a significant hurdle. More critically, proponents argue, the very group engaging in such deliberate obfuscation is precisely the group one doesn't want to be associated with for effective anonymity. Hiding requires blending with the ordinary, not merely mixing with others who are also actively trying to hide — the latter, they contend, is akin to criminals mixing only with other criminals.
This is a valid point. For instance, there's a substantial difference between a messenger app offering end-to-end encryption for all communications by default, versus one requiring users to explicitly create a "secret chat" for encryption. While I personally believe that increased self-custody of Bitcoin in personal wallets, acquisition through direct peer-to-peer payments rather than exchange purchases, and the widespread adoption of the Lightning Network would make tracing significantly harder even without explicit mixing efforts, let us concede, for the sake of argument, that Bitcoin's base-layer anonymity might not drastically improve even in such a future scenario.
Nevertheless, Monero's long-term prospects appear considerably constrained when focusing purely on technical limitations, setting aside economic factors or incentive models for now. While discussions on economics can often be countered with "That's just your speculation," technical constraints present more objective facts and leave less room for dispute.
Monero's most fundamental problem is its lack of scalability. To briefly explain how Monero obfuscates the sender: it includes other addresses alongside the true sender's address in the 'from' field and attaches what appears to be valid signatures for all of them. With a default setting of 10 decoys (plus the real spender, making a ring size of 11), the signature size naturally becomes substantially larger than Bitcoin's. Since an observer cannot determine which of the 11 is the true sender, and these decoys are arbitrary outputs selected from the blockchain belonging to other users, anonymity is indeed enhanced. While the sender cannot generate individually valid signatures for the decoy outputs (as they don't own the private keys), the use of a ring signature mathematically proves that one member of the ring authorized the transaction, allowing it to pass network validation.
The critical issue is that this results in transaction sizes several times larger than Bitcoin's. Bitcoin already faces criticism for being relatively expensive and slow. Monero's structure imposes a burden that is multiples greater. One might question the relationship between transaction data size and transaction fees/speed. However, the perceived slowness of blockchains isn't typically due to inefficient code, but rather the strict limitations imposed on block size (or equivalent throughput constraints) to maintain decentralization. Therefore, larger transaction sizes directly translate into throughput limitations and upward pressure on fees. If someone claims Monero fees are currently lower than Bitcoin's, that is merely a consequence of its significantly lower usage. Should Monero's transaction volume reach even a fraction of Bitcoin's, its current architecture would struggle severely under the load.
To address this, Monero implemented a dynamic block size limit instead of a hardcoded one. However, this is not a comprehensive solution. If the block size increases proportionally with usage, a future where Monero achieves widespread adoption as currency — implying usage potentially hundreds, thousands, or even hundreds of thousands of times greater than today — would render the blockchain size extremely difficult to manage for ordinary node operators. Global internet traffic might be consumed by Monero transactions, or at the very least, the bandwidth and storage costs could exceed what individuals can reasonably bear.
Blockchains, by their nature, must maintain a size manageable enough for individuals to run full nodes, necessitating strict block size limits (or equivalent constraints in blockless designs). This fundamental requirement is the root cause of limited transaction speed and rising fees. Consequently, the standard approach to blockchain scaling involves Layer 2 solutions like the Lightning Network. The problem is, implementing such solutions on Monero is extremely challenging.
Layer 2 solutions, while varying in specific implementation details across different blockchains, generally rely heavily on the transparency of on-chain transactions. They typically involve sophisticated smart contracts built upon the ability to publicly verify on-chain states and events. Monero's inherent opacity, hiding crucial details of on-chain transactions, makes it exceptionally difficult for two mutually untrusting parties to reach the necessary consensus and cryptographic agreements (like establishing payment channels with verifiable state transitions and dispute mechanisms) that underpin such Layer 2 systems. The fact that Monero, despite existing for several years, still lacks a functional, widely adopted Layer 2 implementation suggests that this remains an unsolved and technically formidable challenge. While theoretical proposals exist, their real-world feasibility remains uncertain and would likely require significant breakthroughs in cryptographic protocol design.
Furthermore, Monero faces another severe scaling challenge related to its core privacy mechanism. As mentioned, decoy outputs are used to obscure the true sender. An astute observer might wonder: If a third party cannot distinguish the real spender, could the real spender potentially double-spend their funds later? Or could someone's funds become unusable simply because they were chosen as a decoy in another transaction? Naturally, Monero's developers anticipated this. The solution employed involves key images.
When an output is genuinely spent within a ring signature, a unique cryptographic identifier called a "key image" is derived from the real output and the spender's private key. This derivation is one-way (the key image cannot be used to reveal the original output or key). This key image is recorded on the blockchain. When validating a new transaction, the network checks if the submitted key image has already appeared in the history. If it exists, the transaction is rejected as a double-spend attempt. The crucial implication is that this set of used key images can never be pruned. Deleting historical key images would directly enable double-spending.
Therefore, Monero's state size — the data that full nodes must retain and check against — grows linearly and perpetually with the total number of transactions ever processed on the network.
Summary In summary, Monero faces critical technical hurdles:
Significantly Larger Transaction Sizes: The use of ring signatures for anonymity results in transaction data sizes several times larger than typical cryptocurrencies like Bitcoin.
Inherent Scalability Limitations: The large transaction size, combined with the necessity of strict block throughput limits to preserve decentralization, creates severe scalability bottlenecks regarding transaction speed and cost under significant load. Dynamic block sizes, while helpful in the short term, do not constitute a viable long-term solution for broad decentralization.
Layer 2 Implementation Difficulty: Monero's fundamental opacity makes implementing established Layer 2 scaling solutions (like payment channels) extremely difficult with current approaches. The absence of a widely adopted solution to date indicates that this remains a major unresolved challenge.
Unprunable, Linearly Growing State: The key image mechanism required to prevent double-spending mandates the perpetual storage of data proportional to the entire transaction history, unlike Bitcoin where nodes can prune historical blocks and primarily need to maintain the current UTXO set (whose size depends on usage patterns, not total history).
These technical constraints raise legitimate concerns about Monero's ability to scale effectively and achieve widespread adoption in the long term. While ongoing research may alleviate some of these issues, at present they represent formidable challenges that any privacy-focused cryptocurrency must contend with.
-
@ 79008e78:dfac9395
2025-03-08 07:08:11
Bitcoin Core: The Reference Implementation
ผู้คนจะยอมรับเงินใด ๆ เพื่อแลกเปลี่ยนกับสินค้าและบริการก็ต่อเมื่อคนนั้น ๆ เชื่อว่าเงินนี้จะมีมูลค่าในอนาคต เงินปลอมหรือเงินที่เสื่อมค่าโดยไม่คาดคิดนั้นอาจไม่สามารถใช้ได้ในอนาคต ดังนั้นทุกคนที่รับบิตคอยน์จึงมีแรงจูงใจที่แข็งแกร่งในการตรวจสอบความถูกต้องของบิตคอยน์ที่พวกเขาได้รับ ระบบของบิตคอยน์นั้นถูกออกแบบมาให้เข้าถึง, ป้องกันการปลอมแปลง, การเสื่อมค่า และปัญหาสำคัญอื่น ๆ ได้อย่างสมบูรณ์ได้ด้วยคอมพิวเตอร์ทั่วไป โดยซอฟต์แวร์ที่ให้ฟังก์ชันนี้เรียกว่า Full node ซึ่งทำหน้าที่ตรวจสอบธุรกรรมบิตคอยน์ทุกครั้งที่ได้รับการยืนยันตามกฎของระบบ นอกจากนี้ Full node ยังสามารถให้เครื่องมือและข้อมูลเพื่อทำความเข้าใจการทำงานของบิตคอยน์และสภาพปัจจุบันของเครือข่าย
ในบทนี้เอง เราจะทำการติดตั้ง Bitcoin Core ซึ่งเป็นซอฟต์แวร์ที่ผู้ใช้งาน Full node ส่วนใหญ่เลือกใช้เพื่อเป็นประตูบานแรกในการเข้าถึงระบบนิเวศของบิตคอยน์ เราจะตรวจสอบบล็อก ธุรกรรม และข้อมูลอื่น ๆ จากโหนดของคุณ ซึ่งเป็นข้อมูลที่เชื่อถือได้ (ไม่ใช่เพราะหน่วยงานทรงอำนาจกำหนดให้เป็นเช่นนั้น) แต่เป็นเพราะโหนดของคุณได้ตรวจสอบข้อมูลนั้นอย่างอิสระ ตลอดเนื้อหาที่เหลือในหนังสือเล่มนี้ เราจะใช้ Bitcoin Core เพื่อสร้างและตรวจสอบข้อมูลที่เกี่ยวข้องกับบล็อกเชนและเครือข่าย
จาก Bitcoin สู่ Bitcoin Core
บิตคอยน์เป็นโครงการโอเพ่นซอร์ส โดยซอร์สโค้ดทั้งหมดก็สามารถดาวน์โหลดและใช้งานได้ฟรีภายใต้ใบอณุญาตแบบเปิด (MIT License) นอกจากจะเป็นโอเพ่นซอร์สแล้วบิตคอยน์ยังได้รับการพัฒนาโดยชุมชนอาสาสมัครแบบเปิดกว้าง แน่นอนว่าในช่วงแรกนั้นชุมชนนี้ประกอบด้วย Satoshi Nakamoto เพียงคนเดียว แต่ภายในปี 2023 ซอร์สโค้ดของบิตคอยน์มีผู้ร่วมพัฒนามากกว่า 1,000 คน
เมื่อ Satoshi Nakamoto ได้สร้างซอฟแวร์บิตคอยน์ตัวนี้และพัฒนามันจนเกือบสมบูรณ์ก่อนแล้วจึงเผยแพร่เอกสารไวท์เปเปอร์ เขาน่าจะต้องการให้มั่นใจว่าการใช้งานจริงสามารถทำงานได้ก่อนเผยแพร่เอกสาร โดยซอฟต์แวร์เวอร์ชันแรกที่รู้จักในชื่อ "Bitcoin" นั้นได้รับการปรับปรุงและพัฒนามาอย่างมาก จนได้กลายเป็นสิ่งที่เรารู้จักกันในชื่อ Bitcoin Core และเพื่อแยกความแตกต่างจากการใช้งานอื่น ๆ Bitcoin Core เป็นซอฟต์แวร์ต้นแบบอ้างอิง (reference implementation) ของระบบบิตคอยน์ซึ่งแสดงวิธีการทำงานของแต่ละส่วนในเชิงเทคโนโลยี นอกจากนี้ Bitcoin Core รวมถึงการใช้งานฟังก์ชันทั้งหมดของบิตคอยน์ เช่น กระเป๋าเงิน เครื่องมือตรวจสอบธุรกรรมและบล็อก เครื่องมือสำหรับการสร้างบล็อก และส่วนต่าง ๆ ของการสื่อสารแบบ peer-to-peer ของบิตคอยน์

Bitcoin Development Environment
สำหรับนักพัฒนาที่ต้องการเขียนแอปพลิเคชันเกี่ยวกับบิตคอยน์ ทั้งการตั้งค่าสภาพแวดล้อมสำหรับการพัฒนาพร้อมเครื่องมือ ไลบรารี และซอฟต์แวร์สนับสนุนเป็นสิ่งสำคัญ ซึ่งเนื้อหาในบทนี้นั้นจะเป็นเรื่องทางเทคนิคอลค่อนข้างเยอะ ในบทนี้เราจะอธิบายขั้นตอนการตั้งค่าอย่างละเอียด หากคุณพบว่าเนื้อหานี้ซับซ้อนเกินไป (และไม่ได้ต้องการตั้งค่าสภาพแวดล้อมสำหรับการพัฒนาจริง ๆ) คุณสามารถข้ามไปยังบทถัดไปที่มีเนื้อหาน้อยทางเทคนิคกว่าได้
มาคอมไพล์ Bitcoin core จากซอร์สโค้ดกันเถอะ !!
ซอร์สโค้ดทั้งหมดของ BItcoin Core นั้นสามารถดาวน์โหลดได้ในรูปแบบไฟล์อาร์ไคฟ์หรือโดยการโคลนที่เก็บซอร์สโค้ดจาก GitHub โดยตรง บนหน้าดาวน์โหลดของ Bitcoin Core ให้เลือกเวอร์ชันล่าสุดและดาวน์โหลดไฟล์อัดบีบของซอร์สโค้ด หรือใช้คำสั่ง Git เพื่อสร้างสำเนาซอร์สโค้ดบนเครื่องของคุณจากหน้า GitHub ของ Bitcoin
TIP: ในตัวอย่างหลาย ๆ ส่วนของบทนี้ เราจะใช้ อินเทอร์เฟซบรรทัดคำสั่ง (Command-Line Interface - CLI) ของระบบปฏิบัติการ หรือที่เรียกว่า "shell" ซึ่งสามารถเข้าถึงได้ผ่านแอปพลิเคชัน terminal โดย shell จะแสดง พรอมต์ (prompt) เพื่อรอรับคำสั่งที่คุณพิมพ์ จากนั้นจะแสดงผลลัพธ์ออกมาแล้วรอรับคำสั่งถัดไป
TIP จากหลาม: แบบง่าย ๆ ก็คือไม่ต้องพิมพ์ $ และถ้าพิมพ์จบหนึ่งคำสั่งก็กด enter ซ่ะด้วย
ขั้นตอนในการลง bitcoin core มีดังนี้:
- สั่ง git clone เพื่อทำการสร้างสำเนาของซอร์สโค้ดลงในเครื่องของเรา ``` $ git clone https://github.com/bitcoin/bitcoin.git Cloning into 'bitcoin'... remote: Enumerating objects: 245912, done. remote: Counting objects: 100% (3/3), done. remote: Compressing objects: 100% (2/2), done. remote: Total 245912 (delta 1), reused 2 (delta 1), pack-reused 245909 Receiving objects: 100% (245912/245912), 217.74 MiB | 13.05 MiB/s, done. Resolving deltas: 100% (175649/175649), done.
```
TIP: Git เป็นระบบควบคุมเวอร์ชันแบบกระจายที่ใช้กันอย่างแพร่หลายและเป็นส่วนสำคัญในเครื่องมือของนักพัฒนาซอฟต์แวร์ คุณอาจจำเป็นต้องติดตั้งคำสั่ง git หรือส่วนต่อประสานกราฟิก (GUI) สำหรับ Git บนระบบปฏิบัติการของคุณ หากยังไม่มี
- เมื่อการโคลน Git เสร็จสมบูรณ์แล้ว คุณจะมีสำเนาท้องถิ่นครบถ้วนของที่เก็บซอร์สโค้ดในไดเรกทอรี bitcoin ให้เปลี่ยนไปยังไดเรกทอรีนี้โดยใช้คำสั่ง cd:
``` $ cd bitcoin
3. เลือก version ของ bitcoin core: โดยค่าเริ่มต้น สำเนาจองเราจะซิงโครไนซ์กับโค้ดล่าสุด ซึ่งอาจเป็นเวอร์ชันที่ไม่เสถียรหรือเบต้าของ Bitcoin ก่อนที่จะคอมไพล์โค้ด ให้เลือกเวอร์ชันเฉพาะโดยการตรวจสอบ (checkout) แท็กของการปล่อย (release tag) ซึ่งจะซิงโครไนซ์สำเนาท้องถิ่นกับสแนปช็อตของที่เก็บซอร์สโค้ดที่ระบุด้วยแท็ก แท็กเหล่านี้ถูกใช้งานโดยนักพัฒนาเพื่อระบุเวอร์ชันของโค้ดตามหมายเลขเวอร์ชัน ซึ่งทำได้โดยใช้คำสั่ง git tag$ git tag v0.1.5 v0.1.6test1 v0.10.0 ... v0.11.2 v0.11.2rc1 v0.12.0rc1 v0.12.0rc2 ...รายการแท็กจะแสดงทุกเวอร์ชันที่ปล่อยออกมา โดยทั่วไป release candidates (เวอร์ชันทดสอบ) จะมีต่อท้ายว่า "rc" ส่วนเวอร์ชันเสถียรที่ใช้งานในระบบ production จะไม่มีต่อท้ายอะไรเลย จากรายการด้านบน ให้เลือกเวอร์ชันที่สูงสุด ซึ่งในขณะที่เขียนบทความนี้คือ v24.0.1 เพื่อซิงโครไนซ์โค้ดท้องถิ่นกับเวอร์ชันนี้ ให้ใช้คำสั่ง:$ git checkout v24.0.1 Note: switching to 'v24.0.1'.```
จากนั้นสั่ง git status เพื่อเช็คเวอร์ชัน
Configuring the Bitcoin Core Build
ในโค้ดของบิตคอยน์ที่เราได้ดาวน์โหลดมาในหัวข้อก่อนหน้านั้น มีเอกสารประกอบอยู่หลายไฟล์ โดยคุณสามารถดูเอกสารหลักได้จากไฟล์ README.md ในไดเรกทอรี bitcoin ในบทนี้ เราจะสร้าง daemon (เซิร์ฟเวอร์) ของ Bitcoin Core ซึ่งรู้จักกันในชื่อ bitcoind บน Linux (หรือระบบที่คล้ายกับ Unix) โดยให้ตรวจสอบคำแนะนำสำหรับการคอมไพล์ bitcoind แบบบรรทัดคำสั่งบนแพลตฟอร์มของคุณโดยอ่านไฟล์ doc/build-unix.md นอกจากนี้ ยังมีคำแนะนำสำหรับระบบอื่น ๆ ในไดเรกทอรี doc เช่น build-windows.md สำหรับ Windows จนถึงขณะนี้ คำแนะนำมีให้สำหรับ Android, FreeBSD, NetBSD, OpenBSD, macOS (OSX), Unix
หลังจากนั้นคุณควรตรวจสอบความต้องการเบื้องต้นในการสร้าง (build pre-requisites) ซึ่งระบุไว้ในส่วนแรกของเอกสารการสร้าง สิ่งเหล่านี้คือไลบรารีที่ต้องมีอยู่ในระบบของคุณก่อนที่คุณจะเริ่มคอมไพล์ Bitcoin หากมีไลบรารีที่จำเป็นหายไป กระบวนการสร้างจะล้มเหลวและแสดงข้อผิดพลาด หากเกิดปัญหานี้เพราะคุณพลาด pre-requisite คุณสามารถติดตั้งไลบรารีที่ขาดหายไปแล้วดำเนินการสร้างต่อจากจุดที่ค้างไว้
สมมุติว่า pre-requisite ถูกติดตั้งแล้ว ให้เริ่มกระบวนการสร้างโดยการสร้างชุดสคริปต์สำหรับการสร้างด้วยการรันสคริปต์ autogen.sh:
``` $ ./autogen.sh libtoolize: putting auxiliary files in AC_CONFIG_AUX_DIR, 'build-aux'. libtoolize: copying file 'build-aux/ltmain.sh' libtoolize: putting macros in AC_CONFIG_MACRO_DIRS, 'build-aux/m4'. ... configure.ac:58: installing 'build-aux/missing' src/Makefile.am: installing 'build-aux/depcomp' parallel-tests: installing 'build-aux/test-driver'
``` สคริปต์ autogen.sh นี้จะสร้างชุดสคริปต์ที่กำหนดค่าอัตโนมัติที่จะตรวจสอบระบบของคุณเพื่อค้นหาการตั้งค่าที่ถูกต้องและตรวจสอบให้แน่ใจว่ามีไลบรารีที่จำเป็นสำหรับการคอมไพล์โค้ด โดยสคริปต์ที่สำคัญที่สุดในสคริปต์เหล่านี้คือสคริปต์ configure ซึ่งมีตัวเลือกต่าง ๆ สำหรับการปรับแต่งกระบวนการสร้าง
ใช้ flag --help เพื่อดูตัวเลือกทั้งหมด:
`` $ ./configure --helpconfigure' configures Bitcoin Core 24.0.1 to adapt to many kinds of systems. Usage: ./configure [OPTION]... [VAR=VALUE]... ... Optional Features: --disable-option-checking ignore unrecognized --enable/--with options --disable-FEATURE do not include FEATURE (same as --enable-FEATURE=no) --enable-FEATURE[=ARG] include FEATURE [ARG=yes] --enable-silent-rules less verbose build output (undo: "make V=1") --disable-silent-rules verbose build output (undo: "make V=0") ...```
สคริปต์ configure ช่วยให้คุณสามารถเปิดหรือปิดคุณสมบัติบางอย่างของ bitcoind ผ่านการใช้ flag --enable-FEATURE และ --disable-FEATURE โดยที่ FEATURE แทนชื่อคุณสมบัติที่ระบุในข้อความช่วยเหลือ ในบทนี้ เราจะสร้าง bitcoind ด้วยคุณสมบัติตั้งต้นทั้งหมด โดยไม่ใช้ flag การกำหนดค่าเพิ่มเติม แต่คุณควรตรวจสอบตัวเลือกเหล่านี้เพื่อเข้าใจว่ามีคุณสมบัติเพิ่มเติมอะไรบ้าง หากคุณอยู่ในสภาพแวดล้อมทางการศึกษา ห้องปฏิบัติการคอมพิวเตอร์ หรือมีข้อจำกัดในการติดตั้งโปรแกรม คุณอาจต้องติดตั้งแอปพลิเคชันไว้ในไดเรกทอรี home (เช่นโดยใช้ flag --prefix=$HOME)
ตัวเลือกที่มีประโยชน์สำหรับการกำหนดค่า
- --prefix=$HOME: เปลี่ยนตำแหน่งการติดตั้งเริ่มต้น (ซึ่งโดยปกติคือ /usr/local/) ให้เป็นไดเรกทอรี home ของคุณ หรือเส้นทางที่คุณต้องการ
- --disable-wallet: ใช้เพื่อปิดการใช้งานฟังก์ชัน wallet แบบอ้างอิง
- --with-incompatible-bdb: หากคุณกำลังสร้าง wallet ให้ยอมรับการใช้ไลบรารี Berkeley DB เวอร์ชันที่ไม่เข้ากันได้
- --with-gui=no: ไม่สร้างส่วนติดต่อผู้ใช้แบบกราฟิก (GUI) ซึ่งต้องใช้ไลบรารี Qt โดยตัวเลือกนี้จะสร้างเฉพาะเซิร์ฟเวอร์และ Bitcoin Core แบบ commandline เท่านั้น
```
ต่อไป ให้รันสคริปต์ configure เพื่อให้ระบบตรวจสอบไลบรารีที่จำเป็นทั้งหมดและสร้างสคริปต์สำหรับการสร้างที่ปรับแต่งให้ตรงกับระบบของคุณ:$ ./configure checking for pkg-config... /usr/bin/pkg-config checking pkg-config is at least version 0.9.0... yes checking build system type... x86_64-pc-linux-gnu checking host system type... x86_64-pc-linux-gnu checking for a BSD-compatible install... /usr/bin/install -c ... [many pages of configuration tests follow] ... ```หากทุกอย่างดำเนินไปด้วยดี คำสั่ง configure จะสิ้นสุดด้วยการสร้างสคริปต์การสร้างที่ปรับแต่งให้กับระบบของคุณ แต่หากมีไลบรารีที่หายไปหรือเกิดข้อผิดพลาด คำสั่ง configure จะหยุดและแสดงข้อผิดพลาดแทนที่จะสร้างสคริปต์ในกรณีที่เกิดข้อผิดพลาดขึ้น สาเหตุที่พบบ่อยคือการขาดหายหรือความไม่เข้ากันของไลบรารี ให้ตรวจสอบเอกสารการสร้างอีกครั้งและติดตั้ง pre-requisite ที่ขาดไป จากนั้นรัน configure อีกครั้งเพื่อดูว่าปัญหานั้นได้รับการแก้ไขแล้วหรือไม่
การสร้าง Executable ของ Bitcoin Core
ต่อไป คุณจะทำการคอมไพล์ซอร์สโค้ด กระบวนการนี้อาจใช้เวลาถึงหนึ่งชั่วโมง ขึ้นอยู่กับความเร็วของ CPU และหน่วยความจำที่มีอยู่ หากเกิดข้อผิดพลาด หรือการคอมไพล์ถูกขัดจังหวะ คุณสามารถดำเนินการต่อได้โดยการพิมพ์คำสั่ง make อีกครั้ง
พิมพ์ make เพื่อเริ่มคอมไพล์แอปพลิเคชันที่สามารถรันได้: ``` $ make Making all in src CXX bitcoind-bitcoind.o CXX libbitcoin_node_a-addrdb.o CXX libbitcoin_node_a-addrman.o CXX libbitcoin_node_a-banman.o CXX libbitcoin_node_a-blockencodings.o CXX libbitcoin_node_a-blockfilter.o [... many more compilation messages follow ...]
```
บนระบบที่มีความเร็วและมี CPU หลายคอร์ คุณอาจต้องการตั้งค่าจำนวนงานคอมไพล์แบบขนาน (parallel compile jobs) เช่น การใช้คำสั่ง make -j 2 จะใช้สองคอร์หากมีอยู่ หากทุกอย่างดำเนินไปด้วยดี Bitcoin Core จะถูกคอมไพล์เรียบร้อยแล้ว คุณควรรันชุดการทดสอบหน่วย (unit test suite) ด้วยคำสั่ง make check เพื่อให้แน่ใจว่าไลบรารีที่ลิงค์เข้าด้วยกันไม่มีข้อผิดพลาดอย่าง ขั้นตอนสุดท้ายคือการติดตั้ง executable ต่าง ๆ ลงในระบบของคุณโดยใช้คำสั่ง make install ซึ่งอาจมีการร้องขอรหัสผ่านของผู้ใช้เนื่องจากขั้นตอนนี้ต้องการสิทธิ์ผู้ดูแลระบบ: ``` $ make check && sudo make install Password: Making install in src ../build-aux/install-sh -c -d '/usr/local/lib' libtool: install: /usr/bin/install -c bitcoind /usr/local/bin/bitcoind libtool: install: /usr/bin/install -c bitcoin-cli /usr/local/bin/bitcoin-cli libtool: install: /usr/bin/install -c bitcoin-tx /usr/local/bin/bitcoin-tx ...
```
การติดตั้งเริ่มต้นของ bitcoind จะอยู่ในไดเรกทอรี /usr/local/bin โดยคุณสามารถตรวจสอบว่า Bitcoin Core ถูกติดตั้งเรียบร้อยแล้วโดยใช้คำสั่งเพื่อตรวจสอบตำแหน่งของ executable ดังนี้:
$ which bitcoind /usr/local/bin/bitcoind $ which bitcoin-cli /usr/local/bin/bitcoin-cliมาลองรัน Bitcoin node กันเถอะ
อย่างที่ได้กล่าวในบทก่อนหน้า เครือข่ายแบบเพียร์ทูเพียร์ของบิตคอยน์ประกอบด้วยเครือข่าย "โหนด" ซึ่งส่วนใหญ่รันโดยบุคคลและธุรกิจบางแห่งที่ให้บริการ ผู้ที่รันโหนดบิตคอยน์จะมีมุมมองที่ตรงและน่าเชื่อถือเกี่ยวกับบล๊อกเชนของบิตคอยน์พร้อมสำเนาข้อมูลบิตคอยน์ที่ใช้จ่ายได้ทั้งหมดซึ่งได้รับการตรวจสอบอย่างอิสระโดยระบบของตนเอง การรันโหนดทำให้คุณไม่ต้องพึ่งบุคคลที่สามในการตรวจสอบธุรกรรม นอกจากนี้การใช้โหนดบิตคอยน์เพื่อตรวจสอบธุรกรรมที่ได้รับในกระเป๋าเงินของคุณ ยังช่วยให้คุณมีส่วนร่วมในเครือข่ายบิตคอยน์และช่วยทำให้เครือข่ายมีความแข็งแกร่งมากขึ้นอีกด้วย
การรันโหนดต้องดาวน์โหลดและประมวลผลข้อมูลมากกว่า 500 GB ในช่วงเริ่มแรก และประมาณ 400 MB ของธุรกรรม Bitcoin ต่อวัน ตัวเลขเหล่านี้เป็นของปี 2023 และอาจเพิ่มขึ้นในอนาคต หากคุณปิดโหนดหรือหลุดจากอินเทอร์เน็ตเป็นเวลาหลายวัน โหนดของคุณจะต้องดาวน์โหลดข้อมูลที่พลาดไป ตัวอย่างเช่น หากคุณปิด Bitcoin Core เป็นเวลา 10 วัน คุณจะต้องดาวน์โหลดประมาณ 4 GB ในครั้งถัดไปที่คุณเริ่มใช้งาน
ขึ้นอยู่กับการเลือกของคุณว่าจะทำดัชนีธุรกรรมทั้งหมดและเก็บสำเนาบล๊อกเชนแบบเต็ม คุณอาจต้องใช้พื้นที่ดิสก์มาก - อย่างน้อย 1 TB หากคุณวางแผนจะรัน Bitcoin Core เป็นเวลาหลายปี โดยค่าเริ่มต้นโหนดบิตคอยน์ยังส่งธุรกรรมและบล็อกไปยังโหนดอื่น ๆ (เรียกว่า "เพียร์") ซึ่งจะใช้แบนด์วิดท์อัปโหลดอินเทอร์เน็ต หากการเชื่อมต่ออินเทอร์เน็ตของคุณมีขีดจำกัด มีขีดจำกัดการใช้ข้อมูลต่ำ หรือคิดค่าบริการตามข้อมูล (เมตเตอร์) คุณไม่ควรรันโหนดบิตคอยน์บนระบบนั้น หรือรันโดยจำกัดแบนด์วิดท์ (ดู การกำหนดค่าโหนด Bitcoin Core) คุณอาจเชื่อมต่อโหนดของคุณแทนไปยังเครือข่ายทางเลือก เช่น ผู้ให้บริการข้อมูลดาวเทียมฟรีอย่าง Blockstream Satellite
Tip: Bitcoin Core เก็บสำเนาบล๊อกเชนแบบเต็ม (ตามค่าเริ่มต้น ) พร้อมธุรกรรมเกือบทั้งหมดที่เคยได้รับการยืนยันบนเครือข่าย Bitcoin ตั้งแต่เริ่มต้นในปี 2009 ชุดข้อมูลนี้มีขนาดหลายร้อย GB และจะถูกดาวน์โหลดเพิ่มขึ้นทีละน้อยในช่วงหลายชั่วโมงหรือหลายวัน ขึ้นอยู่กับความเร็ว CPU และการเชื่อมต่ออินเทอร์เน็ตของคุณ Bitcoin Core จะไม่สามารถประมวลผลธุรกรรมหรืออัปเดตยอดคงเหลือของบัญชีจนกว่าชุดข้อมูล blockchain จะดาวน์โหลดเสร็จสมบูรณ์ ตรวจสอบให้แน่ใจว่าคุณมีพื้นที่ดิสก์ แบนด์วิดท์ และเวลาเพียงพอในการซิงโครไนซ์เริ่มแรก คุณสามารถกำหนดค่า Bitcoin Core เพื่อลดขนาด blockchain โดยการทิ้งบล็อกเก่า แต่โปรแกรมยังคงดาวน์โหลดชุดข้อมูลทั้งหมด
TIPจากหลาม agian: ซื้อ NVMe SSD 2TB เป็นอย่างต่ำซ่ะ m.2 ได้ยิ่งดีเลยจ้า
แม้ว่าจะมีข้อกำหนดด้านทรัพยากรเหล่านี้ แต่มีผู้คนหลายพันรายที่รันโหนด Bitcoin บางคนรันบนระบบง่าย ๆ อย่าง Raspberry Pi (คอมพิวเตอร์ราคา 35 เหรียญสหรัฐที่มีขนาดเท่ากับกล่องบุหรี่)
ทำไมคุณถึงอยากรันโหนด? นี่คือเหตุผลที่พบบ่อยที่สุด:
- คุณไม่ต้องการพึ่งบุคคลที่สามในการตรวจสอบธุรกรรมที่คุณได้รับ
- คุณไม่ต้องการเปิดเผยให้บุคคลที่สามรู้ว่าธุรกรรมใดเป็นของกระเป๋าเงินคุณ
- คุณกำลังพัฒนาซอฟต์แวร์ Bitcoin และต้องการพึ่งโหนด Bitcoin เพื่อเข้าถึงเครือข่ายและ blockchain ผ่าน API
- คุณกำลังสร้างแอปพลิเคชันที่ต้องตรวจสอบธุรกรรมตามกฎฉันทามติของ Bitcoin โดยทั่วไป บริษัทซอฟต์แวร์ Bitcoin มักจะรันโหนดหลายโหนด
- คุณต้องการสนับสนุน Bitcoin การรันโหนดที่คุณใช้ตรวจสอบธุรกรรมที่ได้รับในกระเป๋าเงินจะช่วยทำให้เครือข่ายมีความแข็งแกร่งมากขึ้น
หากคุณกำลังอ่านหนังสือเล่มนี้และสนใจความปลอดภัยที่เข้มงวด ความเป็นส่วนตัวที่เหนือกว่า หรือการพัฒนาซอฟต์แวร์ Bitcoin คุณควรรันโหนดของตัวเอง
การกำหนดค่าโหนด Bitcoin Core
Bitcoin Core จะค้นหาไฟล์การกำหนดค่าในไดเรกทอรีข้อมูลทุกครั้งที่เริ่มทำงาน ในส่วนนี้เราจะตรวจสอบตัวเลือกการกำหนดค่าต่าง ๆ และตั้งค่าไฟล์การกำหนดค่า
เพื่อค้นหาไฟล์การกำหนดค่า ให้รัน bitcoind -printtoconsole ในเทอร์มินัลของคุณ และดูบรรทัดแรก ๆ:
$ bitcoind -printtoconsole 2023-01-28T03:21:42Z Bitcoin Core version v24.0.1 2023-01-28T03:21:42Z Using the 'x86_shani(1way,2way)' SHA256 implementation 2023-01-28T03:21:42Z Using RdSeed as an additional entropy source 2023-01-28T03:21:42Z Using RdRand as an additional entropy source 2023-01-28T03:21:42Z Default data directory /home/harding/.bitcoin 2023-01-28T03:21:42Z Using data directory /home/harding/.bitcoin 2023-01-28T03:21:42Z Config file: /home/harding/.bitcoin/bitcoin.conf ... [a lot more debug output] ...tatatipจากหลามอีกครั้ง: สังเกตเห็นหรือไม่ว่าในตัวอย่างนี้ Bitcoin Core กำลังชี้ไปที่ไฟล์การกำหนดค่าที่ไดเรกทอรี /home/harding/.bitcoin/bitcoin.conf ซึ่งจะแตกต่างกันไปขึ้นอยู่กับผู้ใช้และระบบปฏิบัติการ
คุณสามารถกด Ctrl-C เพื่อปิดโหนดหลังจากที่ระบุตำแหน่งไฟล์การกำหนดค่า โดยปกติไฟล์การกำหนดค่าจะอยู่ในไดเรกทอรี .bitcoin ภายใต้โฮมไดเรกทอรีของผู้ใช้ เปิดไฟล์ configuration ด้วยโปรแกรมแก้ไขได้ตามที่คุณชอบ
Bitcoin Core มีตัวเลือกการกำหนดค่ามากกว่า 100 ตัวเลือกที่สามารถปรับเปลี่ยนพฤติกรรมของโหนดเครือข่าย การจัดเก็บบล๊อกเชน และแง่มุมอื่น ๆ ของการทำงาน เพื่อดูรายการตัวเลือก ให้รัน bitcoind --help:
$ bitcoind --help Bitcoin Core version v24.0.1 Usage: bitcoind [options] Start Bitcoin Core Options: -? Print this help message and exit -alertnotify=<cmd> Execute command when an alert is raised (%s in cmd is replaced by message) ... [many more options]นี่คือตัวเลือกที่บางประการที่คุณสามารถตั้งในไฟล์ configuration หรือเป็นพารามิเตอร์บรรทัดคำสั่งสำหรับ bitcoind:
- alertnotify: เรียกใช้คำสั่งหรือสคริปต์เพื่อส่งการแจ้งเตือนฉุกเฉินไปยังเจ้าของโหนดนี้
- conf: ตำแหน่งทางเลือกสำหรับไฟล์ configuration เมื่อใช้เป็นพารามิเตอร์ cli สำหรับ bitcoind เท่านั้น เนื่องจากไม่สามารถอยู่ในไฟล์ configuration ที่มันอ้างถึงได้
- datadir: เลือกไดเรกทอรีและระบบไฟล์สำหรับจัดเก็บข้อมูลบล๊อกเชนตามค่าเริ่มต้นนี้คือไดเรกทอรีย่อย .bitcoin ในไดเรกทอรีโฮมของคุณ ขึ้นอยู่กับการกำหนดค่า สามารถใช้พื้นที่ตั้งแต่ประมาณ 10 GB ถึงเกือบ 1 TB ณ ขณะนี้ คาดว่าขนาดสูงสุดจะเพิ่มขึ้นหลายร้อย GB ต่อปี
- prune: ลดความต้องการพื้นที่ดิสก์บล๊อกเชนลงเหลือกี่เมกะไบต์โดยการลบบล็อกเก่า ใช้สำหรับโหนดที่มีทรัพยากรจำกัดซึ่งไม่สามารถบรรจุบล๊อกเชนแบบเต็มได้ ส่วนอื่น ๆ ของระบบจะใช้พื้นที่ดิสก์อื่นที่ไม่สามารถตัดทอนได้ ดังนั้นคุณยังคงต้องมีพื้นที่อย่างน้อยตามที่ระบุในตัวเลือก datadir
- txindex: รักษาดัชนีของธุรกรรมทั้งหมด ช่วยให้คุณสามารถดึงธุรกรรมใด ๆ โดยใช้ ID ของมันได้โดยโปรแกรม โดยที่บล็อกที่มีธุรกรรมนั้นยังไม่ถูกตัดทอน
- dbcache: ขนาดของแคช UTXO ค่าเริ่มต้นคือ 450 เมบิไบต์ (MiB) เพิ่มขนาดนี้บนฮาร์ดแวร์ระดับสูงเพื่ออ่านและเขียนจากดิสก์น้อยลง หรือลดขนาดลงบนฮาร์ดแวร์ระดับต่ำเพื่อประหยัดหน่วยความจำโดยยอมให้ใช้ดิสก์บ่อยขึ้น
- blocksonly: ลดการใช้แบนด์วิดท์โดยการรับเฉพาะบล็อกของธุรกรรมที่ได้รับการยืนยันจากเพียร์ แทนที่จะส่งต่อธุรกรรมที่ยังไม่ได้รับการยืนยัน
- maxmempool: จำกัดพูลหน่วยความจำของธุรกรรมเป็นกี่เมกะไบต์ ใช้เพื่อลดการใช้หน่วยความจำบนโหนดที่มีหน่วยความจำจำกัด
ดัชนีฐานข้อมูลธุรกรรมและตัวเลือก txindex
ตามค่าเริ่มต้น Bitcoin Core จะสร้างฐานข้อมูลที่มีเพียงธุรกรรมที่เกี่ยวข้องกับกระเป๋าเงินของผู้ใช้เท่านั้น หากคุณต้องการสามารถเข้าถึงธุรกรรมใด ๆ ด้วยคำสั่งเช่น getrawtransaction คุณจะต้องกำหนดค่า Bitcoin Core ให้สร้างดัชนีธุรกรรมแบบสมบูรณ์ ซึ่งสามารถทำได้ด้วยตัวเลือก txindex โดยตั้ง txindex=1 ในไฟล์การกำหนดค่า Bitcoin Core หากคุณไม่ได้ตั้งตัวเลือกนี้ตั้งแต่แรกและต่อมาตั้งเป็นการทำดัชนีแบบเต็ม คุณจะต้องรอให้มันสร้างดัชนีใหม่
ตัวอย่างการกำหนดค่าโหนดดัชนีแบบเต็มแสดงวิธีที่คุณอาจรวมตัวเลือกก่อนหน้านี้กับโหนดที่มีดัชนีแบบเต็ม โดยทำงานเป็นแบ็กเอนด์ API สำหรับแอปพลิเคชัน bitcoin
ตัวอย่างที่ 1. การกำหนดค่าโหนดดัชนีแบบเต็ม
alertnotify=myemailscript.sh "Alert: %s" datadir=/lotsofspace/bitcoin txindex=1ตัวอย่างที่ 2. การกำหนดค่าระบบที่มีทรัพยากรจำกัด
alertnotify=myemailscript.sh "Alert: %s" blocksonly=1 prune=5000 dbcache=150 maxmempool=150หลังจากที่คุณแก้ไขไฟล์การกำหนดค่าและตั้งตัวเลือกที่ดีที่สุดตามความต้องการของคุณ คุณสามารถทดสอบ bitcoind ด้วยการกำหนดค่านี้ รัน Bitcoin Core ด้วยตัวเลือก printtoconsole เพื่อรันที่ foreground พร้อมแสดงผลลัพธ์ที่คอนโซล:
$ bitcoind -printtoconsole 2023-01-28T03:43:39Z Bitcoin Core version v24.0.1 2023-01-28T03:43:39Z Using the 'x86_shani(1way,2way)' SHA256 implementation 2023-01-28T03:43:39Z Using RdSeed as an additional entropy source 2023-01-28T03:43:39Z Using RdRand as an additional entropy source 2023-01-28T03:43:39Z Default data directory /home/harding/.bitcoin 2023-01-28T03:43:39Z Using data directory /lotsofspace/bitcoin 2023-01-28T03:43:39Z Config file: /home/harding/.bitcoin/bitcoin.conf 2023-01-28T03:43:39Z Config file arg: [main] blockfilterindex="1" 2023-01-28T03:43:39Z Config file arg: [main] maxuploadtarget="1000" 2023-01-28T03:43:39Z Config file arg: [main] txindex="1" 2023-01-28T03:43:39Z Setting file arg: wallet = ["msig0"] 2023-01-28T03:43:39Z Command-line arg: printtoconsole="" 2023-01-28T03:43:39Z Using at most 125 automatic connections 2023-01-28T03:43:39Z Using 16 MiB out of 16 MiB requested for signature cache 2023-01-28T03:43:39Z Using 16 MiB out of 16 MiB requested for script execution 2023-01-28T03:43:39Z Script verification uses 3 additional threads 2023-01-28T03:43:39Z scheduler thread start 2023-01-28T03:43:39Z [http] creating work queue of depth 16 2023-01-28T03:43:39Z Using random cookie authentication. 2023-01-28T03:43:39Z Generated RPC cookie /lotsofspace/bitcoin/.cookie 2023-01-28T03:43:39Z [http] starting 4 worker threads 2023-01-28T03:43:39Z Using wallet directory /lotsofspace/bitcoin/wallets 2023-01-28T03:43:39Z init message: Verifying wallet(s)… 2023-01-28T03:43:39Z Using BerkeleyDB version Berkeley DB 4.8.30 2023-01-28T03:43:39Z Using /16 prefix for IP bucketing 2023-01-28T03:43:39Z init message: Loading P2P addresses… 2023-01-28T03:43:39Z Loaded 63866 addresses from peers.dat 114ms [... more startup messages ...]คุณสามารถกด Ctrl-C เพื่อหยุดกระบวนการเมื่อคุณพอใจว่ากำลังโหลดการตั้งค่าที่ถูกต้องและทำงานตามที่คาดหวัง
เพื่อรัน Bitcoin Core ที่พื้นหลังเป็นโพรเซส ให้เริ่มด้วยตัวเลือก daemon เช่น bitcoind -daemon
เพื่อตรวจสอบความคืบหน้าและสถานะการทำงานของโหนด Bitcoin ให้เริ่มในโหมด daemon แล้วใช้คำสั่ง bitcoin-cli getblockchaininfo:
``` $ bitcoin-cli getblockchaininfo
{ "chain": "main", "blocks": 0, "headers": 83999, "bestblockhash": "[...]19d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f", "difficulty": 1, "time": 1673379796, "mediantime": 1231006505, "verificationprogress": 3.783041623201835e-09, "initialblockdownload": true, "chainwork": "[...]000000000000000000000000000000000000000000000100010001", "size_on_disk": 89087, "pruned": false, "warnings": "" }
```
นี่แสดงโหนดที่มีความสูงของ blockchain เป็น 0 บล็อก และ 83,999 เฮดเดอร์ โหนดจะดึงเฮดเดอร์ของบล็อกจากเพียร์ของตนก่อนเพื่อค้นหา blockchain ที่มีหลักฐานการทำงานมากที่สุด จากนั้นจึงดำเนินการดาวน์โหลดบล็อกเต็มโดยตรวจสอบความถูกต้องไปพร้อมกัน
เมื่อคุณพอใจกับตัวเลือกการกำหนดค่าที่เลือก คุณควรเพิ่ม Bitcoin Core ลงในสคริปต์เริ่มต้นของระบบปฏิบัติการ เพื่อให้มันทำงานอย่างต่อเนื่องและรีสตาร์ทเมื่อระบบปฏิบัติการรีสตาร์ท คุณจะพบสคริปต์เริ่มต้นตัวอย่างสำหรับระบบปฏิบัติการต่าง ๆ ในไดเรกทอรีซอร์สของ Bitcoin Core ภายใต้ contrib/init และไฟล์ README.md ที่แสดงว่าระบบใดใช้สคริปต์ใด
Bitcoin Core API
Bitcoin Core ใช้อินเทอร์เฟซ JSON-RPC ซึ่งสามารถเข้าถึงได้โดยใช้เครื่องมืออย่าง bitcoin-cli ซึ่งช่วยให้เราสามารถทดลองใช้งานความสามารถต่างๆ แบบโต้ตอบได้ ซึ่งความสามารถเหล่านี้ยังสามารถใช้งานได้ผ่านทาง API ในรูปแบบโปรแกรม เพื่อเริ่มต้น ให้เรียกใช้คำสั่ง help เพื่อดูรายการคำสั่ง Bitcoin Core RPC ที่มีอยู่:
$ bitcoin-cli help +== Blockchain == getbestblockhash getblock "blockhash" ( verbosity ) getblockchaininfo ... walletpassphrase "passphrase" timeout walletpassphrasechange "oldpassphrase" "newpassphrase" walletprocesspsbt "psbt" ( sign "sighashtype" bip32derivs finalize )คำสั่งแต่ละรายการอาจต้องการพารามิเตอร์หลายตัว เพื่อรับความช่วยเหลือเพิ่มเติม คำอธิบายโดยละเอียด และข้อมูลเกี่ยวกับพารามิเตอร์ต่างๆ ให้เพิ่มชื่อคำสั่งหลังคำว่า help ตัวอย่างเช่น เพื่อดูความช่วยเหลือเกี่ยวกับคำสั่ง RPC getblockhash: ``` $ bitcoin-cli help getblockhash getblockhash height Returns hash of block in best-block-chain at height provided. Arguments: 1. height (numeric, required) The height index Result: "hex" (string) The block hash Examples:
bitcoin-cli getblockhash 1000 curl --user myusername --data-binary '{"jsonrpc": "1.0", "id": "curltest", "method": "getblockhash", "params": [1000]}' -H 'content-type: text/plain;' http://127.0.0.1:8332/ ``` ในส่วนท้ายของข้อมูลคำสั่ง help คุณจะเห็นตัวอย่างสองตัวอย่างของคำสั่ง RPC ซึ่งใช้ตัวช่วย bitcoin-cli หรือ HTTP client curl ตัวอย่างเหล่านี้แสดงให้เห็นว่าคุณอาจเรียกใช้คำสั่งได้อย่างไร ลองคัดลอกตัวอย่างแรกและดูผลลัพธ์:
$ bitcoin-cli getblockhash 1000 00000000c937983704a73af28acdec37b049d214adbda81d7e2a3dd146f6ed09ผลลัพธ์คือแฮชของบล็อก ซึ่งจะอธิบายในรายละเอียดเพิ่มเติมในบทต่อไป แต่ในตอนนี้ คำสั่งนี้ควรให้ผลลัพธ์เหมือนกันบนระบบของคุณ ซึ่งแสดงให้เห็นว่าโหนด Bitcoin Core ของคุณกำลังทำงาน กำลังรับคำสั่ง และมีข้อมูลเกี่ยวกับบล็อก 1,000 ที่จะส่งกลับมาให้คุณ
การรับข้อมูลสถานะของ Bitcoin Core
Bitcoin Core ให้รายงานสถานะเกี่ยวกับโมดูลต่างๆ ผ่านอินเตอร์เฟส JSON-RPC คำสั่งที่สำคัญที่สุดรวมถึง getblockchaininfo, getmempoolinfo, getnetworkinfo และ getwalletinfo
คำสั่ง RPC getblockchaininfo ของ Bitcoin ได้ถูกแนะนำไปก่อนหน้านี้แล้ว คำสั่ง getnetworkinfo แสดงข้อมูลพื้นฐานเกี่ยวกับสถานะของโหนดเครือข่าย Bitcoin ใช้ bitcoin-cli เพื่อรันคำสั่งนี้:
$ bitcoin-cli getnetworkinfo { "version": 240001, "subversion": "/Satoshi:24.0.1/", "protocolversion": 70016, "localservices": "0000000000000409", "localservicesnames": [ "NETWORK", "WITNESS", "NETWORK_LIMITED" ], "localrelay": true, "timeoffset": -1, "networkactive": true, "connections": 10, "connections_in": 0, "connections_out": 10, "networks": [ "...detailed information about all networks..." ], "relayfee": 0.00001000, "incrementalfee": 0.00001000, "localaddresses": [ ], "warnings": "" }ซึ่งข้อมูลต่าง ๆ จะถูกส่งคืนในรูปแบบ JavaScript Object Notation (JSON) ซึ่งเป็นรูปแบบที่สามารถ "อ่าน" ได้อย่างง่ายดายโดยทุกภาษาโปรแกรมมิ่ง และยังเป็นรูปแบบที่มนุษย์อ่านได้ง่ายอีกด้วย ในข้อมูลนี้เราเห็นหมายเลขเวอร์ชันสำหรับซอฟต์แวร์ Bitcoin Core และโปรโตคอลบิตคอยน์เราเห็นจำนวนการเชื่อมต่อในปัจจุบันและข้อมูลต่างๆ เกี่ยวกับเครือข่ายบิตคอยน์และการตั้งค่าที่เกี่ยวข้องกับโหนดนี้
TIP: จะใช้เวลาสักระยะ อาจมากกว่าหนึ่งวัน สำหรับ bitcoind ในการอัพเดทให้ทันกับบล็อกล่าสุดของบล็อกเชนปัจจุบัน ในขณะที่มันดาวน์โหลดบล็อกจากโหนดอื่นๆ และตรวจสอบความถูกต้องของทุกธุรกรรมในบล็อกเหล่านั้น—ซึ่งมีเกือบหนึ่งพันล้านธุรกรรม ณ เวลาที่เขียนนี้ คุณสามารถตรวจสอบความคืบหน้าโดยใช้ getblockchaininfo เพื่อดูจำนวนบล็อกที่ทราบ ตัวอย่างในส่วนที่เหลือของบทนี้สมมติว่าคุณอยู่อย่างน้อยที่บล็อก 775,072 เนื่องจากความปลอดภัยของธุรกรรมขึ้นอยู่กับจำ
มาสำรวจและถอดรหัสธุรกรรมของบิตคอยน์กันเถอะ!!
อย่างในบทที่สอง อลิซได้ซื้อสินค้าจากร้านของบ็อบและธุรกรรมของเธอถูกบันทึกลงในบล็อกเชนของบิตคอยน์ โดยเราสามารถใช้ API เพื่อดึงและตรวจสอบธุรกรรมนั้นได้โดยการใช้ txid เป็นพารามิเตอร์:
$ bitcoin-cli getrawtransaction 466200308696215bbc949d5141a49a4138ecdfdfaa2a8029c1f9bcecd1f96177 --ผลลัพธ์ของคำสั่ง 01000000000101eb3ae38f27191aa5f3850dc9cad00492b88b72404f9da13569 8679268041c54a0100000000ffffffff02204e0000000000002251203b41daba 4c9ace578369740f15e5ec880c28279ee7f51b07dca69c7061e07068f8240100 000000001600147752c165ea7be772b2c0acb7f4d6047ae6f4768e0141cf5efe 2d8ef13ed0af21d4f4cb82422d6252d70324f6f4576b727b7d918e521c00b51b e739df2f899c49dc267c0ad280aca6dab0d2fa2b42a45182fc83e81713010000 0000TIP: txid ไม่ใช่สิ่งที่สามารถเชื่อถือได้ขนาดนั้น เพราะการไม่มี txid ในบล๊อกเชนของบิตคอยน์นั้นไม่ได้หมายความว่าธุรกรรมไม่ได้ถูกประมวลผล โดยสิ่งนี้เรียกว่า "transaction malleability" (ความสามารถในการเปลี่ยนแปลงธุรกรรม) เพราะธุรกรรมสามารถถูกแก้ไขก่อนการยืนยันในบล็อก ซึ่งเปลี่ยน txid ของพวกมัน หลังจากธุรกรรมถูกรวมอยู่ในบล็อกแล้ว txid ของมันไม่สามารถเปลี่ยนแปลงได้อีก เว้นแต่จะมีการจัดระเบียบบล็อกเชนใหม่และบล็อกนั้นถูกลบออกจากบล็อกเชนที่ดีที่สุด โดยการจัดระเบียบใหม่เกิดขึ้นได้ยากหลังจากธุรกรรมได้รับการยืนยันหลายครั้งแล้ว
คำสั่ง getrawtransaction จะส่งคืนธุรกรรมที่เข้ารหัสในรูปแบบเลขฐานสิบหกและเพื่อถอดรหัสนั้น เราใช้คำสั่ง decoderawtransaction โดยส่งข้อมูลเลขฐานสิบหกเป็นพารามิเตอร์ คุณสามารถคัดลอกเลขฐานสิบหกที่ส่งคืนโดย getrawtransaction และวางเป็นพารามิเตอร์ให้กับ decoderawtransaction ได้:
$ bitcoin-cli decoderawtransaction 01000000000101eb3ae38f27191aa5f3850dc9cad00492b88b72404f9da135698679268041c54a0100000000ffffffff02204e0000000000002251203b41daba4c9ace578369740f15e5ec880c28279ee7f51b07dca69c7061e07068f8240100000000001600147752c165ea7be772b2c0acb7f4d6047ae6f4768e0141cf5efe2d8ef13ed0af21d4f4cb82422d6252d70324f6f4576b727b7d918e521c00b51be739df2f899c49dc267c0ad280aca6dab0d2fa2b42a45182fc83e817130100000000 --ผลลัพธ์ของคำสั่ง { "txid": "466200308696215bbc949d5141a49a4138ecdfdfaa2a8029c1f9bcecd1f96177", "hash": "f7cdbc7cf8b910d35cc69962e791138624e4eae7901010a6da4c02e7d238cdac", "version": 1, "size": 194, "vsize": 143, "weight": 569, "locktime": 0, "vin": [ { "txid": "4ac541802679866935a19d4f40728bb89204d0cac90d85f3a51a19...aeb", "vout": 1, "scriptSig": { "asm": "", "hex": "" }, "txinwitness": [ "cf5efe2d8ef13ed0af21d4f4cb82422d6252d70324f6f4576b727b7d918e5...301" ], "sequence": 4294967295 } ], "vout": [ { "value": 0.00020000, "n": 0, "scriptPubKey": { "asm": "1 3b41daba4c9ace578369740f15e5ec880c28279ee7f51b07dca...068", "desc": "rawtr(3b41daba4c9ace578369740f15e5ec880c28279ee7f51b...6ev", "hex": "51203b41daba4c9ace578369740f15e5ec880c28279ee7f51b07d...068", "address": "bc1p8dqa4wjvnt890qmfws83te0v3qxzsfu7ul63kp7u56w8q...5qn", "type": "witness_v1_taproot" } }, { "value": 0.00075000, "n": 1, "scriptPubKey": { "asm": "0 7752c165ea7be772b2c0acb7f4d6047ae6f4768e", "desc": "addr(bc1qwafvze0200nh9vkq4jmlf4sy0tn0ga5w0zpkpg)#qq404gts", "hex": "00147752c165ea7be772b2c0acb7f4d6047ae6f4768e", "address": "bc1qwafvze0200nh9vkq4jmlf4sy0tn0ga5w0zpkpg", "type": "witness_v0_keyhash" } } ] }การถอดรหัสธุรกรรมแสดงส่วนประกอบทั้งหมดของธุรกรรมนี้ รวมถึงอินพุตและเอาต์พุตของธุรกรรม ในกรณีนี้เราเห็นว่าธุรกรรมใช้อินพุตหนึ่งรายการและสร้างเอาต์พุตสองรายการ อินพุตของธุรกรรมนี้คือเอาต์พุตจากธุรกรรมที่ได้รับการยืนยันก่อนหน้านี้ (แสดงเป็น txid ของอินพุต) เอาต์พุตทั้งสองรายการสอดคล้องกับการชำระเงินให้บ็อบและเงินทอนกลับให้อลิซ
มาสำรวจบล็อกของบิตคอยน์กัน!!
การสำรวจบล็อกนั้นคล้ายกับการสำรวจธุรกรรม แต่อย่างไรก็ตามบล็อกสามารถอ้างอิงได้ทั้งโดยลำดับของบล็อกหรือโดยแฮชของบล็อก เราใช้คำสั่ง getblockhash ซึ่งรับลำดับของบล็อกเป็นพารามิเตอร์และส่งคืน แฮชของบล็อกนั้น:
$ bitcoin-cli getblockhash 123456 --ผลลัพธ์ของคำสั่ง 0000000000002917ed80650c6174aac8dfc46f5fe36480aaef682ff6cd83c3caตอนนี้เรารู้แฮชสำหรับบล็อกที่เราเลือกแล้ว เราสามารถดูบล็อกนั้นได้ เราใช้คำสั่ง getblock โดยมีแฮชของบล็อกเป็นพารามิเตอร์:$ bitcoin-cli getblockhash 0000000000002917ed80650c6174aac8dfc46f5fe36480aaef682ff6cd83c3ca --ผลลัพธ์ของคำสั่ง { "hash": "0000000000002917ed80650c6174aac8dfc46f5fe36480aaef682ff6cd83c3ca", "confirmations": 651742, "height": 123456, "version": 1, "versionHex": "00000001", "merkleroot": "0e60651a9934e8f0decd1c[...]48fca0cd1c84a21ddfde95033762d86c", "time": 1305200806, "mediantime": 1305197900, "nonce": 2436437219, "bits": "1a6a93b3", "difficulty": 157416.4018436489, "chainwork": "[...]00000000000000000000000000000000000000541788211ac227bc", "nTx": 13, "previousblockhash": "[...]60bc96a44724fd72daf9b92cf8ad00510b5224c6253ac40095", "nextblockhash": "[...]00129f5f02be247070bf7334d3753e4ddee502780c2acaecec6d66", "strippedsize": 4179, "size": 4179, "weight": 16716, "tx": [ "5b75086dafeede555fc8f9a810d8b10df57c46f9f176ccc3dd8d2fa20edd685b", "e3d0425ab346dd5b76f44c222a4bb5d16640a4247050ef82462ab17e229c83b4", "137d247eca8b99dee58e1e9232014183a5c5a9e338001a0109df32794cdcc92e", "5fd167f7b8c417e59106ef5acfe181b09d71b8353a61a55a2f01aa266af5412d", "60925f1948b71f429d514ead7ae7391e0edf965bf5a60331398dae24c6964774", "d4d5fc1529487527e9873256934dfb1e4cdcb39f4c0509577ca19bfad6c5d28f", "7b29d65e5018c56a33652085dbb13f2df39a1a9942bfe1f7e78e97919a6bdea2", "0b89e120efd0a4674c127a76ff5f7590ca304e6a064fbc51adffbd7ce3a3deef", "603f2044da9656084174cfb5812feaf510f862d3addcf70cacce3dc55dab446e", "9a4ed892b43a4df916a7a1213b78e83cd83f5695f635d535c94b2b65ffb144d3", "dda726e3dad9504dce5098dfab5064ecd4a7650bfe854bb2606da3152b60e427", "e46ea8b4d68719b65ead930f07f1f3804cb3701014f8e6d76c4bdbc390893b94", "864a102aeedf53dd9b2baab4eeb898c5083fde6141113e0606b664c41fe15e1f" ] }รายการ confirmations บอกเราถึง ความลึก ของบล็อกนี้—มีกี่บล็อกที่ถูกสร้างทับบนบล็อกนี้ ซึ่งบ่งบอกถึงความยากในการเปลี่ยนแปลงธุรกรรมใดๆ ในบล็อกนี้ ลำดับบอกเราว่ามีกี่บล็อกที่มาก่อนหน้าบล็อกนี้ เราเห็นเวอร์ชันของบล็อก เวลาที่มันถูกสร้าง (ตามข้อมูลของนักขุด) เวลาเฉลี่ยของ 11 บล็อกที่มาก่อนหน้าบล็อกนี้ (การวัดเวลาที่นักขุดปลอมแปลงได้ยากกว่า) และขนาดของบล็อกในการวัดสามแบบต่างกัน (ขนาดดั้งเดิมที่ถูกลบข้อมูลบางส่วนออก, ขนาดเต็ม, และขนาดในหน่วยน้ำหนัก) เรายังเห็นฟิลด์บางอย่างที่ใช้สำหรับความปลอดภัยและหลักฐานการทำงาน (merkle root, nonce, bits, difficulty, และ chainwork) เราจะตรวจสอบสิ่งเหล่านี้โดยละเอียดในส่วนของการขุดในบทที่ 12การใช้อินเตอร์เฟสโปรแกรมของ Bitcoin Core
bitcoin-cli มีประโยชน์มากสำหรับการใช้งาน API ของ Bitcoin Core และการทดสอบฟังก์ชันต่าง ๆ แต่จุดประสงค์หลักของ API คือการเข้าถึงฟังก์ชันด้วยโปรแกรม ในส่วนนี้เราจะสาธิตการเข้าถึง Bitcoin Core จากโปรแกรมอื่น
API ของ Bitcoin Core เป็นอินเตอร์เฟส JSON-RPC โดย JSON เป็นวิธีที่สะดวกมากในการนำเสนอข้อมูลที่ทั้งมนุษย์และโปรแกรมสามารถอ่านได้ง่าย RPC ย่อมาจาก remote procedure call ซึ่งหมายความว่าเรากำลังเรียกใช้กระบวนการ (ฟังก์ชัน) ที่อยู่ห่างไกล (บนโหนด Bitcoin Core) ผ่านโปรโตคอลเครือข่าย ในกรณีนี้ โปรโตคอลเครือข่ายคือ HTTP
เมื่อเราใช้คำสั่ง bitcoin-cli เพื่อขอความช่วยเหลือเกี่ยวกับคำสั่ง มันแสดงตัวอย่างการใช้ curl ซึ่งเป็นไคลเอนต์ HTTP ทางคอมมานด์ไลน์ที่ยืดหยุ่น เพื่อสร้างคำเรียก JSON-RPC เหล่านี้:
$ curl --user myusername --data-binary '{"jsonrpc": "1.0", "id":"curltest", "method": "getblockchaininfo", "params": [] }' -H 'content-type: text/plain;' http://127.0.0.1:8332/คำสั่งนี้แสดงว่า curl ส่งคำขอ HTTP ไปยัง localhost (127.0.0.1) เชื่อมต่อกับพอร์ต RPC เริ่มต้นของ Bitcoin (8332) และส่งคำขอ jsonrpc โดยใช้เมธอดเป็น getblockchaininfo โดยใช้การเข้ารหัสแบบ text/plain
คุณอาจสังเกตว่า curl จะขอให้ส่งข้อมูลประจำตัวไปพร้อมกับคำขอ Bitcoin Core จะสร้างรหัสผ่านแบบสุ่มในแต่ละครั้งที่เริ่มต้นและวางไว้ในไดเรกทอรีข้อมูลภายใต้ชื่อ .cookie โดย bitcoin-cli สามารถอ่านไฟล์รหัสผ่านนี้โดยให้ไดเรกทอรีข้อมูล ในทำนองเดียวกัน คุณสามารถคัดลอกรหัสผ่านและส่งไปยัง curl (หรือตัวครอบ Bitcoin Core RPC ระดับสูงอื่น ๆ ) ตามที่เห็นในการใช้การตรวจสอบสิทธิ์แบบใช้คุกกี้กับ Bitcoin Core
ตัวอย่างที่ 3. การใช้การตรวจสอบสิทธิ์แบบใช้คุกกี้กับ Bitcoin Core
$ cat .bitcoin/.cookie __cookie__:17c9b71cef21b893e1a019f4bc071950c7942f49796ed061b274031b17b19cd0 $ curl --user __cookie__:17c9b71cef21b893e1a019f4bc071950c7942f49796ed061b274031b17b19cd0 --data-binary '{"jsonrpc": "1.0", "id":"curltest", "method": "getblockchaininfo", "params": [] }' -H 'content-type: text/plain;' http://127.0.0.1:8332/ {"result":{"chain":"main","blocks":799278,"headers":799278, "bestblockhash":"000000000000000000018387c50988ec705a95d6f765b206b6629971e6978879", "difficulty":53911173001054.59,"time":1689703111,"mediantime":1689701260, "verificationprogress":0.9999979206082515,"initialblockdownload":false, "chainwork":"00000000000000000000000000000000000000004f3e111bf32bcb47f9dfad5b", "size_on_disk":563894577967,"pruned":false,"warnings":""},"error":null, "id":"curltest"}นอกจากนี้คุณยังสามารถตั้งรหัสผ่านด้วยตัวเองใน ./share/rpcauth/rpcauth.py ภายในไดเรกทอรีของ Bitcoin Core
หากคุณกำลังใช้การเรียก JSON-RPC ในโปรแกรมของคุณเอง คุณสามารถใช้ไลบรารี HTTP ทั่วไปเพื่อสร้างการเรียกได้ คล้ายกับที่แสดงในตัวอย่าง curl ก่อนหน้านี้
อย่างไรก็ตาม มีไลบรารีในภาษาโปรแกรมยอดนิยมส่วนใหญ่ที่ "wrap" API ของ Bitcoin Core ในลักษณะที่ทำให้การใช้งานง่ายขึ้นมาก เราจะใช้ไลบรารี python-bitcoinlib เพื่อทำให้การเข้าถึง API นั้นง่ายขึ้น โดยไลบรารีนี้ไม่ได้เป็นส่วนหนึ่งของโครงการ Bitcoin Core และจำเป็นต้องติดตั้งด้วยวิธีปกติที่คุณติดตั้งไลบรารี Python โปรดจำไว้ว่า การใช้งานนี้ต้องมีอินสแตนซ์ Bitcoin Core ที่กำลังทำงานอยู่ ซึ่งจะถูกใช้เพื่อทำการเรียก JSON-RPC
ตัวอย่างสคริปต์ Python ใน " การทำงาน getblockchaininfo ผ่าน API JSON-RPC ของ Bitcoin Core" ซึ่งทำการเรียก getblockchaininfo อย่างง่ายและพิมพ์พารามิเตอร์ block จากข้อมูลที่ส่งคืนโดย Bitcoin Core
ตัวอย่างที่ 4. การทำงาน getblockchaininfo ผ่าน API JSON-RPC ของ Bitcoin Core ``` from bitcoin.rpc import RawProxy
Create a connection to local Bitcoin Core node
p = RawProxy()
Run the getblockchaininfo command, store the resulting data in info
info = p.getblockchaininfo()
Retrieve the 'blocks' element from the info
print(info['blocks']) --ผลลัพธ์ของคำสั่ง $ python rpc_example.py 773973 ``` มันบอกเราว่าโหนด Bitcoin Core ในเครื่องของเรามีกี่บล็อกในบล็อกเชนของมัน ซึ่งไม่ใช่ผลลัพธ์ที่น่าทึ่ง แต่มันแสดงการใช้งานพื้นฐานของไลบรารีในฐานะอินเตอร์เฟสที่ถูกทำให้ง่ายขึ้นสำหรับ API JSON-RPC ของ Bitcoin Core
ต่อไป เราจะใช้คำสั่ง getrawtransaction และ decodetransaction เพื่อดึงข้อมูลรายละเอียดของการชำระเงินจาก Alice ไปยัง Bob ในส่วนของการดึงข้อมูลธุรกรรมและการวนลูปเอาต์พุตของธุรกรรม เราจะดึงธุรกรรมของ Alice และแสดงรายการเอาต์พุตของธุรกรรม สำหรับแต่ละเอาต์พุต เราจะแสดงที่อยู่ผู้รับและมูลค่า โดยธุรกรรมของ Alice มีเอาต์พุตหนึ่งรายการที่จ่ายให้ Bob และอีกหนึ่งรายการเป็นเงินทอนกลับไปยัง Alice
ตัวอย่างที่ 5 การดึงข้อมูลธุรกรรมและการวนลูปเอาต์พุตของธุรกรรม ``` from bitcoin.rpc import RawProxy p = RawProxy()
Alice's transaction ID
txid = "466200308696215bbc949d5141a49a4138ecdfdfaa2a8029c1f9bcecd1f96177"
First, retrieve the raw transaction in hex
raw_tx = p.getrawtransaction(txid)
Decode the transaction hex into a JSON object
decoded_tx = p.decoderawtransaction(raw_tx)
Retrieve each of the outputs from the transaction
for output in decoded_tx['vout']: print(output['scriptPubKey']['address'], output['value']) --ผลลัพธ์ของคำสั่ง $ python rpc_transaction.py bc1p8dqa4wjvnt890qmfws83te0v3qxzsfu7ul63kp7u56w8qc0qwp5qv995qn 0.00020000 bc1qwafvze0200nh9vkq4jmlf4sy0tn0ga5w0zpkpg 0.00075000 ``` ตัวอย่างทั้งสองข้างต้นค่อนข้างง่าย คุณไม่จำเป็นต้องใช้โปรแกรมในการรันพวกมัน คุณสามารถใช้ตัวช่วย bitcoin-cli ได้ง่าย ๆ แต่อย่างไรก็ตาม ตัวอย่างถัดไปต้องใช้การเรียก RPC หลายร้อยครั้งและแสดงให้เห็นถึงการใช้อินเทอร์เฟซเชิงโปรแกรมได้ชัดเจนยิ่งขึ้น
ในส่วนของการดึงข้อมูลบล็อกและการรวมเอาต์พุตของทุกธุรกรรม เราจะเริ่มต้นด้วยการดึงข้อมูลบล็อก จากนั้นดึงข้อมูลธุรกรรมแต่ละรายการภายในบล็อกโดยอ้างอิงถึง ID ของแต่ละธุรกรรม ต่อมา เราจะวนลูปผ่านเอาต์พุตของแต่ละธุรกรรมและรวมมูลค่าทั้งหมด
ตัวอย่างที่ 6 การดึงข้อมูลบล็อกและการรวมเอาต์พุตของทุกธุรกรรม ``` from bitcoin.rpc import RawProxy p = RawProxy()
The block height where Alice's transaction was recorded
blockheight = 775072
Get the block hash of the block at the given height
blockhash = p.getblockhash(blockheight)
Retrieve the block by its hash
block = p.getblock(blockhash)
Element tx contains the list of all transaction IDs in the block
transactions = block['tx'] block_value = 0
Iterate through each transaction ID in the block
for txid in transactions: tx_value = 0 # Retrieve the raw transaction by ID raw_tx = p.getrawtransaction(txid) # Decode the transaction decoded_tx = p.decoderawtransaction(raw_tx) # Iterate through each output in the transaction for output in decoded_tx['vout']: # Add up the value of each output tx_value = tx_value + output['value'] # Add the value of this transaction to the total block_value = block_value + tx_value print("Total value in block: ", block_value) --ผลลัพธ์ของคำสั่ง $ python rpc_block.py Total value in block: 10322.07722534 ```
โค้ดตัวอย่างของเราคำนวณว่ามูลค่ารวมที่ถูกทำธุรกรรมในบล็อกนี้คือ 10,322.07722534 BTC (รวมถึงรางวัล 25 BTC และค่าธรรมเนียม 0.0909 BTC) ลองเปรียบเทียบกับจำนวนที่รายงานโดยเว็บไซต์สำรวจบล็อก (block explorer) โดยการค้นหาแฮชของบล็อกหรือเลขลำดับของบล็อก เครื่องมือสำรวจบล็อกบางตัวรายงานมูลค่ารวมโดยไม่รวมรางวัลและไม่รวมค่าธรรมเนียม ลองดูว่าคุณสามารถสังเกตเห็นความแตกต่างได้หรือไม่
ไคลเอนต์ทางเลือก, ไลบรารี, และชุดเครื่องมือ
C/C++ Bitcoin Core:การใช้งานอ้างอิงของ Bitcoin JavaScript bcoin: การใช้งานโหนดแบบเต็มรูปแบบที่มีความยืดหยุ่นและขยายได้พร้อม API Bitcore: โหนดเต็มรูปแบบ, API, และไลบรารีโดย Bitpay BitcoinJS: ไลบรารี Bitcoin ที่เขียนด้วย JavaScript ล้วนๆ สำหรับ node.js และเบราว์เซอร์ Java bitcoinj: ไลบรารีไคลเอนต์โหนดเต็มรูปแบบที่เขียนด้วย Java Python python-bitcoinlib: ไลบรารี Bitcoin, ไลบรารีฉันทามติ, และโหนดที่เขียนด้วย Python โดย Peter Todd pycoin: ไลบรารี Bitcoin ที่เขียนด้วย Python โดย Richard Kiss Go btcd: ไคลเอนต์ Bitcoin โหนดเต็มรูปแบบที่เขียนด้วยภาษา Go Rust rust-bitcoin: ไลบรารี Bitcoin ที่เขียนด้วย Rust สำหรับการจัดรูปแบบข้อมูล, การแยกวิเคราะห์, และการเรียกใช้ API Scala bitcoin-s: การใช้งาน Bitcoin ที่เขียนด้วย Scala C# NBitcoin: ไลบรารี Bitcoin ที่ครอบคลุมสำหรับเฟรมเวิร์ก .NET
ยังมีไลบรารีอีกมากมายในภาษาโปรแกรมมิ่งอื่น ๆ อีกหลากหลาย และมีการสร้างขึ้นใหม่อยู่ตลอดเวลา
หากคุณทำตามคำแนะนำในบทนี้ ตอนนี้คุณมี Bitcoin Core ที่ทำงานอยู่และได้เริ่มสำรวจเครือข่ายและบล็อกเชนโดยใช้โหนดของคุณเอง จากนี้ไปคุณสามารถใช้ซอฟต์แวร์ที่คุณควบคุมได้โดยอิสระ—บนคอมพิวเตอร์ที่คุณควบคุม—เพื่อตรวจสอบว่า bitcoin ใด ๆ ที่คุณได้รับปฏิบัติตามกฎทุกข้อในระบบ Bitcoin โดยไม่ต้องไว้วางใจองค์กรภายนอกใด ๆ ในบทต่อไป เราจะเรียนรู้เพิ่มเติมเกี่ยวกับกฎของระบบและวิธีที่โหนดและกระเป๋าเงินของคุณใช้กฎเหล่านั้นเพื่อรักษาความปลอดภัยของเงินของคุณ ปกป้องความเป็นส่วนตัวของคุณ และทำให้การใช้จ่ายและการรับเงินสะดวกสบาย
ฮึ่ ๆ หลาม ๆ มาอีกแล้ว จริง ๆ เนื้อหาของบทที่สามมันจบลงตรงนี้แหละ แต่ว่าถ้าสมมุตืว่าใครลองไปทำตามจริง ๆ แล้วอยากรู้ว่าเราสามารถทำอะไรจาก node ของเราได้อีกบ้าง เลยมีกิจกรรมขำ ๆ มาให้ทำครับ โดยความยากจะมีทั้งหมด 3 ระดับ ดังนี้
- ง่าย (สามารถหาคำตอบได้ด้วย bitcoin-cli command เดียว)
- แฮชของบล๊อก 774698 คืออะไร?
-
signature ของข้อความจาก address นี้ถูกต้องหรือไม่
address: 1E9YwDtYf9R29ekNAfbV7MvB4LNv7v3fGa message: 1E9YwDtYf9R29ekNAfbV7MvB4LNv7v3fGa signature:HCsBcgB+Wcm8kOGMH8IpNeg0H4gjCrlqwDf/GlSXphZGBYxm0QkKEPhh9DTJRp2IDNUhVr0FhP9qCqo2W0recNM= -
ทำได้แหละ (สามารถหาคำตอบได้ด้วย bitcoin-cli command เดียว หรืออาจจะมากกว่าหนึ่ง)
- มี output ใหม่กี่อันที่เกิดในบล๊อก 774698 ?
- ใช้ wallet descriptors หา taproot address ที่ 100 จาก extended public key ที่กำหนดให้ xpub6DLd5RvY42Q5HAmBhHPUbDGdeS9VvsYNauiuN8r6NzbiXSSNWpNVrDGTUScJ9fS2orMtuB3VdxMdUH83fPtwbrizfJg9LwWnGqtL7RTs5h1
-
สร้าง multisig address แบบ P2SH แบบ 1-of-4 จาก publickey ในอินพุตทั้งสี่ของธุรกรรมนี้:37d966a263350fe747f1c606b159987545844a493dd38d84b070027a895c4517
-
ต้องคิดเชิงตรรกะได้เล็กน้อย (สามารถหาคำตอบได้ด้วย bitcoin-cli command และพวก if-else/loop)
- tx ใดในบล็อก 257,343 ที่ใช้เอาท์พุตของ coinbase ของบล็อก 256,128?
- มีเอาต์พุตเดียวที่ยังไม่ได้ใช้งานจากบล็อก 123,321 เอาต์พุตดังกล่าวถูกส่งไปที่ address ไหน
- public key ใดที่ลงนามอินพุต 0 ใน tx นี้:e5969add849689854ac7f28e45628b89f7454b83e9699e551ce14b6f90c86163
ใครทำได้พร้อมแชร์วิธีการใต้โพสต์นี้เดี๋ยวจะมีไดโนเสาร์ส่งแซตเป็นกำลังใจให้เล็กน้อยครับ
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
comentário pertinente de Olavo de Carvalho sobre atribuições indevidas de acontecimentos à "ordem espontânea"
Eis aqui um exemplo entre outros mil, extraído das minhas apostilas de aulas, de como se analisam as relações entre fatores deliberados e casuais na ação histórica. O sr, Beltrão está INFINITAMENTE ABAIXO da possibilidade de discutir essas coisas, e por isso mesmo me atribui uma simploriedade que é dele próprio e não minha:
Já citei mil vezes este parágrafo de Georg Jellinek e vou citá-lo de novo: “Os fenômenos da vida social dividem-se em duas classes: aqueles que são determinados essencialmente por uma vontade diretriz e aqueles que existem ou podem existir sem uma organização devida a atos de vontade. Os primeiros estão submetidos necessariamente a um plano, a uma ordem emanada de uma vontade consciente, em oposição aos segundos, cuja ordenação repousa em forças bem diferentes.”
Essa distinção é crucial para os historiadores e os analistas estratégicos não porque ela é clara em todos os casos, mas precisamente porque não o é. O erro mais comum nessa ordem de estudos reside em atribuir a uma intenção consciente aquilo que resulta de uma descontrolada e às vezes incontrolável combinação de forças, ou, inversamente, em não conseguir enxergar, por trás de uma constelação aparentemente fortuita de circunstâncias, a inteligência que planejou e dirigiu sutilmente o curso dos acontecimentos.
Exemplo do primeiro erro são os Protocolos dos Sábios de Sião, que enxergam por trás de praticamente tudo o que acontece de mau no mundo a premeditação maligna de um número reduzidos de pessoas, uma elite judaica reunida secretamente em algum lugar incerto e não sabido.
O que torna essa fantasia especialmente convincente, decorrido algum tempo da sua publicação, é que alguns dos acontecimentos ali previstos se realizam bem diante dos nossos olhos. O leitor apressado vê nisso uma confirmação, saltando imprudentemente da observação do fato à imputação da autoria. Sim, algumas das idéias anunciadas nos Protocolos foram realizadas, mas não por uma elite distintamente judaica nem muito menos em proveito dos judeus, cuja papel na maioria dos casos consistiu eminentemente em pagar o pato. Muitos grupos ricos e poderosos têm ambições de dominação global e, uma vez publicado o livro, que em certos trechos tem lances de autêntica genialidade estratégica de tipo maquiavélico, era praticamente impossível que nada aprendessem com ele e não tentassem por em prática alguns dos seus esquemas, com a vantagem adicional de que estes já vinham com um bode expiatório pré-fabricado. Também é impossível que no meio ou no topo desses grupos não exista nenhum judeu de origem. Basta portanto um pouquinho de seletividade deformante para trocar a causa pelo efeito e o inocente pelo culpado.
Mas o erro mais comum hoje em dia não é esse. É o contrário: é a recusa obstinada de enxergar alguma premeditação, alguma autoria, mesmo por trás de acontecimentos notavelmente convergentes que, sem isso, teriam de ser explicados pela forca mágica das coincidências, pela ação de anjos e demônios, pela "mão invisível" das forças de mercado ou por hipotéticas “leis da História” ou “constantes sociológicas” jamais provadas, que na imaginação do observador dirigem tudo anonimamente e sem intervenção humana.
As causas geradoras desse erro são, grosso modo:
Primeira: Reduzir as ações humanas a efeitos de forças impessoais e anônimas requer o uso de conceitos genéricos abstratos que dão automaticamente a esse tipo de abordagem a aparência de coisa muito científica. Muito mais científica, para o observador leigo, do que a paciente e meticulosa reconstituição histórica das cadeias de fatos que, sob um véu de confusão, remontam às vezes a uma autoria inicial discreta e quase imperceptível. Como o estudo dos fenômenos histórico-políticos é cada vez mais uma ocupação acadêmica cujo sucesso depende de verbas, patrocínios, respaldo na mídia popular e boas relações com o establishment, é quase inevitável que, diante de uma questão dessa ordem, poucos resistam à tentação de matar logo o problema com duas ou três generalizações elegantes e brilhar como sábios de ocasião em vez de dar-se o trabalho de rastreamentos históricos que podem exigir décadas de pesquisa.
Segunda: Qualquer grupo ou entidade que se aventure a ações histórico-políticas de longo prazo tem de possuir não só os meios de empreendê-las, mas também, necessariamente, os meios de controlar a sua repercussão pública, acentuando o que lhe convém e encobrindo o que possa abortar os resultados pretendidos. Isso implica intervenções vastas, profundas e duradouras no ambiente mental. [Etc. etc. etc.]
(no facebook em 17 de julho de 2013)
-
@ 3589b793:ad53847e
2025-04-30 10:53:29
※本記事は別サービスで2022年5月22日に公開した記事の移植です。
Happy 🍕 Day's Present
まだ邦訳版が出版されていませんがこれまでのシリーズと同じくGitHubにソースコードが公開されています。なんと、現在のライセンスでは個人使用限定なら翻訳や製本が可能です。Macで、翻訳にはPDFをインプットにできるDeepLを用いた環境で、インスタントに製本してKindleなどで読めるようにする方法をまとめました。
手順の概要
- Ruby環境を用意する
- PDF作成ツールをセットアップする
- GitHubのリポジトリを自分のPCにクローンする
- asciidocをPDFに変換する
- DeepLを節約するためにPDFを結合する
- DeepLで翻訳ファイルを作る
- 一冊に製本する
この手法の強み・弱み
翻訳だけならPDFを挟まなくてもGithubなどでプレビューできるコンパイル後のドキュメントの文章をコピーしてDeepLのWebツールにペーストすればよいですが、原著のペーパーブックで438ページある大容量です。熟練のコピペ職人でも年貢を納めて後進(機械やソフトウェア)に道を譲る刻ではないでしょうか?ただし、Pros/Consがあります。
Pros
- 一冊の本になるので毎度のコピペ作業がいらない
- Pizzaを食べながらタブレットやKindleで読める
- 図や表が欠落しない(プロトコルの手順を追った解説が多いため最大の動機でした)
- 2022/6/16追記: DeepLの拡張機能がアップデートされウェブページの丸ごと翻訳が可能になりました。よってウェブ上のgithubの図表付きページをそのまま翻訳できます。
Cons
- Money is power(大容量のためDeepLの有料契約が必要)
- ページを跨いだ文章が統合されずに不自然な翻訳になる(仕様です)
- ~~翻訳できない章が一つある(解決方法がないか調査中です。DeepLさんもっとエラーメッセージ出してくれ。Help me)~~ DeepLサポートに投げたら翻訳できるようになりました。
詳細ステップ
0.Ruby環境を用意する
asciidoctorも新しく入れるなら最新のビルドで良いでしょう。
1.PDF作成ツールをセットアップする
$ gem install asciidoctor asciidoctor-pdf $ brew install gs2.GitHubのリポジトリを自分のPCにクローンする
どこかの作業ディレクトリで以下を実行する
$ git clone git@github.com:lnbook/lnbook.git $ cd lnbook3.asciidocをPDFに変換する
ワイルドカードを用いて本文を根こそぎPDF化します。
$ asciidoctor-pdf 0*.asciidoc 1*.asciidocいろいろ解析の警告が出ますが、ソースのasciidocを弄んでいくなりawsomeライブラリを導入すれば解消できるはずです。しかし如何せん量が多いので心が折れます。いったん無視して"Done is better than perfect"精神で最後までやり切りましょう。そのままGO!
また、お好みに合わせて、htmlで用意されている装丁用の部品も準備しましょう。私は表紙のcover.htmlをピックしました。ソースがhtmlなのでasciidoctorを通さず普通にPDFへ変換します。https://qiita.com/chenglin/items/9c4ed0dd626234b71a2c
4.DeepLを節約するためにPDFを結合する
DeepLでは課金プラン毎に翻訳可能なファイル数が設定されている上に、一本あたりの最大ファイルサイズが10MBです。また、翻訳エラーになる章が含まれていると丸ごとコケます。そのためPDCAサイクルを回し、最適なファイル数を手探りで見つけます。以下が今回導出した解となります。
$ gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_1.pdf 01_introduction.pdf 02_getting_started.pdf 03_how_ln_works.pdf 04_node_client.pdf 05_node_operations.pdf$gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_2_1.pdf 06_lightning_architecture.pdf 07_payment_channels.pdf 08_routing_htlcs.pdf$gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_2_2.pdf 09_channel_operation.pdf 10_onion_routing.asciidoc$ gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_3.pdf 11_gossip_channel_graph.pdf 12_path_finding.pdf 13_wire_protocol.pdf 14_encrypted_transport.pdf 15_payment_requests.pdf 16_security_privacy_ln.pdf 17_conclusion.pdf5. DeepLで翻訳ファイルを作る
PDFファイルを真心を込めた手作業で一つ一つDeepLにアップロードしていき翻訳ファイルを作ります。ファイル名はデフォルトの
[originalName](日本語).pdfのままにしています。6. 一冊に製本する
表紙 + 本文で作成する例です。
$ gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=mastering_ln_jp.pdf cover.pdf "output_1 (日本語).pdf" "output_2_1 (日本語).pdf" "output_2_2 (日本語).pdf" "output_3 (日本語).pdf"コングラチュレーションズ🎉

あなたは『Mastering the Lightning Network』の日本語版を手に入れた!個人使用に限り、あとは煮るなり焼くなりEPUBなりkindleへ送信するなり好き放題だ。
-
@ 7b3f7803:8912e968
2025-03-08 02:28:40
 Libertarians believe in open borders in theory. In practice, open borders don’t work, because, among other things, the combination with a welfare state creates a moral hazard, and the least productive of society end up within the borders of welfare states and drain resources. The social services are paid by the productive people of the country or, in the case of most fiat systems, by currency holders through inflation. Welfare states are much more likely under fiat money and the redistribution goes from native taxpayers to illegal immigrants. Thus, under fiat money, open borders end up being an open wound by which the productive lifeblood of the country bleeds out, despite the theoretical trade-efficiency benefits. As libertarians like to say, open borders and the welfare state don’t mix. In this article, we’ll examine the other sacred cow of libertarian thought: free trade.
Libertarians believe in open borders in theory. In practice, open borders don’t work, because, among other things, the combination with a welfare state creates a moral hazard, and the least productive of society end up within the borders of welfare states and drain resources. The social services are paid by the productive people of the country or, in the case of most fiat systems, by currency holders through inflation. Welfare states are much more likely under fiat money and the redistribution goes from native taxpayers to illegal immigrants. Thus, under fiat money, open borders end up being an open wound by which the productive lifeblood of the country bleeds out, despite the theoretical trade-efficiency benefits. As libertarians like to say, open borders and the welfare state don’t mix. In this article, we’ll examine the other sacred cow of libertarian thought: free trade.Free Trade without Libertarian Ideals
 Free trade is very similar to free movement of labor in that it works great in theory, but not in practice, especially under fiat money. In a libertarian free-market world, free trade works. But that assumes a whole host of libertarian ideals like sound money, non-interfering governments, and minimal aggression. Once those ideals are violated, such as with government intervention in the market, similar moral hazards and long-term costs come with them, making free trade about as libertarian as a fractional reserve bank.
Free trade is very similar to free movement of labor in that it works great in theory, but not in practice, especially under fiat money. In a libertarian free-market world, free trade works. But that assumes a whole host of libertarian ideals like sound money, non-interfering governments, and minimal aggression. Once those ideals are violated, such as with government intervention in the market, similar moral hazards and long-term costs come with them, making free trade about as libertarian as a fractional reserve bank.An example will illustrate what I’m talking about. Let’s say Portugal subsidizes their wine for export to other countries. The obvious first-order effect is that it makes Portuguese wine cheaper in France, perhaps undercutting the price of French wine. Libertarians would say, that’s great! French customers get cheaper goods, so what’s the problem?
As with any government intervention, there are significant second- and third-order effects in play. Subsidization puts unsubsidized companies at risk, perhaps driving them to bankruptcy. In this case, this might be a French wine maker. Subsidized companies may become zombies instead of dying out. In this case, this might be a Portuguese wine maker that was failing domestically but survives by selling to customers abroad with government subsidies. While French customers benefit in the short run with cheaper prices for wine, they are ultimately hurt because the goods that would have existed without government intervention never come to market. Perhaps French wine makers that went bankrupt were innovating. Perhaps the resources of the zombie Portuguese wine maker would have created something better.
Further, the dependency of French people on Portuguese wine means that something going wrong in Portugal, like a war or subsidy cuts, disrupts the supply and price of wine for France. Now France must meddle in Portugal internationally if it doesn’t want the wine supply to get disrupted. The two countries get entangled in such a way as to become more interventionist internationally. A war involving Portugal now suddenly becomes France’s business and incentivizes military aid or even violence. As usual, the unseen effects of government policy are the most pernicious.
Not Really Free
 In other words, what we call free trade isn’t really free trade. A country exporting to the US may subsidize their products through government intervention, making the product cheaper in the US. This hurts US companies, and they’re forced into choices they never would have had to face without the foreign government intervention. But because the good is crossing borders under the rubric of “free trade,” it’s somehow seen as fair. Of course it’s not, as government intervention distorts the market whether it’s done by our own government or a foreign government.
In other words, what we call free trade isn’t really free trade. A country exporting to the US may subsidize their products through government intervention, making the product cheaper in the US. This hurts US companies, and they’re forced into choices they never would have had to face without the foreign government intervention. But because the good is crossing borders under the rubric of “free trade,” it’s somehow seen as fair. Of course it’s not, as government intervention distorts the market whether it’s done by our own government or a foreign government.So why would a foreign government do this? It gets several benefits through targeted market manipulation. First, it makes its own companies’ products more popular abroad and conversely, makes US companies’ products less popular. This has the dual benefit of growing the foreign government’s firms and shrinking, perhaps bankrupting, the US ones.
Targeted subsidization like this can lead to domination under free trade. It’s not unlike the Amazon strategy of undercutting everyone first and using the monopoly pricing power at scale once everyone else has bankrupted. The global monopoly is tremendously beneficial to the country that has it. Not only is there significant tax revenue over the long term, but also a head start on innovations within that industry and an advantage in production in the adjacent industries around the product.
Second, the manufacturing centralization gives that country leverage geo-politically. A critical product that no one else manufactures means natural alliances with the countries that depend on the product, which is especially useful for smaller countries like Taiwan. Their chip manufacturing industry, holding 60% of global supply (2024), has meant that they’re a critical link for most other countries, and hence, they can use this fact to deter Chinese invasion.
Third, because of the centralization of expertise, more innovations, products, and manufacturing will tend to come within the country. This increased production has cascading benefits, including new industries and national security. China leads the world in drone technology, which undoubtedly has given it an innovation advantage for its military, should it go to war.
Fourth, the capital that flows into the country for investing in the monopolized industry will tend to stay, giving the country more wealth in the form of factories, equipment, and skills. While that capital may nominally be in the hands of foreigners, over time, the ownership of that industry will inevitably transition toward native locals, as the knowledge about how to run such industries gets dissipated within the country.
Currency Devaluation: The Universal Trade Weapon
 It would be one thing if only a specific industry were singled out for government subsidies and then the products dumped into the US as a way to hurt US companies, as that would limit the scope of the damage. But with currency devaluation, a government can subsidize all of its exports at the same time. Indeed, this is something that many countries do. While short-term, this helps US consumers, it hurts US companies and forces them into decisions that aren’t good for the US.
It would be one thing if only a specific industry were singled out for government subsidies and then the products dumped into the US as a way to hurt US companies, as that would limit the scope of the damage. But with currency devaluation, a government can subsidize all of its exports at the same time. Indeed, this is something that many countries do. While short-term, this helps US consumers, it hurts US companies and forces them into decisions that aren’t good for the US.To compete, they have to lower costs by using the same devalued currency to pay their labor as their foreign competition. That is, by relocating their capital, their manufacturing, and even their personnel to the country that’s devaluing the currency. Not only does relocating reduce labor cost, but it also often gets them benefits like tax breaks. This makes US companies de facto multinationals and not only makes them subject to other jurisdictions, but ultimately divides their loyalties. To take advantage of the reduced labor, capital must move to another country and, along with it, future innovation.
Such relocations ultimately leave the company stripped of their manufacturing capability in the US, as local competition will generally fare better over the long run. Much of the value of the industry then is captured by other governments in taxes, development, and even state-owned companies. Free trade, in other words, creates a vulnerability for domestic companies as they can be put at a significant disadvantage compared to foreign counterparts.
Hidden Effects of Foreign Intervention
Unlike the multinationals, small companies have no chance as they’re not big enough to exploit the labor arbitrage. And as is usual in a fiat system, they suffer the most while the giant corporations get the benefits of the supposed “free trade”. Most small companies can’t compete, so we get mostly the bigger companies that survive.
The transition away from domestic manufacturing necessarily means significant disruption. Domestic workers are displaced and have to find new work. Factories and equipment either have to be repurposed or rot. Entire communities that depended on the manufacturing facility now have to figure out new ways to support themselves. It’s no good telling them that they can just do something else. In a currency devaluation scenario, most of the manufacturing leaves and the jobs left are service-oriented or otherwise location-based, like real estate development. There’s a natural limit to location-based industries because the market only grows with the location that you’re servicing. Put another way, you can only have so many people give haircuts or deliver packages in a geographic area. There has to be some manufacturing of goods that can be sold outside the community, or the community will face scarce labor opportunities relative to the population.
You also can’t say the displaced workers can start some other manufacturing business. Such businesses will get out-competed on labor by the currency-devaluing country, so there won’t be much investment available for such a business, and even if there were, such a business would be competing with its hands tied behind its back. So in this scenario, what you end up with are a large pool of unemployed people whom the state subsidizes with welfare.
So when a US company leaves or goes bankrupt due to a foreign government’s subsidies, the disruption alone imposes a significant short-term cost with displaced labor, unused capital goods, and devastated communities.
Mitigations
So how do countries fight back against such a devastating economic weapon? There are a few ways countries have found around this problem of currency devaluation under free trade. First, a country can prevent capital from leaving. This is called capital controls, and many countries, particularly those that manufacture a lot, have them. Try to get money, factories, or equipment out of Malaysia, for example, and you’ll find that they make it quite difficult. Getting the same capital into the country, on the other hand, faces few restrictions. Unfortunately, the US can’t put in capital controls because dollars are its main export. It is, after all, the reserve currency of the world.
Second, you can compete by devaluing your own currency. But that’s very difficult because it requires printing a lot of dollars, and that causes inflation. There’s also no guarantee that a competing country doesn’t devalue its currency again. The US is also in a precarious position as the world’s reserve currency, so devaluing the currency more than it already does will make other holders of the dollar less likely to want to hold it, threatening the reserve currency status.
So the main two mitigations against currency devaluation in a free trade scenario are not available to the US. So what else is there? The remaining option is to drop free trade. The solution, in other words, is to add tariffs. This is how you can nullify the effects of foreign government intervention, by leveling the playing field for US manufacturers.
Tariffs
 One major industry that’s managed to continue being manufactured in the US despite significant foreign competition is cars. Notably, cars have a tariff, which incentivizes their manufacture in the US, even for foreign car makers. The tariff has acted as a way to offset foreign government subsidies and currency debasement.
One major industry that’s managed to continue being manufactured in the US despite significant foreign competition is cars. Notably, cars have a tariff, which incentivizes their manufacture in the US, even for foreign car makers. The tariff has acted as a way to offset foreign government subsidies and currency debasement.The scope of this one industry for the US is huge. There are around 300,000 direct jobs in auto assembly within the US (USTR) and there are an additional 3 million jobs supplying these manufacturers within the US. But the benefits don’t end there. The US is also creating a lot of innovation around cars, such as self-driving and plug-in electric cars. There are many countries that would love to have this industry for themselves, but because of tariffs, auto manufacturing continues in the US.
And though tariffs are seen as a tax on consumers, US car prices are cheap relative to the rest of the world. What surprises a lot of people when they move from the US to other countries is finding out that the same car often costs more abroad (e.g. 25% tariffs keep U.S. prices 20% below Europe’s $40K average, 2024). The downside of tariffs pales next to the downsides of “free trade.”
Free Trade Doesn’t Work with Fiat Money
The sad reality is that while we would love for free trade to work in the ideal libertarian paradise, it won’t in our current fiat-based system. The subsidization by foreign governments to bankrupt US companies or to make them multinational, combined with the unfortunate reality of the US dollar being the world reserve currency, means that free trade guts the US of manufacturing. Tariffs are a reasonable way to protect US manufacturers, particularly smaller ones that can’t go multinational.
What’s more, tariffs make the US less fragile and less dependent on international supply chains. Many of the wars in the past 60 years have been waged because of the entanglements the US has with other countries due to the reliance on international supply chains. Lessening this dependency, if only to prevent a war, has clear value.
Lastly, labor has been devalued significantly by fiat monetary expansion, but at least some of that can be recovered if tariffs create more manufacturing, which in turn adds to the demand for labor. This should reduce the welfare state as more opportunities are made available and fewer unemployed people will be on the rolls.
Conclusion
Fiat money produces a welfare state, which makes open borders unworkable. Fiat money also gives foreign governments a potent economic weapon to use against US companies, and by extension the labor force that powers them. Though currency debasement and capital controls are available to other countries as a defense, for the US, neither of these tools is available due to the fact that the dollar is the world reserve currency. As such, tariffs are a reasonable defense against the fiat subsidization of foreign governments.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Comprimido desodorante
No episódio sei-lá-qual de Aleixo FM Bruno Aleixo diz que os bêbados sempre têm as melhores idéias e daí conta uma idéia que ele teve quando estava bêbado: um comprimido que funciona como desodorante. Ao invés de passar o desodorante spray ou roll-on a pessoa pode só tomar o comprimido e pronto, é muito mais prático e no tempo de frio a pessoa pode vestir a roupa mais rápido, sem precisar ficar passando nada com o tronco todo nu. Quando o Busto lhe pergunta sobre a possibilidade de algo assim ser fabricado ele diz que não sabe, que não é cientista, só tem as idéias.
Essa passagem tão boba de um programa de humor esconde uma verdade sobre a doutrina cientística que permeia a sociedade. A doutrina segundo a qual é da ciência que vêm as inovações tecnológicas e de todos os tipos, e por isso é preciso que o Estado tire dinheiro das pessoas trabalhadoras e dê para os cientistas. Nesse ponto ninguém mais sabe o que é um cientista, foi-se toda a concretude, ficou só o nome: "cientista". Daí vão procurar o tal cientista, é um cara que se formou numa universidade e está fazendo um mestrado. Pronto, é só dar dinheiro pra esse cara e tudo vai ficar bom.
Tirando o problema da desconexão entre realidade e a tese, existe também, é claro, o problema da tese: não faz sentido, que um cientista fique procurando formas de realizar uma idéia, que não se sabe nem se é possível nem se é desejável, que ele ou outra pessoa tiveram, muito pelo contrário (mas não vou dizer aqui o que é que era para o cientista fazer porque isso seria contraditório e eu não acho que devam nem existir cientistas).
O que eu queria dizer mesmo era: todo o aparato científico da nossa sociedade, todos os departamentos, universidades, orçamentos e bolsas e revistas, tudo se resume a um monte de gente tentando descobrir como fazer um comprimido desodorante.
-
@ d08c9312:73efcc9f
2025-04-30 09:59:52
Resolvr CEO, Aaron Daniel, summarizes his keynote speech from the Bitcoin Insurance Summit, April 26, 2025
Introduction
At the inaugural Bitcoin Insurance Summit in Miami, I had the pleasure of sharing two historical parallels that illuminate why "Bitcoin needs insurance, and insurance needs Bitcoin." The insurance industry's reactions to fire and coffee can help us better understand the profound relationship between emerging technologies, risk management, and commercial innovation.
Fire: Why Bitcoin Needs Insurance
The first story explores how the insurance industry's response to catastrophic urban fires shaped modern building safety. Following devastating events like the Great Fire of London (1666) and the Great Chicago Fire (1871), the nascent insurance industry began engaging with fire risk systematically.
Initially, insurers offered private fire brigades to policyholders who displayed their company's fire mark on their buildings. This evolved into increasingly sophisticated risk assessment and pricing models throughout the 19th century:
- Early 19th century: Basic risk classifications with simple underwriting based on rules of thumb
- Mid-19th century: Detailed construction types and cooperative sharing of loss data through trade associations
- Late 19th/Early 20th century: Scientific, data-driven approaches with differentiated rate pricing
The insurance industry fundamentally transformed building construction practices by developing evidence-based standards that would later inform regulatory frameworks. Organizations like the National Board of Fire Underwriters (founded 1866) and Underwriters Laboratories (established 1894) tested and standardized new technologies, turning seemingly risky innovations like electricity into safer, controlled advancements.
This pattern offers a powerful precedent for Bitcoin. Like electricity, Bitcoin represents a new technology that appears inherently risky but has tremendous potential for society. By engaging with Bitcoin rather than avoiding it, the insurance industry can develop evidence-based standards, implement proper controls, and ultimately make the entire Bitcoin ecosystem safer and more robust.
Coffee: Why Insurance Needs Bitcoin
The second story reveals how coffee houses in 17th-century England became commercial hubs that gave birth to modern insurance. Nathaniel Canopius brewed the first documented cup of coffee in England in 1637. But it wasn't until advances in navigation and shipping technology opened new trade lanes that coffee became truly ubiquitous in England. Once global trade blossomed, coffee houses rapidly spread throughout London, becoming centers of business, information exchange, and innovation.
In 1686, Edward Lloyd opened his coffee house catering to sailors, merchants, and shipowners, which would eventually evolve into Lloyd's of London. Similarly, Jonathan's Coffee House became the birthplace of what would become the London Stock Exchange.
These coffee houses functioned as information networks where merchants could access shipping news and trade opportunities, as well as risk management solutions. They created a virtuous cycle: better shipping technology brought more coffee, which fueled commerce and led to better marine insurance and financing, which in turn improved global trade.
Today, we're experiencing a similar technological and financial revolution with Bitcoin. This digital, programmable money moves at the speed of light and operates 24/7 as a nearly $2 trillion asset class. The insurance industry stands to benefit tremendously by embracing this innovation early.
Conclusion
The lessons from history are clear. Just as the insurance industry drove safety improvements by engaging with fire risk, it can help develop standards and best practices for Bitcoin security. And just as coffee houses created commercial networks that revolutionized finance, insurance, and trade, Bitcoin offers new pathways for global commerce and risk management.
For the insurance industry to remain relevant in a rapidly digitizing world, it must engage with Bitcoin rather than avoid it. The companies that recognize this opportunity first will enjoy significant advantages, while those who resist change risk being left behind.
The Bitcoin Insurance Summit represented an important first step in creating the collaborative spaces needed for this transformation—a modern version of those innovative coffee houses that changed the world over three centuries ago.
View Aaron's full keynote:
https://youtu.be/eIjT1H2XuCU
For more information about how Resolvr can help your organization leverage Bitcoin in its operations, contact us today.
-
@ 4e616576:43c4fee8
2025-04-30 09:57:29
asdf
-
@ 04c915da:3dfbecc9
2025-03-07 00:26:37
There is something quietly rebellious about stacking sats. In a world obsessed with instant gratification, choosing to patiently accumulate Bitcoin, one sat at a time, feels like a middle finger to the hype machine. But to do it right, you have got to stay humble. Stack too hard with your head in the clouds, and you will trip over your own ego before the next halving even hits.
Small Wins
Stacking sats is not glamorous. Discipline. Stacking every day, week, or month, no matter the price, and letting time do the heavy lifting. Humility lives in that consistency. You are not trying to outsmart the market or prove you are the next "crypto" prophet. Just a regular person, betting on a system you believe in, one humble stack at a time. Folks get rekt chasing the highs. They ape into some shitcoin pump, shout about it online, then go silent when they inevitably get rekt. The ones who last? They stack. Just keep showing up. Consistency. Humility in action. Know the game is long, and you are not bigger than it.
Ego is Volatile
Bitcoin’s swings can mess with your head. One day you are up 20%, feeling like a genius and the next down 30%, questioning everything. Ego will have you panic selling at the bottom or over leveraging the top. Staying humble means patience, a true bitcoin zen. Do not try to "beat” Bitcoin. Ride it. Stack what you can afford, live your life, and let compounding work its magic.
Simplicity
There is a beauty in how stacking sats forces you to rethink value. A sat is worth less than a penny today, but every time you grab a few thousand, you plant a seed. It is not about flaunting wealth but rather building it, quietly, without fanfare. That mindset spills over. Cut out the noise: the overpriced coffee, fancy watches, the status games that drain your wallet. Humility is good for your soul and your stack. I have a buddy who has been stacking since 2015. Never talks about it unless you ask. Lives in a decent place, drives an old truck, and just keeps stacking. He is not chasing clout, he is chasing freedom. That is the vibe: less ego, more sats, all grounded in life.
The Big Picture
Stack those sats. Do it quietly, do it consistently, and do not let the green days puff you up or the red days break you down. Humility is the secret sauce, it keeps you grounded while the world spins wild. In a decade, when you look back and smile, it will not be because you shouted the loudest. It will be because you stayed the course, one sat at a time. \ \ Stay Humble and Stack Sats. 🫡
-
@ b2d670de:907f9d4a
2025-02-26 18:27:47
This is a list of nostr clients exposed as onion services. The list is currently actively maintained on GitHub. Contributions are always appreciated!
| Client name | Onion URL | Source code URL | Admin | Description | | --- | --- | --- | --- | --- | | Snort | http://agzj5a4be3kgp6yurijk4q7pm2yh4a5nphdg4zozk365yirf7ahuctyd.onion | https://git.v0l.io/Kieran/snort | operator | N/A | | moStard | http://sifbugd5nwdq77plmidkug4y57zuqwqio3zlyreizrhejhp6bohfwkad.onion/ | https://github.com/rafael-xmr/nostrudel/tree/mostard | operator | minimalist monero friendly nostrudel fork | | Nostrudel | http://oxtrnmb4wsb77rmk64q3jfr55fo33luwmsyaoovicyhzgrulleiojsad.onion/ | https://github.com/hzrd149/nostrudel | operator | Runs latest tagged docker image | | Nostrudel Next | http://oxtrnnumsflm7hmvb3xqphed2eqpbrt4seflgmdsjnpgc3ejd6iycuyd.onion/ | https://github.com/hzrd149/nostrudel | operator | Runs latest "next" tagged docker image | | Nsite | http://q457mvdt5smqj726m4lsqxxdyx7r3v7gufzt46zbkop6mkghpnr7z3qd.onion/ | https://github.com/hzrd149/nsite-ts | operator | Runs nsite. You can read more about nsite here. | | Shopstr | http://6fkdn756yryd5wurkq7ifnexupnfwj6sotbtby2xhj5baythl4cyf2id.onion/ | https://github.com/shopstr-eng/shopstr-hidden-service | operator | Runs the latest
serverlessbranch build of Shopstr. | -
@ 460c25e6:ef85065c
2025-02-25 15:20:39
If you don't know where your posts are, you might as well just stay in the centralized Twitter. You either take control of your relay lists, or they will control you. Amethyst offers several lists of relays for our users. We are going to go one by one to help clarify what they are and which options are best for each one.
Public Home/Outbox Relays
Home relays store all YOUR content: all your posts, likes, replies, lists, etc. It's your home. Amethyst will send your posts here first. Your followers will use these relays to get new posts from you. So, if you don't have anything there, they will not receive your updates.
Home relays must allow queries from anyone, ideally without the need to authenticate. They can limit writes to paid users without affecting anyone's experience.
This list should have a maximum of 3 relays. More than that will only make your followers waste their mobile data getting your posts. Keep it simple. Out of the 3 relays, I recommend: - 1 large public, international relay: nos.lol, nostr.mom, relay.damus.io, etc. - 1 personal relay to store a copy of all your content in a place no one can delete. Go to relay.tools and never be censored again. - 1 really fast relay located in your country: paid options like http://nostr.wine are great
Do not include relays that block users from seeing posts in this list. If you do, no one will see your posts.
Public Inbox Relays
This relay type receives all replies, comments, likes, and zaps to your posts. If you are not getting notifications or you don't see replies from your friends, it is likely because you don't have the right setup here. If you are getting too much spam in your replies, it's probably because your inbox relays are not protecting you enough. Paid relays can filter inbox spam out.
Inbox relays must allow anyone to write into them. It's the opposite of the outbox relay. They can limit who can download the posts to their paid subscribers without affecting anyone's experience.
This list should have a maximum of 3 relays as well. Again, keep it small. More than that will just make you spend more of your data plan downloading the same notifications from all these different servers. Out of the 3 relays, I recommend: - 1 large public, international relay: nos.lol, nostr.mom, relay.damus.io, etc. - 1 personal relay to store a copy of your notifications, invites, cashu tokens and zaps. - 1 really fast relay located in your country: go to nostr.watch and find relays in your country
Terrible options include: - nostr.wine should not be here. - filter.nostr.wine should not be here. - inbox.nostr.wine should not be here.
DM Inbox Relays
These are the relays used to receive DMs and private content. Others will use these relays to send DMs to you. If you don't have it setup, you will miss DMs. DM Inbox relays should accept any message from anyone, but only allow you to download them.
Generally speaking, you only need 3 for reliability. One of them should be a personal relay to make sure you have a copy of all your messages. The others can be open if you want push notifications or closed if you want full privacy.
Good options are: - inbox.nostr.wine and auth.nostr1.com: anyone can send messages and only you can download. Not even our push notification server has access to them to notify you. - a personal relay to make sure no one can censor you. Advanced settings on personal relays can also store your DMs privately. Talk to your relay operator for more details. - a public relay if you want DM notifications from our servers.
Make sure to add at least one public relay if you want to see DM notifications.
Private Home Relays
Private Relays are for things no one should see, like your drafts, lists, app settings, bookmarks etc. Ideally, these relays are either local or require authentication before posting AND downloading each user\'s content. There are no dedicated relays for this category yet, so I would use a local relay like Citrine on Android and a personal relay on relay.tools.
Keep in mind that if you choose a local relay only, a client on the desktop might not be able to see the drafts from clients on mobile and vice versa.
Search relays:
This is the list of relays to use on Amethyst's search and user tagging with @. Tagging and searching will not work if there is nothing here.. This option requires NIP-50 compliance from each relay. Hit the Default button to use all available options on existence today: - nostr.wine - relay.nostr.band - relay.noswhere.com
Local Relays:
This is your local storage. Everything will load faster if it comes from this relay. You should install Citrine on Android and write ws://localhost:4869 in this option.
General Relays:
This section contains the default relays used to download content from your follows. Notice how you can activate and deactivate the Home, Messages (old-style DMs), Chat (public chats), and Global options in each.
Keep 5-6 large relays on this list and activate them for as many categories (Home, Messages (old-style DMs), Chat, and Global) as possible.
Amethyst will provide additional recommendations to this list from your follows with information on which of your follows might need the additional relay in your list. Add them if you feel like you are missing their posts or if it is just taking too long to load them.
My setup
Here's what I use: 1. Go to relay.tools and create a relay for yourself. 2. Go to nostr.wine and pay for their subscription. 3. Go to inbox.nostr.wine and pay for their subscription. 4. Go to nostr.watch and find a good relay in your country. 5. Download Citrine to your phone.
Then, on your relay lists, put:
Public Home/Outbox Relays: - nostr.wine - nos.lol or an in-country relay. -
.nostr1.com Public Inbox Relays - nos.lol or an in-country relay -
.nostr1.com DM Inbox Relays - inbox.nostr.wine -
.nostr1.com Private Home Relays - ws://localhost:4869 (Citrine) -
.nostr1.com (if you want) Search Relays - nostr.wine - relay.nostr.band - relay.noswhere.com
Local Relays - ws://localhost:4869 (Citrine)
General Relays - nos.lol - relay.damus.io - relay.primal.net - nostr.mom
And a few of the recommended relays from Amethyst.
Final Considerations
Remember, relays can see what your Nostr client is requesting and downloading at all times. They can track what you see and see what you like. They can sell that information to the highest bidder, they can delete your content or content that a sponsor asked them to delete (like a negative review for instance) and they can censor you in any way they see fit. Before using any random free relay out there, make sure you trust its operator and you know its terms of service and privacy policies.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Zettelkasten
https://writingcooperative.com/zettelkasten-how-one-german-scholar-was-so-freakishly-productive-997e4e0ca125 (um artigo meio estúpido, mas útil).
Esta incrível técnica de salvar notas sem categorias, sem pastas, sem hierarquia predefinida, mas apenas fazendo referências de uma nota à outra e fazendo supostamente surgir uma ordem (ou heterarquia, disseram eles) a partir do caos parece ser o que faltava pra eu conseguir anotar meus pensamentos e idéias de maneira decente, veremos.
Ah, e vou usar esse tal
neuronque também gera sites a partir das notas?, acho que vai ser bom. -
@ 6e0ea5d6:0327f353
2025-02-21 18:15:52
"Malcolm Forbes recounts that a lady, wearing a faded cotton dress, and her husband, dressed in an old handmade suit, stepped off a train in Boston, USA, and timidly made their way to the office of the president of Harvard University. They had come from Palo Alto, California, and had not scheduled an appointment. The secretary, at a glance, thought that those two, looking like country bumpkins, had no business at Harvard.
— We want to speak with the president — the man said in a low voice.
— He will be busy all day — the secretary replied curtly.
— We will wait.
The secretary ignored them for hours, hoping the couple would finally give up and leave. But they stayed there, and the secretary, somewhat frustrated, decided to bother the president, although she hated doing that.
— If you speak with them for just a few minutes, maybe they will decide to go away — she said.
The president sighed in irritation but agreed. Someone of his importance did not have time to meet people like that, but he hated faded dresses and tattered suits in his office. With a stern face, he went to the couple.
— We had a son who studied at Harvard for a year — the woman said. — He loved Harvard and was very happy here, but a year ago he died in an accident, and we would like to erect a monument in his honor somewhere on campus.— My lady — said the president rudely —, we cannot erect a statue for every person who studied at Harvard and died; if we did, this place would look like a cemetery.
— Oh, no — the lady quickly replied. — We do not want to erect a statue. We would like to donate a building to Harvard.
The president looked at the woman's faded dress and her husband's old suit and exclaimed:
— A building! Do you have even the faintest idea of how much a building costs? We have more than seven and a half million dollars' worth of buildings here at Harvard.
The lady was silent for a moment, then said to her husband:
— If that’s all it costs to found a university, why don’t we have our own?
The husband agreed.
The couple, Leland Stanford, stood up and left, leaving the president confused. Traveling back to Palo Alto, California, they established there Stanford University, the second-largest in the world, in honor of their son, a former Harvard student."
Text extracted from: "Mileumlivros - Stories that Teach Values."
Thank you for reading, my friend! If this message helped you in any way, consider leaving your glass “🥃” as a token of appreciation.
A toast to our family!
-
@ 4e616576:43c4fee8
2025-04-30 09:48:05
asdfasdflkjasdf
-
@ daa41bed:88f54153
2025-02-09 16:50:04
There has been a good bit of discussion on Nostr over the past few days about the merits of zaps as a method of engaging with notes, so after writing a rather lengthy article on the pros of a strategic Bitcoin reserve, I wanted to take some time to chime in on the much more fun topic of digital engagement.
Let's begin by defining a couple of things:
Nostr is a decentralized, censorship-resistance protocol whose current biggest use case is social media (think Twitter/X). Instead of relying on company servers, it relies on relays that anyone can spin up and own their own content. Its use cases are much bigger, though, and this article is hosted on my own relay, using my own Nostr relay as an example.
Zap is a tip or donation denominated in sats (small units of Bitcoin) sent from one user to another. This is generally done directly over the Lightning Network but is increasingly using Cashu tokens. For the sake of this discussion, how you transmit/receive zaps will be irrelevant, so don't worry if you don't know what Lightning or Cashu are.
If we look at how users engage with posts and follows/followers on platforms like Twitter, Facebook, etc., it becomes evident that traditional social media thrives on engagement farming. The more outrageous a post, the more likely it will get a reaction. We see a version of this on more visual social platforms like YouTube and TikTok that use carefully crafted thumbnail images to grab the user's attention to click the video. If you'd like to dive deep into the psychology and science behind social media engagement, let me know, and I'd be happy to follow up with another article.
In this user engagement model, a user is given the option to comment or like the original post, or share it among their followers to increase its signal. They receive no value from engaging with the content aside from the dopamine hit of the original experience or having their comment liked back by whatever influencer they provide value to. Ad revenue flows to the content creator. Clout flows to the content creator. Sales revenue from merch and content placement flows to the content creator. We call this a linear economy -- the idea that resources get created, used up, then thrown away. Users create content and farm as much engagement as possible, then the content is forgotten within a few hours as they move on to the next piece of content to be farmed.
What if there were a simple way to give value back to those who engage with your content? By implementing some value-for-value model -- a circular economy. Enter zaps.

Unlike traditional social media platforms, Nostr does not actively use algorithms to determine what content is popular, nor does it push content created for active user engagement to the top of a user's timeline. Yes, there are "trending" and "most zapped" timelines that users can choose to use as their default, but these use relatively straightforward engagement metrics to rank posts for these timelines.
That is not to say that we may not see clients actively seeking to refine timeline algorithms for specific metrics. Still, the beauty of having an open protocol with media that is controlled solely by its users is that users who begin to see their timeline gamed towards specific algorithms can choose to move to another client, and for those who are more tech-savvy, they can opt to run their own relays or create their own clients with personalized algorithms and web of trust scoring systems.
Zaps enable the means to create a new type of social media economy in which creators can earn for creating content and users can earn by actively engaging with it. Like and reposting content is relatively frictionless and costs nothing but a simple button tap. Zaps provide active engagement because they signal to your followers and those of the content creator that this post has genuine value, quite literally in the form of money—sats.

I have seen some comments on Nostr claiming that removing likes and reactions is for wealthy people who can afford to send zaps and that the majority of people in the US and around the world do not have the time or money to zap because they have better things to spend their money like feeding their families and paying their bills. While at face value, these may seem like valid arguments, they, unfortunately, represent the brainwashed, defeatist attitude that our current economic (and, by extension, social media) systems aim to instill in all of us to continue extracting value from our lives.
Imagine now, if those people dedicating their own time (time = money) to mine pity points on social media would instead spend that time with genuine value creation by posting content that is meaningful to cultural discussions. Imagine if, instead of complaining that their posts get no zaps and going on a tirade about how much of a victim they are, they would empower themselves to take control of their content and give value back to the world; where would that leave us? How much value could be created on a nascent platform such as Nostr, and how quickly could it overtake other platforms?
Other users argue about user experience and that additional friction (i.e., zaps) leads to lower engagement, as proven by decades of studies on user interaction. While the added friction may turn some users away, does that necessarily provide less value? I argue quite the opposite. You haven't made a few sats from zaps with your content? Can't afford to send some sats to a wallet for zapping? How about using the most excellent available resource and spending 10 seconds of your time to leave a comment? Likes and reactions are valueless transactions. Social media's real value derives from providing monetary compensation and actively engaging in a conversation with posts you find interesting or thought-provoking. Remember when humans thrived on conversation and discussion for entertainment instead of simply being an onlooker of someone else's life?
If you've made it this far, my only request is this: try only zapping and commenting as a method of engagement for two weeks. Sure, you may end up liking a post here and there, but be more mindful of how you interact with the world and break yourself from blind instinct. You'll thank me later.

-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Criteria for activating Drivechain on Bitcoin
Drivechain is, in essence, just a way to give Bitcoin users the option to deposit their coins in a hashrate escrow. If Bitcoin is about coin ownership, in theory there should be no objection from anyone on users having the option to do that: my keys, my coins etc. In other words: even if you think hashrate escrows are a terrible idea and miners will steal all coins from that, you shouldn't care about what other people do with their own money.
There are only two reasonable objections that could be raised by normal Bitcoin users against Drivechain:
- Drivechain adds code complexity to
bitcoind - Drivechain perverts miner incentives of the Bitcoin chain
If these two objections can be reasonably answered there remains no reason for not activating the Drivechain soft-fork.
1
To address 1 we can just take a look at the code once it's done (which I haven't) but from my understanding the extra validation steps needed for ensuring hashrate escrows work are very minimal and self-contained, they shouldn't affect anything else and the risks of introducing some catastrophic bug are roughly zero (or the same as the risks of any of the dozens of refactors that happen every week on Bitcoin Core).
For the BMM/BIP-301 part, again the surface is very small, but we arguably do not need that at all, since anyprevout (once that is merged) enables blind merge-mining in way that is probably better than BIP-301, and that soft-fork is also very simple, plus already loved and accepted by most of the Bitcoin community, implemented and reviewed on Bitcoin Inquisition and is live on the official Bitcoin Core signet.
2
To address 2 we must only point that BMM ensures that Bitcoin miners don't have to do any extra work to earn basically all the fees that would come from the sidechain, as competition for mining sidechain blocks would bid the fee paid to Bitcoin miners up to the maximum economical amount. It is irrelevant if there is MEV on the sidechain or not, everything that reaches the Bitcoin chain does that in form of fees paid in a single high-fee transaction paid to any Bitcoin miner, regardless of them knowing about the sidechain or not. Therefore, there are no centralization pressure or pervert mining incentives that can affect Bitcoin land.
Sometimes it's argued that Drivechain may facilitate the ocurrence of a transaction paying a fee so high it would create incentives for reorging the Bitcoin chain. There is no reason to believe Drivechain would make this more likely than an actual attack than anyone can already do today or, as has happened, some rich person typing numbers wrong on his wallet. In fact, if a drivechain is consistently paying high fees on its BMM transactions that is an incentive for Bitcoin miners to keep mining those transactions one after the other and not harm the users of sidechain by reorging Bitcoin.
Moreover, there are many factors that exist today that can be seen as centralization vectors for Bitcoin mining: arguably one of them is non-blind merge mining, of which we have a (very convoluted) example on the Stacks shitcoin, and introducing the possibility of blind merge-mining on Bitcoin would basically remove any reasonable argument for having such schemes, therefore reducing the centralizing factor of them.
- Drivechain adds code complexity to
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
idea: Custom multi-use database app
Since 2015 I have this idea of making one app that could be repurposed into a full-fledged app for all kinds of uses, like powering small businesses accounts and so on. Hackable and open as an Excel file, but more efficient, without the hassle of making tables and also using ids and indexes under the hood so different kinds of things can be related together in various ways.
It is not a concrete thing, just a generic idea that has taken multiple forms along the years and may take others in the future. I've made quite a few attempts at implementing it, but never finished any.
I used to refer to it as a "multidimensional spreadsheet".
Can also be related to DabbleDB.
-
@ dc4cd086:cee77c06
2025-02-09 03:35:25
Have you ever wanted to learn from lengthy educational videos but found it challenging to navigate through hours of content? Our new tool addresses this problem by transforming long-form video lectures into easily digestible, searchable content.
Key Features:
Video Processing:
- Automatically downloads YouTube videos, transcripts, and chapter information
- Splits transcripts into sections based on video chapters
Content Summarization:
- Utilizes language models to transform spoken content into clear, readable text
- Formats output in AsciiDoc for improved readability and navigation
- Highlights key terms and concepts with [[term]] notation for potential cross-referencing
Diagram Extraction:
- Analyzes video entropy to identify static diagram/slide sections
- Provides a user-friendly GUI for manual selection of relevant time ranges
- Allows users to pick representative frames from selected ranges
Going Forward:
Currently undergoing a rewrite to improve organization and functionality, but you are welcome to try the current version, though it might not work on every machine. Will support multiple open and closed language models for user choice Free and open-source, allowing for personal customization and integration with various knowledge bases. Just because we might not have it on our official Alexandria knowledge base, you are still welcome to use it on you own personal or community knowledge bases! We want to help find connections between ideas that exist across relays, allowing individuals and groups to mix and match knowledge bases between each other, allowing for any degree of openness you care.
While designed with #Alexandria users in mind, it's available for anyone to use and adapt to their own learning needs.
Screenshots
Frame Selection
This is a screenshot of the frame selection interface. You'll see a signal that represents frame entropy over time. The vertical lines indicate the start and end of a chapter. Within these chapters you can select the frames by clicking and dragging the mouse over the desired range where you think diagram is in that chapter. At the bottom is an option that tells the program to select a specific number of frames from that selection.
Diagram Extraction
This is a screenshot of the diagram extraction interface. For every selection you've made, there will be a set of frames that you can choose from. You can select and deselect as many frames as you'd like to save.
Links
- repo: https://github.com/limina1/video_article_converter
- Nostr Apps 101: https://www.youtube.com/watch?v=Flxa_jkErqE
Output
And now, we have a demonstration of the final result of this tool, with some quick cleaning up. The video we will be using this tool on is titled Nostr Apps 101 by nostr:npub1nxy4qpqnld6kmpphjykvx2lqwvxmuxluddwjamm4nc29ds3elyzsm5avr7 during Nostrasia. The following thread is an analog to the modular articles we are constructing for Alexandria, and I hope it conveys the functionality we want to create in the knowledge space. Note, this tool is the first step! You could use a different prompt that is most appropriate for the specific context of the transcript you are working with, but you can also manually clean up any discrepancies that don't portray the video accurately. You can now view the article on #Alexandria https://next-alexandria.gitcitadel.eu/publication?d=nostr-apps-101
Initially published as chained kind 1's nostr:nevent1qvzqqqqqqypzp5r5hd579v2sszvvzfel677c8dxgxm3skl773sujlsuft64c44ncqy2hwumn8ghj7un9d3shjtnyv9kh2uewd9hj7qgwwaehxw309ahx7uewd3hkctcpzemhxue69uhhyetvv9ujumt0wd68ytnsw43z7qghwaehxw309aex2mrp0yhxummnw3ezucnpdejz7qgewaehxw309aex2mrp0yh8xmn0wf6zuum0vd5kzmp0qqsxunmjy20mvlq37vnrcshkf6sdrtkfjtjz3anuetmcuv8jswhezgc7hglpn
Or view on Coracle https://coracle.social /nevent1qqsxunmjy20mvlq37vnrcshkf6sdrtkfjtjz3anuetmcuv8jswhezgcppemhxue69uhkummn9ekx7mp0qgsdqa9md83tz5yqnrqjw07hhkpmfjpkuv9hlh5v8yhu8z274w9dv7qnnq0s3
-
@ 4e616576:43c4fee8
2025-04-30 09:42:33
lorem ipsum
-
@ e4950c93:1b99eccd
2025-04-30 09:29:25
-
@ e4950c93:1b99eccd
2025-04-30 09:28:38
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
On HTLCs and arbiters
This is another attempt and conveying the same information that should be in Lightning and its fake HTLCs. It assumes you know everything about Lightning and will just highlight a point. This is also valid for PTLCs.
The protocol says HTLCs are trimmed (i.e., not actually added to the commitment transaction) when the cost of redeeming them in fees would be greater than their actual value.
Although this is often dismissed as a non-important fact (often people will say "it's trusted for small payments, no big deal"), but I think it is indeed very important for 3 reasons:
- Lightning absolutely relies on HTLCs actually existing because the payment proof requires them. The entire security of each payment comes from the fact that the payer has a preimage that comes from the payee. Without that, the state of the payment becomes an unsolvable mystery. The inexistence of an HTLC breaks the atomicity between the payment going through and the payer receiving a proof.
- Bitcoin fees are expected to grow with time (arguably the reason Lightning exists in the first place).
- MPP makes payment sizes shrink, therefore more and more of Lightning payments are to be trimmed. As I write this, the mempool is clear and still payments smaller than about 5000sat are being trimmed. Two weeks ago the limit was at 18000sat, which is already below the minimum most MPP splitting algorithms will allow.
Therefore I think it is important that we come up with a different way of ensuring payment proofs are being passed around in the case HTLCs are trimmed.
Channel closures
Worse than not having HTLCs that can be redeemed is the fact that in the current Lightning implementations channels will be closed by the peer once an HTLC timeout is reached, either to fulfill an HTLC for which that peer has a preimage or to redeem back that expired HTLCs the other party hasn't fulfilled.
For the surprise of everybody, nodes will do this even when the HTLCs in question were trimmed and therefore cannot be redeemed at all. It's very important that nodes stop doing that, because it makes no economic sense at all.
However, that is not so simple, because once you decide you're not going to close the channel, what is the next step? Do you wait until the other peer tries to fulfill an expired HTLC and tell them you won't agree and that you must cancel that instead? That could work sometimes if they're honest (and they have no incentive to not be, in this case). What if they say they tried to fulfill it before but you were offline? Now you're confused, you don't know if you were offline or they were offline, or if they are trying to trick you. Then unsolvable issues start to emerge.
Arbiters
One simple idea is to use trusted arbiters for all trimmed HTLC issues.
This idea solves both the protocol issue of getting the preimage to the payer once it is released by the payee -- and what to do with the channels once a trimmed HTLC expires.
A simple design would be to have each node hardcode a set of trusted other nodes that can serve as arbiters. Once a channel is opened between two nodes they choose one node from both lists to serve as their mutual arbiter for that channel.
Then whenever one node tries to fulfill an HTLC but the other peer is unresponsive, they can send the preimage to the arbiter instead. The arbiter will then try to contact the unresponsive peer. If it succeeds, then done, the HTLC was fulfilled offchain. If it fails then it can keep trying until the HTLC timeout. And then if the other node comes back later they can eat the loss. The arbiter will ensure they know they are the ones who must eat the loss in this case. If they don't agree to eat the loss, the first peer may then close the channel and blacklist the other peer. If the other peer believes that both the first peer and the arbiter are dishonest they can remove that arbiter from their list of trusted arbiters.
The same happens in the opposite case: if a peer doesn't get a preimage they can notify the arbiter they hadn't received anything. The arbiter may try to ask the other peer for the preimage and, if that fails, settle the dispute for the side of that first peer, which can proceed to fail the HTLC is has with someone else on that route.
-
@ f683e870:557f5ef2
2025-02-07 14:33:31
After many months of ideation, research, and heads-down building, @nostr:npub1wf4pufsucer5va8g9p0rj5dnhvfeh6d8w0g6eayaep5dhps6rsgs43dgh9 and myself are excited to announce our new project called Vertex.
Vertex’s mission is to provide developers and builders with the most up-to-date and easy-to-use social graph tools.
Our services will enable our future customers to improve the experience they provide by offering:
- Protection against impersonation and DoS attacks
- Personalized discovery and recommendations.
All in an open, transparent and interoperable way.
Open and Interoperable
We have structured our services as NIP-90 Data Vending Machines. We are currently using these DVMs and we are eager to hear what the community thinks and if anyone has suggestions for improvements.
Regardless of their specific structures, using DVMs means one very important thing: no vendor lock-in.
Anyone can start processing the same requests and compete with us to offer the most accurate results at the best price. This is very important for us because we are well aware that services like ours can potentially become a central point of failure. The ease with which we can be replaced by a competitor will keep us on our toes and will continue to motivate us to build better and better experiences for our customers, all while operating in an ethical and open manner.
Speaking of openness, we have released all of our code under the MIT license, which means that anyone can review our algorithms, and any company or power user can run their own copies of Vertex if they so wish.
We are confident in this decision because the value of Vertex is not in the software. It is in the team who designed and implemented it – and now continually improves, manages and runs it to provide the most accurate results with the lowest latency and highest uptime.
What we offer
We currently support three DVMs, but we plan to increase our offering substantially this year.
VerifyReputation: give your users useful and personalized information to asses the reputation of an npub, minimizing the risk of impersonations.RecommendFollows: give your users personalized recommendations about interesting npubs they might want who to follow.SortAuthors: give your users the ability to sort replies, comments, zaps, search results or just about anything using authors’ reputations.
To learn more, watch this 3-minute walk-through video, and visit our website
https://cdn.satellite.earth/6efabff7da55ce848074351b2d640ca3bde4515060d9aba002461a4a4ddad8d8.mp4
We are also considering offering a custom service to help builders clarify and implement their vision for Web of Trust in their own applications or projects. Please reach out if you are interested.
-
@ e4950c93:1b99eccd
2025-04-30 09:27:09
-
@ b17fccdf:b7211155
2025-02-01 18:41:27
Next new resources about the MiniBolt guide have been released:
- 🆕 Roadmap: LINK
- 🆕 Dynamic Network map: LINK
- 🆕 Nostr community: LINK < ~ REMOVE the "[]" symbols from the URL (naddr...) to access
- 🆕 Linktr FOSS (UC) by Gzuuus: LINK
- 🆕 Donate webpage: 🚾 Clearnet LINK || 🧅 Onion LINK
- 🆕 Contact email: hello@minibolt.info
Enjoy it MiniBolter! 💙
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
"Você só aprendeu mesmo uma coisa quando consegue explicar para os outros"
Mentira. Tá certo que existe um ponto em que você acha que sabe algo mas não consegue explicar, mas não necessariamente isso significa não saber. Conseguir explicar não depende de saber, mas de verbalizar. Podemos saber muitas coisas sem as conseguir verbalizar. Aliás, para a maior parte das experiências humanas verbalizar é que é a parte difícil. Por último, é importante dizer que a verbalização é uma abstração e portanto quando alguém tenta explicar algo e se força a fazer uma abstração está arriscando substituir a experiência concreta ou mesmo o conhecimento difuso de algo por aquela abstração e com isso ficar mais burro -- me parece que esse é risco é maior quanto mais prematura for a tentativa de explicação e quando mais sucesso a abstração improvisada fizer.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
Multi-service Graph Reputation protocol
The problem
- Users inside centralized services need to know reputations of other users they're interacting with;
- Building reputation with ratings imposes a big burden on the user and still accomplishes nothing, can be faked, no one cares about these ratings etc.
The ideal solution
Subjective reputation: reputation based on how you rated that person previously, and how other people you trust rated that person, and how other people trusted by people you trust rated that person and so on, in a web-of-trust that actually can give you some insight on the trustworthiness of someone you never met or interacted with.
The problem with the ideal solution
- Most of the times the service that wants to implement this is not as big as Facebook, so it won't have enough people in it for such graphs of reputation to be constructed.
- It is not trivial to build.
My proposed solution:
I've drafted a protocol for an open system based on services publishing their internal reputation records and indexers using these to build graphs, and then serving the graphs back to the services so they can show them to users when it is needed (as HTTP APIs that can be called directly from the user client app or browser).
Crucially, these indexers will gather data from multiple services and cross-link users from these services so the graph is better.
https://github.com/fiatjaf/multi-service-reputation-rfc
The first and single actionable and useful feedback I got, from @bootstrapbandit was that services shouldn't share email addresses in plain text (email addresses and other external relationships users of a service may have are necessary to establish links from users accross services), but I think it is ok if services publish hashes of these email addresses instead. At some point I will update the spec draft and that may have been before the time you're reading this.
Another issue is that services may lie about their reputation records and that will hurt other services and users in these other services that are relying on that data. Maybe indexers will have to do some investigative job here to assert service honesty. Or maybe this entire protocol is just failed and we will actually need a system in which users themselves will publish their own records.
See also
-
@ e4950c93:1b99eccd
2025-04-30 09:24:29
-
@ e4950c93:1b99eccd
2025-04-30 09:23:25
-
@ 0fa80bd3:ea7325de
2025-01-29 15:43:42
Lyn Alden - биткойн евангелист или евангелистка, я пока не понял
npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83aThomas Pacchia - PubKey owner - X - @tpacchia
npub1xy6exlg37pw84cpyj05c2pdgv86hr25cxn0g7aa8g8a6v97mhduqeuhgplcalvadev - Shopstr
npub16dhgpql60vmd4mnydjut87vla23a38j689jssaqlqqlzrtqtd0kqex0nkqCalle - Cashu founder
npub12rv5lskctqxxs2c8rf2zlzc7xx3qpvzs3w4etgemauy9thegr43sf485vgДжек Дорси
npub1sg6plzptd64u62a878hep2kev88swjh3tw00gjsfl8f237lmu63q0uf63m21 ideas
npub1lm3f47nzyf0rjp6fsl4qlnkmzed4uj4h2gnf2vhe3l3mrj85vqks6z3c7lМного адресов. Хз кто надо сортировать
https://github.com/aitechguy/nostr-address-bookФиатДжеф - создатель Ностр - https://github.com/fiatjaf
npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6EVAN KALOUDIS Zues wallet
npub19kv88vjm7tw6v9qksn2y6h4hdt6e79nh3zjcud36k9n3lmlwsleqwte2qdПрограммер Коди https://github.com/CodyTseng/nostr-relay
npub1syjmjy0dp62dhccq3g97fr87tngvpvzey08llyt6ul58m2zqpzps9wf6wlAnna Chekhovich - Managing Bitcoin at The Anti-Corruption Foundation https://x.com/AnyaChekhovich
npub1y2st7rp54277hyd2usw6shy3kxprnmpvhkezmldp7vhl7hp920aq9cfyr7 -
@ e4950c93:1b99eccd
2025-04-30 09:21:52
{kind=link}
{kind=link}