-

@ 2b1964b8:851949fa
2025-03-02 19:00:56
### Routine Picture-in-Picture American Sign Language Interpretation in American Broadcasting
(PiP, ASL)
Picture-in-picture sign language interpretation is a standard feature in news broadcasts across the globe. Why hasn’t America become a leader in picture-in-picture implementation too?
**Misconception.**
There are prevalent misunderstandings about the necessity of ASL interpreters in the media and beyond. As recently as January 2025, an American influencer with ~10M social followers on Instagram and X combined, referred to sign language interpreters during emergency briefings as a distraction.
Such views overlook the fact that, for many deaf individuals, American Sign Language is their primary language. It is wrongly assumed that deaf Americans know—or should know—English. American Sign Language differs in grammatical structure from English. Moreover, human interpreters are able to convey nuances that captions often miss, such as non-manual markers; facial expressions, body movements, head positions utilized in sign language to convey meaning. English is the native language for many hearing Americans, who have access to it throughout the United States without any additional expectation placed upon them.
A deeper understanding reveals that many nations have their own unique signed languages, reflecting their local deaf culture and community — Brazilian Sign Language, British Sign Language, Finnish Sign Language, French Sign Language, Japanese Sign Language, Mexican Sign Language, Nigerian Sign Language, and South African Sign Language, among numerous others.
**Bottom Line:** American Sign Language is the native language for many American-born deaf individuals, and English is the native language for many American-born hearing individuals. It is a one-for-one relationship; both are equal.
In an era where information dissemination is instantaneous, ensuring that mainstream broadcasts are accessible to all citizens is paramount.
### Public Figures Including Language Access In Their Riders
**What's a rider?**
A rider is an addendum or supplemental clause added to a contract that expands or adjusts the contract's terms. Riders are commonly used in agreements for public figures to specify additional requirements such as personal preferences or technical needs.
**A Simple Yet Powerful Action**
Public figures have a unique ability to shape industry standards, and by including language access in their riders, they can make a profound impact with minimal effort.
* On-site American Sign Language interpretation ensures that deaf and hard-of-hearing individuals can fully engage with speeches and live events.
* Open captions (burned-in captions) for all live and post-production interview segments guarantee accessibility across platforms, making spoken content instantly available to a wider audience.
These implements don’t just benefit deaf constitutents—they also support language learners, individuals in sound-sensitive environments and any person who relies on, or simply refers, visual reinforcement to engage with spoken content.
For public figures, adding these 2 requests to a rider is one of the most efficient and immediate ways to promote accessibility. By normalizing language access as a standard expectation, you encourage event organizers, broadcasters, and production teams to adopt these practices universally.
As a result, there will be an industry shift from accessibility as an occasional accommodation to an industry norm, ensuring that future events, interviews, and media content are more accessible for all.
Beyond immediate accessibility, the regular presence of interpreters in public spaces increases awareness of sign language. Seeing interpreters in mainstream media can spark interest among both deaf and hearing children to pursue careers in interpretation, expanding future language access and representation.
### Year-Round Commitment to Accessibility
Too often, language access is only considered when an immediate demand arises, which leads to rushed or inadequate solutions. While some events may include interpretation or captioning, these efforts can fall short when they lack the expertise and coordination necessary for true disability justice. Thoughtful, proactive planning ensures that language access is seamlessly integrated into events, rather than being a reactive measure.
Best practices happen when all key players are involved from the start:
* Accessibility leads with combined production and linguistic knowledge who can ensure accessibility remains central to the purpose rather than allowing themselves to be caught up in the spectacle of an event.
* Language experts who ensure accuracy and cultural competency.
* Production professionals who understand event logistics.
By prioritizing accessibility year-round, organizations create spaces where disability justice is not just accommodated, but expected—ensuring that every audience member, regardless of language needs, has access to information and engagement.
-
@ 97c70a44:ad98e322
2025-01-30 17:15:37
There was a slight dust up recently over a website someone runs removing a listing for an app someone built based on entirely arbitrary criteria. I'm not to going to attempt to speak for either wounded party, but I would like to share my own personal definition for what constitutes a "nostr app" in an effort to help clarify what might be an otherwise confusing and opaque purity test.
In this post, I will be committing the "no true Scotsman" fallacy, in which I start with the most liberal definition I can come up with, and gradually refine it until all that is left is the purest, gleamingest, most imaginary and unattainable nostr app imaginable. As I write this, I wonder if anything built yet will actually qualify. In any case, here we go.
# It uses nostr
The lowest bar for what a "nostr app" might be is an app ("application" - i.e. software, not necessarily a native app of any kind) that has some nostr-specific code in it, but which doesn't take any advantage of what makes nostr distinctive as a protocol.
Examples might include a scraper of some kind which fulfills its charter by fetching data from relays (regardless of whether it validates or retains signatures). Another might be a regular web 2.0 app which provides an option to "log in with nostr" by requesting and storing the user's public key.
In either case, the fact that nostr is involved is entirely neutral. A scraper can scrape html, pdfs, jsonl, whatever data source - nostr relays are just another target. Likewise, a user's key in this scenario is treated merely as an opaque identifier, with no appreciation for the super powers it brings along.
In most cases, this kind of app only exists as a marketing ploy, or less cynically, because it wants to get in on the hype of being a "nostr app", without the developer quite understanding what that means, or having the budget to execute properly on the claim.
# It leverages nostr
Some of you might be wondering, "isn't 'leverage' a synonym for 'use'?" And you would be right, but for one connotative difference. It's possible to "use" something improperly, but by definition leverage gives you a mechanical advantage that you wouldn't otherwise have. This is the second category of "nostr app".
This kind of app gets some benefit out of the nostr protocol and network, but in an entirely selfish fashion. The intention of this kind of app is not to augment the nostr network, but to augment its own UX by borrowing some nifty thing from the protocol without really contributing anything back.
Some examples might include:
- Using nostr signers to encrypt or sign data, and then store that data on a proprietary server.
- Using nostr relays as a kind of low-code backend, but using proprietary event payloads.
- Using nostr event kinds to represent data (why), but not leveraging the trustlessness that buys you.
An application in this category might even communicate to its users via nostr DMs - but this doesn't make it a "nostr app" any more than a website that emails you hot deals on herbal supplements is an "email app". These apps are purely parasitic on the nostr ecosystem.
In the long-term, that's not necessarily a bad thing. Email's ubiquity is self-reinforcing. But in the short term, this kind of "nostr app" can actually do damage to nostr's reputation by over-promising and under-delivering.
# It complements nostr
Next up, we have apps that get some benefit out of nostr as above, but give back by providing a unique value proposition to nostr users as nostr users. This is a bit of a fine distinction, but for me this category is for apps which focus on solving problems that nostr isn't good at solving, leaving the nostr integration in a secondary or supporting role.
One example of this kind of app was Mutiny (RIP), which not only allowed users to sign in with nostr, but also pulled those users' social graphs so that users could send money to people they knew and trusted. Mutiny was doing a great job of leveraging nostr, as well as providing value to users with nostr identities - but it was still primarily a bitcoin wallet, not a "nostr app" in the purest sense.
Other examples are things like Nostr Nests and Zap.stream, whose core value proposition is streaming video or audio content. Both make great use of nostr identities, data formats, and relays, but they're primarily streaming apps. A good litmus test for things like this is: if you got rid of nostr, would it be the same product (even if inferior in certain ways)?
A similar category is infrastructure providers that benefit nostr by their existence (and may in fact be targeted explicitly at nostr users), but do things in a centralized, old-web way; for example: media hosts, DNS registrars, hosting providers, and CDNs.
To be clear here, I'm not casting aspersions (I don't even know what those are, or where to buy them). All the apps mentioned above use nostr to great effect, and are a real benefit to nostr users. But they are not True Scotsmen.
# It embodies nostr
Ok, here we go. This is the crème de la crème, the top du top, the meilleur du meilleur, the bee's knees. The purest, holiest, most chaste category of nostr app out there. The apps which are, indeed, nostr indigitate.
This category of nostr app (see, no quotes this time) can be defined by the converse of the previous category. If nostr was removed from this type of application, would it be impossible to create the same product?
To tease this apart a bit, apps that leverage the technical aspects of nostr are dependent on nostr the *protocol*, while apps that benefit nostr exclusively via network effect are integrated into nostr the *network*. An app that does both things is working in symbiosis with nostr as a whole.
An app that embraces both nostr's protocol and its network becomes an organic extension of every other nostr app out there, multiplying both its competitive moat and its contribution to the ecosystem:
- In contrast to apps that only borrow from nostr on the technical level but continue to operate in their own silos, an application integrated into the nostr network comes pre-packaged with existing users, and is able to provide more value to those users because of other nostr products. On nostr, it's a good thing to advertise your competitors.
- In contrast to apps that only market themselves to nostr users without building out a deep integration on the protocol level, a deeply integrated app becomes an asset to every other nostr app by becoming an organic extension of them through interoperability. This results in increased traffic to the app as other developers and users refer people to it instead of solving their problem on their own. This is the "micro-apps" utopia we've all been waiting for.
Credible exit doesn't matter if there aren't alternative services. Interoperability is pointless if other applications don't offer something your app doesn't. Marketing to nostr users doesn't matter if you don't augment their agency _as nostr users_.
If I had to choose a single NIP that represents the mindset behind this kind of app, it would be NIP 89 A.K.A. "Recommended Application Handlers", which states:
> Nostr's discoverability and transparent event interaction is one of its most interesting/novel mechanics. This NIP provides a simple way for clients to discover applications that handle events of a specific kind to ensure smooth cross-client and cross-kind interactions.
These handlers are the glue that holds nostr apps together. A single event, signed by the developer of an application (or by the application's own account) tells anyone who wants to know 1. what event kinds the app supports, 2. how to link to the app (if it's a client), and (if the pubkey also publishes a kind 10002), 3. which relays the app prefers.
_As a sidenote, NIP 89 is currently focused more on clients, leaving DVMs, relays, signers, etc somewhat out in the cold. Updating 89 to include tailored listings for each kind of supporting app would be a huge improvement to the protocol. This, plus a good front end for navigating these listings (sorry nostrapp.link, close but no cigar) would obviate the evil centralized websites that curate apps based on arbitrary criteria._
Examples of this kind of app obviously include many kind 1 clients, as well as clients that attempt to bring the benefits of the nostr protocol and network to new use cases - whether long form content, video, image posts, music, emojis, recipes, project management, or any other "content type".
To drill down into one example, let's think for a moment about forms. What's so great about a forms app that is built on nostr? Well,
- There is a [spec](https://github.com/nostr-protocol/nips/pull/1190) for forms and responses, which means that...
- Multiple clients can implement the same data format, allowing for credible exit and user choice, even of...
- Other products not focused on forms, which can still view, respond to, or embed forms, and which can send their users via NIP 89 to a client that does...
- Cryptographically sign forms and responses, which means they are self-authenticating and can be sent to...
- Multiple relays, which reduces the amount of trust necessary to be confident results haven't been deliberately "lost".
Show me a forms product that does all of those things, and isn't built on nostr. You can't, because it doesn't exist. Meanwhile, there are plenty of image hosts with APIs, streaming services, and bitcoin wallets which have basically the same levels of censorship resistance, interoperability, and network effect as if they weren't built on nostr.
# It supports nostr
Notice I haven't said anything about whether relays, signers, blossom servers, software libraries, DVMs, and the accumulated addenda of the nostr ecosystem are nostr apps. Well, they are (usually).
This is the category of nostr app that gets none of the credit for doing all of the work. There's no question that they qualify as beautiful nostrcorns, because their value propositions are entirely meaningless outside of the context of nostr. Who needs a signer if you don't have a cryptographic identity you need to protect? DVMs are literally impossible to use without relays. How are you going to find the blossom server that will serve a given hash if you don't know which servers the publishing user has selected to store their content?
In addition to being entirely contextualized by nostr architecture, this type of nostr app is valuable because it does things "the nostr way". By that I mean that they don't simply try to replicate existing internet functionality into a nostr context; instead, they create entirely new ways of putting the basic building blocks of the internet back together.
A great example of this is how Nostr Connect, Nostr Wallet Connect, and DVMs all use relays as brokers, which allows service providers to avoid having to accept incoming network connections. This opens up really interesting possibilities all on its own.
So while I might hesitate to call many of these things "apps", they are certainly "nostr".
# Appendix: it smells like a NINO
So, let's say you've created an app, but when you show it to people they politely smile, nod, and call it a NINO (Nostr In Name Only). What's a hacker to do? Well, here's your handy-dandy guide on how to wash that NINO stench off and Become a Nostr.
You app might be a NINO if:
- There's no NIP for your data format (or you're abusing NIP 78, 32, etc by inventing a sub-protocol inside an existing event kind)
- There's a NIP, but no one knows about it because it's in a text file on your hard drive (or buried in your project's repository)
- Your NIP imposes an incompatible/centralized/legacy web paradigm onto nostr
- Your NIP relies on trusted third (or first) parties
- There's only one implementation of your NIP (yours)
- Your core value proposition doesn't depend on relays, events, or nostr identities
- One or more relay urls are hard-coded into the source code
- Your app depends on a specific relay implementation to work (*ahem*, relay29)
- You don't validate event signatures
- You don't publish events to relays you don't control
- You don't read events from relays you don't control
- You use legacy web services to solve problems, rather than nostr-native solutions
- You use nostr-native solutions, but you've hardcoded their pubkeys or URLs into your app
- You don't use NIP 89 to discover clients and services
- You haven't published a NIP 89 listing for your app
- You don't leverage your users' web of trust for filtering out spam
- You don't respect your users' mute lists
- You try to "own" your users' data
Now let me just re-iterate - it's ok to be a NINO. We need NINOs, because nostr can't (and shouldn't) tackle every problem. You just need to decide whether your app, as a NINO, is actually contributing to the nostr ecosystem, or whether you're just using buzzwords to whitewash a legacy web software product.
If you're in the former camp, great! If you're in the latter, what are you waiting for? Only you can fix your NINO problem. And there are lots of ways to do this, depending on your own unique situation:
- Drop nostr support if it's not doing anyone any good. If you want to build a normal company and make some money, that's perfectly fine.
- Build out your nostr integration - start taking advantage of webs of trust, self-authenticating data, event handlers, etc.
- Work around the problem. Think you need a special relay feature for your app to work? Guess again. Consider encryption, AUTH, DVMs, or better data formats.
- Think your idea is a good one? Talk to other devs or open a PR to the [nips repo](https://github.com/nostr-protocol/nips). No one can adopt your NIP if they don't know about it.
- Keep going. It can sometimes be hard to distinguish a research project from a NINO. New ideas have to be built out before they can be fully appreciated.
- Listen to advice. Nostr developers are friendly and happy to help. If you're not sure why you're getting traction, ask!
I sincerely hope this article is useful for all of you out there in NINO land. Maybe this made you feel better about not passing the totally optional nostr app purity test. Or maybe it gave you some actionable next steps towards making a great NINON (Nostr In Not Only Name) app. In either case, GM and PV.
-
@ 50809a53:e091f164
2025-01-20 22:30:01
For starters, anyone who is interested in curating and managing "notes, lists, bookmarks, kind-1 events, or other stuff" should watch this video:
https://youtu.be/XRpHIa-2XCE
Now, assuming you have watched it, I will proceed assuming you are aware of many of the applications that exist for a very similar purpose. I'll break them down further, following a similar trajectory in order of how I came across them, and a bit about my own path on this journey.
We'll start way back in the early 2000s, before Bitcoin existed. We had https://zim-wiki.org/
It is tried and true, and to this day stands to present an option for people looking for a very simple solution to a potentially complex problem. Zim-Wiki works. But it is limited.
Let's step into the realm of proprietary. Obsidian, Joplin, and LogSeq. The first two are entirely cloud-operative applications, with more of a focus on the true benefit of being a paid service. I will assume anyone reading this is capable of exploring the marketing of these applications, or trying their freemium product, to get a feeling for what they are capable of.
I bring up Obsidian because it is very crucial to understand the market placement of publication. We know social media handles the 'hosting' problem of publishing notes "and other stuff" by harvesting data and making deals with advertisers. But- what Obsidian has evolved to offer is a full service known as 'publish'. This means users can stay in the proprietary pipeline, "from thought to web." all for $8/mo.
See: https://obsidian.md/publish
THIS IS NOSTR'S PRIMARY COMPETITION. WE ARE HERE TO DISRUPT THIS MARKET, WITH NOTES AND OTHER STUFF. WITH RELAYS. WITH THE PROTOCOL.
Now, on to Joplin. I have never used this, because I opted to study the FOSS market and stayed free of any reliance on a paid solution. Many people like Joplin, and I gather the reason is because it has allowed itself to be flexible and good options that integrate with Joplin seems to provide good solutions for users who need that functionality. I see Nostr users recommending Joplin, so I felt it was worthwhile to mention as a case-study option. I myself need to investigate it more, but have found comfort in other solutions.
LogSeq - This is my "other solutions." It seems to be trapped in its proprietary web of funding and constraint. I use it because it turns my desktop into a power-house of note archival. But by using it- I AM TRAPPED TOO. This means LogSeq is by no means a working solution for Nostr users who want a long-term archival option.
But the trap is not a cage. It's merely a box. My notes can be exported to other applications with graphing and node-based information structure. Specifically, I can export these notes to:
- Text
- OPML
- HTML
- and, PNG, for whatever that is worth.
Let's try out the PNG option, just for fun. Here's an exported PNG of my "Games on Nostr" list, which has long been abandoned. I once decided to poll some CornyChat users to see what games they enjoyed- and I documented them in a LogSeq page for my own future reference. You can see it here:
https://i.postimg.cc/qMBPDTwr/image.png
This is a very simple example of how a single "page" or "list" in LogSeq can be multipurpose. It is a small list, with multiple "features" or variables at play. First, I have listed out a variety of complex games that might make sense with "multiplayer" identification that relies on our npubs or nip-05 addresses to aggregate user data. We can ALL imagine playing games like Tetris, Snake, or Catan together with our Nostr identities. But of course we are a long way from breaking into the video game market.
On a mostly irrelevant sidenote- you might notice in my example list, that I seem to be excited about a game called Dot.Hack. I discovered this small game on Itch.io and reached out to the developer on Twitter, in an attempt to purple-pill him, but moreso to inquire about his game. Unfortunately there was no response, even without mention of Nostr. Nonetheless, we pioneer on. You can try the game here: https://propuke.itch.io/planethack
So instead let's focus on the structure of "one working list." The middle section of this list is where I polled users, and simply listed out their suggestions. Of course we discussed these before I documented, so it is note a direct result of a poll, but actually a working interaction of poll results! This is crucial because it separates my list from the aggregated data, and implies its relevance/importance.
The final section of this ONE list- is the beginnings of where I conceptually connect nostr with video game functionality. You can look at this as the beginning of a new graph, which would be "Video Game Operability With Nostr".
These three sections make up one concept within my brain. It exists in other users' brains too- but of course they are not as committed to the concept as myself- the one managing the communal discussion.
With LogSeq- I can grow and expand these lists. These lists can become graphs. Those graphs can become entire catalogues of information than can be shared across the web.
I can replicate this system with bookmarks, ideas, application design, shopping lists, LLM prompting, video/music playlists, friend lists, RELAY lists, the LIST goes ON forever!
So where does that lead us? I think it leads us to kind-1 events. We don't have much in the way of "kind-1 event managers" because most developers would agree that "storing kind-1 events locally" is.. at the very least, not so important. But it could be! If only a superapp existed that could interface seamlessly with nostr, yada yada.. we've heard it all before. We aren't getting a superapp before we have microapps. Basically this means frameworking the protocol before worrying about the all-in-one solution.
So this article will step away from the deep desire for a Nostr-enabled, Rust-built, FOSS, non-commercialized FREEDOM APP, that will exist one day, we hope.
Instead, we will focus on simple attempts of the past. I encourage others to chime in with their experience.
Zim-Wiki is foundational. The user constructs pages, and can then develop them into books.
LogSeq has the right idea- but is constrained in too many ways to prove to be a working solution at this time. However, it is very much worth experimenting with, and investigating, and modelling ourselves after.
https://workflowy.com/ is next on our list. This is great for users who think LogSeq is too complex. They "just want simple notes." Get a taste with WorkFlowy. You will understand why LogSeq is powerful if you see value in WF.
I am writing this article in favor of a redesign of LogSeq to be compatible with Nostr. I have been drafting the idea since before Nostr existed- and with Nostr I truly believe it will be possible. So, I will stop to thank everyone who has made Nostr what it is today. I wouldn't be publishing this without you!
One app I need to investigate more is Zettlr. I will mention it here for others to either discuss or investigate, as it is also mentioned some in the video I opened with. https://www.zettlr.com/
On my path to finding Nostr, before its inception, was a service called Deta.Space. This was an interesting project, not entirely unique or original, but completely fresh and very beginner-friendly. DETA WAS AN AWESOME CLOUD OS. And we could still design a form of Nostr ecosystem that is managed in this way. But, what we have now is excellent, and going forward I only see "additional" or supplemental.
Along the timeline, Deta sunsetted their Space service and launched https://deta.surf/
You might notice they advertise that "This is the future of bookmarks."
I have to wonder if perhaps I got through to them that bookmarking was what their ecosystem could empower. While I have not tried Surf, it looks interested, but does not seem to address what I found most valuable about Deta.Space: https://webcrate.app/
WebCrate was an early bookmarking client for Deta.Space which was likely their most popular application. What was amazing about WebCrate was that it delivered "simple bookmarking." At one point I decided to migrate my bookmarks from other apps, like Pocket and WorkFlowy, into WebCrate.
This ended up being an awful decision, because WebCrate is no longer being developed. However, to much credit of Deta.Space, my WebCrate instance is still running and completely functional. I have since migrated what I deem important into a local LogSeq graph, so my bookmarks are safe. But, the development of WebCrate is note.
WebCrate did not provide a working directory of crates. All creates were contained within a single-level directory. Essentially there were no layers. Just collections of links. This isn't enough for any user to effectively manage their catalogue of notes. With some pressure, I did encourage the German developer to flesh out a form of tagging, which did alleviate the problem to some extent. But as we see with Surf, they have pioneered in another direction.
That brings us back to Nostr. Where can we look for the best solution? There simply isn't one yet. But, we can look at some other options for inspiration.
HedgeDoc: https://hedgedoc.org/
I am eager for someone to fork HedgeDoc and employ Nostr sign-in. This is a small step toward managing information together within the Nostr ecosystem. I will attempt this myself eventually, if no one else does, but I am prioritizing my development in this way:
1. A nostr client that allows the cataloguing and management of relays locally.
2. A LogSeq alternative with Nostr interoperability.
3. HedgeDoc + Nostr is #3 on my list, despite being the easiest option.
Check out HedgeDoc 2.0 if you have any interest in a cooperative Markdown experience on Nostr: https://docs.hedgedoc.dev/
Now, this article should catch up all of my dearest followers, and idols, to where I stand with "bookmarking, note-taking, list-making, kind-1 event management, frameworking, and so on..."
Where it leads us to, is what's possible. Let's take a look at what's possible, once we forego ALL OF THE PROPRIETARY WEB'S BEST OPTIONS:
https://denizaydemir.org/
https://denizaydemir.org/graph/how-logseq-should-build-a-world-knowledge-graph/
https://subconscious.network/
Nostr is even inspired by much of the history that has gone into information management systems. nostr:npub1jlrs53pkdfjnts29kveljul2sm0actt6n8dxrrzqcersttvcuv3qdjynqn I know looks up to Gordon Brander, just as I do. You can read his articles here: https://substack.com/@gordonbrander and they are very much worth reading! Also, I could note that the original version of Highlighter by nostr:npub1l2vyh47mk2p0qlsku7hg0vn29faehy9hy34ygaclpn66ukqp3afqutajft was also inspired partially by WorkFlowy.
About a year ago, I was mesmerized coming across SubText and thinking I had finally found the answer Nostr might even be looking for. But, for now I will just suggest that others read the Readme.md on the SubText Gtihub, as well as articles by Brander.
Good luck everyone. I am here to work with ANYONE who is interested in these type of solution on Nostr.
My first order of business in this space is to spearhead a community of npubs who share this goal. Everyone who is interested in note-taking or list-making or bookmarking is welcome to join. I have created an INVITE-ONLY relay for this very purpose, and anyone is welcome to reach out if they wish to be added to the whitelist. It should be freely readable in the near future, if it is not already, but for now will remain a closed-to-post community to preemptively mitigate attack or spam. Please reach out to me if you wish to join the relay. https://logstr.mycelium.social/
With this article, I hope people will investigate and explore the options available. We have lots of ground to cover, but all of the right resources and manpower to do so. Godspeed, Nostr.
#Nostr #Notes #OtherStuff #LogSec #Joplin #Obsidian
-
@ 7bdef7be:784a5805
2025-01-13 22:36:47
The following script try, using [nak](https://github.com/fiatjaf/nak), to find out the last ten people who have followed a `target_pubkey`, sorted by the most recent. It's possibile to shorten `search_timerange` to speed up the search.
```
#!/usr/bin/env fish
# Target pubkey we're looking for in the tags
set target_pubkey "6e468422dfb74a5738702a8823b9b28168abab8655faacb6853cd0ee15deee93"
set current_time (date +%s)
set search_timerange (math $current_time - 600) # 24 hours = 86400 seconds
set pubkeys (nak req --kind 3 -s $search_timerange wss://relay.damus.io/ wss://nos.lol/ 2>/dev/null | \
jq -r --arg target "$target_pubkey" '
select(. != null and type == "object" and has("tags")) |
select(.tags[] | select(.[0] == "p" and .[1] == $target)) |
.pubkey
' | sort -u)
if test -z "$pubkeys"
exit 1
end
set all_events ""
set extended_search_timerange (math $current_time - 31536000) # One year
for pubkey in $pubkeys
echo "Checking $pubkey"
set events (nak req --author $pubkey -l 5 -k 3 -s $extended_search_timerange wss://relay.damus.io wss://nos.lol 2>/dev/null | \
jq -c --arg target "$target_pubkey" '
select(. != null and type == "object" and has("tags")) |
select(.tags[][] == $target)
' 2>/dev/null)
set count (echo "$events" | jq -s 'length')
if test "$count" -eq 1
set all_events $all_events $events
end
end
if test -n "$all_events"
echo -e "Last people following $target_pubkey:"
echo -e ""
set sorted_events (printf "%s\n" $all_events | jq -r -s '
unique_by(.id) |
sort_by(-.created_at) |
.[] | @json
')
for event in $sorted_events
set npub (echo $event | jq -r '.pubkey' | nak encode npub)
set created_at (echo $event | jq -r '.created_at')
if test (uname) = "Darwin"
set follow_date (date -r "$created_at" "+%Y-%m-%d %H:%M")
else
set follow_date (date -d @"$created_at" "+%Y-%m-%d %H:%M")
end
echo "$follow_date - $npub"
end
end
```
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
## The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
## Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
## Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
## The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
## Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ dd664d5e:5633d319
2025-01-09 21:39:15
# Instructions
1. Place 2 medium-sized, boiled potatoes and a handful of sliced leeks in a pot.

2. Fill the pot with water or vegetable broth, to cover the potatoes twice over.
3. Add a splash of white wine, if you like, and some bouillon powder, if you went with water instead of broth.

4. Bring the soup to a boil and then simmer for 15 minutes.
5. Puree the soup, in the pot, with a hand mixer. It shouldn't be completely smooth, when you're done, but rather have small bits and pieces of the veggies floating around.

6. Bring the soup to a boil, again, and stir in one container (200-250 mL) of heavy cream.
7. Thicken the soup, as needed, and then simmer for 5 more minutes.
8. Garnish with croutons and veggies (here I used sliced green onions and radishes) and serve.

Guten Appetit!
-
@ 3f770d65:7a745b24
2025-01-05 18:56:33
New Year’s resolutions often feel boring and repetitive. Most revolve around getting in shape, eating healthier, or giving up alcohol. While the idea is interesting—using the start of a new calendar year as a catalyst for change—it also seems unnecessary. Why wait for a specific date to make a change? If you want to improve something in your life, you can just do it. You don’t need an excuse.
That’s why I’ve never been drawn to the idea of making a list of resolutions. If I wanted a change, I’d make it happen, without worrying about the calendar. At least, that’s how I felt until now—when, for once, the timing actually gave me a real reason to embrace the idea of New Year’s resolutions.
Enter [Olas](https://olas.app).
If you're a visual creator, you've likely experienced the relentless grind of building a following on platforms like Instagram—endless doomscrolling, ever-changing algorithms, and the constant pressure to stay relevant. But what if there was a better way? Olas is a Nostr-powered alternative to Instagram that prioritizes community, creativity, and value-for-value exchanges. It's a game changer.
Instagram’s failings are well-known. Its algorithm often dictates whose content gets seen, leaving creators frustrated and powerless. Monetization hurdles further alienate creators who are forced to meet arbitrary follower thresholds before earning anything. Additionally, the platform’s design fosters endless comparisons and exposure to negativity, which can take a significant toll on mental health.
Instagram’s algorithms are notorious for keeping users hooked, often at the cost of their mental health. I've spoken about this extensively, most recently at Nostr Valley, explaining how legacy social media is bad for you. You might find yourself scrolling through content that leaves you feeling anxious or drained. Olas takes a fresh approach, replacing "doomscrolling" with "bloomscrolling." This is a common theme across the Nostr ecosystem. The lack of addictive rage algorithms allows the focus to shift to uplifting, positive content that inspires rather than exhausts.
Monetization is another area where Olas will set itself apart. On Instagram, creators face arbitrary barriers to earning—needing thousands of followers and adhering to restrictive platform rules. Olas eliminates these hurdles by leveraging the Nostr protocol, enabling creators to earn directly through value-for-value exchanges. Fans can support their favorite artists instantly, with no delays or approvals required. The plan is to enable a brand new Olas account that can get paid instantly, with zero followers - that's wild.
Olas addresses these issues head-on. Operating on the open Nostr protocol, it removes centralized control over one's content’s reach or one's ability to monetize. With transparent, configurable algorithms, and a community that thrives on mutual support, Olas creates an environment where creators can grow and succeed without unnecessary barriers.
Join me on my New Year's resolution. Join me on Olas and take part in the [#Olas365](https://olas.app/search/olas365) challenge! It’s a simple yet exciting way to share your content. The challenge is straightforward: post at least one photo per day on Olas (though you’re welcome to share more!).
[Download on iOS](https://testflight.apple.com/join/2FMVX2yM).
[Download on Android](https://github.com/pablof7z/olas/releases/) or download via Zapstore.
Let's make waves together.
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
## The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
## Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
* **Enhance LLM Outputs:** By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
* **Support Complex Queries:** Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
## Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
* **Richness of Entities:** Effective retrieval depends on graphs populated with rich, detailed entities.
* **Freedom from Hallucinations:** Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
## Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
* Handle diverse data sources with ease.
* Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
## Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
* **Defining Relationships:** Clarifying how concepts connect within a domain.
* **Validating Graph Structures:** Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
## How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
1. **Assign a Knowledge Champion:** Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
2. **Provide Training:** Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
3. **Leverage Partnerships:** Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
4. **Utilize Tools:** Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
5. **Iterate with Feedback:** Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
## How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
1. **Leverage Existing Ontologies:** Many industries and domains already have open ontologies. For instance:
* **Public Knowledge Graphs:** Resources like Wikipedia’s graph offer a wealth of structured knowledge.
* **Industry Standards:** Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
* **Business Framework Ontology (BFO):** A valuable resource for enterprises looking to define business processes and structures.
1. **Build In-House Expertise:** If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
2. **Utilize LLMs for Ontology Construction:** Interestingly, LLMs themselves can act as a starting point for ontology development:
* **Prompt-Based Extraction:** LLMs can generate draft ontologies by leveraging their extensive training on graph data.
* **Domain Expert Refinement:** Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
## Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
* **Detecting Hallucinations:** Differentiating between genuine insights and AI-generated inaccuracies.
* **Ensuring Completeness:** Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
## LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
* **Generate Skeleton Ontologies:** Prompt LLMs with domain-specific information to draft initial ontology structures.
* **Validate and Refine Ontologies:** Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
## Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
## The Four-Layer Framework
### Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
**Example**: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- **Tip**: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
_Once you have the big picture in mind, it’s time to start breaking it down._
---
### Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
**Example**: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- **Tip**: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
_With your categories in place, you’re ready to dive into the details that bring them to life._
---
### Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
**Example**: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- **Tip**: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
_Now that you’ve mastered the essentials, you can expand your knowledge to include extra material._
---
### Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
**Example**: Learn about rare programming quirks or historical trivia about a language’s development.
- **Tip**: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
---
## Pro Tips for Better Learning
### 1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
### 2. Map It Out
Create visual aids like [diagrams or concept maps](https://excalidraw.com/) to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
### 3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching **exposes any gaps** in your understanding and **helps reinforce** the material.
### 4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to **explore your topic** in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.
**Tip**: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
---
## Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ 3f770d65:7a745b24
2024-12-31 17:03:46
Here are my predictions for Nostr in 2025:
**Decentralization:** The outbox and inbox communication models, sometimes referred to as the Gossip model, will become the standard across the ecosystem. By the end of 2025, all major clients will support these models, providing seamless communication and enhanced decentralization. Clients that do not adopt outbox/inbox by then will be regarded as outdated or legacy systems.
**Privacy Standards:** Major clients such as Damus and Primal will move away from NIP-04 DMs, adopting more secure protocol possibilities like NIP-17 or NIP-104. These upgrades will ensure enhanced encryption and metadata protection. Additionally, NIP-104 MLS tools will drive the development of new clients and features, providing users with unprecedented control over the privacy of their communications.
**Interoperability:** Nostr's ecosystem will become even more interconnected. Platforms like the Olas image-sharing service will expand into prominent clients such as Primal, Damus, Coracle, and Snort, alongside existing integrations with Amethyst, Nostur, and Nostrudel. Similarly, audio and video tools like Nostr Nests and Zap.stream will gain seamless integration into major clients, enabling easy participation in live events across the ecosystem.
**Adoption and Migration:** Inspired by early pioneers like Fountain and Orange Pill App, more platforms will adopt Nostr for authentication, login, and social systems. In 2025, a significant migration from a high-profile application platform with hundreds of thousands of users will transpire, doubling Nostr’s daily activity and establishing it as a cornerstone of decentralized technologies.
-
@ 6e468422:15deee93
2024-12-21 19:25:26
We didn't hear them land on earth, nor did we see them. The spores were not visible to the naked eye. Like dust particles, they softly fell, unhindered, through our atmosphere, covering the earth. It took us a while to realize that something extraordinary was happening on our planet. In most places, the mushrooms didn't grow at all. The conditions weren't right. In some places—mostly rocky places—they grew large enough to be noticeable. People all over the world posted pictures online. "White eggs," they called them. It took a bit until botanists and mycologists took note. Most didn't realize that we were dealing with a species unknown to us.
We aren't sure who sent them. We aren't even sure if there is a "who" behind the spores. But once the first portals opened up, we learned that these mushrooms aren't just a quirk of biology. The portals were small at first—minuscule, even. Like a pinhole camera, we were able to glimpse through, but we couldn't make out much. We were only able to see colors and textures if the conditions were right. We weren't sure what we were looking at.
We still don't understand why some mushrooms open up, and some don't. Most don't. What we do know is that they like colder climates and high elevations. What we also know is that the portals don't stay open for long. Like all mushrooms, the flush only lasts for a week or two. When a portal opens, it looks like the mushroom is eating a hole into itself at first. But the hole grows, and what starts as a shimmer behind a grey film turns into a clear picture as the egg ripens. When conditions are right, portals will remain stable for up to three days. Once the fruit withers, the portal closes, and the mushroom decays.
The eggs grew bigger year over year. And with it, the portals. Soon enough, the portals were big enough to stick your finger through. And that's when things started to get weird...
-
@ 20986fb8:cdac21b3
2024-12-18 03:19:36
### **English**
#### Introducing YakiHonne: Write Without Limits
YakiHonne is the ultimate text editor designed to help you express yourself creatively, no matter the language.
**Features you'll love:**
- 🌟 **Rich Formatting**: Add headings, bold, italics, and more.
- 🌏 **Multilingual Support**: Seamlessly write in English, Chinese, Arabic, and Japanese.
- 🔗 **Interactive Links**: [Learn more about YakiHonne](https://yakihonne.com).
**Benefits:**
1. Easy to use.
2. Enhance readability with customizable styles.
3. Supports various complex formats including LateX.
> "YakiHonne is a game-changer for content creators."
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install [NVapi](https://github.com/sammcj/NVApi) to monitor my GPUs in Home Assistant.
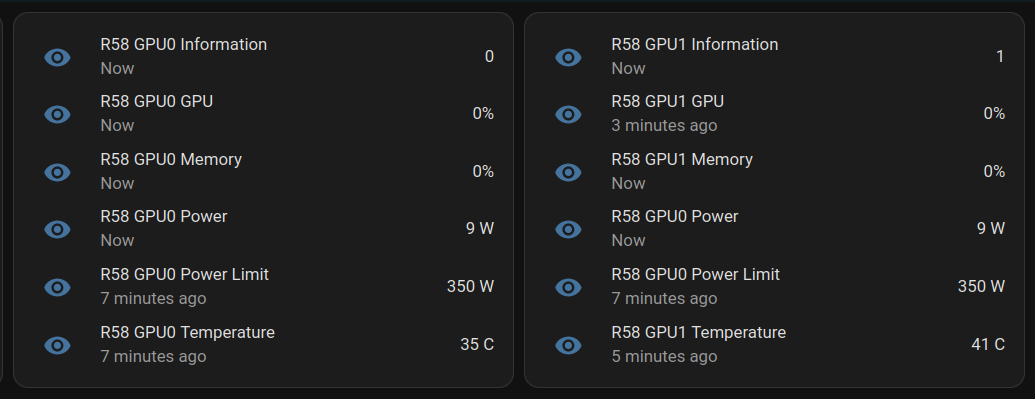
**NVApi** is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- **GPU Utilization Monitoring**: Utilization, memory usage, temperature, fan speed, and power consumption.
- **Automated Power Limiting**: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- **Cross-GPU Coordination**: Total power budget applies across multiple GPUs in the same system.
- **PCIe Link Speed Management**: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- **Home Assistant Integration**: Uses the built-in RESTful platform and template sensors.
## Getting the Data
```
sudo apt install golang-go
git clone https://github.com/sammcj/NVApi.git
cd NVapi
go run main.go -port 9999 -rate 1
curl http://localhost:9999/gpu
```
Response for a single GPU:
```
[
{
"index": 0,
"name": "NVIDIA GeForce RTX 4090",
"gpu_utilisation": 0,
"memory_utilisation": 0,
"power_watts": 16,
"power_limit_watts": 450,
"memory_total_gb": 23.99,
"memory_used_gb": 0.46,
"memory_free_gb": 23.52,
"memory_usage_percent": 2,
"temperature": 38,
"processes": [],
"pcie_link_state": "not managed"
}
]
```
Response for multiple GPUs:
```
[
{
"index": 0,
"name": "NVIDIA GeForce RTX 3090",
"gpu_utilisation": 0,
"memory_utilisation": 0,
"power_watts": 14,
"power_limit_watts": 350,
"memory_total_gb": 24,
"memory_used_gb": 0.43,
"memory_free_gb": 23.57,
"memory_usage_percent": 2,
"temperature": 36,
"processes": [],
"pcie_link_state": "not managed"
},
{
"index": 1,
"name": "NVIDIA RTX A4000",
"gpu_utilisation": 0,
"memory_utilisation": 0,
"power_watts": 10,
"power_limit_watts": 140,
"memory_total_gb": 15.99,
"memory_used_gb": 0.56,
"memory_free_gb": 15.43,
"memory_usage_percent": 3,
"temperature": 41,
"processes": [],
"pcie_link_state": "not managed"
}
]
```
# Start at Boot
Create `/etc/systemd/system/nvapi.service`:
```
[Unit]
Description=Run NVapi
After=network.target
[Service]
Type=simple
Environment="GOPATH=/home/ansible/go"
WorkingDirectory=/home/ansible/NVapi
ExecStart=/usr/bin/go run main.go -port 9999 -rate 1
Restart=always
User=ansible
# Environment="GPU_TEMP_CHECK_INTERVAL=5"
# Environment="GPU_TOTAL_POWER_CAP=400"
# Environment="GPU_0_LOW_TEMP=40"
# Environment="GPU_0_MEDIUM_TEMP=70"
# Environment="GPU_0_LOW_TEMP_LIMIT=135"
# Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
# Environment="GPU_0_HIGH_TEMP_LIMIT=100"
# Environment="GPU_1_LOW_TEMP=45"
# Environment="GPU_1_MEDIUM_TEMP=75"
# Environment="GPU_1_LOW_TEMP_LIMIT=140"
# Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
# Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install]
WantedBy=multi-user.target
```
## Home Assistant
Add to Home Assistant `configuration.yaml` and restart HA (completely).
For a single GPU, this works:
```
sensor:
- platform: rest
name: MYPC GPU Information
resource: http://mypc:9999
method: GET
headers:
Content-Type: application/json
value_template: "{{ value_json[0].index }}"
json_attributes:
- name
- gpu_utilisation
- memory_utilisation
- power_watts
- power_limit_watts
- memory_total_gb
- memory_used_gb
- memory_free_gb
- memory_usage_percent
- temperature
scan_interval: 1 # seconds
- platform: template
sensors:
mypc_gpu_0_gpu:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_memory:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_power:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_power_limit:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_temperature:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}"
unit_of_measurement: "°C"
```
For multiple GPUs:
```
rest:
scan_interval: 1
resource: http://mypc:9999
sensor:
- name: "MYPC GPU0 Information"
value_template: "{{ value_json[0].index }}"
json_attributes_path: "$.0"
json_attributes:
- name
- gpu_utilisation
- memory_utilisation
- power_watts
- power_limit_watts
- memory_total_gb
- memory_used_gb
- memory_free_gb
- memory_usage_percent
- temperature
- name: "MYPC GPU1 Information"
value_template: "{{ value_json[1].index }}"
json_attributes_path: "$.1"
json_attributes:
- name
- gpu_utilisation
- memory_utilisation
- power_watts
- power_limit_watts
- memory_total_gb
- memory_used_gb
- memory_free_gb
- memory_usage_percent
- temperature
- platform: template
sensors:
mypc_gpu_0_gpu:
friendly_name: "MYPC GPU0 GPU"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_memory:
friendly_name: "MYPC GPU0 Memory"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_power:
friendly_name: "MYPC GPU0 Power"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_power_limit:
friendly_name: "MYPC GPU0 Power Limit"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_temperature:
friendly_name: "MYPC GPU0 Temperature"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}"
unit_of_measurement: "C"
- platform: template
sensors:
mypc_gpu_1_gpu:
friendly_name: "MYPC GPU1 GPU"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_1_memory:
friendly_name: "MYPC GPU1 Memory"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_1_power:
friendly_name: "MYPC GPU1 Power"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}"
unit_of_measurement: "W"
mypc_gpu_1_power_limit:
friendly_name: "MYPC GPU1 Power Limit"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}"
unit_of_measurement: "W"
mypc_gpu_1_temperature:
friendly_name: "MYPC GPU1 Temperature"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}"
unit_of_measurement: "C"
```
Basic entity card:
```
type: entities
entities:
- entity: sensor.mypc_gpu_0_gpu
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_memory
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_power
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_power_limit
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_temperature
secondary_info: last-updated
```
# Ansible Role
```
---
- name: install go
become: true
package:
name: golang-go
state: present
- name: git clone
git:
repo: "https://github.com/sammcj/NVApi.git"
dest: "/home/ansible/NVapi"
update: yes
force: true
# go run main.go -port 9999 -rate 1
- name: install systemd service
become: true
copy:
src: nvapi.service
dest: /etc/systemd/system/nvapi.service
- name: Reload systemd daemons, enable, and restart nvapi
become: true
systemd:
name: nvapi
daemon_reload: yes
enabled: yes
state: restarted
```
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
### Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
### Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
- **Scoperta.** Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
- **Efficienza.** La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
### Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
### Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
### Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
### Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
### Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
### Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\
https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
@ dd664d5e:5633d319
2024-12-14 15:25:56

Christmas season hasn't actually started, yet, in Roman #Catholic Germany. We're in Advent until the evening of the 24th of December, at which point Christmas begins (with the Nativity, at Vespers), and continues on for 40 days until Mariä Lichtmess (Presentation of Christ in the temple) on February 2nd.
It's 40 days because that's how long the post-partum isolation is, before women were allowed back into the temple (after a ritual cleansing).

That is the day when we put away all of the Christmas decorations and bless the candles, for the next year. (Hence, the British name "Candlemas".) It used to also be when household staff would get paid their cash wages and could change employer. And it is the day precisely in the middle of winter.

Between Christmas Eve and Candlemas are many celebrations, concluding with the Twelfth Night called Epiphany or Theophany. This is the day some Orthodox celebrate Christ's baptism, so traditions rotate around blessing of waters.

The Monday after Epiphany was the start of the farming season, in England, so that Sunday all of the ploughs were blessed, but the practice has largely died out.

Our local tradition is for the altar servers to dress as the wise men and go door-to-door, carrying their star and looking for the Baby Jesus, who is rumored to be lying in a manger.

They collect cash gifts and chocolates, along the way, and leave the generous their powerful blessing, written over the door. The famous 20 * C + M + B * 25 blessing means "Christus mansionem benedicat" (Christ, bless this house), or "Caspar, Melchior, Balthasar" (the names of the three kings), depending upon who you ask.
They offer the cash to the Baby Jesus (once they find him in the church's Nativity scene), but eat the sweets, themselves. It is one of the biggest donation-collections in the world, called the "Sternsinger" (star singers). The money goes from the German children, to help children elsewhere, and they collect around €45 million in cash and coins, every year.

As an interesting aside:
The American "groundhog day", derives from one of the old farmers' sayings about Candlemas, brought over by the Pennsylvania Dutch. It says, that if the badger comes out of his hole and sees his shadow, then it'll remain cold for 4 more weeks. When they moved to the USA, they didn't have any badgers around, so they switched to groundhogs, as they also hibernate in winter.
-
@ d0bf8568:4db3e76f
2024-12-12 21:26:52
Depuis sa création en 2009, Bitcoin suscite débats passionnés. Pour certains, il s’agit d’une tentative utopique d’émancipation du pouvoir étatique, inspirée par une philosophie libertarienne radicale. Pour d’autres, c'est une réponse pragmatique à un système monétaire mondial jugé défaillant. Ces deux perspectives, souvent opposées, méritent d’être confrontées pour mieux comprendre les enjeux et les limites de cette révolution monétaire.

### La critique économique de Bitcoin
David Cayla, dans ses dernières contributions, perçoit Bitcoin comme une tentative de réaliser une « utopie libertarienne ». Selon lui, les inventeurs des cryptomonnaies cherchent à créer une monnaie détachée de l’État et des rapports sociaux traditionnels, en s’inspirant de l’école autrichienne d’économie. Cette école, incarnée par des penseurs comme Friedrich Hayek, prône une monnaie privée et indépendante de l’intervention politique.
Cayla reproche à Bitcoin de nier la dimension intrinsèquement sociale et politique de la monnaie. Pour lui, toute monnaie repose sur la confiance collective et la régulation étatique. En rendant la monnaie exogène et dénuée de dette, Bitcoin chercherait à éviter les interactions sociales au profit d’une logique purement individuelle. Selon cette analyse, Bitcoin serait une illusion, incapable de remplacer les monnaies traditionnelles qui sont des « biens publics » soutenus par des institutions.
Cependant, cette critique semble minimiser la légitimité des motivations derrière Bitcoin. La crise financière de 2008, marquée par des abus systémiques et des sauvetages bancaires controversés, a largement érodé la confiance dans les systèmes monétaires centralisés. Bitcoin n’est pas qu’une réaction idéologique : c’est une tentative de créer un système monétaire transparent, immuable et résistant aux manipulations.
### La perspective maximaliste
Pour les bitcoiners, Bitcoin n’est pas une utopie mais une réponse pragmatique à un problème réel : la centralisation excessive et les défaillances des monnaies fiat. Contrairement à ce que Cayla affirme, Bitcoin ne cherche pas à nier la société, mais à protéger les individus de la coercition étatique. En déplaçant la confiance des institutions vers un protocole neutre et transparent, Bitcoin redéfinit les bases des échanges monétaires.
L’accusation selon laquelle Bitcoin serait « asocial » ignore son écosystème communautaire mondial. Les bitcoiners collaborent activement à l’amélioration du réseau, organisent des événements éducatifs et développent des outils inclusifs. Bitcoin n’est pas un rejet des rapports sociaux, mais une tentative de les reconstruire sur des bases plus justes et transparentes.
Un maximaliste insisterait également sur l’émergence historique de la monnaie. Contrairement à l’idée que l’État aurait toujours créé la monnaie, de nombreux exemples montrent que celle-ci émergeait souvent du marché, avant d’être capturée par les gouvernements pour financer des guerres ou imposer des monopoles. Bitcoin réintroduit une monnaie à l’abri des manipulations politiques, similaire aux systèmes basés sur l’or, mais en mieux : numérique, immuable et accessible.
### Utopie contre réalité
Si Cayla critique l’absence de dette dans Bitcoin, Nous y voyons une vertu. La « monnaie-dette » actuelle repose sur un système de création monétaire inflationniste qui favorise les inégalités et l’érosion du pouvoir d’achat. En limitant son offre à 21 millions d’unités, Bitcoin offre une alternative saine et prévisible, loin des politiques monétaires arbitraires.
Cependant, les maximalistes ne nient pas que Bitcoin ait encore des défis à relever. La volatilité de sa valeur, sa complexité technique pour les nouveaux utilisateurs, et les tensions entre réglementation et liberté individuelle sont des questions ouvertes. Mais pour autant, ces épreuves ne remettent pas en cause sa pertinence. Au contraire, elles illustrent l’importance de réfléchir à des modèles alternatifs.
### Conclusion : un débat essentiel
Bitcoin n’est pas une utopie libertarienne, mais une révolution monétaire sans précédent. Les critiques de Cayla, bien qu’intellectuellement stimulantes, manquent de saisir l’essence de Bitcoin : une monnaie qui libère les individus des abus systémiques des États et des institutions centralisées. Loin de simplement avoir un « potentiel », Bitcoin est déjà en train de redéfinir les rapports entre la monnaie, la société et la liberté. Bitcoin offre une expérience unique : celle d’une monnaie mondiale, neutre et décentralisée, qui redonne le pouvoir aux individus. Que l’on soit sceptique ou enthousiaste, il est clair que Bitcoin oblige à repenser les rapports entre monnaie, société et État.
En fin de compte, le débat sur Bitcoin n’est pas seulement une querelle sur sa légitimité, mais une interrogation sur la manière dont il redessine les rapports sociaux et sociétaux autour de la monnaie. En rendant le pouvoir monétaire à chaque individu, Bitcoin propose un modèle où les interactions économiques peuvent être réalisées sans coercition, renforçant ainsi la confiance mutuelle et les communautés globales. Cette discussion, loin d’être close, ne fait que commencer.
-
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
## MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.
## Graph Basics
- A standard **graph** has a set of **nodes** (or vertices) and **edges** (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
## Hypergraph
- A **hypergraph** extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a **hyperedge**, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
## Metagraph
- A **metagraph** allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
## Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
## Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
## Directed Metagraph where edges are not used as nodes and could not contain subgraphs
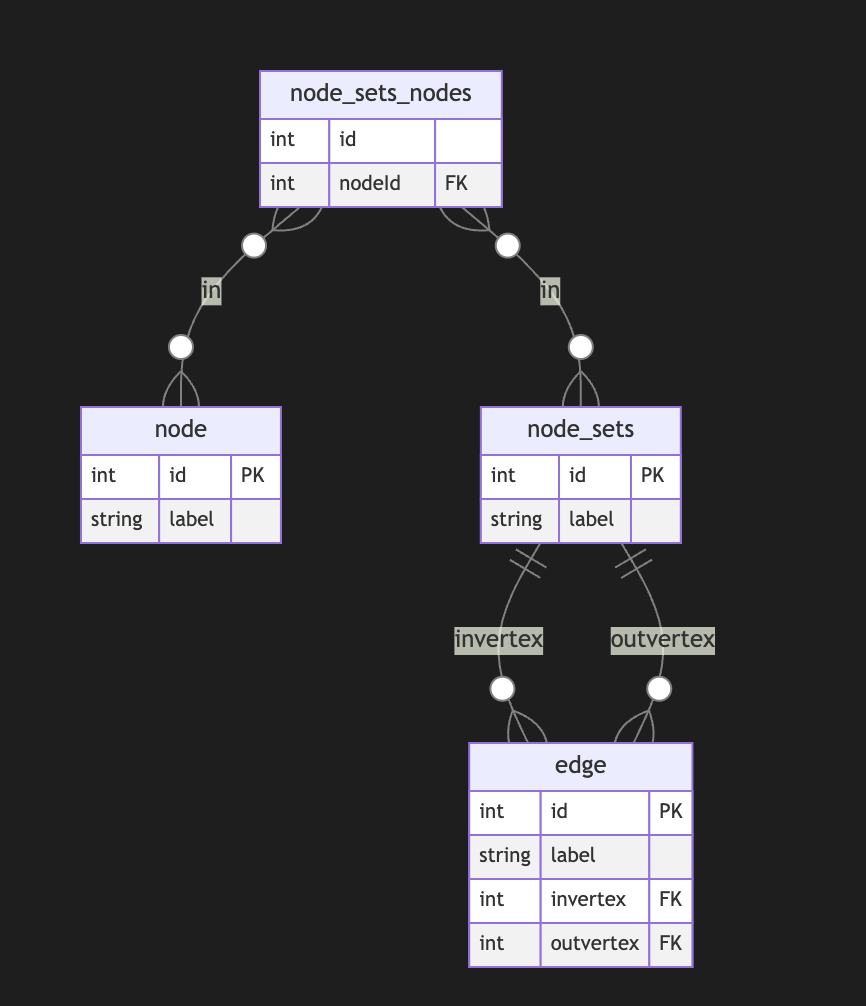
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
## Directed Metagraph where edges are not used as nodes and could contain subgraphs
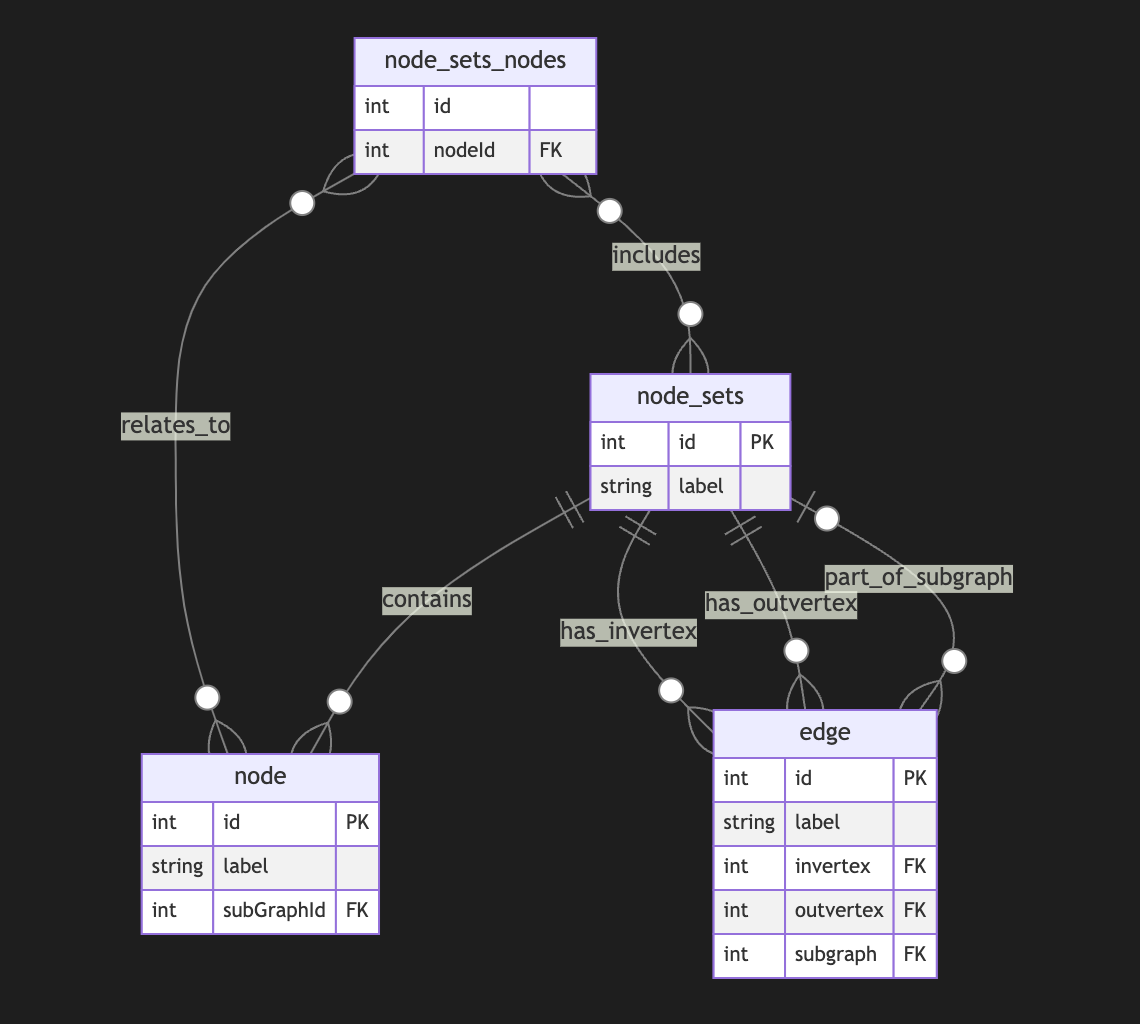
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.
## Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
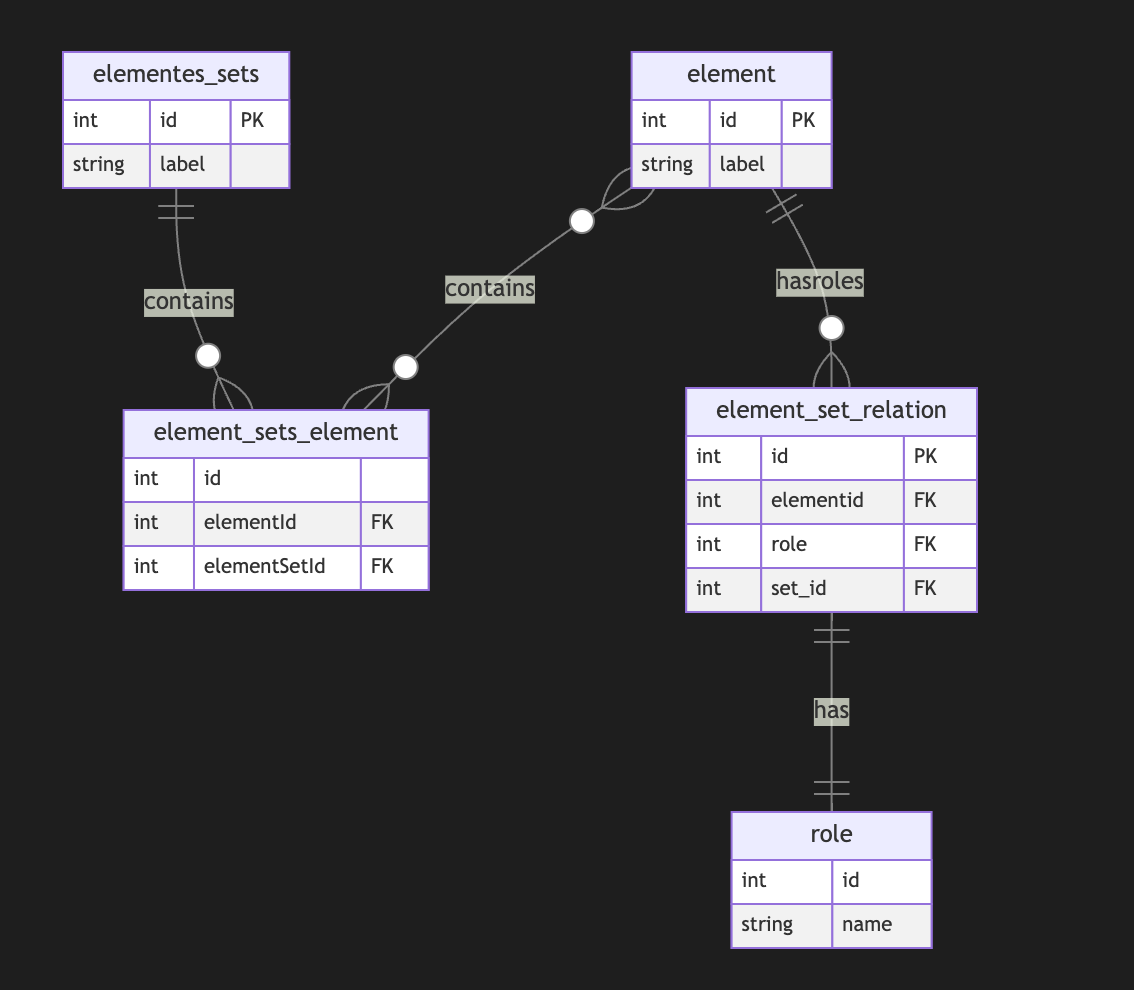
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.
Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose.
-
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
## The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
## Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like **Lisp** emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
## Lisp: The Earlier AI-Language
**Lisp**, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
## Prolog: Formal Logic and Deductive Reasoning
In the 1970s, **Prolog** was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out **how** to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
## Solvers and Their Role in Complementing LLMs
One of the most powerful features of **Prolog** and similar logic-based systems is their use of **solvers**. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a **solver** can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling **constraint satisfaction problems** — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating **neurosymbolic methods** that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
## Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a **graph of rules**. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a **graph of rules**, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable **modular reasoning**, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of **neural fluency** with **rule-based structure** gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform **deductive reasoning** alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
## Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where **neurosymbolic approaches** shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
**Personal Knowledge Graphs (PKGs)** come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a **graph of rules** that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using **deductive databases** to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
## My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling **knowledge graphs using deductive databases**, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
**Prolog** and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a **graph of rules** that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
## Why It Matters for LLM Employment
Using **neurosymbolic RAG (retrieval-augmented generation)** in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of **neural fluency** with **symbolic accuracy and deductive power** is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
## Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
## Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
## RDF and Advanced Topics
## Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
## Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
## Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
## Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
## Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
## Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
## Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and **temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory** and **semantic memory**. And we also have a lot of theories, right?
## Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
> do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
## Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
## Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a **hybrid clock** or some **global clock** that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
## Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
## Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ a39d19ec:3d88f61e
2024-11-21 12:05:09
A state-controlled money supply can influence the development of socialist policies and practices in various ways. Although the relationship is not deterministic, state control over the money supply can contribute to a larger role of the state in the economy and facilitate the implementation of socialist ideals.
## Fiscal Policy Capabilities
When the state manages the money supply, it gains the ability to implement fiscal policies that can lead to an expansion of social programs and welfare initiatives. Funding these programs by creating money can enhance the state's influence over the economy and move it closer to a socialist model. The Soviet Union, for instance, had a centralized banking system that enabled the state to fund massive industrialization and social programs, significantly expanding the state's role in the economy.
## Wealth Redistribution
Controlling the money supply can also allow the state to influence economic inequality through monetary policies, effectively redistributing wealth and reducing income disparities. By implementing low-interest loans or providing financial assistance to disadvantaged groups, the state can narrow the wealth gap and promote social equality, as seen in many European welfare states.
## Central Planning
A state-controlled money supply can contribute to increased central planning, as the state gains more influence over the economy. Central banks, which are state-owned or heavily influenced by the state, play a crucial role in managing the money supply and facilitating central planning. This aligns with socialist principles that advocate for a planned economy where resources are allocated according to social needs rather than market forces.
## Incentives for Staff
Staff members working in state institutions responsible for managing the money supply have various incentives to keep the system going. These incentives include job security, professional expertise and reputation, political alignment, regulatory capture, institutional inertia, and legal and administrative barriers. While these factors can differ among individuals, they can collectively contribute to the persistence of a state-controlled money supply system.
In conclusion, a state-controlled money supply can facilitate the development of socialist policies and practices by enabling fiscal policies, wealth redistribution, and central planning. The staff responsible for managing the money supply have diverse incentives to maintain the system, further ensuring its continuation. However, it is essential to note that many factors influence the trajectory of an economic system, and the relationship between state control over the money supply and socialism is not inevitable.
-
@ a39d19ec:3d88f61e
2024-11-17 10:48:56
This week's functional 3d print is the "Dino Clip".

## Dino Clip
I printed it some years ago for my son, so he would have his own clip for cereal bags.
Now it is used to hold a bag of dog food close.
The design by "Sneaks" is a so called "print in place". This means that the whole clip with moving parts is printed in one part, without the need for assembly after the print.

The clip is very strong, and I would print it again if I need a "heavy duty" clip for more rigid or big bags.
Link to the file at [Printables](https://www.printables.com/model/64493-dino-clip-mechanical-cam-chip-clip-print-in-place)
-
@ 4ba8e86d:89d32de4
2024-11-14 09:17:14
Tutorial feito por nostr:nostr:npub1rc56x0ek0dd303eph523g3chm0wmrs5wdk6vs0ehd0m5fn8t7y4sqra3tk poste original abaixo:
Parte 1 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/263585/tutorial-debloat-de-celulares-android-via-adb-parte-1
Parte 2 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/index.php/263586/tutorial-debloat-de-celulares-android-via-adb-parte-2
Quando o assunto é privacidade em celulares, uma das medidas comumente mencionadas é a remoção de bloatwares do dispositivo, também chamado de debloat. O meio mais eficiente para isso sem dúvidas é a troca de sistema operacional. Custom Rom’s como LineageOS, GrapheneOS, Iodé, CalyxOS, etc, já são bastante enxutos nesse quesito, principalmente quanto não é instalado os G-Apps com o sistema. No entanto, essa prática pode acabar resultando em problemas indesejados como a perca de funções do dispositivo, e até mesmo incompatibilidade com apps bancários, tornando este método mais atrativo para quem possui mais de um dispositivo e separando um apenas para privacidade.
Pensando nisso, pessoas que possuem apenas um único dispositivo móvel, que são necessitadas desses apps ou funções, mas, ao mesmo tempo, tem essa visão em prol da privacidade, buscam por um meio-termo entre manter a Stock rom, e não ter seus dados coletados por esses bloatwares. Felizmente, a remoção de bloatwares é possível e pode ser realizada via root, ou mais da maneira que este artigo irá tratar, via adb.
## O que são bloatwares?
Bloatware é a junção das palavras bloat (inchar) + software (programa), ou seja, um bloatware é basicamente um programa inútil ou facilmente substituível — colocado em seu dispositivo previamente pela fabricante e operadora — que está no seu dispositivo apenas ocupando espaço de armazenamento, consumindo memória RAM e pior, coletando seus dados e enviando para servidores externos, além de serem mais pontos de vulnerabilidades.
## O que é o adb?
O Android Debug Brigde, ou apenas adb, é uma ferramenta que se utiliza das permissões de usuário shell e permite o envio de comandos vindo de um computador para um dispositivo Android exigindo apenas que a depuração USB esteja ativa, mas também pode ser usada diretamente no celular a partir do Android 11, com o uso do Termux e a depuração sem fio (ou depuração wifi). A ferramenta funciona normalmente em dispositivos sem root, e também funciona caso o celular esteja em Recovery Mode.
Requisitos:
Para computadores:
• Depuração USB ativa no celular;
• Computador com adb;
• Cabo USB;
Para celulares:
• Depuração sem fio (ou depuração wifi) ativa no celular;
• Termux;
• Android 11 ou superior;
Para ambos:
• Firewall NetGuard instalado e configurado no celular;
• Lista de bloatwares para seu dispositivo;
## Ativação de depuração:
Para ativar a Depuração USB em seu dispositivo, pesquise como ativar as opções de desenvolvedor de seu dispositivo, e lá ative a depuração. No caso da depuração sem fio, sua ativação irá ser necessária apenas no momento que for conectar o dispositivo ao Termux.
## Instalação e configuração do NetGuard
O NetGuard pode ser instalado através da própria Google Play Store, mas de preferência instale pela F-Droid ou Github para evitar telemetria.
F-Droid:
https://f-droid.org/packages/eu.faircode.netguard/
Github: https://github.com/M66B/NetGuard/releases
Após instalado, configure da seguinte maneira:
Configurações → padrões (lista branca/negra) → ative as 3 primeiras opções (bloquear wifi, bloquear dados móveis e aplicar regras ‘quando tela estiver ligada’);
Configurações → opções avançadas → ative as duas primeiras (administrar aplicativos do sistema e registrar acesso a internet);
Com isso, todos os apps estarão sendo bloqueados de acessar a internet, seja por wifi ou dados móveis, e na página principal do app basta permitir o acesso a rede para os apps que você vai usar (se necessário). Permita que o app rode em segundo plano sem restrição da otimização de bateria, assim quando o celular ligar, ele já estará ativo.
## Lista de bloatwares
Nem todos os bloatwares são genéricos, haverá bloatwares diferentes conforme a marca, modelo, versão do Android, e até mesmo região.
Para obter uma lista de bloatwares de seu dispositivo, caso seu aparelho já possua um tempo de existência, você encontrará listas prontas facilmente apenas pesquisando por elas. Supondo que temos um Samsung Galaxy Note 10 Plus em mãos, basta pesquisar em seu motor de busca por:
```
Samsung Galaxy Note 10 Plus bloatware list
```
Provavelmente essas listas já terão inclusas todos os bloatwares das mais diversas regiões, lhe poupando o trabalho de buscar por alguma lista mais específica.
Caso seu aparelho seja muito recente, e/ou não encontre uma lista pronta de bloatwares, devo dizer que você acaba de pegar em merda, pois é chato para um caralho pesquisar por cada aplicação para saber sua função, se é essencial para o sistema ou se é facilmente substituível.
### De antemão já aviso, que mais para frente, caso vossa gostosura remova um desses aplicativos que era essencial para o sistema sem saber, vai acabar resultando na perda de alguma função importante, ou pior, ao reiniciar o aparelho o sistema pode estar quebrado, lhe obrigando a seguir com uma formatação, e repetir todo o processo novamente.
## Download do adb em computadores
Para usar a ferramenta do adb em computadores, basta baixar o pacote chamado SDK platform-tools, disponível através deste link: https://developer.android.com/tools/releases/platform-tools. Por ele, você consegue o download para Windows, Mac e Linux.
Uma vez baixado, basta extrair o arquivo zipado, contendo dentro dele uma pasta chamada platform-tools que basta ser aberta no terminal para se usar o adb.
## Download do adb em celulares com Termux.
Para usar a ferramenta do adb diretamente no celular, antes temos que baixar o app Termux, que é um emulador de terminal linux, e já possui o adb em seu repositório. Você encontra o app na Google Play Store, mas novamente recomendo baixar pela F-Droid ou diretamente no Github do projeto.
F-Droid: https://f-droid.org/en/packages/com.termux/
Github: https://github.com/termux/termux-app/releases
## Processo de debloat
Antes de iniciarmos, é importante deixar claro que não é para você sair removendo todos os bloatwares de cara sem mais nem menos, afinal alguns deles precisam antes ser substituídos, podem ser essenciais para você para alguma atividade ou função, ou até mesmo são insubstituíveis.
Alguns exemplos de bloatwares que a substituição é necessária antes da remoção, é o Launcher, afinal, é a interface gráfica do sistema, e o teclado, que sem ele só é possível digitar com teclado externo. O Launcher e teclado podem ser substituídos por quaisquer outros, minha recomendação pessoal é por aqueles que respeitam sua privacidade, como Pie Launcher e Simple Laucher, enquanto o teclado pelo OpenBoard e FlorisBoard, todos open-source e disponíveis da F-Droid.
Identifique entre a lista de bloatwares, quais você gosta, precisa ou prefere não substituir, de maneira alguma você é obrigado a remover todos os bloatwares possíveis, modifique seu sistema a seu bel-prazer. O NetGuard lista todos os apps do celular com o nome do pacote, com isso você pode filtrar bem qual deles não remover.
Um exemplo claro de bloatware insubstituível e, portanto, não pode ser removido, é o com.android.mtp, um protocolo onde sua função é auxiliar a comunicação do dispositivo com um computador via USB, mas por algum motivo, tem acesso a rede e se comunica frequentemente com servidores externos. Para esses casos, e melhor solução mesmo é bloquear o acesso a rede desses bloatwares com o NetGuard.
MTP tentando comunicação com servidores externos:
## Executando o adb shell
No computador
Faça backup de todos os seus arquivos importantes para algum armazenamento externo, e formate seu celular com o hard reset. Após a formatação, e a ativação da depuração USB, conecte seu aparelho e o pc com o auxílio de um cabo USB. Muito provavelmente seu dispositivo irá apenas começar a carregar, por isso permita a transferência de dados, para que o computador consiga se comunicar normalmente com o celular.
Já no pc, abra a pasta platform-tools dentro do terminal, e execute o seguinte comando:
```
./adb start-server
```
O resultado deve ser:
*daemon not running; starting now at tcp:5037
*daemon started successfully
E caso não apareça nada, execute:
```
./adb kill-server
```
E inicie novamente.
Com o adb conectado ao celular, execute:
```
./adb shell
```
Para poder executar comandos diretamente para o dispositivo. No meu caso, meu celular é um Redmi Note 8 Pro, codinome Begonia.
Logo o resultado deve ser:
begonia:/ $
Caso ocorra algum erro do tipo:
adb: device unauthorized.
This adb server’s $ADB_VENDOR_KEYS is not set
Try ‘adb kill-server’ if that seems wrong.
Otherwise check for a confirmation dialog on your device.
Verifique no celular se apareceu alguma confirmação para autorizar a depuração USB, caso sim, autorize e tente novamente. Caso não apareça nada, execute o kill-server e repita o processo.
## No celular
Após realizar o mesmo processo de backup e hard reset citado anteriormente, instale o Termux e, com ele iniciado, execute o comando:
```
pkg install android-tools
```
Quando surgir a mensagem “Do you want to continue? [Y/n]”, basta dar enter novamente que já aceita e finaliza a instalação
Agora, vá até as opções de desenvolvedor, e ative a depuração sem fio. Dentro das opções da depuração sem fio, terá uma opção de emparelhamento do dispositivo com um código, que irá informar para você um código em emparelhamento, com um endereço IP e porta, que será usado para a conexão com o Termux.
Para facilitar o processo, recomendo que abra tanto as configurações quanto o Termux ao mesmo tempo, e divida a tela com os dois app’s, como da maneira a seguir:
Para parear o Termux com o dispositivo, não é necessário digitar o ip informado, basta trocar por “localhost”, já a porta e o código de emparelhamento, deve ser digitado exatamente como informado. Execute:
```
adb pair localhost:porta CódigoDeEmparelhamento
```
De acordo com a imagem mostrada anteriormente, o comando ficaria “adb pair localhost:41255 757495”.
Com o dispositivo emparelhado com o Termux, agora basta conectar para conseguir executar os comandos, para isso execute:
```
adb connect localhost:porta
```
Obs: a porta que você deve informar neste comando não é a mesma informada com o código de emparelhamento, e sim a informada na tela principal da depuração sem fio.
Pronto! Termux e adb conectado com sucesso ao dispositivo, agora basta executar normalmente o adb shell:
```
adb shell
```
Remoção na prática
Com o adb shell executado, você está pronto para remover os bloatwares. No meu caso, irei mostrar apenas a remoção de um app (Google Maps), já que o comando é o mesmo para qualquer outro, mudando apenas o nome do pacote.
Dentro do NetGuard, verificando as informações do Google Maps:
Podemos ver que mesmo fora de uso, e com a localização do dispositivo desativado, o app está tentando loucamente se comunicar com servidores externos, e informar sabe-se lá que peste. Mas sem novidades até aqui, o mais importante é que podemos ver que o nome do pacote do Google Maps é com.google.android.apps.maps, e para o remover do celular, basta executar:
```
pm uninstall –user 0 com.google.android.apps.maps
```
E pronto, bloatware removido! Agora basta repetir o processo para o resto dos bloatwares, trocando apenas o nome do pacote.
Para acelerar o processo, você pode já criar uma lista do bloco de notas com os comandos, e quando colar no terminal, irá executar um atrás do outro.
Exemplo de lista:
Caso a donzela tenha removido alguma coisa sem querer, também é possível recuperar o pacote com o comando:
```
cmd package install-existing nome.do.pacote
```
## Pós-debloat
Após limpar o máximo possível o seu sistema, reinicie o aparelho, caso entre no como recovery e não seja possível dar reboot, significa que você removeu algum app “essencial” para o sistema, e terá que formatar o aparelho e repetir toda a remoção novamente, desta vez removendo poucos bloatwares de uma vez, e reiniciando o aparelho até descobrir qual deles não pode ser removido. Sim, dá trabalho… quem mandou querer privacidade?
Caso o aparelho reinicie normalmente após a remoção, parabéns, agora basta usar seu celular como bem entender! Mantenha o NetGuard sempre executando e os bloatwares que não foram possíveis remover não irão se comunicar com servidores externos, passe a usar apps open source da F-Droid e instale outros apps através da Aurora Store ao invés da Google Play Store.
Referências:
Caso você seja um Australopithecus e tenha achado este guia difícil, eis uma videoaula (3:14:40) do Anderson do canal Ciberdef, realizando todo o processo: http://odysee.com/@zai:5/Como-remover-at%C3%A9-200-APLICATIVOS-que-colocam-a-sua-PRIVACIDADE-E-SEGURAN%C3%87A-em-risco.:4?lid=6d50f40314eee7e2f218536d9e5d300290931d23
Pdf’s do Anderson citados na videoaula: créditos ao anon6837264
http://eternalcbrzpicytj4zyguygpmkjlkddxob7tptlr25cdipe5svyqoqd.onion/file/3863a834d29285d397b73a4af6fb1bbe67c888d72d30/t-05e63192d02ffd.pdf
Processo de instalação do Termux e adb no celular: https://youtu.be/APolZrPHSms
-
@ a10260a2:caa23e3e
2024-11-10 04:35:34
nostr:npub1nkmta4dmsa7pj25762qxa6yqxvrhzn7ug0gz5frp9g7p3jdscnhsu049fn added support for [classified listings (NIP-99)](https://github.com/sovbiz/Cypher-Nostr-Edition/commit/cd3bf585c77a85421de031db1d8ebd3911ba670d) about a month ago and recently announced this update that allows for creating/editing listings and blog posts via the dashboard.
In other words, listings created on the website are also able to be viewed and edited on other Nostr apps like Amethyst and Shopstr. Interoperability FTW.
I took some screenshots to give you an idea of how things work.
The [home page](https://cypher.space/) is clean with the ability to search for profiles by name, npub, or Nostr address (NIP-05).

Clicking login allows signing in with a browser extension.
The dashboard gives an overview of the amount of notes posted (both short and long form) and products listed.
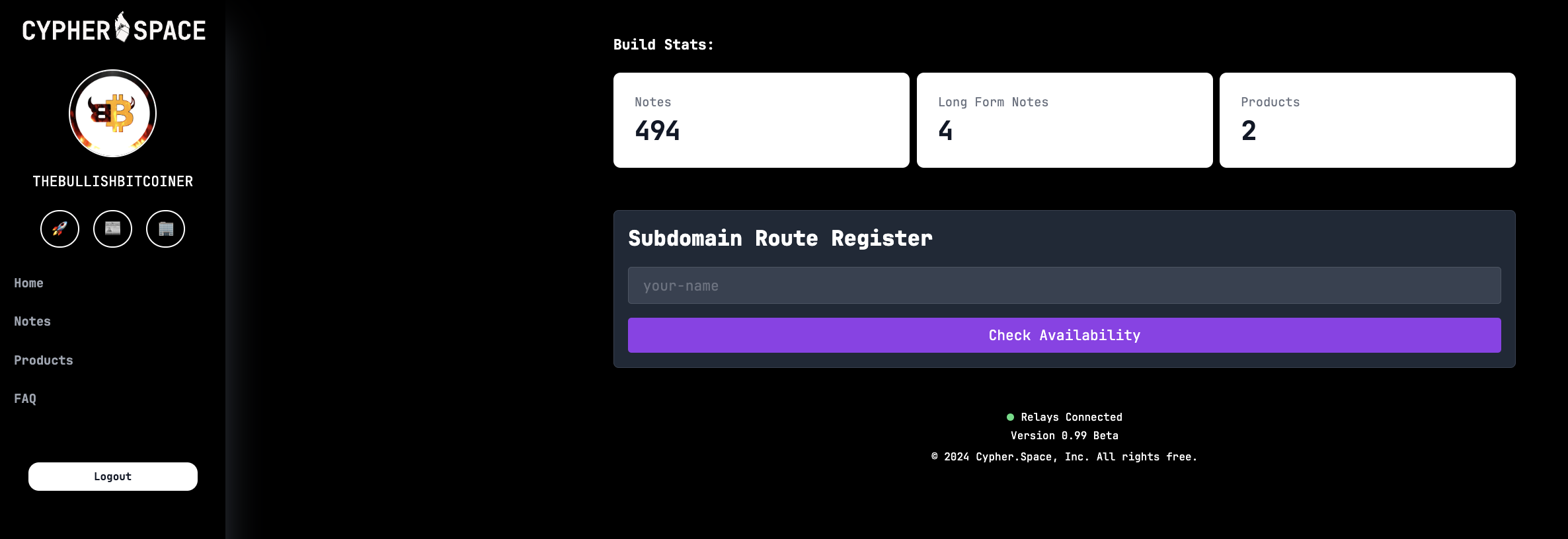
Existing blog posts (i.e. long form notes) are synced.

Same for product listings. There’s a nice interface to create new ones and preview them before publishing.
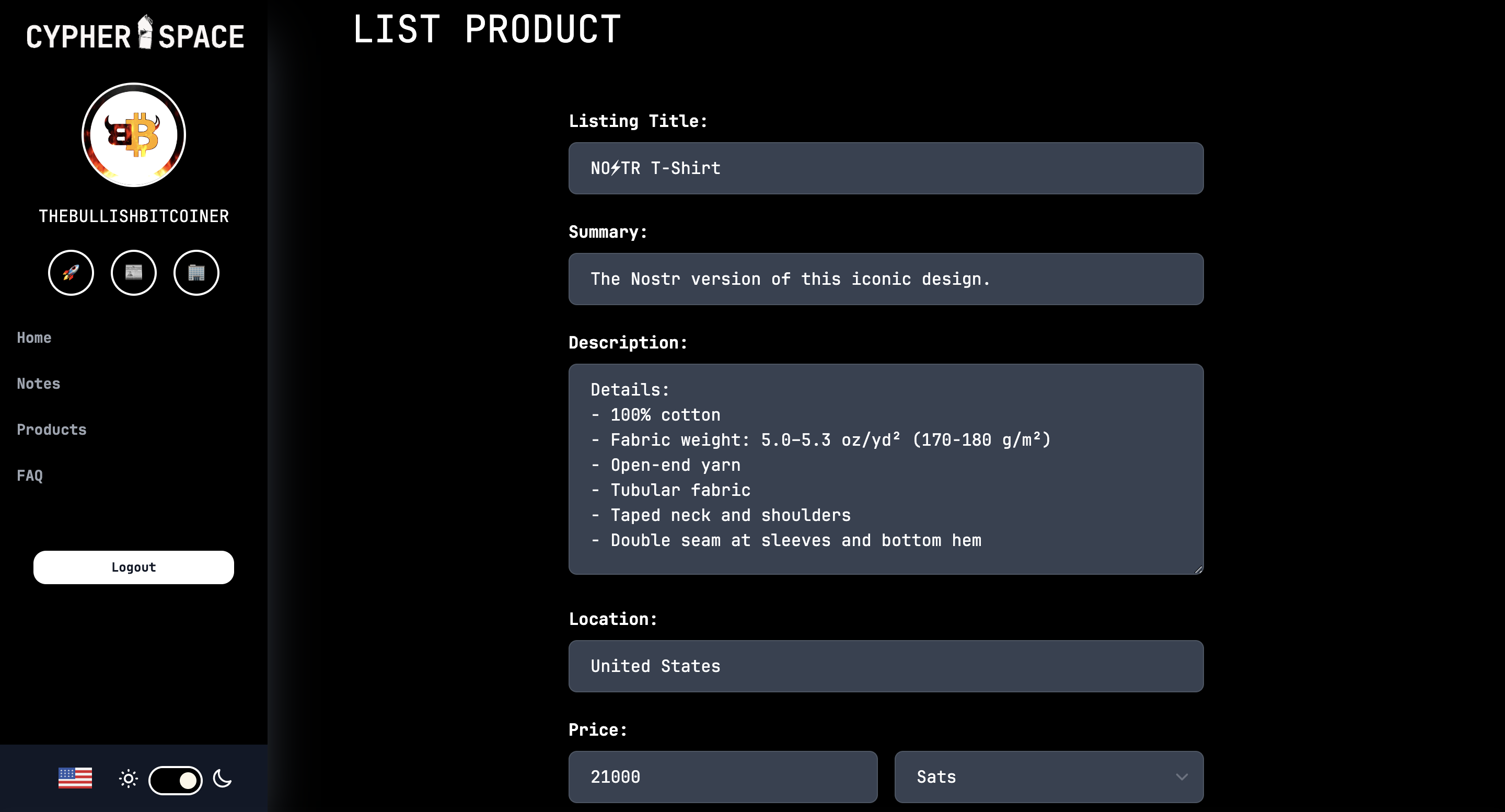
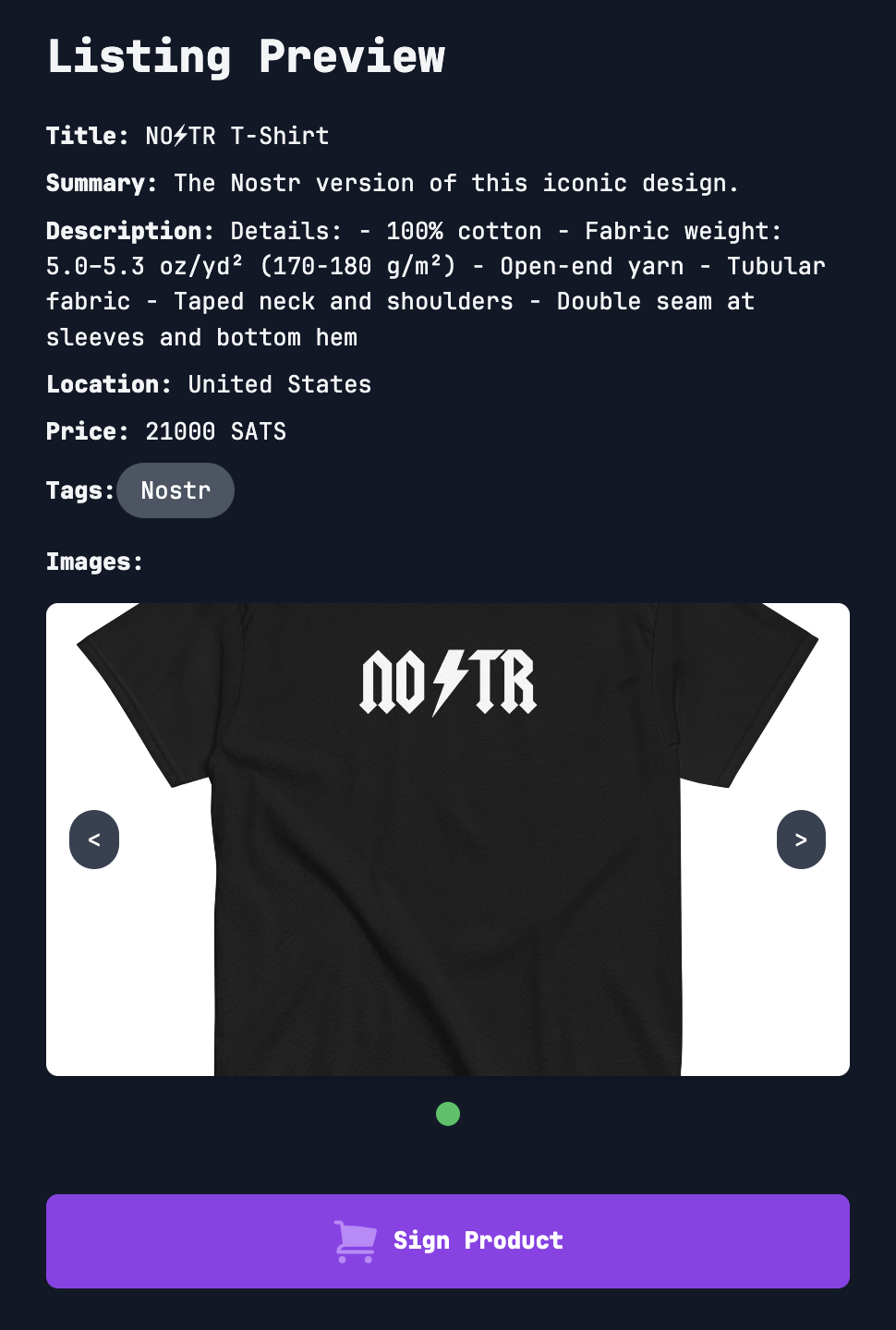
That’s all for now. As you can see, super slick stuff!
Bullish on Cypher.
So much so I had to support the project and buy a subdomain. 😎
https://bullish.cypher.space
originally posted at https://stacker.news/items/760592
-
@ 35f3a26c:92ddf231
2024-11-09 17:10:57
## "Files" by Google new feature
"Files" by Google added a "feature"... "Smart Search", you can toggle it to OFF and it is highly recommended to do so.
- 
Toggle the Smart Search to OFF, otherwise, google will search and index every picture, video and document in your device, no exceptions, anything you have ever photographed and you forgot, any document you have downloaded or article, etc...
## How this could affect you?
Google is actively combating child abuse and therefore it has built in its "AI" a very aggressive algorithm searching of material that "IT THINKS" is related, therefore the following content could be flagged:
- [ ] Pictures of you and your children in the beach
- [ ] Pictures or videos which are innocent in nature but the "AI" "thinks" are not
- [ ] Articles you may have save for research to write your next essay that have links to flagged information or sites
***The results:***
- [ ] Your google account will be canceled
- [ ] You will be flagged as a criminal across the digital world
You think this is non sense? Think again:
https://www.nytimes.com/2022/08/21/technology/google-surveillance-toddler-photo.html
## How to switch it off:
1. Open files by Google
2. Tap on Menu -> Settings
3. Turn OFF Smart Search
## But you can do more for your privacy and the security of your family
1. Stop using google apps, if possible get rid off of Google OS and use Graphene OS
2. Go to Settings -> Apps
3. Search for Files by Google
4. Unistall the app, if you can't disable it
5. Keep doing that with most Google apps that are not a must if you have not switched already to GrapheneOS
***Remember, Google keeps advocating for privacy, but as many others have pointed out repeatedly, they are the first ones lobbying for the removal of your privacy by regulation and draconian laws, their hypocrisy knows no limits***
## Recommendation:
I would assume you have installed F-Droid in your android, or Obtainium if you are more advanced, if so, consider "Simple File Manager Pro" by Tibor Kaputa, this dev has a suite of apps that are basic needs and the best feature in my opinion is that not one of his apps connect to the internet, contacts, gallery, files, phone, etc.
- 
> Note
> As most people, we all love the convenience of technology, it makes our lives easier, however, our safety and our family safety should go first, between technology being miss-used and abused by corporations and cyber-criminals data mining and checking for easy targets to attack for profit, we need to keep our guard up. Learning is key, resist the use of new tech if you do not understand the privacy trade offs, no matter how appealing and convenient it looks like. .
***Please leave your comments with your favorite FOSS Files app!***
-
@ 3bf0c63f:aefa459d
2024-11-07 14:56:17
# The case against edits
Direct edits are a centralizing force on Nostr, a slippery slope that should not be accepted.
Edits are fine in other, more specialized event kinds, but the `kind:1` space shouldn't be compromised with such a push towards centralization, because [`kind:1` is the public square of Nostr, where all focus should be on decentralization and censorship-resistance](cd8ce2b7).
- _Why?_
Edits introduce too much complexity. If edits are widespread, all clients now have to download dozens of extra events at the same time while users are browsing a big feed of notes which are already coming from dozens of different relays using complicated outbox-model-based querying, then for each event they have to open yet another subscription to these relays -- or perform some other complicated batching of subscriptions which then requires more complexity on the event handling side and then when associating these edits with the original events. I can only imagine this will hurt apps performance, but it definitely raises the barrier to entry and thus necessarily decreases Nostr decentralization.
Some clients may be implemneted in way such that they download tons of events and then store them in a local databases, from which they then construct the feed that users see. Such clients may make edits potentially easier to deal with -- but this is hardly an answer to the point above, since such clients are already more complex to implement in the first place.
- _What do you have against complex clients?_
The point is not to say that all clients should be simple, but that it should be simple to write a client -- or at least as simple as physically possible.
You may not be thinking about it, but if you believe in the promise of Nostr then we should expect to see Nostr feeds in many other contexts other than on a big super app in a phone -- we should see Nostr notes being referenced from and injected in unrelated webpages, unrelated apps, hardware devices, comment sections and so on. All these micro-clients will have to implement some complicated edit-fetching logic now?
- _But aren't we already fetching likes and zaps and other things, why not fetch edits too?_
Likes, zaps and other similar things are optional. It's perfectly fine to use Nostr without seeing likes and/or zaps -- and, believe me, it does happen quite a lot. The point is basically that likes or zaps don't affect the content of the main post at all, while edits do.
- _But edits are optional!_
No, they are not optional. If edits become widespread they necessarily become mandatory. Any client that doesn't implement edits will be displaying false information to its users and their experience will be completely broken.
- _That's fine, as people will just move to clients that support edits!_
Exactly, that is what I expect to happen too, and this is why I am saying edits are a centralizing force that we should be fighting against, not embracing.
If you understand that edits are a centralizing force, then you must automatically agree that they aren't a desirable feature, given that if you are reading this now, with Nostr being so small, there is a 100% chance you care about decentralization and you're not just some kind of lazy influencer that is only doing this for money.
- _All other social networks support editing!_
This is not true at all. Bluesky has 10x more users than Nostr and doesn't support edits. Instagram doesn't support editing pictures after they're posted, and doesn't support editing comments. Tiktok doesn't support editing videos or comments after they're posted. YouTube doesn't support editing videos after they're posted. Most famously, email, the most widely used and widespread "social app" out there, does not support edits of any kind. Twitter didn't support edits for the first 15 years of its life, and, although some people complained, it didn't hurt the platform at all -- arguably it benefitted it.
If edits are such a straightforward feature to add that won't hurt performance, that won't introduce complexity, and also that is such an essential feature users could never live without them, then why don't these centralized platforms have edits on everything already? There must be something there.
- _Eventually someone will implement edits anyway, so why bother to oppose edits now?_
Once Nostr becomes big enough, maybe it will be already shielded from such centralizing forces by its sheer volume of users and quantity of clients, maybe not, we will see. All I'm saying is that we shouldn't just push for bad things now just because of a potential future in which they might come.
- _The market will decide what is better._
The market has decided for Facebook, Instagram, Twitter and TikTok. If we were to follow what the market had decided we wouldn't be here, and you wouldn't be reading this post.
- _OK, you have convinced me, edits are not good for the protocol. But what do we do about the users who just want to fix their typos?_
There are many ways. The annotations spec, for example, provides a simple way to append things to a note without being a full-blown edit, and they fall back gracefully to normal replies in clients that don't implement the full annotations spec.
Eventually we could have annotations that are expressed in form of simple (human-readable?) diffs that can be applied directly to the post, but fall back, again, to comments.
Besides these, a very simple idea that wasn't tried yet on Nostr yet is the idea that has been tried for emails and seems to work very well: delaying a post after the "submit" button is clicked and giving the user the opportunity to cancel and edit it again before it is actually posted.
Ultimately, if edits are so necessary, then maybe we could come up with a way to implement edits that is truly optional and falls back cleanly for clients that don't support them directly and don't hurt the protocol very much. Let's think about it and not rush towards defeat.
-
@ a367f9eb:0633efea
2024-11-05 08:48:41
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The [reporting](https://www.reuters.com/technology/artificial-intelligence/chinese-researchers-develop-ai-model-military-use-back-metas-llama-2024-11-01/) purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
> In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
>
> The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
> In a June paper reviewed by[ Reuters](https://www.reuters.com/technology/artificial-intelligence/chinese-researchers-develop-ai-model-military-use-back-metas-llama-2024-11-01/), six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
>
> The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the *Star Trek* episode “[A Taste of Armageddon](https://en.wikipedia.org/wiki/A_Taste_of_Armageddon)“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over [one million open-source LLMs](https://huggingface.co/models) available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are [potentially](https://bigthink.com/business/the-trillion-dollar-ai-race-to-create-digital-god/) trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American[ infrastructure](https://www.nbcnews.com/tech/security/chinese-hackers-cisa-cyber-5-years-us-infrastructure-attack-rcna137706),[ data](https://www.cnn.com/2024/10/05/politics/chinese-hackers-us-telecoms/index.html), and yes, [your credit history](https://thespectator.com/topic/chinese-communist-party-credit-history-equifax/)?
**As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much[ many times](https://consumerchoicecenter.org/made-in-china-sold-in-china/).**
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
## **Open-source matters**
When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various [licensing schemes](https://opensource.org/licenses) – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also [open-source](https://github.com/bitcoin), which has allowed [thousands](https://bitcoinmagazine.com/business/bitcoin-is-money-for-enemies) of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
## **Open-source is for your friends, and enemies**
In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to[ Hugging Face](https://huggingface.co/), download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put [export controls](https://www.reuters.com/technology/us-lawmakers-unveil-bill-make-it-easier-restrict-exports-ai-models-2024-05-10/) on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see[ The Crypto Wars](https://en.wikipedia.org/wiki/Export_of_cryptography_from_the_United_States)). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
## **Limiting open-source threatens our own advancement**
If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “[Hundred Year Marathon](https://www.amazon.com/Hundred-Year-Marathon-Strategy-Replace-Superpower/dp/1250081343)” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with [trillions of dollars’](https://www.economist.com/china/2024/11/04/in-some-areas-of-military-strength-china-has-surpassed-america) worth of investments that span far beyond AI chatbots and skip logic protocols.
The [theft](https://www.technologyreview.com/2023/06/20/1075088/chinese-amazon-seller-counterfeit-lawsuit/) of intellectual property at factories in Shenzhen, or in US courts by [third-party litigation funding](https://nationalinterest.org/blog/techland/litigation-finance-exposes-our-judicial-system-foreign-exploitation-210207) coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
*Originally published on the website of the [Consumer Choice Center](https://consumerchoicecenter.org/open-source-is-for-everyone-even-your-adversaries/).*
-
@ 9349d012:d3e98946
2024-11-05 00:42:37
## Chef's notes
2 cups pureed pumpkin
2 cups white sugar
3 eggs, beaten
1/2 cup olive oil
1 tablespoon cinnamon
1 1/2 teaspoon baking powder
1 teaspoon baking soda
1/2 teaspoon salt
2 1/4 cups flour
1/4 cup chopped pecans
Preheat oven to 350 degrees Fahrenheit. Coat a bread pan with olive oil. Mix all ingredients minus nuts, leaving the flour for last, and adding it in 2 parts. Stir until combined. Pour the batter into the bread pan and sprinkle chopped nuts down the middle of the batter, lenghtwise. Bake for an hour and ten minutes or until a knife insert in the middle of the pan comes out clean. Allow bread to cool in the pan for five mintes, then use knife to loosen the edges of the loaf and pop out of the pan. Rest on a rack or plate until cool enough to slice. Spread bread slices with Plugra butter and serve.
https://cookeatloveshare.com/pumpkin-bread/
## Details
- ⏲️ Prep time: 30 minutes
- 🍳 Cook time: 1 hour and ten minutes
- 🍽️ Servings: 6
## Ingredients
- See Chef's Notes
## Directions
1. See Chef's Notes
-
@ 09fbf8f3:fa3d60f0
2024-11-02 08:00:29
> ### 第三方API合集:
---
免责申明:
在此推荐的 OpenAI API Key 由第三方代理商提供,所以我们不对 API Key 的 有效性 和 安全性 负责,请你自行承担购买和使用 API Key 的风险。
| 服务商 | 特性说明 | Proxy 代理地址 | 链接 |
| --- | --- | --- | --- |
| AiHubMix | 使用 OpenAI 企业接口,全站模型价格为官方 86 折(含 GPT-4 )| https://aihubmix.com/v1 | [官网](https://aihubmix.com?aff=mPS7) |
| OpenAI-HK | OpenAI的API官方计费模式为,按每次API请求内容和返回内容tokens长度来定价。每个模型具有不同的计价方式,以每1,000个tokens消耗为单位定价。其中1,000个tokens约为750个英文单词(约400汉字)| https://api.openai-hk.com/ | [官网](https://openai-hk.com/?i=45878) |
| CloseAI | CloseAI是国内规模最大的商用级OpenAI代理平台,也是国内第一家专业OpenAI中转服务,定位于企业级商用需求,面向企业客户的线上服务提供高质量稳定的官方OpenAI API 中转代理,是百余家企业和多家科研机构的专用合作平台。 | https://api.openai-proxy.org | [官网](https://www.closeai-asia.com/) |
| OpenAI-SB | 需要配合Telegram 获取api key | https://api.openai-sb.com | [官网](https://www.openai-sb.com/) |
` 持续更新。。。`
---
### 推广:
访问不了openai,去`低调云`购买VPN。
官网:https://didiaocloud.xyz
邀请码:`w9AjVJit`
价格低至1元。
-
@ 06639a38:655f8f71
2024-11-01 22:32:51
One year ago I wrote the article [Why Nostr resonates](https://sebastix.nl/blog/why-nostr-resonates/) in Dutch and English after I visited the Bitcoin Amsterdam 2023 conference and the Nostrdam event. It got published at [bitcoinfocus.nl](https://bitcoinfocus.nl/2023/11/02/278-waarom-nostr-resoneert/) (translated in Dutch). The main reason why I wrote that piece is that I felt that my gut feeling was tellinng me that Nostr is going to change many things on the web.
After the article was published, one of the first things I did was setting up this page on my website: [https://sebastix.nl/nostr-research-and-development](https://sebastix.nl/nostr-research-and-development). The page contains this section (which I updated on 31-10-2024):

One metric I would like to highlight is the number of repositories on Github. Compared to a year ago, there are already more than 1130 repositories now on Github tagged with Nostr. Let's compare this number to other social media protocols and decentralized platforms (24-10-2024):
* Fediverse: 522
* ATProto: 159
* Scuttlebot: 49
* Farcaster: 202
* Mastodon: 1407
* ActivityPub: 444
Nostr is growing. FYI there are many Nostr repositories not hosted on Github, so the total number of Nostr reposities is higher. I know that many devs are using their own Git servers to host it. We're even capable of setting up Nostr native Git repositories (for example, see [https://gitworkshop.dev/repos](https://gitworkshop.dev/repos)). Eventually, Nostr will make Github (and other platforms) absolute.
Let me continue summarizing my personal Nostr highlights of last year.
## Organising Nostr meetups

This is me playing around with the NostrDebug tool showing how you can query data from Nostr relays. Jurjen is standing behind me. He is one of the people I've met this year who I'm sure I will have a long-term friendship with.
## OpenSats grant for Nostr-PHP


In December 2023 I submitted my application for a OpenSats grant for the further development of the Nostr-PHP helper library. After some months I finally got the message that my application was approved... When I got the message I was really stoked and excited. It's a great form of appreciation for the work I had done so far and with this grant I get the opportunity to take the work to another higher level. So please check out the work done for so far:
* [https://nostr-php.dev](https://nostr-php.dev)
* [https://github.com/nostrver-se/nostr-php](https://github.com/nostrver-se/nostr-php)
## Meeting Dries

One of my goosebumps moments I had in 2022 when I saw that the founder and tech lead of Drupal Dries Buytaert posted '[Nostr, love at first sight](https://dri.es/nostr-love-at-first-sight)' on his blog. These types of moments are very rare moment where two different worlds merge where I wouldn't expect it. Later on I noticed that Dries would come to the yearly Dutch Drupal event. For me this was a perfect opportunity to meet him in person and have some Nostr talks. I admire the work he is doing for Drupal and the community. I hope we can bridge Nostr stuff in some way to Drupal. In general this applies for any FOSS project out there.
[Here](https://sebastix.nl/blog/photodump-and-highlights-drupaljam-2024/) is my recap of that Drupal event.
## Attending Nostriga

A conference where history is made and written. I felt it immediately at the first sessions I attended. I will never forget the days I had at Nostriga. I don't have the words to describe what it brought to me.

I also pushed myself out of my comfort zone by giving a keynote called 'POSSE with Nostr - how we pivot away from API's with one of Nostr superpowers'. I'm not sure if this is something I would do again, but I've learned a lot from it.
You can find the presentation [here](https://nostriga.nostrver.se/). It is recorded, but I'm not sure if and when it gets published.
## Nostr billboard advertisement

This advertisment was shown on a billboard beside the [A58 highway in The Netherlands](https://www.google.nl/maps/@51.5544315,4.5607291,3a,75y,34.72h,93.02t/data=!3m6!1e1!3m4!1sdQv9nm3J9SdUQCD0caFR-g!2e0!7i16384!8i8192?coh=205409&entry=ttu) from September 2nd till September 16th 2024. You can find all the assets and more footage of the billboard ad here: [https://gitlab.com/sebastix-group/nostr/nostr-ads](https://gitlab.com/sebastix-group/nostr/nostr-ads). My goal was to set an example of how we could promote Nostr in more traditional ways and inspire others to do the same. In Brazil a fundraiser was achieved to do something similar there: [https://geyser.fund/project/nostrifybrazil](https://geyser.fund/project/nostrifybrazil).
## Volunteering at Nostr booths growNostr

This was such a great motivating experience. Attending as a volunteer at the Nostr booth during the Bitcoin Amsterdam 2024 conference. Please read my note with all the lessons I learned [here](https://nostrver.se/note/my-learned-nostr-lessons-nostr-booth-bitcoin-amsterdam-2024).
## The other stuff
* The Nostr related blog articles I wrote past year:
* [**Run a Nostr relay with your own policies**](https://sebastix.nl/blog/run-a-nostr-relay-with-your-own-policies/) (02-04-2024)
* [**Why social networks should be based on commons**](https://sebastix.nl/blog/why-social-networks-should-be-based-on-commons/) (03-01-2024)
* [**How could Drupal adopt Nostr?**](https://sebastix.nl/blog/how-could-drupal-adopt-nostr/) (30-12-2023)
* [**Nostr integration for CCHS.social**](https://sebastix.nl/blog/nostr-integration-for-cchs-social-drupal-cms/) (21-12-2023)
* [https://ccns.nostrver.se](https://ccns.nostrver.se)
CCNS stands for Community Curated Nostr Stuff. At the end of 2023 I started to build this project. I forked an existing Drupal project of mine (https://cchs.social) to create a link aggregation website inspired by stacker.news. At the beginning of 2024 I also joined the TopBuilder 2024 contest which was a productive period getting to know new people in the Bitcoin and Nostr space.
* [https://nuxstr.nostrver.se](https://nuxstr.nostrver.se)
PHP is not my only language I use to build stuff. As a fullstack webdeveloper I also work with Javascript. Many Nostr clients are made with Javascript frameworks or other more client-side focused tools. Vuejs is currently my Javascript framework I'm the most convenient with. With Vuejs I started to tinker around with Nuxt combined with NDK and so I created a starter template for Vue / Nuxt developers.
* [ZapLamp](nostr:npub1nfrsmpqln23ls7y3e4m29c22x3qaq9wmmr7zkfcttty2nk2kd6zs9re52s)
This is a neat DIY package from LNbits. Powered by an Arduino ESP32 dev board it was running a 24/7 livestream on zap.stream at my office. It flashes when you send a zap to the npub of the ZapLamp.
* [https://nosto.re](https://nosto.re)
Since the beginning when the Blossom spec was published by @hzrd49 and @StuartBowman I immediately took the opportunity to tinker with it. I'm also running a relay for transmitting Blossom Nostr events `wss://relay.nosto.re`.
* [Relays I maintain](https://nostrver.se/note/relays-i-maintain)
I really enjoy to tinker with different relays implementations. Relays are the fundamental base layer to let Nostr work.
I'm still sharing my contributions on [https://nostrver.se/](https://nostrver.se/) where I publish my weekly Nostr related stuff I worked on. This website is built with Drupal where I use the Nostr Simple Publish and Nostr long-form content NIP-23 modules to crosspost the notes and long-form content to the Nostr network (like this piece of content you're reading).
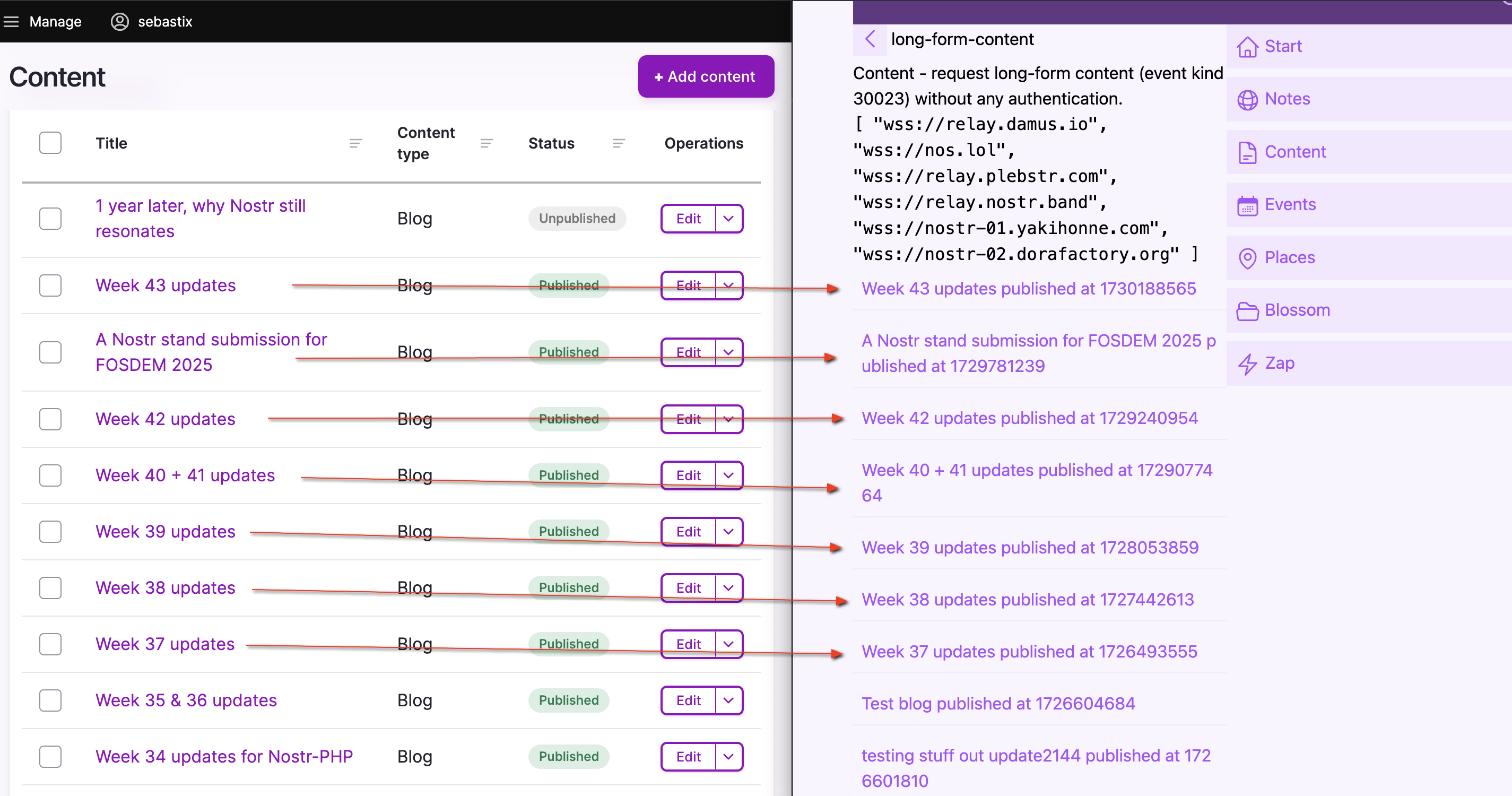
## The Nostr is the people
Just like the web, the web is people: [https://www.youtube.com/watch?v=WCgvkslCzTo](https://www.youtube.com/watch?v=WCgvkslCzTo)
> the people on nostr are some of the smartest and coolest i’ve ever got to know. who cares if it doesn’t take over the world. It’s done more than i could ever ask for. - [@jb55](nostr:note1fsfqja9kkvzuhe5yckff3gkkeqe7upxqljg2g4nkjzp5u9y7t25qx43uch)
Here are some Nostriches who I'm happy to have met and who influenced my journey in Nostr in a positive way.
* Jurjen
* Bitpopart
* Arjen
* Jeroen
* Alex Gleason
* Arnold Lubach
* Nathan Day
* Constant
* fiatjaf
* Sync
## Coming year
Generally I will continue doing what I've done last year. Besides the time I spent on Nostr stuff, I'm also very busy with Drupal related work for my customers. I hope I can get the opportunity to work on a paid client project related to Nostr. It will be even better when I can combine my Drupal expertise with Nostr for projects paid by customers.
### Building a new Nostr application
When I look at my Nostr backlog where I just put everything in with ideas and notes, there are quite some interesting concepts there for building new Nostr applications. Filtering out, I think these three are the most exciting ones:
* nEcho, a micro app for optimizing your reach via Nostr (NIP-65)
* Nostrides.cc platform where you can share Nostr activity events (NIP-113)
* A child-friendly video web app with parent-curated content (NIP-71)
### Nostr & Drupal
When working out a new idea for a Nostr client, I'm trying to combine my expertises into one solution. That's why I also build and maintain some Nostr contrib modules for Drupal.
* [Nostr Simple Publish](https://www.drupal.org/project/nostr_simple_publish)
Drupal module to cross-post notes from Drupal to Nostr
* [Nostr long-form content NIP-23](https://www.drupal.org/project/nostr_content_nip23)
Drupal module to cross-post Markdown formatted content from Drupal to Nostr
* [Nostr internet identifier NIP-05](https://www.drupal.org/project/nostr_id_nip05)
Drupal module to setup Nostr internet identifier addresses with Drupal.
* [Nostr NDK](https://drupal.org/project/nostr_dev_kit)
Includes the Javascript library Nostr Dev Kit (NDK) in a Drupal project.
One of my (very) ambitious goals is to build a Drupal powered Nostr (website) package with the following main features:
* Able to login into Drupal with your Nostr keypair
* Cross-post content to the Nostr network
* Fetch your Nostr content from the Nostr content
* Serve as a content management system (CMS) for your Nostr events
* Serve as a framework to build a hybrid Nostr web application
* Run and maintain a Nostr relay with custom policies
* Usable as a feature rich progressive web app
* Use it as a remote signer
These are just some random ideas as my Nostr + Drupal backlog is way longer than this.
### Nostr-PHP
With all the newly added and continues being updated NIPs in the protocol, this helper library will never be finished. As the sole maintainer of this library I would like to invite others to join as a maintainer or just be a contributor to the library. PHP is big on the web, but there are not many PHP developers active yet using Nostr. Also PHP as a programming language is really pushing forward keeping up with the latest innovations.
### Grow Nostr outside the Bitcoin community
We are working out a submission to host a Nostr stand at FOSDEM 2025. If approved, it will be the first time (as far as I know) that Nostr could be present at a conference outside the context of Bitcoin. The audience at FOSDEM is mostly technical oriented, so I'm really curious what type of feedback we will receive.
Let's finish this article with some random Nostr photos from last year. Cheers!






-
@ 3f770d65:7a745b24
2024-10-29 17:38:20
**Amber**
[Amber](https://github.com/greenart7c3/Amber) is a Nostr event signer for Android that allows users to securely segregate their private key (nsec) within a single, dedicated application. Designed to function as a NIP-46 signing device, Amber ensures your smartphone can sign events without needing external servers or additional hardware, keeping your private key exposure to an absolute minimum. This approach aligns with the security rationale of NIP-46, which states that each additional system handling private keys increases potential vulnerability. With Amber, no longer do users need to enter their private key into various Nostr applications.
<img src="https://cdn.satellite.earth/b42b649a16b8f51b48f482e304135ad325ec89386b5614433334431985d4d60d.jpg">
Amber is supported by a growing list of apps, including [Amethyst](https://www.amethyst.social/), [0xChat](https://0xchat.com/#/), [Voyage](https://github.com/dluvian/voyage), [Fountain](https://fountain.fm/), and [Pokey](https://github.com/KoalaSat/pokey), as well as any web application that supports NIP-46 NSEC bunkers, such as [Nostr Nests](https://nostrnests.com), [Coracle](https://coracle.social), [Nostrudel](https://nostrudel.ninja), and more. With expanding support, Amber provides an easy solution for secure Nostr key management across numerous platforms.
<img src="https://cdn.satellite.earth/5b5d4fb9925fabb0005eafa291c47c33778840438438679dfad5662a00644c90.jpg">
Amber supports both native and web-based Nostr applications, aiming to eliminate the need for browser extensions or web servers. Key features include offline signing, multiple account support, and NIP-46 compatibility, and includes a simple UI for granular permissions management. Amber is designed to support signing events in the background, enhancing flexibility when you select the "remember my choice" option, eliminating the need to constantly be signing events for applications that you trust. You can download the app from it's [GitHub](https://github.com/greenart7c3/Amber) page, via [Obtainium ](https://github.com/ImranR98/Obtainium)or Zap.store.
To log in with Amber, simply tap the "Login with Amber" button or icon in a supported application, or you can paste the NSEC bunker connection string directly into the login box. For example, use a connection string like this: bunker://npub1tj2dmc4udvgafxxxxxxxrtgne8j8l6rgrnaykzc8sys9mzfcz@relay.nsecbunker.com.
<img src="https://cdn.satellite.earth/ca2156bfa084ee16dceea0739e671dd65c5f8d92d0688e6e59cc97faac199c3b.jpg">
---
**Citrine**
[Citrine](https://github.com/greenart7c3/Citrine) is a Nostr relay built specifically for Android, allowing Nostr clients on Android devices to seamlessly send and receive events through a relay running directly on their smartphone. This mobile relay setup offers Nostr users enhanced flexibility, enabling them to manage, share, and back up all their Nostr data locally on their device. Citrine’s design supports independence and data security by keeping data accessible and under user control.
<img src="https://cdn.satellite.earth/46bbc10ca2efb3ca430fcb07ec3fe6629efd7e065ac9740d6079e62296e39273.jpg">
With features tailored to give users greater command over their data, Citrine allows easy export and import of the database, restoration of contact lists in case of client malfunctions, and detailed relay management options like port configuration, custom icons, user management, and on-demand relay start/stop. Users can even activate TOR access, letting others connect securely to their Nostr relay directly on their phone. Future updates will include automatic broadcasting when the device reconnects to the internet, along with content resolver support to expand its functionality.
Once you have your Citrine relay fully configured, simply add it to the Private and Local relay sections in Amethyst's relay configuration.
<img src="https://cdn.satellite.earth/6ea01b68009b291770d5b11314ccb3d7ba05fe25cb783e6e1ea977bb21d55c09.jpg">
---
**Pokey**
[Pokey](https://github.com/KoalaSat/pokey) for Android is a brand new, real-time notification tool for Nostr. Pokey allows users to receive live updates for their Nostr events and enabling other apps to access and interact with them. Designed for seamless integration within a user's Nostr relays, Pokey lets users stay informed of activity as it happens, with speed and the flexibility to manage which events trigger notifications on their mobile device.
<img src="https://cdn.satellite.earth/62ec76cc36254176e63f97f646a33e2c7abd32e14226351fa0dd8684177b50a2.jpg">
Pokey currently supports connections with Amber, offering granular notification settings so users can tailor alerts to their preferences. Planned features include broadcasting events to other apps, authenticating to relays, built-in Tor support, multi-account handling, and InBox relay management. These upcoming additions aim to make Pokey a fantastic tool for Nostr notifications across the ecosystem.
---
**Zap.store**
[Zap.store](https://github.com/zapstore/zapstore/) is a permissionless app store powered by Nostr and your trusted social graph. Built to offer a decentralized approach to app recommendations, zap.store enables you to check if friends like Alice follow, endorse, or verify an app’s SHA256 hash. This trust-based, social proof model brings app discovery closer to real-world recommendations from friends and family, bypassing centralized app curation. Unlike conventional app stores and other third party app store solutions like Obtainium, zap.store empowers users to see which apps their contacts actively interact with, providing a higher level of confidence and transparency.
<img src="https://cdn.satellite.earth/fd162229a404b317306916ae9f320a7280682431e933795f708d480e15affa23.jpg">
Currently available on Android, zap.store aims to expand to desktop, PWAs, and other platforms soon. You can get started by installing [Zap.store](https://github.com/zapstore/zapstore/) on your favorite Android device, and install all of the applications mentioned above.
---
Android's openness goes hand in hand with Nostr's openness. Enjoy exploring both expanding ecosystems.
-
@ 1739d937:3e3136ef
2024-10-29 16:57:08
This update marks a major milestone for the project. I know, with certainty, that MLS messaging over Nostr is going to work. That might sound a little crazy after so many months working on the project, and I was pretty confident, but until you’ve got running code, it’s all conjecture.
Late last week, I released a video of a working prototype of [White Noise](https://github.com/erskingardner/whitenoise) that shows the full flow; creating groups, inviting other users to join those groups, accepting invites, and sending messages back-and-forth. I’m thrilled that I’ve gotten this far but also appalled that it’s taken so long and disgusted at the state of the code in the app (I’ve been told I have unrelenting standards 😅).
If you missed the video last week...
nostr:note125cuk0zetc7sshw52v5zaq9apq3rq7e2x587tr2c96t7z7sjs59svwv0fj
## What's Next?
In this update, I want to cover a few things about how I'm planning to proceed and how I’m splitting code out of the app into libraries that will help other developers implement MLS messaging in their own Nostr clients.
First off, many of you know that I've been building White Noise as a Rust app using the [Tauri](https://tauri.app) framework. The [OpenMLS](https://github.com/openmls/openmls) implementation is also written in Rust (with bindings for many other languages). So, when you hear me talking about library code, think Rust crates for now.
The first library, called [openmls-nostr](https://github.com/erskingardner/openmls-nostr), is an extension/abstraction on top of the openmls implementation of the MLS spec that helps Nostr clients interact more easily with that implementation in a way that feels native to Nostr. Mostly this will be helping developers interact with MLS primitives and ensure that they’re creating, validating, and serializing these objects in the right way at the right times.
The second isn’t a new library as a big contribution to the already excellent [rust-nostr](https://github.com/rust-nostr) library from nostr:npub1drvpzev3syqt0kjrls50050uzf25gehpz9vgdw08hvex7e0vgfeq0eseet. The methods that will go in rust-nostr are highly abstracted and based specifically on the requirements of NIP-104. Mostly this will be helping developers to take those MLS primitives and publish or query them as Nostr events at the right times and to/from the right relays.
Most of this code was originally written directly in the White Noise library so this week I've started to pull code for both of those libraries out and move it to its new home. While I’ve been at it, I've been writing some tests and trying to document things.
An unfortunate offshoot of this is that the usable builds of White Noise are going to take a touch longer. I promise it’s still a very high priority but at this point I need to clean a few things up based on what I've learned thus far.
Another thing that is slowing down release is that; behind the scenes of the dev work, I’ve been battling with Apple for nearly 2 months now to get a proper developer team set up so that we can publish the app via TestFlight for MacOS and iOS. I’ve also been recently learning the intricacies of Android publishing (oh my dear god there are so many devices, OS versions, etc.).
With that in mind, if you know anyone who can help get me up to speed on CI/CD, release pipelines, and multi-platform distribution please hit me up. I would love to learn more and hopefully shortcut some of the pain.
Thanks again so much for all the support over the last few months! It means a lot to me and is a huge part of what is keeping me going on this. 🙏
-
@ 3bf0c63f:aefa459d
2024-10-26 14:18:23
# `kind:1` maximalism and the future of other stuff and Nostr decentralization
These two problems exist on Nostr today, and they look unrelated at first:
1. People adding more stuff to `kind:1` notes, such as making them editable, or adding special corky syntax thas has to be parsed and rendered in complicated UIs;
2. The _discovery_ of "other stuff" content (i.e. long-form articles, podcasts, calendar events, livestreams etc) is hard due to the fact that most people only use microblogging clients and they often don't appear there for them.
Point **2** above has 3 different solutions:
- **a.** Just publish everything as `kind:1` notes;
- **b.** Publish different things as different kinds, but make microblogging clients fetch all the event kinds from people you follow, then render them natively or use NIP-31, or NIP-89 to point users to other clients that would render them better;
- **c.** Publish different things as different kinds, and reference them in `kind:1` notes that would act as announcements to these other events, also relying on NIP-31 and NIP-89 for displaying references and recommending other clients.
Solution **a** is obviously very bad, so I won't address it.
For a while I have believed solution **b** was the correct one, and many others seem to tacitly agree with it, given that some clients have been fetching more and more event kinds and going out of their way to render them in the same feed where only `kind:1` notes were originally expected to be.
I don't think clients doing that is necessarily bad, but I do think this have some centralizing effects on the protocol, as it pushes clients to become bigger and bigger, raising the barrier to entry into the `kind:1` realm. And also in the past I have talked about the fact that I disliked that some clients would display my long-form articles as if they were normal `kind:1` notes and just dump them into the feeds of whoever was following me: nostr:nevent1qqsdk90k9k30vtzwpj6grxys9mvsegu5kkwd4jmpyhlmtjnxet2rvggprpmhxue69uhhyetvv9ujumn0wdmksetjv5hxxmmdqy8hwumn8ghj7mn0wd68ytnddaksygpm7rrrljungc6q0tuh5hj7ue863q73qlheu4vywtzwhx42a7j9n5hae35c
These and other reasons have made me switch my preference to solution **c**, as it gives the most flexibility to the publisher: whoever wants to announce stuff so it can be _discovered_ can, whoever doesn't don't have to. And it allows microblogging clients the freedom to render just render tweets and having a straightforward barrier between what they can render and what is just a link to an external app or webapp (of course they can always opt to render the referenced content in-app if they want).
It also makes the case for microapps more evident. If all microblogging clients become superapps that can render recipe events perfectly why would anyone want to use a dedicated recipes app? I guess there are still reasons, but blurring the line between content kinds in superapps would definitely remove some of the reasons and eventually kill all the microapps.
---
That brings us back to point **1** above (the overcomplication of `kind:1` events): if solution **c** is what we're going to, that makes `kind:1` events very special in Nostr, and not just another kind among others. Microblogging clients become the central plaza of Nostr, thus protecting their neutrality and decentralization much more important. Having a lot of clients with different userbases, doing things in slightly different ways, is essential for that decentralization.
It's ok if Nostr ends up having just 2 recipe-sharing clients, but it must have dozens of microblogging clients -- and maybe not even full-blown microblogging clients, but other apps that somehow deal with `kind:1` events in multiple ways. It's ok if implementing a client for public audio-rooms is very hard and complicated, but at the same time it should be very simple to write a client that can render a `kind:1` note referencing an audio-room and linking to that dedicated client.
I hope you got my point and agreed because this article is ended.
-
@ ec42c765:328c0600
2024-10-21 07:42:48
# 2024年3月
フィリピンのセブ島へ旅行。初海外。

Nostrに投稿したらこんなリプライが
nostr:nevent1qqsff87kdxh6szf9pe3egtruwfz2uw09rzwr6zwpe7nxwtngmagrhhqc2qwq5
nostr:nevent1qqs9c8fcsw0mcrfuwuzceeq9jqg4exuncvhas5lhrvzpedeqhh30qkcstfluj
(ビットコイン関係なく普通の旅行のつもりで行ってた。というか常にビットコインのこと考えてるわけではないんだけど…)
#### そういえばフィリピンでビットコイン決済できるお店って多いのかな?
### 海外でビットコイン決済ってなんかかっこいいな!
## やりたい!
<br>
-----------
<br>
# ビットコイン決済してみよう! in セブ島
[BTCMap](https://btcmap.org/map#14/10.31403/123.91797) でビットコイン決済できるところを探す
本場はビットコインアイランドと言われてるボラカイ島みたいだけど
セブにもそれなりにあった!

なんでもいいからビットコイン決済したいだけなので近くて買いやすい店へ
いざタピオカミルクティー屋!

ちゃんとビットコインのステッカーが貼ってある!

つたない英語とGoogle翻訳を使ってビットコイン決済できるか店員に聞いたら
### 店員「ビットコインで支払いはできません」
(えーーーー、なんで…ステッカー貼ってあるやん…。)
まぁなんか知らんけどできないらしい。
店員に色々質問したかったけど質問する英語力もないのでする気が起きなかった
結局、せっかく店まで足を運んだので普通に現金でタピオカミルクティーを買った
<br>
タピオカミルクティー
話題になってた時も特に興味なくて飲んでなかったので、これが初タピオカミルクティーになった
法定通貨の味がした。

### どこでもいいからなんでもいいから
### 海外でビットコイン決済してみたい
<br>
-----------
<br>
# ビットコイン決済させてくれ! in ボラカイ島
ビットコインアイランドと呼ばれるボラカイ島はめちゃくちゃビットコイン決済できるとこが多いらしい
でもやめてしまった店も多いらしい
でも300もあったならいくつかはできるとこあるやろ!
nostr:nevent1qqsw0n6utldy6y970wcmc6tymk20fdjxt6055890nh8sfjzt64989cslrvd9l
行くしかねぇ!
<br>
## ビットコインアイランドへ
フィリピンの国内線だぁ

```
行き方:
Mactan-Cebu International Airport
↓飛行機
Godofredo P. Ramos Airport (Caticlan International Airport, Boracay Airport)
↓バスなど
Caticlan フェリーターミナル
↓船
ボラカイ島
料金:
飛行機(受託手荷物付き)
往復 21,000円くらい
空港~ボラカイ島のホテルまで(バス、船、諸経費)
往復 3,300円くらい
(klookからSouthwest Toursを利用)
このページが色々詳しい
https://smaryu.com/column/d/91761/
```
空港おりたらSouthwestのバスに乗る
事前にネットで申し込みをしている場合は5番窓口へ

港!

船!(めっちゃ速い)

ボラカイついた!

### ボラカイ島の移動手段
セブの移動はgrabタクシーが使えるがボラカイにはない。
ネットで検索するとトライシクルという三輪タクシーがおすすめされている。

(トライシクル:開放的で風がきもちいい)
トライシクルの欠点はふっかけられるので値切り交渉をしないといけないところ。
最初に300phpくらいを提示され、行き先によるけど150phpくらいまでは下げられる。
これはこれで楽しい値切り交渉だけど、個人的にはトライシクルよりバスの方が気楽。
Hop On Hop Off バス:
https://www.hohoboracay.com/pass.php
一日乗り放題250phpなので往復や途中でどこか立ち寄ったりを考えるとお得。

バスは現金が使えないので事前にどこかでカードを買うか車内で買う。
私は何も知らずに乗って車内で乗務員さんから現金でカードを買った。
バスは狭い島内を数本がグルグル巡回してるので20~30分に1本くらいは来るイメージ。
逆にトライシクルは待たなくても捕まえればすぐに乗れるところがいいところかもしれない。
<br>
## 現実
ボラカイ島 BTC Map

BTC決済できるとこめっちゃある
<br>
さっそく店に行く!
「bitcoin accepted here」のステッカーを見つける!
店員にビットコイン支払いできるか聞く!
できないと言われる!
<br>
もう一軒行く
「bitcoin accepted here」のステッカーを見つける
店員にビットコイン支払いできるか聞く
できないと言われる
<br>
5件くらいは回った
全部できない!
<br>
悲しい
<br>
で、ネットでビットコインアイランドで検索してみると
旅行日の一か月前くらいにアップロードされた動画があったので見てみた
要約
- ビットコイン決済はpouch.phというスタートアップ企業がボラカイ島の店にシステムを導入した
- ビットコインアイランドとすることで観光客が10%~30%増加つまり数百~千人程度のビットコインユーザーが来ると考えた
- しかし実際には3~5人だった
- 結果的に200の店舗がビットコイン決済を導入しても使われたのはごく一部だった
- ビットコイン決済があまり使われないので店員がやり方を忘れてしまった
- 店は関心を失いpouchのアプリを消した
https://youtu.be/uaqx6794ipc?si=Afq58BowY1ZrkwaQ
<iframe width="560" height="315" src="https://www.youtube.com/embed/uaqx6794ipc?si=S3kf0K49Z4NASxJt&start=254" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
なるほどね~
しゃあないわ
<br>
## 聖地巡礼
動画内でpouchのオフィスだったところが紹介されていた
これは半年以上前の画像らしい

現在はオフィスが閉鎖されビットコインの看板は色あせている

おもしろいからここに行ってみよう!となった
で行ってみた
看板の色、更に薄くなってね!?

記念撮影

これはこれで楽しかった
場所はこの辺
https://maps.app.goo.gl/WhpEV35xjmUw367A8
ボラカイ島の中心部の結構いいとこ
みんな~ビットコイン(の残骸)の聖地巡礼、行こうぜ!
<br>
## 最後の店
Nattoさんから情報が
<blockquote class="twitter-tweet"><p lang="ja" dir="ltr">なんかあんまりネットでも今年になってからの情報はないような…<a href="https://t.co/hiO2R28sfO">https://t.co/hiO2R28sfO</a><br><br>ここは比較的最近…?<a href="https://t.co/CHLGZuUz04">https://t.co/CHLGZuUz04</a></p>— Natto (@madeofsoya) <a href="https://twitter.com/madeofsoya/status/1771219778906014156?ref_src=twsrc%5Etfw">March 22, 2024</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
もうこれで最後だと思ってダメもとで行ってみた
なんだろうアジア料理屋さん?

もはや信頼度0の「bitcoin accepted here」

ビットコイン払いできますか?
店員「できますよ」
え?ほんとに?ビットコイン払いできる?
店員「できます」
できる!!!!
なんかできるらしい。
<br>
適当に商品を注文して
印刷されたQRコードを出されたので読み取る
ここでスマートに決済できればよかったのだが結構慌てた
自分は英語がわからないし相手はビットコインがわからない
それにビットコイン決済は日本で1回したことがあるだけだった

どうもライトニングアドレスのようだ
送金額はこちらで指定しないといけない
店員はフィリピンペソ建ての金額しか教えてくれない
何sats送ればいいのか分からない
ここでめっちゃ混乱した
でもウォレットの設定変えればいいと気付いた
普段円建てにしているのをフィリピンペソ建てに変更すればいいだけだった
設定を変更したら相手が提示している金額を入力して送金
送金は2、3秒で完了した
<br>
やった!
### 海外でビットコイン決済したぞ!
ログ

PORK CHAR SIU BUN とかいうやつを買った

普通にめっちゃおいしかった
なんかビットコイン決済できることにビビッて焦って一品しか注文しなかったけどもっと頼めばよかった
ここです。みなさん行ってください。
Bunbun Boracay
https://maps.app.goo.gl/DX8UWM8Y6sEtzYyK6
### めでたしめでたし
<br>
-----------
<br>
# 以下、普通の観光写真
## セブ島
ジンベエザメと泳いだ

スミロン島でシュノーケリング

市場の路地裏のちょっとしたダウンタウン?スラム?をビビりながら歩いた

## ボホール島
なんか変な山

メガネザル

現地の子供が飛び込みを披露してくれた

## ボラカイ島
ビーチ


夕日

藻

ボラカイ島にはいくつかビーチがあって宿が多いところに近い南西のビーチ、ホワイトビーチは藻が多かった(時期によるかも)
北側のプカシェルビーチは全然藻もなく、水も綺麗でめちゃくちゃよかった

プカシェルビーチ



<br>
-----------
<br>
# おわり!
-
@ 8947a945:9bfcf626
2024-10-17 08:06:55
[](https://stock.adobe.com/stock-photo/id/1010191703)
**สวัสดีทุกคนบน Nostr ครับ** รวมไปถึง **watchers**และ **ผู้ติดตาม**ของผมจาก Deviantart และ platform งานศิลปะอื่นๆนะครับ
ตั้งแต่ต้นปี 2024 ผมใช้ AI เจนรูปงานตัวละครสาวๆจากอนิเมะ และเปิด exclusive content ให้สำหรับผู้ที่ชื่นชอบผลงานของผมเป็นพิเศษ
ผมโพสผลงานผมทั้งหมดไว้ที่เวบ Deviantart และค่อยๆสร้างฐานผู้ติดตามมาเรื่อยๆอย่างค่อยเป็นค่อยไปมาตลอดครับ ทุกอย่างเติบโตไปเรื่อยๆของมัน ส่วนตัวผมมองว่ามันเป็นพิร์ตธุรกิจออนไลน์ ของผมพอร์ตนึงได้เลย
**เมื่อวันที่ 16 กย.2024** มีผู้ติดตามคนหนึ่งส่งข้อความส่วนตัวมาหาผม บอกว่าชื่นชอบผลงานของผมมาก ต้องการจะขอซื้อผลงาน แต่ขอซื้อเป็น NFT นะ เสนอราคาซื้อขายต่อชิ้นที่สูงมาก หลังจากนั้นผมกับผู้ซื้อคนนี้พูดคุยกันในเมล์ครับ

### นี่คือข้อสรุปสั่นๆจากการต่อรองซื้อขายครับ
(หลังจากนี้ผมขอเรียกผู้ซื้อว่า scammer นะครับ เพราะไพ่มันหงายมาแล้ว ว่าเขาคือมิจฉาชีพ)

- Scammer รายแรก เลือกผลงานที่จะซื้อ เสนอราคาซื้อที่สูงมาก แต่ต้องเป็นเวบไซต์ NFTmarket place ที่เขากำหนดเท่านั้น มันทำงานอยู่บน ERC20 ผมเข้าไปดูเวบไซต์ที่ว่านี้แล้วรู้สึกว่ามันดูแปลกๆครับ คนที่จะลงขายผลงานจะต้องใช้ email ในการสมัครบัญชีซะก่อน ถึงจะผูก wallet อย่างเช่น metamask ได้ เมื่อผูก wallet แล้วไม่สามารถเปลี่ยนได้ด้วย ตอนนั้นผมใช้ wallet ที่ไม่ได้ link กับ HW wallet ไว้ ทดลองสลับ wallet ไปๆมาๆ มันทำไม่ได้ แถมลอง log out แล้ว เลข wallet ก็ยังคาอยู่อันเดิม อันนี้มันดูแปลกๆแล้วหนึ่งอย่าง เวบนี้ค่า ETH ในการ mint **0.15 - 0.2 ETH** … ตีเป็นเงินบาทนี่แพงบรรลัยอยู่นะครับ

- Scammer รายแรกพยายามชักจูงผม หว่านล้อมผมว่า แหม เดี๋ยวเขาก็มารับซื้องานผมน่า mint งานเสร็จ รีบบอกเขานะ เดี๋ยวเขารีบกดซื้อเลย พอขายได้กำไร ผมก็ได้ค่า gas คืนได้ แถมยังได้กำไรอีก ไม่มีอะไรต้องเสีนจริงมั้ย แต่มันเป้นความโชคดีครับ เพราะตอนนั้นผมไม่เหลือทุนสำรองที่จะมาซื้อ ETH ได้ ผมเลยต่อรองกับเขาตามนี้ครับ :
1. ผมเสนอว่า เอางี้มั้ย ผมส่งผลงานของผมแบบ low resolution ให้ก่อน แลกกับให้เขาช่วยโอน ETH ที่เป็นค่า mint งานมาให้หน่อย พอผมได้ ETH แล้ว ผมจะ upscale งานของผม แล้วเมล์ไปให้ ใจแลกใจกันไปเลย ... เขาไม่เอา
2. ผมเสนอให้ไปซื้อที่ร้านค้าออนไลน์ buymeacoffee ของผมมั้ย จ่ายเป็น USD ... เขาไม่เอา
3. ผมเสนอให้ซื้อขายผ่าน PPV lightning invoice ที่ผมมีสิทธิ์เข้าถึง เพราะเป็น creator ของ Creatr ... เขาไม่เอา
4. ผมยอกเขาว่างั้นก็รอนะ รอเงินเดือนออก เขาบอก ok
สัปดาห์ถัดมา มี scammer คนที่สองติดต่อผมเข้ามา ใช้วิธีการใกล้เคียงกัน แต่ใช้คนละเวบ แถมเสนอราคาซื้อที่สูงกว่าคนแรกมาก เวบที่สองนี้เลวร้ายค่าเวบแรกอีกครับ คือต้องใช้เมล์สมัครบัญชี ไม่สามารถผูก metamask ได้ พอสมัครเสร็จจะได้ wallet เปล่าๆมาหนึ่งอัน ผมต้องโอน ETH เข้าไปใน wallet นั้นก่อน เพื่อเอาไปเป็นค่า mint NFT **0.2 ETH**
ผมบอก scammer รายที่สองว่า ต้องรอนะ เพราะตอนนี้กำลังติดต่อซื้อขายอยู่กับผู้ซื้อรายแรกอยู่ ผมกำลังรอเงินเพื่อมาซื้อ ETH เป็นต้นทุนดำเนินงานอยู่ คนคนนี้ขอให้ผมส่งเวบแรกไปให้เขาดูหน่อย หลังจากนั้นไม่นานเขาเตือนผมมาว่าเวบแรกมันคือ scam นะ ไม่สามารถถอนเงินออกมาได้ เขายังส่งรูป cap หน้าจอที่คุยกับผู้เสียหายจากเวบแรกมาให้ดูว่าเจอปัญหาถอนเงินไม่ได้ ไม่พอ เขายังบลัฟ opensea ด้วยว่าลูกค้าขายงานได้ แต่ถอนเงินไม่ได้
**Opensea ถอนเงินไม่ได้ ตรงนี้แหละครับคือตัวกระตุกต่อมเอ๊ะของผมดังมาก** เพราะ opensea อ่ะ ผู้ใช้ connect wallet เข้ากับ marketplace โดยตรง ซื้อขายกันเกิดขึ้น เงินวิ่งเข้าวิ่งออก wallet ของแต่ละคนโดยตรงเลย opensea เก็บแค่ค่า fee ในการใช้ platform ไม่เก็บเงินลูกค้าไว้ แถมปีนี้ค่า gas fee ก็ถูกกว่า bull run cycle 2020 มาก ตอนนี้ค่า gas fee ประมาณ 0.0001 ETH (แต่มันก็แพงกว่า BTC อยู่ดีอ่ะครับ)
ผมเลยเอาเรื่องนี้ไปปรึกษาพี่บิท แต่แอดมินมาคุยกับผมแทน ทางแอดมินแจ้งว่ายังไม่เคยมีเพื่อนๆมาปรึกษาเรื่องนี้ กรณีที่ผมทักมาถามนี่เป็นรายแรกเลย แต่แอดมินให้ความเห็นไปในทางเดียวกับสมมุติฐานของผมว่าน่าจะ scam ในเวลาเดียวกับผมเอาเรื่องนี้ไปถามในเพจ NFT community คนไทนด้วย ได้รับการ confirm ชัดเจนว่า scam และมีคนไม่น้อยโดนหลอก หลังจากที่ผมรู้ที่มาแล้ว ผมเลยเล่นสงครามปั่นประสาท scammer ทั้งสองคนนี้ครับ เพื่อดูว่าหลอกหลวงมิจฉาชีพจริงมั้ย
โดยวันที่ 30 กย. ผมเลยปั่นประสาน scammer ทั้งสองรายนี้ โดยการ mint ผลงานที่เขาเสนอซื้อนั่นแหละ ขึ้น opensea
แล้วส่งข้อความไปบอกว่า
mint ให้แล้วนะ แต่เงินไม่พอจริงๆว่ะโทษที เลย mint ขึ้น opensea แทน พอดีบ้านจน ทำได้แค่นี้ไปถึงแค่ opensea รีบไปซื้อล่ะ มีคนจ้องจะคว้างานผมเยอะอยู่ ผมไม่คิด royalty fee ด้วยนะเฮ้ย เอาไปขายต่อไม่ต้องแบ่งกำไรกับผม
เท่านั้นแหละครับ สงครามจิตวิทยาก็เริ่มขึ้น แต่เขาจนมุม กลืนน้ำลายตัวเอง
ช็อตเด็ดคือ
เขา : เนี่ยอุส่ารอ บอกเพื่อนในทีมว่าวันจันทร์ที่ 30 กย. ได้ของแน่ๆ เพื่อนๆในทีมเห็นงานผมแล้วมันสวยจริง เลยใส่เงินเต็มที่ 9.3ETH (+ capture screen ส่งตัวเลขยอดเงินมาให้ดู)ไว้รอโดยเฉพาะเลยนะ
ผม : เหรอ ... งั้น ขอดู wallet address ที่มี transaction มาให้ดูหน่อยสิ
เขา : 2ETH นี่มัน 5000$ เลยนะ
ผม : แล้วไง ขอดู wallet address ที่มีการเอายอดเงิน 9.3ETH มาให้ดูหน่อย ไหนบอกว่าเตรียมเงินไว้มากแล้วนี่ ขอดูหน่อย ว่าใส่ไว้เมื่อไหร่ ... เอามาแค่ adrress นะเว้ย ไม่ต้องทะลึ่งส่ง seed มาให้
เขา : ส่งรูปเดิม 9.3 ETH มาให้ดู
ผม : รูป screenshot อ่ะ มันไม่มีความหมายหรอกเว้ย ตัดต่อเอาก็ได้ง่ายจะตาย เอา transaction hash มาดู ไหนว่าเตรียมเงินไว้รอ 9.3ETH แล้วอยากซื้องานผมจนตัวสั่นเลยไม่ใช่เหรอ ถ้าจะส่ง wallet address มาให้ดู หรือจะช่วยส่ง 0.15ETH มาให้ยืม mint งานก่อน แล้วมากดซื้อ 2ETH ไป แล้วผมใช้ 0.15ETH คืนให้ก็ได้ จะซื้อหรือไม่ซื้อเนี่ย
เขา : จะเอา address เขาไปทำไม
ผม : ตัดจบ รำคาญ ไม่ขายให้ละ
เขา : 2ETH = 5000 USD เลยนะ
ผม : แล้วไง
ผมเลยเขียนบทความนี้มาเตือนเพื่อนๆพี่ๆทุกคนครับ เผื่อใครกำลังเปิดพอร์ตทำธุรกิจขาย digital art online แล้วจะโชคดี เจอของดีแบบผม
-----------
### ทำไมผมถึงมั่นใจว่ามันคือการหลอกหลวง แล้วคนโกงจะได้อะไร
[](https://stock.adobe.com/stock-photo/id/1010196295)
อันดับแรกไปพิจารณาดู opensea ครับ เป็นเวบ NFTmarketplace ที่ volume การซื้อขายสูงที่สุด เขาไม่เก็บเงินของคนจะซื้อจะขายกันไว้กับตัวเอง เงินวิ่งเข้าวิ่งออก wallet ผู้ซื้อผู้ขายเลย ส่วนทางเวบเก็บค่าธรรมเนียมเท่านั้น แถมค่าธรรมเนียมก็ถูกกว่าเมื่อปี 2020 เยอะ ดังนั้นการที่จะไปลงขายงานบนเวบ NFT อื่นที่ค่า fee สูงกว่ากันเป็นร้อยเท่า ... จะทำไปทำไม
ผมเชื่อว่า scammer โกงเงินเจ้าของผลงานโดยการเล่นกับความโลภและความอ่อนประสบการณ์ของเจ้าของผลงานครับ เมื่อไหร่ก็ตามที่เจ้าของผลงานโอน ETH เข้าไปใน wallet เวบนั้นเมื่อไหร่ หรือเมื่อไหร่ก็ตามที่จ่ายค่า fee ในการ mint งาน เงินเหล่านั้นสิ่งเข้ากระเป๋า scammer ทันที แล้วก็จะมีการเล่นตุกติกต่อแน่นอนครับ เช่นถอนไม่ได้ หรือซื้อไม่ได้ ต้องโอนเงินมาเพิ่มเพื่อปลดล็อค smart contract อะไรก็ว่าไป แล้วคนนิสัยไม่ดีพวกเนี้ย ก็จะเล่นกับความโลภของคน เอาราคาเสนอซื้อที่สูงโคตรๆมาล่อ ... อันนี้ไม่ว่ากัน เพราะบนโลก NFT รูปภาพบางรูปที่ไม่ได้มีความเป็นศิลปะอะไรเลย มันดันขายกันได้ 100 - 150 ETH ศิลปินที่พยายามสร้างตัวก็อาจจะมองว่า ผลงานเรามีคนรับซื้อ 2 - 4 ETH ต่องานมันก็มากพอแล้ว (จริงๆมากเกินจนน่าตกใจด้วยซ้ำครับ)
บนโลกของ BTC ไม่ต้องเชื่อใจกัน โอนเงินไปหากันได้ ปิดสมุดบัญชีได้โดยไม่ต้องเชื่อใจกัน
บบโลกของ ETH **"code is law"** smart contract มีเขียนอยู่แล้ว ไปอ่าน มันไม่ได้ยากมากในการทำความเข้าใจ ดังนั้น การจะมาเชื่อคำสัญญาจากคนด้วยกัน เป็นอะไรที่ไม่มีเหตุผล
ผมไปเล่าเรื่องเหล่านี้ให้กับ community งานศิลปะ ก็มีทั้งเสียงตอบรับที่ดี และไม่ดีปนกันไป มีบางคนยืนยันเสียงแข็งไปในทำนองว่า ไอ้เรื่องแบบเนี้ยไม่ได้กินเขาหรอก เพราะเขาตั้งใจแน่วแน่ว่างานศิลป์ของเขา เขาไม่เอาเข้ามายุ่งในโลก digital currency เด็ดขาด ซึ่งผมก็เคารพมุมมองเขาครับ แต่มันจะดีกว่ามั้ย ถ้าเราเปิดหูเปิดตาให้ทันเทคโนโลยี โดยเฉพาะเรื่อง digital currency , blockchain โดนโกงทีนึงนี่คือหมดตัวกันง่ายกว่าเงิน fiat อีก
อยากจะมาเล่าให้ฟังครับ และอยากให้ช่วยแชร์ไปให้คนรู้จักด้วย จะได้ระวังตัวกัน
## Note
- ภาพประกอบ cyber security ทั้งสองนี่ของผมเองครับ ทำเอง วางขายบน AdobeStock
- อีกบัญชีนึงของผม "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw กำลังค่อยๆเอาผลงานจากโลกข้างนอกเข้ามา nostr ครับ ตั้งใจจะมาสร้างงานศิลปะในนี้ เพื่อนๆที่ชอบงาน จะได้ไม่ต้องออกไปหาที่ไหน
ผลงานของผมครับ
- Anime girl fanarts : [HikariHarmony](https://linktr.ee/hikariharmonypatreon)
- [HikariHarmony on Nostr](https://shorturl.at/I8Nu4)
- General art : [KeshikiRakuen](https://linktr.ee/keshikirakuen)
- KeshikiRakuen อาจจะเป็นบัญชี nostr ที่สามของผม ถ้าไหวครับ
-
@ 8947a945:9bfcf626
2024-10-17 07:33:00
[](https://stock.adobe.com/stock-photo/id/1010191703)
**Hello everyone on Nostr** and all my **watchers**and **followers**from DeviantArt, as well as those from other art platforms
I have been creating and sharing AI-generated anime girl fanart since the beginning of 2024 and have been running member-exclusive content on Patreon.
I also publish showcases of my artworks to Deviantart. I organically build up my audience from time to time. I consider it as one of my online businesses of art. Everything is slowly growing
**On September 16**, I received a DM from someone expressing interest in purchasing my art in NFT format and offering a very high price for each piece. We later continued the conversation via email.

### Here’s a brief overview of what happened

- The first scammer selected the art they wanted to buy and offered a high price for each piece.
They provided a URL to an NFT marketplace site running on the Ethereum (ETH) mainnet or ERC20. The site appeared suspicious, requiring email sign-up and linking a MetaMask wallet. However, I couldn't change the wallet address later.
The minting gas fees were quite expensive, ranging from **0.15 to 0.2 ETH**

- The scammers tried to convince me that the high profits would easily cover the minting gas fees, so I had nothing to lose.
Luckily, I didn’t have spare funds to purchase ETH for the gas fees at the time, so I tried negotiating with them as follows:
1. I offered to send them a lower-quality version of my art via email in exchange for the minting gas fees, but they refused.
2. I offered them the option to pay in USD through Buy Me a Coffee shop here, but they refused.
3. I offered them the option to pay via Bitcoin using the Lightning Network invoice , but they refused.
4. I asked them to wait until I could secure the funds, and they agreed to wait.
The following week, a second scammer approached me with a similar offer, this time at an even higher price and through a different NFT marketplace website.
This second site also required email registration, and after navigating to the dashboard, it asked for a minting fee of **0.2 ETH**. However, the site provided a wallet address for me instead of connecting a MetaMask wallet.
I told the second scammer that I was waiting to make a profit from the first sale, and they asked me to show them the first marketplace. They then warned me that the first site was a scam and even sent screenshots of victims, including one from OpenSea saying that Opensea is not paying.
**This raised a red flag**, and I began suspecting I might be getting scammed. On OpenSea, funds go directly to users' wallets after transactions, and OpenSea charges a much lower platform fee compared to the previous crypto bull run in 2020. Minting fees on OpenSea are also significantly cheaper, around 0.0001 ETH per transaction.
I also consulted with Thai NFT artist communities and the ex-chairman of the Thai Digital Asset Association. According to them, no one had reported similar issues, but they agreed it seemed like a scam.
After confirming my suspicions with my own research and consulting with the Thai crypto community, I decided to test the scammers’ intentions by doing the following
I minted the artwork they were interested in, set the price they offered, and listed it for sale on OpenSea. I then messaged them, letting them know the art was available and ready to purchase, with no royalty fees if they wanted to resell it.
They became upset and angry, insisting I mint the art on their chosen platform, claiming they had already funded their wallet to support me. When I asked for proof of their wallet address and transactions, they couldn't provide any evidence that they had enough funds.
Here’s what I want to warn all artists in the DeviantArt community or other platforms
If you find yourself in a similar situation, be aware that scammers may be targeting you.
-----------
### My Perspective why I Believe This is a Scam and What the Scammers Gain
[](https://stock.adobe.com/stock-photo/id/1010196295)
From my experience with BTC and crypto since 2017, here's why I believe this situation is a scam, and what the scammers aim to achieve
First, looking at OpenSea, the largest NFT marketplace on the ERC20 network, they do not hold users' funds. Instead, funds from transactions go directly to users’ wallets. OpenSea’s platform fees are also much lower now compared to the crypto bull run in 2020. This alone raises suspicion about the legitimacy of other marketplaces requiring significantly higher fees.
I believe the scammers' tactic is to lure artists into paying these exorbitant minting fees, which go directly into the scammers' wallets. They convince the artists by promising to purchase the art at a higher price, making it seem like there's no risk involved. In reality, the artist has already lost by paying the minting fee, and no purchase is ever made.
In the world of Bitcoin (BTC), the principle is "Trust no one" and “Trustless finality of transactions” In other words, transactions are secure and final without needing trust in a third party.
In the world of Ethereum (ETH), the philosophy is "Code is law" where everything is governed by smart contracts deployed on the blockchain. These contracts are transparent, and even basic code can be read and understood. Promises made by people don’t override what the code says.
I also discuss this issue with art communities. Some people have strongly expressed to me that they want nothing to do with crypto as part of their art process. I completely respect that stance.
However, I believe it's wise to keep your eyes open, have some skin in the game, and not fall into scammers’ traps. Understanding the basics of crypto and NFTs can help protect you from these kinds of schemes.
If you found this article helpful, please share it with your fellow artists.
Until next time
Take care
## Note
- Both cyber security images are mine , I created and approved by AdobeStock to put on sale
- I'm working very hard to bring all my digital arts into Nostr to build my Sats business here to my another npub "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw
Link to my full gallery
- Anime girl fanarts : [HikariHarmony](https://linktr.ee/hikariharmonypatreon)
- [HikariHarmony on Nostr](https://shorturl.at/I8Nu4)
- General art : [KeshikiRakuen](https://linktr.ee/keshikirakuen)
-
@ e88a691e:27850411
2024-10-11 13:17:16
# An opinionated guide to Sauna.
By NVK [🌐](https://primal.net/nvk) [🐦](https://twitter.com/nvk)
## Introduction
Updated from the Sauna, October 7th 2024
After years of experimenting with different sauna types, I’ve developed strong opinions on the subject. The purpose of this article is to share these opinions with anyone who is interested in them and, hopefully, help others get more out of their sauna experience.
I’m certain my opinions will offend some, including all the people who (in my view) are doing it wrong. I know that saunas are important to many cultures around the world and that my strongly held opinions may offend some of those cultures.
Mind you, although I grew up in South America, I do have a fair amount of slavic blood in me. When I was a child, my grandfather regularly took me with him to the shvitz. One of my fondest memories from this time was the “Scottish Bath”, which involves standing against the sauna wall, execution-style, so that someone can spray you with freezing water from a high pressure hose. I’ve never heard of this outside of South American and can’t attest to whether it has any real Scottish origins.
The various health claims about using a sauna are beyond the scope of this article. All I have to say is that, like many things in my life, like Bitcoin, the meat/keto diet, and fasting, I find sauna to be yet another cheat code to life: it’s a simple thing that just makes life a lot better. If you want a good primer on scientific health benefits of sauna, I recommend starting with [this article by Rhonda Patric](https://www.foundmyfitness.com/topics/sauna). She goes in depth.
To be clear, it should go without saying that I am not a medical expert or professional. None of the opinions below are, or should be interpreted as, medical advice. There are many people for whom sauna use is not recommended. It would be prudent for any sauna user to consult with his or her doctor before entering a sauna.
_Thanks to S. for taking the time to do a very helpful first review of this article. And thanks to The Wife for helping make my words legible and helping me make time to sauna–I don’t know which sacrifice was bigger._
## Banya or Nothing
When I talk about saunas, I’m talking about a sauna with a stove, either wood or electric, that allows for steam. I call this “Banya style”. To be clear, I’m distinguishing between saunas and steam baths. Steam baths have their own place, but they aren’t my thing and I don’t consider them saunas.
A breakdown of the main types of saunas may be helpful, so you know which to avoid:
1. Wet saunas, which are typically cedar rooms with wood burning or electric stoves onto which you throw liquid to create steam (I call this “Banya style”);
2. Dry saunas, which are typically cedar rooms with wood burning or electric stoves without added steam (like Korean style saunas); and
3. Infrared saunas, which, unlike traditional saunas, don’t heat the surrounding air. Instead, they use infrared panels to warm your body directly.
In my opinion, it’s Banya style or nothing. I’m not a huge fan of dry saunas, and I don’t even bother with infrared saunas. Infrared is a fiat-shitcoin. I want steam!
## How to Sauna
### Sauna Etiquette
If you read no other part of this already-too-long-article, read this.
Saunas are social places. There are proper ways of being in a sauna with others, and there are ways to do it wrong. You don’t want to be the person who ruins it for everyone. Here are some important etiquette tips:
**Silence vs. Chatting:** It’s not a question of whether you have to stay silent in a sauna or if it’s ok to talk. It depends on the circumstances and who else is around. If you’re using a sauna that isn’t your own, ask the staff about the preferred custom. The noise level in a sauna differs depending on the group in the sauna at a particular time. If you do want to chat with others, there’s nothing wrong with that. But, pay attention to whether there are others in the sauna who'd prefer it quiet. And definitely do NOT be obnoxiously loud – yes, I’m looking at you bachelor(ette) group who just discovered the Russian Banya.
**Coming and Going:** People rotate in and out of the sauna at different paces, so there will be people coming and going during your shvitz. But there are ways to come and go that are considerate and proper.
Keep the f-ing door closed (which was the working title of this article). Once you leave, don’t come back inside moments later. Doing so disturbs your fellow sauna users, lets out the all-important steam, and prevents the sauna from reaching an appropriate temperature.
If you’re in the sauna with a group of friends, try to coordinate your comings and goings so you’re all on the same cycle.
If you can only last 5 min at a sauna, don’t go in too often at the risk of ruining it for others (assuming it’s not your own private sauna).
Be fast when closing the sauna door when you come or leave. Otherwise, you will get dirty looks from others and may even hear mumbles of “quick quick, fast fast” from a Gray Beard. And you will deserve it.
Never open the door right after someone puts water on the stove to make steam. It’s all about the steam. Don’t waste it.
**Controlling the heat:** if you can’t handle the heat in the sauna, don’t just turn the heat down, because it ruins it for others. Instead, go to a lower bench or get out and take your break. Saunas are meant to be hot. That’s the whole point.
**Personal Hygiene:** Shower before you go into the sauna. Don’t wear perfume, smelly deodorant, or fragrant lotions. Smells get amplified in a sauna. Have a towel under you, don't leave your drippings behind. Best yet, make a Z with your towel, this covers your butt and down under your feet.
**Clothing:** sauna is not a place for wearing clothing. It is a place to get back to nature. If you are shy, just wrap a towel around yourself. People ask if I don't feel awkward, the answer is no. Who cares, humans naked is not novel. In many countries, it is strictly forbidden to wear clothing or bring anything but a towel into the sauna. It's understandable that may not be possible in North American public saunas on mix gender "family" days. If you have to wear something, then wear something 100% cotton or marino wool. You don't want plastic being backed into your genitals. One more thing, leave the watch out as it gets hot and will burn you. Also, flip-flops/sandals, stay outside.
Some saunas sell body scrubs and masks for you to apply before or in the sauna. Note that once in the heat, these can get goopy and drippy and may melt into your eyes and mouth. So (in this opinionated guides’ wife’s opinion), they are better in theory than reality.
**Adding Oils and scents:** As discussed below, it can be nice to add certain oils and other scents to the steam. But if there are others in the sauna, ask first before you do.
**Where and how to sit:** Hot air rises. So, the higher benches are hotter and the lower benches are cooler. If you are a newbie, pick a lower bench so you don’t have to leave as quickly and open the door unnecessarily.
It’s great to lay down in the sauna, but if it gets crowded, sit up to make room for others.
When moving around to find your seat, don’t walk on the benches in your sandals. Leave your sandals outside the sauna or on the sauna floor.
### Sauna Temperature
In most proper Russian style Banyas you will find temperatures of 80-95 degrees celsius, which, in my opinion, is the best range. Thats near your body. "Offical" on the dial will he 100-120C. But sometimes you want to take it a little easier or last a little longer in the sauna. In these cases, 65-85 at body, dial at 80-100. degrees celsius will do.
However, if your sauna is below 85 degrees celsius on the dial, you might as well just go hide under your bed sheets and not waste your time.
At some saunas in hotels, gyms, or spas, you may not be allowed to set the sauna as high as you’d like (see below). There are many tricks to circumvent these frustrating restrictions, but my legal counsel has advised me not to go into any details here.
### Sauna Duration
The amount of time you spend in the sauna is a matter of personal preference and depends on the number of cycles you do (more on cycles, below).
For your first round, my opinion is that most people should try to last 15 minutes in the sauna. If a sauna is at the proper temperature, most people will struggle to stay inside any longer. If you can stay inside for 20-30 minutes, your sauna is probably too cold and/or there is not enough steam. Many saunas have hourglasses inside to keep time, and I’ve never seen a sauna hourglass with more than 15 minutes, which should be a good hint.
My preferred is;
Cold Plunge => Sauna 15 min => Cold Plunge => Hydrate with Salt & Water, Rest 5-10min => Sauna 15min => Cold Plunge => Hydrate with Salt & Water, Rest 5-10min => Sauna 15min => Cold Plunge => Hydrate with Salt & Water, Rest
if you can rest in the sun even better (no sunscreen poison please). You can add alcohol drinks to the hydration if you feel comfortable with that. But only add food after the last cycle.
For subsequent rounds, hydration starts to play a bigger role in how long you stay inside. Most people seem to last longer on their first round than on their second or third. If you can do 15 minutes on your second round, great. But 5-10 minutes is also fine.
### Sauna Cycles
The traditional Russian Banya method (and in this writer’s opinion, the best method) is to do sauna cycles. Go into the sauna and just stay as long as you can take it (up to 15 minutes or so). Then take a cold shower and/or cold plunge (see below). Then robe-up and go relax with water, tea or beer. Once you start feeling “normal” again, repeat. For me, three cycles is the sweet spot. I’ll do more cycles if I’m spending the day at the Banya facility. If I’m at home, where I often sauna every other day, I find just one or two cycles does the trick. Sometimes I add a cycle or two on the weekend.
Occasionally, I like to go into the sauna as it’s warming up and before it reaches optimum heat (i.e. at around 60 degree celsius). This way, I can stay longer in the sauna for my first round (about 30-40 minutes). If I take this approach, I generally only do one more short round after my cold plunge.
### Cold showers and plunges
In my experience, you want to take a cold shower or a cold plunge (or both, plunge is better) after the sauna cycle.After you come out of the sauna, immediately jump into cold plunge for a bit, i don't like to stay too long. Some Banya facilities will have a bucket filled with cold water that you can pull with a string to let the water pour over you, pull a couple times. The banyas may also have a cold pool of water into which you can plunge for a bit.

If I’m at my country place, after I get out of the sauna I jump into the cold lake. If it’s winter, I like to roll in the snow, which is satisfying. Some cultures would say that it’s not a real sauna experience unless you roll in at least one foot of snow.
After your cold shower or plunge, put on a warm robe and go relax before going back into the sauna. I like to relax for 5-20 minutes, depending on how much time I have. This allows the body’s temperature to decrease slowly. I do not recommend going directly back into the sauna after your cold plunge. If you don’t give yourself enough time after the cold plunge, you will overheat and won’t last very long when you return to the sauna.
### Position
There really are no rules here. The way you position yourself in the sauna depends on your mood and preference, and there are many options. For example, you can sauna seated with your legs hanging down or with your knees up. You can lie down if there’s room. My favorite position is to lie down on my back with my legs up against the wall and, assuming the ceiling is low enough, with my feet stretched against the ceiling. This is a great way to stretch the hamstrings (check out stretching under “Sauna Activities”, below).
Choosing whether to sit on a higher bencher or lower bench is the best way to control the temperature you experience without adjusting the room temperature itself. You will notice the heat in the sauna increases exponentially every inch you go up. If you are struggling to stay in the sauna but don’t want to get out just yet, try moving down to a lower bench to last a little longer. Lying on the floor is the coolest spot and a great place for kids to start getting exposed to saunas.
- - -
#### There is no shame in going to lower benches or even the floor, there is only shame in opening the door before 15min
- - -
### Getting Steamy
Without steam, the sauna would just be a sad, hot oven (I’m looking at you, infrared sauna).
The steam in the sauna has many benefits but most importantly it increases the thermal coupling of your body to the air and it feels great.
The amount of steam in the sauna is a matter of personal taste. You don’t want to make it into a steam room (remember, steam rooms are NOT saunas). But, you do want the sauna to be very moist. I find that two to four ladles of water in a mid-size sauna every five to seven minutes does the trick. Keep it between 50-60% humidity.
I keep a bucket of water in the sauna at all times so that I can continue to ladle water as I shvitz. Make sure to get a wood bucket and a metal ladle with a wooden handle. Wood ladles will crack, and if the handle is metal, it’ll burn you when you grab it.
If, when you enter the sauna, it’s already been on for a while, the wood is likely to already be wet and the sauna full of steam, so you may not need to add too much water. However, if you’ve just turned on the sauna and the wood walls are dry, you will need to ladle more water to make the air moist enough. If the sauna is too moist for comfort, open the door and let it dry out a bit (obviously, only do this in a private sauna).
Essential oils and even beer can all be added to the water to create scented steam. I recommend starting your sauna with just water, and add the scent as you get going.
You can try all sorts of different essential oils. I’ve tried everything from oak and cedar to tangerine and cinnamon (gag) essential oil. In the end, there are really only two oils that are worth it, in my opinion. The first is eucalyptus. I’ve experimented with different types of eucalyptus oil, and the variety you use makes a difference. My favorite is eucalyptus globulus. I also like diluted pine tar oil.
When you settle on your essential oil, add a healthy dose of the oil to the ladle filled with water. Never put the oil onto the oven directly. It’ll just burn.
In a few Russian facilities, I’ve seen Gray Beards pour Russian beer onto the oven and it was actually quite nice. It’s almost like being in a cozy bakery while you sweat
Some people like to place a salt brick or compressed solid blocks in their sauna from time to time. Put the salt block on the stove and pour water over it. The steam takes on a saltiness that feels nice. If a salt block is not available, you can get a cast iron teapot, fill it up with salt water, and place it on top of the stove.
And for my most important steam tip, I recommend using the “towel spin”. This is an effective and underrated technique to help circulate steam in the sauna. After creating steam, take your towel above your head and spin it around hard, like a ceiling fan. This movement works like a convection oven and spreads and equalizes the heat and steam throughout the room. It might make the folks sitting lower down in the sauna a little hotter, but that's what they’re there for, isn’t it?
### Hydration
Being hydrated is important to having a positive sauna experience. You will lose a lot of your body’s water in the sauna. Ideally, start to hydrate well up to an hour before your sauna. I like to add a pinch of salt to my water to encourage water retention.
Do not bring any drinks into the sauna (the exception being a dedicated steam-beer, see above). Have your water or beverage when you’re outside the sauna, resting. If you find you need to drink water inside the sauna in order to cool yourself down, then it’s time for you to get out and allow your body a cool-down.
When you’re outside the sauna, don’t immediately down a glass of super cold water because you will cool down your internal body too fast. Personally, I like to drink warm tea after my first two cycles. After my second cycle, I enjoy a beer (pre-keto days), soup, or vodka drink. When non-keto, I do enjoy adult drinks in the cycles.
If you are doing a sauna while on a multi-day fast, you need to have water and salt, at a minimum. Otherwise, you will deplete your natural reserve of electrolytes and not be able to think straight.
### Sauna Frequency
When it comes to frequency, if you are not in the equatorial heat do it every day. I now do mornings and end of day if I can. so 2x 2-3x cycles. In the summer, living in a hot & humid location, I sauna a lot less frequently. My desire to sauna is greatly diminished because I spend a lot of time in the sun and heat.
### What to wear
**Sauna Hat:** I highly recommend wearing a Russian/Finish style wool hat when you’re inside the sauna. It may seem counterintuitive, but wearing a hat keeps your head cooler. An overheated head is not good for your brain. Wearing the hat stops you from overheating and lets you stay longer in the sauna. The temperature in a sauna is significantly hotter the higher in the room you are, and one’s head is at the top of the body (for most people). So protect your brain in style with a felt sauna hat. If you don’t have a felt sauna hat, buy one. They are easily found online. But in the meantime, you can wrap a dry towel around your head. Don’t forget to take your sauna hat off as you relax between cycles so your head can cool down.

**Clothing:** These days, many public saunas will have family days, men-only days, and women-only days. For obvious reasons, you’re only allowed to sauna naked if you’re attending one of the single-sex days.
If you’re at home, there’s no good reason to wear shorts or a bathing suit. Sauna naked. It's a lot more pleasant.
If you do wear clothing in the sauna, be careful with items with materials like metal or plastic attached. Things like pins, buttons, or string-ends will get very hot and probably burn you. Remember to take off any heat-conductive jewelry and leave your smart watch outside, as the heat will ruin its battery.
Don’t wear your robe inside the sauna. A robe is what you wear outside when relaxing or eating. If you wear it inside, you’ll overheat (and look like an idiot). Go ahead and sweat out that body shame robe-free. You can bring a towel into the sauna to sit on, if you want.
Shoes or sandals are highly recommended in public facilities. I mean, there are many people walking around wet. Ew. But keep your sandals outside the sauna itself, or on the sauna floor.
### Sauna activities.
Don’t overthink it. Sitting in a sauna is activity enough, in my opinion. But there are some sauna activities you can do:
**Veniks/Viht beating:** these are bundles of leaves (commonly birch, oak, or eucalyptus) that are pre-soaked in hot water. Someone with both strength and capacity to exert themselves in the heat will beat your whole body with the leaves. This exfoliates your skin and also gets the plant oils to permeate your skin. And it’s very relaxing. If you’re at a sauna facility, don’t just grab any bundle you see lying around - that belongs to someone else and veniks aren’t shared. You have to bring your own or buy them at the front desk.
**Stretching:** this is a great activity to do in the sauna, but make sure to go very easy. Your muscles will be super warm and you don’t want to overdo it and hurt yourself.
**Exercise or Sex:** your heart better be in good shape if you try out these high intensity activities in the sauna. If you engage in the latter, you better be in your own home sauna. With respect to the former, I think doing some leg-ups can be very satisfying.
**Phone use:** If you’re at home, it’s nice to use your sauna time to shit-post on Twitter or read an article, if you feel like it. Just keep your phone close to the colder, lower parts near the floor or it’ll overheat and shut down. You can also place the phone outside of the air vent and play a [podcast! The Bitcoin.review is great ;)](https://bitcoin.review)
**Napping:** I don’t recommend this. If you fall asleep or pass out, you will probably die due to overheating or dehydration.
**Chatting:** Saunas are great places for conversations (subject to the caveats I address above). Note that nowadays, microphone modules are both very tiny and can withstand high temperatures, so it’s no longer recommended to reenact mafia movie sauna scenes.
**Eating and Drinking:** As discussed above, never have food or drink inside the sauna. But when you finish your sauna, take advantage of whatever snacks the facility offers. For Russian joints, the soups, fish roe and dry salty fish snacks are great. Again, don’t eat before your sauna; wait until you’re done. Some places will have bottled salty-ish lake water, and beer seems to be a good source of salts and re-hydration. Vodka drinks are nice sometimes, too. My favorites are vodka with beet juice and horseradish, vodka with pickle juice, or just a chilled shot of Zubrowka (vodka infused with bison grass). Teas are also very enjoyable post-sauna. I prefer non-caffeinated berry teas. Some Banyas even offer free tea to patrons.

## Ready to Sweat It Out?
Thanks to this fantastic guide to sauna, you’re now feeling confident and excited to seek out a solid sauna. So where do you go?
## Where to Find a Sauna
**Spas:** Spas are not the best place to have an optimal sauna experience. Saunas at spas are typically not hot enough and spas have annoying staff whose job it is to enforce idiotic rules and practices that prevent you from having a real sauna experience.
**Gyms & Hotels:** These are some of the worst places to sauna. For liability reasons, these saunas tend to be too cold and there are often mechanisms that prevent you from raising the temperature. Here, you’ll often see saunas with glass doors, which may look chic, but are inefficient and stupid because they don’t seal properly and leak steam. Gyms and hotels are high traffic areas, so people who don’t know what they are doing are constantly coming and going from the sauna, which, as we discussed, is a sauna no-no. If you still want to try the sauna at your gym or hotel, I recommend going in naked. It’ll deter people from joining you and ruining the little steam you managed to get going.
**Traditional bath houses (Banyas):** These usually offer a great experience because they deliver a super hot sauna, good cold baths and plunges, delicious food and drinks, and knowledgeable staff.
**Home:** Yes, you can build a great sauna in your own home! You can create a small space in your basement, turn a closet or cold room into a sauna, or just add an outdoor hut or barrel sauna in your backyard. This is the best way for you to control the whole experience and do it often. As with anything, the easier it is to access, the more you will do it.
_Build it. They will Come_
Many people have asked me for details about sauna building. If you’re ready to build your own personal home sauna, here are some important considerations.
#### Materials
Saunas are insulated rooms, most commonly finished with cedar tung and groove slats. Cedar is used because it doesn’t rot with moisture. You don’t want treated wood as it will release all the bad stuff that keeps the wood from rotting into the air when heated. Cedar interior is often placed over a vapor barrier, followed by insulation and then the outer wall. Many outdoor saunas are not insulated. They simply have a single layer of cedar 2x6 planks functioning as both the interior and exterior. Non-insulated saunas need much more heating power in the winter.
#### Structure
For indoor saunas, you may want to find a bricklayer to build something for you. Traditional facilities often have brick-lined rooms and very large wood-burning stoves.
You can buy prefab outdoor saunas, which are often sheds or barrels. After experimenting with both, I’ve concluded that barrel saunas are inferior, even though that’s what I have at my country property. This is because barrels have concave ceilings and inner walls. This means the benches are lower and the curve makes the topmost part of the ceiling (and the hottest part) the furthest from you, or inaccessible. The spinning towel trick really helps in the barrel.
When it comes to buying a sauna, go with the most traditional structure possible. They are based on thousands of years of evolution and knowledge.
Portable tent saunas are fun, but impractical because you have to set them up before each use.
Bench height inside the sauna is important. I think the top-most bench should be very near the ceiling. This way, when you’re lying down, you can use the ceiling to stretch the hamstrings. As a rule of thumb, bench length should allow you to lie down completely. It is also nice to have at least one lower bench for visitors or less intense sauna days.

#### Sauna Ovens
There are two main types of sauna ovens: wood burning and electrical (with gas heating being available, but not common). If the location you are building allows for it, go with electrical. It’s practical and easy to get going quickly. This means you will use it more often. Wood burning saunas are romantic and smell great, but it is a lot more work to get a fire going, especially in the winter.
Opt for oven sizes that are recommended or above recommended for the size of the sauna. A larger oven means more thermic inertia, more rocks for steam, and therefore less time to warm up the room. Bigger is better. The Scandinavians make the best quality ovens.
#### Oven controllers
There are two types of temperature control devices: the analog cooking-style or the digital type. I think, due to liability and safety, all ovens have a timer that max out at one hour.
The digital oven controllers are fantastic and I have one in the city in my basement sauna.
However, you have to consider your environment. For me, temperatures in the winter can reach below -30C and in the summer, over 40C. This massive range can take a toll on outdoor equipment and materials. For this reason, I opted for an analog controller for my outdoor sauna in the country, since the weather will likely ruin the electronics of the digital controller.
I would avoid ovens with analog pre-heat timers. They are great in theory, but the implementation is utter garbage. The timer won’t be precise and it’ll just lead to frustration, for example, when you thought you set the oven to start in three hours, but it actually started in two hours and already turned off.
#### Important Sauna Gear
Windows are nice to have, especially if you have a view to enjoy. Opt for at least a cedar door with a little window. Do not go with modern glass door styles. They are crap. They have gaps, no insulation, and let in too much light.
Saunas need thermometers and hygrometers (to measure humidity). The thermometers should be rated for saunas and be visible inside. This is both for safety and bragging rights.
I think having an hourglass inside your sauna is a must. Being able to know for sure how long you’ve been inside is important, since your sense of timing inside the sauna may be off depending on the state of your mind and body on a given day. You shouldn’t wear a watch inside the sauna, since it’ll overheat or break. Having a clock visible from the inside is also a good idea, especially if you sauna often and have a wife and kids who you don’t want to leave you.
Air circulation is an often-overlooked but important part of a sauna design. Saunas should not have stale air. The best sauna design creates natural “real convection” by placing an air intake under the oven wall and another at the top opposite wall. This allows fresh air to enter the sauna while in use. Be sure to add regulators, since you don’t want to cool the sauna or expel all steam. Without regulators you may get too much or too little air in. With too much air, you may cool the sauna down too much and/or lose too much steam.
#### Nice Things to Have
Lights are optional but welcome additions. It can be unpleasant to have no lighting at all, especially in an outdoor sauna on a cold, dark night. Lights should be warm-temperature and low power. I recommend an oven light, since they don’t sweat the heat (get it?) and are often low power.
Put a baking tray under your oven–thank me later.
Wood “pillows” for your head are nice and don’t get sweat-stained and stinky, like a fabric pillow.
Keep some extra felt hats near your sauna so when you or your guests forget their hat, you still have easy access to one.
I like to keep a couple of essential oils on the floor of the sauna, for easy access. If you keep the oils too high in the sauna, they’ll get too hot and spoil.
I place some duck boards over floor tiles in the sauna to prevent cold feet.
I also like to keep a small, natural broom inside the sauna to sweep up any dirt or leaves that come into the sauna on people’s feet.
## Final words
As you can tell, I have some strong opinions when it comes to the proper way to enjoy a sauna. My hope is that my musings will help you to maximize your own sauna experience.. If you follow this guide, I’m certain you will benefit from and enjoy the sauna as much as I do and, just maybe, you too will develop your own strongly held opinions that will most definitely offend me.
### Thanks for reading, please close the F-ing door.
ps, you can get a Bitcoin Honey Badger Sauna Hat [here](https://store.coinkite.com/store/ht-sauna)
- EOF
-
@ 4ba8e86d:89d32de4
2024-10-07 13:37:38
O que é Cwtch?
Cwtch (/kʊtʃ/ - uma palavra galesa que pode ser traduzida aproximadamente como “um abraço que cria um lugar seguro”) é um protocolo de mensagens multipartidário descentralizado, que preserva a privacidade, que pode ser usado para construir aplicativos resistentes a metadados.
Como posso pronunciar Cwtch?
Como "kutch", para rimar com "butch".
Descentralizado e Aberto : Não existe “serviço Cwtch” ou “rede Cwtch”. Os participantes do Cwtch podem hospedar seus próprios espaços seguros ou emprestar sua infraestrutura para outras pessoas que buscam um espaço seguro. O protocolo Cwtch é aberto e qualquer pessoa é livre para criar bots, serviços e interfaces de usuário e integrar e interagir com o Cwtch.
Preservação de privacidade : toda a comunicação no Cwtch é criptografada de ponta a ponta e ocorre nos serviços cebola Tor v3.
Resistente a metadados : O Cwtch foi projetado de forma que nenhuma informação seja trocada ou disponibilizada a ninguém sem seu consentimento explícito, incluindo mensagens durante a transmissão e metadados de protocolo
Uma breve história do bate-papo resistente a metadados
Nos últimos anos, a conscientização pública sobre a necessidade e os benefícios das soluções criptografadas de ponta a ponta aumentou com aplicativos como Signal , Whatsapp e Wire. que agora fornecem aos usuários comunicações seguras.
No entanto, essas ferramentas exigem vários níveis de exposição de metadados para funcionar, e muitos desses metadados podem ser usados para obter detalhes sobre como e por que uma pessoa está usando uma ferramenta para se comunicar.
Uma ferramenta que buscou reduzir metadados é o Ricochet lançado pela primeira vez em 2014. Ricochet usou os serviços cebola Tor v2 para fornecer comunicação criptografada segura de ponta a ponta e para proteger os metadados das comunicações.
Não havia servidores centralizados que auxiliassem no roteamento das conversas do Ricochet. Ninguém além das partes envolvidas em uma conversa poderia saber que tal conversa está ocorrendo.
Ricochet tinha limitações; não havia suporte para vários dispositivos, nem existe um mecanismo para suportar a comunicação em grupo ou para um usuário enviar mensagens enquanto um contato está offline.
Isto tornou a adoção do Ricochet uma proposta difícil; mesmo aqueles em ambientes que seriam melhor atendidos pela resistência aos metadados, sem saber que ela existe.
Além disso, qualquer solução para comunicação descentralizada e resistente a metadados enfrenta problemas fundamentais quando se trata de eficiência, privacidade e segurança de grupo conforme definido pelo consenso e consistência da transcrição.
Alternativas modernas ao Ricochet incluem Briar , Zbay e Ricochet Refresh - cada ferramenta procura otimizar para um conjunto diferente de compensações, por exemplo, Briar procura permitir que as pessoas se comuniquem mesmo quando a infraestrutura de rede subjacente está inoperante, ao mesmo tempo que fornece resistência à vigilância de metadados.
O projeto Cwtch começou em 2017 como um protocolo de extensão para Ricochet, fornecendo conversas em grupo por meio de servidores não confiáveis, com o objetivo de permitir aplicativos descentralizados e resistentes a metadados como listas compartilhadas e quadros de avisos.
Uma versão alfa do Cwtch foi lançada em fevereiro de 2019 e, desde então, a equipe do Cwtch dirigida pela OPEN PRIVACY RESEARCH SOCIETY conduziu pesquisa e desenvolvimento em cwtch e nos protocolos, bibliotecas e espaços de problemas subjacentes.
Modelo de Risco.
Sabe-se que os metadados de comunicações são explorados por vários adversários para minar a segurança dos sistemas, para rastrear vítimas e para realizar análises de redes sociais em grande escala para alimentar a vigilância em massa. As ferramentas resistentes a metadados estão em sua infância e faltam pesquisas sobre a construção e a experiência do usuário de tais ferramentas.
https://nostrcheck.me/media/public/nostrcheck.me_9475702740746681051707662826.webp
O Cwtch foi originalmente concebido como uma extensão do protocolo Ricochet resistente a metadados para suportar comunicações assíncronas de grupos multiponto por meio do uso de infraestrutura anônima, descartável e não confiável.
Desde então, o Cwtch evoluiu para um protocolo próprio. Esta seção descreverá os vários riscos conhecidos que o Cwtch tenta mitigar e será fortemente referenciado no restante do documento ao discutir os vários subcomponentes da Arquitetura Cwtch.
Modelo de ameaça.
É importante identificar e compreender que os metadados são omnipresentes nos protocolos de comunicação; é de facto necessário que tais protocolos funcionem de forma eficiente e em escala. No entanto, as informações que são úteis para facilitar peers e servidores também são altamente relevantes para adversários que desejam explorar tais informações.
Para a definição do nosso problema, assumiremos que o conteúdo de uma comunicação é criptografado de tal forma que um adversário é praticamente incapaz de quebrá-lo veja tapir e cwtch para detalhes sobre a criptografia que usamos, e como tal nos concentraremos em o contexto para os metadados de comunicação.
Procuramos proteger os seguintes contextos de comunicação:
• Quem está envolvido em uma comunicação? Pode ser possível identificar pessoas ou simplesmente identificadores de dispositivos ou redes. Por exemplo, “esta comunicação envolve Alice, uma jornalista, e Bob, um funcionário público”.
• Onde estão os participantes da conversa? Por exemplo, “durante esta comunicação, Alice estava na França e Bob estava no Canadá”.
• Quando ocorreu uma conversa? O momento e a duração da comunicação podem revelar muito sobre a natureza de uma chamada, por exemplo, “Bob, um funcionário público, conversou com Alice ao telefone por uma hora ontem à noite. Esta é a primeira vez que eles se comunicam.” *Como a conversa foi mediada? O fato de uma conversa ter ocorrido por meio de um e-mail criptografado ou não criptografado pode fornecer informações úteis. Por exemplo, “Alice enviou um e-mail criptografado para Bob ontem, enquanto eles normalmente enviam apenas e-mails de texto simples um para o outro”.
• Sobre o que é a conversa? Mesmo que o conteúdo da comunicação seja criptografado, às vezes é possível derivar um contexto provável de uma conversa sem saber exatamente o que é dito, por exemplo, “uma pessoa ligou para uma pizzaria na hora do jantar” ou “alguém ligou para um número conhecido de linha direta de suicídio na hora do jantar”. 3 horas da manhã."
Além das conversas individuais, também procuramos defender-nos contra ataques de correlação de contexto, através dos quais múltiplas conversas são analisadas para obter informações de nível superior:
• Relacionamentos: Descobrir relações sociais entre um par de entidades analisando a frequência e a duração de suas comunicações durante um período de tempo. Por exemplo, Carol e Eve ligam uma para a outra todos os dias durante várias horas seguidas.
• Cliques: Descobrir relações sociais entre um grupo de entidades que interagem entre si. Por exemplo, Alice, Bob e Eva se comunicam entre si.
• Grupos vagamente conectados e indivíduos-ponte: descobrir grupos que se comunicam entre si através de intermediários, analisando cadeias de comunicação (por exemplo, toda vez que Alice fala com Bob, ela fala com Carol quase imediatamente depois; Bob e Carol nunca se comunicam).
• Padrão de Vida: Descobrir quais comunicações são cíclicas e previsíveis. Por exemplo, Alice liga para Eve toda segunda-feira à noite por cerca de uma hora.
Ataques Ativos
Ataques de deturpação.
O Cwtch não fornece registro global de nomes de exibição e, como tal, as pessoas que usam o Cwtch são mais vulneráveis a ataques baseados em declarações falsas, ou seja, pessoas que fingem ser outras pessoas:
O fluxo básico de um desses ataques é o seguinte, embora também existam outros fluxos:
•Alice tem um amigo chamado Bob e outro chamado Eve
• Eve descobre que Alice tem um amigo chamado Bob
• Eve cria milhares de novas contas para encontrar uma que tenha uma imagem/chave pública semelhante à de Bob (não será idêntica, mas pode enganar alguém por alguns minutos)
• Eve chama essa nova conta de "Eve New Account" e adiciona Alice como amiga.
• Eve então muda seu nome em "Eve New Account" para "Bob"
• Alice envia mensagens destinadas a "Bob" para a conta falsa de Bob de Eve
Como os ataques de declarações falsas são inerentemente uma questão de confiança e verificação, a única maneira absoluta de evitá-los é os usuários validarem absolutamente a chave pública. Obviamente, isso não é o ideal e, em muitos casos, simplesmente não acontecerá .
Como tal, pretendemos fornecer algumas dicas de experiência do usuário na interface do usuário para orientar as pessoas na tomada de decisões sobre confiar em contas e/ou distinguir contas que possam estar tentando se representar como outros usuários.
Uma nota sobre ataques físicos
A Cwtch não considera ataques que exijam acesso físico (ou equivalente) à máquina do usuário como praticamente defensáveis. No entanto, no interesse de uma boa engenharia de segurança, ao longo deste documento ainda nos referiremos a ataques ou condições que exigem tal privilégio e indicaremos onde quaisquer mitigações que implementámos falharão.
Um perfil Cwtch.
Os usuários podem criar um ou mais perfis Cwtch. Cada perfil gera um par de chaves ed25519 aleatório compatível com Tor.
Além do material criptográfico, um perfil também contém uma lista de Contatos (outras chaves públicas do perfil Cwtch + dados associados sobre esse perfil, como apelido e (opcionalmente) mensagens históricas), uma lista de Grupos (contendo o material criptográfico do grupo, além de outros dados associados, como apelido do grupo e mensagens históricas).
Conversões entre duas partes: ponto a ponto
https://nostrcheck.me/media/public/nostrcheck.me_2186338207587396891707662879.webp
Para que duas partes participem de uma conversa ponto a ponto, ambas devem estar on-line, mas apenas uma precisa estar acessível por meio do serviço Onion. Por uma questão de clareza, muitas vezes rotulamos uma parte como “ponto de entrada” (aquele que hospeda o serviço cebola) e a outra parte como “ponto de saída” (aquele que se conecta ao serviço cebola).
Após a conexão, ambas as partes adotam um protocolo de autenticação que:
• Afirma que cada parte tem acesso à chave privada associada à sua identidade pública.
• Gera uma chave de sessão efêmera usada para criptografar todas as comunicações futuras durante a sessão.
Esta troca (documentada com mais detalhes no protocolo de autenticação ) é negável offline , ou seja, é possível para qualquer parte falsificar transcrições desta troca de protocolo após o fato e, como tal - após o fato - é impossível provar definitivamente que a troca aconteceu de forma alguma.
Após o protocolo de autenticação, as duas partes podem trocar mensagens livremente.
Conversas em Grupo e Comunicação Ponto a Servidor
Ao iniciar uma conversa em grupo, é gerada uma chave aleatória para o grupo, conhecida como Group Key. Todas as comunicações do grupo são criptografadas usando esta chave. Além disso, o criador do grupo escolhe um servidor Cwtch para hospedar o grupo. Um convite é gerado, incluindo o Group Key, o servidor do grupo e a chave do grupo, para ser enviado aos potenciais membros.
Para enviar uma mensagem ao grupo, um perfil se conecta ao servidor do grupo e criptografa a mensagem usando a Group Key, gerando também uma assinatura sobre o Group ID, o servidor do grupo e a mensagem. Para receber mensagens do grupo, um perfil se conecta ao servidor e baixa as mensagens, tentando descriptografá-las usando a Group Key e verificando a assinatura.
Detalhamento do Ecossistema de Componentes
O Cwtch é composto por várias bibliotecas de componentes menores, cada uma desempenhando um papel específico. Algumas dessas bibliotecas incluem:
- abertoprivacidade/conectividade: Abstração de rede ACN, atualmente suportando apenas Tor.
- cwtch.im/tapir: Biblioteca para construção de aplicativos p2p em sistemas de comunicação anônimos.
- cwtch.im/cwtch: Biblioteca principal para implementação do protocolo/sistema Cwtch.
- cwtch.im/libcwtch-go: Fornece ligações C para Cwtch para uso em implementações de UI.
TAPIR: Uma Visão Detalhada
Projetado para substituir os antigos canais de ricochete baseados em protobuf, o Tapir fornece uma estrutura para a construção de aplicativos anônimos.
Está dividido em várias camadas:
• Identidade - Um par de chaves ed25519, necessário para estabelecer um serviço cebola Tor v3 e usado para manter uma identidade criptográfica consistente para um par.
• Conexões – O protocolo de rede bruto que conecta dois pares. Até agora, as conexões são definidas apenas através do Tor v3 Onion Services.
• Aplicativos - As diversas lógicas que permitem um determinado fluxo de informações em uma conexão. Os exemplos incluem transcrições criptográficas compartilhadas, autenticação, proteção contra spam e serviços baseados em tokens. Os aplicativos fornecem recursos que podem ser referenciados por outros aplicativos para determinar se um determinado peer tem a capacidade de usar um determinado aplicativo hospedado.
• Pilhas de aplicativos - Um mecanismo para conectar mais de um aplicativo, por exemplo, a autenticação depende de uma transcrição criptográfica compartilhada e o aplicativo peer cwtch principal é baseado no aplicativo de autenticação.
Identidade.
Um par de chaves ed25519, necessário para estabelecer um serviço cebola Tor v3 e usado para manter uma identidade criptográfica consistente para um peer.
InitializeIdentity - de um par de chaves conhecido e persistente:i,I
InitializeEphemeralIdentity - de um par de chaves aleatório: ie,Ie
Aplicativos de transcrição.
Inicializa uma transcrição criptográfica baseada em Merlin que pode ser usada como base de protocolos baseados em compromisso de nível superior
O aplicativo de transcrição entrará em pânico se um aplicativo tentar substituir uma transcrição existente por uma nova (aplicando a regra de que uma sessão é baseada em uma e apenas uma transcrição).
Merlin é uma construção de transcrição baseada em STROBE para provas de conhecimento zero. Ele automatiza a transformação Fiat-Shamir, para que, usando Merlin, protocolos não interativos possam ser implementados como se fossem interativos.
Isto é significativamente mais fácil e menos sujeito a erros do que realizar a transformação manualmente e, além disso, também fornece suporte natural para:
• protocolos multi-round com fases alternadas de commit e desafio;
• separação natural de domínios, garantindo que os desafios estejam vinculados às afirmações a serem provadas;
• enquadramento automático de mensagens, evitando codificação ambígua de dados de compromisso;
• e composição do protocolo, usando uma transcrição comum para vários protocolos.
Finalmente, o Merlin também fornece um gerador de números aleatórios baseado em transcrição como defesa profunda contra ataques de entropia ruim (como reutilização de nonce ou preconceito em muitas provas). Este RNG fornece aleatoriedade sintética derivada de toda a transcrição pública, bem como dos dados da testemunha do provador e uma entrada auxiliar de um RNG externo.
Conectividade
Cwtch faz uso do Tor Onion Services (v3) para todas as comunicações entre nós.
Fornecemos o pacote openprivacy/connectivity para gerenciar o daemon Tor e configurar e desmontar serviços cebola através do Tor.
Criptografia e armazenamento de perfil.
Os perfis são armazenados localmente no disco e criptografados usando uma chave derivada de uma senha conhecida pelo usuário (via pbkdf2).
Observe que, uma vez criptografado e armazenado em disco, a única maneira de recuperar um perfil é recuperando a senha - como tal, não é possível fornecer uma lista completa de perfis aos quais um usuário pode ter acesso até inserir uma senha.
Perfis não criptografados e a senha padrão
Para lidar com perfis "não criptografados" (ou seja, que não exigem senha para serem abertos), atualmente criamos um perfil com uma senha codificada de fato .
Isso não é o ideal, preferiríamos confiar no material de chave fornecido pelo sistema operacional, de modo que o perfil fosse vinculado a um dispositivo específico, mas esses recursos são atualmente uma colcha de retalhos - também notamos, ao criar um perfil não criptografado, pessoas que usam Cwtch estão explicitamente optando pelo risco de que alguém com acesso ao sistema de arquivos possa descriptografar seu perfil.
Vulnerabilidades Relacionadas a Imagens e Entrada de Dados
Imagens Maliciosas
O Cwtch enfrenta desafios na renderização de imagens, com o Flutter utilizando Skia, embora o código subjacente não seja totalmente seguro para a memória.
Realizamos testes de fuzzing nos componentes Cwtch e encontramos um bug de travamento causado por um arquivo GIF malformado, levando a falhas no kernel. Para mitigar isso, adotamos a política de sempre habilitar cacheWidth e/ou cacheHeight máximo para widgets de imagem.
Identificamos o risco de imagens maliciosas serem renderizadas de forma diferente em diferentes plataformas, como evidenciado por um bug no analisador PNG da Apple.
Riscos de Entrada de Dados
Um risco significativo é a interceptação de conteúdo ou metadados por meio de um Input Method Editor (IME) em dispositivos móveis. Mesmo aplicativos IME padrão podem expor dados por meio de sincronização na nuvem, tradução online ou dicionários pessoais.
Implementamos medidas de mitigação, como enableIMEPersonalizedLearning: false no Cwtch 1.2, mas a solução completa requer ações em nível de sistema operacional e é um desafio contínuo para a segurança móvel.
Servidor Cwtch.
O objetivo do protocolo Cwtch é permitir a comunicação em grupo através de infraestrutura não confiável .
Ao contrário dos esquemas baseados em retransmissão, onde os grupos atribuem um líder, um conjunto de líderes ou um servidor confiável de terceiros para garantir que cada membro do grupo possa enviar e receber mensagens em tempo hábil (mesmo que os membros estejam offline) - infraestrutura não confiável tem o objetivo de realizar essas propriedades sem a suposição de confiança.
O artigo original do Cwtch definia um conjunto de propriedades que se esperava que os servidores Cwtch fornecessem:
• O Cwtch Server pode ser usado por vários grupos ou apenas um.
• Um servidor Cwtch, sem a colaboração de um membro do grupo, nunca deve aprender a identidade dos participantes de um grupo.
• Um servidor Cwtch nunca deve aprender o conteúdo de qualquer comunicação.
• Um servidor Cwtch nunca deve ser capaz de distinguir mensagens como pertencentes a um grupo específico.
Observamos aqui que essas propriedades são um superconjunto dos objetivos de design das estruturas de Recuperação de Informações Privadas.
Melhorias na Eficiência e Segurança
Eficiência do Protocolo
Atualmente, apenas um protocolo conhecido, o PIR ingênuo, atende às propriedades desejadas para garantir a privacidade na comunicação do grupo Cwtch. Este método tem um impacto direto na eficiência da largura de banda, especialmente para usuários em dispositivos móveis. Em resposta a isso, estamos ativamente desenvolvendo novos protocolos que permitem negociar garantias de privacidade e eficiência de maneiras diversas.
Os servidores, no momento desta escrita, permitem o download completo de todas as mensagens armazenadas, bem como uma solicitação para baixar mensagens específicas a partir de uma determinada mensagem. Quando os pares ingressam em um grupo em um novo servidor, eles baixam todas as mensagens do servidor inicialmente e, posteriormente, apenas as mensagens novas.
Mitigação de Análise de Metadados
Essa abordagem permite uma análise moderada de metadados, pois o servidor pode enviar novas mensagens para cada perfil suspeito exclusivo e usar essas assinaturas de mensagens exclusivas para rastrear sessões ao longo do tempo. Essa preocupação é mitigada por dois fatores:
1. Os perfis podem atualizar suas conexões a qualquer momento, resultando em uma nova sessão do servidor.
2. Os perfis podem ser "ressincronizados" de um servidor a qualquer momento, resultando em uma nova chamada para baixar todas as mensagens. Isso é comumente usado para buscar mensagens antigas de um grupo.
Embora essas medidas imponham limites ao que o servidor pode inferir, ainda não podemos garantir resistência total aos metadados. Para soluções futuras para esse problema, consulte Niwl.
Proteção contra Pares Maliciosos
Os servidores enfrentam o risco de spam gerado por pares, representando uma ameaça significativa à eficácia do sistema Cwtch. Embora tenhamos implementado um mecanismo de proteção contra spam no protótipo do Cwtch, exigindo que os pares realizem alguma prova de trabalho especificada pelo servidor, reconhecemos que essa não é uma solução robusta na presença de um adversário determinado com recursos significativos.
Pacotes de Chaves
Os servidores Cwtch se identificam por meio de pacotes de chaves assinados, contendo uma lista de chaves necessárias para garantir a segurança e resistência aos metadados na comunicação do grupo Cwtch. Esses pacotes de chaves geralmente incluem três chaves: uma chave pública do serviço Tor v3 Onion para o Token Board, uma chave pública do Tor v3 Onion Service para o Token Service e uma chave pública do Privacy Pass.
Para verificar os pacotes de chaves, os perfis que os importam do servidor utilizam o algoritmo trust-on-first-use (TOFU), verificando a assinatura anexada e a existência de todos os tipos de chave. Se o perfil já tiver importado o pacote de chaves do servidor anteriormente, todas as chaves são consideradas iguais.
Configuração prévia do aplicativo para ativar o Relé do Cwtch.
No Android, a hospedagem de servidor não está habilitada, pois essa opção não está disponível devido às limitações dos dispositivos Android. Essa funcionalidade está reservada apenas para servidores hospedados em desktops.
No Android, a única forma direta de importar uma chave de servidor é através do grupo de teste Cwtch, garantindo assim acesso ao servidor Cwtch.
Primeiro passo é Habilitar a opção de grupo no Cwtch que está em fase de testes. Clique na opção no canto superior direito da tela de configuração e pressione o botão para acessar as configurações do Cwtch.
Você pode alterar o idioma para Português do Brasil.Depois, role para baixo e selecione a opção para ativar os experimentos. Em seguida, ative a opção para habilitar o chat em grupo e a pré-visualização de imagens e fotos de perfil, permitindo que você troque sua foto de perfil.
https://link.storjshare.io/raw/jvss6zxle26jdguwaegtjdixhfka/production/f0ca039733d48895001261ab25c5d2efbaf3bf26e55aad3cce406646f9af9d15.MP4
Próximo passo é Criar um perfil.
Pressione o + botão de ação no canto inferior direito e selecione "Novo perfil" ou aberta no botão + adicionar novo perfil.
- Selecione um nome de exibição
- Selecione se deseja proteger
este perfil e salvo localmente com criptografia forte:
Senha: sua conta está protegida de outras pessoas que possam usar este dispositivo
Sem senha: qualquer pessoa que tenha acesso a este dispositivo poderá acessar este perfil.
Preencha sua senha e digite-a novamente
Os perfis são armazenados localmente no disco e criptografados usando uma chave derivada de uma senha conhecida pelo usuário (via pbkdf2).
Observe que, uma vez criptografado e armazenado em disco, a única maneira de recuperar um perfil é recuperando a chave da senha - como tal, não é possível fornecer uma lista completa de perfis aos quais um usuário pode ter acesso até inserir um senha.
https://link.storjshare.io/raw/jxqbqmur2lcqe2eym5thgz4so2ya/production/8f9df1372ec7e659180609afa48be22b12109ae5e1eda9ef1dc05c1325652507.MP4
O próximo passo é adicionar o FuzzBot, que é um bot de testes e de desenvolvimento.
Contato do FuzzBot: 4y2hxlxqzautabituedksnh2ulcgm2coqbure6wvfpg4gi2ci25ta5ad.
Ao enviar o comando "testgroup-invite" para o FuzzBot, você receberá um convite para entrar no Grupo Cwtch Test. Ao ingressar no grupo, você será automaticamente conectado ao servidor Cwtch. Você pode optar por sair do grupo a qualquer momento ou ficar para conversar e tirar dúvidas sobre o aplicativo e outros assuntos. Depois, você pode configurar seu próprio servidor Cwtch, o que é altamente recomendável.
https://link.storjshare.io/raw/jvji25zclkoqcouni5decle7if7a/production/ee3de3540a3e3dca6e6e26d303e12c2ef892a5d7769029275b8b95ffc7468780.MP4
Agora você pode utilizar o aplicativo normalmente. Algumas observações que notei: se houver demora na conexão com outra pessoa, ambas devem estar online. Se ainda assim a conexão não for estabelecida, basta clicar no ícone de reset do Tor para restabelecer a conexão com a outra pessoa.
Uma introdução aos perfis Cwtch.
Com Cwtch você pode criar um ou mais perfis . Cada perfil gera um par de chaves ed25519 aleatório compatível com a Rede Tor.
Este é o identificador que você pode fornecer às pessoas e que elas podem usar para entrar em contato com você via Cwtch.
Cwtch permite criar e gerenciar vários perfis separados. Cada perfil está associado a um par de chaves diferente que inicia um serviço cebola diferente.
Gerenciar Na inicialização, o Cwtch abrirá a tela Gerenciar Perfis. Nessa tela você pode:
- Crie um novo perfil.
- Desbloquear perfis.
- Criptografados existentes.
- Gerenciar perfis carregados.
- Alterando o nome de exibição de um perfil.
- Alterando a senha de um perfil
Excluindo um perfil.
- Alterando uma imagem de perfil.
Backup ou exportação de um perfil.
Na tela de gerenciamento de perfil:
1. Selecione o lápis ao lado do perfil que você deseja editar
2. Role para baixo até a parte inferior da tela.
3. Selecione "Exportar perfil"
4. Escolha um local e um nome de arquivo.
5.confirme.
Uma vez confirmado, o Cwtch colocará uma cópia do perfil no local indicado. Este arquivo é criptografado no mesmo nível do perfil.
Este arquivo pode ser importado para outra instância do Cwtch em qualquer dispositivo.
Importando um perfil.
1. Pressione o +botão de ação no canto inferior direito e selecione "Importar perfil"
2. Selecione um arquivo de perfil Cwtch exportado para importar
3. Digite a senha associada ao perfil e confirme.
Uma vez confirmado, o Cwtch tentará descriptografar o arquivo fornecido usando uma chave derivada da senha fornecida. Se for bem-sucedido, o perfil aparecerá na tela Gerenciamento de perfil e estará pronto para uso.
OBSERVAÇÃO
Embora um perfil possa ser importado para vários dispositivos, atualmente apenas uma versão de um perfil pode ser usada em todos os dispositivos ao mesmo tempo.
As tentativas de usar o mesmo perfil em vários dispositivos podem resultar em problemas de disponibilidade e falhas de mensagens.
Qual é a diferença entre uma conexão ponto a ponto e um grupo cwtch?
As conexões ponto a ponto Cwtch permitem que 2 pessoas troquem mensagens diretamente. As conexões ponto a ponto nos bastidores usam serviços cebola Tor v3 para fornecer uma conexão criptografada e resistente a metadados. Devido a esta conexão direta, ambas as partes precisam estar online ao mesmo tempo para trocar mensagens.
Os Grupos Cwtch permitem que várias partes participem de uma única conversa usando um servidor não confiável (que pode ser fornecido por terceiros ou auto-hospedado). Os operadores de servidores não conseguem saber quantas pessoas estão em um grupo ou o que está sendo discutido. Se vários grupos estiverem hospedados em um único servidor, o servidor não conseguirá saber quais mensagens pertencem a qual grupo sem a conivência de um membro do grupo. Ao contrário das conversas entre pares, as conversas em grupo podem ser conduzidas de forma assíncrona, para que todos num grupo não precisem estar online ao mesmo tempo.
Por que os grupos cwtch são experimentais?
Mensagens em grupo resistentes a metadados ainda são um problema em aberto . Embora a versão que fornecemos no Cwtch Beta seja projetada para ser segura e com metadados privados, ela é bastante ineficiente e pode ser mal utilizada. Como tal, aconselhamos cautela ao usá-lo e apenas o fornecemos como um recurso opcional.
Como posso executar meu próprio servidor Cwtch?
A implementação de referência para um servidor Cwtch é de código aberto . Qualquer pessoa pode executar um servidor Cwtch, e qualquer pessoa com uma cópia do pacote de chaves públicas do servidor pode hospedar grupos nesse servidor sem que o operador tenha acesso aos metadados relacionados ao grupo .
https://git.openprivacy.ca/cwtch.im/server
https://docs.openprivacy.ca/cwtch-security-handbook/server.html
Como posso desligar o Cwtch?
O painel frontal do aplicativo possui um ícone do botão "Shutdown Cwtch" (com um 'X'). Pressionar este botão irá acionar uma caixa de diálogo e, na confirmação, o Cwtch será desligado e todos os perfis serão descarregados.
Suas doações podem fazer a diferença no projeto Cwtch? O Cwtch é um projeto dedicado a construir aplicativos que preservam a privacidade, oferecendo comunicação de grupo resistente a metadados. Além disso, o projeto também desenvolve o Cofre, formulários da web criptografados para ajudar mútua segura. Suas contribuições apoiam iniciativas importantes, como a divulgação de violações de dados médicos em Vancouver e pesquisas sobre a segurança do voto eletrônico na Suíça. Ao doar, você está ajudando a fechar o ciclo, trabalhando com comunidades marginalizadas para identificar e corrigir lacunas de privacidade. Além disso, o projeto trabalha em soluções inovadoras, como a quebra de segredos através da criptografia de limite para proteger sua privacidade durante passagens de fronteira. E também tem a infraestrutura: toda nossa infraestrutura é open source e sem fins lucrativos. Conheça também o Fuzzytags, uma estrutura criptográfica probabilística para marcação resistente a metadados. Sua doação é crucial para continuar o trabalho em prol da privacidade e segurança online. Contribua agora com sua doação
https://openprivacy.ca/donate/
onde você pode fazer sua doação em bitcoin e outras moedas, e saiba mais sobre os projetos.
https://openprivacy.ca/work/
Link sobre Cwtch
https://cwtch.im/
https://git.openprivacy.ca/cwtch.im/cwtch
https://docs.cwtch.im/docs/intro
https://docs.openprivacy.ca/cwtch-security-handbook/
Baixar #CwtchDev
cwtch.im/download/
https://play.google.com/store/apps/details?id=im.cwtch.flwtch
-
@ e6817453:b0ac3c39
2024-10-06 11:21:27
Hey folks, today we're diving into an exciting and emerging topic: personal artificial intelligence (PAI) and its connection to sovereignty, privacy, and ethics. With the rapid advancements in AI, there's a growing interest in the development of personal AI agents that can work on behalf of the user, acting autonomously and providing tailored services. However, as with any new technology, there are several critical factors that shape the future of PAI. Today, we'll explore three key pillars: privacy and ownership, explainability, and bias.
<iframe width="560" height="315" src="https://www.youtube.com/embed/fehgwnSUcqQ?si=nPK7UOFr19BT5ifm" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
### 1. Privacy and Ownership: Foundations of Personal AI
At the heart of personal AI, much like self-sovereign identity (SSI), is the concept of ownership. For personal AI to be truly effective and valuable, users must own not only their data but also the computational power that drives these systems. This autonomy is essential for creating systems that respect the user's privacy and operate independently of large corporations.
In this context, privacy is more than just a feature—it's a fundamental right. Users should feel safe discussing sensitive topics with their AI, knowing that their data won’t be repurposed or misused by big tech companies. This level of control and data ownership ensures that users remain the sole beneficiaries of their information and computational resources, making privacy one of the core pillars of PAI.
### 2. Bias and Fairness: The Ethical Dilemma of LLMs
Most of today’s AI systems, including personal AI, rely heavily on large language models (LLMs). These models are trained on vast datasets that represent snapshots of the internet, but this introduces a critical ethical challenge: bias. The datasets used for training LLMs can be full of biases, misinformation, and viewpoints that may not align with a user’s personal values.
This leads to one of the major issues in AI ethics for personal AI—how do we ensure fairness and minimize bias in these systems? The training data that LLMs use can introduce perspectives that are not only unrepresentative but potentially harmful or unfair. As users of personal AI, we need systems that are free from such biases and can be tailored to our individual needs and ethical frameworks.
Unfortunately, training models that are truly unbiased and fair requires vast computational resources and significant investment. While large tech companies have the financial means to develop and train these models, individual users or smaller organizations typically do not. This limitation means that users often have to rely on pre-trained models, which may not fully align with their personal ethics or preferences. While fine-tuning models with personalized datasets can help, it's not a perfect solution, and bias remains a significant challenge.
### 3. Explainability: The Need for Transparency
One of the most frustrating aspects of modern AI is the lack of explainability. Many LLMs operate as "black boxes," meaning that while they provide answers or make decisions, it's often unclear how they arrived at those conclusions. For personal AI to be effective and trustworthy, it must be transparent. Users need to understand how the AI processes information, what data it relies on, and the reasoning behind its conclusions.
Explainability becomes even more critical when AI is used for complex decision-making, especially in areas that impact other people. If an AI is making recommendations, judgments, or decisions, it’s crucial for users to be able to trace the reasoning process behind those actions. Without this transparency, users may end up relying on AI systems that provide flawed or biased outcomes, potentially causing harm.
This lack of transparency is a major hurdle for personal AI development. Current LLMs, as mentioned earlier, are often opaque, making it difficult for users to trust their outputs fully. The explainability of AI systems will need to be improved significantly to ensure that personal AI can be trusted for important tasks.
### Addressing the Ethical Landscape of Personal AI
As personal AI systems evolve, they will increasingly shape the ethical landscape of AI. We’ve already touched on the three core pillars—privacy and ownership, bias and fairness, and explainability. But there's more to consider, especially when looking at the broader implications of personal AI development.
Most current AI models, particularly those from big tech companies like Facebook, Google, or OpenAI, are closed systems. This means they are aligned with the goals and ethical frameworks of those companies, which may not always serve the best interests of individual users. Open models, such as Meta's LLaMA, offer more flexibility and control, allowing users to customize and refine the AI to better meet their personal needs. However, the challenge remains in training these models without significant financial and technical resources.
There’s also the temptation to use uncensored models that aren’t aligned with the values of large corporations, as they provide more freedom and flexibility. But in reality, models that are entirely unfiltered may introduce harmful or unethical content. It’s often better to work with aligned models that have had some of the more problematic biases removed, even if this limits some aspects of the system’s freedom.
The future of personal AI will undoubtedly involve a deeper exploration of these ethical questions. As AI becomes more integrated into our daily lives, the need for privacy, fairness, and transparency will only grow. And while we may not yet be able to train personal AI models from scratch, we can continue to shape and refine these systems through curated datasets and ongoing development.
### Conclusion
In conclusion, personal AI represents an exciting new frontier, but one that must be navigated with care. Privacy, ownership, bias, and explainability are all essential pillars that will define the future of these systems. As we continue to develop personal AI, we must remain vigilant about the ethical challenges they pose, ensuring that they serve the best interests of users while remaining transparent, fair, and aligned with individual values.
If you have any thoughts or questions on this topic, feel free to reach out—I’d love to continue the conversation!
-
@ e6817453:b0ac3c39
2024-09-30 14:52:23
In the modern world of AI, managing vast amounts of data while keeping it relevant and accessible is a significant challenge, mainly when dealing with large language models (LLMs) and vector databases. One approach that has gained prominence in recent years is integrating vector search with metadata, especially in retrieval-augmented generation (RAG) pipelines. Vector search and metadata enable faster and more accurate data retrieval. However, the process of pre- and post-search filtering results plays a crucial role in ensuring data relevance.
<iframe width="560" height="315" src="https://www.youtube.com/embed/BkNqu51et9U?si=lne0jWxdrZPxSgd1" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen></iframe>
## The Vector Search and Metadata Challenge
In a typical vector search, you create embeddings from chunks of text, such as a PDF document. These embeddings allow the system to search for similar items and retrieve them based on relevance. The challenge, however, arises when you need to combine vector search results with structured metadata. For example, you may have timestamped text-based content and want to retrieve the most relevant content within a specific date range. This is where metadata becomes critical in refining search results.
Unfortunately, most vector databases treat metadata as a secondary feature, isolating it from the primary vector search process. As a result, handling queries that combine vectors and metadata can become a challenge, particularly when the search needs to account for a dynamic range of filters, such as dates or other structured data.
## LibSQL and vector search metadata
LibSQL is a more general-purpose SQLite-based database that adds vector capabilities to regular data. Vectors are presented as blob columns of regular tables. It makes vector embeddings and metadata a first-class citizen that naturally builds deep integration of these data points.
```
create table if not exists conversation (
id varchar(36) primary key not null,
startDate real,
endDate real,
summary text,
vectorSummary F32_BLOB(512)
);
```
It solves the challenge of metadata and vector search and eliminates impedance between vector data and regular structured data points in the same storage.
As you can see, you can access vector-like data and start date in the same query.
```
select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance
from conversation
where
${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''}
${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''}
${distance ? `and distance <= ${distance}` : ''}
order by distance
limit ${top};
```
**vector\_distance\_cos** calculated as distance allows us to make a primitive vector search that does a full scan and calculates distances on rows. We could optimize it with CTE and limit search and distance calculations to a much smaller subset of data.
This approach could be calculation intensive and fail on large amounts of data.
Libsql offers a way more effective vector search based on FlashDiskANN vector indexed.
```
vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) i
```
**vector\_top\_k** is a table function that searches for the top of the newly created vector search index. As you can see, we could use only vector as a function parameter, and other columns could be used outside of the table function. So, to use a vector index together with different columns, we need to apply some strategies.
Now we get a classical problem of integration vector search results with metadata queries.
## Post-Filtering: A Common Approach
The most widely adopted method in these pipelines is **post-filtering**. In this approach, the system first retrieves data based on vector similarities and then applies metadata filters. For example, imagine you’re conducting a vector search to retrieve conversations relevant to a specific question. Still, you also want to ensure these conversations occurred in the past week.
Post-filtering allows the system to retrieve the most relevant vector-based results and subsequently filter out any that don’t meet the metadata criteria, such as date range. This method is efficient when vector similarity is the primary factor driving the search, and metadata is only applied as a secondary filter.
```
const sqlQuery = `
select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance
from vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) i
inner join conversation c on i.id = c.rowid
where
${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''}
${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''}
${distance ? `and distance <= ${distance}` : ''}
order by distance
limit ${top};
```
However, there are some limitations. For example, the initial vector search may yield fewer results or omit some relevant data before applying the metadata filter. If the search window is narrow enough, this can lead to complete results.
One working strategy is to make the top value in vector\_top\_K much bigger. Be careful, though, as the function's default max number of results is around 200 rows.
## Pre-Filtering: A More Complex Approach
Pre-filtering is a more intricate approach but can be more effective in some instances. In pre-filtering, metadata is used as the primary filter before vector search takes place. This means that only data that meets the metadata criteria is passed into the vector search process, limiting the scope of the search right from the beginning.
While this approach can significantly reduce the amount of irrelevant data in the final results, it comes with its own challenges. For example, pre-filtering requires a deeper understanding of the data structure and may necessitate denormalizing the data or creating separate pre-filtered tables. This can be resource-intensive and, in some cases, impractical for dynamic metadata like date ranges.
In certain use cases, pre-filtering might outperform post-filtering. For instance, when the metadata (e.g., specific date ranges) is the most important filter, pre-filtering ensures the search is conducted only on the most relevant data.
## Pre-filtering with distance-based filtering
So, we are getting back to an old concept. We do prefiltering instead of using a vector index.
```
WITH FilteredDates AS (
SELECT
c.id,
c.startDate,
c.endDate,
c.summary,
c.vectorSummary
FROM
YourTable c
WHERE
${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''}
${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''}
),
DistanceCalculation AS (
SELECT
fd.id,
fd.startDate,
fd.endDate,
fd.summary,
fd.vectorSummary,
vector_distance_cos(fd.vectorSummary, vector(${vector})) AS distance
FROM
FilteredDates fd
)
SELECT
dc.id,
dc.startDate,
dc.endDate,
dc.summary,
dc.distance
FROM
DistanceCalculation dc
WHERE
1=1
${distance ? `AND dc.distance <= ${distance}` : ''}
ORDER BY
dc.distance
LIMIT ${top};
```
It makes sense if the filter produces small data and distance calculation happens on the smaller data set.
As a pro of this approach, you have full control over the data and get all results without omitting some typical values for extensive index searches.
## Choosing Between Pre and Post-Filtering
Both pre-filtering and post-filtering have their advantages and disadvantages. Post-filtering is more accessible to implement, especially when vector similarity is the primary search factor, but it can lead to incomplete results. Pre-filtering, on the other hand, can yield more accurate results but requires more complex data handling and optimization.
In practice, many systems combine both strategies, depending on the query. For example, they might start with a broad pre-filtering based on metadata (like date ranges) and then apply a more targeted vector search with post-filtering to refine the results further.
## **Conclusion**
Vector search with metadata filtering offers a powerful approach for handling large-scale data retrieval in LLMs and RAG pipelines. Whether you choose pre-filtering or post-filtering—or a combination of both—depends on your application's specific requirements. As vector databases continue to evolve, future innovations that combine these two approaches more seamlessly will help improve data relevance and retrieval efficiency further.
-
@ 9358c676:9f2912fc
2024-09-24 12:29:11
### **OBJECTIVES**
To establish a guideline for the management of Acute Community-Acquired Pneumonia (CAP) in our center, for both outpatient and hospitalized patients, with the aim of:
* Reducing morbidity and mortality associated with the condition.
* Improving the quality of medical care and optimizing hospital resources.
* Delaying the progression of antimicrobial resistance.
### **SCOPE**
All patients over 16 years of age diagnosed with Acute Community-Acquired Pneumonia who are being followed by our institution in an outpatient or inpatient setting.
### **RESPONSIBILITIES**
Physicians from the Medical Clinic, Medical Emergency, Coronary Unit, and Intensive Care Service. Nursing Coordination. Pharmacy Service. Infection Control Committee.
### **REFERENCES AND BIBLIOGRAPHY**
1. Community-Acquired Pneumonia in Adults. Recommendations for its management. Lopardo et al. MEDICINA (Buenos Aires) 2015; 75: 245-257. Argentine Society of Infectiology. ISSN 0025-7680
2. Diagnosis and Treatment of Adults with Community-acquired Pneumonia. An Official Clinical Practice Guideline of the American Thoracic Society and Infectious Diseases Society of America. 2019. American Journal of Respiratory and Critical Care Medicine Volume 200 Number 7 | October 1, 2019. DOI: 10.1164 rccm.201908-1581ST
3. ERS/ESICM/ESCMID/ALAT guidelines for the management of severe community-acquired pneumonia. Intensive Care Med (2023) 49:615–632 https://doi.org/10.1007/s00134-023-07033-8
4. Antimicrobial resistance. WHO. https://www.who.int/news-room/fact-sheets/detail/antimicrobial resistance
5. Internal Medicine. Farreras-Rosman. Volume I. Elsevier. 2008 Edition.
6. Considerations for the Responsible Use of Antibiotics in COVID-19. Argentine Society of Infectiology. 2020. https://drive.google.com/file/d/1BmXD5x6rEpSqDIc8urccdqLcZKkP3U7X/view
7. Penicillin Allergy. Castells M. New England Journal of Medicine, 381(24), 2338–2351. doi:10.1056 nejmra1807761
### **INTRODUCTION**
Pneumonia is one of the leading causes of morbidity and mortality worldwide, affecting patients of all ages and with various risk factors. Proper management in both outpatient and hospital settings is crucial for improving clinical outcomes and reducing associated complications.
This document aims to standardize and optimize the treatment of pneumonia based on the most current evidence and recommendations from leading scientific organizations. It seeks to be a practical tool for healthcare professionals, providing a clear and concise approach to the diagnosis, treatment, and follow-up of patients with pneumonia.
### **FOUNDATIONS. HOSPITAL SITUATION ANALYSIS:**
* Pneumonias represent a significant burden on the healthcare system due to their high prevalence and potential severity, underscoring the need for a standardized approach.
* A clinical guideline facilitates decision-making, ensuring that all healthcare professionals follow a uniform protocol that integrates best practices, thereby reducing variability in treatments. This allows for better resource utilization, optimizing antibiotic use and reducing the emergence of antimicrobial resistance.
* Antimicrobial resistance has been proposed by the World Health Organization (WHO) and related organizations as the leading cause of death and hospital expenditure by the year 2050.
* Pneumonias in our center, in their various presentations, have shown significant prevalence in hospitalizations according to measurements taken in 2024.
* In our center, antibiotics, as a whole, have been the main source of financial losses related to drugs during the billing cycle from June 2023 to July 2024.
### **EPIDEMIOLOGICAL SITUATION:**
Pneumonias represent a global incidence of 1.26 cases per 1000 inhabitants. It has been documented in some centers that this incidence can increase in patients over 65 years of age, representing 34 cases per 1000 inhabitants. Outpatient mortality varies between 0.1% and 5%, but can reach up to 50% in hospitalized patients, especially those requiring Intensive Care Unit stay.
The main risk factors for developing pneumonia are:
* Chronic Heart Disease.
* Chronic Respiratory Disease.
* Chronic Kidney Disease.
* Advanced-stage HIV infection.
* Immunosuppressed. Solid Organ Transplant. Hematopoietic Stem Cell Transplantation.
* Diabetes mellitus.
* Neoplasms.
* Smoking.
* Chronic use of Corticosteroids or Proton Pump Inhibitors.
* Multiple Myeloma and Hypogammaglobulinemia.
* Anatomical or Functional Asplenia.
The main causative agents of acute community-acquired pneumonia in our setting are:
* Respiratory Viruses (Influenza, SARS-CoV2, RSV).
* Streptococcus pneumoniae.
* Haemophilus influenzae.
* Staphylococcus aureus.
* Mycoplasma pneumoniae and Chlamydophila pneumoniae.
It should be noted that Streptococcus pneumoniae shows a good sensitivity pattern to penicillin and continues to be the most frequent causative microorganism. Haemophilus influenzae only shows beta-lactamase production in 10% to 23% of cases. Staphylococcus aureus in our setting has a low incidence of methicillin resistance, although this possibility should be considered in certain situations and severe clinical presentations. Given these considerations, beta-lactams remain the first-line treatment.
Regarding Pseudomonas aeruginosa isolates, they will only be relevant in patients with risk factors such as bronchiectasis, cystic fibrosis, prior treatment with corticosteroids, or broad-spectrum antibiotics.
Emerging pathogens of some relevance include the eventual emergence of cases caused by Leptospira interrogans, Legionella pneumophila, and Hantavirus. These cases should always be associated with a specific epidemiological link.
### **DIAGNOSIS**
The diagnosis of pneumonia is based on clinical and imaging criteria. For the diagnosis of Acute Community-Acquired Pneumonia, we will consider:
Symptoms and Clinical Signs (at least 1 of the following):
* Fever.
* Altered general condition.
* Cough.
* Sputum production.
* Chest pain.
* Dyspnea.
* Hemoptysis.
plus
Radiopacity on Chest X-ray (Alveolar consolidation with or without air bronchogram, interstitial pattern, bronchiectasis, cavitation, pleural effusion, new radiopacity, etc.). It is always recommended to request both frontal and lateral views.
Chest CT remains a method with greater sensitivity and specificity for evaluating lung parenchyma compared to conventional X-ray in infectious pathology. However, a simple chest X-ray is an adequate method for the initial evaluation of the condition and its complications, which is why a CT scan is not recommended as an initial method for evaluating pneumonia and should always be preceded by a conventional chest X-ray.
CT studies should be considered in the following situations:
* Respiratory failure.
* Evaluation or suspicion of differential diagnoses to Acute Community-Acquired Pneumonia.
* Evaluation or suspicion of complications of Acute Community-Acquired Pneumonia.
* Evaluation of radiological patterns that are not entirely clear on the chest X-ray.
### **CHOICE OF CARE SITE AND TREATMENT**
For the choice of care site and treatment of pneumonia, it is recommended to complement clinical criteria with validated mortality scores associated with risk factors and clinical status.
CURB-65 (1 point for each item):
* Confusion
* Elevated urea greater than 90 mg/dl
* Respiratory rate greater than 30/minute
* Systolic blood pressure < 90 mmHg or diastolic blood pressure < 60 mmHg
* Age equal to or greater than 65 years
Results:
* Groups 0 to 1: Outpatient management.
* Groups 1-2: Admission to General Ward.
* Groups 3-5: Admission to Intensive Care Unit.
* Appendix: A pulse oximetry reading of less than 92% is recommended as an independent factor for inpatient management under expert recommendation to complement the score.
### **COMPLEMENTARY STUDIES AND CULTURE SAMPLING**
Once the diagnosis is completed, the patient's risk stratification and the choice of admission site are made, the following complementary studies and culture sampling are recommended to proceed with the patient's study during treatment.
Outpatient patient:
* Pulse Oximetry.
* Laboratory routine (complete blood count, glucose, urea, creatinine, liver function tests).
Inpatient patient in general ward:
* Pulse Oximetry.
* Laboratory routine (complete blood count, glucose, urea, creatinine, liver function tests). Acid-base status if pulse oximetry is less than 92%.
* Sputum sample (Gram stain, culture, antibiogram).
* Blood cultures.
* In the presence of pleural effusion: Thoracentesis. Physical-chemical study for Light's Criteria. Direct and Culture of Pleural Fluid.
Inpatient patient in intensive care unit:
* Pulse Oximetry.
* Laboratory routine (complete blood count, glucose, urea, creatinine, liver function tests) plus acid-base status.
* Sputum sample (Gram stain, culture, antibiogram). Tracheal aspirate, Mini-BAL, or BAL sampling for patients requiring ARM upon admission.
* Blood cultures.
* Urinary antigen for detection of Streptococcus pneumoniae, if available in microbiology.
* In the presence of pleural effusion: Thoracentesis. Physical-chemical study for Light's Criteria. Direct and Culture of Pleural Fluid.
Special considerations for Viral Pneumonias:
* We recommend performing a viral panel for Influenza A/B for any pneumonia presenting at least 1 risk factor mentioned during periods of viral circulation in the community.
* We recommend performing a viral panel for SARS-CoV2 for any pneumonia presenting at least 1 risk factor mentioned during periods of viral circulation in the community or having epidemiological criteria of a suspected COVID-19 case.
* The Infection Control Committee will timely inform based on the National Epidemiological Bulletin about the presence of circulating respiratory viruses in our setting.
Special considerations for Atypical Pneumonias and HIV Testing:
* We recommend serological testing for IgM/IgG for Chlamydia and Mycoplasma for any pneumonia presenting a subacute evolution at the time of clinical presentation or clinical-radiological dissociation in its presentation.
* In the suspicion of pneumonia caused by emerging pathogens (Legionella pneumophila, Leptospira interrogans, Hantavirus), consider the necessary epidemiological link as a prior epidemiological background before requesting specific diagnostic tests.
* HIV testing is recommended for all pneumonias, with special emphasis on those that do not present the conventional risk factors mentioned.
### **ANTIMICROBIAL TREATMENT AND DURATION OF TREATMENT:**
Directed antimicrobial treatment will be based on the present risk factors and the choice of care site and treatment.
**Outpatient patient <65 years and without risk factors:**
First choice:
* Amoxicillin 875mg/12h orally for 5-7 days.
Scheme for history of allergy to Beta-Lactams:
* Clarithromycin 500mg/12h orally for 5 days or
* Azithromycin 500-1000mg/day for 5 days.
**Outpatient patient >65 years or with at least 1 risk factor:**
First choice:
* Amoxicillin-Clavulanate 1g/12h orally for 7 days.
Scheme for history of allergy to Beta-Lactams:
* Clarithromycin 500mg/12h orally for 5 days or
* Azithromycin 500-1000mg/day orally for 5 days.
**Inpatient patient in General Ward <65 years and without risk factors:**
First choice:
* Ampicillin-Sulbactam 1.5g/6h IV +/- Clarithromycin 500mg/12h orally/IV for 5-7 days.
Scheme for history of allergy to Beta-Lactams:
* Ceftriaxone 1g/day IV for 5-7 days.
**Inpatient patient in General Ward >65 years or with at least 1 risk factor:**
First choice:
* Ampicillin-Sulbactam 1.5g/6h IV for 7 days +/- Clarithromycin 500mg/12h orally/IV for 5 days.
Scheme for history of allergy to Beta-Lactams:
* Ceftriaxone 1g/day IV for 7 days.
**Inpatient patient in Intensive Care Unit:**
First choice:
* Ampicillin-Sulbactam 1.5g/6h IV for 7 days +/- Clarithromycin 500mg/12h orally/IV for 5 days.
Scheme for history of allergy to Beta-Lactams:
* Ceftriaxone 1-2g/day IV for 7 days.
**Special Considerations for Inpatients:**
Scheme for risk factors for Pseudomonas aeruginosa*:
* Piperacillin/Tazobactam 4.5g/6h IV or Cefepime 2g/8h IV for 7 days +/- Clarithromycin 500mg/12h orally/IV for 5 days.
Scheme for risk factors for Methicillin-Resistant Staphylococcus aureus**:
* Add to conventional scheme: Vancomycin 15-20mg/kg/8-12h IV +/- Clindamycin 600mg/8h IV for 7-14 days.
**Aspiration Pneumonia:**
First choice:
* Ampicillin-Sulbactam 1.5g/6h IV for 5-7 days.
*Risk factors for Pseudomonas aeruginosa: Bronchiectasis, cystic fibrosis, prior treatment with corticosteroids or broad-spectrum antibiotics. Documented isolates in respiratory cultures of Pseudomonas aeruginosa.
**Risk factors for Methicillin-Resistant Staphylococcus aureus: Previously healthy young patients with severe, necrotizing, and rapidly progressive pneumonia, cavitary infiltrates, hemoptysis, prior influenza, intravenous drug users, rash, leukopenia, recent or concomitant skin and soft tissue infections.
The routine use of corticosteroids in pneumonia is not recommended.
### **CONSIDERATIONS ON ANTIMICROBIALS IN VIRAL AND ATYPICAL PNEUMONIAS:**
In the case of a concomitant antigen test or PCR for Influenza A/B or SARS-CoV2, the following treatment recommendations are made:
**Influenza Virus A/B:**
First choice:
* Oseltamivir 75mg every 12 hours orally for 5 days.
Other considerations:
* In cases of Respiratory Failure in ARM or Obesity: Oseltamivir 150mg every 12 hours orally for 5 days.
* Concomitant antimicrobial treatment is recommended as there is documented frequent association of Influenza Virus and Streptococcus pneumoniae.
**COVID-19:**
* First choice is conventional treatment with dexamethasone 8 mg IV for 10 days in the event of respiratory failure.
* Routine antimicrobial treatment is not recommended for COVID-19; therefore, upon a positive SARS-CoV2 test, it is recommended to discontinue antimicrobials.
Consider maintaining concomitant antimicrobial treatment only in suspected bacterial infection due to severe presentation:
* Focal alveolar consolidation +/- air bronchogram in imaging studies plus 1 of the following: sepsis, risk factors, and/or immunosuppression.
**Atypical Pneumonias with Seroconversion for Chlamydia or Mycoplasma:**
First choice:
* Clarithromycin 500mg every 12 hours IV/orally for 14 days.
* Azithromycin 500-1000mg/day IV/orally for 14 days.
* Doxycycline 100mg every 12 hours IV/orally for 14 days.
### **CONSIDERATIONS ON PENICILLIN AND OTHER BETA-LACTAM ALLERGIES:**
Patients who report penicillin allergy are often misclassified. It is documented that more than 95% of patients who report penicillin allergy can receive beta-lactams without any complications. Additionally, penicillin hypersensitivity diminishes over the years.
Allergy to one beta-lactam does not imply the impossibility of using the entire spectrum of beta-lactams, as there are only a few cases of cross-hypersensitivity.
Therefore, we recommend the safe use of beta-lactams except in cases of a reported or documented history of severe allergy to penicillin (anaphylaxis).
In doubtful cases or confirmed allergy events during hospitalization, a consultation with an Allergy Specialist is available to evaluate the case.
### **FOLLOW-UP IN OUTPATIENT TREATMENT MODALITY**
Patients undergoing pneumonia treatment in an outpatient setting can continue their treatment at home, considering advising them to seek further consultation in case of alarm signs (fever that does not subside after 48 to 72 hours, dyspnea, hemoptysis, chest pain, etc.). Nevertheless, it is good practice to consider a follow-up consultation in the emergency department or clinic after 48 to 72 hours of starting antibiotic therapy.
It is not routinely recommended to repeat a chest X-ray or CT scan to evaluate the evolution of pneumonia under outpatient treatment. Only in the case of suspected complications or unfavorable evolution. A follow-up at the end of treatment with the primary care physician is suggested.
### **FOLLOW-UP IN INPATIENT TREATMENT MODALITY**
For hospitalized patients, we should consider transitioning from parenteral medication to oral when the following conditions are met
* Completion of 48 hours of parenteral treatment.
* Presence of a 24-hour afebrile period, with hemodynamic stability and significant clinical improvement.
* Availability of the oral route.
It is not routinely recommended to repeat a chest X-ray or CT scan to evaluate the evolution of pneumonia under outpatient or inpatient treatment. Only in the case of suspected complications or unfavorable evolution.
### **PREVENTION**
The prevention of pneumonia is based on timely immunization with pneumococcal vaccines, influenza vaccination, and COVID-19 vaccination according to the immunization recommendations and current schedule from the Ministry of Health.
### **ICD-11 CODING**
* CA40 - Pneumonia.
* CA40.0 - Bacterial Pneumonia.
* CA40.1 - Viral Bronchopneumonia.
* CA40.2 - Fungal Pneumonia.
* CA40.Z - Pneumonia, organism unspecified.
### Autor
**Kamo Weasel - MD Infectious Diseases - MD Internal Medicine - #DocChain Community**
npub1jdvvva54m8nchh3t708pav99qk24x6rkx2sh0e7jthh0l8efzt7q9y7jlj
-
@ fa984bd7:58018f52
2024-08-16 13:22:12
-
@ da18e986:3a0d9851
2024-08-14 13:58:24
After months of development I am excited to officially announce the first version of DVMDash (v0.1). DVMDash is a monitoring and debugging tool for all Data Vending Machine (DVM) activity on Nostr. The website is live at [https://dvmdash.live](https://dvmdash.live) and the code is available on [Github](https://github.com/dtdannen/dvmdash).
Data Vending Machines ([NIP-90](https://github.com/nostr-protocol/nips/blob/master/90.md)) offload computationally expensive tasks from relays and clients in a decentralized, free-market manner. They are especially useful for AI tools, algorithmic processing of user’s feeds, and many other use cases.
The long term goal of DVMDash is to become 1) a place to easily see what’s happening in the DVM ecosystem with metrics and graphs, and 2) provide real-time tools to help developers monitor, debug, and improve their DVMs.
DVMDash aims to enable users to answer these types of questions at a glance:
* What’s the most popular DVM right now?
* How much money is being paid to image generation DVMs?
* Is any DVM down at the moment? When was the last time that DVM completed a task?
* Have any DVMs failed to deliver after accepting payment? Did they refund that payment?
* How long does it take this DVM to respond?
* For task X, what’s the average amount of time it takes for a DVM to complete the task?
* … and more
For developers working with DVMs there is now a visual, graph based tool that shows DVM-chain activity. DVMs have already started calling other DVMs to assist with work. Soon, we will have humans in the loop monitoring DVM activity, or completing tasks themselves. The activity trace of which DVM is being called as part of a sub-task from another DVM will become complicated, especially because these decisions will be made at run-time and are not known ahead of time. Building a tool to help users and developers understand where a DVM is in this activity trace, whether it’s gotten stuck or is just taking a long time, will be invaluable. *For now, the website only shows 1 step of a dvm chain from a user's request.*
One of the main designs for the site is that it is highly _clickable_, meaning whenever you see a DVM, Kind, User, or Event ID, you can click it and open that up in a new page to inspect it.
Another aspect of this website is that it should be fast. If you submit a DVM request, you should see it in DVMDash within seconds, as well as events from DVMs interacting with your request. I have attempted to obtain DVM events from relays as quickly as possible and compute metrics over them within seconds.
This project makes use of a nosql database and graph database, currently set to use mongo db and neo4j, for which there are free, community versions that can be run locally.
Finally, I’m grateful to nostr:npub10pensatlcfwktnvjjw2dtem38n6rvw8g6fv73h84cuacxn4c28eqyfn34f for supporting this project.
## Features in v0.1:
### Global Network Metrics:
This page shows the following metrics:
- **DVM Requests:** Number of unencrypted DVM requests (kind 5000-5999)
- **DVM Results:** Number of unencrypted DVM results (kind 6000-6999)
- **DVM Request Kinds Seen:** Number of unique kinds in the Kind range 5000-5999 (except for known non-DVM kinds 5666 and 5969)
- **DVM Result Kinds Seen:** Number of unique kinds in the Kind range 6000-6999 (except for known non-DVM kinds 6666 and 6969)
- **DVM Pub Keys Seen:** Number of unique pub keys that have written a kind 6000-6999 (except for known non-DVM kinds) or have published a kind 31990 event that specifies a ‘k’ tag value between 5000-5999
- **DVM Profiles (NIP-89) Seen**: Number of 31990 that have a ‘k’ tag value for kind 5000-5999
- **Most Popular DVM**: The DVM that has produced the most result events (kind 6000-6999)
- **Most Popular Kind**: The Kind in range 5000-5999 that has the most requests by users.
- **24 hr DVM Requests**: Number of kind 5000-5999 events created in the last 24 hrs
- **24 hr DVM Results**: Number of kind 6000-6999 events created in the last 24 hours
- **1 week DVM Requests**: Number of kind 5000-5999 events created in the last week
- **1 week DVM Results**: Number of kind 6000-6999 events created in the last week
- **Unique Users of DVMs**: Number of unique pubkeys of kind 5000-5999 events
- **Total Sats Paid to DVMs**:
- This is an estimate.
- This value is likely a lower bound as it does not take into consideration subscriptions paid to DVMs
- This is calculated by counting the values of all invoices where:
- A DVM published a kind 7000 event requesting payment and containing an invoice
- The DVM later provided a DVM Result for the same job for which it requested payment.
- The assumption is that the invoice was paid, otherwise the DVM would not have done the work
- Note that because there are multiple ways to pay a DVM such as lightning invoices, ecash, and subscriptions, there is no guaranteed way to know whether a DVM has been paid. Additionally, there is no way to know that a DVM completed the job because some DVMs may not publish a final result event and instead send the user a DM or take some other kind of action.
### Recent Requests:
This page shows the most recent 3 events per kind, sorted by created date. You should always be able to find the last 3 events here of all DVM kinds.
### DVM Browser:
This page will either show a profile of a specific DVM, or when no DVM is given in the url, it will show a table of all DVMs with some high level stats. Users can click on a DVM in the table to load the DVM specific page.
### Kind Browser:
This page will either show data on a specific kind including all DVMs that have performed jobs of that kind, or when no kind is given, it will show a table summarizing activity across all Kinds.
### Debug:
This page shows the graph based visualization of all events, users, and DVMs involved in a single job as well as a table of all events in order from oldest to newest. When no event is given, this page shows the 200 most recent events where the user can click on an event in order to debug that job. The graph-based visualization allows the user to zoom in and out and move around the graph, as well as double click on any node in the graph (except invoices) to open up that event, user, or dvm in a new page.
### Playground:
This page is currently under development and may not work at the moment. If it does work, in the current state you can login with NIP-07 extension and broadcast a 5050 event with some text and then the page will show you events from DVMs. This page will be used to interact with DVMs live. A current good alternative to this feature, for some but not all kinds, is [https://vendata.io/](https://vendata.io/).
## Looking to the Future
I originally built DVMDash out of Fear-of-Missing-Out (FOMO); I wanted to make AI systems that were comprised of DVMs but my day job was taking up a lot of my time. I needed to know when someone was performing a new task or launching a new AI or Nostr tool!
I have a long list of DVMs and Agents I hope to build and I needed DVMDash to help me do it; I hope it helps you achieve your goals with Nostr, DVMs, and even AI. To this end, I wish for this tool to be useful to others, so if you would like a feature, please [submit a git issue here](https://github.com/dtdannen/dvmdash/issues/new) or _note_ me on Nostr!
### Immediate Next Steps:
- Refactoring code and removing code that is no longer used
- Improve documentation to run the project locally
- Adding a metric for number of encrypted requests
- Adding a metric for number of encrypted results
### Long Term Goals:
- Add more metrics based on community feedback
- Add plots showing metrics over time
- Add support for showing a multi-dvm chain in the graph based visualizer
- Add a real-time mode where the pages will auto update (currently the user must refresh the page)
- ... Add support for user requested features!
## Acknowledgements
There are some fantastic people working in the DVM space right now. Thank you to nostr:npub1drvpzev3syqt0kjrls50050uzf25gehpz9vgdw08hvex7e0vgfeq0eseet for making python bindings for nostr_sdk and for the recent asyncio upgrades! Thank you to nostr:npub1nxa4tywfz9nqp7z9zp7nr7d4nchhclsf58lcqt5y782rmf2hefjquaa6q8 for answering lots of questions about DVMs and for making the nostrdvm library. Thank you to nostr:npub1l2vyh47mk2p0qlsku7hg0vn29faehy9hy34ygaclpn66ukqp3afqutajft for making the original DVM NIP and [vendata.io](https://vendata.io/) which I use all the time for testing!
P.S. I rushed to get this out in time for Nostriga 2024; code refactoring will be coming :)
-
@ 76c71aae:3e29cafa
2024-08-13 04:30:00
On social media and in the Nostr space in particular, there’s been a lot of debate about the idea of supporting deletion and editing of notes.
Some people think they’re vital features to have, others believe that more honest and healthy social media will come from getting rid of these features. The discussion about these features quickly turns to the feasibility of completely deleting something on a decentralized protocol. We quickly get to the “We can’t really delete anything from the internet, or a decentralized network.” argument. This crowds out how Delete and Edit can mimic elements of offline interactions, how they can be used as social signals.
When it comes to issues of deletion and editing content, what matters more is if the creator can communicate their intentions around their content. Sure, on the internet, with decentralized protocols, there’s no way to be sure something’s deleted. It’s not like taking a piece of paper and burning it. Computers make copies of things all the time, computers don’t like deleting things. In particular, distributed systems tend to use a Kafka architecture with immutable logs, it’s just easier to keep everything around, as deleting and reindexing is hard. Even if the software could be made to delete something, there’s always screenshots, or even pictures of screens. We can’t provably make something disappear.
What we need to do in our software is clearly express intention. A delete is actually a kind of retraction. “I no longer want to associate myself with this content, please stop showing it to people as part of what I’ve published, stop highlighting it, stop sharing it.” Even if a relay or other server keeps a copy, and keeps sharing it, being able to clearly state “hello world, this thing I said, was a mistake, please get rid of it.” Just giving users the chance to say “I deleted this” is a way of showing intention. It’s also a way of signaling that feedback has been heard. Perhaps the post was factually incorrect or perhaps it was mean and the person wants to remove what they said. In an IRL conversation, for either of these scenarios there is some dialogue where the creator of the content is learning something and taking action based on what they’ve learned.
Without delete or edit, there is no option to signal to the rest of the community that you have learned something because of how the content is structured today. On most platforms a reply or response stating one’s learning will be lost often in a deluge of replies on the original post and subsequent posts are often not seen especially when the original goes viral. By providing tools like delete and edit we give people a chance to signal that they have heard the feedback and taken action.
The Nostr Protocol supports delete and expiring notes. It was one of the reasons we switched from secure scuttlebutt to build on Nostr. Our nos.social app offers delete and while we know that not all relays will honor this, we believe it’s important to provide social signaling tools as a means of making the internet more humane.
We believe that the power to learn from each other is more important than the need to police through moral outrage which is how the current platforms and even some Nostr clients work today.
It’s important that we don’t say Nostr doesn’t support delete. Not all apps need to support requesting a delete, some might want to call it a retraction. It is important that users know there is no way to enforce a delete and not all relays may honor their request.
Edit is similar, although not as widely supported as delete. It’s a creator making a clear statement that they’ve created a new version of their content. Maybe it’s a spelling error, or a new version of the content, or maybe they’re changing it altogether. Freedom online means freedom to retract a statement, freedom to update a statement, freedom to edit your own content. By building on these freedoms, we’ll make Nostr a space where people feel empowered and in control of their own media.
-
@ 0e8c41eb:95ff0faa
2024-07-08 14:36:14
## Chef's notes
Sprinkle a pinch of salt in a bowl. Sift 275 grams of flour above it. Make a well in the center of the flour and sprinkle the yeast into it. Add 50 grams of butter, 25 grams of sugar, and the egg. Pour in the milk and knead the dough with the mixer or by hand into a smooth dough. If necessary, add a bit more flour if the dough is too sticky. Form the dough into a ball. Let the dough rise covered with cling film at room temperature for 1 hour.
Peel the apples. Cut the apples and apricots into pieces. Cook the fruit with 150 grams of sugar and 50 ml of water in 15 minutes into a thick compote. Let this fruit filling cool.
Knead the dough again briefly and roll it out to a round sheet of about 28-30 cm in diameter, so that it fits well over the baking tin. Press the dough into the tin and press it well into the corners. Let the dough rise again for 10 minutes and cut off the excess edges.
Spread the fruit filling over the dough.
Mix the rest of the flour with the remaining 100 grams of butter and 100 grams of sugar and knead it with your fingers into a crumbly mixture. Sprinkle this crumble mixture over the fruit filling. Bake the tart in the preheated oven at 200°C for about 30 minutes until golden brown.
Variations:
Only apple? Make this tart with 1 kilo of apples.
High or low? You can also bake the crumble tart in a low tart tin of 30 cm diameter. If the fruit filling is a bit too voluminous, you can make double the crumble mixture and sprinkle it over the larger surface area.
Additional needs:
Mixer with dough hooks or food processor
Cling film
Round baking tin with a diameter of 28-30 cm, greased
## Details
- ⏲️ Prep time: 45 min + 1 hour Rising
- 🍳 Cook time: 30 minutes
- 🍽️ Servings: 8
## Ingredients
- 375 grams flour
- 1 packet dried yeast (7 grams)
- 125 grams unsalted butter, at room temperature
- 275 grams sugar
- 1 egg
- 100 ml milk, at room temperature
- 500 grams apples
- 500 grams apricots (fresh or from a can)
## Directions
1. Sprinkle a pinch of salt in a bowl. Sift 275 grams of flour above it. Make a well in the center of the flour and sprinkle the yeast into it. Add 50 grams of butter, 25 grams of sugar, and the egg. Pour in the milk and knead the dough with the mixer or by hand into a smooth dough. If necessary, add a bit more flour if the dough is too sticky. Form the dough into a ball. Let the dough rise covered with cling film at room temperature for 1 hour.
2. Peel the apples. Cut the apples and apricots into pieces. Cook the fruit with 150 grams of sugar and 50 ml of water in 15 minutes into a thick compote. Let this fruit filling cool.
3. Knead the dough again briefly and roll it out to a round sheet of about 28-30 cm in diameter, so that it fits well over the baking tin. Press the dough into the tin and press it well into the corners. Let the dough rise again for 10 minutes and cut off the excess edges.
4. Spread the fruit filling over the dough.
-
@ 6871d8df:4a9396c1
2024-06-12 22:10:51
# Embracing AI: A Case for AI Accelerationism
In an era where artificial intelligence (AI) development is at the forefront of technological innovation, a counter-narrative championed by a group I refer to as the 'AI Decels'—those advocating for the deceleration of AI advancements— seems to be gaining significant traction. After tuning into a recent episode of the [Joe Rogan Podcast](https://fountain.fm/episode/0V35t9YBkOMVM4WRVLYp), I realized that the prevailing narrative around AI was heading in a dangerous direction. Rogan had Aza Raskin and Tristan Harris, technology safety advocates, who released a talk called '[The AI Dilemma](https://www.youtube.com/watch?v=xoVJKj8lcNQ),' on for a discussion. You may know them from the popular documentary '[The Social Dilemma](https://www.thesocialdilemma.com/)' on the dangers of social media. It became increasingly clear that the cautionary stance dominating this discourse might be tipping the scales too far, veering towards an over-regulated future that stifles innovation rather than fostering it.

## Are we moving too fast?
While acknowledging AI's benefits, Aza and Tristan fear it could be dangerous if not guided by ethical standards and safeguards. They believe AI development is moving too quickly and that the right incentives for its growth are not in place. They are concerned about the possibility of "civilizational overwhelm," where advanced AI technology far outpaces 21st-century governance. They fear a scenario where society and its institutions cannot manage or adapt to the rapid changes and challenges introduced by AI.
They argue for regulating and slowing down AI development due to rapid, uncontrolled advancement driven by competition among companies like Google, OpenAI, and Microsoft. They claim this race can lead to unsafe releases of new technologies, with AI systems exhibiting unpredictable, emergent behaviors, posing significant societal risks. For instance, AI can inadvertently learn tasks like sentiment analysis or human emotion understanding, creating potential for misuse in areas like biological weapons or cybersecurity vulnerabilities.
Moreover, AI companies' profit-driven incentives often conflict with the public good, prioritizing market dominance over safety and ethics. This misalignment can lead to technologies that maximize engagement or profits at societal expense, similar to the negative impacts seen with social media. To address these issues, they suggest government regulation to realign AI companies' incentives with safety, ethical considerations, and public welfare. Implementing responsible development frameworks focused on long-term societal impacts is essential for mitigating potential harm.
## This isn't new
Though the premise of their concerns seems reasonable, it's dangerous and an all too common occurrence with the emergence of new technologies. For example, in their example in the podcast, they refer to the technological breakthrough of oil. Oil as energy was a technological marvel and changed the course of human civilization. The embrace of oil — now the cornerstone of industry in our age — revolutionized how societies operated, fueled economies, and connected the world in unprecedented ways. Yet recently, as ideas of its environmental and geopolitical ramifications propagated, the narrative around oil has shifted.
Tristan and Aza detail this shift and claim that though the period was great for humanity, we didn't have another technology to go to once the technological consequences became apparent. The problem with that argument is that we did innovate to a better alternative: nuclear. However, at its technological breakthrough, it was met with severe suspicions, from safety concerns to ethical debates over its use. This overregulation due to these concerns caused a decades-long stagnation in nuclear innovation, where even today, we are still stuck with heavy reliance on coal and oil. The scare tactics and fear-mongering had consequences, and, interestingly, they don't see the parallels with their current deceleration stance on AI.
These examples underscore a critical insight: the initial anxiety surrounding new technologies is a natural response to the unknowns they introduce. Yet, history shows that too much anxiety can stifle the innovation needed to address the problems posed by current technologies. The cycle of discovery, fear, adaptation, and eventual acceptance reveals an essential truth—progress requires not just the courage to innovate but also the resilience to navigate the uncertainties these innovations bring.
Moreover, believing we can predict and plan for all AI-related unknowns reflects overconfidence in our understanding and foresight. History shows that technological progress, marked by unexpected outcomes and discoveries, defies such predictions. The evolution from the printing press to the internet underscores progress's unpredictability. Hence, facing AI's future requires caution, curiosity, and humility. Acknowledging our limitations and embracing continuous learning and adaptation will allow us to harness AI's potential responsibly, illustrating that embracing our uncertainties, rather than pretending to foresee them, is vital to innovation.
The journey of technological advancement is fraught with both promise and trepidation. Historically, each significant leap forward, from the dawn of the industrial age to the digital revolution, has been met with a mix of enthusiasm and apprehension. Aza Raskin and Tristan Harris's thesis in the 'AI Dilemma' embodies the latter.
## Who defines "safe?"
When slowing down technologies for safety or ethical reasons, the issue arises of who gets to define what "safe" or “ethical” mean? This inquiry is not merely technical but deeply ideological, touching the very core of societal values and power dynamics. For example, the push for Diversity, Equity, and Inclusion (DEI) initiatives shows how specific ideological underpinnings can shape definitions of safety and decency.
Take the case of the initial release of Google's AI chatbot, Gemini, which chose the ideology of its creators over truth. Luckily, the answers were so ridiculous that the pushback was sudden and immediate. My worry, however, is if, in correcting this, they become experts in making the ideological capture much more subtle. Large bureaucratic institutions' top-down safety enforcement creates a fertile ground for ideological capture of safety standards.

I claim that the issue is not the technology itself but the lens through which we view and regulate it. Suppose the gatekeepers of 'safety' are aligned with a singular ideology. In that case, AI development would skew to serve specific ends, sidelining diverse perspectives and potentially stifling innovative thought and progress.
In the podcast, Tristan and Aza suggest such manipulation as a solution. They propose using AI for consensus-building and creating "shared realities" to address societal challenges. In practice, this means that when individuals' viewpoints seem to be far apart, we can leverage AI to "bridge the gap." How they bridge the gap and what we would bridge it toward is left to the imagination, but to me, it is clear. Regulators will inevitably influence it from the top down, which, in my opinion, would be the opposite of progress.
In navigating this terrain, we must advocate for a pluralistic approach to defining safety, encompassing various perspectives and values achieved through market forces rather than a governing entity choosing winners. The more players that can play the game, the more wide-ranging perspectives will catalyze innovation to flourish.
## Ownership & Identity
Just because we should accelerate AI forward does not mean I do not have my concerns. When I think about what could be the most devastating for society, I don't believe we have to worry about a Matrix-level dystopia; I worry about freedom. As I explored in "[Whose data is it anyway?](https://cwilbzz.com/whose-data-is-it-anyway/)," my concern gravitates toward the issues of data ownership and the implications of relinquishing control over our digital identities. This relinquishment threatens our privacy and the integrity of the content we generate, leaving it susceptible to the inclinations and profit of a few dominant tech entities.
To counteract these concerns, a paradigm shift towards decentralized models of data ownership is imperative. Such standards would empower individuals with control over their digital footprints, ensuring that we develop AI systems with diverse, honest, and truthful perspectives rather than the massaged, narrow viewpoints of their creators. This shift safeguards individual privacy and promotes an ethical framework for AI development that upholds the principles of fairness and impartiality.
As we stand at the crossroads of technological innovation and ethical consideration, it is crucial to advocate for systems that place data ownership firmly in the hands of users. By doing so, we can ensure that the future of AI remains truthful, non-ideological, and aligned with the broader interests of society.
## But what about the Matrix?
I know I am in the minority on this, but I feel that the concerns of AGI (Artificial General Intelligence) are generally overblown. I am not scared of reaching the point of AGI, and I think the idea that AI will become so intelligent that we will lose control of it is unfounded and silly. Reaching AGI is not reaching consciousness; being worried about it spontaneously gaining consciousness is a misplaced fear. It is a tool created by humans for humans to enhance productivity and achieve specific outcomes.
At a technical level, large language models (LLMs) are trained on extensive datasets and learning patterns from language and data through a technique called "unsupervised learning" (meaning the data is untagged). They predict the next word in sentences, refining their predictions through feedback to improve coherence and relevance. When queried, LLMs generate responses based on learned patterns, simulating an understanding of language to provide contextually appropriate answers. They will only answer based on the datasets that were inputted and scanned.
AI will never be "alive," meaning that AI lacks inherent agency, consciousness, and the characteristics of life, not capable of independent thought or action. AI cannot act independently of human control. Concerns about AI gaining autonomy and posing a threat to humanity are based on a misunderstanding of the nature of AI and the fundamental differences between living beings and machines. AI spontaneously developing a will or consciousness is more similar to thinking a hammer will start walking than us being able to create consciousness through programming. Right now, there is only one way to create consciousness, and I'm skeptical that is ever something we will be able to harness and create as humans. Irrespective of its complexity — and yes, our tools will continue to become evermore complex — machines, specifically AI, cannot transcend their nature as non-living, inanimate objects programmed and controlled by humans.

The advancement of AI should be seen as enhancing human capabilities, not as a path toward creating autonomous entities with their own wills. So, while AI will continue to evolve, improve, and become more powerful, I believe it will remain under human direction and control without the existential threats often sensationalized in discussions about AI's future.
With this framing, we should not view the race toward AGI as something to avoid. This will only make the tools we use more powerful, making us more productive. With all this being said, AGI is still much farther away than many believe.
Today's AI excels in specific, narrow tasks, known as narrow or weak AI. These systems operate within tightly defined parameters, achieving remarkable efficiency and accuracy that can sometimes surpass human performance in those specific tasks. Yet, this is far from the versatile and adaptable functionality that AGI represents.
Moreover, the exponential growth of computational power observed in the past decades does not directly translate to an equivalent acceleration in achieving AGI. AI's impressive feats are often the result of massive data inputs and computing resources tailored to specific tasks. These successes do not inherently bring us closer to understanding or replicating the general problem-solving capabilities of the human mind, which again would only make the tools more potent in _our_ hands.
While AI will undeniably introduce challenges and change the aspects of conflict and power dynamics, these challenges will primarily stem from humans wielding this powerful tool rather than the technology itself. AI is a mirror reflecting our own biases, values, and intentions. The crux of future AI-related issues lies not in the technology's inherent capabilities but in how it is used by those wielding it. This reality is at odds with the idea that we should slow down development as our biggest threat will come from those who are not friendly to us.
## AI Beget's AI
While the unknowns of AI development and its pitfalls indeed stir apprehension, it's essential to recognize the power of market forces and human ingenuity in leveraging AI to address these challenges. History is replete with examples of new technologies raising concerns, only for those very technologies to provide solutions to the problems they initially seemed to exacerbate. It looks silly and unfair to think of fighting a war with a country that never embraced oil and was still primarily getting its energy from burning wood.

The evolution of AI is no exception to this pattern. As we venture into uncharted territories, the potential issues that arise with AI—be it ethical concerns, use by malicious actors, biases in decision-making, or privacy intrusions—are not merely obstacles but opportunities for innovation. It is within the realm of possibility, and indeed, probability, that AI will play a crucial role in solving the problems it creates. The idea that there would be no incentive to address and solve these problems is to underestimate the fundamental drivers of technological progress.
Market forces, fueled by the demand for better, safer, and more efficient solutions, are powerful catalysts for positive change. When a problem is worth fixing, it invariably attracts the attention of innovators, researchers, and entrepreneurs eager to solve it. This dynamic has driven progress throughout history, and AI is poised to benefit from this problem-solving cycle.
Thus, rather than viewing AI's unknowns as sources of fear, we should see them as sparks of opportunity. By tackling the challenges posed by AI, we will harness its full potential to benefit humanity. By fostering an ecosystem that encourages exploration, innovation, and problem-solving, we can ensure that AI serves as a force for good, solving problems as profound as those it might create. This is the optimism we must hold onto—a belief in our collective ability to shape AI into a tool that addresses its own challenges and elevates our capacity to solve some of society's most pressing issues.
## An AI Future
The reality is that it isn't whether AI will lead to unforeseen challenges—it undoubtedly will, as has every major technological leap in history. The real issue is whether we let fear dictate our path and confine us to a standstill or embrace AI's potential to address current and future challenges.
The approach to solving potential AI-related problems with stringent regulations and a slowdown in innovation is akin to cutting off the nose to spite the face. It's a strategy that risks stagnating the U.S. in a global race where other nations will undoubtedly continue their AI advancements. This perspective dangerously ignores that AI, much like the printing press of the past, has the power to democratize information, empower individuals, and dismantle outdated power structures.
The way forward is not less AI but more of it, more innovation, optimism, and curiosity for the remarkable technological breakthroughs that will come. We must recognize that the solution to AI-induced challenges lies not in retreating but in advancing our capabilities to innovate and adapt.
AI represents a frontier of limitless possibilities. If wielded with foresight and responsibility, it's a tool that can help solve some of the most pressing issues we face today. There are certainly challenges ahead, but I trust that with problems come solutions. Let's keep the AI Decels from steering us away from this path with their doomsday predictions. Instead, let's embrace AI with the cautious optimism it deserves, forging a future where technology and humanity advance to heights we can't imagine.
-
@ 3bf0c63f:aefa459d
2024-05-21 12:38:08
# Bitcoin transactions explained
A transaction is a piece of data that takes **inputs** and produces **outputs**. Forget about the blockchain thing, Bitcoin is actually just a big tree of transactions. The blockchain is just a way to keep transactions ordered.
Imagine you have 10 satoshis. That means you have them in an unspent transaction output (**UTXO**). You want to spend them, so you create a transaction. The transaction should reference unspent outputs as its inputs. Every transaction has an immutable id, so you use that id plus the index of the output (because transactions can have multiple outputs). Then you specify a **script** that unlocks that transaction and related signatures, then you specify outputs along with a **script** that locks these outputs.

As you can see, there's this lock/unlocking thing and there are inputs and outputs. Inputs must be unlocked by fulfilling the conditions specified by the person who created the transaction they're in. And outputs must be locked so anyone wanting to spend those outputs will need to unlock them.
For most of the cases locking and unlocking means specifying a **public key** whose controller (the person who has the corresponding **private key**) will be able to spend. Other fancy things are possible too, but we can ignore them for now.
Back to the 10 satoshis you want to spend. Since you've successfully referenced 10 satoshis and unlocked them, now you can specify the outputs (this is all done in a single step). You can specify one output of 10 satoshis, two of 5, one of 3 and one of 7, three of 3 and so on. The sum of outputs can't be more than 10. And if the sum of outputs is less than 10 the difference goes to fees. In the first days of Bitcoin you didn't need any fees, but now you do, otherwise your transaction won't be included in any block.

If you're still interested in transactions maybe you could take a look at [this small chapter](https://github.com/bitcoinbook/bitcoinbook/blob/6d1c26e1640ae32b28389d5ae4caf1214c2be7db/ch06_transactions.adoc) of that Andreas Antonopoulos book.
If you hate Andreas Antonopoulos because he is a communist shitcoiner or don't want to read more than half a page, go here: <https://en.bitcoin.it/wiki/Coin_analogy>
-
@ fa984bd7:58018f52
2024-02-28 22:15:25
I have recently launched Wikifreedia, which is a different take on how Wikipedia-style systems can work.
Yes, it's built on nostr, but that's not the most interesting part.
The fascinating aspect is that there is no "official" entry on any topic. Anyone can create or edit any entry and build their own take about what they care about.
Think the entry about Mao is missing something? Go ahead and edit it, you don't need to ask for permission from anyone.
Stuart Bowman put it best on a #SovEng hike:
> The path to truth is in the integration of opposites.
Since launching Wikifreedia, less than a week ago, quite a few people asked me if it would be possible to import ALL of wikipedia into it.
Yes. Yes it would.
I initially started looking into it to make it happen as I am often quick to jump into action.
But, after thinking about it, *I am not convinced importing all of Wikipedia is the way to go*.
The magical thing about building an encyclopedia with no canonical entry on any topic is that each individual can bring to light the part they are interested the most about a certain topic, it can be dozens or hundreds, or perhaps more, entries that focus on the edges of a topic.
Whereas, Wikipedia, in their Quijotean approach to truth, have focused on the impossible path of seeking neutrality.
Humans can't be neutral, we have biases.
Show me an unbiased human and I'll show you a lifeless human.
*Biases are good*. Having an opinion is good. Seeking neutrality is seeking to devoid our views and opinions of humanity.
Importing Wikipedia would mean importing a massive amount of colorless trivia, a few interesting tidbits, but, more important than anything, a vast amount of watered-down useless information.
All edges of the truth having been neutered by a democratic process that searches for a single truth via consensus.
# "What's the worst that could happen?"
Sure, importing wikipedia would simply be *one* more entry on each topic.
Yes.
But culture has incredibly strong momentum.
And if the culture that develops in this type of media is that of exclusively watered-down comfortable truths, then some magic could be lost.
If people who are passionate or have a unique perspective about a topic feel like the "right approach" is to use the wikipedia-based article then I would see this as an extremely negative action.
### An alternative
An idea we discussed on the #SovEng hike was, what if the wikipedia entry is processed by different "AI agents" with different perspectives.
Perhaps instead of blankly importing the "Napoleon" article, an LLM trained to behave as a 1850s russian peasant could be asked to write a wiki about Napoleon. And then an agent tried to behave like Margaret Thatcher could write one.
Etc, etc.
Embrace the chaos. Embrace the bias.
-
@ 6871d8df:4a9396c1
2024-02-24 22:42:16
In an era where data seems to be as valuable as currency, the prevailing trend in AI starkly contrasts with the concept of personal data ownership. The explosion of AI and the ensuing race have made it easy to overlook where the data is coming from. The current model, dominated by big tech players, involves collecting vast amounts of user data and selling it to AI companies for training LLMs. Reddit recently penned a 60 million dollar deal, Google guards and mines Youtube, and more are going this direction. But is that their data to sell? Yes, it's on their platforms, but without the users to generate it, what would they monetize? To me, this practice raises significant ethical questions, as it assumes that user data is a commodity that companies can exploit at will.
The heart of the issue lies in the ownership of data. Why, in today's digital age, do we not retain ownership of our data? Why can't our data follow us, under our control, to wherever we want to go? These questions echo the broader sentiment that while some in the tech industry — such as the blockchain-first crypto bros — recognize the importance of data ownership, their "blockchain for everything solutions," to me, fall significantly short in execution.
Reddit further complicates this with its current move to IPO, which, on the heels of the large data deal, might reinforce the mistaken belief that user-generated data is a corporate asset. Others, no doubt, will follow suit. This underscores the urgent need for a paradigm shift towards recognizing and respecting user data as personal property.
In my perfect world, the digital landscape would undergo a revolutionary transformation centered around the empowerment and sovereignty of individual data ownership. Platforms like Twitter, Reddit, Yelp, YouTube, and Stack Overflow, integral to our digital lives, would operate on a fundamentally different premise: user-owned data.
In this envisioned future, data ownership would not just be a concept but a practice, with public and private keys ensuring the authenticity and privacy of individual identities. This model would eliminate the private data silos that currently dominate, where companies profit from selling user data without consent. Instead, data would traverse a decentralized protocol akin to the internet, prioritizing user control and transparency.
The cornerstone of this world would be a meritocratic digital ecosystem. Success for companies would hinge on their ability to leverage user-owned data to deliver unparalleled value rather than their capacity to gatekeep and monetize information. If a company breaks my trust, I can move to a competitor, and my data, connections, and followers will come with me. This shift would herald an era where consent, privacy, and utility define the digital experience, ensuring that the benefits of technology are equitably distributed and aligned with the users' interests and rights.
The conversation needs to shift fundamentally. We must challenge this trajectory and advocate for a future where data ownership and privacy are not just ideals but realities. If we continue on our current path without prioritizing individual data rights, the future of digital privacy and autonomy is bleak. Big tech's dominance allows them to treat user data as a commodity, potentially selling and exploiting it without consent. This imbalance has already led to users being cut off from their digital identities and connections when platforms terminate accounts, underscoring the need for a digital ecosystem that empowers user control over data. Without changing direction, we risk a future where our content — and our freedoms by consequence — are controlled by a few powerful entities, threatening our rights and the democratic essence of the digital realm. We must advocate for a shift towards data ownership by individuals to preserve our digital freedoms and democracy.
-
@ fa984bd7:58018f52
2024-01-31 15:00:00
I just hit the big red PUBLISH button on NDK 2.4.
(well, actually, I did it from the command line, the big red button is imaginary)
## Codename: Safely Embrace the Chaos
Nostr is a, mostly, friendly environment with not too many developers and no ill-intent among them.
But this will not always be the case. Compatibility issues, mistakes, and all kinds of chaos is to be expected.
This version of NDK introduces validation at the library-level so that clients built using NDK can rely on some guarantees on handled-kinds that events they are consuming comply with what is defined on their respective NIPs.
An example?
NIP-88, recurring subscriptions, defines that Tier events should have amount tags of what subscribers are expected to pay and the cadence.
Prior to NDK 2.4 some malformed events would render like this:
https://i.nostr.build/Y4JG.png
But with NDK 2.4 the malformed parts of the events don't reach the client code.
https://i.nostr.build/wAgJ.png
This is just a beginning, but event-validation is now moving into the library!
-
@ 3bf0c63f:aefa459d
2024-01-15 11:15:06
# Pequenos problemas que o Estado cria para a sociedade e que não são sempre lembrados
- **vale-transporte**: transferir o custo com o transporte do funcionário para um terceiro o estimula a morar longe de onde trabalha, já que morar perto é normalmente mais caro e a economia com transporte é inexistente.
- **atestado médico**: o direito a faltar o trabalho com atestado médico cria a exigência desse atestado para todas as situações, substituindo o livre acordo entre patrão e empregado e sobrecarregando os médicos e postos de saúde com visitas desnecessárias de assalariados resfriados.
- **prisões**: com dinheiro mal-administrado, burocracia e péssima alocação de recursos -- problemas que empresas privadas em competição (ou mesmo sem qualquer competição) saberiam resolver muito melhor -- o Estado fica sem presídios, com os poucos existentes entupidos, muito acima de sua alocação máxima, e com isto, segundo a bizarra corrente de responsabilidades que culpa o juiz que condenou o criminoso por sua morte na cadeia, juízes deixam de condenar à prisão os bandidos, soltando-os na rua.
- **justiça**: entrar com processos é grátis e isto faz proliferar a atividade dos advogados que se dedicam a criar problemas judiciais onde não seria necessário e a entupir os tribunais, impedindo-os de fazer o que mais deveriam fazer.
- **justiça**: como a justiça só obedece às leis e ignora acordos pessoais, escritos ou não, as pessoas não fazem acordos, recorrem sempre à justiça estatal, e entopem-na de assuntos que seriam muito melhor resolvidos entre vizinhos.
- **leis civis**: as leis criadas pelos parlamentares ignoram os costumes da sociedade e são um incentivo a que as pessoas não respeitem nem criem normas sociais -- que seriam maneiras mais rápidas, baratas e satisfatórias de resolver problemas.
- **leis de trãnsito**: quanto mais leis de trânsito, mais serviço de fiscalização são delegados aos policiais, que deixam de combater crimes por isto (afinal de contas, eles não querem de fato arriscar suas vidas combatendo o crime, a fiscalização é uma excelente desculpa para se esquivarem a esta responsabilidade).
- **financiamento educacional**: é uma espécie de subsídio às faculdades privadas que faz com que se criem cursos e mais cursos que são cada vez menos recheados de algum conhecimento ou técnica útil e cada vez mais inúteis.
- **leis de tombamento**: são um incentivo a que o dono de qualquer área ou construção "histórica" destrua todo e qualquer vestígio de história que houver nele antes que as autoridades descubram, o que poderia não acontecer se ele pudesse, por exemplo, usar, mostrar e se beneficiar da história daquele local sem correr o risco de perder, de fato, a sua propriedade.
- **zoneamento urbano**: torna as cidades mais espalhadas, criando uma necessidade gigantesca de carros, ônibus e outros meios de transporte para as pessoas se locomoverem das zonas de moradia para as zonas de trabalho.
- **zoneamento urbano**: faz com que as pessoas percam horas no trânsito todos os dias, o que é, além de um desperdício, um atentado contra a sua saúde, que estaria muito melhor servida numa caminhada diária entre a casa e o trabalho.
- **zoneamento urbano**: torna ruas e as casas menos seguras criando zonas enormes, tanto de residências quanto de indústrias, onde não há movimento de gente alguma.
- **escola obrigatória + currículo escolar nacional**: emburrece todas as crianças.
- **leis contra trabalho infantil**: tira das crianças a oportunidade de aprender ofícios úteis e levar um dinheiro para ajudar a família.
- **licitações**: como não existem os critérios do mercado para decidir qual é o melhor prestador de serviço, criam-se comissões de pessoas que vão decidir coisas. isto incentiva os prestadores de serviço que estão concorrendo na licitação a tentar comprar os membros dessas comissões. isto, fora a corrupção, gera problemas reais: __(i)__ a escolha dos serviços acaba sendo a pior possível, já que a empresa prestadora que vence está claramente mais dedicada a comprar comissões do que a fazer um bom trabalho (este problema afeta tantas áreas, desde a construção de estradas até a qualidade da merenda escolar, que é impossível listar aqui); __(ii)__ o processo corruptor acaba, no longo prazo, eliminando as empresas que prestavam e deixando para competir apenas as corruptas, e a qualidade tende a piorar progressivamente.
- **cartéis**: o Estado em geral cria e depois fica refém de vários grupos de interesse. o caso dos taxistas contra o Uber é o que está na moda hoje (e o que mostra como os Estados se comportam da mesma forma no mundo todo).
- **multas**: quando algum indivíduo ou empresa comete uma fraude financeira, ou causa algum dano material involuntário, as vítimas do caso são as pessoas que sofreram o dano ou perderam dinheiro, mas o Estado tem sempre leis que prevêem multas para os responsáveis. A justiça estatal é sempre muito rígida e rápida na aplicação dessas multas, mas relapsa e vaga no que diz respeito à indenização das vítimas. O que em geral acontece é que o Estado aplica uma enorme multa ao responsável pelo mal, retirando deste os recursos que dispunha para indenizar as vítimas, e se retira do caso, deixando estas desamparadas.
- **desapropriação**: o Estado pode pegar qualquer propriedade de qualquer pessoa mediante uma indenização que é necessariamente inferior ao valor da propriedade para o seu presente dono (caso contrário ele a teria vendido voluntariamente).
- **seguro-desemprego**: se há, por exemplo, um prazo mínimo de 1 ano para o sujeito ter direito a receber seguro-desemprego, isto o incentiva a planejar ficar apenas 1 ano em cada emprego (ano este que será sucedido por um período de desemprego remunerado), matando todas as possibilidades de aprendizado ou aquisição de experiência naquela empresa específica ou ascensão hierárquica.
- **previdência**: a previdência social tem todos os defeitos de cálculo do mundo, e não importa muito ela ser uma forma horrível de poupar dinheiro, porque ela tem garantias bizarras de longevidade fornecidas pelo Estado, além de ser compulsória. Isso serve para criar no imaginário geral a idéia da __aposentadoria__, uma época mágica em que todos os dias serão finais de semana. A idéia da aposentadoria influencia o sujeito a não se preocupar em ter um emprego que faça sentido, mas sim em ter um trabalho qualquer, que o permita se aposentar.
- **regulamentação impossível**: milhares de coisas são proibidas, há regulamentações sobre os aspectos mais mínimos de cada empreendimento ou construção ou espaço. se todas essas regulamentações fossem exigidas não haveria condições de produção e todos morreriam. portanto, elas não são exigidas. porém, o Estado, ou um agente individual imbuído do poder estatal pode, se desejar, exigi-las todas de um cidadão inimigo seu. qualquer pessoa pode viver a vida inteira sem cumprir nem 10% das regulamentações estatais, mas viverá também todo esse tempo com medo de se tornar um alvo de sua exigência, num estado de terror psicológico.
- **perversão de critérios**: para muitas coisas sobre as quais a sociedade normalmente chegaria a um valor ou comportamento "razoável" espontaneamente, o Estado dita regras. estas regras muitas vezes não são obrigatórias, são mais "sugestões" ou limites, como o salário mínimo, ou as 44 horas semanais de trabalho. a sociedade, porém, passa a usar esses valores como se fossem o normal. são raras, por exemplo, as ofertas de emprego que fogem à regra das 44h semanais.
- **inflação**: subir os preços é difícil e constrangedor para as empresas, pedir aumento de salário é difícil e constrangedor para o funcionário. a inflação força as pessoas a fazer isso, mas o aumento não é automático, como alguns economistas podem pensar (enquanto alguns outros ficam muito satisfeitos de que esse processo seja demorado e difícil).
- **inflação**: a inflação destrói a capacidade das pessoas de julgar preços entre concorrentes usando a própria memória.
- **inflação**: a inflação destrói os cálculos de lucro/prejuízo das empresas e prejudica enormemente as decisões empresariais que seriam baseadas neles.
- **inflação**: a inflação redistribui a riqueza dos mais pobres e mais afastados do sistema financeiro para os mais ricos, os bancos e as megaempresas.
- **inflação**: a inflação estimula o endividamento e o consumismo.
- **lixo:** ao prover coleta e armazenamento de lixo "grátis para todos" o Estado incentiva a criação de lixo. se tivessem que pagar para que recolhessem o seu lixo, as pessoas (e conseqüentemente as empresas) se empenhariam mais em produzir coisas usando menos plástico, menos embalagens, menos sacolas.
- **leis contra crimes financeiros:** ao criar legislação para dificultar acesso ao sistema financeiro por parte de criminosos a dificuldade e os custos para acesso a esse mesmo sistema pelas pessoas de bem cresce absurdamente, levando a um percentual enorme de gente incapaz de usá-lo, para detrimento de todos -- e no final das contas os grandes criminosos ainda conseguem burlar tudo.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# IPFS problems: Community
I was an avid IPFS user until yesterday. Many many times I asked simple questions for which I couldn't find an answer on the internet in the #ipfs IRC channel on Freenode. Most of the times I didn't get an answer, and even when I got it was rarely by someone who knew IPFS deeply. I've had issues go unanswered on js-ipfs repositories for year – one of these was raising awareness of a problem that then got fixed some months later by a complete rewrite, I closed my own issue after realizing that by myself some couple of months later, I don't think the people responsible for the rewrite were ever acknowledge that he had fixed my issue.
Some days ago I asked some questions about how the IPFS protocol worked internally, sincerely trying to understand the inefficiencies in finding and fetching content over IPFS. I pointed it would be a good idea to have a drawing showing that so people would understand the difficulties (which I didn't) and wouldn't be pissed off by the slowness. I was told to read the whitepaper. I had already the whitepaper, but read again the relevant parts. The whitepaper doesn't explain anything about the DHT and how IPFS finds content. I said that in the room, was told to read again.
Before anyone misread this section, I want to say I understand it's a pain to keep answering people on IRC if you're busy developing stuff of interplanetary importance, and that I'm not paying anyone nor I have the right to be answered. On the other hand, if you're developing a super-important protocol, financed by many millions of dollars and a lot of people are hitting their heads against your software and there's no one to help them; you're always busy but never delivers anything that brings joy to your users, something is very wrong. I sincerely don't know what IPFS developers are working on, I wouldn't doubt they're working on important things if they said that, but what I see – and what many other users see (take a look at the IPFS Discourse forum) is bugs, bugs all over the place, confusing UX, and almost no help.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Castas hindus em nova chave
Shudras buscam o máximo bem para os seus próprios corpos; vaishyas o máximo bem para a sua própria vida terrena e a da sua família; kshatriyas o máximo bem para a sociedade e este mundo terreno; brâmanes buscam o máximo bem.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Thoughts on Nostr key management
On [Why I don't like NIP-26 as a solution for key management](nostr:naddr1qqyrgceh89nxgdmzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ctgmx78) I talked about multiple techniques that could be used to tackle the problem of key management on Nostr.
Here are some ideas that work in tandem:
- [NIP-41](https://github.com/nostr-protocol/nips/blob/master/41.md) (stateless key invalidation)
- [NIP-46](https://github.com/nostr-protocol/nips/blob/master/46.md) (Nostr Connect)
- [NIP-07](https://github.com/nostr-protocol/nips/blob/master/07.md) (signer browser extension)
- [Connected hardware signing devices](https://lnbits.github.io/nostr-signing-device/installer/)
- other things like musig or frostr keys used in conjunction with a semi-trusted server; or other kinds of trusted software, like a dedicated signer on a mobile device that can sign on behalf of other apps; or even a separate protocol that some people decide to use as the source of truth for their keys, and some clients might decide to use that automatically
- there are probably many other ideas
Some premises I have in my mind (that may be flawed) that base my thoughts on these matters (and cause me to not worry too much) are that
- For the vast majority of people, Nostr keys aren't a target as valuable as Bitcoin keys, so they will probably be ok even without any solution;
- Even when you lose everything, identity can be recovered -- slowly and painfully, but still --, unlike money;
- Nostr is not trying to replace all other forms of online communication (even though when I think about this I can't imagine one thing that wouldn't be nice to replace with Nostr) or of offline communication, so there will always be ways.
- For the vast majority of people, losing keys and starting fresh isn't a big deal. It is a big deal when you have followers and an online persona and your life depends on that, but how many people are like that? In the real world I see people deleting social media accounts all the time and creating new ones, people losing their phone numbers or other accounts associated with their phone numbers, and not caring very much -- they just find a way to notify friends and family and move on.
We can probably come up with some specs to ease the "manual" recovery process, like social attestation and explicit signaling -- i.e., Alice, Bob and Carol are friends; Alice loses her key; Bob sends a new Nostr event kind to the network saying what is Alice's new key; depending on how much Carol trusts Bob, she can automatically start following that and remove the old key -- or something like that.
---
One nice thing about some of these proposals, like NIP-41, or the social-recovery method, or the external-source-of-truth-method, is that they don't have to be implemented in any client, they can live in standalone single-purpose microapps that users open or visit only every now and then, and these can then automatically update their follow lists with the latest news from keys that have changed according to multiple methods.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# IPFS problems: Shitcoinery
IPFS was advertised to the Ethereum community since the beggining as a way to "store" data for their "dApps". I don't think this is harmful in any way, but for some reason it may have led IPFS developers to focus too much on Ethereum stuff. Once I watched a talk showing libp2p developers – despite being ignored by the Ethereum team (that ended up creating their own agnostic p2p library) – dedicating an enourmous amount of work on getting a libp2p app running in the browser talking to a normal Ethereum node.
The always somewhat-abandoned "Awesome IPFS" site is a big repository of "dApps", some of which don't even have their landing page up anymore, useless Ethereum smart contracts that for some reason use IPFS to store whatever the useless data their users produce.
Again, per se it isn't a problem that Ethereum people are using IPFS, but it is at least confusing, maybe misleading, that when you search for IPFS most of the use-cases are actually Ethereum useless-cases.
## See also
* [Bitcoin](nostr:naddr1qqyryveexumnyd3kqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7nywz4), the only non-shitcoin
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Economics
Just a bunch of somewhat-related notes.
* [notes on "Economic Action Beyond the Extent of the Market", Per Bylund](nostr:naddr1qqyxxepsx3skgvenqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cf5cy3p)
* [Mises' interest rate theory](nostr:naddr1qqyr2dtrxycr2dmrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c97asm3)
* [Profits, not wages, as the originary factor](nostr:naddr1qqyrge3hxa3rqce4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7x67pu)
* [Reisman on opportunity cost](nostr:naddr1qqyrswtr89nxvepkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cwx7t3v)
* [Money Supply Measurement](nostr:naddr1qqyr2v3cxcunserzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cya65m9)
* [Per Bylund's insight](nostr:naddr1qqyxvdtzxscxzcenqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cuq3unj)
* [Maybe a new approach to the Austrian Business Cycle Theory, some disorganized thoughts](nostr:naddr1qqyrvdecvccxxcejqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cl9wc86)
* [An argument according to which fractional-reserve banking is merely theft and nothing else](nostr:naddr1qqyrywt9v5exydenqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cfks90r)
* [Conjecture and criticism](nostr:naddr1qqyrqde5x9snqvfnqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ce4glh8)
* [Qual é o economista? (piadas)](nostr:naddr1qqyx2vmrx93xgdpjqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c0ckmsx)
* [UBI calculations](nostr:naddr1qqyryenpxe3ryvf4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cuurj42)
* [Donations on the internet](nostr:naddr1qqyrqwp4xsmnsvtxqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cex8903)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# tempreites
My first library to get stars on GitHub, was a very stupid templating library that used just HTML and HTML attributes ("DSL-free"). I was inspired by <http://microjs.com/> at the time and ended up not using the library. Probably no one ever did.
- <https://github.com/fiatjaf/tempreites>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# nix
Pra instalar o [neuron](797984e3.md) fui forçado a baixar e instalar o [nix](https://nixos.org/download.html). Não consegui me lembrar por que não estava usando até hoje aquele maravilhoso sistema de instalar pacotes desde a primeira vez que tentei, anos atrás.
Que sofrimento pra fazer funcionar com o `fish`, mas até que bem menos sofrimento que da outra vez. Tive que instalar um tal de `fish-foreign-environment` (usando o próprio nix!, já que a outra opção era o `oh-my-fish` ou qualquer outra porcaria dessas) e aí usá-lo para aplicar as definições de shell para bash direto no `fish`.
E aí lembrei também que o `/nix/store` fica cheio demais, o negócio instala tudo que existe neste mundo a partir do zero. É só para computadores muito ricos, mas vamos ver como vai ser. Estou gostando do neuron (veja, estou usando como diário), então vou ter que deixar o nix aí.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# O Bitcoin como um sistema social humano
Afinal de contas, o que é o Bitcoin? Não vou responder a essa pergunta explicando o que é uma "blockchain" ou coisa que o valha, como todos fazem muito pessimamente. [A melhor explicação em português que eu já vi está aqui](nostr:naddr1qqrky6t5vdhkjmspz9mhxue69uhkv6tpw34xze3wvdhk6q3q80cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsxpqqqp65wp3k3fu), mas mesmo assim qualquer explicação jamais será definitiva.
A explicação apenas do protocolo, do que faz um programa `bitcoind` sendo executado em um computador e como ele se comunica com outros em outros computadores, e os incentivos que estão em jogo para garantir com razoável probabilidade que se chegará a um consenso sobre quem é dono de qual parte de qual transação, apesar de não ser complicada demais, exigirá do iniciante que seja compreendida muitas vezes antes que ele se possa se sentir confortável para dizer que entende um pouco.
E essa parte _técnica_, apesar de ter sido o insight fundamental que gerou o evento miraculoso chamado Bitcoin, não é a parte mais importante, hoje. Se fosse, várias dessas outras moedas seriam concorrentes do Bitcoin, mas não são, e jamais poderão ser, porque elas não estão nem próximas de ter os outros elementos que compõem o Bitcoin. São eles:
1. A estrutura
O Bitcoin é um sistema composto de partes independentes.
Existem programadores que trabalham no protocolo e aplicações, e dia após dia novos programadores chegam e outros saem, e eles trabalham às vezes em conjunto, às vezes sem que um se dê conta do outro, às vezes por conta própria, às vezes pagos por empresas interessadas.
Existem os usuários que realizam validação completa, isto é, estão rodando algum programa do Bitcoin e contribuindo para a difusão dos blocos, das transações, rejeitando usuários malignos e evitando ataques de mineradores mal-intencionados.
Existem os poupadores, acumuladores ou os proprietários de bitcoins, que conhecem as possibilidades que o mundo reserva para o Bitcoin, esperam o dia em que o padrão-Bitcoin será uma realidade mundial e por isso mesmo atributem aos seus bitcoins valores muito mais altos do que os preços atuais de mercado, agarrando-se a eles.
Especuladores de "criptomoedas" não fazem parte desse sistema, nem tampouco empresas que [aceitam pagamento](https://bitpay.com/) em bitcoins para imediatamente venderem tudo em troca de dinheiro estatal, e menos ainda [gente que usa bitcoins](https://www.investimentobitcoin.com/) e [a própria marca Bitcoin](https://www.xdex.com.br/) para aplicar seus golpes e coisas parecidas.
2. A cultura
Mencionei que há empresas que pagam programadores para trabalharem no código aberto do BitcoinCore ou de outros programas relacionados à rede Bitcoin -- ou mesmo em aplicações não necessariamente ligadas à camada fundamental do protocolo. Nenhuma dessas empresas interessadas, porém, controla o Bitcoin, e isso é o elemento principal da cultura do Bitcoin.
O propósito do Bitcoin sempre foi ser uma rede aberta, sem chefes, sem política envolvida, sem necessidade de pedir autorização para participar. O fato do próprio Satoshi Nakamoto ter voluntariamente desaparecido das discussões foi fundamental para que o Bitcoin não fosse visto como um sistema dependente dele ou que ele fosse entendido como o chefe. Em outras "criptomoedas" nada disso aconteceu. O chefe supremo do Ethereum continua por aí mandando e desmandando e inventando novos elementos para o protocolo que são automaticamente aceitos por toda a comunidade, o mesmo vale para o Zcash, EOS, Ripple, Litecoin e até mesmo para o Bitcoin Cash. Pior ainda: Satoshi Nakamoto saiu sem nenhum dinheiro, nunca mexeu nos milhares de bitcoins que ele gerou nos primeiros blocos -- enquanto os líderes dessas porcarias supramencionadas cobraram uma fortuna pelo direito de uso dos seus primeiros usuários ou estão aí a até hoje receber dividendos.
Tudo isso e mais outras coisas -- a mentalidade anti-estatal e entusiasta de sistemas p2p abertos dos membros mais proeminentes da comunidade, por exemplo -- faz com que um ar de liberdade e suspeito de tentativas de centralização da moeda sejam percebidos e execrados.
3. A história
A noção de que o Bitcoin não pode ser controlado por ninguém passou em 2017 por [dois testes](https://www.forbes.com/sites/ktorpey/2019/04/23/this-key-part-of-bitcoins-history-is-what-separates-it-from-competitors/#49869b41ae5e) e saiu deles muito reforçada: o primeiro foi a divisão entre Bitcoin (BTC) e Bitcoin Cash (BCH), uma obra de engenharia social que teve um sucesso mediano em roubar parte da marca e dos usuários do verdadeiro Bitcoin e depois a tentativa de tomada por completo do Bitcoin promovida por mais ou menos as mesmas partes interessadas chamada SegWit2x, que fracassou por completo, mas não sem antes atrapalhar e difundir mentiras para todos os lados. Esses dois fracassos provaram que o Bitcoin, mesmo sendo uma comunidade desorganizada, sem líderes claros, está imune à [captura por grupos interessados](https://en.wikipedia.org/wiki/Regulatory_capture), o que é mais um milagre -- ou, como dizem, um [ponto de Schelling](https://en.wikipedia.org/wiki/Focal_point_(game_theory)).
Esse período crucial na história do Bitcoin fez com ficasse claro que _hard-forks_ são essencialmente incompatíveis com a natureza do protocolo, de modo que no futuro não haverá a possibilidade de uma sugestão como a de imprimir mais bitcoins do que o que estava programado sejam levadas a sério (mas, claro, sempre há a possibilidade da cultura toda se perder, as pessoas esquecerem a história e o Bitcoin ser cooptado, eis a importância da auto-educação e da difusão desses princípios).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# O caso da Grêmio TV
enquanto vinha se conduzindo pela plataforma superior daquela arena que se pensava totalmente preenchida por adeptos da famosa equipe do Grêmio de Porto Alegre, viu-se, como por obra de algum nigromante - dos muitos que existem e estão a todo momento a fazer más obras e a colocar-se no caminhos dos que procuram, se não fazer o bem acima de todas as coisas, a pelo menos não fazer o mal no curso da realização dos seus interesses -, o discretíssimo jornalista a ser xingado e moído em palavras por uma horda de malandrinos a cinco ou seis passos dele surgida que cantavam e moviam seus braços em movimentos que não se pode classificar senão como bárbaros, e assim cantavam:
Grêmio TV
pior que o SBT !
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# My stupid introduction to Haskell
While I was writing my first small program on Haskell (really simple, but functional webapp) in December 2017 I only knew vaguely what was the style of things, some basic notions about functions, pure functions and so on (I've read about a third of [LYAH](http://learnyouahaskell.com/chapters)).
An enourmous amount of questions began to appear in my head while I read tutorials and documentation. Here I present some of the questions and the insights I got that solved them. Technically, they may be wrong, but they helped me advance in the matter, so I'm writing them down while I still can -- If I keep working with Haskell I'll probably get to know more and so my new insights will replace the previous ones, and the new ones won't be useful for total begginers anymore.
---
Here we go:
- **Why do modules have odd names?**
- modules are the things you import, like `Data.Time.Clock` or `Web.Scotty`.
- packages are the things you install, like 'time' or 'scotty'
- packages can contain any number of modules they like
- a module is just a collection of functions
- a package is just a collection of modules
- a package is just name you choose to associate your collection of modules with when you're publishing it to Hackage or whatever
- the module names you choose when you're writing a package can be anything, and these are the names people will have to `import` when they want to use you functions
- if you're from Javascript, Python or anything similar, you'll expect to be importing/writing the name of the package directly in your code, but in Haskell you'll actually be writing the name of the module, which may have nothing to do with the name of the package
- people choose things that make sense, like for `aeson` instead of `import Aeson` you'll be doing `import Data.Aeson`, `import Data.Aeson.Types` etc. why the `Data`? because they thought it would be nice. dealing with JSON is a form of dealing with data, so be it.
- you just have to check the package documentation to see which modules it exposes.
- **What is `data User = User { name :: Text }`?**
- a data type definition. means you'll have a function `User` that will take a Text parameter and output a `User` record or something like that.
- you can also have `Animal = Giraffe { color :: Text } | Human { name :: Text }`, so you'll have two functions, Giraffe and Human, each can take a different set of parameters, but they will both yield an Animal.
- then, in the functions that take an Animal parameter you must typematch to see if the animal is a giraffe or a human.
- **What is a monad?**
- a monad is a context, an environment.
- when you're in the context of a monad you can write imperative code.
- you do that when you use the keyword `do`.
- in the context of a monad, all values are prefixed by the monad type,
- thus, in the `IO` monad all `Text` is `IO Text` and so on.
- some monads have a relationship with others, so values from that monad can be turned into values from another monad and passed between context easily.
- for exampĺe, [scotty](https://www.stackage.org/haddock/lts-9.18/scotty-0.11.0/Web-Scotty.html)'s `ActionM` and `IO`. `ActionM` is just a subtype of `IO` or something like that.
- when you write imperative code inside a monad you can do assignments like `varname <- func x y`
- in these situations some transformation is done by the `<-`, I believe it is that the pure value returned by `func` is being transformed into a monad value. so if `func` returns `Text`, now varname is of type `IO Text` (if we're in the IO monad).
- so it will not work (and it can be confusing) if you try to concatenate functions like `varname <- transform $ func x y`, but you can somehow do
- `varname <- func x y`
- `othervarname <- transform varname`
- or you can do other fancy things you'll get familiar with later, like `varname <- fmap transform $ func x y`
- why? I don't know.
- **How do I deal with Maybe, Either or other crazy stuff?**
"ok, I understand what is a Maybe: it is a value that could be something or nothing. but how do I use that in my program?"
- you don't! you turn it into other thing. for example, you use [fromMaybe](http://hackage.haskell.org/package/base-4.10.1.0/docs/Data-Maybe.html#v:fromMaybe), a function that takes a default value and that's it. if your `Maybe` is `Just x` you get `x`, if it is `Nothing` you get the default value.
- using only that function you can already do whatever there is to be done with Maybes.
- you can also manipulate the values inside the `Maybe`, for example:
- if you have a `Maybe Person` and `Person` has a `name` which is `Text`, you can apply a function that turns `Maybe Person` into `Maybe Text` AND ONLY THEN you apply the default value (which would be something like the `"unnamed"`) and take the name from inside the `Maybe`.
- basically these things (`Maybe`, `Either`, `IO` also!) are just tags. they tag the value, and you can do things with the values inside them, or you can remove the values.
- besides the example above with Maybes and the `fromMaybe` function, you can also remove the values by using `case` -- for example:
- `case x of`
- `Left error -> error`
- `Right success -> success`
- `case y of`
- `Nothing -> "nothing!"`
- `Just value -> value`
- (in some cases I believe you can't remove the values, but in these cases you'll also don't need to)
- for example, for values tagged with the IO, you can't remove the IO and turn these values into pure values, but you don't need that, you can just take the value from the outside world, so it's a IO Text, apply functions that modify that value inside IO, then output the result to the user -- this is enough to make a complete program, any complete program.
- **JSON and interfaces (or instances?)**
- using [Aeson](https://hackage.haskell.org/package/aeson-1.2.3.0/docs/Data-Aeson.html) is easy, you just have to implement the `ToJSON` and `FromJSON` interfaces.
- "interface" is not the correct name, but I don't care.
- `ToJSON`, for example, requires a function named `toJSON`, so you do
- `instance ToJSON YourType where`
- `toJSON (YourType your type values) = object []` ... etc.
- I believe lots of things require interface implementation like this and it can be confusing, but once you know the mystery of implementing functions for interfaces everything is solved.
- `FromJSON` is a little less intuitive at the beggining, and I don't know if I did it correctly, but it is working here. Anyway, if you're trying to do that, I can only tell you to follow the types, copy examples from other places on the internet and don't care about the meaning of symbols.
## See also
* [Haskell Monoids](nostr:naddr1qqyrzcmrvcmrqwtpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cktq992)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Classless Templates
There are way too many hours being wasted in making themes for blogs. And then comes a new blog framework, it requires new themes. Old themes can't be used because they relied on different ways of rendering the website. Everything is a mess.
Classless was an attempt at solving it. It probably didn't work because I wasn't the best person to make themes and showcase the thing.
Basically everybody would agree on a simple HTML template that could fit blogs and simple websites very easily. Then other people would make pure-CSS themes expecting that template to be in place.
No classes were needed, only a fixed structure of `header`. `main`, `article` etc.
With **flexbox** and **grid** CSS was enough to make this happen.
The templates that were available were all ported by me from other templates I saw on the web, and there was a simple one I created for my old website.
- <https://github.com/fiatjaf/classless>
- <https://classless.alhur.es/>
- <https://classless.alhur.es/themes/>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# The "Drivechain will replace altcoins" argument
The argument that [Drivechain](nostr:naddr1qq9xgunfwejkx6rpd9hqzythwden5te0ve5kzar2v9nzucm0d5pzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqvzqqqr4gumtjfnp) will replace shitcoins is _not_ that people will [sell their shitcoins](https://twitter.com/craigwarmke/status/1680371502246514688) or that the existing shitcoins will instantly vanish. The argument is about a change _at the margin_ that eventually ends up killing the shitcoins or reducing them to their original insignificance.
**What does "at the margin" mean?** For example, when the price of the coconut drops a little in relation to bananas, does that mean that everybody will stop buying bananas and will buy only coconuts now? No. Does it mean there will be [zero](https://twitter.com/GoingParabolic/status/1680319173744836609) increase in the amount of coconuts sold? Also no. What happens is that there is a small number of people who would have preferred to buy coconuts if only they were a little less expensive but end up buying bananas instead. When the price of coconut drops these people buy coconuts and don't buy bananas.
The argument is that the same thing will happen when Drivechain is activated: there are some people today (yes, believe me) that would have preferred to work within the Bitcoin ecosystem but end up working on shitcoins. In a world with Drivechain these people would be working on the Bitcoin ecosystem, for the benefit of Bitcoin and the Bitcoiners.
Why would they prefer Bitcoin? Because Bitcoin has a bigger network-effect. When these people come, they increase Bitocin's network-effect even more, and if they don't go to the shitcoins they reduce the shitcoins' network-effect. Those changes in network-effect contribute to bringing others who were a little further from the margin and the thing compounds until the shitcoins are worthless.
Who are these people at the margin? I don't know, but they certainly exist. I would guess the Stark people are one famous example, but there are many others. In the past, examples included Roger Ver, Zooko Wilcox, Riccardo Spagni and Vitalik Buterin. And before you start screaming that these people are shitcoiners (which they are) imagine how much bigger Bitcoin could have been today if they and their entire communities (yes, I know, of awful people) were using and working for Bitcoin today. Remember that phrase about Bitcoin being for enemies?
### But everything that has been invented in the altcoin world is awful, we don't need any of that!
You and me should not be the ones judging what is good and what is not for others, but both you and me and others will benefit if these things can be done in a way that increases Bitcoin network-effect and pays fees to Bitcoin miners.
Also, there is a much stronger point you may have not considered: if you believe all altcoiners are scammers that means we have only seen the things that were invented by scammers, since all honest people that had good ideas decided to not implement them as the only way to do it would be to create a scammy shitcoin. One example is [Bitcoin Hivemind](nostr:naddr1qqyxs6tkv4kkjmnyqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cd3vm3c).
If it is possible to do these ideas without creating shitcoins we may start to see new things that are actually good.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A list of things artificial intelligence is not doing
If AI is so good why can't it:
- write good glue code that wraps a documented HTTP API?
- make good translations using available books and respective published translations?
- extract meaningful and relevant numbers from news articles?
- write mathematical models that fit perfectly to available data better than any human?
- play videogames without cheating (i.e. simulating human vision, attention and click speed)?
- turn pure HTML pages into pretty designs by generating CSS
- predict the weather
- calculate building foundations
- determine stock values of companies from publicly available numbers
- smartly and automatically test software to uncover bugs before releases
- predict sports matches from the ball and the players' movement on the screen
- continuously improve niche/local search indexes based on user input and and reaction to results
- control traffic lights
- predict sports matches from news articles, and teams and players' history
This was posted first on [Twitter](https://twitter.com/fiatjaf/status/1477942802805837827).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Um algoritmo imbecil da evolução
Suponha que você queira escrever a palavra BANANA partindo de OOOOOO e usando só alterações aleatórias das letras. As alterações se dão por meio da multiplicação da palavra original em várias outras, cada uma com uma mudança diferente.
No primeiro período, surgem BOOOOO e OOOOZO. E então o ambiente decide que todas as palavras que não começam com um B estão eliminadas. Sobra apenas BOOOOO e o algoritmo continua.
É fácil explicar conceber a evolução das espécies acontecendo dessa maneira, se você controlar sempre a parte em que o ambiente decide quem vai sobrar.
Porém, há apenas duas opções:
1. Se o ambiente decidir as coisas de maneira aleatória, a chance de você chegar na palavra correta usando esse método é tão pequena que pode ser considerada nula.
2. Se o ambiente decidir as coisas de maneira pensada, caímos no //design inteligente//.
Acredito que isso seja uma enunciação decente do argumento ["no free lunch"](https://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization) aplicado à crítica do darwinismo por William Dembski.
A resposta darwinista consiste em dizer que não existe essa BANANA como objetivo final. Que as palavras podem ir se alterando aleatoriamente, e o que sobrar sobrou, não podemos dizer que um objetivo foi atingido ou deixou de sê-lo. E aí os defensores do design inteligente dirão que o resultado ao qual chegamos não pode ter sido fruto de um processo aleatório. BANANA é qualitativamente diferente de AYZOSO, e aí há várias maneiras de "provar" que sim usando modelos matemáticos e tal.
Fico com a impressão, porém, de que essa coisa só pode ser resolvida como sim ou não mediante uma discussão das premissas, e chega um ponto em que não há mais provas matemáticas possíveis, apenas subjetividade.
Daí eu me lembro da minha humilde solução ao problema do cão que aperta as teclas aleatoriamente de um teclado e escreve as obras completas de Shakespeare: mesmo que ele o faça, nada daquilo terá sentido sem uma inteligência de tipo humano ali para lê-las e perceber que não se trata de uma bagunça, mas sim de um texto com sentido para ele. O milagre se dá não no momento em que o cão tropeça no teclado, mas no momento em que o homem olha para a tela.
Se o algoritmo da evolução chegou à palavra BANANA ou UXJHTR não faz diferença pra ela, mas faz diferença para nós, que temos uma inteligência humana, e estamos observando aquilo. O homem também pensaria que há //algo// por trás daquele evento do cão que digita as obras de Shakespeare, e como seria possível alguém em sã consciência pensar que não?
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Per Bylund's insight
The firm doesn't exist because, like [Coase said](https://en.wikipedia.org/?curid=83030), it is inefficient to operate in a fully open-market and production processes need some bubbles of central planning.
Instead, what happens is that a firm is created because an entrepreneur is doing a new thing (and here I imagine that doing an old thing in a new context also counts as doing a new thing, but I didn't read his book), and for that new thing there is no market, there are no specialized workers offering the services needed, nor other businesses offering the higher-order goods that entrepreneur wants, so he must do all by himself.
So the entrepreneur goes and hires workers and buys materials more generic than he wanted and commands these to build what he wants exactly. It is less efficient than if he could buy the precise services and goods he wanted and combine those to yield the product he envisaged, but it accomplishes the goal.
Later, when that specific market evolves, it's natural that specialized workers and producers of the specific factors begin to appear, and the market gets decentralized.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# `OP_CHECKTEMPLATEVERIFY` and the "covenants" drama
There are many ideas for "covenants" (I don't think this concept helps in the specific case of examining proposals, but fine). Some people think "we" (it's not obvious who is included in this group) should somehow examine them and come up with the perfect synthesis.
It is not clear what form this magic gathering of ideas will take and who (or which ideas) will be allowed to speak, but suppose it happens and there is intense research and conversations and people (ideas) really enjoy themselves in the process.
What are we left with at the end? Someone has to actually commit the time and put the effort and come up with a concrete proposal to be implemented on Bitcoin, and whatever the result is it will have trade-offs. Some great features will not make into this proposal, others will make in a worsened form, and some will be contemplated very nicely, there will be some extra costs related to maintenance or code complexity that will have to be taken. Someone, a concreate person, will decide upon these things using their own personal preferences and biases, and many people will not be pleased with their choices.
That has already happened. Jeremy Rubin has already conjured all the covenant ideas in a magic gathering that lasted more than 3 years and came up with a synthesis that has the best trade-offs he could find. CTV is the result of that operation.
---
The fate of CTV in the popular opinion illustrated by the thoughtless responses it has evoked such as "can we do better?" and "we need more review and research and more consideration of other ideas for covenants" is a preview of what would probably happen if these suggestions were followed again and someone spent the next 3 years again considering ideas, talking to other researchers and came up with a new synthesis. Again, that person would be faced with "can we do better?" responses from people that were not happy enough with the choices.
And unless some famous Bitcoin Core or retired Bitcoin Core developers were personally attracted by this synthesis then they would take some time to review and give their blessing to this new synthesis.
To summarize the argument of this article, the actual question in the current CTV drama is that there exists hidden criteria for proposals to be accepted by the general community into Bitcoin, and no one has these criteria clear in their minds. It is not as simple not as straightforward as "do research" nor it is as humanly impossible as "get consensus", it has a much bigger social element into it, but I also do not know what is the exact form of these hidden criteria.
This is said not to blame anyone -- except the ignorant people who are not aware of the existence of these things and just keep repeating completely false and unhelpful advice for Jeremy Rubin and are not self-conscious enough to ever realize what they're doing.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# IPFS problems: Conceit
IPFS is trying to do many things. The IPFS leaders are revolutionaries who think they're smarter than the rest of the entire industry.
The fact that they've first proposed a protocol for peer-to-peer distribution of immutable, content-addressed objects, then later tried to fix [that same problem](nostr:naddr1qqyrqen9xf3nvdpeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cmdjnnj) using their own half-baked solution (IPNS) is one example.
Other examples are their odd appeal to decentralization in a very non-specific way, their excessive [flirtation with Ethereum](nostr:naddr1qqyxxdpev5cnsvpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cta4a2e) and their never-to-be-finished can-never-work-as-advertised _Filecoin_ project.
They could have focused on just making the infrastructure for distribution of objects through hashes (not saying this would actually be a good idea, but it had some potential) over a peer-to-peer network, but in trying to reinvent the entire internet they screwed everything up.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Replacing the web with something saner
This is a simplification, but let's say that basically there are just 3 kinds of websites:
1. Websites with content: text, images, videos;
2. Websites that run full apps that do a ton of interactive stuff;
3. Websites with some interactive content that uses JavaScript, or "mini-apps";
In a saner world we would have 3 different ways of serving and using these. 1 would be "the web" (and it was for a while, although I'm not claiming here that the past is always better and wanting to get back to the glorious old days).
1 would stay as "the web", just static sites, styled with CSS, no JavaScript whatsoever, but designers can still thrive and make they look pretty. Or it could also be something like [Gemini](https://gemini.circumlunar.space/). Maybe the two protocols could coexist.
2 would be downloadable native apps, much easier to write and maintain for developers (considering that multi-platform and cross-compilation is easy today and getting easier), faster, more polished experience for users, more powerful, integrates better with the computer.
(Remember that since no one would be striving to make the same app run both on browsers and natively no one would have any need for Electron or other inefficient bloated solutions, just pure native UI, like the Telegram app, have you seen that? It's fast.)
But 2 is mostly for apps that people use every day, something like Google Docs, email (although email is also broken technology), Netflix, Twitter, Trello and so on, and all those hundreds of niche SaaS that people pay monthly fees to use, each tailored to a different industry (although most of functions they all implement are the same everywhere). What do we do with dynamic open websites like StackOverflow, for example, where one needs to not only read, but also search and interact in multiple ways? What about that website that asks you a bunch of questions and then discovers the name of the person you're thinking about? What about that mini-app that calculates the hash of your provided content or shrinks your video, or that one that hosts your image without asking any questions?
All these and tons of others would fall into category 3, that of instantly loaded apps that you don't have to install, and yet they run in a sandbox.
The key for making category 3 worth investing time into is coming up with some solid grounds, simple enough that anyone can implement in multiple different ways, but not giving the app too much choices.
Telegram or Discord bots are super powerful platforms that can accomodate most kinds of app in them. They can't beat a native app specifically made with one purpose, but they allow anyone to provide instantly usable apps with very low overhead, and since the experience is so simple, intuitive and fast, users tend to like it and sometimes even pay for their services. There could exist a protocol that brings apps like that to the open world of (I won't say "web") domains and the websockets protocol -- with multiple different clients, each making their own decisions on how to display the content sent by the servers that are powering these apps.
Another idea is that of [Alan Kay](https://www.quora.com/Should-web-browsers-have-stuck-to-being-document-viewers/answer/Alan-Kay-11): to design a nice little OS/virtual machine that can load these apps and run them. Kinda like browsers are today, but providing a more well-thought, native-like experience and framework, but still sandboxed. And I add: abstracting away details about design, content disposition and so on.
---
These 3 kinds of programs could coexist peacefully. 2 are just standalone programs, they can do anything and each will be its own thing. 1 and 3, however, are still similar to browsers of today in the sense that you need clients to interact with servers and show to the user what they are asking. But by simplifying everything and separating the scopes properly these clients would be easy to write, efficient, small, the environment would be open and the internet would be saved.
## See also
- [On the state of programs and browsers](nostr:naddr1qqyxgdfe8qexvd34qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cd7nk4m)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# nostr - Notes and Other Stuff Transmitted by Relays
The simplest open protocol that is able to create a censorship-resistant global "social" network once and for all.
It doesn't rely on any trusted central server, hence it is resilient; it is based on cryptographic keys and signatures, so it is tamperproof; it does not rely on P2P techniques, therefore it works.
## Very short summary of how it works, if you don't plan to read anything else:
Everybody runs a client. It can be a native client, a web client, etc. To publish something, you write a post, sign it with your key and send it to multiple relays (servers hosted by someone else, or yourself). To get updates from other people, you ask multiple relays if they know anything about these other people. Anyone can run a relay. A relay is very simple and dumb. It does nothing besides accepting posts from some people and forwarding to others. Relays don't have to be trusted. Signatures are verified on the client side.
## This is needed because other solutions are broken:
### The problem with Twitter
- Twitter has ads;
- Twitter uses bizarre techniques to keep you addicted;
- Twitter doesn't show an actual historical feed from people you follow;
- Twitter bans people;
- Twitter shadowbans people.
- Twitter has a lot of spam.
### The problem with Mastodon and similar programs
- User identities are attached to domain names controlled by third-parties;
- Server owners can ban you, just like Twitter; Server owners can also block other servers;
- Migration between servers is an afterthought and can only be accomplished if servers cooperate. It doesn't work in an adversarial environment (all followers are lost);
- There are no clear incentives to run servers, therefore they tend to be run by enthusiasts and people who want to have their name attached to a cool domain. Then, users are subject to the despotism of a single person, which is often worse than that of a big company like Twitter, and they can't migrate out;
- Since servers tend to be run amateurishly, they are often abandoned after a while — which is effectively the same as banning everybody;
- It doesn't make sense to have a ton of servers if updates from every server will have to be painfully pushed (and saved!) to a ton of other servers. This point is exacerbated by the fact that servers tend to exist in huge numbers, therefore more data has to be passed to more places more often;
- For the specific example of video sharing, ActivityPub enthusiasts realized it would be completely impossible to transmit video from server to server the way text notes are, so they decided to keep the video hosted only from the single instance where it was posted to, which is similar to the Nostr approach.
### The problem with SSB (Secure Scuttlebutt)
- It doesn't have many problems. I think it's great. In fact, I was going to use it as a basis for this, but
- its protocol is too complicated because it wasn't thought about being an open protocol at all. It was just written in JavaScript in probably a quick way to solve a specific problem and grew from that, therefore it has weird and unnecessary quirks like signing a JSON string which must strictly follow the rules of [_ECMA-262 6th Edition_](https://www.ecma-international.org/ecma-262/6.0/#sec-json.stringify);
- It insists on having a chain of updates from a single user, which feels unnecessary to me and something that adds bloat and rigidity to the thing — each server/user needs to store all the chain of posts to be sure the new one is valid. Why? (Maybe they have a good reason);
- It is not as simple as Nostr, as it was primarily made for P2P syncing, with "pubs" being an afterthought;
- Still, it may be worth considering using SSB instead of this custom protocol and just adapting it to the client-relay server model, because reusing a standard is always better than trying to get people in a new one.
### The problem with other solutions that require everybody to run their own server
- They require everybody to run their own server;
- Sometimes people can still be censored in these because domain names can be censored.
## How does Nostr work?
- There are two components: __clients__ and __relays__. Each user runs a client. Anyone can run a relay.
- Every user is identified by a public key. Every post is signed. Every client validates these signatures.
- Clients fetch data from relays of their choice and publish data to other relays of their choice. A relay doesn't talk to another relay, only directly to users.
- For example, to "follow" someone a user just instructs their client to query the relays it knows for posts from that public key.
- On startup, a client queries data from all relays it knows for all users it follows (for example, all updates from the last day), then displays that data to the user chronologically.
- A "post" can contain any kind of structured data, but the most used ones are going to find their way into the standard so all clients and relays can handle them seamlessly.
## How does it solve the problems the networks above can't?
- **Users getting banned and servers being closed**
- A relay can block a user from publishing anything there, but that has no effect on them as they can still publish to other relays. Since users are identified by a public key, they don't lose their identities and their follower base when they get banned.
- Instead of requiring users to manually type new relay addresses (although this should also be supported), whenever someone you're following posts a server recommendation, the client should automatically add that to the list of relays it will query.
- If someone is using a relay to publish their data but wants to migrate to another one, they can publish a server recommendation to that previous relay and go;
- If someone gets banned from many relays such that they can't get their server recommendations broadcasted, they may still let some close friends know through other means with which relay they are publishing now. Then, these close friends can publish server recommendations to that new server, and slowly, the old follower base of the banned user will begin finding their posts again from the new relay.
- All of the above is valid too for when a relay ceases its operations.
- **Censorship-resistance**
- Each user can publish their updates to any number of relays.
- A relay can charge a fee (the negotiation of that fee is outside of the protocol for now) from users to publish there, which ensures censorship-resistance (there will always be some Russian server willing to take your money in exchange for serving your posts).
- **Spam**
- If spam is a concern for a relay, it can require payment for publication or some other form of authentication, such as an email address or phone, and associate these internally with a pubkey that then gets to publish to that relay — or other anti-spam techniques, like hashcash or captchas. If a relay is being used as a spam vector, it can easily be unlisted by clients, which can continue to fetch updates from other relays.
- **Data storage**
- For the network to stay healthy, there is no need for hundreds of active relays. In fact, it can work just fine with just a handful, given the fact that new relays can be created and spread through the network easily in case the existing relays start misbehaving. Therefore, the amount of data storage required, in general, is relatively less than Mastodon or similar software.
- Or considering a different outcome: one in which there exist hundreds of niche relays run by amateurs, each relaying updates from a small group of users. The architecture scales just as well: data is sent from users to a single server, and from that server directly to the users who will consume that. It doesn't have to be stored by anyone else. In this situation, it is not a big burden for any single server to process updates from others, and having amateur servers is not a problem.
- **Video and other heavy content**
- It's easy for a relay to reject large content, or to charge for accepting and hosting large content. When information and incentives are clear, it's easy for the market forces to solve the problem.
- **Techniques to trick the user**
- Each client can decide how to best show posts to users, so there is always the option of just consuming what you want in the manner you want — from using an AI to decide the order of the updates you'll see to just reading them in chronological order.
## FAQ
- **This is very simple. Why hasn't anyone done it before?**
I don't know, but I imagine it has to do with the fact that people making social networks are either companies wanting to make money or P2P activists who want to make a thing completely without servers. They both fail to see the specific mix of both worlds that Nostr uses.
- **How do I find people to follow?**
First, you must know them and get their public key somehow, either by asking or by seeing it referenced somewhere. Once you're inside a Nostr social network you'll be able to see them interacting with other people and then you can also start following and interacting with these others.
- **How do I find relays? What happens if I'm not connected to the same relays someone else is?**
You won't be able to communicate with that person. But there are hints on events that can be used so that your client software (or you, manually) knows how to connect to the other person's relay and interact with them. There are other ideas on how to solve this too in the future but we can't ever promise perfect reachability, no protocol can.
- **Can I know how many people are following me?**
No, but you can get some estimates if relays cooperate in an extra-protocol way.
- **What incentive is there for people to run relays?**
The question is misleading. It assumes that relays are free dumb pipes that exist such that people can move data around through them. In this case yes, the incentives would not exist. This in fact could be said of DHT nodes in all other p2p network stacks: what incentive is there for people to run DHT nodes?
- **Nostr enables you to move between server relays or use multiple relays but if these relays are just on AWS or Azure what’s the difference?**
There are literally thousands of VPS providers scattered all around the globe today, there is not only AWS or Azure. AWS or Azure are exactly the providers used by single centralized service providers that need a lot of scale, and even then not just these two. For smaller relay servers any VPS will do the job very well.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# "House" dos economistas e o Estado
Falta um gênio pra produzir um seriado tipo House só que com economistas. O House do seriado seria um austríaco é o "everybody lies" seria uma premissa segundo a qual o Estado é sempre a causa de todos os problemas.
Situações bem cabeludas poderiam ser apresentadas de maneira que parecesse muito que a causa era ganância ou o mau-caratismo dos agentes, mas na investigação quase sempre se descobriria que a causa era o Estado.
Parece ridículo, mas se eu descrevesse House assim aqui também pareceria. A execução é que importa.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# notes on "Economic Action Beyond the Extent of the Market", Per Bylund
Source: <https://www.youtube.com/watch?v=7St6pCipCB0>
Markets work by dividing labour, but that's not as easy as it seems in the Adam Smith's example of a pin factory, because
1. a pin factory is not a market, so there is some guidance and orientation, some sort of central planning, inside there that a market doesn't have;
2. it is not clear how exactly the production process will be divided, it is not obvious as in "you cut the thread, I plug the head".
Dividing the labour may produce efficiency, but it also makes each independent worker in the process more fragile, as they become dependent on the others.
This is partially solved by having a lot of different workers, so you do not depend on only one.
If you have many, however, they must agree on where one part of the production process starts and where it ends, otherwise one's outputs will not necessarily coincide with other's inputs, and everything is more-or-less broken.
That means some level of standardization is needed. And indeed the market has constant incentives to standardization.
The statist economist discourse about standardization is that only when the government comes with a law that creates some sort of standardization then economic development can flourish, but in fact the market creates standardization all the time. Some examples of standardization include:
* programming languages, operating systems, internet protocols, CPU architectures;
* plates, forks, knifes, glasses, tables, chairs, beds, mattresses, bathrooms;
* building with concrete, brick and mortar;
* money;
* musical instruments;
* light bulbs;
* CD, DVD, VHS formats and others alike;
* services that go into every production process, like lunch services, restaurants, bakeries, cleaning services, security services, secretaries, attendants, porters;
* multipurpose steel bars;
* practically any tool that normal people use and require a little experience to get going, like a drilling machine or a sanding machine; etc.
Of course it is not that you find standardization in all places. Specially when the market is smaller or new, standardization may have not arrived.
There remains the truth, however, that division of labour has the potential of doing good.
More than that: every time there are more than one worker doing the same job in the same place of a division of labour chain, there's incentive to create a new subdivision of labour.
From the fact that there are at least more than one person doing the same job as another in our society we must conclude that someone must come up with an insight about an efficient way to divide the labour between these workers (and probably actually implement it), that hasn't happened for all kinds of jobs.
But to come up with division of labour outside of a factory, some market actors must come up with a way of dividing the labour, actually, determining where will one labour stop and other start (and that almost always needs some adjustments and in fact extra labour to hit the tips), and also these actors must bear the uncertainty and fragility that division of labour brings when there are not a lot of different workers and standardization and all that.
In fact, when an entrepreneur comes with a radical new service to the market, a service that does not fit in the current standard of division of labour, he must explain to his potential buyers what is the service and how the buyer can benefit from it and what he will have to do to adapt its current production process to bear with that new service. That's has happened not long ago with
* services that take food orders from the internet and relay these to the restaurants;
* hostels for cheap accommodation for young travellers;
* Uber, Airbnb, services that take orders and bring homemade food from homes to consumers and similars;
* all kinds of software-as-a-service;
* electronic monitoring service for power generators;
* mining planning and mining planning software; and many other industry-specific services.
## See also
* [Profits, not wages, as the originary factor](nostr:naddr1qqyrge3hxa3rqce4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7x67pu)
* [Per Bylund's insight](nostr:naddr1qqyxvdtzxscxzcenqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cuq3unj)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# litepub
A Go library that abstracts all the burdensome ActivityPub things and provides just the right amount of helpers necessary to integrate an existing website into the "fediverse" (what an odious name). Made for the [gravity]() integration.
- <https://godoc.org/github.com/fiatjaf/litepub>
## See also
-
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Ripple and the problem of the decentralized commit
This is about [Ryan Fugger's Ripple](nostr:naddr1qqyxgenyxe3rzvf4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8pp8zu).
The summary is: unless everybody is good and well-connected at all times a transaction can always be left in a half-committed state, which creates confusion, erodes trust and benefits no one.
If you're unconvinced consider the following protocol flow:
1. A finds a route (A--B--C--D) between her and D somehow;
2. A "prepares" a payment to B, tells B to do the same with C and so on (to prepare means to give B a conditional IOU that will be valid as long as the full payment completes);
3. When the chain of prepared messages reaches D, D somehow "commits" the payment.
4. After the commit, A now _really does_ owe B and so on, and D _really_ knows it has been effectively paid by A (in the form of debt from C) so it can ship goods to A.
The most obvious (but wrong) way of structuring this would be for the entire payment chain to be dependent on the reveal of some secret. For example, the "prepare" messages could contain something like "I will pay you as long as you know `p` such that `sha256(p) == h`".
The payment flow then starts with D presenting A with an invoice that contains `h`, so D knows `p`, but no one else knows. A can then send the "prepare" message to B and B do the same until it reaches D.
When it reaches D, D can be sure that C will pay him because he knows `p` such that `sha256(p) == h`. He then reveals `p` to C, C now reveals it to B and B to A. When A gets it it has a proof that D has received his payment, therefore it is happy to settle it later with B and can prove to an external arbitrator that he has indeed paid D in case D doesn't deliver his products.
## Issues with the naïve flow above
### What if D never reveals `p` to C?
Then no one knows what happened. And then 10 years later he arrives at C's house (remember they are friends or have a trust relationship somehow) and demands his payment, and shows `p` to her in a piece of paper. Or worse: go directly to the court and shows C's message that says "I will pay you as long as you know `p` such that `sha256(p) == h`" (but with an actual number instead of "h") and the corresponding `p`. Now the judge has to decide in favor of D.
Now C was supposed to do the same with B, but C is not playing with this anymore, has lost all contact with B after they did their final settlement many years ago, no one was expecting this.
This clearly can't work. There must be a timeout for these payments.
### What if we have a timeout?
Now what if we say the payment expires in one hour. D cannot hold the payment hostage and reveal `p` after 10 years. It must either reveal it before the timeout or conditional IOU will be void. Solves everything!
Except no, now it's the time we reach the most dark void of the protocol, the flaw that sucks its life into the abyss: subjectivity and ambiguity.
The big issue is that we don't have an independent judge to assert, for example, that D has indeed "revealed" `p` to C in time. C must acknowledge that voluntarily. C could do it using messages over the internet, but these messages are not reliable. C is not reliable. Clocks are not synchronized. Also if we now require C to confirm it has received `p` from D then the "prepare" message means nothing, as for D now just knowing `p` is not enough to claim before an arbitrator that C owes her -- because, again, D also must prove it has shown `p` to C before the timeout, therefore it needs a new signed acknowledgement from C, or from some other party.
Let's see a few examples.
### Subjectivity and perverse incentives
D could send `p` to C, and C acknowledge it, but then when C goes to B and send it B will not acknowledge it, and claim it's past the time. Now C loses money.
Maybe C can not acknowledge it received anything from D before checking first with B? But B will have to check with A too! And it subverts the entire flow of the thing. And now A has a "proof of payment" (knowledge of `p`) without even having to acknowledge anything! In this case knowing `p` or not becomes meaningless as everybody knows `p` without acknowleding it to anyone else.
But even if A is honest and sends an "acknowledge" message to B, now B can just sit quiet and enjoy the credit it has just earned from A without ever acknowleding anything to C. It's perverted incentives in every step.
### Ambiguity
But isn't this a protocol based on trust?, you ask, isn't C trusting that B will behave honestly already? Therefore if B is dishonest C just has to acknowledge his loss and break his chain of trust with B.
No, because C will not know what happened. B can say "I could have sent you an acknowledgement, but was waiting for A, and A didn't send anything" and C won't ever know if that was true. Or B could say "what? You didn't send me `p` at all", and that could be true. B could have been offline when A sent it, there could have been a broken connection or many other things, and B continues: "I was waiting for you to present me with `p`, but you didn't, therefore the payment timed out, you can't come here with `p` now, because now A won't accept it anymore from me". That could be true or could be false, who knows?
Therefore it is impossible for trust relationships and reputations to be maintained in such a system without "good fences".[^ln-solution][^ln-issue]
[^ln-solution]: The [Lightning Network has a solution](nostr:naddr1qqyx2vekxg6rsvejqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccs2twc) for the problem of the decentralized commit.
[^ln-issue]: Ironically this same ambiguity problem [is being faced by the Lightning Network community](https://lists.linuxfoundation.org/pipermail/lightning-dev/2020-October/002826.html) when trying to create a reputation/payment system to prevent routing abuses. It seems simple when you first think about it: "let each node manage its own trust", but in fact it is somewhat impossible.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Mises' interest rate theory
Inspired by [Bob Murphy's thesis](http://consultingbyrpm.com/uploads/Dissertation.pdf) against the "pure time preference theory" (see also this [series of podcasts](https://www.bobmurphyshow.com/episodes/ep-31-capital-and-interest-in-the-austrian-tradition-part-3-of-3/)) -- or blatantly copying it -- here are some thoughts on Mises' most wrong take:
* Mises asserts that the market rate of interest is _not_ the originary rate of interest, because the market rate involves entrepreneurial decisions, risk, uncertainty etc. No one lends money with 100% guarantee that it will be paid back in the market and so. But if that is true, where can we see that originary interest? We're supposed to account for its existence and be sure that it is logically there in every trade between present and future, because it's a _category of action_. But then it seems odd to me that it has anything to do with the actual interest.
* Mises criticizes the notion of "profit" from classical economists because it mashed together gains deriving from speculation, risk, other stuff and originary interest -- but that's only because he assumes originary interest as a given (because it's a category of action and so on). If he didn't he could have just not cited originary interest in the list of things that give rise to "profit" and all would be fine.
* Mixing the two points above, it seems very odd to think that we should look for interest as a component of profit. It seems indeed to be very classifical-economist take. It would be still compatible with Mises'sworldview -- indeed more compatible -- that we looked for profit as a component of interest: when someone lends some 100 and is paid 110 that is profit. Plain simple. Why he did that and why the other person paid isn't for the economist to analyse, or to dissect the extra 10 into 9 interest, 1 risk remuneration or anything like that. If the borrower hadn't paid it would be a 100 loss or a 109 loss?
* In other moments, Mises talks about the originary rate of interest being the same for all things: apples and bicycles and anything else. But wasn't each person supposed to have its own valuation of each good -- including goods in the present and in the future? Is Mises going to say that it's impossible for someone to value an orange in the future more than a bycicle in the future in comparison with these same goods in the present? (The very "more" in the previous sentence shows us that Mises was incurring in cardinal value calculations when coming up with this theory -- and I hadn't noticed it until after I finished typing the phrase.) In other words: what if someone prefers orange, bycicle, bycicle in the future, orange in the future? That doesn't seem to fit. What is the rate of interest?
* Also, on the point above, what if someone has different rates of interest for goods in different timeframes? For example, someone may prefer a bycicle now a little more than a bycicle tomorrow, but very very much more than a bycicle in two days. That also breaks the notion of "originary interest" as an universal rate.
* Now maybe I misunderstood everything, maybe Mises was talking about originary interest as a rate defined by the market. And he clearly says that. That if the rate of interest is bigger on some market entrepreneurs will invest capital in that one until it equalizes with rates in other markets. But all that fits better with the plain notion of profit than with this poorly-crafted notion of originary interest. If you're up to defining and (Mises forbid?) measuring the neutral rate of interest you'll have to arbitrarily choose some businesses to be part of the "market" while excluding others.
* By the way, wasn't originary interest a category of action? How can a category of action be defined and ultimately _fixed_ by entrepreneurial action in a market?
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Thafne venceu o Soletrando 2008.
As palavras que Thafne teve que soletrar: "ocioso", "hermético", "glossário", "argênteo", "morfossintaxe", "infra-hepático", "hagiológio". Enquanto isso Eder recebia: "intramuscular", "destilação", "inabitável", "subcutâneo", "homogeneidade", "predecessor", "displicência", "subconsciência", "psicroestesia" (isto segundo [o site da folha][0], donde certamente faltam algumas palavras de Thafne). Sério, "argênteo"? Não é errado dizer que a Globo tentou promover o menino pobre da escola pública do sertão contra a riquinha de Curitiba.
O mais espetacular disto é que deu errado e o Brasil inteiro torceu pela Thafne, o que se verifica com uma simples busca no Google. Eis aqui alguns exemplos:
* [O problema de Thafne][1] traz comentários tentando incriminar o governo do Estado de Minas Gerais com a vitória forçada de Eder.
* [este vídeo mostrando os erros do programa e a vitória triunfal, embora parcial, de Thafne,][2] traz a brilhante descrição "globo de puleira quis complicar a vida da menina!!!!!!!!!!!!!!!!!!!!!!"
* [este vídeo, com o mesmo conteúdo,][3], porém chamado "Thafne versus Luciano Huck, o confronto do século", tem, além disto, vários comentários de francos torcedores de Thafne:
* "Nossa isso é burrice porq o doutor falou duas vezes como o luciano não prestou atenção logo thafine deu duas patadas no luciano... Proxima luciano presta atenção na pronuncia"
* "ele nao pronunciou errado porque é burro, isso foi pra manipular o resultado"
* "Gabriel o Bostador ficou pianinho. Babaca do krl"
* "Pena que ela perdeu :("
* "verdade... ela que ganhou, o outro só ficou com o título :S"
* "A menina deu um banho nesse que além de idiota é BURRO."
* e muitos, muitos outros.
* [Globo Erra e Luciano Huck dá Vexame][4], um breve artigo descrevendo alguns dos pontos em que Eder foi favorecido.
* [esta comunidade do Orkut][5], apenas a maior dentre várias que foram criadas.
O movimento de apoio a Thafne é um exemplo entre poucos de união total da nação em prol de uma causa.
[0]: <http://www1.folha.uol.com.br/ilustrada/2008/05/407470-aluno-de-escola-publica-de-minas-vence-soletrando-huck-da-vexame.shtml>
[1]: <https://misenews.wordpress.com/2012/06/22/o-problema-de-thafne/>
[2]: <https://www.youtube.com/watch?v=lNW_QAiptsY>
[3]: <https://www.youtube.com/watch?v=Va8XxXgnY-c>
[4]: <https://www.putsgrilo.com.br/televisao/soletrando-globo-erra-e-luciano-huck-da-vexame/>
[5]: <http://orkut.google.com/c54999457.html>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Democracy as a failed open-network protocol
In the context of protocols for peer-to-peer open computer networks -- those in which new actors can freely enter and immediately start participating in the protocol --, without any central entity, specially without any central human mind judging things from the top --, it's common for decisions about the protocol to be thought taking in consideration all the possible ways a rogue peer can disrupt the entire network, abuse it, make the experience terrible for others. The protocol design must account for all incentives in play and how they will affect each participant, always having in mind that each participant may be acting in a purely egoistical self-interested manner, not caring at all about the health of the network (even though most participants won't be like that). So a protocol, to be successful, must have incentives aligned such that self-interested actors cannot profit by hurting others and will gain most by cooperating (whatever that means in the envisaged context), or there must be a way for other peers to detect attacks and other kinds of harm or attempted harm and neutralize these.
Since computers are very fast, protocols can be designed to be executed many times per day by peers involved, and since the internet is a very open place to which people of various natures are connected, many open-network protocols with varied goals have been tried in large scale and most of them failed and were shut down (or kept existing, but offering a bad experience and in a much more limited scope than they were expected to be). Often the failure of a protocol leads to knowledge about its shortcomings being more-or-less widespread and agreed upon, and these lead to the development of a better protocol the next time something with similar goals is tried.
Ideally **democracies** are supposed to be an open-entry network in the same sense as these computer networks, and although that is a noble goal, it's one full of shortcomings. Democracies are supposed to the governing protocol of States that have the power to do basically anything with the lives of millions of citizens.
One simple inference we may take from the history of computer peer-to-peer protocols is that the ones that work better are those that are simple and small in scope (**Bitcoin**, for example, is very simple; **BitTorrent** is also very simple and very limited in what it tries to do and the number of participants that get involved in each run of the protocol).
Democracies, as we said above, are the opposite of that. Besides being in a very hard position to achieve success as an open protocol, democracies also suffer from the fact that they take a long time to run, so it's hard to see where it is failing every time.
The fundamental incentives of democracy, i.e. the rules of the protocol, posed by the separation of powers and checks-and-balances are basically the same in every place and in every epoch since the XIII century, and even today most people who dedicate their lives to the subject still don't see how [they're completely flawed](nostr:naddr1qqyrzc3nvenxxdpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cjc4mf0).
The system of checks and balances was thought from the armchair of a couple of political theorists who had never done anything like that in their lives, didn't have any experience dealing with very adversarial environments like the internet -- and probably couldn't even imagine that the future users of their network were going to be creatures completely different than themselves and their fellow philosophers and aristocrats who all shared the same worldview (and how fast that future would come!).
## Also
* [The illusion of checks and balances](nostr:naddr1qqyrzc3nvenxxdpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cjc4mf0)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Bolo
It seems that from 1987 to around 2000 there was a big community of people who played this game called ["Bolo"][wikipedia]. It was a game in which people controlled a tank and killed others while trying to capture bases in team matches. Always 2 teams, from 2 to 16 total players, games could last from 10 minutes to 12 hours. I'm still trying to understand all this.
The game looks silly from some [videos][videos] you can find today, but apparently it was very deep in strategy because people developed [strategy][strategy-guide] [guides][pillbox-guide] and [wrote][letter-1] [extensively][letter-2] about it and [Netscape even supported `bolo:` URLs][clickable-links] out of the box.
> The two most important elements on the map are pillboxes and bases. Pillboxes are originally neutral, meaning that they shoot at every tank that happens to get in its range. They shoot fast and with deadly accuracy. You can shoot the pillbox with your tank, and you can see how damaged it is by looking at it. Once the pillbox is subdued, you may run over it, which will pick it up. You may place the pillbox where you want to put it (where it is clear), if you've enough trees to build it back up.
> Trees are harvested by sending your man outside your tank to forest the trees. Your man (also called a builder) can also lay mines, build roads, and build walls. Once you have placed a pillbox, it will not shoot at you, but only your enemies. Therefore, pillboxes are often used to protect your bases.
That quote was taken from this ["augmented FAQ"][augmented-faq] written by some user. Apparently there were many FAQs for this game. A FAQ is after all just a simple, clear and direct to the point way of writing about anything, previously known as [summa][summa][^summa-k], it doesn't have to be related to any actually frequently asked question.
More unexpected Bolo writings include [an etiquette guide][etiquette], an [anthropology study][anthropology] and [some wonderings on the reverse pill war tactic][reverse-pill].
[videos]: https://www.youtube.com/results?search_query=winbolo
[wikipedia]: https://en.wikipedia.org/wiki/Bolo_(1987_video_game)
[clickable-links]: http://web.archive.org/web/19980214020327/http://boloweb.stanford.edu/BoloWeb.html
[faq]: https://web.archive.org/web/20070518233700/http://bishop.mc.duke.edu/bolo/guides/stuartfaq.html
[letter-1]: http://web.archive.org/web/19961214060949/http://rost.abo.fi/~gpappas/Bolo/News/mikael-bl.html
[letter-2]: http://web.archive.org/web/19961214060959/http://rost.abo.fi/~gpappas/Bolo/News/mikael-kev.html
[strategy-guide]: http://web.archive.org/web/19961214052754/http://rost.abo.fi/~gpappas/Bolo/guide.html
[etiquette]: http://web.archive.org/web/19961214052805/http://rost.abo.fi/~gpappas/Bolo/etiquette.html
[pillbox-guide]: http://web.archive.org/web/19961214052818/http://rost.abo.fi/~gpappas/Bolo/PBguide/pbguide1.html
[anthropology]: http://web.archive.org/web/19961214052830/http://rost.abo.fi/~gpappas/Bolo/anthropology.html
[reverse-pill]: http://web.archive.org/web/19990428023004/http://powered.cs.yale.edu:8000/%7Ebayliss/bolo.html
[augmented-faq]: http://web.archive.org/web/19970118071637/http://rost.abo.fi/~gpappas/Bolo/faq.html
[summa]: https://en.wikipedia.org/wiki/Summa
[^summa-k]: It's not the same thing, but I couldn't help but notice the similarity.