-
 @ 4961e68d:a2212e1c
2025-05-02 07:47:16
@ 4961e68d:a2212e1c
2025-05-02 07:47:16热死人了
-
@ 4961e68d:a2212e1c
2025-05-02 07:46:46
热死人了!
-
@ 21335073:a244b1ad
2025-05-01 01:51:10
Please respect Virginia Giuffre’s memory by refraining from asking about the circumstances or theories surrounding her passing.
Since Virginia Giuffre’s death, I’ve reflected on what she would want me to say or do. This piece is my attempt to honor her legacy.
When I first spoke with Virginia, I was struck by her unshakable hope. I had grown cynical after years in the anti-human trafficking movement, worn down by a broken system and a government that often seemed complicit. But Virginia’s passion, creativity, and belief that survivors could be heard reignited something in me. She reminded me of my younger, more hopeful self. Instead of warning her about the challenges ahead, I let her dream big, unburdened by my own disillusionment. That conversation changed me for the better, and following her lead led to meaningful progress.
Virginia was one of the bravest people I’ve ever known. As a survivor of Epstein, Maxwell, and their co-conspirators, she risked everything to speak out, taking on some of the world’s most powerful figures.
She loved when I said, “Epstein isn’t the only Epstein.” This wasn’t just about one man—it was a call to hold all abusers accountable and to ensure survivors find hope and healing.
The Epstein case often gets reduced to sensational details about the elite, but that misses the bigger picture. Yes, we should be holding all of the co-conspirators accountable, we must listen to the survivors’ stories. Their experiences reveal how predators exploit vulnerabilities, offering lessons to prevent future victims.
You’re not powerless in this fight. Educate yourself about trafficking and abuse—online and offline—and take steps to protect those around you. Supporting survivors starts with small, meaningful actions. Free online resources can guide you in being a safe, supportive presence.
When high-profile accusations arise, resist snap judgments. Instead of dismissing survivors as “crazy,” pause to consider the trauma they may be navigating. Speaking out or coping with abuse is never easy. You don’t have to believe every claim, but you can refrain from attacking accusers online.
Society also fails at providing aftercare for survivors. The government, often part of the problem, won’t solve this. It’s up to us. Prevention is critical, but when abuse occurs, step up for your loved ones and community. Protect the vulnerable. it’s a challenging but a rewarding journey.
If you’re contributing to Nostr, you’re helping build a censorship resistant platform where survivors can share their stories freely, no matter how powerful their abusers are. Their voices can endure here, offering strength and hope to others. This gives me great hope for the future.
Virginia Giuffre’s courage was a gift to the world. It was an honor to know and serve her. She will be deeply missed. My hope is that her story inspires others to take on the powerful.
-
@ 52b4a076:e7fad8bd
2025-04-28 00:48:57
I have been recently building NFDB, a new relay DB. This post is meant as a short overview.
Regular relays have challenges
Current relay software have significant challenges, which I have experienced when hosting Nostr.land: - Scalability is only supported by adding full replicas, which does not scale to large relays. - Most relays use slow databases and are not optimized for large scale usage. - Search is near-impossible to implement on standard relays. - Privacy features such as NIP-42 are lacking. - Regular DB maintenance tasks on normal relays require extended downtime. - Fault-tolerance is implemented, if any, using a load balancer, which is limited. - Personalization and advanced filtering is not possible. - Local caching is not supported.
NFDB: A scalable database for large relays
NFDB is a new database meant for medium-large scale relays, built on FoundationDB that provides: - Near-unlimited scalability - Extended fault tolerance - Instant loading - Better search - Better personalization - and more.
Search
NFDB has extended search capabilities including: - Semantic search: Search for meaning, not words. - Interest-based search: Highlight content you care about. - Multi-faceted queries: Easily filter by topic, author group, keywords, and more at the same time. - Wide support for event kinds, including users, articles, etc.
Personalization
NFDB allows significant personalization: - Customized algorithms: Be your own algorithm. - Spam filtering: Filter content to your WoT, and use advanced spam filters. - Topic mutes: Mute topics, not keywords. - Media filtering: With Nostr.build, you will be able to filter NSFW and other content - Low data mode: Block notes that use high amounts of cellular data. - and more
Other
NFDB has support for many other features such as: - NIP-42: Protect your privacy with private drafts and DMs - Microrelays: Easily deploy your own personal microrelay - Containers: Dedicated, fast storage for discoverability events such as relay lists
Calcite: A local microrelay database
Calcite is a lightweight, local version of NFDB that is meant for microrelays and caching, meant for thousands of personal microrelays.
Calcite HA is an additional layer that allows live migration and relay failover in under 30 seconds, providing higher availability compared to current relays with greater simplicity. Calcite HA is enabled in all Calcite deployments.
For zero-downtime, NFDB is recommended.
Noswhere SmartCache
Relays are fixed in one location, but users can be anywhere.
Noswhere SmartCache is a CDN for relays that dynamically caches data on edge servers closest to you, allowing: - Multiple regions around the world - Improved throughput and performance - Faster loading times
routerd
routerdis a custom load-balancer optimized for Nostr relays, integrated with SmartCache.routerdis specifically integrated with NFDB and Calcite HA to provide fast failover and high performance.Ending notes
NFDB is planned to be deployed to Nostr.land in the coming weeks.
A lot more is to come. 👀️️️️️️
-
@ 91bea5cd:1df4451c
2025-04-26 10:16:21
O Contexto Legal Brasileiro e o Consentimento
No ordenamento jurídico brasileiro, o consentimento do ofendido pode, em certas circunstâncias, afastar a ilicitude de um ato que, sem ele, configuraria crime (como lesão corporal leve, prevista no Art. 129 do Código Penal). Contudo, o consentimento tem limites claros: não é válido para bens jurídicos indisponíveis, como a vida, e sua eficácia é questionável em casos de lesões corporais graves ou gravíssimas.
A prática de BDSM consensual situa-se em uma zona complexa. Em tese, se ambos os parceiros são adultos, capazes, e consentiram livre e informadamente nos atos praticados, sem que resultem em lesões graves permanentes ou risco de morte não consentido, não haveria crime. O desafio reside na comprovação desse consentimento, especialmente se uma das partes, posteriormente, o negar ou alegar coação.
A Lei Maria da Penha (Lei nº 11.340/2006)
A Lei Maria da Penha é um marco fundamental na proteção da mulher contra a violência doméstica e familiar. Ela estabelece mecanismos para coibir e prevenir tal violência, definindo suas formas (física, psicológica, sexual, patrimonial e moral) e prevendo medidas protetivas de urgência.
Embora essencial, a aplicação da lei em contextos de BDSM pode ser delicada. Uma alegação de violência por parte da mulher, mesmo que as lesões ou situações decorram de práticas consensuais, tende a receber atenção prioritária das autoridades, dada a presunção de vulnerabilidade estabelecida pela lei. Isso pode criar um cenário onde o parceiro masculino enfrenta dificuldades significativas em demonstrar a natureza consensual dos atos, especialmente se não houver provas robustas pré-constituídas.
Outros riscos:
Lesão corporal grave ou gravíssima (art. 129, §§ 1º e 2º, CP), não pode ser justificada pelo consentimento, podendo ensejar persecução penal.
Crimes contra a dignidade sexual (arts. 213 e seguintes do CP) são de ação pública incondicionada e independem de representação da vítima para a investigação e denúncia.
Riscos de Falsas Acusações e Alegação de Coação Futura
Os riscos para os praticantes de BDSM, especialmente para o parceiro que assume o papel dominante ou que inflige dor/restrição (frequentemente, mas não exclusivamente, o homem), podem surgir de diversas frentes:
- Acusações Externas: Vizinhos, familiares ou amigos que desconhecem a natureza consensual do relacionamento podem interpretar sons, marcas ou comportamentos como sinais de abuso e denunciar às autoridades.
- Alegações Futuras da Parceira: Em caso de término conturbado, vingança, arrependimento ou mudança de perspectiva, a parceira pode reinterpretar as práticas passadas como abuso e buscar reparação ou retaliação através de uma denúncia. A alegação pode ser de que o consentimento nunca existiu ou foi viciado.
- Alegação de Coação: Uma das formas mais complexas de refutar é a alegação de que o consentimento foi obtido mediante coação (física, moral, psicológica ou econômica). A parceira pode alegar, por exemplo, que se sentia pressionada, intimidada ou dependente, e que seu "sim" não era genuíno. Provar a ausência de coação a posteriori é extremamente difícil.
- Ingenuidade e Vulnerabilidade Masculina: Muitos homens, confiando na dinâmica consensual e na parceira, podem negligenciar a necessidade de precauções. A crença de que "isso nunca aconteceria comigo" ou a falta de conhecimento sobre as implicações legais e o peso processual de uma acusação no âmbito da Lei Maria da Penha podem deixá-los vulneráveis. A presença de marcas físicas, mesmo que consentidas, pode ser usada como evidência de agressão, invertendo o ônus da prova na prática, ainda que não na teoria jurídica.
Estratégias de Prevenção e Mitigação
Não existe um método infalível para evitar completamente o risco de uma falsa acusação, mas diversas medidas podem ser adotadas para construir um histórico de consentimento e reduzir vulnerabilidades:
- Comunicação Explícita e Contínua: A base de qualquer prática BDSM segura é a comunicação constante. Negociar limites, desejos, palavras de segurança ("safewords") e expectativas antes, durante e depois das cenas é crucial. Manter registros dessas negociações (e-mails, mensagens, diários compartilhados) pode ser útil.
-
Documentação do Consentimento:
-
Contratos de Relacionamento/Cena: Embora a validade jurídica de "contratos BDSM" seja discutível no Brasil (não podem afastar normas de ordem pública), eles servem como forte evidência da intenção das partes, da negociação detalhada de limites e do consentimento informado. Devem ser claros, datados, assinados e, idealmente, reconhecidos em cartório (para prova de data e autenticidade das assinaturas).
-
Registros Audiovisuais: Gravar (com consentimento explícito para a gravação) discussões sobre consentimento e limites antes das cenas pode ser uma prova poderosa. Gravar as próprias cenas é mais complexo devido a questões de privacidade e potencial uso indevido, mas pode ser considerado em casos específicos, sempre com consentimento mútuo documentado para a gravação.
Importante: a gravação deve ser com ciência da outra parte, para não configurar violação da intimidade (art. 5º, X, da Constituição Federal e art. 20 do Código Civil).
-
-
Testemunhas: Em alguns contextos de comunidade BDSM, a presença de terceiros de confiança durante negociações ou mesmo cenas pode servir como testemunho, embora isso possa alterar a dinâmica íntima do casal.
- Estabelecimento Claro de Limites e Palavras de Segurança: Definir e respeitar rigorosamente os limites (o que é permitido, o que é proibido) e as palavras de segurança é fundamental. O desrespeito a uma palavra de segurança encerra o consentimento para aquele ato.
- Avaliação Contínua do Consentimento: O consentimento não é um cheque em branco; ele deve ser entusiástico, contínuo e revogável a qualquer momento. Verificar o bem-estar do parceiro durante a cena ("check-ins") é essencial.
- Discrição e Cuidado com Evidências Físicas: Ser discreto sobre a natureza do relacionamento pode evitar mal-entendidos externos. Após cenas que deixem marcas, é prudente que ambos os parceiros estejam cientes e de acordo, talvez documentando por fotos (com data) e uma nota sobre a consensualidade da prática que as gerou.
- Aconselhamento Jurídico Preventivo: Consultar um advogado especializado em direito de família e criminal, com sensibilidade para dinâmicas de relacionamento alternativas, pode fornecer orientação personalizada sobre as melhores formas de documentar o consentimento e entender os riscos legais específicos.
Observações Importantes
- Nenhuma documentação substitui a necessidade de consentimento real, livre, informado e contínuo.
- A lei brasileira protege a "integridade física" e a "dignidade humana". Práticas que resultem em lesões graves ou que violem a dignidade de forma não consentida (ou com consentimento viciado) serão ilegais, independentemente de qualquer acordo prévio.
- Em caso de acusação, a existência de documentação robusta de consentimento não garante a absolvição, mas fortalece significativamente a defesa, ajudando a demonstrar a natureza consensual da relação e das práticas.
-
A alegação de coação futura é particularmente difícil de prevenir apenas com documentos. Um histórico consistente de comunicação aberta (whatsapp/telegram/e-mails), respeito mútuo e ausência de dependência ou controle excessivo na relação pode ajudar a contextualizar a dinâmica como não coercitiva.
-
Cuidado com Marcas Visíveis e Lesões Graves Práticas que resultam em hematomas severos ou lesões podem ser interpretadas como agressão, mesmo que consentidas. Evitar excessos protege não apenas a integridade física, mas também evita questionamentos legais futuros.
O que vem a ser consentimento viciado
No Direito, consentimento viciado é quando a pessoa concorda com algo, mas a vontade dela não é livre ou plena — ou seja, o consentimento existe formalmente, mas é defeituoso por alguma razão.
O Código Civil brasileiro (art. 138 a 165) define várias formas de vício de consentimento. As principais são:
Erro: A pessoa se engana sobre o que está consentindo. (Ex.: A pessoa acredita que vai participar de um jogo leve, mas na verdade é exposta a práticas pesadas.)
Dolo: A pessoa é enganada propositalmente para aceitar algo. (Ex.: Alguém mente sobre o que vai acontecer durante a prática.)
Coação: A pessoa é forçada ou ameaçada a consentir. (Ex.: "Se você não aceitar, eu termino com você" — pressão emocional forte pode ser vista como coação.)
Estado de perigo ou lesão: A pessoa aceita algo em situação de necessidade extrema ou abuso de sua vulnerabilidade. (Ex.: Alguém em situação emocional muito fragilizada é induzida a aceitar práticas que normalmente recusaria.)
No contexto de BDSM, isso é ainda mais delicado: Mesmo que a pessoa tenha "assinado" um contrato ou dito "sim", se depois ela alegar que seu consentimento foi dado sob medo, engano ou pressão psicológica, o consentimento pode ser considerado viciado — e, portanto, juridicamente inválido.
Isso tem duas implicações sérias:
-
O crime não se descaracteriza: Se houver vício, o consentimento é ignorado e a prática pode ser tratada como crime normal (lesão corporal, estupro, tortura, etc.).
-
A prova do consentimento precisa ser sólida: Mostrando que a pessoa estava informada, lúcida, livre e sem qualquer tipo de coação.
Consentimento viciado é quando a pessoa concorda formalmente, mas de maneira enganada, forçada ou pressionada, tornando o consentimento inútil para efeitos jurídicos.
Conclusão
Casais que praticam BDSM consensual no Brasil navegam em um terreno que exige não apenas confiança mútua e comunicação excepcional, mas também uma consciência aguçada das complexidades legais e dos riscos de interpretações equivocadas ou acusações mal-intencionadas. Embora o BDSM seja uma expressão legítima da sexualidade humana, sua prática no Brasil exige responsabilidade redobrada. Ter provas claras de consentimento, manter a comunicação aberta e agir com prudência são formas eficazes de se proteger de falsas alegações e preservar a liberdade e a segurança de todos os envolvidos. Embora leis controversas como a Maria da Penha sejam "vitais" para a proteção contra a violência real, os praticantes de BDSM, e em particular os homens nesse contexto, devem adotar uma postura proativa e prudente para mitigar os riscos inerentes à potencial má interpretação ou instrumentalização dessas práticas e leis, garantindo que a expressão de sua consensualidade esteja resguardada na medida do possível.
Importante: No Brasil, mesmo com tudo isso, o Ministério Público pode denunciar por crime como lesão corporal grave, estupro ou tortura, independente de consentimento. Então a prudência nas práticas é fundamental.
Aviso Legal: Este artigo tem caráter meramente informativo e não constitui aconselhamento jurídico. As leis e interpretações podem mudar, e cada situação é única. Recomenda-se buscar orientação de um advogado qualificado para discutir casos específicos.
Se curtiu este artigo faça uma contribuição, se tiver algum ponto relevante para o artigo deixe seu comentário.
-
@ 3bf0c63f:aefa459d
2025-04-25 18:55:52
Report of how the money Jack donated to the cause in December 2022 has been misused so far.
Bounties given
March 2025
- Dhalsim: 1,110,540 - Work on Nostr wiki data processing
February 2025
- BOUNTY* NullKotlinDev: 950,480 - Twine RSS reader Nostr integration
- Dhalsim: 2,094,584 - Work on Hypothes.is Nostr fork
- Constant, Biz and J: 11,700,588 - Nostr Special Forces
January 2025
- Constant, Biz and J: 11,610,987 - Nostr Special Forces
- BOUNTY* NullKotlinDev: 843,840 - Feeder RSS reader Nostr integration
- BOUNTY* NullKotlinDev: 797,500 - ReadYou RSS reader Nostr integration
December 2024
- BOUNTY* tijl: 1,679,500 - Nostr integration into RSS readers yarr and miniflux
- Constant, Biz and J: 10,736,166 - Nostr Special Forces
- Thereza: 1,020,000 - Podcast outreach initiative
November 2024
- Constant, Biz and J: 5,422,464 - Nostr Special Forces
October 2024
- Nostrdam: 300,000 - hackathon prize
- Svetski: 5,000,000 - Latin America Nostr events contribution
- Quentin: 5,000,000 - nostrcheck.me
June 2024
- Darashi: 5,000,000 - maintaining nos.today, searchnos, search.nos.today and other experiments
- Toshiya: 5,000,000 - keeping the NIPs repo clean and other stuff
May 2024
- James: 3,500,000 - https://github.com/jamesmagoo/nostr-writer
- Yakihonne: 5,000,000 - spreading the word in Asia
- Dashu: 9,000,000 - https://github.com/haorendashu/nostrmo
February 2024
- Viktor: 5,000,000 - https://github.com/viktorvsk/saltivka and https://github.com/viktorvsk/knowstr
- Eric T: 5,000,000 - https://github.com/tcheeric/nostr-java
- Semisol: 5,000,000 - https://relay.noswhere.com/ and https://hist.nostr.land relays
- Sebastian: 5,000,000 - Drupal stuff and nostr-php work
- tijl: 5,000,000 - Cloudron, Yunohost and Fraidycat attempts
- Null Kotlin Dev: 5,000,000 - AntennaPod attempt
December 2023
- hzrd: 5,000,000 - Nostrudel
- awayuki: 5,000,000 - NOSTOPUS illustrations
- bera: 5,000,000 - getwired.app
- Chris: 5,000,000 - resolvr.io
- NoGood: 10,000,000 - nostrexplained.com stories
October 2023
- SnowCait: 5,000,000 - https://nostter.vercel.app/ and other tools
- Shaun: 10,000,000 - https://yakihonne.com/, events and work on Nostr awareness
- Derek Ross: 10,000,000 - spreading the word around the world
- fmar: 5,000,000 - https://github.com/frnandu/yana
- The Nostr Report: 2,500,000 - curating stuff
- james magoo: 2,500,000 - the Obsidian plugin: https://github.com/jamesmagoo/nostr-writer
August 2023
- Paul Miller: 5,000,000 - JS libraries and cryptography-related work
- BOUNTY tijl: 5,000,000 - https://github.com/github-tijlxyz/wikinostr
- gzuus: 5,000,000 - https://nostree.me/
July 2023
- syusui-s: 5,000,000 - rabbit, a tweetdeck-like Nostr client: https://syusui-s.github.io/rabbit/
- kojira: 5,000,000 - Nostr fanzine, Nostr discussion groups in Japan, hardware experiments
- darashi: 5,000,000 - https://github.com/darashi/nos.today, https://github.com/darashi/searchnos, https://github.com/darashi/murasaki
- jeff g: 5,000,000 - https://nostr.how and https://listr.lol, plus other contributions
- cloud fodder: 5,000,000 - https://nostr1.com (open-source)
- utxo.one: 5,000,000 - https://relaying.io (open-source)
- Max DeMarco: 10,269,507 - https://www.youtube.com/watch?v=aA-jiiepOrE
- BOUNTY optout21: 1,000,000 - https://github.com/optout21/nip41-proto0 (proposed nip41 CLI)
- BOUNTY Leo: 1,000,000 - https://github.com/leo-lox/camelus (an old relay thing I forgot exactly)
June 2023
- BOUNTY: Sepher: 2,000,000 - a webapp for making lists of anything: https://pinstr.app/
- BOUNTY: Kieran: 10,000,000 - implement gossip algorithm on Snort, implement all the other nice things: manual relay selection, following hints etc.
- Mattn: 5,000,000 - a myriad of projects and contributions to Nostr projects: https://github.com/search?q=owner%3Amattn+nostr&type=code
- BOUNTY: lynn: 2,000,000 - a simple and clean git nostr CLI written in Go, compatible with William's original git-nostr-tools; and implement threaded comments on https://github.com/fiatjaf/nocomment.
- Jack Chakany: 5,000,000 - https://github.com/jacany/nblog
- BOUNTY: Dan: 2,000,000 - https://metadata.nostr.com/
April 2023
- BOUNTY: Blake Jakopovic: 590,000 - event deleter tool, NIP dependency organization
- BOUNTY: koalasat: 1,000,000 - display relays
- BOUNTY: Mike Dilger: 4,000,000 - display relays, follow event hints (Gossip)
- BOUNTY: kaiwolfram: 5,000,000 - display relays, follow event hints, choose relays to publish (Nozzle)
- Daniele Tonon: 3,000,000 - Gossip
- bu5hm4nn: 3,000,000 - Gossip
- BOUNTY: hodlbod: 4,000,000 - display relays, follow event hints
March 2023
- Doug Hoyte: 5,000,000 sats - https://github.com/hoytech/strfry
- Alex Gleason: 5,000,000 sats - https://gitlab.com/soapbox-pub/mostr
- verbiricha: 5,000,000 sats - https://badges.page/, https://habla.news/
- talvasconcelos: 5,000,000 sats - https://migrate.nostr.com, https://read.nostr.com, https://write.nostr.com/
- BOUNTY: Gossip model: 5,000,000 - https://camelus.app/
- BOUNTY: Gossip model: 5,000,000 - https://github.com/kaiwolfram/Nozzle
- BOUNTY: Bounty Manager: 5,000,000 - https://nostrbounties.com/
February 2023
- styppo: 5,000,000 sats - https://hamstr.to/
- sandwich: 5,000,000 sats - https://nostr.watch/
- BOUNTY: Relay-centric client designs: 5,000,000 sats https://bountsr.org/design/2023/01/26/relay-based-design.html
- BOUNTY: Gossip model on https://coracle.social/: 5,000,000 sats
- Nostrovia Podcast: 3,000,000 sats - https://nostrovia.org/
- BOUNTY: Nostr-Desk / Monstr: 5,000,000 sats - https://github.com/alemmens/monstr
- Mike Dilger: 5,000,000 sats - https://github.com/mikedilger/gossip
January 2023
- ismyhc: 5,000,000 sats - https://github.com/Galaxoid-Labs/Seer
- Martti Malmi: 5,000,000 sats - https://iris.to/
- Carlos Autonomous: 5,000,000 sats - https://github.com/BrightonBTC/bija
- Koala Sat: 5,000,000 - https://github.com/KoalaSat/nostros
- Vitor Pamplona: 5,000,000 - https://github.com/vitorpamplona/amethyst
- Cameri: 5,000,000 - https://github.com/Cameri/nostream
December 2022
- William Casarin: 7 BTC - splitting the fund
- pseudozach: 5,000,000 sats - https://nostr.directory/
- Sondre Bjellas: 5,000,000 sats - https://notes.blockcore.net/
- Null Dev: 5,000,000 sats - https://github.com/KotlinGeekDev/Nosky
- Blake Jakopovic: 5,000,000 sats - https://github.com/blakejakopovic/nostcat, https://github.com/blakejakopovic/nostreq and https://github.com/blakejakopovic/NostrEventPlayground
-
@ 21211e6f:8cd9242f
2025-04-22 12:48:33
This is a public note.
-
@ 21211e6f:8cd9242f
2025-04-21 18:30:48
This is a public post.
-
@ e3ba5e1a:5e433365
2025-04-15 11:03:15
Prelude
I wrote this post differently than any of my others. It started with a discussion with AI on an OPSec-inspired review of separation of powers, and evolved into quite an exciting debate! I asked Grok to write up a summary in my overall writing style, which it got pretty well. I've decided to post it exactly as-is. Ultimately, I think there are two solid ideas driving my stance here:
- Perfect is the enemy of the good
- Failure is the crucible of success
Beyond that, just some hard-core belief in freedom, separation of powers, and operating from self-interest.
Intro
Alright, buckle up. I’ve been chewing on this idea for a while, and it’s time to spit it out. Let’s look at the U.S. government like I’d look at a codebase under a cybersecurity audit—OPSEC style, no fluff. Forget the endless debates about what politicians should do. That’s noise. I want to talk about what they can do, the raw powers baked into the system, and why we should stop pretending those powers are sacred. If there’s a hole, either patch it or exploit it. No half-measures. And yeah, I’m okay if the whole thing crashes a bit—failure’s a feature, not a bug.
The Filibuster: A Security Rule with No Teeth
You ever see a firewall rule that’s more theater than protection? That’s the Senate filibuster. Everyone acts like it’s this untouchable guardian of democracy, but here’s the deal: a simple majority can torch it any day. It’s not a law; it’s a Senate preference, like choosing tabs over spaces. When people call killing it the “nuclear option,” I roll my eyes. Nuclear? It’s a button labeled “press me.” If a party wants it gone, they’ll do it. So why the dance?
I say stop playing games. Get rid of the filibuster. If you’re one of those folks who thinks it’s the only thing saving us from tyranny, fine—push for a constitutional amendment to lock it in. That’s a real patch, not a Post-it note. Until then, it’s just a vulnerability begging to be exploited. Every time a party threatens to nuke it, they’re admitting it’s not essential. So let’s stop pretending and move on.
Supreme Court Packing: Because Nine’s Just a Number
Here’s another fun one: the Supreme Court. Nine justices, right? Sounds official. Except it’s not. The Constitution doesn’t say nine—it’s silent on the number. Congress could pass a law tomorrow to make it 15, 20, or 42 (hitchhiker’s reference, anyone?). Packing the court is always on the table, and both sides know it. It’s like a root exploit just sitting there, waiting for someone to log in.
So why not call the bluff? If you’re in power—say, Trump’s back in the game—say, “I’m packing the court unless we amend the Constitution to fix it at nine.” Force the issue. No more shadowboxing. And honestly? The court’s got way too much power anyway. It’s not supposed to be a super-legislature, but here we are, with justices’ ideologies driving the bus. That’s a bug, not a feature. If the court weren’t such a kingmaker, packing it wouldn’t even matter. Maybe we should be talking about clipping its wings instead of just its size.
The Executive Should Go Full Klingon
Let’s talk presidents. I’m not saying they should wear Klingon armor and start shouting “Qapla’!”—though, let’s be real, that’d be awesome. I’m saying the executive should use every scrap of power the Constitution hands them. Enforce the laws you agree with, sideline the ones you don’t. If Congress doesn’t like it, they’ve got tools: pass new laws, override vetoes, or—here’s the big one—cut the budget. That’s not chaos; that’s the system working as designed.
Right now, the real problem isn’t the president overreaching; it’s the bureaucracy. It’s like a daemon running in the background, eating CPU and ignoring the user. The president’s supposed to be the one steering, but the administrative state’s got its own agenda. Let the executive flex, push the limits, and force Congress to check it. Norms? Pfft. The Constitution’s the spec sheet—stick to it.
Let the System Crash
Here’s where I get a little spicy: I’m totally fine if the government grinds to a halt. Deadlock isn’t a disaster; it’s a feature. If the branches can’t agree, let the president veto, let Congress starve the budget, let enforcement stall. Don’t tell me about “essential services.” Nothing’s so critical it can’t take a breather. Shutdowns force everyone to the table—debate, compromise, or expose who’s dropping the ball. If the public loses trust? Good. They’ll vote out the clowns or live with the circus they elected.
Think of it like a server crash. Sometimes you need a hard reboot to clear the cruft. If voters keep picking the same bad admins, well, the country gets what it deserves. Failure’s the best teacher—way better than limping along on autopilot.
States Are the Real MVPs
If the feds fumble, states step up. Right now, states act like junior devs waiting for the lead engineer to sign off. Why? Federal money. It’s a leash, and it’s tight. Cut that cash, and states will remember they’re autonomous. Some will shine, others will tank—looking at you, California. And I’m okay with that. Let people flee to better-run states. No bailouts, no excuses. States are like competing startups: the good ones thrive, the bad ones pivot or die.
Could it get uneven? Sure. Some states might turn into sci-fi utopias while others look like a post-apocalyptic vidya game. That’s the point—competition sorts it out. Citizens can move, markets adjust, and failure’s a signal to fix your act.
Chaos Isn’t the Enemy
Yeah, this sounds messy. States ignoring federal law, external threats poking at our seams, maybe even a constitutional crisis. I’m not scared. The Supreme Court’s there to referee interstate fights, and Congress sets the rules for state-to-state play. But if it all falls apart? Still cool. States can sort it without a babysitter—it’ll be ugly, but freedom’s worth it. External enemies? They’ll either unify us or break us. If we can’t rally, we don’t deserve the win.
Centralizing power to avoid this is like rewriting your app in a single thread to prevent race conditions—sure, it’s simpler, but you’re begging for a deadlock. Decentralized chaos lets states experiment, lets people escape, lets markets breathe. States competing to cut regulations to attract businesses? That’s a race to the bottom for red tape, but a race to the top for innovation—workers might gripe, but they’ll push back, and the tension’s healthy. Bring it—let the cage match play out. The Constitution’s checks are enough if we stop coddling the system.
Why This Matters
I’m not pitching a utopia. I’m pitching a stress test. The U.S. isn’t a fragile porcelain doll; it’s a rugged piece of hardware built to take some hits. Let it fail a little—filibuster, court, feds, whatever. Patch the holes with amendments if you want, or lean into the grind. Either way, stop fearing the crash. It’s how we debug the republic.
So, what’s your take? Ready to let the system rumble, or got a better way to secure the code? Hit me up—I’m all ears.
-
@ 91bea5cd:1df4451c
2025-04-15 06:27:28
Básico
bash lsblk # Lista todos os diretorios montados.Para criar o sistema de arquivos:
bash mkfs.btrfs -L "ThePool" -f /dev/sdxCriando um subvolume:
bash btrfs subvolume create SubVolMontando Sistema de Arquivos:
bash mount -o compress=zlib,subvol=SubVol,autodefrag /dev/sdx /mntLista os discos formatados no diretório:
bash btrfs filesystem show /mntAdiciona novo disco ao subvolume:
bash btrfs device add -f /dev/sdy /mntLista novamente os discos do subvolume:
bash btrfs filesystem show /mntExibe uso dos discos do subvolume:
bash btrfs filesystem df /mntBalancea os dados entre os discos sobre raid1:
bash btrfs filesystem balance start -dconvert=raid1 -mconvert=raid1 /mntScrub é uma passagem por todos os dados e metadados do sistema de arquivos e verifica as somas de verificação. Se uma cópia válida estiver disponível (perfis de grupo de blocos replicados), a danificada será reparada. Todas as cópias dos perfis replicados são validadas.
iniciar o processo de depuração :
bash btrfs scrub start /mntver o status do processo de depuração Btrfs em execução:
bash btrfs scrub status /mntver o status do scrub Btrfs para cada um dos dispositivos
bash btrfs scrub status -d / data btrfs scrub cancel / dataPara retomar o processo de depuração do Btrfs que você cancelou ou pausou:
btrfs scrub resume / data
Listando os subvolumes:
bash btrfs subvolume list /ReportsCriando um instantâneo dos subvolumes:
Aqui, estamos criando um instantâneo de leitura e gravação chamado snap de marketing do subvolume de marketing.
bash btrfs subvolume snapshot /Reports/marketing /Reports/marketing-snapAlém disso, você pode criar um instantâneo somente leitura usando o sinalizador -r conforme mostrado. O marketing-rosnap é um instantâneo somente leitura do subvolume de marketing
bash btrfs subvolume snapshot -r /Reports/marketing /Reports/marketing-rosnapForçar a sincronização do sistema de arquivos usando o utilitário 'sync'
Para forçar a sincronização do sistema de arquivos, invoque a opção de sincronização conforme mostrado. Observe que o sistema de arquivos já deve estar montado para que o processo de sincronização continue com sucesso.
bash btrfs filsystem sync /ReportsPara excluir o dispositivo do sistema de arquivos, use o comando device delete conforme mostrado.
bash btrfs device delete /dev/sdc /ReportsPara sondar o status de um scrub, use o comando scrub status com a opção -dR .
bash btrfs scrub status -dR / RelatóriosPara cancelar a execução do scrub, use o comando scrub cancel .
bash $ sudo btrfs scrub cancel / ReportsPara retomar ou continuar com uma depuração interrompida anteriormente, execute o comando de cancelamento de depuração
bash sudo btrfs scrub resume /Reportsmostra o uso do dispositivo de armazenamento:
btrfs filesystem usage /data
Para distribuir os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID (incluindo o dispositivo de armazenamento recém-adicionado) montados no diretório /data , execute o seguinte comando:
sudo btrfs balance start --full-balance /data
Pode demorar um pouco para espalhar os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID se ele contiver muitos dados.
Opções importantes de montagem Btrfs
Nesta seção, vou explicar algumas das importantes opções de montagem do Btrfs. Então vamos começar.
As opções de montagem Btrfs mais importantes são:
**1. acl e noacl
**ACL gerencia permissões de usuários e grupos para os arquivos/diretórios do sistema de arquivos Btrfs.
A opção de montagem acl Btrfs habilita ACL. Para desabilitar a ACL, você pode usar a opção de montagem noacl .
Por padrão, a ACL está habilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem acl por padrão.
**2. autodefrag e noautodefrag
**Desfragmentar um sistema de arquivos Btrfs melhorará o desempenho do sistema de arquivos reduzindo a fragmentação de dados.
A opção de montagem autodefrag permite a desfragmentação automática do sistema de arquivos Btrfs.
A opção de montagem noautodefrag desativa a desfragmentação automática do sistema de arquivos Btrfs.
Por padrão, a desfragmentação automática está desabilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem noautodefrag por padrão.
**3. compactar e compactar-forçar
**Controla a compactação de dados no nível do sistema de arquivos do sistema de arquivos Btrfs.
A opção compactar compacta apenas os arquivos que valem a pena compactar (se compactar o arquivo economizar espaço em disco).
A opção compress-force compacta todos os arquivos do sistema de arquivos Btrfs, mesmo que a compactação do arquivo aumente seu tamanho.
O sistema de arquivos Btrfs suporta muitos algoritmos de compactação e cada um dos algoritmos de compactação possui diferentes níveis de compactação.
Os algoritmos de compactação suportados pelo Btrfs são: lzo , zlib (nível 1 a 9) e zstd (nível 1 a 15).
Você pode especificar qual algoritmo de compactação usar para o sistema de arquivos Btrfs com uma das seguintes opções de montagem:
- compress=algoritmo:nível
- compress-force=algoritmo:nível
Para obter mais informações, consulte meu artigo Como habilitar a compactação do sistema de arquivos Btrfs .
**4. subvol e subvolid
**Estas opções de montagem são usadas para montar separadamente um subvolume específico de um sistema de arquivos Btrfs.
A opção de montagem subvol é usada para montar o subvolume de um sistema de arquivos Btrfs usando seu caminho relativo.
A opção de montagem subvolid é usada para montar o subvolume de um sistema de arquivos Btrfs usando o ID do subvolume.
Para obter mais informações, consulte meu artigo Como criar e montar subvolumes Btrfs .
**5. dispositivo
A opção de montagem de dispositivo** é usada no sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs.
Em alguns casos, o sistema operacional pode falhar ao detectar os dispositivos de armazenamento usados em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs. Nesses casos, você pode usar a opção de montagem do dispositivo para especificar os dispositivos que deseja usar para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar a opção de montagem de dispositivo várias vezes para carregar diferentes dispositivos de armazenamento para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar o nome do dispositivo (ou seja, sdb , sdc ) ou UUID , UUID_SUB ou PARTUUID do dispositivo de armazenamento com a opção de montagem do dispositivo para identificar o dispositivo de armazenamento.
Por exemplo,
- dispositivo=/dev/sdb
- dispositivo=/dev/sdb,dispositivo=/dev/sdc
- dispositivo=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d
- device=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d,device=UUID_SUB=f7ce4875-0874-436a-b47d-3edef66d3424
**6. degraded
A opção de montagem degradada** permite que um RAID Btrfs seja montado com menos dispositivos de armazenamento do que o perfil RAID requer.
Por exemplo, o perfil raid1 requer a presença de 2 dispositivos de armazenamento. Se um dos dispositivos de armazenamento não estiver disponível em qualquer caso, você usa a opção de montagem degradada para montar o RAID mesmo que 1 de 2 dispositivos de armazenamento esteja disponível.
**7. commit
A opção commit** mount é usada para definir o intervalo (em segundos) dentro do qual os dados serão gravados no dispositivo de armazenamento.
O padrão é definido como 30 segundos.
Para definir o intervalo de confirmação para 15 segundos, você pode usar a opção de montagem commit=15 (digamos).
**8. ssd e nossd
A opção de montagem ssd** informa ao sistema de arquivos Btrfs que o sistema de arquivos está usando um dispositivo de armazenamento SSD, e o sistema de arquivos Btrfs faz a otimização SSD necessária.
A opção de montagem nossd desativa a otimização do SSD.
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem de SSD será habilitada. Caso contrário, a opção de montagem nossd é habilitada.
**9. ssd_spread e nossd_spread
A opção de montagem ssd_spread** tenta alocar grandes blocos contínuos de espaço não utilizado do SSD. Esse recurso melhora o desempenho de SSDs de baixo custo (baratos).
A opção de montagem nossd_spread desativa o recurso ssd_spread .
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem ssd_spread será habilitada. Caso contrário, a opção de montagem nossd_spread é habilitada.
**10. descarte e nodiscard
Se você estiver usando um SSD que suporte TRIM enfileirado assíncrono (SATA rev3.1), a opção de montagem de descarte** permitirá o descarte de blocos de arquivos liberados. Isso melhorará o desempenho do SSD.
Se o SSD não suportar TRIM enfileirado assíncrono, a opção de montagem de descarte prejudicará o desempenho do SSD. Nesse caso, a opção de montagem nodiscard deve ser usada.
Por padrão, a opção de montagem nodiscard é usada.
**11. norecovery
Se a opção de montagem norecovery** for usada, o sistema de arquivos Btrfs não tentará executar a operação de recuperação de dados no momento da montagem.
**12. usebackuproot e nousebackuproot
Se a opção de montagem usebackuproot for usada, o sistema de arquivos Btrfs tentará recuperar qualquer raiz de árvore ruim/corrompida no momento da montagem. O sistema de arquivos Btrfs pode armazenar várias raízes de árvore no sistema de arquivos. A opção de montagem usebackuproot** procurará uma boa raiz de árvore e usará a primeira boa que encontrar.
A opção de montagem nousebackuproot não verificará ou recuperará raízes de árvore inválidas/corrompidas no momento da montagem. Este é o comportamento padrão do sistema de arquivos Btrfs.
**13. space_cache, space_cache=version, nospace_cache e clear_cache
A opção de montagem space_cache** é usada para controlar o cache de espaço livre. O cache de espaço livre é usado para melhorar o desempenho da leitura do espaço livre do grupo de blocos do sistema de arquivos Btrfs na memória (RAM).
O sistema de arquivos Btrfs suporta 2 versões do cache de espaço livre: v1 (padrão) e v2
O mecanismo de cache de espaço livre v2 melhora o desempenho de sistemas de arquivos grandes (tamanho de vários terabytes).
Você pode usar a opção de montagem space_cache=v1 para definir a v1 do cache de espaço livre e a opção de montagem space_cache=v2 para definir a v2 do cache de espaço livre.
A opção de montagem clear_cache é usada para limpar o cache de espaço livre.
Quando o cache de espaço livre v2 é criado, o cache deve ser limpo para criar um cache de espaço livre v1 .
Portanto, para usar o cache de espaço livre v1 após a criação do cache de espaço livre v2 , as opções de montagem clear_cache e space_cache=v1 devem ser combinadas: clear_cache,space_cache=v1
A opção de montagem nospace_cache é usada para desabilitar o cache de espaço livre.
Para desabilitar o cache de espaço livre após a criação do cache v1 ou v2 , as opções de montagem nospace_cache e clear_cache devem ser combinadas: clear_cache,nosapce_cache
**14. skip_balance
Por padrão, a operação de balanceamento interrompida/pausada de um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs será retomada automaticamente assim que o sistema de arquivos Btrfs for montado. Para desabilitar a retomada automática da operação de equilíbrio interrompido/pausado em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs, você pode usar a opção de montagem skip_balance .**
**15. datacow e nodatacow
A opção datacow** mount habilita o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs. É o comportamento padrão.
Se você deseja desabilitar o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs para os arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatacow .
**16. datasum e nodatasum
A opção datasum** mount habilita a soma de verificação de dados para arquivos recém-criados do sistema de arquivos Btrfs. Este é o comportamento padrão.
Se você não quiser que o sistema de arquivos Btrfs faça a soma de verificação dos dados dos arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatasum .
Perfis Btrfs
Um perfil Btrfs é usado para informar ao sistema de arquivos Btrfs quantas cópias dos dados/metadados devem ser mantidas e quais níveis de RAID devem ser usados para os dados/metadados. O sistema de arquivos Btrfs contém muitos perfis. Entendê-los o ajudará a configurar um RAID Btrfs da maneira que você deseja.
Os perfis Btrfs disponíveis são os seguintes:
single : Se o perfil único for usado para os dados/metadados, apenas uma cópia dos dados/metadados será armazenada no sistema de arquivos, mesmo se você adicionar vários dispositivos de armazenamento ao sistema de arquivos. Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
dup : Se o perfil dup for usado para os dados/metadados, cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos manterá duas cópias dos dados/metadados. Assim, 50% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
raid0 : No perfil raid0 , os dados/metadados serão divididos igualmente em todos os dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, não haverá dados/metadados redundantes (duplicados). Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser usado. Se, em qualquer caso, um dos dispositivos de armazenamento falhar, todo o sistema de arquivos será corrompido. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid0 .
raid1 : No perfil raid1 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a uma falha de unidade. Mas você pode usar apenas 50% do espaço total em disco. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1 .
raid1c3 : No perfil raid1c3 , três cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a duas falhas de unidade, mas você pode usar apenas 33% do espaço total em disco. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c3 .
raid1c4 : No perfil raid1c4 , quatro cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a três falhas de unidade, mas você pode usar apenas 25% do espaço total em disco. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c4 .
raid10 : No perfil raid10 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos, como no perfil raid1 . Além disso, os dados/metadados serão divididos entre os dispositivos de armazenamento, como no perfil raid0 .
O perfil raid10 é um híbrido dos perfis raid1 e raid0 . Alguns dos dispositivos de armazenamento formam arrays raid1 e alguns desses arrays raid1 são usados para formar um array raid0 . Em uma configuração raid10 , o sistema de arquivos pode sobreviver a uma única falha de unidade em cada uma das matrizes raid1 .
Você pode usar 50% do espaço total em disco na configuração raid10 . Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid10 .
raid5 : No perfil raid5 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Uma única paridade será calculada e distribuída entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid5 , o sistema de arquivos pode sobreviver a uma única falha de unidade. Se uma unidade falhar, você pode adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir da paridade distribuída das unidades em execução.
Você pode usar 1 00x(N-1)/N % do total de espaços em disco na configuração raid5 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid5 .
raid6 : No perfil raid6 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Duas paridades serão calculadas e distribuídas entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid6 , o sistema de arquivos pode sobreviver a duas falhas de unidade ao mesmo tempo. Se uma unidade falhar, você poderá adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir das duas paridades distribuídas das unidades em execução.
Você pode usar 100x(N-2)/N % do espaço total em disco na configuração raid6 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid6 .
-
@ 9223d2fa:b57e3de7
2025-04-15 02:54:00
12,600 steps
-
@ 0fa80bd3:ea7325de
2025-04-09 21:19:39
DAOs promised decentralization. They offered a system where every member could influence a project's direction, where money and power were transparently distributed, and decisions were made through voting. All of it recorded immutably on the blockchain, free from middlemen.
But something didn’t work out. In practice, most DAOs haven’t evolved into living, self-organizing organisms. They became something else: clubs where participation is unevenly distributed. Leaders remained - only now without formal titles. They hold influence through control over communications, task framing, and community dynamics. Centralization still exists, just wrapped in a new package.
But there's a second, less obvious problem. Crowds can’t create strategy. In DAOs, people vote for what "feels right to the majority." But strategy isn’t about what feels good - it’s about what’s necessary. Difficult, unpopular, yet forward-looking decisions often fail when put to a vote. A founder’s vision is a risk. But in healthy teams, it’s that risk that drives progress. In DAOs, risk is almost always diluted until it becomes something safe and vague.
Instead of empowering leaders, DAOs often neutralize them. This is why many DAOs resemble consensus machines. Everyone talks, debates, and participates, but very little actually gets done. One person says, “Let’s jump,” and five others respond, “Let’s discuss that first.” This dynamic might work for open forums, but not for action.
Decentralization works when there’s trust and delegation, not just voting. Until DAOs develop effective systems for assigning roles, taking ownership, and acting with flexibility, they will keep losing ground to old-fashioned startups led by charismatic founders with a clear vision.
We’ve seen this in many real-world cases. Take MakerDAO, one of the most mature and technically sophisticated DAOs. Its governance token (MKR) holders vote on everything from interest rates to protocol upgrades. While this has allowed for transparency and community involvement, the process is often slow and bureaucratic. Complex proposals stall. Strategic pivots become hard to implement. And in 2023, a controversial proposal to allocate billions to real-world assets passed only narrowly, after months of infighting - highlighting how vision and execution can get stuck in the mud of distributed governance.
On the other hand, Uniswap DAO, responsible for the largest decentralized exchange, raised governance participation only after launching a delegation system where token holders could choose trusted representatives. Still, much of the activity is limited to a small group of active contributors. The vast majority of token holders remain passive. This raises the question: is it really community-led, or just a formalized power structure with lower transparency?
Then there’s ConstitutionDAO, an experiment that went viral. It raised over $40 million in days to try and buy a copy of the U.S. Constitution. But despite the hype, the DAO failed to win the auction. Afterwards, it struggled with refund logistics, communication breakdowns, and confusion over governance. It was a perfect example of collective enthusiasm without infrastructure or planning - proof that a DAO can raise capital fast but still lack cohesion.
Not all efforts have failed. Projects like Gitcoin DAO have made progress by incentivizing small, individual contributions. Their quadratic funding mechanism rewards projects based on the number of contributors, not just the size of donations, helping to elevate grassroots initiatives. But even here, long-term strategy often falls back on a core group of organizers rather than broad community consensus.
The pattern is clear: when the stakes are low or the tasks are modular, DAOs can coordinate well. But when bold moves are needed—when someone has to take responsibility and act under uncertainty DAOs often freeze. In the name of consensus, they lose momentum.
That’s why the organization of the future can’t rely purely on decentralization. It must encourage individual initiative and the ability to take calculated risks. People need to see their contribution not just as a vote, but as a role with clear actions and expected outcomes. When the situation demands, they should be empowered to act first and present the results to the community afterwards allowing for both autonomy and accountability. That’s not a flaw in the system. It’s how real progress happens.
-
@ c066aac5:6a41a034
2025-04-05 16:58:58
I’m drawn to extremities in art. The louder, the bolder, the more outrageous, the better. Bold art takes me out of the mundane into a whole new world where anything and everything is possible. Having grown up in the safety of the suburban midwest, I was a bit of a rebellious soul in search of the satiation that only came from the consumption of the outrageous. My inclination to find bold art draws me to NOSTR, because I believe NOSTR can be the place where the next generation of artistic pioneers go to express themselves. I also believe that as much as we are able, were should invite them to come create here.
My Background: A Small Side Story
My father was a professional gamer in the 80s, back when there was no money or glory in the avocation. He did get a bit of spotlight though after the fact: in the mid 2000’s there were a few parties making documentaries about that era of gaming as well as current arcade events (namely 2007’sChasing GhostsandThe King of Kong: A Fistful of Quarters). As a result of these documentaries, there was a revival in the arcade gaming scene. My family attended events related to the documentaries or arcade gaming and I became exposed to a lot of things I wouldn’t have been able to find. The producer ofThe King of Kong: A Fistful of Quarters had previously made a documentary calledNew York Dollwhich was centered around the life of bassist Arthur Kane. My 12 year old mind was blown: The New York Dolls were a glam-punk sensation dressed in drag. The music was from another planet. Johnny Thunders’ guitar playing was like Chuck Berry with more distortion and less filter. Later on I got to meet the Galaga record holder at the time, Phil Day, in Ottumwa Iowa. Phil is an Australian man of high intellect and good taste. He exposed me to great creators such as Nick Cave & The Bad Seeds, Shakespeare, Lou Reed, artists who created things that I had previously found inconceivable.
I believe this time period informed my current tastes and interests, but regrettably I think it also put coals on the fire of rebellion within. I stopped taking my parents and siblings seriously, the Christian faith of my family (which I now hold dearly to) seemed like a mundane sham, and I felt I couldn’t fit in with most people because of my avant-garde tastes. So I write this with the caveat that there should be a way to encourage these tastes in children without letting them walk down the wrong path. There is nothing inherently wrong with bold art, but I’d advise parents to carefully find ways to cultivate their children’s tastes without completely shutting them down and pushing them away as a result. My parents were very loving and patient during this time; I thank God for that.
With that out of the way, lets dive in to some bold artists:
Nicolas Cage: Actor
There is an excellent video by Wisecrack on Nicolas Cage that explains him better than I will, which I will linkhere. Nicolas Cage rejects the idea that good acting is tied to mere realism; all of his larger than life acting decisions are deliberate choices. When that clicked for me, I immediately realized the man is a genius. He borrows from Kabuki and German Expressionism, art forms that rely on exaggeration to get the message across. He has even created his own acting style, which he calls Nouveau Shamanic. He augments his imagination to go from acting to being. Rather than using the old hat of method acting, he transports himself to a new world mentally. The projects he chooses to partake in are based on his own interests or what he considers would be a challenge (making a bad script good for example). Thus it doesn’t matter how the end result comes out; he has already achieved his goal as an artist. Because of this and because certain directors don’t know how to use his talents, he has a noticeable amount of duds in his filmography. Dig around the duds, you’ll find some pure gold. I’d personally recommend the filmsPig, Joe, Renfield, and his Christmas film The Family Man.
Nick Cave: Songwriter
What a wild career this man has had! From the apocalyptic mayhem of his band The Birthday Party to the pensive atmosphere of his albumGhosteen, it seems like Nick Cave has tried everything. I think his secret sauce is that he’s always working. He maintains an excellent newsletter calledThe Red Hand Files, he has written screenplays such asLawless, he has written books, he has made great film scores such asThe Assassination of Jesse James by the Coward Robert Ford, the man is religiously prolific. I believe that one of the reasons he is prolific is that he’s not afraid to experiment. If he has an idea, he follows it through to completion. From the albumMurder Ballads(which is comprised of what the title suggests) to his rejected sequel toGladiator(Gladiator: Christ Killer), he doesn’t seem to be afraid to take anything on. This has led to some over the top works as well as some deeply personal works. Albums likeSkeleton TreeandGhosteenwere journeys through the grief of his son’s death. The Boatman’s Callis arguably a better break-up album than anything Taylor Swift has put out. He’s not afraid to be outrageous, he’s not afraid to offend, but most importantly he’s not afraid to be himself. Works I’d recommend include The Birthday Party’sLive 1981-82, Nick Cave & The Bad Seeds’The Boatman’s Call, and the filmLawless.
Jim Jarmusch: Director
I consider Jim’s films to be bold almost in an ironic sense: his works are bold in that they are, for the most part, anti-sensational. He has a rule that if his screenplays are criticized for a lack of action, he makes them even less eventful. Even with sensational settings his films feel very close to reality, and they demonstrate the beauty of everyday life. That's what is bold about his art to me: making the sensational grounded in reality while making everyday reality all the more special. Ghost Dog: The Way of the Samurai is about a modern-day African-American hitman who strictly follows the rules of the ancient Samurai, yet one can resonate with the humanity of a seemingly absurd character. Only Lovers Left Aliveis a vampire love story, but in the middle of a vampire romance one can see their their own relationships in a new deeply human light. Jim’s work reminds me that art reflects life, and that there is sacred beauty in seemingly mundane everyday life. I personally recommend his filmsPaterson,Down by Law, andCoffee and Cigarettes.
NOSTR: We Need Bold Art
NOSTR is in my opinion a path to a better future. In a world creeping slowly towards everything apps, I hope that the protocol where the individual owns their data wins over everything else. I love freedom and sovereignty. If NOSTR is going to win the race of everything apps, we need more than Bitcoin content. We need more than shirtless bros paying for bananas in foreign countries and exercising with girls who have seductive accents. Common people cannot see themselves in such a world. NOSTR needs to catch the attention of everyday people. I don’t believe that this can be accomplished merely by introducing more broadly relevant content; people are searching for content that speaks to them. I believe that NOSTR can and should attract artists of all kinds because NOSTR is one of the few places on the internet where artists can express themselves fearlessly. Getting zaps from NOSTR’s value-for-value ecosystem has far less friction than crowdfunding a creative project or pitching investors that will irreversibly modify an artist’s vision. Having a place where one can post their works without fear of censorship should be extremely enticing. Having a place where one can connect with fellow humans directly as opposed to a sea of bots should seem like the obvious solution. If NOSTR can become a safe haven for artists to express themselves and spread their work, I believe that everyday people will follow. The banker whose stressful job weighs on them will suddenly find joy with an original meme made by a great visual comedian. The programmer for a healthcare company who is drowning in hopeless mundanity could suddenly find a new lust for life by hearing the song of a musician who isn’t afraid to crowdfund their their next project by putting their lighting address on the streets of the internet. The excel guru who loves independent film may find that NOSTR is the best way to support non corporate movies. My closing statement: continue to encourage the artists in your life as I’m sure you have been, but while you’re at it give them the purple pill. You may very well be a part of building a better future.
-
@ 04c915da:3dfbecc9
2025-03-26 20:54:33
Capitalism is the most effective system for scaling innovation. The pursuit of profit is an incredibly powerful human incentive. Most major improvements to human society and quality of life have resulted from this base incentive. Market competition often results in the best outcomes for all.
That said, some projects can never be monetized. They are open in nature and a business model would centralize control. Open protocols like bitcoin and nostr are not owned by anyone and if they were it would destroy the key value propositions they provide. No single entity can or should control their use. Anyone can build on them without permission.
As a result, open protocols must depend on donation based grant funding from the people and organizations that rely on them. This model works but it is slow and uncertain, a grind where sustainability is never fully reached but rather constantly sought. As someone who has been incredibly active in the open source grant funding space, I do not think people truly appreciate how difficult it is to raise charitable money and deploy it efficiently.
Projects that can be monetized should be. Profitability is a super power. When a business can generate revenue, it taps into a self sustaining cycle. Profit fuels growth and development while providing projects independence and agency. This flywheel effect is why companies like Google, Amazon, and Apple have scaled to global dominance. The profit incentive aligns human effort with efficiency. Businesses must innovate, cut waste, and deliver value to survive.
Contrast this with non monetized projects. Without profit, they lean on external support, which can dry up or shift with donor priorities. A profit driven model, on the other hand, is inherently leaner and more adaptable. It is not charity but survival. When survival is tied to delivering what people want, scale follows naturally.
The real magic happens when profitable, sustainable businesses are built on top of open protocols and software. Consider the many startups building on open source software stacks, such as Start9, Mempool, and Primal, offering premium services on top of the open source software they build out and maintain. Think of companies like Block or Strike, which leverage bitcoin’s open protocol to offer their services on top. These businesses amplify the open software and protocols they build on, driving adoption and improvement at a pace donations alone could never match.
When you combine open software and protocols with profit driven business the result are lean, sustainable companies that grow faster and serve more people than either could alone. Bitcoin’s network, for instance, benefits from businesses that profit off its existence, while nostr will expand as developers monetize apps built on the protocol.
Capitalism scales best because competition results in efficiency. Donation funded protocols and software lay the groundwork, while market driven businesses build on top. The profit incentive acts as a filter, ensuring resources flow to what works, while open systems keep the playing field accessible, empowering users and builders. Together, they create a flywheel of innovation, growth, and global benefit.
-
@ 04c915da:3dfbecc9
2025-03-25 17:43:44
One of the most common criticisms leveled against nostr is the perceived lack of assurance when it comes to data storage. Critics argue that without a centralized authority guaranteeing that all data is preserved, important information will be lost. They also claim that running a relay will become prohibitively expensive. While there is truth to these concerns, they miss the mark. The genius of nostr lies in its flexibility, resilience, and the way it harnesses human incentives to ensure data availability in practice.
A nostr relay is simply a server that holds cryptographically verifiable signed data and makes it available to others. Relays are simple, flexible, open, and require no permission to run. Critics are right that operating a relay attempting to store all nostr data will be costly. What they miss is that most will not run all encompassing archive relays. Nostr does not rely on massive archive relays. Instead, anyone can run a relay and choose to store whatever subset of data they want. This keeps costs low and operations flexible, making relay operation accessible to all sorts of individuals and entities with varying use cases.
Critics are correct that there is no ironclad guarantee that every piece of data will always be available. Unlike bitcoin where data permanence is baked into the system at a steep cost, nostr does not promise that every random note or meme will be preserved forever. That said, in practice, any data perceived as valuable by someone will likely be stored and distributed by multiple entities. If something matters to someone, they will keep a signed copy.
Nostr is the Streisand Effect in protocol form. The Streisand effect is when an attempt to suppress information backfires, causing it to spread even further. With nostr, anyone can broadcast signed data, anyone can store it, and anyone can distribute it. Try to censor something important? Good luck. The moment it catches attention, it will be stored on relays across the globe, copied, and shared by those who find it worth keeping. Data deemed important will be replicated across servers by individuals acting in their own interest.
Nostr’s distributed nature ensures that the system does not rely on a single point of failure or a corporate overlord. Instead, it leans on the collective will of its users. The result is a network where costs stay manageable, participation is open to all, and valuable verifiable data is stored and distributed forever.
-
@ 21335073:a244b1ad
2025-03-18 20:47:50
Warning: This piece contains a conversation about difficult topics. Please proceed with caution.
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book Cypherpunks, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
Course: - The creation of the internet and computers - The fight for cryptography - The tech supply chain from the ground up (example: human rights violations in the supply chain) - Corporate tech - Freedom tech - Data privacy - Digital privacy rights - AI (history-current) - Online safety (predators, scams, catfishing, extortion) - Bitcoin - Laws - How to deal with online hate and harassment - Information on who to contact if you are being abused online or offline - Algorithms - How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ 21335073:a244b1ad
2025-03-18 14:43:08
Warning: This piece contains a conversation about difficult topics. Please proceed with caution.
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book Cypherpunks, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
Course: - The creation of the internet and computers - The fight for cryptography - The tech supply chain from the ground up (example: human rights violations in the supply chain) - Corporate tech - Freedom tech - Data privacy - Digital privacy rights - AI (history-current) - Online safety (predators, scams, catfishing, extortion) - Bitcoin - Laws - How to deal with online hate and harassment - Information on who to contact if you are being abused online or offline - Algorithms - How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ 21335073:a244b1ad
2025-03-15 23:00:40
I want to see Nostr succeed. If you can think of a way I can help make that happen, I’m open to it. I’d like your suggestions.
My schedule’s shifting soon, and I could volunteer a few hours a week to a Nostr project. I won’t have more total time, but how I use it will change.
Why help? I care about freedom. Nostr’s one of the most powerful freedom tools I’ve seen in my lifetime. If I believe that, I should act on it.
I don’t care about money or sats. I’m not rich, I don’t have extra cash. That doesn’t drive me—freedom does. I’m volunteering, not asking for pay.
I’m not here for clout. I’ve had enough spotlight in my life; it doesn’t move me. If I wanted clout, I’d be on Twitter dropping basic takes. Clout’s easy. Freedom’s hard. I’d rather help anonymously. No speaking at events—small meetups are cool for the vibe, but big conferences? Not my thing. I’ll never hit a huge Bitcoin conference. It’s just not my scene.
That said, I could be convinced to step up if it’d really boost Nostr—as long as it’s legal and gets results.
In this space, I’d watch for social engineering. I watch out for it. I’m not here to make friends, just to help. No shade—you all seem great—but I’ve got a full life and awesome friends irl. I don’t need your crew or to be online cool. Connect anonymously if you want; I’d encourage it.
I’m sick of watching other social media alternatives grow while Nostr kinda stalls. I could trash-talk, but I’d rather do something useful.
Skills? I’m good at spotting social media problems and finding possible solutions. I won’t overhype myself—that’s weird—but if you’re responding, you probably see something in me. Perhaps you see something that I don’t see in myself.
If you need help now or later with Nostr projects, reach out. Nostr only—nothing else. Anonymous contact’s fine. Even just a suggestion on how I can pitch in, no project attached, works too. 💜
Creeps or harassment will get blocked or I’ll nuke my simplex code if it becomes a problem.
https://simplex.chat/contact#/?v=2-4&smp=smp%3A%2F%2FSkIkI6EPd2D63F4xFKfHk7I1UGZVNn6k1QWZ5rcyr6w%3D%40smp9.simplex.im%2FbI99B3KuYduH8jDr9ZwyhcSxm2UuR7j0%23%2F%3Fv%3D1-2%26dh%3DMCowBQYDK2VuAyEAS9C-zPzqW41PKySfPCEizcXb1QCus6AyDkTTjfyMIRM%253D%26srv%3Djssqzccmrcws6bhmn77vgmhfjmhwlyr3u7puw4erkyoosywgl67slqqd.onion
-
@ 04c915da:3dfbecc9
2025-03-13 19:39:28
In much of the world, it is incredibly difficult to access U.S. dollars. Local currencies are often poorly managed and riddled with corruption. Billions of people demand a more reliable alternative. While the dollar has its own issues of corruption and mismanagement, it is widely regarded as superior to the fiat currencies it competes with globally. As a result, Tether has found massive success providing low cost, low friction access to dollars. Tether claims 400 million total users, is on track to add 200 million more this year, processes 8.1 million transactions daily, and facilitates $29 billion in daily transfers. Furthermore, their estimates suggest nearly 40% of users rely on it as a savings tool rather than just a transactional currency.
Tether’s rise has made the company a financial juggernaut. Last year alone, Tether raked in over $13 billion in profit, with a lean team of less than 100 employees. Their business model is elegantly simple: hold U.S. Treasuries and collect the interest. With over $113 billion in Treasuries, Tether has turned a straightforward concept into a profit machine.
Tether’s success has resulted in many competitors eager to claim a piece of the pie. This has triggered a massive venture capital grift cycle in USD tokens, with countless projects vying to dethrone Tether. Due to Tether’s entrenched network effect, these challengers face an uphill battle with little realistic chance of success. Most educated participants in the space likely recognize this reality but seem content to perpetuate the grift, hoping to cash out by dumping their equity positions on unsuspecting buyers before they realize the reality of the situation.
Historically, Tether’s greatest vulnerability has been U.S. government intervention. For over a decade, the company operated offshore with few allies in the U.S. establishment, making it a major target for regulatory action. That dynamic has shifted recently and Tether has seized the opportunity. By actively courting U.S. government support, Tether has fortified their position. This strategic move will likely cement their status as the dominant USD token for years to come.
While undeniably a great tool for the millions of users that rely on it, Tether is not without flaws. As a centralized, trusted third party, it holds the power to freeze or seize funds at its discretion. Corporate mismanagement or deliberate malpractice could also lead to massive losses at scale. In their goal of mitigating regulatory risk, Tether has deepened ties with law enforcement, mirroring some of the concerns of potential central bank digital currencies. In practice, Tether operates as a corporate CBDC alternative, collaborating with authorities to surveil and seize funds. The company proudly touts partnerships with leading surveillance firms and its own data reveals cooperation in over 1,000 law enforcement cases, with more than $2.5 billion in funds frozen.
The global demand for Tether is undeniable and the company’s profitability reflects its unrivaled success. Tether is owned and operated by bitcoiners and will likely continue to push forward strategic goals that help the movement as a whole. Recent efforts to mitigate the threat of U.S. government enforcement will likely solidify their network effect and stifle meaningful adoption of rival USD tokens or CBDCs. Yet, for all their achievements, Tether is simply a worse form of money than bitcoin. Tether requires trust in a centralized entity, while bitcoin can be saved or spent without permission. Furthermore, Tether is tied to the value of the US Dollar which is designed to lose purchasing power over time, while bitcoin, as a truly scarce asset, is designed to increase in purchasing power with adoption. As people awaken to the risks of Tether’s control, and the benefits bitcoin provides, bitcoin adoption will likely surpass it.
-
@ 21335073:a244b1ad
2025-03-12 00:40:25
Before I saw those X right-wing political “influencers” parading their Epstein binders in that PR stunt, I’d already posted this on Nostr, an open protocol.
“Today, the world’s attention will likely fixate on Epstein, governmental failures in addressing horrific abuse cases, and the influential figures who perpetrate such acts—yet few will center the victims and survivors in the conversation. The survivors of Epstein went to law enforcement and very little happened. The survivors tried to speak to the corporate press and the corporate press knowingly covered for him. In situations like these social media can serve as one of the only ways for a survivor’s voice to be heard.
It’s becoming increasingly evident that the line between centralized corporate social media and the state is razor-thin, if it exists at all. Time and again, the state shields powerful abusers when it’s politically expedient to do so. In this climate, a survivor attempting to expose someone like Epstein on a corporate tech platform faces an uphill battle—there’s no assurance their voice would even break through. Their story wouldn’t truly belong to them; it’d be at the mercy of the platform, subject to deletion at a whim. Nostr, though, offers a lifeline—a censorship-resistant space where survivors can share their truths, no matter how untouchable the abuser might seem. A survivor could remain anonymous here if they took enough steps.
Nostr holds real promise for amplifying survivor voices. And if you’re here daily, tossing out memes, take heart: you’re helping build a foundation for those who desperately need to be heard.“
That post is untouchable—no CEO, company, employee, or government can delete it. Even if I wanted to, I couldn’t take it down myself. The post will outlive me on the protocol.
The cozy alliance between the state and corporate social media hit me hard during that right-wing X “influencer” PR stunt. Elon owns X. Elon’s a special government employee. X pays those influencers to post. We don’t know who else pays them to post. Those influencers are spurred on by both the government and X to manage the Epstein case narrative. It wasn’t survivors standing there, grinning for photos—it was paid influencers, gatekeepers orchestrating yet another chance to re-exploit the already exploited.
The bond between the state and corporate social media is tight. If the other Epsteins out there are ever to be unmasked, I wouldn’t bet on a survivor’s story staying safe with a corporate tech platform, the government, any social media influencer, or mainstream journalist. Right now, only a protocol can hand survivors the power to truly own their narrative.
I don’t have anything against Elon—I’ve actually been a big supporter. I’m just stating it as I see it. X isn’t censorship resistant and they have an algorithm that they choose not the user. Corporate tech platforms like X can be a better fit for some survivors. X has safety tools and content moderation, making it a solid option for certain individuals. Grok can be a big help for survivors looking for resources or support! As a survivor, you know what works best for you, and safety should always come first—keep that front and center.
That said, a protocol is a game-changer for cases where the powerful are likely to censor. During China's # MeToo movement, survivors faced heavy censorship on social media platforms like Weibo and WeChat, where posts about sexual harassment were quickly removed, and hashtags like # MeToo or "woyeshi" were blocked by government and platform filters. To bypass this, activists turned to blockchain technology encoding their stories—like Yue Xin’s open letter about a Peking University case—into transaction metadata. This made the information tamper-proof and publicly accessible, resisting censorship since blockchain data can’t be easily altered or deleted.
I posted this on X 2/28/25. I wanted to try my first long post on a nostr client. The Epstein cover up is ongoing so it’s still relevant, unfortunately.
If you are a survivor or loved one who is reading this and needs support please reach out to: National Sexual Assault Hotline 24/7 https://rainn.org/
Hours: Available 24 hours
-
@ 0c469779:4b21d8b0
2025-03-11 10:52:49
Sobre el amor
Mi percepción del amor cambió con el tiempo. Leer literatura rusa, principalmente a Dostoevsky, te cambia la perspectiva sobre el amor y la vida en general.
Por mucho tiempo mi visión sobre la vida es que la misma se basa en el sufrimiento: también la Biblia dice esto. El amor es igual, en el amor se sufre y se banca a la otra persona. El problema es que hay una distinción de sufrimientos que por mucho tiempo no tuve en cuenta. Está el sufrimiento del sacrificio y el sufrimiento masoquista. Para mí eran indistintos.
Para mí el ideal era Aliosha y Natasha de Humillados y Ofendidos: estar con alguien que me amase tanto como Natasha a Aliosha, un amor inclusive autodestructivo para Natasha, pero real. Tiene algo de épico, inalcanzable. Un sufrimiento extremo, redentor, es una vara altísima que en la vida cotidiana no se manifiesta. O el amor de Sonia a Raskolnikov, quien se fue hasta Siberia mientras estuvo en prisión para que no se quede solo en Crimen y Castigo.
Este es el tipo de amor que yo esperaba. Y como no me pasó nada tan extremo y las situaciones que llegan a ocurrir en mi vida están lejos de ser tan extremas, me parecía hasta poco lo que estaba pidiendo y que nadie pueda quedarse conmigo me parecía insuficiente.
Ahora pienso que el amor no tiene por qué ser así. Es un pensamiento nuevo que todavía estoy construyendo, y me di cuenta cuando fui a la iglesia, a pesar de que no soy cristiano. La filosofía cristiana me gusta. Va conmigo. Tiene un enfoque de humildad, superación y comunidad que me recuerda al estoicismo.
El amor se trata de resaltar lo mejor que hay en el otro. Se trata de ser un plus, de ayudar. Por eso si uno no está en su mejor etapa, si no se está cómodo con uno mismo, no se puede amar de verdad. El amor empieza en uno mismo.
Los libros son un espejo, no necesariamente vas a aprender de ellos, sino que te muestran quién sos. Resaltás lo que te importa. Por eso a pesar de saber los tipos de amores que hay en los trabajos de Dostoevsky, cometí los mismos errores varias veces.
Ser mejor depende de uno mismo y cada día se pone el granito de arena.
-
@ 04c915da:3dfbecc9
2025-03-10 23:31:30
Bitcoin has always been rooted in freedom and resistance to authority. I get that many of you are conflicted about the US Government stacking but by design we cannot stop anyone from using bitcoin. Many have asked me for my thoughts on the matter, so let’s rip it.
Concern
One of the most glaring issues with the strategic bitcoin reserve is its foundation, built on stolen bitcoin. For those of us who value private property this is an obvious betrayal of our core principles. Rather than proof of work, the bitcoin that seeds this reserve has been taken by force. The US Government should return the bitcoin stolen from Bitfinex and the Silk Road.
Usually stolen bitcoin for the reserve creates a perverse incentive. If governments see a bitcoin as a valuable asset, they will ramp up efforts to confiscate more bitcoin. The precedent is a major concern, and I stand strongly against it, but it should be also noted that governments were already seizing coin before the reserve so this is not really a change in policy.
Ideally all seized bitcoin should be burned, by law. This would align incentives properly and make it less likely for the government to actively increase coin seizures. Due to the truly scarce properties of bitcoin, all burned bitcoin helps existing holders through increased purchasing power regardless. This change would be unlikely but those of us in policy circles should push for it regardless. It would be best case scenario for American bitcoiners and would create a strong foundation for the next century of American leadership.
Optimism
The entire point of bitcoin is that we can spend or save it without permission. That said, it is a massive benefit to not have one of the strongest governments in human history actively trying to ruin our lives.
Since the beginning, bitcoiners have faced horrible regulatory trends. KYC, surveillance, and legal cases have made using bitcoin and building bitcoin businesses incredibly difficult. It is incredibly important to note that over the past year that trend has reversed for the first time in a decade. A strategic bitcoin reserve is a key driver of this shift. By holding bitcoin, the strongest government in the world has signaled that it is not just a fringe technology but rather truly valuable, legitimate, and worth stacking.
This alignment of incentives changes everything. The US Government stacking proves bitcoin’s worth. The resulting purchasing power appreciation helps all of us who are holding coin and as bitcoin succeeds our government receives direct benefit. A beautiful positive feedback loop.
Realism
We are trending in the right direction. A strategic bitcoin reserve is a sign that the state sees bitcoin as an asset worth embracing rather than destroying. That said, there is a lot of work left to be done. We cannot be lulled into complacency, the time to push forward is now, and we cannot take our foot off the gas. We have a seat at the table for the first time ever. Let's make it worth it.
We must protect the right to free usage of bitcoin and other digital technologies. Freedom in the digital age must be taken and defended, through both technical and political avenues. Multiple privacy focused developers are facing long jail sentences for building tools that protect our freedom. These cases are not just legal battles. They are attacks on the soul of bitcoin. We need to rally behind them, fight for their freedom, and ensure the ethos of bitcoin survives this new era of government interest. The strategic reserve is a step in the right direction, but it is up to us to hold the line and shape the future.
-
@ 4857600b:30b502f4
2025-03-10 12:09:35
At this point, we should be arresting, not firing, any FBI employee who delays, destroys, or withholds information on the Epstein case. There is ZERO explanation I will accept for redacting anything for “national security” reasons. A lot of Trump supporters are losing patience with Pam Bondi. I will give her the benefit of the doubt for now since the corruption within the whole security/intelligence apparatus of our country runs deep. However, let’s not forget that probably Trump’s biggest mistakes in his first term involved picking weak and easily corruptible (or blackmailable) officials. It seemed every month a formerly-loyal person did a complete 180 degree turn and did everything they could to screw him over, regardless of the betrayal’s effect on the country or whatever principles that person claimed to have. I think he’s fixed his screening process, but since we’re talking about the FBI, we know they have the power to dig up any dirt or blackmail material available, or just make it up. In the Epstein case, it’s probably better to go after Bondi than give up a treasure trove of blackmail material against the long list of members on his client list.
-
@ 4925ea33:025410d8
2025-03-08 00:38:48
1. O que é um Aromaterapeuta?

O aromaterapeuta é um profissional especializado na prática da Aromaterapia, responsável pelo uso adequado de óleos essenciais, ervas aromáticas, águas florais e destilados herbais para fins terapêuticos.
A atuação desse profissional envolve diferentes métodos de aplicação, como inalação, uso tópico, sempre considerando a segurança e a necessidade individual do cliente. A Aromaterapia pode auxiliar na redução do estresse, alívio de dores crônicas, relaxamento muscular e melhora da respiração, entre outros benefícios.
Além disso, os aromaterapeutas podem trabalhar em conjunto com outros profissionais da saúde para oferecer um tratamento complementar em diversas condições. Como já mencionado no artigo sobre "Como evitar processos alérgicos na prática da Aromaterapia", é essencial ter acompanhamento profissional, pois os óleos essenciais são altamente concentrados e podem causar reações adversas se utilizados de forma inadequada.
2. Como um Aromaterapeuta Pode Ajudar?

Você pode procurar um aromaterapeuta para diferentes necessidades, como:
✔ Questões Emocionais e Psicológicas
Auxílio em momentos de luto, divórcio, demissão ou outras situações desafiadoras.
Apoio na redução do estresse, ansiedade e insônia.
Vale lembrar que, em casos de transtornos psiquiátricos, a Aromaterapia deve ser usada como terapia complementar, associada ao tratamento médico.
✔ Questões Físicas
Dores musculares e articulares.
Problemas respiratórios como rinite, sinusite e tosse.
Distúrbios digestivos leves.
Dores de cabeça e enxaquecas. Nesses casos, a Aromaterapia pode ser um suporte, mas não substitui a medicina tradicional para identificar a origem dos sintomas.
✔ Saúde da Pele e Cabelos
Tratamento para acne, dermatites e psoríase.
Cuidados com o envelhecimento precoce da pele.
Redução da queda de cabelo e controle da oleosidade do couro cabeludo.
✔ Bem-estar e Qualidade de Vida
Melhora da concentração e foco, aumentando a produtividade.
Estímulo da disposição e energia.
Auxílio no equilíbrio hormonal (TPM, menopausa, desequilíbrios hormonais).
Com base nessas necessidades, o aromaterapeuta irá indicar o melhor tratamento, calculando doses, sinergias (combinação de óleos essenciais), diluições e técnicas de aplicação, como inalação, uso tópico ou difusão.
3. Como Funciona uma Consulta com um Aromaterapeuta?

Uma consulta com um aromaterapeuta é um atendimento personalizado, onde são avaliadas as necessidades do cliente para a criação de um protocolo adequado. O processo geralmente segue estas etapas:
✔ Anamnese (Entrevista Inicial)
Perguntas sobre saúde física, emocional e estilo de vida.
Levantamento de sintomas, histórico médico e possíveis alergias.
Definição dos objetivos da terapia (alívio do estresse, melhora do sono, dores musculares etc.).
✔ Escolha dos Óleos Essenciais
Seleção dos óleos mais indicados para o caso.
Consideração das propriedades terapêuticas, contraindicações e combinações seguras.
✔ Definição do Método de Uso
O profissional indicará a melhor forma de aplicação, que pode ser:
Inalação: difusores, colares aromáticos, vaporização.
Uso tópico: massagens, óleos corporais, compressas.
Banhos aromáticos e escalda-pés. Todas as diluições serão ajustadas de acordo com a segurança e a necessidade individual do cliente.
✔ Plano de Acompanhamento
Instruções detalhadas sobre o uso correto dos óleos essenciais.
Orientação sobre frequência e duração do tratamento.
Possibilidade de retorno para ajustes no protocolo.
A consulta pode ser realizada presencialmente ou online, dependendo do profissional.
Quer saber como a Aromaterapia pode te ajudar? Agende uma consulta comigo e descubra os benefícios dos óleos essenciais para o seu bem-estar!
-
@ 04c915da:3dfbecc9
2025-03-07 00:26:37
There is something quietly rebellious about stacking sats. In a world obsessed with instant gratification, choosing to patiently accumulate Bitcoin, one sat at a time, feels like a middle finger to the hype machine. But to do it right, you have got to stay humble. Stack too hard with your head in the clouds, and you will trip over your own ego before the next halving even hits.
Small Wins
Stacking sats is not glamorous. Discipline. Stacking every day, week, or month, no matter the price, and letting time do the heavy lifting. Humility lives in that consistency. You are not trying to outsmart the market or prove you are the next "crypto" prophet. Just a regular person, betting on a system you believe in, one humble stack at a time. Folks get rekt chasing the highs. They ape into some shitcoin pump, shout about it online, then go silent when they inevitably get rekt. The ones who last? They stack. Just keep showing up. Consistency. Humility in action. Know the game is long, and you are not bigger than it.
Ego is Volatile
Bitcoin’s swings can mess with your head. One day you are up 20%, feeling like a genius and the next down 30%, questioning everything. Ego will have you panic selling at the bottom or over leveraging the top. Staying humble means patience, a true bitcoin zen. Do not try to "beat” Bitcoin. Ride it. Stack what you can afford, live your life, and let compounding work its magic.
Simplicity
There is a beauty in how stacking sats forces you to rethink value. A sat is worth less than a penny today, but every time you grab a few thousand, you plant a seed. It is not about flaunting wealth but rather building it, quietly, without fanfare. That mindset spills over. Cut out the noise: the overpriced coffee, fancy watches, the status games that drain your wallet. Humility is good for your soul and your stack. I have a buddy who has been stacking since 2015. Never talks about it unless you ask. Lives in a decent place, drives an old truck, and just keeps stacking. He is not chasing clout, he is chasing freedom. That is the vibe: less ego, more sats, all grounded in life.
The Big Picture
Stack those sats. Do it quietly, do it consistently, and do not let the green days puff you up or the red days break you down. Humility is the secret sauce, it keeps you grounded while the world spins wild. In a decade, when you look back and smile, it will not be because you shouted the loudest. It will be because you stayed the course, one sat at a time. \ \ Stay Humble and Stack Sats. 🫡
-
@ 04c915da:3dfbecc9
2025-03-04 17:00:18
This piece is the first in a series that will focus on things I think are a priority if your focus is similar to mine: building a strong family and safeguarding their future.
Choosing the ideal place to raise a family is one of the most significant decisions you will ever make. For simplicity sake I will break down my thought process into key factors: strong property rights, the ability to grow your own food, access to fresh water, the freedom to own and train with guns, and a dependable community.
A Jurisdiction with Strong Property Rights
Strong property rights are essential and allow you to build on a solid foundation that is less likely to break underneath you. Regions with a history of limited government and clear legal protections for landowners are ideal. Personally I think the US is the single best option globally, but within the US there is a wide difference between which state you choose. Choose carefully and thoughtfully, think long term. Obviously if you are not American this is not a realistic option for you, there are other solid options available especially if your family has mobility. I understand many do not have this capability to easily move, consider that your first priority, making movement and jurisdiction choice possible in the first place.
Abundant Access to Fresh Water
Water is life. I cannot overstate the importance of living somewhere with reliable, clean, and abundant freshwater. Some regions face water scarcity or heavy regulations on usage, so prioritizing a place where water is plentiful and your rights to it are protected is critical. Ideally you should have well access so you are not tied to municipal water supplies. In times of crisis or chaos well water cannot be easily shutoff or disrupted. If you live in an area that is drought prone, you are one drought away from societal chaos. Not enough people appreciate this simple fact.
Grow Your Own Food
A location with fertile soil, a favorable climate, and enough space for a small homestead or at the very least a garden is key. In stable times, a small homestead provides good food and important education for your family. In times of chaos your family being able to grow and raise healthy food provides a level of self sufficiency that many others will lack. Look for areas with minimal restrictions, good weather, and a culture that supports local farming.
Guns
The ability to defend your family is fundamental. A location where you can legally and easily own guns is a must. Look for places with a strong gun culture and a political history of protecting those rights. Owning one or two guns is not enough and without proper training they will be a liability rather than a benefit. Get comfortable and proficient. Never stop improving your skills. If the time comes that you must use a gun to defend your family, the skills must be instinct. Practice. Practice. Practice.
A Strong Community You Can Depend On
No one thrives alone. A ride or die community that rallies together in tough times is invaluable. Seek out a place where people know their neighbors, share similar values, and are quick to lend a hand. Lead by example and become a good neighbor, people will naturally respond in kind. Small towns are ideal, if possible, but living outside of a major city can be a solid balance in terms of work opportunities and family security.
Let me know if you found this helpful. My plan is to break down how I think about these five key subjects in future posts.
-
@ 6389be64:ef439d32
2025-02-27 21:32:12
GA, plebs. The latest episode of Bitcoin And is out, and, as always, the chicanery is running rampant. Let’s break down the biggest topics I covered, and if you want the full, unfiltered rant, make sure to listen to the episode linked below.
House Democrats’ MEME Act: A Bad Joke?
House Democrats are proposing a bill to ban presidential meme coins, clearly aimed at Trump’s and Melania’s ill-advised token launches. While grifters launching meme coins is bad, this bill is just as ridiculous. If this legislation moves forward, expect a retaliatory strike exposing how politicians like Pelosi and Warren mysteriously amassed their fortunes. Will it pass? Doubtful. But it’s another sign of the government’s obsession with regulating everything except itself.
Senate Banking’s First Digital Asset Hearing: The Real Target Is You
Cynthia Lummis chaired the first digital asset hearing, and—surprise!—it was all about control. The discussion centered on stablecoins, AML, and KYC regulations, with witnesses suggesting Orwellian measures like freezing stablecoin transactions unless pre-approved by authorities. What was barely mentioned? Bitcoin. They want full oversight of stablecoins, which is really about controlling financial freedom. Expect more nonsense targeting self-custody wallets under the guise of stopping “bad actors.”
Bank of America and PayPal Want In on Stablecoins
Bank of America’s CEO openly stated they’ll launch a stablecoin as soon as regulation allows. Meanwhile, PayPal’s CEO paid for a hat using Bitcoin—not their own stablecoin, Pi USD. Why wouldn’t he use his own product? Maybe he knows stablecoins aren’t what they’re hyped up to be. Either way, the legacy financial system is gearing up to flood the market with stablecoins, not because they love crypto, but because it’s a tool to extend U.S. dollar dominance.
MetaPlanet Buys the Dip
Japan’s MetaPlanet issued $13.4M in bonds to buy more Bitcoin, proving once again that institutions see the writing on the wall. Unlike U.S. regulators who obsess over stablecoins, some companies are actually stacking sats.
UK Expands Crypto Seizure Powers
Across the pond, the UK government is pushing legislation to make it easier to seize and destroy crypto linked to criminal activity. While they frame it as going after the bad guys, it’s another move toward centralized control and financial surveillance.
Bitcoin Tools & Tech: Arc, SatoChip, and Nunchuk
Some bullish Bitcoin developments: ARC v0.5 is making Bitcoin’s second layer more efficient, SatoChip now supports Taproot and Nostr, and Nunchuk launched a group wallet with chat, making multisig collaboration easier.
The Bottom Line
The state is coming for financial privacy and control, and stablecoins are their weapon of choice. Bitcoiners need to stay focused, keep their coins in self-custody, and build out parallel systems. Expect more regulatory attacks, but don’t let them distract you—just keep stacking and transacting in ways they can’t control.
🎧 Listen to the full episode here: https://fountain.fm/episode/PYITCo18AJnsEkKLz2Ks
💰 Support the show by boosting sats on Podcasting 2.0! and I will see you on the other side.
-
@ 04c915da:3dfbecc9
2025-02-25 03:55:08
Here’s a revised timeline of macro-level events from The Mandibles: A Family, 2029–2047 by Lionel Shriver, reimagined in a world where Bitcoin is adopted as a widely accepted form of money, altering the original narrative’s assumptions about currency collapse and economic control. In Shriver’s original story, the failure of Bitcoin is assumed amid the dominance of the bancor and the dollar’s collapse. Here, Bitcoin’s success reshapes the economic and societal trajectory, decentralizing power and challenging state-driven outcomes.
Part One: 2029–2032
-
2029 (Early Year)\ The United States faces economic strain as the dollar weakens against global shifts. However, Bitcoin, having gained traction emerges as a viable alternative. Unlike the original timeline, the bancor—a supranational currency backed by a coalition of nations—struggles to gain footing as Bitcoin’s decentralized adoption grows among individuals and businesses worldwide, undermining both the dollar and the bancor.
-
2029 (Mid-Year: The Great Renunciation)\ Treasury bonds lose value, and the government bans Bitcoin, labeling it a threat to sovereignty (mirroring the original bancor ban). However, a Bitcoin ban proves unenforceable—its decentralized nature thwarts confiscation efforts, unlike gold in the original story. Hyperinflation hits the dollar as the U.S. prints money, but Bitcoin’s fixed supply shields adopters from currency devaluation, creating a dual-economy split: dollar users suffer, while Bitcoin users thrive.
-
2029 (Late Year)\ Dollar-based inflation soars, emptying stores of goods priced in fiat currency. Meanwhile, Bitcoin transactions flourish in underground and online markets, stabilizing trade for those plugged into the bitcoin ecosystem. Traditional supply chains falter, but peer-to-peer Bitcoin networks enable local and international exchange, reducing scarcity for early adopters. The government’s gold confiscation fails to bolster the dollar, as Bitcoin’s rise renders gold less relevant.
-
2030–2031\ Crime spikes in dollar-dependent urban areas, but Bitcoin-friendly regions see less chaos, as digital wallets and smart contracts facilitate secure trade. The U.S. government doubles down on surveillance to crack down on bitcoin use. A cultural divide deepens: centralized authority weakens in Bitcoin-adopting communities, while dollar zones descend into lawlessness.
-
2032\ By this point, Bitcoin is de facto legal tender in parts of the U.S. and globally, especially in tech-savvy or libertarian-leaning regions. The federal government’s grip slips as tax collection in dollars plummets—Bitcoin’s traceability is low, and citizens evade fiat-based levies. Rural and urban Bitcoin hubs emerge, while the dollar economy remains fractured.
Time Jump: 2032–2047
- Over 15 years, Bitcoin solidifies as a global reserve currency, eroding centralized control. The U.S. government adapts, grudgingly integrating bitcoin into policy, though regional autonomy grows as Bitcoin empowers local economies.
Part Two: 2047
-
2047 (Early Year)\ The U.S. is a hybrid state: Bitcoin is legal tender alongside a diminished dollar. Taxes are lower, collected in BTC, reducing federal overreach. Bitcoin’s adoption has decentralized power nationwide. The bancor has faded, unable to compete with Bitcoin’s grassroots momentum.
-
2047 (Mid-Year)\ Travel and trade flow freely in Bitcoin zones, with no restrictive checkpoints. The dollar economy lingers in poorer areas, marked by decay, but Bitcoin’s dominance lifts overall prosperity, as its deflationary nature incentivizes saving and investment over consumption. Global supply chains rebound, powered by bitcoin enabled efficiency.
-
2047 (Late Year)\ The U.S. is a patchwork of semi-autonomous zones, united by Bitcoin’s universal acceptance rather than federal control. Resource scarcity persists due to past disruptions, but economic stability is higher than in Shriver’s original dystopia—Bitcoin’s success prevents the authoritarian slide, fostering a freer, if imperfect, society.
Key Differences
- Currency Dynamics: Bitcoin’s triumph prevents the bancor’s dominance and mitigates hyperinflation’s worst effects, offering a lifeline outside state control.
- Government Power: Centralized authority weakens as Bitcoin evades bans and taxation, shifting power to individuals and communities.
- Societal Outcome: Instead of a surveillance state, 2047 sees a decentralized, bitcoin driven world—less oppressive, though still stratified between Bitcoin haves and have-nots.
This reimagining assumes Bitcoin overcomes Shriver’s implied skepticism to become a robust, adopted currency by 2029, fundamentally altering the novel’s bleak trajectory.
-
-
@ 6e0ea5d6:0327f353
2025-02-21 18:15:52
"Malcolm Forbes recounts that a lady, wearing a faded cotton dress, and her husband, dressed in an old handmade suit, stepped off a train in Boston, USA, and timidly made their way to the office of the president of Harvard University. They had come from Palo Alto, California, and had not scheduled an appointment. The secretary, at a glance, thought that those two, looking like country bumpkins, had no business at Harvard.
— We want to speak with the president — the man said in a low voice.
— He will be busy all day — the secretary replied curtly.
— We will wait.
The secretary ignored them for hours, hoping the couple would finally give up and leave. But they stayed there, and the secretary, somewhat frustrated, decided to bother the president, although she hated doing that.
— If you speak with them for just a few minutes, maybe they will decide to go away — she said.
The president sighed in irritation but agreed. Someone of his importance did not have time to meet people like that, but he hated faded dresses and tattered suits in his office. With a stern face, he went to the couple.
— We had a son who studied at Harvard for a year — the woman said. — He loved Harvard and was very happy here, but a year ago he died in an accident, and we would like to erect a monument in his honor somewhere on campus.— My lady — said the president rudely —, we cannot erect a statue for every person who studied at Harvard and died; if we did, this place would look like a cemetery.
— Oh, no — the lady quickly replied. — We do not want to erect a statue. We would like to donate a building to Harvard.
The president looked at the woman's faded dress and her husband's old suit and exclaimed:
— A building! Do you have even the faintest idea of how much a building costs? We have more than seven and a half million dollars' worth of buildings here at Harvard.
The lady was silent for a moment, then said to her husband:
— If that’s all it costs to found a university, why don’t we have our own?
The husband agreed.
The couple, Leland Stanford, stood up and left, leaving the president confused. Traveling back to Palo Alto, California, they established there Stanford University, the second-largest in the world, in honor of their son, a former Harvard student."
Text extracted from: "Mileumlivros - Stories that Teach Values."
Thank you for reading, my friend! If this message helped you in any way, consider leaving your glass “🥃” as a token of appreciation.
A toast to our family!
-
@ 4857600b:30b502f4
2025-02-20 19:09:11
Mitch McConnell, a senior Republican senator, announced he will not seek reelection.
At 83 years old and with health issues, this decision was expected. After seven terms, he leaves a significant legacy in U.S. politics, known for his strategic maneuvering.
McConnell stated, “My current term in the Senate will be my last.” His retirement marks the end of an influential political era.
-
@ 94a6a78a:0ddf320e
2025-02-19 21:10:15
Nostr is a revolutionary protocol that enables decentralized, censorship-resistant communication. Unlike traditional social networks controlled by corporations, Nostr operates without central servers or gatekeepers. This openness makes it incredibly powerful—but also means its success depends entirely on users, developers, and relay operators.
If you believe in free speech, decentralization, and an open internet, there are many ways to support and strengthen the Nostr ecosystem. Whether you're a casual user, a developer, or someone looking to contribute financially, every effort helps build a more robust network.
Here’s how you can get involved and make a difference.
1️⃣ Use Nostr Daily
The simplest and most effective way to contribute to Nostr is by using it regularly. The more active users, the stronger and more valuable the network becomes.
✅ Post, comment, and zap (send micro-payments via Bitcoin’s Lightning Network) to keep conversations flowing.\ ✅ Engage with new users and help them understand how Nostr works.\ ✅ Try different Nostr clients like Damus, Amethyst, Snort, or Primal and provide feedback to improve the experience.
Your activity keeps the network alive and helps encourage more developers and relay operators to invest in the ecosystem.
2️⃣ Run Your Own Nostr Relay
Relays are the backbone of Nostr, responsible for distributing messages across the network. The more independent relays exist, the stronger and more censorship-resistant Nostr becomes.
✅ Set up your own relay to help decentralize the network further.\ ✅ Experiment with relay configurations and different performance optimizations.\ ✅ Offer public or private relay services to users looking for high-quality infrastructure.
If you're not technical, you can still support relay operators by subscribing to a paid relay or donating to open-source relay projects.
3️⃣ Support Paid Relays & Infrastructure
Free relays have helped Nostr grow, but they struggle with spam, slow speeds, and sustainability issues. Paid relays help fund better infrastructure, faster message delivery, and a more reliable experience.
✅ Subscribe to a paid relay to help keep it running.\ ✅ Use premium services like media hosting (e.g., Azzamo Blossom) to decentralize content storage.\ ✅ Donate to relay operators who invest in long-term infrastructure.
By funding Nostr’s decentralized backbone, you help ensure its longevity and reliability.
4️⃣ Zap Developers, Creators & Builders
Many people contribute to Nostr without direct financial compensation—developers who build clients, relay operators, educators, and content creators. You can support them with zaps! ⚡
✅ Find developers working on Nostr projects and send them a zap.\ ✅ Support content creators and educators who spread awareness about Nostr.\ ✅ Encourage builders by donating to open-source projects.
Micro-payments via the Lightning Network make it easy to directly support the people who make Nostr better.
5️⃣ Develop New Nostr Apps & Tools
If you're a developer, you can build on Nostr’s open protocol to create new apps, bots, or tools. Nostr is permissionless, meaning anyone can develop for it.
✅ Create new Nostr clients with unique features and user experiences.\ ✅ Build bots or automation tools that improve engagement and usability.\ ✅ Experiment with decentralized identity, authentication, and encryption to make Nostr even stronger.
With no corporate gatekeepers, your projects can help shape the future of decentralized social media.
6️⃣ Promote & Educate Others About Nostr
Adoption grows when more people understand and use Nostr. You can help by spreading awareness and creating educational content.
✅ Write blogs, guides, and tutorials explaining how to use Nostr.\ ✅ Make videos or social media posts introducing new users to the protocol.\ ✅ Host discussions, Twitter Spaces, or workshops to onboard more people.
The more people understand and trust Nostr, the stronger the ecosystem becomes.
7️⃣ Support Open-Source Nostr Projects
Many Nostr tools and clients are built by volunteers, and open-source projects thrive on community support.
✅ Contribute code to existing Nostr projects on GitHub.\ ✅ Report bugs and suggest features to improve Nostr clients.\ ✅ Donate to developers who keep Nostr free and open for everyone.
If you're not a developer, you can still help with testing, translations, and documentation to make projects more accessible.
🚀 Every Contribution Strengthens Nostr
Whether you:
✔️ Post and engage daily\ ✔️ Zap creators and developers\ ✔️ Run or support relays\ ✔️ Build new apps and tools\ ✔️ Educate and onboard new users
Every action helps make Nostr more resilient, decentralized, and unstoppable.
Nostr isn’t just another social network—it’s a movement toward a free and open internet. If you believe in digital freedom, privacy, and decentralization, now is the time to get involved.
-
@ 9e69e420:d12360c2
2025-02-17 17:12:01
President Trump has intensified immigration enforcement, likening it to a wartime effort. Despite pouring resources into the U.S. Immigration and Customs Enforcement (ICE), arrest numbers are declining and falling short of goals. ICE fell from about 800 daily arrests in late January to fewer than 600 in early February.
Critics argue the administration is merely showcasing efforts with ineffectiveness, while Trump seeks billions more in funding to support his deportation agenda. Increased involvement from various federal agencies is intended to assist ICE, but many lack specific immigration training.
Challenges persist, as fewer immigrants are available for quick deportation due to a decline in illegal crossings. Local sheriffs are also pressured by rising demands to accommodate immigrants, which may strain resources further.
-
@ fd208ee8:0fd927c1
2025-02-15 07:37:01
E-cash are coupons or tokens for Bitcoin, or Bitcoin debt notes that the mint issues. The e-cash states, essentially, "IoU 2900 sats".
They're redeemable for Bitcoin on Lightning (hard money), and therefore can be used as cash (softer money), so long as the mint has a good reputation. That means that they're less fungible than Lightning because the e-cash from one mint can be more or less valuable than the e-cash from another. If a mint is buggy, offline, or disappears, then the e-cash is unreedemable.
It also means that e-cash is more anonymous than Lightning, and that the sender and receiver's wallets don't need to be online, to transact. Nutzaps now add the possibility of parking transactions one level farther out, on a relay. The same relays that cannot keep npub profiles and follow lists consistent will now do monetary transactions.
What we then have is * a transaction on a relay that triggers * a transaction on a mint that triggers * a transaction on Lightning that triggers * a transaction on Bitcoin.
Which means that every relay that stores the nuts is part of a wildcat banking system. Which is fine, but relay operators should consider whether they wish to carry the associated risks and liabilities. They should also be aware that they should implement the appropriate features in their relay, such as expiration tags (nuts rot after 2 weeks), and to make sure that only expired nuts are deleted.
There will be plenty of specialized relays for this, so don't feel pressured to join in, and research the topic carefully, for yourself.
https://github.com/nostr-protocol/nips/blob/master/60.md https://github.com/nostr-protocol/nips/blob/master/61.md
-
@ 0fa80bd3:ea7325de
2025-02-14 23:24:37
intro
The Russian state made me a Bitcoiner. In 1991, it devalued my grandmother's hard-earned savings. She worked tirelessly in the kitchen of a dining car on the Moscow–Warsaw route. Everything she had saved for my sister and me to attend university vanished overnight. This story is similar to what many experienced, including Wences Casares. The pain and injustice of that time became my first lessons about the fragility of systems and the value of genuine, incorruptible assets, forever changing my perception of money and my trust in government promises.
In 2014, I was living in Moscow, running a trading business, and frequently traveling to China. One day, I learned about the Cypriot banking crisis and the possibility of moving money through some strange thing called Bitcoin. At the time, I didn’t give it much thought. Returning to the idea six months later, as a business-oriented geek, I eagerly began studying the topic and soon dove into it seriously.
I spent half a year reading articles on a local online journal, BitNovosti, actively participating in discussions, and eventually joined the editorial team as a translator. That’s how I learned about whitepapers, decentralization, mining, cryptographic keys, and colored coins. About Satoshi Nakamoto, Silk Road, Mt. Gox, and BitcoinTalk. Over time, I befriended the journal’s owner and, leveraging my management experience, later became an editor. I was drawn to the crypto-anarchist stance and commitment to decentralization principles. We wrote about the economic, historical, and social preconditions for Bitcoin’s emergence, and it was during this time that I fully embraced the idea.
It got to the point where I sold my apartment and, during the market's downturn, bought 50 bitcoins, just after the peak price of $1,200 per coin. That marked the beginning of my first crypto winter. As an editor, I organized workflows, managed translators, developed a YouTube channel, and attended conferences in Russia and Ukraine. That’s how I learned about Wences Casares and even wrote a piece about him. I also met Mikhail Chobanyan (Ukrainian exchange Kuna), Alexander Ivanov (Waves project), Konstantin Lomashuk (Lido project), and, of course, Vitalik Buterin. It was a time of complete immersion, 24/7, and boundless hope.
After moving to the United States, I expected the industry to grow rapidly, attended events, but the introduction of BitLicense froze the industry for eight years. By 2017, it became clear that the industry was shifting toward gambling and creating tokens for the sake of tokens. I dismissed this idea as unsustainable. Then came a new crypto spring with the hype around beautiful NFTs – CryptoPunks and apes.
I made another attempt – we worked on a series called Digital Nomad Country Club, aimed at creating a global project. The proceeds from selling images were intended to fund the development of business tools for people worldwide. However, internal disagreements within the team prevented us from completing the project.
With Trump’s arrival in 2025, hope was reignited. I decided that it was time to create a project that society desperately needed. As someone passionate about history, I understood that destroying what exists was not the solution, but leaving everything as it was also felt unacceptable. You can’t destroy the system, as the fiery crypto-anarchist voices claimed.
With an analytical mindset (IQ 130) and a deep understanding of the freest societies, I realized what was missing—not only in Russia or the United States but globally—a Bitcoin-native system for tracking debts and financial interactions. This could return control of money to ordinary people and create horizontal connections parallel to state systems. My goal was to create, if not a Bitcoin killer app, then at least to lay its foundation.
At the inauguration event in New York, I rediscovered the Nostr project. I realized it was not only technologically simple and already quite popular but also perfectly aligned with my vision. For the past month and a half, using insights and experience gained since 2014, I’ve been working full-time on this project.
-
@ e3ba5e1a:5e433365
2025-02-13 06:16:49
My favorite line in any Marvel movie ever is in “Captain America.” After Captain America launches seemingly a hopeless assault on Red Skull’s base and is captured, we get this line:
“Arrogance may not be a uniquely American trait, but I must say, you do it better than anyone.”
Yesterday, I came across a comment on the song Devil Went Down to Georgia that had a very similar feel to it:
America has seemingly always been arrogant, in a uniquely American way. Manifest Destiny, for instance. The rest of the world is aware of this arrogance, and mocks Americans for it. A central point in modern US politics is the deriding of racist, nationalist, supremacist Americans.
That’s not what I see. I see American Arrogance as not only a beautiful statement about what it means to be American. I see it as an ode to the greatness of humanity in its purest form.
For most countries, saying “our nation is the greatest” is, in fact, twinged with some level of racism. I still don’t have a problem with it. Every group of people should be allowed to feel pride in their accomplishments. The destruction of the human spirit since the end of World War 2, where greatness has become a sin and weakness a virtue, has crushed the ability of people worldwide to strive for excellence.
But I digress. The fears of racism and nationalism at least have a grain of truth when applied to other nations on the planet. But not to America.
That’s because the definition of America, and the prototype of an American, has nothing to do with race. The definition of Americanism is freedom. The founding of America is based purely on liberty. On the God-given rights of every person to live life the way they see fit.
American Arrogance is not a statement of racial superiority. It’s barely a statement of national superiority (though it absolutely is). To me, when an American comments on the greatness of America, it’s a statement about freedom. Freedom will always unlock the greatness inherent in any group of people. Americans are definitionally better than everyone else, because Americans are freer than everyone else. (Or, at least, that’s how it should be.)
In Devil Went Down to Georgia, Johnny is approached by the devil himself. He is challenged to a ridiculously lopsided bet: a golden fiddle versus his immortal soul. He acknowledges the sin in accepting such a proposal. And yet he says, “God, I know you told me not to do this. But I can’t stand the affront to my honor. I am the greatest. The devil has nothing on me. So God, I’m gonna sin, but I’m also gonna win.”
Libertas magnitudo est
-
@ daa41bed:88f54153
2025-02-09 16:50:04
There has been a good bit of discussion on Nostr over the past few days about the merits of zaps as a method of engaging with notes, so after writing a rather lengthy article on the pros of a strategic Bitcoin reserve, I wanted to take some time to chime in on the much more fun topic of digital engagement.
Let's begin by defining a couple of things:
Nostr is a decentralized, censorship-resistance protocol whose current biggest use case is social media (think Twitter/X). Instead of relying on company servers, it relies on relays that anyone can spin up and own their own content. Its use cases are much bigger, though, and this article is hosted on my own relay, using my own Nostr relay as an example.
Zap is a tip or donation denominated in sats (small units of Bitcoin) sent from one user to another. This is generally done directly over the Lightning Network but is increasingly using Cashu tokens. For the sake of this discussion, how you transmit/receive zaps will be irrelevant, so don't worry if you don't know what Lightning or Cashu are.
If we look at how users engage with posts and follows/followers on platforms like Twitter, Facebook, etc., it becomes evident that traditional social media thrives on engagement farming. The more outrageous a post, the more likely it will get a reaction. We see a version of this on more visual social platforms like YouTube and TikTok that use carefully crafted thumbnail images to grab the user's attention to click the video. If you'd like to dive deep into the psychology and science behind social media engagement, let me know, and I'd be happy to follow up with another article.
In this user engagement model, a user is given the option to comment or like the original post, or share it among their followers to increase its signal. They receive no value from engaging with the content aside from the dopamine hit of the original experience or having their comment liked back by whatever influencer they provide value to. Ad revenue flows to the content creator. Clout flows to the content creator. Sales revenue from merch and content placement flows to the content creator. We call this a linear economy -- the idea that resources get created, used up, then thrown away. Users create content and farm as much engagement as possible, then the content is forgotten within a few hours as they move on to the next piece of content to be farmed.
What if there were a simple way to give value back to those who engage with your content? By implementing some value-for-value model -- a circular economy. Enter zaps.

Unlike traditional social media platforms, Nostr does not actively use algorithms to determine what content is popular, nor does it push content created for active user engagement to the top of a user's timeline. Yes, there are "trending" and "most zapped" timelines that users can choose to use as their default, but these use relatively straightforward engagement metrics to rank posts for these timelines.
That is not to say that we may not see clients actively seeking to refine timeline algorithms for specific metrics. Still, the beauty of having an open protocol with media that is controlled solely by its users is that users who begin to see their timeline gamed towards specific algorithms can choose to move to another client, and for those who are more tech-savvy, they can opt to run their own relays or create their own clients with personalized algorithms and web of trust scoring systems.
Zaps enable the means to create a new type of social media economy in which creators can earn for creating content and users can earn by actively engaging with it. Like and reposting content is relatively frictionless and costs nothing but a simple button tap. Zaps provide active engagement because they signal to your followers and those of the content creator that this post has genuine value, quite literally in the form of money—sats.

I have seen some comments on Nostr claiming that removing likes and reactions is for wealthy people who can afford to send zaps and that the majority of people in the US and around the world do not have the time or money to zap because they have better things to spend their money like feeding their families and paying their bills. While at face value, these may seem like valid arguments, they, unfortunately, represent the brainwashed, defeatist attitude that our current economic (and, by extension, social media) systems aim to instill in all of us to continue extracting value from our lives.
Imagine now, if those people dedicating their own time (time = money) to mine pity points on social media would instead spend that time with genuine value creation by posting content that is meaningful to cultural discussions. Imagine if, instead of complaining that their posts get no zaps and going on a tirade about how much of a victim they are, they would empower themselves to take control of their content and give value back to the world; where would that leave us? How much value could be created on a nascent platform such as Nostr, and how quickly could it overtake other platforms?
Other users argue about user experience and that additional friction (i.e., zaps) leads to lower engagement, as proven by decades of studies on user interaction. While the added friction may turn some users away, does that necessarily provide less value? I argue quite the opposite. You haven't made a few sats from zaps with your content? Can't afford to send some sats to a wallet for zapping? How about using the most excellent available resource and spending 10 seconds of your time to leave a comment? Likes and reactions are valueless transactions. Social media's real value derives from providing monetary compensation and actively engaging in a conversation with posts you find interesting or thought-provoking. Remember when humans thrived on conversation and discussion for entertainment instead of simply being an onlooker of someone else's life?
If you've made it this far, my only request is this: try only zapping and commenting as a method of engagement for two weeks. Sure, you may end up liking a post here and there, but be more mindful of how you interact with the world and break yourself from blind instinct. You'll thank me later.

-
@ e3ba5e1a:5e433365
2025-02-05 17:47:16
I got into a friendly discussion on X regarding health insurance. The specific question was how to deal with health insurance companies (presumably unfairly) denying claims? My answer, as usual: get government out of it!
The US healthcare system is essentially the worst of both worlds:
- Unlike full single payer, individuals incur high costs
- Unlike a true free market, regulation causes increases in costs and decreases competition among insurers
I'm firmly on the side of moving towards the free market. (And I say that as someone living under a single payer system now.) Here's what I would do:
- Get rid of tax incentives that make health insurance tied to your employer, giving individuals back proper freedom of choice.
- Reduce regulations significantly.
-
In the short term, some people will still get rejected claims and other obnoxious behavior from insurance companies. We address that in two ways:
- Due to reduced regulations, new insurance companies will be able to enter the market offering more reliable coverage and better rates, and people will flock to them because they have the freedom to make their own choices.
- Sue the asses off of companies that reject claims unfairly. And ideally, as one of the few legitimate roles of government in all this, institute new laws that limit the ability of fine print to allow insurers to escape their responsibilities. (I'm hesitant that the latter will happen due to the incestuous relationship between Congress/regulators and insurers, but I can hope.)
Will this magically fix everything overnight like politicians normally promise? No. But it will allow the market to return to a healthy state. And I don't think it will take long (order of magnitude: 5-10 years) for it to come together, but that's just speculation.
And since there's a high correlation between those who believe government can fix problems by taking more control and demanding that only credentialed experts weigh in on a topic (both points I strongly disagree with BTW): I'm a trained actuary and worked in the insurance industry, and have directly seen how government regulation reduces competition, raises prices, and harms consumers.
And my final point: I don't think any prior art would be a good comparison for deregulation in the US, it's such a different market than any other country in the world for so many reasons that lessons wouldn't really translate. Nonetheless, I asked Grok for some empirical data on this, and at best the results of deregulation could be called "mixed," but likely more accurately "uncertain, confused, and subject to whatever interpretation anyone wants to apply."
https://x.com/i/grok/share/Zc8yOdrN8lS275hXJ92uwq98M
-
@ 91bea5cd:1df4451c
2025-02-04 17:24:50
Definição de ULID:
Timestamp 48 bits, Aleatoriedade 80 bits Sendo Timestamp 48 bits inteiro, tempo UNIX em milissegundos, Não ficará sem espaço até o ano 10889 d.C. e Aleatoriedade 80 bits, Fonte criptograficamente segura de aleatoriedade, se possível.
Gerar ULID
```sql
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE FUNCTION generate_ulid() RETURNS TEXT AS $$ DECLARE -- Crockford's Base32 encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; timestamp BYTEA = E'\000\000\000\000\000\000'; output TEXT = '';
unix_time BIGINT; ulid BYTEA; BEGIN -- 6 timestamp bytes unix_time = (EXTRACT(EPOCH FROM CLOCK_TIMESTAMP()) * 1000)::BIGINT; timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql VOLATILE; ```
ULID TO UUID
```sql CREATE OR REPLACE FUNCTION parse_ulid(ulid text) RETURNS bytea AS $$ DECLARE -- 16byte bytes bytea = E'\x00000000 00000000 00000000 00000000'; v char[]; -- Allow for O(1) lookup of index values dec integer[] = ARRAY[ 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 255, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31 ]; BEGIN IF NOT ulid ~* '^[0-7][0-9ABCDEFGHJKMNPQRSTVWXYZ]{25}$' THEN RAISE EXCEPTION 'Invalid ULID: %', ulid; END IF;
v = regexp_split_to_array(ulid, '');
-- 6 bytes timestamp (48 bits) bytes = SET_BYTE(bytes, 0, (dec[ASCII(v[1])] << 5) | dec[ASCII(v[2])]); bytes = SET_BYTE(bytes, 1, (dec[ASCII(v[3])] << 3) | (dec[ASCII(v[4])] >> 2)); bytes = SET_BYTE(bytes, 2, (dec[ASCII(v[4])] << 6) | (dec[ASCII(v[5])] << 1) | (dec[ASCII(v[6])] >> 4)); bytes = SET_BYTE(bytes, 3, (dec[ASCII(v[6])] << 4) | (dec[ASCII(v[7])] >> 1)); bytes = SET_BYTE(bytes, 4, (dec[ASCII(v[7])] << 7) | (dec[ASCII(v[8])] << 2) | (dec[ASCII(v[9])] >> 3)); bytes = SET_BYTE(bytes, 5, (dec[ASCII(v[9])] << 5) | dec[ASCII(v[10])]);
-- 10 bytes of entropy (80 bits); bytes = SET_BYTE(bytes, 6, (dec[ASCII(v[11])] << 3) | (dec[ASCII(v[12])] >> 2)); bytes = SET_BYTE(bytes, 7, (dec[ASCII(v[12])] << 6) | (dec[ASCII(v[13])] << 1) | (dec[ASCII(v[14])] >> 4)); bytes = SET_BYTE(bytes, 8, (dec[ASCII(v[14])] << 4) | (dec[ASCII(v[15])] >> 1)); bytes = SET_BYTE(bytes, 9, (dec[ASCII(v[15])] << 7) | (dec[ASCII(v[16])] << 2) | (dec[ASCII(v[17])] >> 3)); bytes = SET_BYTE(bytes, 10, (dec[ASCII(v[17])] << 5) | dec[ASCII(v[18])]); bytes = SET_BYTE(bytes, 11, (dec[ASCII(v[19])] << 3) | (dec[ASCII(v[20])] >> 2)); bytes = SET_BYTE(bytes, 12, (dec[ASCII(v[20])] << 6) | (dec[ASCII(v[21])] << 1) | (dec[ASCII(v[22])] >> 4)); bytes = SET_BYTE(bytes, 13, (dec[ASCII(v[22])] << 4) | (dec[ASCII(v[23])] >> 1)); bytes = SET_BYTE(bytes, 14, (dec[ASCII(v[23])] << 7) | (dec[ASCII(v[24])] << 2) | (dec[ASCII(v[25])] >> 3)); bytes = SET_BYTE(bytes, 15, (dec[ASCII(v[25])] << 5) | dec[ASCII(v[26])]);
RETURN bytes; END $$ LANGUAGE plpgsql IMMUTABLE;
CREATE OR REPLACE FUNCTION ulid_to_uuid(ulid text) RETURNS uuid AS $$ BEGIN RETURN encode(parse_ulid(ulid), 'hex')::uuid; END $$ LANGUAGE plpgsql IMMUTABLE; ```
UUID to ULID
```sql CREATE OR REPLACE FUNCTION uuid_to_ulid(id uuid) RETURNS text AS $$ DECLARE encoding bytea = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; output text = ''; uuid_bytes bytea = uuid_send(id); BEGIN
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 1) & 7) << 2) | ((GET_BYTE(uuid_bytes, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 2) & 1) << 4) | ((GET_BYTE(uuid_bytes, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 3) & 15) << 1) | ((GET_BYTE(uuid_bytes, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 4) & 3) << 3) | ((GET_BYTE(uuid_bytes, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 6) & 7) << 2) | ((GET_BYTE(uuid_bytes, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 7) & 1) << 4) | ((GET_BYTE(uuid_bytes, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 8) & 15) << 1) | ((GET_BYTE(uuid_bytes, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 9) & 3) << 3) | ((GET_BYTE(uuid_bytes, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 11) & 7) << 2) | ((GET_BYTE(uuid_bytes, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 12) & 1) << 4) | ((GET_BYTE(uuid_bytes, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 13) & 15) << 1) | ((GET_BYTE(uuid_bytes, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 14) & 3) << 3) | ((GET_BYTE(uuid_bytes, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql IMMUTABLE; ```
Gera 11 Digitos aleatórios: YBKXG0CKTH4
```sql -- Cria a extensão pgcrypto para gerar uuid CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Cria a função para gerar ULID CREATE OR REPLACE FUNCTION gen_lrandom() RETURNS TEXT AS $$ DECLARE ts_millis BIGINT; ts_chars TEXT; random_bytes BYTEA; random_chars TEXT; base32_chars TEXT := '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; i INT; BEGIN -- Pega o timestamp em milissegundos ts_millis := FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000)::BIGINT;
-- Converte o timestamp para base32 ts_chars := ''; FOR i IN REVERSE 0..11 LOOP ts_chars := ts_chars || substr(base32_chars, ((ts_millis >> (5 * i)) & 31) + 1, 1); END LOOP; -- Gera 10 bytes aleatórios e converte para base32 random_bytes := gen_random_bytes(10); random_chars := ''; FOR i IN 0..9 LOOP random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) >> 3) & 31) + 1, 1); IF i < 9 THEN random_chars := random_chars || substr(base32_chars, (((get_byte(random_bytes, i) & 7) << 2) | (get_byte(random_bytes, i + 1) >> 6)) & 31 + 1, 1); ELSE random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) & 7) << 2) + 1, 1); END IF; END LOOP; -- Concatena o timestamp e os caracteres aleatórios RETURN ts_chars || random_chars;END; $$ LANGUAGE plpgsql; ```
Exemplo de USO
```sql -- Criação da extensão caso não exista CREATE EXTENSION IF NOT EXISTS pgcrypto; -- Criação da tabela pessoas CREATE TABLE pessoas ( ID UUID DEFAULT gen_random_uuid ( ) PRIMARY KEY, nome TEXT NOT NULL );
-- Busca Pessoa na tabela SELECT * FROM "pessoas" WHERE uuid_to_ulid ( ID ) = '252FAC9F3V8EF80SSDK8PXW02F'; ```
Fontes
- https://github.com/scoville/pgsql-ulid
- https://github.com/geckoboard/pgulid
-
@ 91bea5cd:1df4451c
2025-02-04 17:15:57
Definição de ULID:
Timestamp 48 bits, Aleatoriedade 80 bits Sendo Timestamp 48 bits inteiro, tempo UNIX em milissegundos, Não ficará sem espaço até o ano 10889 d.C. e Aleatoriedade 80 bits, Fonte criptograficamente segura de aleatoriedade, se possível.
Gerar ULID
```sql
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE FUNCTION generate_ulid() RETURNS TEXT AS $$ DECLARE -- Crockford's Base32 encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; timestamp BYTEA = E'\000\000\000\000\000\000'; output TEXT = '';
unix_time BIGINT; ulid BYTEA; BEGIN -- 6 timestamp bytes unix_time = (EXTRACT(EPOCH FROM CLOCK_TIMESTAMP()) * 1000)::BIGINT; timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql VOLATILE; ```
ULID TO UUID
```sql CREATE OR REPLACE FUNCTION parse_ulid(ulid text) RETURNS bytea AS $$ DECLARE -- 16byte bytes bytea = E'\x00000000 00000000 00000000 00000000'; v char[]; -- Allow for O(1) lookup of index values dec integer[] = ARRAY[ 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 255, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31 ]; BEGIN IF NOT ulid ~* '^[0-7][0-9ABCDEFGHJKMNPQRSTVWXYZ]{25}$' THEN RAISE EXCEPTION 'Invalid ULID: %', ulid; END IF;
v = regexp_split_to_array(ulid, '');
-- 6 bytes timestamp (48 bits) bytes = SET_BYTE(bytes, 0, (dec[ASCII(v[1])] << 5) | dec[ASCII(v[2])]); bytes = SET_BYTE(bytes, 1, (dec[ASCII(v[3])] << 3) | (dec[ASCII(v[4])] >> 2)); bytes = SET_BYTE(bytes, 2, (dec[ASCII(v[4])] << 6) | (dec[ASCII(v[5])] << 1) | (dec[ASCII(v[6])] >> 4)); bytes = SET_BYTE(bytes, 3, (dec[ASCII(v[6])] << 4) | (dec[ASCII(v[7])] >> 1)); bytes = SET_BYTE(bytes, 4, (dec[ASCII(v[7])] << 7) | (dec[ASCII(v[8])] << 2) | (dec[ASCII(v[9])] >> 3)); bytes = SET_BYTE(bytes, 5, (dec[ASCII(v[9])] << 5) | dec[ASCII(v[10])]);
-- 10 bytes of entropy (80 bits); bytes = SET_BYTE(bytes, 6, (dec[ASCII(v[11])] << 3) | (dec[ASCII(v[12])] >> 2)); bytes = SET_BYTE(bytes, 7, (dec[ASCII(v[12])] << 6) | (dec[ASCII(v[13])] << 1) | (dec[ASCII(v[14])] >> 4)); bytes = SET_BYTE(bytes, 8, (dec[ASCII(v[14])] << 4) | (dec[ASCII(v[15])] >> 1)); bytes = SET_BYTE(bytes, 9, (dec[ASCII(v[15])] << 7) | (dec[ASCII(v[16])] << 2) | (dec[ASCII(v[17])] >> 3)); bytes = SET_BYTE(bytes, 10, (dec[ASCII(v[17])] << 5) | dec[ASCII(v[18])]); bytes = SET_BYTE(bytes, 11, (dec[ASCII(v[19])] << 3) | (dec[ASCII(v[20])] >> 2)); bytes = SET_BYTE(bytes, 12, (dec[ASCII(v[20])] << 6) | (dec[ASCII(v[21])] << 1) | (dec[ASCII(v[22])] >> 4)); bytes = SET_BYTE(bytes, 13, (dec[ASCII(v[22])] << 4) | (dec[ASCII(v[23])] >> 1)); bytes = SET_BYTE(bytes, 14, (dec[ASCII(v[23])] << 7) | (dec[ASCII(v[24])] << 2) | (dec[ASCII(v[25])] >> 3)); bytes = SET_BYTE(bytes, 15, (dec[ASCII(v[25])] << 5) | dec[ASCII(v[26])]);
RETURN bytes; END $$ LANGUAGE plpgsql IMMUTABLE;
CREATE OR REPLACE FUNCTION ulid_to_uuid(ulid text) RETURNS uuid AS $$ BEGIN RETURN encode(parse_ulid(ulid), 'hex')::uuid; END $$ LANGUAGE plpgsql IMMUTABLE; ```
UUID to ULID
```sql CREATE OR REPLACE FUNCTION uuid_to_ulid(id uuid) RETURNS text AS $$ DECLARE encoding bytea = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; output text = ''; uuid_bytes bytea = uuid_send(id); BEGIN
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 1) & 7) << 2) | ((GET_BYTE(uuid_bytes, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 2) & 1) << 4) | ((GET_BYTE(uuid_bytes, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 3) & 15) << 1) | ((GET_BYTE(uuid_bytes, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 4) & 3) << 3) | ((GET_BYTE(uuid_bytes, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 6) & 7) << 2) | ((GET_BYTE(uuid_bytes, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 7) & 1) << 4) | ((GET_BYTE(uuid_bytes, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 8) & 15) << 1) | ((GET_BYTE(uuid_bytes, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 9) & 3) << 3) | ((GET_BYTE(uuid_bytes, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 11) & 7) << 2) | ((GET_BYTE(uuid_bytes, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 12) & 1) << 4) | ((GET_BYTE(uuid_bytes, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 13) & 15) << 1) | ((GET_BYTE(uuid_bytes, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 14) & 3) << 3) | ((GET_BYTE(uuid_bytes, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql IMMUTABLE; ```
Gera 11 Digitos aleatórios: YBKXG0CKTH4
```sql -- Cria a extensão pgcrypto para gerar uuid CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Cria a função para gerar ULID CREATE OR REPLACE FUNCTION gen_lrandom() RETURNS TEXT AS $$ DECLARE ts_millis BIGINT; ts_chars TEXT; random_bytes BYTEA; random_chars TEXT; base32_chars TEXT := '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; i INT; BEGIN -- Pega o timestamp em milissegundos ts_millis := FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000)::BIGINT;
-- Converte o timestamp para base32 ts_chars := ''; FOR i IN REVERSE 0..11 LOOP ts_chars := ts_chars || substr(base32_chars, ((ts_millis >> (5 * i)) & 31) + 1, 1); END LOOP; -- Gera 10 bytes aleatórios e converte para base32 random_bytes := gen_random_bytes(10); random_chars := ''; FOR i IN 0..9 LOOP random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) >> 3) & 31) + 1, 1); IF i < 9 THEN random_chars := random_chars || substr(base32_chars, (((get_byte(random_bytes, i) & 7) << 2) | (get_byte(random_bytes, i + 1) >> 6)) & 31 + 1, 1); ELSE random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) & 7) << 2) + 1, 1); END IF; END LOOP; -- Concatena o timestamp e os caracteres aleatórios RETURN ts_chars || random_chars;END; $$ LANGUAGE plpgsql; ```
Exemplo de USO
```sql -- Criação da extensão caso não exista CREATE EXTENSION IF NOT EXISTS pgcrypto; -- Criação da tabela pessoas CREATE TABLE pessoas ( ID UUID DEFAULT gen_random_uuid ( ) PRIMARY KEY, nome TEXT NOT NULL );
-- Busca Pessoa na tabela SELECT * FROM "pessoas" WHERE uuid_to_ulid ( ID ) = '252FAC9F3V8EF80SSDK8PXW02F'; ```
Fontes
- https://github.com/scoville/pgsql-ulid
- https://github.com/geckoboard/pgulid
-
@ e3ba5e1a:5e433365
2025-02-04 08:29:00
President Trump has started rolling out his tariffs, something I blogged about in November. People are talking about these tariffs a lot right now, with many people (correctly) commenting on how consumers will end up with higher prices as a result of these tariffs. While that part is true, I’ve seen a lot of people taking it to the next, incorrect step: that consumers will pay the entirety of the tax. I put up a poll on X to see what people thought, and while the right answer got a lot of votes, it wasn't the winner.

For purposes of this blog post, our ultimate question will be the following:
- Suppose apples currently sell for $1 each in the entire United States.
- There are domestic sellers and foreign sellers of apples, all receiving the same price.
- There are no taxes or tariffs on the purchase of apples.
- The question is: if the US federal government puts a $0.50 import tariff per apple, what will be the change in the following:
- Number of apples bought in the US
- Price paid by buyers for apples in the US
- Post-tax price received by domestic apple producers
- Post-tax price received by foreign apple producers
Before we can answer that question, we need to ask an easier, first question: before instituting the tariff, why do apples cost $1?
And finally, before we dive into the details, let me provide you with the answers to the ultimate question. I recommend you try to guess these answers before reading this, and if you get it wrong, try to understand why:
- The number of apples bought will go down
- The buyers will pay more for each apple they buy, but not the full amount of the tariff
- Domestic apple sellers will receive a higher price per apple
- Foreign apple sellers will receive a lower price per apple, but not lowered by the full amount of the tariff
In other words, regardless of who sends the payment to the government, both taxed parties (domestic buyers and foreign sellers) will absorb some of the costs of the tariff, while domestic sellers will benefit from the protectionism provided by tariffs and be able to sell at a higher price per unit.
Marginal benefit
All of the numbers discussed below are part of a helper Google Sheet I put together for this analysis. Also, apologies about the jagged lines in the charts below, I hadn’t realized before starting on this that there are some difficulties with creating supply and demand charts in Google Sheets.
Let’s say I absolutely love apples, they’re my favorite food. How much would I be willing to pay for a single apple? You might say “$1, that’s the price in the supermarket,” and in many ways you’d be right. If I walk into supermarket A, see apples on sale for $50, and know that I can buy them at supermarket B for $1, I’ll almost certainly leave A and go buy at B.
But that’s not what I mean. What I mean is: how high would the price of apples have to go everywhere so that I’d no longer be willing to buy a single apple? This is a purely personal, subjective opinion. It’s impacted by how much money I have available, other expenses I need to cover, and how much I like apples. But let’s say the number is $5.
How much would I be willing to pay for another apple? Maybe another $5. But how much am I willing to pay for the 1,000th apple? 10,000th? At some point, I’ll get sick of apples, or run out of space to keep the apples, or not be able to eat, cook, and otherwise preserve all those apples before they rot.
The point being: I’ll be progressively willing to spend less and less money for each apple. This form of analysis is called marginal benefit: how much benefit (expressed as dollars I’m willing to spend) will I receive from each apple? This is a downward sloping function: for each additional apple I buy (quantity demanded), the price I’m willing to pay goes down. This is what gives my personal demand curve. And if we aggregate demand curves across all market participants (meaning: everyone interested in buying apples), we end up with something like this:
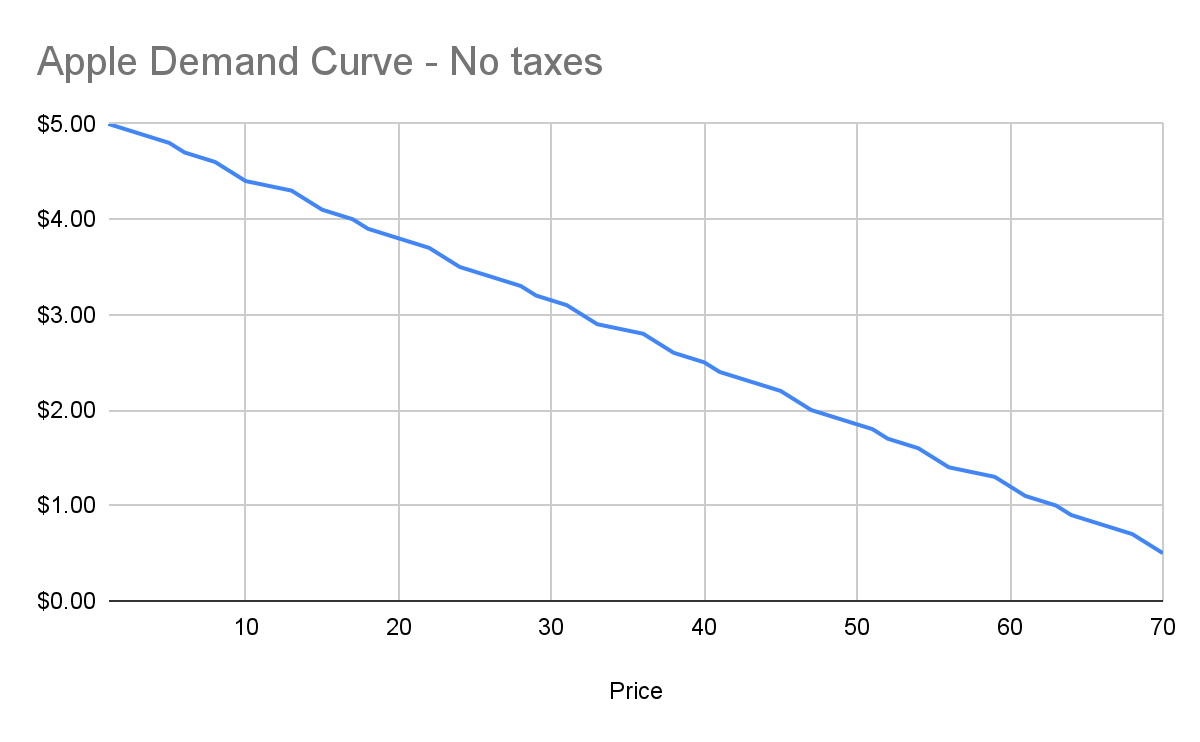
Assuming no changes in people’s behavior and other conditions in the market, this chart tells us how many apples will be purchased by our buyers at each price point between $0.50 and $5. And ceteris paribus (all else being equal), this will continue to be the demand curve for apples.
Marginal cost
Demand is half the story of economics. The other half is supply, or: how many apples will I sell at each price point? Supply curves are upward sloping: the higher the price, the more a person or company is willing and able to sell a product.
Let’s understand why. Suppose I have an apple orchard. It’s a large property right next to my house. With about 2 minutes of effort, I can walk out of my house, find the nearest tree, pick 5 apples off the tree, and call it a day. 5 apples for 2 minutes of effort is pretty good, right?
Yes, there was all the effort necessary to buy the land, and plant the trees, and water them… and a bunch more than I likely can’t even guess at. We’re going to ignore all of that for our analysis, because for short-term supply-and-demand movement, we can ignore these kinds of sunk costs. One other simplification: in reality, supply curves often start descending before ascending. This accounts for achieving efficiencies of scale after the first number of units purchased. But since both these topics are unneeded for understanding taxes, I won’t go any further.
Anyway, back to my apple orchard. If someone offers me $0.50 per apple, I can do 2 minutes of effort and get $2.50 in revenue, which equates to a $75/hour wage for me. I’m more than happy to pick apples at that price!
However, let’s say someone comes to buy 10,000 apples from me instead. I no longer just walk out to my nearest tree. I’m going to need to get in my truck, drive around, spend the day in the sun, pay for gas, take a day off of my day job (let’s say it pays me $70/hour). The costs go up significantly. Let’s say it takes 5 days to harvest all those apples myself, it costs me $100 in fuel and other expenses, and I lose out on my $70/hour job for 5 days. We end up with:
- Total expenditure: $100 + $70 * 8 hours a day * 5 days \== $2900
- Total revenue: $5000 (10,000 apples at $0.50 each)
- Total profit: $2100
So I’m still willing to sell the apples at this price, but it’s not as attractive as before. And as the number of apples purchased goes up, my costs keep increasing. I’ll need to spend more money on fuel to travel more of my property. At some point I won’t be able to do the work myself anymore, so I’ll need to pay others to work on the farm, and they’ll be slower at picking apples than me (less familiar with the property, less direct motivation, etc.). The point being: at some point, the number of apples can go high enough that the $0.50 price point no longer makes me any money.
This kind of analysis is called marginal cost. It refers to the additional amount of expenditure a seller has to spend in order to produce each additional unit of the good. Marginal costs go up as quantity sold goes up. And like demand curves, if you aggregate this data across all sellers, you get a supply curve like this:
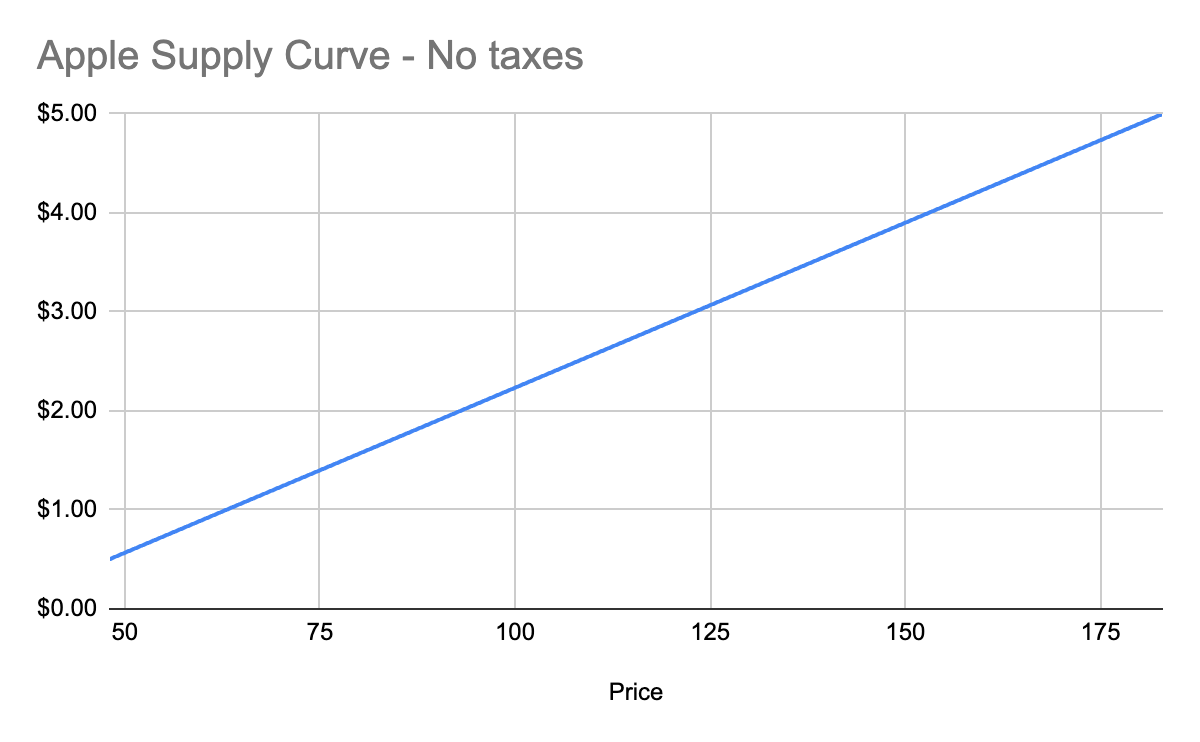
Equilibrium price
We now know, for every price point, how many apples buyers will purchase, and how many apples sellers will sell. Now we find the equilibrium: where the supply and demand curves meet. This point represents where the marginal benefit a buyer would receive from the next buyer would be less than the cost it would take the next seller to make it. Let’s see it in a chart:
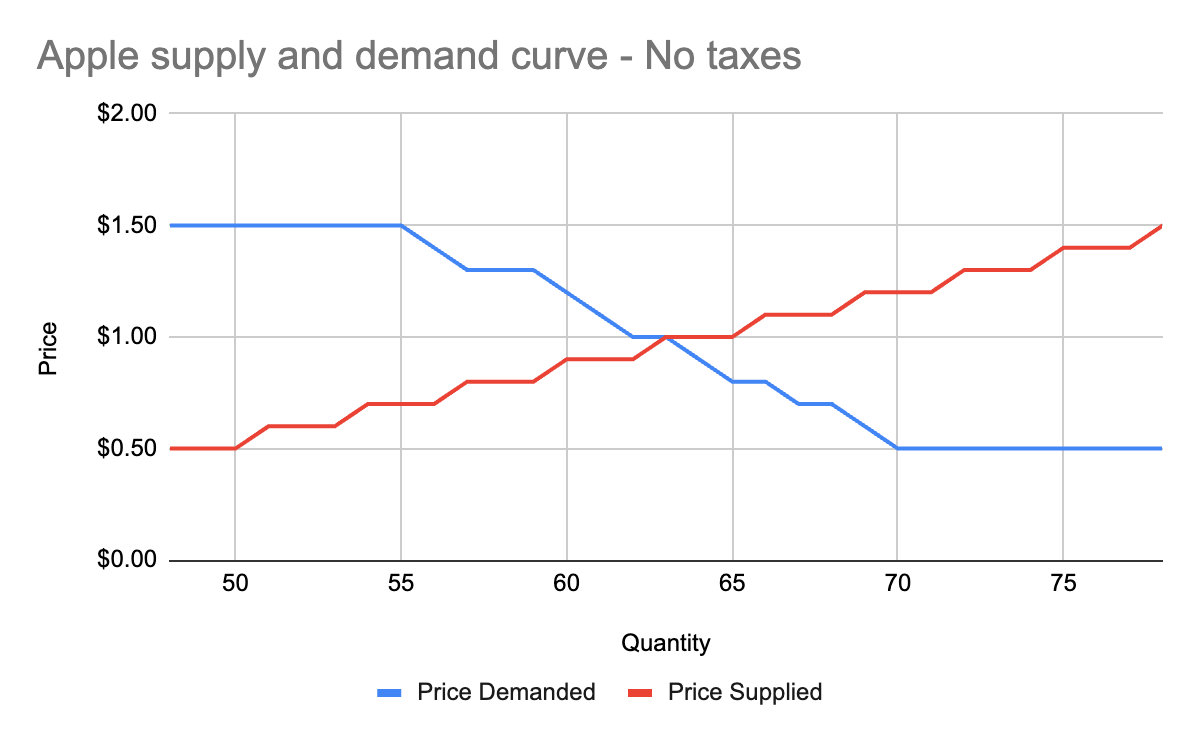
You’ll notice that these two graphs cross at the $1 price point, where 63 apples are both demanded (bought by consumers) and supplied (sold by producers). This is our equilibrium price. We also have a visualization of the surplus created by these trades. Everything to the left of the equilibrium point and between the supply and demand curves represents surplus: an area where someone is receiving something of more value than they give. For example:
- When I bought my first apple for $1, but I was willing to spend $5, I made $4 of consumer surplus. The consumer portion of the surplus is everything to the left of the equilibrium point, between the supply and demand curves, and above the equilibrium price point.
- When a seller sells his first apple for $1, but it only cost $0.50 to produce it, the seller made $0.50 of producer surplus. The producer portion of the surplus is everything to the left of the equilibrium point, between the supply and demand curves, and below the equilibrium price point.
Another way of thinking of surplus is “every time someone got a better price than they would have been willing to take.”
OK, with this in place, we now have enough information to figure out how to price in the tariff, which we’ll treat as a negative externality.
Modeling taxes
Alright, the government has now instituted a $0.50 tariff on every apple sold within the US by a foreign producer. We can generally model taxes by either increasing the marginal cost of each unit sold (shifting the supply curve up), or by decreasing the marginal benefit of each unit bought (shifting the demand curve down). In this case, since only some of the producers will pay the tax, it makes more sense to modify the supply curve.
First, let’s see what happens to the foreign seller-only supply curve when you add in the tariff:
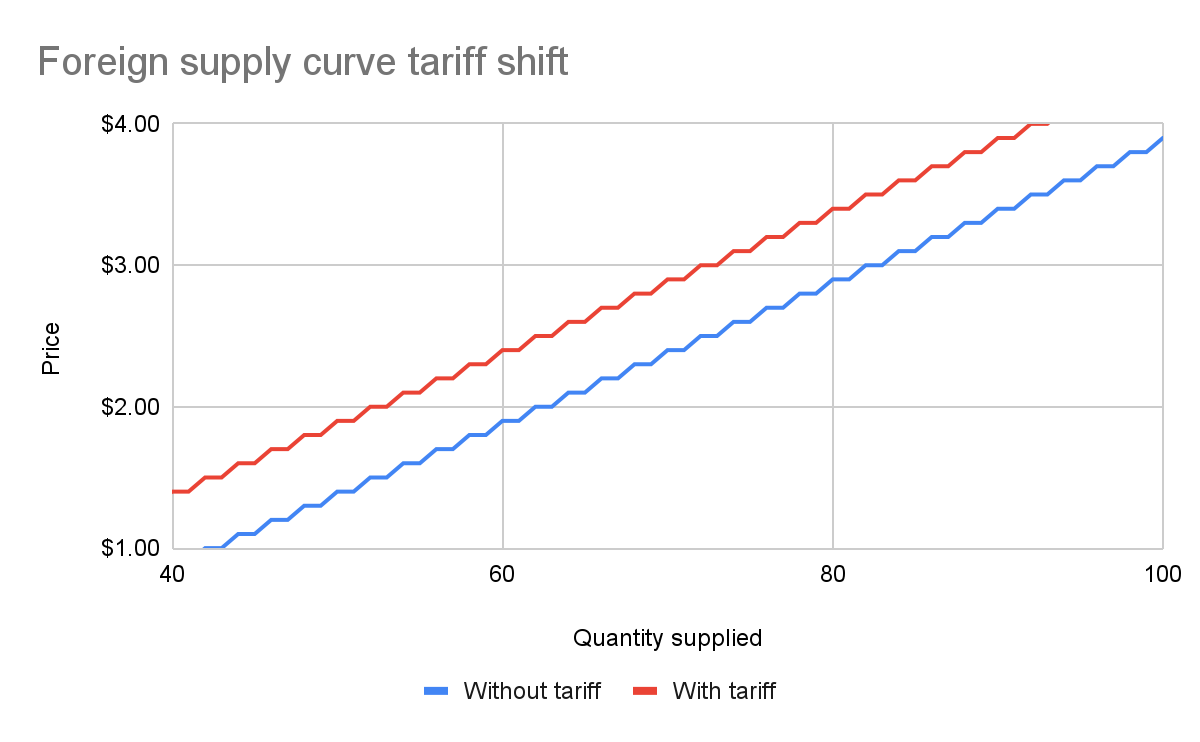
With the tariff in place, for each quantity level, the price at which the seller will sell is $0.50 higher than before the tariff. That makes sense: if I was previously willing to sell my 82nd apple for $3, I would now need to charge $3.50 for that apple to cover the cost of the tariff. We see this as the tariff “pushing up” or “pushing left” the original supply curve.
We can add this new supply curve to our existing (unchanged) supply curve for domestic-only sellers, and we end up with a result like this:
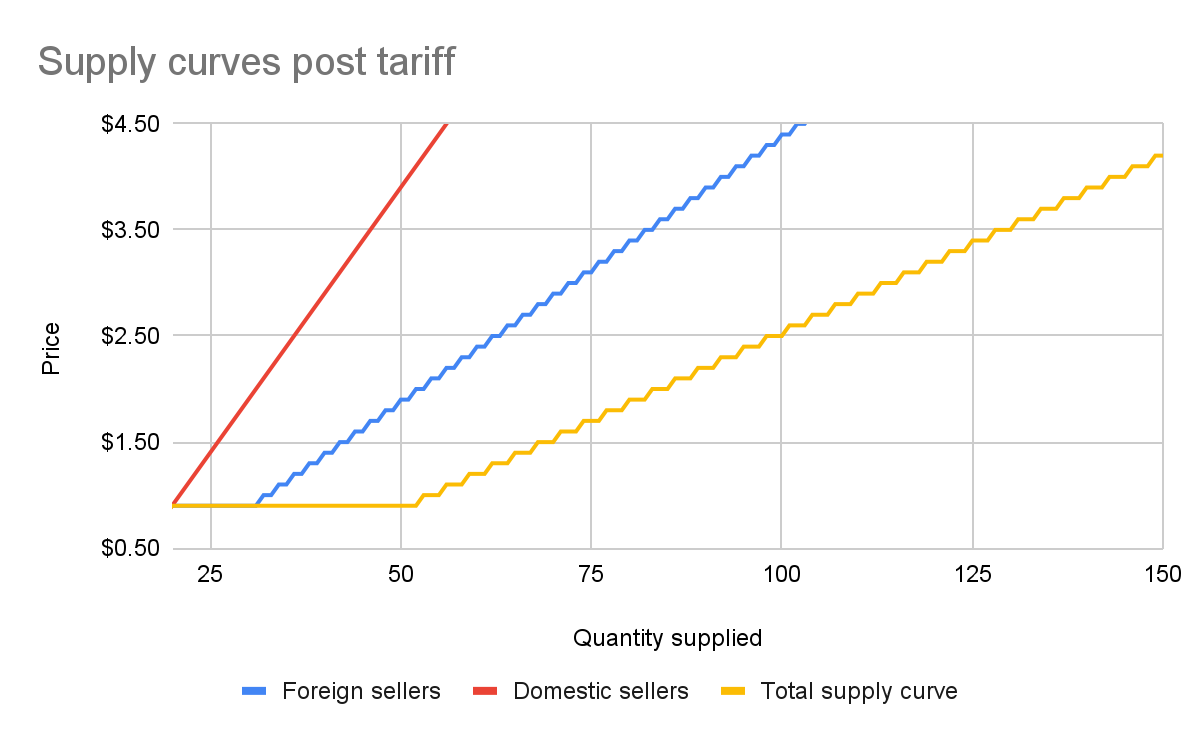
The total supply curve adds up the individual foreign and domestic supply curves. At each price point, we add up the total quantity each group would be willing to sell to determine the total quantity supplied for each price point. Once we have that cumulative supply curve defined, we can produce an updated supply-and-demand chart including the tariff:
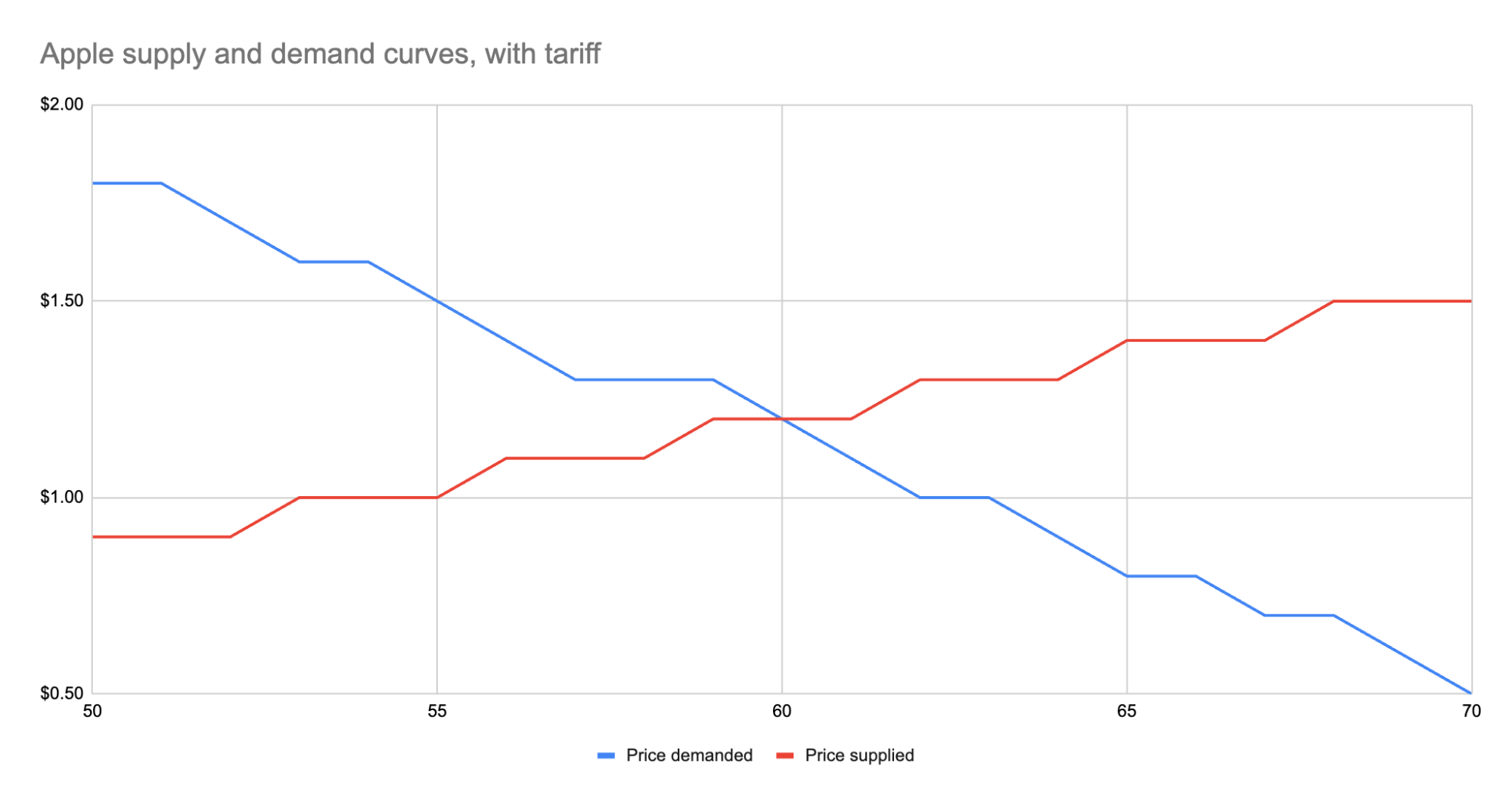
As we can see, the equilibrium has shifted:
- The equilibrium price paid by consumers has risen from $1 to $1.20.
- The total number of apples purchased has dropped from 63 apples to 60 apples.
- Consumers therefore received 3 less apples. They spent $72 for these 60 apples, whereas previously they spent $63 for 3 more apples, a definite decrease in consumer surplus.
- Foreign producers sold 36 of those apples (see the raw data in the linked Google Sheet), for a gross revenue of $43.20. However, they also need to pay the tariff to the US government, which accounts for $18, meaning they only receive $25.20 post-tariff. Previously, they sold 42 apples at $1 each with no tariff to be paid, meaning they took home $42.
- Domestic producers sold the remaining 24 apples at $1.20, giving them a revenue of $28.80. Since they don’t pay the tariff, they take home all of that money. By contrast, previously, they sold 21 apples at $1, for a take-home of $21.
- The government receives $0.50 for each of the 60 apples sold, or in other words receives $30 in revenue it wouldn’t have received otherwise.
We could be more specific about the surpluses, and calculate the actual areas for consumer surplus, producer surplus, inefficiency from the tariff, and government revenue from the tariff. But I won’t bother, as those calculations get slightly more involved. Instead, let’s just look at the aggregate outcomes:
- Consumers were unquestionably hurt. Their price paid went up by $0.20 per apple, and received less apples.
- Foreign producers were also hurt. Their price received went down from the original $1 to the new post-tariff price of $1.20, minus the $0.50 tariff. In other words: foreign producers only receive $0.70 per apple now. This hurt can be mitigated by shifting sales to other countries without a tariff, but the pain will exist regardless.
- Domestic producers scored. They can sell less apples and make more revenue doing it.
- And the government walked away with an extra $30.
Hopefully you now see the answer to the original questions. Importantly, while the government imposed a $0.50 tariff, neither side fully absorbed that cost. Consumers paid a bit more, foreign producers received a bit less. The exact details of how that tariff was split across the groups is mediated by the relevant supply and demand curves of each group. If you want to learn more about this, the relevant search term is “price elasticity,” or how much a group’s quantity supplied or demanded will change based on changes in the price.
Other taxes
Most taxes are some kind of a tax on trade. Tariffs on apples is an obvious one. But the same applies to income tax (taxing the worker for the trade of labor for money) or payroll tax (same thing, just taxing the employer instead). Interestingly, you can use the same model for analyzing things like tax incentives. For example, if the government decided to subsidize domestic apple production by giving the domestic producers a $0.50 bonus for each apple they sell, we would end up with a similar kind of analysis, except instead of the foreign supply curve shifting up, we’d see the domestic supply curve shifting down.
And generally speaking, this is what you’ll always see with government involvement in the economy. It will result in disrupting an existing equilibrium, letting the market readjust to a new equilibrium, and incentivization of some behavior, causing some people to benefit and others to lose out. We saw with the apple tariff, domestic producers and the government benefited while others lost.
You can see the reverse though with tax incentives. If I give a tax incentive of providing a deduction (not paying income tax) for preschool, we would end up with:
- Government needs to make up the difference in tax revenue, either by raising taxes on others or printing more money (leading to inflation). Either way, those paying the tax or those holding government debased currency will pay a price.
- Those people who don’t use the preschool deduction will receive no benefit, so they simply pay a cost.
- Those who do use the preschool deduction will end up paying less on tax+preschool than they would have otherwise.
This analysis is fully amoral. It’s not saying whether providing subsidized preschool is a good thing or not, it simply tells you where the costs will be felt, and points out that such government interference in free economic choice does result in inefficiencies in the system. Once you have that knowledge, you’re more well educated on making a decision about whether the costs of government intervention are worth the benefits.
-
@ 9e69e420:d12360c2
2025-02-01 11:16:04
Federal employees must remove pronouns from email signatures by the end of the day. This directive comes from internal memos tied to two executive orders signed by Donald Trump. The orders target diversity and equity programs within the government.

CDC, Department of Transportation, and Department of Energy employees were affected. Staff were instructed to make changes in line with revised policy prohibiting certain language.
One CDC employee shared frustration, stating, “In my decade-plus years at CDC, I've never been told what I can and can't put in my email signature.” The directive is part of a broader effort to eliminate DEI initiatives from federal discourse.
-
@ 97c70a44:ad98e322
2025-01-30 17:15:37
There was a slight dust up recently over a website someone runs removing a listing for an app someone built based on entirely arbitrary criteria. I'm not to going to attempt to speak for either wounded party, but I would like to share my own personal definition for what constitutes a "nostr app" in an effort to help clarify what might be an otherwise confusing and opaque purity test.
In this post, I will be committing the "no true Scotsman" fallacy, in which I start with the most liberal definition I can come up with, and gradually refine it until all that is left is the purest, gleamingest, most imaginary and unattainable nostr app imaginable. As I write this, I wonder if anything built yet will actually qualify. In any case, here we go.
It uses nostr
The lowest bar for what a "nostr app" might be is an app ("application" - i.e. software, not necessarily a native app of any kind) that has some nostr-specific code in it, but which doesn't take any advantage of what makes nostr distinctive as a protocol.
Examples might include a scraper of some kind which fulfills its charter by fetching data from relays (regardless of whether it validates or retains signatures). Another might be a regular web 2.0 app which provides an option to "log in with nostr" by requesting and storing the user's public key.
In either case, the fact that nostr is involved is entirely neutral. A scraper can scrape html, pdfs, jsonl, whatever data source - nostr relays are just another target. Likewise, a user's key in this scenario is treated merely as an opaque identifier, with no appreciation for the super powers it brings along.
In most cases, this kind of app only exists as a marketing ploy, or less cynically, because it wants to get in on the hype of being a "nostr app", without the developer quite understanding what that means, or having the budget to execute properly on the claim.
It leverages nostr
Some of you might be wondering, "isn't 'leverage' a synonym for 'use'?" And you would be right, but for one connotative difference. It's possible to "use" something improperly, but by definition leverage gives you a mechanical advantage that you wouldn't otherwise have. This is the second category of "nostr app".
This kind of app gets some benefit out of the nostr protocol and network, but in an entirely selfish fashion. The intention of this kind of app is not to augment the nostr network, but to augment its own UX by borrowing some nifty thing from the protocol without really contributing anything back.
Some examples might include:
- Using nostr signers to encrypt or sign data, and then store that data on a proprietary server.
- Using nostr relays as a kind of low-code backend, but using proprietary event payloads.
- Using nostr event kinds to represent data (why), but not leveraging the trustlessness that buys you.
An application in this category might even communicate to its users via nostr DMs - but this doesn't make it a "nostr app" any more than a website that emails you hot deals on herbal supplements is an "email app". These apps are purely parasitic on the nostr ecosystem.
In the long-term, that's not necessarily a bad thing. Email's ubiquity is self-reinforcing. But in the short term, this kind of "nostr app" can actually do damage to nostr's reputation by over-promising and under-delivering.
It complements nostr
Next up, we have apps that get some benefit out of nostr as above, but give back by providing a unique value proposition to nostr users as nostr users. This is a bit of a fine distinction, but for me this category is for apps which focus on solving problems that nostr isn't good at solving, leaving the nostr integration in a secondary or supporting role.
One example of this kind of app was Mutiny (RIP), which not only allowed users to sign in with nostr, but also pulled those users' social graphs so that users could send money to people they knew and trusted. Mutiny was doing a great job of leveraging nostr, as well as providing value to users with nostr identities - but it was still primarily a bitcoin wallet, not a "nostr app" in the purest sense.
Other examples are things like Nostr Nests and Zap.stream, whose core value proposition is streaming video or audio content. Both make great use of nostr identities, data formats, and relays, but they're primarily streaming apps. A good litmus test for things like this is: if you got rid of nostr, would it be the same product (even if inferior in certain ways)?
A similar category is infrastructure providers that benefit nostr by their existence (and may in fact be targeted explicitly at nostr users), but do things in a centralized, old-web way; for example: media hosts, DNS registrars, hosting providers, and CDNs.
To be clear here, I'm not casting aspersions (I don't even know what those are, or where to buy them). All the apps mentioned above use nostr to great effect, and are a real benefit to nostr users. But they are not True Scotsmen.
It embodies nostr
Ok, here we go. This is the crème de la crème, the top du top, the meilleur du meilleur, the bee's knees. The purest, holiest, most chaste category of nostr app out there. The apps which are, indeed, nostr indigitate.
This category of nostr app (see, no quotes this time) can be defined by the converse of the previous category. If nostr was removed from this type of application, would it be impossible to create the same product?
To tease this apart a bit, apps that leverage the technical aspects of nostr are dependent on nostr the protocol, while apps that benefit nostr exclusively via network effect are integrated into nostr the network. An app that does both things is working in symbiosis with nostr as a whole.
An app that embraces both nostr's protocol and its network becomes an organic extension of every other nostr app out there, multiplying both its competitive moat and its contribution to the ecosystem:
- In contrast to apps that only borrow from nostr on the technical level but continue to operate in their own silos, an application integrated into the nostr network comes pre-packaged with existing users, and is able to provide more value to those users because of other nostr products. On nostr, it's a good thing to advertise your competitors.
- In contrast to apps that only market themselves to nostr users without building out a deep integration on the protocol level, a deeply integrated app becomes an asset to every other nostr app by becoming an organic extension of them through interoperability. This results in increased traffic to the app as other developers and users refer people to it instead of solving their problem on their own. This is the "micro-apps" utopia we've all been waiting for.
Credible exit doesn't matter if there aren't alternative services. Interoperability is pointless if other applications don't offer something your app doesn't. Marketing to nostr users doesn't matter if you don't augment their agency as nostr users.
If I had to choose a single NIP that represents the mindset behind this kind of app, it would be NIP 89 A.K.A. "Recommended Application Handlers", which states:
Nostr's discoverability and transparent event interaction is one of its most interesting/novel mechanics. This NIP provides a simple way for clients to discover applications that handle events of a specific kind to ensure smooth cross-client and cross-kind interactions.
These handlers are the glue that holds nostr apps together. A single event, signed by the developer of an application (or by the application's own account) tells anyone who wants to know 1. what event kinds the app supports, 2. how to link to the app (if it's a client), and (if the pubkey also publishes a kind 10002), 3. which relays the app prefers.
As a sidenote, NIP 89 is currently focused more on clients, leaving DVMs, relays, signers, etc somewhat out in the cold. Updating 89 to include tailored listings for each kind of supporting app would be a huge improvement to the protocol. This, plus a good front end for navigating these listings (sorry nostrapp.link, close but no cigar) would obviate the evil centralized websites that curate apps based on arbitrary criteria.
Examples of this kind of app obviously include many kind 1 clients, as well as clients that attempt to bring the benefits of the nostr protocol and network to new use cases - whether long form content, video, image posts, music, emojis, recipes, project management, or any other "content type".
To drill down into one example, let's think for a moment about forms. What's so great about a forms app that is built on nostr? Well,
- There is a spec for forms and responses, which means that...
- Multiple clients can implement the same data format, allowing for credible exit and user choice, even of...
- Other products not focused on forms, which can still view, respond to, or embed forms, and which can send their users via NIP 89 to a client that does...
- Cryptographically sign forms and responses, which means they are self-authenticating and can be sent to...
- Multiple relays, which reduces the amount of trust necessary to be confident results haven't been deliberately "lost".
Show me a forms product that does all of those things, and isn't built on nostr. You can't, because it doesn't exist. Meanwhile, there are plenty of image hosts with APIs, streaming services, and bitcoin wallets which have basically the same levels of censorship resistance, interoperability, and network effect as if they weren't built on nostr.
It supports nostr
Notice I haven't said anything about whether relays, signers, blossom servers, software libraries, DVMs, and the accumulated addenda of the nostr ecosystem are nostr apps. Well, they are (usually).
This is the category of nostr app that gets none of the credit for doing all of the work. There's no question that they qualify as beautiful nostrcorns, because their value propositions are entirely meaningless outside of the context of nostr. Who needs a signer if you don't have a cryptographic identity you need to protect? DVMs are literally impossible to use without relays. How are you going to find the blossom server that will serve a given hash if you don't know which servers the publishing user has selected to store their content?
In addition to being entirely contextualized by nostr architecture, this type of nostr app is valuable because it does things "the nostr way". By that I mean that they don't simply try to replicate existing internet functionality into a nostr context; instead, they create entirely new ways of putting the basic building blocks of the internet back together.
A great example of this is how Nostr Connect, Nostr Wallet Connect, and DVMs all use relays as brokers, which allows service providers to avoid having to accept incoming network connections. This opens up really interesting possibilities all on its own.
So while I might hesitate to call many of these things "apps", they are certainly "nostr".
Appendix: it smells like a NINO
So, let's say you've created an app, but when you show it to people they politely smile, nod, and call it a NINO (Nostr In Name Only). What's a hacker to do? Well, here's your handy-dandy guide on how to wash that NINO stench off and Become a Nostr.
You app might be a NINO if:
- There's no NIP for your data format (or you're abusing NIP 78, 32, etc by inventing a sub-protocol inside an existing event kind)
- There's a NIP, but no one knows about it because it's in a text file on your hard drive (or buried in your project's repository)
- Your NIP imposes an incompatible/centralized/legacy web paradigm onto nostr
- Your NIP relies on trusted third (or first) parties
- There's only one implementation of your NIP (yours)
- Your core value proposition doesn't depend on relays, events, or nostr identities
- One or more relay urls are hard-coded into the source code
- Your app depends on a specific relay implementation to work (ahem, relay29)
- You don't validate event signatures
- You don't publish events to relays you don't control
- You don't read events from relays you don't control
- You use legacy web services to solve problems, rather than nostr-native solutions
- You use nostr-native solutions, but you've hardcoded their pubkeys or URLs into your app
- You don't use NIP 89 to discover clients and services
- You haven't published a NIP 89 listing for your app
- You don't leverage your users' web of trust for filtering out spam
- You don't respect your users' mute lists
- You try to "own" your users' data
Now let me just re-iterate - it's ok to be a NINO. We need NINOs, because nostr can't (and shouldn't) tackle every problem. You just need to decide whether your app, as a NINO, is actually contributing to the nostr ecosystem, or whether you're just using buzzwords to whitewash a legacy web software product.
If you're in the former camp, great! If you're in the latter, what are you waiting for? Only you can fix your NINO problem. And there are lots of ways to do this, depending on your own unique situation:
- Drop nostr support if it's not doing anyone any good. If you want to build a normal company and make some money, that's perfectly fine.
- Build out your nostr integration - start taking advantage of webs of trust, self-authenticating data, event handlers, etc.
- Work around the problem. Think you need a special relay feature for your app to work? Guess again. Consider encryption, AUTH, DVMs, or better data formats.
- Think your idea is a good one? Talk to other devs or open a PR to the nips repo. No one can adopt your NIP if they don't know about it.
- Keep going. It can sometimes be hard to distinguish a research project from a NINO. New ideas have to be built out before they can be fully appreciated.
- Listen to advice. Nostr developers are friendly and happy to help. If you're not sure why you're getting traction, ask!
I sincerely hope this article is useful for all of you out there in NINO land. Maybe this made you feel better about not passing the totally optional nostr app purity test. Or maybe it gave you some actionable next steps towards making a great NINON (Nostr In Not Only Name) app. In either case, GM and PV.
-
@ 0fa80bd3:ea7325de
2025-01-30 04:28:30
"Degeneration" or "Вырождение" ![[photo_2025-01-29 23.23.15.jpeg]]
A once-functional object, now eroded by time and human intervention, stripped of its original purpose. Layers of presence accumulate—marks, alterations, traces of intent—until the very essence is obscured. Restoration is paradoxical: to reclaim, one must erase. Yet erasure is an impossibility, for to remove these imprints is to deny the existence of those who shaped them.
The work stands as a meditation on entropy, memory, and the irreversible dialogue between creation and decay.
-
@ 0fa80bd3:ea7325de
2025-01-29 15:43:42
Lyn Alden - биткойн евангелист или евангелистка, я пока не понял
npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83aThomas Pacchia - PubKey owner - X - @tpacchia
npub1xy6exlg37pw84cpyj05c2pdgv86hr25cxn0g7aa8g8a6v97mhduqeuhgplcalvadev - Shopstr
npub16dhgpql60vmd4mnydjut87vla23a38j689jssaqlqqlzrtqtd0kqex0nkqCalle - Cashu founder
npub12rv5lskctqxxs2c8rf2zlzc7xx3qpvzs3w4etgemauy9thegr43sf485vgДжек Дорси
npub1sg6plzptd64u62a878hep2kev88swjh3tw00gjsfl8f237lmu63q0uf63m21 ideas
npub1lm3f47nzyf0rjp6fsl4qlnkmzed4uj4h2gnf2vhe3l3mrj85vqks6z3c7lМного адресов. Хз кто надо сортировать
https://github.com/aitechguy/nostr-address-bookФиатДжеф - создатель Ностр - https://github.com/fiatjaf
npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6EVAN KALOUDIS Zues wallet
npub19kv88vjm7tw6v9qksn2y6h4hdt6e79nh3zjcud36k9n3lmlwsleqwte2qdПрограммер Коди https://github.com/CodyTseng/nostr-relay
npub1syjmjy0dp62dhccq3g97fr87tngvpvzey08llyt6ul58m2zqpzps9wf6wlAnna Chekhovich - Managing Bitcoin at The Anti-Corruption Foundation https://x.com/AnyaChekhovich
npub1y2st7rp54277hyd2usw6shy3kxprnmpvhkezmldp7vhl7hp920aq9cfyr7 -
@ 0fa80bd3:ea7325de
2025-01-29 14:44:48
![[yedinaya-rossiya-bear.png]]
1️⃣ Be where the bear roams. Stay in its territory, where it hunts for food. No point setting a trap in your backyard if the bear’s chilling in the forest.
2️⃣ Set a well-hidden trap. Bury it, disguise it, and place the bait right in the center. Bears are omnivores—just like secret police KGB agents. And what’s the tastiest bait for them? Money.
3️⃣ Wait for the bear to take the bait. When it reaches in, the trap will snap shut around its paw. It’ll be alive, but stuck. No escape.
Now, what you do with a trapped bear is another question... 😏
-
@ 0fa80bd3:ea7325de
2025-01-29 05:55:02
The land that belongs to the indigenous peoples of Russia has been seized by a gang of killers who have unleashed a war of extermination. They wipe out anyone who refuses to conform to their rules. Those who disagree and stay behind are tortured and killed in prisons and labor camps. Those who flee lose their homeland, dissolve into foreign cultures, and fade away. And those who stand up to protect their people are attacked by the misled and deceived. The deceived die for the unchecked greed of a single dictator—thousands from both sides, people who just wanted to live, raise their kids, and build a future.
Now, they are forced to make an impossible choice: abandon their homeland or die. Some perish on the battlefield, others lose themselves in exile, stripped of their identity, scattered in a world that isn’t theirs.
There’s been endless debate about how to fix this, how to clear the field of the weeds that choke out every new sprout, every attempt at change. But the real problem? We can’t play by their rules. We can’t speak their language or use their weapons. We stand for humanity, and no matter how righteous our cause, we will not multiply suffering. Victory doesn’t come from matching the enemy—it comes from staying ahead, from using tools they haven’t mastered yet. That’s how wars are won.
Our only resource is the will of the people to rewrite the order of things. Historian Timothy Snyder once said that a nation cannot exist without a city. A city is where the most active part of a nation thrives. But the cities are occupied. The streets are watched. Gatherings are impossible. They control the money. They control the mail. They control the media. And any dissent is crushed before it can take root.
So I started asking myself: How do we stop this fragmentation? How do we create a space where people can rebuild their connections when they’re ready? How do we build a self-sustaining network, where everyone contributes and benefits proportionally, while keeping their freedom to leave intact? And more importantly—how do we make it spread, even in occupied territory?
In 2009, something historic happened: the internet got its own money. Thanks to Satoshi Nakamoto, the world took a massive leap forward. Bitcoin and decentralized ledgers shattered the idea that money must be controlled by the state. Now, to move or store value, all you need is an address and a key. A tiny string of text, easy to carry, impossible to seize.
That was the year money broke free. The state lost its grip. Its biggest weapon—physical currency—became irrelevant. Money became purely digital.
The internet was already a sanctuary for information, a place where people could connect and organize. But with Bitcoin, it evolved. Now, value itself could flow freely, beyond the reach of authorities.
Think about it: when seedlings are grown in controlled environments before being planted outside, they get stronger, survive longer, and bear fruit faster. That’s how we handle crops in harsh climates—nurture them until they’re ready for the wild.
Now, picture the internet as that controlled environment for ideas. Bitcoin? It’s the fertile soil that lets them grow. A testing ground for new models of interaction, where concepts can take root before they move into the real world. If nation-states are a battlefield, locked in a brutal war for territory, the internet is boundless. It can absorb any number of ideas, any number of people, and it doesn’t run out of space.
But for this ecosystem to thrive, people need safe ways to communicate, to share ideas, to build something real—without surveillance, without censorship, without the constant fear of being erased.
This is where Nostr comes in.
Nostr—"Notes and Other Stuff Transmitted by Relays"—is more than just a messaging protocol. It’s a new kind of city. One that no dictator can seize, no corporation can own, no government can shut down.
It’s built on decentralization, encryption, and individual control. Messages don’t pass through central servers—they are relayed through independent nodes, and users choose which ones to trust. There’s no master switch to shut it all down. Every person owns their identity, their data, their connections. And no one—no state, no tech giant, no algorithm—can silence them.
In a world where cities fall and governments fail, Nostr is a city that cannot be occupied. A place for ideas, for networks, for freedom. A city that grows stronger the more people build within it.
-
@ 9e69e420:d12360c2
2025-01-26 15:26:44
Secretary of State Marco Rubio issued new guidance halting spending on most foreign aid grants for 90 days, including military assistance to Ukraine. This immediate order shocked State Department officials and mandates “stop-work orders” on nearly all existing foreign assistance awards.
While it allows exceptions for military financing to Egypt and Israel, as well as emergency food assistance, it restricts aid to key allies like Ukraine, Jordan, and Taiwan. The guidance raises potential liability risks for the government due to unfulfilled contracts.
A report will be prepared within 85 days to recommend which programs to continue or discontinue.
-
@ 9e69e420:d12360c2
2025-01-26 01:31:31
Chef's notes
arbitray
- test
- of
- chefs notes
hedding 2
Details
- ⏲️ Prep time: 20
- 🍳 Cook time: 1 hour
- 🍽️ Servings: 5
Ingredients
- Test ingredient
- 2nd test ingredient
Directions
- Bake
- Cool
-
@ 9e69e420:d12360c2
2025-01-25 22:16:54
President Trump plans to withdraw 20,000 U.S. troops from Europe and expects European allies to contribute financially to the remaining military presence. Reported by ANSA, Trump aims to deliver this message to European leaders since taking office. A European diplomat noted, “the costs cannot be borne solely by American taxpayers.”
The Pentagon hasn't commented yet. Trump has previously sought lower troop levels in Europe and had ordered cuts during his first term. The U.S. currently maintains around 65,000 troops in Europe, with total forces reaching 100,000 since the Ukraine invasion. Trump's new approach may shift military focus to the Pacific amid growing concerns about China.
-
@ 6be5cc06:5259daf0
2025-01-21 20:58:37
A seguir, veja como instalar e configurar o Privoxy no Pop!_OS.
1. Instalar o Tor e o Privoxy
Abra o terminal e execute:
bash sudo apt update sudo apt install tor privoxyExplicação:
- Tor: Roteia o tráfego pela rede Tor.
- Privoxy: Proxy avançado que intermedia a conexão entre aplicativos e o Tor.
2. Configurar o Privoxy
Abra o arquivo de configuração do Privoxy:
bash sudo nano /etc/privoxy/configNavegue até a última linha (atalho:
Ctrl+/depoisCtrl+Vpara navegar diretamente até a última linha) e insira:bash forward-socks5 / 127.0.0.1:9050 .Isso faz com que o Privoxy envie todo o tráfego para o Tor através da porta 9050.
Salve (
CTRL+OeEnter) e feche (CTRL+X) o arquivo.
3. Iniciar o Tor e o Privoxy
Agora, inicie e habilite os serviços:
bash sudo systemctl start tor sudo systemctl start privoxy sudo systemctl enable tor sudo systemctl enable privoxyExplicação:
- start: Inicia os serviços.
- enable: Faz com que iniciem automaticamente ao ligar o PC.
4. Configurar o Navegador Firefox
Para usar a rede Tor com o Firefox:
- Abra o Firefox.
- Acesse Configurações → Configurar conexão.
- Selecione Configuração manual de proxy.
- Configure assim:
- Proxy HTTP:
127.0.0.1 - Porta:
8118(porta padrão do Privoxy) - Domínio SOCKS (v5):
127.0.0.1 - Porta:
9050
- Proxy HTTP:
- Marque a opção "Usar este proxy também em HTTPS".
- Clique em OK.
5. Verificar a Conexão com o Tor
Abra o navegador e acesse:
text https://check.torproject.org/Se aparecer a mensagem "Congratulations. This browser is configured to use Tor.", a configuração está correta.
Dicas Extras
- Privoxy pode ser ajustado para bloquear anúncios e rastreadores.
- Outros aplicativos também podem ser configurados para usar o Privoxy.
-
@ 9e69e420:d12360c2
2025-01-21 19:31:48
Oregano oil is a potent natural compound that offers numerous scientifically-supported health benefits.
Active Compounds
The oil's therapeutic properties stem from its key bioactive components: - Carvacrol and thymol (primary active compounds) - Polyphenols and other antioxidant
Antimicrobial Properties
Bacterial Protection The oil demonstrates powerful antibacterial effects, even against antibiotic-resistant strains like MRSA and other harmful bacteria. Studies show it effectively inactivates various pathogenic bacteria without developing resistance.
Antifungal Effects It effectively combats fungal infections, particularly Candida-related conditions like oral thrush, athlete's foot, and nail infections.
Digestive Health Benefits
Oregano oil supports digestive wellness by: - Promoting gastric juice secretion and enzyme production - Helping treat Small Intestinal Bacterial Overgrowth (SIBO) - Managing digestive discomfort, bloating, and IBS symptoms
Anti-inflammatory and Antioxidant Effects
The oil provides significant protective benefits through: - Powerful antioxidant activity that fights free radicals - Reduction of inflammatory markers in the body - Protection against oxidative stress-related conditions
Respiratory Support
It aids respiratory health by: - Loosening mucus and phlegm - Suppressing coughs and throat irritation - Supporting overall respiratory tract function
Additional Benefits
Skin Health - Improves conditions like psoriasis, acne, and eczema - Supports wound healing through antibacterial action - Provides anti-aging benefits through antioxidant properties
Cardiovascular Health Studies show oregano oil may help: - Reduce LDL (bad) cholesterol levels - Support overall heart health
Pain Management The oil demonstrates effectiveness in: - Reducing inflammation-related pain - Managing muscle discomfort - Providing topical pain relief
Safety Note
While oregano oil is generally safe, it's highly concentrated and should be properly diluted before use Consult a healthcare provider before starting supplementation, especially if taking other medications.
-
@ b17fccdf:b7211155
2025-01-21 18:16:58
Next new resources about the MiniBolt guide have been released:
- 🆕 Roadmap: LINK
- 🆕 Network Map: LINK
- 🆕 Nostr community: LINK
- 🆕 Linktr FOSS (UC) by Gzuuus: LINK
- 🆕 Donate webpage: 🚾 Clearnet LINK || 🧅 Onion LINK
- 🆕 Contact email: hello@minibolt.info
Enjoy it MiniBolter! 💙
-
@ b17fccdf:b7211155
2025-01-21 17:07:47
-
@ b17fccdf:b7211155
2025-01-21 17:02:21
The past 26 August, Tor introduced officially a proof-of-work (PoW) defense for onion services designed to prioritize verified network traffic as a deterrent against denial of service (DoS) attacks.
~ > This feature at the moment, is deactivate by default, so you need to follow these steps to activate this on a MiniBolt node:
- Make sure you have the latest version of Tor installed, at the time of writing this post, which is v0.4.8.6. Check your current version by typing
tor --versionExample of expected output:
Tor version 0.4.8.6. This build of Tor is covered by the GNU General Public License (https://www.gnu.org/licenses/gpl-3.0.en.html) Tor is running on Linux with Libevent 2.1.12-stable, OpenSSL 3.0.9, Zlib 1.2.13, Liblzma 5.4.1, Libzstd N/A and Glibc 2.36 as libc. Tor compiled with GCC version 12.2.0~ > If you have v0.4.8.X, you are OK, if not, type
sudo apt update && sudo apt upgradeand confirm to update.- Basic PoW support can be checked by running this command:
tor --list-modulesExpected output:
relay: yes dirauth: yes dircache: yes pow: **yes**~ > If you have
pow: yes, you are OK- Now go to the torrc file of your MiniBolt and add the parameter to enable PoW for each hidden service added
sudo nano /etc/tor/torrcExample:
```
Hidden Service BTC RPC Explorer
HiddenServiceDir /var/lib/tor/hidden_service_btcrpcexplorer/ HiddenServiceVersion 3 HiddenServicePoWDefensesEnabled 1 HiddenServicePort 80 127.0.0.1:3002 ```
~ > Bitcoin Core and LND use the Tor control port to automatically create the hidden service, requiring no action from the user. We have submitted a feature request in the official GitHub repositories to explore the need for the integration of Tor's PoW defense into the automatic creation process of the hidden service. You can follow them at the following links:
- Bitcoin Core: https://github.com/lightningnetwork/lnd/issues/8002
- LND: https://github.com/bitcoin/bitcoin/issues/28499
More info:
- https://blog.torproject.org/introducing-proof-of-work-defense-for-onion-services/
- https://gitlab.torproject.org/tpo/onion-services/onion-support/-/wikis/Documentation/PoW-FAQ
Enjoy it MiniBolter! 💙
-
@ b17fccdf:b7211155
2025-01-21 16:56:24
It turns out that Ubuntu Linux installations of Ubuntu 23.04, 22.04.3 LTS, and installs done since April 2023 that accepted the Snap version update haven't been following Ubuntu's own recommended security best practices for their security pocket configuration for packages.
A new Subiquity release was issued to fix this problem while those on affected Ubuntu systems already installed are recommended to manually edit their
/etc/apt/sources.listfile.If you didn't install MiniBolt recently, you are affected by this bug, and we need to fix that manually if not we want to install all since cero. Anyway, if you installed Minibolt recently, we recommend you review that.
Follow these easy steps to review and fix this:
- Edit the
sources-listfile:
sudo nano /etc/apt/sources.list- Search now for every line that includes '-security' (without quotes) (normally at the end of the file) and change the URL to --> http://security.ubuntu.com/ubuntu
~ > For example, from http://es.archive.ubuntu.com/ubuntu (or the extension corresponding to your country) to --> http://security.ubuntu.com/ubuntu
~> Real case, Spain location, before fix:
``` deb http://es.archive.ubuntu.com/ubuntu jammy-security main restricted
deb-src http://es.archive.ubuntu.com/ubuntu jammy-security main restricted
deb http://es.archive.ubuntu.com/ubuntu jammy-security universe
deb-src http://es.archive.ubuntu.com/ubuntu jammy-security universe
deb http://es.archive.ubuntu.com/ubuntu jammy-security multiverse
deb-src http://es.archive.ubuntu.com/ubuntu jammy-security multiverse
```
After fix:
``` deb http://security.ubuntu.com/ubuntu jammy-security main restricted
deb-src http://es.archive.ubuntu.com/ubuntu jammy-security main restricted
deb http://security.ubuntu.com/ubuntu jammy-security universe
deb-src http://es.archive.ubuntu.com/ubuntu jammy-security universe
deb http://security.ubuntu.com/ubuntu jammy-security multiverse
deb-src http://es.archive.ubuntu.com/ubuntu jammy-security multiverse
```
Save and exit
Note: If you have already these lines changed, you are not affected by this bug, and is not necessary to do anything. Simply exit the editor by doing Ctrl-X
- Finally, type the next command to refresh the repository pointers:
sudo apt update- And optionally take the opportunity to update the system by doing:
sudo apt full-upgradeMore context:
- https://wiki.ubuntu.com/SecurityTeam/FAQ#What_repositories_and_pockets_should_I_use_to_make_sure_my_systems_are_up_to_date.3F
- https://bugs.launchpad.net/subiquity/+bug/2033977
- https://www.phoronix.com/news/Ubuntu-Security-Pocket-Issue
- Edit the
-
@ b17fccdf:b7211155
2025-01-21 16:49:27
What's changed
- New method for Bitcoin Core signature check, click ~ >HERE< ~
- GitHub repo of Bitcoin Core release attestations (Guix), click ~ >HERE< ~
History:
~ > PR that caused the broken and obsolescence of the old signature verification process, click ~ >HERE< ~
~ > New GitHub folder of Bitcoin Core repo that stores the signatures, click ~ >HERE< ~
Thanks to nostr:npub1gzuushllat7pet0ccv9yuhygvc8ldeyhrgxuwg744dn5khnpk3gs3ea5ds for building the command that made magic possible 🧙♂️🧡
Enjoy it MiniBolter! 💙
-
@ b17fccdf:b7211155
2025-01-21 16:40:01
Important notice to MiniBolt node runners:
~ > It turns out that the I2P devs have opened an issue on the Bitcoin Core GitHub repo commenting that because they gave the option to enable the
notransit=trueparameter in the official documentation:[...] If you prefer not to relay any public I2P traffic and only allow I2P traffic from programs connecting through the SAM proxy, e.g. Bitcoin Core, you can set the no transit option to true [...] are having a heavy load on the I2P network since last December 19. Also comment that it is advisable to share as much bandwidth and transit tunnels as we can, to increase anonymity with coverage traffic, by contributing more to the I2p network than we consume.
So they ask that we deactivate that option that you use activated. With all this, he already updated the "Privacy" section by removing that setting.
The steps to delete this configuration once we have already configured it, are the following:
- With the "admin" user, stop i2pd:
sudo systemctl stop i2pd- Comment line 93 with "#" at the beginning of it (notransit = true), save and exit
sudo nano /var/lib/i2pd/i2pd.conf --line numbers- Start i2pd again:
sudo systemctl start i2pd- And that's it, you could take a look at Bitcoin Core to see that it has detected i2pd running again after the reboot with:
tail --lines 500 -f /home/bitcoin/.bitcoin/debug.log~ > If you don't see that I2P is up in Bitcoin Core after the restart,
sudo systemctl restart bitcoindand look again at the logs of the same.
More info in the rollback commit, see ~> HERE < ~
-
@ b17fccdf:b7211155
2025-01-21 16:30:11
Your MiniBolt is on a home local network, you want to expose it on the public Internet (clearnet) without exposing your public IP, without Firewall rules, without NAT port forwarding, without risk, easy and cheap?
Go to the bonus guide by clicking ~ >HERE <~
Enjoy it MiniBolter! 💙
-
@ b17fccdf:b7211155
2025-01-21 16:23:44
Build your nostr relay step by step on your MiniBolt node! (easily adaptable to other environment) No need to trust anyone else! Be sovereign!
~> Go to the bonus guide by clicking ~> HERE< ~
~> This guide includes a complete extra section to cover the different processes for using nostr as a user and relay operator.
PS: The MiniBolt project has its FREE relay, be free to connect by adding to your favorite client the next address:
wss://relay.minibolt.info~> Let a review on noStrudel or Coracle of your experience using it.
Remember, Nostr is freedom! Stay resilient! 💜 🛡️💪
-
@ 6be5cc06:5259daf0
2025-01-21 01:51:46
Bitcoin: Um sistema de dinheiro eletrônico direto entre pessoas.
Satoshi Nakamoto
satoshin@gmx.com
www.bitcoin.org
Resumo
O Bitcoin é uma forma de dinheiro digital que permite pagamentos diretos entre pessoas, sem a necessidade de um banco ou instituição financeira. Ele resolve um problema chamado gasto duplo, que ocorre quando alguém tenta gastar o mesmo dinheiro duas vezes. Para evitar isso, o Bitcoin usa uma rede descentralizada onde todos trabalham juntos para verificar e registrar as transações.
As transações são registradas em um livro público chamado blockchain, protegido por uma técnica chamada Prova de Trabalho. Essa técnica cria uma cadeia de registros que não pode ser alterada sem refazer todo o trabalho já feito. Essa cadeia é mantida pelos computadores que participam da rede, e a mais longa é considerada a verdadeira.
Enquanto a maior parte do poder computacional da rede for controlada por participantes honestos, o sistema continuará funcionando de forma segura. A rede é flexível, permitindo que qualquer pessoa entre ou saia a qualquer momento, sempre confiando na cadeia mais longa como prova do que aconteceu.
1. Introdução
Hoje, quase todos os pagamentos feitos pela internet dependem de bancos ou empresas como processadores de pagamento (cartões de crédito, por exemplo) para funcionar. Embora esse sistema seja útil, ele tem problemas importantes porque é baseado em confiança.
Primeiro, essas empresas podem reverter pagamentos, o que é útil em caso de erros, mas cria custos e incertezas. Isso faz com que pequenas transações, como pagar centavos por um serviço, se tornem inviáveis. Além disso, os comerciantes são obrigados a desconfiar dos clientes, pedindo informações extras e aceitando fraudes como algo inevitável.
Esses problemas não existem no dinheiro físico, como o papel-moeda, onde o pagamento é final e direto entre as partes. No entanto, não temos como enviar dinheiro físico pela internet sem depender de um intermediário confiável.
O que precisamos é de um sistema de pagamento eletrônico baseado em provas matemáticas, não em confiança. Esse sistema permitiria que qualquer pessoa enviasse dinheiro diretamente para outra, sem depender de bancos ou processadores de pagamento. Além disso, as transações seriam irreversíveis, protegendo vendedores contra fraudes, mas mantendo a possibilidade de soluções para disputas legítimas.
Neste documento, apresentamos o Bitcoin, que resolve o problema do gasto duplo usando uma rede descentralizada. Essa rede cria um registro público e protegido por cálculos matemáticos, que garante a ordem das transações. Enquanto a maior parte da rede for controlada por pessoas honestas, o sistema será seguro contra ataques.
2. Transações
Para entender como funciona o Bitcoin, é importante saber como as transações são realizadas. Imagine que você quer transferir uma "moeda digital" para outra pessoa. No sistema do Bitcoin, essa "moeda" é representada por uma sequência de registros que mostram quem é o atual dono. Para transferi-la, você adiciona um novo registro comprovando que agora ela pertence ao próximo dono. Esse registro é protegido por um tipo especial de assinatura digital.
O que é uma assinatura digital?
Uma assinatura digital é como uma senha secreta, mas muito mais segura. No Bitcoin, cada usuário tem duas chaves: uma "chave privada", que é secreta e serve para criar a assinatura, e uma "chave pública", que pode ser compartilhada com todos e é usada para verificar se a assinatura é válida. Quando você transfere uma moeda, usa sua chave privada para assinar a transação, provando que você é o dono. A próxima pessoa pode usar sua chave pública para confirmar isso.
Como funciona na prática?
Cada "moeda" no Bitcoin é, na verdade, uma cadeia de assinaturas digitais. Vamos imaginar o seguinte cenário:
- A moeda está com o Dono 0 (você). Para transferi-la ao Dono 1, você assina digitalmente a transação com sua chave privada. Essa assinatura inclui o código da transação anterior (chamado de "hash") e a chave pública do Dono 1.
- Quando o Dono 1 quiser transferir a moeda ao Dono 2, ele assinará a transação seguinte com sua própria chave privada, incluindo também o hash da transação anterior e a chave pública do Dono 2.
- Esse processo continua, formando uma "cadeia" de transações. Qualquer pessoa pode verificar essa cadeia para confirmar quem é o atual dono da moeda.
Resolvendo o problema do gasto duplo
Um grande desafio com moedas digitais é o "gasto duplo", que é quando uma mesma moeda é usada em mais de uma transação. Para evitar isso, muitos sistemas antigos dependiam de uma entidade central confiável, como uma casa da moeda, que verificava todas as transações. No entanto, isso criava um ponto único de falha e centralizava o controle do dinheiro.
O Bitcoin resolve esse problema de forma inovadora: ele usa uma rede descentralizada onde todos os participantes (os "nós") têm acesso a um registro completo de todas as transações. Cada nó verifica se as transações são válidas e se a moeda não foi gasta duas vezes. Quando a maioria dos nós concorda com a validade de uma transação, ela é registrada permanentemente na blockchain.
Por que isso é importante?
Essa solução elimina a necessidade de confiar em uma única entidade para gerenciar o dinheiro, permitindo que qualquer pessoa no mundo use o Bitcoin sem precisar de permissão de terceiros. Além disso, ela garante que o sistema seja seguro e resistente a fraudes.
3. Servidor Timestamp
Para assegurar que as transações sejam realizadas de forma segura e transparente, o sistema Bitcoin utiliza algo chamado de "servidor de registro de tempo" (timestamp). Esse servidor funciona como um registro público que organiza as transações em uma ordem específica.
Ele faz isso agrupando várias transações em blocos e criando um código único chamado "hash". Esse hash é como uma impressão digital que representa todo o conteúdo do bloco. O hash de cada bloco é amplamente divulgado, como se fosse publicado em um jornal ou em um fórum público.
Esse processo garante que cada bloco de transações tenha um registro de quando foi criado e que ele existia naquele momento. Além disso, cada novo bloco criado contém o hash do bloco anterior, formando uma cadeia contínua de blocos conectados — conhecida como blockchain.
Com isso, se alguém tentar alterar qualquer informação em um bloco anterior, o hash desse bloco mudará e não corresponderá ao hash armazenado no bloco seguinte. Essa característica torna a cadeia muito segura, pois qualquer tentativa de fraude seria imediatamente detectada.
O sistema de timestamps é essencial para provar a ordem cronológica das transações e garantir que cada uma delas seja única e autêntica. Dessa forma, ele reforça a segurança e a confiança na rede Bitcoin.
4. Prova-de-Trabalho
Para implementar o registro de tempo distribuído no sistema Bitcoin, utilizamos um mecanismo chamado prova-de-trabalho. Esse sistema é semelhante ao Hashcash, desenvolvido por Adam Back, e baseia-se na criação de um código único, o "hash", por meio de um processo computacionalmente exigente.
A prova-de-trabalho envolve encontrar um valor especial que, quando processado junto com as informações do bloco, gere um hash que comece com uma quantidade específica de zeros. Esse valor especial é chamado de "nonce". Encontrar o nonce correto exige um esforço significativo do computador, porque envolve tentativas repetidas até que a condição seja satisfeita.
Esse processo é importante porque torna extremamente difícil alterar qualquer informação registrada em um bloco. Se alguém tentar mudar algo em um bloco, seria necessário refazer o trabalho de computação não apenas para aquele bloco, mas também para todos os blocos que vêm depois dele. Isso garante a segurança e a imutabilidade da blockchain.
A prova-de-trabalho também resolve o problema de decidir qual cadeia de blocos é a válida quando há múltiplas cadeias competindo. A decisão é feita pela cadeia mais longa, pois ela representa o maior esforço computacional já realizado. Isso impede que qualquer indivíduo ou grupo controle a rede, desde que a maioria do poder de processamento seja mantida por participantes honestos.
Para garantir que o sistema permaneça eficiente e equilibrado, a dificuldade da prova-de-trabalho é ajustada automaticamente ao longo do tempo. Se novos blocos estiverem sendo gerados rapidamente, a dificuldade aumenta; se estiverem sendo gerados muito lentamente, a dificuldade diminui. Esse ajuste assegura que novos blocos sejam criados aproximadamente a cada 10 minutos, mantendo o sistema estável e funcional.
5. Rede
A rede Bitcoin é o coração do sistema e funciona de maneira distribuída, conectando vários participantes (ou nós) para garantir o registro e a validação das transações. Os passos para operar essa rede são:
-
Transmissão de Transações: Quando alguém realiza uma nova transação, ela é enviada para todos os nós da rede. Isso é feito para garantir que todos estejam cientes da operação e possam validá-la.
-
Coleta de Transações em Blocos: Cada nó agrupa as novas transações recebidas em um "bloco". Este bloco será preparado para ser adicionado à cadeia de blocos (a blockchain).
-
Prova-de-Trabalho: Os nós competem para resolver a prova-de-trabalho do bloco, utilizando poder computacional para encontrar um hash válido. Esse processo é como resolver um quebra-cabeça matemático difícil.
-
Envio do Bloco Resolvido: Quando um nó encontra a solução para o bloco (a prova-de-trabalho), ele compartilha esse bloco com todos os outros nós na rede.
-
Validação do Bloco: Cada nó verifica o bloco recebido para garantir que todas as transações nele contidas sejam válidas e que nenhuma moeda tenha sido gasta duas vezes. Apenas blocos válidos são aceitos.
-
Construção do Próximo Bloco: Os nós que aceitaram o bloco começam a trabalhar na criação do próximo bloco, utilizando o hash do bloco aceito como base (hash anterior). Isso mantém a continuidade da cadeia.
Resolução de Conflitos e Escolha da Cadeia Mais Longa
Os nós sempre priorizam a cadeia mais longa, pois ela representa o maior esforço computacional já realizado, garantindo maior segurança. Se dois blocos diferentes forem compartilhados simultaneamente, os nós trabalharão no primeiro bloco recebido, mas guardarão o outro como uma alternativa. Caso o segundo bloco eventualmente forme uma cadeia mais longa (ou seja, tenha mais blocos subsequentes), os nós mudarão para essa nova cadeia.
Tolerância a Falhas
A rede é robusta e pode lidar com mensagens que não chegam a todos os nós. Uma transação não precisa alcançar todos os nós de imediato; basta que chegue a um número suficiente deles para ser incluída em um bloco. Da mesma forma, se um nó não receber um bloco em tempo hábil, ele pode solicitá-lo ao perceber que está faltando quando o próximo bloco é recebido.
Esse mecanismo descentralizado permite que a rede Bitcoin funcione de maneira segura, confiável e resiliente, sem depender de uma autoridade central.
6. Incentivo
O incentivo é um dos pilares fundamentais que sustenta o funcionamento da rede Bitcoin, garantindo que os participantes (nós) continuem operando de forma honesta e contribuindo com recursos computacionais. Ele é estruturado em duas partes principais: a recompensa por mineração e as taxas de transação.
Recompensa por Mineração
Por convenção, o primeiro registro em cada bloco é uma transação especial que cria novas moedas e as atribui ao criador do bloco. Essa recompensa incentiva os mineradores a dedicarem poder computacional para apoiar a rede. Como não há uma autoridade central para emitir moedas, essa é a maneira pela qual novas moedas entram em circulação. Esse processo pode ser comparado ao trabalho de garimpeiros, que utilizam recursos para colocar mais ouro em circulação. No caso do Bitcoin, o "recurso" consiste no tempo de CPU e na energia elétrica consumida para resolver a prova-de-trabalho.
Taxas de Transação
Além da recompensa por mineração, os mineradores também podem ser incentivados pelas taxas de transação. Se uma transação utiliza menos valor de saída do que o valor de entrada, a diferença é tratada como uma taxa, que é adicionada à recompensa do bloco contendo essa transação. Com o passar do tempo e à medida que o número de moedas em circulação atinge o limite predeterminado, essas taxas de transação se tornam a principal fonte de incentivo, substituindo gradualmente a emissão de novas moedas. Isso permite que o sistema opere sem inflação, uma vez que o número total de moedas permanece fixo.
Incentivo à Honestidade
O design do incentivo também busca garantir que os participantes da rede mantenham um comportamento honesto. Para um atacante que consiga reunir mais poder computacional do que o restante da rede, ele enfrentaria duas escolhas:
- Usar esse poder para fraudar o sistema, como reverter transações e roubar pagamentos.
- Seguir as regras do sistema, criando novos blocos e recebendo recompensas legítimas.
A lógica econômica favorece a segunda opção, pois um comportamento desonesto prejudicaria a confiança no sistema, diminuindo o valor de todas as moedas, incluindo aquelas que o próprio atacante possui. Jogar dentro das regras não apenas maximiza o retorno financeiro, mas também preserva a validade e a integridade do sistema.
Esse mecanismo garante que os incentivos econômicos estejam alinhados com o objetivo de manter a rede segura, descentralizada e funcional ao longo do tempo.
7. Recuperação do Espaço em Disco
Depois que uma moeda passa a estar protegida por muitos blocos na cadeia, as informações sobre as transações antigas que a geraram podem ser descartadas para economizar espaço em disco. Para que isso seja possível sem comprometer a segurança, as transações são organizadas em uma estrutura chamada "árvore de Merkle". Essa árvore funciona como um resumo das transações: em vez de armazenar todas elas, guarda apenas um "hash raiz", que é como uma assinatura compacta que representa todo o grupo de transações.
Os blocos antigos podem, então, ser simplificados, removendo as partes desnecessárias dessa árvore. Apenas a raiz do hash precisa ser mantida no cabeçalho do bloco, garantindo que a integridade dos dados seja preservada, mesmo que detalhes específicos sejam descartados.
Para exemplificar: imagine que você tenha vários recibos de compra. Em vez de guardar todos os recibos, você cria um documento e lista apenas o valor total de cada um. Mesmo que os recibos originais sejam descartados, ainda é possível verificar a soma com base nos valores armazenados.
Além disso, o espaço ocupado pelos blocos em si é muito pequeno. Cada bloco sem transações ocupa apenas cerca de 80 bytes. Isso significa que, mesmo com blocos sendo gerados a cada 10 minutos, o crescimento anual em espaço necessário é insignificante: apenas 4,2 MB por ano. Com a capacidade de armazenamento dos computadores crescendo a cada ano, esse espaço continuará sendo trivial, garantindo que a rede possa operar de forma eficiente sem problemas de armazenamento, mesmo a longo prazo.
8. Verificação de Pagamento Simplificada
É possível confirmar pagamentos sem a necessidade de operar um nó completo da rede. Para isso, o usuário precisa apenas de uma cópia dos cabeçalhos dos blocos da cadeia mais longa (ou seja, a cadeia com maior esforço de trabalho acumulado). Ele pode verificar a validade de uma transação ao consultar os nós da rede até obter a confirmação de que tem a cadeia mais longa. Para isso, utiliza-se o ramo Merkle, que conecta a transação ao bloco em que ela foi registrada.
Entretanto, o método simplificado possui limitações: ele não pode confirmar uma transação isoladamente, mas sim assegurar que ela ocupa um lugar específico na cadeia mais longa. Dessa forma, se um nó da rede aprova a transação, os blocos subsequentes reforçam essa aceitação.
A verificação simplificada é confiável enquanto a maioria dos nós da rede for honesta. Contudo, ela se torna vulnerável caso a rede seja dominada por um invasor. Nesse cenário, um atacante poderia fabricar transações fraudulentas que enganariam o usuário temporariamente até que o invasor obtivesse controle completo da rede.
Uma estratégia para mitigar esse risco é configurar alertas nos softwares de nós completos. Esses alertas identificam blocos inválidos, sugerindo ao usuário baixar o bloco completo para confirmar qualquer inconsistência. Para maior segurança, empresas que realizam pagamentos frequentes podem preferir operar seus próprios nós, reduzindo riscos e permitindo uma verificação mais direta e confiável.
9. Combinando e Dividindo Valor
No sistema Bitcoin, cada unidade de valor é tratada como uma "moeda" individual, mas gerenciar cada centavo como uma transação separada seria impraticável. Para resolver isso, o Bitcoin permite que valores sejam combinados ou divididos em transações, facilitando pagamentos de qualquer valor.
Entradas e Saídas
Cada transação no Bitcoin é composta por:
- Entradas: Representam os valores recebidos em transações anteriores.
- Saídas: Correspondem aos valores enviados, divididos entre os destinatários e, eventualmente, o troco para o remetente.
Normalmente, uma transação contém:
- Uma única entrada com valor suficiente para cobrir o pagamento.
- Ou várias entradas combinadas para atingir o valor necessário.
O valor total das saídas nunca excede o das entradas, e a diferença (se houver) pode ser retornada ao remetente como troco.
Exemplo Prático
Imagine que você tem duas entradas:
- 0,03 BTC
- 0,07 BTC
Se deseja enviar 0,08 BTC para alguém, a transação terá:
- Entrada: As duas entradas combinadas (0,03 + 0,07 BTC = 0,10 BTC).
- Saídas: Uma para o destinatário (0,08 BTC) e outra como troco para você (0,02 BTC).
Essa flexibilidade permite que o sistema funcione sem precisar manipular cada unidade mínima individualmente.
Difusão e Simplificação
A difusão de transações, onde uma depende de várias anteriores e assim por diante, não representa um problema. Não é necessário armazenar ou verificar o histórico completo de uma transação para utilizá-la, já que o registro na blockchain garante sua integridade.
10. Privacidade
O modelo bancário tradicional oferece um certo nível de privacidade, limitando o acesso às informações financeiras apenas às partes envolvidas e a um terceiro confiável (como bancos ou instituições financeiras). No entanto, o Bitcoin opera de forma diferente, pois todas as transações são publicamente registradas na blockchain. Apesar disso, a privacidade pode ser mantida utilizando chaves públicas anônimas, que desvinculam diretamente as transações das identidades das partes envolvidas.
Fluxo de Informação
- No modelo tradicional, as transações passam por um terceiro confiável que conhece tanto o remetente quanto o destinatário.
- No Bitcoin, as transações são anunciadas publicamente, mas sem revelar diretamente as identidades das partes. Isso é comparável a dados divulgados por bolsas de valores, onde informações como o tempo e o tamanho das negociações (a "fita") são públicas, mas as identidades das partes não.
Protegendo a Privacidade
Para aumentar a privacidade no Bitcoin, são adotadas as seguintes práticas:
- Chaves Públicas Anônimas: Cada transação utiliza um par de chaves diferentes, dificultando a associação com um proprietário único.
- Prevenção de Ligação: Ao usar chaves novas para cada transação, reduz-se a possibilidade de links evidentes entre múltiplas transações realizadas pelo mesmo usuário.
Riscos de Ligação
Embora a privacidade seja fortalecida, alguns riscos permanecem:
- Transações multi-entrada podem revelar que todas as entradas pertencem ao mesmo proprietário, caso sejam necessárias para somar o valor total.
- O proprietário da chave pode ser identificado indiretamente por transações anteriores que estejam conectadas.
11. Cálculos
Imagine que temos um sistema onde as pessoas (ou computadores) competem para adicionar informações novas (blocos) a um grande registro público (a cadeia de blocos ou blockchain). Este registro é como um livro contábil compartilhado, onde todos podem verificar o que está escrito.
Agora, vamos pensar em um cenário: um atacante quer enganar o sistema. Ele quer mudar informações já registradas para beneficiar a si mesmo, por exemplo, desfazendo um pagamento que já fez. Para isso, ele precisa criar uma versão alternativa do livro contábil (a cadeia de blocos dele) e convencer todos os outros participantes de que essa versão é a verdadeira.
Mas isso é extremamente difícil.
Como o Ataque Funciona
Quando um novo bloco é adicionado à cadeia, ele depende de cálculos complexos que levam tempo e esforço. Esses cálculos são como um grande quebra-cabeça que precisa ser resolvido.
- Os “bons jogadores” (nós honestos) estão sempre trabalhando juntos para resolver esses quebra-cabeças e adicionar novos blocos à cadeia verdadeira.
- O atacante, por outro lado, precisa resolver quebra-cabeças sozinho, tentando “alcançar” a cadeia honesta para que sua versão alternativa pareça válida.
Se a cadeia honesta já está vários blocos à frente, o atacante começa em desvantagem, e o sistema está projetado para que a dificuldade de alcançá-los aumente rapidamente.
A Corrida Entre Cadeias
Você pode imaginar isso como uma corrida. A cada bloco novo que os jogadores honestos adicionam à cadeia verdadeira, eles se distanciam mais do atacante. Para vencer, o atacante teria que resolver os quebra-cabeças mais rápido que todos os outros jogadores honestos juntos.
Suponha que:
- A rede honesta tem 80% do poder computacional (ou seja, resolve 8 de cada 10 quebra-cabeças).
- O atacante tem 20% do poder computacional (ou seja, resolve 2 de cada 10 quebra-cabeças).
Cada vez que a rede honesta adiciona um bloco, o atacante tem que "correr atrás" e resolver mais quebra-cabeças para alcançar.
Por Que o Ataque Fica Cada Vez Mais Improvável?
Vamos usar uma fórmula simples para mostrar como as chances de sucesso do atacante diminuem conforme ele precisa "alcançar" mais blocos:
P = (q/p)^z
- q é o poder computacional do atacante (20%, ou 0,2).
- p é o poder computacional da rede honesta (80%, ou 0,8).
- z é a diferença de blocos entre a cadeia honesta e a cadeia do atacante.
Se o atacante está 5 blocos atrás (z = 5):
P = (0,2 / 0,8)^5 = (0,25)^5 = 0,00098, (ou, 0,098%)
Isso significa que o atacante tem menos de 0,1% de chance de sucesso — ou seja, é muito improvável.
Se ele estiver 10 blocos atrás (z = 10):
P = (0,2 / 0,8)^10 = (0,25)^10 = 0,000000095, (ou, 0,0000095%).
Neste caso, as chances de sucesso são praticamente nulas.
Um Exemplo Simples
Se você jogar uma moeda, a chance de cair “cara” é de 50%. Mas se precisar de 10 caras seguidas, sua chance já é bem menor. Se precisar de 20 caras seguidas, é quase impossível.
No caso do Bitcoin, o atacante precisa de muito mais do que 20 caras seguidas. Ele precisa resolver quebra-cabeças extremamente difíceis e alcançar os jogadores honestos que estão sempre à frente. Isso faz com que o ataque seja inviável na prática.
Por Que Tudo Isso é Seguro?
- A probabilidade de sucesso do atacante diminui exponencialmente. Isso significa que, quanto mais tempo passa, menor é a chance de ele conseguir enganar o sistema.
- A cadeia verdadeira (honesta) está protegida pela força da rede. Cada novo bloco que os jogadores honestos adicionam à cadeia torna mais difícil para o atacante alcançar.
E Se o Atacante Tentar Continuar?
O atacante poderia continuar tentando indefinidamente, mas ele estaria gastando muito tempo e energia sem conseguir nada. Enquanto isso, os jogadores honestos estão sempre adicionando novos blocos, tornando o trabalho do atacante ainda mais inútil.
Assim, o sistema garante que a cadeia verdadeira seja extremamente segura e que ataques sejam, na prática, impossíveis de ter sucesso.
12. Conclusão
Propusemos um sistema de transações eletrônicas que elimina a necessidade de confiança, baseando-se em assinaturas digitais e em uma rede peer-to-peer que utiliza prova de trabalho. Isso resolve o problema do gasto duplo, criando um histórico público de transações imutável, desde que a maioria do poder computacional permaneça sob controle dos participantes honestos. A rede funciona de forma simples e descentralizada, com nós independentes que não precisam de identificação ou coordenação direta. Eles entram e saem livremente, aceitando a cadeia de prova de trabalho como registro do que ocorreu durante sua ausência. As decisões são tomadas por meio do poder de CPU, validando blocos legítimos, estendendo a cadeia e rejeitando os inválidos. Com este mecanismo de consenso, todas as regras e incentivos necessários para o funcionamento seguro e eficiente do sistema são garantidos.
Faça o download do whitepaper original em português: https://bitcoin.org/files/bitcoin-paper/bitcoin_pt_br.pdf
-
@ 3f770d65:7a745b24
2025-01-19 21:48:49
The recent shutdown of TikTok in the United States due to a potential government ban serves as a stark reminder how fragile centralized platforms truly are under the surface. While these platforms offer convenience, a more polished user experience, and connectivity, they are ultimately beholden to governments, corporations, and other authorities. This makes them vulnerable to censorship, regulation, and outright bans. In contrast, Nostr represents a shift in how we approach online communication and content sharing. Built on the principles of decentralization and user choice, Nostr cannot be banned, because it is not a platform—it is a protocol.
PROTOCOLS, NOT PLATFORMS.
At the heart of Nostr's philosophy is user choice, a feature that fundamentally sets it apart from legacy platforms. In centralized systems, the user experience is dictated by a single person or governing entity. If the platform decides to filter, censor, or ban specific users or content, individuals are left with little action to rectify the situation. They must either accept the changes or abandon the platform entirely, often at the cost of losing their social connections, their data, and their identity.
What's happening with TikTok could never happen on Nostr. With Nostr, the dynamics are completely different. Because it is a protocol, not a platform, no single entity controls the ecosystem. Instead, the protocol enables a network of applications and relays that users can freely choose from. If a particular application or relay implements policies that a user disagrees with, such as censorship, filtering, or even government enforced banning, they are not trapped or abandoned. They have the freedom to move to another application or relay with minimal effort.
THIS IS POWERFUL.
Take, for example, the case of a relay that decides to censor specific content. On a legacy platform, this would result in frustration and a loss of access for users. On Nostr, however, users can simply connect to a different relay that does not impose such restrictions. Similarly, if an application introduces features or policies that users dislike, they can migrate to a different application that better suits their preferences, all while retaining their identity and social connections.
The same principles apply to government bans and censorship. A government can ban a specific application or even multiple applications, just as it can block one relay or several relays. China has implemented both tactics, yet Chinese users continue to exist and actively participate on Nostr, demonstrating Nostr's ability to resistant censorship.
How? Simply, it turns into a game of whack-a-mole. When one relay is censored, another quickly takes its place. When one application is banned, another emerges. Users can also bypass these obstacles by running their own relays and applications directly from their homes or personal devices, eliminating reliance on larger entities or organizations and ensuring continuous access.
AGAIN, THIS IS POWERUFL.
Nostr's open and decentralized design makes it resistant to the kinds of government intervention that led to TikTok's outages this weekend and potential future ban in the next 90 days. There is no central server to target, no company to regulate, and no single point of failure. (Insert your CEO jokes here). As long as there are individuals running relays and applications, users continue creating notes and sending zaps.
Platforms like TikTok can be silenced with the stroke of a pen, leaving millions of users disconnected and abandoned. Social communication should not be silenced so incredibly easily. No one should have that much power over social interactions.
Will we on-board a massive wave of TikTokers in the coming hours or days? I don't know.
TikTokers may not be ready for Nostr yet, and honestly, Nostr may not be ready for them either. The ecosystem still lacks the completely polished applications, tools, and services they’re accustomed to. This is where we say "we're still early". They may not be early adopters like the current Nostr user base. Until we bridge that gap, they’ll likely move to the next centralized platform, only to face another government ban or round of censorship in the future. But eventually, there will come a tipping point, a moment when they’ve had enough. When that time comes, I hope we’re prepared. If we’re not, we risk missing a tremendous opportunity to onboard people who genuinely need Nostr’s freedom.
Until then, to all of the Nostr developers out there, keep up the great work and keep building. Your hard work and determination is needed.
-
@ cff1720e:15c7e2b2
2025-01-19 17:48:02
Einleitung\ \ Schwierige Dinge einfach zu erklären ist der Anspruch von ELI5 (explain me like I'm 5). Das ist in unserer hoch technisierten Welt dringend erforderlich, denn nur mit dem Verständnis der Technologien können wir sie richtig einsetzen und weiter entwickeln.\ Ich starte meine Serie mit Nostr, einem relativ neuen Internet-Protokoll. Was zum Teufel ist ein Internet-Protokoll? Formal beschrieben sind es internationale Standards, die dafür sorgen, dass das Internet seit über 30 Jahren ziemlich gut funktioniert. Es ist die Sprache, in der sich die Rechner miteinander unterhalten und die auch Sie täglich nutzen, vermutlich ohne es bewusst wahrzunehmen. http(s) transportiert ihre Anfrage an einen Server (z.B. Amazon), und html sorgt dafür, dass aus den gelieferten Daten eine schöne Seite auf ihrem Bildschirm entsteht. Eine Mail wird mit smtp an den Mailserver gesendet und mit imap von ihm abgerufen, und da alle den Standard verwenden, funktioniert das mit jeder App auf jedem Betriebssystem und mit jedem Mail-Provider. Und mit einer Mail-Adresse wie roland@pareto.space können sie sogar jederzeit umziehen, egal wohin. Cool, das ist state of the art! Aber warum funktioniert das z.B. bei Chat nicht, gibt es da kein Protokoll? Doch, es heißt IRC (Internet Relay Chat → merken sie sich den Namen), aber es wird so gut wie nicht verwendet. Die Gründe dafür sind nicht technischer Natur, vielmehr wurden mit Apps wie Facebook, Twitter, WhatsApp, Telegram, Instagram, TikTok u.a. bewusst Inkompatibilitäten und Nutzerabhängigkeiten geschaffen um Profite zu maximieren.

Warum Nostr?
Da das Standard-Protokoll nicht genutzt wird, hat jede App ihr eigenes, und wir brauchen eine handvoll Apps um uns mit allen Bekannten auszutauschen. Eine Mobilfunknummer ist Voraussetzung für jedes Konto, damit können die App-Hersteller die Nutzer umfassend tracken und mit dem Verkauf der Informationen bis zu 30 USD je Konto und Monat verdienen. Der Nutzer ist nicht mehr Kunde, er ist das Produkt! Der Werbe-SPAM ist noch das kleinste Problem bei diesem Geschäftsmodell. Server mit Millionen von Nutzerdaten sind ein “honey pot”, dementsprechend oft werden sie gehackt und die Zugangsdaten verkauft. 2024 wurde auch der Twitter-Account vom damaligen Präsidenten Joe Biden gehackt, niemand wusste mehr wer die Nachrichten verfasst hat (vorher auch nicht), d.h. die Authentizität der Inhalte ist bei keinem dieser Anbieter gewährleistet. Im selben Jahr wurde der Telegram-Gründer in Frankreich in Beugehaft genommen, weil er sich geweigert hatte Hintertüren in seine Software einzubauen. Nun kann zum Schutz "unserer Demokratie” praktisch jeder mitlesen, was sie mit wem an Informationen austauschen, z.B. darüber welches Shampoo bestimmte Politiker verwenden.
Und wer tatsächlich glaubt er könne Meinungsfreiheit auf sozialen Medien praktizieren, findet sich schnell in der Situation von Donald Trump wieder (seinerzeit amtierender Präsident), dem sein Twitter-Konto 2021 abgeschaltet wurde (Cancel-Culture). Die Nutzerdaten, also ihr Profil, ihre Kontakte, Dokumente, Bilder, Videos und Audiofiles - gehören ihnen ohnehin nicht mehr sondern sind Eigentum des Plattform-Betreibers; lesen sie sich mal die AGB's durch. Aber nein, keine gute Idee, das sind hunderte Seiten und sie werden permanent geändert. Alle nutzen also Apps, deren Technik sie nicht verstehen, deren Regeln sie nicht kennen, wo sie keine Rechte haben und die ihnen die Resultate ihres Handelns stehlen. Was würde wohl der Fünfjährige sagen, wenn ihm seine ältere Schwester anbieten würde, alle seine Spielzeuge zu “verwalten” und dann auszuhändigen wenn er brav ist? “Du spinnst wohl”, und damit beweist der Knirps mehr Vernunft als die Mehrzahl der Erwachsenen. \ \ Resümee: keine Standards, keine Daten, keine Rechte = keine Zukunft!

\ Wie funktioniert Nostr?
Die Entwickler von Nostr haben erkannt dass sich das Server-Client-Konzept in ein Master-Slave-Konzept verwandelt hatte. Der Master ist ein Synonym für Zentralisierung und wird zum “single point of failure”, der zwangsläufig Systeme dysfunktional macht. In einem verteilten Peer2Peer-System gibt es keine Master mehr sondern nur gleichberechtigte Knoten (Relays), auf denen die Informationen gespeichert werden. Indem man Informationen auf mehreren Relays redundant speichert, ist das System in jeglicher Hinsicht resilienter. Nicht nur die Natur verwendet dieses Prinzip seit Jahrmillionen erfolgreich, auch das Internet wurde so konzipiert (das ARPAnet wurde vom US-Militär für den Einsatz in Kriegsfällen unter massiven Störungen entwickelt). Alle Nostr-Daten liegen auf Relays und der Nutzer kann wählen zwischen öffentlichen (zumeist kostenlosen) und privaten Relays, z.B. für geschlossene Gruppen oder zum Zwecke von Daten-Archivierung. Da Dokumente auf mehreren Relays gespeichert sind, werden statt URL's (Locator) eindeutige Dokumentnamen (URI's = Identifier) verwendet, broken Links sind damit Vergangenheit und Löschungen / Verluste ebenfalls.\ \ Jedes Dokument (Event genannt) wird vom Besitzer signiert, es ist damit authentisch und fälschungssicher und kann nur vom Ersteller gelöscht werden. Dafür wird ein Schlüsselpaar verwendet bestehend aus privatem (nsec) und öffentlichem Schlüssel (npub) wie aus der Mailverschlüsselung (PGP) bekannt. Das repräsentiert eine Nostr-Identität, die um Bild, Namen, Bio und eine lesbare Nostr-Adresse ergänzt werden kann (z.B. roland@pareto.space ), mehr braucht es nicht um alle Ressourcen des Nostr-Ökosystems zu nutzen. Und das besteht inzwischen aus über hundert Apps mit unterschiedlichen Fokussierungen, z.B. für persönliche verschlüsselte Nachrichten (DM → OxChat), Kurznachrichten (Damus, Primal), Blogbeiträge (Pareto), Meetups (Joinstr), Gruppen (Groups), Bilder (Olas), Videos (Amethyst), Audio-Chat (Nostr Nests), Audio-Streams (Tunestr), Video-Streams (Zap.Stream), Marktplätze (Shopstr) u.v.a.m. Die Anmeldung erfolgt mit einem Klick (single sign on) und den Apps stehen ALLE Nutzerdaten zur Verfügung (Profil, Daten, Kontakte, Social Graph → Follower, Bookmarks, Comments, etc.), im Gegensatz zu den fragmentierten Datensilos der Gegenwart.\ \ Resümee: ein offener Standard, alle Daten, alle Rechte = große Zukunft!
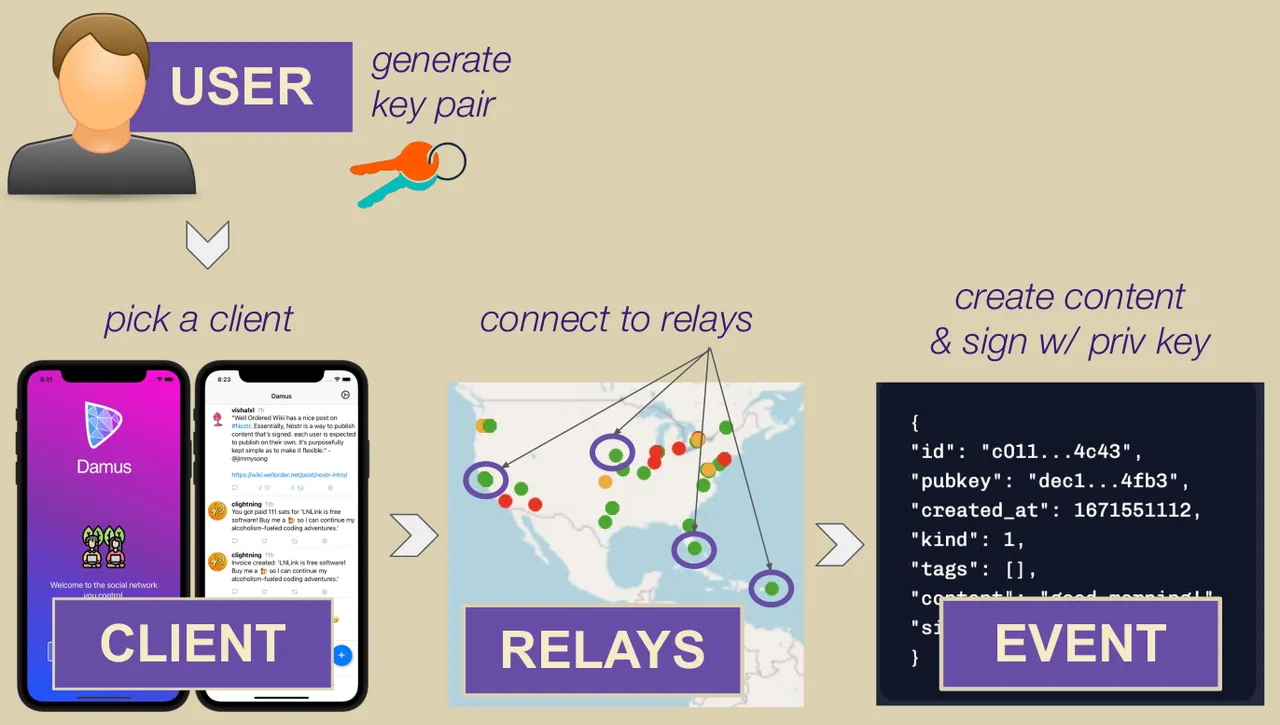
\ Warum ist Nostr die Zukunft des Internet?
“Baue Dein Haus nicht auf einem fremden Grundstück” gilt auch im Internet - für alle App-Entwickler, Künstler, Journalisten und Nutzer, denn auch ihre Daten sind werthaltig. Nostr garantiert das Eigentum an den Daten, und überwindet ihre Fragmentierung. Weder die Nutzung noch die kreativen Freiheiten werden durch maßlose Lizenz- und Nutzungsbedingungen eingeschränkt. Aus passiven Nutzern werden durch Interaktion aktive Teilnehmer, Co-Creatoren in einer Sharing-Ökonomie (Value4Value). OpenSource schafft endlich wieder Vertrauen in die Software und ihre Anbieter. Offene Standards ermöglichen den Entwicklern mehr Kooperation und schnellere Entwicklung, für die Anwender garantieren sie Wahlfreiheit. Womit wir letztmalig zu unserem Fünfjährigen zurückkehren. Kinder lieben Lego über alles, am meisten die Maxi-Box “Classic”, weil sie damit ihre Phantasie im Kombinieren voll ausleben können. Erwachsene schenken ihnen dann die viel zu teuren Themenpakete, mit denen man nur eine Lösung nach Anleitung bauen kann. “Was stimmt nur mit meinen Eltern nicht, wann sind die denn falsch abgebogen?" fragt sich der Nachwuchs zu Recht. Das Image lässt sich aber wieder aufpolieren, wenn sie ihren Kindern Nostr zeigen, denn die Vorteile verstehen sogar Fünfjährige.

\ Das neue Internet ist dezentral. Das neue Internet ist selbstbestimmt. Nostr ist das neue Internet.
https://nostr.net/ \ https://start.njump.me/
Hier das Interview zum Thema mit Radio Berliner Morgenröte
-
@ 9e69e420:d12360c2
2025-01-19 04:48:31
A new report from the National Sports Shooting Foundation (NSSF) shows that civilian firearm possession exceeded 490 million in 2022. The total from 1990 to 2022 is estimated at 491.3 million firearms. In 2022, over ten million firearms were domestically produced, leading to a total of 16,045,911 firearms available in the U.S. market.
Of these, 9,873,136 were handguns, 4,195,192 were rifles, and 1,977,583 were shotguns. Handgun availability aligns with the concealed carry and self-defense market, as all states allow concealed carry, with 29 having constitutional carry laws.
-
@ f9cf4e94:96abc355
2025-01-18 06:09:50
Para esse exemplo iremos usar: | Nome | Imagem | Descrição | | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | | Raspberry PI B+ |
 | Cortex-A53 (ARMv8) 64-bit a 1.4GHz e 1 GB de SDRAM LPDDR2, |
| Pen drive |
| Cortex-A53 (ARMv8) 64-bit a 1.4GHz e 1 GB de SDRAM LPDDR2, |
| Pen drive |  | 16Gb |
| 16Gb |Recomendo que use o Ubuntu Server para essa instalação. Você pode baixar o Ubuntu para Raspberry Pi aqui. O passo a passo para a instalação do Ubuntu no Raspberry Pi está disponível aqui. Não instale um desktop (como xubuntu, lubuntu, xfce, etc.).
Passo 1: Atualizar o Sistema 🖥️
Primeiro, atualize seu sistema e instale o Tor:
bash apt update apt install tor
Passo 2: Criar o Arquivo de Serviço
nrs.service🔧Crie o arquivo de serviço que vai gerenciar o servidor Nostr. Você pode fazer isso com o seguinte conteúdo:
```unit [Unit] Description=Nostr Relay Server Service After=network.target
[Service] Type=simple WorkingDirectory=/opt/nrs ExecStart=/opt/nrs/nrs-arm64 Restart=on-failure
[Install] WantedBy=multi-user.target ```
Passo 3: Baixar o Binário do Nostr 🚀
Baixe o binário mais recente do Nostr aqui no GitHub.
Passo 4: Criar as Pastas Necessárias 📂
Agora, crie as pastas para o aplicativo e o pendrive:
bash mkdir -p /opt/nrs /mnt/edriver
Passo 5: Listar os Dispositivos Conectados 🔌
Para saber qual dispositivo você vai usar, liste todos os dispositivos conectados:
bash lsblk
Passo 6: Formatando o Pendrive 💾
Escolha o pendrive correto (por exemplo,
/dev/sda) e formate-o:bash mkfs.vfat /dev/sda
Passo 7: Montar o Pendrive 💻
Monte o pendrive na pasta
/mnt/edriver:bash mount /dev/sda /mnt/edriver
Passo 8: Verificar UUID dos Dispositivos 📋
Para garantir que o sistema monte o pendrive automaticamente, liste os UUID dos dispositivos conectados:
bash blkid
Passo 9: Alterar o
fstabpara Montar o Pendrive Automáticamente 📝Abra o arquivo
/etc/fstabe adicione uma linha para o pendrive, com o UUID que você obteve no passo anterior. A linha deve ficar assim:fstab UUID=9c9008f8-f852 /mnt/edriver vfat defaults 0 0
Passo 10: Copiar o Binário para a Pasta Correta 📥
Agora, copie o binário baixado para a pasta
/opt/nrs:bash cp nrs-arm64 /opt/nrs
Passo 11: Criar o Arquivo de Configuração 🛠️
Crie o arquivo de configuração com o seguinte conteúdo e salve-o em
/opt/nrs/config.yaml:yaml app_env: production info: name: Nostr Relay Server description: Nostr Relay Server pub_key: "" contact: "" url: http://localhost:3334 icon: https://external-content.duckduckgo.com/iu/?u= https://public.bnbstatic.com/image/cms/crawler/COINCU_NEWS/image-495-1024x569.png base_path: /mnt/edriver negentropy: true
Passo 12: Copiar o Serviço para o Diretório de Systemd ⚙️
Agora, copie o arquivo
nrs.servicepara o diretório/etc/systemd/system/:bash cp nrs.service /etc/systemd/system/Recarregue os serviços e inicie o serviço
nrs:bash systemctl daemon-reload systemctl enable --now nrs.service
Passo 13: Configurar o Tor 🌐
Abra o arquivo de configuração do Tor
/var/lib/tor/torrce adicione a seguinte linha:torrc HiddenServiceDir /var/lib/tor/nostr_server/ HiddenServicePort 80 127.0.0.1:3334
Passo 14: Habilitar e Iniciar o Tor 🧅
Agora, ative e inicie o serviço Tor:
bash systemctl enable --now tor.serviceO Tor irá gerar um endereço
.onionpara o seu servidor Nostr. Você pode encontrá-lo no arquivo/var/lib/tor/nostr_server/hostname.
Observações ⚠️
- Com essa configuração, os dados serão salvos no pendrive, enquanto o binário ficará no cartão SD do Raspberry Pi.
- O endereço
.oniondo seu servidor Nostr será algo como:ws://y3t5t5wgwjif<exemplo>h42zy7ih6iwbyd.onion.
Agora, seu servidor Nostr deve estar configurado e funcionando com Tor! 🥳
Se este artigo e as informações aqui contidas forem úteis para você, convidamos a considerar uma doação ao autor como forma de reconhecimento e incentivo à produção de novos conteúdos.
-
@ 6389be64:ef439d32
2025-01-16 15:44:06
Black Locust can grow up to 170 ft tall
Grows 3-4 ft. per year
Native to North America
Cold hardy in zones 3 to 8

Firewood
- BLT wood, on a pound for pound basis is roughly half that of Anthracite Coal
- Since its growth is fast, firewood can be plentiful
Timber

- Rot resistant due to a naturally produced robinin in the wood
- 100 year life span in full soil contact! (better than cedar performance)
- Fence posts
- Outdoor furniture
- Outdoor decking
- Sustainable due to its fast growth and spread
- Can be coppiced (cut to the ground)
- Can be pollarded (cut above ground)
- Its dense wood makes durable tool handles, boxes (tool), and furniture
- The wood is tougher than hickory, which is tougher than hard maple, which is tougher than oak.
- A very low rate of expansion and contraction
- Hardwood flooring
- The highest tensile beam strength of any American tree
- The wood is beautiful
Legume
- Nitrogen fixer
- Fixes the same amount of nitrogen per acre as is needed for 200-bushel/acre corn
- Black walnuts inter-planted with locust as “nurse” trees were shown to rapidly increase their growth [[Clark, Paul M., and Robert D. Williams. (1978) Black walnut growth increased when interplanted with nitrogen-fixing shrubs and trees. Proceedings of the Indiana Academy of Science, vol. 88, pp. 88-91.]]
Bees

- The edible flower clusters are also a top food source for honey bees
Shade Provider

- Its light, airy overstory provides dappled shade
- Planted on the west side of a garden it provides relief during the hottest part of the day
- (nitrogen provider)
- Planted on the west side of a house, its quick growth soon shades that side from the sun
Wind-break

- Fast growth plus it's feathery foliage reduces wind for animals, crops, and shelters
Fodder
- Over 20% crude protein
- 4.1 kcal/g of energy
- Baertsche, S.R, M.T. Yokoyama, and J.W. Hanover (1986) Short rotation, hardwood tree biomass as potential ruminant feed-chemical composition, nylon bag ruminal degradation and ensilement of selected species. J. Animal Sci. 63 2028-2043
-
@ 6389be64:ef439d32
2025-01-14 01:31:12
Bitcoin is more than money, more than an asset, and more than a store of value. Bitcoin is a Prime Mover, an enabler and it ignites imaginations. It certainly fueled an idea in my mind. The idea integrates sensors, computational prowess, actuated machinery, power conversion, and electronic communications to form an autonomous, machined creature roaming forests and harvesting the most widespread and least energy-dense fuel source available. I call it the Forest Walker and it eats wood, and mines Bitcoin.
I know what you're thinking. Why not just put Bitcoin mining rigs where they belong: in a hosted facility sporting electricity from energy-dense fuels like natural gas, climate-controlled with excellent data piping in and out? Why go to all the trouble building a robot that digests wood creating flammable gasses fueling an engine to run a generator powering Bitcoin miners? It's all about synergy.
Bitcoin mining enables the realization of multiple, seemingly unrelated, yet useful activities. Activities considered un-profitable if not for Bitcoin as the Prime Mover. This is much more than simply mining the greatest asset ever conceived by humankind. It’s about the power of synergy, which Bitcoin plays only one of many roles. The synergy created by this system can stabilize forests' fire ecology while generating multiple income streams. That’s the realistic goal here and requires a brief history of American Forest management before continuing.
Smokey The Bear
In 1944, the Smokey Bear Wildfire Prevention Campaign began in the United States. “Only YOU can prevent forest fires” remains the refrain of the Ad Council’s longest running campaign. The Ad Council is a U.S. non-profit set up by the American Association of Advertising Agencies and the Association of National Advertisers in 1942. It would seem that the U.S. Department of the Interior was concerned about pesky forest fires and wanted them to stop. So, alongside a national policy of extreme fire suppression they enlisted the entire U.S. population to get onboard via the Ad Council and it worked. Forest fires were almost obliterated and everyone was happy, right? Wrong.
Smokey is a fantastically successful bear so forest fires became so few for so long that the fuel load - dead wood - in forests has become very heavy. So heavy that when a fire happens (and they always happen) it destroys everything in its path because the more fuel there is the hotter that fire becomes. Trees, bushes, shrubs, and all other plant life cannot escape destruction (not to mention homes and businesses). The soil microbiology doesn’t escape either as it is burned away even in deeper soils. To add insult to injury, hydrophobic waxy residues condense on the soil surface, forcing water to travel over the ground rather than through it eroding forest soils. Good job, Smokey. Well done, Sir!
Most terrestrial ecologies are “fire ecologies”. Fire is a part of these systems’ fuel load and pest management. Before we pretended to “manage” millions of acres of forest, fires raged over the world, rarely damaging forests. The fuel load was always too light to generate fires hot enough to moonscape mountainsides. Fires simply burned off the minor amounts of fuel accumulated since the fire before. The lighter heat, smoke, and other combustion gasses suppressed pests, keeping them in check and the smoke condensed into a plant growth accelerant called wood vinegar, not a waxy cap on the soil. These fires also cleared out weak undergrowth, cycled minerals, and thinned the forest canopy, allowing sunlight to penetrate to the forest floor. Without a fire’s heat, many pine tree species can’t sow their seed. The heat is required to open the cones (the seed bearing structure) of Spruce, Cypress, Sequoia, Jack Pine, Lodgepole Pine and many more. Without fire forests can’t have babies. The idea was to protect the forests, and it isn't working.
So, in a world of fire, what does an ally look like and what does it do?
Meet The Forest Walker

For the Forest Walker to work as a mobile, autonomous unit, a solid platform that can carry several hundred pounds is required. It so happens this chassis already exists but shelved.
Introducing the Legged Squad Support System (LS3). A joint project between Boston Dynamics, DARPA, and the United States Marine Corps, the quadrupedal robot is the size of a cow, can carry 400 pounds (180 kg) of equipment, negotiate challenging terrain, and operate for 24 hours before needing to refuel. Yes, it had an engine. Abandoned in 2015, the thing was too noisy for military deployment and maintenance "under fire" is never a high-quality idea. However, we can rebuild it to act as a platform for the Forest Walker; albeit with serious alterations. It would need to be bigger, probably. Carry more weight? Definitely. Maybe replace structural metal with carbon fiber and redesign much as 3D printable parts for more effective maintenance.
The original system has a top operational speed of 8 miles per hour. For our purposes, it only needs to move about as fast as a grazing ruminant. Without the hammering vibrations of galloping into battle, shocks of exploding mortars, and drunken soldiers playing "Wrangler of Steel Machines", time between failures should be much longer and the overall energy consumption much lower. The LS3 is a solid platform to build upon. Now it just needs to be pulled out of the mothballs, and completely refitted with outboard equipment.
The Small Branch Chipper

When I say “Forest fuel load” I mean the dead, carbon containing litter on the forest floor. Duff (leaves), fine-woody debris (small branches), and coarse woody debris (logs) are the fuel that feeds forest fires. Walk through any forest in the United States today and you will see quite a lot of these materials. Too much, as I have described. Some of these fuel loads can be 8 tons per acre in pine and hardwood forests and up to 16 tons per acre at active logging sites. That’s some big wood and the more that collects, the more combustible danger to the forest it represents. It also provides a technically unlimited fuel supply for the Forest Walker system.
The problem is that this detritus has to be chewed into pieces that are easily ingestible by the system for the gasification process (we’ll get to that step in a minute). What we need is a wood chipper attached to the chassis (the LS3); its “mouth”.
A small wood chipper handling material up to 2.5 - 3.0 inches (6.3 - 7.6 cm) in diameter would eliminate a substantial amount of fuel. There is no reason for Forest Walker to remove fallen trees. It wouldn’t have to in order to make a real difference. It need only identify appropriately sized branches and grab them. Once loaded into the chipper’s intake hopper for further processing, the beast can immediately look for more “food”. This is essentially kindling that would help ignite larger logs. If it’s all consumed by Forest Walker, then it’s not present to promote an aggravated conflagration.
I have glossed over an obvious question: How does Forest Walker see and identify branches and such? LiDaR (Light Detection and Ranging) attached to Forest Walker images the local area and feed those data to onboard computers for processing. Maybe AI plays a role. Maybe simple machine learning can do the trick. One thing is for certain: being able to identify a stick and cause robotic appendages to pick it up is not impossible.
Great! We now have a quadrupedal robot autonomously identifying and “eating” dead branches and other light, combustible materials. Whilst strolling through the forest, depleting future fires of combustibles, Forest Walker has already performed a major function of this system: making the forest safer. It's time to convert this low-density fuel into a high-density fuel Forest Walker can leverage. Enter the gasification process.
The Gassifier

The gasifier is the heart of the entire system; it’s where low-density fuel becomes the high-density fuel that powers the entire system. Biochar and wood vinegar are process wastes and I’ll discuss why both are powerful soil amendments in a moment, but first, what’s gasification?
Reacting shredded carbonaceous material at high temperatures in a low or no oxygen environment converts the biomass into biochar, wood vinegar, heat, and Synthesis Gas (Syngas). Syngas consists primarily of hydrogen, carbon monoxide, and methane. All of which are extremely useful fuels in a gaseous state. Part of this gas is used to heat the input biomass and keep the reaction temperature constant while the internal combustion engine that drives the generator to produce electrical power consumes the rest.
Critically, this gasification process is “continuous feed”. Forest Walker must intake biomass from the chipper, process it to fuel, and dump the waste (CO2, heat, biochar, and wood vinegar) continuously. It cannot stop. Everything about this system depends upon this continual grazing, digestion, and excretion of wastes just as a ruminal does. And, like a ruminant, all waste products enhance the local environment.
When I first heard of gasification, I didn’t believe that it was real. Running an electric generator from burning wood seemed more akin to “conspiracy fantasy” than science. Not only is gasification real, it’s ancient technology. A man named Dean Clayton first started experiments on gasification in 1699 and in 1901 gasification was used to power a vehicle. By the end of World War II, there were 500,000 Syngas powered vehicles in Germany alone because of fossil fuel rationing during the war. The global gasification market was $480 billion in 2022 and projected to be as much as $700 billion by 2030 (Vantage Market Research). Gasification technology is the best choice to power the Forest Walker because it’s self-contained and we want its waste products.
Biochar: The Waste

Biochar (AKA agricultural charcoal) is fairly simple: it’s almost pure, solid carbon that resembles charcoal. Its porous nature packs large surface areas into small, 3 dimensional nuggets. Devoid of most other chemistry, like hydrocarbons (methane) and ash (minerals), biochar is extremely lightweight. Do not confuse it with the charcoal you buy for your grill. Biochar doesn’t make good grilling charcoal because it would burn too rapidly as it does not contain the multitude of flammable components that charcoal does. Biochar has several other good use cases. Water filtration, water retention, nutrient retention, providing habitat for microscopic soil organisms, and carbon sequestration are the main ones that we are concerned with here.
Carbon has an amazing ability to adsorb (substances stick to and accumulate on the surface of an object) manifold chemistries. Water, nutrients, and pollutants tightly bind to carbon in this format. So, biochar makes a respectable filter and acts as a “battery” of water and nutrients in soils. Biochar adsorbs and holds on to seven times its weight in water. Soil containing biochar is more drought resilient than soil without it. Adsorbed nutrients, tightly sequestered alongside water, get released only as plants need them. Plants must excrete protons (H+) from their roots to disgorge water or positively charged nutrients from the biochar's surface; it's an active process.
Biochar’s surface area (where adsorption happens) can be 500 square meters per gram or more. That is 10% larger than an official NBA basketball court for every gram of biochar. Biochar’s abundant surface area builds protective habitats for soil microbes like fungi and bacteria and many are critical for the health and productivity of the soil itself.
The “carbon sequestration” component of biochar comes into play where “carbon credits” are concerned. There is a financial market for carbon. Not leveraging that market for revenue is foolish. I am climate agnostic. All I care about is that once solid carbon is inside the soil, it will stay there for thousands of years, imparting drought resiliency, fertility collection, nutrient buffering, and release for that time span. I simply want as much solid carbon in the soil because of the undeniably positive effects it has, regardless of any climactic considerations.
Wood Vinegar: More Waste

Another by-product of the gasification process is wood vinegar (Pyroligneous acid). If you have ever seen Liquid Smoke in the grocery store, then you have seen wood vinegar. Principally composed of acetic acid, acetone, and methanol wood vinegar also contains ~200 other organic compounds. It would seem intuitive that condensed, liquefied wood smoke would at least be bad for the health of all living things if not downright carcinogenic. The counter intuition wins the day, however. Wood vinegar has been used by humans for a very long time to promote digestion, bowel, and liver health; combat diarrhea and vomiting; calm peptic ulcers and regulate cholesterol levels; and a host of other benefits.
For centuries humans have annually burned off hundreds of thousands of square miles of pasture, grassland, forest, and every other conceivable terrestrial ecosystem. Why is this done? After every burn, one thing becomes obvious: the almost supernatural growth these ecosystems exhibit after the burn. How? Wood vinegar is a component of this growth. Even in open burns, smoke condenses and infiltrates the soil. That is when wood vinegar shows its quality.
This stuff beefs up not only general plant growth but seed germination as well and possesses many other qualities that are beneficial to plants. It’s a pesticide, fungicide, promotes beneficial soil microorganisms, enhances nutrient uptake, and imparts disease resistance. I am barely touching a long list of attributes here, but you want wood vinegar in your soil (alongside biochar because it adsorbs wood vinegar as well).
The Internal Combustion Engine

Conversion of grazed forage to chemical, then mechanical, and then electrical energy completes the cycle. The ICE (Internal Combustion Engine) converts the gaseous fuel output from the gasifier to mechanical energy, heat, water vapor, and CO2. It’s the mechanical energy of a rotating drive shaft that we want. That rotation drives the electric generator, which is the heartbeat we need to bring this monster to life. Luckily for us, combined internal combustion engine and generator packages are ubiquitous, delivering a defined energy output given a constant fuel input. It’s the simplest part of the system.
The obvious question here is whether the amount of syngas provided by the gasification process will provide enough energy to generate enough electrons to run the entire system or not. While I have no doubt the energy produced will run Forest Walker's main systems the question is really about the electrons left over. Will it be enough to run the Bitcoin mining aspect of the system? Everything is a budget.
CO2 Production For Growth

Plants are lollipops. No matter if it’s a tree or a bush or a shrubbery, the entire thing is mostly sugar in various formats but mostly long chain carbohydrates like lignin and cellulose. Plants need three things to make sugar: CO2, H2O and light. In a forest, where tree densities can be quite high, CO2 availability becomes a limiting growth factor. It’d be in the forest interests to have more available CO2 providing for various sugar formation providing the organism with food and structure.
An odd thing about tree leaves, the openings that allow gasses like the ever searched for CO2 are on the bottom of the leaf (these are called stomata). Not many stomata are topside. This suggests that trees and bushes have evolved to find gasses like CO2 from below, not above and this further suggests CO2 might be in higher concentrations nearer the soil.
The soil life (bacterial, fungi etc.) is constantly producing enormous amounts of CO2 and it would stay in the soil forever (eventually killing the very soil life that produces it) if not for tidal forces. Water is everywhere and whether in pools, lakes, oceans or distributed in “moist” soils water moves towards to the moon. The water in the soil and also in the water tables below the soil rise toward the surface every day. When the water rises, it expels the accumulated gasses in the soil into the atmosphere and it’s mostly CO2. It’s a good bet on how leaves developed high populations of stomata on the underside of leaves. As the water relaxes (the tide goes out) it sucks oxygenated air back into the soil to continue the functions of soil life respiration. The soil “breathes” albeit slowly.
The gasses produced by the Forest Walker’s internal combustion engine consist primarily of CO2 and H2O. Combusting sugars produce the same gasses that are needed to construct the sugars because the universe is funny like that. The Forest Walker is constantly laying down these critical construction elements right where the trees need them: close to the ground to be gobbled up by the trees.
The Branch Drones

During the last ice age, giant mammals populated North America - forests and otherwise. Mastodons, woolly mammoths, rhinos, short-faced bears, steppe bison, caribou, musk ox, giant beavers, camels, gigantic ground-dwelling sloths, glyptodons, and dire wolves were everywhere. Many were ten to fifteen feet tall. As they crashed through forests, they would effectively cleave off dead side-branches of trees, halting the spread of a ground-based fire migrating into the tree crown ("laddering") which is a death knell for a forest.
These animals are all extinct now and forests no longer have any manner of pruning services. But, if we build drones fitted with cutting implements like saws and loppers, optical cameras and AI trained to discern dead branches from living ones, these drones could effectively take over pruning services by identifying, cutting, and dropping to the forest floor, dead branches. The dropped branches simply get collected by the Forest Walker as part of its continual mission.
The drones dock on the back of the Forest Walker to recharge their batteries when low. The whole scene would look like a grazing cow with some flies bothering it. This activity breaks the link between a relatively cool ground based fire and the tree crowns and is a vital element in forest fire control.
The Bitcoin Miner

Mining is one of four monetary incentive models, making this system a possibility for development. The other three are US Dept. of the Interior, township, county, and electrical utility company easement contracts for fuel load management, global carbon credits trading, and data set sales. All the above depends on obvious questions getting answered. I will list some obvious ones, but this is not an engineering document and is not the place for spreadsheets. How much Bitcoin one Forest Walker can mine depends on everything else. What amount of biomass can we process? Will that biomass flow enough Syngas to keep the lights on? Can the chassis support enough mining ASICs and supporting infrastructure? What does that weigh and will it affect field performance? How much power can the AC generator produce?
Other questions that are more philosophical persist. Even if a single Forest Walker can only mine scant amounts of BTC per day, that pales to how much fuel material it can process into biochar. We are talking about millions upon millions of forested acres in need of fuel load management. What can a single Forest Walker do? I am not thinking in singular terms. The Forest Walker must operate as a fleet. What could 50 do? 500?
What is it worth providing a service to the world by managing forest fuel loads? Providing proof of work to the global monetary system? Seeding soil with drought and nutrient resilience by the excretion, over time, of carbon by the ton? What did the last forest fire cost?
The Mesh Network

What could be better than one bitcoin mining, carbon sequestering, forest fire squelching, soil amending behemoth? Thousands of them, but then they would need to be able to talk to each other to coordinate position, data handling, etc. Fitted with a mesh networking device, like goTenna or Meshtastic LoRa equipment enables each Forest Walker to communicate with each other.
Now we have an interconnected fleet of Forest Walkers relaying data to each other and more importantly, aggregating all of that to the last link in the chain for uplink. Well, at least Bitcoin mining data. Since block data is lightweight, transmission of these data via mesh networking in fairly close quartered environs is more than doable. So, how does data transmit to the Bitcoin Network? How do the Forest Walkers get the previous block data necessary to execute on mining?
Back To The Chain

Getting Bitcoin block data to and from the network is the last puzzle piece. The standing presumption here is that wherever a Forest Walker fleet is operating, it is NOT within cell tower range. We further presume that the nearest Walmart Wi-Fi is hours away. Enter the Blockstream Satellite or something like it.
A separate, ground-based drone will have two jobs: To stay as close to the nearest Forest Walker as it can and to provide an antennae for either terrestrial or orbital data uplink. Bitcoin-centric data is transmitted to the "uplink drone" via the mesh networked transmitters and then sent on to the uplink and the whole flow goes in the opposite direction as well; many to one and one to many.
We cannot transmit data to the Blockstream satellite, and it will be up to Blockstream and companies like it to provide uplink capabilities in the future and I don't doubt they will. Starlink you say? What’s stopping that company from filtering out block data? Nothing because it’s Starlink’s system and they could decide to censor these data. It seems we may have a problem sending and receiving Bitcoin data in back country environs.
But, then again, the utility of this system in staunching the fuel load that creates forest fires is extremely useful around forested communities and many have fiber, Wi-Fi and cell towers. These communities could be a welcoming ground zero for first deployments of the Forest Walker system by the home and business owners seeking fire repression. In the best way, Bitcoin subsidizes the safety of the communities.
Sensor Packages
LiDaR

The benefit of having a Forest Walker fleet strolling through the forest is the never ending opportunity for data gathering. A plethora of deployable sensors gathering hyper-accurate data on everything from temperature to topography is yet another revenue generator. Data is valuable and the Forest Walker could generate data sales to various government entities and private concerns.
LiDaR (Light Detection and Ranging) can map topography, perform biomass assessment, comparative soil erosion analysis, etc. It so happens that the Forest Walker’s ability to “see,” to navigate about its surroundings, is LiDaR driven and since it’s already being used, we can get double duty by harvesting that data for later use. By using a laser to send out light pulses and measuring the time it takes for the reflection of those pulses to return, very detailed data sets incrementally build up. Eventually, as enough data about a certain area becomes available, the data becomes useful and valuable.
Forestry concerns, both private and public, often use LiDaR to build 3D models of tree stands to assess the amount of harvest-able lumber in entire sections of forest. Consulting companies offering these services charge anywhere from several hundred to several thousand dollars per square kilometer for such services. A Forest Walker generating such assessments on the fly while performing its other functions is a multi-disciplinary approach to revenue generation.
pH, Soil Moisture, and Cation Exchange Sensing

The Forest Walker is quadrupedal, so there are four contact points to the soil. Why not get a pH data point for every step it takes? We can also gather soil moisture data and cation exchange capacities at unheard of densities because of sampling occurring on the fly during commission of the system’s other duties. No one is going to build a machine to do pH testing of vast tracts of forest soils, but that doesn’t make the data collected from such an endeavor valueless. Since the Forest Walker serves many functions at once, a multitude of data products can add to the return on investment component.
Weather Data

Temperature, humidity, pressure, and even data like evapotranspiration gathered at high densities on broad acre scales have untold value and because the sensors are lightweight and don’t require large power budgets, they come along for the ride at little cost. But, just like the old mantra, “gas, grass, or ass, nobody rides for free”, these sensors provide potential revenue benefits just by them being present.
I’ve touched on just a few data genres here. In fact, the question for universities, governmental bodies, and other institutions becomes, “How much will you pay us to attach your sensor payload to the Forest Walker?”
Noise Suppression

Only you can prevent Metallica filling the surrounds with 120 dB of sound. Easy enough, just turn the car stereo off. But what of a fleet of 50 Forest Walkers operating in the backcountry or near a township? 500? 5000? Each one has a wood chipper, an internal combustion engine, hydraulic pumps, actuators, and more cooling fans than you can shake a stick at. It’s a walking, screaming fire-breathing dragon operating continuously, day and night, twenty-four hours a day, three hundred sixty-five days a year. The sound will negatively affect all living things and that impacts behaviors. Serious engineering consideration and prowess must deliver a silencing blow to the major issue of noise.
It would be foolish to think that a fleet of Forest Walkers could be silent, but if not a major design consideration, then the entire idea is dead on arrival. Townships would not allow them to operate even if they solved the problem of widespread fuel load and neither would governmental entities, and rightly so. Nothing, not man nor beast, would want to be subjected to an eternal, infernal scream even if it were to end within days as the fleet moved further away after consuming what it could. Noise and heat are the only real pollutants of this system; taking noise seriously from the beginning is paramount.
Fire Safety

A “fire-breathing dragon” is not the worst description of the Forest Walker. It eats wood, combusts it at very high temperatures and excretes carbon; and it does so in an extremely flammable environment. Bad mix for one Forest Walker, worse for many. One must take extreme pains to ensure that during normal operation, a Forest Walker could fall over, walk through tinder dry brush, or get pounded into the ground by a meteorite from Krypton and it wouldn’t destroy epic swaths of trees and baby deer. I envision an ultimate test of a prototype to include dowsing it in grain alcohol while it’s wrapped up in toilet paper like a pledge at a fraternity party. If it runs for 72 hours and doesn’t set everything on fire, then maybe outside entities won’t be fearful of something that walks around forests with a constant fire in its belly.
The Wrap

How we think about what can be done with and adjacent to Bitcoin is at least as important as Bitcoin’s economic standing itself. For those who will tell me that this entire idea is without merit, I say, “OK, fine. You can come up with something, too.” What can we plug Bitcoin into that, like a battery, makes something that does not work, work? That’s the lesson I get from this entire exercise. No one was ever going to hire teams of humans to go out and "clean the forest". There's no money in that. The data collection and sales from such an endeavor might provide revenues over the break-even point but investment demands Alpha in this day and age. But, plug Bitcoin into an almost viable system and, voilà! We tip the scales to achieve lift-off.
Let’s face it, we haven’t scratched the surface of Bitcoin’s forcing function on our minds. Not because it’s Bitcoin, but because of what that invention means. The question that pushes me to approach things this way is, “what can we create that one system’s waste is another system’s feedstock?” The Forest Walker system’s only real waste is the conversion of low entropy energy (wood and syngas) into high entropy energy (heat and noise). All other output is beneficial to humanity.
Bitcoin, I believe, is the first product of a new mode of human imagination. An imagination newly forged over the past few millennia of being lied to, stolen from, distracted and otherwise mis-allocated to a black hole of the nonsensical. We are waking up.
What I have presented is not science fiction. Everything I have described here is well within the realm of possibility. The question is one of viability, at least in terms of the detritus of the old world we find ourselves departing from. This system would take a non-trivial amount of time and resources to develop. I think the system would garner extensive long-term contracts from those who have the most to lose from wildfires, the most to gain from hyperaccurate data sets, and, of course, securing the most precious asset in the world. Many may not see it that way, for they seek Alpha and are therefore blind to other possibilities. Others will see only the possibilities; of thinking in a new way, of looking at things differently, and dreaming of what comes next.
-
@ e3ba5e1a:5e433365
2025-01-13 16:47:27
My blog posts and reading material have both been on a decidedly economics-heavy slant recently. The topic today, incentives, squarely falls into the category of economics. However, when I say economics, I’m not talking about “analyzing supply and demand curves.” I’m talking about the true basis of economics: understanding how human beings make decisions in a world of scarcity.
A fair definition of incentive is “a reward or punishment that motivates behavior to achieve a desired outcome.” When most people think about economic incentives, they’re thinking of money. If I offer my son $5 if he washes the dishes, I’m incentivizing certain behavior. We can’t guarantee that he’ll do what I want him to do, but we can agree that the incentive structure itself will guide and ultimately determine what outcome will occur.
The great thing about monetary incentives is how easy they are to talk about and compare. “Would I rather make $5 washing the dishes or $10 cleaning the gutters?” But much of the world is incentivized in non-monetary ways too. For example, using the “punishment” half of the definition above, I might threaten my son with losing Nintendo Switch access if he doesn’t wash the dishes. No money is involved, but I’m still incentivizing behavior.
And there are plenty of incentives beyond our direct control! My son is also incentivized to not wash dishes because it’s boring, or because he has some friends over that he wants to hang out with, or dozens of other things. Ultimately, the conflicting array of different incentive structures placed on him will ultimately determine what actions he chooses to take.
Why incentives matter
A phrase I see often in discussions—whether they are political, parenting, economic, or business—is “if they could just do…” Each time I see that phrase, I cringe a bit internally. Usually, the underlying assumption of the statement is “if people would behave contrary to their incentivized behavior then things would be better.” For example:
- If my kids would just go to bed when I tell them, they wouldn’t be so cranky in the morning.
- If people would just use the recycling bin, we wouldn’t have such a landfill problem.
- If people would just stop being lazy, our team would deliver our project on time.
In all these cases, the speakers are seemingly flummoxed as to why the people in question don’t behave more rationally. The problem is: each group is behaving perfectly rationally.
- The kids have a high time preference, and care more about the joy of staying up now than the crankiness in the morning. Plus, they don’t really suffer the consequences of morning crankiness, their parents do.
- No individual suffers much from their individual contribution to a landfill. If they stopped growing the size of the landfill, it would make an insignificant difference versus the amount of effort they need to engage in to properly recycle.
- If a team doesn’t properly account for the productivity of individuals on a project, each individual receives less harm from their own inaction. Sure, the project may be delayed, company revenue may be down, and they may even risk losing their job when the company goes out of business. But their laziness individually won’t determine the entirety of that outcome. By contrast, they greatly benefit from being lazy by getting to relax at work, go on social media, read a book, or do whatever else they do when they’re supposed to be working.

My point here is that, as long as you ignore the reality of how incentives drive human behavior, you’ll fail at getting the outcomes you want.
If everything I wrote up until now made perfect sense, you understand the premise of this blog post. The rest of it will focus on a bunch of real-world examples to hammer home the point, and demonstrate how versatile this mental model is.
Running a company
Let’s say I run my own company, with myself as the only employee. My personal revenue will be 100% determined by my own actions. If I decide to take Tuesday afternoon off and go fishing, I’ve chosen to lose that afternoon’s revenue. Implicitly, I’ve decided that the enjoyment I get from an afternoon of fishing is greater than the potential revenue. You may think I’m being lazy, but it’s my decision to make. In this situation, the incentive–money–is perfectly aligned with my actions.
Compare this to a typical company/employee relationship. I might have a bank of Paid Time Off (PTO) days, in which case once again my incentives are relatively aligned. I know that I can take off 15 days throughout the year, and I’ve chosen to use half a day for the fishing trip. All is still good.
What about unlimited time off? Suddenly incentives are starting to misalign. I don’t directly pay a price for not showing up to work on Tuesday. Or Wednesday as well, for that matter. I might ultimately be fired for not doing my job, but that will take longer to work its way through the system than simply not making any money for the day taken off.
Compensation overall falls into this misaligned incentive structure. Let’s forget about taking time off. Instead, I work full time on a software project I’m assigned. But instead of using the normal toolchain we’re all used to at work, I play around with a new programming language. I get the fun and joy of playing with new technology, and potentially get to pad my resume a bit when I’m ready to look for a new job. But my current company gets slower results, less productivity, and is forced to subsidize my extracurricular learning.
When a CEO has a bonus structure based on profitability, he’ll do everything he can to make the company profitable. This might include things that actually benefit the company, like improving product quality, reducing internal red tape, or finding cheaper vendors. But it might also include destructive practices, like slashing the R\&D budget to show massive profits this year, in exchange for a catastrophe next year when the next version of the product fails to ship.

Or my favorite example. My parents owned a business when I was growing up. They had a back office where they ran operations like accounting. All of the furniture was old couches from our house. After all, any money they spent on furniture came right out of their paychecks! But in a large corporate environment, each department is generally given a budget for office furniture, a budget which doesn’t roll over year-to-year. The result? Executives make sure to spend the entire budget each year, often buying furniture far more expensive than they would choose if it was their own money.
There are plenty of details you can quibble with above. It’s in a company’s best interest to give people downtime so that they can come back recharged. Having good ergonomic furniture can in fact increase productivity in excess of the money spent on it. But overall, the picture is pretty clear: in large corporate structures, you’re guaranteed to have mismatches between the company’s goals and the incentive structure placed on individuals.
Using our model from above, we can lament how lazy, greedy, and unethical the employees are for doing what they’re incentivized to do instead of what’s right. But that’s simply ignoring the reality of human nature.
Moral hazard
Moral hazard is a situation where one party is incentivized to take on more risk because another party will bear the consequences. Suppose I tell my son when he turns 21 (or whatever legal gambling age is) that I’ll cover all his losses for a day at the casino, but he gets to keep all the winnings.
What do you think he’s going to do? The most logical course of action is to place the largest possible bets for as long as possible, asking me to cover each time he loses, and taking money off the table and into his bank account each time he wins.

But let’s look at a slightly more nuanced example. I go to a bathroom in the mall. As I’m leaving, I wash my hands. It will take me an extra 1 second to turn off the water when I’m done washing. That’s a trivial price to pay. If I don’t turn off the water, the mall will have to pay for many liters of wasted water, benefiting no one. But I won’t suffer any consequences at all.
This is also a moral hazard, but most people will still turn off the water. Why? Usually due to some combination of other reasons such as:
- We’re so habituated to turning off the water that we don’t even consider not turning it off. Put differently, the mental effort needed to not turn off the water is more expensive than the 1 second of time to turn it off.
- Many of us have been brought up with a deep guilt about wasting resources like water. We have an internal incentive structure that makes the 1 second to turn off the water much less costly than the mental anguish of the waste we created.
- We’re afraid we’ll be caught by someone else and face some kind of social repercussions. (Or maybe more than social. Are you sure there isn’t a law against leaving the water tap on?)
Even with all that in place, you may notice that many public bathrooms use automatic water dispensers. Sure, there’s a sanitation reason for that, but it’s also to avoid this moral hazard.
A common denominator in both of these is that the person taking the action that causes the liability (either the gambling or leaving the water on) is not the person who bears the responsibility for that liability (the father or the mall owner). Generally speaking, the closer together the person making the decision and the person incurring the liability are, the smaller the moral hazard.
It’s easy to demonstrate that by extending the casino example a bit. I said it was the father who was covering the losses of the gambler. Many children (though not all) would want to avoid totally bankrupting their parents, or at least financially hurting them. Instead, imagine that someone from the IRS shows up at your door, hands you a credit card, and tells you you can use it at a casino all day, taking home all the chips you want. The money is coming from the government. How many people would put any restriction on how much they spend?
And since we’re talking about the government already…
Government moral hazards
As I was preparing to write this blog post, the California wildfires hit. The discussions around those wildfires gave a huge number of examples of moral hazards. I decided to cherry-pick a few for this post.
The first and most obvious one: California is asking for disaster relief funds from the federal government. That sounds wonderful. These fires were a natural disaster, so why shouldn’t the federal government pitch in and help take care of people?
The problem is, once again, a moral hazard. In the case of the wildfires, California and Los Angeles both had ample actions they could have taken to mitigate the destruction of this fire: better forest management, larger fire department, keeping the water reservoirs filled, and probably much more that hasn’t come to light yet.
If the federal government bails out California, it will be a clear message for the future: your mistakes will be fixed by others. You know what kind of behavior that incentivizes? More risky behavior! Why spend state funds on forest management and extra firefighters—activities that don’t win politicians a lot of votes in general—when you could instead spend it on a football stadium, higher unemployment payments, or anything else, and then let the feds cover the cost of screw-ups.
You may notice that this is virtually identical to the 2008 “too big to fail” bail-outs. Wall Street took insanely risky behavior, reaped huge profits for years, and when they eventually got caught with their pants down, the rest of us bailed them out. “Privatizing profits, socializing losses.”

And here’s the absolute best part of this: I can’t even truly blame either California or Wall Street. (I mean, I do blame them, I think their behavior is reprehensible, but you’ll see what I mean.) In a world where the rules of the game implicitly include the bail-out mentality, you would be harming your citizens/shareholders/investors if you didn’t engage in that risky behavior. Since everyone is on the hook for those socialized losses, your best bet is to maximize those privatized profits.
There’s a lot more to government and moral hazard, but I think these two cases demonstrate the crux pretty solidly. But let’s leave moral hazard behind for a bit and get to general incentivization discussions.
Non-monetary competition
At least 50% of the economics knowledge I have comes from the very first econ course I took in college. That professor was amazing, and had some very colorful stories. I can’t vouch for the veracity of the two I’m about to share, but they definitely drive the point home.
In the 1970s, the US had an oil shortage. To “fix” this problem, they instituted price caps on gasoline, which of course resulted in insufficient gasoline. To “fix” this problem, they instituted policies where, depending on your license plate number, you could only fill up gas on certain days of the week. (Irrelevant detail for our point here, but this just resulted in people filling up their tanks more often, no reduction in gas usage.)
Anyway, my professor’s wife had a friend. My professor described in great detail how attractive this woman was. I’ll skip those details here since this is a PG-rated blog. In any event, she never had any trouble filling up her gas tank any day of the week. She would drive up, be told she couldn’t fill up gas today, bat her eyes at the attendant, explain how helpless she was, and was always allowed to fill up gas.
This is a demonstration of non-monetary compensation. Most of the time in a free market, capitalist economy, people are compensated through money. When price caps come into play, there’s a limit to how much monetary compensation someone can receive. And in that case, people find other ways of competing. Like this woman’s case: through using flirtatious behavior to compensate the gas station workers to let her cheat the rules.
The other example was much more insidious. Santa Monica had a problem: it was predominantly wealthy and white. They wanted to fix this problem, and decided to put in place rent controls. After some time, they discovered that Santa Monica had become wealthier and whiter, the exact opposite of their desired outcome. Why would that happen?
Someone investigated, and ended up interviewing a landlady that demonstrated the reason. She was an older white woman, and admittedly racist. Prior to the rent controls, she would list her apartments in the newspaper, and would be legally obligated to rent to anyone who could afford it. Once rent controls were in place, she took a different tact. She knew that she would only get a certain amount for the apartment, and that the demand for apartments was higher than the supply. That meant she could be picky.
She ended up finding tenants through friends-of-friends. Since it wasn’t an official advertisement, she wasn’t legally required to rent it out if someone could afford to pay. Instead, she got to interview people individually and then make them an offer. Normally, that would have resulted in receiving a lower rental price, but not under rent controls.
So who did she choose? A young, unmarried, wealthy, white woman. It made perfect sense. Women were less intimidating and more likely to maintain the apartment better. Wealthy people, she determined, would be better tenants. (I have no idea if this is true in practice or not, I’m not a landlord myself.) Unmarried, because no kids running around meant less damage to the property. And, of course, white. Because she was racist, and her incentive structure made her prefer whites.
You can deride her for being racist, I won’t disagree with you. But it’s simply the reality. Under the non-rent-control scenario, her profit motive for money outweighed her racism motive. But under rent control, the monetary competition was removed, and she was free to play into her racist tendencies without facing any negative consequences.
Bureaucracy
These were the two examples I remember for that course. But non-monetary compensation pops up in many more places. One highly pertinent example is bureaucracies. Imagine you have a government office, or a large corporation’s acquisition department, or the team that apportions grants at a university. In all these cases, you have a group of people making decisions about handing out money that has no monetary impact on them. If they give to the best qualified recipients, they receive no raises. If they spend the money recklessly on frivolous projects, they face no consequences.
Under such an incentivization scheme, there’s little to encourage the bureaucrats to make intelligent funding decisions. Instead, they’ll be incentivized to spend the money where they recognize non-monetary benefits. This is why it’s so common to hear about expensive meals, gift bags at conferences, and even more inappropriate ways of trying to curry favor with those that hold the purse strings.
Compare that ever so briefly with the purchases made by a small mom-and-pop store like my parents owned. Could my dad take a bribe to buy from a vendor who’s ripping him off? Absolutely he could! But he’d lose more on the deal than he’d make on the bribe, since he’s directly incentivized by the deal itself. It would make much more sense for him to go with the better vendor, save $5,000 on the deal, and then treat himself to a lavish $400 meal to celebrate.
Government incentivized behavior
This post is getting longer in the tooth than I’d intended, so I’ll finish off with this section and make it a bit briefer. Beyond all the methods mentioned above, government has another mechanism for modifying behavior: through directly changing incentives via legislation, regulation, and monetary policy. Let’s see some examples:
- Artificial modification of interest rates encourages people to take on more debt than they would in a free capital market, leading to malinvestment and a consumer debt crisis, and causing the boom-bust cycle we all painfully experience.
- Going along with that, giving tax breaks on interest payments further artificially incentivizes people to take on debt that they wouldn’t otherwise.
- During COVID-19, at some points unemployment benefits were greater than minimum wage, incentivizing people to rather stay home and not work than get a job, leading to reduced overall productivity in the economy and more printed dollars for benefits. In other words, it was a perfect recipe for inflation.
- The tax code gives deductions to “help” people. That might be true, but the real impact is incentivizing people to make decisions they wouldn’t have otherwise. For example, giving out tax deductions on children encourages having more kids. Tax deductions on childcare and preschools incentivizes dual-income households. Whether or not you like the outcomes, it’s clear that it’s government that’s encouraging these outcomes to happen.
- Tax incentives cause people to engage in behavior they wouldn’t otherwise (daycare+working mother, for example).
- Inflation means that the value of your money goes down over time, which encourages people to spend more today, when their money has a larger impact. (Milton Friedman described this as high living.)
Conclusion
The idea here is simple, and fully encapsulated in the title: incentives determine outcomes. If you want to know how to get a certain outcome from others, incentivize them to want that to happen. If you want to understand why people act in seemingly irrational ways, check their incentives. If you’re confused why leaders (and especially politicians) seem to engage in destructive behavior, check their incentives.
We can bemoan these realities all we want, but they are realities. While there are some people who have a solid internal moral and ethical code, and that internal code incentivizes them to behave against their externally-incentivized interests, those people are rare. And frankly, those people are self-defeating. People should take advantage of the incentives around them. Because if they don’t, someone else will.
(If you want a literary example of that last comment, see the horse in Animal Farm.)
How do we improve the world under these conditions? Make sure the incentives align well with the overall goals of society. To me, it’s a simple formula:
- Focus on free trade, value for value, as the basis of a society. In that system, people are always incentivized to provide value to other people.
- Reduce the size of bureaucracies and large groups of all kinds. The larger an organization becomes, the farther the consequences of decisions are from those who make them.
- And since the nature of human beings will be to try and create areas where they can control the incentive systems to their own benefits, make that as difficult as possible. That comes in the form of strict limits on government power, for example.
And even if you don’t want to buy in to this conclusion, I hope the rest of the content was educational, and maybe a bit entertaining!
-
@ 3f770d65:7a745b24
2025-01-12 21:03:36
I’ve been using Notedeck for several months, starting with its extremely early and experimental alpha versions, all the way to its current, more stable alpha releases. The journey has been fascinating, as I’ve had the privilege of watching it evolve from a concept into a functional and promising tool.
In its earliest stages, Notedeck was raw—offering glimpses of its potential but still far from practical for daily use. Even then, the vision behind it was clear: a platform designed to redefine how we interact with Nostr by offering flexibility and power for all users.
I'm very bullish on Notedeck. Why? Because Will Casarin is making it! Duh! 😂
Seriously though, if we’re reimagining the web and rebuilding portions of the Internet, it’s important to recognize the potential of Notedeck. If Nostr is reimagining the web, then Notedeck is reimagining the Nostr client.
Notedeck isn’t just another Nostr app—it’s more a Nostr browser that functions more like an operating system with micro-apps. How cool is that?
Much like how Google's Chrome evolved from being a web browser with a task manager into ChromeOS, a full blown operating system, Notedeck aims to transform how we interact with the Nostr. It goes beyond individual apps, offering a foundation for a fully integrated ecosystem built around Nostr.
As a Nostr evangelist, I love to scream INTEROPERABILITY and tout every application's integrations. Well, Notedeck has the potential to be one of the best platforms to showcase these integrations in entirely new and exciting ways.
Do you want an Olas feed of images? Add the media column.
Do you want a feed of live video events? Add the zap.stream column.
Do you want Nostr Nests or audio chats? Add that column to your Notedeck.
Git? Email? Books? Chat and DMs? It's all possible.
Not everyone wants a super app though, and that’s okay. As with most things in the Nostr ecosystem, flexibility is key. Notedeck gives users the freedom to choose how they engage with it—whether it’s simply following hashtags or managing straightforward feeds. You'll be able to tailor Notedeck to fit your needs, using it as extensively or minimally as you prefer.
Notedeck is designed with a local-first approach, utilizing Nostr content stored directly on your device via the local nostrdb. This will enable a plethora of advanced tools such as search and filtering, the creation of custom feeds, and the ability to develop personalized algorithms across multiple Notedeck micro-applications—all with unparalleled flexibility.
Notedeck also supports multicast. Let's geek out for a second. Multicast is a method of communication where data is sent from one source to multiple destinations simultaneously, but only to devices that wish to receive the data. Unlike broadcast, which sends data to all devices on a network, multicast targets specific receivers, reducing network traffic. This is commonly used for efficient data distribution in scenarios like streaming, conferencing, or large-scale data synchronization between devices.
In a local first world where each device holds local copies of your nostr nodes, and each device transparently syncs with each other on the local network, each node becomes a backup. Your data becomes antifragile automatically. When a node goes down it can resync and recover from other nodes. Even if not all nodes have a complete collection, negentropy can pull down only what is needed from each device. All this can be done without internet.
-Will Casarin
In the context of Notedeck, multicast would allow multiple devices to sync their Nostr nodes with each other over a local network without needing an internet connection. Wild.
Notedeck aims to offer full customization too, including the ability to design and share custom skins, much like Winamp. Users will also be able to create personalized columns and, in the future, share their setups with others. This opens the door for power users to craft tailored Nostr experiences, leveraging their expertise in the protocol and applications. By sharing these configurations as "Starter Decks," they can simplify onboarding and showcase the best of Nostr’s ecosystem.
Nostr’s “Other Stuff” can often be difficult to discover, use, or understand. Many users doesn't understand or know how to use web browser extensions to login to applications. Let's not even get started with nsecbunkers. Notedeck will address this challenge by providing a native experience that brings these lesser-known applications, tools, and content into a user-friendly and accessible interface, making exploration seamless. However, that doesn't mean Notedeck should disregard power users that want to use nsecbunkers though - hint hint.
For anyone interested in watching Nostr be developed live, right before your very eyes, Notedeck’s progress serves as a reminder of what’s possible when innovation meets dedication. The current alpha is already demonstrating its ability to handle complex use cases, and I’m excited to see how it continues to grow as it moves toward a full release later this year.
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ 37fe9853:bcd1b039
2025-01-11 15:04:40
yoyoaa
-
@ 62033ff8:e4471203
2025-01-11 15:00:24
收录的内容中 kind=1的部分,实话说 质量不高。 所以我增加了kind=30023 长文的article,但是更新的太少,多个relays 的服务器也没有多少长文。
所有搜索nostr如果需要产生价值,需要有高质量的文章和新闻。 而且现在有很多机器人的文章充满着浪费空间的作用,其他作用都用不上。
https://www.duozhutuan.com 目前放的是给搜索引擎提供搜索的原材料。没有做UI给人类浏览。所以看上去是粗糙的。 我并没有打算去做一个发microblog的 web客户端,那类的客户端太多了。
我觉得nostr社区需要解决的还是应用。如果仅仅是microblog 感觉有点够呛
幸运的是npub.pro 建站这样的,我觉得有点意思。
yakihonne 智能widget 也有意思
我做的TaskQ5 我自己在用了。分布式的任务系统,也挺好的。
-
@ 23b0e2f8:d8af76fc
2025-01-08 18:17:52
Necessário
- Um Android que você não use mais (a câmera deve estar funcionando).
- Um cartão microSD (opcional, usado apenas uma vez).
- Um dispositivo para acompanhar seus fundos (provavelmente você já tem um).
Algumas coisas que você precisa saber
- O dispositivo servirá como um assinador. Qualquer movimentação só será efetuada após ser assinada por ele.
- O cartão microSD será usado para transferir o APK do Electrum e garantir que o aparelho não terá contato com outras fontes de dados externas após sua formatação. Contudo, é possível usar um cabo USB para o mesmo propósito.
- A ideia é deixar sua chave privada em um dispositivo offline, que ficará desligado em 99% do tempo. Você poderá acompanhar seus fundos em outro dispositivo conectado à internet, como seu celular ou computador pessoal.
O tutorial será dividido em dois módulos:
- Módulo 1 - Criando uma carteira fria/assinador.
- Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
No final, teremos:
- Uma carteira fria que também servirá como assinador.
- Um dispositivo para acompanhar os fundos da carteira.

Módulo 1 - Criando uma carteira fria/assinador
-
Baixe o APK do Electrum na aba de downloads em https://electrum.org/. Fique à vontade para verificar as assinaturas do software, garantindo sua autenticidade.
-
Formate o cartão microSD e coloque o APK do Electrum nele. Caso não tenha um cartão microSD, pule este passo.

- Retire os chips e acessórios do aparelho que será usado como assinador, formate-o e aguarde a inicialização.

- Durante a inicialização, pule a etapa de conexão ao Wi-Fi e rejeite todas as solicitações de conexão. Após isso, você pode desinstalar aplicativos desnecessários, pois precisará apenas do Electrum. Certifique-se de que Wi-Fi, Bluetooth e dados móveis estejam desligados. Você também pode ativar o modo avião.\ (Curiosidade: algumas pessoas optam por abrir o aparelho e danificar a antena do Wi-Fi/Bluetooth, impossibilitando essas funcionalidades.)

- Insira o cartão microSD com o APK do Electrum no dispositivo e instale-o. Será necessário permitir instalações de fontes não oficiais.
- No Electrum, crie uma carteira padrão e gere suas palavras-chave (seed). Anote-as em um local seguro. Caso algo aconteça com seu assinador, essas palavras permitirão o acesso aos seus fundos novamente. (Aqui entra seu método pessoal de backup.)

Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
-
Criar uma carteira somente leitura em outro dispositivo, como seu celular ou computador pessoal, é uma etapa bastante simples. Para este tutorial, usaremos outro smartphone Android com Electrum. Instale o Electrum a partir da aba de downloads em https://electrum.org/ ou da própria Play Store. (ATENÇÃO: O Electrum não existe oficialmente para iPhone. Desconfie se encontrar algum.)
-
Após instalar o Electrum, crie uma carteira padrão, mas desta vez escolha a opção Usar uma chave mestra.

- Agora, no assinador que criamos no primeiro módulo, exporte sua chave pública: vá em Carteira > Detalhes da carteira > Compartilhar chave mestra pública.

-
Escaneie o QR gerado da chave pública com o dispositivo de consulta. Assim, ele poderá acompanhar seus fundos, mas sem permissão para movimentá-los.
-
Para receber fundos, envie Bitcoin para um dos endereços gerados pela sua carteira: Carteira > Addresses/Coins.
-
Para movimentar fundos, crie uma transação no dispositivo de consulta. Como ele não possui a chave privada, será necessário assiná-la com o dispositivo assinador.

- No assinador, escaneie a transação não assinada, confirme os detalhes, assine e compartilhe. Será gerado outro QR, desta vez com a transação já assinada.

- No dispositivo de consulta, escaneie o QR da transação assinada e transmita-a para a rede.
Conclusão
Pontos positivos do setup:
- Simplicidade: Basta um dispositivo Android antigo.
- Flexibilidade: Funciona como uma ótima carteira fria, ideal para holders.
Pontos negativos do setup:
- Padronização: Não utiliza seeds no padrão BIP-39, você sempre precisará usar o electrum.
- Interface: A aparência do Electrum pode parecer antiquada para alguns usuários.
Nesse ponto, temos uma carteira fria que também serve para assinar transações. O fluxo de assinar uma transação se torna: Gerar uma transação não assinada > Escanear o QR da transação não assinada > Conferir e assinar essa transação com o assinador > Gerar QR da transação assinada > Escanear a transação assinada com qualquer outro dispositivo que possa transmiti-la para a rede.
Como alguns devem saber, uma transação assinada de Bitcoin é praticamente impossível de ser fraudada. Em um cenário catastrófico, você pode mesmo que sem internet, repassar essa transação assinada para alguém que tenha acesso à rede por qualquer meio de comunicação. Mesmo que não queiramos que isso aconteça um dia, esse setup acaba por tornar essa prática possível.
-
@ 207ad2a0:e7cca7b0
2025-01-07 03:46:04
Quick context: I wanted to check out Nostr's longform posts and this blog post seemed like a good one to try and mirror. It's originally from my free to read/share attempt to write a novel, but this post here is completely standalone - just describing how I used AI image generation to make a small piece of the work.
Hold on, put your pitchforks down - outside of using Grammerly & Emacs for grammatical corrections - not a single character was generated or modified by computers; a non-insignificant portion of my first draft originating on pen & paper. No AI is ~~weird and crazy~~ imaginative enough to write like I do. The only successful AI contribution you'll find is a single image, the map, which I heavily edited. This post will go over how I generated and modified an image using AI, which I believe brought some value to the work, and cover a few quick thoughts about AI towards the end.
Let's be clear, I can't draw, but I wanted a map which I believed would improve the story I was working on. After getting abysmal results by prompting AI with text only I decided to use "Diffuse the Rest," a Stable Diffusion tool that allows you to provide a reference image + description to fine tune what you're looking for. I gave it this Microsoft Paint looking drawing:

and after a number of outputs, selected this one to work on:
The image is way better than the one I provided, but had I used it as is, I still feel it would have decreased the quality of my work instead of increasing it. After firing up Gimp I cropped out the top and bottom, expanded the ocean and separated the landmasses, then copied the top right corner of the large landmass to replace the bottom left that got cut off. Now we've got something that looks like concept art: not horrible, and gets the basic idea across, but it's still due for a lot more detail.
The next thing I did was add some texture to make it look more map like. I duplicated the layer in Gimp and applied the "Cartoon" filter to both for some texture. The top layer had a much lower effect strength to give it a more textured look, while the lower layer had a higher effect strength that looked a lot like mountains or other terrain features. Creating a layer mask allowed me to brush over spots to display the lower layer in certain areas, giving it some much needed features.
At this point I'd made it to where I felt it may improve the work instead of detracting from it - at least after labels and borders were added, but the colors seemed artificial and out of place. Luckily, however, this is when PhotoFunia could step in and apply a sketch effect to the image.
At this point I was pretty happy with how it was looking, it was close to what I envisioned and looked very visually appealing while still being a good way to portray information. All that was left was to make the white background transparent, add some minor details, and add the labels and borders. Below is the exact image I wound up using:
Overall, I'm very satisfied with how it turned out, and if you're working on a creative project, I'd recommend attempting something like this. It's not a central part of the work, but it improved the chapter a fair bit, and was doable despite lacking the talent and not intending to allocate a budget to my making of a free to read and share story.
The AI Generated Elephant in the Room
If you've read my non-fiction writing before, you'll know that I think AI will find its place around the skill floor as opposed to the skill ceiling. As you saw with my input, I have absolutely zero drawing talent, but with some elbow grease and an existing creative direction before and after generating an image I was able to get something well above what I could have otherwise accomplished. Outside of the lowest common denominators like stock photos for the sole purpose of a link preview being eye catching, however, I doubt AI will be wholesale replacing most creative works anytime soon. I can assure you that I tried numerous times to describe the map without providing a reference image, and if I used one of those outputs (or even just the unedited output after providing the reference image) it would have decreased the quality of my work instead of improving it.
I'm going to go out on a limb and expect that AI image, text, and video is all going to find its place in slop & generic content (such as AI generated slop replacing article spinners and stock photos respectively) and otherwise be used in a supporting role for various creative endeavors. For people working on projects like I'm working on (e.g. intended budget $0) it's helpful to have an AI capable of doing legwork - enabling projects to exist or be improved in ways they otherwise wouldn't have. I'm also guessing it'll find its way into more professional settings for grunt work - think a picture frame or fake TV show that would exist in the background of an animated project - likely a detail most people probably wouldn't notice, but that would save the creators time and money and/or allow them to focus more on the essential aspects of said work. Beyond that, as I've predicted before: I expect plenty of emails will be generated from a short list of bullet points, only to be summarized by the recipient's AI back into bullet points.
I will also make a prediction counter to what seems mainstream: AI is about to peak for a while. The start of AI image generation was with Google's DeepDream in 2015 - image recognition software that could be run in reverse to "recognize" patterns where there were none, effectively generating an image from digital noise or an unrelated image. While I'm not an expert by any means, I don't think we're too far off from that a decade later, just using very fine tuned tools that develop more coherent images. I guess that we're close to maxing out how efficiently we're able to generate images and video in that manner, and the hard caps on how much creative direction we can have when using AI - as well as the limits to how long we can keep it coherent (e.g. long videos or a chronologically consistent set of images) - will prevent AI from progressing too far beyond what it is currently unless/until another breakthrough occurs.
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
- Enhance LLM Outputs: By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
- Support Complex Queries: Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
- Richness of Entities: Effective retrieval depends on graphs populated with rich, detailed entities.
- Freedom from Hallucinations: Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
- Handle diverse data sources with ease.
- Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
- Defining Relationships: Clarifying how concepts connect within a domain.
- Validating Graph Structures: Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
- Assign a Knowledge Champion: Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
- Provide Training: Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
- Leverage Partnerships: Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
- Utilize Tools: Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
- Iterate with Feedback: Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
-
Leverage Existing Ontologies: Many industries and domains already have open ontologies. For instance:
-
Public Knowledge Graphs: Resources like Wikipedia’s graph offer a wealth of structured knowledge.
- Industry Standards: Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
-
Business Framework Ontology (BFO): A valuable resource for enterprises looking to define business processes and structures.
-
Build In-House Expertise: If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
-
Utilize LLMs for Ontology Construction: Interestingly, LLMs themselves can act as a starting point for ontology development:
-
Prompt-Based Extraction: LLMs can generate draft ontologies by leveraging their extensive training on graph data.
- Domain Expert Refinement: Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
- Detecting Hallucinations: Differentiating between genuine insights and AI-generated inaccuracies.
- Ensuring Completeness: Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
- Generate Skeleton Ontologies: Prompt LLMs with domain-specific information to draft initial ontology structures.
- Validate and Refine Ontologies: Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
The Four-Layer Framework
Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
Example: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- Tip: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
Once you have the big picture in mind, it’s time to start breaking it down.
Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
Example: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- Tip: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
With your categories in place, you’re ready to dive into the details that bring them to life.
Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
Example: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- Tip: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
Now that you’ve mastered the essentials, you can expand your knowledge to include extra material.
Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
Example: Learn about rare programming quirks or historical trivia about a language’s development.
- Tip: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
Pro Tips for Better Learning
1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
2. Map It Out
Create visual aids like diagrams or concept maps to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching exposes any gaps in your understanding and helps reinforce the material.
4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to explore your topic in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.Tip: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ 1bda7e1f:bb97c4d9
2025-01-02 05:19:08
Tldr
- Nostr is an open and interoperable protocol
- You can integrate it with workflow automation tools to augment your experience
- n8n is a great low/no-code workflow automation tool which you can host yourself
- Nostrobots allows you to integrate Nostr into n8n
- In this blog I create some workflow automations for Nostr
- A simple form to delegate posting notes
- Push notifications for mentions on multiple accounts
- Push notifications for your favourite accounts when they post a note
- All workflows are provided as open source with MIT license for you to use
Inter-op All The Things
Nostr is a new open social protocol for the internet. This open nature exciting because of the opportunities for interoperability with other technologies. In Using NFC Cards with Nostr I explored the
nostr:URI to launch Nostr clients from a card tap.The interoperability of Nostr doesn't stop there. The internet has many super-powers, and Nostr is open to all of them. Simply, there's no one to stop it. There is no one in charge, there are no permissioned APIs, and there are no risks of being de-platformed. If you can imagine technologies that would work well with Nostr, then any and all of them can ride on or alongside Nostr rails.
My mental model for why this is special is Google Wave ~2010. Google Wave was to be the next big platform. Lars was running it and had a big track record from Maps. I was excited for it. Then, Google pulled the plug. And, immediately all the time and capital invested in understanding and building on the platform was wasted.
This cannot happen to Nostr, as there is no one to pull the plug, and maybe even no plug to pull.
So long as users demand Nostr, Nostr will exist, and that is a pretty strong guarantee. It makes it worthwhile to invest in bringing Nostr into our other applications.
All we need are simple ways to plug things together.
Nostr and Workflow Automation
Workflow automation is about helping people to streamline their work. As a user, the most common way I achieve this is by connecting disparate systems together. By setting up one system to trigger another or to move data between systems, I can solve for many different problems and become way more effective.
n8n for workflow automation
Many workflow automation tools exist. My favourite is n8n. n8n is a low/no-code workflow automation platform which allows you to build all kinds of workflows. You can use it for free, you can self-host it, it has a user-friendly UI and useful API. Vs Zapier it can be far more elaborate. Vs Make.com I find it to be more intuitive in how it abstracts away the right parts of the code, but still allows you to code when you need to.
Most importantly you can plug anything into n8n: You have built-in nodes for specific applications. HTTP nodes for any other API-based service. And community nodes built by individual community members for any other purpose you can imagine.
Eating my own dogfood
It's very clear to me that there is a big design space here just demanding to be explored. If you could integrate Nostr with anything, what would you do?
In my view the best way for anyone to start anything is by solving their own problem first (aka "scratching your own itch" and "eating your own dogfood"). As I get deeper into Nostr I find myself controlling multiple Npubs – to date I have a personal Npub, a brand Npub for a community I am helping, an AI assistant Npub, and various testing Npubs. I need ways to delegate access to those Npubs without handing over the keys, ways to know if they're mentioned, and ways to know if they're posting.
I can build workflows with n8n to solve these issues for myself to start with, and keep expanding from there as new needs come up.
Running n8n with Nostrobots
I am mostly non-technical with a very helpful AI. To set up n8n to work with Nostr and operate these workflows should be possible for anyone with basic technology skills.
- I have a cheap VPS which currently runs my HAVEN Nostr Relay and Albyhub Lightning Node in Docker containers,
- My objective was to set up n8n to run alongside these in a separate Docker container on the same server, install the required nodes, and then build and host my workflows.
Installing n8n
Self-hosting n8n could not be easier. I followed n8n's Docker-Compose installation docs–
- Install Docker and Docker-Compose if you haven't already,
- Create your
docker-compose.ymland.envfiles from the docs, - Create your data folder
sudo docker volume create n8n_data, - Start your container with
sudo docker compose up -d, - Your n8n instance should be online at port
5678.
n8n is free to self-host but does require a license. Enter your credentials into n8n to get your free license key. You should now have access to the Workflow dashboard and can create and host any kind of workflows from there.
Installing Nostrobots
To integrate n8n nicely with Nostr, I used the Nostrobots community node by Ocknamo.
In n8n parlance a "node" enables certain functionality as a step in a workflow e.g. a "set" node sets a variable, a "send email" node sends an email. n8n comes with all kinds of "official" nodes installed by default, and Nostr is not amongst them. However, n8n also comes with a framework for community members to create their own "community" nodes, which is where Nostrobots comes in.
You can only use a community node in a self-hosted n8n instance (which is what you have if you are running in Docker on your own server, but this limitation does prevent you from using n8n's own hosted alternative).
To install a community node, see n8n community node docs. From your workflow dashboard–
- Click the "..." in the bottom left corner beside your username, and click "settings",
- Cilck "community nodes" left sidebar,
- Click "Install",
- Enter the "npm Package Name" which is
n8n-nodes-nostrobots, - Accept the risks and click "Install",
- Nostrobots is now added to your n8n instance.
Using Nostrobots
Nostrobots gives you nodes to help you build Nostr-integrated workflows–
- Nostr Write – for posting Notes to the Nostr network,
- Nostr Read – for reading Notes from the Nostr network, and
- Nostr Utils – for performing certain conversions you may need (e.g. from bech32 to hex).
Nostrobots has good documentation on each node which focuses on simple use cases.
Each node has a "convenience mode" by default. For example, the "Read" Node by default will fetch Kind 1 notes by a simple filter, in Nostrobots parlance a "Strategy". For example, with Strategy set to "Mention" the node will accept a pubkey and fetch all Kind 1 notes that Mention the pubkey within a time period. This is very good for quick use.
What wasn't clear to me initially (until Ocknamo helped me out) is that advanced use cases are also possible.
Each node also has an advanced mode. For example, the "Read" Node can have "Strategy" set to "RawFilter(advanced)". Now the node will accept json (anything you like that complies with NIP-01). You can use this to query Notes (Kind 1) as above, and also Profiles (Kind 0), Follow Lists (Kind 3), Reactions (Kind 7), Zaps (Kind 9734/9735), and anything else you can think of.
Creating and adding workflows
With n8n and Nostrobots installed, you can now create or add any kind of Nostr Workflow Automation.
- Click "Add workflow" to go to the workflow builder screen,
- If you would like to build your own workflow, you can start with adding any node. Click "+" and see what is available. Type "Nostr" to explore the Nostrobots nodes you have added,
- If you would like to add workflows that someone else has built, click "..." in the top right. Then click "import from URL" and paste in the URL of any workflow you would like to use (including the ones I share later in this article).
Nostr Workflow Automations
It's time to build some things!
A simple form to post a note to Nostr
I started very simply. I needed to delegate the ability to post to Npubs that I own in order that a (future) team can test things for me. I don't want to worry about managing or training those people on how to use keys, and I want to revoke access easily.
I needed a basic form with credentials that posted a Note.
For this I can use a very simple workflow–
- A n8n Form node – Creates a form for users to enter the note they wish to post. Allows for the form to be protected by a username and password. This node is the workflow "trigger" so that the workflow runs each time the form is submitted.
- A Set node – Allows me to set some variables, in this case I set the relays that I intend to use. I typically add a Set node immediately following the trigger node, and put all the variables I need in this. It helps to make the workflows easier to update and maintain.
- A Nostr Write node (from Nostrobots) – Writes a Kind-1 note to the Nostr network. It accepts Nostr credentials, the output of the Form node, and the relays from the Set node, and posts the Note to those relays.
Once the workflow is built, you can test it with the testing form URL, and set it to "Active" to use the production form URL. That's it. You can now give posting access to anyone for any Npub. To revoke access, simply change the credentials or set to workflow to "Inactive".
It may also be the world's simplest Nostr client.
You can find the Nostr Form to Post a Note workflow here.
Push notifications on mentions and new notes
One of the things Nostr is not very good at is push notifications. Furthermore I have some unique itches to scratch. I want–
- To make sure I never miss a note addressed to any of my Npubs – For this I want a push notification any time any Nostr user mentions any of my Npubs,
- To make sure I always see all notes from key accounts – For this I need a push notification any time any of my Npubs post any Notes to the network,
- To get these notifications on all of my devices – Not just my phone where my Nostr regular client lives, but also on each of my laptops to suit wherever I am working that day.
I needed to build a Nostr push notifications solution.
To build this workflow I had to string a few ideas together–
- Triggering the node on a schedule – Nostrobots does not include a trigger node. As every workflow starts with a trigger we needed a different method. I elected to run the workflow on a schedule of every 10-minutes. Frequent enough to see Notes while they are hot, but infrequent enough to not burden public relays or get rate-limited,
- Storing a list of Npubs in a Nostr list – I needed a way to store the list of Npubs that trigger my notifications. I initially used an array defined in the workflow, this worked fine. Then I decided to try Nostr lists (NIP-51, kind 30000). By defining my list of Npubs as a list published to Nostr I can control my list from within a Nostr client (e.g. Listr.lol or Nostrudel.ninja). Not only does this "just work", but because it's based on Nostr lists automagically Amethyst client allows me to browse that list as a Feed, and everyone I add gets notified in their Mentions,
- Using specific relays – I needed to query the right relays, including my own HAVEN relay inbox for notes addressed to me, and wss://purplepag.es for Nostr profile metadata,
- Querying Nostr events (with Nostrobots) – I needed to make use of many different Nostr queries and use quite a wide range of what Nostrobots can do–
- I read the EventID of my Kind 30000 list, to return the desired pubkeys,
- For notifications on mentions, I read all Kind 1 notes that mention that pubkey,
- For notifications on new notes, I read all Kind 1 notes published by that pubkey,
- Where there are notes, I read the Kind 0 profile metadata event of that pubkey to get the displayName of the relevant Npub,
- I transform the EventID into a Nevent to help clients find it.
- Using the Nostr URI – As I did with my NFC card article, I created a link with the
nostr:URI prefix so that my phone's native client opens the link by default, - Push notifications solution – I needed a push notifications solution. I found many with n8n integrations and chose to go with Pushover which supports all my devices, has a free trial, and is unfairly cheap with a $5-per-device perpetual license.
Once the workflow was built, lists published, and Pushover installed on my phone, I was fully set up with push notifications on Nostr. I have used these workflows for several weeks now and made various tweaks as I went. They are feeling robust and I'd welcome you to give them a go.
You can find the Nostr Push Notification If Mentioned here and If Posts a Note here.
In speaking with other Nostr users while I was building this, there are all kind of other needs for push notifications too – like on replies to a certain bookmarked note, or when a followed Npub starts streaming on zap.stream. These are all possible.
Use my workflows
I have open sourced all my workflows at my Github with MIT license and tried to write complete docs, so that you can import them into your n8n and configure them for your own use.
To import any of my workflows–
- Click on the workflow of your choice, e.g. "Nostr_Push_Notify_If_Mentioned.json",
- Click on the "raw" button to view the raw JSON, ex any Github page layout,
- Copy that URL,
- Enter that URL in the "import from URL" dialog mentioned above.
To configure them–
- Prerequisites, credentials, and variables are all stated,
- In general any variables required are entered into a Set Node that follows the trigger node,
- Pushover has some extra setup but is very straightforward and documented in the workflow.
What next?
Over my first four blogs I explored creating a good Nostr setup with Vanity Npub, Lightning Payments, Nostr Addresses at Your Domain, and Personal Nostr Relay.
Then in my latest two blogs I explored different types of interoperability with NFC cards and now n8n Workflow Automation.
Thinking ahead n8n can power any kind of interoperability between Nostr and any other legacy technology solution. On my mind as I write this:
- Further enhancements to posting and delegating solutions and forms (enhanced UI or different note kinds),
- Automated or scheduled posting (such as auto-liking everything Lyn Alden posts),
- Further enhancements to push notifications, on new and different types of events (such as notifying me when I get a new follower, on replies to certain posts, or when a user starts streaming),
- All kinds of bridges, such as bridging notes to and from Telegram, Slack, or Campfire. Or bridging RSS or other event feeds to Nostr,
- All kinds of other automation (such as BlackCoffee controlling a coffee machine),
- All kinds of AI Assistants and Agents,
In fact I have already released an open source workflow for an AI Assistant, and will share more about that in my next blog.
Please be sure to let me know if you think there's another Nostr topic you'd like to see me tackle.
GM Nostr.
-
@ f9cf4e94:96abc355
2024-12-31 20:18:59
Scuttlebutt foi iniciado em maio de 2014 por Dominic Tarr ( dominictarr ) como uma rede social alternativa off-line, primeiro para convidados, que permite aos usuários obter controle total de seus dados e privacidade. Secure Scuttlebutt (ssb) foi lançado pouco depois, o que coloca a privacidade em primeiro plano com mais recursos de criptografia.
Se você está se perguntando de onde diabos veio o nome Scuttlebutt:
Este termo do século 19 para uma fofoca vem do Scuttlebutt náutico: “um barril de água mantido no convés, com um buraco para uma xícara”. A gíria náutica vai desde o hábito dos marinheiros de se reunir pelo boato até a fofoca, semelhante à fofoca do bebedouro.

Marinheiros se reunindo em torno da rixa. ( fonte )
Dominic descobriu o termo boato em um artigo de pesquisa que leu.
Em sistemas distribuídos, fofocar é um processo de retransmissão de mensagens ponto a ponto; as mensagens são disseminadas de forma análoga ao “boca a boca”.
Secure Scuttlebutt é um banco de dados de feeds imutáveis apenas para acréscimos, otimizado para replicação eficiente para protocolos ponto a ponto. Cada usuário tem um log imutável somente para acréscimos no qual eles podem gravar. Eles gravam no log assinando mensagens com sua chave privada. Pense em um feed de usuário como seu próprio diário de bordo, como um diário de bordo (ou diário do capitão para os fãs de Star Trek), onde eles são os únicos autorizados a escrever nele, mas têm a capacidade de permitir que outros amigos ou colegas leiam ao seu diário de bordo, se assim o desejarem.
Cada mensagem possui um número de sequência e a mensagem também deve fazer referência à mensagem anterior por seu ID. O ID é um hash da mensagem e da assinatura. A estrutura de dados é semelhante à de uma lista vinculada. É essencialmente um log somente de acréscimo de JSON assinado. Cada item adicionado a um log do usuário é chamado de mensagem.
Os logs do usuário são conhecidos como feed e um usuário pode seguir os feeds de outros usuários para receber suas atualizações. Cada usuário é responsável por armazenar seu próprio feed. Quando Alice assina o feed de Bob, Bob baixa o log de feed de Alice. Bob pode verificar se o registro do feed realmente pertence a Alice verificando as assinaturas. Bob pode verificar as assinaturas usando a chave pública de Alice.

Estrutura de alto nível de um feed
Pubs são servidores de retransmissão conhecidos como “super peers”. Pubs conectam usuários usuários e atualizações de fofocas a outros usuários conectados ao Pub. Um Pub é análogo a um pub da vida real, onde as pessoas vão para se encontrar e se socializar. Para ingressar em um Pub, o usuário deve ser convidado primeiro. Um usuário pode solicitar um código de convite de um Pub; o Pub simplesmente gerará um novo código de convite, mas alguns Pubs podem exigir verificação adicional na forma de verificação de e-mail ou, com alguns Pubs, você deve pedir um código em um fórum público ou chat. Pubs também podem mapear aliases de usuário, como e-mails ou nome de usuário, para IDs de chave pública para facilitar os pares de referência.
Depois que o Pub enviar o código de convite ao usuário, o usuário resgatará o código, o que significa que o Pub seguirá o usuário, o que permite que o usuário veja as mensagens postadas por outros membros do Pub, bem como as mensagens de retransmissão do Pub pelo usuário a outros membros do Pub.
Além de retransmitir mensagens entre pares, os Pubs também podem armazenar as mensagens. Se Alice estiver offline e Bob transmitir atualizações de feed, Alice perderá a atualização. Se Alice ficar online, mas Bob estiver offline, não haverá como ela buscar o feed de Bob. Mas com um Pub, Alice pode buscar o feed no Pub mesmo se Bob estiver off-line porque o Pub está armazenando as mensagens. Pubs são úteis porque assim que um colega fica online, ele pode sincronizar com o Pub para receber os feeds de seus amigos potencialmente offline.
Um usuário pode, opcionalmente, executar seu próprio servidor Pub e abri-lo ao público ou permitir que apenas seus amigos participem, se assim o desejarem. Eles também podem ingressar em um Pub público. Aqui está uma lista de Pubs públicos em que todos podem participar . Explicaremos como ingressar em um posteriormente neste guia. Uma coisa importante a observar é que o Secure Scuttlebutt em uma rede social somente para convidados significa que você deve ser “puxado” para entrar nos círculos sociais. Se você responder às mensagens, os destinatários não serão notificados, a menos que estejam seguindo você de volta. O objetivo do SSB é criar “ilhas” isoladas de redes pares, ao contrário de uma rede pública onde qualquer pessoa pode enviar mensagens a qualquer pessoa.

Perspectivas dos participantes
Scuttlebot
O software Pub é conhecido como servidor Scuttlebutt (servidor ssb ), mas também é conhecido como “Scuttlebot” e
sbotna linha de comando. O servidor SSB adiciona comportamento de rede ao banco de dados Scuttlebutt (SSB). Estaremos usando o Scuttlebot ao longo deste tutorial.Os logs do usuário são conhecidos como feed e um usuário pode seguir os feeds de outros usuários para receber suas atualizações. Cada usuário é responsável por armazenar seu próprio feed. Quando Alice assina o feed de Bob, Bob baixa o log de feed de Alice. Bob pode verificar se o registro do feed realmente pertence a Alice verificando as assinaturas. Bob pode verificar as assinaturas usando a chave pública de Alice.
Estrutura de alto nível de um feed
Pubs são servidores de retransmissão conhecidos como “super peers”. Pubs conectam usuários usuários e atualizações de fofocas a outros usuários conectados ao Pub. Um Pub é análogo a um pub da vida real, onde as pessoas vão para se encontrar e se socializar. Para ingressar em um Pub, o usuário deve ser convidado primeiro. Um usuário pode solicitar um código de convite de um Pub; o Pub simplesmente gerará um novo código de convite, mas alguns Pubs podem exigir verificação adicional na forma de verificação de e-mail ou, com alguns Pubs, você deve pedir um código em um fórum público ou chat. Pubs também podem mapear aliases de usuário, como e-mails ou nome de usuário, para IDs de chave pública para facilitar os pares de referência.
Depois que o Pub enviar o código de convite ao usuário, o usuário resgatará o código, o que significa que o Pub seguirá o usuário, o que permite que o usuário veja as mensagens postadas por outros membros do Pub, bem como as mensagens de retransmissão do Pub pelo usuário a outros membros do Pub.
Além de retransmitir mensagens entre pares, os Pubs também podem armazenar as mensagens. Se Alice estiver offline e Bob transmitir atualizações de feed, Alice perderá a atualização. Se Alice ficar online, mas Bob estiver offline, não haverá como ela buscar o feed de Bob. Mas com um Pub, Alice pode buscar o feed no Pub mesmo se Bob estiver off-line porque o Pub está armazenando as mensagens. Pubs são úteis porque assim que um colega fica online, ele pode sincronizar com o Pub para receber os feeds de seus amigos potencialmente offline.
Um usuário pode, opcionalmente, executar seu próprio servidor Pub e abri-lo ao público ou permitir que apenas seus amigos participem, se assim o desejarem. Eles também podem ingressar em um Pub público. Aqui está uma lista de Pubs públicos em que todos podem participar . Explicaremos como ingressar em um posteriormente neste guia. Uma coisa importante a observar é que o Secure Scuttlebutt em uma rede social somente para convidados significa que você deve ser “puxado” para entrar nos círculos sociais. Se você responder às mensagens, os destinatários não serão notificados, a menos que estejam seguindo você de volta. O objetivo do SSB é criar “ilhas” isoladas de redes pares, ao contrário de uma rede pública onde qualquer pessoa pode enviar mensagens a qualquer pessoa.

Perspectivas dos participantes
Pubs - Hubs
Pubs públicos
| Pub Name | Operator | Invite Code | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | |
scuttle.us| @Ryan |scuttle.us:8008:@WqcuCOIpLtXFRw/9vOAQJti8avTZ9vxT9rKrPo8qG6o=.ed25519~/ZUi9Chpl0g1kuWSrmehq2EwMQeV0Pd+8xw8XhWuhLE=| | pub1.upsocial.com | @freedomrules |pub1.upsocial.com:8008:@gjlNF5Cyw3OKZxEoEpsVhT5Xv3HZutVfKBppmu42MkI=.ed25519~lMd6f4nnmBZEZSavAl4uahl+feajLUGqu8s2qdoTLi8=| | Monero Pub | @Denis |xmr-pub.net:8008:@5hTpvduvbDyMLN2IdzDKa7nx7PSem9co3RsOmZoyyCM=.ed25519~vQU+r2HUd6JxPENSinUWdfqrJLlOqXiCbzHoML9iVN4=| | FreeSocial | @Jarland |pub.freesocial.co:8008:@ofYKOy2p9wsaxV73GqgOyh6C6nRGFM5FyciQyxwBd6A=.ed25519~ye9Z808S3KPQsV0MWr1HL0/Sh8boSEwW+ZK+8x85u9w=| |ssb.vpn.net.br| @coffeverton |ssb.vpn.net.br:8008:@ze8nZPcf4sbdULvknEFOCbVZtdp7VRsB95nhNw6/2YQ=.ed25519~D0blTolH3YoTwSAkY5xhNw8jAOjgoNXL/+8ZClzr0io=| | gossip.noisebridge.info | Noisebridge Hackerspace @james.network |gossip.noisebridge.info:8008:@2NANnQVdsoqk0XPiJG2oMZqaEpTeoGrxOHJkLIqs7eY=.ed25519~JWTC6+rPYPW5b5zCion0gqjcJs35h6JKpUrQoAKWgJ4=|Pubs privados
Você precisará entrar em contato com os proprietários desses bares para receber um convite.
| Pub Name | Operator | Contact | | --------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------- | |
many.butt.nz| @dinosaur | mikey@enspiral.com | |one.butt.nz| @dinosaur | mikey@enspiral.com | |ssb.mikey.nz| @dinosaur | mikey@enspiral.com | | ssb.celehner.com | @cel | cel@celehner.com |Pubs muito grandes
Aviso: embora tecnicamente funcione usar um convite para esses pubs, você provavelmente se divertirá se o fizer devido ao seu tamanho (muitas coisas para baixar, risco para bots / spammers / idiotas)
| Pub Name | Operator | Invite Code | | --------------------------------------- | ----------------------------------------------- | ------------------------------------------------------------ | |
scuttlebutt.de| SolSoCoG |scuttlebutt.de:8008:@yeh/GKxlfhlYXSdgU7CRLxm58GC42za3tDuC4NJld/k=.ed25519~iyaCpZ0co863K9aF+b7j8BnnHfwY65dGeX6Dh2nXs3c=| |Lohn's Pub| @lohn |p.lohn.in:8018:@LohnKVll9HdLI3AndEc4zwGtfdF/J7xC7PW9B/JpI4U=.ed25519~z3m4ttJdI4InHkCtchxTu26kKqOfKk4woBb1TtPeA/s=| | Scuttle Space | @guil-dot | Visit scuttle.space | |SSB PeerNet US-East| timjrobinson |us-east.ssbpeer.net:8008:@sTO03jpVivj65BEAJMhlwtHXsWdLd9fLwyKAT1qAkc0=.ed25519~sXFc5taUA7dpGTJITZVDCRy2A9jmkVttsr107+ufInU=| | Hermies | s | net:hermies.club:8008~shs:uMYDVPuEKftL4SzpRGVyQxLdyPkOiX7njit7+qT/7IQ=:SSB+Room+PSK3TLYC2T86EHQCUHBUHASCASE18JBV24= |GUI - Interface Gráfica do Utilizador(Usuário)
Patchwork - Uma GUI SSB (Descontinuado)
Patchwork é o aplicativo de mensagens e compartilhamento descentralizado construído em cima do SSB . O protocolo scuttlebutt em si não mantém um conjunto de feeds nos quais um usuário está interessado, então um cliente é necessário para manter uma lista de feeds de pares em que seu respectivo usuário está interessado e seguindo.

Fonte: scuttlebutt.nz
Quando você instala e executa o Patchwork, você só pode ver e se comunicar com seus pares em sua rede local. Para acessar fora de sua LAN, você precisa se conectar a um Pub. Um pub é apenas para convidados e eles retransmitem mensagens entre você e seus pares fora de sua LAN e entre outros Pubs.
Lembre-se de que você precisa seguir alguém para receber mensagens dessa pessoa. Isso reduz o envio de mensagens de spam para os usuários. Os usuários só veem as respostas das pessoas que seguem. Os dados são sincronizados no disco para funcionar offline, mas podem ser sincronizados diretamente com os pares na sua LAN por wi-fi ou bluetooth.
Patchbay - Uma GUI Alternativa
Patchbay é um cliente de fofoca projetado para ser fácil de modificar e estender. Ele usa o mesmo banco de dados que Patchwork e Patchfoo , então você pode facilmente dar uma volta com sua identidade existente.

Planetary - GUI para IOS

Planetary é um app com pubs pré-carregados para facilitar integração.
Manyverse - GUI para Android

Manyverse é um aplicativo de rede social com recursos que você esperaria: posts, curtidas, perfis, mensagens privadas, etc. Mas não está sendo executado na nuvem de propriedade de uma empresa, em vez disso, as postagens de seus amigos e todos os seus dados sociais vivem inteiramente em seu telefone .
Fontes
-
https://scuttlebot.io/
-
https://decentralized-id.com/decentralized-web/scuttlebot/#plugins
-
https://medium.com/@miguelmota/getting-started-with-secure-scuttlebut-e6b7d4c5ecfd
-
Secure Scuttlebutt : um protocolo de banco de dados global.
-
-
@ 3f770d65:7a745b24
2024-12-31 17:03:46
Here are my predictions for Nostr in 2025:
Decentralization: The outbox and inbox communication models, sometimes referred to as the Gossip model, will become the standard across the ecosystem. By the end of 2025, all major clients will support these models, providing seamless communication and enhanced decentralization. Clients that do not adopt outbox/inbox by then will be regarded as outdated or legacy systems.
Privacy Standards: Major clients such as Damus and Primal will move away from NIP-04 DMs, adopting more secure protocol possibilities like NIP-17 or NIP-104. These upgrades will ensure enhanced encryption and metadata protection. Additionally, NIP-104 MLS tools will drive the development of new clients and features, providing users with unprecedented control over the privacy of their communications.
Interoperability: Nostr's ecosystem will become even more interconnected. Platforms like the Olas image-sharing service will expand into prominent clients such as Primal, Damus, Coracle, and Snort, alongside existing integrations with Amethyst, Nostur, and Nostrudel. Similarly, audio and video tools like Nostr Nests and Zap.stream will gain seamless integration into major clients, enabling easy participation in live events across the ecosystem.
Adoption and Migration: Inspired by early pioneers like Fountain and Orange Pill App, more platforms will adopt Nostr for authentication, login, and social systems. In 2025, a significant migration from a high-profile application platform with hundreds of thousands of users will transpire, doubling Nostr’s daily activity and establishing it as a cornerstone of decentralized technologies.
-
@ e97aaffa:2ebd765d
2024-12-31 16:47:12
Último dia do ano, momento para tirar o pó da bola de cristal, para fazer reflexões, previsões e desejos para o próximo ano e seguintes.
Ano após ano, o Bitcoin evoluiu, foi ultrapassando etapas, tornou-se cada vez mais mainstream. Está cada vez mais difícil fazer previsões sobre o Bitcoin, já faltam poucas barreiras a serem ultrapassadas e as que faltam são altamente complexas ou tem um impacto profundo no sistema financeiro ou na sociedade. Estas alterações profundas tem que ser realizadas lentamente, porque uma alteração rápida poderia resultar em consequências terríveis, poderia provocar um retrocesso.
Código do Bitcoin
No final de 2025, possivelmente vamos ter um fork, as discussões sobre os covenants já estão avançadas, vão acelerar ainda mais. Já existe um consenso relativamente alto, a favor dos covenants, só falta decidir que modelo será escolhido. Penso que até ao final do ano será tudo decidido.
Depois dos covenants, o próximo foco será para a criptografia post-quantum, que será o maior desafio que o Bitcoin enfrenta. Criar uma criptografia segura e que não coloque a descentralização em causa.
Espero muito de Ark, possivelmente a inovação do ano, gostaria de ver o Nostr a furar a bolha bitcoinheira e que o Cashu tivesse mais reconhecimento pelos bitcoiners.
Espero que surjam avanços significativos no BitVM2 e BitVMX.
Não sei o que esperar das layer 2 de Bitcoin, foram a maior desilusão de 2024. Surgiram com muita força, mas pouca coisa saiu do papel, foi uma mão cheia de nada. Uma parte dos projetos caiu na tentação da shitcoinagem, na criação de tokens, que tem um único objetivo, enriquecer os devs e os VCs.
Se querem ser levados a sério, têm que ser sérios.
“À mulher de César não basta ser honesta, deve parecer honesta”
Se querem ter o apoio dos bitcoiners, sigam o ethos do Bitcoin.
Neste ponto a atitude do pessoal da Ark é exemplar, em vez de andar a chorar no Twitter para mudar o código do Bitcoin, eles colocaram as mãos na massa e criaram o protocolo. É claro que agora está meio “coxo”, funciona com uma multisig ou com os covenants na Liquid. Mas eles estão a criar um produto, vão demonstrar ao mercado que o produto é bom e útil. Com a adoção, a comunidade vai perceber que o Ark necessita dos covenants para melhorar a interoperabilidade e a soberania.
É este o pensamento certo, que deveria ser seguido pelos restantes e futuros projetos. É seguir aquele pensamento do J.F. Kennedy:
“Não perguntem o que é que o vosso país pode fazer por vocês, perguntem o que é que vocês podem fazer pelo vosso país”
Ou seja, não fiquem à espera que o bitcoin mude, criem primeiro as inovações/tecnologia, ganhem adoção e depois demonstrem que a alteração do código camada base pode melhorar ainda mais o vosso projeto. A necessidade é que vai levar a atualização do código.
Reservas Estratégicas de Bitcoin
Bancos centrais
Com a eleição de Trump, emergiu a ideia de uma Reserva Estratégia de Bitcoin, tornou este conceito mainstream. Foi um pivot, a partir desse momento, foram enumerados os políticos de todo o mundo a falar sobre o assunto.
A Senadora Cynthia Lummis foi mais além e propôs um programa para adicionar 200 mil bitcoins à reserva ao ano, até 1 milhão de Bitcoin. Só que isto está a criar uma enorme expectativa na comunidade, só que pode resultar numa enorme desilusão. Porque no primeiro ano, o Trump em vez de comprar os 200 mil, pode apenas adicionar na reserva, os 198 mil que o Estado já tem em sua posse. Se isto acontecer, possivelmente vai resultar numa forte queda a curto prazo. Na minha opinião os bancos centrais deveriam seguir o exemplo de El Salvador, fazer um DCA diário.
Mais que comprar bitcoin, para mim, o mais importante é a criação da Reserva, é colocar o Bitcoin ao mesmo nível do ouro, o impacto para o resto do mundo será tremendo, a teoria dos jogos na sua plenitude. Muitos outros bancos centrais vão ter que comprar, para não ficarem atrás, além disso, vai transmitir uma mensagem à generalidade da população, que o Bitcoin é “afinal é algo seguro, com valor”.
Mas não foi Trump que iniciou esta teoria dos jogos, mas sim foi a primeira vítima dela. É o próprio Trump que o admite, que os EUA necessitam da reserva para não ficar atrás da China. Além disso, desde que os EUA utilizaram o dólar como uma arma, com sanção contra a Rússia, surgiram boatos de que a Rússia estaria a utilizar o Bitcoin para transações internacionais. Que foram confirmados recentemente, pelo próprio governo russo. Também há poucos dias, ainda antes deste reconhecimento público, Putin elogiou o Bitcoin, ao reconhecer que “Ninguém pode proibir o bitcoin”, defendendo como uma alternativa ao dólar. A narrativa está a mudar.
Já existem alguns países com Bitcoin, mas apenas dois o fizeram conscientemente (El Salvador e Butão), os restantes têm devido a apreensões. Hoje são poucos, mas 2025 será o início de uma corrida pelos bancos centrais. Esta corrida era algo previsível, o que eu não esperava é que acontecesse tão rápido.
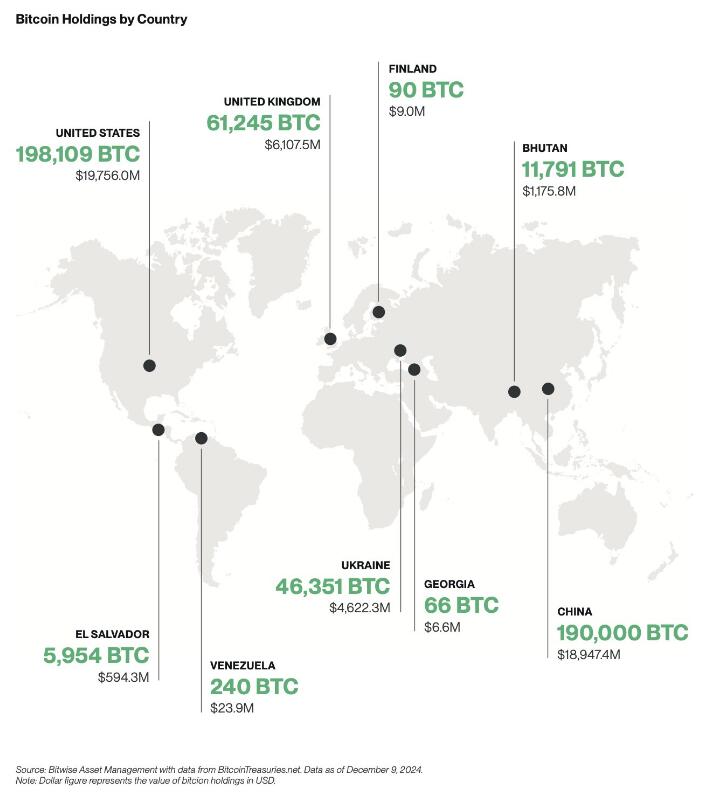
Empresas
A criação de reservas estratégicas não vai ficar apenas pelos bancos centrais, também vai acelerar fortemente nas empresas em 2025.
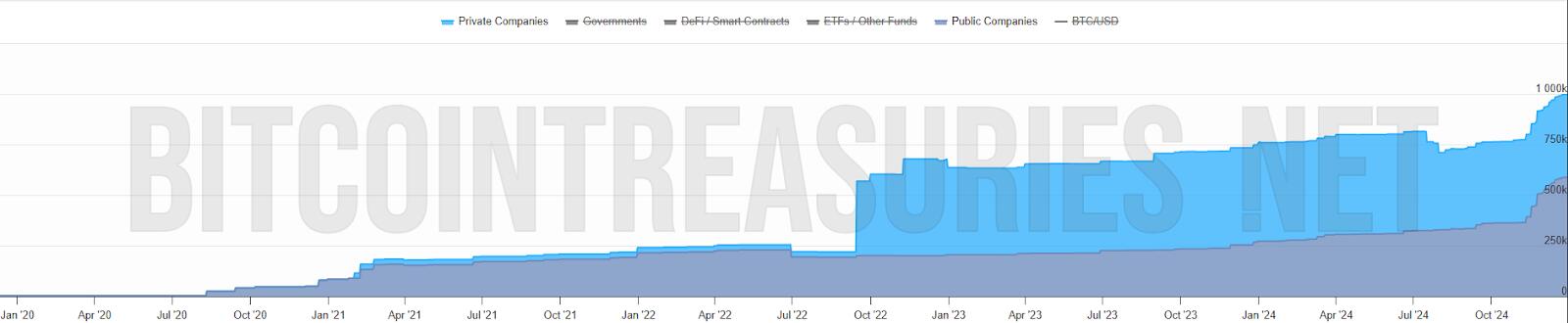
Mas as empresas não vão seguir a estratégia do Saylor, vão comprar bitcoin sem alavancagem, utilizando apenas os tesouros das empresas, como uma proteção contra a inflação. Eu não sou grande admirador do Saylor, prefiro muito mais, uma estratégia conservadora, sem qualquer alavancagem. Penso que as empresas vão seguir a sugestão da BlackRock, que aconselha um alocações de 1% a 3%.
Penso que 2025, ainda não será o ano da entrada das 6 magníficas (excepto Tesla), será sobretudo empresas de pequena e média dimensão. As magníficas ainda tem uma cota muito elevada de shareholders com alguma idade, bastante conservadores, que têm dificuldade em compreender o Bitcoin, foi o que aconteceu recentemente com a Microsoft.
Também ainda não será em 2025, talvez 2026, a inclusão nativamente de wallet Bitcoin nos sistema da Apple Pay e da Google Pay. Seria um passo gigante para a adoção a nível mundial.
ETFs
Os ETFs para mim são uma incógnita, tenho demasiadas dúvidas, como será 2025. Este ano os inflows foram superiores a 500 mil bitcoins, o IBIT foi o lançamento de ETF mais bem sucedido da história. O sucesso dos ETFs, deve-se a 2 situações que nunca mais se vão repetir. O mercado esteve 10 anos à espera pela aprovação dos ETFs, a procura estava reprimida, isso foi bem notório nos primeiros meses, os inflows foram brutais.
Também se beneficiou por ser um mercado novo, não existia orderbook de vendas, não existia um mercado interno, praticamente era só inflows. Agora o mercado já estabilizou, a maioria das transações já são entre clientes dos próprios ETFs. Agora só uma pequena percentagem do volume das transações diárias vai resultar em inflows ou outflows.
Estes dois fenómenos nunca mais se vão repetir, eu não acredito que o número de inflows em BTC supere os número de 2024, em dólares vai superar, mas em btc não acredito que vá superar.
Mas em 2025 vão surgir uma infindável quantidade de novos produtos, derivativos, novos ETFs de cestos com outras criptos ou cestos com ativos tradicionais. O bitcoin será adicionado em produtos financeiros já existentes no mercado, as pessoas vão passar a deter bitcoin, sem o saberem.
Com o fim da operação ChokePoint 2.0, vai surgir uma nova onda de adoção e de produtos financeiros. Possivelmente vamos ver bancos tradicionais a disponibilizar produtos ou serviços de custódia aos seus clientes.
Eu adoraria ver o crescimento da adoção do bitcoin como moeda, só que a regulamentação não vai ajudar nesse processo.
Preço
Eu acredito que o topo deste ciclo será alcançado no primeiro semestre, posteriormente haverá uma correção. Mas desta vez, eu acredito que a correção será muito menor que as anteriores, inferior a 50%, esta é a minha expectativa. Espero estar certo.
Stablecoins de dólar
Agora saindo um pouco do universo do Bitcoin, acho importante destacar as stablecoins.
No último ciclo, eu tenho dividido o tempo, entre continuar a estudar o Bitcoin e estudar o sistema financeiro, as suas dinâmicas e o comportamento humano. Isto tem sido o meu foco de reflexão, imaginar a transformação que o mundo vai sofrer devido ao padrão Bitcoin. É uma ilusão acreditar que a transição de um padrão FIAT para um padrão Bitcoin vai ser rápida, vai existir um processo transitório que pode demorar décadas.
Com a re-entrada de Trump na Casa Branca, prometendo uma política altamente protecionista, vai provocar uma forte valorização do dólar, consequentemente as restantes moedas do mundo vão derreter. Provocando uma inflação generalizada, gerando uma corrida às stablecoins de dólar nos países com moedas mais fracas. Trump vai ter uma política altamente expansionista, vai exportar dólares para todo o mundo, para financiar a sua própria dívida. A desigualdade entre os pobres e ricos irá crescer fortemente, aumentando a possibilidade de conflitos e revoltas.
“Casa onde não há pão, todos ralham e ninguém tem razão”
Será mais lenha, para alimentar a fogueira, vai gravar os conflitos geopolíticos já existentes, ficando as sociedade ainda mais polarizadas.
Eu acredito que 2025, vai haver um forte crescimento na adoção das stablecoins de dólares, esse forte crescimento vai agravar o problema sistémico que são as stablecoins. Vai ser o início do fim das stablecoins, pelo menos, como nós conhecemos hoje em dia.
Problema sistémico
O sistema FIAT não nasceu de um dia para outro, foi algo que foi construído organicamente, ou seja, foi evoluindo ao longo dos anos, sempre que havia um problema/crise, eram criadas novas regras ou novas instituições para minimizar os problemas. Nestes quase 100 anos, desde os acordos de Bretton Woods, a evolução foram tantas, tornaram o sistema financeiro altamente complexo, burocrático e nada eficiente.
Na prática é um castelo de cartas construído sobre outro castelo de cartas e que por sua vez, foi construído sobre outro castelo de cartas.
As stablecoins são um problema sistémico, devido às suas reservas em dólares e o sistema financeiro não está preparado para manter isso seguro. Com o crescimento das reservas ao longo dos anos, foi se agravando o problema.
No início a Tether colocava as reservas em bancos comerciais, mas com o crescimento dos dólares sob gestão, criou um problema nos bancos comerciais, devido à reserva fracionária. Essas enormes reservas da Tether estavam a colocar em risco a própria estabilidade dos bancos.
A Tether acabou por mudar de estratégia, optou por outros ativos, preferencialmente por títulos do tesouro/obrigações dos EUA. Só que a Tether continua a crescer e não dá sinais de abrandamento, pelo contrário.
Até o próprio mundo cripto, menosprezava a gravidade do problema da Tether/stablecoins para o resto do sistema financeiro, porque o marketcap do cripto ainda é muito pequeno. É verdade que ainda é pequeno, mas a Tether não o é, está no top 20 dos maiores detentores de títulos do tesouros dos EUA e está ao nível dos maiores bancos centrais do mundo. Devido ao seu tamanho, está a preocupar os responsáveis/autoridades/reguladores dos EUA, pode colocar em causa a estabilidade do sistema financeiro global, que está assente nessas obrigações.
Os títulos do tesouro dos EUA são o colateral mais utilizado no mundo, tanto por bancos centrais, como por empresas, é a charneira da estabilidade do sistema financeiro. Os títulos do tesouro são um assunto muito sensível. Na recente crise no Japão, do carry trade, o Banco Central do Japão tentou minimizar a desvalorização do iene através da venda de títulos dos EUA. Esta operação, obrigou a uma viagem de emergência, da Secretaria do Tesouro dos EUA, Janet Yellen ao Japão, onde disponibilizou liquidez para parar a venda de títulos por parte do Banco Central do Japão. Essa forte venda estava desestabilizando o mercado.
Os principais detentores de títulos do tesouros são institucionais, bancos centrais, bancos comerciais, fundo de investimento e gestoras, tudo administrado por gestores altamente qualificados, racionais e que conhecem a complexidade do mercado de obrigações.
O mundo cripto é seu oposto, é naife com muita irracionalidade e uma forte pitada de loucura, na sua maioria nem faz a mínima ideia como funciona o sistema financeiro. Essa irracionalidade pode levar a uma “corrida bancária”, como aconteceu com o UST da Luna, que em poucas horas colapsou o projeto. Em termos de escala, a Luna ainda era muito pequena, por isso, o problema ficou circunscrito ao mundo cripto e a empresas ligadas diretamente ao cripto.
Só que a Tether é muito diferente, caso exista algum FUD, que obrigue a Tether a desfazer-se de vários biliões ou dezenas de biliões de dólares em títulos num curto espaço de tempo, poderia provocar consequências terríveis em todo o sistema financeiro. A Tether é grande demais, é já um problema sistémico, que vai agravar-se com o crescimento em 2025.
Não tenham dúvidas, se existir algum problema, o Tesouro dos EUA vai impedir a venda dos títulos que a Tether tem em sua posse, para salvar o sistema financeiro. O problema é, o que vai fazer a Tether, se ficar sem acesso às venda das reservas, como fará o redeem dos dólares?
Como o crescimento do Tether é inevitável, o Tesouro e o FED estão com um grande problema em mãos, o que fazer com o Tether?
Mas o problema é que o atual sistema financeiro é como um curto cobertor: Quanto tapas a cabeça, destapas os pés; Ou quando tapas os pés, destapas a cabeça. Ou seja, para resolver o problema da guarda reservas da Tether, vai criar novos problemas, em outros locais do sistema financeiro e assim sucessivamente.
Conta mestre
Uma possível solução seria dar uma conta mestre à Tether, dando o acesso direto a uma conta no FED, semelhante à que todos os bancos comerciais têm. Com isto, a Tether deixaria de necessitar os títulos do tesouro, depositando o dinheiro diretamente no banco central. Só que isto iria criar dois novos problemas, com o Custodia Bank e com o restante sistema bancário.
O Custodia Bank luta há vários anos contra o FED, nos tribunais pelo direito a ter licença bancária para um banco com full-reserves. O FED recusou sempre esse direito, com a justificativa que esse banco, colocaria em risco toda a estabilidade do sistema bancário existente, ou seja, todos os outros bancos poderiam colapsar. Perante a existência em simultâneo de bancos com reserva fracionária e com full-reserves, as pessoas e empresas iriam optar pelo mais seguro. Isso iria provocar uma corrida bancária, levando ao colapso de todos os bancos com reserva fracionária, porque no Custodia Bank, os fundos dos clientes estão 100% garantidos, para qualquer valor. Deixaria de ser necessário limites de fundos de Garantia de Depósitos.
Eu concordo com o FED nesse ponto, que os bancos com full-reserves são uma ameaça a existência dos restantes bancos. O que eu discordo do FED, é a origem do problema, o problema não está nos bancos full-reserves, mas sim nos que têm reserva fracionária.
O FED ao conceder uma conta mestre ao Tether, abre um precedente, o Custodia Bank irá o aproveitar, reclamando pela igualdade de direitos nos tribunais e desta vez, possivelmente ganhará a sua licença.
Ainda há um segundo problema, com os restantes bancos comerciais. A Tether passaria a ter direitos similares aos bancos comerciais, mas os deveres seriam muito diferentes. Isto levaria os bancos comerciais aos tribunais para exigir igualdade de tratamento, é uma concorrência desleal. Isto é o bom dos tribunais dos EUA, são independentes e funcionam, mesmo contra o estado. Os bancos comerciais têm custos exorbitantes devido às políticas de compliance, como o KYC e AML. Como o governo não vai querer aliviar as regras, logo seria a Tether, a ser obrigada a fazer o compliance dos seus clientes.
A obrigação do KYC para ter stablecoins iriam provocar um terramoto no mundo cripto.
Assim, é pouco provável que seja a solução para a Tether.
FED
Só resta uma hipótese, ser o próprio FED a controlar e a gerir diretamente as stablecoins de dólar, nacionalizado ou absorvendo as existentes. Seria uma espécie de CBDC. Isto iria provocar um novo problema, um problema diplomático, porque as stablecoins estão a colocar em causa a soberania monetária dos outros países. Atualmente as stablecoins estão um pouco protegidas porque vivem num limbo jurídico, mas a partir do momento que estas são controladas pelo governo americano, tudo muda. Os países vão exigir às autoridades americanas medidas que limitem o uso nos seus respectivos países.
Não existe uma solução boa, o sistema FIAT é um castelo de cartas, qualquer carta que se mova, vai provocar um desmoronamento noutro local. As autoridades não poderão adiar mais o problema, terão que o resolver de vez, senão, qualquer dia será tarde demais. Se houver algum problema, vão colocar a responsabilidade no cripto e no Bitcoin. Mas a verdade, a culpa é inteiramente dos políticos, da sua incompetência em resolver os problemas a tempo.
Será algo para acompanhar futuramente, mas só para 2026, talvez…
É curioso, há uns anos pensava-se que o Bitcoin seria a maior ameaça ao sistema ao FIAT, mas afinal, a maior ameaça aos sistema FIAT é o próprio FIAT(stablecoins). A ironia do destino.
Isto é como uma corrida, o Bitcoin é aquele atleta que corre ao seu ritmo, umas vezes mais rápido, outras vezes mais lento, mas nunca pára. O FIAT é o atleta que dá tudo desde da partida, corre sempre em velocidade máxima. Só que a vida e o sistema financeiro não é uma prova de 100 metros, mas sim uma maratona.
Europa
2025 será um ano desafiante para todos europeus, sobretudo devido à entrada em vigor da regulamentação (MiCA). Vão começar a sentir na pele a regulamentação, vão agravar-se os problemas com os compliance, problemas para comprovar a origem de fundos e outras burocracias. Vai ser lindo.
O Travel Route passa a ser obrigatório, os europeus serão obrigados a fazer o KYC nas transações. A Travel Route é uma suposta lei para criar mais transparência, mas prática, é uma lei de controle, de monitorização e para limitar as liberdades individuais dos cidadãos.
O MiCA também está a colocar problemas nas stablecoins de Euro, a Tether para já preferiu ficar de fora da europa. O mais ridículo é que as novas regras obrigam os emissores a colocar 30% das reservas em bancos comerciais. Os burocratas europeus não compreendem que isto coloca em risco a estabilidade e a solvência dos próprios bancos, ficam propensos a corridas bancárias.
O MiCA vai obrigar a todas as exchanges a estar registadas em solo europeu, ficando vulnerável ao temperamento dos burocratas. Ainda não vai ser em 2025, mas a UE vai impor políticas de controle de capitais, é inevitável, as exchanges serão obrigadas a usar em exclusividade stablecoins de euro, as restantes stablecoins serão deslistadas.
Todas estas novas regras do MiCA, são extremamente restritas, não é para garantir mais segurança aos cidadãos europeus, mas sim para garantir mais controle sobre a população. A UE está cada vez mais perto da autocracia, do que da democracia. A minha única esperança no horizonte, é que o sucesso das políticas cripto nos EUA, vai obrigar a UE a recuar e a aligeirar as regras, a teoria dos jogos é implacável. Mas esse recuo, nunca acontecerá em 2025, vai ser um longo período conturbado.
Recessão
Os mercados estão todos em máximos históricos, isto não é sustentável por muito tempo, suspeito que no final de 2025 vai acontecer alguma correção nos mercados. A queda só não será maior, porque os bancos centrais vão imprimir dinheiro, muito dinheiro, como se não houvesse amanhã. Vão voltar a resolver os problemas com a injeção de liquidez na economia, é empurrar os problemas com a barriga, em de os resolver. Outra vez o efeito Cantillon.
Será um ano muito desafiante a nível político, onde o papel dos políticos será fundamental. A crise política na França e na Alemanha, coloca a UE órfã, sem um comandante ao leme do navio. 2025 estará condicionado pelas eleições na Alemanha, sobretudo no resultado do AfD, que podem colocar em causa a propriedade UE e o euro.
Possivelmente, só o fim da guerra poderia minimizar a crise, algo que é muito pouco provável acontecer.
Em Portugal, a economia parece que está mais ou menos equilibrada, mas começam a aparecer alguns sinais preocupantes. Os jogos de sorte e azar estão em máximos históricos, batendo o recorde de 2014, época da grande crise, não é um bom sinal, possivelmente já existe algum desespero no ar.
A Alemanha é o motor da Europa, quanto espirra, Portugal constipa-se. Além do problema da Alemanha, a Espanha também está à beira de uma crise, são os países que mais influenciam a economia portuguesa.
Se existir uma recessão mundial, terá um forte impacto no turismo, que é hoje em dia o principal motor de Portugal.
Brasil
Brasil é algo para acompanhar em 2025, sobretudo a nível macro e a nível político. Existe uma possibilidade de uma profunda crise no Brasil, sobretudo na sua moeda. O banco central já anda a queimar as reservas para minimizar a desvalorização do Real.
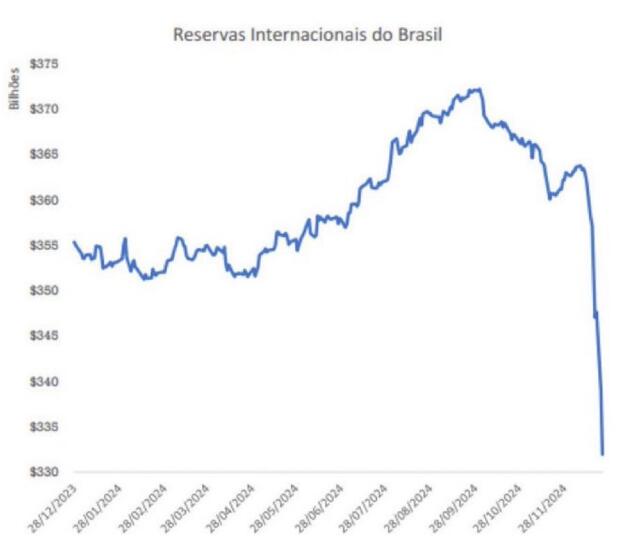
Sem mudanças profundas nas políticas fiscais, as reservas vão se esgotar. As políticas de controle de capitais são um cenário plausível, será interesse de acompanhar, como o governo irá proceder perante a existência do Bitcoin e stablecoins. No Brasil existe um forte adoção, será um bom case study, certamente irá repetir-se em outros países num futuro próximo.
Os próximos tempos não serão fáceis para os brasileiros, especialmente para os que não têm Bitcoin.
Blockchain
Em 2025, possivelmente vamos ver os primeiros passos da BlackRock para criar a primeira bolsa de valores, exclusivamente em blockchain. Eu acredito que a BlackRock vai criar uma própria blockchain, toda controlada por si, onde estarão os RWAs, para fazer concorrência às tradicionais bolsas de valores. Será algo interessante de acompanhar.
Estas são as minhas previsões, eu escrevi isto muito em cima do joelho, certamente esqueci-me de algumas coisas, se for importante acrescentarei nos comentários. A maioria das previsões só acontecerá após 2025, mas fica aqui a minha opinião.
Isto é apenas a minha opinião, Don’t Trust, Verify!
-
@ f9cf4e94:96abc355
2024-12-30 19:02:32
Na era das grandes navegações, piratas ingleses eram autorizados pelo governo para roubar navios.
A única coisa que diferenciava um pirata comum de um corsário é que o último possuía a “Carta do Corso”, que funcionava como um “Alvará para o roubo”, onde o governo Inglês legitimava o roubo de navios por parte dos corsários. É claro, que em troca ele exigia uma parte da espoliação.
Bastante similar com a maneira que a Receita Federal atua, não? Na verdade, o caso é ainda pior, pois o governo fica com toda a riqueza espoliada, e apenas repassa um mísero salário para os corsários modernos, os agentes da receita federal.
Porém eles “justificam” esse roubo ao chamá-lo de imposto, e isso parece acalmar os ânimos de grande parte da população, mas não de nós. Não é por acaso que 'imposto' é o particípio passado do verbo 'impor'. Ou seja, é aquilo que resulta do cumprimento obrigatório -- e não voluntário -- de todos os cidadãos. Se não for 'imposto' ninguém paga. Nem mesmo seus defensores. Isso mostra o quanto as pessoas realmente apreciam os serviços do estado.
Apenas volte um pouco na história: os primeiros pagadores de impostos eram fazendeiros cujos territórios foram invadidos por nômades que pastoreavam seu gado. Esses invasores nômades forçavam os fazendeiros a lhes pagar uma fatia de sua renda em troca de "proteção". O fazendeiro que não concordasse era assassinado.
Os nômades perceberam que era muito mais interessante e confortável apenas cobrar uma taxa de proteção em vez de matar o fazendeiro e assumir suas posses. Cobrando uma taxa, eles obtinham o que necessitavam. Já se matassem os fazendeiros, eles teriam de gerenciar por conta própria toda a produção da fazenda. Daí eles entenderam que, ao não assassinarem todos os fazendeiros que encontrassem pelo caminho, poderiam fazer desta prática um modo de vida.
Assim nasceu o governo.
Não assassinar pessoas foi o primeiro serviço que o governo forneceu. Como temos sorte em ter à nossa disposição esta instituição!
Assim, não deixa de ser curioso que algumas pessoas digam que os impostos são pagos basicamente para impedir que aconteça exatamente aquilo que originou a existência do governo. O governo nasceu da extorsão. Os fazendeiros tinham de pagar um "arrego" para seu governo. Caso contrário, eram assassinados. Quem era a real ameaça? O governo. A máfia faz a mesma coisa.
Mas existe uma forma de se proteger desses corsários modernos. Atualmente, existe uma propriedade privada que NINGUÉM pode tirar de você, ela é sua até mesmo depois da morte. É claro que estamos falando do Bitcoin. Fazendo as configurações certas, é impossível saber que você tem bitcoin. Nem mesmo o governo americano consegue saber.
brasil #bitcoinbrasil #nostrbrasil #grownostr #bitcoin
-
@ 16d11430:61640947
2024-12-23 16:47:01
At the intersection of philosophy, theology, physics, biology, and finance lies a terrifying truth: the fiat monetary system, in its current form, is not just an economic framework but a silent, relentless force actively working against humanity's survival. It isn't simply a failed financial model—it is a systemic engine of destruction, both externally and within the very core of our biological existence.
The Philosophical Void of Fiat
Philosophy has long questioned the nature of value and the meaning of human existence. From Socrates to Kant, thinkers have pondered the pursuit of truth, beauty, and virtue. But in the modern age, the fiat system has hijacked this discourse. The notion of "value" in a fiat world is no longer rooted in human potential or natural resources—it is abstracted, manipulated, and controlled by central authorities with the sole purpose of perpetuating their own power. The currency is not a reflection of society’s labor or resources; it is a representation of faith in an authority that, more often than not, breaks that faith with reckless monetary policies and hidden inflation.
The fiat system has created a kind of ontological nihilism, where the idea of true value, rooted in work, creativity, and family, is replaced with speculative gambling and short-term gains. This betrayal of human purpose at the systemic level feeds into a philosophical despair: the relentless devaluation of effort, the erosion of trust, and the abandonment of shared human values. In this nihilistic economy, purpose and meaning become increasingly difficult to find, leaving millions to question the very foundation of their existence.
Theological Implications: Fiat and the Collapse of the Sacred
Religious traditions have long linked moral integrity with the stewardship of resources and the preservation of life. Fiat currency, however, corrupts these foundational beliefs. In the theological narrative of creation, humans are given dominion over the Earth, tasked with nurturing and protecting it for future generations. But the fiat system promotes the exact opposite: it commodifies everything—land, labor, and life—treating them as mere transactions on a ledger.
This disrespect for creation is an affront to the divine. In many theologies, creation is meant to be sustained, a delicate balance that mirrors the harmony of the divine order. Fiat systems—by continuously printing money and driving inflation—treat nature and humanity as expendable resources to be exploited for short-term gains, leading to environmental degradation and societal collapse. The creation narrative, in which humans are called to be stewards, is inverted. The fiat system, through its unholy alliance with unrestrained growth and unsustainable debt, is destroying the very creation it should protect.
Furthermore, the fiat system drives idolatry of power and wealth. The central banks and corporations that control the money supply have become modern-day gods, their decrees shaping the lives of billions, while the masses are enslaved by debt and inflation. This form of worship isn't overt, but it is profound. It leads to a world where people place their faith not in God or their families, but in the abstract promises of institutions that serve their own interests.
Physics and the Infinite Growth Paradox
Physics teaches us that the universe is finite—resources, energy, and space are all limited. Yet, the fiat system operates under the delusion of infinite growth. Central banks print money without concern for natural limits, encouraging an economy that assumes unending expansion. This is not only an economic fallacy; it is a physical impossibility.
In thermodynamics, the Second Law states that entropy (disorder) increases over time in any closed system. The fiat system operates as if the Earth were an infinite resource pool, perpetually able to expand without consequence. The real world, however, does not bend to these abstract concepts of infinite growth. Resources are finite, ecosystems are fragile, and human capacity is limited. Fiat currency, by promoting unsustainable consumption and growth, accelerates the depletion of resources and the degradation of natural systems that support life itself.
Even the financial “growth” driven by fiat policies leads to unsustainable bubbles—inflated stock markets, real estate, and speculative assets that burst and leave ruin in their wake. These crashes aren’t just economic—they have profound biological consequences. The cycles of boom and bust undermine communities, erode social stability, and increase anxiety and depression, all of which affect human health at a biological level.
Biology: The Fiat System and the Destruction of Human Health
Biologically, the fiat system is a cancerous growth on human society. The constant chase for growth and the devaluation of work leads to chronic stress, which is one of the leading causes of disease in modern society. The strain of living in a system that values speculation over well-being results in a biological feedback loop: rising anxiety, poor mental health, physical diseases like cardiovascular disorders, and a shortening of lifespans.
Moreover, the focus on profit and short-term returns creates a biological disconnect between humans and the planet. The fiat system fuels industries that destroy ecosystems, increase pollution, and deplete resources at unsustainable rates. These actions are not just environmentally harmful; they directly harm human biology. The degradation of the environment—whether through toxic chemicals, pollution, or resource extraction—has profound biological effects on human health, causing respiratory diseases, cancers, and neurological disorders.
The biological cost of the fiat system is not a distant theory; it is being paid every day by millions in the form of increased health risks, diseases linked to stress, and the growing burden of mental health disorders. The constant uncertainty of an inflation-driven economy exacerbates these conditions, creating a society of individuals whose bodies and minds are under constant strain. We are witnessing a systemic biological unraveling, one in which the very act of living is increasingly fraught with pain, instability, and the looming threat of collapse.
Finance as the Final Illusion
At the core of the fiat system is a fundamental illusion—that financial growth can occur without any real connection to tangible value. The abstraction of currency, the manipulation of interest rates, and the constant creation of new money hide the underlying truth: the system is built on nothing but faith. When that faith falters, the entire system collapses.
This illusion has become so deeply embedded that it now defines the human experience. Work no longer connects to production or creation—it is reduced to a transaction on a spreadsheet, a means to acquire more fiat currency in a world where value is ephemeral and increasingly disconnected from human reality.
As we pursue ever-expanding wealth, the fundamental truths of biology—interdependence, sustainability, and balance—are ignored. The fiat system’s abstract financial models serve to disconnect us from the basic realities of life: that we are part of an interconnected world where every action has a reaction, where resources are finite, and where human health, both mental and physical, depends on the stability of our environment and our social systems.
The Ultimate Extermination
In the end, the fiat system is not just an economic issue; it is a biological, philosophical, theological, and existential threat to the very survival of humanity. It is a force that devalues human effort, encourages environmental destruction, fosters inequality, and creates pain at the core of the human biological condition. It is an economic framework that leads not to prosperity, but to extermination—not just of species, but of the very essence of human well-being.
To continue on this path is to accept the slow death of our species, one based not on natural forces, but on our own choice to worship the abstract over the real, the speculative over the tangible. The fiat system isn't just a threat; it is the ultimate self-inflicted wound, a cultural and financial cancer that, if left unchecked, will destroy humanity’s chance for survival and peace.
-
@ a367f9eb:0633efea
2024-12-22 21:35:22
I’ll admit that I was wrong about Bitcoin. Perhaps in 2013. Definitely 2017. Probably in 2018-2019. And maybe even today.
Being wrong about Bitcoin is part of finally understanding it. It will test you, make you question everything, and in the words of BTC educator and privacy advocate Matt Odell, “Bitcoin will humble you”.
I’ve had my own stumbles on the way.
In a very public fashion in 2017, after years of using Bitcoin, trying to start a company with it, using it as my primary exchange vehicle between currencies, and generally being annoying about it at parties, I let out the bear.
In an article published in my own literary magazine Devolution Review in September 2017, I had a breaking point. The article was titled “Going Bearish on Bitcoin: Cryptocurrencies are the tulip mania of the 21st century”.
It was later republished in Huffington Post and across dozens of financial and crypto blogs at the time with another, more appropriate title: “Bitcoin Has Become About The Payday, Not Its Potential”.
As I laid out, my newfound bearishness had little to do with the technology itself or the promise of Bitcoin, and more to do with the cynical industry forming around it:
In the beginning, Bitcoin was something of a revolution to me. The digital currency represented everything from my rebellious youth.
It was a decentralized, denationalized, and digital currency operating outside the traditional banking and governmental system. It used tools of cryptography and connected buyers and sellers across national borders at minimal transaction costs.
…
The 21st-century version (of Tulip mania) has welcomed a plethora of slick consultants, hazy schemes dressed up as investor possibilities, and too much wishy-washy language for anything to really make sense to anyone who wants to use a digital currency to make purchases.
While I called out Bitcoin by name at the time, on reflection, I was really talking about the ICO craze, the wishy-washy consultants, and the altcoin ponzis.
What I was articulating — without knowing it — was the frame of NgU, or “numbers go up”. Rather than advocating for Bitcoin because of its uncensorability, proof-of-work, or immutability, the common mentality among newbies and the dollar-obsessed was that Bitcoin mattered because its price was a rocket ship.
And because Bitcoin was gaining in price, affinity tokens and projects that were imperfect forks of Bitcoin took off as well.
The price alone — rather than its qualities — were the reasons why you’d hear Uber drivers, finance bros, or your gym buddy mention Bitcoin. As someone who came to Bitcoin for philosophical reasons, that just sat wrong with me.
Maybe I had too many projects thrown in my face, or maybe I was too frustrated with the UX of Bitcoin apps and sites at the time. No matter what, I’ve since learned something.
I was at least somewhat wrong.
My own journey began in early 2011. One of my favorite radio programs, Free Talk Live, began interviewing guests and having discussions on the potential of Bitcoin. They tied it directly to a libertarian vision of the world: free markets, free people, and free banking. That was me, and I was in. Bitcoin was at about $5 back then (NgU).
I followed every article I could, talked about it with guests on my college radio show, and became a devoted redditor on r/Bitcoin. At that time, at least to my knowledge, there was no possible way to buy Bitcoin where I was living. Very weak.
I was probably wrong. And very wrong for not trying to acquire by mining or otherwise.
The next year, after moving to Florida, Bitcoin was a heavy topic with a friend of mine who shared the same vision (and still does, according to the Celsius bankruptcy documents). We talked about it with passionate leftists at Occupy Tampa in 2012, all the while trying to explain the ills of Keynesian central banking, and figuring out how to use Coinbase.
I began writing more about Bitcoin in 2013, writing a guide on “How to Avoid Bank Fees Using Bitcoin,” discussing its potential legalization in Germany, and interviewing Jeremy Hansen, one of the first political candidates in the U.S. to accept Bitcoin donations.
Even up until that point, I thought Bitcoin was an interesting protocol for sending and receiving money quickly, and converting it into fiat. The global connectedness of it, plus this cypherpunk mentality divorced from government control was both useful and attractive. I thought it was the perfect go-between.
But I was wrong.
When I gave my first public speech on Bitcoin in Vienna, Austria in December 2013, I had grown obsessed with Bitcoin’s adoption on dark net markets like Silk Road.
My theory, at the time, was the number and price were irrelevant. The tech was interesting, and a novel attempt. It was unlike anything before. But what was happening on the dark net markets, which I viewed as the true free market powered by Bitcoin, was even more interesting. I thought these markets would grow exponentially and anonymous commerce via BTC would become the norm.
While the price was irrelevant, it was all about buying and selling goods without permission or license.
Now I understand I was wrong.
Just because Bitcoin was this revolutionary technology that embraced pseudonymity did not mean that all commerce would decentralize as well. It did not mean that anonymous markets were intended to be the most powerful layer in the Bitcoin stack.
What I did not even anticipate is something articulated very well by noted Bitcoin OG Pierre Rochard: Bitcoin as a savings technology.
The ability to maintain long-term savings, practice self-discipline while stacking stats, and embrace a low-time preference was just not something on the mind of the Bitcoiners I knew at the time.
Perhaps I was reading into the hype while outwardly opposing it. Or perhaps I wasn’t humble enough to understand the true value proposition that many of us have learned years later.
In the years that followed, I bought and sold more times than I can count, and I did everything to integrate it into passion projects. I tried to set up a company using Bitcoin while at my university in Prague.
My business model depended on university students being technologically advanced enough to have a mobile wallet, own their keys, and be able to make transactions on a consistent basis. Even though I was surrounded by philosophically aligned people, those who would advance that to actually put Bitcoin into practice were sparse.
This is what led me to proclaim that “Technological Literacy is Doomed” in 2016.
And I was wrong again.
Indeed, since that time, the UX of Bitcoin-only applications, wallets, and supporting tech has vastly improved and onboarded millions more people than anyone thought possible. The entrepreneurship, coding excellence, and vision offered by Bitcoiners of all stripes have renewed a sense in me that this project is something built for us all — friends and enemies alike.
While many of us were likely distracted by flashy and pumpy altcoins over the years (me too, champs), most of us have returned to the Bitcoin stable.
Fast forward to today, there are entire ecosystems of creators, activists, and developers who are wholly reliant on the magic of Bitcoin’s protocol for their life and livelihood. The options are endless. The FUD is still present, but real proof of work stands powerfully against those forces.
In addition, there are now dozens of ways to use Bitcoin privately — still without custodians or intermediaries — that make it one of the most important assets for global humanity, especially in dictatorships.
This is all toward a positive arc of innovation, freedom, and pure independence. Did I see that coming? Absolutely not.
Of course, there are probably other shots you’ve missed on Bitcoin. Price predictions (ouch), the short-term inflation hedge, or the amount of institutional investment. While all of these may be erroneous predictions in the short term, we have to realize that Bitcoin is a long arc. It will outlive all of us on the planet, and it will continue in its present form for the next generation.
Being wrong about the evolution of Bitcoin is no fault, and is indeed part of the learning curve to finally understanding it all.
When your family or friends ask you about Bitcoin after your endless sessions explaining market dynamics, nodes, how mining works, and the genius of cryptographic signatures, try to accept that there is still so much we have to learn about this decentralized digital cash.
There are still some things you’ve gotten wrong about Bitcoin, and plenty more you’ll underestimate or get wrong in the future. That’s what makes it a beautiful journey. It’s a long road, but one that remains worth it.
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install NVapi to monitor my GPUs in Home Assistant.
NVApi is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- GPU Utilization Monitoring: Utilization, memory usage, temperature, fan speed, and power consumption.
- Automated Power Limiting: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- Cross-GPU Coordination: Total power budget applies across multiple GPUs in the same system.
- PCIe Link Speed Management: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- Home Assistant Integration: Uses the built-in RESTful platform and template sensors.
Getting the Data
sudo apt install golang-go git clone https://github.com/sammcj/NVApi.git cd NVapi go run main.go -port 9999 -rate 1 curl http://localhost:9999/gpuResponse for a single GPU:
[ { "index": 0, "name": "NVIDIA GeForce RTX 4090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 16, "power_limit_watts": 450, "memory_total_gb": 23.99, "memory_used_gb": 0.46, "memory_free_gb": 23.52, "memory_usage_percent": 2, "temperature": 38, "processes": [], "pcie_link_state": "not managed" } ]Response for multiple GPUs:
[ { "index": 0, "name": "NVIDIA GeForce RTX 3090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 14, "power_limit_watts": 350, "memory_total_gb": 24, "memory_used_gb": 0.43, "memory_free_gb": 23.57, "memory_usage_percent": 2, "temperature": 36, "processes": [], "pcie_link_state": "not managed" }, { "index": 1, "name": "NVIDIA RTX A4000", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 10, "power_limit_watts": 140, "memory_total_gb": 15.99, "memory_used_gb": 0.56, "memory_free_gb": 15.43, "memory_usage_percent": 3, "temperature": 41, "processes": [], "pcie_link_state": "not managed" } ]Start at Boot
Create
/etc/systemd/system/nvapi.service:``` [Unit] Description=Run NVapi After=network.target
[Service] Type=simple Environment="GOPATH=/home/ansible/go" WorkingDirectory=/home/ansible/NVapi ExecStart=/usr/bin/go run main.go -port 9999 -rate 1 Restart=always User=ansible
Environment="GPU_TEMP_CHECK_INTERVAL=5"
Environment="GPU_TOTAL_POWER_CAP=400"
Environment="GPU_0_LOW_TEMP=40"
Environment="GPU_0_MEDIUM_TEMP=70"
Environment="GPU_0_LOW_TEMP_LIMIT=135"
Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
Environment="GPU_0_HIGH_TEMP_LIMIT=100"
Environment="GPU_1_LOW_TEMP=45"
Environment="GPU_1_MEDIUM_TEMP=75"
Environment="GPU_1_LOW_TEMP_LIMIT=140"
Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install] WantedBy=multi-user.target ```
Home Assistant
Add to Home Assistant
configuration.yamland restart HA (completely).For a single GPU, this works: ``` sensor: - platform: rest name: MYPC GPU Information resource: http://mypc:9999 method: GET headers: Content-Type: application/json value_template: "{{ value_json[0].index }}" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature scan_interval: 1 # seconds
- platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}" unit_of_measurement: "°C" ```
For multiple GPUs: ``` rest: scan_interval: 1 resource: http://mypc:9999 sensor: - name: "MYPC GPU0 Information" value_template: "{{ value_json[0].index }}" json_attributes_path: "$.0" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature - name: "MYPC GPU1 Information" value_template: "{{ value_json[1].index }}" json_attributes_path: "$.1" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature
-
platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC GPU0 GPU" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC GPU0 Memory" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC GPU0 Power" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC GPU0 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC GPU0 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}" unit_of_measurement: "C"
-
platform: template sensors: mypc_gpu_1_gpu: friendly_name: "MYPC GPU1 GPU" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_memory: friendly_name: "MYPC GPU1 Memory" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_power: friendly_name: "MYPC GPU1 Power" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_1_power_limit: friendly_name: "MYPC GPU1 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_1_temperature: friendly_name: "MYPC GPU1 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}" unit_of_measurement: "C"
```
Basic entity card:
type: entities entities: - entity: sensor.mypc_gpu_0_gpu secondary_info: last-updated - entity: sensor.mypc_gpu_0_memory secondary_info: last-updated - entity: sensor.mypc_gpu_0_power secondary_info: last-updated - entity: sensor.mypc_gpu_0_power_limit secondary_info: last-updated - entity: sensor.mypc_gpu_0_temperature secondary_info: last-updatedAnsible Role
```
-
name: install go become: true package: name: golang-go state: present
-
name: git clone git: repo: "https://github.com/sammcj/NVApi.git" dest: "/home/ansible/NVapi" update: yes force: true
go run main.go -port 9999 -rate 1
-
name: install systemd service become: true copy: src: nvapi.service dest: /etc/systemd/system/nvapi.service
-
name: Reload systemd daemons, enable, and restart nvapi become: true systemd: name: nvapi daemon_reload: yes enabled: yes state: restarted ```
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
-
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
-
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\ https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
-
@ e83b66a8:b0526c2b
2024-12-11 09:16:23
I watched Tucker Carlson interview Roger Ver last night.
I know we have our differences with Roger, and he has some less than pleasant personality traits, but he is facing 109 years in jail for tax evasion. While the charges may be technically correct, he should be able to pay the taxes and a fine and walk free. Even if we accept he did wrong, a minor prison term such as 6 months to 2 years would be appropriate in this case.
We all know the severe penalty is an over reach by US authorities looking to make the whole crypto community scared about using any form of crypto as money.
The US and many governments know they have lost the battle of Bitcoin as a hard asset, but this happened as a result of the Nash equilibrium, whereby you are forced to play a game that doesn’t benefit you, because not playing that game disadvantages you further. I.e. Governments loose control of the asset, but that asset is able to shore up their balance sheet and prevent your economy from failing (potentially).
The war against Bitcoin (and other cryptos) as a currency, whereby you can use your Bitcoin to buy anything anywhere from a pint of milk in the local shop, to a house or car and everything in-between is a distant goal and one that is happening slowly. But it is happening and these are the new battle lines.
Part of that battle is self custody, part is tax and part are the money transmitting laws.
Roger’s case is also being used as a weapon of fear.
I don’t hate Roger, the problem I have with Bitcoin cash is that you cannot run a full node from your home and if you can’t do this, it is left to large corporations to run the blockchain. Large corporations are much easier to control and coerce than thousands, perhaps millions of individuals. Just as China banned Bitcoin mining, so in this scenario it would be possible for governments to ban full nodes and enforce that ban by shutting down companies that attempted to do so.
Also, if a currency like Bitcoin cash scaled to Visa size, then Bitcoin Cash the company would become the new Visa / Mastercard and only the technology would change. However, even Visa and Mastercard don’t keep transaction logs for years, that would require enormous amount of storage and have little benefit. Nobody needs a global ledger that keeps a record of every coffee purchased in every coffee shop since the beginning of blockchain time.
This is why Bitcoin with a layer 2 payment system like Lightning is a better proposition than large blockchain cryptos. Once a payment channel is closed, the transactions are forgotten in the same way Visa and Mastercard only keep a transaction history for 1 or 2 years.
This continues to allow the freedom for anybody, anywhere to verify the money they hold and the transactions they perform along with everybody else. We have consensus by verification.
-
@ 6389be64:ef439d32
2024-12-09 23:50:41
Resilience is the ability to withstand shocks, adapt, and bounce back. It’s an essential quality in nature and in life. But what if we could take resilience a step further? What if, instead of merely surviving, a system could improve when faced with stress? This concept, known as anti-fragility, is not just theoretical—it’s practical. Combining two highly resilient natural tools, comfrey and biochar, reveals how we can create systems that thrive under pressure and grow stronger with each challenge.
Comfrey: Nature’s Champion of Resilience
Comfrey is a plant that refuses to fail. Once its deep roots take hold, it thrives in poor soils, withstands drought, and regenerates even after being cut down repeatedly. It’s a hardy survivor, but comfrey doesn’t just endure—it contributes. Known as a dynamic accumulator, it mines nutrients from deep within the earth and brings them to the surface, making them available for other plants.
Beyond its ecological role, comfrey has centuries of medicinal use, earning the nickname "knitbone." Its leaves can heal wounds and restore health, a perfect metaphor for resilience. But as impressive as comfrey is, its true potential is unlocked when paired with another resilient force: biochar.
Biochar: The Silent Powerhouse of Soil Regeneration
Biochar, a carbon-rich material made by burning organic matter in low-oxygen conditions, is a game-changer for soil health. Its unique porous structure retains water, holds nutrients, and provides a haven for beneficial microbes. Soil enriched with biochar becomes drought-resistant, nutrient-rich, and biologically active—qualities that scream resilience.
Historically, ancient civilizations in the Amazon used biochar to transform barren soils into fertile agricultural hubs. Known as terra preta, these soils remain productive centuries later, highlighting biochar’s remarkable staying power.
Yet, like comfrey, biochar’s potential is magnified when it’s part of a larger system.
The Synergy: Comfrey and Biochar Together
Resilience turns into anti-fragility when systems go beyond mere survival and start improving under stress. Combining comfrey and biochar achieves exactly that.
-
Nutrient Cycling and Retention\ Comfrey’s leaves, rich in nitrogen, potassium, and phosphorus, make an excellent mulch when cut and dropped onto the soil. However, these nutrients can wash away in heavy rains. Enter biochar. Its porous structure locks in the nutrients from comfrey, preventing runoff and keeping them available for plants. Together, they create a system that not only recycles nutrients but amplifies their effectiveness.
-
Water Management\ Biochar holds onto water making soil not just drought-resistant but actively water-efficient, improving over time with each rain and dry spell.
-
Microbial Ecosystems\ Comfrey enriches soil with organic matter, feeding microbial life. Biochar provides a home for these microbes, protecting them and creating a stable environment for them to multiply. Together, they build a thriving soil ecosystem that becomes more fertile and resilient with each passing season.
Resilient systems can withstand shocks, but anti-fragile systems actively use those shocks to grow stronger. Comfrey and biochar together form an anti-fragile system. Each addition of biochar enhances water and nutrient retention, while comfrey regenerates biomass and enriches the soil. Over time, the system becomes more productive, less dependent on external inputs, and better equipped to handle challenges.
This synergy demonstrates the power of designing systems that don’t just survive—they thrive.
Lessons Beyond the Soil
The partnership of comfrey and biochar offers a valuable lesson for our own lives. Resilience is an admirable trait, but anti-fragility takes us further. By combining complementary strengths and leveraging stress as an opportunity, we can create systems—whether in soil, business, or society—that improve under pressure.
Nature shows us that resilience isn’t the end goal. When we pair resilient tools like comfrey and biochar, we unlock a system that evolves, regenerates, and becomes anti-fragile. By designing with anti-fragility in mind, we don’t just bounce back, we bounce forward.
By designing with anti-fragility in mind, we don’t just bounce back, we bounce forward.
-
-
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.Graph Basics
- A standard graph has a set of nodes (or vertices) and edges (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
Hypergraph
- A hypergraph extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a hyperedge, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
Metagraph
- A metagraph allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.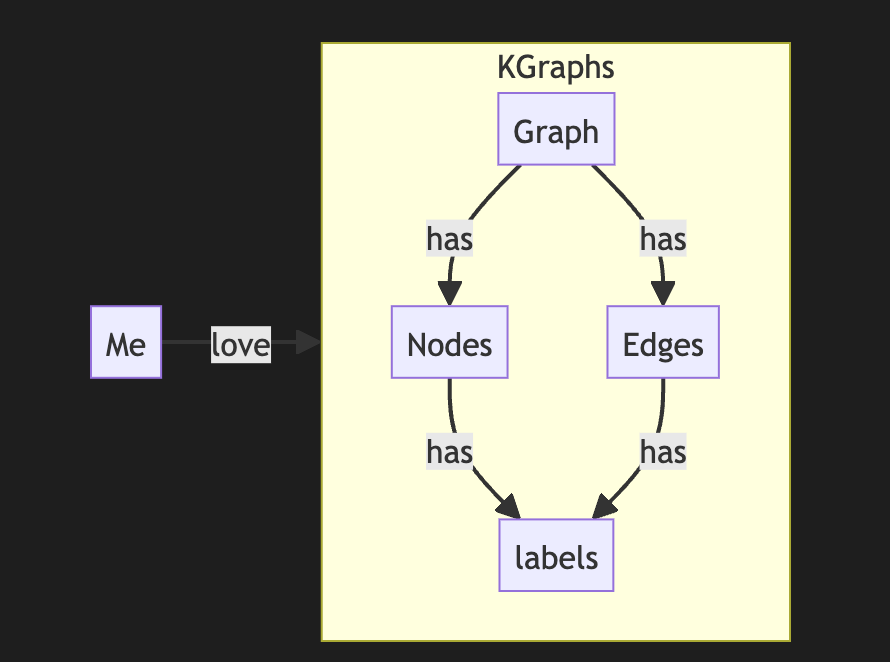
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
Directed Metagraph where edges are not used as nodes and could not contain subgraphs
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
Directed Metagraph where edges are not used as nodes and could contain subgraphs
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose. -
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like Lisp emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
Lisp: The Earlier AI-Language
Lisp, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
Prolog: Formal Logic and Deductive Reasoning
In the 1970s, Prolog was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out how to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
Solvers and Their Role in Complementing LLMs
One of the most powerful features of Prolog and similar logic-based systems is their use of solvers. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a solver can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling constraint satisfaction problems — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating neurosymbolic methods that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a graph of rules. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a graph of rules, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable modular reasoning, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of neural fluency with rule-based structure gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform deductive reasoning alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where neurosymbolic approaches shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
Personal Knowledge Graphs (PKGs) come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a graph of rules that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using deductive databases to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling knowledge graphs using deductive databases, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
Prolog and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a graph of rules that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
Why It Matters for LLM Employment
Using neurosymbolic RAG (retrieval-augmented generation) in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of neural fluency with symbolic accuracy and deductive power is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
RDF and Advanced Topics
Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory and semantic memory. And we also have a lot of theories, right?
Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a hybrid clock or some global clock that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ e31e84c4:77bbabc0
2024-12-02 10:44:07
Bitcoin and Fixed Income was Written By Wyatt O’Rourke. If you enjoyed this article then support his writing, directly, by donating to his lightning wallet: ultrahusky3@primal.net
Fiduciary duty is the obligation to act in the client’s best interests at all times, prioritizing their needs above the advisor’s own, ensuring honesty, transparency, and avoiding conflicts of interest in all recommendations and actions.
This is something all advisors in the BFAN take very seriously; after all, we are legally required to do so. For the average advisor this is a fairly easy box to check. All you essentially have to do is have someone take a 5-minute risk assessment, fill out an investment policy statement, and then throw them in the proverbial 60/40 portfolio. You have thousands of investment options to choose from and you can reasonably explain how your client is theoretically insulated from any move in the \~markets\~. From the traditional financial advisor perspective, you could justify nearly anything by putting a client into this type of portfolio. All your bases were pretty much covered from return profile, regulatory, compliance, investment options, etc. It was just too easy. It became the household standard and now a meme.
As almost every real bitcoiner knows, the 60/40 portfolio is moving into psyop territory, and many financial advisors get clowned on for defending this relic on bitcoin twitter. I’m going to specifically poke fun at the ‘40’ part of this portfolio.
The ‘40’ represents fixed income, defined as…
An investment type that provides regular, set interest payments, such as bonds or treasury securities, and returns the principal at maturity. It’s generally considered a lower-risk asset class, used to generate stable income and preserve capital.
Historically, this part of the portfolio was meant to weather the volatility in the equity markets and represent the “safe” investments. Typically, some sort of bond.
First and foremost, the fixed income section is most commonly constructed with U.S. Debt. There are a couple main reasons for this. Most financial professionals believe the same fairy tale that U.S. Debt is “risk free” (lol). U.S. debt is also one of the largest and most liquid assets in the market which comes with a lot of benefits.
There are many brilliant bitcoiners in finance and economics that have sounded the alarm on the U.S. debt ticking time bomb. I highly recommend readers explore the work of Greg Foss, Lawrence Lepard, Lyn Alden, and Saifedean Ammous. My very high-level recap of their analysis:
-
A bond is a contract in which Party A (the borrower) agrees to repay Party B (the lender) their principal plus interest over time.
-
The U.S. government issues bonds (Treasury securities) to finance its operations after tax revenues have been exhausted.
-
These are traditionally viewed as “risk-free” due to the government’s historical reliability in repaying its debts and the strength of the U.S. economy
-
U.S. bonds are seen as safe because the government has control over the dollar (world reserve asset) and, until recently (20 some odd years), enjoyed broad confidence that it would always honor its debts.
-
This perception has contributed to high global demand for U.S. debt but, that is quickly deteriorating.
-
The current debt situation raises concerns about sustainability.
-
The U.S. has substantial obligations, and without sufficient productivity growth, increasing debt may lead to a cycle where borrowing to cover interest leads to more debt.
-
This could result in more reliance on money creation (printing), which can drive inflation and further debt burdens.
In the words of Lyn Alden “Nothing stops this train”
Those obligations are what makes up the 40% of most the fixed income in your portfolio. So essentially you are giving money to one of the worst capital allocators in the world (U.S. Gov’t) and getting paid back with printed money.
As someone who takes their fiduciary responsibility seriously and understands the debt situation we just reviewed, I think it’s borderline negligent to put someone into a classic 60% (equities) / 40% (fixed income) portfolio without serious scrutiny of the client’s financial situation and options available to them. I certainly have my qualms with equities at times, but overall, they are more palatable than the fixed income portion of the portfolio. I don’t like it either, but the money is broken and the unit of account for nearly every equity or fixed income instrument (USD) is fraudulent. It’s a paper mache fade that is quite literally propped up by the money printer.
To briefly be as most charitable as I can – It wasn’t always this way. The U.S. Dollar used to be sound money, we used to have government surplus instead of mathematically certain deficits, The U.S. Federal Government didn’t used to have a money printing addiction, and pre-bitcoin the 60/40 portfolio used to be a quality portfolio management strategy. Those times are gone.
Now the fun part. How does bitcoin fix this?
Bitcoin fixes this indirectly. Understanding investment criteria changes via risk tolerance, age, goals, etc. A client may still have a need for “fixed income” in the most literal definition – Low risk yield. Now you may be thinking that yield is a bad word in bitcoin land, you’re not wrong, so stay with me. Perpetual motion machine crypto yield is fake and largely where many crypto scams originate. However, that doesn’t mean yield in the classic finance sense does not exist in bitcoin, it very literally does. Fortunately for us bitcoiners there are many other smart, driven, and enterprising bitcoiners that understand this problem and are doing something to address it. These individuals are pioneering new possibilities in bitcoin and finance, specifically when it comes to fixed income.
Here are some new developments –
Private Credit Funds – The Build Asset Management Secured Income Fund I is a private credit fund created by Build Asset Management. This fund primarily invests in bitcoin-backed, collateralized business loans originated by Unchained, with a secured structure involving a multi-signature, over-collateralized setup for risk management. Unchained originates loans and sells them to Build, which pools them into the fund, enabling investors to share in the interest income.
Dynamics
- Loan Terms: Unchained issues loans at interest rates around 14%, secured with a 2/3 multi-signature vault backed by a 40% loan-to-value (LTV) ratio.
- Fund Mechanics: Build buys these loans from Unchained, thus providing liquidity to Unchained for further loan originations, while Build manages interest payments to investors in the fund.
Pros
- The fund offers a unique way to earn income via bitcoin-collateralized debt, with protection against rehypothecation and strong security measures, making it attractive for investors seeking exposure to fixed income with bitcoin.
Cons
- The fund is only available to accredited investors, which is a regulatory standard for private credit funds like this.
Corporate Bonds – MicroStrategy Inc. (MSTR), a business intelligence company, has leveraged its corporate structure to issue bonds specifically to acquire bitcoin as a reserve asset. This approach allows investors to indirectly gain exposure to bitcoin’s potential upside while receiving interest payments on their bond investments. Some other publicly traded companies have also adopted this strategy, but for the sake of this article we will focus on MSTR as they are the biggest and most vocal issuer.
Dynamics
-
Issuance: MicroStrategy has issued senior secured notes in multiple offerings, with terms allowing the company to use the proceeds to purchase bitcoin.
-
Interest Rates: The bonds typically carry high-yield interest rates, averaging around 6-8% APR, depending on the specific issuance and market conditions at the time of issuance.
-
Maturity: The bonds have varying maturities, with most structured for multi-year terms, offering investors medium-term exposure to bitcoin’s value trajectory through MicroStrategy’s holdings.
Pros
-
Indirect Bitcoin exposure with income provides a unique opportunity for investors seeking income from bitcoin-backed debt.
-
Bonds issued by MicroStrategy offer relatively high interest rates, appealing for fixed-income investors attracted to the higher risk/reward scenarios.
Cons
-
There are credit risks tied to MicroStrategy’s financial health and bitcoin’s performance. A significant drop in bitcoin prices could strain the company’s ability to service debt, increasing credit risk.
-
Availability: These bonds are primarily accessible to institutional investors and accredited investors, limiting availability for retail investors.
Interest Payable in Bitcoin – River has introduced an innovative product, bitcoin Interest on Cash, allowing clients to earn interest on their U.S. dollar deposits, with the interest paid in bitcoin.
Dynamics
-
Interest Payment: Clients earn an annual interest rate of 3.8% on their cash deposits. The accrued interest is converted to Bitcoin daily and paid out monthly, enabling clients to accumulate Bitcoin over time.
-
Security and Accessibility: Cash deposits are insured up to $250,000 through River’s banking partner, Lead Bank, a member of the FDIC. All Bitcoin holdings are maintained in full reserve custody, ensuring that client assets are not lent or leveraged.
Pros
-
There are no hidden fees or minimum balance requirements, and clients can withdraw their cash at any time.
-
The 3.8% interest rate provides a predictable income stream, akin to traditional fixed-income investments.
Cons
-
While the interest rate is fixed, the value of the Bitcoin received as interest can fluctuate, introducing potential variability in the investment’s overall return.
-
Interest rate payments are on the lower side
Admittedly, this is a very small list, however, these types of investments are growing more numerous and meaningful. The reality is the existing options aren’t numerous enough to service every client that has a need for fixed income exposure. I challenge advisors to explore innovative options for fixed income exposure outside of sovereign debt, as that is most certainly a road to nowhere. It is my wholehearted belief and call to action that we need more options to help clients across the risk and capital allocation spectrum access a sound money standard.
Additional Resources
-
River: The future of saving is here: Earn 3.8% on cash. Paid in Bitcoin.
-
MicroStrategy: MicroStrategy Announces Pricing of Offering of Convertible Senior Notes
Bitcoin and Fixed Income was Written By Wyatt O’Rourke. If you enjoyed this article then support his writing, directly, by donating to his lightning wallet: ultrahusky3@primal.net
-
-
@ f982dbf2:46fe23d6
2024-11-30 19:16:47
New content edited 2
-
@ a849beb6:b327e6d2
2024-11-23 15:03:47

\ \ It was another historic week for both bitcoin and the Ten31 portfolio, as the world’s oldest, largest, most battle-tested cryptocurrency climbed to new all-time highs each day to close out the week just shy of the $100,000 mark. Along the way, bitcoin continued to accumulate institutional and regulatory wins, including the much-anticipated approval and launch of spot bitcoin ETF options and the appointment of several additional pro-bitcoin Presidential cabinet officials. The timing for this momentum was poetic, as this week marked the second anniversary of the pico-bottom of the 2022 bear market, a level that bitcoin has now hurdled to the tune of more than 6x despite the litany of bitcoin obituaries published at the time. The entirety of 2024 and especially the past month have further cemented our view that bitcoin is rapidly gaining a sense of legitimacy among institutions, fiduciaries, and governments, and we remain optimistic that this trend is set to accelerate even more into 2025.
Several Ten31 portfolio companies made exciting announcements this week that should serve to further entrench bitcoin’s institutional adoption. AnchorWatch, a first of its kind bitcoin insurance provider offering 1:1 coverage with its innovative use of bitcoin’s native properties, announced it has been designated a Lloyd’s of London Coverholder, giving the company unique, blue-chip status as it begins to write bitcoin insurance policies of up to $100 million per policy starting next month. Meanwhile, Battery Finance Founder and CEO Andrew Hohns appeared on CNBC to delve into the launch of Battery’s pioneering private credit strategy which fuses bitcoin and conventional tangible assets in a dual-collateralized structure that offers a compelling risk/return profile to both lenders and borrowers. Both companies are clearing a path for substantially greater bitcoin adoption in massive, untapped pools of capital, and Ten31 is proud to have served as lead investor for AnchorWatch’s Seed round and as exclusive capital partner for Battery.
As the world’s largest investor focused entirely on bitcoin, Ten31 has deployed nearly $150 million across two funds into more than 30 of the most promising and innovative companies in the ecosystem like AnchorWatch and Battery, and we expect 2025 to be the best year yet for both bitcoin and our portfolio. Ten31 will hold a first close for its third fund at the end of this year, and investors in that close will benefit from attractive incentives and a strong initial portfolio. Visit ten31.vc/funds to learn more and get in touch to discuss participating.\ \ Portfolio Company Spotlight
Primal is a first of its kind application for the Nostr protocol that combines a client, caching service, analytics tools, and more to address several unmet needs in the nascent Nostr ecosystem. Through the combination of its sleek client application and its caching service (built on a completely open source stack), Primal seeks to offer an end-user experience as smooth and easy as that of legacy social media platforms like Twitter and eventually many other applications, unlocking the vast potential of Nostr for the next billion people. Primal also offers an integrated wallet (powered by Strike BLACK) that substantially reduces onboarding and UX frictions for both Nostr and the lightning network while highlighting bitcoin’s unique power as internet-native, open-source money.
Selected Portfolio News
AnchorWatch announced it has achieved Llody’s Coverholder status, allowing the company to provide unique 1:1 bitcoin insurance offerings starting in December.\ \ Battery Finance Founder and CEO Andrew Hohns appeared on CNBC to delve into the company’s unique bitcoin-backed private credit strategy.
Primal launched version 2.0, a landmark update that adds a feed marketplace, robust advanced search capabilities, premium-tier offerings, and many more new features.
Debifi launched its new iOS app for Apple users seeking non-custodial bitcoin-collateralized loans.
Media
Strike Founder and CEO Jack Mallers joined Bloomberg TV to discuss the strong volumes the company has seen over the past year and the potential for a US bitcoin strategic reserve.
Primal Founder and CEO Miljan Braticevic joined The Bitcoin Podcast to discuss the rollout of Primal 2.0 and the future of Nostr.
Ten31 Managing Partner Marty Bent appeared on BlazeTV to discuss recent changes in the regulatory environment for bitcoin.
Zaprite published a customer testimonial video highlighting the popularity of its offerings across the bitcoin ecosystem.
Market Updates
Continuing its recent momentum, bitcoin reached another new all-time high this week, clocking in just below $100,000 on Friday. Bitcoin has now reached a market cap of nearly $2 trillion, putting it within 3% of the market caps of Amazon and Google.
After receiving SEC and CFTC approval over the past month, long-awaited options on spot bitcoin ETFs were fully approved and launched this week. These options should help further expand bitcoin’s institutional liquidity profile, with potentially significant implications for price action over time.
The new derivatives showed strong performance out of the gate, with volumes on options for BlackRock’s IBIT reaching nearly $2 billion on just the first day of trading despite surprisingly tight position limits for the vehicles.
Meanwhile, the underlying spot bitcoin ETF complex had yet another banner week, pulling in $3.4 billion in net inflows.
New reports suggested President-elect Donald Trump’s social media company is in advanced talks to acquire crypto trading platform Bakkt, potentially the latest indication of the incoming administration’s stance toward the broader “crypto” ecosystem.
On the macro front, US housing starts declined M/M again in October on persistently high mortgage rates and weather impacts. The metric remains well below pre-COVID levels.
Pockets of the US commercial real estate market remain challenged, as the CEO of large Florida developer Related indicated that developers need further rate cuts “badly” to maintain project viability.
US Manufacturing PMI increased slightly M/M, but has now been in contraction territory (<50) for well over two years.
The latest iteration of the University of Michigan’s popular consumer sentiment survey ticked up following this month’s election results, though so did five-year inflation expectations, which now sit comfortably north of 3%.
Regulatory Update
After weeks of speculation, the incoming Trump administration appointed hedge fund manager Scott Bessent to head up the US Treasury. Like many of Trump’s cabinet selections so far, Bessent has been a public advocate for bitcoin.
Trump also appointed Cantor Fitzgerald CEO Howard Lutnick – another outspoken bitcoin bull – as Secretary of the Commerce Department.
Meanwhile, the Trump team is reportedly considering creating a new “crypto czar” role to sit within the administration. While it’s unclear at this point what that role would entail, one report indicated that the administration’s broader “crypto council” is expected to move forward with plans for a strategic bitcoin reserve.
Various government lawyers suggested this week that the Trump administration is likely to be less aggressive in seeking adversarial enforcement actions against bitcoin and “crypto” in general, as regulatory bodies appear poised to shift resources and focus elsewhere.
Other updates from the regulatory apparatus were also directionally positive for bitcoin, most notably FDIC Chairman Martin Gruenberg’s confirmation that he plans to resign from his post at the end of President Biden’s term.
Many critics have alleged Gruenberg was an architect of “Operation Chokepoint 2.0,” which has created banking headwinds for bitcoin companies over the past several years, so a change of leadership at the department is likely yet another positive for the space.
SEC Chairman Gary Gensler also officially announced he plans to resign at the start of the new administration. Gensler has been the target of much ire from the broader “crypto” space, though we expect many projects outside bitcoin may continue to struggle with questions around the Howey Test.
Overseas, a Chinese court ruled that it is not illegal for individuals to hold cryptocurrency, even though the country is still ostensibly enforcing a ban on crypto transactions.
Noteworthy
The incoming CEO of Charles Schwab – which administers over $9 trillion in client assets – suggested the platform is preparing to “get into” spot bitcoin offerings and that he “feels silly” for having waited this long. As this attitude becomes more common among traditional finance players, we continue to believe that the number of acquirers coming to market for bitcoin infrastructure capabilities will far outstrip the number of available high quality assets.
BlackRock’s 2025 Thematic Outlook notes a “renewed sense of optimism” on bitcoin among the asset manager’s client base due to macro tailwinds and the improving regulatory environment. Elsewhere, BlackRock’s head of digital assets indicated the firm does not view bitcoin as a “risk-on” asset.
MicroStrategy, which was a sub-$1 billion market cap company less than five years ago, briefly breached a $100 billion equity value this week as it continues to aggressively acquire bitcoin. The company now holds nearly 350,000 bitcoin on its balance sheet.
Notably, Allianz SE, Germany’s largest insurer, spoke for 25% of MicroStrategy’s latest $3 billion convertible note offering this week, suggesting growing appetite for bitcoin proxy exposure among more restricted pools of capital.
The ongoing meltdown of fintech middleware provider Synapse has left tens of thousands of customers with nearly 100% deposit haircuts as hundreds of millions in funds remain missing, the latest unfortunate case study in the fragility of much of the US’s legacy banking stack.
Travel
-
BitcoinMENA, Dec 9-10
-
Nashville BitDevs, Dec 10
-
Austin BitDevs, Dec 19
-
-
@ 87730827:746b7d35
2024-11-20 09:27:53
Original: https://techreport.com/crypto-news/brazil-central-bank-ban-monero-stablecoins/
Brazilian’s Central Bank Will Ban Monero and Algorithmic Stablecoins in the Country
Brazil proposes crypto regulations banning Monero and algorithmic stablecoins and enforcing strict compliance for exchanges.
KEY TAKEAWAYS
- The Central Bank of Brazil has proposed regulations prohibiting privacy-centric cryptocurrencies like Monero.
- The regulations categorize exchanges into intermediaries, custodians, and brokers, each with specific capital requirements and compliance standards.
- While the proposed rules apply to cryptocurrencies, certain digital assets like non-fungible tokens (NFTs) are still ‘deregulated’ in Brazil.

In a Notice of Participation announcement, the Brazilian Central Bank (BCB) outlines regulations for virtual asset service providers (VASPs) operating in the country.
In the document, the Brazilian regulator specifies that privacy-focused coins, such as Monero, must be excluded from all digital asset companies that intend to operate in Brazil.
Let’s unpack what effect these regulations will have.
Brazil’s Crackdown on Crypto Fraud
If the BCB’s current rule is approved, exchanges dealing with coins that provide anonymity must delist these currencies or prevent Brazilians from accessing and operating these assets.
The Central Bank argues that currencies like Monero make it difficult and even prevent the identification of users, thus creating problems in complying with international AML obligations and policies to prevent the financing of terrorism.
According to the Central Bank of Brazil, the bans aim to prevent criminals from using digital assets to launder money. In Brazil, organized criminal syndicates such as the Primeiro Comando da Capital (PCC) and Comando Vermelho have been increasingly using digital assets for money laundering and foreign remittances.
… restriction on the supply of virtual assets that contain characteristics of fragility, insecurity or risks that favor fraud or crime, such as virtual assets designed to favor money laundering and terrorist financing practices by facilitating anonymity or difficulty identification of the holder.
The Central Bank has identified that removing algorithmic stablecoins is essential to guarantee the safety of users’ funds and avoid events such as when Terraform Labs’ entire ecosystem collapsed, losing billions of investors’ dollars.
The Central Bank also wants to control all digital assets traded by companies in Brazil. According to the current proposal, the national regulator will have the power to ask platforms to remove certain listed assets if it considers that they do not meet local regulations.
However, the regulations will not include NFTs, real-world asset (RWA) tokens, RWA tokens classified as securities, and tokenized movable or real estate assets. These assets are still ‘deregulated’ in Brazil.
Monero: What Is It and Why Is Brazil Banning It?
Monero ($XMR) is a cryptocurrency that uses a protocol called CryptoNote. It launched in 2013 and ‘erases’ transaction data, preventing the sender and recipient addresses from being publicly known. The Monero network is based on a proof-of-work (PoW) consensus mechanism, which incentivizes miners to add blocks to the blockchain.
Like Brazil, other nations are banning Monero in search of regulatory compliance. Recently, Dubai’s new digital asset rules prohibited the issuance of activities related to anonymity-enhancing cryptocurrencies such as $XMR.
Furthermore, exchanges such as Binance have already announced they will delist Monero on their global platforms due to its anonymity features. Kraken did the same, removing Monero for their European-based users to comply with MiCA regulations.
Data from Chainalysis shows that Brazil is the seventh-largest Bitcoin market in the world.

In Latin America, Brazil is the largest market for digital assets. Globally, it leads in the innovation of RWA tokens, with several companies already trading this type of asset.
In Closing
Following other nations, Brazil’s regulatory proposals aim to combat illicit activities such as money laundering and terrorism financing.
Will the BCB’s move safeguard people’s digital assets while also stimulating growth and innovation in the crypto ecosystem? Only time will tell.
References
Cassio Gusson is a journalist passionate about technology, cryptocurrencies, and the nuances of human nature. With a career spanning roles as Senior Crypto Journalist at CriptoFacil and Head of News at CoinTelegraph, he offers exclusive insights on South America’s crypto landscape. A graduate in Communication from Faccamp and a post-graduate in Globalization and Culture from FESPSP, Cassio explores the intersection of governance, decentralization, and the evolution of global systems.
-
@ 5e5fc143:393d5a2c
2024-11-19 10:20:25
Now test old reliable front end Stay tuned more later Keeping this as template long note for debugging in future as come across few NIP-33 post edit issues
-
@ af9c48b7:a3f7aaf4
2024-11-18 20:26:07
Chef's notes
This simple, easy, no bake desert will surely be the it at you next family gathering. You can keep it a secret or share it with the crowd that this is a healthy alternative to normal pie. I think everyone will be amazed at how good it really is.
Details
- ⏲️ Prep time: 30
- 🍳 Cook time: 0
- 🍽️ Servings: 8
Ingredients
- 1/3 cup of Heavy Cream- 0g sugar, 5.5g carbohydrates
- 3/4 cup of Half and Half- 6g sugar, 3g carbohydrates
- 4oz Sugar Free Cool Whip (1/2 small container) - 0g sugar, 37.5g carbohydrates
- 1.5oz box (small box) of Sugar Free Instant Chocolate Pudding- 0g sugar, 32g carbohydrates
- 1 Pecan Pie Crust- 24g sugar, 72g carbohydrates
Directions
- The total pie has 30g of sugar and 149.50g of carboydrates. So if you cut the pie into 8 equal slices, that would come to 3.75g of sugar and 18.69g carbohydrates per slice. If you decided to not eat the crust, your sugar intake would be .75 gram per slice and the carborytrates would be 9.69g per slice. Based on your objective, you could use only heavy whipping cream and no half and half to further reduce your sugar intake.
- Mix all wet ingredients and the instant pudding until thoroughly mixed and a consistent color has been achieved. The heavy whipping cream causes the mixture to thicken the more you mix it. So, I’d recommend using an electric mixer. Once you are satisfied with the color, start mixing in the whipping cream until it has a consistent “chocolate” color thorough. Once your satisfied with the color, spoon the mixture into the pie crust, smooth the top to your liking, and then refrigerate for one hour before serving.
-
@ 41e6f20b:06049e45
2024-11-17 17:33:55
Let me tell you a beautiful story. Last night, during the speakers' dinner at Monerotopia, the waitress was collecting tiny tips in Mexican pesos. I asked her, "Do you really want to earn tips seriously?" I then showed her how to set up a Cake Wallet, and she started collecting tips in Monero, reaching 0.9 XMR. Of course, she wanted to cash out to fiat immediately, but it solved a real problem for her: making more money. That amount was something she would never have earned in a single workday. We kept talking, and I promised to give her Zoom workshops. What can I say? I love people, and that's why I'm a natural orange-piller.
-
@ 4ba8e86d:89d32de4
2024-11-14 09:17:14
Tutorial feito por nostr:nostr:npub1rc56x0ek0dd303eph523g3chm0wmrs5wdk6vs0ehd0m5fn8t7y4sqra3tk poste original abaixo:
Parte 1 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/263585/tutorial-debloat-de-celulares-android-via-adb-parte-1
Parte 2 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/index.php/263586/tutorial-debloat-de-celulares-android-via-adb-parte-2
Quando o assunto é privacidade em celulares, uma das medidas comumente mencionadas é a remoção de bloatwares do dispositivo, também chamado de debloat. O meio mais eficiente para isso sem dúvidas é a troca de sistema operacional. Custom Rom’s como LineageOS, GrapheneOS, Iodé, CalyxOS, etc, já são bastante enxutos nesse quesito, principalmente quanto não é instalado os G-Apps com o sistema. No entanto, essa prática pode acabar resultando em problemas indesejados como a perca de funções do dispositivo, e até mesmo incompatibilidade com apps bancários, tornando este método mais atrativo para quem possui mais de um dispositivo e separando um apenas para privacidade. Pensando nisso, pessoas que possuem apenas um único dispositivo móvel, que são necessitadas desses apps ou funções, mas, ao mesmo tempo, tem essa visão em prol da privacidade, buscam por um meio-termo entre manter a Stock rom, e não ter seus dados coletados por esses bloatwares. Felizmente, a remoção de bloatwares é possível e pode ser realizada via root, ou mais da maneira que este artigo irá tratar, via adb.
O que são bloatwares?
Bloatware é a junção das palavras bloat (inchar) + software (programa), ou seja, um bloatware é basicamente um programa inútil ou facilmente substituível — colocado em seu dispositivo previamente pela fabricante e operadora — que está no seu dispositivo apenas ocupando espaço de armazenamento, consumindo memória RAM e pior, coletando seus dados e enviando para servidores externos, além de serem mais pontos de vulnerabilidades.
O que é o adb?
O Android Debug Brigde, ou apenas adb, é uma ferramenta que se utiliza das permissões de usuário shell e permite o envio de comandos vindo de um computador para um dispositivo Android exigindo apenas que a depuração USB esteja ativa, mas também pode ser usada diretamente no celular a partir do Android 11, com o uso do Termux e a depuração sem fio (ou depuração wifi). A ferramenta funciona normalmente em dispositivos sem root, e também funciona caso o celular esteja em Recovery Mode.
Requisitos:
Para computadores:
• Depuração USB ativa no celular; • Computador com adb; • Cabo USB;
Para celulares:
• Depuração sem fio (ou depuração wifi) ativa no celular; • Termux; • Android 11 ou superior;
Para ambos:
• Firewall NetGuard instalado e configurado no celular; • Lista de bloatwares para seu dispositivo;
Ativação de depuração:
Para ativar a Depuração USB em seu dispositivo, pesquise como ativar as opções de desenvolvedor de seu dispositivo, e lá ative a depuração. No caso da depuração sem fio, sua ativação irá ser necessária apenas no momento que for conectar o dispositivo ao Termux.
Instalação e configuração do NetGuard
O NetGuard pode ser instalado através da própria Google Play Store, mas de preferência instale pela F-Droid ou Github para evitar telemetria.
F-Droid: https://f-droid.org/packages/eu.faircode.netguard/
Github: https://github.com/M66B/NetGuard/releases
Após instalado, configure da seguinte maneira:
Configurações → padrões (lista branca/negra) → ative as 3 primeiras opções (bloquear wifi, bloquear dados móveis e aplicar regras ‘quando tela estiver ligada’);
Configurações → opções avançadas → ative as duas primeiras (administrar aplicativos do sistema e registrar acesso a internet);
Com isso, todos os apps estarão sendo bloqueados de acessar a internet, seja por wifi ou dados móveis, e na página principal do app basta permitir o acesso a rede para os apps que você vai usar (se necessário). Permita que o app rode em segundo plano sem restrição da otimização de bateria, assim quando o celular ligar, ele já estará ativo.
Lista de bloatwares
Nem todos os bloatwares são genéricos, haverá bloatwares diferentes conforme a marca, modelo, versão do Android, e até mesmo região.
Para obter uma lista de bloatwares de seu dispositivo, caso seu aparelho já possua um tempo de existência, você encontrará listas prontas facilmente apenas pesquisando por elas. Supondo que temos um Samsung Galaxy Note 10 Plus em mãos, basta pesquisar em seu motor de busca por:
Samsung Galaxy Note 10 Plus bloatware listProvavelmente essas listas já terão inclusas todos os bloatwares das mais diversas regiões, lhe poupando o trabalho de buscar por alguma lista mais específica.
Caso seu aparelho seja muito recente, e/ou não encontre uma lista pronta de bloatwares, devo dizer que você acaba de pegar em merda, pois é chato para um caralho pesquisar por cada aplicação para saber sua função, se é essencial para o sistema ou se é facilmente substituível.
De antemão já aviso, que mais para frente, caso vossa gostosura remova um desses aplicativos que era essencial para o sistema sem saber, vai acabar resultando na perda de alguma função importante, ou pior, ao reiniciar o aparelho o sistema pode estar quebrado, lhe obrigando a seguir com uma formatação, e repetir todo o processo novamente.
Download do adb em computadores
Para usar a ferramenta do adb em computadores, basta baixar o pacote chamado SDK platform-tools, disponível através deste link: https://developer.android.com/tools/releases/platform-tools. Por ele, você consegue o download para Windows, Mac e Linux.
Uma vez baixado, basta extrair o arquivo zipado, contendo dentro dele uma pasta chamada platform-tools que basta ser aberta no terminal para se usar o adb.
Download do adb em celulares com Termux.
Para usar a ferramenta do adb diretamente no celular, antes temos que baixar o app Termux, que é um emulador de terminal linux, e já possui o adb em seu repositório. Você encontra o app na Google Play Store, mas novamente recomendo baixar pela F-Droid ou diretamente no Github do projeto.
F-Droid: https://f-droid.org/en/packages/com.termux/
Github: https://github.com/termux/termux-app/releases
Processo de debloat
Antes de iniciarmos, é importante deixar claro que não é para você sair removendo todos os bloatwares de cara sem mais nem menos, afinal alguns deles precisam antes ser substituídos, podem ser essenciais para você para alguma atividade ou função, ou até mesmo são insubstituíveis.
Alguns exemplos de bloatwares que a substituição é necessária antes da remoção, é o Launcher, afinal, é a interface gráfica do sistema, e o teclado, que sem ele só é possível digitar com teclado externo. O Launcher e teclado podem ser substituídos por quaisquer outros, minha recomendação pessoal é por aqueles que respeitam sua privacidade, como Pie Launcher e Simple Laucher, enquanto o teclado pelo OpenBoard e FlorisBoard, todos open-source e disponíveis da F-Droid.
Identifique entre a lista de bloatwares, quais você gosta, precisa ou prefere não substituir, de maneira alguma você é obrigado a remover todos os bloatwares possíveis, modifique seu sistema a seu bel-prazer. O NetGuard lista todos os apps do celular com o nome do pacote, com isso você pode filtrar bem qual deles não remover.
Um exemplo claro de bloatware insubstituível e, portanto, não pode ser removido, é o com.android.mtp, um protocolo onde sua função é auxiliar a comunicação do dispositivo com um computador via USB, mas por algum motivo, tem acesso a rede e se comunica frequentemente com servidores externos. Para esses casos, e melhor solução mesmo é bloquear o acesso a rede desses bloatwares com o NetGuard.
MTP tentando comunicação com servidores externos:
Executando o adb shell
No computador
Faça backup de todos os seus arquivos importantes para algum armazenamento externo, e formate seu celular com o hard reset. Após a formatação, e a ativação da depuração USB, conecte seu aparelho e o pc com o auxílio de um cabo USB. Muito provavelmente seu dispositivo irá apenas começar a carregar, por isso permita a transferência de dados, para que o computador consiga se comunicar normalmente com o celular.
Já no pc, abra a pasta platform-tools dentro do terminal, e execute o seguinte comando:
./adb start-serverO resultado deve ser:
daemon not running; starting now at tcp:5037 daemon started successfully
E caso não apareça nada, execute:
./adb kill-serverE inicie novamente.
Com o adb conectado ao celular, execute:
./adb shellPara poder executar comandos diretamente para o dispositivo. No meu caso, meu celular é um Redmi Note 8 Pro, codinome Begonia.
Logo o resultado deve ser:
begonia:/ $
Caso ocorra algum erro do tipo:
adb: device unauthorized. This adb server’s $ADB_VENDOR_KEYS is not set Try ‘adb kill-server’ if that seems wrong. Otherwise check for a confirmation dialog on your device.
Verifique no celular se apareceu alguma confirmação para autorizar a depuração USB, caso sim, autorize e tente novamente. Caso não apareça nada, execute o kill-server e repita o processo.
No celular
Após realizar o mesmo processo de backup e hard reset citado anteriormente, instale o Termux e, com ele iniciado, execute o comando:
pkg install android-toolsQuando surgir a mensagem “Do you want to continue? [Y/n]”, basta dar enter novamente que já aceita e finaliza a instalação
Agora, vá até as opções de desenvolvedor, e ative a depuração sem fio. Dentro das opções da depuração sem fio, terá uma opção de emparelhamento do dispositivo com um código, que irá informar para você um código em emparelhamento, com um endereço IP e porta, que será usado para a conexão com o Termux.
Para facilitar o processo, recomendo que abra tanto as configurações quanto o Termux ao mesmo tempo, e divida a tela com os dois app’s, como da maneira a seguir:
Para parear o Termux com o dispositivo, não é necessário digitar o ip informado, basta trocar por “localhost”, já a porta e o código de emparelhamento, deve ser digitado exatamente como informado. Execute:
adb pair localhost:porta CódigoDeEmparelhamentoDe acordo com a imagem mostrada anteriormente, o comando ficaria “adb pair localhost:41255 757495”.
Com o dispositivo emparelhado com o Termux, agora basta conectar para conseguir executar os comandos, para isso execute:
adb connect localhost:portaObs: a porta que você deve informar neste comando não é a mesma informada com o código de emparelhamento, e sim a informada na tela principal da depuração sem fio.
Pronto! Termux e adb conectado com sucesso ao dispositivo, agora basta executar normalmente o adb shell:
adb shellRemoção na prática Com o adb shell executado, você está pronto para remover os bloatwares. No meu caso, irei mostrar apenas a remoção de um app (Google Maps), já que o comando é o mesmo para qualquer outro, mudando apenas o nome do pacote.
Dentro do NetGuard, verificando as informações do Google Maps:
Podemos ver que mesmo fora de uso, e com a localização do dispositivo desativado, o app está tentando loucamente se comunicar com servidores externos, e informar sabe-se lá que peste. Mas sem novidades até aqui, o mais importante é que podemos ver que o nome do pacote do Google Maps é com.google.android.apps.maps, e para o remover do celular, basta executar:
pm uninstall –user 0 com.google.android.apps.mapsE pronto, bloatware removido! Agora basta repetir o processo para o resto dos bloatwares, trocando apenas o nome do pacote.
Para acelerar o processo, você pode já criar uma lista do bloco de notas com os comandos, e quando colar no terminal, irá executar um atrás do outro.
Exemplo de lista:
Caso a donzela tenha removido alguma coisa sem querer, também é possível recuperar o pacote com o comando:
cmd package install-existing nome.do.pacotePós-debloat
Após limpar o máximo possível o seu sistema, reinicie o aparelho, caso entre no como recovery e não seja possível dar reboot, significa que você removeu algum app “essencial” para o sistema, e terá que formatar o aparelho e repetir toda a remoção novamente, desta vez removendo poucos bloatwares de uma vez, e reiniciando o aparelho até descobrir qual deles não pode ser removido. Sim, dá trabalho… quem mandou querer privacidade?
Caso o aparelho reinicie normalmente após a remoção, parabéns, agora basta usar seu celular como bem entender! Mantenha o NetGuard sempre executando e os bloatwares que não foram possíveis remover não irão se comunicar com servidores externos, passe a usar apps open source da F-Droid e instale outros apps através da Aurora Store ao invés da Google Play Store.
Referências: Caso você seja um Australopithecus e tenha achado este guia difícil, eis uma videoaula (3:14:40) do Anderson do canal Ciberdef, realizando todo o processo: http://odysee.com/@zai:5/Como-remover-at%C3%A9-200-APLICATIVOS-que-colocam-a-sua-PRIVACIDADE-E-SEGURAN%C3%87A-em-risco.:4?lid=6d50f40314eee7e2f218536d9e5d300290931d23
Pdf’s do Anderson citados na videoaula: créditos ao anon6837264 http://eternalcbrzpicytj4zyguygpmkjlkddxob7tptlr25cdipe5svyqoqd.onion/file/3863a834d29285d397b73a4af6fb1bbe67c888d72d30/t-05e63192d02ffd.pdf
Processo de instalação do Termux e adb no celular: https://youtu.be/APolZrPHSms
-
@ bcea2b98:7ccef3c9
2024-11-09 17:01:32
Weekends are the perfect time to unwind, explore, or spend time doing what we love. How would you spend your ideal weekend? Would it be all about relaxation, or would you be out and about?
For me, an ideal weekend would start with a slow Saturday morning, a good book and coffee. Then I would spend the afternoon exploring local trails and looking for snacks. Then always a slow Sunday night hopefully.
originally posted at https://stacker.news/items/760492
-
@ fd208ee8:0fd927c1
2024-11-08 08:08:30
You have no idea
I regularly read comments from people, on here, wondering how it's possible to marry -- or even simply be friends! -- with someone who doesn't agree with you on politics. I see this sentiment expressed quite often, usually in the context of Bitcoin, or whatever pig is currently being chased through the village, as they say around here.

It seems rather sensible, but I don't think it's as hard, as people make it out to be. Further, I think it's a dangerous precondition to set, for your interpersonal relationships, because the political field is constantly in flux. If you determine who you will love, by their opinions, do you stop loving them if their opinions change, or if the opinions they have become irrelevant and a new set of opinions are needed -- and their new ones don't match your new ones? We could see this happen to relationships en masse, during the Covid Era, and I think it happens every day, in a slow grind toward the disintegration of interpersonal discourse.
I suspect many people do stop loving, at that point, as they never really loved the other person for their own sake, they loved the other person because they thought the other person was exactly like they are. But no two people are alike, and the longer you are in a relationship with someone else, the more the initial giddiness wears off and the trials and tribulations add up, the more you notice how very different you actually are. This is the point, where best friends and romantic couples say, We just grew apart.
But you were always apart. You were always two different people. You just didn't notice, until now.

I've also always been surprised at how many same-party relationships disintegrate because of some disagreement over some particular detail of some particular topic, that they generally agree on. To me, it seems like an irrelevant side-topic, but they can't stand to be with this person... and they stomp off. So, I tend to think that it's less that opinions need to align to each other, but rather than opinions need to align in accordance with the level of interpersonal tolerance they can bring into the relationship.
I was raised by relaxed revolutionaries
Maybe I see things this way because my parents come from two diverging political, cultural, national, and ethnic backgrounds, and are prone to disagreeing about a lot of "important" (to people outside their marriage) things, but still have one of the healthiest, most-fruitful, and most long-running marriages of anyone I know, from that generation. My parents, you see, aren't united by their opinions. They're united by their relationship, which is something outside of opinions. Beyond opinions. Relationships are what turn two different people into one, cohesive unit, so that they slowly grow together. Eventually, even their faces merge, and their biological clocks tick to the same rhythm. They eventually become one entity that contains differing opinions about the same topics.
It's like magic, but it's the result of a mindset, not a worldview. Or, as I like to quip:
The best way to stay married, is to not get divorced.

My parents simply determined early on, that they would stay together, and whenever they would find that they disagreed on something that didn't directly pertain to their day-to-day existence with each other they would just agree-to-disagree about that, or roll their eyes, and move on. You do you. Live and let live.
My parents have some of the most strongly held personal opinions of any people I've ever met, but they're also incredibly tolerant and can get along with nearly anyone, so their friends are a confusing hodgepodge of people we liked and found interesting enough to keep around. Which makes their house parties really fun, and highly unusual, in this day and age of mutual-damnation across the aisle.

The things that did affect them, directly, like which school the children should attend or which country they should live in, etc. were things they'd sit down and discuss, and somehow one opinion would emerge, and they'd again... move on.
And that's how my husband and I also live our lives, and it's been working surprisingly well. No topics are off-limits to discussion (so long as you don't drone on for too long), nobody has to give up deeply held beliefs, or stop agitating for the political decisions they prefer.
You see, we didn't like that the other always had the same opinion. We liked that the other always held their opinions strongly. That they were passionate about their opinions. That they were willing to voice their opinions; sacrifice to promote their opinions. And that they didn't let anyone browbeat or cow them, for their opinions, not even their best friends or their spouse. But that they were open to listening to the other side, and trying to wrap their mind around the possibility that they might just be wrong about something.

We married each other because we knew: this person really cares, this person has thought this through, and they're in it, to win it. What "it" is, is mostly irrelevant, so long as it doesn't entail torturing small animals in the basement, or raising the children on a diet of Mountain Dew and porn, or something.
Live and let live. At least, it's never boring. At least, there's always something to ~~argue~~ talk about. At least, we never think... we've just grown apart.
