-

@ e3ba5e1a:5e433365
2025-02-05 17:47:16
I got into a [friendly discussion](https://x.com/snoyberg/status/1887007888117252142) on X regarding health insurance. The specific question was how to deal with health insurance companies (presumably unfairly) denying claims? My answer, as usual: get government out of it!
The US healthcare system is essentially the worst of both worlds:
* Unlike full single payer, individuals incur high costs
* Unlike a true free market, regulation causes increases in costs and decreases competition among insurers
I'm firmly on the side of moving towards the free market. (And I say that as someone living under a single payer system now.) Here's what I would do:
* Get rid of tax incentives that make health insurance tied to your employer, giving individuals back proper freedom of choice.
* Reduce regulations significantly.
* In the short term, some people will still get rejected claims and other obnoxious behavior from insurance companies. We address that in two ways:
1. Due to reduced regulations, new insurance companies will be able to enter the market offering more reliable coverage and better rates, and people will flock to them because they have the freedom to make their own choices.
2. Sue the asses off of companies that reject claims unfairly. And ideally, as one of the few legitimate roles of government in all this, institute new laws that limit the ability of fine print to allow insurers to escape their responsibilities. (I'm hesitant that the latter will happen due to the incestuous relationship between Congress/regulators and insurers, but I can hope.)
Will this magically fix everything overnight like politicians normally promise? No. But it will allow the market to return to a healthy state. And I don't think it will take long (order of magnitude: 5-10 years) for it to come together, but that's just speculation.
And since there's a high correlation between those who believe government can fix problems by taking more control and demanding that only credentialed experts weigh in on a topic (both points I strongly disagree with BTW): I'm a trained actuary and worked in the insurance industry, and have directly seen how government regulation reduces competition, raises prices, and harms consumers.
And my final point: I don't think any prior art would be a good comparison for deregulation in the US, it's such a different market than any other country in the world for so many reasons that lessons wouldn't really translate. Nonetheless, I asked Grok for some empirical data on this, and at best the results of deregulation could be called "mixed," but likely more accurately "uncertain, confused, and subject to whatever interpretation anyone wants to apply."
https://x.com/i/grok/share/Zc8yOdrN8lS275hXJ92uwq98M
-
@ 91bea5cd:1df4451c
2025-02-04 17:24:50
### Definição de ULID:
Timestamp 48 bits, Aleatoriedade 80 bits
Sendo Timestamp 48 bits inteiro, tempo UNIX em milissegundos, Não ficará sem espaço até o ano 10889 d.C.
e Aleatoriedade 80 bits, Fonte criptograficamente segura de aleatoriedade, se possível.
#### Gerar ULID
```sql
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE FUNCTION generate_ulid()
RETURNS TEXT
AS $$
DECLARE
-- Crockford's Base32
encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
timestamp BYTEA = E'\\000\\000\\000\\000\\000\\000';
output TEXT = '';
unix_time BIGINT;
ulid BYTEA;
BEGIN
-- 6 timestamp bytes
unix_time = (EXTRACT(EPOCH FROM CLOCK_TIMESTAMP()) * 1000)::BIGINT;
timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes
ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
-- Encode the entropy
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
RETURN output;
END
$$
LANGUAGE plpgsql
VOLATILE;
```
#### ULID TO UUID
```sql
CREATE OR REPLACE FUNCTION parse_ulid(ulid text) RETURNS bytea AS $$
DECLARE
-- 16byte
bytes bytea = E'\\x00000000 00000000 00000000 00000000';
v char[];
-- Allow for O(1) lookup of index values
dec integer[] = ARRAY[
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 0, 1, 2,
3, 4, 5, 6, 7, 8, 9, 255, 255, 255,
255, 255, 255, 255, 10, 11, 12, 13, 14, 15,
16, 17, 1, 18, 19, 1, 20, 21, 0, 22,
23, 24, 25, 26, 255, 27, 28, 29, 30, 31,
255, 255, 255, 255, 255, 255, 10, 11, 12, 13,
14, 15, 16, 17, 1, 18, 19, 1, 20, 21,
0, 22, 23, 24, 25, 26, 255, 27, 28, 29,
30, 31
];
BEGIN
IF NOT ulid ~* '^[0-7][0-9ABCDEFGHJKMNPQRSTVWXYZ]{25}$' THEN
RAISE EXCEPTION 'Invalid ULID: %', ulid;
END IF;
v = regexp_split_to_array(ulid, '');
-- 6 bytes timestamp (48 bits)
bytes = SET_BYTE(bytes, 0, (dec[ASCII(v[1])] << 5) | dec[ASCII(v[2])]);
bytes = SET_BYTE(bytes, 1, (dec[ASCII(v[3])] << 3) | (dec[ASCII(v[4])] >> 2));
bytes = SET_BYTE(bytes, 2, (dec[ASCII(v[4])] << 6) | (dec[ASCII(v[5])] << 1) | (dec[ASCII(v[6])] >> 4));
bytes = SET_BYTE(bytes, 3, (dec[ASCII(v[6])] << 4) | (dec[ASCII(v[7])] >> 1));
bytes = SET_BYTE(bytes, 4, (dec[ASCII(v[7])] << 7) | (dec[ASCII(v[8])] << 2) | (dec[ASCII(v[9])] >> 3));
bytes = SET_BYTE(bytes, 5, (dec[ASCII(v[9])] << 5) | dec[ASCII(v[10])]);
-- 10 bytes of entropy (80 bits);
bytes = SET_BYTE(bytes, 6, (dec[ASCII(v[11])] << 3) | (dec[ASCII(v[12])] >> 2));
bytes = SET_BYTE(bytes, 7, (dec[ASCII(v[12])] << 6) | (dec[ASCII(v[13])] << 1) | (dec[ASCII(v[14])] >> 4));
bytes = SET_BYTE(bytes, 8, (dec[ASCII(v[14])] << 4) | (dec[ASCII(v[15])] >> 1));
bytes = SET_BYTE(bytes, 9, (dec[ASCII(v[15])] << 7) | (dec[ASCII(v[16])] << 2) | (dec[ASCII(v[17])] >> 3));
bytes = SET_BYTE(bytes, 10, (dec[ASCII(v[17])] << 5) | dec[ASCII(v[18])]);
bytes = SET_BYTE(bytes, 11, (dec[ASCII(v[19])] << 3) | (dec[ASCII(v[20])] >> 2));
bytes = SET_BYTE(bytes, 12, (dec[ASCII(v[20])] << 6) | (dec[ASCII(v[21])] << 1) | (dec[ASCII(v[22])] >> 4));
bytes = SET_BYTE(bytes, 13, (dec[ASCII(v[22])] << 4) | (dec[ASCII(v[23])] >> 1));
bytes = SET_BYTE(bytes, 14, (dec[ASCII(v[23])] << 7) | (dec[ASCII(v[24])] << 2) | (dec[ASCII(v[25])] >> 3));
bytes = SET_BYTE(bytes, 15, (dec[ASCII(v[25])] << 5) | dec[ASCII(v[26])]);
RETURN bytes;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
CREATE OR REPLACE FUNCTION ulid_to_uuid(ulid text) RETURNS uuid AS $$
BEGIN
RETURN encode(parse_ulid(ulid), 'hex')::uuid;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
```
#### UUID to ULID
```sql
CREATE OR REPLACE FUNCTION uuid_to_ulid(id uuid) RETURNS text AS $$
DECLARE
encoding bytea = '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
output text = '';
uuid_bytes bytea = uuid_send(id);
BEGIN
-- Encode the timestamp
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 224) >> 5));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 1) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 1) & 7) << 2) | ((GET_BYTE(uuid_bytes, 2) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 2) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 2) & 1) << 4) | ((GET_BYTE(uuid_bytes, 3) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 3) & 15) << 1) | ((GET_BYTE(uuid_bytes, 4) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 4) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 4) & 3) << 3) | ((GET_BYTE(uuid_bytes, 5) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 5) & 31)));
-- Encode the entropy
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 6) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 6) & 7) << 2) | ((GET_BYTE(uuid_bytes, 7) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 7) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 7) & 1) << 4) | ((GET_BYTE(uuid_bytes, 8) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 8) & 15) << 1) | ((GET_BYTE(uuid_bytes, 9) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 9) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 9) & 3) << 3) | ((GET_BYTE(uuid_bytes, 10) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 10) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 11) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 11) & 7) << 2) | ((GET_BYTE(uuid_bytes, 12) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 12) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 12) & 1) << 4) | ((GET_BYTE(uuid_bytes, 13) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 13) & 15) << 1) | ((GET_BYTE(uuid_bytes, 14) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 14) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 14) & 3) << 3) | ((GET_BYTE(uuid_bytes, 15) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 15) & 31)));
RETURN output;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
```
#### Gera 11 Digitos aleatórios: YBKXG0CKTH4
```sql
-- Cria a extensão pgcrypto para gerar uuid
CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Cria a função para gerar ULID
CREATE OR REPLACE FUNCTION gen_lrandom()
RETURNS TEXT AS $$
DECLARE
ts_millis BIGINT;
ts_chars TEXT;
random_bytes BYTEA;
random_chars TEXT;
base32_chars TEXT := '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
i INT;
BEGIN
-- Pega o timestamp em milissegundos
ts_millis := FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000)::BIGINT;
-- Converte o timestamp para base32
ts_chars := '';
FOR i IN REVERSE 0..11 LOOP
ts_chars := ts_chars || substr(base32_chars, ((ts_millis >> (5 * i)) & 31) + 1, 1);
END LOOP;
-- Gera 10 bytes aleatórios e converte para base32
random_bytes := gen_random_bytes(10);
random_chars := '';
FOR i IN 0..9 LOOP
random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) >> 3) & 31) + 1, 1);
IF i < 9 THEN
random_chars := random_chars || substr(base32_chars, (((get_byte(random_bytes, i) & 7) << 2) | (get_byte(random_bytes, i + 1) >> 6)) & 31 + 1, 1);
ELSE
random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) & 7) << 2) + 1, 1);
END IF;
END LOOP;
-- Concatena o timestamp e os caracteres aleatórios
RETURN ts_chars || random_chars;
END;
$$ LANGUAGE plpgsql;
```
#### Exemplo de USO
```sql
-- Criação da extensão caso não exista
CREATE EXTENSION
IF
NOT EXISTS pgcrypto;
-- Criação da tabela pessoas
CREATE TABLE pessoas ( ID UUID DEFAULT gen_random_uuid ( ) PRIMARY KEY, nome TEXT NOT NULL );
-- Busca Pessoa na tabela
SELECT
*
FROM
"pessoas"
WHERE
uuid_to_ulid ( ID ) = '252FAC9F3V8EF80SSDK8PXW02F';
```
### Fontes
- https://github.com/scoville/pgsql-ulid
- https://github.com/geckoboard/pgulid
-
@ 91bea5cd:1df4451c
2025-02-04 17:15:57
### Definição de ULID:
Timestamp 48 bits, Aleatoriedade 80 bits
Sendo Timestamp 48 bits inteiro, tempo UNIX em milissegundos, Não ficará sem espaço até o ano 10889 d.C.
e Aleatoriedade 80 bits, Fonte criptograficamente segura de aleatoriedade, se possível.
#### Gerar ULID
```sql
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE FUNCTION generate_ulid()
RETURNS TEXT
AS $$
DECLARE
-- Crockford's Base32
encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
timestamp BYTEA = E'\\000\\000\\000\\000\\000\\000';
output TEXT = '';
unix_time BIGINT;
ulid BYTEA;
BEGIN
-- 6 timestamp bytes
unix_time = (EXTRACT(EPOCH FROM CLOCK_TIMESTAMP()) * 1000)::BIGINT;
timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER);
timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes
ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
-- Encode the entropy
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
RETURN output;
END
$$
LANGUAGE plpgsql
VOLATILE;
```
#### ULID TO UUID
```sql
CREATE OR REPLACE FUNCTION parse_ulid(ulid text) RETURNS bytea AS $$
DECLARE
-- 16byte
bytes bytea = E'\\x00000000 00000000 00000000 00000000';
v char[];
-- Allow for O(1) lookup of index values
dec integer[] = ARRAY[
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
255, 255, 255, 255, 255, 255, 255, 0, 1, 2,
3, 4, 5, 6, 7, 8, 9, 255, 255, 255,
255, 255, 255, 255, 10, 11, 12, 13, 14, 15,
16, 17, 1, 18, 19, 1, 20, 21, 0, 22,
23, 24, 25, 26, 255, 27, 28, 29, 30, 31,
255, 255, 255, 255, 255, 255, 10, 11, 12, 13,
14, 15, 16, 17, 1, 18, 19, 1, 20, 21,
0, 22, 23, 24, 25, 26, 255, 27, 28, 29,
30, 31
];
BEGIN
IF NOT ulid ~* '^[0-7][0-9ABCDEFGHJKMNPQRSTVWXYZ]{25}$' THEN
RAISE EXCEPTION 'Invalid ULID: %', ulid;
END IF;
v = regexp_split_to_array(ulid, '');
-- 6 bytes timestamp (48 bits)
bytes = SET_BYTE(bytes, 0, (dec[ASCII(v[1])] << 5) | dec[ASCII(v[2])]);
bytes = SET_BYTE(bytes, 1, (dec[ASCII(v[3])] << 3) | (dec[ASCII(v[4])] >> 2));
bytes = SET_BYTE(bytes, 2, (dec[ASCII(v[4])] << 6) | (dec[ASCII(v[5])] << 1) | (dec[ASCII(v[6])] >> 4));
bytes = SET_BYTE(bytes, 3, (dec[ASCII(v[6])] << 4) | (dec[ASCII(v[7])] >> 1));
bytes = SET_BYTE(bytes, 4, (dec[ASCII(v[7])] << 7) | (dec[ASCII(v[8])] << 2) | (dec[ASCII(v[9])] >> 3));
bytes = SET_BYTE(bytes, 5, (dec[ASCII(v[9])] << 5) | dec[ASCII(v[10])]);
-- 10 bytes of entropy (80 bits);
bytes = SET_BYTE(bytes, 6, (dec[ASCII(v[11])] << 3) | (dec[ASCII(v[12])] >> 2));
bytes = SET_BYTE(bytes, 7, (dec[ASCII(v[12])] << 6) | (dec[ASCII(v[13])] << 1) | (dec[ASCII(v[14])] >> 4));
bytes = SET_BYTE(bytes, 8, (dec[ASCII(v[14])] << 4) | (dec[ASCII(v[15])] >> 1));
bytes = SET_BYTE(bytes, 9, (dec[ASCII(v[15])] << 7) | (dec[ASCII(v[16])] << 2) | (dec[ASCII(v[17])] >> 3));
bytes = SET_BYTE(bytes, 10, (dec[ASCII(v[17])] << 5) | dec[ASCII(v[18])]);
bytes = SET_BYTE(bytes, 11, (dec[ASCII(v[19])] << 3) | (dec[ASCII(v[20])] >> 2));
bytes = SET_BYTE(bytes, 12, (dec[ASCII(v[20])] << 6) | (dec[ASCII(v[21])] << 1) | (dec[ASCII(v[22])] >> 4));
bytes = SET_BYTE(bytes, 13, (dec[ASCII(v[22])] << 4) | (dec[ASCII(v[23])] >> 1));
bytes = SET_BYTE(bytes, 14, (dec[ASCII(v[23])] << 7) | (dec[ASCII(v[24])] << 2) | (dec[ASCII(v[25])] >> 3));
bytes = SET_BYTE(bytes, 15, (dec[ASCII(v[25])] << 5) | dec[ASCII(v[26])]);
RETURN bytes;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
CREATE OR REPLACE FUNCTION ulid_to_uuid(ulid text) RETURNS uuid AS $$
BEGIN
RETURN encode(parse_ulid(ulid), 'hex')::uuid;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
```
#### UUID to ULID
```sql
CREATE OR REPLACE FUNCTION uuid_to_ulid(id uuid) RETURNS text AS $$
DECLARE
encoding bytea = '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
output text = '';
uuid_bytes bytea = uuid_send(id);
BEGIN
-- Encode the timestamp
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 224) >> 5));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 1) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 1) & 7) << 2) | ((GET_BYTE(uuid_bytes, 2) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 2) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 2) & 1) << 4) | ((GET_BYTE(uuid_bytes, 3) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 3) & 15) << 1) | ((GET_BYTE(uuid_bytes, 4) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 4) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 4) & 3) << 3) | ((GET_BYTE(uuid_bytes, 5) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 5) & 31)));
-- Encode the entropy
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 6) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 6) & 7) << 2) | ((GET_BYTE(uuid_bytes, 7) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 7) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 7) & 1) << 4) | ((GET_BYTE(uuid_bytes, 8) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 8) & 15) << 1) | ((GET_BYTE(uuid_bytes, 9) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 9) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 9) & 3) << 3) | ((GET_BYTE(uuid_bytes, 10) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 10) & 31)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 11) & 248) >> 3));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 11) & 7) << 2) | ((GET_BYTE(uuid_bytes, 12) & 192) >> 6)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 12) & 62) >> 1));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 12) & 1) << 4) | ((GET_BYTE(uuid_bytes, 13) & 240) >> 4)));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 13) & 15) << 1) | ((GET_BYTE(uuid_bytes, 14) & 128) >> 7)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 14) & 124) >> 2));
output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 14) & 3) << 3) | ((GET_BYTE(uuid_bytes, 15) & 224) >> 5)));
output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 15) & 31)));
RETURN output;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
```
#### Gera 11 Digitos aleatórios: YBKXG0CKTH4
```sql
-- Cria a extensão pgcrypto para gerar uuid
CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Cria a função para gerar ULID
CREATE OR REPLACE FUNCTION gen_lrandom()
RETURNS TEXT AS $$
DECLARE
ts_millis BIGINT;
ts_chars TEXT;
random_bytes BYTEA;
random_chars TEXT;
base32_chars TEXT := '0123456789ABCDEFGHJKMNPQRSTVWXYZ';
i INT;
BEGIN
-- Pega o timestamp em milissegundos
ts_millis := FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000)::BIGINT;
-- Converte o timestamp para base32
ts_chars := '';
FOR i IN REVERSE 0..11 LOOP
ts_chars := ts_chars || substr(base32_chars, ((ts_millis >> (5 * i)) & 31) + 1, 1);
END LOOP;
-- Gera 10 bytes aleatórios e converte para base32
random_bytes := gen_random_bytes(10);
random_chars := '';
FOR i IN 0..9 LOOP
random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) >> 3) & 31) + 1, 1);
IF i < 9 THEN
random_chars := random_chars || substr(base32_chars, (((get_byte(random_bytes, i) & 7) << 2) | (get_byte(random_bytes, i + 1) >> 6)) & 31 + 1, 1);
ELSE
random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) & 7) << 2) + 1, 1);
END IF;
END LOOP;
-- Concatena o timestamp e os caracteres aleatórios
RETURN ts_chars || random_chars;
END;
$$ LANGUAGE plpgsql;
```
#### Exemplo de USO
```sql
-- Criação da extensão caso não exista
CREATE EXTENSION
IF
NOT EXISTS pgcrypto;
-- Criação da tabela pessoas
CREATE TABLE pessoas ( ID UUID DEFAULT gen_random_uuid ( ) PRIMARY KEY, nome TEXT NOT NULL );
-- Busca Pessoa na tabela
SELECT
*
FROM
"pessoas"
WHERE
uuid_to_ulid ( ID ) = '252FAC9F3V8EF80SSDK8PXW02F';
```
### Fontes
- https://github.com/scoville/pgsql-ulid
- https://github.com/geckoboard/pgulid
-
@ e3ba5e1a:5e433365
2025-02-04 08:29:00
President Trump has started rolling out his tariffs, something I [blogged about in November](https://www.snoyman.com/blog/2024/11/steelmanning-tariffs/). People are talking about these tariffs a lot right now, with many people (correctly) commenting on how consumers will end up with higher prices as a result of these tariffs. While that part is true, I’ve seen a lot of people taking it to the next, incorrect step: that consumers will pay the entirety of the tax. I [put up a poll on X](https://x.com/snoyberg/status/1886035800019599808) to see what people thought, and while the right answer got a lot of votes, it wasn't the winner.

For purposes of this blog post, our ultimate question will be the following:
* Suppose apples currently sell for $1 each in the entire United States.
* There are domestic sellers and foreign sellers of apples, all receiving the same price.
* There are no taxes or tariffs on the purchase of apples.
* The question is: if the US federal government puts a $0.50 import tariff per apple, what will be the change in the following:
* Number of apples bought in the US
* Price paid by buyers for apples in the US
* Post-tax price received by domestic apple producers
* Post-tax price received by foreign apple producers
Before we can answer that question, we need to ask an easier, first question: before instituting the tariff, why do apples cost $1?
And finally, before we dive into the details, let me provide you with the answers to the ultimate question. I recommend you try to guess these answers before reading this, and if you get it wrong, try to understand why:
1. The number of apples bought will go down
2. The buyers will pay more for each apple they buy, but not the full amount of the tariff
3. Domestic apple sellers will receive a *higher* price per apple
4. Foreign apple sellers will receive a *lower* price per apple, but not lowered by the full amount of the tariff
In other words, regardless of who sends the payment to the government, both taxed parties (domestic buyers and foreign sellers) will absorb some of the costs of the tariff, while domestic sellers will benefit from the protectionism provided by tariffs and be able to sell at a higher price per unit.
## Marginal benefit
All of the numbers discussed below are part of a [helper Google Sheet](https://docs.google.com/spreadsheets/d/14ZbkWpw1B9Q1UDB9Yh47DmdKQfIafVVBKbDUsSIfGZw/edit?usp=sharing) I put together for this analysis. Also, apologies about the jagged lines in the charts below, I hadn’t realized before starting on this that there are [some difficulties with creating supply and demand charts in Google Sheets](https://superuser.com/questions/1359731/how-to-create-a-supply-demand-style-chart).
Let’s say I absolutely love apples, they’re my favorite food. How much would I be willing to pay for a single apple? You might say “$1, that’s the price in the supermarket,” and in many ways you’d be right. If I walk into supermarket A, see apples on sale for $50, and know that I can buy them at supermarket B for $1, I’ll almost certainly leave A and go buy at B.
But that’s not what I mean. What I mean is: how high would the price of apples have to go *everywhere* so that I’d no longer be willing to buy a single apple? This is a purely personal, subjective opinion. It’s impacted by how much money I have available, other expenses I need to cover, and how much I like apples. But let’s say the number is $5.
How much would I be willing to pay for another apple? Maybe another $5. But how much am I willing to pay for the 1,000th apple? 10,000th? At some point, I’ll get sick of apples, or run out of space to keep the apples, or not be able to eat, cook, and otherwise preserve all those apples before they rot.
The point being: I’ll be progressively willing to spend less and less money for each apple. This form of analysis is called *marginal benefit*: how much benefit (expressed as dollars I’m willing to spend) will I receive from each apple? This is a downward sloping function: for each additional apple I buy (quantity demanded), the price I’m willing to pay goes down. This is what gives my personal *demand curve*. And if we aggregate demand curves across all market participants (meaning: everyone interested in buying apples), we end up with something like this:
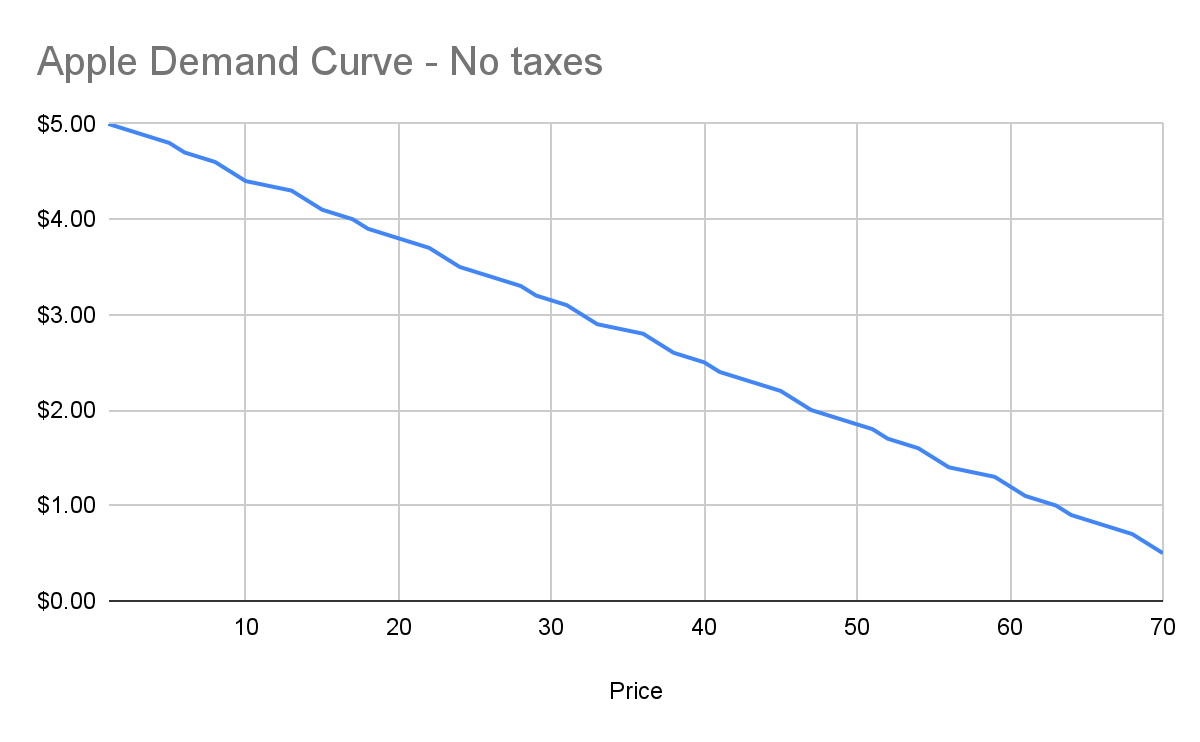
Assuming no changes in people’s behavior and other conditions in the market, this chart tells us how many apples will be purchased by our buyers at each price point between $0.50 and $5. And ceteris paribus (all else being equal), this will continue to be the demand curve for apples.
## Marginal cost
Demand is half the story of economics. The other half is supply, or: how many apples will I sell at each price point? Supply curves are upward sloping: the higher the price, the more a person or company is willing and able to sell a product.
Let’s understand why. Suppose I have an apple orchard. It’s a large property right next to my house. With about 2 minutes of effort, I can walk out of my house, find the nearest tree, pick 5 apples off the tree, and call it a day. 5 apples for 2 minutes of effort is pretty good, right?
Yes, there was all the effort necessary to buy the land, and plant the trees, and water them… and a bunch more than I likely can’t even guess at. We’re going to ignore all of that for our analysis, because for short-term supply-and-demand movement, we can ignore these kinds of *sunk costs*. One other simplification: in reality, supply curves often start descending before ascending. This accounts for achieving efficiencies of scale after the first number of units purchased. But since both these topics are unneeded for understanding taxes, I won’t go any further.
Anyway, back to my apple orchard. If someone offers me $0.50 per apple, I can do 2 minutes of effort and get $2.50 in revenue, which equates to a $75/hour wage for me. I’m more than happy to pick apples at that price\!
However, let’s say someone comes to buy 10,000 apples from me instead. I no longer just walk out to my nearest tree. I’m going to need to get in my truck, drive around, spend the day in the sun, pay for gas, take a day off of my day job (let’s say it pays me $70/hour). The costs go up significantly. Let’s say it takes 5 days to harvest all those apples myself, it costs me $100 in fuel and other expenses, and I lose out on my $70/hour job for 5 days. We end up with:
* Total expenditure: $100 \+ $70 \* 8 hours a day \* 5 days \== $2900
* Total revenue: $5000 (10,000 apples at $0.50 each)
* Total profit: $2100
So I’m still willing to sell the apples at this price, but it’s not as attractive as before. And as the number of apples purchased goes up, my costs keep increasing. I’ll need to spend more money on fuel to travel more of my property. At some point I won’t be able to do the work myself anymore, so I’ll need to pay others to work on the farm, and they’ll be slower at picking apples than me (less familiar with the property, less direct motivation, etc.). The point being: at some point, the number of apples can go high enough that the $0.50 price point no longer makes me any money.
This kind of analysis is called *marginal cost*. It refers to the additional amount of expenditure a seller has to spend in order to produce each additional unit of the good. Marginal costs go up as quantity sold goes up. And like demand curves, if you aggregate this data across all sellers, you get a supply curve like this:
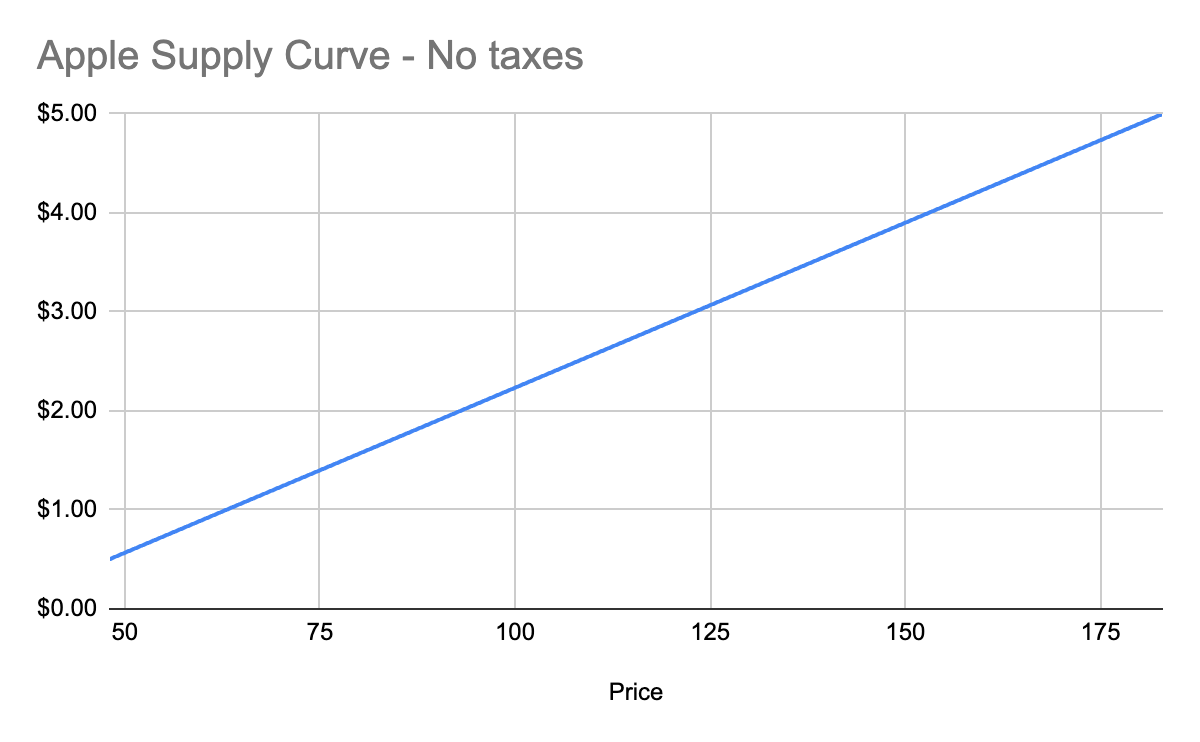
## Equilibrium price
We now know, for every price point, how many apples buyers will purchase, and how many apples sellers will sell. Now we find the equilibrium: where the supply and demand curves meet. This point represents where the marginal benefit a buyer would receive from the next buyer would be less than the cost it would take the next seller to make it. Let’s see it in a chart:
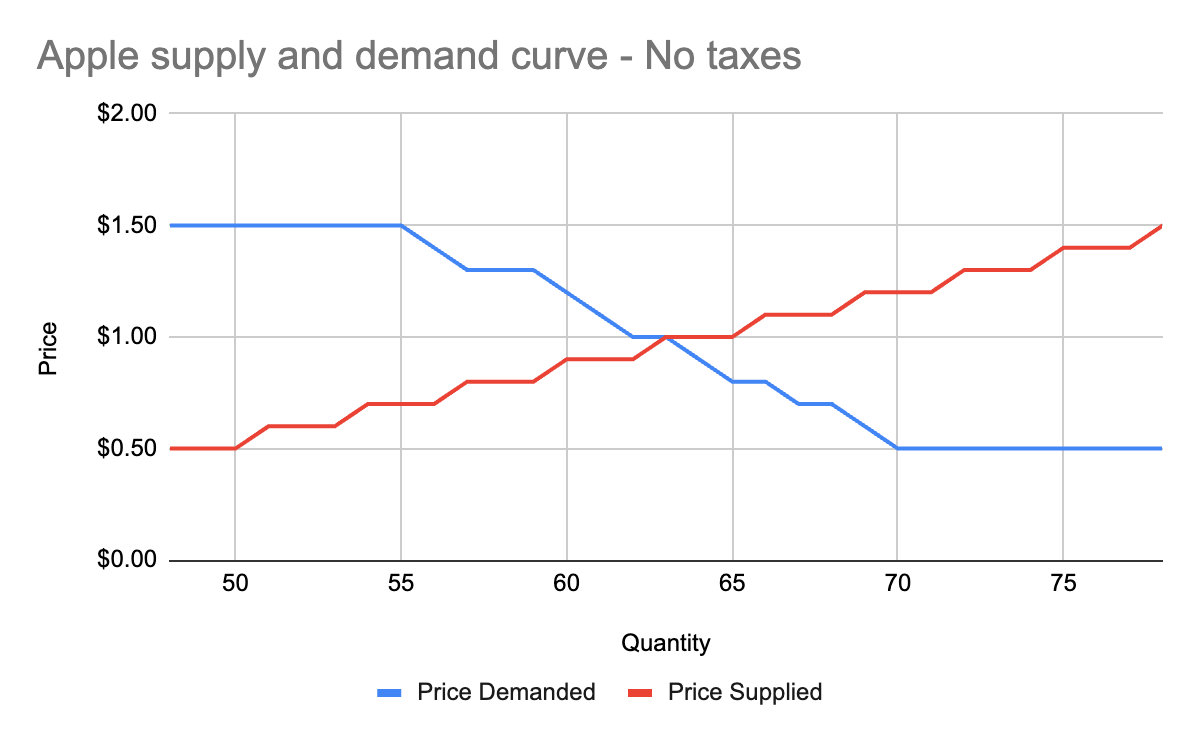
You’ll notice that these two graphs cross at the $1 price point, where 63 apples are both demanded (bought by consumers) and supplied (sold by producers). This is our equilibrium price. We also have a visualization of the *surplus* created by these trades. Everything to the left of the equilibrium point and between the supply and demand curves represents surplus: an area where someone is receiving something of more value than they give. For example:
* When I bought my first apple for $1, but I was willing to spend $5, I made $4 of consumer surplus. The consumer portion of the surplus is everything to the left of the equilibrium point, between the supply and demand curves, and above the equilibrium price point.
* When a seller sells his first apple for $1, but it only cost $0.50 to produce it, the seller made $0.50 of producer surplus. The producer portion of the surplus is everything to the left of the equilibrium point, between the supply and demand curves, and below the equilibrium price point.
Another way of thinking of surplus is “every time someone got a better price than they would have been willing to take.”
OK, with this in place, we now have enough information to figure out how to price in the tariff, which we’ll treat as a negative externality.
## Modeling taxes
Alright, the government has now instituted a $0.50 tariff on every apple sold within the US by a foreign producer. We can generally model taxes by either increasing the marginal cost of each unit sold (shifting the supply curve up), or by decreasing the marginal benefit of each unit bought (shifting the demand curve down). In this case, since only some of the producers will pay the tax, it makes more sense to modify the supply curve.
First, let’s see what happens to the foreign seller-only supply curve when you add in the tariff:
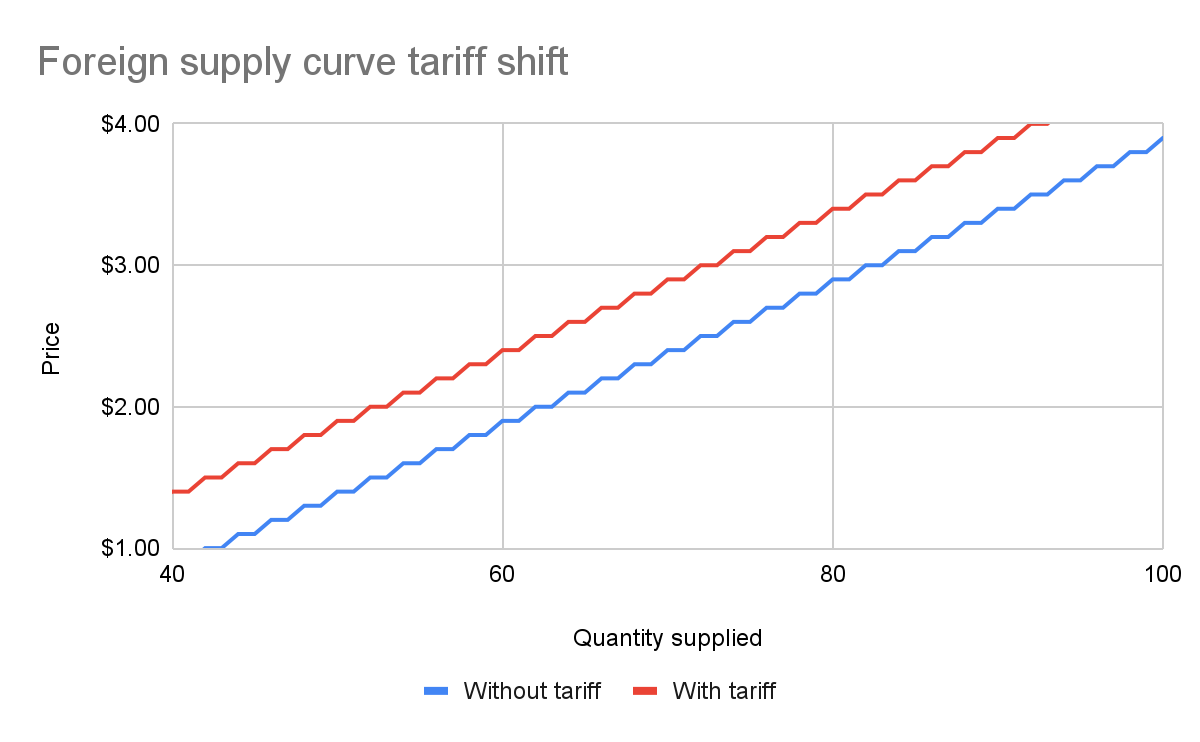
With the tariff in place, for each quantity level, the price at which the seller will sell is $0.50 higher than before the tariff. That makes sense: if I was previously willing to sell my 82nd apple for $3, I would now need to charge $3.50 for that apple to cover the cost of the tariff. We see this as the tariff “pushing up” or “pushing left” the original supply curve.
We can add this new supply curve to our existing (unchanged) supply curve for domestic-only sellers, and we end up with a result like this:
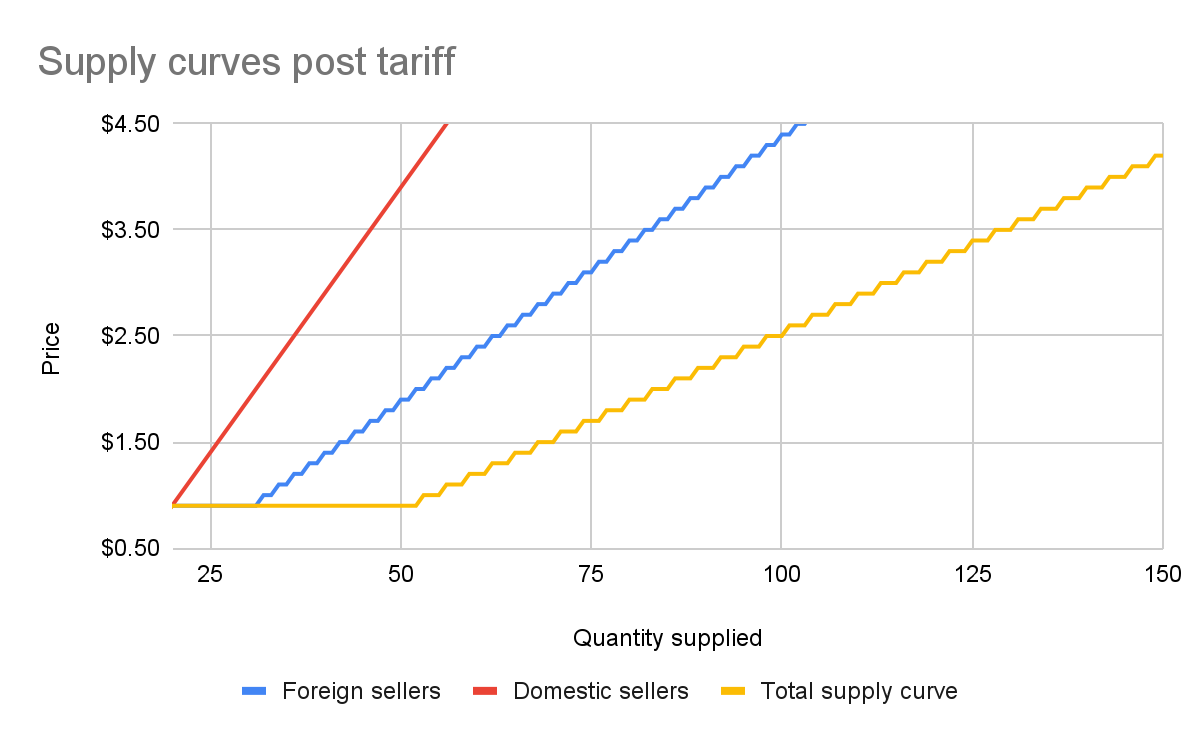
The total supply curve adds up the individual foreign and domestic supply curves. At each price point, we add up the total quantity each group would be willing to sell to determine the total quantity supplied for each price point. Once we have that cumulative supply curve defined, we can produce an updated supply-and-demand chart including the tariff:
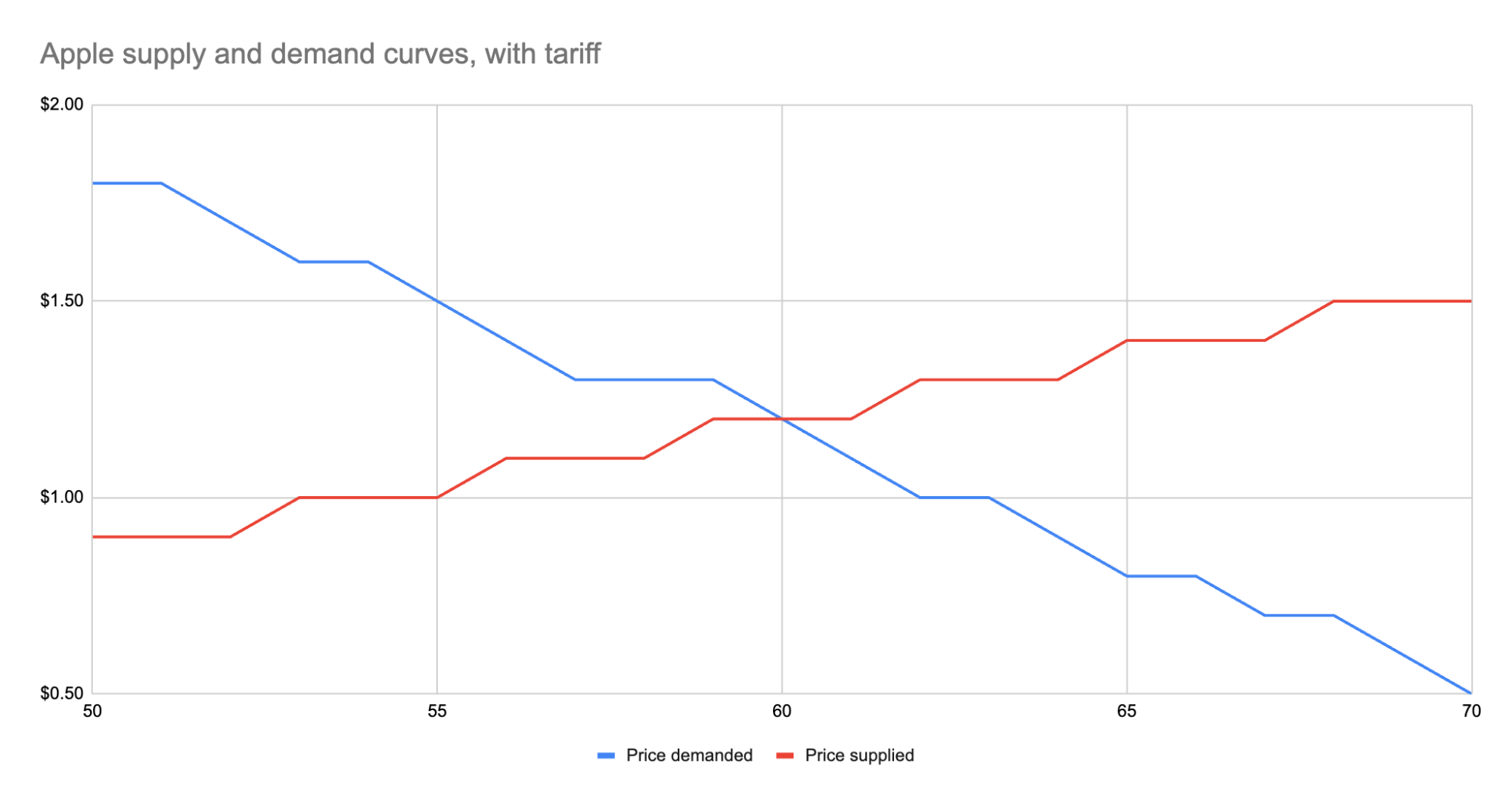
As we can see, the equilibrium has shifted:
* The equilibrium price paid by consumers has risen from $1 to $1.20.
* The total number of apples purchased has dropped from 63 apples to 60 apples.
* Consumers therefore received 3 less apples. They spent $72 for these 60 apples, whereas previously they spent $63 for 3 more apples, a definite decrease in consumer surplus.
* Foreign producers sold 36 of those apples (see the raw data in the linked Google Sheet), for a gross revenue of $43.20. However, they also need to pay the tariff to the US government, which accounts for $18, meaning they only receive $25.20 post-tariff. Previously, they sold 42 apples at $1 each with no tariff to be paid, meaning they took home $42.
* Domestic producers sold the remaining 24 apples at $1.20, giving them a revenue of $28.80. Since they don’t pay the tariff, they take home all of that money. By contrast, previously, they sold 21 apples at $1, for a take-home of $21.
* The government receives $0.50 for each of the 60 apples sold, or in other words receives $30 in revenue it wouldn’t have received otherwise.
We could be more specific about the surpluses, and calculate the actual areas for consumer surplus, producer surplus, inefficiency from the tariff, and government revenue from the tariff. But I won’t bother, as those calculations get slightly more involved. Instead, let’s just look at the aggregate outcomes:
* Consumers were unquestionably hurt. Their price paid went up by $0.20 per apple, and received less apples.
* Foreign producers were also hurt. Their price received went down from the original $1 to the new post-tariff price of $1.20, minus the $0.50 tariff. In other words: foreign producers only receive $0.70 per apple now. This hurt can be mitigated by shifting sales to other countries without a tariff, but the pain will exist regardless.
* Domestic producers scored. They can sell less apples and make more revenue doing it.
* And the government walked away with an extra $30.
Hopefully you now see the answer to the original questions. Importantly, while the government imposed a $0.50 tariff, neither side fully absorbed that cost. Consumers paid a bit more, foreign producers received a bit less. The exact details of how that tariff was split across the groups is mediated by the relevant supply and demand curves of each group. If you want to learn more about this, the relevant search term is “price elasticity,” or how much a group’s quantity supplied or demanded will change based on changes in the price.
## Other taxes
Most taxes are some kind of a tax on trade. Tariffs on apples is an obvious one. But the same applies to income tax (taxing the worker for the trade of labor for money) or payroll tax (same thing, just taxing the employer instead). Interestingly, you can use the same model for analyzing things like tax incentives. For example, if the government decided to subsidize domestic apple production by giving the domestic producers a $0.50 bonus for each apple they sell, we would end up with a similar kind of analysis, except instead of the foreign supply curve shifting up, we’d see the domestic supply curve shifting down.
And generally speaking, this is what you’ll *always* see with government involvement in the economy. It will result in disrupting an existing equilibrium, letting the market readjust to a new equilibrium, and incentivization of some behavior, causing some people to benefit and others to lose out. We saw with the apple tariff, domestic producers and the government benefited while others lost.
You can see the reverse though with tax incentives. If I give a tax incentive of providing a deduction (not paying income tax) for preschool, we would end up with:
* Government needs to make up the difference in tax revenue, either by raising taxes on others or printing more money (leading to inflation). Either way, those paying the tax or those holding government debased currency will pay a price.
* Those people who don’t use the preschool deduction will receive no benefit, so they simply pay a cost.
* Those who do use the preschool deduction will end up paying less on tax+preschool than they would have otherwise.
This analysis is fully amoral. It’s not saying whether providing subsidized preschool is a good thing or not, it simply tells you where the costs will be felt, and points out that such government interference in free economic choice does result in inefficiencies in the system. Once you have that knowledge, you’re more well educated on making a decision about whether the costs of government intervention are worth the benefits.
-
@ 9e69e420:d12360c2
2025-02-01 11:16:04

Federal employees must remove pronouns from email signatures by the end of the day. This directive comes from internal memos tied to two executive orders signed by Donald Trump. The orders target diversity and equity programs within the government.

CDC, Department of Transportation, and Department of Energy employees were affected. Staff were instructed to make changes in line with revised policy prohibiting certain language.
One CDC employee shared frustration, stating, “In my decade-plus years at CDC, I've never been told what I can and can't put in my email signature.” The directive is part of a broader effort to eliminate DEI initiatives from federal discourse.
-
@ 97c70a44:ad98e322
2025-01-30 17:15:37
There was a slight dust up recently over a website someone runs removing a listing for an app someone built based on entirely arbitrary criteria. I'm not to going to attempt to speak for either wounded party, but I would like to share my own personal definition for what constitutes a "nostr app" in an effort to help clarify what might be an otherwise confusing and opaque purity test.
In this post, I will be committing the "no true Scotsman" fallacy, in which I start with the most liberal definition I can come up with, and gradually refine it until all that is left is the purest, gleamingest, most imaginary and unattainable nostr app imaginable. As I write this, I wonder if anything built yet will actually qualify. In any case, here we go.
# It uses nostr
The lowest bar for what a "nostr app" might be is an app ("application" - i.e. software, not necessarily a native app of any kind) that has some nostr-specific code in it, but which doesn't take any advantage of what makes nostr distinctive as a protocol.
Examples might include a scraper of some kind which fulfills its charter by fetching data from relays (regardless of whether it validates or retains signatures). Another might be a regular web 2.0 app which provides an option to "log in with nostr" by requesting and storing the user's public key.
In either case, the fact that nostr is involved is entirely neutral. A scraper can scrape html, pdfs, jsonl, whatever data source - nostr relays are just another target. Likewise, a user's key in this scenario is treated merely as an opaque identifier, with no appreciation for the super powers it brings along.
In most cases, this kind of app only exists as a marketing ploy, or less cynically, because it wants to get in on the hype of being a "nostr app", without the developer quite understanding what that means, or having the budget to execute properly on the claim.
# It leverages nostr
Some of you might be wondering, "isn't 'leverage' a synonym for 'use'?" And you would be right, but for one connotative difference. It's possible to "use" something improperly, but by definition leverage gives you a mechanical advantage that you wouldn't otherwise have. This is the second category of "nostr app".
This kind of app gets some benefit out of the nostr protocol and network, but in an entirely selfish fashion. The intention of this kind of app is not to augment the nostr network, but to augment its own UX by borrowing some nifty thing from the protocol without really contributing anything back.
Some examples might include:
- Using nostr signers to encrypt or sign data, and then store that data on a proprietary server.
- Using nostr relays as a kind of low-code backend, but using proprietary event payloads.
- Using nostr event kinds to represent data (why), but not leveraging the trustlessness that buys you.
An application in this category might even communicate to its users via nostr DMs - but this doesn't make it a "nostr app" any more than a website that emails you hot deals on herbal supplements is an "email app". These apps are purely parasitic on the nostr ecosystem.
In the long-term, that's not necessarily a bad thing. Email's ubiquity is self-reinforcing. But in the short term, this kind of "nostr app" can actually do damage to nostr's reputation by over-promising and under-delivering.
# It complements nostr
Next up, we have apps that get some benefit out of nostr as above, but give back by providing a unique value proposition to nostr users as nostr users. This is a bit of a fine distinction, but for me this category is for apps which focus on solving problems that nostr isn't good at solving, leaving the nostr integration in a secondary or supporting role.
One example of this kind of app was Mutiny (RIP), which not only allowed users to sign in with nostr, but also pulled those users' social graphs so that users could send money to people they knew and trusted. Mutiny was doing a great job of leveraging nostr, as well as providing value to users with nostr identities - but it was still primarily a bitcoin wallet, not a "nostr app" in the purest sense.
Other examples are things like Nostr Nests and Zap.stream, whose core value proposition is streaming video or audio content. Both make great use of nostr identities, data formats, and relays, but they're primarily streaming apps. A good litmus test for things like this is: if you got rid of nostr, would it be the same product (even if inferior in certain ways)?
A similar category is infrastructure providers that benefit nostr by their existence (and may in fact be targeted explicitly at nostr users), but do things in a centralized, old-web way; for example: media hosts, DNS registrars, hosting providers, and CDNs.
To be clear here, I'm not casting aspersions (I don't even know what those are, or where to buy them). All the apps mentioned above use nostr to great effect, and are a real benefit to nostr users. But they are not True Scotsmen.
# It embodies nostr
Ok, here we go. This is the crème de la crème, the top du top, the meilleur du meilleur, the bee's knees. The purest, holiest, most chaste category of nostr app out there. The apps which are, indeed, nostr indigitate.
This category of nostr app (see, no quotes this time) can be defined by the converse of the previous category. If nostr was removed from this type of application, would it be impossible to create the same product?
To tease this apart a bit, apps that leverage the technical aspects of nostr are dependent on nostr the *protocol*, while apps that benefit nostr exclusively via network effect are integrated into nostr the *network*. An app that does both things is working in symbiosis with nostr as a whole.
An app that embraces both nostr's protocol and its network becomes an organic extension of every other nostr app out there, multiplying both its competitive moat and its contribution to the ecosystem:
- In contrast to apps that only borrow from nostr on the technical level but continue to operate in their own silos, an application integrated into the nostr network comes pre-packaged with existing users, and is able to provide more value to those users because of other nostr products. On nostr, it's a good thing to advertise your competitors.
- In contrast to apps that only market themselves to nostr users without building out a deep integration on the protocol level, a deeply integrated app becomes an asset to every other nostr app by becoming an organic extension of them through interoperability. This results in increased traffic to the app as other developers and users refer people to it instead of solving their problem on their own. This is the "micro-apps" utopia we've all been waiting for.
Credible exit doesn't matter if there aren't alternative services. Interoperability is pointless if other applications don't offer something your app doesn't. Marketing to nostr users doesn't matter if you don't augment their agency _as nostr users_.
If I had to choose a single NIP that represents the mindset behind this kind of app, it would be NIP 89 A.K.A. "Recommended Application Handlers", which states:
> Nostr's discoverability and transparent event interaction is one of its most interesting/novel mechanics. This NIP provides a simple way for clients to discover applications that handle events of a specific kind to ensure smooth cross-client and cross-kind interactions.
These handlers are the glue that holds nostr apps together. A single event, signed by the developer of an application (or by the application's own account) tells anyone who wants to know 1. what event kinds the app supports, 2. how to link to the app (if it's a client), and (if the pubkey also publishes a kind 10002), 3. which relays the app prefers.
_As a sidenote, NIP 89 is currently focused more on clients, leaving DVMs, relays, signers, etc somewhat out in the cold. Updating 89 to include tailored listings for each kind of supporting app would be a huge improvement to the protocol. This, plus a good front end for navigating these listings (sorry nostrapp.link, close but no cigar) would obviate the evil centralized websites that curate apps based on arbitrary criteria._
Examples of this kind of app obviously include many kind 1 clients, as well as clients that attempt to bring the benefits of the nostr protocol and network to new use cases - whether long form content, video, image posts, music, emojis, recipes, project management, or any other "content type".
To drill down into one example, let's think for a moment about forms. What's so great about a forms app that is built on nostr? Well,
- There is a [spec](https://github.com/nostr-protocol/nips/pull/1190) for forms and responses, which means that...
- Multiple clients can implement the same data format, allowing for credible exit and user choice, even of...
- Other products not focused on forms, which can still view, respond to, or embed forms, and which can send their users via NIP 89 to a client that does...
- Cryptographically sign forms and responses, which means they are self-authenticating and can be sent to...
- Multiple relays, which reduces the amount of trust necessary to be confident results haven't been deliberately "lost".
Show me a forms product that does all of those things, and isn't built on nostr. You can't, because it doesn't exist. Meanwhile, there are plenty of image hosts with APIs, streaming services, and bitcoin wallets which have basically the same levels of censorship resistance, interoperability, and network effect as if they weren't built on nostr.
# It supports nostr
Notice I haven't said anything about whether relays, signers, blossom servers, software libraries, DVMs, and the accumulated addenda of the nostr ecosystem are nostr apps. Well, they are (usually).
This is the category of nostr app that gets none of the credit for doing all of the work. There's no question that they qualify as beautiful nostrcorns, because their value propositions are entirely meaningless outside of the context of nostr. Who needs a signer if you don't have a cryptographic identity you need to protect? DVMs are literally impossible to use without relays. How are you going to find the blossom server that will serve a given hash if you don't know which servers the publishing user has selected to store their content?
In addition to being entirely contextualized by nostr architecture, this type of nostr app is valuable because it does things "the nostr way". By that I mean that they don't simply try to replicate existing internet functionality into a nostr context; instead, they create entirely new ways of putting the basic building blocks of the internet back together.
A great example of this is how Nostr Connect, Nostr Wallet Connect, and DVMs all use relays as brokers, which allows service providers to avoid having to accept incoming network connections. This opens up really interesting possibilities all on its own.
So while I might hesitate to call many of these things "apps", they are certainly "nostr".
# Appendix: it smells like a NINO
So, let's say you've created an app, but when you show it to people they politely smile, nod, and call it a NINO (Nostr In Name Only). What's a hacker to do? Well, here's your handy-dandy guide on how to wash that NINO stench off and Become a Nostr.
You app might be a NINO if:
- There's no NIP for your data format (or you're abusing NIP 78, 32, etc by inventing a sub-protocol inside an existing event kind)
- There's a NIP, but no one knows about it because it's in a text file on your hard drive (or buried in your project's repository)
- Your NIP imposes an incompatible/centralized/legacy web paradigm onto nostr
- Your NIP relies on trusted third (or first) parties
- There's only one implementation of your NIP (yours)
- Your core value proposition doesn't depend on relays, events, or nostr identities
- One or more relay urls are hard-coded into the source code
- Your app depends on a specific relay implementation to work (*ahem*, relay29)
- You don't validate event signatures
- You don't publish events to relays you don't control
- You don't read events from relays you don't control
- You use legacy web services to solve problems, rather than nostr-native solutions
- You use nostr-native solutions, but you've hardcoded their pubkeys or URLs into your app
- You don't use NIP 89 to discover clients and services
- You haven't published a NIP 89 listing for your app
- You don't leverage your users' web of trust for filtering out spam
- You don't respect your users' mute lists
- You try to "own" your users' data
Now let me just re-iterate - it's ok to be a NINO. We need NINOs, because nostr can't (and shouldn't) tackle every problem. You just need to decide whether your app, as a NINO, is actually contributing to the nostr ecosystem, or whether you're just using buzzwords to whitewash a legacy web software product.
If you're in the former camp, great! If you're in the latter, what are you waiting for? Only you can fix your NINO problem. And there are lots of ways to do this, depending on your own unique situation:
- Drop nostr support if it's not doing anyone any good. If you want to build a normal company and make some money, that's perfectly fine.
- Build out your nostr integration - start taking advantage of webs of trust, self-authenticating data, event handlers, etc.
- Work around the problem. Think you need a special relay feature for your app to work? Guess again. Consider encryption, AUTH, DVMs, or better data formats.
- Think your idea is a good one? Talk to other devs or open a PR to the [nips repo](https://github.com/nostr-protocol/nips). No one can adopt your NIP if they don't know about it.
- Keep going. It can sometimes be hard to distinguish a research project from a NINO. New ideas have to be built out before they can be fully appreciated.
- Listen to advice. Nostr developers are friendly and happy to help. If you're not sure why you're getting traction, ask!
I sincerely hope this article is useful for all of you out there in NINO land. Maybe this made you feel better about not passing the totally optional nostr app purity test. Or maybe it gave you some actionable next steps towards making a great NINON (Nostr In Not Only Name) app. In either case, GM and PV.
-
@ 9e69e420:d12360c2
2025-01-30 12:23:04
Tech stocks have taken a hit globally after China's DeepSeek launched a competitive AI chatbot at a much lower cost than US counterparts. This has stirred market fears of a $1.2 trillion loss across tech companies when trading opens in New York.
DeepSeek’s chatbot quickly topped download charts and surprised experts with its capabilities, developed for only $5.6 million.
The Nasdaq dropped over 3% in premarket trading, with major firms like Nvidia falling more than 10%. SoftBank also saw losses shortly after investing in a significant US AI venture.
Venture capitalist Marc Andreessen called it “AI’s Sputnik moment,” highlighting its potential impact on the industry.
![] (https://www.telegraph.co.uk/content/dam/business/2025/01/27/TELEMMGLPICT000409807198_17379939060750_trans_NvBQzQNjv4BqgsaO8O78rhmZrDxTlQBjdGLvJF5WfpqnBZShRL_tOZw.jpeg)
-
@ 0fa80bd3:ea7325de
2025-01-30 04:28:30
**"Degeneration"** or **"Вырождение"**
![[photo_2025-01-29 23.23.15.jpeg]]
A once-functional object, now eroded by time and human intervention, stripped of its original purpose. Layers of presence accumulate—marks, alterations, traces of intent—until the very essence is obscured. Restoration is paradoxical: to reclaim, one must erase. Yet erasure is an impossibility, for to remove these imprints is to deny the existence of those who shaped them.
The work stands as a meditation on entropy, memory, and the irreversible dialogue between creation and decay.
-
@ 0fa80bd3:ea7325de
2025-01-29 15:43:42
Lyn Alden - биткойн евангелист или евангелистка, я пока не понял
```
npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83a
```
Thomas Pacchia - PubKey owner - X - @tpacchia
```
npub1xy6exlg37pw84cpyj05c2pdgv86hr25cxn0g7aa8g8a6v97mhduqeuhgpl
```
calvadev - Shopstr
```
npub16dhgpql60vmd4mnydjut87vla23a38j689jssaqlqqlzrtqtd0kqex0nkq
```
Calle - Cashu founder
```
npub12rv5lskctqxxs2c8rf2zlzc7xx3qpvzs3w4etgemauy9thegr43sf485vg
```
Джек Дорси
```
npub1sg6plzptd64u62a878hep2kev88swjh3tw00gjsfl8f237lmu63q0uf63m
```
21 ideas
```
npub1lm3f47nzyf0rjp6fsl4qlnkmzed4uj4h2gnf2vhe3l3mrj85vqks6z3c7l
```
Много адресов. Хз кто надо сортировать
```
https://github.com/aitechguy/nostr-address-book
```
ФиатДжеф - создатель Ностр - https://github.com/fiatjaf
```
npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6
```
EVAN KALOUDIS Zues wallet
```
npub19kv88vjm7tw6v9qksn2y6h4hdt6e79nh3zjcud36k9n3lmlwsleqwte2qd
```
Программер Коди https://github.com/CodyTseng/nostr-relay
```
npub1syjmjy0dp62dhccq3g97fr87tngvpvzey08llyt6ul58m2zqpzps9wf6wl
```
Anna Chekhovich - Managing Bitcoin at The Anti-Corruption Foundation
https://x.com/AnyaChekhovich
```
npub1y2st7rp54277hyd2usw6shy3kxprnmpvhkezmldp7vhl7hp920aq9cfyr7
```
-
@ 0fa80bd3:ea7325de
2025-01-29 14:44:48
![[yedinaya-rossiya-bear.png]]
1️⃣ Be where the bear roams. Stay in its territory, where it hunts for food. No point setting a trap in your backyard if the bear’s chilling in the forest.
2️⃣ Set a well-hidden trap. Bury it, disguise it, and place the bait right in the center. Bears are omnivores—just like secret police KGB agents. And what’s the tastiest bait for them? Money.
3️⃣ Wait for the bear to take the bait. When it reaches in, the trap will snap shut around its paw. It’ll be alive, but stuck. No escape.
Now, what you do with a trapped bear is another question... 😏
-
@ 0fa80bd3:ea7325de
2025-01-29 05:55:02
The land that belongs to the indigenous peoples of Russia has been seized by a gang of killers who have unleashed a war of extermination. They wipe out anyone who refuses to conform to their rules. Those who disagree and stay behind are tortured and killed in prisons and labor camps. Those who flee lose their homeland, dissolve into foreign cultures, and fade away. And those who stand up to protect their people are attacked by the misled and deceived. The deceived die for the unchecked greed of a single dictator—thousands from both sides, people who just wanted to live, raise their kids, and build a future.
Now, they are forced to make an impossible choice: abandon their homeland or die. Some perish on the battlefield, others lose themselves in exile, stripped of their identity, scattered in a world that isn’t theirs.
There’s been endless debate about how to fix this, how to clear the field of the weeds that choke out every new sprout, every attempt at change. But the real problem? We can’t play by their rules. We can’t speak their language or use their weapons. We stand for humanity, and no matter how righteous our cause, we will not multiply suffering. Victory doesn’t come from matching the enemy—it comes from staying ahead, from using tools they haven’t mastered yet. That’s how wars are won.
Our only resource is the **will of the people** to rewrite the order of things. Historian Timothy Snyder once said that a nation cannot exist without a city. A city is where the most active part of a nation thrives. But the cities are occupied. The streets are watched. Gatherings are impossible. They control the money. They control the mail. They control the media. And any dissent is crushed before it can take root.
So I started asking myself: **How do we stop this fragmentation?** How do we create a space where people can **rebuild their connections** when they’re ready? How do we build a **self-sustaining network**, where everyone contributes and benefits proportionally, while keeping their freedom to leave intact? And more importantly—**how do we make it spread, even in occupied territory?**
In 2009, something historic happened: **the internet got its own money.** Thanks to **Satoshi Nakamoto**, the world took a massive leap forward. Bitcoin and decentralized ledgers shattered the idea that money must be controlled by the state. Now, to move or store value, all you need is an address and a key. A tiny string of text, easy to carry, impossible to seize.
That was the year money broke free. The state lost its grip. Its biggest weapon—physical currency—became irrelevant. Money became **purely digital.**
The internet was already **a sanctuary for information**, a place where people could connect and organize. But with Bitcoin, it evolved. Now, **value itself** could flow freely, beyond the reach of authorities.
Think about it: when seedlings are grown in controlled environments before being planted outside, they **get stronger, survive longer, and bear fruit faster.** That’s how we handle crops in harsh climates—nurture them until they’re ready for the wild.
Now, picture the internet as that **controlled environment** for **ideas**. Bitcoin? It’s the **fertile soil** that lets them grow. A testing ground for new models of interaction, where concepts can take root before they move into the real world. If **nation-states are a battlefield, locked in a brutal war for territory, the internet is boundless.** It can absorb any number of ideas, any number of people, and it doesn’t **run out of space.**
But for this ecosystem to thrive, people need safe ways to communicate, to share ideas, to build something real—**without surveillance, without censorship, without the constant fear of being erased.**
This is where **Nostr** comes in.
Nostr—"Notes and Other Stuff Transmitted by Relays"—is more than just a messaging protocol. **It’s a new kind of city.** One that **no dictator can seize**, no corporation can own, no government can shut down.
It’s built on **decentralization, encryption, and individual control.** Messages don’t pass through central servers—they are relayed through independent nodes, and users choose which ones to trust. There’s no master switch to shut it all down. Every person owns their identity, their data, their connections. And no one—no state, no tech giant, no algorithm—can silence them.
In a world where cities fall and governments fail, **Nostr is a city that cannot be occupied.** A place for ideas, for networks, for freedom. A city that grows stronger **the more people build within it**.
-
@ 9e69e420:d12360c2
2025-01-26 15:26:44
Secretary of State Marco Rubio issued new guidance halting spending on most foreign aid grants for 90 days, including military assistance to Ukraine. This immediate order shocked State Department officials and mandates “stop-work orders” on nearly all existing foreign assistance awards.
While it allows exceptions for military financing to Egypt and Israel, as well as emergency food assistance, it restricts aid to key allies like Ukraine, Jordan, and Taiwan. The guidance raises potential liability risks for the government due to unfulfilled contracts.
A report will be prepared within 85 days to recommend which programs to continue or discontinue.