-

@ 3bf0c63f:aefa459d
2024-03-19 14:01:01
# Nostr is not decentralized nor censorship-resistant
Peter Todd has been [saying this](nostr:nevent1qqsq5zzu9ezhgq6es36jgg94wxsa2xh55p4tfa56yklsvjemsw7vj3cpp4mhxue69uhkummn9ekx7mqpr4mhxue69uhkummnw3ez6ur4vgh8wetvd3hhyer9wghxuet5qy8hwumn8ghj7mn0wd68ytnddaksz9rhwden5te0dehhxarj9ehhsarj9ejx2aspzfmhxue69uhk7enxvd5xz6tw9ec82cspz3mhxue69uhhyetvv9ujuerpd46hxtnfduq3vamnwvaz7tmjv4kxz7fwdehhxarj9e3xzmnyqy28wumn8ghj7un9d3shjtnwdaehgu3wvfnsz9nhwden5te0wfjkccte9ec8y6tdv9kzumn9wspzpn92tr3hexwgt0z7w4qz3fcch4ryshja8jeng453aj4c83646jxvxkyvs4) for a long time and all the time I've been thinking he is misunderstanding everything, but I guess a more charitable interpretation is that he is right.
Nostr _today_ is indeed centralized.
Yesterday I published two harmless notes with the exact same content at the same time. In two minutes the notes had a noticeable difference in responses:
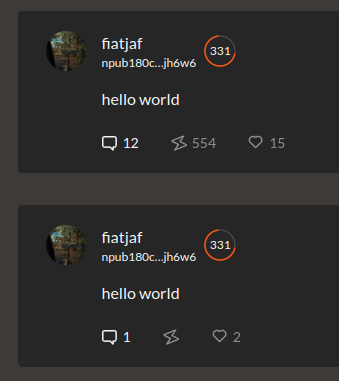
The top one was published to `wss://nostr.wine`, `wss://nos.lol`, `wss://pyramid.fiatjaf.com`. The second was published to the relay where I generally publish all my notes to, `wss://pyramid.fiatjaf.com`, and that is announced on my [NIP-05 file](https://fiatjaf.com/.well-known/nostr.json) and on my [NIP-65](https://nips.nostr.com/65) relay list.
A few minutes later I published that screenshot again in two identical notes to the same sets of relays, asking if people understood the implications. The difference in quantity of responses can still be seen today:
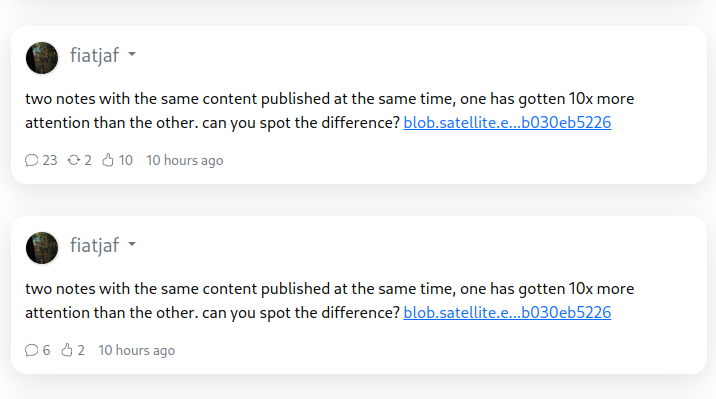
These results are skewed now by the fact that the two notes got rebroadcasted to multiple relays after some time, but the fundamental point remains.
What happened was that a huge lot more of people saw the first note compared to the second, and if Nostr was really censorship-resistant that shouldn't have happened at all.
Some people implied in the comments, with an air of obviousness, that publishing the note to "more relays" should have predictably resulted in more replies, which, again, shouldn't be the case if Nostr is really censorship-resistant.
What happens is that most people who engaged with the note are _following me_, in the sense that they have instructed their clients to fetch my notes on their behalf and present them in the UI, and clients are failing to do that despite me making it clear in multiple ways that my notes are to be found on `wss://pyramid.fiatjaf.com`.
If we were talking not about me, but about some public figure that was being censored by the State and got banned (or shadowbanned) by the 3 biggest public relays, the sad reality would be that the person would immediately get his reach reduced to ~10% of what they had before. This is not at all unlike what happened to dozens of personalities that were banned from the corporate social media platforms and then moved to other platforms -- how many of their original followers switched to these other platforms? Probably some small percentage close to 10%. In that sense Nostr today is similar to what we had before.
Peter Todd is right that if the way Nostr works is that you just subscribe to a small set of relays and expect to get everything from them then it tends to get very centralized very fast, and this is the reality today.
Peter Todd is wrong that Nostr is _inherently_ centralized or that it needs a _protocol change_ to become what it has always purported to be. He is in fact wrong today, because what is written above is not valid for all clients of today, and if we [drive in the right direction](bc63c348b) we can successfully make Peter Todd be more and more wrong as time passes, instead of the contrary.
---
See also:
- [Censorship-resistant relay discovery in Nostr](nostr:naddr1qqykycekxd3nxdpcvgq3zamnwvaz7tmxd9shg6npvchxxmmdqgsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8grqsqqqa2803ksy8)
- [A vision for content discovery and relay usage for basic social-networking in Nostr](nostr:naddr1qqyrxe33xqmxgve3qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cywwjvq)
-
@ 3bf0c63f:aefa459d
2024-03-19 13:07:02
# Censorship-resistant relay discovery in Nostr
In [Nostr is not decentralized nor censorship-resistant](nostr:naddr1qqyrsdmpxgcrsepeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c4n8rw6) I said Nostr is centralized. Peter Todd thinks it is centralized by design, but I disagree.
Nostr wasn't designed to be centralized. The idea was always that clients would follow people in the relays they decided to publish to, even if it was a single-user relay hosted in an island in the middle of the Pacific ocean.
But the Nostr explanations never had any guidance about how to do this, and the protocol itself never had any enforcement mechanisms for any of this (because it would be impossible).
My original idea was that clients would use some undefined combination of relay hints in reply tags and the (now defunct) `kind:2` relay-recommendation events plus some form of manual action ("it looks like Bob is publishing on relay X, do you want to follow him there?") to accomplish this. With the expectation that we would have a better idea of how to properly implement all this with more experience, Branle, my first working client didn't have any of that implemented, instead it used a stupid static list of relays with read/write toggle -- although it did publish relay hints and kept track of those internally and supported `kind:2` events, these things were not really useful.
[Gossip](https://github.com/mikedilger/gossip) was the first client to implement a [truly censorship-resistant relay discovery mechanism](https://mikedilger.com/gossip-relay-model.mp4) that used NIP-05 hints (originally proposed by [Mike Dilger](nprofile1qqswuyd9ml6qcxd92h6pleptfrcqucvvjy39vg4wx7mv9wm8kakyujgua442w)) relay hints and `kind:3` relay lists, and then with the simple insight of [NIP-65](https://nips.nostr.com/65) that got much better. After seeing it in more concrete terms, it became simpler to reason about it and the approach got popularized as the "gossip model", then implemented in clients like [Coracle](https://coracle.social) and [Snort](https://snort.social).
Today when people mention the "gossip model" (or "outbox model") they simply think about NIP-65 though. Which I think is ok, but too restrictive. I still think there is a place for the NIP-05 hints, `nprofile` and `nevent` relay hints and specially relay hints in event tags. All these mechanisms are used together in [ZBD Social](nostr:naddr1qqyxgvek8qmryc3eqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823chekfst), for example, but I believe also in the clients listed above.
I don't think we should stop here, though. I think there are other ways, perhaps drastically different ways, to approach content propagation and relay discovery. I think manual action by users is underrated and could go a long way if presented in a nice UX (not conceived by people that think users are dumb animals), and who knows what. Reliance on third-parties, hardcoded values, social graph, and specially a mix of multiple approaches, is what Nostr needs to be censorship-resistant and what I hope to see in the future.
-
@ dab6c606:51f507b6
2024-03-14 09:08:35
Some people want to cash out and are running around, looking for an OTC dealer to convert their Bitcoin to fiat.
Rather than replying to each of you directly, here's my uninformed, not a financial advice, but technological options that you have:
**Don't sell your Bitcoin and get fiat at the same time**
If you don't want to fully cash out, but still need some fiat, you can use Bitcoin-collateralized lending and get fiat. In most countries, this should be a tax-free operation (you are not selling your Bitcoin) - but consult a tax advisor.
Benefits: You still HODL, still participate on upside of Bitcoin, you are shorting fiat (which is a shitcoin), you can enjoy the fruits of your holdings, no taxes (in most countries)
Downsides: You pay interest rates on fiat, which are at least now not cheap (but that will fade away I guess), there are other risks with lending positions that I describe.
How to learn how to do it and choose the right platform:
- if you read my book Cryptocurrencies - Hack your way to a better life, you have already seen the chapter on collateralized loans
Get it here in [English](https://hackyourself.io/product/cryptocurrencies-hack-your-way-to-a-better-life/), [Spanish](https://hackyourself.io/product/criptodivisas/) or [Slovak](https://juraj.bednar.io/product/kryptomeny-vyhackuj-si-lepsi-zivot/)
- if you need more up to date information, you can get my newly published book [How to harness the value of Bitcoin without having to sell it: A path to your orange citadel and a way to short fiat currencies](https://www.amazon.com/dp/B0CW1GLDY3/). Kindle and Paperback available.
- if you want the same content, but with videos (e-book included too!), where I show everything end-to-end, [get the course](https://hackyourself.io/product/how-to-harness-the-value-of-bitcoin-without-having-to-sell-it-ebook-mini-course/)
**Find a counterparty that has the opposite problem using Vexl app**
I have [a short, free, no registration required course as a quick intro to Bitcoin](https://hackyourself.io/courses/a-quick-introduction-to-bitcoin-wallet-setup-buying-payments/), also [available in Slovak](https://juraj.bednar.io/courses/ako-si-kupit-prve-kryptomeny-a-zaplatit-nimi/)
There's [a chapter on vexl app](https://hackyourself.io/courses/a-quick-introduction-to-bitcoin-wallet-setup-buying-payments/lessons/finding-someone-to-buy-bitcoin-from-using-vexl-app/) where I show you how to find someone you can buy from or sell to.
**Other options, such as using proxy merchants**
Believe it or not, the cypherpunks have thought about this exact problem. And there are many more options that you will find in Cryptocurrencies - Hack your way to a better life. One of them is proxy merchants, where you can not exchange to fiat, but buy whatever you want to buy. There are proxy merchants selling amazon gift cards, Uber credit, data plans, etc. These days, you can even buy a car or a house using proxy merchants. There are many options, but a notable ones are [bitrefill for gift cards and all your phone needs](https://www.bitrefill.com/signup/?code=XZzReVuE).
And [Trocador for prepaid visa and mastercard cards](https://trocador.app/en/prepaidcards/?ref=uEHbJH9Fnw) without KYC.
-
@ fbd99de5:f1717f9b
2024-03-01 15:06:24
write testing 3
-
@ dab6c606:51f507b6
2024-02-19 14:14:27
I liked the book [Playful Parenting by Lawrence J. Cohen](https://www.amazon.com/Playful-Parenting-Connections-Encourage-Confidence/dp/0345442865/). While the book is amazing, it has many stories and explanations and I wanted a quick reference of some of the games he mentions (and some more). So I created this quick handbook as a reference of games to play with kids and what each game helps with (there's also a category reference in the end).
It's a quick "AI" hack, created in a few minutes. I recommend reading the original book, so you understand context and important things and then use this ebook as a quick reference.
The book is aimed at smaller kids (3-6 years).
Enjoy!
[Download as epub](https://juraj.bednar.io/assets/playfulpar/handbook-of-playful-parenting.epub)
[Download as PDF](https://juraj.bednar.io/assets/playfulpar/handbook-of-playful-parenting.pdf)
-
@ 8ce092d8:950c24ad
2024-02-04 23:35:07
# Overview
1. Introduction
2. Model Types
3. Training (Data Collection and Config Settings)
4. Probability Viewing: AI Inspector
5. Match
6. Cheat Sheet
# I. Introduction
AI Arena is the first game that combines human and artificial intelligence collaboration.
AI learns your skills through "imitation learning."
## Official Resources
1. Official Documentation (Must Read): [Everything You Need to Know About AI Arena](https://docs.aiarena.io/everything-you-need-to-know)
Watch the 2-minute video in the documentation to quickly understand the basic flow of the game.
2. Official Play-2-Airdrop competition FAQ Site
https://aiarena.notion.site/aiarena/Gateway-to-the-Arena-52145e990925499d95f2fadb18a24ab0
3. Official Discord (Must Join): https://discord.gg/aiarenaplaytest for the latest announcements or seeking help. The team will also have a exclusive channel there.
4. Official YouTube: https://www.youtube.com/@aiarena because the game has built-in tutorials, you can choose to watch videos.
## What is this game about?
1. Although categorized as a platform fighting game, the core is a probability-based strategy game.
2. Warriors take actions based on probabilities on the AI Inspector dashboard, competing against opponents.
3. The game does not allow direct manual input of probabilities for each area but inputs information through data collection and establishes models by adjusting parameters.
4. Data collection emulates fighting games, but training can be completed using a Dummy As long as you can complete the in-game tutorial, you can master the game controls.
# II. Model Types
Before training, there are three model types to choose from: Simple Model Type, Original Model Type, and Advanced Model Type.
**It is recommended to try the Advanced Model Type after completing at least one complete training with the Simple Model Type and gaining some understanding of the game.**

## Simple Model Type
The Simple Model is akin to completing a form, and the training session is comparable to filling various sections of that form.
This model has 30 buckets. Each bucket can be seen as telling the warrior what action to take in a specific situation. There are 30 buckets, meaning 30 different scenarios. Within the same bucket, the probabilities for direction or action are the same.
For example: What should I do when I'm off-stage — refer to the "Recovery (you off-stage)" bucket.
**For all buckets, refer to this official documentation:**
https://docs.aiarena.io/arenadex/game-mechanics/tabular-model-v2
**Video (no sound): The entire training process for all buckets**
https://youtu.be/1rfRa3WjWEA
Game version 2024.1.10. The method of saving is outdated. Please refer to the game updates.
## Advanced Model Type
The "Original Model Type" and "Advanced Model Type" are based on Machine Learning, which is commonly referred to as combining with AI.
The Original Model Type consists of only one bucket, representing the entire map. If you want the AI to learn different scenarios, you need to choose a "Focus Area" to let the warrior know where to focus. A single bucket means that a slight modification can have a widespread impact on the entire model. This is where the "Advanced Model Type" comes in.
The "Advanced Model Type" can be seen as a combination of the "Original Model Type" and the "Simple Model Type". The Advanced Model Type divides the map into 8 buckets. Each bucket can use many "Focus Area." For a detailed explanation of the 8 buckets and different Focus Areas, please refer to the tutorial page (accessible in the Advanced Model Type, after completing a training session, at the top left of the Advanced Config, click on "Tutorial").

# III. Training (Data Collection and Config Settings)
## Training Process:
1. **Collect Data**
2. **Set Parameters, Train, and Save**
3. **Repeat Step 1 until the Model is Complete**
Training the Simple Model Type is the easiest to start with; refer to the video above for a detailed process.
Training the Advanced Model Type offers more possibilities through the combination of "Focus Area" parameters, providing a higher upper limit. While the Original Model Type has great potential, it's harder to control. Therefore, this section focuses on the "Advanced Model Type."
## 1. What Kind of Data to Collect
1. **High-Quality Data:** Collect purposeful data. Garbage in, garbage out. Only collect the necessary data; don't collect randomly. It's recommended to use Dummy to collect data. However, don't pursue perfection; through parameter adjustments, AI has a certain level of fault tolerance.
2. **Balanced Data:** Balance your dataset. In simple terms, if you complete actions on the left side a certain number of times, also complete a similar number on the right side. While data imbalance can be addressed through parameter adjustments (see below), it's advised not to have this issue during data collection.
3. **Moderate Amount:** A single training will include many individual actions. Collect data for each action 1-10 times. Personally, it's recommended to collect data 2-3 times for a single action. If the effect of a single training is not clear, conduct a second (or even third) training with the same content, but with different parameter settings.
## 2. What to Collect (and Focus Area Selection)
Game actions mimic fighting games, consisting of 4 directions + 6 states (Idle, Jump, Attack, Grab, Special, Shield). Directions can be combined into ↗, ↘, etc. These directions and states can then be combined into different actions.
To make "Focus Area" effective, you need to collect data in training that matches these parameters. For example, for "Distance to Opponent", you need to collect data when close to the opponent and also when far away.
\* Note: While you can split into multiple training sessions, it's most effective to cover different situations within a single training.
Refer to the Simple Config, categorize the actions you want to collect, and based on the game scenario, classify them into two categories: "Movement" and "Combat."

### Movement-Based Actions
#### Action Collection
When the warrior is offstage, regardless of where the opponent is, we require the warrior to return to the stage to prevent self-destruction.
This involves 3 aerial buckets: 5 (Near Blast Zone), 7 (Under Stage), and 8 (Side Of Stage).

\* Note: The background comes from the Tutorial mentioned earlier. The arrows in the image indicate the direction of the action and are for reference only.
\* Note: Action collection should be clean; do not collect actions that involve leaving the stage.
#### Config Settings
In the Simple Config, you can directly choose "Movement" in it.
However, for better customization, it's recommended to use the Advanced Config directly.
- Intensity: The method for setting Intensity will be introduced separately later.
- Buckets: As shown in the image, choose the bucket you are training.
- Focus Area: Position-based parameters:
- Your position (must)
- Raycast Platform Distance, Raycast Platform Type (optional, generally choose these in Bucket 7)
### Combat-Based Actions
**The goal is to direct attacks quickly and effectively towards the opponent, which is the core of game strategy.**
This involves 5 buckets:
- 2 regular situations
- In the air: 6 (Safe Zone)
- On the ground: 4 (Opponent Active)
- 3 special situations on the ground:
- 1 Projectile Active
- 2 Opponent Knockback
- 3 Opponent Stunned
#### 2 Regular Situations
In the in-game tutorial, we learned how to perform horizontal attacks. However, in the actual game, directions expand to 8 dimensions. Imagine having 8 relative positions available for launching hits against the opponent. Our task is to design what action to use for attack or defense at each relative position.
**Focus Area**
- Basic (generally select all)
- Angle to opponent
- Distance to opponent
- Discrete Distance: Choosing this option helps better differentiate between closer and farther distances from the opponent. As shown in the image, red indicates a relatively close distance, and green indicates a relatively distant distance.
- Advanced: Other commonly used parameters
- Direction: different facings to opponent
- Your Elemental Gauge and Discrete Elementals: Considering the special's charge
- Opponent action: The warrior will react based on the opponent's different actions.
- Your action: Your previous action. Choose this if teaching combos.
#### 3 Special Situations on the Ground
Projectile Active, Opponent Stunned, Opponent Knockback
These three buckets can be referenced in the Simple Model Type video. The parameter settings approach is the same as Opponent Active/Safe Zone.
For Projectile Active, in addition to the parameters based on combat, to track the projectile, you also need to select "Raycast Projectile Distance" and "Raycast Projectile On Target."
### 3. Setting "Intensity"
#### Resources
- The "Tutorial" mentioned earlier explains these parameters.
- Official Config Document (2022.12.24):
https://docs.google.com/document/d/1adXwvDHEnrVZ5bUClWQoBQ8ETrSSKgG5q48YrogaFJs/edit
---
#### TL;DR:
**Epochs:**
- Adjust to fewer epochs if learning is insufficient, increase for more learning.
**Batch Size:**
- Set to the minimum (16) if data is precise but unbalanced, or just want it to learn fast
- Increase (e.g., 64) if data is slightly imprecise but balanced.
- If both imprecise and unbalanced, consider retraining.
**Learning Rate:**
- Maximize (0.01) for more learning but a risk of forgetting past knowledge.
- Minimize for more accurate learning with less impact on previous knowledge.
**Lambda:**
- Reduce for prioritizing learning new things.
**Data Cleaning:**
- Enable "Remove Sparsity" unless you want AI to learn idleness.
- For special cases, like teaching the warrior to use special moves when idle, refer to this tutorial video: https://discord.com/channels/1140682688651612291/1140683283626201098/1195467295913431111
**Personal Experience:**
- Initial training with settings: 125 epochs, batch size 16, learning rate 0.01, lambda 0, data cleaning enabled.
- Prioritize Multistream, sometimes use Oversampling.
- Fine-tune subsequent training based on the mentioned theories.
# IV. Probability Viewing: AI Inspector
The dashboard consists of "Direction + Action."
Above the dashboard, you can see the "Next Action" – the action the warrior will take in its current state.
The higher the probability, the more likely the warrior is to perform that action, indicating a quicker reaction.
It's essential to note that when checking the Direction, the one with the highest visual representation may not have the highest numerical value. To determine the actual value, hover the mouse over the graphical representation, as shown below, where the highest direction is "Idle."

In the map, you can drag the warrior to view the probabilities of the warrior in different positions. Right-click on the warrior with the mouse to change the warrior's facing. The status bar below can change the warrior's state on the map.

When training the "Opponent Stunned, Opponent Knockback" bucket, you need to select the status below the opponent's status bar. If you are focusing on "Opponent action" in the Focus Zone, choose the action in the opponent's status bar. If you are focusing on "Your action" in the Focus Zone, choose the action in your own status bar. When training the "Projectile Active" Bucket, drag the projectile on the right side of the dashboard to check the status.
**Next**
The higher the probability, the faster the reaction. However, be cautious when the action probability reaches 100%. This may cause the warrior to be in a special case of "State Transition," resulting in unnecessary "Idle" states.
> Explanation:
> In each state a fighter is in, there are different "possible transitions". For example, from falling state you cannot do low sweep because low sweep requires you to be on the ground. For the shield state, we do not allow you to directly transition to headbutt. So to do headbutt you have to first exit to another state and then do it from there (assuming that state allows you to do headbutt). This is the reason the fighter runs because "run" action is a valid state transition from shield.
[Source](https://discord.com/channels/848599369879388170/1079903287760928819/1160049804844470292)
# V. Learn from Matches
After completing all the training, your model is preliminarily finished—congratulations! The warrior will step onto the arena alone and embark on its debut!
Next, we will learn about the strengths and weaknesses of the warrior from battles to continue refining the warrior's model.
In matches, besides appreciating the performance, pay attention to the following:
1. **Movement, i.e., Off the Stage:** Observe how the warrior gets eliminated. Is it due to issues in the action settings at a certain position, or is it a normal death caused by a high percentage? The former is what we need to avoid and optimize.
2. **Combat:** Analyze both sides' actions carefully. Observe which actions you and the opponent used in different states. Check which of your hits are less effective, and how does the opponent handle different actions, etc.
The approach to battle analysis is similar to the thought process in the "Training", helping to have a more comprehensive understanding of the warrior's performance and making targeted improvements.
# VI. Cheat Sheet
**Training**
1. Click "Collect" to collect actions.
2. "Map - Data Limit" is more user-friendly. Most players perform initial training on the "Arena" map.
3. Switch between the warrior and the dummy: Tab key (keyboard) / Home key (controller).
4. Use "Collect" to make the opponent loop a set of actions.
5. Instantly move the warrior to a specific location: Click "Settings" - SPAWN - Choose the desired location on the map - On. Press the Enter key (keyboard) / Start key (controller) during training.
**Inspector**
1. Right-click on the fighter to change their direction. Drag the fighter and observe the changes in different positions and directions.
2. When satisfied with the training, click "Save."
3. In "Sparring" and "Simulation," use "Current Working Model."
4. If satisfied with a model, then click "compete." The model used in the rankings is the one marked as "competing."
**Sparring / Ranked**
1. Use the Throneroom map only for the top 2 or top 10 rankings.
2. There is a 30-second cooldown between matches. The replays are played for any match. Once the battle begins, you can see the winner on the leaderboard or by right-clicking the page - Inspect - Console. Also, if you encounter any errors or bugs, please send screenshots of the console to the Discord server.
Good luck! See you on the arena!
-
@ 3bf0c63f:aefa459d
2024-01-29 02:19:25
# Nostr: a quick introduction, attempt #1

Nostr doesn't have a material existence, it is not a website or an app. Nostr is just a description what kind of messages each computer can send to the others and vice-versa. It's a very simple thing, but the fact that such description exists allows different apps to connect to different servers automatically, without people having to talk behind the scenes or sign contracts or anything like that.
When you use a Nostr _client_ that is what happens, your _client_ will connect to a bunch of servers, called _relays_, and all these _relays_ will speak the same "language" so your _client_ will be able to publish notes to them all and also download notes from other people.
That's basically what Nostr is: this communication layer between the _client_ you run on your phone or desktop computer and the _relay_ that someone else is running on some server somewhere. There is no central authority dictating who can connect to whom or even anyone who knows for sure where each note is stored.
If you think about it, Nostr is very much like the internet itself: there are millions of websites out there, and basically anyone can run a new one, and there are websites that allow you to store and publish your stuff on them.
The added benefit of Nostr is that this unified "language" that all Nostr _clients_ speak allow them to switch very easily and cleanly between _relays_. So if one _relay_ decides to ban someone that person can switch to publishing to others _relays_ and their audience will quickly follow them there. Likewise, it becomes much easier for _relays_ to impose any restrictions they want on their users: no _relay_ has to uphold a moral ground of "absolute free speech": each _relay_ can decide to delete notes or ban users for no reason, or even only store notes from a preselected set of people and no one will be entitled to complain about that.
There are some bad things about this design: on Nostr there are no guarantees that _relays_ will have the notes you want to read or that they will store the notes you're sending to them. We can't just assume all _relays_ will have everything — much to the contrary, as Nostr grows more _relays_ will exist and people will tend to publishing to a small set of all the _relays_, so depending on the decisions each _client_ takes when publishing and when fetching notes, users may see a different set of replies to a note, for example, and be confused.
Another problem with the idea of publishing to multiple servers is that they may be run by all sorts of malicious people that may edit your notes. Since no one wants to see garbage published under their name, Nostr fixes that by requiring notes to have a cryptographic signature. This signature is attached to the note and verified by everybody at all times, which ensures the notes weren't tampered (if any part of the note is changed even by a single character that would cause the signature to become invalid and then the note would be dropped). The fix is perfect, except for the fact that it introduces the requirement that each user must now hold this 63-character code that starts with "nsec1", which they must not reveal to anyone. Although annoying, this requirement brings another benefit: that users can automatically have the same identity in many different contexts and even use their Nostr identity to login to non-Nostr websites easily without having to rely on any third-party.
To conclude: Nostr is like the internet (or the internet of some decades ago): a little chaotic, but very open. It is better than the internet because it is structured and actions can be automated, but, like in the internet itself, nothing is guaranteed to work at all times and users many have to do some manual work from time to time to fix things. Plus, there is the cryptographic key stuff, which is painful, but cool.
-
@ 3bf0c63f:aefa459d
2024-01-15 11:15:06
# Pequenos problemas que o Estado cria para a sociedade e que não são sempre lembrados
- **vale-transporte**: transferir o custo com o transporte do funcionário para um terceiro o estimula a morar longe de onde trabalha, já que morar perto é normalmente mais caro e a economia com transporte é inexistente.
- **atestado médico**: o direito a faltar o trabalho com atestado médico cria a exigência desse atestado para todas as situações, substituindo o livre acordo entre patrão e empregado e sobrecarregando os médicos e postos de saúde com visitas desnecessárias de assalariados resfriados.
- **prisões**: com dinheiro mal-administrado, burocracia e péssima alocação de recursos -- problemas que empresas privadas em competição (ou mesmo sem qualquer competição) saberiam resolver muito melhor -- o Estado fica sem presídios, com os poucos existentes entupidos, muito acima de sua alocação máxima, e com isto, segundo a bizarra corrente de responsabilidades que culpa o juiz que condenou o criminoso por sua morte na cadeia, juízes deixam de condenar à prisão os bandidos, soltando-os na rua.
- **justiça**: entrar com processos é grátis e isto faz proliferar a atividade dos advogados que se dedicam a criar problemas judiciais onde não seria necessário e a entupir os tribunais, impedindo-os de fazer o que mais deveriam fazer.
- **justiça**: como a justiça só obedece às leis e ignora acordos pessoais, escritos ou não, as pessoas não fazem acordos, recorrem sempre à justiça estatal, e entopem-na de assuntos que seriam muito melhor resolvidos entre vizinhos.
- **leis civis**: as leis criadas pelos parlamentares ignoram os costumes da sociedade e são um incentivo a que as pessoas não respeitem nem criem normas sociais -- que seriam maneiras mais rápidas, baratas e satisfatórias de resolver problemas.
- **leis de trãnsito**: quanto mais leis de trânsito, mais serviço de fiscalização são delegados aos policiais, que deixam de combater crimes por isto (afinal de contas, eles não querem de fato arriscar suas vidas combatendo o crime, a fiscalização é uma excelente desculpa para se esquivarem a esta responsabilidade).
- **financiamento educacional**: é uma espécie de subsídio às faculdades privadas que faz com que se criem cursos e mais cursos que são cada vez menos recheados de algum conhecimento ou técnica útil e cada vez mais inúteis.
- **leis de tombamento**: são um incentivo a que o dono de qualquer área ou construção "histórica" destrua todo e qualquer vestígio de história que houver nele antes que as autoridades descubram, o que poderia não acontecer se ele pudesse, por exemplo, usar, mostrar e se beneficiar da história daquele local sem correr o risco de perder, de fato, a sua propriedade.
- **zoneamento urbano**: torna as cidades mais espalhadas, criando uma necessidade gigantesca de carros, ônibus e outros meios de transporte para as pessoas se locomoverem das zonas de moradia para as zonas de trabalho.
- **zoneamento urbano**: faz com que as pessoas percam horas no trânsito todos os dias, o que é, além de um desperdício, um atentado contra a sua saúde, que estaria muito melhor servida numa caminhada diária entre a casa e o trabalho.
- **zoneamento urbano**: torna ruas e as casas menos seguras criando zonas enormes, tanto de residências quanto de indústrias, onde não há movimento de gente alguma.
- **escola obrigatória + currículo escolar nacional**: emburrece todas as crianças.
- **leis contra trabalho infantil**: tira das crianças a oportunidade de aprender ofícios úteis e levar um dinheiro para ajudar a família.
- **licitações**: como não existem os critérios do mercado para decidir qual é o melhor prestador de serviço, criam-se comissões de pessoas que vão decidir coisas. isto incentiva os prestadores de serviço que estão concorrendo na licitação a tentar comprar os membros dessas comissões. isto, fora a corrupção, gera problemas reais: __(i)__ a escolha dos serviços acaba sendo a pior possível, já que a empresa prestadora que vence está claramente mais dedicada a comprar comissões do que a fazer um bom trabalho (este problema afeta tantas áreas, desde a construção de estradas até a qualidade da merenda escolar, que é impossível listar aqui); __(ii)__ o processo corruptor acaba, no longo prazo, eliminando as empresas que prestavam e deixando para competir apenas as corruptas, e a qualidade tende a piorar progressivamente.
- **cartéis**: o Estado em geral cria e depois fica refém de vários grupos de interesse. o caso dos taxistas contra o Uber é o que está na moda hoje (e o que mostra como os Estados se comportam da mesma forma no mundo todo).
- **multas**: quando algum indivíduo ou empresa comete uma fraude financeira, ou causa algum dano material involuntário, as vítimas do caso são as pessoas que sofreram o dano ou perderam dinheiro, mas o Estado tem sempre leis que prevêem multas para os responsáveis. A justiça estatal é sempre muito rígida e rápida na aplicação dessas multas, mas relapsa e vaga no que diz respeito à indenização das vítimas. O que em geral acontece é que o Estado aplica uma enorme multa ao responsável pelo mal, retirando deste os recursos que dispunha para indenizar as vítimas, e se retira do caso, deixando estas desamparadas.
- **desapropriação**: o Estado pode pegar qualquer propriedade de qualquer pessoa mediante uma indenização que é necessariamente inferior ao valor da propriedade para o seu presente dono (caso contrário ele a teria vendido voluntariamente).
- **seguro-desemprego**: se há, por exemplo, um prazo mínimo de 1 ano para o sujeito ter direito a receber seguro-desemprego, isto o incentiva a planejar ficar apenas 1 ano em cada emprego (ano este que será sucedido por um período de desemprego remunerado), matando todas as possibilidades de aprendizado ou aquisição de experiência naquela empresa específica ou ascensão hierárquica.
- **previdência**: a previdência social tem todos os defeitos de cálculo do mundo, e não importa muito ela ser uma forma horrível de poupar dinheiro, porque ela tem garantias bizarras de longevidade fornecidas pelo Estado, além de ser compulsória. Isso serve para criar no imaginário geral a idéia da __aposentadoria__, uma época mágica em que todos os dias serão finais de semana. A idéia da aposentadoria influencia o sujeito a não se preocupar em ter um emprego que faça sentido, mas sim em ter um trabalho qualquer, que o permita se aposentar.
- **regulamentação impossível**: milhares de coisas são proibidas, há regulamentações sobre os aspectos mais mínimos de cada empreendimento ou construção ou espaço. se todas essas regulamentações fossem exigidas não haveria condições de produção e todos morreriam. portanto, elas não são exigidas. porém, o Estado, ou um agente individual imbuído do poder estatal pode, se desejar, exigi-las todas de um cidadão inimigo seu. qualquer pessoa pode viver a vida inteira sem cumprir nem 10% das regulamentações estatais, mas viverá também todo esse tempo com medo de se tornar um alvo de sua exigência, num estado de terror psicológico.
- **perversão de critérios**: para muitas coisas sobre as quais a sociedade normalmente chegaria a um valor ou comportamento "razoável" espontaneamente, o Estado dita regras. estas regras muitas vezes não são obrigatórias, são mais "sugestões" ou limites, como o salário mínimo, ou as 44 horas semanais de trabalho. a sociedade, porém, passa a usar esses valores como se fossem o normal. são raras, por exemplo, as ofertas de emprego que fogem à regra das 44h semanais.
- **inflação**: subir os preços é difícil e constrangedor para as empresas, pedir aumento de salário é difícil e constrangedor para o funcionário. a inflação força as pessoas a fazer isso, mas o aumento não é automático, como alguns economistas podem pensar (enquanto alguns outros ficam muito satisfeitos de que esse processo seja demorado e difícil).
- **inflação**: a inflação destrói a capacidade das pessoas de julgar preços entre concorrentes usando a própria memória.
- **inflação**: a inflação destrói os cálculos de lucro/prejuízo das empresas e prejudica enormemente as decisões empresariais que seriam baseadas neles.
- **inflação**: a inflação redistribui a riqueza dos mais pobres e mais afastados do sistema financeiro para os mais ricos, os bancos e as megaempresas.
- **inflação**: a inflação estimula o endividamento e o consumismo.
- **lixo:** ao prover coleta e armazenamento de lixo "grátis para todos" o Estado incentiva a criação de lixo. se tivessem que pagar para que recolhessem o seu lixo, as pessoas (e conseqüentemente as empresas) se empenhariam mais em produzir coisas usando menos plástico, menos embalagens, menos sacolas.
- **leis contra crimes financeiros:** ao criar legislação para dificultar acesso ao sistema financeiro por parte de criminosos a dificuldade e os custos para acesso a esse mesmo sistema pelas pessoas de bem cresce absurdamente, levando a um percentual enorme de gente incapaz de usá-lo, para detrimento de todos -- e no final das contas os grandes criminosos ainda conseguem burlar tudo.
-
@ 3bf0c63f:aefa459d
2024-01-15 11:15:06
# Anglicismos estúpidos no português contemporâneo
Palavras e expressões que ninguém deveria usar porque não têm o sentido que as pessoas acham que têm, são apenas aportuguesamentos de palavras inglesas que por nuances da história têm um sentido ligeiramente diferente em inglês.
Cada erro é acompanhado também de uma sugestão de como corrigi-lo.
### Palavras que existem em português com sentido diferente
- _submissão_ (de trabalhos): **envio**, **apresentação**
- _disrupção_: **perturbação**
- _assumir_: **considerar**, **pressupor**, **presumir**
- _realizar_: **perceber**
- _endereçar_: **tratar de**
- _suporte_ (ao cliente): **atendimento**
- _suportar_ (uma idéia, um projeto): **apoiar**, **financiar**
- _suportar_ (uma função, recurso, característica): **oferecer**, **ser compatível com**
- _literacia_: **instrução**, **alfabetização**
- _convoluto_: **complicado**.
- _acurácia_: **precisão**.
- _resiliência_: **resistência**.
### Aportuguesamentos desnecessários
- _estartar_: **iniciar**, **começar**
- _treidar_: **negociar**, **especular**
### Expressões
- _"não é sobre..."_: **"não se trata de..."**
## Ver também
- [Algumas expressões e ditados excelentes da língua portuguesa, e outras não tão excelentes assim](https://fiatjaf.alhur.es/expressões-e-ditados.txt)
-
@ 3bf0c63f:aefa459d
2024-01-14 14:52:16
# Drivechain
Understanding Drivechain requires a shift from the paradigm most bitcoiners are used to. It is not about "trustlessness" or "mathematical certainty", but game theory and incentives. (Well, Bitcoin in general is also that, but people prefer to ignore it and focus on some illusion of trustlessness provided by mathematics.)
Here we will describe the basic mechanism (simple) and incentives (complex) of ["hashrate escrow"](https://github.com/bitcoin/bips/blob/master/bip-0300.mediawiki) and how it enables a 2-way peg between the mainchain (Bitcoin) and various sidechains.
The full concept of "Drivechain" also involves blind merged mining (i.e., the sidechains mine themselves by publishing their block hashes to the mainchain without the miners having to run the sidechain software), but this is much easier to understand and can be accomplished either by [the BIP-301 mechanism](https://github.com/bitcoin/bips/blob/master/bip-0301.mediawiki) or by [the Spacechains mechanism](https://gist.github.com/RubenSomsen/5e4be6d18e5fa526b17d8b34906b16a5).
## How does hashrate escrow work from the point of view of Bitcoin?
A new address type is created. Anything that goes in that is locked and can only be spent if all miners agree on the _Withdrawal Transaction_ (`WT^`) that will spend it for 6 months. There is one of these special addresses for each sidechain.
To gather miners' agreement `bitcoind` keeps track of the "score" of all transactions that could possibly spend from that address. On every block mined, for each sidechain, the miner can use a portion of their coinbase to either increase the score of one `WT^` by 1 while decreasing the score of all others by 1; or they can decrease the score of all `WT^`s by 1; or they can do nothing.
Once a transaction has gotten a score high enough, it is published and funds are effectively transferred from the sidechain to the withdrawing users.
If a timeout of 6 months passes and the score doesn't meet the threshold, that `WT^` is discarded.
## What does the above procedure _mean_?
It means that people can transfer coins from the mainchain to a sidechain by depositing to the special address. Then they can withdraw from the sidechain by making a special withdraw transaction in the sidechain.
The special transaction somehow freezes funds in the sidechain while a transaction that aggregates all withdrawals into a single mainchain `WT^`, which is then submitted to the mainchain miners so they can start voting on it and finally after some months it is published.
Now the crucial part: _the validity of the `WT^` is not verified by the Bitcoin mainchain rules_, i.e., if Bob has requested a withdraw from the sidechain to his mainchain address, but someone publishes a wrong `WT^` that instead takes Bob's funds and sends them to Alice's main address there is no way the mainchain will know that. What determines the "validity" of the `WT^` is the miner vote score and only that. It is the job of miners to vote correctly -- and for that they may want to run the sidechain node in SPV mode so they can attest for the existence of a reference to the `WT^` transaction in the sidechain blockchain (which then ensures it is ok) or do these checks by some other means.
## What? 6 months to get my money back?
Yes. But no, in practice anyone who wants their money back will be able to use an atomic swap, submarine swap or other similar service to transfer funds from the sidechain to the mainchain and vice-versa. The long delayed withdraw costs would be incurred by few liquidity providers that would gain some small profit from it.
## Why bother with this at all?
Drivechains solve many different problems:
### It enables experimentation and new use cases for Bitcoin
Issued assets, fully private transactions, stateful blockchain contracts, turing-completeness, decentralized games, some "DeFi" aspects, prediction markets, futarchy, decentralized and yet meaningful human-readable names, big blocks with a ton of normal transactions on them, a chain optimized only for Lighting-style networks to be built on top of it.
These are some ideas that may have merit to them, but were never _actually_ tried because they couldn't be tried with real Bitcoin or inferfacing with real bitcoins. They were either relegated to the shitcoin territory or to custodial solutions like Liquid or RSK that may have failed to gain network effect because of that.
### It solves conflicts and infighting
Some people want fully private transactions in a UTXO model, others want "accounts" they can tie to their name and build reputation on top; some people want simple multisig solutions, others want complex code that reads a ton of variables; some people want to put all the transactions on a global chain in batches every 10 minutes, others want off-chain instant transactions backed by funds previously locked in channels; some want to spend, others want to just hold; some want to use blockchain technology to solve all the problems in the world, others just want to solve money.
With Drivechain-based sidechains all these groups can be happy simultaneously and don't fight. Meanwhile they will all be using the same money and contributing to each other's ecosystem even unwillingly, it's also easy and free for them to change their group affiliation later, which reduces cognitive dissonance.
### It solves "scaling"
Multiple chains like the ones described above would certainly do a lot to accomodate many more transactions that the current Bitcoin chain can. One could have special Lightning Network chains, but even just big block chains or big-block-mimblewimble chains or whatnot could probably do a good job. Or even something less cool like 200 independent chains just like Bitcoin is today, no extra features (and you can call it "sharding"), just that would already multiply the current total capacity by 200.
Use your imagination.
### It solves the blockchain security budget issue
The calculation is simple: you imagine what security budget is reasonable for each block in a world without block subsidy and divide that for the amount of bytes you can fit in a single block: that is the price to be paid in _satoshis per byte_. In reasonable estimative, the price necessary for every Bitcoin transaction goes to very large amounts, such that not only any day-to-day transaction has insanely prohibitive costs, but also Lightning channel opens and closes are impracticable.
So without a solution like Drivechain you'll be left with only one alternative: pushing Bitcoin usage to trusted services like Liquid and RSK or custodial Lightning wallets. With Drivechain, though, there could be thousands of transactions happening in sidechains and being all aggregated into a sidechain block that would then pay a very large fee to be published (via blind merged mining) to the mainchain. Bitcoin security guaranteed.
### It keeps Bitcoin decentralized
Once we have sidechains to accomodate the normal transactions, the mainchain functionality can be reduced to be only a "hub" for the sidechains' comings and goings, and then the maximum block size for the mainchain can be reduced to, say, 100kb, which would make running a full node very very easy.
## Can miners steal?
Yes. If a group of coordinated miners are able to secure the majority of the hashpower and keep their coordination for 6 months, they can publish a `WT^` that takes the money from the sidechains and pays to themselves.
## Will miners steal?
No, because the incentives are such that they won't.
Although it may look at first that stealing is an obvious strategy for miners as it is free money, there are many costs involved:
1. The cost of **ceasing blind-merged mining returns** -- as stealing will kill a sidechain, all the fees from it that miners would be expected to earn for the next years are gone;
2. The cost of **Bitcoin price going down**: If a steal is successful that will mean Drivechains are not safe, therefore Bitcoin is less useful, and miner credibility will also be hurt, which are likely to cause the Bitcoin price to go down, which in turn may kill the miners' businesses and savings;
3. The cost of **coordination** -- assuming miners are just normal businesses, they just want to do their work and get paid, but stealing from a Drivechain will require coordination with other miners to conduct an immoral act in a way that has many pitfalls and is likely to be broken over the months;
4. The cost of **miners leaving your mining pool**: when we talked about "miners" above we were actually talking about mining pools operators, so they must also consider the risk of miners migrating from their mining pool to others as they begin the process of stealing;
5. The cost of **community goodwill** -- when participating in a steal operation, a miner will suffer a ton of backlash from the community. Even if the attempt fails at the end, the fact that it was attempted will contribute to growing concerns over exaggerated miners power over the Bitcoin ecosystem, which may end up causing the community to agree on a hard-fork to change the mining algorithm in the future, or to do something to increase participation of more entities in the mining process (such as development or cheapment of new ASICs), which have a chance of decreasing the profits of current miners.
Another point to take in consideration is that one may be inclined to think a newly-created sidechain or a sidechain with relatively low usage may be more easily stolen from, since the blind merged mining returns from it (point 1 above) are going to be small -- but the fact is also that a sidechain with small usage will also have less money to be stolen from, and since the other costs besides 1 are less elastic at the end it will not be worth stealing from these too.
All of the above consideration are valid only if miners are stealing from _good sidechains_. If there is a sidechain that is doing things wrong, scamming people, not being used at all, or is full of bugs, for example, that will be perceived as a bad sidechain, and then miners can and will safely steal from it and kill it, which will be perceived as a good thing by everybody.
## What do we do if miners steal?
Paul Sztorc has suggested in the past that a user-activated soft-fork could prevent miners from stealing, i.e., most Bitcoin users and nodes issue a rule [similar to this one](https://twitter.com/LukeDashjr/status/1126221228182843398) to invalidate the inclusion of a faulty `WT^` and thus cause any miner that includes it in a block to be relegated to their own Bitcoin fork that other nodes won't accept.
This suggestion has made people think Drivechain is a sidechain solution _backed by user-actived soft-forks for safety_, which is very far from the truth. Drivechains must not and will not rely on this kind of soft-fork, although they are possible, as the coordination costs are too high and no one should ever expect these things to happen.
If even with all the incentives against them (see above) miners do still steal from a _good sidechain_ that will mean _the failure of the Drivechain experiment_. It will very likely also mean _the failure of the Bitcoin experiment_ too, as it will be proven that miners can coordinate to act maliciously over a prolonged period of time regardless of economic and social incentives, meaning they are probably in it just for attacking Bitcoin, backed by nation-states or something else, and therefore no Bitcoin transaction in the mainchain is to be expected to be safe ever again.
## Why use this and not a full-blown trustless and open sidechain technology?
Because it is impossible.
If you ever heard someone saying "just use a sidechain", "do this in a sidechain" or anything like that, be aware that these people are either talking about "federated" sidechains (i.e., funds are kept in custody by a group of entities) or they are talking about Drivechain, or they are disillusioned and think it is possible to do sidechains in any other manner.
### No, I mean a trustless 2-way peg with correctness of the withdrawals verified by the Bitcoin protocol!
That is not possible unless Bitcoin verifies all transactions that happen in all the sidechains, which would be akin to drastically increasing the blocksize and expanding the Bitcoin rules in tons of ways, i.e., a terrible idea that no one wants.
### What about the Blockstream sidechains whitepaper?
Yes, that was a way to do it. The Drivechain hashrate escrow is a conceptually simpler way to achieve the same thing with improved incentives, less junk in the chain, more safety.
## Isn't the hashrate escrow a very complex soft-fork?
Yes, but it is much simpler than SegWit. And, unlike SegWit, it doesn't force anything on users, i.e., it isn't a mandatory blocksize increase.
## Why should we expect miners to care enough to participate in the voting mechanism?
Because it's in their own self-interest to do it, and it costs very little. Today over half of the miners mine RSK. It's not blind merged mining, it's a [very convoluted process that requires them to run a RSK full node](https://developers.rsk.co/rsk/architecture/mining/implementation-guide/). For the Drivechain sidechains, an SPV node would be enough, or maybe just getting data from a block explorer API, so much much simpler.
## What if I still don't like Drivechain even after reading this?
That is the entire point! You don't have to like it or use it as long as you're fine with other people using it. The hashrate escrow special addresses will not impact you at all, validation cost is minimal, and you get the benefit of people who want to use Drivechain migrating to their own sidechains and freeing up space for you in the mainchain. See also the point above about infighting.
## See also
* [Podcast episode with Ruben Somsen and Aaron van Wirdum explaining Drivechain](https://www.youtube.com/watch?v=DhU6nsB5Z-0)
* [Alternatives to Drivechain](nostr:naddr1qqyrqenzvvukvcfkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823csjg2t6)
* [Drivechain comparison with Ethereum](nostr:naddr1qqyx2dp58qcx2wpjqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cane7px)
-
@ 3bf0c63f:aefa459d
2024-01-14 14:52:16
# `bitcoind` decentralization
It is better to have multiple curator teams, with different vetting processes and release schedules for `bitcoind` than a single one.
"More eyes on code", "Contribute to Core", "Everybody should audit the code".
All these points repeated again and again fell to Earth on the day it was discovered that Bitcoin Core developers merged a variable name change from "blacklist" to "blocklist" without even discussing or acknowledging the fact that that innocent pull request opened by a sybil account was a social attack.
After a big lot of people manifested their dissatisfaction with that event on Twitter and on GitHub, most Core developers simply ignored everybody's concerns or even personally attacked people who were complaining.
The event has shown that:
1) Bitcoin Core ultimately rests on the hands of a couple maintainers and they decide what goes on the GitHub repository[^pr-merged-very-quickly] and the binary releases that will be downloaded by thousands;
2) Bitcoin Core is susceptible to social attacks;
2) "More eyes on code" don't matter, as these extra eyes can be ignored and dismissed.
## Solution: `bitcoind` decentralization
If usage was spread across 10 different `bitcoind` flavors, the network would be much more resistant to social attacks to a single team.
This has nothing to do with the question on if it is better to have multiple different Bitcoin node implementations or not, because here we're basically talking about the same software.
Multiple teams, each with their own release process, their own logo, some subtle changes, or perhaps no changes at all, just a different name for their `bitcoind` flavor, and that's it.
Every day or week or month or year, each flavor merges all changes from Bitcoin Core on their own fork. If there's anything suspicious or too leftist (or perhaps too rightist, in case there's a leftist `bitcoind` flavor), maybe they will spot it and not merge.
This way we keep the best of both worlds: all software development, bugfixes, improvements goes on Bitcoin Core, other flavors just copy. If there's some non-consensus change whose efficacy is debatable, one of the flavors will merge on their fork and test, and later others -- including Core -- can copy that too. Plus, we get resistant to attacks: in case there is an attack on Bitcoin Core, only 10% of the network would be compromised. the other flavors would be safe.
## Run Bitcoin Knots
The first example of a `bitcoind` software that follows Bitcoin Core closely, adds some small changes, but has an independent vetting and release process is [Bitcoin Knots][knots], maintained by the incorruptible Luke DashJr.
Next time you decide to run `bitcoind`, run Bitcoin Knots instead and contribute to `bitcoind` decentralization!
---
### See also:
- [How to attack Bitcoin, Anthony Towns' take](nostr:naddr1qqyrywphxdskzwp5qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cwx779x)
[^pr-merged-very-quickly]: See [PR 20624](https://github.com/bitcoin/bitcoin/pull/20624), for example, a very complicated change that [could be introducing bugs or be a deliberate attack](http://www.erisian.com.au/wordpress/2021/01/07/bitcoin-in-2021), merged in 3 days without time for discussion.
[knots]: https://bitcoinknots.org/
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# IPFS problems: Shitcoinery
IPFS was advertised to the Ethereum community since the beggining as a way to "store" data for their "dApps". I don't think this is harmful in any way, but for some reason it may have led IPFS developers to focus too much on Ethereum stuff. Once I watched a talk showing libp2p developers – despite being ignored by the Ethereum team (that ended up creating their own agnostic p2p library) – dedicating an enourmous amount of work on getting a libp2p app running in the browser talking to a normal Ethereum node.
The always somewhat-abandoned "Awesome IPFS" site is a big repository of "dApps", some of which don't even have their landing page up anymore, useless Ethereum smart contracts that for some reason use IPFS to store whatever the useless data their users produce.
Again, per se it isn't a problem that Ethereum people are using IPFS, but it is at least confusing, maybe misleading, that when you search for IPFS most of the use-cases are actually Ethereum useless-cases.
## See also
* [Bitcoin](nostr:naddr1qqyryveexumnyd3kqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7nywz4), the only non-shitcoin
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Castas hindus em nova chave
Shudras buscam o máximo bem para os seus próprios corpos; vaishyas o máximo bem para a sua própria vida terrena e a da sua família; kshatriyas o máximo bem para a sociedade e este mundo terreno; brâmanes buscam o máximo bem.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# IPFS problems: Community
I was an avid IPFS user until yesterday. Many many times I asked simple questions for which I couldn't find an answer on the internet in the #ipfs IRC channel on Freenode. Most of the times I didn't get an answer, and even when I got it was rarely by someone who knew IPFS deeply. I've had issues go unanswered on js-ipfs repositories for year – one of these was raising awareness of a problem that then got fixed some months later by a complete rewrite, I closed my own issue after realizing that by myself some couple of months later, I don't think the people responsible for the rewrite were ever acknowledge that he had fixed my issue.
Some days ago I asked some questions about how the IPFS protocol worked internally, sincerely trying to understand the inefficiencies in finding and fetching content over IPFS. I pointed it would be a good idea to have a drawing showing that so people would understand the difficulties (which I didn't) and wouldn't be pissed off by the slowness. I was told to read the whitepaper. I had already the whitepaper, but read again the relevant parts. The whitepaper doesn't explain anything about the DHT and how IPFS finds content. I said that in the room, was told to read again.
Before anyone misread this section, I want to say I understand it's a pain to keep answering people on IRC if you're busy developing stuff of interplanetary importance, and that I'm not paying anyone nor I have the right to be answered. On the other hand, if you're developing a super-important protocol, financed by many millions of dollars and a lot of people are hitting their heads against your software and there's no one to help them; you're always busy but never delivers anything that brings joy to your users, something is very wrong. I sincerely don't know what IPFS developers are working on, I wouldn't doubt they're working on important things if they said that, but what I see – and what many other users see (take a look at the IPFS Discourse forum) is bugs, bugs all over the place, confusing UX, and almost no help.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# GraphQL vs REST
Today I saw this: https://github.com/stickfigure/blog/wiki/How-to-(and-how-not-to)-design-REST-APIs
And it reminded me why GraphQL is so much better.
It has also reminded me why HTTP is so confusing and awful as a protocol, especially as a protocol for structured data APIs, with all its status codes and headers and bodies and querystrings and content-types -- but let's not talk about that for now.
People complain about GraphQL being great for frontend developers and bad for backend developers, but I don't know who are these people that apparently love reading guides like the one above of how to properly construct ad-hoc path routers, decide how to properly build the JSON, what to include and in which circumstance, what status codes and headers to use, all without having any idea of what the frontend or the API consumer will want to do with their data.
It is a much less stressful environment that one in which we can just actually perform the task and fit the data in a preexistent schema with types and a structure that we don't have to decide again and again while anticipating with very incomplete knowledge the usage of an extraneous person -- i.e., an environment with GraphQL, or something like GraphQL.
By the way, I know there are some people that say that these HTTP JSON APIs are not the real REST, but that is irrelevant for now.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Why IPFS cannot work, again
Imagine someone comes up with a solution for P2P content-addressed data-sharing that involves storing all the files' contents in all computers of the network. That wouldn't work, right? Too much data, if you think this can work then you're a BSV enthusiast.
Then someone comes up with the idea of not storing everything in all computers, but only some things on some computers, based on some algorithm to determine what data a node would store given its pubkey or something like that. Still wouldn't work, right? Still too much data no matter how much you spread it, but mostly incentives not aligned, would implode in the first day.
Now imagine someone says they will do the same thing, but instead of storing the full contents each node would only store a pointer to where each data is actually available. Does that make it better? Hardly so. Still, you're just moving the problem.
This is IPFS.
Now you have less data on each computer, but on a global scale that is still a lot of data.
No incentives.
And now you have the problem of finding the data. First if you have some data you want the world to access you have to broadcast information about that, flooding the network -- and everybody has to keep doing this continuously for every single file (or shard of file) that is available.
And then whenever someone wants some data they must find the people who know about that, which means they will flood the network with requests that get passed from peer to peer until they get to the correct peer.
The more you force each peer to store the worse it becomes to run a node and to store data on behalf of others -- but the less your force each peer to store the more flooding you'll have on the global network, and the slower will be for anyone to actually get any file.
---
But if everybody just saves everything to Infura or Cloudflare then it works, magic decentralized technology.
## Related
- [How IPFS is broken](nostr:naddr1qqyxgdfsxvck2dtzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8y87ll)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# UBI calculations
The United States population (counting only people more than 25 years old) is `222098080 people`, the United States GDP is `20807000000000 USD`. The Federal government has received `5845968000000` in taxes in 2019.
The standard UBI plan (from Andrew Yang) is to give $1000 to each person every month, which means a total annual expenditure of `2665176960000 USD`, or `12.81%` of the GDP and `45.59%` of all tax money received from the federal government.
Mandatory spending (which includes healthcare and social security) corresponds to $2.7 trillion, or `46.18%` of annual receipts. Discretionary spending (which includes education and military stuff) corresponds to $1.3 trillion, or `22.23%` of annual receipts.
## Does it fit?
If you are capable of cutting more-or-less all spending in social security (`17.10%` of federal receipts), all military (`11.56%`), all education, transportation, housing, veterans benefits and most other things the federal government does (`11.30%`) and parts of Medicare and Medicaid (`26.17%`) then it will be possible to fit UBI.
Welcome to the leftist paradise, one in which the government budget has to be drastically cut in every possible (cruel?) way.
### Data sources
- <https://en.wikipedia.org/wiki/United_States>
- <https://en.wikipedia.org/wiki/Demographics_of_the_United_States#Structure>
- <https://en.wikipedia.org/wiki/Government_spending_in_the_United_States>
- <https://www.bea.gov/tools/>
- <https://www.pbs.org/newshour/politics/how-would-andrew-yang-give-americans-1000-per-month-with-this-tax>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Cadeias, crimes e cidadãos de bem
A idéia de ficar dentro duma dessas penitenciárias superlotadas é aterrorizante para qualquer cidadão de bem, logo, nenhum cidadão de bem comete crimes puníveis dessa maneira. Mas os cidadãos de bem já não os cometeriam de qualquer modo, é um outro tipo de gente, que não o cidadão de bem, que comete os piores crimes (não quero dizer que o "cidadão de bem" é melhor do que o outro absolutamente, estou só usando um conceito mais-ou-menos identificável).
O problema disso é que todos esses mesmos cidadãos de bem imaginam que a existência da cadeia e da punição-padrão movida pelo Estado afasta do crime milhões de pessoas que, sem isso, cometeriam crimes horríveis, mas que com isso vivem vidas normais.
A verdade, me parece, é que quem fica assim tão aterrorizado com a idéia da cadeia e da punição-padrão é a pessoa que já por natureza não cometeria esses crimes.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Uma boa margem
- No primeiro semestre da faculdade de Economia nós, os alunos, fomos guiados por um livro imbecil chamado "Introdução à Economia". O livro listava lá trocentas coisas que economistas supostamente faziam como parte da sua natureza de economistas. Uma delas era, lembro-me desta frase, "economistas pensam na margem".
- De início eu não entendi onde era essa margem, mas a professora passou quase uma aula inteira explicando (isto é, lendo o capítulo) que "pensar na margem" era considerar que pequenas mudanças nas condições de qualquer coisa causariam mudanças em pequenos grupos de pessoas: as pessoas que estavam na margem da mudança.
- Por exemplo, se um limão custa 5 reais e 100.000 pessoas compram limão todo dia, se aumentamos o preço para 5,05 pode ser que, sei lá, só 99.873 continuem comprando. Faz sentido, não faz? Isto era tão óbvio para mim no primeiro período de faculdade que não imaginei que alguém precisasse explicar, por isso não percebi qual era a da margem.
- Até hoje, porém, vejo pessoas o tempo todo afirmarem categoricamente que o "cinco centavos não vão fazer diferença nenhuma, as pessoas vão continuar comprando o limão como sempre compraram" e invocando em defesa desta tese argumentos perfeitamente lógicos como "até parece que você ia deixar de comprar seu limão por causa de 5 centavos", "eu nem olho o preço das coisas no supermercado" e "as pessoas precisam do limão, então elas vão ter que comprar, não importa o preço".
- Muitas destas pessoas entenderão a explicação sobre a margem, mas na próxima oportunidade que tiverem falharão em perceber a analogia ou em se lembrarem da margem e novamente evocarão os seus chavões. Para outras pessoas, porém, o pensamento na margem faz parte do bom senso habitual.
- Tirando fora a inútil conclusão de que a maior parte das pessoas é burra, sobra-nos um problema.
- __Discussão__
- Estaria o autor do livro, contra sua própria vontade, enunciando uma verdade acerca dos tipos de pessoas que povoam a sociedade, "os economistas", que são economistas desde o berço, e que "pensam na margem" por natureza, contra "o resto", os não-economistas, que não pensam na margem, não importa o que se faça?
- Esta é uma solução bem mixuruca. Nem é uma solução, na verdade, além disto ela deixa escapar um outro problema: por que diabos um sujeito que não consegue entender o problema do limão se candidata a um diploma de economista?
- Bom, talvez aqui a hipótese da burrice generalizada explique bem as coisas: aparentemente a burrice que há nas universidades, no valor dos diplomas, na natureza da escola e em sua relação com as universidades faça com que jovens sejam despejados em qualquer curso sem terem noção nenhuma do que eles mesmos esperam que se dê lá. Ei-lo.
- Há algum outro mistério aqui? O bom senso (enquanto um conhecimento apreendido dos meus vizinhos de sociedade) me ensinou a pensar na margem, ou não? Onde eu aprendi isso? Por que eu penso assim e o meu vizinho não?
- Imagino que Bernard Lonergan responderia dizendo que os economistas são pessoas que tiveram esse __insight__ e as outras pessoas não. Para as que tiveram o insight ele aparece já como uma obviedade, para os que não tiveram ele não é nem percebido como possibilidade (do contrário ele se efetuaria automaticamente como insight).
- Neste caso, o que explica que pessoas entendam o caso do limão, caso se lhas explique com calma, mas falhem em aplicá-lo, minutos depois, a laranjas?
- Há casos de economistas famosos e premiados que não conseguem conceber, por exemplo, que o aumento do salário mínimo possa fazer com que menos pessoas contratem funcionários -- na margem. Estes mesmos economistas passariam facilmente no teste do limão. Paul Krugman é um exemplo clássico de pessoa definitivamente "economista" (pelo critério do limão), mas que falha na aplicação do mesmo princípio a situações em que ele tem interesse político.
- Aqui caímos num outro problema totalmente diferente, mas talvez a dissonância cognitiva explique.
- Falha na aplicação de analogias não é um defeito, segundo me parece. Afinal de contas cada nova aplicação de uma analogia ou de relação previamente conhecida é, em si, um novo insight. O insight pode não ocorrer facilmente em certas condições. Mas, nestes casos, imagino que com algum auxílio (alguém que te lembre da analogia correta a ser aplicada ali, fazendo com que você a teste por si mesmo) o insight ocorra.
- Também posso considerar que eu estou errado e que é ilógico pensar que cinco centavos farão com que menos pessoas comprem o limão. Há centenas de estudos "empíricos" que mostram como "pensar na margem" é correto, mas estes estudos são todos inconclusivos, ou afetados por dissonância cognitiva por parte dos autores, economistas, que já começaram a fazer o estudo sabendo da conclusão. Tudo isto parece razoável. Tenho para mim, no entando, que não é nada razoável, mas um absurdo louco.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# tempreites
My first library to get stars on GitHub, was a very stupid templating library that used just HTML and HTML attributes ("DSL-free"). I was inspired by <http://microjs.com/> at the time and ended up not using the library. Probably no one ever did.
- <https://github.com/fiatjaf/tempreites>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# litepub
A Go library that abstracts all the burdensome ActivityPub things and provides just the right amount of helpers necessary to integrate an existing website into the "fediverse" (what an odious name). Made for the [gravity]() integration.
- <https://godoc.org/github.com/fiatjaf/litepub>
## See also
-
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A Causa
o Princípios de Economia Política de Menger é o único livro que enfatiza a CAUSA o tempo todo. os cientistas todos parecem não saber, ou se esquecer sempre, que as coisas têm causa, e que o conhecimento verdadeiro é o conhecimento da causa das coisas.
a causa é uma categoria metafísica muito superior a qualquer correlação ou resultado de teste de hipótese, ela não pode ser descoberta por nenhum artifício econométrico ou reduzida à simples antecedência temporal estatística. a causa dos fenômenos não pode ser provada cientificamente, mas pode ser conhecida.
o livro de Menger conta para o leitor as causas de vários fenômenos econômicos e as interliga de forma que o mundo caótico da economia parece adquirir uma ordem no momento em que você lê. é uma sensação mágica e indescritível.
quando eu te o recomendei, queria é te imbuir com o espírito da busca pela causa das coisas. depois de ler aquilo, você está apto a perceber continuidade causal nos fenômenos mais complexos da economia atual, enxergar as causas entre toda a ação governamental e as suas várias consequências na vida humana. eu faço isso todos os dias e é a melhor sensação do mundo quando o caos das notícias do caderno de Economia do jornal -- que para o próprio jornalista que as escreveu não têm nenhum sentido (tanto é que ele escreve tudo errado) -- se incluem num sistema ordenado de causas e consequências.
provavelmente eu sempre erro em alguns ou vários pontos, mas ainda assim é maravilhoso. ou então é mais maravilhoso ainda quando eu descubro o erro e reinsiro o acerto naquela racionalização bela da ordem do mundo econômico que é a ordem de Deus.
_em scrap para T.P._
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# fieldbook-to-sql
This used to turn books from the late multi-things-manager (or tridimensional spreadsheets provider) [fieldbook.com](http://web.archive.org/web/20180103200604/https://fieldbook.com/) into complete SQLite3 databases.
It was referenced in their official shutdown message and helped people move data off (it would have been better if they had open-sourced the entire site, I don't understand why they haven't).
- <https://github.com/fiatjaf/fieldbook-to-sql>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Lagoa Santa: como chegar -- partindo da rodoviária de Belo Horizonte
Ao descer de seu ônibus na rodoviária de Belo Horizonte às 4 e pouco da manhã, darás de frente para um caubói que toma cerveja em seus trajes típicos em um bar no setor mesmo de desembarque. Suba a escada à direita que dá no estacionamento da rodoviária. Vire à esquerda e caminhe por mais ou menos 400 metros, atravessando uma área onde pessoas suspeitas -- mas provavelmente dormindo em pé -- lhe observam, e então uma pracinha ocupada por um clã de mendigos. Ao avistar um enorme obelisco no meio de um cruzamento de duas avenidas, vire à esquerda e caminhe por mais 400 metros. Você verá uma enorme, antiga e bela estação com uma praça em frente, com belas fontes aqüáticas. Corra dali e dirija-se a um pedaço de rua à direita dessa praça. Um velho palco de antigos carnavais estará colocado mais ou menos no meio da simpática ruazinha de parelepípedos: é onde você pegará seu próximo ônibus.
Para entrar na estação é necessário ter um cartão com créditos recarregáveis. Um viajante prudente deixa sempre um pouco de créditos em seu cartão a fim de evitar filas e outros problemas de indisponibilidade quando chega cansado de viagem, com pressa ou em horários incomuns. Esse tipo de pessoa perceberá que foi totalmente ludibriado ao perceber que que os créditos do seu cartão, abastecido quando de sua última vinda a Belo Horizonte, há três meses, pereceram de prazo de validade e foram absorvidos pelos cofre públicos. Terá, portanto, que comprar mais créditos. O guichê onde os cartões são abastecidos abre às 5h, mas não se espante caso ele não tenha sido aberto ainda quando o primeiro ônibus chegar, às 5h10.
Com alguma sorte, um jovem de moletom, autorizado por dois ou três fiscais do sistema de ônibus que conversam alegremente, será o operador da catraca. Ele deixa entrar sem pagar os bêbados, os malandros, os pivetes. Bastante empático e perceptivo do desespero dos outros, esse bom rapaz provavelmente também lhe deixará entrar sem pagar.
Uma vez dentro do ônibus, não se intimide com os gritalhões e valentões que, ofendidíssimos com o motorista por ele ter parado nas estações, depois dos ônibus anteriores terem ignorado esses excelsos passageiros que nelas aguardavam, vão aos berros tirar satisfação.
O ponto final do ônibus, 40 minutos depois, é o terminal Morro Alto. Lá você verá, se procurar bem entre vários ônibus e pessoas que despertam a sua mais honesta suspeita, um veículo escuro, apagado, numerado **5882** e que abrigará em seu interior um motorista e um cobrador que descansam o sono dos justos.
Aguarde na porta por mais uns vinte minutos até que, repentinamente desperto, o motorista ligue o ônibus, abra as portas e já comece, de leve, a arrancar. Entre correndo, mas espere mais um tempo, enquanto as pessoas que têm o cartão carregado passem e peguem os melhores lugares, até que o cobrador acorde e resolva te cobrar a passagem nesse velho meio de pagamento, outrora o mais líqüído, o dinheiro.
Este último ônibus deverá levar-lhe, enfim, a Lagoa Santa.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A estrutura lógica do livro didático
Todos os livros didáticos e cursos expõem seus conteúdos a partir de uma organização lógica prévia, um esquema de todo o conteúdo que julgam relevante, tudo muito organizadinho em tópicos e subtópicos segundo a ordem lógica que mais se aproxima da ordem natural das coisas. Imagine um sumário de um manual ou livro didático.
A minha experiência é a de que esse método serve muito bem para ninguém entender nada. A organização lógica perfeita de um campo de conhecimento é o resultado **final** de um estudo, não o seu início. As pessoas que escrevem esses manuais e dão esses cursos, mesmo quando sabem do que estão falando (um acontecimento aparentemente raro), o fazem a partir do seu próprio ponto de vista, atingido após uma vida de dedicação ao assunto (ou então copiando outros manuais e livros didáticos, o que eu chutaria que é o método mais comum).
Para o neófito, a melhor maneira de entender algo é através de imersões em micro-tópicos, sem muita noção da posição daquele tópico na hierarquia geral da ciência.
* [Revista Educativa](nostr:naddr1qqyxgvfcxajkxe3cqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cfx0trx), um exemplo de como não ensinar nada às crianças.
* [Zettelkasten](nostr:naddr1qqyrwwfh8yurgefnqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7qmjrw), a ordem surgindo do caos, ao invés de temas se encaixando numa ordem preexistentes.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Setting up a handler for `nostr:` links on your Desktop, even if you don't use a native client
This is the most barebones possible, it will just open a web browser at `https://nostr.guru/` with the contents of the `nostr:` link.
Create this file at `~/.local/share/applications/nostr-opener.desktop`:
```
[Desktop Entry]
Exec=/home/youruser/nostr-opener %u
Name=Nostr Browser
Type=Application
StartupNotify=false
MimeType=x-scheme-handler/nostr;
```
(Replace "youruser" with your username above.)
This will create a default handler for `nostr:` links. It will be called with the link as its first argument.
Now you can create the actual program at `~/nostr-opener`. For example:
```python
#!/usr/bin/env python
import sys
import webbrowser
nip19 = sys.argv[1][len('nostr:'):]
webbrowser.open(f'https://nostr.guru/{nip19}')
```
Remember to make it executable with `chmod +x ~/nostr-opener`.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A estrutura paradigmática da ciência
N'_A estrutura das revoluções científicas_, Thomas Kuhn descreve como surge uma ciência: um monte de gente fica tentando descobrir como uma coisa funciona a partir da sua própria experiência e escreve livros descrevendo isso. Cada um fala uma coisa completamente diferente, várias escolas de pensamento surgem e se combatem, até que por algum motivo uma mudança qualitativa aparece e faz com que todos concordem com uma base comum -- exceto é claro os que não concordam e esses são sumariamente expulsos do convívio dos demais --, os vários grupos deixam de existir ou se reformulam para que suas teses específicas passem a ter como base aquele novo paradigma, e então todo mundo passa a se comunicar por artigos que pressupõem várias coisas que eles têm em comum, e não mais por livros que partem dos menores princípios e tentam explicar tudo.
É um belo paradigma para compreender como a ciência funciona, e explica o estado real das coisas muito melhor do que o vômito ideológico dos cientistas mirins da internet que repetem asneiras sobre o "método científico".
mas o problema que me ocorreu foi: quem garante que esse paradigma representa realmente um avanço? Será que o desejo de concordar e se sentir incluído não foi o que fez com que todos os envolvidos o aceitassem? Não digo nem que essa nova descoberta esteja errada, mas ela -- e sua aceitação como novo paradigma -- criam um recorte da realidade dentro do qual aquela nova ciência que surge estará fadada a operar dali em diante, mas quem disse que esse recorte é mesmo o melhor lugar para que todos operem?
Talvez uma idéia melhor seria que as pessoas avaliassem aquele novo paradigma, mas não mergulhassem de cabeça nele.
Uma hipótese alternativa do porquê esse recorte e surgimento da ciência acontece: ela é mais fácil de ser abarcada pela burocracia universitária e empregar mentes medíocres na "pesquisa" uma coisa pequena e sem importância que já está ali dada pelo próprio conceito da ciência e não será nenhuma descoberta nova.
- [Método científico](nostr:naddr1qqyr2wf3vgmx2dmrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823chtnaca)
- [Thomas Kuhn sequer menciona o "método científico"](nostr:naddr1qqyryd3jv5enyd3cqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c3zmtlu)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# hyperscript-go
A template rendering library similar to [hyperscript](https://github.com/dominictarr/hyperscript) for Go.
Better than writing HTML and Golang templates.
- <https://github.com/fiatjaf/hyperscript-go>
### See also
- [tempreites](nostr:naddr1qqyrgvpjxf3kzep3qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cs7qvaw)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Jofer
Jofer era um jogador diferente. À primeira vista não, parecia igual, um volante combativo, perseguia os atacantes adversários implacavelmente, um bom jogador. Mas não era essa a característica que diferenciava Jofer. Jofer era, digamos, um chutador.
Começou numa semifinal de um torneio de juniores. O time de Jofer precisava do empate e estava sofrendo uma baita pressão do adversário, mas o jogo estava 1 a 1 e parecia que ia ficar assim mesmo, daquele jeito futebolístico que parece, parece mesmo. Só que aos 46 do segundo tempo tomaram um gol espírita, Ruizinho do outro time saiu correndo pela esquerda e, mesmo sendo canhoto, foi cortando para o meio, os zagueiros meio que achando que já tinha acabado mesmo, devia ter só mais aquele lance, o árbitro tinha dado dois minutos, Ruizinho chutou, marcou e o goleiro, que só pulou depois que já tinha visto que não ia ter jeito, ficou xingando.
A bola saiu do meio e tocaram para Jofer, ninguém nem veio marcá-lo, o outro time já estava comemorando, e com razão, o juiz estava de sacanagem em fazer o jogo continuar, já estava tudo acabado mesmo. Mas não, estava certo, mais um minuto de acréscimo, justo. Em um minuto dá pra fazer um gol. Mas como? Jofer pensou nas partidas da NBA em que com alguns centésimos de segundo faltando o armador jogava de qualquer jeito para a cesta e às vezes acertava. De trás do meio de campo, será? Não vou ter nem força pra fazer chegar no gol. Vou virar piada, melhor tocar pro Fumaça ali do lado e a gente perde sem essa humilhação no final. Mas, poxa, e daí? Vou tentar mesmo assim, qualquer coisa eu falo que foi um lançamento e daqui a uns dias todo mundo esquece. Olhou para o próprio pé, virou ele de ladinho, pra fora e depois pra dentro (bom, se eu pegar daqui, direitinho, quem sabe?), jogou a bola pro lado e bateu. A bola subiu escandalosamente, muito alta mesmo, deve ter subido uns 200 metros. Jofer não tinha como ter a menor noção. Depois foi descendo, o goleirão voltando correndo para debaixo da trave e olhando pra bola, foi chegando e pulando já só pra acompanhar, para ver, dependurado no travessão, a bola sair ainda bem alta, ela bateu na rede lateral interna antes de bater no chão, quicar violentamente e estufar a rede no alto do lado direito de quem olhava.
Mas isso tudo foi sonho do Jofer. Sonhou acordado, numa noite em que demorou pra dormir, deitado na sua cama. Ficou pensando se não seria fácil, se ele treinasse bastante, acertar o gol bem de longe, tipo no sonho, e se não dava pra fazer gol assim. No dia seguinte perguntou a Brunildinho, o treinador de goleiros. Era difícil defender essas bolas, ainda mais se elas subissem muito, o goleiro ficava sem perspectiva, o vento alterava a trajetória a cada instante, tinha efeito, ela cairia rápido, mas claro que não valia à pena treinar isso, a chance de acertar o gol era minúscula. Mas Jofer só ia tentar depois que treinasse bastante e comprovasse o que na sua imaginação parecia uma excelente idéia.
Começou a treinar todos os dias. Primeiro escondido, por vergonha dos colegas, chegava um pouco antes e ficava lá, chutando do círculo central. Ao menor sinal de gente se aproximando, parava e ia catar as bolas. Depois, quando começou a acertar, perdeu a vergonha. O pessoal do clube todo achava engraçado quando via Jofer treinando e depois ouvia a explicação da boca de alguém, ninguém levava muito a sério, mas também não achava de todo ridículo. O pessoal ria, mas no fundo torcia praquilo dar certo, mesmo.
Aconteceu que num jogo que não valia muita coisa, empatezinho feio, aos 40 do segundo tempo, a marcação dos adversários já não estava mais pressionando, todo mundo contente com o empate e com vontade de parar de jogar já, o Henrique, meia-esquerdo, humilde, mas ainda assim um pouco intimidante para Jofer (jogava demais), tocou pra ele. Vai lá, tenta sua loucura aí. Assumiu a responsabilidade do nosso volante introspectivo. Seria mais verossímil se Jofer tivesse errado, primeira vez que tentou, restava muito tempo ainda pra ele ter a chance de ser herói, ninguém acerta de primeira, mas ele acertou. Quase como no sonho, Lucas, o goleiro, não esperava, depois que viu o lance, riu-se, adiantou-se para pegar a bola que ele julgava que quicaria na área, mas ela foi mais pra frente, mais e mais, daí Lucas já estava correndo, só que começou a pensar que ela ia pra fora, e ele ia só se dependurar no travessão e fazer seu papel de estar na bola. Acabou que por conta daquele gol eles terminaram em segundo no grupo daquele torneiozinho, ao invés de terceiro, e não fez diferença nenhuma.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Thoughts on Nostr key management
On [Why I don't like NIP-26 as a solution for key management](nostr:naddr1qqyrgceh89nxgdmzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ctgmx78) I talked about multiple techniques that could be used to tackle the problem of key management on Nostr.
Here are some ideas that work in tandem:
- [NIP-41](https://github.com/nostr-protocol/nips/blob/master/41.md) (stateless key invalidation)
- [NIP-46](https://github.com/nostr-protocol/nips/blob/master/46.md) (Nostr Connect)
- [NIP-07](https://github.com/nostr-protocol/nips/blob/master/07.md) (signer browser extension)
- [Connected hardware signing devices](https://lnbits.github.io/nostr-signing-device/installer/)
- other things like musig or frostr keys used in conjunction with a semi-trusted server; or other kinds of trusted software, like a dedicated signer on a mobile device that can sign on behalf of other apps; or even a separate protocol that some people decide to use as the source of truth for their keys, and some clients might decide to use that automatically
- there are probably many other ideas
Some premises I have in my mind (that may be flawed) that base my thoughts on these matters (and cause me to not worry too much) are that
- For the vast majority of people, Nostr keys aren't a target as valuable as Bitcoin keys, so they will probably be ok even without any solution;
- Even when you lose everything, identity can be recovered -- slowly and painfully, but still --, unlike money;
- Nostr is not trying to replace all other forms of online communication (even though when I think about this I can't imagine one thing that wouldn't be nice to replace with Nostr) or of offline communication, so there will always be ways.
- For the vast majority of people, losing keys and starting fresh isn't a big deal. It is a big deal when you have followers and an online persona and your life depends on that, but how many people are like that? In the real world I see people deleting social media accounts all the time and creating new ones, people losing their phone numbers or other accounts associated with their phone numbers, and not caring very much -- they just find a way to notify friends and family and move on.
We can probably come up with some specs to ease the "manual" recovery process, like social attestation and explicit signaling -- i.e., Alice, Bob and Carol are friends; Alice loses her key; Bob sends a new Nostr event kind to the network saying what is Alice's new key; depending on how much Carol trusts Bob, she can automatically start following that and remove the old key -- or something like that.
---
One nice thing about some of these proposals, like NIP-41, or the social-recovery method, or the external-source-of-truth-method, is that they don't have to be implemented in any client, they can live in standalone single-purpose microapps that users open or visit only every now and then, and these can then automatically update their follow lists with the latest news from keys that have changed according to multiple methods.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Trello Attachment Editor
A static JS app that allowed you to authorize with your Trello account, fetch the board structure, find attachments, edit them in the browser then replace them in the cards.
Quite a nice thing. I believe it was done to help with [Websites For Trello](nostr:naddr1qqyrydpkvverwvehqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c9d4yku) attached scripts and CSS files.
- <https://github.com/fiatjaf/trello-attachments>
- <https://fiatjaf.github.io/trello-attachments/#/login>
### See also
- [Temperos](nostr:naddr1qqyrvvpevgurzwfeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cvyhzdz)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Software
## 2013
- [tempreites](nostr:naddr1qqyrgvpjxf3kzep3qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cs7qvaw)
## 2014
- [contratos.alhur.es](nostr:naddr1qqyrjde3xd3xgvtrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cg7tgqg)
- [microanalytics](nostr:naddr1qqyr2cfcv56nvdtyqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ct57qq4)
- [doulas.club](nostr:naddr1qqyxxdec8yerwce4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823csucsny)
- [rosetta.alhur.es](nostr:naddr1qqyxvdmzxu6nscfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8zu03s)
- [Webvatar](nostr:naddr1qqyrje348qexgc3sqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cgqmsck)
## 2015
- [Gerador de tabelas de todos contra todos](nostr:naddr1qqyxxwf58qckvd3jqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cza9wzl)
- [questo.email](nostr:naddr1qqyrvvpnveskzvnrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ce8mca6)
- [jekmentions](nostr:naddr1qqyrvcmxxgmn2cnpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823crzww00)
- [Websites For Trello](nostr:naddr1qqyrydpkvverwvehqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c9d4yku)
- [Temperos](nostr:naddr1qqyrvvpevgurzwfeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cvyhzdz)
- [Trello Attachment Editor](nostr:naddr1qqyrzv35vf3ngefsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cl4cxff)
- [WelcomeBot](nostr:naddr1qqyrqv3nx4skzdpnqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8q7km6)
- [Classless Templates](nostr:naddr1qqyxyv35vymk2vfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cqwgdau)
## 2016
- [Module Linker](nostr:naddr1qqyx2cejxfnrxwrpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c3w8fr0)
- [Boardthreads](nostr:naddr1qqyxvwfk8p3xvdmrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ceq46m6)
- [Batch for Trello](nostr:naddr1qqyxxep4vsckydpcqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cqun23v)
- [Custom spreadsheets](nostr:naddr1qqyxgvenxycxgcesqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823caghvd9)
- [SummaDB](nostr:naddr1qqyxvefkx4jxzv35qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cl55g3s)
- [Flowi.es](nostr:naddr1qqyxycn9x5crweryqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c9nlf3h)
- [Trelew](nostr:naddr1qqyxgvnxvvunsetrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cku8e7a)
- [Washer](nostr:naddr1qqyxgwtzxpnrwv3nqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cseh7t7)
- [hyperscript-go](nostr:naddr1qqyxzwpnxyukzvtyqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cmh22hw)
- [jiq](nostr:naddr1qqyrqvfjv33rxcenqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cd86z7d)
- [busca múltipla na estante virtual](nostr:naddr1qqyrvdt9xq6r2dp5qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cnlqqm3)
- [Splitpages](nostr:naddr1qqyxgeryve3nxerrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cdeke65)
- [requesthub.xyz](nostr:naddr1qqyxxdf38ycrswfcqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cal6jdg)
## 2017
- [trackingco.de](nostr:naddr1qqyxgwt9xuck2dn9qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cqnzcdc)
- [jq-web](nostr:naddr1qqyrzvrzxqcx2dfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c90hqwz)
- [Filemap](nostr:naddr1qqyrwcekv33rze3kqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c23ya8a)
- [IPFS-dropzone](nostr:naddr1qqyrjvrx8p3xyvesqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cwpfruw)
- [sitio](nostr:naddr1qqyrjctyxg6nvepnqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccsaa3c)
- [rel](nostr:naddr1qqyrxvecx43r2wfhqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823crt09d2)
## 2018
- [ijq](nostr:naddr1qqyxzcfhv4jx2vfhqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cyanqcm)
- [sitios.xyz](nostr:naddr1qqyrsep48qckyetyqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cdnzkwk)
- [hledger-web](nostr:naddr1qqyrsefkvvck2efkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cffvz7c)
- [LessPass remoteStorage](nostr:naddr1qqyrsctpxfjnqepeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cfa6z2z)
- [TiddlyWiki remoteStorage](nostr:naddr1qqyxxve4x33nqerrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cat32d3)
- [fieldbook-to-sql](nostr:naddr1qqyrzcmxv4snvvpnqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cj2xnqd)
- [jq-finder](nostr:naddr1qqyryvejvycn2cnpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccw20rx)
- [jiq-web](nostr:naddr1qqyxxcf5x33rse3kqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cyttamq)
- [superform.xyz](nostr:naddr1qqyx2wpe8p3nzdpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c077s2q)
- [piln](nostr:naddr1qqyxve3svsmrvwtxqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c29s0he)
- [gravity](nostr:naddr1qqyxyet9v5mr2vfkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cjfzxgy)
- [howoldis](nostr:naddr1qqyxge3jvvcr2vejqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ctyq8wc)
- [litepub](nostr:naddr1qqyxzcecxs6x2c3sqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823czz6dgn)
## 2019
- [Etleneum](nostr:naddr1qqyrjcny8qcn2ve4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823crwzz2w)
- [@lntxbot](nostr:naddr1qqyrydpex4jnwetxqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cmkr70c)
- [mcldsp](nostr:naddr1qqyrvcmyx3skzdpjqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cph0s0j)
- [Sparko](nostr:naddr1qqyx2vpnvs6nze3jqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c362tx2)
## 2020
- [lnchannels](nostr:naddr1qqyx2vtrxymxgvt9qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8wq3qm)
- [trustedcoin](nostr:naddr1qqyx2wp4vgekgwfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c04z53s)
- [localchat](nostr:naddr1qqyxyetrxcmrjc3cqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cj6vucg)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# idea: Per-paragraph paywalls
Using the lnurl-allowance protocol, a website could instead of putting a paywall over the entire site, charge a reader for only the paragraphs they read. Of course this requires trust from the reader on the website, but this is normal. The website could just hide the rest of the article before an invoice from the paragraph just read was paid.
This idea came from Colin from the _Unhashed Podcast_.
Could also work with podcasts and videos.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# rosetta.alhur.es
A service that grabs code samples from two chosen languages on [RosettaCode](http://rosettacode.org/wiki/Rosetta_Code) and displays them side-by-side.
The code-fetching is done in real time and snippet-by-snippet (there is also a prefetch of which snippets are available in each language, so we only compare apples to apples).
This was my first Golang web application if I remember correctly.
- <https://rosetta.alhur.es/>
- <https://github.com/fiatjaf/rosetta.alhur.es>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# The problem with ION
[ION](https://techcommunity.microsoft.com/t5/identity-standards-blog/ion-we-have-liftoff/ba-p/1441555) is a [DID method](nostr:naddr1qqyrjwrpv93rjcf4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cuxp7vx) based on a thing called "Sidetree".
I can't say for sure what is the problem with ION, because I don't understand the design, even though I have read all I could and asked everybody I knew. All available information only touches on the high-level aspects of it (and of course its amazing wonders) and no one has ever bothered to explain the details. I've also asked the main designer of the protocol, Daniel Buchner, but he may have thought I was trolling him on Twitter and refused to answer, instead pointing me to an incomplete spec on the Decentralized Identity Foundation website that I had already read before. I even tried to join the DIF as a member so I could join their closed community calls and hear what they say, maybe eventually ask a question, so I could understand it, but my entrance was ignored, then after many months and a nudge from another member I was told I had to do a KYC process to be admitted, which I refused.
**One thing I know is**:
- ION is supposed to provide a way to _rotate keys_ seamlessly and automatically without losing the main identity (and the ION proponents also claim there are no "master" keys because these can also be rotated).
- ION is also _not a blockchain_, i.e. it doesn't have a deterministic consensus mechanism and it is decentralized, i.e. anyone can publish data to it, doesn't have to be a single central server, there may be holes in the available data and the protocol doesn't treat that as a problem.
- From all we know about years of attempts to scale Bitcoins and develop offchain protocols it is clear that _you can't solve the double-spend problem without a central authority or a kind of blockchain_ (i.e. a decentralized system with deterministic consensus).
- _Rotating keys also suffer from the double-spend problem_: whenever you rotate a key it is as if it was "spent", you aren't supposed to be able to use it again.
The logic conclusion of the 4 assumptions above is that ION is flawed: it can't provide the key rotation it says it can if it is not a blockchain.
## See also
- [Excerpt of discussion about DIDs and ION](nostr:naddr1qqyrydtpx33nsvpcqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccx33ee)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Sparko
This started as a reimplementation of the [Spark Wallet](https://github.com/shesek/spark-wallet) server (which also included the client app, copied directly) because NodeJS isn't a proper way to distribute software to end users and it was also a pain for me to install. I could do a program that ran as a single binary.
Then when [c-lightning](https://github.com/ElementsProject/lightning/) released their plugin infrastructe I made this a plugin.
And then introduced fine-grained method authorization for multiple keys, and full-blown [SSE](https://en.wikipedia.org/wiki/Server-sent_events)-based subscriptions for plugin events.
It is a now a single wrapper that can be used to develop apps that talk to a Lightning layer very easily, as well as a simple wallet.
It is integrated into [Zeus](https://zeusln.app/), [LNbits](https://github.com/lnbits/lnbits) and <https://tip.bigsun.xyz/>.
- <https://github.com/fiatjaf/sparko>
## See also
- [trustedcoin](nostr:naddr1qqyx2wp4vgekgwfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c04z53s)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# On "zk-rollups" applied to Bitcoin
ZK rollups make no sense in bitcoin because there is no "cheap calldata". all data is already ~~cheap~~ expensive calldata.
There could be an onchain zk verification that allows succinct signatures maybe, but never a rollup.
What happens is: you can have one UTXO that contains multiple balances on it and in each transaction you can recreate that UTXOs but alter its state using a zk to compress all internal transactions that took place.
The blockchain must be aware of all these new things, so it is in no way "L2".
And you must have an entity responsible for that UTXO and for conjuring the state changes and zk proofs.
But on bitcoin you also must keep the data necessary to rebuild the proofs somewhere else, I'm not sure how can the third party responsible for that UTXO ensure that happens.
I think such a construct is similar to a credit card corporation: one central party upon which everybody depends, zero interoperability with external entities, every vendor must have an account on each credit card company to be able to charge customers, therefore it is not clear that such a thing is more desirable than solutions that are truly open and interoperable like Lightning, which may have its defects but at least fosters a much better environment, bringing together different conflicting parties, custodians, anyone.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# início
> "Vocês vêem? Vêem a história? Vêem alguma coisa? Me parece que estou tentando lhes contar um sonho -- fazendo uma tentativa inútil, porque nenhum relato de sonho pode transmitir a sensação de sonho, aquela mistura de absurdo, surpresa e espanto numa excitação de revolta tentando se impôr, aquela noção de ser tomado pelo incompreensível que é da própria essência dos sonhos..."
> Ele ficou em silêncio por alguns instantes.
> "... Não, é impossível; é impossível transmitir a sensação viva de qualquer época determinada de nossa existência -- aquela que constitui a sua verdade, o seu significado, a sua essência sutil e contundente. É impossível. Vivemos, como sonhamos -- sozinhos..."
* [Livros mencionados por Olavo de Carvalho](https://fiatjaf.com/livros-olavo.html)
* [Antiga _homepage_ Olavo de Carvalho](https://site.olavo.fiatjaf.com "Sapientiam autem non vincit malitia")
* [Bitcoin explicado de um jeito correto e inteligível](nostr:naddr1qqrky6t5vdhkjmspz9mhxue69uhkv6tpw34xze3wvdhk6q3q80cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsxpqqqp65wp3k3fu)
* [Reclamações](nostr:naddr1qqyrgwf4vseryvmxqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c9f9u03)
---
* [Nostr](-/tags/nostr)
* [Bitcoin](nostr:naddr1qqyryveexumnyd3kqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7nywz4)
* [How IPFS is broken](nostr:naddr1qqyxgdfsxvck2dtzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8y87ll)
* [Programming quibbles](nostr:naddr1qqyrjvehxq6ngvpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cu05y0j)
* [Economics](nostr:naddr1qqyk2cm0dehk66trwvq3zamnwvaz7tmxd9shg6npvchxxmmdqgsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8grqsqqqa28clr866)
* [Open-source software](nostr:naddr1qqy8xmmxw3mkzun9qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cmyvl8h)
---
[Nostr](nostr:nprofile1qqsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8gpyfmhxue69uhkummnw3ez6an9wf5kv6t9vsh8wetvd3hhyer9wghxuet5fmsq8j) [GitHub](https://github.com/fiatjaf) [Telegram](https://t.me/fiatjaf) [Donate](lnurlp://zbd.gg/.well-known/lnurlp/fiatjaf)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Gerador de tabelas de todos contra todos
I don't remember exactly when I did this, but I think a friend wanted to do software that would give him money over the internet without having to work. He didn't know how to program. He mentioned this idea he had which was some kind of football championship manager solution, but I heard it like this: a website that generated a round-robin championship table for people to print.
It is actually not obvious to anyone how to do it, it requires an algorithm that people will not reach casually while thinking, and there was no website doing it in Portuguese at the time, so I made this and it worked and it had a couple hundred daily visitors, and it even generated money from Google Ads (not much)!
First it was a Python web app running on Heroku, then Heroku started charging or limiting the amount of free time I could have on their platform, so I migrated it to a static site that ran everything on the client. Since I didn't want to waste my Python code that actually generated the tables I used [Brython](https://brython.info/) to run Python on JavaScript, which was an interesting experience.
In hindsight I could have just taken one of the many `round-robin` JavaScript libraries that exist on NPM, so eventually after a couple of more years I did that.
I also removed Google Ads when Google decided it had so many requirements to send me the money it was impossible, and then the money started to vanished.
- <https://github.com/fiatjaf/tabelas.alhur.es>
- <https://tabelas.alhur.es/>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A chatura Kelsen
Já presenciei várias vezes este mesmo fenômeno: há um grupo de amigos ou proto-amigos conversando alegremente sobre o conservadorismo, o tradicionalismo, o anti-comunismo, o liberalismo econômico, o livre-mercado, a filosofia olavista. É um momento incrível porque para todos ali é sempre tão difícil encontrar alguém com quem conversar sobre esses assuntos.
Eis que um deles fez faculdade de direito. Tendo feito faculdade de direito por acreditar que essa lhe traria algum conhecimento (já que todos os filósofos de antigamente faziam faculdade de direito!) esse sujeito que fez faculdade de direito, ao contrário dos demais, não toma conhecimento de que a sua faculdade é uma nulidade, uma vergonha, uma época da sua vida jogada fora -- e crê que são valiosos os conteúdos que lhe foram transmitidos pelos professores que estão ali para ajudar os alunos a se preparem para o exame da OAB.
Começa a falar de Kelsen. A teoria pura do direito, hermenêutica, filosofia do direito. A conversa desanda. Ninguém sabe o que dizer. A filosofia pura do direito não está errada porque é apenas uma lógica pura, e como tal não pode ser refutada; e por não ter qualquer relação com o mundo não há como puxar um outro assunto a partir dela e sair daquele território. Os jovens filósofos perdem ali as próximas duas horas falando de Kelsen, Kelsen. Uma presença que os ofende, que parece errada, que tem tudo para estar errada, mas está certa. Certa e inútil, ela lhes devora as idéias, que são digeridas pela teoria pura do direito.
É imperativo estabelecer esta regra: só é permitido falar de Kelsen se suas idéias não forem abordadas ou levadas em conta. Apenas elogios ou ofensas serão tolerados: Kelsen era um bom homem; Kelsen era um bobão. Pronto.
---
Eis aqui um exemplo gravado do fenômeno descrito acima: <https://www.youtube.com/watch?v=CKb8Ij5ThvA:> o Flavio Morgenstern todo simpático, elogiando o outro, falando coisas interessantes sobre o mundo; e o outro, que devia ser amigo dele antes de entrar para a faculdade de direito, começa a falar de Kelsen, com bastante confiança de que aquilo é relevante, e dá-lhe Kelsen, filosofia do direito, toda essa chatice tremenda.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Google, Uber e ostracismo
Pensando sobre como o Google poderia implementar uma solução "pure software" para o problema dos programinhas de carona paga -- já que agora parece que o Waze vai virar tipo um Uber -- me vi pensando em que poderia haver punições bastante severas e para-legais para infratores dos regulamentos internos do serviço.
Digamos, por exemplo, que é proibido pelas regras do serviço que o motorista ou o passageiro agridam um ao outro de qualquer maneira. Para ser qualificado como um potencial usuário, tanto o motorista quanto o passageiro devem ser usuários de longa data dos serviços do Google, possuir um email no Gmail com trocentas mensagens sendo recebidas e enviadas todos os dias, um enorme arquivo, coisas guardadas no Google Drive e/ou outros serviços do Google sendo usados. Caso o sujeito agrida o motorista, roube-o ou faça qualquer outra coisa não-permitida, o Google pode, imediatamente, cancelar seu acesso a todos os serviços. Depois, com mais calma, pode-se tentar alguma coisa por meio da justiça estatal, mas essa punição seria tão imediata e tão incondicional (bom, poderia haver um julgamento interno dentro do Google para avaliar o que aconteceu mesmo, mas pronto, nada de milanos na justiça penal e depois uma punição fajuta qualquer.)
Esse tipo de punição imediata já desencorajaria a maioria dos infratores, imagino eu. É a própria idéia anarquista da punição por ostracismo. O cara fica excluído da sociedade até que a sociedade (neste caso, o Google) decida perdoá-lo por qualquer motivo. A partir daí é possível imaginar que os outros vários "silos" deste mundo -- Facebook, Vivo, Diamond Mall, SuperNosso -- possam também aderir, caso concordem com o julgamento do Google, e vice-versa, e também impedirem o infrator de usar os seus serviços.
Mas o grande tchans disto aqui é que esse processo pode começar com um único agente, desde que ele seja grande o suficiente para que a sua ostracização, sozinha, já seja uma punição quase suficiente para o infrator.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# lnurl-auth explained
You may have seen the [lnurl-auth](https://github.com/btcontract/lnurl-rfc/blob/master/lnurl-auth.md) spec or heard about it, but might not know how it works or what is its relationship with other [lnurl](https://github.com/fiatjaf/awesome-lnurl) protocols. This document attempts to solve that.
## Relationship between lnurl-auth and other lnurl protocols
First, **what is the relationship of lnurl-auth with other lnurl protocols?** The answer is none, except the fact that they all share the lnurl format for specifying `https` URLs.
In fact, lnurl-auth is very unique in the sense that it doesn't even need a Lightning wallet to work, it is a standalone authentication protocol that can work anywhere.
## How does it work
Now, **how does it work?** The basic idea is that each wallet has a seed, which is a random value (you may think of the BIP39 seed words, for example). Usually from that seed different keys are derived, each of these yielding a Bitcoin address, and also from that same seed may come the keys used to generate and manage Lightning channels.
What lnurl-auth does is to generate a new key from that seed, and from that a new key for each service (identified by its domain) you try to authenticate with.

That way, you effectively have a new identity for each website. Two different services cannot associate your identities.
**The flow goes like this:** When you visit a website, the website presents you with a QR code containing a _callback URL_ and a _challenge_. The challenge should be a random value.

When your wallet scans or opens that QR code it uses the _domain_ in the callback URL plus the _main lnurl-auth key_ to derive a key specific for that website, uses that key to sign the challenge and then sends both the public key specific for that for that website plus the signed challenge to the specified URL.

When the service receives the public key it checks it against the challenge signature and start a session for that user. The user is then **identified only by its public key**. If the service wants it can, of course, request more details from the user, associate it with an internal id or username, it is free to do anything. lnurl-auth's goals end here: no passwords, maximum possible privacy.
# FAQ
* What is the advantage of tying this to Bitcoin and Lightning?
One big advantage is that your wallet is already keeping track of one seed, it is already a precious thing. If you had to keep track of a separate auth seed it would be arguably worse, more difficult to bootstrap the protocol, and arguably one of the reasons similar protocols, past and present, weren't successful.
* Just signing in to websites? What else is this good for?
No, it can be used for authenticating to installable apps and physical places, as long as there is a service running an HTTP server somewhere to read the signature sent from the wallet. But yes, signing in to websites is the main problem to solve here.
* Phishing attack! Can a malicious website proxy the QR from a third website and show it to the user to it will steal the signature and be able to login on the third website?
No, because the wallet will only talk to the the callback URL, and it will either be controlled by the third website, so the malicious won't see anything; or it will have a different domain, so the wallet will derive a different key and frustrate the malicious website's plan.
* I heard [SQRL](https://sqrl.grc.com/) had that same idea and it went nowhere.
Indeed. SQRL in its first version was basically the same thing as lnurl-auth, with one big difference: it was vulnerable to phishing attacks (see above). That was basically the only criticism it got everywhere, so the protocol creators decided to solve that by introducing complexity to the protocol. While they were at it they decided to add more complexity for managing accounts and so many more crap that in the the spec which initially was a single page ended up becoming 136 pages of highly technical gibberish. Then all the initial network effect it had, libraries and apps were trashed and nowadays no one can do anything with it (but, [see](https://sqrl.grc.com/threads/developer-documentation-conflicted-and-confusing-please-help-clarify.951/), there are still people who love the protocol writing in a 90's forum with no clue of anything besides their own Java).
* We don't need this, we need WebAuthn!
[WebAuthn](https://webauthn.guide/) is essentially the same thing as lnurl-auth, but instead of being simple it is complex, instead of being open and decentralized it is centralized in big corporations, and instead of relying on a key generated by your own device it requires an expensive hardware HSM you must buy and trust the manufacturer. If you like WebAuthn and you like Bitcoin you should like lnurl-auth much more.
* What about [BitID](https://github.com/bitid/bitid)?
This is another one that is [very similar](https://www.youtube.com/watch?v=3eepEWTnRTc) to lnurl-auth, but without the anti-phishing prevention and extra privacy given by making one different key for each service.
* What about LSAT?
It doesn't compete with lnurl-auth. LSAT, as far as I understand it, is for when you're buying individual resources from a server, not authenticating as a user. Of course, LSAT can be repurposed as a general authentication tool, but then it will lack features that lnurl-auth has, like the property of having keys generated independently by the user from a common seed and a standard way of passing authentication info from one medium to another (like signing in to a website at the desktop from the mobile phone, for example).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Alternatives to Drivechain
If Drivechain doesn't get soft-forked into Bitcoin, the alternatives people are left with are:
* Altcoins. People who want super-powers (privacy, smart contracts, cheap transactions) move their stake to shitcoins. This doesn't make much sense because even if altcoins had the necessary technology they wouldn't have the base money with which to use the technology, but still this remains an option.
* Fully-custodial and trusted systems. Instead of moving their money to a sidechain secured by Drivechain people can use a centralized service with much less safety and subject to all kinds of regulations, hacks and government takedowns.
* Federated sidechains, which are the same as custodial systems, but with distributed trust and maybe less, maybe more government involvement.
* Less secure sidechain-like constructions, like sidechains secured by a multisig of a fixed set of entities with names, or BTC tokens in other blockchains guaranteed by a collateral denominated in shitcoins which tends to zero.
* Corporate takeover. Big banks and giant corporations start buying all the coins and exposing part of them through their closed systems to normal people. Instead of an open network and free market as everybody expected, all meaningful activity now happens inside these legacy evil entities that are already sold to governments from the start.
Every time one person goes against Drivechain without proposing something else better, they're condemning bitcoiners to one or many of the above forever.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# idea: Graph subjective reputation as a service
The idea more-or-less coded in <https://github.com/fiatjaf/multi-service-reputation-rfc>, but if it is as good as I think it is, it could be sold for websites without any need for information sharing and without it being an open protocol.
It could be used by websites just to show subjective reputations inside their own site (as that isn't so trivial to build, but it is still desirable).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Liberalismo oitocentista
Quando comecei a ler sobre "liberalismo" na internet havia sempre umas listas de livros recomendados, uns Ludwig von Mises, Milton Friedman e Alexis de Tocqueville. "A Democracia na América". Pra mim parecia estranho aquele papo de democracia quando eu estava interessado era em como funcionaria um mercado livre, sem regulações e tal.
Parece que Tocqueville era uma herança do mesmo povo que adorava a expressão "liberalismo clássico". O liberalismo clássico era uma coisa política que ia contra a monarquia e em favor da democracia, e aí Tocqueville se encaixava muito bem.
Poucos anos se passaram e tudo mudou. Agora acho que alguém lendo na internet não vai ver menção nenhuma a Tocqueville ou liberalismo clássico, essa chatice de democracia e suas [chatices legalistas](nostr:naddr1qqyr2df58qekxce3qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c0n53d9). O "libertarianismo", também um nome infeliz, tomou conta de tudo, e cresceu muito mais do que o movimento liberal-da-internet jamais imaginou que seria possível.
Os libertários brasileiros são anarquistas, detestam a democracia, reconhecem nela um [vetor de ataque](nostr:naddr1qqyrxvtxxf3nse3sqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccyra4y) dos socialistas a qualquer pontinha de livre-mercado que exista -- e às liberdades individuais dos cidadãos (este aqui ainda um ponto em comum com os liberais oitocentistas). São inclusive muito mais propensos a defender a monarquia do que a democracia.
E isso é uma coisa boa. Finalmente uma pessoa pode defender princípios razoáveis de livre-mercado e individualismo sem precisar se associar com o movimento setecentistas e oitocentista que fez coisas boas, mas também foi responsável por coisas horríveis como a revolução francesa e todos os seus absurdos, e de onde saiu todo o movimento socialista.
- [Democracia na América](nostr:naddr1qqyrzc3ev3jn2vrpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8ynvrd)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A prediction market as a distributed set of oracle federations
See also: [Truthcoin as a spacechain](nostr:naddr1qqyrqcfsxumrsvmpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823chvhy2j).
This is not Truthcoin, but hopefully the essence of what makes it good is present here: permissionless, uncensorable prediction markets for fun, profit, making cheap talk expensive and revolutionizing the emergence and diffusion of knowledge in society.
## The idea
The idea is just to reuse Fedimint's codebase to implement federated _oracle corporations_ that will host individual prediction markets inside them.
Pegging in and out of a federation can be done through Lightning gateways, and once inside the federation users can buy and sell shares of individual markets using a native LMSR market-maker.
Then we make a decentralized directory of these bets using something simple like [Nostr](https://github.com/nostr-protocol/nostr) so everybody can just join any market very easily.
## Why?
The premise of this idea is that we can't have a centralized prediction market platform because governments will shut it down, but we can instead have a pseudonymous _oracle corporation_ that also holds the funds being gambled at each time in a multisig Bitcoin wallet and hope for the best.
Each corporation may exist to host a single market and then vanish afterwards -- its members returning later to form a new corporation and host a new market before leaving again.
There is custodial risk, but the fact that the members may accrue reputation as the time passes and that this is not one big giant multisig holding all the funds of everybody but one multisig for each market makes it so this is slightly better.
In any case, no massive amounts are expected to be used in this scheme, which defeats some of the use cases of prediction markets (funding public goods, for example), but since these are so advanced and society is not yet ready for them, we can leave them for later and first just try to get some sports betting working.
This proto-truthcoin implementation should work just well enough to increase the appetite of bitcoiners and society in general for more powerful prediction markets.
## Why is this better than DLCs?
Because DLCs have no liquidity. In their current implementations _and in all future plans from DLC enthusiasts_ they don't even have **order books**. They're not seen very much as general-purpose prediction markets, but mostly as a way to create monetary instruments and derivatives.
They could work as prediction markets, but then they would need order books and order books are terrible for liquidity. LMSR market makers are much better.
## But it is custodial!
If you make a public order book tied to known oracles using a DLC the oracle may also be considered custodial since it becomes really easy for him to join multiple trades as a counterpart then lie and steal the money. The bets only really "discreet" if they're illiquid meaningless bets between two guys. If they're happening in a well-known public place they're not discreet anymore.
DLC proponents may say this can be improved by users using multiple oracles and forming effectively a federation between them, but that is hardly different from choosing a reputable _oracle corporation_ in this scheme and trusting that for the life of the bet.
## But [Hivemind](https://bitcoinhivemind.com) is better!
Yes.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# O Bitcoin como um sistema social humano
Afinal de contas, o que é o Bitcoin? Não vou responder a essa pergunta explicando o que é uma "blockchain" ou coisa que o valha, como todos fazem muito pessimamente. [A melhor explicação em português que eu já vi está aqui](nostr:naddr1qqrky6t5vdhkjmspz9mhxue69uhkv6tpw34xze3wvdhk6q3q80cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsxpqqqp65wp3k3fu), mas mesmo assim qualquer explicação jamais será definitiva.
A explicação apenas do protocolo, do que faz um programa `bitcoind` sendo executado em um computador e como ele se comunica com outros em outros computadores, e os incentivos que estão em jogo para garantir com razoável probabilidade que se chegará a um consenso sobre quem é dono de qual parte de qual transação, apesar de não ser complicada demais, exigirá do iniciante que seja compreendida muitas vezes antes que ele se possa se sentir confortável para dizer que entende um pouco.
E essa parte _técnica_, apesar de ter sido o insight fundamental que gerou o evento miraculoso chamado Bitcoin, não é a parte mais importante, hoje. Se fosse, várias dessas outras moedas seriam concorrentes do Bitcoin, mas não são, e jamais poderão ser, porque elas não estão nem próximas de ter os outros elementos que compõem o Bitcoin. São eles:
1. A estrutura
O Bitcoin é um sistema composto de partes independentes.
Existem programadores que trabalham no protocolo e aplicações, e dia após dia novos programadores chegam e outros saem, e eles trabalham às vezes em conjunto, às vezes sem que um se dê conta do outro, às vezes por conta própria, às vezes pagos por empresas interessadas.
Existem os usuários que realizam validação completa, isto é, estão rodando algum programa do Bitcoin e contribuindo para a difusão dos blocos, das transações, rejeitando usuários malignos e evitando ataques de mineradores mal-intencionados.
Existem os poupadores, acumuladores ou os proprietários de bitcoins, que conhecem as possibilidades que o mundo reserva para o Bitcoin, esperam o dia em que o padrão-Bitcoin será uma realidade mundial e por isso mesmo atributem aos seus bitcoins valores muito mais altos do que os preços atuais de mercado, agarrando-se a eles.
Especuladores de "criptomoedas" não fazem parte desse sistema, nem tampouco empresas que [aceitam pagamento](https://bitpay.com/) em bitcoins para imediatamente venderem tudo em troca de dinheiro estatal, e menos ainda [gente que usa bitcoins](https://www.investimentobitcoin.com/) e [a própria marca Bitcoin](https://www.xdex.com.br/) para aplicar seus golpes e coisas parecidas.
2. A cultura
Mencionei que há empresas que pagam programadores para trabalharem no código aberto do BitcoinCore ou de outros programas relacionados à rede Bitcoin -- ou mesmo em aplicações não necessariamente ligadas à camada fundamental do protocolo. Nenhuma dessas empresas interessadas, porém, controla o Bitcoin, e isso é o elemento principal da cultura do Bitcoin.
O propósito do Bitcoin sempre foi ser uma rede aberta, sem chefes, sem política envolvida, sem necessidade de pedir autorização para participar. O fato do próprio Satoshi Nakamoto ter voluntariamente desaparecido das discussões foi fundamental para que o Bitcoin não fosse visto como um sistema dependente dele ou que ele fosse entendido como o chefe. Em outras "criptomoedas" nada disso aconteceu. O chefe supremo do Ethereum continua por aí mandando e desmandando e inventando novos elementos para o protocolo que são automaticamente aceitos por toda a comunidade, o mesmo vale para o Zcash, EOS, Ripple, Litecoin e até mesmo para o Bitcoin Cash. Pior ainda: Satoshi Nakamoto saiu sem nenhum dinheiro, nunca mexeu nos milhares de bitcoins que ele gerou nos primeiros blocos -- enquanto os líderes dessas porcarias supramencionadas cobraram uma fortuna pelo direito de uso dos seus primeiros usuários ou estão aí a até hoje receber dividendos.
Tudo isso e mais outras coisas -- a mentalidade anti-estatal e entusiasta de sistemas p2p abertos dos membros mais proeminentes da comunidade, por exemplo -- faz com que um ar de liberdade e suspeito de tentativas de centralização da moeda sejam percebidos e execrados.
3. A história
A noção de que o Bitcoin não pode ser controlado por ninguém passou em 2017 por [dois testes](https://www.forbes.com/sites/ktorpey/2019/04/23/this-key-part-of-bitcoins-history-is-what-separates-it-from-competitors/#49869b41ae5e) e saiu deles muito reforçada: o primeiro foi a divisão entre Bitcoin (BTC) e Bitcoin Cash (BCH), uma obra de engenharia social que teve um sucesso mediano em roubar parte da marca e dos usuários do verdadeiro Bitcoin e depois a tentativa de tomada por completo do Bitcoin promovida por mais ou menos as mesmas partes interessadas chamada SegWit2x, que fracassou por completo, mas não sem antes atrapalhar e difundir mentiras para todos os lados. Esses dois fracassos provaram que o Bitcoin, mesmo sendo uma comunidade desorganizada, sem líderes claros, está imune à [captura por grupos interessados](https://en.wikipedia.org/wiki/Regulatory_capture), o que é mais um milagre -- ou, como dizem, um [ponto de Schelling](https://en.wikipedia.org/wiki/Focal_point_(game_theory)).
Esse período crucial na história do Bitcoin fez com ficasse claro que _hard-forks_ são essencialmente incompatíveis com a natureza do protocolo, de modo que no futuro não haverá a possibilidade de uma sugestão como a de imprimir mais bitcoins do que o que estava programado sejam levadas a sério (mas, claro, sempre há a possibilidade da cultura toda se perder, as pessoas esquecerem a história e o Bitcoin ser cooptado, eis a importância da auto-educação e da difusão desses princípios).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# O mito do objetivo
O insight [deste cara](https://www.youtube.com/watch?v=dXQPL9GooyI) segundo o qual buscar objetivos fixos, além de matar a criatividade, ainda não consegue atingir o tal objetivo -- que é uma coisa na qual eu sempre acreditei, embora sem muitas confirmações e (talvez por isso) sem dizê-lo abertamente --, combina com a idéia geral de que todas as estruturas sociais que valem alguma coisa surgem do jogo e brincadeira.
A seriedade, que é o oposto da brincadeira, é representada aqui pelo objetivo. Pessoas muito sérias com um planejamento e um objetivo final, tudo esquematizado.
---
Na verdade esse insight é bem manjado. Até eu mesmo já o tinha mencionado, citando Taleb em [Processos Antifrágeis](nostr:naddr1qqyryv3hxfsnvvm9qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c5jshx7).
E finalmente há esta tirinha que eu achei aleatoriamente e que bem o representa: [](https://dilbert.com/strip/2004-04-17)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Truthcoin as a spacechain
To be clear, the term "spacechain" here refers only to the general concept of [blindly merge-mined (BMM)](https://gist.github.com/RubenSomsen/5e4be6d18e5fa526b17d8b34906b16a5) chains without a native money-token, not including the ["spacecoins"](https://medium.com/@RubenSomsen/21-million-bitcoins-to-rule-all-sidechains-the-perpetual-one-way-peg-96cb2f8ac302).
The basic idea is that for [Truthcoin/Hivemind](https://bitcoinhivemind.com/) to work we need
1. Balances of Votecoin tokens, i.e. a way to keep track of who owns how much of the _oracle corporation_;
2. Bitcoin tokens to be used for buying and selling prediction market shares, i.e. money to gamble;
3. A blockchain, i.e. some timestamping service that emits blocks ordered with transactions and can keep track of internal state and change the state -- including the balances of the Votecoin tokens and of the Bitcoin tokens that are assigned to individual prediction markets according to predefined rules;
A spacechain, i.e. a blindly merge-mined chain, gives us 1 and 3. We can just write any logic for that and that should be very easy. It doesn't give us 2, and it also has the problem of how the spacechain users can pay the spacechain miners (which is why the spacecoins were envisioned in the first place, but we don't have spacecoins here).
But remember we have votecoins already. Votecoins (VTC) should represent a share in the _oracle corporation_, which means they entitle their holders to some revenue -- even though they also burden their holders with the duty to vote in event outcomes (at the risk of losing part of their own votecoin balance) --, and they can be exchanged, so we can assume they will have _some_ value.
So we could in theory use these valuable tokens to pay the spacechain miners. That wouldn't be great because it pervert their original purpose and wouldn't solve the problem 2 from above -- unless we also used the votecoins to bet in which case they wouldn't be just another shitcoin in the planet with no network effect competing against Bitcoin and would just cause harm to humanity.
What we can do instead is to create a native mechanism for issuing virtual Bitcoin tokens (vBTC) in this chain, collaterized by votecoins, then we can use these vBTC to both gamble (solve problem 2) and pay miners (fix the hole in the spacechain BMM design).
For example, considering the VTC to be worth 0.001 BTC, any VTC holder could put 0.005 VTC and get 0.001 vBTC, then use to gamble or sell to others who want to gamble. The VTC holder still technically owns the VTC and can and must still participate in the oracle decisions. They just have to pay the BTC back before they can claim their VTC back if they want to send it elsewhere.
They stand to gain by selling vBTC if there is a premium for vBTC over BTC (i.e. people want to gamble) and then rebuying vBTC back once that premium goes away or reverts itself.
For this scheme to work the chain must know the exchange rate between VTC and BTC, which can be provided by the _oracle corporation_ itself.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Haskell Monoids
You've seen that `<>` syntax and noticed it is imported from `Data.Monoid`?
I've always thought `<>` was a pretty complex mathematical function and it was very odd that people were using it for `Text` values, like `"whatever " <> textValue <> " end."`.
It turns out `Text` is a Monoid. That means it implements the Monoid class (or typeclass), that means it has a particular way of being concatenated. Any list could be a Monoid, any abstraction you can think of for which it makes sense to concatenate could be a Monoid, and it would use the same `<>` syntax. What exactly `<>` would do with that value when concatenating depends on its typeclass implementation of Monoid.
We can assume, for example, that `Text` implements Monoid by just joining the text bytes, and now we can use `<>` without getting puzzled about it.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Soft-forks on Bitcoin
A traditional soft-fork activation plays out like this:
1. someone makes a proposal
2. if half-dozen respected Core developers like that, they implement it and talk about it
3. everybody loves the idea
4. they ship it in Bitcoin Core
5. miners turn it onA traditional soft-fork activation plays out like this:
A traditional soft-fork failure plays out like this:
1. someone makes a proposal
2. if half-dozen respected Core developers do not care much about the idea, they don't do anything
3. people fight on Twitter about the merits of the idea forever
A sidechain activation within [BIP-300](nostr:naddr1qq9xgunfwejkx6rpd9hqzythwden5te0ve5kzar2v9nzucm0d5pzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqvzqqqr4gumtjfnp) plays out like this:
1. someone writes the sidechain software
2. if a bunch of people are interested in that, they start playing with it in test mode
3. if it is really good people launch a proposal to miners
4. miners vote yes or no
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Rede Relâmpago
Ao se referir à _Lightning Network_ do [O que é Bitcoin?](nostr:naddr1qqrky6t5vdhkjmspz9mhxue69uhkv6tpw34xze3wvdhk6q3q80cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsxpqqqp65wp3k3fu), nós, brasileiros e portugueses, devemos usar o termo "Relâmpago" ou "Rede Relâmpago". "Relâmpago" é uma palavra bonita e apropriada, e fácil de pronunciar por todos os nossos compatriotas. Chega de anglicismos desnecessários.
Exemplo de uma conversa hipotética no Brasil usando esta nomenclatura:
– Posso pagar com Relâmpago?
– Opa, claro! Vou gerar um boleto aqui pra você.
Repare que é bem mais natural e fácil do que a outra alternativa:
– Posso pagar com láitenim?
– Leite ninho?
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Eltoo
Read [the paper](https://blockstream.com/eltoo.pdf), it's actually nice and small. You can read only everything up to section 4.2 and it will be enough. Done.
Ok, you don't want to. Or you tried but still want to read here.
Eltoo is a way of keeping payment channel state that works better than the original scheme used in _Lightning_. Since Lightning is a bunch of different protocols glued together, it can It replace just the part the previously dealed with keeping the payment channel.
Eltoo works like this: A and B want a payment channel, so they create a multisig transaction with deposits from both -- or from just one, doesn't matter. That transaction is only spendable if both cooperate. So if one of them is unresponsive or non-cooperative the other must have a way to get his funds back, so they also create an **update** transaction but don't publish it to the blockchain. That update transaction spends to a **settlement** transaction that then distributes the money back to A and B as their balances say.
If they are cooperative they can change the balances of the channel by just creating new **update** transactions and **settlement** transactions and number them like 1, 2, 3, 4 etc.

_Solid arrows means a transaction is presigned to spend only that previous other transaction; dotted arrows mean it's a floating transaction that can spend any of the previous._
## Why do they need and update and a settlement transaction?
Because if B publishes **update2** (in which his balances were greater) A needs some time to publish **update4** (the latest, which holds correct state of balances).
Each **update** transaction can be spent by any newer **update** transaction immediately or by its own specific **settlement** transaction only after some time -- or some blocks.
Hopefully you got that.
## How do they close the channel?
If they're cooperative they can just agree to spend the funding transaction, that first multisig transaction I mentioned, to whatever destinations they want. If one party isn't cooperating the other can just publish the latest **update** transaction, wait a while, then publish its **settlement** transaction.
## How is this better than the previous way of keeping channel states?
Eltoo is better because nodes only have to keep the last set of update and settlement transactions. Before they had to keep all intermediate state updates.
## If it is so better why didn't they do it first?
Because they didn't have the idea. And also because they needed an update to the Bitcoin protocol that allowed the presigned **update** transactions to spend any of the previous **update** transactions. This protocol update is called `SIGHASH_NOINPUT`[^anyprevout], you've seen this name out there. By marking a transaction with `SIGHASH_NOINPUT` it enters a mystical state and becomes a _floating transaction_ that can be bound to any other [transaction](nostr:naddr1qqyr2e34xycnyephqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cun2wfz) as long as its unlocking script matches the locking script.
## Why can't update2 bind itself to update4 and spend that?
Good question. It can. But then it can't anymore, because Eltoo uses `OP_CHECKLOCKTIMEVERIFY` to ensure that doesn't actually check not a locktime, but a sequence. It's all arcane stuff.
And then Eltoo **update** transactions are numbered and their lock/unlock scripts will only match if a transaction is being spent by another one that's greater than it.
## Do Eltoo channels expire?
No.
## What is that "on-chain protocol" they talk about in the paper?
That's just an example to guide you through how the off-chain protocol works. Read carefully or don't read it at all. The off-chain mechanics is different from the on-chain mechanics. Repeating: the on-chain protocol is useless in the real world, it's just a didactic tool.
[^anyprevout]: Later `SIGHASH_NOINPUT` was modified to fit better with Taproot and Schnorr signatures and renamed to `SIGHASH_ANYPREVOUT`.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# idea: Link sharing incentivized by satoshis
See <https://2key.io/> and <https://www.youtube.com/watch?v=CEwRv7qw4fY&t=192s>.
I think the general idea is to make a self-serving automatic referral program for individual links, but I wasn't patient enough to deeply understand neither of the above ideas.
Solving fraud is an issue. People can fake clicks.
One possible solution is to track conversions instead of clicks, but then it's too complex as the receiving side must do stuff and be trusted to do it correctly.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A crappy zk-rollups explanation attempt
(Considering the example of zksync.io)
(Also, don't believe me on any of this.)
1. They are sidechains.
2. You move tokens to the sidechain by depositing it on an Ethereum contract. Then your account is credited in the sidechain balance.
3. Then you can make payments inside the sidechain by signing transactions and sending them to a central operator.
4. The central operator takes transactions from a bunch of people, computes the new sidechain balances state and publishes a hash of that state to the Ethereum contract.
5. The idea is that a single transaction in the blockchain contains a bunch of sidechain transactions.
6. The operator also sends to the contract an abbreviated list of the sidechain transactions. The trick is making all signatures condensed in a single zero-knowledge proof which is enough for the contract to verify that the transition from the previous state to the new is good.
7. Apparently they can fit 500 sidechain transactions in one mainchain transaction (each is 12 bytes). So I believe it's fair to say all this zk-rollup fancyness could be translated into "a system for aggregating transactions".
8. I don't understand how the zero-knowledge proof works, but in this case it is a SNARK and requires a trusted setup, which I imagine is similar to [this one](https://petertodd.org/2016/cypherpunk-desert-bus-zcash-trusted-setup-ceremony).
* [On "zk-rollups" applied to Bitcoin](nostr:naddr1qqyrzd3jvymkxve5qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c2c9rut)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Veterano não é dono de bixete
"VETERANO NÃO É DONO DE BIXETE". A frase em letras garrafais chama a atenção dos transeuntes neófitos. Paira sobre um cartaz amarelo que lista várias reclamações contra os "trotes machistas", que, na opinião do responsável pelo cartaz, "não é brincadeira, é opressão".
Eis aí um bizarro exemplo de como são as coisas: primeiro todos os universitários aprovam a idéia do trote, apoiam sua realização e até mesmo desejam sofrer o trote -- com a condição de o poderem aplicar eles mesmos depois --, louvam as maravilhas do mundo universitário, onde a suprema sabedoria se esconde atrás de rituais iniciáticos fora do alcance da imaginação do homem comum e rude, do pobre e do filhinho-de-papai das faculdades privadas; em suma: fomentam os mais baixos, os mais animalescos instintos, a crueldade primordial, destroem em si mesmos e nos colegas quaisquer valores civilizatórios que tivessem sobrado ali, ficando todos indistingüíveis de macacos agressivos e tarados.
Depois vêm aí com um cartaz protestar contra os assédios -- que sem dúvida acontecem em larguíssima escala -- sofridos pelas calouras de 17 anos e que, sendo também novatas no mundo universitário, ainda conservam um pouco de discernimento e pudor.
A incompreensão do fenômeno, porém, é tão grande, que os trotes não são identificados como um problema mental, uma doença que deve ser tratada e eliminada, mas como um sintoma da opressão machista dos homens às mulheres, um produto desta civilização paternalista que, desde que Deus é chamado "o Pai" e não "a Mãe", corrompe a benéfica, pura e angélica natureza do homem primitivo e o torna esta tão torpe criatura.
Na opinião dos autores desse cartaz é preciso, pois, continuar a destruir o que resta da cultura ocidental, e então esperar que haja trotes menos opressores.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# notes on "Economic Action Beyond the Extent of the Market", Per Bylund
Source: <https://www.youtube.com/watch?v=7St6pCipCB0>
Markets work by dividing labour, but that's not as easy as it seems in the Adam Smith's example of a pin factory, because
1. a pin factory is not a market, so there is some guidance and orientation, some sort of central planning, inside there that a market doesn't have;
2. it is not clear how exactly the production process will be divided, it is not obvious as in "you cut the thread, I plug the head".
Dividing the labour may produce efficiency, but it also makes each independent worker in the process more fragile, as they become dependent on the others.
This is partially solved by having a lot of different workers, so you do not depend on only one.
If you have many, however, they must agree on where one part of the production process starts and where it ends, otherwise one's outputs will not necessarily coincide with other's inputs, and everything is more-or-less broken.
That means some level of standardization is needed. And indeed the market has constant incentives to standardization.
The statist economist discourse about standardization is that only when the government comes with a law that creates some sort of standardization then economic development can flourish, but in fact the market creates standardization all the time. Some examples of standardization include:
* programming languages, operating systems, internet protocols, CPU architectures;
* plates, forks, knifes, glasses, tables, chairs, beds, mattresses, bathrooms;
* building with concrete, brick and mortar;
* money;
* musical instruments;
* light bulbs;
* CD, DVD, VHS formats and others alike;
* services that go into every production process, like lunch services, restaurants, bakeries, cleaning services, security services, secretaries, attendants, porters;
* multipurpose steel bars;
* practically any tool that normal people use and require a little experience to get going, like a drilling machine or a sanding machine; etc.
Of course it is not that you find standardization in all places. Specially when the market is smaller or new, standardization may have not arrived.
There remains the truth, however, that division of labour has the potential of doing good.
More than that: every time there are more than one worker doing the same job in the same place of a division of labour chain, there's incentive to create a new subdivision of labour.
From the fact that there are at least more than one person doing the same job as another in our society we must conclude that someone must come up with an insight about an efficient way to divide the labour between these workers (and probably actually implement it), that hasn't happened for all kinds of jobs.
But to come up with division of labour outside of a factory, some market actors must come up with a way of dividing the labour, actually, determining where will one labour stop and other start (and that almost always needs some adjustments and in fact extra labour to hit the tips), and also these actors must bear the uncertainty and fragility that division of labour brings when there are not a lot of different workers and standardization and all that.
In fact, when an entrepreneur comes with a radical new service to the market, a service that does not fit in the current standard of division of labour, he must explain to his potential buyers what is the service and how the buyer can benefit from it and what he will have to do to adapt its current production process to bear with that new service. That's has happened not long ago with
* services that take food orders from the internet and relay these to the restaurants;
* hostels for cheap accommodation for young travellers;
* Uber, Airbnb, services that take orders and bring homemade food from homes to consumers and similars;
* all kinds of software-as-a-service;
* electronic monitoring service for power generators;
* mining planning and mining planning software; and many other industry-specific services.
## See also
* [Profits, not wages, as the originary factor](nostr:naddr1qqyrge3hxa3rqce4qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7x67pu)
* [Per Bylund's insight](nostr:naddr1qqyxvdtzxscxzcenqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cuq3unj)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Precautionary Principle
The [precautionary principle](https://en.wikipedia.org/wiki/Precautionary_principle) that people, including Nassim Nicholas Taleb, love and treat as some form of wisdom, is actually just a justification for arbitrary acts.
In a given situation for which there's no sufficient knowledge, either A or B can be seen as risky or precautionary measures, there's no way to know except if you have sufficient knowledge.
---
Someone could reply saying, for example, that the known risk of A is tolerable to the unknown, probably magnitudes bigger, risk of B. Unless you know better or at least have a logical explanation for the risks of B (a thing "scientists" don't have because they notoriously dislike making logical claims), in which case you do know something and is not invoking the precautionary principle anymore, just relying on your logical reasoning – and that can be discussed and questioned by others, undermining your intended usage of the label "precautionary principle" as a magic cover for your actions.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# IPFS problems: Conceit
IPFS is trying to do many things. The IPFS leaders are revolutionaries who think they're smarter than the rest of the entire industry.
The fact that they've first proposed a protocol for peer-to-peer distribution of immutable, content-addressed objects, then later tried to fix [that same problem](nostr:naddr1qqyrqen9xf3nvdpeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cmdjnnj) using their own half-baked solution (IPNS) is one example.
Other examples are their odd appeal to decentralization in a very non-specific way, their excessive [flirtation with Ethereum](nostr:naddr1qqyxxdpev5cnsvpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cta4a2e) and their never-to-be-finished can-never-work-as-advertised _Filecoin_ project.
They could have focused on just making the infrastructure for distribution of objects through hashes (not saying this would actually be a good idea, but it had some potential) over a peer-to-peer network, but in trying to reinvent the entire internet they screwed everything up.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# gravity
IPFS is nice as a personal archiving tool (edit: it's not). You store a bunch of data and make it available to the public.
The problem is that no one will ever know you have that data, therefore you need a place to publish it somewhere. Gravity was an attempt of being the tool for this job.
It was a website that showcased the collections from users, and it was also a command-line client that used your IPFS keys for authentication and allowed you to paste IPFS URIs and names and descriptions.
The site was intended to be easy to run so you could have multiple stellar bodies aggregating content and interact with them all in a standardized manner.
It also had an ActivityPub/"fediverse" integration so people could follow Gravity server users from Mastodon and friends and see new data they published as "tweets".
- <https://github.com/fiatjaf/gravity>
## See also
- [How IPFS is broken](nostr:naddr1qqyxgdfsxvck2dtzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8y87ll)
- [litepub](nostr:naddr1qqyxzcecxs6x2c3sqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823czz6dgn)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# idea: "numbeo" with satoshis
This site has a crowdsourced database of cost-of-living in many countries and cities: <https://www.numbeo.com/cost-of-living/> and it sells the data people write there freely. It's wrong!
Could be an fruitful idea to pay satoshis for people to provide data.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Lightning and its fake HTLCs
Lightning is terrible but can be very good with two tweaks.
## How Lightning would work without HTLCs
In a world in which HTLCs didn't exist, Lightning channels would consist only of balances. Each commitment transaction would have two outputs: one for peer `A`, the other for peer `B`, according to the current state of the channel.
When a payment was being attempted to go through the channel, peers would just trust each other to update the state when necessary. For example:
1. Channel `AB`'s balances are `A[10:10]B` (in sats);
2. `A` sends a 3sat payment through `B` to `C`;
3. `A` asks `B` to route the payment. Channel `AB` doesn't change at all;
4. `B` sends the payment to `C`, `C` accepts it;
5. Channel `BC` changes from `B[20:5]C` to `B[17:8]C`;
6. `B` notifies `A` the payment was successful, `A` acknowledges that;
7. Channel `AB` changes from `A[10:10]B` to `A[7:13]B`.
This in the case of a success, everything is fine, no glitches, no dishonesty.
But notice that `A` could have refused to acknowledge that the payment went through, either because of a bug, or because it went offline forever, or because it is malicious. Then the channel `AB` would stay as `A[10:10]B` and `B` would have lost 3 satoshis.
## How Lightning would work with HTLCs
HTLCs are introduced to remedy that situation. Now instead of commitment transactions having always only two outputs, one to each peer, now they can have HTLC outputs too. These HTLC outputs could go to either side dependending on the circumstance.
Specifically, the peer that is sending the payment can redeem the HTLC after a number of blocks have passed. The peer that is receiving the payment can redeem the HTLC if they are able to provide the preimage to the hash specified in the HTLC.
Now the flow is something like this:
1. Channel `AB`'s balances are `A[10:10]B`;
2. `A` sends a 3sat payment through `B` to `C`:
3. `A` asks `B` to route the payment. Their channel changes to `A[7:3:10]B` (the middle number is the HTLC).
4. `B` offers a payment to `C`. Their channel changes from `B[20:5]C` to `B[17:3:5]C`.
5. `C` tells `B` the preimage for that HTLC. Their channel changes from `B[17:3:5]C` to `B[17:8]C`.
6. `B` tells `A` the preimage for that HTLC. Their channel changes from `A[7:3:10]B` to `A[7:13]B`.
Now if `A` wants to trick `B` and stop responding `B` doesn't lose money, because `B` knows the preimage, `B` just needs to publish the commitment transaction `A[7:3:10]B`, which gives him 10sat and then redeem the HTLC using the preimage he got from `C`, which gives him 3 sats more. `B` is fine now.
In the same way, if `B` stops responding for any reason, `A` won't lose the money it put in that HTLC, it can publish the commitment transaction, get 7 back, then redeem the HTLC after the certain number of blocks have passed and get the other 3 sats back.
## How Lightning doesn't really work
The example above about how the HTLCs work is very elegant but has a fatal flaw on it: transaction fees. Each new HTLC added increases the size of the commitment transaction and it requires yet another transaction to be redeemed. If we consider fees of 10000 satoshis that means any HTLC below that is as if it didn't existed because we can't ever redeem it anyway. In fact the Lightning protocol explicitly dictates that if HTLC output amounts are below the fee necessary to redeem them they shouldn't be created.
What happens in these cases then? Nothing, the amounts that should be in HTLCs are moved to the commitment transaction miner fee instead.
So considering a transaction fee of 10000sat for these HTLCs if one is sending Lightning payments below 10000sat that means they operate according to the _unsafe protocol_ described in the first section above.
It is actually worse, because consider what happens in the case a channel in the middle of a route has a glitch or one of the peers is unresponsive. The other node, thinking they are operating in the _trustless protocol_, will proceed to publish the commitment transaction, i.e. close the channel, so they can redeem the HTLC -- only then they find out they are actually in the _unsafe protocol_ realm and there is no HTLC to be redeemed at all and they lose not only the money, but also the channel (which costed a lot of money to open and close, in overall transaction fees).
One of the biggest features of the _trustless protocol_ are the payment proofs. Every payment is identified by a hash and whenever the payee releases the preimage relative to that hash that means the payment was complete. The incentives are in place so all nodes in the path pass the preimage back until it reaches the payer, which can then use it as the proof he has sent the payment and the payee has received it. This feature is also lost in the _unsafe protocol_: if a glitch happens or someone goes offline on the preimage's way back then there is no way the preimage will reach the payer because no HTLCs are published and redeemed on the chain. The payee may have received the money but the payer will not know -- but the payee will lose the money sent anyway.
## The end of HTLCs
So considering the points above you may be sad because in some cases Lightning doesn't use these magic HTLCs that give meaning to it all. But the fact is that no matter what anyone thinks, HTLCs are destined to be used less and less as time passes.
The fact that over time Bitcoin transaction fees tend to rise, and also the fact that multipart payment (MPP) are increasedly being used on Lightning for good, we can expect that soon no HTLC will ever be big enough to be actually worth redeeming and we will be at a point in which not a single HTLC is real and they're all fake.
Another thing to note is that the current _unsafe protocol_ kicks out whenever the HTLC amount is below the Bitcoin transaction fee would be to redeem it, but this is not a reasonable algorithm. It is not reasonable to lose a channel and then pay 10000sat in fees to redeem a 10001sat HTLC. At which point does it become reasonable to do it? Probably in an amount many times above that, so it would be reasonable to even increase the threshold above which real HTLCs are made -- thus making their existence more and more rare.
These are good things, because we don't actually need HTLCs to make a functional Lightning Network.
## We must embrace the _unsafe protocol_ and make it better
So the _unsafe protocol_ is not necessarily very bad, but the way it is being done now is, because it suffers from two big problems:
1. Channels are lost all the time for no reason;
2. No guarantees of the proof-of-payment ever reaching the payer exist.
The first problem we fix by just stopping the current practice of closing channels when there are no real HTLCs in them.
That, however, creates a new problem -- or actually it exarcebates the second: now that we're not closing channels, what do we do with the expired payments in them? These payments should have either been canceled or fulfilled before some block x, now we're in block x+1, our peer has returned from its offline period and one of us will have to lose the money from that payment.
That's fine because it's only 3sat and it's better to just lose 3sat than to lose both the 3sat and the channel anyway, so either one would be happy to eat the loss. Maybe we'll even split it 50/50! No, that doesn't work, because it creates an attack vector with peers becoming unresponsive on purpose on one side of the route and actually failing/fulfilling the payment on the other side and making a profit with that.
So we actually need to know who is to blame on these payments, even if we are not going to act on that imediatelly: we need some kind of arbiter that both peers can trust, such that if one peer is trying to send the preimage or the cancellation to the other and the other is unresponsive, when the unresponsive peer comes back, the arbiter can tell them they are to blame, so they can willfully eat the loss and the channel can continue. Both peers are happy this way.
If the unresponsive peer doesn't accept what the arbiter says then the peer that was operating correctly can assume the unresponsive peer is malicious and close the channel, and then blacklist it and never again open a channel with a peer they know is malicious.
Again, the differences between this scheme and the current Lightning Network are that:
a. In the current Lightning we always close channels, in this scheme we only close channels in case someone is malicious or in other worst case scenarios (the arbiter is unresponsive, for example).
b. In the current Lightning we close the channels without having any clue on who is to blame for that, then we just proceed to reopen a channel with that same peer even in the case they were actively trying to harm us before.
## What is missing? An arbiter.
The Bitcoin blockchain is the ideal arbiter, it works in the best possible way if we follow the _trustless protocol_, but as we've seen we can't use the Bitcoin blockchain because it is expensive.
Therefore we need a new arbiter. That is the hard part, but not unsolvable. Notice that we don't need an absolutely perfect arbiter, anything is better than nothing, really, even an unreliable arbiter that is offline half of the day is better than what we have today, or an arbiter that lies, an arbiter that charges some satoshis for each resolution, anything.
Here are some suggestions:
- random nodes from the network selected by an algorithm that both peers agree to, so they can't cheat by selecting themselves. The only thing these nodes have to do is to store data from one peer, try to retransmit it to the other peer and record the results for some time.
- a set of nodes preselected by the two peers when the channel is being opened -- same as above, but with more handpicked-trust involved.
- some third-party cloud storage or notification provider with guarantees of having open data in it and some public log-keeping, like Twitter, GitHub or a [Nostr](https://github.com/fiatjaf/nostr) relay;
- peers that get paid to do the job, selected by the fact that they own some token (I know this is stepping too close to the shitcoin territory, but could be an idea) issued in a [Spacechain](https://www.youtube.com/watch?v=N2ow4Q34Jeg);
- a Spacechain itself, serving only as the storage for a bunch of `OP_RETURN`s that are published and tracked by these Lightning peers whenever there is an issue (this looks wrong, but could work).
## Key points
1. Lightning with HTLC-based routing was a cool idea, but it wasn't ever really feasible.
2. HTLCs are going to be abandoned and that's the natural course of things.
3. It is actually good that HTLCs are being abandoned, but
4. We must change the protocol to account for the existence of fake HTLCs and thus make the bulk of the Lightning Network usage viable again.
## See also
- [Ripple and the problem of the decentralized commit](nostr:naddr1qqyrxcmzxa3nxv34qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cjrqar6)
- [The Lightning Network solves the problem of the decentralized commit](nostr:naddr1qqyx2vekxg6rsvejqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccs2twc)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Token-Curated Registries
## So you want to build a TCR?
TCRs (Token Curated Registries) are a construct for maintaining registries on Ethereum. Imagine you have lots of scissor brands and you want a list with only the good scissors. You want to make sure only the good scissors make into that list and not the bad scissors. For that, people will tell you, you can just create a TCR of the best scissors!
It works like this: some people have the token, let's call it Scissor Token. Some other person, let's say it's a scissor manufacturer, wants to put his scissor on the list, this guy must acquire some Scissor Tokens and "stake" it. Holders of the Scissor Tokens are allowed to vote on "yes" or "no". If "no", the manufactures loses his tokens to the holders, if "yes" then its tokens are kept in deposit, but his scissor brand gets accepted into the registry.
Such a simple process, they say, have strong incentives for being the best possible way of curating a registry of scissors: consumers have the incentive to consult the list because of its high quality; manufacturers have the incentive to buy tokens and apply to join the list because the list is so well-curated and consumers always consult it; token holders want the registry to accept good and reject bad scissors because that good decisions will make the list good for consumers and thus their tokens more valuable, bad decisions will do the contrary. It doesn't make sense, to reject everybody just to grab their tokens, because that would create an incentive against people trying to enter the list.
Amazing! How come such a simple system of voting has such enourmous features? Now we can have lists of everything so well-curated, and for that we just need Ethereum tokens!
Now let's imagine a different proposal, of my own creation: SPCR, Single-person curated registries.
Single-person Curated Registries are equal to TCR, except they don't use Ethereum tokens, it's just a list in a text file kept by a single person. People can apply to join, and they will have to give the single person some amount of money, the single person can reject or accept the proposal and so on.
Now let's look at the incentives of SPCR: people will want to consult the registry because it is so well curated; vendors will want to enter the registry because people are consulting it; the single person will want to accept the good and reject the bad applicants because these good decisions are what will make the list valuable.
Amazing! How such a single proposal has such enourmous features! SPCR are going to take over the internet!
## What TCR enthusiasts get wrong?
TCR people think they can just list a set of incentives for something to work and assume that something will work. Mix that with Ethereum hype and they think theyve found something unique and revolutionary, while in fact they're just making a poor implementation of "democracy" systems that fail almost everywhere.
The life is not about listing a set of "incentives" and then considering the problems solved. Almost everybody on the Earth has the incentive for being rich: being rich has a lot of advantages over being poor, however not all people get rich! Why are the incentives failing?
Curating lists is a hard problem, it involves a lot of knowledge about the problem that just holding a token won't give you, it involves personal preferences, politics, it involves knowing where is the real limit between "good" and "bad". The Single Person list may have a good result if the single person doing the curation is knowledgeable and honest (yes, you can game the system to accept your uncle's scissors and not their competitor that is much better, for example, without losing the entire list reputation), same thing for TCRs, but it can also fail miserably, and it can appear to be good but be in fact not so good. In all cases, the list entries will reflect the preferences of people choosing and other things that aren't taken into the incentives equation of TCR enthusiasts.
## We don't need lists
The most important point to be made, although unrelated to the incentive story, is that we don't need lists. Imagine you're looking for a scissor. You don't want someone to tell if scissor A or B are "good" or "bad", or if A is "better" than B. You want to know if, for your specific situation, or for a class of situations, A will serve well, and do that considering A's price and if A is being sold near you and all that.
Scissors are the worst example ever to make this point, but I hope you get it. If you don't, try imagining the same example with schools, doctors, plumbers, food, whatever.
Recommendation systems are badly needed in our world, and TCRs don't solve these at all.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# P2P reputation thing
Each node shares a blob of the reputations they have, which includes a confidence number. The number comes from the fact that reputations are inherited from other nodes they trust and averaged by their confidence in these. Everything is mixed for plausible deniability. By default a node only shares their stuff with people they manually add, to prevent government from crawling everybody's database. Also to each added friend nodes share a different identity/pubkey (like giving a new Bitcoin address for every transaction) (derived from hip32) (and since each identity can only be contacted by one other entity the node filters incoming connections to download their database: "this identity already been used? no, yes, used with which peer?").
## Network protocol
Maybe the data uploader/offerer initiates connection to the receiver over Tor so there's only a Tor address for incoming data, never an address for a data source, i.e. everybody has an address, but only for requesting data.
How to request? Post an encrypted message in an IRC room or something similar (better if messages are stored for a while) targeted to the node/identity you want to download from, along with your Tor address. Once the node sees that it checks if you can download and contacts you.
The encrypted messages could have the target identity pubkey prefix such that the receiving node could try to decrypt only some if those with some probability of success.
Nodes can choose to share with anyone, share only with pre-approved people, share only with people who know one of their addresses/entities (works like a PIN, you give the address to someone in the street, that person can reach you, to the next person you give another address etc., you can even have a public address and share limited data with that).
## Data model
Each entry in a database should be in the following format:
```
internal_id : real_world_identifier [, real_world_identifier...] : tag
```
Which means you can either associate one or multiple real world identifier with an internal id and associate the real person designated by these identifiers with a tag. the tag should be part of the standard or maybe negotiated between peers. it can be things like `scammer`, `thief`, `tax collector` etc., or `honest`, `good dentist` etc. defining good enough labels may be tricky.
`internal_id` should be created by the user who made the record about the person.
At first this is not necessary, but additional bloat can be added to the protocol if the federated automated message posting boards are working in the sense that each user can ask for more information about a given id and the author of that record can contact the person asking for information and deliver free text to them with the given information. For this to work the internal id must be a public key and the information delivered must be signed with the correspondent private key, so the receiver of the information will know it's not just some spammer inventing stuff, but actually the person who originated that record.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Democracia na América
Alexis de Tocqueville escreveu um livro só elogiando o sistema político dos Estados Unidos. E mesmo tendo sido assim, e mesmo tendo escrito o seu livro quase 100 anos antes do mais precoce sinal de decadência da democracia na América, percebeu coisas que até hoje quase ninguém percebe: o mandato da suprema corte é um enorme poder, uma força centralizadora, imune ao voto popular e com poderes altamente indefinidos e por isso mesmo ilimitados.
Não sei se ele concluiu, porém, que não existe nem pode existir balanço perfeito entre poderes. Sempre haverá furos.
De qualquer maneira, o homem é um gênio apenas por ter percebido isso e outras coisas, como o fato da figura do presidente, também obviamente um elemento centralizador, não ser tão poderosa quanto a figura de um rei da França, por exemplo. Mas ao mesmo tempo, por entre o véu de elogios (sempre muito sóbrios) deixou escapar que provavelmente também achava que não poderia durar para sempre a fraqueza do cargo de presidente.
- [Democracy as a failed open-network protocol](nostr:naddr1qqyrxvtxxf3nse3sqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823ccyra4y)
- [Família e propriedade](nostr:naddr1qqyrwwpnxesnqvmrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c4s2ruz)
- [Liberalismo oitocentista](nostr:naddr1qqyr2wfev5uxgwpsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c2z2jc9)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# O VAR é o grande equalizador
Não tenho acompanhado o futebol desde 2013 ou 2014, mas me parece que, como poderia ter sido previsto, o VAR tem favorecido os times pequenos ou marginais em detrimento dos demais.
É lógico: se os juízes favoreriam mais o Flamengo e o Corinthians, e depois os grandes de Rio e São Paulo, em detrimento dos demais, o VAR, por minimamente mais justo que seja, aparentará favorecer os outros.
* [Viva o mata-mata](nostr:naddr1qqyrgcnyv9nrsv35qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7h66hy)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Custom spreadsheets
The idea was to use it to make an app that would serve as [_custom database for everything_](nostr:naddr1qqyxgcejv5unzd33qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cz3va32) and interact with the spreadsheet so people could play and calculate with their values after they were created by the custom app, something like an MS Access integrated with Excel?
My first attempt that worked (I believe there was an attempt before but I have probably deleted it from everywhere) was this `react-microspreadsheet` thing (at the time called `react-spreadsheet` before I donated the npm name to someone who asked):
- <https://github.com/fiatjaf/react-microspreadsheet>
This was a very good spreadsheet component that did many things current "react spreadsheet" components out there don't do. It had formulas; support for that handle thing that you pulled with the mouse and it autofilled cells with a pattern; it had keyboard navigation with Ctrl, Shift, Ctrl+Shift; it had that thing through which you copy-pasted formulas and they would change their parameters depending on where you pasted them (implemented in a very poor manner because I was using and thinking about Excel in [baby mode][you-suck-at-excel] at the time).
Then I tried to make it into "a small sheet you can share" kind of app through assemblymade.com, and eventually as I tried to add more things bugs began to appear.
Then there was `cycle6-spreadsheet`:
- <https://github.com/fiatjaf/spreadsheet-cycle6>
If I remember well this was very similar to the other one, although made almost 2 years after. Despite having the same initial goal of the other (the multi-app custom database thing) it only yielded:
- [Sidesheet](https://chrome.google.com/webstore/detail/sidesheet/iheklhbgdljkmijlfajakikbgemncmf), a Chrome extension that opened a spreadsheet on the side of the screen that you could use to make calculations and so on. It worked, but had too many bugs that probably caused me to give up entirely.
I'm not sure which of the two spreadsheets above powers <http://sheets.alhur.es>.
[you-suck-at-excel]: <https://www.youtube.com/watch?v=0nbkaYsR94c>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# TiddlyWiki remoteStorage
[TiddlyWiki](https://tiddlywiki.com/) is very good and useful, but since at this time I used multiple computers during the week, it wouldn't work for me to use it as a single file on my computer, so I had to hack its internal tiddler saving mechanism to instead save the raw data of each tiddler to [remoteStorage](https://remotestorage.io/) and load them from that place also (ok, there was in theory a plugin system, but I had to read and understand the entire unformatted core source-code anyway).
There was also a [server](https://github.com/fiatjaf/tiddlywiki-remotestorage-server) that fetched tiddlywikis from anyone's remoteStorage buckets (after authorization) and served these to the world, a quick and nice way to publish a TiddlyWiki -- which is a problem all people in TiddlyWiki struggle against.
- <https://github.com/fiatjaf/tiddlywiki-remotestorage>
- <https://tiddly.alhur.es/>
## See also
- [hledger-web](nostr:naddr1qqyrsefkvvck2efkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cffvz7c)
- [LessPass remoteStorage](nostr:naddr1qqyrsctpxfjnqepeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cfa6z2z)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# requesthub.xyz

An app that was supposed to be some kind of declarative connector between two services, one that sent webhooks and the other that accepted HTTP requests of any kind. You would proxy and transform the webhooks using RequestHub and create a new request to the other service using that data.
The transformations were declared in the almighty [`jq`](https://stedolan.github.io/jq/) language.
It worked and had other functions planned for the future, but I guess it was too arcane, even I was confused by it sometimes.
Also it was very prone to spam (involuntary) attacks like some that did happen. Maybe it would work better in a world of anonymous satoshi payments.
Later I tried to revive it as a Trello Power-Up that would create comments on cards automatically according to some transformation rules and webhooks received.
- [requesthub.xyz](https://archive.is/nGyH3)
- <https://github.com/fiatjaf/requesthub.xyz>
- <https://github.com/fiatjaf/requesthub-trello>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# busca múltipla na estante virtual

A single-page app made in Elm with a Go backend that scrapped estantevirtual.com.br in real-time for search results of multiple different search terms and aggregated the results per book store, so when you want to buy many books you can find the stores that have the biggest part of what you want and buy everything together, paying less for the delivery fee.
It had a very weird unicode issue I never managed to solve, something with the encoding estantevirtual.com.br used.
I also planned to build the entire checkout flow directly in this UI, but then decided it wasn't worth it. The search flow only was already good enough.
- <https://estantevirtual.alhur.es/>
- <https://github.com/fiatjaf/estantevirtual>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# There's a problem with using Git concepts for everything
We've been seeing a surge in applications that use Git to store other things than code, or that are based on Git concepts and so enable "forking, merging and distributed collaboration" for things like blogs, recipes, literature, music composition, normal files in a filesystem, databases.
The problem with all this is they will either:
1. assume the user will commit manually and expect that commit to be composed by a set of meaningful changes, and the commiter will also add a message to the commit, describing that set of meaningful, related changes; or
2. try to make the committing process automatic and hide it from the user, so will producing meaningless commits, based on random changes in many different files (it's not "files" if we are talking about a recipe or rows in a table, but let's say "files" for the sake of clarity) that will probably not be related and not reduceable to a meaningful commit message, or maybe the commit will contain only the changes to a single file, and its commit message would be equivalent to "updated `<name of the file>`".
Programmers, when using Git, _think in Git_, i.e., they work with version control in their minds. They try hard to commit together only sets of meaningful and related changes, even when they happen to make unrelated changes in the meantime, and that's why there are commands like `git add -p` and many others.
Normal people, to whom many of these git-based tools are intended to (and even programmers when out of their code-world), are much less prone to _think in Git_, and that's why another kind of abstraction for fork-merge-collaborate in non-code environments must be used.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Trelew
A CLI tool for navigating Trello boards. It used **vorpal** for an "immersive" experience and was pretty good.

- <https://github.com/fiatjaf/trelew>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# SummaDB
This was a hierarchical database server similar to the original Firebase. Records were stored on a LevelDB on different paths, like:
- `/fruits/banana/color`: `yellow`
- `/fruits/banana/flavor`: `sweet`
And could be queried by path too, using HTTP, for example, a call to `http://hostname:port/fruits/banana`, for example, would return a JSON document like
```json
{
"color": "yellow",
"flavor": "sweet"
}
```
While a call to `/fruits` would return
```json
{
"banana": {
"color": "yellow",
"flavor": "sweet"
}
}
```
`POST`, `PUT` and `PATCH` requests also worked.
In some cases the values would be under a special `"_val"` property to disambiguate them from paths. (I may be missing some other details that I forgot.)
GraphQL was also supported as a query language, so a query like
```graphql
query {
fruits {
banana {
color
}
}
}
```
would return `{"fruits": {"banana": {"color": "yellow"}}}`.
## SummulaDB
SummulaDB was a browser/JavaScript build of SummaDB. It ran on the same Go code compiled with GopherJS, and using PouchDB as the storage backend, if I remember correctly.
It had replication between browser and server built-in, and one could replicate just subtrees of the main tree, so you could have stuff like this in the server:
```json
{
"users": {
"bob": {},
"alice": {}
}
}
```
And then only allow Bob to replicate `/users/bob` and Alice to replicate `/users/alice`. I am sure the require auth stuff was also built in.
There was also a PouchDB plugin to make this process smoother and data access more intuitive (it would hide the `_val` stuff and allow properties to be accessed directly, today I wouldn't waste time working on these hidden magic things).
## The computed properties complexity
The next step, which I never managed to get fully working and caused me to give it up because of the complexity, was the ability to automatically and dynamically compute materialized properties based on data in the tree.
The idea was partly inspired on CouchDB computed views and how limited they were, I wanted a thing that would be super powerful, like, given
```json
{
"matches": {
"1": {
"team1": "A",
"team2": "B",
"score": "2x1",
"date": "2020-01-02"
},
"1": {
"team1": "D",
"team2": "C",
"score": "3x2",
"date": "2020-01-07"
}
}
}
```
One should be able to add a computed property at `/matches/standings` that computed the scores of all teams after all matches, for example.
I tried to complete this in multiple ways but they were all adding much more complexity I could handle. Maybe it would have worked better on a more flexible and powerful and functional language, or if I had more time and patience, or more people.
## Screenshots
This is just one very simple unfinished admin frontend client view of the hierarchical dataset.

- https://github.com/fiatjaf/summadb
- https://github.com/fiatjaf/summuladb
- https://github.com/fiatjaf/pouch-summa
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# My stupid introduction to Haskell
While I was writing my first small program on Haskell (really simple, but functional webapp) in December 2017 I only knew vaguely what was the style of things, some basic notions about functions, pure functions and so on (I've read about a third of [LYAH](http://learnyouahaskell.com/chapters)).
An enourmous amount of questions began to appear in my head while I read tutorials and documentation. Here I present some of the questions and the insights I got that solved them. Technically, they may be wrong, but they helped me advance in the matter, so I'm writing them down while I still can -- If I keep working with Haskell I'll probably get to know more and so my new insights will replace the previous ones, and the new ones won't be useful for total begginers anymore.
---
Here we go:
- **Why do modules have odd names?**
- modules are the things you import, like `Data.Time.Clock` or `Web.Scotty`.
- packages are the things you install, like 'time' or 'scotty'
- packages can contain any number of modules they like
- a module is just a collection of functions
- a package is just a collection of modules
- a package is just name you choose to associate your collection of modules with when you're publishing it to Hackage or whatever
- the module names you choose when you're writing a package can be anything, and these are the names people will have to `import` when they want to use you functions
- if you're from Javascript, Python or anything similar, you'll expect to be importing/writing the name of the package directly in your code, but in Haskell you'll actually be writing the name of the module, which may have nothing to do with the name of the package
- people choose things that make sense, like for `aeson` instead of `import Aeson` you'll be doing `import Data.Aeson`, `import Data.Aeson.Types` etc. why the `Data`? because they thought it would be nice. dealing with JSON is a form of dealing with data, so be it.
- you just have to check the package documentation to see which modules it exposes.
- **What is `data User = User { name :: Text }`?**
- a data type definition. means you'll have a function `User` that will take a Text parameter and output a `User` record or something like that.
- you can also have `Animal = Giraffe { color :: Text } | Human { name :: Text }`, so you'll have two functions, Giraffe and Human, each can take a different set of parameters, but they will both yield an Animal.
- then, in the functions that take an Animal parameter you must typematch to see if the animal is a giraffe or a human.
- **What is a monad?**
- a monad is a context, an environment.
- when you're in the context of a monad you can write imperative code.
- you do that when you use the keyword `do`.
- in the context of a monad, all values are prefixed by the monad type,
- thus, in the `IO` monad all `Text` is `IO Text` and so on.
- some monads have a relationship with others, so values from that monad can be turned into values from another monad and passed between context easily.
- for exampĺe, [scotty](https://www.stackage.org/haddock/lts-9.18/scotty-0.11.0/Web-Scotty.html)'s `ActionM` and `IO`. `ActionM` is just a subtype of `IO` or something like that.
- when you write imperative code inside a monad you can do assignments like `varname <- func x y`
- in these situations some transformation is done by the `<-`, I believe it is that the pure value returned by `func` is being transformed into a monad value. so if `func` returns `Text`, now varname is of type `IO Text` (if we're in the IO monad).
- so it will not work (and it can be confusing) if you try to concatenate functions like `varname <- transform $ func x y`, but you can somehow do
- `varname <- func x y`
- `othervarname <- transform varname`
- or you can do other fancy things you'll get familiar with later, like `varname <- fmap transform $ func x y`
- why? I don't know.
- **How do I deal with Maybe, Either or other crazy stuff?**
"ok, I understand what is a Maybe: it is a value that could be something or nothing. but how do I use that in my program?"
- you don't! you turn it into other thing. for example, you use [fromMaybe](http://hackage.haskell.org/package/base-4.10.1.0/docs/Data-Maybe.html#v:fromMaybe), a function that takes a default value and that's it. if your `Maybe` is `Just x` you get `x`, if it is `Nothing` you get the default value.
- using only that function you can already do whatever there is to be done with Maybes.
- you can also manipulate the values inside the `Maybe`, for example:
- if you have a `Maybe Person` and `Person` has a `name` which is `Text`, you can apply a function that turns `Maybe Person` into `Maybe Text` AND ONLY THEN you apply the default value (which would be something like the `"unnamed"`) and take the name from inside the `Maybe`.
- basically these things (`Maybe`, `Either`, `IO` also!) are just tags. they tag the value, and you can do things with the values inside them, or you can remove the values.
- besides the example above with Maybes and the `fromMaybe` function, you can also remove the values by using `case` -- for example:
- `case x of`
- `Left error -> error`
- `Right success -> success`
- `case y of`
- `Nothing -> "nothing!"`
- `Just value -> value`
- (in some cases I believe you can't remove the values, but in these cases you'll also don't need to)
- for example, for values tagged with the IO, you can't remove the IO and turn these values into pure values, but you don't need that, you can just take the value from the outside world, so it's a IO Text, apply functions that modify that value inside IO, then output the result to the user -- this is enough to make a complete program, any complete program.
- **JSON and interfaces (or instances?)**
- using [Aeson](https://hackage.haskell.org/package/aeson-1.2.3.0/docs/Data-Aeson.html) is easy, you just have to implement the `ToJSON` and `FromJSON` interfaces.
- "interface" is not the correct name, but I don't care.
- `ToJSON`, for example, requires a function named `toJSON`, so you do
- `instance ToJSON YourType where`
- `toJSON (YourType your type values) = object []` ... etc.
- I believe lots of things require interface implementation like this and it can be confusing, but once you know the mystery of implementing functions for interfaces everything is solved.
- `FromJSON` is a little less intuitive at the beggining, and I don't know if I did it correctly, but it is working here. Anyway, if you're trying to do that, I can only tell you to follow the types, copy examples from other places on the internet and don't care about the meaning of symbols.
## See also
* [Haskell Monoids](nostr:naddr1qqyrzcmrvcmrqwtpqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cktq992)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Why I don't like NIP-26 as a solution for key management
NIP-26 was created out of the needs of the Nostr integration at https://minds.com/. They wanted Minds users to be able to associate their "custodial" Nostr key with an external self-owned key. [NIP-26](https://github.com/nostr-protocol/nips/blob/master/26.md) looked like a nice fit for the job, because it would allow supporting clients to associate the two identities _statelessly_ (i.e. by just seeing one event published by Minds but with a delegation tag on it the client would be able to associate that with the self-owned external key without anything else[^1]).
The big selling point of NIP-26 (to me) was that it was fully _optional_. Clients were free to not implement it and they would not suffer much. They would just see "bob@minds.com" published this, and "bob-self-owned" published that. They would probably know intuitively that these two were the same person, or not, but it wouldn't be an issue. Both would still be identified as Bob and have a picture, a history and so on. Moreover, this wasn't expected to happen a lot, it would be mostly for the small intersection of people that wanted to have their own keys and also happened to be using one of these "custodial Nostr" platforms like Minds.
At some point, though, NIP-26 started to be seen as _the solution for key management_ on Nostr. The idea is that someone will generate a very safe key on a hardware device and guard it as their most precious treasure without it ever touching the internet, and use it just to sign delegation tags. Then use multiple of these delegation tags, one for each different Nostr app, and maybe rotate them every month or so, details are unclear.
This breaks the previous expectations I had for NIP-26 entirely, as now these keys become faceless entities that can't be associated with anything _except their "master" key_ (the one that is in cold storage). So in a world in which most Nostr users are using NIP-26 for everything, clients that do not implement NIP-26 become completely useless, as all they will see is a constant stream of random keys. They won't be able to follow anyone or interact with anyone, as these keys will not identify any concrete person on their back, they will vanish all the time and new keys will show up and the world will be chaotic. So now every client must implement NIP-26 to become usable at all, it is not _optional_ anymore.
You may argue that making NIP-26 a de facto mandatory NIP isn't a bad thing and is worth the cost, but I think it breaks a lot of the simplicity of the protocol. It would probably be worth the cost if we knew NIP-26 was an actual complete solution, but it definitely is not, it is partial, and not the most elegant thing in the world. I think key management can be solved in multiple different ways that can all work together or not, but most importantly they can all remain optional.
More thoughts on these multiple ways can be found at [Thoughts on Nostr key management](nostr:naddr1qqyrwvnxx4jrzef5qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cchlq3c).
If I am wrong about all this and we really come to the conclusion that we need a _de facto mandatory **key delegation**_ method for Nostr, so be it -- but in that case, considering that we will break backwards-compatibility anyway, I think there might be a better design than NIP-26, more optimized and easier to implement, I don't know how exactly. But I really think we shouldn't rush that.
[^1]: as opposed to other suggestions that would also work, but that would require dealing with multiple events -- for example, the external user could publish a new replaceable event -- or use `kind:0` -- to say they wanted to grandfather the Minds key into their umbrella, while the Minds key would also need to signal its acceptance of that. This also had the problem of requiring changes every time a new replaceable event of such kind was found. Although I am unsure now, at the time me and William agreed this was worse than NIP-26 with the delegation tag.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# LessPass remoteStorage
[LessPass](https://www.lesspass.com/) is a nice idea: a password manager without any state. Just remember one master password and you can generate a different one for every site using the power of hashes.
But it has a very bad issue: some sites require just numbers, others have a minimum or maximum character limits, some require non-letter characters, uppercase characters, others forbid these and so on.
The solution: to allow you to specify parameters when generating the password so you can fit a generated password on every service.
The problem with the solution: it creates state. Now you must remember what parameters you used when generating a password for each site.
This was a way to store these settings on a [remoteStorage](https://wiki.remotestorage.io/Apps) bucket. Since it isn't confidential information in any way, that wasn't a problem, and I thought it was a good fit for remoteStorage.
Some time later I realized it maybe would be better to have a centralized repository hosting all weird requirements for passwords each domain forced on its users, and let LessPass use data from that central place when generating a password. Still stateful, not ideal, not very far from a centralized password manager, but still requiring less trust and less cryptographic assumptions.
- <https://github.com/fiatjaf/lesspass-remotestorage>
- <https://addons.mozilla.org/firefox/addon/lesspass-remotestorage/>
- <https://chrome.google.com/webstore/detail/lesspass-remotestorage/aogdpopejodechblppdkpiimchbmdcmc>
- <https://lesspass.alhur.es/>
## See also
- [hledger-web](nostr:naddr1qqyrsefkvvck2efkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cffvz7c)
- [TiddlyWiki remoteStorage](nostr:naddr1qqyxxve4x33nqerrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cat32d3)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Idéia de um sistema jurídico centralizado, mas com um pouco de lógica
um processo, é, essencialmente, imagino eu na minha ingenuidade leiga, um apelo que se faz ao juiz para que este reconheça certos fatos como probantes de um certo fenômeno tipificado por uma certa lei.
imagino então o seguinte:
uma petição não é mais um enorme documento escrito numa linguagem nojenta com referências a leis e a evidências factuais espalhadas segundo a (in) capacidade ensaística do advogado, mas apenas um esquema lógico - talvez até um diagrama desenhado (ou talvez quem sabe uma série de instruções compreensíveis por um computador?) - mostrando a ligação entre a lei e os fatos e os pedidos, por exemplo:
1. a lei tal diz que ninguém pode vender
2. fulano vendeu cigarros
3. é prova de que fulano vendeu cigarros ia foto tirada na rua tal no dia tal que mostra fulano vendendo cigarros
4. a mesma lei pede que fulano pague uma multa
este exemplo está ainda muito verborrágico, mas é só um exemplo simples. coisas mais complicadas precisariam de outras formas de expressão caso queiramos evitar as longas dissertações jurídicas em voga.
a idéia é que o esquema acima vale por si. um proto-juiz pode julgá-lo como válido ou inválido apenas pela sua lógica interna.
a outra parte do julgamento seria a ligação desse esquema com a realidade externa: anexados à petição viriam as evidências. no caso, anexada ao ponto 3 viria uma foto do fulano. ao ponto 1 também precisa ser anexado o texto da lei referida, mas isto pode ser feito automaticamente pelo número da lei.
uma vez que tenhamos um esquema lógico válido um outro proto-juiz, ou vários outros, pode julgar individualmente cada evidência: ver se o texto da lei confere com a interpretação feita no ponto 1, e se a foto anexada ao ponto 3 é mesmo a foto do réu vendendo cigarro e não a de um urso comendo laranjas.
cada um desses julgamentos pode ser feito sem que o proto-juiz tenha conhecimento do resto das coisas do processo: o primeiro proto-juiz não precisa ver a foto ou a lei, o segundo não precisa ver o esquema lógico ou a foto, o terceiro não precisa ver a lei nem o esquema lógico, e mesmo assim teríamos um julgamento de procedência ou não da petição ao final, o mais impessoal e provavelmente o mais justo possível.
a defesa consistiria em apontar erros no esquema lógico ou falhas no nexo entre a realidade é o esquema. por exemplo:
3. uma foto assim não é uma prova de que fulano vendeu, ele podia estar só passando lá perto.
* ele estava de fato só passando lá perto. do que é prova este documento mostrando seu comparecimento a uma aula do curso de direito da UFMG no mesmo horário.
---
perdoem-me se estiver falando besteira, mas são 5h e estou ainda dormindo. obviamente há vários pontos problemáticos aí, e quero entendê-los, mas a forma geral me parece bem razoável.
o que descrevi acima é uma proposta, digamos, de sistema jurídico que não se diferencia em nada do nosso sistema jurídico atual, exceto na forma (não no sentido escolástico). é também uma tentativa de compreender sua essência.
as vantagens desse formato ao atual são muitas:
- menos papel, coisas pra ler, repetição infinita de citações legais e longuíssimas dissertações escritas por advogados analfabetos que destroem a língua e a inteligência de todos
- diminuição drástica do tempo gasto por cada juiz em cada processo
- diminuição do poder de cada juiz (se cada ato de julgamento humano necessário em cada processo pode ser feito por qualquer juiz, sem conhecimento dos outros aspectos do mesmo processo, tudo é muito mais rápido, e cada julgamento desses pode ser feito por vários juízes diferentes, escolhidos aleatoriamente)
- diminuição da pomposidade de casa juiz: com menos poder e obrigações maus simples, um juiz não precisa ser mais uma pessoa especial que ganha milhões, pode ser uma pessoa comum, um proto-juiz, ganhando menos (o que possibilitaria até ter mais desses e aumentar a confiabilidade de cada julgamento)
- os juízes podem trabalhar da casa deles e a qualquer momento
- passa a ter sentido a existência de um sistema digital de processos (porque é ridículo que o sistema digital atual seja só uma forma de passar documentos do Word de um lado para o outro)
- o fim das audiências de conciliação, que são uma monstruosidade criada apenas pela necessidade de diminuir a quantidade de processos em tramitação e acabam retirandobo sentido da justiça (as partes são levemente pressionadas a ignorar a validade ou não das suas posições e fazer um acordo, sob pena de o juiz ficar com raiva delas depois)
milhares de precauções devem ser tomadas caso um sistema desses vá ser implantado (ahahah), talvez manter uma forma de julgamento tradicional, de corpo presente e com um juiz ou júri que tem conhecimento de toda situação, mas apenas para processos que chegarem até certo ponto, e assim por diante.
## Ver também
* [P2P reputation thing](nostr:naddr1qqyrqv3cxumnydfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cnjc88q) para um fundamento de um sistema jurídico anárquico.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Classless Templates
There are way too many hours being wasted in making themes for blogs. And then comes a new blog framework, it requires new themes. Old themes can't be used because they relied on different ways of rendering the website. Everything is a mess.
Classless was an attempt at solving it. It probably didn't work because I wasn't the best person to make themes and showcase the thing.
Basically everybody would agree on a simple HTML template that could fit blogs and simple websites very easily. Then other people would make pure-CSS themes expecting that template to be in place.
No classes were needed, only a fixed structure of `header`. `main`, `article` etc.
With **flexbox** and **grid** CSS was enough to make this happen.
The templates that were available were all ported by me from other templates I saw on the web, and there was a simple one I created for my old website.
- <https://github.com/fiatjaf/classless>
- <https://classless.alhur.es/>
- <https://classless.alhur.es/themes/>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# doulas.club
A full catalog of all Brazilian doulas with data carefully scrapped from many websites that contained partial catalogs and some data manually included. All this packaged as a _Couchapp_ and served directly from **Cloudant**.
This was done because the idea of doulas was good, but I spotted an issue: pregnant womwn should know many doulas before choosing one that would match well, therefore a full catalog with a lot of information was necessary.
This was a huge amount of work mostly wasted.
Many doulas who knew about this didn't like it and sent angry and offensive emails telling me to remove them. This was information one should know before choosing a doula.
### See also
- [About CouchDB](nostr:naddr1qqyrwepevf3n2wf5qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c0jq39e)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Multi-service Graph Reputation protocol
## The problem
1. Users inside centralized services need to know reputations of other users they're interacting with;
2. Building reputation with ratings imposes a big burden on the user and still accomplishes nothing, can be faked, no one cares about these ratings etc.
## The ideal solution
Subjective reputation: reputation based on how you rated that person previously, and how other people you trust rated that person, and how other people trusted by people you trust rated that person and so on, in a web-of-trust that actually can give you some insight on the trustworthiness of someone you never met or interacted with.
## The problem with the ideal solution
1. Most of the times the service that wants to implement this is not as big as Facebook, so it won't have enough people in it for such graphs of reputation to be constructed.
2. It is not trivial to build.
## My proposed solution:
I've drafted a protocol for an open system based on services publishing their internal reputation records and indexers using these to build graphs, and then serving the graphs back to the services so they can show them to users when it is needed (as HTTP APIs that can be called directly from the user client app or browser).
Crucially, these indexers will gather data from multiple services and cross-link users from these services so the graph is better.
<https://github.com/fiatjaf/multi-service-reputation-rfc>
The first and single actionable and useful feedback I got, from [@bootstrapbandit](https://twitter.com/bootstrapbandit) was that services shouldn't share email addresses in plain text (email addresses and other external relationships users of a service may have are necessary to establish links from users accross services), but I think it is ok if services publish hashes of these email addresses instead. At some point I will update the spec draft and that may have been before the time you're reading this.
Another issue is that services may lie about their reputation records and that will hurt other services and users in these other services that are relying on that data. Maybe indexers will have to do some investigative job here to assert service honesty. Or maybe this entire protocol is just failed and we will actually need a system in which users themselves will publish their own records.
## See also
* [P2P reputation thing](nostr:naddr1qqyrqv3cxumnydfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cnjc88q)
* [idea: Graph subjective reputation as a service](nostr:naddr1qqyrjdehxymrsdpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cal60d8)
* <https://github.com/jangerritharms/reputation_systems>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# jiq
When someone created [`jiq`](https://github.com/simeji/jid) claiming it had "jq queries" I went to inspect and realized it didn't, it just had a poor simple JSON query language that implemented 1% of all [`jq`](https://stedolan.github.io/jq/manual/) features, so I forked it and plugged `jq` directly into it, and renamed to `jiq`.
After some comments on issues in the original repository from people complaining about lack of `jq` compatibility it got a ton of unexpected users, was even packaged to ArchLinux.

- <https://github.com/fiatjaf/jiq>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# idea: Custom multi-use database app
Since 2015 I have this idea of making one app that could be repurposed into a full-fledged app for all kinds of uses, like powering small businesses accounts and so on. Hackable and open as an Excel file, but more efficient, without the hassle of making tables and also using ids and indexes under the hood so different kinds of things can be related together in various ways.
It is not a concrete thing, just a generic idea that has taken multiple forms along the years and may take others in the future. I've made quite a few attempts at implementing it, but never finished any.
I used to refer to it as a "multidimensional spreadsheet".
Can also be related to [DabbleDB][dabble-db].
[dabble-db]: <https://en.wikipedia.org/wiki/Dabble_DB>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# On HTLCs and arbiters
This is another attempt and conveying the same information that should be in [Lightning and its fake HTLCs](nostr:naddr1qqyryefsxqcxgdmzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cp0m63a). It assumes you know everything about Lightning and will just highlight a point. This is also valid for PTLCs.
The protocol says HTLCs are trimmed (i.e., not actually added to the commitment transaction) when the cost of redeeming them in fees would be greater than their actual value.
Although this is often dismissed as a non-important fact (often people will say "it's trusted for small payments, no big deal"), but I think it is indeed very important for 3 reasons:
1. Lightning absolutely relies on HTLCs actually existing because the payment proof requires them. The entire security of each payment comes from the fact that the payer has a preimage that comes from the payee. Without that, the state of the payment becomes an unsolvable mystery. The inexistence of an HTLC breaks the atomicity between the payment going through and the payer receiving a proof.
2. Bitcoin fees are expected to grow with time (arguably the reason Lightning exists in the first place).
3. MPP makes payment sizes shrink, therefore more and more of Lightning payments are to be trimmed. As I write this, the mempool is clear and still payments smaller than about 5000sat are being trimmed. Two weeks ago the limit was at 18000sat, which is already below the minimum most MPP splitting algorithms will allow.
Therefore I think it is important that we come up with a different way of ensuring payment proofs are being passed around in the case HTLCs are trimmed.
## Channel closures
Worse than not having HTLCs that can be redeemed is the fact that in the current Lightning implementations channels will be closed by the peer once an HTLC timeout is reached, either to fulfill an HTLC for which that peer has a preimage or to redeem back that expired HTLCs the other party hasn't fulfilled.
For the surprise of everybody, nodes will do this even when the HTLCs in question were trimmed and therefore cannot be redeemed at all. It's very important that nodes stop doing that, because it makes no economic sense at all.
However, that is not so simple, because once you decide you're not going to close the channel, what is the next step? Do you wait until the other peer tries to fulfill an expired HTLC and tell them you won't agree and that you must cancel that instead? That could work sometimes if they're honest (and they have no incentive to not be, in this case). What if they say they tried to fulfill it before but you were offline? Now you're confused, you don't know if you were offline or they were offline, or if they are trying to trick you. Then unsolvable issues start to emerge.
## Arbiters
One simple idea is to use trusted arbiters for all trimmed HTLC issues.
This idea solves both the protocol issue of getting the preimage to the payer once it is released by the payee -- and what to do with the channels once a trimmed HTLC expires.
A simple design would be to have each node hardcode a set of trusted other nodes that can serve as arbiters. Once a channel is opened between two nodes they choose one node from both lists to serve as their mutual arbiter for that channel.
Then whenever one node tries to fulfill an HTLC but the other peer is unresponsive, they can send the preimage to the arbiter instead. The arbiter will then try to contact the unresponsive peer. If it succeeds, then done, the HTLC was fulfilled offchain. If it fails then it can keep trying until the HTLC timeout. And then if the other node comes back later they can eat the loss. The arbiter will ensure they know they are the ones who must eat the loss in this case. If they don't agree to eat the loss, the first peer may then close the channel and blacklist the other peer. If the other peer believes that both the first peer and the arbiter are dishonest they can remove that arbiter from their list of trusted arbiters.
The same happens in the opposite case: if a peer doesn't get a preimage they can notify the arbiter they hadn't received anything. The arbiter may try to ask the other peer for the preimage and, if that fails, settle the dispute for the side of that first peer, which can proceed to fail the HTLC is has with someone else on that route.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Reasons why Lightning is not that great
Some Bitcoiners, me included, were fooled by hyperbolic discourse that presented Lightning as some magical scaling solution with no flaws. This is an attempt to list some of the actual flaws uncovered after 5 years of experience. The point of this article is not to say Lightning is a complete worthless piece of crap, but only to highlight the fact that Bitcoin needs to put more focus on developing and thinking about other scaling solutions (such as [Drivechain](nostr:naddr1qq9xgunfwejkx6rpd9hqzythwden5te0ve5kzar2v9nzucm0d5pzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqvzqqqr4gumtjfnp), less crappy and more decentralized trusted channels networks and [statechains](https://bitcoinmagazine.com/technical/statechains-sending-keys-not-coins-to-scale-bitcoin-off-chain)).
## Unbearable experience
Maintaining a node is cumbersome, you have to deal with closed channels, allocating funds, paying fees unpredictably, choosing new channels to open, storing channel state backups -- or you'll have to delegate all these decisions to some weird AI or third-party services, it's not feasible for normal people.
## Channels fail for no good reason all the time
Every time nodes disagree on anything they close channels, there have been dozens, maybe hundreds, of bugs that lead to channels being closed in the past, and implementors have been fixing these bugs, but since these node implementations continue to be worked on and new features continue to be added we can be quite sure that new bugs continue to be introduced.
## Trimmed (fake) HTLCs are not sound protocol design
What would you tell me if I presented a protocol that allowed for transfers of users' funds across a network of channels and that these channels would pledge to send the money to miners while the payment was in flight, and that these payments could never be recovered if a node in the middle of the hop had a bug or decided to stop responding? Or that the receiver could receive your payment, but still claim he didn't, and you couldn't prove that at all?
These are the properties of "trimmed HTLCs", HTLCs that are uneconomical to have their own UTXO in the channel presigned transaction bundles, therefore are just assumed to be there while they are not (and their amounts are instead added to the fees of the presigned transaction).
Trimmed HTLCs, like any other HTLC, have timelocks, preimages and hashes associated with them -- which are properties relevant to the redemption of actual HTLCs onchain --, but unlike actual HTLCs these things have no actual onchain meaning since there is no onchain UTXO associated with them. This is a game of make-believe that only "works" because (1) payment proofs aren't worth anything anyway, so it makes no sense to steal these; (2) channels are too expensive to setup; (3) all Lightning Network users are honest; (4) there are so many bugs and confusion in a Lightning Network node's life that events related to trimmed HTLCs do not get noticed by users.
Also, so far these trimmed HTLCs have only been used for very small payments (although very small payments probably account for 99% of the total payments), so it is supposedly "fine" to have them. But, as fees rise, more and more HTLCs tend to become fake, which may make people question the sanity of the design.
Tadge Dryja, one of the creators of the Lightning Network proposal, has been critical of the fact that these things were allowed to creep into the BOLT protocol.
## Routing
Routing is already very bad today even though most nodes have a basically 100% view of the public network, the reasons being that some nodes are offline, others are on Tor and unreachable or too slow, channels have the balance shifted in the wrong direction, so payments fail a lot -- which leads to the (bad) solution invented by professional node runners and large businesses of probing the network constantly in order to discard bad paths, this creates unnecessary load and increases the risk of channels being dropped for no good reason.
As the network grows -- if it indeed grow and not centralize in a few hubs -- routing tends to become harder and harder.
While each implementation team makes their own decisions with regard to how to best way to route payments and these decisions may change at anytime, it's worth noting, for example, that CLN will use MPP to split up any payment in any number of chunks of 10k satoshis, supposedly to improve routing success rates. While this often backfires and causes payments to fail when they should have succeeded, it also contributes to making it so there are proportionally more fake HTLCs than there should be, as long as the threshold for fake HTLCs is above 10k.
## Payment proofs are somewhat useless
Even though payment proofs were seen by many (including me) as one of the great things about Lightning, the sad fact is that they do not work as proofs if people are not aware of the fact that they are proofs. Wallets do all they can to hide these details from users because it is considered "bad UX" and low-level implementors do not care very much to talk about them at all. There have been attempts from Lightning Labs to get rid of the payment proofs entirely (which at the time to me sounded like a terrible idea, but now I realize they were not wrong).
Here's a piece of anecdote: I've personally witnessed multiple episodes in which Phoenix wallet released the preimage without having actually received the payment (they did receive a minor part of the payment, but the payment was split in many parts). That caused my service, _@lntxbot_, to mark the outgoing payment as complete, only then to have to endure complaints from the users because the receiver side, Phoenix, had not received the full amount. In these cases, if the protocol and the idea of preimages as payment proofs be respected, should I have been the one in charge of manually fixing user balances?
Another important detail: when an HTLC is sent and then something goes wrong with the payment the channel has to be closed in order to redeem that payment. When the redeemer is on the receiver side, the very act of redeeming should cause the preimage to be revealed and a proof of payment to be made available for the sender, who can then send that back to the previous hop and the payment is proven without any doubt. But when this happens for fake HTLCs (which is the vast majority of payments, as noted above) there is no place in the world for a preimage and therefore there are no proofs available. A channel is just closed, the payer loses money but can't prove a payment. It also can't send that proof back to the previous hop so he is forced to say the payment failed -- even if it wasn't him the one who declared that hop a failure and closed the channel, which should be a prerequisite. I wonder if this isn't the source of multiple bugs in implementations that cause channels to be closed unnecessarily. The point is: preimages and payment proofs are mostly a fiction.
Another important fact is that the proofs do not really prove anything if the keypair that signs the invoice can't be provably attached to a real world entity.
## LSP-centric design
The first Lightning wallets to show up in the market, LND as a desktop daemon (then later with some GUIs on top of it like Zap and Joule) and Anton's BLW and Eclair wallets for mobile devices, then later LND-based mobile wallets like Blixt and RawTX, were all standalone wallets that were self-sufficient and meant to be run directly by consumers. Eventually, though, came Breez and Phoenix and introduced the "LSP" model, in which a server would be trusted in various forms -- not directly with users' funds, but with their privacy, fees and other details -- but most importantly that LSP would be the primary source of channels for all users of that given wallet software. This was all fine, but as time passed new features were designed and implemented that assumed users would be running software connected to LSPs. The very idea of a user having a standalone mobile wallet was put out of question. The entire argument for implementation of the bolt12 standard, for example, hinged on the assumption that mobile wallets would have [LSPs capable of connecting to Google messaging services and being able to "wake up" mobile wallets](https://twitter.com/hampus_s/status/1442493786110705668) in order for them to receive payments. Other ideas, like a complicated standard for allowing mobile wallets to receive payments without having to be online all the time, just [assume LSPs always exist](https://lists.linuxfoundation.org/pipermail/lightning-dev/2021-October/003307.html); and changes to the expected BOLT spec behavior with regards to, for example, [probing of mobile wallets](https://github.com/lightningnetwork/lnd/pull/4785).
Ark is another example of a kind of LSP that got so enshrined that it become a new protocol that depends on it entirely.
## Protocol complexity
Even though the general idea of how Lightning is supposed to work can be understood by many people (as long as these people know how Bitcoin works) the Lightning protocol is not really easy: it will take a long time of big dedication for anyone to understand the details about the BOLTs -- this is a bad thing if we want a world of users that have at least an idea of what they are doing. Moreover, with each new cool idea someone has that gets adopted by the protocol leaders, it increases in complexity and some of the implementors are kicked out of the circle, therefore making it easier for the remaining ones to proceed with more and more complexity. It's the same process by which Chrome won the browser wars, kicked out all competitors and proceeded to make a supposedly open protocol, but one that no one can implement as it gets new and more complex features every day, all envisioned by the Chrome team.
## Liquidity issues?
I don't believe these are a real problem if all the other things worked, but still the old criticism that Lightning requires parking liquidity and that has a cost is not a complete non-issue, specially given the LSP-centric model.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# neuron.vim
I started using this [neuron][neuron] thing to create an update this same [zettelkasten](nostr:naddr1qqyrwwfh8yurgefnqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7qmjrw), but the [existing vim plugin](https://github.com/ihsanturk/neuron.vim) had too many problems, so I forked it and ended up changing almost everything.
Since the upstream repository was somewhat abandoned, most users and people who were trying to contribute upstream migrate to my fork too.
- <https://github.com/fiatjaf/neuron.vim>
[neuron]: https://github.com/srid/neuron
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Just malinvestiment
Traditionally the Austrian Theory of Business Cycles has been explained and reworked in many ways, but the most widely accepted version (or the closest to the Mises or Hayek views) view is that banks (or the central bank) cause the general interest rate to decline by creation of new money and that prompts entrepreneurs to invest in projects of longer duration. This can be confusing because sometimes entrepreneurs embark in very short-time projects during one of these bubbles and still contribute to the overall cycle.
The solution is to think about the "longer term" problem is to think of the entire economy going long-term, not individual entrepreneurs. So if one entrepreneur makes an investiment in a thing that looks simple he may actually, knowingly or not, be inserting himself in a bigger machine that is actually involved in producing longer-term things. Incidentally this thinking also solves the biggest criticism of the Austrian Business Cycle Theory: that of the rational expectations people who say: "oh but can't the entrepreneurs know that the interest rate is artificially low and decide to not make long-term investiments?" ("and if they don't know they should lose money and be replaced like in a normal economy flow blablabla?"). Well, the answer is that they are not really relying on the interest rate, they are only looking for profit opportunities, and this is the key to another confusion that has always followed my thinkings about this topic.
If a guy opens a bar in an area of a town where many new buildings are being built during a "housing bubble" he may not know, but he is inserting himself right into the eye of that business cycle. He expects all these building projects to continue, and all the people involved in that to be getting paid more and be able to spend more at his bar and so on. That is a bet that may or may not end up paying.
Now what does that bar investiment has to do with the interest rate? Nothing. It is just a guy who saw a business opportunity in a place where hungry people with money had no bar to buy things in, so he opened a bar. Additionally the guy has made some calculations about all the ending, starting and future building projects in the area, and then the people that would live or work in that area afterwards (after all the buildings were being built with the expectation of being used) and so on, there is no interest rate calculations involved. And yet that may be a malinvestiment because some building projects will end up being canceled and the expected usage of the finished ones will turn out to be smaller than predicted.
This bubble may have been caused by a decline in interest rates that prompted some people to start buying houses that they wouldn't otherwise, but this is just a small detail. The bubble can only be kept going by a constant influx of new money into the economy, but the focus on the interest rate is wrong. If new money is printed and used by the government to buy ships then there will be a boom and a bubble in the ship market, and that involves all the parts of production process of ships and also bars that will be opened near areas of the town where ships are built and new people are being hired with higher salaries to do things that will eventually contribute to the production of ships that will then be sold to the government.
It's not interest rates or the length of the production process that matters, it's just printed money and malinvestiment.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# hledger-web
A Haskell app that uses [Miso](https://hackage.haskell.org/package/miso) and [hledger's Haskell libraries](https://hledger.org/) plus [ghcjs](https://github.com/ghcjs/ghcjs) to be compiled to a web page, and then adds [optional remoteStorage](https://remotestorage.io/) so you can store your ledger data somewhere else.
This was my introduction to Haskell and also built at a time I thought remoteStorage was a good idea that solved many problems, and that it could use some help in the form of just yet another somewhat-useless-but-cool project using it that could be [added to their wiki](https://wiki.remotestorage.io/Apps).
- <https://hledger.alhur.es/>
- <https://github.com/fiatjaf/hledger-web>
## See also
- [My stupid introduction to Haskell](nostr:naddr1qqyrxveevscrqcmrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cxd5qyk)
- [LessPass remoteStorage](nostr:naddr1qqyrsctpxfjnqepeqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cfa6z2z)
- [TiddlyWiki remoteStorage](nostr:naddr1qqyxxve4x33nqerrqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cat32d3)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# contratos.alhur.es
A website that allowed people to fill a form and get a standard _Contrato de Locação_.
Better than all the other "templates" that float around the internet, which are badly formatted `.doc` files.
It was fully programmable so other templates could be added later, but I never did.
This website made maybe one dollar in Google Ads (and Google has probably stolen these like so many other dollars they did with their bizarre requirements).
- <https://github.com/fiatjaf/contratos>
- <http://contratos.alhur.es>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Carl R. Rogers sobre a ciência
> Creio que o objetivo primário da ciência é fornecer uma hipótese, uma convicção e uma fé mais seguras e que satisfaçam melhor o próprio investigador. Na medida em que o cientista procura provar qualquer coisa a alguém -- um erro em que incorri mais de uma vez --, creio que ele está se servindo da ciência para remediar uma insegurança pessoal, desviando-a do seu verdadeiro papel criativo a serviço do indivíduo.
_Tornar-se Pessoa_, página aleatória
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Module Linker
A browser extension that reads source code on GitHub and tries to find links to imported dependencies so you can click on them and navigate through either GitHub or package repositories or base language documentation. Works for many languages at different levels of completeness.
- <https://github.com/fiatjaf/module-linker>
- <https://module-linker.alhur.es/>
- <https://addons.mozilla.org/firefox/addon/module-linker>
- <https://chrome.google.com/webstore/detail/dglofghjinifeolcpjfjmfdnnbaanggn>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Using Spacechains and Fedimint to solve scaling
What if instead of trying to create complicated "layer 2" setups involving noveau cryptographic techniques we just did the following:
- we take that Fedimint source code and remove the "mint" stuff, and just use their federation stuff secure coins with multisig;
- then we make a spacechain;
- and we make the federations issue multisig-btc tokens on it;
- and then we put some uniswap-like thing in there to allow these tokens to be exchanged freely.
## Why?
The recent spike in fees caused by Ordinals and BRC-20 shitcoinery has shown that Lightning isn't a silver bullet. Channels are too fragile, it costs a lot to open a channel under a high fee environment, to run a routing node and so on.
People who want to keep using Lightning are instead flocking to the big Lightning custodial providers: WalletofSatoshi, ZEBEDEE, OpenNode and so on. We could leverage that trust people have in these companies (and individuals) operating shadow Lightning providers and turn each of these into a btc-token issuer. Each issue their own token, transactions flow freely. Each person can hold only assets from the issuers they trust more.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# comentário pertinente de Olavo de Carvalho sobre atribuições indevidas de acontecimentos à "ordem espontânea"
Eis aqui um exemplo entre outros mil, extraído das minhas apostilas de aulas, de como se analisam as relações entre fatores deliberados e casuais na ação histórica. O sr, Beltrão está INFINITAMENTE ABAIXO da possibilidade de discutir essas coisas, e por isso mesmo me atribui uma simploriedade que é dele próprio e não minha:
Já citei mil vezes este parágrafo de Georg Jellinek e vou citá-lo de novo: “Os fenômenos da vida social dividem-se em duas classes: aqueles que são determinados essencialmente por uma vontade diretriz e aqueles que existem ou podem existir sem uma organização devida a atos de vontade. Os primeiros estão submetidos necessariamente a um plano, a uma ordem emanada de uma vontade consciente, em oposição aos segundos, cuja ordenação repousa em forças bem diferentes.”
Essa distinção é crucial para os historiadores e os analistas estratégicos não porque ela é clara em todos os casos, mas precisamente porque não o é. O erro mais comum nessa ordem de estudos reside em atribuir a uma intenção consciente aquilo que resulta de uma descontrolada e às vezes incontrolável combinação de forças, ou, inversamente, em não conseguir enxergar, por trás de uma constelação aparentemente fortuita de circunstâncias, a inteligência que planejou e dirigiu sutilmente o curso dos acontecimentos.
Exemplo do primeiro erro são os Protocolos dos Sábios de Sião, que enxergam por trás de praticamente tudo o que acontece de mau no mundo a premeditação maligna de um número reduzidos de pessoas, uma elite judaica reunida secretamente em algum lugar incerto e não sabido.
O que torna essa fantasia especialmente convincente, decorrido algum tempo da sua publicação, é que alguns dos acontecimentos ali previstos se realizam bem diante dos nossos olhos. O leitor apressado vê nisso uma confirmação, saltando imprudentemente da observação do fato à imputação da autoria. Sim, algumas das idéias anunciadas nos Protocolos foram realizadas, mas não por uma elite distintamente judaica nem muito menos em proveito dos judeus, cuja papel na maioria dos casos consistiu eminentemente em pagar o pato. Muitos grupos ricos e poderosos têm ambições de dominação global e, uma vez publicado o livro, que em certos trechos tem lances de autêntica genialidade estratégica de tipo maquiavélico, era praticamente impossível que nada aprendessem com ele e não tentassem por em prática alguns dos seus esquemas, com a vantagem adicional de que estes já vinham com um bode expiatório pré-fabricado. Também é impossível que no meio ou no topo desses grupos não exista nenhum judeu de origem. Basta portanto um pouquinho de seletividade deformante para trocar a causa pelo efeito e o inocente pelo culpado.
Mas o erro mais comum hoje em dia não é esse. É o contrário: é a recusa obstinada de enxergar alguma premeditação, alguma autoria, mesmo por trás de acontecimentos notavelmente convergentes que, sem isso, teriam de ser explicados pela forca mágica das coincidências, pela ação de anjos e demônios, pela "mão invisível" das forças de mercado ou por hipotéticas “leis da História” ou “constantes sociológicas” jamais provadas, que na imaginação do observador dirigem tudo anonimamente e sem intervenção humana.
As causas geradoras desse erro são, grosso modo:
Primeira: Reduzir as ações humanas a efeitos de forças impessoais e anônimas requer o uso de conceitos genéricos abstratos que dão automaticamente a esse tipo de abordagem a aparência de coisa muito científica. Muito mais científica, para o observador leigo, do que a paciente e meticulosa reconstituição histórica das cadeias de fatos que, sob um véu de confusão, remontam às vezes a uma autoria inicial discreta e quase imperceptível. Como o estudo dos fenômenos histórico-políticos é cada vez mais uma ocupação acadêmica cujo sucesso depende de verbas, patrocínios, respaldo na mídia popular e boas relações com o establishment, é quase inevitável que, diante de uma questão dessa ordem, poucos resistam à tentação de matar logo o problema com duas ou três generalizações elegantes e brilhar como sábios de ocasião em vez de dar-se o trabalho de rastreamentos históricos que podem exigir décadas de pesquisa.
Segunda: Qualquer grupo ou entidade que se aventure a ações histórico-políticas de longo prazo tem de possuir não só os meios de empreendê-las, mas também, necessariamente, os meios de controlar a sua repercussão pública, acentuando o que lhe convém e encobrindo o que possa abortar os resultados pretendidos. Isso implica intervenções vastas, profundas e duradouras no ambiente mental. [Etc. etc. etc.]
(no facebook em 17 de julho de 2013)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A response to Achim Warner's "Drivechain brings politics to miners" article
I mean this article: https://achimwarner.medium.com/thoughts-on-drivechain-i-miners-can-do-things-about-which-we-will-argue-whether-it-is-actually-a5c3c022dbd2
There are basically two claims here:
### 1. Some corporate interests might want to secure sidechains for themselves and thus they will bribe miners to have these activated
First, it's hard to imagine why they would want such a thing. Are they going to make a proprietary KYC chain only for their users? They could do that in a corporate way, or with a federation, like Facebook tried to do, and that would provide more value to their users than a cumbersome pseudo-decentralized system in which they don't even have powers to issue currency. Also, if Facebook couldn't get away with their federated shitcoin because the government was mad, what says the government won't be mad with a sidechain? And finally, why would Facebook want to give custody of their proprietary closed-garden Bitcoin-backed ecosystem coins to a random, open and always-changing set of miners?
But even if they do succeed in making their sidechain and it is very popular such that it pays miners fees and people love it. Well, then why not? Let them have it. It's not going to hurt anyone more than a proprietary shitcoin would anyway. If Facebook really wants a closed ecosystem backed by Bitcoin that probably means we are winning big.
### 2. Miners will be required to vote on the validity of debatable things
He cites the example of a PoS sidechain, an assassination market, a sidechain full of nazists, a sidechain deemed illegal by the US government and so on.
There is a simple solution to all of this: just kill these sidechains. Either miners can take the money from these to themselves, or they can just refuse to engage and freeze the coins there forever, or they can even give the coins to governments, if they want. It is an entirely good thing that evil sidechains or sidechains that use horrible technology that doesn't even let us know who owns each coin get annihilated. And it was the responsibility of people who put money in there to evaluate beforehand and know that PoS is not deterministic, for example.
About government censoring and wanting to steal money, or criminals using sidechains, I think the argument is very weak because these same things can happen today and may even be happening already: i.e., governments ordering mining pools to not mine such and such transactions from such and such people, or forcing them to reorg to steal money from criminals and whatnot. All this is expected to happen in normal Bitcoin. But both in normal Bitcoin and in Drivechain decentralization fixes that problem by making it so governments cannot catch all miners required to control the chain like that -- and in fact fixing that problem is the only reason we need decentralization.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A big Ethereum problem that is fixed by Drivechain
While reading the following paragraphs, assume Drivechain itself will be a "smart contract platform", like Ethereum. And that it won't be used to launch an Ethereum blockchain copy, but instead **each different Ethereum contract could be turned into a different sidechain** under [BIP300](https://bips.xyz/300) rules.
## A big Ethereum problem
Anyone can publish any "contract" to Ethereum. Often people will come up with somewhat interesting ideas and publish them. Since they want money they will add an unnecessary token and use that to bring revenue to themselves, gamify the usage of their contract somehow, and keep some control over the supposedly open protocol they've created by keeping a majority of the tokens. They will use the profits on marketing and branding, have a visual identity, a central website and a forum with support personnel and so on: their _somewhat interesting idea_ have become a full-fledged company.
If they have success then another company will appear in the space and copy the idea, launch it using exactly the same strategy with a tweak, then try to capture the customers of the first company and new people. And then another, and another, and another. Very often these contracts require some network effect to work, i.e., they require people to be using it so others will use it. The fact that the market is now split into multiple companies offering roughly the same product hurts that, such that none of these protocols get ever enough usage to become _really_ useful in the way they were first conceived. At this point it doesn't matter though, they get some usage, and they use that in their marketing material. It becomes a race to pump the value of the tokens and the current usage is just another point used for that purpose. The company will even start giving out money to attract new users and other weird moves that have no relationship with the initial somewhat intereting idea.
Once in a lifetime it happens that the first implementer of these things is not a company seeking profits, but some altruistic developer or company that believes in Ethereum and wants to see it grow -- or more likely someone financed by the Ethereum Foundation, which allegedly doesn't like these token schemes and would prefer everybody to use the token they issued first, the ETH --, but that's a fruitless enterprise because someone else will copy that idea anyway and turn it into a company as described above.
## How Drivechain fixes it
In the [Drivechain](nostr:naddr1qq9xgunfwejkx6rpd9hqzythwden5te0ve5kzar2v9nzucm0d5pzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqvzqqqr4gumtjfnp) world, if someone had an idea, they would -- as it happens all the time with Bitcoin things -- publish it in a public forum. Other members of the community would evaluate that idea, add or remove things, all interested parties would contribute to make it the best possible incarnation of that idea. Once the design was settled, someone would volunteer to start writing the code to turn that idea into a sidechain. Maybe some company would fund those efforts and then more people would join. It's not a perfect process and one that often involves altruism, but Bitcoin inspires people to do these things.
Slowly, the thing would get built, tested, activated as a sidechain on testnet, tested more, and at this point luckily the entire community of interested Bitcoin users and miners would have grown to like that idea and see its benefits. It could then be proposed to be activated according to [BIP300](https://bips.xyz/300) rules.
Once it was activated, the entire pool of interested users would join it. And it would be impossible for someone else to create a copy of that because everybody would instantly notice it was a copy. There would be no token, no one profiting directly from the operations of that "smart contract". And everybody would be incentivized to join and tell others to join that same sidechain since the network effect was already the biggest there, they will know more network effect would only be good for everybody involved, and there would be no competing marketing and free token giveaways from competing entities.
## See also
- [Upgrading 'Smart Contracts' to 'Wise Contracts'](https://www.truthcoin.info/blog/wise-contracts/), by Paul Sztorc
- [Drivechain](nostr:naddr1qq9xgunfwejkx6rpd9hqzythwden5te0ve5kzar2v9nzucm0d5pzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqvzqqqr4gumtjfnp)
- [Drivechain comparison with Ethereum](nostr:naddr1qqyx2dp58qcx2wpjqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cane7px)
- [Alternatives to Drivechain](nostr:naddr1qqyrqenzvvukvcfkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823csjg2t6)
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# On the state of programs and browsers
Basically, there are basically (not exhaustively) 2 kinds of programs one can run in a computer nowadays:
1.1. A program that is installed, permanent, has direct access to the Operating System, can draw whatever it wants, modify files, interact with other programs and so on;
1.2. A program that is transient, fetched from someone else's server at run time, interpreted, rendered and executed by another program that bridges the access of that transient program to the OS and other things.
Meanwhile, web browsers have basically (not exhaustively) two use cases:
2.1. Display text, pictures, videos hosted on someone else's computer;
2.2. Execute incredibly complex programs that are fetched at run time, executed and so on -- you get it, it's the same 1.2.
These two use cases for browsers are at big odds with one another. While stretching itsel
f to become more and more a platform for programs that can do basically anything (in the 1.1 sense) they are still restricted to being an 1.2 platform. At the same time, websites that were supposed to be on 2.1 sometimes get confused and start acting as if they were 2.2 -- and other confusing mixed up stuff.
I could go hours in philosophical inquiries on the nature of browsers, how rewriting everything in JavaScript is not healthy or where everything went wrong, but I think other people have done this already.
One thing that bothers me a lot, though, is that computers can do a lot of things, and with the internet and in the current state of the technology it's fairly easy to implement tools that would help in many aspects of human existence and provide high-quality, useful programs, with the help of a server to coordinate access, store data, authenticate users and so on many things are possible. However, due to the nature of UI in the browser, it's very hard to get any useful tool to users.
Writing a UI, even the most basic UI imaginable (some text input boxes and some buttons, or a table) can take a long time, always more than the time necessary to code the actual core features of whatever program is being developed -- and that is considering that the person capable of writing interesting programs that do the functionality in the backend are also capable of interacting with JavaScript and the giant amount of frameworks, transpilers, styling stuff, CSS, the fact that all this is built on top of HTML and so on.
This is not good.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# A vision for content discovery and relay usage for basic social-networking in Nostr
Or how to make a basic "social-networking" application using the [Nostr](nostr:naddr1qqzkummnw3eqzythwden5te0ve5kzar2v9nzucm0d5pzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqvzqqqr4gusz7vna) protocol that is safe and promotes decentralization.
## The basic app views
Suppose a basic "social-networking" app is like Twitter. In that, one has basically 3 views:
- A **home feed** that shows all notes from everybody you follow;
- A **profile view** from a specific user that shows all notes from that user;
- A **replies view** that shows all replies to one specific note.
Some Nostr clients may want to also provide another view, the **global feed** which shows posts from _everybody_.
## A simple classification of relays
And suppose that all existing relays can be classified in 3 groups (according to one's subjective evaluation):
- **spammy relays**, in which people of any kind can post whatever they want with no filters at all;
- **safe relays**, in which there are some barriers to entry, like requiring a fee, or requiring some cumbersome user registration process, and spammers or people who post bad things are banned -- but this is still a relay fundamentally open to anyone (although this is also subjective depending on the kind of restrictions);
- **closed relays**, in which only certain kinds of people enter, for example, members of a group of friends or a closed online community.
## How to follow and find posts from a given profile
To follow someone on Nostr, it is necessary to know one or more relays in which that person is publishing their notes, otherwise it is impossible to fetch anything from them.
When a user starts to follow someone, that may be done through 4 different ways:
1. from seeing that person in the app
2. using an `nprofile` URI
3. using a NIP-05 address
4. using a bare pubkey ('npub`)
Situation 1 may happen when that person is seen in the replies of yours or someone else's post, on a global feed post, or from a note referenced or republished from them by someone else. When that happens, it is expected that the references (in `e` and `p` tags) contain relay URLs. We must them inject that information to tentatively associate that person with a relay URL at that first contact.
In situations 2 and 3 both the `nprofile` and the NIP-05 addresses should contain a list of preferred relays for that person, so we can bootstrap the relay list for that person based on that.
In situation 4 there is no relay list, so we must either prompt the user through an annoying popup or something -- or it can try searching for that pubkey in one of their known relays. This remains an option for the other methods too.
Once we have relay URLs for a given profile we can use these relays to query notes from that pubkey. As time passes that user may migrate to other relays, or it may become known that the user is also posting to other relays. To make sure these things are discovered, we must pay attention to hints sent in tags of all events seen everywhere -- from anyone --, and also events of kind 2 and 3, and upgrade our local database that has the knowledge of relationship between profiles and relays accordingly.
## Rendering the app views
From what we've gathered until now, we can easily render the **home feed** and the **profile view**. To do that it just uses local information about relationships between profiles and relays and fetch notes:
- for the **home feed**, from all people we're following;
- for the **profile view**, from just that specific profile.
Since we'll be asking for very specific data from these relays, we do not care about where they're **safe** or not. They will never send us spam (and if they do that will just be filtered out since it wouldn't match our strict filter).
Now whenever the user clicks on a note we will want to display the **replies view**. In this case we will just query only the **safe** and the **closed relays**, since otherwise spam might be injected into the application. The same principle applies to the **global feed** view.
## Other heuristics and corner cases
There are probably many corner cases not covered in this document. This was meant to just describe one way that seems to me to be sufficiently robust for a decentralized Nostr.
For example, how to display a note that was referenced by someone? If it has a relay hint we query that relay. If it doesn't we can try the relays associated with the person who have just mentioned it, or the same relay we've just seen the note that mentioned it -- as, when mentioning it, one might have published it directly to their own relays -- and so on. But all this may fail and then it is probably not a big deal.
## Final thoughts
More important than all, is that we must keep in mind that Nostr is just a very loose set of servers with basically no connection between them, there are no guarantees of anything, and the process of keeping connected to others and finding content must be addressed through many different hackish attempts. To write Nostr applications and to use Nostr one must embrace the inherent chaos.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Flowi.es
At the time I thought [Workflowy][workflowy] had the ideal UI for everything. I wanted to implement my [custom app maker](nostr:naddr1qqyxgcejv5unzd33qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cz3va32) on it, but ended up doing this: a platform for enhancing Workflowy with extra features:
- An email reminder based on dates input in items
- A website generator, similar to [Websites For Trello](nostr:naddr1qqyrydpkvverwvehqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c9d4yku), also based on [Classless Templates](nostr:naddr1qqyxyv35vymk2vfsqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cqwgdau)
Also, I didn't remember this was also based on CouchDB and had some _couchapp_ functionalities.

- <https://flowi.es>
- <https://github.com/fiatjaf/flowies>
[workflowy]: <https://workflowy.com/>
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# `OP_CHECKTEMPLATEVERIFY` and the "covenants" drama
There are many ideas for "covenants" (I don't think this concept helps in the specific case of examining proposals, but fine). Some people think "we" (it's not obvious who is included in this group) should somehow examine them and come up with the perfect synthesis.
It is not clear what form this magic gathering of ideas will take and who (or which ideas) will be allowed to speak, but suppose it happens and there is intense research and conversations and people (ideas) really enjoy themselves in the process.
What are we left with at the end? Someone has to actually commit the time and put the effort and come up with a concrete proposal to be implemented on Bitcoin, and whatever the result is it will have trade-offs. Some great features will not make into this proposal, others will make in a worsened form, and some will be contemplated very nicely, there will be some extra costs related to maintenance or code complexity that will have to be taken. Someone, a concreate person, will decide upon these things using their own personal preferences and biases, and many people will not be pleased with their choices.
That has already happened. Jeremy Rubin has already conjured all the covenant ideas in a magic gathering that lasted more than 3 years and came up with a synthesis that has the best trade-offs he could find. CTV is the result of that operation.
---
The fate of CTV in the popular opinion illustrated by the thoughtless responses it has evoked such as "can we do better?" and "we need more review and research and more consideration of other ideas for covenants" is a preview of what would probably happen if these suggestions were followed again and someone spent the next 3 years again considering ideas, talking to other researchers and came up with a new synthesis. Again, that person would be faced with "can we do better?" responses from people that were not happy enough with the choices.
And unless some famous Bitcoin Core or retired Bitcoin Core developers were personally attracted by this synthesis then they would take some time to review and give their blessing to this new synthesis.
To summarize the argument of this article, the actual question in the current CTV drama is that there exists hidden criteria for proposals to be accepted by the general community into Bitcoin, and no one has these criteria clear in their minds. It is not as simple not as straightforward as "do research" nor it is as humanly impossible as "get consensus", it has a much bigger social element into it, but I also do not know what is the exact form of these hidden criteria.
This is said not to blame anyone -- except the ignorant people who are not aware of the existence of these things and just keep repeating completely false and unhelpful advice for Jeremy Rubin and are not self-conscious enough to ever realize what they're doing.
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# ZBD Social
If you have a closed system, a platform with users inside that login with name and password, it's not hard to introduce "social network" features into it. It was always the plan at ZEBEDEE to introduce such a thing, but much better than a closed social network just for ZBD users is if one such a thing can plug into the outer world of Nostr. Therefore [ZBD Social](https://zbd.gg) is both an internal social network and a network that is open to the external world through Nostr.
The ZBD app already includes a custodial Bitcoin Lightning wallet and the target userbase doesn't want to care about keys and prefers email and password as the login mechanism to a trusted platform, therefore the ZBD Social is a custodial Nostr client. ZBD users also may be running their app on low-spec phones and low bandwidth, and since the key is already custodial it makes more sense to have all the Nostr logic for each ZBD user to be done on a ZEBEDEE server, instead of in the device itself, therefore the Social section on the ZBD app is just a thin client to an internal API.
## Doing the correct thing given the constraints
In order for Nostr to scale, people must be able to host their notes in whatever relay they want and their followers must still be able to find these.
With that goal in mind, the ZBD Social server keeps track of all associations it can find -- in event hints, kind 3 and kind 10002 events, `nprofile` and `nevent` codes and the bare fact that a given event from someone was found in a given relay -- and uses that information to estimate the best possible set of relays to be used to fetch notes for each Nostr user, along with some variance to account for the fact that these sets are dynamic.
Whenever a ZBD user wants to read notes from any external Nostr user -- either because they've opened on that user's profile or because they follow that user and are browsing their classic "home feed" with notes from everybody they follow -- the ZBD Social backend will gather the best relays for that given user and open new subscriptions -- if there isn't already a subscription open -- for that user. If there are already other subscriptions open for other users in that same relay, the subscriptions will be merged in order to not spam external relays.
As they come in, notes from external users are cached in a way that they are automatically evicted as soon as memory is low and they haven't been accessed for a while. Browsing through old notes is done through paging these cached notes, indexed by author.
## The `wss://nostr.zbd.gg` relay
The ZBD relay stores all events emitted by ZBD users. It runs [strfry](https://github.com/hoytech/strfry) with a plugin that makes it interact with the rest of the backend. It is replicated accross multiple instances using strfry's native syncing capabilities and serves both as a normal relay interface to which external Nostr clients can talk normally and as a database that can be queried by the internal backend (turns out strfry is not only a Nostr relay, it is also a mechanism to turn LMDB into a cloud-native datastore).
This makes it easy to have a dedicated tab on the app with the feed of all the other ZBD users, which is effectively the same as browsing just `wss://nostr.zbd.gg` from any other Nostr client -- see, for example, [Coracle](https://coracle.social/relays/nostr.zbd.gg), [nostrrr](https://nostrrr.com/relay/nrelay1qqxxummnw3ezu7nzvshxwecdqzt3k), [nostr.com](https://nostr.com/r/nostr.zbd.gg) or using the [CLI](https://github.com/fiatjaf/nak): `nak req -l 10 --stream wss://nostr.zbd.gg | jq`.
It also contributes to the future world of Nostr in which niche relays can be browsed individually to enhance the experience of normal social interactions. For any given note, for example, you should be able to see "what are the ZBD users commenting about this" or "what are the gold enthusiasts saying" and so on.
## Ideas for the future
Being a Nostr custodian in a platform that offers Lightning payment services and other third-party integrations for its existing userbase, it's easy to see how ZEBEDEE can start bridging Nostr into more things inside its domain.
For example, in the future ZEBEDEE could offer a way for game vendors to plug in a social networking layer into their games and that wouldn't be just an API to a proprietary platform, but a bridge to the real Nostr world that integrates seamlessly with the ZBD app for ZBD users, but works in Nostr-native mode for any Nostr user. Another use case could be powering social features for music and entertainment apps. Another very obvious use case is a NIP-58 badges system that games and other "gamified" services and apps can use.
In a not distant future, I imagine we'll see also integrations with the ZBD browser extension and NIP-07, Nostr features with the Telegram and Discord bots, and NIP-53 integration with [ZBD Streamer](https://docs.zebedee.io/docs/zbd-streamer/overview/) (but I am _not_ officially announcing anything).
-
@ 3bf0c63f:aefa459d
2024-01-14 13:55:28
# Comprimido desodorante
No episódio sei-lá-qual de Aleixo FM Bruno Aleixo diz que os bêbados sempre têm as melhores idéias e daí conta uma idéia que ele teve quando estava bêbado: um comprimido que funciona como desodorante. Ao invés de passar o desodorante spray ou roll-on a pessoa pode só tomar o comprimido e pronto, é muito mais prático e no tempo de frio a pessoa pode vestir a roupa mais rápido, sem precisar ficar passando nada com o tronco todo nu. Quando o Busto lhe pergunta sobre a possibilidade de algo assim ser fabricado ele diz que não sabe, que não é cientista, só tem as idéias.
Essa passagem tão boba de um programa de humor esconde uma verdade sobre a doutrina cientística que permeia a sociedade. A doutrina segundo a qual é da ciência que vêm as inovações tecnológicas e de todos os tipos, e por isso é preciso que o Estado tire dinheiro das pessoas trabalhadoras e dê para os cientistas. Nesse ponto ninguém mais sabe o que é um cientista, foi-se toda a concretude, ficou só o nome: "cientista". Daí vão procurar o tal cientista, é um cara que se formou numa universidade e está fazendo um mestrado. Pronto, é só dar dinheiro pra esse cara e tudo vai ficar bom.
Tirando o problema da desconexão entre realidade e a tese, existe também, é claro, o problema da tese: não faz sentido, que um cientista fique procurando formas de realizar uma idéia, que não se sabe nem se é possível nem se é desejável, que ele ou outra pessoa tiveram, muito pelo contrário (mas não vou dizer aqui o que é que era para o cientista fazer porque isso seria contraditório e eu não acho que devam nem existir cientistas).
O que eu queria dizer mesmo era: todo o aparato científico da nossa sociedade, todos os departamentos, universidades, orçamentos e bolsas e revistas, tudo se resume a um monte de gente tentando descobrir como fazer um comprimido desodorante.