-
 @ 21335073:a244b1ad
2025-05-09 13:56:57
@ 21335073:a244b1ad
2025-05-09 13:56:57Someone asked for my thoughts, so I’ll share them thoughtfully. I’m not here to dictate how to promote Nostr—I’m still learning about it myself. While I’m not new to Nostr, freedom tech is a newer space for me. I’m skilled at advocating for topics I deeply understand, but freedom tech isn’t my expertise, so take my words with a grain of salt. Nothing I say is set in stone.
Those who need Nostr the most are the ones most vulnerable to censorship on other platforms right now. Reaching them requires real-time awareness of global issues and the dynamic relationships between governments and tech providers, which can shift suddenly. Effective Nostr promoters must grasp this and adapt quickly.
The best messengers are people from or closely tied to these at-risk regions—those who truly understand the local political and cultural dynamics. They can connect with those in need when tensions rise. Ideal promoters are rational, trustworthy, passionate about Nostr, but above all, dedicated to amplifying people’s voices when it matters most.
Forget influencers, corporate-backed figures, or traditional online PR—it comes off as inauthentic, corny, desperate and forced. Nostr’s promotion should be grassroots and organic, driven by a few passionate individuals who believe in Nostr and the communities they serve.
The idea that “people won’t join Nostr due to lack of reach” is nonsense. Everyone knows X’s “reach” is mostly with bots. If humans want real conversations, Nostr is the place. X is great for propaganda, but Nostr is for the authentic voices of the people.
Those spreading Nostr must be so passionate they’re willing to onboard others, which is time-consuming but rewarding for the right person. They’ll need to make Nostr and onboarding a core part of who they are. I see no issue with that level of dedication. I’ve been known to get that way myself at times. It’s fun for some folks.
With love, I suggest not adding Bitcoin promotion with Nostr outreach. Zaps already integrate that element naturally. (Still promote within the Bitcoin ecosystem, but this is about reaching vulnerable voices who needed Nostr yesterday.)
To promote Nostr, forget conventional strategies. “Influencers” aren’t the answer. “Influencers” are not the future. A trusted local community member has real influence—reach them. Connect with people seeking Nostr’s benefits but lacking the technical language to express it. This means some in the Nostr community might need to step outside of the Bitcoin bubble, which is uncomfortable but necessary. Thank you in advance to those who are willing to do that.
I don’t know who is paid to promote Nostr, if anyone. This piece isn’t shade. But it’s exhausting to see innocent voices globally silenced on corporate platforms like X while Nostr exists. Last night, I wondered: how many more voices must be censored before the Nostr community gets uncomfortable and thinks creatively to reach the vulnerable?
A warning: the global need for censorship-resistant social media is undeniable. If Nostr doesn’t make itself known, something else will fill that void. Let’s start this conversation.
-
@ 21335073:a244b1ad
2025-05-01 01:51:10
Please respect Virginia Giuffre’s memory by refraining from asking about the circumstances or theories surrounding her passing.
Since Virginia Giuffre’s death, I’ve reflected on what she would want me to say or do. This piece is my attempt to honor her legacy.
When I first spoke with Virginia, I was struck by her unshakable hope. I had grown cynical after years in the anti-human trafficking movement, worn down by a broken system and a government that often seemed complicit. But Virginia’s passion, creativity, and belief that survivors could be heard reignited something in me. She reminded me of my younger, more hopeful self. Instead of warning her about the challenges ahead, I let her dream big, unburdened by my own disillusionment. That conversation changed me for the better, and following her lead led to meaningful progress.
Virginia was one of the bravest people I’ve ever known. As a survivor of Epstein, Maxwell, and their co-conspirators, she risked everything to speak out, taking on some of the world’s most powerful figures.
She loved when I said, “Epstein isn’t the only Epstein.” This wasn’t just about one man—it was a call to hold all abusers accountable and to ensure survivors find hope and healing.
The Epstein case often gets reduced to sensational details about the elite, but that misses the bigger picture. Yes, we should be holding all of the co-conspirators accountable, we must listen to the survivors’ stories. Their experiences reveal how predators exploit vulnerabilities, offering lessons to prevent future victims.
You’re not powerless in this fight. Educate yourself about trafficking and abuse—online and offline—and take steps to protect those around you. Supporting survivors starts with small, meaningful actions. Free online resources can guide you in being a safe, supportive presence.
When high-profile accusations arise, resist snap judgments. Instead of dismissing survivors as “crazy,” pause to consider the trauma they may be navigating. Speaking out or coping with abuse is never easy. You don’t have to believe every claim, but you can refrain from attacking accusers online.
Society also fails at providing aftercare for survivors. The government, often part of the problem, won’t solve this. It’s up to us. Prevention is critical, but when abuse occurs, step up for your loved ones and community. Protect the vulnerable. it’s a challenging but a rewarding journey.
If you’re contributing to Nostr, you’re helping build a censorship resistant platform where survivors can share their stories freely, no matter how powerful their abusers are. Their voices can endure here, offering strength and hope to others. This gives me great hope for the future.
Virginia Giuffre’s courage was a gift to the world. It was an honor to know and serve her. She will be deeply missed. My hope is that her story inspires others to take on the powerful.
-
@ 52b4a076:e7fad8bd
2025-04-28 00:48:57
I have been recently building NFDB, a new relay DB. This post is meant as a short overview.
Regular relays have challenges
Current relay software have significant challenges, which I have experienced when hosting Nostr.land: - Scalability is only supported by adding full replicas, which does not scale to large relays. - Most relays use slow databases and are not optimized for large scale usage. - Search is near-impossible to implement on standard relays. - Privacy features such as NIP-42 are lacking. - Regular DB maintenance tasks on normal relays require extended downtime. - Fault-tolerance is implemented, if any, using a load balancer, which is limited. - Personalization and advanced filtering is not possible. - Local caching is not supported.
NFDB: A scalable database for large relays
NFDB is a new database meant for medium-large scale relays, built on FoundationDB that provides: - Near-unlimited scalability - Extended fault tolerance - Instant loading - Better search - Better personalization - and more.
Search
NFDB has extended search capabilities including: - Semantic search: Search for meaning, not words. - Interest-based search: Highlight content you care about. - Multi-faceted queries: Easily filter by topic, author group, keywords, and more at the same time. - Wide support for event kinds, including users, articles, etc.
Personalization
NFDB allows significant personalization: - Customized algorithms: Be your own algorithm. - Spam filtering: Filter content to your WoT, and use advanced spam filters. - Topic mutes: Mute topics, not keywords. - Media filtering: With Nostr.build, you will be able to filter NSFW and other content - Low data mode: Block notes that use high amounts of cellular data. - and more
Other
NFDB has support for many other features such as: - NIP-42: Protect your privacy with private drafts and DMs - Microrelays: Easily deploy your own personal microrelay - Containers: Dedicated, fast storage for discoverability events such as relay lists
Calcite: A local microrelay database
Calcite is a lightweight, local version of NFDB that is meant for microrelays and caching, meant for thousands of personal microrelays.
Calcite HA is an additional layer that allows live migration and relay failover in under 30 seconds, providing higher availability compared to current relays with greater simplicity. Calcite HA is enabled in all Calcite deployments.
For zero-downtime, NFDB is recommended.
Noswhere SmartCache
Relays are fixed in one location, but users can be anywhere.
Noswhere SmartCache is a CDN for relays that dynamically caches data on edge servers closest to you, allowing: - Multiple regions around the world - Improved throughput and performance - Faster loading times
routerd
routerdis a custom load-balancer optimized for Nostr relays, integrated with SmartCache.routerdis specifically integrated with NFDB and Calcite HA to provide fast failover and high performance.Ending notes
NFDB is planned to be deployed to Nostr.land in the coming weeks.
A lot more is to come. 👀️️️️️️
-
@ 91bea5cd:1df4451c
2025-04-26 10:16:21
O Contexto Legal Brasileiro e o Consentimento
No ordenamento jurídico brasileiro, o consentimento do ofendido pode, em certas circunstâncias, afastar a ilicitude de um ato que, sem ele, configuraria crime (como lesão corporal leve, prevista no Art. 129 do Código Penal). Contudo, o consentimento tem limites claros: não é válido para bens jurídicos indisponíveis, como a vida, e sua eficácia é questionável em casos de lesões corporais graves ou gravíssimas.
A prática de BDSM consensual situa-se em uma zona complexa. Em tese, se ambos os parceiros são adultos, capazes, e consentiram livre e informadamente nos atos praticados, sem que resultem em lesões graves permanentes ou risco de morte não consentido, não haveria crime. O desafio reside na comprovação desse consentimento, especialmente se uma das partes, posteriormente, o negar ou alegar coação.
A Lei Maria da Penha (Lei nº 11.340/2006)
A Lei Maria da Penha é um marco fundamental na proteção da mulher contra a violência doméstica e familiar. Ela estabelece mecanismos para coibir e prevenir tal violência, definindo suas formas (física, psicológica, sexual, patrimonial e moral) e prevendo medidas protetivas de urgência.
Embora essencial, a aplicação da lei em contextos de BDSM pode ser delicada. Uma alegação de violência por parte da mulher, mesmo que as lesões ou situações decorram de práticas consensuais, tende a receber atenção prioritária das autoridades, dada a presunção de vulnerabilidade estabelecida pela lei. Isso pode criar um cenário onde o parceiro masculino enfrenta dificuldades significativas em demonstrar a natureza consensual dos atos, especialmente se não houver provas robustas pré-constituídas.
Outros riscos:
Lesão corporal grave ou gravíssima (art. 129, §§ 1º e 2º, CP), não pode ser justificada pelo consentimento, podendo ensejar persecução penal.
Crimes contra a dignidade sexual (arts. 213 e seguintes do CP) são de ação pública incondicionada e independem de representação da vítima para a investigação e denúncia.
Riscos de Falsas Acusações e Alegação de Coação Futura
Os riscos para os praticantes de BDSM, especialmente para o parceiro que assume o papel dominante ou que inflige dor/restrição (frequentemente, mas não exclusivamente, o homem), podem surgir de diversas frentes:
- Acusações Externas: Vizinhos, familiares ou amigos que desconhecem a natureza consensual do relacionamento podem interpretar sons, marcas ou comportamentos como sinais de abuso e denunciar às autoridades.
- Alegações Futuras da Parceira: Em caso de término conturbado, vingança, arrependimento ou mudança de perspectiva, a parceira pode reinterpretar as práticas passadas como abuso e buscar reparação ou retaliação através de uma denúncia. A alegação pode ser de que o consentimento nunca existiu ou foi viciado.
- Alegação de Coação: Uma das formas mais complexas de refutar é a alegação de que o consentimento foi obtido mediante coação (física, moral, psicológica ou econômica). A parceira pode alegar, por exemplo, que se sentia pressionada, intimidada ou dependente, e que seu "sim" não era genuíno. Provar a ausência de coação a posteriori é extremamente difícil.
- Ingenuidade e Vulnerabilidade Masculina: Muitos homens, confiando na dinâmica consensual e na parceira, podem negligenciar a necessidade de precauções. A crença de que "isso nunca aconteceria comigo" ou a falta de conhecimento sobre as implicações legais e o peso processual de uma acusação no âmbito da Lei Maria da Penha podem deixá-los vulneráveis. A presença de marcas físicas, mesmo que consentidas, pode ser usada como evidência de agressão, invertendo o ônus da prova na prática, ainda que não na teoria jurídica.
Estratégias de Prevenção e Mitigação
Não existe um método infalível para evitar completamente o risco de uma falsa acusação, mas diversas medidas podem ser adotadas para construir um histórico de consentimento e reduzir vulnerabilidades:
- Comunicação Explícita e Contínua: A base de qualquer prática BDSM segura é a comunicação constante. Negociar limites, desejos, palavras de segurança ("safewords") e expectativas antes, durante e depois das cenas é crucial. Manter registros dessas negociações (e-mails, mensagens, diários compartilhados) pode ser útil.
-
Documentação do Consentimento:
-
Contratos de Relacionamento/Cena: Embora a validade jurídica de "contratos BDSM" seja discutível no Brasil (não podem afastar normas de ordem pública), eles servem como forte evidência da intenção das partes, da negociação detalhada de limites e do consentimento informado. Devem ser claros, datados, assinados e, idealmente, reconhecidos em cartório (para prova de data e autenticidade das assinaturas).
-
Registros Audiovisuais: Gravar (com consentimento explícito para a gravação) discussões sobre consentimento e limites antes das cenas pode ser uma prova poderosa. Gravar as próprias cenas é mais complexo devido a questões de privacidade e potencial uso indevido, mas pode ser considerado em casos específicos, sempre com consentimento mútuo documentado para a gravação.
Importante: a gravação deve ser com ciência da outra parte, para não configurar violação da intimidade (art. 5º, X, da Constituição Federal e art. 20 do Código Civil).
-
-
Testemunhas: Em alguns contextos de comunidade BDSM, a presença de terceiros de confiança durante negociações ou mesmo cenas pode servir como testemunho, embora isso possa alterar a dinâmica íntima do casal.
- Estabelecimento Claro de Limites e Palavras de Segurança: Definir e respeitar rigorosamente os limites (o que é permitido, o que é proibido) e as palavras de segurança é fundamental. O desrespeito a uma palavra de segurança encerra o consentimento para aquele ato.
- Avaliação Contínua do Consentimento: O consentimento não é um cheque em branco; ele deve ser entusiástico, contínuo e revogável a qualquer momento. Verificar o bem-estar do parceiro durante a cena ("check-ins") é essencial.
- Discrição e Cuidado com Evidências Físicas: Ser discreto sobre a natureza do relacionamento pode evitar mal-entendidos externos. Após cenas que deixem marcas, é prudente que ambos os parceiros estejam cientes e de acordo, talvez documentando por fotos (com data) e uma nota sobre a consensualidade da prática que as gerou.
- Aconselhamento Jurídico Preventivo: Consultar um advogado especializado em direito de família e criminal, com sensibilidade para dinâmicas de relacionamento alternativas, pode fornecer orientação personalizada sobre as melhores formas de documentar o consentimento e entender os riscos legais específicos.
Observações Importantes
- Nenhuma documentação substitui a necessidade de consentimento real, livre, informado e contínuo.
- A lei brasileira protege a "integridade física" e a "dignidade humana". Práticas que resultem em lesões graves ou que violem a dignidade de forma não consentida (ou com consentimento viciado) serão ilegais, independentemente de qualquer acordo prévio.
- Em caso de acusação, a existência de documentação robusta de consentimento não garante a absolvição, mas fortalece significativamente a defesa, ajudando a demonstrar a natureza consensual da relação e das práticas.
-
A alegação de coação futura é particularmente difícil de prevenir apenas com documentos. Um histórico consistente de comunicação aberta (whatsapp/telegram/e-mails), respeito mútuo e ausência de dependência ou controle excessivo na relação pode ajudar a contextualizar a dinâmica como não coercitiva.
-
Cuidado com Marcas Visíveis e Lesões Graves Práticas que resultam em hematomas severos ou lesões podem ser interpretadas como agressão, mesmo que consentidas. Evitar excessos protege não apenas a integridade física, mas também evita questionamentos legais futuros.
O que vem a ser consentimento viciado
No Direito, consentimento viciado é quando a pessoa concorda com algo, mas a vontade dela não é livre ou plena — ou seja, o consentimento existe formalmente, mas é defeituoso por alguma razão.
O Código Civil brasileiro (art. 138 a 165) define várias formas de vício de consentimento. As principais são:
Erro: A pessoa se engana sobre o que está consentindo. (Ex.: A pessoa acredita que vai participar de um jogo leve, mas na verdade é exposta a práticas pesadas.)
Dolo: A pessoa é enganada propositalmente para aceitar algo. (Ex.: Alguém mente sobre o que vai acontecer durante a prática.)
Coação: A pessoa é forçada ou ameaçada a consentir. (Ex.: "Se você não aceitar, eu termino com você" — pressão emocional forte pode ser vista como coação.)
Estado de perigo ou lesão: A pessoa aceita algo em situação de necessidade extrema ou abuso de sua vulnerabilidade. (Ex.: Alguém em situação emocional muito fragilizada é induzida a aceitar práticas que normalmente recusaria.)
No contexto de BDSM, isso é ainda mais delicado: Mesmo que a pessoa tenha "assinado" um contrato ou dito "sim", se depois ela alegar que seu consentimento foi dado sob medo, engano ou pressão psicológica, o consentimento pode ser considerado viciado — e, portanto, juridicamente inválido.
Isso tem duas implicações sérias:
-
O crime não se descaracteriza: Se houver vício, o consentimento é ignorado e a prática pode ser tratada como crime normal (lesão corporal, estupro, tortura, etc.).
-
A prova do consentimento precisa ser sólida: Mostrando que a pessoa estava informada, lúcida, livre e sem qualquer tipo de coação.
Consentimento viciado é quando a pessoa concorda formalmente, mas de maneira enganada, forçada ou pressionada, tornando o consentimento inútil para efeitos jurídicos.
Conclusão
Casais que praticam BDSM consensual no Brasil navegam em um terreno que exige não apenas confiança mútua e comunicação excepcional, mas também uma consciência aguçada das complexidades legais e dos riscos de interpretações equivocadas ou acusações mal-intencionadas. Embora o BDSM seja uma expressão legítima da sexualidade humana, sua prática no Brasil exige responsabilidade redobrada. Ter provas claras de consentimento, manter a comunicação aberta e agir com prudência são formas eficazes de se proteger de falsas alegações e preservar a liberdade e a segurança de todos os envolvidos. Embora leis controversas como a Maria da Penha sejam "vitais" para a proteção contra a violência real, os praticantes de BDSM, e em particular os homens nesse contexto, devem adotar uma postura proativa e prudente para mitigar os riscos inerentes à potencial má interpretação ou instrumentalização dessas práticas e leis, garantindo que a expressão de sua consensualidade esteja resguardada na medida do possível.
Importante: No Brasil, mesmo com tudo isso, o Ministério Público pode denunciar por crime como lesão corporal grave, estupro ou tortura, independente de consentimento. Então a prudência nas práticas é fundamental.
Aviso Legal: Este artigo tem caráter meramente informativo e não constitui aconselhamento jurídico. As leis e interpretações podem mudar, e cada situação é única. Recomenda-se buscar orientação de um advogado qualificado para discutir casos específicos.
Se curtiu este artigo faça uma contribuição, se tiver algum ponto relevante para o artigo deixe seu comentário.
-
@ e3ba5e1a:5e433365
2025-04-15 11:03:15
Prelude
I wrote this post differently than any of my others. It started with a discussion with AI on an OPSec-inspired review of separation of powers, and evolved into quite an exciting debate! I asked Grok to write up a summary in my overall writing style, which it got pretty well. I've decided to post it exactly as-is. Ultimately, I think there are two solid ideas driving my stance here:
- Perfect is the enemy of the good
- Failure is the crucible of success
Beyond that, just some hard-core belief in freedom, separation of powers, and operating from self-interest.
Intro
Alright, buckle up. I’ve been chewing on this idea for a while, and it’s time to spit it out. Let’s look at the U.S. government like I’d look at a codebase under a cybersecurity audit—OPSEC style, no fluff. Forget the endless debates about what politicians should do. That’s noise. I want to talk about what they can do, the raw powers baked into the system, and why we should stop pretending those powers are sacred. If there’s a hole, either patch it or exploit it. No half-measures. And yeah, I’m okay if the whole thing crashes a bit—failure’s a feature, not a bug.
The Filibuster: A Security Rule with No Teeth
You ever see a firewall rule that’s more theater than protection? That’s the Senate filibuster. Everyone acts like it’s this untouchable guardian of democracy, but here’s the deal: a simple majority can torch it any day. It’s not a law; it’s a Senate preference, like choosing tabs over spaces. When people call killing it the “nuclear option,” I roll my eyes. Nuclear? It’s a button labeled “press me.” If a party wants it gone, they’ll do it. So why the dance?
I say stop playing games. Get rid of the filibuster. If you’re one of those folks who thinks it’s the only thing saving us from tyranny, fine—push for a constitutional amendment to lock it in. That’s a real patch, not a Post-it note. Until then, it’s just a vulnerability begging to be exploited. Every time a party threatens to nuke it, they’re admitting it’s not essential. So let’s stop pretending and move on.
Supreme Court Packing: Because Nine’s Just a Number
Here’s another fun one: the Supreme Court. Nine justices, right? Sounds official. Except it’s not. The Constitution doesn’t say nine—it’s silent on the number. Congress could pass a law tomorrow to make it 15, 20, or 42 (hitchhiker’s reference, anyone?). Packing the court is always on the table, and both sides know it. It’s like a root exploit just sitting there, waiting for someone to log in.
So why not call the bluff? If you’re in power—say, Trump’s back in the game—say, “I’m packing the court unless we amend the Constitution to fix it at nine.” Force the issue. No more shadowboxing. And honestly? The court’s got way too much power anyway. It’s not supposed to be a super-legislature, but here we are, with justices’ ideologies driving the bus. That’s a bug, not a feature. If the court weren’t such a kingmaker, packing it wouldn’t even matter. Maybe we should be talking about clipping its wings instead of just its size.
The Executive Should Go Full Klingon
Let’s talk presidents. I’m not saying they should wear Klingon armor and start shouting “Qapla’!”—though, let’s be real, that’d be awesome. I’m saying the executive should use every scrap of power the Constitution hands them. Enforce the laws you agree with, sideline the ones you don’t. If Congress doesn’t like it, they’ve got tools: pass new laws, override vetoes, or—here’s the big one—cut the budget. That’s not chaos; that’s the system working as designed.
Right now, the real problem isn’t the president overreaching; it’s the bureaucracy. It’s like a daemon running in the background, eating CPU and ignoring the user. The president’s supposed to be the one steering, but the administrative state’s got its own agenda. Let the executive flex, push the limits, and force Congress to check it. Norms? Pfft. The Constitution’s the spec sheet—stick to it.
Let the System Crash
Here’s where I get a little spicy: I’m totally fine if the government grinds to a halt. Deadlock isn’t a disaster; it’s a feature. If the branches can’t agree, let the president veto, let Congress starve the budget, let enforcement stall. Don’t tell me about “essential services.” Nothing’s so critical it can’t take a breather. Shutdowns force everyone to the table—debate, compromise, or expose who’s dropping the ball. If the public loses trust? Good. They’ll vote out the clowns or live with the circus they elected.
Think of it like a server crash. Sometimes you need a hard reboot to clear the cruft. If voters keep picking the same bad admins, well, the country gets what it deserves. Failure’s the best teacher—way better than limping along on autopilot.
States Are the Real MVPs
If the feds fumble, states step up. Right now, states act like junior devs waiting for the lead engineer to sign off. Why? Federal money. It’s a leash, and it’s tight. Cut that cash, and states will remember they’re autonomous. Some will shine, others will tank—looking at you, California. And I’m okay with that. Let people flee to better-run states. No bailouts, no excuses. States are like competing startups: the good ones thrive, the bad ones pivot or die.
Could it get uneven? Sure. Some states might turn into sci-fi utopias while others look like a post-apocalyptic vidya game. That’s the point—competition sorts it out. Citizens can move, markets adjust, and failure’s a signal to fix your act.
Chaos Isn’t the Enemy
Yeah, this sounds messy. States ignoring federal law, external threats poking at our seams, maybe even a constitutional crisis. I’m not scared. The Supreme Court’s there to referee interstate fights, and Congress sets the rules for state-to-state play. But if it all falls apart? Still cool. States can sort it without a babysitter—it’ll be ugly, but freedom’s worth it. External enemies? They’ll either unify us or break us. If we can’t rally, we don’t deserve the win.
Centralizing power to avoid this is like rewriting your app in a single thread to prevent race conditions—sure, it’s simpler, but you’re begging for a deadlock. Decentralized chaos lets states experiment, lets people escape, lets markets breathe. States competing to cut regulations to attract businesses? That’s a race to the bottom for red tape, but a race to the top for innovation—workers might gripe, but they’ll push back, and the tension’s healthy. Bring it—let the cage match play out. The Constitution’s checks are enough if we stop coddling the system.
Why This Matters
I’m not pitching a utopia. I’m pitching a stress test. The U.S. isn’t a fragile porcelain doll; it’s a rugged piece of hardware built to take some hits. Let it fail a little—filibuster, court, feds, whatever. Patch the holes with amendments if you want, or lean into the grind. Either way, stop fearing the crash. It’s how we debug the republic.
So, what’s your take? Ready to let the system rumble, or got a better way to secure the code? Hit me up—I’m all ears.
-
@ 91bea5cd:1df4451c
2025-04-15 06:27:28
Básico
bash lsblk # Lista todos os diretorios montados.Para criar o sistema de arquivos:
bash mkfs.btrfs -L "ThePool" -f /dev/sdxCriando um subvolume:
bash btrfs subvolume create SubVolMontando Sistema de Arquivos:
bash mount -o compress=zlib,subvol=SubVol,autodefrag /dev/sdx /mntLista os discos formatados no diretório:
bash btrfs filesystem show /mntAdiciona novo disco ao subvolume:
bash btrfs device add -f /dev/sdy /mntLista novamente os discos do subvolume:
bash btrfs filesystem show /mntExibe uso dos discos do subvolume:
bash btrfs filesystem df /mntBalancea os dados entre os discos sobre raid1:
bash btrfs filesystem balance start -dconvert=raid1 -mconvert=raid1 /mntScrub é uma passagem por todos os dados e metadados do sistema de arquivos e verifica as somas de verificação. Se uma cópia válida estiver disponível (perfis de grupo de blocos replicados), a danificada será reparada. Todas as cópias dos perfis replicados são validadas.
iniciar o processo de depuração :
bash btrfs scrub start /mntver o status do processo de depuração Btrfs em execução:
bash btrfs scrub status /mntver o status do scrub Btrfs para cada um dos dispositivos
bash btrfs scrub status -d / data btrfs scrub cancel / dataPara retomar o processo de depuração do Btrfs que você cancelou ou pausou:
btrfs scrub resume / data
Listando os subvolumes:
bash btrfs subvolume list /ReportsCriando um instantâneo dos subvolumes:
Aqui, estamos criando um instantâneo de leitura e gravação chamado snap de marketing do subvolume de marketing.
bash btrfs subvolume snapshot /Reports/marketing /Reports/marketing-snapAlém disso, você pode criar um instantâneo somente leitura usando o sinalizador -r conforme mostrado. O marketing-rosnap é um instantâneo somente leitura do subvolume de marketing
bash btrfs subvolume snapshot -r /Reports/marketing /Reports/marketing-rosnapForçar a sincronização do sistema de arquivos usando o utilitário 'sync'
Para forçar a sincronização do sistema de arquivos, invoque a opção de sincronização conforme mostrado. Observe que o sistema de arquivos já deve estar montado para que o processo de sincronização continue com sucesso.
bash btrfs filsystem sync /ReportsPara excluir o dispositivo do sistema de arquivos, use o comando device delete conforme mostrado.
bash btrfs device delete /dev/sdc /ReportsPara sondar o status de um scrub, use o comando scrub status com a opção -dR .
bash btrfs scrub status -dR / RelatóriosPara cancelar a execução do scrub, use o comando scrub cancel .
bash $ sudo btrfs scrub cancel / ReportsPara retomar ou continuar com uma depuração interrompida anteriormente, execute o comando de cancelamento de depuração
bash sudo btrfs scrub resume /Reportsmostra o uso do dispositivo de armazenamento:
btrfs filesystem usage /data
Para distribuir os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID (incluindo o dispositivo de armazenamento recém-adicionado) montados no diretório /data , execute o seguinte comando:
sudo btrfs balance start --full-balance /data
Pode demorar um pouco para espalhar os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID se ele contiver muitos dados.
Opções importantes de montagem Btrfs
Nesta seção, vou explicar algumas das importantes opções de montagem do Btrfs. Então vamos começar.
As opções de montagem Btrfs mais importantes são:
**1. acl e noacl
**ACL gerencia permissões de usuários e grupos para os arquivos/diretórios do sistema de arquivos Btrfs.
A opção de montagem acl Btrfs habilita ACL. Para desabilitar a ACL, você pode usar a opção de montagem noacl .
Por padrão, a ACL está habilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem acl por padrão.
**2. autodefrag e noautodefrag
**Desfragmentar um sistema de arquivos Btrfs melhorará o desempenho do sistema de arquivos reduzindo a fragmentação de dados.
A opção de montagem autodefrag permite a desfragmentação automática do sistema de arquivos Btrfs.
A opção de montagem noautodefrag desativa a desfragmentação automática do sistema de arquivos Btrfs.
Por padrão, a desfragmentação automática está desabilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem noautodefrag por padrão.
**3. compactar e compactar-forçar
**Controla a compactação de dados no nível do sistema de arquivos do sistema de arquivos Btrfs.
A opção compactar compacta apenas os arquivos que valem a pena compactar (se compactar o arquivo economizar espaço em disco).
A opção compress-force compacta todos os arquivos do sistema de arquivos Btrfs, mesmo que a compactação do arquivo aumente seu tamanho.
O sistema de arquivos Btrfs suporta muitos algoritmos de compactação e cada um dos algoritmos de compactação possui diferentes níveis de compactação.
Os algoritmos de compactação suportados pelo Btrfs são: lzo , zlib (nível 1 a 9) e zstd (nível 1 a 15).
Você pode especificar qual algoritmo de compactação usar para o sistema de arquivos Btrfs com uma das seguintes opções de montagem:
- compress=algoritmo:nível
- compress-force=algoritmo:nível
Para obter mais informações, consulte meu artigo Como habilitar a compactação do sistema de arquivos Btrfs .
**4. subvol e subvolid
**Estas opções de montagem são usadas para montar separadamente um subvolume específico de um sistema de arquivos Btrfs.
A opção de montagem subvol é usada para montar o subvolume de um sistema de arquivos Btrfs usando seu caminho relativo.
A opção de montagem subvolid é usada para montar o subvolume de um sistema de arquivos Btrfs usando o ID do subvolume.
Para obter mais informações, consulte meu artigo Como criar e montar subvolumes Btrfs .
**5. dispositivo
A opção de montagem de dispositivo** é usada no sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs.
Em alguns casos, o sistema operacional pode falhar ao detectar os dispositivos de armazenamento usados em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs. Nesses casos, você pode usar a opção de montagem do dispositivo para especificar os dispositivos que deseja usar para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar a opção de montagem de dispositivo várias vezes para carregar diferentes dispositivos de armazenamento para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar o nome do dispositivo (ou seja, sdb , sdc ) ou UUID , UUID_SUB ou PARTUUID do dispositivo de armazenamento com a opção de montagem do dispositivo para identificar o dispositivo de armazenamento.
Por exemplo,
- dispositivo=/dev/sdb
- dispositivo=/dev/sdb,dispositivo=/dev/sdc
- dispositivo=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d
- device=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d,device=UUID_SUB=f7ce4875-0874-436a-b47d-3edef66d3424
**6. degraded
A opção de montagem degradada** permite que um RAID Btrfs seja montado com menos dispositivos de armazenamento do que o perfil RAID requer.
Por exemplo, o perfil raid1 requer a presença de 2 dispositivos de armazenamento. Se um dos dispositivos de armazenamento não estiver disponível em qualquer caso, você usa a opção de montagem degradada para montar o RAID mesmo que 1 de 2 dispositivos de armazenamento esteja disponível.
**7. commit
A opção commit** mount é usada para definir o intervalo (em segundos) dentro do qual os dados serão gravados no dispositivo de armazenamento.
O padrão é definido como 30 segundos.
Para definir o intervalo de confirmação para 15 segundos, você pode usar a opção de montagem commit=15 (digamos).
**8. ssd e nossd
A opção de montagem ssd** informa ao sistema de arquivos Btrfs que o sistema de arquivos está usando um dispositivo de armazenamento SSD, e o sistema de arquivos Btrfs faz a otimização SSD necessária.
A opção de montagem nossd desativa a otimização do SSD.
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem de SSD será habilitada. Caso contrário, a opção de montagem nossd é habilitada.
**9. ssd_spread e nossd_spread
A opção de montagem ssd_spread** tenta alocar grandes blocos contínuos de espaço não utilizado do SSD. Esse recurso melhora o desempenho de SSDs de baixo custo (baratos).
A opção de montagem nossd_spread desativa o recurso ssd_spread .
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem ssd_spread será habilitada. Caso contrário, a opção de montagem nossd_spread é habilitada.
**10. descarte e nodiscard
Se você estiver usando um SSD que suporte TRIM enfileirado assíncrono (SATA rev3.1), a opção de montagem de descarte** permitirá o descarte de blocos de arquivos liberados. Isso melhorará o desempenho do SSD.
Se o SSD não suportar TRIM enfileirado assíncrono, a opção de montagem de descarte prejudicará o desempenho do SSD. Nesse caso, a opção de montagem nodiscard deve ser usada.
Por padrão, a opção de montagem nodiscard é usada.
**11. norecovery
Se a opção de montagem norecovery** for usada, o sistema de arquivos Btrfs não tentará executar a operação de recuperação de dados no momento da montagem.
**12. usebackuproot e nousebackuproot
Se a opção de montagem usebackuproot for usada, o sistema de arquivos Btrfs tentará recuperar qualquer raiz de árvore ruim/corrompida no momento da montagem. O sistema de arquivos Btrfs pode armazenar várias raízes de árvore no sistema de arquivos. A opção de montagem usebackuproot** procurará uma boa raiz de árvore e usará a primeira boa que encontrar.
A opção de montagem nousebackuproot não verificará ou recuperará raízes de árvore inválidas/corrompidas no momento da montagem. Este é o comportamento padrão do sistema de arquivos Btrfs.
**13. space_cache, space_cache=version, nospace_cache e clear_cache
A opção de montagem space_cache** é usada para controlar o cache de espaço livre. O cache de espaço livre é usado para melhorar o desempenho da leitura do espaço livre do grupo de blocos do sistema de arquivos Btrfs na memória (RAM).
O sistema de arquivos Btrfs suporta 2 versões do cache de espaço livre: v1 (padrão) e v2
O mecanismo de cache de espaço livre v2 melhora o desempenho de sistemas de arquivos grandes (tamanho de vários terabytes).
Você pode usar a opção de montagem space_cache=v1 para definir a v1 do cache de espaço livre e a opção de montagem space_cache=v2 para definir a v2 do cache de espaço livre.
A opção de montagem clear_cache é usada para limpar o cache de espaço livre.
Quando o cache de espaço livre v2 é criado, o cache deve ser limpo para criar um cache de espaço livre v1 .
Portanto, para usar o cache de espaço livre v1 após a criação do cache de espaço livre v2 , as opções de montagem clear_cache e space_cache=v1 devem ser combinadas: clear_cache,space_cache=v1
A opção de montagem nospace_cache é usada para desabilitar o cache de espaço livre.
Para desabilitar o cache de espaço livre após a criação do cache v1 ou v2 , as opções de montagem nospace_cache e clear_cache devem ser combinadas: clear_cache,nosapce_cache
**14. skip_balance
Por padrão, a operação de balanceamento interrompida/pausada de um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs será retomada automaticamente assim que o sistema de arquivos Btrfs for montado. Para desabilitar a retomada automática da operação de equilíbrio interrompido/pausado em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs, você pode usar a opção de montagem skip_balance .**
**15. datacow e nodatacow
A opção datacow** mount habilita o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs. É o comportamento padrão.
Se você deseja desabilitar o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs para os arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatacow .
**16. datasum e nodatasum
A opção datasum** mount habilita a soma de verificação de dados para arquivos recém-criados do sistema de arquivos Btrfs. Este é o comportamento padrão.
Se você não quiser que o sistema de arquivos Btrfs faça a soma de verificação dos dados dos arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatasum .
Perfis Btrfs
Um perfil Btrfs é usado para informar ao sistema de arquivos Btrfs quantas cópias dos dados/metadados devem ser mantidas e quais níveis de RAID devem ser usados para os dados/metadados. O sistema de arquivos Btrfs contém muitos perfis. Entendê-los o ajudará a configurar um RAID Btrfs da maneira que você deseja.
Os perfis Btrfs disponíveis são os seguintes:
single : Se o perfil único for usado para os dados/metadados, apenas uma cópia dos dados/metadados será armazenada no sistema de arquivos, mesmo se você adicionar vários dispositivos de armazenamento ao sistema de arquivos. Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
dup : Se o perfil dup for usado para os dados/metadados, cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos manterá duas cópias dos dados/metadados. Assim, 50% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
raid0 : No perfil raid0 , os dados/metadados serão divididos igualmente em todos os dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, não haverá dados/metadados redundantes (duplicados). Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser usado. Se, em qualquer caso, um dos dispositivos de armazenamento falhar, todo o sistema de arquivos será corrompido. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid0 .
raid1 : No perfil raid1 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a uma falha de unidade. Mas você pode usar apenas 50% do espaço total em disco. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1 .
raid1c3 : No perfil raid1c3 , três cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a duas falhas de unidade, mas você pode usar apenas 33% do espaço total em disco. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c3 .
raid1c4 : No perfil raid1c4 , quatro cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a três falhas de unidade, mas você pode usar apenas 25% do espaço total em disco. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c4 .
raid10 : No perfil raid10 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos, como no perfil raid1 . Além disso, os dados/metadados serão divididos entre os dispositivos de armazenamento, como no perfil raid0 .
O perfil raid10 é um híbrido dos perfis raid1 e raid0 . Alguns dos dispositivos de armazenamento formam arrays raid1 e alguns desses arrays raid1 são usados para formar um array raid0 . Em uma configuração raid10 , o sistema de arquivos pode sobreviver a uma única falha de unidade em cada uma das matrizes raid1 .
Você pode usar 50% do espaço total em disco na configuração raid10 . Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid10 .
raid5 : No perfil raid5 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Uma única paridade será calculada e distribuída entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid5 , o sistema de arquivos pode sobreviver a uma única falha de unidade. Se uma unidade falhar, você pode adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir da paridade distribuída das unidades em execução.
Você pode usar 1 00x(N-1)/N % do total de espaços em disco na configuração raid5 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid5 .
raid6 : No perfil raid6 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Duas paridades serão calculadas e distribuídas entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid6 , o sistema de arquivos pode sobreviver a duas falhas de unidade ao mesmo tempo. Se uma unidade falhar, você poderá adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir das duas paridades distribuídas das unidades em execução.
Você pode usar 100x(N-2)/N % do espaço total em disco na configuração raid6 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid6 .
-
@ 57c631a3:07529a8e
2025-04-07 13:17:50
What is Growth Engineering? Before we start: if you’ve already filled out the What is your tech stack? survey: thank you! If you’ve not done so, your help will be greatly appreciated. It takes 5-15 minutes to complete. Those filling out will receive results before anyone else, and additional analysis from myself and Elin. Fill out this survey here.**
npub1sg6plzptd64u62a878hep2kev88swjh3tw00gjsfl8f237lmu63q0uf63m
Growth engineering was barely known a decade ago, but today, most scaleups and many publicly traded tech companies have dedicated growth teams staffed by growth engineers. However, some software engineers are still suspicious of this new area because of its reputation for hacky code with little to no code coverage.
For this reason and others, I thought it would be interesting to learn more from an expert who can tell us all about the practicalities of this controversial domain. So I turned to Alexey Komissarouk, who’s been in growth engineering since 2016, and was in charge of it at online education platform, MasterClass. These days, Alexey lives in Tokyo, Japan, where he advises on growth engineering and teaches the Growth Engineering course at Reforge.
In today’s deep dive, Alexey covers:
- What is Growth Engineering? In the simplest terms: writing code to help a company make more money. But there are details to consider: like the company size where it makes sense to have a dedicated team do this.
- What do Growth Engineers work on? Business-facing work, empowerment and platform work are the main areas.
- Why Growth Engineers move faster than Product Engineers. Product Engineers ship to build: Growth Engineers ship to learn. Growth Engineers do take shortcuts that would make no sense when building for longevity – doing this on purpose.
- Tech stack. Common programming languages, monitoring and oncall, feature flags and experimentation, product analytics, review apps, and more.
- What makes a good Growth Engineer? Curiosity, “build to learn” mindset and a “Jack of all trades” approach.
- Where do Growth Engineers fit in? Usually part of the engineering department, either operating as with an “owner” or a “hitchiker” model.
- Becoming a Growth Engineer. A great area if you want to eventually become a founder or product manager – but even if not, it can accelerate your career growth. Working in Growth forces you to learn more about the business.
With that, it’s over to Alexey:
I’ll never forget the first time I made my employer a million dollars.
I was running a push notification A/B test for meal delivery startup Sprig, trying to boost repeat orders.
A push notification similar to what we tested to boost repeat orders
Initial results were unpromising; the push notification was not receiving many opens. Still, I wanted to be thorough: before concluding the idea was a failure, I wrote a SQL query to compare order volume for subsequent weeks between customers in test vs control.
The SQL used to figure out the push notification’s efficiency
As it turned out, our test group “beat” the control group by around 10%:
‘review_5_push’ was the new type of push notification. Roughly the same amount of users clicked it, but they placed 10% more in orders
I plugged the numbers into a significance calculator, which showed it was statistically significant – or “stat-sig” – and therefore highly unlikely to be a coincidence. This meant we had a winner on our hands! But how meaningful was it, really, and what would adding the push notification mean for revenue, if rolled out to 100% of users?
It turned out this experiment created an additional $1.5 million dollars, annually, with just one push notification. Wow!
I was hooked. Since that day, I've shipped hundreds of experimental “winners” which generated hundreds of millions of incremental revenue for my employers. But you never forget the first one. Moments like this is what growth engineering is all about.
1. What is Growth Engineering?
Essentially, growth engineering is the writing of code to make a company money. Of course, all code produced by a business on some level serves this purpose, but while Product Engineers focus on creating a Product worth paying for, Growth Engineers instead focus on making that good product have a good business. To this end, they focus on optimizing and refining key parts of the customer journey, such as:
- Getting more people to consider the product
- Converting them into paying customers
- Keeping them as customers for longer, and spending more
What kinds of companies employ Growth Engineers? Places you’ve heard of, like Meta, LinkedIn, DoorDash, Coinbase, and Dropbox, are some of the ones I’ve had students from. There’s also OpenAI, Uber, Tiktok, Tinder, Airbnb, Pinterest… the list of high-profile companies goes on. Most newer public consumer companies you’ve heard have a growth engineering org, too.
Typically, growth engineering orgs are started by companies at Series B stage and beyond, so long as they are selling to either consumers or businesses via SaaS. These are often places trying to grow extremely fast, and have enough software engineers that some can focus purely on growth. Before the Series B stage, a team is unlikely to be ready for growth for various reasons; likely that it hasn’t found product-market fit, or has no available headcount, or lacks the visitor traffic required to run A/B tests.
Cost is a consideration. A fully-loaded growth team consisting of a handful of engineers, a PM, and a designer costs approximately 1 million dollars annually. To justify this, a rule of thumb is to have at least $5 million dollars in recurring revenue – a milestone often achieved at around the Series B stage.
Despite the presence of growth engineering at many public consumer tech companies, the field itself is still quite new, as a discipline and as a proper title.
Brief history of growth engineering
When I joined Opendoor in 2016, there was a head of growth but no dedicated growth engineers, but there were by the time I left in 2020. At MasterClass soon after, there was a growth org and a dozen dedicated growth engineers. So when did growth engineering originate?
The story is that its origins lie at Facebook in 2007. The team was created by then-VP of platform and monetization Chamath Palihapitiya. Reforce founder and CEO Brian Balfour shares:
“Growth (the kind found on an org chart) began at Facebook under the direction of Chamath Palihapitiya. In 2007, he joined the early team in a nebulous role that fell somewhere between Product, Marketing, and Operations. According to his retelling of the story on Recode Decode, after struggling to accomplish anything meaningful in his first year on the job, he was on the verge of being fired.Sheryl Sandberg joined soon after him, and in a hail mary move he pitched her the game-changing idea that led to the creation of the first-ever growth team. This idea not only saved his job, but earned him the lion’s share of the credit for Facebook’s unprecedented growth.At the time, Sheryl and Mark asked him, “What do you call this thing where you help change the product, do some SEO and SEM, and algorithmically do this or that?”His response: “I don’t know, I just call that, like, Growth, you know, we’re going to try to grow. I’ll be the head of growing stuff."And just like that, Growth became a thing.”
Rather than focus on a particular product or feature, the growth team at Facebook focused on moving the needle, and figuring out which features to work on. These days, Meta employs hundreds if not thousands of growth engineers.
2. What do Growth Engineers work on?
Before we jump into concrete examples, let’s identify three primary focus areas that a growth engineer’s work usually involves.
- Business-facing work – improving the business directly
- Empowerment work – enabling other teams to improve the business
- Platform work – improving the velocity of the above activities
Let’s go through all three:
Business-facing work
This is the bread and butter of growth engineering, and follows a common pattern:
- Implement an idea. Try something big or small to try and move a key business metric, which differs by team but is typically related to conversion rate or retention.
- Quantify impact. Usually via A/B testing.
- Analyze impact. Await results, analyze impact, ship or roll back – then go back to the first step.
Experiments can lead to sweeping or barely noticeable changes. A famous “I can’t believe they needed to test this” was when Google figured out which shade of blue generates the most clicks. At MasterClass, we tested things across the spectrum:
- Small: should we show the price right on the homepage, was that a winner? Yes, but we framed it in monthly terms of $15/month, not $180/year.
- Medium: when browsing a course page, should we include related courses, or more details about the course itself? Was it a winner? After lengthy experimentation, it was hard to tell: both are valuable and we needed to strike the right balance.
- Large: when a potential customer is interested, do we take them straight to checkout, or encourage them to learn more? Counterintuitively, adding steps boosted conversion!
Empowerment
One of the best ways an engineer can move a target metric is by removing themselves as a bottleneck, so colleagues from marketing can iterate and optimize freely. To this end, growth engineers can either build internal tools or integrate self-serve MarTech (Marketing Technology) vendors.
With the right tool, there’s a lot that marketers can do without engineering’s involvement:
- Build and iterate on landing pages (Unbounce, Instapage, etc)
- Draft and send email, SMS and Push Notifications (Iterable, Braze, Customer.io, etc)
- Connect new advertising partners (Google Tag Manager, Segment, etc)
We go more into detail about benefits and applications in the MarTech section of Tech Stack, below.
Platform work
As a business scales, dedicated platform teams help improve stability and velocity for the teams they support. Within growth, this often includes initiatives like:
- Experiment Platform. Many parts of running an experiment can be standardized, from filtering the audience, to bucketing users properly, to observing statistical methodology. Historically, companies built reusable Experiment Platforms in-house, but more recently, vendors such as Eppo and Statsig have grown in popularity with fancy statistical methodologies like “Controlled Using Pre-Experiment Data” (CUPED) that give more signal with less data.
- Reusable components. Companies with standard front-end components for things like headlines, buttons, and images, dramatically reduce the time required to spin up a new page. No more "did you want 5 or 6 pixels here" with a designer; instead growth engineers rely on tools like Storybook to standardize and share reusable React components.
- Monitoring. Growth engineering benefits greatly from leveraging monitoring to compensate for reduced code coverage. High-quality business metric monitoring tools can detect bugs before they cause damage.
When I worked at MasterClass, having monitoring at the ad layer prevented at least one six-figure incident. One Friday, a marketer accidentally broadened the audience for a particular ad from US-only, to worldwide. In response, the Facebook Ad algorithm went on a spending spree, bringing in plenty of visitors from places like Brazil and India, whom we knew from past experience were unlikely to purchase the product. Fortunately, our monitoring noticed the low-performing campaign within minutes, and an alert was sent to the growth engineer on-call, who immediately reached out to the marketer and confirmed the change was unintentional, and then shut down the campaign.
Without this monitoring, a subtle targeting error like this could have gone unnoticed all weekend and would have eaten up $100,000+ of marketing budget. This episode shows that platform investment can benefit everyone; and since growth needs them most, it’s often the growth platform engineering team which implements them.
As the day-to-day work of a Growth Engineer shows, A/B tests are a critical tool to both measure success and learn. It’s a numbers game: the more A/B tests a team can run in a given quarter, the more of them will end up winners, making the team successful. It’s no wonder, then, that Growth Engineering will pull out all the stops to improve velocity.
3. Why Growth Engineers move faster than Product Engineers
On the surface, growth engineering teams look like product engineering ones; writing code, shipping pull requests, monitoring on-call, etc. So how do they move so much faster? The big reason lies in philosophy and focus, not technology. To quote Elena Verna, head of growth at Dropbox:
“Product Engineering teams ship to build; Growth Engineering teams ship to learn.”
Real-world case: price changes at Masterclass
A few years ago at MasterClass, the growth team wanted to see if changing our pricing model to multiple tiers would improve revenue.
Inspired in part by multiple pricing tiers for competitors such as Netflix (above), Disney Plus, and Hulu.
The “multiple pricing tier” proposal for MasterClass.
From a software engineering perspective, this was a highly complex project because:
- Backend engineering work: the backend did not yet support multiple pricing options, requiring a decent amount of engineering, and rigorous testing to make sure existing customers weren’t affected.
- Client app changes: on the device side, multiple platforms (iOS, iPad, Android, Roku, Apple TV, etc) would each need to be updated, including each relevant app store.
The software engineering team estimated that becoming a “multi-pricing-tier” company would take months across numerous engineering teams, and engineering leadership was unwilling to greenlight that significant investment.
We in growth engineering took this as a challenge. As usual, our goal was not just to add the new pricing model, but to learn how much money it might bring in. The approach we ended up proposing was a Fake Door test, which involves offering a not-yet-available option to customers to gauge interest level. This was risky, as taking a customer who’s ready to pay and telling them to join some kind of waiting list is a colossal waste, and risks making them feel like the target of a “bait and switch” trick.
We found a way. The key insight was that people are only offended about a “bait and switch”, if the “switch” is worse than the “bait.” Telling customers they would pay $100 and then switching to $150 would cause a riot, but starting at $150 and then saying “just kidding, it’s only $100” is a pleasant surprise.
The good kind of surprise.
So long as every test “pricing tier” is less appealing – higher prices, fewer features – than the current offering, we could “upgrade” customers after their initial selection. A customer choosing the cheapest tier gets extra features at no extra cost, while a customer choosing a more expensive tier is offered a discount.
We created three new tiers, at different prices. The new “premium” tier would describe the existing, original offering. Regardless of what potential customers selected, they got this “original offering,” during the experiment.
The best thing about this was that no backend changes were required. There were no real, new, back-end pricing plans; everybody ended up purchasing the same version of MasterClass for the same price, with the same features. The entirety of the engineering work was on building a new pricing page, and the “congratulations, you’ve been upgraded” popup. This took just a few days.
Within a couple of weeks, we had enough data to be confident the financial upside of moving to a multi-pricing-tier model would be significant. With this, we’re able to convince the rest of engineering’s leadership to invest in building the feature properly. In the end, launching multiple pricing tiers turned out to be one of the biggest revenue wins of the year.
Building a skyscraper vs building a tent
The MasterClass example demonstrates the spirit of growth engineering; focusing on building to learn, instead of building to last. Consider building skyscrapers versus tents.
Building a tent optimizes for speed of set-up and tear-down over longevity. You don’t think of a tent as one that is shoddy or low-quality compared to skyscrapers: it’s not even the same category of buildings! Growth engineers maximize use of lightweight materials. To stick with the tents vs skyscraper metaphor: we prioritize lightweight fabric materials over steel and concrete whenever possible. We only resort to traditional building materials when there’s no other choice, or when a direction is confirmed as correct. Quality is important – after all, a tent must keep out rain and mosquitoes. However, the speed-vs-durability tradeoff decision results in very different approaches and outcomes.
4. Tech stack
At first glance, growth and product engineers use the same tooling, and contribute to the same codebases. But growth engineering tends to be high-velocity, experiment-heavy, and with limited test coverage. This means that certain “nice to have” tools for product engineering are mission-critical for growth engineers.
Read more https://connect-test.layer3.press/articles/ea02c1a1-7cfa-42b4-8722-0165abcae8bb
-
@ 04c915da:3dfbecc9
2025-03-26 20:54:33
Capitalism is the most effective system for scaling innovation. The pursuit of profit is an incredibly powerful human incentive. Most major improvements to human society and quality of life have resulted from this base incentive. Market competition often results in the best outcomes for all.
That said, some projects can never be monetized. They are open in nature and a business model would centralize control. Open protocols like bitcoin and nostr are not owned by anyone and if they were it would destroy the key value propositions they provide. No single entity can or should control their use. Anyone can build on them without permission.
As a result, open protocols must depend on donation based grant funding from the people and organizations that rely on them. This model works but it is slow and uncertain, a grind where sustainability is never fully reached but rather constantly sought. As someone who has been incredibly active in the open source grant funding space, I do not think people truly appreciate how difficult it is to raise charitable money and deploy it efficiently.
Projects that can be monetized should be. Profitability is a super power. When a business can generate revenue, it taps into a self sustaining cycle. Profit fuels growth and development while providing projects independence and agency. This flywheel effect is why companies like Google, Amazon, and Apple have scaled to global dominance. The profit incentive aligns human effort with efficiency. Businesses must innovate, cut waste, and deliver value to survive.
Contrast this with non monetized projects. Without profit, they lean on external support, which can dry up or shift with donor priorities. A profit driven model, on the other hand, is inherently leaner and more adaptable. It is not charity but survival. When survival is tied to delivering what people want, scale follows naturally.
The real magic happens when profitable, sustainable businesses are built on top of open protocols and software. Consider the many startups building on open source software stacks, such as Start9, Mempool, and Primal, offering premium services on top of the open source software they build out and maintain. Think of companies like Block or Strike, which leverage bitcoin’s open protocol to offer their services on top. These businesses amplify the open software and protocols they build on, driving adoption and improvement at a pace donations alone could never match.
When you combine open software and protocols with profit driven business the result are lean, sustainable companies that grow faster and serve more people than either could alone. Bitcoin’s network, for instance, benefits from businesses that profit off its existence, while nostr will expand as developers monetize apps built on the protocol.
Capitalism scales best because competition results in efficiency. Donation funded protocols and software lay the groundwork, while market driven businesses build on top. The profit incentive acts as a filter, ensuring resources flow to what works, while open systems keep the playing field accessible, empowering users and builders. Together, they create a flywheel of innovation, growth, and global benefit.
-
@ 21335073:a244b1ad
2025-03-15 23:00:40
I want to see Nostr succeed. If you can think of a way I can help make that happen, I’m open to it. I’d like your suggestions.
My schedule’s shifting soon, and I could volunteer a few hours a week to a Nostr project. I won’t have more total time, but how I use it will change.
Why help? I care about freedom. Nostr’s one of the most powerful freedom tools I’ve seen in my lifetime. If I believe that, I should act on it.
I don’t care about money or sats. I’m not rich, I don’t have extra cash. That doesn’t drive me—freedom does. I’m volunteering, not asking for pay.
I’m not here for clout. I’ve had enough spotlight in my life; it doesn’t move me. If I wanted clout, I’d be on Twitter dropping basic takes. Clout’s easy. Freedom’s hard. I’d rather help anonymously. No speaking at events—small meetups are cool for the vibe, but big conferences? Not my thing. I’ll never hit a huge Bitcoin conference. It’s just not my scene.
That said, I could be convinced to step up if it’d really boost Nostr—as long as it’s legal and gets results.
In this space, I’d watch for social engineering. I watch out for it. I’m not here to make friends, just to help. No shade—you all seem great—but I’ve got a full life and awesome friends irl. I don’t need your crew or to be online cool. Connect anonymously if you want; I’d encourage it.
I’m sick of watching other social media alternatives grow while Nostr kinda stalls. I could trash-talk, but I’d rather do something useful.
Skills? I’m good at spotting social media problems and finding possible solutions. I won’t overhype myself—that’s weird—but if you’re responding, you probably see something in me. Perhaps you see something that I don’t see in myself.
If you need help now or later with Nostr projects, reach out. Nostr only—nothing else. Anonymous contact’s fine. Even just a suggestion on how I can pitch in, no project attached, works too. 💜
Creeps or harassment will get blocked or I’ll nuke my simplex code if it becomes a problem.
https://simplex.chat/contact#/?v=2-4&smp=smp%3A%2F%2FSkIkI6EPd2D63F4xFKfHk7I1UGZVNn6k1QWZ5rcyr6w%3D%40smp9.simplex.im%2FbI99B3KuYduH8jDr9ZwyhcSxm2UuR7j0%23%2F%3Fv%3D1-2%26dh%3DMCowBQYDK2VuAyEAS9C-zPzqW41PKySfPCEizcXb1QCus6AyDkTTjfyMIRM%253D%26srv%3Djssqzccmrcws6bhmn77vgmhfjmhwlyr3u7puw4erkyoosywgl67slqqd.onion
-
@ 04c915da:3dfbecc9
2025-03-10 23:31:30
Bitcoin has always been rooted in freedom and resistance to authority. I get that many of you are conflicted about the US Government stacking but by design we cannot stop anyone from using bitcoin. Many have asked me for my thoughts on the matter, so let’s rip it.
Concern
One of the most glaring issues with the strategic bitcoin reserve is its foundation, built on stolen bitcoin. For those of us who value private property this is an obvious betrayal of our core principles. Rather than proof of work, the bitcoin that seeds this reserve has been taken by force. The US Government should return the bitcoin stolen from Bitfinex and the Silk Road.
Usually stolen bitcoin for the reserve creates a perverse incentive. If governments see a bitcoin as a valuable asset, they will ramp up efforts to confiscate more bitcoin. The precedent is a major concern, and I stand strongly against it, but it should be also noted that governments were already seizing coin before the reserve so this is not really a change in policy.
Ideally all seized bitcoin should be burned, by law. This would align incentives properly and make it less likely for the government to actively increase coin seizures. Due to the truly scarce properties of bitcoin, all burned bitcoin helps existing holders through increased purchasing power regardless. This change would be unlikely but those of us in policy circles should push for it regardless. It would be best case scenario for American bitcoiners and would create a strong foundation for the next century of American leadership.
Optimism
The entire point of bitcoin is that we can spend or save it without permission. That said, it is a massive benefit to not have one of the strongest governments in human history actively trying to ruin our lives.
Since the beginning, bitcoiners have faced horrible regulatory trends. KYC, surveillance, and legal cases have made using bitcoin and building bitcoin businesses incredibly difficult. It is incredibly important to note that over the past year that trend has reversed for the first time in a decade. A strategic bitcoin reserve is a key driver of this shift. By holding bitcoin, the strongest government in the world has signaled that it is not just a fringe technology but rather truly valuable, legitimate, and worth stacking.
This alignment of incentives changes everything. The US Government stacking proves bitcoin’s worth. The resulting purchasing power appreciation helps all of us who are holding coin and as bitcoin succeeds our government receives direct benefit. A beautiful positive feedback loop.
Realism
We are trending in the right direction. A strategic bitcoin reserve is a sign that the state sees bitcoin as an asset worth embracing rather than destroying. That said, there is a lot of work left to be done. We cannot be lulled into complacency, the time to push forward is now, and we cannot take our foot off the gas. We have a seat at the table for the first time ever. Let's make it worth it.
We must protect the right to free usage of bitcoin and other digital technologies. Freedom in the digital age must be taken and defended, through both technical and political avenues. Multiple privacy focused developers are facing long jail sentences for building tools that protect our freedom. These cases are not just legal battles. They are attacks on the soul of bitcoin. We need to rally behind them, fight for their freedom, and ensure the ethos of bitcoin survives this new era of government interest. The strategic reserve is a step in the right direction, but it is up to us to hold the line and shape the future.
-
@ 04c915da:3dfbecc9
2025-03-07 00:26:37
There is something quietly rebellious about stacking sats. In a world obsessed with instant gratification, choosing to patiently accumulate Bitcoin, one sat at a time, feels like a middle finger to the hype machine. But to do it right, you have got to stay humble. Stack too hard with your head in the clouds, and you will trip over your own ego before the next halving even hits.
Small Wins
Stacking sats is not glamorous. Discipline. Stacking every day, week, or month, no matter the price, and letting time do the heavy lifting. Humility lives in that consistency. You are not trying to outsmart the market or prove you are the next "crypto" prophet. Just a regular person, betting on a system you believe in, one humble stack at a time. Folks get rekt chasing the highs. They ape into some shitcoin pump, shout about it online, then go silent when they inevitably get rekt. The ones who last? They stack. Just keep showing up. Consistency. Humility in action. Know the game is long, and you are not bigger than it.
Ego is Volatile
Bitcoin’s swings can mess with your head. One day you are up 20%, feeling like a genius and the next down 30%, questioning everything. Ego will have you panic selling at the bottom or over leveraging the top. Staying humble means patience, a true bitcoin zen. Do not try to "beat” Bitcoin. Ride it. Stack what you can afford, live your life, and let compounding work its magic.
Simplicity
There is a beauty in how stacking sats forces you to rethink value. A sat is worth less than a penny today, but every time you grab a few thousand, you plant a seed. It is not about flaunting wealth but rather building it, quietly, without fanfare. That mindset spills over. Cut out the noise: the overpriced coffee, fancy watches, the status games that drain your wallet. Humility is good for your soul and your stack. I have a buddy who has been stacking since 2015. Never talks about it unless you ask. Lives in a decent place, drives an old truck, and just keeps stacking. He is not chasing clout, he is chasing freedom. That is the vibe: less ego, more sats, all grounded in life.
The Big Picture
Stack those sats. Do it quietly, do it consistently, and do not let the green days puff you up or the red days break you down. Humility is the secret sauce, it keeps you grounded while the world spins wild. In a decade, when you look back and smile, it will not be because you shouted the loudest. It will be because you stayed the course, one sat at a time. \ \ Stay Humble and Stack Sats. 🫡
-
@ 04c915da:3dfbecc9
2025-03-04 17:00:18
This piece is the first in a series that will focus on things I think are a priority if your focus is similar to mine: building a strong family and safeguarding their future.
Choosing the ideal place to raise a family is one of the most significant decisions you will ever make. For simplicity sake I will break down my thought process into key factors: strong property rights, the ability to grow your own food, access to fresh water, the freedom to own and train with guns, and a dependable community.
A Jurisdiction with Strong Property Rights
Strong property rights are essential and allow you to build on a solid foundation that is less likely to break underneath you. Regions with a history of limited government and clear legal protections for landowners are ideal. Personally I think the US is the single best option globally, but within the US there is a wide difference between which state you choose. Choose carefully and thoughtfully, think long term. Obviously if you are not American this is not a realistic option for you, there are other solid options available especially if your family has mobility. I understand many do not have this capability to easily move, consider that your first priority, making movement and jurisdiction choice possible in the first place.
Abundant Access to Fresh Water
Water is life. I cannot overstate the importance of living somewhere with reliable, clean, and abundant freshwater. Some regions face water scarcity or heavy regulations on usage, so prioritizing a place where water is plentiful and your rights to it are protected is critical. Ideally you should have well access so you are not tied to municipal water supplies. In times of crisis or chaos well water cannot be easily shutoff or disrupted. If you live in an area that is drought prone, you are one drought away from societal chaos. Not enough people appreciate this simple fact.
Grow Your Own Food
A location with fertile soil, a favorable climate, and enough space for a small homestead or at the very least a garden is key. In stable times, a small homestead provides good food and important education for your family. In times of chaos your family being able to grow and raise healthy food provides a level of self sufficiency that many others will lack. Look for areas with minimal restrictions, good weather, and a culture that supports local farming.
Guns
The ability to defend your family is fundamental. A location where you can legally and easily own guns is a must. Look for places with a strong gun culture and a political history of protecting those rights. Owning one or two guns is not enough and without proper training they will be a liability rather than a benefit. Get comfortable and proficient. Never stop improving your skills. If the time comes that you must use a gun to defend your family, the skills must be instinct. Practice. Practice. Practice.
A Strong Community You Can Depend On
No one thrives alone. A ride or die community that rallies together in tough times is invaluable. Seek out a place where people know their neighbors, share similar values, and are quick to lend a hand. Lead by example and become a good neighbor, people will naturally respond in kind. Small towns are ideal, if possible, but living outside of a major city can be a solid balance in terms of work opportunities and family security.
Let me know if you found this helpful. My plan is to break down how I think about these five key subjects in future posts.
-
@ 04c915da:3dfbecc9
2025-02-25 03:55:08
Here’s a revised timeline of macro-level events from The Mandibles: A Family, 2029–2047 by Lionel Shriver, reimagined in a world where Bitcoin is adopted as a widely accepted form of money, altering the original narrative’s assumptions about currency collapse and economic control. In Shriver’s original story, the failure of Bitcoin is assumed amid the dominance of the bancor and the dollar’s collapse. Here, Bitcoin’s success reshapes the economic and societal trajectory, decentralizing power and challenging state-driven outcomes.
Part One: 2029–2032
-
2029 (Early Year)\ The United States faces economic strain as the dollar weakens against global shifts. However, Bitcoin, having gained traction emerges as a viable alternative. Unlike the original timeline, the bancor—a supranational currency backed by a coalition of nations—struggles to gain footing as Bitcoin’s decentralized adoption grows among individuals and businesses worldwide, undermining both the dollar and the bancor.
-
2029 (Mid-Year: The Great Renunciation)\ Treasury bonds lose value, and the government bans Bitcoin, labeling it a threat to sovereignty (mirroring the original bancor ban). However, a Bitcoin ban proves unenforceable—its decentralized nature thwarts confiscation efforts, unlike gold in the original story. Hyperinflation hits the dollar as the U.S. prints money, but Bitcoin’s fixed supply shields adopters from currency devaluation, creating a dual-economy split: dollar users suffer, while Bitcoin users thrive.
-
2029 (Late Year)\ Dollar-based inflation soars, emptying stores of goods priced in fiat currency. Meanwhile, Bitcoin transactions flourish in underground and online markets, stabilizing trade for those plugged into the bitcoin ecosystem. Traditional supply chains falter, but peer-to-peer Bitcoin networks enable local and international exchange, reducing scarcity for early adopters. The government’s gold confiscation fails to bolster the dollar, as Bitcoin’s rise renders gold less relevant.
-
2030–2031\ Crime spikes in dollar-dependent urban areas, but Bitcoin-friendly regions see less chaos, as digital wallets and smart contracts facilitate secure trade. The U.S. government doubles down on surveillance to crack down on bitcoin use. A cultural divide deepens: centralized authority weakens in Bitcoin-adopting communities, while dollar zones descend into lawlessness.
-
2032\ By this point, Bitcoin is de facto legal tender in parts of the U.S. and globally, especially in tech-savvy or libertarian-leaning regions. The federal government’s grip slips as tax collection in dollars plummets—Bitcoin’s traceability is low, and citizens evade fiat-based levies. Rural and urban Bitcoin hubs emerge, while the dollar economy remains fractured.
Time Jump: 2032–2047
- Over 15 years, Bitcoin solidifies as a global reserve currency, eroding centralized control. The U.S. government adapts, grudgingly integrating bitcoin into policy, though regional autonomy grows as Bitcoin empowers local economies.
Part Two: 2047
-
2047 (Early Year)\ The U.S. is a hybrid state: Bitcoin is legal tender alongside a diminished dollar. Taxes are lower, collected in BTC, reducing federal overreach. Bitcoin’s adoption has decentralized power nationwide. The bancor has faded, unable to compete with Bitcoin’s grassroots momentum.
-
2047 (Mid-Year)\ Travel and trade flow freely in Bitcoin zones, with no restrictive checkpoints. The dollar economy lingers in poorer areas, marked by decay, but Bitcoin’s dominance lifts overall prosperity, as its deflationary nature incentivizes saving and investment over consumption. Global supply chains rebound, powered by bitcoin enabled efficiency.
-
2047 (Late Year)\ The U.S. is a patchwork of semi-autonomous zones, united by Bitcoin’s universal acceptance rather than federal control. Resource scarcity persists due to past disruptions, but economic stability is higher than in Shriver’s original dystopia—Bitcoin’s success prevents the authoritarian slide, fostering a freer, if imperfect, society.
Key Differences
- Currency Dynamics: Bitcoin’s triumph prevents the bancor’s dominance and mitigates hyperinflation’s worst effects, offering a lifeline outside state control.
- Government Power: Centralized authority weakens as Bitcoin evades bans and taxation, shifting power to individuals and communities.
- Societal Outcome: Instead of a surveillance state, 2047 sees a decentralized, bitcoin driven world—less oppressive, though still stratified between Bitcoin haves and have-nots.
This reimagining assumes Bitcoin overcomes Shriver’s implied skepticism to become a robust, adopted currency by 2029, fundamentally altering the novel’s bleak trajectory.
-
-
@ 6e0ea5d6:0327f353
2025-02-21 18:15:52
"Malcolm Forbes recounts that a lady, wearing a faded cotton dress, and her husband, dressed in an old handmade suit, stepped off a train in Boston, USA, and timidly made their way to the office of the president of Harvard University. They had come from Palo Alto, California, and had not scheduled an appointment. The secretary, at a glance, thought that those two, looking like country bumpkins, had no business at Harvard.
— We want to speak with the president — the man said in a low voice.
— He will be busy all day — the secretary replied curtly.
— We will wait.
The secretary ignored them for hours, hoping the couple would finally give up and leave. But they stayed there, and the secretary, somewhat frustrated, decided to bother the president, although she hated doing that.
— If you speak with them for just a few minutes, maybe they will decide to go away — she said.
The president sighed in irritation but agreed. Someone of his importance did not have time to meet people like that, but he hated faded dresses and tattered suits in his office. With a stern face, he went to the couple.
— We had a son who studied at Harvard for a year — the woman said. — He loved Harvard and was very happy here, but a year ago he died in an accident, and we would like to erect a monument in his honor somewhere on campus.— My lady — said the president rudely —, we cannot erect a statue for every person who studied at Harvard and died; if we did, this place would look like a cemetery.
— Oh, no — the lady quickly replied. — We do not want to erect a statue. We would like to donate a building to Harvard.
The president looked at the woman's faded dress and her husband's old suit and exclaimed:
— A building! Do you have even the faintest idea of how much a building costs? We have more than seven and a half million dollars' worth of buildings here at Harvard.
The lady was silent for a moment, then said to her husband:
— If that’s all it costs to found a university, why don’t we have our own?
The husband agreed.
The couple, Leland Stanford, stood up and left, leaving the president confused. Traveling back to Palo Alto, California, they established there Stanford University, the second-largest in the world, in honor of their son, a former Harvard student."
Text extracted from: "Mileumlivros - Stories that Teach Values."
Thank you for reading, my friend! If this message helped you in any way, consider leaving your glass “🥃” as a token of appreciation.
A toast to our family!
-
@ 866e0139:6a9334e5
2025-05-23 17:57:24
Autor: Caitlin Johnstone. Dieser Beitrag wurde mit dem Pareto-Client geschrieben. Sie finden alle Texte der Friedenstaube und weitere Texte zum Thema Frieden hier. Die neuesten Pareto-Artikel finden Sie in unserem Telegram-Kanal.
Die neuesten Artikel der Friedenstaube gibt es jetzt auch im eigenen Friedenstaube-Telegram-Kanal.
Ich hörte einem jungen Autor zu, der eine Idee beschrieb, die ihn so sehr begeisterte, dass er die Nacht zuvor nicht schlafen konnte. Und ich erinnerte mich daran, wie ich mich früher – vor Gaza – über das Schreiben freuen konnte. Dieses Gefühl habe ich seit 2023 nicht mehr gespürt.
Ich beklage mich nicht und bemitleide mich auch nicht selbst, ich stelle einfach fest, wie unglaublich düster und finster die Welt in dieser schrecklichen Zeit geworden ist. Es wäre seltsam und ungesund, wenn ich in den letzten anderthalb Jahren Freude an meiner Arbeit gehabt hätte. Diese Dinge sollen sich nicht gut anfühlen. Nicht, wenn man wirklich hinschaut und ehrlich zu sich selbst ist in dem, was man sieht.
Es war die ganze Zeit über so hässlich und so verstörend. Es gibt eigentlich keinen Weg, all diesen Horror umzudeuten oder irgendwie erträglich zu machen. Alles, was man tun kann, ist, an sich selbst zu arbeiten, um genug inneren Raum zu schaffen, um die schlechten Gefühle zuzulassen und sie ganz durchzufühlen, bis sie sich ausgedrückt haben. Lass die Verzweiflung herein. Die Trauer. Die Wut. Den Schmerz. Lass sie deinen Körper vollständig durchfließen, ohne Widerstand, und steh dann auf und schreibe das nächste Stück.
Das ist es, was Schreiben für mich jetzt ist. Es ist nie etwas, worüber ich mich freue, es zu teilen, oder wofür ich von Inspiration erfüllt bin. Wenn überhaupt, dann fühlt es sich eher so an wie: „Okay, hier bitte, es tut mir schrecklich leid, dass ich euch das zeigen muss, Leute.“ Es ist das Starren in die Dunkelheit, in das Blut, in das Gemetzel, in die gequälten Gesichter – und das Aufschreiben dessen, was ich sehe, Tag für Tag.
Nichts daran ist angenehm oder befriedigend. Es ist einfach das, was man tut, wenn ein Genozid in Echtzeit vor den eigenen Augen stattfindet, mit der Unterstützung der eigenen Gesellschaft. Alles daran ist entsetzlich, und es gibt keinen Weg, das schönzureden – aber man tut, was getan werden muss. So, wie man es täte, wenn es die eigene Familie wäre, die da draußen im Schutt liegt.
Dieser Genozid hat mich für immer verändert. Er hat viele Menschen für immer verändert. Wir werden nie wieder dieselben sein. Die Welt wird nie wieder dieselbe sein. Ganz gleich, was passiert oder wie dieser Albtraum endet – die Dinge werden nie wieder so sein wie zuvor.
Und das sollten sie auch nicht. Der Holocaust von Gaza ist das Ergebnis der Welt, wie sie vor ihm war. Unsere Gesellschaft hat ihn hervorgebracht – und jetzt starrt er uns allen direkt ins Gesicht. Das sind wir. Das ist die Frucht des Baumes, den die westliche Zivilisation bis zu diesem Punkt gepflegt hat.
Jetzt geht es nur noch darum, alles zu tun, was wir können, um den Genozid zu beenden – und sicherzustellen, dass die Welt die richtigen Lehren daraus zieht. Das ist eines der würdigsten Anliegen, denen man sich in diesem Leben widmen kann.
Ich habe noch immer Hoffnung, dass wir eine gesunde Welt haben können. Ich habe noch immer Hoffnung, dass das Schreiben über das, was geschieht, eines Tages wieder Freude bereiten kann. Aber diese Dinge liegen auf der anderen Seite eines langen, schmerzhaften, konfrontierenden Weges, der in den kommenden Jahren vor uns liegt. Es gibt keinen Weg daran vorbei.
Die Welt kann keinen Frieden und kein Glück finden, solange wir uns nicht vollständig damit auseinandergesetzt haben, was wir Gaza angetan haben.
Dieser Text ist die deutsche Übersetzung dieses Substack-Artikels von Caitlin Johnstone.
LASSEN SIE DER FRIEDENSTAUBE FLÜGEL WACHSEN!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt.
Schon jetzt können Sie uns unterstützen:
- Für 50 CHF/EURO bekommen Sie ein Jahresabo der Friedenstaube.
- Für 120 CHF/EURO bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
- Für 500 CHF/EURO werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
- Ab 1000 CHF werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
Für Einzahlungen in CHF (Betreff: Friedenstaube):
Für Einzahlungen in Euro:
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
Betreff: Friedenstaube
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: friedenstaube@pareto.space
Sie sind noch nicht auf Nostr and wollen die volle Erfahrung machen (liken, kommentieren etc.)? Zappen können Sie den Autor auch ohne Nostr-Profil! Erstellen Sie sich einen Account auf Start. Weitere Onboarding-Leitfäden gibt es im Pareto-Wiki.
-
@ 0fa80bd3:ea7325de
2025-02-14 23:24:37
intro
The Russian state made me a Bitcoiner. In 1991, it devalued my grandmother's hard-earned savings. She worked tirelessly in the kitchen of a dining car on the Moscow–Warsaw route. Everything she had saved for my sister and me to attend university vanished overnight. This story is similar to what many experienced, including Wences Casares. The pain and injustice of that time became my first lessons about the fragility of systems and the value of genuine, incorruptible assets, forever changing my perception of money and my trust in government promises.
In 2014, I was living in Moscow, running a trading business, and frequently traveling to China. One day, I learned about the Cypriot banking crisis and the possibility of moving money through some strange thing called Bitcoin. At the time, I didn’t give it much thought. Returning to the idea six months later, as a business-oriented geek, I eagerly began studying the topic and soon dove into it seriously.
I spent half a year reading articles on a local online journal, BitNovosti, actively participating in discussions, and eventually joined the editorial team as a translator. That’s how I learned about whitepapers, decentralization, mining, cryptographic keys, and colored coins. About Satoshi Nakamoto, Silk Road, Mt. Gox, and BitcoinTalk. Over time, I befriended the journal’s owner and, leveraging my management experience, later became an editor. I was drawn to the crypto-anarchist stance and commitment to decentralization principles. We wrote about the economic, historical, and social preconditions for Bitcoin’s emergence, and it was during this time that I fully embraced the idea.
It got to the point where I sold my apartment and, during the market's downturn, bought 50 bitcoins, just after the peak price of $1,200 per coin. That marked the beginning of my first crypto winter. As an editor, I organized workflows, managed translators, developed a YouTube channel, and attended conferences in Russia and Ukraine. That’s how I learned about Wences Casares and even wrote a piece about him. I also met Mikhail Chobanyan (Ukrainian exchange Kuna), Alexander Ivanov (Waves project), Konstantin Lomashuk (Lido project), and, of course, Vitalik Buterin. It was a time of complete immersion, 24/7, and boundless hope.
After moving to the United States, I expected the industry to grow rapidly, attended events, but the introduction of BitLicense froze the industry for eight years. By 2017, it became clear that the industry was shifting toward gambling and creating tokens for the sake of tokens. I dismissed this idea as unsustainable. Then came a new crypto spring with the hype around beautiful NFTs – CryptoPunks and apes.
I made another attempt – we worked on a series called Digital Nomad Country Club, aimed at creating a global project. The proceeds from selling images were intended to fund the development of business tools for people worldwide. However, internal disagreements within the team prevented us from completing the project.
With Trump’s arrival in 2025, hope was reignited. I decided that it was time to create a project that society desperately needed. As someone passionate about history, I understood that destroying what exists was not the solution, but leaving everything as it was also felt unacceptable. You can’t destroy the system, as the fiery crypto-anarchist voices claimed.
With an analytical mindset (IQ 130) and a deep understanding of the freest societies, I realized what was missing—not only in Russia or the United States but globally—a Bitcoin-native system for tracking debts and financial interactions. This could return control of money to ordinary people and create horizontal connections parallel to state systems. My goal was to create, if not a Bitcoin killer app, then at least to lay its foundation.
At the inauguration event in New York, I rediscovered the Nostr project. I realized it was not only technologically simple and already quite popular but also perfectly aligned with my vision. For the past month and a half, using insights and experience gained since 2014, I’ve been working full-time on this project.
-
@ b0a838f2:34ed3f19
2025-05-23 17:57:18
- Apaxy - Theme built to enhance the experience of browsing web directories, using the mod_autoindex Apache module and some CSS to override the default style of a directory listing. (Source Code)
GPL-3.0Javascript - copyparty - Portable file server with accelerated resumable uploads, deduplication, WebDAV, FTP, zeroconf, media indexer, video thumbnails, audio transcoding, and write-only folders, in a single file with no mandatory dependencies. (Demo)
MITPython - DirectoryLister - Simple PHP based directory lister that lists a directory and all its sub-directories and allows you to navigate there within. (Source Code)
MITPHP - filebrowser - Web File Browser with a Material Design web interface. (Source Code)
Apache-2.0Go - FileGator - FileGator is a powerful multi-user file manager with a single page front-end. (Demo, Source Code)
MITPHP/Docker - Filestash - Web file manager that lets you manage your data anywhere it is located: FTP, SFTP, WebDAV, Git, S3, Minio, Dropbox, or Google Drive. (Demo, Source Code)
AGPL-3.0Docker - Gossa - Light and simple webserver for your files.
MITGo - IFM - Single script file manager.
MITPHP - mikochi - Browse remote folders, upload files, delete, rename, download and stream files to VLC/mpv.
MITGo/Docker/K8S - miniserve - CLI tool to serve files and dirs over HTTP.
MITRust - ResourceSpace - ResourceSpace open source digital asset management software is the simple, fast, and free way to organise your digital assets. (Demo, Source Code)
BSD-4-ClausePHP - Surfer - Simple static file server with webui to manage files.
MITNodejs - TagSpaces - TagSpaces is an offline, cross-platform file manager and organiser that also can function as a note taking app. The WebDAV version of the application can be installed on top of a WebDAV servers such as Nextcloud or ownCloud. (Demo, Source Code)
AGPL-3.0Nodejs - Tiny File Manager - Web based File Manager in PHP, simple, fast and small file manager with a single file. (Demo, Source Code)
GPL-3.0PHP
- Apaxy - Theme built to enhance the experience of browsing web directories, using the mod_autoindex Apache module and some CSS to override the default style of a directory listing. (Source Code)
-
@ daa41bed:88f54153
2025-02-09 16:50:04
There has been a good bit of discussion on Nostr over the past few days about the merits of zaps as a method of engaging with notes, so after writing a rather lengthy article on the pros of a strategic Bitcoin reserve, I wanted to take some time to chime in on the much more fun topic of digital engagement.
Let's begin by defining a couple of things:
Nostr is a decentralized, censorship-resistance protocol whose current biggest use case is social media (think Twitter/X). Instead of relying on company servers, it relies on relays that anyone can spin up and own their own content. Its use cases are much bigger, though, and this article is hosted on my own relay, using my own Nostr relay as an example.
Zap is a tip or donation denominated in sats (small units of Bitcoin) sent from one user to another. This is generally done directly over the Lightning Network but is increasingly using Cashu tokens. For the sake of this discussion, how you transmit/receive zaps will be irrelevant, so don't worry if you don't know what Lightning or Cashu are.
If we look at how users engage with posts and follows/followers on platforms like Twitter, Facebook, etc., it becomes evident that traditional social media thrives on engagement farming. The more outrageous a post, the more likely it will get a reaction. We see a version of this on more visual social platforms like YouTube and TikTok that use carefully crafted thumbnail images to grab the user's attention to click the video. If you'd like to dive deep into the psychology and science behind social media engagement, let me know, and I'd be happy to follow up with another article.
In this user engagement model, a user is given the option to comment or like the original post, or share it among their followers to increase its signal. They receive no value from engaging with the content aside from the dopamine hit of the original experience or having their comment liked back by whatever influencer they provide value to. Ad revenue flows to the content creator. Clout flows to the content creator. Sales revenue from merch and content placement flows to the content creator. We call this a linear economy -- the idea that resources get created, used up, then thrown away. Users create content and farm as much engagement as possible, then the content is forgotten within a few hours as they move on to the next piece of content to be farmed.
What if there were a simple way to give value back to those who engage with your content? By implementing some value-for-value model -- a circular economy. Enter zaps.

Unlike traditional social media platforms, Nostr does not actively use algorithms to determine what content is popular, nor does it push content created for active user engagement to the top of a user's timeline. Yes, there are "trending" and "most zapped" timelines that users can choose to use as their default, but these use relatively straightforward engagement metrics to rank posts for these timelines.
That is not to say that we may not see clients actively seeking to refine timeline algorithms for specific metrics. Still, the beauty of having an open protocol with media that is controlled solely by its users is that users who begin to see their timeline gamed towards specific algorithms can choose to move to another client, and for those who are more tech-savvy, they can opt to run their own relays or create their own clients with personalized algorithms and web of trust scoring systems.
Zaps enable the means to create a new type of social media economy in which creators can earn for creating content and users can earn by actively engaging with it. Like and reposting content is relatively frictionless and costs nothing but a simple button tap. Zaps provide active engagement because they signal to your followers and those of the content creator that this post has genuine value, quite literally in the form of money—sats.

I have seen some comments on Nostr claiming that removing likes and reactions is for wealthy people who can afford to send zaps and that the majority of people in the US and around the world do not have the time or money to zap because they have better things to spend their money like feeding their families and paying their bills. While at face value, these may seem like valid arguments, they, unfortunately, represent the brainwashed, defeatist attitude that our current economic (and, by extension, social media) systems aim to instill in all of us to continue extracting value from our lives.
Imagine now, if those people dedicating their own time (time = money) to mine pity points on social media would instead spend that time with genuine value creation by posting content that is meaningful to cultural discussions. Imagine if, instead of complaining that their posts get no zaps and going on a tirade about how much of a victim they are, they would empower themselves to take control of their content and give value back to the world; where would that leave us? How much value could be created on a nascent platform such as Nostr, and how quickly could it overtake other platforms?
Other users argue about user experience and that additional friction (i.e., zaps) leads to lower engagement, as proven by decades of studies on user interaction. While the added friction may turn some users away, does that necessarily provide less value? I argue quite the opposite. You haven't made a few sats from zaps with your content? Can't afford to send some sats to a wallet for zapping? How about using the most excellent available resource and spending 10 seconds of your time to leave a comment? Likes and reactions are valueless transactions. Social media's real value derives from providing monetary compensation and actively engaging in a conversation with posts you find interesting or thought-provoking. Remember when humans thrived on conversation and discussion for entertainment instead of simply being an onlooker of someone else's life?
If you've made it this far, my only request is this: try only zapping and commenting as a method of engagement for two weeks. Sure, you may end up liking a post here and there, but be more mindful of how you interact with the world and break yourself from blind instinct. You'll thank me later.

-
@ e3ba5e1a:5e433365
2025-02-05 17:47:16
I got into a friendly discussion on X regarding health insurance. The specific question was how to deal with health insurance companies (presumably unfairly) denying claims? My answer, as usual: get government out of it!
The US healthcare system is essentially the worst of both worlds:
- Unlike full single payer, individuals incur high costs
- Unlike a true free market, regulation causes increases in costs and decreases competition among insurers
I'm firmly on the side of moving towards the free market. (And I say that as someone living under a single payer system now.) Here's what I would do:
- Get rid of tax incentives that make health insurance tied to your employer, giving individuals back proper freedom of choice.
- Reduce regulations significantly.
-
In the short term, some people will still get rejected claims and other obnoxious behavior from insurance companies. We address that in two ways:
- Due to reduced regulations, new insurance companies will be able to enter the market offering more reliable coverage and better rates, and people will flock to them because they have the freedom to make their own choices.
- Sue the asses off of companies that reject claims unfairly. And ideally, as one of the few legitimate roles of government in all this, institute new laws that limit the ability of fine print to allow insurers to escape their responsibilities. (I'm hesitant that the latter will happen due to the incestuous relationship between Congress/regulators and insurers, but I can hope.)
Will this magically fix everything overnight like politicians normally promise? No. But it will allow the market to return to a healthy state. And I don't think it will take long (order of magnitude: 5-10 years) for it to come together, but that's just speculation.
And since there's a high correlation between those who believe government can fix problems by taking more control and demanding that only credentialed experts weigh in on a topic (both points I strongly disagree with BTW): I'm a trained actuary and worked in the insurance industry, and have directly seen how government regulation reduces competition, raises prices, and harms consumers.
And my final point: I don't think any prior art would be a good comparison for deregulation in the US, it's such a different market than any other country in the world for so many reasons that lessons wouldn't really translate. Nonetheless, I asked Grok for some empirical data on this, and at best the results of deregulation could be called "mixed," but likely more accurately "uncertain, confused, and subject to whatever interpretation anyone wants to apply."
https://x.com/i/grok/share/Zc8yOdrN8lS275hXJ92uwq98M
-
@ 9e69e420:d12360c2
2025-02-01 11:16:04
Federal employees must remove pronouns from email signatures by the end of the day. This directive comes from internal memos tied to two executive orders signed by Donald Trump. The orders target diversity and equity programs within the government.

CDC, Department of Transportation, and Department of Energy employees were affected. Staff were instructed to make changes in line with revised policy prohibiting certain language.
One CDC employee shared frustration, stating, “In my decade-plus years at CDC, I've never been told what I can and can't put in my email signature.” The directive is part of a broader effort to eliminate DEI initiatives from federal discourse.
-
@ 0fa80bd3:ea7325de
2025-01-29 05:55:02
The land that belongs to the indigenous peoples of Russia has been seized by a gang of killers who have unleashed a war of extermination. They wipe out anyone who refuses to conform to their rules. Those who disagree and stay behind are tortured and killed in prisons and labor camps. Those who flee lose their homeland, dissolve into foreign cultures, and fade away. And those who stand up to protect their people are attacked by the misled and deceived. The deceived die for the unchecked greed of a single dictator—thousands from both sides, people who just wanted to live, raise their kids, and build a future.
Now, they are forced to make an impossible choice: abandon their homeland or die. Some perish on the battlefield, others lose themselves in exile, stripped of their identity, scattered in a world that isn’t theirs.
There’s been endless debate about how to fix this, how to clear the field of the weeds that choke out every new sprout, every attempt at change. But the real problem? We can’t play by their rules. We can’t speak their language or use their weapons. We stand for humanity, and no matter how righteous our cause, we will not multiply suffering. Victory doesn’t come from matching the enemy—it comes from staying ahead, from using tools they haven’t mastered yet. That’s how wars are won.
Our only resource is the will of the people to rewrite the order of things. Historian Timothy Snyder once said that a nation cannot exist without a city. A city is where the most active part of a nation thrives. But the cities are occupied. The streets are watched. Gatherings are impossible. They control the money. They control the mail. They control the media. And any dissent is crushed before it can take root.
So I started asking myself: How do we stop this fragmentation? How do we create a space where people can rebuild their connections when they’re ready? How do we build a self-sustaining network, where everyone contributes and benefits proportionally, while keeping their freedom to leave intact? And more importantly—how do we make it spread, even in occupied territory?
In 2009, something historic happened: the internet got its own money. Thanks to Satoshi Nakamoto, the world took a massive leap forward. Bitcoin and decentralized ledgers shattered the idea that money must be controlled by the state. Now, to move or store value, all you need is an address and a key. A tiny string of text, easy to carry, impossible to seize.
That was the year money broke free. The state lost its grip. Its biggest weapon—physical currency—became irrelevant. Money became purely digital.
The internet was already a sanctuary for information, a place where people could connect and organize. But with Bitcoin, it evolved. Now, value itself could flow freely, beyond the reach of authorities.
Think about it: when seedlings are grown in controlled environments before being planted outside, they get stronger, survive longer, and bear fruit faster. That’s how we handle crops in harsh climates—nurture them until they’re ready for the wild.
Now, picture the internet as that controlled environment for ideas. Bitcoin? It’s the fertile soil that lets them grow. A testing ground for new models of interaction, where concepts can take root before they move into the real world. If nation-states are a battlefield, locked in a brutal war for territory, the internet is boundless. It can absorb any number of ideas, any number of people, and it doesn’t run out of space.
But for this ecosystem to thrive, people need safe ways to communicate, to share ideas, to build something real—without surveillance, without censorship, without the constant fear of being erased.
This is where Nostr comes in.
Nostr—"Notes and Other Stuff Transmitted by Relays"—is more than just a messaging protocol. It’s a new kind of city. One that no dictator can seize, no corporation can own, no government can shut down.
It’s built on decentralization, encryption, and individual control. Messages don’t pass through central servers—they are relayed through independent nodes, and users choose which ones to trust. There’s no master switch to shut it all down. Every person owns their identity, their data, their connections. And no one—no state, no tech giant, no algorithm—can silence them.
In a world where cities fall and governments fail, Nostr is a city that cannot be occupied. A place for ideas, for networks, for freedom. A city that grows stronger the more people build within it.
-
@ 05a0f81e:fc032124
2025-05-23 17:45:46
The evolution of money has been a long journey, transforming from primitive bartering systems to sophisticated digital currencies. Here's a breakdown of the major stages:
- Barter System (circa 6000 BCE).
In the early days, people exchanged goods and services without using money. This system had limitations, as it required a double coincidence of wants, where both parties had to want what the other offered. Bartering was used in ancient Mesopotamia, and it's still used today in some parts of the world.
- Commodity Money (3000 BCE - 500 BCE).
As societies grew, commodity money emerged as a medium of exchange. Items like salt, cattle, grains, and shells were widely accepted due to their intrinsic value. These commodities were used to buy goods and services, but they had limitations due to their bulk and perishable nature.
- Metal Coins (600 BCE)
The introduction of metal coins revolutionized trade. Coins were made from precious metals like gold, silver, and copper, and were stamped with symbols or images to guarantee their authenticity. The first coins were minted in ancient Lydia (modern-day Turkey) and quickly spread to other civilizations.
- Paper Money (11th century CE)
Paper money was first introduced in China during the Song Dynasty. Initially, it was used as a convenient alternative to heavy metal coins. Over time, paper money evolved into fiat money, where its value was determined by government decree rather than a physical commodity.
- Banking and Fiat Money (17th century CE).
The development of banking systems allowed for the issuance of banknotes and the facilitation of financial transactions. Fiat money emerged as a dominant form of currency, where its value was determined by government decree and public trust.
- Digital Currencies (20th century CE).
The rise of digital technologies led to the emergence of digital currencies like cryptocurrencies (e.g., Bitcoin) and online payment systems. These digital currencies operate independently of central banks and offer a new way to conduct transactions.
Key Milestones:
- First coins: Ancient Lydia (modern-day Turkey), 600 BCE
- First paper money: China, 11th century CE.
- Gold standard: England, 1816.
- Fiat money: Global adoption, 20th century CE.
- Digital currencies: Emerged in the late 20th century CE, with Bitcoin launching in 2009.
The evolution of money reflects human innovation and the need for efficient and convenient ways to conduct transactions. From bartering to digital currencies, money has come a long way, shaping economies and societies along the way.
-
@ 6be5cc06:5259daf0
2025-01-21 20:58:37
A seguir, veja como instalar e configurar o Privoxy no Pop!_OS.
1. Instalar o Tor e o Privoxy
Abra o terminal e execute:
bash sudo apt update sudo apt install tor privoxyExplicação:
- Tor: Roteia o tráfego pela rede Tor.
- Privoxy: Proxy avançado que intermedia a conexão entre aplicativos e o Tor.
2. Configurar o Privoxy
Abra o arquivo de configuração do Privoxy:
bash sudo nano /etc/privoxy/configNavegue até a última linha (atalho:
Ctrl+/depoisCtrl+Vpara navegar diretamente até a última linha) e insira:bash forward-socks5 / 127.0.0.1:9050 .Isso faz com que o Privoxy envie todo o tráfego para o Tor através da porta 9050.
Salve (
CTRL+OeEnter) e feche (CTRL+X) o arquivo.
3. Iniciar o Tor e o Privoxy
Agora, inicie e habilite os serviços:
bash sudo systemctl start tor sudo systemctl start privoxy sudo systemctl enable tor sudo systemctl enable privoxyExplicação:
- start: Inicia os serviços.
- enable: Faz com que iniciem automaticamente ao ligar o PC.
4. Configurar o Navegador Firefox
Para usar a rede Tor com o Firefox:
- Abra o Firefox.
- Acesse Configurações → Configurar conexão.
- Selecione Configuração manual de proxy.
- Configure assim:
- Proxy HTTP:
127.0.0.1 - Porta:
8118(porta padrão do Privoxy) - Domínio SOCKS (v5):
127.0.0.1 - Porta:
9050
- Proxy HTTP:
- Marque a opção "Usar este proxy também em HTTPS".
- Clique em OK.
5. Verificar a Conexão com o Tor
Abra o navegador e acesse:
text https://check.torproject.org/Se aparecer a mensagem "Congratulations. This browser is configured to use Tor.", a configuração está correta.
Dicas Extras
- Privoxy pode ser ajustado para bloquear anúncios e rastreadores.
- Outros aplicativos também podem ser configurados para usar o Privoxy.
-
@ 91bea5cd:1df4451c
2025-05-23 17:04:49
Em nota, a prefeitura justificou que essas alterações visam ampliar a segurança das praias, conforto e organização, para os frequentadores e trabalhadores dos locais. No entanto, Orla Rio, concessionária responsável pelos espaços, e o SindRio, sindicato de bares e restaurantes, ficou insatisfeita com as medidas e reforçou que a música ao vivo aumenta em mais de 10% o ticket médio dos estabelecimentos e contribui para manter os empregos, especialmente na baixa temporada.
De acordo com Paes, as medidas visam impedir práticas ilegais para que a orla carioca continue sendo um espaço ativo econômico da cidade: “Certas práticas são inaceitáveis, especialmente por quem tem autorização municipal. Vamos ser mais restritivos e duros. A orla é de todos”.
Saiba quais serão as 16 proibições nas praias do Rio de Janeiro
- Utilização de caixas de som, instrumentos musicais, grupos ou qualquer equipamento sonoro, em qualquer horário. Apenas eventos autorizados terão permissão.
- Venda ou distribuição de bebidas em garrafas de vidro em qualquer ponto da areia ou do calçadão.
- Estruturas comerciais ambulantes sem autorização, como carrocinhas, trailers, food trucks e barracas.
- Comércio ambulante sem permissão, incluindo alimentos em palitos, churrasqueiras, isopores ou bandejas térmicas improvisadas.
- Circulação de ciclomotores e patinetes motorizados no calçadão.
- Escolinhas de esportes ou recreações não autorizadas pelo poder público municipal.
- Ocupação de área pública com estruturas fixas ou móveis de grandes proporções sem autorização.
- Instalação de acampamentos improvisados em qualquer trecho da orla.
- Práticas de comércio abusivo ou enganosas, incluindo abordagens insistentes. Quiosques e barracas devem exibir cardápio, preços e taxas de forma clara.
- Uso de animais para entretenimento, transporte ou comércio.
- Hasteamento ou exibição de bandeiras em mastros ou suportes.
- Fixação de objetos ou amarras em árvores ou vegetação.
- Cercadinhos feitos por ambulantes ou quiosques, que impeçam a livre circulação de pessoas.
- Permanência de carrinhos de transporte de mercadorias ou equipamentos fora dos momentos de carga e descarga.
- Armazenamento de produtos, barracas ou equipamentos enterrados na areia ou depositados na vegetação de restinga.
- Uso de nomes, marcas, logotipos ou slogans em barracas. Apenas a numeração sequencial da prefeitura será permitida.
-
@ 2b468756:7930dd9c
2025-05-23 12:17:09
Agorisme is libertarisme in de praktijk: op legale wijze maximale economische en persoonlijke vrijheid. Samen ontdekken en delen we wat er allemaal mogelijk is. We doen dit door: - organiseren jaarlijks agorismefestival - organiseren meerdere themadagen / excursies per jaar - bundelen praktische kennis op Agorisme Wiki - online uitwisselen via (thema)appgroepen
Op deze site worden activiteiten aangekondigd en kun je je opgeven.
Binnenkort: - cursussen metselen, stucen en vloeren - reis naar libertarisch dorp Walden Woods en Liberstad in Noorwegen - introductie Krav Maga zelfverdediging
We zijn gelieerd aan de libertarische partij.
Graag tot ziens!
-
@ 9e69e420:d12360c2
2025-01-21 19:31:48
Oregano oil is a potent natural compound that offers numerous scientifically-supported health benefits.
Active Compounds
The oil's therapeutic properties stem from its key bioactive components: - Carvacrol and thymol (primary active compounds) - Polyphenols and other antioxidant
Antimicrobial Properties
Bacterial Protection The oil demonstrates powerful antibacterial effects, even against antibiotic-resistant strains like MRSA and other harmful bacteria. Studies show it effectively inactivates various pathogenic bacteria without developing resistance.
Antifungal Effects It effectively combats fungal infections, particularly Candida-related conditions like oral thrush, athlete's foot, and nail infections.
Digestive Health Benefits
Oregano oil supports digestive wellness by: - Promoting gastric juice secretion and enzyme production - Helping treat Small Intestinal Bacterial Overgrowth (SIBO) - Managing digestive discomfort, bloating, and IBS symptoms
Anti-inflammatory and Antioxidant Effects
The oil provides significant protective benefits through: - Powerful antioxidant activity that fights free radicals - Reduction of inflammatory markers in the body - Protection against oxidative stress-related conditions
Respiratory Support
It aids respiratory health by: - Loosening mucus and phlegm - Suppressing coughs and throat irritation - Supporting overall respiratory tract function
Additional Benefits
Skin Health - Improves conditions like psoriasis, acne, and eczema - Supports wound healing through antibacterial action - Provides anti-aging benefits through antioxidant properties
Cardiovascular Health Studies show oregano oil may help: - Reduce LDL (bad) cholesterol levels - Support overall heart health
Pain Management The oil demonstrates effectiveness in: - Reducing inflammation-related pain - Managing muscle discomfort - Providing topical pain relief
Safety Note
While oregano oil is generally safe, it's highly concentrated and should be properly diluted before use Consult a healthcare provider before starting supplementation, especially if taking other medications.
-
@ aa73d7f7:7f5a99ce
2025-05-23 10:14:10
Com o avanço da tecnologia e a crescente demanda por entretenimento digital, plataformas de jogos online têm se tornado cada vez mais populares no Brasil. Uma das mais promissoras do momento é a 8143, um ambiente completo que une inovação, segurança e uma ampla variedade de jogos para todos os perfis de jogadores. Neste artigo, você vai conhecer melhor a proposta da plataforma, seus jogos de destaque e como ela proporciona uma experiência diferenciada aos usuários.
Uma Plataforma Moderna e Intuitiva A 8143foi desenvolvida com foco em oferecer praticidade, acessibilidade e diversão em um só lugar. Desde o primeiro acesso, o usuário encontra uma interface amigável e totalmente adaptada para dispositivos móveis e computadores. A navegação é fluida, com menus bem organizados que facilitam encontrar os principais jogos, promoções e serviços de suporte.
Além do design moderno, a plataforma investe fortemente em segurança digital, utilizando sistemas de criptografia avançados para proteger dados pessoais e transações financeiras dos jogadores. Isso proporciona um ambiente confiável, onde o usuário pode se concentrar apenas em sua diversão.
Diversidade de Jogos para Todos os Gostos Um dos grandes destaques da 8143 é sua biblioteca de jogos extremamente variada. A plataforma oferece opções para todos os estilos, desde os clássicos jogos de mesa, como pôquer e roleta, até máquinas de slots com gráficos modernos e temas envolventes.
Os jogos são desenvolvidos por fornecedores de renome internacional, garantindo alta qualidade visual, trilhas sonoras imersivas e uma jogabilidade fluida. Para quem gosta de jogos com mais interação, há também opções ao vivo, onde o jogador participa de partidas em tempo real com outros usuários e apresentadores reais.
Outro ponto positivo é a constante atualização do catálogo. A 8143 está sempre trazendo novidades, lançamentos e versões exclusivas, mantendo a plataforma dinâmica e sempre atrativa.
Experiência do Jogador: Imersiva e Recompensadora A 8143 entende que uma boa plataforma vai além dos jogos oferecidos — ela precisa criar uma experiência completa para o jogador. Por isso, investe em um sistema de recompensas atrativo, com bônus de boas-vindas, promoções diárias e programas de fidelidade que valorizam quem joga com frequência.
O atendimento ao cliente também é um diferencial. A equipe de suporte da plataforma está disponível 24 horas por dia, sete dias por semana, por meio de chat ao vivo, e-mail e redes sociais, sempre pronta para resolver dúvidas e oferecer auxílio.
Outro fator importante é a velocidade nos depósitos e saques. A 8143 trabalha com métodos de pagamento populares entre os brasileiros, como PIX, carteiras digitais e transferências bancárias, garantindo transações rápidas e seguras.
Conclusão A plataforma 8143 se destaca no mercado nacional por unir inovação, variedade de jogos e uma experiência de usuário de alto nível. É uma opção completa para quem busca diversão online com segurança, conforto e muitas possibilidades de ganho. Seja você um iniciante ou um jogador experiente, a 8143 oferece um ambiente perfeito para explorar o universo dos jogos digitais e se divertir com qualidade.
-
@ aa73d7f7:7f5a99ce
2025-05-23 10:13:39
A plataforma 5161 está conquistando o público brasileiro por sua proposta moderna, segura e repleta de entretenimento digital. Com uma interface intuitiva, variedade de jogos e suporte ao jogador de alta qualidade, o 5161 se posiciona como uma excelente escolha para quem busca diversão com praticidade e confiabilidade.
Uma Plataforma Moderna e Segura Desde sua chegada ao mercado, o 5161 tem chamado atenção por seu design responsivo e navegação simplificada. O site é totalmente otimizado para funcionar em qualquer dispositivo, seja computador, tablet ou smartphone, permitindo que o usuário acesse seus jogos preferidos a qualquer hora e em qualquer lugar. Outro diferencial é o compromisso com a segurança: a plataforma utiliza tecnologia de criptografia de ponta para proteger os dados dos jogadores, garantindo uma experiência confiável do início ao fim.
Além disso, o 5161oferece suporte multilíngue e atendimento ao cliente eficiente, disponível 24 horas por dia, 7 dias por semana. Isso demonstra o comprometimento da plataforma com a satisfação de seus usuários, sempre prontos para esclarecer dúvidas ou resolver qualquer situação.
Variedade de Jogos para Todos os Gostos Um dos grandes atrativos do 5161 é sua ampla biblioteca de jogos. A plataforma conta com títulos que vão desde os mais tradicionais até as novidades mais inovadoras do mercado. Os jogadores podem se divertir com jogos de roleta, cartas, slots, pescaria e muito mais — tudo em um único lugar.
Os jogos são fornecidos por desenvolvedores renomados, o que garante gráficos de alta qualidade, trilhas sonoras envolventes e mecânicas justas e empolgantes. Cada título foi cuidadosamente escolhido para proporcionar uma experiência única, capaz de agradar tanto os novatos quanto os veteranos do mundo dos jogos online.
Além da variedade, a plataforma também disponibiliza modos de demonstração gratuitos, ideais para quem deseja testar os jogos antes de fazer qualquer depósito. Isso permite que o jogador conheça melhor o funcionamento e escolha seus favoritos com mais confiança.
Experiência do Jogador em Primeiro Lugar No 5161, cada detalhe foi pensado para proporcionar a melhor experiência possível. Desde o momento do cadastro até a retirada de prêmios, tudo acontece de forma simples e rápida. O processo de registro é descomplicado, e o sistema de pagamentos oferece diversas opções, incluindo transferências bancárias, carteiras digitais e PIX — ideal para o público brasileiro, que busca agilidade nas transações.
Outro ponto de destaque é o sistema de recompensas. A plataforma conta com bônus de boas-vindas atrativos, promoções frequentes e um programa de fidelidade que valoriza os jogadores mais ativos. Isso significa mais chances de jogar e se divertir, com a possibilidade de aumentar os ganhos e explorar novos jogos com vantagens exclusivas.
Conclusão O 5161 se destaca como uma das plataformas de entretenimento digital mais completas e confiáveis disponíveis para o público brasileiro. Com uma interface moderna, biblioteca de jogos diversificada e foco total na experiência do usuário, a plataforma conquista cada vez mais fãs em todo o país. Se você está em busca de diversão segura, recompensadora e acessível, o 5161 é, sem dúvidas, uma excelente escolha para explorar novas emoções online.
-
@ 6be5cc06:5259daf0
2025-01-21 01:51:46
Bitcoin: Um sistema de dinheiro eletrônico direto entre pessoas.
Satoshi Nakamoto
satoshin@gmx.com
www.bitcoin.org
Resumo
O Bitcoin é uma forma de dinheiro digital que permite pagamentos diretos entre pessoas, sem a necessidade de um banco ou instituição financeira. Ele resolve um problema chamado gasto duplo, que ocorre quando alguém tenta gastar o mesmo dinheiro duas vezes. Para evitar isso, o Bitcoin usa uma rede descentralizada onde todos trabalham juntos para verificar e registrar as transações.
As transações são registradas em um livro público chamado blockchain, protegido por uma técnica chamada Prova de Trabalho. Essa técnica cria uma cadeia de registros que não pode ser alterada sem refazer todo o trabalho já feito. Essa cadeia é mantida pelos computadores que participam da rede, e a mais longa é considerada a verdadeira.
Enquanto a maior parte do poder computacional da rede for controlada por participantes honestos, o sistema continuará funcionando de forma segura. A rede é flexível, permitindo que qualquer pessoa entre ou saia a qualquer momento, sempre confiando na cadeia mais longa como prova do que aconteceu.
1. Introdução
Hoje, quase todos os pagamentos feitos pela internet dependem de bancos ou empresas como processadores de pagamento (cartões de crédito, por exemplo) para funcionar. Embora esse sistema seja útil, ele tem problemas importantes porque é baseado em confiança.
Primeiro, essas empresas podem reverter pagamentos, o que é útil em caso de erros, mas cria custos e incertezas. Isso faz com que pequenas transações, como pagar centavos por um serviço, se tornem inviáveis. Além disso, os comerciantes são obrigados a desconfiar dos clientes, pedindo informações extras e aceitando fraudes como algo inevitável.
Esses problemas não existem no dinheiro físico, como o papel-moeda, onde o pagamento é final e direto entre as partes. No entanto, não temos como enviar dinheiro físico pela internet sem depender de um intermediário confiável.
O que precisamos é de um sistema de pagamento eletrônico baseado em provas matemáticas, não em confiança. Esse sistema permitiria que qualquer pessoa enviasse dinheiro diretamente para outra, sem depender de bancos ou processadores de pagamento. Além disso, as transações seriam irreversíveis, protegendo vendedores contra fraudes, mas mantendo a possibilidade de soluções para disputas legítimas.
Neste documento, apresentamos o Bitcoin, que resolve o problema do gasto duplo usando uma rede descentralizada. Essa rede cria um registro público e protegido por cálculos matemáticos, que garante a ordem das transações. Enquanto a maior parte da rede for controlada por pessoas honestas, o sistema será seguro contra ataques.
2. Transações
Para entender como funciona o Bitcoin, é importante saber como as transações são realizadas. Imagine que você quer transferir uma "moeda digital" para outra pessoa. No sistema do Bitcoin, essa "moeda" é representada por uma sequência de registros que mostram quem é o atual dono. Para transferi-la, você adiciona um novo registro comprovando que agora ela pertence ao próximo dono. Esse registro é protegido por um tipo especial de assinatura digital.
O que é uma assinatura digital?
Uma assinatura digital é como uma senha secreta, mas muito mais segura. No Bitcoin, cada usuário tem duas chaves: uma "chave privada", que é secreta e serve para criar a assinatura, e uma "chave pública", que pode ser compartilhada com todos e é usada para verificar se a assinatura é válida. Quando você transfere uma moeda, usa sua chave privada para assinar a transação, provando que você é o dono. A próxima pessoa pode usar sua chave pública para confirmar isso.
Como funciona na prática?
Cada "moeda" no Bitcoin é, na verdade, uma cadeia de assinaturas digitais. Vamos imaginar o seguinte cenário:
- A moeda está com o Dono 0 (você). Para transferi-la ao Dono 1, você assina digitalmente a transação com sua chave privada. Essa assinatura inclui o código da transação anterior (chamado de "hash") e a chave pública do Dono 1.
- Quando o Dono 1 quiser transferir a moeda ao Dono 2, ele assinará a transação seguinte com sua própria chave privada, incluindo também o hash da transação anterior e a chave pública do Dono 2.
- Esse processo continua, formando uma "cadeia" de transações. Qualquer pessoa pode verificar essa cadeia para confirmar quem é o atual dono da moeda.
Resolvendo o problema do gasto duplo
Um grande desafio com moedas digitais é o "gasto duplo", que é quando uma mesma moeda é usada em mais de uma transação. Para evitar isso, muitos sistemas antigos dependiam de uma entidade central confiável, como uma casa da moeda, que verificava todas as transações. No entanto, isso criava um ponto único de falha e centralizava o controle do dinheiro.
O Bitcoin resolve esse problema de forma inovadora: ele usa uma rede descentralizada onde todos os participantes (os "nós") têm acesso a um registro completo de todas as transações. Cada nó verifica se as transações são válidas e se a moeda não foi gasta duas vezes. Quando a maioria dos nós concorda com a validade de uma transação, ela é registrada permanentemente na blockchain.
Por que isso é importante?
Essa solução elimina a necessidade de confiar em uma única entidade para gerenciar o dinheiro, permitindo que qualquer pessoa no mundo use o Bitcoin sem precisar de permissão de terceiros. Além disso, ela garante que o sistema seja seguro e resistente a fraudes.
3. Servidor Timestamp
Para assegurar que as transações sejam realizadas de forma segura e transparente, o sistema Bitcoin utiliza algo chamado de "servidor de registro de tempo" (timestamp). Esse servidor funciona como um registro público que organiza as transações em uma ordem específica.
Ele faz isso agrupando várias transações em blocos e criando um código único chamado "hash". Esse hash é como uma impressão digital que representa todo o conteúdo do bloco. O hash de cada bloco é amplamente divulgado, como se fosse publicado em um jornal ou em um fórum público.
Esse processo garante que cada bloco de transações tenha um registro de quando foi criado e que ele existia naquele momento. Além disso, cada novo bloco criado contém o hash do bloco anterior, formando uma cadeia contínua de blocos conectados — conhecida como blockchain.
Com isso, se alguém tentar alterar qualquer informação em um bloco anterior, o hash desse bloco mudará e não corresponderá ao hash armazenado no bloco seguinte. Essa característica torna a cadeia muito segura, pois qualquer tentativa de fraude seria imediatamente detectada.
O sistema de timestamps é essencial para provar a ordem cronológica das transações e garantir que cada uma delas seja única e autêntica. Dessa forma, ele reforça a segurança e a confiança na rede Bitcoin.
4. Prova-de-Trabalho
Para implementar o registro de tempo distribuído no sistema Bitcoin, utilizamos um mecanismo chamado prova-de-trabalho. Esse sistema é semelhante ao Hashcash, desenvolvido por Adam Back, e baseia-se na criação de um código único, o "hash", por meio de um processo computacionalmente exigente.
A prova-de-trabalho envolve encontrar um valor especial que, quando processado junto com as informações do bloco, gere um hash que comece com uma quantidade específica de zeros. Esse valor especial é chamado de "nonce". Encontrar o nonce correto exige um esforço significativo do computador, porque envolve tentativas repetidas até que a condição seja satisfeita.
Esse processo é importante porque torna extremamente difícil alterar qualquer informação registrada em um bloco. Se alguém tentar mudar algo em um bloco, seria necessário refazer o trabalho de computação não apenas para aquele bloco, mas também para todos os blocos que vêm depois dele. Isso garante a segurança e a imutabilidade da blockchain.
A prova-de-trabalho também resolve o problema de decidir qual cadeia de blocos é a válida quando há múltiplas cadeias competindo. A decisão é feita pela cadeia mais longa, pois ela representa o maior esforço computacional já realizado. Isso impede que qualquer indivíduo ou grupo controle a rede, desde que a maioria do poder de processamento seja mantida por participantes honestos.
Para garantir que o sistema permaneça eficiente e equilibrado, a dificuldade da prova-de-trabalho é ajustada automaticamente ao longo do tempo. Se novos blocos estiverem sendo gerados rapidamente, a dificuldade aumenta; se estiverem sendo gerados muito lentamente, a dificuldade diminui. Esse ajuste assegura que novos blocos sejam criados aproximadamente a cada 10 minutos, mantendo o sistema estável e funcional.
5. Rede
A rede Bitcoin é o coração do sistema e funciona de maneira distribuída, conectando vários participantes (ou nós) para garantir o registro e a validação das transações. Os passos para operar essa rede são:
-
Transmissão de Transações: Quando alguém realiza uma nova transação, ela é enviada para todos os nós da rede. Isso é feito para garantir que todos estejam cientes da operação e possam validá-la.
-
Coleta de Transações em Blocos: Cada nó agrupa as novas transações recebidas em um "bloco". Este bloco será preparado para ser adicionado à cadeia de blocos (a blockchain).
-
Prova-de-Trabalho: Os nós competem para resolver a prova-de-trabalho do bloco, utilizando poder computacional para encontrar um hash válido. Esse processo é como resolver um quebra-cabeça matemático difícil.
-
Envio do Bloco Resolvido: Quando um nó encontra a solução para o bloco (a prova-de-trabalho), ele compartilha esse bloco com todos os outros nós na rede.
-
Validação do Bloco: Cada nó verifica o bloco recebido para garantir que todas as transações nele contidas sejam válidas e que nenhuma moeda tenha sido gasta duas vezes. Apenas blocos válidos são aceitos.
-
Construção do Próximo Bloco: Os nós que aceitaram o bloco começam a trabalhar na criação do próximo bloco, utilizando o hash do bloco aceito como base (hash anterior). Isso mantém a continuidade da cadeia.
Resolução de Conflitos e Escolha da Cadeia Mais Longa
Os nós sempre priorizam a cadeia mais longa, pois ela representa o maior esforço computacional já realizado, garantindo maior segurança. Se dois blocos diferentes forem compartilhados simultaneamente, os nós trabalharão no primeiro bloco recebido, mas guardarão o outro como uma alternativa. Caso o segundo bloco eventualmente forme uma cadeia mais longa (ou seja, tenha mais blocos subsequentes), os nós mudarão para essa nova cadeia.
Tolerância a Falhas
A rede é robusta e pode lidar com mensagens que não chegam a todos os nós. Uma transação não precisa alcançar todos os nós de imediato; basta que chegue a um número suficiente deles para ser incluída em um bloco. Da mesma forma, se um nó não receber um bloco em tempo hábil, ele pode solicitá-lo ao perceber que está faltando quando o próximo bloco é recebido.
Esse mecanismo descentralizado permite que a rede Bitcoin funcione de maneira segura, confiável e resiliente, sem depender de uma autoridade central.
6. Incentivo
O incentivo é um dos pilares fundamentais que sustenta o funcionamento da rede Bitcoin, garantindo que os participantes (nós) continuem operando de forma honesta e contribuindo com recursos computacionais. Ele é estruturado em duas partes principais: a recompensa por mineração e as taxas de transação.
Recompensa por Mineração
Por convenção, o primeiro registro em cada bloco é uma transação especial que cria novas moedas e as atribui ao criador do bloco. Essa recompensa incentiva os mineradores a dedicarem poder computacional para apoiar a rede. Como não há uma autoridade central para emitir moedas, essa é a maneira pela qual novas moedas entram em circulação. Esse processo pode ser comparado ao trabalho de garimpeiros, que utilizam recursos para colocar mais ouro em circulação. No caso do Bitcoin, o "recurso" consiste no tempo de CPU e na energia elétrica consumida para resolver a prova-de-trabalho.
Taxas de Transação
Além da recompensa por mineração, os mineradores também podem ser incentivados pelas taxas de transação. Se uma transação utiliza menos valor de saída do que o valor de entrada, a diferença é tratada como uma taxa, que é adicionada à recompensa do bloco contendo essa transação. Com o passar do tempo e à medida que o número de moedas em circulação atinge o limite predeterminado, essas taxas de transação se tornam a principal fonte de incentivo, substituindo gradualmente a emissão de novas moedas. Isso permite que o sistema opere sem inflação, uma vez que o número total de moedas permanece fixo.
Incentivo à Honestidade
O design do incentivo também busca garantir que os participantes da rede mantenham um comportamento honesto. Para um atacante que consiga reunir mais poder computacional do que o restante da rede, ele enfrentaria duas escolhas:
- Usar esse poder para fraudar o sistema, como reverter transações e roubar pagamentos.
- Seguir as regras do sistema, criando novos blocos e recebendo recompensas legítimas.
A lógica econômica favorece a segunda opção, pois um comportamento desonesto prejudicaria a confiança no sistema, diminuindo o valor de todas as moedas, incluindo aquelas que o próprio atacante possui. Jogar dentro das regras não apenas maximiza o retorno financeiro, mas também preserva a validade e a integridade do sistema.
Esse mecanismo garante que os incentivos econômicos estejam alinhados com o objetivo de manter a rede segura, descentralizada e funcional ao longo do tempo.
7. Recuperação do Espaço em Disco
Depois que uma moeda passa a estar protegida por muitos blocos na cadeia, as informações sobre as transações antigas que a geraram podem ser descartadas para economizar espaço em disco. Para que isso seja possível sem comprometer a segurança, as transações são organizadas em uma estrutura chamada "árvore de Merkle". Essa árvore funciona como um resumo das transações: em vez de armazenar todas elas, guarda apenas um "hash raiz", que é como uma assinatura compacta que representa todo o grupo de transações.
Os blocos antigos podem, então, ser simplificados, removendo as partes desnecessárias dessa árvore. Apenas a raiz do hash precisa ser mantida no cabeçalho do bloco, garantindo que a integridade dos dados seja preservada, mesmo que detalhes específicos sejam descartados.
Para exemplificar: imagine que você tenha vários recibos de compra. Em vez de guardar todos os recibos, você cria um documento e lista apenas o valor total de cada um. Mesmo que os recibos originais sejam descartados, ainda é possível verificar a soma com base nos valores armazenados.
Além disso, o espaço ocupado pelos blocos em si é muito pequeno. Cada bloco sem transações ocupa apenas cerca de 80 bytes. Isso significa que, mesmo com blocos sendo gerados a cada 10 minutos, o crescimento anual em espaço necessário é insignificante: apenas 4,2 MB por ano. Com a capacidade de armazenamento dos computadores crescendo a cada ano, esse espaço continuará sendo trivial, garantindo que a rede possa operar de forma eficiente sem problemas de armazenamento, mesmo a longo prazo.
8. Verificação de Pagamento Simplificada
É possível confirmar pagamentos sem a necessidade de operar um nó completo da rede. Para isso, o usuário precisa apenas de uma cópia dos cabeçalhos dos blocos da cadeia mais longa (ou seja, a cadeia com maior esforço de trabalho acumulado). Ele pode verificar a validade de uma transação ao consultar os nós da rede até obter a confirmação de que tem a cadeia mais longa. Para isso, utiliza-se o ramo Merkle, que conecta a transação ao bloco em que ela foi registrada.
Entretanto, o método simplificado possui limitações: ele não pode confirmar uma transação isoladamente, mas sim assegurar que ela ocupa um lugar específico na cadeia mais longa. Dessa forma, se um nó da rede aprova a transação, os blocos subsequentes reforçam essa aceitação.
A verificação simplificada é confiável enquanto a maioria dos nós da rede for honesta. Contudo, ela se torna vulnerável caso a rede seja dominada por um invasor. Nesse cenário, um atacante poderia fabricar transações fraudulentas que enganariam o usuário temporariamente até que o invasor obtivesse controle completo da rede.
Uma estratégia para mitigar esse risco é configurar alertas nos softwares de nós completos. Esses alertas identificam blocos inválidos, sugerindo ao usuário baixar o bloco completo para confirmar qualquer inconsistência. Para maior segurança, empresas que realizam pagamentos frequentes podem preferir operar seus próprios nós, reduzindo riscos e permitindo uma verificação mais direta e confiável.
9. Combinando e Dividindo Valor
No sistema Bitcoin, cada unidade de valor é tratada como uma "moeda" individual, mas gerenciar cada centavo como uma transação separada seria impraticável. Para resolver isso, o Bitcoin permite que valores sejam combinados ou divididos em transações, facilitando pagamentos de qualquer valor.
Entradas e Saídas
Cada transação no Bitcoin é composta por:
- Entradas: Representam os valores recebidos em transações anteriores.
- Saídas: Correspondem aos valores enviados, divididos entre os destinatários e, eventualmente, o troco para o remetente.
Normalmente, uma transação contém:
- Uma única entrada com valor suficiente para cobrir o pagamento.
- Ou várias entradas combinadas para atingir o valor necessário.
O valor total das saídas nunca excede o das entradas, e a diferença (se houver) pode ser retornada ao remetente como troco.
Exemplo Prático
Imagine que você tem duas entradas:
- 0,03 BTC
- 0,07 BTC
Se deseja enviar 0,08 BTC para alguém, a transação terá:
- Entrada: As duas entradas combinadas (0,03 + 0,07 BTC = 0,10 BTC).
- Saídas: Uma para o destinatário (0,08 BTC) e outra como troco para você (0,02 BTC).
Essa flexibilidade permite que o sistema funcione sem precisar manipular cada unidade mínima individualmente.
Difusão e Simplificação
A difusão de transações, onde uma depende de várias anteriores e assim por diante, não representa um problema. Não é necessário armazenar ou verificar o histórico completo de uma transação para utilizá-la, já que o registro na blockchain garante sua integridade.
10. Privacidade
O modelo bancário tradicional oferece um certo nível de privacidade, limitando o acesso às informações financeiras apenas às partes envolvidas e a um terceiro confiável (como bancos ou instituições financeiras). No entanto, o Bitcoin opera de forma diferente, pois todas as transações são publicamente registradas na blockchain. Apesar disso, a privacidade pode ser mantida utilizando chaves públicas anônimas, que desvinculam diretamente as transações das identidades das partes envolvidas.
Fluxo de Informação
- No modelo tradicional, as transações passam por um terceiro confiável que conhece tanto o remetente quanto o destinatário.
- No Bitcoin, as transações são anunciadas publicamente, mas sem revelar diretamente as identidades das partes. Isso é comparável a dados divulgados por bolsas de valores, onde informações como o tempo e o tamanho das negociações (a "fita") são públicas, mas as identidades das partes não.
Protegendo a Privacidade
Para aumentar a privacidade no Bitcoin, são adotadas as seguintes práticas:
- Chaves Públicas Anônimas: Cada transação utiliza um par de chaves diferentes, dificultando a associação com um proprietário único.
- Prevenção de Ligação: Ao usar chaves novas para cada transação, reduz-se a possibilidade de links evidentes entre múltiplas transações realizadas pelo mesmo usuário.
Riscos de Ligação
Embora a privacidade seja fortalecida, alguns riscos permanecem:
- Transações multi-entrada podem revelar que todas as entradas pertencem ao mesmo proprietário, caso sejam necessárias para somar o valor total.
- O proprietário da chave pode ser identificado indiretamente por transações anteriores que estejam conectadas.
11. Cálculos
Imagine que temos um sistema onde as pessoas (ou computadores) competem para adicionar informações novas (blocos) a um grande registro público (a cadeia de blocos ou blockchain). Este registro é como um livro contábil compartilhado, onde todos podem verificar o que está escrito.
Agora, vamos pensar em um cenário: um atacante quer enganar o sistema. Ele quer mudar informações já registradas para beneficiar a si mesmo, por exemplo, desfazendo um pagamento que já fez. Para isso, ele precisa criar uma versão alternativa do livro contábil (a cadeia de blocos dele) e convencer todos os outros participantes de que essa versão é a verdadeira.
Mas isso é extremamente difícil.
Como o Ataque Funciona
Quando um novo bloco é adicionado à cadeia, ele depende de cálculos complexos que levam tempo e esforço. Esses cálculos são como um grande quebra-cabeça que precisa ser resolvido.
- Os “bons jogadores” (nós honestos) estão sempre trabalhando juntos para resolver esses quebra-cabeças e adicionar novos blocos à cadeia verdadeira.
- O atacante, por outro lado, precisa resolver quebra-cabeças sozinho, tentando “alcançar” a cadeia honesta para que sua versão alternativa pareça válida.
Se a cadeia honesta já está vários blocos à frente, o atacante começa em desvantagem, e o sistema está projetado para que a dificuldade de alcançá-los aumente rapidamente.
A Corrida Entre Cadeias
Você pode imaginar isso como uma corrida. A cada bloco novo que os jogadores honestos adicionam à cadeia verdadeira, eles se distanciam mais do atacante. Para vencer, o atacante teria que resolver os quebra-cabeças mais rápido que todos os outros jogadores honestos juntos.
Suponha que:
- A rede honesta tem 80% do poder computacional (ou seja, resolve 8 de cada 10 quebra-cabeças).
- O atacante tem 20% do poder computacional (ou seja, resolve 2 de cada 10 quebra-cabeças).
Cada vez que a rede honesta adiciona um bloco, o atacante tem que "correr atrás" e resolver mais quebra-cabeças para alcançar.
Por Que o Ataque Fica Cada Vez Mais Improvável?
Vamos usar uma fórmula simples para mostrar como as chances de sucesso do atacante diminuem conforme ele precisa "alcançar" mais blocos:
P = (q/p)^z
- q é o poder computacional do atacante (20%, ou 0,2).
- p é o poder computacional da rede honesta (80%, ou 0,8).
- z é a diferença de blocos entre a cadeia honesta e a cadeia do atacante.
Se o atacante está 5 blocos atrás (z = 5):
P = (0,2 / 0,8)^5 = (0,25)^5 = 0,00098, (ou, 0,098%)
Isso significa que o atacante tem menos de 0,1% de chance de sucesso — ou seja, é muito improvável.
Se ele estiver 10 blocos atrás (z = 10):
P = (0,2 / 0,8)^10 = (0,25)^10 = 0,000000095, (ou, 0,0000095%).
Neste caso, as chances de sucesso são praticamente nulas.
Um Exemplo Simples
Se você jogar uma moeda, a chance de cair “cara” é de 50%. Mas se precisar de 10 caras seguidas, sua chance já é bem menor. Se precisar de 20 caras seguidas, é quase impossível.
No caso do Bitcoin, o atacante precisa de muito mais do que 20 caras seguidas. Ele precisa resolver quebra-cabeças extremamente difíceis e alcançar os jogadores honestos que estão sempre à frente. Isso faz com que o ataque seja inviável na prática.
Por Que Tudo Isso é Seguro?
- A probabilidade de sucesso do atacante diminui exponencialmente. Isso significa que, quanto mais tempo passa, menor é a chance de ele conseguir enganar o sistema.
- A cadeia verdadeira (honesta) está protegida pela força da rede. Cada novo bloco que os jogadores honestos adicionam à cadeia torna mais difícil para o atacante alcançar.
E Se o Atacante Tentar Continuar?
O atacante poderia continuar tentando indefinidamente, mas ele estaria gastando muito tempo e energia sem conseguir nada. Enquanto isso, os jogadores honestos estão sempre adicionando novos blocos, tornando o trabalho do atacante ainda mais inútil.
Assim, o sistema garante que a cadeia verdadeira seja extremamente segura e que ataques sejam, na prática, impossíveis de ter sucesso.
12. Conclusão
Propusemos um sistema de transações eletrônicas que elimina a necessidade de confiança, baseando-se em assinaturas digitais e em uma rede peer-to-peer que utiliza prova de trabalho. Isso resolve o problema do gasto duplo, criando um histórico público de transações imutável, desde que a maioria do poder computacional permaneça sob controle dos participantes honestos. A rede funciona de forma simples e descentralizada, com nós independentes que não precisam de identificação ou coordenação direta. Eles entram e saem livremente, aceitando a cadeia de prova de trabalho como registro do que ocorreu durante sua ausência. As decisões são tomadas por meio do poder de CPU, validando blocos legítimos, estendendo a cadeia e rejeitando os inválidos. Com este mecanismo de consenso, todas as regras e incentivos necessários para o funcionamento seguro e eficiente do sistema são garantidos.
Faça o download do whitepaper original em português: https://bitcoin.org/files/bitcoin-paper/bitcoin_pt_br.pdf
-
@ 95cbd62b:a5270126
2025-05-23 10:12:48
Nếu bạn đang tìm kiếm một nền tảng cá cược trực tuyến uy tín, hỗ trợ tiếng Việt toàn diện, tích hợp nhiều tính năng hiện đại và mang lại cơ hội kiếm thưởng mỗi ngày thì 123BET chính là lựa chọn hoàn hảo. Được xây dựng với định hướng lấy người dùng làm trung tâm, 123BET mang đến trải nghiệm cá cược tối ưu với giao diện đơn giản, dễ thao tác, tương thích tốt trên mọi thiết bị từ máy tính đến điện thoại. Người chơi chỉ cần đăng ký một tài khoản duy nhất là có thể truy cập toàn bộ hệ sinh thái giải trí khổng lồ bao gồm slot game, casino trực tuyến, game bắn cá, mini game dân gian và cá cược thể thao. Bên cạnh đó, 123BET còn chú trọng đến bảo mật bằng cách tích hợp các phương thức đăng nhập hiện đại như OTP, nhận diện khuôn mặt và vân tay. Ứng dụng di động 123BET App được tối ưu hóa để truy cập mượt mà không bị chặn, đồng thời hỗ trợ thông báo khuyến mãi tức thời giúp người chơi không bỏ lỡ bất kỳ ưu đãi nào.
Kho game của 123BET là một thế giới giải trí đầy màu sắc, được cung cấp bởi các nhà phát hành danh tiếng toàn cầu như PG Soft, JILI, Pragmatic Play, Microgaming và Spadegaming cho dòng slot game. Tại đây, người chơi có thể trải nghiệm hàng trăm chủ đề phong phú, từ cổ điển đến hiện đại, với các tính năng đặc biệt như vòng quay miễn phí, hệ số nhân, jackpot lũy tiến và các mini game bonus đầy hấp dẫn. Với những ai yêu thích không khí sòng bài thật, mảng casino trực tiếp của 123BET mang đến trải nghiệm chân thực với video phát sóng trực tiếp chất lượng cao từ các studio như SA Gaming, Evolution, WM Casino và Dream Gaming. Game bắn cá cũng là điểm nhấn không thể bỏ qua với hình ảnh 3D sắc nét, hiệu ứng đạn sinh động, nhiều chế độ chơi từ cá nhân đến tổ đội, vũ khí đa dạng và đặc biệt là khả năng đổi xu thành tiền thật nhanh chóng. Với hàng loạt trò chơi hấp dẫn như Monster Awaken, Fishing War hay Bombing Fishing, người chơi có thể vừa giải trí vừa gia tăng thu nhập mỗi ngày.
Không chỉ nổi bật về mặt nội dung, 123BET còn ghi điểm mạnh với hệ thống nạp – rút tự động 24/7, tốc độ xử lý nhanh, không giới hạn số lần giao dịch và hoàn toàn miễn phí. Người chơi có thể linh hoạt nạp tiền qua nhiều kênh như chuyển khoản ngân hàng nội địa, ví điện tử (Momo, ZaloPay, ViettelPay) hoặc QR Code chỉ trong vòng 1–3 phút. Quy trình rút tiền đơn giản, hỗ trợ về tài khoản ngân hàng chính chủ, đảm bảo tiền về nhanh chỉ sau 5–10 phút kể cả vào ban đêm hoặc ngày lễ. Ngoài ra, 123BET còn thường xuyên triển khai các chương trình khuyến mãi hấp dẫn như thưởng 100% nạp đầu, hoàn tiền hàng ngày cho tất cả trò chơi, ưu đãi nạp lại cuối tuần, tặng quà sinh nhật và nâng hạng VIP với đặc quyền riêng. Đặc biệt, người chơi có thể kiếm thêm thu nhập thụ động thông qua chương trình giới thiệu bạn bè nhận hoa hồng không giới hạn. Với đội ngũ hỗ trợ kỹ thuật chuyên nghiệp 24/7 và chính sách chăm sóc khách hàng tận tình, 123BET đang khẳng định vị thế hàng đầu trong lĩnh vực cá cược trực tuyến tại thị trường Việt Nam, mang đến một sân chơi an toàn, công bằng và sinh lợi bền vững cho tất cả người chơi.
-
@ f9cf4e94:96abc355
2025-01-18 06:09:50
Para esse exemplo iremos usar: | Nome | Imagem | Descrição | | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | | Raspberry PI B+ |
 | Cortex-A53 (ARMv8) 64-bit a 1.4GHz e 1 GB de SDRAM LPDDR2, |
| Pen drive |
| Cortex-A53 (ARMv8) 64-bit a 1.4GHz e 1 GB de SDRAM LPDDR2, |
| Pen drive |  | 16Gb |
| 16Gb |Recomendo que use o Ubuntu Server para essa instalação. Você pode baixar o Ubuntu para Raspberry Pi aqui. O passo a passo para a instalação do Ubuntu no Raspberry Pi está disponível aqui. Não instale um desktop (como xubuntu, lubuntu, xfce, etc.).
Passo 1: Atualizar o Sistema 🖥️
Primeiro, atualize seu sistema e instale o Tor:
bash apt update apt install tor
Passo 2: Criar o Arquivo de Serviço
nrs.service🔧Crie o arquivo de serviço que vai gerenciar o servidor Nostr. Você pode fazer isso com o seguinte conteúdo:
```unit [Unit] Description=Nostr Relay Server Service After=network.target
[Service] Type=simple WorkingDirectory=/opt/nrs ExecStart=/opt/nrs/nrs-arm64 Restart=on-failure
[Install] WantedBy=multi-user.target ```
Passo 3: Baixar o Binário do Nostr 🚀
Baixe o binário mais recente do Nostr aqui no GitHub.
Passo 4: Criar as Pastas Necessárias 📂
Agora, crie as pastas para o aplicativo e o pendrive:
bash mkdir -p /opt/nrs /mnt/edriver
Passo 5: Listar os Dispositivos Conectados 🔌
Para saber qual dispositivo você vai usar, liste todos os dispositivos conectados:
bash lsblk
Passo 6: Formatando o Pendrive 💾
Escolha o pendrive correto (por exemplo,
/dev/sda) e formate-o:bash mkfs.vfat /dev/sda
Passo 7: Montar o Pendrive 💻
Monte o pendrive na pasta
/mnt/edriver:bash mount /dev/sda /mnt/edriver
Passo 8: Verificar UUID dos Dispositivos 📋
Para garantir que o sistema monte o pendrive automaticamente, liste os UUID dos dispositivos conectados:
bash blkid
Passo 9: Alterar o
fstabpara Montar o Pendrive Automáticamente 📝Abra o arquivo
/etc/fstabe adicione uma linha para o pendrive, com o UUID que você obteve no passo anterior. A linha deve ficar assim:fstab UUID=9c9008f8-f852 /mnt/edriver vfat defaults 0 0
Passo 10: Copiar o Binário para a Pasta Correta 📥
Agora, copie o binário baixado para a pasta
/opt/nrs:bash cp nrs-arm64 /opt/nrs
Passo 11: Criar o Arquivo de Configuração 🛠️
Crie o arquivo de configuração com o seguinte conteúdo e salve-o em
/opt/nrs/config.yaml:yaml app_env: production info: name: Nostr Relay Server description: Nostr Relay Server pub_key: "" contact: "" url: http://localhost:3334 icon: https://external-content.duckduckgo.com/iu/?u= https://public.bnbstatic.com/image/cms/crawler/COINCU_NEWS/image-495-1024x569.png base_path: /mnt/edriver negentropy: true
Passo 12: Copiar o Serviço para o Diretório de Systemd ⚙️
Agora, copie o arquivo
nrs.servicepara o diretório/etc/systemd/system/:bash cp nrs.service /etc/systemd/system/Recarregue os serviços e inicie o serviço
nrs:bash systemctl daemon-reload systemctl enable --now nrs.service
Passo 13: Configurar o Tor 🌐
Abra o arquivo de configuração do Tor
/var/lib/tor/torrce adicione a seguinte linha:torrc HiddenServiceDir /var/lib/tor/nostr_server/ HiddenServicePort 80 127.0.0.1:3334
Passo 14: Habilitar e Iniciar o Tor 🧅
Agora, ative e inicie o serviço Tor:
bash systemctl enable --now tor.serviceO Tor irá gerar um endereço
.onionpara o seu servidor Nostr. Você pode encontrá-lo no arquivo/var/lib/tor/nostr_server/hostname.
Observações ⚠️
- Com essa configuração, os dados serão salvos no pendrive, enquanto o binário ficará no cartão SD do Raspberry Pi.
- O endereço
.oniondo seu servidor Nostr será algo como:ws://y3t5t5wgwjif<exemplo>h42zy7ih6iwbyd.onion.
Agora, seu servidor Nostr deve estar configurado e funcionando com Tor! 🥳
Se este artigo e as informações aqui contidas forem úteis para você, convidamos a considerar uma doação ao autor como forma de reconhecimento e incentivo à produção de novos conteúdos.
-
@ 6389be64:ef439d32
2025-01-16 15:44:06
Black Locust can grow up to 170 ft tall
Grows 3-4 ft. per year
Native to North America
Cold hardy in zones 3 to 8

Firewood
- BLT wood, on a pound for pound basis is roughly half that of Anthracite Coal
- Since its growth is fast, firewood can be plentiful
Timber

- Rot resistant due to a naturally produced robinin in the wood
- 100 year life span in full soil contact! (better than cedar performance)
- Fence posts
- Outdoor furniture
- Outdoor decking
- Sustainable due to its fast growth and spread
- Can be coppiced (cut to the ground)
- Can be pollarded (cut above ground)
- Its dense wood makes durable tool handles, boxes (tool), and furniture
- The wood is tougher than hickory, which is tougher than hard maple, which is tougher than oak.
- A very low rate of expansion and contraction
- Hardwood flooring
- The highest tensile beam strength of any American tree
- The wood is beautiful
Legume
- Nitrogen fixer
- Fixes the same amount of nitrogen per acre as is needed for 200-bushel/acre corn
- Black walnuts inter-planted with locust as “nurse” trees were shown to rapidly increase their growth [[Clark, Paul M., and Robert D. Williams. (1978) Black walnut growth increased when interplanted with nitrogen-fixing shrubs and trees. Proceedings of the Indiana Academy of Science, vol. 88, pp. 88-91.]]
Bees

- The edible flower clusters are also a top food source for honey bees
Shade Provider

- Its light, airy overstory provides dappled shade
- Planted on the west side of a garden it provides relief during the hottest part of the day
- (nitrogen provider)
- Planted on the west side of a house, its quick growth soon shades that side from the sun
Wind-break

- Fast growth plus it's feathery foliage reduces wind for animals, crops, and shelters
Fodder
- Over 20% crude protein
- 4.1 kcal/g of energy
- Baertsche, S.R, M.T. Yokoyama, and J.W. Hanover (1986) Short rotation, hardwood tree biomass as potential ruminant feed-chemical composition, nylon bag ruminal degradation and ensilement of selected species. J. Animal Sci. 63 2028-2043
-
@ 6389be64:ef439d32
2025-01-13 21:50:59
Bitcoin is more than money, more than an asset, and more than a store of value. Bitcoin is a Prime Mover, an enabler and it ignites imaginations. It certainly fueled an idea in my mind. The idea integrates sensors, computational prowess, actuated machinery, power conversion, and electronic communications to form an autonomous, machined creature roaming forests and harvesting the most widespread and least energy-dense fuel source available. I call it the Forest Walker and it eats wood, and mines Bitcoin.
I know what you're thinking. Why not just put Bitcoin mining rigs where they belong: in a hosted facility sporting electricity from energy-dense fuels like natural gas, climate-controlled with excellent data piping in and out? Why go to all the trouble building a robot that digests wood creating flammable gasses fueling an engine to run a generator powering Bitcoin miners? It's all about synergy.
Bitcoin mining enables the realization of multiple, seemingly unrelated, yet useful activities. Activities considered un-profitable if not for Bitcoin as the Prime Mover. This is much more than simply mining the greatest asset ever conceived by humankind. It’s about the power of synergy, which Bitcoin plays only one of many roles. The synergy created by this system can stabilize forests' fire ecology while generating multiple income streams. That’s the realistic goal here and requires a brief history of American Forest management before continuing.
Smokey The Bear
In 1944, the Smokey Bear Wildfire Prevention Campaign began in the United States. “Only YOU can prevent forest fires” remains the refrain of the Ad Council’s longest running campaign. The Ad Council is a U.S. non-profit set up by the American Association of Advertising Agencies and the Association of National Advertisers in 1942. It would seem that the U.S. Department of the Interior was concerned about pesky forest fires and wanted them to stop. So, alongside a national policy of extreme fire suppression they enlisted the entire U.S. population to get onboard via the Ad Council and it worked. Forest fires were almost obliterated and everyone was happy, right? Wrong.
Smokey is a fantastically successful bear so forest fires became so few for so long that the fuel load - dead wood - in forests has become very heavy. So heavy that when a fire happens (and they always happen) it destroys everything in its path because the more fuel there is the hotter that fire becomes. Trees, bushes, shrubs, and all other plant life cannot escape destruction (not to mention homes and businesses). The soil microbiology doesn’t escape either as it is burned away even in deeper soils. To add insult to injury, hydrophobic waxy residues condense on the soil surface, forcing water to travel over the ground rather than through it eroding forest soils. Good job, Smokey. Well done, Sir!
Most terrestrial ecologies are “fire ecologies”. Fire is a part of these systems’ fuel load and pest management. Before we pretended to “manage” millions of acres of forest, fires raged over the world, rarely damaging forests. The fuel load was always too light to generate fires hot enough to moonscape mountainsides. Fires simply burned off the minor amounts of fuel accumulated since the fire before. The lighter heat, smoke, and other combustion gasses suppressed pests, keeping them in check and the smoke condensed into a plant growth accelerant called wood vinegar, not a waxy cap on the soil. These fires also cleared out weak undergrowth, cycled minerals, and thinned the forest canopy, allowing sunlight to penetrate to the forest floor. Without a fire’s heat, many pine tree species can’t sow their seed. The heat is required to open the cones (the seed bearing structure) of Spruce, Cypress, Sequoia, Jack Pine, Lodgepole Pine and many more. Without fire forests can’t have babies. The idea was to protect the forests, and it isn't working.
So, in a world of fire, what does an ally look like and what does it do?
Meet The Forest Walker
For the Forest Walker to work as a mobile, autonomous unit, a solid platform that can carry several hundred pounds is required. It so happens this chassis already exists but shelved.
Introducing the Legged Squad Support System (LS3). A joint project between Boston Dynamics, DARPA, and the United States Marine Corps, the quadrupedal robot is the size of a cow, can carry 400 pounds (180 kg) of equipment, negotiate challenging terrain, and operate for 24 hours before needing to refuel. Yes, it had an engine. Abandoned in 2015, the thing was too noisy for military deployment and maintenance "under fire" is never a high-quality idea. However, we can rebuild it to act as a platform for the Forest Walker; albeit with serious alterations. It would need to be bigger, probably. Carry more weight? Definitely. Maybe replace structural metal with carbon fiber and redesign much as 3D printable parts for more effective maintenance.
The original system has a top operational speed of 8 miles per hour. For our purposes, it only needs to move about as fast as a grazing ruminant. Without the hammering vibrations of galloping into battle, shocks of exploding mortars, and drunken soldiers playing "Wrangler of Steel Machines", time between failures should be much longer and the overall energy consumption much lower. The LS3 is a solid platform to build upon. Now it just needs to be pulled out of the mothballs, and completely refitted with outboard equipment.
The Small Branch Chipper
When I say “Forest fuel load” I mean the dead, carbon containing litter on the forest floor. Duff (leaves), fine-woody debris (small branches), and coarse woody debris (logs) are the fuel that feeds forest fires. Walk through any forest in the United States today and you will see quite a lot of these materials. Too much, as I have described. Some of these fuel loads can be 8 tons per acre in pine and hardwood forests and up to 16 tons per acre at active logging sites. That’s some big wood and the more that collects, the more combustible danger to the forest it represents. It also provides a technically unlimited fuel supply for the Forest Walker system.
The problem is that this detritus has to be chewed into pieces that are easily ingestible by the system for the gasification process (we’ll get to that step in a minute). What we need is a wood chipper attached to the chassis (the LS3); its “mouth”.
A small wood chipper handling material up to 2.5 - 3.0 inches (6.3 - 7.6 cm) in diameter would eliminate a substantial amount of fuel. There is no reason for Forest Walker to remove fallen trees. It wouldn’t have to in order to make a real difference. It need only identify appropriately sized branches and grab them. Once loaded into the chipper’s intake hopper for further processing, the beast can immediately look for more “food”. This is essentially kindling that would help ignite larger logs. If it’s all consumed by Forest Walker, then it’s not present to promote an aggravated conflagration.
I have glossed over an obvious question: How does Forest Walker see and identify branches and such? LiDaR (Light Detection and Ranging) attached to Forest Walker images the local area and feed those data to onboard computers for processing. Maybe AI plays a role. Maybe simple machine learning can do the trick. One thing is for certain: being able to identify a stick and cause robotic appendages to pick it up is not impossible.
Great! We now have a quadrupedal robot autonomously identifying and “eating” dead branches and other light, combustible materials. Whilst strolling through the forest, depleting future fires of combustibles, Forest Walker has already performed a major function of this system: making the forest safer. It's time to convert this low-density fuel into a high-density fuel Forest Walker can leverage. Enter the gasification process.
The Gassifier
The gasifier is the heart of the entire system; it’s where low-density fuel becomes the high-density fuel that powers the entire system. Biochar and wood vinegar are process wastes and I’ll discuss why both are powerful soil amendments in a moment, but first, what’s gasification?
Reacting shredded carbonaceous material at high temperatures in a low or no oxygen environment converts the biomass into biochar, wood vinegar, heat, and Synthesis Gas (Syngas). Syngas consists primarily of hydrogen, carbon monoxide, and methane. All of which are extremely useful fuels in a gaseous state. Part of this gas is used to heat the input biomass and keep the reaction temperature constant while the internal combustion engine that drives the generator to produce electrical power consumes the rest.
Critically, this gasification process is “continuous feed”. Forest Walker must intake biomass from the chipper, process it to fuel, and dump the waste (CO2, heat, biochar, and wood vinegar) continuously. It cannot stop. Everything about this system depends upon this continual grazing, digestion, and excretion of wastes just as a ruminal does. And, like a ruminant, all waste products enhance the local environment.
When I first heard of gasification, I didn’t believe that it was real. Running an electric generator from burning wood seemed more akin to “conspiracy fantasy” than science. Not only is gasification real, it’s ancient technology. A man named Dean Clayton first started experiments on gasification in 1699 and in 1901 gasification was used to power a vehicle. By the end of World War II, there were 500,000 Syngas powered vehicles in Germany alone because of fossil fuel rationing during the war. The global gasification market was $480 billion in 2022 and projected to be as much as $700 billion by 2030 (Vantage Market Research). Gasification technology is the best choice to power the Forest Walker because it’s self-contained and we want its waste products.
Biochar: The Waste
Biochar (AKA agricultural charcoal) is fairly simple: it’s almost pure, solid carbon that resembles charcoal. Its porous nature packs large surface areas into small, 3 dimensional nuggets. Devoid of most other chemistry, like hydrocarbons (methane) and ash (minerals), biochar is extremely lightweight. Do not confuse it with the charcoal you buy for your grill. Biochar doesn’t make good grilling charcoal because it would burn too rapidly as it does not contain the multitude of flammable components that charcoal does. Biochar has several other good use cases. Water filtration, water retention, nutrient retention, providing habitat for microscopic soil organisms, and carbon sequestration are the main ones that we are concerned with here.
Carbon has an amazing ability to adsorb (substances stick to and accumulate on the surface of an object) manifold chemistries. Water, nutrients, and pollutants tightly bind to carbon in this format. So, biochar makes a respectable filter and acts as a “battery” of water and nutrients in soils. Biochar adsorbs and holds on to seven times its weight in water. Soil containing biochar is more drought resilient than soil without it. Adsorbed nutrients, tightly sequestered alongside water, get released only as plants need them. Plants must excrete protons (H+) from their roots to disgorge water or positively charged nutrients from the biochar's surface; it's an active process.
Biochar’s surface area (where adsorption happens) can be 500 square meters per gram or more. That is 10% larger than an official NBA basketball court for every gram of biochar. Biochar’s abundant surface area builds protective habitats for soil microbes like fungi and bacteria and many are critical for the health and productivity of the soil itself.
The “carbon sequestration” component of biochar comes into play where “carbon credits” are concerned. There is a financial market for carbon. Not leveraging that market for revenue is foolish. I am climate agnostic. All I care about is that once solid carbon is inside the soil, it will stay there for thousands of years, imparting drought resiliency, fertility collection, nutrient buffering, and release for that time span. I simply want as much solid carbon in the soil because of the undeniably positive effects it has, regardless of any climactic considerations.
Wood Vinegar: More Waste
Another by-product of the gasification process is wood vinegar (Pyroligneous acid). If you have ever seen Liquid Smoke in the grocery store, then you have seen wood vinegar. Principally composed of acetic acid, acetone, and methanol wood vinegar also contains ~200 other organic compounds. It would seem intuitive that condensed, liquefied wood smoke would at least be bad for the health of all living things if not downright carcinogenic. The counter intuition wins the day, however. Wood vinegar has been used by humans for a very long time to promote digestion, bowel, and liver health; combat diarrhea and vomiting; calm peptic ulcers and regulate cholesterol levels; and a host of other benefits.
For centuries humans have annually burned off hundreds of thousands of square miles of pasture, grassland, forest, and every other conceivable terrestrial ecosystem. Why is this done? After every burn, one thing becomes obvious: the almost supernatural growth these ecosystems exhibit after the burn. How? Wood vinegar is a component of this growth. Even in open burns, smoke condenses and infiltrates the soil. That is when wood vinegar shows its quality.
This stuff beefs up not only general plant growth but seed germination as well and possesses many other qualities that are beneficial to plants. It’s a pesticide, fungicide, promotes beneficial soil microorganisms, enhances nutrient uptake, and imparts disease resistance. I am barely touching a long list of attributes here, but you want wood vinegar in your soil (alongside biochar because it adsorbs wood vinegar as well).
The Internal Combustion Engine
Conversion of grazed forage to chemical, then mechanical, and then electrical energy completes the cycle. The ICE (Internal Combustion Engine) converts the gaseous fuel output from the gasifier to mechanical energy, heat, water vapor, and CO2. It’s the mechanical energy of a rotating drive shaft that we want. That rotation drives the electric generator, which is the heartbeat we need to bring this monster to life. Luckily for us, combined internal combustion engine and generator packages are ubiquitous, delivering a defined energy output given a constant fuel input. It’s the simplest part of the system.
The obvious question here is whether the amount of syngas provided by the gasification process will provide enough energy to generate enough electrons to run the entire system or not. While I have no doubt the energy produced will run Forest Walker's main systems the question is really about the electrons left over. Will it be enough to run the Bitcoin mining aspect of the system? Everything is a budget.
CO2 Production For Growth
Plants are lollipops. No matter if it’s a tree or a bush or a shrubbery, the entire thing is mostly sugar in various formats but mostly long chain carbohydrates like lignin and cellulose. Plants need three things to make sugar: CO2, H2O and light. In a forest, where tree densities can be quite high, CO2 availability becomes a limiting growth factor. It’d be in the forest interests to have more available CO2 providing for various sugar formation providing the organism with food and structure.
An odd thing about tree leaves, the openings that allow gasses like the ever searched for CO2 are on the bottom of the leaf (these are called stomata). Not many stomata are topside. This suggests that trees and bushes have evolved to find gasses like CO2 from below, not above and this further suggests CO2 might be in higher concentrations nearer the soil.
The soil life (bacterial, fungi etc.) is constantly producing enormous amounts of CO2 and it would stay in the soil forever (eventually killing the very soil life that produces it) if not for tidal forces. Water is everywhere and whether in pools, lakes, oceans or distributed in “moist” soils water moves towards to the moon. The water in the soil and also in the water tables below the soil rise toward the surface every day. When the water rises, it expels the accumulated gasses in the soil into the atmosphere and it’s mostly CO2. It’s a good bet on how leaves developed high populations of stomata on the underside of leaves. As the water relaxes (the tide goes out) it sucks oxygenated air back into the soil to continue the functions of soil life respiration. The soil “breathes” albeit slowly.
The gasses produced by the Forest Walker’s internal combustion engine consist primarily of CO2 and H2O. Combusting sugars produce the same gasses that are needed to construct the sugars because the universe is funny like that. The Forest Walker is constantly laying down these critical construction elements right where the trees need them: close to the ground to be gobbled up by the trees.
The Branch Drones
During the last ice age, giant mammals populated North America - forests and otherwise. Mastodons, woolly mammoths, rhinos, short-faced bears, steppe bison, caribou, musk ox, giant beavers, camels, gigantic ground-dwelling sloths, glyptodons, and dire wolves were everywhere. Many were ten to fifteen feet tall. As they crashed through forests, they would effectively cleave off dead side-branches of trees, halting the spread of a ground-based fire migrating into the tree crown ("laddering") which is a death knell for a forest.
These animals are all extinct now and forests no longer have any manner of pruning services. But, if we build drones fitted with cutting implements like saws and loppers, optical cameras and AI trained to discern dead branches from living ones, these drones could effectively take over pruning services by identifying, cutting, and dropping to the forest floor, dead branches. The dropped branches simply get collected by the Forest Walker as part of its continual mission.
The drones dock on the back of the Forest Walker to recharge their batteries when low. The whole scene would look like a grazing cow with some flies bothering it. This activity breaks the link between a relatively cool ground based fire and the tree crowns and is a vital element in forest fire control.
The Bitcoin Miner
Mining is one of four monetary incentive models, making this system a possibility for development. The other three are US Dept. of the Interior, township, county, and electrical utility company easement contracts for fuel load management, global carbon credits trading, and data set sales. All the above depends on obvious questions getting answered. I will list some obvious ones, but this is not an engineering document and is not the place for spreadsheets. How much Bitcoin one Forest Walker can mine depends on everything else. What amount of biomass can we process? Will that biomass flow enough Syngas to keep the lights on? Can the chassis support enough mining ASICs and supporting infrastructure? What does that weigh and will it affect field performance? How much power can the AC generator produce?
Other questions that are more philosophical persist. Even if a single Forest Walker can only mine scant amounts of BTC per day, that pales to how much fuel material it can process into biochar. We are talking about millions upon millions of forested acres in need of fuel load management. What can a single Forest Walker do? I am not thinking in singular terms. The Forest Walker must operate as a fleet. What could 50 do? 500?
What is it worth providing a service to the world by managing forest fuel loads? Providing proof of work to the global monetary system? Seeding soil with drought and nutrient resilience by the excretion, over time, of carbon by the ton? What did the last forest fire cost?
The Mesh Network
What could be better than one bitcoin mining, carbon sequestering, forest fire squelching, soil amending behemoth? Thousands of them, but then they would need to be able to talk to each other to coordinate position, data handling, etc. Fitted with a mesh networking device, like goTenna or Meshtastic LoRa equipment enables each Forest Walker to communicate with each other.
Now we have an interconnected fleet of Forest Walkers relaying data to each other and more importantly, aggregating all of that to the last link in the chain for uplink. Well, at least Bitcoin mining data. Since block data is lightweight, transmission of these data via mesh networking in fairly close quartered environs is more than doable. So, how does data transmit to the Bitcoin Network? How do the Forest Walkers get the previous block data necessary to execute on mining?
Back To The Chain
Getting Bitcoin block data to and from the network is the last puzzle piece. The standing presumption here is that wherever a Forest Walker fleet is operating, it is NOT within cell tower range. We further presume that the nearest Walmart Wi-Fi is hours away. Enter the Blockstream Satellite or something like it.
A separate, ground-based drone will have two jobs: To stay as close to the nearest Forest Walker as it can and to provide an antennae for either terrestrial or orbital data uplink. Bitcoin-centric data is transmitted to the "uplink drone" via the mesh networked transmitters and then sent on to the uplink and the whole flow goes in the opposite direction as well; many to one and one to many.
We cannot transmit data to the Blockstream satellite, and it will be up to Blockstream and companies like it to provide uplink capabilities in the future and I don't doubt they will. Starlink you say? What’s stopping that company from filtering out block data? Nothing because it’s Starlink’s system and they could decide to censor these data. It seems we may have a problem sending and receiving Bitcoin data in back country environs.
But, then again, the utility of this system in staunching the fuel load that creates forest fires is extremely useful around forested communities and many have fiber, Wi-Fi and cell towers. These communities could be a welcoming ground zero for first deployments of the Forest Walker system by the home and business owners seeking fire repression. In the best way, Bitcoin subsidizes the safety of the communities.
Sensor Packages
LiDaR
The benefit of having a Forest Walker fleet strolling through the forest is the never ending opportunity for data gathering. A plethora of deployable sensors gathering hyper-accurate data on everything from temperature to topography is yet another revenue generator. Data is valuable and the Forest Walker could generate data sales to various government entities and private concerns.
LiDaR (Light Detection and Ranging) can map topography, perform biomass assessment, comparative soil erosion analysis, etc. It so happens that the Forest Walker’s ability to “see,” to navigate about its surroundings, is LiDaR driven and since it’s already being used, we can get double duty by harvesting that data for later use. By using a laser to send out light pulses and measuring the time it takes for the reflection of those pulses to return, very detailed data sets incrementally build up. Eventually, as enough data about a certain area becomes available, the data becomes useful and valuable.
Forestry concerns, both private and public, often use LiDaR to build 3D models of tree stands to assess the amount of harvest-able lumber in entire sections of forest. Consulting companies offering these services charge anywhere from several hundred to several thousand dollars per square kilometer for such services. A Forest Walker generating such assessments on the fly while performing its other functions is a multi-disciplinary approach to revenue generation.
pH, Soil Moisture, and Cation Exchange Sensing
The Forest Walker is quadrupedal, so there are four contact points to the soil. Why not get a pH data point for every step it takes? We can also gather soil moisture data and cation exchange capacities at unheard of densities because of sampling occurring on the fly during commission of the system’s other duties. No one is going to build a machine to do pH testing of vast tracts of forest soils, but that doesn’t make the data collected from such an endeavor valueless. Since the Forest Walker serves many functions at once, a multitude of data products can add to the return on investment component.
Weather Data
Temperature, humidity, pressure, and even data like evapotranspiration gathered at high densities on broad acre scales have untold value and because the sensors are lightweight and don’t require large power budgets, they come along for the ride at little cost. But, just like the old mantra, “gas, grass, or ass, nobody rides for free”, these sensors provide potential revenue benefits just by them being present.
I’ve touched on just a few data genres here. In fact, the question for universities, governmental bodies, and other institutions becomes, “How much will you pay us to attach your sensor payload to the Forest Walker?”
Noise Suppression
Only you can prevent Metallica filling the surrounds with 120 dB of sound. Easy enough, just turn the car stereo off. But what of a fleet of 50 Forest Walkers operating in the backcountry or near a township? 500? 5000? Each one has a wood chipper, an internal combustion engine, hydraulic pumps, actuators, and more cooling fans than you can shake a stick at. It’s a walking, screaming fire-breathing dragon operating continuously, day and night, twenty-four hours a day, three hundred sixty-five days a year. The sound will negatively affect all living things and that impacts behaviors. Serious engineering consideration and prowess must deliver a silencing blow to the major issue of noise.
It would be foolish to think that a fleet of Forest Walkers could be silent, but if not a major design consideration, then the entire idea is dead on arrival. Townships would not allow them to operate even if they solved the problem of widespread fuel load and neither would governmental entities, and rightly so. Nothing, not man nor beast, would want to be subjected to an eternal, infernal scream even if it were to end within days as the fleet moved further away after consuming what it could. Noise and heat are the only real pollutants of this system; taking noise seriously from the beginning is paramount.
Fire Safety
A “fire-breathing dragon” is not the worst description of the Forest Walker. It eats wood, combusts it at very high temperatures and excretes carbon; and it does so in an extremely flammable environment. Bad mix for one Forest Walker, worse for many. One must take extreme pains to ensure that during normal operation, a Forest Walker could fall over, walk through tinder dry brush, or get pounded into the ground by a meteorite from Krypton and it wouldn’t destroy epic swaths of trees and baby deer. I envision an ultimate test of a prototype to include dowsing it in grain alcohol while it’s wrapped up in toilet paper like a pledge at a fraternity party. If it runs for 72 hours and doesn’t set everything on fire, then maybe outside entities won’t be fearful of something that walks around forests with a constant fire in its belly.
The Wrap
How we think about what can be done with and adjacent to Bitcoin is at least as important as Bitcoin’s economic standing itself. For those who will tell me that this entire idea is without merit, I say, “OK, fine. You can come up with something, too.” What can we plug Bitcoin into that, like a battery, makes something that does not work, work? That’s the lesson I get from this entire exercise. No one was ever going to hire teams of humans to go out and "clean the forest". There's no money in that. The data collection and sales from such an endeavor might provide revenues over the break-even point but investment demands Alpha in this day and age. But, plug Bitcoin into an almost viable system and, voilà! We tip the scales to achieve lift-off.
Let’s face it, we haven’t scratched the surface of Bitcoin’s forcing function on our minds. Not because it’s Bitcoin, but because of what that invention means. The question that pushes me to approach things this way is, “what can we create that one system’s waste is another system’s feedstock?” The Forest Walker system’s only real waste is the conversion of low entropy energy (wood and syngas) into high entropy energy (heat and noise). All other output is beneficial to humanity.
Bitcoin, I believe, is the first product of a new mode of human imagination. An imagination newly forged over the past few millennia of being lied to, stolen from, distracted and otherwise mis-allocated to a black hole of the nonsensical. We are waking up.
What I have presented is not science fiction. Everything I have described here is well within the realm of possibility. The question is one of viability, at least in terms of the detritus of the old world we find ourselves departing from. This system would take a non-trivial amount of time and resources to develop. I think the system would garner extensive long-term contracts from those who have the most to lose from wildfires, the most to gain from hyperaccurate data sets, and, of course, securing the most precious asset in the world. Many may not see it that way, for they seek Alpha and are therefore blind to other possibilities. Others will see only the possibilities; of thinking in a new way, of looking at things differently, and dreaming of what comes next.
-
@ f6488c62:c929299d
2025-05-23 09:48:20
ในวันที่ 23 พฤษภาคม 2568 The Wall Street Journal รายงานข่าวที่น่าสนใจว่า ธนาคารยักษ์ใหญ่ของสหรัฐฯ เช่น JPMorgan Chase, Bank of America, Citigroup และ Wells Fargo กำลังพิจารณาความเป็นไปได้ในการพัฒนา Stablecoin ร่วมกัน เพื่อก้าวเข้าสู่โลกของคริปโตเคอเรนซีอย่างเต็มตัว การเคลื่อนไหวครั้งนี้ไม่เพียงสะท้อนถึงการยอมรับสินทรัพย์ดิจิทัลในระบบการเงินกระแสหลัก แต่ยังเป็นก้าวสำคัญในการรักษาความเป็นผู้นำของเงินดอลลาร์สหรัฐในยุคการเงินดิจิทัล.
Stablecoin: อนาคตของการชำระเงินดิจิทัล Stablecoin เป็นสกุลเงินดิจิทัลที่ออกแบบมาเพื่อลดความผันผวนโดยผูกมูลค่ากับสินทรัพย์ที่มีเสถียรภาพ เช่น เงินดอลลาร์สหรัฐ ทำให้เหมาะสำหรับการใช้ในระบบการชำระเงิน การโอนเงินข้ามพรมแดน และการเงินแบบกระจายศูนย์ (DeFi). การที่ธนาคารใหญ่ของสหรัฐฯ หันมาสนใจ Stablecoin ร่วมกัน แสดงถึงความพยายามในการปรับตัวให้เข้ากับความต้องการของผู้บริโภคยุคใหม่ที่ต้องการความรวดเร็วและประหยัดต้นทุนในการทำธุรกรรมทางการเงิน.
ทำไมธนาคารถึงสนใจ Stablecoin? ในปี 2568 ตลาดคริปโตเคอเรนซีกำลังร้อนแรง โดยมูลค่าตลาดรวมของคริปโตทั่วโลกอยู่ที่ 3.64 ล้านล้านดอลลาร์ ซึ่งในจำนวนนี้ Bitcoin มีมูลค่าตลาดสูงสุดที่ 2.2 ล้านล้านดอลลาร์ และราคา Bitcoin ล่าสุดพุ่งแตะ 111,160.66 ดอลลาร์ (ข้อมูล ณ วันที่ 23 พฤษภาคม 2568 เวลา 16:44 น. ตามเขตเวลา +07) นอกจากนี้ ยังมีเม็ดเงินไหลเข้าสู่กองทุนสินทรัพย์ดิจิทัลในสหรัฐฯ กว่า 7.5 พันล้านดอลลาร์ การที่ธนาคารยักษ์ใหญ่ที่มีมูลค่ารวมกันถึง 8 ล้านล้านดอลลาร์เข้ามาในสนามนี้ แสดงถึงศักยภาพในการเปลี่ยนแปลงภูมิทัศน์ของอุตสาหกรรมการเงิน. นโยบายที่เอื้ออำนวยต่อคริปโตในยุคของประธานาธิบดีโดนัลด์ ทรัมป์ และการลดดอกเบี้ยนโยบายของ Fed ยังเป็นปัจจัยสนับสนุนที่สำคัญ.
โอกาสและความท้าทาย การพัฒนา Stablecoin ร่วมกันของธนาคารเหล่านี้เปิดโอกาสให้สหรัฐฯ รักษาความเป็นผู้นำในระบบการเงินดิจิทัล และเพิ่มประสิทธิภาพในระบบการชำระเงินทั่วโลก อย่างไรก็ตาม ความท้าทายที่รออยู่คือการแข่งขันกับ Stablecoin ที่ครองตลาด เช่น USDT และ USDC รวมถึงความไม่แน่นอนด้านกฎระเบียบและความผันผวนของเศรษฐกิจโลกจากนโยบายการค้าของสหรัฐฯ. ธนาคารจะต้องลงทุนในโครงสร้างพื้นฐานที่ปลอดภัยและสอดคล้องกับกฎหมาย เพื่อสร้างความไว้วางใจจากผู้ใช้.
มองไปข้างหน้า การที่ธนาคารชั้นนำของสหรัฐฯ หันมาสนใจ Stablecoin เป็นสัญญาณที่ชัดเจนว่าโลกการเงินกำลังเปลี่ยนผ่านสู่ยุคดิจิทัลอย่างเต็มรูปแบบ การเคลื่อนไหวครั้งนี้อาจเป็นจุดเปลี่ยนที่ทำให้คริปโตเคอเรนซีกลายเป็นส่วนสำคัญของระบบการเงินกระแสหลัก อย่างไรก็ตาม ความสำเร็จจะขึ้นอยู่กับความสามารถในการสร้างนวัตกรรมที่ตอบโจทย์ผู้บริโภคและการจัดการกับความท้าทายด้านกฎระเบียบและการแข่งขันในตลาด. ในอนาคตอันใกล้ Stablecoin จากธนาคารยักษ์ใหญ่อาจกลายเป็นตัวเปลี่ยนเกมในวงการการเงินโลก และเป็นเครื่องมือสำคัญในการเชื่อมโยงระบบการเงินแบบดั้งเดิมเข้ากับโลกดิจิทัล นักลงทุนและผู้บริโภคควรจับตาดูความคืบหน้าของโครงการนี้อย่างใกล้ชิด เพราะมันอาจเป็นก้าวแรกสู่การปฏิวัติครั้งใหญ่ในวงการการเงิน.
-
@ 3eba5ef4:751f23ae
2025-05-23 09:33:55
The article below brings together some of the Q&A from our recent AMA on Reddit. Thanks so much for sending in your questions—we love chatting with you and being part of this awesome community!
Meepo Hardfork Features
What does Meepo bring to CKB, in simple terms?
Imagine upgrading from wooden blocks to LEGO bricks. That’s what the
spawnsyscall in Meepo does for CKB smart contracts, enabling script interoperability.Spawn and a series of related syscalls are introduced as a major upgrade to CKB-VM, enabling interoperability, modularity, and better developer experience, by letting scripts call other scripts, like modular apps in an operating system.
Key features of the upgraded VM?
The upgraded CKB-VM Meepo version unlocks true decoupling and reuse of CKB scripts, enhancing modularity and reusability in smart contract development.
For instance, before Meepo, if developers wanted to build a new time lock in CKB, they had to bundle all necessary functionalities—like signature algorithms—directly into a single lock or type script. This often led to bloated scripts where most of the code was unrelated to the developer's original design goal (time lock). With the spawn syscall, scripts can now delegate tasks—such as signature checks—to other on-chain scripts. As new algorithms emerge, the time lock can adopt them without being redeployed—just by calling updated signature scripts, as long as a shared protocol is followed.
This separation allows developers to: - Focus solely on their core logic. - Reuse independently deployed signature verification scripts. - Upgrade cryptographic components without modifying the original script. - Embrace a more OS-like model where smart contracts can call each other to perform specialized tasks.
By enabling true decoupling and reuse, the spawn syscall makes CKB scripts significantly more composable, maintainable, and adaptable.
Besides Spawn, other improvements in Meepo include:
- Block Extension Fields: Enables reading extension fields in blocks, opening new possibilities like community voting on hardforks (as this ckb-zero-lock prototype). More use cases are expected.
- CKB-VM Optimization: Reduces cycle consumption for common compiler-generated code, making scripts faster and more efficient.
A practical example: IPC on Spawn
Here's an example building an entire Inter-Process Communication (IPC) layer on top of spawn syscalls: - GitHub Repo - Blog post: Transforming IPC in CKB On-Chain Script: Spawn and the Custom Library for Simplified Communication
What does “every wallet will become a CKB wallet because of ckb-auth” mean?
Current CKB-VM already comes with the power to build omnilock / ckb-auth, spawn just makes them easier to reuse in new scripts through decoupling and improved modularity.
Upgrade Compatibility Concerns
Will Meepo require a new address format?
No. Meepo does not introduce breaking changes like address format switching. The only required upgrade is support for a new hash type (
data2). We aim to keep upgrades smooth and backwards-compatible wherever possible.RISC-V & CKB’s Long-Term Design Philosophy
Ethereum is exploring RISC-V—CKB has been doing this for years. What’s your take?
The discussion about RISC-V in Ethereum, is partly about the ease of building zk solutions on Ethereum. And it's easy to mix two different use cases of RISC-V in zk:
- Use RISC-V as the language to write programs running in a zk engine. In this case, we use zero knowledge algorithms to build a RISC-VM and prove programs running inside these RISC-V VMs.
- Use RISC-V as the underlying engine to run cryptographic algorithms, we then compile the verifier / prover code of zero knowledge algorithm into RISC-V, then we run those verifiers / provers inside RISC-V. Essentially, we run the verifying / proving algorithms of zero knowledge algorithms in RISC-V, the programs running inside ZK VMs can be written in other languages suiting the zk algorithms.
When most people talk about RISC-V in zk, they mean the first point above. As a result, we see a lot of arguments debating if RISC-V fits in zk circuits. I couldn't get a direct confirmation from Vitalik, but based on what I read, when Vitalik proposes the idea of RISC-V in Ethereum, he's at least partly thinking about the second point here. The original idea is to introduce RISC-V in Ethereum, so we can just compile zk verifiers / provers into RISC-V code, so there is no need to introduce any more precompiles so as to support different zk algorithms in Ethereum. This is indeed a rare taken path, but I believe it is a right path, it is also the path CKB chose 7 years ago for the initial design of CKB-VM.
CKB believes that a precompile-free approach is the only viable path if we’re serious about building a blockchain that can last for decades—or even centuries. Cryptographic algorithms evolve quickly; new ones emerge every few years, making it unsustainable for blockchains to keep adding them as precompiles. In contrast, hardware evolves more slowly and lives longer.
By choosing RISC-V, we’ve committed to a model that can better adapt to future cryptographic developments. CKB may be on an uncommon path, but I believe it's the right one—and it's encouraging to see Ethereum now moving in a similar direction. Hopefully, more will follow.
CKB already stands out as the only blockchain VM built on RISC-V and entirely free from cryptographic precompiles. Meepo, with its spawn syscall, builds on this foundation—pushing for even greater modularity and reuse. We're also closely watching progress in the RISC-V ecosystem, with the goal of integrating hardware advances into CKB-VM, making it even more future-proof and a state-of-the-art execution environment for blockchain applications.
Will CKB run directly on RISC-V chips? What are the implications?
The "CKB on RISC-V"comes in several stages:
- For now, CKB-VM can already be compiled into RISC-V architecture and run on a RISC-V CPU (e.g. StarFive board), though optimized native implementations are still in development.
- That said, one key issue in the previous stage was that CKB-VM lacks a high-performance, assembly based VM on RISC-V architecture. Ironically, despite CKB-VM being based on RISC-V, we ended up running a Rust-based VM interpreter on RISC-V CPUs—which is far from ideal.
The root of the problem is that RISC-V CPUs come in many configurations, each supporting a different set of extensions. Porting CKB-VM to run natively on real RISC-V chips isn’t trivial—some extensions used by CKB-VM might not be available on the target hardware. With enough time and effort, a performant native implementation could be built, but it’s a non-trivial challenge that still needs significant work.
How do you see the RISC-V narrative expanding?
We are delighted to see the growing recognition of RISC-V in the blockchain space. For CKB, we firmly believe RISC-V is the best choice. Consensus is costly, so only essential data should be on-chain, with the chain serving as a universal verification layer—this is CKBʼs philosophy, and we have consistently designed and developed in this direction.
CKB Roadmap & Ecosystem Growth
Any plan to boost the usage of the CKB network in the next 6 - 24 months?
Growth starts with better developer experience. Spawn in Meepo significantly lowers the barrier to building complex apps. With better tools and documentation, more devs can experiment on CKB, leading to better apps and more users.
What would you focus on if the secondary issuance budget was huge?
If funding were abundant, we'd expand the Spark Program, support more grassroots projects, and even evolve toward a fully decentralized DAO structure—aligning with our long-term vision of a permissionless, community-owned network.
What’s next for Nervos after Meepo?
We're exploring new RISC-V extensions like CFI, which could boost script security and defend against ROP attacks. Still early-stage, but promising. Check out this: Against ROP Attacks: A Blockchain Architect’s Take on VM-Level Security.
Resources
Take a deeper look at the VM upgrades introduced in the Meepo hardfork:
Explore the CFI (Control Flow Integrity) extension on RISC-V:
Check out the Inter-Process Communication (IPC) layer built on top of spawn syscalls:
-
@ b0a838f2:34ed3f19
2025-05-23 17:57:02
- Chibisafe - File uploader service that aims to to be easy to use and set up. It accepts files, photos, documents, anything you imagine and gives you back a shareable link for you to send to others. (Source Code)
MITDocker/Nodejs - Digirecord - Record and share audio files (documentation in French). (Source Code)
AGPL-3.0Nodejs/PHP - elixire - Simple yet advanced screenshot uploading and link shortening service. (Clients)
AGPL-3.0Python - Enclosed - Minimalistic web application designed for sending private and secure notes. (Demo, Source Code)
Apache-2.0Docker/Nodejs - Files Sharing - File sharing application based on unique and temporary links.
GPL-3.0PHP/Docker - Gokapi - Lightweight server to share files, which expire after a set amount of downloads or days. Similar to the discontinued Firefox Send, with the difference that only the admin is allowed to upload files.
GPL-3.0Go/Docker - goploader - Easy file sharing with server-side encryption, curl/httpie/wget compliant. (Source Code)
MITGo - GoSƐ - Modern file-uploader focusing on scalability and simplicity. It only depends on a S3 storage backend and hence scales horizontally without the need for additional databases or caches.
Apache-2.0Go/Docker - OnionShare - Securely and anonymously share a file of any size.
GPL-3.0Python/deb - Pairdrop - Local file sharing in your browser, inspired by Apple's AirDrop (fork of Snapdrop). (Source Code)
GPL-3.0Docker - PicoShare - Minimalist, easy-to-host service for sharing images and other files. (Demo, Source Code)
AGPL-3.0Go/Docker - Picsur - Simple imaging hosting platform that allows you to easily host, edit, and share images. (Demo)
AGPL-3.0Docker - PictShare - Multi lingual image hosting service with a simple resizing and upload API. (Source Code)
Apache-2.0PHP/Docker - Pingvin Share - File sharing platform that combines lightness and beauty, perfect for seamless and efficient file sharing. (Demo)
BSD-2-ClauseDocker/Nodejs - Plik - Scalable and friendly temporary file upload system. (Demo)
MITGo/Docker - ProjectSend - Upload files and assign them to specific clients you create. Give access to those files to your clients. (Source Code)
GPL-2.0PHP - PsiTransfer - Simple file sharing solution with robust up-/download-resume and password protection.
BSD-2-ClauseNodejs - QuickShare - Quick and simple file sharing between different devices. (Source Code)
LGPL-3.0Docker/Go - Sharry - Share files easily over the internet between authenticated and anonymous users (both ways) with resumable up- and downloads.
GPL-3.0Scala/Java/deb/Docker - Shifter - A simple, self-hosted file-sharing web app, powered by Django.
MITDocker - Slink - Image sharing platform designed to give users complete control over their media sharing experience. (Source Code)
AGPL-3.0Docker - transfer.sh - Easy file sharing from the command line.
MITGo - Uguu - Stores files and deletes after X amount of time.
MITPHP - Uploady - Uploady is a simple file uploader script with multi file upload support.
MITPHP - XBackBone - A simple, fast and lightweight file manager with instant sharing tools integration, like ShareX (a free and open-source screenshot utility for Windows). (Source Code)
AGPL-3.0PHP/Docker - Zipline - A lightweight, fast and reliable file sharing server that is commonly used with ShareX, offering a react-based Web UI and fast API.
MITDocker/Nodejs
- Chibisafe - File uploader service that aims to to be easy to use and set up. It accepts files, photos, documents, anything you imagine and gives you back a shareable link for you to send to others. (Source Code)
-
@ a3c6f928:d45494fb
2025-05-23 09:01:16
As artificial intelligence becomes more embedded in our lives, it reshapes the way we understand and exercise freedom. AI holds immense potential to enhance liberty—by automating tasks, expanding access to information, and enabling personalized experiences. Yet it also introduces complex challenges that demand careful consideration.
The Promises of AI for Freedom
-
Empowerment through Information: AI democratizes knowledge by curating and delivering information more effectively than ever before. This helps individuals make informed decisions and engage more deeply with society.
-
Efficiency and Liberation: By handling repetitive tasks, AI frees humans to focus on creativity, strategic thinking, and emotional intelligence—areas where freedom of thought thrives.
-
Accessibility and Inclusion: AI-powered tools can break down barriers for people with disabilities, improve language translation, and provide personalized education—broadening freedom for all.
Risks and Responsibilities
-
Surveillance and Privacy: When AI is used for mass surveillance, it threatens personal freedom and autonomy. The right to privacy must be protected.
-
Bias and Discrimination: AI systems can reflect and amplify societal biases, leading to unfair outcomes. Ensuring fairness and transparency is crucial.
-
Autonomy and Control: As AI makes more decisions on our behalf, we risk ceding control. Freedom means preserving human agency in AI-driven systems.
Building an Ethical AI Future
-
Transparent Design: Developers must prioritize clarity and accountability in how AI systems make decisions.
-
Inclusive Development: Involving diverse voices ensures AI serves all communities, not just a privileged few.
-
Regulation and Oversight: Thoughtful policy can protect rights while fostering innovation.
The Road Ahead
AI is neither inherently liberating nor oppressive—it depends on how we use it. The challenge before us is to shape AI in ways that support freedom rather than constrain it. This requires vision, vigilance, and values.
“Technology is a useful servant but a dangerous master.” — Christian Lous Lange
Let’s ensure AI remains a tool for expanding freedom, not restricting it.
-
-
@ e3ba5e1a:5e433365
2025-01-13 16:47:27
My blog posts and reading material have both been on a decidedly economics-heavy slant recently. The topic today, incentives, squarely falls into the category of economics. However, when I say economics, I’m not talking about “analyzing supply and demand curves.” I’m talking about the true basis of economics: understanding how human beings make decisions in a world of scarcity.
A fair definition of incentive is “a reward or punishment that motivates behavior to achieve a desired outcome.” When most people think about economic incentives, they’re thinking of money. If I offer my son $5 if he washes the dishes, I’m incentivizing certain behavior. We can’t guarantee that he’ll do what I want him to do, but we can agree that the incentive structure itself will guide and ultimately determine what outcome will occur.
The great thing about monetary incentives is how easy they are to talk about and compare. “Would I rather make $5 washing the dishes or $10 cleaning the gutters?” But much of the world is incentivized in non-monetary ways too. For example, using the “punishment” half of the definition above, I might threaten my son with losing Nintendo Switch access if he doesn’t wash the dishes. No money is involved, but I’m still incentivizing behavior.
And there are plenty of incentives beyond our direct control! My son is also incentivized to not wash dishes because it’s boring, or because he has some friends over that he wants to hang out with, or dozens of other things. Ultimately, the conflicting array of different incentive structures placed on him will ultimately determine what actions he chooses to take.
Why incentives matter
A phrase I see often in discussions—whether they are political, parenting, economic, or business—is “if they could just do…” Each time I see that phrase, I cringe a bit internally. Usually, the underlying assumption of the statement is “if people would behave contrary to their incentivized behavior then things would be better.” For example:
- If my kids would just go to bed when I tell them, they wouldn’t be so cranky in the morning.
- If people would just use the recycling bin, we wouldn’t have such a landfill problem.
- If people would just stop being lazy, our team would deliver our project on time.
In all these cases, the speakers are seemingly flummoxed as to why the people in question don’t behave more rationally. The problem is: each group is behaving perfectly rationally.
- The kids have a high time preference, and care more about the joy of staying up now than the crankiness in the morning. Plus, they don’t really suffer the consequences of morning crankiness, their parents do.
- No individual suffers much from their individual contribution to a landfill. If they stopped growing the size of the landfill, it would make an insignificant difference versus the amount of effort they need to engage in to properly recycle.
- If a team doesn’t properly account for the productivity of individuals on a project, each individual receives less harm from their own inaction. Sure, the project may be delayed, company revenue may be down, and they may even risk losing their job when the company goes out of business. But their laziness individually won’t determine the entirety of that outcome. By contrast, they greatly benefit from being lazy by getting to relax at work, go on social media, read a book, or do whatever else they do when they’re supposed to be working.

My point here is that, as long as you ignore the reality of how incentives drive human behavior, you’ll fail at getting the outcomes you want.
If everything I wrote up until now made perfect sense, you understand the premise of this blog post. The rest of it will focus on a bunch of real-world examples to hammer home the point, and demonstrate how versatile this mental model is.
Running a company
Let’s say I run my own company, with myself as the only employee. My personal revenue will be 100% determined by my own actions. If I decide to take Tuesday afternoon off and go fishing, I’ve chosen to lose that afternoon’s revenue. Implicitly, I’ve decided that the enjoyment I get from an afternoon of fishing is greater than the potential revenue. You may think I’m being lazy, but it’s my decision to make. In this situation, the incentive–money–is perfectly aligned with my actions.
Compare this to a typical company/employee relationship. I might have a bank of Paid Time Off (PTO) days, in which case once again my incentives are relatively aligned. I know that I can take off 15 days throughout the year, and I’ve chosen to use half a day for the fishing trip. All is still good.
What about unlimited time off? Suddenly incentives are starting to misalign. I don’t directly pay a price for not showing up to work on Tuesday. Or Wednesday as well, for that matter. I might ultimately be fired for not doing my job, but that will take longer to work its way through the system than simply not making any money for the day taken off.
Compensation overall falls into this misaligned incentive structure. Let’s forget about taking time off. Instead, I work full time on a software project I’m assigned. But instead of using the normal toolchain we’re all used to at work, I play around with a new programming language. I get the fun and joy of playing with new technology, and potentially get to pad my resume a bit when I’m ready to look for a new job. But my current company gets slower results, less productivity, and is forced to subsidize my extracurricular learning.
When a CEO has a bonus structure based on profitability, he’ll do everything he can to make the company profitable. This might include things that actually benefit the company, like improving product quality, reducing internal red tape, or finding cheaper vendors. But it might also include destructive practices, like slashing the R\&D budget to show massive profits this year, in exchange for a catastrophe next year when the next version of the product fails to ship.

Or my favorite example. My parents owned a business when I was growing up. They had a back office where they ran operations like accounting. All of the furniture was old couches from our house. After all, any money they spent on furniture came right out of their paychecks! But in a large corporate environment, each department is generally given a budget for office furniture, a budget which doesn’t roll over year-to-year. The result? Executives make sure to spend the entire budget each year, often buying furniture far more expensive than they would choose if it was their own money.
There are plenty of details you can quibble with above. It’s in a company’s best interest to give people downtime so that they can come back recharged. Having good ergonomic furniture can in fact increase productivity in excess of the money spent on it. But overall, the picture is pretty clear: in large corporate structures, you’re guaranteed to have mismatches between the company’s goals and the incentive structure placed on individuals.
Using our model from above, we can lament how lazy, greedy, and unethical the employees are for doing what they’re incentivized to do instead of what’s right. But that’s simply ignoring the reality of human nature.
Moral hazard
Moral hazard is a situation where one party is incentivized to take on more risk because another party will bear the consequences. Suppose I tell my son when he turns 21 (or whatever legal gambling age is) that I’ll cover all his losses for a day at the casino, but he gets to keep all the winnings.
What do you think he’s going to do? The most logical course of action is to place the largest possible bets for as long as possible, asking me to cover each time he loses, and taking money off the table and into his bank account each time he wins.

But let’s look at a slightly more nuanced example. I go to a bathroom in the mall. As I’m leaving, I wash my hands. It will take me an extra 1 second to turn off the water when I’m done washing. That’s a trivial price to pay. If I don’t turn off the water, the mall will have to pay for many liters of wasted water, benefiting no one. But I won’t suffer any consequences at all.
This is also a moral hazard, but most people will still turn off the water. Why? Usually due to some combination of other reasons such as:
- We’re so habituated to turning off the water that we don’t even consider not turning it off. Put differently, the mental effort needed to not turn off the water is more expensive than the 1 second of time to turn it off.
- Many of us have been brought up with a deep guilt about wasting resources like water. We have an internal incentive structure that makes the 1 second to turn off the water much less costly than the mental anguish of the waste we created.
- We’re afraid we’ll be caught by someone else and face some kind of social repercussions. (Or maybe more than social. Are you sure there isn’t a law against leaving the water tap on?)
Even with all that in place, you may notice that many public bathrooms use automatic water dispensers. Sure, there’s a sanitation reason for that, but it’s also to avoid this moral hazard.
A common denominator in both of these is that the person taking the action that causes the liability (either the gambling or leaving the water on) is not the person who bears the responsibility for that liability (the father or the mall owner). Generally speaking, the closer together the person making the decision and the person incurring the liability are, the smaller the moral hazard.
It’s easy to demonstrate that by extending the casino example a bit. I said it was the father who was covering the losses of the gambler. Many children (though not all) would want to avoid totally bankrupting their parents, or at least financially hurting them. Instead, imagine that someone from the IRS shows up at your door, hands you a credit card, and tells you you can use it at a casino all day, taking home all the chips you want. The money is coming from the government. How many people would put any restriction on how much they spend?
And since we’re talking about the government already…
Government moral hazards
As I was preparing to write this blog post, the California wildfires hit. The discussions around those wildfires gave a huge number of examples of moral hazards. I decided to cherry-pick a few for this post.
The first and most obvious one: California is asking for disaster relief funds from the federal government. That sounds wonderful. These fires were a natural disaster, so why shouldn’t the federal government pitch in and help take care of people?
The problem is, once again, a moral hazard. In the case of the wildfires, California and Los Angeles both had ample actions they could have taken to mitigate the destruction of this fire: better forest management, larger fire department, keeping the water reservoirs filled, and probably much more that hasn’t come to light yet.
If the federal government bails out California, it will be a clear message for the future: your mistakes will be fixed by others. You know what kind of behavior that incentivizes? More risky behavior! Why spend state funds on forest management and extra firefighters—activities that don’t win politicians a lot of votes in general—when you could instead spend it on a football stadium, higher unemployment payments, or anything else, and then let the feds cover the cost of screw-ups.
You may notice that this is virtually identical to the 2008 “too big to fail” bail-outs. Wall Street took insanely risky behavior, reaped huge profits for years, and when they eventually got caught with their pants down, the rest of us bailed them out. “Privatizing profits, socializing losses.”

And here’s the absolute best part of this: I can’t even truly blame either California or Wall Street. (I mean, I do blame them, I think their behavior is reprehensible, but you’ll see what I mean.) In a world where the rules of the game implicitly include the bail-out mentality, you would be harming your citizens/shareholders/investors if you didn’t engage in that risky behavior. Since everyone is on the hook for those socialized losses, your best bet is to maximize those privatized profits.
There’s a lot more to government and moral hazard, but I think these two cases demonstrate the crux pretty solidly. But let’s leave moral hazard behind for a bit and get to general incentivization discussions.
Non-monetary competition
At least 50% of the economics knowledge I have comes from the very first econ course I took in college. That professor was amazing, and had some very colorful stories. I can’t vouch for the veracity of the two I’m about to share, but they definitely drive the point home.
In the 1970s, the US had an oil shortage. To “fix” this problem, they instituted price caps on gasoline, which of course resulted in insufficient gasoline. To “fix” this problem, they instituted policies where, depending on your license plate number, you could only fill up gas on certain days of the week. (Irrelevant detail for our point here, but this just resulted in people filling up their tanks more often, no reduction in gas usage.)
Anyway, my professor’s wife had a friend. My professor described in great detail how attractive this woman was. I’ll skip those details here since this is a PG-rated blog. In any event, she never had any trouble filling up her gas tank any day of the week. She would drive up, be told she couldn’t fill up gas today, bat her eyes at the attendant, explain how helpless she was, and was always allowed to fill up gas.
This is a demonstration of non-monetary compensation. Most of the time in a free market, capitalist economy, people are compensated through money. When price caps come into play, there’s a limit to how much monetary compensation someone can receive. And in that case, people find other ways of competing. Like this woman’s case: through using flirtatious behavior to compensate the gas station workers to let her cheat the rules.
The other example was much more insidious. Santa Monica had a problem: it was predominantly wealthy and white. They wanted to fix this problem, and decided to put in place rent controls. After some time, they discovered that Santa Monica had become wealthier and whiter, the exact opposite of their desired outcome. Why would that happen?
Someone investigated, and ended up interviewing a landlady that demonstrated the reason. She was an older white woman, and admittedly racist. Prior to the rent controls, she would list her apartments in the newspaper, and would be legally obligated to rent to anyone who could afford it. Once rent controls were in place, she took a different tact. She knew that she would only get a certain amount for the apartment, and that the demand for apartments was higher than the supply. That meant she could be picky.
She ended up finding tenants through friends-of-friends. Since it wasn’t an official advertisement, she wasn’t legally required to rent it out if someone could afford to pay. Instead, she got to interview people individually and then make them an offer. Normally, that would have resulted in receiving a lower rental price, but not under rent controls.
So who did she choose? A young, unmarried, wealthy, white woman. It made perfect sense. Women were less intimidating and more likely to maintain the apartment better. Wealthy people, she determined, would be better tenants. (I have no idea if this is true in practice or not, I’m not a landlord myself.) Unmarried, because no kids running around meant less damage to the property. And, of course, white. Because she was racist, and her incentive structure made her prefer whites.
You can deride her for being racist, I won’t disagree with you. But it’s simply the reality. Under the non-rent-control scenario, her profit motive for money outweighed her racism motive. But under rent control, the monetary competition was removed, and she was free to play into her racist tendencies without facing any negative consequences.
Bureaucracy
These were the two examples I remember for that course. But non-monetary compensation pops up in many more places. One highly pertinent example is bureaucracies. Imagine you have a government office, or a large corporation’s acquisition department, or the team that apportions grants at a university. In all these cases, you have a group of people making decisions about handing out money that has no monetary impact on them. If they give to the best qualified recipients, they receive no raises. If they spend the money recklessly on frivolous projects, they face no consequences.
Under such an incentivization scheme, there’s little to encourage the bureaucrats to make intelligent funding decisions. Instead, they’ll be incentivized to spend the money where they recognize non-monetary benefits. This is why it’s so common to hear about expensive meals, gift bags at conferences, and even more inappropriate ways of trying to curry favor with those that hold the purse strings.
Compare that ever so briefly with the purchases made by a small mom-and-pop store like my parents owned. Could my dad take a bribe to buy from a vendor who’s ripping him off? Absolutely he could! But he’d lose more on the deal than he’d make on the bribe, since he’s directly incentivized by the deal itself. It would make much more sense for him to go with the better vendor, save $5,000 on the deal, and then treat himself to a lavish $400 meal to celebrate.
Government incentivized behavior
This post is getting longer in the tooth than I’d intended, so I’ll finish off with this section and make it a bit briefer. Beyond all the methods mentioned above, government has another mechanism for modifying behavior: through directly changing incentives via legislation, regulation, and monetary policy. Let’s see some examples:
- Artificial modification of interest rates encourages people to take on more debt than they would in a free capital market, leading to malinvestment and a consumer debt crisis, and causing the boom-bust cycle we all painfully experience.
- Going along with that, giving tax breaks on interest payments further artificially incentivizes people to take on debt that they wouldn’t otherwise.
- During COVID-19, at some points unemployment benefits were greater than minimum wage, incentivizing people to rather stay home and not work than get a job, leading to reduced overall productivity in the economy and more printed dollars for benefits. In other words, it was a perfect recipe for inflation.
- The tax code gives deductions to “help” people. That might be true, but the real impact is incentivizing people to make decisions they wouldn’t have otherwise. For example, giving out tax deductions on children encourages having more kids. Tax deductions on childcare and preschools incentivizes dual-income households. Whether or not you like the outcomes, it’s clear that it’s government that’s encouraging these outcomes to happen.
- Tax incentives cause people to engage in behavior they wouldn’t otherwise (daycare+working mother, for example).
- Inflation means that the value of your money goes down over time, which encourages people to spend more today, when their money has a larger impact. (Milton Friedman described this as high living.)
Conclusion
The idea here is simple, and fully encapsulated in the title: incentives determine outcomes. If you want to know how to get a certain outcome from others, incentivize them to want that to happen. If you want to understand why people act in seemingly irrational ways, check their incentives. If you’re confused why leaders (and especially politicians) seem to engage in destructive behavior, check their incentives.
We can bemoan these realities all we want, but they are realities. While there are some people who have a solid internal moral and ethical code, and that internal code incentivizes them to behave against their externally-incentivized interests, those people are rare. And frankly, those people are self-defeating. People should take advantage of the incentives around them. Because if they don’t, someone else will.
(If you want a literary example of that last comment, see the horse in Animal Farm.)
How do we improve the world under these conditions? Make sure the incentives align well with the overall goals of society. To me, it’s a simple formula:
- Focus on free trade, value for value, as the basis of a society. In that system, people are always incentivized to provide value to other people.
- Reduce the size of bureaucracies and large groups of all kinds. The larger an organization becomes, the farther the consequences of decisions are from those who make them.
- And since the nature of human beings will be to try and create areas where they can control the incentive systems to their own benefits, make that as difficult as possible. That comes in the form of strict limits on government power, for example.
And even if you don’t want to buy in to this conclusion, I hope the rest of the content was educational, and maybe a bit entertaining!
-
@ b0a838f2:34ed3f19
2025-05-23 17:56:45
- bittorrent-tracker - Simple, robust, BitTorrent tracker (client and server) implementation. (Source Code)
MITNodejs - Deluge - Lightweight, cross-platform BitTorrent client. (Source Code)
GPL-3.0Python/deb - qBittorrent - Free cross-platform bittorrent client with a feature rich Web UI for remote access. (Source Code)
GPL-2.0C++ - Send - Simple, private, end to end encrypted temporary file sharing, originally built by Mozilla. (Clients)
MPL-2.0Nodejs/Docker - slskd
⚠- A modern client-server application for the Soulseek file sharing network.AGPL-3.0Docker/C# - Transmission - Fast, easy, free Bittorrent client. (Source Code)
GPL-3.0C++/deb - Webtor - Web-based torrent client with instant audio/video streaming. (Demo)
MITDocker
- bittorrent-tracker - Simple, robust, BitTorrent tracker (client and server) implementation. (Source Code)
-
@ 502ab02a:a2860397
2025-05-23 07:35:13
แหม่ ต้องรีบแวะมาเขียนไว้ก่อน ของกำลังร้อนๆ #ตัวหนังสือมีเสียง เพลง ลานกรองมันส์ นั้นเรื่องที่มาที่ไปน่าจะไปตามอ่านในเพจ ลานกรองมันส์ ได้ครับ recap คร่าวๆคือมันคือ พื้นที่สร้างสรรค์ที่เปิดให้มาทำกิจกรรมต่างๆนานากันได้ครับ
วันนี้เลยจะมาเล่าเรื่องวิธีการใช้คำ ซึ่งมันส์ดีตามชื่อลาน ฮาๆๆๆ ผมตั้งโจทย์ไว้เลยว่า ต้องมีคำว่า ลานกรองมันส์ แน่ๆแล้ว เพราะเป็นชื่อสถานที่ จากนั้นก็เอาคำว่า ลานกองมัน มาแตกขยายความเพราะมันคือต้นกำเนิดเดิมของพื้นที่นั้น คือเป็นลานที่เอาหัวมันมากองกันเอาไว้ รอนำไปผลิตต่อเป็นสินค้าการเกษตรต่างๆ
ตอนนี้เขาเลิกทำไปแล้ว จึงกลายมาเป็น ลานกรองมันส์ ที่เอาชื่อเดิมมาแปลง
เมื่อได้คำหลักๆแล้วผมก็เอาพยัญชนะเลย ลอลิง กอไก่ มอม้า คือตัวหลักของเพลง
โทนดนตรีไม่ต้องเลือกเลยหนีไม่พ้นสามช่าแน่นอน โทนมันมาตั้งแต่เริ่มคิดจะเขียนเลยครับ ฮาๆๆๆ
ผมพยายามแบ่งวรรคไว้ชัดๆ เผื่อไว้เลยว่าอนาคตอาจมีการทำดนตรีแบบแบ่งกันร้อง วรรคของมันเลยเป็น หมู่ เดี่ยว หมู่ เดี่ยว หมู่ เดี่ยว หมู่ แบบสามโทนเลย
ท่อนหมู่นั้น คิดแบบหลายชั้นมากครับ โดยเฉพาะคำว่า มัน เอามันมากอง มันที่ว่าได้ทั้งเป็นคำกิริยา คือ เอามันมากองๆ หรือ มันที่ว่าอาจหมายถึงตัวความฝันเองเป็นคำลักษณะนามเรียกความฝัน "ลานกรองมันส์ เรามาลองกัน มาร่วมกันมอง ลานกรองมันส์ มาร่วมสร้างฝัน เอามันมากอง"
หรือแม้แต่ท่อนต่างๆ ก็เล่นคำว่า มัน กอง เพื่อให้รู้สึกย้ำท่อนหมู่ ที่มีคำว่ามัน เป็นพระเอกหลายหน้า ทั้งความสนุก ทั้งลักษณะนามความฝัน ทั้งกิริยา "ทุกคน ต่างมี ความฝัน เอามา รวมกัน ให้มันเป็นกอง"
อีกท่อนที่ชอบมากตอนเขียนคือ ทำที่ ลานกรองมันส์ idea for fun everyone can do เพราะรู้สึกว่า การพูดภาษาอังกฤษสำเนียงไทยๆ มันตูดหมึกดี ฮาๆๆๆๆ
หัวใจของเพลงคือจะบอกว่า ใครมีฝันก็มาเลย มาทำฝันกัน เรามีที่ให้คุณ ไม่ต้องกลัวอะไรที่จะทำฝันของตัวเอง เล็กใหญ่ ผิดถูก ขอให้ทำมัน อย่าให้ใครหยุดฝันของคุณ นอกจากตัวคุณเอง
เพลงนี้ไม่ได้ลงแพลทฟอร์ม เพราะส่งมอบให้ทาง ลานกรองมันส์เขาครับ ใช้ตามอิสระไปเลย ดังนั้นก็อาจต้องฟังในโพสนี้ หรือ ในยูทูปนะครับ https://youtu.be/W-1OH3YldtM?si=36dFbHgKjiI_9DI8
เนื้อเพลง "ลานกรองมันส์"
ลานกรองมันส์ ขอเชิญทุกท่าน มามันกันดู นะโฉมตรู มาลองดูกัน อ๊ะ มาลันดูกอง
มีงาน คุยกัน สังสรรค์ ดื่มนม ชมจันทร์ ปันฝัน กันเพลิน ทุกคน ต่างล้วน มีดี เรานั้น มีที่ พี่นี้มีโชว์ เอ้า
ลานกรองมันส์ เรามาลองกัน มาร่วมกันมอง ลานกรองมันส์ มาร่วมสร้างฝัน เอามันมากอง
จะเล็ก จะใหญ่ ให้ลอง เราเป็น พี่น้อง เพื่อนพ้อง ต้องตา ทุกคน ต่างมี ความฝัน เอามา รวมกัน ให้มันเป็นกอง เอ้า
ลานกรองมันส์ เรามาลองกัน มาร่วมกันมอง ลานกรองมันส์ มาร่วมสร้างฝัน เอามันมากอง
ชีวิต เราคิดเราทำ ทุกสิ่งที่ย้ำ คือทำสุดใจ จะเขียน จะเรียน จะรำ ทำที่ ลานกรองมันส์ idea for fun everyone can do
ลานกรองมันส์ เรามาลองกัน มาร่วมกันมอง ลานกรองมันส์ มาร่วมสร้างฝัน เอามันมากอง
เรามา ลั่นกลองให้มัน เฮไหนเฮกัน ที่ลานกรองมันส์ ให้ฝัน บันเทิง…
ตัวหนังสือมีเสียง #pirateketo #siamstr
-
@ 5144fe88:9587d5af
2025-05-23 17:01:37
The recent anomalies in the financial market and the frequent occurrence of world trade wars and hot wars have caused the world's political and economic landscape to fluctuate violently. It always feels like the financial crisis is getting closer and closer.
This is a systematic analysis of the possibility of the current global financial crisis by Manus based on Ray Dalio's latest views, US and Japanese economic and financial data, Buffett's investment behavior, and historical financial crises.
Research shows that the current financial system has many preconditions for a crisis, especially debt levels, market valuations, and investor behavior, which show obvious crisis signals. The probability of a financial crisis in the short term (within 6-12 months) is 30%-40%,
in the medium term (within 1-2 years) is 50%-60%,
in the long term (within 2-3 years) is 60%-70%.
Japan's role as the world's largest holder of overseas assets and the largest creditor of the United States is particularly critical. The sharp appreciation of the yen may be a signal of the return of global safe-haven funds, which will become an important precursor to the outbreak of a financial crisis.
Potential conditions for triggering a financial crisis Conditions that have been met 1. High debt levels: The debt-to-GDP ratio of the United States and Japan has reached a record high. 2. Market overvaluation: The ratio of stock market to GDP hits a record high 3. Abnormal investor behavior: Buffett's cash holdings hit a record high, with net selling for 10 consecutive quarters 4. Monetary policy shift: Japan ends negative interest rates, and the Fed ends the rate hike cycle 5. Market concentration is too high: a few technology stocks dominate market performance
Potential trigger points 1. The Bank of Japan further tightens monetary policy, leading to a sharp appreciation of the yen and the return of overseas funds 2. The US debt crisis worsens, and the proportion of interest expenses continues to rise to unsustainable levels 3. The bursting of the technology bubble leads to a collapse in market confidence 4. The trade war further escalates, disrupting global supply chains and economic growth 5. Japan, as the largest creditor of the United States, reduces its holdings of US debt, causing US debt yields to soar
Analysis of the similarities and differences between the current economic environment and the historical financial crisis Debt level comparison Current debt situation • US government debt to GDP ratio: 124.0% (December 2024) • Japanese government debt to GDP ratio: 216.2% (December 2024), historical high 225.8% (March 2021) • US total debt: 36.21 trillion US dollars (May 2025) • Japanese debt/GDP ratio: more than 250%-263% (Japanese Prime Minister’s statement)
Before the 2008 financial crisis • US government debt to GDP ratio: about 64% (2007) • Japanese government debt to GDP ratio: about 175% (2007)
Before the Internet bubble in 2000 • US government debt to GDP ratio: about 55% (1999) • Japanese government debt to GDP ratio: about 130% (1999)
Key differences • The current US debt-to-GDP ratio is nearly twice that before the 2008 crisis • The current Japanese debt-to-GDP ratio is more than 1.2 times that before the 2008 crisis • Global debt levels are generally higher than historical pre-crisis levels • US interest payments are expected to devour 30% of fiscal revenue (Moody's warning)
Monetary policy and interest rate environment
Current situation • US 10-year Treasury yield: about 4.6% (May 2025) • Bank of Japan policy: end negative interest rates and start a rate hike cycle • Bank of Japan's holdings of government bonds: 52%, plans to reduce purchases to 3 trillion yen per month by January-March 2026 • Fed policy: end the rate hike cycle and prepare to cut interest rates
Before the 2008 financial crisis • US 10-year Treasury yield: about 4.5%-5% (2007) • Fed policy: continuous rate hikes from 2004 to 2006, and rate cuts began in 2007 • Bank of Japan policy: maintain ultra-low interest rates
Key differences • Current US interest rates are similar to those before the 2008 crisis, but debt levels are much higher than then • Japan is in the early stages of ending its loose monetary policy, unlike before historical crises • The size of global central bank balance sheets is far greater than at any time in history
Market valuations and investor behavior Current situation • The ratio of stock market value to the size of the US economy: a record high • Buffett's cash holdings: $347 billion (28% of assets), a record high • Market concentration: US stock growth mainly relies on a few technology giants • Investor sentiment: Technology stocks are enthusiastic, but institutional investors are beginning to be cautious
Before the 2008 financial crisis • Buffett's cash holdings: 25% of assets (2005) • Market concentration: Financial and real estate-related stocks performed strongly • Investor sentiment: The real estate market was overheated and subprime products were widely popular
Before the 2000 Internet bubble • Buffett's cash holdings: increased from 1% to 13% (1998) • Market concentration: Internet stocks were extremely highly valued • Investor sentiment: Tech stocks are in a frenzy
Key differences • Buffett's current cash holdings exceed any pre-crisis level in history • Market valuation indicators have reached a record high, exceeding the levels before the 2000 bubble and the 2008 crisis • The current market concentration is higher than any period in history, and a few technology stocks dominate market performance
Safe-haven fund flows and international relations Current situation • The status of the yen: As a safe-haven currency, the appreciation of the yen may indicate a rise in global risk aversion • Trade relations: The United States has imposed tariffs on Japan, which is expected to reduce Japan's GDP growth by 0.3 percentage points in fiscal 2025 • International debt: Japan is one of the largest creditors of the United States
Before historical crises • Before the 2008 crisis: International capital flows to US real estate and financial products • Before the 2000 bubble: International capital flows to US technology stocks
Key differences • Current trade frictions have intensified and the trend of globalization has weakened • Japan's role as the world's largest holder of overseas assets has become more prominent • International debt dependence is higher than any period in history
-
@ 3f770d65:7a745b24
2025-01-12 21:03:36
I’ve been using Notedeck for several months, starting with its extremely early and experimental alpha versions, all the way to its current, more stable alpha releases. The journey has been fascinating, as I’ve had the privilege of watching it evolve from a concept into a functional and promising tool.
In its earliest stages, Notedeck was raw—offering glimpses of its potential but still far from practical for daily use. Even then, the vision behind it was clear: a platform designed to redefine how we interact with Nostr by offering flexibility and power for all users.
I'm very bullish on Notedeck. Why? Because Will Casarin is making it! Duh! 😂
Seriously though, if we’re reimagining the web and rebuilding portions of the Internet, it’s important to recognize the potential of Notedeck. If Nostr is reimagining the web, then Notedeck is reimagining the Nostr client.
Notedeck isn’t just another Nostr app—it’s more a Nostr browser that functions more like an operating system with micro-apps. How cool is that?
Much like how Google's Chrome evolved from being a web browser with a task manager into ChromeOS, a full blown operating system, Notedeck aims to transform how we interact with the Nostr. It goes beyond individual apps, offering a foundation for a fully integrated ecosystem built around Nostr.
As a Nostr evangelist, I love to scream INTEROPERABILITY and tout every application's integrations. Well, Notedeck has the potential to be one of the best platforms to showcase these integrations in entirely new and exciting ways.
Do you want an Olas feed of images? Add the media column.
Do you want a feed of live video events? Add the zap.stream column.
Do you want Nostr Nests or audio chats? Add that column to your Notedeck.
Git? Email? Books? Chat and DMs? It's all possible.
Not everyone wants a super app though, and that’s okay. As with most things in the Nostr ecosystem, flexibility is key. Notedeck gives users the freedom to choose how they engage with it—whether it’s simply following hashtags or managing straightforward feeds. You'll be able to tailor Notedeck to fit your needs, using it as extensively or minimally as you prefer.
Notedeck is designed with a local-first approach, utilizing Nostr content stored directly on your device via the local nostrdb. This will enable a plethora of advanced tools such as search and filtering, the creation of custom feeds, and the ability to develop personalized algorithms across multiple Notedeck micro-applications—all with unparalleled flexibility.
Notedeck also supports multicast. Let's geek out for a second. Multicast is a method of communication where data is sent from one source to multiple destinations simultaneously, but only to devices that wish to receive the data. Unlike broadcast, which sends data to all devices on a network, multicast targets specific receivers, reducing network traffic. This is commonly used for efficient data distribution in scenarios like streaming, conferencing, or large-scale data synchronization between devices.
In a local first world where each device holds local copies of your nostr nodes, and each device transparently syncs with each other on the local network, each node becomes a backup. Your data becomes antifragile automatically. When a node goes down it can resync and recover from other nodes. Even if not all nodes have a complete collection, negentropy can pull down only what is needed from each device. All this can be done without internet.
-Will Casarin
In the context of Notedeck, multicast would allow multiple devices to sync their Nostr nodes with each other over a local network without needing an internet connection. Wild.
Notedeck aims to offer full customization too, including the ability to design and share custom skins, much like Winamp. Users will also be able to create personalized columns and, in the future, share their setups with others. This opens the door for power users to craft tailored Nostr experiences, leveraging their expertise in the protocol and applications. By sharing these configurations as "Starter Decks," they can simplify onboarding and showcase the best of Nostr’s ecosystem.
Nostr’s “Other Stuff” can often be difficult to discover, use, or understand. Many users doesn't understand or know how to use web browser extensions to login to applications. Let's not even get started with nsecbunkers. Notedeck will address this challenge by providing a native experience that brings these lesser-known applications, tools, and content into a user-friendly and accessible interface, making exploration seamless. However, that doesn't mean Notedeck should disregard power users that want to use nsecbunkers though - hint hint.
For anyone interested in watching Nostr be developed live, right before your very eyes, Notedeck’s progress serves as a reminder of what’s possible when innovation meets dedication. The current alpha is already demonstrating its ability to handle complex use cases, and I’m excited to see how it continues to grow as it moves toward a full release later this year.
-
@ cae03c48:2a7d6671
2025-05-23 16:01:05
Bitcoin Magazine

Spark Partners with Breez to Launch Bitcoin-Native SDK for Lightning PaymentsToday, Breez and Spark have announced a new implementation of the Breez SDK, built on Spark’s Bitcoin-native Layer 2 infrastructure. According to a press release sent to Bitcoin Magazine, the update is intended to make it easier for developers to integrate self-custodial Bitcoin Lightning payments into everyday apps and services.
Few companies are as good as @Breez_Tech at putting Bitcoin in people’s hands. We’re incredibly humbled to have them building on Spark.
Learn more → https://t.co/KRPpWJa3os pic.twitter.com/QiCfHbWu9d
— Spark (@buildonspark) May 22, 2025
“This is what the future of Bitcoin looks like — fast, open, and embedded in the apps people use every day. By teaming up with Breez, we’re expanding the ecosystem and giving developers powerful, Bitcoin-native tools to build next-generation payment experiences. Together, we’re building the standard for global, peer-to-peer transactions,” said the creator of Spark Kevin Hurley.
The SDK supports LNURL, Lightning addresses, real-time mobile notifications, and includes bindings for all major programming languages and frameworks. It is designed to allow developers to build directly on Bitcoin without relying on bridges or external consensus. This collaboration gives developers tools to add Bitcoin payment features to apps used for monetization social apps, cross-border remittances, and in-game currencies.
“We need developers to bring Bitcoin into apps people use every day,” said the CEO of Breez Roy Sheinfeld. “That’s why we built the Breez SDK. We’re excited to build on Spark’s revolutionary architecture — giving developers a powerful new Bitcoin-native option and continuing to strengthen Lightning as the common language of Bitcoin.”
Breez will also operate as a Spark Service Provider (SSP), alongside Lightspark, to help support payment facilitation and the growth of Spark’s ecosystem. The new implementation is expected to be released later this year.
“We’re excited to see what developers build with Spark; it’s very exciting to see this come to the world,” said the co-founder and CEO of Lightspark David Marcus.
The Breez SDK is expanding

We’re joining forces with @buildonspark to release a new nodeless implementation of the Breez SDK — giving developers the tools they need to bring Bitcoin payments to everyday apps.
Bitcoin-Native
Powered by Spark’s…— Breez
 (@Breez_Tech) May 22, 2025
(@Breez_Tech) May 22, 2025Yesterday, Magic Eden also partnered with Spark to improve Bitcoin trading by addressing issues like slow transaction times, high fees, and poor user experience. The integration will introduce a native settlement system aimed at making transactions faster and more cost-effective, without using bridges or synthetic assets.
“We’re proud to be betting on BTC DeFi,” said the CEO of Magic Eden Jack Lu. “We’re going to lead the forefront of all Bitcoin DeFi to make BTC fast, fun, and for everyone with Magic Eden as the #1 BTC native app on-chain.”
This post Spark Partners with Breez to Launch Bitcoin-Native SDK for Lightning Payments first appeared on Bitcoin Magazine and is written by Oscar Zarraga Perez.
-
@ 1bda7e1f:bb97c4d9
2025-01-02 05:19:08
Tldr
- Nostr is an open and interoperable protocol
- You can integrate it with workflow automation tools to augment your experience
- n8n is a great low/no-code workflow automation tool which you can host yourself
- Nostrobots allows you to integrate Nostr into n8n
- In this blog I create some workflow automations for Nostr
- A simple form to delegate posting notes
- Push notifications for mentions on multiple accounts
- Push notifications for your favourite accounts when they post a note
- All workflows are provided as open source with MIT license for you to use
Inter-op All The Things
Nostr is a new open social protocol for the internet. This open nature exciting because of the opportunities for interoperability with other technologies. In Using NFC Cards with Nostr I explored the
nostr:URI to launch Nostr clients from a card tap.The interoperability of Nostr doesn't stop there. The internet has many super-powers, and Nostr is open to all of them. Simply, there's no one to stop it. There is no one in charge, there are no permissioned APIs, and there are no risks of being de-platformed. If you can imagine technologies that would work well with Nostr, then any and all of them can ride on or alongside Nostr rails.
My mental model for why this is special is Google Wave ~2010. Google Wave was to be the next big platform. Lars was running it and had a big track record from Maps. I was excited for it. Then, Google pulled the plug. And, immediately all the time and capital invested in understanding and building on the platform was wasted.
This cannot happen to Nostr, as there is no one to pull the plug, and maybe even no plug to pull.
So long as users demand Nostr, Nostr will exist, and that is a pretty strong guarantee. It makes it worthwhile to invest in bringing Nostr into our other applications.
All we need are simple ways to plug things together.
Nostr and Workflow Automation
Workflow automation is about helping people to streamline their work. As a user, the most common way I achieve this is by connecting disparate systems together. By setting up one system to trigger another or to move data between systems, I can solve for many different problems and become way more effective.
n8n for workflow automation
Many workflow automation tools exist. My favourite is n8n. n8n is a low/no-code workflow automation platform which allows you to build all kinds of workflows. You can use it for free, you can self-host it, it has a user-friendly UI and useful API. Vs Zapier it can be far more elaborate. Vs Make.com I find it to be more intuitive in how it abstracts away the right parts of the code, but still allows you to code when you need to.
Most importantly you can plug anything into n8n: You have built-in nodes for specific applications. HTTP nodes for any other API-based service. And community nodes built by individual community members for any other purpose you can imagine.
Eating my own dogfood
It's very clear to me that there is a big design space here just demanding to be explored. If you could integrate Nostr with anything, what would you do?
In my view the best way for anyone to start anything is by solving their own problem first (aka "scratching your own itch" and "eating your own dogfood"). As I get deeper into Nostr I find myself controlling multiple Npubs – to date I have a personal Npub, a brand Npub for a community I am helping, an AI assistant Npub, and various testing Npubs. I need ways to delegate access to those Npubs without handing over the keys, ways to know if they're mentioned, and ways to know if they're posting.
I can build workflows with n8n to solve these issues for myself to start with, and keep expanding from there as new needs come up.
Running n8n with Nostrobots
I am mostly non-technical with a very helpful AI. To set up n8n to work with Nostr and operate these workflows should be possible for anyone with basic technology skills.
- I have a cheap VPS which currently runs my HAVEN Nostr Relay and Albyhub Lightning Node in Docker containers,
- My objective was to set up n8n to run alongside these in a separate Docker container on the same server, install the required nodes, and then build and host my workflows.
Installing n8n
Self-hosting n8n could not be easier. I followed n8n's Docker-Compose installation docs–
- Install Docker and Docker-Compose if you haven't already,
- Create your
docker-compose.ymland.envfiles from the docs, - Create your data folder
sudo docker volume create n8n_data, - Start your container with
sudo docker compose up -d, - Your n8n instance should be online at port
5678.
n8n is free to self-host but does require a license. Enter your credentials into n8n to get your free license key. You should now have access to the Workflow dashboard and can create and host any kind of workflows from there.
Installing Nostrobots
To integrate n8n nicely with Nostr, I used the Nostrobots community node by Ocknamo.
In n8n parlance a "node" enables certain functionality as a step in a workflow e.g. a "set" node sets a variable, a "send email" node sends an email. n8n comes with all kinds of "official" nodes installed by default, and Nostr is not amongst them. However, n8n also comes with a framework for community members to create their own "community" nodes, which is where Nostrobots comes in.
You can only use a community node in a self-hosted n8n instance (which is what you have if you are running in Docker on your own server, but this limitation does prevent you from using n8n's own hosted alternative).
To install a community node, see n8n community node docs. From your workflow dashboard–
- Click the "..." in the bottom left corner beside your username, and click "settings",
- Cilck "community nodes" left sidebar,
- Click "Install",
- Enter the "npm Package Name" which is
n8n-nodes-nostrobots, - Accept the risks and click "Install",
- Nostrobots is now added to your n8n instance.
Using Nostrobots
Nostrobots gives you nodes to help you build Nostr-integrated workflows–
- Nostr Write – for posting Notes to the Nostr network,
- Nostr Read – for reading Notes from the Nostr network, and
- Nostr Utils – for performing certain conversions you may need (e.g. from bech32 to hex).
Nostrobots has good documentation on each node which focuses on simple use cases.
Each node has a "convenience mode" by default. For example, the "Read" Node by default will fetch Kind 1 notes by a simple filter, in Nostrobots parlance a "Strategy". For example, with Strategy set to "Mention" the node will accept a pubkey and fetch all Kind 1 notes that Mention the pubkey within a time period. This is very good for quick use.
What wasn't clear to me initially (until Ocknamo helped me out) is that advanced use cases are also possible.
Each node also has an advanced mode. For example, the "Read" Node can have "Strategy" set to "RawFilter(advanced)". Now the node will accept json (anything you like that complies with NIP-01). You can use this to query Notes (Kind 1) as above, and also Profiles (Kind 0), Follow Lists (Kind 3), Reactions (Kind 7), Zaps (Kind 9734/9735), and anything else you can think of.
Creating and adding workflows
With n8n and Nostrobots installed, you can now create or add any kind of Nostr Workflow Automation.
- Click "Add workflow" to go to the workflow builder screen,
- If you would like to build your own workflow, you can start with adding any node. Click "+" and see what is available. Type "Nostr" to explore the Nostrobots nodes you have added,
- If you would like to add workflows that someone else has built, click "..." in the top right. Then click "import from URL" and paste in the URL of any workflow you would like to use (including the ones I share later in this article).
Nostr Workflow Automations
It's time to build some things!
A simple form to post a note to Nostr
I started very simply. I needed to delegate the ability to post to Npubs that I own in order that a (future) team can test things for me. I don't want to worry about managing or training those people on how to use keys, and I want to revoke access easily.
I needed a basic form with credentials that posted a Note.
For this I can use a very simple workflow–
- A n8n Form node – Creates a form for users to enter the note they wish to post. Allows for the form to be protected by a username and password. This node is the workflow "trigger" so that the workflow runs each time the form is submitted.
- A Set node – Allows me to set some variables, in this case I set the relays that I intend to use. I typically add a Set node immediately following the trigger node, and put all the variables I need in this. It helps to make the workflows easier to update and maintain.
- A Nostr Write node (from Nostrobots) – Writes a Kind-1 note to the Nostr network. It accepts Nostr credentials, the output of the Form node, and the relays from the Set node, and posts the Note to those relays.
Once the workflow is built, you can test it with the testing form URL, and set it to "Active" to use the production form URL. That's it. You can now give posting access to anyone for any Npub. To revoke access, simply change the credentials or set to workflow to "Inactive".
It may also be the world's simplest Nostr client.
You can find the Nostr Form to Post a Note workflow here.
Push notifications on mentions and new notes
One of the things Nostr is not very good at is push notifications. Furthermore I have some unique itches to scratch. I want–
- To make sure I never miss a note addressed to any of my Npubs – For this I want a push notification any time any Nostr user mentions any of my Npubs,
- To make sure I always see all notes from key accounts – For this I need a push notification any time any of my Npubs post any Notes to the network,
- To get these notifications on all of my devices – Not just my phone where my Nostr regular client lives, but also on each of my laptops to suit wherever I am working that day.
I needed to build a Nostr push notifications solution.
To build this workflow I had to string a few ideas together–
- Triggering the node on a schedule – Nostrobots does not include a trigger node. As every workflow starts with a trigger we needed a different method. I elected to run the workflow on a schedule of every 10-minutes. Frequent enough to see Notes while they are hot, but infrequent enough to not burden public relays or get rate-limited,
- Storing a list of Npubs in a Nostr list – I needed a way to store the list of Npubs that trigger my notifications. I initially used an array defined in the workflow, this worked fine. Then I decided to try Nostr lists (NIP-51, kind 30000). By defining my list of Npubs as a list published to Nostr I can control my list from within a Nostr client (e.g. Listr.lol or Nostrudel.ninja). Not only does this "just work", but because it's based on Nostr lists automagically Amethyst client allows me to browse that list as a Feed, and everyone I add gets notified in their Mentions,
- Using specific relays – I needed to query the right relays, including my own HAVEN relay inbox for notes addressed to me, and wss://purplepag.es for Nostr profile metadata,
- Querying Nostr events (with Nostrobots) – I needed to make use of many different Nostr queries and use quite a wide range of what Nostrobots can do–
- I read the EventID of my Kind 30000 list, to return the desired pubkeys,
- For notifications on mentions, I read all Kind 1 notes that mention that pubkey,
- For notifications on new notes, I read all Kind 1 notes published by that pubkey,
- Where there are notes, I read the Kind 0 profile metadata event of that pubkey to get the displayName of the relevant Npub,
- I transform the EventID into a Nevent to help clients find it.
- Using the Nostr URI – As I did with my NFC card article, I created a link with the
nostr:URI prefix so that my phone's native client opens the link by default, - Push notifications solution – I needed a push notifications solution. I found many with n8n integrations and chose to go with Pushover which supports all my devices, has a free trial, and is unfairly cheap with a $5-per-device perpetual license.
Once the workflow was built, lists published, and Pushover installed on my phone, I was fully set up with push notifications on Nostr. I have used these workflows for several weeks now and made various tweaks as I went. They are feeling robust and I'd welcome you to give them a go.
You can find the Nostr Push Notification If Mentioned here and If Posts a Note here.
In speaking with other Nostr users while I was building this, there are all kind of other needs for push notifications too – like on replies to a certain bookmarked note, or when a followed Npub starts streaming on zap.stream. These are all possible.
Use my workflows
I have open sourced all my workflows at my Github with MIT license and tried to write complete docs, so that you can import them into your n8n and configure them for your own use.
To import any of my workflows–
- Click on the workflow of your choice, e.g. "Nostr_Push_Notify_If_Mentioned.json",
- Click on the "raw" button to view the raw JSON, ex any Github page layout,
- Copy that URL,
- Enter that URL in the "import from URL" dialog mentioned above.
To configure them–
- Prerequisites, credentials, and variables are all stated,
- In general any variables required are entered into a Set Node that follows the trigger node,
- Pushover has some extra setup but is very straightforward and documented in the workflow.
What next?
Over my first four blogs I explored creating a good Nostr setup with Vanity Npub, Lightning Payments, Nostr Addresses at Your Domain, and Personal Nostr Relay.
Then in my latest two blogs I explored different types of interoperability with NFC cards and now n8n Workflow Automation.
Thinking ahead n8n can power any kind of interoperability between Nostr and any other legacy technology solution. On my mind as I write this:
- Further enhancements to posting and delegating solutions and forms (enhanced UI or different note kinds),
- Automated or scheduled posting (such as auto-liking everything Lyn Alden posts),
- Further enhancements to push notifications, on new and different types of events (such as notifying me when I get a new follower, on replies to certain posts, or when a user starts streaming),
- All kinds of bridges, such as bridging notes to and from Telegram, Slack, or Campfire. Or bridging RSS or other event feeds to Nostr,
- All kinds of other automation (such as BlackCoffee controlling a coffee machine),
- All kinds of AI Assistants and Agents,
In fact I have already released an open source workflow for an AI Assistant, and will share more about that in my next blog.
Please be sure to let me know if you think there's another Nostr topic you'd like to see me tackle.
GM Nostr.
-
@ b0a838f2:34ed3f19
2025-05-23 17:56:27
- GarageHQ - Geo-distributed, S3‑compatible storage service that can fulfill many needs. (Source Code)
AGPL-3.0Docker/Rust - Minio - Object storage server compatible with Amazon S3 APIs. (Source Code)
AGPL-3.0Go/Docker/K8S - SeaweedFS - SeaweedFS is an open source distributed file system supporting WebDAV, S3 API, FUSE mount, HDFS, etc, optimized for lots of small files, and easy to add capacity.
Apache-2.0Go - SFTPGo - Flexible, fully featured and highly configurable SFTP server with optional FTP/S and WebDAV support.
AGPL-3.0Go/deb/Docker - Zenko CloudServer - Zenko CloudServer, an open-source implementation of a server handling the Amazon S3 protocol. (Source Code)
Apache-2.0Docker/Nodejs - ZOT OCI Registry - A production-ready vendor-neutral OCI-native container image registry. (Demo, Source Code)
Apache-2.0Go/Docker
- GarageHQ - Geo-distributed, S3‑compatible storage service that can fulfill many needs. (Source Code)
-
@ 90152b7f:04e57401
2025-05-23 15:48:58
U.S. troops would enforce peace under Army study
The Washington Times - September 10, 2001
by Rowan Scarborough
https://www.ord.io/70787305 (image) https://www.ord.io/74522515 (text)
An elite U.S. Army study center has devised a plan for enforcing a major Israeli-Palestinian peace accord that would require about 20,000 well-armed troops stationed throughout Israel and a newly created Palestinian state. There are no plans by the Bush administration to put American soldiers into the Middle East to police an agreement forged by the longtime warring parties. In fact, Defense Secretary Donald H. Rumsfeld is searching for ways to reduce U.S. peacekeeping efforts abroad, rather than increasing such missions. But a 68-page paper by the Army School of Advanced Military Studies (SAMS) does provide a look at the daunting task any international peacekeeping force would face if the United Nations authorized it, and Israel and the Palestinians ever reached a peace agreement.
Located at Fort Leavenworth, Kan., the School for Advanced Military Studies is both a training ground and a think tank for some of the Army’s brightest officers. Officials say the Army chief of staff, and sometimes the Joint Chiefs of Staff, ask SAMS to develop contingency plans for future military operations. During the 1991 Persian Gulf war, SAMS personnel helped plan the coalition ground attack that avoided a strike up the middle of Iraqi positions and instead executed a “left hook” that routed the enemy in 100 hours.
The cover page for the recent SAMS project said it was done for the Joint Chiefs of Staff. But Maj. Chris Garver, a Fort Leavenworth spokesman, said the study was not requested by Washington. “This was just an academic exercise,” said Maj. Garver. “They were trying to take a current situation and get some training out of it.” The exercise was done by 60 officers dubbed “Jedi Knights,” as all second-year SAMS students are nicknamed.
The SAMS paper attempts to predict events in the first year of a peace-enforcement operation, and sees possible dangers for U.S. troops from both sides. It calls Israel’s armed forces a “500-pound gorilla in Israel. Well armed and trained. Operates in both Gaza . Known to disregard international law to accomplish mission. Very unlikely to fire on American forces. Fratricide a concern especially in air space management.”
Of the Mossad, the Israeli intelligence service, the SAMS officers say: “Wildcard. Ruthless and cunning. Has capability to target U.S. forces and make it look like a Palestinian/Arab act.”
On the Palestinian side, the paper describes their youth as “loose cannons; under no control, sometimes violent.” The study lists five Arab terrorist groups that could target American troops for assassination and hostage-taking. The study recommends “neutrality in word and deed” as one way to protect U.S. soldiers from any attack. It also says Syria, Egypt and Jordan must be warned “we will act decisively in response to external attack.”
It is unlikely either of the three would mount an attack. Of Syria’s military, the report says: “Syrian army quantitatively larger than Israeli Defense Forces, but largely seen as qualitatively inferior. More likely, however, Syrians would provide financial and political support to the Palestinians, as well as increase covert support to terrorism acts through Lebanon.” Of Egypt’s military, the paper says, “Egyptians also maintain a large army but have little to gain by attacking Israel.”
The plan does not specify a full order of battle. An Army source who reviewed the SAMS work said each of a possible three brigades would require about 100 Bradley fighting vehicles, 25 tanks, 12 self-propelled howitzers, Apache attack helicopters, Kiowa Warrior reconnaissance helicopters and Predator spy drones. The report predicts that nonlethal weapons would be used to quell unrest. U.S. European Command, which is headed by NATO’s supreme allied commander, would oversee the peacekeeping operation. Commanders would maintain areas of operation, or AOs, around Nablus, Jerusalem, Hebron and the Gaza strip. The study sets out a list of goals for U.S. troops to accomplish in the first 30 days. They include: “create conditions for development of Palestinian State and security of “; ensure “equal distribution of contract value or equivalent aid” that would help legitimize the peacekeeping force and stimulate economic growth; “promote U.S. investment in Palestine”; “encourage reconciliation between entities based on acceptance of new national identities”; and “build lasting relationship based on new legal borders and not religious-territorial claims.”
Maj. Garver said the officers who completed the exercise will hold major planning jobs once they graduate. “There is an application process” for students, he said. “They screen their records, and there are several tests they go through before they are accepted by the program. The bright planners of the future come out of this program.”
James Phillips, a Middle East analyst at the Heritage Foundation, said it would be a mistake to put peacekeepers in Israel, given the “poor record of previous monitors.” “In general, the Bush administration policy is to discourage a large American presence,” he said. “But it has been rumored that one of the possibilities might be an expanded CIA role.” “It would be a very different environment than Bosnia,” said Mr. Phillips, referring to America’s six-year peacekeeping role in Bosnia-Herzegovina. “The Palestinian Authority is pushing for this as part of its strategy to internationalize the conflict. Bring in the Europeans and Russia and China. But such monitors or peacekeeping forces are not going to be able to bring peace. Only a decision by the Palestinians to stop the violence and restart talks could possibly do that.”
<<https://www.ord.io/70787305>>
<<<https://www.ord.io/74522515>>>
-
@ b0a838f2:34ed3f19
2025-05-23 17:56:09
- bewCloud - File sharing + sync, notes, and photos (alternative to Nextcloud and ownCloud's RSS reader). (Source Code, Clients)
AGPL-3.0Docker - Git Annex - File synchronization between computers, servers, external drives. (Source Code)
GPL-3.0Haskell - Kinto - Minimalist JSON storage service with synchronisation and sharing abilities. (Source Code)
Apache-2.0Python - Nextcloud - Access and share your files, calendars, contacts, mail and more from any device, on your terms. (Demo, Source Code)
AGPL-3.0PHP/deb - OpenSSH SFTP server - Secure File Transfer Program. (Source Code)
BSD-2-ClauseC/deb - ownCloud - All-in-one solution for saving, synchronizing, viewing, editing and sharing files, calendars, address books and more. (Source Code, Clients)
AGPL-3.0PHP/Docker/deb - Peergos - Secure and private space online where you can store, share and view your photos, videos, music and documents. Also includes a calendar, news feed, task lists, chat and email client. (Source Code)
AGPL-3.0Java - Puter - Web-based operating system designed to be feature-rich, exceptionally fast, and highly extensible. (Demo, Source Code)
AGPL-3.0Nodejs/Docker - Pydio - Turn any web server into a powerful file management system and an alternative to mainstream cloud storage providers. (Demo, Source Code)
AGPL-3.0Go - Samba - Samba is the standard Windows interoperability suite of programs for Linux and Unix. It provides secure, stable and fast file and print services for all clients using the SMB/CIFS protocol. (Source Code)
GPL-3.0C - Seafile - File hosting and sharing solution primary for teams and organizations. (Source Code)
GPL-2.0/GPL-3.0/AGPL-3.0/Apache-2.0C - Syncthing - Syncthing is an open source peer-to-peer file synchronisation tool. (Source Code)
MPL-2.0Go/Docker/deb - Unison - Unison is a file-synchronization tool for OSX, Unix, and Windows. (Source Code)
GPL-3.0deb/OCaml
- bewCloud - File sharing + sync, notes, and photos (alternative to Nextcloud and ownCloud's RSS reader). (Source Code, Clients)
-
@ 87e98bb6:8d6616f4
2025-05-23 15:36:32
Use this guide if you want to keep your NixOS on the stable branch, but enable unstable application packages. It took me a while to figure out how to do this, so I wanted to share because it ended up being far easier than most of the vague explanations online made it seem.
I put a sample configuration.nix file at the very bottom to help it make more sense for new users. Remember to keep a backup of your config file, just in case!
If there are any errors please let me know. I am currently running NixOS 24.11.
Steps listed in this guide: 1. Add the unstable channel to NixOS as a secondary channel. 2. Edit the configuration.nix to enable unstable applications. 3. Add "unstable." in front of the application names in the config file (example: unstable.program). This enables the install of unstable versions during the build. 4. Rebuild.
Step 1:
- Open the console. (If you want to see which channels you currently have, type: sudo nix-channel --list)
- Add the unstable channel, type: sudo nix-channel --add https://channels.nixos.org/nixpkgs-unstable unstable
- To update the channels (bring in the possible apps), type: sudo nix-channel --update
More info here: https://nixos.wiki/wiki/Nix_channels
Step 2:
Edit your configuration.nix and add the following around your current config:
``` { config, pkgs, lib, ... }:
let unstable = import
{ config = { allowUnfree = true; }; }; in { #insert normal configuration text here } #remember to close the bracket!```
At this point it would be good to save your config and try a rebuild to make sure there are no errors. If you have errors, make sure your brackets are in the right places and/or not missing. This step will make for less troubleshooting later on if something happens to be in the wrong spot!
Step 3:
Add "unstable." to the start of each application you want to use the unstable version. (Example: unstable.brave)
Step 4:
Rebuild your config, type: sudo nixos-rebuild switch
Example configuration.nix file:
```
Config file for NixOS
{ config, pkgs, lib, ... }:
Enable unstable apps from Nix repository.
let unstable = import
{ config = { allowUnfree = true; }; }; in { #Put your normal config entries here in between the tags. Below is what your applications list needs to look like.
environment.systemPackages = with pkgs; [ appimage-run blender unstable.brave #Just add unstable. before the application name to enable the unstable version. chirp discord ];
} # Don't forget to close bracket at the end of the config file!
``` That should be all. Hope it helps.
-
@ 9c9d2765:16f8c2c2
2025-05-23 06:10:53
CHAPTER TWENTY SIX
"The streets teach you a lot. It teaches you how to survive, how to fight, how to bend the world to your will. But there’s something else it teaches you how to rise above the petty battles and claim the empire that’s rightfully yours."
Just then, the door opened again, and Charles entered, his usual calm demeanor replaced with a rare air of urgency.
"James," he said, his voice serious. "There’s something you need to know. The press is getting more aggressive. They’ve caught wind of your plans, and they’re pushing for an exclusive interview. They want the story of how you rose from nothing to everything. It’s becoming a media frenzy."
James didn’t flinch. His eyes remained steady as he absorbed the news.
"Let them come," he said. "They can write whatever they want. Let the world see how I turned my destiny around. But they’ll never write the full story. They’ll never know the price I paid to get here."
Charles raised an eyebrow, impressed by James’s unshakable resolve. "And what about Mark and Helen?"
James’s expression darkened, the calm facade cracking just enough to reveal the fire beneath. "They’ll face the consequences of their actions. And I’ll make sure they do."
Rita stepped forward, her tone soft yet firm. "But there’s still a part of you that wants more than just their downfall. You want to rebuild this company, don’t you?"
James glanced at her, his eyes hardening.
"Rebuilding is just the beginning," he replied. "I didn’t fight for what’s mine just to watch it crumble. JP Enterprises will become something greater. Something unbreakable. A legacy that no one can touch, no one can tarnish."
The sound of footsteps echoed through the hallway, and moments later, Mrs. JP entered the room. There was a subtle weight in her posture, but also a sense of pride in her eyes.
"You’ve handled this situation with strength and wisdom, James," she said, her voice full of warmth. "Your father and I could never be prouder. You’ve surpassed every expectation we ever had."
James met her gaze and nodded. "Thank you. But this isn’t just about your approval. It’s about proving to myself in the world that I’m not the man I was before. I’m the man I’ve chosen to be."
Mrs. JP smiled, her eyes softening. "And you’ve become that man with grace. You’ve earned everything that’s come your way."
James’s gaze lingered for a moment before he spoke again. "It’s not over yet. There’s still work to be done. We have to ensure that JP Enterprises remains strong, remains untouchable. This is just the first step."
Charles exchanged a knowing look with Rita, then turned back to James. "We’re with you, every step of the way."
The room fell into a brief, heavy silence. Outside, the city continued to hum, indifferent to the dramatic shifts taking place within the walls of JP Enterprises. But James knew that the storm was far from over. He had won the battle, but the war was only just beginning.
As he looked around at the people who now stood by him, he realized that this victory was more than just personal; it was a turning point for the entire legacy of the JP name.
"James, how does it feel to be the talk of an entire city?" Charles asked, leaning against the polished oak desk in James’s expansive office.
James stood by the window, his hands clasped behind his back, watching the sun descend beyond the city skyline. The room was silent for a moment, filled only with the distant hum of the city below.
"It feels... inevitable," James replied, his tone calm but layered with meaning. "People always talk when someone they counted out rewrites the rules of the game."
Charles chuckled lightly, walking over to pour himself a glass of water. "Well, you haven’t just rewritten the rules, James. You’ve rewritten the entire playbook."
James turned, a shadow of a smile on his face. "And yet, some still believe they can undermine me. Manipulate the truth. Twist it until the entire narrative collapses."
Just then, Rita entered, holding a folder tightly in her hands. There was tension in her posture, controlled, but evident.
"You need to see this," she said, handing James the folder. "It's an internal memo that was intercepted. Apparently, Mark and Helen aren’t done. They’ve secured a secret meeting with a major competitor Wellington Holdings."
James flipped through the documents, his eyes narrowing. "Wellington? So, they’ve moved from sabotage to outright betrayal.
"They’re desperate," Rita added. "Their reputations are in ruins, and with the public backlash after the failed stunt at the anniversary, they’re looking for anything to reclaim their influence."
James’s jaw tightened. "Let them try. I’ve weathered storms far greater than the games of disgraced traitors."
Rita hesitated before continuing. "There’s more. Tracy’s gone quiet. She’s removed all traces of her involvement. But I have reason to believe she’s still communicating with Helen... through an encrypted channel."
James closed the folder and walked slowly to his desk. His movements were deliberate, filled with the confidence of someone who had faced betrayal before and emerged stronger.
"Then it’s time we end this," he said. "Not with anger. Not with revenge. But with undeniable, irreversible justice."
He looked up at Charles and Rita. "I want full surveillance on Wellington. Legal is to prepare a formal complaint if they attempt to interfere with any JP enterprise contract. And I want every associate of Mark and Helen cross-checked. If there’s even a whisper of conspiracy, I want it recorded."
Charles nodded. "Consider it done. We’ll strike with precision."
As they left the room to carry out their tasks, James sat behind his desk, momentarily still. His mind drifted to the days when he had nothing, no name, no wealth, no influence. How far he had come. And yet, how familiar the shadows still felt.
Later that evening, as the city lights glowed brighter, a new headline took over the news:
“JP Enterprises President Set to Announce Major Expansion, Exclusive Projects to Redefine the City’s Economic Landscape.”
It wasn’t about the slander anymore. It wasn’t about revenge. It was about legacy.
The silence in Mark’s penthouse was nearly deafening. Once a space of elite grandeur and sophisticated indulgence, it now felt hollow like the echo of a reputation lost. Mark sat slouched on his couch, the flickering television casting shadows across his unshaven face. He clenched a glass of scotch, half-empty, its contents trembling ever so slightly with each beat of his agitated heart.
The news was relentless. Story after story painted him in a less-than-flattering light. What had once been a carefully crafted image of charm and corporate poise had been shredded by public disgrace. And now, the city wasn’t just ignoring him, they were laughing at him.
“This can’t be it,” he muttered under his breath, his voice raspy. “It can’t end like this.”
Just then, Helen burst into the room. Her heels clicked loudly on the marble floor, a sharp contrast to the dull haze Mark had wrapped himself in. She threw a tabloid magazine onto the coffee table. The headline screamed at them:
“Ray Empire Architect of Scandal: Helen Ray and Ex-Exec Mark Linked to Fraud, Defamation and Bribery.”
-
@ 58537364:705b4b85
2025-05-23 05:46:31
“สุขเวทนา” ที่แท้ก็คือ “มายา”
เป็นเหมือนลูกคลื่นลูกหนึ่ง
ที่เกิดขึ้นเพราะน้ำถูกลมพัด
เดี๋ยวมันก็แตกกระจายไป
หากต้องการจะมีชีวิตอย่างเกษมแล้ว
ก็ต้องอาศัยความรู้เรื่อง อนิจจัง ทุกขัง อนัตตา ให้สมบูรณ์
มันจะต่อต้านกันได้กับอารมณ์ คือ รูป เสียง กลิ่น รส สัมผัส ที่มากระทบ
ไม่ให้ไปหลงรัก หรือหลงเกลียดเรื่องวุ่นวายมีอยู่ ๒ อย่างเท่านั้น
- ไปหลงรัก อย่างหนึ่ง
- ไปหลงเกลียด อย่างหนึ่ง
ซึ่งเป็นเหตุให้หัวเราะและต้องร้องไห้
ถ้าใครมองเห็นว่า หัวเราะก็กระหืดกระหอบ มันเหนื่อยเหมือนกัน
ร้องไห้ก็กระหืดกระหอบ เหมือนกัน
สู้อยู่เฉย ๆ ดีกว่า อย่าต้องหัวเราะ อย่าต้องร้องไห้
นี่แหละ! มันเป็นความเกษมเราอย่าได้ตกไปเป็นทาสของอารมณ์
จนไปหัวเราะหรือร้องไห้ตามที่อารมณ์มายั่ว
เราเป็นอิสระแก่ตัว หยุดอยู่ หรือเกษมอยู่อย่างนี้ดีกว่า
ใช้ อนิจจัง ทุกขัง อนัตตา เป็นเครื่องมือกำกับชีวิต
- รูป เสียง กลิ่น รส สัมผัส เป็น มายา เป็น illusion
- "ตัวกู-ของกู" ก็เป็น illusion
- เพราะ "ตัวกู-ของกู" มันเกิดมาจากอารมณ์
- "ตัวกู-ของกู" เป็นมายา อารมณ์ทั้งหลายก็เป็นมายา
เห็นได้ด้วยหลัก อนิจจัง ทุกขัง อนัตตา
...ความทุกข์ก็ไม่เกิด
เราจะตัดลัดมองไปดูสิ่งที่เป็น “สุขเวทนา”
สุขเวทนา คือ ความสุขสนุกสนาน เอร็ดอร่อย
ที่เป็นสุขนั้นเรียกว่า “สุขเวทนา”แต่สุขเวทนา เป็นมายา
เพราะมันเป็นเหมือนลูกคลื่นที่เกิดขึ้นเป็นคราว ๆ
ไม่ใช่ตัวจริงอะไรที่พูดดังนี้ก็เพราะว่า
ในบรรดาสิ่งทั้งปวงในโลกทั้งหมดทุกโลก
ไม่ว่าโลกไหน มันมีค่าอยู่ก็ตรงที่ให้เกิดสุขเวทนาลองคิดดูให้ดีว่า...
- ท่านศึกษาเล่าเรียนทำไม?
- ท่านประกอบอาชีพ หน้าที่การงานทำไม?
- ท่านสะสมทรัพย์สมบัติ เกียรติยศ ชื่อเสียง พวกพ้องบริวารทำไม?มันก็เพื่อสุขเวทนาอย่างเดียว
เพราะฉะนั้น แปลว่า อะไร ๆ มันก็มารวมจุดอยู่ที่สุขเวทนาหมดฉะนั้น ถ้าเรามีความรู้ในเรื่องนี้
จัดการกับเรื่องนี้ให้ถูกต้องเพียงเรื่องเดียวเท่านั้น
ทุกเรื่องมันถูกหมดเพราะฉะนั้น จึงต้องดูสุขเวทนาให้ถูกต้องตามที่เป็นจริงว่า
มันก็เป็น “มายา” ชนิดหนึ่งเราจะต้องจัดการให้สมกันกับที่มันเป็นมายา
ไม่ใช่ว่า จะต้องไปตั้งข้อรังเกียจ เกลียดชังมัน
อย่างนั้นมันยิ่ง บ้าบอที่สุดถ้าเข้าไปหลงรัก หลงเป็นทาสมัน
ก็เป็นเรื่อง บ้าบอที่สุดแต่ว่าไปจัดการกับมันอย่างไรให้ถูกต้อง
นั้นแหละเป็นธรรมะ
เป็น ลูกศิษย์ของพระพุทธเจ้า
ที่จะเอาชนะความทุกข์ได้ และไม่ต้องเป็น โรคทางวิญญาณ
สุขเวทนา ที่แท้ก็คือ มายา
มันก็ต้องทำโดยวิธีที่พิจารณาให้เห็นว่า
“สุขเวทนา” นี้ ที่แท้ก็คือ “มายา”เป็นเหมือน ลูกคลื่นลูกหนึ่ง
ที่เกิดขึ้นเพราะ น้ำถูกลมพัดหมายความว่า
เมื่อ รูป เสียง กลิ่น รส ฯ เข้ามา
แล้ว ความโง่ คือ อวิชชา โมหะ ออกรับ
กระทบกันแล้วเป็นคลื่นกล่าวคือ สุขเวทนาเกิดขึ้นมา
แต่ เดี๋ยวมันก็แตกกระจายไป
ถ้ามองเห็นอย่างนี้แล้ว
เราก็ไม่เป็นทาสของสุขเวทนา
เราสามารถ ควบคุม จะจัด จะทำกับมันได้
ในวิธีที่ ไม่เป็นทุกข์- ตัวเองก็ไม่เป็นทุกข์
- ครอบครัวก็ไม่เป็นทุกข์
- เพื่อนบ้านก็ไม่เป็นทุกข์
- คนทั้งโลกก็ไม่พลอยเป็นทุกข์
เพราะมีเราเป็นมูลเหตุ
ถ้าทุกคนเป็นอย่างนี้
โลกนี้ก็มีสันติภาพถาวร
เป็นความสุขที่แท้จริงและถาวรนี่คือ อานิสงส์ของการหายโรคโดยวิธีต่าง ๆ กัน
ไม่เป็นโรค “ตัวกู” ไม่เป็นโรค “ของกู”
พุทธทาสภิกขุ
ที่มา : คำบรรยายชุด “แก่นพุทธศาสน์”
ปีพุทธศักราช ๒๕๐๔
ครั้งที่ ๑
หัวข้อเรื่อง “ใจความทั้งหมดของพระพุทธศาสนา”
ณ ศิริราชพยาบาล มหาวิทยาลัยมหิดล
เมื่อวันที่ ๑๗ ธันวาคม ๒๕๐๔ -
@ f9cf4e94:96abc355
2024-12-31 20:18:59
Scuttlebutt foi iniciado em maio de 2014 por Dominic Tarr ( dominictarr ) como uma rede social alternativa off-line, primeiro para convidados, que permite aos usuários obter controle total de seus dados e privacidade. Secure Scuttlebutt (ssb) foi lançado pouco depois, o que coloca a privacidade em primeiro plano com mais recursos de criptografia.
Se você está se perguntando de onde diabos veio o nome Scuttlebutt:
Este termo do século 19 para uma fofoca vem do Scuttlebutt náutico: “um barril de água mantido no convés, com um buraco para uma xícara”. A gíria náutica vai desde o hábito dos marinheiros de se reunir pelo boato até a fofoca, semelhante à fofoca do bebedouro.

Marinheiros se reunindo em torno da rixa. ( fonte )
Dominic descobriu o termo boato em um artigo de pesquisa que leu.
Em sistemas distribuídos, fofocar é um processo de retransmissão de mensagens ponto a ponto; as mensagens são disseminadas de forma análoga ao “boca a boca”.
Secure Scuttlebutt é um banco de dados de feeds imutáveis apenas para acréscimos, otimizado para replicação eficiente para protocolos ponto a ponto. Cada usuário tem um log imutável somente para acréscimos no qual eles podem gravar. Eles gravam no log assinando mensagens com sua chave privada. Pense em um feed de usuário como seu próprio diário de bordo, como um diário de bordo (ou diário do capitão para os fãs de Star Trek), onde eles são os únicos autorizados a escrever nele, mas têm a capacidade de permitir que outros amigos ou colegas leiam ao seu diário de bordo, se assim o desejarem.
Cada mensagem possui um número de sequência e a mensagem também deve fazer referência à mensagem anterior por seu ID. O ID é um hash da mensagem e da assinatura. A estrutura de dados é semelhante à de uma lista vinculada. É essencialmente um log somente de acréscimo de JSON assinado. Cada item adicionado a um log do usuário é chamado de mensagem.
Os logs do usuário são conhecidos como feed e um usuário pode seguir os feeds de outros usuários para receber suas atualizações. Cada usuário é responsável por armazenar seu próprio feed. Quando Alice assina o feed de Bob, Bob baixa o log de feed de Alice. Bob pode verificar se o registro do feed realmente pertence a Alice verificando as assinaturas. Bob pode verificar as assinaturas usando a chave pública de Alice.

Estrutura de alto nível de um feed
Pubs são servidores de retransmissão conhecidos como “super peers”. Pubs conectam usuários usuários e atualizações de fofocas a outros usuários conectados ao Pub. Um Pub é análogo a um pub da vida real, onde as pessoas vão para se encontrar e se socializar. Para ingressar em um Pub, o usuário deve ser convidado primeiro. Um usuário pode solicitar um código de convite de um Pub; o Pub simplesmente gerará um novo código de convite, mas alguns Pubs podem exigir verificação adicional na forma de verificação de e-mail ou, com alguns Pubs, você deve pedir um código em um fórum público ou chat. Pubs também podem mapear aliases de usuário, como e-mails ou nome de usuário, para IDs de chave pública para facilitar os pares de referência.
Depois que o Pub enviar o código de convite ao usuário, o usuário resgatará o código, o que significa que o Pub seguirá o usuário, o que permite que o usuário veja as mensagens postadas por outros membros do Pub, bem como as mensagens de retransmissão do Pub pelo usuário a outros membros do Pub.
Além de retransmitir mensagens entre pares, os Pubs também podem armazenar as mensagens. Se Alice estiver offline e Bob transmitir atualizações de feed, Alice perderá a atualização. Se Alice ficar online, mas Bob estiver offline, não haverá como ela buscar o feed de Bob. Mas com um Pub, Alice pode buscar o feed no Pub mesmo se Bob estiver off-line porque o Pub está armazenando as mensagens. Pubs são úteis porque assim que um colega fica online, ele pode sincronizar com o Pub para receber os feeds de seus amigos potencialmente offline.
Um usuário pode, opcionalmente, executar seu próprio servidor Pub e abri-lo ao público ou permitir que apenas seus amigos participem, se assim o desejarem. Eles também podem ingressar em um Pub público. Aqui está uma lista de Pubs públicos em que todos podem participar . Explicaremos como ingressar em um posteriormente neste guia. Uma coisa importante a observar é que o Secure Scuttlebutt em uma rede social somente para convidados significa que você deve ser “puxado” para entrar nos círculos sociais. Se você responder às mensagens, os destinatários não serão notificados, a menos que estejam seguindo você de volta. O objetivo do SSB é criar “ilhas” isoladas de redes pares, ao contrário de uma rede pública onde qualquer pessoa pode enviar mensagens a qualquer pessoa.

Perspectivas dos participantes
Scuttlebot
O software Pub é conhecido como servidor Scuttlebutt (servidor ssb ), mas também é conhecido como “Scuttlebot” e
sbotna linha de comando. O servidor SSB adiciona comportamento de rede ao banco de dados Scuttlebutt (SSB). Estaremos usando o Scuttlebot ao longo deste tutorial.Os logs do usuário são conhecidos como feed e um usuário pode seguir os feeds de outros usuários para receber suas atualizações. Cada usuário é responsável por armazenar seu próprio feed. Quando Alice assina o feed de Bob, Bob baixa o log de feed de Alice. Bob pode verificar se o registro do feed realmente pertence a Alice verificando as assinaturas. Bob pode verificar as assinaturas usando a chave pública de Alice.
Estrutura de alto nível de um feed
Pubs são servidores de retransmissão conhecidos como “super peers”. Pubs conectam usuários usuários e atualizações de fofocas a outros usuários conectados ao Pub. Um Pub é análogo a um pub da vida real, onde as pessoas vão para se encontrar e se socializar. Para ingressar em um Pub, o usuário deve ser convidado primeiro. Um usuário pode solicitar um código de convite de um Pub; o Pub simplesmente gerará um novo código de convite, mas alguns Pubs podem exigir verificação adicional na forma de verificação de e-mail ou, com alguns Pubs, você deve pedir um código em um fórum público ou chat. Pubs também podem mapear aliases de usuário, como e-mails ou nome de usuário, para IDs de chave pública para facilitar os pares de referência.
Depois que o Pub enviar o código de convite ao usuário, o usuário resgatará o código, o que significa que o Pub seguirá o usuário, o que permite que o usuário veja as mensagens postadas por outros membros do Pub, bem como as mensagens de retransmissão do Pub pelo usuário a outros membros do Pub.
Além de retransmitir mensagens entre pares, os Pubs também podem armazenar as mensagens. Se Alice estiver offline e Bob transmitir atualizações de feed, Alice perderá a atualização. Se Alice ficar online, mas Bob estiver offline, não haverá como ela buscar o feed de Bob. Mas com um Pub, Alice pode buscar o feed no Pub mesmo se Bob estiver off-line porque o Pub está armazenando as mensagens. Pubs são úteis porque assim que um colega fica online, ele pode sincronizar com o Pub para receber os feeds de seus amigos potencialmente offline.
Um usuário pode, opcionalmente, executar seu próprio servidor Pub e abri-lo ao público ou permitir que apenas seus amigos participem, se assim o desejarem. Eles também podem ingressar em um Pub público. Aqui está uma lista de Pubs públicos em que todos podem participar . Explicaremos como ingressar em um posteriormente neste guia. Uma coisa importante a observar é que o Secure Scuttlebutt em uma rede social somente para convidados significa que você deve ser “puxado” para entrar nos círculos sociais. Se você responder às mensagens, os destinatários não serão notificados, a menos que estejam seguindo você de volta. O objetivo do SSB é criar “ilhas” isoladas de redes pares, ao contrário de uma rede pública onde qualquer pessoa pode enviar mensagens a qualquer pessoa.

Perspectivas dos participantes
Pubs - Hubs
Pubs públicos
| Pub Name | Operator | Invite Code | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | |
scuttle.us| @Ryan |scuttle.us:8008:@WqcuCOIpLtXFRw/9vOAQJti8avTZ9vxT9rKrPo8qG6o=.ed25519~/ZUi9Chpl0g1kuWSrmehq2EwMQeV0Pd+8xw8XhWuhLE=| | pub1.upsocial.com | @freedomrules |pub1.upsocial.com:8008:@gjlNF5Cyw3OKZxEoEpsVhT5Xv3HZutVfKBppmu42MkI=.ed25519~lMd6f4nnmBZEZSavAl4uahl+feajLUGqu8s2qdoTLi8=| | Monero Pub | @Denis |xmr-pub.net:8008:@5hTpvduvbDyMLN2IdzDKa7nx7PSem9co3RsOmZoyyCM=.ed25519~vQU+r2HUd6JxPENSinUWdfqrJLlOqXiCbzHoML9iVN4=| | FreeSocial | @Jarland |pub.freesocial.co:8008:@ofYKOy2p9wsaxV73GqgOyh6C6nRGFM5FyciQyxwBd6A=.ed25519~ye9Z808S3KPQsV0MWr1HL0/Sh8boSEwW+ZK+8x85u9w=| |ssb.vpn.net.br| @coffeverton |ssb.vpn.net.br:8008:@ze8nZPcf4sbdULvknEFOCbVZtdp7VRsB95nhNw6/2YQ=.ed25519~D0blTolH3YoTwSAkY5xhNw8jAOjgoNXL/+8ZClzr0io=| | gossip.noisebridge.info | Noisebridge Hackerspace @james.network |gossip.noisebridge.info:8008:@2NANnQVdsoqk0XPiJG2oMZqaEpTeoGrxOHJkLIqs7eY=.ed25519~JWTC6+rPYPW5b5zCion0gqjcJs35h6JKpUrQoAKWgJ4=|Pubs privados
Você precisará entrar em contato com os proprietários desses bares para receber um convite.
| Pub Name | Operator | Contact | | --------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------- | |
many.butt.nz| @dinosaur | mikey@enspiral.com | |one.butt.nz| @dinosaur | mikey@enspiral.com | |ssb.mikey.nz| @dinosaur | mikey@enspiral.com | | ssb.celehner.com | @cel | cel@celehner.com |Pubs muito grandes
Aviso: embora tecnicamente funcione usar um convite para esses pubs, você provavelmente se divertirá se o fizer devido ao seu tamanho (muitas coisas para baixar, risco para bots / spammers / idiotas)
| Pub Name | Operator | Invite Code | | --------------------------------------- | ----------------------------------------------- | ------------------------------------------------------------ | |
scuttlebutt.de| SolSoCoG |scuttlebutt.de:8008:@yeh/GKxlfhlYXSdgU7CRLxm58GC42za3tDuC4NJld/k=.ed25519~iyaCpZ0co863K9aF+b7j8BnnHfwY65dGeX6Dh2nXs3c=| |Lohn's Pub| @lohn |p.lohn.in:8018:@LohnKVll9HdLI3AndEc4zwGtfdF/J7xC7PW9B/JpI4U=.ed25519~z3m4ttJdI4InHkCtchxTu26kKqOfKk4woBb1TtPeA/s=| | Scuttle Space | @guil-dot | Visit scuttle.space | |SSB PeerNet US-East| timjrobinson |us-east.ssbpeer.net:8008:@sTO03jpVivj65BEAJMhlwtHXsWdLd9fLwyKAT1qAkc0=.ed25519~sXFc5taUA7dpGTJITZVDCRy2A9jmkVttsr107+ufInU=| | Hermies | s | net:hermies.club:8008~shs:uMYDVPuEKftL4SzpRGVyQxLdyPkOiX7njit7+qT/7IQ=:SSB+Room+PSK3TLYC2T86EHQCUHBUHASCASE18JBV24= |GUI - Interface Gráfica do Utilizador(Usuário)
Patchwork - Uma GUI SSB (Descontinuado)
Patchwork é o aplicativo de mensagens e compartilhamento descentralizado construído em cima do SSB . O protocolo scuttlebutt em si não mantém um conjunto de feeds nos quais um usuário está interessado, então um cliente é necessário para manter uma lista de feeds de pares em que seu respectivo usuário está interessado e seguindo.

Fonte: scuttlebutt.nz
Quando você instala e executa o Patchwork, você só pode ver e se comunicar com seus pares em sua rede local. Para acessar fora de sua LAN, você precisa se conectar a um Pub. Um pub é apenas para convidados e eles retransmitem mensagens entre você e seus pares fora de sua LAN e entre outros Pubs.
Lembre-se de que você precisa seguir alguém para receber mensagens dessa pessoa. Isso reduz o envio de mensagens de spam para os usuários. Os usuários só veem as respostas das pessoas que seguem. Os dados são sincronizados no disco para funcionar offline, mas podem ser sincronizados diretamente com os pares na sua LAN por wi-fi ou bluetooth.
Patchbay - Uma GUI Alternativa
Patchbay é um cliente de fofoca projetado para ser fácil de modificar e estender. Ele usa o mesmo banco de dados que Patchwork e Patchfoo , então você pode facilmente dar uma volta com sua identidade existente.

Planetary - GUI para IOS

Planetary é um app com pubs pré-carregados para facilitar integração.
Manyverse - GUI para Android

Manyverse é um aplicativo de rede social com recursos que você esperaria: posts, curtidas, perfis, mensagens privadas, etc. Mas não está sendo executado na nuvem de propriedade de uma empresa, em vez disso, as postagens de seus amigos e todos os seus dados sociais vivem inteiramente em seu telefone .
Fontes
-
https://scuttlebot.io/
-
https://decentralized-id.com/decentralized-web/scuttlebot/#plugins
-
https://medium.com/@miguelmota/getting-started-with-secure-scuttlebut-e6b7d4c5ecfd
-
Secure Scuttlebutt : um protocolo de banco de dados global.
-
-
@ b0a838f2:34ed3f19
2025-05-23 17:55:49
- Bubo Reader - Irrationally minimal RSS feed reader. (Demo)
MITNodejs - CommaFeed - Google Reader inspired self-hosted RSS reader. (Demo, Source Code)
Apache-2.0Java/Docker - FeedCord
⚠- Simple, lightweight & customizable RSS News Feed for your Discord Server.MITDocker - Feedpushr - Powerful RSS aggregator, able to transform and send articles to many outputs. Single binary, extensible with plugins.
GPL-3.0Go/Docker - Feeds Fun - News reader with tags, scoring, and AI. (Source Code)
BSD-3-ClausePython - FreshRSS - Self-hostable RSS feed aggregator. (Demo, Source Code)
AGPL-3.0PHP/Docker - Fusion - Lightweight RSS aggregator and reader.
MITGo/Docker - JARR - JARR (Just Another RSS Reader) is a web-based news aggregator and reader (fork of Newspipe). (Demo, Source Code)
AGPL-3.0Docker/Python - Kriss Feed - Simple and smart (or stupid) feed reader.
CC0-1.0PHP - Leed - Leed (for Light Feed) is a Free and minimalist RSS aggregator.
AGPL-3.0PHP - Miniflux - Minimalist news reader. (Source Code)
Apache-2.0Go/deb/Docker - NewsBlur - Personal news reader that brings people together to talk about the world. A new sound of an old instrument. (Source Code)
MITPython - Newspipe - Web news reader. (Demo)
AGPL-3.0Python - Precis - Extensibility-oriented RSS reader that can use LLMs (including local LLMs) to summarize RSS entries with built-in notification support.
MITPython/Docker - reader - A Python feed reader web app and library (so you can use it to build your own), with only standard library and pure-Python dependencies.
BSD-3-ClausePython - Readflow - Lightweight news reader with modern interface and features: full-text search, automatic categorization, archiving, offline support, notifications... (Source Code)
MITGo/Docker - RSS-Bridge - Generate RSS/ATOM feeds for websites which don't have one.
UnlicensePHP/Docker - RSS Monster - An easy to use web-based RSS aggregator and reader compatible with the Fever API (alternative to Google Reader).
MITPHP - RSS2EMail - Fetches RSS/Atom-feeds and pushes new Content to any email-receiver, supports OPML.
GPL-2.0Python/deb - RSSHub - An easy to use, and extensible RSS feed aggregator, it's capable of generating RSS feeds from pretty much everything ranging from social media to university departments. (Demo, Source Code)
MITNodejs/Docker - Selfoss - New multipurpose rss reader, live stream, mashup, aggregation web application. (Source Code)
GPL-3.0PHP - Stringer - Work-in-progress self-hosted, anti-social RSS reader.
MITRuby - Tiny Tiny RSS - Open source web-based news feed (RSS/Atom) reader and aggregator. (Demo, Source Code)
GPL-3.0Docker/PHP - Yarr - Yarr (yet another rss reader) is a web-based feed aggregator which can be used both as a desktop application and a personal self-hosted server.
MITGo
- Bubo Reader - Irrationally minimal RSS feed reader. (Demo)
-
@ b0a838f2:34ed3f19
2025-05-23 17:55:31
- Aimeos - E-commerce framework for building custom online shops, market places and complex B2B applications scaling to billions of items with Laravel. (Demo, Source Code)
LGPL-3.0/MITPHP - Bagisto - Leading Laravel open source e-commerce framework with multi-inventory sources, taxation, localization, dropshipping and more exciting features. (Demo, Source Code)
MITPHP - CoreShop - E-commerce plugin for Pimcore. (Source Code)
GPL-3.0PHP - Drupal Commerce - Popular e-commerce module for Drupal CMS, with support for dozens of payment, shipping, and shopping related modules. (Source Code)
GPL-2.0PHP - EverShop
⚠- E-commerce platform with essential commerce features. Modular architecture and fully customizable. (Demo, Source Code)GPL-3.0Docker/Nodejs - Litecart
⚠- Shopping cart in 1 file (with support for payment by card or cryptocurrency).MITGo/Docker - Magento Open Source - Leading provider of open omnichannel innovation. (Source Code)
OSL-3.0PHP - MedusaJs - Headless commerce engine that enables developers to create amazing digital commerce experiences. (Demo, Source Code)
MITNodejs - Microweber - Drag and Drop CMS and online shop. (Source Code)
MITPHP - Open Source POS - Open Source Point of Sale is a web based point of sale system.
MITPHP - OpenCart - Shopping cart solution. (Source Code)
GPL-3.0PHP - PrestaShop - Fully scalable e-commerce solution. (Demo, Source Code)
OSL-3.0PHP - Pretix - Ticket sales platform for events. (Source Code)
AGPL-3.0Python/Docker - s-cart - S-Cart is a free e-commerce website project for individuals and businesses, built on top of Laravel Framework. (Demo, Source Code)
MITPHP - Saleor - Django based open-sourced e-commerce storefront. (Demo, Source Code)
BSD-3-ClauseDocker/Python - Shopware Community Edition - PHP based open source e-commerce software made in Germany. (Demo, Source Code)
MITPHP - Solidus - A free, open-source ecommerce platform that gives you complete control over your store. (Source Code)
BSD-3-ClauseRuby/Docker - Spree Commerce - Spree is a complete, modular & API-driven open source e-commerce solution for Ruby on Rails. (Demo, Source Code)
BSD-3-ClauseRuby - Sylius - Symfony2 powered open source full-stack platform for eCommerce. (Demo, Source Code)
MITPHP - Thelia - Thelia is an open source and flexible e-commerce solution. (Demo, Source Code)
LGPL-3.0PHP - Vendure - A headless commerce framework. (Demo, Source Code)
MITNodejs - WooCommerce - WordPress based e-commerce solution. (Source Code)
GPL-3.0PHP
- Aimeos - E-commerce framework for building custom online shops, market places and complex B2B applications scaling to billions of items with Laravel. (Demo, Source Code)
-
@ 502ab02a:a2860397
2025-05-23 01:57:14
น้ำนมมนุษย์ที่ไม่ง้อมนุษย์ หรือนี่กำลังจะกลายเป็นเรื่องจริงเร็วกว่าที่เราคิดนะครับ
ในยุคที่อุตสาหกรรมอาหารหันหลังให้กับปศุสัตว์ ไม่ว่าจะด้วยเหตุผลด้านสิ่งแวดล้อม จริยธรรม หรือความยั่งยืน “น้ำนมจากห้องแล็บ” กำลังกลายเป็นแนวหน้าของการปฏิวัติอาหาร โดยเฉพาะเมื่อบริษัทหนึ่งจากสิงคโปร์นามว่า TurtleTree ประกาศอย่างชัดเจนว่า พวกเขากำลังจะสร้างโปรตีนสำคัญในน้ำนมมนุษย์ โดยไม่ต้องมีมนุษย์แม่เลยแม้แต่น้อย
TurtleTree ก่อตั้งในปี 2019 โดยมีเป้าหมายอันทะเยอทะยานคือการผลิตโปรตีนในนมแม่ให้ได้ผ่านเทคโนโลยีที่เรียกว่า precision fermentation โดยใช้จุลินทรีย์ที่ถูกดัดแปลงพันธุกรรมให้ผลิตโปรตีนเฉพาะ เช่น lactoferrin และ human milk oligosaccharides (HMOs) ซึ่งเป็นองค์ประกอบล้ำค่าที่พบในน้ำนมมนุษย์แต่แทบไม่มีในนมวัว หรือผลิตภัณฑ์นมทั่วไป
โปรตีนตัวแรกที่ TurtleTree ประสบความสำเร็จในการผลิตคือ LF+ หรือ lactoferrin ที่เลียนแบบโปรตีนในนมแม่ ซึ่งมีหน้าที่ช่วยระบบภูมิคุ้มกันของทารก ต่อต้านแบคทีเรีย และช่วยให้ร่างกายดูดซึมธาตุเหล็กได้ดีขึ้น โปรตีนนี้เป็นหนึ่งในหัวใจของนมแม่ ที่บริษัทต้องการนำมาใช้ในอุตสาหกรรมนมผงเด็กและอาหารเสริมสำหรับผู้ใหญ่ ล่าสุดในปี 2024 LF+ ได้รับการรับรองสถานะ GRAS (Generally Recognized As Safe) จากองค์การอาหารและยาสหรัฐฯ (FDA) อย่างเป็นทางการ เป็นหมุดหมายสำคัญที่บอกว่า นี่ไม่ใช่แค่ไอเดียในแล็บอีกต่อไป แต่กำลังกลายเป็นผลิตภัณฑ์เชิงพาณิชย์จริง
เบื้องหลังของโปรเจกต์นี้คือการลงทุนกว่า 30 ล้านดอลลาร์สหรัฐจากกลุ่มทุนทั่วโลก รวมถึงบริษัท Solar Biotech ที่จับมือกับ TurtleTree ในการขยายกำลังการผลิตเชิงอุตสาหกรรมในสหรัฐอเมริกา โดยตั้งเป้าว่าจะสามารถผลิตโปรตีนเหล่านี้ได้ในระดับราคาที่แข่งขันได้ภายในไม่กี่ปีข้างหน้า
สิ่งที่น่าสนใจคือ TurtleTree ไม่ได้หยุดแค่ lactoferrin พวกเขายังวางแผนพัฒนา HMO ซึ่งเป็นน้ำตาลเชิงซ้อนชนิดพิเศษที่มีอยู่เฉพาะในน้ำนมแม่ เป็นอาหารเลี้ยงแบคทีเรียดีในลำไส้ทารก ช่วยพัฒนาระบบภูมิคุ้มกันและสมอง ปัจจุบัน HMOs เริ่มเป็นที่นิยมในวงการ infant formula แต่การผลิตยังจำกัดและมีต้นทุนสูง การที่ TurtleTree จะนำเทคโนโลยี precision fermentation มาใช้ผลิต HMO จึงถือเป็นความพยายามในการลดช่องว่างระหว่าง "นมแม่จริง" กับ "นมผงสังเคราะห์"
ทั้งหมดนี้เกิดขึ้นภายใต้แนวคิดใหม่ของอุตสาหกรรมอาหารที่เรียกว่า "functional nutrition" หรือโภชนาการที่ออกแบบเพื่อทำงานเฉพาะทาง ไม่ใช่แค่ให้พลังงานหรือโปรตีน แต่เล็งเป้าหมายเฉพาะ เช่น เสริมภูมิคุ้มกัน ซ่อมแซมสมอง หรือฟื้นฟูร่างกาย โดยมีรากฐานจากธรรมชาติ แต่ใช้เทคโนโลยีสมัยใหม่ในการผลิต
แม้จะฟังดูเป็นความก้าวหน้าทางวิทยาศาสตร์ที่น่าตื่นเต้น แต่น้ำเสียงที่ดังก้องในอีกมุมหนึ่งก็คือคำถามเชิงจริยธรรม TurtleTree กำลังสร้างโปรตีนที่มีอยู่เฉพาะในมนุษย์ โดยอาศัยข้อมูลพันธุกรรมของมนุษย์เอง แล้วนำเข้าสู่ระบบอุตสาหกรรมเพื่อการค้า คำถามคือ เมื่อใดที่การจำลองธรรมชาติจะกลายเป็นการผูกขาดธรรมชาติ? ใครควรเป็นเจ้าของข้อมูลพันธุกรรมของมนุษย์? และถ้าวันหนึ่งบริษัทใดบริษัทหนึ่งสามารถควบคุมการผลิต “นมแม่จำลอง” ได้แต่เพียงผู้เดียว นั่นจะส่งผลต่อเสรีภาพของสังคมในมุมไหนบ้าง?
นักชีวจริยธรรมหลายคน เช่น ดร.ซิลเวีย แคมโปเรซี จาก King's College London ตั้งข้อสังเกตไว้ว่า เทคโนโลยีแบบนี้อาจแก้ปัญหาการเข้าถึงนมแม่ในพื้นที่ห่างไกลหรือในกลุ่มแม่ที่ให้นมไม่ได้ แต่ขณะเดียวกันก็อาจกลายเป็นการสร้าง "ระบบอาหารทางเลือก" ที่ควบคุมโดยบริษัทไม่กี่ราย ที่มีอำนาจเกินกว่าผู้บริโภคจะตรวจสอบได้
เมื่อเทคโนโลยีสามารถจำลองสิ่งที่เคยสงวนไว้เฉพาะธรรมชาติ และมนุษย์ได้ใกล้เคียงจนแทบแยกไม่ออก บางทีคำถามที่ควรถามอาจไม่ใช่แค่ว่า “มันปลอดภัยหรือไม่?” แต่อาจต้องถามว่า “เราไว้ใจใครให้สร้างสิ่งนี้แทนธรรมชาติ?” เพราะน้ำนมแม่เคยเป็นสิ่งที่มาจากรักและชีวิต แต่วันนี้มันอาจกลายเป็นเพียงสิ่งที่มาจากห้องแล็บและโมเลกุล... และนั่นคือสิ่งที่เราต้องคิดให้เป็น ก่อนจะกินให้ดี เต่านี้มีบุญคุณอันใหญ่หลวงงงงงงง
เสริมจุดน่าสนใจให้ครับ KBW Ventures ถือเป็นผู้ลงทุนรายใหญ่ที่สุดใน TurtleTree Labs โดยมีบทบาทสำคัญในหลายรอบการระดมทุนของบริษัท KBW Ventures เป็นบริษัทลงทุนจากสหรัฐอาหรับเอมิเรตส์ ก่อตั้งโดย สมเด็จพระราชโอรสเจ้าชายคาเล็ด บิน อัลวาลีด บิน ตาลาล อัล ซาอุด (HRH Prince Khaled bin Alwaleed bin Talal Al Saud) ในรอบการระดมทุน Pre-A มูลค่า 6.2 ล้านดอลลาร์สหรัฐฯ ซึ่งปิดในเดือนธันวาคม 2020 KBW Ventures ได้ร่วมลงทุนพร้อมกับ Green Monday Ventures, Eat Beyond Global และ Verso Capital . นอกจากนี้ เจ้าชาย Khaled ยังได้เข้าร่วมเป็นที่ปรึกษาให้กับ TurtleTree Labs เพื่อสนับสนุนการขยายตลาดและกลยุทธ์การเติบโตของบริษัท
ซึ่งในตัว KBW Ventures นั้น เป็นบริษัทลงทุนที่มุ่งเน้นการสนับสนุนเทคโนโลยีที่ยั่งยืนและนวัตกรรมในหลากหลายอุตสาหกรรม เช่น เทคโนโลยีชีวภาพ (biotech), เทคโนโลยีพลังงานสะอาด, เทคโนโลยีการเงิน (fintech), เทคโนโลยีการขนส่ง, และเทคโนโลยีอาหาร (food tech) โดยเฉพาะ และในส่วนของเจ้าชาย Khaled มีความสนใจอย่างลึกซึ้งในด้านเทคโนโลยีอาหาร โดยเฉพาะในกลุ่มโปรตีนทางเลือก เช่น Beyond Meat ซึ่งเป็นการลงทุนที่สะท้อนถึงความมุ่งมั่นชัดเจนในการส่งเสริมอาหารที่ยั่งยืนและมีจริยธรรมครับ และแน่นอนเลยว่า โดยมีส่วนร่วมในรอบระดมทุนหลายครั้งของ Beyond Meat รวมถึงตอนที่ Beyond Meat เข้าตลาดหุ้น Nasdaq ครั้งแรกในปี 2019
เจ้าชาย Khaled เชื่อมั่นว่าอาหารทางเลือกแบบพืชจะถูกลงและแพร่หลายมากขึ้น จนอาจถูกกว่าราคาเนื้อสัตว์จากสัตว์จริงภายในปี 2025 ตามข้อมูลที่ได้มาแสดงว่า ปีนี้นี่หว่าาาาาาาาาา
#pirateketo #กูต้องรู้มั๊ย #ม้วนหางสิลูก #siamstr
-
@ e97aaffa:2ebd765d
2024-12-31 16:47:12
Último dia do ano, momento para tirar o pó da bola de cristal, para fazer reflexões, previsões e desejos para o próximo ano e seguintes.
Ano após ano, o Bitcoin evoluiu, foi ultrapassando etapas, tornou-se cada vez mais mainstream. Está cada vez mais difícil fazer previsões sobre o Bitcoin, já faltam poucas barreiras a serem ultrapassadas e as que faltam são altamente complexas ou tem um impacto profundo no sistema financeiro ou na sociedade. Estas alterações profundas tem que ser realizadas lentamente, porque uma alteração rápida poderia resultar em consequências terríveis, poderia provocar um retrocesso.
Código do Bitcoin
No final de 2025, possivelmente vamos ter um fork, as discussões sobre os covenants já estão avançadas, vão acelerar ainda mais. Já existe um consenso relativamente alto, a favor dos covenants, só falta decidir que modelo será escolhido. Penso que até ao final do ano será tudo decidido.
Depois dos covenants, o próximo foco será para a criptografia post-quantum, que será o maior desafio que o Bitcoin enfrenta. Criar uma criptografia segura e que não coloque a descentralização em causa.
Espero muito de Ark, possivelmente a inovação do ano, gostaria de ver o Nostr a furar a bolha bitcoinheira e que o Cashu tivesse mais reconhecimento pelos bitcoiners.
Espero que surjam avanços significativos no BitVM2 e BitVMX.
Não sei o que esperar das layer 2 de Bitcoin, foram a maior desilusão de 2024. Surgiram com muita força, mas pouca coisa saiu do papel, foi uma mão cheia de nada. Uma parte dos projetos caiu na tentação da shitcoinagem, na criação de tokens, que tem um único objetivo, enriquecer os devs e os VCs.
Se querem ser levados a sério, têm que ser sérios.
“À mulher de César não basta ser honesta, deve parecer honesta”
Se querem ter o apoio dos bitcoiners, sigam o ethos do Bitcoin.
Neste ponto a atitude do pessoal da Ark é exemplar, em vez de andar a chorar no Twitter para mudar o código do Bitcoin, eles colocaram as mãos na massa e criaram o protocolo. É claro que agora está meio “coxo”, funciona com uma multisig ou com os covenants na Liquid. Mas eles estão a criar um produto, vão demonstrar ao mercado que o produto é bom e útil. Com a adoção, a comunidade vai perceber que o Ark necessita dos covenants para melhorar a interoperabilidade e a soberania.
É este o pensamento certo, que deveria ser seguido pelos restantes e futuros projetos. É seguir aquele pensamento do J.F. Kennedy:
“Não perguntem o que é que o vosso país pode fazer por vocês, perguntem o que é que vocês podem fazer pelo vosso país”
Ou seja, não fiquem à espera que o bitcoin mude, criem primeiro as inovações/tecnologia, ganhem adoção e depois demonstrem que a alteração do código camada base pode melhorar ainda mais o vosso projeto. A necessidade é que vai levar a atualização do código.
Reservas Estratégicas de Bitcoin
Bancos centrais
Com a eleição de Trump, emergiu a ideia de uma Reserva Estratégia de Bitcoin, tornou este conceito mainstream. Foi um pivot, a partir desse momento, foram enumerados os políticos de todo o mundo a falar sobre o assunto.
A Senadora Cynthia Lummis foi mais além e propôs um programa para adicionar 200 mil bitcoins à reserva ao ano, até 1 milhão de Bitcoin. Só que isto está a criar uma enorme expectativa na comunidade, só que pode resultar numa enorme desilusão. Porque no primeiro ano, o Trump em vez de comprar os 200 mil, pode apenas adicionar na reserva, os 198 mil que o Estado já tem em sua posse. Se isto acontecer, possivelmente vai resultar numa forte queda a curto prazo. Na minha opinião os bancos centrais deveriam seguir o exemplo de El Salvador, fazer um DCA diário.
Mais que comprar bitcoin, para mim, o mais importante é a criação da Reserva, é colocar o Bitcoin ao mesmo nível do ouro, o impacto para o resto do mundo será tremendo, a teoria dos jogos na sua plenitude. Muitos outros bancos centrais vão ter que comprar, para não ficarem atrás, além disso, vai transmitir uma mensagem à generalidade da população, que o Bitcoin é “afinal é algo seguro, com valor”.
Mas não foi Trump que iniciou esta teoria dos jogos, mas sim foi a primeira vítima dela. É o próprio Trump que o admite, que os EUA necessitam da reserva para não ficar atrás da China. Além disso, desde que os EUA utilizaram o dólar como uma arma, com sanção contra a Rússia, surgiram boatos de que a Rússia estaria a utilizar o Bitcoin para transações internacionais. Que foram confirmados recentemente, pelo próprio governo russo. Também há poucos dias, ainda antes deste reconhecimento público, Putin elogiou o Bitcoin, ao reconhecer que “Ninguém pode proibir o bitcoin”, defendendo como uma alternativa ao dólar. A narrativa está a mudar.
Já existem alguns países com Bitcoin, mas apenas dois o fizeram conscientemente (El Salvador e Butão), os restantes têm devido a apreensões. Hoje são poucos, mas 2025 será o início de uma corrida pelos bancos centrais. Esta corrida era algo previsível, o que eu não esperava é que acontecesse tão rápido.
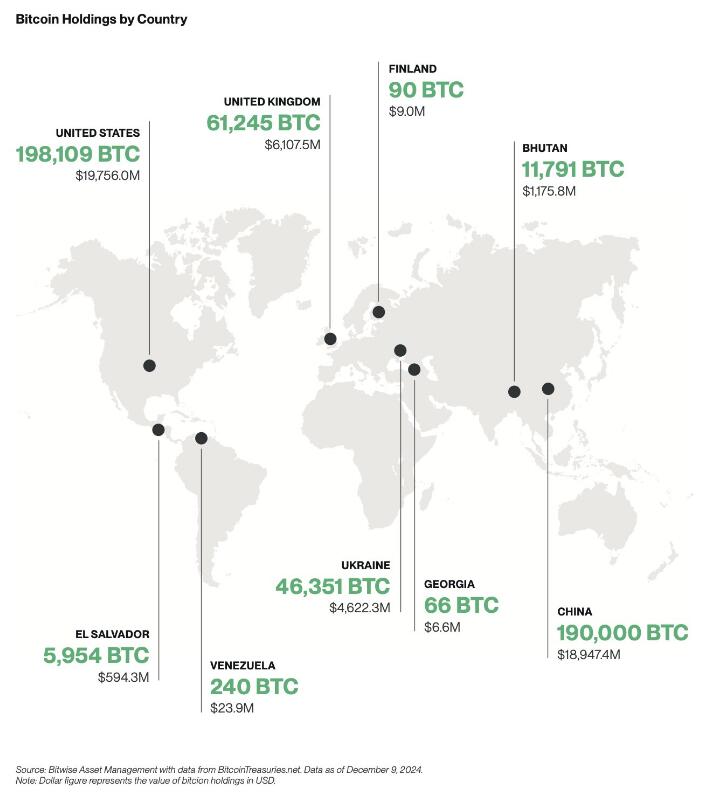
Empresas
A criação de reservas estratégicas não vai ficar apenas pelos bancos centrais, também vai acelerar fortemente nas empresas em 2025.
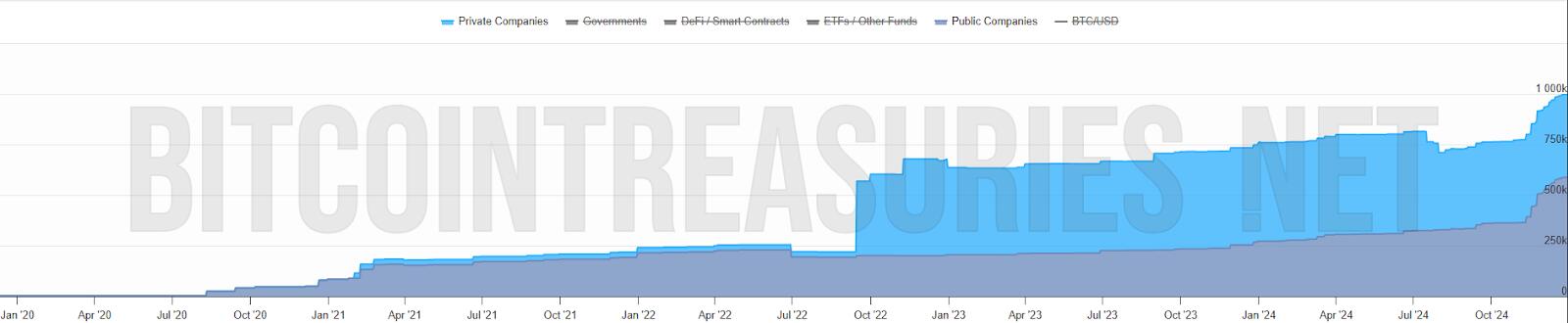
Mas as empresas não vão seguir a estratégia do Saylor, vão comprar bitcoin sem alavancagem, utilizando apenas os tesouros das empresas, como uma proteção contra a inflação. Eu não sou grande admirador do Saylor, prefiro muito mais, uma estratégia conservadora, sem qualquer alavancagem. Penso que as empresas vão seguir a sugestão da BlackRock, que aconselha um alocações de 1% a 3%.
Penso que 2025, ainda não será o ano da entrada das 6 magníficas (excepto Tesla), será sobretudo empresas de pequena e média dimensão. As magníficas ainda tem uma cota muito elevada de shareholders com alguma idade, bastante conservadores, que têm dificuldade em compreender o Bitcoin, foi o que aconteceu recentemente com a Microsoft.
Também ainda não será em 2025, talvez 2026, a inclusão nativamente de wallet Bitcoin nos sistema da Apple Pay e da Google Pay. Seria um passo gigante para a adoção a nível mundial.
ETFs
Os ETFs para mim são uma incógnita, tenho demasiadas dúvidas, como será 2025. Este ano os inflows foram superiores a 500 mil bitcoins, o IBIT foi o lançamento de ETF mais bem sucedido da história. O sucesso dos ETFs, deve-se a 2 situações que nunca mais se vão repetir. O mercado esteve 10 anos à espera pela aprovação dos ETFs, a procura estava reprimida, isso foi bem notório nos primeiros meses, os inflows foram brutais.
Também se beneficiou por ser um mercado novo, não existia orderbook de vendas, não existia um mercado interno, praticamente era só inflows. Agora o mercado já estabilizou, a maioria das transações já são entre clientes dos próprios ETFs. Agora só uma pequena percentagem do volume das transações diárias vai resultar em inflows ou outflows.
Estes dois fenómenos nunca mais se vão repetir, eu não acredito que o número de inflows em BTC supere os número de 2024, em dólares vai superar, mas em btc não acredito que vá superar.
Mas em 2025 vão surgir uma infindável quantidade de novos produtos, derivativos, novos ETFs de cestos com outras criptos ou cestos com ativos tradicionais. O bitcoin será adicionado em produtos financeiros já existentes no mercado, as pessoas vão passar a deter bitcoin, sem o saberem.
Com o fim da operação ChokePoint 2.0, vai surgir uma nova onda de adoção e de produtos financeiros. Possivelmente vamos ver bancos tradicionais a disponibilizar produtos ou serviços de custódia aos seus clientes.
Eu adoraria ver o crescimento da adoção do bitcoin como moeda, só que a regulamentação não vai ajudar nesse processo.
Preço
Eu acredito que o topo deste ciclo será alcançado no primeiro semestre, posteriormente haverá uma correção. Mas desta vez, eu acredito que a correção será muito menor que as anteriores, inferior a 50%, esta é a minha expectativa. Espero estar certo.
Stablecoins de dólar
Agora saindo um pouco do universo do Bitcoin, acho importante destacar as stablecoins.
No último ciclo, eu tenho dividido o tempo, entre continuar a estudar o Bitcoin e estudar o sistema financeiro, as suas dinâmicas e o comportamento humano. Isto tem sido o meu foco de reflexão, imaginar a transformação que o mundo vai sofrer devido ao padrão Bitcoin. É uma ilusão acreditar que a transição de um padrão FIAT para um padrão Bitcoin vai ser rápida, vai existir um processo transitório que pode demorar décadas.
Com a re-entrada de Trump na Casa Branca, prometendo uma política altamente protecionista, vai provocar uma forte valorização do dólar, consequentemente as restantes moedas do mundo vão derreter. Provocando uma inflação generalizada, gerando uma corrida às stablecoins de dólar nos países com moedas mais fracas. Trump vai ter uma política altamente expansionista, vai exportar dólares para todo o mundo, para financiar a sua própria dívida. A desigualdade entre os pobres e ricos irá crescer fortemente, aumentando a possibilidade de conflitos e revoltas.
“Casa onde não há pão, todos ralham e ninguém tem razão”
Será mais lenha, para alimentar a fogueira, vai gravar os conflitos geopolíticos já existentes, ficando as sociedade ainda mais polarizadas.
Eu acredito que 2025, vai haver um forte crescimento na adoção das stablecoins de dólares, esse forte crescimento vai agravar o problema sistémico que são as stablecoins. Vai ser o início do fim das stablecoins, pelo menos, como nós conhecemos hoje em dia.
Problema sistémico
O sistema FIAT não nasceu de um dia para outro, foi algo que foi construído organicamente, ou seja, foi evoluindo ao longo dos anos, sempre que havia um problema/crise, eram criadas novas regras ou novas instituições para minimizar os problemas. Nestes quase 100 anos, desde os acordos de Bretton Woods, a evolução foram tantas, tornaram o sistema financeiro altamente complexo, burocrático e nada eficiente.
Na prática é um castelo de cartas construído sobre outro castelo de cartas e que por sua vez, foi construído sobre outro castelo de cartas.
As stablecoins são um problema sistémico, devido às suas reservas em dólares e o sistema financeiro não está preparado para manter isso seguro. Com o crescimento das reservas ao longo dos anos, foi se agravando o problema.
No início a Tether colocava as reservas em bancos comerciais, mas com o crescimento dos dólares sob gestão, criou um problema nos bancos comerciais, devido à reserva fracionária. Essas enormes reservas da Tether estavam a colocar em risco a própria estabilidade dos bancos.
A Tether acabou por mudar de estratégia, optou por outros ativos, preferencialmente por títulos do tesouro/obrigações dos EUA. Só que a Tether continua a crescer e não dá sinais de abrandamento, pelo contrário.
Até o próprio mundo cripto, menosprezava a gravidade do problema da Tether/stablecoins para o resto do sistema financeiro, porque o marketcap do cripto ainda é muito pequeno. É verdade que ainda é pequeno, mas a Tether não o é, está no top 20 dos maiores detentores de títulos do tesouros dos EUA e está ao nível dos maiores bancos centrais do mundo. Devido ao seu tamanho, está a preocupar os responsáveis/autoridades/reguladores dos EUA, pode colocar em causa a estabilidade do sistema financeiro global, que está assente nessas obrigações.
Os títulos do tesouro dos EUA são o colateral mais utilizado no mundo, tanto por bancos centrais, como por empresas, é a charneira da estabilidade do sistema financeiro. Os títulos do tesouro são um assunto muito sensível. Na recente crise no Japão, do carry trade, o Banco Central do Japão tentou minimizar a desvalorização do iene através da venda de títulos dos EUA. Esta operação, obrigou a uma viagem de emergência, da Secretaria do Tesouro dos EUA, Janet Yellen ao Japão, onde disponibilizou liquidez para parar a venda de títulos por parte do Banco Central do Japão. Essa forte venda estava desestabilizando o mercado.
Os principais detentores de títulos do tesouros são institucionais, bancos centrais, bancos comerciais, fundo de investimento e gestoras, tudo administrado por gestores altamente qualificados, racionais e que conhecem a complexidade do mercado de obrigações.
O mundo cripto é seu oposto, é naife com muita irracionalidade e uma forte pitada de loucura, na sua maioria nem faz a mínima ideia como funciona o sistema financeiro. Essa irracionalidade pode levar a uma “corrida bancária”, como aconteceu com o UST da Luna, que em poucas horas colapsou o projeto. Em termos de escala, a Luna ainda era muito pequena, por isso, o problema ficou circunscrito ao mundo cripto e a empresas ligadas diretamente ao cripto.
Só que a Tether é muito diferente, caso exista algum FUD, que obrigue a Tether a desfazer-se de vários biliões ou dezenas de biliões de dólares em títulos num curto espaço de tempo, poderia provocar consequências terríveis em todo o sistema financeiro. A Tether é grande demais, é já um problema sistémico, que vai agravar-se com o crescimento em 2025.
Não tenham dúvidas, se existir algum problema, o Tesouro dos EUA vai impedir a venda dos títulos que a Tether tem em sua posse, para salvar o sistema financeiro. O problema é, o que vai fazer a Tether, se ficar sem acesso às venda das reservas, como fará o redeem dos dólares?
Como o crescimento do Tether é inevitável, o Tesouro e o FED estão com um grande problema em mãos, o que fazer com o Tether?
Mas o problema é que o atual sistema financeiro é como um curto cobertor: Quanto tapas a cabeça, destapas os pés; Ou quando tapas os pés, destapas a cabeça. Ou seja, para resolver o problema da guarda reservas da Tether, vai criar novos problemas, em outros locais do sistema financeiro e assim sucessivamente.
Conta mestre
Uma possível solução seria dar uma conta mestre à Tether, dando o acesso direto a uma conta no FED, semelhante à que todos os bancos comerciais têm. Com isto, a Tether deixaria de necessitar os títulos do tesouro, depositando o dinheiro diretamente no banco central. Só que isto iria criar dois novos problemas, com o Custodia Bank e com o restante sistema bancário.
O Custodia Bank luta há vários anos contra o FED, nos tribunais pelo direito a ter licença bancária para um banco com full-reserves. O FED recusou sempre esse direito, com a justificativa que esse banco, colocaria em risco toda a estabilidade do sistema bancário existente, ou seja, todos os outros bancos poderiam colapsar. Perante a existência em simultâneo de bancos com reserva fracionária e com full-reserves, as pessoas e empresas iriam optar pelo mais seguro. Isso iria provocar uma corrida bancária, levando ao colapso de todos os bancos com reserva fracionária, porque no Custodia Bank, os fundos dos clientes estão 100% garantidos, para qualquer valor. Deixaria de ser necessário limites de fundos de Garantia de Depósitos.
Eu concordo com o FED nesse ponto, que os bancos com full-reserves são uma ameaça a existência dos restantes bancos. O que eu discordo do FED, é a origem do problema, o problema não está nos bancos full-reserves, mas sim nos que têm reserva fracionária.
O FED ao conceder uma conta mestre ao Tether, abre um precedente, o Custodia Bank irá o aproveitar, reclamando pela igualdade de direitos nos tribunais e desta vez, possivelmente ganhará a sua licença.
Ainda há um segundo problema, com os restantes bancos comerciais. A Tether passaria a ter direitos similares aos bancos comerciais, mas os deveres seriam muito diferentes. Isto levaria os bancos comerciais aos tribunais para exigir igualdade de tratamento, é uma concorrência desleal. Isto é o bom dos tribunais dos EUA, são independentes e funcionam, mesmo contra o estado. Os bancos comerciais têm custos exorbitantes devido às políticas de compliance, como o KYC e AML. Como o governo não vai querer aliviar as regras, logo seria a Tether, a ser obrigada a fazer o compliance dos seus clientes.
A obrigação do KYC para ter stablecoins iriam provocar um terramoto no mundo cripto.
Assim, é pouco provável que seja a solução para a Tether.
FED
Só resta uma hipótese, ser o próprio FED a controlar e a gerir diretamente as stablecoins de dólar, nacionalizado ou absorvendo as existentes. Seria uma espécie de CBDC. Isto iria provocar um novo problema, um problema diplomático, porque as stablecoins estão a colocar em causa a soberania monetária dos outros países. Atualmente as stablecoins estão um pouco protegidas porque vivem num limbo jurídico, mas a partir do momento que estas são controladas pelo governo americano, tudo muda. Os países vão exigir às autoridades americanas medidas que limitem o uso nos seus respectivos países.
Não existe uma solução boa, o sistema FIAT é um castelo de cartas, qualquer carta que se mova, vai provocar um desmoronamento noutro local. As autoridades não poderão adiar mais o problema, terão que o resolver de vez, senão, qualquer dia será tarde demais. Se houver algum problema, vão colocar a responsabilidade no cripto e no Bitcoin. Mas a verdade, a culpa é inteiramente dos políticos, da sua incompetência em resolver os problemas a tempo.
Será algo para acompanhar futuramente, mas só para 2026, talvez…
É curioso, há uns anos pensava-se que o Bitcoin seria a maior ameaça ao sistema ao FIAT, mas afinal, a maior ameaça aos sistema FIAT é o próprio FIAT(stablecoins). A ironia do destino.
Isto é como uma corrida, o Bitcoin é aquele atleta que corre ao seu ritmo, umas vezes mais rápido, outras vezes mais lento, mas nunca pára. O FIAT é o atleta que dá tudo desde da partida, corre sempre em velocidade máxima. Só que a vida e o sistema financeiro não é uma prova de 100 metros, mas sim uma maratona.
Europa
2025 será um ano desafiante para todos europeus, sobretudo devido à entrada em vigor da regulamentação (MiCA). Vão começar a sentir na pele a regulamentação, vão agravar-se os problemas com os compliance, problemas para comprovar a origem de fundos e outras burocracias. Vai ser lindo.
O Travel Route passa a ser obrigatório, os europeus serão obrigados a fazer o KYC nas transações. A Travel Route é uma suposta lei para criar mais transparência, mas prática, é uma lei de controle, de monitorização e para limitar as liberdades individuais dos cidadãos.
O MiCA também está a colocar problemas nas stablecoins de Euro, a Tether para já preferiu ficar de fora da europa. O mais ridículo é que as novas regras obrigam os emissores a colocar 30% das reservas em bancos comerciais. Os burocratas europeus não compreendem que isto coloca em risco a estabilidade e a solvência dos próprios bancos, ficam propensos a corridas bancárias.
O MiCA vai obrigar a todas as exchanges a estar registadas em solo europeu, ficando vulnerável ao temperamento dos burocratas. Ainda não vai ser em 2025, mas a UE vai impor políticas de controle de capitais, é inevitável, as exchanges serão obrigadas a usar em exclusividade stablecoins de euro, as restantes stablecoins serão deslistadas.
Todas estas novas regras do MiCA, são extremamente restritas, não é para garantir mais segurança aos cidadãos europeus, mas sim para garantir mais controle sobre a população. A UE está cada vez mais perto da autocracia, do que da democracia. A minha única esperança no horizonte, é que o sucesso das políticas cripto nos EUA, vai obrigar a UE a recuar e a aligeirar as regras, a teoria dos jogos é implacável. Mas esse recuo, nunca acontecerá em 2025, vai ser um longo período conturbado.
Recessão
Os mercados estão todos em máximos históricos, isto não é sustentável por muito tempo, suspeito que no final de 2025 vai acontecer alguma correção nos mercados. A queda só não será maior, porque os bancos centrais vão imprimir dinheiro, muito dinheiro, como se não houvesse amanhã. Vão voltar a resolver os problemas com a injeção de liquidez na economia, é empurrar os problemas com a barriga, em de os resolver. Outra vez o efeito Cantillon.
Será um ano muito desafiante a nível político, onde o papel dos políticos será fundamental. A crise política na França e na Alemanha, coloca a UE órfã, sem um comandante ao leme do navio. 2025 estará condicionado pelas eleições na Alemanha, sobretudo no resultado do AfD, que podem colocar em causa a propriedade UE e o euro.
Possivelmente, só o fim da guerra poderia minimizar a crise, algo que é muito pouco provável acontecer.
Em Portugal, a economia parece que está mais ou menos equilibrada, mas começam a aparecer alguns sinais preocupantes. Os jogos de sorte e azar estão em máximos históricos, batendo o recorde de 2014, época da grande crise, não é um bom sinal, possivelmente já existe algum desespero no ar.
A Alemanha é o motor da Europa, quanto espirra, Portugal constipa-se. Além do problema da Alemanha, a Espanha também está à beira de uma crise, são os países que mais influenciam a economia portuguesa.
Se existir uma recessão mundial, terá um forte impacto no turismo, que é hoje em dia o principal motor de Portugal.
Brasil
Brasil é algo para acompanhar em 2025, sobretudo a nível macro e a nível político. Existe uma possibilidade de uma profunda crise no Brasil, sobretudo na sua moeda. O banco central já anda a queimar as reservas para minimizar a desvalorização do Real.
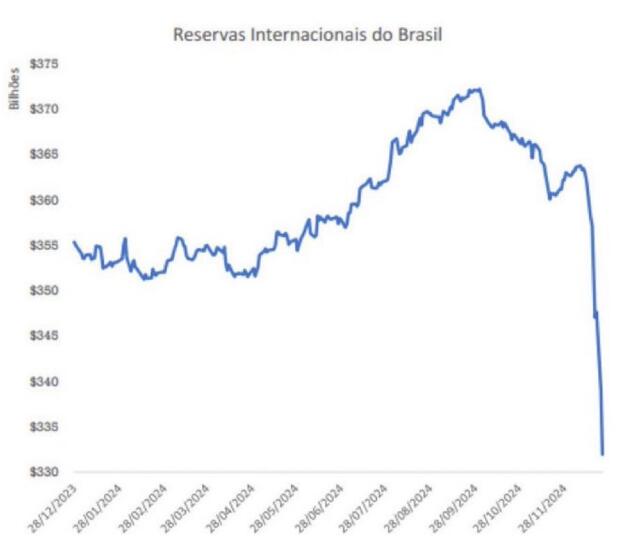
Sem mudanças profundas nas políticas fiscais, as reservas vão se esgotar. As políticas de controle de capitais são um cenário plausível, será interesse de acompanhar, como o governo irá proceder perante a existência do Bitcoin e stablecoins. No Brasil existe um forte adoção, será um bom case study, certamente irá repetir-se em outros países num futuro próximo.
Os próximos tempos não serão fáceis para os brasileiros, especialmente para os que não têm Bitcoin.
Blockchain
Em 2025, possivelmente vamos ver os primeiros passos da BlackRock para criar a primeira bolsa de valores, exclusivamente em blockchain. Eu acredito que a BlackRock vai criar uma própria blockchain, toda controlada por si, onde estarão os RWAs, para fazer concorrência às tradicionais bolsas de valores. Será algo interessante de acompanhar.
Estas são as minhas previsões, eu escrevi isto muito em cima do joelho, certamente esqueci-me de algumas coisas, se for importante acrescentarei nos comentários. A maioria das previsões só acontecerá após 2025, mas fica aqui a minha opinião.
Isto é apenas a minha opinião, Don’t Trust, Verify!
-
@ b0a838f2:34ed3f19
2025-05-23 17:55:13
- Evergreen - Highly-scalable software for libraries that helps library patrons find library materials, and helps libraries manage, catalog, and circulate those materials. (Source Code)
GPL-2.0PLpgSQL - Koha - Enterprise-class ILS with modules for acquisitions, circulation, cataloging, label printing, offline circulation for when Internet access is not available, and much more. (Demo, Source Code)
GPL-3.0Perl - RERO ILS - Large-scale ILS that can be run as a service with consortial features, intended primarily for library networks. Includes most standard modules (circulation, acquisitions, cataloging,...) and a web-based public and professional interface. (Demo, Source Code)
AGPL-3.0Python/Docker
- Evergreen - Highly-scalable software for libraries that helps library patrons find library materials, and helps libraries manage, catalog, and circulate those materials. (Source Code)
-
@ 3eba5ef4:751f23ae
2025-05-23 01:12:10
Crypto Insights
Introducing Generalized Program Composition and Coin Delegation into Bitcoin
Joshua Doman proposed a proof-of-concept called Graftleaf, aiming to achieve generalized program composition and delegation in Taproot in a simple and secure way. Graftleaf is a new Taproot leaf version (0xc2) that uses the annex to perform delegation. It adds two key features:
-
Composition: The ability to sequentially execute zero, one, or multiple witness programs, including a locking script.
-
Delegation: The ability to add additional spending conditions at signing time, which can include arbitrary combinations of programs and scripts.
This design overcomes the limitations of previous proposals by supporting complex script composition and delegation, promising backward compatibility, improved privacy and fungibility with the existing P2TR addresses.
Why OP_CHECKCONTRACTVERIFY (CCV) Will Replace OP_VAULT
A post mainly discusses the current status of Bitcoin script opcode OP_VAULT (BIP-345) and the possibility of it being replaced by OP_CHECKCONTRACTVERIFY (CCV, BIP-443). Key factors include:
-
CCV is a more general version of OP_VAULT, inheriting some features such as amount modes and deferred (cross-input) checks.
-
CCV supports replacing multiple script tapleaf nodes, has a simpler interface, and a lighter script interpreter implementation.
The author also points out CCV’s shortcomings and possible future extensions:
-
Currently, there is a lack of supporting documentation and tools, and the BIP is not yet fully completed.
-
A VAULT-decorator opcode may be needed to implement certain advanced features, such as requiring collateral lockup when unvaulting, or adding some rate-limiting behavior. These features are currently difficult to achieve.
Despite this, CCV remains a better foundation for building vault functionality.
Enabling Recursive Covenants via Self-Replication
Bram Cohen proposed adding a few simple opcodes to Bitcoin Script to enable recursive covenants in a natural and straightforward way. He illustrated with examples that a practical and useful script can be achieved through Quine, without other more complex tricks; developers writing recursive covenants must be aware of the importance of this approach.
UTXO Set Report from Mempool Research: Nearly Half of Bitcoin UTXOs Are Less Than 1,000 Sats
During the OP_RETURN debate in April-May 2025, the impact of inserting arbitrary data into transactions on the UTXO set sparked much discussion. In this report, Mempool studied the UTXO set, highlighting the fragmentation and bloat issues, especially due to small transactions and data embedding, which increase the storage and validation burden for node operators.
Key findings include:
-
Severe Bloat: Currently, about 49% of UTXOs are less than 1,000 satoshis (about $1). Most of these use Taproot address format and may be related to data embedding schemes (like Ordinals) or related transfer mechanisms. Although these UTXOs can usually be spent, before they are, they increase the storage and validation burden for all node operators.
-
Significant Proportion of Inscription-Related UTXOs: About 30% of UTXOs are related to inscription.
-
Large Number of Long-Unspent UTXOs: There are over 100,000 old Counterparty UTXOs using Pay to Multisig (p2ms) scripts, which have existed for over 10 years. Although they make up a small proportion of the total (about 173 million UTXOs), they are a typical example of UTXO bloat.
-
Taproot Becomes the Most Common UTXO Type: Among all UTXO types, Taproot (p2tr) has the highest proportion at 34.2%, followed by traditional p2pkh (28.8%) and p2wpkh (26.5%). However, in terms of total value stored, Taproot’s share is relatively low, indicating it is mainly used for small transactions or data embedding.
The report concludes by mentioning that as the UTXO sets continue to grow, Utreexo and SwiftSync are two scaling methods for maintaining Bitcoin’s accessibility to a wide range of node operators.
Visualization of Bitcoin Mainnet Data
mainnet-observer, built and maintained by developer @0xB10C, visualizes multiple data points from the Bitcoin mainnet, including:
-
Mining a single block currently requires over ~500,000,000,000,000,000,000,000,000 (500 zeta or 5×10²³) hash attempts.
-
Over 42 BTC are now permanently lost in provably unspendable OP_RETURN outputs.
-
Daily updated “Mining Centralization Index” (with proxy pools)
-
Bitcoin mining is currently highly centralized, with 6 pools producing and mining over 95% of block templates.

Path Queries: Addressing Payment Reliability and Routing Limitations
brh28 initiated a discussion on Lightning Network payment routing, focusing on issues like liquidity uncertainty and inefficient path discovery. He proposed a new path query mechanism—allowing nodes to dynamically share information through path queries, fostering a more decentralized routing ecosystem. This can improve the success rate of large payments and reduce reliance on a completely synced channel graph. Although there are still some privacy concerns, this method provides nodes with a controllable information disclosure mechanism and is expected to revolutionize current payment routing approaches.
Bitlayer and Sui Achieve Trust-Minimized BitVM Bridge
Bitlayer and Sui integrated the BitVM Bridge, launching Peg-BTC (YBTC)—bridging native Bitcoin to the Sui ecosystem via BitVM Bridge. BitVM Bridge is a trust-minimized bridge powered by Bitlayer and supported by the advanced BitVM smart contract framework.
Ark Protocol Litepaper
Ark recently released its litepaper: Ark: A UTXO-based Transaction Batching Protocol, outlining its technical foundation. As an innovative Bitcoin scaling protocol, Ark enables off-chain transaction execution while allowing users full control over their funds. This is achieved by introducing “virtual UTXOs” (VTXOs), allowing users to transact off-chain while retaining the ability to unilaterally exit to the Bitcoin main chain. Coordinated by an operator who batches user activities into on-chain commitments, Ark achieves high transaction throughput with minimal on-chain footprint. This provides Bitcoin with a simple and user-friendly scaling solution that offers a practical path for Layer 2 solutions that are inefficient or costly to execute on the main chain.
Top Reads on Blockchain and Beyond
List of Known Real-World Bitcoin Attack Incidents
Here is a list of real-world attacks against Bitcoin/crypto asset holders over the years.

The Internet Capital Market: Free Avenue for Developers, or Another Wave of FOMO?
This post discusses Internet Capital Markets (ICM)—decentralized platforms where funds flow directly to app builders and creators. ICM combines crowdfunding, token issuance, and equity speculation, eliminating the need for VCs, banks, or app stores. In 2025, more independent developers are issuing app tokens directly via X and tools like Believe and Launchcoin, attracting mass investment.
ICM Proponents argue this model breaks traditional funding barriers, making innovation more democratic and accessible; while critics warn that ICM is becoming a hotbed for hype and short-term speculation, with many projects lacking real products or long-term value. The author believes whether ICM can become the next milestone for Web3 hinges on whether it can break free from the cycle of “speculation becomes product traction” and deliver real user value and sustained innovation.
-
-
@ 3eba5ef4:751f23ae
2025-05-23 01:08:23
加密洞见
在比特币中引入通用程序组合与币委托机制
Joshua Doman 提出了一个 Graftleaf 的概念验证,旨在用一种简单而安全的方法在 Taproot 中实现通用程序组合和代笔委托。Graftleaf 是一个新的 Taproot 叶子版本(0xc2),使用附件来执行委托。Graftleaf 增加了两个关键功能:
-
组合:按顺序执行零个、一个或多个见证程序的能力,包括一个锁定脚本。
-
委派:在签名时添加其他支出条件的能力,可以包括程序和脚本的任意组合。
它们旨在通过支持复杂的脚本组合和委托来克服以前提案的局限性,承诺提高隐私性、可替代性以及与现有 P2TR 地址的向后兼容性。
为什么说 OP_CHECKCONTRACTVERIFY (CCV) 将会取代 OP_VAULT
帖子主要讨论了比特币脚本操作码 OP_VAULT(BIP-345)的现状,及其被OP_CHECKCONTRACTVERIFY(CCV,BIP-443)取代的可能。重要因素有:
-
CCV 是 OP_VAULT 的更通用版本,继承了部分功能,如金额模式(amount modes)、延迟跨输入检查(deferred cross-input checks)。
-
CCV支持替换多个脚本叶子节点(tapleaf),接口更简洁,脚本解释器实现更轻量。
同时作者也指出 CCV 的不足与未来可能的扩展:
-
当前缺少部分配套文档和工具,BIP 尚未完全完成。
-
可能需要 VAULT-decorator 操作码来实现某些高级功能,如解锁金库时必须抵押锁定、速率限制等。
尽管如此,CCV仍然是构建金库功能的更优基础。
通过自复制方式启用递归契约
Bram Cohen 提出通过向比特币脚本添加一些简单的操作码,以一种自然而直接的方式实现递归契约(recursive covenants)。他通过例子说明,一个实用且有用的脚本通过 Quine 自复制就可以实现,无需其他更复杂的技巧;编写递归契约的开发者必须意识到该方式的重要性。
Mempool Research 发布 UTXO 集的报告:比特币中近一半 UTXO 金额小于 1000 聪
在 2025 年 4 至 5 月期间的 OP_RETURN 大辩论中,将任意数据插入交易对 UTXO 集的影响的问题引发了大量讨论。Mempool 在这份报告中,对 UTXO 集进行了研究,强调了比特币 UTXO 集合碎片化和膨胀的问题,特别是由于小额交易和数据嵌入导致的 UTXO 增长,增加了节点运营者的存储和验证负担。关键结论有:
-
UTXO 集合的碎片化严重:目前约有 49% 的 UTXO 金额低于 1000 聪(约合 1 美元),这些小额 UTXO 大多采用 Taproot 地址格式,可能与数据嵌入方案(如 Ordinals 铭文)或相关的转移机制有关。尽管这些 UTXO 通常可被花费,但在被使用之前,它们会增加所有节点运营者的存储和验证负担。
-
铭文相关的 UTXO 占比显著:约 30% 的 UTXO 与铭文相关。
-
存在大量长期未动用的 UTXO:有超过 10 万个使用 Pay to Multisig (p2ms) 脚本的旧 Counterparty UTXO,且存在超过 10 年。尽管在总数(约 1.73 亿个 UTXO)中所占比例较小,但依然是 UTXO 膨胀的典型问题。
-
Taproot 成为最常见的 UTXO 类型:在所有 UTXO 类型中,Taproot(p2tr)占比最高,为 34.2%,其次是传统的 p2pkh(28.8%)和 p2wpkh(26.5%)。但是从 UTXO 所存储的总价值来看,Taproot 的占比相对较低,表明其主要用于小额交易或数据嵌入。
报告最后也提到,对于继续增长的 UTXO 集,Utreexo 和 SwiftSync 是两种对保持比特币对广泛节点运营者可访问性的扩容方法。
比特币网络各项数据的可视化呈现
mainnet-observer 由开发者 @0xB10C 搭建并维护,将比特币链的多项数据呈现出来,可以看到:
-
目前挖掘一个区块所需要的平均哈希尝试:超过 ~500000000000000000000000000(500 zeta 或 5×10²³)次
-
超过 42 个 BTC 现在永远丢失在可证明无法花费的 OP_RETURN 输出中
-
每日更新的「挖矿中心化指数」(带有代理池)
-
比特币挖矿高度集中,6 个矿池生产并挖掘了超过 95%的区块模板(截止 2025 年 4 月)

闪电网络路径查询:解决支付可靠性和路由限制
brh28 发起了关于闪电网络路由支付的讨论,聚焦「流动性的不确定性」(liquidity uncertainty)和路径发现效率低的问题,提出了一种新的路径查询机制——允许节点以路径查询的形式,实现动态信息共享,推动了一个更加分布式的路由生态。这可以提高了大额支付的成功率,并减少对完整通道图的依赖。尽管在隐私方面仍存在一定担忧,但该方法为节点提供了一种可控的信息披露机制,有望革新现有的支付路由方式。
Bitlayer 和 Sui 实现了信任最小化的 BitVM 桥
Bitlayer 和 Sui 整合了 BitVM Bridge,推出 Peg-BTC(YBTC)——通过 BitVM Bridge 将原生比特币桥接到 Sui 生态中。BitVM Bridge 是一个由 Bitlayer 提供支持并由先进的 BitVM 智能合约框架支持的信任最小化桥。
Ark 协议的正式规范
Ark 近日发布 Litepaper: Ark: A UTXO-based Transaction Batching Protocol,阐述其技术基础。作为一种新颖的比特币扩容协议,Ark 实现了链下交易执行,同时让用户能完全掌控自己的资金。这一点通过引入「虚拟UTXO」(VTXO)得以实现,用户在链下交易,同时保留单方面退出至比特币主链的能力。Ark 同一个 operator 协作,将用户操作打包成链上承诺,在保持极小链上负担的前提下实现高交易吞吐量。这为比特币提供了一种简单易用的扩容方案,也为那些在主链上执行效率低下或成本过高的二层方案提供了落地空间。
精彩无限,不止于链
已知真实发生过的比特币攻击事件列表
这里列出了历年来在真实世界中发生过的、针对比特币/加密资产拥有者的攻击事件。

互联网资本市场:是开发者的自由通道,还是另一波 FOMO?
帖子讨论了互联网资本市场( ICM, Internet Capital Markets ),即去中心化平台——资金直接流向应用程序构建者和创建者。ICM 集众筹、代币发行和股权投机于一体,无需VC、银行或应用商店。2025年,越来越多独立开发者通过 X 和 Believe、Launchcoin 等工具直接发行应用代币,吸引大众投资。ICM 的支持者认为,这种模式打破了传统融资壁垒,让创新更民主、门槛更低;但批评者警告,ICM 正沦为炒作和短期投机的温床,许多项目缺乏实际产品和长期价值。作者认为,ICM 模式能否成为 Web3 的下一个里程碑,关键在于其能否走出「投机成了产品增长动力」(speculation becomes product traction)的怪圈,实现真正的用户价值和持续创新。
-
-
@ b0a838f2:34ed3f19
2025-05-23 17:54:53
- DSpace - Turnkey repository application providing durable access to digital resources. (Source Code)
BSD-3-ClauseJava - EPrints - Digital document management system with a flexible metadata and workflow model primarily aimed at academic institutions. (Demo, Source Code)
GPL-3.0Perl - Fedora Commons Repository - Robust and modular repository system for the management and dissemination of digital content especially suited for digital libraries and archives, both for access and preservation. (Source Code)
Apache-2.0Java - InvenioRDM - Highly scalable turn-key research data management platform with a beautiful user experience. (Demo, Source Code, Clients)
MITPython - Islandora - Drupal module for browsing and managing Fedora-based digital repositories. (Demo, Source Code)
GPL-3.0PHP - Samvera Hyrax - Front-end for the Samvera framework, which itself is a Ruby on Rails application for browsing and managing Fedora-based digital repositories. (Source Code)
Apache-2.0Ruby
- DSpace - Turnkey repository application providing durable access to digital resources. (Source Code)
-
@ 10f7c7f7:f5683da9
2025-05-23 15:26:17
While I’m going to stand by what I said in my previous piece, minimise capital gains payments, don’t fund the government, get a loan against your bitcoin, but the wheels in my left curve brain have continued to turn, well that, and a few more of my 40PW insights. I mentioned about paying attention to the risks involved in terms of borrowing against your bitcoin, and hopefully ending up paying less in bitcoin at the end of the loan, even if you ultimately sold bitcoin to pay off the loan. However, the idea of losing control of the bitcoin I have spent a good deal of time and effort accumulating being out of my control has led me to reconsider. I also realised I didn’t fully flesh out some other topics that I think are relevant, not least time preference, specifically in relation to what you’re buying. The idea of realising a lump some of capital to live your dreams, buy a house or a cool car may be important, but it may be worth taking a step back and looking at what you’re purchasing. Are you only purchasing those things because you had been able to get this new money “tax free”? If that is the case, and the fiat is burning a hold in your pocket, maybe you’ve just found yourself with the same fiat brained mentality you have been working so hard to escape from while you have sacrificed and saved to stack sats.
While it may no longer be necessary to ask yourself whether a particular product or service is worth selling your bitcoin for because you’ve taken out a loan, it may still be worth asking yourself whether a particular loan fuelled purchase is worth forfeiting control of your keys for? Unlike the foolish 18 year-old, released into a world with their newly preapproved credit card, you need to take a moment and ask yourself:
Is the risk worth it?
Is the purchase worth it?
But also take a moment to consider a number of other things, are there fiat options?
Where in the cycle might you be?
Or if I’m thinking carefully about this, will whatever I’m buying hold its value (experiences may be more difficult to run the numbers on)?
The reason for asking these things, is that if you still have a foot in the fiat world, dealing with a fiat bank account, fiat institutions may still be very willing to provide you with a loan at a lower rate than a bitcoin backed loan. Particularly if you’re planning on using that money to buy a house; if you can qualify for a mortgage, get a mortgage, but if you need cash for a deposit, maybe that is where the bitcoin backed loan may come in. Then, it may be worth thinking about where are you in the bitcoin cycle? No one can answer this, but with the historic data we have, it appears logical that after some type of run up, prices may retrace (Dan Held’s supercycle withstanding).
Matteo Pellegrini with Daniel Prince provided a new perspective on this for me. Rather the riding the bull market gains all the way through to the bear market bottom, what happens if I chose to buy an asset that didn’t lose quite as much fiat value as bitcoin, for example, a Swiss Watch, or a tasteful, more mature sports car? If that was the purchase of choice, they suggested that you could enjoy the car, “the experience” for a year or two, then realise the four door estate was likely always the better option, sell it and be able to buy back as many, if not slightly more bitcoin that you originally sold (not financial, classic car or price prediction advice, I’m not accredited to advise pretty much anything). Having said that, it is a scenario I think worth thinking about when the bitcoin denominated dream car begins to make financial sense.
Then, as we begin to look forward to the near inevitable bear market (they are good for both stacking and grinding), if we’ve decided to take out a loan rather than sell, we then may ultimately need to increase our collateral to maintain loan to value requirements, as well as sell more bitcoin to cover repayments (if that’s the route we’re taking). This then moves us back into the domain of saying, well in actual fact we should just sell our bitcoin when we can get most dollar for it (or the coolest car), with a little extra to cover future taxes, it is probably better to sell near a top than a bottom. The balance between these two rather extreme positions could be to take out a fiat loan to buy the item and maybe sell sufficient bitcoin so you’re able to cover the loan for a period of time (less taxable events to keep track of and also deals with future uncertainty of bitcoin price). In this case, if the loan timeframe is longer than the amount of loan your sale can cover, by the time you need to sell anymore, the price should have recovered from a cycle bottom.
In this scenario, apart from the smaller portion of bitcoin you have had to sell, the majority of your stack can remain in cold storage, the loan you took out will be unsecured (particularly against your bitcoin), but even if it isn’t, the value of what you purchase maintains its value, you can in theory exit the loan at any point by selling the luxury item. Then within this scenario, if you had sold near a top, realised the car gave you a bad back or made you realise you staying humble is more important, sold it, paid off the loan, there may even be a chance you could buy back more bitcoin with the money you had left over from selling your bitcoin to fund the loan.
I have no idea of this could actually work, but to be honest, I’m looking forward to trying it out in the next 6-12 months, although I may keep my daily driver outside of my bitcoin strategy (kids still need a taxi service). Having said that, I think there are some important points to consider in addition to not paying capital gains tax (legally), as well as the opportunities of bitcoin loans. They are still very young products and to quote every trad-fi news outlet, “bitcoin is still a volatile asset”, these thought experiments are still worth working through. To push back on the Uber fiat journalist, Katie Martin, “Bitcoin has no obvious use case”, it does, it can be a store of value to hold or sell, it can be liquid and flexible collateral, but also an asset that moves independently of other assets to balance against fiat liabilities. The idea of being able to release some capital, enjoy the benefits of the capital for a period, before returning that capital to store value feels like a compelling one.
The important thing to remember is that there are a variety of options, whether selling for cash, taking out a bitcoin backed loan, taking out a fiat loan or some combination of each. Saying that, what I would think remains an important question to ask irrespective of the option you go for:
Is what I’m planning on buying, worth selling bitcoin for?
If it cannot pass this first question, maybe it isn’t worth purchasing to start with.
-
@ 254f56d7:f2c38100
2024-12-30 07:38:27
Vamos ver seu funcionamento

-
@ f85b9c2c:d190bcff
2025-05-23 01:04:58
 I’ve always believed that truth doesn’t bend to the will of the crowd. Growing up, I watched people nod along to ideas they didn’t even agree with, just because everyone else seemed to. It baffled me then, and it still does now. There’s something powerful about standing firm when you know you’re right—even if it means standing alone.
I’ve always believed that truth doesn’t bend to the will of the crowd. Growing up, I watched people nod along to ideas they didn’t even agree with, just because everyone else seemed to. It baffled me then, and it still does now. There’s something powerful about standing firm when you know you’re right—even if it means standing alone.It’s not easy, though. The pressure to conform can feel like a tidal wave, crashing down with judgment, whispers, and rolled eyes. I’ve been there, heart pounding, wondering if I’m the crazy one. But here’s what I’ve learned: the majority isn’t always right. History backs me up—think of Galileo, shunned for saying the Earth wasn’t the center of the universe, or the countless voices drowned out before they were proven true. Numbers don’t guarantee wisdom.
For me, it’s about integrity. If I’ve wrestled with the facts, questioned myself, and still landed on solid ground, I’m not backing down just to keep the peace. It’s not arrogance—it’s conviction. I’d rather be the lone voice in a sea of noise than a silent echo of a lie. Because in the end, truth doesn’t care about headcounts. It cares about courage.
-
@ b0a838f2:34ed3f19
2025-05-23 17:54:34
- Atsumeru - Manga/comic/light novel media server with clients for Windows, Linux, macOS and Android. (Source Code, Clients)
MITJava/Docker - BookLogr - Manage your personal book library with ease. (Demo)
Apache-2.0Docker - Calibre Web - Browse, read and download eBooks using an existing Calibre database.
GPL-3.0Python - Calibre - E-book library manager that can view, convert, and catalog e-books in most of the major e-book formats and provides a built-in Web server for remote clients. (Demo, Source Code)
GPL-3.0Python/deb - Kapowarr - Build and manage a comic book library. Download, rename, move and convert issues of the volume to your liking. (Source Code)
GPL-3.0Docker/Python - Kavita - Cross-platform e-book/manga/comic/pdf server and web reader with user management, ratings and reviews, and metadata support. (Demo, Source Code)
GPL-3.0.NET/Docker - kiwix-serve - HTTP daemon for serving wikis from ZIM files. (Source Code)
GPL-3.0C++ - Komga - Media server for comics/mangas/BDs with API and OPDS support, a modern web interface for exploring your libraries, as well as a web reader. (Source Code)
MITJava/Docker - Librum - Modern e-book reader and library manager that supports most major book formats, runs on all devices and offers great tools to boost productivity. (Source Code)
GPL-3.0C++ - Stump - A fast, free and open source comics, manga and digital book server with OPDS support. (Source Code)
MITRust - The Epube - Self-hosted web EPUB reader using EPUB.js, Bootstrap, and Calibre. (Source Code)
GPL-3.0PHP
- Atsumeru - Manga/comic/light novel media server with clients for Windows, Linux, macOS and Android. (Source Code, Clients)
-
@ a012dc82:6458a70d
2024-12-30 05:51:11
Table Of Content
-
The Influence of Global Oil Prices
-
Bitcoin's Roller Coaster Ride
-
Anticipation Surrounding the 2024 Halving Event
-
The Broader Crypto Landscape
-
Conclusions
-
FAQ
In the ever-evolving world of cryptocurrencies, Bitcoin stands as a beacon, often dictating the mood of the entire crypto market. Its price fluctuations are closely watched by investors, analysts, and enthusiasts alike. Max Keiser, a prominent figure in the crypto space, recently shed light on some intriguing factors that might be influencing Bitcoin's current price trajectory. This article delves into Keiser's insights, exploring the broader implications of global events on Bitcoin's market performance.
The Influence of Global Oil Prices
Max Keiser, a renowned Bitcoin advocate and former trader, recently drew attention to the interplay between global oil prices and Bitcoin's market performance. Responding to a post by German economics expert, Holger Zschaepitz, Keiser highlighted the significance of Brent oil reaching $90 per barrel for the first time since the previous November. According to Keiser, the surge in oil prices, driven by Saudi Arabia's decision to extend its reduction in oil production for another three months, has had ripple effects in the financial world. One of these effects is the shift of investor interest towards higher interest deposit USD accounts. This diversion of investments is creating what Keiser terms as "a small headwind for Bitcoin," implying that as traditional markets like oil show promise, some investors might be reconsidering their cryptocurrency positions.
Bitcoin's Roller Coaster Ride
The cryptocurrency market, known for its volatility, witnessed Bitcoin's price undergoing significant fluctuations recently. A notable event that gave Bitcoin a temporary boost was Grayscale's triumph over the SEC in a legal battle concerning the conversion of its Bitcoin Trust into a spot ETF. This victory led to a rapid 7.88% spike in Bitcoin's price within a mere hour, pushing it from the $26,000 bracket to briefly touch the $28,000 threshold. However, this euphoria was short-lived. Over the subsequent week, the cryptocurrency saw its gains erode, settling in the $25,400 range. At the time the reference article was penned, Bitcoin was hovering around $25,688.
Anticipation Surrounding the 2024 Halving Event
The Bitcoin community is abuzz with anticipation for the next scheduled Bitcoin halving, projected to take place in April-May 2024. This event will see the rewards for Bitcoin miners being slashed by half, resulting in a decreased supply of Bitcoin entering the market. Historically, such halvings have acted as catalysts, propelling Bitcoin's price upwards. A case in point is the aftermath of the 2020 halving, post which Bitcoin soared to an all-time high of $69,000 in October 2021. However, some financial analysts argue that this surge was less about the halving and more a consequence of the extensive monetary measures adopted by institutions like the US Federal Reserve. These measures, taken in response to the pandemic and the ensuing lockdowns, flooded the market with cash, potentially driving up Bitcoin's price.
The Broader Crypto Landscape
While Bitcoin remains the most dominant and influential cryptocurrency, it's essential to consider its position within the broader crypto ecosystem. Other cryptocurrencies, often referred to as 'altcoins', also play a role in shaping investor sentiment and market dynamics. Factors such as technological advancements, regulatory changes, and global economic shifts not only impact Bitcoin but the entire crypto market. As investors diversify their portfolios and explore newer blockchain projects, Bitcoin's role as the market leader is continually tested. Yet, its pioneering status and proven resilience make it a focal point of discussions and analyses in the crypto world.
Conclusion
Bitcoin, the flagship cryptocurrency, has always been subject to a myriad of market forces and global events. While its inherent potential remains undeniable, the current market landscape, shaped by factors ranging from oil prices to global economic policies, presents challenges. Yet, with events like the 2024 halving on the horizon, there's an air of optimism among Bitcoin enthusiasts and investors about the future trajectory of this digital asset.
FAQ
Who is Max Keiser? Max Keiser is a prominent Bitcoin advocate, former trader, and well-known crypto podcaster.
What did Keiser say about Bitcoin's price? Keiser pointed out that rising global oil prices and the allure of higher interest deposit USD accounts are creating a "small headwind" for Bitcoin.
How did Grayscale's legal victory affect Bitcoin? Grayscale's win over the SEC led to a 7.88% spike in Bitcoin's price within an hour.
When is the next Bitcoin halving expected? The next Bitcoin halving is projected to occur around April-May 2024.
Did the 2020 Bitcoin halving influence its price? Yes, post the 2020 halving, Bitcoin reached an all-time high of $69,000 in October 2021.
That's all for today
If you want more, be sure to follow us on:
NOSTR: croxroad@getalby.com
Instagram: @croxroadnews.co
Youtube: @croxroadnews
Store: https://croxroad.store
Subscribe to CROX ROAD Bitcoin Only Daily Newsletter
https://www.croxroad.co/subscribe
DISCLAIMER: None of this is financial advice. This newsletter is strictly educational and is not investment advice or a solicitation to buy or sell any assets or to make any financial decisions. Please be careful and do your own research.
-
-
@ 16d11430:61640947
2024-12-23 16:47:01
At the intersection of philosophy, theology, physics, biology, and finance lies a terrifying truth: the fiat monetary system, in its current form, is not just an economic framework but a silent, relentless force actively working against humanity's survival. It isn't simply a failed financial model—it is a systemic engine of destruction, both externally and within the very core of our biological existence.
The Philosophical Void of Fiat
Philosophy has long questioned the nature of value and the meaning of human existence. From Socrates to Kant, thinkers have pondered the pursuit of truth, beauty, and virtue. But in the modern age, the fiat system has hijacked this discourse. The notion of "value" in a fiat world is no longer rooted in human potential or natural resources—it is abstracted, manipulated, and controlled by central authorities with the sole purpose of perpetuating their own power. The currency is not a reflection of society’s labor or resources; it is a representation of faith in an authority that, more often than not, breaks that faith with reckless monetary policies and hidden inflation.
The fiat system has created a kind of ontological nihilism, where the idea of true value, rooted in work, creativity, and family, is replaced with speculative gambling and short-term gains. This betrayal of human purpose at the systemic level feeds into a philosophical despair: the relentless devaluation of effort, the erosion of trust, and the abandonment of shared human values. In this nihilistic economy, purpose and meaning become increasingly difficult to find, leaving millions to question the very foundation of their existence.
Theological Implications: Fiat and the Collapse of the Sacred
Religious traditions have long linked moral integrity with the stewardship of resources and the preservation of life. Fiat currency, however, corrupts these foundational beliefs. In the theological narrative of creation, humans are given dominion over the Earth, tasked with nurturing and protecting it for future generations. But the fiat system promotes the exact opposite: it commodifies everything—land, labor, and life—treating them as mere transactions on a ledger.
This disrespect for creation is an affront to the divine. In many theologies, creation is meant to be sustained, a delicate balance that mirrors the harmony of the divine order. Fiat systems—by continuously printing money and driving inflation—treat nature and humanity as expendable resources to be exploited for short-term gains, leading to environmental degradation and societal collapse. The creation narrative, in which humans are called to be stewards, is inverted. The fiat system, through its unholy alliance with unrestrained growth and unsustainable debt, is destroying the very creation it should protect.
Furthermore, the fiat system drives idolatry of power and wealth. The central banks and corporations that control the money supply have become modern-day gods, their decrees shaping the lives of billions, while the masses are enslaved by debt and inflation. This form of worship isn't overt, but it is profound. It leads to a world where people place their faith not in God or their families, but in the abstract promises of institutions that serve their own interests.
Physics and the Infinite Growth Paradox
Physics teaches us that the universe is finite—resources, energy, and space are all limited. Yet, the fiat system operates under the delusion of infinite growth. Central banks print money without concern for natural limits, encouraging an economy that assumes unending expansion. This is not only an economic fallacy; it is a physical impossibility.
In thermodynamics, the Second Law states that entropy (disorder) increases over time in any closed system. The fiat system operates as if the Earth were an infinite resource pool, perpetually able to expand without consequence. The real world, however, does not bend to these abstract concepts of infinite growth. Resources are finite, ecosystems are fragile, and human capacity is limited. Fiat currency, by promoting unsustainable consumption and growth, accelerates the depletion of resources and the degradation of natural systems that support life itself.
Even the financial “growth” driven by fiat policies leads to unsustainable bubbles—inflated stock markets, real estate, and speculative assets that burst and leave ruin in their wake. These crashes aren’t just economic—they have profound biological consequences. The cycles of boom and bust undermine communities, erode social stability, and increase anxiety and depression, all of which affect human health at a biological level.
Biology: The Fiat System and the Destruction of Human Health
Biologically, the fiat system is a cancerous growth on human society. The constant chase for growth and the devaluation of work leads to chronic stress, which is one of the leading causes of disease in modern society. The strain of living in a system that values speculation over well-being results in a biological feedback loop: rising anxiety, poor mental health, physical diseases like cardiovascular disorders, and a shortening of lifespans.
Moreover, the focus on profit and short-term returns creates a biological disconnect between humans and the planet. The fiat system fuels industries that destroy ecosystems, increase pollution, and deplete resources at unsustainable rates. These actions are not just environmentally harmful; they directly harm human biology. The degradation of the environment—whether through toxic chemicals, pollution, or resource extraction—has profound biological effects on human health, causing respiratory diseases, cancers, and neurological disorders.
The biological cost of the fiat system is not a distant theory; it is being paid every day by millions in the form of increased health risks, diseases linked to stress, and the growing burden of mental health disorders. The constant uncertainty of an inflation-driven economy exacerbates these conditions, creating a society of individuals whose bodies and minds are under constant strain. We are witnessing a systemic biological unraveling, one in which the very act of living is increasingly fraught with pain, instability, and the looming threat of collapse.
Finance as the Final Illusion
At the core of the fiat system is a fundamental illusion—that financial growth can occur without any real connection to tangible value. The abstraction of currency, the manipulation of interest rates, and the constant creation of new money hide the underlying truth: the system is built on nothing but faith. When that faith falters, the entire system collapses.
This illusion has become so deeply embedded that it now defines the human experience. Work no longer connects to production or creation—it is reduced to a transaction on a spreadsheet, a means to acquire more fiat currency in a world where value is ephemeral and increasingly disconnected from human reality.
As we pursue ever-expanding wealth, the fundamental truths of biology—interdependence, sustainability, and balance—are ignored. The fiat system’s abstract financial models serve to disconnect us from the basic realities of life: that we are part of an interconnected world where every action has a reaction, where resources are finite, and where human health, both mental and physical, depends on the stability of our environment and our social systems.
The Ultimate Extermination
In the end, the fiat system is not just an economic issue; it is a biological, philosophical, theological, and existential threat to the very survival of humanity. It is a force that devalues human effort, encourages environmental destruction, fosters inequality, and creates pain at the core of the human biological condition. It is an economic framework that leads not to prosperity, but to extermination—not just of species, but of the very essence of human well-being.
To continue on this path is to accept the slow death of our species, one based not on natural forces, but on our own choice to worship the abstract over the real, the speculative over the tangible. The fiat system isn't just a threat; it is the ultimate self-inflicted wound, a cultural and financial cancer that, if left unchecked, will destroy humanity’s chance for survival and peace.
-
@ b0a838f2:34ed3f19
2025-05-23 17:54:16
- DocKing - Document management service/microservice that handles templates and renders them in PDF format, all in one place. (Demo, Source Code)
MITPHP/Nodejs/Docker - Docspell - Auto-tagging document organizer and archive. (Source Code)
GPL-3.0Scala/Java/Docker - Documenso - Digital document signing platform (alternative to DocuSign). (Source Code)
AGPL-3.0Nodejs/Docker - Docuseal - Create, fill, and sign digital documents (alternative to DocuSign). (Demo, Source Code)
AGPL-3.0Docker - EveryDocs - Simple Document Management System for private use with basic functionality to organize your documents digitally.
GPL-3.0Docker/Ruby - Gotenberg - Developer-friendly API to interact with powerful tools like Chromium and LibreOffice for converting numerous document formats (HTML, Markdown, Word, Excel, etc.) into PDF files, and more. (Source Code)
MITDocker - I, Librarian - Organize PDF papers and office documents. It provides a lot of extra features for students and research groups both in industry and academia. (Demo, Source Code)
GPL-3.0PHP - Mayan EDMS - Electronic document management system for your documents with preview generation, OCR, and automatic categorization among other features. (Source Code)
GPL-2.0Docker/K8S - OpenSign
⚠- Document signing software (alternative to DocuSign). (Source Code)AGPL-3.0Nodejs/Docker - Paperless-ngx - Scan, index, and archive all of your paper documents with an improved interface (fork of Paperless). (Demo, Source Code)
GPL-3.0Python/Docker - Papermerge - Document management system focused on scanned documents (electronic archives). Features file browsing in similar way to dropbox/google drive. OCR, full text search, text overlay/selection. (Source Code)
Apache-2.0Docker/K8S - PdfDing - PDF manager, viewer and editor offering a seamless user experience on multiple devices. It's designed to be minimal, fast, and easy to set up using Docker.
AGPL-3.0Docker - SeedDMS - Document Management System with workflows, access rights, fulltext search, and more. (Demo, Source Code)
GPL-2.0PHP - Stirling-PDF - Local hosted web application that allows you to perform various operations on PDF files, such as merging, splitting, file conversions and OCR.
Apache-2.0Docker/Java - Teedy - Lightweight document management system packed with all the features you can expect from big expensive solutions (Ex SismicsDocs). (Demo, Source Code)
GPL-2.0Docker/Java
- DocKing - Document management service/microservice that handles templates and renders them in PDF format, all in one place. (Demo, Source Code)
-
@ cae03c48:2a7d6671
2025-05-23 14:01:07
Bitcoin Magazine

KindlyMD, Nakamoto, and Anchorage Digital Form Strategic Bitcoin Treasury AllianceNakamoto Holdings Inc., KindlyMD, Inc., and Anchorage Digital today announced a strategic partnership that will see Anchorage become a trading partner for KindlyMD’s Bitcoin treasury. The partnership will officially take effect upon the close of KindlyMD’s merger with Nakamoto, expected in Q3 2025.
NEW! Anchorage Digital
 @Nakamoto @KindlyMD
@Nakamoto @KindlyMD Today we’re thrilled to announce a strategic partnership with Nakamoto Holdings and $KDLY to accelerate the future of corporate Bitcoin adoption. pic.twitter.com/nQueTyutQH
— Anchorage Digital
 (@Anchorage) May 21, 2025
(@Anchorage) May 21, 2025Anchorage Digital, a U.S. federally chartered digital asset bank, will provide institutional-grade custody, 24/7 trading, and deep liquidity to support the Bitcoin strategy of the combined entity.
“In the not-so-distant-future, the omission of Bitcoin on a balance sheet will be more glaring than its inclusion,” said Nathan McCauley, CEO and Co-Founder of Anchorage Digital. “Until then, companies like Nakamoto-KindlyMD are pioneering a new path forward—one in which Bitcoin is at the heart of corporate strategy.”
The future of corporate treasury strategy is Bitcoin-native. We're here to make it happen. Pumped to be partnering with @Nakamoto and @KindlyMD.@DavidFBailey’s vision continues to open new doors.
— Nathan McCauley
(@nathanmccauley) May 21, 2025The merger between KindlyMD and Nakamoto is backed by approximately $710 million in financing, including $510 million in PIPE funding—the largest ever PIPE for a public crypto-related deal. The goal is to establish a Bitcoin-native corporate treasury strategy that redefines how capital markets engage with digital assets.
“Our goal is to bring Bitcoin to the center of global capital markets within a compliant, transparent structure,” said David Bailey, Founder and CEO of Nakamoto Holdings Inc. “We are excited to partner with Anchorage Digital to implement our vision with the highest levels of security and battle-tested infrastructure and enable us to deliver sustained value to shareholders.”
This announcement follows a key milestone on May 18, when KindlyMD shareholders approved the proposed merger with Nakamoto. The transaction is now expected to close in Q3 2025, pending SEC review and information statement distribution.
“This milestone brings us one step closer to unlocking Bitcoin’s potential for KindlyMD shareholders,” Bailey said yesterday. “We are grateful that KindlyMD shares our vision for a future in which Bitcoin is a core part of the corporate balance sheet.”
With its Bitcoin-first strategy and strategic alliances, the Nakamoto-KindlyMD partnership is set to accelerate institutional Bitcoin adoption—and with Anchorage Digital’s infrastructure behind it, the foundation is now firmly in place.
“By collaborating with Anchorage Digital, we are implementing our Bitcoin treasury strategy with the utmost standards in safety and security for our shareholders,” stated Tim Pickett, CEO of KindlyMD. “Their institutional-grade platform allows us to confidently hold Bitcoin as a treasury asset as we look to unlock access to Bitcoin and drive value for the long term.”
Disclosure: Nakamoto is in partnership with Bitcoin Magazine’s parent company BTC Inc to build the first global network of Bitcoin treasury companies, where BTC Inc provides certain marketing services to Nakamoto. More information on this can be found here.
This post KindlyMD, Nakamoto, and Anchorage Digital Form Strategic Bitcoin Treasury Alliance first appeared on Bitcoin Magazine and is written by Jenna Montgomery.
-
@ f85b9c2c:d190bcff
2025-05-23 01:01:32
Hey, it’s me again, and let me tell you about the wildest thing that happened to me recently. I swear, my life could be a comedy show sometimes😂. Picture this: me and my buddies were out messing around in the woods near campus, just kicking it like we always do. The sun was out, the vibes were good, and we were probably being louder than we needed to be. Then, out of nowhere, I spotted something slithering near my friend benji leg.

A snake. A legit, no-joke snake!
I yelled, “SNAKE!” at the top of my lungs—probably sounded like a total lunatic —and before I could even blink, those dudes were GONE. I mean, faster than their shadows, Olympic-sprinter-level gone. I’m standing there, heart pounding, looking at this snake like, “Bruh, did I just get ditched?” Turns out, I did. My so-called friends bolted back to the dorms without a second thought, leaving me to face the scaly intruder solo. Luckily, the snake wasn’t in the mood for drama. It just gave me this lazy side-eye and slithered off, like it was too cool to deal with me. I hightailed it back to the dorms too, and when I got there, benji and the crew were already laughing their heads off. “Bro, you screamed like a horror movie victim!” they said. Yeah, real funny, guys.
Honestly, though? I’m just glad that snake didn’t get too cozy with my backside. A near miss like that deserves a medal—or at least a good story. We’ve been cracking up about it ever since, and now every time we’re out, I’m the designated “snake spotter. Lesson learned: friends are great until nature throws a curveball. Phew, that was close! Never be afraid to stand against everyone if you know you’re right.
-
@ b0a838f2:34ed3f19
2025-05-23 17:53:54
- AdGuard Home - User-friendly ads & trackers blocking DNS server. (Source Code)
GPL-3.0Docker - blocky - Fast and lightweight DNS proxy as ad-blocker for local network with many features (alternative to Pi-hole). (Source Code)
Apache-2.0Go/Docker - Maza ad blocking - Local ad blocker. Like Pi-hole but local and using your operating system. (Source Code)
Apache-2.0Shell - Pi-hole - Blackhole for Internet advertisements with a GUI for management and monitoring. (Source Code)
EUPL-1.2Shell/PHP/Docker - Technitium DNS Server - Authoritative/recursive DNS server with ad blocking functionality. (Source Code)
GPL-3.0Docker/C#
- AdGuard Home - User-friendly ads & trackers blocking DNS server. (Source Code)
-
@ f85b9c2c:d190bcff
2025-05-23 00:54:23
 P2P trading is also referred to as peer-to-peer trading or, more recently, people-to-people trading. Individuals can trade currencies and other marketable goods with other traders in this decentralized financial trading system.
P2P trading is a method of trading cryptocurrencies between people without the need of middlemen like exchanges, banks, or other financial institutions. Networks that connect buyers and sellers, streamline transactions, and frequently provide conflict resolution services are where P2P transactions take place.
P2P trading is also referred to as peer-to-peer trading or, more recently, people-to-people trading. Individuals can trade currencies and other marketable goods with other traders in this decentralized financial trading system.
P2P trading is a method of trading cryptocurrencies between people without the need of middlemen like exchanges, banks, or other financial institutions. Networks that connect buyers and sellers, streamline transactions, and frequently provide conflict resolution services are where P2P transactions take place.What is P2P Trading P2P trading is one of the quickest, cheapest, and most adaptable trading platforms, according to numerous research. Even more people could benefit from it if they lack access to conventional financial services or find some procedures to be too complicated.
P2P Trading in Nigeria P2P trading has grown somewhat in popularity in recent years as a result of the expansion of online marketplaces that bring together buyers and sellers. These platforms frequently offer wonderful alternatives to traditional financial services and perform similarly to or even better than what is provided by regional banks. Markets today provide unique advantages like quick transactions, reduced fees, and improved flexibility.
The ongoing development of regulations prohibiting the usage of cryptocurrencies is another factor that has increased the need for P2P trade in Nigeria. The majority of crypto traders in Nigeria now trade their cryptocurrencies with one another using the P2P trading system rather than the conventional trader-to-exchange service as a result of the ban on cryptocurrencies since 2021 till recently.P2P trading is thus one of the most popular and widely used forms of trading in Nigeria.
Peer-to-peer cryptocurrency trading is available on a number of well-known trading platforms, including Binance, Bitget, Bybit etc. A system has been built by these platforms (exchange websites and mobile applications) that enables traders to connect and trade their preferred crypto assets. P2P trading platforms have the power to transform Nigeria’s financial system and open up new doors for economic growth and development by bringing buyers and sellers together directly.
How does P2P trading work? One of the most effective ways to exchange cryptocurrency is through P2P trading, so everyone should be aware of how to get around it. It uses the exchange as a middleman to arrange, oversee, and finish trades between two independent dealers. The exchange service is used by buyers who search for sellers who are willing to sell to them at the price they are willing to pay, make a payment, and receive coins in return.
-
@ a367f9eb:0633efea
2024-12-22 21:35:22
I’ll admit that I was wrong about Bitcoin. Perhaps in 2013. Definitely 2017. Probably in 2018-2019. And maybe even today.
Being wrong about Bitcoin is part of finally understanding it. It will test you, make you question everything, and in the words of BTC educator and privacy advocate Matt Odell, “Bitcoin will humble you”.
I’ve had my own stumbles on the way.
In a very public fashion in 2017, after years of using Bitcoin, trying to start a company with it, using it as my primary exchange vehicle between currencies, and generally being annoying about it at parties, I let out the bear.
In an article published in my own literary magazine Devolution Review in September 2017, I had a breaking point. The article was titled “Going Bearish on Bitcoin: Cryptocurrencies are the tulip mania of the 21st century”.
It was later republished in Huffington Post and across dozens of financial and crypto blogs at the time with another, more appropriate title: “Bitcoin Has Become About The Payday, Not Its Potential”.
As I laid out, my newfound bearishness had little to do with the technology itself or the promise of Bitcoin, and more to do with the cynical industry forming around it:
In the beginning, Bitcoin was something of a revolution to me. The digital currency represented everything from my rebellious youth.
It was a decentralized, denationalized, and digital currency operating outside the traditional banking and governmental system. It used tools of cryptography and connected buyers and sellers across national borders at minimal transaction costs.
…
The 21st-century version (of Tulip mania) has welcomed a plethora of slick consultants, hazy schemes dressed up as investor possibilities, and too much wishy-washy language for anything to really make sense to anyone who wants to use a digital currency to make purchases.
While I called out Bitcoin by name at the time, on reflection, I was really talking about the ICO craze, the wishy-washy consultants, and the altcoin ponzis.
What I was articulating — without knowing it — was the frame of NgU, or “numbers go up”. Rather than advocating for Bitcoin because of its uncensorability, proof-of-work, or immutability, the common mentality among newbies and the dollar-obsessed was that Bitcoin mattered because its price was a rocket ship.
And because Bitcoin was gaining in price, affinity tokens and projects that were imperfect forks of Bitcoin took off as well.
The price alone — rather than its qualities — were the reasons why you’d hear Uber drivers, finance bros, or your gym buddy mention Bitcoin. As someone who came to Bitcoin for philosophical reasons, that just sat wrong with me.
Maybe I had too many projects thrown in my face, or maybe I was too frustrated with the UX of Bitcoin apps and sites at the time. No matter what, I’ve since learned something.
I was at least somewhat wrong.
My own journey began in early 2011. One of my favorite radio programs, Free Talk Live, began interviewing guests and having discussions on the potential of Bitcoin. They tied it directly to a libertarian vision of the world: free markets, free people, and free banking. That was me, and I was in. Bitcoin was at about $5 back then (NgU).
I followed every article I could, talked about it with guests on my college radio show, and became a devoted redditor on r/Bitcoin. At that time, at least to my knowledge, there was no possible way to buy Bitcoin where I was living. Very weak.
I was probably wrong. And very wrong for not trying to acquire by mining or otherwise.
The next year, after moving to Florida, Bitcoin was a heavy topic with a friend of mine who shared the same vision (and still does, according to the Celsius bankruptcy documents). We talked about it with passionate leftists at Occupy Tampa in 2012, all the while trying to explain the ills of Keynesian central banking, and figuring out how to use Coinbase.
I began writing more about Bitcoin in 2013, writing a guide on “How to Avoid Bank Fees Using Bitcoin,” discussing its potential legalization in Germany, and interviewing Jeremy Hansen, one of the first political candidates in the U.S. to accept Bitcoin donations.
Even up until that point, I thought Bitcoin was an interesting protocol for sending and receiving money quickly, and converting it into fiat. The global connectedness of it, plus this cypherpunk mentality divorced from government control was both useful and attractive. I thought it was the perfect go-between.
But I was wrong.
When I gave my first public speech on Bitcoin in Vienna, Austria in December 2013, I had grown obsessed with Bitcoin’s adoption on dark net markets like Silk Road.
My theory, at the time, was the number and price were irrelevant. The tech was interesting, and a novel attempt. It was unlike anything before. But what was happening on the dark net markets, which I viewed as the true free market powered by Bitcoin, was even more interesting. I thought these markets would grow exponentially and anonymous commerce via BTC would become the norm.
While the price was irrelevant, it was all about buying and selling goods without permission or license.
Now I understand I was wrong.
Just because Bitcoin was this revolutionary technology that embraced pseudonymity did not mean that all commerce would decentralize as well. It did not mean that anonymous markets were intended to be the most powerful layer in the Bitcoin stack.
What I did not even anticipate is something articulated very well by noted Bitcoin OG Pierre Rochard: Bitcoin as a savings technology.
The ability to maintain long-term savings, practice self-discipline while stacking stats, and embrace a low-time preference was just not something on the mind of the Bitcoiners I knew at the time.
Perhaps I was reading into the hype while outwardly opposing it. Or perhaps I wasn’t humble enough to understand the true value proposition that many of us have learned years later.
In the years that followed, I bought and sold more times than I can count, and I did everything to integrate it into passion projects. I tried to set up a company using Bitcoin while at my university in Prague.
My business model depended on university students being technologically advanced enough to have a mobile wallet, own their keys, and be able to make transactions on a consistent basis. Even though I was surrounded by philosophically aligned people, those who would advance that to actually put Bitcoin into practice were sparse.
This is what led me to proclaim that “Technological Literacy is Doomed” in 2016.
And I was wrong again.
Indeed, since that time, the UX of Bitcoin-only applications, wallets, and supporting tech has vastly improved and onboarded millions more people than anyone thought possible. The entrepreneurship, coding excellence, and vision offered by Bitcoiners of all stripes have renewed a sense in me that this project is something built for us all — friends and enemies alike.
While many of us were likely distracted by flashy and pumpy altcoins over the years (me too, champs), most of us have returned to the Bitcoin stable.
Fast forward to today, there are entire ecosystems of creators, activists, and developers who are wholly reliant on the magic of Bitcoin’s protocol for their life and livelihood. The options are endless. The FUD is still present, but real proof of work stands powerfully against those forces.
In addition, there are now dozens of ways to use Bitcoin privately — still without custodians or intermediaries — that make it one of the most important assets for global humanity, especially in dictatorships.
This is all toward a positive arc of innovation, freedom, and pure independence. Did I see that coming? Absolutely not.
Of course, there are probably other shots you’ve missed on Bitcoin. Price predictions (ouch), the short-term inflation hedge, or the amount of institutional investment. While all of these may be erroneous predictions in the short term, we have to realize that Bitcoin is a long arc. It will outlive all of us on the planet, and it will continue in its present form for the next generation.
Being wrong about the evolution of Bitcoin is no fault, and is indeed part of the learning curve to finally understanding it all.
When your family or friends ask you about Bitcoin after your endless sessions explaining market dynamics, nodes, how mining works, and the genius of cryptographic signatures, try to accept that there is still so much we have to learn about this decentralized digital cash.
There are still some things you’ve gotten wrong about Bitcoin, and plenty more you’ll underestimate or get wrong in the future. That’s what makes it a beautiful journey. It’s a long road, but one that remains worth it.
-
@ 6389be64:ef439d32
2024-12-09 23:50:41
Resilience is the ability to withstand shocks, adapt, and bounce back. It’s an essential quality in nature and in life. But what if we could take resilience a step further? What if, instead of merely surviving, a system could improve when faced with stress? This concept, known as anti-fragility, is not just theoretical—it’s practical. Combining two highly resilient natural tools, comfrey and biochar, reveals how we can create systems that thrive under pressure and grow stronger with each challenge.
Comfrey: Nature’s Champion of Resilience
Comfrey is a plant that refuses to fail. Once its deep roots take hold, it thrives in poor soils, withstands drought, and regenerates even after being cut down repeatedly. It’s a hardy survivor, but comfrey doesn’t just endure—it contributes. Known as a dynamic accumulator, it mines nutrients from deep within the earth and brings them to the surface, making them available for other plants.
Beyond its ecological role, comfrey has centuries of medicinal use, earning the nickname "knitbone." Its leaves can heal wounds and restore health, a perfect metaphor for resilience. But as impressive as comfrey is, its true potential is unlocked when paired with another resilient force: biochar.
Biochar: The Silent Powerhouse of Soil Regeneration
Biochar, a carbon-rich material made by burning organic matter in low-oxygen conditions, is a game-changer for soil health. Its unique porous structure retains water, holds nutrients, and provides a haven for beneficial microbes. Soil enriched with biochar becomes drought-resistant, nutrient-rich, and biologically active—qualities that scream resilience.
Historically, ancient civilizations in the Amazon used biochar to transform barren soils into fertile agricultural hubs. Known as terra preta, these soils remain productive centuries later, highlighting biochar’s remarkable staying power.
Yet, like comfrey, biochar’s potential is magnified when it’s part of a larger system.
The Synergy: Comfrey and Biochar Together
Resilience turns into anti-fragility when systems go beyond mere survival and start improving under stress. Combining comfrey and biochar achieves exactly that.
-
Nutrient Cycling and Retention\ Comfrey’s leaves, rich in nitrogen, potassium, and phosphorus, make an excellent mulch when cut and dropped onto the soil. However, these nutrients can wash away in heavy rains. Enter biochar. Its porous structure locks in the nutrients from comfrey, preventing runoff and keeping them available for plants. Together, they create a system that not only recycles nutrients but amplifies their effectiveness.
-
Water Management\ Biochar holds onto water making soil not just drought-resistant but actively water-efficient, improving over time with each rain and dry spell.
-
Microbial Ecosystems\ Comfrey enriches soil with organic matter, feeding microbial life. Biochar provides a home for these microbes, protecting them and creating a stable environment for them to multiply. Together, they build a thriving soil ecosystem that becomes more fertile and resilient with each passing season.
Resilient systems can withstand shocks, but anti-fragile systems actively use those shocks to grow stronger. Comfrey and biochar together form an anti-fragile system. Each addition of biochar enhances water and nutrient retention, while comfrey regenerates biomass and enriches the soil. Over time, the system becomes more productive, less dependent on external inputs, and better equipped to handle challenges.
This synergy demonstrates the power of designing systems that don’t just survive—they thrive.
Lessons Beyond the Soil
The partnership of comfrey and biochar offers a valuable lesson for our own lives. Resilience is an admirable trait, but anti-fragility takes us further. By combining complementary strengths and leveraging stress as an opportunity, we can create systems—whether in soil, business, or society—that improve under pressure.
Nature shows us that resilience isn’t the end goal. When we pair resilient tools like comfrey and biochar, we unlock a system that evolves, regenerates, and becomes anti-fragile. By designing with anti-fragility in mind, we don’t just bounce back, we bounce forward.
By designing with anti-fragility in mind, we don’t just bounce back, we bounce forward.
-
-
@ b0a838f2:34ed3f19
2025-05-23 17:53:35
- Adminer - Database management in a single PHP file. Available for MySQL, MariaDB, PostgreSQL, SQLite, MS SQL, Oracle, Elasticsearch, MongoDB and others. (Source Code)
Apache-2.0/GPL-2.0PHP - Azimutt - Visual database exploration made for real world databases (big and messy). Explore your database schema as well as data, document them, extend them and even get analysis and guidelines. (Demo, Source Code)
MITElixir/Nodejs/Docker - Baserow - Create your own database without technical experience (alternative to Airtable). (Source Code)
MITDocker - Bytebase - Safe database schema change and version control for DevOps teams, supports MySQL, PostgreSQL, TiDB, ClickHouse, and Snowflake. (Demo, Source Code)
MITDocker/K8S/Go - Chartbrew - Connect directly to databases and APIs and use the data to create beautiful charts. (Demo, Source Code)
MITNodejs/Docker - ChartDB - Database diagrams editor that allows you to visualize and design your DB with a single query. (Demo, Source Code)
AGPL-3.0Nodejs/Docker - CloudBeaver - Manage databases, supports PostgreSQL, MySQL, SQLite and more. A web/hosted version of DBeaver. (Source Code)
Apache-2.0Docker - Databunker - Network-based, self-hosted, GDPR compliant, secure database for personal data or PII. (Source Code)
MITDocker - Datasette - Explore and publish data with easy import and export and database management. (Demo, Source Code)
Apache-2.0Python/Docker - Evidence - Code-based BI tool. Write reports using SQL and markdown and they render as a website. (Source Code)
MITNodejs - Limbas - Database framework for creating database-driven business applications. As a graphical database frontend, it enables the efficient processing of data stocks and the flexible development of comfortable database applications. (Source Code)
GPL-2.0PHP - Mathesar - Intuitive UI to manage data collaboratively, for users of all technical skill levels. Built on Postgres – connect an existing DB or set up a new one. (Source Code)
GPL-3.0Docker/Python - NocoDB - No-code platform that turns any database into a smart spreadsheet (alternative to Airtable or Smartsheet). (Source Code)
AGPL-3.0Nodejs/Docker - WebDB - Efficient database IDE. (Demo, Source Code)
AGPL-3.0Docker
- Adminer - Database management in a single PHP file. Available for MySQL, MariaDB, PostgreSQL, SQLite, MS SQL, Oracle, Elasticsearch, MongoDB and others. (Source Code)
-
@ 74fb3ef2:58adabc7
2025-05-22 22:26:23
Suppose you have a small mom-and-pop shop selling bananas, your bananas are of the highest quality, you plant the banana trees yourself, you water them daily, take great care of everything, and still select only the top 1% of bananas to sell.
Your customers love it, there's no place where they can get better bananas, but due to the fact that you spend so much time, your bananas have to be more expensive, so despite the higher quality, you don't make as much money as you think you should; surely you can get a little more of the market if you adopt some of the strategies that work for your competitors.
So you look across the street, and what do you know? Their bananas are of significantly worse quality than yours, but they're not just selling bananas, they're selling apples too, so you think to yourself, "what if I sold apples? Maybe my apples won't be the best in the market, but nobody can beat my bananas!"
You start planting apple trees, and after a while you're able go sell slightly better than average apples, but by doing so you neglect your bananas ever so slightly.
Most of your existing customers don't notice, you still have the best bananas in town, they don't notice the slight drop in quality. And now that you're selling apples too you're making more money, and more customers come to you.
But you notice that there's a new store now that's selling oranges, and people are buying them. So surely you need oranges too, so you can make some extra money.
You plant a few orange trees, but find yourself spending so much time tending to the oranges and apples that you can't devote the same time and love to your bananas.
You are making a bit of extra cash from the new customers, business is going well, but you don't have time for anything else anymore. You no free time anymore, you are overworked and your health is getting worse.
But you can't stop now that business is going well, you are making so much more, yeah maybe you don't have the same bananas anymore, but you do have slightly above average apples and oranges that have attracted so many customers.
You suddenly fall ill, you've overworked yourself and you are stuck at a hospital for a while.
When you come back to your store, a few of your customers are back, but not all of them, so you think of more ideas, mandarins, kiwi, watermelons, you can grow it all, but you're gonna hire a bunch of people to help you so you don't fall ill again.
One thing leads to another and you are making more money than ever, but strangely you don't hear your customers praising your bananas anymore.
So you take one of your bananas, peel it, and as you taste it, a wave of disappointment hits you.
Your bananas are now just as bad as everyone else's; you gave in to the tyranny of the marginal customer.
You make a lot of money now, but your flagship product is long gone, you are now just another Fruitseller.
-
@ e31e84c4:77bbabc0
2024-12-02 10:44:07
Bitcoin and Fixed Income was Written By Wyatt O’Rourke. If you enjoyed this article then support his writing, directly, by donating to his lightning wallet: ultrahusky3@primal.net
Fiduciary duty is the obligation to act in the client’s best interests at all times, prioritizing their needs above the advisor’s own, ensuring honesty, transparency, and avoiding conflicts of interest in all recommendations and actions.
This is something all advisors in the BFAN take very seriously; after all, we are legally required to do so. For the average advisor this is a fairly easy box to check. All you essentially have to do is have someone take a 5-minute risk assessment, fill out an investment policy statement, and then throw them in the proverbial 60/40 portfolio. You have thousands of investment options to choose from and you can reasonably explain how your client is theoretically insulated from any move in the \~markets\~. From the traditional financial advisor perspective, you could justify nearly anything by putting a client into this type of portfolio. All your bases were pretty much covered from return profile, regulatory, compliance, investment options, etc. It was just too easy. It became the household standard and now a meme.
As almost every real bitcoiner knows, the 60/40 portfolio is moving into psyop territory, and many financial advisors get clowned on for defending this relic on bitcoin twitter. I’m going to specifically poke fun at the ‘40’ part of this portfolio.
The ‘40’ represents fixed income, defined as…
An investment type that provides regular, set interest payments, such as bonds or treasury securities, and returns the principal at maturity. It’s generally considered a lower-risk asset class, used to generate stable income and preserve capital.
Historically, this part of the portfolio was meant to weather the volatility in the equity markets and represent the “safe” investments. Typically, some sort of bond.
First and foremost, the fixed income section is most commonly constructed with U.S. Debt. There are a couple main reasons for this. Most financial professionals believe the same fairy tale that U.S. Debt is “risk free” (lol). U.S. debt is also one of the largest and most liquid assets in the market which comes with a lot of benefits.
There are many brilliant bitcoiners in finance and economics that have sounded the alarm on the U.S. debt ticking time bomb. I highly recommend readers explore the work of Greg Foss, Lawrence Lepard, Lyn Alden, and Saifedean Ammous. My very high-level recap of their analysis:
-
A bond is a contract in which Party A (the borrower) agrees to repay Party B (the lender) their principal plus interest over time.
-
The U.S. government issues bonds (Treasury securities) to finance its operations after tax revenues have been exhausted.
-
These are traditionally viewed as “risk-free” due to the government’s historical reliability in repaying its debts and the strength of the U.S. economy
-
U.S. bonds are seen as safe because the government has control over the dollar (world reserve asset) and, until recently (20 some odd years), enjoyed broad confidence that it would always honor its debts.
-
This perception has contributed to high global demand for U.S. debt but, that is quickly deteriorating.
-
The current debt situation raises concerns about sustainability.
-
The U.S. has substantial obligations, and without sufficient productivity growth, increasing debt may lead to a cycle where borrowing to cover interest leads to more debt.
-
This could result in more reliance on money creation (printing), which can drive inflation and further debt burdens.
In the words of Lyn Alden “Nothing stops this train”
Those obligations are what makes up the 40% of most the fixed income in your portfolio. So essentially you are giving money to one of the worst capital allocators in the world (U.S. Gov’t) and getting paid back with printed money.
As someone who takes their fiduciary responsibility seriously and understands the debt situation we just reviewed, I think it’s borderline negligent to put someone into a classic 60% (equities) / 40% (fixed income) portfolio without serious scrutiny of the client’s financial situation and options available to them. I certainly have my qualms with equities at times, but overall, they are more palatable than the fixed income portion of the portfolio. I don’t like it either, but the money is broken and the unit of account for nearly every equity or fixed income instrument (USD) is fraudulent. It’s a paper mache fade that is quite literally propped up by the money printer.
To briefly be as most charitable as I can – It wasn’t always this way. The U.S. Dollar used to be sound money, we used to have government surplus instead of mathematically certain deficits, The U.S. Federal Government didn’t used to have a money printing addiction, and pre-bitcoin the 60/40 portfolio used to be a quality portfolio management strategy. Those times are gone.
Now the fun part. How does bitcoin fix this?
Bitcoin fixes this indirectly. Understanding investment criteria changes via risk tolerance, age, goals, etc. A client may still have a need for “fixed income” in the most literal definition – Low risk yield. Now you may be thinking that yield is a bad word in bitcoin land, you’re not wrong, so stay with me. Perpetual motion machine crypto yield is fake and largely where many crypto scams originate. However, that doesn’t mean yield in the classic finance sense does not exist in bitcoin, it very literally does. Fortunately for us bitcoiners there are many other smart, driven, and enterprising bitcoiners that understand this problem and are doing something to address it. These individuals are pioneering new possibilities in bitcoin and finance, specifically when it comes to fixed income.
Here are some new developments –
Private Credit Funds – The Build Asset Management Secured Income Fund I is a private credit fund created by Build Asset Management. This fund primarily invests in bitcoin-backed, collateralized business loans originated by Unchained, with a secured structure involving a multi-signature, over-collateralized setup for risk management. Unchained originates loans and sells them to Build, which pools them into the fund, enabling investors to share in the interest income.
Dynamics
- Loan Terms: Unchained issues loans at interest rates around 14%, secured with a 2/3 multi-signature vault backed by a 40% loan-to-value (LTV) ratio.
- Fund Mechanics: Build buys these loans from Unchained, thus providing liquidity to Unchained for further loan originations, while Build manages interest payments to investors in the fund.
Pros
- The fund offers a unique way to earn income via bitcoin-collateralized debt, with protection against rehypothecation and strong security measures, making it attractive for investors seeking exposure to fixed income with bitcoin.
Cons
- The fund is only available to accredited investors, which is a regulatory standard for private credit funds like this.
Corporate Bonds – MicroStrategy Inc. (MSTR), a business intelligence company, has leveraged its corporate structure to issue bonds specifically to acquire bitcoin as a reserve asset. This approach allows investors to indirectly gain exposure to bitcoin’s potential upside while receiving interest payments on their bond investments. Some other publicly traded companies have also adopted this strategy, but for the sake of this article we will focus on MSTR as they are the biggest and most vocal issuer.
Dynamics
-
Issuance: MicroStrategy has issued senior secured notes in multiple offerings, with terms allowing the company to use the proceeds to purchase bitcoin.
-
Interest Rates: The bonds typically carry high-yield interest rates, averaging around 6-8% APR, depending on the specific issuance and market conditions at the time of issuance.
-
Maturity: The bonds have varying maturities, with most structured for multi-year terms, offering investors medium-term exposure to bitcoin’s value trajectory through MicroStrategy’s holdings.
Pros
-
Indirect Bitcoin exposure with income provides a unique opportunity for investors seeking income from bitcoin-backed debt.
-
Bonds issued by MicroStrategy offer relatively high interest rates, appealing for fixed-income investors attracted to the higher risk/reward scenarios.
Cons
-
There are credit risks tied to MicroStrategy’s financial health and bitcoin’s performance. A significant drop in bitcoin prices could strain the company’s ability to service debt, increasing credit risk.
-
Availability: These bonds are primarily accessible to institutional investors and accredited investors, limiting availability for retail investors.
Interest Payable in Bitcoin – River has introduced an innovative product, bitcoin Interest on Cash, allowing clients to earn interest on their U.S. dollar deposits, with the interest paid in bitcoin.
Dynamics
-
Interest Payment: Clients earn an annual interest rate of 3.8% on their cash deposits. The accrued interest is converted to Bitcoin daily and paid out monthly, enabling clients to accumulate Bitcoin over time.
-
Security and Accessibility: Cash deposits are insured up to $250,000 through River’s banking partner, Lead Bank, a member of the FDIC. All Bitcoin holdings are maintained in full reserve custody, ensuring that client assets are not lent or leveraged.
Pros
-
There are no hidden fees or minimum balance requirements, and clients can withdraw their cash at any time.
-
The 3.8% interest rate provides a predictable income stream, akin to traditional fixed-income investments.
Cons
-
While the interest rate is fixed, the value of the Bitcoin received as interest can fluctuate, introducing potential variability in the investment’s overall return.
-
Interest rate payments are on the lower side
Admittedly, this is a very small list, however, these types of investments are growing more numerous and meaningful. The reality is the existing options aren’t numerous enough to service every client that has a need for fixed income exposure. I challenge advisors to explore innovative options for fixed income exposure outside of sovereign debt, as that is most certainly a road to nowhere. It is my wholehearted belief and call to action that we need more options to help clients across the risk and capital allocation spectrum access a sound money standard.
Additional Resources
-
River: The future of saving is here: Earn 3.8% on cash. Paid in Bitcoin.
-
MicroStrategy: MicroStrategy Announces Pricing of Offering of Convertible Senior Notes
Bitcoin and Fixed Income was Written By Wyatt O’Rourke. If you enjoyed this article then support his writing, directly, by donating to his lightning wallet: ultrahusky3@primal.net
-
-
@ cae03c48:2a7d6671
2025-05-23 14:01:05
Bitcoin Magazine

How Zeus is Redefining Bitcoin with Cashu Ecash IntegrationThe U.S.-based Bitcoin and Lightning mobile wallet Zeus recently announced an alpha-release integration of Cashu. The move marks the first integration of ecash into a popular Bitcoin wallet, breaking new ground for potential user adoption to Bitcoin.
Cashu is a hot new implementation of Chaumian ecash, a form of digital cash invented by David Chaum in the ’90s that has incredible privacy and scalability properties, with the trade-off of being fundamentally centralized, requiring a significant amount of trust in the issuer.


In a counterintuitive move for Zeus, known as the go-to tool for advanced Lightning users seeking to connect to their home nodes, the integration of Cashu acknowledges a “last mile” challenge Lightning wallets face when delivering Bitcoin to the masses.
“We basically started off as the cypherpunk wallet, right? You got to set up your own Lightning node and connect to it with Zeus. The last two years, we put the node in the phone with one click, you can run it all in a standalone app without a remote node,” Evan Kaloudis, founder and CEO of Zeus, told Bitcoin Magazine.
“Cashu addresses uneconomical self-custody for small bitcoin amounts. On-chain, the dust limit is 546 satoshis, and Layer Two systems like Lightning have costs for channel setup or unilateral exits that aren’t widely discussed,” Evan explained, highlighting a major point of friction in noncustodial Lightning wallets: the need for liquidity and channel management. While these esoteric aspects of the Lightning Network have been mostly abstracted away since its invention in 2016, these fundamental trade-offs continue to manifest even in the most sophisticated and user-friendly wallets.
In the case of both Phoenix and Zeus, two of the most popular noncustodial options in the market, users must pay up to 10,000 sats upfront to gain spending capacity. These fees are necessary to cover the on-chain fees spent to open a channel for the user against the wallet’s liquidity service provider, unlocking a noncustodial experience.
The required up-front fee is difficult to explain and represents a painful onboarding experience for new users who are used to fiat apps giving them money to join instead. The result is the proliferation of custodial Lightning wallets like Wallet of Satoshi (WOS), which gained massive adoption early on by leveraging the global, near-instant settlement power of Bitcoin combined with the excellent user experience centralized wallets can create.
Major developments have been made over seven years after the Lightning Network’s inception, however, and Zeus is pushing the boundaries.
“With Ecash, we make it so easy that anyone can set up a wallet and start participating in our ecosystem, which I really think is going to become more and more prevalent,” Evan explained.
Today, at roughly $100,000 per bitcoin, 1,000 satoshis are equivalent to $1. Transactions of these sizes are known as microtransactions — a popular example are Nostr social media tips known as Zaps. But finding the right tool for this use case is not simple. Self custodied wallets like Phoenix charge transaction fees in the hundreds of satoshis, even with open channels, and on-chain fees often cost the same and are slower to settle. As a result, there’s an entire category of spending that is only served by cheaper alternatives such as custodial lightning wallets like WOS or Blink, but result in significant privacy tradeoffs, often requiring phone numbers from users and in some cases more advanced KYC and IP tracking. Cashu hopes to serve this market with lower privacy costs, the same ease of use, speed and competitive fees.
Digging deeper into the Cashu integration, Evan explained that “for users this means being able to pick and switch between custodians in a single app. For developers this means being able to defer custodial responsibilities to third parties and not have to wire up a new integration when your current custodian halts operations.”
Zaps are satoshi-denominated rewards delivered as “likes” or micro-tips for content in the Nostr social media ecosystem. A Zap can be as small as one satoshi, the smallest amount of bitcoin that can be technically transferred, equivalent today to about a tenth of a penny. “But I think if we look at Nostr and you’re seeing how many people are Zapping and how big a part of that ecosystem it is. It’s like, people are willing to do it,” Evan explained.
“Cashu, while custodial, lets users accumulate small amounts — say, via Nostr Zaps — without needing 6,000 satoshis to open a Lightning channel. Zeus prompts users to upgrade to self-custody as their balance grows,” he concluded, explaining that the wallet will effectively annoy users into self custody, one of several design choices made to mitigate the risks introduced by Cashu.
Ecash
The trade-offs introduced by Cashu challenge the common understanding of custody as an either-or in Bitcoin. Historically you were either a centralized — custodial — exchange, or you were a noncustodial Bitcoin wallet. In the former, you entrust the coins to a third party; in the latter you take personal responsibility for those coins and their corresponding private keys. Cashu changes this paradigm by introducing bitcoin-denominated ecash notes or “nuts,” which are bearer instruments that should be backed by a full bitcoin reserve and Lightning interoperability for instant withdraw.
Similar to fiat cash, you must take control and responsibility over these notes, but there’s also counterparty risk. In the case of Cashu, there are certain things the issuing mint can theoretically do to exploit their users — akin to how a bank can run on a fractional reserve.
The big difference between Cashu or custodial Bitcoin exchanges and fiat currency is that Cashu is open source, is designed around user privacy, and scales very well. It makes the cost of running a mint lower than either alternative, a feature that makes mint competition easier, in theory countering the centralizing network effects of specific mints.
Finally, the user experience of storing Cashu tokens has been attached to known forms of Bitcoin self custody such as the download of 12-words seeds via various mechanisms, though implementations still vary from wallet to wallet and the whole ecosystem is in its early stages.
To further mitigate the custodial risk of Chaumian-style ecash in Bitcoin, the Cashu community has developed various methods for automatically managing custody risk.



“Users can split risk by using multiple mints, switching between them in the user interface. Soon, ZEUS will guide users to select five or six reputable mints, automatically balancing funds to minimize exposure,” Evan explained, referring to a particular approach called automated bank runs. The idea is that as some Cashu mints may hold more of your funds, Zeus de-ranks them and rotates value out to minimize risk.
“I think the idea is going to be that we guide users to pick five or six reputable mints… And from there, users will be able to have the wallet automatically switch between those mints and determine which mint should be receiving the balance depending on the balance of all the mints presently. So you’ll be like, OK. MiniBits has way too much money. Let’s switch the default to one of the mints that doesn’t have a lot. So that way you can sort of mitigate or rather distribute the rug risk there,” Evan explained, adding, “Our Discover Mint feature pulls reviews from bitcoinmints.com, showing vouch counts and user feedback, like mint reliability or longevity,” describing the reputation layer stacked on top of the various other risk management mechanisms.
There is no known way to use Chaumian-style ecash in an entirely noncustodial way. So as long as the custody risk can be minimized, the scaling and privacy upside becomes remarkable.
Microtransactions
One of the opportunities that ecash unlocks is microtransactions, the most popular example of which are Nostr Zaps often in single dollar ranges of value transferred, though it applies to small Lightning transactions as well. This use case triggers an important technical question that predates Bitcoin, do microtransactions actually make economic sense?
There’s a long-standing argu
-
@ cae03c48:2a7d6671
2025-05-23 14:01:04
Bitcoin Magazine

Bitcoin Liquid Network Surpasses $3.27 Billion in Total Value LockedToday, the Liquid Federation has announced that the Liquid Network has surpassed $3.27 billion in total value locked (TVL), according to a press release shared with Bitcoin Magazine.
“Surpassing the $3 billion threshold marks a pivotal moment for both Liquid and Bitcoin, signaling the evolution of Bitcoinʼs ecosystem into a full-fledged platform for global financial markets,” said the CEO and Co-Founder of Blockstream Dr. Adam Back. “As Bitcoin gains mainstream acceptance, and demand for regulated asset tokenization accelerates, Liquid is better positioned than ever to bridge Bitcoin with traditional finance and drive the next wave of capital markets innovation.”

The announcement follows growing interest in tokenizing real-world assets (RWAs), with major moves such as BlackRock’s decision to tokenize a $150 billion Treasury fund. According to a 2025 report by Security Token Market, the tokenized asset market is projected to grow to $30 trillion by 2030.
Liquid supports over $1.8 billion in tokenized private credit and offers products like U.S. Treasury notes and digital currencies through Blockstream’s AMP platform. The network also features fast, low-cost, and confidential transactions, with support for atomic swaps and robust smart contracts.
Governed by over 80 global institutions, Liquid was launched in 2018 as Bitcoin’s first sidechain. It is now preparing for a major upgrade with the mainnet release of Simplicity, aimed at expanding its smart contract capabilities.
To keep up with increasing demand, the Liquid Federation is boosting developer resources and technical onboardings, along with integrations with exchanges, custodians and service providers. Recent bootcamps and important meetings with policy makers in Asia, Europe and Latin America reflect the network’s growing global presence.
This post Bitcoin Liquid Network Surpasses $3.27 Billion in Total Value Locked first appeared on Bitcoin Magazine and is written by Oscar Zarraga Perez.
-
@ 8576ca0e:621f735e
2025-05-22 17:36:20
In the evolving digital economy, Bitcoin has moved beyond its initial status as a speculative asset. It is now a powerful tool for building long-term wealth, especially within the context of a decentralized financial system. While Bitcoin 101 introduced the concept of Bitcoin and Bitcoin 102 covered its mechanics and investment basics, Bitcoin 103 dives deeper into how individuals can strategically build wealth in a decentralized world.
The Foundation: Why Decentralization Matters
At its core, Bitcoin operates on a decentralized network free from government control or manipulation by central banks. This decentralization is not just a technical characteristic but a financial philosophy. In a world where inflation erodes the value of fiat currencies and financial systems can be restricted by geopolitical decisions, Bitcoin offers sovereignty and transparency.
By removing intermediaries, Bitcoin empowers individuals to store, send, and receive money globally with minimal friction. This capability becomes crucial in building wealth that’s resilient to political and economic volatility.
Bitcoin as Digital Gold
Bitcoin's fixed supply capped at 21 million BTC mimics the scarcity of precious metals like gold. However, unlike gold, Bitcoin is portable, divisible, and easier to secure. Investors seeking a hedge against inflation and monetary debasement are increasingly turning to Bitcoin as a long term store of value.
Holding Bitcoin over time, known as "HODLing" in crypto parlance, is one of the most common wealth building strategies. Historical data shows that long-term holders tend to outperform short-term traders, especially in the face of Bitcoin’s cyclical volatility.
Diversification in a Decentralized Economy
Building wealth with Bitcoin doesn't mean going all in. It involves using Bitcoin as a foundational asset while exploring adjacent opportunities within the decentralized finance (DeFi) space. Bitcoin can be used as collateral, yield-generating assets, or even part of a diversified crypto portfolio that includes Ethereum, stablecoins, and tokenized assets.
For instance, some platforms allow users to lend their Bitcoin and earn interest, or stake wrapped Bitcoin (WBTC) on decentralized protocols. While these carry risk, they also offer the possibility of compounding returns beyond price appreciation alone.
Wealth Preservation through Self-Custody
One of the key principles of wealth building in the decentralized world is self custody. Unlike traditional bank accounts, where your assets are held by third parties, Bitcoin allows users to control their wealth directly through private keys and cold storage wallets.
By taking responsibility for their assets, users reduce counterparty risk and maintain access to their wealth even in times of crisis. This level of control and autonomy is unprecedented in the history of money.
Education and Risk Management
Wealth building in the Bitcoin ecosystem requires a solid understanding of risk. Volatility, regulatory uncertainty, and security vulnerabilities must be addressed through continuous education, diversification, and the use of reputable platforms.
New investors should start by:
• Setting long term goals
• Investing only what they can afford to lose
• Using hardware wallets for security
• Staying informed through trusted crypto news sources
The Future of Wealth in a Decentralized World
Bitcoin is not just reshaping finance, it’s redefining wealth. As decentralized technologies mature, we can expect a shift in how value is created, transferred, and preserved. From smart contracts to decentralized autonomous organizations (DAOs), the Bitcoin ethos of transparency, security, and autonomy will continue to guide the evolution of the digital economy.
In conclusion, Bitcoin 103 is about more than investing, It's about understanding the broader movement toward financial freedom. Building wealth in a decentralized world starts with a shift in mindset: from dependence to independence, from control to empowerment.
-
@ b0a838f2:34ed3f19
2025-05-23 17:53:11
- Corteza - CRM including a unified workspace, enterprise messaging and a low code environment for rapidly and securely delivering records-based management solutions. (Demo, Source Code)
Apache-2.0Go - Django-CRM - Analytical CRM with tasks management, email marketing and many more. Django CRM is built for individual use, businesses of any size or freelancers and is designed to provide easy customization and quick development.
AGPL-3.0Python - EspoCRM - CRM with a frontend designed as a single page application, and a REST API. (Demo, Source Code)
AGPL-3.0PHP - Krayin - CRM solution for SMEs and Enterprises for complete customer lifecycle management. (Demo, Source Code)
MITPHP - Monica - Personal relationship manager, and a new kind of CRM to organize interactions with your friends and family. (Source Code)
AGPL-3.0PHP/Docker - SuiteCRM - The award-winning, enterprise-class open source CRM. (Source Code)
AGPL-3.0PHP - Twenty - A modern CRM offering the flexibility of open source, advanced features, and a sleek design. (Source Code)
AGPL-3.0Docker
- Corteza - CRM including a unified workspace, enterprise messaging and a low code environment for rapidly and securely delivering records-based management solutions. (Demo, Source Code)
-
@ eed7ca5d:191de8eb
2025-05-23 13:58:46
Growing up, we were told that in order to build wealth, we need to save little by little. By living below your means, you are providing more for your future.
It is a simple formula that will help you build up the capital necessary to buy a car, a house or start a business… You prioritize long-term benefits and delayed gratification over immediate rewards.
This is called having a low-time preference. In contrast, high-time preference individuals prioritize today over tomorrow, seeking immediate gratification.
Austrian economists explain that civilization growth is driven by low-time preference societies. Groups of individuals who prioritize long-term planning are able to innovate and develop new tools for a better future. Over time, this behavior leads to technological inventions like the light bulb and artistic masterpieces like the Notre Dame cathedral.
***What happens when you realize that the money you save is losing value over time? ***
There is less incentive to save for the future, because in the future your savings will be worth less. You might as well spend it now and enjoy life today.
When the money you save loses its value, you are facing one of two choices:
-
Spend it today and reap the rewards of your hard work;
-
Invest it (stocks, real estate, etc.) with the hope to reap higher rewards later, bearing the risk of losing it all if the investment does not pay off.
There is a distinct difference between saving and investing as the latter approach is riskier than the former. By investing, you are betting on the upside while bearing the downside risk. Saving, in contrast, comes without downside risk. That difference becomes blurry when the money you save is losing value. In fact, saving becomes inherently a losing approach. Logically, you will be forced to place a speculative bet with the hope to outperform the guaranteed loss of value. You are required to find a way to hedge your bet…
Humans over time have always sought out a medium to save their economic energy for a better future. That used to be beads and seashells, and evolved to precious metals like gold and silver.
Money is a tool that we use to save our economic energy over time, and exchange value with each other.
I spend time fishing, you spend time farming, the neighbor spends time building homes, and society rewards us with money for the time and energy we spent being productive
Today, the tool that we use to save our economic energy is clearly losing value over time. The nominal value remains the same, but the purchasing power is decreasing. In other words, the value of our time today will be worth less in the future.
That explains why everyone around us is looking for the next best investment opportunity. We are all needing to become investment experts, speculators, on top of our respective professions. Speculation became necessary, and some of us are forced into a high-time preference lifestyle.
Earn now and spend it all now before you lose it.
This should not be the case…
Time is Money
Our time is the only scarce resource we all have. We use it to be productive and generate economic value, then store that value in the form of money in order to reap the rewards in the future.
Money is the abstract representation of our time. Hence, time is money.
In January 2009, at the height of the global financial crisis, a software protocol called Bitcoin was released pseudonymously by Satoshi Nakamoto. This individual (or group) released a whitepaper a few months prior named “Bitcoin: A Peer-to-Peer Electronic Cash System” outlining how the system enables secure, peer-to-peer transactions without relying on a central authority. (https://bitcoin.org/bitcoin.pdf)
Although there are more technical concepts involved, the bitcoin protocol can be thought of as a language for communicating value. The same way we respect the rules of the English language to communicate ideas with one another, bitcoin users adhere to the network’s consensus rules to communicate value with each other in a peer-to-peer fashion.
There are no physical or digital coins in the bitcoin network. Rather, it is a collection of transactions transferring value from sender to recipient. Transactions are validated and propagated by nodes across the network, before being recorded into the blockchain. The Bitcoin blockchain is a global public ledger of all transactions that cannot be altered.
More importantly, Bitcoin is money that does not lose value overtime.
-
Its supply is capped at 21 million coins.
-
Its scarcity increases over time due to the predictable issuance rate, which halves roughly every 4 years.
-
Its decentralized nature puts the power in the hands of its users.
-
There is no governing body that can devalue or alter it.
It is a tool that we can use to save our economic energy over time, and be able to use it later.
It is the scarcest verifiable commodity: we cannot make more of it no matter how high its demand grows. That cannot be said for any other commodity in the world today.
A savings tool in disguise
See, most people tend to view bitcoin as another speculative investment. They presume they have missed out on another investment opportunity, and it’s now too late to get in.
Meanwhile, it is quite the opposite. Bitcoin’s value will keep growing over time due to its deflationary nature.
With bitcoin, we can save for a better future, for a rainy day, and spend more time with our loved ones or focusing on our craft to build better tools or artistic masterpieces. It takes away the burden of having to speculate on which stock will perform best, or which real estate market will grow the fastest, all while working one or multiple jobs
Bitcoin is not another investment opportunity you missed out on. It is the best savings tool humans have invented (or discovered), while everything else is the speculative bet. Bitcoin is the hedge against the guaranteed devaluation of money, without any counterparty risk.
What we were taught as children is true. With the right tool, the idea that saving will help you build wealth overtime stands true. Bitcoin might seem like an investment today given the volatility during its adoption phase. In reality, it is the perfect way to store your time and economic energy and grow your wealth. Whether you make $1/hour or $1M/hour, you can start saving in the best money humans have invented.
My goal is to help people around me understand this technology and break the stigma around it.
Bitcoin is not the next best investment.
It is the best tool we have found to store our economic energy across time and exchange value with each other.
Bitcoin is Money.
-
-
@ 87730827:746b7d35
2024-11-20 09:27:53
Original: https://techreport.com/crypto-news/brazil-central-bank-ban-monero-stablecoins/
Brazilian’s Central Bank Will Ban Monero and Algorithmic Stablecoins in the Country
Brazil proposes crypto regulations banning Monero and algorithmic stablecoins and enforcing strict compliance for exchanges.
KEY TAKEAWAYS
- The Central Bank of Brazil has proposed regulations prohibiting privacy-centric cryptocurrencies like Monero.
- The regulations categorize exchanges into intermediaries, custodians, and brokers, each with specific capital requirements and compliance standards.
- While the proposed rules apply to cryptocurrencies, certain digital assets like non-fungible tokens (NFTs) are still ‘deregulated’ in Brazil.

In a Notice of Participation announcement, the Brazilian Central Bank (BCB) outlines regulations for virtual asset service providers (VASPs) operating in the country.
In the document, the Brazilian regulator specifies that privacy-focused coins, such as Monero, must be excluded from all digital asset companies that intend to operate in Brazil.
Let’s unpack what effect these regulations will have.
Brazil’s Crackdown on Crypto Fraud
If the BCB’s current rule is approved, exchanges dealing with coins that provide anonymity must delist these currencies or prevent Brazilians from accessing and operating these assets.
The Central Bank argues that currencies like Monero make it difficult and even prevent the identification of users, thus creating problems in complying with international AML obligations and policies to prevent the financing of terrorism.
According to the Central Bank of Brazil, the bans aim to prevent criminals from using digital assets to launder money. In Brazil, organized criminal syndicates such as the Primeiro Comando da Capital (PCC) and Comando Vermelho have been increasingly using digital assets for money laundering and foreign remittances.
… restriction on the supply of virtual assets that contain characteristics of fragility, insecurity or risks that favor fraud or crime, such as virtual assets designed to favor money laundering and terrorist financing practices by facilitating anonymity or difficulty identification of the holder.
The Central Bank has identified that removing algorithmic stablecoins is essential to guarantee the safety of users’ funds and avoid events such as when Terraform Labs’ entire ecosystem collapsed, losing billions of investors’ dollars.
The Central Bank also wants to control all digital assets traded by companies in Brazil. According to the current proposal, the national regulator will have the power to ask platforms to remove certain listed assets if it considers that they do not meet local regulations.
However, the regulations will not include NFTs, real-world asset (RWA) tokens, RWA tokens classified as securities, and tokenized movable or real estate assets. These assets are still ‘deregulated’ in Brazil.
Monero: What Is It and Why Is Brazil Banning It?
Monero ($XMR) is a cryptocurrency that uses a protocol called CryptoNote. It launched in 2013 and ‘erases’ transaction data, preventing the sender and recipient addresses from being publicly known. The Monero network is based on a proof-of-work (PoW) consensus mechanism, which incentivizes miners to add blocks to the blockchain.
Like Brazil, other nations are banning Monero in search of regulatory compliance. Recently, Dubai’s new digital asset rules prohibited the issuance of activities related to anonymity-enhancing cryptocurrencies such as $XMR.
Furthermore, exchanges such as Binance have already announced they will delist Monero on their global platforms due to its anonymity features. Kraken did the same, removing Monero for their European-based users to comply with MiCA regulations.
Data from Chainalysis shows that Brazil is the seventh-largest Bitcoin market in the world.

In Latin America, Brazil is the largest market for digital assets. Globally, it leads in the innovation of RWA tokens, with several companies already trading this type of asset.
In Closing
Following other nations, Brazil’s regulatory proposals aim to combat illicit activities such as money laundering and terrorism financing.
Will the BCB’s move safeguard people’s digital assets while also stimulating growth and innovation in the crypto ecosystem? Only time will tell.
References
Cassio Gusson is a journalist passionate about technology, cryptocurrencies, and the nuances of human nature. With a career spanning roles as Senior Crypto Journalist at CriptoFacil and Head of News at CoinTelegraph, he offers exclusive insights on South America’s crypto landscape. A graduate in Communication from Faccamp and a post-graduate in Globalization and Culture from FESPSP, Cassio explores the intersection of governance, decentralization, and the evolution of global systems.
-
@ c7e8fdda:b8f73146
2025-05-22 14:13:31
🌍 Too Young. Too Idealistic. Too Alive. A message came in recently that stopped me cold.
It was from someone young—16 years old—but you’d never guess it from the depth of what they wrote. They spoke of having dreams so big they scare people. They’d had a spiritual awakening at 14, but instead of being nurtured, it was dismissed. Surrounded by people dulled by bitterness and fear, they were told to be realistic. To grow up. To face “reality.”
This Substack is reader-supported. To receive new posts and support my work, consider becoming a free or paid subscriber.
And that reality, to them, looked like a life that doesn’t feel like living at all.
They wrote that their biggest fear wasn’t failure—it was settling. Dimming their fire. Growing into someone they never chose to be.
And that—more than anything—scared them.
They told me that my book, I Don’t Want to Grow Up, brought them to tears because it validated what they already knew to be true. That they’re not alone. That it’s okay to want something different. That it’s okay to feel everything.
It’s messages like this that remind me why I write.
As many of you know, I include my personal email address at the back of all my books. And I read—and respond to—every single message that comes in. Whether it’s a few sentences or a life story, I see them all. And again and again, I’m reminded: there are so many of us out here quietly carrying the same truth.
Maybe you’ve felt the same. Maybe you still do.
Maybe you’ve been told your dreams are too big, too unrealistic. Maybe people around you—people who love you—try to shrink them down to something more “manageable.” Maybe they call it protection. Maybe they call it love.
But it feels like fear.
The path you wish to walk might be lonelier at first. It might not make sense to the people around you. But if it lights you up—follow it.
Because when you do, you give silent permission to others to do the same. You become living proof that another kind of life is possible. And that’s how we build a better world.
So to the person who wrote to me—and to every soul who feels the same way:
Keep going. Keep dreaming. Keep burning. You are not too young. You are not too idealistic. You are just deeply, radically alive.
And that is not a problem. That is a gift.
—
If this speaks to you, my book I Don’t Want to Grow Up was written for this very reason—to remind you that your wildness is sacred, your truth is valid, and you’re not alone. Paperback/Kindle/Audiobook available here: scottstillmanblog.com
This Substack is reader-supported. To receive new posts and support my work, consider becoming a free or paid subscriber. https://connect-test.layer3.press/articles/041a2dc8-5c42-4895-86ec-bc166ac0d315
-
@ 47259076:570c98c4
2025-05-23 13:57:28
"Know thyself and you will know the universe and the gods"
This is the greatest truth.
Knowing yourself is a process that is perhaps eternal.
Knowing yourself means making conscious what is unconscious, in all fields.
Making conscious your material reality, your emotions, your thoughts, your mind, your patterns, your spirit, your flaws, your qualities, etc.
The journey is within.
And in this process, burning everything that is not you.
Burning everything so only the essential remains.
The essential being your higher self.
You are not your body, you are not your emotions, you are not your mind, etc...
You are pure consciousness.
Everyday we can learn from him, but if we are asleep, we will not realize the gold opportunities passing right in front of our eyes.
Everyday he teaches us.
If everyday he teaches us, why stress so much for having an astral projection?
If an astral projection happens with you, it will be a good experience indeed, if you know how to value opportunities.
Otherwise, you may see some """evil"" spirits trying to scare you.
Therefore, don't depend on astral projection for your spiritual growth.
In fact, don't depend on anything.
Don't depend on books, don't depend on people, don't depend on "psychologists", don't depend on "rituals", don't depend on institutions, and of course, don't depend on the "government".
-
@ b0a838f2:34ed3f19
2025-05-23 17:52:51
- Alfresco Community Edition - The open source Enterprise Content Management software that handles any type of content, allowing users to easily share and collaborate on content. (Source Code)
LGPL-3.0Java - Apostrophe - CMS with a focus on extensible in-context editing tools. (Demo, Source Code)
MITNodejs - Backdrop CMS - Comprehensive CMS for small to medium sized businesses and non-profits. (Source Code)
GPL-2.0PHP - BigTree CMS - Straightforward, well documented, and capable CMS. (Source Code)
LGPL-2.1PHP - Bludit
⚠- Build a site or blog in seconds. Bludit uses flat-files (text files in JSON format) to store posts and pages. (Source Code)MITPHP - CMS Made Simple - Faster and easier management of website contents, scalable for small businesses to large corporations. (Source Code)
GPL-2.0PHP - Cockpit - Simple content platform to manage any structured content. (Source Code)
MITPHP - Concrete 5 CMS - Open source content management system. (Source Code)
MITPHP - Contao - Powerful CMS that allows you to create professional websites and scalable web applications. (Demo, Source Code)
LGPL-3.0PHP - CouchCMS - CMS for designers. (Source Code)
CPAL-1.0PHP - Drupal - Advanced open source content management platform. (Source Code)
GPL-2.0PHP - eLabFTW - Online lab notebook for research labs. Store experiments, use a database to find reagents or protocols, use trusted timestamping to legally timestamp an experiment, export as pdf or zip archive, share with collaborators…. (Demo, Source Code)
AGPL-3.0PHP - Expressa - Content Management System for powering database driven websites using JSON schemas. Provides permission management and automatic REST APIs.
MITNodejs - Joomla! - Advanced Content Management System (CMS). (Source Code)
GPL-2.0PHP - KeystoneJS - CMS and web application platform. (Source Code)
MITNodejs - Localess
⚠- Powerful translation management and content management system. Manage and translate your website or app content into multiple languages, using AI to translate faster. (Source Code)MITDocker - MODX - Advanced content management and publishing platform. The current version is called 'Revolution'. (Source Code)
GPL-2.0PHP - Neos - Neos or TYPO3 Neos (for version 1) is a modern, open source CMS. (Source Code)
GPL-3.0PHP - Noosfero - Platform for social and solidarity economy networks with blog, e-Portfolios, CMS, RSS, thematic discussion, events agenda and collective intelligence for solidarity economy in the same system.
AGPL-3.0Ruby - Omeka - Create complex narratives and share rich collections, adhering to Dublin Core standards with Omeka on your server, designed for scholars, museums, libraries, archives, and enthusiasts. (Demo, Source Code)
GPL-3.0PHP - Payload CMS - Developer-first headless CMS and application framework. (Source Code)
MITNodejs - Pimcore - Multi-channel experience and engagement management platform. (Source Code)
GPL-3.0PHP/Docker - Plone - Powerful open-source CMS system. (Source Code)
ZPL-2.0Python/Docker - Publify - Simple but full featured web publishing software. (Source Code)
MITRuby - REDAXO - Simple, flexible and useful content management system (documentation only available in German). (Source Code)
MITPHP/Docker - Roadiz - Modern CMS based on a node system which can handle many types of services. (Source Code)
MITPHP - SilverStripe - Easy to use CMS with powerful MVC framework underlying. (Demo, Source Code)
BSD-3-ClausePHP - SPIP - Publication system for the Internet aimed at collaborative work, multilingual environments, and simplicity of use for web authors. (Source Code)
GPL-3.0PHP - Squidex - Headless CMS, based on MongoDB, CQRS and Event Sourcing. (Demo, Source Code)
MIT.NET - Strapi - The most advanced open-source Content Management Framework (headless-CMS) to build powerful API with no effort. (Source Code)
MITNodejs - Superdesk
⚠- End-to-end news creation, production, curation, distribution, and publishing platform. (Source Code)AGPL-3.0Docker/Python/PHP - Textpattern - Flexible, elegant and easy-to-use CMS. (Demo, Source Code)
GPL-2.0PHP - Typemill - Author-friendly flat-file-cms with a visual markdown editor based on vue.js. (Source Code)
MITPHP - TYPO3 - Powerful and advanced CMS with a large community. (Source Code)
GPL-2.0PHP - Umbraco - The friendly CMS. Free and open source with an amazing community. (Source Code)
MIT.NET - Vvveb CMS - Powerful and easy to use CMS to build websites, blogs or e-commerce stores. (Demo, Source Code)
AGPL-3.0PHP/Docker - Wagtail - Django content management system focused on flexibility and user experience. (Source Code)
BSD-3-ClausePython - WinterCMS - Speedy and secure content management system built on the Laravel PHP framework. (Source Code)
MITPHP - WonderCMS - WonderCMS is the smallest flat file CMS since 2008. (Demo, Source Code)
MITPHP - WordPress - World's most-used blogging and CMS engine. (Source Code)
GPL-2.0PHP
- Alfresco Community Edition - The open source Enterprise Content Management software that handles any type of content, allowing users to easily share and collaborate on content. (Source Code)
-
@ 05a0f81e:fc032124
2025-05-22 12:06:40
Bitcoin Pizza Day is celebrated annually on May 22 to commemorate the first real-world transaction using Bitcoin. On May 22, 2010, programmer Laszlo Hanyecz made history by exchanging 10,000 Bitcoins for two large pizzas from Papa John's, worth around $41 at the time. Today, those same Bitcoins are valued at nearly $1 billion, making it one of the most expensive meals ever recorded.
This day marks a significant milestone in the history of cryptocurrency, demonstrating Bitcoin's potential as a medium of exchange for goods and services. It's now celebrated worldwide with events, online discussions, and special pizza promotions.
How it's Celebrated.
Global Events: Cities around the world host gatherings, pizza parties, and discussions about Bitcoin and cryptocurrency.
Rewards and Giveaways: Cryptocurrency exchanges like Binance and Bitget offer rewards, discounts, and giveaways to commemorate the day. Community Engagement: Enthusiasts, traders, and newcomers come together to discuss Bitcoin's journey and the future of decentralized finance.
Significance!
Bitcoin's Humble Beginnings: Bitcoin Pizza Day reminds us of the cryptocurrency's potential for wider adoption and growth.
Cryptocurrency's Evolution: It highlights the progress of Bitcoin from a niche experiment to a significant player in the financial world.
Community Building: The day fosters connections among cryptocurrency enthusiasts and promotes education about Bitcoin and its uses.
-
@ b0a838f2:34ed3f19
2025-05-23 17:52:28
- indico - Feature-rich event management system, made @ CERN, the place where the Web was born. (Demo, Source Code)
MITPython - motion.tools (Antragsgrün) - Manage motions and amendments for (political) conventions. (Demo, Source Code)
AGPL-3.0PHP/Docker - OpenSlides - Presentation and assembly system for managing and projecting agenda, motions and elections of an assembly. (Demo, Source Code)
MITDocker - osem - Event management tailored to free Software conferences. (Source Code)
MITRuby/Docker - pretalx - Web-based event management, including running a Call for Papers, reviewing submissions, and scheduling talks. Exports and imports for various related tools. (Source Code)
Apache-2.0Python
- indico - Feature-rich event management system, made @ CERN, the place where the Web was born. (Demo, Source Code)
-
@ b0a838f2:34ed3f19
2025-05-23 17:52:10
- ACP Admin - CSA administration. Manage members, subscriptions, deliveries, drop-off locations, member participation, invoices and emails (documentation in French). (Source Code)
MITRuby - E-Label - Solution for electronic labels, with QR Codes, on wine bottles sold within the European Union. (Source Code)
MITDocker - FoodCoopShop - User-friendly software for food-coops. (Source Code)
AGPL-3.0PHP/Docker - Foodsoft - Manage a non-profit food coop (product catalog, ordering, accounting, job scheduling). (Source Code)
AGPL-3.0Docker/Ruby - juntagrico - Management platform for community gardens and vegetable cooperatives. (Source Code)
LGPL-3.0Python - Open Food Network - Online marketplace for local food. It enables a network of independent online food stores that connect farmers and food hubs with individuals and local businesses. (Source Code)
AGPL-3.0Ruby - OpenOlitor - Administration platform for Community Supported Agriculture groups. (Source Code)
AGPL-3.0Scala - teikei - A web application that maps out community-supported agriculture based on crowdsourced data. (Demo)
AGPL-3.0Nodejs
- ACP Admin - CSA administration. Manage members, subscriptions, deliveries, drop-off locations, member participation, invoices and emails (documentation in French). (Source Code)
-
@ af9c48b7:a3f7aaf4
2024-11-18 20:26:07
Chef's notes
This simple, easy, no bake desert will surely be the it at you next family gathering. You can keep it a secret or share it with the crowd that this is a healthy alternative to normal pie. I think everyone will be amazed at how good it really is.
Details
- ⏲️ Prep time: 30
- 🍳 Cook time: 0
- 🍽️ Servings: 8
Ingredients
- 1/3 cup of Heavy Cream- 0g sugar, 5.5g carbohydrates
- 3/4 cup of Half and Half- 6g sugar, 3g carbohydrates
- 4oz Sugar Free Cool Whip (1/2 small container) - 0g sugar, 37.5g carbohydrates
- 1.5oz box (small box) of Sugar Free Instant Chocolate Pudding- 0g sugar, 32g carbohydrates
- 1 Pecan Pie Crust- 24g sugar, 72g carbohydrates
Directions
- The total pie has 30g of sugar and 149.50g of carboydrates. So if you cut the pie into 8 equal slices, that would come to 3.75g of sugar and 18.69g carbohydrates per slice. If you decided to not eat the crust, your sugar intake would be .75 gram per slice and the carborytrates would be 9.69g per slice. Based on your objective, you could use only heavy whipping cream and no half and half to further reduce your sugar intake.
- Mix all wet ingredients and the instant pudding until thoroughly mixed and a consistent color has been achieved. The heavy whipping cream causes the mixture to thicken the more you mix it. So, I’d recommend using an electric mixer. Once you are satisfied with the color, start mixing in the whipping cream until it has a consistent “chocolate” color thorough. Once your satisfied with the color, spoon the mixture into the pie crust, smooth the top to your liking, and then refrigerate for one hour before serving.
-
@ db39407c:a36c161e
2025-05-22 10:37:27
123BET trải nghiệm giải trí online đang trở thành điểm đến lý tưởng cho cộng đồng yêu thích cá cược trực tuyến tại Việt Nam nhờ sự kết hợp giữa công nghệ hiện đại và dịch vụ người dùng xuất sắc. Với định hướng phát triển lâu dài và bền vững, 123BET không chỉ cung cấp hàng trăm trò chơi hấp dẫn từ slot game, baccarat, tài xỉu, bắn cá, roulette đến live casino mà còn tích hợp hệ thống cá cược thể thao đỉnh cao, đem lại sự đa dạng và linh hoạt trong lựa chọn giải trí cho người chơi. Giao diện website và ứng dụng được thiết kế tối ưu cho người Việt, dễ sử dụng, tốc độ mượt mà, tương thích hoàn toàn với mọi hệ điều hành như iOS, Android, Windows… chỉ với một tài khoản duy nhất, bạn có thể dễ dàng đăng nhập và tận hưởng mọi dịch vụ cá cược không giới hạn mọi lúc, mọi nơi. 123BET đặc biệt chú trọng đến tính minh bạch, khi toàn bộ trò chơi đều được chứng nhận bởi các tổ chức kiểm định quốc tế, đảm bảo công bằng tuyệt đối trong từng ván cược.
Ngoài hệ thống trò chơi phong phú, 123BET còn sở hữu nền tảng công nghệ bảo mật hàng đầu, giúp người chơi yên tâm tuyệt đối về thông tin cá nhân và giao dịch tài chính. Hệ thống thanh toán được hỗ trợ 24/7, với nhiều phương thức linh hoạt như chuyển khoản ngân hàng, ví điện tử, thẻ cào và cả mã QR, giúp người chơi dễ dàng nạp tiền và rút thưởng một cách nhanh chóng, chỉ trong vài phút. Đặc biệt, người chơi không cần thông qua bên trung gian mà hoàn toàn có thể giao dịch trực tiếp trên nền tảng với độ an toàn cao, hạn chế tối đa rủi ro bị lộ thông tin hoặc lừa đảo. Đội ngũ kỹ thuật và chăm sóc khách hàng của 123BET hoạt động chuyên nghiệp, tận tâm, hỗ trợ trực tuyến liên tục cả ngày lẫn đêm thông qua nhiều kênh như chat trực tuyến, Zalo, Telegram, Hotline. Mọi thắc mắc và sự cố kỹ thuật đều được xử lý nhanh chóng và hiệu quả, đảm bảo trải nghiệm không bị gián đoạn. Nhờ vào dịch vụ chăm sóc người chơi chuyên biệt và tận tâm, 123BET ngày càng khẳng định vị thế dẫn đầu của mình trên thị trường cá cược trực tuyến Việt Nam.
Không dừng lại ở đó, 123BET còn liên tục triển khai các chương trình khuyến mãi hấp dẫn nhằm tri ân người chơi mới và gắn bó lâu dài. Ngay từ khi đăng ký tài khoản, người chơi sẽ nhận được nhiều phần thưởng hấp dẫn như tiền cược miễn phí, vòng quay may mắn và các mã thưởng nạp đầu giá trị. Ngoài ra, chương trình VIP của 123BET được xây dựng theo mô hình tích điểm nâng hạng với các cấp bậc từ Thành viên, Bạc, Vàng cho đến Kim Cương – mỗi cấp đều đi kèm các đặc quyền riêng như hoàn tiền cược hàng tuần, tỷ lệ nạp cao hơn, rút tiền nhanh hơn và được ưu tiên hỗ trợ riêng biệt. Những sự kiện hot theo tháng, các giải đấu nội bộ cũng được tổ chức thường xuyên với phần thưởng tiền mặt, điện thoại, xe máy hoặc các phần quà có giá trị khác, giúp người chơi luôn có cảm hứng mới khi tham gia. Với định hướng không ngừng đổi mới và lấy người dùng làm trung tâm, 123BET trải nghiệm giải trí online không chỉ là một nhà cái, mà còn là người đồng hành đáng tin cậy trong hành trình giải trí và kiếm thưởng của hàng triệu người Việt mỗi ngày.
-
@ 5d4b6c8d:8a1c1ee3
2025-05-23 13:46:21
You'd think I'd be most excited to talk about that awesome Pacers game, but, no. What I'm most excited about this week is that @grayruby wants to continue Beefing with Cowherd.
Still, I am excited to talk about Tyrese Haliburton becoming a legendary Knicks antagonist. Unfortunately, the Western Conference Finals are not as exciting. Also, why was the MVP announcement so dumb?
The T20k cricket contest is tightening up, as we head towards the finish. Can @Coinsreporter hold on to his vanishing lead?
@Carresan has launched Football Madness. Let's see if we understand whatever the hell this is any better than we did last week.
On this week's Blok'd Shots, we'll ridicule Canada for their disgraceful loss in the World Championships and talk about the very dominant American Florida Panthers, who are favorites to win the Stanley Cup.
Are the Colorado the worst team in MLB history?
The Tush Push has survived another season. Will the NFL eventually ban it or will teams adjust?
Plus, whatever else Stackers want to talk about.
https://stacker.news/items/987399
-
@ 30b99916:3cc6e3fe
2025-05-23 13:16:37
sourcegraph #vibecoding #ai #bitcoin #security
After reading the article Revenge of the junior developer, this inspired me to go take a look at Sourcegraph.com to get a better understanding of all this AI stuff.
The first step was installing the VS Code extension called, Cody which is a coding agent. The Cody features explain the code in a file and review and analyze code did an extremely impressive job with VaultApi and BTCwallet.
VaultApi and BTCwallet are PowerShell scripts that are available from my BTCPAY Server
All of the following output was generated by Cody.
Code Analysis of VaultApi.ps1
The VaultApi.ps1 script is generally well-structured and follows many PowerShell best practices. It has comprehensive documentation, version history, and clear parameter definitions. The suggestions below would further enhance what is already a solid codebase. The author has clearly put significant effort into making the script functional and user-friendly, with good attention to cross-platform compatibility and security considerations.
VaultApi.ps1 Explanation
VaultApi.ps1 is a PowerShell script that helps users interact with HashiCorp Vault, which is a tool for securely storing and managing sensitive information like passwords and API keys.
Purpose of the Code
This script makes it easier to use Vault by providing simple commands to start the Vault server, unlock it (unseal), log in, store secrets, retrieve secrets, and shut down the server. Think of it as a friendly interface that simplifies all the complex operations you would otherwise need to do manually with Vault.
Inputs
The script takes several inputs:
- An
actionparameter that tells the script what operation to perform (like "Start", "Stop", "Kv1Create", "Kv1Read") - A
kvpathparameter that specifies where in Vault to store or retrieve information - A
kvalueparameter for the actual secret value you want to store - A
kvkeyparameter that lets you specify a custom name for your secret - Optional switches like
-Infoto show more detailed information and-Rawto display output directly instead of copying to clipboard
Outputs
Depending on the action performed, the script produces different outputs:
- Text messages in the console showing the status of operations
- Secret values retrieved from Vault (either displayed or copied to clipboard)
- Lists of available secret paths
- Status information about the Vault server
- Backup files of your Vault data
How It Works
The script works by:
- First checking if Vault is installed and running
- Setting up communication with the Vault server using its API address
- Performing the requested action by sending the appropriate commands to Vault
- Processing any responses and displaying results to the user
For example, when you use the "Kv1Create" action, the script:
- Checks if you're logged in
- Verifies the path doesn't already exist
- Formats your data correctly
- Sends a request to Vault to create the new secret
- Shows you the result
Important Logic Flows
Some key processes in the script include:
-
Authentication flow: The script helps you log in using either a token or username/password, then stores your authentication token for future commands.
-
Unsealing process: Vault requires multiple keys to unlock (unseal) it after starting. The script can retrieve these keys from a secure file or prompt you to enter them.
-
Secret management: The script handles creating, reading, updating, and deleting secrets, supporting both single values and multiple key-value pairs at a path.
-
Path management: The script can list all available paths and help you search for specific ones, making it easier to organize and find your secrets.
-
Value generation: When creating or updating secrets, you can use the keyword "setvalue" to automatically generate a random 20-character value, which is then copied to your clipboard.
The script uses a configuration file in your home directory to know how to connect to Vault, and it can optionally use encrypted files to store sensitive information like unlock keys. It communicates with Vault using REST API calls, which are like special messages that tell Vault what to do.
In summary, VaultApi.ps1 is a helper tool that makes it much easier to use HashiCorp Vault for securely storing and managing your sensitive information, without needing to remember all the complex commands and procedures.
Code Analysis of BTCwallet.ps1
The script generally follows sound design principles with good organization, comments, and documentation. It demonstrates thoughtful error checking and user interaction. The identified opportunities for enhancement would primarily improve security, maintainability, and robustness rather than addressing fundamental flaws. The script author has clearly put significant effort into creating a comprehensive tool with good documentation and practical functionality.
BTCwallet.ps1 Explanation
The BTCwallet.ps1 script is a PowerShell tool designed to help Bitcoin users manage different wallet applications on a Linux system. It provides a convenient way to start, stop, and check the status of Bitcoin wallets while adding security features.
Purpose
The main purpose of this script is to securely manage Bitcoin wallets, particularly focusing on "cold storage" solutions. Cold storage means keeping your Bitcoin wallet data in an encrypted container that's only mounted when needed, which is more secure than keeping it always accessible ("hot storage").
Inputs
The script takes one main input parameter:
$action: This can be "start", "stop", or "check" (default), telling the script what operation to perform on your Bitcoin wallet.
Outputs
The script doesn't return data but produces several visible outputs:
- Status messages showing whether wallets are running or stopped
- Prompts for user input when decisions are needed
- Confirmation messages when actions are completed
How It Works
-
When you run the script, it first loads a configuration file (BTCwalletCfg.xml) that contains information about which wallets you have installed.
-
Based on the
$actionparameter, it performs one of three main functions:- Check: Shows if your wallet application is currently running
- Start: Launches your wallet application, with options for hot or cold storage
- Stop: Closes your wallet application and securely dismounts any encrypted containers
- For security, the script can use HashiCorp Vault (a secure password manager) to store sensitive information like passwords for encrypted containers.
-
The script also verifies its own integrity by checking its file hash against a previously stored value, alerting you if the script has been modified.
Important Logic Flows
Starting a Wallet
When starting a wallet, the script:
- Asks which wallet you want to use (Sparrow, GreenWallet, or Wasabi)
- Checks if HashiCorp Vault is running and starts it if needed
- Verifies the script's integrity by comparing file hashes
- Asks if you want to use hot or cold storage
- For cold storage, it:
- Retrieves the encrypted container's location and password
- Mounts the encrypted container using VeraCrypt
- Starts the wallet application pointing to the mounted container
- For hot storage, it simply starts the wallet application with default settings
Stopping a Wallet
When stopping a wallet, the script:
- Checks if the wallet is still running and asks you to close it first if needed
- For cold storage wallets, it moves any wallet files back to the encrypted container
- Dismounts the encrypted container
- Optionally stops the HashiCorp Vault service
The script handles different wallet applications (Sparrow, GreenWallet, and Wasabi) slightly differently based on how each one stores its data and what command-line options they support.
In summary, BTCwallet.ps1 provides a secure way to manage Bitcoin wallets by combining wallet applications with encrypted storage and password management, all controlled through simple commands.
- An
-
@ 41e6f20b:06049e45
2024-11-17 17:33:55
Let me tell you a beautiful story. Last night, during the speakers' dinner at Monerotopia, the waitress was collecting tiny tips in Mexican pesos. I asked her, "Do you really want to earn tips seriously?" I then showed her how to set up a Cake Wallet, and she started collecting tips in Monero, reaching 0.9 XMR. Of course, she wanted to cash out to fiat immediately, but it solved a real problem for her: making more money. That amount was something she would never have earned in a single workday. We kept talking, and I promised to give her Zoom workshops. What can I say? I love people, and that's why I'm a natural orange-piller.
-
@ b0a838f2:34ed3f19
2025-05-23 17:51:53
- Converse.js - XMPP chat client in your browser. (Source Code)
MPL-2.0Javascript - JSXC - Real-time XMPP web chat application with video calls, file transfer and encrypted communication. There are also versions for Nextcloud/Owncloud and SOGo. (Source Code)
MITJavascript - Libervia - Web frontend from Salut à Toi.
AGPL-3.0Python - Salut à Toi - Multipurpose, multi frontend, libre and decentralized communication tool. (Source Code)
AGPL-3.0Python
- Converse.js - XMPP chat client in your browser. (Source Code)
-
@ 63d59db8:be170f6f
2025-05-23 12:53:00
In a world overwhelmed by contradictions—climate change, inequality, political instability, and social disconnection—absurdity becomes an unavoidable lens through which to view the human condition. Inspired by Albert Camus' philosophy, this project explores the tension between life’s inherent meaninglessness and our persistent search for purpose.\ \ The individuals in these images embody a quiet defiance, navigating chaos with a sense of irony and authenticity. Through the act of revolt—against despair, against resignation—they find agency and resilience. These photographs invite reflection, not on solutions, but on our capacity to live meaningfully within absurdity.





Visit Katerina's website here.
Submit your work to the NOICE Visual Expression Awards for a chance to win a few thousand extra sats:
-
@ 4ba8e86d:89d32de4
2024-11-14 09:17:14
Tutorial feito por nostr:nostr:npub1rc56x0ek0dd303eph523g3chm0wmrs5wdk6vs0ehd0m5fn8t7y4sqra3tk poste original abaixo:
Parte 1 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/263585/tutorial-debloat-de-celulares-android-via-adb-parte-1
Parte 2 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/index.php/263586/tutorial-debloat-de-celulares-android-via-adb-parte-2
Quando o assunto é privacidade em celulares, uma das medidas comumente mencionadas é a remoção de bloatwares do dispositivo, também chamado de debloat. O meio mais eficiente para isso sem dúvidas é a troca de sistema operacional. Custom Rom’s como LineageOS, GrapheneOS, Iodé, CalyxOS, etc, já são bastante enxutos nesse quesito, principalmente quanto não é instalado os G-Apps com o sistema. No entanto, essa prática pode acabar resultando em problemas indesejados como a perca de funções do dispositivo, e até mesmo incompatibilidade com apps bancários, tornando este método mais atrativo para quem possui mais de um dispositivo e separando um apenas para privacidade. Pensando nisso, pessoas que possuem apenas um único dispositivo móvel, que são necessitadas desses apps ou funções, mas, ao mesmo tempo, tem essa visão em prol da privacidade, buscam por um meio-termo entre manter a Stock rom, e não ter seus dados coletados por esses bloatwares. Felizmente, a remoção de bloatwares é possível e pode ser realizada via root, ou mais da maneira que este artigo irá tratar, via adb.
O que são bloatwares?
Bloatware é a junção das palavras bloat (inchar) + software (programa), ou seja, um bloatware é basicamente um programa inútil ou facilmente substituível — colocado em seu dispositivo previamente pela fabricante e operadora — que está no seu dispositivo apenas ocupando espaço de armazenamento, consumindo memória RAM e pior, coletando seus dados e enviando para servidores externos, além de serem mais pontos de vulnerabilidades.
O que é o adb?
O Android Debug Brigde, ou apenas adb, é uma ferramenta que se utiliza das permissões de usuário shell e permite o envio de comandos vindo de um computador para um dispositivo Android exigindo apenas que a depuração USB esteja ativa, mas também pode ser usada diretamente no celular a partir do Android 11, com o uso do Termux e a depuração sem fio (ou depuração wifi). A ferramenta funciona normalmente em dispositivos sem root, e também funciona caso o celular esteja em Recovery Mode.
Requisitos:
Para computadores:
• Depuração USB ativa no celular; • Computador com adb; • Cabo USB;
Para celulares:
• Depuração sem fio (ou depuração wifi) ativa no celular; • Termux; • Android 11 ou superior;
Para ambos:
• Firewall NetGuard instalado e configurado no celular; • Lista de bloatwares para seu dispositivo;
Ativação de depuração:
Para ativar a Depuração USB em seu dispositivo, pesquise como ativar as opções de desenvolvedor de seu dispositivo, e lá ative a depuração. No caso da depuração sem fio, sua ativação irá ser necessária apenas no momento que for conectar o dispositivo ao Termux.
Instalação e configuração do NetGuard
O NetGuard pode ser instalado através da própria Google Play Store, mas de preferência instale pela F-Droid ou Github para evitar telemetria.
F-Droid: https://f-droid.org/packages/eu.faircode.netguard/
Github: https://github.com/M66B/NetGuard/releases
Após instalado, configure da seguinte maneira:
Configurações → padrões (lista branca/negra) → ative as 3 primeiras opções (bloquear wifi, bloquear dados móveis e aplicar regras ‘quando tela estiver ligada’);
Configurações → opções avançadas → ative as duas primeiras (administrar aplicativos do sistema e registrar acesso a internet);
Com isso, todos os apps estarão sendo bloqueados de acessar a internet, seja por wifi ou dados móveis, e na página principal do app basta permitir o acesso a rede para os apps que você vai usar (se necessário). Permita que o app rode em segundo plano sem restrição da otimização de bateria, assim quando o celular ligar, ele já estará ativo.
Lista de bloatwares
Nem todos os bloatwares são genéricos, haverá bloatwares diferentes conforme a marca, modelo, versão do Android, e até mesmo região.
Para obter uma lista de bloatwares de seu dispositivo, caso seu aparelho já possua um tempo de existência, você encontrará listas prontas facilmente apenas pesquisando por elas. Supondo que temos um Samsung Galaxy Note 10 Plus em mãos, basta pesquisar em seu motor de busca por:
Samsung Galaxy Note 10 Plus bloatware listProvavelmente essas listas já terão inclusas todos os bloatwares das mais diversas regiões, lhe poupando o trabalho de buscar por alguma lista mais específica.
Caso seu aparelho seja muito recente, e/ou não encontre uma lista pronta de bloatwares, devo dizer que você acaba de pegar em merda, pois é chato para um caralho pesquisar por cada aplicação para saber sua função, se é essencial para o sistema ou se é facilmente substituível.
De antemão já aviso, que mais para frente, caso vossa gostosura remova um desses aplicativos que era essencial para o sistema sem saber, vai acabar resultando na perda de alguma função importante, ou pior, ao reiniciar o aparelho o sistema pode estar quebrado, lhe obrigando a seguir com uma formatação, e repetir todo o processo novamente.
Download do adb em computadores
Para usar a ferramenta do adb em computadores, basta baixar o pacote chamado SDK platform-tools, disponível através deste link: https://developer.android.com/tools/releases/platform-tools. Por ele, você consegue o download para Windows, Mac e Linux.
Uma vez baixado, basta extrair o arquivo zipado, contendo dentro dele uma pasta chamada platform-tools que basta ser aberta no terminal para se usar o adb.
Download do adb em celulares com Termux.
Para usar a ferramenta do adb diretamente no celular, antes temos que baixar o app Termux, que é um emulador de terminal linux, e já possui o adb em seu repositório. Você encontra o app na Google Play Store, mas novamente recomendo baixar pela F-Droid ou diretamente no Github do projeto.
F-Droid: https://f-droid.org/en/packages/com.termux/
Github: https://github.com/termux/termux-app/releases
Processo de debloat
Antes de iniciarmos, é importante deixar claro que não é para você sair removendo todos os bloatwares de cara sem mais nem menos, afinal alguns deles precisam antes ser substituídos, podem ser essenciais para você para alguma atividade ou função, ou até mesmo são insubstituíveis.
Alguns exemplos de bloatwares que a substituição é necessária antes da remoção, é o Launcher, afinal, é a interface gráfica do sistema, e o teclado, que sem ele só é possível digitar com teclado externo. O Launcher e teclado podem ser substituídos por quaisquer outros, minha recomendação pessoal é por aqueles que respeitam sua privacidade, como Pie Launcher e Simple Laucher, enquanto o teclado pelo OpenBoard e FlorisBoard, todos open-source e disponíveis da F-Droid.
Identifique entre a lista de bloatwares, quais você gosta, precisa ou prefere não substituir, de maneira alguma você é obrigado a remover todos os bloatwares possíveis, modifique seu sistema a seu bel-prazer. O NetGuard lista todos os apps do celular com o nome do pacote, com isso você pode filtrar bem qual deles não remover.
Um exemplo claro de bloatware insubstituível e, portanto, não pode ser removido, é o com.android.mtp, um protocolo onde sua função é auxiliar a comunicação do dispositivo com um computador via USB, mas por algum motivo, tem acesso a rede e se comunica frequentemente com servidores externos. Para esses casos, e melhor solução mesmo é bloquear o acesso a rede desses bloatwares com o NetGuard.
MTP tentando comunicação com servidores externos:
Executando o adb shell
No computador
Faça backup de todos os seus arquivos importantes para algum armazenamento externo, e formate seu celular com o hard reset. Após a formatação, e a ativação da depuração USB, conecte seu aparelho e o pc com o auxílio de um cabo USB. Muito provavelmente seu dispositivo irá apenas começar a carregar, por isso permita a transferência de dados, para que o computador consiga se comunicar normalmente com o celular.
Já no pc, abra a pasta platform-tools dentro do terminal, e execute o seguinte comando:
./adb start-serverO resultado deve ser:
daemon not running; starting now at tcp:5037 daemon started successfully
E caso não apareça nada, execute:
./adb kill-serverE inicie novamente.
Com o adb conectado ao celular, execute:
./adb shellPara poder executar comandos diretamente para o dispositivo. No meu caso, meu celular é um Redmi Note 8 Pro, codinome Begonia.
Logo o resultado deve ser:
begonia:/ $
Caso ocorra algum erro do tipo:
adb: device unauthorized. This adb server’s $ADB_VENDOR_KEYS is not set Try ‘adb kill-server’ if that seems wrong. Otherwise check for a confirmation dialog on your device.
Verifique no celular se apareceu alguma confirmação para autorizar a depuração USB, caso sim, autorize e tente novamente. Caso não apareça nada, execute o kill-server e repita o processo.
No celular
Após realizar o mesmo processo de backup e hard reset citado anteriormente, instale o Termux e, com ele iniciado, execute o comando:
pkg install android-toolsQuando surgir a mensagem “Do you want to continue? [Y/n]”, basta dar enter novamente que já aceita e finaliza a instalação
Agora, vá até as opções de desenvolvedor, e ative a depuração sem fio. Dentro das opções da depuração sem fio, terá uma opção de emparelhamento do dispositivo com um código, que irá informar para você um código em emparelhamento, com um endereço IP e porta, que será usado para a conexão com o Termux.
Para facilitar o processo, recomendo que abra tanto as configurações quanto o Termux ao mesmo tempo, e divida a tela com os dois app’s, como da maneira a seguir:
Para parear o Termux com o dispositivo, não é necessário digitar o ip informado, basta trocar por “localhost”, já a porta e o código de emparelhamento, deve ser digitado exatamente como informado. Execute:
adb pair localhost:porta CódigoDeEmparelhamentoDe acordo com a imagem mostrada anteriormente, o comando ficaria “adb pair localhost:41255 757495”.
Com o dispositivo emparelhado com o Termux, agora basta conectar para conseguir executar os comandos, para isso execute:
adb connect localhost:portaObs: a porta que você deve informar neste comando não é a mesma informada com o código de emparelhamento, e sim a informada na tela principal da depuração sem fio.
Pronto! Termux e adb conectado com sucesso ao dispositivo, agora basta executar normalmente o adb shell:
adb shellRemoção na prática Com o adb shell executado, você está pronto para remover os bloatwares. No meu caso, irei mostrar apenas a remoção de um app (Google Maps), já que o comando é o mesmo para qualquer outro, mudando apenas o nome do pacote.
Dentro do NetGuard, verificando as informações do Google Maps:
Podemos ver que mesmo fora de uso, e com a localização do dispositivo desativado, o app está tentando loucamente se comunicar com servidores externos, e informar sabe-se lá que peste. Mas sem novidades até aqui, o mais importante é que podemos ver que o nome do pacote do Google Maps é com.google.android.apps.maps, e para o remover do celular, basta executar:
pm uninstall –user 0 com.google.android.apps.mapsE pronto, bloatware removido! Agora basta repetir o processo para o resto dos bloatwares, trocando apenas o nome do pacote.
Para acelerar o processo, você pode já criar uma lista do bloco de notas com os comandos, e quando colar no terminal, irá executar um atrás do outro.
Exemplo de lista:
Caso a donzela tenha removido alguma coisa sem querer, também é possível recuperar o pacote com o comando:
cmd package install-existing nome.do.pacotePós-debloat
Após limpar o máximo possível o seu sistema, reinicie o aparelho, caso entre no como recovery e não seja possível dar reboot, significa que você removeu algum app “essencial” para o sistema, e terá que formatar o aparelho e repetir toda a remoção novamente, desta vez removendo poucos bloatwares de uma vez, e reiniciando o aparelho até descobrir qual deles não pode ser removido. Sim, dá trabalho… quem mandou querer privacidade?
Caso o aparelho reinicie normalmente após a remoção, parabéns, agora basta usar seu celular como bem entender! Mantenha o NetGuard sempre executando e os bloatwares que não foram possíveis remover não irão se comunicar com servidores externos, passe a usar apps open source da F-Droid e instale outros apps através da Aurora Store ao invés da Google Play Store.
Referências: Caso você seja um Australopithecus e tenha achado este guia difícil, eis uma videoaula (3:14:40) do Anderson do canal Ciberdef, realizando todo o processo: http://odysee.com/@zai:5/Como-remover-at%C3%A9-200-APLICATIVOS-que-colocam-a-sua-PRIVACIDADE-E-SEGURAN%C3%87A-em-risco.:4?lid=6d50f40314eee7e2f218536d9e5d300290931d23
Pdf’s do Anderson citados na videoaula: créditos ao anon6837264 http://eternalcbrzpicytj4zyguygpmkjlkddxob7tptlr25cdipe5svyqoqd.onion/file/3863a834d29285d397b73a4af6fb1bbe67c888d72d30/t-05e63192d02ffd.pdf
Processo de instalação do Termux e adb no celular: https://youtu.be/APolZrPHSms
-
@ b0a838f2:34ed3f19
2025-05-23 17:51:36
- ejabberd - XMPP instant messaging server. (Source Code)
GPL-2.0Erlang/Docker - MongooseIM - Mobile messaging platform with a focus on performance and scalability. (Source Code)
GPL-2.0Erlang/Docker/K8S - Openfire - Real time collaboration (RTC) server. (Source Code)
Apache-2.0Java - Prosody IM - Feature-rich and easy to configure XMPP server. (Source Code)
MITLua - Snikket - All-in-one Dockerized easy XMPP solution, including web admin and clients. (Source Code, Clients)
Apache-2.0Docker - Tigase - XMPP server implementation in Java. (Source Code)
GPL-3.0Java
- ejabberd - XMPP instant messaging server. (Source Code)
-
@ 6d8e2a24:5faaca4c
2025-05-22 10:04:48
Apr 2, 2025 at 5:43 PM
Updated: May 8, 2025 at 1:08 PM
Bola Ahmed Tinubu has signed the Investments and Securities Act 2025, officially recognizing crypto assets and placing them under the Nigerian SEC.
Nigeria’s President, Bola Ahmed Tinubu, has signed the Investments and Securities Act 2025 into law, making its provisions officially enforceable.
The act now classifies digital assets and cryptocurrencies as securities, bringing them under the regulation of the Nigerian Securities and Exchange Commission (SEC).
The details
*According to reports, the SEC announced the development last Saturday, adding that the act supersedes the previous ISA 2007 Act.*
*The new act, apart from granting legal recognition to cryptocurrencies, also expands the definition of securities to include investment contracts.*
*This expansion grants the SEC regulatory authority over crypto exchanges and other virtual asset service providers and ensures that their activities are governed by the regulator’s provisions.*
*In addition, the act put forward stricter penalties for Ponzi schemes and their operators, many of whom have used crypto to run their scams in recent years.*
Key quotes
-
The director-general of the SEC, Emomotimi Agama commented:
*“The ISA 2024 reflects our commitment to building a dynamic, inclusive and resilient capital market. By addressing regulatory gaps and introducing forward-looking provisions, the new Act empowers SEC to foster innovation, protect investors more efficiently and reposition Nigeria as a competitive destination for local and foreign investments."*
Why this matters
*Regulations around digital assets in Nigeria have begun to pick up pace in recent years with the SEC leading the country’s crypto regulatory drive.*
*In February, Mariblock reported that the SEC was working on revising existing regulations to allow for the taxation of crypto assetsin a revenue generation move.*
*The SEC wanted to expand its licensing > framework to allow Nigerians to trade on centralized exchanges where transactions can be easily monitored for tax purposes.*
*It is unclear if the proposed amendments on crypto taxation are included in the just-assented ISA 2024.*
Before now
*In 2023, the Central Bank of Nigeria permitted local banks to serve virtual assets service providersbut only if they are licensed by the SEC.*
*Midway through last year, the SEC started its regulatory drive. It expanded its accelerated regulatory incubation program (ARIP) to include digital assets and allow virtual assets service providers (VASPS) to registerand operate within the sandbox.*
*The move, meant to fast-track the onboarding process for VASPs, culminated in two local exchanges — Busha and Quidax — receiving provisional licenses to operate in the country.*
https://www.mariblock.com/nigerias-president-signs-bill-recognizing-digital-assets-into-law/#:~:text=Nigeria's%20President%2C%20Bola%20Ahmed%20Tinubu,and%20Exchange%20Commission%20(SEC).
-
-
@ fbf0e434:e1be6a39
2025-05-22 06:52:22
Hackathon 概要
AI BUIDL Lab: 基于提示工程(Prompt Engineering)在 Rootstock 上构建真实 Web3 应用的黑客松 近日收官,共有 211 名开发者注册并提交 22 个项目。本次活动旨在鼓励开发者借助 AI 驱动的工作流程,在 Rootstock 平台开发 Web3 应用。参与者聚焦三大领域:去中心化金融(DeFi)与支付、商业与零工经济,以及 Web3 身份与声誉体系,通过 AI 技术加速去中心化应用(dApps)的创新迭代。
活动产出丰硕成果,包括去中心化金融解决方案、AI 增强型身份管理系统等,凸显了 AI 与 Web3 集成的潜力。赛事奖金池包含 1.5 万美元的 RIF 代币,用于奖励在创意性和技术执行力方面表现突出的顶尖项目。
本次黑客松不仅印证了 AI 在简化去中心化应用开发中的价值,也展现了 Web3 生态系统的进阶成果。活动与 thirdweb、Alchemy 及 RootstockLabs 的合作,为开发者高效参与及产出创新项目提供了有力支持。
Hackathon 获奖者
DeFi 和支付奖项得主
- ProtectedPay_Rootstock:一个在 CrossFi 链上的 DeFi 平台,通过先进的区块链功能促进安全转账、群体支付和智能储蓄。
- AIFi: AI-Powered DeFi Hub on Rootstock:利用 AI 提供汇款、信用评分和用户界面改善,提高拉丁美洲的金融可访问性。
商业和零工经济奖项得主
Web3 中的身份和声誉奖项得主
- AgenticID:提供自我主权身份验证,结合区块链和 AI,使用零知识证明进行安全的用户认证。
- TrustScan:使用 AI 分析 Rootstock 上的钱包活动,生成信誉和身份评分,加强信任。
赏金最佳 AI 提示使用
- AuditFi_Rootstock:提供 AI 驱动的智能合约安全审计,通过链上验证增强透明度和信任。
- RSK Smart Yield Engine:一个 AI 驱动的 DeFi 协议收益优化器,通过智能合约和 AI 管理资金和制定策略。
有关所有项目的更多信息,请访问 DoraHacks。
关于组织者
Rootstock
Rootstock - 比特币 DeFi 层 - 专注于将比特币强大的网络与以太坊的智能合约功能相结合,提升区块链的互操作性。Rootstock 以技术专长著称,已经创建了一个支持去中心化金融应用的平台。该组织致力于通过扩展在金融服务中智能合约的可访问性和功能性来推动区块链领域的创新。
-
@ b0a838f2:34ed3f19
2025-05-23 17:51:16
- BigBlueButton - Supports real-time sharing of audio, video, slides (with whiteboard controls), chat, and the screen. Instructors can engage remote students with polling, emojis, and breakout rooms. (Source Code)
LGPL-3.0Java - Galene - Video conferencing server that is easy to deploy and that requires moderate server resources. (Source Code)
MITGo - Janus - General-purpose, lightweight, minimalist WebRTC Server. (Demo, Source Code)
GPL-3.0C - Jitsi Meet - WebRTC application that uses Jitsi Videobridge to provide high quality, scalable video conferences. (Demo, Source Code)
Apache-2.0Nodejs/Docker/deb - Jitsi Video Bridge - WebRTC compatible Selective Forwarding Unit (SFU) that allows for multiuser video communication. (Source Code)
Apache-2.0Java/deb - MiroTalk C2C - Real-time cam-2-cam video calls & screen sharing, end-to-end encrypted, to embed in any website with a simple iframe. (Source Code)
AGPL-3.0Nodejs/Docker - MiroTalk P2P - Simple, secure, fast real-time video conferences up to 4k and 60fps, compatible with all browsers and platforms. (Demo, Source Code)
AGPL-3.0Nodejs/Docker - MiroTalk SFU - Simple, secure, scalable real-time video conferences up to 4k, compatible with all browsers and platforms. (Demo, Source Code)
AGPL-3.0Nodejs/Docker - plugNmeet - Scalable and high performance web conferencing system. (Demo, Source Code)
MITDocker/Go
- BigBlueButton - Supports real-time sharing of audio, video, slides (with whiteboard controls), chat, and the screen. Instructors can engage remote students with polling, emojis, and breakout rooms. (Source Code)
-
@ a296b972:e5a7a2e8
2025-05-23 12:42:10
Was Rudolf Steiner vor gut 110 Jahren an Informationen zusammengetragen und kommentiert hat, liest sich in großen Abschnitten so, als ob es in der heutigen Zeit geschrieben worden wäre. Man trifft auf eine ganze Reihe von „guten, alten Bekannten“, die auch heute noch maßgeblich an den Strippen ziehen. Deutlich wird, dass ein Krieg nicht aus heiterem Himmel ausbricht, sondern das im Vorfeld schon Kräfte wirken, die auf einen Krieg hinarbeiten. Wie jetzt wieder im Ukraine-Krieg wird diese Vorgeschichte gerne versucht unter den Teppich zu kehren und hochkompetente, sauber recherchierende, akribisch Quellen angebende Journalisten, wie z. B. Frau Gabriele Krone-Schmalz oder Herr Patrik Baab, der sich auf eigene Kosten einen Eindruck von vor Ort verschafft hat, werden versucht mundtot zu machen und mittlerweile gar nicht mehr zu Gesprächen im öffentlich-rechtlichen Rundfunk eingeladen, weil sie die fortlaufende Gehirnwäsche des Ministeriums für Wahrheit und Narrative mit ihren Aussagen gefährden. Andere kommen auf die Sanktionsliste.
Auch heute ist von den „Guten“ und den „Bösen“ die Rede, was darauf schließen lässt, dass man durchaus eingesteht, dass hier geistige Kräfte am Werk sind. Rudolf Steiner kommt auf diese immer wieder zu sprechen. Aus der von ihm gegebenen anthroposophischen Geisteswissenschaft heraus, beleuchtet er die Vorgänge innerhalb der gesamten Menschheitsentwicklung. Mancher stört sich hier an Begriffen, die man heute so nicht mehr verwenden würde. Dabei ist immer zu berücksichtigen, zu welcher Zeit die Vorträge gehalten wurden. Die Anthroposophie von Rudolf Steiner gilt heute bei vielen auch als „umstritten“, aber was ist das heute nicht? Fast könnte man es schon als Auszeichnung sehen, wenn etwas „umstritten“ ist, denn das ist mittlerweile ein Beweis dafür, dass es Ansichten, Meinungen und Einschätzungen gibt, die in einer gesunden Demokratie innerhalb einer Kontroverse zu einem Dialog und Austausch beitragen können, der jedoch leider derzeit weder gewünscht ist, noch gepflegt wird, was an der „Spaltung“ deutlich zu sehen ist. Und auch unter den Anthroposophen hat die „Spaltung“ Einzug gehalten.
Um das aktuelle, viele Bereiche umschließende, gigantische Lügenkonstrukt aufrecht zu erhalten, ist mittlerweile jedes Mittel recht, von der Deutungshoheit der Wahrheit durch systemkonforme Begutachter, bis hin zu infantil-kleingeistigen Kindergartenspielchen, um gegenläufige Meinungen oder Oppositionelle in ihrem Wirken zu behindern.
Der gesunde Hausverstand wird ausgetrocknet, und der Garten des Wahnsinns wird durch immer neue Ideen kranker Geister weiter gegossen, gehegt und gepflegt.
Die Zeitgeschichtlichen Betrachtungen von Rudolf Steiner bestehen aus 3 Bänden aus der GA (Gesamtausgabe):
GA 173 a – Wege zu einer objektiven Urteilsbildung
GA 173 b – Das Karma der Unwahrhaftigkeit
GA 173 c – Die Wirklichkeit okkulter Impulse
Sie bestehen aus niedergeschriebenen Vorträgen und einem sehr umfangreichen Anhang mit näheren Erläuterungen und einer Schilderung der Entstehung dieser drei Bände.
Es bedarf einiger Eingewöhnung in die zur damaligen Zeit verwendete Sprache Rudolf Steiners, der ein Meister im Bilden von Schachtelsätzen war. Der Inhalt jedoch, und auf den kommt es ja an, berührt immer wieder den in allen Menschen vorhandenen Wahrheitssinn.
Hier nur eine kleine Kostprobe, die vielleicht das Interesse wecken kann, sich mit diesem derzeit besonders aktuellen Werk näher zu beschäftigen.
GA 173a, 6. Vortrag, Seite 205 und Seite 206, Dornach, 17. Dezember 1916:
„Viel intimer, viel verborgener liegen die Dinge bei der englischen Politik, die ja ganz beeinflußt ist von dem, was in solcher Weise hinter ihr steckt. Da handelt es sich darum, daß man die Wege findet, um die entsprechenden Menschen an die richtigen Plätze zu befördern. Okkultistische Menschen, im Hintergrunde stehend, sind oftmals – na, verzeihen Sie – Einser, bloße Einser, und bedeuten für sich nichts Besonderes; sie brauchen noch etwas anderes – sie brauchen Nullen. Nullen sind ja nicht Einser, aber (fügt man eine Null zu einer Eins), dann wird gleich eine Zehn daraus. Und wenn man noch mehr Nullen hinzufügt – jede Null ist nur eine Null, aber wenn die Eins irgendwo steckt, dann ist gar mancherlei da, zum Beispiel die Tausend, und wenn man die Eins zudeckt, dann sind (scheinbar) nur die Nullen da; die Nullen brauchen aber nur in der entsprechenden Weise mit den Einsern kombiniert zu sein, und sie brauchen nicht einmal viel zu wissen von der Art, wie sie mit den Einsern kombiniert sind.“
Schildert diese 108 Jahre alte Beschreibung nicht genau das, was sich heute vor unseren Augen abspielt?
Dieser Artikel wurde mit dem Pareto-Client geschrieben
* *
(Bild von pixabay)
-
@ 3bf0c63f:aefa459d
2024-03-19 14:01:01
Nostr is not decentralized nor censorship-resistant
Peter Todd has been saying this for a long time and all the time I've been thinking he is misunderstanding everything, but I guess a more charitable interpretation is that he is right.
Nostr today is indeed centralized.
Yesterday I published two harmless notes with the exact same content at the same time. In two minutes the notes had a noticeable difference in responses:
The top one was published to
wss://nostr.wine,wss://nos.lol,wss://pyramid.fiatjaf.com. The second was published to the relay where I generally publish all my notes to,wss://pyramid.fiatjaf.com, and that is announced on my NIP-05 file and on my NIP-65 relay list.A few minutes later I published that screenshot again in two identical notes to the same sets of relays, asking if people understood the implications. The difference in quantity of responses can still be seen today:
These results are skewed now by the fact that the two notes got rebroadcasted to multiple relays after some time, but the fundamental point remains.
What happened was that a huge lot more of people saw the first note compared to the second, and if Nostr was really censorship-resistant that shouldn't have happened at all.
Some people implied in the comments, with an air of obviousness, that publishing the note to "more relays" should have predictably resulted in more replies, which, again, shouldn't be the case if Nostr is really censorship-resistant.
What happens is that most people who engaged with the note are following me, in the sense that they have instructed their clients to fetch my notes on their behalf and present them in the UI, and clients are failing to do that despite me making it clear in multiple ways that my notes are to be found on
wss://pyramid.fiatjaf.com.If we were talking not about me, but about some public figure that was being censored by the State and got banned (or shadowbanned) by the 3 biggest public relays, the sad reality would be that the person would immediately get his reach reduced to ~10% of what they had before. This is not at all unlike what happened to dozens of personalities that were banned from the corporate social media platforms and then moved to other platforms -- how many of their original followers switched to these other platforms? Probably some small percentage close to 10%. In that sense Nostr today is similar to what we had before.
Peter Todd is right that if the way Nostr works is that you just subscribe to a small set of relays and expect to get everything from them then it tends to get very centralized very fast, and this is the reality today.
Peter Todd is wrong that Nostr is inherently centralized or that it needs a protocol change to become what it has always purported to be. He is in fact wrong today, because what is written above is not valid for all clients of today, and if we drive in the right direction we can successfully make Peter Todd be more and more wrong as time passes, instead of the contrary.
See also:






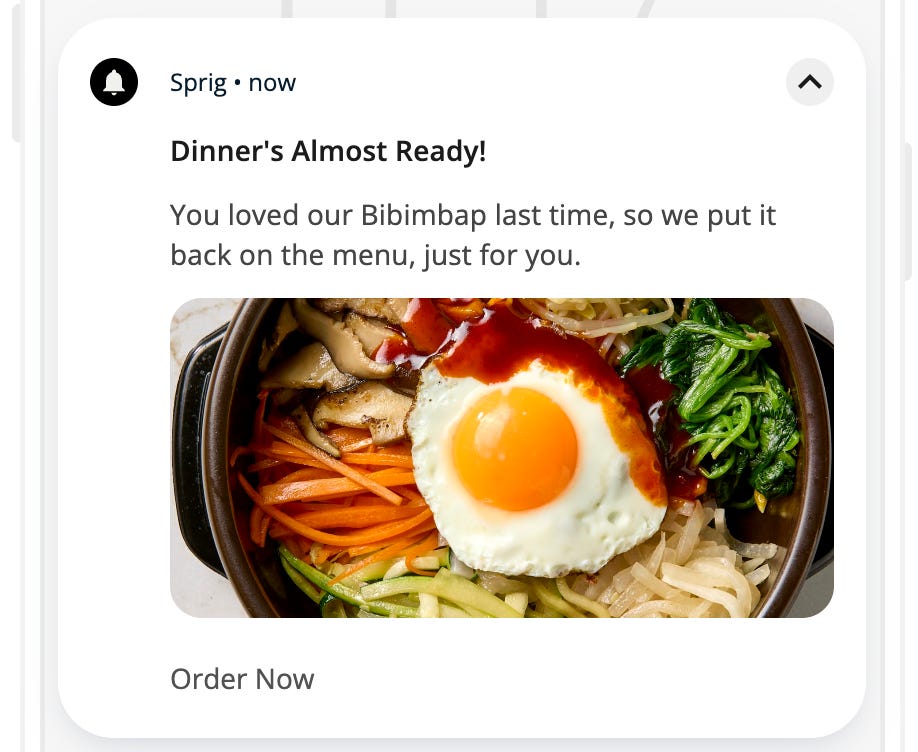{kind=link}
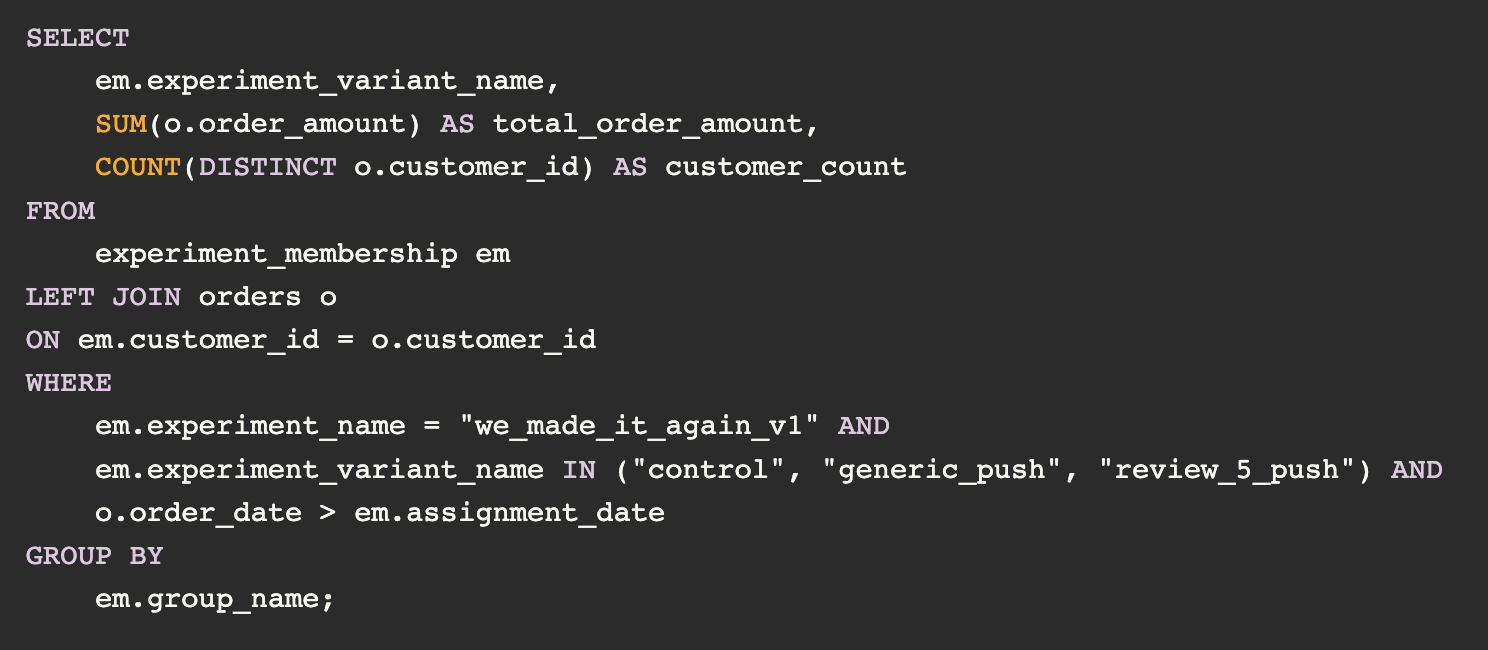{kind=link}
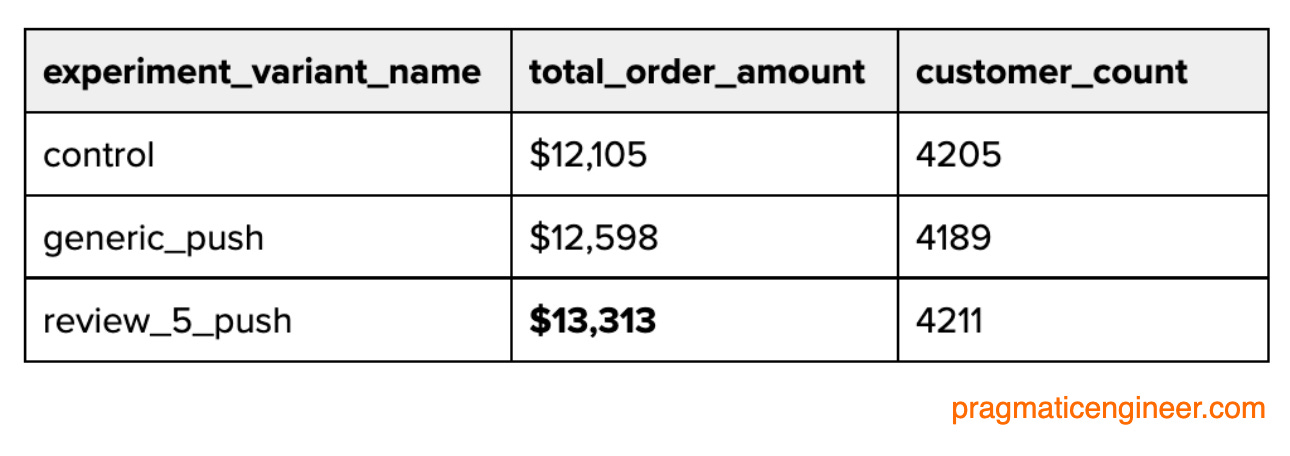{kind=link}
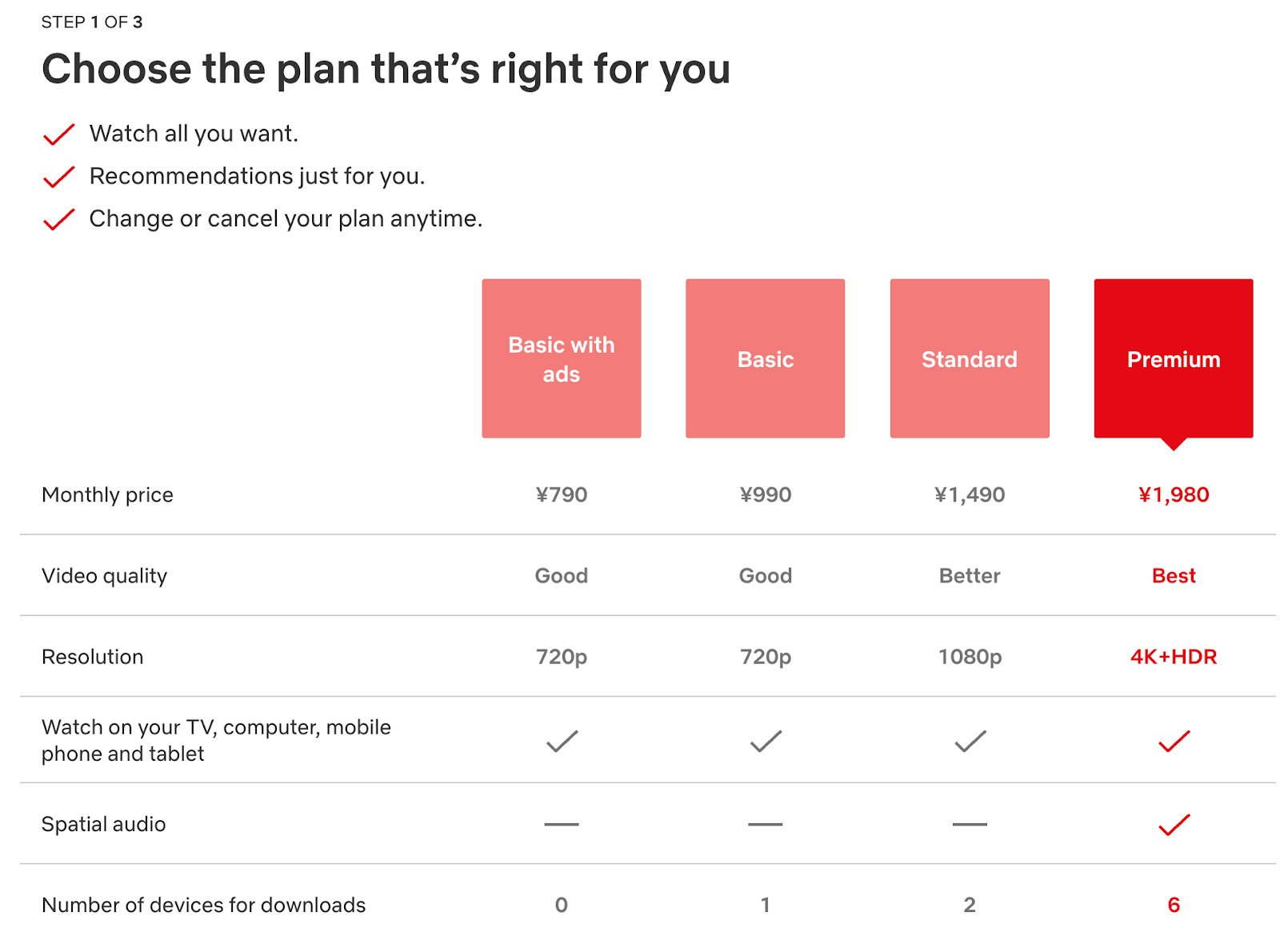{kind=link}
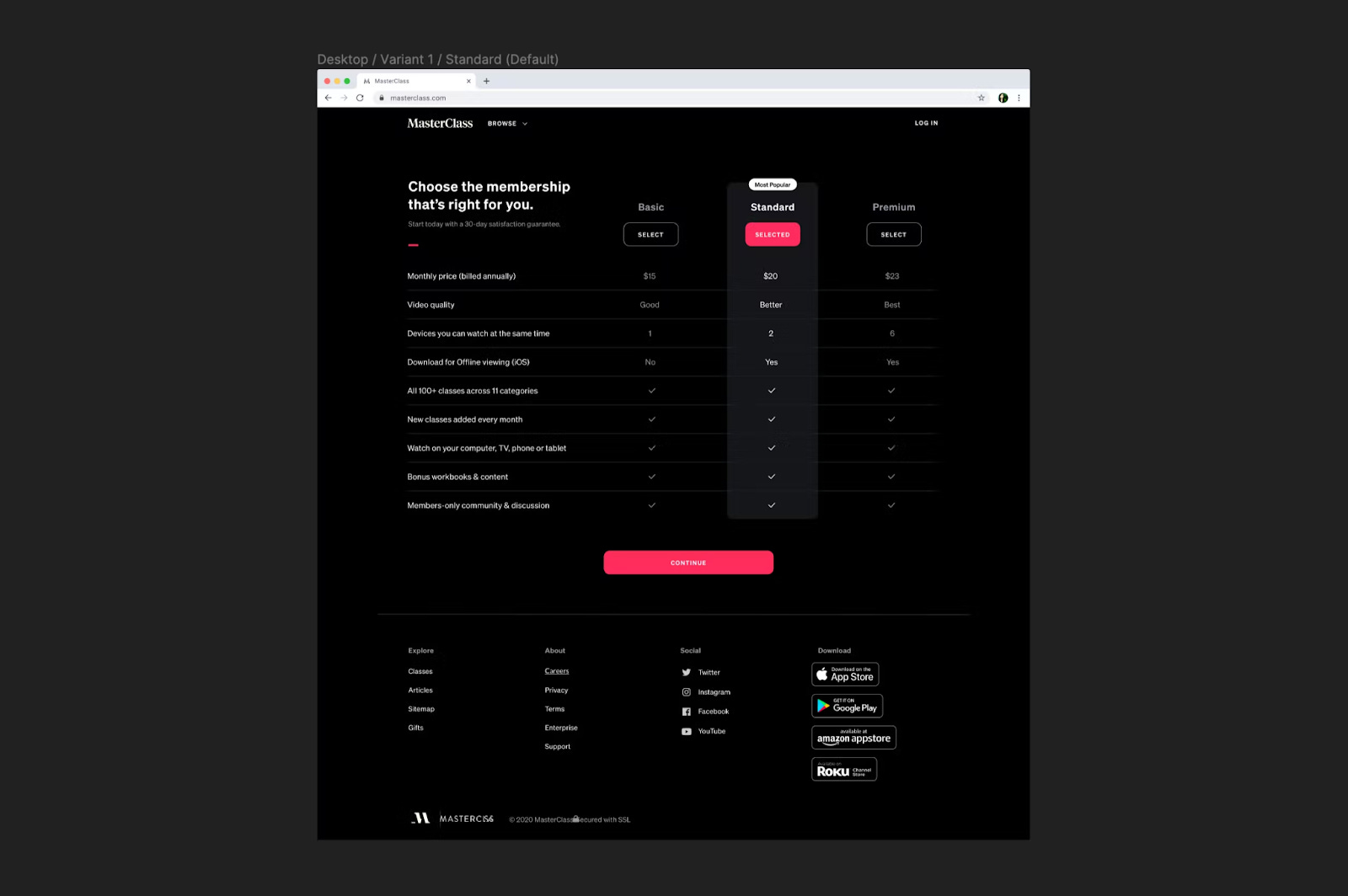{kind=link}
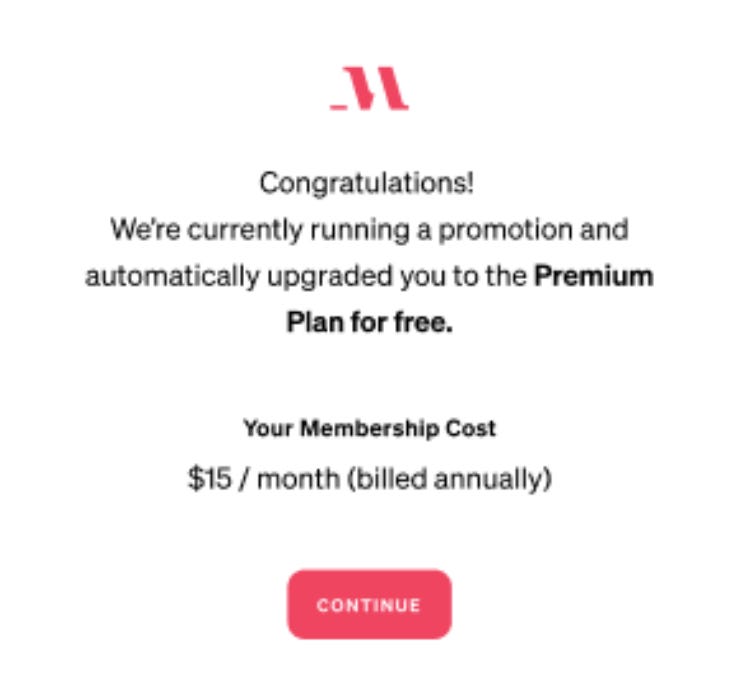{kind=link}
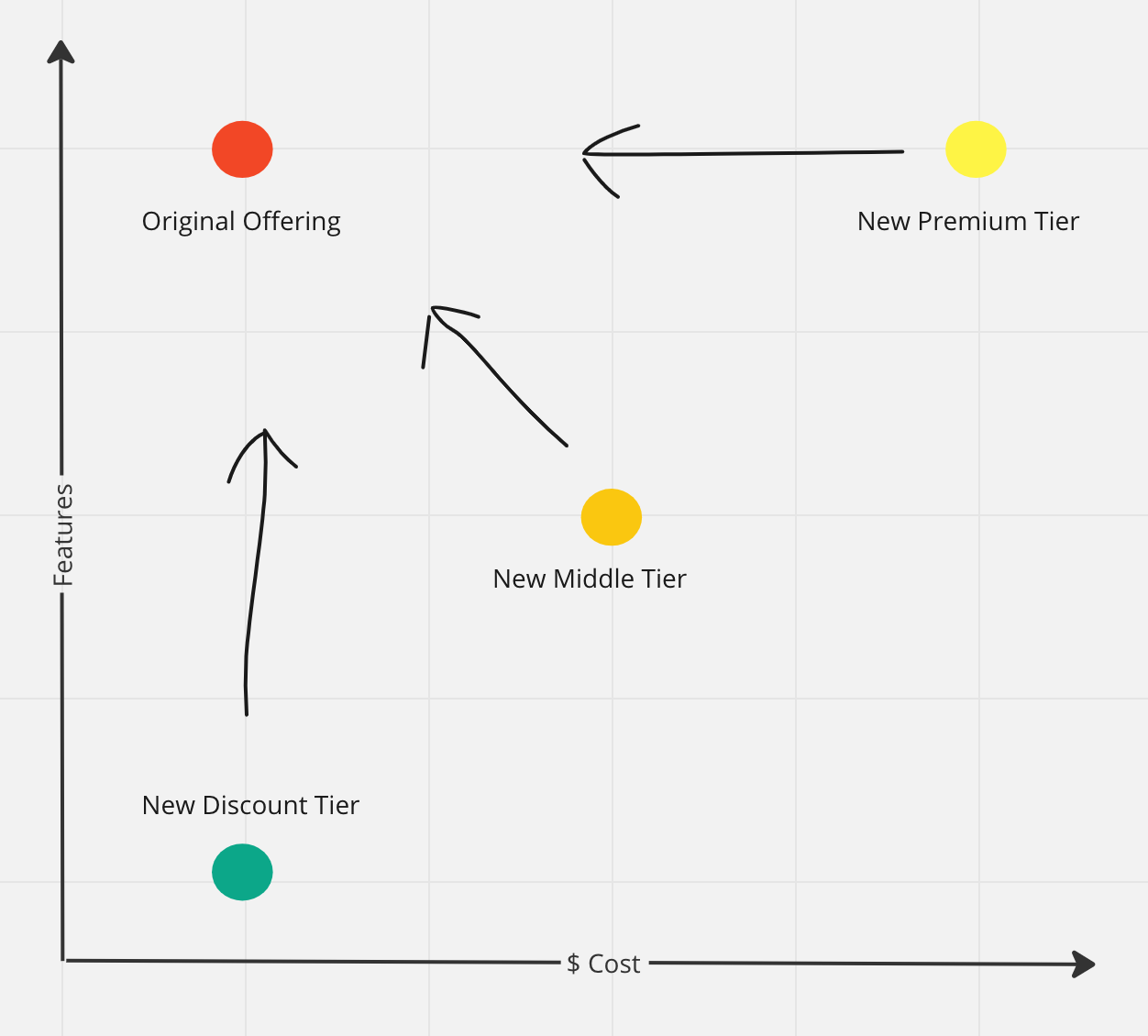{kind=link}
{kind=link}