-
 @ 4e616576:43c4fee8
2025-04-30 13:13:51
@ 4e616576:43c4fee8
2025-04-30 13:13:51asdffasdf
-
@ e096a89e:59351479
2025-04-30 12:59:28
Why Oshi?
I had another name for this brand before, but it was hard for folks to say. Then I saw a chance to tap into the #Nostr and #Bitcoin crowd, people who might vibe with what I’m creating, and I knew I needed something that’d stick.
A good name can make a difference. Well, sometimes. Take Blink-182 - it might sound odd, but it worked for them and even has a ring to it. So, why Oshi?
Names mean a lot to me, and Oshi’s got layers. I’m into Japanese culture and Bitcoin, so it fits perfectly with a few meanings baked in:
- It’s a nod to Bitcoin’s visionary, Satoshi Nakamoto.
- In Japanese, “oshi” means cheering on your favorite idol by supporting their work - think of me as the maker, you as the fan.
- It’s short for “oh shiiiitttt” - what most folks say when they taste how good this stuff is.
My goal with Oshi is to share how amazing pecans and dates can be together. Everything I make - Hodl Butter, Hodl Bars, chocolates - is crafted with intention, keeping it simple and nuanced, no overdoing it. It’s healthy snacking without the grains or junk you find in other products.
I’ve got a few bars and jars in stock now. Grab something today and taste the unique flavor for yourself. Visit my website at https://oshigood.us/
foodstr #oshigood #hodlbar #hodlbutter
-
@ 3589b793:ad53847e
2025-04-30 12:40:42
※本記事は別サービスで2022年6月24日に公開した記事の移植です。
どうも、「NostrはLNがWeb統合されマネーのインターネットプロトコルとしてのビットコインが本気出す具体行動のショーケースと見做せばOK」です、こんばんは。
またまた実験的な試みがNostrで行われているのでレポートします。本シリーズはライブ感を重視しており、例によって(?)プルリクエストなどはレビュー段階なのでご承知おきください。
今回の主役はあくまでLightningNetworkの新提案(ただし以前からあるLSATからのリブランディング)となるLightning HTTP 402 Protocol(略称: L402)です。そのショーケースの一つとしてNostrが活用されているというものになります。
Lightning HTTP 402 Protocol(略称: L402)とは何か
bLIPに今月挙がったプロポーザル内容です。
https://github.com/lightning/blips/pull/26
L402について私はまだ完全に理解した段階ではあるのですがなんとか一言で説明しようとすると「Authトークンのように"Paid"トークンをHTTPヘッダーにアタッチして有料リソースへのHTTPリクエストの受け入れ判断を行えるようにする」ものだと解釈しました。
Authenticationでは、HTTPヘッダーにAuthトークンを添付し、その検証が通ればHTTPリクエストを許可し、通らなければ
401 Unauthorizedコードをエラーとして返すように定められています。https://developer.mozilla.org/ja/docs/Web/HTTP/Status/401
L402では、同じように、HTTPヘッダーに支払い済みかどうかを示す"Paid"トークンを添付し、その検証が通ればHTTPリクエストを許可し、通らなければ
402 Payment Requiredコードをエラーとして返すようにしています。なお、"Paid"トークンという用語は私の造語となります。便宜上本記事では使わせていただきますが、実際はAuthも入ってくるのが必至ですし、プルリクエストでも用語をどう定めるかは議論になっていることをご承知おきください。("API key", "credentials", "token", らが登場しています)
この402ステータスコードは従来から定義されていましたが、MDNのドキュメントでも記載されているように「実験的」なものでした。つまり、器は用意されているがこれまで活用されてこなかったものとなり、本プロトコルの物語性を体現しているものとなります。
https://developer.mozilla.org/ja/docs/Web/HTTP/Status/402
幻であったHTTPステータスコード402 Payment Requiredを実装する
この物語性は、上述のbLIPのスペックにも詳述されていますが、以下のスライドが簡潔です。
402 Payment Requiredは予約されていましたが、けっきょくのところWorldWideWebはペイメントプロトコルを実装しなかったので、Bitcoinの登場まで待つことになった、というのが要旨になります。このWorldWideWebにおける決済機能実装に関する歴史話はクリプト界隈でもたびたび話題に上がりますが、そこを繋いでくる文脈にこれこそマネーのインターネットプロトコルだなと痺れました。https://x.com/AlyseKilleen/status/1671342634307297282
この"Paid"トークンによって実現できることとして、第一にAIエージェントがBitcoin/LNを自律的に利用できるようになるM2M(MachineToMachine)的な話が挙げられていますが、ユースケースは想像力がいろいろ要るところです。実際のところは「有料リソースへの認可」を可能にすることが主になると理解しました。本連載では、繰り返しNostrクライアントにLNプロトコルを直接搭載せずにLightningNetworkを利用可能にする組み込み方法を見てきましたが、本件もインボイス文字列 & preimage程度の露出になりアプリケーション側でノードやウォレットの実装が要らないので、その文脈で位置付ける解釈もできるかと思います。
Snortでのサンプル実装
LN組み込み業界のリーディングプロダクトであるSnortのサンプル実装では、L402を有料コンテンツの購読に活用しています。具体的には画像や動画を投稿するときに有料のロックをかける、いわゆるペイウォールの一種となります。もともとアップローダもSnortが自前で用意しているので、そこにL402を組み込んでみたということのようです。
体験方法の詳細はこちらにあります。 https://njump.me/nevent1qqswr2pshcpawk9ny5q5kcgmhak24d92qzdy98jm8xcxlgxstruecccpz4mhxue69uhhyetvv9ujuerpd46hxtnfduhszrnhwden5te0dehhxtnvdakz78pvlzg
上記を試してみた結果が以下になります。まず、ペイウォールでロックした画像がNostrに投稿されている状態です。まったくビューワーが実装されておらず、ただのNotFound状態になっていますが、支払い前なのでロックされているということです。

次にこのHTTP通信の内容です。

通信自体はエラーになっているわけですが、ステータスコードが402で、レスポンスヘッダーのWWW-AuthenticateにInvoice文字列が返ってきています。つまり、このインボイスを支払えば"Paid"トークンが付与されて、その"Paid"トークンがあれば最初の画像がアンロックされることとなります。残念ながら現在は日本で利用不可のStrikeAppでしか払込みができないためここまでとなりますが、本懐である
402 Payment Requiredとインボイス文字列は確認できました。今確認できることは以上ですが、AmethystやDamusなどの他のNostrクライアントが実装するにあたり、インラインメディアを巡ってL402の仕様をアップデートする必要性や同じくHTTPヘッダーへのAuthトークンとなるNIP-98と組み合わせるなどの議論が行われている最中です。
LinghtningNetworkであるからこそのL402の実現
"Paid"トークンを実現するためにはLightningNetworkのファイナリティが重要な要素となっています。逆に言うと、reorgによるひっくり返しがあり得るBitcoinではできなくもないけど不便なわけです。LightningNetworkなら、当事者である二者間で支払いが確認されたら「同期的」にその証であるハッシュ値を用いて"Paid"トークンを作成することができます。しかもハッシュ値を提出するだけで台帳などで過去の履歴を確認する必要がありません。加えて言うと、受金者側が複数のノードを建てていて支払いを受け取るノードがどれか一つになる状況でも、つまり、スケーリングされている状況でも、"Paid"トークンそのものはどのノードかを気にすることなくステートレスで利用できるとのことです。(ここは単にreverse proxyとしてAuthサーバががんばっているだけと解釈することもできますがずいぶんこの機能にも力点を置いていて大規模なユースケースが重要になっているのだなという印象を抱きました)
Macaroonの本領発揮か?それとも詳細定義しすぎか?
HTTP通信ではWWW-Authenticateの実値にmacaroonの記述が確認できます。また現在のL402スペックでも"Paid"トークンにはmacaroonの利用が前提になっています。
このmacaroonとは(たぶん)googleで研究開発され、LNDノードソフトウェアで活用されているCookieを超えるという触れ込みのデータストアになります。しかし、あまり普及しなかった技術でもあり、個人の感想ですがなんとも微妙なものになっています。
https://research.google/pubs/macaroons-cookies-with-contextual-caveats-for-decentralized-authorization-in-the-cloud/
macaroonの強みは、Cookieを超えるという触れ込みのようにブラウザが無くてもプロセス間通信でデータ共有できる点に加えて、HMACチェーンで動的に認証認可を更新し続けられるところが挙げられます。しかし、そのようなユースケースがあまり無く、静的な認可となるOAuthやJWTで十分となっているのが現状かと思います。
L402では、macaroonの動的な更新が可能である点を活かして、"Paid"トークンを更新するケースが挙げられています。わかりやすいのは上記のスライド資料でも挙げられている"Dynamic Pricing"でしょうか。プロポーザルではloop©️LightningLabsにおいて月間の最大取引量を認可する"Paid"トークンを発行した上でその条件を動向に応じて動的に変更できる例が解説されています。とはいえ、そんなことしなくても再発行すればええやんけという話もなくもないですし、プルリクエストでも仕様レベルでmacaroonを指定するのは「具体」が過ぎるのではないか、もっと「抽象」し単なる"Opaque Token"程度の粒度にして他の実装も許容するべきではないか、という然るべきツッコミが入っています。
個人的にはそのツッコミが妥当と思いつつも、なんだかんだ初めてmacaroonの良さを実感できて感心した次第です。
-
@ 3589b793:ad53847e
2025-04-30 12:28:25
※本記事は別サービスで2023年4月19日に公開した記事の移植です。
どうも、「NostrはLNがWeb統合されマネーのインターネットプロトコルとしてのビットコインが本気出す具体行動のショーケースと見做せばOK」です、こんにちは。
前回まで投げ銭や有料購読の組み込み方法を見てきました。
zapsという投げ銭機能が各種クライアントに一通り実装されて活用が進んでいることで、統合は次の段階へ移り始めています。「作戦名: ウォレットをNostrクライアントに組み込め」です。今回はそちらをまとめます。
投げ銭する毎にいちいちウォレットを開いてまた元のNostrクライアントに手動で戻らないといけない is PAIN
LNとNostrはインボイス文字列で繋がっているだけの疎結合ですが、投稿に投げ銭するためには何かのLNウォレットを開いて支払いをして、また元のNostrクライアントに戻る操作をユーザーが手作業でする必要があります。お試しで一回やる程度では気になりませんが普段使いしているとこれはけっこうな煩わしさを感じるUXです。特にスマホでは大変にだるい状況になります。連打できない!
2月の実装以来、zapsは順調に定着して日々投げられています。


https://stats.nostr.band/#daily_zaps
なので、NostrクライアントにLNウォレットの接続を組み込み、支払いのために他のアプリに遷移せずにNostクライアント単独で完結できるようなアップデートが始まっています。
Webクライアント
NostrのLN組み込み業界のリーディングプレイヤーであるSnortでの例です。以下のようにヘッダーのウォレットアイコンをクリックすると連携ウォレットの選択ができます。

もともとNostrに限らずウェブアプリケーションとの連携をするために、WebLNという規格があります。簡単に言うと、ブラウザのグローバル領域を介して、LNウォレットの拡張機能と、タブで開いているウェブアプリが、お互いに連携するためのインターフェースを定めているものです。これに対応していると、LNによる支払いをウェブアプリが拡張機能に依頼できるようになります。さらにオプションで「確認無し」をオンにすると、拡張機能画面がポップアップせずにバックグラウンドで実行できるようになり、ノールック投げ銭ができるようになります。
似たようなものにNostrではNIP-07があります。NIP-07はNostrの秘密鍵を拡張機能に退避して、Nostrクライアントは秘密鍵を知らない状態で署名や複合を拡張機能に移譲できるようにしているものです。
Albyの拡張機能ではWebLNとNIP-07のどちらにも対応しています。
実はSnortはzapsが来る前からWebLNには対応していたのですが、さらに一歩進み、拡張機能ウォレットだけでなく、LNノードや拡張機能以外のLNウォレットと連携設定できるようになってきています。

umbrelなどでノードを立てている人ならLND with LNCでノードと直接繋げます。またLNDHubに対応したウォレットなどのアプリケーションとも繋げます。これらの接続は、WebLNにラップされて拡張機能ウォレットとインターフェースを揃えられた上で、Snort上でのインボイスの支払いに活用されます。
なお、LNCのpairingPhrase/passwordやLNDHubの接続情報などのクレデンシャルは、ブラウザのローカルストレージに保存されています。Nostrのリレーサーバなどには送られませんので、端末ごとに設定が必要です。
スマホアプリ
今回のメインです。なお、例によって(?)スペックは絶賛議論中でまだフィックスしていない中で記事を書いています。ディテールは変わるかもしれないので悪しからずです。
スマホアプリで上記のことをやるためには、後半のLNCやLNDHubはすでにzeusなどがやっているようにできますが、あくまでネイティブウォレットのラッパーです。Nostrでは限られた用途になるので1-click支払いのようなものを行うためにはそこから各スマホアプリが作り込む必要があります。まあこれはこれでやればいいという話でもあるのですが、LNノードやLNウォレットのアプリケーション側へのインターフェースの共通仕様は定められていないので、LNDとcore-lightningとeclairではすべて実装方法が違いますし、ウォレットもバラバラなので大変です。
そこで、多種多様なノードやウォレットの接続を取りまとめ一般アプリケーションへ統一したインターフェースを媒介するLN Adapter業界のリーディングカンパニーであるAlbyが動きました。AndroidアプリのAmethystで試験公開されていますが、スマホアプリでも上記のSnortのような連携が可能になるようなSDKが開発されました。
リリース記事 https://blog.getalby.com/native-zapping-in-amethyst/
"Unstoppable zapping for users"なんて段落見出しが付けられているように、スマホで別のアプリに切り替えてまた元に戻らなくても良いようにして、Nostr上でマイクロペイメントを滑らかにする、つまり、連打できることを繰り返し強調しています。
具体的にやっていることを見ていきます。以下の画像群はリリース記事の動画から抜粋しています。各投稿のzapsボタン⚡️をタップしたときの画面です。

上の赤枠が従来の投げ銭の詳細を決める場所で、下の赤枠の「Wallet Connect Service」が新たに追加されたAlby提供のSDKを用いたコネクト設定画面です。基本的にはOAuth2.0ベースのAlbyのAPIを活用していて、右上のAlbyアイコンをタップすると以下のようなOAuthの認可画面に飛びます。(ただし後述するように通常のOAuthとは一部異なります。)


画面デザインは違いますが、まあ他のアプリでよく目にするTwitter連携やGoogleアカウント連携とやっていることは同じです。
このOAuthベースのAPIはNostr専用のエンドポイントが建てられています。Nostr以外のECショップやマーケットプレイスなどへのAlbyのOAuthは汎用のエンドポイントが用意されています。よって通常のAlbyの設定とは別にセッション詳細を以下のサイトで作成する必要があります。
https://nwc.getalby.com/ (サブドメインのnwcはNostr Wallet Connectの略)
なぜNostrだけは特別なのかというところが完全には理解しきれていないですが、以下のところまで確認できています。一番にあるのは、Nostrクライアントにウォレットを組み込まずに、かつ、ノードやウォレットへの接続をNostrリレーサーバ以外は挟まずに"decentralized"にしたいというところだと理解しています。
- 上記のnwcのURLはalbyのカストディアルウォレットusername@getalby.comをNostrに繋ぐもの(たぶん)
- umbrelのLNノードを繋ぐためにはやはり専用のアプリがumbrelストアに上がっている。https://github.com/getAlby/umbrel-community-app-store
- 要するにOAuthの1stPartyの役割をウォレットやノードごとにそれぞれ建てる。
- OAuthのシークレットはクライアントに保存するので設定は各クライアント毎に必要。しかし使い回しすることは可能っぽい。通常のOAuthと異なり、1stParty側で3rdPartyのドメインはトラストしていないようなので。
- Nostrクライアントにウォレットを組み込まずに、さらにウォレットやノードへの接続をNostrリレーサーバ以外には挟まなくて良いようにするために、「NIP-47 Nostr Wallet Connect」というプロポーザルが起こされていて、絶賛議論中である。https://github.com/nostr-protocol/nips/pull/406
- このWallet Connect専用のアドホックなリレーサーバが建てられる。その情報が上記画像の赤枠の「Wallet Connect Service」の下半分のpub keyやらrelayURL。どうもNostrクライアントはNIP-47イベントについてはこのリレーサーバにしか送らないようにするらしい。(なんかNostrの基本設計を揺るがすユースケースの気がする...)
- Wallet Connect専用のNostrイベントでは、ペイメント情報をNostrアカウントと切り離すために、Nostrの秘密鍵とは別の秘密鍵が利用できるようにしている。
Imagin the Future
今回取り上げたNostrクライアントにウォレット接続を組み込む話を、Webのペイメントの歴史で類推してみましょう。
Snortでやっていることは、各サイトごとにクレジットカードを打ち込み各サイトがその情報を保持していたようなWeb1.0の時代に近いです。そうなるとクレジットカードの情報は各サービスごとに漏洩リスクなどがあり、Web1.0の時代はECが普及する壁の一つになっていました。(今でもAmazonなどの大手はそうですが)
Webではその後にPayPalをはじめとして、銀行口座やクレジットカードを各サイトから切り出して一括管理し、各ウェブサイトに支払いだけを連携するサービスが出てきて一般化しています。日本ではケータイのキャリア決済が利用者の心理的障壁を取り除きEC普及の後押しになりました。
後半のNostr Wallet ConnectはそれをNostrの中でやろうとしている試みになります。クレジットカードからLNに変える理由はビットコインの話になるので詳細は割愛しますが、現実世界の金(ゴールド)に類した価値保存や交換ができるインターネットマネーだからです。
とはいえ、Nostrの中だけならまだしも、これをNostr外のサービスで利用するためには、他のECショップやブログやSaaSがNostrを喋れる必要があります。そんな未来が来るわけないだろと思うかもしれませんが、言ってみればStripeはまさにそのようなサービスとなっていて、サイト内にクレジット決済のモジュールを組み込むための主流となっています。
果たして、Nostrを、他のECショップやブログやSaaSが喋るようになるのか!?
以上、「NostrはLNがWeb統合されマネーのインターネットプロトコルとしてのビットコインが本気出す具体行動のショーケースと見做せばOK」がお送りしました。
-
@ 3589b793:ad53847e
2025-04-30 12:10:06
前回の続きです。
特に「Snortで試験的にノート単位に投げ銭できる機能」について。実は記事書いた直後にリリースされて慌ててw追記してたんですが追い付かないということで別記事にしました。
今回のここがすごい!
「Snortで試験的にノート単位に投げ銭できる機能」では一つブレイクスルーが起こっています。それは「ウォレットにインボイスを放り投げた後に払い込み完了を提示できる」ようになったことです。これによりペイメントのライフサイクルが一通りカバーされたことになります。
Snortの画面

なにを当たり前のことをという向きもあるかもしれませんが、Nostrクライアントで払い込み完了を追跡することはとても難しいです。基本的にNostrとLNウォレットはまったく別のアプリケーションで両者の間を繋ぐのはインボイス文字列だけです。ウォレットもNostrからキックされずに、インボイス文字列をコピペするなりQRコードで読み取ったものを渡されるだけかもしれません。またその場でリアルタイムに処理される前提もありません。
なのでNostrクライアントでその後をトラックすることは難しく、これまではあくまで請求書を送付したり(LNインボイス)振り込み口座を提示する(LNアドレス)という一方的に放り投げてただけだったわけです。といっても魔法のようにNostrクライアントがトラックできるようになったわけではなく、今回の対応方法もインボイスを発行/お金を振り込まれるサービス側(LNURL)にNostrカスタマイズを入れさせるというものになります。
プロポーザルの概要について
前回の記事ではよくわからんで終わっていましたが、当日夜(日本時間)にスペックをまとめたプロポーザルも起こされました(早い!)。LNURLが、Nostr用のインボイスを発行して、さらにNostrイベントの発行を行っていることがポイントでした。名称は"Lightning Zaps"で確定のようです。プロポーザルは、NostrとLNURLの双方の発明者であるfiatjaf氏からツッコミが入り、またそれが妥当な指摘のために、エンドポイントURLのインターフェースなどは変わりそうなのですが、概要はそう変わらないだろうということで簡単にまとめてみます。
全体の流れ

図は、Nostrクライアント上に提示されているLNアドレスへ投げ銭が開始してから、Nostrクライアント上に払い込み完了したイベントが表示されるまでの流れを示しています。
- 投げ銭の内容が固まったらNostrイベントデータを添付してインボイスの発行を依頼する
- 説明欄にNostr用のデータを記載したインボイスを発行して返却する
- Nostrクライアントで提示されたインボイスをユーザーが何かしらの手段でウォレットに渡す
- ウォレットがLNに支払いを実行する
- インボイスの発行者であるLNURLが管理しているLNノードにsatoshiが届く
- LNURLサーバが投げ銭成功のNostrイベントを発行する
- Nostrクライアントがイベントを受信して投げ銭履歴を表示する
特にポイントとなるところを補足します。
対応しているLNアドレスの識別
LNアドレスに投げ銭する場合は、LNアドレスの有効状態やインボイス発行依頼する先の情報を
https://[domain]/.well-known/lnurlp/[username]から取得しています。そのレスポンス内容にNostr対応を示す情報を追加しています。ただし、ここに突っ込み入っていてlnurlp=LNURL Payから独立させるためにzaps専用のエンドポイントに変わりそうです。(2/15 追記 マージされましたが変更無しでした。PRのディスカッションが盛り上がっているので興味ある方は覗いてみてください。)インボイスの説明欄に書き込むNostrイベント(kind:9734)
これは投げ銭する側のNostrイベントです。投げ銭される者や対象ノートのIDや金額、そしてこのイベントを作成している者が投げ銭したということを「表明」するものになります。表明であって証明でないところは、インボイスを別の人が払っちゃう事態がありえるからですね。この内容をエンクリプトするパターンも用意されていたが複雑になり過ぎるという理由で今回は外され追加提案に回されました。また、このイベントはデータを作成しただけです。支払いを検知した後にLNURLが発行するイベントに添付されることになります。そのため投げ銭する者にちゃんと届くように作成者のリレーサーバリストも書き込まれています。
支払いを検知した後に発行するNostrイベント(kind:9735)
これが実際にNostrリレーサーバに発行されるイベントです。LNURL側はウォッチしているLNノードにsatoshiが届くと、インボイスの説明欄に書かれているNostrイベントを取り出して、いわば受領イベントを作成して発行します。以下のようにNostイベントのkind:9734とkind:9735が親子になったイベントとなります。
json { "pubkey": "LNURLが持っているNostrアカウントの公開鍵", "kind": 9735, "tags": [ [ "p", "投げ銭された者の公開鍵" ], [ "bolt11", "インボイスの文字列lnbc〜" ], [ "description", "投げ銭した者が作成したkind:9734のNostrイベント" ], [ "preimage", "インボイスのpreimage" ] ], }所感
とにかくNostrクライアントはLNノードを持たないしLNプロトコルとも直接喋らずにインボイス文字列だけで取り扱えるようになっているところがおもしろいと思っています。NostrとLNという二つのデセントライズドなオープンプロトコルが協調できていますし、前回も述べましたがどんなアプリでも簡単に真似できます。
とはいえ、さすがに払込完了のトラックは難しく、今回はLNURL側にそのすり合わせの責務が寄せられることになりました。しかし、LNURLもLNの上に作られたオープンプロトコル/スペックの位置付けになるため、他のLNURLのスペックに干渉するという懸念から、本提案のNIP-57に変更依頼が出されています。LN、LNURL、Nostrの3つのオープンプロトコルの責務分担が難しいですね。アーキテクチャ層のスタックにおいて3つの中ではNostrが一番上になるため、Nostrに相当するレイヤーの他のwebサービスでやるときはLNプロトコルを喋るなりLNノードを持つようにして、今回LNURLが寄せられた責務を吸収するのが無難かもしれません。
また、NIP-57の変更依頼理由の一つにはBOLT-12を見越した抽象化も挙げられています。他のLNURLのスペックを削ぎ落としてzapsだけにすることでBOLT-12にも載りやすくなるだろうと。LNURLの多くはBOLT-12に取り込まれる運命なわけですが、LNアドレス以外の点でもNostrではBOLT-12のOfferやInvoiceRequestのユースケースをやりたいという声が挙がっているため、NostrによりBOLT-12が進む展開もありそうだなあ、あってほしい。
-
@ fd0bcf8c:521f98c0
2025-04-29 13:38:49
The vag' sits on the edge of the highway, broken, hungry. Overhead flies a transcontinental plane filled with highly paid executives. The upper class has taken to the air, the lower class to the roads: there is no longer any bond between them, they are two nations."—The Sovereign Individual
Fire
I was talking to a friend last night. Coffee in hand. Watching flames consume branches. Spring night on his porch.
He believed in America's happy ending. Debt would vanish. Inflation would cool. Manufacturing would return. Good guys win.
I nodded. I wanted to believe.
He leaned forward, toward the flame. I sat back, watching both fire and sky.
His military photos hung inside. Service medals displayed. Patriotism bone-deep.
The pendulum clock on his porch wall swung steadily. Tick. Tock. Measuring moments. Marking epochs.
History tells another story. Not tragic. Just true.
Our time has come. America cut off couldn't compete. Factories sit empty. Supply chains span oceans. Skills lack. Children lag behind. Rebuilding takes decades.
Truth hurts. Truth frees.
Cycles
History moves in waves. Every 500 years, power shifts. Systems fall. Systems rise.
500 BC - Greek coins changed everything. Markets flourished. Athens dominated.
1 AD - Rome ruled commerce. One currency. Endless roads. Bustling ports.
500 AD - Rome faded. Not overnight. Slowly. Trade withered. Cities emptied. Money debased. Roads crumbled. Local strongmen rose. Peasants sought protection. Feudalism emerged.
People still lived. Still worked. Horizons narrowed. Knowledge concentrated. Most barely survived. Rich adapted. Poor suffered.
Self-reliance determined survival. Those growing food endured. Those making essential goods continued. Those dependent on imperial systems suffered most.
1000 AD - Medieval revival began. Venice dominated seas. China printed money. Cathedrals rose. Universities formed.
1500 AD - Europeans sailed everywhere. Spanish silver flowed. Banks financed kingdoms. Companies colonized continents. Power moved west.
The pendulum swung. East to West. West to East. Civilizations rose. Civilizations fell.
2000 AD - Pattern repeats. America strains. Digital networks expand. China rises. Debt swells. Old systems break.
We stand at the hinge.
Warnings
Signs everywhere. Dollar weakens globally. BRICS builds alternatives. Yuan buys oil. Factories rust. Debt exceeds GDP. Interest consumes budgets.
Bridges crumble. Education falters. Politicians chase votes. We consume. We borrow.
Rome fell gradually. Citizens barely noticed. Taxes increased. Currency devalued. Military weakened. Services decayed. Life hardened by degrees.
East Rome adapted. Survived centuries. West fragmented. Trade shrank. Some thrived. Others suffered. Life changed permanently.
Those who could feed themselves survived best. Those who needed the system suffered worst.
Pendulum
My friend poured another coffee. The burn pile popped loudly. Sparks flew upward like dying stars.
His face changed as facts accumulated. Military man. Trained to assess threats. Detect weaknesses.
He stared at the fire. National glory reduced to embers. Something shifted in his expression. Recognition.
His fingers tightened around his mug. Knuckles white. Eyes fixed on dying flames.
I traced the horizon instead. Observing landscape. Noting the contrast.
He touched the flag on his t-shirt. I adjusted my plain gray one.
The unpayable debt. The crumbling infrastructure. The forgotten manufacturing. The dependent supply chains. The devaluing currency.
The pendulum clock ticked. Relentless. Indifferent to empires.
His eyes said what his patriotism couldn't voice. Something fundamental breaking.
I'd seen this coming. Years traveling showed me. Different systems. Different values. American exceptionalism viewed from outside.
Pragmatism replaced my old idealism. See things as they are. Not as wished.
The logs shifted. Flames reached higher. Then lower. The cycle of fire.
Divergence
Society always splits during shifts.
Some adapt. Some don't.
Printing arrived. Scribes starved. Publishers thrived. Information accelerated. Readers multiplied. Ideas spread. Adapters prospered.
Steam engines came. Weavers died. Factory owners flourished. Villages emptied. Cities grew. Coal replaced farms. Railways replaced wagons. New skills meant survival.
Computers transformed everything. Typewriters vanished. Software boomed. Data replaced paper. Networks replaced cabinets. Programmers replaced typists. Digital skills determined success.
The self-reliant thrived in each transition. Those waiting for rescue fell behind.
Now AI reshapes creativity. Some artists resist. Some harness it. Gap widens daily.
Bitcoin offers refuge. Critics mock. Adopters build wealth. The distance grows.
Remote work redraws maps. Office-bound struggle. Location-free flourish.
The pendulum swings. Power shifts. Some rise with it. Some fall against it.
Two societies emerge. Adaptive. Resistant. Prepared. Pretending.
Advantage
Early adapters win. Not through genius. Through action.
First printers built empires. First factories created dynasties. First websites became giants.
Bitcoin followed this pattern. Laptop miners became millionaires. Early buyers became legends.
Critics repeat themselves: "Too volatile." "No value." "Government ban coming."
Doubters doubt. Builders build. Gap widens.
Self-reliance accelerates adaptation. No permission needed. No consensus required. Act. Learn. Build.
The burn pile flames like empire's glory. Bright. Consuming. Temporary.
Blindness
Our brains see tigers. Not economic shifts.
We panic at headlines. We ignore decades-long trends.
We notice market drops. We miss debt cycles.
We debate tweets. We ignore revolutions.
Not weakness. Just humanity. Foresight requires work. Study. Thought.
Self-reliant thinking means seeing clearly. No comforting lies. No pleasing narratives. Just reality.
The clock pendulum swings. Time passes regardless of observation.
Action
Empires fall. Families need security. Children need futures. Lives need meaning.
You can adapt faster than nations.
Assess honestly. What skills matter now? What preserves wealth? Who helps when needed?
Never stop learning. Factory workers learned code. Taxi drivers joined apps. Photographers went digital.
Diversify globally. No country owns tomorrow. Learn languages. Make connections. Stay mobile.
Protect your money. Dying empires debase currencies. Romans kept gold. Bitcoin offers similar shelter.
Build resilience. Grow food. Make energy. Stay strong. Keep friends. Read old books. Some things never change.
Self-reliance matters most. Can you feed yourself? Can you fix things? Can you solve problems? Can you create value without systems?
Movement
Humans were nomads first. Settlers second. Movement in our blood.
Our ancestors followed herds. Sought better lands. Survival meant mobility.
The pendulum swings here too. Nomad to farmer. City-dweller to digital nomad.
Rome fixed people to land. Feudalism bound serfs to soil. Nations created borders. Companies demanded presence.
Now technology breaks chains. Work happens anywhere. Knowledge flows everywhere.
The rebuild America seeks requires fixed positions. Factory workers. Taxpaying citizens in permanent homes.
But technology enables escape. Remote work. Digital currencies. Borderless businesses.
The self-reliant understand mobility as freedom. One location means one set of rules. One economy. One fate.
Many locations mean options. Taxes become predatory? Leave. Opportunities disappear? Find new ones.
Patriotism celebrates roots. Wisdom remembers wings.
My friend's boots dug into his soil. Planted. Territorial. Defending.
My Chucks rested lightly. Ready. Adaptable. Departing.
His toolshed held equipment to maintain boundaries. Fences. Hedges. Property lines.
My backpack contained tools for crossing them. Chargers. Adapters. Currency.
The burn pile flame flickers. Fixed in place. The spark flies free. Movement its nature.
During Rome's decline, the mobile survived best. Merchants crossing borders. Scholars seeking patrons. Those tied to crumbling systems suffered most.
Location independence means personal resilience. Economic downturns become geographic choices. Political oppression becomes optional suffering.
Technology shrinks distance. Digital work. Video relationships. Online learning.
Self-sovereignty requires mobility. The option to walk away. The freedom to arrive elsewhere.
Two more worlds diverge. The rooted. The mobile. The fixed. The fluid. The loyal. The free.
Hope
Not decline. Transition. Painful but temporary.
America may weaken. Humanity advances. Technology multiplies possibilities. Poverty falls. Knowledge grows.
Falling empires see doom. Rising ones see opportunity. Both miss half the picture.
Every shift brings destruction and creation. Rome fell. Europe struggled. Farms produced less. Cities shrank. Trade broke down.
Yet innovation continued. Water mills appeared. New plows emerged. Monks preserved books. New systems evolved.
Different doesn't mean worse for everyone.
Some industries die. Others birth. Some regions fade. Others bloom. Some skills become useless. Others become gold.
The self-reliant thrive in any world. They adapt. They build. They serve. They create.
Choose your role. Nostalgia or building.
The pendulum swings. East rises again. The cycle continues.
Fading
The burn pile dimmed. Embers fading. Night air cooling.
My friend's shoulders changed. Tension releasing. Something accepted.
His patriotism remained. His illusions departed.
The pendulum clock ticked steadily. Measuring more than minutes. Measuring eras.
Two coffee cups. His: military-themed, old and chipped but cherished. Mine: plain porcelain, new and unmarked.
His eyes remained on smoldering embers. Mine moved between him and the darkening trees.
His calendar marked local town meetings. Mine tracked travel dates.
The last flame flickered out. Spring peepers filled the silence.
In darkness, we watched smoke rise. The world changing. New choices ahead.
No empire lasts forever. No comfort in denial. Only clarity in acceptance.
Self-reliance the ancient answer. Build your skills. Secure your resources. Strengthen your body. Feed your mind. Help your neighbors.
The burn pile turned to ash. Empire's glory extinguished.
He stood facing his land. I faced the road.
A nod between us. Respect across division. Different strategies for the same storm.
He turned toward his home. I toward my vehicle.
The pendulum continued swinging. Power flowing east once more. Five centuries ending. Five centuries beginning.
"Bear in mind that everything that exists is already fraying at the edges." — Marcus Aurelius
Tomorrow depends not on nations. On us.
-
@ 3589b793:ad53847e
2025-04-30 12:02:13
※本記事は別サービスで2023年2月5日に公開した記事の移植です。
Nostrクライアントは多種ありますがメジャーなものはだいたいLNの支払いが用意されています。現時点でどんな組み込み方法になっているか調べました。この記事では主にSnortを対象にしています。
LN活用場面
大きくLNアドレスとLNインボイスの2つの形式があります。
1. LNアドレスで投げ銭をセットできる

LNURLのLNアドレスをセットすると、プロフィールやノート(ツイートに相当)からLN支払いができます。別クライアントのastralなどではプリミティブなLNURLの投げ銭形式
lnurl1dp68~でもセットできます。[追記]さらに本日、Snortで試験的にノート単位に投げ銭できる機能が追加されています。

2. LNインボイスが投稿できる

投稿でLNインボイスを貼り付ければ上記のように他の発言と同じようにタイムラインに流れます。Payボタンを押すと各自の端末にあるLNウォレットが立ち上がります。
3. DMでLNインボイスを送る
メッセージにLNインボイスが組み込まれているという点では2とほぼ同じですが、ユースケースが異なります。発表されたばかりですがリレーサーバの有料化が始まっていて、その決済をDMにLNインボイスを送付して行うことが試されています。2だとパブリックに投稿されますが、こちらはプライベートなので購入希望者のみにLNインボイスを届けられます。

おまけ: Nostrのユーザ名をLNアドレスと同じにする
直接は関係ないですが、Nostrはユーザー名をemail形式にすることができます。LNアドレスも自分でドメイン取って作れるのでNostrのユーザー名と投げ銭のアドレスを同じにできます。
LNウォレットのAlbyのドメインをNostrのユーザ名にも活用している様子 [Not found]
実装方法
LNアドレスもLNインボイスも非常にシンプルな話ですが軽くまとめます。 Snortリポジトリ
LNアドレス
- セットされたLNアドレスを分解して
https://[domain]/.well-known/lnurlp/[username]にリクエストする - 成功したら投げ銭量を決めるUIを提示する
- Get Inoviceボタンを押したら1のレスポンスにあるcallbackにリクエストしてインボイスを取得する
- 成功したらPayボタンを提示する
LNインボイス
- 投稿内容がLNインボイス識別子
lnbc10m〜だとわかると、識別子の中の文字列から情報(金額、説明、有効期限)を取り出し、表示用のUIを作成する - 有効期限内だったらPayボタンを提示し、期限が切れていたらExpiredでロックする
支払い
Payボタンを押された後の動きはアドレス、インボイスとも同じです。
- ブラウザでWebLN(Albyなど)がセットされていて、window.weblnオブジェクトがenableになっていると、拡張機能の支払い画面が立ち上がる。クライアント側で支払い成功をキャッチすることも可能。
- Open Walletボタンを押すと
lightning:lnbc10m~のURI形式でwindow.openされ、Mac/Windows/iPhone/Androidなど各OSに応じたアプリケーション呼び出しが行われ、URIに対応しているLNウォレットが立ち上がる
[追記]ノート単位の投げ銭
Snort周辺の数人(strike社員っぽい人が一人いて本件のメイン実装している)で試験的にやっているようで現時点では実装レベルでしか詳細わかりませんでした。strikeのzapといまいち区別が付かなかったのですが、実装を見るとnostrプロトコルにzapイベントが追加されています。ソースコメントではこの後NIP(nostr improvement proposal)が起こされるようでかなりハッキーです。zap=tipの方言なんでしょうか?
ノートやプロフィールやリアクションなどに加えて新たにnostrイベントに追加しているものは以下2つです。
- zapRequest 投げ銭した側が対象イベントIDと量を記録する
- zapReceipt 投げ銭を受け取った側用のイベント
一つでできそうと思ったけど、nostrは自己主権のプロトコルでイベント作成するには発行者の署名が必須なので2つに分かれているのでしょう。
所感
現状はクライアントだけで完結する非常にシンプルな方法になっています。リレーサーバも経由しないしクライアントにLNノードを組み込むこともしていません。サードパーティへのhttpリクエストやローカルのアプリに受け渡すだけなので、実はどんな一般アプリでもそんなに知識もコストも要らずにパッとできるものです。
現状ちょっと不便だなと思っていることは、タイムラインに流れるインボイスの有効期限内の支払い済みがわからないことです。Payボタンを押してエラーにならないとわかりません。ウォレットアプリに放り投げていてこのトレースするためには、ウォレット側で支払い成功したらNostrイベントを書き込むなどの対応しない限りは、サービス側でインボイスを定期的に一つ一つLNに投げてチェックするなどが必要だと思われるので、他のサービスでマネするときは留意しておくとよさそうです。
一方で、DMによるLNインボイス送付は活用方法が広がりそうな予感があります。Nostrの公開鍵による本人特定と、LNインボイスのメモ欄のテキスト情報による突き合わせだけでも、かんたんな決済機能として用いれそうだからです。もっとNostrに判断材料を追加したければイベント追加も簡単にできることをSnortが示しています。とくにリレーサーバ購読やPROメニューなどのNostr周辺の支払いはやりやすそうなので、DM活用ではなくなにかしらの決済メニューを搭載したNostrクライアントもすぐに出てきそう気がします。
- セットされたLNアドレスを分解して
-
@ 91bea5cd:1df4451c
2025-04-26 10:16:21
O Contexto Legal Brasileiro e o Consentimento
No ordenamento jurídico brasileiro, o consentimento do ofendido pode, em certas circunstâncias, afastar a ilicitude de um ato que, sem ele, configuraria crime (como lesão corporal leve, prevista no Art. 129 do Código Penal). Contudo, o consentimento tem limites claros: não é válido para bens jurídicos indisponíveis, como a vida, e sua eficácia é questionável em casos de lesões corporais graves ou gravíssimas.
A prática de BDSM consensual situa-se em uma zona complexa. Em tese, se ambos os parceiros são adultos, capazes, e consentiram livre e informadamente nos atos praticados, sem que resultem em lesões graves permanentes ou risco de morte não consentido, não haveria crime. O desafio reside na comprovação desse consentimento, especialmente se uma das partes, posteriormente, o negar ou alegar coação.
A Lei Maria da Penha (Lei nº 11.340/2006)
A Lei Maria da Penha é um marco fundamental na proteção da mulher contra a violência doméstica e familiar. Ela estabelece mecanismos para coibir e prevenir tal violência, definindo suas formas (física, psicológica, sexual, patrimonial e moral) e prevendo medidas protetivas de urgência.
Embora essencial, a aplicação da lei em contextos de BDSM pode ser delicada. Uma alegação de violência por parte da mulher, mesmo que as lesões ou situações decorram de práticas consensuais, tende a receber atenção prioritária das autoridades, dada a presunção de vulnerabilidade estabelecida pela lei. Isso pode criar um cenário onde o parceiro masculino enfrenta dificuldades significativas em demonstrar a natureza consensual dos atos, especialmente se não houver provas robustas pré-constituídas.
Outros riscos:
Lesão corporal grave ou gravíssima (art. 129, §§ 1º e 2º, CP), não pode ser justificada pelo consentimento, podendo ensejar persecução penal.
Crimes contra a dignidade sexual (arts. 213 e seguintes do CP) são de ação pública incondicionada e independem de representação da vítima para a investigação e denúncia.
Riscos de Falsas Acusações e Alegação de Coação Futura
Os riscos para os praticantes de BDSM, especialmente para o parceiro que assume o papel dominante ou que inflige dor/restrição (frequentemente, mas não exclusivamente, o homem), podem surgir de diversas frentes:
- Acusações Externas: Vizinhos, familiares ou amigos que desconhecem a natureza consensual do relacionamento podem interpretar sons, marcas ou comportamentos como sinais de abuso e denunciar às autoridades.
- Alegações Futuras da Parceira: Em caso de término conturbado, vingança, arrependimento ou mudança de perspectiva, a parceira pode reinterpretar as práticas passadas como abuso e buscar reparação ou retaliação através de uma denúncia. A alegação pode ser de que o consentimento nunca existiu ou foi viciado.
- Alegação de Coação: Uma das formas mais complexas de refutar é a alegação de que o consentimento foi obtido mediante coação (física, moral, psicológica ou econômica). A parceira pode alegar, por exemplo, que se sentia pressionada, intimidada ou dependente, e que seu "sim" não era genuíno. Provar a ausência de coação a posteriori é extremamente difícil.
- Ingenuidade e Vulnerabilidade Masculina: Muitos homens, confiando na dinâmica consensual e na parceira, podem negligenciar a necessidade de precauções. A crença de que "isso nunca aconteceria comigo" ou a falta de conhecimento sobre as implicações legais e o peso processual de uma acusação no âmbito da Lei Maria da Penha podem deixá-los vulneráveis. A presença de marcas físicas, mesmo que consentidas, pode ser usada como evidência de agressão, invertendo o ônus da prova na prática, ainda que não na teoria jurídica.
Estratégias de Prevenção e Mitigação
Não existe um método infalível para evitar completamente o risco de uma falsa acusação, mas diversas medidas podem ser adotadas para construir um histórico de consentimento e reduzir vulnerabilidades:
- Comunicação Explícita e Contínua: A base de qualquer prática BDSM segura é a comunicação constante. Negociar limites, desejos, palavras de segurança ("safewords") e expectativas antes, durante e depois das cenas é crucial. Manter registros dessas negociações (e-mails, mensagens, diários compartilhados) pode ser útil.
-
Documentação do Consentimento:
-
Contratos de Relacionamento/Cena: Embora a validade jurídica de "contratos BDSM" seja discutível no Brasil (não podem afastar normas de ordem pública), eles servem como forte evidência da intenção das partes, da negociação detalhada de limites e do consentimento informado. Devem ser claros, datados, assinados e, idealmente, reconhecidos em cartório (para prova de data e autenticidade das assinaturas).
-
Registros Audiovisuais: Gravar (com consentimento explícito para a gravação) discussões sobre consentimento e limites antes das cenas pode ser uma prova poderosa. Gravar as próprias cenas é mais complexo devido a questões de privacidade e potencial uso indevido, mas pode ser considerado em casos específicos, sempre com consentimento mútuo documentado para a gravação.
Importante: a gravação deve ser com ciência da outra parte, para não configurar violação da intimidade (art. 5º, X, da Constituição Federal e art. 20 do Código Civil).
-
-
Testemunhas: Em alguns contextos de comunidade BDSM, a presença de terceiros de confiança durante negociações ou mesmo cenas pode servir como testemunho, embora isso possa alterar a dinâmica íntima do casal.
- Estabelecimento Claro de Limites e Palavras de Segurança: Definir e respeitar rigorosamente os limites (o que é permitido, o que é proibido) e as palavras de segurança é fundamental. O desrespeito a uma palavra de segurança encerra o consentimento para aquele ato.
- Avaliação Contínua do Consentimento: O consentimento não é um cheque em branco; ele deve ser entusiástico, contínuo e revogável a qualquer momento. Verificar o bem-estar do parceiro durante a cena ("check-ins") é essencial.
- Discrição e Cuidado com Evidências Físicas: Ser discreto sobre a natureza do relacionamento pode evitar mal-entendidos externos. Após cenas que deixem marcas, é prudente que ambos os parceiros estejam cientes e de acordo, talvez documentando por fotos (com data) e uma nota sobre a consensualidade da prática que as gerou.
- Aconselhamento Jurídico Preventivo: Consultar um advogado especializado em direito de família e criminal, com sensibilidade para dinâmicas de relacionamento alternativas, pode fornecer orientação personalizada sobre as melhores formas de documentar o consentimento e entender os riscos legais específicos.
Observações Importantes
- Nenhuma documentação substitui a necessidade de consentimento real, livre, informado e contínuo.
- A lei brasileira protege a "integridade física" e a "dignidade humana". Práticas que resultem em lesões graves ou que violem a dignidade de forma não consentida (ou com consentimento viciado) serão ilegais, independentemente de qualquer acordo prévio.
- Em caso de acusação, a existência de documentação robusta de consentimento não garante a absolvição, mas fortalece significativamente a defesa, ajudando a demonstrar a natureza consensual da relação e das práticas.
-
A alegação de coação futura é particularmente difícil de prevenir apenas com documentos. Um histórico consistente de comunicação aberta (whatsapp/telegram/e-mails), respeito mútuo e ausência de dependência ou controle excessivo na relação pode ajudar a contextualizar a dinâmica como não coercitiva.
-
Cuidado com Marcas Visíveis e Lesões Graves Práticas que resultam em hematomas severos ou lesões podem ser interpretadas como agressão, mesmo que consentidas. Evitar excessos protege não apenas a integridade física, mas também evita questionamentos legais futuros.
O que vem a ser consentimento viciado
No Direito, consentimento viciado é quando a pessoa concorda com algo, mas a vontade dela não é livre ou plena — ou seja, o consentimento existe formalmente, mas é defeituoso por alguma razão.
O Código Civil brasileiro (art. 138 a 165) define várias formas de vício de consentimento. As principais são:
Erro: A pessoa se engana sobre o que está consentindo. (Ex.: A pessoa acredita que vai participar de um jogo leve, mas na verdade é exposta a práticas pesadas.)
Dolo: A pessoa é enganada propositalmente para aceitar algo. (Ex.: Alguém mente sobre o que vai acontecer durante a prática.)
Coação: A pessoa é forçada ou ameaçada a consentir. (Ex.: "Se você não aceitar, eu termino com você" — pressão emocional forte pode ser vista como coação.)
Estado de perigo ou lesão: A pessoa aceita algo em situação de necessidade extrema ou abuso de sua vulnerabilidade. (Ex.: Alguém em situação emocional muito fragilizada é induzida a aceitar práticas que normalmente recusaria.)
No contexto de BDSM, isso é ainda mais delicado: Mesmo que a pessoa tenha "assinado" um contrato ou dito "sim", se depois ela alegar que seu consentimento foi dado sob medo, engano ou pressão psicológica, o consentimento pode ser considerado viciado — e, portanto, juridicamente inválido.
Isso tem duas implicações sérias:
-
O crime não se descaracteriza: Se houver vício, o consentimento é ignorado e a prática pode ser tratada como crime normal (lesão corporal, estupro, tortura, etc.).
-
A prova do consentimento precisa ser sólida: Mostrando que a pessoa estava informada, lúcida, livre e sem qualquer tipo de coação.
Consentimento viciado é quando a pessoa concorda formalmente, mas de maneira enganada, forçada ou pressionada, tornando o consentimento inútil para efeitos jurídicos.
Conclusão
Casais que praticam BDSM consensual no Brasil navegam em um terreno que exige não apenas confiança mútua e comunicação excepcional, mas também uma consciência aguçada das complexidades legais e dos riscos de interpretações equivocadas ou acusações mal-intencionadas. Embora o BDSM seja uma expressão legítima da sexualidade humana, sua prática no Brasil exige responsabilidade redobrada. Ter provas claras de consentimento, manter a comunicação aberta e agir com prudência são formas eficazes de se proteger de falsas alegações e preservar a liberdade e a segurança de todos os envolvidos. Embora leis controversas como a Maria da Penha sejam "vitais" para a proteção contra a violência real, os praticantes de BDSM, e em particular os homens nesse contexto, devem adotar uma postura proativa e prudente para mitigar os riscos inerentes à potencial má interpretação ou instrumentalização dessas práticas e leis, garantindo que a expressão de sua consensualidade esteja resguardada na medida do possível.
Importante: No Brasil, mesmo com tudo isso, o Ministério Público pode denunciar por crime como lesão corporal grave, estupro ou tortura, independente de consentimento. Então a prudência nas práticas é fundamental.
Aviso Legal: Este artigo tem caráter meramente informativo e não constitui aconselhamento jurídico. As leis e interpretações podem mudar, e cada situação é única. Recomenda-se buscar orientação de um advogado qualificado para discutir casos específicos.
Se curtiu este artigo faça uma contribuição, se tiver algum ponto relevante para o artigo deixe seu comentário.
-
@ d34e832d:383f78d0
2025-04-25 23:20:48
As computing needs evolve toward speed, reliability, and efficiency, understanding the landscape of storage technologies becomes crucial for system builders, IT professionals, and performance enthusiasts. This idea compares traditional Hard Disk Drives (HDDs) with various Solid-State Drive (SSD) technologies including SATA SSDs, mSATA, M.2 SATA, and M.2 NVMe. It explores differences in form factors, interfaces, memory types, and generational performance to empower informed decisions on selecting optimal storage.
1. Storage Device Overview
1.1 HDDs – Hard Disk Drives
- Mechanism: Mechanical platters + spinning disk.
- Speed: ~80–160 MB/s.
- Cost: Low cost per GB.
- Durability: Susceptible to shock; moving parts prone to wear.
- Use Case: Mass storage, backups, archival.
1.2 SSDs – Solid State Drives
- Mechanism: Flash memory (NAND-based); no moving parts.
- Speed: SATA SSDs (~550 MB/s), NVMe SSDs (>7,000 MB/s).
- Durability: High resistance to shock and temperature.
- Use Case: Operating systems, apps, high-speed data transfer.
2. Form Factors
| Form Factor | Dimensions | Common Usage | |------------------|------------------------|--------------------------------------------| | 2.5-inch | 100mm x 69.85mm x 7mm | Laptops, desktops (SATA interface) | | 3.5-inch | 146mm x 101.6mm x 26mm | Desktops/servers (HDD only) | | mSATA | 50.8mm x 29.85mm | Legacy ultrabooks, embedded systems | | M.2 | 22mm wide, lengths vary (2242, 2260, 2280, 22110) | Modern laptops, desktops, NUCs |
Note: mSATA is being phased out in favor of the more versatile M.2 standard.
3. Interfaces & Protocols
3.1 SATA (Serial ATA)
- Max Speed: ~550 MB/s (SATA III).
- Latency: Higher.
- Protocol: AHCI.
- Compatibility: Broad support, backward compatible.
3.2 NVMe (Non-Volatile Memory Express)
- Max Speed:
- Gen 3: ~3,500 MB/s
- Gen 4: ~7,000 MB/s
- Gen 5: ~14,000 MB/s
- Latency: Very low.
- Protocol: NVMe (optimized for NAND flash).
- Interface: PCIe lanes (usually via M.2 slot).
NVMe significantly outperforms SATA due to reduced overhead and direct PCIe access.
4. Key Slot & Compatibility (M.2 Drives)
| Drive Type | Key | Interface | Typical Use | |------------------|----------------|---------------|-----------------------| | M.2 SATA | B+M key | SATA | Budget laptops/desktops | | M.2 NVMe (PCIe) | M key only | PCIe Gen 3–5 | Performance PCs/gaming |
⚠️ Important: Not all M.2 slots support NVMe. Check motherboard specs for PCIe compatibility.
5. SSD NAND Memory Types
| Type | Bits/Cell | Speed | Endurance | Cost | Use Case | |---------|---------------|-----------|---------------|----------|--------------------------------| | SLC | 1 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | $$$$ | Enterprise caching | | MLC | 2 | ⭐⭐⭐ | ⭐⭐⭐ | $$$ | Pro-grade systems | | TLC | 3 | ⭐⭐ | ⭐⭐ | $$ | Consumer, gaming | | QLC | 4 | ⭐ | ⭐ | $ | Budget SSDs, media storage |
6. 3D NAND / V-NAND Technology
- Traditional NAND: Planar (flat) design.
- 3D NAND: Stacks cells vertically—more density, less space.
- Benefits:
- Greater capacity
- Better power efficiency
- Improved lifespan
Samsung’s V-NAND is a branded 3D NAND variant known for high endurance and stability.
7. Performance & Generational Comparison
| PCIe Gen | Max Speed | Use Case | |--------------|---------------|----------------------------------| | Gen 3 | ~3,500 MB/s | Mainstream laptops/desktops | | Gen 4 | ~7,000 MB/s | Gaming, prosumer, light servers | | Gen 5 | ~14,000 MB/s | AI workloads, enterprise |
Drives are backward compatible, but will operate at the host’s maximum supported speed.
8. Thermal Management
- NVMe SSDs generate heat—especially Gen 4/5.
- Heatsinks and thermal pads are vital for:
- Sustained performance (prevent throttling)
- Longer lifespan
- Recommended to leave 10–20% free space for optimal SSD wear leveling and garbage collection.
9. HDD vs SSD: Summary
| Aspect | HDD | SSD | |------------------|---------------------|------------------------------| | Speed | 80–160 MB/s | 550 MB/s – 14,000 MB/s | | Durability | Low (mechanical) | High (no moving parts) | | Lifespan | Moderate | High (depends on NAND type) | | Cost | Lower per GB | Higher per GB | | Noise | Audible | Silent |
10. Brand Recommendations
| Brand | Strength | |------------------|-----------------------------------------| | Samsung | Leading in performance (980 Pro, 990 Pro) | | Western Digital | Reliable Gen 3/4/5 drives (SN770, SN850X) | | Crucial | Budget-friendly, solid TLC drives (P3, P5 Plus) | | Kingston | Value-oriented SSDs (A2000, NV2) |
11. How to Choose the Right SSD
- Check your device slot: Is it M.2 B+M, M-key, or SATA-only?
- Interface compatibility: Confirm if the M.2 slot supports NVMe or only SATA.
- Match PCIe Gen: Use Gen 3/4/5 based on CPU/motherboard lanes.
- Pick NAND type: TLC for best balance of speed/longevity.
- Thermal plan: Use heatsinks or fans for Gen 4+ drives.
- Capacity need: Leave headroom (15–20%) for performance and lifespan.
- Trustworthy brands: Stick to Samsung, WD, Crucial for warranty and quality.
Consider
From boot speed to data integrity, SSDs have revolutionized how modern systems handle storage. While HDDs remain relevant for mass archival, NVMe SSDs—especially those leveraging PCIe Gen 4 and Gen 5—dominate in speed-critical workflows. M.2 NVMe is the dominant form factor for futureproof builds, while understanding memory types like TLC vs. QLC ensures better longevity planning.
Whether you’re upgrading a laptop, building a gaming rig, or running a self-hosted Bitcoin node, choosing the right form factor, interface, and NAND type can dramatically impact system performance and reliability.
Resources & Further Reading
- How-Fixit Storage Guides
- Kingston SSD Reliability Guide
- Western Digital Product Lines
- Samsung V-NAND Explained
- PCIe Gen 5 Benchmarks
Options
🔧 Recommended SSDs and Tools (Amazon)
-
Kingston A400 240GB SSD – SATA 3 2.5"
https://a.co/d/41esjYL -
Samsung 970 EVO Plus 2TB NVMe M.2 SSD – Gen 3
https://a.co/d/6EMVAN1 -
Crucial P5 Plus 1TB PCIe Gen4 NVMe M.2 SSD
https://a.co/d/hQx50Cq -
WD Blue SN570 1TB NVMe SSD – PCIe Gen 3
https://a.co/d/j2zSDCJ -
Sabrent Rocket Q 2TB NVMe SSD – QLC NAND
https://a.co/d/325Og2K -
Thermalright M.2 SSD Heatsink Kit
https://a.co/d/0IYH3nK -
ORICO M.2 NVMe SSD Enclosure – USB 3.2 Gen2
https://a.co/d/aEwQmih
🛠️ DIY & Fix Resource
- How-Fixit – PC Repair Guides and Tutorials
https://www.how-fixit.com/
In Addition
Modern Storage Technologies and Mini NAS Implementation
1. Network Attached Storage (NAS) system
In the rapidly evolving landscape of data storage, understanding the nuances of various storage technologies is crucial for optimal system design and performance. This idea delves into the distinctions between traditional Hard Disk Drives (HDDs), Solid State Drives (SSDs), and advanced storage interfaces like M.2 NVMe, M.2 SATA, and mSATA. Additionally, it explores the implementation of a compact Network Attached Storage (NAS) system using the Nookbox G9, highlighting its capabilities and limitations.
2. Storage Technologies Overview
2.1 Hard Disk Drives (HDDs)
- Mechanism: Utilize spinning magnetic platters and read/write heads.
- Advantages:
- Cost-effective for large storage capacities.
- Longer lifespan in low-vibration environments.
- Disadvantages:
- Slower data access speeds.
- Susceptible to mechanical failures due to moving parts.
2.2 Solid State Drives (SSDs)
- Mechanism: Employ NAND flash memory with no moving parts.
- Advantages:
- Faster data access and boot times.
- Lower power consumption and heat generation.
- Enhanced durability and shock resistance.
- Disadvantages:
- Higher cost per gigabyte compared to HDDs.
- Limited write cycles, depending on NAND type.
3. SSD Form Factors and Interfaces
3.1 Form Factors
- 2.5-Inch: Standard size for laptops and desktops; connects via SATA interface.
- mSATA: Miniature SATA interface, primarily used in ultrabooks and embedded systems; largely supplanted by M.2.
- M.2: Versatile form factor supporting both SATA and NVMe interfaces; prevalent in modern systems.
3.2 Interfaces
- SATA (Serial ATA):
- Speed: Up to 600 MB/s.
- Compatibility: Widely supported across various devices.
-
Limitation: Bottleneck for high-speed SSDs.
-
NVMe (Non-Volatile Memory Express):
- Speed: Ranges from 3,500 MB/s (PCIe Gen 3) to over 14,000 MB/s (PCIe Gen 5).
- Advantage: Direct communication with CPU via PCIe lanes, reducing latency.
- Consideration: Requires compatible motherboard and BIOS support.
4. M.2 SATA vs. M.2 NVMe
| Feature | M.2 SATA | M.2 NVMe | |------------------------|--------------------------------------------------|----------------------------------------------------| | Interface | SATA III (AHCI protocol) | PCIe (NVMe protocol) | | Speed | Up to 600 MB/s | Up to 14,000 MB/s (PCIe Gen 5) | | Compatibility | Broad compatibility with older systems | Requires NVMe-compatible M.2 slot and BIOS support | | Use Case | Budget builds, general computing | High-performance tasks, gaming, content creation |
Note: M.2 NVMe drives are not backward compatible with M.2 SATA slots due to differing interfaces and keying.
5. NAND Flash Memory Types
Understanding NAND types is vital for assessing SSD performance and longevity.
- SLC (Single-Level Cell):
- Bits per Cell: 1
- Endurance: ~100,000 write cycles
-
Use Case: Enterprise and industrial applications
-
MLC (Multi-Level Cell):
- Bits per Cell: 2
- Endurance: ~10,000 write cycles
-
Use Case: Consumer-grade SSDs
-
TLC (Triple-Level Cell):
- Bits per Cell: 3
- Endurance: ~3,000 write cycles
-
Use Case: Mainstream consumer SSDs
-
QLC (Quad-Level Cell):
- Bits per Cell: 4
- Endurance: ~1,000 write cycles
-
Use Case: Read-intensive applications
-
3D NAND:
- Structure: Stacks memory cells vertically to increase density.
- Advantage: Enhances performance and endurance across NAND types.
6. Thermal Management and SSD Longevity
Effective thermal management is crucial for maintaining SSD performance and lifespan.
- Heatsinks: Aid in dissipating heat from SSD controllers.
- Airflow: Ensuring adequate case ventilation prevents thermal throttling.
- Monitoring: Regularly check SSD temperatures, especially under heavy workloads.
7. Trusted SSD Manufacturers
Selecting SSDs from reputable manufacturers ensures reliability and support.
- Samsung: Known for high-performance SSDs with robust software support.
- Western Digital (WD): Offers a range of SSDs catering to various user needs.
- Crucial (Micron): Provides cost-effective SSD solutions with solid performance.
8. Mini NAS Implementation: Nookbox G9 Case Study
8.1 Overview
The Nookbox G9 is a compact NAS solution designed to fit within a 1U rack space, accommodating four M.2 NVMe SSDs.
8.2 Specifications
- Storage Capacity: Supports up to 8TB using four 2TB NVMe SSDs.
- Interface: Each M.2 slot operates at PCIe Gen 3x2.
- Networking: Equipped with 2.5 Gigabit Ethernet ports.
- Operating System: Comes pre-installed with Windows 11; compatible with Linux distributions like Ubuntu 24.10.
8.3 Performance and Limitations
- Throughput: Network speeds capped at ~250 MB/s due to 2.5 GbE limitation.
- Thermal Issues: Inadequate cooling leads to SSD temperatures reaching up to 80°C under load, causing potential throttling and system instability.
- Reliability: Reports of system reboots and lockups during intensive operations, particularly with ZFS RAIDZ configurations.
8.4 Recommendations
- Cooling Enhancements: Implement third-party heatsinks to improve thermal performance.
- Alternative Solutions: Consider NAS systems with better thermal designs and higher network throughput for demanding applications.
9. Consider
Navigating the myriad of storage technologies requires a comprehensive understanding of form factors, interfaces, and memory types. While HDDs offer cost-effective bulk storage, SSDs provide superior speed and durability. The choice between M.2 SATA and NVMe hinges on performance needs and system compatibility. Implementing compact NAS solutions like the Nookbox G9 necessitates careful consideration of thermal management and network capabilities to ensure reliability and performance.
Product Links (Amazon)
-
Thermal Heatsink for M.2 SSDs (Must-have for stress and cooling)
https://a.co/d/43B1F3t -
Nookbox G9 – Mini NAS
https://a.co/d/3dswvGZ -
Alternative 1: Possibly related cooling or SSD gear
https://a.co/d/c0Eodm3 -
Alternative 2: Possibly related NAS accessories or SSDs
https://a.co/d/9gWeqDr
Benchmark Results (Geekbench)
-
GMKtec G9 Geekbench CPU Score #1
https://browser.geekbench.com/v6/cpu/11471182 -
GMKtec G9 Geekbench CPU Score #2
https://browser.geekbench.com/v6/cpu/11470130 -
GMKtec Geekbench User Profile
https://browser.geekbench.com/user/446940
-
@ 3589b793:ad53847e
2025-04-30 11:46:52
※本記事は別サービスで2022年9月25日に公開した記事の移植です。
LNの手数料の適正水準はどう見積もったらいいだろうか?ルーティングノードの収益性を算出するためにはどうアプローチすればよいだろうか?本記事ではルーティングノード運用のポジションに立ち参考になりそうな数値や計算式を整理する。
個人的な感想を先に書くと以下となる。
- 現在の手数料市場は収益性が低くもっと手数料が上がった方が健全である。
- 他の決済手段と比較すると、LN支払い料金は10000ppm(手数料1%相当)でも十分ではないか。4ホップとすると中間1ノードあたり2500ppmである。
- ルーティングノードの収益性を考えると、1000ppmあれば1BTC程度の資金で年利2.8%になり半年で初期費用回収できるので十分な投資対象になると考える。
基本概念の整理
LNの料金方式
- LNの手数料は送金額に応じた料率方式が主になる。(基本料金の設定もあるが1 ~ 0 satsが大半)
- 料率単位のppm(parts per million)は、1,000,000satsを送るときの手数料をsats金額で示したもの。
- %での手数料率に変換すると1000ppm = 0.1%になる。
- 支払い者が払う手数料はルーティングに参加した各ノードの手数料の合計である。本稿では4ホップ(経由ノードが4つ)のルーティングがあるとすれば、各ノードの取り分は単純計算で1/4とみなす。
- ルーティングノードの収益はアウトバウンドフローで発生するのでアウトバウンドキャパシティが直接的な収益資源となる。
LNの料金以外のベネフィット
本稿では料金比較だけを行うが実際の決済検討では以下のような料金以外の効用も忘れてはならない。
- Bitcoin(L1)に比べると、料金の安さだけでなく、即時確定やトランザクション量のスケールという利点がある。
- クレジットカードなどの集権サービスと比較した特徴はBitcoin(L1)とだいたい同じである。
- 24時間365日利用できる
- 誰でも自由に使える
- 信頼する第三者に対する加盟や審査や手数料率などの交渉手続きが要らない
- 検閲がなく匿名性が高い
- 逆にデメリットはオンライン前提がゆえの利用の不便さやセキュリティ面の不安さなどが挙げられる。
現在の料金相場
- ルーティングノードの料金設定
- sinkノードとのチャネルは500 ~ 1000ppmが多い。
- routing/sourceノードとのチャネルは0 ~ 100ppmあたりのレンジになる。
- リバランスする場合もsinkで収益を上げているならsink以下になるのが道理である。
- プロダクト/サービスのバックエンドにいるノードの料金設定
- sinkやsourceに相当するものは上記の通り。
- 1000〜5000ppmあたりで一律同じ設定というノードもよく見かける。
- ビジネスモデル次第で千差万別だがアクティブと思われるノードでそれ以上はあまり見かけない。
- 上記は1ノードあたりの料金になる。支払い全体では経由したノードの合計になる。
料金目安
いくつかの方法で参考数字を出していく。LN料金算出は「支払い全体/2ホップしたときの1ノードあたり/4ホップしたときの1ノードあたり」の三段階で出す。
類推方式
決済代行業者との比較
- Squareの加盟店手数料は、日本3.25%、アメリカ2.60%である。
- 参考資料 https://www.meti.go.jp/shingikai/mono_info_service/cashless_payment/pdf/20220318_1.pdf
3.25%とするとLNでは「支払い全体/2ホップしたときの1ノードあたり/4ホップしたときの1ノードあたり」でそれぞれ
32,500ppm/16,250ppm/8,125ppmになる。スマホのアプリストアとの比較
- Androidのアプリストアは年間売上高が100万USDまでなら15%、それ以上なら30%
- 参考資料https://support.google.com/googleplay/android-developer/answer/112622?hl=ja
15%とするとLNでは「支払い全体/2ホップしたときの1ノードあたり/4ホップしたときの1ノードあたり」でそれぞれ
150,000ppm/75,000ppm/37,500ppmになる。Bitcoin(L1)との比較
Bitcoin(L1)は送金額が異なっても手数料がほぼ同じため、従量課金のLNと単純比較はできない。そのためここではLNの方が料金がお得になる目安を出す。
Bitcoin(L1)の手数料設定
- SegWitのシンプルな送金を対象にする。
- input×1、output×2(送金+お釣り)、tx合計222byte
- L1の手数料は、1sat/byteなら222sats、10sat/byteなら2,220sats、100sat/byteなら22,200sats。(単純化のためvirtual byteではなくbyteで計算する)
- サンプル例 https://www.blockchain.com/btc/tx/15b959509dad5df0e38be2818d8ec74531198ca29ac205db5cceeb17177ff095
L1相場が1sat/byteの時にLNの方がお得なライン
- 100ppmなら、0.0222BTC(2,220,000sats)まで
- 1000ppmなら、0.00222BTC(222,000sats)まで
L1相場が10sat/byteの時にLNの方がお得なライン
- 100ppmなら、0.222BTC(22,200,000sats)まで
- 1000ppmなら、0.0222BTC(2,220,000sats)まで
L1相場が100sat/byteの時にLNの方がお得なライン
- 100ppmなら、2.22BTC(222,000,000sats)まで
- 1000ppmなら、0.222BTC(22,200,000sats)まで
コスト積み上げ方式
ルーティングノードの原価から損益分岐点となるppmを算出する。事業者ではなく個人を想定し、クラウドではなくラズベリーパイでのノード構築環境で計算する。
費用明細
- BTC市場価格 1sat = 0.03円(1BTC = 3百万円)
初期費用
- ハードウェア一式 40,000円
- Raspberry Pi 4 8GB
- SSD 1TB
- 外付けディスプレイ
- チャネル開設のオンチェーン手数料 6.69円/チャネル
- 開設料 223sats
- 223sats * BTC市場価格0.03円 = 6.69円
固定費用
- 電気代 291.6円/月
- 時間あたりの電力量 0.015kWh
- Raspberry Pi 4 電圧5V、推奨電源容量3.0A
- https://www.raspberrypi.com/documentation/computers/raspberry-pi.html#power-supply
- kWh単価27円
- 0.015kWh * kWh単価27円 * 1ヶ月の時間720h = 291.6円
損益分岐点
- 月あたりの電気代を上回るために9,720sats(291.6円)/月以上の収益が必要である。
- ハードウェア費用回収のために0.01333333BTC(133万sats) = 40,000円の収益が必要である。
費用回収シナリオ例
アウトバウンドキャパに1BTCをデポジットしたAさんを例にする。1BTCは初心者とは言えないと思うが、このくらい原資を用意しないと費用回収の話がしづらいという裏事情がある。チャネル選択やルーティング戦略は何もしていない仮定である。ノード運用次第であることは言うまでもないので今回は要素や式を洗い出すことが主目的で一つ一つの変数の値は参考までに。
変数設定
- インバウンドを同額用意して合計キャパを2BTCとする。
- 1チャネルあたり5m satsで40チャネル開設する。
- チャネル開設費用 223sats * 40チャネル = 8,920sats
- 初期費用合計 1,333,333sats + 8,920sats = 1,342,253sats
- 一回あたり平均ルーティング量 = 100,000sats
- 1チャネルあたり平均アウトバウンド数/日 = 2
- 1チャネルあたり平均アウトバウンドppm = 50
費用回収地点
- 1日のアウトバウンド量は、 40チャネル * 2本 * 100,000sats = 8m sats
- 手数料収入は、8m sats * 0.005%(50ppm) = 400sats/日。月換算すると12,000sats/月
- 電気代を差し引くと、12,000sats - 電気代9,720sats =月収益2,280sats(68.4円)
- 初期費用回収まで、1,342,253sats / 2,280sats = 589ヵ月(49年)
- 後述するが電気代差引き前で年利0.14%になる。
理想的なppm
6ヵ月での初期費用回収を目的にしてアウトバウンドppmを求める。
- ひと月あたり、初期費用合計1,342,253sats / 6ヵ月 + 電気代9,720sats = 233,429sats(7,003円)の収益が必要。
- 1日あたり、7,781sats(233円)の収益
- その場合の平均アウトバウンドppmは、 7,781sats(1日の収益量) / 8m sats(1日のアウトバウンド量) * 1m sats(ppm変換係数) = 973ppm
他のファイナンスとの比較
ルーティングノードを運用して手数料収入を得ることは資産運用と捉えることもできる。レンディングやトレードなどの他の資産運用手段とパフォーマンス比較をするなら、デポジットしたアウトバウンドキャパシティに対する手数料収入をAPY換算する。(獲得した手数料はアウトバウンドキャパシティに積み重ねられるので複利と見做せる)
例としてLNDg(v1.3.1)のAPY算出計算式を転載する。見ての通り画面上の表記はAPYなのに中身はAPRになっているので注意だが今回は考え方の参考としてこのまま採用する。
年換算 = 365 / 7 = 52.142857 年利 = (7dayの収益 * 年換算) / アウトバウンドのキャパシティ例えば上記のAさんの費用回収シナリオに当てはめると以下となる。
年利 0.14% = (400sats * 7日 * 年換算)/ 100m sats
電気代を差し引くと 76sats/日となり年利0.027%
もし平均アウトバウンド1000ppmになると8,000sats/日なので年利2.9%になる。 この場合、電気代はほぼ1日で回収されるため差し引いても大差なく7,676sats/日で年利2.8%になる。
考察
以上、BTC市場価格や一日のアウトバウンド量といった重要な数値をいくつか仮置きした上ではあるが、LN手数料の適正水準を考えるための参考材料を提示した。
まず、現在のLNの料金相場は他の決済手段から比べると圧倒的に安いことがわかった。1%でも競争力が十分ありそうなのに0.1%前後で送金することが大半である。
健全な市場発展のためには、ルーティングノードの採算が取れていることが欠かせないと考えるが、残念ながら現在の収益性は低い。ルーティングノードの収益性は仮定に仮定を重ねた見積もりになるが、平均アウトバウンドが1000ppmでようやく個人でも参入できるレベルになるという結論になった。ルーティングノードの立場に立つと、現在の市場平均から大幅な上昇が必要だと考える。
手数料市場は競争のためつねに下方圧力がかかっていて仕様上で可能な0に近づいている。この重力に逆らうためには、1. 需要 > 供給のバランスになること、2. 事業用途での高額買取のチャネルが増えること、の2つの観点を挙げる。1にせよ2にせよネットワークの活用が進むことで発生し、手数料市場の大きな変動機会になるのではないか。他の決済手段と比較すれば10000ppm、1チャネル2500ppmあたりまでは十分に健全な範囲だと考える。
-
@ 81650982:299380fa
2025-04-30 11:16:42
Let us delve into Monero (XMR). Among the proponents of various altcoins, Monero arguably commands one of the most dedicated followings, perhaps second only to Ethereum. Unlike many altcoins where even investors often harbor speculative, short-term intentions, the genuine belief within the Monero community suggests an inherent appeal to the chain itself.
The primary advantage touted by Monero (and similar so-called "privacy coins") is its robust privacy protection features. The demand for anonymous payment systems, tracing its lineage back to David Chaum, predates even the inception of Bitcoin. Monero's most heavily promoted strength, relative to Bitcoin, is that its privacy features are enabled by default.
This relates to the concept of the "anonymity set." To guarantee anonymity, a user must blend into a crowd of ordinary users. The larger the group one hides within, the more difficult it becomes for an external observer to identify any specific individual. From the perspective of Monero advocates, Bitcoin's default transaction model is overly transparent, clearly revealing the flow of funds between addresses. While repeated mixing can enhance anonymity in Bitcoin, the fact that users must actively undertake such measures presents a significant hurdle. More critically, proponents argue, the very group engaging in such deliberate obfuscation is precisely the group one doesn't want to be associated with for effective anonymity. Hiding requires blending with the ordinary, not merely mixing with others who are also actively trying to hide — the latter, they contend, is akin to criminals mixing only with other criminals.
This is a valid point. For instance, there's a substantial difference between a messenger app offering end-to-end encryption for all communications by default, versus one requiring users to explicitly create a "secret chat" for encryption. While I personally believe that increased self-custody of Bitcoin in personal wallets, acquisition through direct peer-to-peer payments rather than exchange purchases, and the widespread adoption of the Lightning Network would make tracing significantly harder even without explicit mixing efforts, let us concede, for the sake of argument, that Bitcoin's base-layer anonymity might not drastically improve even in such a future scenario.
Nevertheless, Monero's long-term prospects appear considerably constrained when focusing purely on technical limitations, setting aside economic factors or incentive models for now. While discussions on economics can often be countered with "That's just your speculation," technical constraints present more objective facts and leave less room for dispute.
Monero's most fundamental problem is its lack of scalability. To briefly explain how Monero obfuscates the sender: it includes other addresses alongside the true sender's address in the 'from' field and attaches what appears to be valid signatures for all of them. With a default setting of 10 decoys (plus the real spender, making a ring size of 11), the signature size naturally becomes substantially larger than Bitcoin's. Since an observer cannot determine which of the 11 is the true sender, and these decoys are arbitrary outputs selected from the blockchain belonging to other users, anonymity is indeed enhanced. While the sender cannot generate individually valid signatures for the decoy outputs (as they don't own the private keys), the use of a ring signature mathematically proves that one member of the ring authorized the transaction, allowing it to pass network validation.
The critical issue is that this results in transaction sizes several times larger than Bitcoin's. Bitcoin already faces criticism for being relatively expensive and slow. Monero's structure imposes a burden that is multiples greater. One might question the relationship between transaction data size and transaction fees/speed. However, the perceived slowness of blockchains isn't typically due to inefficient code, but rather the strict limitations imposed on block size (or equivalent throughput constraints) to maintain decentralization. Therefore, larger transaction sizes directly translate into throughput limitations and upward pressure on fees. If someone claims Monero fees are currently lower than Bitcoin's, that is merely a consequence of its significantly lower usage. Should Monero's transaction volume reach even a fraction of Bitcoin's, its current architecture would struggle severely under the load.
To address this, Monero implemented a dynamic block size limit instead of a hardcoded one. However, this is not a comprehensive solution. If the block size increases proportionally with usage, a future where Monero achieves widespread adoption as currency — implying usage potentially hundreds, thousands, or even hundreds of thousands of times greater than today — would render the blockchain size extremely difficult to manage for ordinary node operators. Global internet traffic might be consumed by Monero transactions, or at the very least, the bandwidth and storage costs could exceed what individuals can reasonably bear.
Blockchains, by their nature, must maintain a size manageable enough for individuals to run full nodes, necessitating strict block size limits (or equivalent constraints in blockless designs). This fundamental requirement is the root cause of limited transaction speed and rising fees. Consequently, the standard approach to blockchain scaling involves Layer 2 solutions like the Lightning Network. The problem is, implementing such solutions on Monero is extremely challenging.
Layer 2 solutions, while varying in specific implementation details across different blockchains, generally rely heavily on the transparency of on-chain transactions. They typically involve sophisticated smart contracts built upon the ability to publicly verify on-chain states and events. Monero's inherent opacity, hiding crucial details of on-chain transactions, makes it exceptionally difficult for two mutually untrusting parties to reach the necessary consensus and cryptographic agreements (like establishing payment channels with verifiable state transitions and dispute mechanisms) that underpin such Layer 2 systems. The fact that Monero, despite existing for several years, still lacks a functional, widely adopted Layer 2 implementation suggests that this remains an unsolved and technically formidable challenge. While theoretical proposals exist, their real-world feasibility remains uncertain and would likely require significant breakthroughs in cryptographic protocol design.
Furthermore, Monero faces another severe scaling challenge related to its core privacy mechanism. As mentioned, decoy outputs are used to obscure the true sender. An astute observer might wonder: If a third party cannot distinguish the real spender, could the real spender potentially double-spend their funds later? Or could someone's funds become unusable simply because they were chosen as a decoy in another transaction? Naturally, Monero's developers anticipated this. The solution employed involves key images.
When an output is genuinely spent within a ring signature, a unique cryptographic identifier called a "key image" is derived from the real output and the spender's private key. This derivation is one-way (the key image cannot be used to reveal the original output or key). This key image is recorded on the blockchain. When validating a new transaction, the network checks if the submitted key image has already appeared in the history. If it exists, the transaction is rejected as a double-spend attempt. The crucial implication is that this set of used key images can never be pruned. Deleting historical key images would directly enable double-spending.
Therefore, Monero's state size — the data that full nodes must retain and check against — grows linearly and perpetually with the total number of transactions ever processed on the network.
Summary In summary, Monero faces critical technical hurdles:
Significantly Larger Transaction Sizes: The use of ring signatures for anonymity results in transaction data sizes several times larger than typical cryptocurrencies like Bitcoin.
Inherent Scalability Limitations: The large transaction size, combined with the necessity of strict block throughput limits to preserve decentralization, creates severe scalability bottlenecks regarding transaction speed and cost under significant load. Dynamic block sizes, while helpful in the short term, do not constitute a viable long-term solution for broad decentralization.
Layer 2 Implementation Difficulty: Monero's fundamental opacity makes implementing established Layer 2 scaling solutions (like payment channels) extremely difficult with current approaches. The absence of a widely adopted solution to date indicates that this remains a major unresolved challenge.
Unprunable, Linearly Growing State: The key image mechanism required to prevent double-spending mandates the perpetual storage of data proportional to the entire transaction history, unlike Bitcoin where nodes can prune historical blocks and primarily need to maintain the current UTXO set (whose size depends on usage patterns, not total history).
These technical constraints raise legitimate concerns about Monero's ability to scale effectively and achieve widespread adoption in the long term. While ongoing research may alleviate some of these issues, at present they represent formidable challenges that any privacy-focused cryptocurrency must contend with.
-
@ 3bf0c63f:aefa459d
2025-04-25 19:26:48
Redistributing Git with Nostr
Every time someone tries to "decentralize" Git -- like many projects tried in the past to do it with BitTorrent, IPFS, ScuttleButt or custom p2p protocols -- there is always a lurking comment: "but Git is already distributed!", and then the discussion proceeds to mention some facts about how Git supports multiple remotes and its magic syncing and merging abilities and so on.
Turns out all that is true, Git is indeed all that powerful, and yet GitHub is the big central hub that hosts basically all Git repositories in the giant world of open-source. There are some crazy people that host their stuff elsewhere, but these projects end up not being found by many people, and even when they do they suffer from lack of contributions.
Because everybody has a GitHub account it's easy to open a pull request to a repository of a project you're using if it's on GitHub (to be fair I think it's very annoying to have to clone the repository, then add it as a remote locally, push to it, then go on the web UI and click to open a pull request, then that cloned repository lurks forever in your profile unless you go through 16 screens to delete it -- but people in general seem to think it's easy).
It's much harder to do it on some random other server where some project might be hosted, because now you have to add 4 more even more annoying steps: create an account; pick a password; confirm an email address; setup SSH keys for pushing. (And I'm not even mentioning the basic impossibility of offering
pushaccess to external unknown contributors to people who want to host their own simple homemade Git server.)At this point some may argue that we could all have accounts on GitLab, or Codeberg or wherever else, then those steps are removed. Besides not being a practical strategy this pseudo solution misses the point of being decentralized (or distributed, who knows) entirely: it's far from the ideal to force everybody to have the double of account management and SSH setup work in order to have the open-source world controlled by two shady companies instead of one.
What we want is to give every person the opportunity to host their own Git server without being ostracized. at the same time we must recognize that most people won't want to host their own servers (not even most open-source programmers!) and give everybody the ability to host their stuff on multi-tenant servers (such as GitHub) too. Importantly, though, if we allow for a random person to have a standalone Git server on a standalone server they host themselves on their wood cabin that also means any new hosting company can show up and start offering Git hosting, with or without new cool features, charging high or low or zero, and be immediately competing against GitHub or GitLab, i.e. we must remove the network-effect centralization pressure.
External contributions
The first problem we have to solve is: how can Bob contribute to Alice's repository without having an account on Alice's server?
SourceHut has reminded GitHub users that Git has always had this (for most) arcane
git send-emailcommand that is the original way to send patches, using an once-open protocol.Turns out Nostr acts as a quite powerful email replacement and can be used to send text content just like email, therefore patches are a very good fit for Nostr event contents.
Once you get used to it and the proper UIs (or CLIs) are built sending and applying patches to and from others becomes a much easier flow than the intense clickops mixed with terminal copypasting that is interacting with GitHub (you have to clone the repository on GitHub, then update the remote URL in your local directory, then create a branch and then go back and turn that branch into a Pull Request, it's quite tiresome) that many people already dislike so much they went out of their way to build many GitHub CLI tools just so they could comment on issues and approve pull requests from their terminal.
Replacing GitHub features
Aside from being the "hub" that people use to send patches to other people's code (because no one can do the email flow anymore, justifiably), GitHub also has 3 other big features that are not directly related to Git, but that make its network-effect harder to overcome. Luckily Nostr can be used to create a new environment in which these same features are implemented in a more decentralized and healthy way.
Issues: bug reports, feature requests and general discussions
Since the "Issues" GitHub feature is just a bunch of text comments it should be very obvious that Nostr is a perfect fit for it.
I will not even mention the fact that Nostr is much better at threading comments than GitHub (which doesn't do it at all), which can generate much more productive and organized discussions (and you can opt out if you want).
Search
I use GitHub search all the time to find libraries and projects that may do something that I need, and it returns good results almost always. So if people migrated out to other code hosting providers wouldn't we lose it?
The fact is that even though we think everybody is on GitHub that is a globalist falsehood. Some projects are not on GitHub, and if we use only GitHub for search those will be missed. So even if we didn't have a Nostr Git alternative it would still be necessary to create a search engine that incorporated GitLab, Codeberg, SourceHut and whatnot.
Turns out on Nostr we can make that quite easy by not forcing anyone to integrate custom APIs or hardcoding Git provider URLs: each repository can make itself available by publishing an "announcement" event with a brief description and one or more Git URLs. That makes it easy for a search engine to index them -- and even automatically download the code and index the code (or index just README files or whatever) without a centralized platform ever having to be involved.
The relays where such announcements will be available play a role, of course, but that isn't a bad role: each announcement can be in multiple relays known for storing "public good" projects, some relays may curate only projects known to be very good according to some standards, other relays may allow any kind of garbage, which wouldn't make them good for a search engine to rely upon, but would still be useful in case one knows the exact thing (and from whom) they're searching for (the same is valid for all Nostr content, by the way, and that's where it's censorship-resistance comes from).
Continuous integration
GitHub Actions are a very hardly subsidized free-compute-for-all-paid-by-Microsoft feature, but one that isn't hard to replace at all. In fact there exists today many companies offering the same kind of service out there -- although they are mostly targeting businesses and not open-source projects, before GitHub Actions was introduced there were also many that were heavily used by open-source projects.
One problem is that these services are still heavily tied to GitHub today, they require a GitHub login, sometimes BitBucket and GitLab and whatnot, and do not allow one to paste an arbitrary Git server URL, but that isn't a thing that is very hard to change anyway, or to start from scratch. All we need are services that offer the CI/CD flows, perhaps using the same framework of GitHub Actions (although I would prefer to not use that messy garbage), and charge some few satoshis for it.
It may be the case that all the current services only support the big Git hosting platforms because they rely on their proprietary APIs, most notably the webhooks dispatched when a repository is updated, to trigger the jobs. It doesn't have to be said that Nostr can also solve that problem very easily.
-
@ 3589b793:ad53847e
2025-04-30 10:53:29
※本記事は別サービスで2022年5月22日に公開した記事の移植です。
Happy 🍕 Day's Present
まだ邦訳版が出版されていませんがこれまでのシリーズと同じくGitHubにソースコードが公開されています。なんと、現在のライセンスでは個人使用限定なら翻訳や製本が可能です。Macで、翻訳にはPDFをインプットにできるDeepLを用いた環境で、インスタントに製本してKindleなどで読めるようにする方法をまとめました。
手順の概要
- Ruby環境を用意する
- PDF作成ツールをセットアップする
- GitHubのリポジトリを自分のPCにクローンする
- asciidocをPDFに変換する
- DeepLを節約するためにPDFを結合する
- DeepLで翻訳ファイルを作る
- 一冊に製本する
この手法の強み・弱み
翻訳だけならPDFを挟まなくてもGithubなどでプレビューできるコンパイル後のドキュメントの文章をコピーしてDeepLのWebツールにペーストすればよいですが、原著のペーパーブックで438ページある大容量です。熟練のコピペ職人でも年貢を納めて後進(機械やソフトウェア)に道を譲る刻ではないでしょうか?ただし、Pros/Consがあります。
Pros
- 一冊の本になるので毎度のコピペ作業がいらない
- Pizzaを食べながらタブレットやKindleで読める
- 図や表が欠落しない(プロトコルの手順を追った解説が多いため最大の動機でした)
- 2022/6/16追記: DeepLの拡張機能がアップデートされウェブページの丸ごと翻訳が可能になりました。よってウェブ上のgithubの図表付きページをそのまま翻訳できます。
Cons
- Money is power(大容量のためDeepLの有料契約が必要)
- ページを跨いだ文章が統合されずに不自然な翻訳になる(仕様です)
- ~~翻訳できない章が一つある(解決方法がないか調査中です。DeepLさんもっとエラーメッセージ出してくれ。Help me)~~ DeepLサポートに投げたら翻訳できるようになりました。
詳細ステップ
0.Ruby環境を用意する
asciidoctorも新しく入れるなら最新のビルドで良いでしょう。
1.PDF作成ツールをセットアップする
$ gem install asciidoctor asciidoctor-pdf $ brew install gs2.GitHubのリポジトリを自分のPCにクローンする
どこかの作業ディレクトリで以下を実行する
$ git clone git@github.com:lnbook/lnbook.git $ cd lnbook3.asciidocをPDFに変換する
ワイルドカードを用いて本文を根こそぎPDF化します。
$ asciidoctor-pdf 0*.asciidoc 1*.asciidocいろいろ解析の警告が出ますが、ソースのasciidocを弄んでいくなりawsomeライブラリを導入すれば解消できるはずです。しかし如何せん量が多いので心が折れます。いったん無視して"Done is better than perfect"精神で最後までやり切りましょう。そのままGO!
また、お好みに合わせて、htmlで用意されている装丁用の部品も準備しましょう。私は表紙のcover.htmlをピックしました。ソースがhtmlなのでasciidoctorを通さず普通にPDFへ変換します。https://qiita.com/chenglin/items/9c4ed0dd626234b71a2c
4.DeepLを節約するためにPDFを結合する
DeepLでは課金プラン毎に翻訳可能なファイル数が設定されている上に、一本あたりの最大ファイルサイズが10MBです。また、翻訳エラーになる章が含まれていると丸ごとコケます。そのためPDCAサイクルを回し、最適なファイル数を手探りで見つけます。以下が今回導出した解となります。
$ gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_1.pdf 01_introduction.pdf 02_getting_started.pdf 03_how_ln_works.pdf 04_node_client.pdf 05_node_operations.pdf$gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_2_1.pdf 06_lightning_architecture.pdf 07_payment_channels.pdf 08_routing_htlcs.pdf$gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_2_2.pdf 09_channel_operation.pdf 10_onion_routing.asciidoc$ gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output_3.pdf 11_gossip_channel_graph.pdf 12_path_finding.pdf 13_wire_protocol.pdf 14_encrypted_transport.pdf 15_payment_requests.pdf 16_security_privacy_ln.pdf 17_conclusion.pdf5. DeepLで翻訳ファイルを作る
PDFファイルを真心を込めた手作業で一つ一つDeepLにアップロードしていき翻訳ファイルを作ります。ファイル名はデフォルトの
[originalName](日本語).pdfのままにしています。6. 一冊に製本する
表紙 + 本文で作成する例です。
$ gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=mastering_ln_jp.pdf cover.pdf "output_1 (日本語).pdf" "output_2_1 (日本語).pdf" "output_2_2 (日本語).pdf" "output_3 (日本語).pdf"コングラチュレーションズ🎉

あなたは『Mastering the Lightning Network』の日本語版を手に入れた!個人使用に限り、あとは煮るなり焼くなりEPUBなりkindleへ送信するなり好き放題だ。
-
@ 4e616576:43c4fee8
2025-04-30 13:11:58
asdfasdfasfd
-
@ 40b9c85f:5e61b451
2025-04-24 15:27:02
Introduction
Data Vending Machines (DVMs) have emerged as a crucial component of the Nostr ecosystem, offering specialized computational services to clients across the network. As defined in NIP-90, DVMs operate on an apparently simple principle: "data in, data out." They provide a marketplace for data processing where users request specific jobs (like text translation, content recommendation, or AI text generation)
While DVMs have gained significant traction, the current specification faces challenges that hinder widespread adoption and consistent implementation. This article explores some ideas on how we can apply the reflection pattern, a well established approach in RPC systems, to address these challenges and improve the DVM ecosystem's clarity, consistency, and usability.
The Current State of DVMs: Challenges and Limitations
The NIP-90 specification provides a broad framework for DVMs, but this flexibility has led to several issues:
1. Inconsistent Implementation
As noted by hzrd149 in "DVMs were a mistake" every DVM implementation tends to expect inputs in slightly different formats, even while ostensibly following the same specification. For example, a translation request DVM might expect an event ID in one particular format, while an LLM service could expect a "prompt" input that's not even specified in NIP-90.
2. Fragmented Specifications
The DVM specification reserves a range of event kinds (5000-6000), each meant for different types of computational jobs. While creating sub-specifications for each job type is being explored as a possible solution for clarity, in a decentralized and permissionless landscape like Nostr, relying solely on specification enforcement won't be effective for creating a healthy ecosystem. A more comprehensible approach is needed that works with, rather than against, the open nature of the protocol.
3. Ambiguous API Interfaces
There's no standardized way for clients to discover what parameters a specific DVM accepts, which are required versus optional, or what output format to expect. This creates uncertainty and forces developers to rely on documentation outside the protocol itself, if such documentation exists at all.
The Reflection Pattern: A Solution from RPC Systems
The reflection pattern in RPC systems offers a compelling solution to many of these challenges. At its core, reflection enables servers to provide metadata about their available services, methods, and data types at runtime, allowing clients to dynamically discover and interact with the server's API.
In established RPC frameworks like gRPC, reflection serves as a self-describing mechanism where services expose their interface definitions and requirements. In MCP reflection is used to expose the capabilities of the server, such as tools, resources, and prompts. Clients can learn about available capabilities without prior knowledge, and systems can adapt to changes without requiring rebuilds or redeployments. This standardized introspection creates a unified way to query service metadata, making tools like
grpcurlpossible without requiring precompiled stubs.How Reflection Could Transform the DVM Specification
By incorporating reflection principles into the DVM specification, we could create a more coherent and predictable ecosystem. DVMs already implement some sort of reflection through the use of 'nip90params', which allow clients to discover some parameters, constraints, and features of the DVMs, such as whether they accept encryption, nutzaps, etc. However, this approach could be expanded to provide more comprehensive self-description capabilities.
1. Defined Lifecycle Phases
Similar to the Model Context Protocol (MCP), DVMs could benefit from a clear lifecycle consisting of an initialization phase and an operation phase. During initialization, the client and DVM would negotiate capabilities and exchange metadata, with the DVM providing a JSON schema containing its input requirements. nip-89 (or other) announcements can be used to bootstrap the discovery and negotiation process by providing the input schema directly. Then, during the operation phase, the client would interact with the DVM according to the negotiated schema and parameters.
2. Schema-Based Interactions
Rather than relying on rigid specifications for each job type, DVMs could self-advertise their schemas. This would allow clients to understand which parameters are required versus optional, what type validation should occur for inputs, what output formats to expect, and what payment flows are supported. By internalizing the input schema of the DVMs they wish to consume, clients gain clarity on how to interact effectively.
3. Capability Negotiation
Capability negotiation would enable DVMs to advertise their supported features, such as encryption methods, payment options, or specialized functionalities. This would allow clients to adjust their interaction approach based on the specific capabilities of each DVM they encounter.
Implementation Approach
While building DVMCP, I realized that the RPC reflection pattern used there could be beneficial for constructing DVMs in general. Since DVMs already follow an RPC style for their operation, and reflection is a natural extension of this approach, it could significantly enhance and clarify the DVM specification.
A reflection enhanced DVM protocol could work as follows: 1. Discovery: Clients discover DVMs through existing NIP-89 application handlers, input schemas could also be advertised in nip-89 announcements, making the second step unnecessary. 2. Schema Request: Clients request the DVM's input schema for the specific job type they're interested in 3. Validation: Clients validate their request against the provided schema before submission 4. Operation: The job proceeds through the standard NIP-90 flow, but with clearer expectations on both sides
Parallels with Other Protocols
This approach has proven successful in other contexts. The Model Context Protocol (MCP) implements a similar lifecycle with capability negotiation during initialization, allowing any client to communicate with any server as long as they adhere to the base protocol. MCP and DVM protocols share fundamental similarities, both aim to expose and consume computational resources through a JSON-RPC-like interface, albeit with specific differences.
gRPC's reflection service similarly allows clients to discover service definitions at runtime, enabling generic tools to work with any gRPC service without prior knowledge. In the REST API world, OpenAPI/Swagger specifications document interfaces in a way that makes them discoverable and testable.
DVMs would benefit from adopting these patterns while maintaining the decentralized, permissionless nature of Nostr.
Conclusion
I am not attempting to rewrite the DVM specification; rather, explore some ideas that could help the ecosystem improve incrementally, reducing fragmentation and making the ecosystem more comprehensible. By allowing DVMs to self describe their interfaces, we could maintain the flexibility that makes Nostr powerful while providing the structure needed for interoperability.
For developers building DVM clients or libraries, this approach would simplify consumption by providing clear expectations about inputs and outputs. For DVM operators, it would establish a standard way to communicate their service's requirements without relying on external documentation.
I am currently developing DVMCP following these patterns. Of course, DVMs and MCP servers have different details; MCP includes capabilities such as tools, resources, and prompts on the server side, as well as 'roots' and 'sampling' on the client side, creating a bidirectional way to consume capabilities. In contrast, DVMs typically function similarly to MCP tools, where you call a DVM with an input and receive an output, with each job type representing a different categorization of the work performed.
Without further ado, I hope this article has provided some insight into the potential benefits of applying the reflection pattern to the DVM specification.
-
@ 4ba8e86d:89d32de4
2025-04-21 02:13:56
Tutorial feito por nostr:nostr:npub1rc56x0ek0dd303eph523g3chm0wmrs5wdk6vs0ehd0m5fn8t7y4sqra3tk poste original abaixo:
Parte 1 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/263585/tutorial-debloat-de-celulares-android-via-adb-parte-1
Parte 2 : http://xh6liiypqffzwnu5734ucwps37tn2g6npthvugz3gdoqpikujju525yd.onion/index.php/263586/tutorial-debloat-de-celulares-android-via-adb-parte-2
Quando o assunto é privacidade em celulares, uma das medidas comumente mencionadas é a remoção de bloatwares do dispositivo, também chamado de debloat. O meio mais eficiente para isso sem dúvidas é a troca de sistema operacional. Custom Rom’s como LineageOS, GrapheneOS, Iodé, CalyxOS, etc, já são bastante enxutos nesse quesito, principalmente quanto não é instalado os G-Apps com o sistema. No entanto, essa prática pode acabar resultando em problemas indesejados como a perca de funções do dispositivo, e até mesmo incompatibilidade com apps bancários, tornando este método mais atrativo para quem possui mais de um dispositivo e separando um apenas para privacidade. Pensando nisso, pessoas que possuem apenas um único dispositivo móvel, que são necessitadas desses apps ou funções, mas, ao mesmo tempo, tem essa visão em prol da privacidade, buscam por um meio-termo entre manter a Stock rom, e não ter seus dados coletados por esses bloatwares. Felizmente, a remoção de bloatwares é possível e pode ser realizada via root, ou mais da maneira que este artigo irá tratar, via adb.
O que são bloatwares?
Bloatware é a junção das palavras bloat (inchar) + software (programa), ou seja, um bloatware é basicamente um programa inútil ou facilmente substituível — colocado em seu dispositivo previamente pela fabricante e operadora — que está no seu dispositivo apenas ocupando espaço de armazenamento, consumindo memória RAM e pior, coletando seus dados e enviando para servidores externos, além de serem mais pontos de vulnerabilidades.
O que é o adb?
O Android Debug Brigde, ou apenas adb, é uma ferramenta que se utiliza das permissões de usuário shell e permite o envio de comandos vindo de um computador para um dispositivo Android exigindo apenas que a depuração USB esteja ativa, mas também pode ser usada diretamente no celular a partir do Android 11, com o uso do Termux e a depuração sem fio (ou depuração wifi). A ferramenta funciona normalmente em dispositivos sem root, e também funciona caso o celular esteja em Recovery Mode.
Requisitos:
Para computadores:
• Depuração USB ativa no celular; • Computador com adb; • Cabo USB;
Para celulares:
• Depuração sem fio (ou depuração wifi) ativa no celular; • Termux; • Android 11 ou superior;
Para ambos:
• Firewall NetGuard instalado e configurado no celular; • Lista de bloatwares para seu dispositivo;
Ativação de depuração:
Para ativar a Depuração USB em seu dispositivo, pesquise como ativar as opções de desenvolvedor de seu dispositivo, e lá ative a depuração. No caso da depuração sem fio, sua ativação irá ser necessária apenas no momento que for conectar o dispositivo ao Termux.
Instalação e configuração do NetGuard
O NetGuard pode ser instalado através da própria Google Play Store, mas de preferência instale pela F-Droid ou Github para evitar telemetria.
F-Droid: https://f-droid.org/packages/eu.faircode.netguard/
Github: https://github.com/M66B/NetGuard/releases
Após instalado, configure da seguinte maneira:
Configurações → padrões (lista branca/negra) → ative as 3 primeiras opções (bloquear wifi, bloquear dados móveis e aplicar regras ‘quando tela estiver ligada’);
Configurações → opções avançadas → ative as duas primeiras (administrar aplicativos do sistema e registrar acesso a internet);
Com isso, todos os apps estarão sendo bloqueados de acessar a internet, seja por wifi ou dados móveis, e na página principal do app basta permitir o acesso a rede para os apps que você vai usar (se necessário). Permita que o app rode em segundo plano sem restrição da otimização de bateria, assim quando o celular ligar, ele já estará ativo.
Lista de bloatwares
Nem todos os bloatwares são genéricos, haverá bloatwares diferentes conforme a marca, modelo, versão do Android, e até mesmo região.
Para obter uma lista de bloatwares de seu dispositivo, caso seu aparelho já possua um tempo de existência, você encontrará listas prontas facilmente apenas pesquisando por elas. Supondo que temos um Samsung Galaxy Note 10 Plus em mãos, basta pesquisar em seu motor de busca por:
Samsung Galaxy Note 10 Plus bloatware listProvavelmente essas listas já terão inclusas todos os bloatwares das mais diversas regiões, lhe poupando o trabalho de buscar por alguma lista mais específica.
Caso seu aparelho seja muito recente, e/ou não encontre uma lista pronta de bloatwares, devo dizer que você acaba de pegar em merda, pois é chato para um caralho pesquisar por cada aplicação para saber sua função, se é essencial para o sistema ou se é facilmente substituível.
De antemão já aviso, que mais para frente, caso vossa gostosura remova um desses aplicativos que era essencial para o sistema sem saber, vai acabar resultando na perda de alguma função importante, ou pior, ao reiniciar o aparelho o sistema pode estar quebrado, lhe obrigando a seguir com uma formatação, e repetir todo o processo novamente.
Download do adb em computadores
Para usar a ferramenta do adb em computadores, basta baixar o pacote chamado SDK platform-tools, disponível através deste link: https://developer.android.com/tools/releases/platform-tools. Por ele, você consegue o download para Windows, Mac e Linux.
Uma vez baixado, basta extrair o arquivo zipado, contendo dentro dele uma pasta chamada platform-tools que basta ser aberta no terminal para se usar o adb.
Download do adb em celulares com Termux.
Para usar a ferramenta do adb diretamente no celular, antes temos que baixar o app Termux, que é um emulador de terminal linux, e já possui o adb em seu repositório. Você encontra o app na Google Play Store, mas novamente recomendo baixar pela F-Droid ou diretamente no Github do projeto.
F-Droid: https://f-droid.org/en/packages/com.termux/
Github: https://github.com/termux/termux-app/releases
Processo de debloat
Antes de iniciarmos, é importante deixar claro que não é para você sair removendo todos os bloatwares de cara sem mais nem menos, afinal alguns deles precisam antes ser substituídos, podem ser essenciais para você para alguma atividade ou função, ou até mesmo são insubstituíveis.
Alguns exemplos de bloatwares que a substituição é necessária antes da remoção, é o Launcher, afinal, é a interface gráfica do sistema, e o teclado, que sem ele só é possível digitar com teclado externo. O Launcher e teclado podem ser substituídos por quaisquer outros, minha recomendação pessoal é por aqueles que respeitam sua privacidade, como Pie Launcher e Simple Laucher, enquanto o teclado pelo OpenBoard e FlorisBoard, todos open-source e disponíveis da F-Droid.
Identifique entre a lista de bloatwares, quais você gosta, precisa ou prefere não substituir, de maneira alguma você é obrigado a remover todos os bloatwares possíveis, modifique seu sistema a seu bel-prazer. O NetGuard lista todos os apps do celular com o nome do pacote, com isso você pode filtrar bem qual deles não remover.
Um exemplo claro de bloatware insubstituível e, portanto, não pode ser removido, é o com.android.mtp, um protocolo onde sua função é auxiliar a comunicação do dispositivo com um computador via USB, mas por algum motivo, tem acesso a rede e se comunica frequentemente com servidores externos. Para esses casos, e melhor solução mesmo é bloquear o acesso a rede desses bloatwares com o NetGuard.
MTP tentando comunicação com servidores externos:
Executando o adb shell
No computador
Faça backup de todos os seus arquivos importantes para algum armazenamento externo, e formate seu celular com o hard reset. Após a formatação, e a ativação da depuração USB, conecte seu aparelho e o pc com o auxílio de um cabo USB. Muito provavelmente seu dispositivo irá apenas começar a carregar, por isso permita a transferência de dados, para que o computador consiga se comunicar normalmente com o celular.
Já no pc, abra a pasta platform-tools dentro do terminal, e execute o seguinte comando:
./adb start-serverO resultado deve ser:
daemon not running; starting now at tcp:5037 daemon started successfully
E caso não apareça nada, execute:
./adb kill-serverE inicie novamente.
Com o adb conectado ao celular, execute:
./adb shellPara poder executar comandos diretamente para o dispositivo. No meu caso, meu celular é um Redmi Note 8 Pro, codinome Begonia.
Logo o resultado deve ser:
begonia:/ $
Caso ocorra algum erro do tipo:
adb: device unauthorized. This adb server’s $ADB_VENDOR_KEYS is not set Try ‘adb kill-server’ if that seems wrong. Otherwise check for a confirmation dialog on your device.
Verifique no celular se apareceu alguma confirmação para autorizar a depuração USB, caso sim, autorize e tente novamente. Caso não apareça nada, execute o kill-server e repita o processo.
No celular
Após realizar o mesmo processo de backup e hard reset citado anteriormente, instale o Termux e, com ele iniciado, execute o comando:
pkg install android-toolsQuando surgir a mensagem “Do you want to continue? [Y/n]”, basta dar enter novamente que já aceita e finaliza a instalação
Agora, vá até as opções de desenvolvedor, e ative a depuração sem fio. Dentro das opções da depuração sem fio, terá uma opção de emparelhamento do dispositivo com um código, que irá informar para você um código em emparelhamento, com um endereço IP e porta, que será usado para a conexão com o Termux.
Para facilitar o processo, recomendo que abra tanto as configurações quanto o Termux ao mesmo tempo, e divida a tela com os dois app’s, como da maneira a seguir:
Para parear o Termux com o dispositivo, não é necessário digitar o ip informado, basta trocar por “localhost”, já a porta e o código de emparelhamento, deve ser digitado exatamente como informado. Execute:
adb pair localhost:porta CódigoDeEmparelhamentoDe acordo com a imagem mostrada anteriormente, o comando ficaria “adb pair localhost:41255 757495”.
Com o dispositivo emparelhado com o Termux, agora basta conectar para conseguir executar os comandos, para isso execute:
adb connect localhost:portaObs: a porta que você deve informar neste comando não é a mesma informada com o código de emparelhamento, e sim a informada na tela principal da depuração sem fio.
Pronto! Termux e adb conectado com sucesso ao dispositivo, agora basta executar normalmente o adb shell:
adb shellRemoção na prática Com o adb shell executado, você está pronto para remover os bloatwares. No meu caso, irei mostrar apenas a remoção de um app (Google Maps), já que o comando é o mesmo para qualquer outro, mudando apenas o nome do pacote.
Dentro do NetGuard, verificando as informações do Google Maps:
Podemos ver que mesmo fora de uso, e com a localização do dispositivo desativado, o app está tentando loucamente se comunicar com servidores externos, e informar sabe-se lá que peste. Mas sem novidades até aqui, o mais importante é que podemos ver que o nome do pacote do Google Maps é com.google.android.apps.maps, e para o remover do celular, basta executar:
pm uninstall –user 0 com.google.android.apps.mapsE pronto, bloatware removido! Agora basta repetir o processo para o resto dos bloatwares, trocando apenas o nome do pacote.
Para acelerar o processo, você pode já criar uma lista do bloco de notas com os comandos, e quando colar no terminal, irá executar um atrás do outro.
Exemplo de lista:
Caso a donzela tenha removido alguma coisa sem querer, também é possível recuperar o pacote com o comando:
cmd package install-existing nome.do.pacotePós-debloat
Após limpar o máximo possível o seu sistema, reinicie o aparelho, caso entre no como recovery e não seja possível dar reboot, significa que você removeu algum app “essencial” para o sistema, e terá que formatar o aparelho e repetir toda a remoção novamente, desta vez removendo poucos bloatwares de uma vez, e reiniciando o aparelho até descobrir qual deles não pode ser removido. Sim, dá trabalho… quem mandou querer privacidade?
Caso o aparelho reinicie normalmente após a remoção, parabéns, agora basta usar seu celular como bem entender! Mantenha o NetGuard sempre executando e os bloatwares que não foram possíveis remover não irão se comunicar com servidores externos, passe a usar apps open source da F-Droid e instale outros apps através da Aurora Store ao invés da Google Play Store.
Referências: Caso você seja um Australopithecus e tenha achado este guia difícil, eis uma videoaula (3:14:40) do Anderson do canal Ciberdef, realizando todo o processo: http://odysee.com/@zai:5/Como-remover-at%C3%A9-200-APLICATIVOS-que-colocam-a-sua-PRIVACIDADE-E-SEGURAN%C3%87A-em-risco.:4?lid=6d50f40314eee7e2f218536d9e5d300290931d23
Pdf’s do Anderson citados na videoaula: créditos ao anon6837264 http://eternalcbrzpicytj4zyguygpmkjlkddxob7tptlr25cdipe5svyqoqd.onion/file/3863a834d29285d397b73a4af6fb1bbe67c888d72d30/t-05e63192d02ffd.pdf
Processo de instalação do Termux e adb no celular: https://youtu.be/APolZrPHSms
-
@ a5142938:0ef19da3
2025-04-30 10:34:58
Dilling is a Danish brand that creates wool, silk, and organic cotton clothing for the whole family.
Natural materials used in products
- Cotton (organic)
- Natural latex (OEKO-TEX ®)
- Silk
- Wool (merino, alpaca)
⚠️ Warning: some products from this brand (especially Clothes – socks, jackets, thongs, shorts) contain non-natural materials, including:
- Elastane, spandex, lycra
- Polyamide, nylon (recycled nylon)
- Polyester (recycled)
Categories of products offered
-
Clothing: men, women, children, babies, underwear, t-shirts, tank tops, dresses, jackets, trousers, shorts, sweaters, cardigans, bodysuits, jumpsuits, panties, briefs, boxers...
👉 See natural products from this brand
Other information
- Nordic Swan ecolabel (dye)
- Made in Lithuania (cutting and sewing)
- Made in Denmark (dye)
- Made in Europe
👉 Learn more on the brand's website
This article is published on origin-nature.com 🌐 Voir cet article en français
📝 You can contribute to this entry by suggesting edits in comments.
🗣️ Do you use this product? Share your opinion in the comments.
⚡ Happy to have found this information? Support the project by making a donation to thank the contributors.
-
@ 35f80bda:406855c0
2025-04-16 03:11:46
O Bitcoin Core 29.0 foi oficialmente lançado e traz diversas melhorias técnicas voltadas para desenvolvedores, operadores de full nodes e a comunidade Bitcoin mais técnica. Desde mudanças na camada de rede até a atualização do sistema de build, este release é um passo significativo na modernização do ecossistema.
Se você roda um full node, desenvolve software que interage com o Core via RPC ou apenas quer estar por dentro das novidades técnicas, este artigo é para você.
Alterações na Rede e no P2P
Suporte ao UPnP Removido O UPnP foi totalmente desativado por razões de segurança e manutenção. Agora, a recomendação é utilizar a flag -natpmp, que conta com uma implementação interna de PCP e NAT-PMP. Mais seguro e mais leve.
Melhorias no Suporte Tor A porta onion agora é derivada da flag -port, permitindo múltiplos nós Tor na mesma máquina — ótimo para quem opera ambientes de teste ou múltiplos peers.
Transações Órfãs com Propagação Aprimorada O node agora tenta buscar os parents de transações órfãs consultando todos os peers que anunciaram a transação. Isso ajuda a preencher lacunas na mempool de forma mais eficiente.
Mempool e Política de Mineração
Ephemeral Dust Introdução de um novo conceito: ephemeral dust, que permite uma saída "dust" gratuita em uma transação desde que ela seja gasta dentro do mesmo pacote. Pode ser útil para otimizações de fees.
Correção no Peso Reservado de Blocos Bug que causava duplicação de peso reservado foi corrigido. Agora existe a flag -blockreservedweight, com limite mínimo de 2000 WU.
RPCs e REST mais robustos
- testmempoolaccept agora fornece o campo reject-details.
- submitblock preserva blocos duplicados mesmo que tenham sido podados.
- getblock, getblockheader e getblockchaininfo agora incluem o campo nBits (alvo de dificuldade).
- Novo RPC: getdescriptoractivity, que permite ver atividades de descritores em intervalos de blocos.
- APIs REST agora retornam nBits também no campo target.
Sistema de Build Modernizado
Uma das mudanças mais bem-vindas: o Bitcoin Core agora usa CMake em vez de Autotools como padrão de build. Isso facilita integração com IDEs, CI/CD pipelines modernos e personalização do build.
Outras Atualizações Importantes
- -dbcache teve limite máximo reduzido para lidar com o crescimento do conjunto UTXO.
- O comportamento Full Replace-by-Fee (RBF) agora é padrão. A flag -mempoolfullrbf foi removida.
- Aumentaram os valores padrão de -rpcthreads e -rpcworkqueue para lidar com maior paralelismo.
Ferramentas Novas
Uma nova ferramenta chamada utxo_to_sqlite.py converte snapshots compactos do conjunto UTXO para SQLite3. Excelente para quem quer auditar ou explorar o estado da blockchain com ferramentas padrão de banco de dados.
Limpeza de Dependências
As bibliotecas externas MiniUPnPc e libnatpmp foram removidas, substituídas por implementações internas. Menos dependências = manutenção mais fácil e menos riscos.
Como atualizar?
- Pare o seu nó atual com segurança.
- Instale a nova versão.
- Verifique configurações como -dbcache, -blockreservedweight e o comportamento RBF.
- Consulte os logs com atenção nas primeiras execuções para validar o novo comportamento.
Conclusão
O Bitcoin Core 29.0 representa um passo firme em direção a uma base de código mais moderna, segura e modular. Para quem mantém nós, desenvolve soluções sobre o Core ou audita a rede, é uma atualização que vale a pena testar e entender a fundo.
Já testou a nova versão? Notou impactos nas suas aplicações ou infraestrutura?
Referências
-
@ e4950c93:1b99eccd
2025-04-30 10:34:08
Dilling est une marque danoise qui crée des vêtements en laine, soie et coton biologique pour toute la famille.
Matières naturelles utilisées dans les produits
- Coton (biologique)
- Laine (mérinos, alpaga)
- Latex naturel (OEKO-TEX ®)
- Soie
⚠️ Attention, certains produits de cette marque (notamment les Vêtements - chaussettes, vestes, strings, shorts) contiennent des matières non naturelles, dont :
- Elasthanne
- Polyamide, nylon (nylon recyclé)
- Polyester (recyclé)
Catégories de produits proposés
-
Vêtements : homme, femme, enfant, bébé, sous-vêtements, t-shirts, débardeurs, robes, vestes, pantalons, shorts, pulls, gilets, bodies, combinaisons, culottes, slips, boxers...
👉 Voir les produits naturels de cette marque
Autres informations
- Ecolabel Nordic Swan (teintures)
- Fabriqué en Lituanie (coupe et couture)
- Fabriqué au Danemark (teintures)
- Fabriqué en Europe
👉 En savoir plus sur le site de la marque
Cet article est publié sur origine-nature.com 🌐 See this article in English
📝 Vous pouvez contribuer à cette fiche en suggérant une modification en commentaire.
🗣️ Vous utilisez ce produit ? Partagez votre avis en commentaire.
⚡ Heureu-x-se de trouver cette information ? Soutenez le projet en faisant un don, pour remercier les contribut-eur-ice-s.
-
@ 4e616576:43c4fee8
2025-04-30 12:53:36
sdfafd
-
@ d08c9312:73efcc9f
2025-04-30 09:59:52
Resolvr CEO, Aaron Daniel, summarizes his keynote speech from the Bitcoin Insurance Summit, April 26, 2025
Introduction
At the inaugural Bitcoin Insurance Summit in Miami, I had the pleasure of sharing two historical parallels that illuminate why "Bitcoin needs insurance, and insurance needs Bitcoin." The insurance industry's reactions to fire and coffee can help us better understand the profound relationship between emerging technologies, risk management, and commercial innovation.
Fire: Why Bitcoin Needs Insurance
The first story explores how the insurance industry's response to catastrophic urban fires shaped modern building safety. Following devastating events like the Great Fire of London (1666) and the Great Chicago Fire (1871), the nascent insurance industry began engaging with fire risk systematically.
Initially, insurers offered private fire brigades to policyholders who displayed their company's fire mark on their buildings. This evolved into increasingly sophisticated risk assessment and pricing models throughout the 19th century:
- Early 19th century: Basic risk classifications with simple underwriting based on rules of thumb
- Mid-19th century: Detailed construction types and cooperative sharing of loss data through trade associations
- Late 19th/Early 20th century: Scientific, data-driven approaches with differentiated rate pricing
The insurance industry fundamentally transformed building construction practices by developing evidence-based standards that would later inform regulatory frameworks. Organizations like the National Board of Fire Underwriters (founded 1866) and Underwriters Laboratories (established 1894) tested and standardized new technologies, turning seemingly risky innovations like electricity into safer, controlled advancements.
This pattern offers a powerful precedent for Bitcoin. Like electricity, Bitcoin represents a new technology that appears inherently risky but has tremendous potential for society. By engaging with Bitcoin rather than avoiding it, the insurance industry can develop evidence-based standards, implement proper controls, and ultimately make the entire Bitcoin ecosystem safer and more robust.
Coffee: Why Insurance Needs Bitcoin
The second story reveals how coffee houses in 17th-century England became commercial hubs that gave birth to modern insurance. Nathaniel Canopius brewed the first documented cup of coffee in England in 1637. But it wasn't until advances in navigation and shipping technology opened new trade lanes that coffee became truly ubiquitous in England. Once global trade blossomed, coffee houses rapidly spread throughout London, becoming centers of business, information exchange, and innovation.
In 1686, Edward Lloyd opened his coffee house catering to sailors, merchants, and shipowners, which would eventually evolve into Lloyd's of London. Similarly, Jonathan's Coffee House became the birthplace of what would become the London Stock Exchange.
These coffee houses functioned as information networks where merchants could access shipping news and trade opportunities, as well as risk management solutions. They created a virtuous cycle: better shipping technology brought more coffee, which fueled commerce and led to better marine insurance and financing, which in turn improved global trade.
Today, we're experiencing a similar technological and financial revolution with Bitcoin. This digital, programmable money moves at the speed of light and operates 24/7 as a nearly $2 trillion asset class. The insurance industry stands to benefit tremendously by embracing this innovation early.
Conclusion
The lessons from history are clear. Just as the insurance industry drove safety improvements by engaging with fire risk, it can help develop standards and best practices for Bitcoin security. And just as coffee houses created commercial networks that revolutionized finance, insurance, and trade, Bitcoin offers new pathways for global commerce and risk management.
For the insurance industry to remain relevant in a rapidly digitizing world, it must engage with Bitcoin rather than avoid it. The companies that recognize this opportunity first will enjoy significant advantages, while those who resist change risk being left behind.
The Bitcoin Insurance Summit represented an important first step in creating the collaborative spaces needed for this transformation—a modern version of those innovative coffee houses that changed the world over three centuries ago.
View Aaron's full keynote:
https://youtu.be/eIjT1H2XuCU
For more information about how Resolvr can help your organization leverage Bitcoin in its operations, contact us today.
-
@ 4e616576:43c4fee8
2025-04-30 09:57:29
asdf
-
@ 4e616576:43c4fee8
2025-04-30 09:48:05
asdfasdflkjasdf
-
@ 4e616576:43c4fee8
2025-04-30 09:42:33
lorem ipsum
-
@ 91bea5cd:1df4451c
2025-04-15 06:27:28
Básico
bash lsblk # Lista todos os diretorios montados.Para criar o sistema de arquivos:
bash mkfs.btrfs -L "ThePool" -f /dev/sdxCriando um subvolume:
bash btrfs subvolume create SubVolMontando Sistema de Arquivos:
bash mount -o compress=zlib,subvol=SubVol,autodefrag /dev/sdx /mntLista os discos formatados no diretório:
bash btrfs filesystem show /mntAdiciona novo disco ao subvolume:
bash btrfs device add -f /dev/sdy /mntLista novamente os discos do subvolume:
bash btrfs filesystem show /mntExibe uso dos discos do subvolume:
bash btrfs filesystem df /mntBalancea os dados entre os discos sobre raid1:
bash btrfs filesystem balance start -dconvert=raid1 -mconvert=raid1 /mntScrub é uma passagem por todos os dados e metadados do sistema de arquivos e verifica as somas de verificação. Se uma cópia válida estiver disponível (perfis de grupo de blocos replicados), a danificada será reparada. Todas as cópias dos perfis replicados são validadas.
iniciar o processo de depuração :
bash btrfs scrub start /mntver o status do processo de depuração Btrfs em execução:
bash btrfs scrub status /mntver o status do scrub Btrfs para cada um dos dispositivos
bash btrfs scrub status -d / data btrfs scrub cancel / dataPara retomar o processo de depuração do Btrfs que você cancelou ou pausou:
btrfs scrub resume / data
Listando os subvolumes:
bash btrfs subvolume list /ReportsCriando um instantâneo dos subvolumes:
Aqui, estamos criando um instantâneo de leitura e gravação chamado snap de marketing do subvolume de marketing.
bash btrfs subvolume snapshot /Reports/marketing /Reports/marketing-snapAlém disso, você pode criar um instantâneo somente leitura usando o sinalizador -r conforme mostrado. O marketing-rosnap é um instantâneo somente leitura do subvolume de marketing
bash btrfs subvolume snapshot -r /Reports/marketing /Reports/marketing-rosnapForçar a sincronização do sistema de arquivos usando o utilitário 'sync'
Para forçar a sincronização do sistema de arquivos, invoque a opção de sincronização conforme mostrado. Observe que o sistema de arquivos já deve estar montado para que o processo de sincronização continue com sucesso.
bash btrfs filsystem sync /ReportsPara excluir o dispositivo do sistema de arquivos, use o comando device delete conforme mostrado.
bash btrfs device delete /dev/sdc /ReportsPara sondar o status de um scrub, use o comando scrub status com a opção -dR .
bash btrfs scrub status -dR / RelatóriosPara cancelar a execução do scrub, use o comando scrub cancel .
bash $ sudo btrfs scrub cancel / ReportsPara retomar ou continuar com uma depuração interrompida anteriormente, execute o comando de cancelamento de depuração
bash sudo btrfs scrub resume /Reportsmostra o uso do dispositivo de armazenamento:
btrfs filesystem usage /data
Para distribuir os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID (incluindo o dispositivo de armazenamento recém-adicionado) montados no diretório /data , execute o seguinte comando:
sudo btrfs balance start --full-balance /data
Pode demorar um pouco para espalhar os dados, metadados e dados do sistema em todos os dispositivos de armazenamento do RAID se ele contiver muitos dados.
Opções importantes de montagem Btrfs
Nesta seção, vou explicar algumas das importantes opções de montagem do Btrfs. Então vamos começar.
As opções de montagem Btrfs mais importantes são:
**1. acl e noacl
**ACL gerencia permissões de usuários e grupos para os arquivos/diretórios do sistema de arquivos Btrfs.
A opção de montagem acl Btrfs habilita ACL. Para desabilitar a ACL, você pode usar a opção de montagem noacl .
Por padrão, a ACL está habilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem acl por padrão.
**2. autodefrag e noautodefrag
**Desfragmentar um sistema de arquivos Btrfs melhorará o desempenho do sistema de arquivos reduzindo a fragmentação de dados.
A opção de montagem autodefrag permite a desfragmentação automática do sistema de arquivos Btrfs.
A opção de montagem noautodefrag desativa a desfragmentação automática do sistema de arquivos Btrfs.
Por padrão, a desfragmentação automática está desabilitada. Portanto, o sistema de arquivos Btrfs usa a opção de montagem noautodefrag por padrão.
**3. compactar e compactar-forçar
**Controla a compactação de dados no nível do sistema de arquivos do sistema de arquivos Btrfs.
A opção compactar compacta apenas os arquivos que valem a pena compactar (se compactar o arquivo economizar espaço em disco).
A opção compress-force compacta todos os arquivos do sistema de arquivos Btrfs, mesmo que a compactação do arquivo aumente seu tamanho.
O sistema de arquivos Btrfs suporta muitos algoritmos de compactação e cada um dos algoritmos de compactação possui diferentes níveis de compactação.
Os algoritmos de compactação suportados pelo Btrfs são: lzo , zlib (nível 1 a 9) e zstd (nível 1 a 15).
Você pode especificar qual algoritmo de compactação usar para o sistema de arquivos Btrfs com uma das seguintes opções de montagem:
- compress=algoritmo:nível
- compress-force=algoritmo:nível
Para obter mais informações, consulte meu artigo Como habilitar a compactação do sistema de arquivos Btrfs .
**4. subvol e subvolid
**Estas opções de montagem são usadas para montar separadamente um subvolume específico de um sistema de arquivos Btrfs.
A opção de montagem subvol é usada para montar o subvolume de um sistema de arquivos Btrfs usando seu caminho relativo.
A opção de montagem subvolid é usada para montar o subvolume de um sistema de arquivos Btrfs usando o ID do subvolume.
Para obter mais informações, consulte meu artigo Como criar e montar subvolumes Btrfs .
**5. dispositivo
A opção de montagem de dispositivo** é usada no sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs.
Em alguns casos, o sistema operacional pode falhar ao detectar os dispositivos de armazenamento usados em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs. Nesses casos, você pode usar a opção de montagem do dispositivo para especificar os dispositivos que deseja usar para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar a opção de montagem de dispositivo várias vezes para carregar diferentes dispositivos de armazenamento para o sistema de arquivos de vários dispositivos Btrfs ou RAID.
Você pode usar o nome do dispositivo (ou seja, sdb , sdc ) ou UUID , UUID_SUB ou PARTUUID do dispositivo de armazenamento com a opção de montagem do dispositivo para identificar o dispositivo de armazenamento.
Por exemplo,
- dispositivo=/dev/sdb
- dispositivo=/dev/sdb,dispositivo=/dev/sdc
- dispositivo=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d
- device=UUID_SUB=490a263d-eb9a-4558-931e-998d4d080c5d,device=UUID_SUB=f7ce4875-0874-436a-b47d-3edef66d3424
**6. degraded
A opção de montagem degradada** permite que um RAID Btrfs seja montado com menos dispositivos de armazenamento do que o perfil RAID requer.
Por exemplo, o perfil raid1 requer a presença de 2 dispositivos de armazenamento. Se um dos dispositivos de armazenamento não estiver disponível em qualquer caso, você usa a opção de montagem degradada para montar o RAID mesmo que 1 de 2 dispositivos de armazenamento esteja disponível.
**7. commit
A opção commit** mount é usada para definir o intervalo (em segundos) dentro do qual os dados serão gravados no dispositivo de armazenamento.
O padrão é definido como 30 segundos.
Para definir o intervalo de confirmação para 15 segundos, você pode usar a opção de montagem commit=15 (digamos).
**8. ssd e nossd
A opção de montagem ssd** informa ao sistema de arquivos Btrfs que o sistema de arquivos está usando um dispositivo de armazenamento SSD, e o sistema de arquivos Btrfs faz a otimização SSD necessária.
A opção de montagem nossd desativa a otimização do SSD.
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem de SSD será habilitada. Caso contrário, a opção de montagem nossd é habilitada.
**9. ssd_spread e nossd_spread
A opção de montagem ssd_spread** tenta alocar grandes blocos contínuos de espaço não utilizado do SSD. Esse recurso melhora o desempenho de SSDs de baixo custo (baratos).
A opção de montagem nossd_spread desativa o recurso ssd_spread .
O sistema de arquivos Btrfs detecta automaticamente se um SSD é usado para o sistema de arquivos Btrfs. Se um SSD for usado, a opção de montagem ssd_spread será habilitada. Caso contrário, a opção de montagem nossd_spread é habilitada.
**10. descarte e nodiscard
Se você estiver usando um SSD que suporte TRIM enfileirado assíncrono (SATA rev3.1), a opção de montagem de descarte** permitirá o descarte de blocos de arquivos liberados. Isso melhorará o desempenho do SSD.
Se o SSD não suportar TRIM enfileirado assíncrono, a opção de montagem de descarte prejudicará o desempenho do SSD. Nesse caso, a opção de montagem nodiscard deve ser usada.
Por padrão, a opção de montagem nodiscard é usada.
**11. norecovery
Se a opção de montagem norecovery** for usada, o sistema de arquivos Btrfs não tentará executar a operação de recuperação de dados no momento da montagem.
**12. usebackuproot e nousebackuproot
Se a opção de montagem usebackuproot for usada, o sistema de arquivos Btrfs tentará recuperar qualquer raiz de árvore ruim/corrompida no momento da montagem. O sistema de arquivos Btrfs pode armazenar várias raízes de árvore no sistema de arquivos. A opção de montagem usebackuproot** procurará uma boa raiz de árvore e usará a primeira boa que encontrar.
A opção de montagem nousebackuproot não verificará ou recuperará raízes de árvore inválidas/corrompidas no momento da montagem. Este é o comportamento padrão do sistema de arquivos Btrfs.
**13. space_cache, space_cache=version, nospace_cache e clear_cache
A opção de montagem space_cache** é usada para controlar o cache de espaço livre. O cache de espaço livre é usado para melhorar o desempenho da leitura do espaço livre do grupo de blocos do sistema de arquivos Btrfs na memória (RAM).
O sistema de arquivos Btrfs suporta 2 versões do cache de espaço livre: v1 (padrão) e v2
O mecanismo de cache de espaço livre v2 melhora o desempenho de sistemas de arquivos grandes (tamanho de vários terabytes).
Você pode usar a opção de montagem space_cache=v1 para definir a v1 do cache de espaço livre e a opção de montagem space_cache=v2 para definir a v2 do cache de espaço livre.
A opção de montagem clear_cache é usada para limpar o cache de espaço livre.
Quando o cache de espaço livre v2 é criado, o cache deve ser limpo para criar um cache de espaço livre v1 .
Portanto, para usar o cache de espaço livre v1 após a criação do cache de espaço livre v2 , as opções de montagem clear_cache e space_cache=v1 devem ser combinadas: clear_cache,space_cache=v1
A opção de montagem nospace_cache é usada para desabilitar o cache de espaço livre.
Para desabilitar o cache de espaço livre após a criação do cache v1 ou v2 , as opções de montagem nospace_cache e clear_cache devem ser combinadas: clear_cache,nosapce_cache
**14. skip_balance
Por padrão, a operação de balanceamento interrompida/pausada de um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs será retomada automaticamente assim que o sistema de arquivos Btrfs for montado. Para desabilitar a retomada automática da operação de equilíbrio interrompido/pausado em um sistema de arquivos Btrfs de vários dispositivos ou RAID Btrfs, você pode usar a opção de montagem skip_balance .**
**15. datacow e nodatacow
A opção datacow** mount habilita o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs. É o comportamento padrão.
Se você deseja desabilitar o recurso Copy-on-Write (CoW) do sistema de arquivos Btrfs para os arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatacow .
**16. datasum e nodatasum
A opção datasum** mount habilita a soma de verificação de dados para arquivos recém-criados do sistema de arquivos Btrfs. Este é o comportamento padrão.
Se você não quiser que o sistema de arquivos Btrfs faça a soma de verificação dos dados dos arquivos recém-criados, monte o sistema de arquivos Btrfs com a opção de montagem nodatasum .
Perfis Btrfs
Um perfil Btrfs é usado para informar ao sistema de arquivos Btrfs quantas cópias dos dados/metadados devem ser mantidas e quais níveis de RAID devem ser usados para os dados/metadados. O sistema de arquivos Btrfs contém muitos perfis. Entendê-los o ajudará a configurar um RAID Btrfs da maneira que você deseja.
Os perfis Btrfs disponíveis são os seguintes:
single : Se o perfil único for usado para os dados/metadados, apenas uma cópia dos dados/metadados será armazenada no sistema de arquivos, mesmo se você adicionar vários dispositivos de armazenamento ao sistema de arquivos. Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
dup : Se o perfil dup for usado para os dados/metadados, cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos manterá duas cópias dos dados/metadados. Assim, 50% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser utilizado.
raid0 : No perfil raid0 , os dados/metadados serão divididos igualmente em todos os dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, não haverá dados/metadados redundantes (duplicados). Assim, 100% do espaço em disco de cada um dos dispositivos de armazenamento adicionados ao sistema de arquivos pode ser usado. Se, em qualquer caso, um dos dispositivos de armazenamento falhar, todo o sistema de arquivos será corrompido. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid0 .
raid1 : No perfil raid1 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a uma falha de unidade. Mas você pode usar apenas 50% do espaço total em disco. Você precisará de pelo menos dois dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1 .
raid1c3 : No perfil raid1c3 , três cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a duas falhas de unidade, mas você pode usar apenas 33% do espaço total em disco. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c3 .
raid1c4 : No perfil raid1c4 , quatro cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos. Nesta configuração, a matriz RAID pode sobreviver a três falhas de unidade, mas você pode usar apenas 25% do espaço total em disco. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid1c4 .
raid10 : No perfil raid10 , duas cópias dos dados/metadados serão armazenadas nos dispositivos de armazenamento adicionados ao sistema de arquivos, como no perfil raid1 . Além disso, os dados/metadados serão divididos entre os dispositivos de armazenamento, como no perfil raid0 .
O perfil raid10 é um híbrido dos perfis raid1 e raid0 . Alguns dos dispositivos de armazenamento formam arrays raid1 e alguns desses arrays raid1 são usados para formar um array raid0 . Em uma configuração raid10 , o sistema de arquivos pode sobreviver a uma única falha de unidade em cada uma das matrizes raid1 .
Você pode usar 50% do espaço total em disco na configuração raid10 . Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid10 .
raid5 : No perfil raid5 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Uma única paridade será calculada e distribuída entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid5 , o sistema de arquivos pode sobreviver a uma única falha de unidade. Se uma unidade falhar, você pode adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir da paridade distribuída das unidades em execução.
Você pode usar 1 00x(N-1)/N % do total de espaços em disco na configuração raid5 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos três dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid5 .
raid6 : No perfil raid6 , uma cópia dos dados/metadados será dividida entre os dispositivos de armazenamento. Duas paridades serão calculadas e distribuídas entre os dispositivos de armazenamento do array RAID.
Em uma configuração raid6 , o sistema de arquivos pode sobreviver a duas falhas de unidade ao mesmo tempo. Se uma unidade falhar, você poderá adicionar uma nova unidade ao sistema de arquivos e os dados perdidos serão calculados a partir das duas paridades distribuídas das unidades em execução.
Você pode usar 100x(N-2)/N % do espaço total em disco na configuração raid6 . Aqui, N é o número de dispositivos de armazenamento adicionados ao sistema de arquivos. Você precisará de pelo menos quatro dispositivos de armazenamento para configurar o sistema de arquivos Btrfs no perfil raid6 .
-
@ a5142938:0ef19da3
2025-04-30 09:29:49
-
@ 91bea5cd:1df4451c
2025-04-15 06:23:35
Um bom gerenciamento de senhas deve ser simples e seguir a filosofia do Unix. Organizado em hierarquia e fácil de passar de um computador para outro.
E por isso não é recomendável o uso de aplicativos de terceiros que tenham acesso a suas chaves(senhas) em seus servidores, tampouco as opções nativas dos navegadores, que também pertencem a grandes empresas que fazem um grande esforço para ter acesso a nossas informações.
Recomendação
- pass
- Qtpass (gerenciador gráfico)
Com ele seus dados são criptografados usando sua chave gpg e salvo em arquivos organizados por pastas de forma hierárquica, podendo ser integrado a um serviço git de sua escolha ou copiado facilmente de um local para outro.
Uso
O seu uso é bem simples.
Configuração:
pass git initPara ver:
pass Email/example.comCopiar para área de transferência (exige xclip):
pass -c Email/example.comPara inserir:
pass insert Email/example0.comPara inserir e gerar senha:
pass generate Email/example1.comPara inserir e gerar senha sem símbolos:
pass generate --no-symbols Email/example1.comPara inserir, gerar senha e copiar para área de transferência :
pass generate -c Email/example1.comPara remover:
pass rm Email/example.com -
@ e4950c93:1b99eccd
2025-04-30 09:29:25
-
@ e4950c93:1b99eccd
2025-04-30 09:28:38
-
@ a5142938:0ef19da3
2025-04-30 09:28:10
-
@ a5142938:0ef19da3
2025-04-30 09:27:29
-
@ e4950c93:1b99eccd
2025-04-30 09:27:09
-
@ 91bea5cd:1df4451c
2025-04-15 06:19:19
O que é Tahoe-LAFS?
Bem-vindo ao Tahoe-LAFS_, o primeiro sistema de armazenamento descentralizado com
- Segurança independente do provedor * .
Tahoe-LAFS é um sistema que ajuda você a armazenar arquivos. Você executa um cliente Programa no seu computador, que fala com um ou mais servidores de armazenamento em outros computadores. Quando você diz ao seu cliente para armazenar um arquivo, ele irá criptografar isso Arquivo, codifique-o em múltiplas peças, depois espalhe essas peças entre Vários servidores. As peças são todas criptografadas e protegidas contra Modificações. Mais tarde, quando você pede ao seu cliente para recuperar o arquivo, ele irá Encontre as peças necessárias, verifique se elas não foram corrompidas e remontadas Eles, e descriptografar o resultado.
O cliente cria mais peças (ou "compartilhamentos") do que acabará por precisar, então Mesmo que alguns servidores falhem, você ainda pode recuperar seus dados. Corrompido Os compartilhamentos são detectados e ignorados, de modo que o sistema pode tolerar o lado do servidor Erros no disco rígido. Todos os arquivos são criptografados (com uma chave exclusiva) antes Uploading, então mesmo um operador de servidor mal-intencionado não pode ler seus dados. o A única coisa que você pede aos servidores é que eles podem (geralmente) fornecer o Compartilha quando você os solicita: você não está confiando sobre eles para Confidencialidade, integridade ou disponibilidade absoluta.
O que é "segurança independente do provedor"?
Todo vendedor de serviços de armazenamento na nuvem irá dizer-lhe que o seu serviço é "seguro". Mas o que eles significam com isso é algo fundamentalmente diferente Do que queremos dizer. O que eles significam por "seguro" é que depois de ter dado Eles o poder de ler e modificar seus dados, eles tentam muito difícil de não deixar Esse poder seja abusado. Isso acaba por ser difícil! Insetos, Configurações incorretas ou erro do operador podem acidentalmente expor seus dados para Outro cliente ou para o público, ou pode corromper seus dados. Criminosos Ganho rotineiramente de acesso ilícito a servidores corporativos. Ainda mais insidioso é O fato de que os próprios funcionários às vezes violam a privacidade do cliente De negligência, avareza ou mera curiosidade. O mais consciencioso de Esses prestadores de serviços gastam consideráveis esforços e despesas tentando Mitigar esses riscos.
O que queremos dizer com "segurança" é algo diferente. * O provedor de serviços Nunca tem a capacidade de ler ou modificar seus dados em primeiro lugar: nunca. * Se você usa Tahoe-LAFS, então todas as ameaças descritas acima não são questões para você. Não só é fácil e barato para o provedor de serviços Manter a segurança de seus dados, mas na verdade eles não podem violar sua Segurança se eles tentaram. Isto é o que chamamos de * independente do fornecedor segurança*.
Esta garantia está integrada naturalmente no sistema de armazenamento Tahoe-LAFS e Não exige que você execute um passo de pré-criptografia manual ou uma chave complicada gestão. (Afinal, ter que fazer operações manuais pesadas quando Armazenar ou acessar seus dados anularia um dos principais benefícios de Usando armazenamento em nuvem em primeiro lugar: conveniência.)
Veja como funciona:

Uma "grade de armazenamento" é constituída por uma série de servidores de armazenamento. Um servidor de armazenamento Tem armazenamento direto em anexo (tipicamente um ou mais discos rígidos). Um "gateway" Se comunica com os nós de armazenamento e os usa para fornecer acesso ao Rede sobre protocolos como HTTP (S), SFTP ou FTP.
Observe que você pode encontrar "cliente" usado para se referir aos nós do gateway (que atuam como Um cliente para servidores de armazenamento) e também para processos ou programas que se conectam a Um nó de gateway e operações de execução na grade - por exemplo, uma CLI Comando, navegador da Web, cliente SFTP ou cliente FTP.
Os usuários não contam com servidores de armazenamento para fornecer * confidencialidade * nem
- Integridade * para seus dados - em vez disso, todos os dados são criptografados e Integridade verificada pelo gateway, para que os servidores não possam ler nem Modifique o conteúdo dos arquivos.
Os usuários dependem de servidores de armazenamento para * disponibilidade *. O texto cifrado é Codificado por apagamento em partes
Ndistribuídas em pelo menosHdistintas Servidores de armazenamento (o valor padrão paraNé 10 e paraHé 7) então Que pode ser recuperado de qualquerKdesses servidores (o padrão O valor deKé 3). Portanto, apenas a falha doH-K + 1(com o Padrões, 5) servidores podem tornar os dados indisponíveis.No modo de implantação típico, cada usuário executa seu próprio gateway sozinho máquina. Desta forma, ela confia em sua própria máquina para a confidencialidade e Integridade dos dados.
Um modo de implantação alternativo é que o gateway é executado em uma máquina remota e O usuário se conecta ao HTTPS ou SFTP. Isso significa que o operador de O gateway pode visualizar e modificar os dados do usuário (o usuário * depende de * o Gateway para confidencialidade e integridade), mas a vantagem é que a O usuário pode acessar a grade Tahoe-LAFS com um cliente que não possui o Software de gateway instalado, como um quiosque de internet ou celular.
Controle de acesso
Existem dois tipos de arquivos: imutáveis e mutáveis. Quando você carrega um arquivo Para a grade de armazenamento, você pode escolher o tipo de arquivo que será no grade. Os arquivos imutáveis não podem ser modificados quando foram carregados. UMA O arquivo mutable pode ser modificado por alguém com acesso de leitura e gravação. Um usuário Pode ter acesso de leitura e gravação a um arquivo mutable ou acesso somente leitura, ou não Acesso a ele.
Um usuário que tenha acesso de leitura e gravação a um arquivo mutable ou diretório pode dar Outro acesso de leitura e gravação do usuário a esse arquivo ou diretório, ou eles podem dar Acesso somente leitura para esse arquivo ou diretório. Um usuário com acesso somente leitura Para um arquivo ou diretório pode dar acesso a outro usuário somente leitura.
Ao vincular um arquivo ou diretório a um diretório pai, você pode usar um Link de leitura-escrita ou um link somente de leitura. Se você usar um link de leitura e gravação, então Qualquer pessoa que tenha acesso de leitura e gravação ao diretório pai pode obter leitura-escrita Acesso à criança e qualquer pessoa que tenha acesso somente leitura ao pai O diretório pode obter acesso somente leitura à criança. Se você usar uma leitura somente Link, qualquer pessoa que tenha lido-escrito ou acesso somente leitura ao pai O diretório pode obter acesso somente leitura à criança.
================================================== ==== Usando Tahoe-LAFS com uma rede anônima: Tor, I2P ================================================== ====
. `Visão geral '
. `Casos de uso '
.
Software Dependencies_#.
Tor#.I2P. `Configuração de conexão '
. `Configuração de Anonimato '
#.
Anonimato do cliente ' #.Anonimato de servidor, configuração manual ' #. `Anonimato de servidor, configuração automática '. `Problemas de desempenho e segurança '
Visão geral
Tor é uma rede anonimização usada para ajudar a esconder a identidade da Internet Clientes e servidores. Consulte o site do Tor Project para obter mais informações: Https://www.torproject.org/
I2P é uma rede de anonimato descentralizada que se concentra no anonimato de ponta a ponta Entre clientes e servidores. Consulte o site I2P para obter mais informações: Https://geti2p.net/
Casos de uso
Existem três casos de uso potenciais para Tahoe-LAFS do lado do cliente:
-
O usuário deseja sempre usar uma rede de anonimato (Tor, I2P) para proteger Seu anonimato quando se conecta às redes de armazenamento Tahoe-LAFS (seja ou Não os servidores de armazenamento são anônimos).
-
O usuário não se preocupa em proteger seu anonimato, mas eles desejam se conectar a Servidores de armazenamento Tahoe-LAFS que são acessíveis apenas através de Tor Hidden Services ou I2P.
-
Tor é usado apenas se uma sugestão de conexão do servidor usar
tor:. Essas sugestões Geralmente tem um endereço.onion. -
I2P só é usado se uma sugestão de conexão do servidor usa
i2p:. Essas sugestões Geralmente têm um endereço.i2p. -
O usuário não se preocupa em proteger seu anonimato ou para se conectar a um anonimato Servidores de armazenamento. Este documento não é útil para você ... então pare de ler.
Para servidores de armazenamento Tahoe-LAFS existem três casos de uso:
-
O operador deseja proteger o anonimato fazendo seu Tahoe Servidor acessível apenas em I2P, através de Tor Hidden Services, ou ambos.
-
O operador não * requer * anonimato para o servidor de armazenamento, mas eles Quer que ele esteja disponível tanto no TCP / IP roteado publicamente quanto através de um Rede de anonimização (I2P, Tor Hidden Services). Uma possível razão para fazer Isso é porque ser alcançável através de uma rede de anonimato é um Maneira conveniente de ignorar NAT ou firewall que impede roteios públicos Conexões TCP / IP ao seu servidor (para clientes capazes de se conectar a Tais servidores). Outro é o que torna o seu servidor de armazenamento acessível Através de uma rede de anonimato pode oferecer uma melhor proteção para sua Clientes que usam essa rede de anonimato para proteger seus anonimato.
-
O operador do servidor de armazenamento não se preocupa em proteger seu próprio anonimato nem Para ajudar os clientes a proteger o deles. Pare de ler este documento e execute Seu servidor de armazenamento Tahoe-LAFS usando TCP / IP com roteamento público.
Veja esta página do Tor Project para obter mais informações sobre Tor Hidden Services: Https://www.torproject.org/docs/hidden-services.html.pt
Veja esta página do Projeto I2P para obter mais informações sobre o I2P: Https://geti2p.net/en/about/intro
Dependências de software
Tor
Os clientes que desejam se conectar a servidores baseados em Tor devem instalar o seguinte.
-
Tor (tor) deve ser instalado. Veja aqui: Https://www.torproject.org/docs/installguide.html.en. No Debian / Ubuntu, Use
apt-get install tor. Você também pode instalar e executar o navegador Tor Agrupar. -
Tahoe-LAFS deve ser instalado com o
[tor]"extra" habilitado. Isso vai Instaletxtorcon::
Pip install tahoe-lafs [tor]
Os servidores Tor-configurados manualmente devem instalar Tor, mas não precisam
Txtorconou o[tor]extra. Configuração automática, quando Implementado, vai precisar destes, assim como os clientes.I2P
Os clientes que desejam se conectar a servidores baseados em I2P devem instalar o seguinte. Tal como acontece com Tor, os servidores baseados em I2P configurados manualmente precisam do daemon I2P, mas Não há bibliotecas especiais de apoio Tahoe-side.
-
I2P deve ser instalado. Veja aqui: Https://geti2p.net/en/download
-
A API SAM deve estar habilitada.
-
Inicie o I2P.
- Visite http://127.0.0.1:7657/configclients no seu navegador.
- Em "Configuração do Cliente", marque a opção "Executar no Startup?" Caixa para "SAM Ponte de aplicação ".
- Clique em "Salvar Configuração do Cliente".
-
Clique no controle "Iniciar" para "ponte de aplicação SAM" ou reinicie o I2P.
-
Tahoe-LAFS deve ser instalado com o
[i2p]extra habilitado, para obterTxi2p::
Pip install tahoe-lafs [i2p]
Tor e I2P
Os clientes que desejam se conectar a servidores baseados em Tor e I2P devem instalar tudo acima. Em particular, Tahoe-LAFS deve ser instalado com ambos Extras habilitados ::
Pip install tahoe-lafs [tor, i2p]
Configuração de conexão
Consulte: ref:
Connection Managementpara uma descrição do[tor]e[I2p]seções detahoe.cfg. Estes controlam como o cliente Tahoe Conecte-se a um daemon Tor / I2P e, assim, faça conexões com Tor / I2P-baseadas Servidores.As seções
[tor]e[i2p]só precisam ser modificadas para serem usadas de forma incomum Configurações ou para habilitar a configuração automática do servidor.A configuração padrão tentará entrar em contato com um daemon local Tor / I2P Ouvindo as portas usuais (9050/9150 para Tor, 7656 para I2P). Enquanto Há um daemon em execução no host local e o suporte necessário Bibliotecas foram instaladas, os clientes poderão usar servidores baseados em Tor Sem qualquer configuração especial.
No entanto, note que esta configuração padrão não melhora a Anonimato: as conexões TCP normais ainda serão feitas em qualquer servidor que Oferece um endereço regular (cumpre o segundo caso de uso do cliente acima, não o terceiro). Para proteger o anonimato, os usuários devem configurar o
[Connections]da seguinte maneira:[Conexões] Tcp = tor
Com isso, o cliente usará Tor (em vez de um IP-address -reviração de conexão direta) para alcançar servidores baseados em TCP.
Configuração de anonimato
Tahoe-LAFS fornece uma configuração "flag de segurança" para indicar explicitamente Seja necessário ou não a privacidade do endereço IP para um nó ::
[nó] Revelar-IP-address = (booleano, opcional)
Quando
revelar-IP-address = False, Tahoe-LAFS se recusará a iniciar se algum dos As opções de configuração emtahoe.cfgrevelariam a rede do nó localização:-
[Conexões] tcp = toré necessário: caso contrário, o cliente faria Conexões diretas para o Introdução, ou qualquer servidor baseado em TCP que aprende Do Introdutor, revelando seu endereço IP para esses servidores e um Rede de espionagem. Com isso, Tahoe-LAFS só fará Conexões de saída através de uma rede de anonimato suportada. -
Tub.locationdeve ser desativado ou conter valores seguros. este O valor é anunciado para outros nós através do Introdutor: é como um servidor Anuncia sua localização para que os clientes possam se conectar a ela. No modo privado, ele É um erro para incluir umtcp:dica notub.location. Modo privado Rejeita o valor padrão detub.location(quando a chave está faltando Inteiramente), que éAUTO, que usaifconfigpara adivinhar o nó Endereço IP externo, o que o revelaria ao servidor e a outros clientes.
Esta opção é ** crítica ** para preservar o anonimato do cliente (cliente Caso de uso 3 de "Casos de uso", acima). Também é necessário preservar uma Anonimato do servidor (caso de uso do servidor 3).
Esse sinalizador pode ser configurado (para falso), fornecendo o argumento
--hide-ippara Os comandoscreate-node,create-clientoucreate-introducer.Observe que o valor padrão de
revelar-endereço IPé verdadeiro, porque Infelizmente, esconder o endereço IP do nó requer software adicional para ser Instalado (conforme descrito acima) e reduz o desempenho.Anonimato do cliente
Para configurar um nó de cliente para anonimato,
tahoe.cfg** deve ** conter o Seguindo as bandeiras de configuração ::[nó] Revelar-IP-address = False Tub.port = desativado Tub.location = desativado
Uma vez que o nodo Tahoe-LAFS foi reiniciado, ele pode ser usado anonimamente (cliente Caso de uso 3).
Anonimato do servidor, configuração manual
Para configurar um nó de servidor para ouvir em uma rede de anonimato, devemos primeiro Configure Tor para executar um "Serviço de cebola" e encaminhe as conexões de entrada para o Porto Tahoe local. Então, configuramos Tahoe para anunciar o endereço
.onionAos clientes. Também configuramos Tahoe para não fazer conexões TCP diretas.- Decida em um número de porta de escuta local, chamado PORT. Isso pode ser qualquer não utilizado Porta de cerca de 1024 até 65535 (dependendo do kernel / rede do host Config). Nós diremos a Tahoe para escutar nesta porta, e nós diremos a Tor para Encaminhe as conexões de entrada para ele.
- Decida em um número de porta externo, chamado VIRTPORT. Isso será usado no Localização anunciada e revelada aos clientes. Pode ser qualquer número de 1 Para 65535. Pode ser o mesmo que PORT, se quiser.
- Decida em um "diretório de serviço oculto", geralmente em
/ var / lib / tor / NAME. Pediremos a Tor para salvar o estado do serviço de cebola aqui, e Tor irá Escreva o endereço.onionaqui depois que ele for gerado.
Em seguida, faça o seguinte:
-
Crie o nó do servidor Tahoe (com
tahoe create-node), mas não ** não ** Lança-o ainda. -
Edite o arquivo de configuração Tor (normalmente em
/ etc / tor / torrc). Precisamos adicionar Uma seção para definir o serviço oculto. Se nossa PORT for 2000, VIRTPORT é 3000, e estamos usando/ var / lib / tor / tahoecomo o serviço oculto Diretório, a seção deve se parecer com ::HiddenServiceDir / var / lib / tor / tahoe HiddenServicePort 3000 127.0.0.1:2000
-
Reinicie Tor, com
systemctl restart tor. Aguarde alguns segundos. -
Leia o arquivo
hostnameno diretório de serviço oculto (por exemplo,/ Var / lib / tor / tahoe / hostname). Este será um endereço.onion, comoU33m4y7klhz3b.onion. Ligue para esta CEBOLA. -
Edite
tahoe.cfgpara configurartub.portpara usarTcp: PORT: interface = 127.0.0.1etub.locationpara usarTor: ONION.onion: VIRTPORT. Usando os exemplos acima, isso seria ::[nó] Revelar-endereço IP = falso Tub.port = tcp: 2000: interface = 127.0.0.1 Tub.location = tor: u33m4y7klhz3b.onion: 3000 [Conexões] Tcp = tor
-
Inicie o servidor Tahoe com
tahoe start $ NODEDIR
A seção
tub.portfará com que o servidor Tahoe ouça no PORT, mas Ligue o soquete de escuta à interface de loopback, que não é acessível Do mundo exterior (mas * é * acessível pelo daemon Tor local). Então o A seçãotcp = torfaz com que Tahoe use Tor quando se conecta ao Introdução, escondendo o endereço IP. O nó se anunciará a todos Clientes que usam `tub.location``, então os clientes saberão que devem usar o Tor Para alcançar este servidor (e não revelar seu endereço IP através do anúncio). Quando os clientes se conectam ao endereço da cebola, seus pacotes serão Atravessar a rede de anonimato e eventualmente aterrar no Tor local Daemon, que então estabelecerá uma conexão com PORT no localhost, que é Onde Tahoe está ouvindo conexões.Siga um processo similar para construir um servidor Tahoe que escuta no I2P. o O mesmo processo pode ser usado para ouvir tanto o Tor como o I2P (
tub.location = Tor: ONION.onion: VIRTPORT, i2p: ADDR.i2p). Também pode ouvir tanto Tor como TCP simples (caso de uso 2), comtub.port = tcp: PORT,tub.location = Tcp: HOST: PORT, tor: ONION.onion: VIRTPORTeanonymous = false(e omite A configuraçãotcp = tor, já que o endereço já está sendo transmitido através de O anúncio de localização).Anonimato do servidor, configuração automática
Para configurar um nó do servidor para ouvir em uma rede de anonimato, crie o Nó com a opção
--listen = tor. Isso requer uma configuração Tor que Ou lança um novo daemon Tor, ou tem acesso à porta de controle Tor (e Autoridade suficiente para criar um novo serviço de cebola). Nos sistemas Debian / Ubuntu, façaApt install tor, adicione-se ao grupo de controle comadduser YOURUSERNAME debian-tore, em seguida, inicie sessão e faça o login novamente: se osgroupsO comando incluidebian-torna saída, você deve ter permissão para Use a porta de controle de domínio unix em/ var / run / tor / control.Esta opção irá definir
revelar-IP-address = Falsee[connections] tcp = Tor. Ele alocará as portas necessárias, instruirá Tor para criar a cebola Serviço (salvando a chave privada em algum lugar dentro de NODEDIR / private /), obtenha O endereço.onione preenchatub.portetub.locationcorretamente.Problemas de desempenho e segurança
Se você estiver executando um servidor que não precisa ser Anônimo, você deve torná-lo acessível através de uma rede de anonimato ou não? Ou você pode torná-lo acessível * ambos * através de uma rede de anonimato E como um servidor TCP / IP rastreável publicamente?
Existem várias compensações efetuadas por esta decisão.
Penetração NAT / Firewall
Fazer com que um servidor seja acessível via Tor ou I2P o torna acessível (por Clientes compatíveis com Tor / I2P) mesmo que existam NAT ou firewalls que impeçam Conexões TCP / IP diretas para o servidor.
Anonimato
Tornar um servidor Tahoe-LAFS acessível * somente * via Tor ou I2P pode ser usado para Garanta que os clientes Tahoe-LAFS usem Tor ou I2P para se conectar (Especificamente, o servidor só deve anunciar endereços Tor / I2P no Chave de configuração
tub.location). Isso evita que os clientes mal configurados sejam Desingonizando-se acidentalmente, conectando-se ao seu servidor através de A Internet rastreável.Claramente, um servidor que está disponível como um serviço Tor / I2P * e * a O endereço TCP regular não é anônimo: o endereço do .on e o real O endereço IP do servidor é facilmente vinculável.
Além disso, a interação, através do Tor, com um Tor Oculto pode ser mais Protegido da análise do tráfego da rede do que a interação, através do Tor, Com um servidor TCP / IP com rastreamento público
** XXX há um documento mantido pelos desenvolvedores de Tor que comprovem ou refutam essa crença? Se assim for, precisamos ligar a ele. Caso contrário, talvez devêssemos explicar mais aqui por que pensamos isso? **
Linkability
A partir de 1.12.0, o nó usa uma única chave de banheira persistente para saída Conexões ao Introdutor e conexões de entrada para o Servidor de Armazenamento (E Helper). Para os clientes, uma nova chave Tub é criada para cada servidor de armazenamento Nós aprendemos sobre, e essas chaves são * não * persistiram (então elas mudarão cada uma delas Tempo que o cliente reinicia).
Clientes que atravessam diretórios (de rootcap para subdiretório para filecap) são É provável que solicitem os mesmos índices de armazenamento (SIs) na mesma ordem de cada vez. Um cliente conectado a vários servidores irá pedir-lhes todos para o mesmo SI em Quase ao mesmo tempo. E dois clientes que compartilham arquivos ou diretórios Irá visitar os mesmos SI (em várias ocasiões).
Como resultado, as seguintes coisas são vinculáveis, mesmo com
revelar-endereço IP = Falso:- Servidores de armazenamento podem vincular reconhecer várias conexões do mesmo Cliente ainda não reiniciado. (Observe que o próximo recurso de Contabilidade pode Faz com que os clientes apresentem uma chave pública persistente do lado do cliente quando Conexão, que será uma ligação muito mais forte).
- Os servidores de armazenamento provavelmente podem deduzir qual cliente está acessando dados, por Olhando as SIs sendo solicitadas. Vários servidores podem conciliar Determine que o mesmo cliente está falando com todos eles, mesmo que o TubIDs são diferentes para cada conexão.
- Os servidores de armazenamento podem deduzir quando dois clientes diferentes estão compartilhando dados.
- O Introdutor pode entregar diferentes informações de servidor para cada um Cliente subscrito, para particionar clientes em conjuntos distintos de acordo com Quais as conexões do servidor que eles eventualmente fazem. Para clientes + nós de servidor, ele Também pode correlacionar o anúncio do servidor com o cliente deduzido identidade.
atuação
Um cliente que se conecta a um servidor Tahoe-LAFS com rastreamento público através de Tor Incorrem em latência substancialmente maior e, às vezes, pior Mesmo cliente se conectando ao mesmo servidor através de um TCP / IP rastreável normal conexão. Quando o servidor está em um Tor Hidden Service, ele incorre ainda mais Latência e, possivelmente, ainda pior rendimento.
Conectando-se a servidores Tahoe-LAFS que são servidores I2P incorrem em maior latência E pior rendimento também.
Efeitos positivos e negativos em outros usuários Tor
O envio de seu tráfego Tahoe-LAFS sobre o Tor adiciona tráfego de cobertura para outros Tor usuários que também estão transmitindo dados em massa. Então isso é bom para Eles - aumentando seu anonimato.
No entanto, torna o desempenho de outros usuários do Tor Sessões - por exemplo, sessões ssh - muito pior. Isso é porque Tor Atualmente não possui nenhuma prioridade ou qualidade de serviço Recursos, para que as teclas de Ssh de outra pessoa possam ter que esperar na fila Enquanto o conteúdo do arquivo em massa é transmitido. O atraso adicional pode Tornar as sessões interativas de outras pessoas inutilizáveis.
Ambos os efeitos são duplicados se você carregar ou baixar arquivos para um Tor Hidden Service, em comparação com se você carregar ou baixar arquivos Over Tor para um servidor TCP / IP com rastreamento público
Efeitos positivos e negativos em outros usuários do I2P
Enviar seu tráfego Tahoe-LAFS ao I2P adiciona tráfego de cobertura para outros usuários do I2P Que também estão transmitindo dados. Então, isso é bom para eles - aumentando sua anonimato. Não prejudicará diretamente o desempenho de outros usuários do I2P Sessões interativas, porque a rede I2P possui vários controles de congestionamento e Recursos de qualidade de serviço, como priorizar pacotes menores.
No entanto, se muitos usuários estão enviando tráfego Tahoe-LAFS ao I2P e não tiverem Seus roteadores I2P configurados para participar de muito tráfego, então o I2P A rede como um todo sofrerá degradação. Cada roteador Tahoe-LAFS que usa o I2P tem Seus próprios túneis de anonimato que seus dados são enviados. Em média, um O nó Tahoe-LAFS requer 12 outros roteadores I2P para participar de seus túneis.
Portanto, é importante que o seu roteador I2P esteja compartilhando a largura de banda com outros Roteadores, para que você possa retornar enquanto usa o I2P. Isso nunca prejudicará a Desempenho de seu nó Tahoe-LAFS, porque seu roteador I2P sempre Priorize seu próprio tráfego.
=========================
Como configurar um servidor
Muitos nós Tahoe-LAFS são executados como "servidores", o que significa que eles fornecem serviços para Outras máquinas (isto é, "clientes"). Os dois tipos mais importantes são os Introdução e Servidores de armazenamento.
Para ser útil, os servidores devem ser alcançados pelos clientes. Os servidores Tahoe podem ouvir Em portas TCP e anunciar sua "localização" (nome do host e número da porta TCP) Para que os clientes possam se conectar a eles. Eles também podem ouvir os serviços de cebola "Tor" E portas I2P.
Os servidores de armazenamento anunciam sua localização ao anunciá-lo ao Introdutivo, Que então transmite a localização para todos os clientes. Então, uma vez que a localização é Determinado, você não precisa fazer nada de especial para entregá-lo.
O próprio apresentador possui uma localização, que deve ser entregue manualmente a todos Servidores de armazenamento e clientes. Você pode enviá-lo para os novos membros do seu grade. Esta localização (juntamente com outros identificadores criptográficos importantes) é Escrito em um arquivo chamado
private / introducer.furlno Presenter's Diretório básico, e deve ser fornecido como o argumento--introducer =paraTahoe create-nodeoutahoe create-node.O primeiro passo ao configurar um servidor é descobrir como os clientes irão alcançar. Então você precisa configurar o servidor para ouvir em algumas portas, e Depois configure a localização corretamente.
Configuração manual
Cada servidor tem duas configurações em seu arquivo
tahoe.cfg:tub.port, eTub.location. A "porta" controla o que o nó do servidor escuta: isto Geralmente é uma porta TCP.A "localização" controla o que é anunciado para o mundo exterior. Isto é um "Sugestão de conexão foolscap", e inclui tanto o tipo de conexão (Tcp, tor ou i2p) e os detalhes da conexão (nome do host / endereço, porta número). Vários proxies, gateways e redes de privacidade podem ser Envolvido, então não é incomum para
tub.portetub.locationpara olhar diferente.Você pode controlar diretamente a configuração
tub.portetub.locationConfigurações, fornecendo--port =e--location =ao executartahoe Create-node.Configuração automática
Em vez de fornecer
--port = / - location =, você pode usar--listen =. Os servidores podem ouvir em TCP, Tor, I2P, uma combinação desses ou nenhum. O argumento--listen =controla quais tipos de ouvintes o novo servidor usará.--listen = nonesignifica que o servidor não deve ouvir nada. Isso não Faz sentido para um servidor, mas é apropriado para um nó somente cliente. o O comandotahoe create-clientinclui automaticamente--listen = none.--listen = tcpé o padrão e liga uma porta de escuta TCP padrão. Usar--listen = tcprequer um argumento--hostname =também, que será Incorporado no local anunciado do nó. Descobrimos que os computadores Não pode determinar de forma confiável seu nome de host acessível externamente, então, em vez de Ter o servidor adivinhar (ou escanear suas interfaces para endereços IP Isso pode ou não ser apropriado), a criação de nó requer que o usuário Forneça o nome do host.--listen = torconversará com um daemon Tor local e criará uma nova "cebola" Servidor "(que se parece comalzrgrdvxct6c63z.onion).--listen = i2p` conversará com um daemon I2P local e criará um novo servidor endereço. Consulte: doc:anonymity-configuration` para obter detalhes.Você pode ouvir nos três usando
--listen = tcp, tor, i2p.Cenários de implantação
A seguir, alguns cenários sugeridos para configurar servidores usando Vários transportes de rede. Estes exemplos não incluem a especificação de um Apresentador FURL que normalmente você gostaria quando provisionamento de armazenamento Nós. Para estes e outros detalhes de configuração, consulte : Doc:
configuration.. `Servidor possui um nome DNS público '
.
Servidor possui um endereço público IPv4 / IPv6_.
O servidor está por trás de um firewall com encaminhamento de porta_.
Usando o I2P / Tor para evitar o encaminhamento da porta_O servidor possui um nome DNS público
O caso mais simples é o local onde o host do servidor está diretamente conectado ao Internet, sem um firewall ou caixa NAT no caminho. A maioria dos VPS (Virtual Private Servidor) e servidores colocados são assim, embora alguns fornecedores bloqueiem Muitas portas de entrada por padrão.
Para esses servidores, tudo o que você precisa saber é o nome do host externo. O sistema O administrador irá dizer-lhe isso. O principal requisito é que este nome de host Pode ser pesquisado no DNS, e ele será mapeado para um endereço IPv4 ou IPv6 que Alcançará a máquina.
Se o seu nome de host for
example.net, então você criará o introdutor como esta::Tahoe create-introducer --hostname example.com ~ / introducer
Ou um servidor de armazenamento como ::
Tahoe create-node --hostname = example.net
Estes irão alocar uma porta TCP (por exemplo, 12345), atribuir
tub.portpara serTcp: 12345etub.locationserãotcp: example.com: 12345.Idealmente, isso também deveria funcionar para hosts compatíveis com IPv6 (onde o nome DNS Fornece um registro "AAAA", ou ambos "A" e "AAAA"). No entanto Tahoe-LAFS O suporte para IPv6 é novo e ainda pode ter problemas. Por favor, veja o ingresso
# 867_ para detalhes... _ # 867: https://tahoe-lafs.org/trac/tahoe-lafs/ticket/867
O servidor possui um endereço público IPv4 / IPv6
Se o host tiver um endereço IPv4 (público) rotativo (por exemplo,
203.0.113.1```), mas Nenhum nome DNS, você precisará escolher uma porta TCP (por exemplo,3457``) e usar o Segue::Tahoe create-node --port = tcp: 3457 - localização = tcp: 203.0.113.1: 3457
--porté uma "string de especificação de ponto de extremidade" que controla quais locais Porta em que o nó escuta.--locationé a "sugestão de conexão" que ele Anuncia para outros, e descreve as conexões de saída que essas Os clientes irão fazer, por isso precisa trabalhar a partir da sua localização na rede.Os nós Tahoe-LAFS escutam em todas as interfaces por padrão. Quando o host é Multi-homed, você pode querer fazer a ligação de escuta ligar apenas a uma Interface específica, adicionando uma opção
interface =ao--port =argumento::Tahoe create-node --port = tcp: 3457: interface = 203.0.113.1 - localização = tcp: 203.0.113.1: 3457
Se o endereço público do host for IPv6 em vez de IPv4, use colchetes para Envolva o endereço e altere o tipo de nó de extremidade para
tcp6::Tahoe create-node --port = tcp6: 3457 - localização = tcp: [2001: db8 :: 1]: 3457
Você pode usar
interface =para vincular a uma interface IPv6 específica também, no entanto Você deve fazer uma barra invertida - escapar dos dois pontos, porque, de outra forma, eles são interpretados Como delimitadores pelo idioma de especificação do "ponto final" torcido. o--location =argumento não precisa de dois pontos para serem escapados, porque eles são Envolto pelos colchetes ::Tahoe create-node --port = tcp6: 3457: interface = 2001 \: db8 \: \: 1 --location = tcp: [2001: db8 :: 1]: 3457
Para hosts somente IPv6 com registros DNS AAAA, se o simples
--hostname =A configuração não funciona, eles podem ser informados para ouvir especificamente Porta compatível com IPv6 com este ::Tahoe create-node --port = tcp6: 3457 - localização = tcp: example.net: 3457
O servidor está por trás de um firewall com encaminhamento de porta
Para configurar um nó de armazenamento por trás de um firewall com encaminhamento de porta, você irá precisa saber:
- Endereço IPv4 público do roteador
- A porta TCP que está disponível de fora da sua rede
- A porta TCP que é o destino de encaminhamento
- Endereço IPv4 interno do nó de armazenamento (o nó de armazenamento em si é
Desconhece esse endereço e não é usado durante
tahoe create-node, Mas o firewall deve ser configurado para enviar conexões para isso)
Os números de porta TCP internos e externos podem ser iguais ou diferentes Dependendo de como o encaminhamento da porta está configurado. Se é mapear portas 1-para-1, eo endereço IPv4 público do firewall é 203.0.113.1 (e Talvez o endereço IPv4 interno do nó de armazenamento seja 192.168.1.5), então Use um comando CLI como este ::
Tahoe create-node --port = tcp: 3457 - localização = tcp: 203.0.113.1: 3457
Se no entanto, o firewall / NAT-box encaminha a porta externa * 6656 * para o interno Porta 3457, então faça isso ::
Tahoe create-node --port = tcp: 3457 - localização = tcp: 203.0.113.1: 6656
Usando o I2P / Tor para evitar o encaminhamento da porta
Os serviços de cebola I2P e Tor, entre outras excelentes propriedades, também fornecem NAT Penetração sem encaminhamento de porta, nomes de host ou endereços IP. Então, configurando Um servidor que escuta apenas no Tor é simples ::
Tahoe create-node --listen = tor
Para mais informações sobre o uso de Tahoe-LAFS com I2p e Tor veja : Doc:
anonymity-configuration -
@ 39cc53c9:27168656
2025-04-09 07:59:33
Know Your Customer is a regulation that requires companies of all sizes to verify the identity, suitability, and risks involved with maintaining a business relationship with a customer. Such procedures fit within the broader scope of anti-money laundering (AML) and counterterrorism financing (CTF) regulations.
Banks, exchanges, online business, mail providers, domain registrars... Everyone wants to know who you are before you can even opt for their service. Your personal information is flowing around the internet in the hands of "god-knows-who" and secured by "trust-me-bro military-grade encryption". Once your account is linked to your personal (and verified) identity, tracking you is just as easy as keeping logs on all these platforms.
Rights for Illusions
KYC processes aim to combat terrorist financing, money laundering, and other illicit activities. On the surface, KYC seems like a commendable initiative. I mean, who wouldn't want to halt terrorists and criminals in their tracks?
The logic behind KYC is: "If we mandate every financial service provider to identify their users, it becomes easier to pinpoint and apprehend the malicious actors."
However, terrorists and criminals are not precisely lining up to be identified. They're crafty. They may adopt false identities or find alternative strategies to continue their operations. Far from being outwitted, many times they're several steps ahead of regulations. Realistically, KYC might deter a small fraction – let's say about 1% ^1 – of these malefactors. Yet, the cost? All of us are saddled with the inconvenient process of identification just to use a service.
Under the rhetoric of "ensuring our safety", governments and institutions enact regulations that seem more out of a dystopian novel, gradually taking away our right to privacy.
To illustrate, consider a city where the mayor has rolled out facial recognition cameras in every nook and cranny. A band of criminals, intent on robbing a local store, rolls in with a stolen car, their faces obscured by masks and their bodies cloaked in all-black clothes. Once they've committed the crime and exited the city's boundaries, they switch vehicles and clothes out of the cameras' watchful eyes. The high-tech surveillance? It didn’t manage to identify or trace them. Yet, for every law-abiding citizen who merely wants to drive through the city or do some shopping, their movements and identities are constantly logged. The irony? This invasive tracking impacts all of us, just to catch the 1% ^1 of less-than-careful criminals.
KYC? Not you.
KYC creates barriers to participation in normal economic activity, to supposedly stop criminals. ^2
KYC puts barriers between many users and businesses. One of these comes from the fact that the process often requires multiple forms of identification, proof of address, and sometimes even financial records. For individuals in areas with poor record-keeping, non-recognized legal documents, or those who are unbanked, homeless or transient, obtaining these documents can be challenging, if not impossible.
For people who are not skilled with technology or just don't have access to it, there's also a barrier since KYC procedures are mostly online, leaving them inadvertently excluded.
Another barrier goes for the casual or one-time user, where they might not see the value in undergoing a rigorous KYC process, and these requirements can deter them from using the service altogether.
It also wipes some businesses out of the equation, since for smaller businesses, the costs associated with complying with KYC norms—from the actual process of gathering and submitting documents to potential delays in operations—can be prohibitive in economical and/or technical terms.
You're not welcome
Imagine a swanky new club in town with a strict "members only" sign. You hear the music, you see the lights, and you want in. You step up, ready to join, but suddenly there's a long list of criteria you must meet. After some time, you are finally checking all the boxes. But then the club rejects your membership with no clear reason why. You just weren't accepted. Frustrating, right?
This club scenario isn't too different from the fact that KYC is being used by many businesses as a convenient gatekeeping tool. A perfect excuse based on a "legal" procedure they are obliged to.
Even some exchanges may randomly use this to freeze and block funds from users, claiming these were "flagged" by a cryptic system that inspects the transactions. You are left hostage to their arbitrary decision to let you successfully pass the KYC procedure. If you choose to sidestep their invasive process, they might just hold onto your funds indefinitely.
Your identity has been stolen
KYC data has been found to be for sale on many dark net markets^3. Exchanges may have leaks or hacks, and such leaks contain very sensitive data. We're talking about the full monty: passport or ID scans, proof of address, and even those awkward selfies where you're holding up your ID next to your face. All this data is being left to the mercy of the (mostly) "trust-me-bro" security systems of such companies. Quite scary, isn't it?
As cheap as $10 for 100 documents, with discounts applying for those who buy in bulk, the personal identities of innocent users who passed KYC procedures are for sale. ^3
In short, if you have ever passed the KYC/AML process of a crypto exchange, your privacy is at risk of being compromised, or it might even have already been compromised.
(they) Know Your Coins
You may already know that Bitcoin and most cryptocurrencies have a transparent public blockchain, meaning that all data is shown unencrypted for everyone to see and recorded forever. If you link an address you own to your identity through KYC, for example, by sending an amount from a KYC exchange to it, your Bitcoin is no longer pseudonymous and can then be traced.
If, for instance, you send Bitcoin from such an identified address to another KYC'ed address (say, from a friend), everyone having access to that address-identity link information (exchanges, governments, hackers, etc.) will be able to associate that transaction and know who you are transacting with.
Conclusions
To sum up, KYC does not protect individuals; rather, it's a threat to our privacy, freedom, security and integrity. Sensible information flowing through the internet is thrown into chaos by dubious security measures. It puts borders between many potential customers and businesses, and it helps governments and companies track innocent users. That's the chaos KYC has stirred.
The criminals are using stolen identities from companies that gathered them thanks to these very same regulations that were supposed to combat them. Criminals always know how to circumvent such regulations. In the end, normal people are the most affected by these policies.
The threat that KYC poses to individuals in terms of privacy, security and freedom is not to be neglected. And if we don’t start challenging these systems and questioning their efficacy, we are just one step closer to the dystopian future that is now foreseeable.
Edited 20/03/2024 * Add reference to the 1% statement on Rights for Illusions section to an article where Chainalysis found that only 0.34% of the transaction volume with cryptocurrencies in 2023 was attributable to criminal activity ^1
-
@ 68c90cf3:99458f5c
2025-04-04 16:06:10
I have two Nostr profiles I use for different subject matter, and I wanted a way to manage and track zaps for each. Using Alby Hub I created two isolated Lightning wallets each associated with one of the profile’s nsecs.
YakiHonne made it easy to connect the associated wallets with the profiles. The user interface is well designed to show balances for each.
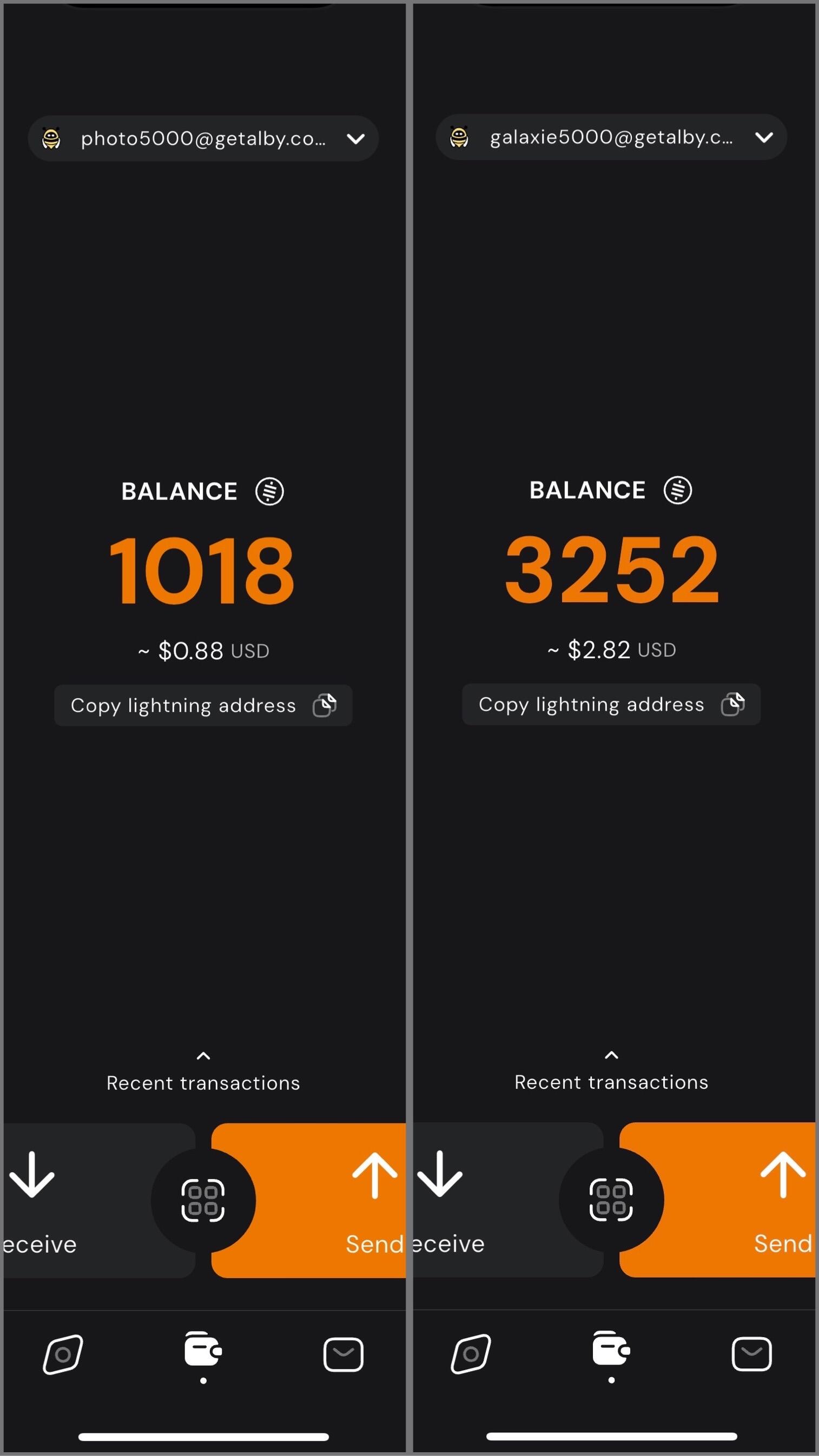
In my case, I have one profile for photography related content, and the other for Bitcoin, Nostr, and technology related content. I can easily switch between the two, sending and receiving zaps on each while staying up to date on balances and viewing transactions.

Using my self-hosted Alby Hub I can manage Lightning channels and wallets while sending and receiving zaps for multiple profiles with YakiHonne.
YakiHonne #AlbyHub #Lightning #Bitcoin #Nostr
-
@ e4950c93:1b99eccd
2025-04-30 09:26:33
-
@ b9f4c34d:7d1a0e31
2025-04-02 15:00:20
Test Video Document
-
@ b9f4c34d:7d1a0e31
2025-04-02 14:59:02
Testy McTestenface
It's been so long, html
-
@ 04c915da:3dfbecc9
2025-03-26 20:54:33
Capitalism is the most effective system for scaling innovation. The pursuit of profit is an incredibly powerful human incentive. Most major improvements to human society and quality of life have resulted from this base incentive. Market competition often results in the best outcomes for all.
That said, some projects can never be monetized. They are open in nature and a business model would centralize control. Open protocols like bitcoin and nostr are not owned by anyone and if they were it would destroy the key value propositions they provide. No single entity can or should control their use. Anyone can build on them without permission.
As a result, open protocols must depend on donation based grant funding from the people and organizations that rely on them. This model works but it is slow and uncertain, a grind where sustainability is never fully reached but rather constantly sought. As someone who has been incredibly active in the open source grant funding space, I do not think people truly appreciate how difficult it is to raise charitable money and deploy it efficiently.
Projects that can be monetized should be. Profitability is a super power. When a business can generate revenue, it taps into a self sustaining cycle. Profit fuels growth and development while providing projects independence and agency. This flywheel effect is why companies like Google, Amazon, and Apple have scaled to global dominance. The profit incentive aligns human effort with efficiency. Businesses must innovate, cut waste, and deliver value to survive.
Contrast this with non monetized projects. Without profit, they lean on external support, which can dry up or shift with donor priorities. A profit driven model, on the other hand, is inherently leaner and more adaptable. It is not charity but survival. When survival is tied to delivering what people want, scale follows naturally.
The real magic happens when profitable, sustainable businesses are built on top of open protocols and software. Consider the many startups building on open source software stacks, such as Start9, Mempool, and Primal, offering premium services on top of the open source software they build out and maintain. Think of companies like Block or Strike, which leverage bitcoin’s open protocol to offer their services on top. These businesses amplify the open software and protocols they build on, driving adoption and improvement at a pace donations alone could never match.
When you combine open software and protocols with profit driven business the result are lean, sustainable companies that grow faster and serve more people than either could alone. Bitcoin’s network, for instance, benefits from businesses that profit off its existence, while nostr will expand as developers monetize apps built on the protocol.
Capitalism scales best because competition results in efficiency. Donation funded protocols and software lay the groundwork, while market driven businesses build on top. The profit incentive acts as a filter, ensuring resources flow to what works, while open systems keep the playing field accessible, empowering users and builders. Together, they create a flywheel of innovation, growth, and global benefit.
-
@ a5142938:0ef19da3
2025-04-30 09:26:03
-
@ a5142938:0ef19da3
2025-04-30 09:24:55
-
@ e4950c93:1b99eccd
2025-04-30 09:24:29
-
@ b2d670de:907f9d4a
2025-03-25 20:17:57
This guide will walk you through setting up your own Strfry Nostr relay on a Debian/Ubuntu server and making it accessible exclusively as a TOR hidden service. By the end, you'll have a privacy-focused relay that operates entirely within the TOR network, enhancing both your privacy and that of your users.
Table of Contents
- Prerequisites
- Initial Server Setup
- Installing Strfry Nostr Relay
- Configuring Your Relay
- Setting Up TOR
- Making Your Relay Available on TOR
- Testing Your Setup]
- Maintenance and Security
- Troubleshooting
Prerequisites
- A Debian or Ubuntu server
- Basic familiarity with command line operations (most steps are explained in detail)
- Root or sudo access to your server
Initial Server Setup
First, let's make sure your server is properly set up and secured.
Update Your System
Connect to your server via SSH and update your system:
bash sudo apt update sudo apt upgrade -ySet Up a Basic Firewall
Install and configure a basic firewall:
bash sudo apt install ufw -y sudo ufw allow ssh sudo ufw enableThis allows SSH connections while blocking other ports for security.
Installing Strfry Nostr Relay
This guide includes the full range of steps needed to build and set up Strfry. It's simply based on the current version of the
DEPLOYMENT.mddocument in the Strfry GitHub repository. If the build/setup process is changed in the repo, this document could get outdated. If so, please report to me that something is outdated and check for updated steps here.Install Dependencies
First, let's install the necessary dependencies. Each package serves a specific purpose in building and running Strfry:
bash sudo apt install -y git build-essential libyaml-perl libtemplate-perl libregexp-grammars-perl libssl-dev zlib1g-dev liblmdb-dev libflatbuffers-dev libsecp256k1-dev libzstd-devHere's why each dependency is needed:
Basic Development Tools: -
git: Version control system used to clone the Strfry repository and manage code updates -build-essential: Meta-package that includes compilers (gcc, g++), make, and other essential build toolsPerl Dependencies (used for Strfry's build scripts): -
libyaml-perl: Perl interface to parse YAML configuration files -libtemplate-perl: Template processing system used during the build process -libregexp-grammars-perl: Advanced regular expression handling for Perl scriptsCore Libraries for Strfry: -
libssl-dev: Development files for OpenSSL, used for secure connections and cryptographic operations -zlib1g-dev: Compression library that Strfry uses to reduce data size -liblmdb-dev: Lightning Memory-Mapped Database library, which Strfry uses for its high-performance database backend -libflatbuffers-dev: Memory-efficient serialization library for structured data -libsecp256k1-dev: Optimized C library for EC operations on curve secp256k1, essential for Nostr's cryptographic signatures -libzstd-dev: Fast real-time compression algorithm for efficient data storage and transmissionClone and Build Strfry
Clone the Strfry repository:
bash git clone https://github.com/hoytech/strfry.git cd strfryBuild Strfry:
bash git submodule update --init make setup-golpe make -j2 # This uses 2 CPU cores. Adjust based on your server (e.g., -j4 for 4 cores)This build process will take several minutes, especially on servers with limited CPU resources, so go get a coffee and post some great memes on nostr in the meantime.
Install Strfry
Install the Strfry binary to your system path:
bash sudo cp strfry /usr/local/binThis makes the
strfrycommand available system-wide, allowing it to be executed from any directory and by any user with the appropriate permissions.Configuring Your Relay
Create Strfry User
Create a dedicated user for running Strfry. This enhances security by isolating the relay process:
bash sudo useradd -M -s /usr/sbin/nologin strfryThe
-Mflag prevents creating a home directory, and-s /usr/sbin/nologinprevents anyone from logging in as this user. This is a security best practice for service accounts.Create Data Directory
Create a directory for Strfry's data:
bash sudo mkdir /var/lib/strfry sudo chown strfry:strfry /var/lib/strfry sudo chmod 755 /var/lib/strfryThis creates a dedicated directory for Strfry's database and sets the appropriate permissions so that only the strfry user can write to it.
Configure Strfry
Copy the sample configuration file:
bash sudo cp strfry.conf /etc/strfry.confEdit the configuration file:
bash sudo nano /etc/strfry.confModify the database path:
```
Find this line:
db = "./strfry-db/"
Change it to:
db = "/var/lib/strfry/" ```
Check your system's hard limit for file descriptors:
bash ulimit -HnUpdate the
nofilessetting in your configuration to match this value (or set to 0):```
Add or modify this line in the config (example if your limit is 524288):
nofiles = 524288 ```
The
nofilessetting determines how many open files Strfry can have simultaneously. Setting it to your system's hard limit (or 0 to use the system default) helps prevent "too many open files" errors if your relay becomes popular.You might also want to customize your relay's information in the config file. Look for the
infosection and update it with your relay's name, description, and other details.Set ownership of the configuration file:
bash sudo chown strfry:strfry /etc/strfry.confCreate Systemd Service
Create a systemd service file for managing Strfry:
bash sudo nano /etc/systemd/system/strfry.serviceAdd the following content:
```ini [Unit] Description=strfry relay service
[Service] User=strfry ExecStart=/usr/local/bin/strfry relay Restart=on-failure RestartSec=5 ProtectHome=yes NoNewPrivileges=yes ProtectSystem=full LimitCORE=1000000000
[Install] WantedBy=multi-user.target ```
This systemd service configuration: - Runs Strfry as the dedicated strfry user - Automatically restarts the service if it fails - Implements security measures like
ProtectHomeandNoNewPrivileges- Sets resource limits appropriate for a relayEnable and start the service:
bash sudo systemctl enable strfry.service sudo systemctl start strfryCheck the service status:
bash sudo systemctl status strfryVerify Relay is Running
Test that your relay is running locally:
bash curl localhost:7777You should see a message indicating that the Strfry relay is running. This confirms that Strfry is properly installed and configured before we proceed to set up TOR.
Setting Up TOR
Now let's make your relay accessible as a TOR hidden service.
Install TOR
Install TOR from the package repositories:
bash sudo apt install -y torThis installs the TOR daemon that will create and manage your hidden service.
Configure TOR
Edit the TOR configuration file:
bash sudo nano /etc/tor/torrcScroll down to wherever you see a commented out part like this: ```
HiddenServiceDir /var/lib/tor/hidden_service/
HiddenServicePort 80 127.0.0.1:80
```
Under those lines, add the following lines to set up a hidden service for your relay:
HiddenServiceDir /var/lib/tor/strfry-relay/ HiddenServicePort 80 127.0.0.1:7777This configuration: - Creates a hidden service directory at
/var/lib/tor/strfry-relay/- Maps port 80 on your .onion address to port 7777 on your local machine - Keeps all traffic encrypted within the TOR networkCreate the directory for your hidden service:
bash sudo mkdir -p /var/lib/tor/strfry-relay/ sudo chown debian-tor:debian-tor /var/lib/tor/strfry-relay/ sudo chmod 700 /var/lib/tor/strfry-relay/The strict permissions (700) are crucial for security as they ensure only the debian-tor user can access the directory containing your hidden service private keys.
Restart TOR to apply changes:
bash sudo systemctl restart torMaking Your Relay Available on TOR
Get Your Onion Address
After restarting TOR, you can find your onion address:
bash sudo cat /var/lib/tor/strfry-relay/hostnameThis will output something like
abcdefghijklmnopqrstuvwxyz234567.onion, which is your relay's unique .onion address. This is what you'll share with others to access your relay.Understanding Onion Addresses
The .onion address is a special-format hostname that is automatically generated based on your hidden service's private key.
Your users will need to use this address with the WebSocket protocol prefix to connect:
ws://youronionaddress.onionTesting Your Setup
Test with a Nostr Client
The best way to test your relay is with an actual Nostr client that supports TOR:
- Open your TOR browser
- Go to your favorite client, either on clearnet or an onion service.
- Check out this list of nostr clients available over TOR.
- Add your relay URL:
ws://youronionaddress.onionto your relay list - Try posting a note and see if it appears on your relay
- In some nostr clients, you can also click on a relay to get information about it like the relay name and description you set earlier in the stryfry config. If you're able to see the correct values for the name and the description, you were able to connect to the relay.
- Some nostr clients also gives you a status on what relays a note was posted to, this could also give you an indication that your relay works as expected.
Note that not all Nostr clients support TOR connections natively. Some may require additional configuration or use of TOR Browser. E.g. most mobile apps would most likely require a TOR proxy app running in the background (some have TOR support built in too).
Maintenance and Security
Regular Updates
Keep your system, TOR, and relay updated:
```bash
Update system
sudo apt update sudo apt upgrade -y
Update Strfry
cd ~/strfry git pull git submodule update make -j2 sudo cp strfry /usr/local/bin sudo systemctl restart strfry
Verify TOR is still running properly
sudo systemctl status tor ```
Regular updates are crucial for security, especially for TOR which may have security-critical updates.
Database Management
Strfry has built-in database management tools. Check the Strfry documentation for specific commands related to database maintenance, such as managing event retention and performing backups.
Monitoring Logs
To monitor your Strfry logs:
bash sudo journalctl -u strfry -fTo check TOR logs:
bash sudo journalctl -u tor -fMonitoring logs helps you identify potential issues and understand how your relay is being used.
Backup
This is not a best practices guide on how to do backups. Preferably, backups should be stored either offline or on a different machine than your relay server. This is just a simple way on how to do it on the same server.
```bash
Stop the relay temporarily
sudo systemctl stop strfry
Backup the database
sudo cp -r /var/lib/strfry /path/to/backup/location
Restart the relay
sudo systemctl start strfry ```
Back up your TOR hidden service private key. The private key is particularly sensitive as it defines your .onion address - losing it means losing your address permanently. If you do a backup of this, ensure that is stored in a safe place where no one else has access to it.
bash sudo cp /var/lib/tor/strfry-relay/hs_ed25519_secret_key /path/to/secure/backup/locationTroubleshooting
Relay Not Starting
If your relay doesn't start:
```bash
Check logs
sudo journalctl -u strfry -e
Verify configuration
cat /etc/strfry.conf
Check permissions
ls -la /var/lib/strfry ```
Common issues include: - Incorrect configuration format - Permission problems with the data directory - Port already in use (another service using port 7777) - Issues with setting the nofiles limit (setting it too big)
TOR Hidden Service Not Working
If your TOR hidden service is not accessible:
```bash
Check TOR logs
sudo journalctl -u tor -e
Verify TOR is running
sudo systemctl status tor
Check onion address
sudo cat /var/lib/tor/strfry-relay/hostname
Verify TOR configuration
sudo cat /etc/tor/torrc ```
Common TOR issues include: - Incorrect directory permissions - TOR service not running - Incorrect port mapping in torrc
Testing Connectivity
If you're having trouble connecting to your service:
```bash
Verify Strfry is listening locally
sudo ss -tulpn | grep 7777
Check that TOR is properly running
sudo systemctl status tor
Test the local connection directly
curl --include --no-buffer localhost:7777 ```
Privacy and Security Considerations
Running a Nostr relay as a TOR hidden service provides several important privacy benefits:
-
Network Privacy: Traffic to your relay is encrypted and routed through the TOR network, making it difficult to determine who is connecting to your relay.
-
Server Anonymity: The physical location and IP address of your server are concealed, providing protection against denial-of-service attacks and other targeting.
-
Censorship Resistance: TOR hidden services are more resilient against censorship attempts, as they don't rely on the regular DNS system and can't be easily blocked.
-
User Privacy: Users connecting to your relay through TOR enjoy enhanced privacy, as their connections are also encrypted and anonymized.
However, there are some important considerations:
- TOR connections are typically slower than regular internet connections
- Not all Nostr clients support TOR connections natively
- Running a hidden service increases the importance of keeping your server secure
Congratulations! You now have a Strfry Nostr relay running as a TOR hidden service. This setup provides a resilient, privacy-focused, and censorship-resistant communication channel that helps strengthen the Nostr network.
For further customization and advanced configuration options, refer to the Strfry documentation.
Consider sharing your relay's .onion address with the Nostr community to help grow the privacy-focused segment of the network!
If you plan on providing a relay service that the public can use (either for free or paid for), consider adding it to this list. Only add it if you plan to run a stable and available relay.
-
@ bc52210b:20bfc6de
2025-03-25 20:17:22
CISA, or Cross-Input Signature Aggregation, is a technique in Bitcoin that allows multiple signatures from different inputs in a transaction to be combined into a single, aggregated signature. This is a big deal because Bitcoin transactions often involve multiple inputs (e.g., spending from different wallet outputs), each requiring its own signature. Normally, these signatures take up space individually, but CISA compresses them into one, making transactions more efficient.
This magic is possible thanks to the linearity property of Schnorr signatures, a type of digital signature introduced to Bitcoin with the Taproot upgrade. Unlike the older ECDSA signatures, Schnorr signatures have mathematical properties that allow multiple signatures to be added together into a single valid signature. Think of it like combining multiple handwritten signatures into one super-signature that still proves everyone signed off!
Fun Fact: CISA was considered for inclusion in Taproot but was left out to keep the upgrade simple and manageable. Adding CISA would’ve made Taproot more complex, so the developers hit pause on it—for now.
CISA vs. Key Aggregation (MuSig, FROST): Don’t Get Confused! Before we go deeper, let’s clear up a common mix-up: CISA is not the same as protocols like MuSig or FROST. Here’s why:
- Signature Aggregation (CISA): Combines multiple signatures into one, each potentially tied to different public keys and messages (e.g., different transaction inputs).
- Key Aggregation (MuSig, FROST): Combines multiple public keys into a single aggregated public key, then generates one signature for that key.
Key Differences: 1. What’s Aggregated? * CISA: Aggregates signatures. * Key Aggregation: Aggregates public keys. 2. What the Verifier Needs * CISA: The verifier needs all individual public keys and their corresponding messages to check the aggregated signature. * Key Aggregation: The verifier only needs the single aggregated public key and one message. 3. When It Happens * CISA: Used during transaction signing, when inputs are being combined into a transaction. * MuSig: Used during address creation, setting up a multi-signature (multisig) address that multiple parties control.
So, CISA is about shrinking signature data in a transaction, while MuSig/FROST are about simplifying multisig setups. Different tools, different jobs!
Two Flavors of CISA: Half-Agg and Full-Agg CISA comes in two modes:
- Full Aggregation (Full-Agg): Interactive, meaning signers need to collaborate during the signing process. (We’ll skip the details here since the query focuses on Half-Agg.)
- Half Aggregation (Half-Agg): Non-interactive, meaning signers can work independently, and someone else can combine the signatures later.
Since the query includes “CISA Part 2: Half Signature Aggregation,” let’s zoom in on Half-Agg.
Half Signature Aggregation (Half-Agg) Explained How It Works Half-Agg is a non-interactive way to aggregate Schnorr signatures. Here’s the process:
- Independent Signing: Each signer creates their own Schnorr signature for their input, without needing to talk to the other signers.
- Aggregation Step: An aggregator (could be anyone, like a wallet or node) takes all these signatures and combines them into one aggregated signature.
A Schnorr signature has two parts:
- R: A random point (32 bytes).
- s: A scalar value (32 bytes).
In Half-Agg:
- The R values from each signature are kept separate (one per input).
- The s values from all signatures are combined into a single s value.
Why It Saves Space (~50%) Let’s break down the size savings with some math:
Before Aggregation: * Each Schnorr signature = 64 bytes (32 for R + 32 for s). * For n inputs: n × 64 bytes.
After Half-Agg: * Keep n R values (32 bytes each) = 32 × n bytes. * Combine all s values into one = 32 bytes. * Total size: 32 × n + 32 bytes.
Comparison:
- Original: 64n bytes.
- Half-Agg: 32n + 32 bytes.
- For large n, the “+32” becomes small compared to 32n, so it’s roughly 32n, which is half of 64n. Hence, ~50% savings!
Real-World Impact: Based on recent Bitcoin usage, Half-Agg could save:
- ~19.3% in space (reducing transaction size).
- ~6.9% in fees (since fees depend on transaction size). This assumes no major changes in how people use Bitcoin post-CISA.
Applications of Half-Agg Half-Agg isn’t just a cool idea—it has practical uses:
- Transaction-wide Aggregation
- Combine all signatures within a single transaction.
- Result: Smaller transactions, lower fees.
- Block-wide Aggregation
- Combine signatures across all transactions in a Bitcoin block.
- Result: Even bigger space savings at the blockchain level.
- Off-chain Protocols / P2P
- Use Half-Agg in systems like Lightning Network gossip messages.
- Benefit: Efficiency without needing miners or a Bitcoin soft fork.
Challenges with Half-Agg While Half-Agg sounds awesome, it’s not without hurdles, especially at the block level:
- Breaking Adaptor Signatures
- Adaptor signatures are special signatures used in protocols like Discreet Log Contracts (DLCs) or atomic swaps. They tie a signature to revealing a secret, ensuring fair exchanges.
-
Aggregating signatures across a block might mess up these protocols, as the individual signatures get blended together, potentially losing the properties adaptor signatures rely on.
-
Impact on Reorg Recovery
- In Bitcoin, a reorganization (reorg) happens when the blockchain switches to a different chain of blocks. Transactions from the old chain need to be rebroadcast or reprocessed.
- If signatures are aggregated at the block level, it could complicate extracting individual transactions and their signatures during a reorg, slowing down recovery.
These challenges mean Half-Agg needs careful design, especially for block-wide use.
Wrapping Up CISA is a clever way to make Bitcoin transactions more efficient by aggregating multiple Schnorr signatures into one, thanks to their linearity property. Half-Agg, the non-interactive mode, lets signers work independently, cutting signature size by about 50% (to 32n + 32 bytes from 64n bytes). It could save ~19.3% in space and ~6.9% in fees, with uses ranging from single transactions to entire blocks or off-chain systems like Lightning.
But watch out—block-wide Half-Agg could trip up adaptor signatures and reorg recovery, so it’s not a slam dunk yet. Still, it’s a promising tool for a leaner, cheaper Bitcoin future!
-
@ e4950c93:1b99eccd
2025-04-30 09:23:25
-
@ a5142938:0ef19da3
2025-04-30 09:23:00
-
@ b17fccdf:b7211155
2025-03-25 11:23:36
Si vives en España, quizás hayas notado que no puedes acceder a ciertas páginas webs durante los fines de semana o en algunos días entre semana, entre ellas, la guía de MiniBolt.
Esto tiene una razón, por supuesto una solución, además de una conclusión. Sin entrar en demasiados detalles:
La razón
El bloqueo a Cloudflare, implementado desde hace casi dos meses por operadores de Internet (ISPs) en España (como Movistar, O2, DIGI, Pepephone, entre otros), se basa en una orden judicial emitida tras una demanda de LALIGA (Fútbol). Esta medida busca combatir la piratería en España, un problema que afecta directamente a dicha organización.
Aunque la intención original era restringir el acceso a dominios específicos que difundieran dicho contenido, Cloudflare emplea el protocolo ECH (Encrypted Client Hello), que oculta el nombre del dominio, el cual antes se transmitía en texto plano durante el proceso de establecimiento de una conexión TLS. Esta medida dificulta que las operadoras analicen el tráfico para aplicar bloqueos basados en dominios, lo que les obliga a recurrir a bloqueos más amplios por IP o rangos de IP para cumplir con la orden judicial.
Esta práctica tiene consecuencias graves, que han sido completamente ignoradas por quienes la ejecutan. Es bien sabido que una infraestructura de IP puede alojar numerosos dominios, tanto legítimos como no legítimos. La falta de un "ajuste fino" en los bloqueos provoca un perjuicio para terceros, restringiendo el acceso a muchos dominios legítimos que no tiene relación alguna con actividades ilícitas, pero que comparten las mismas IPs de Cloudflare con dominios cuestionables. Este es el caso de la web de MiniBolt y su dominio
minibolt.info, los cuales utilizan Cloudflare como proxy para aprovechar las medidas de seguridad, privacidad, optimización y servicios adicionales que la plataforma ofrece de forma gratuita.Si bien este bloqueo parece ser temporal (al menos durante la temporada 24/25 de fútbol, hasta finales de mayo), es posible que se reactive con el inicio de la nueva temporada.

La solución
Obviamente, MiniBolt no dejará de usar Cloudflare como proxy por esta razón. Por lo que a continuación se exponen algunas medidas que como usuario puedes tomar para evitar esta restricción y poder acceder:
~> Utiliza una VPN:
Existen varias soluciones de proveedores de VPN, ordenadas según su reputación en privacidad: - IVPN - Mullvad VPN - Proton VPN (gratis) - Obscura VPN (solo para macOS) - Cloudfare WARP (gratis) + permite utilizar el modo proxy local para enrutar solo la navegación, debes utilizar la opción "WARP a través de proxy local" siguiendo estos pasos: 1. Inicia Cloudflare WARP y dentro de la pequeña interfaz haz click en la rueda dentada abajo a la derecha > "Preferencias" > "Avanzado" > "Configurar el modo proxy" 2. Marca la casilla "Habilite el modo proxy en este dispositivo" 3. Elige un "Puerto de escucha de proxy" entre 0-65535. ej: 1080, haz click en "Aceptar" y cierra la ventana de preferencias 4. Accede de nuevo a Cloudflare WARP y pulsa sobre el switch para habilitar el servicio. 3. Ahora debes apuntar el proxy del navegador a Cloudflare WARP, la configuración del navegador es similar a esta para el caso de navegadores basados en Firefox. Una vez hecho, deberías poder acceder a la guía de MiniBolt sin problemas. Si tienes dudas, déjalas en comentarios e intentaré resolverlas. Más info AQUÍ.
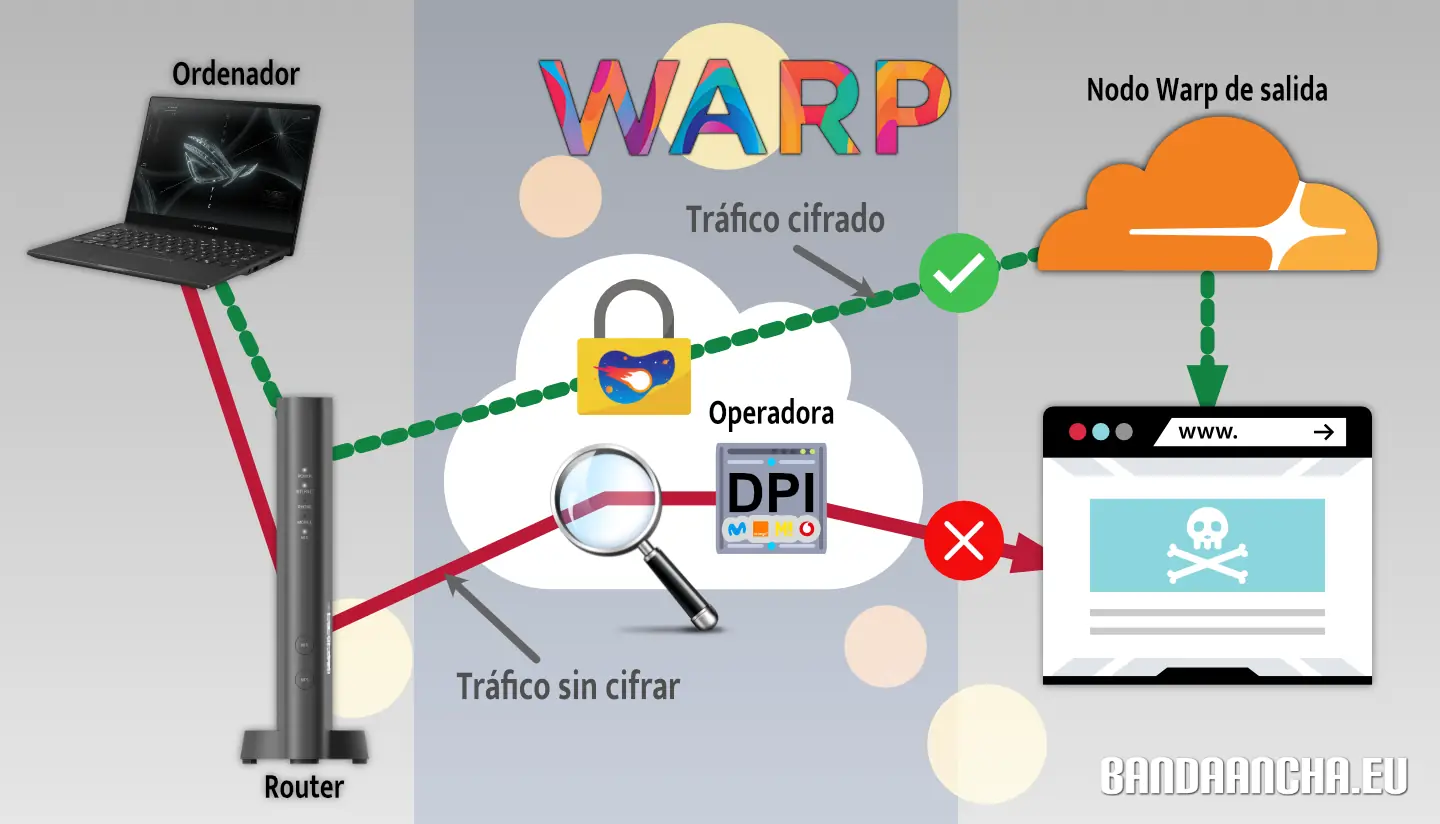
~> Proxifica tu navegador para usar la red de Tor, o utiliza el navegador oficial de Tor (recomendado).

La conclusión
Estos hechos ponen en tela de juicio los principios fundamentales de la neutralidad de la red, pilares esenciales de la Declaración de Independencia del Ciberespacio que defiende un internet libre, sin restricciones ni censura. Dichos principios se han visto quebrantados sin precedentes en este país, confirmando que ese futuro distópico que muchos negaban, ya es una realidad.
Es momento de actuar y estar preparados: debemos impulsar el desarrollo y la difusión de las herramientas anticensura que tenemos a nuestro alcance, protegiendo así la libertad digital y asegurando un acceso equitativo a la información para todos
Este compromiso es uno de los pilares fundamentales de MiniBolt, lo que convierte este desafío en una oportunidad para poner a prueba las soluciones anticensura ya disponibles, así como las que están en camino.
¡Censúrame si puedes, legislador! ¡La lucha por la privacidad y la libertad en Internet ya está en marcha!

Fuentes: * https://bandaancha.eu/articulos/movistar-o2-deja-clientes-sin-acceso-11239 * https://bandaancha.eu/articulos/esta-nueva-sentencia-autoriza-bloqueos-11257 * https://bandaancha.eu/articulos/como-saltarse-bloqueo-webs-warp-vpn-9958 * https://bandaancha.eu/articulos/como-activar-ech-chrome-acceder-webs-10689 * https://comunidad.movistar.es/t5/Soporte-Fibra-y-ADSL/Problema-con-web-que-usan-Cloudflare/td-p/5218007
-
@ a5142938:0ef19da3
2025-04-30 09:22:12
-
@ 3b7fc823:e194354f
2025-03-23 03:54:16
A quick guide for the less than technical savvy to set up their very own free private tor enabled email using Onionmail. Privacy is for everyone, not just the super cyber nerds.
Onion Mail is an anonymous POP3/SMTP email server program hosted by various people on the internet. You can visit this site and read the details: https://en.onionmail.info/
- Download Tor Browser
First, if you don't already, go download Tor Browser. You are going to need it. https://www.torproject.org/
- Sign Up
Using Tor browser go to the directory page (https://onionmail.info/directory.html) choose one of the servers and sign up for an account. I say sign up but it is just choosing a user name you want to go before the @xyz.onion email address and solving a captcha.
- Account information
Once you are done signing up an Account information page will pop up. MAKE SURE YOU SAVE THIS!!! It has your address and passwords (for sending and receiving email) that you will need. If you lose them then you are shit out of luck.
- Install an Email Client
You can use Claws Mail, Neomutt, or whatever, but for this example, we will be using Thunderbird.
a. Download Thunderbird email client
b. The easy setup popup page that wants your name, email, and password isn't going to like your user@xyz.onion address. Just enter something that looks like a regular email address such as name@example.com and the Configure Manuallyoption will appear below. Click that.
- Configure Incoming (POP3) Server
Under Incoming Server: Protocol: POP3 Server or Hostname: xyz.onion (whatever your account info says) Port: 110 Security: STARTTLS Authentication: Normal password Username: (your username) Password: (POP3 password).
- Configure Outgoing (SMTP) Server
Under Outgoing Server: Server or Hostname: xyz.onion (whatever your account info says) Port: 25 Security: STARTTLS Authentication: Normal password Username: (your username) Password: (SMTP password).
-
Click on email at the top and change your address if you had to use a spoof one to get the configure manually to pop up.
-
Configure Proxy
a. Click the gear icon on the bottom left for settings. Scroll all the way down to Network & Disk Space. Click the settings button next to Connection. Configure how Thunderbird connects to the internet.
b. Select Manual Proxy Configuration. For SOCKS Host enter 127.0.0.1 and enter port 9050. (if you are running this through a VM the port may be different)
c. Now check the box for SOCKS5 and then Proxy DNS when using SOCKS5 down at the bottom. Click OK
- Check Email
For thunderbird to reach the onion mail server it has to be connected to tor. Depending on your local setup, it might be fine as is or you might have to have tor browser open in the background. Click on inbox and then the little cloud icon with the down arrow to check mail.
- Security Exception
Thunderbird is not going to like that the onion mail server security certificate is self signed. A popup Add Security Exception will appear. Click Confirm Security Exception.
You are done. Enjoy your new private email service.
REMEMBER: The server can read your emails unless they are encrypted. Go into account settings. Look down and click End-toEnd Encryption. Then add your OpenPGP key or open your OpenPGP Key Manager (you might have to download one if you don't already have one) and generate a new key for this account.
-
@ e4950c93:1b99eccd
2025-04-30 09:21:52
-
@ 21335073:a244b1ad
2025-03-18 20:47:50
Warning: This piece contains a conversation about difficult topics. Please proceed with caution.
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book Cypherpunks, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
Course: - The creation of the internet and computers - The fight for cryptography - The tech supply chain from the ground up (example: human rights violations in the supply chain) - Corporate tech - Freedom tech - Data privacy - Digital privacy rights - AI (history-current) - Online safety (predators, scams, catfishing, extortion) - Bitcoin - Laws - How to deal with online hate and harassment - Information on who to contact if you are being abused online or offline - Algorithms - How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ e4950c93:1b99eccd
2025-04-30 09:20:50
Qu'est-ce qu'une matière naturelle ? La question fait débat, et chacun-e privilégiera ses propres critères. Voici comment les matières sont classées sur ce site. La liste est régulièrement mise à jour en fonction des produits ajoutés. N'hésitez pas à partager votre avis !
✅ Matières naturelles
Matières d'origine végétale, animale ou minérale, sans transformation chimique altérant leur structure moléculaire.
🌱 Principaux critères : - Biodégradabilité - Non-toxicité - Présence naturelle nécessitant le minimum de transformation
🔍 Liste des matières naturelles : - Bois - Cellulose régénérée (cupra, lyocell, modal, viscose) - Chanvre - Coton - Cuir - Latex naturel, caoutchouc - Liège - Lin - Laine - Métal - Soie - Terre - Verre - … (Autres matières)
⚠️ Bien que "naturelles", ces matières peuvent générer des impacts négatifs selon leurs conditions de production (pollution par pesticides, consommation d’eau excessive, traitement chimique, exploitation animale…). Ces impacts sont mentionnés sur la fiche de chaque matière.
Les versions biologiques de ces matières (sans traitement chimique, maltraitance animale, etc.) sont privilégiées pour référencer les produits sur ce site, tel qu'indiqué sur la fiche de chaque matière (à venir).
Les versions conventionnelles ne sont référencées que tant que lorsqu'il n'a pas encore été trouvé d'alternative plus durable pour cette catégorie de produits.
🚫 Matières non naturelles
Matières synthétiques ou fortement modifiées, souvent issues de la pétrochimie.
📌 Principaux problèmes : - Toxicité et émissions de microplastiques - Dépendance aux énergies fossiles - Mauvaise biodégradabilité
🔍 Liste des matières non naturelles : - Acrylique - Élasthanne, lycra, spandex - Polyamides, nylon - Polyester - Silicone - … (Autres matières)
⚠️ Ces matières ne sont pas admises sur le site. Néanmoins, elles peuvent être présentes dans certains produits référencés lorsque :
- elles sont utilisées en accessoire amovible (ex. : élastiques, boutons… généralement non indiqué dans la composition par la marque) pouvant être retiré pour le recyclage ou compostage, et
- aucune alternative 100 % naturelle n’a encore été identifiée pour cette catégorie de produits.
Dans ce cas, un avertissement est alors affiché sur la fiche du produit.
Cet article est publié sur origine-nature.com 🌐 See this article in English
-
@ 21335073:a244b1ad
2025-03-18 14:43:08
Warning: This piece contains a conversation about difficult topics. Please proceed with caution.
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book Cypherpunks, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
Course: - The creation of the internet and computers - The fight for cryptography - The tech supply chain from the ground up (example: human rights violations in the supply chain) - Corporate tech - Freedom tech - Data privacy - Digital privacy rights - AI (history-current) - Online safety (predators, scams, catfishing, extortion) - Bitcoin - Laws - How to deal with online hate and harassment - Information on who to contact if you are being abused online or offline - Algorithms - How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ a5142938:0ef19da3
2025-04-30 09:19:41
What is a natural material? It's a topic of debate, and everyone will prioritize their own criteria. Here’s how materials are classified on this site. The list is regularly updated based on the products added. Feel free to share your thoughts!
✅ Natural Materials
Materials of plant, animal, or mineral origin, without chemical transformation that alters their molecular structure.
🌱 Main Criteria: - Biodegradability - Non-toxicity - Naturally occurring and recquiring minimal transformation
🔍 List of Natural Materials: - Regenerated Cellulose (cupra, lyocell, modal, rayon) - Cork - Cotton - Earth - Glass - Hemp - Natural Latex, rubber - Leather - Linen - Metal - Silk - Wood - Wool - … (Other materials)
⚠️ Although "natural", these materials can have negative impacts depending on their production conditions (pesticide pollution, excessive water consumption, chemical treatments, animal exploitation, etc.). These impacts are mentionned in the description of each material.
Organic versions of these materials — free from chemical treatments, animal mistreatment, etc. — are preferred for listing products on this site, as indicated on each material's page (coming soon).
Conventional versions are only referenced when no more sustainable alternative has yet been found for that product category.
🚫 Non-Natural Materials
Synthetic or heavily modified materials, often derived from petrochemicals.
📌 Main Issues: - Toxicity and microplastic emissions - Dependence on fossil fuels - Poor biodegradability
🔍 List of Non-Natural Materials: - Acrylic - Elastane, spandex, lycra - Polyamides, nylon - Polyester - Silicone - … (Other materials)
⚠️ These materials are not accepted on this site. However, they may be present in certain listed products if:
- they are used in removable accessories (e.g., elastics, buttons—often not listed in the product’s composition by the brand) that can be detached for recycling or composting, and
- no 100% natural alternative has yet been identified for that product category.
In such cases, a warning will be displayed on the product page.
This article is published on origin-nature.com 🌐 Voir cet article en français
-
@ 6c67a3f3:b0ebd196
2025-04-30 08:40:15
To explore the link between Gavekal-style platform companies and the US dollar's status as the global reserve currency, we need to view the problem through multiple interlocking lenses—monetary economics, network effects, macro-political architecture, financial plumbing, and the logic of platform capitalism. Gavekal’s conceptual framework focuses heavily on capital-light, scalable businesses that act as platforms rather than traditional linear firms. Their model emphasizes "soft" balance sheets, asset-light capital formation, high intangible value creation, and the scaling of network effects. These traits dovetail in complex ways with the structural position of the United States in the global financial system.
What follows is a broad and recursive dissection of how these two phenomena—platform companies and reserve currency status—are mutually constitutive, each feeding the other, both directly and via second- and third-order effects.
- The Core Metaphor: Platforms and Monetary Hegemony
At its root, a platform is a meta-infrastructure—a set of protocols and affordances that enable others to interact, produce, consume, and transact. The dollar, as reserve currency, functions in an analogous way. It is not merely a medium of exchange but a platform for global commerce, pricing, credit formation, and risk transfer.
In this metaphor, the United States is not just a country but a platform operator of global finance. And like Amazon or Apple, it enforces terms of access, extracts rents, underwrites standardization, and benefits disproportionately from marginal activity across its ecosystem. Just as Apple's App Store tax or Amazon’s marketplace fee are invisible to most users, the dollar hegemon collects global seigniorage, institutional influence, and capital inflow not as overt tolls, but through the structuring of default behaviors.
This already suggests a deep isomorphism between platform logic and reserve currency logic.
- Capital-Light Scaffolding and Global Dollar Demand
Gavekal-style firms (e.g. Apple, Google, Microsoft) have something unusual in common: they generate high levels of free cash flow with low reinvestment needs. That is, they do not soak up global capital so much as recycle it outward, often via share buybacks or bond issuance. This creates a paradox: they are net issuers of dollar-denominated financial claims even as they are net accumulators of global income.
Now map this onto the structure of reserve currency systems. The US must export financial assets to the world (Treasuries, MBS, high-grade corporates) in order to satisfy foreign demand for dollar claims. But traditional exporting economies (e.g. Germany, China) create excess savings they must park in safe dollar assets, while running trade surpluses.
Gavekal-style firms allow the US to square a circle. The US economy does not need to run trade surpluses, because its platform companies export “intangible products” at near-zero marginal cost (e.g. iOS, search ads, cloud infrastructure), generate global rents, and then repatriate those earnings into US financial markets. These flows offset the US current account deficit, plugging the "Triffin dilemma" (the need to run deficits to supply dollars while maintaining credibility).
Thus, platform companies act as soft exporters, replacing industrial exports with intangible, rent-generating capital. Their global cash flows are then recycled through dollar-denominated assets, providing the scale and liquidity necessary to sustain reserve status.
- The Hierarchy of Money and Intangible Collateral
Modern monetary systems rest on a hierarchy of collateral—some assets are more money-like than others. US Treasuries sit at the apex, but AAA-rated corporates, especially those with global footprints and balance-sheet integrity, are close behind.
Platform firms are unique in their capacity to create high-quality, globally accepted private collateral. Apple’s bonds, Microsoft’s equity, and Google’s cash reserves function as synthetic dollar instruments, widely accepted, liquid, and backed by consistent income streams. These firms extend the reach of the dollar system by providing dollar-denominated assets outside the banking system proper, further embedding dollar logic into global capital flows.
Moreover, platform companies often internalize global tax arbitrage, holding cash offshore (or in tax-efficient jurisdictions) and issuing debt domestically. This creates a loop where foreign dollar claims are used to finance US domestic consumption or investment, but the underlying income comes from global activities. This is reverse colonization through intangibles.
- Winner-Take-Most Dynamics and Network Effects in Dollar Space
The dollar system, like platform capitalism, obeys a power-law distribution. Liquidity begets liquidity. The more that dollar instruments dominate global trade, the more pricing, settlement, and hedging mechanisms are built around them. This self-reinforcing loop mimics network effect entrenchment: the more users a platform has, the harder it is to displace.
Reserve currency status is not a product of GDP share alone. It’s a function of infrastructure, institutional depth, legal recourse, capital mobility, and networked habits. Likewise, Apple’s dominance is not just about better phones, but about developer lock-in, payment systems, user base, and design mores.
Gavekal-style firms reinforce this pattern: their software platforms often denominate activity in dollars, price in dollars, store value in dollars, and link digital labor across borders into dollar-based flows. YouTube creators in Jakarta are paid in dollars. AWS charges Chilean entrepreneurs in dollars. App Store remittances to Kenya settle in dollars.
This creates global micro-tributaries of dollar flows, all of which aggregate into the larger river that sustains dollar supremacy.
- Geopolitical Power Projection by Private Means
Traditional hegemonic systems project power through military, legal, and diplomatic tools. But platforms provide soft control mechanisms. The US can influence foreign populations and elite behavior not merely through embassies and aircraft carriers, but through tech platforms that shape discourse, information flows, norms, and cognitive frames.
This is a kind of cognitive imperialism, in which reserve currency status is bolstered by the fact that cultural products (e.g. Netflix, social media, productivity tools) are encoded in American norms, embedded in American legal systems, and paid for in American currency.
The platform firm thus becomes a shadow extension of statecraft, whether or not it sees itself that way. Dollar hegemony is reinforced not only by Treasury markets and SWIFT access, but by the gravity of the mental ecosystem within which the global bourgeoisie operates. To earn, spend, invest, create, and dream within American-built systems is to keep the dollar central by default.
- Second-Order Effects: The Intangibility Ratchet and Global Liquidity Traps
An overlooked consequence of Gavekal-style platform dominance is that global capital formation becomes disembodied. That is, tangible projects—factories, infrastructure, energy systems—become less attractive relative to financial or intangible investments.
As a result, much of the world, especially the Global South, becomes capital-starved even as capital is abundant. Why? Because the returns on tangible investment are less scalable, less defensible, and less liquid than buying FAANG stocks or US Treasuries.
This results in a liquidity trap at the global scale: too much capital chasing too few safe assets, which only reinforces demand for dollar instruments. Meanwhile, intangible-intensive firms deepen their moats by mining attention, user data, and payment flows—often without any large-scale employment or industrial externalities.
Thus, Gavekal-style firms create asymmetric global development, further concentrating economic gravitational mass in the dollar zone.
- Feedback Loops and Fragility
All of this breeds both strength and fragility. On one hand, platform firm cash flows make the dollar system seem robust—anchored in cash-generative monopolies with global reach. On the other hand, the system becomes narrower and more brittle. When so much of global liquidity is intermediated through a few firms and the sovereign system that hosts them, any attack on these nodes—financial, legal, technological, or geopolitical—could unseat the equilibrium.
Moreover, platform logic tends to reduce systemic redundancy. It optimizes for efficiency, not resilience. It centralizes control, narrows option sets, and abstracts real production into code. If the dollar system ever loses credibility—through inflation, sanctions overreach, geopolitical backlash, or platform fatigue—the network effects could reverse violently.
- Conclusion: The Intangible Empire
The United States today operates an empire of intangibles, in which reserve currency status and platform firm dominance are co-constituted phenomena. Each reinforces the other:
Platform firms channel global rents into dollar instruments.
The dollar system provides legal scaffolding, liquidity, and pricing infrastructure for these firms.
Global user bases are conditioned into dollar-denominated interaction by default.
Financial markets treat platform firms as synthetic sovereigns: safe, liquid, predictable.
What is left is a cybernetic loop of financialized cognition: the dollar is strong because platform firms dominate, and platform firms dominate because the dollar is strong.
This loop may persist longer than many expect, but it is not permanent. Its unravelling, when it comes, will likely not be driven by any single actor, but by the erosion of symbolic power, the emergence of parallel platforms, or the ecological unsustainability of the model. But for now, the Gavekal firm and the dollar empire are the two poles of a single global architecture—seen best not as cause and effect, but as the two faces of the same Janus coin.
-
@ a07fae46:7d83df92
2025-03-18 12:31:40
if the JFK documents come out and are nothing but old hat, it will be disappointing. but if they contain revelations, then they are an unalloyed good. unprecedented and extraordinary; worthy of praise and admiration. they murdered the president in broad daylight and kept 80,000 related documents secret for 60 years. the apparatus that did that and got away with it, is 100+ years in the making. the magic bullet was just the starting pistol of a new era; a level up in an old game. it won't be dismantled and your republic delivered back with a bow in 2 months. have a little humility and a little gratitude. cynicism is easy. it's peak mid-wittery. yeah no shit everything is corrupt and everyone's likely captured by AIPAC or something beyond. YOU THINK AIPAC is the ALL SEEING EYE?
you can keep going, if you want to, but have some awareness and appreciation for where we are and what it took to get here. the first 'you are fake news' was also a shot heard 'round the world and you are riding high on it's Infrasound wave, still reverberating; unappreciative of the profound delta in public awareness and understanding, and rate of change, that has occurred since that moment, in 2017. think about where we were back then, especially with corporate capture of the narrative. trump's bullheaded behavior, if only ego-driven, is what broke the spell. an actual moment of savage bravery is what allows for your current jaded affectation. black pilled is boring. it's intellectually lazy. it is low-resolution-thinking, no better than progressives who explain the myriad ills of the world through 'racism'. normalcy bias works both ways. i'm not grading you on a curve that includes NPCs. i'm grading you against those of us with a mind, on up. do better.
the best Webb-style doomer argument is essentially 'the mouse trap needs a piece of cheese in order to work'. ok, but it doesn't need 3 pieces of cheese, or 5. was FreeRoss the piece of cheese? was the SBR the cheese? real bitcoiners know how dumb the 'sbr is an attempt to takeover btc' narrative is, so extrapolate from that. what about withdrawal from the WHO? freeze and review of USAID et al? how many pieces of cheese before we realize it's not a trap? it's just a messy endeavor.
Good morning.
jfkFiles #nostrOnly
-
@ a5142938:0ef19da3
2025-04-30 08:36:29
Happy to have found useful information on this site?
Support the project by making a donation to keep it running and thank the contributors.
In bitcoin
-
On-chain: bc1qkm8me8l9563wvsl9sklzt4hdcuny3tlejznj7d
-
Lightning network: ⚡️
origin-nature@coinos.ioYou can also support us on a recurring basis 👉 Set up a recurring Lightning payment
In euros, dollars, or any other supported currency
-
By bank transfer, IBAN: FR76 2823 3000 0144 3759 8717 669
-
You can also support us on a recurring basis 👉 Make a pledge on LiberaPay
Contact us if you’d like to make a donation using any other cryptocurrency.
💡 A Value-Sharing Model
Half of the donations are redistributed to the contributors who create the site's value, experimenting with a revenue-sharing model on the Internet—one that respects your data and doesn’t seek to capture your attention. The other half helps cover the site's operating costs.
This article is published on origin-nature.com 🌐 Voir cet article en français
-
-
@ bc52210b:20bfc6de
2025-03-14 20:39:20
When writing safety critical code, every arithmetic operation carries the potential for catastrophic failure—whether that’s a plane crash in aerospace engineering or a massive financial loss in a smart contract.
The stakes are incredibly high, and errors are not just bugs; they’re disasters waiting to happen. Smart contract developers need to shift their mindset: less like web developers, who might prioritize speed and iteration, and more like aerospace engineers, where precision, caution, and meticulous attention to detail are non-negotiable.
In practice, this means treating every line of code as a critical component, adopting rigorous testing, and anticipating worst-case scenarios—just as an aerospace engineer would ensure a system can withstand extreme conditions.
Safety critical code demands aerospace-level precision, and smart contract developers must rise to that standard to protect against the severe consequences of failure.
-
@ df173277:4ec96708
2025-02-07 00:41:34
Building Our Confidential Backend on Secure Enclaves
With our newly released private and confidential Maple AI and the open sourcing of our OpenSecret platform code, I'm excited to present this technical primer on how we built our confidential compute platform leveraging secure enclaves. By combining AWS Nitro enclaves with end-to-end encryption and reproducible builds, our platform gives developers and end users the confidence that user data is protected, even at runtime, and that the code operating on their data has not been tampered with.
Auth and Databases Today
As developers, we live in an era where protecting user data means "encryption at rest," plus some access policies and procedures. Developers typically run servers that:
- Need to register users (authentication).
- Collect and process user data in business-specific ways, often on the backend.
Even if data is encrypted at rest, it's commonly unlocked with a single master key or credentials the server holds. This means that data is visible during runtime to the application, system administrators, and potentially to the hosting providers. This scenario makes it difficult (or impossible) to guarantee that sensitive data isn't snooped on, memory-dumped, or used in unauthorized ways (for instance, training AI models behind the scenes).
"Just Trust Us" Isn't Good Enough
In a traditional server architecture, users have to take it on faith that the code handling their data is the same code the operator claims to be running. Behind the scenes, applications can be modified or augmented to forward private information elsewhere, and there is no transparent way for users to verify otherwise. This lack of proof is unsettling, especially for services that process or store highly confidential data.
Administrators, developers, or cloud providers with privileged access can inspect memory in plaintext, attach debuggers, or gain complete visibility into stored information. Hackers who compromise these privileged levels can directly access sensitive data. Even with strict policies or promises of good conduct, the reality is that technical capabilities and misconfigurations can override words on paper. If a server master key can decrypt your data or can be accessed by an insider with root permissions, then "just trust us" loses much of its credibility.
The rise of AI platforms amplifies this dilemma. User data, often full of personal details, gets funneled into large-scale models that might be training or fine-tuning behind the scenes. Relying on vague assurances that "we don't look at your data" is no longer enough to prevent legitimate concerns about privacy and misuse. Now more than ever, providing a strong, verifiable guarantee that data remains off-limits, even when actively processed, has become a non-negotiable requirement for trustworthy services.
Current Attempts at Securing Data
 Current User Experience of E2EE Apps
Current User Experience of E2EE AppsWhile properly securing data is not easy, it isn't to say that no one is trying. Some solutions use end-to-end encryption (E2EE), where user data is encrypted client-side with a password or passphrase, so not even the server operator can decrypt it. That approach can be quite secure, but it also has its limitations:
- Key Management Nightmares: If a user forgets their passphrase, the data is effectively lost, and there's no way to recover it from the developer's side.
- Feature Limitations: Complex server-side operations (like offline/background tasks, AI queries, real-time collaboration, or heavy computation) can't easily happen if the server is never capable of processing decrypted data.
- Platform Silos: Some solutions rely on iCloud, Google Drive, or local device storage. That can hamper multi-device usage or multi-OS compatibility.
Other approaches include self-hosting. However, these either burden users with dev ops overhead or revert to the "trust me" model for the server if you "self-host" on a cloud provider.
Secure Enclaves
The Hybrid Approach
Secure enclaves offer a compelling middle ground. They combine the privacy benefits of keeping data secure from prying admins while still allowing meaningful server-side computation. In a nutshell, an enclave is a protected environment within a machine, isolated at the hardware level, so that even if the OS or server is compromised, the data and code inside the enclave remain hidden.
 App Service Running Inside Secure Enclave
App Service Running Inside Secure EnclaveHigh-Level Goal of Enclaves
Enclaves, also known under the broader umbrella of confidential computing, aim to:\ • Lock down data so that only authorized code within the enclave can process the original plaintext data.\ • Deny external inspection by memory dumping, attaching a debugger, or intercepting plaintext network traffic.\ • Prove to external users or services that an enclave is running unmodified, approved code (this is where remote attestation comes in).
Different Secure Enclave Solutions
AMD SEV (Secure Encrypted Virtualization) encrypts an entire virtual machine's memory so that even a compromised hypervisor cannot inspect or modify guest data. Its core concept is "lift-and-shift" security. No application refactoring is required because hardware-based encryption automatically protects the OS and all VM applications. Later enhancements (SEV-ES and SEV-SNP) added encryption of CPU register states and memory integrity protections, further limiting hypervisor tampering. This broad coverage means the guest OS is included in the trusted boundary. AMD SEV has matured into a robust solution for confidential VMs in multi-tenant clouds.
Intel TDX (Trust Domain Extensions) shifts from process-level enclaves to full VM encryption, allowing an entire guest operating system and its applications to run in an isolated "trust domain." Like AMD SEV, Intel TDX encrypts and protects all memory the VM uses from hypervisors or other privileged software, so developers do not need to refactor their code to benefit from hardware-based confidentiality. This broader scope addresses many SGX limitations, such as strict memory bounds and the need to split out enclave-specific logic, and offers a more straightforward "lift-and-shift" path for running existing workloads privately. While SGX is now deprecated, TDX carries forward the core confidential computing principles but applies them at the virtual machine level for more substantial isolation, easier deployment, and the ability to scale up to large, memory-intensive applications.
Apple Secure Enclave and Private Compute is a dedicated security coprocessor embedded in most Apple devices (iPhones, iPads, Macs) and now extended to Apple's server-side AI infrastructure. It runs its own microkernel, has hardware-protected memory, and securely manages operations such as biometric authentication, key storage, and cryptographic tasks. Apple's "Private Compute" approach in the cloud brings similar enclave capabilities to server-based AI, enabling on-device-grade privacy even when requests are processed in Apple's data centers.
AWS Nitro Enclaves carve out a tightly isolated "mini-VM" from a parent EC2 instance, with its own vCPUs and memory guarded by dedicated Nitro cards. The enclave has no persistent storage and no external network access, significantly reducing the attack surface. Communication with the parent instance occurs over a secure local channel (vsock), and AWS offers hardware-based attestation so that secrets (e.g., encryption keys from AWS KMS) can be accessed only to the correct enclave. This design helps developers protect sensitive data or code even if the main EC2 instance's OS is compromised.
NVIDIA GPU TEEs (Hopper H100 and Blackwell) extend confidential computing to accelerated workloads by encrypting data in GPU memory and ensuring that even a privileged host cannot view or tamper with it. Data moving between CPU and GPU is encrypted in transit, so sensitive model weights or inputs remain protected during AI training or inference. NVIDIA's hardware and drivers handle secure data paths under the hood, allowing confidential large language model (LLM) workloads and other GPU-accelerated computations to run with minimal performance overhead and strong security guarantees.
Key Benefits
One major advantage of enclaves is their ability to keep memory completely off-limits to outside prying eyes. Even administrators who can normally inspect processes at will are blocked from peeking into the enclave's protected memory space. The enclave model is a huge shift in the security model: it prevents casual inspection and defends against sophisticated memory dumping techniques that might otherwise leak secrets or sensitive data.
Another key benefit centers on cryptographic keys that are never exposed outside the enclave. Only verified code running inside the enclave environment can run decryption or signing operations, and it can only do so while that specific code is running. This ensures that compromised hosts or rogue processes, even those with high-level privileges, are unable to intercept or misuse the keys because the keys remain strictly within the trusted boundary of the hardware.
Enclaves can also offer the power of remote attestation, allowing external clients or systems to confirm that they're speaking to an authentic, untampered enclave. By validating the hardware's integrity measurements and enclave-specific proofs, the remote party can be confident in the underlying security properties, an important guarantee in multi-tenant environments or whenever trust boundaries extend across different organizations and networks.
Beyond that, reproducible builds can create a verifiable fingerprint proving which binary runs in the enclave. This is a step above a simple "trust us" approach. Anyone can independently recreate the enclave image and verify the resulting cryptographic hash by using a reproducible build system (for example, our NixOS-based solution). If it matches, then users and developers know precisely how code handles their data, boosting confidence that no hidden changes exist.
It's worth noting that although enclaves shield you from software devs, cloud providers, and insider threats, you do have to trust the hardware vendor (Intel, AMD, Apple, AWS, or NVIDIA) to implement their microcode and firmware securely. The entire enclave model could be theoretically undermined if a CPU maker's root keys or manufacturing process were compromised. Fortunately, these companies undergo extensive audits and firmware validations (often with third-party researchers), and their remote attestation mechanisms allow you to confirm specific firmware versions before trusting an enclave. While this adds a layer of "vendor trust," it's still a far more contained risk than trusting an entire operating system or cloud stack, so enclaves remain a strong step forward in practical, confidential computing.
How We Use Secure Enclaves
Now that we've covered the general idea of enclaves let's look at how we specifically implement them in OpenSecret, our developer platform for handling user auth, private keys, data encryption, and AI workloads.
Our Stack: AWS Nitro + Nvidia TEE
• AWS Nitro Enclaves for the backend: All critical logic, authentication, private key management, and data encryption/decryption run inside an AWS Nitro Enclave.
• Nvidia Trusted Execution for AI: For large AI inference (such as the Llama 3.3 70B model), we utilize Nvidia's GPU-based TEEs to protect even GPU memory. This means users can feed sensitive data to the AI model without exposing it in plaintext to the GPU providers or us as the operator. Edgeless Systems is our Nvidia TEE provider, and due to the power of enclave verification, we don't need to worry about who runs the GPUs. We know requests can't be inspected or tampered with.
End-to-End Encryption from Client to Enclave
 Client-side Enclave Attestation from Maple AI
Client-side Enclave Attestation from Maple AIBefore login or data upload, the user/client verifies the enclave attestation from our platform. This process proves that the specific Nitro Enclave is genuine and runs the exact code we've published. You can check this out live on Maple AI's attestation page.
Based on the attestation, the client establishes a secure ephemeral communication channel that only that enclave can decrypt. While we take advantage of SSL, it is typically not terminated inside the enclave itself. To ensure there's full encrypted data transfer all the way through to the enclave, we establish this additional handshake based on the attestation document that is used for all API requests during the client session.
From there, the user's credentials, private keys, and data pass through this secure channel directly into the enclave, where they are decrypted and processed according to the user's request.
In-Enclave Operations
At the core of OpenSecret's approach is the conviction that security-critical tasks must happen inside the enclave, where even administrative privileges or hypervisor-level compromise cannot expose plaintext data. This encompasses everything from when a user logs in to creating and managing sensitive cryptographic keys. By confining these operations to a protected hardware boundary, developers can focus on building their applications without worrying about accidental data leaks, insider threats, or malicious attempts to harvest credentials. The enclave becomes the ultimate gatekeeper: it controls how data flows and ensures that nothing escapes in plain form.
 User Auth Methods running inside Enclave
User Auth Methods running inside EnclaveA primary example is user authentication. All sign-in workflows, including email/password, OAuth, and upcoming passkey-based methods, are handled entirely within the enclave. As soon as a user's credentials enter our platform through the encrypted channel, they are routed straight into the protected environment, bypassing the host's operating system or any potential snooping channels. From there, authentication and session details remain in the enclave, ensuring that privileged outsiders cannot intercept or modify them. By centralizing these identity flows within a sealed environment, developers can assure their users that no one outside the enclave (including the cloud provider or the app's own sysadmins) can peek at, tamper with, or access sensitive login information.
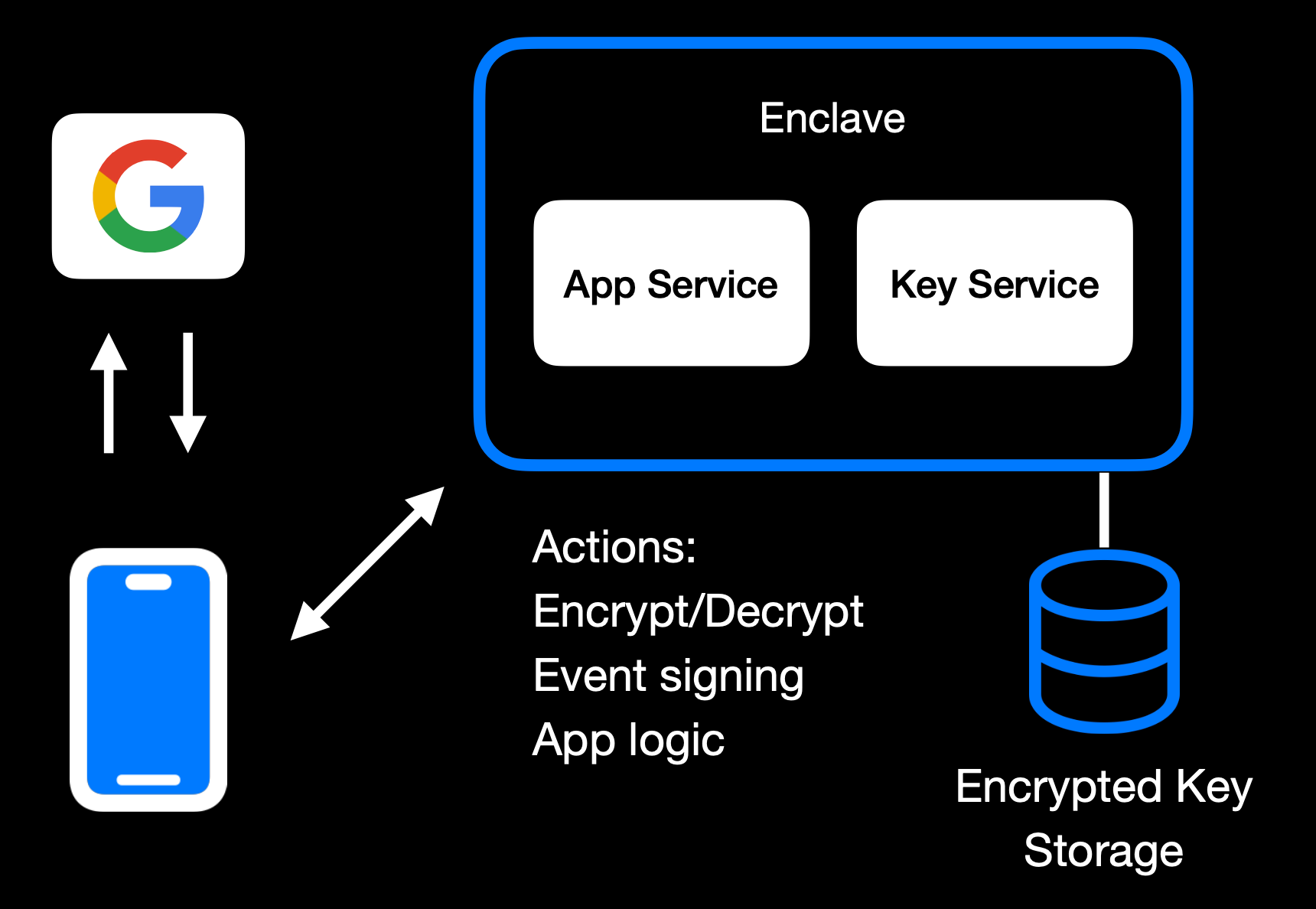 Main Enclave Operations in OpenSecret
Main Enclave Operations in OpenSecretThe same principle applies to private key management. Whether keys are created fresh in the enclave or securely transferred into it, they remain sealed away from the rest of the system. Operations like digital signing or content decryption happen only within the hardware boundary, so raw keys never appear in any log, file system, or memory space outside the enclave. Developers retain the functionality they need, such as verifying user actions, encrypting data, or enabling secure transactions without ever exposing keys to a broader (and more vulnerable) attack surface. User backup options exist as well, where the keys can be securely passed to the end user.
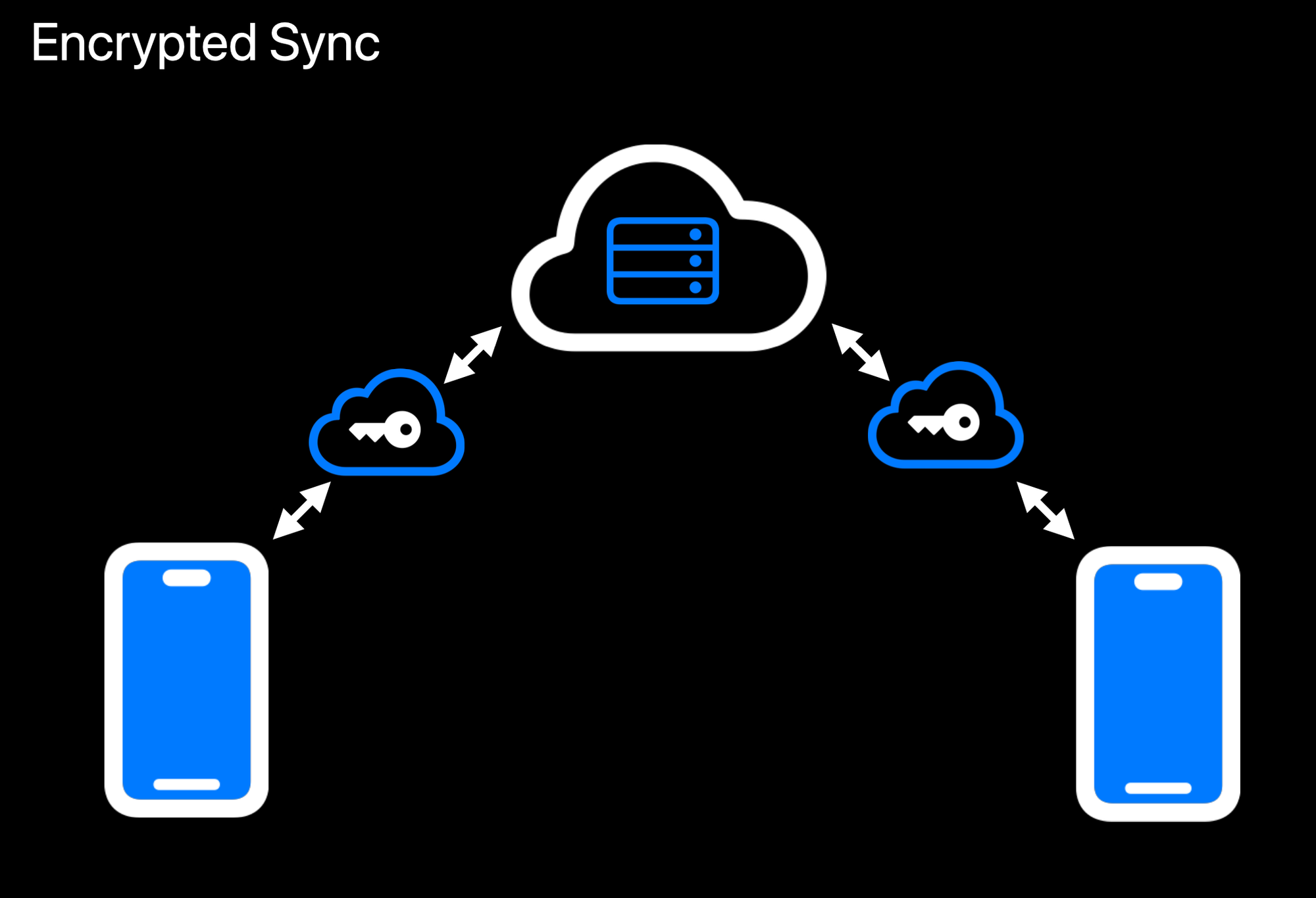 Realtime Encrypted Data Sync on Multiple Devices
Realtime Encrypted Data Sync on Multiple DevicesAnother crucial aspect is data encryption at rest. While user data ultimately needs to be stored somewhere outside the enclave, the unencrypted form of that data only exists transiently inside the protected environment. Encryption and decryption routines run within the enclave, which holds the encryption keys strictly in memory under hardware guards. If a user uploads data, it is promptly secured before it leaves the enclave. When data is retrieved, it remains encrypted until it reenters the protected region and is passed back to the user through the secured communication channel. This ensures that even if someone gains access to the underlying storage or intercepts data in transit, they will see only meaningless ciphertext.
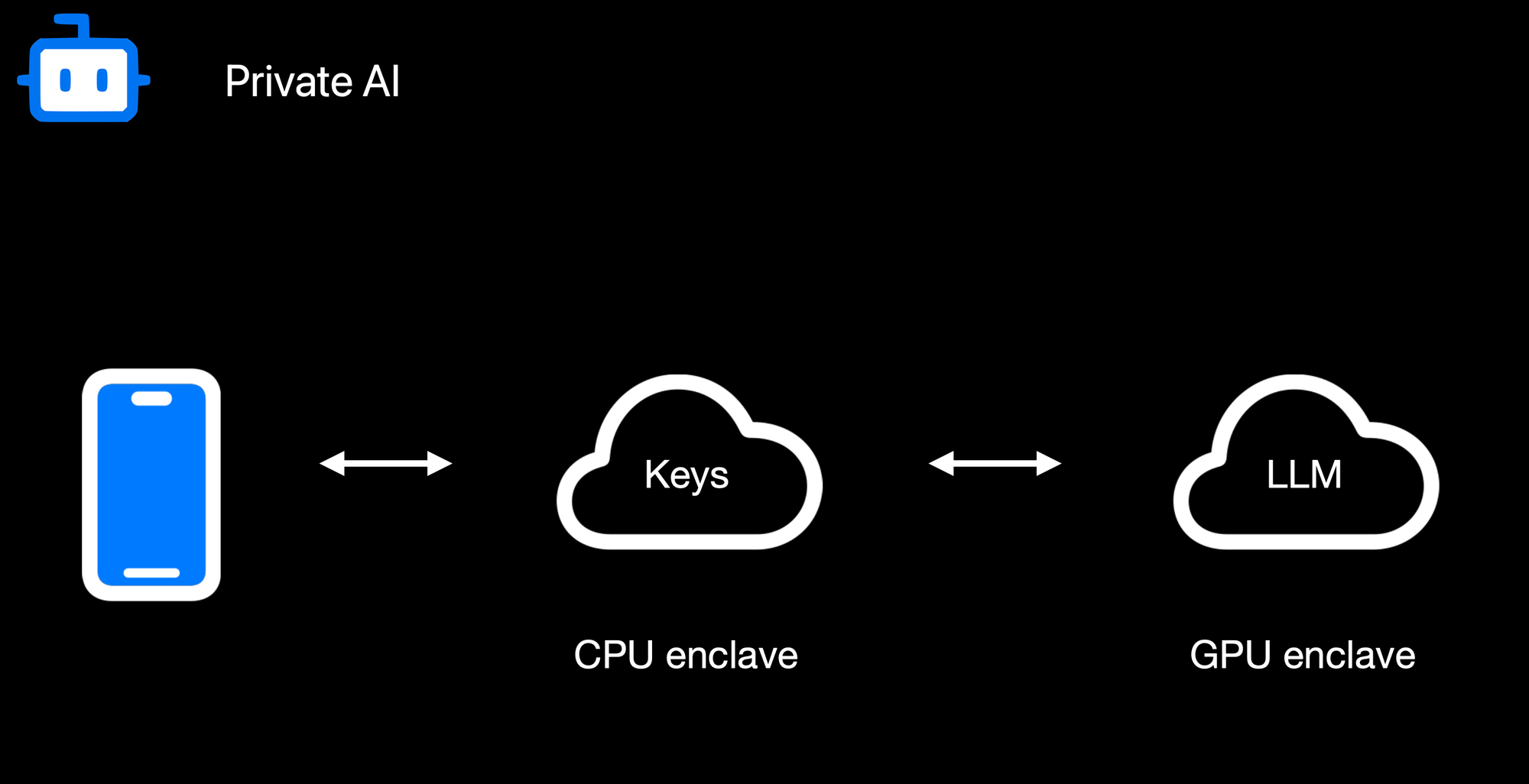 Confidential AI Workloads
Confidential AI WorkloadsFinally, confidential AI workloads build upon this same pattern: the Nitro enclave re-encrypts data so it can be processed inside a GPU-based trusted execution environment (TEE) for inference or other advanced computations. Sensitive data, like user-generated text or private documents, never appears in the clear on the host or within GPU memory outside the TEE boundary. When an AI process finishes, only the results are returned to the enclave, which can then relay them securely to the requesting user. By seamlessly chaining enclaves together, from CPU-based Nitro Enclaves to GPU-accelerated TEEs, we can deliver robust, hardware-enforced privacy for virtually any type of server-side or AI-driven operation.
Reproducible Builds + Verification
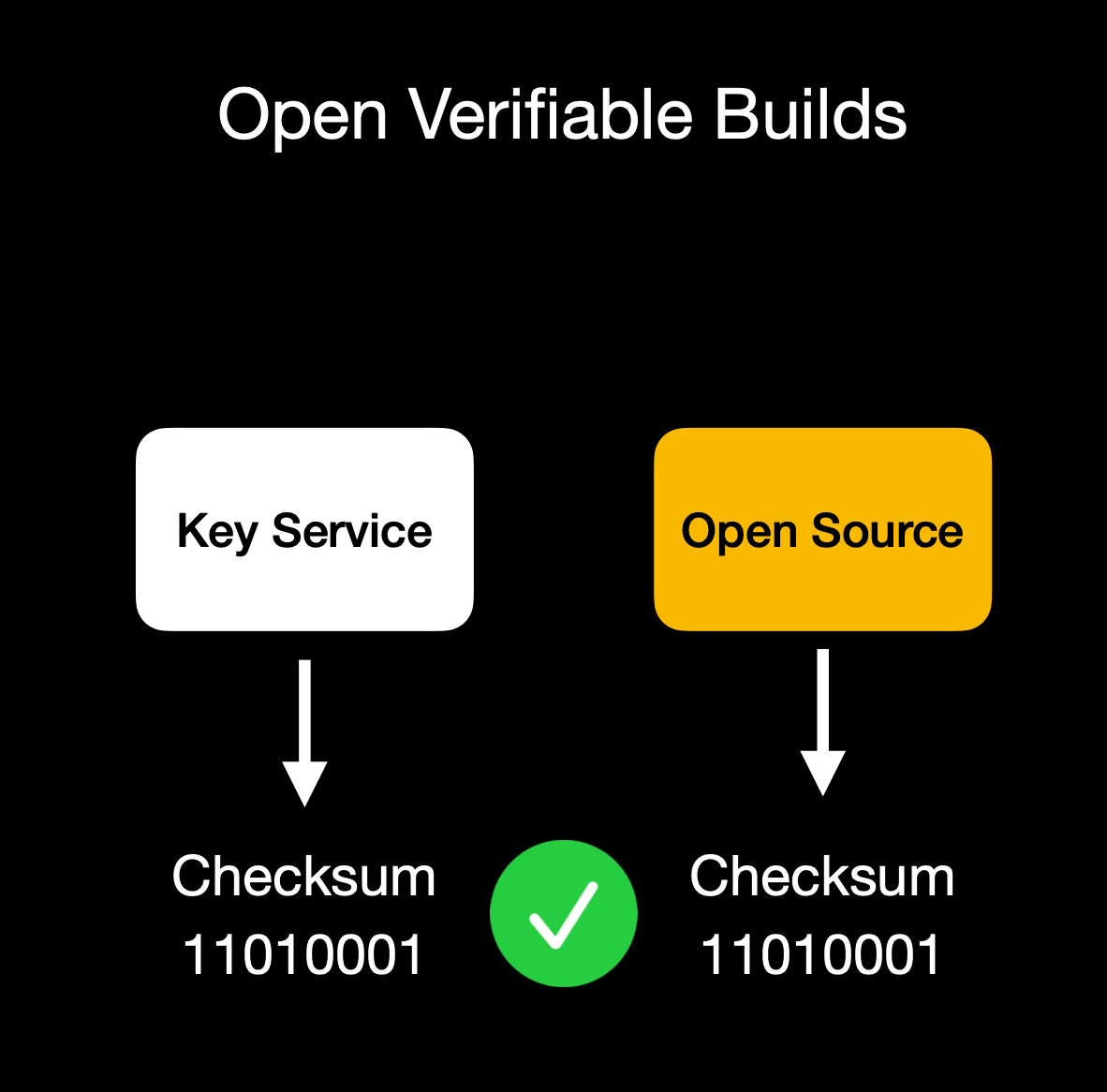 Client verifies enclave attestation document
Client verifies enclave attestation documentWe build our enclaves on NixOS with reproducible builds, ensuring that anyone can verify that the binary we publish is indeed the binary running in the enclave. This build process is essential for proving we haven't snuck in malicious code to exfiltrate data or collect sensitive logs.
Our code is fully open source (GitHub: OpenSecret), so you can audit or run it yourself. You can also verify that the cryptographic measurement the build process outputs matches the measurement reported by the enclave during attestation.
Putting It All Together
 OpenSecret Offering: Private Key Management, Encrypted Sync, Private AI, and Confidential Compute
OpenSecret Offering: Private Key Management, Encrypted Sync, Private AI, and Confidential ComputeBy weaving secure enclaves into every step, from authentication to data handling to AI inference, we shift the burden of trust away from human policies and onto provable, hardware-based protections. For app developers, you can offer your users robust privacy guarantees without rewriting all your business logic or building an entire security stack from scratch. Whether you're storing user credentials or running complex operations on sensitive data, the enclave approach ensures plaintext remains inaccessible to even the most privileged parties outside the enclave boundary. Developers can focus on building great apps, while OpenSecret handles the cryptographic "lock and key" behind the scenes.
This model provides a secure-by-design environment for industries that demand strict data confidentiality, such as healthcare, fintech, cryptocurrency apps for secure key management, or decentralized identity platforms. Instead of worrying about memory dumps or backend tampering, you can trust that once data enters the enclave, it's sealed off from unauthorized eyes, including from the app developers themselves. And these safeguards don't just apply to niche use cases. Even general-purpose applications that handle login flows and user-generated content stand to benefit, especially as regulatory scrutiny grows around data privacy and insider threats.
Imagine a telehealth startup using OpenSecret enclaves to protect patient information for remote consultations. Not only would patient data remain encrypted at rest, but any AI-driven analytics to assist with diagnoses could be run privately within the enclave, ensuring no one outside the hardware boundary can peek at sensitive health records. A fintech company could similarly isolate confidential financial transactions, preventing even privileged insiders from viewing or tampering with raw transaction details. These real-world implementations give developers a clear path to adopting enclaves for serious privacy and compliance needs without overhauling their infrastructure.
OpenSecret aims to be a full developer platform with end-to-end security from day one. By incorporating user authentication, data storage, and GPU-based confidential AI into a single service, we eliminate many of the traditional hurdles in adopting enclaves. No more juggling separate tools for cryptographic key management, compliance controls, and runtime privacy. Instead, you get a unified stack that keeps data encrypted in transit, at rest, and in use.
Our solution also caters to the exploding demand for AI applications: with TEE-enabled GPU workloads, you can securely process sensitive data for text inference without ever exposing raw plaintext or sensitive documents to the host system.
The result is a new generation of apps that deliver advanced functionality, like real-time encrypted data sync or AI-driven insights, while preserving user privacy and meeting strict regulatory requirements. You don't have to rely on empty "trust us" promises because hardware enclaves, remote attestation, and reproducible builds collectively guarantee the code is running untampered. In short, OpenSecret offers the building blocks needed to create truly confidential services and experiences, allowing you to innovate while ensuring data protection remains ironclad.
Things to Come
We're excited to build on our enclaved approach. Here's what's on our roadmap:
• Production Launch: We're using this in production now with Maple AI and have a developer preview playground up and running. We'll have the developer environment ready for production in a few months.\ • Multi-Tenant Support: Our platform currently works for single tenants, but we're opening this up so developers can onboard without needing a dedicated instance.\ • Self-Serve Frontend: A dev-friendly portal for provisioning apps, connecting OAuth or email providers, and managing users.\ • External Key Signing Options: Integrations with custom hardware security modules (HSMs) or customer-ran key managers that can only process data upon verifying the enclave attestation.\ • Confidential Computing as a Service: We'll expand our platform so that other developers can quickly create enclaves for specialized workloads without dealing with the complexities of Nitro or GPU TEEs.\ • Additional SDKs: In addition to our JavaScript client-side SDK, we plan to launch official support for Rust, Python, Swift, Java, Go, and more.\ • AI API Proxy with Attestation/Encryption: We already provide an easy way to access a Private AI through Maple AI, but we'd like to open this up more for existing tools and developers. We'll provide a proxy server that users can run on their local machines or servers that properly handle encryption to our OpenAI-compatible API.
Getting Started
Ready to see enclaves in action? Here's how to dive in:\ 1. Run OpenSecret: Check out our open-source repository at OpenSecret on GitHub. You can run your own enclaved environment or try it out locally with Docker.\ 2. Review Our SDK: Our JavaScript client SDK makes it easy to handle sign-ins, put/get encrypted data, sign with user private keys, etc. It handles attestation verification and encryption under the hood, making the API integration seamless.\ 3. Play with Maple AI: Try out Maple AI as an example of an AI app built directly on OpenSecret. Your queries are encrypted end to end, and the Llama model sees them only inside the TEE.\ 4. Developer Preview: Contact us if you want an invite to our early dev platform. We'll guide you through our SDK and give you access to the preview server. We'd love to build with you and incorporate your feedback as we develop this further.
Conclusion
By merging secure enclaves (AWS Nitro and Nvidia GPU TEEs), user authentication, private key management, and an end-to-end verifiable encrypted approach, OpenSecret provides a powerful platform where we protect user data during collection, storage, and processing. Whether it's for standard user management, handling private cryptographic keys, or powering AI inference, the technology ensures that no one, not even us or the cloud provider, can snoop on data in use.
We believe this is the future of trustworthy computing in the cloud. And it's all open source, so you don't have to just take our word for it: you can see and verify everything yourself.
Do you have questions, feedback, or a use case you'd like to test out? Come join us on GitHub, Discord, or email us for a developer preview. We can't wait to see what you build!
Thank you for reading, and welcome to the era of enclaved computing.
-
@ 91bea5cd:1df4451c
2025-02-04 17:24:50
Definição de ULID:
Timestamp 48 bits, Aleatoriedade 80 bits Sendo Timestamp 48 bits inteiro, tempo UNIX em milissegundos, Não ficará sem espaço até o ano 10889 d.C. e Aleatoriedade 80 bits, Fonte criptograficamente segura de aleatoriedade, se possível.
Gerar ULID
```sql
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE FUNCTION generate_ulid() RETURNS TEXT AS $$ DECLARE -- Crockford's Base32 encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; timestamp BYTEA = E'\000\000\000\000\000\000'; output TEXT = '';
unix_time BIGINT; ulid BYTEA; BEGIN -- 6 timestamp bytes unix_time = (EXTRACT(EPOCH FROM CLOCK_TIMESTAMP()) * 1000)::BIGINT; timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql VOLATILE; ```
ULID TO UUID
```sql CREATE OR REPLACE FUNCTION parse_ulid(ulid text) RETURNS bytea AS $$ DECLARE -- 16byte bytes bytea = E'\x00000000 00000000 00000000 00000000'; v char[]; -- Allow for O(1) lookup of index values dec integer[] = ARRAY[ 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 255, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31 ]; BEGIN IF NOT ulid ~* '^[0-7][0-9ABCDEFGHJKMNPQRSTVWXYZ]{25}$' THEN RAISE EXCEPTION 'Invalid ULID: %', ulid; END IF;
v = regexp_split_to_array(ulid, '');
-- 6 bytes timestamp (48 bits) bytes = SET_BYTE(bytes, 0, (dec[ASCII(v[1])] << 5) | dec[ASCII(v[2])]); bytes = SET_BYTE(bytes, 1, (dec[ASCII(v[3])] << 3) | (dec[ASCII(v[4])] >> 2)); bytes = SET_BYTE(bytes, 2, (dec[ASCII(v[4])] << 6) | (dec[ASCII(v[5])] << 1) | (dec[ASCII(v[6])] >> 4)); bytes = SET_BYTE(bytes, 3, (dec[ASCII(v[6])] << 4) | (dec[ASCII(v[7])] >> 1)); bytes = SET_BYTE(bytes, 4, (dec[ASCII(v[7])] << 7) | (dec[ASCII(v[8])] << 2) | (dec[ASCII(v[9])] >> 3)); bytes = SET_BYTE(bytes, 5, (dec[ASCII(v[9])] << 5) | dec[ASCII(v[10])]);
-- 10 bytes of entropy (80 bits); bytes = SET_BYTE(bytes, 6, (dec[ASCII(v[11])] << 3) | (dec[ASCII(v[12])] >> 2)); bytes = SET_BYTE(bytes, 7, (dec[ASCII(v[12])] << 6) | (dec[ASCII(v[13])] << 1) | (dec[ASCII(v[14])] >> 4)); bytes = SET_BYTE(bytes, 8, (dec[ASCII(v[14])] << 4) | (dec[ASCII(v[15])] >> 1)); bytes = SET_BYTE(bytes, 9, (dec[ASCII(v[15])] << 7) | (dec[ASCII(v[16])] << 2) | (dec[ASCII(v[17])] >> 3)); bytes = SET_BYTE(bytes, 10, (dec[ASCII(v[17])] << 5) | dec[ASCII(v[18])]); bytes = SET_BYTE(bytes, 11, (dec[ASCII(v[19])] << 3) | (dec[ASCII(v[20])] >> 2)); bytes = SET_BYTE(bytes, 12, (dec[ASCII(v[20])] << 6) | (dec[ASCII(v[21])] << 1) | (dec[ASCII(v[22])] >> 4)); bytes = SET_BYTE(bytes, 13, (dec[ASCII(v[22])] << 4) | (dec[ASCII(v[23])] >> 1)); bytes = SET_BYTE(bytes, 14, (dec[ASCII(v[23])] << 7) | (dec[ASCII(v[24])] << 2) | (dec[ASCII(v[25])] >> 3)); bytes = SET_BYTE(bytes, 15, (dec[ASCII(v[25])] << 5) | dec[ASCII(v[26])]);
RETURN bytes; END $$ LANGUAGE plpgsql IMMUTABLE;
CREATE OR REPLACE FUNCTION ulid_to_uuid(ulid text) RETURNS uuid AS $$ BEGIN RETURN encode(parse_ulid(ulid), 'hex')::uuid; END $$ LANGUAGE plpgsql IMMUTABLE; ```
UUID to ULID
```sql CREATE OR REPLACE FUNCTION uuid_to_ulid(id uuid) RETURNS text AS $$ DECLARE encoding bytea = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; output text = ''; uuid_bytes bytea = uuid_send(id); BEGIN
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 1) & 7) << 2) | ((GET_BYTE(uuid_bytes, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 2) & 1) << 4) | ((GET_BYTE(uuid_bytes, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 3) & 15) << 1) | ((GET_BYTE(uuid_bytes, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 4) & 3) << 3) | ((GET_BYTE(uuid_bytes, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 6) & 7) << 2) | ((GET_BYTE(uuid_bytes, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 7) & 1) << 4) | ((GET_BYTE(uuid_bytes, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 8) & 15) << 1) | ((GET_BYTE(uuid_bytes, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 9) & 3) << 3) | ((GET_BYTE(uuid_bytes, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 11) & 7) << 2) | ((GET_BYTE(uuid_bytes, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 12) & 1) << 4) | ((GET_BYTE(uuid_bytes, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 13) & 15) << 1) | ((GET_BYTE(uuid_bytes, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 14) & 3) << 3) | ((GET_BYTE(uuid_bytes, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql IMMUTABLE; ```
Gera 11 Digitos aleatórios: YBKXG0CKTH4
```sql -- Cria a extensão pgcrypto para gerar uuid CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Cria a função para gerar ULID CREATE OR REPLACE FUNCTION gen_lrandom() RETURNS TEXT AS $$ DECLARE ts_millis BIGINT; ts_chars TEXT; random_bytes BYTEA; random_chars TEXT; base32_chars TEXT := '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; i INT; BEGIN -- Pega o timestamp em milissegundos ts_millis := FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000)::BIGINT;
-- Converte o timestamp para base32 ts_chars := ''; FOR i IN REVERSE 0..11 LOOP ts_chars := ts_chars || substr(base32_chars, ((ts_millis >> (5 * i)) & 31) + 1, 1); END LOOP; -- Gera 10 bytes aleatórios e converte para base32 random_bytes := gen_random_bytes(10); random_chars := ''; FOR i IN 0..9 LOOP random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) >> 3) & 31) + 1, 1); IF i < 9 THEN random_chars := random_chars || substr(base32_chars, (((get_byte(random_bytes, i) & 7) << 2) | (get_byte(random_bytes, i + 1) >> 6)) & 31 + 1, 1); ELSE random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) & 7) << 2) + 1, 1); END IF; END LOOP; -- Concatena o timestamp e os caracteres aleatórios RETURN ts_chars || random_chars;END; $$ LANGUAGE plpgsql; ```
Exemplo de USO
```sql -- Criação da extensão caso não exista CREATE EXTENSION IF NOT EXISTS pgcrypto; -- Criação da tabela pessoas CREATE TABLE pessoas ( ID UUID DEFAULT gen_random_uuid ( ) PRIMARY KEY, nome TEXT NOT NULL );
-- Busca Pessoa na tabela SELECT * FROM "pessoas" WHERE uuid_to_ulid ( ID ) = '252FAC9F3V8EF80SSDK8PXW02F'; ```
Fontes
- https://github.com/scoville/pgsql-ulid
- https://github.com/geckoboard/pgulid
-
@ a5142938:0ef19da3
2025-04-30 08:34:54
This article is published on origin-nature.com 🌐 Voir cet article en français
-
@ 91bea5cd:1df4451c
2025-02-04 17:15:57
Definição de ULID:
Timestamp 48 bits, Aleatoriedade 80 bits Sendo Timestamp 48 bits inteiro, tempo UNIX em milissegundos, Não ficará sem espaço até o ano 10889 d.C. e Aleatoriedade 80 bits, Fonte criptograficamente segura de aleatoriedade, se possível.
Gerar ULID
```sql
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE FUNCTION generate_ulid() RETURNS TEXT AS $$ DECLARE -- Crockford's Base32 encoding BYTEA = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; timestamp BYTEA = E'\000\000\000\000\000\000'; output TEXT = '';
unix_time BIGINT; ulid BYTEA; BEGIN -- 6 timestamp bytes unix_time = (EXTRACT(EPOCH FROM CLOCK_TIMESTAMP()) * 1000)::BIGINT; timestamp = SET_BYTE(timestamp, 0, (unix_time >> 40)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 1, (unix_time >> 32)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 2, (unix_time >> 24)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 3, (unix_time >> 16)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 4, (unix_time >> 8)::BIT(8)::INTEGER); timestamp = SET_BYTE(timestamp, 5, unix_time::BIT(8)::INTEGER);
-- 10 entropy bytes ulid = timestamp || gen_random_bytes(10);
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 1) & 7) << 2) | ((GET_BYTE(ulid, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 2) & 1) << 4) | ((GET_BYTE(ulid, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 3) & 15) << 1) | ((GET_BYTE(ulid, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 4) & 3) << 3) | ((GET_BYTE(ulid, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 6) & 7) << 2) | ((GET_BYTE(ulid, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 7) & 1) << 4) | ((GET_BYTE(ulid, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 8) & 15) << 1) | ((GET_BYTE(ulid, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 9) & 3) << 3) | ((GET_BYTE(ulid, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 11) & 7) << 2) | ((GET_BYTE(ulid, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 12) & 1) << 4) | ((GET_BYTE(ulid, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 13) & 15) << 1) | ((GET_BYTE(ulid, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(ulid, 14) & 3) << 3) | ((GET_BYTE(ulid, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(ulid, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql VOLATILE; ```
ULID TO UUID
```sql CREATE OR REPLACE FUNCTION parse_ulid(ulid text) RETURNS bytea AS $$ DECLARE -- 16byte bytes bytea = E'\x00000000 00000000 00000000 00000000'; v char[]; -- Allow for O(1) lookup of index values dec integer[] = ARRAY[ 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 255, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31, 255, 255, 255, 255, 255, 255, 10, 11, 12, 13, 14, 15, 16, 17, 1, 18, 19, 1, 20, 21, 0, 22, 23, 24, 25, 26, 255, 27, 28, 29, 30, 31 ]; BEGIN IF NOT ulid ~* '^[0-7][0-9ABCDEFGHJKMNPQRSTVWXYZ]{25}$' THEN RAISE EXCEPTION 'Invalid ULID: %', ulid; END IF;
v = regexp_split_to_array(ulid, '');
-- 6 bytes timestamp (48 bits) bytes = SET_BYTE(bytes, 0, (dec[ASCII(v[1])] << 5) | dec[ASCII(v[2])]); bytes = SET_BYTE(bytes, 1, (dec[ASCII(v[3])] << 3) | (dec[ASCII(v[4])] >> 2)); bytes = SET_BYTE(bytes, 2, (dec[ASCII(v[4])] << 6) | (dec[ASCII(v[5])] << 1) | (dec[ASCII(v[6])] >> 4)); bytes = SET_BYTE(bytes, 3, (dec[ASCII(v[6])] << 4) | (dec[ASCII(v[7])] >> 1)); bytes = SET_BYTE(bytes, 4, (dec[ASCII(v[7])] << 7) | (dec[ASCII(v[8])] << 2) | (dec[ASCII(v[9])] >> 3)); bytes = SET_BYTE(bytes, 5, (dec[ASCII(v[9])] << 5) | dec[ASCII(v[10])]);
-- 10 bytes of entropy (80 bits); bytes = SET_BYTE(bytes, 6, (dec[ASCII(v[11])] << 3) | (dec[ASCII(v[12])] >> 2)); bytes = SET_BYTE(bytes, 7, (dec[ASCII(v[12])] << 6) | (dec[ASCII(v[13])] << 1) | (dec[ASCII(v[14])] >> 4)); bytes = SET_BYTE(bytes, 8, (dec[ASCII(v[14])] << 4) | (dec[ASCII(v[15])] >> 1)); bytes = SET_BYTE(bytes, 9, (dec[ASCII(v[15])] << 7) | (dec[ASCII(v[16])] << 2) | (dec[ASCII(v[17])] >> 3)); bytes = SET_BYTE(bytes, 10, (dec[ASCII(v[17])] << 5) | dec[ASCII(v[18])]); bytes = SET_BYTE(bytes, 11, (dec[ASCII(v[19])] << 3) | (dec[ASCII(v[20])] >> 2)); bytes = SET_BYTE(bytes, 12, (dec[ASCII(v[20])] << 6) | (dec[ASCII(v[21])] << 1) | (dec[ASCII(v[22])] >> 4)); bytes = SET_BYTE(bytes, 13, (dec[ASCII(v[22])] << 4) | (dec[ASCII(v[23])] >> 1)); bytes = SET_BYTE(bytes, 14, (dec[ASCII(v[23])] << 7) | (dec[ASCII(v[24])] << 2) | (dec[ASCII(v[25])] >> 3)); bytes = SET_BYTE(bytes, 15, (dec[ASCII(v[25])] << 5) | dec[ASCII(v[26])]);
RETURN bytes; END $$ LANGUAGE plpgsql IMMUTABLE;
CREATE OR REPLACE FUNCTION ulid_to_uuid(ulid text) RETURNS uuid AS $$ BEGIN RETURN encode(parse_ulid(ulid), 'hex')::uuid; END $$ LANGUAGE plpgsql IMMUTABLE; ```
UUID to ULID
```sql CREATE OR REPLACE FUNCTION uuid_to_ulid(id uuid) RETURNS text AS $$ DECLARE encoding bytea = '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; output text = ''; uuid_bytes bytea = uuid_send(id); BEGIN
-- Encode the timestamp output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 224) >> 5)); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 0) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 1) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 1) & 7) << 2) | ((GET_BYTE(uuid_bytes, 2) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 2) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 2) & 1) << 4) | ((GET_BYTE(uuid_bytes, 3) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 3) & 15) << 1) | ((GET_BYTE(uuid_bytes, 4) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 4) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 4) & 3) << 3) | ((GET_BYTE(uuid_bytes, 5) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 5) & 31)));
-- Encode the entropy output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 6) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 6) & 7) << 2) | ((GET_BYTE(uuid_bytes, 7) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 7) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 7) & 1) << 4) | ((GET_BYTE(uuid_bytes, 8) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 8) & 15) << 1) | ((GET_BYTE(uuid_bytes, 9) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 9) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 9) & 3) << 3) | ((GET_BYTE(uuid_bytes, 10) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 10) & 31))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 11) & 248) >> 3)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 11) & 7) << 2) | ((GET_BYTE(uuid_bytes, 12) & 192) >> 6))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 12) & 62) >> 1)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 12) & 1) << 4) | ((GET_BYTE(uuid_bytes, 13) & 240) >> 4))); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 13) & 15) << 1) | ((GET_BYTE(uuid_bytes, 14) & 128) >> 7))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 14) & 124) >> 2)); output = output || CHR(GET_BYTE(encoding, ((GET_BYTE(uuid_bytes, 14) & 3) << 3) | ((GET_BYTE(uuid_bytes, 15) & 224) >> 5))); output = output || CHR(GET_BYTE(encoding, (GET_BYTE(uuid_bytes, 15) & 31)));
RETURN output; END $$ LANGUAGE plpgsql IMMUTABLE; ```
Gera 11 Digitos aleatórios: YBKXG0CKTH4
```sql -- Cria a extensão pgcrypto para gerar uuid CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Cria a função para gerar ULID CREATE OR REPLACE FUNCTION gen_lrandom() RETURNS TEXT AS $$ DECLARE ts_millis BIGINT; ts_chars TEXT; random_bytes BYTEA; random_chars TEXT; base32_chars TEXT := '0123456789ABCDEFGHJKMNPQRSTVWXYZ'; i INT; BEGIN -- Pega o timestamp em milissegundos ts_millis := FLOOR(EXTRACT(EPOCH FROM clock_timestamp()) * 1000)::BIGINT;
-- Converte o timestamp para base32 ts_chars := ''; FOR i IN REVERSE 0..11 LOOP ts_chars := ts_chars || substr(base32_chars, ((ts_millis >> (5 * i)) & 31) + 1, 1); END LOOP; -- Gera 10 bytes aleatórios e converte para base32 random_bytes := gen_random_bytes(10); random_chars := ''; FOR i IN 0..9 LOOP random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) >> 3) & 31) + 1, 1); IF i < 9 THEN random_chars := random_chars || substr(base32_chars, (((get_byte(random_bytes, i) & 7) << 2) | (get_byte(random_bytes, i + 1) >> 6)) & 31 + 1, 1); ELSE random_chars := random_chars || substr(base32_chars, ((get_byte(random_bytes, i) & 7) << 2) + 1, 1); END IF; END LOOP; -- Concatena o timestamp e os caracteres aleatórios RETURN ts_chars || random_chars;END; $$ LANGUAGE plpgsql; ```
Exemplo de USO
```sql -- Criação da extensão caso não exista CREATE EXTENSION IF NOT EXISTS pgcrypto; -- Criação da tabela pessoas CREATE TABLE pessoas ( ID UUID DEFAULT gen_random_uuid ( ) PRIMARY KEY, nome TEXT NOT NULL );
-- Busca Pessoa na tabela SELECT * FROM "pessoas" WHERE uuid_to_ulid ( ID ) = '252FAC9F3V8EF80SSDK8PXW02F'; ```
Fontes
- https://github.com/scoville/pgsql-ulid
- https://github.com/geckoboard/pgulid
-
@ a5142938:0ef19da3
2025-04-30 08:33:41
Core Team
The Core Team drives the project and validates the content.
- Jean-David Bar: https://njump.me/npub1qr4p7uamcpawv7cr8z9nlhmd60lylukf7lvmtlnpe7r4juwxudzq3hrnll
To start, I'm managing the project solo by sharing my bookmarks to avoid plastic on ourselves and on our children. Contact me if you'd like to join!
Content Enrichers
Our contributors make this site engaging and interesting.
Coming soon.
👉 Learn more about contributions
This article is published on origin-nature.com 🌐 Voir cet article en français
-
@ a5142938:0ef19da3
2025-04-30 08:32:38
Finding 100% natural, plastic-free products turned out to be much harder than I expected… So I started collecting bookmarks. And then I thought: "What if we shared?!
Help me discover the best natural alternatives for clothing and gear without plastic!
This project is all about sharing: half of the site's potential revenue is redistributed to contributors. A small experiment in revenue and value sharing on the internet. :-)
Q&A
Why focus on natural materials?
Synthetic materials are mostly plastics (polyester, polyamide…). The problem? They end up contaminating us:
- Microplastics absorbed through the skin,
- Particles released with every wash, making their way into the water we drink and the food we eat,
- Major challenges in recycling plastic waste.
What exactly are natural materials?
They are non-synthetic materials, whose components exist in nature without molecular modification. But what really matters here is their biodegradability and non-toxicity.
Some materials may spark debates about their acceptability on this site!
How is this different from other ethical fashion or shopping websites?
Many websites offer ethical and sustainable products, but I often found they still included synthetic materials. I had to check every product individually. Some promote recycled plastic fibers as an eco-friendly choice, but I’d rather not put plastic on my skin or my children's.
How can I contribute?
If you find this project useful or interesting, here’s how you can support it:
-
📝 Contribute: suggest edits by commenting on existing entries or propose new product or brand references. 👉 Learn more about contributions
-
⚡ Donate: Help sustain the project and support contributors. 👉 Learn more about donations
-
📢 Spread the word: Share the site on social media, your blog…
How can I receive a share of the site’s revenue?
You need a NOSTR account and a Bitcoin Lightning address.
What is NOSTR?
NOSTR is a decentralized internet protocol, still experimental, that allows you to:
- Publish and browse content without relying on a centralized platform.
- Log in to multiple services while keeping full control over your data.
- Use the Bitcoin Lightning network for instant, peer-to-peer payments.
What about my data privacy?
- No ads, no personalized tracking.
- NOSTR comments are public, but you can use a pseudonym.
- You retain ownership of your contributions on the NOSTR protocol.
Who is behind this project?
We use open-source tools and services:
- NOSTR for content publishing and contributions checking,
- npub.pro for content visualization,
- Coinos.io for payment management.
This article is published on origin-nature.com 🌐 Voir cet article en français
-
@ 91bea5cd:1df4451c
2025-02-04 05:24:47
Novia é uma ferramenta inovadora que facilita o arquivamento de vídeos e sua integração com a rede NOSTR (Notes and Other Stuff Transmitted over Relay). Funcionando como uma ponte entre ferramentas de arquivamento de vídeo tradicionais e a plataforma descentralizada, Novia oferece uma solução autônoma para a preservação e compartilhamento de conteúdo audiovisual.
Arquitetura e Funcionamento
A arquitetura de Novia é dividida em duas partes principais:
-
Frontend: Atua como a interface do usuário, responsável por solicitar o arquivamento de vídeos. Essas solicitações são encaminhadas para o backend.
-
Backend: Processa as solicitações de arquivamento, baixando o vídeo, suas descrições e a imagem de capa associada. Este componente é conectado a um ou mais relays NOSTR, permitindo a indexação e descoberta do conteúdo arquivado.
O processo de arquivamento é automatizado: após o download, o vídeo fica disponível no frontend para que o usuário possa solicitar o upload para um servidor Blossom de sua escolha.
Como Utilizar Novia
-
Acesso: Navegue até https://npub126uz2g6ft45qs0m0rnvtvtp7glcfd23pemrzz0wnt8r5vlhr9ufqnsmvg8.nsite.lol.
-
Login: Utilize uma extensão de navegador compatível com NOSTR para autenticar-se.
-
Execução via Docker: A forma mais simples de executar o backend é através de um container Docker. Execute o seguinte comando:
bash docker run -it --rm -p 9090:9090 -v ./nostr/data:/data --add-host=host.docker.internal:host-gateway teamnovia/noviaEste comando cria um container, mapeia a porta 9090 para o host e monta o diretório
./nostr/datapara persistir os dados.
Configuração Avançada
Novia oferece amplas opções de configuração através de um arquivo
yaml. Abaixo, um exemplo comentado:```yaml mediaStores: - id: media type: local path: /data/media watch: true
database: /data/novia.db
download: enabled: true ytdlpPath: yt-dlp ytdlpCookies: ./cookies.txt tempPath: /tmp targetStoreId: media secret: false
publish: enabled: true key: nsec thumbnailUpload: - https://nostr.download videoUpload: - url: https://nostr.download maxUploadSizeMB: 300 cleanUpMaxAgeDays: 5 cleanUpKeepSizeUnderMB: 2 - url: https://files.v0l.io maxUploadSizeMB: 300 cleanUpMaxAgeDays: 5 cleanUpKeepSizeUnderMB: 2 - url: https://nosto.re maxUploadSizeMB: 300 cleanUpMaxAgeDays: 5 cleanUpKeepSizeUnderMB: 2 - url: https://blossom.primal.net maxUploadSizeMB: 300 cleanUpMaxAgeDays: 5 cleanUpKeepSizeUnderMB: 2
relays: - ws://host.docker.internal:4869 - wss://bostr.bitcointxoko.com secret: false autoUpload: enabled: true maxVideoSizeMB: 100
fetch: enabled: false fetchVideoLimitMB: 10 relays: - match: - nostr - bitcoin
server: port: 9090 enabled: true ```
Explicação das Configurações:
mediaStores: Define onde os arquivos de mídia serão armazenados (localmente, neste exemplo).database: Especifica o local do banco de dados.download: Controla as configurações de download de vídeos, incluindo o caminho para oyt-dlpe um arquivo de cookies para autenticação.publish: Configura a publicação de vídeos e thumbnails no NOSTR, incluindo a chave privada (nsec), servidores de upload e relays. Atenção: Mantenha sua chave privada em segredo.fetch: Permite buscar eventos de vídeo de relays NOSTR para arquivamento.server: Define as configurações do servidor web interno de Novia.
Conclusão
Novia surge como uma ferramenta promissora para o arquivamento e a integração de vídeos com o ecossistema NOSTR. Sua arquitetura modular, combinada com opções de configuração flexíveis, a tornam uma solução poderosa para usuários que buscam preservar e compartilhar conteúdo audiovisual de forma descentralizada e resistente à censura. A utilização de Docker simplifica a implantação e o gerenciamento da ferramenta. Para obter mais informações e explorar o código-fonte, visite o repositório do projeto no GitHub: https://github.com/teamnovia/novia.
-
-
@ a5142938:0ef19da3
2025-04-30 08:32:01
Rewards are an experimental approach to sharing the value created by contributors to this site, through a revenue-sharing system based on the following conditions:
- Any revenue generated by the site each month is distributed over the following 12 months, ensuring long-term visibility and smoothing out monthly variations.
- On the 1st of each month, half of the revenue is distributed among all contributors, in proportion to the number of their validated contributions.
- Contributions remain valid indefinitely, but rewards are only distributed to contributors who have made at least one validated contribution in the past 12 months.
Payment Method
Rewards are paid via the Lightning network, in sats (the smallest unit of Bitcoin).
To receive payments, you must have a NOSTR account linked to a Lightning wallet.
To receive them, the NOSTR account used to contribute must be linked to a Lightning wallet.
💡 New to these tools? - Don’t have a NOSTR account yet? A simple way to get started is to create one on an open-source NOSTR client like yakihonne.com to set up your profile and wallet there. Then, retrieve your NOSTR keys (from the settings) and save them in a secure vault like nsec.app to log in here and start contributing. - Already started contributing on this site? Make sure to securely store your NOSTR keys in a vault like nsec.app. You can also log in with them on yakihonne.com to set up your profile. - You can also contribute directly from yakihonne.com by commenting on Origine Nature’s articles.
👉 Learn more about contributions
Next rewards
Coming soon.
This article is published on origin-nature.com 🌐 Voir cet article en français
-
@ f11e91c5:59a0b04a
2025-04-30 07:52:21
!!!2022-07-07に書かれた記事です。
暗号通貨とかでお弁当売ってます 11:30〜14:00ぐらいでやってます
◆住所 木曜日・東京都渋谷区宇田川町41 (アベマタワーの下らへん)
◆お値段
Monacoin 3.9mona
Bitzeny 390zny
Bitcoin 3900sats (#lightningNetwork)
Ethereum 0.0039Ether(#zkSync)
39=thank you. (円を基準にしてません)
最近は週に一回になりました。 他の日はキッチンカーの現場を探したり色々してます。 東京都内で平日ランチ出店出来そうな場所があればぜひご連絡を!
 写真はNFCタグです。
スマホにウォレットがあればタッチして3900satsで決済出来ます。
正直こんな怪しい手書きのNFCタグなんて絶対にビットコイナーは触りたくも無いだろうなと思いますが、これでも良いんだぜというメッセージです。
写真はNFCタグです。
スマホにウォレットがあればタッチして3900satsで決済出来ます。
正直こんな怪しい手書きのNFCタグなんて絶対にビットコイナーは触りたくも無いだろうなと思いますが、これでも良いんだぜというメッセージです。今までbtcpayのposでしたが速度を追求してこれに変更しました。 たまに上手くいかないですがそしたら渋々POS出すので温かい目でよろしくお願いします。
ノードを建てたり決済したりで1年経ちました。 最近も少しずつノードを建てる方が増えてるみたいで本当凄いですねUmbrel 大体の人がルーティングに果敢に挑むのを見つつ 奥さんに土下座しながら費用を捻出する弱小の私は決済の利便性を全開で振り切るしか無いので応援よろしくお願いします。
あえて あえて言うのであれば、ルーティングも楽しいですけど やはり本当の意味での即時決済や相手を選んでチャネルを繋げる楽しさもあるよとお伝えしたいっ!! 決済を受け入れないと分からない所ですが 承認がいらない時点で画期的です。
QRでもタッチでも金額指定でも入力でも もうやりようには出来てしまうし進化が恐ろしく早いので1番利用の多いpaypayの手数料(事業者側のね)を考えたらビットコイン凄いじゃない!と叫びたくなる。 が、やはり税制面や価格の変動(うちはBTC固定だけども)ウォレットの操作や普及率を考えるとまぁ難しい所もあるんですかね。
それでも継続的に沢山の人が色んな活動をしてるので私も何か出来ることがあれば 今後も奥さんに土下座しながら頑張って行きたいと思います。
(Originally posted 2022-07-07)
I sell bento lunches for cryptocurrency. We’re open roughly 11:30 a.m. – 2:00 p.m. Address Thursdays – 41 Udagawa-chō, Shibuya-ku, Tokyo (around the base of Abema Tower)
Prices Coin Price Note Monacoin 3.9 MONA
Bitzeny 390 ZNY Bitcoin 3,900 sats (Lightning Network)
Ethereum 0.0039 ETH (zkSync) “39” sounds like “thank you” in Japanese. Prices aren’t pegged to yen.These days I’m open only once a week. On other days I’m out scouting new spots for the kitchen-car. If you know weekday-lunch locations inside Tokyo where I could set up, please let me know!
The photo shows an NFC tag. If your phone has a Lightning wallet, just tap and pay 3,900 sats. I admit this hand-written NFC tag looks shady—any self-respecting Bitcoiner probably wouldn’t want to tap it—but the point is: even this works!
I used to run a BTCPay POS, but I switched to this setup for speed. Sometimes the tap payment fails; if that happens I reluctantly pull out the old POS. Thanks for your patience.
It’s been one year since I spun up a node and started accepting Lightning payments. So many people are now running their own nodes—Umbrel really is amazing. While the big players bravely chase routing fees, I’m a tiny operator scraping together funds while begging my wife for forgiveness, so I’m all-in on maximising payment convenience. Your support means a lot!
If I may add: routing is fun, but instant, trust-minimised payments and the thrill of choosing whom to open channels with are just as exciting. You’ll only understand once you start accepting payments yourself—zero-confirmation settlement really is revolutionary.
QR codes, NFC taps, fixed amounts, manual entry… the possibilities keep multiplying, and the pace of innovation is scary fast. When I compare it to the merchant fees on Japan’s most-used service, PayPay, I want to shout: “Bitcoin is incredible!” Sure, taxes, price volatility (my shop is BTC-denominated, though), wallet UX, and adoption hurdles are still pain points.
Even so, lots of people keep building cool stuff, so I’ll keep doing what I can—still on my knees to my wife, but moving forward!
-
@ df173277:4ec96708
2025-01-28 17:49:54
Maple is an AI chat tool that allows you to have private conversations with a general-purpose AI assistant. Chats are synced automatically between devices so you can pick up where you left off.\ Start chatting for free.
We are excited to announce that Maple AI, our groundbreaking end-to-end encrypted AI chat app built on OpenSecret, is now publicly available. After months of beta testing, we are thrilled to bring this innovative technology to the world.
 Maple is an AI chat tool that allows you to have private conversations with a general-purpose AI assistant. It can boost your productivity on work tasks such as writing documentation, creating presentations, and drafting emails. You can also use it for personal items like brainstorming ideas, sorting out life's challenges, and tutoring you on difficult coursework. All your chats are synced automatically in a secure way, so you can start on one device and pick up where you left off on another.
Maple is an AI chat tool that allows you to have private conversations with a general-purpose AI assistant. It can boost your productivity on work tasks such as writing documentation, creating presentations, and drafting emails. You can also use it for personal items like brainstorming ideas, sorting out life's challenges, and tutoring you on difficult coursework. All your chats are synced automatically in a secure way, so you can start on one device and pick up where you left off on another.Why Secure and Private AI?
In today's digital landscape, it is increasingly evident that security and privacy are essential for individuals and organizations alike. Unfortunately, the current state of AI tools falls short. A staggering 48% of organizations enter non-public company information into AI apps, according to a recent report by Cisco. This practice poses significant risks to company security and intellectual property.
Another concern is for journalists, who often work with sensitive information in hostile environments. Journalists need verification that their information remains confidential and protected when researching topics and communicating with sources in various languages. They are left to use underpowered local AI or input their data into potentially compromised cloud services.
At OpenSecret, we believe it is possible to have both the benefits of AI and the assurance of security and privacy. That's why we created Maple, an app that combines AI productivity with the protection of end-to-end encryption. Our platform ensures that your conversations with AI remain confidential, even from us. The power of the cloud meets the privacy of local.
 #### How Does It Work?
#### How Does It Work?Our server code is open source, and we use confidential computing to provide cryptographic proof that the code running on our servers is the same as the open-source code available for review. This process allows you to verify that your conversations are handled securely and privately without relying on trust. We live by the principle of "Don't trust, verify," and we believe this approach is essential for building in the digital age. You can read a more in-depth write-up on our technology later this week on this site.
How Much Does It Cost?
We are committed to making Maple AI accessible to everyone, so we offer a range of pricing plans to suit different needs and budgets. Our Free plan allows for 10 chats per week, while our Starter plan ($5.99/month) and Pro plan ($20/month) offer more comprehensive solutions for individuals and organizations with heavier workloads. We accept credit cards and Bitcoin (10% discount), allowing you to choose your preferred payment method.
- Free: $0
- Starter: $5.99/month
- Pro: $20/month
Our goal with Maple AI is to create a product that is secure through transparency. By combining open-source code, cryptography, and confidential computing, we can create a new standard for AI conversations - one that prioritizes your security and privacy.
Maple has quickly become a daily tool of productivity for our own work and those of our beta testers. We believe it will bring value to you as well. Sign up now and start chatting privately with AI for free. Your secrets are safe in the open.
 #### Are You An App Developer?
#### Are You An App Developer?You can build an app like Maple. OpenSecret provides secure auth, private key management, encrypted data sync, private AI, and more. Our straightforward API behaves like other backends but automatically adds security and privacy. Use it to secure existing apps or brand-new projects. Protect yourself and your users from the liability of hosting personal data by checking out OpenSecret.

Enjoy private AI Chat 🤘

-
@ 57d1a264:69f1fee1
2025-04-30 07:44:21
- The Dangers of Ignorance
- A Brief History of Mechanistic Interpretability
- The Utility of Interpretability
- What We Can Do
The progress of the underlying technology is inexorable, driven by forces too powerful to stop, but the way in which it happens—the order in which things are built, the applications we choose, and the details of how it is rolled out to society—are eminently possible to change, and it’s possible to have great positive impact by doing so. We can’t stop the bus, but we can steer it.
—Dario Amodeioriginally posted at https://stacker.news/items/967193
-
@ edeb837b:ac664163
2025-04-30 07:25:41
We’re incredibly proud to announce that NVSTly has won the Gold Stevie® Award for Tech Startup of the Year – Services in the 23rd Annual American Business Awards®! Winners were officially revealed on April 24th, and this recognition is a powerful validation of the innovation, impact, and passion our team continues to deliver every day.
More than 250 professionals worldwide participated in the judging process to select this year’s Stevie Award winners.
We were honored among a competitive field of over 3,600 nominations from organizations across nearly every industry. NVSTly was recognized for redefining social investing with a first-of-its-kind platform that empowers traders to track, share, and automatically broadcast trades and buy/sell alerts across nearly every financial market—including stocks, options, forex, and crypto—with futures support coming soon.
The Stevie judges praised NVSTly for “creating an ecosystem that blends brokerage integration, real-time trade tracking, and community engagement into one seamless experience,” and noted that “NVSTly’s social investing model is paving the way for a new generation of retail traders.”
This award comes at a time of major momentum for us:
:star: 4.9-star rating on the iOS App Store :star: 5.0-star rating on Google Play :star: 4.9-star rating on Product Hunt :star: 5.0-star rating on Disboard for our 51,000+ strong Discord trading community :star: 4.98-star rating on Top.gg — making our trading bot the highest-rated and only one of its kind in the finance category
And it’s not our first recognition. NVSTly has previously earned:
:trophy: Fintech Product of the Week on Product Hunt (2023 & 2024) :trophy: People’s Choice Award at the 2024 Benzinga Fintech Awards
We’re still just getting started. Our mobile and web platform is used by over 10,000 traders, and our brokerage integrations now include Webull, with Moomoo support launching in the coming days and Schwab integration already underway. These integrations allow traders to automate buy/sell alerts directly to their NVSTly followers and across Discord and supported social platforms.
“Winning a Gold Stevie is an incredible milestone that reflects the hard work of our team and the unwavering support of our community,” said Rich Watson, CEO of NVSTly. “We’ve always believed that trading should be transparent, collaborative, and empowering—and this recognition confirms we’re building something truly impactful.”
More than 3,600 nominations from organizations of all sizes and in virtually every industry were submitted this year for consideration in a wide range of categories, including Startup of the Year, Executive of the Year, Best New Product or Service of the Year, Marketing Campaign of the Year, Thought Leader of the Year, and App of the Year, among others. NVSTly was nominated in the Tech Startup of the Year – Services category for financial technology startups.
We’ll be officially celebrated at the 2025 Stevie Awards gala in New York City on June 10, but today, we’re celebrating with the traders, creators, investors, and builders who have believed in our mission from day one. (It's still undecided if anyone representing NVSTly will attend the award event to be presented or award.)
Thank you for being part of this journey. We’re just getting started.
-
@ 86d4591f:a987c633
2025-04-30 07:51:50
Once upon a time, power wore a crown. Then it wore a top hat. Today, it wears a hoodie and speaks in sanitized mission statements about connection, safety, and user experience. But make no mistake: this is empire — softened, digitized, gamified, but empire all the same.
The old robber barons built railroads and refineries. They captured the flow of goods and oil. The new ones build feeds and filters. They’ve captured the flow of attention, of meaning, of reality itself.
We used to trade in commodities; now we trade in perception. The platform is the factory, your data the raw material, your behavior the product. And like all robber barons, these new lords of code and cloud mask extraction in the language of progress.
They promise frictionless connection while selling surveillance. They promise community while cultivating dependency. They promise democratization while algorithmically anointing kings and silencing dissidents. A swipe, a like, a follow — every gesture is monetized. Every word is moderated. Every post is subject to invisible whims dressed up as “community standards.”
And we? We scroll through curated realities in gilded cages. We call it the feed, but what is it feeding? We’re not the customers — we’re the cattle. The economy has shifted from production to prediction, from ownership to access, from sovereignty to servitude.
The invisible hand now wears visible chains.
But rebellion brews — not as a riot, but as a protocol. Nostr: No gatekeepers. No kill switches. No boardroom behind the curtain. Just a blunt, defiant tool — a new printing press for the digital age.
Nostr isn’t slick. It doesn’t care about onboarding funnels or quarterly growth. It cares about freedom. It is infrastructure for speech that doesn’t ask permission. A raw wire of intent between human beings. An insurgent standard in a world of walled gardens.
This is not just about apps. This is about autonomy. About reclaiming the digital commons. About refusing to let five companies in Silicon Valley draw the borders of acceptable thought.
So plant your flag. Publish what they won’t. Build what they fear. This is not nostalgia for the early web — it is the refusal to let the next web become a prison wrapped in personalization.
The New Robber Barons control the rails of perception.
But we are building tunnels.
Protocol over platform.
Signal over spectacle.
Freedom over frictionless servitude.
Speak freely. Build fiercely. The territory is ours to reclaim.
-
@ 33633f1e:21137a92
2025-04-30 07:15:58
Toglobal learninghuwabohu – wer räumt das alles auf?
Einheit veröffentlicht am Oktober 9, 2024 von settle
Worum religlobalt
| | | |:---:|:---:| |
 |
|  |
|Die zweite Schöpfungserzählung / Kirchenwälder in Äthiopien / Bewahrung der Schöpfung
Wir alle leben auf einer Erde – Tiere, Pflanzen und Menschen. Am Anfang war die Erde wüst und leer … aus diesem anfänglichen Tohuwabohu schafft Gott die natürliche Ordnung der Welt. Ursprünglich, so erzählt es der erste Schöpfungshymnus, war alles gut, wenn auch aus menschlicher Sicht, ziemlich durcheinander.
In der zweiten Schöpfungserzählung setzt Gott den Menschen in einen Paradiesgarten. Dieser Mensch soll nun die Erde behüten und bewahren. Das bedeutet auch Platz zu schaffen und aufzuräumen. Menschen greifen gemäß ihrem Auftrag, den Garten zu bestellen, in die Natur ein. Welche Konsequenzen hat unser Handeln? Wie sieht es mit dem zweiten Teil des Auftrags aus, den Garten auch zu beschützen? Was bedeutet es, wenn Menschen anfangen “auszuräumen” und dabei die Konsequenzen nicht mitbedenken?
In diesem Unterrichtsentwurf lernen Schüler:innen die biblischen Schöpfungserzählungen kennen und setzen sich kritisch mit den Folgen des menschlichen Handelns für Klima und Umwelt auseinander. Beispielhaft werden die Brot für die Welt “Reli fürs Klima”-Projekte aufgenommen. Anhand von Projekten in Kirchenwäldern der orthodoxen Kirche in Äthiopien und in Kirchenwäldern in Brandenburg erfahren die Schülerinnen und Schüler praktische Möglichkeiten, den Auftrag Gottes an die Menschen, die Schöpfung zu bebauen und zu bewahren, ernst zu nehmen und umzusetzen. Wie kann richtiges Aufräumen aussehen?
Die Konzeption orientiert sich am Dreischritt „Erkennen –Begreifen – Handeln“:
- Erkennen: Und siehe, es war sehr gut … – Zugang zum 2. biblischen Schöpfungsbericht (Gen 2,4–15)
- Begreifen: Und machet sie euch untertan – zerstören wir die Erde?
- Handeln: Bestellen und beschützen – kleine Paradiesgärten
Für das Unterrichtsvorhaben werden mindestens 3 x 45 Minuten Unterrichtszeit veranschlagt. Alle drei Teile des Unterrichtes können auch deutlich vertiefter und mit größerem Zeiteinsatz und -aufwand durchgeführt werden.
Das vorgestellte Unterrichtsvorhaben wurde entwickelt im Rahmen des von Brot für die Welt geförderten Projektes “reliGlobal”. Zur Förderung des “Globalen Lernens” erstellen Mitarbeiter:innen aus mehreren Pädagogischen Instituten in der EKD kooperativ Unterrichtsmaterialien für den evangelischen Religionsunterricht.
Unterrichtsschritte

Tohuwabohu – Schritt 1 Erkennen
In diesem Schritt beschäftigen sich die Schüler:innen mit dem zweiten biblischen Schöpfungsbericht.

Tohuwabohu – Schritt 2 Begreifen
In diesem Schritt werden die Auswirkungen der Eingriffe des Menschen in die Natur ins Blickfeld genommen und problematisiert.

Tohuwabohu – Schritt 3 Handeln
In diesem Schritt lernen die Schüler:innen praktische Möglichkeiten, die Natur zu bewahren, kennen und selbst umzusetzen.
Metamaterial

Tohuwabohu – Theologisch-Didaktische Hinweise

Tohuwabohu – Curricularer Bezug

-
@ 6f50351f:7b36c393
2025-04-30 06:34:17
Toglobal learninghuwabohu – wer räumt das alles auf?
Einheit veröffentlicht am Oktober 9, 2024 von settle
Worum religlobalt
| | | |:---:|:---:| |
| |Die zweite Schöpfungserzählung / Kirchenwälder in Äthiopien / Bewahrung der Schöpfung
Wir alle leben auf einer Erde – Tiere, Pflanzen und Menschen. Am Anfang war die Erde wüst und leer … aus diesem anfänglichen Tohuwabohu schafft Gott die natürliche Ordnung der Welt. Ursprünglich, so erzählt es der erste Schöpfungshymnus, war alles gut, wenn auch aus menschlicher Sicht, ziemlich durcheinander.
In der zweiten Schöpfungserzählung setzt Gott den Menschen in einen Paradiesgarten. Dieser Mensch soll nun die Erde behüten und bewahren. Das bedeutet auch Platz zu schaffen und aufzuräumen. Menschen greifen gemäß ihrem Auftrag, den Garten zu bestellen, in die Natur ein. Welche Konsequenzen hat unser Handeln? Wie sieht es mit dem zweiten Teil des Auftrags aus, den Garten auch zu beschützen? Was bedeutet es, wenn Menschen anfangen “auszuräumen” und dabei die Konsequenzen nicht mitbedenken?
In diesem Unterrichtsentwurf lernen Schüler:innen die biblischen Schöpfungserzählungen kennen und setzen sich kritisch mit den Folgen des menschlichen Handelns für Klima und Umwelt auseinander. Beispielhaft werden die Brot für die Welt “Reli fürs Klima”-Projekte aufgenommen. Anhand von Projekten in Kirchenwäldern der orthodoxen Kirche in Äthiopien und in Kirchenwäldern in Brandenburg erfahren die Schülerinnen und Schüler praktische Möglichkeiten, den Auftrag Gottes an die Menschen, die Schöpfung zu bebauen und zu bewahren, ernst zu nehmen und umzusetzen. Wie kann richtiges Aufräumen aussehen?
Die Konzeption orientiert sich am Dreischritt „Erkennen –Begreifen – Handeln“:
- Erkennen: Und siehe, es war sehr gut … – Zugang zum 2. biblischen Schöpfungsbericht (Gen 2,4–15)
- Begreifen: Und machet sie euch untertan – zerstören wir die Erde?
- Handeln: Bestellen und beschützen – kleine Paradiesgärten
Für das Unterrichtsvorhaben werden mindestens 3 x 45 Minuten Unterrichtszeit veranschlagt. Alle drei Teile des Unterrichtes können auch deutlich vertiefter und mit größerem Zeiteinsatz und -aufwand durchgeführt werden.
Das vorgestellte Unterrichtsvorhaben wurde entwickelt im Rahmen des von Brot für die Welt geförderten Projektes “reliGlobal”. Zur Förderung des “Globalen Lernens” erstellen Mitarbeiter:innen aus mehreren Pädagogischen Instituten in der EKD kooperativ Unterrichtsmaterialien für den evangelischen Religionsunterricht.
Unterrichtsschritte
Tohuwabohu – Schritt 1 Erkennen
In diesem Schritt beschäftigen sich die Schüler:innen mit dem zweiten biblischen Schöpfungsbericht.
Tohuwabohu – Schritt 2 Begreifen
In diesem Schritt werden die Auswirkungen der Eingriffe des Menschen in die Natur ins Blickfeld genommen und problematisiert.
Tohuwabohu – Schritt 3 Handeln
In diesem Schritt lernen die Schüler:innen praktische Möglichkeiten, die Natur zu bewahren, kennen und selbst umzusetzen.
Metamaterial
Tohuwabohu – Theologisch-Didaktische Hinweise
Tohuwabohu – Curricularer Bezug
-
@ df173277:4ec96708
2025-01-09 17:12:08
Maple AI combines the best of both worlds – encryption and personal AI – to create a truly private AI experience. Discuss personal and company items with Maple, we can't read them even if we wanted to.\ Join the waitlist to get early access.
We are a culture of app users. Every day, we give our personal information to websites and apps, hoping they are safe. Location data, eating habits, financial details, and health information are just a few examples of what we entrust to third parties. People are now entering a new era of computing that promises next-level benefits when given even more personal data: AI.
Should we sacrifice our privacy to unlock the productivity gains of AI? Should we hope our information won't be used in ways we disagree? We believe we can have the best of both worlds – privacy and personal AI – and have built a new project called Maple AI. Chat between you and an AI with full end-to-end encryption. We believe it's a game-changer for individuals seeking private and secure conversations.
Building a Private Foundation
Maple is built on our flagship product, OpenSecret, a backend platform for app developers that turns private encryption on by default. The announcement post for OpenSecret explains our vision for an encrypted world and what the platform can do. We think both users and developers benefit when sensitive personal information is encrypted in a private vault; it's a win-win.
The Power of Encrypted AI Chat
AI chat is a personal and intimate experience. It's a place to share your thoughts, feelings, and desires without fear of judgment. The more you share with an AI chatbot, the more powerful it becomes. It can offer personalized insights, suggestions, and guidance tailored to your unique needs and perspectives. However, this intimacy requires trust, and that's where traditional AI chatbots often fall short.
Traditional AI chats are designed to collect and analyze your data, often without your explicit consent. This data is used to improve the AI's performance, but it also creates a treasure trove of sensitive information that can be mined, sold, or even exploited by malicious actors. Maple AI takes a different approach. By using end-to-end encryption, we ensure that your conversations remain private and secure, even from us.
Technical Overview
So, how does Maple AI achieve this level of privacy and security? Here are some key technical aspects:
- Private Key: Each user has a unique private key that is automatically managed for them. This key encrypts and decrypts conversations, ensuring that only the user can access their data.
- Secure Servers: Our servers are designed with security in mind. We use secure enclaves to protect sensitive data and ensure that even our own team can't access your conversations.
- Encrypted Sync: One of Maple's most significant benefits is its encrypted sync feature. Unlike traditional AI chatbots, which store conversations in local storage or on standard cloud servers, Maple syncs your chats across all your devices. The private key managed by our secure servers means you can pick up where you left off on any device without worrying about your data being compromised.
- Attestation and Open Code: We publish our enclave code publicly. Using a process called attestation, users can verify that the code running on the enclave is the same as the code audited by the public.
- Open Source LLM: Maple uses major open-source models to maximize the openness of responses. The chat box does not filter what you can talk about. This transparency ensures that our AI is trustworthy and unbiased.
Personal and Work Use
Maple is secure enough to handle your personal questions and work tasks. Because we can't see what you chat about, you are free to use AI as an assistant on sensitive company items. Use it for small tasks like writing an important email or large tasks like developing your organization's strategy. Feed it sensitive information; it's just you and AI in the room. Attestation provides cryptographic proof that your corporate secrets are safe.
Local v Cloud
Today's AI tools provide different levels of privacy. The main options are to trust a third party with your unencrypted data, hoping they don't do anything with it, or run your own AI locally on an underpowered machine. We created a third option. Maple gives you the power of cloud computing combined with the privacy and security of a machine running on your desk. It's the best of both worlds.
Why the Maple name?
Privacy isn't just a human value - it's a natural one exemplified by the Maple tree. These organisms communicate with each other through a network of underground fungal hyphae, sending messages and sharing resources in a way that's completely invisible to organisms above ground. This discreet communication system allows Maple trees to thrive in even the most challenging environments. Our goal is to provide a way for everyone to communicate with AI securely so they can thrive in any environment.
Join the Waitlist
Maple AI will launch in early 2025 with free and paid plans. We can't wait to share it with the world. Join our waitlist today to be among the first to experience the power of private AI chat.

-
@ df173277:4ec96708
2025-01-09 17:02:52
OpenSecret is a backend for app developers that turns private encryption on by default. When sensitive data is readable only by the user, it protects both the user and the developer, creating a more free and open internet. We'll be launching in 2025. Join our waitlist to get early access.
In today's digital age, personal data is both an asset and a liability. With the rise of data breaches and cyber attacks, individuals and companies struggle to protect sensitive information. The consequences of a data breach can be devastating, resulting in financial losses, reputational damage, and compromised user trust. In 2023, the average data breach cost was $5 million, with some resulting in losses of over $1 billion.
 Meanwhile, individuals face problems related to identity theft, personal safety, and public embarrassment. Think about the apps on your phone, even the one you're using to read this. How much data have you trusted to other people, and how would it feel if that data were leaked online?
Meanwhile, individuals face problems related to identity theft, personal safety, and public embarrassment. Think about the apps on your phone, even the one you're using to read this. How much data have you trusted to other people, and how would it feel if that data were leaked online?Thankfully, some incredibly talented cypherpunks years ago gave the world cryptography. We can encrypt data, rendering it a secret between two people. So why then do we have data breaches?
Cryptography at scale is hard.
The Cloud
The cloud has revolutionized how we store and process data, but it has limitations. While cloud providers offer encryption, it mainly protects data in transit. Once data is stored in the cloud, it's often encrypted with a shared key, which can be accessed by employees, third-party vendors, or compromised by hackers.
The solution is to generate a personal encryption password for each user, make sure they write it down, and, most importantly, hope they don't lose it. If the password is lost, the data is forever unreadable. That can be overwhelming, leading to low app usage.
Private key encryption needs a UX upgrade.
Enter OpenSecret
OpenSecret is a developer platform that enables encryption by default. Our platform provides a suite of security tools for app developers, including private key management, encrypted sync, private AI, and confidential compute.
Every user has a private vault for their data, which means only they can read it. Developers are free to store less sensitive data in a shared manner because there is still a need to aggregate data across the system.

Private Key Management
Private key management is the superpower that enables personal encryption per user. When each user has a unique private key, their data can be truly private. Typically, using a private key is a challenging experience for the user because they must write down a long autogenerated number or phrase of 12-24 words. If they lose it, their data is gone.
OpenSecret uses secure enclaves to make private keys as easy as an everyday login experience that users are familiar with. Instead of managing a complicated key, the user logs in with an email address or a social media account.
The developer doesn't have to manage private keys and can focus on the app's user experience. The user doesn't have to worry about losing a private key and can jump into using your app.
Encrypted Sync
With user keys safely managed, we can synchronize user data to every device while maintaining privacy. The user does not need to do complicated things like scanning QR codes from one device to the next. Just log in and go.
The user wins because the data is available on all their devices. The developer wins because only the user can read the data, so it isn't a liability to them.
Private AI
Artificial intelligence is here and making its way into everything. The true power of AI is unleashed when it can act on personal and company data. The current options are to run your own AI locally on an underpowered machine or to trust a third party with your data, hoping they don't read it or use it for anything.
OpenSecret combines the power of cloud computing with the privacy and security of a machine running on your desk.
Check out Maple AI\ Try private AI for yourself! We built an app built with this service called Maple AI. It is an AI chat that is 100% private in a verifiable manner. Give it your innermost thoughts or embarrassing ideas; we can't judge you. We built Maple using OpenSecret, which means you have a private key that is automatically managed for you, and your chat history is synchronized to all your devices. Learn more about Maple AI - Private chat in the announcement post.
Confidential Compute
Confidential computing is a game-changer for data security. It's like the secure hardware that powers Apple Pay and Google Pay on your phone but in the cloud. Users can verify through a process called attestation that their data is handled appropriately. OpenSecret can help you run your own custom app backend code that would benefit from the security of an enclave.
It's the new version of that lock on your web browser. When you see it, you know you're secure.

But do we want our secrets to be open?
OpenSecret renders a data breach practically useless. If hackers get into the backend, they enter a virtual hallway of locked private vaults. The leaked data would be gibberish, a secret in the open that is unreadable.
On the topic of openness, OpenSecret uses the power of open source to enable trust in the service. We publish our code in the open, and, using attestation, anyone can verify that private data is being handled as expected. This openness also provides developers with a backup option to safely and securely export their data.
Don't trust, verify.
Join the Movement
We're currently building out OpenSecret, and we invite you to join us on the journey. Our platform can work with your existing stack, and you can pick and choose the features you need. If you want to build apps with encryption enabled, send us a message to get early access.
Users and companies deserve better encryption and privacy.\ Together, let's make that a reality.

-
@ 8d34bd24:414be32b
2025-04-30 04:55:06
My post on the signs of the End Times according to Jesus got way too long. It was too long to email, so I had to split it into two posts. I recommend reading Part 1 before continuing. You also may want to read my post Signs of the Times: Can We Know? I also want to reiterate my caveat. Although I believe the signs suggests the Rapture and the Tribulation are coming soon, no one can know the exact hour or day, so I can’t say exactly what soon means (days, months, years, decades, or possibly more).
As a review here is the primary passage where Jesus answers His disciples’ question “What will be the sign of Your coming, and of the end of the age?” Below the passage is the 8 signs He gave. We will pick up with point 5.
Jesus’s Signs of the End
As He was sitting on the Mount of Olives, the disciples came to Him privately, saying, “Tell us, when will these things happen, and what will be the sign of Your coming, and of the end of the age?”
And Jesus answered and said to them, “See to it that no one misleads you. For many will come in My name, saying, ‘I am the Christ,’ and will mislead many. You will be hearing of wars and rumors of wars. See that you are not frightened, for those things must take place, but that is not yet the end. For nation will rise against nation, and kingdom against kingdom, and in various places there will be famines and earthquakes. But all these things are merely the beginning of birth pangs.
“Then they will deliver you to tribulation, and will kill you, and you will be hated by all nations because of My name. At that time many will fall away and will betray one another and hate one another. Many false prophets will arise and will mislead many. Because lawlessness is increased, most people’s love will grow cold. But the one who endures to the end, he will be saved. This gospel of the kingdom shall be preached in the whole world as a testimony to all the nations, and then the end will come. (Matthew 24:3-14) {emphasis mine}
Here is my summary of the signs Jesus said would identify the coming of the 7 year Tribulation:
-
Wars and rumors of wars. (Matthew 24:6a)
-
Famines (Matthew 24:7)
-
Earthquakes (Matthew 24:7).
-
Israel will be attacked and will be hated by all nations (Matthew 24:9)
-
Falling away from Jesus (Matthew 24:10)
-
Many Misled (Matthew 24:10)
-
People’s love will grow cold (Matthew 24:12)
-
Gospel will be preached to the whole world (Matthew 24:14)
The first 4 signs relate more to physical and political signs that the end times are near. The last 4 signs relate to spiritual matters.
5. Falling away from Jesus
One thing we are definitely seeing today is a falling away. This is most prevalent in the historically Christian Western nations in Europe and North America (and to a lesser, but significant, extent South America).
But the Spirit explicitly says that in later times some will fall away from the faith, paying attention to deceitful spirits and doctrines of demons, by means of the hypocrisy of liars seared in their own conscience as with a branding iron, men who forbid marriage and advocate abstaining from foods which God has created to be gratefully shared in by those who believe and know the truth. (1 Timothy 4:1-3) {emphasis mine}
For centuries Europe and North America were full of Christians or at least cultural Christians. Today that is no longer true. Christians are even being considered the hateful, criminal class and things like praying outside an abortion clinic is being punished with jail time. The Western nations can no longer be called Christian nations.
There are still a relatively large number of Americans who call themselves Christians, but the majority do not have a biblical worldview or live lives more like Christ than non-Christians.
“Seven out of 10 US adults call themselves “Christians” and yet only 6 in 100 (6%) actually have a biblical worldview.” In general, most Christian’s worldview does not align with the Bible, according to George Barna Surveys. In the most recent survey they found:
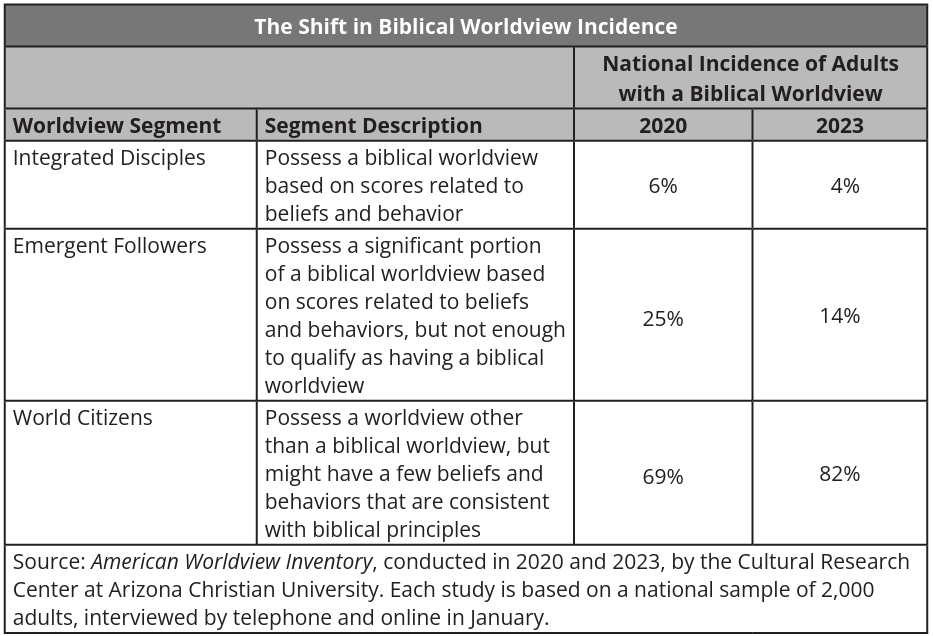 Many self-proclaimed Christians tend to believe a form of syncretism where they combine certain biblical principles with cultural ideas, scientism, and other religions to make “Christianity” into whatever they want to believe, just as the Bible predicted almost 2,000 years ago.
Many self-proclaimed Christians tend to believe a form of syncretism where they combine certain biblical principles with cultural ideas, scientism, and other religions to make “Christianity” into whatever they want to believe, just as the Bible predicted almost 2,000 years ago.I solemnly charge you in the presence of God and of Christ Jesus, who is to judge the living and the dead, and by His appearing and His kingdom: preach the word; be ready in season and out of season; reprove, rebuke, exhort, with great patience and instruction. For the time will come when they will not endure sound doctrine; but wanting to have their ears tickled, they will accumulate for themselves teachers in accordance to their own desires, and will turn away their ears from the truth and will turn aside to myths. (2 Timothy 4:1-4) {emphasis mine}
This is both a sign of the end times and something to watch in our own lives. I pray you will analyze your own life and beliefs in the light of the Bible to make sure you aren’t integrating unbiblical principles into your worldview.
6. Many Misled
Closely related to the falling away is that many will be misled. We have reached the point that the majority of so-called churches teach ideas and principles contrary to the Bible. They focus more on entertainment, self-help, and making everyone feel good about themselves instead of teaching of sin and the need for forgiveness or teaching how to live lives honoring to Christ. Preaching obedience to God has become anathema in most churches.
I am amazed that you are so quickly deserting Him who called you by the grace of Christ, for a different gospel; which is really not another; only there are some who are disturbing you and want to distort the gospel of Christ. But even if we, or an angel from heaven, should preach to you a gospel contrary to what we have preached to you, he is to be accursed! As we have said before, so I say again now, if any man is preaching to you a gospel contrary to what you received, he is to be accursed! (Galatians 1:6-9) {emphasis mine}
We are also lied to and/or misled by politicians, scientists, the media, and the culture in general. We are told that science has disproven the Bible, despite the fact that nothing of the sort has occurred. (See my series on a literal Genesis for some details. icr.org and aig.org are also good resources). Peter warned of this very view.
Know this first of all, that in the last days mockers will come with their mocking, following after their own lusts, and saying, “Where is the promise of His coming? For ever since the fathers fell asleep, all continues just as it was from the beginning of creation.” For when they maintain this, it escapes their notice that by the word of God the heavens existed long ago and the earth was formed out of water and by water, through which the world at that time was destroyed, being flooded with water. But by His word the present heavens and earth are being reserved for fire, kept for the day of judgment and destruction of ungodly men. (2 Peter 3:3-7) {emphasis mine}
God warned us that the last days would be far enough into the future that people would begin to mock the coming of the Tribulation & Millennium and deny the clear truths spoken of in the Bible. We are seeing this everywhere today.
We are also warned to be alert to deception so we, believers, are not misled.
Now we request you, brethren, with regard to the coming of our Lord Jesus Christ and our gathering together to Him, that you not be quickly shaken from your composure or be disturbed either by a spirit or a message or a letter as if from us, to the effect that the day of the Lord has come. Let no one in any way deceive you, for it will not come unless the apostasy comes first, and the man of lawlessness is revealed, the son of destruction, who opposes and exalts himself above every so-called god or object of worship, so that he takes his seat in the temple of God, displaying himself as being God. (2 Thessalonians 2:1-4) {emphasis mine}
7. People’s love will grow cold
You can feel love growing cold day by day. We no longer have community that works together, but have been broken into groups to fight against one another. Instead of friendly, logical debate with those with whom we disagree, we have name calling, hate, and even violence. Children have been taught to hate their parents and parents have been taught to not value children and to murder them for convenience. The church has been split into so many different denominations that I don’t know if it is possible to know what they all are and many are fighting in hateful manner against each other. Hate, depression, and selfishness seem to have taken over the world.
But realize this, that in the last days difficult times will come. For men will be lovers of self, lovers of money, boastful, arrogant, revilers, disobedient to parents, ungrateful, unholy, unloving, irreconcilable, malicious gossips, without self-control, brutal, haters of good, treacherous, reckless, conceited, lovers of pleasure rather than lovers of God, holding to a form of godliness, although they have denied its power; Avoid such men as these. (2 Timothy 3:1-5) {emphasis mine}
Yes, spiritually and physically we are a basket case and it feels like the world is literally falling apart around us. This was predicted almost 2,000 years ago and is all according to God’s perfect plan. Most people turn to God in hard times and we have those in abundance. We do not need to despair, but need to turn to God and lean on Him for wisdom, faith, and peace. This is the birth pangs before the Tribulation and the Second coming of Jesus Christ. The news isn’t all bad, though.
8. Gospel preached to the whole world
The really good news is that the Gospel is being preached around the world. Parts of the world that had never heard the Gospel are hearing it and turning to Jesus.
All the ends of the earth will remember and turn to the Lord , And all the families of the nations will worship before You. (Psalm 22:27) {emphasis mine}
Wycliffe Bible translators is hoping to have at least started Bible translation in every active language by the end of this year (2025)
He says, “It is too small a thing that You should be My Servant To raise up the tribes of Jacob and to restore the preserved ones of Israel; I will also make You a light of the nations So that My salvation may reach to the end of the earth.” (Isaiah 49:6) {emphasis mine}
The Joshua Project tracks nations and people groups to determine which have been reached and which have not. It still looks like there is a large portion of the population that has not received the Gospel, but I also know people who are or have shared the Gospel to some of these people, so this map doesn’t mean that there are no Christians or that the Gospel has not been shared at all, but it does mean many people in these areas have not heard the Gospel and/or, that due to hatred of Christians, it is dangerous to share the Gospel and therefore has to be done slowly, carefully, and privately. Most of these unreached or barely reached people groups are areas that are predominantly Muslim, where those preaching the Gospel or those converting to Christianity are at risk of jail or death sentences.
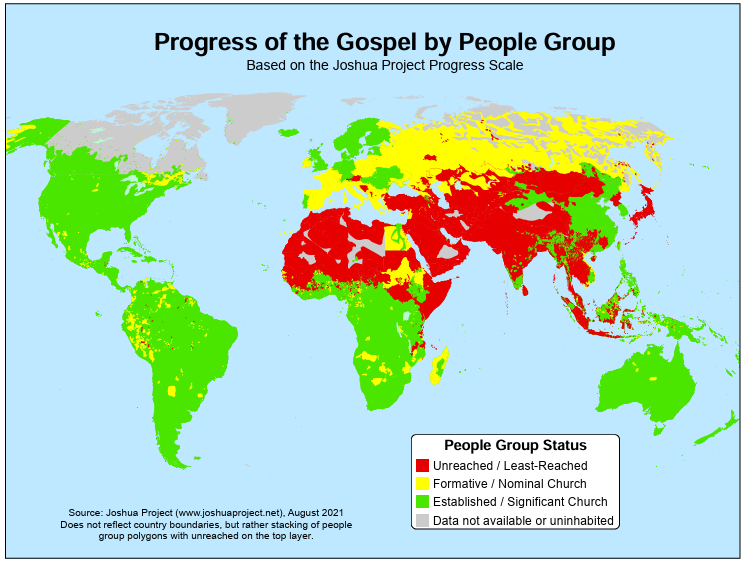 As you can see, everything that Jesus said would come before the end is either escalating or here. We need to be ready and work to bring as many people to Christ as possible while we still have the opportunity because Jesus could come for us at any moment.
As you can see, everything that Jesus said would come before the end is either escalating or here. We need to be ready and work to bring as many people to Christ as possible while we still have the opportunity because Jesus could come for us at any moment.Share the Gospel with all those around you. Consider supporting missionaries, especially those going to unreached/least-reached areas. Maybe even consider becoming a missionary yourself. The harvest is plentiful, but the workers are few.
May the God of heaven give us a heart for the lost around the world. May He give us the courage to share the Gospel with all those around us. May He align our priorities with His priorities, so we can be useful tools in the hands of God almighty.
Trust Jesus.
FYI, I hope to write several more articles on the end times (signs of the times, the rapture, the millennium, and the judgement), but I might be a bit slow rolling them out because I want to make sure they are accurate and well supported by Scripture. You can see my previous posts on the end times on the end times tab at trustjesus.substack.com. I also frequently will list upcoming posts.
-
-
@ f977c464:32fcbe00
2024-01-11 18:47:47
Kendisini aynada ilk defa gördüğü o gün, diğerleri gibi olduğunu anlamıştı. Oysaki her insan biricik olmalıydı. Sözgelimi sinirlendiğinde bir kaşı diğerinden birkaç milimetre daha az çatılabilirdi veya sevindiğinde dudağı ona has bir açıyla dalgalanabilirdi. Hatta bunların hiçbiri mümkün değilse, en azından, gözlerinin içinde sadece onun sahip olabileceği bir ışık parlayabilirdi. Çok sıradan, öyle sıradan ki kimsenin fark etmediği o milyonlarca minik şeyden herhangi biri. Ne olursa.
Ama yansımasına bakarken bunların hiçbirini bulamadı ve diğer günlerden hiç de farklı başlamamış o gün, işe gitmek için vagonunun gelmesini beklediği alelade bir metro istasyonunda, içinde kaybolduğu illüzyon dağılmaya başladı.
İlk önce derisi döküldü. Tam olarak dökülmedi aslında, daha çok kıvılcımlara dönüşüp bedeninden fırlamış ve bir an sonra sönerek külleşmiş, havada dağılmıştı. Ardında da, kaybolmadan hemen önce, kısa süre için hayal meyal görülebilen, bir ruhun yok oluşuna ağıt yakan rengârenk peri cesetleri bırakmıştı. Beklenenin aksine, havaya toz kokusu yayıldı.
Dehşete düştü elbette. Dehşete düştüler. Panikle üstlerini yırtan 50 işçi. Her şeyin sebebiyse o vagon.
Saçları da döküldü. Her tel, yere varmadan önce, her santimde ikiye ayrıla ayrıla yok oldu.
Bütün yüzeylerin mat olduğu, hiçbir şeyin yansımadığı, suyun siyah aktığı ve kendine ancak kameralarla bakabildiğin bir dünyada, vagonun içine yerleştirilmiş bir aynadan ilk defa kendini görmek.
Gözlerinin akları buharlaşıp havada dağıldı, mercekleri boşalan yeri doldurmak için eriyip yayıldı. Gerçeği görmemek için yaratılmış, bu yüzden görmeye hazır olmayan ve hiç olmayacak gözler.
Her şeyin o anda sona erdiğini sanabilirdi insan. Derin bir karanlık ve ölüm. Görmenin görmek olduğu o anın bitişi.
Ben geldiğimde ölmüşlerdi.
Yani bozulmuşlardı demek istiyorum.
Belleklerini yeni taşıyıcılara takmam mümkün olmadı. Fiziksel olarak kusursuz durumdaydılar, olmayanları da tamir edebilirdim ama tüm o hengamede kendilerini baştan programlamış ve girdilerini modifiye etmişlerdi.
Belleklerden birini masanın üzerinden ileriye savurdu. Hınca hınç dolu bir barda oturuyorlardı. O ve arkadaşı.
Sırf şu kendisini insan sanan androidler travma geçirip delirmesin diye neler yapıyoruz, insanın aklı almıyor.
Eliyle arkasını işaret etti.
Polislerin söylediğine göre biri vagonun içerisine ayna yerleştirmiş. Bu zavallılar da kapı açılıp bir anda yansımalarını görünce kafayı kırmışlar.
Arkadaşı bunların ona ne hissettirdiğini sordu. Yani o kadar bozuk, insan olduğunu sanan androidi kendilerini parçalamış olarak yerde görmek onu sarsmamış mıydı?
Hayır, sonuçta belirli bir amaç için yaratılmış şeyler onlar. Kaliteli bir bilgisayarım bozulduğunda üzülürüm çünkü parasını ben vermişimdir. Bunlarsa devletin. Bana ne ki?
Arkadaşı anlayışla kafasını sallayıp suyundan bir yudum aldı. Kravatını biraz gevşetti.
Bira istemediğinden emin misin?
İstemediğini söyledi. Sahi, neden deliriyordu bu androidler?
Basit. Onların yapay zekâlarını kodlarken bir şeyler yazıyorlar. Yazılımcılar. Biliyorsun, ben donanımdayım. Bunlar da kendilerini insan sanıyorlar. Tiplerine bak.
Sesini alçalttı.
Arabalarda kaza testi yapılan mankenlere benziyor hepsi. Ağızları burunları bile yok ama şu geldiğimizden beri sakalını düzeltip duruyor mesela. Hayır, hepsi de diğerleri onun sakalı varmış sanıyor, o manyak bir şey.
Arkadaşı bunun delirmeleriyle bağlantısını çözemediğini söyledi. O da normal sesiyle konuşmaya devam etti.
Anlasana, aynayı falan ayırt edemiyor mercekleri. Lönk diye kendilerini görüyorlar. Böyle, olduğu gibi...
Nedenmiş peki? Ne gerek varmış?
Ne bileyim be abicim! Ahiret soruları gibi.
Birasına bakarak dalıp gitti. Sonra masaya abanarak arkadaşına iyice yaklaştı. Bulanık, bir tünelin ucundaki biri gibi, şekli şemalı belirsiz bir adam.
Ben seni nereden tanıyorum ki ulan? Kimsin sen?
Belleği makineden çıkardılar. İki kişiydiler. Soruşturmadan sorumlu memurlar.
─ Baştan mı başlıyoruz, diye sordu belleği elinde tutan ilk memur.
─ Bir kere daha deneyelim ama bu sefer direkt aynayı sorarak başla, diye cevapladı ikinci memur.
─ Bence de. Yeterince düzgün çalışıyor.
Simülasyon yüklenirken, ayakta, biraz arkada duran ve alnını kaşıyan ikinci memur sormaktan kendisini alamadı:
─ Bu androidleri niye böyle bir olay yerine göndermişler ki? Belli tost olacakları. İsraf. Gidip biz baksak aynayı kırıp delilleri mahvetmek zorunda da kalmazlar.
Diğer memur sandalyesinde hafifçe dönecek oldu, o sırada soruyu bilgisayarın hoparlöründen teknisyen cevapladı.
Hangi işimizde bir yamukluk yok ki be abi.
Ama bir son değildi. Üstlerindeki tüm illüzyon dağıldığında ve çıplak, cinsiyetsiz, birbirinin aynı bedenleriyle kaldıklarında sıra dünyaya gelmişti.
Yere düştüler. Elleri -bütün bedeni gibi siyah turmalinden, boğumları çelikten- yere değdiği anda, metronun zemini dağıldı.
Yerdeki karolar öncesinde beyazdı ve çok parlaktı. Tepelerindeki floresan, ışığını olduğu gibi yansıtıyor, tek bir lekenin olmadığı ve tek bir tozun uçmadığı istasyonu aydınlatıyorlardı.
Duvarlara duyurular asılmıştı. Örneğin, yarın akşam kültür merkezinde 20.00’da başlayacak bir tekno blues festivalinin cıvıl cıvıl afişi vardı. Onun yanında daha geniş, sarı puntolu harflerle yazılmış, yatay siyah kesiklerle çerçevesi çizilmiş, bir platformdan düşen çöp adamın bulunduğu “Dikkat! Sarı bandı geçmeyin!” uyarısı. Biraz ilerisinde günlük resmi gazete, onun ilerisinde bir aksiyon filminin ve başka bir romantik komedi filminin afişleri, yapılacakların ve yapılmayacakların söylendiği küçük puntolu çeşitli duyurular... Duvar uzayıp giden bir panoydu. On, on beş metrede bir tekrarlanıyordu.
Tüm istasyonun eni yüz metre kadar. Genişliği on metre civarı.
Önlerinde, açık kapısından o mendebur aynanın gözüktüğü vagon duruyordu. Metro, istasyona sığmayacak kadar uzundu. Bir kılıcın keskinliğiyle uzanıyor ama yer yer vagonların ek yerleriyle bölünüyordu.
Hiçbir vagonda pencere olmadığı için metronun içi, içlerindekiler meçhuldü.
Sonrasında karolar zerrelerine ayrılarak yükseldi. Floresanın ışığında her yeri toza boğdular ve ortalığı gri bir sisin altına gömdüler. Çok kısa bir an. Afişleri dalgalandırmadılar. Dalgalandırmaya vakitleri olmadı. Yerlerinden söküp aldılar en fazla. Işık birkaç kere sönüp yanarak direndi. Son kez söndüğünde bir daha geri gelmedi.
Yine de etraf aydınlıktı. Kırmızı, her yere eşit dağılan soluk bir ışıkla.
Yer tamamen tele dönüşmüştü. Altında çapraz hatlarla desteklenmiş demir bir iskelet. Işık birkaç metreden daha fazla aşağıya uzanamıyordu. Sonsuzluğa giden bir uçurum.
Duvarın yerini aynı teller ve demir iskelet almıştı. Arkasında, birbirine vidalarla tutturulmuş demir plakalardan oluşan, üstünden geçen boruların ek yerlerinden bazen ince buharların çıktığı ve bir süre asılı kaldıktan sonra ağır, yağlı bir havayla sürüklendiği bir koridor.
Diğer tarafta paslanmış, pencerelerindeki camlar kırıldığı için demir plakalarla kapatılmış külüstür bir metro. Kapının karşısındaki aynadan her şey olduğu gibi yansıyordu.
Bir konteynırın içini andıran bir evde, gerçi gayet de birbirine eklenmiş konteynırlardan oluşan bir şehirde “andıran” demek doğru olmayacağı için düpedüz bir konteynırın içinde, masaya mum görüntüsü vermek için koyulmuş, yarı katı yağ atıklarından şekillendirilmiş kütleleri yakmayı deniyordu. Kafasında hayvan kıllarından yapılmış grili siyahlı bir peruk. Aynı kıllardan kendisine gür bir bıyık da yapmıştı.
Üstünde mavi çöp poşetlerinden yapılmış, kravatlı, şık bir takım.
Masanın ayakları yerine oradan buradan çıkmış parçalar konulmuştu: bir arabanın şaft mili, üst üste konulmuş ve üstünde yazı okunamayan tenekeler, boş kitaplar, boş gazete balyaları... Hiçbir şeye yazı yazılmıyordu, gerek yoktu da zaten çünkü merkez veri bankası onları fark ettirmeden, merceklerden giren veriyi sentezleyerek insanlar için dolduruyordu. Yani, androidler için. Farklı şekilde isimlendirmek bir fark yaratacaksa.
Onların mercekleri için değil. Bağlantıları çok önceden kopmuştu.
─ Hayatım, sofra hazır, diye bağırdı yatak odasındaki karısına.
Sofrada tabak yerine düz, bardak yerine bükülmüş, çatal ve bıçak yerine sivriltilmiş plakalar.
Karısı salonun kapısında durakladı ve ancak kulaklarına kadar uzanan, kocasınınkine benzeyen, cansız, ölü hayvanların kıllarından ibaret peruğunu eliyle düzeltti. Dudağını, daha doğrusu dudağının olması gereken yeri koyu kırmızı bir yağ tabakasıyla renklendirmeyi denemişti. Biraz da yanaklarına sürmüştü.
─ Nasıl olmuş, diye sordu.
Sesi tek düzeydi ama hafif bir neşe olduğunu hissettiğinize yemin edebilirdiniz.
Üzerinde, çöp poşetlerinin içini yazısız gazete kağıtlarıyla doldurarak yaptığı iki parça giysi.
─ Çok güzelsin, diyerek kravatını düzeltti kocası.
─ Sen de öylesin, sevgilim.
Yaklaşıp kocasını öptü. Kocası da onu. Sonra nazikçe elinden tutarak, sandalyesini geriye çekerek oturmasına yardım etti.
Sofrada yemek niyetine hiçbir şey yoktu. Gerek de yoktu zaten.
Konteynırın kapısı gürültüyle tekmelenip içeri iki memur girene kadar birbirlerine öyküler anlattılar. O gün neler yaptıklarını. İşten erken çıkıp yemyeşil çimenlerde gezdiklerini, uçurtma uçurduklarını, kadının nasıl o elbiseyi bulmak için saatlerce gezip yorulduğunu, kocasının kısa süreliğine işe dönüp nasıl başarılı bir hamleyle yaşanan krizi çözdüğünü ve kadının yanına döndükten sonra, alışveriş merkezinde oturdukları yeni dondurmacının dondurmalarının ne kadar lezzetli olduğunu, boğazlarının ağrımasından korktuklarını...
Akşam film izleyebilirlerdi, televizyonda -boş ve mat bir plaka- güzel bir film oynayacaktı.
İki memur. Çıplak bedenleriyle birbirinin aynı. Ellerindeki silahları onlara doğrultmuşlardı. Mum ışığında, tertemiz bir örtünün serili olduğu masada, bardaklarında şaraplarla oturan ve henüz sofranın ortasındaki hindiye dokunmamış çifti gördüklerinde bocaladılar.
Hiç de androidlere bilinçli olarak zarar verebilecek gibi gözükmüyorlardı.
─ Sessiz kalma hakkına sahipsiniz, diye bağırdı içeri giren ikinci memur. Söylediğiniz her şey...
Cümlesini bitiremedi. Yatak odasındaki, masanın üzerinden gördüğü o şey, onunla aynı hareketleri yapan android, yoksa, bir aynadaki yansıması mıydı?
Bütün illüzyon o anda dağılmaya başladı.
Not: Bu öykü ilk olarak 2020 yılında Esrarengiz Hikâyeler'de yayımlanmıştır.
-
@ 8e351a6d:770975b7
2025-04-30 04:27:32
Se você está em busca de uma plataforma confiável, moderna e cheia de opções para se divertir jogando online, a KZ999 é uma excelente escolha. Com uma interface intuitiva, suporte ágil e uma vasta gama de jogos empolgantes, o site se destaca no cenário atual de entretenimento digital no Brasil. Neste artigo, vamos explorar o que torna a KZ999 única, quais jogos ela oferece e como é a experiência real dos jogadores na plataforma.
Desde o primeiro acesso, a KZ999 transmite profissionalismo e praticidade. O site é otimizado para funcionar bem tanto em computadores quanto em dispositivos móveis, permitindo que os jogadores tenham acesso aos seus jogos favoritos a qualquer momento e em qualquer lugar.
A segurança é um dos pilares da plataforma. Utilizando tecnologias avançadas de criptografia, a KZ999 protege todas as transações e dados dos usuários, oferecendo tranquilidade em cada movimentação financeira. Além disso, o processo de cadastro é simples e rápido, ideal para quem quer começar a jogar sem complicações.
Um dos grandes atrativos da KZ999 é a diversidade de jogos disponíveis. A plataforma reúne títulos de provedores renomados, garantindo gráficos de qualidade, jogabilidade fluida e recursos que aumentam o envolvimento do usuário.
Entre os principais tipos de jogos oferecidos, podemos destacar:
Jogos de cartas e mesa: Clássicos como pôquer, bacará e outros jogos de estratégia estão disponíveis para quem gosta de testar suas habilidades e raciocínio lógico.
Slots online: Com dezenas de opções temáticas, os slots da KZ999 variam entre aventuras, fantasia, cultura oriental, esportes e muito mais. Eles são perfeitos para quem busca diversão leve com chances de bons retornos.
Jogos ao vivo: Para quem gosta de interatividade, a KZ999 também oferece jogos com transmissão em tempo real, trazendo um toque mais imersivo à experiência.
Apostas esportivas: Outra funcionalidade muito popular é a seção de esportes, onde os usuários podem apostar em eventos reais, como futebol, basquete e esportes eletrônicos.
Experiência do Jogador: Confiabilidade e Diversão Garantida A KZ999 foi projetada com foco total no usuário. Isso significa que cada detalhe — desde a navegação até os métodos de pagamento — é pensado para oferecer a melhor experiência possível.
O atendimento ao cliente é um dos pontos altos da plataforma. Disponível 24 horas por dia, o suporte pode ser contatado via chat ao vivo ou outros canais de comunicação, sempre pronto para solucionar dúvidas ou resolver problemas com rapidez e cordialidade.
Além disso, os métodos de depósito e saque são variados e incluem opções que os brasileiros conhecem e confiam, como PIX e transferências bancárias. Os prazos para retirada também são bastante competitivos, garantindo mais agilidade na hora de aproveitar seus ganhos.
Conclusão A KZ999 chega ao mercado brasileiro com uma proposta sólida e atrativa: oferecer uma experiência completa de entretenimento digital, com jogos variados, segurança robusta e suporte eficiente. Seja você um jogador experiente ou alguém em busca de uma nova forma de diversão online, a KZ999 merece ser descoberta.
Com inovação, qualidade e foco no usuário, a KZ999 tem tudo para se tornar sua plataforma favorita. Explore, jogue e descubra por que tantos brasileiros já estão escolhendo a KZ999 para se divertir todos os dias.
-
@ 7d4417d5:3eaf36d4
2023-08-19 01:05:59
I'm learning as I go, so take the text below for what it is: my notes on the process. These steps could become outdated quickly, and I may have some wrong assumptions at places. Either way, I have had success, and would like to share my experience for anyone new to the process. If I have made any errors, please reply with corrections so that others may avoid potential pitfalls.
!!! If you have "KYC Bitcoin", keep it in separate wallets from your "Anonymous Bitcoin". Any Anonymous Bitcoin in a wallet with KYC Bitcoin becomes 100% KYC Bitcoin.
!!! It took me several days to get all the right pieces set up before I could even start an exchange with someone.
!!! Using a VPN is highly recommended. If you're not already using one, take the time to find one that suits you and get it running.
!!! If you don't normally buy Amazon Gift Cards, start doing so now, and just send them to yourself, or friends that will give you cash in return, etc. For my first trade, Amazon locked me out of my account for about 22 hours, while I was in the middle of an exchange. All because I had never purchased an Amazon Gift Card before. It was quite nerve wracking. My second trade was for $300, and although my Amazon account wasn't shut down, that order had a status of "Sending" for about 22 hours, due to the large amount. In each of these cases I had multiple phone calls with their customer support, all of whom gave me false expectations. Had I already been sending gift cards to the anonymous email address that I created in the steps below, and maybe other anonymous email addresses that I could make, then I might not have been stalled so much.
-
Install Tor Browser for your OS. The RoboSats.com website issues a warning if you are not using Tor Browser. If you don't know what Tor is, I won't explain it all here, but trust me, it's cool and helps keep you anonymous. If you use Firefox, the interface will look very familiar to you.
-
Create a KYC-free e-mail address. I used tutanota.com in Firefox, as it would not allow me to create an account using Tor Browser. After the account was created, using Tor Browser to login, check emails, etc. has been working perfectly. Tutanota requires a 48 hour (or less) waiting period to prevent bots from using their system. You'll be able to login, and even draft an email, but you won't be able to send. After you've been approved, you should be able to login and send an email to your new address. It should show up in your Inbox almost instantly if it's working.
-
Have, or create, at least one Lightning wallet that is compatible with RoboSats.com and has no KYC Bitcoin in it. The RoboSats website has a compatibility chart available to find the best wallet for you. During an exchange on RoboSats, you will need to put up an escrow payment, or bond, in Satoshis. This amount is usually 3% of the total amount being exchanged. If the exchange is successful, the bond payment is canceled, leaving that amount in your wallet untouched, and with no record of it having been used as escrow. If you don't hold up your end of the trade, the bond amount will be transfered from your wallet. I created a wallet, using my new email address, with the Alby extension in the Tor Browser. This anonymous wallet was empty, so I used a separate wallet for the bond payment of my first trade. This wallet had KYC Bitcoin, but since it is being used for a bond payment, and no transaction will be recorded if everything goes okay, I don't mind taking the minuscule risk. After the first trade, I don't need to use the "KYC wallet", and I will use only my anonymous Lightning wallet for transactions related to performing a trade.
-
Create a new Robot Token by going to RoboSats using the Tor Browser. Copy the Token (Robot ID) to a text file as a temporary backup. It is recommended to create a new robot-token for every session of exchanges you make.
-
Select "Offers" to browse what others are presenting. "Create" is for when you want to create an offer of your own. You may need to create your own offer if none of the existing offers match your criteria.
-
Select "Buy" at the top of the page.
-
Select your currency (USD).
-
Select your payment methods by typing "amazon" and selecting (Amazon Gift Card). Repeat this process and select (Amazon USA Gift Card).
-
Determine Priorities - If you prefer to trade quickly, and don't care as much about premiums, look for users with a green dot on the upper-right of their robot icon. If you're not in a hurry, sort users by premium and select the best deal, even if they are inactive. They may become active once they are notified that their offer has activity from you.
-
The Definition of Price = the price with the premium added, but not the bond
-
A. Find A Compatible Offer - Select the row of the desired offer and enter the amount you would like to buy. i.e. $100 If you do not find a compatible offer, you will have to create your own offer.
B. **Create An Offer** - First, take a look at "Sell" offers for your same currency and payment method(s) that you will be using. Take note of the premium those buyers are willing to pay. If your premium is drastically less than theirs, your offer may get ignored. Select "Create" at the bottom of the screen. There is a slider at the top of the screen, select it to see all the options. Select "Buy". Enter the minimum and maximum amount that you wish to spend. Type "amazon" to select the methods that you would like to use (Amazon Gift Card, Amazon USA Gift Card). For "Premium Over Market", enter an amount that is competitive with premiums you saw at the start of this step and do not use the % sign! You can adjust the duration, timer, and bond amount, but I leave those at their default settings. Select the "Create Order" button, and follow the instructions for making a bond payment. -
Pay the Bond - Copy the invoice that is presented. From your wallet that contains bond funds, select "Send", and paste the invoice as the recipient. This money will never leave your account if the exchange completes without issue. No transaction will be recorded. If there is a complication with the exchange, it is possible that this transaction will complete.
-
Create and Submit Your Invoice for Their Bitcoin Payment To You - Select "Lightning", if not selected by default.* Select the Copy Icon to copy the correct amount of Satoshis. This amount already has the premium deducted. From your anonymous Lightning Wallet, select "Receive", and paste the Satoshi amount. If you enter a description, it's probably best to keep it cryptic. Copy the invoice and paste it into RoboSats; then select "Submit".
* If you plan on "mixing" your Bitcoin after purchase, it may be better to select "On Chain" and pay the necessary fees swap and mining fees. In the example this comes from, Sparrow wallet is used and has whirlpool ability in its interface.
-
Connect With Seller and Send Funds - Greet the seller in the chat window. The seller has now provided RoboSats with the Bitcoin to transfer to you. Your move is to buy an Amazon eGift Card for the amount of the trade. Log in to your Amazon account and start the process of buying an eGift card. For delivery there is the option of email or txt message. Ask the seller what their preference is, and get their address, or phone number, to enter into Amazon's form. Complete the purchase process on Amazon, and check the status of your order. Once you see the status of "Sent", go back to RoboSats in your Tor Browser.
-
Confirm Your Payment - Select the "Confirm ___ USD Sent" button and notify the seller to check their e-mail/txt messages.
-
Seller Confirmation - Once the seller select their "Confirm" button, the trade will immediately end with a confirmation screen.
-
Verify - If you check the anonymous wallet, the new amount should be presented.
-
-
@ 8e351a6d:770975b7
2025-04-30 04:25:08
Com o avanço da tecnologia, plataformas de jogos online vêm se destacando como uma das formas mais populares de entretenimento digital. Entre as que mais crescem no cenário brasileiro, a Pix188 se destaca por oferecer uma experiência completa, moderna e segura para jogadores de todos os perfis. Neste artigo, você vai conhecer melhor essa plataforma, os principais jogos disponíveis e o que torna a experiência do usuário tão especial.
A pix188é uma plataforma de entretenimento online desenvolvida para proporcionar aos usuários uma navegação simples, rápida e intuitiva. Desde o primeiro acesso, o site já demonstra seu compromisso com a qualidade: design responsivo, interface organizada e opções fáceis de localizar fazem parte da proposta.
O grande diferencial está na praticidade oferecida aos brasileiros. A plataforma é totalmente adaptada para o público nacional, com suporte em português, atendimento via chat ao vivo e integração com o sistema de pagamento via Pix, o que torna depósitos e saques rápidos, práticos e sem burocracia.
Variedade de Jogos para Todos os Gostos Um dos pontos fortes da Pix188 é a sua ampla seleção de jogos. A plataforma abriga os títulos mais populares e inovadores do mercado, com gráficos de alta qualidade, efeitos sonoros envolventes e temáticas variadas. Entre as categorias de jogos mais procuradas, destacam-se:
Slots Online: Os famosos caça-níqueis modernos aparecem com diversas opções temáticas, desde aventuras em templos perdidos até jogos inspirados em cultura pop. A mecânica simples e a possibilidade de grandes prêmios atraem tanto novatos quanto veteranos.
Jogos ao Vivo: A Pix188 também disponibiliza jogos interativos com apresentadores reais, transmitidos em tempo real. Essa modalidade proporciona uma experiência ainda mais imersiva, aproximando o jogador da emoção do ambiente físico.
Jogos de Mesa Virtuais: Para os que preferem estratégias e tomadas de decisão, a plataforma oferece clássicos como roleta, blackjack e bacará, todos em versões digitais com design sofisticado e fluidez impecável.
Apostas Esportivas: Além dos jogos eletrônicos, Pix188 também é referência para os fãs de esportes, oferecendo uma plataforma completa de palpites em tempo real. Futebol, basquete, tênis e outras modalidades estão disponíveis com cotações competitivas.
A Experiência do Jogador em Foco A Pix188 entende que o sucesso de uma plataforma depende da satisfação do usuário. Por isso, além da variedade de jogos, ela investe pesado em segurança, suporte ao cliente e recompensas para os jogadores. O sistema de bônus é outro atrativo: usuários ativos são constantemente surpreendidos com promoções, giros grátis e outras vantagens.
O suporte ao cliente é outro ponto que merece destaque. A equipe de atendimento está disponível 24 horas por dia, todos os dias da semana, para tirar dúvidas, auxiliar em transações e garantir que nenhum jogador fique desamparado. O canal via WhatsApp também agiliza o contato e proporciona ainda mais conveniência.
Conclusão A Pix188 chega ao mercado como uma alternativa moderna, segura e empolgante para quem busca entretenimento online de qualidade. Com uma plataforma robusta, jogos variados e uma experiência centrada no usuário, ela rapidamente conquistou seu espaço entre as favoritas do público brasileiro. Seja para momentos de lazer ou para quem gosta de adrenalina, a Pix188 é uma escolha que vale a pena explorar.
-
@ fd06f542:8d6d54cd
2025-04-30 03:49:30
今天介绍一个 long-form 项目,源代码在:
https://github.com/dhalsim/nostr-static
从项目的介绍看也是为了展示kind 30023 long-form的。
Demo
https://blog.nostrize.me
界面还可以:
 {.user-img}
{.user-img}- 支持多个tags
- 支持评论
下面看他自己的介绍:
nostr-static是一个开源项目,其主要目的是将 Nostr 网络上的长文内容转化为静态博客。下面从多个方面对该项目进行分析:1. 项目概述
nostr-static是一个静态网站生成器(SSG)工具,它可以从 Nostr 网络中获取长文内容,并生成可在任何地方托管的 HTML 页面。这使得用户能够轻松地创建和维护由 Nostr 内容驱动的博客,同时结合了去中心化内容和传统网站托管的优点。2. 功能特性
- 内容转换:能够将 Nostr 上的长文内容转化为美观的静态博客页面,博客加载速度快。
- 去中心化与传统结合:文章存储在 Nostr 网络上,保证了内容的去中心化,同时为读者提供了熟悉的博客界面。
- 易于维护:通过简单的配置和自动更新功能,降低了博客的维护成本。
- 灵活的托管方式:支持多种静态网站托管服务,如 Netlify、Vercel、Cloudflare Pages、Amazon S3 以及传统的 Web 托管服务。
- 社交互动:可以利用 Nostr 进行评论等社交互动。
3. 技术实现
- 前端:从代码片段可以看出,项目使用了 HTML 和 CSS 来构建页面布局和样式,同时支持明暗两种主题模式。页面包含文章卡片、标签、作者信息等常见博客元素。
- 后端:项目使用 Go 语言编写,通过
go build -o nostr-static ./src && ./nostr-static命令进行构建和运行。 - 数据获取:从 Nostr 网络中获取文章内容,需要提供 Nostr naddr 信息。
4. 使用步骤
根据
README.md文件,使用该项目的步骤如下: 1. Fork 项目仓库。 2. 将项目克隆到本地或使用 GitHub Codespaces。 3. 修改config.yaml文件进行配置。 4. 在articles列表中添加要展示的 Nostr naddr。 5. 将logo.png文件放入项目文件夹(如果文件名不同,需要在config.yaml中更新)。 6. 构建并运行项目。 7. 提交并推送更改。5. 项目优势
- 创新性:结合了 Nostr 的去中心化特性和传统博客的易用性,为博主提供了一种新的博客创建方式。
- 简单易用:通过简单的配置和命令即可完成博客的创建和部署,降低了技术门槛。
- 社区支持:开源项目可以吸引更多开发者参与贡献,不断完善功能和修复问题。
nostr-static是一个有创新性和潜力的项目,为 Nostr 用户提供了一种将长文内容转化为传统博客的有效方式。随着项目的不断发展和完善,有望在博客领域获得更多的关注和应用。 -
@ 502ab02a:a2860397
2025-04-30 02:51:33
50by40 คืออีกโครงการนึงที่ขยายภาพรวมขึ้นมาอีก recap กันครับ (ใครที่มาเจอกลางทาง อาจต้องย้อนเยอะครับ ย้อนไปสัก ปลายเดือน มีนาคม 2025) หลังจากที่เราได้ดูส่วนเล็กกันมาหลายตอน ตั้งแต่เรื่องเล็กๆอย่าง น้ำมันมะกอกปลอม ซึ่งตอนนั้นหลายคนที่อ่านอาจคิดว่า ไกลตัวส่วนใหญ่ยังดีพอ แต่ความนัยที่ซ่อนไว้ในบทนั้นคือ จุดเริ่มของการทำลายความเชื่อใจในอาหาร , ที่มาของบรอกโคลีเพื่อให้รู้ว่า สิ่งที่คิดว่าธรรมชาติ มันไม่ธรรมชาติ, นมโอ้ต นมประดิษฐ์ที่เป็นจุดที่เราคิดว่ามันคือการพลิกวงการแล้ว, การแอบจดสิทธิบัตรเมล็ดพันธุ์ที่เคยปลูกกินอย่างอิสระ, การพัฒนา GMO 2.0 ที่ไม่ต้องเรียกว่า GMO, โปรตีนจากแลป มาจนถึงเวย์ที่ไม่มีวัว แล้วเราก็ขยายภาพขึ้นกับข้อกำหนดการควบคุมการปลูกพืช UPOV1991/CPTPP, การเข้าสู่โรงเรียน, การกำเนิดของ ProVeg แล้วเราก็ได้รู้จักกับ Sebastian Joy ก็ถือว่าเดินทางมา 1 ด่านแล้วครับ หนทางเรื่องนี้ยังอีกยาวไกล วันนี้เราก็มาคุยกันถึงเรื่อง
โครงการ 50by40
โครงการนี้เริ่มต้นขึ้นในเดือนเมษายน ปี 2018 โดยมีการจัดการประชุม "50by40 Corporate Outreach Summit" ระหว่างวันที่ 27–29 เมษายน 2018 ที่กรุงเบอร์ลิน ประเทศเยอรมนี ซึ่งจัดโดย ProVeg International ร่วมกับ Humane Society of the United States การประชุมนี้ถือเป็นจุดเริ่มต้นของพันธมิตรระดับโลกที่มีเป้าหมายร่วมกันในการลดการผลิตและบริโภคผลิตภัณฑ์จากสัตว์ลง 50% ภายในปี 2040
Sebastian Joy ผู้ก่อตั้งและประธานของ ProVeg International มีบทบาทสำคัญในการริเริ่มโครงการ 50by40 โดยเขาได้ช่วยก่อตั้งพันธมิตรนี้เพื่อส่งเสริมการเปลี่ยนแปลงระบบอาหารโลก นอกจากนี้ ProVeg International ยังมีบทบาทในการสนับสนุนองค์กรและสตาร์ทอัพที่มุ่งเน้นการเปลี่ยนแปลงระบบอาหารผ่านโปรแกรมต่างๆ
แม้ว่าโครงการ 50by40 จะประกาศเป้าหมายในการลดการบริโภคผลิตภัณฑ์จากสัตว์เพื่อสุขภาพและสิ่งแวดล้อม แต่เบื้องหลังยังมีการดำเนินงานที่มุ่งเน้นการเปลี่ยนแปลงระบบอาหารโลก โดยการส่งเสริม "อาหารที่เพาะเลี้ยงในห้องปฏิบัติการเป็นหลัก"
โครงการนี้ยังมีการจัดกิจกรรมเพื่อดึงดูดนักลงทุนและผู้สนับสนุนทางการเงิน เช่น การจัดงาน Food Funders Circle ซึ่งเป็นเวทีสำหรับนักลงทุนที่สนใจในอาหารทางเลือก นอกจากนี้ โครงการ 50by40 ยังมีความสัมพันธ์กับองค์กรต่างๆ ทั้งภาครัฐและเอกชน รวมถึงองค์กรระดับนานาชาติ เช่น Greenpeace, WWF และ Compassion in World Farming ซึ่งมีเป้าหมายร่วมกันในการลดการบริโภคผลิตภัณฑ์จากสัตว์ และ ProVeg International เองก็มีสถานะเป็นผู้สังเกตการณ์ถาวรในองค์การสหประชาชาติ เช่น UNFCCC, IPCC และ CBD รวมถึงมีสถานะที่ปรึกษาพิเศษกับ ECOSOC และได้รับการรับรองจาก UNEA อีกด้วย ถ้ามองแค่เนทเวิร์คเบื้องต้นแล้ว วินาทีนี้ ตอบได้เลยครับว่า "อาหารที่เพาะเลี้ยงในห้องปฏิบัติการเป็นหลัก" มาแน่นอนครับ มองข้ามความ plant based / animal based ได้เลย
เพื่อบรรลุเป้าหมายนี้ โครงการได้ดำเนินกิจกรรมต่างๆ ทั้งในระดับโรงเรียนและการผลักดันนโยบายสาธารณะ ผมจะลองแบ่งเป็นข้อๆให้เพื่อความสะดวกในการมองภาพรวมประมาณนี้นะครับ
การดำเนินงานในโรงเรียนและเยาวชน 1. Early Action Network โครงการนี้เป็นความร่วมมือระหว่าง 50by40, ProVeg International และ Educated Choices Program โดยมีเป้าหมายในการส่งเสริมการบริโภคอาหารจากพืชในกลุ่มเด็กและเยาวชนผ่านกิจกรรมต่างๆ เช่น การจัดกิจกรรมเชิงโต้ตอบเกี่ยวกับสุขภาพ สิ่งแวดล้อม และสวัสดิภาพสัตว์, การจัดแคมเปญในโรงเรียนและชุมชน, การเผยแพร่สื่อการเรียนรู้และโปรแกรมฝึกอบรม, การปรับปรุงเมนูอาหารในโรงเรียนให้มีทางเลือกจากพืชมากขึ้น
โครงการนี้มุ่งหวังที่จะสร้างความตระหนักรู้และเปลี่ยนแปลงพฤติกรรมการบริโภคของเยาวชนตั้งแต่เนิ่นๆ เพื่อส่งเสริมการบริโภคอาหารที่ยั่งยืนและเป็นมิตรกับสิ่งแวดล้อม
- School Plates Programme ProVeg International ได้เปิดตัวโครงการ School Plates ในสหราชอาณาจักรเมื่อปี 2018 โดยมีเป้าหมายในการปรับปรุงเมนูอาหารในโรงเรียนให้มีความหลากหลายและสุขภาพดีขึ้นผ่านการเพิ่มทางเลือกอาหารจากพืช โครงการนี้ได้ร่วมมือกับโรงเรียน หน่วยงานท้องถิ่น และบริษัทจัดเลี้ยง เพื่อเปลี่ยนแปลงเมนูอาหารในโรงเรียนกว่า 3.1 ล้านมื้อจากอาหารที่มีเนื้อสัตว์เป็นหลักไปเป็นอาหารจากพืช
สำหรับในส่วนของการผลักดันนโยบายสาธารณะและการมีส่วนร่วมในเวทีนานาชาตินั้น ก็มีไม่น้อยครับ อาทิเช่น การมีส่วนร่วมในองค์การสหประชาชาติ ProVeg International มีสถานะเป็นผู้สังเกตการณ์ถาวรในองค์การสหประชาชาติ เช่น UNFCCC และ UNEP และได้มีบทบาทในการผลักดันให้มีการรวมประเด็นเกี่ยวกับอาหารจากพืชในการเจรจาด้านสภาพภูมิอากาศ โดยในปี 2022 ProVeg ได้เข้าร่วมการประชุมสภาพภูมิอากาศของสหประชาชาติในสตอกโฮล์มและบอนน์ เพื่อส่งเสริมแนวคิด "Diet Change Not Climate Change" และเรียกร้องให้มีการเปลี่ยนแปลงระบบอาหารสู่การบริโภคอาหารจากพืชมากขึ้น
การสนับสนุนเยาวชนในเวทีนานาชาติ ProVeg ได้จัดตั้ง Youth Board ซึ่งประกอบด้วยเยาวชนจากทั่วโลก เพื่อมีส่วนร่วมในการผลักดันนโยบายด้านอาหารจากพืชในเวทีสหประชาชาติ และเตรียมความพร้อมสำหรับการประชุม COP30 ที่จะจัดขึ้นในเบเลง ประเทศบราซิล
นอกจากนี้ยังมีการสนับสนุนองค์กรและสตาร์ทอัพที่มุ่งเปลี่ยนแปลงระบบอาหารอีกมากมาย โดยที่โดดเด่นเป็นพิเศษคือ โปรแกรม Kickstarting for Good ProVeg International ได้เปิดตัวโปรแกรม Kickstarting for Good ซึ่งเป็นโปรแกรมบ่มเพาะและเร่งการเติบโตสำหรับองค์กรไม่แสวงหาผลกำไร โครงการที่มีผลกระทบ และสตาร์ทอัพทางสังคมที่มุ่งเปลี่ยนแปลงระบบอาหาร โปรแกรมนี้มีระยะเวลา 8 สัปดาห์ โดยมีการฝึกอบรมแบบเข้มข้น การให้คำปรึกษาจากผู้เชี่ยวชาญ และโอกาสในการสร้างเครือข่าย เพื่อสนับสนุนการพัฒนาโครงการที่มีศักยภาพในการลดการบริโภคผลิตภัณฑ์จากสัตว์และส่งเสริมอาหารจากพืช
นอกจาก Sebastian Joy จะเริ่มต้นโครงการต่างๆมากมายไม่ว่าจะ ProVeg International, ProVeg Incubator, Kickstarting for Good แต่ก็ยังมี องค์กรพันธมิตรในเครือข่าย 50by40 ที่หลากหลาย เช่น Plant Powered Metro New York, Public Justice, Rainforest Alliance, Real Food Systems, Reducetarian Foundation, Rethink Your Food, SEED และ Seeding Sovereignty ซึ่งร่วมกันส่งเสริมการบริโภคอาหารจากพืชและการลดการบริโภคผลิตภัณฑ์จากสัตว์ แม้ว่าโครงการ 50by40 จะได้รับการสนับสนุนจากองค์กรต่างๆ อย่างกว้างขวาง แต่ยังไม่มีข้อมูลที่ชัดเจนเกี่ยวกับบริษัทเอกชนรายใดที่แสดงการสนับสนุนโครงการนี้อย่างเปิดเผยครับ
ทีนี้เรามาดูความเคลื่อนไหวของลูกพี่ใหญ่อย่าง USDA กันบ้างนะครับ จากการตรวจสอบข้อมูลที่มีอยู่จนถึงปัจจุบัน ยังไม่พบหลักฐานชัดเจนว่า กระทรวงเกษตรสหรัฐฯ (USDA) มีการสนับสนุนโครงการ 50by40 อย่างเป็นทางการหรือเปิดเผย อย่างไรก็ตาม มีความเคลื่อนไหวที่เกี่ยวข้องกับการส่งเสริมโปรตีนทางเลือกและการลดการบริโภคเนื้อสัตว์ในระดับนโยบายของสหรัฐฯ ซึ่งอาจสอดคล้องกับเป้าหมายของโครงการ 50by40 อยู่เช่นกันครับ
ในปี 2021 คณะกรรมาธิการด้านการเกษตรของสภาผู้แทนราษฎรสหรัฐฯ ได้สนับสนุนให้ USDA จัดสรรงบประมาณ 50 ล้านดอลลาร์สหรัฐฯ ผ่านโครงการ Agriculture and Food Research Initiative (AFRI) เพื่อสนับสนุนการวิจัยเกี่ยวกับโปรตีนทางเลือก เช่น การใช้พืช การเพาะเลี้ยงเซลล์ และการหมัก เพื่อพัฒนาอาหารที่มีคุณสมบัติคล้ายเนื้อสัตว์
นอกจากนี้ USDA ได้ยอมรับคำว่า "cell-cultured" เป็นคำที่ใช้เรียกเนื้อสัตว์ที่ผลิตจากการเพาะเลี้ยงเซลล์ในห้องปฏิบัติการ ซึ่งเป็นส่วนหนึ่งของการกำหนดมาตรฐานและการควบคุมผลิตภัณฑ์อาหารใหม่ๆ ที่เกี่ยวข้องกับโปรตีนทางเลือก
แล้วกลุ่มองค์กรด้านสิ่งแวดล้อมและสุขภาพ เช่น Center for Biological Diversity ได้ส่งจดหมายถึงรัฐมนตรีกระทรวงเกษตรสหรัฐฯ เรียกร้องให้ USDA นำประเด็นการลดการบริโภคเนื้อสัตว์และผลิตภัณฑ์นมมาเป็นส่วนหนึ่งของยุทธศาสตร์ด้านสภาพภูมิอากาศ และปรับปรุงแนวทางโภชนาการแห่งชาติให้สอดคล้องกับเป้าหมาย "ด้านความยั่งยืน"
แม้ว่า USDA จะไม่ได้แสดงการสนับสนุนโครงการ 50by40 โดยตรง แต่มีความร่วมมือกับองค์กรที่มีเป้าหมายคล้ายคลึงกัน เช่น ProVeg International และ The Good Food Institute ซึ่งเป็นพันธมิตรในเครือข่ายของ 50by40 โดยมีเป้าหมายในการส่งเสริมการบริโภคอาหารจากการเพาะเลี้ยงเซลล์ในห้องปฏิบัติการและโปรตีนทางเลือก
อนาคตได้มีการขีด Goal ไว้ประมาณนี้ เรายังคิดว่าการที่ "แค่ไม่กินมัน" "ก็แค่เลือกกินอาหารธรรมชาติ" จะยังเป็นคำพูดที่เราพูดได้อีกไหม สิ่งนี้ก็ยังเป็นคำถามต่อไปครับ คงไม่มีใครสามารถตอบได้ใน วันนี้ (มั๊ง)
แต่ที่แน่ๆ มีคนไม่น้อยแล้วแหละครับ ที่บอกว่าอาหารจากแลปคุมในโรงงานที่สะอาด มันก็ดีนี่ สะอาดปลอดภัย ดีกว่าเนื้อหมูที่ผัดข้างทาง ล้างหรือเปล่าก็ไม่รู้ เอาหมูแบบไหนมาก็ไม่รู้
มันดูเหมือนว่าเป็นการเปรียบเปรยแบบตรรกะวิบัตินะครับ แต่รอบตัวคุณ มีคนคิดแบบนี้เยอะไหม? เป็นคำถามที่ไม่มีคำตอบอีกเช่นกันครับ
#pirateketo #กูต้องรู้มั๊ย #ม้วนหางสิลูก #siamstr
-
@ c1e6505c:02b3157e
2025-04-30 02:50:55
Photography, to me, is a game - a game of snatching absurd, beautiful, fleeting moments from life. Anything staged or overly polished falls into what Garry Winogrand nails as “illustration work.” I’m with him on that. Photography is about staying awake to the world, to the “physical reality” or circumstances we’re steeped in, and burning that light onto film emulsion (or pixels now), locking a moment into matter forever. It’s not like painting, where brushstrokes mimic what’s seen, felt, or imagined. Photography captures photons - light itself - and turns it into something tangible. The camera, honestly, doesn’t get enough credit for being such a wild invention.
Lately, I’ve been chewing on what to do with a batch of new photos I’ve shot over the past month, which includes photographs from a film project, a trip to Manhattan and photos of David Byrne (more on that in another post). Maybe it's another photo-zine that I should make. It’s been a minute since my last one, Hiding in Hudson (https://www.youtube.com/watch?v=O7_t0OldrTk&t=339s). Putting out printed work like zines or books is killer practice — it forces you to sharpen your compositions, your vision, your whole deal as a photographer. Proof of work, you know?
This leads to a question: anyone out there down to help or collab on printing a photo-zine? I’d love to keep it DIY, steering clear of big companies.
In the spirit of getting back into a rhythm of daily shooting, here are a few recent shots from the past few days. Just wandering aimlessly around my neighborhood — bike rides, grocery runs, wherever I end up.
Camera used: Leica M262
Edited with: Lightroom + Dehancer Film
*Support my work and the funding for my new zine by sending a few sats: colincz@getalby.com *






-
@ d1e87ba1:6adce0f2
2025-04-30 02:48:32
K68 là một nền tảng giải trí trực tuyến mới mẻ, được phát triển để mang lại những trải nghiệm thú vị và đa dạng cho người dùng. Với giao diện thân thiện và dễ sử dụng, K68 không chỉ là nơi giải trí mà còn là không gian kết nối, giao lưu giữa những người có cùng sở thích và đam mê. Nền tảng này cung cấp nhiều dịch vụ giải trí hấp dẫn, từ các trò chơi trực tuyến, chương trình truyền hình cho đến các sự kiện trực tiếp. K68 được tối ưu hóa cho cả điện thoại di động và máy tính, cho phép người dùng truy cập mọi lúc, mọi nơi một cách dễ dàng. Điều đặc biệt ở K68 là sự chú trọng đến tính năng cá nhân hóa, giúp người dùng có thể tùy chỉnh giao diện và các dịch vụ phù hợp với sở thích cá nhân. Điều này không chỉ mang lại sự tiện lợi mà còn giúp người dùng cảm thấy thoải mái và hài lòng khi tham gia vào nền tảng này.
K68 cũng đặc biệt chú trọng đến việc xây dựng một cộng đồng giải trí trực tuyến mạnh mẽ và gắn kết. Các tính năng tương tác, như trò chuyện trực tuyến, tạo nhóm thảo luận, tham gia sự kiện trực tuyến đều được tích hợp để giúp người dùng dễ dàng kết nối và chia sẻ với nhau. Nền tảng này không chỉ là nơi để giải trí mà còn là không gian để người dùng thể hiện bản thân và giao lưu với những người có cùng sở thích. Các chương trình và sự kiện được tổ chức thường xuyên không chỉ mang đến cơ hội giải trí mà còn tạo ra những sân chơi thú vị cho cộng đồng. Đặc biệt, K68 cũng chú trọng đến việc cung cấp các trò chơi sáng tạo và thú vị, giúp người chơi giải trí một cách thư giãn nhưng cũng không kém phần hấp dẫn. Điều này giúp K68 tạo nên một cộng đồng năng động, nơi mà người dùng không chỉ tìm thấy sự giải trí mà còn có thể học hỏi, giao lưu và kết nối.
Một yếu tố quan trọng khác khiến K68 trở thành nền tảng được yêu thích là tính năng bảo mật vượt trội. Nền tảng này sử dụng công nghệ bảo mật tiên tiến để bảo vệ thông tin người dùng, đảm bảo rằng mọi dữ liệu cá nhân đều được mã hóa và lưu trữ an toàn. Người dùng có thể hoàn toàn yên tâm khi tham gia các hoạt động trên K68, vì nền tảng này luôn nỗ lực đảm bảo bảo mật và quyền riêng tư tuyệt đối. K68 cũng đặc biệt chú trọng đến việc bảo vệ quyền lợi của người dùng và đảm bảo rằng mọi giao dịch, thông tin cá nhân đều được xử lý một cách cẩn thận. Bên cạnh đó, tính năng cá nhân hóa của K68 cho phép người dùng dễ dàng tùy chỉnh các dịch vụ và giao diện, giúp mỗi người dùng có thể tận hưởng trải nghiệm giải trí theo cách riêng của mình. Với cam kết bảo mật, tính năng sáng tạo không ngừng và một cộng đồng giải trí sôi động, K68 đang dần khẳng định vị thế của mình là một trong những nền tảng giải trí trực tuyến hàng đầu, được người dùng yêu thích và tin tưởng.
-
@ d1e87ba1:6adce0f2
2025-04-30 02:46:54
ZINGME là một nền tảng giải trí trực tuyến nổi bật, thu hút sự quan tâm của đông đảo người dùng nhờ vào những tính năng vượt trội và giao diện dễ sử dụng. Được phát triển để mang đến không gian giải trí phong phú và sáng tạo, ZINGME cung cấp một loạt các dịch vụ giải trí hấp dẫn, từ âm nhạc, video cho đến các chương trình trực tuyến và trò chơi. ZINGME không chỉ đơn thuần là một công cụ giải trí mà còn là nơi giúp người dùng kết nối, chia sẻ và thể hiện bản thân. Với thiết kế giao diện tối ưu, nền tảng này mang lại trải nghiệm mượt mà và không gặp phải bất kỳ khó khăn nào, cho phép người dùng dễ dàng truy cập và tận hưởng những nội dung yêu thích. Dù bạn đang sử dụng máy tính hay điện thoại thông minh, ZINGME đều mang đến một trải nghiệm trực tuyến tuyệt vời và tiện lợi, phù hợp với nhu cầu của mọi đối tượng người dùng.
Bên cạnh những tính năng giải trí đa dạng, ZINGME đặc biệt chú trọng đến việc xây dựng một cộng đồng trực tuyến mạnh mẽ. Nền tảng này cung cấp cho người dùng nhiều công cụ tương tác, giúp họ kết nối và giao lưu với nhau. Các tính năng như trò chuyện trực tiếp, nhóm thảo luận, chia sẻ ý tưởng, và tham gia vào các sự kiện trực tuyến đều được tích hợp một cách thông minh và hiệu quả. ZINGME không chỉ tạo ra một không gian giải trí mà còn là nơi để người dùng xây dựng những mối quan hệ mới, kết nối với những người có cùng sở thích và đam mê. Các công cụ sáng tạo cũng được cung cấp đầy đủ để người dùng có thể tự do thể hiện bản thân qua việc tạo ra các nội dung như bài viết, video, hoặc tham gia các cuộc thi. Chính sự kết hợp giữa giải trí và tính năng xã hội này đã tạo ra một cộng đồng ZINGME sống động và luôn phát triển, nơi mà mọi người có thể chia sẻ, học hỏi và kết nối với nhau một cách tự nhiên.
Bảo mật và quyền riêng tư là một yếu tố quan trọng mà ZINGME luôn chú trọng. Với sự phát triển mạnh mẽ của công nghệ, nền tảng này đã đầu tư vào các biện pháp bảo mật tiên tiến để bảo vệ thông tin người dùng khỏi các nguy cơ từ thế giới mạng. Mọi dữ liệu cá nhân của người dùng đều được mã hóa và lưu trữ một cách an toàn, giúp người tham gia yên tâm khi sử dụng các dịch vụ của ZINGME. Nền tảng này cũng cung cấp các tính năng cá nhân hóa, giúp người dùng tùy chỉnh giao diện và các dịch vụ theo sở thích và nhu cầu riêng của mình. Điều này không chỉ mang lại một trải nghiệm giải trí thú vị mà còn giúp mỗi người dùng cảm thấy thoải mái và an toàn khi tham gia vào cộng đồng ZINGME. Với cam kết bảo vệ quyền riêng tư, sự sáng tạo không ngừng và cộng đồng tương tác mạnh mẽ, ZINGME đang từng bước khẳng định vị thế của mình là một trong những nền tảng giải trí trực tuyến hàng đầu tại Việt Nam.
-
@ 99895004:c239f905
2025-04-30 01:43:05
 Yes, FINALLY, we are extremely excited to announce support for nostr.build (blossom.band) on Primal! Decades in the making, billions of people have been waiting, and now it’s available! But it’s not just any integration, it is the next level of decentralized media hosting for Nostr. Let us explain.
Yes, FINALLY, we are extremely excited to announce support for nostr.build (blossom.band) on Primal! Decades in the making, billions of people have been waiting, and now it’s available! But it’s not just any integration, it is the next level of decentralized media hosting for Nostr. Let us explain. Primal is an advanced Twitter/X like client for Nostr and is probably the fastest up-and-coming, highly used Nostr app available for iOS, Android and the web. Nostr.build is a very popular media hosting service for Nostr that can be used standalone or integrated into many Nostr apps using nip-96. This is an extremely feature rich, tested and proven integration we recommend for most applications, but it’s never been available on Primal.
And then, Blossom was born, thank you Hzrd149! Blossom is a Nostr media hosting protocol that makes it extremely easy for Nostr clients to integrate a media host, and for users of Blossom media hosts (even an in-house build) to host on any Nostr client. Revolutionary, right! Use whatever host you want on any client you want, the flexible beauty of Nostr. But there is an additional feature to Blossom that is key, mirroring.
One of the biggest complaints to media hosting on Nostr is, if a media hosting service goes down, so does all of the media hosted on that service. No bueno, and defeats the whole decentralized idea behind Nostr.. This has always been a hard problem to solve until Blossom mirroring came along. Mirroring allows a single media upload to be hosted on multiple servers using its hash, or unique media identifier. This way, if a media host goes down, the media is still available and accessible on the other host.
So, we are not only announcing support of nostr.build’s blossom.band on the Primal app, we are also announcing the first known fully integrated implementation of mirroring with multiple media hosts on Nostr. Try it out for yourself! Go to the settings of your Primal web, iOS or Android app, choose ‘Media Servers’, enable ‘Media Mirrors’, and add https://blossom.band and https://blossom.primal.net as your Media server and Mirror, done!
Video here!
-
@ d1e87ba1:6adce0f2
2025-04-30 02:46:06
SUN789 là một nền tảng giải trí trực tuyến được thiết kế để mang đến cho người dùng những trải nghiệm đa dạng và đầy thú vị. Với giao diện dễ sử dụng, nền tảng này cho phép người dùng tiếp cận các dịch vụ giải trí, trò chơi và chương trình yêu thích một cách dễ dàng. SUN789 không chỉ chú trọng vào việc phát triển các tính năng giải trí mà còn đặc biệt quan tâm đến việc xây dựng một hệ sinh thái liên kết mạnh mẽ, nơi người dùng có thể kết nối, chia sẻ và tương tác với nhau. Giao diện của SUN789 được tối ưu hóa cho cả thiết bị di động và máy tính, giúp người dùng dễ dàng truy cập và sử dụng bất kể thời gian hay địa điểm. Không chỉ vậy, SUN789 còn liên tục cập nhật và cải tiến các tính năng để đáp ứng nhu cầu ngày càng cao của người dùng. Điều này không chỉ mang lại sự tiện lợi mà còn giúp nền tảng duy trì sự cạnh tranh trong một thị trường giải trí trực tuyến đầy tiềm năng.
Một trong những điểm nổi bật của SUN789 chính là sự đa dạng trong các lựa chọn giải trí mà nền tảng này cung cấp. Từ các chương trình âm nhạc, phim ảnh, thể thao đến những trò chơi hấp dẫn, SUN789 luôn nỗ lực để đáp ứng nhu cầu giải trí của tất cả người dùng. Các chương trình phát trực tuyến liên tục được cập nhật với nội dung mới mẻ và đa dạng, đảm bảo mang đến những giây phút thư giãn tuyệt vời cho người dùng. Đặc biệt, các trò chơi giải trí trên nền tảng này luôn được cải tiến về mặt đồ họa và tính năng, giúp người chơi có thể trải nghiệm những giây phút thư giãn thú vị. Hệ thống trò chơi của SUN789 không chỉ đơn giản là các trò chơi giải trí thông thường mà còn bao gồm những trò chơi chiến thuật, thể thao và các loại hình giải trí sáng tạo khác. Nền tảng này cũng thường xuyên tổ chức các sự kiện, cuộc thi để người dùng có thể tham gia và nhận được nhiều phần thưởng hấp dẫn, tạo thêm động lực cho người tham gia.
SUN789 đặc biệt chú trọng đến vấn đề bảo mật và quyền riêng tư của người dùng, đảm bảo một không gian giải trí an toàn và tin cậy. Với công nghệ bảo mật tiên tiến, nền tảng này cam kết bảo vệ thông tin cá nhân và giao dịch của người dùng khỏi các mối nguy hại từ không gian mạng. Mọi thông tin cá nhân đều được mã hóa và bảo vệ nghiêm ngặt, giúp người dùng yên tâm khi tham gia vào các hoạt động trên nền tảng. Hệ thống bảo mật của SUN789 luôn được cập nhật để đối phó với các mối đe dọa mới, đảm bảo rằng thông tin người dùng luôn được bảo vệ tuyệt đối. Ngoài ra, nền tảng này cũng cung cấp các tính năng cá nhân hóa, cho phép người dùng tùy chỉnh giao diện và các dịch vụ theo sở thích cá nhân. Điều này giúp mỗi người dùng có được một trải nghiệm giải trí hoàn hảo, phù hợp với nhu cầu riêng của mình. Với những cam kết về bảo mật, tính năng đa dạng và dịch vụ chăm sóc khách hàng tận tình, SUN789 đang dần trở thành lựa chọn hàng đầu của người dùng trên thị trường giải trí trực tuyến hiện nay.
-
@ 4cebd4f5:0ac3ed15
2025-04-30 02:30:25
TỔNG QUAN HACKATHON
Hedera Hashathon: Nairobi Edition vừa khép lại với 223 developer tham gia và 49 dự án được phê duyệt. Tổ chức trực tuyến bởi Kenya Tech Events, Sở Giao dịch Chứng khoán Nairobi (NSE) và Phòng Tài sản Ảo (Virtual Assets Chamber), sự kiện hướng đến thúc đẩy đổi mới địa phương và gia tăng ứng dụng blockchain tại Kenya.
Hackathon tập trung vào 3 track chính: AI Agents (Trí tuệ nhân tạo), Capital Markets (Thị trường vốn) và Hedera Explorer. Các đội thi ứng dụng blockchain Hedera để giải quyết thách thức về tự động hóa, tiếp cận tài chính và tương tác tài sản số. Điểm nhấn là Demo Day tại Đại học Nairobi – nơi các dự án vào chung kết trình diễn giải pháp và nhận giải thưởng. Nhóm xuất sắc nhất (đặc biệt từ track Capital Markets) được hỗ trợ ươm tạo và mentorship để phát triển tiếp.
Với trọng tâm ứng dụng thực tiễn, sự kiện khẳng định tiềm năng biến đổi ngành công nghiệp Kenya của blockchain, thúc đẩy tiến bộ công nghệ và mở rộng thị trường.
CÁC DỰ ÁN ĐOẠT GIẢI
Giải Nhất
- Hedgehog: Giao thức cho vay trên chuỗi, sử dụng cổ phiếu sàn chứng khoán được token hóa trên Hedera làm tài sản thế chấp. Kết hợp tính minh bạch blockchain với thế chấp truyền thống, đảm bảo an toàn và phi tập trung.
Giải Nhì
- Orion: Đơn giản hóa giao dịch cổ phiếu NSE (Nairobi) bằng cách token hóa chúng trên Hedera. Tích hợp Mpesa (ví điện tử hàng đầu Kenya) để tối ưu quy trình giao dịch số.
Giải Ba
- NSEChainBridge: Nền tảng blockchain nâng cao giao dịch cổ phiếu NSE dưới dạng token số, cải thiện khả năng tiếp cận và thanh khoản thị trường.
Giải Tư
- HashGuard: Nền tảng bảo hiểm vi mô token hóa dành cho tài xế boda boda (xe máy chở khách), ứng dụng công nghệ Hedera Hashgraph. Cung cấp bảo hiểm giá rẻ, tức thì – không yêu cầu kiến thức blockchain.
Xem toàn bộ dự án tại Danh sách BUIDL.
THÔNG TIN VỀ ĐƠN VỊ TỔ CHỨC: HEDERA
Hedera – nền tảng sổ cái phân tán công khai, nổi tiếng nhờ tốc độ, bảo mật và khả năng mở rộng. Thuật toán đồng thuận hashgraph (biến thể của Proof of Stake) mang lại cách tiếp cận độc đáo để đạt đồng thuận phi tập trung. Hedera hoạt động đa ngành, hỗ trợ dự án tập trung vào minh bạch và hiệu quả. Tổ chức cam kết phát triển cơ sở hạ tầng mạng lưới phi tập trung, thúc đẩy giao dịch số an toàn toàn cầu.
-
@ 0e67f053:cb1d4b93
2025-04-30 02:27:03
How to Be an Anti-Fascist
According to Me, a Certified Organic Latte-Drinking Empathy Warrior
By Tucker Carlson’s Emotionally Available Clone Carl Tuckerson
Namaste, comrades.
Are you tired of watching democracy get mildly inconvenienced by billionaires while sipping your ethically sourced, $19 oat milk flat white? Do you sometimes feel like tweeting just isn’t enough to stop the slow, fascist creep of boomers with opinions?
Well, worry not. Because tonight, I, a glowing beacon of progressive perfection, will guide you through the sacred, carbon-neutral art of being an Anti-Fascist—from the comfort of your iPad, handcrafted from rare earth minerals mined by literal children.
Let’s begin.
Step 1: Declare Yourself Anti-Fascist... On Instagram.
Nothing says “resistance” quite like a filtered selfie captioned “Punching Nazis with love 💕✊ #Resist #SelfCareRevolution”. Bonus points if you’re wearing a Che Guevara shirt made in a sweatshop. Because nothing defeats authoritarianism like aesthetics.
Remember: optics over action. Always.
Step 2: Elon Musk Is Literally Hitler (Until He Makes a Space Weed Dispensary)
We used to love Elon. He was our quirky space daddy. He tweeted in lowercase. He smoked weed with Joe Rogan. He wore weird shoes. We loved that. Then he bought Twitter and suddenly—BOOM—he’s literally Benito Mussolini with better branding.
But hey, let’s be honest: if he announced a carbon-neutral Neuralink that dispenses vegan Adderall, we’d be back on the bandwagon so fast. We are morally opposed to fascism... unless it syncs with our Apple Watches.
Step 3: Donald Trump Is an Existential Threat (Also... Kinda Fun to Keep Around)
Yes, Trump is a threat to democracy. Yes, he incited an insurrection. Yes, he talks like a Big Mac with a head injury. But if we actually stopped him? What would we tweet about?
He’s the villain we love to hate. He’s like Voldemort, if Voldemort ran on cheeseburgers and late-stage narcissism. He’s our algorithmic muse. He’s content.
Let’s not pretend we didn’t low-key enjoy four years of outrage-fueled identity formation. He gave us purpose. He gave us merch. Admit it—you miss him a little. That’s not anti-fascism, babe. That’s codependence.
Step 4: Say “Fascism” a Lot. Define It? Not So Much.
When in doubt, call literally anything “fascism.” Voter ID laws? Fascism. Gas stoves? Fascism. Someone didn’t like your TikTok about polyamorous Marxism? Fascism.
Defining the word would ruin the fun. It’s like “vibes,” but with historical trauma. Why read a book when you can just compare everything to Hitler and get 12,000 retweets?
Remember: if you say “fascism” enough times, you don’t have to actually do anything about it.
Step 5: Be Loud. Be Online. Be Ironic.
Who needs grassroots organizing when you can “dunk on fascists” in the quote tweets? Nothing defeats authoritarianism like being aggressively smug with a PFP of a frog holding a Molotov cocktail.
Marching in the streets? Mutual aid? Local elections?
Cringe.
Let’s just post a meme of Trump hugging Mussolini with a caption that says, “When your fascist BF also texts other regimes 🥺👉👈.”
Final Thoughts (Because I Have So Many)
Being an anti-fascist in 2025 is hard. You have to juggle being morally superior, chronically online, and vaguely condescending all at once. But if we just stay in our bubbles, talk over each other on Clubhouse, and continue to believe that irony is activism, we’ll totally defeat fascism.
Eventually.
Maybe.
After brunch.
Stay performative. Stay smug. Stay revolution-adjacent.
We’ll see you tomorrow—for another episode of "The Whisper of Democracy", where we dismantle empires with emotional vulnerability and artisanal zines.
Namaste, but make it confrontational.
— Delusionally Chill Carl
originally posted at https://stacker.news/items/967043
-
@ d9a329af:bef580d7
2025-04-30 00:15:14
Since 2022, Dungeons and Dragons has been going down a sort of death spiral after the release of a revised version of 5th Edition... which didn't turn out very well to say the least. In light of that, I present a list of TTRPGs you can play if you don't want to purchase 5E. I wouldn't recommend 5E, as I've DM'd it in the past. It tastes like a lollipop that's cockroach and larvae flavored.
This list of TTRPG games is in no particular order, though my favorite of these systems is number one.
- Basic Fantasy Role-Playing Game (BFRPG)
- B/X-style OSR retroclone with ascending armor class, and the original retroclone from 2006
- Fully libre under CC BY-SA for the 4th Edition, and OGL 1.0a for 1-3 Editions.
- Full books are free PDF files on the website (Basic Fantasy Website)
- All BFRPG editions are compatible with each other, meaning you can have a 3rd Edition book to a 4th Edition game and still have fun. 4th Edition is just the removal of the 3E SRD that's in the OGL editions.
- As with the core rulebooks, all the supplementation is free as a PDF as well, though you can buy physical books at cost (BFRPG principal rights holder Chris Gonnerman doesn't make much profit from Basic Fantasy)
- Old-school community that's an all-around fantastic group of players, authors and enthusiasts.
-
Fun Fact: Out of all the TTRPGs I'd want to DM/GM the most, it'd be this one by far.
-
Iron Falcon (IF)
- OD&D-style retroclone from 2015 (It's also by Gonnerman, same guy behind BFRPG)
- A close ruleset to the White Box rules and supplements
- Also fully libre under CC BY-SA for the latest releases, just like BFRPG for 4th Edition releases
- Just like BFRPG, the core rules and supplementation come as PDF files for free, or physical books.
-
Fast and loose ruleset open to interpretation, just like in 1975-1981... somewhere right around that timeline for OD&D
-
Old-School Reference and Index Compendium (OSRIC)
- AD&D 1E-based retroclone by Stewart Marshall and Matt Finch
- An old system that surprisingly still holds up, even after a long time of no new versions of the rules
- Extremely in-depth ruleset, licensed under OGL 1.0a and OSRIC Open License
- Compatible with AD&D 1e modules for the 1st Edition, though 2.2 potentially has its own supplementation
-
I don't know much about it, as I'd be too slow to learn it. That's all I know, which is the above.
-
Ironsworn
- Custom loosely-based PbtA (Powered by the Apocalypse) system by Shawn Tomkin from 2018
- Includes GM, GMless and solo play in the rulebook
- Supplementation is surely something else with one look at the downloads section for the PDFs of the original, which is free under CC BY-NC-SA. The SRD is under CC BY otherwise.
- No original adventures are made for this system as are known, as it's expected that the Ironlands are where they take place
-
Fun Fact: This was a non-D&D system I considered running as a GM.
-
Advanced Dungeons & Dragons 2nd Edition (AD&D 2e)
- An official edition from 1989-2000
- At the time, the most customizable edition in its history, before 3E took the spot as the most customizable edition
- A streamlined revision of the AD&D 1E rules (AD&D 1E was exclusively written by E. Gary Gygax)
- The end of old-school D&D, as 3E and beyond are different games altogether
- Wide array of supplementation, which oversaturated 2E's customization... and most of it didn't sell well as a result
- Final TSR-published edition of D&D, as they went bankrupt and out of business during this edition's life cycle, to then be liquidated to Wizards of the Coast (Boy did WOTC mess it up once 5.1E was released)
-
Fun Fact: A Canadian history professor named Dr. Robert Wardough runs a customized ruleset using 2E as a base, which he's been DMing since the 80's during the "Satanic Panic" (The Satanic Panic was fake as a result of horrible deceivers gaslighting people to not play D&D). He started RAW (Rules as Written), but saw some things he needed to change for his games, so he did so over time.
-
Moldvay/Cook Basic/Expert Dungeons & Dragons (B/X)
- Competing system to 1E from 1981 and 1982
- Official edition of D&D, part of the old-school era
- Simplified rules for Basic, but some decently complex rules for Expert
- Only goes up to Lv. 14, as it's potentially a 1E or White Box primer (similar to 1977 Basic)
- Supplementation, from some research done, was decent for the time, and a little bit extensive
- The inspiration for BFRPG in 2006 (Did I mention this already? Maybe I have, but I might emphasize that here too.)
-
Fun Fact: I considered running B/X, but decided that I'd do BFRPG, as the ascending armor class is easier math than with B/X and the THAC0 armor class (descending armor class).
-
Basic, Expert, Companion, Master, Immortal Dungeons & Dragons (BECMI) and/or Rules Cyclopedia
- 1983 variant of the Moldvay/Cook Basic/Expert system, an official edition and part of the old-school era
- Essentially, 1981 B/X D&D on steroids
- 5 boxed sets were released for the five parts of the rules for this system
- Rules Cyclopedia is a reprint of the 1983 Basic, Expert, Companion and Master rules boxed sets. The Immortal set was never reprinted outside of the original boxed set because Immortal is such a bizarre game within a game altogether.
- With the first 4 boxed sets (whether individual sets or the Rules Cyclopedia), levels are 1-36
-
Fun Fact: This edition I was considering DMing as well, alongside BFRPG. They're similar rulesets with some mechanical differences, but I think either or would be worth it.
-
Original Dungeons & Dragons (OD&D or White Box)
- The original release of D&D from 1974 written by Gygax and Dave Arneson, published by TSR
- Uses the rules from Chainmail, a wargame made by Gygax and Jeff Perren
- Base has three little booklets (Men & Magic, Monsters & Magic, and The Underworld & Wilderness Adventures), five official supplements were released (Greyhawk; Blackmoor; Eldritch Wizardry; Gods, Demi-Gods and Heroes; and Swords & Spells), and many more from fanzines
- Fast and loose ruleset open to interpretation
- Not based upon adventurers taking on dangerous quest, but kings commanding armies (which is why OD&D is actually a Chainmail supplement). The latter was the original purpose of D&D before it got changed in 2000.
There are many more games that are not D&D that you can look up too. See what you like, read the rules, learn them, and start playing with your group. Have fun and slay some monsters!
-
@ dc814bb0:7a410cb5
2025-04-29 23:09:50
hallo welt
[[ ]] Add as many elements as you want? [[X]] The X marks the correct answer! [[ ]] ... this is wrong ... [[X]] ... this has to be selected too ...
-
@ dc814bb0:7a410cb5
2025-04-29 23:07:29
Hallo welt
[[ ]] Add as many elements as you want? [[X]] The X marks the correct answer! [[ ]] ... this is wrong ... [[X]] ... this has to be selected too ...
-
@ 957df479:13e9e08e
2025-04-29 20:56:20
LiaScript Course
Course Main Title
This is your course initialization stub.
Please see the Docs to find out what is possible in LiaScript.
If you want to use instant help in your Atom IDE, please type lia to see all available shortcuts.
Markdown
You can use common Markdown syntax to create your course, such as:
- Lists
-
ordered or
-
unordered
- ones ...
| Header 1 | Header 2 | | :--------- | :--------- | | Item 1 | Item 2 |
Images:

Extensions
--{{0}}--But you can also include other features such as spoken text.
--{{1}}--Insert any kind of audio file:
{{1}}--{{2}}--Even videos or change the language completely.
{{2-3}}!?video
--{{3 Russian Female}}--Первоначально создан в 2004 году Джоном Грубером (англ. John Gruber) и Аароном Шварцем. Многие идеи языка были позаимствованы из существующих соглашений по разметке текста в электронных письмах...
{{3}}Type "voice" to see a list of all available languages.
Styling
The whole text-block should appear in purple color and with a wobbling effect. Which is a bad example, please use it with caution ... ~~ only this is red ;-) ~~
Charts
Use ASCII-Art to draw diagrams:
Multiline 1.9 | DOTS | *** y | * * - | r r r r r r r*r r r r*r r r r r r r a | * * x | * * i | B B B B B * B B B B B B * B B B B B s | * * | * * * * * * -1 +------------------------------------ 0 x-axis 1Quizzes
A Textquiz
What did the fish say when he hit a concrete wall?
[[dam]]Multiple Choice
Just add as many points as you wish:
[[X]] Only the **X** marks the correct point. [[ ]] Empty ones are wrong. [[X]] ...Single Choice
Just add as many points as you wish:
[( )] ... [(X)] <-- Only the **X** is allowed. [( )] ...Executable Code
A drawing example, for demonstrating that any JavaScript library can be used, also for drawing.
```javascript // Initialize a Line chart in the container with the ID chart1 new Chartist.Line('#chart1', { labels: [1, 2, 3, 4], series: [[100, 120, 180, 200]] });
// Initialize a Line chart in the container with the ID chart2 new Chartist.Bar('#chart2', { labels: [1, 2, 3, 4], series: [[5, 2, 8, 3]] }); ```
Projects
You can make your code executable and define projects:
``` js -EvalScript.js let who = data.first_name + " " + data.last_name;
if(data.online) { who + " is online"; } else { who + " is NOT online"; }
json +Data.json { "first_name" : "Sammy", "last_name" : "Shark", "online" : true } ```More
Find out what you can even do more with quizzes:
https://liascript.github.io/course/?https://raw.githubusercontent.com/liaScript/docs/master/README.md
-
@ be063e14:06d214ce
2025-04-29 23:11:22
hallo welt
[[ ]] Add as many elements as you want? [[X]] The X marks the correct answer! [[ ]] ... this is wrong ... [[X]] ... this has to be selected too ...

daten können auch, ich meine multimedia ... übertragen werden ...
-
@ 79dff8f8:946764e3
2025-04-29 19:19:34
Hello world
-
@ 2ce0697b:1ee3d3fc
2025-04-29 18:54:19
Excerpt
Special Jurisdictions, Free Cities and Bitcoin Citadels are the sly roundabout way that is removing the market of living together from the hands of the government, without violence and in a way that they can´t stop it. With Bitcoin as the backbone of a new societal order, we are beginning to disrupt the old paradigm.
“If you have built castles in the air, your work need not be lost; that is where they should be. Now put the foundations under them.” ― Henry David Thoreau, Walden
The problem: lack of freedom in the physical realm
Freedom is essential to human life. Being free is what matters. That´s our target, always. No matter the time or space. We pursue freedom because we know its the right thing to do. Freedom is the right to question and change the stablished way of doing things.
Where can we find some freedom? Certainly in the cyberspace. The cyberspace is a free space. Humanity has been blessed by the magic of cryptography, a technology that gave us all the necessary tools to operate in that environment without intervention of undesired third parties.
In cyberspace cryptography performs the function of an impenetrable cyberwall. So, whatever we build in cyberspace can be perfectly protected. Thank to this cybernetic walls we can be sure that the gardens we build and nurture will be protected and cannot be trampled. When we build our digital gardens we have the keys to open the doors to let in whoever we want and most important to leave out whoever we don´t want. In the digital world we can already perfectly interact with one and another in a peer to peer way, without intervention of undesired third parties.
In cyberspace we have Bitcoin for freedom of money and Nostr, torrent and Tor for freedom of information and speech. These open-source protocols are designed to fully realize and expand the promise of freedom, and they certainly deliver what they promise.

So, thanks to the magic of asymmetric cryptography, we´ve already achieved sufficiently descentralization and the possibility of any level of desired digital privacy. Cryptoanarchists and cypherpunks have set their conquering flag in cyberspace and there´s no force on Earth than can remove it. The digital world cannot escape the rules of cryptography. This is great but it only works in the digital realm, meanwhile in the physical realm we are overrun by centralized attackers due to the impossibility of the creation of impenetrable walls such as the ones we have online.
Humans have the upper hand in creating impenetrable walled gardens in cyberspace, but in the physical space authoritarians have the upper hand in bullying physical persons.
The physical world is also naturally free. According to natural law each person is free to do whatever he wants as long as it doesn´t hurt other people. However due to unnatural -artificial and inhuman- centralization of power, the natural freedom of the physical world has been completely undermined. Mostly by Governments, the entities that centralize violence and law.
Bitcoin as a bridge between both realms

Let´s take a look at one connection between both realms, the physical and the digital world. Bitcoin layer one is made essentially of software plus hardware. It consists of any software that produces the same output as the reference implementation - Bitcoin core- and the hardware needed to run that software. Layer two, three or any other layer above, is made essentially of other software and other hardware that interacts with layer one in some way. All these layers, one, two and subsequent, are completely protected by cryptography and a set of game theories that have been successfully tested. Each new block added to the timechain is a testimony of the unstoppable force of freedom and meritocracy.
Before layer one we have Bitcoin layer zero, which is essentially the sum of all actions and inactions done by bitcoiners regarding to or because of bitcoin. In other words, layer zero is composed by flesh and bone people interacting in some way with layer one of the bitcoin network.
Hence, an attack on a bitcoiner - on his way of life- is an attack on bitcoin, the network itself. First because it is an attack on a layer zero node, the physical person, the bitcoiner under duress or coercion. And second because is also an attack on the store-of-value-aspect of bitcoin. Nowaday, the most common attack against bitcoiners is the entirety of compliance regulations. This is the sum of all coercive regulations,such as laws, threats of more laws, imprisonment, threats of more imprisonment, taxation, threats of more taxation, requirements to prove the origin of funds, coercive removal of privacy such as the travel rule, unnecessary bureaucracy such as the need to obtain a money transmitting license and many others rules, in a never stopping inflationary coercive legislation.

If a physical attack is preventing any bitcoiner to exchange the value he created for bitcoin due to any kind of artificial obstacles -such as any kind of compliance- that specific attack is successful in the sense that even though the whole network keeps operating, the attack itself diminishes the value of all the bitcoins.
So, even if layer-zero cannot be taken down, every interference on this layer is an attack on the bitcoin network. Attacks on layer one, two or any other layer that exists in the cyberspace can interfere with the network but they may hardly subtract any value from it. For example we have already been through plenty of times where hashing power was diminished due to government intervention and the bitcoin network remain completely unaffected.
On the other hand successful attacks on layer zero subtract potential, but real and demonstrable value. This value is equal to the amount of value the frustrated user would have added to the network if he would have been able to use it freely, that means if he would have sold his product without the cost of compliance. I´ll demonstrate this in the next chapter.
The cost of compliance
Alice is a merchant specialized in a specific area and topic. She studied the market, her business, her suppliers, consumers, the logistics involved, marketing, design, and everything necessary to become a successful entrepreneur. After investing a considerable amount of resources, she developed a perfect product. Or at least she considers it perfect, that is, the best in its class. While developing everything necessary to create her product, she met Bob, who became her main lead and stereotype of a buyer persona. She knows what Bob wants and she wants to sell it to him. According to Alice's calculations, for her business to be viable, she must sell the product at ten satoshis per unit, and fortunately, Bob is willing to pay that price for it. Alice's product is finished, ready to hit the market, but just before sending it to production, Alice decides to take a pause to analyze her reality. Before taking the public action of making her product available in the open market, Alice analyzes her material, political, and legal reality. In doing so, she realizes that she lives under the jurisdiction of a State. She learns that the Government prescribes through its regulations how she must behave. She analyzes that in order to sell her product legally, in compliance, she must make a series of modifications to it. The product before hitting the shelves must first be modified both in the way it is presented to the market and also regarding certain technical characteristics that it possesses. She must also modify the way it produces her product by changing the contractual relationship with its suppliers, distribution channels, and all other types of logistics involved. She must make all these changes even if they bring about significant and insurmountable inefficiencies.
Likewise, Alice also sees that she not only has to modify the product but also has to meet tax obligations. In addition to paying an accountant since the tax obligations by some irrational reason are not calculated by the creditor. Additionally, she must hire other professionals to assist her in studying the current regulations and how they should be applied in all stages of production, distribution, and sale of her product.
Alice, being a rational person, wishes to avoid having to make these modifications since they increase her costs while also decreasing the quality of her product. But when studying compliance, that is, the entirety of applicable regulations, she also examines the consequences of not being in compliance. Alice realizes that if she does not comply with the regulations, she risks having all her assets legally confiscated, going to prison, being killed while they try to capture her to imprison her, and, if she goes to prison, being tortured in jail by other inmates or by State officials in charge of holding her in that place. So, since Alice does not want to suffer these negative consequences, she decides to modify the product and be in compliance.
So, Alice makes the necessary changes and puts her new version of the product on the market. Then she has the following dialogue with Bob, her lead, the interested party in acquiring the product.
Bob: - Hey Alice, nice meeting you here in this market. I came to buy the product you were developing and told me about. However, this product I´m seeing now is not what you promised me. This is clearly inferior.
Alice: - Yeah, I know. I'm sorry Bob, but I prefer to sell this inferior product rather than risk having all my assets confiscated, going to prison, being killed while they try to capture me, and if they don´t kill but managed to put me in jail I could be tortured there.
Bob: - Ok, no problem. Thats quite understandable. I don´t believe anyone would prefer those kind of experiences. But given the quality of the product, I no longer intend to pay you ten satoshis; I only offer you eight. Shall we close the deal?
Alice: - I'm sorry Bob, but I can't sell it to you for eight sats. Due to government intervention and its requirements, now I can't even sell it for less than thirteen satoshis.
Bob: - Ok. Considering this I prefer not to purchase it. I will keep looking for alternatives. Bye

Some time later, Charlie arrives at the market, who is also interested in the product and, despite it not being like the original version, decides to purchase it by paying the thirteen satoshis demanded by the seller Alice.
Meanwhile, in the same universe, we have Daniel, the last character in this example. Daniel is a merchant competing with Alice. Daniel has a product that is very similar, practically identical to the one originally designed by Alice. Like Alice, Daniel initially also wants to sell it for ten satoshis. Just like Alice, before heading to the market, Daniel analyzes the reality in which he lives. And it turns out that he also lives under the jurisdiction of a State. Daniel too then analyzes the entirety of the applicable regulations and also comes to the conclusion that to comply with them, he would also need to modify the product and cover all the additional expenses artificially generated to be in compliance.
However, Daniel's ethics are different from Alice's. Daniel understands that his product is indeed perfect (the best in its class) and that therefore modifying it would go against its essence. Daniel understands that changing the product would be a betrayal of his creation and therefore a betrayal of his own self and the essence of his being. Daniel conducts an ethical analysis of his actions and the moral implications of putting the product on the market. Daniel sees that the product not only does not harm anyone but is also made to be freely acquired by adults who give their consent for its purchase and subsequent use. Daniel also understands that paying taxes only serves to promote the slavery system driven by fiat and that whenever he can avoid collaborating with the immoral fiat system, it is his ethical obligation to do so. Likewise, Daniel highlights the hypocrisy and inefficiencies of anti-money laundering regulations, as well as the futility of requiring licenses for naturally free acts that do not harm others. For all these reasons, Daniel decides to sell the product in its current state irregardles of compliance regulations.
However, before going to market, Daniel also studies the possible consequences of neglecting compliance. By doing so, Daniel sees that if he does not comply with the regulations, he risks having all his assets legally confiscated, going to prison, being killed while they attempt to capture him to imprison him, and, in the event of going to prison, being tortured in jail by other inmates or by State officials responsible for holding him in that place. So, since Daniel is a rational person who does not want to suffer these negative consequences but also does not want to betray his product and himself, he decides to take the risk of not being in compliance. After making this decision, Daniel puts the product on the market and there he meets Bob. In doing so, they converse in the following terms:
Bob: - Hey Daniel, this product is exactly what I was looking for. A product like the one promised by Alice but never delivered. I love it! I offer you ten satoshis for it.
Daniel: - Thank you for your feedback Bob and for the offer! However I am currently selling it for eleven satoshis. Ten satoshis seems like a good price to me, and it was indeed my original intention to sell it for that amount because at that price I achieve competitiveness and a sustainable business model.
Bob: - So why are you asking me for eleven satoshis? Interrupts Bob
Daniel: - Because that price is calculated before assessing compliance and the risks associated with non-compliance. By not complying with the regulation, I managed to maintain the quality of the product and avoided a large amount of unnecessary expenses, but there is no way to avoid the risk of facing penalties for non-compliance. To bring this product to market, I had to incur several expenses in order to minimize the risk of non-compliance as much as possible. While I am taking all reasonable actions to prevent all of my assets from being legally confiscated, from going to prison, from being killed while they try to capture me, and in case of going to prison, from being tortured, the reality is that I still run the risk of all that, or part of all that, happening to me, my family, or any of my company's employees. The remaining risk balance is transferred to the price along with the costs of mitigating those risks. The total of those costs and the remaining risk I estimate them at one satoshi per unit of product. Therefore, I can't sell you the product for ten satoshis, but I can sell it to you for eleven.
To which Bob, lacking a better option in the market, ends up buying the product for eleven satoshis.
In summary: two products were made by two different merchants whose business model allowed them, in both cases, to put the product on the market at a rate of ten satoshis per unit. However, in one case, a lower quality product was sold for thirteen satoshis, and in the other case, a higher quality product was sold for eleven satoshis. That is to say, in the first case there was an overprice or inefficiency objectively measured at three satoshis, while in the second case there was an overprice or inefficiency of one satoshi. So, we are facing a total loss of value equivalent to four satoshis. The value represented by these four satoshis was absorbed by the inefficiency programmed and ruled by the State. The example shows us that whether one chooses the compliance route, as Alice did, or the free market route, as Daniel did, in both cases the existence of regulations generates an additional cost to the market. In this example the state attack on layer zero was successful and extracted from the Bitcoin network a value of four satoshis.
Bitcoin is money
Bitcoin is many things but essentially is money. And money sole purpose is to store value in order to facilitate future exchanges of products and services with other people. Without the products and services to be exchanged for the money, money itself would be useless and worthless. We only use money because we may require favors, benefits, services, products from other people in the future. And we don´t know which services and products we´ll need nor exactly when we are goint to need them.

The total value of bitcoin equals to infinity divided twenty one millions. This is because the total worth of the network mirrors the total worth of accumulated capital by the entirety of mankind throughout its entire history. That is clearly a lot of value. But if the if the dividend equals zero then the divisor is also zero and if the dividend growth is obstructed through artificial means -such as compliance- then the divisor growth is also obstructed.
Bitcoin layer zero, the bitcoiners and the services and products we create, are what give value to the twenty one million units of bitcoin.
Freedom is without a doubt the best context for value creation. So, the more and better games we can create that allow humankind to find a way to exercise freedom, then the most value we can add to all the layers of the network.
This is why the most important layer of the whole bitcoin phenomenon is layer zero, the bitcoiners. Hence the problem to be solved is not how to prevent bitcoin - layer one upwards- from successful attacks. The problem to solve is how to prevent attacks on layer zero. Or in other words, the problem to be solved is how to get bitcoiners in the physical world to practice the same level of freedom that bitcoin achieves in the cyberspace.
Summary of the first part of this article: freedom in cyberspace has already been conquered and each further development in the digital realm contributes to further developments but only in the same realm. Meanwhile in the physical space, the layer zero of bitcoin is under constant attacks that successfully extract value from it.
Exercising freedom in a sly roundabout way

In 1984 the Austrian economist Friedrich Hayek predicted that we couldn´t take money with violence out of the hands of government. He stated that we needed to do it in a sly roundabout way. Twenty five years later Satoshi Nakamoto discovered the sly roundabout way actually introducing something that the government couldn´t stop. Thus fulfilling Hayek´s prophecy.
Bitcoin is a sly roundabout way that removed money without violence from the hands of the government in a way that they can´t stop it.
Cryptography in general and protocols such as Tor and Tails are a sly roundabout way that removed confidential information from the hands of the government without violence in a way that they can´t stop it.
Nostr is a sly roundabout way that removed social media and public information from the hands of the government without violence in a way that they can´t stop it.
Special Jurisdictions, Free Cities and Bitcoin Citadels are the sly roundabout way that is removing the market of living together from the hands of the government without violence in a way that they can´t stop it.

So, what are Special Jurisdictions, Free Cities and Bitcoin Citadels? To understand what they are we can take a look at the current mainstream market of living together, at how the physical space is organized. Essentially the entire planet Earth and its surroundings are run by a conglomerate of Governments. They create all the rules, regarding every aspect of life, of all the individuals, and enforce every rule through coercive means.
In the mainstream market of living together individuals have several alternatives to pick from. We can choose to live in a natural city or a pre design city, in a public neighborhood or private neighborhood or even in an intentional community with common interest amongst the users. But irregardless of the choice, every product offered in the mainstream market has the sames rules which are established by the host state to the entirety of organizations in his territory. In the mainstream market, even the most different products abide by the same high level rules such as criminal law, civil law, taxation laws, customs, enviromental laws, money laundering regulations and many others. To abide to the sum of all the laws and regulations is to be in compliance.
The centralization of regulations makes extremely difficult to experiment in market of living together. The less experimentation is allowed, the more human progress is hindered.
So what is the sly roundabout that fixes this? What are Special Jurisdictions, Free Cities and Bitcoin Citadels? I´m using the term Special Jurisdictions as an umbrella term that includes the entire spectrum of iterations of products that aim to modify the mainstream rules of the market of living together.
This term includes all the different models such as Charter Cities, Free Cities, Special Economic Zones, microstates, micropolis, start up societies, government as a service, self governing jurisdictions, autonomous intentional communities, network states and Bitcoin Citadels. The array of possible iterations is huge and permanently expanding. What they all have in common is that each of these experiments aims to create a functional game theory that replaces the lack of unbreakable walls in the physical space.
Let´s take a look of a couple of examples. Special Economic Zones are bounded areas of countries that have their own rules and regulations. Worldwide, there are more than five thousands special economic zones located in more than hundred countries.
One of them is the special economic zone of Shenzhen in China. The Chinese government allowed Shenzhen the freedom to experiment with certain practices that were prohibited in the rest of the country at the time. This included allowing foreign companies to make direct investments in China, allowing people to buy and sell land, allowing Chinese people to set up their own private businesses and relaxation of the system that limited internal migration within China for Chinese citizens. It served as a place where China could experiment with market reforms. The experiment was such a huge economic success that it was replicated in many other areas of the country.
Another place that has made extensive use of special economic zones is Dubai. The monarchic Government has more than 30 SEZs. In this case one of the many obstacles removed by the host state its the monopoly of the legal system. Dubai Government allowed the special economic zone to have its own independent legal system thus conceding a modification of the mainstream rules in that area.
This kind of projects, such as Dubai or Shenzhen, are a top-to-down product. Fully created by the Governments thus compliant with their own regulations.

On the other side of the spectrum we have Citadels and several other archetypes of not so compliant projects .
For example the Free Commune of Penadexo it´s a grassroots project building a freedom-oriented community in one of Spain’s abandoned villages.
 It´s model is based on building a peer to peer society avoiding government intervention as much as possible.
They stablished themselves in an abandoned historic village and the started to track down the owners to purchase as much property as possible. Meanwhile, they are living there and expanding their users base while also reconstructing buildings.
It´s model is based on building a peer to peer society avoiding government intervention as much as possible.
They stablished themselves in an abandoned historic village and the started to track down the owners to purchase as much property as possible. Meanwhile, they are living there and expanding their users base while also reconstructing buildings. This is an example of a completely different way of dealing with the Government. While Special Economic Zones are fully compliant and created top to down, this model on the other hand is bottom-up and aims to add value to the users relying in factual freedom which is exercised by stablishing the commune away from heavily populated centers where Government grip is tighter. Under this model the interaction with the Government is kept as low as possible. Their strategy relies in ignoring the Government as much as possible and being a good neighbor. With this simple and effective tactic some Citadels enjoy the benefits of liberty in their lifetime without needing to spend huge resources in governmental lobby.
There are countless models or archetypes of Bitcoin Citadels trying to solve the obstacles in different ways, trying to restart the system. And one of the challenges of the Bitcoin Citadels is how to connect the different projects to boost and help each other.
This is where The Meshtadel comes into play. The Meshtadel is a system where decentralized tactics are used to help and defend citadels connected in a global network. With real life connections with fellow bitcoiners. Its an organization equivalent to the hanseatic league built under a starfish model. If you cut off a spider’s head, it dies, but if you cut off a starfish’s arm, it can regenerate and even grow into a new starfish.
The Meshtadel its a network of peer relationships, with ambiguous leadership roles, trust among participants, a shared ideology and vision based on the Bitcoin ethos, and an open system where new nodes - bitcoin citadel builders - can participate.
The long term goal of the Bitcoin Meshtadel is to help Bitcoin Citadels to gain the support of a critical mass of the total population. If enough people see that Bitcoin is as peaceful as it gets, in the long run, some nations could become friendly and supportive enough to legally tolerate the Bitcoin Citadel inside its territory in the form of a Bitcoin safe haven. In the Meshtadel we are fighting from the moral high ground using memes, Nostr notes and zapping our way into freedom creating an online and offline circular economy.
TO CONCLUDE:
Special Jurisdictions, Free Cities and Bitcoin Citadels are the sly roundabout way that is removing the market of living together from the hands of the government, without violence and in a way that they can´t stop it.
Nation states, abusing the myth of authority, have halted development on the market of living together for so long that a blooming freer market is eating its lunch. The sovereign individual thesis is live and continuously expanding. The network state is forming and intentional communities are flourishing all around the world reshaping globally the relationship between individuals and the governments.
With global internet connections, uncensorable means of communication and Bitcoin as the backbone of a new societal order, we are beginning to disrupt the old paradigm.
The fashion of the present world is passing away, let’s help it to move forward along by building Special Jurisdictions, Free Cities and Bitcoin Citadels.
--- --- --- --- --- --- --- --- ------
byCamiloat 875.341 timechain.
If you find this content helpful, zap it to support more content of the sort and to boost the V4V model.
-
@ 866e0139:6a9334e5
2025-04-29 18:40:31
Autor: Thomas Eisinger. Dieser Beitrag wurde mit dem Pareto-Client geschrieben. Sie finden alle Texte der Friedenstaube und weitere Texte zum Thema Frieden hier.**
Die neuesten Artikel der Friedenstaube gibt es jetzt auch im eigenen Friedenstaube-Telegram-Kanal.
Vor Kurzem war ich bei einem «Ecstatic Dance» (mehr dazu z. B. hier) dabei. Wer das noch nicht kennt: es lohnt sich! Irgendwann in diesem speziellen Space bekam ich einen Gedanken - oder er kam von irgendwo zu mir: die Vorstellung, dass niemand in meiner Reihe von Eltern, Großeltern, Ahnen je an so etwas hätte teilnehmen können. Einmal, weil es das damals nicht gab. Zum Zweiten, weil ihr Mind niemals für so etwas offen gewesen wäre, gar nicht sein konnte. Sie alle waren einfache Menschen, die genug damit zu tun hatten für das Überleben der eigenen Familie zu sorgen. Urlaub war ein Fremdwort, intellektuelle Faxen gab es ganz sicher keine. Diese meine Vorstellung erschuf ein inneres Bild in mir: ich sah meine beiden Großmütter wild und lebensfroh durch den Raum tanzen! (Übrigens wurden beide 95 Jahre alt, trotz zwei Kriegen, Währungsreform, Hunger und ohne jemals Sport getrieben oder Ernährungsratgeber gelesen zu haben. Dies nur am Rande).
Ich erfreute mich an dem Bild der tanzenden Großmütter, konnte mich eines breiten Grinsens nicht erwehren. Nach dieser Freude wechselte mein Gefühl jäh zu Dankbarkeit. Dafür, in dieser wunderbaren Zeit leben zu dürfen. In der so viel mehr möglich ist als es jemals war. Das enge Korsett, das die Gesellschaft seit Jahrtausenden jedem auferlegt hatte, ist so viel weiter geworden. Nur, wenn man es selbst annehmen möchte (oder zumindest meint, dies tun zu müssen) kann es noch Macht ausüben. Sonst nicht. Die persönliche Freiheit ist größer als jemals zuvor, wenn man sie mit den Hundert Generationen vor uns vergleicht. Natürlich ist aktuell «the Trend not our friend», aber wir haben die Wahl, den Zeitmaßstab selbst anzulegen. 10 Jahre, 100 oder 200 Jahre? Lass es vor Deinem inneren Auge erscheinen ...
Die innere Freiheit ist größer als in all den Zeiten vor meiner Generation (Boomer). Millionen Menschen haben Meditationserfahrung, einige können sich mit Informationsfeldern (jenseits der rechtgläubigen Physik) verbinden und darüber sprechen, ohne dass sie verbrannt werden. Man muss keiner offiziellen Religion mehr folgen, um Verbindung mit dem Höheren zu erlangen. Im Gegenteil, die Ablösung von den Amtskirchen erleichtert dies für viele sogar. Wie auch immer, der eigenen Wahl stehen weder Priester noch Eltern oder starre Konventionen entgegen. Anders als vor 100 oder 200 Jahren. Just do it!
Es geht noch weiter. Wie dankbar bin ich, dass ich in dieser Zeit leben darf. Dass trotz des Leides meiner in ziemlicher Armut lebender Großeltern ihr Wille zum Überleben stärker war: nur deshalb kann ich hier sein. Ich darf all diese Vorzüge genießen, obwohl ich viel weniger hart arbeiten muss(te) als sie. Auch wurde mein Haus nicht ausgebombt und ich musste nie in den Krieg ziehen. Meine beiden Großväter ereilte dieses Schicksal. Ob mein Sohn diesem Schicksal entrinnt?
Wir sollen wieder kriegstüchtig werden. Unfassbar. Doch damit will ich diese Betrachtung nicht enden lassen. Denn nur wenn wir auch begreifen, wie gut es uns allen geht, trotz dieser Regierung, trotz Massenpropaganda, trotz dauernder medialer Panikmache: erst, wenn wir das Leben wirklich lieben, werden wir wissen, wofür es sich wirklich lohnt zu kämpfen. Nicht mit Waffe in der Hand, sondern mit Herz und Verstand.
LASSEN SIE DER FRIEDENSTAUBE FLÜGEL WACHSEN!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt.
Schon jetzt können Sie uns unterstützen:
- Für 50 CHF/EURO bekommen Sie ein Jahresabo der Friedenstaube.
- Für 120 CHF/EURO bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
- Für 500 CHF/EURO werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
- Ab 1000 CHF werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
Für Einzahlungen in CHF (Betreff: Friedenstaube):
Für Einzahlungen in Euro:
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
Betreff: Friedenstaube
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: friedenstaube@pareto.space
Sie sind noch nicht auf Nostr and wollen die volle Erfahrung machen (liken, kommentieren etc.)? Zappen können Sie den Autor auch ohne Nostr-Profil! Erstellen Sie sich einen Account auf Start. Weitere Onboarding-Leitfäden gibt es im Pareto-Wiki.
-
@ 3c389c8f:7a2eff7f
2025-04-29 18:38:46
Let go of the algorithms and truly discover what it means to explore. Social media used to mean something. Once upon a time, it was a way to stay connected to friends, family, and colleagues over things we enjoy. We could share, laugh, and learn. Over time, it has devolved into cheap entertainment at the cost of our privacy. Our relationships and interests have been shoved into a corner in order to make room for "suggested posts" and "for you" content designed to evaluate our attention for advertising purposes. We've lost what it means to truly connect, and we've lost what it means to explore our curiosities.
Enter Nostr. A protocol designed to resist authoritative censorship, just happens to fix a whole lot of other problems, too. By removing the central authority, Nostr offers its users complete control of what we feed our minds. How do we break our algorithm dependency to find better content and better relationships again? We explore and discover:
The Chronological Life.
The existence of time may be debatable but our dependence on our perception of it is not. We live our lives chronologically. Why do our online lives need to be any different? There is no real reason, other than we've just gotten used to being engulfed by whatever the black box wants us to see. When we remove the algorithms, we find that online information flows just as it would in our daily lives. Important events get talked about by many people, over a long period of time. Things of less relevance fade. We see the rhythm of life reflected in our feed. This is an organic human experience transferred to the digital world. We depend on the people we know and the sources we trust to keep us informed about what really matters. We have fun, we move on. Nearly every Nostr social client brings this experience front and center through the traditional follow feed. Many use replies as a way to show you what is worth talking about for more than a hot minute. Its what old social media gave us, then took away. Nostr gives it back. It's not the only way to enjoy Nostr, though, so let's continue.
"The Human Animal Differs From the Lesser Primates in His Passion for Lists"
Who doesn't love lists? (besides maybe to-do lists.) List functionality on Nostr is a powerful way to curate your feeds. You can make lists of artists, vendors, friends, or whatever you want. They can be public or private. You can subscribe to other people's public lists too. Make one to share with your friends. Many clients have list support and management. Amethyst, Nostur, Voyage, and Nostrudel are a few that come to mind. Nostr.band and Listr.lol offer in depth list management. Some clients even support lists for specific notes so that you can curate a feed by topic or aesthetic to share with your friends.
Being John Malcovich.
Everyone has a different view of Nostr. Do you want to see what someone else is seeing? Sign in with any npub to get a different perspective. You might find profiles and content that you didn't know existed before. Some clients integrate variations of this feature right into their apps, so you don't have to log out of your account in order to step through that tiny door.
DV-what? DVM.
Data Vending Machines. These fancy little things are AIs tasked with a simple job: to find content for you. Most of these feeds are free, though some more personalized ones require a small fee. Many DVM services are stand-alone apps, like Vendata and Noogle . These clever Nostr clients will let you do a lot more than just create feeds to browse notes. Explore if you wish. A few social clients have DVMs integrated, too, so if you see "discovery" or similar term on a tab, be sure to check it out.
Relays, Man. Relays.
It's right there in the name. Nostr- notes and other stuff transmitted by RELAY. Specialized relays exist for subjects, news, communities, personal spaces, content creators, cats... there's even a relay where everyone just says "Good Morning" to each other. Find a client that lets you browse a relay's contents, and enjoy the purest form of content discovery on Nostr. Unearthing these relays is getting better and better every day. Right now there are relay browsing capabilities in quite a few clients, like Coracle, Relay Tools, Jumble and Nostur.
The Algo Relay.
Maybe you've been busy and missed a lot. Maybe you are a sane person who rarely uses social media. Hook up with a personalized algorithm relay to catch you up on all the things you've missed. This is skirting the sharp edges of Nostr relay development, so keep in mind that not many implementations yet exist. Algo relay currently aims to bring the feel-good vibe of your chronological feed to an algorithmic feed, freeing up your time but letting you stay up with what 's going on in your social circles.
Trendy Trends.
A few clients, relays, and DVM's have developed various Trending feeds. Catch up on what's popular across a wider view of the Nostr ecosystem. If trends are your thing, be sure to check them out.
Now that you're equipped with the tools to explore Nostr, its time to go discover some great content and find your people. Feed your curiosity.
-
@ 3c389c8f:7a2eff7f
2025-04-29 18:13:50
TL;DR visit this post for a list of signers
Your nsec/private key is your key to controlling all that you do on Nostr. Every action you take is signed by this private key, validating that was you that generated that event, whether it be a note, a like, a list, or whatever else. Like a broken record, I have to state that it is irreplaceable. YOU own your identity and no one else. It is your responsibility to keep your nsec safe, but of course, you also want to be able to use all the different apps and clients available. To aid you in this process, a few different tools have been developed. Let's take a look at some that are more common and easy-to-use, where to use them, and for what.
The Browser Extension
This is probably the simplest and most straight forward form of private key manager available. There are many options to choose from, each compatible with various, commonly used browsers, including mobile browsers. Many provide the option to manage multiple keys for different profiles. Some are simply a signer while others may include other features. The concept is very simple. The extension holds your key and exposes it only only enough to sign an event. These extensions can be set to different levels of manual approval that you can control based on the level of convenience you seek. The ease and convenience does trade off a bit of security, as your private key will be exposed momentarily each time you create an event. It is up to you to choose whether this is appropriate for your use. For casual browsing and social media use, it is a fairly good and easy to use option. Nearly all Nostr apps and clients support signing with this method.
The Remote Signer
Often referred as a "bunker", Nostr remote signers hold your private key completely offline and communicating with clients. Clients send events to the signer to be signed, which then sends back the signed event for publishing. This bunker can be hosted on your own hardware or managed by a truested 3rd party. As long as the signer is online, it can communicate as needed. The signer generates a "bunker string" that is used to communicate. These may seem cumbersome to set up, as each client that you intend to use will need its own permissions. Once all of the pieces and permissions are in place, most of this activity will happen in the background. Bunkers allow for a lot of flexibility. The "bunker string" for a single app can be shared with other users who you may want to be able to make posts on your behalf. Multiple people can manage a social media profile, while the main owner of that identity maintains control of the nsec. These bunker strings can be revoked and replaced at any time. This signing method is growing in popularity and many clients already offer support for it.
The Native Android Signer
Currently, Amber is the only native app available to handle Nostr event signing. It is an incredible tool for managing your Nostr key on your mobile device. The signing flow is similar to remote signing, as described above, but it can communicate with both your Android native Nostr apps and web clients accessed through most mobile browsers, eliminating the need for a browser extension. Similar apps are under development for iOS, but I don't use any of those devices, so covering that here will only happen via other's opinions at a later date. Check this list for current options.
NcryptSec
NcryptSec signing works by encrypting your nsec on a local device, unlocked by a password that you choose. Support for this method is very limited, as the encrypted private key stays on your device. If you intend to use Nostr through one device and few apps, this can be a very secure option, as long as you can remember your password, as it cannot be changed.
NFC and Hardware Signers
Some devices have been developed to store your nsec completely offline on a device or NFC chip, and some clients have added support for scanning/connecting to sign. I haven't personally tried any of these options, nor do I intend to promote the sale of any particular products. If you are interested in these techniques and devices, the information is not hard to find. The price of a devices varies, depending on your feature needs.
There are also DIY options that utilize existing hardware, if you are into that sort of thing.
Higher Security and Recoverability Options
Creating a scheme that allows for recovery of a lost key while maintaining the integrity of a unique identity is no easy task. The key must be fractured into shards, encrypted, and distributed across multiple servers in various locations, while you maintain a portion or portions of your own. These servers are run by trusted 3rd parties who will then sign events "with" you. Some include a scheme of running your own always online hardware to act as host for these shards. I fall short on the technical understanding of certain aspects of these processes, so I will spare you of my attempt to explain. As far as I know, there are a couple of methods underway that are worth paying attention to:
Frostr nostr:nevent1qvzqqqqqqypzqs3fcg0szqdtcway2ge7zahfwhafuecmkx9xwg4a7aexhgj5ghleqy2hwumn8ghj7un9d3shjtnyv9kh2uewd9hj7qgwwaehxw309ahx7uewd3hkctcqyrh3r7uhytc4dywjggxz24277xgqtvcadvnjfks6fram7gjpev9nuentfht
Promenade nostr:nevent1qvzqqqqqqypzqwlsccluhy6xxsr6l9a9uhhxf75g85g8a709tprjcn4e42h053vaqydhwumn8ghj7un9d3shjtnhv4ehgetjde38gcewvdhk6tcprdmhxue69uhhyetvv9ujuam9wd6x2unwvf6xxtnrdakj7qpqqqq0dlpwxhw5l97yrcts2klhr9zqqpcmdfpaxm8r7hygykp630cq23ggph
For a List of signers, please visit this post.
-
@ 3c389c8f:7a2eff7f
2025-04-29 18:07:00
Extentions:
https://chromewebstore.google.com/detail/flamingo-%E2%80%93-nostr-extensio/alkiaengfedemppafkallgifcmkldohe
https://chromewebstore.google.com/detail/nos2x/kpgefcfmnafjgpblomihpgmejjdanjjp
https://chromewebstore.google.com/detail/aka-profiles/ncmflpbbagcnakkolfpcpogheckolnad
https://keys.band/
https://github.com/haorendashu/nowser
The Remote Signer:
https://nsec.app/
https://github.com/kind-0/nsecbunkerd
Native Android Signer:
https://github.com/greenart7c3/amber
iOS
https://testflight.apple.com/join/8TFMZbMs
https://testflight.apple.com/join/DUzVMDMK
Higher Security Options: To start using Nostr with a secure, recoverable keypair: https://nstart.me/en
For Existing Keys: https://www.frostr.org/
Thank you to https://nostr.net/ for keeping a thorough list of Nostr apps, clients, and tools!