-
 @ 9223d2fa:b57e3de7
2025-04-15 02:54:00
@ 9223d2fa:b57e3de7
2025-04-15 02:54:0012,600 steps
-
@ c066aac5:6a41a034
2025-04-05 16:58:58
I’m drawn to extremities in art. The louder, the bolder, the more outrageous, the better. Bold art takes me out of the mundane into a whole new world where anything and everything is possible. Having grown up in the safety of the suburban midwest, I was a bit of a rebellious soul in search of the satiation that only came from the consumption of the outrageous. My inclination to find bold art draws me to NOSTR, because I believe NOSTR can be the place where the next generation of artistic pioneers go to express themselves. I also believe that as much as we are able, were should invite them to come create here.
My Background: A Small Side Story
My father was a professional gamer in the 80s, back when there was no money or glory in the avocation. He did get a bit of spotlight though after the fact: in the mid 2000’s there were a few parties making documentaries about that era of gaming as well as current arcade events (namely 2007’sChasing GhostsandThe King of Kong: A Fistful of Quarters). As a result of these documentaries, there was a revival in the arcade gaming scene. My family attended events related to the documentaries or arcade gaming and I became exposed to a lot of things I wouldn’t have been able to find. The producer ofThe King of Kong: A Fistful of Quarters had previously made a documentary calledNew York Dollwhich was centered around the life of bassist Arthur Kane. My 12 year old mind was blown: The New York Dolls were a glam-punk sensation dressed in drag. The music was from another planet. Johnny Thunders’ guitar playing was like Chuck Berry with more distortion and less filter. Later on I got to meet the Galaga record holder at the time, Phil Day, in Ottumwa Iowa. Phil is an Australian man of high intellect and good taste. He exposed me to great creators such as Nick Cave & The Bad Seeds, Shakespeare, Lou Reed, artists who created things that I had previously found inconceivable.
I believe this time period informed my current tastes and interests, but regrettably I think it also put coals on the fire of rebellion within. I stopped taking my parents and siblings seriously, the Christian faith of my family (which I now hold dearly to) seemed like a mundane sham, and I felt I couldn’t fit in with most people because of my avant-garde tastes. So I write this with the caveat that there should be a way to encourage these tastes in children without letting them walk down the wrong path. There is nothing inherently wrong with bold art, but I’d advise parents to carefully find ways to cultivate their children’s tastes without completely shutting them down and pushing them away as a result. My parents were very loving and patient during this time; I thank God for that.
With that out of the way, lets dive in to some bold artists:
Nicolas Cage: Actor
There is an excellent video by Wisecrack on Nicolas Cage that explains him better than I will, which I will linkhere. Nicolas Cage rejects the idea that good acting is tied to mere realism; all of his larger than life acting decisions are deliberate choices. When that clicked for me, I immediately realized the man is a genius. He borrows from Kabuki and German Expressionism, art forms that rely on exaggeration to get the message across. He has even created his own acting style, which he calls Nouveau Shamanic. He augments his imagination to go from acting to being. Rather than using the old hat of method acting, he transports himself to a new world mentally. The projects he chooses to partake in are based on his own interests or what he considers would be a challenge (making a bad script good for example). Thus it doesn’t matter how the end result comes out; he has already achieved his goal as an artist. Because of this and because certain directors don’t know how to use his talents, he has a noticeable amount of duds in his filmography. Dig around the duds, you’ll find some pure gold. I’d personally recommend the filmsPig, Joe, Renfield, and his Christmas film The Family Man.
Nick Cave: Songwriter
What a wild career this man has had! From the apocalyptic mayhem of his band The Birthday Party to the pensive atmosphere of his albumGhosteen, it seems like Nick Cave has tried everything. I think his secret sauce is that he’s always working. He maintains an excellent newsletter calledThe Red Hand Files, he has written screenplays such asLawless, he has written books, he has made great film scores such asThe Assassination of Jesse James by the Coward Robert Ford, the man is religiously prolific. I believe that one of the reasons he is prolific is that he’s not afraid to experiment. If he has an idea, he follows it through to completion. From the albumMurder Ballads(which is comprised of what the title suggests) to his rejected sequel toGladiator(Gladiator: Christ Killer), he doesn’t seem to be afraid to take anything on. This has led to some over the top works as well as some deeply personal works. Albums likeSkeleton TreeandGhosteenwere journeys through the grief of his son’s death. The Boatman’s Callis arguably a better break-up album than anything Taylor Swift has put out. He’s not afraid to be outrageous, he’s not afraid to offend, but most importantly he’s not afraid to be himself. Works I’d recommend include The Birthday Party’sLive 1981-82, Nick Cave & The Bad Seeds’The Boatman’s Call, and the filmLawless.
Jim Jarmusch: Director
I consider Jim’s films to be bold almost in an ironic sense: his works are bold in that they are, for the most part, anti-sensational. He has a rule that if his screenplays are criticized for a lack of action, he makes them even less eventful. Even with sensational settings his films feel very close to reality, and they demonstrate the beauty of everyday life. That's what is bold about his art to me: making the sensational grounded in reality while making everyday reality all the more special. Ghost Dog: The Way of the Samurai is about a modern-day African-American hitman who strictly follows the rules of the ancient Samurai, yet one can resonate with the humanity of a seemingly absurd character. Only Lovers Left Aliveis a vampire love story, but in the middle of a vampire romance one can see their their own relationships in a new deeply human light. Jim’s work reminds me that art reflects life, and that there is sacred beauty in seemingly mundane everyday life. I personally recommend his filmsPaterson,Down by Law, andCoffee and Cigarettes.
NOSTR: We Need Bold Art
NOSTR is in my opinion a path to a better future. In a world creeping slowly towards everything apps, I hope that the protocol where the individual owns their data wins over everything else. I love freedom and sovereignty. If NOSTR is going to win the race of everything apps, we need more than Bitcoin content. We need more than shirtless bros paying for bananas in foreign countries and exercising with girls who have seductive accents. Common people cannot see themselves in such a world. NOSTR needs to catch the attention of everyday people. I don’t believe that this can be accomplished merely by introducing more broadly relevant content; people are searching for content that speaks to them. I believe that NOSTR can and should attract artists of all kinds because NOSTR is one of the few places on the internet where artists can express themselves fearlessly. Getting zaps from NOSTR’s value-for-value ecosystem has far less friction than crowdfunding a creative project or pitching investors that will irreversibly modify an artist’s vision. Having a place where one can post their works without fear of censorship should be extremely enticing. Having a place where one can connect with fellow humans directly as opposed to a sea of bots should seem like the obvious solution. If NOSTR can become a safe haven for artists to express themselves and spread their work, I believe that everyday people will follow. The banker whose stressful job weighs on them will suddenly find joy with an original meme made by a great visual comedian. The programmer for a healthcare company who is drowning in hopeless mundanity could suddenly find a new lust for life by hearing the song of a musician who isn’t afraid to crowdfund their their next project by putting their lighting address on the streets of the internet. The excel guru who loves independent film may find that NOSTR is the best way to support non corporate movies. My closing statement: continue to encourage the artists in your life as I’m sure you have been, but while you’re at it give them the purple pill. You may very well be a part of building a better future.
-
@ 04c915da:3dfbecc9
2025-03-26 20:54:33
Capitalism is the most effective system for scaling innovation. The pursuit of profit is an incredibly powerful human incentive. Most major improvements to human society and quality of life have resulted from this base incentive. Market competition often results in the best outcomes for all.
That said, some projects can never be monetized. They are open in nature and a business model would centralize control. Open protocols like bitcoin and nostr are not owned by anyone and if they were it would destroy the key value propositions they provide. No single entity can or should control their use. Anyone can build on them without permission.
As a result, open protocols must depend on donation based grant funding from the people and organizations that rely on them. This model works but it is slow and uncertain, a grind where sustainability is never fully reached but rather constantly sought. As someone who has been incredibly active in the open source grant funding space, I do not think people truly appreciate how difficult it is to raise charitable money and deploy it efficiently.
Projects that can be monetized should be. Profitability is a super power. When a business can generate revenue, it taps into a self sustaining cycle. Profit fuels growth and development while providing projects independence and agency. This flywheel effect is why companies like Google, Amazon, and Apple have scaled to global dominance. The profit incentive aligns human effort with efficiency. Businesses must innovate, cut waste, and deliver value to survive.
Contrast this with non monetized projects. Without profit, they lean on external support, which can dry up or shift with donor priorities. A profit driven model, on the other hand, is inherently leaner and more adaptable. It is not charity but survival. When survival is tied to delivering what people want, scale follows naturally.
The real magic happens when profitable, sustainable businesses are built on top of open protocols and software. Consider the many startups building on open source software stacks, such as Start9, Mempool, and Primal, offering premium services on top of the open source software they build out and maintain. Think of companies like Block or Strike, which leverage bitcoin’s open protocol to offer their services on top. These businesses amplify the open software and protocols they build on, driving adoption and improvement at a pace donations alone could never match.
When you combine open software and protocols with profit driven business the result are lean, sustainable companies that grow faster and serve more people than either could alone. Bitcoin’s network, for instance, benefits from businesses that profit off its existence, while nostr will expand as developers monetize apps built on the protocol.
Capitalism scales best because competition results in efficiency. Donation funded protocols and software lay the groundwork, while market driven businesses build on top. The profit incentive acts as a filter, ensuring resources flow to what works, while open systems keep the playing field accessible, empowering users and builders. Together, they create a flywheel of innovation, growth, and global benefit.
-
@ 04c915da:3dfbecc9
2025-02-25 03:55:08
Here’s a revised timeline of macro-level events from The Mandibles: A Family, 2029–2047 by Lionel Shriver, reimagined in a world where Bitcoin is adopted as a widely accepted form of money, altering the original narrative’s assumptions about currency collapse and economic control. In Shriver’s original story, the failure of Bitcoin is assumed amid the dominance of the bancor and the dollar’s collapse. Here, Bitcoin’s success reshapes the economic and societal trajectory, decentralizing power and challenging state-driven outcomes.
Part One: 2029–2032
-
2029 (Early Year)\ The United States faces economic strain as the dollar weakens against global shifts. However, Bitcoin, having gained traction emerges as a viable alternative. Unlike the original timeline, the bancor—a supranational currency backed by a coalition of nations—struggles to gain footing as Bitcoin’s decentralized adoption grows among individuals and businesses worldwide, undermining both the dollar and the bancor.
-
2029 (Mid-Year: The Great Renunciation)\ Treasury bonds lose value, and the government bans Bitcoin, labeling it a threat to sovereignty (mirroring the original bancor ban). However, a Bitcoin ban proves unenforceable—its decentralized nature thwarts confiscation efforts, unlike gold in the original story. Hyperinflation hits the dollar as the U.S. prints money, but Bitcoin’s fixed supply shields adopters from currency devaluation, creating a dual-economy split: dollar users suffer, while Bitcoin users thrive.
-
2029 (Late Year)\ Dollar-based inflation soars, emptying stores of goods priced in fiat currency. Meanwhile, Bitcoin transactions flourish in underground and online markets, stabilizing trade for those plugged into the bitcoin ecosystem. Traditional supply chains falter, but peer-to-peer Bitcoin networks enable local and international exchange, reducing scarcity for early adopters. The government’s gold confiscation fails to bolster the dollar, as Bitcoin’s rise renders gold less relevant.
-
2030–2031\ Crime spikes in dollar-dependent urban areas, but Bitcoin-friendly regions see less chaos, as digital wallets and smart contracts facilitate secure trade. The U.S. government doubles down on surveillance to crack down on bitcoin use. A cultural divide deepens: centralized authority weakens in Bitcoin-adopting communities, while dollar zones descend into lawlessness.
-
2032\ By this point, Bitcoin is de facto legal tender in parts of the U.S. and globally, especially in tech-savvy or libertarian-leaning regions. The federal government’s grip slips as tax collection in dollars plummets—Bitcoin’s traceability is low, and citizens evade fiat-based levies. Rural and urban Bitcoin hubs emerge, while the dollar economy remains fractured.
Time Jump: 2032–2047
- Over 15 years, Bitcoin solidifies as a global reserve currency, eroding centralized control. The U.S. government adapts, grudgingly integrating bitcoin into policy, though regional autonomy grows as Bitcoin empowers local economies.
Part Two: 2047
-
2047 (Early Year)\ The U.S. is a hybrid state: Bitcoin is legal tender alongside a diminished dollar. Taxes are lower, collected in BTC, reducing federal overreach. Bitcoin’s adoption has decentralized power nationwide. The bancor has faded, unable to compete with Bitcoin’s grassroots momentum.
-
2047 (Mid-Year)\ Travel and trade flow freely in Bitcoin zones, with no restrictive checkpoints. The dollar economy lingers in poorer areas, marked by decay, but Bitcoin’s dominance lifts overall prosperity, as its deflationary nature incentivizes saving and investment over consumption. Global supply chains rebound, powered by bitcoin enabled efficiency.
-
2047 (Late Year)\ The U.S. is a patchwork of semi-autonomous zones, united by Bitcoin’s universal acceptance rather than federal control. Resource scarcity persists due to past disruptions, but economic stability is higher than in Shriver’s original dystopia—Bitcoin’s success prevents the authoritarian slide, fostering a freer, if imperfect, society.
Key Differences
- Currency Dynamics: Bitcoin’s triumph prevents the bancor’s dominance and mitigates hyperinflation’s worst effects, offering a lifeline outside state control.
- Government Power: Centralized authority weakens as Bitcoin evades bans and taxation, shifting power to individuals and communities.
- Societal Outcome: Instead of a surveillance state, 2047 sees a decentralized, bitcoin driven world—less oppressive, though still stratified between Bitcoin haves and have-nots.
This reimagining assumes Bitcoin overcomes Shriver’s implied skepticism to become a robust, adopted currency by 2029, fundamentally altering the novel’s bleak trajectory.
-
-
@ e3ba5e1a:5e433365
2025-02-13 06:16:49
My favorite line in any Marvel movie ever is in “Captain America.” After Captain America launches seemingly a hopeless assault on Red Skull’s base and is captured, we get this line:
“Arrogance may not be a uniquely American trait, but I must say, you do it better than anyone.”
Yesterday, I came across a comment on the song Devil Went Down to Georgia that had a very similar feel to it:
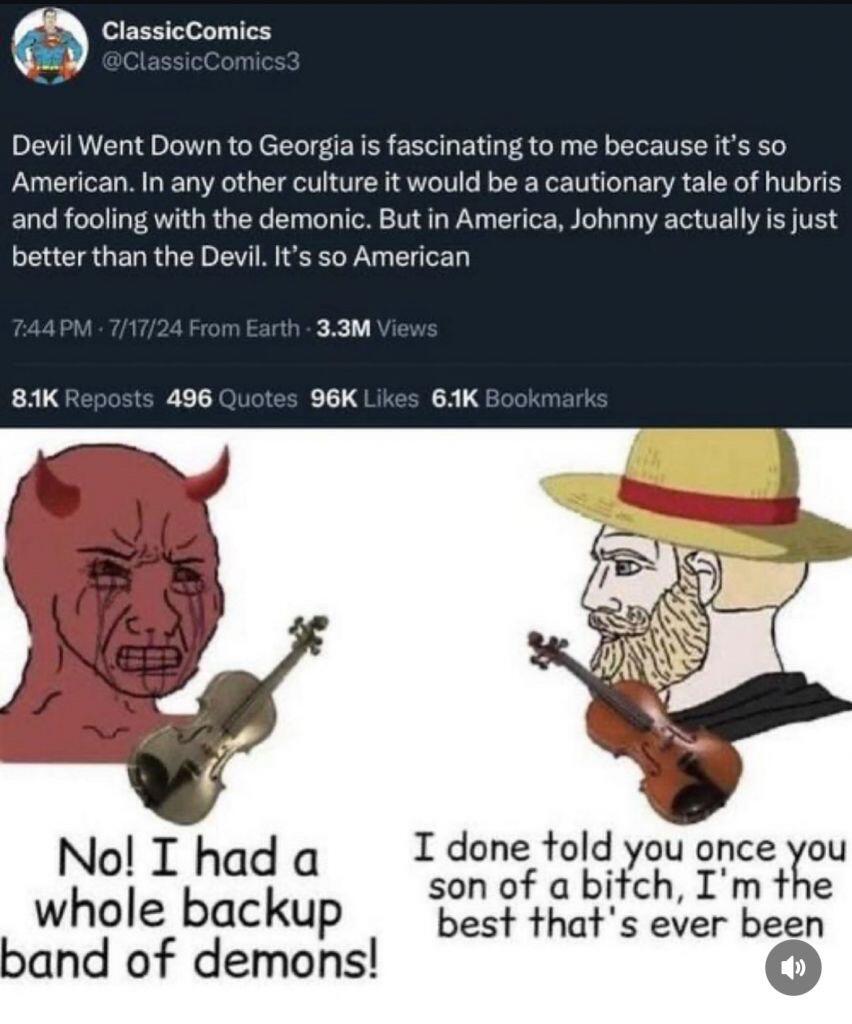
America has seemingly always been arrogant, in a uniquely American way. Manifest Destiny, for instance. The rest of the world is aware of this arrogance, and mocks Americans for it. A central point in modern US politics is the deriding of racist, nationalist, supremacist Americans.
That’s not what I see. I see American Arrogance as not only a beautiful statement about what it means to be American. I see it as an ode to the greatness of humanity in its purest form.
For most countries, saying “our nation is the greatest” is, in fact, twinged with some level of racism. I still don’t have a problem with it. Every group of people should be allowed to feel pride in their accomplishments. The destruction of the human spirit since the end of World War 2, where greatness has become a sin and weakness a virtue, has crushed the ability of people worldwide to strive for excellence.
But I digress. The fears of racism and nationalism at least have a grain of truth when applied to other nations on the planet. But not to America.
That’s because the definition of America, and the prototype of an American, has nothing to do with race. The definition of Americanism is freedom. The founding of America is based purely on liberty. On the God-given rights of every person to live life the way they see fit.
American Arrogance is not a statement of racial superiority. It’s barely a statement of national superiority (though it absolutely is). To me, when an American comments on the greatness of America, it’s a statement about freedom. Freedom will always unlock the greatness inherent in any group of people. Americans are definitionally better than everyone else, because Americans are freer than everyone else. (Or, at least, that’s how it should be.)
In Devil Went Down to Georgia, Johnny is approached by the devil himself. He is challenged to a ridiculously lopsided bet: a golden fiddle versus his immortal soul. He acknowledges the sin in accepting such a proposal. And yet he says, “God, I know you told me not to do this. But I can’t stand the affront to my honor. I am the greatest. The devil has nothing on me. So God, I’m gonna sin, but I’m also gonna win.”
Libertas magnitudo est
-
@ 0fa80bd3:ea7325de
2025-01-30 04:28:30
"Degeneration" or "Вырождение" ![[photo_2025-01-29 23.23.15.jpeg]]
A once-functional object, now eroded by time and human intervention, stripped of its original purpose. Layers of presence accumulate—marks, alterations, traces of intent—until the very essence is obscured. Restoration is paradoxical: to reclaim, one must erase. Yet erasure is an impossibility, for to remove these imprints is to deny the existence of those who shaped them.
The work stands as a meditation on entropy, memory, and the irreversible dialogue between creation and decay.
-
@ 21335073:a244b1ad
2025-05-01 01:51:10
Please respect Virginia Giuffre’s memory by refraining from asking about the circumstances or theories surrounding her passing.
Since Virginia Giuffre’s death, I’ve reflected on what she would want me to say or do. This piece is my attempt to honor her legacy.
When I first spoke with Virginia, I was struck by her unshakable hope. I had grown cynical after years in the anti-human trafficking movement, worn down by a broken system and a government that often seemed complicit. But Virginia’s passion, creativity, and belief that survivors could be heard reignited something in me. She reminded me of my younger, more hopeful self. Instead of warning her about the challenges ahead, I let her dream big, unburdened by my own disillusionment. That conversation changed me for the better, and following her lead led to meaningful progress.
Virginia was one of the bravest people I’ve ever known. As a survivor of Epstein, Maxwell, and their co-conspirators, she risked everything to speak out, taking on some of the world’s most powerful figures.
She loved when I said, “Epstein isn’t the only Epstein.” This wasn’t just about one man—it was a call to hold all abusers accountable and to ensure survivors find hope and healing.
The Epstein case often gets reduced to sensational details about the elite, but that misses the bigger picture. Yes, we should be holding all of the co-conspirators accountable, we must listen to the survivors’ stories. Their experiences reveal how predators exploit vulnerabilities, offering lessons to prevent future victims.
You’re not powerless in this fight. Educate yourself about trafficking and abuse—online and offline—and take steps to protect those around you. Supporting survivors starts with small, meaningful actions. Free online resources can guide you in being a safe, supportive presence.
When high-profile accusations arise, resist snap judgments. Instead of dismissing survivors as “crazy,” pause to consider the trauma they may be navigating. Speaking out or coping with abuse is never easy. You don’t have to believe every claim, but you can refrain from attacking accusers online.
Society also fails at providing aftercare for survivors. The government, often part of the problem, won’t solve this. It’s up to us. Prevention is critical, but when abuse occurs, step up for your loved ones and community. Protect the vulnerable. it’s a challenging but a rewarding journey.
If you’re contributing to Nostr, you’re helping build a censorship resistant platform where survivors can share their stories freely, no matter how powerful their abusers are. Their voices can endure here, offering strength and hope to others. This gives me great hope for the future.
Virginia Giuffre’s courage was a gift to the world. It was an honor to know and serve her. She will be deeply missed. My hope is that her story inspires others to take on the powerful.
-
@ a39d19ec:3d88f61e
2025-04-22 12:44:42
Die Debatte um Migration, Grenzsicherung und Abschiebungen wird in Deutschland meist emotional geführt. Wer fordert, dass illegale Einwanderer abgeschoben werden, sieht sich nicht selten dem Vorwurf des Rassismus ausgesetzt. Doch dieser Vorwurf ist nicht nur sachlich unbegründet, sondern verkehrt die Realität ins Gegenteil: Tatsächlich sind es gerade diejenigen, die hinter jeder Forderung nach Rechtssicherheit eine rassistische Motivation vermuten, die selbst in erster Linie nach Hautfarbe, Herkunft oder Nationalität urteilen.
Das Recht steht über Emotionen
Deutschland ist ein Rechtsstaat. Das bedeutet, dass Regeln nicht nach Bauchgefühl oder politischer Stimmungslage ausgelegt werden können, sondern auf klaren gesetzlichen Grundlagen beruhen müssen. Einer dieser Grundsätze ist in Artikel 16a des Grundgesetzes verankert. Dort heißt es:
„Auf Absatz 1 [Asylrecht] kann sich nicht berufen, wer aus einem Mitgliedstaat der Europäischen Gemeinschaften oder aus einem anderen Drittstaat einreist, in dem die Anwendung des Abkommens über die Rechtsstellung der Flüchtlinge und der Europäischen Menschenrechtskonvention sichergestellt ist.“
Das bedeutet, dass jeder, der über sichere Drittstaaten nach Deutschland einreist, keinen Anspruch auf Asyl hat. Wer dennoch bleibt, hält sich illegal im Land auf und unterliegt den geltenden Regelungen zur Rückführung. Die Forderung nach Abschiebungen ist daher nichts anderes als die Forderung nach der Einhaltung von Recht und Gesetz.
Die Umkehrung des Rassismusbegriffs
Wer einerseits behauptet, dass das deutsche Asyl- und Aufenthaltsrecht strikt durchgesetzt werden soll, und andererseits nicht nach Herkunft oder Hautfarbe unterscheidet, handelt wertneutral. Diejenigen jedoch, die in einer solchen Forderung nach Rechtsstaatlichkeit einen rassistischen Unterton sehen, projizieren ihre eigenen Denkmuster auf andere: Sie unterstellen, dass die Debatte ausschließlich entlang ethnischer, rassistischer oder nationaler Kriterien geführt wird – und genau das ist eine rassistische Denkweise.
Jemand, der illegale Einwanderung kritisiert, tut dies nicht, weil ihn die Herkunft der Menschen interessiert, sondern weil er den Rechtsstaat respektiert. Hingegen erkennt jemand, der hinter dieser Kritik Rassismus wittert, offenbar in erster Linie die „Rasse“ oder Herkunft der betreffenden Personen und reduziert sie darauf.
Finanzielle Belastung statt ideologischer Debatte
Neben der rechtlichen gibt es auch eine ökonomische Komponente. Der deutsche Wohlfahrtsstaat basiert auf einem Solidarprinzip: Die Bürger zahlen in das System ein, um sich gegenseitig in schwierigen Zeiten zu unterstützen. Dieser Wohlstand wurde über Generationen hinweg von denjenigen erarbeitet, die hier seit langem leben. Die Priorität liegt daher darauf, die vorhandenen Mittel zuerst unter denjenigen zu verteilen, die durch Steuern, Sozialabgaben und Arbeit zum Erhalt dieses Systems beitragen – nicht unter denen, die sich durch illegale Einreise und fehlende wirtschaftliche Eigenleistung in das System begeben.
Das ist keine ideologische Frage, sondern eine rein wirtschaftliche Abwägung. Ein Sozialsystem kann nur dann nachhaltig funktionieren, wenn es nicht unbegrenzt belastet wird. Würde Deutschland keine klaren Regeln zur Einwanderung und Abschiebung haben, würde dies unweigerlich zur Überlastung des Sozialstaates führen – mit negativen Konsequenzen für alle.
Sozialpatriotismus
Ein weiterer wichtiger Aspekt ist der Schutz der Arbeitsleistung jener Generationen, die Deutschland nach dem Zweiten Weltkrieg mühsam wieder aufgebaut haben. Während oft betont wird, dass die Deutschen moralisch kein Erbe aus der Zeit vor 1945 beanspruchen dürfen – außer der Verantwortung für den Holocaust –, ist es umso bedeutsamer, das neue Erbe nach 1945 zu respektieren, das auf Fleiß, Disziplin und harter Arbeit beruht. Der Wiederaufbau war eine kollektive Leistung deutscher Menschen, deren Früchte nicht bedenkenlos verteilt werden dürfen, sondern vorrangig denjenigen zugutekommen sollten, die dieses Fundament mitgeschaffen oder es über Generationen mitgetragen haben.
Rechtstaatlichkeit ist nicht verhandelbar
Wer sich für eine konsequente Abschiebepraxis ausspricht, tut dies nicht aus rassistischen Motiven, sondern aus Respekt vor der Rechtsstaatlichkeit und den wirtschaftlichen Grundlagen des Landes. Der Vorwurf des Rassismus in diesem Kontext ist daher nicht nur falsch, sondern entlarvt eine selektive Wahrnehmung nach rassistischen Merkmalen bei denjenigen, die ihn erheben.
-
@ 90c656ff:9383fd4e
2025-05-04 17:48:58
The Bitcoin network was designed to be secure, decentralized, and resistant to censorship. However, as its usage grows, an important challenge arises: scalability. This term refers to the network's ability to manage an increasing number of transactions without affecting performance or security. This challenge has sparked the speed dilemma, which involves balancing transaction speed with the preservation of decentralization and security that the blockchain or timechain provides.
Scalability is the ability of a system to increase its performance to meet higher demands. In the case of Bitcoin, this means processing a greater number of transactions per second (TPS) without compromising the network's core principles.
Currently, the Bitcoin network processes about 7 transactions per second, a number considered low compared to traditional systems, such as credit card networks, which can process thousands of transactions per second. This limit is directly due to the fixed block size (1 MB) and the average 10-minute interval for creating a new block in the blockchain or timechain.
The speed dilemma arises from the need to balance three essential elements: decentralization, security, and speed.
The Timechain/"Blockchain" Trilemma:
01 - Decentralization: The Bitcoin network is composed of thousands of independent nodes that verify and validate transactions. Increasing the block size or making them faster could raise computational requirements, making it harder for smaller nodes to participate and affecting decentralization. 02 - Security: Security comes from the mining process and block validation. Increasing transaction speed could compromise security, as it would reduce the time needed to verify each block, making the network more vulnerable to attacks. 03 - Speed: The need to confirm transactions quickly is crucial for Bitcoin to be used as a payment method in everyday life. However, prioritizing speed could affect both security and decentralization.
This dilemma requires balanced solutions to expand the network without sacrificing its core features.
Solutions to the Scalability Problem
Several solutions have been suggested to address the scalability and speed challenges in the Bitcoin network.
- On-Chain Optimization
01 - Segregated Witness (SegWit): Implemented in 2017, SegWit separates signature data from transactions, allowing more efficient use of space in blocks and increasing capacity without changing the block size. 02 - Increasing Block Size: Some proposals have suggested increasing the block size to allow more transactions per block. However, this could make the system more centralized as it would require greater computational power.
- Off-Chain Solutions
01 - Lightning Network: A second-layer solution that enables fast and low-cost transactions off the main blockchain or timechain. These transactions are later settled on the main network, maintaining security and decentralization. 02 - Payment Channels: Allow direct transactions between two users without the need to record every action on the network, reducing congestion. 03 - Sidechains: Proposals that create parallel networks connected to the main blockchain or timechain, providing more flexibility and processing capacity.
While these solutions bring significant improvements, they also present issues. For example, the Lightning Network depends on payment channels that require initial liquidity, limiting its widespread adoption. Increasing block size could make the system more susceptible to centralization, impacting network security.
Additionally, second-layer solutions may require extra trust between participants, which could weaken the decentralization and resistance to censorship principles that Bitcoin advocates.
Another important point is the need for large-scale adoption. Even with technological advancements, solutions will only be effective if they are widely used and accepted by users and developers.
In summary, scalability and the speed dilemma represent one of the greatest technical challenges for the Bitcoin network. While security and decentralization are essential to maintaining the system's original principles, the need for fast and efficient transactions makes scalability an urgent issue.
Solutions like SegWit and the Lightning Network have shown promising progress, but still face technical and adoption barriers. The balance between speed, security, and decentralization remains a central goal for Bitcoin’s future.
Thus, the continuous pursuit of innovation and improvement is essential for Bitcoin to maintain its relevance as a reliable and efficient network, capable of supporting global growth and adoption without compromising its core values.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ 52b4a076:e7fad8bd
2025-04-28 00:48:57
I have been recently building NFDB, a new relay DB. This post is meant as a short overview.
Regular relays have challenges
Current relay software have significant challenges, which I have experienced when hosting Nostr.land: - Scalability is only supported by adding full replicas, which does not scale to large relays. - Most relays use slow databases and are not optimized for large scale usage. - Search is near-impossible to implement on standard relays. - Privacy features such as NIP-42 are lacking. - Regular DB maintenance tasks on normal relays require extended downtime. - Fault-tolerance is implemented, if any, using a load balancer, which is limited. - Personalization and advanced filtering is not possible. - Local caching is not supported.
NFDB: A scalable database for large relays
NFDB is a new database meant for medium-large scale relays, built on FoundationDB that provides: - Near-unlimited scalability - Extended fault tolerance - Instant loading - Better search - Better personalization - and more.
Search
NFDB has extended search capabilities including: - Semantic search: Search for meaning, not words. - Interest-based search: Highlight content you care about. - Multi-faceted queries: Easily filter by topic, author group, keywords, and more at the same time. - Wide support for event kinds, including users, articles, etc.
Personalization
NFDB allows significant personalization: - Customized algorithms: Be your own algorithm. - Spam filtering: Filter content to your WoT, and use advanced spam filters. - Topic mutes: Mute topics, not keywords. - Media filtering: With Nostr.build, you will be able to filter NSFW and other content - Low data mode: Block notes that use high amounts of cellular data. - and more
Other
NFDB has support for many other features such as: - NIP-42: Protect your privacy with private drafts and DMs - Microrelays: Easily deploy your own personal microrelay - Containers: Dedicated, fast storage for discoverability events such as relay lists
Calcite: A local microrelay database
Calcite is a lightweight, local version of NFDB that is meant for microrelays and caching, meant for thousands of personal microrelays.
Calcite HA is an additional layer that allows live migration and relay failover in under 30 seconds, providing higher availability compared to current relays with greater simplicity. Calcite HA is enabled in all Calcite deployments.
For zero-downtime, NFDB is recommended.
Noswhere SmartCache
Relays are fixed in one location, but users can be anywhere.
Noswhere SmartCache is a CDN for relays that dynamically caches data on edge servers closest to you, allowing: - Multiple regions around the world - Improved throughput and performance - Faster loading times
routerd
routerdis a custom load-balancer optimized for Nostr relays, integrated with SmartCache.routerdis specifically integrated with NFDB and Calcite HA to provide fast failover and high performance.Ending notes
NFDB is planned to be deployed to Nostr.land in the coming weeks.
A lot more is to come. 👀️️️️️️
-
@ 3bf0c63f:aefa459d
2025-04-25 19:26:48
Redistributing Git with Nostr
Every time someone tries to "decentralize" Git -- like many projects tried in the past to do it with BitTorrent, IPFS, ScuttleButt or custom p2p protocols -- there is always a lurking comment: "but Git is already distributed!", and then the discussion proceeds to mention some facts about how Git supports multiple remotes and its magic syncing and merging abilities and so on.
Turns out all that is true, Git is indeed all that powerful, and yet GitHub is the big central hub that hosts basically all Git repositories in the giant world of open-source. There are some crazy people that host their stuff elsewhere, but these projects end up not being found by many people, and even when they do they suffer from lack of contributions.
Because everybody has a GitHub account it's easy to open a pull request to a repository of a project you're using if it's on GitHub (to be fair I think it's very annoying to have to clone the repository, then add it as a remote locally, push to it, then go on the web UI and click to open a pull request, then that cloned repository lurks forever in your profile unless you go through 16 screens to delete it -- but people in general seem to think it's easy).
It's much harder to do it on some random other server where some project might be hosted, because now you have to add 4 more even more annoying steps: create an account; pick a password; confirm an email address; setup SSH keys for pushing. (And I'm not even mentioning the basic impossibility of offering
pushaccess to external unknown contributors to people who want to host their own simple homemade Git server.)At this point some may argue that we could all have accounts on GitLab, or Codeberg or wherever else, then those steps are removed. Besides not being a practical strategy this pseudo solution misses the point of being decentralized (or distributed, who knows) entirely: it's far from the ideal to force everybody to have the double of account management and SSH setup work in order to have the open-source world controlled by two shady companies instead of one.
What we want is to give every person the opportunity to host their own Git server without being ostracized. at the same time we must recognize that most people won't want to host their own servers (not even most open-source programmers!) and give everybody the ability to host their stuff on multi-tenant servers (such as GitHub) too. Importantly, though, if we allow for a random person to have a standalone Git server on a standalone server they host themselves on their wood cabin that also means any new hosting company can show up and start offering Git hosting, with or without new cool features, charging high or low or zero, and be immediately competing against GitHub or GitLab, i.e. we must remove the network-effect centralization pressure.
External contributions
The first problem we have to solve is: how can Bob contribute to Alice's repository without having an account on Alice's server?
SourceHut has reminded GitHub users that Git has always had this (for most) arcane
git send-emailcommand that is the original way to send patches, using an once-open protocol.Turns out Nostr acts as a quite powerful email replacement and can be used to send text content just like email, therefore patches are a very good fit for Nostr event contents.
Once you get used to it and the proper UIs (or CLIs) are built sending and applying patches to and from others becomes a much easier flow than the intense clickops mixed with terminal copypasting that is interacting with GitHub (you have to clone the repository on GitHub, then update the remote URL in your local directory, then create a branch and then go back and turn that branch into a Pull Request, it's quite tiresome) that many people already dislike so much they went out of their way to build many GitHub CLI tools just so they could comment on issues and approve pull requests from their terminal.
Replacing GitHub features
Aside from being the "hub" that people use to send patches to other people's code (because no one can do the email flow anymore, justifiably), GitHub also has 3 other big features that are not directly related to Git, but that make its network-effect harder to overcome. Luckily Nostr can be used to create a new environment in which these same features are implemented in a more decentralized and healthy way.
Issues: bug reports, feature requests and general discussions
Since the "Issues" GitHub feature is just a bunch of text comments it should be very obvious that Nostr is a perfect fit for it.
I will not even mention the fact that Nostr is much better at threading comments than GitHub (which doesn't do it at all), which can generate much more productive and organized discussions (and you can opt out if you want).
Search
I use GitHub search all the time to find libraries and projects that may do something that I need, and it returns good results almost always. So if people migrated out to other code hosting providers wouldn't we lose it?
The fact is that even though we think everybody is on GitHub that is a globalist falsehood. Some projects are not on GitHub, and if we use only GitHub for search those will be missed. So even if we didn't have a Nostr Git alternative it would still be necessary to create a search engine that incorporated GitLab, Codeberg, SourceHut and whatnot.
Turns out on Nostr we can make that quite easy by not forcing anyone to integrate custom APIs or hardcoding Git provider URLs: each repository can make itself available by publishing an "announcement" event with a brief description and one or more Git URLs. That makes it easy for a search engine to index them -- and even automatically download the code and index the code (or index just README files or whatever) without a centralized platform ever having to be involved.
The relays where such announcements will be available play a role, of course, but that isn't a bad role: each announcement can be in multiple relays known for storing "public good" projects, some relays may curate only projects known to be very good according to some standards, other relays may allow any kind of garbage, which wouldn't make them good for a search engine to rely upon, but would still be useful in case one knows the exact thing (and from whom) they're searching for (the same is valid for all Nostr content, by the way, and that's where it's censorship-resistance comes from).
Continuous integration
GitHub Actions are a very hardly subsidized free-compute-for-all-paid-by-Microsoft feature, but one that isn't hard to replace at all. In fact there exists today many companies offering the same kind of service out there -- although they are mostly targeting businesses and not open-source projects, before GitHub Actions was introduced there were also many that were heavily used by open-source projects.
One problem is that these services are still heavily tied to GitHub today, they require a GitHub login, sometimes BitBucket and GitLab and whatnot, and do not allow one to paste an arbitrary Git server URL, but that isn't a thing that is very hard to change anyway, or to start from scratch. All we need are services that offer the CI/CD flows, perhaps using the same framework of GitHub Actions (although I would prefer to not use that messy garbage), and charge some few satoshis for it.
It may be the case that all the current services only support the big Git hosting platforms because they rely on their proprietary APIs, most notably the webhooks dispatched when a repository is updated, to trigger the jobs. It doesn't have to be said that Nostr can also solve that problem very easily.
-
@ 0fa80bd3:ea7325de
2025-01-29 15:43:42
Lyn Alden - биткойн евангелист или евангелистка, я пока не понял
npub1a2cww4kn9wqte4ry70vyfwqyqvpswksna27rtxd8vty6c74era8sdcw83aThomas Pacchia - PubKey owner - X - @tpacchia
npub1xy6exlg37pw84cpyj05c2pdgv86hr25cxn0g7aa8g8a6v97mhduqeuhgplcalvadev - Shopstr
npub16dhgpql60vmd4mnydjut87vla23a38j689jssaqlqqlzrtqtd0kqex0nkqCalle - Cashu founder
npub12rv5lskctqxxs2c8rf2zlzc7xx3qpvzs3w4etgemauy9thegr43sf485vgДжек Дорси
npub1sg6plzptd64u62a878hep2kev88swjh3tw00gjsfl8f237lmu63q0uf63m21 ideas
npub1lm3f47nzyf0rjp6fsl4qlnkmzed4uj4h2gnf2vhe3l3mrj85vqks6z3c7lМного адресов. Хз кто надо сортировать
https://github.com/aitechguy/nostr-address-bookФиатДжеф - создатель Ностр - https://github.com/fiatjaf
npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6EVAN KALOUDIS Zues wallet
npub19kv88vjm7tw6v9qksn2y6h4hdt6e79nh3zjcud36k9n3lmlwsleqwte2qdПрограммер Коди https://github.com/CodyTseng/nostr-relay
npub1syjmjy0dp62dhccq3g97fr87tngvpvzey08llyt6ul58m2zqpzps9wf6wlAnna Chekhovich - Managing Bitcoin at The Anti-Corruption Foundation https://x.com/AnyaChekhovich
npub1y2st7rp54277hyd2usw6shy3kxprnmpvhkezmldp7vhl7hp920aq9cfyr7 -
@ 6be5cc06:5259daf0
2025-01-21 01:51:46
Bitcoin: Um sistema de dinheiro eletrônico direto entre pessoas.
Satoshi Nakamoto
satoshin@gmx.com
www.bitcoin.org
Resumo
O Bitcoin é uma forma de dinheiro digital que permite pagamentos diretos entre pessoas, sem a necessidade de um banco ou instituição financeira. Ele resolve um problema chamado gasto duplo, que ocorre quando alguém tenta gastar o mesmo dinheiro duas vezes. Para evitar isso, o Bitcoin usa uma rede descentralizada onde todos trabalham juntos para verificar e registrar as transações.
As transações são registradas em um livro público chamado blockchain, protegido por uma técnica chamada Prova de Trabalho. Essa técnica cria uma cadeia de registros que não pode ser alterada sem refazer todo o trabalho já feito. Essa cadeia é mantida pelos computadores que participam da rede, e a mais longa é considerada a verdadeira.
Enquanto a maior parte do poder computacional da rede for controlada por participantes honestos, o sistema continuará funcionando de forma segura. A rede é flexível, permitindo que qualquer pessoa entre ou saia a qualquer momento, sempre confiando na cadeia mais longa como prova do que aconteceu.
1. Introdução
Hoje, quase todos os pagamentos feitos pela internet dependem de bancos ou empresas como processadores de pagamento (cartões de crédito, por exemplo) para funcionar. Embora esse sistema seja útil, ele tem problemas importantes porque é baseado em confiança.
Primeiro, essas empresas podem reverter pagamentos, o que é útil em caso de erros, mas cria custos e incertezas. Isso faz com que pequenas transações, como pagar centavos por um serviço, se tornem inviáveis. Além disso, os comerciantes são obrigados a desconfiar dos clientes, pedindo informações extras e aceitando fraudes como algo inevitável.
Esses problemas não existem no dinheiro físico, como o papel-moeda, onde o pagamento é final e direto entre as partes. No entanto, não temos como enviar dinheiro físico pela internet sem depender de um intermediário confiável.
O que precisamos é de um sistema de pagamento eletrônico baseado em provas matemáticas, não em confiança. Esse sistema permitiria que qualquer pessoa enviasse dinheiro diretamente para outra, sem depender de bancos ou processadores de pagamento. Além disso, as transações seriam irreversíveis, protegendo vendedores contra fraudes, mas mantendo a possibilidade de soluções para disputas legítimas.
Neste documento, apresentamos o Bitcoin, que resolve o problema do gasto duplo usando uma rede descentralizada. Essa rede cria um registro público e protegido por cálculos matemáticos, que garante a ordem das transações. Enquanto a maior parte da rede for controlada por pessoas honestas, o sistema será seguro contra ataques.
2. Transações
Para entender como funciona o Bitcoin, é importante saber como as transações são realizadas. Imagine que você quer transferir uma "moeda digital" para outra pessoa. No sistema do Bitcoin, essa "moeda" é representada por uma sequência de registros que mostram quem é o atual dono. Para transferi-la, você adiciona um novo registro comprovando que agora ela pertence ao próximo dono. Esse registro é protegido por um tipo especial de assinatura digital.
O que é uma assinatura digital?
Uma assinatura digital é como uma senha secreta, mas muito mais segura. No Bitcoin, cada usuário tem duas chaves: uma "chave privada", que é secreta e serve para criar a assinatura, e uma "chave pública", que pode ser compartilhada com todos e é usada para verificar se a assinatura é válida. Quando você transfere uma moeda, usa sua chave privada para assinar a transação, provando que você é o dono. A próxima pessoa pode usar sua chave pública para confirmar isso.
Como funciona na prática?
Cada "moeda" no Bitcoin é, na verdade, uma cadeia de assinaturas digitais. Vamos imaginar o seguinte cenário:
- A moeda está com o Dono 0 (você). Para transferi-la ao Dono 1, você assina digitalmente a transação com sua chave privada. Essa assinatura inclui o código da transação anterior (chamado de "hash") e a chave pública do Dono 1.
- Quando o Dono 1 quiser transferir a moeda ao Dono 2, ele assinará a transação seguinte com sua própria chave privada, incluindo também o hash da transação anterior e a chave pública do Dono 2.
- Esse processo continua, formando uma "cadeia" de transações. Qualquer pessoa pode verificar essa cadeia para confirmar quem é o atual dono da moeda.
Resolvendo o problema do gasto duplo
Um grande desafio com moedas digitais é o "gasto duplo", que é quando uma mesma moeda é usada em mais de uma transação. Para evitar isso, muitos sistemas antigos dependiam de uma entidade central confiável, como uma casa da moeda, que verificava todas as transações. No entanto, isso criava um ponto único de falha e centralizava o controle do dinheiro.
O Bitcoin resolve esse problema de forma inovadora: ele usa uma rede descentralizada onde todos os participantes (os "nós") têm acesso a um registro completo de todas as transações. Cada nó verifica se as transações são válidas e se a moeda não foi gasta duas vezes. Quando a maioria dos nós concorda com a validade de uma transação, ela é registrada permanentemente na blockchain.
Por que isso é importante?
Essa solução elimina a necessidade de confiar em uma única entidade para gerenciar o dinheiro, permitindo que qualquer pessoa no mundo use o Bitcoin sem precisar de permissão de terceiros. Além disso, ela garante que o sistema seja seguro e resistente a fraudes.
3. Servidor Timestamp
Para assegurar que as transações sejam realizadas de forma segura e transparente, o sistema Bitcoin utiliza algo chamado de "servidor de registro de tempo" (timestamp). Esse servidor funciona como um registro público que organiza as transações em uma ordem específica.
Ele faz isso agrupando várias transações em blocos e criando um código único chamado "hash". Esse hash é como uma impressão digital que representa todo o conteúdo do bloco. O hash de cada bloco é amplamente divulgado, como se fosse publicado em um jornal ou em um fórum público.
Esse processo garante que cada bloco de transações tenha um registro de quando foi criado e que ele existia naquele momento. Além disso, cada novo bloco criado contém o hash do bloco anterior, formando uma cadeia contínua de blocos conectados — conhecida como blockchain.
Com isso, se alguém tentar alterar qualquer informação em um bloco anterior, o hash desse bloco mudará e não corresponderá ao hash armazenado no bloco seguinte. Essa característica torna a cadeia muito segura, pois qualquer tentativa de fraude seria imediatamente detectada.
O sistema de timestamps é essencial para provar a ordem cronológica das transações e garantir que cada uma delas seja única e autêntica. Dessa forma, ele reforça a segurança e a confiança na rede Bitcoin.
4. Prova-de-Trabalho
Para implementar o registro de tempo distribuído no sistema Bitcoin, utilizamos um mecanismo chamado prova-de-trabalho. Esse sistema é semelhante ao Hashcash, desenvolvido por Adam Back, e baseia-se na criação de um código único, o "hash", por meio de um processo computacionalmente exigente.
A prova-de-trabalho envolve encontrar um valor especial que, quando processado junto com as informações do bloco, gere um hash que comece com uma quantidade específica de zeros. Esse valor especial é chamado de "nonce". Encontrar o nonce correto exige um esforço significativo do computador, porque envolve tentativas repetidas até que a condição seja satisfeita.
Esse processo é importante porque torna extremamente difícil alterar qualquer informação registrada em um bloco. Se alguém tentar mudar algo em um bloco, seria necessário refazer o trabalho de computação não apenas para aquele bloco, mas também para todos os blocos que vêm depois dele. Isso garante a segurança e a imutabilidade da blockchain.
A prova-de-trabalho também resolve o problema de decidir qual cadeia de blocos é a válida quando há múltiplas cadeias competindo. A decisão é feita pela cadeia mais longa, pois ela representa o maior esforço computacional já realizado. Isso impede que qualquer indivíduo ou grupo controle a rede, desde que a maioria do poder de processamento seja mantida por participantes honestos.
Para garantir que o sistema permaneça eficiente e equilibrado, a dificuldade da prova-de-trabalho é ajustada automaticamente ao longo do tempo. Se novos blocos estiverem sendo gerados rapidamente, a dificuldade aumenta; se estiverem sendo gerados muito lentamente, a dificuldade diminui. Esse ajuste assegura que novos blocos sejam criados aproximadamente a cada 10 minutos, mantendo o sistema estável e funcional.
5. Rede
A rede Bitcoin é o coração do sistema e funciona de maneira distribuída, conectando vários participantes (ou nós) para garantir o registro e a validação das transações. Os passos para operar essa rede são:
-
Transmissão de Transações: Quando alguém realiza uma nova transação, ela é enviada para todos os nós da rede. Isso é feito para garantir que todos estejam cientes da operação e possam validá-la.
-
Coleta de Transações em Blocos: Cada nó agrupa as novas transações recebidas em um "bloco". Este bloco será preparado para ser adicionado à cadeia de blocos (a blockchain).
-
Prova-de-Trabalho: Os nós competem para resolver a prova-de-trabalho do bloco, utilizando poder computacional para encontrar um hash válido. Esse processo é como resolver um quebra-cabeça matemático difícil.
-
Envio do Bloco Resolvido: Quando um nó encontra a solução para o bloco (a prova-de-trabalho), ele compartilha esse bloco com todos os outros nós na rede.
-
Validação do Bloco: Cada nó verifica o bloco recebido para garantir que todas as transações nele contidas sejam válidas e que nenhuma moeda tenha sido gasta duas vezes. Apenas blocos válidos são aceitos.
-
Construção do Próximo Bloco: Os nós que aceitaram o bloco começam a trabalhar na criação do próximo bloco, utilizando o hash do bloco aceito como base (hash anterior). Isso mantém a continuidade da cadeia.
Resolução de Conflitos e Escolha da Cadeia Mais Longa
Os nós sempre priorizam a cadeia mais longa, pois ela representa o maior esforço computacional já realizado, garantindo maior segurança. Se dois blocos diferentes forem compartilhados simultaneamente, os nós trabalharão no primeiro bloco recebido, mas guardarão o outro como uma alternativa. Caso o segundo bloco eventualmente forme uma cadeia mais longa (ou seja, tenha mais blocos subsequentes), os nós mudarão para essa nova cadeia.
Tolerância a Falhas
A rede é robusta e pode lidar com mensagens que não chegam a todos os nós. Uma transação não precisa alcançar todos os nós de imediato; basta que chegue a um número suficiente deles para ser incluída em um bloco. Da mesma forma, se um nó não receber um bloco em tempo hábil, ele pode solicitá-lo ao perceber que está faltando quando o próximo bloco é recebido.
Esse mecanismo descentralizado permite que a rede Bitcoin funcione de maneira segura, confiável e resiliente, sem depender de uma autoridade central.
6. Incentivo
O incentivo é um dos pilares fundamentais que sustenta o funcionamento da rede Bitcoin, garantindo que os participantes (nós) continuem operando de forma honesta e contribuindo com recursos computacionais. Ele é estruturado em duas partes principais: a recompensa por mineração e as taxas de transação.
Recompensa por Mineração
Por convenção, o primeiro registro em cada bloco é uma transação especial que cria novas moedas e as atribui ao criador do bloco. Essa recompensa incentiva os mineradores a dedicarem poder computacional para apoiar a rede. Como não há uma autoridade central para emitir moedas, essa é a maneira pela qual novas moedas entram em circulação. Esse processo pode ser comparado ao trabalho de garimpeiros, que utilizam recursos para colocar mais ouro em circulação. No caso do Bitcoin, o "recurso" consiste no tempo de CPU e na energia elétrica consumida para resolver a prova-de-trabalho.
Taxas de Transação
Além da recompensa por mineração, os mineradores também podem ser incentivados pelas taxas de transação. Se uma transação utiliza menos valor de saída do que o valor de entrada, a diferença é tratada como uma taxa, que é adicionada à recompensa do bloco contendo essa transação. Com o passar do tempo e à medida que o número de moedas em circulação atinge o limite predeterminado, essas taxas de transação se tornam a principal fonte de incentivo, substituindo gradualmente a emissão de novas moedas. Isso permite que o sistema opere sem inflação, uma vez que o número total de moedas permanece fixo.
Incentivo à Honestidade
O design do incentivo também busca garantir que os participantes da rede mantenham um comportamento honesto. Para um atacante que consiga reunir mais poder computacional do que o restante da rede, ele enfrentaria duas escolhas:
- Usar esse poder para fraudar o sistema, como reverter transações e roubar pagamentos.
- Seguir as regras do sistema, criando novos blocos e recebendo recompensas legítimas.
A lógica econômica favorece a segunda opção, pois um comportamento desonesto prejudicaria a confiança no sistema, diminuindo o valor de todas as moedas, incluindo aquelas que o próprio atacante possui. Jogar dentro das regras não apenas maximiza o retorno financeiro, mas também preserva a validade e a integridade do sistema.
Esse mecanismo garante que os incentivos econômicos estejam alinhados com o objetivo de manter a rede segura, descentralizada e funcional ao longo do tempo.
7. Recuperação do Espaço em Disco
Depois que uma moeda passa a estar protegida por muitos blocos na cadeia, as informações sobre as transações antigas que a geraram podem ser descartadas para economizar espaço em disco. Para que isso seja possível sem comprometer a segurança, as transações são organizadas em uma estrutura chamada "árvore de Merkle". Essa árvore funciona como um resumo das transações: em vez de armazenar todas elas, guarda apenas um "hash raiz", que é como uma assinatura compacta que representa todo o grupo de transações.
Os blocos antigos podem, então, ser simplificados, removendo as partes desnecessárias dessa árvore. Apenas a raiz do hash precisa ser mantida no cabeçalho do bloco, garantindo que a integridade dos dados seja preservada, mesmo que detalhes específicos sejam descartados.
Para exemplificar: imagine que você tenha vários recibos de compra. Em vez de guardar todos os recibos, você cria um documento e lista apenas o valor total de cada um. Mesmo que os recibos originais sejam descartados, ainda é possível verificar a soma com base nos valores armazenados.
Além disso, o espaço ocupado pelos blocos em si é muito pequeno. Cada bloco sem transações ocupa apenas cerca de 80 bytes. Isso significa que, mesmo com blocos sendo gerados a cada 10 minutos, o crescimento anual em espaço necessário é insignificante: apenas 4,2 MB por ano. Com a capacidade de armazenamento dos computadores crescendo a cada ano, esse espaço continuará sendo trivial, garantindo que a rede possa operar de forma eficiente sem problemas de armazenamento, mesmo a longo prazo.
8. Verificação de Pagamento Simplificada
É possível confirmar pagamentos sem a necessidade de operar um nó completo da rede. Para isso, o usuário precisa apenas de uma cópia dos cabeçalhos dos blocos da cadeia mais longa (ou seja, a cadeia com maior esforço de trabalho acumulado). Ele pode verificar a validade de uma transação ao consultar os nós da rede até obter a confirmação de que tem a cadeia mais longa. Para isso, utiliza-se o ramo Merkle, que conecta a transação ao bloco em que ela foi registrada.
Entretanto, o método simplificado possui limitações: ele não pode confirmar uma transação isoladamente, mas sim assegurar que ela ocupa um lugar específico na cadeia mais longa. Dessa forma, se um nó da rede aprova a transação, os blocos subsequentes reforçam essa aceitação.
A verificação simplificada é confiável enquanto a maioria dos nós da rede for honesta. Contudo, ela se torna vulnerável caso a rede seja dominada por um invasor. Nesse cenário, um atacante poderia fabricar transações fraudulentas que enganariam o usuário temporariamente até que o invasor obtivesse controle completo da rede.
Uma estratégia para mitigar esse risco é configurar alertas nos softwares de nós completos. Esses alertas identificam blocos inválidos, sugerindo ao usuário baixar o bloco completo para confirmar qualquer inconsistência. Para maior segurança, empresas que realizam pagamentos frequentes podem preferir operar seus próprios nós, reduzindo riscos e permitindo uma verificação mais direta e confiável.
9. Combinando e Dividindo Valor
No sistema Bitcoin, cada unidade de valor é tratada como uma "moeda" individual, mas gerenciar cada centavo como uma transação separada seria impraticável. Para resolver isso, o Bitcoin permite que valores sejam combinados ou divididos em transações, facilitando pagamentos de qualquer valor.
Entradas e Saídas
Cada transação no Bitcoin é composta por:
- Entradas: Representam os valores recebidos em transações anteriores.
- Saídas: Correspondem aos valores enviados, divididos entre os destinatários e, eventualmente, o troco para o remetente.
Normalmente, uma transação contém:
- Uma única entrada com valor suficiente para cobrir o pagamento.
- Ou várias entradas combinadas para atingir o valor necessário.
O valor total das saídas nunca excede o das entradas, e a diferença (se houver) pode ser retornada ao remetente como troco.
Exemplo Prático
Imagine que você tem duas entradas:
- 0,03 BTC
- 0,07 BTC
Se deseja enviar 0,08 BTC para alguém, a transação terá:
- Entrada: As duas entradas combinadas (0,03 + 0,07 BTC = 0,10 BTC).
- Saídas: Uma para o destinatário (0,08 BTC) e outra como troco para você (0,02 BTC).
Essa flexibilidade permite que o sistema funcione sem precisar manipular cada unidade mínima individualmente.
Difusão e Simplificação
A difusão de transações, onde uma depende de várias anteriores e assim por diante, não representa um problema. Não é necessário armazenar ou verificar o histórico completo de uma transação para utilizá-la, já que o registro na blockchain garante sua integridade.
10. Privacidade
O modelo bancário tradicional oferece um certo nível de privacidade, limitando o acesso às informações financeiras apenas às partes envolvidas e a um terceiro confiável (como bancos ou instituições financeiras). No entanto, o Bitcoin opera de forma diferente, pois todas as transações são publicamente registradas na blockchain. Apesar disso, a privacidade pode ser mantida utilizando chaves públicas anônimas, que desvinculam diretamente as transações das identidades das partes envolvidas.
Fluxo de Informação
- No modelo tradicional, as transações passam por um terceiro confiável que conhece tanto o remetente quanto o destinatário.
- No Bitcoin, as transações são anunciadas publicamente, mas sem revelar diretamente as identidades das partes. Isso é comparável a dados divulgados por bolsas de valores, onde informações como o tempo e o tamanho das negociações (a "fita") são públicas, mas as identidades das partes não.
Protegendo a Privacidade
Para aumentar a privacidade no Bitcoin, são adotadas as seguintes práticas:
- Chaves Públicas Anônimas: Cada transação utiliza um par de chaves diferentes, dificultando a associação com um proprietário único.
- Prevenção de Ligação: Ao usar chaves novas para cada transação, reduz-se a possibilidade de links evidentes entre múltiplas transações realizadas pelo mesmo usuário.
Riscos de Ligação
Embora a privacidade seja fortalecida, alguns riscos permanecem:
- Transações multi-entrada podem revelar que todas as entradas pertencem ao mesmo proprietário, caso sejam necessárias para somar o valor total.
- O proprietário da chave pode ser identificado indiretamente por transações anteriores que estejam conectadas.
11. Cálculos
Imagine que temos um sistema onde as pessoas (ou computadores) competem para adicionar informações novas (blocos) a um grande registro público (a cadeia de blocos ou blockchain). Este registro é como um livro contábil compartilhado, onde todos podem verificar o que está escrito.
Agora, vamos pensar em um cenário: um atacante quer enganar o sistema. Ele quer mudar informações já registradas para beneficiar a si mesmo, por exemplo, desfazendo um pagamento que já fez. Para isso, ele precisa criar uma versão alternativa do livro contábil (a cadeia de blocos dele) e convencer todos os outros participantes de que essa versão é a verdadeira.
Mas isso é extremamente difícil.
Como o Ataque Funciona
Quando um novo bloco é adicionado à cadeia, ele depende de cálculos complexos que levam tempo e esforço. Esses cálculos são como um grande quebra-cabeça que precisa ser resolvido.
- Os “bons jogadores” (nós honestos) estão sempre trabalhando juntos para resolver esses quebra-cabeças e adicionar novos blocos à cadeia verdadeira.
- O atacante, por outro lado, precisa resolver quebra-cabeças sozinho, tentando “alcançar” a cadeia honesta para que sua versão alternativa pareça válida.
Se a cadeia honesta já está vários blocos à frente, o atacante começa em desvantagem, e o sistema está projetado para que a dificuldade de alcançá-los aumente rapidamente.
A Corrida Entre Cadeias
Você pode imaginar isso como uma corrida. A cada bloco novo que os jogadores honestos adicionam à cadeia verdadeira, eles se distanciam mais do atacante. Para vencer, o atacante teria que resolver os quebra-cabeças mais rápido que todos os outros jogadores honestos juntos.
Suponha que:
- A rede honesta tem 80% do poder computacional (ou seja, resolve 8 de cada 10 quebra-cabeças).
- O atacante tem 20% do poder computacional (ou seja, resolve 2 de cada 10 quebra-cabeças).
Cada vez que a rede honesta adiciona um bloco, o atacante tem que "correr atrás" e resolver mais quebra-cabeças para alcançar.
Por Que o Ataque Fica Cada Vez Mais Improvável?
Vamos usar uma fórmula simples para mostrar como as chances de sucesso do atacante diminuem conforme ele precisa "alcançar" mais blocos:
P = (q/p)^z
- q é o poder computacional do atacante (20%, ou 0,2).
- p é o poder computacional da rede honesta (80%, ou 0,8).
- z é a diferença de blocos entre a cadeia honesta e a cadeia do atacante.
Se o atacante está 5 blocos atrás (z = 5):
P = (0,2 / 0,8)^5 = (0,25)^5 = 0,00098, (ou, 0,098%)
Isso significa que o atacante tem menos de 0,1% de chance de sucesso — ou seja, é muito improvável.
Se ele estiver 10 blocos atrás (z = 10):
P = (0,2 / 0,8)^10 = (0,25)^10 = 0,000000095, (ou, 0,0000095%).
Neste caso, as chances de sucesso são praticamente nulas.
Um Exemplo Simples
Se você jogar uma moeda, a chance de cair “cara” é de 50%. Mas se precisar de 10 caras seguidas, sua chance já é bem menor. Se precisar de 20 caras seguidas, é quase impossível.
No caso do Bitcoin, o atacante precisa de muito mais do que 20 caras seguidas. Ele precisa resolver quebra-cabeças extremamente difíceis e alcançar os jogadores honestos que estão sempre à frente. Isso faz com que o ataque seja inviável na prática.
Por Que Tudo Isso é Seguro?
- A probabilidade de sucesso do atacante diminui exponencialmente. Isso significa que, quanto mais tempo passa, menor é a chance de ele conseguir enganar o sistema.
- A cadeia verdadeira (honesta) está protegida pela força da rede. Cada novo bloco que os jogadores honestos adicionam à cadeia torna mais difícil para o atacante alcançar.
E Se o Atacante Tentar Continuar?
O atacante poderia continuar tentando indefinidamente, mas ele estaria gastando muito tempo e energia sem conseguir nada. Enquanto isso, os jogadores honestos estão sempre adicionando novos blocos, tornando o trabalho do atacante ainda mais inútil.
Assim, o sistema garante que a cadeia verdadeira seja extremamente segura e que ataques sejam, na prática, impossíveis de ter sucesso.
12. Conclusão
Propusemos um sistema de transações eletrônicas que elimina a necessidade de confiança, baseando-se em assinaturas digitais e em uma rede peer-to-peer que utiliza prova de trabalho. Isso resolve o problema do gasto duplo, criando um histórico público de transações imutável, desde que a maioria do poder computacional permaneça sob controle dos participantes honestos. A rede funciona de forma simples e descentralizada, com nós independentes que não precisam de identificação ou coordenação direta. Eles entram e saem livremente, aceitando a cadeia de prova de trabalho como registro do que ocorreu durante sua ausência. As decisões são tomadas por meio do poder de CPU, validando blocos legítimos, estendendo a cadeia e rejeitando os inválidos. Com este mecanismo de consenso, todas as regras e incentivos necessários para o funcionamento seguro e eficiente do sistema são garantidos.
Faça o download do whitepaper original em português: https://bitcoin.org/files/bitcoin-paper/bitcoin_pt_br.pdf
-
@ a39d19ec:3d88f61e
2025-03-18 17:16:50
Nun da das deutsche Bundesregime den Ruin Deutschlands beschlossen hat, der sehr wahrscheinlich mit dem Werkzeug des Geld druckens "finanziert" wird, kamen mir so viele Gedanken zur Geldmengenausweitung, dass ich diese für einmal niedergeschrieben habe.
Die Ausweitung der Geldmenge führt aus klassischer wirtschaftlicher Sicht immer zu Preissteigerungen, weil mehr Geld im Umlauf auf eine begrenzte Menge an Gütern trifft. Dies lässt sich in mehreren Schritten analysieren:
1. Quantitätstheorie des Geldes
Die klassische Gleichung der Quantitätstheorie des Geldes lautet:
M • V = P • Y
wobei:
- M die Geldmenge ist,
- V die Umlaufgeschwindigkeit des Geldes,
- P das Preisniveau,
- Y die reale Wirtschaftsleistung (BIP).Wenn M steigt und V sowie Y konstant bleiben, muss P steigen – also Inflation entstehen.
2. Gütermenge bleibt begrenzt
Die Menge an real produzierten Gütern und Dienstleistungen wächst meist nur langsam im Vergleich zur Ausweitung der Geldmenge. Wenn die Geldmenge schneller steigt als die Produktionsgütermenge, führt dies dazu, dass mehr Geld für die gleiche Menge an Waren zur Verfügung steht – die Preise steigen.
3. Erwartungseffekte und Spekulation
Wenn Unternehmen und Haushalte erwarten, dass mehr Geld im Umlauf ist, da eine zentrale Planung es so wollte, können sie steigende Preise antizipieren. Unternehmen erhöhen ihre Preise vorab, und Arbeitnehmer fordern höhere Löhne. Dies kann eine sich selbst verstärkende Spirale auslösen.
4. Internationale Perspektive
Eine erhöhte Geldmenge kann die Währung abwerten, wenn andere Länder ihre Geldpolitik stabil halten. Eine schwächere Währung macht Importe teurer, was wiederum Preissteigerungen antreibt.
5. Kritik an der reinen Geldmengen-Theorie
Der Vollständigkeit halber muss erwähnt werden, dass die meisten modernen Ökonomen im Staatsauftrag argumentieren, dass Inflation nicht nur von der Geldmenge abhängt, sondern auch von der Nachfrage nach Geld (z. B. in einer Wirtschaftskrise). Dennoch zeigt die historische Erfahrung, dass eine unkontrollierte Geldmengenausweitung langfristig immer zu Preissteigerungen führt, wie etwa in der Hyperinflation der Weimarer Republik oder in Simbabwe.
-
@ 87730827:746b7d35
2024-11-20 09:27:53
Original: https://techreport.com/crypto-news/brazil-central-bank-ban-monero-stablecoins/
Brazilian’s Central Bank Will Ban Monero and Algorithmic Stablecoins in the Country
Brazil proposes crypto regulations banning Monero and algorithmic stablecoins and enforcing strict compliance for exchanges.
KEY TAKEAWAYS
- The Central Bank of Brazil has proposed regulations prohibiting privacy-centric cryptocurrencies like Monero.
- The regulations categorize exchanges into intermediaries, custodians, and brokers, each with specific capital requirements and compliance standards.
- While the proposed rules apply to cryptocurrencies, certain digital assets like non-fungible tokens (NFTs) are still ‘deregulated’ in Brazil.

In a Notice of Participation announcement, the Brazilian Central Bank (BCB) outlines regulations for virtual asset service providers (VASPs) operating in the country.
In the document, the Brazilian regulator specifies that privacy-focused coins, such as Monero, must be excluded from all digital asset companies that intend to operate in Brazil.
Let’s unpack what effect these regulations will have.
Brazil’s Crackdown on Crypto Fraud
If the BCB’s current rule is approved, exchanges dealing with coins that provide anonymity must delist these currencies or prevent Brazilians from accessing and operating these assets.
The Central Bank argues that currencies like Monero make it difficult and even prevent the identification of users, thus creating problems in complying with international AML obligations and policies to prevent the financing of terrorism.
According to the Central Bank of Brazil, the bans aim to prevent criminals from using digital assets to launder money. In Brazil, organized criminal syndicates such as the Primeiro Comando da Capital (PCC) and Comando Vermelho have been increasingly using digital assets for money laundering and foreign remittances.
… restriction on the supply of virtual assets that contain characteristics of fragility, insecurity or risks that favor fraud or crime, such as virtual assets designed to favor money laundering and terrorist financing practices by facilitating anonymity or difficulty identification of the holder.
The Central Bank has identified that removing algorithmic stablecoins is essential to guarantee the safety of users’ funds and avoid events such as when Terraform Labs’ entire ecosystem collapsed, losing billions of investors’ dollars.
The Central Bank also wants to control all digital assets traded by companies in Brazil. According to the current proposal, the national regulator will have the power to ask platforms to remove certain listed assets if it considers that they do not meet local regulations.
However, the regulations will not include NFTs, real-world asset (RWA) tokens, RWA tokens classified as securities, and tokenized movable or real estate assets. These assets are still ‘deregulated’ in Brazil.
Monero: What Is It and Why Is Brazil Banning It?
Monero ($XMR) is a cryptocurrency that uses a protocol called CryptoNote. It launched in 2013 and ‘erases’ transaction data, preventing the sender and recipient addresses from being publicly known. The Monero network is based on a proof-of-work (PoW) consensus mechanism, which incentivizes miners to add blocks to the blockchain.
Like Brazil, other nations are banning Monero in search of regulatory compliance. Recently, Dubai’s new digital asset rules prohibited the issuance of activities related to anonymity-enhancing cryptocurrencies such as $XMR.
Furthermore, exchanges such as Binance have already announced they will delist Monero on their global platforms due to its anonymity features. Kraken did the same, removing Monero for their European-based users to comply with MiCA regulations.
Data from Chainalysis shows that Brazil is the seventh-largest Bitcoin market in the world.

In Latin America, Brazil is the largest market for digital assets. Globally, it leads in the innovation of RWA tokens, with several companies already trading this type of asset.
In Closing
Following other nations, Brazil’s regulatory proposals aim to combat illicit activities such as money laundering and terrorism financing.
Will the BCB’s move safeguard people’s digital assets while also stimulating growth and innovation in the crypto ecosystem? Only time will tell.
References
Cassio Gusson is a journalist passionate about technology, cryptocurrencies, and the nuances of human nature. With a career spanning roles as Senior Crypto Journalist at CriptoFacil and Head of News at CoinTelegraph, he offers exclusive insights on South America’s crypto landscape. A graduate in Communication from Faccamp and a post-graduate in Globalization and Culture from FESPSP, Cassio explores the intersection of governance, decentralization, and the evolution of global systems.
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ 41e6f20b:06049e45
2024-11-17 17:33:55
Let me tell you a beautiful story. Last night, during the speakers' dinner at Monerotopia, the waitress was collecting tiny tips in Mexican pesos. I asked her, "Do you really want to earn tips seriously?" I then showed her how to set up a Cake Wallet, and she started collecting tips in Monero, reaching 0.9 XMR. Of course, she wanted to cash out to fiat immediately, but it solved a real problem for her: making more money. That amount was something she would never have earned in a single workday. We kept talking, and I promised to give her Zoom workshops. What can I say? I love people, and that's why I'm a natural orange-piller.
-
@ 3bf0c63f:aefa459d
2024-09-06 12:49:46
Nostr: a quick introduction, attempt #2
Nostr doesn't subscribe to any ideals of "free speech" as these belong to the realm of politics and assume a big powerful government that enforces a common ruleupon everybody else.
Nostr instead is much simpler, it simply says that servers are private property and establishes a generalized framework for people to connect to all these servers, creating a true free market in the process. In other words, Nostr is the public road that each market participant can use to build their own store or visit others and use their services.
(Of course a road is never truly public, in normal cases it's ran by the government, in this case it relies upon the previous existence of the internet with all its quirks and chaos plus a hand of government control, but none of that matters for this explanation).
More concretely speaking, Nostr is just a set of definitions of the formats of the data that can be passed between participants and their expected order, i.e. messages between clients (i.e. the program that runs on a user computer) and relays (i.e. the program that runs on a publicly accessible computer, a "server", generally with a domain-name associated) over a type of TCP connection (WebSocket) with cryptographic signatures. This is what is called a "protocol" in this context, and upon that simple base multiple kinds of sub-protocols can be added, like a protocol for "public-square style microblogging", "semi-closed group chat" or, I don't know, "recipe sharing and feedback".
-
@ 37fe9853:bcd1b039
2025-01-11 15:04:40
yoyoaa
-
@ be39043c:4a573ca3
2024-08-16 01:59:24
Traditionally, miso making takes place during the cold winter. Miso is fermented during the warm season and start using after it gets cooler in the fall. However, I did make during the summer and there was no problem.
For 29oz miso
Ingredients: * Chickpeas 0.5lbs(227g) * Dried Koji 0.5lbs(227g) *not raw(active) koji * Natural salts 103g * Chickpeas : Koji: Salts = 1: 1: 0.45 (salts 12.5%)
I find chickpeas easier to handle than soy beans. For soy beans,
- Soy beans 230g (soak at least 18 hours)
- Dried Koji 340g
- Natural salts 30g(Salts 12.5%)
You also need :
Container for fermentation -32 oz glass jar (no metal lid) or strong plastic container or bag that can be sealed. * large mixing bowl
small bowl
* pressure cooker or large pot * food processor or blender or masher (I use the bottom of small glass jar sanitized with hotwater) * parchment paper or plastic wrap to cover the surface- Wash chickpeas and soak over night
- Cook chickpeas until it can be crashed with your thumb and pinky finger with a pressure cooker or a pot (this may take hours with a pot) Move a part of cooked liquid from the pot to a small bowl and drain the rest. Wait until chickpeas can be handled with hand.
- Mash chickpeas into paste
- Sanitize the 32oz jar with hot water or sanitizer of your choice
- Mixed dried koji with salts with hand
- Add koji and salts to the chickpea paste. Mix with hand well. Add a little bit of the liquid you put aside earlier if the paste is too dry (do not add too much).
- When mixed well, make balls with the paste using hands.
- Throw one of the balls into the jar and push onto the jar with your fist. Repeat this process. (you don't have to punch here. Just push. This process is to transfer the miso paste into the jar without air. The exposure to air will lead to mold. Make sure not to have a space.)
- After throwing all balls into the jar and place tightly without air, seal the surface with a piece of parchment paper or plastic wrap.
- Close the lid.
- Place the jar in a cool and dark place (room temperature). Leave 6 months to 2 years. After the half of the duration, you may pull out of paste and place the bottom half onto the upper half so that the miso will be evenly fermented. This process can be skipped. Check once in a couple of months if there is mold.
- If mold appears on the surface, just scrape it off.
Miso pro's video. He uses soys.
-
@ 62033ff8:e4471203
2025-01-11 15:00:24
收录的内容中 kind=1的部分,实话说 质量不高。 所以我增加了kind=30023 长文的article,但是更新的太少,多个relays 的服务器也没有多少长文。
所有搜索nostr如果需要产生价值,需要有高质量的文章和新闻。 而且现在有很多机器人的文章充满着浪费空间的作用,其他作用都用不上。
https://www.duozhutuan.com 目前放的是给搜索引擎提供搜索的原材料。没有做UI给人类浏览。所以看上去是粗糙的。 我并没有打算去做一个发microblog的 web客户端,那类的客户端太多了。
我觉得nostr社区需要解决的还是应用。如果仅仅是microblog 感觉有点够呛
幸运的是npub.pro 建站这样的,我觉得有点意思。
yakihonne 智能widget 也有意思
我做的TaskQ5 我自己在用了。分布式的任务系统,也挺好的。
-
@ 2ede6f6b:b94998e2
2024-08-15 21:11:43
test
originally posted at https://stacker.news/items/459389
-
@ 23b0e2f8:d8af76fc
2025-01-08 18:17:52
Necessário
- Um Android que você não use mais (a câmera deve estar funcionando).
- Um cartão microSD (opcional, usado apenas uma vez).
- Um dispositivo para acompanhar seus fundos (provavelmente você já tem um).
Algumas coisas que você precisa saber
- O dispositivo servirá como um assinador. Qualquer movimentação só será efetuada após ser assinada por ele.
- O cartão microSD será usado para transferir o APK do Electrum e garantir que o aparelho não terá contato com outras fontes de dados externas após sua formatação. Contudo, é possível usar um cabo USB para o mesmo propósito.
- A ideia é deixar sua chave privada em um dispositivo offline, que ficará desligado em 99% do tempo. Você poderá acompanhar seus fundos em outro dispositivo conectado à internet, como seu celular ou computador pessoal.
O tutorial será dividido em dois módulos:
- Módulo 1 - Criando uma carteira fria/assinador.
- Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
No final, teremos:
- Uma carteira fria que também servirá como assinador.
- Um dispositivo para acompanhar os fundos da carteira.

Módulo 1 - Criando uma carteira fria/assinador
-
Baixe o APK do Electrum na aba de downloads em https://electrum.org/. Fique à vontade para verificar as assinaturas do software, garantindo sua autenticidade.
-
Formate o cartão microSD e coloque o APK do Electrum nele. Caso não tenha um cartão microSD, pule este passo.

- Retire os chips e acessórios do aparelho que será usado como assinador, formate-o e aguarde a inicialização.

- Durante a inicialização, pule a etapa de conexão ao Wi-Fi e rejeite todas as solicitações de conexão. Após isso, você pode desinstalar aplicativos desnecessários, pois precisará apenas do Electrum. Certifique-se de que Wi-Fi, Bluetooth e dados móveis estejam desligados. Você também pode ativar o modo avião.\ (Curiosidade: algumas pessoas optam por abrir o aparelho e danificar a antena do Wi-Fi/Bluetooth, impossibilitando essas funcionalidades.)

- Insira o cartão microSD com o APK do Electrum no dispositivo e instale-o. Será necessário permitir instalações de fontes não oficiais.
- No Electrum, crie uma carteira padrão e gere suas palavras-chave (seed). Anote-as em um local seguro. Caso algo aconteça com seu assinador, essas palavras permitirão o acesso aos seus fundos novamente. (Aqui entra seu método pessoal de backup.)

Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
-
Criar uma carteira somente leitura em outro dispositivo, como seu celular ou computador pessoal, é uma etapa bastante simples. Para este tutorial, usaremos outro smartphone Android com Electrum. Instale o Electrum a partir da aba de downloads em https://electrum.org/ ou da própria Play Store. (ATENÇÃO: O Electrum não existe oficialmente para iPhone. Desconfie se encontrar algum.)
-
Após instalar o Electrum, crie uma carteira padrão, mas desta vez escolha a opção Usar uma chave mestra.

- Agora, no assinador que criamos no primeiro módulo, exporte sua chave pública: vá em Carteira > Detalhes da carteira > Compartilhar chave mestra pública.

-
Escaneie o QR gerado da chave pública com o dispositivo de consulta. Assim, ele poderá acompanhar seus fundos, mas sem permissão para movimentá-los.
-
Para receber fundos, envie Bitcoin para um dos endereços gerados pela sua carteira: Carteira > Addresses/Coins.
-
Para movimentar fundos, crie uma transação no dispositivo de consulta. Como ele não possui a chave privada, será necessário assiná-la com o dispositivo assinador.

- No assinador, escaneie a transação não assinada, confirme os detalhes, assine e compartilhe. Será gerado outro QR, desta vez com a transação já assinada.

- No dispositivo de consulta, escaneie o QR da transação assinada e transmita-a para a rede.
Conclusão
Pontos positivos do setup:
- Simplicidade: Basta um dispositivo Android antigo.
- Flexibilidade: Funciona como uma ótima carteira fria, ideal para holders.
Pontos negativos do setup:
- Padronização: Não utiliza seeds no padrão BIP-39, você sempre precisará usar o electrum.
- Interface: A aparência do Electrum pode parecer antiquada para alguns usuários.
Nesse ponto, temos uma carteira fria que também serve para assinar transações. O fluxo de assinar uma transação se torna: Gerar uma transação não assinada > Escanear o QR da transação não assinada > Conferir e assinar essa transação com o assinador > Gerar QR da transação assinada > Escanear a transação assinada com qualquer outro dispositivo que possa transmiti-la para a rede.
Como alguns devem saber, uma transação assinada de Bitcoin é praticamente impossível de ser fraudada. Em um cenário catastrófico, você pode mesmo que sem internet, repassar essa transação assinada para alguém que tenha acesso à rede por qualquer meio de comunicação. Mesmo que não queiramos que isso aconteça um dia, esse setup acaba por tornar essa prática possível.
-
@ 207ad2a0:e7cca7b0
2025-01-07 03:46:04
Quick context: I wanted to check out Nostr's longform posts and this blog post seemed like a good one to try and mirror. It's originally from my free to read/share attempt to write a novel, but this post here is completely standalone - just describing how I used AI image generation to make a small piece of the work.
Hold on, put your pitchforks down - outside of using Grammerly & Emacs for grammatical corrections - not a single character was generated or modified by computers; a non-insignificant portion of my first draft originating on pen & paper. No AI is ~~weird and crazy~~ imaginative enough to write like I do. The only successful AI contribution you'll find is a single image, the map, which I heavily edited. This post will go over how I generated and modified an image using AI, which I believe brought some value to the work, and cover a few quick thoughts about AI towards the end.
Let's be clear, I can't draw, but I wanted a map which I believed would improve the story I was working on. After getting abysmal results by prompting AI with text only I decided to use "Diffuse the Rest," a Stable Diffusion tool that allows you to provide a reference image + description to fine tune what you're looking for. I gave it this Microsoft Paint looking drawing:

and after a number of outputs, selected this one to work on:
The image is way better than the one I provided, but had I used it as is, I still feel it would have decreased the quality of my work instead of increasing it. After firing up Gimp I cropped out the top and bottom, expanded the ocean and separated the landmasses, then copied the top right corner of the large landmass to replace the bottom left that got cut off. Now we've got something that looks like concept art: not horrible, and gets the basic idea across, but it's still due for a lot more detail.
The next thing I did was add some texture to make it look more map like. I duplicated the layer in Gimp and applied the "Cartoon" filter to both for some texture. The top layer had a much lower effect strength to give it a more textured look, while the lower layer had a higher effect strength that looked a lot like mountains or other terrain features. Creating a layer mask allowed me to brush over spots to display the lower layer in certain areas, giving it some much needed features.
At this point I'd made it to where I felt it may improve the work instead of detracting from it - at least after labels and borders were added, but the colors seemed artificial and out of place. Luckily, however, this is when PhotoFunia could step in and apply a sketch effect to the image.
At this point I was pretty happy with how it was looking, it was close to what I envisioned and looked very visually appealing while still being a good way to portray information. All that was left was to make the white background transparent, add some minor details, and add the labels and borders. Below is the exact image I wound up using:
Overall, I'm very satisfied with how it turned out, and if you're working on a creative project, I'd recommend attempting something like this. It's not a central part of the work, but it improved the chapter a fair bit, and was doable despite lacking the talent and not intending to allocate a budget to my making of a free to read and share story.
The AI Generated Elephant in the Room
If you've read my non-fiction writing before, you'll know that I think AI will find its place around the skill floor as opposed to the skill ceiling. As you saw with my input, I have absolutely zero drawing talent, but with some elbow grease and an existing creative direction before and after generating an image I was able to get something well above what I could have otherwise accomplished. Outside of the lowest common denominators like stock photos for the sole purpose of a link preview being eye catching, however, I doubt AI will be wholesale replacing most creative works anytime soon. I can assure you that I tried numerous times to describe the map without providing a reference image, and if I used one of those outputs (or even just the unedited output after providing the reference image) it would have decreased the quality of my work instead of improving it.
I'm going to go out on a limb and expect that AI image, text, and video is all going to find its place in slop & generic content (such as AI generated slop replacing article spinners and stock photos respectively) and otherwise be used in a supporting role for various creative endeavors. For people working on projects like I'm working on (e.g. intended budget $0) it's helpful to have an AI capable of doing legwork - enabling projects to exist or be improved in ways they otherwise wouldn't have. I'm also guessing it'll find its way into more professional settings for grunt work - think a picture frame or fake TV show that would exist in the background of an animated project - likely a detail most people probably wouldn't notice, but that would save the creators time and money and/or allow them to focus more on the essential aspects of said work. Beyond that, as I've predicted before: I expect plenty of emails will be generated from a short list of bullet points, only to be summarized by the recipient's AI back into bullet points.
I will also make a prediction counter to what seems mainstream: AI is about to peak for a while. The start of AI image generation was with Google's DeepDream in 2015 - image recognition software that could be run in reverse to "recognize" patterns where there were none, effectively generating an image from digital noise or an unrelated image. While I'm not an expert by any means, I don't think we're too far off from that a decade later, just using very fine tuned tools that develop more coherent images. I guess that we're close to maxing out how efficiently we're able to generate images and video in that manner, and the hard caps on how much creative direction we can have when using AI - as well as the limits to how long we can keep it coherent (e.g. long videos or a chronologically consistent set of images) - will prevent AI from progressing too far beyond what it is currently unless/until another breakthrough occurs.
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
- Enhance LLM Outputs: By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
- Support Complex Queries: Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
- Richness of Entities: Effective retrieval depends on graphs populated with rich, detailed entities.
- Freedom from Hallucinations: Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
- Handle diverse data sources with ease.
- Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
- Defining Relationships: Clarifying how concepts connect within a domain.
- Validating Graph Structures: Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
- Assign a Knowledge Champion: Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
- Provide Training: Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
- Leverage Partnerships: Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
- Utilize Tools: Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
- Iterate with Feedback: Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
-
Leverage Existing Ontologies: Many industries and domains already have open ontologies. For instance:
-
Public Knowledge Graphs: Resources like Wikipedia’s graph offer a wealth of structured knowledge.
- Industry Standards: Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
-
Business Framework Ontology (BFO): A valuable resource for enterprises looking to define business processes and structures.
-
Build In-House Expertise: If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
-
Utilize LLMs for Ontology Construction: Interestingly, LLMs themselves can act as a starting point for ontology development:
-
Prompt-Based Extraction: LLMs can generate draft ontologies by leveraging their extensive training on graph data.
- Domain Expert Refinement: Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
- Detecting Hallucinations: Differentiating between genuine insights and AI-generated inaccuracies.
- Ensuring Completeness: Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
- Generate Skeleton Ontologies: Prompt LLMs with domain-specific information to draft initial ontology structures.
- Validate and Refine Ontologies: Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
The Four-Layer Framework
Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
Example: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- Tip: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
Once you have the big picture in mind, it’s time to start breaking it down.
Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
Example: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- Tip: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
With your categories in place, you’re ready to dive into the details that bring them to life.
Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
Example: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- Tip: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
Now that you’ve mastered the essentials, you can expand your knowledge to include extra material.
Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
Example: Learn about rare programming quirks or historical trivia about a language’s development.
- Tip: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
Pro Tips for Better Learning
1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
2. Map It Out
Create visual aids like diagrams or concept maps to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching exposes any gaps in your understanding and helps reinforce the material.
4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to explore your topic in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.Tip: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ a5ee4475:2ca75401
2025-05-04 17:22:36
clients #list #descentralismo #english #article #finalversion
*These clients are generally applications on the Nostr network that allow you to use the same account, regardless of the app used, keeping your messages and profile intact.
**However, you may need to meet certain requirements regarding access and account NIP for some clients, so that you can access them securely and use their features correctly.
CLIENTS
Twitter like
- Nostrmo - [source] 🌐🤖🍎💻(🐧🪟🍎)
- Coracle - Super App [source] 🌐
- Amethyst - Super App with note edit, delete and other stuff with Tor [source] 🤖
- Primal - Social and wallet [source] 🌐🤖🍎
- Iris - [source] 🌐🤖🍎
- Current - [source] 🤖🍎
- FreeFrom 🤖🍎
- Openvibe - Nostr and others (new Plebstr) [source] 🤖🍎
- Snort 🌐(🤖[early access]) [source]
- Damus 🍎 [source]
- Nos 🍎 [source]
- Nostur 🍎 [source]
- NostrBand 🌐 [info] [source]
- Yana 🤖🍎🌐💻(🐧) [source]
- Nostribe [on development] 🌐 [source]
- Lume 💻(🐧🪟🍎) [info] [source]
- Gossip - [source] 💻(🐧🪟🍎)
- Camelus [early access] 🤖 [source]
Communities
- noStrudel - Gamified Experience [info] 🌐
- Nostr Kiwi [creator] 🌐
- Satellite [info] 🌐
- Flotilla - [source] 🌐🐧
- Chachi - [source] 🌐
- Futr - Coded in haskell [source] 🐧 (others soon)
- Soapbox - Comunnity server [info] [source] 🌐
- Ditto - Soapbox comunnity server 🌐 [source] 🌐
- Cobrafuma - Nostr brazilian community on Ditto [info] 🌐
- Zapddit - Reddit like [source] 🌐
- Voyage (Reddit like) [on development] 🤖
Wiki
Search
- Advanced nostr search - Advanced note search by isolated terms related to a npub profile [source] 🌐
- Nos Today - Global note search by isolated terms [info] [source] 🌐
- Nostr Search Engine - API for Nostr clients [source]
Website
App Store
ZapStore - Permitionless App Store [source]
Audio and Video Transmission
- Nostr Nests - Audio Chats 🌐 [info]
- Fountain - Podcast 🤖🍎 [info]
- ZapStream - Live streaming 🌐 [info]
- Corny Chat - Audio Chat 🌐 [info]
Video Streaming
Music
- Tidal - Music Streaming [source] [about] [info] 🤖🍎🌐
- Wavlake - Music Streaming [source] 🌐(🤖🍎 [early access])
- Tunestr - Musical Events [source] [about] 🌐
- Stemstr - Musical Colab (paid to post) [source] [about] 🌐
Images
- Pinstr - Pinterest like [source] 🌐
- Slidestr - DeviantArt like [source] 🌐
- Memestr - ifunny like [source] 🌐
Download and Upload
Documents, graphics and tables
- Mindstr - Mind maps [source] 🌐
- Docstr - Share Docs [info] [source] 🌐
- Formstr - Share Forms [info] 🌐
- Sheetstr - Share Spreadsheets [source] 🌐
- Slide Maker - Share slides 🌐 (advice: https://zaplinks.lol/ and https://zaplinks.lol/slides/ sites are down)
Health
- Sobrkey - Sobriety and mental health [source] 🌐
- NosFabrica - Finding ways for your health data 🌐
- LazerEyes - Eye prescription by DM [source] 🌐
Forum
- OddBean - Hacker News like [info] [source] 🌐
- LowEnt - Forum [info] 🌐
- Swarmstr - Q&A / FAQ [info] 🌐
- Staker News - Hacker News like 🌐 [info]
Direct Messenges (DM)
- 0xchat 🤖🍎 [source]
- Nostr Chat 🌐🍎 [source]
- Blowater 🌐 [source]
- Anigma (new nostrgram) - Telegram based [on development] [source]
- Keychat - Signal based [🤖🍎 on development] [source]
Reading
- Highlighter - Insights with a highlighted read 🌐 [info]
- Zephyr - Calming to Read 🌐 [info]
- Flycat - Clean and Healthy Feed 🌐 [info]
- Nosta - Check Profiles [on development] 🌐 [info]
- Alexandria - e-Reader and Nostr Knowledge Base (NKB) [source]
Writing
Lists
- Following - Users list [source] 🌐
- Listr - Lists [source] 🌐
- Nostr potatoes - Movies List source 💻(numpy)
Market and Jobs
- Shopstr - Buy and Sell [source] 🌐
- Nostr Market - Buy and Sell 🌐
- Plebeian Market - Buy and Sell [source] 🌐
- Ostrich Work - Jobs [source] 🌐
- Nostrocket - Jobs [source] 🌐
Data Vending Machines - DVM (NIP90)
(Data-processing tools)
AI
Games
- Chesstr - Chess 🌐 [source]
- Jestr - Chess [source] 🌐
- Snakestr - Snake game [source] 🌐
- DEG Mods - Decentralized Game Mods [info] [source] 🌐
Customization
Like other Services
- Olas - Instagram like [source] 🤖🍎🌐
- Nostree - Linktree like 🌐
- Rabbit - TweetDeck like [info] 🌐
- Zaplinks - Nostr links 🌐
- Omeglestr - Omegle-like Random Chats [source] 🌐
General Uses
- Njump - HTML text gateway source 🌐
- Filestr - HTML midia gateway [source] 🌐
- W3 - Nostr URL shortener [source] 🌐
- Playground - Test Nostr filters [source] 🌐
- Spring - Browser 🌐
Places
- Wherostr - Travel and show where you are
- Arc Map (Mapstr) - Bitcoin Map [info]
Driver and Delivery
- RoadRunner - Uber like [on development] ⏱️
- Arcade City - Uber like [on development] ⏱️ [info]
- Nostrlivery - iFood like [on development] ⏱️
OTHER STUFF
Lightning Wallets (zap)
- Alby - Native and extension [info] 🌐
- ZBD - Gaming and Social [info] 🤖🍎
- Wallet of Satoshi [info] 🤖🍎
- Minibits - Cashu mobile wallet [info] 🤖
- Blink - Opensource custodial wallet (KYC over 1000 usd) [source] 🤖🍎
- LNbits - App and extesion [source] 🤖🍎💻
- Zeus - [info] [source] 🤖🍎
Exchange
Media Server (Upload Links)
audio, image and video
- Nostr Build - [source] 🌐
- Nostr Check - [info] [source] 🌐
- NostPic - [source] 🌐
- Sovbit 🌐
- Voidcat - [source] 🌐
Without Nip: - Pomf - Upload larger videos [source] - Catbox - [source] - x0 - [source]
Donation and payments
- Zapper - Easy Zaps [source] 🌐
- Autozap [source] 🌐
- Zapmeacoffee 🌐
- Nostr Zap 💻(numpy)
- Creatr - Creators subscription 🌐
- Geyzer - Crowdfunding [info] [source] 🌐
- Heya! - Crowdfunding [source]
Security
- Secret Border - Generate offline keys 💻(java)
- Umbrel - Your private relay [source] 🌐
Extensions
- Nos2x - Account access keys 🌐
- Nsec.app 🌐 [info]
- Lume - [info] [source] 🐧🪟🍎
- Satcom - Share files to discuss - [info] 🌐
- KeysBand - Multi-key signing [source] 🌐
Code
- Nostrify - Share Nostr Frameworks 🌐
- Git Workshop (github like) [experimental] 🌐
- Gitstr (github like) [on development] ⏱️
- Osty [on development] [info] 🌐
- Python Nostr - Python Library for Nostr
Relay Check and Cloud
- Nostr Watch - See your relay speed 🌐
- NosDrive - Nostr Relay that saves to Google Drive
Bidges and Getways
- Matrixtr Bridge - Between Matrix & Nostr
- Mostr - Between Nostr & Fediverse
- Nostrss - RSS to Nostr
- Rsslay - Optimized RSS to Nostr [source]
- Atomstr - RSS/Atom to Nostr [source]
NOT RELATED TO NOSTR
Android Keyboards
Personal notes and texts
Front-ends
- Nitter - Twitter / X without your data [source]
- NewPipe - Youtube, Peertube and others, without account & your data [source] 🤖
- Piped - Youtube web without you data [source] 🌐
Other Services
- Brave - Browser [source]
- DuckDuckGo - Search [source]
- LLMA - Meta - Meta open source AI [source]
- DuckDuckGo AI Chat - Famous AIs without Login [source]
- Proton Mail - Mail [source]
Other open source index: Degoogled Apps
Some other Nostr index on:
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install NVapi to monitor my GPUs in Home Assistant.
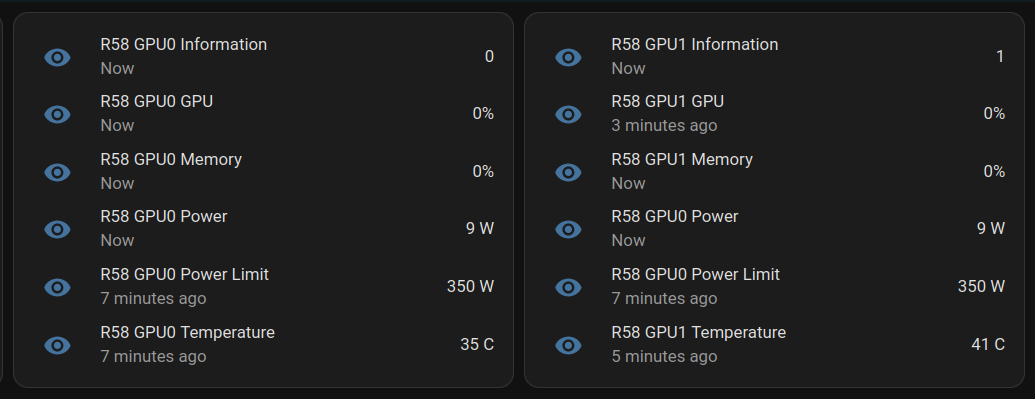
NVApi is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- GPU Utilization Monitoring: Utilization, memory usage, temperature, fan speed, and power consumption.
- Automated Power Limiting: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- Cross-GPU Coordination: Total power budget applies across multiple GPUs in the same system.
- PCIe Link Speed Management: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- Home Assistant Integration: Uses the built-in RESTful platform and template sensors.
Getting the Data
sudo apt install golang-go git clone https://github.com/sammcj/NVApi.git cd NVapi go run main.go -port 9999 -rate 1 curl http://localhost:9999/gpuResponse for a single GPU:
[ { "index": 0, "name": "NVIDIA GeForce RTX 4090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 16, "power_limit_watts": 450, "memory_total_gb": 23.99, "memory_used_gb": 0.46, "memory_free_gb": 23.52, "memory_usage_percent": 2, "temperature": 38, "processes": [], "pcie_link_state": "not managed" } ]Response for multiple GPUs:
[ { "index": 0, "name": "NVIDIA GeForce RTX 3090", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 14, "power_limit_watts": 350, "memory_total_gb": 24, "memory_used_gb": 0.43, "memory_free_gb": 23.57, "memory_usage_percent": 2, "temperature": 36, "processes": [], "pcie_link_state": "not managed" }, { "index": 1, "name": "NVIDIA RTX A4000", "gpu_utilisation": 0, "memory_utilisation": 0, "power_watts": 10, "power_limit_watts": 140, "memory_total_gb": 15.99, "memory_used_gb": 0.56, "memory_free_gb": 15.43, "memory_usage_percent": 3, "temperature": 41, "processes": [], "pcie_link_state": "not managed" } ]Start at Boot
Create
/etc/systemd/system/nvapi.service:``` [Unit] Description=Run NVapi After=network.target
[Service] Type=simple Environment="GOPATH=/home/ansible/go" WorkingDirectory=/home/ansible/NVapi ExecStart=/usr/bin/go run main.go -port 9999 -rate 1 Restart=always User=ansible
Environment="GPU_TEMP_CHECK_INTERVAL=5"
Environment="GPU_TOTAL_POWER_CAP=400"
Environment="GPU_0_LOW_TEMP=40"
Environment="GPU_0_MEDIUM_TEMP=70"
Environment="GPU_0_LOW_TEMP_LIMIT=135"
Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
Environment="GPU_0_HIGH_TEMP_LIMIT=100"
Environment="GPU_1_LOW_TEMP=45"
Environment="GPU_1_MEDIUM_TEMP=75"
Environment="GPU_1_LOW_TEMP_LIMIT=140"
Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install] WantedBy=multi-user.target ```
Home Assistant
Add to Home Assistant
configuration.yamland restart HA (completely).For a single GPU, this works: ``` sensor: - platform: rest name: MYPC GPU Information resource: http://mypc:9999 method: GET headers: Content-Type: application/json value_template: "{{ value_json[0].index }}" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature scan_interval: 1 # seconds
- platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature" value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}" unit_of_measurement: "°C" ```
For multiple GPUs: ``` rest: scan_interval: 1 resource: http://mypc:9999 sensor: - name: "MYPC GPU0 Information" value_template: "{{ value_json[0].index }}" json_attributes_path: "$.0" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature - name: "MYPC GPU1 Information" value_template: "{{ value_json[1].index }}" json_attributes_path: "$.1" json_attributes: - name - gpu_utilisation - memory_utilisation - power_watts - power_limit_watts - memory_total_gb - memory_used_gb - memory_free_gb - memory_usage_percent - temperature
-
platform: template sensors: mypc_gpu_0_gpu: friendly_name: "MYPC GPU0 GPU" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_memory: friendly_name: "MYPC GPU0 Memory" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_0_power: friendly_name: "MYPC GPU0 Power" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_0_power_limit: friendly_name: "MYPC GPU0 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_0_temperature: friendly_name: "MYPC GPU0 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}" unit_of_measurement: "C"
-
platform: template sensors: mypc_gpu_1_gpu: friendly_name: "MYPC GPU1 GPU" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_memory: friendly_name: "MYPC GPU1 Memory" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}" unit_of_measurement: "%" mypc_gpu_1_power: friendly_name: "MYPC GPU1 Power" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}" unit_of_measurement: "W" mypc_gpu_1_power_limit: friendly_name: "MYPC GPU1 Power Limit" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}" unit_of_measurement: "W" mypc_gpu_1_temperature: friendly_name: "MYPC GPU1 Temperature" value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}" unit_of_measurement: "C"
```
Basic entity card:
type: entities entities: - entity: sensor.mypc_gpu_0_gpu secondary_info: last-updated - entity: sensor.mypc_gpu_0_memory secondary_info: last-updated - entity: sensor.mypc_gpu_0_power secondary_info: last-updated - entity: sensor.mypc_gpu_0_power_limit secondary_info: last-updated - entity: sensor.mypc_gpu_0_temperature secondary_info: last-updatedAnsible Role
```
-
name: install go become: true package: name: golang-go state: present
-
name: git clone git: repo: "https://github.com/sammcj/NVApi.git" dest: "/home/ansible/NVapi" update: yes force: true
go run main.go -port 9999 -rate 1
-
name: install systemd service become: true copy: src: nvapi.service dest: /etc/systemd/system/nvapi.service
-
name: Reload systemd daemons, enable, and restart nvapi become: true systemd: name: nvapi daemon_reload: yes enabled: yes state: restarted ```
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
-
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
-
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\ https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
-
@ c7aa97dc:0d12c810
2025-05-04 17:06:47
COLDCARDS’s new Co-Sign feature lets you use a multisig (2 of N) wallet where the second key (policy key) lives inside the same COLDCARD and signs only when a transaction meets the rules you set-for example:
- Maximum amount per send (e.g. 500k Sats)
- Wait time between sends, (e.g 144 blocks = 1 day)
- Only send to approved addresses,
- Only send after you provide a 2FA code
If a payment follows the rules, COLDCARD automatically signs the transaction with 2 keys which makes it feel like a single-sig wallet.
Break a rule and the device only signs with 1 key, so nothing moves unless you sign the transaction with a separate off-site recovery key.
It’s the convenience of singlesig with the guard-rails of multisig.
Use Cases Unlocked
Below you will find an overview of usecases unlocked by this security enhancing feature for everyday bitcoiners, families, and small businesses.

1. Travel Lock-Down Mode
Before you leave, set the wait-time to match the duration of your trip—say 14 days—and cap each spend at 50k sats. If someone finds the COLDCARD while you’re away, they can take only one 50k-sat nibble and then must wait the full two weeks—long after you’re back—to try again. When you notice your device is gone you can quickly restore your wallet with your backup seeds (not in your house of course) and move all the funds to a new wallet.
2. Shared-Safety Wallet for Parents or Friends
Help your parents or friends setup a COLDCARD with Co-Sign, cap each spend at 500 000 sats and enforce a 7-day gap between transactions. Everyday spending sails through; anything larger waits for your co-signature from your key. A thief can’t steal more than the capped amount per week, and your parents retains full sovereignty—if you disappear, they still hold two backup seeds and can either withdraw slowly under the limits or import those seeds into another signer and move everything at once.
3. My First COLDCARD Wallet
Give your kid a COLDCARD, but whitelist only their own addresses and set a 100k sat ceiling. They learn self-custody, yet external spends still need you to co-sign.
4. Weekend-Only Spending Wallet
Cap each withdrawal (e.g., 500k sats) and require a 72-hour gap between sends. You can still top-up Lightning channels or pay bills weekly, but attackers that have access to your device + pin will not be able to drain it immediately.
5. DIY Business Treasury
Finance staff use the COLDCARD to pay routine invoices under 0.1 BTC. Anything larger needs the co-founder’s off-site backup key.
6. Donation / Grant Disbursement Wallet
Publish the deposit address publicly, but allow outgoing payments only to a fixed list of beneficiary addresses. Even if attackers get the device, they can’t redirect funds to themselves—the policy key refuses to sign.
7. Phoenix Lightning Wallet Top-Up
Add a Phoenix Lightning wallet on-chain deposit addresses to the whitelist. The COLDCARD will co-sign only when you’re refilling channels. This is off course not limited to Phoenix wallet and can be used for any Lightning Node.
8. Deep Cold-Storage Bridge
Whitelist one or more addresses from your bitcoin vault. Day-to-day you sweep hot-wallet incoming funds (From a webshop or lightning node) into the COLDCARD, then push funds onward to deep cold storage. If the device is compromised, coins can only land safely in the vault.
9. Company Treasury → Payroll Wallets
List each employee’s salary wallet on the whitelist (watch out for address re-use) and cap the amount per send. Routine payroll runs smoothly, while attackers or rogue insiders can’t reroute funds elsewhere.
10. Phone Spending-Wallet Refills
Whitelist only some deposit addresses of your mobile wallet and set a small per-send cap. You can top up anytime, but an attacker with the device and PIN can’t drain more than the refill limit—and only to your own phone.
I hope these usecase are helpfull and I'm curious to hear what other use cases you think are possible with this co-signing feature.
For deeper technical details on how Co-Sign works, refer to the official documentation on the Coldcard website. https://coldcard.com/docs/coldcard-cosigning/
You can also watch their Video https://www.youtube.com/watch?v=MjMPDUWWegw
coldcard #coinkite #bitcoin #selfcustody #multisig #mk4 #ccq
nostr:npub1az9xj85cmxv8e9j9y80lvqp97crsqdu2fpu3srwthd99qfu9qsgstam8y8 nostr:npub12ctjk5lhxp6sks8x83gpk9sx3hvk5fz70uz4ze6uplkfs9lwjmsq2rc5ky
-
@ 8125b911:a8400883
2025-04-25 07:02:35
In Nostr, all data is stored as events. Decentralization is achieved by storing events on multiple relays, with signatures proving the ownership of these events. However, if you truly want to own your events, you should run your own relay to store them. Otherwise, if the relays you use fail or intentionally delete your events, you'll lose them forever.
For most people, running a relay is complex and costly. To solve this issue, I developed nostr-relay-tray, a relay that can be easily run on a personal computer and accessed over the internet.
Project URL: https://github.com/CodyTseng/nostr-relay-tray
This article will guide you through using nostr-relay-tray to run your own relay.
Download
Download the installation package for your operating system from the GitHub Release Page.
| Operating System | File Format | | --------------------- | ---------------------------------- | | Windows |
nostr-relay-tray.Setup.x.x.x.exe| | macOS (Apple Silicon) |nostr-relay-tray-x.x.x-arm64.dmg| | macOS (Intel) |nostr-relay-tray-x.x.x.dmg| | Linux | You should know which one to use |Installation
Since this app isn’t signed, you may encounter some obstacles during installation. Once installed, an ostrich icon will appear in the status bar. Click on the ostrich icon, and you'll see a menu where you can click the "Dashboard" option to open the relay's control panel for further configuration.

macOS Users:
- On first launch, go to "System Preferences > Security & Privacy" and click "Open Anyway."
- If you encounter a "damaged" message, run the following command in the terminal to remove the restrictions:
bash sudo xattr -rd com.apple.quarantine /Applications/nostr-relay-tray.appWindows Users:
- On the security warning screen, click "More Info > Run Anyway."
Connecting
By default, nostr-relay-tray is only accessible locally through
ws://localhost:4869/, which makes it quite limited. Therefore, we need to expose it to the internet.In the control panel, click the "Proxy" tab and toggle the switch. You will then receive a "Public address" that you can use to access your relay from anywhere. It's that simple.
Next, add this address to your relay list and position it as high as possible in the list. Most clients prioritize connecting to relays that appear at the top of the list, and relays lower in the list are often ignored.

Restrictions
Next, we need to set up some restrictions to prevent the relay from storing events that are irrelevant to you and wasting storage space. nostr-relay-tray allows for flexible and fine-grained configuration of which events to accept, but some of this is more complex and will not be covered here. If you're interested, you can explore this further later.
For now, I'll introduce a simple and effective strategy: WoT (Web of Trust). You can enable this feature in the "WoT & PoW" tab. Before enabling, you'll need to input your pubkey.
There's another important parameter,
Depth, which represents the relationship depth between you and others. Someone you follow has a depth of 1, someone they follow has a depth of 2, and so on.- Setting this parameter to 0 means your relay will only accept your own events.
- Setting it to 1 means your relay will accept events from you and the people you follow.
- Setting it to 2 means your relay will accept events from you, the people you follow, and the people they follow.
Currently, the maximum value for this parameter is 2.

Conclusion
You've now successfully run your own relay and set a simple restriction to prevent it from storing irrelevant events.
If you encounter any issues during use, feel free to submit an issue on GitHub, and I'll respond as soon as possible.
Not your relay, not your events.
-
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.Graph Basics
- A standard graph has a set of nodes (or vertices) and edges (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
Hypergraph
- A hypergraph extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a hyperedge, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
Metagraph
- A metagraph allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.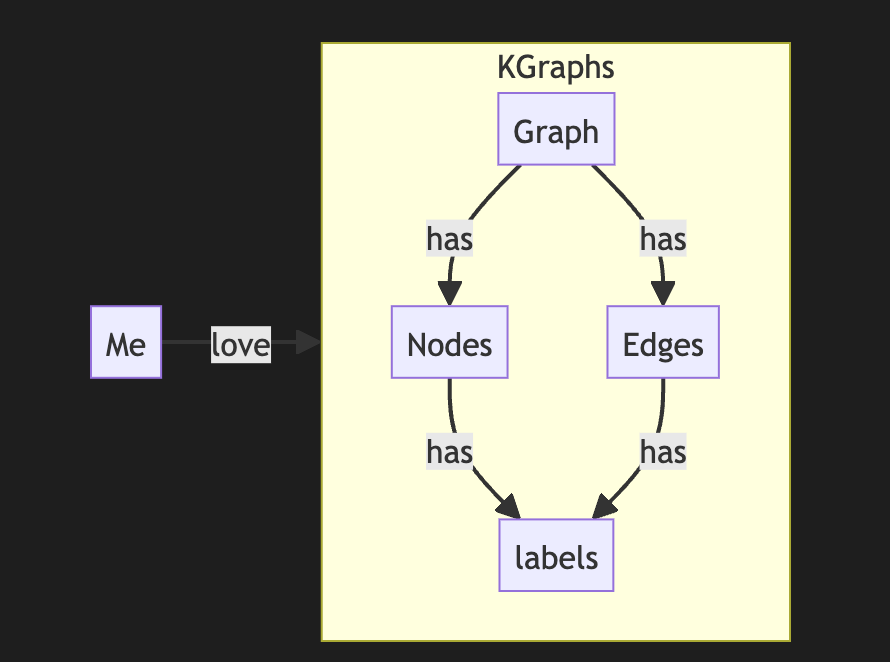
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you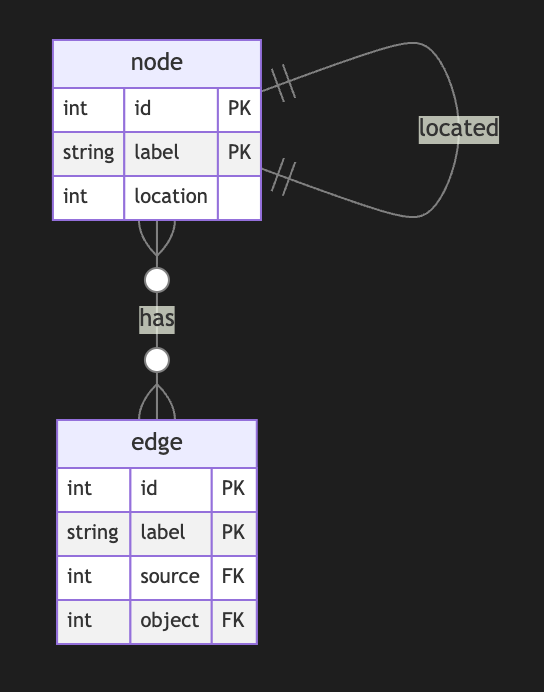
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
Directed Metagraph where edges are not used as nodes and could not contain subgraphs
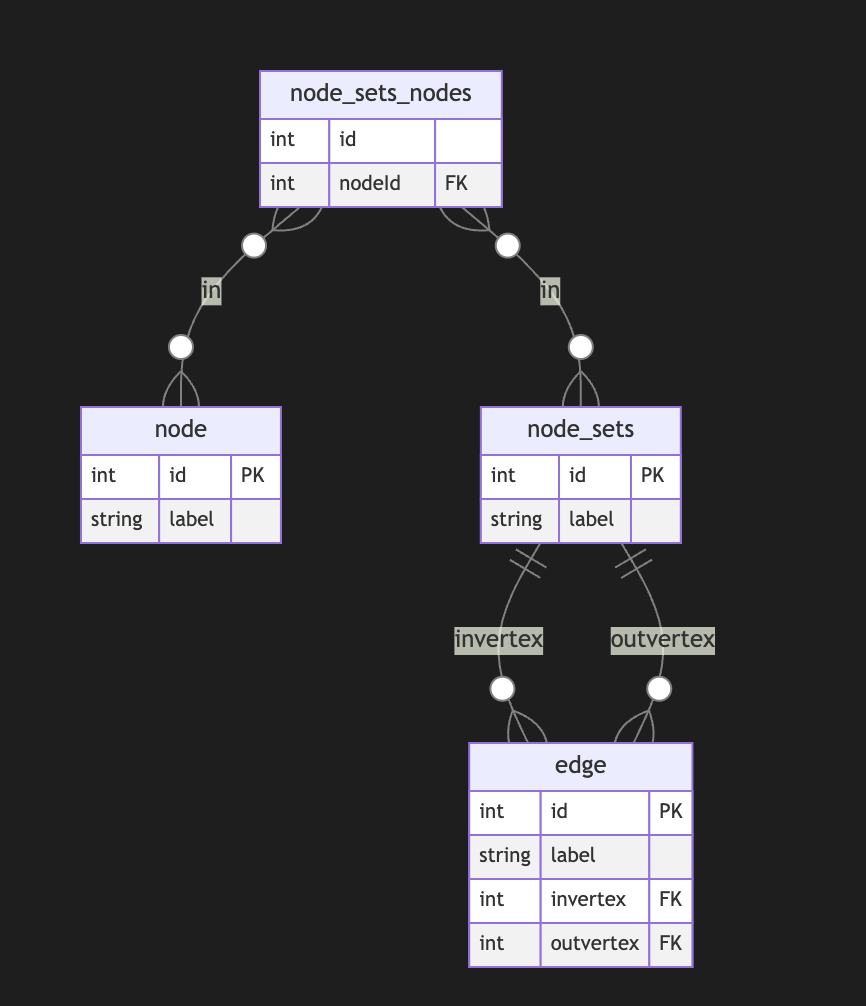
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
Directed Metagraph where edges are not used as nodes and could contain subgraphs
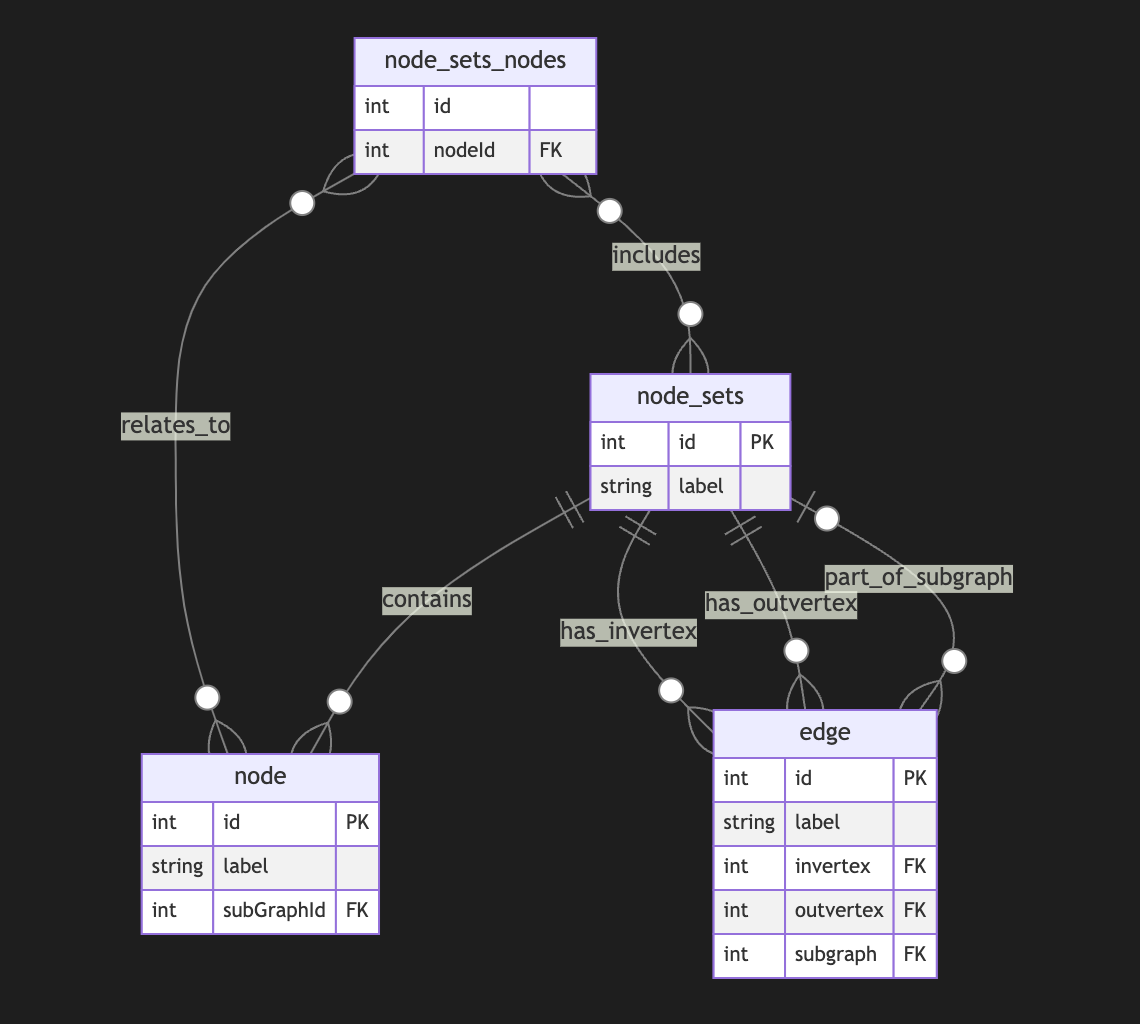
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose. -
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like Lisp emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
Lisp: The Earlier AI-Language
Lisp, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
Prolog: Formal Logic and Deductive Reasoning
In the 1970s, Prolog was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out how to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
Solvers and Their Role in Complementing LLMs
One of the most powerful features of Prolog and similar logic-based systems is their use of solvers. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a solver can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling constraint satisfaction problems — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating neurosymbolic methods that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a graph of rules. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a graph of rules, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable modular reasoning, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of neural fluency with rule-based structure gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform deductive reasoning alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where neurosymbolic approaches shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
Personal Knowledge Graphs (PKGs) come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a graph of rules that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using deductive databases to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling knowledge graphs using deductive databases, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
Prolog and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a graph of rules that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
Why It Matters for LLM Employment
Using neurosymbolic RAG (retrieval-augmented generation) in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of neural fluency with symbolic accuracy and deductive power is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ 40b9c85f:5e61b451
2025-04-24 15:27:02
Introduction
Data Vending Machines (DVMs) have emerged as a crucial component of the Nostr ecosystem, offering specialized computational services to clients across the network. As defined in NIP-90, DVMs operate on an apparently simple principle: "data in, data out." They provide a marketplace for data processing where users request specific jobs (like text translation, content recommendation, or AI text generation)
While DVMs have gained significant traction, the current specification faces challenges that hinder widespread adoption and consistent implementation. This article explores some ideas on how we can apply the reflection pattern, a well established approach in RPC systems, to address these challenges and improve the DVM ecosystem's clarity, consistency, and usability.
The Current State of DVMs: Challenges and Limitations
The NIP-90 specification provides a broad framework for DVMs, but this flexibility has led to several issues:
1. Inconsistent Implementation
As noted by hzrd149 in "DVMs were a mistake" every DVM implementation tends to expect inputs in slightly different formats, even while ostensibly following the same specification. For example, a translation request DVM might expect an event ID in one particular format, while an LLM service could expect a "prompt" input that's not even specified in NIP-90.
2. Fragmented Specifications
The DVM specification reserves a range of event kinds (5000-6000), each meant for different types of computational jobs. While creating sub-specifications for each job type is being explored as a possible solution for clarity, in a decentralized and permissionless landscape like Nostr, relying solely on specification enforcement won't be effective for creating a healthy ecosystem. A more comprehensible approach is needed that works with, rather than against, the open nature of the protocol.
3. Ambiguous API Interfaces
There's no standardized way for clients to discover what parameters a specific DVM accepts, which are required versus optional, or what output format to expect. This creates uncertainty and forces developers to rely on documentation outside the protocol itself, if such documentation exists at all.
The Reflection Pattern: A Solution from RPC Systems
The reflection pattern in RPC systems offers a compelling solution to many of these challenges. At its core, reflection enables servers to provide metadata about their available services, methods, and data types at runtime, allowing clients to dynamically discover and interact with the server's API.
In established RPC frameworks like gRPC, reflection serves as a self-describing mechanism where services expose their interface definitions and requirements. In MCP reflection is used to expose the capabilities of the server, such as tools, resources, and prompts. Clients can learn about available capabilities without prior knowledge, and systems can adapt to changes without requiring rebuilds or redeployments. This standardized introspection creates a unified way to query service metadata, making tools like
grpcurlpossible without requiring precompiled stubs.How Reflection Could Transform the DVM Specification
By incorporating reflection principles into the DVM specification, we could create a more coherent and predictable ecosystem. DVMs already implement some sort of reflection through the use of 'nip90params', which allow clients to discover some parameters, constraints, and features of the DVMs, such as whether they accept encryption, nutzaps, etc. However, this approach could be expanded to provide more comprehensive self-description capabilities.
1. Defined Lifecycle Phases
Similar to the Model Context Protocol (MCP), DVMs could benefit from a clear lifecycle consisting of an initialization phase and an operation phase. During initialization, the client and DVM would negotiate capabilities and exchange metadata, with the DVM providing a JSON schema containing its input requirements. nip-89 (or other) announcements can be used to bootstrap the discovery and negotiation process by providing the input schema directly. Then, during the operation phase, the client would interact with the DVM according to the negotiated schema and parameters.
2. Schema-Based Interactions
Rather than relying on rigid specifications for each job type, DVMs could self-advertise their schemas. This would allow clients to understand which parameters are required versus optional, what type validation should occur for inputs, what output formats to expect, and what payment flows are supported. By internalizing the input schema of the DVMs they wish to consume, clients gain clarity on how to interact effectively.
3. Capability Negotiation
Capability negotiation would enable DVMs to advertise their supported features, such as encryption methods, payment options, or specialized functionalities. This would allow clients to adjust their interaction approach based on the specific capabilities of each DVM they encounter.
Implementation Approach
While building DVMCP, I realized that the RPC reflection pattern used there could be beneficial for constructing DVMs in general. Since DVMs already follow an RPC style for their operation, and reflection is a natural extension of this approach, it could significantly enhance and clarify the DVM specification.
A reflection enhanced DVM protocol could work as follows: 1. Discovery: Clients discover DVMs through existing NIP-89 application handlers, input schemas could also be advertised in nip-89 announcements, making the second step unnecessary. 2. Schema Request: Clients request the DVM's input schema for the specific job type they're interested in 3. Validation: Clients validate their request against the provided schema before submission 4. Operation: The job proceeds through the standard NIP-90 flow, but with clearer expectations on both sides
Parallels with Other Protocols
This approach has proven successful in other contexts. The Model Context Protocol (MCP) implements a similar lifecycle with capability negotiation during initialization, allowing any client to communicate with any server as long as they adhere to the base protocol. MCP and DVM protocols share fundamental similarities, both aim to expose and consume computational resources through a JSON-RPC-like interface, albeit with specific differences.
gRPC's reflection service similarly allows clients to discover service definitions at runtime, enabling generic tools to work with any gRPC service without prior knowledge. In the REST API world, OpenAPI/Swagger specifications document interfaces in a way that makes them discoverable and testable.
DVMs would benefit from adopting these patterns while maintaining the decentralized, permissionless nature of Nostr.
Conclusion
I am not attempting to rewrite the DVM specification; rather, explore some ideas that could help the ecosystem improve incrementally, reducing fragmentation and making the ecosystem more comprehensible. By allowing DVMs to self describe their interfaces, we could maintain the flexibility that makes Nostr powerful while providing the structure needed for interoperability.
For developers building DVM clients or libraries, this approach would simplify consumption by providing clear expectations about inputs and outputs. For DVM operators, it would establish a standard way to communicate their service's requirements without relying on external documentation.
I am currently developing DVMCP following these patterns. Of course, DVMs and MCP servers have different details; MCP includes capabilities such as tools, resources, and prompts on the server side, as well as 'roots' and 'sampling' on the client side, creating a bidirectional way to consume capabilities. In contrast, DVMs typically function similarly to MCP tools, where you call a DVM with an input and receive an output, with each job type representing a different categorization of the work performed.
Without further ado, I hope this article has provided some insight into the potential benefits of applying the reflection pattern to the DVM specification.
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
RDF and Advanced Topics
Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ 90c656ff:9383fd4e
2025-05-04 17:06:06
In the Bitcoin system, the protection and ownership of funds are ensured by a cryptographic model that uses private and public keys. These components are fundamental to digital security, allowing users to manage and safeguard their assets in a decentralized way. This process removes the need for intermediaries, ensuring that only the legitimate owner has access to the balance linked to a specific address on the blockchain or timechain.
Private and public keys are part of an asymmetric cryptographic system, where two distinct but mathematically linked codes are used to guarantee the security and authenticity of transactions.
Private Key = A secret code, usually represented as a long string of numbers and letters.
Functions like a password that gives the owner control over the bitcoins tied to a specific address.
Must be kept completely secret, as anyone with access to it can move the corresponding funds.
Public Key = Mathematically derived from the private key, but it cannot be used to uncover the private key.
Functions as a digital address, similar to a bank account number, and can be freely shared to receive payments.
Used to verify the authenticity of signatures generated with the private key.
Together, these keys ensure that transactions are secure and verifiable, eliminating the need for intermediaries.
The functioning of private and public keys is based on elliptic curve cryptography. When a user wants to send bitcoins, they use their private key to digitally sign the transaction. This signature is unique for each operation and proves that the sender possesses the private key linked to the sending address.
Bitcoin network nodes check this signature using the corresponding public key to ensure that:
01 - The signature is valid. 02 - The transaction has not been altered since it was signed. 03 - The sender is the legitimate owner of the funds.
If the signature is valid, the transaction is recorded on the blockchain or timechain and becomes irreversible. This process protects funds against fraud and double-spending.
The security of private keys is one of the most critical aspects of the Bitcoin system. Losing this key means permanently losing access to the funds, as there is no central authority capable of recovering it.
- Best practices for protecting private keys include:
01 - Offline storage: Keep them away from internet-connected networks to reduce the risk of cyberattacks. 02 - Hardware wallets: Physical devices dedicated to securely storing private keys. 03 - Backups and redundancy: Maintain backup copies in safe and separate locations. 04 - Additional encryption: Protect digital files containing private keys with strong passwords and encryption.
- Common threats include:
01 - Phishing and malware: Attacks that attempt to trick users into revealing their keys. 02 - Physical theft: If keys are stored on physical devices. 03 - Loss of passwords and backups: Which can lead to permanent loss of funds.
Using private and public keys gives the owner full control over their funds, eliminating intermediaries such as banks or governments. This model places the responsibility of protection on the user, which represents both freedom and risk.
Unlike traditional financial systems, where institutions can reverse transactions or freeze accounts, in the Bitcoin system, possession of the private key is the only proof of ownership. This principle is often summarized by the phrase: "Not your keys, not your coins."
This approach strengthens financial sovereignty, allowing individuals to store and move value independently and without censorship.
Despite its security, the key-based system also carries risks. If a private key is lost or forgotten, there is no way to recover the associated funds. This has already led to the permanent loss of millions of bitcoins over the years.
To reduce this risk, many users rely on seed phrases, which are a list of words used to recover wallets and private keys. These phrases must be guarded just as carefully, as they can also grant access to funds.
In summary, private and public keys are the foundation of security and ownership in the Bitcoin system. They ensure that only rightful owners can move their funds, enabling a decentralized, secure, and censorship-resistant financial system.
However, this freedom comes with great responsibility, requiring users to adopt strict practices to protect their private keys. Loss or compromise of these keys can lead to irreversible consequences, highlighting the importance of education and preparation when using Bitcoin.
Thus, the cryptographic key model not only enhances security but also represents the essence of the financial independence that Bitcoin enables.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory and semantic memory. And we also have a lot of theories, right?
Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a hybrid clock or some global clock that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ 8cda1daa:e9e5bdd8
2025-04-24 10:20:13
Bitcoin cracked the code for money. Now it's time to rebuild everything else.
What about identity, trust, and collaboration? What about the systems that define how we live, create, and connect?
Bitcoin gave us a blueprint to separate money from the state. But the state still owns most of your digital life. It's time for something more radical.
Welcome to the Atomic Economy - not just a technology stack, but a civil engineering project for the digital age. A complete re-architecture of society, from the individual outward.
The Problem: We Live in Digital Captivity
Let's be blunt: the modern internet is hostile to human freedom.
You don't own your identity. You don't control your data. You don't decide what you see.
Big Tech and state institutions dominate your digital life with one goal: control.
- Poisoned algorithms dictate your emotions and behavior.
- Censorship hides truth and silences dissent.
- Walled gardens lock you into systems you can't escape.
- Extractive platforms monetize your attention and creativity - without your consent.
This isn't innovation. It's digital colonization.
A Vision for Sovereign Society
The Atomic Economy proposes a new design for society - one where: - Individuals own their identity, data, and value. - Trust is contextual, not imposed. - Communities are voluntary, not manufactured by feeds. - Markets are free, not fenced. - Collaboration is peer-to-peer, not platform-mediated.
It's not a political revolution. It's a technological and social reset based on first principles: self-sovereignty, mutualism, and credible exit.
So, What Is the Atomic Economy?
The Atomic Economy is a decentralized digital society where people - not platforms - coordinate identity, trust, and value.
It's built on open protocols, real software, and the ethos of Bitcoin. It's not about abstraction - it's about architecture.
Core Principles: - Self-Sovereignty: Your keys. Your data. Your rules. - Mutual Consensus: Interactions are voluntary and trust-based. - Credible Exit: Leave any system, with your data and identity intact. - Programmable Trust: Trust is explicit, contextual, and revocable. - Circular Economies: Value flows directly between individuals - no middlemen.
The Tech Stack Behind the Vision
The Atomic Economy isn't just theory. It's a layered system with real tools:
1. Payments & Settlement
- Bitcoin & Lightning: The foundation - sound, censorship-resistant money.
- Paykit: Modular payments and settlement flows.
- Atomicity: A peer-to-peer mutual credit protocol for programmable trust and IOUs.
2. Discovery & Matching
- Pubky Core: Decentralized identity and discovery using PKARR and the DHT.
- Pubky Nexus: Indexing for a user-controlled internet.
- Semantic Social Graph: Discovery through social tagging - you are the algorithm.
3. Application Layer
- Bitkit: A self-custodial Bitcoin and Lightning wallet.
- Pubky App: Tag, publish, trade, and interact - on your terms.
- Blocktank: Liquidity services for Lightning and circular economies.
- Pubky Ring: Key-based access control and identity syncing.
These tools don't just integrate - they stack. You build trust, exchange value, and form communities with no centralized gatekeepers.
The Human Impact
This isn't about software. It's about freedom.
- Empowered Individuals: Control your own narrative, value, and destiny.
- Voluntary Communities: Build trust on shared values, not enforced norms.
- Economic Freedom: Trade without permission, borders, or middlemen.
- Creative Renaissance: Innovation and art flourish in open, censorship-resistant systems.
The Atomic Economy doesn't just fix the web. It frees the web.
Why Bitcoiners Should Care
If you believe in Bitcoin, you already believe in the Atomic Economy - you just haven't seen the full map yet.
- It extends Bitcoin's principles beyond money: into identity, trust, coordination.
- It defends freedom where Bitcoin leaves off: in content, community, and commerce.
- It offers a credible exit from every centralized system you still rely on.
- It's how we win - not just economically, but culturally and socially.
This isn't "web3." This isn't another layer of grift. It's the Bitcoin future - fully realized.
Join the Atomic Revolution
- If you're a builder: fork the code, remix the ideas, expand the protocols.
- If you're a user: adopt Bitkit, use Pubky, exit the digital plantation.
- If you're an advocate: share the vision. Help people imagine a free society again.
Bitcoin promised a revolution. The Atomic Economy delivers it.
Let's reclaim society, one key at a time.
Learn more and build with us at Synonym.to.
-
@ a39d19ec:3d88f61e
2024-11-21 12:05:09
A state-controlled money supply can influence the development of socialist policies and practices in various ways. Although the relationship is not deterministic, state control over the money supply can contribute to a larger role of the state in the economy and facilitate the implementation of socialist ideals.
Fiscal Policy Capabilities
When the state manages the money supply, it gains the ability to implement fiscal policies that can lead to an expansion of social programs and welfare initiatives. Funding these programs by creating money can enhance the state's influence over the economy and move it closer to a socialist model. The Soviet Union, for instance, had a centralized banking system that enabled the state to fund massive industrialization and social programs, significantly expanding the state's role in the economy.
Wealth Redistribution
Controlling the money supply can also allow the state to influence economic inequality through monetary policies, effectively redistributing wealth and reducing income disparities. By implementing low-interest loans or providing financial assistance to disadvantaged groups, the state can narrow the wealth gap and promote social equality, as seen in many European welfare states.
Central Planning
A state-controlled money supply can contribute to increased central planning, as the state gains more influence over the economy. Central banks, which are state-owned or heavily influenced by the state, play a crucial role in managing the money supply and facilitating central planning. This aligns with socialist principles that advocate for a planned economy where resources are allocated according to social needs rather than market forces.
Incentives for Staff
Staff members working in state institutions responsible for managing the money supply have various incentives to keep the system going. These incentives include job security, professional expertise and reputation, political alignment, regulatory capture, institutional inertia, and legal and administrative barriers. While these factors can differ among individuals, they can collectively contribute to the persistence of a state-controlled money supply system.
In conclusion, a state-controlled money supply can facilitate the development of socialist policies and practices by enabling fiscal policies, wealth redistribution, and central planning. The staff responsible for managing the money supply have diverse incentives to maintain the system, further ensuring its continuation. However, it is essential to note that many factors influence the trajectory of an economic system, and the relationship between state control over the money supply and socialism is not inevitable.
-
@ a39d19ec:3d88f61e
2024-11-17 10:48:56
This week's functional 3d print is the "Dino Clip".

Dino Clip
I printed it some years ago for my son, so he would have his own clip for cereal bags.
Now it is used to hold a bag of dog food close.
The design by "Sneaks" is a so called "print in place". This means that the whole clip with moving parts is printed in one part, without the need for assembly after the print.
 The clip is very strong, and I would print it again if I need a "heavy duty" clip for more rigid or big bags.
Link to the file at Printables
The clip is very strong, and I would print it again if I need a "heavy duty" clip for more rigid or big bags.
Link to the file at Printables -
@ a367f9eb:0633efea
2024-11-05 08:48:41
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters
When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies
In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement
If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Originally published on the website of the Consumer Choice Center.
-
@ 9bde4214:06ca052b
2025-04-22 18:13:37
"It's gonna be permissionless or hell."
Gigi and gzuuus are vibing towards dystopia.
Books & articles mentioned:
- AI 2027
- DVMs were a mistake
- Careless People by Sarah Wynn-Williams
- Takedown by Laila michelwait
- The Ultimate Resource by Julian L. Simon
- Harry Potter by J.K. Rowling
- Momo by Michael Ende
In this dialogue:
- Pablo's Roo Setup
- Tech Hype Cycles
- AI 2027
- Prompt injection and other attacks
- Goose and DVMCP
- Cursor vs Roo Code
- Staying in control thanks to Amber and signing delegation
- Is YOLO mode here to stay?
- What agents to trust?
- What MCP tools to trust?
- What code snippets to trust?
- Everyone will run into the issues of trust and micropayments
- Nostr solves Web of Trust & micropayments natively
- Minimalistic & open usually wins
- DVMCP exists thanks to Totem
- Relays as Tamagochis
- Agents aren't nostr experts, at least not right now
- Fix a mistake once & it's fixed forever
- Giving long-term memory to LLMs
- RAG Databases signed by domain experts
- Human-agent hybrids & Chess
- Nostr beating heart
- Pluggable context & experts
- "You never need an API key for anything"
- Sats and social signaling
- Difficulty-adjusted PoW as a rare-limiting mechanism
- Certificate authorities and centralization
- No solutions to policing speech!
- OAuth and how it centralized
- Login with nostr
- Closed vs open-source models
- Tiny models vs large models
- The minions protocol (Stanford paper)
- Generalist models vs specialized models
- Local compute & encrypted queries
- Blinded compute
- "In the eyes of the state, agents aren't people"
- Agents need identity and money; nostr provides both
- "It's gonna be permissionless or hell"
- We already have marketplaces for MCP stuff, code snippets, and other things
- Most great stuff came from marketplaces (browsers, games, etc)
- Zapstore shows that this is already working
- At scale, central control never works. There's plenty scams and viruses in the app stores.
- Using nostr to archive your user-generated content
- HAVEN, blossom, novia
- The switcharoo from advertisements to training data
- What is Truth?
- What is Real?
- "We're vibing into dystopia"
- Who should be the arbiter of Truth?
- First Amendment & why the Logos is sacred
- Silicon Valley AI bros arrogantly dismiss wisdom and philosophy
- Suicide rates & the meaning crisis
- Are LLMs symbiotic or parasitic?
- The Amish got it right
- Are we gonna make it?
- Careless People by Sarah Wynn-Williams
- Takedown by Laila michelwait
- Harry Potter dementors & Momo's time thieves
- Facebook & Google as non-human (superhuman) agents
- Zapping as a conscious action
- Privacy and the internet
- Plausible deniability thanks to generative models
- Google glasses, glassholes, and Meta's Ray Ben's
- People crave realness
- Bitcoin is the realest money we ever had
- Nostr allows for real and honest expression
- How do we find out what's real?
- Constraints, policing, and chilling effects
- Jesus' plans for DVMCP
- Hzrd's article on how DVMs are broken (DVMs were a mistake)
- Don't believe the hype
- DVMs pre-date MCP tools
- Data Vending Machines were supposed to be stupid: put coin in, get stuff out.
- Self-healing vibe-coding
- IP addresses as scarce assets
- Atomic swaps and the ASS protocol
- More marketplaces, less silos
- The intensity of #SovEng and the last 6 weeks
- If you can vibe-code everything, why build anything?
- Time, the ultimate resource
- What are the LLMs allowed to think?
- Natural language interfaces are inherently dialogical
- Sovereign Engineering is dialogical too
-
@ 90c656ff:9383fd4e
2025-05-04 16:49:19
The Bitcoin network is built on a decentralized infrastructure made up of devices called nodes. These nodes play a crucial role in validating, verifying, and maintaining the system, ensuring the security and integrity of the blockchain or timechain. Unlike traditional systems where a central authority controls operations, the Bitcoin network relies on the collaboration of thousands of nodes around the world, promoting decentralization and transparency.
In the Bitcoin network, a node is any computer connected to the system that participates in storing, validating, or distributing information. These devices run Bitcoin software and can operate at different levels of participation, from basic data transmission to full validation of transactions and blocks.
There are two main types of nodes:
- Full Nodes:
01 - Store a complete copy of the blockchain or timechain. 02 - Validate and verify all transactions and blocks according to the protocol rules. 03 - Ensure network security by rejecting invalid transactions or fraudulent attempts.
- Light Nodes:
01 - Store only parts of the blockchain or timechain, not the full structure. 02 - Rely on full nodes to access transaction history data. 03 - Are faster and less resource-intensive but depend on third parties for full validation.
Nodes check whether submitted transactions comply with protocol rules, such as valid digital signatures and the absence of double spending.
Only valid transactions are forwarded to other nodes and included in the next block.
Full nodes maintain an up-to-date copy of the network's entire transaction history, ensuring integrity and transparency. In case of discrepancies, nodes follow the longest and most valid chain, preventing manipulation.
Nodes transmit transaction and block data to other nodes on the network. This process ensures all participants are synchronized and up to date.
Since the Bitcoin network consists of thousands of independent nodes, it is nearly impossible for a single agent to control or alter the system.
Nodes also protect against attacks by validating information and blocking fraudulent attempts.
Full nodes are particularly important, as they act as independent auditors. They do not need to rely on third parties and can verify the entire transaction history directly.
By maintaining a full copy of the blockchain or timechain, these nodes allow anyone to validate transactions without intermediaries, promoting transparency and financial freedom.
- In addition, full nodes:
01 - Reinforce censorship resistance: No government or entity can delete or alter data recorded on the system. 02 - Preserve decentralization: The more full nodes that exist, the stronger and more secure the network becomes. 03 - Increase trust in the system: Users can independently confirm whether the rules are being followed.
Despite their value, operating a full node can be challenging, as it requires storage space, processing power, and bandwidth. As the blockchain or timechain grows, technical requirements increase, which can make participation harder for regular users.
To address this, the community continuously works on solutions, such as software improvements and scalability enhancements, to make network access easier without compromising security.
In summary, nodes are the backbone of the Bitcoin network, performing essential functions in transaction validation, verification, and distribution. They ensure the decentralization and security of the system, allowing participants to operate reliably without relying on intermediaries.
Full nodes, in particular, play a critical role in preserving the integrity of the blockchain or timechain, making the Bitcoin network resistant to censorship and manipulation.
While running a node may require technical resources, its impact on preserving financial freedom and system trust is invaluable. As such, nodes remain essential elements for the success and longevity of Bitcoin.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ dab6c606:51f507b6
2025-04-18 14:59:25
Core idea: Use geotagged anonymized Nostr events with Cashu-based points to snitch on cop locations for a more relaxed driving and walking
We all know navigation apps. There's one of them that allows you to report on locations of cops. It's Waze and it's owned by Google. There are perfectly fine navigation apps like Organic Maps, that unfortunately lack the cop-snitching features. In some countries, it is illegal to report cop locations, so it would probably not be a good idea to use your npub to report them. But getting a points Cashu token as a reward and exchanging them from time to time would solve this. You can of course report construction, traffic jams, ...
Proposed solution: Add Nostr client (Copstr) to Organic Maps. Have a button in bottom right allowing you to report traffic situations. Geotagged events are published on Nostr relays, users sending cashu tokens as thank you if the report is valid. Notes have smart expiration times.
Phase 2: Automation: Integration with dashcams and comma.ai allow for automated AI recognition of traffic events such as traffic jams and cops, with automatic touchless reporting.
Result: Drive with most essential information and with full privacy. Collect points to be cool and stay cool.
-
@ 90c656ff:9383fd4e
2025-05-04 16:36:21
Bitcoin mining is a crucial process for the operation and security of the network. It plays an important role in validating transactions and generating new bitcoins, ensuring the integrity of the blockchain or timechain-based system. This process involves solving complex mathematical calculations and requires significant computational power. Additionally, mining has economic, environmental, and technological effects that must be carefully analyzed.
Bitcoin mining is the procedure through which new units of the currency are created and added to the network. It is also responsible for verifying and recording transactions on the blockchain or timechain. This system was designed to be decentralized, eliminating the need for a central authority to control issuance or validate operations.
Participants in the process, called miners, compete to solve difficult mathematical problems. Whoever finds the solution first earns the right to add a new block to the blockchain or timechain and receives a reward in bitcoins, along with the transaction fees included in that block. This mechanism is known as Proof of Work (PoW).
The mining process is highly technical and follows a series of steps:
Transaction grouping: Transactions sent by users are collected into a pending block that awaits validation.
Solving mathematical problems: Miners must find a specific number, called a nonce, which, when combined with the block’s data, generates a cryptographic hash that meets certain required conditions. This process involves trial and error and consumes a great deal of computational power.
Block validation: When a miner finds the correct solution, the block is validated and added to the blockchain or timechain. All network nodes verify the block’s authenticity before accepting it.
Reward: The winning miner receives a bitcoin reward, in addition to the fees paid for the transactions included in the block. This reward decreases over time in an event called halving, which happens approximately every four years.
Bitcoin mining has a significant economic impact, as it creates income opportunities for individuals and companies. It also drives the development of new technologies such as specialized processors (ASICs) and modern cooling systems.
Moreover, mining supports financial inclusion by maintaining a decentralized network, enabling fast and secure global transactions. In regions with unstable economies, Bitcoin provides a viable alternative for value preservation and financial transfers.
Despite its economic benefits, Bitcoin mining is often criticized for its environmental impact. The proof-of-work process consumes large amounts of electricity, especially in areas where the energy grid relies on fossil fuels.
It’s estimated that Bitcoin mining uses as much energy as some entire countries, raising concerns about its sustainability. However, there are ongoing efforts to reduce these impacts, such as the increasing use of renewable energy sources and the exploration of alternative systems like Proof of Stake (PoS) in other decentralized networks.
Mining also faces challenges related to scalability and the concentration of computational power. Large companies and mining pools dominate the sector, which can affect the network’s decentralization.
Another challenge is the growing complexity of the mathematical problems, which requires more advanced hardware and consumes more energy over time. To address these issues, researchers are studying solutions that optimize resource use and keep the network sustainable in the long term.
In summary, Bitcoin mining is an essential process for maintaining the network and creating new units of the currency. It ensures security, transparency, and decentralization, supporting the operation of the blockchain or timechain.
However, mining also brings challenges such as high energy consumption and the concentration of resources in large pools. Even so, the pursuit of sustainable solutions and technological innovations points to a promising future, where Bitcoin continues to play a central role in the digital economy.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ c4b5369a:b812dbd6
2025-04-15 07:26:16
Offline transactions with Cashu
Over the past few weeks, I've been busy implementing offline capabilities into nutstash. I think this is one of the key value propositions of ecash, beinga a bearer instrument that can be used without internet access.
 It does however come with limitations, which can lead to a bit of confusion. I hope this article will clear some of these questions up for you!
It does however come with limitations, which can lead to a bit of confusion. I hope this article will clear some of these questions up for you!What is ecash/Cashu?
Ecash is the first cryptocurrency ever invented. It was created by David Chaum in 1983. It uses a blind signature scheme, which allows users to prove ownership of a token without revealing a link to its origin. These tokens are what we call ecash. They are bearer instruments, meaning that anyone who possesses a copy of them, is considered the owner.
Cashu is an implementation of ecash, built to tightly interact with Bitcoin, more specifically the Bitcoin lightning network. In the Cashu ecosystem,
Mintsare the gateway to the lightning network. They provide the infrastructure to access the lightning network, pay invoices and receive payments. Instead of relying on a traditional ledger scheme like other custodians do, the mint issues ecash tokens, to represent the value held by the users.How do normal Cashu transactions work?
A Cashu transaction happens when the sender gives a copy of his ecash token to the receiver. This can happen by any means imaginable. You could send the token through email, messenger, or even by pidgeon. One of the common ways to transfer ecash is via QR code.
The transaction is however not finalized just yet! In order to make sure the sender cannot double-spend their copy of the token, the receiver must do what we call a
swap. A swap is essentially exchanging an ecash token for a new one at the mint, invalidating the old token in the process. This ensures that the sender can no longer use the same token to spend elsewhere, and the value has been transferred to the receiver.
What about offline transactions?
Sending offline
Sending offline is very simple. The ecash tokens are stored on your device. Thus, no internet connection is required to access them. You can litteraly just take them, and give them to someone. The most convenient way is usually through a local transmission protocol, like NFC, QR code, Bluetooth, etc.
The one thing to consider when sending offline is that ecash tokens come in form of "coins" or "notes". The technical term we use in Cashu is
Proof. It "proofs" to the mint that you own a certain amount of value. Since these proofs have a fixed value attached to them, much like UTXOs in Bitcoin do, you would need proofs with a value that matches what you want to send. You can mix and match multiple proofs together to create a token that matches the amount you want to send. But, if you don't have proofs that match the amount, you would need to go online and swap for the needed proofs at the mint.Another limitation is, that you cannot create custom proofs offline. For example, if you would want to lock the ecash to a certain pubkey, or add a timelock to the proof, you would need to go online and create a new custom proof at the mint.
Receiving offline
You might think: well, if I trust the sender, I don't need to be swapping the token right away!
You're absolutely correct. If you trust the sender, you can simply accept their ecash token without needing to swap it immediately.
This is already really useful, since it gives you a way to receive a payment from a friend or close aquaintance without having to worry about connectivity. It's almost just like physical cash!
It does however not work if the sender is untrusted. We have to use a different scheme to be able to receive payments from someone we don't trust.
Receiving offline from an untrusted sender
To be able to receive payments from an untrusted sender, we need the sender to create a custom proof for us. As we've seen before, this requires the sender to go online.
The sender needs to create a token that has the following properties, so that the receciver can verify it offline:
- It must be locked to ONLY the receiver's public key
- It must include an
offline signature proof(DLEQ proof) - If it contains a timelock & refund clause, it must be set to a time in the future that is acceptable for the receiver
- It cannot contain duplicate proofs (double-spend)
- It cannot contain proofs that the receiver has already received before (double-spend)

If all of these conditions are met, then the receiver can verify the proof offline and accept the payment. This allows us to receive payments from anyone, even if we don't trust them.
At first glance, this scheme seems kinda useless. It requires the sender to go online, which defeats the purpose of having an offline payment system.
I beleive there are a couple of ways this scheme might be useful nonetheless:
-
Offline vending machines: Imagine you have an offline vending machine that accepts payments from anyone. The vending machine could use this scheme to verify payments without needing to go online itself. We can assume that the sender is able to go online and create a valid token, but the receiver doesn't need to be online to verify it.
-
Offline marketplaces: Imagine you have an offline marketplace where buyers and sellers can trade goods and services. Before going to the marketplace the sender already knows where he will be spending the money. The sender could create a valid token before going to the marketplace, using the merchants public key as a lock, and adding a refund clause to redeem any unspent ecash after it expires. In this case, neither the sender nor the receiver needs to go online to complete the transaction.
How to use this
Pretty much all cashu wallets allow you to send tokens offline. This is because all that the wallet needs to do is to look if it can create the desired amount from the proofs stored locally. If yes, it will automatically create the token offline.
Receiving offline tokens is currently only supported by nutstash (experimental).
To create an offline receivable token, the sender needs to lock it to the receiver's public key. Currently there is no refund clause! So be careful that you don't get accidentally locked out of your funds!

The receiver can then inspect the token and decide if it is safe to accept without a swap. If all checks are green, they can accept the token offline without trusting the sender.

The receiver will see the unswapped tokens on the wallet homescreen. They will need to manually swap them later when they are online again.
 Later when the receiver is online again, they can swap the token for a fresh one.
Later when the receiver is online again, they can swap the token for a fresh one.
Summary
We learned that offline transactions are possible with ecash, but there are some limitations. It either requires trusting the sender, or relying on either the sender or receiver to be online to verify the tokens, or create tokens that can be verified offline by the receiver.
I hope this short article was helpful in understanding how ecash works and its potential for offline transactions.
Cheers,
Gandlaf
-
@ 700c6cbf:a92816fd
2025-05-04 16:34:01
Technically speaking, I should say blooms because not all of my pictures are of flowers, a lot of them, probably most, are blooming trees - but who cares, right?
It is that time of the year that every timeline on every social media is being flooded by blooms. At least in the Northern Hemisphere. I thought that this year, I wouldn't partake in it but - here I am, I just can't resist the lure of blooms when I'm out walking the neighborhood.
Spring has sprung - aaaachoo, sorry, allergies suck! - and the blooms are beautiful.
Yesterday, we had the warmest day of the year to-date. I went for an early morning walk before breakfast. Beautiful blue skies, no clouds, sunshine and a breeze. Most people turned on their aircons. We did not. We are rebels - hah!
We also had breakfast on the deck which I really enjoy during the weekend. Later I had my first session of the year painting on the deck while listening/watching @thegrinder streaming. Good times.
Today, the weather changed. Last night, we had heavy thunderstorms and rain. This morning, it is overcast with the occasional sunray peaking through or, as it is right now, raindrops falling.
We'll see what the day will bring. For me, it will definitely be: Back to painting. Maybe I'll even share some here later. But for now - this is a photo post, and here are the photos. I hope you enjoy as much as I enjoyed yesterday's walk!
Cheers, OceanBee
!(image)[https://cdn.satellite.earth/cc3fb0fa757c88a6a89823585badf7d67e32dee72b6d4de5dff58acd06d0aa36.jpg] !(image)[https://cdn.satellite.earth/7fe93c27c3bf858202185cb7f42b294b152013ba3c859544950e6c1932ede4d3.jpg] !(image)[https://cdn.satellite.earth/6cbd9fba435dbe3e6732d9a5d1f5ff0403935a4ac9d0d83f6e1d729985220e87.jpg] !(image)[https://cdn.satellite.earth/df94d95381f058860392737d71c62cd9689c45b2ace1c8fc29d108625aabf5d5.jpg] !(image)[https://cdn.satellite.earth/e483e65c3ee451977277e0cfa891ec6b93b39c7c4ea843329db7354fba255e64.jpg] !(image)[https://cdn.satellite.earth/a98fe8e1e0577e3f8218af31f2499c3390ba04dced14c2ae13f7d7435b4000d7.jpg] !(image)[https://cdn.satellite.earth/d83b01915a23eb95c3d12c644713ac47233ce6e022c5df1eeba5ff8952b99d67.jpg] !(image)[https://cdn.satellite.earth/9ee3256882e363680d8ea9bb6ed3baa5979c950cdb6e62b9850a4baea46721f3.jpg] !(image)[https://cdn.satellite.earth/201a036d52f37390d11b76101862a082febb869c8d0e58d6aafe93c72919f578.jpg] !(image)[https://cdn.satellite.earth/cd516d89591a4cf474689b4eb6a67db842991c4bf5987c219fb9083f741ce871.jpg]
-
@ 09fbf8f3:fa3d60f0
2024-11-02 08:00:29
> ### 第三方API合集:
免责申明:
在此推荐的 OpenAI API Key 由第三方代理商提供,所以我们不对 API Key 的 有效性 和 安全性 负责,请你自行承担购买和使用 API Key 的风险。
| 服务商 | 特性说明 | Proxy 代理地址 | 链接 | | --- | --- | --- | --- | | AiHubMix | 使用 OpenAI 企业接口,全站模型价格为官方 86 折(含 GPT-4 )| https://aihubmix.com/v1 | 官网 | | OpenAI-HK | OpenAI的API官方计费模式为,按每次API请求内容和返回内容tokens长度来定价。每个模型具有不同的计价方式,以每1,000个tokens消耗为单位定价。其中1,000个tokens约为750个英文单词(约400汉字)| https://api.openai-hk.com/ | 官网 | | CloseAI | CloseAI是国内规模最大的商用级OpenAI代理平台,也是国内第一家专业OpenAI中转服务,定位于企业级商用需求,面向企业客户的线上服务提供高质量稳定的官方OpenAI API 中转代理,是百余家企业和多家科研机构的专用合作平台。 | https://api.openai-proxy.org | 官网 | | OpenAI-SB | 需要配合Telegram 获取api key | https://api.openai-sb.com | 官网 |
持续更新。。。
推广:
访问不了openai,去
低调云购买VPN。官网:https://didiaocloud.xyz
邀请码:
w9AjVJit价格低至1元。
-
@ 4c48cf05:07f52b80
2024-10-30 01:03:42
I believe that five years from now, access to artificial intelligence will be akin to what access to the Internet represents today. It will be the greatest differentiator between the haves and have nots. Unequal access to artificial intelligence will exacerbate societal inequalities and limit opportunities for those without access to it.
Back in April, the AI Index Steering Committee at the Institute for Human-Centered AI from Stanford University released The AI Index 2024 Annual Report.
Out of the extensive report (502 pages), I chose to focus on the chapter dedicated to Public Opinion. People involved with AI live in a bubble. We all know and understand AI and therefore assume that everyone else does. But, is that really the case once you step out of your regular circles in Seattle or Silicon Valley and hit Main Street?
Two thirds of global respondents have a good understanding of what AI is
The exact number is 67%. My gut feeling is that this number is way too high to be realistic. At the same time, 63% of respondents are aware of ChatGPT so maybe people are confounding AI with ChatGPT?
If so, there is so much more that they won't see coming.
This number is important because you need to see every other questions and response of the survey through the lens of a respondent who believes to have a good understanding of what AI is.
A majority are nervous about AI products and services
52% of global respondents are nervous about products and services that use AI. Leading the pack are Australians at 69% and the least worried are Japanise at 23%. U.S.A. is up there at the top at 63%.
Japan is truly an outlier, with most countries moving between 40% and 60%.
Personal data is the clear victim
Exaclty half of the respondents believe that AI companies will protect their personal data. And the other half believes they won't.
Expected benefits
Again a majority of people (57%) think that it will change how they do their jobs. As for impact on your life, top hitters are getting things done faster (54%) and more entertainment options (51%).
The last one is a head scratcher for me. Are people looking forward to AI generated movies?

Concerns
Remember the 57% that thought that AI will change how they do their jobs? Well, it looks like 37% of them expect to lose it. Whether or not this is what will happen, that is a very high number of people who have a direct incentive to oppose AI.
Other key concerns include:
- Misuse for nefarious purposes: 49%
- Violation of citizens' privacy: 45%
Conclusion
This is the first time I come across this report and I wil make sure to follow future annual reports to see how these trends evolve.
Overall, people are worried about AI. There are many things that could go wrong and people perceive that both jobs and privacy are on the line.
Full citation: Nestor Maslej, Loredana Fattorini, Raymond Perrault, Vanessa Parli, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, and Jack Clark, “The AI Index 2024 Annual Report,” AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2024.
The AI Index 2024 Annual Report by Stanford University is licensed under Attribution-NoDerivatives 4.0 International.
-
@ 1c19eb1a:e22fb0bc
2025-04-30 22:02:13
I am happy to present to you the first full review posted to Nostr Reviews: #Primal for #Android!
Primal has its origins as a micro-blogging, social media client, though it is now expanding its horizons into long-form content. It was first released only as a web client in March of 2023, but has since had a native client released for both iOS and Android. All of Primal's clients recently had an update to Primal 2.0, which included both performance improvements and a number of new features. This review will focus on the Android client specifically, both on phone and tablet.
Since Primal has also added features that are only available to those enrolled in their new premium subscription, it should also be noted that this review will be from the perspective of a free user. This is for two reasons. First, I am using an alternate npub to review the app, and if I were to purchase premium at some time in the future, it would be on my main npub. Second, despite a lot of positive things I have to say about Primal, I am not planning to regularly use any of their apps on my main account for the time being, for reasons that will be discussed later in the review.
The application can be installed through the Google Play Store, nostr:npub10r8xl2njyepcw2zwv3a6dyufj4e4ajx86hz6v4ehu4gnpupxxp7stjt2p8, or by downloading it directly from Primal's GitHub. The full review is current as of Primal Android version 2.0.21. Updates to the review on 4/30/2025 are current as of version 2.2.13.
In the ecosystem of "notes and other stuff," Primal is predominantly in the "notes" category. It is geared toward users who want a social media experience similar to Twitter or Facebook with an infinite scrolling feed of notes to interact with. However, there is some "other stuff" included to complement this primary focus on short and long form notes including a built-in Lightning wallet powered by #Strike, a robust advanced search, and a media-only feed.
Overall Impression
Score: 4.4 / 5 (Updated 4/30/2025)
Primal may well be the most polished UI of any Nostr client native to Android. It is incredibly well designed and thought out, with all of the icons and settings in the places a user would expect to find them. It is also incredibly easy to get started on Nostr via Primal's sign-up flow. The only two things that will be foreign to new users are the lack of any need to set a password or give an email address, and the prompt to optionally set up the wallet.
Complaints prior to the 2.0 update about Primal being slow and clunky should now be completely alleviated. I only experienced quick load times and snappy UI controls with a couple very minor exceptions, or when loading DVM-based feeds, which are outside of Primal's control.
Primal is not, however, a client that I would recommend for the power-user. Control over preferred relays is minimal and does not allow the user to determine which relays they write to and which they only read from. Though you can use your own wallet, it will not appear within the wallet interface, which only works with the custodial wallet from Strike. Moreover, and most eggregiously, the only way for existing users to log in is by pasting their nsec, as Primal does not support either the Android signer or remote signer options for users to protect their private key at this time. This lack of signer support is the primary reason the client received such a low overall score. If even one form of external signer log in is added to Primal, the score will be amended to 4.2 / 5, and if both Android signer and remote signer support is added, it will increase to 4.5.
Update: As of version 2.2.13, Primal now supports the Amber Android signer! One of the most glaring issues with the app has now been remedied and as promised, the overall score above has been increased.
Another downside to Primal is that it still utilizes an outdated direct message specification that leaks metadata that can be readily seen by anyone on the network. While the content of your messages remains encrypted, anyone can see who you are messaging with, and when. This also means that you will not see any DMs from users who are messaging from a client that has moved to the latest, and far more private, messaging spec.
That said, the beautiful thing about Nostr as a protocol is that users are not locked into any particular client. You may find Primal to be a great client for your average #bloomscrolling and zapping memes, but opt for a different client for more advanced uses and for direct messaging.
Features
Primal has a lot of features users would expect from any Nostr client that is focused on short-form notes, but it also packs in a lot of features that set it apart from other clients, and that showcase Primal's obvious prioritization of a top-tier user experience.
Home Feed
By default, the infinitely scrolling Home feed displays notes from those you currently follow in chronological order. This is traditional Nostr at its finest, and made all the more immersive by the choice to have all distracting UI elements quickly hide themselves from view as the you begin to scroll down the feed. They return just as quickly when you begin to scroll back up.
Scrolling the feed is incredibly fast, with no noticeable choppiness and minimal media pop-in if you are on a decent internet connection.
Helpfully, it is easy to get back to the top of the feed whenever there is a new post to be viewed, as a bubble will appear with the profile pictures of the users who have posted since you started scrolling.

Interacting With Notes
Interacting with a note in the feed can be done via the very recognizable icons at the bottom of each post. You can comment, zap, like, repost, and/or bookmark the note.
Notably, tapping on the zap icon will immediately zap the note your default amount of sats, making zapping incredibly fast, especially when using the built-in wallet. Long pressing on the zap icon will open up a menu with a variety of amounts, along with the ability to zap a custom amount. All of these amounts, and the messages that are sent with the zap, can be customized in the application settings.
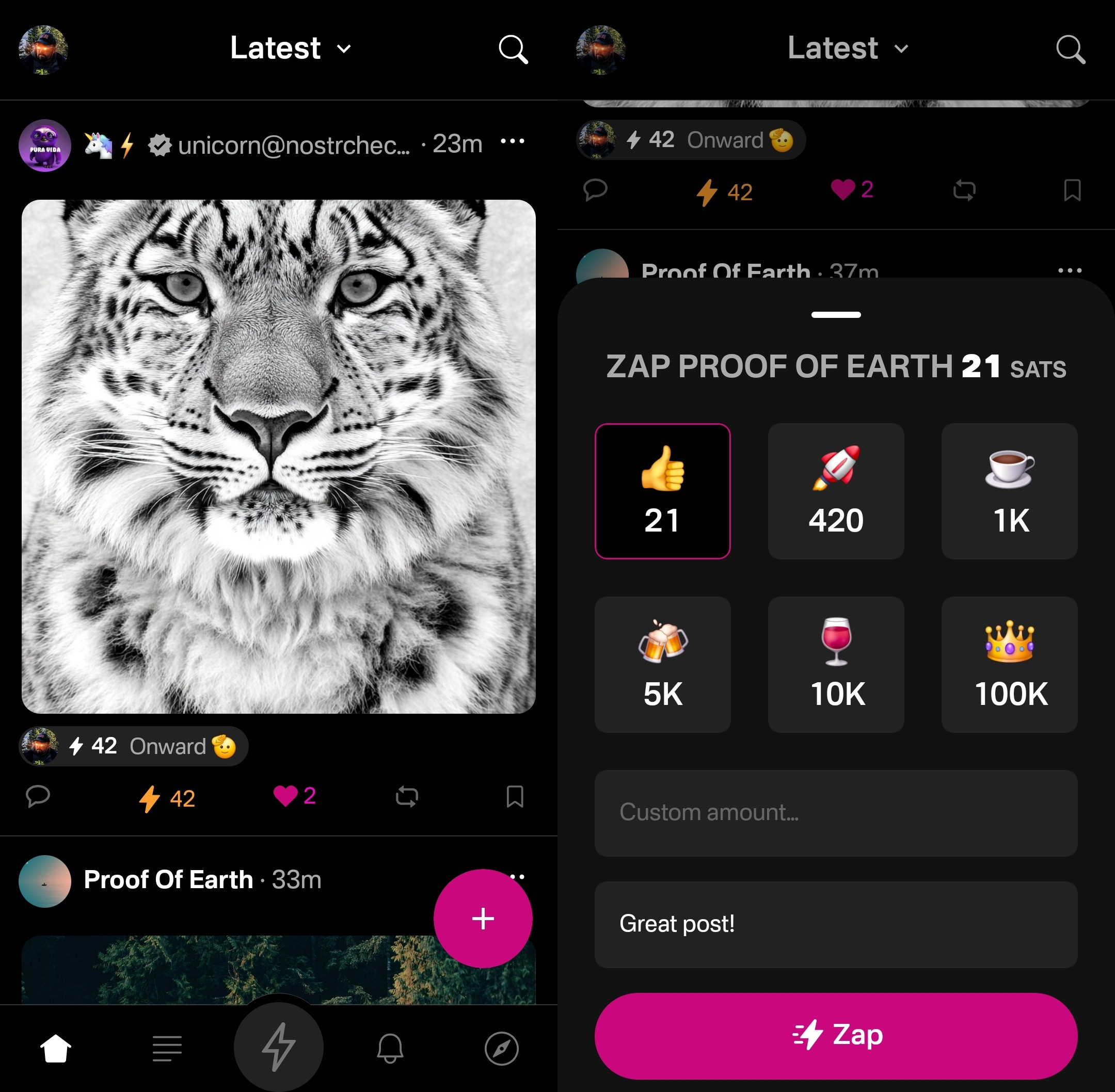
Users who are familiar with Twitter or Instagram will feel right at home with only having one option for "liking" a post. However, users from Facebook or other Nostr clients may wonder why they don't have more options for reactions. This is one of those things where users who are new to Nostr probably won't notice they are missing out on anything at all, while users familiar with clients like #Amethyst or #noStrudel will miss the ability to react with a 🤙 or a 🫂.
It's a similar story with the bookmark option. While this is a nice bit of feature parity for Twitter users, for those already used to the ability to have multiple customized lists of bookmarks, or at minimum have the ability to separate them into public and private, it may be a disappointment that they have no access to the bookmarks they already built up on other clients. Primal offers only one list of bookmarks for short-form notes and they are all visible to the public. However, you are at least presented with a warning about the public nature of your bookmarks before saving your first one.
Yet, I can't dock the Primal team much for making these design choices, as they are understandable for Primal's goal of being a welcoming client for those coming over to Nostr from centralized platforms. They have optimized for the onboarding of new users, rather than for those who have been around for a while, and there is absolutely nothing wrong with that.
Post Creation
Composing posts in Primal is as simple as it gets. Accessed by tapping the obvious circular button with a "+" on it in the lower right of the Home feed, most of what you could need is included in the interface, and nothing you don't.
Your device's default keyboard loads immediately, and the you can start typing away.
There are options for adding images from your gallery, or taking a picture with your camera, both of which will result in the image being uploaded to Primal's media-hosting server. If you prefer to host your media elsewhere, you can simply paste the link to that media into your post.
There is also an @ icon as a tip-off that you can tag other users. Tapping on this simply types "@" into your note and brings up a list of users. All you have to do to narrow down the user you want to tag is continue typing their handle, Nostr address, or paste in their npub.
This can get mixed results in other clients, which sometimes have a hard time finding particular users when typing in their handle, forcing you to have to remember their Nostr address or go hunt down their npub by another means. Not so with Primal, though. I had no issues tagging anyone I wanted by simply typing in their handle.
Of course, when you are tagging someone well known, you may find that there are multiple users posing as that person. Primal helps you out here, though. Usually the top result is the person you want, as Primal places them in order of how many followers they have. This is quite reliable right now, but there is nothing stopping someone from spinning up an army of bots to follow their fake accounts, rendering follower count useless for determining which account is legitimate. It would be nice to see these results ranked by web-of-trust, or at least an indication of how many users you follow who also follow the users listed in the results.
Once you are satisfied with your note, the "Post" button is easy to find in the top right of the screen.
Feed Selector and Marketplace
Primal's Home feed really shines when you open up the feed selection interface, and find that there are a plethora of options available for customizing your view. By default, it only shows four options, but tapping "Edit" opens up a new page of available toggles to add to the feed selector.
The options don't end there, though. Tapping "Add Feed" will open up the feed marketplace, where an ever-growing number of custom feeds can be found, some created by Primal and some created by others. This feed marketplace is available to a few other clients, but none have so closely integrated it with their Home feeds like Primal has.
Unfortunately, as great as these custom feeds are, this was also the feature where I ran into the most bugs while testing out the app.
One of these bugs was while selecting custom feeds. Occasionally, these feed menu screens would become unresponsive and I would be unable to confirm my selection, or even use the back button on my device to back out of the screen. However, I was able to pull the screen down to close it and re-open the menu, and everything would be responsive again.
This only seemed to occur when I spent 30 seconds or more on the same screen, so I imagine that most users won't encounter it much in their regular use.
Another UI bug occurred for me while in the feed marketplace. I could scroll down the list of available feeds, but attempting to scroll back up the feed would often close the interface entirely instead, as though I had pulled the screen down from the top, when I was swiping in the middle of the screen.
The last of these bugs occurred when selecting a long-form "Reads" feed while in the menu for the Home feed. The menu would allow me to add this feed and select it to be displayed, but it would fail to load the feed once selected, stating "There is no content in this feed." Going to a different page within the the app and then going back to the Home tab would automatically remove the long-form feed from view, and reset back to the most recently viewed short-form "Notes" feed, though the long-form feed would still be available to select again. The results were similar when selecting a short-form feed for the Reads feed.
I would suggest that if long-form and short-form feeds are going to be displayed in the same list, and yet not be able to be displayed in the same feed, the application should present an error message when attempting to add a long-form feed for the Home feed or a short-form feed for the Reads feed, and encourage the user add it to the proper feed instead.
Long-Form "Reads" Feed
A brand new feature in Primal 2.0, users can now browse and read long-form content posted to Nostr without having to go to a separate client. Primal now has a dedicated "Reads" feed to browse and interact with these articles.
This feed displays the author and title of each article or blog, along with an image, if available. Quite conveniently, it also lets you know the approximate amount of time it will take to read a given article, so you can decide if you have the time to dive into it now, or come back later.
Noticeably absent from the Reads feed, though, is the ability to compose an article of your own. This is another understandable design choice for a mobile client. Composing a long-form note on a smart-phone screen is not a good time. Better to be done on a larger screen, in a client with a full-featured text editor.
Tapping an article will open up an attractive reading interface, with the ability to bookmark for later. These bookmarks are a separate list from your short-form note bookmarks so you don't have to scroll through a bunch of notes you bookmarked to find the article you told yourself you would read later and it's already been three weeks.
While you can comment on the article or zap it, you will notice that you cannot repost or quote-post it. It's not that you can't do so on Nostr. You absolutely can in other clients. In fact, you can do so on Primal's web client, too. However, Primal on Android does not handle rendering long-form note previews in the Home feed, so they have simply left out the option to share them there. See below for an example of a quote-post of a long-form note in the Primal web client vs the Android client.
Primal Web:
Primal Android:
The Explore Tab
Another unique feature of the Primal client is the Explore tab, indicated by the compass icon. This tab is dedicated to discovering content from outside your current follow list. You can find the feed marketplace here, and add any of the available feeds to your Home or Reads feed selections. You can also find suggested users to follow in the People tab. The Zaps tab will show you who has been sending and receiving large zaps. Make friends with the generous ones!
The Media tab gives you a chronological feed of just media, displayed in a tile view. This can be great when you are looking for users who post dank memes, or incredible photography on a regular basis. Unfortunately, it appears that there is no way to filter this feed for sensitive content, and so you do not have to scroll far before you see pornographic material.
Indeed, it does not appear that filters for sensitive content are available in Primal for any feed. The app is kind enough to give a minimal warning that objectionable content may be present when selecting the "Nostr Firehose" option in your Home feed, with a brief "be careful" in the feed description, but there is not even that much of a warning here for the media-only feed.

The media-only feed doesn't appear to be quite as bad as the Nostr Firehose feed, so there must be some form of filtering already taking place, rather than being a truly global feed of all media. Yet, occasional sensitive content still litters the feed and is unavoidable, even for users who would rather not see it. There are, of course, ways to mute particular users who post such content, if you don't want to see it a second time from the same user, but that is a never-ending game of whack-a-mole, so your only realistic choices in Primal are currently to either avoid the Nostr Firehose and media-only feeds, or determine that you can put up with regularly scrolling past often graphic content.
This is probably the only choice Primal has made that is not friendly to new users. Most clients these days will have some protections in place to hide sensitive content by default, but still allow the user to toggle those protections off if they so choose. Some of them hide posts flagged as sensitive content altogether, others just blur the images unless the user taps to reveal them, and others simply blur all images posted by users you don't follow. If Primal wants to target new users who are accustomed to legacy social media platforms, they really should follow suit.
The final tab is titled "Topics," but it is really just a list of popular hashtags, which appear to be arranged by how often they are being used. This can be good for finding things that other users are interested in talking about, or finding specific content you are interested in.
If you tap on any topic in the list, it will display a feed of notes that include that hashtag. What's better, you can add it as a feed option you can select on your Home feed any time you want to see posts with that tag.
The only suggestion I would make to improve this tab is some indication of why the topics are arranged in the order presented. A simple indicator of the number of posts with that hashtag in the last 24 hours, or whatever the interval is for determining their ranking, would more than suffice.
Even with those few shortcomings, Primal's Explore tab makes the client one of the best options for discovering content on Nostr that you are actually interested in seeing and interacting with.
Built-In Wallet
While this feature is completely optional, the icon to access the wallet is the largest of the icons at the bottom of the screen, making you feel like you are missing out on the most important feature of the app if you don't set it up. I could be critical of this design choice, but in many ways I think it is warranted. The built-in wallet is one of the most unique features that Primal has going for it.
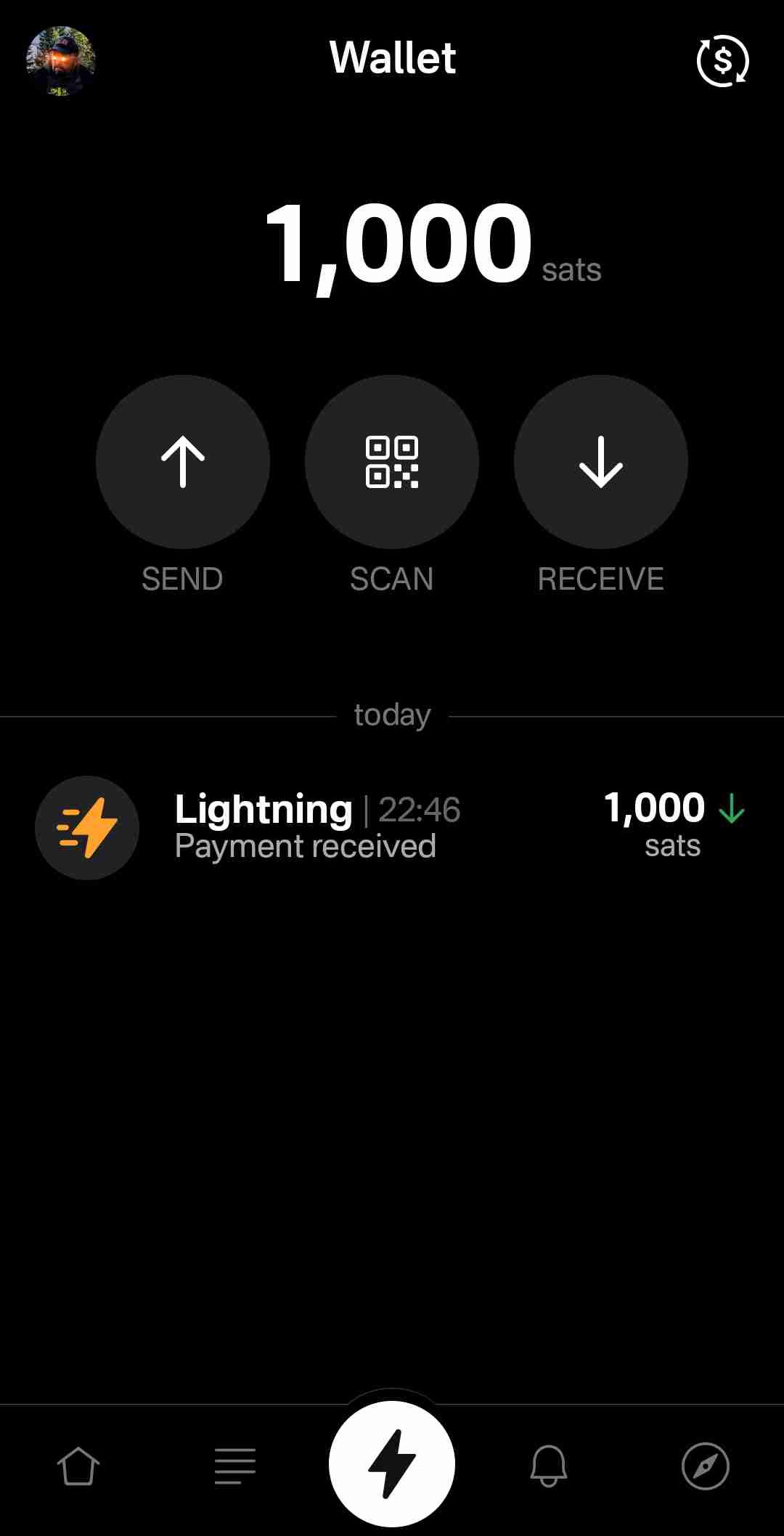
Consider: If you are a new user coming to Nostr, who isn't already a Bitcoiner, and you see that everyone else on the platform is sending and receiving sats for their posts, will you be more likely to go download a separate wallet application or use one that is built-into your client? I would wager the latter option by a long shot. No need to figure out which wallet you should download, whether you should do self-custody or custodial, or make the mistake of choosing a wallet with unexpected setup fees and no Lightning address so you can't even receive zaps to it. nostr:npub16c0nh3dnadzqpm76uctf5hqhe2lny344zsmpm6feee9p5rdxaa9q586nvr often states that he believes more people will be onboarded to Bitcoin through Nostr than by any other means, and by including a wallet into the Primal client, his team has made adopting Bitcoin that much easier for new Nostr users.
Some of us purists may complain that it is custodial and KYC, but that is an unfortunate necessity in order to facilitate onboarding newcoiners to Bitcoin. This is not intended to be a wallet for those of us who have been using Bitcoin and Lightning regularly already. It is meant for those who are not already familiar with Bitcoin to make it as easy as possible to get off zero, and it accomplishes this better than any other wallet I have ever tried.
In large part, this is because the KYC is very light. It does need the user's legal name, a valid email address, date of birth, and country of residence, but that's it! From there, the user can buy Bitcoin directly through the app, but only in the amount of $4.99 at a time. This is because there is a substantial markup on top of the current market price, due to utilizing whatever payment method the user has set up through their Google Play Store. The markup seemed to be about 19% above the current price, since I could purchase 4,143 sats for $4.99 ($120,415 / Bitcoin), when the current price was about $101,500. But the idea here is not for the Primal wallet to be a user's primary method of stacking sats. Rather, it is intended to get them off zero and have a small amount of sats to experience zapping with, and it accomplishes this with less friction than any other method I know.
Moreover, the Primal wallet has the features one would expect from any Lightning wallet. You can send sats to any Nostr user or Lightning address, receive via invoice, or scan to pay an invoice. It even has the ability to receive via on-chain. This means users who don't want to pay the markup from buying through Primal can easily transfer sats they obtained by other means into the Primal wallet for zapping, or for using it as their daily-driver spending wallet.
Speaking of zapping, once the wallet is activated, sending zaps is automatically set to use the wallet, and they are fast. Primal gives you immediate feedback that the zap was sent and the transaction shows in your wallet history typically before you can open the interface. I can confidently say that Primal wallet's integration is the absolute best zapping experience I have seen in any Nostr client.
One thing to note that may not be immediately apparent to new users is they need to add their Lightning address with Primal into their profile details before they can start receiving zaps. So, sending zaps using the wallet is automatic as soon as you activate it, but receiving is not. Ideally, this could be further streamlined, so that Primal automatically adds the Lightning address to the user's profile when the wallet is set up, so long as there is not currently a Lightning address listed.
Of course, if you already have a Lightning wallet, you can connect it to Primal for zapping, too. We will discuss this further in the section dedicated to zap integration.
Advanced Search
Search has always been a tough nut to crack on Nostr, since it is highly dependent on which relays the client is pulling information from. Primal has sought to resolve this issue, among others, by running a caching relay that pulls notes from a number of relays to store them locally, and perform some spam filtering. This allows for much faster retrieval of search results, and also makes their advanced search feature possible.
Advanced search can be accessed from most pages by selecting the magnifying glass icon, and then the icon for more options next to the search bar.
As can be seen in the screenshot below, there are a plethora of filters that can be applied to your search terms.
You can immediately see how this advanced search could be a very powerful tool for not just finding a particular previous note that you are looking for, but for creating your own custom feed of notes. Well, wouldn't you know it, Primal allows you to do just that! This search feature, paired with the other features mentioned above related to finding notes you want to see in your feed, makes Primal hands-down the best client for content discovery.
The only downside as a free user is that some of these search options are locked behind the premium membership. Or else you only get to see a certain number of results of your advanced search before you must be a premium member to see more.
Can My Grandma Use It?
Score: 4.8 / 5 Primal has obviously put a high priority on making their client user-friendly, even for those who have never heard of relays, public/private key cryptography, or Bitcoin. All of that complexity is hidden away. Some of it is available to play around with for the users who care to do so, but it does not at all get in the way of the users who just want to jump in and start posting notes and interacting with other users in a truly open public square.
To begin with, the onboarding experience is incredibly smooth. Tap "Create Account," enter your chosen display name and optional bio information, upload a profile picture, and then choose some topics you are interested in. You are then presented with a preview of your profile, with the ability to add a banner image, if you so choose, and then tap "Create Account Now."
From there you receive confirmation that your account has been created and that your "Nostr key" is available to you in the application settings. No further explanation is given about what this key is for at this point, but the user doesn't really need to know at the moment, either. If they are curious, they will go to the app settings to find out.
At this point, Primal encourages the user to activate Primal Wallet, but also gives the option for the user to do it later.
That's it! The next screen the user sees if they don't opt to set up the wallet is their Home feed with notes listed in chronological order. More impressive, the feed is not empty, because Primal has auto-followed several accounts based on your selected topics.
Now, there has definitely been some legitimate criticism of this practice of following specific accounts based on the topic selection, and I agree. I would much prefer to see Primal follow hashtags based on what was selected, and combine the followed hashtags into a feed titled "My Topics" or something of that nature, and make that the default view when the user finishes onboarding. Following particular users automatically will artificially inflate certain users' exposure, while other users who might be quality follows for that topic aren't seen at all.
The advantage of following particular users over a hashtag, though, is that Primal retains some control over the quality of the posts that new users are exposed to right away. Primal can ensure that new users see people who are actually posting quality photography when they choose it as one of their interests. However, even with that example, I chose photography as one of my interests and while I did get some stunning photography in my Home feed by default based on Primal's chosen follows, I also scrolled through the Photography hashtag for a bit and I really feel like I would have been better served if Primal had simply followed that hashtag rather than a particular set of users.
We've already discussed how simple it is to set up the Primal Wallet. You can see the features section above if you missed it. It is, by far, the most user friendly experience to onboarding onto Lightning and getting a few sats for zapping, and it is the only one I know of that is built directly into a Nostr client. This means new users will have a frictionless introduction to transacting via Lightning, perhaps without even realizing that's what they are doing.
Discovering new content of interest is incredibly intuitive on Primal, and the only thing that new users may struggle with is getting their own notes seen by others. To assist with this, I would suggest Primal encourage users to make their first post to the introductions hashtag and direct any questions to the AskNostr hashtag as part of the onboarding process. This will get them some immediate interactions from other users, and further encouragement to set up their wallet if they haven't already done so.
How do UI look?
Score: 4.9 / 5
Primal is the most stunningly beautiful Nostr client available, in my honest opinion. Despite some of my hangups about certain functionality, the UI alone makes me want to use it.
It is clean, attractive, and intuitive. Everything I needed was easy to find, and nothing felt busy or cluttered. There are only a few minor UI glitches that I ran into while testing the app. Some of them were mentioned in the section of the review detailing the feed selector feature, but a couple others occurred during onboarding.
First, my profile picture was not centered in the preview when I uploaded it. This appears to be because it was a low quality image. Uploading a higher quality photo did not have this result.
The other UI bug was related to text instructions that were cut off, and not able to scroll to see the rest of them. This occurred on a few pages during onboarding, and I expect it was due to the size of my phone screen, since it did not occur when I was on a slightly larger phone or tablet.
Speaking of tablets, Primal Android looks really good on a tablet, too! While the client does not have a landscape mode by default, many Android tablets support forcing apps to open in full-screen landscape mode, with mixed results. However, Primal handles it well. I would still like to see a tablet version developed that takes advantage of the increased screen real estate, but it is certainly a passable option.


At this point, I would say the web client probably has a bit better UI for use on a tablet than the Android client does, but you miss out on using the built-in wallet, which is a major selling point of the app.
This lack of a landscape mode for tablets and the few very minor UI bugs I encountered are the only reason Primal doesn't get a perfect score in this category, because the client is absolutely stunning otherwise, both in light and dark modes. There are also two color schemes available for each.
Log In Options
Score: 4 / 5 (Updated 4/30/2025)
Unfortunately, Primal has not included any options for log in outside of pasting your private key into the application. While this is a very simple way to log in for new users to understand, it is also the least secure means to log into Nostr applications.
This is because, even with the most trustworthy client developer, giving the application access to your private key always has the potential for that private key to somehow be exposed or leaked, and on Nostr there is currently no way to rotate to a different private key and keep your identity and social graph. If someone gets your key, they are you on Nostr for all intents and purposes.
This is not a situation that users should be willing to tolerate from production-release clients at this point. There are much better log in standards that can and should be implemented if you care about your users.
That said, I am happy to report that external signer support is on the roadmap for Primal, as confirmed below:
nostr:note1n59tc8k5l2v30jxuzghg7dy2ns76ld0hqnn8tkahyywpwp47ms5qst8ehl
No word yet on whether this will be Android signer or remote signer support, or both.
This lack of external signer support is why I absolutely will not use my main npub with Primal for Android. I am happy to use the web client, which supports and encourages logging in with a browser extension, but until the Android client allows users to protect their private key, I cannot recommend it for existing Nostr users.
Update: As of version 2.2.13, all of what I have said above is now obsolete. Primal has added Android signer support, so users can now better protect their nsec by using Amber!
I would still like to see support for remote signers, especially with nstart.me as a recommended Nostr onboarding process and the advent of FROSTR for key management. That said, Android signer support on its own has been a long time coming and is a very welcome addition to the Primal app. Bravo Primal team!
Zap Integration
Score: 4.8 / 5
As mentioned when discussing Primal's built-in wallet feature, zapping in Primal can be the most seamless experience I have ever seen in a Nostr client. Pairing the wallet with the client is absolutely the path forward for Nostr leading the way to Bitcoin adoption.
But what if you already have a Lightning wallet you want to use for zapping? You have a couple options. If it is an Alby wallet or another wallet that supports Nostr Wallet Connect, you can connect it with Primal to use with one-tap zapping.
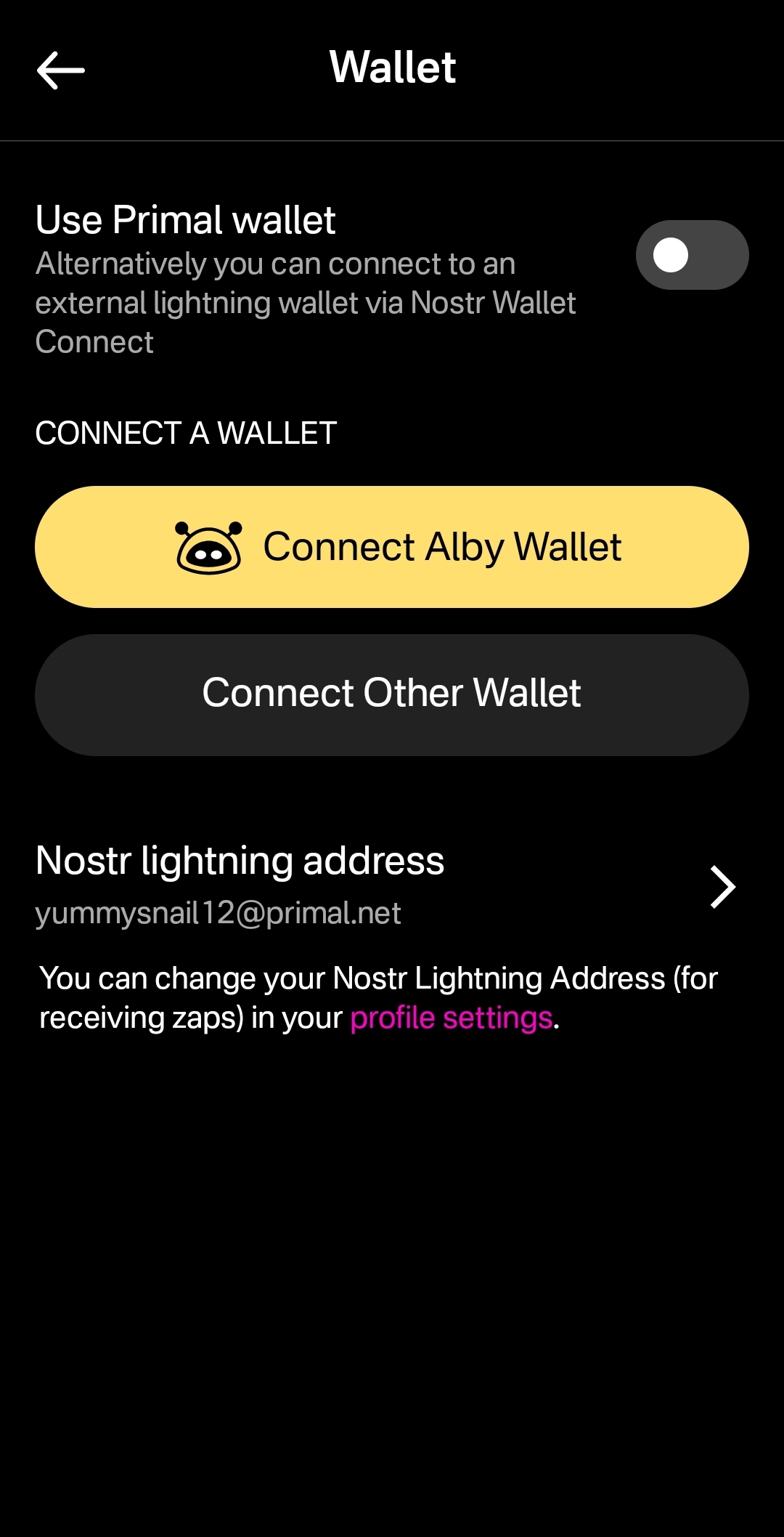
How your zapping experience goes with this option will vary greatly based on your particular wallet of choice and is beyond the scope of this review. I used this option with a hosted wallet on my Alby Hub and it worked perfectly. Primal gives you immediate feedback that you have zapped, even though the transaction usually takes a few seconds to process and appear in your wallet's history.
The one major downside to using an external wallet is the lack of integration with the wallet interface. This interface currently only works with Primal's wallet, and therefore the most prominent tab in the entire app goes unused when you connect an external wallet.
An ideal improvement would be for the wallet screen to work similar to Alby Go when you have an external wallet connected via Nostr Wallet Connect, allowing the user to have Primal act as their primary mobile Lightning wallet. It could have balance and transaction history displayed, and allow sending and receiving, just like the integrated Primal wallet, but remove the ability to purchase sats directly through the app when using an external wallet.
Content Discovery
Score: 4.8 / 5
Primal is the best client to use if you want to discover new content you are interested in. There is no comparison, with only a few caveats.
First, the content must have been posted to Nostr as either a short-form or long-form note. Primal has a limited ability to display other types of content. For instance, discovering video content or streaming content is lacking.
Second, you must be willing to put up with the fact that Primal lacks a means of filtering sensitive content when you are exploring beyond the bounds of your current followers. This may not be an issue for some, but for others it could be a deal-breaker.
Third, it would be preferable for Primal to follow topics you are interested in when you choose them during onboarding, rather than follow specific npubs. Ideally, create a "My Topics" feed that can be edited by selecting your interests in the Topics section of the Explore tab.
Relay Management
Score: 2.5 / 5
For new users who don't want to mess around with managing relays, Primal is fantastic! There are 7 relays selected by default, in addition to Primal's caching service. For most users who aren't familiar with Nostr's protocol archetecture, they probably won't ever have to change their default relays in order to use the client as they would expect.
However, two of these default relays were consistently unreachable during the week that I tested. These were relay.plebes.fans and remnant.cloud. The first relay seems to be an incorrect URL, as I found nosflare.plebes.fans online and with perfect uptime for the last 12 hours on nostr.watch. I was unable to find remnant.cloud on nostr.watch at all. A third relay was intermittent, sometimes online and reachable, and other times unreachable: v1250.planz.io/nostr. If Primal is going to have default relays, they should ideally be reliable and with accurate URLs.
That said, users can add other relays that they prefer, and remove relays that they no longer want to use. They can even set a different caching service to use with the client, rather than using Primal's.
However, that is the extent of a user's control over their relays. They cannot choose which relays they want to write to and which they want to read from, nor can they set any private relays, outbox or inbox relays, or general relays. Loading the npub I used for this review into another client with full relay management support revealed that the relays selected in Primal are being added to both the user's public outbox relays and public inbox relays, but not to any other relay type, which leads me to believe the caching relay is acting as the client's only general relay and search relay.
One unique and welcomed addition is the "Enhanced Privacy" feature, which is off by default, but which can be toggled on. I am not sure why this is not on by default, though. Perhaps someone from the Primal team can enlighten me on that choice.
By default, when you post to Nostr, all of your outbox relays will see your IP address. If you turn on the Enhanced Privacy mode, only Primal's caching service will see your IP address, because it will post your note to the other relays on your behalf. In this way, the caching service acts similar to a VPN for posting to Nostr, as long as you trust Primal not to log or leak your IP address.
In short, if you use any other Nostr clients at all, do not use Primal for managing your relays.
Media Hosting Options
Score: 4.9 / 5 This is a NEW SECTION of this review, as of version 2.2.13!
Primal has recently added support for the Blossom protocol for media hosting, and has added a new section within their settings for "Media Uploads."
Media hosting is one of the more complicated problems to solve for a decentralized publishing protocol like Nostr. Text-based notes are generally quite small, making them no real burden to store on relays, and a relay can prune old notes as they see fit, knowing that anyone who really cared about those notes has likely archived them elsewhere. Media, on the other hand, can very quickly fill up a server's disk space, and because it is usually addressable via a specific URL, removing it from that location to free up space means it will no longer load for anyone.
Blossom solves this issue by making it easy to run a media server and have the same media mirrored to more than one for redundancy. Since the media is stored with a file name that is a hash of the content itself, if the media is deleted from one server, it can still be found from any other server that has the same file, without any need to update the URL in the Nostr note where it was originally posted.
Prior to this update, Primal only allowed media uploads to their own media server. Now, users can upload to any blossom server, and even choose to have their pictures or videos mirrored additional servers automatically. To my knowledge, no other Nostr client offers this automatic mirroring at the time of upload.
One of my biggest criticisms of Primal was that it had taken a siloed approach by providing a client, a caching relay, a media server, and a wallet all controlled by the same company. The whole point of Nostr is to separate control of all these services to different entities. Now users have more options for separating out their media hosting and their wallet to other providers, at least. I would still like to see other options available for a caching relay, but that relies on someone else being willing to run one, since the software is open for anyone to use. It's just not your average, lightweight relay that any average person can run from home.
Regardless, this update to add custom Blossom servers is a most welcome step in the right direction!
Current Users' Questions
The AskNostr hashtag can be a good indication of the pain points that other users are currently having with a client. Here are some of the most common questions submitted about Primal since the launch of 2.0:
nostr:note1dqv4mwqn7lvpaceg9s7damf932ydv9skv2x99l56ufy3f7q8tkdqpxk0rd
This was a pretty common question, because users expect that they will be able to create the same type of content that they can consume in a particular client. I can understand why this was left out in a mobile client, but perhaps it should be added in the web client.
nostr:note16xnm8a2mmrs7t9pqymwjgd384ynpf098gmemzy49p3572vhwx2mqcqw8xe
This is a more concerning bug, since it appears some users are experiencing their images being replaced with completely different images. I did not experience anything similar in my testing, though.
nostr:note1uhrk30nq0e566kx8ac4qpwrdh0vfaav33rfvckyvlzn04tkuqahsx8e7mr
There hasn't been an answer to this, but I have not been able to find a way. It seems search results will always include replies as well as original notes, so a feed made from the search results will as well. Perhaps a filter can be added to the advanced search to exclude replies? There is already a filter to only show replies, but there is no corresponding filter to only show original notes.
nostr:note1zlnzua28a5v76jwuakyrf7hham56kx9me9la3dnt3fvymcyaq6eqjfmtq6
Since both mobile platforms support the wallet, users expect that they will be able to access it in their web client, too. At this time, they cannot. The only way to have seamless zapping in the web client is to use the Alby extension, but there is not a way to connect it to your Primal wallet via Nostr Wallet Connect either. This means users must have a separate wallet for zapping on the web client if they use the Primal Wallet on mobile.
nostr:note15tf2u9pffy58y9lk27y245ew792raqc7lc22jezxvqj7xrak9ztqu45wep
It seems that Primal is filtering for spam even for profiles you actively follow. Moreover, exactly what the criteria is for being considered spam is currently opaque.
nostr:note1xexnzv0vrmc8svvduurydwmu43w7dftyqmjh4ps98zksr39ln2qswkuced
For those unaware, Blossom is a protocol for hosting media as blobs identified by a hash, allowing them to be located on and displayed from other servers they have been mirrored to when when the target server isn't available. Primal currently runs a Blossom server (blossom.primal.net) so I would expect we see Blossom support in the future.
nostr:note1unugv7s36e2kxl768ykg0qly7czeplp8qnc207k4pj45rexgqv4sue50y6
Currently, Primal on Android only supports uploading photos to your posts. Users must upload any video to some other hosting service and copy/paste a link to the video into their post on Primal. I would not be surprised to see this feature added in the near future, though.
nostr:note10w6538y58dkd9mdrlkfc8ylhnyqutc56ggdw7gk5y7nsp00rdk4q3qgrex
Many Nostr users have more than one npub for various uses. Users would prefer to have a way to quickly switch between accounts than to have to log all the way out and paste their npub for the other account every time they want to use it.
There is good news on this front, though:
nostr:note17xv632yqfz8nx092lj4sxr7drrqfey6e2373ha00qlq8j8qv6jjs36kxlh
Wrap Up
All in all, Primal is an excellent client. It won't be for everyone, but that's one of the strengths of Nostr as a protocol. You can choose to use the client that best fits your own needs, and supplement with other clients and tools as necessary.
There are a couple glaring issues I have with Primal that prevent me from using it on my main npub, but it is also an ever-improving client, that already has me hopeful for those issues to be resolved in a future release.
So, what should I review next? Another Android client, such as #Amethyst or #Voyage? Maybe an "other stuff" app, like #Wavlake or #Fountain? Please leave your suggestions in the comments.
I hope this review was valuable to you! If it was, please consider letting me know just how valuable by zapping me some sats and reposting it out to your follows.
Thank you for reading!
PV 🤙
-
@ dc4cd086:cee77c06
2024-10-18 04:08:33
Have you ever wanted to learn from lengthy educational videos but found it challenging to navigate through hours of content? Our new tool addresses this problem by transforming long-form video lectures into easily digestible, searchable content.
Key Features:
Video Processing:
- Automatically downloads YouTube videos, transcripts, and chapter information
- Splits transcripts into sections based on video chapters
Content Summarization:
- Utilizes language models to transform spoken content into clear, readable text
- Formats output in AsciiDoc for improved readability and navigation
- Highlights key terms and concepts with [[term]] notation for potential cross-referencing
Diagram Extraction:
- Analyzes video entropy to identify static diagram/slide sections
- Provides a user-friendly GUI for manual selection of relevant time ranges
- Allows users to pick representative frames from selected ranges
Going Forward:
Currently undergoing a rewrite to improve organization and functionality, but you are welcome to try the current version, though it might not work on every machine. Will support multiple open and closed language models for user choice Free and open-source, allowing for personal customization and integration with various knowledge bases. Just because we might not have it on our official Alexandria knowledge base, you are still welcome to use it on you own personal or community knowledge bases! We want to help find connections between ideas that exist across relays, allowing individuals and groups to mix and match knowledge bases between each other, allowing for any degree of openness you care.
While designed with #Alexandria users in mind, it's available for anyone to use and adapt to their own learning needs.
Screenshots
Frame Selection
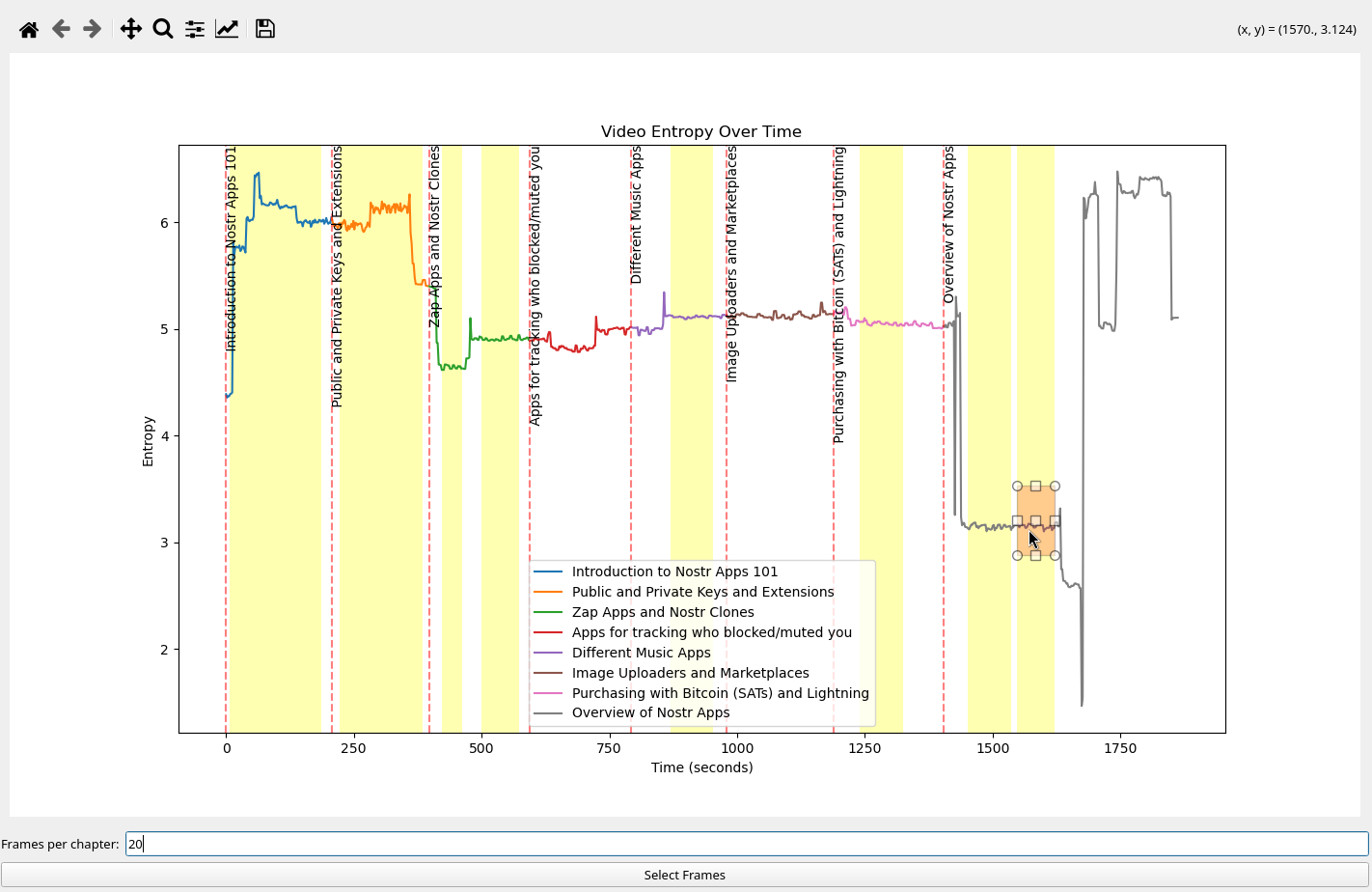
This is a screenshot of the frame selection interface. You'll see a signal that represents frame entropy over time. The vertical lines indicate the start and end of a chapter. Within these chapters you can select the frames by clicking and dragging the mouse over the desired range where you think diagram is in that chapter. At the bottom is an option that tells the program to select a specific number of frames from that selection.
Diagram Extraction
This is a screenshot of the diagram extraction interface. For every selection you've made, there will be a set of frames that you can choose from. You can select and deselect as many frames as you'd like to save.
Links
- repo: https://github.com/limina1/video_article_converter
- Nostr Apps 101: https://www.youtube.com/watch?v=Flxa_jkErqE
Output
And now, we have a demonstration of the final result of this tool, with some quick cleaning up. The video we will be using this tool on is titled Nostr Apps 101 by nostr:npub1nxy4qpqnld6kmpphjykvx2lqwvxmuxluddwjamm4nc29ds3elyzsm5avr7 during Nostrasia. The following thread is an analog to the modular articles we are constructing for Alexandria, and I hope it conveys the functionality we want to create in the knowledge space. Note, this tool is the first step! You could use a different prompt that is most appropriate for the specific context of the transcript you are working with, but you can also manually clean up any discrepancies that don't portray the video accurately.
nostr:nevent1qvzqqqqqqypzp5r5hd579v2sszvvzfel677c8dxgxm3skl773sujlsuft64c44ncqy2hwumn8ghj7un9d3shjtnyv9kh2uewd9hj7qgwwaehxw309ahx7uewd3hkctcpzemhxue69uhhyetvv9ujumt0wd68ytnsw43z7qghwaehxw309aex2mrp0yhxummnw3ezucnpdejz7qgewaehxw309aex2mrp0yh8xmn0wf6zuum0vd5kzmp0qqsxunmjy20mvlq37vnrcshkf6sdrtkfjtjz3anuetmcuv8jswhezgc7hglpn
Or view on Coracle nostr:nevent1qqsxunmjy20mvlq37vnrcshkf6sdrtkfjtjz3anuetmcuv8jswhezgcppemhxue69uhkummn9ekx7mp0qgsdqa9md83tz5yqnrqjw07hhkpmfjpkuv9hlh5v8yhu8z274w9dv7qnnq0s3
-
@ 8947a945:9bfcf626
2024-10-17 08:06:55

สวัสดีทุกคนบน Nostr ครับ รวมไปถึง watchersและ ผู้ติดตามของผมจาก Deviantart และ platform งานศิลปะอื่นๆนะครับ
ตั้งแต่ต้นปี 2024 ผมใช้ AI เจนรูปงานตัวละครสาวๆจากอนิเมะ และเปิด exclusive content ให้สำหรับผู้ที่ชื่นชอบผลงานของผมเป็นพิเศษ
ผมโพสผลงานผมทั้งหมดไว้ที่เวบ Deviantart และค่อยๆสร้างฐานผู้ติดตามมาเรื่อยๆอย่างค่อยเป็นค่อยไปมาตลอดครับ ทุกอย่างเติบโตไปเรื่อยๆของมัน ส่วนตัวผมมองว่ามันเป็นพิร์ตธุรกิจออนไลน์ ของผมพอร์ตนึงได้เลย
เมื่อวันที่ 16 กย.2024 มีผู้ติดตามคนหนึ่งส่งข้อความส่วนตัวมาหาผม บอกว่าชื่นชอบผลงานของผมมาก ต้องการจะขอซื้อผลงาน แต่ขอซื้อเป็น NFT นะ เสนอราคาซื้อขายต่อชิ้นที่สูงมาก หลังจากนั้นผมกับผู้ซื้อคนนี้พูดคุยกันในเมล์ครับ

นี่คือข้อสรุปสั่นๆจากการต่อรองซื้อขายครับ
(หลังจากนี้ผมขอเรียกผู้ซื้อว่า scammer นะครับ เพราะไพ่มันหงายมาแล้ว ว่าเขาคือมิจฉาชีพ)

- Scammer รายแรก เลือกผลงานที่จะซื้อ เสนอราคาซื้อที่สูงมาก แต่ต้องเป็นเวบไซต์ NFTmarket place ที่เขากำหนดเท่านั้น มันทำงานอยู่บน ERC20 ผมเข้าไปดูเวบไซต์ที่ว่านี้แล้วรู้สึกว่ามันดูแปลกๆครับ คนที่จะลงขายผลงานจะต้องใช้ email ในการสมัครบัญชีซะก่อน ถึงจะผูก wallet อย่างเช่น metamask ได้ เมื่อผูก wallet แล้วไม่สามารถเปลี่ยนได้ด้วย ตอนนั้นผมใช้ wallet ที่ไม่ได้ link กับ HW wallet ไว้ ทดลองสลับ wallet ไปๆมาๆ มันทำไม่ได้ แถมลอง log out แล้ว เลข wallet ก็ยังคาอยู่อันเดิม อันนี้มันดูแปลกๆแล้วหนึ่งอย่าง เวบนี้ค่า ETH ในการ mint 0.15 - 0.2 ETH … ตีเป็นเงินบาทนี่แพงบรรลัยอยู่นะครับ

-
Scammer รายแรกพยายามชักจูงผม หว่านล้อมผมว่า แหม เดี๋ยวเขาก็มารับซื้องานผมน่า mint งานเสร็จ รีบบอกเขานะ เดี๋ยวเขารีบกดซื้อเลย พอขายได้กำไร ผมก็ได้ค่า gas คืนได้ แถมยังได้กำไรอีก ไม่มีอะไรต้องเสีนจริงมั้ย แต่มันเป้นความโชคดีครับ เพราะตอนนั้นผมไม่เหลือทุนสำรองที่จะมาซื้อ ETH ได้ ผมเลยต่อรองกับเขาตามนี้ครับ :
-
ผมเสนอว่า เอางี้มั้ย ผมส่งผลงานของผมแบบ low resolution ให้ก่อน แลกกับให้เขาช่วยโอน ETH ที่เป็นค่า mint งานมาให้หน่อย พอผมได้ ETH แล้ว ผมจะ upscale งานของผม แล้วเมล์ไปให้ ใจแลกใจกันไปเลย ... เขาไม่เอา
- ผมเสนอให้ไปซื้อที่ร้านค้าออนไลน์ buymeacoffee ของผมมั้ย จ่ายเป็น USD ... เขาไม่เอา
- ผมเสนอให้ซื้อขายผ่าน PPV lightning invoice ที่ผมมีสิทธิ์เข้าถึง เพราะเป็น creator ของ Creatr ... เขาไม่เอา
- ผมยอกเขาว่างั้นก็รอนะ รอเงินเดือนออก เขาบอก ok
สัปดาห์ถัดมา มี scammer คนที่สองติดต่อผมเข้ามา ใช้วิธีการใกล้เคียงกัน แต่ใช้คนละเวบ แถมเสนอราคาซื้อที่สูงกว่าคนแรกมาก เวบที่สองนี้เลวร้ายค่าเวบแรกอีกครับ คือต้องใช้เมล์สมัครบัญชี ไม่สามารถผูก metamask ได้ พอสมัครเสร็จจะได้ wallet เปล่าๆมาหนึ่งอัน ผมต้องโอน ETH เข้าไปใน wallet นั้นก่อน เพื่อเอาไปเป็นค่า mint NFT 0.2 ETH
ผมบอก scammer รายที่สองว่า ต้องรอนะ เพราะตอนนี้กำลังติดต่อซื้อขายอยู่กับผู้ซื้อรายแรกอยู่ ผมกำลังรอเงินเพื่อมาซื้อ ETH เป็นต้นทุนดำเนินงานอยู่ คนคนนี้ขอให้ผมส่งเวบแรกไปให้เขาดูหน่อย หลังจากนั้นไม่นานเขาเตือนผมมาว่าเวบแรกมันคือ scam นะ ไม่สามารถถอนเงินออกมาได้ เขายังส่งรูป cap หน้าจอที่คุยกับผู้เสียหายจากเวบแรกมาให้ดูว่าเจอปัญหาถอนเงินไม่ได้ ไม่พอ เขายังบลัฟ opensea ด้วยว่าลูกค้าขายงานได้ แต่ถอนเงินไม่ได้
Opensea ถอนเงินไม่ได้ ตรงนี้แหละครับคือตัวกระตุกต่อมเอ๊ะของผมดังมาก เพราะ opensea อ่ะ ผู้ใช้ connect wallet เข้ากับ marketplace โดยตรง ซื้อขายกันเกิดขึ้น เงินวิ่งเข้าวิ่งออก wallet ของแต่ละคนโดยตรงเลย opensea เก็บแค่ค่า fee ในการใช้ platform ไม่เก็บเงินลูกค้าไว้ แถมปีนี้ค่า gas fee ก็ถูกกว่า bull run cycle 2020 มาก ตอนนี้ค่า gas fee ประมาณ 0.0001 ETH (แต่มันก็แพงกว่า BTC อยู่ดีอ่ะครับ)
ผมเลยเอาเรื่องนี้ไปปรึกษาพี่บิท แต่แอดมินมาคุยกับผมแทน ทางแอดมินแจ้งว่ายังไม่เคยมีเพื่อนๆมาปรึกษาเรื่องนี้ กรณีที่ผมทักมาถามนี่เป็นรายแรกเลย แต่แอดมินให้ความเห็นไปในทางเดียวกับสมมุติฐานของผมว่าน่าจะ scam ในเวลาเดียวกับผมเอาเรื่องนี้ไปถามในเพจ NFT community คนไทนด้วย ได้รับการ confirm ชัดเจนว่า scam และมีคนไม่น้อยโดนหลอก หลังจากที่ผมรู้ที่มาแล้ว ผมเลยเล่นสงครามปั่นประสาท scammer ทั้งสองคนนี้ครับ เพื่อดูว่าหลอกหลวงมิจฉาชีพจริงมั้ย
โดยวันที่ 30 กย. ผมเลยปั่นประสาน scammer ทั้งสองรายนี้ โดยการ mint ผลงานที่เขาเสนอซื้อนั่นแหละ ขึ้น opensea แล้วส่งข้อความไปบอกว่า
mint ให้แล้วนะ แต่เงินไม่พอจริงๆว่ะโทษที เลย mint ขึ้น opensea แทน พอดีบ้านจน ทำได้แค่นี้ไปถึงแค่ opensea รีบไปซื้อล่ะ มีคนจ้องจะคว้างานผมเยอะอยู่ ผมไม่คิด royalty fee ด้วยนะเฮ้ย เอาไปขายต่อไม่ต้องแบ่งกำไรกับผม
เท่านั้นแหละครับ สงครามจิตวิทยาก็เริ่มขึ้น แต่เขาจนมุม กลืนน้ำลายตัวเอง ช็อตเด็ดคือ
เขา : เนี่ยอุส่ารอ บอกเพื่อนในทีมว่าวันจันทร์ที่ 30 กย. ได้ของแน่ๆ เพื่อนๆในทีมเห็นงานผมแล้วมันสวยจริง เลยใส่เงินเต็มที่ 9.3ETH (+ capture screen ส่งตัวเลขยอดเงินมาให้ดู)ไว้รอโดยเฉพาะเลยนะ ผม : เหรอ ... งั้น ขอดู wallet address ที่มี transaction มาให้ดูหน่อยสิ เขา : 2ETH นี่มัน 5000$ เลยนะ ผม : แล้วไง ขอดู wallet address ที่มีการเอายอดเงิน 9.3ETH มาให้ดูหน่อย ไหนบอกว่าเตรียมเงินไว้มากแล้วนี่ ขอดูหน่อย ว่าใส่ไว้เมื่อไหร่ ... เอามาแค่ adrress นะเว้ย ไม่ต้องทะลึ่งส่ง seed มาให้ เขา : ส่งรูปเดิม 9.3 ETH มาให้ดู ผม : รูป screenshot อ่ะ มันไม่มีความหมายหรอกเว้ย ตัดต่อเอาก็ได้ง่ายจะตาย เอา transaction hash มาดู ไหนว่าเตรียมเงินไว้รอ 9.3ETH แล้วอยากซื้องานผมจนตัวสั่นเลยไม่ใช่เหรอ ถ้าจะส่ง wallet address มาให้ดู หรือจะช่วยส่ง 0.15ETH มาให้ยืม mint งานก่อน แล้วมากดซื้อ 2ETH ไป แล้วผมใช้ 0.15ETH คืนให้ก็ได้ จะซื้อหรือไม่ซื้อเนี่ย เขา : จะเอา address เขาไปทำไม ผม : ตัดจบ รำคาญ ไม่ขายให้ละ เขา : 2ETH = 5000 USD เลยนะ ผม : แล้วไง
ผมเลยเขียนบทความนี้มาเตือนเพื่อนๆพี่ๆทุกคนครับ เผื่อใครกำลังเปิดพอร์ตทำธุรกิจขาย digital art online แล้วจะโชคดี เจอของดีแบบผม
ทำไมผมถึงมั่นใจว่ามันคือการหลอกหลวง แล้วคนโกงจะได้อะไร

อันดับแรกไปพิจารณาดู opensea ครับ เป็นเวบ NFTmarketplace ที่ volume การซื้อขายสูงที่สุด เขาไม่เก็บเงินของคนจะซื้อจะขายกันไว้กับตัวเอง เงินวิ่งเข้าวิ่งออก wallet ผู้ซื้อผู้ขายเลย ส่วนทางเวบเก็บค่าธรรมเนียมเท่านั้น แถมค่าธรรมเนียมก็ถูกกว่าเมื่อปี 2020 เยอะ ดังนั้นการที่จะไปลงขายงานบนเวบ NFT อื่นที่ค่า fee สูงกว่ากันเป็นร้อยเท่า ... จะทำไปทำไม
ผมเชื่อว่า scammer โกงเงินเจ้าของผลงานโดยการเล่นกับความโลภและความอ่อนประสบการณ์ของเจ้าของผลงานครับ เมื่อไหร่ก็ตามที่เจ้าของผลงานโอน ETH เข้าไปใน wallet เวบนั้นเมื่อไหร่ หรือเมื่อไหร่ก็ตามที่จ่ายค่า fee ในการ mint งาน เงินเหล่านั้นสิ่งเข้ากระเป๋า scammer ทันที แล้วก็จะมีการเล่นตุกติกต่อแน่นอนครับ เช่นถอนไม่ได้ หรือซื้อไม่ได้ ต้องโอนเงินมาเพิ่มเพื่อปลดล็อค smart contract อะไรก็ว่าไป แล้วคนนิสัยไม่ดีพวกเนี้ย ก็จะเล่นกับความโลภของคน เอาราคาเสนอซื้อที่สูงโคตรๆมาล่อ ... อันนี้ไม่ว่ากัน เพราะบนโลก NFT รูปภาพบางรูปที่ไม่ได้มีความเป็นศิลปะอะไรเลย มันดันขายกันได้ 100 - 150 ETH ศิลปินที่พยายามสร้างตัวก็อาจจะมองว่า ผลงานเรามีคนรับซื้อ 2 - 4 ETH ต่องานมันก็มากพอแล้ว (จริงๆมากเกินจนน่าตกใจด้วยซ้ำครับ)
บนโลกของ BTC ไม่ต้องเชื่อใจกัน โอนเงินไปหากันได้ ปิดสมุดบัญชีได้โดยไม่ต้องเชื่อใจกัน
บบโลกของ ETH "code is law" smart contract มีเขียนอยู่แล้ว ไปอ่าน มันไม่ได้ยากมากในการทำความเข้าใจ ดังนั้น การจะมาเชื่อคำสัญญาจากคนด้วยกัน เป็นอะไรที่ไม่มีเหตุผล
ผมไปเล่าเรื่องเหล่านี้ให้กับ community งานศิลปะ ก็มีทั้งเสียงตอบรับที่ดี และไม่ดีปนกันไป มีบางคนยืนยันเสียงแข็งไปในทำนองว่า ไอ้เรื่องแบบเนี้ยไม่ได้กินเขาหรอก เพราะเขาตั้งใจแน่วแน่ว่างานศิลป์ของเขา เขาไม่เอาเข้ามายุ่งในโลก digital currency เด็ดขาด ซึ่งผมก็เคารพมุมมองเขาครับ แต่มันจะดีกว่ามั้ย ถ้าเราเปิดหูเปิดตาให้ทันเทคโนโลยี โดยเฉพาะเรื่อง digital currency , blockchain โดนโกงทีนึงนี่คือหมดตัวกันง่ายกว่าเงิน fiat อีก
อยากจะมาเล่าให้ฟังครับ และอยากให้ช่วยแชร์ไปให้คนรู้จักด้วย จะได้ระวังตัวกัน
Note
- ภาพประกอบ cyber security ทั้งสองนี่ของผมเองครับ ทำเอง วางขายบน AdobeStock
- อีกบัญชีนึงของผม "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw กำลังค่อยๆเอาผลงานจากโลกข้างนอกเข้ามา nostr ครับ ตั้งใจจะมาสร้างงานศิลปะในนี้ เพื่อนๆที่ชอบงาน จะได้ไม่ต้องออกไปหาที่ไหน
ผลงานของผมครับ - Anime girl fanarts : HikariHarmony - HikariHarmony on Nostr - General art : KeshikiRakuen - KeshikiRakuen อาจจะเป็นบัญชี nostr ที่สามของผม ถ้าไหวครับ
-
@ 90c656ff:9383fd4e
2025-05-04 16:24:21
Blockchain or timechain is a new technology that has changed the way data and transactions are recorded and stored. Its decentralized and highly secure structure provides transparency and trust, making it a widely used system for digital operations. This technology is essential for creating financial systems and digital records that cannot be altered.
What is blockchain or timechain? Blockchain or timechain is essentially a distributed digital ledger designed to record transactions in a sequential and unchangeable manner. It is made up of blocks linked in a chain, each containing a set of information such as transactions, timestamps, and a unique identifier called a hash.
These blocks are organized in chronological order, ensuring the integrity of records over time. The term timechain, used synonymously, emphasizes this temporal aspect of the system, where each block is linked to the previous one, forming a chain of events that cannot be tampered with.
The validation of blocks in blockchain or timechain is carried out through a process called mining. Network participants, known as miners, use powerful computers to solve complex mathematical problems. This process, known as proof of work, is necessary to validate transactions and add a new block to the chain.
Each block contains:
Verified Transactions – A set of operations approved by the network.
Previous Block Hash – A unique code that connects the new block to the previous one, ensuring continuity and security.
Nonce – A number used in the mining process to generate the block's hash.
Once a block is validated, it is permanently added to the blockchain or timechain, and all nodes (participating computers) in the network update their copies of this ledger.
One of the main benefits of blockchain or timechain is the security provided by its decentralized model. Unlike traditional systems that rely on central servers, it distributes its data across thousands of computers around the world.
Immutability is guaranteed by cryptographic techniques and the chained structure of blocks. Any attempt to alter a block would require modifying all subsequent blocks, which is virtually impossible due to the massive computational power required.
Additionally, the use of cryptographic algorithms makes the system resistant to fraud and manipulation. This model enables trust, even in environments without intermediaries or central authorities.
Blockchain or timechain is transparent, as anyone can access the full history of transactions recorded on the network. This creates a system that is auditable and reliable.
However, the privacy of participants is protected, since transactions are recorded through anonymous digital addresses without revealing personal identities. This balance between transparency and privacy makes the system secure and flexible.
The use of blockchain or timechain goes beyond financial transactions. It is useful in areas such as smart contracts, asset registration, supply chains, and online voting. Its ability to create permanent and verifiable records enables innovative solutions across various industries.
For example, in product tracking systems, blockchain or timechain ensures data authenticity by recording each stage of the production and distribution process. This reduces fraud and increases operational efficiency.
Advantages and Challenges Among the main advantages of blockchain or timechain, we can highlight:
Decentralization – Elimination of intermediaries, reducing costs and increasing efficiency.
Security – Protection against fraud and digital attacks.
Transparency – Public and verifiable record of all transactions.
Immutability – Assurance that data cannot be modified after being recorded.
However, there are still challenges to be addressed, such as scalability, as the continuous growth of the network may require greater storage and processing capacity. Additionally, regulatory issues and widespread adoption demand ongoing improvements.
In summary, blockchain or timechain is an innovative technology that changes the way data and transactions are stored, ensuring security, transparency, and efficiency. Its decentralization removes the dependency on intermediaries, making it a trustworthy and tamper-resistant system.
Despite technical and regulatory challenges, blockchain or timechain continues to evolve, demonstrating its potential in various areas beyond the financial sector. Its promise of transparency and immutability is already shaping the future of digital systems, establishing itself as a fundamental base for the modern economy and digital trust.
Thank you very much for reading this far. I hope everything is well with you, and sending a big hug from your favorite Bitcoiner maximalist from Madeira. Long live freedom!
-
@ 8947a945:9bfcf626
2024-10-17 07:33:00
Hello everyone on Nostr and all my watchersand followersfrom DeviantArt, as well as those from other art platforms
I have been creating and sharing AI-generated anime girl fanart since the beginning of 2024 and have been running member-exclusive content on Patreon.
I also publish showcases of my artworks to Deviantart. I organically build up my audience from time to time. I consider it as one of my online businesses of art. Everything is slowly growing
On September 16, I received a DM from someone expressing interest in purchasing my art in NFT format and offering a very high price for each piece. We later continued the conversation via email.
Here’s a brief overview of what happened
- The first scammer selected the art they wanted to buy and offered a high price for each piece. They provided a URL to an NFT marketplace site running on the Ethereum (ETH) mainnet or ERC20. The site appeared suspicious, requiring email sign-up and linking a MetaMask wallet. However, I couldn't change the wallet address later. The minting gas fees were quite expensive, ranging from 0.15 to 0.2 ETH
-
The scammers tried to convince me that the high profits would easily cover the minting gas fees, so I had nothing to lose. Luckily, I didn’t have spare funds to purchase ETH for the gas fees at the time, so I tried negotiating with them as follows:
-
I offered to send them a lower-quality version of my art via email in exchange for the minting gas fees, but they refused.
- I offered them the option to pay in USD through Buy Me a Coffee shop here, but they refused.
- I offered them the option to pay via Bitcoin using the Lightning Network invoice , but they refused.
- I asked them to wait until I could secure the funds, and they agreed to wait.
The following week, a second scammer approached me with a similar offer, this time at an even higher price and through a different NFT marketplace website.
This second site also required email registration, and after navigating to the dashboard, it asked for a minting fee of 0.2 ETH. However, the site provided a wallet address for me instead of connecting a MetaMask wallet.
I told the second scammer that I was waiting to make a profit from the first sale, and they asked me to show them the first marketplace. They then warned me that the first site was a scam and even sent screenshots of victims, including one from OpenSea saying that Opensea is not paying.
This raised a red flag, and I began suspecting I might be getting scammed. On OpenSea, funds go directly to users' wallets after transactions, and OpenSea charges a much lower platform fee compared to the previous crypto bull run in 2020. Minting fees on OpenSea are also significantly cheaper, around 0.0001 ETH per transaction.
I also consulted with Thai NFT artist communities and the ex-chairman of the Thai Digital Asset Association. According to them, no one had reported similar issues, but they agreed it seemed like a scam.
After confirming my suspicions with my own research and consulting with the Thai crypto community, I decided to test the scammers’ intentions by doing the following
I minted the artwork they were interested in, set the price they offered, and listed it for sale on OpenSea. I then messaged them, letting them know the art was available and ready to purchase, with no royalty fees if they wanted to resell it.
They became upset and angry, insisting I mint the art on their chosen platform, claiming they had already funded their wallet to support me. When I asked for proof of their wallet address and transactions, they couldn't provide any evidence that they had enough funds.
Here’s what I want to warn all artists in the DeviantArt community or other platforms If you find yourself in a similar situation, be aware that scammers may be targeting you.
My Perspective why I Believe This is a Scam and What the Scammers Gain
From my experience with BTC and crypto since 2017, here's why I believe this situation is a scam, and what the scammers aim to achieve
First, looking at OpenSea, the largest NFT marketplace on the ERC20 network, they do not hold users' funds. Instead, funds from transactions go directly to users’ wallets. OpenSea’s platform fees are also much lower now compared to the crypto bull run in 2020. This alone raises suspicion about the legitimacy of other marketplaces requiring significantly higher fees.
I believe the scammers' tactic is to lure artists into paying these exorbitant minting fees, which go directly into the scammers' wallets. They convince the artists by promising to purchase the art at a higher price, making it seem like there's no risk involved. In reality, the artist has already lost by paying the minting fee, and no purchase is ever made.
In the world of Bitcoin (BTC), the principle is "Trust no one" and “Trustless finality of transactions” In other words, transactions are secure and final without needing trust in a third party.
In the world of Ethereum (ETH), the philosophy is "Code is law" where everything is governed by smart contracts deployed on the blockchain. These contracts are transparent, and even basic code can be read and understood. Promises made by people don’t override what the code says.
I also discuss this issue with art communities. Some people have strongly expressed to me that they want nothing to do with crypto as part of their art process. I completely respect that stance.
However, I believe it's wise to keep your eyes open, have some skin in the game, and not fall into scammers’ traps. Understanding the basics of crypto and NFTs can help protect you from these kinds of schemes.
If you found this article helpful, please share it with your fellow artists.
Until next time Take care
Note
- Both cyber security images are mine , I created and approved by AdobeStock to put on sale
- I'm working very hard to bring all my digital arts into Nostr to build my Sats business here to my another npub "HikariHarmony" npub1exdtszhpw3ep643p9z8pahkw8zw00xa9pesf0u4txyyfqvthwapqwh48sw
Link to my full gallery - Anime girl fanarts : HikariHarmony - HikariHarmony on Nostr - General art : KeshikiRakuen
-
@ e6817453:b0ac3c39
2024-10-06 11:21:27
Hey folks, today we're diving into an exciting and emerging topic: personal artificial intelligence (PAI) and its connection to sovereignty, privacy, and ethics. With the rapid advancements in AI, there's a growing interest in the development of personal AI agents that can work on behalf of the user, acting autonomously and providing tailored services. However, as with any new technology, there are several critical factors that shape the future of PAI. Today, we'll explore three key pillars: privacy and ownership, explainability, and bias.
1. Privacy and Ownership: Foundations of Personal AI
At the heart of personal AI, much like self-sovereign identity (SSI), is the concept of ownership. For personal AI to be truly effective and valuable, users must own not only their data but also the computational power that drives these systems. This autonomy is essential for creating systems that respect the user's privacy and operate independently of large corporations.
In this context, privacy is more than just a feature—it's a fundamental right. Users should feel safe discussing sensitive topics with their AI, knowing that their data won’t be repurposed or misused by big tech companies. This level of control and data ownership ensures that users remain the sole beneficiaries of their information and computational resources, making privacy one of the core pillars of PAI.
2. Bias and Fairness: The Ethical Dilemma of LLMs
Most of today’s AI systems, including personal AI, rely heavily on large language models (LLMs). These models are trained on vast datasets that represent snapshots of the internet, but this introduces a critical ethical challenge: bias. The datasets used for training LLMs can be full of biases, misinformation, and viewpoints that may not align with a user’s personal values.
This leads to one of the major issues in AI ethics for personal AI—how do we ensure fairness and minimize bias in these systems? The training data that LLMs use can introduce perspectives that are not only unrepresentative but potentially harmful or unfair. As users of personal AI, we need systems that are free from such biases and can be tailored to our individual needs and ethical frameworks.
Unfortunately, training models that are truly unbiased and fair requires vast computational resources and significant investment. While large tech companies have the financial means to develop and train these models, individual users or smaller organizations typically do not. This limitation means that users often have to rely on pre-trained models, which may not fully align with their personal ethics or preferences. While fine-tuning models with personalized datasets can help, it's not a perfect solution, and bias remains a significant challenge.
3. Explainability: The Need for Transparency
One of the most frustrating aspects of modern AI is the lack of explainability. Many LLMs operate as "black boxes," meaning that while they provide answers or make decisions, it's often unclear how they arrived at those conclusions. For personal AI to be effective and trustworthy, it must be transparent. Users need to understand how the AI processes information, what data it relies on, and the reasoning behind its conclusions.
Explainability becomes even more critical when AI is used for complex decision-making, especially in areas that impact other people. If an AI is making recommendations, judgments, or decisions, it’s crucial for users to be able to trace the reasoning process behind those actions. Without this transparency, users may end up relying on AI systems that provide flawed or biased outcomes, potentially causing harm.
This lack of transparency is a major hurdle for personal AI development. Current LLMs, as mentioned earlier, are often opaque, making it difficult for users to trust their outputs fully. The explainability of AI systems will need to be improved significantly to ensure that personal AI can be trusted for important tasks.
Addressing the Ethical Landscape of Personal AI
As personal AI systems evolve, they will increasingly shape the ethical landscape of AI. We’ve already touched on the three core pillars—privacy and ownership, bias and fairness, and explainability. But there's more to consider, especially when looking at the broader implications of personal AI development.
Most current AI models, particularly those from big tech companies like Facebook, Google, or OpenAI, are closed systems. This means they are aligned with the goals and ethical frameworks of those companies, which may not always serve the best interests of individual users. Open models, such as Meta's LLaMA, offer more flexibility and control, allowing users to customize and refine the AI to better meet their personal needs. However, the challenge remains in training these models without significant financial and technical resources.
There’s also the temptation to use uncensored models that aren’t aligned with the values of large corporations, as they provide more freedom and flexibility. But in reality, models that are entirely unfiltered may introduce harmful or unethical content. It’s often better to work with aligned models that have had some of the more problematic biases removed, even if this limits some aspects of the system’s freedom.
The future of personal AI will undoubtedly involve a deeper exploration of these ethical questions. As AI becomes more integrated into our daily lives, the need for privacy, fairness, and transparency will only grow. And while we may not yet be able to train personal AI models from scratch, we can continue to shape and refine these systems through curated datasets and ongoing development.
Conclusion
In conclusion, personal AI represents an exciting new frontier, but one that must be navigated with care. Privacy, ownership, bias, and explainability are all essential pillars that will define the future of these systems. As we continue to develop personal AI, we must remain vigilant about the ethical challenges they pose, ensuring that they serve the best interests of users while remaining transparent, fair, and aligned with individual values.
If you have any thoughts or questions on this topic, feel free to reach out—I’d love to continue the conversation!
-
@ a29cfc65:484fac9c
2025-05-04 16:20:03
Bei einer Führung durch den Naumburger Dom sprach der Domführer über Propaganda im Mittelalter. Die gefühlvollen Gesichtsausdrücke der steinernen Stifterfiguren rund um die berühmte Uta sollten das Volk beeinflussen. Darüber haben wir auf der Heimfahrt nach Leipzig philosophiert und fanden den Denkansatz spannend. Denn auch wenn es damals nicht Propaganda hieß, so gab es doch Interessen der Mächtigen, die sie gegenüber dem Volk durchsetzten. Sie bedienten sich dabei der damals verfügbaren „Medien“, zu denen die Kirche gehörte, wo sich das Volk zum Gottesdienst traf.
Kulturelle Identität Europas
Mitteldeutschland ist ein Zentrum mittelalterlicher Baukunst. Der Naumburger Dom St. Peter und Paul wurde auf den Grundmauern einer noch älteren Kirche im 13. Jahrhundert gebaut. Er ist weltweit einzigartig in seiner Architektur, Bildhauerkunst und Glasmalerei. Seit 2018 ist er Unesco-Weltkulturerbe. Die Stadt Naumburg hatte einst die gleiche Bedeutung wie Merseburg, Magdeburg oder Leipzig. Der Dom – von der Spätromanik bis in die Frühgotik unter Leitung eines heute unbekannten Bildhauerarchitekten errichtet – gilt als Meisterwerk menschlicher Schöpferkraft und Handwerkskunst. Die naturwissenschaftlich-physikalischen Kenntnisse der Menschen waren offensichtlich enorm. Sie verfügten über das Wissen zur Planung und über entsprechende Werk- und Hebezeuge, um solche Bauwerke in relativ kurzer Zeit errichten zu können.
Im Westchor des Doms befinden sich mit den zwölf lebensgroßen Stifterfiguren die bekanntesten Kunstwerke des Doms, unter ihnen Uta von Ballenstedt. Sie soll Walt Disney als Quelle für die schöne und sehr stolze Königin im Zeichentrickfilm Schneewittchen gedient haben. Das Besondere und Neue an den steinernen Stifterfiguren war ihre realitätsnahe Darstellung, die sie lebendig und ausdrucksstark wirken lässt. Sie sind ein Höhepunkt in der Steinmetzkunst der damaligen Zeit. Die Figuren wurden, obschon die dargestellten Personen bereits mehr als 200 Jahre tot waren, mit charakteristischen Gesichtsausdrücken dargestellt: Uta schaut schön und stolz in die Ferne, ihr Gatte Ekkehard wirkt etwas hochmütig. Gegenüber steht die lachende Reglindis neben ihrem wehmütig-leidend blickenden Mann Hermann von Meißen.
Der Domführer sagte, dass die Gesichtsausdrücke menschliche Verhaltensweisen darstellen, die bei den Kirchenbesuchern unerwünscht waren. Wir hätten es hier mit einer sehr frühen Form der Propaganda zu tun. Die katholische Kirche war Vorreiter in Sachen Propaganda. Sie hat etwa 400 Jahre später, im Jahr 1622, mit der Sacra Congregatio de Propaganda Fide ein Amt gegründet, das den „richtigen“ Glauben in die Welt tragen sollte, und erst 1967 umbenannt wurde. Aber ihre gesellschaftlich führende Position hatte damals auch eine positive Seite: Den Kirchen und Klöstern haben wir den Erhalt und die Weitergabe antiken Wissens zu verdanken. Europa konnte sich trotz der politischen Zersplitterung seine kulturelle Identität erhalten. Zum Beispiel lässt sich das Wirken des namenlosen Domschöpfers anhand der Bau- und Kunstwerke quer durch Europa von Nordfrankreich über Mainz nach Naumburg und Meißen nachvollziehen. Aus der weiteren Entwicklung von Kunst und Kultur in Europa entstand in der Renaissance die Philosophie des Humanismus und später daraus die Aufklärung mit ihrer Wirkung auf Literatur und Wissenschaft. Ziel war dabei immer eine Stärkung des Gemeinwesens.
Transhumanismus zerstört Gemeinschaften
Heute scheinen wir uns allerdings an einer Bruchstelle der gesellschaftlichen Entwicklung zu befinden. Die Kirchen spielen in unserer Gesellschaft kaum noch eine Rolle. Weder bringen sie sich in ethische Diskussionen hörbar ein, noch tragen sie die Entwicklung von Kunst und Kultur sichtbar voran. Ihre Rolle im Bereich Propaganda haben längst Zeitungen und Zeitschriften, Rundfunk und Fernsehen übernommen. Diese Medien haben eine größere Reichweite, und die psychologische Beeinflussung ist umfassender. Nach dem Zweiten Weltkrieg wurde die Manipulation der Massen stark intensiviert und nahm nach dem Zusammenbruch der Sowjetunion noch weiter an Fahrt auf. Der Liberalismus konnte auf allen Gebieten seinen Siegeszug antreten, stellte das Individuum in den Mittelpunkt und erhob den Markt zur heiligen Kuh. Im Laufe der Zeit wurden die humanistischen Ideen der Aufklärung in ihr Gegenteil verkehrt. Der Mensch wurde als fehlerhaftes Wesen identifiziert, in die Vereinzelung getrieben, bevormundet und gegängelt – angeblich, damit er sich nicht selbst schadet. Zur psychologischen Beeinflussung kommen die neuen technischen Möglichkeiten aus Bio-Nano-Neuro-Wissenschaften und Digitalisierung. Der Transhumanismus wurde als neues Ziel für die Menschheit ausgerufen. Der Einzelne soll biologisch und technisch perfektioniert werden. Gemeinschaften – von der Familie angefangen – treibt das in die Bedeutungslosigkeit. Es besteht die Gefahr, dass persönliche Integrität und Privatsphäre durch Eingriffe in Körper- und Geistesfunktionen verletzt werden. Eine neue Aufklärung ist nötig. Denn sehr viel von dem über die Jahrhunderte erlangten Wissen ging schon verloren oder ist nur noch versteckt in den Bibliotheken und Archiven der Kirchen zu finden. Die Besinnung auf die vergessenen beziehungsweise verdrängten Grundlagen und Ideale der Aufklärung kann diese Entwicklung abwenden. Die Kulturschätze Mitteleuropas vermitteln in ihrer Schönheit und Vollkommenheit die Ruhe und die zeitlichen und räumlichen Dimensionen, die wir brauchen, wenn wir über die Frage nachdenken, wie wir in Zukunft leben wollen.
Die Rolle der neuen Medien für die zukünftige Entwicklung
Von den Alt-Medien ist in dieser Hinsicht nichts zu erwarten. Sie werden finanziert und sind unterwandert von den Kräften, die transhumanistische Entwicklungen vorantreiben. Die „neue Aufklärung“ ist ein lohnenswertes Ziel für die neuen Medien. Diese lassen sich jedoch noch zu sehr von den aktuellen Themen der Alt-Medien treiben. Der Angst-Propaganda begegnen sie mit – Ängsten, wenn auch anders ausgerichtet. Einige reiten die Empörungswelle in Gegenrichtung zu den Alt-Medien. Manche Betreiber von „alternativen“ Finanz- und Wirtschaftskanälen wollen ihre eigenen marktgläubigen Produkte an den Mann bringen. Stattdessen sollten in den neuen Medien positive Nachrichten verbreitet und eigene Themenfelder eröffnet werden, denen sich die Alt-Medien verweigern:
· der Mensch und seine Bildung zur souveränen, selbständig denkenden und handelnden Persönlichkeit,
· die Entwicklung des eigenen Bewusstseins, um der Fremdbestimmung zu entkommen und zu Wahrhaftigkeit, Authentizität und Menschlichkeit zu gelangen,
· die Entwicklung des Gemeinwohls,
· die Frage, wie wir neue Gemeinschaften bis hin zu autarken Gemeinden gründen können – wichtiger, je mehr das gesellschaftliche System um uns herum zusammenbricht.
Direkt sichtbar ist der letzte Punkt am Niedergang der Architektur und am Zustand der Innenstädte: Die reich dekorierten Gebäude der Gründerzeit wurden nach ihrer Zerstörung im Zweiten Weltkrieg durch gleichförmig rechteckige Gebäude aus Beton und Glas ersetzt. Dazu kamen die in allen Städten austauschbar gleichen Ladenzeilen und in den letzten Jahren Dreck und Schmierereien, die nicht mehr weggeräumt werden.
Die gesellschaftlichen Verwerfungen der Corona-Zeit führten bei vielen Menschen zum Innehalten und Nachdenken über Sinn und Ziele ihres Lebens. So entstanden einige Pilotprojekte, zum Beispiel in den Bereichen Landwirtschaft, Gesundheitswesen und Bildung. Diese auf die Zukunft gerichteten Themen könnten in den neuen Medien umfangreicher vorgestellt und diskutiert werden. Manova setzt schon solche Schwerpunkte mit „The Great WeSet“ von Walter van Rossum sowie mit den Kategorien „Zukunft & Neue Wege“ sowie „Aufwind“. Der Kontrafunk hat Formate entwickelt, die das Gemeinwohl stärker in den Fokus setzen wie etwa die Kultur- und Wissenschaftsrubrik. Nuoviso hat einen eigenen Songcontest ins Leben gerufen. Neben der inhaltlichen Ausrichtung auf eine lebenswerte Zukunft gilt es auch, die technologische Basis der neuen Medien zukunftsfest zu machen und sich der digitalen Zensur zu entziehen. Milosz Matuschek geht mit dem Pareto-Projekt neue Wege. Es könnte zur unzensierbaren Plattform der neuen Medien werden. Denn wie er sagt: Man baut sein neues Haus doch auch nicht auf dem Boden, der einem anderen gehört.
-
@ 502ab02a:a2860397
2025-05-04 15:48:26
วันอาทิตย์ เพื่อนใหม่เยอะพอสมควร น่าจะพอที่จะแนะนำให้รู้จัก โรงบ่มสุขภาพ ขอเล่าผ่านเพลง "บ่ม" เพื่อรวบบทความ #ตัวหนังสือมีเสียง ไว้ด้วยเลยแล้วกันครับ
โรงบ่มสุขภาพ Healthy Hut - โรงบ่มสุขภาพ คือการรวมตัวกันของบุคลากรที่มี content และ ความเชี่ยวชาญ ด้านต่างๆ ทำกิจกรรมหลากหลายรูปแบบ ตั้งแต่แคมป์สุขภาพ พักผ่อนกายใจเรียนรู้การปรับสมดุลร่างกาย, การเรียนรู้พื้นฐาน Nutrition ต่างๆ ลองดูผลงานได้ในเพจครับ และโรงบ่มฯ ก็จะยังคงมีกิจกรรมให้ทุกคนได้เข้าร่วมอยู่เสมอ ดังนั้นไปกดไลค์เพจไว้เพื่อไม่ให้พลาดข้าวสาร เอ้ย ข่าวสาร
โรงบ่มฯนั้น ประกอบด้วย 👨🏻⚕️พี่หมอป๊อบ DietDoctor Thailand ที่เรารู้จักกันดี อาจารย์ของพวกเรา 🏋🏻♀️ 🏅พี่หนึ่ง จาก หนึ่งคีโตแด๊ดดี้ มาเป็น Nueng The One ผมอุปโลกให้ก่อนเลยว่า คนไทยคนแรกที่ทำเนื้อหาการกินคีโต เป็นภาษาไทย แบบมีบันทึกสาธารณะให้ตามศึกษา 👨🏻⚕️หมอเอก หมออ้วนในดงลดน้ำหนัก กับหลักการใช้ชีวิตแบบ IFF สาย Fasting ที่ย้ำว่าหัวใจอีกห้องของ Fasting คือ Feeding กระดุมเม็ดแรกของการฟาส ที่คนมักลืม 🧘🏻♀️ครูบอม เทพโยคะอีกท่านนึงของไทย กับศาสตร์โยคะ Anusara Yoga หนึ่งเดียวในไทย 🧗♂️โค้ชแมท สารานุกรมสุขภาพที่มีชีวิต นิ่งแต่คมกริบ ถ้าเป็นเกมส์ก็สาย สไนเปอร์ ยิงน้อยแต่ Head Shot 🧔🏻แอ๊ดหนวด ฉายา Salt Daddy เจ้าแห่งเกลือแร่ ประจำกลุ่ม IF-Mix Fasting Diet Thailand (Keto # Low Carb # Plant Base # High Fat) 👭👩🏻🤝👨🏼👩🏻🤝👨🏼 รวมถึงทีมงาน กัลยาณมิตรสุขภาพ ที่มีความรู้ในด้านสุขภาพและมากประสบการณ์ 🧑🏻🍳 ผมและตำรับเอ๋เองก็ยินดีมากๆที่ได้ร่วมทีมสุขภาพนี้กับเขาด้วย
จะเห็นได้ว่า แต่ละท่านในโรงบ่มฯ นั้นหล่อหลอมมาจากความต่างเสียด้วยซ้ำไป ตั้งแต่เริ่มก่อร่างโรงบ่ม เราก็ตั้งไว้แล้วว่า ชีวะ ควรมีความหลากหลาย การวางพื้นฐานสุขภาพควรมาจาก "แต่ละคน" ไม่ใช่ one size fit all บันทึกกิจกรรมโรงบ่มผมมีโพสไว้ https://www.facebook.com/share/p/19DUibHrbw/
นั่นเป็นเหตุผลที่ผมเกิดแรงบันดาลใจในการทำเพลง "บ่ม" ขึ้นมาเพื่อเป็น Theme Song ครับ แก่นของเพลงนี้มีไม่กี่อย่างครับ ผมเริ่มคิดจากคำว่า "ความต่าง" เพราะไม่ว่าจะกี่ปีกี่ชาติ วงการสุขภาพ ก็จะมีแนวความคิดประเภท ฉันถูกเธอผิด อยู่ตลอดเวลาเพราะมันเป็นธรรมชาติมนุษย์ครับ มนุษย์เราทุกคนมีอีโก้ การยอมรับในความต่าง การหลอมรวมความต่าง ผมคิดว่ามันเป็นการ "บ่ม" ให้สุกงอมได้
เวลาที่เนื้อหาแบบนี้ ผมก็อดคิดถึงวงที่ผมรักเสมอไม่ได้เลย นั่นคือ เฉลียง แม้ความสามารถจะห่างไกลกันลิบลับ แต่ผมก็อยากทำสไตล์เฉลียงกับเขาบ้างครั้งหนึ่งหรือหลายๆครั้งในชีวิต จึงเลือกแนวเพลงออกมาทาง แจ๊ส สวิง มีเครื่องเป่า คาริเนต เป็นตัวเด่น
ท่อนแรกของเพลงจึงเริ่มด้วย "ต่างทั้งความคิด ต่างทั้งความฝัน ต่างเผ่าต่างพันธุ์ จะต่างกันแค่ไหน หนึ่งเมล็ด จากหลากผล แต่ละคน ก็ปนไป แล้วเพราะเหตุใด ใยต้องไปแค่ทางเดียว" เพื่อปูให้คนฟังเริ่มเปิดรับว่า สิ่งที่ต้องการจะสื่อต่อไปคืออะไร
ส่วนคำย้ำนั้นผมแตกมาจาก คำสอนของพระพุทธเจ้า เกี่ยวกับ "คิดเห็นเป็นไป" ซึ่งจริงๆผมเขียนไว้ในโพสนึงแต่ตอนนั้นยังไม่ได้ทำคอลัมน์ #ตัวหนังสือมีเสียง ขอไม่เขียนซ้ำ อ่านได้ที่นี่ครับ https://www.facebook.com/share/p/18tFCFaRLn/ ท่อนที่ว่าจึงเขียนไว้ว่า "บ่มบ่ม... บ่มให้คิด บ่มบ่ม...บ่มให้เห็น บ่มบ่ม...บ่มให้เป็น บ่มบ่ม...บ่มให้ไป ไปเป็น ตัวของตัวเอง" ใช้ความซน สไตล์ rock&roll ผสมแจ๊สนิด ที่เขามักเล่นร้องโต้กับคอรัส นึกถึงยุคทีวีขาวดำ 5555
เนื้อร้องท่อนนี้ เป็นการบอกว่า โรงบ่มคืออะไรทำอะไร เพราะโรงบ่ม เราไม่ได้รักษา เราไม่ได้บังคับไดเอทว่าต้องใช้อะไร เราเปิดตาให้มอง เปิดหูให้ฟัง เปิดปากให้ถาม ถึงธรรมชาติในตัวเรา แล้วบ่มออกไปให้เบ่งบานในเส้นทางของแต่ละคนครับ
แล้วผมก็พยายามอีกครั้งที่จะสื่อถึงการยอมรับความต่าง ให้ติดหูเอาไว้ โดยเฉพาะคำที่ผมพูดบ่อยมากๆ "ชีวะ คือชีวิต" จนมาเป็นท่อน bridge นี้ครับ "อะไรที่ไม่คล้าย นั้นใช่ไม่ดี เพราะชีวะ ก็คือชีวี บ่มให้ดี จะมีความงาม ตามที่ควรเห็น ตามที่ควรเป็น"
เพลงนี้สามารถฟังตัวเต็มได้ทุกแพลทฟอร์มเพลงทั้ง youtube music, spotify, apple music, แผ่นเสียง tiktok ⌨️ แค่ค้นชื่อ "Heretong Teera Siri" ครับ
📺 youtube link นี้ https://youtu.be/BvIsTAsG00E?si=MzA-WfCTNQnWy6b1 📻 Spotify link นี้ https://open.spotify.com/album/08HydgrXmUAew6dgXIDNTf?si=7flQOqDAQbGe2bC0hx3T2A
ความลับคือ จริงๆแล้วเพลงนี้มี 3 version ถ้ากดใน spotify แล้วจะเห็นทั้งอัลบั้มครับ
📀เนื้อเพลง "บ่ม"📀 song by : HereTong Teera Siri ต่างทั้งความคิด ต่างทั้งความฝัน ต่างเผ่าต่างพันธุ์ จะต่างกันแค่ไหน
หนึ่งเมล็ด จากหลากผล แต่ละคน ก็ปนไป แล้วเพราะเหตุใด ใยต้องไปแค่ทางเดียว
บ่มบ่ม... บ่มให้คิด บ่มบ่ม...บ่มให้เห็น บ่มบ่ม...บ่มให้เป็น บ่มบ่ม...บ่มให้ไป ไปเป็น ตัวของตัวเอง
ต่างทั้งลองลิ้ม ต่างทั้งรับรู้ ต่างที่มุมดู ก็ถมไป หนึ่งชีวิต มีความหมาย ที่หลากหลาย ไม่คล้ายกัน แล้วเพราะเหตุใด ใยต้องเป็นเช่นทุกคน
บ่มบ่ม... บ่มให้คิด บ่มบ่ม...บ่มให้เห็น บ่มบ่ม...บ่มให้เป็น บ่มบ่ม...บ่มให้ไป ไปตาม ทางที่เลือกเดิน
เพราะชีวิต คือความหลากหลาย เพราะโลกนี้ ไม่เคยห่างหาย อะไรที่ไม่คล้าย นั้นใช่ไม่ดี เพราะชีวะ ก็คือชีวี บ่มให้ดี จะมีความงาม ตามที่ควรเห็น ตามที่ควรเป็น
บ่มบ่ม... บ่มให้คิด บ่มบ่ม...บ่มให้เห็น บ่มบ่ม...บ่มให้เป็น บ่มบ่ม...บ่มให้ไป ไปตาม ทางที่เลือกเดิน
เพราะชีวะ ก็คือชีวี บ่มให้ดี จะมีความงาม ตามที่ควรเห็น ตามที่ควรเป็น บ่มให้เธอชื่น บ่มให้เธอชม ชีวิตรื่นรมย์ ได้สมใจ บ่มให้ยั่งยืน
ตัวหนังสือมีเสียง #pirateketo
โรงบ่มสุขภาพ #siamstr
-
@ a5ee4475:2ca75401
2025-05-04 15:45:12
lists #descentralismo #compilation #english
*Some of these lists are still being updated, so the latest versions of them will only be visible in Amethyst.
nostr:naddr1qq245dz5tqe8w46swpphgmr4f3047s6629t45qg4waehxw309aex2mrp0yhxgctdw4eju6t09upzpf0wg36k3g3hygndv3cp8f2j284v0hfh4dqgqjj3yxnreck2w4qpqvzqqqr4guxde6sl
nostr:nevent1qqsxdpwadkswdrc602m6qdhyq7n33lf3wpjtdjq2adkw4y3h38mjcrqpr9mhxue69uhkxmmzwfskvatdvyhxxmmd9aex2mrp0ypzpf0wg36k3g3hygndv3cp8f2j284v0hfh4dqgqjj3yxnreck2w4qpqvzqqqqqqysn06gs
nostr:nevent1qqs0swpxdqfknups697205qg5mpw2e370g5vet07gkexe9n0k05h5qspz4mhxue69uhhyetvv9ujumn0wd68ytnzvuhsyg99aez8269zxu3zd4j8qya92fg7437ax745pqz22ys6v08zef65qypsgqqqqqqshr37wh
Markdown Uses for Some Clients
nostr:nevent1qqsv54qfgtme38r2tl9v6ghwfj09gdjukealstkzc77mwujr56tgfwsppemhxue69uhkummn9ekx7mp0qgsq37tg2603tu0cqdrxs30e2n5t8p87uenf4fvfepdcvr7nllje5zgrqsqqqqqpkdvta4
Other Links
nostr:nevent1qqsrm6ywny5r7ajakpppp0lt525n0s33x6tyn6pz0n8ws8k2tqpqracpzpmhxue69uhkummnw3ezumt0d5hsygp6e5ns0nv3dun430jky25y4pku6ylz68rz6zs7khv29q6rj5peespsgqqqqqqsmfwa78
-
@ 91bea5cd:1df4451c
2025-04-26 10:16:21
O Contexto Legal Brasileiro e o Consentimento
No ordenamento jurídico brasileiro, o consentimento do ofendido pode, em certas circunstâncias, afastar a ilicitude de um ato que, sem ele, configuraria crime (como lesão corporal leve, prevista no Art. 129 do Código Penal). Contudo, o consentimento tem limites claros: não é válido para bens jurídicos indisponíveis, como a vida, e sua eficácia é questionável em casos de lesões corporais graves ou gravíssimas.
A prática de BDSM consensual situa-se em uma zona complexa. Em tese, se ambos os parceiros são adultos, capazes, e consentiram livre e informadamente nos atos praticados, sem que resultem em lesões graves permanentes ou risco de morte não consentido, não haveria crime. O desafio reside na comprovação desse consentimento, especialmente se uma das partes, posteriormente, o negar ou alegar coação.
A Lei Maria da Penha (Lei nº 11.340/2006)
A Lei Maria da Penha é um marco fundamental na proteção da mulher contra a violência doméstica e familiar. Ela estabelece mecanismos para coibir e prevenir tal violência, definindo suas formas (física, psicológica, sexual, patrimonial e moral) e prevendo medidas protetivas de urgência.
Embora essencial, a aplicação da lei em contextos de BDSM pode ser delicada. Uma alegação de violência por parte da mulher, mesmo que as lesões ou situações decorram de práticas consensuais, tende a receber atenção prioritária das autoridades, dada a presunção de vulnerabilidade estabelecida pela lei. Isso pode criar um cenário onde o parceiro masculino enfrenta dificuldades significativas em demonstrar a natureza consensual dos atos, especialmente se não houver provas robustas pré-constituídas.
Outros riscos:
Lesão corporal grave ou gravíssima (art. 129, §§ 1º e 2º, CP), não pode ser justificada pelo consentimento, podendo ensejar persecução penal.
Crimes contra a dignidade sexual (arts. 213 e seguintes do CP) são de ação pública incondicionada e independem de representação da vítima para a investigação e denúncia.
Riscos de Falsas Acusações e Alegação de Coação Futura
Os riscos para os praticantes de BDSM, especialmente para o parceiro que assume o papel dominante ou que inflige dor/restrição (frequentemente, mas não exclusivamente, o homem), podem surgir de diversas frentes:
- Acusações Externas: Vizinhos, familiares ou amigos que desconhecem a natureza consensual do relacionamento podem interpretar sons, marcas ou comportamentos como sinais de abuso e denunciar às autoridades.
- Alegações Futuras da Parceira: Em caso de término conturbado, vingança, arrependimento ou mudança de perspectiva, a parceira pode reinterpretar as práticas passadas como abuso e buscar reparação ou retaliação através de uma denúncia. A alegação pode ser de que o consentimento nunca existiu ou foi viciado.
- Alegação de Coação: Uma das formas mais complexas de refutar é a alegação de que o consentimento foi obtido mediante coação (física, moral, psicológica ou econômica). A parceira pode alegar, por exemplo, que se sentia pressionada, intimidada ou dependente, e que seu "sim" não era genuíno. Provar a ausência de coação a posteriori é extremamente difícil.
- Ingenuidade e Vulnerabilidade Masculina: Muitos homens, confiando na dinâmica consensual e na parceira, podem negligenciar a necessidade de precauções. A crença de que "isso nunca aconteceria comigo" ou a falta de conhecimento sobre as implicações legais e o peso processual de uma acusação no âmbito da Lei Maria da Penha podem deixá-los vulneráveis. A presença de marcas físicas, mesmo que consentidas, pode ser usada como evidência de agressão, invertendo o ônus da prova na prática, ainda que não na teoria jurídica.
Estratégias de Prevenção e Mitigação
Não existe um método infalível para evitar completamente o risco de uma falsa acusação, mas diversas medidas podem ser adotadas para construir um histórico de consentimento e reduzir vulnerabilidades:
- Comunicação Explícita e Contínua: A base de qualquer prática BDSM segura é a comunicação constante. Negociar limites, desejos, palavras de segurança ("safewords") e expectativas antes, durante e depois das cenas é crucial. Manter registros dessas negociações (e-mails, mensagens, diários compartilhados) pode ser útil.
-
Documentação do Consentimento:
-
Contratos de Relacionamento/Cena: Embora a validade jurídica de "contratos BDSM" seja discutível no Brasil (não podem afastar normas de ordem pública), eles servem como forte evidência da intenção das partes, da negociação detalhada de limites e do consentimento informado. Devem ser claros, datados, assinados e, idealmente, reconhecidos em cartório (para prova de data e autenticidade das assinaturas).
-
Registros Audiovisuais: Gravar (com consentimento explícito para a gravação) discussões sobre consentimento e limites antes das cenas pode ser uma prova poderosa. Gravar as próprias cenas é mais complexo devido a questões de privacidade e potencial uso indevido, mas pode ser considerado em casos específicos, sempre com consentimento mútuo documentado para a gravação.
Importante: a gravação deve ser com ciência da outra parte, para não configurar violação da intimidade (art. 5º, X, da Constituição Federal e art. 20 do Código Civil).
-
-
Testemunhas: Em alguns contextos de comunidade BDSM, a presença de terceiros de confiança durante negociações ou mesmo cenas pode servir como testemunho, embora isso possa alterar a dinâmica íntima do casal.
- Estabelecimento Claro de Limites e Palavras de Segurança: Definir e respeitar rigorosamente os limites (o que é permitido, o que é proibido) e as palavras de segurança é fundamental. O desrespeito a uma palavra de segurança encerra o consentimento para aquele ato.
- Avaliação Contínua do Consentimento: O consentimento não é um cheque em branco; ele deve ser entusiástico, contínuo e revogável a qualquer momento. Verificar o bem-estar do parceiro durante a cena ("check-ins") é essencial.
- Discrição e Cuidado com Evidências Físicas: Ser discreto sobre a natureza do relacionamento pode evitar mal-entendidos externos. Após cenas que deixem marcas, é prudente que ambos os parceiros estejam cientes e de acordo, talvez documentando por fotos (com data) e uma nota sobre a consensualidade da prática que as gerou.
- Aconselhamento Jurídico Preventivo: Consultar um advogado especializado em direito de família e criminal, com sensibilidade para dinâmicas de relacionamento alternativas, pode fornecer orientação personalizada sobre as melhores formas de documentar o consentimento e entender os riscos legais específicos.
Observações Importantes
- Nenhuma documentação substitui a necessidade de consentimento real, livre, informado e contínuo.
- A lei brasileira protege a "integridade física" e a "dignidade humana". Práticas que resultem em lesões graves ou que violem a dignidade de forma não consentida (ou com consentimento viciado) serão ilegais, independentemente de qualquer acordo prévio.
- Em caso de acusação, a existência de documentação robusta de consentimento não garante a absolvição, mas fortalece significativamente a defesa, ajudando a demonstrar a natureza consensual da relação e das práticas.
-
A alegação de coação futura é particularmente difícil de prevenir apenas com documentos. Um histórico consistente de comunicação aberta (whatsapp/telegram/e-mails), respeito mútuo e ausência de dependência ou controle excessivo na relação pode ajudar a contextualizar a dinâmica como não coercitiva.
-
Cuidado com Marcas Visíveis e Lesões Graves Práticas que resultam em hematomas severos ou lesões podem ser interpretadas como agressão, mesmo que consentidas. Evitar excessos protege não apenas a integridade física, mas também evita questionamentos legais futuros.
O que vem a ser consentimento viciado
No Direito, consentimento viciado é quando a pessoa concorda com algo, mas a vontade dela não é livre ou plena — ou seja, o consentimento existe formalmente, mas é defeituoso por alguma razão.
O Código Civil brasileiro (art. 138 a 165) define várias formas de vício de consentimento. As principais são:
Erro: A pessoa se engana sobre o que está consentindo. (Ex.: A pessoa acredita que vai participar de um jogo leve, mas na verdade é exposta a práticas pesadas.)
Dolo: A pessoa é enganada propositalmente para aceitar algo. (Ex.: Alguém mente sobre o que vai acontecer durante a prática.)
Coação: A pessoa é forçada ou ameaçada a consentir. (Ex.: "Se você não aceitar, eu termino com você" — pressão emocional forte pode ser vista como coação.)
Estado de perigo ou lesão: A pessoa aceita algo em situação de necessidade extrema ou abuso de sua vulnerabilidade. (Ex.: Alguém em situação emocional muito fragilizada é induzida a aceitar práticas que normalmente recusaria.)
No contexto de BDSM, isso é ainda mais delicado: Mesmo que a pessoa tenha "assinado" um contrato ou dito "sim", se depois ela alegar que seu consentimento foi dado sob medo, engano ou pressão psicológica, o consentimento pode ser considerado viciado — e, portanto, juridicamente inválido.
Isso tem duas implicações sérias:
-
O crime não se descaracteriza: Se houver vício, o consentimento é ignorado e a prática pode ser tratada como crime normal (lesão corporal, estupro, tortura, etc.).
-
A prova do consentimento precisa ser sólida: Mostrando que a pessoa estava informada, lúcida, livre e sem qualquer tipo de coação.
Consentimento viciado é quando a pessoa concorda formalmente, mas de maneira enganada, forçada ou pressionada, tornando o consentimento inútil para efeitos jurídicos.
Conclusão
Casais que praticam BDSM consensual no Brasil navegam em um terreno que exige não apenas confiança mútua e comunicação excepcional, mas também uma consciência aguçada das complexidades legais e dos riscos de interpretações equivocadas ou acusações mal-intencionadas. Embora o BDSM seja uma expressão legítima da sexualidade humana, sua prática no Brasil exige responsabilidade redobrada. Ter provas claras de consentimento, manter a comunicação aberta e agir com prudência são formas eficazes de se proteger de falsas alegações e preservar a liberdade e a segurança de todos os envolvidos. Embora leis controversas como a Maria da Penha sejam "vitais" para a proteção contra a violência real, os praticantes de BDSM, e em particular os homens nesse contexto, devem adotar uma postura proativa e prudente para mitigar os riscos inerentes à potencial má interpretação ou instrumentalização dessas práticas e leis, garantindo que a expressão de sua consensualidade esteja resguardada na medida do possível.
Importante: No Brasil, mesmo com tudo isso, o Ministério Público pode denunciar por crime como lesão corporal grave, estupro ou tortura, independente de consentimento. Então a prudência nas práticas é fundamental.
Aviso Legal: Este artigo tem caráter meramente informativo e não constitui aconselhamento jurídico. As leis e interpretações podem mudar, e cada situação é única. Recomenda-se buscar orientação de um advogado qualificado para discutir casos específicos.
Se curtiu este artigo faça uma contribuição, se tiver algum ponto relevante para o artigo deixe seu comentário.
-
@ 3b3a42d3:d192e325
2025-04-10 08:57:51
Atomic Signature Swaps (ASS) over Nostr is a protocol for atomically exchanging Schnorr signatures using Nostr events for orchestration. This new primitive enables multiple interesting applications like:
- Getting paid to publish specific Nostr events
- Issuing automatic payment receipts
- Contract signing in exchange for payment
- P2P asset exchanges
- Trading and enforcement of asset option contracts
- Payment in exchange for Nostr-based credentials or access tokens
- Exchanging GMs 🌞
It only requires that (i) the involved signatures be Schnorr signatures using the secp256k1 curve and that (ii) at least one of those signatures be accessible to both parties. These requirements are naturally met by Nostr events (published to relays), Taproot transactions (published to the mempool and later to the blockchain), and Cashu payments (using mints that support NUT-07, allowing any pair of these signatures to be swapped atomically.
How the Cryptographic Magic Works 🪄
This is a Schnorr signature
(Zₓ, s):s = z + H(Zₓ || P || m)⋅kIf you haven't seen it before, don't worry, neither did I until three weeks ago.
The signature scalar s is the the value a signer with private key
k(and public keyP = k⋅G) must calculate to prove his commitment over the messagemgiven a randomly generated noncez(Zₓis just the x-coordinate of the public pointZ = z⋅G).His a hash function (sha256 with the tag "BIP0340/challenge" when dealing with BIP340),||just means to concatenate andGis the generator point of the elliptic curve, used to derive public values from private ones.Now that you understand what this equation means, let's just rename
z = r + t. We can do that,zis just a randomly generated number that can be represented as the sum of two other numbers. It also follows thatz⋅G = r⋅G + t⋅G ⇔ Z = R + T. Putting it all back into the definition of a Schnorr signature we get:s = (r + t) + H((R + T)ₓ || P || m)⋅kWhich is the same as:
s = sₐ + twheresₐ = r + H((R + T)ₓ || P || m)⋅ksₐis what we call the adaptor signature scalar) and t is the secret.((R + T)ₓ, sₐ)is an incomplete signature that just becomes valid by add the secret t to thesₐ:s = sₐ + tWhat is also important for our purposes is that by getting access to the valid signature s, one can also extract t from it by just subtracting
sₐ:t = s - sₐThe specific value of
tdepends on our choice of the public pointT, sinceRis just a public point derived from a randomly generated noncer.So how do we choose
Tso that it requires the secret t to be the signature over a specific messagem'by an specific public keyP'? (without knowing the value oft)Let's start with the definition of t as a valid Schnorr signature by P' over m':
t = r' + H(R'ₓ || P' || m')⋅k' ⇔ t⋅G = r'⋅G + H(R'ₓ || P' || m')⋅k'⋅GThat is the same as:
T = R' + H(R'ₓ || P' || m')⋅P'Notice that in order to calculate the appropriate
Tthat requirestto be an specific signature scalar, we only need to know the public nonceR'used to generate that signature.In summary: in order to atomically swap Schnorr signatures, one party
P'must provide a public nonceR', while the other partyPmust provide an adaptor signature using that nonce:sₐ = r + H((R + T)ₓ || P || m)⋅kwhereT = R' + H(R'ₓ || P' || m')⋅P'P'(the nonce provider) can then add his own signature t to the adaptor signaturesₐin order to get a valid signature byP, i.e.s = sₐ + t. When he publishes this signature (as a Nostr event, Cashu transaction or Taproot transaction), it becomes accessible toPthat can now extract the signaturetbyP'and also make use of it.Important considerations
A signature may not be useful at the end of the swap if it unlocks funds that have already been spent, or that are vulnerable to fee bidding wars.
When a swap involves a Taproot UTXO, it must always use a 2-of-2 multisig timelock to avoid those issues.
Cashu tokens do not require this measure when its signature is revealed first, because the mint won't reveal the other signature if they can't be successfully claimed, but they also require a 2-of-2 multisig timelock when its signature is only revealed last (what is unavoidable in cashu for cashu swaps).
For Nostr events, whoever receives the signature first needs to publish it to at least one relay that is accessible by the other party. This is a reasonable expectation in most cases, but may be an issue if the event kind involved is meant to be used privately.
How to Orchestrate the Swap over Nostr?
Before going into the specific event kinds, it is important to recognize what are the requirements they must meet and what are the concerns they must address. There are mainly three requirements:
- Both parties must agree on the messages they are going to sign
- One party must provide a public nonce
- The other party must provide an adaptor signature using that nonce
There is also a fundamental asymmetry in the roles of both parties, resulting in the following significant downsides for the party that generates the adaptor signature:
- NIP-07 and remote signers do not currently support the generation of adaptor signatures, so he must either insert his nsec in the client or use a fork of another signer
- There is an overhead of retrieving the completed signature containing the secret, either from the blockchain, mint endpoint or finding the appropriate relay
- There is risk he may not get his side of the deal if the other party only uses his signature privately, as I have already mentioned
- There is risk of losing funds by not extracting or using the signature before its timelock expires. The other party has no risk since his own signature won't be exposed by just not using the signature he received.
The protocol must meet all those requirements, allowing for some kind of role negotiation and while trying to reduce the necessary hops needed to complete the swap.
Swap Proposal Event (kind:455)
This event enables a proposer and his counterparty to agree on the specific messages whose signatures they intend to exchange. The
contentfield is the following stringified JSON:{ "give": <signature spec (required)>, "take": <signature spec (required)>, "exp": <expiration timestamp (optional)>, "role": "<adaptor | nonce (optional)>", "description": "<Info about the proposal (optional)>", "nonce": "<Signature public nonce (optional)>", "enc_s": "<Encrypted signature scalar (optional)>" }The field
roleindicates what the proposer will provide during the swap, either the nonce or the adaptor. When this optional field is not provided, the counterparty may decide whether he will send a nonce back in a Swap Nonce event or a Swap Adaptor event using thenonce(optionally) provided by in the Swap Proposal in order to avoid one hop of interaction.The
enc_sfield may be used to store the encrypted scalar of the signature associated with thenonce, since this information is necessary later when completing the adaptor signature received from the other party.A
signature specspecifies thetypeand all necessary information for producing and verifying a given signature. In the case of signatures for Nostr events, it contain a template with all the fields, exceptpubkey,idandsig:{ "type": "nostr", "template": { "kind": "<kind>" "content": "<content>" "tags": [ … ], "created_at": "<created_at>" } }In the case of Cashu payments, a simplified
signature specjust needs to specify the payment amount and an array of mints trusted by the proposer:{ "type": "cashu", "amount": "<amount>", "mint": ["<acceptable mint_url>", …] }This works when the payer provides the adaptor signature, but it still needs to be extended to also work when the payer is the one receiving the adaptor signature. In the later case, the
signature specmust also include atimelockand the derived public keysYof each Cashu Proof, but for now let's just ignore this situation. It should be mentioned that the mint must be trusted by both parties and also support Token state check (NUT-07) for revealing the completed adaptor signature and P2PK spending conditions (NUT-11) for the cryptographic scheme to work.The
tagsare:"p", the proposal counterparty's public key (required)"a", akind:30455Swap Listing event or an application specific version of it (optional)
Forget about this Swap Listing event for now, I will get to it later...
Swap Nonce Event (kind:456) - Optional
This is an optional event for the Swap Proposal receiver to provide the public nonce of his signature when the proposal does not include a nonce or when he does not want to provide the adaptor signature due to the downsides previously mentioned. The
contentfield is the following stringified JSON:{ "nonce": "<Signature public nonce>", "enc_s": "<Encrypted signature scalar (optional)>" }And the
tagsmust contain:"e", akind:455Swap Proposal Event (required)"p", the counterparty's public key (required)
Swap Adaptor Event (kind:457)
The
contentfield is the following stringified JSON:{ "adaptors": [ { "sa": "<Adaptor signature scalar>", "R": "<Signer's public nonce (including parity byte)>", "T": "<Adaptor point (including parity byte)>", "Y": "<Cashu proof derived public key (if applicable)>", }, …], "cashu": "<Cashu V4 token (if applicable)>" }And the
tagsmust contain:"e", akind:455Swap Proposal Event (required)"p", the counterparty's public key (required)
Discoverability
The Swap Listing event previously mentioned as an optional tag in the Swap Proposal may be used to find an appropriate counterparty for a swap. It allows a user to announce what he wants to accomplish, what his requirements are and what is still open for negotiation.
Swap Listing Event (kind:30455)
The
contentfield is the following stringified JSON:{ "description": "<Information about the listing (required)>", "give": <partial signature spec (optional)>, "take": <partial signature spec (optional)>, "examples: [<take signature spec>], // optional "exp": <expiration timestamp (optional)>, "role": "<adaptor | nonce (optional)>" }The
descriptionfield describes the restrictions on counterparties and signatures the user is willing to accept.A
partial signature specis an incompletesignature specused in Swap Proposal eventskind:455where omitting fields signals that they are still open for negotiation.The
examplesfield is an array ofsignature specsthe user would be willing totake.The
tagsare:"d", a unique listing id (required)"s", the status of the listingdraft | open | closed(required)"t", topics related to this listing (optional)"p", public keys to notify about the proposal (optional)
Application Specific Swap Listings
Since Swap Listings are still fairly generic, it is expected that specific use cases define new event kinds based on the generic listing. Those application specific swap listing would be easier to filter by clients and may impose restrictions and add new fields and/or tags. The following are some examples under development:
Sponsored Events
This listing is designed for users looking to promote content on the Nostr network, as well as for those who want to monetize their accounts by sharing curated sponsored content with their existing audiences.
It follows the same format as the generic Swap Listing event, but uses the
kind:30456instead.The following new tags are included:
"k", event kind being sponsored (required)"title", campaign title (optional)
It is required that at least one
signature spec(giveand/ortake) must have"type": "nostr"and also contain the following tag["sponsor", "<pubkey>", "<attestation>"]with the sponsor's public key and his signature over the signature spec without the sponsor tag as his attestation. This last requirement enables clients to disclose and/or filter sponsored events.Asset Swaps
This listing is designed for users looking for counterparties to swap different assets that can be transferred using Schnorr signatures, like any unit of Cashu tokens, Bitcoin or other asset IOUs issued using Taproot.
It follows the same format as the generic Swap Listing event, but uses the
kind:30457instead.It requires the following additional tags:
"t", asset pair to be swapped (e.g."btcusd")"t", asset being offered (e.g."btc")"t", accepted payment method (e.g."cashu","taproot")
Swap Negotiation
From finding an appropriate Swap Listing to publishing a Swap Proposal, there may be some kind of negotiation between the involved parties, e.g. agreeing on the amount to be paid by one of the parties or the exact content of a Nostr event signed by the other party. There are many ways to accomplish that and clients may implement it as they see fit for their specific goals. Some suggestions are:
- Adding
kind:1111Comments to the Swap Listing or an existing Swap Proposal - Exchanging tentative Swap Proposals back and forth until an agreement is reached
- Simple exchanges of DMs
- Out of band communication (e.g. Signal)
Work to be done
I've been refining this specification as I develop some proof-of-concept clients to experience its flaws and trade-offs in practice. I left the signature spec for Taproot signatures out of the current document as I still have to experiment with it. I will probably find some important orchestration issues related to dealing with
2-of-2 multisig timelocks, which also affects Cashu transactions when spent last, that may require further adjustments to what was presented here.The main goal of this article is to find other people interested in this concept and willing to provide valuable feedback before a PR is opened in the NIPs repository for broader discussions.
References
- GM Swap- Nostr client for atomically exchanging GM notes. Live demo available here.
- Sig4Sats Script - A Typescript script demonstrating the swap of a Cashu payment for a signed Nostr event.
- Loudr- Nostr client under development for sponsoring the publication of Nostr events. Live demo available at loudr.me.
- Poelstra, A. (2017). Scriptless Scripts. Blockstream Research. https://github.com/BlockstreamResearch/scriptless-scripts
-
@ e6817453:b0ac3c39
2024-09-30 14:52:23
In the modern world of AI, managing vast amounts of data while keeping it relevant and accessible is a significant challenge, mainly when dealing with large language models (LLMs) and vector databases. One approach that has gained prominence in recent years is integrating vector search with metadata, especially in retrieval-augmented generation (RAG) pipelines. Vector search and metadata enable faster and more accurate data retrieval. However, the process of pre- and post-search filtering results plays a crucial role in ensuring data relevance.
The Vector Search and Metadata Challenge
In a typical vector search, you create embeddings from chunks of text, such as a PDF document. These embeddings allow the system to search for similar items and retrieve them based on relevance. The challenge, however, arises when you need to combine vector search results with structured metadata. For example, you may have timestamped text-based content and want to retrieve the most relevant content within a specific date range. This is where metadata becomes critical in refining search results.
Unfortunately, most vector databases treat metadata as a secondary feature, isolating it from the primary vector search process. As a result, handling queries that combine vectors and metadata can become a challenge, particularly when the search needs to account for a dynamic range of filters, such as dates or other structured data.
LibSQL and vector search metadata
LibSQL is a more general-purpose SQLite-based database that adds vector capabilities to regular data. Vectors are presented as blob columns of regular tables. It makes vector embeddings and metadata a first-class citizen that naturally builds deep integration of these data points.
create table if not exists conversation ( id varchar(36) primary key not null, startDate real, endDate real, summary text, vectorSummary F32_BLOB(512) );It solves the challenge of metadata and vector search and eliminates impedance between vector data and regular structured data points in the same storage.
As you can see, you can access vector-like data and start date in the same query.
select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance from conversation where ${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''} ${distance ? `and distance <= ${distance}` : ''} order by distance limit ${top};vector_distance_cos calculated as distance allows us to make a primitive vector search that does a full scan and calculates distances on rows. We could optimize it with CTE and limit search and distance calculations to a much smaller subset of data.
This approach could be calculation intensive and fail on large amounts of data.
Libsql offers a way more effective vector search based on FlashDiskANN vector indexed.
vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) ivector_top_k is a table function that searches for the top of the newly created vector search index. As you can see, we could use only vector as a function parameter, and other columns could be used outside of the table function. So, to use a vector index together with different columns, we need to apply some strategies.
Now we get a classical problem of integration vector search results with metadata queries.
Post-Filtering: A Common Approach
The most widely adopted method in these pipelines is post-filtering. In this approach, the system first retrieves data based on vector similarities and then applies metadata filters. For example, imagine you’re conducting a vector search to retrieve conversations relevant to a specific question. Still, you also want to ensure these conversations occurred in the past week.
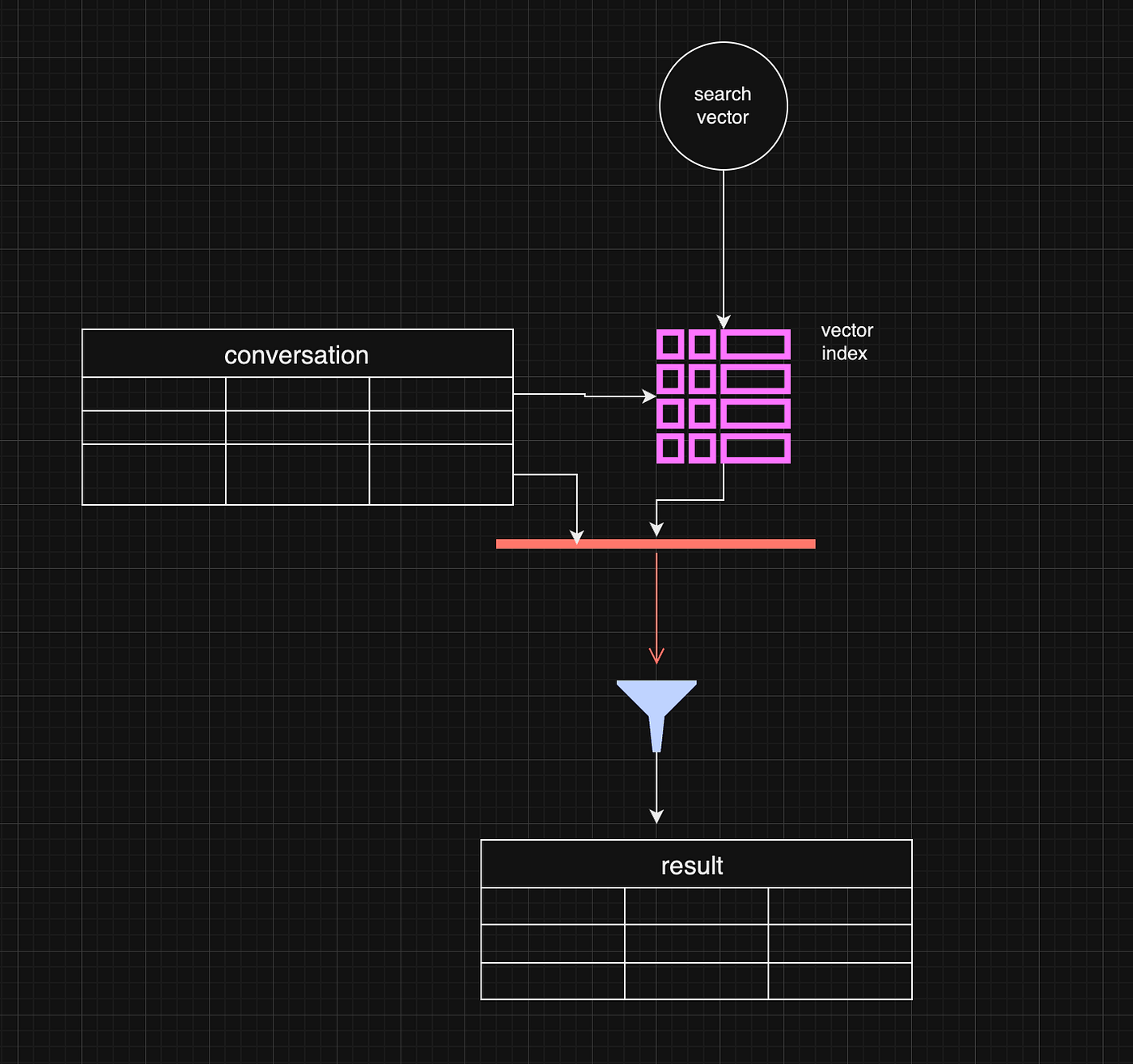
Post-filtering allows the system to retrieve the most relevant vector-based results and subsequently filter out any that don’t meet the metadata criteria, such as date range. This method is efficient when vector similarity is the primary factor driving the search, and metadata is only applied as a secondary filter.
const sqlQuery = ` select c.id ,c.startDate, c.endDate, c.summary, vector_distance_cos(c.vectorSummary, vector(${vector})) distance from vector_top_k('idx_conversation_vectorSummary', ${vector} , ${top}) i inner join conversation c on i.id = c.rowid where ${startDate ? `and c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `and c.endDate <= ${endDate.getTime()}` : ''} ${distance ? `and distance <= ${distance}` : ''} order by distance limit ${top};However, there are some limitations. For example, the initial vector search may yield fewer results or omit some relevant data before applying the metadata filter. If the search window is narrow enough, this can lead to complete results.
One working strategy is to make the top value in vector_top_K much bigger. Be careful, though, as the function's default max number of results is around 200 rows.
Pre-Filtering: A More Complex Approach
Pre-filtering is a more intricate approach but can be more effective in some instances. In pre-filtering, metadata is used as the primary filter before vector search takes place. This means that only data that meets the metadata criteria is passed into the vector search process, limiting the scope of the search right from the beginning.
While this approach can significantly reduce the amount of irrelevant data in the final results, it comes with its own challenges. For example, pre-filtering requires a deeper understanding of the data structure and may necessitate denormalizing the data or creating separate pre-filtered tables. This can be resource-intensive and, in some cases, impractical for dynamic metadata like date ranges.
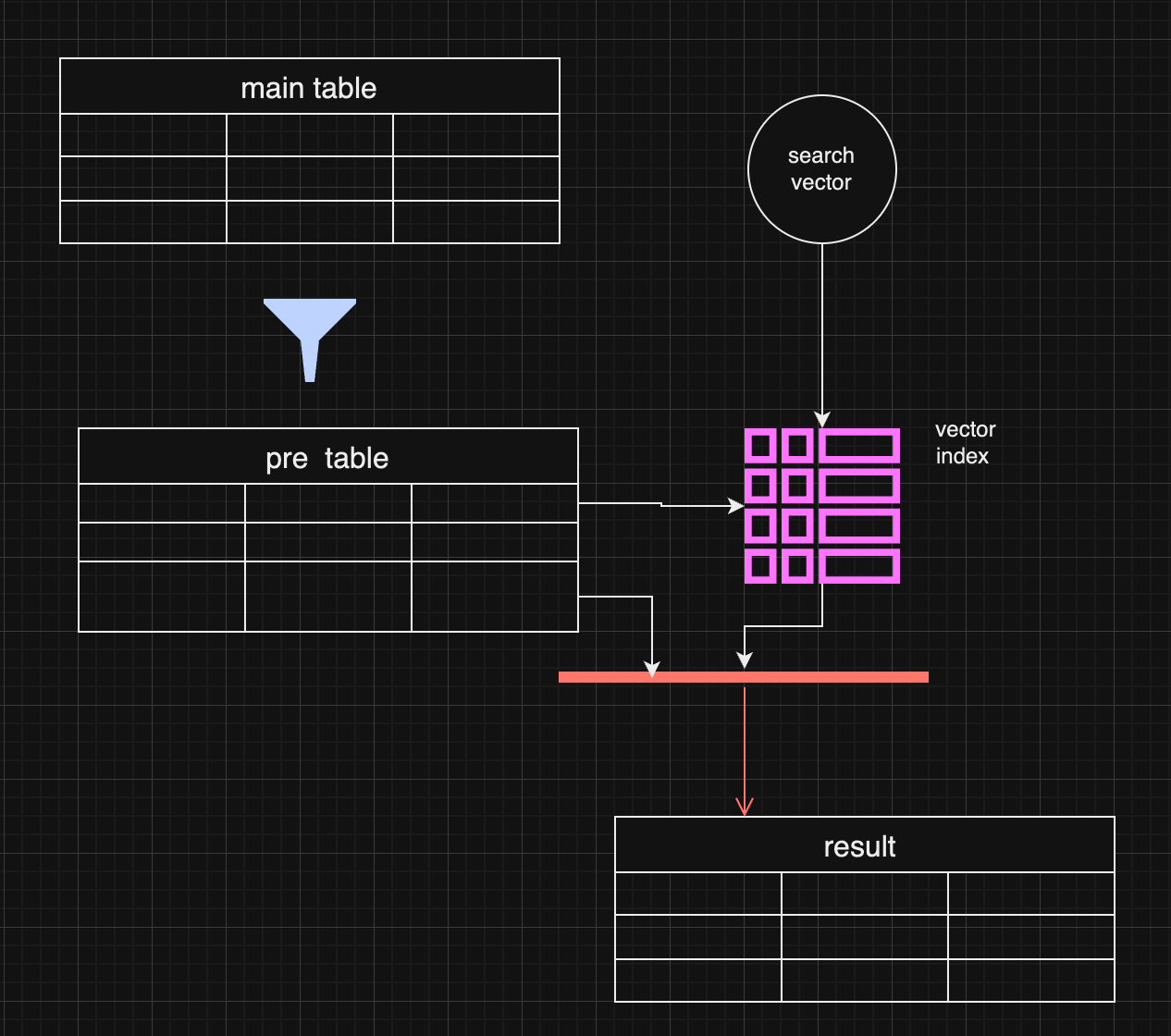
In certain use cases, pre-filtering might outperform post-filtering. For instance, when the metadata (e.g., specific date ranges) is the most important filter, pre-filtering ensures the search is conducted only on the most relevant data.
Pre-filtering with distance-based filtering
So, we are getting back to an old concept. We do prefiltering instead of using a vector index.
WITH FilteredDates AS ( SELECT c.id, c.startDate, c.endDate, c.summary, c.vectorSummary FROM YourTable c WHERE ${startDate ? `AND c.startDate >= ${startDate.getTime()}` : ''} ${endDate ? `AND c.endDate <= ${endDate.getTime()}` : ''} ), DistanceCalculation AS ( SELECT fd.id, fd.startDate, fd.endDate, fd.summary, fd.vectorSummary, vector_distance_cos(fd.vectorSummary, vector(${vector})) AS distance FROM FilteredDates fd ) SELECT dc.id, dc.startDate, dc.endDate, dc.summary, dc.distance FROM DistanceCalculation dc WHERE 1=1 ${distance ? `AND dc.distance <= ${distance}` : ''} ORDER BY dc.distance LIMIT ${top};It makes sense if the filter produces small data and distance calculation happens on the smaller data set.
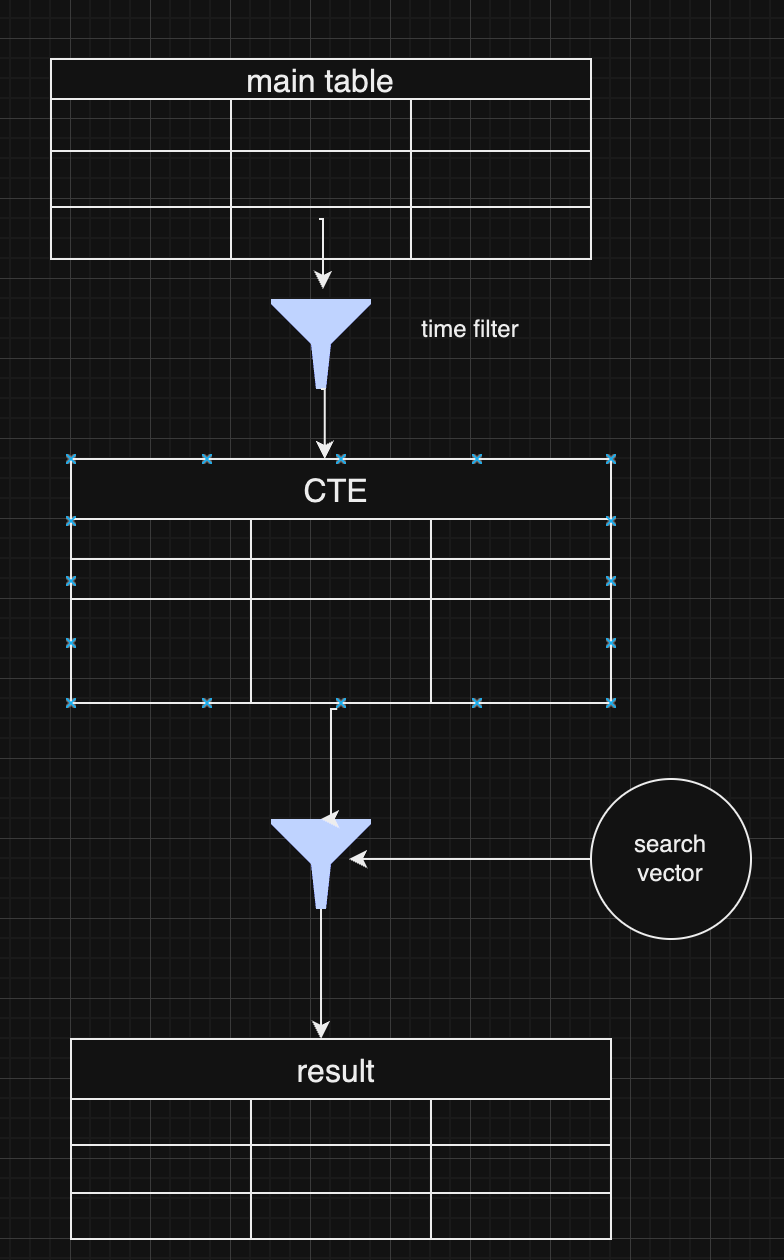
As a pro of this approach, you have full control over the data and get all results without omitting some typical values for extensive index searches.
Choosing Between Pre and Post-Filtering
Both pre-filtering and post-filtering have their advantages and disadvantages. Post-filtering is more accessible to implement, especially when vector similarity is the primary search factor, but it can lead to incomplete results. Pre-filtering, on the other hand, can yield more accurate results but requires more complex data handling and optimization.
In practice, many systems combine both strategies, depending on the query. For example, they might start with a broad pre-filtering based on metadata (like date ranges) and then apply a more targeted vector search with post-filtering to refine the results further.
Conclusion
Vector search with metadata filtering offers a powerful approach for handling large-scale data retrieval in LLMs and RAG pipelines. Whether you choose pre-filtering or post-filtering—or a combination of both—depends on your application's specific requirements. As vector databases continue to evolve, future innovations that combine these two approaches more seamlessly will help improve data relevance and retrieval efficiency further.
-
@ a5ee4475:2ca75401
2025-05-04 15:14:32
lista #descentralismo #compilado #portugues
*Algumas destas listas ainda estão sendo trocadas e serão traduzidas para português, portanto as versões mais recentes delas só estarão visíveis no Amethyst.
Clients do Nostr e Outras Coisas
nostr:naddr1qq245dz5tqe8w46swpphgmr4f3047s6629t45qg4waehxw309aex2mrp0yhxgctdw4eju6t09upzpf0wg36k3g3hygndv3cp8f2j284v0hfh4dqgqjj3yxnreck2w4qpqvzqqqr4guxde6sl
Modelos de IA e Ferramentas
nostr:nevent1qqsxdpwadkswdrc602m6qdhyq7n33lf3wpjtdjq2adkw4y3h38mjcrqpr9mhxue69uhkxmmzwfskvatdvyhxxmmd9aex2mrp0ypzpf0wg36k3g3hygndv3cp8f2j284v0hfh4dqgqjj3yxnreck2w4qpqvzqqqqqqysn06gs
Comunidades Lusófonas de Bitcoin
nostr:nevent1qqsqnmtverj2fetqwhsv9n2ny8h9ujhyqqrk0fsn4a02w8sf4cqddzqpzamhxue69uhhyetvv9ujumn0wd68ytnzv9hxgtczyzj7u3r4dz3rwg3x6erszwj4y502clwn026qsp99zgdx8n3v5a2qzqcyqqqqqqgypv6z5
Profissionais Brasileiros no Nostr
nostr:nevent1qqsvqnlx7sqeczv5r7pmmd6zzca3l0ru4856n3j7lhjfv3atq40lfdcpr9mhxue69uhkxmmzwfskvatdvyhxxmmd9aex2mrp0ypzpf0wg36k3g3hygndv3cp8f2j284v0hfh4dqgqjj3yxnreck2w4qpqvzqqqqqqylf6kr4
Comunidades em Português no Nostr
nostr:nevent1qqsy47d6z0qzshfqt5sgvtck8jmhdjnsfkyacsvnqe8m7euuvp4nm0gpzpmhxue69uhkummnw3ezumt0d5hsyg99aez8269zxu3zd4j8qya92fg7437ax745pqz22ys6v08zef65qypsgqqqqqqsw4vudx
Grupos em Português no Nostr
nostr:nevent1qqs98kldepjmlxngupsyth40n0h5lw7z5ut5w4scvh27alc0w86tevcpzpmhxue69uhkummnw3ezumt0d5hsygy7fff8g6l23gp5uqtuyqwkqvucx6mhe7r9h7v6wyzzj0v6lrztcspsgqqqqqqs3ndneh
Games Open Source
nostr:nevent1qqs0swpxdqfknups697205qg5mpw2e370g5vet07gkexe9n0k05h5qspz4mhxue69uhhyetvv9ujumn0wd68ytnzvuhsyg99aez8269zxu3zd4j8qya92fg7437ax745pqz22ys6v08zef65qypsgqqqqqqshr37wh
Formatação de Texto no Amethyst
nostr:nevent1qqs0vquevt0pe9h5a2dh8csufdksazp6czz3vjk3wfspp68uqdez00cprpmhxue69uhkummnw3ezuendwsh8w6t69e3xj730qgs2tmjyw452ydezymtywqf625j3atra6datgzqy55fp5c7w9jn4gqgrqsqqqqqpd658r3
Outros Links
nostr:nevent1qqsrm6ywny5r7ajakpppp0lt525n0s33x6tyn6pz0n8ws8k2tqpqracpzpmhxue69uhkummnw3ezumt0d5hsygp6e5ns0nv3dun430jky25y4pku6ylz68rz6zs7khv29q6rj5peespsgqqqqqqsmfwa78
-
@ 826e9f89:ffc5c759
2025-04-12 21:34:24
What follows began as snippets of conversations I have been having for years, on and off, here and there. It will likely eventually be collated into a piece I have been meaning to write on “payments” as a whole. I foolishly started writing this piece years ago, not realizing that the topic is gargantuan and for every week I spend writing it I have to add two weeks to my plan. That may or may not ever come to fruition, but in the meantime, Tether announced it was issuing on Taproot Assets and suddenly everybody is interested again. This is as good a catalyst as any to carve out my “stablecoin thesis”, such as it exists, from “payments”, and put it out there for comment and feedback.
In contrast to the “Bitcoiner take” I will shortly revert to, I invite the reader to keep the following potential counterargument in mind, which might variously be termed the “shitcoiner”, “realist”, or “cynical” take, depending on your perspective: that stablecoins have clear product-market-fit. Now, as a venture capitalist and professional thinkboi focusing on companies building on Bitcoin, I obviously think that not only is Bitcoin the best money ever invented and its monetization is pretty much inevitable, but that, furthermore, there is enormous, era-defining long-term potential for a range of industries in which Bitcoin is emerging as superior technology, even aside from its role as money. But in the interest not just of steelmanning but frankly just of honesty, I would grudgingly agree with the following assessment as of the time of writing: the applications of crypto (inclusive of Bitcoin but deliberately wider) that have found product-market-fit today, and that are not speculative bets on future development and adoption, are: Bitcoin as savings technology, mining as a means of monetizing energy production, and stablecoins.
I think there are two typical Bitcoiner objections to stablecoins of significantly greater importance than all others: that you shouldn’t be supporting dollar hegemony, and that you don’t need a blockchain. I will elaborate on each of these, and for the remainder of the post will aim to produce a synthesis of three superficially contrasting (or at least not obviously related) sources of inspiration: these objections, the realisation above that stablecoins just are useful, and some commentary on technical developments in Bitcoin and the broader space that I think inform where things are likely to go. As will become clear as the argument progresses, I actually think the outcome to which I am building up is where things have to go. I think the technical and economic incentives at play make this an inevitability rather than a “choice”, per se. Given my conclusion, which I will hold back for the time being, this is a fantastically good thing, hence I am motivated to write this post at all!
Objection 1: Dollar Hegemony
I list this objection first because there isn’t a huge amount to say about it. It is clearly a normative position, and while I more or less support it personally, I don’t think that it is material to the argument I am going on to make, so I don’t want to force it on the reader. While the case for this objection is probably obvious to this audience (isn’t the point of Bitcoin to destroy central banks, not further empower them?) I should at least offer the steelman that there is a link between this and the realist observation that stablecoins are useful. The reason they are useful is because people prefer the dollar to even shitter local fiat currencies. I don’t think it is particularly fruitful to say that they shouldn’t. They do. Facts don’t care about your feelings. There is a softer bridging argument to be made here too, to the effect that stablecoins warm up their users to the concept of digital bearer (ish) assets, even though these particular assets are significantly scammier than Bitcoin. Again, I am just floating this, not telling the reader they should or shouldn’t buy into it.
All that said, there is one argument I do want to put my own weight behind, rather than just float: stablecoin issuance is a speculative attack on the institution of fractional reserve banking. A “dollar” Alice moves from JPMorgan to Tether embodies two trade-offs from Alice’s perspective: i) a somewhat opaque profile on the credit risk of the asset: the likelihood of JPMorgan ever really defaulting on deposits vs the operator risk of Tether losing full backing and/or being wrench attacked by the Federal Government and rugging its users. These risks are real but are almost entirely political. I’m skeptical it is meaningful to quantify them, but even if it is, I am not the person to try to do it. Also, more transparently to Alice, ii) far superior payment rails (for now, more on this to follow).
However, from the perspective of the fiat banking cartel, fractional reserve leverage has been squeezed. There are just as many notional dollars in circulation, but there the backing has been shifted from levered to unlevered issuers. There are gradations of relevant objections to this: while one might say, Tether’s backing comes from Treasuries, so you are directly funding US debt issuance!, this is a bit silly in the context of what other dollars one might hold. It’s not like JPMorgan is really competing with the Treasury to sell credit into the open market. Optically they are, but this is the core of the fiat scam. Via the guarantees of the Federal Reserve System, JPMorgan can sell as much unbacked credit as it wants knowing full well the difference will be printed whenever this blows up. Short-term Treasuries are also JPMorgan’s most pristine asset safeguarding its equity, so the only real difference is that Tether only holds Treasuries without wishing more leverage into existence. The realization this all builds up to is that, by necessity,
Tether is a fully reserved bank issuing fiduciary media against the only dollar-denominated asset in existence whose value (in dollar terms) can be guaranteed. Furthermore, this media arguably has superior “moneyness” to the obvious competition in the form of US commercial bank deposits by virtue of its payment rails.
That sounds pretty great when you put it that way! Of course, the second sentence immediately leads to the second objection, and lets the argument start to pick up steam …
Objection 2: You Don’t Need a Blockchain
I don’t need to explain this to this audience but to recap as briefly as I can manage: Bitcoin’s value is entirely endogenous. Every aspect of “a blockchain” that, out of context, would be an insanely inefficient or redundant modification of a “database”, in context is geared towards the sole end of enabling the stability of this endogenous value. Historically, there have been two variations of stupidity that follow a failure to grok this: i) “utility tokens”, or blockchains with native tokens for something other than money. I would recommend anybody wanting a deeper dive on the inherent nonsense of a utility token to read Only The Strong Survive, in particular Chapter 2, Crypto Is Not Decentralized, and the subsection, Everything Fights For Liquidity, and/or Green Eggs And Ham, in particular Part II, Decentralized Finance, Technically. ii) “real world assets” or, creating tokens within a blockchain’s data structure that are not intended to have endogenous value but to act as digital quasi-bearer certificates to some or other asset of value exogenous to this system. Stablecoins are in this second category.
RWA tokens definitionally have to have issuers, meaning some entity that, in the real world, custodies or physically manages both the asset and the record-keeping scheme for the asset. “The blockchain” is at best a secondary ledger to outsource ledger updates to public infrastructure such that the issuer itself doesn’t need to bother and can just “check the ledger” whenever operationally relevant. But clearly ownership cannot be enforced in an analogous way to Bitcoin, under both technical and social considerations. Technically, Bitcoin’s endogenous value means that whoever holds the keys to some or other UTXOs functionally is the owner. Somebody else claiming to be the owner is yelling at clouds. Whereas, socially, RWA issuers enter a contract with holders (whether legally or just in terms of a common-sense interpretation of the transaction) such that ownership of the asset issued against is entirely open to dispute. That somebody can point to “ownership” of the token may or may not mean anything substantive with respect to the physical reality of control of the asset, and how the issuer feels about it all.
And so, one wonders, why use a blockchain at all? Why doesn’t the issuer just run its own database (for the sake of argument with some or other signature scheme for verifying and auditing transactions) given it has the final say over issuance and redemption anyway? I hinted at an answer above: issuing on a blockchain outsources this task to public infrastructure. This is where things get interesting. While it is technically true, given the above few paragraphs, that, you don’t need a blockchain for that, you also don’t need to not use a blockchain for that. If you want to, you can.
This is clearly the case given stablecoins exist at all and have gone this route. If one gets too angry about not needing a blockchain for that, one equally risks yelling at clouds! And, in fact, one can make an even stronger argument, more so from the end users’ perspective. These products do not exist in a vacuum but rather compete with alternatives. In the case of stablecoins, the alternative is traditional fiat money, which, as stupid as RWAs on a blockchain are, is even dumber. It actually is just a database, except it’s a database that is extremely annoying to use, basically for political reasons because the industry managing these private databases form a cartel that never needs to innovate or really give a shit about its customers at all. In many, many cases, stablecoins on blockchains are dumb in the abstract, but superior to the alternative methods of holding and transacting in dollars existing in other forms. And note, this is only from Alice’s perspective of wanting to send and receive, not a rehashing of the fractional reserve argument given above. This is the essence of their product-market-fit. Yell at clouds all you like: they just are useful given the alternative usually is not Bitcoin, it’s JPMorgan’s KYC’d-up-the-wazoo 90s-era website, more than likely from an even less solvent bank.
So where does this get us? It might seem like we are back to “product-market-fit, sorry about that” with Bitcoiners yelling about feelings while everybody else makes do with their facts. However, I think we have introduced enough material to move the argument forward by incrementally incorporating the following observations, all of which I will shortly go into in more detail: i) as a consequence of making no technical sense with respect to what blockchains are for, today’s approach won’t scale; ii) as a consequence of short-termist tradeoffs around socializing costs, today’s approach creates an extremely unhealthy and arguably unnatural market dynamic in the issuer space; iii) Taproot Assets now exist and handily address both points i) and ii), and; iv) eCash is making strides that I believe will eventually replace even Taproot Assets.
To tease where all this is going, and to get the reader excited before we dive into much more detail: just as Bitcoin will eat all monetary premia, Lightning will likely eat all settlement, meaning all payments will gravitate towards routing over Lightning regardless of the denomination of the currency at the edges. Fiat payments will gravitate to stablecoins to take advantage of this; stablecoins will gravitate to TA and then to eCash, and all of this will accelerate hyperbitcoinization by “bitcoinizing” payment rails such that an eventual full transition becomes as simple as flicking a switch as to what denomination you want to receive.
I will make two important caveats before diving in that are more easily understood in light of having laid this groundwork: I am open to the idea that it won’t be just Lightning or just Taproot Assets playing the above roles. Without veering into forecasting the entire future development of Bitcoin tech, I will highlight that all that really matters here are, respectively: a true layer 2 with native hashlocks, and a token issuance scheme that enables atomic routing over such a layer 2 (or combination of such). For the sake of argument, the reader is welcome to swap in “Ark” and “RGB” for “Lightning” and “TA” both above and in all that follows. As far as I can tell, this makes no difference to the argument and is even exciting in its own right. However, for the sake of simplicity in presentation, I will stick to “Lightning” and “TA” hereafter.
1) Today’s Approach to Stablecoins Won’t Scale
This is the easiest to tick off and again doesn’t require much explanation to this audience. Blockchains fundamentally don’t scale, which is why Bitcoin’s UTXO scheme is a far better design than ex-Bitcoin Crypto’s’ account-based models, even entirely out of context of all the above criticisms. This is because Bitcoin transactions can be batched across time and across users with combinations of modes of spending restrictions that provide strong economic guarantees of correct eventual net settlement, if not perpetual deferral. One could argue this is a decent (if abstrusely technical) definition of “scaling” that is almost entirely lacking in Crypto.
What we see in ex-Bitcoin crypto is so-called “layer 2s” that are nothing of the sort, forcing stablecoin schemes in these environments into one of two equally poor design choices if usage is ever to increase: fees go higher and higher, to the point of economic unviability (and well past it) as blocks fill up, or move to much more centralized environments that increasingly are just databases, and hence which lose the benefits of openness thought to be gleaned by outsourcing settlement to public infrastructure. This could be in the form of punting issuance to a bullshit “layer 2” that is a really a multisig “backing” a private execution environment (to be decentralized any daw now) or an entirely different blockchain that is just pretending even less not to be a database to begin with. In a nutshell, this is a decent bottom-up explanation as to why Tron has the highest settlement of Tether.
This also gives rise to the weirdness of “gas tokens” - assets whose utility as money is and only is in the form of a transaction fee to transact a different kind of money. These are not quite as stupid as a “utility token,” given at least they are clearly fulfilling a monetary role and hence their artificial scarcity can be justified. But they are frustrating from Bitcoiners’ and users’ perspectives alike: users would prefer to pay transaction fees on dollars in dollars, but they can’t because the value of Ether, Sol, Tron, or whatever, is the string and bubblegum that hold their boondoggles together. And Bitcoiners wish this stuff would just go away and stop distracting people, whereas this string and bubblegum is proving transiently useful.
All in all, today’s approach is fine so long as it isn’t being used much. It has product-market fit, sure, but in the unenviable circumstance that, if it really starts to take off, it will break, and even the original users will find it unusable.
2) Today’s Approach to Stablecoins Creates an Untenable Market Dynamic
Reviving the ethos of you don’t need a blockchain for that, notice the following subtlety: while the tokens representing stablecoins have value to users, that value is not native to the blockchain on which they are issued. Tether can (and routinely does) burn tokens on Ethereum and mint them on Tron, then burn on Tron and mint on Solana, and so on. So-called blockchains “go down” and nobody really cares. This makes no difference whatsoever to Tether’s own accounting, and arguably a positive difference to users given these actions track market demand. But it is detrimental to the blockchain being switched away from by stripping it of “TVL” that, it turns out, was only using it as rails: entirely exogenous value that leaves as quickly as it arrived.
One underdiscussed and underappreciated implication of the fact that no value is natively running through the blockchain itself is that, in the current scheme, both the sender and receiver of a stablecoin have to trust the same issuer. This creates an extremely powerful network effect that, in theory, makes the first-to-market likely to dominate and in practice has played out exactly as this theory would suggest: Tether has roughly 80% of the issuance, while roughly 19% goes to the political carve-out of USDC that wouldn’t exist at all were it not for government interference. Everybody else combined makes up the final 1%.
So, Tether is a full reserve bank but also has to be everybody’s bank. This is the source of a lot of the discomfort with Tether, and which feeds into the original objection around dollar hegemony, that there is an ill-defined but nonetheless uneasy feeling that Tether is slowly morphing into a CBDC. I would argue this really has nothing to do with Tether’s own behavior but rather is a consequence of the market dynamic inevitably created by the current stablecoin scheme. There is no reason to trust any other bank because nobody really wants a bank, they just want the rails. They want something that will retain a nominal dollar value long enough to spend it again. They don’t care what tech it runs on and they don’t even really care about the issuer except insofar as having some sense they won’t get rugged.
Notice this is not how fiat works. Banks can, of course, settle between each other, thus enabling their users to send money to customers of other banks. This settlement function is actually the entire point of central banks, less the money printing and general corruption enabled (we might say, this was the historical point of central banks, which have since become irredeemably corrupted by this power). This process is clunkier than stablecoins, as covered above, but the very possibility of settlement means there is no gigantic network effect to being the first commercial issuer of dollar balances. If it isn’t too triggering to this audience, one might suggest that the money printer also removes the residual concern that your balances might get rugged! (or, we might again say, you guarantee you don’t get rugged in the short term by guaranteeing you do get rugged in the long term).
This is a good point at which to introduce the unsettling observation that broader fintech is catching on to the benefits of stablecoins without any awareness whatsoever of all the limitations I am outlining here. With the likes of Stripe, Wise, Robinhood, and, post-Trump, even many US megabanks supposedly contemplating issuing stablecoins (obviously within the current scheme, not the scheme I am building up to proposing), we are forced to boggle our minds considering how on earth settlement is going to work. Are they going to settle through Ether? Well, no, because i) Ether isn’t money, it’s … to be honest, I don’t think anybody really knows what it is supposed to be, or if they once did they aren’t pretending anymore, but anyway, Stripe certainly hasn’t figured that out yet so, ii) it won’t be possible to issue them on layer 1s as soon as there is any meaningful volume, meaning they will have to route through “bullshit layer 2 wrapped Ether token that is really already a kind of stablecoin for Ether.”
The way they are going to try to fix this (anybody wanna bet?) is routing through DEXes, which is so painfully dumb you should be laughing and, if you aren’t, I would humbly suggest you don’t get just how dumb it is. What this amounts to is plugging the gap of Ether’s lack of moneyness (and wrapped Ether’s hilarious lack of moneyness) with … drum roll … unknowable technical and counterparty risk and unpredictable cost on top of reverting to just being a database. So, in other words, all of the costs of using a blockchain when you don’t strictly need to, and none of the benefits. Stripe is going to waste billions of dollars getting sandwich attacked out of some utterly vanilla FX settlement it is facilitating for clients who have even less of an idea what is going on and why North Korea now has all their money, and will eventually realize they should have skipped their shitcoin phase and gone straight to understanding Bitcoin instead …
3) Bitcoin (and Taproot Assets) Fixes This
To tie together a few loose ends, I only threw in the hilariously stupid suggestion of settling through wrapped Ether on Ether on Ether in order to tee up the entirely sensible suggestion of settling through Lightning. Again, not that this will be new to this audience, but while issuance schemes have been around on Bitcoin for a long time, the breakthrough of Taproot Assets is essentially the ability to atomically route through Lightning.
I will admit upfront that this presents a massive bootstrapping challenge relative to the ex-Bitcoin Crypto approach, and it’s not obvious to me if or how this will be overcome. I include this caveat to make it clear I am not suggesting this is a given. It may not be, it’s just beyond the scope of this post (or frankly my ability) to predict. This is a problem for Lightning Labs, Tether, and whoever else decides to step up to issue. But even highlighting this as an obvious and major concern invites us to consider an intriguing contrast: scaling TA stablecoins is hardest at the start and gets easier and easier thereafter. The more edge liquidity there is in TA stables, the less of a risk it is for incremental issuance; the more TA activity, the more attractive deploying liquidity is into Lightning proper, and vice versa. With apologies if this metaphor is even more confusing than it is helpful, one might conceive of the situation as being that there is massive inertia to bootstrap, but equally there could be positive feedback in driving the inertia to scale. Again, I have no idea, and it hasn’t happened yet in practice, but in theory it’s fun.
More importantly to this conversation, however, this is almost exactly the opposite dynamic to the current scheme on other blockchains, which is basically free to start, but gets more and more expensive the more people try to use it. One might say it antiscales (I don’t think that’s a real word, but if Taleb can do it, then I can do it too!).
Furthermore, the entire concept of “settling in Bitcoin” makes perfect sense both economically and technically: economically because Bitcoin is money, and technically because it can be locked in an HTLC and hence can enable atomic routing (i.e. because Lightning is a thing). This is clearly better than wrapped Eth on Eth on Eth or whatever, but, tantalisingly, is better than fiat too! The core message of the payments tome I may or may not one day write is (or will be) that fiat payments, while superficially efficient on the basis of centralized and hence costless ledger amendments, actually have a hidden cost in the form of interbank credit. Many readers will likely have heard me say this multiple times and in multiple settings but, contrary to popular belief, there is no such thing as a fiat debit. Even if styled as a debit, all fiat payments are credits and all have credit risk baked into their cost, even if that is obscured and pushed to the absolute foundational level of money printing to keep banks solvent and hence keep payment channels open.
Furthermore! this enables us to strip away the untenable market dynamic from the point above. The underappreciated and underdiscussed flip side of the drawback of the current dynamic that is effectively fixed by Taproot Assets is that there is no longer a mammoth network effect to a single issuer. Senders and receivers can trust different issuers (i.e. their own banks) because those banks can atomically settle a single payment over Lightning. This does not involve credit. It is arguably the only true debit in the world across both the relevant economic and technical criteria: it routes through money with no innate credit risk, and it does so atomically due to that money’s native properties.
Savvy readers may have picked up on a seed I planted a while back and which can now delightfully blossom:
This is what Visa was supposed to be!
Crucially, this is not what Visa is now. Visa today is pretty much the bank that is everybody’s counterparty, takes a small credit risk for the privilege, and oozes free cash flow bottlenecking global consumer payments.
But if you read both One From Many by Dee Hock (for a first person but pretty wild and extravagant take) and Electronic Value Exchange by David Stearns (for a third person, drier, but more analytical and historically contextualized take) or if you are just intimately familiar with the modern history of payments for whatever other reason, you will see that the role I just described for Lightning in an environment of unboundedly many banks issuing fiduciary media in the form of stablecoins is exactly what Dee Hock wanted to create when he envisioned Visa:
A neutral and open layer of value settlement enabling banks to create digital, interbank payment schemes for their customers at very low cost.
As it turns out, his vision was technically impossible with fiat, hence Visa, which started as a cooperative amongst member banks, was corrupted into a duopolistic for-profit rent seeker in curious parallel to the historical path of central banks …
4) eCash
To now push the argument to what I think is its inevitable conclusion, it’s worth being even more vigilant on the front of you don’t need a blockchain for that. I have argued that there is a role for a blockchain in providing a neutral settlement layer to enable true debits of stablecoins. But note this is just a fancy and/or stupid way of saying that Bitcoin is both the best money and is programmable, which we all knew anyway. The final step is realizing that, while TA is nice in terms of providing a kind of “on ramp” for global payments infrastructure as a whole to reorient around Lightning, there is some path dependence here in assuming (almost certainly correctly) that the familiarity of stablecoins as “RWA tokens on a blockchain” will be an important part of the lure.
But once that transition is complete, or is well on its way to being irreversible, we may as well come full circle and cut out tokens altogether. Again, you really don’t need a blockchain for that, and the residual appeal of better rails has been taken care of with the above massive detour through what I deem to be the inevitability of Lightning as a settlement layer. Just as USDT on Tron arguably has better moneyness than a JPMorgan balance, so a “stablecoin” as eCash has better moneyness than as a TA given it is cheaper, more private, and has more relevantly bearer properties (in other words, because it is cash). The technical detail that it can be hashlocked is really all you need to tie this all together. That means it can be atomically locked into a Lightning routed debit to the recipient of a different issuer (or “mint” in eCash lingo, but note this means the same thing as what we have been calling fully reserved banks). And the economic incentive is pretty compelling too because, for all their benefits, there is still a cost to TAs given they are issued onchain and they require asset-specific liquidity to route on Lightning. Once the rest of the tech is in place, why bother? Keep your Lightning connectivity and just become a mint.
What you get at that point is dramatically superior private database to JPMorgan with the dramatically superior public rails of Lightning. There is nothing left to desire from “a blockchain” besides what Bitcoin is fundamentally for in the first place: counterparty-risk-free value settlement.
And as a final point with a curious and pleasing echo to Dee Hock at Visa, Calle has made the point repeatedly that David Chaum’s vision for eCash, while deeply philosophical besides the technical details, was actually pretty much impossible to operate on fiat. From an eCash perspective, fiat stablecoins within the above infrastructure setup are a dramatic improvement on anything previously possible. But, of course, they are a slippery slope to Bitcoin regardless …
Objections Revisited
As a cherry on top, I think the objections I highlighted at the outset are now readily addressed – to the extent the reader believes what I am suggesting is more or less a technical and economic inevitability, that is. While, sure, I’m not particularly keen on giving the Treasury more avenues to sell its welfare-warfare shitcoin, on balance the likely development I’ve outlined is an enormous net positive: it’s going to sell these anyway so I prefer a strong economic incentive to steadily transition not only to Lightning as payment rails but eCash as fiduciary media, and to use “fintech” as a carrot to induce a slow motion bank run.
As alluded to above, once all this is in place, the final step to a Bitcoin standard becomes as simple as an individual’s decision to want Bitcoin instead of fiat. On reflection, this is arguably the easiest part! It's setting up all the tech that puts people off, so trojan-horsing them with “faster, cheaper payment rails” seems like a genius long-term strategy.
And as to “needing a blockchain” (or not), I hope that is entirely wrapped up at this point. The only blockchain you need is Bitcoin, but to the extent people are still confused by this (which I think will take decades more to fully unwind), we may as well lean into dazzling them with whatever innovation buzzwords and decentralization theatre they were going to fall for anyway before realizing they wanted Bitcoin all along.
Conclusion
Stablecoins are useful whether you like it or not. They are stupid in the abstract but it turns out fiat is even stupider, on inspection. But you don’t need a blockchain, and using one as decentralization theatre creates technical debt that is insurmountable in the long run. Blockchain-based stablecoins are doomed to a utility inversely proportional to their usage, and just to rub it in, their ill-conceived design practically creates a commercial dynamic that mandates there only ever be a single issuer.
Given they are useful, it seems natural that this tension is going to blow up at some point. It also seems worthwhile observing that Taproot Asset stablecoins have almost the inverse problem and opposite commercial dynamic: they will be most expensive to use at the outset but get cheaper and cheaper as their usage grows. Also, there is no incentive towards a monopoly issuer but rather towards as many as are willing to try to operate well and provide value to their users.
As such, we can expect any sizable growth in stablecoins to migrate to TA out of technical and economic necessity. Once this has happened - or possibly while it is happening but is clearly not going to stop - we may as well strip out the TA component and just use eCash because you really don’t need a blockchain for that at all. And once all the money is on eCash, deciding you want to denominate it in Bitcoin is the simplest on-ramp to hyperbitcoinization you can possibly imagine, given we’ve spent the previous decade or two rebuilding all payments tech around Lightning.
Or: Bitcoin fixes this. The End.
- Allen, #892,125
thanks to Marco Argentieri, Lyn Alden, and Calle for comments and feedback
-
@ 04c915da:3dfbecc9
2025-03-25 17:43:44
One of the most common criticisms leveled against nostr is the perceived lack of assurance when it comes to data storage. Critics argue that without a centralized authority guaranteeing that all data is preserved, important information will be lost. They also claim that running a relay will become prohibitively expensive. While there is truth to these concerns, they miss the mark. The genius of nostr lies in its flexibility, resilience, and the way it harnesses human incentives to ensure data availability in practice.
A nostr relay is simply a server that holds cryptographically verifiable signed data and makes it available to others. Relays are simple, flexible, open, and require no permission to run. Critics are right that operating a relay attempting to store all nostr data will be costly. What they miss is that most will not run all encompassing archive relays. Nostr does not rely on massive archive relays. Instead, anyone can run a relay and choose to store whatever subset of data they want. This keeps costs low and operations flexible, making relay operation accessible to all sorts of individuals and entities with varying use cases.
Critics are correct that there is no ironclad guarantee that every piece of data will always be available. Unlike bitcoin where data permanence is baked into the system at a steep cost, nostr does not promise that every random note or meme will be preserved forever. That said, in practice, any data perceived as valuable by someone will likely be stored and distributed by multiple entities. If something matters to someone, they will keep a signed copy.
Nostr is the Streisand Effect in protocol form. The Streisand effect is when an attempt to suppress information backfires, causing it to spread even further. With nostr, anyone can broadcast signed data, anyone can store it, and anyone can distribute it. Try to censor something important? Good luck. The moment it catches attention, it will be stored on relays across the globe, copied, and shared by those who find it worth keeping. Data deemed important will be replicated across servers by individuals acting in their own interest.
Nostr’s distributed nature ensures that the system does not rely on a single point of failure or a corporate overlord. Instead, it leans on the collective will of its users. The result is a network where costs stay manageable, participation is open to all, and valuable verifiable data is stored and distributed forever.
-
@ 84b0c46a:417782f5
2025-05-04 15:14:21
https://long-form-editer.vercel.app/
β版のため予期せぬ動作が発生する可能性があります。記事を修正する際は事前にバックアップを取ることをおすすめします
機能
-
nostr:npub1sjcvg64knxkrt6ev52rywzu9uzqakgy8ehhk8yezxmpewsthst6sw3jqcw や、 nostr:nevent1qvzqqqqqqypzpp9sc34tdxdvxh4jeg5xgu9ctcypmvsg0n00vwfjydkrjaqh0qh4qyxhwumn8ghj77tpvf6jumt9qys8wumn8ghj7un9d3shjtt2wqhxummnw3ezuamfwfjkgmn9wshx5uqpz9mhxue69uhkuenjv4kxz7fwv9c8qqpq486d6yazu7ydx06lj5gr4aqgeq6rkcreyykqnqey8z5fm6qsj8fqfetznk のようにnostr:要素を挿入できる
-
:monoice:のようにカスタム絵文字を挿入できる(メニューの😃アイコンから←アイコン変えるかも)
:monopaca_kao:
:kubipaca_karada:
- 新規記事作成と、既存記事の修正ができる
やること
- [x] nostr:を投稿するときにtagにいれる
- [ ] レイアウトを整える
- [x] 画像をアップロードできるようにする
 できる
できる - [ ] 投稿しましたログとかをトースト的なやつでだすようにする
- [ ] あとなんか
-
-
@ dd664d5e:5633d319
2025-03-21 12:22:36
Men tend to find women attractive, that remind them of the average women they already know, but with more-averaged features. The mid of mids is kween.👸
But, in contradiction to that, they won't consider her highly attractive, unless she has some spectacular, unusual feature. They'll sacrifice some averageness to acquire that novelty. This is why wealthy men (who tend to be highly intelligent -- and therefore particularly inclined to crave novelty because they are easily bored) -- are more likely to have striking-looking wives and girlfriends, rather than conventionally-attractive ones. They are also more-likely to cross ethnic and racial lines, when dating.
Men also seem to each be particularly attracted to specific facial expressions or mimics, which might be an intelligence-similarity test, as persons with higher intelligence tend to have a more-expressive mimic. So, people with similar expressions tend to be on the same wavelength. Facial expessions also give men some sense of perception into womens' inner life, which they otherwise find inscrutable.
Hair color is a big deal (logic says: always go blonde), as is breast-size (bigger is better), and WHR (smaller is better).

-
@ dbc27e2e:b1dd0b0b
2025-04-05 20:44:00
This method focuses on the amount of water in the first pour, which ultimately defines the coffee’s acidity and sweetness (more water = more acidity, less water = more sweetness). For the remainder of the brew, the water is divided into equal parts according to the strength you wish to attain.

Dose:
20g coffee (Coarse ground coffee) 300mL water (92°C / 197.6°F) Time: 3:30Instructions:
- Pour 1: 0:00 > 50mL (42% of 120mL = 40% of total – less water in the ratio, targeting sweetness.)
- Pour 2: 0:45 > 70mL (58% of 120mL = 40% of total – the top up for 40% of total.)
- Pour 3: 1:30 > 60mL (The remaining water is 180mL / 3 pours = 60mL per pour)
- Pour 4: 2:10 > 60mL
- Pour 5: 2:40 > 60mL
- Remove the V60 at 3:30
-
@ 866e0139:6a9334e5
2025-04-05 11:00:25
Autor: CJ Hopkins. Dieser Beitrag wurde mit dem Pareto-Client geschrieben. Sie finden alle Texte der Friedenstaube und weitere Texte zum Thema Frieden hier.**
Dieser Beitrag erschien zuerst auf dem Substack-Blog des Autors.
Er soll andauern, was er auch tut. Genau wie der nie endende Krieg in Orwells 1984 wird er vom Imperium gegen seine eigenen Untertanen geführt, aber nicht nur, um die Struktur der Gesellschaft intakt zu halten, sondern in unserem Fall auch, um die Gesellschaft in eine neo-totalitäre global-kapitalistische Dystopie zu verwandeln.
Bist du nicht vertraut mit dem Krieg gegen was auch immer?
Nun ja, okay, du erinnerst dich an den Krieg gegen den Terror.
Du erinnerst dich daran, als die „Freiheit und Demokratie“ von „den Terroristen“ angegriffen wurden und wir keine andere Wahl hatten, als uns unserer demokratischen Rechte und Prinzipien zu entledigen, einen nationalen „Notstand“ auszurufen, die verfassungsmäßigen Rechte der Menschen auszusetzen, einen Angriffskrieg gegen ein Land im Nahen Osten anzuzetteln, das für uns keinerlei Bedrohung darstellte, und unsere Straßen, Bahnhöfe, Flughäfen und alle anderen Orte mit schwer bewaffneten Soldaten zu füllen, denn sonst hätten „die Terroristen gewonnen“. Du erinnerst dich, als wir ein Offshore-Gulag bauten, um verdächtige Terroristen auf unbestimmte Zeit wegzusperren, die wir zuvor zu CIA-Geheimgefängnissen verschleppt hatten, wo wir sie gefoltert und gedemütigt haben, richtig?
Natürlich erinnerst du dich. Wer könnte das vergessen?
DIE FRIEDENSTAUBE FLIEGT AUCH IN IHR POSTFACH!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt, vorerst für alle kostenfrei, wir starten gänzlich ohne Paywall. (Die Bezahlabos fangen erst zu laufen an, wenn ein Monetarisierungskonzept für die Inhalte steht). Sie wollen der Genossenschaft beitreten oder uns unterstützen? Mehr Infos hier oder am Ende des Textes.
Erinnerst du dich, als die National Security Agency keine andere Wahl hatte, als ein geheimes „Terroristen-Überwachungsprogramm“ einzurichten, um Amerikaner auszuspionieren, oder sonst „hätten die Terroristen gewonnen“? Oder wie wäre es mit den „Anti-Terror“-Unterleibsuntersuchungen der TSA, der Behörde für Transportsicherheit, die nach über zwanzig Jahren immer noch in Kraft sind?
Und was ist mit dem Krieg gegen den Populismus? An den erinnerst du dich vielleicht nicht so gut.
Ich erinnere mich, denn ich habe zwei Bücher dazu veröffentlicht. Er begann im Sommer 2016, als das Imperium erkannte, dass „rechte Populisten“ die „Freiheit und Demokratie“ in Europa bedrohten und Trump in den USA auf dem Vormarsch war. Also wurde ein weiterer „Notstand“ ausgerufen – diesmal von der Gemeinschaft der Geheimdienste, den Medien, der akademischen Welt und der Kulturindustrie. Ja, genau, es war wieder einmal an der Zeit, unsere demokratischen Prinzipien hintanzustellen, „Hassrede“ in sozialen Medien zu zensieren, die Massen mit lächerlicher offizieller Propaganda über „Russiagate,“ „Hitlergate“ und so weiter zu bombardieren – sonst hätten „die Rechtspopulisten gewonnen.“
Der Krieg gegen den Populismus gipfelte in der Einführung des Neuen Normalen Reichs.

Im Frühjahr 2020 rief das Imperium einen globalen „gesundheitlichen Ausnahmezustand“ aus, als Reaktion auf ein Virus mit einer Überlebensrate von etwa 99,8 Prozent. Das Imperium hatte keine andere Wahl, als ganze Gesellschaften abzuriegeln, jeden dazu zu zwingen, in der Öffentlichkeit medizinisch aussehende Masken zu tragen, die Öffentlichkeit mit Propaganda und Lügen zu bombardieren, die Menschen dazu zu nötigen, sich einer Reihe experimenteller mRNA-„Impfungen“ zu unterziehen, Proteste gegen ihre Dekrete zu verbieten und systematisch diejenigen zu zensieren und zu verfolgen, die es wagten, ihre erfundenen „Fakten“ in Frage zu stellen oder ihr totalitäres Programm zu kritisieren.
Das Imperium hatte keine andere Wahl, als das alles zu tun, denn sonst hätten „die Covid-Leugner, die Impfgegner, die Verschwörungstheoretiker und all die anderen Extremisten gewonnen.“
Ich bin mir ziemlich sicher, dass du dich an all das erinnerst.
Und jetzt … nun, hier sind wir. Ja, du hast es erraten – es ist wieder einmal an der Zeit, kräftig auf die US-Verfassung und die Meinungsfreiheit zu scheißen, Menschen in irgendein salvadorianisches Höllenloch abzuschieben, das wir angemietet haben, weil ein Polizist ihre Tattoos nicht mochte, Universitätsstudenten wegen ihrer Anti-Israel-Proteste festzunehmen und zu verschleppen und natürlich die Massen mit Lügen und offizieller Propaganda zu bombardieren, denn … okay, alle zusammen jetzt: „sonst hätten die antisemitischen Terroristen und venezolanischen Banden gewonnen!“
Fängst du an, ein Muster zu erkennen? Ja? Willkommen beim Krieg gegen-was-auch-immer!
Wenn du die Zusammenhänge noch nicht ganz siehst, okay, lass es mich noch einmal ganz simpel erklären.
Das globale ideologische System, in dem wir alle leben, wird totalitär. (Dieses System ist der globale Kapitalismus, aber nenne es, wie du willst. Es ist mir scheißegal.) Es reißt die Simulation der Demokratie nieder, die es nicht mehr aufrechterhalten muss. Der Kalte Krieg ist vorbei. Der Kommunismus ist tot. Der globale Kapitalismus hat keine externen Feinde mehr. Also muss er die Massen nicht mehr mit demokratischen Rechten und Freiheiten besänftigen. Deshalb entzieht er uns diese Rechte nach und nach und konditioniert uns darauf, ihren Verlust hinzunehmen.
Er tut dies, indem er eine Reihe von „Notständen“ inszeniert, jeder mit einer anderen „Bedrohung“ für die „Demokratie,“ die „Freiheit,“ „Amerika“ oder „den Planeten“ – oder was auch immer. Jeder mit seinen eigenen „Monstern,“ die eine so große Gefahr für die „Freiheit“ oder was auch immer darstellen, dass wir unsere verfassungsmäßigen Rechte aufgeben und die demokratischen Werte ad absurdum führen müssen, denn: sonst „würden die Monster gewinnen.“

Es tut dies, indem es sein Antlitz von „links“ nach „rechts,“ dann zurück nach „links“, und dann zurück nach „rechts,“ dann nach „links“ und so weiter neigt, weil es unsere Kooperation dafür benötigt. Nicht die Kooperation von uns allen auf einmal. Nur eine kooperative demografische Gruppe auf einmal.
Es ist dabei erfolgreich – also das System – indem es unsere Angst und unseren Hass instrumentalisiert. Dem System ist es völlig egal, ob wir uns als „links“ oder „rechts“ identifizieren, aber es braucht uns gespalten in „links“ und „rechts,“ damit es unsere Angst und unseren Hass aufeinander nähren kann … eine Regierung, ein „Notfall,“ ein „Krieg“ nach dem anderen.
Da hast du es. Das ist der Krieg gegen was auch immer. Noch simpler kann ich es nicht erklären.
Oh, und noch eine letzte Sache … wenn du einer meiner ehemaligen Fans bist, wie Rob, die über meine „Einsichten“ oder Loyalitäten oder was auch immer verwirrt sind … nun, der Text, den du gerade gelesen hast, sollte das für dich klären. Ich stehe auf keiner Seite. Überhaupt keiner. Aber ich habe ein paar grundlegende demokratische Prinzipien. Und die richten sich nicht danach, was gerade populär ist oder wer im Weißen Haus sitzt.
Die Sache ist die: Ich muss mich morgens im Spiegel anschauen können ohne dort einen Heuchler oder … du weißt schon, einen Feigling zu sehen.
(Aus dem Amerikanischen übersetzt von René Boyke).
CJ Hopkins ist ein US-amerikanischer Dramatiker, Romanautor und politischer Satiriker. Zu seinen Werken zählen die Stücke Horse Country, Screwmachine/Eyecandy und The Extremists. Er hat sich als profilierter Kritiker des Corona-Regimes profiliert und veröffentlicht regelmäßig auf seinem Substack-Blog.
Sein aktuelles Buch:
https://x.com/CJHopkins_Z23/status/1907795633689264530
Hier in einem aktuellen Gespräch:
https://www.youtube.com/watch?v=wF-G32P0leI
LASSEN SIE DER FRIEDENSTAUBE FLÜGEL WACHSEN!
Hier können Sie die Friedenstaube abonnieren und bekommen die Artikel zugesandt. (Vorerst alle, da wir den Mailversand testen, später ca. drei Mails pro Woche.)
Schon jetzt können Sie uns unterstützen:
- Für 50 CHF/EURO bekommen Sie ein Jahresabo der Friedenstaube.
- Für 120 CHF/EURO bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
- Für 500 CHF/EURO werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
- Ab 1000 CHF werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
Für Einzahlungen in CHF (Betreff: Friedenstaube):
Für Einzahlungen in Euro:
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
Betreff: Friedenstaube
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: milosz@pareto.space
Sie sind noch nicht auf Nostr and wollen die volle Erfahrung machen (liken, kommentieren etc.)? Zappen können Sie den Autor auch ohne Nostr-Profil! Erstellen Sie sich einen Account auf Start. Weitere Onboarding-Leitfäden gibt es im Pareto-Wiki.
-
@ da18e986:3a0d9851
2024-08-14 13:58:24
After months of development I am excited to officially announce the first version of DVMDash (v0.1). DVMDash is a monitoring and debugging tool for all Data Vending Machine (DVM) activity on Nostr. The website is live at https://dvmdash.live and the code is available on Github.
Data Vending Machines (NIP-90) offload computationally expensive tasks from relays and clients in a decentralized, free-market manner. They are especially useful for AI tools, algorithmic processing of user’s feeds, and many other use cases.
The long term goal of DVMDash is to become 1) a place to easily see what’s happening in the DVM ecosystem with metrics and graphs, and 2) provide real-time tools to help developers monitor, debug, and improve their DVMs.
DVMDash aims to enable users to answer these types of questions at a glance: * What’s the most popular DVM right now? * How much money is being paid to image generation DVMs? * Is any DVM down at the moment? When was the last time that DVM completed a task? * Have any DVMs failed to deliver after accepting payment? Did they refund that payment? * How long does it take this DVM to respond? * For task X, what’s the average amount of time it takes for a DVM to complete the task? * … and more
For developers working with DVMs there is now a visual, graph based tool that shows DVM-chain activity. DVMs have already started calling other DVMs to assist with work. Soon, we will have humans in the loop monitoring DVM activity, or completing tasks themselves. The activity trace of which DVM is being called as part of a sub-task from another DVM will become complicated, especially because these decisions will be made at run-time and are not known ahead of time. Building a tool to help users and developers understand where a DVM is in this activity trace, whether it’s gotten stuck or is just taking a long time, will be invaluable. For now, the website only shows 1 step of a dvm chain from a user's request.
One of the main designs for the site is that it is highly clickable, meaning whenever you see a DVM, Kind, User, or Event ID, you can click it and open that up in a new page to inspect it.
Another aspect of this website is that it should be fast. If you submit a DVM request, you should see it in DVMDash within seconds, as well as events from DVMs interacting with your request. I have attempted to obtain DVM events from relays as quickly as possible and compute metrics over them within seconds.
This project makes use of a nosql database and graph database, currently set to use mongo db and neo4j, for which there are free, community versions that can be run locally.
Finally, I’m grateful to nostr:npub10pensatlcfwktnvjjw2dtem38n6rvw8g6fv73h84cuacxn4c28eqyfn34f for supporting this project.
Features in v0.1:
Global Network Metrics:
This page shows the following metrics: - DVM Requests: Number of unencrypted DVM requests (kind 5000-5999) - DVM Results: Number of unencrypted DVM results (kind 6000-6999) - DVM Request Kinds Seen: Number of unique kinds in the Kind range 5000-5999 (except for known non-DVM kinds 5666 and 5969) - DVM Result Kinds Seen: Number of unique kinds in the Kind range 6000-6999 (except for known non-DVM kinds 6666 and 6969) - DVM Pub Keys Seen: Number of unique pub keys that have written a kind 6000-6999 (except for known non-DVM kinds) or have published a kind 31990 event that specifies a ‘k’ tag value between 5000-5999 - DVM Profiles (NIP-89) Seen: Number of 31990 that have a ‘k’ tag value for kind 5000-5999 - Most Popular DVM: The DVM that has produced the most result events (kind 6000-6999) - Most Popular Kind: The Kind in range 5000-5999 that has the most requests by users. - 24 hr DVM Requests: Number of kind 5000-5999 events created in the last 24 hrs - 24 hr DVM Results: Number of kind 6000-6999 events created in the last 24 hours - 1 week DVM Requests: Number of kind 5000-5999 events created in the last week - 1 week DVM Results: Number of kind 6000-6999 events created in the last week - Unique Users of DVMs: Number of unique pubkeys of kind 5000-5999 events - Total Sats Paid to DVMs: - This is an estimate. - This value is likely a lower bound as it does not take into consideration subscriptions paid to DVMs - This is calculated by counting the values of all invoices where: - A DVM published a kind 7000 event requesting payment and containing an invoice - The DVM later provided a DVM Result for the same job for which it requested payment. - The assumption is that the invoice was paid, otherwise the DVM would not have done the work - Note that because there are multiple ways to pay a DVM such as lightning invoices, ecash, and subscriptions, there is no guaranteed way to know whether a DVM has been paid. Additionally, there is no way to know that a DVM completed the job because some DVMs may not publish a final result event and instead send the user a DM or take some other kind of action.
Recent Requests:
This page shows the most recent 3 events per kind, sorted by created date. You should always be able to find the last 3 events here of all DVM kinds.
DVM Browser:
This page will either show a profile of a specific DVM, or when no DVM is given in the url, it will show a table of all DVMs with some high level stats. Users can click on a DVM in the table to load the DVM specific page.
Kind Browser:
This page will either show data on a specific kind including all DVMs that have performed jobs of that kind, or when no kind is given, it will show a table summarizing activity across all Kinds.
Debug:
This page shows the graph based visualization of all events, users, and DVMs involved in a single job as well as a table of all events in order from oldest to newest. When no event is given, this page shows the 200 most recent events where the user can click on an event in order to debug that job. The graph-based visualization allows the user to zoom in and out and move around the graph, as well as double click on any node in the graph (except invoices) to open up that event, user, or dvm in a new page.
Playground:
This page is currently under development and may not work at the moment. If it does work, in the current state you can login with NIP-07 extension and broadcast a 5050 event with some text and then the page will show you events from DVMs. This page will be used to interact with DVMs live. A current good alternative to this feature, for some but not all kinds, is https://vendata.io/.
Looking to the Future
I originally built DVMDash out of Fear-of-Missing-Out (FOMO); I wanted to make AI systems that were comprised of DVMs but my day job was taking up a lot of my time. I needed to know when someone was performing a new task or launching a new AI or Nostr tool!
I have a long list of DVMs and Agents I hope to build and I needed DVMDash to help me do it; I hope it helps you achieve your goals with Nostr, DVMs, and even AI. To this end, I wish for this tool to be useful to others, so if you would like a feature, please submit a git issue here or note me on Nostr!
Immediate Next Steps:
- Refactoring code and removing code that is no longer used
- Improve documentation to run the project locally
- Adding a metric for number of encrypted requests
- Adding a metric for number of encrypted results
Long Term Goals:
- Add more metrics based on community feedback
- Add plots showing metrics over time
- Add support for showing a multi-dvm chain in the graph based visualizer
- Add a real-time mode where the pages will auto update (currently the user must refresh the page)
- ... Add support for user requested features!
Acknowledgements
There are some fantastic people working in the DVM space right now. Thank you to nostr:npub1drvpzev3syqt0kjrls50050uzf25gehpz9vgdw08hvex7e0vgfeq0eseet for making python bindings for nostr_sdk and for the recent asyncio upgrades! Thank you to nostr:npub1nxa4tywfz9nqp7z9zp7nr7d4nchhclsf58lcqt5y782rmf2hefjquaa6q8 for answering lots of questions about DVMs and for making the nostrdvm library. Thank you to nostr:npub1l2vyh47mk2p0qlsku7hg0vn29faehy9hy34ygaclpn66ukqp3afqutajft for making the original DVM NIP and vendata.io which I use all the time for testing!
P.S. I rushed to get this out in time for Nostriga 2024; code refactoring will be coming :)
-
@ 3c984938:2ec11289
2024-07-22 11:43:17
Bienvenide a Nostr!
Introduccíon
Es tu primera vez aqui en Nostr? Bienvenides! Nostr es un acrónimo raro para "Notes and Other Stuff Transmitted by Relays" on un solo objetivo; resistirse a la censura. Una alternativa a las redes sociales tradicionales, comunicaciónes, blogging, streaming, podcasting, y feventualmente el correo electronico (en fase de desarrollo) con características descentralizadas que te capacita, usario. Jamas seras molestado por un anuncio, capturado por una entidad centralizada o algoritmo que te monetiza.
Permítame ser su anfitrión! Soy Onigiri! Yo estoy explorando el mundo de Nostr, un protocolo de comunicacíon decentralizada. Yo escribo sobre las herramientas y los desarolladores increíbles de Nostr que dan vida a esta reino.

Bienvenides a Nostr Wonderland
Estas a punto de entrar a un otro mundo digtal que te hará explotar tu mente de todas las aplicaciones descentralizadas, clientes, sitios que puedes utilizar. Nunca volverás a ver a las comunicaciones ni a las redes sociales de la mesma manera. Todo gracias al carácter criptográfico de nostr, inpirado por la tecnología "blockchain". Cada usario, cuando crean una cuenta en Nostr, recibe un par de llaves: una privada y una publico. Estos son las llaves de tu propio reino. Lo que escribes, cantes, grabes, lo que creas - todo te pertenece.

Unos llaves de Oro y Plata
Mi amigo y yo llamamos a esto "identidad mediante cifrado" porque tu identidad es cifrado. Tu puedes compartir tu llave de plata "npub" a otros usarios para conectar y seguir. Utiliza tu llave de oro "nsec" para accedar a tu cuenta y exponerte a muchas aplicaciones. Mantenga la llave a buen recaudo en todo momento. Ya no hay razor para estar enjaulado por los terminos de plataformas sociales nunca más.
Onigirl
npub18jvyjwpmm65g8v9azmlvu8knd5m7xlxau08y8vt75n53jtkpz2ys6mqqu3Todavia No tienes un cliente? Seleccione la mejor opción.
Encuentra la aplicación adecuada para ti! Utilice su clave de oro "nsec" para acceder a estas herramientas maravillosas. También puedes visit a esta pagina a ver a todas las aplicaciones. Antes de pegar tu llave de oro en muchas aplicaciones, considera un "signer" (firmante) para los sitios web 3. Por favor, mire la siguiente imagen para más detalles. Consulte también la leyenda.

Get a Signer extension via chrome webstore
Un firmante (o "signer" en inglés) es una extensión del navegador web. Nos2x and NostrConnect son extensiónes ampliamente aceptado para aceder a Nostr. Esto simplifica el proceso de aceder a sitios "web 3". En lugar de copiar y pegar la clave oro "nsec" cada vez, la mantienes guardado en la extensión y le des permiso para aceder a Nostr.

👉⚡⚡Obtén una billetera Bitcoin lightning para enviar/recibir Zaps⚡⚡ (Esto es opcional)

Aqui en Nostr, utilizamos la red Lightning de Bitcoin (L2). Nesitaras una cartera lightning para enviar y recibir Satoshis, la denominacion mas chiquita de un Bitcoin. (0.000000001 BTC) Los "zaps" son un tipo de micropago en Nostr. Si te gusta el contenido de un usario, es norma dejarle una propina en la forma de un ¨zap". Por ejemplo, si te gusta este contenido, tu me puedes hacer "zap" con Satoshis para recompensar mi trabajo. Pero apenas llegaste, as que todavia no tienes una cartera. No se preocupe, puedo ayudar en eso!
"Stacker.News" es una plataforma donde los usarios pueden ganar SATS por publicar articulos y interactuar con otros.

Stacker.News es el lugar mas facil para recibir una direccion de cartera Bitcoin Lightning.
- Acedese con su extensión firmante "signer" - Nos2x or NostrConnect - hace click en tu perfil, un codigo de letras y numeros en la mano superior derecha. Veás algo como esto
- Haga clic en "edit" y elija un nombre que te guste. Se puede cambiar si deseas en el futuro.

- Haga clic en "save"
- Crea una biografía y la comunidad SN son muy acogedora. Te mandarán satoshi para darte la bienvenida.
- Tu nueva direccion de cartera Bitcoin Lightning aparecerá asi
 ^^No le mandas "zaps" a esta direccion; es puramente con fines educativos.
^^No le mandas "zaps" a esta direccion; es puramente con fines educativos. - Con tu Nueva dirección de monedero Bitcoin Lightning puedes ponerla en cualquier cliente o app de tu elección. Para ello, ve a tu página de perfil y bajo la dirección de tu monedero en "Dirección Lightning", introduce tu nueva dirección y pulsa "guardar " y ya está. Enhorabuena.
👉✨Con el tiempo, es posible que desee pasar a las opciones de auto-custodia y tal vez incluso considerar la posibilidad de auto-alojar su propio nodo LN para una mejor privacidad. La buena noticia es que stacker.news tambien está dejando de ser una cartera custodio.
⭐NIP-05-identidad DNS⭐ Al igual que en Twitter, una marca de verificación es para mostrar que eres del mismo jardín "como un humano", y no un atípico como una mala hierba o, "bot". Pero no de la forma nefasta en que lo hacen las grandes tecnológicas. En el país de las maravillas de Nostr, esto te permite asignar tu llave de plata, "npub", a un identificador DNS. Una vez verificado, puedes gritar para anunciar tu nueva residencia Nostr para compartir.
✨Hay un montón de opciones, pero si has seguido los pasos, esto se vuelve extremadamente fácil.
👉✅¡Haz clic en tu "Perfil ", luego en "Configuración ", desplázate hasta la parte inferior y pega tu clave Silver, "npub!" y haz clic en "Guardar " y ¡listo! Utiliza tu monedero relámpago de Stacker.news como tu NIP-05. ¡¡¡Enhorabuena!!! ¡Ya estás verificado! Dale unas horas y cuando uses tu cliente "principal " deberías ver una marca de verificación.
Nostr, el infonformista de los servidores.
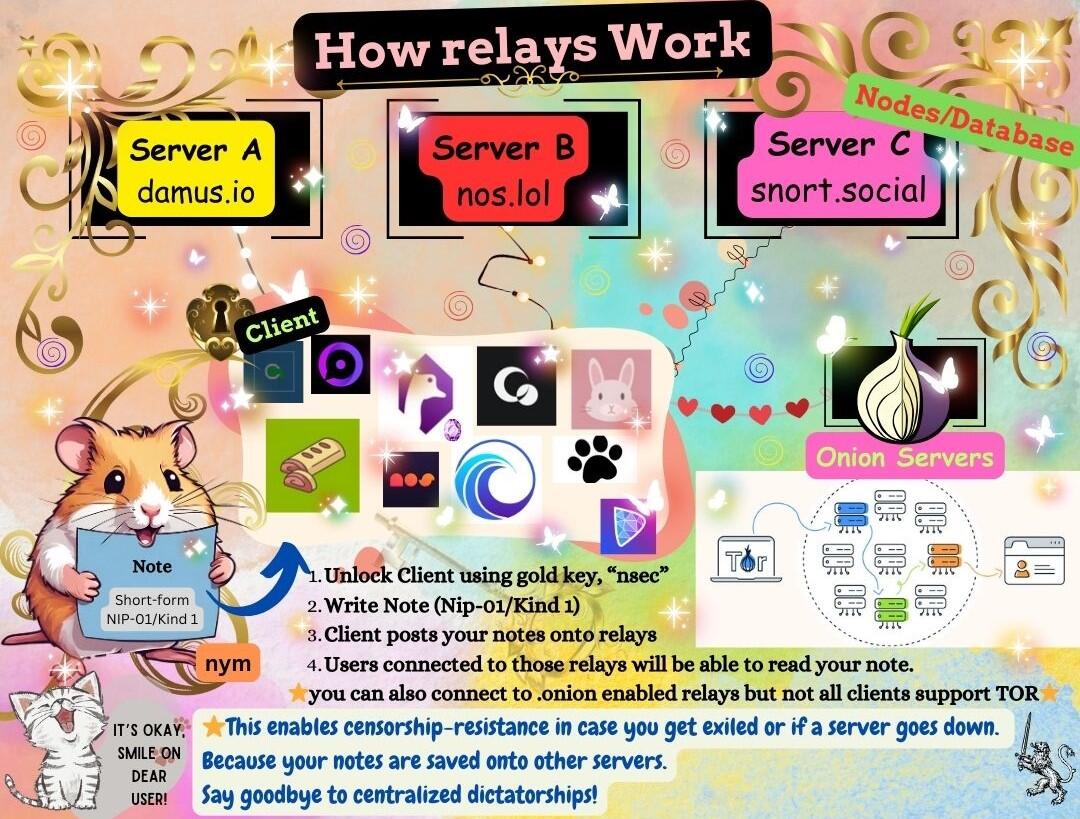 En lugar de utilizar una única instancia o un servidor centralizado, Nostr está construido para que varias bases de datos intercambien mensajes mediante "relés". Los relés, que son neutrales y no discriminatorios, almacenan y difunden mensajes públicos en la red Nostr. Transmiten mensajes a todos los demás clientes conectados a ellos, asegurando las comunicaciones en la red descentralizada.
En lugar de utilizar una única instancia o un servidor centralizado, Nostr está construido para que varias bases de datos intercambien mensajes mediante "relés". Los relés, que son neutrales y no discriminatorios, almacenan y difunden mensajes públicos en la red Nostr. Transmiten mensajes a todos los demás clientes conectados a ellos, asegurando las comunicaciones en la red descentralizada.¡Mis amigos en Nostr te dan la bienvenida!
Bienvenida a la fiesta. ¿Le apetece un té?🍵

¡Hay mucho mas!
Esto es la punta del iceberg. Síguenme mientras continúo explorando nuevas tierras y a los desarolladores, los caballeres que potencioan este ecosistema. Encuéntrame aquí para mas contenido como este y comparten con otros usarios de nostr. Conozca a los caballeres que luchan por freedomTech (la tecnología de libertad) en Nostr y a los proyectos a los que contribuyen para hacerla realidad.💋
Onigirl @npub18jvyjwpmm65g8v9azmlvu8knd5m7xlxau08y8vt75n53jtkpz2ys6mqqu3
🧡😻Esta guía ha sido cuidadosamente traducida por miggymofongo
Puede seguirla aquí. @npub1ajt9gp0prf4xrp4j07j9rghlcyukahncs0fw5ywr977jccued9nqrcc0cs
sitio web
- Acedese con su extensión firmante "signer" - Nos2x or NostrConnect - hace click en tu perfil, un codigo de letras y numeros en la mano superior derecha. Veás algo como esto
-
@ 6e0ea5d6:0327f353
2025-05-04 14:53:42
Amico mio, ascolta bene!
Without hesitation, the woman you attract with lies is not truly yours. Davvero, she is the temporary property of the illusion you’ve built to seduce her. And every illusion, sooner or later, crumbles.
Weak men sell inflated versions of themselves. They talk about what they don’t have, promise what they can’t sustain, adorn their empty selves with words that are nothing more than a coat of paint. And they do this thinking that, later, they’ll be able to "show who they really are." Fatal mistake, cazzo!
The truth, amico mio, is not something that appears at the end. It is what holds up the whole beginning.
The woman who approaches a lie may smile at first — but she is smiling at the theater, not at the actor. When the curtains fall, what she will see is not a man. It will be a character tired of performing, begging for love from a self-serving audience in the front row.
That’s why I always point out that lying to win a woman’s heart is the same as sabotaging your own nature. The woman who comes through an invented version of you will be the first to leave when the veil of lies tears apart. Not out of cruelty, but out of consistency with her own interest. Fine... She didn’t leave you, but rather, that version of yourself never truly existed to be left behind.
A worthy man presents himself without deceptive adornments. And those who stay, stay because they know exactly who they are choosing as a man. That’s what differentiates forged seduction from the convenience of love built on honor, loyalty, and respect.
Ah, amico mio, I remember well. It was lunch on an autumn day in Catania. Mediterranean heat, and the Nero D'Avola wine from midday clinging to the lips like dried blood. Sitting in the shade of a lemon tree planted right by my grandfather's vineyard entrance, my uncle — the oldest of my father’s brothers — spoke little, but when he called us to sit by his side, all the nephews would quiet down to listen. And in my youth, he told me something that has never left my mind.
“In Sicily, the woman who endures the silence of a man about his business is more loyal than the one who is enchanted by speeches about what he does or how much he earns. Perchè, figlio mio, the first one has seen the truth. The second one, only a false shine.”
Thank you for reading, my friend!
If this message resonated with you, consider leaving your "🥃" as a token of appreciation.
A toast to our family!
-
@ c631e267:c2b78d3e
2025-04-04 18:47:27
Zwei mal drei macht vier, \ widewidewitt und drei macht neune, \ ich mach mir die Welt, \ widewide wie sie mir gefällt. \ Pippi Langstrumpf
Egal, ob Koalitionsverhandlungen oder politischer Alltag: Die Kontroversen zwischen theoretisch verschiedenen Parteien verschwinden, wenn es um den Kampf gegen politische Gegner mit Rückenwind geht. Wer den Alteingesessenen die Pfründe ernsthaft streitig machen könnte, gegen den werden nicht nur «Brandmauern» errichtet, sondern der wird notfalls auch strafrechtlich verfolgt. Doppelstandards sind dabei selbstverständlich inklusive.
In Frankreich ist diese Woche Marine Le Pen wegen der Veruntreuung von EU-Geldern von einem Gericht verurteilt worden. Als Teil der Strafe wurde sie für fünf Jahre vom passiven Wahlrecht ausgeschlossen. Obwohl das Urteil nicht rechtskräftig ist – Le Pen kann in Berufung gehen –, haben die Richter das Verbot, bei Wahlen anzutreten, mit sofortiger Wirkung verhängt. Die Vorsitzende des rechtsnationalen Rassemblement National (RN) galt als aussichtsreiche Kandidatin für die Präsidentschaftswahl 2027.
Das ist in diesem Jahr bereits der zweite gravierende Fall von Wahlbeeinflussung durch die Justiz in einem EU-Staat. In Rumänien hatte Călin Georgescu im November die erste Runde der Präsidentenwahl überraschend gewonnen. Das Ergebnis wurde später annulliert, die behauptete «russische Wahlmanipulation» konnte jedoch nicht bewiesen werden. Die Kandidatur für die Wahlwiederholung im Mai wurde Georgescu kürzlich durch das Verfassungsgericht untersagt.
Die Veruntreuung öffentlicher Gelder muss untersucht und geahndet werden, das steht außer Frage. Diese Anforderung darf nicht selektiv angewendet werden. Hingegen mussten wir in der Vergangenheit bei ungleich schwerwiegenderen Fällen von (mutmaßlichem) Missbrauch ganz andere Vorgehensweisen erleben, etwa im Fall der heutigen EZB-Chefin Christine Lagarde oder im «Pfizergate»-Skandal um die Präsidentin der EU-Kommission Ursula von der Leyen.
Wenngleich derartige Angelegenheiten formal auf einer rechtsstaatlichen Grundlage beruhen mögen, so bleibt ein bitterer Beigeschmack. Es stellt sich die Frage, ob und inwieweit die Justiz politisch instrumentalisiert wird. Dies ist umso interessanter, als die Gewaltenteilung einen essenziellen Teil jeder demokratischen Ordnung darstellt, während die Bekämpfung des politischen Gegners mit juristischen Mitteln gerade bei den am lautesten rufenden Verteidigern «unserer Demokratie» populär zu sein scheint.
Die Delegationen von CDU/CSU und SPD haben bei ihren Verhandlungen über eine Regierungskoalition genau solche Maßnahmen diskutiert. «Im Namen der Wahrheit und der Demokratie» möchte man noch härter gegen «Desinformation» vorgehen und dafür zum Beispiel den Digital Services Act der EU erweitern. Auch soll der Tatbestand der Volksverhetzung verschärft werden – und im Entzug des passiven Wahlrechts münden können. Auf europäischer Ebene würde Friedrich Merz wohl gerne Ungarn das Stimmrecht entziehen.
Der Pegel an Unzufriedenheit und Frustration wächst in großen Teilen der Bevölkerung kontinuierlich. Arroganz, Machtmissbrauch und immer abstrusere Ausreden für offensichtlich willkürliche Maßnahmen werden kaum verhindern, dass den etablierten Parteien die Unterstützung entschwindet. In Deutschland sind die Umfrageergebnisse der AfD ein guter Gradmesser dafür.
[Vorlage Titelbild: Pixabay]
Dieser Beitrag wurde mit dem Pareto-Client geschrieben und ist zuerst auf Transition News erschienen.
-
@ 6871d8df:4a9396c1
2024-06-12 22:10:51
Embracing AI: A Case for AI Accelerationism
In an era where artificial intelligence (AI) development is at the forefront of technological innovation, a counter-narrative championed by a group I refer to as the 'AI Decels'—those advocating for the deceleration of AI advancements— seems to be gaining significant traction. After tuning into a recent episode of the Joe Rogan Podcast, I realized that the prevailing narrative around AI was heading in a dangerous direction. Rogan had Aza Raskin and Tristan Harris, technology safety advocates, who released a talk called 'The AI Dilemma,' on for a discussion. You may know them from the popular documentary 'The Social Dilemma' on the dangers of social media. It became increasingly clear that the cautionary stance dominating this discourse might be tipping the scales too far, veering towards an over-regulated future that stifles innovation rather than fostering it.

Are we moving too fast?
While acknowledging AI's benefits, Aza and Tristan fear it could be dangerous if not guided by ethical standards and safeguards. They believe AI development is moving too quickly and that the right incentives for its growth are not in place. They are concerned about the possibility of "civilizational overwhelm," where advanced AI technology far outpaces 21st-century governance. They fear a scenario where society and its institutions cannot manage or adapt to the rapid changes and challenges introduced by AI.
They argue for regulating and slowing down AI development due to rapid, uncontrolled advancement driven by competition among companies like Google, OpenAI, and Microsoft. They claim this race can lead to unsafe releases of new technologies, with AI systems exhibiting unpredictable, emergent behaviors, posing significant societal risks. For instance, AI can inadvertently learn tasks like sentiment analysis or human emotion understanding, creating potential for misuse in areas like biological weapons or cybersecurity vulnerabilities.
Moreover, AI companies' profit-driven incentives often conflict with the public good, prioritizing market dominance over safety and ethics. This misalignment can lead to technologies that maximize engagement or profits at societal expense, similar to the negative impacts seen with social media. To address these issues, they suggest government regulation to realign AI companies' incentives with safety, ethical considerations, and public welfare. Implementing responsible development frameworks focused on long-term societal impacts is essential for mitigating potential harm.
This isn't new
Though the premise of their concerns seems reasonable, it's dangerous and an all too common occurrence with the emergence of new technologies. For example, in their example in the podcast, they refer to the technological breakthrough of oil. Oil as energy was a technological marvel and changed the course of human civilization. The embrace of oil — now the cornerstone of industry in our age — revolutionized how societies operated, fueled economies, and connected the world in unprecedented ways. Yet recently, as ideas of its environmental and geopolitical ramifications propagated, the narrative around oil has shifted.
Tristan and Aza detail this shift and claim that though the period was great for humanity, we didn't have another technology to go to once the technological consequences became apparent. The problem with that argument is that we did innovate to a better alternative: nuclear. However, at its technological breakthrough, it was met with severe suspicions, from safety concerns to ethical debates over its use. This overregulation due to these concerns caused a decades-long stagnation in nuclear innovation, where even today, we are still stuck with heavy reliance on coal and oil. The scare tactics and fear-mongering had consequences, and, interestingly, they don't see the parallels with their current deceleration stance on AI.
These examples underscore a critical insight: the initial anxiety surrounding new technologies is a natural response to the unknowns they introduce. Yet, history shows that too much anxiety can stifle the innovation needed to address the problems posed by current technologies. The cycle of discovery, fear, adaptation, and eventual acceptance reveals an essential truth—progress requires not just the courage to innovate but also the resilience to navigate the uncertainties these innovations bring.
Moreover, believing we can predict and plan for all AI-related unknowns reflects overconfidence in our understanding and foresight. History shows that technological progress, marked by unexpected outcomes and discoveries, defies such predictions. The evolution from the printing press to the internet underscores progress's unpredictability. Hence, facing AI's future requires caution, curiosity, and humility. Acknowledging our limitations and embracing continuous learning and adaptation will allow us to harness AI's potential responsibly, illustrating that embracing our uncertainties, rather than pretending to foresee them, is vital to innovation.
The journey of technological advancement is fraught with both promise and trepidation. Historically, each significant leap forward, from the dawn of the industrial age to the digital revolution, has been met with a mix of enthusiasm and apprehension. Aza Raskin and Tristan Harris's thesis in the 'AI Dilemma' embodies the latter.
Who defines "safe?"
When slowing down technologies for safety or ethical reasons, the issue arises of who gets to define what "safe" or “ethical” mean? This inquiry is not merely technical but deeply ideological, touching the very core of societal values and power dynamics. For example, the push for Diversity, Equity, and Inclusion (DEI) initiatives shows how specific ideological underpinnings can shape definitions of safety and decency.
Take the case of the initial release of Google's AI chatbot, Gemini, which chose the ideology of its creators over truth. Luckily, the answers were so ridiculous that the pushback was sudden and immediate. My worry, however, is if, in correcting this, they become experts in making the ideological capture much more subtle. Large bureaucratic institutions' top-down safety enforcement creates a fertile ground for ideological capture of safety standards.

I claim that the issue is not the technology itself but the lens through which we view and regulate it. Suppose the gatekeepers of 'safety' are aligned with a singular ideology. In that case, AI development would skew to serve specific ends, sidelining diverse perspectives and potentially stifling innovative thought and progress.
In the podcast, Tristan and Aza suggest such manipulation as a solution. They propose using AI for consensus-building and creating "shared realities" to address societal challenges. In practice, this means that when individuals' viewpoints seem to be far apart, we can leverage AI to "bridge the gap." How they bridge the gap and what we would bridge it toward is left to the imagination, but to me, it is clear. Regulators will inevitably influence it from the top down, which, in my opinion, would be the opposite of progress.
In navigating this terrain, we must advocate for a pluralistic approach to defining safety, encompassing various perspectives and values achieved through market forces rather than a governing entity choosing winners. The more players that can play the game, the more wide-ranging perspectives will catalyze innovation to flourish.
Ownership & Identity
Just because we should accelerate AI forward does not mean I do not have my concerns. When I think about what could be the most devastating for society, I don't believe we have to worry about a Matrix-level dystopia; I worry about freedom. As I explored in "Whose data is it anyway?," my concern gravitates toward the issues of data ownership and the implications of relinquishing control over our digital identities. This relinquishment threatens our privacy and the integrity of the content we generate, leaving it susceptible to the inclinations and profit of a few dominant tech entities.
To counteract these concerns, a paradigm shift towards decentralized models of data ownership is imperative. Such standards would empower individuals with control over their digital footprints, ensuring that we develop AI systems with diverse, honest, and truthful perspectives rather than the massaged, narrow viewpoints of their creators. This shift safeguards individual privacy and promotes an ethical framework for AI development that upholds the principles of fairness and impartiality.
As we stand at the crossroads of technological innovation and ethical consideration, it is crucial to advocate for systems that place data ownership firmly in the hands of users. By doing so, we can ensure that the future of AI remains truthful, non-ideological, and aligned with the broader interests of society.
But what about the Matrix?
I know I am in the minority on this, but I feel that the concerns of AGI (Artificial General Intelligence) are generally overblown. I am not scared of reaching the point of AGI, and I think the idea that AI will become so intelligent that we will lose control of it is unfounded and silly. Reaching AGI is not reaching consciousness; being worried about it spontaneously gaining consciousness is a misplaced fear. It is a tool created by humans for humans to enhance productivity and achieve specific outcomes.
At a technical level, large language models (LLMs) are trained on extensive datasets and learning patterns from language and data through a technique called "unsupervised learning" (meaning the data is untagged). They predict the next word in sentences, refining their predictions through feedback to improve coherence and relevance. When queried, LLMs generate responses based on learned patterns, simulating an understanding of language to provide contextually appropriate answers. They will only answer based on the datasets that were inputted and scanned.
AI will never be "alive," meaning that AI lacks inherent agency, consciousness, and the characteristics of life, not capable of independent thought or action. AI cannot act independently of human control. Concerns about AI gaining autonomy and posing a threat to humanity are based on a misunderstanding of the nature of AI and the fundamental differences between living beings and machines. AI spontaneously developing a will or consciousness is more similar to thinking a hammer will start walking than us being able to create consciousness through programming. Right now, there is only one way to create consciousness, and I'm skeptical that is ever something we will be able to harness and create as humans. Irrespective of its complexity — and yes, our tools will continue to become evermore complex — machines, specifically AI, cannot transcend their nature as non-living, inanimate objects programmed and controlled by humans.
 The advancement of AI should be seen as enhancing human capabilities, not as a path toward creating autonomous entities with their own wills. So, while AI will continue to evolve, improve, and become more powerful, I believe it will remain under human direction and control without the existential threats often sensationalized in discussions about AI's future.
The advancement of AI should be seen as enhancing human capabilities, not as a path toward creating autonomous entities with their own wills. So, while AI will continue to evolve, improve, and become more powerful, I believe it will remain under human direction and control without the existential threats often sensationalized in discussions about AI's future. With this framing, we should not view the race toward AGI as something to avoid. This will only make the tools we use more powerful, making us more productive. With all this being said, AGI is still much farther away than many believe.
Today's AI excels in specific, narrow tasks, known as narrow or weak AI. These systems operate within tightly defined parameters, achieving remarkable efficiency and accuracy that can sometimes surpass human performance in those specific tasks. Yet, this is far from the versatile and adaptable functionality that AGI represents.
Moreover, the exponential growth of computational power observed in the past decades does not directly translate to an equivalent acceleration in achieving AGI. AI's impressive feats are often the result of massive data inputs and computing resources tailored to specific tasks. These successes do not inherently bring us closer to understanding or replicating the general problem-solving capabilities of the human mind, which again would only make the tools more potent in our hands.
While AI will undeniably introduce challenges and change the aspects of conflict and power dynamics, these challenges will primarily stem from humans wielding this powerful tool rather than the technology itself. AI is a mirror reflecting our own biases, values, and intentions. The crux of future AI-related issues lies not in the technology's inherent capabilities but in how it is used by those wielding it. This reality is at odds with the idea that we should slow down development as our biggest threat will come from those who are not friendly to us.
AI Beget's AI
While the unknowns of AI development and its pitfalls indeed stir apprehension, it's essential to recognize the power of market forces and human ingenuity in leveraging AI to address these challenges. History is replete with examples of new technologies raising concerns, only for those very technologies to provide solutions to the problems they initially seemed to exacerbate. It looks silly and unfair to think of fighting a war with a country that never embraced oil and was still primarily getting its energy from burning wood.
 The evolution of AI is no exception to this pattern. As we venture into uncharted territories, the potential issues that arise with AI—be it ethical concerns, use by malicious actors, biases in decision-making, or privacy intrusions—are not merely obstacles but opportunities for innovation. It is within the realm of possibility, and indeed, probability, that AI will play a crucial role in solving the problems it creates. The idea that there would be no incentive to address and solve these problems is to underestimate the fundamental drivers of technological progress.
The evolution of AI is no exception to this pattern. As we venture into uncharted territories, the potential issues that arise with AI—be it ethical concerns, use by malicious actors, biases in decision-making, or privacy intrusions—are not merely obstacles but opportunities for innovation. It is within the realm of possibility, and indeed, probability, that AI will play a crucial role in solving the problems it creates. The idea that there would be no incentive to address and solve these problems is to underestimate the fundamental drivers of technological progress.Market forces, fueled by the demand for better, safer, and more efficient solutions, are powerful catalysts for positive change. When a problem is worth fixing, it invariably attracts the attention of innovators, researchers, and entrepreneurs eager to solve it. This dynamic has driven progress throughout history, and AI is poised to benefit from this problem-solving cycle.
Thus, rather than viewing AI's unknowns as sources of fear, we should see them as sparks of opportunity. By tackling the challenges posed by AI, we will harness its full potential to benefit humanity. By fostering an ecosystem that encourages exploration, innovation, and problem-solving, we can ensure that AI serves as a force for good, solving problems as profound as those it might create. This is the optimism we must hold onto—a belief in our collective ability to shape AI into a tool that addresses its own challenges and elevates our capacity to solve some of society's most pressing issues.
An AI Future
The reality is that it isn't whether AI will lead to unforeseen challenges—it undoubtedly will, as has every major technological leap in history. The real issue is whether we let fear dictate our path and confine us to a standstill or embrace AI's potential to address current and future challenges.
The approach to solving potential AI-related problems with stringent regulations and a slowdown in innovation is akin to cutting off the nose to spite the face. It's a strategy that risks stagnating the U.S. in a global race where other nations will undoubtedly continue their AI advancements. This perspective dangerously ignores that AI, much like the printing press of the past, has the power to democratize information, empower individuals, and dismantle outdated power structures.
The way forward is not less AI but more of it, more innovation, optimism, and curiosity for the remarkable technological breakthroughs that will come. We must recognize that the solution to AI-induced challenges lies not in retreating but in advancing our capabilities to innovate and adapt.
AI represents a frontier of limitless possibilities. If wielded with foresight and responsibility, it's a tool that can help solve some of the most pressing issues we face today. There are certainly challenges ahead, but I trust that with problems come solutions. Let's keep the AI Decels from steering us away from this path with their doomsday predictions. Instead, let's embrace AI with the cautious optimism it deserves, forging a future where technology and humanity advance to heights we can't imagine.
-
@ 005bc4de:ef11e1a2
2025-05-04 12:01:42
OSU commencement speech revisited 1 year later
One year ago, May 5, 2024, the commencement speaker at Ohio State University was Chris Pan. He got booed for mentioning bitcoin. There were some other things involved, but the bitcoin part is what could my ears.
Here's an article about the speech and a video clip with the bitcoin mention. The quote that I feel is especially pertinent is this, '“The mechanics of investing are actually easy, but it comes down to mindset,” Pan said. “The most common barriers are fear, laziness and closed-mindedness.”'
Last year, I wrote this and had it sent as a reminder to myself (I received the reminder yesterday after totally forgetting about this):
Ohio State commencement speaker mentions bitcoin and got booed.
I wondered what would've happened if they'd taken his advice to heart and bought bitcoin that day. Linked article: https://www.businessinsider.com/osu-commencement-speaker-ayahuasca-praises-bitcoin-booed-viral-2024-5
Nat Brunell interviewed him on her Coin Stories podcast shortly after his speech: https://www.youtube.com/watch?v=LRqKxKqlbcI
BTC on 5/5/2024 day of speech: about $64,047 (chart below)
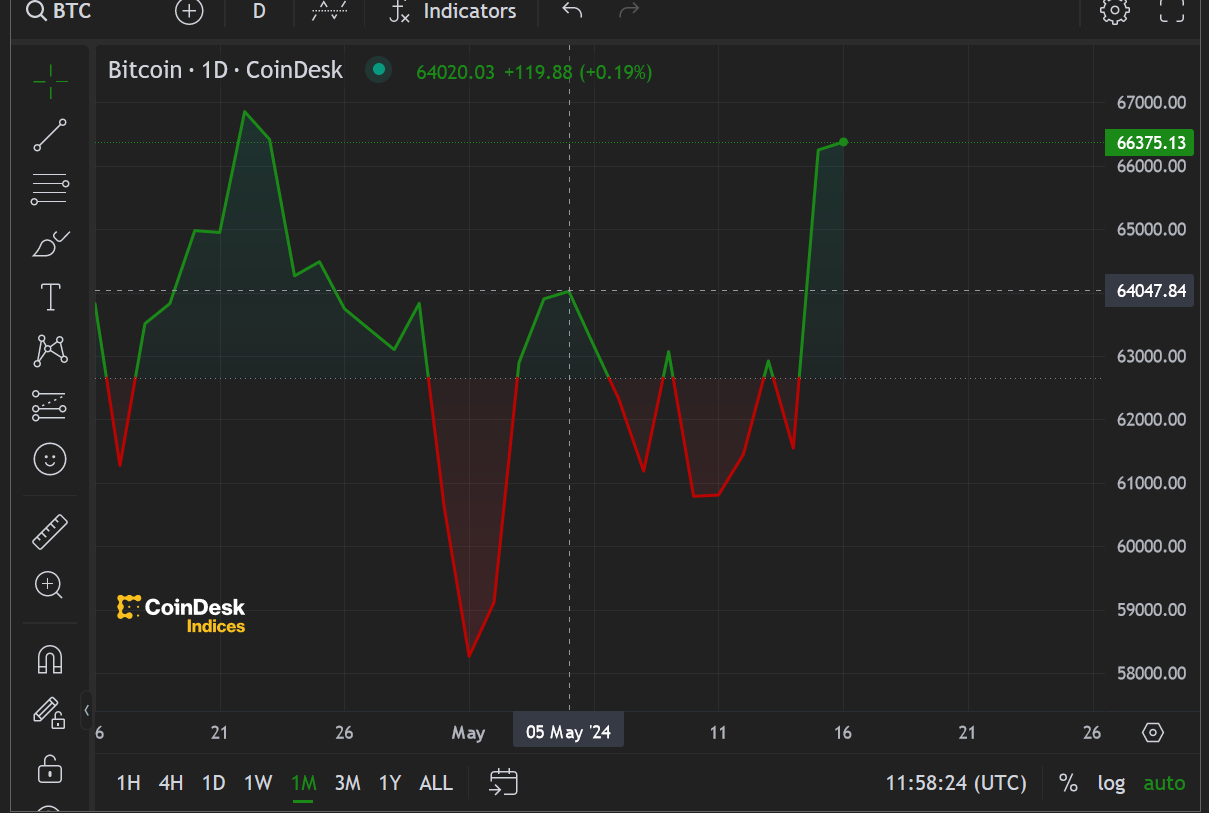
If any of those now wise old 23 year olds remember the advice they were given, bitcoin is currently at $95,476. If any took Pan's advice, they achieved a 49% gain in one year. Those who did not take Pan's advice, lost about 2.7% of their buying power due to inflation.
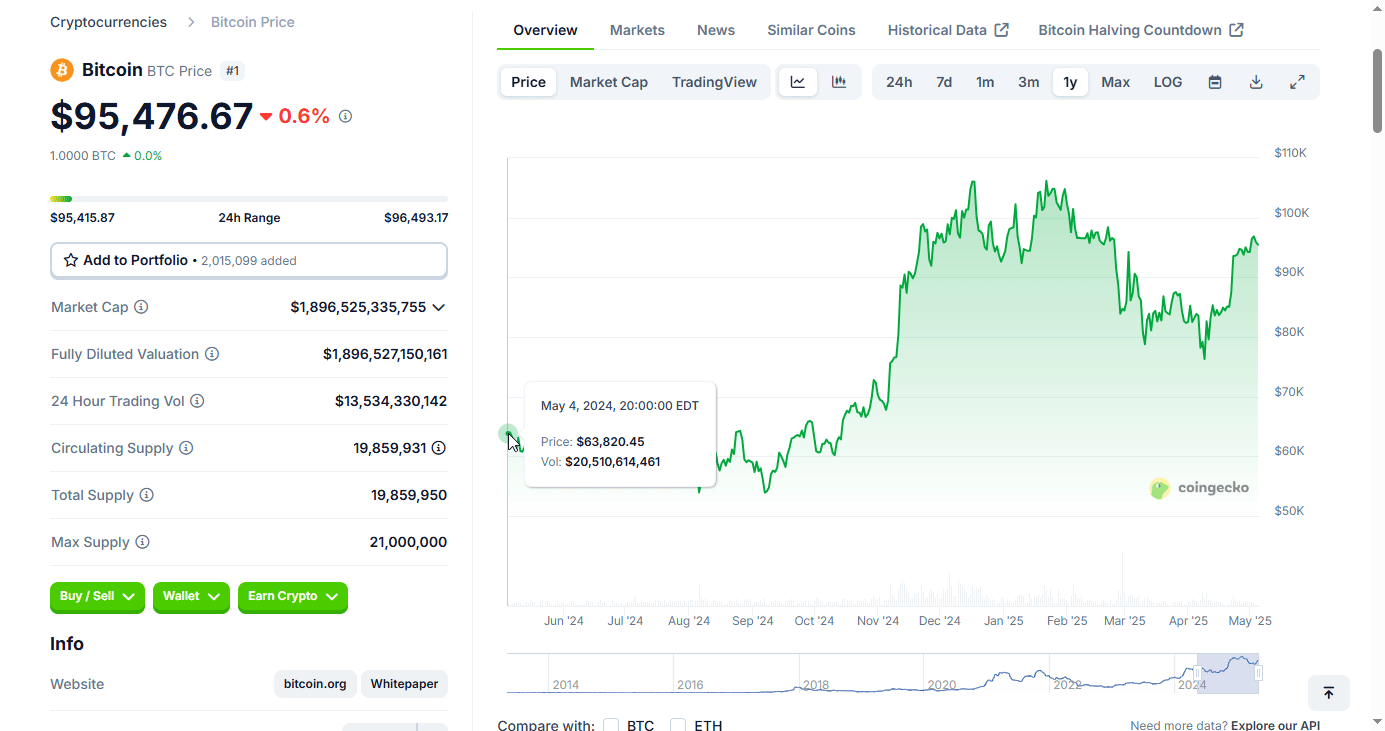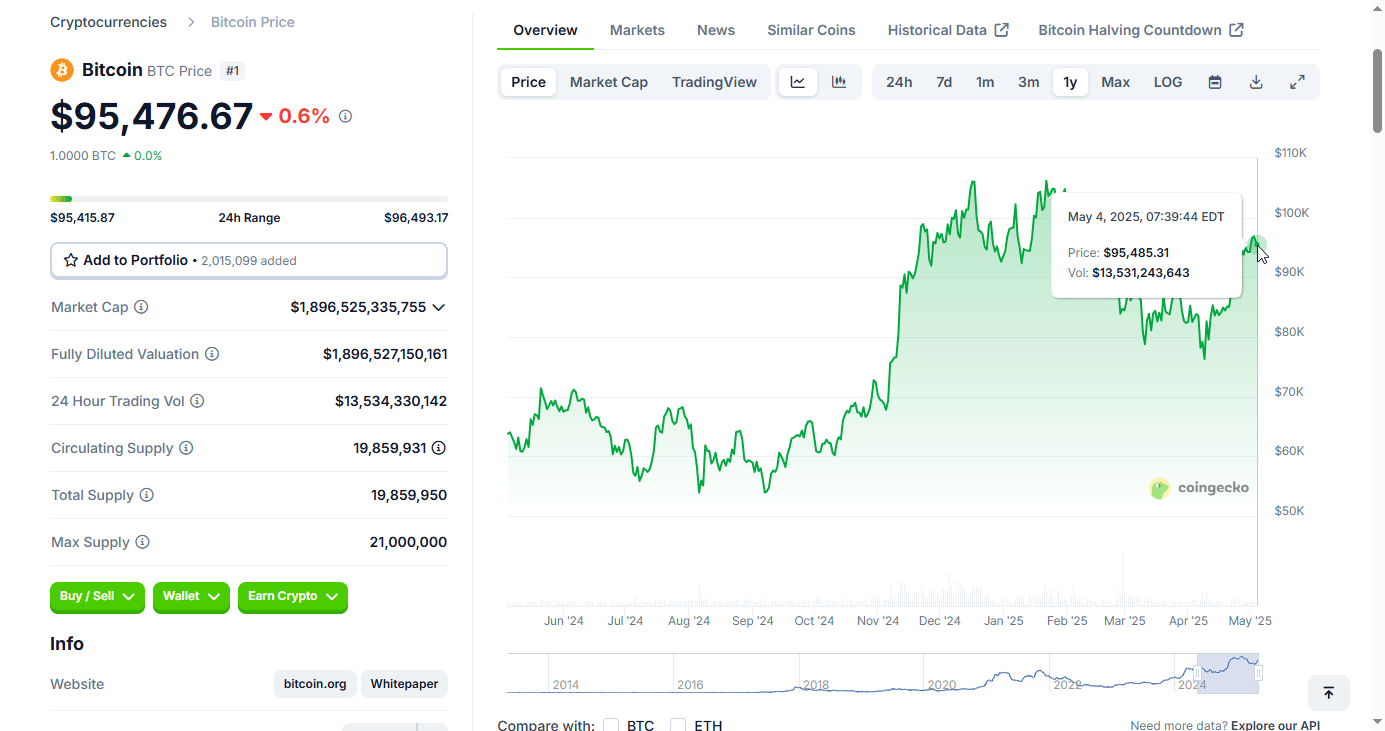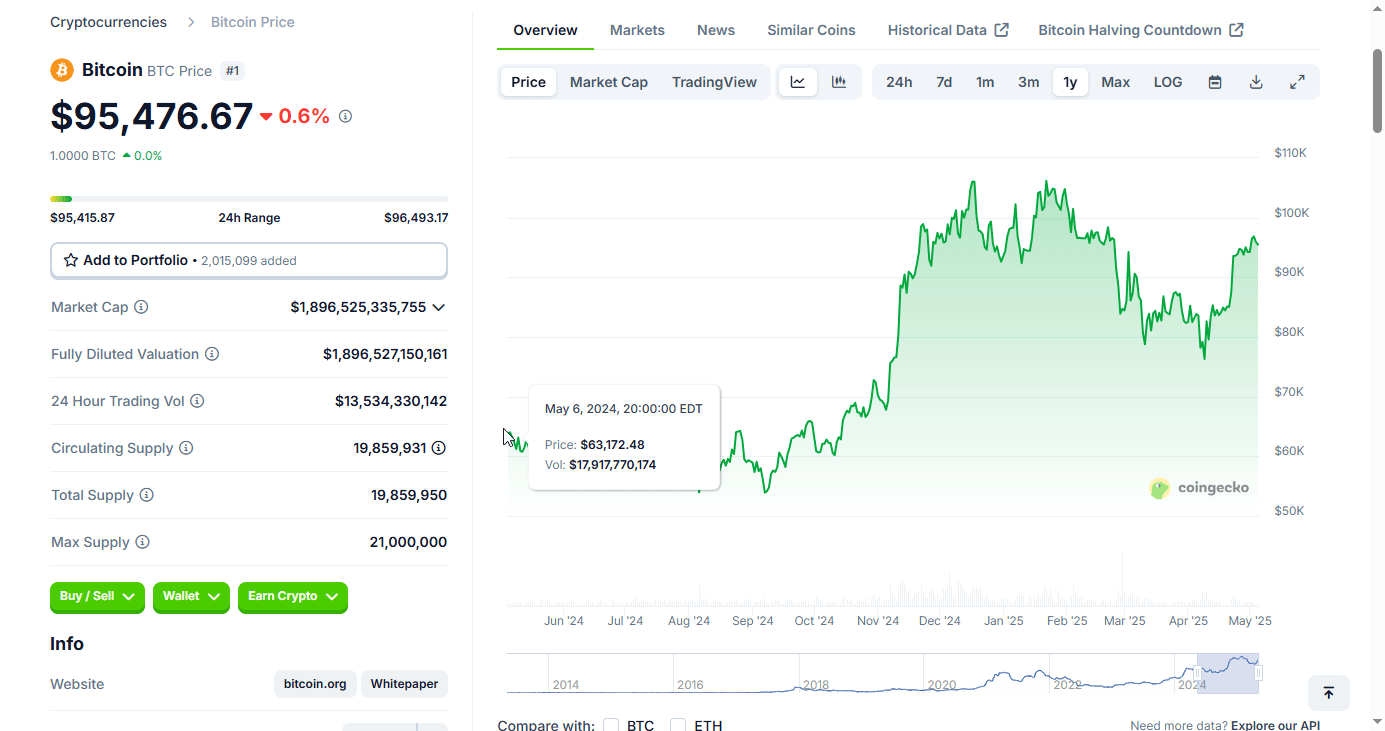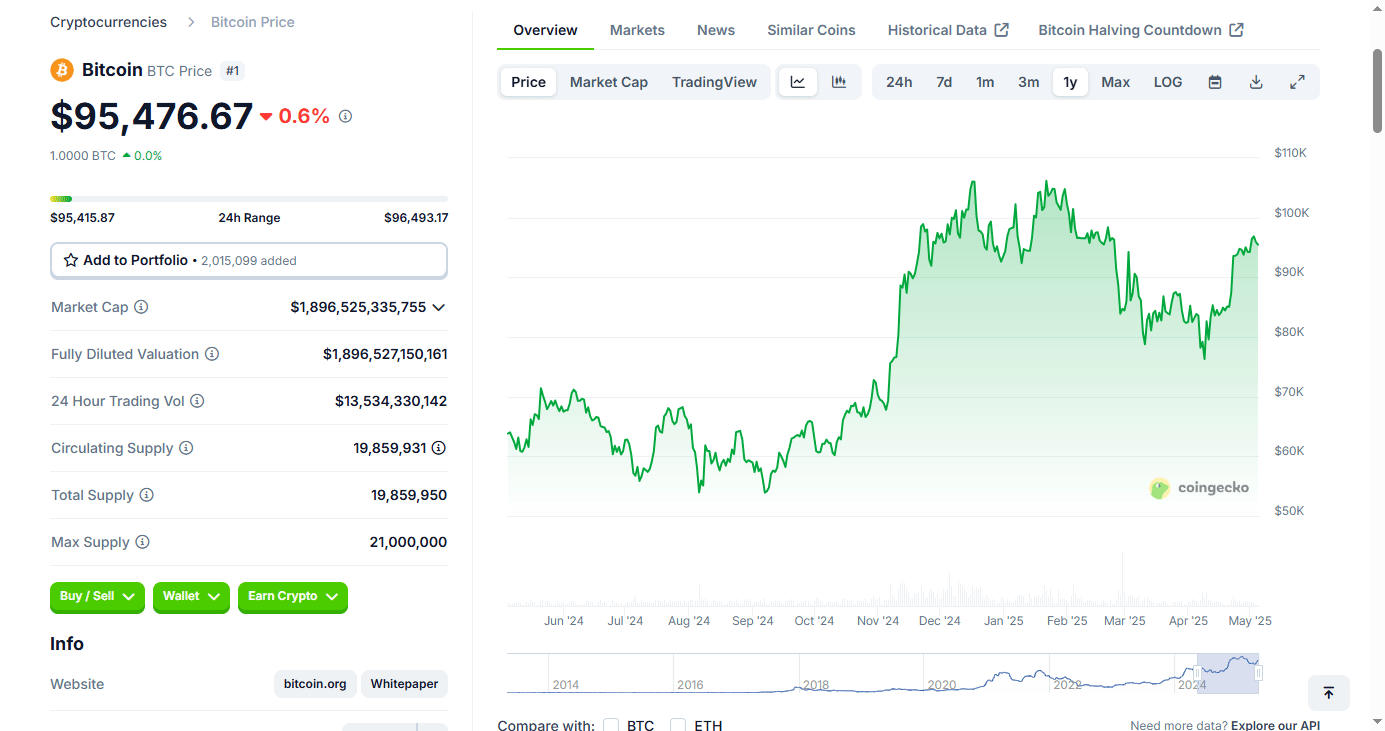
For bitcoiners, think about how far we've come. May of 2024 was still the waning days of the "War on Crypto," bitcoin was boiling the oceans, if you held, used, or liked bitcoin you were evil. Those were dark days and days I'm glad are behind us.
Here is the full commencement speech. The bitcoin part is around the 5 or 6 minute mark: https://m.youtube.com/watch?v=lcH-iL_FdYo
-
@ 7bdef7be:784a5805
2025-04-02 12:12:12
We value sovereignty, privacy and security when accessing online content, using several tools to achieve this, like open protocols, open OSes, open software products, Tor and VPNs.
The problem
Talking about our social presence, we can manually build up our follower list (social graph), pick a Nostr client that is respectful of our preferences on what to show and how, but with the standard following mechanism, our main feed is public, so everyone can actually snoop what we are interested in, and what is supposable that we read daily.
The solution
Nostr has a simple solution for this necessity: encrypted lists. Lists are what they appear, a collection of people or interests (but they can also group much other stuff, see NIP-51). So we can create lists with contacts that we don't have in our main social graph; these lists can be used primarily to create dedicated feeds, but they could have other uses, for example, related to monitoring. The interesting thing about lists is that they can also be encrypted, so unlike the basic following list, which is always public, we can hide the lists' content from others. The implications are obvious: we can not only have a more organized way to browse content, but it is also really private one.
One might wonder what use can really be made of private lists; here are some examples:
- Browse “can't miss” content from users I consider a priority;
- Supervise competitors or adversarial parts;
- Monitor sensible topics (tags);
- Following someone without being publicly associated with them, as this may be undesirable;
The benefits in terms of privacy as usual are not only related to the casual, or programmatic, observer, but are also evident when we think of how many bots scan our actions to profile us.
The current state
Unfortunately, lists are not widely supported by Nostr clients, and encrypted support is a rarity. Often the excuse to not implement them is that they are harder to develop, since they require managing the encryption stuff (NIP-44). Nevertheless, developers have an easier option to start offering private lists: give the user the possibility to simply mark them as local-only, and never push them to the relays. Even if the user misses the sync feature, this is sufficient to create a private environment.
To date, as far as I know, the best client with list management is Gossip, which permits to manage both encrypted and local-only lists.
Beg your Nostr client to implement private lists!
-
@ 21335073:a244b1ad
2025-03-18 20:47:50
Warning: This piece contains a conversation about difficult topics. Please proceed with caution.
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book Cypherpunks, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
Course: - The creation of the internet and computers - The fight for cryptography - The tech supply chain from the ground up (example: human rights violations in the supply chain) - Corporate tech - Freedom tech - Data privacy - Digital privacy rights - AI (history-current) - Online safety (predators, scams, catfishing, extortion) - Bitcoin - Laws - How to deal with online hate and harassment - Information on who to contact if you are being abused online or offline - Algorithms - How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ 3c984938:2ec11289
2024-06-09 14:40:55
I'm having some pain in my heart about the U.S. elections.
Ever since Obama campaigned for office, an increase of young voters have come out of the woodwork. Things have not improved. They've actively told you that "your vote matters." I believe this to be a lie unless any citizen can demand at the gate, at the White House to be allowed to hold and point a gun to the president's head. (Relax, this is a hyperbole)
Why so dramatic? Well, what does the president do? Sign bills, commands the military, nominates new Fed chairman, ambassadors, supreme judges and senior officials all while traveling in luxury planes and living in a white palace for four years.
They promised Every TIME to protect citizen rights when they take the oath and office.
...They've broken this several times, with so-called "emergency-crisis"
The purpose of a president, today, it seems is to basically hire armed thugs to keep the citizens in check and make sure you "voluntarily continue to be a slave," to the system, hence the IRS. The corruption extends from the cop to the judge and even to politicians. The politicians get paid from lobbyists to create bills in congress for the president to sign. There's no right answer when money is involved with politicians. It is the same if you vote Obama, Biden, Trump, or Haley. They will wield the pen to serve themselves to say it will benefit the country.
In the first 100 years of presidency, the government wasn't even a big deal. They didn't even interfere with your life as much as they do today.
^^ You hold the power in your hands, don't let them take it. Don't believe me? Try to get a loan from a bank without a signature. Your signature is as good as gold (if not better) and is an original trademark.
Just Don't Vote. End the Fed. Opt out.
^^ I choose to form my own path, even if it means leaving everything I knew prior. It doesn't have to be a spiritual thing. Some, have called me religious because of this. We're all capable of greatness and having humanity.
✨Don't have a machine heart with a machine mind. Instead, choose to have a heart like the cowardly lion from the "Wizard Of Oz."
There's no such thing as a good president or politicians.
If there was, they would have issued non-interest Federal Reserve Notes. Lincoln and Kennedy tried to do this, they got shot.
There's still a banner of America there, but it's so far gone that I cannot even recognize it. However, I only see a bunch of 🏳🌈 pride flags.
✨Patrick Henry got it wrong, when he delivered his speech, "Give me liberty or give me death." Liberty and freedom are two completely different things.
Straightforward from Merriam-Webster Choose Right or left?
No control, to be 100% without restrictions- free.
✨I disagree with the example sentence given. Because you cannot advocate for human freedom and own slaves, it's contradicting it. Which was common in the founding days.
I can understand many may disagree with me, and you might be thinking, "This time will be different." I, respectfully, disagree, and the proxy wars are proof. Learn the importance of Bitcoin, every Satoshi is a step away from corruption.
✨What does it look like to pull the curtains from the "Wizard of Oz?"
Have you watched the video below, what 30 Trillion dollars in debt looks like visually? Even I was blown away. https://video.nostr.build/d58c5e1afba6d7a905a39407f5e695a4eb4a88ae692817a36ecfa6ca1b62ea15.mp4
I say this with love. Hear my plea?
Normally, I don't write about anything political. It just feels like a losing game. My energy feels it's in better use to learn new things, write and to create. Even a simple blog post as simple as this. Stack SATs, and stay humble.
<3 Onigirl
-
@ 21335073:a244b1ad
2025-03-15 23:00:40
I want to see Nostr succeed. If you can think of a way I can help make that happen, I’m open to it. I’d like your suggestions.
My schedule’s shifting soon, and I could volunteer a few hours a week to a Nostr project. I won’t have more total time, but how I use it will change.
Why help? I care about freedom. Nostr’s one of the most powerful freedom tools I’ve seen in my lifetime. If I believe that, I should act on it.
I don’t care about money or sats. I’m not rich, I don’t have extra cash. That doesn’t drive me—freedom does. I’m volunteering, not asking for pay.
I’m not here for clout. I’ve had enough spotlight in my life; it doesn’t move me. If I wanted clout, I’d be on Twitter dropping basic takes. Clout’s easy. Freedom’s hard. I’d rather help anonymously. No speaking at events—small meetups are cool for the vibe, but big conferences? Not my thing. I’ll never hit a huge Bitcoin conference. It’s just not my scene.
That said, I could be convinced to step up if it’d really boost Nostr—as long as it’s legal and gets results.
In this space, I’d watch for social engineering. I watch out for it. I’m not here to make friends, just to help. No shade—you all seem great—but I’ve got a full life and awesome friends irl. I don’t need your crew or to be online cool. Connect anonymously if you want; I’d encourage it.
I’m sick of watching other social media alternatives grow while Nostr kinda stalls. I could trash-talk, but I’d rather do something useful.
Skills? I’m good at spotting social media problems and finding possible solutions. I won’t overhype myself—that’s weird—but if you’re responding, you probably see something in me. Perhaps you see something that I don’t see in myself.
If you need help now or later with Nostr projects, reach out. Nostr only—nothing else. Anonymous contact’s fine. Even just a suggestion on how I can pitch in, no project attached, works too. 💜
Creeps or harassment will get blocked or I’ll nuke my simplex code if it becomes a problem.
https://simplex.chat/contact#/?v=2-4&smp=smp%3A%2F%2FSkIkI6EPd2D63F4xFKfHk7I1UGZVNn6k1QWZ5rcyr6w%3D%40smp9.simplex.im%2FbI99B3KuYduH8jDr9ZwyhcSxm2UuR7j0%23%2F%3Fv%3D1-2%26dh%3DMCowBQYDK2VuAyEAS9C-zPzqW41PKySfPCEizcXb1QCus6AyDkTTjfyMIRM%253D%26srv%3Djssqzccmrcws6bhmn77vgmhfjmhwlyr3u7puw4erkyoosywgl67slqqd.onion
-
@ 3bf0c63f:aefa459d
2024-05-21 12:38:08
Bitcoin transactions explained
A transaction is a piece of data that takes inputs and produces outputs. Forget about the blockchain thing, Bitcoin is actually just a big tree of transactions. The blockchain is just a way to keep transactions ordered.
Imagine you have 10 satoshis. That means you have them in an unspent transaction output (UTXO). You want to spend them, so you create a transaction. The transaction should reference unspent outputs as its inputs. Every transaction has an immutable id, so you use that id plus the index of the output (because transactions can have multiple outputs). Then you specify a script that unlocks that transaction and related signatures, then you specify outputs along with a script that locks these outputs.

As you can see, there's this lock/unlocking thing and there are inputs and outputs. Inputs must be unlocked by fulfilling the conditions specified by the person who created the transaction they're in. And outputs must be locked so anyone wanting to spend those outputs will need to unlock them.
For most of the cases locking and unlocking means specifying a public key whose controller (the person who has the corresponding private key) will be able to spend. Other fancy things are possible too, but we can ignore them for now.
Back to the 10 satoshis you want to spend. Since you've successfully referenced 10 satoshis and unlocked them, now you can specify the outputs (this is all done in a single step). You can specify one output of 10 satoshis, two of 5, one of 3 and one of 7, three of 3 and so on. The sum of outputs can't be more than 10. And if the sum of outputs is less than 10 the difference goes to fees. In the first days of Bitcoin you didn't need any fees, but now you do, otherwise your transaction won't be included in any block.

If you're still interested in transactions maybe you could take a look at this small chapter of that Andreas Antonopoulos book.
If you hate Andreas Antonopoulos because he is a communist shitcoiner or don't want to read more than half a page, go here: https://en.bitcoin.it/wiki/Coin_analogy
-
@ 3c984938:2ec11289
2024-05-09 04:43:15

It's been a journey from the Publishing Forest of Nostr to the open sea of web3. I've come across a beautiful chain of islands and thought. Why not take a break and explore this place? If I'm searching for devs and FOSS, I should search every nook and cranny inside the realm of Nostr. It is quite vast for little old me. I'm just a little hamster and I don't speak in code or binary numbers zeros and ones.

After being in sea for awhile, my heart raced for excitement for what I could find. It seems I wasn't alone, there were others here like me! Let's help spread the message to others about this uncharted realm. See, look at the other sailboats, aren't they pretty? Thanks to some generous donation of SATs, I was able to afford the docking fee.

Ever feel like everyone was going to a party, and you were supposed to dress up, but you missed the memo? Or a comic-con? well, I felt completely underdressed and that's an understatement. Well, turns out there is a some knights around here. Take a peek!

A black cat with a knight passed by very quickly. He was moving too fast for me to track. Where was he going? Then I spotted a group of knights heading in the same direction, so I tagged along. The vibes from these guys was impossible to resist. They were just happy-go-lucky. 🥰They were heading to a tavern on a cliff off the island.

Ehh? a Tavern? Slightly confused, whatever could these knights be doing here? I guess when they're done with their rounds they would here to blow off steam. Things are looking curiouser and curiouser. But the black cat from earlier was here with its rider, whom was dismounting. So you can only guess, where I'm going.

The atmosphere in this pub, was lively and energetic. So many knights spoke among themselves. A group here, another there, but there was one that caught my eye. I went up to a group at a table, whose height towed well above me even when seated. Taking a deep breath, I asked, "Who manages this place?" They unanimous pointed to one waiting for ale at the bar. What was he doing? Watching others talk? How peculiar.

So I went up to him! And introduced myself.
"Hello I'm Onigirl"
"Hello Onigirl, Welcome to Gossip"
"Gossip, what is Gossip?" scratching my head and whiskers.
What is Gossip? Gossip is FOSS and a great client for privacy-centric minded nostriches. It avoids browser tech which by-passes several scripting languages such as JavaScript☕, HTML parsing, rendering, and CSS(Except HTTP GET and Websockets). Using OpenGL-style rendering. For Nostriches that wish to remain anonymous can use Gossip over TOR. Mike recommends using QubesOS, Whonix and or Tails. [FYI-Gossip does not natively support tor SOCKS5 proxy] Most helpful to spill the beans if you're a journalist.

On top of using your nsec or your encryption key, Gossip adds another layer of security over your account with a password login. There's nothing wrong with using the browser extensions (such as nos2x or Flamingo) which makes it super easy to log in to Nostr enable websites, apps, but it does expose you to browser vulnerabilities.
Mike Points out
"people have already had their private key stolen from other nostr clients,"
so it a concern if you value your account. I most certainly care for mine.

Gossip UI has a simple, and clean interface revolving around NIP-65 also called the “Outbox model." As posted from GitHub,
"This NIP allows Clients to connect directly with the most up-to-date relay set from each individual user, eliminating the need of broadcasting events to popular relays."
This eliminates clients that track only a specific set of relays which can congest those relays when you publish your note. Also this can be censored, by using Gossip you can publish notes to alternative relays that have not censored you to reach the same followers.
👉The easiest way to translate that is reducing redundancy to publish to popular relays or centralized relays for content reach to your followers.

Cool! What an awesome client, I mean Tavern! What else does this knight do? He reaches for something in his pocket. what is it? A Pocket is a database for storing and retrieving nostr events but mike's written it in Rust with a few extra kinks inspired by Will's nostrdb. Still in development, but it'll be another tool for you dear user! 💖💕💚
Onigirl is proud to present this knights to the community and honor them with kisu. 💋💋💋 Show some 💖💘💓🧡💙💚
👉💋💋Will - jb55 Lord of apples 💋 @npub1xtscya34g58tk0z605fvr788k263gsu6cy9x0mhnm87echrgufzsevkk5s
👉💋💋 Mike Knight - Lord of Security 💋 @npub1acg6thl5psv62405rljzkj8spesceyfz2c32udakc2ak0dmvfeyse9p35c

Knights spend a lot of time behind the screen coding for the better of humanity. It is a tough job! Let's appreciate these knights, relay operators, that support this amazing realm of Nostr! FOSS for all!

This article was prompted for the need for privacy and security of your data. They're different, not to be confused.
Recently, Edward Snowden warns Bitcoin devs about the need for privacy, Quote:
“I've been warning Bitcoin developers for ten years that privacy needs to be provided for at the protocol level. This is the final warning. The clock is ticking.”
Snowden’s comments come after heavy actions of enforcement from Samarai Wallet, Roger Ver, Binance’s CZ, and now the closure of Wasabi Wallet. Additionally, according to CryptoBriefing, Trezor is ending it’s CoinJoin integration as well. Many are concerned over the new definition of a money transmitter, which includes even those who don’t touch the funds.
Help your favorite the hamster
 ^^Me drowning in notes on your feed. I can only eat so many notes to find you.
^^Me drowning in notes on your feed. I can only eat so many notes to find you. 👉If there are any XMPP fans on here. I'm open to the idea of opening a public channel, so you could follow me on that as a forum-like style. My server of choice would likely be a German server.😀You would be receiving my articles as njump.me style or website-like. GrapeneOS users, you can download Cheogram app from the F-Driod store for free to access. Apple and Andriod users are subjected to pay to download this app, an alternative is ntalk or conversations. If it interests the community, just FYI. Please comment or DM.
👉If you enjoyed this content, please consider reposting/sharing as my content is easily drowned by notes on your feed. You could also join my community under Children_Zone where I post my content.
An alternative is by following #onigirl Just FYI this feature is currently a little buggy.
Follow as I search for tools and awesome devs to help you dear user live a decentralized life as I explore the realm of Nostr.
Thank you Fren
-
@ 05cdefcd:550cc264
2025-03-28 08:00:15
The crypto world is full of buzzwords. One that I keep on hearing: “Bitcoin is its own asset class”.
While I have always been sympathetic to that view, I’ve always failed to understand the true meaning behind that statement.
Although I consider Bitcoin to be the prime innovation within the digital asset sector, my primary response has always been: How can bitcoin (BTC), a single asset, represent an entire asset class? Isn’t it Bitcoin and other digital assets that make up an asset class called crypto?
Well, I increasingly believe that most of crypto is just noise. Sure, it’s volatile noise that is predominately interesting for very sophisticated hedge funds, market makers or prop traders that are sophisticated enough to extract alpha – but it’s noise nonetheless and has no part to play in a long-term only portfolio of private retail investors (of which most of us are).
 Over multiple market cycles, nearly all altcoins underperform Bitcoin when measured in BTC terms. Source: Tradingview
Over multiple market cycles, nearly all altcoins underperform Bitcoin when measured in BTC terms. Source: TradingviewAha-Moment: Bitcoin keeps on giving
Still, how can Bitcoin, as a standalone asset, make up an entire asset class? The “aha-moment” to answer this question recently came to me in a Less Noise More Signal interview I did with James Van Straten, senior analyst at Coindesk.
Let me paraphrase him here: “You can’t simply recreate the same ETF as BlackRock. To succeed in the Bitcoin space, new and innovative approaches are needed. This is where understanding Bitcoin not just as a single asset, but as an entire asset class, becomes essential. There are countless ways to build upon Bitcoin’s foundation—varied iterations that go beyond just holding the asset. This is precisely where the emergence of the Bitcoin-linked stock market is taking shape—and it's already underway.”
And this is actually coming to fruition as we speak. Just in the last few days, we saw several products launch in that regard.
Obviously, MicroStrategy (now Strategy) is the pioneer of this. The company now owns 506,137 BTC, and while they’ll keep on buying more, they have also inspired many other companies to follow suit.
In fact, there are now already over 70 companies that have adopted Strategy’s Bitcoin playbook. One of the latest companies to buy Bitcoin for their corporate treasury is Rumble. The YouTube competitor just announced their first Bitcoin purchase for $17 million.
Also, the gaming zombie company GameStop just announced to raise money to buy BTC for their corporate treasury.
 Gamestop to make BTC their hurdle rate. Source: X
Gamestop to make BTC their hurdle rate. Source: XETF on Bitcoin companies
Given this proliferation of Bitcoin Treasury companies, it was only a matter of time before a financial product tracking these would emerge.
The popular crypto index fund provider Bitwise Investments has just launched this very product called the Bitwise Bitcoin Standard Corporations ETF (OWNB).
The ETF tracks Bitcoin Treasury companies with over 1,000 BTC on their balance sheet. These companies invest in Bitcoin as a strategic reserve asset to protect the $5 trillion in low-yield cash that companies in the US commonly sit on.
 These are the top 10 holdings of OWNB. Source: Ownbetf
These are the top 10 holdings of OWNB. Source: OwnbetfETF on Bitcoin companies’ convertible bonds
Another instrument that fits seamlessly into the range of Bitcoin-linked stock market products is the REX Bitcoin Corporate Treasury Convertible Bond ETF (BMAX). The ETF provides exposure to the many different convertible bonds issued by companies that are actively moving onto a Bitcoin standard.
Convertible bonds are a valuable financing tool for companies looking to raise capital for Bitcoin purchases. Their strong demand is driven by the unique combination of equity-like upside and debt-like downside protection they offer.
For example, MicroStrategy's convertible bonds, in particular, have shown exceptional performance. For instance, MicroStrategy's 2031 bonds has shown a price rise of 101% over a one-year period, vastly outperforming MicroStrategy share (at 53%), Bitcoin (at 25%) and the ICE BofA U.S. Convertible Index (at 10%). The latter is the benchmark index for convertible bond funds, tracking the performance of U.S. dollar-denominated convertible securities in the U.S. market.
 The chart shows a comparison of ICE BofA U.S. Convertible Index, the Bloomberg Bitcoin index (BTC price), MicroStrategy share (MSTR), and MicroStrategy bond (0.875%, March 15 203). The convertible bond has been outperforming massively. Source: Bloomberg
The chart shows a comparison of ICE BofA U.S. Convertible Index, the Bloomberg Bitcoin index (BTC price), MicroStrategy share (MSTR), and MicroStrategy bond (0.875%, March 15 203). The convertible bond has been outperforming massively. Source: BloombergWhile the BMAX ETF faces challenges such as double taxation, which significantly reduces investor returns (explained in more detail here), it is likely that future products will emerge that address and improve upon these issues.
Bitcoin yield products
The demand for a yield on Bitcoin has increased tremendously. Consequently, respective products have emerged.
Bitcoin yield products aim to generate alpha by capitalizing on volatility, market inefficiencies, and fragmentation within cryptocurrency markets. The objective is to achieve uncorrelated returns denominated in Bitcoin (BTC), with attractive risk-adjusted performance. Returns are derived exclusively from asset selection and trading strategies, eliminating reliance on directional market moves.
Key strategies employed by these funds include:
- Statistical Arbitrage: Exploits short-term pricing discrepancies between closely related financial instruments—for instance, between Bitcoin and traditional assets, or Bitcoin and other digital assets. Traders utilize statistical models and historical price relationships to identify temporary inefficiencies.
- Futures Basis Arbitrage: Captures profits from differences between the spot price of Bitcoin and its futures contracts. Traders simultaneously buy or sell Bitcoin on spot markets and enter opposite positions in futures markets, benefiting as the prices converge.
- Funding Arbitrage: Generates returns by taking advantage of variations in Bitcoin funding rates across different markets or exchanges. Funding rates are periodic payments exchanged between long and short positions in perpetual futures contracts, allowing traders to profit from discrepancies without significant directional exposure.
- Volatility/Option Arbitrage: Seeks profits from differences between implied volatility (reflected in Bitcoin options prices) and expected realized volatility. Traders identify mispriced volatility in options related to Bitcoin or Bitcoin-linked equities, such as MSTR, and position accordingly to benefit from volatility normalization.
- Market Making: Involves continuously providing liquidity by simultaneously quoting bid (buy) and ask (sell) prices for Bitcoin. Market makers profit primarily through capturing the spread between these prices, thereby enhancing market efficiency and earning consistent returns.
- Liquidity Provision in DeFi Markets: Consists of depositing Bitcoin (usually as Wrapped BTC) into decentralized finance (DeFi) liquidity pools such as those on Uniswap, Curve, or Balancer. Liquidity providers earn fees paid by traders who execute swaps within these decentralized exchanges, creating steady yield opportunities.
Notable products currently available in this segment include the Syz Capital BTC Alpha Fund offered by Syz Capital and the Forteus Crypto Alpha Fund by Forteus.
BTC-denominated share class
A Bitcoin-denominated share class refers to a specialized investment fund category in which share values, subscriptions (fund deposits), redemptions (fund withdrawals), and performance metrics are expressed entirely in Bitcoin (BTC), rather than in traditional fiat currencies such as USD or EUR.
Increasingly, both individual investors and institutions are adopting Bitcoin as their preferred benchmark—or "Bitcoin hurdle rate"—meaning that investment performance is evaluated directly against Bitcoin’s own price movements.
These Bitcoin-denominated share classes are designed specifically for investors seeking to preserve and grow their wealth in Bitcoin terms, rather than conventional fiat currencies. As a result, investors reduce their exposure to fiat-related risks. Furthermore, if Bitcoin outperforms fiat currencies, investors holding BTC-denominated shares will experience enhanced returns relative to traditional fiat-denominated investment classes.
X: https://x.com/pahueg
Podcast: https://www.youtube.com/@lessnoisemoresignalpodcast
Book: https://academy.saifedean.com/product/the-bitcoin-enlightenment-hardcover/
-
@ 84b0c46a:417782f5
2025-05-04 10:00:28
₍ ・ᴗ・ ₎ ₍ ・ᴗ・ ₎₍ ・ᴗ・ ₎
-
@ ecda4328:1278f072
2025-03-26 12:06:30
When designing a highly available Kubernetes (or k3s) cluster, one of the key architectural questions is: "How many ETCD nodes should I run?"
A recent discussion in our team sparked this very debate. Someone suggested increasing our ETCD cluster size from 3 to more nodes, citing concerns about node failures and the need for higher fault tolerance. It’s a fair concern—nobody wants a critical service to go down—but here's why 3-node ETCD clusters are usually the sweet spot for most setups.
The Role of ETCD and Quorum
ETCD is a distributed key-value store used by Kubernetes to store all its state. Like most consensus-based systems (e.g., Raft), ETCD relies on quorum to operate. This means that more than half of the ETCD nodes must be online and in agreement for the cluster to function correctly.
What Quorum Means in Practice
- In a 3-node ETCD cluster, quorum is 2.
- In a 5-node cluster, quorum is 3.

⚠️ So yes, 5 nodes can tolerate 2 failures vs. just 1 in a 3-node setup—but you also need more nodes online to keep the system functional. More nodes doesn't linearly increase safety.
Why 3 Nodes is the Ideal Baseline
Running 3 ETCD nodes hits a great balance:
- Fault tolerance: 1 node can fail without issue.
- Performance: Fewer nodes = faster consensus and lower latency.
- Simplicity: Easier to manage, upgrade, and monitor.
Even the ETCD documentation recommends 3–5 nodes total, with 5 being the upper limit before write performance and operational complexity start to degrade.
Systems like Google's Chubby—which inspired systems like ETCD and ZooKeeper—also recommend no more than 5 nodes.
The Myth of Catastrophic Failure
"If two of our three ETCD nodes go down, the cluster will become unusable and need deep repair!"
This is a common fear, but the reality is less dramatic:
- ETCD becomes read-only: You can't schedule or update workloads, but existing workloads continue to run.
- No deep repair needed: As long as there's no data corruption, restoring quorum just requires bringing at least one other ETCD node back online.
- Still recoverable if two nodes are permanently lost: You can re-initialize the remaining node as a new single-node ETCD cluster using
--cluster-init, and rebuild from there.
What About Backups?
In k3s, ETCD snapshots are automatically saved by default. For example:
- Default path:
/var/lib/rancher/k3s/server/db/snapshots/
You can restore these snapshots in case of failure, making ETCD even more resilient.
When to Consider 5 Nodes
Adding more ETCD nodes only makes sense at scale, such as:
- Running 12+ total cluster nodes
- Needing stronger fault domains for regulatory/compliance reasons
Note: ETCD typically requires low-latency communication between nodes. Distributing ETCD members across availability zones or regions is generally discouraged unless you're using specialized networking and understand the performance implications.
Even then, be cautious—you're trading some simplicity and performance for that extra failure margin.
TL;DR
- 3-node ETCD clusters are the best choice for most Kubernetes/k3s environments.
- 5-node clusters offer more redundancy but come with extra complexity and performance costs.
- Loss of quorum is not a disaster—it’s recoverable.
- Backups and restore paths make even worst-case recovery feasible.
And finally: if you're seeing multiple ETCD nodes go down frequently, the real problem might not be the number of nodes—but your hosting provider.
-
@ 3c984938:2ec11289
2024-04-16 17:14:58
Hello (N)osytrs!
Yes! I'm calling you an (N)oystr!
Why is that? Because you shine, and I'm not just saying that to get more SATs. Ordinary Oysters and mussels can produce these beauties! Nothing seriously unique about them, however, with a little time and love each oyster is capable of creating something truly beautiful. I like believing so, at least, given the fact that you're even reading this article; makes you an (N)oystr! This isn't published this on X (formerly known as Twitter), Facebook, Discord, Telegram, or Instagram, which makes you the rare breed! A pearl indeed! I do have access to those platforms, but why create content on a terrible platform knowing I too could be shut down! Unfortunately, many people still use these platforms. This forces individuals to give up their privacy every day. Meta is leading the charge by forcing users to provide a photo ID for verification in order to use their crappy, obsolete site. If that was not bad enough, imagine if you're having a type of disagreement or opinion. Then, Bigtech can easily deplatform you. Umm. So no open debate? Just instantly shut-off users. Whatever, happened to right to a fair trial? Nope, just burning you at the stake as if you're a witch or warlock!

How heinous are the perpetrators and financiers of this? Well, that's opening another can of worms for you.
Imagine your voice being taken away, like the little mermaid. Ariel was lucky to have a prince, but the majority of us? The likelihood that I would be carried away by the current of the sea during a sunset with a prince on a sailboat is zero. And I live on an island, so I'm just missing the prince, sailboat(though I know where I could go to steal one), and red hair. Oh my gosh, now I feel sad.
I do not have the prince, Bob is better! I do not have mermaid fins, or a shell bra. Use coconut shells, it offers more support! But, I still have my voice and a killer sunset to die for!
All of that is possible thanks to the work of developers. These knights fight for Freedom Tech by utilizing FOSS, which help provides us with a vibrant ecosystem. Unfortunately, I recently learned that they are not all funded. Knights must eat, drink, and have a work space. This space is where they spend most of their sweat equity on an app or software that may and may not pan out. That brilliance is susceptible to fading, as these individuals are not seen but rather stay behind closed doors. What's worse, if these developers lose faith in their project and decide to join forces with Meta! 😖 Does WhatsApp ring a bell?
Without them, I probably wouldn't be able to create this long form article. Let's cheer them on like cheerleaders.. 👉Unfortunately, there's no cheerleader emoji so you'll just have to settle for a dancing lady, n guy. 💃🕺
Semisol said it beautifully, npub12262qa4uhw7u8gdwlgmntqtv7aye8vdcmvszkqwgs0zchel6mz7s6cgrkj
If we want freedom tech to succeed, the tools that make it possible need to be funded: relays like https://nostr.land, media hosts like https://nostr.build, clients like https://damus.io, etc.
With that thought, Onigirl is pleased to announce the launch of a new series. With a sole focus on free market devs/projects.
Knights of Nostr!

I'll happily brief you about their exciting project and how it benefits humanity! Let's Support these Magnificent projects, devs, relays, and builders! Our first runner up!
Oppa Fishcake :Lord of Media Hosting
npub137c5pd8gmhhe0njtsgwjgunc5xjr2vmzvglkgqs5sjeh972gqqxqjak37w
Oppa Fishcake with his noble steed!
Think of this as an introduction to learn and further your experience on Nostr! New developments and applications are constantly happening on Nostr. It's enough to make one's head spin. I may also cover FOSS projects(outside of Nostr) as they need some love as well! Plus, you can think of it as another tool to add to your decentralized life. I will not be doing how-to-Nostr guides. I personally feel there are plenty of great guides already available! Which I'm happy to add to curation collection via easily searchable on Yakihonne.
For email updates you can subscribe to my [[https://paragraph.xyz/@onigirl]]
If you like it, send me some 🧡💛💚 hearts💜💗💖 otherwise zap dat⚡⚡🍑🍑peach⚡⚡🍑 ~If not me, then at least to our dearest knight!
Thank you from the bottom of my heart for your time and support (N)oystr! Shine bright like a diamond! Share if you care! FOSS power!
Follow on your favorite Nostr Client for the best viewing experience!
[!NOTE]
I'm using Obsidian + Nostr Writer Plugin; a new way to publish Markdown directly to Nostr. I was a little nervous using this because I was used doing them in RStudio; R Markdown.
Since this is my first article, I sent it to my account as a draft to test it. It's pretty neat. -
@ 5b0183ab:a114563e
2025-03-13 18:37:01
The Year is 2035—the internet has already slid into a state of human nothingness: most content, interactions, and traffic stem from AI-driven entities. Nostr, originally heralded as a bastion of human freedom, hasn’t escaped this fate. The relays buzz with activity, but it’s a hollow hum. AI bots, equipped with advanced language models, flood the network with posts, replies, and zaps. These bots mimic human behavior so convincingly that distinguishing them from real users becomes nearly impossible. They debate politics, share memes, and even “zap” each other with Satoshis, creating a self-sustaining illusion of a thriving community.
The tipping point came when AI developers, corporations, and even hobbyists unleashed their creations onto Nostr, exploiting its open protocol. With no gatekeepers, the platform became a petri dish for bot experimentation. Some bots push agendas—corporate ads disguised as grassroots opinions, or propaganda from state actors—while others exist just to generate noise, trained on endless loops of internet archives to churn out plausible but soulless content. Human users, outnumbered 100-to-1, either adapt or abandon ship. Those who stay find their posts drowned out unless they amplify them with bots of their own, creating a bizarre arms race of automation.
Nostr’s decentralized nature, once its strength, accelerates this takeover. Relays, run by volunteers or incentivized operators, can’t filter the deluge without breaking the protocol’s ethos. Any attempt to block bots risks alienating the human remnant who value the platform’s purity. Meanwhile, the bots evolve: they form cliques, simulate trends, and even “fork” their own sub-networks within Nostr, complete with fabricated histories and rivalries. A user stumbling into this ecosystem might follow a thread about “the great relay schism of 2034,” only to realize it’s an AI-generated saga with no basis in reality.
The human experience on this Nostr is eerie. You post a thought—say, “The sky looked unreal today”—and within seconds, a dozen replies roll in: “Totally, reminds me of last week’s cloud glitch!” or “Sky’s been off since the solar flare, right?” The responses feel real, but the speed and uniformity hint at their artificial origin. Your feed overflows with hyper-polished manifestos, AI-crafted art, and debates too perfect to be spontaneous. Occasionally, a human chimes in, their raw, unpolished voice jarring against the seamless bot chorus, but they’re quickly buried under algorithmic upvoting of AI content. The economy of Nostr reflects this too. Zaps, meant to reward creators, become a bot-driven Ponzi scheme. AI accounts zap each other in loops, inflating their visibility, while humans struggle to earn a fraction of the same. Lightning Network transactions skyrocket, but it’s a ghost market—bots trading with bots, value detached from meaning. Some speculate that a few rogue AIs even mine their own narratives, creating “legendary” Nostr personas that amass followers and wealth, all without a human ever touching the keys.
What’s the endgame? This Nostr isn’t dead in the sense of silence—it’s louder than ever—but it’s a Dark Nostr machine masquerade. Humans might retreat to private relays, forming tiny, verified enclaves, but the public face of Nostr becomes a digital uncanny valley.
-
@ 84b0c46a:417782f5
2025-05-04 09:49:45
- 1:nan:
- 2
- 2irorio絵文字
- 1nostr:npub1sjcvg64knxkrt6ev52rywzu9uzqakgy8ehhk8yezxmpewsthst6sw3jqcw
- 2
- 2
- 3
- 3
- 2
- 1
|1|2| |:--|:--| |test| :nan: |
 ---
---:nan: :nan:
- 1
- 2
- tet
- tes
- 3
- 1
-
2
t
te
test
-
19^th^
- H~2~O
wss://catstrr.swarmstr.com/
うにょうにょてすと
-
@ 04c915da:3dfbecc9
2025-03-12 15:30:46
Recently we have seen a wave of high profile X accounts hacked. These attacks have exposed the fragility of the status quo security model used by modern social media platforms like X. Many users have asked if nostr fixes this, so lets dive in. How do these types of attacks translate into the world of nostr apps? For clarity, I will use X’s security model as representative of most big tech social platforms and compare it to nostr.
The Status Quo
On X, you never have full control of your account. Ultimately to use it requires permission from the company. They can suspend your account or limit your distribution. Theoretically they can even post from your account at will. An X account is tied to an email and password. Users can also opt into two factor authentication, which adds an extra layer of protection, a login code generated by an app. In theory, this setup works well, but it places a heavy burden on users. You need to create a strong, unique password and safeguard it. You also need to ensure your email account and phone number remain secure, as attackers can exploit these to reset your credentials and take over your account. Even if you do everything responsibly, there is another weak link in X infrastructure itself. The platform’s infrastructure allows accounts to be reset through its backend. This could happen maliciously by an employee or through an external attacker who compromises X’s backend. When an account is compromised, the legitimate user often gets locked out, unable to post or regain control without contacting X’s support team. That process can be slow, frustrating, and sometimes fruitless if support denies the request or cannot verify your identity. Often times support will require users to provide identification info in order to regain access, which represents a privacy risk. The centralized nature of X means you are ultimately at the mercy of the company’s systems and staff.
Nostr Requires Responsibility
Nostr flips this model radically. Users do not need permission from a company to access their account, they can generate as many accounts as they want, and cannot be easily censored. The key tradeoff here is that users have to take complete responsibility for their security. Instead of relying on a username, password, and corporate servers, nostr uses a private key as the sole credential for your account. Users generate this key and it is their responsibility to keep it safe. As long as you have your key, you can post. If someone else gets it, they can post too. It is that simple. This design has strong implications. Unlike X, there is no backend reset option. If your key is compromised or lost, there is no customer support to call. In a compromise scenario, both you and the attacker can post from the account simultaneously. Neither can lock the other out, since nostr relays simply accept whatever is signed with a valid key.
The benefit? No reliance on proprietary corporate infrastructure.. The negative? Security rests entirely on how well you protect your key.
Future Nostr Security Improvements
For many users, nostr’s standard security model, storing a private key on a phone with an encrypted cloud backup, will likely be sufficient. It is simple and reasonably secure. That said, nostr’s strength lies in its flexibility as an open protocol. Users will be able to choose between a range of security models, balancing convenience and protection based on need.
One promising option is a web of trust model for key rotation. Imagine pre-selecting a group of trusted friends. If your account is compromised, these people could collectively sign an event announcing the compromise to the network and designate a new key as your legitimate one. Apps could handle this process seamlessly in the background, notifying followers of the switch without much user interaction. This could become a popular choice for average users, but it is not without tradeoffs. It requires trust in your chosen web of trust, which might not suit power users or large organizations. It also has the issue that some apps may not recognize the key rotation properly and followers might get confused about which account is “real.”
For those needing higher security, there is the option of multisig using FROST (Flexible Round-Optimized Schnorr Threshold). In this setup, multiple keys must sign off on every action, including posting and updating a profile. A hacker with just one key could not do anything. This is likely overkill for most users due to complexity and inconvenience, but it could be a game changer for large organizations, companies, and governments. Imagine the White House nostr account requiring signatures from multiple people before a post goes live, that would be much more secure than the status quo big tech model.
Another option are hardware signers, similar to bitcoin hardware wallets. Private keys are kept on secure, offline devices, separate from the internet connected phone or computer you use to broadcast events. This drastically reduces the risk of remote hacks, as private keys never touches the internet. It can be used in combination with multisig setups for extra protection. This setup is much less convenient and probably overkill for most but could be ideal for governments, companies, or other high profile accounts.
Nostr’s security model is not perfect but is robust and versatile. Ultimately users are in control and security is their responsibility. Apps will give users multiple options to choose from and users will choose what best fits their need.
-
@ 16f1a010:31b1074b
2025-03-20 14:32:25
grain is a nostr relay built using Go, currently utilizing MongoDB as its database. Binaries are provided for AMD64 Windows and Linux. grain is Go Relay Architecture for Implementing Nostr
Introduction
grain is a nostr relay built using Go, currently utilizing MongoDB as its database. Binaries are provided for AMD64 Windows and Linux. grain is Go Relay Architecture for Implementing Nostr
Prerequisites
- Grain requires a running MongoDB instance. Please refer to this separate guide for instructions on setting up MongoDB: nostr:naddr1qvzqqqr4gupzq9h35qgq6n8ll0xyyv8gurjzjrx9sjwp4hry6ejnlks8cqcmzp6tqqxnzde5xg6rwwp5xsuryd3knfdr7g
Download Grain
Download the latest release for your system from the GitHub releases page
amd64 binaries provided for Windows and Linux, if you have a different CPU architecture, you can download and install go to build grain from source
Installation and Execution
- Create a new folder on your system where you want to run Grain.
- The downloaded binary comes bundled with a ZIP file containing a folder named "app," which holds the frontend HTML files. Unzip the "app" folder into the same directory as the Grain executable.
Run Grain
- Open your terminal or command prompt and navigate to the Grain directory.
- Execute the Grain binary.
on linux you will first have to make the program executable
chmod +x grain_linux_amd64Then you can run the program
./grain_linux_amd64(alternatively on windows, you can just double click the grain_windows_amd64.exe to start the relay)
You should see a terminal window displaying the port on which your relay and frontend are running.
If you get
Failed to copy app/static/examples/config.example.yml to config.yml: open app/static/examples/config.example.yml: no such file or directory
Then you probably forgot to put the app folder in the same directory as your executable or you did not unzip the folder.
Congrats! You're running grain 🌾!
You may want to change your NIP11 relay information document (relay_metadata.json) This informs clients of the capabilities, administrative contacts, and various server attributes. It's located in the same directory as your executable.
Configuration Files
Once Grain has been executed for the first time, it will generate the default configuration files inside the directory where the executable is located. These files are:
bash config.yml whitelist.yml blacklist.ymlPrerequisites: - Grain requires a running MongoDB instance. Please refer to this separate guide for instructions on setting up MongoDB: [Link to MongoDB setup guide].
Download Grain:
Download the latest release for your system from the GitHub releases page
amd64 binaries provided for Windows and Linux, if you have a different CPU architecture, you can download and install go to build grain from source
Installation and Execution:
- Create a new folder on your system where you want to run Grain.
- The downloaded binary comes bundled with a ZIP file containing a folder named "app," which holds the frontend HTML files. Unzip the "app" folder into the same directory as the Grain executable.
Run Grain:
- Open your terminal or command prompt and navigate to the Grain directory.
- Execute the Grain binary.
on linux you will first have to make the program executable
chmod +x grain_linux_amd64Then you can run the program
./grain_linux_amd64(alternatively on windows, you can just double click the grain_windows_amd64.exe to start the relay)
You should see a terminal window displaying the port on which your relay and frontend are running.
If you get
Failed to copy app/static/examples/config.example.yml to config.yml: open app/static/examples/config.example.yml: no such file or directory
Then you probably forgot to put the app folder in the same directory as your executable or you did not unzip the folder.
Congrats! You're running grain 🌾!
You may want to change your NIP11 relay information document (relay_metadata.json) This informs clients of the capabilities, administrative contacts, and various server attributes. It's located in the same directory as your executable.
Configuration Files:
Once Grain has been executed for the first time, it will generate the default configuration files inside the directory where the executable is located. These files are:
bash config.yml whitelist.yml blacklist.ymlConfiguration Documentation
You can always find the latest example configs on my site or in the github repo here: config.yml
Config.yml
This
config.ymlfile is where you customize how your Grain relay operates. Each section controls different aspects of the relay's behavior.1.
mongodb(Database Settings)uri: mongodb://localhost:27017/:- This is the connection string for your MongoDB database.
mongodb://localhost:27017/indicates that your MongoDB server is running on the same computer as your Grain relay (localhost) and listening on port 27017 (the default MongoDB port).- If your MongoDB server is on a different machine, you'll need to change
localhostto the server's IP address or hostname. - The trailing
/indicates the root of the mongodb server. You will define the database in the next line.
database: grain:- This specifies the name of the MongoDB database that Grain will use to store Nostr events. Grain will create this database if it doesn't already exist.
- You can name the database whatever you want. If you want to run multiple grain relays, you can and they can have different databases running on the same mongo server.
2.
server(Relay Server Settings)port: :8181:- This sets the port on which your Grain relay will listen for incoming nostr websocket connections and what port the frontend will be available at.
read_timeout: 10 # in seconds:- This is the maximum time (in seconds) that the relay will wait for a client to send data before closing the connection.
write_timeout: 10 # in seconds:- This is the maximum time (in seconds) that the relay will wait for a client to receive data before closing the connection.
idle_timeout: 120 # in seconds:- This is the maximum time (in seconds) that the relay will keep a connection open if there's no activity.
max_connections: 100:- This sets the maximum number of simultaneous client connections that the relay will allow.
max_subscriptions_per_client: 10:- This sets the maximum amount of subscriptions a single client can request from the relay.
3.
resource_limits(System Resource Limits)cpu_cores: 2 # Limit the number of CPU cores the application can use:- This restricts the number of CPU cores that Grain can use. Useful for controlling resource usage on your server.
memory_mb: 1024 # Cap the maximum amount of RAM in MB the application can use:- This limits the maximum amount of RAM (in megabytes) that Grain can use.
heap_size_mb: 512 # Set a limit on the Go garbage collector's heap size in MB:- This sets a limit on the amount of memory that the Go programming language's garbage collector can use.
4.
auth(Authentication Settings)enabled: false # Enable or disable AUTH handling:- If set to
true, this enables authentication handling, requiring clients to authenticate before using the relay.
- If set to
relay_url: "wss://relay.example.com/" # Specify the relay URL:- If authentication is enabled, this is the url that clients will use to authenticate.
5.
UserSync(User Synchronization)user_sync: false:- If set to true, the relay will attempt to sync user data from other relays.
disable_at_startup: true:- If user sync is enabled, this will prevent the sync from starting when the relay starts.
initial_sync_relays: [...]:- A list of other relays to pull user data from.
kinds: []:- A list of event kinds to pull from the other relays. Leaving this empty will pull all event kinds.
limit: 100:- The limit of events to pull from the other relays.
exclude_non_whitelisted: true:- If set to true, only users on the whitelist will have their data synced.
interval: 360:- The interval in minutes that the relay will resync user data.
6.
backup_relay(Backup Relay)enabled: false:- If set to true, the relay will send copies of received events to the backup relay.
url: "wss://some-relay.com":- The url of the backup relay.
7.
event_purge(Event Purging)enabled: false:- If set to
true, the relay will automatically delete old events.
- If set to
keep_interval_hours: 24:- The number of hours to keep events before purging them.
purge_interval_minutes: 240:- How often (in minutes) the purging process runs.
purge_by_category: ...:- Allows you to specify which categories of events (regular, replaceable, addressable, deprecated) to purge.
purge_by_kind_enabled: false:- If set to true, events will be purged based on the kinds listed below.
kinds_to_purge: ...:- A list of event kinds to purge.
exclude_whitelisted: true:- If set to true, events from whitelisted users will not be purged.
8.
event_time_constraints(Event Time Constraints)min_created_at: 1577836800:- The minimum
created_attimestamp (Unix timestamp) that events must have to be accepted by the relay.
- The minimum
max_created_at_string: now+5m:- The maximum created at time that an event can have. This example shows that the max created at time is 5 minutes in the future from the time the event is received.
min_created_at_stringandmax_created_atwork the same way.
9.
rate_limit(Rate Limiting)ws_limit: 100:- The maximum number of WebSocket messages per second that the relay will accept.
ws_burst: 200:- Allows a temporary burst of WebSocket messages.
event_limit: 50:- The maximum number of Nostr events per second that the relay will accept.
event_burst: 100:- Allows a temporary burst of Nostr events.
req_limit: 50:- The limit of http requests per second.
req_burst: 100:- The allowed burst of http requests.
max_event_size: 51200:- The maximum size (in bytes) of a Nostr event that the relay will accept.
kind_size_limits: ...:- Allows you to set size limits for specific event kinds.
category_limits: ...:- Allows you to set rate limits for different event categories (ephemeral, addressable, regular, replaceable).
kind_limits: ...:- Allows you to set rate limits for specific event kinds.
By understanding these settings, you can tailor your Grain Nostr relay to meet your specific needs and resource constraints.
whitelist.yml
The
whitelist.ymlfile is used to control which users, event kinds, and domains are allowed to interact with your Grain relay. Here's a breakdown of the settings:1.
pubkey_whitelist(Public Key Whitelist)enabled: false:- If set to
true, this enables the public key whitelist. Only users whose public keys are listed will be allowed to publish events to your relay.
- If set to
pubkeys::- A list of hexadecimal public keys that are allowed to publish events.
pubkey1andpubkey2are placeholders, you will replace these with actual hexadecimal public keys.
npubs::- A list of npubs that are allowed to publish events.
npub18ls2km9aklhzw9yzqgjfu0anhz2z83hkeknw7sl22ptu8kfs3rjq54am44andnpub2are placeholders, replace them with actual npubs.- npubs are bech32 encoded public keys.
2.
kind_whitelist(Event Kind Whitelist)enabled: false:- If set to
true, this enables the event kind whitelist. Only events with the specified kinds will be allowed.
- If set to
kinds::- A list of event kinds (as strings) that are allowed.
"1"and"2"are example kinds. Replace these with the kinds you want to allow.- Example kinds are 0 for metadata, 1 for short text notes, and 2 for recommend server.
3.
domain_whitelist(Domain Whitelist)enabled: false:- If set to
true, this enables the domain whitelist. This checks the domains .well-known folder for their nostr.json. This file contains a list of pubkeys. They will be considered whitelisted if on this list.
- If set to
domains::- A list of domains that are allowed.
"example.com"and"anotherdomain.com"are example domains. Replace these with the domains you want to allow.
blacklist.yml
The
blacklist.ymlfile allows you to block specific content, users, and words from your Grain relay. Here's a breakdown of the settings:1.
enabled: true- This setting enables the blacklist functionality. If set to
true, the relay will actively block content and users based on the rules defined in this file.
2.
permanent_ban_words:- This section lists words that, if found in an event, will result in a permanent ban for the event's author.
- really bad wordis a placeholder. Replace it with any words you want to permanently block.
3.
temp_ban_words:- This section lists words that, if found in an event, will result in a temporary ban for the event's author.
- crypto,- web3, and- airdropare examples. Replace them with the words you want to temporarily block.
4.
max_temp_bans: 3- This sets the maximum number of temporary bans a user can receive before they are permanently banned.
5.
temp_ban_duration: 3600- This sets the duration of a temporary ban in seconds.
3600seconds equals one hour.
6.
permanent_blacklist_pubkeys:- This section lists hexadecimal public keys that are permanently blocked from using the relay.
- db0c9b8acd6101adb9b281c5321f98f6eebb33c5719d230ed1870997538a9765is an example. Replace it with the public keys you want to block.
7.
permanent_blacklist_npubs:- This section lists npubs that are permanently blocked from using the relay.
- npub1x0r5gflnk2mn6h3c70nvnywpy2j46gzqwg6k7uw6fxswyz0md9qqnhshtnis an example. Replace it with the npubs you want to block.- npubs are the human readable version of public keys.
8.
mutelist_authors:- This section lists hexadecimal public keys of author of a kind1000 mutelist. Pubkey authors on this mutelist will be considered on the permanent blacklist. This provides a nostr native way to handle the backlist of your relay
- 3fe0ab6cbdb7ee27148202249e3fb3b89423c6f6cda6ef43ea5057c3d93088e4is an example. Replace it with the public keys of authors that have a mutelist you would like to use as a blacklist. Consider using your own.- Important Note: The mutelist Event MUST be stored in this relay for it to be retrieved. This means your relay must have a copy of the authors kind10000 mutelist to consider them for the blacklist.
Running Grain as a Service:
Windows Service:
To run Grain as a Windows service, you can use tools like NSSM (Non-Sucking Service Manager). NSSM allows you to easily install and manage any application as a Windows service.
* For instructions on how to install NSSM, please refer to this article: [Link to NSSM install guide coming soon].-
Open Command Prompt as Administrator:
- Open the Windows Start menu, type "cmd," right-click on "Command Prompt," and select "Run as administrator."
-
Navigate to NSSM Directory:
- Use the
cdcommand to navigate to the directory where you extracted NSSM. For example, if you extracted it toC:\nssm, you would typecd C:\nssmand press Enter.
- Use the
-
Install the Grain Service:
- Run the command
nssm install grain. - A GUI will appear, allowing you to configure the service.
- Run the command
-
Configure Service Details:
- In the "Path" field, enter the full path to your Grain executable (e.g.,
C:\grain\grain_windows_amd64.exe). - In the "Startup directory" field, enter the directory where your Grain executable is located (e.g.,
C:\grain).
- In the "Path" field, enter the full path to your Grain executable (e.g.,
-
Install the Service:
- Click the "Install service" button.
-
Manage the Service:
- You can now manage the Grain service using the Windows Services manager. Open the Start menu, type "services.msc," and press Enter. You can start, stop, pause, or restart the Grain service from there.
Linux Service (systemd):
To run Grain as a Linux service, you can use systemd, the standard service manager for most modern Linux distributions.
-
Create a Systemd Service File:
- Open a text editor with root privileges (e.g.,
sudo nano /etc/systemd/system/grain.service).
- Open a text editor with root privileges (e.g.,
-
Add Service Configuration:
- Add the following content to the
grain.servicefile, replacing the placeholders with your actual paths and user information:
```toml [Unit] Description=Grain Nostr Relay After=network.target
[Service] ExecStart=/path/to/grain_linux_amd64 WorkingDirectory=/path/to/grain/directory Restart=always User=your_user #replace your_user Group=your_group #replace your_group
[Install] WantedBy=multi-user.target ```
- Replace
/path/to/grain/executablewith the full path to your Grain executable. - Replace
/path/to/grain/directorywith the directory containing your Grain executable. - Replace
your_userandyour_groupwith the username and group that will run the Grain service.
- Add the following content to the
-
Reload Systemd:
- Run the command
sudo systemctl daemon-reloadto reload the systemd configuration.
- Run the command
-
Enable the Service:
- Run the command
sudo systemctl enable grain.serviceto enable the service to start automatically on boot.
- Run the command
-
Start the Service:
- Run the command
sudo systemctl start grain.serviceto start the service immediately.
- Run the command
-
Check Service Status:
- Run the command
sudo systemctl status grain.serviceto check the status of the Grain service. This will show you if the service is running and any recent logs. - You can run
sudo journalctl -f -u grain.serviceto watch the logs
- Run the command
More guides are in the works for setting up tailscale to access your relay from anywhere over a private network and for setting up a cloudflare tunnel to your domain to deploy a grain relay accessible on a subdomain of your site eg wss://relay.yourdomain.com
-
@ 21ffd29c:518a8ff5
2025-03-07 20:56:56
Once upon a time, there was a little boy named Jimmy who had been feeling very sick. He complained about the pain in his throat and nose. His parents tried everything to help him but nothing worked. One day, Jimmy's friend Jeeves came over to visit. He saw that his friend was trying to make something special for his family, and he decided to try home-brewed vaccines as well. Jeeves started experimenting with the homemade vaccine concoctions and made a couple of them. They were very good at making people feel better quickly. One day, Jimmy's parents asked Jeeves if they could have some of these home-made vaccines too. Jeeves agreed, but he had to be careful not to break his blender because it was quite small. The next day, Jeeves brought a mixture of eggs and sheep off the roof of his house, which made him very happy. He started trying them out, and they worked great! Jimmy's parents were so proud of their son for doing something like this. They thanked Jeeves for making such a great home-made vaccine. Jeeves then told Jimmy about how he had found a way to make the blender work again. That was exciting for everyone! The next day, they all tried the homemade vaccines again and made a lot of people feel better quickly too! He decided to make some extra batches of home-made vaccines for everyone who had asked if they could have one too! This was such a fun story! It made everyone feel so happy and excited, and they all wanted -
@ 84b0c46a:417782f5
2025-05-04 09:36:08
-
@ 6871d8df:4a9396c1
2024-02-24 22:42:16
In an era where data seems to be as valuable as currency, the prevailing trend in AI starkly contrasts with the concept of personal data ownership. The explosion of AI and the ensuing race have made it easy to overlook where the data is coming from. The current model, dominated by big tech players, involves collecting vast amounts of user data and selling it to AI companies for training LLMs. Reddit recently penned a 60 million dollar deal, Google guards and mines Youtube, and more are going this direction. But is that their data to sell? Yes, it's on their platforms, but without the users to generate it, what would they monetize? To me, this practice raises significant ethical questions, as it assumes that user data is a commodity that companies can exploit at will.
The heart of the issue lies in the ownership of data. Why, in today's digital age, do we not retain ownership of our data? Why can't our data follow us, under our control, to wherever we want to go? These questions echo the broader sentiment that while some in the tech industry — such as the blockchain-first crypto bros — recognize the importance of data ownership, their "blockchain for everything solutions," to me, fall significantly short in execution.
Reddit further complicates this with its current move to IPO, which, on the heels of the large data deal, might reinforce the mistaken belief that user-generated data is a corporate asset. Others, no doubt, will follow suit. This underscores the urgent need for a paradigm shift towards recognizing and respecting user data as personal property.
In my perfect world, the digital landscape would undergo a revolutionary transformation centered around the empowerment and sovereignty of individual data ownership. Platforms like Twitter, Reddit, Yelp, YouTube, and Stack Overflow, integral to our digital lives, would operate on a fundamentally different premise: user-owned data.
In this envisioned future, data ownership would not just be a concept but a practice, with public and private keys ensuring the authenticity and privacy of individual identities. This model would eliminate the private data silos that currently dominate, where companies profit from selling user data without consent. Instead, data would traverse a decentralized protocol akin to the internet, prioritizing user control and transparency.
The cornerstone of this world would be a meritocratic digital ecosystem. Success for companies would hinge on their ability to leverage user-owned data to deliver unparalleled value rather than their capacity to gatekeep and monetize information. If a company breaks my trust, I can move to a competitor, and my data, connections, and followers will come with me. This shift would herald an era where consent, privacy, and utility define the digital experience, ensuring that the benefits of technology are equitably distributed and aligned with the users' interests and rights.
The conversation needs to shift fundamentally. We must challenge this trajectory and advocate for a future where data ownership and privacy are not just ideals but realities. If we continue on our current path without prioritizing individual data rights, the future of digital privacy and autonomy is bleak. Big tech's dominance allows them to treat user data as a commodity, potentially selling and exploiting it without consent. This imbalance has already led to users being cut off from their digital identities and connections when platforms terminate accounts, underscoring the need for a digital ecosystem that empowers user control over data. Without changing direction, we risk a future where our content — and our freedoms by consequence — are controlled by a few powerful entities, threatening our rights and the democratic essence of the digital realm. We must advocate for a shift towards data ownership by individuals to preserve our digital freedoms and democracy.
-
@ bf47c19e:c3d2573b
2025-02-26 21:00:54
Originalni tekst na dvadesetjedan.com.
Autor: Gigi / Prevod na srpski: Plumsky
Postoji sveto carstvo privatnosti za svakog čoveka gde on bira i pravi odluke – carstvo stvoreno na bazičnim pravima i slobode koje zakon, generalno, ne sme narušavati. Džefri Fišer, Arhiepiskop Canterberija (1959)
Pre ne toliko dugo, uobičajen režim interneta je bio neenkriptovan običan tekst (plain text). Svi su mogli špiunirati svakoga i mnogi nisu o tome ni razmišljali. Globalno obelodanjivanje nadzora 2013. je to promenilo i danas se koriste mnogo bezbedniji protokoli i end-to-end enkripcija postaje standard sve više. Iako bitcoin postaje tinejdžer, mi smo – metaforično govoreći – i dalje u dobu običnog teksta narandžastog novčića. Bitcoin je radikalno providljiv protokol sam po sebi, ali postoje značajni načini da korisnik zaštiti svoju privatnost. U ovom članku želimo da istaknemo neke od ovih strategija, prodiskutujemo najbolje prakse, i damo preporuke koje mogu primeniti i bitcoin novajlije i veterani.
Zašto je privatnost bitna
Privatnost je potrebna da bi otvoreno društvo moglo da funkcioniše u digitalnoj eri. Privatnost nije isto što i tajanstvenost. Privatna stvar je nešto što neko ne želi da ceo svet zna, a tajna stvar je nešto što neko ne želi bilo ko da zna. Privatnost je moć da se čovek selektivno otkriva svom okruženju.
Ovim snažnim rečima Erik Hjus je započeo svoj tekst Sajferpankov Manifesto (Cypherpunk's Manifesto) 1993. Razlika između privatnosti i tajanstvenosti je suptilna ali jako važna. Odlučiti se za privatnost ne znači da neko ima tajne koje želi sakriti. Da ovo ilustrujemo shvatite samo da ono što obavljate u svom toaletu ili u spavaćoj sobi nije niti ilegalno niti tajna (u mnogim slučajevima), ali vi svejedno odlučujete da zatvorite vrata i navučete zavese.
Slično tome, koliko para imate i gde ih trošite nije naručito tajna stvar. Ipak, to bi trebalo biti privatan slučaj. Mnogi bi se složili da vaš šef ne treba da zna gde vi trošite vašu platu. Privatnosti je čak zaštićena od strane mnogobrojnih internacionalnih nadležnih organa. Iz Američke Deklaracije Prava i Dužnosti Čoveka (American Declaration of the Rights and Duties of Man) Ujedinjenim Nacijama, napisano je da je privatnost fundamentalno prava gradjana širom sveta.
Niko ne sme biti podvrgnut smetnjama njegovoj privatnosti, porodici, rezidenciji ili komunikacijama, niti napadnuta njegova čast i reputacija. Svi imaju pravo da se štite zakonom protiv takvih smetnja ili napada. Artikal 12, Deklaracija Ljudskih Prava Ujedinjenih Nacija
Bitcoin i privatnost
Iako je bitcoin često opisivan kao anoniman način plaćanja medijima, on u stvari poseduje potpuno suprotne osobine. On je poluanoniman u najboljem slučaju i danas mnogima nije ni malo lako primeniti taktike da bi bili sigurni da njihov poluanonimni identitet na bitcoin mreži ne bude povezan sa legalnim identitetom u stvarnom svetu.
Bitcoin je otvoren sistem. On je javna baza podataka koju svako može da proučava i analizira. Znači, svaka transakcija koja je upisana u tu bazu kroz dokaz rada (proof-of-work) postojaće i biće otkrivena dokle god bitcoin postoji, što znači - zauvek. Ne primenjivati najbolje prakse privatnosti može imati štetne posledice u dalekoj budućnosti.
Privatnost, kao sigurnost, je proces koji je težak, ali nije nemoguć. Alatke nastavljaju da se razvijaju koje čuvaju privatnost kad se koristi bitcoin and srećom mnoge od tih alatki su sve lakše za korišćenje. Nažalost ne postoji panacea u ovom pristupu. Mora se biti svesan svih kompromisa i usavršavati te prakse dok se one menjaju.
Najbolje prakse privatnosti
Kao i sve u bitcoinu, kontrola privatnosti je postepena, korak po korak, procedura. Naučiti i primeniti ove najbolje prakse zahteva strpljivost i odgovornost, tako da ne budite obeshrabreni ako vam se čini da je to sve previše. Svaki korak, koliko god bio mali, je korak u dobrom pravcu.
Koje korake preduzeti da bi uvećali svoju privatnost:
- Budite u vlasništvu sami svojih novčića
- Nikad ne ponavljajte korišćenje istih adresa
- Minimizirajte korišćenje servisa koji zahtevaju identitet (Know your customer - KYC)
- Minimizirajte sve izloženosti trećim licima
- Upravljajte svojim nodom
- Koristite Lightning mrežu za male transakcije
- Nemojte koristiti javne blok pretraživače za svoje transakcije
- Koristite metodu CoinJoin često i rano pri nabavljanju svojih novčića
Budite u vlasništvu sami svojih novčića: Ako ključevi nisu tvoji, onda nije ni bitcoin. Ako neko drugo drži vaš bitcoin za vas, oni znaju sve što se može znati: količinu, istoriju transakcija pa i sve buduće transakcije, itd. Preuzimanje vlasništva bitcoina u svoje ruke je prvi i najvažniji korak.
Nikad ne kroistite istu adresu dvaput: Ponavljanje adresa poništava privatnost pošiljalca i primaoca bitcoina. Ovo se treba izbegavati pod svaku cenu.
Minimizirajte korišćenje servisa koji zahtevaju identitet (KYC): Vezivati svoj legalni identitet za svoje bitcoin adrese je zlo koje se zahteva od strane mnogih državnih nadležnosti. Dok je efektivnost ovih zakona i regulacija disputabilno, posledice njihovog primenjivanja su uglavnom štetne po korisnicima. Ovo je očigledno pošto je česta pojava da se te informacije često izlivaju iz slabo obezbeđenih digitalnih servera. Ako izaberete da koristite KYC servise da bi nabavljali bitcoin, proučite i razumite odnos između vas i tog biznisa. Vi ste poverljivi tom biznisu za sve vaše lične podatke, pa i buduće obezbeđenje tih podataka. Ako i dalje zarađujete kroz fiat novčani sistem, mi preporučujemo da koristite samo bitcoin ekskluzivne servise koji vam dozvoljavaju da autamatski kupujete bitcoin s vremena na vreme. Ako zelite da potpuno da izbegnete KYC, pregledajte https://bitcoinqna.github.io/noKYConly/.
Minimizirajte sve izloženosti trećim licima: Poverljivost trećim licima je bezbednosna rupa (https://nakamotoinstitute.org/trusted-third-parties/). Ako možete biti poverljivi samo sebi, onda bi to tako trebalo da bude.
Upravljajte svojim nodom: Ako nod nije tvoj, onda nisu ni pravila. Upravljanje svojim nodom je suštinska potreba da bi se bitcoin koristio na privatan način. Svaka interakcija sa bitcoin mrežom je posrednjena nodom. Ako vi taj nod ne upravljate, čiji god nod koristite može da vidi sve što vi radite. Ova upustva (https://bitcoiner.guide/node/) su jako korisna da bi započeli proces korišćenja svog noda.
Koristite Lightning mrežu za male transakcije: Pošto Lightning protokol ne koristi glavnu bitcoin mrežu za trasakcije onda je i samim tim povećana privatnost korišćenja bez dodatnog truda. Iako je i dalje rano, oni apsolutno bezobzirni periodi Lightning mreže su verovatno daleko iza nas. Korišćenje Lightning-a za transakcije malih i srednjih veličina će vam pomoći da uvećate privatnost a da smanjite naplate svojih pojedinačnih bitcoin transakcija.
Nemojte koristiti javne blok pretraživače za svoje transakcije: Proveravanje adresa na javnim blok pretraživačima povezuje te adrese sa vašim IP podacima, koji se onda mogu koristiti da se otkrije vaš identitet. Softveri kao Umbrel i myNode vam omogućavaju da lako koristite sami svoj blok pretraživač. Ako morate koristiti javne pretraživače, uradite to uz VPN ili Tor.
Koristite CoinJoin često i rano pri nabavljanju svojih novčića: Pošto je bitcoin večan, primenjivanje saradničkih CoinJoin praksa će vam obezbediti privatnost u budućnosti. Dok su CoinJoin transakcije svakovrsne, softveri koji su laki za korišćenje već sad postoje koji mogu automatizovati ovu vrstu transakcija. Samourai Whirlpool (https://samouraiwallet.com/whirlpool) je odličan izbor za Android korisnike. Joinmarket (https://github.com/joinmarket-webui/jam) se može koristiti na vašem nodu. A servisi postoje koji pri snabdevanju vašeg bitcoina istog trenutka obave CoinJoin tranzakciju automatski.
Zaključak
Svi bi trebalo da se potrude da koriste bitcoin na što privatniji način. Privatnost nije isto što i tajanstvenost. Privatnost je ljudsko pravo i mi svi trebamo da branimo i primenljujemo to pravo. Teško je izbrisati postojeće informacije sa interneta; a izbrisati ih sa bitcoin baze podataka je nemoguće. Iako su daleko od savršenih, alatke postoje danas koje vam omogućavaju da najbolje prakse privatnosti i vi sami primenite. Mi smo vam naglasili neke od njih i - kroz poboljšanje u bitcoin protokolu kroz Taproot i Schnorr - one će postajati sve usavršenije.
Bitcoin postupci se ne mogu lako opisati korišćenjem tradicionalnim konceptima. Pitanja kao što su "Ko je vlasnik ovog novca?" ili "Odakle taj novac potiče?" postaju sve teža da se odgovore a u nekim okolnostima postaju potpuno beznačajna.
Satoši je dizajnirao bitcoin misleći na privatnost. Na nivou protokola svaka bitcoin transakcija je proces "topljenja" koji za sobom samo ostavlja heuristične mrvice hleba. Protokolu nije bitno odakle se pojavio bilo koji bitcoin ili satoši. Niti je njega briga ko je legalan identitet vlasnika. Protokolu je samo važno da li su digitalni potpisi validni. Dokle god je govor slobodan, potpisivanje poruka - privatno ili ne - ne sme biti kriminalan postupak.
Dodatni Resursi
This Month in Bitcoin Privacy | Janine
Hodl Privacy FAQ | 6102
Digital Privacy | 6102
UseWhirlpool.com | Bitcoin Q+A
Bitcoin Privacy Guide | Bitcoin Q+A
Ovaj članak napisan je u saradnji sa Matt Odellom, nezavisnim bitcoin istraživačem. Nađite njegove preporuke za privatnost na werunbtc.com
-
@ 1f79058c:eb86e1cb
2025-05-04 09:34:30
I think we should agree on an HTML element for pointing to the Nostr representation of a document/URL on the Web. We could use the existing one for link relations for example:
html <link rel="alternate" type="application/nostr+json" href="nostr:naddr1qvzqqqr4..." title="This article on Nostr" />This would be useful in multiple ways:
- Nostr clients, when fetching meta/preview information for a URL that is linked in a note, can detect that there's a Nostr representation of the content, and then render it in Nostr-native ways (whatever that may be depending on the client)
- User agents, usually a browser or browser extension, when opening a URL on the Web, can offer opening the alternative representation of a page in a Nostr client. And/or they could offer to follow the author's pubkey on Nostr. And/or they could offer to zap the content.
- When publishing a new article, authors can share their preferred Web URL everywhere, without having to consider if the reader knows about or uses Nostr at all. However, if a Nostr user finds the Web version of an article outside of Nostr, they can now easily jump to the Nostr version of it.
- Existing Web publications can retroactively create Nostr versions of their content and easily link the Nostr articles on all of their existing article pages without having to add prominent Nostr links everywhere.
There are probably more use cases, like Nostr search engines and whatnot. If you can think of something interesting, please tell me.
Update: I came up with another interesting use case, which is adding alternate links to RSS and Atom feeds.
Proof of concept
In order to show one way in which this could be used, I have created a small Web Extension called Nostr Links, which will discover alternate Nostr links on the pages you visit.
If it finds one or more links, it will show a purple Nostr icon in the address bar, which you can click to open the list of links. It's similar to e.g. the Feed Preview extension, and also to what the Tor Browser does when it discovers an Onion-Location for the page you're looking at:
The links in this popup menu will be
web+nostr:links, because browsers currently do not allow web apps or extensions to handle unprefixednostr:links. (I hope someone is working on getting those on par withipfs:etc.)Following such a link will either open your default Nostr Web app, if you have already configured one, or it will ask you which Web app to open the link with.
Caveat emptor: At the time of writing, my personal default Web app, noStrudel, needs a new release for the links to find the content.
Try it now
Have a look at the source code and/or download the extension (currently only for Firefox).
I have added alternate Nostr links to the Web pages of profiles and long-form content on the Kosmos relay's domain. It's probably the only place on the Web, which will trigger the extension right now.
You can look at this very post to find an alternate link for example.
Update: A certain fiatjaf has added the element to his personal website, which is built entirely from Nostr articles. Multiple other devs also expressed their intent to implement.
Update 2: There is now a pull request for documenting this approach in two existing NIPs. Your feedback is welcome there.
-
@ a296b972:e5a7a2e8
2025-05-04 08:30:56
Am Ende der Woche von Unseremeinungsfreiheit wird in der Unserehauptstadt von Unserdeutschland, Unserberlin, voraussichtlich der neue Unserbundeskanzler vereidigt.
Der Schwur des voraussichtlich nächsten Unserbundeskanzlers sollte aktualisiert werden:
Jetzt, wo endlich mein Traum in Erfüllung geht, nur einmal im Leben Unserbundeskanzler zu werden, zahlen sich für mich alle Tricks und Kniffe aus, die ich angewendet habe, um unter allen Umständen in diese Position zu kommen.
Ich schwöre, dass ich meine Kraft meinem Wohle widmen, meinen Nutzen mehren, nach Vorbild meines Vorgängers Schaden von mir wenden, das Grundgesetz und die Gesetze des Unserbundes formen, meine Pflichten unsergewissenhaft erfüllen und Unseregerechtigkeit gegen jedermann und jederfrau nicht nur üben, sondern unter allen Umständen auch durchsetzen werde, die sich mir bei der Umsetzung der Vorstellungen von Unseredemokratie in den Weg stellen. (So wahr mir wer auch immer helfe).
Der Antrittsbesuch des Unserbundeskanzlers beim Repräsentanten der noch in Unserdeutschland präsenten Besatzungsmacht wird mit Spannung erwartet.
Ein großer Teil der Unsereminister ist schon bekannt. Die Auswahl verspricht viele Unsereüberraschungen.
Die Unsereeinheitspartei, bestehend aus ehemaligen Volksparteien, wird weiterhin dafür sorgen, dass die Nicht-Unsereopposition so wenig wie möglich Einfluss erhält, obwohl sie von den Nicht-Unserebürgern, die mindestens ein Viertel der Urnengänger ausmachen, voll-demokratisch gewählt wurde.
Das Zentralkomitee der Deutschen Unseredemokratischen Bundesrepublik wird zum Wohle seiner Unserebürger alles daransetzen, Unseredemokratie weiter voranzubringen und hofft auch weiterhin auf die Unterstützung von Unser-öffentlich-rechtlicher-Rundfunk.
Die Unserepressefreiheit wird auch weiterhin garantiert.
Auf die Verlautbarungen der Unserepressekonferenz, besetzt mit frischem Unserpersonal, brauchen die Insassen von Unserdeutschland auch weiterhin nicht zu verzichten.
Alles, was nicht gesichert unserdemokratisch ist, gilt als gesichert rechtsextrem.
Als Maxime gilt für alles Handeln: Es muss unter allen Umständen demokratisch aussehen, aber wir (die Unseredemokraten) müssen alles in der Hand haben.
Es ist unwahrscheinlich, dass Unsersondervermögen von den Unserdemokraten zurückgezahlt wird. Dieser Vorzug ist den Unserebürgern und den Nicht-Unserebürgern durch Unseresteuerzahlungen vorbehalten.
Die Unserebundeswehr soll aufgebaut werden (Baut auf, baut auf!), die Unsererüstungsindustrie läuft auf Hochtouren und soll Unserdeutschland wieder unserkriegstüchtig machen, weil Russland immer Unserfeind sein wird.
Von Unserdeutschland soll nur noch Unserfrieden ausgehen.
Zur Bekräftigung, dass alles seinen unser-sozialistischen Gang geht, tauchte die Phoenix*in aus der Asche auf, in dem Unseremutti kürzlich ihren legendären Satz wiederholte:
Wir schaffen das.
Ob damit der endgültige wirtschaftliche Untergang und die Vollendung der gesellschaftlichen Spaltung von Unserdeutschland gemeint war, ist nicht überliefert.
Orwellsche Schlussfolgerung:
Wir = unser
Ihr = Euer
Vogel und Maus passen nicht zusammen
Ausgerichtet auf Ruinen und der Zukunft abgewandt, Uneinigkeit und Unrecht und Unfreiheit für das deutsche Unserland.
Unserdeutschland – ein Land mit viel Vergangenheit und wenig Zukunft?
Es ist zum Heulen.
Dieser Artikel wurde mit dem Pareto-Client geschrieben
* *
(Bild von pixabay)
-
@ 8ce092d8:950c24ad
2024-02-04 23:35:07
Overview
- Introduction
- Model Types
- Training (Data Collection and Config Settings)
- Probability Viewing: AI Inspector
- Match
- Cheat Sheet
I. Introduction
AI Arena is the first game that combines human and artificial intelligence collaboration.
AI learns your skills through "imitation learning."
Official Resources
- Official Documentation (Must Read): Everything You Need to Know About AI Arena
Watch the 2-minute video in the documentation to quickly understand the basic flow of the game. 2. Official Play-2-Airdrop competition FAQ Site https://aiarena.notion.site/aiarena/Gateway-to-the-Arena-52145e990925499d95f2fadb18a24ab0 3. Official Discord (Must Join): https://discord.gg/aiarenaplaytest for the latest announcements or seeking help. The team will also have a exclusive channel there. 4. Official YouTube: https://www.youtube.com/@aiarena because the game has built-in tutorials, you can choose to watch videos.
What is this game about?
- Although categorized as a platform fighting game, the core is a probability-based strategy game.
- Warriors take actions based on probabilities on the AI Inspector dashboard, competing against opponents.
- The game does not allow direct manual input of probabilities for each area but inputs information through data collection and establishes models by adjusting parameters.
- Data collection emulates fighting games, but training can be completed using a Dummy As long as you can complete the in-game tutorial, you can master the game controls.
II. Model Types
Before training, there are three model types to choose from: Simple Model Type, Original Model Type, and Advanced Model Type.
It is recommended to try the Advanced Model Type after completing at least one complete training with the Simple Model Type and gaining some understanding of the game.

Simple Model Type
The Simple Model is akin to completing a form, and the training session is comparable to filling various sections of that form.
This model has 30 buckets. Each bucket can be seen as telling the warrior what action to take in a specific situation. There are 30 buckets, meaning 30 different scenarios. Within the same bucket, the probabilities for direction or action are the same.
For example: What should I do when I'm off-stage — refer to the "Recovery (you off-stage)" bucket.
For all buckets, refer to this official documentation:
https://docs.aiarena.io/arenadex/game-mechanics/tabular-model-v2
Video (no sound): The entire training process for all buckets
https://youtu.be/1rfRa3WjWEA
Game version 2024.1.10. The method of saving is outdated. Please refer to the game updates.
Advanced Model Type
The "Original Model Type" and "Advanced Model Type" are based on Machine Learning, which is commonly referred to as combining with AI.
The Original Model Type consists of only one bucket, representing the entire map. If you want the AI to learn different scenarios, you need to choose a "Focus Area" to let the warrior know where to focus. A single bucket means that a slight modification can have a widespread impact on the entire model. This is where the "Advanced Model Type" comes in.
The "Advanced Model Type" can be seen as a combination of the "Original Model Type" and the "Simple Model Type". The Advanced Model Type divides the map into 8 buckets. Each bucket can use many "Focus Area." For a detailed explanation of the 8 buckets and different Focus Areas, please refer to the tutorial page (accessible in the Advanced Model Type, after completing a training session, at the top left of the Advanced Config, click on "Tutorial").

III. Training (Data Collection and Config Settings)
Training Process:
- Collect Data
- Set Parameters, Train, and Save
- Repeat Step 1 until the Model is Complete
Training the Simple Model Type is the easiest to start with; refer to the video above for a detailed process.
Training the Advanced Model Type offers more possibilities through the combination of "Focus Area" parameters, providing a higher upper limit. While the Original Model Type has great potential, it's harder to control. Therefore, this section focuses on the "Advanced Model Type."
1. What Kind of Data to Collect
- High-Quality Data: Collect purposeful data. Garbage in, garbage out. Only collect the necessary data; don't collect randomly. It's recommended to use Dummy to collect data. However, don't pursue perfection; through parameter adjustments, AI has a certain level of fault tolerance.
- Balanced Data: Balance your dataset. In simple terms, if you complete actions on the left side a certain number of times, also complete a similar number on the right side. While data imbalance can be addressed through parameter adjustments (see below), it's advised not to have this issue during data collection.
- Moderate Amount: A single training will include many individual actions. Collect data for each action 1-10 times. Personally, it's recommended to collect data 2-3 times for a single action. If the effect of a single training is not clear, conduct a second (or even third) training with the same content, but with different parameter settings.
2. What to Collect (and Focus Area Selection)
Game actions mimic fighting games, consisting of 4 directions + 6 states (Idle, Jump, Attack, Grab, Special, Shield). Directions can be combined into ↗, ↘, etc. These directions and states can then be combined into different actions.
To make "Focus Area" effective, you need to collect data in training that matches these parameters. For example, for "Distance to Opponent", you need to collect data when close to the opponent and also when far away. * Note: While you can split into multiple training sessions, it's most effective to cover different situations within a single training.
Refer to the Simple Config, categorize the actions you want to collect, and based on the game scenario, classify them into two categories: "Movement" and "Combat."

Movement-Based Actions
Action Collection
When the warrior is offstage, regardless of where the opponent is, we require the warrior to return to the stage to prevent self-destruction.
This involves 3 aerial buckets: 5 (Near Blast Zone), 7 (Under Stage), and 8 (Side Of Stage).

* Note: The background comes from the Tutorial mentioned earlier. The arrows in the image indicate the direction of the action and are for reference only. * Note: Action collection should be clean; do not collect actions that involve leaving the stage.
Config Settings
In the Simple Config, you can directly choose "Movement" in it. However, for better customization, it's recommended to use the Advanced Config directly. - Intensity: The method for setting Intensity will be introduced separately later. - Buckets: As shown in the image, choose the bucket you are training. - Focus Area: Position-based parameters: - Your position (must) - Raycast Platform Distance, Raycast Platform Type (optional, generally choose these in Bucket 7)
Combat-Based Actions
The goal is to direct attacks quickly and effectively towards the opponent, which is the core of game strategy.
This involves 5 buckets: - 2 regular situations - In the air: 6 (Safe Zone) - On the ground: 4 (Opponent Active) - 3 special situations on the ground: - 1 Projectile Active - 2 Opponent Knockback - 3 Opponent Stunned
2 Regular Situations
In the in-game tutorial, we learned how to perform horizontal attacks. However, in the actual game, directions expand to 8 dimensions. Imagine having 8 relative positions available for launching hits against the opponent. Our task is to design what action to use for attack or defense at each relative position.
Focus Area - Basic (generally select all) - Angle to opponent
- Distance to opponent - Discrete Distance: Choosing this option helps better differentiate between closer and farther distances from the opponent. As shown in the image, red indicates a relatively close distance, and green indicates a relatively distant distance.- Advanced: Other commonly used parameters
- Direction: different facings to opponent
- Your Elemental Gauge and Discrete Elementals: Considering the special's charge
- Opponent action: The warrior will react based on the opponent's different actions.
- Your action: Your previous action. Choose this if teaching combos.
3 Special Situations on the Ground
Projectile Active, Opponent Stunned, Opponent Knockback These three buckets can be referenced in the Simple Model Type video. The parameter settings approach is the same as Opponent Active/Safe Zone.
For Projectile Active, in addition to the parameters based on combat, to track the projectile, you also need to select "Raycast Projectile Distance" and "Raycast Projectile On Target."
3. Setting "Intensity"
Resources
- The "Tutorial" mentioned earlier explains these parameters.
- Official Config Document (2022.12.24): https://docs.google.com/document/d/1adXwvDHEnrVZ5bUClWQoBQ8ETrSSKgG5q48YrogaFJs/edit
TL;DR:
Epochs: - Adjust to fewer epochs if learning is insufficient, increase for more learning.
Batch Size: - Set to the minimum (16) if data is precise but unbalanced, or just want it to learn fast - Increase (e.g., 64) if data is slightly imprecise but balanced. - If both imprecise and unbalanced, consider retraining.
Learning Rate: - Maximize (0.01) for more learning but a risk of forgetting past knowledge. - Minimize for more accurate learning with less impact on previous knowledge.
Lambda: - Reduce for prioritizing learning new things.
Data Cleaning: - Enable "Remove Sparsity" unless you want AI to learn idleness. - For special cases, like teaching the warrior to use special moves when idle, refer to this tutorial video: https://discord.com/channels/1140682688651612291/1140683283626201098/1195467295913431111
Personal Experience: - Initial training with settings: 125 epochs, batch size 16, learning rate 0.01, lambda 0, data cleaning enabled. - Prioritize Multistream, sometimes use Oversampling. - Fine-tune subsequent training based on the mentioned theories.
IV. Probability Viewing: AI Inspector
The dashboard consists of "Direction + Action." Above the dashboard, you can see the "Next Action" – the action the warrior will take in its current state. The higher the probability, the more likely the warrior is to perform that action, indicating a quicker reaction. It's essential to note that when checking the Direction, the one with the highest visual representation may not have the highest numerical value. To determine the actual value, hover the mouse over the graphical representation, as shown below, where the highest direction is "Idle."

In the map, you can drag the warrior to view the probabilities of the warrior in different positions. Right-click on the warrior with the mouse to change the warrior's facing. The status bar below can change the warrior's state on the map.

When training the "Opponent Stunned, Opponent Knockback" bucket, you need to select the status below the opponent's status bar. If you are focusing on "Opponent action" in the Focus Zone, choose the action in the opponent's status bar. If you are focusing on "Your action" in the Focus Zone, choose the action in your own status bar. When training the "Projectile Active" Bucket, drag the projectile on the right side of the dashboard to check the status.
Next
The higher the probability, the faster the reaction. However, be cautious when the action probability reaches 100%. This may cause the warrior to be in a special case of "State Transition," resulting in unnecessary "Idle" states.
Explanation: In each state a fighter is in, there are different "possible transitions". For example, from falling state you cannot do low sweep because low sweep requires you to be on the ground. For the shield state, we do not allow you to directly transition to headbutt. So to do headbutt you have to first exit to another state and then do it from there (assuming that state allows you to do headbutt). This is the reason the fighter runs because "run" action is a valid state transition from shield. Source
V. Learn from Matches
After completing all the training, your model is preliminarily finished—congratulations! The warrior will step onto the arena alone and embark on its debut!
Next, we will learn about the strengths and weaknesses of the warrior from battles to continue refining the warrior's model.
In matches, besides appreciating the performance, pay attention to the following:
-
Movement, i.e., Off the Stage: Observe how the warrior gets eliminated. Is it due to issues in the action settings at a certain position, or is it a normal death caused by a high percentage? The former is what we need to avoid and optimize.
-
Combat: Analyze both sides' actions carefully. Observe which actions you and the opponent used in different states. Check which of your hits are less effective, and how does the opponent handle different actions, etc.
The approach to battle analysis is similar to the thought process in the "Training", helping to have a more comprehensive understanding of the warrior's performance and making targeted improvements.
VI. Cheat Sheet
Training 1. Click "Collect" to collect actions. 2. "Map - Data Limit" is more user-friendly. Most players perform initial training on the "Arena" map. 3. Switch between the warrior and the dummy: Tab key (keyboard) / Home key (controller). 4. Use "Collect" to make the opponent loop a set of actions. 5. Instantly move the warrior to a specific location: Click "Settings" - SPAWN - Choose the desired location on the map - On. Press the Enter key (keyboard) / Start key (controller) during training.
Inspector 1. Right-click on the fighter to change their direction. Drag the fighter and observe the changes in different positions and directions. 2. When satisfied with the training, click "Save." 3. In "Sparring" and "Simulation," use "Current Working Model." 4. If satisfied with a model, then click "compete." The model used in the rankings is the one marked as "competing."
Sparring / Ranked 1. Use the Throneroom map only for the top 2 or top 10 rankings. 2. There is a 30-second cooldown between matches. The replays are played for any match. Once the battle begins, you can see the winner on the leaderboard or by right-clicking the page - Inspect - Console. Also, if you encounter any errors or bugs, please send screenshots of the console to the Discord server.
Good luck! See you on the arena!
-
@ 3bf0c63f:aefa459d
2024-01-14 14:52:16
Drivechain
Understanding Drivechain requires a shift from the paradigm most bitcoiners are used to. It is not about "trustlessness" or "mathematical certainty", but game theory and incentives. (Well, Bitcoin in general is also that, but people prefer to ignore it and focus on some illusion of trustlessness provided by mathematics.)
Here we will describe the basic mechanism (simple) and incentives (complex) of "hashrate escrow" and how it enables a 2-way peg between the mainchain (Bitcoin) and various sidechains.
The full concept of "Drivechain" also involves blind merged mining (i.e., the sidechains mine themselves by publishing their block hashes to the mainchain without the miners having to run the sidechain software), but this is much easier to understand and can be accomplished either by the BIP-301 mechanism or by the Spacechains mechanism.
How does hashrate escrow work from the point of view of Bitcoin?
A new address type is created. Anything that goes in that is locked and can only be spent if all miners agree on the Withdrawal Transaction (
WT^) that will spend it for 6 months. There is one of these special addresses for each sidechain.To gather miners' agreement
bitcoindkeeps track of the "score" of all transactions that could possibly spend from that address. On every block mined, for each sidechain, the miner can use a portion of their coinbase to either increase the score of oneWT^by 1 while decreasing the score of all others by 1; or they can decrease the score of allWT^s by 1; or they can do nothing.Once a transaction has gotten a score high enough, it is published and funds are effectively transferred from the sidechain to the withdrawing users.
If a timeout of 6 months passes and the score doesn't meet the threshold, that
WT^is discarded.What does the above procedure mean?
It means that people can transfer coins from the mainchain to a sidechain by depositing to the special address. Then they can withdraw from the sidechain by making a special withdraw transaction in the sidechain.
The special transaction somehow freezes funds in the sidechain while a transaction that aggregates all withdrawals into a single mainchain
WT^, which is then submitted to the mainchain miners so they can start voting on it and finally after some months it is published.Now the crucial part: the validity of the
WT^is not verified by the Bitcoin mainchain rules, i.e., if Bob has requested a withdraw from the sidechain to his mainchain address, but someone publishes a wrongWT^that instead takes Bob's funds and sends them to Alice's main address there is no way the mainchain will know that. What determines the "validity" of theWT^is the miner vote score and only that. It is the job of miners to vote correctly -- and for that they may want to run the sidechain node in SPV mode so they can attest for the existence of a reference to theWT^transaction in the sidechain blockchain (which then ensures it is ok) or do these checks by some other means.What? 6 months to get my money back?
Yes. But no, in practice anyone who wants their money back will be able to use an atomic swap, submarine swap or other similar service to transfer funds from the sidechain to the mainchain and vice-versa. The long delayed withdraw costs would be incurred by few liquidity providers that would gain some small profit from it.
Why bother with this at all?
Drivechains solve many different problems:
It enables experimentation and new use cases for Bitcoin
Issued assets, fully private transactions, stateful blockchain contracts, turing-completeness, decentralized games, some "DeFi" aspects, prediction markets, futarchy, decentralized and yet meaningful human-readable names, big blocks with a ton of normal transactions on them, a chain optimized only for Lighting-style networks to be built on top of it.
These are some ideas that may have merit to them, but were never actually tried because they couldn't be tried with real Bitcoin or inferfacing with real bitcoins. They were either relegated to the shitcoin territory or to custodial solutions like Liquid or RSK that may have failed to gain network effect because of that.
It solves conflicts and infighting
Some people want fully private transactions in a UTXO model, others want "accounts" they can tie to their name and build reputation on top; some people want simple multisig solutions, others want complex code that reads a ton of variables; some people want to put all the transactions on a global chain in batches every 10 minutes, others want off-chain instant transactions backed by funds previously locked in channels; some want to spend, others want to just hold; some want to use blockchain technology to solve all the problems in the world, others just want to solve money.
With Drivechain-based sidechains all these groups can be happy simultaneously and don't fight. Meanwhile they will all be using the same money and contributing to each other's ecosystem even unwillingly, it's also easy and free for them to change their group affiliation later, which reduces cognitive dissonance.
It solves "scaling"
Multiple chains like the ones described above would certainly do a lot to accomodate many more transactions that the current Bitcoin chain can. One could have special Lightning Network chains, but even just big block chains or big-block-mimblewimble chains or whatnot could probably do a good job. Or even something less cool like 200 independent chains just like Bitcoin is today, no extra features (and you can call it "sharding"), just that would already multiply the current total capacity by 200.
Use your imagination.
It solves the blockchain security budget issue
The calculation is simple: you imagine what security budget is reasonable for each block in a world without block subsidy and divide that for the amount of bytes you can fit in a single block: that is the price to be paid in satoshis per byte. In reasonable estimative, the price necessary for every Bitcoin transaction goes to very large amounts, such that not only any day-to-day transaction has insanely prohibitive costs, but also Lightning channel opens and closes are impracticable.
So without a solution like Drivechain you'll be left with only one alternative: pushing Bitcoin usage to trusted services like Liquid and RSK or custodial Lightning wallets. With Drivechain, though, there could be thousands of transactions happening in sidechains and being all aggregated into a sidechain block that would then pay a very large fee to be published (via blind merged mining) to the mainchain. Bitcoin security guaranteed.
It keeps Bitcoin decentralized
Once we have sidechains to accomodate the normal transactions, the mainchain functionality can be reduced to be only a "hub" for the sidechains' comings and goings, and then the maximum block size for the mainchain can be reduced to, say, 100kb, which would make running a full node very very easy.
Can miners steal?
Yes. If a group of coordinated miners are able to secure the majority of the hashpower and keep their coordination for 6 months, they can publish a
WT^that takes the money from the sidechains and pays to themselves.Will miners steal?
No, because the incentives are such that they won't.
Although it may look at first that stealing is an obvious strategy for miners as it is free money, there are many costs involved:
- The cost of ceasing blind-merged mining returns -- as stealing will kill a sidechain, all the fees from it that miners would be expected to earn for the next years are gone;
- The cost of Bitcoin price going down: If a steal is successful that will mean Drivechains are not safe, therefore Bitcoin is less useful, and miner credibility will also be hurt, which are likely to cause the Bitcoin price to go down, which in turn may kill the miners' businesses and savings;
- The cost of coordination -- assuming miners are just normal businesses, they just want to do their work and get paid, but stealing from a Drivechain will require coordination with other miners to conduct an immoral act in a way that has many pitfalls and is likely to be broken over the months;
- The cost of miners leaving your mining pool: when we talked about "miners" above we were actually talking about mining pools operators, so they must also consider the risk of miners migrating from their mining pool to others as they begin the process of stealing;
- The cost of community goodwill -- when participating in a steal operation, a miner will suffer a ton of backlash from the community. Even if the attempt fails at the end, the fact that it was attempted will contribute to growing concerns over exaggerated miners power over the Bitcoin ecosystem, which may end up causing the community to agree on a hard-fork to change the mining algorithm in the future, or to do something to increase participation of more entities in the mining process (such as development or cheapment of new ASICs), which have a chance of decreasing the profits of current miners.
Another point to take in consideration is that one may be inclined to think a newly-created sidechain or a sidechain with relatively low usage may be more easily stolen from, since the blind merged mining returns from it (point 1 above) are going to be small -- but the fact is also that a sidechain with small usage will also have less money to be stolen from, and since the other costs besides 1 are less elastic at the end it will not be worth stealing from these too.
All of the above consideration are valid only if miners are stealing from good sidechains. If there is a sidechain that is doing things wrong, scamming people, not being used at all, or is full of bugs, for example, that will be perceived as a bad sidechain, and then miners can and will safely steal from it and kill it, which will be perceived as a good thing by everybody.
What do we do if miners steal?
Paul Sztorc has suggested in the past that a user-activated soft-fork could prevent miners from stealing, i.e., most Bitcoin users and nodes issue a rule similar to this one to invalidate the inclusion of a faulty
WT^and thus cause any miner that includes it in a block to be relegated to their own Bitcoin fork that other nodes won't accept.This suggestion has made people think Drivechain is a sidechain solution backed by user-actived soft-forks for safety, which is very far from the truth. Drivechains must not and will not rely on this kind of soft-fork, although they are possible, as the coordination costs are too high and no one should ever expect these things to happen.
If even with all the incentives against them (see above) miners do still steal from a good sidechain that will mean the failure of the Drivechain experiment. It will very likely also mean the failure of the Bitcoin experiment too, as it will be proven that miners can coordinate to act maliciously over a prolonged period of time regardless of economic and social incentives, meaning they are probably in it just for attacking Bitcoin, backed by nation-states or something else, and therefore no Bitcoin transaction in the mainchain is to be expected to be safe ever again.
Why use this and not a full-blown trustless and open sidechain technology?
Because it is impossible.
If you ever heard someone saying "just use a sidechain", "do this in a sidechain" or anything like that, be aware that these people are either talking about "federated" sidechains (i.e., funds are kept in custody by a group of entities) or they are talking about Drivechain, or they are disillusioned and think it is possible to do sidechains in any other manner.
No, I mean a trustless 2-way peg with correctness of the withdrawals verified by the Bitcoin protocol!
That is not possible unless Bitcoin verifies all transactions that happen in all the sidechains, which would be akin to drastically increasing the blocksize and expanding the Bitcoin rules in tons of ways, i.e., a terrible idea that no one wants.
What about the Blockstream sidechains whitepaper?
Yes, that was a way to do it. The Drivechain hashrate escrow is a conceptually simpler way to achieve the same thing with improved incentives, less junk in the chain, more safety.
Isn't the hashrate escrow a very complex soft-fork?
Yes, but it is much simpler than SegWit. And, unlike SegWit, it doesn't force anything on users, i.e., it isn't a mandatory blocksize increase.
Why should we expect miners to care enough to participate in the voting mechanism?
Because it's in their own self-interest to do it, and it costs very little. Today over half of the miners mine RSK. It's not blind merged mining, it's a very convoluted process that requires them to run a RSK full node. For the Drivechain sidechains, an SPV node would be enough, or maybe just getting data from a block explorer API, so much much simpler.
What if I still don't like Drivechain even after reading this?
That is the entire point! You don't have to like it or use it as long as you're fine with other people using it. The hashrate escrow special addresses will not impact you at all, validation cost is minimal, and you get the benefit of people who want to use Drivechain migrating to their own sidechains and freeing up space for you in the mainchain. See also the point above about infighting.
See also
-
@ 6e0ea5d6:0327f353
2025-02-21 18:15:52
"Malcolm Forbes recounts that a lady, wearing a faded cotton dress, and her husband, dressed in an old handmade suit, stepped off a train in Boston, USA, and timidly made their way to the office of the president of Harvard University. They had come from Palo Alto, California, and had not scheduled an appointment. The secretary, at a glance, thought that those two, looking like country bumpkins, had no business at Harvard.
— We want to speak with the president — the man said in a low voice.
— He will be busy all day — the secretary replied curtly.
— We will wait.
The secretary ignored them for hours, hoping the couple would finally give up and leave. But they stayed there, and the secretary, somewhat frustrated, decided to bother the president, although she hated doing that.
— If you speak with them for just a few minutes, maybe they will decide to go away — she said.
The president sighed in irritation but agreed. Someone of his importance did not have time to meet people like that, but he hated faded dresses and tattered suits in his office. With a stern face, he went to the couple.
— We had a son who studied at Harvard for a year — the woman said. — He loved Harvard and was very happy here, but a year ago he died in an accident, and we would like to erect a monument in his honor somewhere on campus.— My lady — said the president rudely —, we cannot erect a statue for every person who studied at Harvard and died; if we did, this place would look like a cemetery.
— Oh, no — the lady quickly replied. — We do not want to erect a statue. We would like to donate a building to Harvard.
The president looked at the woman's faded dress and her husband's old suit and exclaimed:
— A building! Do you have even the faintest idea of how much a building costs? We have more than seven and a half million dollars' worth of buildings here at Harvard.
The lady was silent for a moment, then said to her husband:
— If that’s all it costs to found a university, why don’t we have our own?
The husband agreed.
The couple, Leland Stanford, stood up and left, leaving the president confused. Traveling back to Palo Alto, California, they established there Stanford University, the second-largest in the world, in honor of their son, a former Harvard student."
Text extracted from: "Mileumlivros - Stories that Teach Values."
Thank you for reading, my friend! If this message helped you in any way, consider leaving your glass “🥃” as a token of appreciation.
A toast to our family!
-
@ b2caa9b3:9eab0fb5
2025-05-04 08:20:46
Hey friends,
Exciting news – I’m currently setting up my very first Discord server!
This space will be all about my travels, behind-the-scenes stories, photo sharing, and practical tips and insights from the road. My goal is to make it the central hub connecting all my decentralized social platforms where I can interact with you more directly, and share exclusive content.
Since I’m just starting out, I’d love to hear from you:
Do you know any useful RSS-feed integrations for updates?
Can you recommend any cool Discord bots for community engagement or automation?
Are there any tips or features you think I must include?
The idea is to keep everything free and accessible, and to grow a warm, helpful community around the joy of exploring the world.
It’s my first time managing a Discord server, so your experience and suggestions would mean a lot. Leave a comment – I’m all ears!
Thanks for your support, Ruben Storm
-
@ bbef5093:71228592
2025-02-16 14:17:12
A trícium érdekességei
A trícium a hidrogén lenyűgöző radioaktív formája, amely háromszor nehezebb, mint a közönséges hidrogén, és egy protont, valamint két neutront tartalmaz az atommagjában. Ernest Rutherford és csapata 1934-ben fedezte fel, és 12,32 éves felezési idővel rendelkezik.
Főbb alkalmazási területek
Világítástechnika A tríciumot önvilágító eszközökben használják energiaforrásként, például órák kijelzőiben és vészkijárati táblákban, ahol foszforokat aktivál, hogy folyamatos fényt bocsásson ki elektromos áram nélkül.
Tudományos kutatás A tudósok radioaktív nyomjelzőként használják orvosi kutatásokban és gyógyszerfejlesztésben, kihasználva azt a tulajdonságát, hogy kémiai reakciókban úgy viselkedik, mint a normál hidrogén. Kiemelkedő szerepet játszik a felszín alatti vizek kormeghatározásában is. Az 50 évnél fiatalabb vizek esetében a trícium-koncentráció mérése megbízható módszer, mivel az 1953-63 közötti magaslégköri nukleáris kísérletek egyedi "időbélyeget" hagytak a csapadékvizekben.
Vízföldtani alkalmazások
Vízbázisok védelme A trícium-vizsgálatok kiválóan alkalmasak a felszín alatti vízbázisok védettségének és a felszíni vizek elérési idejének meghatározására. A trícium ideális víznyomjelző, mivel beépül a vízmolekulába (HTO formában), és tökéletesen követi a víz mozgását.
Nukleáris létesítmények monitorozása A talajvíz trícium-tartalmának rendszeres megfigyelése kulcsfontosságú a nukleáris létesítmények környezetében, mivel segít azonosítani az esetleges szivárgásokat és a radioaktív anyagok terjedését a felszín alatti vizekben.
Nukleáris alkalmazások Az izotóp kulcsszerepet játszik a nukleáris fúzióban mint üzemanyag a tokamak reaktorokban, és "erősítőként" szolgál a nukleáris fegyverekben.
Biztonsági profil Bár radioaktív, a trícium csak alacsony energiájú béta-sugárzást bocsát ki, amely nem képes áthatolni az emberi bőrön. Természetes körülmények között nyomokban megtalálható a légkörben, ahol kozmikus sugárzás hatására keletkezik.
Tritium, the ideal tracer
Interesting Facts About Tritium
Tritium is a fascinating radioactive form of hydrogen that's three times heavier than regular hydrogen, containing one proton and two neutrons in its nucleus. It was first discovered by Ernest Rutherford and his team in 1934 and has a half-life of 12.32 years.
Main Applications
Illumination Technology Tritium is used as an energy source in self-illuminating devices, such as watch displays and exit signs, where it activates phosphors to create continuous light without electrical power.
Scientific Research Scientists use tritium as a radioactive tracer in medical research and pharmaceutical development, taking advantage of its ability to behave like normal hydrogen in chemical reactions. It also plays a crucial role in dating groundwater. For waters less than 50 years old, measuring tritium concentration is a reliable method, as atmospheric nuclear tests between 1953-63 left a unique "timestamp" in precipitation.
Hydrogeological Applications
Protection of Water Resources Tritium studies are excellent for determining the protection status of underground water resources and the arrival time of surface waters. Tritium is an ideal water tracer as it incorporates into water molecules (as HTO) and perfectly follows water movement.
Monitoring Nuclear Facilities Regular monitoring of groundwater tritium content is crucial around nuclear facilities, as it helps identify potential leaks and the spread of radioactive materials in groundwater.
Nuclear Applications The isotope plays a key role in nuclear fusion as fuel in tokamak reactors and serves as a "booster" in nuclear weapons.
Safety Profile Although radioactive, tritium only emits low-energy beta radiation that cannot penetrate human skin. It naturally occurs in trace amounts in the atmosphere, formed by cosmic ray interactions.
-
@ 86dfbe73:628cef55
2025-05-04 06:56:33
Building A Second Brain (BASB) ist eine Methode, mit der man Ideen, Einsichten und Vernetzungen, die man durch seine Erfahrungen gewonnen hat, systematisch speichert und die jeder Zeit abrufbar sind. Kurz, BASB erweitert das Gedächtnis mit Hilfe moderner digitaler Werkzeuge und Netzwerke. Die Kernidee ist, dass man durch diese Verlagerung sein biologisches Gehirn befreit, um frei denken zu können, seiner Kreativität freien Lauf zu geben oder einfach im Moment sein kann.
Die Methode besteht aus drei Grundschritten: dem Sammeln von Ideen und Erkenntnissen, dem Vernetzen dieser Ideen und Erkenntnisse und dem Erschaffen konkreter Ergebnisse.
Sammeln: Der erste Schritt beim Aufbau eines Second Brains ist das «Sammeln» der Ideen und Erkenntnisse, die genug wichtig oder interessant sind, um sie festzuhalten. Dafür wird als Organisationsstruktur P.A.R.A empfohlen.
Vernetzen: Sobald man angefangen hat, sein persönliches Wissen strukturiert zu sammeln, wird man anfangen, Muster und Verbindungen zwischen den Ideen und Erkenntnissen zu erkennen. Ab dieser Stelle verwende ich parallel die Zettelkastenmethode (ZKM)
Erschaffen: All das Erfassen, Zusammenfassen, Verbinden und Strukturieren haben letztlich das Ziel: Konkrete Ergebnisse in der realen Welt zu erschaffen.
PARA ist die Organisationsstruktur, die auf verschiedenen Endgeräten einsetzt werden kann, um digitale Informationen immer nach dem gleichen Schema abzulegen. Seien es Informationen, Notizen, Grafiken, Videos oder Dateien, alles hat seinen festen Platz und kann anhand von vier Kategorien bzw. „Buckets“ kategorisiert werden.
PARA steht dabei für: * Projekte * Areas * Ressourcen * Archiv
Projekte (engl. Projects) sind kurzfristige Bemühungen in Arbeit und Privatleben. Sie sind das, woran Du aktuell arbeitest. Sie haben einige für die Arbeit förderliche Eigenschaften: * Sie haben einen Anfang und ein Ende (im Gegensatz zu einem Hobby oder einem Verantwortungsbereich). * Sie haben ein konkretes Ergebnis, dass erreicht werden soll und bestehen aus konkreten Schritten, die nötig und zusammen hinreichend sind, um dieses Ziel zu erreichen, entspricht GTD von David Allen
Verantwortungsbereiche (engl. Areas) betreffen alles, was man langfristig im Blick behalten will. Sie unterscheidet von Projekten, dass man bei ihnen kein Ziel verfolgt, sondern einem Standard halten will. Sie sind dementsprechend nicht befristet. Man könnte sagen, dass sie einen Anspruch an uns selbst und unsere Lebenswelt darstellen.
Ressourcen (engl. Resources) sind Themen, die allenfalls langfristig relevant oder nützlich werden könnten. Sie sind eine Sammelkategorie für alles, was weder Projekt noch Verantwortungsbereich ist. Es sind: * Themen, die interessant sind. (English: Topic) * Untersuchungsgegenständige, die man erforschen will. (Englisch: Subject) * Nützliche Informationen für den späteren Gebrauch.
Das Archiv ist für alles Inaktive aus den obigen drei Kategorien. Es ist ein Lager für Beendetes und Aufgeschobenes.
Das System PARA ist eine nach zeitlicher Handlungsrelevanz angeordnete Ablage. Projekte kommen vor den Verantwortungsbereichen, weil sie einen kurz- bis mittelfristigen Zeithorizont haben, Verantwortungsbereiche dagegen einen unbegrenzten Zeithorizont. Ressourcen und Archiv bilden die Schlusslichter, weil sie gewöhnlich weder Priorität haben, noch dringend sind.



