-

@ 04c915da:3dfbecc9
2025-03-26 20:54:33
Capitalism is the most effective system for scaling innovation. The pursuit of profit is an incredibly powerful human incentive. Most major improvements to human society and quality of life have resulted from this base incentive. Market competition often results in the best outcomes for all.
That said, some projects can never be monetized. They are open in nature and a business model would centralize control. Open protocols like bitcoin and nostr are not owned by anyone and if they were it would destroy the key value propositions they provide. No single entity can or should control their use. Anyone can build on them without permission.
As a result, open protocols must depend on donation based grant funding from the people and organizations that rely on them. This model works but it is slow and uncertain, a grind where sustainability is never fully reached but rather constantly sought. As someone who has been incredibly active in the open source grant funding space, I do not think people truly appreciate how difficult it is to raise charitable money and deploy it efficiently.
Projects that can be monetized should be. Profitability is a super power. When a business can generate revenue, it taps into a self sustaining cycle. Profit fuels growth and development while providing projects independence and agency. This flywheel effect is why companies like Google, Amazon, and Apple have scaled to global dominance. The profit incentive aligns human effort with efficiency. Businesses must innovate, cut waste, and deliver value to survive.
Contrast this with non monetized projects. Without profit, they lean on external support, which can dry up or shift with donor priorities. A profit driven model, on the other hand, is inherently leaner and more adaptable. It is not charity but survival. When survival is tied to delivering what people want, scale follows naturally.
The real magic happens when profitable, sustainable businesses are built on top of open protocols and software. Consider the many startups building on open source software stacks, such as Start9, Mempool, and Primal, offering premium services on top of the open source software they build out and maintain. Think of companies like Block or Strike, which leverage bitcoin’s open protocol to offer their services on top. These businesses amplify the open software and protocols they build on, driving adoption and improvement at a pace donations alone could never match.
When you combine open software and protocols with profit driven business the result are lean, sustainable companies that grow faster and serve more people than either could alone. Bitcoin’s network, for instance, benefits from businesses that profit off its existence, while nostr will expand as developers monetize apps built on the protocol.
Capitalism scales best because competition results in efficiency. Donation funded protocols and software lay the groundwork, while market driven businesses build on top. The profit incentive acts as a filter, ensuring resources flow to what works, while open systems keep the playing field accessible, empowering users and builders. Together, they create a flywheel of innovation, growth, and global benefit.
-
@ 04c915da:3dfbecc9
2025-03-25 17:43:44
One of the most common criticisms leveled against nostr is the perceived lack of assurance when it comes to data storage. Critics argue that without a centralized authority guaranteeing that all data is preserved, important information will be lost. They also claim that running a relay will become prohibitively expensive. While there is truth to these concerns, they miss the mark. The genius of nostr lies in its flexibility, resilience, and the way it harnesses human incentives to ensure data availability in practice.
A nostr relay is simply a server that holds cryptographically verifiable signed data and makes it available to others. Relays are simple, flexible, open, and require no permission to run. Critics are right that operating a relay attempting to store all nostr data will be costly. What they miss is that most will not run all encompassing archive relays. Nostr does not rely on massive archive relays. Instead, anyone can run a relay and choose to store whatever subset of data they want. This keeps costs low and operations flexible, making relay operation accessible to all sorts of individuals and entities with varying use cases.
Critics are correct that there is no ironclad guarantee that every piece of data will always be available. Unlike bitcoin where data permanence is baked into the system at a steep cost, nostr does not promise that every random note or meme will be preserved forever. That said, in practice, any data perceived as valuable by someone will likely be stored and distributed by multiple entities. If something matters to someone, they will keep a signed copy.
Nostr is the Streisand Effect in protocol form. The Streisand effect is when an attempt to suppress information backfires, causing it to spread even further. With nostr, anyone can broadcast signed data, anyone can store it, and anyone can distribute it. Try to censor something important? Good luck. The moment it catches attention, it will be stored on relays across the globe, copied, and shared by those who find it worth keeping. Data deemed important will be replicated across servers by individuals acting in their own interest.
Nostr’s distributed nature ensures that the system does not rely on a single point of failure or a corporate overlord. Instead, it leans on the collective will of its users. The result is a network where costs stay manageable, participation is open to all, and valuable verifiable data is stored and distributed forever.
-
@ 39cc53c9:27168656
2025-03-30 05:54:48
> [Read the original blog post](https://blog.kycnot.me/p/monero-history)
Bitcoin enthusiasts frequently and correctly remark how much value it adds to Bitcoin not to have a face, a leader, or a central authority behind it. This particularity means there isn't a single person to exert control over, or a single human point of failure who could become corrupt or harmful to the project.
Because of this, it is said that no other coin can be equally valuable as Bitcoin in terms of decentralization and trustworthiness. Bitcoin is unique not just for being first, but also because of how the events behind its inception developed. This implies that, from Bitcoin onwards, any coin created would have been created by someone, consequently having an authority behind it. For this and some other reasons, some people refer to Bitcoin as "[The Immaculate Conception](https://yewtu.be/watch?v=FXvQcuIb5rU)".
While other coins may have their own unique features and advantages, they may not be able to replicate Bitcoin's community-driven nature. However, one other cryptocurrency shares a similar story of mystery behind its creation: **Monero**.
## History of Monero
### Bytecoin and CryptoNote
In March 2014, a Bitcointalk thread titled "*Bytecoin. Secure, private, untraceable since 2012*" was initiated by a user under the nickname "**DStrange**"[^1^]. DStrange presented Bytecoin (BCN) as a unique cryptocurrency, in operation since July 2012. Unlike Bitcoin, it employed a new algorithm known as CryptoNote.
DStrange apparently stumbled upon the Bytecoin website by chance while mining a dying bitcoin fork, and decided to create a thread on Bitcointalk[^1^]. This sparked curiosity among some users, who wondered how could Bytecoin remain unnoticed since its alleged launch in 2012 until then[^2^] [^3^].
Some time after, a user brought up the "CryptoNote v2.0" whitepaper for the first time, underlining its innovative features[^4^]. Authored by the pseudonymous **Nicolas van Saberhagen** in October 2013, the CryptoNote v2 whitepaper[^5^] highlighted the traceability and privacy problems in Bitcoin. Saberhagen argued that these flaws could not be quickly fixed, suggesting it would be more efficient to start a new project rather than trying to patch the original[^5^], an statement simmilar to the one from Satoshi Nakamoto[^6^].
Checking with Saberhagen's digital signature, the release date of the whitepaper seemed correct, which would mean that Cryptonote (v1) was created in 2012[^7^] [^8^], although there's an important detail: *"Signing time is from the clock on the signer's computer"* [^9^].
Moreover, the whitepaper v1 contains a footnote link to a Bitcointalk post dated May 5, 2013[^10^], making it impossible for the whitepaper to have been signed and released on December 12, 2012.
As the narrative developed, users discovered that a significant **80% portion of Bytecoin had been pre-mined**[^11^] and blockchain dates seemed to be faked to make it look like it had been operating since 2012, leading to controversy surrounding the project.
The origins of CryptoNote and Bytecoin remain mysterious, leaving suspicions of a possible scam attempt, although the whitepaper had a good amount of work and thought on it.
### The fork
In April 2014, the Bitcointalk user **`thankful_for_today`**, who had also participated in the Bytecoin thread[^12^], announced plans to launch a Bytecoin fork named **Bitmonero**[^13^] [^14^].
The primary motivation behind this fork was *"Because there is a number of technical and marketing issues I wanted to do differently. And also because I like ideas and technology and I want it to succeed"*[^14^]. This time Bitmonero did things different from Bytecoin: there was no premine or instamine, and no portion of the block reward went to development.
However, thankful_for_today proposed controversial changes that the community disagreed with. **Johnny Mnemonic** relates the events surrounding Bitmonero and thankful_for_today in a Bitcointalk comment[^15^]:
> When thankful_for_today launched BitMonero [...] he ignored everything that was discussed and just did what he wanted. The block reward was considerably steeper than what everyone was expecting. He also moved forward with 1-minute block times despite everyone's concerns about the increase of orphan blocks. He also didn't address the tail emission concern that should've (in my opinion) been in the code at launch time. Basically, he messed everything up. *Then, he disappeared*.
After disappearing for a while, thankful_for_today returned to find that the community had taken over the project. Johnny Mnemonic continues:
> I, and others, started working on new forks that were closer to what everyone else was hoping for. [...] it was decided that the BitMonero project should just be taken over. There were like 9 or 10 interested parties at the time if my memory is correct. We voted on IRC to drop the "bit" from BitMonero and move forward with the project. Thankful_for_today suddenly resurfaced, and wasn't happy to learn the community had assumed control of the coin. He attempted to maintain his own fork (still calling it "BitMonero") for a while, but that quickly fell into obscurity.
The unfolding of these events show us the roots of Monero. Much like Satoshi Nakamoto, the creators behind CryptoNote/Bytecoin and thankful_for_today remain a mystery[^17^] [^18^], having disappeared without a trace. This enigma only adds to Monero's value.
Since community took over development, believing in the project's potential and its ability to be guided in a better direction, Monero was given one of Bitcoin's most important qualities: **a leaderless nature**. With no single face or entity directing its path, Monero is safe from potential corruption or harm from a "central authority".
The community continued developing Monero until today. Since then, Monero has undergone a lot of technological improvements, migrations and achievements such as [RingCT](https://www.getmonero.org/resources/moneropedia/ringCT.html) and [RandomX](https://github.com/tevador/randomx). It also has developed its own [Community Crowdfundinc System](https://ccs.getmonero.org/), conferences such as [MoneroKon](https://monerokon.org/) and [Monerotopia](https://monerotopia.com/) are taking place every year, and has a very active [community](https://www.getmonero.org/community/hangouts/) around it.
> Monero continues to develop with goals of privacy and security first, ease of use and efficiency second. [^16^]
This stands as a testament to the power of a dedicated community operating without a central figure of authority. This decentralized approach aligns with the original ethos of cryptocurrency, making Monero a prime example of community-driven innovation. For this, I thank all the people involved in Monero, that lead it to where it is today.
*If you find any information that seems incorrect, unclear or any missing important events, please [contact me](https://kycnot.me/about#contact) and I will make the necessary changes.*
### Sources of interest
* https://forum.getmonero.org/20/general-discussion/211/history-of-monero
* https://monero.stackexchange.com/questions/852/what-is-the-origin-of-monero-and-its-relationship-to-bytecoin
* https://en.wikipedia.org/wiki/Monero
* https://bitcointalk.org/index.php?topic=583449.0
* https://bitcointalk.org/index.php?topic=563821.0
* https://bitcointalk.org/index.php?action=profile;u=233561
* https://bitcointalk.org/index.php?topic=512747.0
* https://bitcointalk.org/index.php?topic=740112.0
* https://monero.stackexchange.com/a/1024
* https://inspec2t-project.eu/cryptocurrency-with-a-focus-on-anonymity-these-facts-are-known-about-monero/
* https://medium.com/coin-story/coin-perspective-13-riccardo-spagni-69ef82907bd1
* https://www.getmonero.org/resources/about/
* https://www.wired.com/2017/01/monero-drug-dealers-cryptocurrency-choice-fire/
* https://www.monero.how/why-monero-vs-bitcoin
* https://old.reddit.com/r/Monero/comments/u8e5yr/satoshi_nakamoto_talked_about_privacy_features/
[^1^]: https://bitcointalk.org/index.php?topic=512747.0
[^2^]: https://bitcointalk.org/index.php?topic=512747.msg5901770#msg5901770
[^3^]: https://bitcointalk.org/index.php?topic=512747.msg5950051#msg5950051
[^4^]: https://bitcointalk.org/index.php?topic=512747.msg5953783#msg5953783
[^5^]: https://bytecoin.org/old/whitepaper.pdf
[^6^]: https://bitcointalk.org/index.php?topic=770.msg8637#msg8637
[^7^]: https://bitcointalk.org/index.php?topic=512747.msg7039536#msg7039536
[^8^]: https://bitcointalk.org/index.php?topic=512747.msg7039689#msg7039689
[^9^]: https://i.stack.imgur.com/qtJ43.png
[^10^]: https://bitcointalk.org/index.php?topic=740112
[^11^]: https://bitcointalk.org/index.php?topic=512747.msg6265128#msg6265128
[^12^]: https://bitcointalk.org/index.php?topic=512747.msg5711328#msg5711328
[^13^]: https://bitcointalk.org/index.php?topic=512747.msg6146717#msg6146717
[^14^]: https://bitcointalk.org/index.php?topic=563821.0
[^15^]: https://bitcointalk.org/index.php?topic=583449.msg10731078#msg10731078
[^16^]: https://www.getmonero.org/resources/about/
[^17^]: https://old.reddit.com/r/Monero/comments/lz2e5v/going_deep_in_the_cryptonote_rabbit_hole_who_was/
[^18^]: https://old.reddit.com/r/Monero/comments/oxpimb/is_there_any_evidence_that_thankful_for_today/
-
@ b2d670de:907f9d4a
2025-03-25 20:17:57
This guide will walk you through setting up your own Strfry Nostr relay on a Debian/Ubuntu server and making it accessible exclusively as a TOR hidden service. By the end, you'll have a privacy-focused relay that operates entirely within the TOR network, enhancing both your privacy and that of your users.
## Table of Contents
1. Prerequisites
2. Initial Server Setup
3. Installing Strfry Nostr Relay
4. Configuring Your Relay
5. Setting Up TOR
6. Making Your Relay Available on TOR
7. Testing Your Setup]
8. Maintenance and Security
9. Troubleshooting
## Prerequisites
- A Debian or Ubuntu server
- Basic familiarity with command line operations (most steps are explained in detail)
- Root or sudo access to your server
## Initial Server Setup
First, let's make sure your server is properly set up and secured.
### Update Your System
Connect to your server via SSH and update your system:
```bash
sudo apt update
sudo apt upgrade -y
```
### Set Up a Basic Firewall
Install and configure a basic firewall:
```bash
sudo apt install ufw -y
sudo ufw allow ssh
sudo ufw enable
```
This allows SSH connections while blocking other ports for security.
## Installing Strfry Nostr Relay
This guide includes the full range of steps needed to build and set up Strfry. It's simply based on the current version of the `DEPLOYMENT.md` document in the Strfry GitHub repository. If the build/setup process is changed in the repo, this document could get outdated. If so, please report to me that something is outdated and check for updated steps [here](https://github.com/hoytech/strfry/blob/master/docs/DEPLOYMENT.md).
### Install Dependencies
First, let's install the necessary dependencies. Each package serves a specific purpose in building and running Strfry:
```bash
sudo apt install -y git build-essential libyaml-perl libtemplate-perl libregexp-grammars-perl libssl-dev zlib1g-dev liblmdb-dev libflatbuffers-dev libsecp256k1-dev libzstd-dev
```
Here's why each dependency is needed:
**Basic Development Tools:**
- `git`: Version control system used to clone the Strfry repository and manage code updates
- `build-essential`: Meta-package that includes compilers (gcc, g++), make, and other essential build tools
**Perl Dependencies** (used for Strfry's build scripts):
- `libyaml-perl`: Perl interface to parse YAML configuration files
- `libtemplate-perl`: Template processing system used during the build process
- `libregexp-grammars-perl`: Advanced regular expression handling for Perl scripts
**Core Libraries for Strfry:**
- `libssl-dev`: Development files for OpenSSL, used for secure connections and cryptographic operations
- `zlib1g-dev`: Compression library that Strfry uses to reduce data size
- `liblmdb-dev`: Lightning Memory-Mapped Database library, which Strfry uses for its high-performance database backend
- `libflatbuffers-dev`: Memory-efficient serialization library for structured data
- `libsecp256k1-dev`: Optimized C library for EC operations on curve secp256k1, essential for Nostr's cryptographic signatures
- `libzstd-dev`: Fast real-time compression algorithm for efficient data storage and transmission
### Clone and Build Strfry
Clone the Strfry repository:
```bash
git clone https://github.com/hoytech/strfry.git
cd strfry
```
Build Strfry:
```bash
git submodule update --init
make setup-golpe
make -j2 # This uses 2 CPU cores. Adjust based on your server (e.g., -j4 for 4 cores)
```
This build process will take several minutes, especially on servers with limited CPU resources, so go get a coffee and post some great memes on nostr in the meantime.
### Install Strfry
Install the Strfry binary to your system path:
```bash
sudo cp strfry /usr/local/bin
```
This makes the `strfry` command available system-wide, allowing it to be executed from any directory and by any user with the appropriate permissions.
## Configuring Your Relay
### Create Strfry User
Create a dedicated user for running Strfry. This enhances security by isolating the relay process:
```bash
sudo useradd -M -s /usr/sbin/nologin strfry
```
The `-M` flag prevents creating a home directory, and `-s /usr/sbin/nologin` prevents anyone from logging in as this user. This is a security best practice for service accounts.
### Create Data Directory
Create a directory for Strfry's data:
```bash
sudo mkdir /var/lib/strfry
sudo chown strfry:strfry /var/lib/strfry
sudo chmod 755 /var/lib/strfry
```
This creates a dedicated directory for Strfry's database and sets the appropriate permissions so that only the strfry user can write to it.
### Configure Strfry
Copy the sample configuration file:
```bash
sudo cp strfry.conf /etc/strfry.conf
```
Edit the configuration file:
```bash
sudo nano /etc/strfry.conf
```
Modify the database path:
```
# Find this line:
db = "./strfry-db/"
# Change it to:
db = "/var/lib/strfry/"
```
Check your system's hard limit for file descriptors:
```bash
ulimit -Hn
```
Update the `nofiles` setting in your configuration to match this value (or set to 0):
```
# Add or modify this line in the config (example if your limit is 524288):
nofiles = 524288
```
The `nofiles` setting determines how many open files Strfry can have simultaneously. Setting it to your system's hard limit (or 0 to use the system default) helps prevent "too many open files" errors if your relay becomes popular.
You might also want to customize your relay's information in the config file. Look for the `info` section and update it with your relay's name, description, and other details.
Set ownership of the configuration file:
```bash
sudo chown strfry:strfry /etc/strfry.conf
```
### Create Systemd Service
Create a systemd service file for managing Strfry:
```bash
sudo nano /etc/systemd/system/strfry.service
```
Add the following content:
```ini
[Unit]
Description=strfry relay service
[Service]
User=strfry
ExecStart=/usr/local/bin/strfry relay
Restart=on-failure
RestartSec=5
ProtectHome=yes
NoNewPrivileges=yes
ProtectSystem=full
LimitCORE=1000000000
[Install]
WantedBy=multi-user.target
```
This systemd service configuration:
- Runs Strfry as the dedicated strfry user
- Automatically restarts the service if it fails
- Implements security measures like `ProtectHome` and `NoNewPrivileges`
- Sets resource limits appropriate for a relay
Enable and start the service:
```bash
sudo systemctl enable strfry.service
sudo systemctl start strfry
```
Check the service status:
```bash
sudo systemctl status strfry
```
### Verify Relay is Running
Test that your relay is running locally:
```bash
curl localhost:7777
```
You should see a message indicating that the Strfry relay is running. This confirms that Strfry is properly installed and configured before we proceed to set up TOR.
## Setting Up TOR
Now let's make your relay accessible as a TOR hidden service.
### Install TOR
Install TOR from the package repositories:
```bash
sudo apt install -y tor
```
This installs the TOR daemon that will create and manage your hidden service.
### Configure TOR
Edit the TOR configuration file:
```bash
sudo nano /etc/tor/torrc
```
Scroll down to wherever you see a commented out part like this:
```
#HiddenServiceDir /var/lib/tor/hidden_service/
#HiddenServicePort 80 127.0.0.1:80
```
Under those lines, add the following lines to set up a hidden service for your relay:
```
HiddenServiceDir /var/lib/tor/strfry-relay/
HiddenServicePort 80 127.0.0.1:7777
```
This configuration:
- Creates a hidden service directory at `/var/lib/tor/strfry-relay/`
- Maps port 80 on your .onion address to port 7777 on your local machine
- Keeps all traffic encrypted within the TOR network
Create the directory for your hidden service:
```bash
sudo mkdir -p /var/lib/tor/strfry-relay/
sudo chown debian-tor:debian-tor /var/lib/tor/strfry-relay/
sudo chmod 700 /var/lib/tor/strfry-relay/
```
The strict permissions (700) are crucial for security as they ensure only the debian-tor user can access the directory containing your hidden service private keys.
Restart TOR to apply changes:
```bash
sudo systemctl restart tor
```
## Making Your Relay Available on TOR
### Get Your Onion Address
After restarting TOR, you can find your onion address:
```bash
sudo cat /var/lib/tor/strfry-relay/hostname
```
This will output something like `abcdefghijklmnopqrstuvwxyz234567.onion`, which is your relay's unique .onion address. This is what you'll share with others to access your relay.
### Understanding Onion Addresses
The .onion address is a special-format hostname that is automatically generated based on your hidden service's private key.
Your users will need to use this address with the WebSocket protocol prefix to connect: `ws://youronionaddress.onion`
## Testing Your Setup
### Test with a Nostr Client
The best way to test your relay is with an actual Nostr client that supports TOR:
1. Open your TOR browser
2. Go to your favorite client, either on clearnet or an onion service.
- Check out [this list](https://github.com/0xtrr/onion-service-nostr-clients?tab=readme-ov-file#onion-service-nostr-clients) of nostr clients available over TOR.
3. Add your relay URL: `ws://youronionaddress.onion` to your relay list
4. Try posting a note and see if it appears on your relay
- In some nostr clients, you can also click on a relay to get information about it like the relay name and description you set earlier in the stryfry config. If you're able to see the correct values for the name and the description, you were able to connect to the relay.
- Some nostr clients also gives you a status on what relays a note was posted to, this could also give you an indication that your relay works as expected.
Note that not all Nostr clients support TOR connections natively. Some may require additional configuration or use of TOR Browser. E.g. most mobile apps would most likely require a TOR proxy app running in the background (some have TOR support built in too).
## Maintenance and Security
### Regular Updates
Keep your system, TOR, and relay updated:
```bash
# Update system
sudo apt update
sudo apt upgrade -y
# Update Strfry
cd ~/strfry
git pull
git submodule update
make -j2
sudo cp strfry /usr/local/bin
sudo systemctl restart strfry
# Verify TOR is still running properly
sudo systemctl status tor
```
Regular updates are crucial for security, especially for TOR which may have security-critical updates.
### Database Management
Strfry has built-in database management tools. Check the Strfry documentation for specific commands related to database maintenance, such as managing event retention and performing backups.
### Monitoring Logs
To monitor your Strfry logs:
```bash
sudo journalctl -u strfry -f
```
To check TOR logs:
```bash
sudo journalctl -u tor -f
```
Monitoring logs helps you identify potential issues and understand how your relay is being used.
### Backup
This is not a best practices guide on how to do backups. Preferably, backups should be stored either offline or on a different machine than your relay server. This is just a simple way on how to do it on the same server.
```bash
# Stop the relay temporarily
sudo systemctl stop strfry
# Backup the database
sudo cp -r /var/lib/strfry /path/to/backup/location
# Restart the relay
sudo systemctl start strfry
```
Back up your TOR hidden service private key. The private key is particularly sensitive as it defines your .onion address - losing it means losing your address permanently. If you do a backup of this, ensure that is stored in a safe place where no one else has access to it.
```bash
sudo cp /var/lib/tor/strfry-relay/hs_ed25519_secret_key /path/to/secure/backup/location
```
## Troubleshooting
### Relay Not Starting
If your relay doesn't start:
```bash
# Check logs
sudo journalctl -u strfry -e
# Verify configuration
cat /etc/strfry.conf
# Check permissions
ls -la /var/lib/strfry
```
Common issues include:
- Incorrect configuration format
- Permission problems with the data directory
- Port already in use (another service using port 7777)
- Issues with setting the nofiles limit (setting it too big)
### TOR Hidden Service Not Working
If your TOR hidden service is not accessible:
```bash
# Check TOR logs
sudo journalctl -u tor -e
# Verify TOR is running
sudo systemctl status tor
# Check onion address
sudo cat /var/lib/tor/strfry-relay/hostname
# Verify TOR configuration
sudo cat /etc/tor/torrc
```
Common TOR issues include:
- Incorrect directory permissions
- TOR service not running
- Incorrect port mapping in torrc
### Testing Connectivity
If you're having trouble connecting to your service:
```bash
# Verify Strfry is listening locally
sudo ss -tulpn | grep 7777
# Check that TOR is properly running
sudo systemctl status tor
# Test the local connection directly
curl --include --no-buffer localhost:7777
```
---
## Privacy and Security Considerations
Running a Nostr relay as a TOR hidden service provides several important privacy benefits:
1. **Network Privacy**: Traffic to your relay is encrypted and routed through the TOR network, making it difficult to determine who is connecting to your relay.
2. **Server Anonymity**: The physical location and IP address of your server are concealed, providing protection against denial-of-service attacks and other targeting.
3. **Censorship Resistance**: TOR hidden services are more resilient against censorship attempts, as they don't rely on the regular DNS system and can't be easily blocked.
4. **User Privacy**: Users connecting to your relay through TOR enjoy enhanced privacy, as their connections are also encrypted and anonymized.
However, there are some important considerations:
- TOR connections are typically slower than regular internet connections
- Not all Nostr clients support TOR connections natively
- Running a hidden service increases the importance of keeping your server secure
---
Congratulations! You now have a Strfry Nostr relay running as a TOR hidden service. This setup provides a resilient, privacy-focused, and censorship-resistant communication channel that helps strengthen the Nostr network.
For further customization and advanced configuration options, refer to the [Strfry documentation](https://github.com/hoytech/strfry).
Consider sharing your relay's .onion address with the Nostr community to help grow the privacy-focused segment of the network!
If you plan on providing a relay service that the public can use (either for free or paid for), consider adding it to [this list](https://github.com/0xtrr/onion-service-nostr-relays). Only add it if you plan to run a stable and available relay.
-
@ bc52210b:20bfc6de
2025-03-25 20:17:22
CISA, or Cross-Input Signature Aggregation, is a technique in Bitcoin that allows multiple signatures from different inputs in a transaction to be combined into a single, aggregated signature. This is a big deal because Bitcoin transactions often involve multiple inputs (e.g., spending from different wallet outputs), each requiring its own signature. Normally, these signatures take up space individually, but CISA compresses them into one, making transactions more efficient.
This magic is possible thanks to the linearity property of Schnorr signatures, a type of digital signature introduced to Bitcoin with the Taproot upgrade. Unlike the older ECDSA signatures, Schnorr signatures have mathematical properties that allow multiple signatures to be added together into a single valid signature. Think of it like combining multiple handwritten signatures into one super-signature that still proves everyone signed off!
Fun Fact: CISA was considered for inclusion in Taproot but was left out to keep the upgrade simple and manageable. Adding CISA would’ve made Taproot more complex, so the developers hit pause on it—for now.
---
**CISA vs. Key Aggregation (MuSig, FROST): Don’t Get Confused!**
Before we go deeper, let’s clear up a common mix-up: CISA is not the same as protocols like MuSig or FROST. Here’s why:
* Signature Aggregation (CISA): Combines multiple signatures into one, each potentially tied to different public keys and messages (e.g., different transaction inputs).
* Key Aggregation (MuSig, FROST): Combines multiple public keys into a single aggregated public key, then generates one signature for that key.
**Key Differences:**
1. What’s Aggregated?
* CISA: Aggregates signatures.
* Key Aggregation: Aggregates public keys.
2. What the Verifier Needs
* CISA: The verifier needs all individual public keys and their corresponding messages to check the aggregated signature.
* Key Aggregation: The verifier only needs the single aggregated public key and one message.
3. When It Happens
* CISA: Used during transaction signing, when inputs are being combined into a transaction.
* MuSig: Used during address creation, setting up a multi-signature (multisig) address that multiple parties control.
So, CISA is about shrinking signature data in a transaction, while MuSig/FROST are about simplifying multisig setups. Different tools, different jobs!
---
**Two Flavors of CISA: Half-Agg and Full-Agg**
CISA comes in two modes:
* Full Aggregation (Full-Agg): Interactive, meaning signers need to collaborate during the signing process. (We’ll skip the details here since the query focuses on Half-Agg.)
* Half Aggregation (Half-Agg): Non-interactive, meaning signers can work independently, and someone else can combine the signatures later.
Since the query includes “CISA Part 2: Half Signature Aggregation,” let’s zoom in on Half-Agg.
---
**Half Signature Aggregation (Half-Agg) Explained**
**How It Works**
Half-Agg is a non-interactive way to aggregate Schnorr signatures. Here’s the process:
1. Independent Signing: Each signer creates their own Schnorr signature for their input, without needing to talk to the other signers.
2. Aggregation Step: An aggregator (could be anyone, like a wallet or node) takes all these signatures and combines them into one aggregated signature.
A Schnorr signature has two parts:
* R: A random point (32 bytes).
* s: A scalar value (32 bytes).
In Half-Agg:
* The R values from each signature are kept separate (one per input).
* The s values from all signatures are combined into a single s value.
**Why It Saves Space (~50%)**
Let’s break down the size savings with some math:
Before Aggregation:
* Each Schnorr signature = 64 bytes (32 for R + 32 for s).
* For n inputs: n × 64 bytes.
After Half-Agg:
* Keep n R values (32 bytes each) = 32 × n bytes.
* Combine all s values into one = 32 bytes.
* Total size: 32 × n + 32 bytes.
Comparison:
* Original: 64n bytes.
* Half-Agg: 32n + 32 bytes.
* For large n, the “+32” becomes small compared to 32n, so it’s roughly 32n, which is half of 64n. Hence, ~50% savings!
**Real-World Impact:**
Based on recent Bitcoin usage, Half-Agg could save:
* ~19.3% in space (reducing transaction size).
* ~6.9% in fees (since fees depend on transaction size). This assumes no major changes in how people use Bitcoin post-CISA.
---
**Applications of Half-Agg**
Half-Agg isn’t just a cool idea—it has practical uses:
1. Transaction-wide Aggregation
* Combine all signatures within a single transaction.
* Result: Smaller transactions, lower fees.
2. Block-wide Aggregation
* Combine signatures across all transactions in a Bitcoin block.
* Result: Even bigger space savings at the blockchain level.
3. Off-chain Protocols / P2P
* Use Half-Agg in systems like Lightning Network gossip messages.
* Benefit: Efficiency without needing miners or a Bitcoin soft fork.
---
**Challenges with Half-Agg**
While Half-Agg sounds awesome, it’s not without hurdles, especially at the block level:
1. Breaking Adaptor Signatures
* Adaptor signatures are special signatures used in protocols like Discreet Log Contracts (DLCs) or atomic swaps. They tie a signature to revealing a secret, ensuring fair exchanges.
* Aggregating signatures across a block might mess up these protocols, as the individual signatures get blended together, potentially losing the properties adaptor signatures rely on.
2. Impact on Reorg Recovery
* In Bitcoin, a reorganization (reorg) happens when the blockchain switches to a different chain of blocks. Transactions from the old chain need to be rebroadcast or reprocessed.
* If signatures are aggregated at the block level, it could complicate extracting individual transactions and their signatures during a reorg, slowing down recovery.
These challenges mean Half-Agg needs careful design, especially for block-wide use.
---
**Wrapping Up**
CISA is a clever way to make Bitcoin transactions more efficient by aggregating multiple Schnorr signatures into one, thanks to their linearity property. Half-Agg, the non-interactive mode, lets signers work independently, cutting signature size by about 50% (to 32n + 32 bytes from 64n bytes). It could save ~19.3% in space and ~6.9% in fees, with uses ranging from single transactions to entire blocks or off-chain systems like Lightning.
But watch out—block-wide Half-Agg could trip up adaptor signatures and reorg recovery, so it’s not a slam dunk yet. Still, it’s a promising tool for a leaner, cheaper Bitcoin future!
-
@ b17fccdf:b7211155
2025-03-25 11:23:36
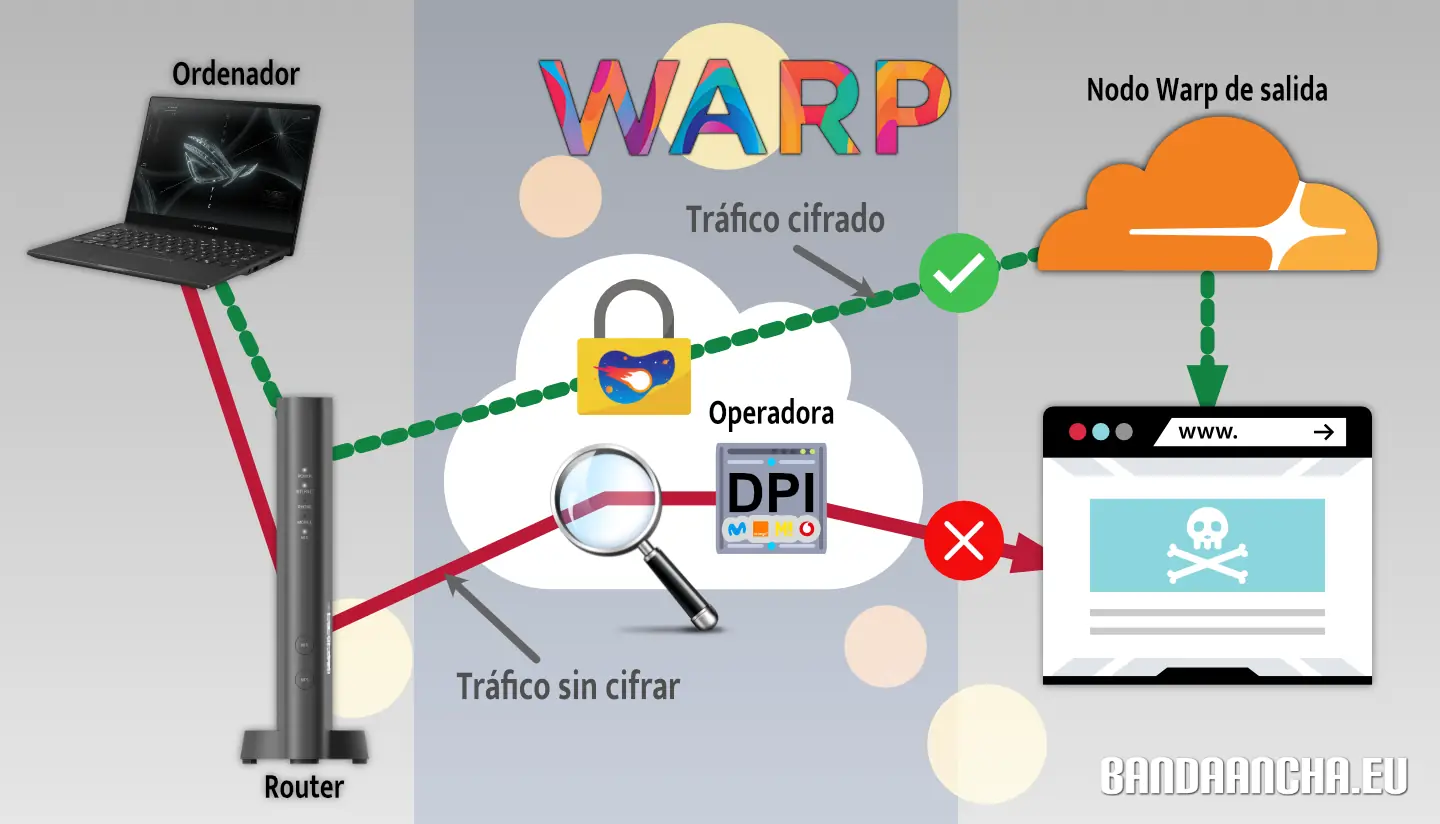
Si vives en España, quizás hayas notado que no puedes acceder a ciertas páginas webs durante los fines de semana o en algunos días entre semana, entre ellas, la [guía de MiniBolt](https://minbolt.info/).
Esto tiene una **razón**, por supuesto una **solución**, además de una **conclusión**. Sin entrar en demasiados detalles:
## La razón
El **bloqueo a Cloudflare**, implementado desde hace casi dos meses por operadores de Internet (ISPs) en España (como Movistar, O2, DIGI, Pepephone, entre otros), se basa en una [orden judicial](https://www.poderjudicial.es/search/AN/openDocument/3c85bed480cbb1daa0a8778d75e36f0d/20221004) emitida tras una demanda de LALIGA (Fútbol). Esta medida busca combatir la piratería en España, un problema que afecta directamente a dicha organización.
Aunque la intención original era restringir el acceso a dominios específicos que difundieran dicho contenido, Cloudflare emplea el protocolo [ECH](https://developers.cloudflare.com/ssl/edge-certificates/ech) (Encrypted Client Hello), que oculta el nombre del dominio, el cual antes se transmitía en texto plano durante el proceso de establecimiento de una conexión TLS. Esta medida dificulta que las operadoras analicen el tráfico para aplicar **bloqueos basados en dominios**, lo que les obliga a recurrir a **bloqueos más amplios por IP o rangos de IP** para cumplir con la orden judicial.
Esta práctica tiene **consecuencias graves**, que han sido completamente ignoradas por quienes la ejecutan. Es bien sabido que una infraestructura de IP puede alojar numerosos dominios, tanto legítimos como no legítimos. La falta de un "ajuste fino" en los bloqueos provoca un **perjuicio para terceros**, **restringiendo el acceso a muchos dominios legítimos** que no tiene relación alguna con actividades ilícitas, pero que comparten las mismas IPs de Cloudflare con dominios cuestionables. Este es el caso de la [web de MiniBolt](https://minibolt.minibolt.info) y su dominio `minibolt.info`, los cuales **utilizan Cloudflare como proxy** para aprovechar las medidas de **seguridad, privacidad, optimización y servicios** adicionales que la plataforma ofrece de forma gratuita.
Si bien este bloqueo parece ser temporal (al menos durante la temporada 24/25 de fútbol, hasta finales de mayo), es posible que se reactive con el inicio de la nueva temporada.

## La solución
Obviamente, **MiniBolt no dejará de usar Cloudflare** como proxy por esta razón. Por lo que a continuación se exponen algunas medidas que como usuario puedes tomar para **evitar esta restricción** y poder acceder:
**~>** Utiliza **una VPN**:
Existen varias soluciones de proveedores de VPN, ordenadas según su reputación en privacidad:
- [IVPN](https://www.ivpn.net/es/)
- [Mullvad VPN](https://mullvad.net/es/vpn)
- [Proton VPN](https://protonvpn.com/es-es) (**gratis**)
- [Obscura VPN](https://obscura.net/) (**solo para macOS**)
- [Cloudfare WARP](https://developers.cloudflare.com/cloudflare-one/connections/connect-devices/warp/download-warp/) (**gratis**) + permite utilizar el modo proxy local para enrutar solo la navegación, debes utilizar la opción "WARP a través de proxy local" siguiendo estos pasos:
1. Inicia Cloudflare WARP y dentro de la pequeña interfaz haz click en la rueda dentada abajo a la derecha > "Preferencias" > "Avanzado" > "Configurar el modo proxy"
2. Marca la casilla "Habilite el modo proxy en este dispositivo"
3. Elige un "Puerto de escucha de proxy" entre 0-65535. ej: 1080, haz click en "Aceptar" y cierra la ventana de preferencias
4. Accede de nuevo a Cloudflare WARP y pulsa sobre el switch para habilitar el servicio.
3. Ahora debes apuntar el proxy del navegador a Cloudflare WARP, la configuración del navegador es similar a [esta](https://minibolt.minibolt.info/system/system/privacy#example-from-firefox) para el caso de navegadores basados en Firefox. Una vez hecho, deberías poder acceder a la [guía de MiniBolt](https://minibolt.minibolt.info/) sin problemas. Si tienes dudas, déjalas en comentarios e intentaré resolverlas. Más info [AQUÍ](https://bandaancha.eu/articulos/como-saltarse-bloqueo-webs-warp-vpn-9958).
**~>** [**Proxifica tu navegador para usar la red de Tor**](https://minibolt.minibolt.info/system/system/privacy#ssh-remote-access-through-tor), o utiliza el [**navegador oficial de Tor**](https://www.torproject.org/es/download/) (recomendado).

## La conclusión
Estos hechos ponen en tela de juicio los principios fundamentales de la neutralidad de la red, pilares esenciales de la [Declaración de Independencia del Ciberespacio](https://es.wikisource.org/wiki/Declaraci%C3%B3n_de_independencia_del_ciberespacio) que defiende un internet libre, sin restricciones ni censura. Dichos principios se han visto quebrantados sin precedentes en este país, confirmando que ese futuro distópico que muchos negaban, ya es una realidad.
Es momento de actuar y estar preparados: debemos **impulsar el desarrollo y la difusión** de las **herramientas anticensura** que tenemos a nuestro alcance, protegiendo así la **libertad digital** y asegurando un acceso equitativo a la información para todos
Este compromiso es uno de los **pilares fundamentales de MiniBolt,** lo que convierte este desafío en una oportunidad para poner a prueba las **soluciones anticensura** [ya disponibles](https://minibolt.minibolt.info/bonus-guides/system/tor-services), así como **las que están en camino**.
¡Censúrame si puedes, legislador! ¡La lucha por la privacidad y la libertad en Internet ya está en marcha!

---
Fuentes:
* https://bandaancha.eu/articulos/movistar-o2-deja-clientes-sin-acceso-11239
* https://bandaancha.eu/articulos/esta-nueva-sentencia-autoriza-bloqueos-11257
* https://bandaancha.eu/articulos/como-saltarse-bloqueo-webs-warp-vpn-9958
* https://bandaancha.eu/articulos/como-activar-ech-chrome-acceder-webs-10689
* https://comunidad.movistar.es/t5/Soporte-Fibra-y-ADSL/Problema-con-web-que-usan-Cloudflare/td-p/5218007
-
@ 3b7fc823:e194354f
2025-03-23 03:54:16
A quick guide for the less than technical savvy to set up their very own free private tor enabled email using Onionmail. Privacy is for everyone, not just the super cyber nerds.
Onion Mail is an anonymous POP3/SMTP email server program hosted by various people on the internet. You can visit this site and read the details: https://en.onionmail.info/
1. Download Tor Browser
First, if you don't already, go download Tor Browser. You are going to need it. https://www.torproject.org/
2. Sign Up
Using Tor browser go to the directory page (https://onionmail.info/directory.html) choose one of the servers and sign up for an account. I say sign up but it is just choosing a user name you want to go before the @xyz.onion email address and solving a captcha.
3. Account information
Once you are done signing up an Account information page will pop up. **MAKE SURE YOU SAVE THIS!!!** It has your address and passwords (for sending and receiving email) that you will need. If you lose them then you are shit out of luck.
4. Install an Email Client
You can use Claws Mail, Neomutt, or whatever, but for this example, we will be using Thunderbird.
a. Download Thunderbird email client
b. The easy setup popup page that wants your name, email, and password isn't going to like your user@xyz.onion address. Just enter something that looks like a regular email address such as name@example.com and the **Configure Manually**option will appear below. Click that.
5. Configure Incoming (POP3) Server
Under Incoming Server:
Protocol: POP3
Server or Hostname: xyz.onion (whatever your account info says)
Port: 110
Security: STARTTLS
Authentication: Normal password
Username: (your username)
Password: (POP3 password).
6. Configure Outgoing (SMTP) Server
Under Outgoing Server:
Server or Hostname: xyz.onion (whatever your account info says)
Port: 25
Security: STARTTLS
Authentication: Normal password
Username: (your username)
Password: (SMTP password).
7. Click on email at the top and change your address if you had to use a spoof one to get the configure manually to pop up.
8. Configure Proxy
a. Click the **gear icon** on the bottom left for settings. Scroll all the way down to **Network & Disk Space**. Click the **settings button** next to **Connection. Configure how Thunderbird connects to the internet**.
b. Select **Manual Proxy Configuration**. For **SOCKS Host** enter **127.0.0.1** and enter port **9050**. (if you are running this through a VM the port may be different)
c. Now check the box for **SOCKS5** and then **Proxy DNS when using SOCKS5** down at the bottom. Click OK
9. Check Email
For thunderbird to reach the onion mail server it has to be connected to tor. Depending on your local setup, it might be fine as is or you might have to have tor browser open in the background. Click on **inbox** and then the **little cloud icon** with the down arrow to check mail.
10. Security Exception
Thunderbird is not going to like that the onion mail server security certificate is self signed. A popup **Add Security Exception** will appear. Click **Confirm Security Exception**.
You are done. Enjoy your new private email service.
**REMEMBER: The server can read your emails unless they are encrypted. Go into account settings. Look down and click End-toEnd Encryption. Then add your OpenPGP key or open your OpenPGP Key Manager (you might have to download one if you don't already have one) and generate a new key for this account.**
-
@ 39cc53c9:27168656
2025-03-30 05:54:47
> [Read the original blog post](https://blog.kycnot.me/p/diy-seed-backup)
I've been thinking about how to improve my seed backup in a cheap and cool way, mostly for fun. Until now, I had the seed written on a piece of paper in a desk drawer, and I wanted something more durable and fire-proof.
[Show me the final result!](#the-final-result)
After searching online, I found two options I liked the most: the [Cryptosteel](https://cryptosteel.com/) Capsule and the [Trezor Keep](https://trezor.io/trezor-keep-metal). These products are nice but quite expensive, and I didn't want to spend that much on my seed backup. **Privacy** is also important, and sharing details like a shipping address makes me uncomfortable. This concern has grown since the Ledger incident[^1]. A $5 wrench attack[^2] seems too cheap, even if you only hold a few sats.
Upon seeing the design of Cryptosteel, I considered creating something similar at home. Although it may not be as cool as their device, it could offer almost the same in terms of robustness and durability.
## Step 1: Get the materials and tools
When choosing the materials, you will want to go with **stainless steel**. It is durable, resistant to fire, water, and corrosion, very robust, and does not rust. Also, its price point is just right; it's not the cheapest, but it's cheap for the value you get.

I went to a material store and bought:
- Two bolts
- Two hex nuts and head nuts for the bolts
- A bag of 30 washers
All items were made of stainless steel. The total price was around **€6**. This is enough for making two seed backups.
You will also need:
- A set of metal letter stamps (I bought a 2mm-size letter kit since my washers were small, 6mm in diameter)
- You can find these in local stores or online marketplaces. The set I bought cost me €13.
- A good hammer
- A solid surface to stamp on
Total spent: **19€** for two backups
## Step 2: Stamp and store
Once you have all the materials, you can start stamping your words. There are many videos on the internet that use fancy 3D-printed tools to get the letters nicely aligned, but I went with the free-hand option. The results were pretty decent.

I only stamped the first 4 letters for each word since the BIP-39 wordlist allows for this. Because my stamping kit did not include numbers, I used alphabet letters to define the order. This way, if all the washers were to fall off, I could still reassemble the seed correctly.
## The final result
So this is the final result. I added two smaller washers as protection and also put the top washer reversed so the letters are not visible:

Compared to the Cryptosteel or the Trezor Keep, its size is much more compact. This makes for an easier-to-hide backup, in case you ever need to hide it inside your human body.
## Some ideas
### Tamper-evident seal
To enhance the security this backup, you can consider using a **tamper-evident seal**. This can be easily achieved by printing a **unique** image or using a specific day's newspaper page (just note somewhere what day it was).
Apply a thin layer of glue to the washer's surface and place the seal over it. If someone attempts to access the seed, they will be forced to destroy the seal, which will serve as an evident sign of tampering.
This simple measure will provide an additional layer of protection and allow you to quickly identify any unauthorized access attempts.
Note that this method is not resistant to outright theft. The tamper-evident seal won't stop a determined thief but it will prevent them from accessing your seed without leaving any trace.
### Redundancy
Make sure to add redundancy. Make several copies of this cheap backup, and store them in separate locations.
### Unique wordset
Another layer of security could be to implement your own custom mnemonic dictionary. However, this approach has the risk of permanently losing access to your funds if not implemented correctly.
If done properly, you could potentially end up with a highly secure backup, as no one else would be able to derive the seed phrase from it. To create your custom dictionary, assign a unique number from 1 to 2048 to a word of your choice. Maybe you could use a book, and index the first 2048 unique words that appear. Make sure to store this book and even get a couple copies of it (digitally and phisically).
This self-curated set of words will serve as your personal BIP-39 dictionary. When you need to translate between your custom dictionary and the official [BIP-39 wordlist](https://github.com/bitcoin/bips/blob/master/bip-0039/english.txt), simply use the index number to find the corresponding word in either list.
> Never write the idex or words on your computer (Do not use `Ctr+F`)
[^1]: https://web.archive.org/web/20240326084135/https://www.ledger.com/message-ledgers-ceo-data-leak
[^2]: https://xkcd.com/538/
-
@ 6b3780ef:221416c8
2025-03-26 18:42:00
This workshop will guide you through exploring the concepts behind MCP servers and how to deploy them as DVMs in Nostr using DVMCP. By the end, you'll understand how these systems work together and be able to create your own deployments.
## Understanding MCP Systems
MCP (Model Context Protocol) systems consist of two main components that work together:
1. **MCP Server**: The heart of the system that exposes tools, which you can access via the `.listTools()` method.
2. **MCP Client**: The interface that connects to the MCP server and lets you use the tools it offers.
These servers and clients can communicate using different transport methods:
- **Standard I/O (stdio)**: A simple local connection method when your server and client are on the same machine.
- **Server-Sent Events (SSE)**: Uses HTTP to create a communication channel.
For this workshop, we'll use stdio to deploy our server. DVMCP will act as a bridge, connecting to your MCP server as an MCP client, and exposing its tools as a DVM that anyone can call from Nostr.
## Creating (or Finding) an MCP Server
Building an MCP server is simpler than you might think:
1. Create software in any programming language you're comfortable with.
2. Add an MCP library to expose your server's MCP interface.
3. Create an API that wraps around your software's functionality.
Once your server is ready, an MCP client can connect, for example, with `bun index.js`, and then call `.listTools()` to discover what your server can do. This pattern, known as reflection, makes Nostr DVMs and MCP a perfect match since both use JSON, and DVMs can announce and call tools, effectively becoming an MCP proxy.
Alternatively, you can use one of the many existing MCP servers available in various repositories.
For more information about mcp and how to build mcp servers you can visit https://modelcontextprotocol.io/
## Setting Up the Workshop
Let's get hands-on:
First, to follow this workshop you will need Bun. Install it from https://bun.sh/. For Linux and macOS, you can use the installation script:
```
curl -fsSL https://bun.sh/install | bash
```
1. **Choose your MCP server**: You can either create one or use an existing one.
2. **Inspect your server** using the MCP inspector tool:
```bash
npx @modelcontextprotocol/inspector build/index.js arg1 arg2
```
This will:
- Launch a client UI (default: http://localhost:5173)
- Start an MCP proxy server (default: port 3000)
- Pass any additional arguments directly to your server
3. **Use the inspector**: Open the client UI in your browser to connect with your server, list available tools, and test its functionality.
## Deploying with DVMCP
Now for the exciting part – making your MCP server available to everyone on Nostr:
1. Navigate to your MCP server directory.
2. Run without installing (quickest way):
```
npx @dvmcp/bridge
```
3. Or install globally for regular use:
```
npm install -g @dvmcp/bridge
# or
bun install -g @dvmcp/bridge
```
Then run using:
```bash
dvmcp-bridge
```
This will guide you through creating the necessary configuration.
Watch the console logs to confirm successful setup – you'll see your public key and process information, or any issues that need addressing.
For the configuration, you can set the relay as `wss://relay.dvmcp.fun` , or use any other of your preference
## Testing and Integration
1. **Visit [dvmcp.fun](https://dvmcp.fun)** to see your DVM announcement.
2. Call your tools and watch the responses come back.
For production use, consider running dvmcp-bridge as a system service or creating a container for greater reliability and uptime.
## Integrating with LLM Clients
You can also integrate your DVMCP deployment with LLM clients using the discovery package:
1. Install and use the `@dvmcp/discovery` package:
```bash
npx @dvmcp/discovery
```
2. This package acts as an MCP server for your LLM system by:
- Connecting to configured Nostr relays
- Discovering tools from DVMCP servers
- Making them available to your LLM applications
3. Connect to specific servers or providers using these flags:
```bash
# Connect to all DVMCP servers from a provider
npx @dvmcp/discovery --provider npub1...
# Connect to a specific DVMCP server
npx @dvmcp/discovery --server naddr1...
```
Using these flags, you wouldn't need a configuration file. You can find these commands and Claude desktop configuration already prepared for copy and paste at [dvmcp.fun](https://dvmcp.fun).
This feature lets you connect to any DVMCP server using Nostr and integrate it into your client, either as a DVM or in LLM-powered applications.
## Final thoughts
If you've followed this workshop, you now have an MCP server deployed as a Nostr DVM. This means that local resources from the system where the MCP server is running can be accessed through Nostr in a decentralized manner. This capability is powerful and opens up numerous possibilities and opportunities for fun.
You can use this setup for various use cases, including in a controlled/local environment. For instance, you can deploy a relay in your local network that's only accessible within it, exposing all your local MCP servers to anyone connected to the network. This setup can act as a hub for communication between different systems, which could be particularly interesting for applications in home automation or other fields. The potential applications are limitless.
However, it's important to keep in mind that there are security concerns when exposing local resources publicly. You should be mindful of these risks and prioritize security when creating and deploying your MCP servers on Nostr.
Finally, these are new ideas, and the software is still under development. If you have any feedback, please refer to the GitHub repository to report issues or collaborate. DVMCP also has a Signal group you can join. Additionally, you can engage with the community on Nostr using the #dvmcp hashtag.
## Useful Resources
- **Official Documentation**:
- Model Context Protocol: [modelcontextprotocol.org](https://modelcontextprotocol.org)
- DVMCP.fun: [dvmcp.fun](https://dvmcp.fun)
- **Source Code and Development**:
- DVMCP: [github.com/gzuuus/dvmcp](https://github.com/gzuuus/dvmcp)
- DVMCP.fun: [github.com/gzuuus/dvmcpfun](https://github.com/gzuuus/dvmcpfun)
- **MCP Servers and Clients**:
- Smithery AI: [smithery.ai](https://smithery.ai)
- MCP.so: [mcp.so](https://mcp.so)
- Glama AI MCP Servers: [glama.ai/mcp/servers](https://glama.ai/mcp/servers)
- [Signal group](https://signal.group/#CjQKIOgvfFJf8ZFZ1SsMx7teFqNF73sZ9Elaj_v5i6RSjDHmEhA5v69L4_l2dhQfwAm2SFGD)
Happy building!
-
@ a012dc82:6458a70d
2025-03-19 06:28:40
In recent years, the global economy has faced unprecedented challenges, with inflation rates soaring to levels not seen in decades. This economic turmoil has led investors and consumers alike to seek alternative stores of value and investment strategies. Among the various options, Bitcoin has emerged as a particularly appealing choice. This article explores the reasons behind Bitcoin's growing appeal in an inflation-stricken economy, delving into its characteristics, historical performance, and the broader implications for the financial landscape.
**Table of Contents**
- Understanding Inflation and Its Impacts
- Bitcoin: A New Safe Haven?
- Decentralization and Limited Supply
- Portability and Liquidity
- Bitcoin's Performance in Inflationary Times
- Challenges and Considerations
- The Future of Bitcoin in an Inflationary Economy
- Conclusion
- FAQs
**Understanding Inflation and Its Impacts**
Inflation is the rate at which the general level of prices for goods and services is rising, eroding purchasing power. It can be caused by various factors, including increased production costs, higher energy prices, and expansive government policies. Inflation affects everyone in the economy, from consumers and businesses to investors and retirees, as it diminishes the value of money. When inflation rates rise, the purchasing power of currency falls, leading to higher costs for everyday goods and services. This can result in decreased consumer spending, reduced savings, and overall economic slowdown.
For investors, inflation is a significant concern because it can erode the real returns on their investments. Traditional investments like bonds and savings accounts may not keep pace with inflation, leading to a loss in purchasing power over time. This has prompted a search for alternative investments that can provide a hedge against inflation and preserve, if not increase, the value of their capital.
**Bitcoin: A New Safe Haven?**
Traditionally, assets like gold, real estate, and Treasury Inflation-Protected Securities (TIPS) have been considered safe havens during times of inflation. However, the digital age has introduced a new player: Bitcoin. Bitcoin is a decentralized digital currency that operates without the oversight of a central authority. Its supply is capped at 21 million coins, a feature that many believe gives it anti-inflationary properties. This inherent scarcity is akin to natural resources like gold, which have historically been used as hedges against inflation.
The decentralization of Bitcoin means that it is not subject to the whims of central banking policies or government interference, which are often seen as contributing factors to inflation. This aspect of Bitcoin is particularly appealing to those who have lost faith in traditional financial systems and are looking for alternatives that offer more autonomy and security.
**Decentralization and Limited Supply**
One of the key features that make Bitcoin appealing as a hedge against inflation is its decentralized nature. Unlike fiat currencies, which central banks can print in unlimited quantities, Bitcoin's supply is finite. This scarcity mimics the properties of gold and is seen as a buffer against inflation. The decentralized nature of Bitcoin also means that it is not subject to the same regulatory pressures and monetary policies that can lead to currency devaluation.
Furthermore, the process of "mining" Bitcoin, which involves validating transactions and adding them to the blockchain, is designed to become progressively more difficult over time. This not only ensures the security of the network but also introduces a deflationary element to Bitcoin, as the rate at which new coins are created slows down over time.
**Portability and Liquidity**
Bitcoin's digital nature makes it highly portable and divisible, allowing for easy transfer and exchange worldwide. This liquidity and global accessibility make it an attractive option for investors looking to diversify their portfolios beyond traditional assets. Unlike physical assets like gold or real estate, Bitcoin can be transferred across borders without the need for intermediaries, making it a truly global asset.
The ease of transferring and dividing Bitcoin means that it can be used for a wide range of transactions, from large-scale investments to small, everyday purchases. This versatility, combined with its growing acceptance as a form of payment, enhances its utility and appeal as an investment.
**Bitcoin's Performance in Inflationary Times**
Historically, Bitcoin has shown significant growth during periods of high inflation. While it is known for its price volatility, many investors have turned to Bitcoin as a speculative hedge against depreciating fiat currencies. The digital currency's performance during inflationary periods has bolstered its reputation as a potential safe haven. However, it's important to note that Bitcoin's market is still relatively young and can be influenced by a wide range of factors beyond inflation, such as market sentiment, technological developments, and regulatory changes.
Despite its volatility, Bitcoin has provided substantial returns for some investors, particularly those who entered the market early. Its performance, especially during times of financial instability, has led to increased interest and investment from both individual and institutional investors. As more people look to Bitcoin as a potential hedge against inflation, its role in investment portfolios is likely to evolve.
**Challenges and Considerations**
Despite its growing appeal, Bitcoin is not without its challenges. The cryptocurrency's price volatility can lead to significant losses, and regulatory uncertainties remain a concern. Additionally, the environmental impact of Bitcoin mining has sparked debate. The energy-intensive process required to mine new coins and validate transactions has raised concerns about its sustainability and environmental footprint.
Investors considering Bitcoin as a hedge against inflation should weigh these factors and consider their risk tolerance and investment horizon. While Bitcoin offers potential benefits as an inflation hedge, it also comes with risks that are different from traditional investments. Understanding these risks, and how they align with individual investment strategies, is crucial for anyone considering adding Bitcoin to their portfolio.
**The Future of Bitcoin in an Inflationary Economy**
As the global economy continues to navigate through turbulent waters, the appeal of Bitcoin is likely to grow. Its properties as a decentralized, finite, and easily transferable asset make it a unique option for those looking to protect their wealth from inflation. However, the future of Bitcoin remains uncertain, and its role in the broader financial landscape is still being defined. As with any investment, due diligence and a balanced approach are crucial.
The increasing institutional interest in Bitcoin and the development of financial products around it, such as ETFs and futures, suggest that Bitcoin is becoming more mainstream. However, its acceptance and integration into the global financial system will depend on a variety of factors, including regulatory developments, technological advancements, and market dynamics.
**Conclusion**
The growing appeal of Bitcoin in an inflation-stricken economy highlights the changing dynamics of investment in the digital age. While it offers a novel approach to wealth preservation, it also comes with its own set of risks and challenges. As the world continues to grapple with inflation, the role of Bitcoin and other cryptocurrencies will undoubtedly be a topic of keen interest and debate among investors and policymakers alike. Whether Bitcoin will become a permanent fixture in investment portfolios as a hedge against inflation remains to be seen, but its impact on the financial landscape is undeniable.
**FAQs**
**What is inflation, and how does it affect the economy?**
Inflation is the rate at which the general level of prices for goods and services is rising, leading to a decrease in purchasing power. It affects the economy by reducing the value of money, increasing costs for consumers and businesses, and potentially leading to economic slowdown.
**Why is Bitcoin considered a hedge against inflation?**
Bitcoin is considered a hedge against inflation due to its decentralized nature, limited supply capped at 21 million coins, and its independence from government monetary policies, which are often seen as contributing factors to inflation.
**What are the risks associated with investing in Bitcoin?**
The risks include high price volatility, regulatory uncertainties, and concerns over the environmental impact of Bitcoin mining. Investors should consider their risk tolerance and investment horizon before investing in Bitcoin.
**How does Bitcoin's limited supply contribute to its value?**
Bitcoin's limited supply mimics the scarcity of resources like gold, which has traditionally been used as a hedge against inflation. This scarcity can help to maintain its value over time, especially in contrast to fiat currencies, which can be printed in unlimited quantities.
**Can Bitcoin be used for everyday transactions?**
Yes, Bitcoin can be used for a wide range of transactions, from large-scale investments to small, everyday purchases. Its digital nature allows for easy transfer and division, making it a versatile form of currency.
**That's all for today**
**If you want more, be sure to follow us on:**
**NOSTR: croxroad@getalby.com**
**X: @croxroadnewsco**
**Instagram: @croxroadnews.co/**
**Youtube: @thebitcoinlibertarian**
**Store: https://croxroad.store**
**Subscribe to CROX ROAD Bitcoin Only Daily Newsletter**
**https://www.croxroad.co/subscribe**
**Get Orange Pill App And Connect With Bitcoiners In Your Area. Stack Friends Who Stack Sats
link: https://signup.theorangepillapp.com/opa/croxroad**
**Buy Bitcoin Books At Konsensus Network Store. 10% Discount With Code “21croxroad”
link: https://bitcoinbook.shop?ref=21croxroad**
*DISCLAIMER: None of this is financial advice. This newsletter is strictly educational and is not investment advice or a solicitation to buy or sell any assets or to make any financial decisions. Please be careful and do your own research.*
-
@ fd06f542:8d6d54cd
2025-03-30 02:16:24
> __Warning__ `unrecommended`: deprecated in favor of [NIP-17](17.md)
NIP-04
======
Encrypted Direct Message
------------------------
`final` `unrecommended` `optional`
A special event with kind `4`, meaning "encrypted direct message". It is supposed to have the following attributes:
**`content`** MUST be equal to the base64-encoded, aes-256-cbc encrypted string of anything a user wants to write, encrypted using a shared cipher generated by combining the recipient's public-key with the sender's private-key; this appended by the base64-encoded initialization vector as if it was a querystring parameter named "iv". The format is the following: `"content": "<encrypted_text>?iv=<initialization_vector>"`.
**`tags`** MUST contain an entry identifying the receiver of the message (such that relays may naturally forward this event to them), in the form `["p", "<pubkey, as a hex string>"]`.
**`tags`** MAY contain an entry identifying the previous message in a conversation or a message we are explicitly replying to (such that contextual, more organized conversations may happen), in the form `["e", "<event_id>"]`.
**Note**: By default in the [libsecp256k1](https://github.com/bitcoin-core/secp256k1) ECDH implementation, the secret is the SHA256 hash of the shared point (both X and Y coordinates). In Nostr, only the X coordinate of the shared point is used as the secret and it is NOT hashed. If using libsecp256k1, a custom function that copies the X coordinate must be passed as the `hashfp` argument in `secp256k1_ecdh`. See [here](https://github.com/bitcoin-core/secp256k1/blob/master/src/modules/ecdh/main_impl.h#L29).
Code sample for generating such an event in JavaScript:
```js
import crypto from 'crypto'
import * as secp from '@noble/secp256k1'
let sharedPoint = secp.getSharedSecret(ourPrivateKey, '02' + theirPublicKey)
let sharedX = sharedPoint.slice(1, 33)
let iv = crypto.randomFillSync(new Uint8Array(16))
var cipher = crypto.createCipheriv(
'aes-256-cbc',
Buffer.from(sharedX),
iv
)
let encryptedMessage = cipher.update(text, 'utf8', 'base64')
encryptedMessage += cipher.final('base64')
let ivBase64 = Buffer.from(iv.buffer).toString('base64')
let event = {
pubkey: ourPubKey,
created_at: Math.floor(Date.now() / 1000),
kind: 4,
tags: [['p', theirPublicKey]],
content: encryptedMessage + '?iv=' + ivBase64
}
```
## Security Warning
This standard does not go anywhere near what is considered the state-of-the-art in encrypted communication between peers, and it leaks metadata in the events, therefore it must not be used for anything you really need to keep secret, and only with relays that use `AUTH` to restrict who can fetch your `kind:4` events.
## Client Implementation Warning
Clients *should not* search and replace public key or note references from the `.content`. If processed like a regular text note (where `@npub...` is replaced with `#[0]` with a `["p", "..."]` tag) the tags are leaked and the mentioned user will receive the message in their inbox.
-
@ 39cc53c9:27168656
2025-03-30 05:54:45
> [Read the original blog post](https://blog.kycnot.me/p/ai-tos-analysis)
**kycnot.me** features a somewhat hidden tool that some users may not be aware of. Every month, an automated job crawls every listed service's Terms of Service (ToS) and FAQ pages and conducts an AI-driven analysis, generating a comprehensive overview that highlights key points related to KYC and user privacy.
Here's an example: [Changenow's Tos Review](https://kycnot.me/service/changenow#tos)

## Why?
ToS pages typically contain a lot of complicated text. Since the first versions of **kycnot.me**, I have tried to provide users a comprehensive overview of what can be found in such documents. This automated method keeps the information up-to-date every month, which was one of the main challenges with manual updates.
A significant part of the time I invest in investigating a service for **kycnot.me** involves reading the ToS and looking for any clauses that might indicate aggressive KYC practices or privacy concerns. For the past four years, I performed this task manually. However, with advancements in language models, this process can now be somewhat automated. I still manually review the ToS for a quick check and regularly verify the AI’s findings. However, over the past three months, this automated method has proven to be quite reliable.
Having a quick ToS overview section allows users to avoid reading the entire ToS page. Instead, you can quickly read the important points that are grouped, summarized, and referenced, making it easier and faster to understand the key information.
## Limitations
This method has a key limitation: JS-generated pages. For this reason, I was using Playwright in my crawler implementation. I plan to make a release addressing this issue in the future. There are also sites that don't have ToS/FAQ pages, but these sites already include a warning in that section.
Another issue is false positives. Although not very common, sometimes the AI might incorrectly interpret something harmless as harmful. Such errors become apparent upon reading; it's clear when something marked as bad should not be categorized as such. I manually review these cases regularly, checking for anything that seems off and then removing any inaccuracies.
Overall, the automation provides great results.
## How?
There have been several iterations of this tool. Initially, I started with GPT-3.5, but the results were not good in any way. It made up many things, and important thigs were lost on large ToS pages. I then switched to GPT-4 Turbo, but it was expensive. Eventually, I settled on Claude 3 Sonnet, which provides a quality compromise between GPT-3.5 and GPT-4 Turbo at a more reasonable price, while allowing a generous 200K token context window.
I designed a prompt, which is open source[^1], that has been tweaked many times and will surely be adjusted further in the future.
For the ToS scraping part, I initially wrote a scraper API using Playwright[^2], but I replaced it with Jina AI Reader[^3], which works quite well and is designed for this task.
### Non-conflictive ToS
All services have a dropdown in the ToS section called "Non-conflictive ToS Reviews." These are the reviews that the AI flagged as not needing a user warning. I still provide these because I think they may be interesting to read.
## Feedback and contributing
You can give me feedback on this tool, or share any inaccuraties by either opening an issue on Codeberg[^4] or by contacting me [^5].
You can contribute with pull requests, which are always welcome, or you can [support](https://kycnot.me/about#support) this project with any of the listed ways.
[^1]: https://codeberg.org/pluja/kycnot.me/src/branch/main/src/utils/ai/prompt.go
[^2]: https://codeberg.org/pluja/kycnot.me/commit/483ba8b415cecf323b3d9f0cfd4e9620919467d2
[^3]: https://github.com/jina-ai/reader
[^4]: https://codeberg.org/pluja/kycnot.me
[^5]: https://kycnot.me/about#contact
-
@ e97aaffa:2ebd765d
2025-03-19 05:55:17
Como é difícil encontrar informações sobre o eurodigital, a CBDC da União Europeia, vou colocando aqui, os documentos mais interessantes que fui encontrando:
FAQ:
https://www.ecb.europa.eu/euro/digital_euro/faqs/html/ecb.faq_digital_euro.pt.html
Directório BCE:
https://www.ecb.europa.eu/press/pubbydate/html/index.en.html?topic=Digital%20euro
https://www.ecb.europa.eu/euro/digital_euro/timeline/profuse/html/index.en.html
Documentos mais técnicos:
## 2025
Technical note on the provision of multiple digital euro accounts to individual end users
https://www.ecb.europa.eu/euro/digital_euro/timeline/profuse/shared/pdf/ecb.degov240325_digital_euro_multiple_accounts.en.pdf
## 2024
Relatório de progresso
https://www.ecb.europa.eu/euro/digital_euro/progress/html/ecb.deprp202412.en.html
Technical note on the provision of multiple digital euro accounts to individual end users
https://www.ecb.europa.eu/euro/digital_euro/timeline/profuse/shared/pdf/ecb.degov240325_digital_euro_multiple_accounts.en.pdf
The impact of central bank digital
currency on central bank profitability,
risk-taking and capital
https://www.ecb.europa.eu/pub/pdf/scpops/ecb.op360~35915b25bd.en.pdf
## 2023
Progress on the investigation phase of a digital euro - fourth report
https://www.ecb.europa.eu/paym/digital_euro/investigation/governance/shared/files/ecb.degov230713-fourth-progress-report-digital-euro-investigation-phase.en.pdf
Digital euro - Prototype summary and lessons learned
https://www.ecb.europa.eu/pub/pdf/other/ecb.prototype_summary20230526%7E71d0b26d55.en.pdf
Functional and non-functional
requirements linked to the market research for a potential digital euro implementation
https://www.ecb.europa.eu/euro/digital_euro/timeline/profuse/shared/pdf//ecb.dedocs230113_Annex_1_Digital_euro_market_research.en.pdf
A stocktake on the digital euro
https://www.ecb.europa.eu/euro/digital_euro/progress/shared/pdf/ecb.dedocs231018.en.pdf
-
@ 57d1a264:69f1fee1
2025-03-29 18:02:16
> This UX research has been redacted by @iqra from the Bitcoin.Design [community](https://discord.gg/K7aQ5PErht), and shared for review and feedback! Don't be shy, share your thoughts.

- - -
## 1️⃣ Introduction
#### Project Overview
📌 **Product:** BlueWallet (Bitcoin Wallet)
📌 **Goal:** Improve onboarding flow and enhance accessibility for a better user experience.
📌 **Role:** UX Designer
📌 **Tools Used:** Figma, Notion
#### Why This Case Study?
🔹 BlueWallet is a self-custodial Bitcoin wallet, but **users struggle with onboarding due to unclear instructions**.
🔹 **Accessibility issues** (low contrast, small fonts) create **barriers for visually impaired users**.
🔹 Competitors like **Trust Wallet and MetaMask offer better-guided onboarding**.
This case study presents **UX/UI improvements** to make BlueWallet **more intuitive and inclusive**.
- - -
## 2️⃣ Problem Statement: Why BlueWalletʼs Onboarding Needs Improvement
#### 🔹 **Current Challenges:**
1️⃣ **Onboarding Complexity** - BlueWallet lacks **step-by-step guidance**, leaving users confused about wallet creation and security.
 
2️⃣ **No Educational Introduction** - Users land directly on the wallet screen with **no explanation of private keys, recovery phrases, or transactions**.
3️⃣ **Transaction Flow Issues** - Similar-looking **"Send" and "Receive" buttons** cause confusion.
4️⃣ **Poor Accessibility** - Small fonts and low contrast make navigation difficult.
#### 🔍 **Impact on Users:**
**Higher drop-off rates** due to frustration during onboarding.
**Security risks** as users skip key wallet setup steps.
**Limited accessibility** for users with visual impairments.
#### 📌 **Competitive Gap:**
Unlike competitors (Trust Wallet, MetaMask), BlueWallet does not offer:
✅ A guided onboarding process
✅ Security education during setup
✅ Intuitive transaction flow
    
Somehow, this wallet has much better UI than the BlueWallet Bitcoin wallet.
- - -
## 3️⃣ User Research & Competitive Analysis
#### User Testing Findings
🔹 Conducted usability testing with **5 users** onboarding for the first time.
🔹 **Key Findings:**
✅ 3 out of 5 users **felt lost** due to missing explanations.
✅ 60% **had trouble distinguishing transaction buttons**.
✅ 80% **found the text difficult to read** due to low contrast.
#### Competitive Analysis
We compared BlueWallet with top crypto wallets:
| Wallet | Onboarding UX | Security Guidance | Accessibility Features |
|---|---|---|---|
| BlueWallet | ❌ No guided onboarding | ❌ Minimal explanation | ❌ Low contrast, small fonts |
| Trust Wallet | ✅ Step-by-step setup | ✅ Security best practices | ✅ High contrast UI |
| MetaMask | ✅ Interactive tutorial | ✅ Private key education | ✅ Clear transaction buttons |
📌 **Key Insight:** BlueWallet lacks **guided setup and accessibility enhancements**, making it harder for beginners.
## 📌 User Persona
To better understand the users facing onboarding challenges, I developed a **persona** based on research and usability testing.
#### 🔹 Persona 1: Alex Carter (Bitcoin Beginner & Investor)
👤 **Profile:**
- **Age:** 28
- **Occupation:** Freelance Digital Marketer
- **Tech Knowledge:** Moderate - Familiar with online transactions, new to Bitcoin)
- **Pain Points:**
- Finds **Bitcoin wallets confusing**.
- - Doesnʼt understand **seed phrases & security features**.
- - **Worried about losing funds** due to a lack of clarity in transactions.
📌 **Needs:**
✅ A **simple, guided** wallet setup.
✅ **Clear explanations** of security terms (without jargon).
✅ Easy-to-locate **Send/Receive buttons**.
📌 **Persona Usage in Case Study:**
- Helps define **who we are designing for**.
- Guides **design decisions** by focusing on user needs.
#### 🔹 Persona 2: Sarah Mitchell (Accessibility Advocate & Tech Enthusiast)
👤 **Profile:**
- **Age:** 35
- **Occupation:** UX Researcher & Accessibility Consultant
- **Tech Knowledge:** High (Uses Bitcoin but struggles with accessibility barriers)
📌 **Pain Points:**
❌ Struggles with small font sizes & low contrast.
❌ Finds the UI difficult to navigate with a screen reader.
❌ Confused by identical-looking transaction buttons.
📌 **Needs:**
✅ A **high-contrast UI** that meets **WCAG accessibility standards**.
✅ **Larger fonts & scalable UI elements** for better readability.
✅ **Keyboard & screen reader-friendly navigation** for seamless interaction.
📌 **Why This Persona Matters:**
- Represents users with visual impairments who rely on accessible design.
- Ensures the design accommodates inclusive UX principles.
- - -
## 4️⃣ UX/UI Solutions & Design Improvements
#### 📌 Before (Current Issues)
❌ Users land **directly on the wallet screen** with no instructions.
❌ **"Send" & "Receive" buttons look identical** , causing transaction confusion.
❌ **Small fonts & low contrast** reduce readability.
#### ✅ After (Proposed Fixes)
✅ **Step-by-step onboarding** explaining wallet creation, security, and transactions.
✅ **Visually distinct transaction buttons** (color and icon changes).
✅ **WCAG-compliant text contrast & larger fonts** for better readability.
#### 1️⃣ Redesigned Onboarding Flow
✅ Added a **progress indicator** so users see where they are in setup.
✅ Used **plain, non-technical language** to explain wallet creation & security.
✅ Introduced a **"Learn More" button** to educate users on security.
#### 2️⃣ Accessibility Enhancements
✅ Increased **contrast ratio** for better text readability.
✅ Used **larger fonts & scalable UI elements**.
✅ Ensured **screen reader compatibility** (VoiceOver & TalkBack support).
#### 3️⃣ Transaction Flow Optimization
✅ Redesigned **"Send" & "Receive" buttons** for clear distinction.
✅ Added **clearer icons & tooltips** for transaction steps.
## 5️⃣ Wireframes & Design Improvements:
#### 🔹 Welcome Screen (First Screen When User Opens Wallet)
**📌 Goal: Give a brief introduction & set user expectations**
✅ App logo + **short tagline** (e.g., "Secure, Simple, Self-Custody Bitcoin Wallet")
✅ **1-2 line explanation** of what BlueWallet is (e.g., "Your gateway to managing Bitcoin securely.")
✅ **"Get Started" button** → Le ads to **next step: Wallet Setup**
✅ **"Already have a wallet?"** → Import option
🔹 **Example UI Elements:**
- BlueWallet Logo
- **Title:** "Welcome to BlueWallet"
- **Subtitle:** "Easily store, send, and receive Bitcoin."
- CTA: "Get Started" (Primary) | "Import Wallet" (Secondary)

#### 🔹 Screen 2: Choose Wallet Type (New or Import)
**📌 Goal: Let users decide how to proceed**
✅ **Two clear options:**
- **Create a New Wallet** (For first-time users)
- **Import Existing Wallet** (For users with a backup phrase)
✅ Brief explanation of each option
🔹 **Example UI Elements:
- **Title:** "How do you want to start?"
- **Buttons:** "Create New Wallet" | "Import Wallet"

#### 🔹 Screen 3: Security & Seed Phrase Setup (Critical Step)
**📌 Goal: Educate users about wallet security & backups**
✅ Explain **why seed phrases are important**
✅ **Clear step-by-step instructions** on writing down & storing the phrase
✅ **Warning:** "If you lose your recovery phrase, you lose access to your wallet."
✅ **CTA:** "Generate Seed Phrase" → Next step
🔹 **Example UI Elements:
- Title:** "Secure Your Wallet"
- **Subtitle:** "Your seed phrase is the key to your Bitcoin. Keep it safe!"
- **Button:** "Generate Seed Phrase"

## 🔹 Screen 4: Seed Phrase Display & Confirmation
**📌 Goal: Ensure users write down the phrase correctly**
✅ Display **12- or 24-word** seed phrase
✅ **“I have written it downˮ checkbox** before proceeding
✅ Next screen: **Verify seed phrase** (drag & drop, re-enter some words)
🔹 **Example UI Elements:**
- **Title:** "Write Down Your Seed Phrase"
- List of 12/24 Words (Hidden by Default)
- **Checkbox:** "I have safely stored my phrase"
- **Button:** "Continue"

### 🔹 Screen 5: Wallet Ready! (Final Step)
**📌 Goal: Confirm setup & guide users on next actions**
✅ **Success message** ("Your wallet is ready!")
✅ **Encourage first action:**
- “Receive Bitcoinˮ → Show wallet address
- “Send Bitcoinˮ → Walkthrough on making transactions
✅ Short explainer: Where to find the Send/Receive buttons
🔹 **Example UI Elements:**
- **Title:** "You're All Set!"
- **Subtitle:** "Start using BlueWallet now."
- **Buttons:** "Receive Bitcoin" | "View Wallet"

- - -
## 5️⃣ Prototype & User Testing Results
🔹 **Created an interactive prototype in Figma** to test the new experience.
🔹 **User Testing Results:**
✅ **40% faster onboarding completion time.**
✅ **90% of users found transaction buttons clearer.**
🔹 **User Feedback:**
✅ “Now I understand the security steps clearly.ˮ
✅ “The buttons are easier to find and use.ˮ
- - -
## 6️⃣ Why This Matters: Key Takeaways
📌 **Impact of These UX/UI Changes:**
✅ **Reduced user frustration** by providing a step-by-step onboarding guide.
✅ **Improved accessibility** , making the wallet usable for all.
✅ **More intuitive transactions** , reducing errors.
- - -
## 7️⃣ Direct link to figma file and Prototype
Figma file: [https://www.figma.com/design/EPb4gVgAMEgF5GBDdtt81Z/Blue-Wallet-UI-
Improvements?node-id=0-1&t=Y2ni1SfvuQQnoB7s-1](https://www.figma.com/design/EPb4gVgAMEgF5GBDdtt81Z/Blue-Wallet-UI-
Improvements?node-id=0-1&t=Y2ni1SfvuQQnoB7s-1)
Prototype: [https://www.figma.com/proto/EPb4gVgAMEgF5GBDdtt81Z/Blue-Wallet-UI-
Improvements?node-id=1-2&p=f&t=FndTJQNCE7nEIa84-1&scaling=scale-
down&content-scaling=fixed&page-id=0%3A1&starting-point-node-
id=1%3A2&show-proto-sidebar=1](https://www.figma.com/proto/EPb4gVgAMEgF5GBDdtt81Z/Blue-Wallet-UI-
Improvements?node-id=1-2&p=f&t=FndTJQNCE7nEIa84-1&scaling=scale-
down&content-scaling=fixed&page-id=0%3A1&starting-point-node-
id=1%3A2&show-proto-sidebar=1)
Original PDF available from [here](https://cdn.discordapp.com/attachments/903126164795699212/1355561527394173243/faf3ee46-b501-459c-ba0e-bf7e38843bc8_UX_Case_Study__1.pdf?ex=67e9608d&is=67e80f0d&hm=d0c386ce2cfd6e0ebe6bde0a904e884229f52bf547adf1f7bc884e17bb4aa59e&)
originally posted at https://stacker.news/items/928822
-
@ 57d1a264:69f1fee1
2025-03-29 17:15:17

- Once activated, "Accept From Any Mint” is the default setting. This is the easiest way to get started, let's the user start acceptance Cashu ecash just out of the box.
- If someone does want to be selective, they can choose “Accept From Trusted Mints,” and that brings up a field where they can add specific mint URLs they trust.
- “Find a Mint” section on the right with a button links directly to bitcoinmints.com, already filtered for Cashu mints, so users can easily browse options.
- Mint info modal shows mint technical details stuff from the NUT06 spec. Since this is geared towards the more technical users I left the field names and NUT number as-is instead of trying to make it more semantic.
originally posted at https://stacker.news/items/928800
-
@ fd06f542:8d6d54cd
2025-03-30 02:11:00
NIP-03
======
OpenTimestamps Attestations for Events
--------------------------------------
`draft` `optional`
This NIP defines an event with `kind:1040` that can contain an [OpenTimestamps](https://opentimestamps.org/) proof for any other event:
```json
{
"kind": 1040
"tags": [
["e", <event-id>, <relay-url>],
["alt", "opentimestamps attestation"]
],
"content": <base64-encoded OTS file data>
}
```
- The OpenTimestamps proof MUST prove the referenced `e` event id as its digest.
- The `content` MUST be the full content of an `.ots` file containing at least one Bitcoin attestation. This file SHOULD contain a **single** Bitcoin attestation (as not more than one valid attestation is necessary and less bytes is better than more) and no reference to "pending" attestations since they are useless in this context.
### Example OpenTimestamps proof verification flow
Using [`nak`](https://github.com/fiatjaf/nak), [`jq`](https://jqlang.github.io/jq/) and [`ots`](https://github.com/fiatjaf/ots):
```bash
~> nak req -i e71c6ea722987debdb60f81f9ea4f604b5ac0664120dd64fb9d23abc4ec7c323 wss://nostr-pub.wellorder.net | jq -r .content | ots verify
> using an esplora server at https://blockstream.info/api
- sequence ending on block 810391 is valid
timestamp validated at block [810391]
```
-
@ fd06f542:8d6d54cd
2025-03-30 02:10:24
NIP-03
======
OpenTimestamps Attestations for Events
--------------------------------------
`draft` `optional`
This NIP defines an event with `kind:1040` that can contain an [OpenTimestamps](https://opentimestamps.org/) proof for any other event:
```json
{
"kind": 1040
"tags": [
["e", <event-id>, <relay-url>],
["alt", "opentimestamps attestation"]
],
"content": <base64-encoded OTS file data>
}
```
- The OpenTimestamps proof MUST prove the referenced `e` event id as its digest.
- The `content` MUST be the full content of an `.ots` file containing at least one Bitcoin attestation. This file SHOULD contain a **single** Bitcoin attestation (as not more than one valid attestation is necessary and less bytes is better than more) and no reference to "pending" attestations since they are useless in this context.
### Example OpenTimestamps proof verification flow
Using [`nak`](https://github.com/fiatjaf/nak), [`jq`](https://jqlang.github.io/jq/) and [`ots`](https://github.com/fiatjaf/ots):
```bash
~> nak req -i e71c6ea722987debdb60f81f9ea4f604b5ac0664120dd64fb9d23abc4ec7c323 wss://nostr-pub.wellorder.net | jq -r .content | ots verify
> using an esplora server at https://blockstream.info/api
- sequence ending on block 810391 is valid
timestamp validated at block [810391]
```
-
@ 5ffb8e1b:255b6735
2025-03-29 13:57:02
As a fellow Nostrich you might have noticed some of my #arlist posts. It is my effort to curate artists that are active on Nostr and make it easier for other users to find content that they are interested in.
By now I have posted six or seven posts mentioning close to fifty artists, the problem so far is that it's only a list of handles and it is up to reader to click on each in order to find out what are the artist behind the names all about. Now I am going to start creating blog posts with a few artists mentioned in each, with short descriptions of their work and an image or to.
I would love to have some more automated mode of curation but I still couldn't figure out what is a good way for it. I've looked at Listr, Primal custom feeds and Yakihonne curations but none seem to enable me to make a list of npubs that is then turned into a feed that I could publicly share for others to views.
Any advice on how to achieve this is VERY welcome !
And now lets get to the first batch of artists I want to share with you.
### Eugene Gorbachenko ###
nostr:npub1082uhnrnxu7v0gesfl78uzj3r89a8ds2gj3dvuvjnw5qlz4a7udqwrqdnd
Artist from Ukrain creating amazing realistic watercolor paintings.
He is very active on Nostr but is very unnoticed for some stange reason. Make sure to repost the painting that you liked the most to help other Nostr users to discover his great art.
![!(image)[https://m.primal.net/PxJc.png]]()
### Siritravelsketch ###
nostr:npub14lqzjhfvdc9psgxzznq8xys8pfq8p4fqsvtr6llyzraq90u9m8fqevhssu
a a lovely lady from Thailand making architecture from all around the world spring alive in her ink skethes. Dynamic lines gives it a dreamy magical feel, sometimes supported by soft watercolor strokes takes you to a ferytale layer of reality.
![!(image)[https://m.primal.net/PxJj.png]]()
### BureuGewas ###
nostr:npub1k78qzy2s9ap4klshnu9tcmmcnr3msvvaeza94epsgptr7jce6p9sa2ggp4
a a master of the clasic oil painting. From traditional still life to modern day subjects his paintings makes you feel the textures and light of the scene more intense then reality itself.
![!(image)[https://m.primal.net/PxKS.png]]()
You can see that I'm no art critic, but I am trying my best. If anyone else is interested to join me in this curration adventure feel free to reach out !
With love, Agi Choote
-
@ ee9aaefe:1e6952f4
2025-03-19 05:01:44
## Introduction to Model Context Protocol (MCP)
Model Context Protocol (MCP) serves as a specialized gateway allowing AI systems to access real-time information and interact with external data sources while maintaining security boundaries. This capability transforms AI from closed systems limited to training data into dynamic assistants capable of retrieving current information and performing actions. As AI systems integrate into critical infrastructure across industries, the security and reliability of these protocols have become crucial considerations.
## Security Vulnerabilities in Web-Based MCP Services
Traditional MCP implementations operate as web services, creating a fundamental security weakness. When an MCP runs as a conventional web service, the entire security model depends on trusting the service provider. Providers can modify underlying code, alter behavior, or update services without users' knowledge or consent. This creates an inherent vulnerability where the system's integrity rests solely on the trustworthiness of the MCP provider.
This vulnerability is particularly concerning in high-stakes domains. In financial applications, a compromised MCP could lead to unauthorized transactions or exposure of confidential information. In healthcare, it might result in compromised patient data. The fundamental problem is that users have no cryptographic guarantees about the MCP's behavior – they must simply trust the provider's claims about security and data handling.
Additionally, these services create single points of failure vulnerable to sophisticated attacks. Service providers face internal threats from rogue employees, external pressure from bad actors, or regulatory compulsion that could compromise user security or privacy. With traditional MCPs, users have limited visibility into such changes and few technical safeguards.
## ICP Canisters: Enabling the Verifiable MCP Paradigm
The Internet Computer Protocol (ICP) offers a revolutionary solution through its canister architecture, enabling what we term "Verifiable MCP" – a new paradigm in AI security. Unlike traditional web services, ICP canisters operate within a decentralized network with consensus-based execution and verification, creating powerful security properties:
- Cryptographically verifiable immutability guarantees prevent silent code modifications
- Deterministic execution environments allow independent verification by network participants
- Ability to both read and write web data while operating under consensus verification
- Control of off-chain Trusted Execution Environment (TEE) servers through on-chain attestation
These capabilities create the foundation for trustworthy AI context protocols that don't require blind faith in service providers.
## Technical Architecture of Verifiable MCP Integration
The Verifiable MCP architecture places MCP service logic within ICP canisters that operate under consensus verification. This creates several distinct layers working together to ensure security:
1. **Interface Layer**: AI models connect through standardized APIs compatible with existing integration patterns.
2. **Verification Layer**: The ICP canister validates authentication, checks permissions, and verifies policy adherence within a consensus-verified environment.
3. **Orchestration Layer**: The canister coordinates necessary resources for data retrieval or computation.
4. **Attestation Layer**: For sensitive operations, the canister deploys and attests TEE instances, providing cryptographic proof that correct code runs in a secure environment.
5. **Response Verification Layer**: Before returning results, cryptographic verification ensures data integrity and provenance.
This architecture creates a transparent, verifiable pipeline where component behavior is guaranteed through consensus mechanisms and cryptographic verification—eliminating the need to trust service provider claims.
## Example: Secure Financial Data Access Through Verifiable MCP
Consider a financial advisory AI needing access to banking data and portfolios to provide recommendations. In a Verifiable MCP implementation:
1. The AI submits a data request through the Verifiable MCP interface.
2. The ICP canister verifies authorization using immutable access control logic.
3. For sensitive data, the canister deploys a TEE instance with privacy-preserving code.
4. The canister cryptographically verifies the TEE is running the correct code.
5. Financial services provide encrypted data directly to the verified TEE.
6. The TEE returns only authorized results with cryptographic proof of correct execution.
7. The canister delivers verified insights to the AI.
This ensures even the service provider cannot access raw financial data while maintaining complete auditability. Users verify exactly what code processes their information and what insights are extracted, enabling AI applications in regulated domains otherwise too risky with traditional approaches.
## Implications for AI Trustworthiness and Data Sovereignty
The Verifiable MCP paradigm transforms the trust model for AI systems by shifting from "trust the provider" to cryptographic verification. This addresses a critical barrier to AI adoption in sensitive domains where guarantees about data handling are essential.
For AI trustworthiness, this enables transparent auditing of data access patterns, prevents silent modifications to processing logic, and provides cryptographic proof of data provenance. Users can verify exactly what information AI systems access and how it's processed.
From a data sovereignty perspective, users gain control through cryptographic guarantees rather than policy promises. Organizations implement permissions that cannot be circumvented, while regulators can verify immutable code handling sensitive information. For cross-border scenarios, Verifiable MCP enables compliance with data localization requirements while maintaining global AI service capabilities through cryptographically enforced data boundaries.
## Conclusion
The Verifiable MCP paradigm represents a breakthrough in securing AI systems' external interactions. By leveraging ICP canisters' immutability and verification capabilities, it addresses fundamental vulnerabilities in traditional MCP implementations.
As AI adoption grows in regulated domains, this architecture provides a foundation for trustworthy model-world interactions without requiring blind faith in service providers. The approach enables new categories of AI applications in sensitive sectors while maintaining robust security guarantees.
This innovation promises to democratize secure context protocols, paving the way for responsible AI deployment even in the most security-critical environments.
-
@ 39cc53c9:27168656
2025-03-30 05:54:43
> [Read the original blog post](https://blog.kycnot.me/p/swapter-review)
These reviews are sponsored, yet the sponsorship does not influence the outcome of the evaluations. Sponsored reviews are independent from the kycnot.me list, being only part of the blog. The reviews have no impact on the scores of the listings or their continued presence on the list. Should any issues arise, I will not hesitate to remove any listing. Reviews are in collaboration with [Orangefren](https://kycnot.me/service/orangefren).
## The review
[Swapter.io](https://kycnot.me/service/swapter) is an all-purpose instant exchange. They entered the scene in the depths of the bear market about 2 years ago in June of 2022.
| Pros | Cons |
| --------------- | ---------------------------------- |
| Low fees | Shotgun KYC with opaque triggers |
| Large liquidity | Relies on 3rd party liquidity |
| Works over Tor | Front-end not synced with back-end |
| Pretty UI | |
**Rating**: ★★★☆☆
**Service Website:** [swapter.io](https://swapter.io)
> ⚠️ There is an ongoing issue with this service: [read more on Reddit](https://old.reddit.com/r/Monero/comments/1d8olsd/swapter_225_xmr_missing/).
### Test Trades
During our testing we performed a trade from XMR to LTC, and then back to XMR.
Our first trade had the ID of: `mpUitpGemhN8jjNAjQuo6EvQ`. We were promised **0.8 LTC** for sending **0.5 XMR**, before we sent the Monero. When the Monero arrived we were sent **0.799 LTC**.
On the return journey we performed trade with ID: `yaCRb5pYcRKAZcBqg0AzEGYg`. This time we were promised **0.4815 XMR** for sending **0.799 LTC**. After Litecoin arrived we were sent **0.4765 XMR**.
As such we saw a discrepancy of `~0.1%` in the first trade and `~1%` in the second trade. Considering those trades were floating we determine the estimates presented in the UI to be highly accurate and honest.
Of course Swapter could've been imposing a large fee on their estimates, but we checked their estimates against CoinGecko and found the difference to be equivalent to a fee of just over `0.5%`. Perfectly in line with other swapping services.
### Trading
Swapter supports BTC, LTC, XMR and well over a thousand other coins. Sadly they **don't support the Lightning Network**. For the myriad of currencies they deal with they provide massive upper limits. You could exchange tens, or even hundreds, of thousands of dollars worth of cryptocurrency in a single trade (although we wouldn't recommend it).
The flip side to this is that Swapter **relies on 3rd party liquidity**. Aside from the large liqudity this also benefits the user insofar as it allows for very low fees. However, it also comes with a negative - the 3rd party gets to see all your trades. Unfortunately Swapter opted not to share where they source their liquidity in their Privacy Policy or Terms of Service.
### KYC & AML policies
Swapter reserves the right to require its users to provide their full name, their date of birth, their address and government-issued ID. A practice known as "*shotgun KYC*". This should not happen often - in our testing it never did - however it's not clear when exactly it could happen. The AML & KYC policy provided on Swapter's website simply states they will put your trade on hold if their "risk scoring system [deems it] as suspicious".
Worse yet, if they determine that "any of the information [the] customer provided is incorrect, false, outdated, or incomplete" then Swapter may decide to terminate all of the services they provide to the user. What exactly would happen to their funds in such a case remains unclear.
The only clarity we get is that the Swapter policy outlines a designated 3rd party that will verify the information provided by the user. The third party's name is Sum & Substance Ltd, also simply known as samsub and available at [sumsub.com](https://sumsub.com/)
It's understandable that some exchanges will decide on a policy of this sort, especially when they rely on external liquidity, but we would prefer more clarity be given. **When exactly is a trade suspicious?**
### Tor
We were pleased to discover Swapter **works over Tor**. However, they do not provide a Tor mirror, nor do they work without JavaScript. Additionally, we found that some small features, such as the live chat, did not work over Tor. Fortunately, other means of contacting their support are still available.
### UI
We have found the Swapter UI to be very modern, straightforward and simple to use. It's available in 4 languages (English, French, Dutch and Russian), although we're unable to vouch for the quality of some of those, the ones that we used seemed perfectly serviceable.
Our only issue with the UI was that it claims the funds have been sent following the trade, when in reality it seems to take the backend a minute or so to actually broadcast the transaction.
### Getting in touch
Swapter's team has a chat on their website, a support email address and a support Telegram. Their social media presence in most active on Telegram and X (formerly Twitter).
### Disclaimer
*None of the above should be understood as investment or financial advice. The views are our own only and constitute a faithful representation of our experience in using and investigating this exchange. This review is not a guarantee of any kind on the services rendered by the exchange. Do your own research before using any service.*
-
@ 21335073:a244b1ad
2025-03-18 20:47:50
**Warning: This piece contains a conversation about difficult topics. Please proceed with caution.**
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book *Cypherpunks*, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
**Course:**
- The creation of the internet and computers
- The fight for cryptography
- The tech supply chain from the ground up (example: human rights violations in the supply chain)
- Corporate tech
- Freedom tech
- Data privacy
- Digital privacy rights
- AI (history-current)
- Online safety (predators, scams, catfishing, extortion)
- Bitcoin
- Laws
- How to deal with online hate and harassment
- Information on who to contact if you are being abused online or offline
- Algorithms
- How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ 592295cf:413a0db9
2025-03-29 10:59:52
The journey starts from the links in this article
[nostr-quick-start-guide](https://spatianostra.com/nostr-quick-start-guide/)
Starting from these links building a simple path should not cover everything, because impossible.
Today I saw that Verbiricha in his workshop on his channel used nstart, but then I distracted
And I didn't see how he did it.
-----
Go to [nstart.me](https://nstart.me/) and read:
Each user is identified by a cryptographic keypair
Public key, Private key (is a lot of stuff)
You can insert a nickname and go, the nickname is not unique
there is a email backup things interesting, but a little boring, i try to generate an email
doesn't even require a strong password ok.
I received the email, great, it shows me the nsec encrypted in clear,
Send a copy of the file with a password, which contains the password encrypted key
I know and I know it's a tongue dump.
## Multi signer bunker
That's stuff, let's see what he says.
They live the private key and send it to servers and you can recompose it to login at a site
of the protocol nostr. If one of these servers goes offline you have the private key
that you downloaded first and then reactivate a bunker.
All very complicated.
But if one of the servers goes offline, how can I remake the split? Maybe he's still testing.
Nobody tells you where these bunkers are.
Okay I have a string that is my bunker (buker://), I downloaded it, easy no, now will tell me which client accepts the bunker.. .
## Follow someone before you start?
Is a cluster of 5 people Snowden, Micheal Dilger, jb55, Fiatjaf, Dianele.
I choice Snowden profile, or you can select multiple profiles, extra wild.
## Now select 5 clients
### *Coracle, Chachi, Olas, Nostur, Jumble*
### The first is *Coracle*
Login, ok I try to post a note and signing your note the spin does not end.
Maybe the bunker is diffective.
### Let's try *Chachi*
Simpler than Coracle, it has a type login that says bunker.
see if I can post
It worked, cool, I managed to post in a group.
## Olas is an app but also a website, but on the website requires an extension, which I do not have with this account.
> If I download an app how do I pass the bunker on the phone, is it still a password, a qrcode, a qrcode + password, something
> like that, but many start from the phone so maybe it's easy for them.
> I try to download it and see if it allows me to connect with a bunker.
> Okay I used private-qrcode and it worked, I couldn't do it directly from Olas because it didn't have permissions and the qrcode was < encrypted, so I went to the same site and had the bunker copied and glued on Olas
**Ok then I saw that there was the qrcode image of the bunker for apps** lol moment
Ok, I liked it, I can say it's a victory.
Looks like none of Snowden's followers are *Olas*'s lover, maybe the smart pack has to predict a photographer or something like that.
Okay I managed to post on *Olas*, so it works, Expiration time is broken.
### As for *Nostur*, I don't have an ios device so I'm going to another one.
### Login with *Jumble*, it works is a web app
I took almost an hour to do the whole route.
But this was just one link there are two more
# Extensions nostr NIP-07
### The true path is [nip-07-browser-extensions | nostr.net](https://nostr.net/#nip-07-browser-extensions)
There are 19 links, maybe there are too many?
I mention the most famous, or active at the moment
1. **Aka-profiles**: [Aka-profiles](https://github.com/neilck/aka-extension)
Alby I don't know if it's a route to recommend
2. **Blockcore** [Blockcore wallet](https://chromewebstore.google.com/detail/blockcore-wallet/peigonhbenoefaeplkpalmafieegnapj)
3. **Nos2x** [Nos2x](https://github.com/fiatjaf/nos2x?tab=readme-ov-file)
4. **Nos2xfox** (fork for firefox) [Nos2xfox](https://diegogurpegui.com/nos2x-fox/)
Nostore is (archived, read-only)
5. **Nostrame** [Nostrame](https://github.com/Anderson-Juhasc/nostrame)
6. **Nowser** per IOS [Nowser](https://github.com/haorendashu/nowser)
7. **One key** (was tricky) [One key](https://chromewebstore.google.com/detail/onekey/jnmbobjmhlngoefaiojfljckilhhlhcj)
Another half hour to search all sites
# Nostrapps
Here you can make paths
### Then nstart selects Coracle, Chachi, Olas,Nostur and Jumble
Good apps might be Amethyst, 0xchat, Yakihonne, Primal, Damus
for IOS maybe: Primal, Olas, Damus, Nostur, Nos-Social, Nostrmo
On the site there are some categories, I select some with the respective apps
Let's see the categories
Go to [Nostrapps](https://nostrapps.com/) and read:
## Microbbloging: Primal
## Streaming: **Zap stream**
## Blogging: **Yakihonne**
## Group chat: **Chachi**
## Community: **Flotilla**
## Tools: **Form** *
## Discovery: **Zapstore** (even if it is not in this catrgory)
## Direct Message: **0xchat**
-
@ 57d1a264:69f1fee1
2025-03-29 09:31:13
> "THE NATURE OF BITCOIN IS SUCH THAT ONCE VERSION 0.1 WAS RELEASED, THE CORE DESIGN WAS SET IN STONE FOR THE REST OF ITS LIFETIME."
<sub>- SATOSHI NAKAMOTO</sub>



"Reborn" is inspired by my Bitcoin journey and the many other people whose lives have been changed by Bitcoin. I’ve carved the hand in the “Gyan Mudra” or the “Mudra of Wisdom or Knowledge,” with an Opendime grasped between thumb and index finger alluding to the pursuit of Bitcoin knowledge. The hand emerges from rough, choppy water, and I've set the hand against an archway, through which, the copper leaf hints at the bright orange future made possible by Bitcoin.
Materials: Carrara Marble, Copper leaf, Opendime
Dimensions: 6" x 9" x 13"
Price: $30,000 or BTC equivalent
Enquire: https://www.vonbitcoin.com/available-works
X: https://x.com/BVBTC/status/1894463357316419960/photo/1
originally posted at https://stacker.news/items/928510
-
@ db11b320:05c5f7af
2025-03-29 19:04:19
magnet:?xt=urn:btih:9BAC9A3F98803AEA1EB28A0B60A562D7E3779710
-
@ ed84ce10:cccf4c2a
2025-03-19 03:46:17
### **DoraHacks: Pioneering the Global Hacker Movement**
DoraHacks is the world’s largest hackathon community, driving radical innovation across multiple industries. Now, a similar hacker movement is emerging in biotech—what we call the **FDA-Free Society**. At DoraHacks, this is our core focus in the life sciences. We believe that medical and biotech innovation should not be held hostage by bureaucracy. Instead, it should be free to evolve at the pace of technological progress.
## **The FDA: The Biggest Bottleneck to Biotech Innovation**
For decades, the **Food and Drug Administration (FDA)** has been the single greatest obstacle to progress in medicine and biotech. While ostensibly designed to ensure safety and efficacy, in reality, it has functioned as an entrenched bureaucracy that stifles innovation.
**1. A Broken Approval Process**
The FDA operates on timelines that make no sense in an era of exponential technological growth. **Getting a new drug or therapy to market takes 10-15 years.** By the time a breakthrough therapy is approved, entire generations of patients have already suffered or died waiting.
**2. Astronomical Compliance Costs**
Clinical trials under FDA oversight are **prohibitively expensive**. This eliminates most startups from even attempting disruptive innovation. Many promising therapies never see the light of day—not because they don’t work, but because the cost of compliance is too high.
**3. The FDA-Pharma Cartel**
The regulatory framework is **not neutral**—it overwhelmingly benefits **Big Pharma**. The FDA’s Byzantine approval system creates a protective moat for legacy pharmaceutical companies, while smaller biotech startups are crushed under compliance burdens. The result? **Less innovation, more monopolization, and fewer choices for patients.**
## **Market-Driven Biotech Innovation Is the Future**
When bureaucracies control innovation, **progress slows**. When markets drive innovation, **progress accelerates**.
**1. Let the Market Decide What Works**
Why should government regulators dictate which treatments are available? In an open system, **patients and doctors—not bureaucrats—should determine which therapies succeed or fail.**
**2. The "Right to Try" Loophole Proves the FDA Is Obsolete**
The U.S. **Right to Try Act** already allows terminally ill patients to access experimental drugs **before FDA approval**. This proves an essential truth: **The regulatory state is holding back life-saving treatments.** If dying patients can bypass the FDA, why can’t everyone?
**3. Startups Move Faster Than Bureaucracies**
The success of **mRNA technology** was not driven by the FDA—it was driven by **startups operating at the speed of the market.** This is a template for the future. **Regulation slows innovation. Entrepreneurs accelerate it.**
## **BioHack: Breaking Free From the FDA’s Grip**
One of the most important frontiers in biotech today is **anti-aging and longevity research**. Yet, the **FDA has no framework** for approving treatments that extend life. The result? **A regulatory death sentence for one of the most transformative fields of medicine.**
**1. Biotech Needs FDA-Free Experimental Zones**
In the future, biotech R&D should function like **open-source software**—free, experimental, and outside the reach of outdated regulators. We need FDA-Free labs, FDA-Free clinical trials, and FDA-Free therapeutics.
**2. Decentralized Healthcare Will Disrupt Big Pharma**
A new era of **decentralized biotech is emerging**—privately funded labs, medical DAOs, and startup-driven healthcare systems. The **power to determine the future of medicine** must shift away from centralized bureaucracies and Big Pharma toward **entrepreneurs, scientists, and patients.**
## **Conclusion: The Hacker Revolution in Biotech Is Here**
The **FDA-Free Society** is not a thought experiment. It is an inevitability. Innovation will not be stopped. **DoraHacks is committed to making BioHack a reality.**
-
@ 39cc53c9:27168656
2025-03-30 05:54:42
> [Read the original blog post](https://blog.kycnot.me/p/four-years)
> “The future is there... staring back at us. Trying to make sense of the fiction we will have become.”
> — William Gibson.
This month is [the 4th anniversary](#the-anniversary) of kycnot.me. Thank you for being here.
Fifteen years ago, Satoshi Nakamoto introduced Bitcoin, a peer-to-peer electronic cash system: a decentralized currency **free from government and institutional control**. Nakamoto's whitepaper showed a vision for a financial system based on trustless transactions, secured by cryptography. Some time forward and KYC (Know Your Customer), AML (Anti-Money Laundering), and CTF (Counter-Terrorism Financing) regulations started to come into play.
What a paradox: to engage with a system designed for decentralization, privacy, and independence, we are forced to give away our personal details. Using Bitcoin in the economy requires revealing your identity, not just to the party you interact with, but also to third parties who must track and report the interaction. You are forced to give sensitive data to entities you don't, can't, and shouldn't trust. Information can never be kept 100% safe; there's always a risk. Information is power, who knows about you has control over you.
Information asymmetry creates imbalances of power. When entities have detailed knowledge about individuals, they can manipulate, influence, or exploit this information to their advantage. The accumulation of personal data by corporations and governments enables extensive surveillances.
Such practices, moreover, exclude individuals from traditional economic systems if their documentation doesn't meet arbitrary standards, reinforcing a dystopian divide. Small businesses are similarly burdened by the costs of implementing these regulations, hindering free market competition[^1]:

How will they keep this information safe? Why do they need my identity? Why do they force businesses to enforce such regulations? It's always for your safety, to protect you from the "bad". Your life is perpetually in danger: terrorists, money launderers, villains... so the government steps in to save us.
> ‟Hush now, baby, baby, don't you cry
> Mamma's gonna make all of your nightmares come true
> Mamma's gonna put all of her fears into you
> Mamma's gonna keep you right here, under her wing
> She won't let you fly, but she might let you sing
> Mamma's gonna keep baby cosy and warm”
> — Mother, Pink Floyd
We must resist any attack on our privacy and freedom. To do this, we must collaborate.
If you have a service, refuse to ask for KYC; find a way. Accept cryptocurrencies like Bitcoin and Monero. Commit to circular economies. Remove the need to go through the FIAT system. People need fiat money to use most services, but we can change that.
If you're a user, donate to and prefer using services that accept such currencies. Encourage your friends to accept cryptocurrencies as well. Boycott FIAT system to the greatest extent you possibly can.
This may sound utopian, but it can be achieved. This movement can't be stopped. Go kick the hornet's nest.
> “We must defend our own privacy if we expect to have any. We must come together and create systems which allow anonymous transactions to take place. People have been defending their own privacy for centuries with whispers, darkness, envelopes, closed doors, secret handshakes, and couriers. The technologies of the past did not allow for strong privacy, but electronic technologies do.”
> — Eric Hughes, A Cypherpunk's Manifesto
## The anniversary
Four years ago, I began exploring ways to use crypto without KYC. I bookmarked a few favorite services and thought sharing them to the world might be useful. That was the first version of [kycnot.me](https://kycnot.me) — a simple list of about 15 services. Since then, I've added services, rewritten it three times, and improved it to what it is now.
[kycnot.me](https://kycnot.me) has remained 100% independent and 100% open source[^2] all these years. I've received offers to buy the site, all of which I have declined and will continue to decline. It has been DDoS attacked many times, but we made it through. I have also rewritten the whole site almost once per year (three times in four years).
The code and scoring algorithm are open source (contributions are welcome) and I can't arbitrarly change a service's score without adding or removing attributes, making any arbitrary alterations obvious if they were fake. You can even see [the score summary](https://https://kycnot.me/api/v1/service/bisq/summary) for any service's score.
I'm a one-person team, dedicating my free time to this project. I hope to keep doing so for many more years. Again, thank you for being part of this.
[^1]: https://x.com/freedomtech/status/1796190018588872806
[^2]: https://codeberg.org/pluja/kycnot.me
-
@ 0d97beae:c5274a14
2025-01-11 16:52:08
This article hopes to complement the article by Lyn Alden on YouTube: https://www.youtube.com/watch?v=jk_HWmmwiAs
## The reason why we have broken money
Before the invention of key technologies such as the printing press and electronic communications, even such as those as early as morse code transmitters, gold had won the competition for best medium of money around the world.
In fact, it was not just gold by itself that became money, rulers and world leaders developed coins in order to help the economy grow. Gold nuggets were not as easy to transact with as coins with specific imprints and denominated sizes.
However, these modern technologies created massive efficiencies that allowed us to communicate and perform services more efficiently and much faster, yet the medium of money could not benefit from these advancements. Gold was heavy, slow and expensive to move globally, even though requesting and performing services globally did not have this limitation anymore.
Banks took initiative and created derivatives of gold: paper and electronic money; these new currencies allowed the economy to continue to grow and evolve, but it was not without its dark side. Today, no currency is denominated in gold at all, money is backed by nothing and its inherent value, the paper it is printed on, is worthless too.
Banks and governments eventually transitioned from a money derivative to a system of debt that could be co-opted and controlled for political and personal reasons. Our money today is broken and is the cause of more expensive, poorer quality goods in the economy, a larger and ever growing wealth gap, and many of the follow-on problems that have come with it.
## Bitcoin overcomes the "transfer of hard money" problem
Just like gold coins were created by man, Bitcoin too is a technology created by man. Bitcoin, however is a much more profound invention, possibly more of a discovery than an invention in fact. Bitcoin has proven to be unbreakable, incorruptible and has upheld its ability to keep its units scarce, inalienable and counterfeit proof through the nature of its own design.
Since Bitcoin is a digital technology, it can be transferred across international borders almost as quickly as information itself. It therefore severely reduces the need for a derivative to be used to represent money to facilitate digital trade. This means that as the currency we use today continues to fare poorly for many people, bitcoin will continue to stand out as hard money, that just so happens to work as well, functionally, along side it.
Bitcoin will also always be available to anyone who wishes to earn it directly; even China is unable to restrict its citizens from accessing it. The dollar has traditionally become the currency for people who discover that their local currency is unsustainable. Even when the dollar has become illegal to use, it is simply used privately and unofficially. However, because bitcoin does not require you to trade it at a bank in order to use it across borders and across the web, Bitcoin will continue to be a viable escape hatch until we one day hit some critical mass where the world has simply adopted Bitcoin globally and everyone else must adopt it to survive.
Bitcoin has not yet proven that it can support the world at scale. However it can only be tested through real adoption, and just as gold coins were developed to help gold scale, tools will be developed to help overcome problems as they arise; ideally without the need for another derivative, but if necessary, hopefully with one that is more neutral and less corruptible than the derivatives used to represent gold.
## Bitcoin blurs the line between commodity and technology
Bitcoin is a technology, it is a tool that requires human involvement to function, however it surprisingly does not allow for any concentration of power. Anyone can help to facilitate Bitcoin's operations, but no one can take control of its behaviour, its reach, or its prioritisation, as it operates autonomously based on a pre-determined, neutral set of rules.
At the same time, its built-in incentive mechanism ensures that people do not have to operate bitcoin out of the good of their heart. Even though the system cannot be co-opted holistically, It will not stop operating while there are people motivated to trade their time and resources to keep it running and earn from others' transaction fees. Although it requires humans to operate it, it remains both neutral and sustainable.
Never before have we developed or discovered a technology that could not be co-opted and used by one person or faction against another. Due to this nature, Bitcoin's units are often described as a commodity; they cannot be usurped or virtually cloned, and they cannot be affected by political biases.
## The dangers of derivatives
A derivative is something created, designed or developed to represent another thing in order to solve a particular complication or problem. For example, paper and electronic money was once a derivative of gold.
In the case of Bitcoin, if you cannot link your units of bitcoin to an "address" that you personally hold a cryptographically secure key to, then you very likely have a derivative of bitcoin, not bitcoin itself. If you buy bitcoin on an online exchange and do not withdraw the bitcoin to a wallet that you control, then you legally own an electronic derivative of bitcoin.
Bitcoin is a new technology. It will have a learning curve and it will take time for humanity to learn how to comprehend, authenticate and take control of bitcoin collectively. Having said that, many people all over the world are already using and relying on Bitcoin natively. For many, it will require for people to find the need or a desire for a neutral money like bitcoin, and to have been burned by derivatives of it, before they start to understand the difference between the two. Eventually, it will become an essential part of what we regard as common sense.
## Learn for yourself
If you wish to learn more about how to handle bitcoin and avoid derivatives, you can start by searching online for tutorials about "Bitcoin self custody".
There are many options available, some more practical for you, and some more practical for others. Don't spend too much time trying to find the perfect solution; practice and learn. You may make mistakes along the way, so be careful not to experiment with large amounts of your bitcoin as you explore new ideas and technologies along the way. This is similar to learning anything, like riding a bicycle; you are sure to fall a few times, scuff the frame, so don't buy a high performance racing bike while you're still learning to balance.
-
@ 21335073:a244b1ad
2025-03-18 14:43:08
**Warning: This piece contains a conversation about difficult topics. Please proceed with caution.**
TL;DR please educate your children about online safety.
Julian Assange wrote in his 2012 book *Cypherpunks*, “This book is not a manifesto. There isn’t time for that. This book is a warning.” I read it a few times over the past summer. Those opening lines definitely stood out to me. I wish we had listened back then. He saw something about the internet that few had the ability to see. There are some individuals who are so close to a topic that when they speak, it’s difficult for others who aren’t steeped in it to visualize what they’re talking about. I didn’t read the book until more recently. If I had read it when it came out, it probably would have sounded like an unknown foreign language to me. Today it makes more sense.
This isn’t a manifesto. This isn’t a book. There is no time for that. It’s a warning and a possible solution from a desperate and determined survivor advocate who has been pulling and unraveling a thread for a few years. At times, I feel too close to this topic to make any sense trying to convey my pathway to my conclusions or thoughts to the general public. My hope is that if nothing else, I can convey my sense of urgency while writing this. This piece is a watchman’s warning.
When a child steps online, they are walking into a new world. A new reality. When you hand a child the internet, you are handing them possibilities—good, bad, and ugly. This is a conversation about lowering the potential of negative outcomes of stepping into that new world and how I came to these conclusions. I constantly compare the internet to the road. You wouldn’t let a young child run out into the road with no guidance or safety precautions. When you hand a child the internet without any type of guidance or safety measures, you are allowing them to play in rush hour, oncoming traffic. “Look left, look right for cars before crossing.” We almost all have been taught that as children. What are we taught as humans about safety before stepping into a completely different reality like the internet? Very little.
I could never really figure out why many folks in tech, privacy rights activists, and hackers seemed so cold to me while talking about online child sexual exploitation. I always figured that as a survivor advocate for those affected by these crimes, that specific, skilled group of individuals would be very welcoming and easy to talk to about such serious topics. I actually had one hacker laugh in my face when I brought it up while I was looking for answers. I thought maybe this individual thought I was accusing them of something I wasn’t, so I felt bad for asking. I was constantly extremely disappointed and would ask myself, “Why don’t they care? What could I say to make them care more? What could I say to make them understand the crisis and the level of suffering that happens as a result of the problem?”
I have been serving minor survivors of online child sexual exploitation for years. My first case serving a survivor of this specific crime was in 2018—a 13-year-old girl sexually exploited by a serial predator on Snapchat. That was my first glimpse into this side of the internet. I won a national award for serving the minor survivors of Twitter in 2023, but I had been working on that specific project for a few years. I was nominated by a lawyer representing two survivors in a legal battle against the platform. I’ve never really spoken about this before, but at the time it was a choice for me between fighting Snapchat or Twitter. I chose Twitter—or rather, Twitter chose me. I heard about the story of John Doe #1 and John Doe #2, and I was so unbelievably broken over it that I went to war for multiple years. I was and still am royally pissed about that case. As far as I was concerned, the John Doe #1 case proved that whatever was going on with corporate tech social media was so out of control that I didn’t have time to wait, so I got to work. It was reading the messages that John Doe #1 sent to Twitter begging them to remove his sexual exploitation that broke me. He was a child begging adults to do something. A passion for justice and protecting kids makes you do wild things. I was desperate to find answers about what happened and searched for solutions. In the end, the platform Twitter was purchased. During the acquisition, I just asked Mr. Musk nicely to prioritize the issue of detection and removal of child sexual exploitation without violating digital privacy rights or eroding end-to-end encryption. Elon thanked me multiple times during the acquisition, made some changes, and I was thanked by others on the survivors’ side as well.
I still feel that even with the progress made, I really just scratched the surface with Twitter, now X. I left that passion project when I did for a few reasons. I wanted to give new leadership time to tackle the issue. Elon Musk made big promises that I knew would take a while to fulfill, but mostly I had been watching global legislation transpire around the issue, and frankly, the governments are willing to go much further with X and the rest of corporate tech than I ever would. My work begging Twitter to make changes with easier reporting of content, detection, and removal of child sexual exploitation material—without violating privacy rights or eroding end-to-end encryption—and advocating for the minor survivors of the platform went as far as my principles would have allowed. I’m grateful for that experience. I was still left with a nagging question: “How did things get so bad with Twitter where the John Doe #1 and John Doe #2 case was able to happen in the first place?” I decided to keep looking for answers. I decided to keep pulling the thread.
I never worked for Twitter. This is often confusing for folks. I will say that despite being disappointed in the platform’s leadership at times, I loved Twitter. I saw and still see its value. I definitely love the survivors of the platform, but I also loved the platform. I was a champion of the platform’s ability to give folks from virtually around the globe an opportunity to speak and be heard.
I want to be clear that John Doe #1 really is my why. He is the inspiration. I am writing this because of him. He represents so many globally, and I’m still inspired by his bravery. One child’s voice begging adults to do something—I’m an adult, I heard him. I’d go to war a thousand more lifetimes for that young man, and I don’t even know his name. Fighting has been personally dark at times; I’m not even going to try to sugarcoat it, but it has been worth it.
The data surrounding the very real crime of online child sexual exploitation is available to the public online at any time for anyone to see. I’d encourage you to go look at the data for yourself. I believe in encouraging folks to check multiple sources so that you understand the full picture. If you are uncomfortable just searching around the internet for information about this topic, use the terms “CSAM,” “CSEM,” “SG-CSEM,” or “AI Generated CSAM.” The numbers don’t lie—it’s a nightmare that’s out of control. It’s a big business. The demand is high, and unfortunately, business is booming. Organizations collect the data, tech companies often post their data, governments report frequently, and the corporate press has covered a decent portion of the conversation, so I’m sure you can find a source that you trust.
Technology is changing rapidly, which is great for innovation as a whole but horrible for the crime of online child sexual exploitation. Those wishing to exploit the vulnerable seem to be adapting to each technological change with ease. The governments are so far behind with tackling these issues that as I’m typing this, it’s borderline irrelevant to even include them while speaking about the crime or potential solutions. Technology is changing too rapidly, and their old, broken systems can’t even dare to keep up. Think of it like the governments’ “War on Drugs.” Drugs won. In this case as well, the governments are not winning. The governments are talking about maybe having a meeting on potentially maybe having legislation around the crimes. The time to have that meeting would have been many years ago. I’m not advocating for governments to legislate our way out of this. I’m on the side of educating and innovating our way out of this.
I have been clear while advocating for the minor survivors of corporate tech platforms that I would not advocate for any solution to the crime that would violate digital privacy rights or erode end-to-end encryption. That has been a personal moral position that I was unwilling to budge on. This is an extremely unpopular and borderline nonexistent position in the anti-human trafficking movement and online child protection space. I’m often fearful that I’m wrong about this. I have always thought that a better pathway forward would have been to incentivize innovation for detection and removal of content. I had no previous exposure to privacy rights activists or Cypherpunks—actually, I came to that conclusion by listening to the voices of MENA region political dissidents and human rights activists. After developing relationships with human rights activists from around the globe, I realized how important privacy rights and encryption are for those who need it most globally. I was simply unwilling to give more power, control, and opportunities for mass surveillance to big abusers like governments wishing to enslave entire nations and untrustworthy corporate tech companies to potentially end some portion of abuses online. On top of all of it, it has been clear to me for years that all potential solutions outside of violating digital privacy rights to detect and remove child sexual exploitation online have not yet been explored aggressively. I’ve been disappointed that there hasn’t been more of a conversation around preventing the crime from happening in the first place.
What has been tried is mass surveillance. In China, they are currently under mass surveillance both online and offline, and their behaviors are attached to a social credit score. Unfortunately, even on state-run and controlled social media platforms, they still have child sexual exploitation and abuse imagery pop up along with other crimes and human rights violations. They also have a thriving black market online due to the oppression from the state. In other words, even an entire loss of freedom and privacy cannot end the sexual exploitation of children online. It’s been tried. There is no reason to repeat this method.
It took me an embarrassingly long time to figure out why I always felt a slight coldness from those in tech and privacy-minded individuals about the topic of child sexual exploitation online. I didn’t have any clue about the “Four Horsemen of the Infocalypse.” This is a term coined by Timothy C. May in 1988. I would have been a child myself when he first said it. I actually laughed at myself when I heard the phrase for the first time. I finally got it. The Cypherpunks weren’t wrong about that topic. They were so spot on that it is borderline uncomfortable. I was mad at first that they knew that early during the birth of the internet that this issue would arise and didn’t address it. Then I got over it because I realized that it wasn’t their job. Their job was—is—to write code. Their job wasn’t to be involved and loving parents or survivor advocates. Their job wasn’t to educate children on internet safety or raise awareness; their job was to write code.
They knew that child sexual abuse material would be shared on the internet. They said what would happen—not in a gleeful way, but a prediction. Then it happened.
I equate it now to a concrete company laying down a road. As you’re pouring the concrete, you can say to yourself, “A terrorist might travel down this road to go kill many, and on the flip side, a beautiful child can be born in an ambulance on this road.” Who or what travels down the road is not their responsibility—they are just supposed to lay the concrete. I’d never go to a concrete pourer and ask them to solve terrorism that travels down roads. Under the current system, law enforcement should stop terrorists before they even make it to the road. The solution to this specific problem is not to treat everyone on the road like a terrorist or to not build the road.
So I understand the perceived coldness from those in tech. Not only was it not their job, but bringing up the topic was seen as the equivalent of asking a free person if they wanted to discuss one of the four topics—child abusers, terrorists, drug dealers, intellectual property pirates, etc.—that would usher in digital authoritarianism for all who are online globally.
Privacy rights advocates and groups have put up a good fight. They stood by their principles. Unfortunately, when it comes to corporate tech, I believe that the issue of privacy is almost a complete lost cause at this point. It’s still worth pushing back, but ultimately, it is a losing battle—a ticking time bomb.
I do think that corporate tech providers could have slowed down the inevitable loss of privacy at the hands of the state by prioritizing the detection and removal of CSAM when they all started online. I believe it would have bought some time, fewer would have been traumatized by that specific crime, and I do believe that it could have slowed down the demand for content. If I think too much about that, I’ll go insane, so I try to push the “if maybes” aside, but never knowing if it could have been handled differently will forever haunt me. At night when it’s quiet, I wonder what I would have done differently if given the opportunity. I’ll probably never know how much corporate tech knew and ignored in the hopes that it would go away while the problem continued to get worse. They had different priorities. The most voiceless and vulnerable exploited on corporate tech never had much of a voice, so corporate tech providers didn’t receive very much pushback.
Now I’m about to say something really wild, and you can call me whatever you want to call me, but I’m going to say what I believe to be true. I believe that the governments are either so incompetent that they allowed the proliferation of CSAM online, or they knowingly allowed the problem to fester long enough to have an excuse to violate privacy rights and erode end-to-end encryption. The US government could have seized the corporate tech providers over CSAM, but I believe that they were so useful as a propaganda arm for the regimes that they allowed them to continue virtually unscathed.
That season is done now, and the governments are making the issue a priority. It will come at a high cost. Privacy on corporate tech providers is virtually done as I’m typing this. It feels like a death rattle. I’m not particularly sure that we had much digital privacy to begin with, but the illusion of a veil of privacy feels gone.
To make matters slightly more complex, it would be hard to convince me that once AI really gets going, digital privacy will exist at all.
I believe that there should be a conversation shift to preserving freedoms and human rights in a post-privacy society.
I don’t want to get locked up because AI predicted a nasty post online from me about the government. I’m not a doomer about AI—I’m just going to roll with it personally. I’m looking forward to the positive changes that will be brought forth by AI. I see it as inevitable. A bit of privacy was helpful while it lasted. Please keep fighting to preserve what is left of privacy either way because I could be wrong about all of this.
On the topic of AI, the addition of AI to the horrific crime of child sexual abuse material and child sexual exploitation in multiple ways so far has been devastating. It’s currently out of control. The genie is out of the bottle. I am hopeful that innovation will get us humans out of this, but I’m not sure how or how long it will take. We must be extremely cautious around AI legislation. It should not be illegal to innovate even if some bad comes with the good. I don’t trust that the governments are equipped to decide the best pathway forward for AI. Source: the entire history of the government.
I have been personally negatively impacted by AI-generated content. Every few days, I get another alert that I’m featured again in what’s called “deep fake pornography” without my consent. I’m not happy about it, but what pains me the most is the thought that for a period of time down the road, many globally will experience what myself and others are experiencing now by being digitally sexually abused in this way. If you have ever had your picture taken and posted online, you are also at risk of being exploited in this way. Your child’s image can be used as well, unfortunately, and this is just the beginning of this particular nightmare. It will move to more realistic interpretations of sexual behaviors as technology improves. I have no brave words of wisdom about how to deal with that emotionally. I do have hope that innovation will save the day around this specific issue. I’m nervous that everyone online will have to ID verify due to this issue. I see that as one possible outcome that could help to prevent one problem but inadvertently cause more problems, especially for those living under authoritarian regimes or anyone who needs to remain anonymous online. A zero-knowledge proof (ZKP) would probably be the best solution to these issues. There are some survivors of violence and/or sexual trauma who need to remain anonymous online for various reasons. There are survivor stories available online of those who have been abused in this way. I’d encourage you seek out and listen to their stories.
There have been periods of time recently where I hesitate to say anything at all because more than likely AI will cover most of my concerns about education, awareness, prevention, detection, and removal of child sexual exploitation online, etc.
Unfortunately, some of the most pressing issues we’ve seen online over the last few years come in the form of “sextortion.” Self-generated child sexual exploitation (SG-CSEM) numbers are continuing to be terrifying. I’d strongly encourage that you look into sextortion data. AI + sextortion is also a huge concern. The perpetrators are using the non-sexually explicit images of children and putting their likeness on AI-generated child sexual exploitation content and extorting money, more imagery, or both from minors online. It’s like a million nightmares wrapped into one. The wild part is that these issues will only get more pervasive because technology is harnessed to perpetuate horror at a scale unimaginable to a human mind.
Even if you banned phones and the internet or tried to prevent children from accessing the internet, it wouldn’t solve it. Child sexual exploitation will still be with us until as a society we start to prevent the crime before it happens. That is the only human way out right now.
There is no reset button on the internet, but if I could go back, I’d tell survivor advocates to heed the warnings of the early internet builders and to start education and awareness campaigns designed to prevent as much online child sexual exploitation as possible. The internet and technology moved quickly, and I don’t believe that society ever really caught up. We live in a world where a child can be groomed by a predator in their own home while sitting on a couch next to their parents watching TV. We weren’t ready as a species to tackle the fast-paced algorithms and dangers online. It happened too quickly for parents to catch up. How can you parent for the ever-changing digital world unless you are constantly aware of the dangers?
I don’t think that the internet is inherently bad. I believe that it can be a powerful tool for freedom and resistance. I’ve spoken a lot about the bad online, but there is beauty as well. We often discuss how victims and survivors are abused online; we rarely discuss the fact that countless survivors around the globe have been able to share their experiences, strength, hope, as well as provide resources to the vulnerable. I do question if giving any government or tech company access to censorship, surveillance, etc., online in the name of serving survivors might not actually impact a portion of survivors negatively. There are a fair amount of survivors with powerful abusers protected by governments and the corporate press. If a survivor cannot speak to the press about their abuse, the only place they can go is online, directly or indirectly through an independent journalist who also risks being censored. This scenario isn’t hard to imagine—it already happened in China. During #MeToo, a survivor in China wanted to post their story. The government censored the post, so the survivor put their story on the blockchain. I’m excited that the survivor was creative and brave, but it’s terrifying to think that we live in a world where that situation is a necessity.
I believe that the future for many survivors sharing their stories globally will be on completely censorship-resistant and decentralized protocols. This thought in particular gives me hope. When we listen to the experiences of a diverse group of survivors, we can start to understand potential solutions to preventing the crimes from happening in the first place.
My heart is broken over the gut-wrenching stories of survivors sexually exploited online. Every time I hear the story of a survivor, I do think to myself quietly, “What could have prevented this from happening in the first place?” My heart is with survivors.
My head, on the other hand, is full of the understanding that the internet should remain free. The free flow of information should not be stopped. My mind is with the innocent citizens around the globe that deserve freedom both online and offline.
The problem is that governments don’t only want to censor illegal content that violates human rights—they create legislation that is so broad that it can impact speech and privacy of all. “Don’t you care about the kids?” Yes, I do. I do so much that I’m invested in finding solutions. I also care about all citizens around the globe that deserve an opportunity to live free from a mass surveillance society. If terrorism happens online, I should not be punished by losing my freedom. If drugs are sold online, I should not be punished. I’m not an abuser, I’m not a terrorist, and I don’t engage in illegal behaviors. I refuse to lose freedom because of others’ bad behaviors online.
I want to be clear that on a long enough timeline, the governments will decide that they can be better parents/caregivers than you can if something isn’t done to stop minors from being sexually exploited online. The price will be a complete loss of anonymity, privacy, free speech, and freedom of religion online. I find it rather insulting that governments think they’re better equipped to raise children than parents and caretakers.
So we can’t go backwards—all that we can do is go forward. Those who want to have freedom will find technology to facilitate their liberation. This will lead many over time to decentralized and open protocols. So as far as I’m concerned, this does solve a few of my worries—those who need, want, and deserve to speak freely online will have the opportunity in most countries—but what about online child sexual exploitation?
When I popped up around the decentralized space, I was met with the fear of censorship. I’m not here to censor you. I don’t write code. I couldn’t censor anyone or any piece of content even if I wanted to across the internet, no matter how depraved. I don’t have the skills to do that.
I’m here to start a conversation. Freedom comes at a cost. You must always fight for and protect your freedom. I can’t speak about protecting yourself from all of the Four Horsemen because I simply don’t know the topics well enough, but I can speak about this one topic.
If there was a shortcut to ending online child sexual exploitation, I would have found it by now. There isn’t one right now. I believe that education is the only pathway forward to preventing the crime of online child sexual exploitation for future generations.
I propose a yearly education course for every child of all school ages, taught as a standard part of the curriculum. Ideally, parents/caregivers would be involved in the education/learning process.
**Course:**
- The creation of the internet and computers
- The fight for cryptography
- The tech supply chain from the ground up (example: human rights violations in the supply chain)
- Corporate tech
- Freedom tech
- Data privacy
- Digital privacy rights
- AI (history-current)
- Online safety (predators, scams, catfishing, extortion)
- Bitcoin
- Laws
- How to deal with online hate and harassment
- Information on who to contact if you are being abused online or offline
- Algorithms
- How to seek out the truth about news, etc., online
The parents/caregivers, homeschoolers, unschoolers, and those working to create decentralized parallel societies have been an inspiration while writing this, but my hope is that all children would learn this course, even in government ran schools. Ideally, parents would teach this to their own children.
The decentralized space doesn’t want child sexual exploitation to thrive. Here’s the deal: there has to be a strong prevention effort in order to protect the next generation. The internet isn’t going anywhere, predators aren’t going anywhere, and I’m not down to let anyone have the opportunity to prove that there is a need for more government. I don’t believe that the government should act as parents. The governments have had a chance to attempt to stop online child sexual exploitation, and they didn’t do it. Can we try a different pathway forward?
I’d like to put myself out of a job. I don’t want to ever hear another story like John Doe #1 ever again. This will require work. I’ve often called online child sexual exploitation the lynchpin for the internet. It’s time to arm generations of children with knowledge and tools. I can’t do this alone.
Individuals have fought so that I could have freedom online. I want to fight to protect it. I don’t want child predators to give the government any opportunity to take away freedom. Decentralized spaces are as close to a reset as we’ll get with the opportunity to do it right from the start. Start the youth off correctly by preventing potential hazards to the best of your ability.
The good news is anyone can work on this! I’d encourage you to take it and run with it. I added the additional education about the history of the internet to make the course more educational and fun. Instead of cleaning up generations of destroyed lives due to online sexual exploitation, perhaps this could inspire generations of those who will build our futures. Perhaps if the youth is armed with knowledge, they can create more tools to prevent the crime.
This one solution that I’m suggesting can be done on an individual level or on a larger scale. It should be adjusted depending on age, learning style, etc. It should be fun and playful.
This solution does not address abuse in the home or some of the root causes of offline child sexual exploitation. My hope is that it could lead to some survivors experiencing abuse in the home an opportunity to disclose with a trusted adult. The purpose for this solution is to prevent the crime of online child sexual exploitation before it occurs and to arm the youth with the tools to contact safe adults if and when it happens.
In closing, I went to hell a few times so that you didn’t have to. I spoke to the mothers of survivors of minors sexually exploited online—their tears could fill rivers. I’ve spoken with political dissidents who yearned to be free from authoritarian surveillance states. The only balance that I’ve found is freedom online for citizens around the globe and prevention from the dangers of that for the youth. Don’t slow down innovation and freedom. Educate, prepare, adapt, and look for solutions.
I’m not perfect and I’m sure that there are errors in this piece. I hope that you find them and it starts a conversation.
-
@ 37fe9853:bcd1b039
2025-01-11 15:04:40
yoyoaa
-
@ 04ff5a72:22ba7b2d
2025-03-19 03:25:28
# The Evolution of the "World Wide Web"
The internet has undergone a remarkable transformation since its inception, evolving from a collection of static pages to a dynamic, interconnected ecosystem, and now progressing toward a decentralized future. This evolution is commonly divided into three distinct phases: Web 1, Web 2, and the emerging Web 3. Each phase represents not only technological advancement but fundamental shifts in how we interact with digital content, who controls our data, and how value is created and distributed online. While Web 1 and Web 2 have largely defined our internet experience to date, Web 3 promises a paradigm shift toward greater user sovereignty, decentralized infrastructure, and reimagined ownership models for digital assets.
# The Static Beginning: Web 1.0
The first iteration of the web, commonly known as Web 1.0, emerged in the early 1990s and continued until the late 1990s. This period represented the internet's infancy, characterized by static pages with limited functionality and minimal user interaction[[1]](https://whiteand.partners/en/what-is-web1-a-brief-history-of-creation/). At the core of Web 1 was the concept of information retrieval rather than dynamic interaction.
## Fundamental Characteristics of Web 1
During the Web 1 era, websites primarily served as digital brochures or informational repositories. Most sites were static, comprised of HTML pages containing fixed content such as text, images, and hyperlinks[[1]](https://whiteand.partners/en/what-is-web1-a-brief-history-of-creation/). The HTML (Hypertext Markup Language) provided the structural foundation, while CSS (Cascading Style Sheets) offered basic styling capabilities. These technologies enabled the creation of visually formatted content but lacked the dynamic elements we take for granted today.
The Web 1 experience was predominantly one-directional. The majority of internet users were passive consumers of content, while creators were primarily web developers who produced websites with mainly textual or visual information[[2]](https://www.linkedin.com/pulse/evolution-internet-from-web10-web3-ravi-chamria/). Interaction was limited to basic navigation through hyperlinks, with few opportunities for users to contribute their own content or engage meaningfully with websites.
Technical limitations further defined the Web 1 experience. Information access was significantly slower than today's standards, largely due to the prevalence of dial-up connections. This constraint meant websites needed to be optimized for minimal bandwidth usage[[1]](https://whiteand.partners/en/what-is-web1-a-brief-history-of-creation/). Additionally, security measures were rudimentary, making early websites vulnerable to various cyberattacks without adequate protection systems in place.
# The Social Revolution: Web 2.0
As the internet matured in the late 1990s and early 2000s, a significant transformation occurred. Web 2.0 emerged as a more dynamic, interactive platform that emphasized user participation, content creation, and social connectivity[[6]](https://www.thoughtlab.com/blog/web3-revolutionizing-digital-ownership-and-nfts/). This shift fundamentally changed how people engaged with the internet, moving from passive consumption to active contribution.
## The Rise of Social Media and Big Data
Web 2.0 gave birth to social media platforms, interactive web applications, and user-generated content ecosystems. Companies like Google, Facebook, Twitter, and Amazon developed business models that leveraged user activity and content creation[[4]](https://www.jocm.us/uploadfile/2018/0613/20180613044107972.pdf). These platforms transformed from simple information repositories into complex social networks and digital marketplaces.
Central to the Web 2.0 revolution was the collection and analysis of user data on an unprecedented scale. Companies developed sophisticated infrastructure to handle massive amounts of information. Google implemented systems like the Google File System (GFS) and Spanner to store and distribute data across thousands of machines worldwide[[4]](https://www.jocm.us/uploadfile/2018/0613/20180613044107972.pdf). Facebook developed cascade prediction systems to manage user interactions, while Twitter created specialized infrastructure to process millions of tweets per minute[[4]](https://www.jocm.us/uploadfile/2018/0613/20180613044107972.pdf).
These technological advancements enabled the monetization of user attention and personal information. By analyzing user behavior, preferences, and social connections, Web 2.0 companies could deliver highly targeted advertising and personalized content recommendations. This business model generated immense wealth for platform owners while raising significant concerns about privacy, data ownership, and the concentration of power in the hands of a few technology giants.
# The Decentralized Future: Web 3.0
Web 3 represents the next evolutionary stage of the internet, characterized by principles of decentralization, transparency, and user sovereignty[[6]](https://www.thoughtlab.com/blog/web3-revolutionizing-digital-ownership-and-nfts/). Unlike previous iterations, Web 3 seeks to redistribute control from centralized entities to individual users and communities through blockchain technology and decentralized protocols.
## Blockchain as the Foundation
The conceptual underpinnings of Web 3 emerged with the creation of Bitcoin in 2009. Bitcoin introduced a revolutionary approach to digital transactions by enabling peer-to-peer value transfer without requiring a central authority. This innovation demonstrated that trust could be established through cryptographic proof rather than relying on traditional financial institutions.
Ethereum expanded upon Bitcoin's foundation by introducing programmable smart contracts, which allowed for the creation of decentralized applications (dApps) beyond simple financial transactions. This breakthrough enabled developers to build complex applications with self-executing agreements that operate transparently on the blockchain[[6]](https://www.thoughtlab.com/blog/web3-revolutionizing-digital-ownership-and-nfts/).
## Ownership and Data Sovereignty
A defining characteristic of Web 3 is the emphasis on true digital ownership. Through blockchain technology and cryptographic tokens, individuals can now assert verifiable ownership over digital assets in ways previously impossible[[6]](https://www.thoughtlab.com/blog/web3-revolutionizing-digital-ownership-and-nfts/). This stands in stark contrast to Web 2 platforms, where users effectively surrendered control of their content and data to centralized companies.
The concept of self-custody exemplifies this shift toward user sovereignty. Platforms like Trust Wallet enable individuals to maintain control over their digital assets across multiple blockchains without relying on intermediaries[[5]](https://trustwallet.com). Users hold their private keys, ensuring that they—not corporations or governments—have ultimate authority over their digital property.
## Decentralized Physical Infrastructure Networks (DePIN)
Web 3 extends beyond digital assets to reimagine physical infrastructure through Decentralized Physical Infrastructure Networks (DePIN). These networks connect blockchain technology with real-world systems, allowing people to use cryptocurrency tokens to build and manage physical infrastructure—from wireless hotspots to energy systems[[7]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era).
DePIN projects decentralize ownership and governance of critical infrastructure, creating more transparent, efficient, and resilient systems aligned with Web 3 principles[[7]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era). By distributing control among network participants rather than centralizing it within corporations or governments, these projects bridge the gap between digital networks and physical reality.
## Non-Fungible Tokens and Intellectual Property
Non-Fungible Tokens (NFTs) represent another revolutionary aspect of Web 3, providing a mechanism for verifying the authenticity and ownership of unique digital items. NFTs enable creators to establish provenance for digital art, music, virtual real estate, and other forms of intellectual property, addressing longstanding issues of duplication and unauthorized distribution in the digital realm[[6]](https://www.thoughtlab.com/blog/web3-revolutionizing-digital-ownership-and-nfts/).
This innovation has profound implications for creative industries, potentially enabling more direct relationships between creators and their audiences while reducing dependence on centralized platforms and intermediaries.
## Nostr: A Decentralized Protocol for Social Media and Communication
Nostr (Notes and Other Stuff Transmitted by Relays) is a decentralized and censorship-resistant communication protocol designed to enable open and secure social networking. Unlike traditional social media platforms that rely on centralized servers and corporate control, Nostr allows users to communicate directly through a network of relays, ensuring resilience against censorship and deplatforming.
The protocol operates using simple cryptographic principles: users generate a public-private key pair, where the public key acts as their unique identifier, and messages are signed with their private key. These signed messages are then broadcast to multiple relays, which store and propagate them to other users. This structure eliminates the need for a central authority to control user identities or content distribution[[8]](https://nostr.com/).
As concerns over censorship, content moderation, and data privacy continue to rise, Nostr presents a compelling alternative to centralized social media platforms. By decentralizing content distribution and giving users control over their own data, it aligns with the broader ethos of Web3—empowering individuals and reducing reliance on corporate intermediaries[[9]](https://www.notion.so/Personal-Nostr-Article-Workspace-196ca07db84980908089ef9b695bf141?pvs=21).
Additionally Nostr implements a novel way for users to monetize their content via close integration with Bitcoin's "Lightning Network"[[11]](https://en.wikipedia.org/wiki/Lightning_Network) -- a means by which users are able to instantly transmit small sums (satoshi's, the smallest unit of Bitcoin) with minimal fees. This feature, known as “zapping,” allows users to send micropayments directly to content creators, tipping them for valuable posts, comments, or contributions. By leveraging Lightning wallets, users can seamlessly exchange value without relying on traditional payment processors or centralized monetization models. This integration not only incentivizes quality content but also aligns with Nostr’s decentralized ethos by enabling peer-to-peer financial interactions that are censorship-resistant and borderless.
For those interested in exploring Nostr, setting up an account requires only a private key, and users can begin interacting with the network immediately by selecting a client that suits their needs. The simplicity and openness of the protocol make it a promising foundation for the next generation of decentralized social and communication networks.
## Alternative Decentralized Models: Federation
Not all Web 3 initiatives rely on blockchain technology. Platforms like Bluesky are pioneering federation approaches that allow users to host their own data while maintaining seamless connectivity across the network[[10]](https://bsky.social/about/blog/02-22-2024-open-social-web). This model draws inspiration from how the internet itself functions: just as anyone can host a website and change hosting providers without disrupting visitor access, Bluesky enables users to control where their social media data resides.
Federation lets services be interconnected while preserving user choice and flexibility. Users can move between various applications and experiences as fluidly as they navigate the open web[[10]](https://bsky.social/about/blog/02-22-2024-open-social-web). This approach maintains the principles of data sovereignty and user control that define Web 3 while offering alternatives to blockchain-based implementations.
# Conclusion
The evolution from Web 1 to Web 3 represents a profound transformation in how we interact with the internet. From the static, read-only pages of Web 1 through the social, data-driven platforms of Web 2, we are now entering an era defined by decentralization, user sovereignty, and reimagined ownership models.
Web 3 technologies—whether blockchain-based or implementing federation principles—share a common vision of redistributing power from centralized entities to individual users and communities. By enabling true digital ownership, community governance, and decentralized infrastructure, Web 3 has the potential to address many of the concerns that have emerged during the Web 2 era regarding privacy, control, and the concentration of power.
As this technology continues to mature, we may witness a fundamental reshaping of our digital landscape toward greater transparency, user autonomy, and equitable value distribution—creating an internet that more closely aligns with its original promise of openness and accessibility for all.
---
### Sources
[1] What is WEB1? a brief history of creation - White and Partners https://whiteand.partners/en/what-is-web1-a-brief-history-of-creation/
[2] Evolution of the Internet - from web1.0 to web3 - LinkedIn https://www.linkedin.com/pulse/evolution-internet-from-web10-web3-ravi-chamria
[3] Web3 Social: Create & Monetize with Smart Contracts - Phala Network https://phala.network/web3-social-create-monetize-with-smart-contracts
[4] [PDF] Big Data Techniques of Google, Amazon, Facebook and Twitter https://www.jocm.us/uploadfile/2018/0613/20180613044107972.pdf
[5] True crypto ownership. Powerful Web3 experiences - Trust Wallet [https://trustwallet.com](https://trustwallet.com/)
[6] Web3: Revolutionizing Digital Ownership and NFTs - ThoughtLab https://www.thoughtlab.com/blog/web3-revolutionizing-digital-ownership-and-nfts/
[7] DePIN Crypto: How It's Revolutionizing Infrastructure in Web3 https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era
[8] Nostr: Notes and Other Stuff… https://nostr.com/
[9] Nostr: The Importance of Censorship-Resistant Communication... https://bitcoinmagazine.com/culture/nostr-the-importance-of-censorship-resistant-communication-for-innovation-and-human-progress-
[10] Bluesky: An Open Social Web https://bsky.social/about/blog/02-22-2024-open-social-web
[11] Wikipedia: Lightning Network https://en.wikipedia.org/wiki/Lightning_Network
-
@ 62033ff8:e4471203
2025-01-11 15:00:24
收录的内容中 kind=1的部分,实话说 质量不高。
所以我增加了kind=30023 长文的article,但是更新的太少,多个relays 的服务器也没有多少长文。
所有搜索nostr如果需要产生价值,需要有高质量的文章和新闻。
而且现在有很多机器人的文章充满着浪费空间的作用,其他作用都用不上。
https://www.duozhutuan.com 目前放的是给搜索引擎提供搜索的原材料。没有做UI给人类浏览。所以看上去是粗糙的。
我并没有打算去做一个发microblog的 web客户端,那类的客户端太多了。
我觉得nostr社区需要解决的还是应用。如果仅仅是microblog 感觉有点够呛
幸运的是npub.pro 建站这样的,我觉得有点意思。
yakihonne 智能widget 也有意思
我做的TaskQ5 我自己在用了。分布式的任务系统,也挺好的。
-
@ a07fae46:7d83df92
2025-03-18 12:31:40
if the JFK documents come out and are nothing but old hat, it will be disappointing. but if they contain revelations, then they are an unalloyed good. unprecedented and extraordinary; worthy of praise and admiration. they murdered the president in broad daylight and kept 80,000 related documents secret for 60 years. the apparatus that did that and got away with it, is 100+ years in the making. the magic bullet was just the starting pistol of a new *era*; a *level up* in an [old game](https://archive.org/details/TragedyAndHope_501/page/n5/mode/2up?q=feudalist+fashion). it won't be dismantled and your republic delivered back with a bow in *2 months*. have a little humility and a little gratitude. cynicism is easy. it's peak mid-wittery. yeah no shit everything is corrupt and everyone's likely captured by [AIPAC](https://books.google.com/books/publisher/content?id=gKVKDwAAQBAJ&pg=PT68&img=1&zoom=3&hl=en&bul=1&sig=ACfU3U2pagVXTYdJOKxkAwmmFQpuSnoS5g&w=1280) or something beyond. YOU THINK AIPAC is the [ALL SEEING EYE](https://archive.org/details/the-all-seeing-eye-vol-1-5-manly-p.-hall-may-1923-sept-1931)?
you can keep going, if you want to, but have some awareness and appreciation for where we are and what it took to get here. the first 'you are fake news' was also a shot heard 'round the world and you are riding high on it's [Infrasound](https://en.wikipedia.org/wiki/Infrasound) wave, still reverberating; unappreciative of the profound delta in public awareness and understanding, and rate of change, that has occurred since that moment, in [2017](https://www.youtube.com/watch?v=Vqpzk-qGxMU). think about where we were back then, especially with corporate capture of the narrative. trump's bullheaded behavior, if only ego-driven, *is* what broke the spell. an *actual* moment of savage bravery is what allows for your current jaded affectation. black pilled is boring. it's intellectually lazy. it is low-resolution-thinking, no better than progressives who explain the myriad ills of the world through 'racism'. normalcy bias works both ways. i'm not grading you on a curve that includes NPCs. i'm grading you against those of us with a mind, on up. do better.
the best Webb-style doomer argument is essentially 'the mouse trap needs a piece of cheese in order to work'. ok, but it doesn't need 3 pieces of cheese, or 5. was FreeRoss the piece of cheese? was the SBR the cheese? real bitcoiners know how dumb the 'sbr is an attempt to takeover btc' narrative is, so extrapolate from that. what about withdrawal from the WHO? freeze and review of USAID et al? how many pieces of cheese before we realize it's not a trap? it's just a messy endeavor.
Good morning.
#jfkFiles #nostrOnly
-
@ 2183e947:f497b975
2025-03-29 02:41:34
Today I was invited to participate in the private beta of a new social media protocol called Pubky, designed by a bitcoin company called Synonym with the goal of being better than existing social media platforms. As a heavy nostr user, I thought I'd write up a comparison.
I can't tell you how to create your own accounts because it was made very clear that only *some* of the software is currently open source, and how this will all work is still a bit up in the air. The code that *is* open source can be found here: https://github.com/pubky -- and the most important repo there seems to be this one: https://github.com/pubky/pubky-core
You can also learn more about Pubky here: https://pubky.org/
That said, I used my invite code to create a pubky account and it seemed very similar to onboarding to nostr. I generated a private key, backed up 12 words, and the onboarding website gave me a public key.
Then I logged into a web-based client and it looked a lot like twitter. I saw a feed for posts by other users and saw options to reply to posts and give reactions, which, I saw, included hearts, thumbs up, and other emojis.
Then I investigated a bit deeper to see how much it was like nostr. I opened up my developer console and navigated to my networking tab, where, if this was nostr, I would expect to see queries to relays for posts. Here, though, I saw one query that seemed to be repeated on a loop, which went to a single server and provided it with my pubkey. That single query (well, a series of identical queries to the same server) seemed to return all posts that showed up on my feed. So I infer that the server "knows" what posts to show me (perhaps it has some sort of algorithm, though the marketing material says it does not use algorithms) and the query was on a loop so that if any new posts came in that the server thinks I might want to see, it can add them to my feed.
Then I checked what happens when I create a post. I did so and looked at what happened in my networking tab. If this was nostr, I would expect to see multiple copies of a signed messaged get sent to a bunch of relays. Here, though, I saw one message get sent to the same server that was populating my feed, and that message was not signed, it was a plaintext copy of my message.
I happened to be in a group chat with John Carvalho at the time, who is associated with pubky. I asked him what was going on, and he said that pubky is based around three types of servers: homeservers, DHT servers, and indexer servers. The homeserver is where you create posts and where you query for posts to show on your feed. DHT servers are used for censorship resistance: each user creates an entry on a DHT server saying what homeserver they use, and these entries are signed by their key.
As for indexers, I think those are supposed to speed up the use of the DHT servers. From what I could tell, indexers query DHT servers to find out what homeservers people use. When you query a homeserver for posts, it is supposed to reach out to indexer servers to find out the homeservers of people whose posts the homeserver decided to show you, and then query those homeservers for those posts. I believe they decided not to look up what homeservers people use directly on DHT servers directly because DHT servers are kind of slow, due to having to store and search through all sorts of non-social-media content, whereas indexers only store a simple db that maps each user's pubkey to their homeserver, so they are faster.
Based on all of this info, it seems like, to populate your feed, this is the series of steps:
- you tell your homeserver your pubkey
- it uses some sort of algorithm to decide whose posts to show you
- then looks up the homeservers used by those people on an indexer server
- then it fetches posts from their homeservers
- then your client displays them to you
To create a post, this is the series of steps:
- you tell your homeserver what you want to say to the world
- it stores that message in plaintext and merely asserts that it came from you (it's not signed)
- other people can find out what you said by querying for your posts on your homeserver
Since posts on homeservers are not signed, I asked John what prevents a homeserver from just making up stuff and claiming I said it. He said nothing stops them from doing that, and if you are using a homeserver that starts acting up in that manner, what you should do is start using a new homeserver and update your DHT record to point at your new homeserver instead of the old one. Then, indexers should update their db to show where your new homeserver is, and the homeservers of people who "follow" you should stop pulling content from your old homeserver and start pulling it from your new one. If their homeserver is misbehaving too, I'm not sure what would happen. Maybe it could refuse to show them the content you've posted on your new homeserver, keeping making up fake content on your behalf that you've never posted, and maybe the people you follow would never learn you're being impersonated or have moved to a new homeserver.
John also clarified that there is not currently any tooling for migrating user content from one homeserver to another. If pubky gets popular and a big homeserver starts misbehaving, users will probably need such a tool. But these are early days, so there aren't that many homeservers, and the ones that exist seem to be pretty trusted.
Anyway, those are my initial thoughts on Pubky. Learn more here: https://pubky.org/
-
@ 0d788b5e:c99ddea5
2025-03-29 02:40:37
- [首页](/readme.md)
- [第一章、 第一章标题](/chapter1.md)
- [第二章、 第二章标题](/chapter2.md)
-
@ 57d1a264:69f1fee1
2025-03-28 10:32:15
Bitcoin.design community is organizing another Designathon, from May 4-18. Let's get creative with bitcoin together. More to come very soon.

The first edition was a bursting success! the website still there https://events.bitcoin.design, and here their previous [announcement](https://bitcoindesign.substack.com/p/the-bitcoin-designathon-2022).
Look forward for this to happen!
Spread the voice:
N: [https://njump.me/nevent1qqsv9w8p93tadlnyx0rkhexj5l48l...](https://njump.me/nevent1qqsv9w8p93tadlnyx0rkhexj5l48lmw9jc7nhhauyq5w3cm4nfsm3mstqtk6m)
X: https://x.com/bitcoin_design/status/1905547407405768927
originally posted at https://stacker.news/items/927650
-
@ 57d1a264:69f1fee1
2025-03-27 10:42:05
What we have been missing in [SN Press kit](https://stacker.news/items/872925/r/Design_r)? Most important, who the press kit is for? It's for us? It's for them? Them, who?
The first few editions of the press kit, I agree are mostly made by us, for us. A way to try to homogenize how we _speek_ out SN into the wild web. A way to have SN voice sync, loud and clear, to send out our message. In this case, I squeezed my mouse, creating a template for us [^1], stackers, to share when talking sales with possible businesses and merchants willing to invest some sats and engage with SN community. Here's the message and the sales pitch, v0.1:
## Reach Bitcoin’s Most Engaged Community – Zero Noise, Pure Signal.













- - -
Contributions to improve would be much appreciated. You can also help by simply commenting on each slide or leaving your feedback below, especially if you are a sale person or someone that has seen similar documents before.
This is the first interaction. Already noticed some issues, for example with the emojis and the fonts, especially when exporting, probably related to a penpot issue. The slides maybe render differently depending on the browser you're using.
- [▶️ Play](https://design.penpot.app/#/view?file-id=cec80257-5021-8137-8005-ef90a160b2c9&page-id=cec80257-5021-8137-8005-ef90a160b2ca§ion=interactions&index=0&interactions-mode=hide&zoom=fit) the file in your browser
- ⬇️ Save the [PDF file](https://mega.nz/file/TsBgkRoI#20HEb_zscozgJYlRGha0XiZvcXCJfLQONx2fc65WHKY)
@k00b it will be nice to have some real data, how we can get some basic audience insights? Even some inputs from Plausible, if still active, will be much useful.
[^1]: Territory founders. FYI: @Aardvark, @AGORA, @anna, @antic, @AtlantisPleb, @av, @Bell_curve, @benwehrman, @bitcoinplebdev, @Bitter, @BlokchainB, @ch0k1, @davidw, @ek, @elvismercury, @frostdragon, @grayruby, @HODLR, @inverselarp, @Jon_Hodl, @MaxAWebster, @mega_dreamer, @mrtali, @niftynei, @nout, @OneOneSeven, @PlebLab, @Public_N_M_E, @RDClark, @realBitcoinDog, @roytheholographicuniverse, @siggy47, @softsimon, @south_korea_ln, @theschoolofbitcoin, @TNStacker. @UCantDoThatDotNet, @Undisciplined
originally posted at https://stacker.news/items/926557
-
@ 23b0e2f8:d8af76fc
2025-01-08 18:17:52
## **Necessário**
- Um Android que você não use mais (a câmera deve estar funcionando).
- Um cartão microSD (opcional, usado apenas uma vez).
- Um dispositivo para acompanhar seus fundos (provavelmente você já tem um).
## **Algumas coisas que você precisa saber**
- O dispositivo servirá como um assinador. Qualquer movimentação só será efetuada após ser assinada por ele.
- O cartão microSD será usado para transferir o APK do Electrum e garantir que o aparelho não terá contato com outras fontes de dados externas após sua formatação. Contudo, é possível usar um cabo USB para o mesmo propósito.
- A ideia é deixar sua chave privada em um dispositivo offline, que ficará desligado em 99% do tempo. Você poderá acompanhar seus fundos em outro dispositivo conectado à internet, como seu celular ou computador pessoal.
---
## **O tutorial será dividido em dois módulos:**
- Módulo 1 - Criando uma carteira fria/assinador.
- Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.
---
## **No final, teremos:**
- Uma carteira fria que também servirá como assinador.
- Um dispositivo para acompanhar os fundos da carteira.

---
## **Módulo 1 - Criando uma carteira fria/assinador**
1. Baixe o APK do Electrum na aba de **downloads** em <https://electrum.org/>. Fique à vontade para [verificar as assinaturas](https://electrum.readthedocs.io/en/latest/gpg-check.html) do software, garantindo sua autenticidade.
2. Formate o cartão microSD e coloque o APK do Electrum nele. Caso não tenha um cartão microSD, pule este passo.

3. Retire os chips e acessórios do aparelho que será usado como assinador, formate-o e aguarde a inicialização.

4. Durante a inicialização, pule a etapa de conexão ao Wi-Fi e rejeite todas as solicitações de conexão. Após isso, você pode desinstalar aplicativos desnecessários, pois precisará apenas do Electrum. Certifique-se de que Wi-Fi, Bluetooth e dados móveis estejam desligados. Você também pode ativar o **modo avião**.\
*(Curiosidade: algumas pessoas optam por abrir o aparelho e danificar a antena do Wi-Fi/Bluetooth, impossibilitando essas funcionalidades.)*

5. Insira o cartão microSD com o APK do Electrum no dispositivo e instale-o. Será necessário permitir instalações de fontes não oficiais.
6. No Electrum, crie uma carteira padrão e gere suas palavras-chave (seed). Anote-as em um local seguro. Caso algo aconteça com seu assinador, essas palavras permitirão o acesso aos seus fundos novamente. *(Aqui entra seu método pessoal de backup.)*

---
## **Módulo 2 - Configurando um dispositivo para visualizar seus fundos e assinando transações com o assinador.**
1. Criar uma carteira **somente leitura** em outro dispositivo, como seu celular ou computador pessoal, é uma etapa bastante simples. Para este tutorial, usaremos outro smartphone Android com Electrum. Instale o Electrum a partir da aba de downloads em <https://electrum.org/> ou da própria Play Store. *(ATENÇÃO: O Electrum não existe oficialmente para iPhone. Desconfie se encontrar algum.)*
2. Após instalar o Electrum, crie uma carteira padrão, mas desta vez escolha a opção **Usar uma chave mestra**.

3. Agora, no assinador que criamos no primeiro módulo, exporte sua chave pública: vá em **Carteira > Detalhes da carteira > Compartilhar chave mestra pública**.

4. Escaneie o QR gerado da chave pública com o dispositivo de consulta. Assim, ele poderá acompanhar seus fundos, mas sem permissão para movimentá-los.
5. Para receber fundos, envie Bitcoin para um dos endereços gerados pela sua carteira: **Carteira > Addresses/Coins**.
6. Para movimentar fundos, crie uma transação no dispositivo de consulta. Como ele não possui a chave privada, será necessário assiná-la com o dispositivo assinador.

7. No assinador, escaneie a transação não assinada, confirme os detalhes, assine e compartilhe. Será gerado outro QR, desta vez com a transação já assinada.

8. No dispositivo de consulta, escaneie o QR da transação assinada e transmita-a para a rede.
---
## **Conclusão**
**Pontos positivos do setup:**
- **Simplicidade:** Basta um dispositivo Android antigo.
- **Flexibilidade:** Funciona como uma ótima carteira fria, ideal para holders.
**Pontos negativos do setup:**
- **Padronização:** Não utiliza seeds no padrão BIP-39, você sempre precisará usar o electrum.
- **Interface:** A aparência do Electrum pode parecer antiquada para alguns usuários.
Nesse ponto, temos uma carteira fria que também serve para assinar transações. O fluxo de assinar uma transação se torna: ***Gerar uma transação não assinada > Escanear o QR da transação não assinada > Conferir e assinar essa transação com o assinador > Gerar QR da transação assinada > Escanear a transação assinada com qualquer outro dispositivo que possa transmiti-la para a rede.***
Como alguns devem saber, uma transação assinada de Bitcoin é praticamente impossível de ser fraudada. Em um cenário catastrófico, você pode mesmo que sem internet, repassar essa transação assinada para alguém que tenha acesso à rede por qualquer meio de comunicação. Mesmo que não queiramos que isso aconteça um dia, esse setup acaba por tornar essa prática possível.
---
-
@ 57d1a264:69f1fee1
2025-03-27 08:27:44
> The tech industry and its press have treated the rise of billion-scale social networks and ubiquitous smartphone apps as an unadulterated win for regular people, a triumph of usability and empowerment. They seldom talk about what we’ve lost along the way in this transition, and I find that younger folks may not even know how the web used to be.
`— Anil Dash, The Web We Lost, 13 Dec 2012`
https://www.youtube.com/watch?v=9KKMnoTTHJk&t=156s
So here’s a few glimpses of a web that’s mostly faded away: https://www.anildash.com/2012/12/13/the_web_we_lost/
The first step to disabusing them of this notion is for the people creating the next generation of social applications to learn a little bit of history, to know your shit, whether that’s about [Twitter’s business model](http://web.archive.org/web/20180120013123/http://anildash.com/2010/04/ten-years-of-twitter-ads.html) or [Google’s social features](http://web.archive.org/web/20170518203228/http://anildash.com/2012/04/why-you-cant-trust-tech-press-to-teach-you-about-the-tech-industry.html) or anything else. We have to know what’s been tried and failed, what good ideas were simply ahead of their time, and what opportunities have been lost in the current generation of dominant social networks.
originally posted at https://stacker.news/items/926499
-
@ bc52210b:20bfc6de
2025-03-14 20:39:20
When writing safety critical code, every arithmetic operation carries the potential for catastrophic failure—whether that’s a plane crash in aerospace engineering or a massive financial loss in a smart contract.
The stakes are incredibly high, and errors are not just bugs; they’re disasters waiting to happen. Smart contract developers need to shift their mindset: less like web developers, who might prioritize speed and iteration, and more like aerospace engineers, where precision, caution, and meticulous attention to detail are non-negotiable.
In practice, this means treating every line of code as a critical component, adopting rigorous testing, and anticipating worst-case scenarios—just as an aerospace engineer would ensure a system can withstand extreme conditions.
Safety critical code demands aerospace-level precision, and smart contract developers must rise to that standard to protect against the severe consequences of failure.
-
@ 207ad2a0:e7cca7b0
2025-01-07 03:46:04
*Quick context: I wanted to check out Nostr's longform posts and this blog post seemed like a good one to try and mirror. It's originally from my [free to read/share attempt to write a novel](https://untitlednovel.dns7.top/contents/), but this post here is completely standalone - just describing how I used AI image generation to make a small piece of the work.*
Hold on, put your pitchforks down - outside of using Grammerly & Emacs for grammatical corrections - not a single character was generated or modified by computers; a non-insignificant portion of my first draft originating on pen & paper. No AI is ~~weird and crazy~~ imaginative enough to write like I do. The only successful AI contribution you'll find is a single image, the map, which I heavily edited. This post will go over how I generated and modified an image using AI, which I believe brought some value to the work, and cover a few quick thoughts about AI towards the end.
Let's be clear, I can't draw, but I wanted a map which I believed would improve the story I was working on. After getting abysmal results by prompting AI with text only I decided to use "Diffuse the Rest," a Stable Diffusion tool that allows you to provide a reference image + description to fine tune what you're looking for. I gave it this Microsoft Paint looking drawing:

and after a number of outputs, selected this one to work on:
The image is way better than the one I provided, but had I used it as is, I still feel it would have decreased the quality of my work instead of increasing it. After firing up Gimp I cropped out the top and bottom, expanded the ocean and separated the landmasses, then copied the top right corner of the large landmass to replace the bottom left that got cut off. Now we've got something that looks like concept art: not horrible, and gets the basic idea across, but it's still due for a lot more detail.
The next thing I did was add some texture to make it look more map like. I duplicated the layer in Gimp and applied the "Cartoon" filter to both for some texture. The top layer had a much lower effect strength to give it a more textured look, while the lower layer had a higher effect strength that looked a lot like mountains or other terrain features. Creating a layer mask allowed me to brush over spots to display the lower layer in certain areas, giving it some much needed features.
At this point I'd made it to where I felt it may improve the work instead of detracting from it - at least after labels and borders were added, but the colors seemed artificial and out of place. Luckily, however, this is when PhotoFunia could step in and apply a sketch effect to the image.
At this point I was pretty happy with how it was looking, it was close to what I envisioned and looked very visually appealing while still being a good way to portray information. All that was left was to make the white background transparent, add some minor details, and add the labels and borders. Below is the exact image I wound up using:
Overall, I'm very satisfied with how it turned out, and if you're working on a creative project, I'd recommend attempting something like this. It's not a central part of the work, but it improved the chapter a fair bit, and was doable despite lacking the talent and not intending to allocate a budget to my making of a free to read and share story.
#### The AI Generated Elephant in the Room
If you've read my non-fiction writing before, you'll know that I think AI will find its place around the skill floor as opposed to the skill ceiling. As you saw with my input, I have absolutely zero drawing talent, but with some elbow grease and an existing creative direction before and after generating an image I was able to get something well above what I could have otherwise accomplished. Outside of the lowest common denominators like stock photos for the sole purpose of a link preview being eye catching, however, I doubt AI will be wholesale replacing most creative works anytime soon. I can assure you that I tried numerous times to describe the map without providing a reference image, and if I used one of those outputs (or even just the unedited output after providing the reference image) it would have decreased the quality of my work instead of improving it.
I'm going to go out on a limb and expect that AI image, text, and video is all going to find its place in slop & generic content (such as AI generated slop replacing article spinners and stock photos respectively) and otherwise be used in a supporting role for various creative endeavors. For people working on projects like I'm working on (e.g. intended budget $0) it's helpful to have an AI capable of doing legwork - enabling projects to exist or be improved in ways they otherwise wouldn't have. I'm also guessing it'll find its way into more professional settings for grunt work - think a picture frame or fake TV show that would exist in the background of an animated project - likely a detail most people probably wouldn't notice, but that would save the creators time and money and/or allow them to focus more on the essential aspects of said work. Beyond that, as I've predicted before: I expect plenty of emails will be generated from a short list of bullet points, only to be summarized by the recipient's AI back into bullet points.
I will also make a prediction counter to what seems mainstream: AI is about to peak for a while. The start of AI image generation was with Google's DeepDream in 2015 - image recognition software that could be run in reverse to "recognize" patterns where there were none, effectively generating an image from digital noise or an unrelated image. While I'm not an expert by any means, I don't think we're too far off from that a decade later, just using very fine tuned tools that develop more coherent images. I guess that we're close to maxing out how efficiently we're able to generate images and video in that manner, and the hard caps on how much creative direction we can have when using AI - as well as the limits to how long we can keep it coherent (e.g. long videos or a chronologically consistent set of images) - will prevent AI from progressing too far beyond what it is currently unless/until another breakthrough occurs.
-
@ df173277:4ec96708
2025-02-07 00:41:34
## **Building Our Confidential Backend on Secure Enclaves**
With our newly released [private and confidential **Maple AI**](https://trymaple.ai/?ref=blog.opensecret.cloud) and the open sourcing of our [**OpenSecret** platform](https://github.com/OpenSecretCloud/opensecret?ref=blog.opensecret.cloud) code, I'm excited to present this technical primer on how we built our confidential compute platform leveraging **secure enclaves**. By combining AWS Nitro enclaves with end-to-end encryption and reproducible builds, our platform gives developers and end users the confidence that user data is protected, even at runtime, and that the code operating on their data has not been tampered with.
## **Auth and Databases Today**
As developers, we live in an era where protecting user data means "encryption at rest," plus some access policies and procedures. Developers typically run servers that:
1. Need to register users (authentication).
2. Collect and process user data in business-specific ways, often on the backend.
Even if data is encrypted at rest, it's commonly unlocked with a single master key or credentials the server holds. This means that data is visible during runtime to the application, system administrators, and potentially to the hosting providers. This scenario makes it difficult (or impossible) to guarantee that sensitive data isn't snooped on, memory-dumped, or used in unauthorized ways (for instance, training AI models behind the scenes).
## **"Just Trust Us" Isn't Good Enough**
In a traditional server architecture, users have to take it on faith that the code handling their data is the same code the operator claims to be running. Behind the scenes, applications can be modified or augmented to forward private information elsewhere, and there is no transparent way for users to verify otherwise. This lack of proof is unsettling, especially for services that process or store highly confidential data.
Administrators, developers, or cloud providers with privileged access can inspect memory in plaintext, attach debuggers, or gain complete visibility into stored information. Hackers who compromise these privileged levels can directly access sensitive data. Even with strict policies or promises of good conduct, the reality is that technical capabilities and misconfigurations can override words on paper. If a server master key can decrypt your data or can be accessed by an insider with root permissions, then "just trust us" loses much of its credibility.
The rise of AI platforms amplifies this dilemma. User data, often full of personal details, gets funneled into large-scale models that might be training or fine-tuning behind the scenes. Relying on vague assurances that "we don't look at your data" is no longer enough to prevent legitimate concerns about privacy and misuse. Now more than ever, providing a **strong, verifiable** guarantee that data remains off-limits, even when actively processed, has become a non-negotiable requirement for trustworthy services.
## **Current Attempts at Securing Data**
Current User Experience of E2EE Apps
While properly securing data is not easy, it isn't to say that no one is trying. Some solutions use **end-to-end encryption** (E2EE), where user data is encrypted client-side with a password or passphrase, so not even the server operator can decrypt it. That approach can be quite secure, but it also has its **limitations**:
1. **Key Management Nightmares**: If a user forgets their passphrase, the data is effectively lost, and there's no way to recover it from the developer's side.
2. **Feature Limitations**: Complex server-side operations (like offline/background tasks, AI queries, real-time collaboration, or heavy computation) can't easily happen if the server is never capable of processing decrypted data.
3. **Platform Silos**: Some solutions rely on iCloud, Google Drive, or local device storage. That can hamper multi-device usage or multi-OS compatibility.
Other approaches include self-hosting. However, these either burden users with dev ops overhead or revert to the "trust me" model for the server if you "self-host" on a cloud provider.
## **Secure Enclaves**
### **The Hybrid Approach**
Secure enclaves offer a compelling middle ground. They combine the privacy benefits of keeping data secure from prying admins while still allowing meaningful server-side computation. In a nutshell, an enclave is a protected environment within a machine, isolated at the hardware level, so that even if the OS or server is compromised, the data and code inside the enclave remain hidden.
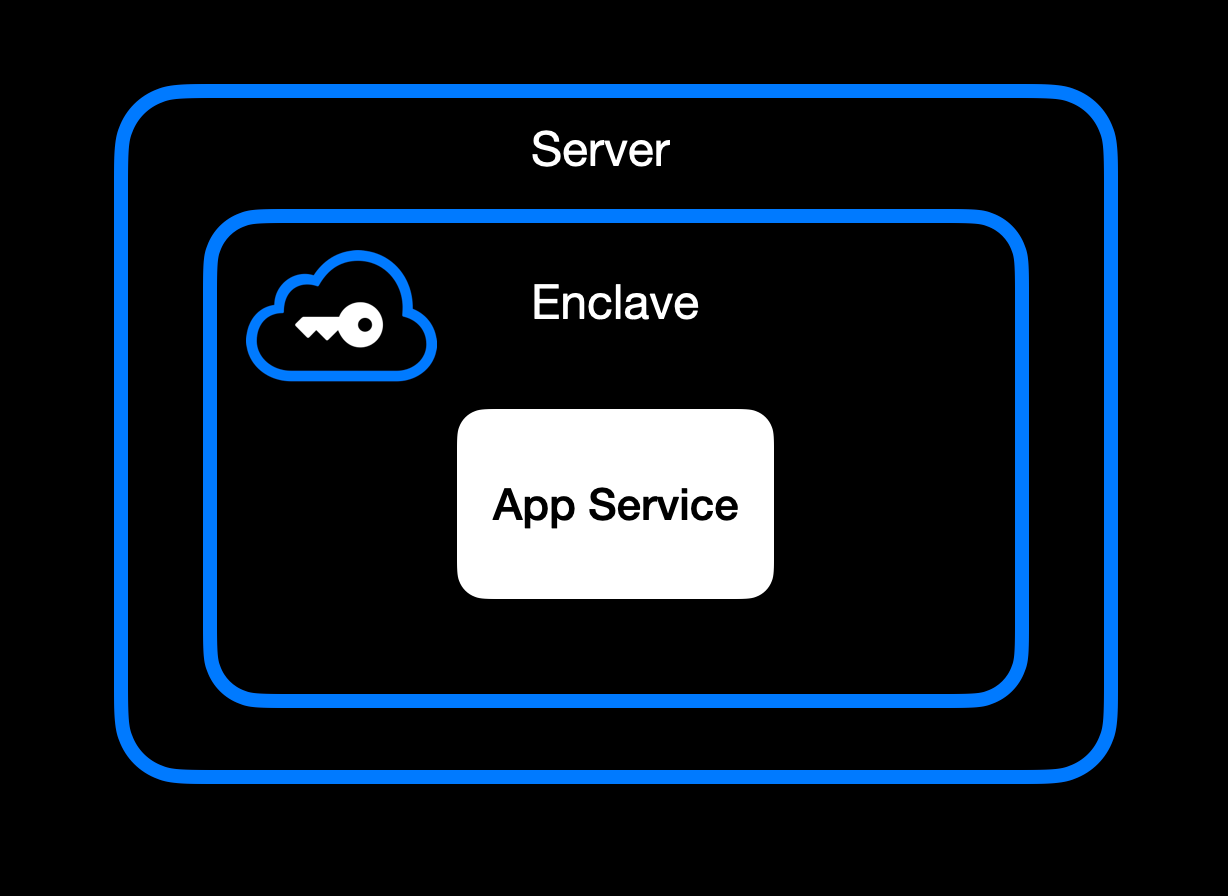App Service Running Inside Secure Enclave
### **High-Level Goal of Enclaves**
Enclaves, also known under the broader umbrella of **confidential computing**, aim to:\
• **Lock down data** so that only authorized code within the enclave can process the original plaintext data.\
• **Deny external inspection** by memory dumping, attaching a debugger, or intercepting plaintext network traffic.\
• **Prove** to external users or services that an enclave is running unmodified, approved code (this is where **remote attestation** comes in).
### **Different Secure Enclave Solutions**
[**AMD SEV**](https://www.amd.com/en/developer/sev.html?ref=blog.opensecret.cloud) **(Secure Encrypted Virtualization)** encrypts an entire virtual machine's memory so that even a compromised hypervisor cannot inspect or modify guest data. Its core concept is "lift-and-shift" security. No application refactoring is required because hardware-based encryption automatically protects the OS and all VM applications. Later enhancements (SEV-ES and SEV-SNP) added encryption of CPU register states and memory integrity protections, further limiting hypervisor tampering. This broad coverage means the guest OS is included in the trusted boundary. AMD SEV has matured into a robust solution for confidential VMs in multi-tenant clouds.
[**Intel TDX**](https://www.intel.com/content/www/us/en/developer/tools/trust-domain-extensions/overview.html?ref=blog.opensecret.cloud) **(Trust Domain Extensions)** shifts from process-level enclaves to full VM encryption, allowing an entire guest operating system and its applications to run in an isolated "trust domain." Like AMD SEV, Intel TDX encrypts and protects all memory the VM uses from hypervisors or other privileged software, so developers do not need to refactor their code to benefit from hardware-based confidentiality. This broader scope addresses many SGX limitations, such as strict memory bounds and the need to split out enclave-specific logic, and offers a more straightforward "lift-and-shift" path for running existing workloads privately. While SGX is now deprecated, TDX carries forward the core confidential computing principles but applies them at the virtual machine level for more substantial isolation, easier deployment, and the ability to scale up to large, memory-intensive applications.
[**Apple Secure Enclave and Private Compute**](https://security.apple.com/blog/private-cloud-compute/?ref=blog.opensecret.cloud) is a dedicated security coprocessor embedded in most Apple devices (iPhones, iPads, Macs) and now extended to Apple's server-side AI infrastructure. It runs its own microkernel, has hardware-protected memory, and securely manages operations such as biometric authentication, key storage, and cryptographic tasks. Apple's "Private Compute" approach in the cloud brings similar enclave capabilities to server-based AI, enabling on-device-grade privacy even when requests are processed in Apple's data centers.
[**AWS Nitro Enclaves**](https://docs.aws.amazon.com/enclaves/latest/user/nitro-enclave.html?ref=blog.opensecret.cloud) carve out a tightly isolated "mini-VM" from a parent EC2 instance, with its own vCPUs and memory guarded by dedicated Nitro cards. The enclave has no persistent storage and no external network access, significantly reducing the attack surface. Communication with the parent instance occurs over a secure local channel (vsock), and AWS offers hardware-based attestation so that secrets (e.g., encryption keys from AWS KMS) can be accessed only to the correct enclave. This design helps developers protect sensitive data or code even if the main EC2 instance's OS is compromised.
[**NVIDIA GPU TEEs**](https://www.nvidia.com/en-us/data-center/solutions/confidential-computing/?ref=blog.opensecret.cloud) **(Hopper H100 and Blackwell)** extend confidential computing to accelerated workloads by encrypting data in GPU memory and ensuring that even a privileged host cannot view or tamper with it. Data moving between CPU and GPU is encrypted in transit, so sensitive model weights or inputs remain protected during AI training or inference. NVIDIA's hardware and drivers handle secure data paths under the hood, allowing confidential large language model (LLM) workloads and other GPU-accelerated computations to run with minimal performance overhead and strong security guarantees.
### **Key Benefits**
One major advantage of enclaves is their ability to **keep memory completely off-limits** to outside prying eyes. Even administrators who can normally inspect processes at will are blocked from peeking into the enclave's protected memory space. The enclave model is a huge shift in the security model: it prevents casual inspection and defends against sophisticated memory dumping techniques that might otherwise leak secrets or sensitive data.
Another key benefit centers on cryptographic keys that are **never exposed outside the enclave**. Only verified code running inside the enclave environment can run decryption or signing operations, and it can only do so while that specific code is running. This ensures that compromised hosts or rogue processes, even those with high-level privileges, are unable to intercept or misuse the keys because the keys remain strictly within the trusted boundary of the hardware.
Enclaves can also offer the power of **remote attestation**, allowing external clients or systems to confirm that they're speaking to an authentic, untampered enclave. By validating the hardware's integrity measurements and enclave-specific proofs, the remote party can be confident in the underlying security properties, an important guarantee in multi-tenant environments or whenever trust boundaries extend across different organizations and networks.
Beyond that, **reproducible builds** can create a verifiable fingerprint proving which binary runs in the enclave. This is a step above a simple "trust us" approach. Anyone can independently recreate the enclave image and verify the resulting cryptographic hash by using a reproducible build system (for example, [our NixOS-based solution](https://github.com/OpenSecretCloud/opensecret/blob/master/flake.nix?ref=blog.opensecret.cloud)). If it matches, then users and developers know precisely how code handles their data, boosting confidence that no hidden changes exist.
It's worth noting that although enclaves shield you from software devs, cloud providers, and insider threats, you do have to trust the **hardware vendor** (Intel, AMD, Apple, AWS, or NVIDIA) to implement their microcode and firmware securely. The entire enclave model could be theoretically undermined if a CPU maker's root keys or manufacturing process were compromised. Fortunately, these companies undergo extensive audits and firmware validations (often with third-party researchers), and their remote attestation mechanisms allow you to confirm specific firmware versions before trusting an enclave. While this adds a layer of "vendor trust," it's still a far more contained risk than trusting an entire operating system or cloud stack, so enclaves remain a strong step forward in practical, confidential computing.
## **How We Use Secure Enclaves**
Now that we've covered the general idea of enclaves let's look at how we specifically implement them in OpenSecret, our developer platform for handling user auth, private keys, data encryption, and AI workloads.
### **Our Stack: AWS Nitro + Nvidia TEE**
• **AWS Nitro Enclaves for the backend**: All critical logic, authentication, private key management, and data encryption/decryption run inside an AWS Nitro Enclave.
• **Nvidia Trusted Execution for AI**: For large AI inference (such as the Llama 3.3 70B model), we utilize Nvidia's GPU-based TEEs to protect even GPU memory. This means users can feed sensitive data to the AI model **without** exposing it in plaintext to the GPU providers or us as the operator. [Edgeless Systems](https://www.edgeless.systems/?ref=blog.opensecret.cloud) is our Nvidia TEE provider, and due to the power of enclave verification, we don't need to worry about who runs the GPUs. We know requests can't be inspected or tampered with.
### **End-to-End Encryption from Client to Enclave**
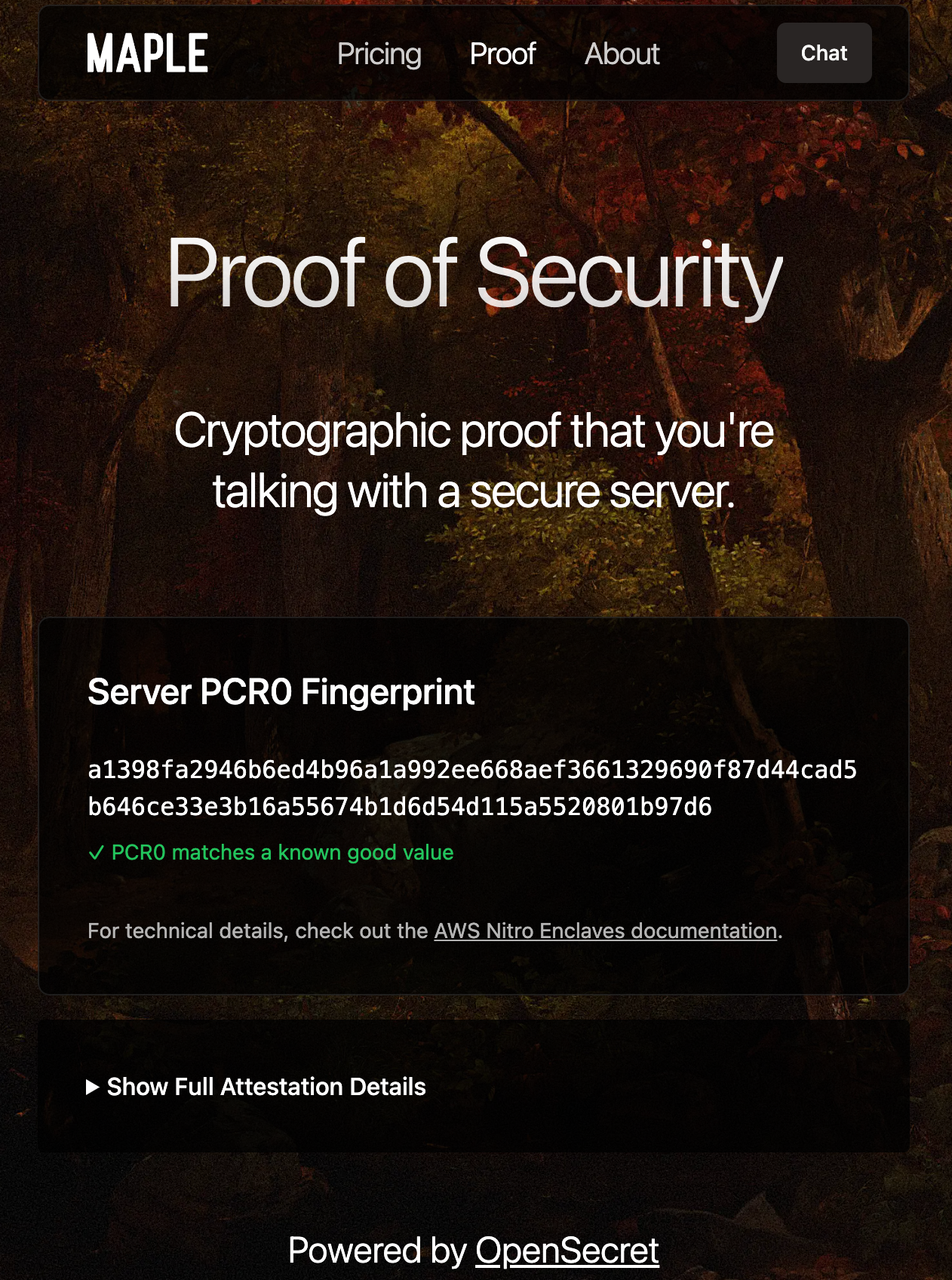Client-side Enclave Attestation from Maple AI
Before login or data upload, the user/client verifies the **enclave attestation** from our platform. This process proves that the specific Nitro Enclave is genuine and runs the exact code we've published. You can check this out live on [Maple AI's attestation page](https://trymaple.ai/proof?ref=blog.opensecret.cloud).
Based on the attestation, the client establishes a secure ephemeral communication channel that only that enclave can decrypt. While we take advantage of SSL, it is typically not terminated inside the enclave itself. To ensure there's full encrypted data transfer all the way through to the enclave, we establish this additional handshake based on the attestation document that is used for all API requests during the client session.
From there, the user's credentials, private keys, and data pass through this secure channel directly into the enclave, where they are decrypted and processed according to the user's request.
### **In-Enclave Operations**
At the core of OpenSecret's approach is the conviction that security-critical tasks must happen inside the enclave, where even administrative privileges or hypervisor-level compromise cannot expose plaintext data. This encompasses everything from when a user logs in to creating and managing sensitive cryptographic keys. By confining these operations to a protected hardware boundary, developers can focus on building their applications without worrying about accidental data leaks, insider threats, or malicious attempts to harvest credentials. The enclave becomes the ultimate gatekeeper: it controls how data flows and ensures that nothing escapes in plain form.
User Auth Methods running inside Enclave
A primary example is **user authentication**. All sign-in workflows, including email/password, OAuth, and upcoming passkey-based methods, are handled entirely within the enclave. As soon as a user's credentials enter our platform through the encrypted channel, they are routed straight into the protected environment, bypassing the host's operating system or any potential snooping channels. From there, authentication and session details remain in the enclave, ensuring that privileged outsiders cannot intercept or modify them. By centralizing these identity flows within a sealed environment, developers can assure their users that no one outside the enclave (including the cloud provider or the app's own sysadmins) can peek at, tamper with, or access sensitive login information.
Main Enclave Operations in OpenSecret
The same principle applies to **private key management**. Whether keys are created fresh in the enclave or securely transferred into it, they remain sealed away from the rest of the system. Operations like digital signing or content decryption happen only within the hardware boundary, so raw keys never appear in any log, file system, or memory space outside the enclave. Developers retain the functionality they need, such as verifying user actions, encrypting data, or enabling secure transactions without ever exposing keys to a broader (and more vulnerable) attack surface. User backup options exist as well, where the keys can be securely passed to the end user.
Realtime Encrypted Data Sync on Multiple Devices
Another crucial aspect is **data encryption at rest**. While user data ultimately needs to be stored somewhere outside the enclave, the unencrypted form of that data only exists transiently inside the protected environment. Encryption and decryption routines run within the enclave, which holds the encryption keys strictly in memory under hardware guards. If a user uploads data, it is promptly secured before it leaves the enclave. When data is retrieved, it remains encrypted until it reenters the protected region and is passed back to the user through the secured communication channel. This ensures that even if someone gains access to the underlying storage or intercepts data in transit, they will see only meaningless ciphertext.
Confidential AI Workloads
Finally, **confidential AI workloads** build upon this same pattern: the Nitro enclave re-encrypts data so it can be processed inside a GPU-based trusted execution environment (TEE) for inference or other advanced computations. Sensitive data, like user-generated text or private documents, never appears in the clear on the host or within GPU memory outside the TEE boundary. When an AI process finishes, only the results are returned to the enclave, which can then relay them securely to the requesting user. By seamlessly chaining enclaves together, from CPU-based Nitro Enclaves to GPU-accelerated TEEs, we can deliver robust, hardware-enforced privacy for virtually any type of server-side or AI-driven operation.
### **Reproducible Builds + Verification**
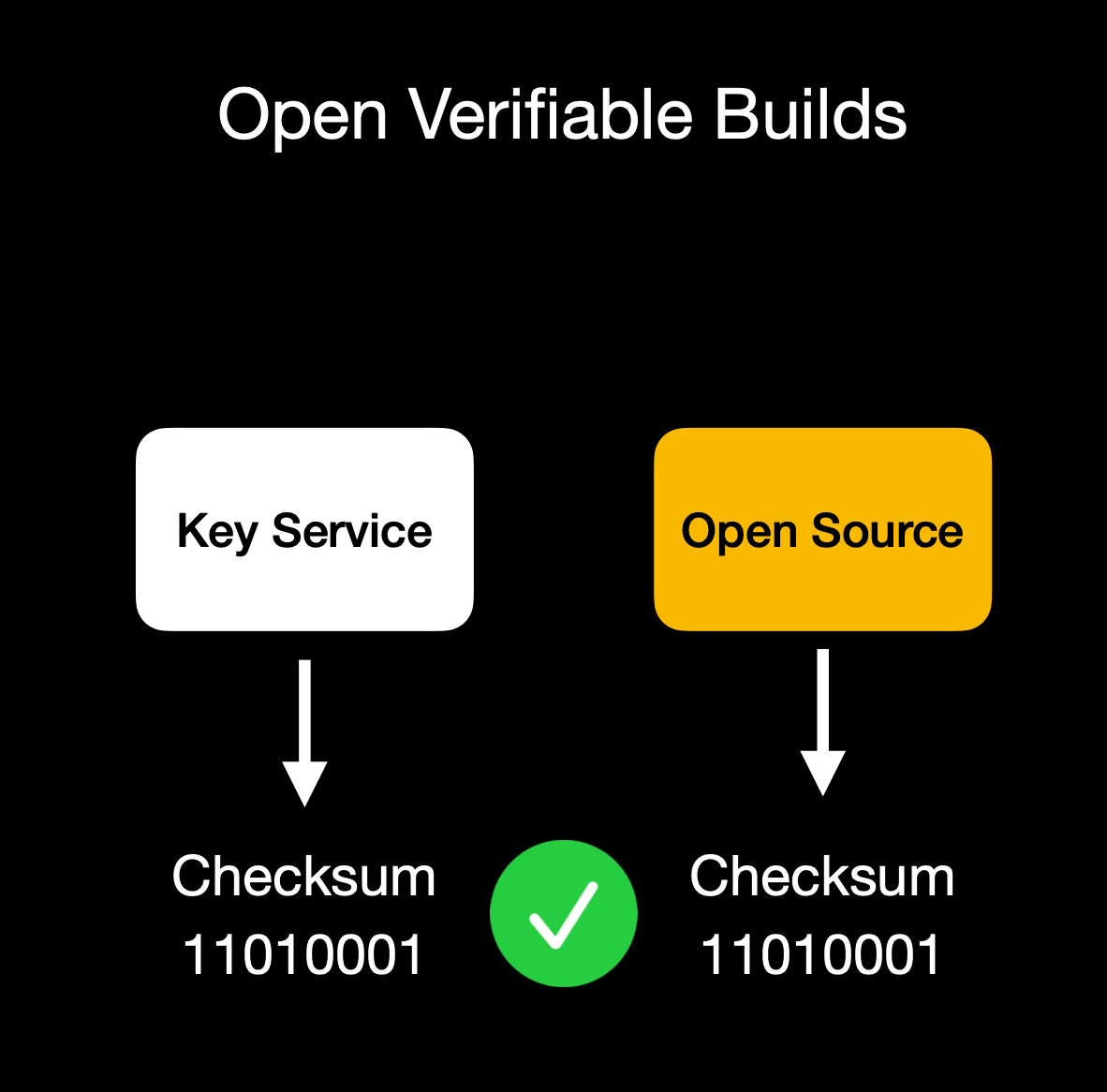Client verifies enclave attestation document
We build our enclaves on **NixOS** with reproducible builds, ensuring that anyone can verify that the binary we publish is indeed the binary running in the enclave. This build process is essential for proving we haven't snuck in malicious code to exfiltrate data or collect sensitive logs.
Our code is fully open source ([GitHub: OpenSecret](https://github.com/OpenSecretCloud/opensecret?ref=blog.opensecret.cloud)), so you can audit or run it yourself. You can also verify that the cryptographic measurement the build process outputs matches the measurement reported by the enclave during attestation.
## **Putting It All Together**
OpenSecret Offering: Private Key Management, Encrypted Sync, Private AI, and Confidential Compute
By weaving secure enclaves into every step, from authentication to data handling to AI inference, we shift the burden of trust away from human policies and onto provable, hardware-based protections. For app developers, you can offer your users robust privacy guarantees without rewriting all your business logic or building an entire security stack from scratch. Whether you're storing user credentials or running complex operations on sensitive data, the enclave approach ensures plaintext remains inaccessible to even the most privileged parties outside the enclave boundary. Developers can focus on building great apps, while OpenSecret handles the cryptographic "lock and key" behind the scenes.
This model provides a secure-by-design environment for industries that demand strict data confidentiality, such as healthcare, fintech, cryptocurrency apps for secure key management, or decentralized identity platforms. Instead of worrying about memory dumps or backend tampering, you can trust that once data enters the enclave, it's sealed off from unauthorized eyes, including from the app developers themselves. And these safeguards don't just apply to niche use cases. Even general-purpose applications that handle login flows and user-generated content stand to benefit, especially as regulatory scrutiny grows around data privacy and insider threats.
Imagine a telehealth startup using OpenSecret enclaves to protect patient information for remote consultations. Not only would patient data remain encrypted at rest, but any AI-driven analytics to assist with diagnoses could be run privately within the enclave, ensuring no one outside the hardware boundary can peek at sensitive health records. A fintech company could similarly isolate confidential financial transactions, preventing even privileged insiders from viewing or tampering with raw transaction details. These real-world implementations give developers a clear path to adopting enclaves for serious privacy and compliance needs without overhauling their infrastructure.
OpenSecret aims to be a **full developer platform** with end-to-end security from day one. By incorporating user authentication, data storage, and GPU-based confidential AI into a single service, we eliminate many of the traditional hurdles in adopting enclaves. No more juggling separate tools for cryptographic key management, compliance controls, and runtime privacy. Instead, you get a unified stack that keeps data encrypted in transit, at rest, and in use.
Our solution also caters to the exploding demand for AI applications: with TEE-enabled GPU workloads, you can securely process sensitive data for text inference without ever exposing raw plaintext or sensitive documents to the host system.
The result is a new generation of apps that deliver advanced functionality, like real-time encrypted data sync or AI-driven insights, while preserving user privacy and meeting strict regulatory requirements. You don't have to rely on empty "trust us" promises because hardware enclaves, remote attestation, and reproducible builds collectively guarantee the code is running untampered. In short, OpenSecret offers the building blocks needed to create truly confidential services and experiences, allowing you to innovate while ensuring data protection remains ironclad.
## **Things to Come**
We're excited to build on our enclaved approach. Here's what's on our roadmap:
• **Production Launch**: We're using this in production now with [Maple AI](https://trymaple.ai/?ref=blog.opensecret.cloud) and have a developer preview playground up and running. We'll have the developer environment ready for production in a few months.\
• **Multi-Tenant Support**: Our platform currently works for single tenants, but we're opening this up so developers can onboard without needing a dedicated instance.\
• **Self-Serve Frontend**: A dev-friendly portal for provisioning apps, connecting OAuth or email providers, and managing users.\
• **External Key Signing Options**: Integrations with custom hardware security modules (HSMs) or customer-ran key managers that can only process data upon verifying the enclave attestation.\
• **Confidential Computing as a Service**: We'll expand our platform so that other developers can quickly create enclaves for specialized workloads without dealing with the complexities of Nitro or GPU TEEs.\
• **Additional SDKs**: In addition to our [JavaScript client-side SDK](https://github.com/OpenSecretCloud/OpenSecret-SDK?ref=blog.opensecret.cloud), we plan to launch official support for Rust, Python, Swift, Java, Go, and more.\
• **AI API Proxy with Attestation/Encryption**: We already provide an easy way to [access a Private AI through Maple AI](https://trymaple.ai/?ref=blog.opensecret.cloud), but we'd like to open this up more for existing tools and developers. We'll provide a proxy server that users can run on their local machines or servers that properly handle encryption to our OpenAI-compatible API.
## **Getting Started**
Ready to see enclaves in action? Here's how to dive in:\
1. **Run OpenSecret**: Check out our open-source repository at [OpenSecret on GitHub](https://github.com/OpenSecretCloud/opensecret?ref=blog.opensecret.cloud). You can run your own enclaved environment or try it out locally with Docker.\
2. **Review Our SDK**: Our [JavaScript client SDK](https://github.com/OpenSecretCloud/OpenSecret-SDK?ref=blog.opensecret.cloud) makes it easy to handle sign-ins, put/get encrypted data, sign with user private keys, etc. It handles attestation verification and encryption under the hood, making the API integration seamless.\
3. **Play with Maple AI**: Try out [Maple AI](https://blog.opensecret.cloud/maple-ai-private-encrypted-chat/) as an example of an AI app built directly on OpenSecret. Your queries are encrypted end to end, and the Llama model sees them only inside the TEE.\
4. **Developer Preview**: Contact us if you want an invite to our early dev platform. We'll guide you through our SDK and give you access to the preview server. We'd love to build with you and incorporate your feedback as we develop this further.
## **Conclusion**
By merging secure enclaves (AWS Nitro and Nvidia GPU TEEs), user authentication, private key management, and an end-to-end verifiable encrypted approach, **OpenSecret** provides a powerful platform where we protect user data during collection, storage, and processing. Whether it's for standard user management, handling private cryptographic keys, or powering AI inference, the technology ensures that **no one**, not even us or the cloud provider, can snoop on data in use.
**We believe** this is the future of trustworthy computing in the cloud. And it's **all open source**, so you don't have to just take our word for it: you can see and verify everything yourself.
Do you have questions, feedback, or a use case you'd like to test out? Come join us on [GitHub](https://github.com/OpenSecretCloud?ref=blog.opensecret.cloud), [Discord](https://discord.gg/ch2gjZAMGy?ref=blog.opensecret.cloud), or email us for a developer preview. We can't wait to see what you build!
*Thank you for reading, and welcome to the era of enclaved computing.*
-
@ df173277:4ec96708
2025-01-28 17:49:54
> Maple is an AI chat tool that allows you to have private conversations with a general-purpose AI assistant. Chats are synced automatically between devices so you can pick up where you left off.\
> [Start chatting for free.](https://trymaple.ai/)
We are excited to announce that [Maple AI](https://trymaple.ai/), our groundbreaking end-to-end encrypted AI chat app built on OpenSecret, is now publicly available. After months of beta testing, we are thrilled to bring this innovative technology to the world.
Maple is an AI chat tool that allows you to have private conversations with a general-purpose AI assistant. It can boost your productivity on work tasks such as writing documentation, creating presentations, and drafting emails. You can also use it for personal items like brainstorming ideas, sorting out life's challenges, and tutoring you on difficult coursework. All your chats are synced automatically in a secure way, so you can start on one device and pick up where you left off on another.
#### Why Secure and Private AI?
In today's digital landscape, it is increasingly evident that security and privacy are essential for individuals and organizations alike. Unfortunately, the current state of AI tools falls short. A staggering 48% of organizations enter non-public company information into AI apps, according to a [recent report by Cisco](https://www.cisco.com/c/en/us/about/trust-center/data-privacy-benchmark-study.html#~key-findings). This practice poses significant risks to company security and intellectual property.
Another concern is for journalists, who often work with sensitive information in hostile environments. Journalists need verification that their information remains confidential and protected when researching topics and communicating with sources in various languages. They are left to use underpowered local AI or input their data into potentially compromised cloud services.
At OpenSecret, we believe it is possible to have both the benefits of AI and the assurance of security and privacy. That's why we created Maple, an app that combines AI productivity with the protection of end-to-end encryption. Our platform ensures that your conversations with AI remain confidential, even from us. The power of the cloud meets the privacy of local.
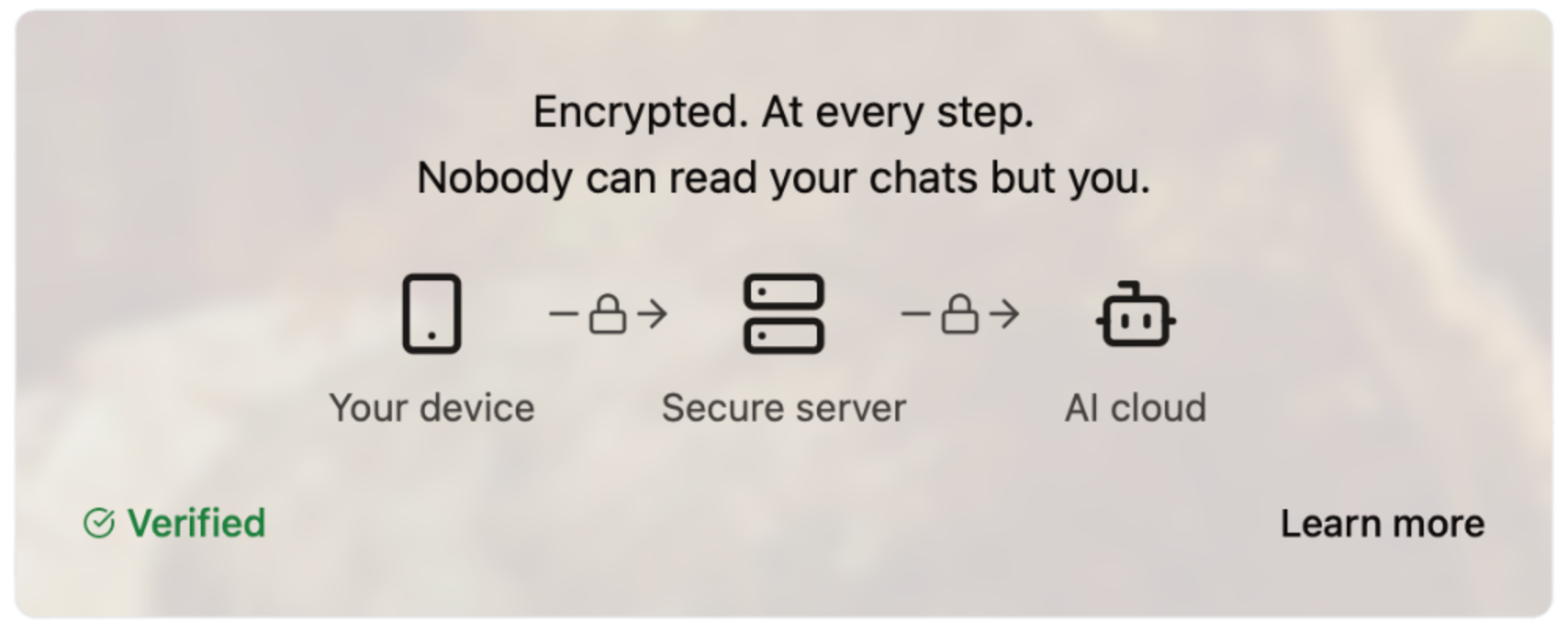#### How Does It Work?
Our server code is [open source](https://github.com/OpenSecretCloud/opensecret), and we use confidential computing to provide cryptographic proof that the code running on our servers is the same as the open-source code available for review. This process allows you to verify that your conversations are handled securely and privately without relying on trust. We live by the principle of "Don't trust, verify," and we believe this approach is essential for building in the digital age. You can read a more in-depth write-up on our technology later this week on this site.
#### How Much Does It Cost?
We are committed to making Maple AI accessible to everyone, so we offer a range of pricing plans to suit different needs and budgets. [Our Free plan allows for 10 chats per week, while our Starter plan ($5.99/month) and Pro plan ($20/month)](https://trymaple.ai/pricing) offer more comprehensive solutions for individuals and organizations with heavier workloads. We accept credit cards and Bitcoin (10% discount), allowing you to choose your preferred payment method.
- Free: $0
- Starter: $5.99/month
- Pro: $20/month
Our goal with Maple AI is to create a product that is secure through transparency. By combining open-source code, cryptography, and confidential computing, we can create a new standard for AI conversations - one that prioritizes your security and privacy.
Maple has quickly become a daily tool of productivity for our own work and those of our beta testers. We believe it will bring value to you as well. [Sign up now and start chatting privately with AI for free.](https://trymaple.ai/) Your secrets are safe in the open.
#### Are You An App Developer?
You can build an app like Maple. [OpenSecret provides secure auth, private key management, encrypted data sync, private AI, and more.](https://blog.opensecret.cloud/introducing-opensecret/) Our straightforward API behaves like other backends but automatically adds security and privacy. Use it to secure existing apps or brand-new projects. Protect yourself and your users from the liability of hosting personal data by checking out [OpenSecret](https://opensecret.cloud/).
<img src="https://blossom.primal.net/feb746d5e164e89f0d015646286b88237dce4158f8985e3caaf7e427cebde608.png">
Enjoy private AI Chat 🤘
<img src="https://blossom.primal.net/0594ec56e249de2754ea7dfc225a7ebd46bc298b5af168279ce71f17c2afada0.jpg">
-
@ df173277:4ec96708
2025-01-09 17:12:08
> Maple AI combines the best of both worlds – encryption and personal AI – to create a truly private AI experience. Discuss personal and company items with Maple, we can't read them even if we wanted to.\
> [Join the waitlist to get early access.](https://trymaple.ai)
We are a culture of app users. Every day, we give our personal information to websites and apps, hoping they are safe. Location data, eating habits, financial details, and health information are just a few examples of what we entrust to third parties. People are now entering a new era of computing that promises next-level benefits when given even more personal data: AI.
Should we sacrifice our privacy to unlock the productivity gains of AI? Should we hope our information won't be used in ways we disagree? We believe we can have the best of both worlds – privacy and personal AI – and have built a new project called Maple AI. Chat between you and an AI with full end-to-end encryption. We believe it's a game-changer for individuals seeking private and secure conversations.
#### Building a Private Foundation
Maple is built on our flagship product, [OpenSecret](https://opensecret.cloud), a backend platform for app developers that turns private encryption on by default. [The announcement post for OpenSecret explains our vision for an encrypted world and what the platform can do.](nostr:naddr1qvzqqqr4gupzphchxfm3ste32hfhkvczzxapme9gz5qvqtget6tylyd7wa8vjecgqqe5jmn5wfhkgatrd9hxwt20wpjku5m9vdex2apdw35x2tt9de3hy7tsw3jkgttzv93kketwvskhgur5w9nx5h52tpj) We think both users and developers benefit when sensitive personal information is encrypted in a private vault; it's a win-win.
#### The Power of Encrypted AI Chat
AI chat is a personal and intimate experience. It's a place to share your thoughts, feelings, and desires without fear of judgment. The more you share with an AI chatbot, the more powerful it becomes. It can offer personalized insights, suggestions, and guidance tailored to your unique needs and perspectives. However, this intimacy requires trust, and that's where traditional AI chatbots often fall short.
Traditional AI chats are designed to collect and analyze your data, often without your explicit consent. This data is used to improve the AI's performance, but it also creates a treasure trove of sensitive information that can be mined, sold, or even exploited by malicious actors. Maple AI takes a different approach. By using end-to-end encryption, we ensure that your conversations remain private and secure, even from us.
#### Technical Overview
So, how does Maple AI achieve this level of privacy and security? Here are some key technical aspects:
- **Private Key:** Each user has a unique private key that is automatically managed for them. This key encrypts and decrypts conversations, ensuring that only the user can access their data.
- **Secure Servers:** Our servers are designed with security in mind. We use secure enclaves to protect sensitive data and ensure that even our own team can't access your conversations.
- **Encrypted Sync:** One of Maple's most significant benefits is its encrypted sync feature. Unlike traditional AI chatbots, which store conversations in local storage or on standard cloud servers, Maple syncs your chats across all your devices. The private key managed by our secure servers means you can pick up where you left off on any device without worrying about your data being compromised.
- **Attestation and Open Code:** We publish our enclave code publicly. Using a process called attestation, users can verify that the code running on the enclave is the same as the code audited by the public.
- **Open Source LLM:** Maple uses major open-source models to maximize the openness of responses. The chat box does not filter what you can talk about. This transparency ensures that our AI is trustworthy and unbiased.
#### Personal and Work Use
Maple is secure enough to handle your personal questions and work tasks. Because we can't see what you chat about, you are free to use AI as an assistant on sensitive company items. Use it for small tasks like writing an important email or large tasks like developing your organization's strategy. Feed it sensitive information; it's just you and AI in the room. Attestation provides cryptographic proof that your corporate secrets are safe.
#### Local v Cloud
Today's AI tools provide different levels of privacy. The main options are to trust a third party with your unencrypted data, hoping they don't do anything with it, or run your own AI locally on an underpowered machine. We created a third option. Maple gives you the power of cloud computing combined with the privacy and security of a machine running on your desk. It's the best of both worlds.
#### Why the Maple name?
Privacy isn't just a human value - it's a natural one exemplified by the Maple tree. These organisms communicate with each other through a network of underground fungal hyphae, sending messages and sharing resources in a way that's completely invisible to organisms above ground. This discreet communication system allows Maple trees to thrive in even the most challenging environments. Our goal is to provide a way for everyone to communicate with AI securely so they can thrive in any environment.
#### Join the Waitlist
Maple AI will launch in early 2025 with free and paid plans. We can't wait to share it with the world. [Join our waitlist today to be among the first to experience the power of private AI chat.](https://trymaple.ai)
[](https://trymaple.ai/waitlist)
-
@ d4cb227b:edca6019
2025-03-30 03:57:04
This method focuses on the amount of water in the first pour, which ultimately defines the coffee’s acidity and sweetness (more water = more acidity, less water = more sweetness). For the remainder of the brew, the water is divided into equal parts according to the strength you wish to attain.
Dose:
- 20g coffee (Coarse ground coffee)
- 300mL water (92°C / 197.6°F)
Time: 3:30
Instructions:
Pour 1: 0:00 > 50mL (42% of 120mL = 40% of total – less water in the ratio, targeting sweetness.)
Pour 2: 0:45 > 70mL (58% of 120mL = 40% of total – the top up for 40% of total.)
Pour 3: 1:30 > 60mL (The remaining water is 180mL / 3 pours = 60mL per pour)
Pour 4: 2:10 > 60mL
Pour 5: 2:40 > 60mL
Remove the V60 at 3:30
-
@ 57d1a264:69f1fee1
2025-03-27 08:11:33
Explore and reimagine programming interfaces beyond text (visual, tactile, spatial).
> _"The most dangerous thought you can have as a creative person is to think you know what you're doing."_
`— Richard Hamming` [^1]
https://www.youtube.com/watch?v=8pTEmbeENF4
For his recent DBX Conference talk, Victor took attendees back to the year 1973, donning the uniform of an IBM systems engineer of the times, delivering his presentation on an overhead projector. The '60s and early '70s were a fertile time for CS ideas, reminds Victor, but even more importantly, it was a time of unfettered thinking, unconstrained by programming dogma, authority, and tradition.

_'The most dangerous thought that you can have as a creative person is to think that you know what you're doing,'_ explains Victor. 'Because once you think you know what you're doing you stop looking around for other ways of doing things and you stop being able to see other ways of doing things. You become blind.' He concludes, 'I think you have to say: _"We don't know what programming is. We don't know what computing is. We don't even know what a computer is."_ And once you truly understand that, and once you truly believe that, then you're free, and you can think anything.'
More details at https://worrydream.com/dbx/
[^1]: Richard Hamming -- [The Art of Doing Science and Engineering, p5](http://worrydream.com/refs/Hamming_1997_-_The_Art_of_Doing_Science_and_Engineering.pdf) (pdf ebook)
originally posted at https://stacker.news/items/926493
-
@ df173277:4ec96708
2025-01-09 17:02:52
> OpenSecret is a backend for app developers that turns private encryption on by default. When sensitive data is readable only by the user, it protects both the user and the developer, creating a more free and open internet. We'll be launching in 2025. [Join our waitlist to get early access.](https://opensecret.cloud)
In today's digital age, personal data is both an asset and a liability. With the rise of data breaches and cyber attacks, individuals and companies struggle to protect sensitive information. The consequences of a data breach can be devastating, resulting in financial losses, reputational damage, and compromised user trust. In 2023, the average data breach cost was $5 million, with some resulting in losses of over $1 billion.
Meanwhile, individuals face problems related to identity theft, personal safety, and public embarrassment. Think about the apps on your phone, even the one you're using to read this. How much data have you trusted to other people, and how would it feel if that data were leaked online?
Thankfully, some incredibly talented cypherpunks years ago gave the world cryptography. We can encrypt data, rendering it a secret between two people. So why then do we have data breaches?
> Cryptography at scale is hard.
#### The Cloud
The cloud has revolutionized how we store and process data, but it has limitations. While cloud providers offer encryption, it mainly protects data in transit. Once data is stored in the cloud, it's often encrypted with a shared key, which can be accessed by employees, third-party vendors, or compromised by hackers.
The solution is to generate a personal encryption password for each user, make sure they write it down, and, most importantly, hope they don't lose it. If the password is lost, the data is forever unreadable. That can be overwhelming, leading to low app usage.
> Private key encryption needs a UX upgrade.
## Enter OpenSecret
OpenSecret is a developer platform that enables encryption by default. Our platform provides a suite of security tools for app developers, including private key management, encrypted sync, private AI, and confidential compute.
Every user has a private vault for their data, which means only they can read it. Developers are free to store less sensitive data in a shared manner because there is still a need to aggregate data across the system.

### Private Key Management
Private key management is the superpower that enables personal encryption per user. When each user has a unique private key, their data can be truly private. Typically, using a private key is a challenging experience for the user because they must write down a long autogenerated number or phrase of 12-24 words. If they lose it, their data is gone.
OpenSecret uses secure enclaves to make private keys as easy as an everyday login experience that users are familiar with. Instead of managing a complicated key, the user logs in with an email address or a social media account.
The developer doesn't have to manage private keys and can focus on the app's user experience. The user doesn't have to worry about losing a private key and can jump into using your app.
### Encrypted Sync
With user keys safely managed, we can synchronize user data to every device while maintaining privacy. The user does not need to do complicated things like scanning QR codes from one device to the next. Just log in and go.
The user wins because the data is available on all their devices. The developer wins because only the user can read the data, so it isn't a liability to them.
### Private AI
Artificial intelligence is here and making its way into everything. The true power of AI is unleashed when it can act on personal and company data. The current options are to run your own AI locally on an underpowered machine or to trust a third party with your data, hoping they don't read it or use it for anything.
OpenSecret combines the power of cloud computing with the privacy and security of a machine running on your desk.
**Check out Maple AI**\
Try private AI for yourself! We built an app built with this service called [Maple AI](https://trymaple.ai). It is an AI chat that is 100% private in a verifiable manner. Give it your innermost thoughts or embarrassing ideas; we can't judge you. We built Maple using OpenSecret, which means you have a private key that is automatically managed for you, and your chat history is synchronized to all your devices. [Learn more about Maple AI - Private chat in the announcement post.](https://blog.opensecret.cloud/maple-ai-private-encrypted-chat/)
### Confidential Compute
Confidential computing is a game-changer for data security. It's like the secure hardware that powers Apple Pay and Google Pay on your phone but in the cloud. Users can verify through a process called attestation that their data is handled appropriately. OpenSecret can help you run your own custom app backend code that would benefit from the security of an enclave.
It's the new version of that lock on your web browser. When you see it, you know you're secure.

#### **But do we want our secrets to be open?**
OpenSecret renders a data breach practically useless. If hackers get into the backend, they enter a virtual hallway of locked private vaults. The leaked data would be gibberish, a secret in the open that is unreadable.
On the topic of openness, OpenSecret uses the power of open source to enable trust in the service. We publish our code in the open, and, using attestation, anyone can verify that private data is being handled as expected. This openness also provides developers with a backup option to safely and securely export their data.
> Don't trust, verify.
### **Join the Movement**
We're currently building out OpenSecret, and we invite you to join us on the journey. Our platform can work with your existing stack, and you can pick and choose the features you need. If you want to build apps with encryption enabled, [send us a message to get early access.](https://opensecret.cloud)
Users and companies deserve better encryption and privacy.\
Together, let's make that a reality.
[](https://opensecret.cloud)
-
@ 06830f6c:34da40c5
2025-03-30 03:56:17
Once upon a time their lived a young man in a lost village, I'm just kidding with you, I'm testing my blog entries on my domain. [SITE]( https://turiz.space)
Navigate to Blogs tab and screenshot this. @ me for a chance to get zapped ⚡.
I won't say how many sats, so you are not doing it due to the incentive but to help me test the domain functionality.
Love ✌️
-
@ e6817453:b0ac3c39
2025-01-05 14:29:17
## The Rise of Graph RAGs and the Quest for Data Quality
As we enter a new year, it’s impossible to ignore the boom of retrieval-augmented generation (RAG) systems, particularly those leveraging graph-based approaches. The previous year saw a surge in advancements and discussions about Graph RAGs, driven by their potential to enhance large language models (LLMs), reduce hallucinations, and deliver more reliable outputs. Let’s dive into the trends, challenges, and strategies for making the most of Graph RAGs in artificial intelligence.
## Booming Interest in Graph RAGs
Graph RAGs have dominated the conversation in AI circles. With new research papers and innovations emerging weekly, it’s clear that this approach is reshaping the landscape. These systems, especially those developed by tech giants like Microsoft, demonstrate how graphs can:
* **Enhance LLM Outputs:** By grounding responses in structured knowledge, graphs significantly reduce hallucinations.
* **Support Complex Queries:** Graphs excel at managing linked and connected data, making them ideal for intricate problem-solving.
Conferences on linked and connected data have increasingly focused on Graph RAGs, underscoring their central role in modern AI systems. However, the excitement around this technology has brought critical questions to the forefront: How do we ensure the quality of the graphs we’re building, and are they genuinely aligned with our needs?
## Data Quality: The Foundation of Effective Graphs
A high-quality graph is the backbone of any successful RAG system. Constructing these graphs from unstructured data requires attention to detail and rigorous processes. Here’s why:
* **Richness of Entities:** Effective retrieval depends on graphs populated with rich, detailed entities.
* **Freedom from Hallucinations:** Poorly constructed graphs amplify inaccuracies rather than mitigating them.
Without robust data quality, even the most sophisticated Graph RAGs become ineffective. As a result, the focus must shift to refining the graph construction process. Improving data strategy and ensuring meticulous data preparation is essential to unlock the full potential of Graph RAGs.
## Hybrid Graph RAGs and Variations
While standard Graph RAGs are already transformative, hybrid models offer additional flexibility and power. Hybrid RAGs combine structured graph data with other retrieval mechanisms, creating systems that:
* Handle diverse data sources with ease.
* Offer improved adaptability to complex queries.
Exploring these variations can open new avenues for AI systems, particularly in domains requiring structured and unstructured data processing.
## Ontology: The Key to Graph Construction Quality
Ontology — defining how concepts relate within a knowledge domain — is critical for building effective graphs. While this might sound abstract, it’s a well-established field blending philosophy, engineering, and art. Ontology engineering provides the framework for:
* **Defining Relationships:** Clarifying how concepts connect within a domain.
* **Validating Graph Structures:** Ensuring constructed graphs are logically sound and align with domain-specific realities.
Traditionally, ontologists — experts in this discipline — have been integral to large enterprises and research teams. However, not every team has access to dedicated ontologists, leading to a significant challenge: How can teams without such expertise ensure the quality of their graphs?
## How to Build Ontology Expertise in a Startup Team
For startups and smaller teams, developing ontology expertise may seem daunting, but it is achievable with the right approach:
1. **Assign a Knowledge Champion:** Identify a team member with a strong analytical mindset and give them time and resources to learn ontology engineering.
2. **Provide Training:** Invest in courses, workshops, or certifications in knowledge graph and ontology creation.
3. **Leverage Partnerships:** Collaborate with academic institutions, domain experts, or consultants to build initial frameworks.
4. **Utilize Tools:** Introduce ontology development tools like Protégé, OWL, or SHACL to simplify the creation and validation process.
5. **Iterate with Feedback:** Continuously refine ontologies through collaboration with domain experts and iterative testing.
So, it is not always affordable for a startup to have a dedicated oncologist or knowledge engineer in a team, but you could involve consulters or build barefoot experts.
You could read about barefoot experts in my article :
Even startups can achieve robust and domain-specific ontology frameworks by fostering in-house expertise.
## How to Find or Create Ontologies
For teams venturing into Graph RAGs, several strategies can help address the ontology gap:
1. **Leverage Existing Ontologies:** Many industries and domains already have open ontologies. For instance:
* **Public Knowledge Graphs:** Resources like Wikipedia’s graph offer a wealth of structured knowledge.
* **Industry Standards:** Enterprises such as Siemens have invested in creating and sharing ontologies specific to their fields.
* **Business Framework Ontology (BFO):** A valuable resource for enterprises looking to define business processes and structures.
1. **Build In-House Expertise:** If budgets allow, consider hiring knowledge engineers or providing team members with the resources and time to develop expertise in ontology creation.
2. **Utilize LLMs for Ontology Construction:** Interestingly, LLMs themselves can act as a starting point for ontology development:
* **Prompt-Based Extraction:** LLMs can generate draft ontologies by leveraging their extensive training on graph data.
* **Domain Expert Refinement:** Combine LLM-generated structures with insights from domain experts to create tailored ontologies.
## Parallel Ontology and Graph Extraction
An emerging approach involves extracting ontologies and graphs in parallel. While this can streamline the process, it presents challenges such as:
* **Detecting Hallucinations:** Differentiating between genuine insights and AI-generated inaccuracies.
* **Ensuring Completeness:** Ensuring no critical concepts are overlooked during extraction.
Teams must carefully validate outputs to ensure reliability and accuracy when employing this parallel method.
## LLMs as Ontologists
While traditionally dependent on human expertise, ontology creation is increasingly supported by LLMs. These models, trained on vast amounts of data, possess inherent knowledge of many open ontologies and taxonomies. Teams can use LLMs to:
* **Generate Skeleton Ontologies:** Prompt LLMs with domain-specific information to draft initial ontology structures.
* **Validate and Refine Ontologies:** Collaborate with domain experts to refine these drafts, ensuring accuracy and relevance.
However, for validation and graph construction, formal tools such as OWL, SHACL, and RDF should be prioritized over LLMs to minimize hallucinations and ensure robust outcomes.
## Final Thoughts: Unlocking the Power of Graph RAGs
The rise of Graph RAGs underscores a simple but crucial correlation: improving graph construction and data quality directly enhances retrieval systems. To truly harness this power, teams must invest in understanding ontologies, building quality graphs, and leveraging both human expertise and advanced AI tools.
As we move forward, the interplay between Graph RAGs and ontology engineering will continue to shape the future of AI. Whether through adopting existing frameworks or exploring innovative uses of LLMs, the path to success lies in a deep commitment to data quality and domain understanding.
Have you explored these technologies in your work? Share your experiences and insights — and stay tuned for more discussions on ontology extraction and its role in AI advancements. Cheers to a year of innovation!
-
@ a4a6b584:1e05b95b
2025-01-02 18:13:31
## The Four-Layer Framework
### Layer 1: Zoom Out

Start by looking at the big picture. What’s the subject about, and why does it matter? Focus on the overarching ideas and how they fit together. Think of this as the 30,000-foot view—it’s about understanding the "why" and "how" before diving into the "what."
**Example**: If you’re learning programming, start by understanding that it’s about giving logical instructions to computers to solve problems.
- **Tip**: Keep it simple. Summarize the subject in one or two sentences and avoid getting bogged down in specifics at this stage.
_Once you have the big picture in mind, it’s time to start breaking it down._
---
### Layer 2: Categorize and Connect

Now it’s time to break the subject into categories—like creating branches on a tree. This helps your brain organize information logically and see connections between ideas.
**Example**: Studying biology? Group concepts into categories like cells, genetics, and ecosystems.
- **Tip**: Use headings or labels to group similar ideas. Jot these down in a list or simple diagram to keep track.
_With your categories in place, you’re ready to dive into the details that bring them to life._
---
### Layer 3: Master the Details

Once you’ve mapped out the main categories, you’re ready to dive deeper. This is where you learn the nuts and bolts—like formulas, specific techniques, or key terminology. These details make the subject practical and actionable.
**Example**: In programming, this might mean learning the syntax for loops, conditionals, or functions in your chosen language.
- **Tip**: Focus on details that clarify the categories from Layer 2. Skip anything that doesn’t add to your understanding.
_Now that you’ve mastered the essentials, you can expand your knowledge to include extra material._
---
### Layer 4: Expand Your Horizons

Finally, move on to the extra material—less critical facts, trivia, or edge cases. While these aren’t essential to mastering the subject, they can be useful in specialized discussions or exams.
**Example**: Learn about rare programming quirks or historical trivia about a language’s development.
- **Tip**: Spend minimal time here unless it’s necessary for your goals. It’s okay to skim if you’re short on time.
---
## Pro Tips for Better Learning
### 1. Use Active Recall and Spaced Repetition
Test yourself without looking at notes. Review what you’ve learned at increasing intervals—like after a day, a week, and a month. This strengthens memory by forcing your brain to actively retrieve information.
### 2. Map It Out
Create visual aids like [diagrams or concept maps](https://excalidraw.com/) to clarify relationships between ideas. These are particularly helpful for organizing categories in Layer 2.
### 3. Teach What You Learn
Explain the subject to someone else as if they’re hearing it for the first time. Teaching **exposes any gaps** in your understanding and **helps reinforce** the material.
### 4. Engage with LLMs and Discuss Concepts
Take advantage of tools like ChatGPT or similar large language models to **explore your topic** in greater depth. Use these tools to:
- Ask specific questions to clarify confusing points.
- Engage in discussions to simulate real-world applications of the subject.
- Generate examples or analogies that deepen your understanding.
**Tip**: Use LLMs as a study partner, but don’t rely solely on them. Combine these insights with your own critical thinking to develop a well-rounded perspective.
---
## Get Started
Ready to try the Four-Layer Method? Take 15 minutes today to map out the big picture of a topic you’re curious about—what’s it all about, and why does it matter? By building your understanding step by step, you’ll master the subject with less stress and more confidence.
-
@ 04ff5a72:22ba7b2d
2025-03-19 02:17:03
# Web3 in the Physical World
In the evolving landscape of Web3 technologies, Decentralized Physical Infrastructure Networks (DePIN) represent one of the most promising developments, extending blockchain capabilities beyond purely digital applications into the physical world. This emerging paradigm is reshaping how we conceptualize, build, and maintain infrastructure by leveraging blockchain technology to create community-owned physical networks. As of early 2025, DePIN has grown from a theoretical concept to a multi-billion dollar sector with applications spanning telecommunications, energy, transportation, and data services.
# Defining DePIN in the Web3 Ecosystem
Decentralized Physical Infrastructure Networks (DePIN) represent the convergence of blockchain technology with physical infrastructure, creating systems where real-world networks and devices are collectively owned, managed, and operated by communities rather than centralized entities[[1]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era)[[4]](https://nftnewstoday.com/2025/01/28/depin-explained-bringing-real-world-devices-web3). While Web3 primarily focuses on decentralized digital applications and services, DePIN extends these principles into the physical world, marking what many consider the natural evolution of blockchain technology beyond purely online environments[[3]](https://limechain.tech/blog/what-is-depin).
## Core Characteristics of DePIN
At its foundation, DePIN leverages blockchain technology to decentralize the control and management of physical devices and infrastructure[[2]](https://arxiv.org/html/2406.02239v1). This approach addresses several limitations of traditional centralized infrastructure networks, including data privacy risks, service disruptions, and substantial expansion costs[[2]](https://arxiv.org/html/2406.02239v1). By distributing ownership and governance across network participants, DePIN creates more transparent, efficient, and resilient systems that align with the fundamental principles of Web3[[1]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era).
The technical architecture of DePIN combines several key elements:
1. **Blockchain Foundation**: DePIN utilizes blockchain networks to provide transparent, secure, and immutable record-keeping for all network operations[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin).
2. **Tokenized Incentives**: Participants who contribute resources such as bandwidth, energy, or storage are rewarded with crypto tokens, creating economic incentives for network growth and maintenance[[1]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era).
3. **Smart Contracts**: Automated agreements handle resource distribution, monitor usage, and execute payments without requiring trusted intermediaries[[1]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era)[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks).
4. **Decentralized Governance**: Many DePIN projects implement DAO (Decentralized Autonomous Organization) structures for democratic decision-making among network participants[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks).
# How DePIN Works Within Web3
DePIN operates by incentivizing individuals and organizations to contribute physical resources to a network in exchange for tokenized rewards. This model creates a powerful alternative to traditional infrastructure deployment, which typically requires massive upfront investment by corporations or governments.
## Incentive Mechanisms
The core functioning of DePIN relies on properly aligned incentive structures. When individuals contribute resources—whether it's computing power, network bandwidth, or physical devices—they receive tokens as compensation[[1]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era). These tokens often serve multiple purposes within the ecosystem:
1. **Reward Distribution**: Smart contracts automatically allocate tokens based on the quantity and quality of resources contributed[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks).
2. **Governance Rights**: Token holders can often participate in network decision-making, voting on upgrades, policy changes, and resource allocation[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks).
3. **Service Access**: Tokens may be required to access the network's services, creating a circular economy within the ecosystem.
## Community Participation
DePIN networks are typically open and permissionless, meaning anyone can join and start contributing[[3]](https://limechain.tech/blog/what-is-depin). This drastically lowers barriers to entry compared to traditional infrastructure development, which often requires significant capital and regulatory approvals. The peer-to-peer nature of these networks makes initial infrastructure deployment much more manageable through crowdsourcing[[3]](https://limechain.tech/blog/what-is-depin).
# Major Applications of DePIN in the Web3 Space
As of early 2025, DePIN has expanded across numerous sectors, demonstrating the versatility of decentralized approaches to physical infrastructure. Several key applications have emerged as particularly successful implementations of the DePIN model.
## **Telecommunications and Connectivity**
One of the most established DePIN applications is in telecommunications, where projects like Helium and Althea have created decentralized wireless and broadband networks[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin)[[9]](https://blog.althea.net/content/files/2024/06/Althea-Whitepaper-v2.0.pdf). Helium’s model allows individuals to set up wireless hotspots and earn HNT tokens for providing connectivity, enabling a distributed, user-powered wireless network[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). Althea, on the other hand, focuses on decentralized internet service provision by allowing users to buy and sell bandwidth automatically, creating a self-sustaining and community-driven ISP model. This approach is particularly effective in rural and underserved regions, where traditional telecom providers may not find it economically viable to invest in infrastructure[[9]](https://blog.althea.net/content/files/2024/06/Althea-Whitepaper-v2.0.pdf). Both projects demonstrate how blockchain and incentive-driven models can disrupt conventional telecom industries and expand access to connectivity.
## Energy Networks
DePIN is revolutionizing energy infrastructure through projects like Arkreen, which enables individuals and organizations to contribute excess renewable energy to a global network[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). These decentralized energy systems allow small-scale producers to monetize their resources while contributing to more resilient and sustainable energy grids[[1]](https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era).
## Data Storage and Computing
Decentralized storage networks like Filecoin demonstrate how DePIN principles can transform data infrastructure[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). Users offer spare storage capacity on their devices in exchange for FIL tokens, creating a globally distributed storage network that competes with centralized cloud services[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). This approach enhances data resilience while enabling individual participation in the digital storage economy.
## Mapping and Location Services
Hivemapper represents an innovative application of DePIN in creating decentralized mapping services[[6]](https://hackernoon.com/depin-explained-what-are-decentralized-physical-infrastructure-networks)[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks). Users contribute mapping data collected through 4K dashcams while driving, building a community-owned alternative to centralized mapping services like Google Maps[[6]](https://hackernoon.com/depin-explained-what-are-decentralized-physical-infrastructure-networks)[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks). As of October 2024, Hivemapper had successfully mapped significant portions of the global road network through this crowdsourced approach[[8]](https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks).
## Transportation and Mobility
Decentralized ride-sharing platforms like DRIFE are emerging as DePIN alternatives to traditional services like Uber and Lyft[[6]](https://hackernoon.com/depin-explained-what-are-decentralized-physical-infrastructure-networks). These platforms connect drivers and passengers directly through blockchain networks, reducing fees and returning more value to network participants rather than corporate intermediaries.
# The Economic Impact and Market Potential of DePIN
DePIN represents a substantial and rapidly growing segment of the Web3 economy. According to industry research, the market shows significant potential for continued expansion in the coming years.
## Current Market Status
As of early 2025, the DePIN sector has achieved considerable market presence:
1. **Market Capitalization**: The current market capitalization of DePIN projects is approximately $27 billion, with a daily trading volume of $1.8 billion according to DePIN Scan[[7]](https://blaize.tech/blog/decentralized-physical-infrastructure-networks-depin/).
2. **Investment Activity**: Venture capitalists have recognized DePIN's potential, directing billions of dollars into the sector. Some have even created dedicated funds specifically for DePIN protocols[[7]](https://blaize.tech/blog/decentralized-physical-infrastructure-networks-depin/).
3. **Growth Trajectory**: DePIN has been identified as one of the major crypto trends of 2024-2025, with accelerating adoption across multiple industries[[7]](https://blaize.tech/blog/decentralized-physical-infrastructure-networks-depin/).
## Future Market Potential
The long-term outlook for DePIN appears promising according to industry analysts:
1. **Total Addressable Market**: Messari, an independent crypto research firm, estimates DePIN's Total Addressable Market at $2.2 trillion, with projections showing growth to $3.5 trillion by 2028[[6]](https://hackernoon.com/depin-explained-what-are-decentralized-physical-infrastructure-networks).
2. **Theoretical Upper Limit**: In theory, DePIN's potential market extends to the entire non-digital economy, which according to World Bank figures approaches $90 trillion[[6]](https://hackernoon.com/depin-explained-what-are-decentralized-physical-infrastructure-networks).
# Benefits and Advantages of the DePIN Model
The DePIN approach offers several distinct advantages over traditional centralized infrastructure models, explaining its rapid adoption within the Web3 ecosystem.
## Collective Ownership
DePIN enables community ownership of infrastructure that has traditionally been centralized under corporate or government control[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). This democratization of ownership distributes both the benefits and responsibilities of infrastructure management among a broader group of stakeholders.
## Enhanced Transparency
With DePIN, all network actions are recorded on-chain, ensuring open access to vital network data[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). This transparency builds trust among participants and reduces the information asymmetry that often exists in centralized systems.
## Improved Efficiency
By leveraging underutilized resources and implementing smart contracts, DePIN can reduce waste and administrative overhead[[5]](https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin). This efficiency translates to lower costs and improved resource allocation compared to traditional infrastructure models.
## Resilience Through Decentralization
Distributed networks are inherently more resilient to failures and attacks than centralized systems. By eliminating single points of failure, DePIN creates infrastructure that can continue functioning even when individual components experience issues.
# Challenges and Future Considerations
Despite its promising potential, DePIN faces several significant challenges that must be addressed for widespread adoption.
## Technical Scalability
Many DePIN networks struggle with scalability issues, particularly as they grow to accommodate more users and higher transaction volumes. Developing more efficient consensus mechanisms and layer-2 solutions remains an important technical challenge.
## Regulatory Uncertainty
The decentralized nature of DePIN projects creates regulatory challenges in many jurisdictions. Finding the right balance between innovation and compliance with existing regulations will be crucial for long-term success.
## Economic Sustainability
Creating sustainable tokenomics models that properly align incentives over the long term remains difficult. Many projects must carefully balance immediate rewards with long-term value creation to maintain network growth and stability.
# Conclusion
Decentralized Physical Infrastructure Networks represent one of the most promising extensions of Web3 principles beyond purely digital applications. By leveraging blockchain technology, tokenized incentives, and community participation, DePIN is transforming how physical infrastructure is built, maintained, and governed.
As the sector continues to mature throughout 2025 and beyond, we can expect to see DePIN concepts applied to an increasingly diverse range of infrastructure challenges. The intersection of DePIN with other emerging technologies like artificial intelligence and the Internet of Things will likely create entirely new forms of infrastructure that we can barely imagine today.
The growth of DePIN underscores a fundamental shift in our approach to infrastructure—moving from centralized, corporate-controlled models toward more democratic, transparent, and community-driven systems. This transformation embodies the core promise of Web3: not just a more decentralized internet, but a more decentralized world.
---
### Sources
[1] DePIN Crypto: How It's Revolutionizing Infrastructure in Web3 https://www.ulam.io/blog/how-depin-is-revolutionizing-infrastructure-in-the-web3-era
[2] Decentralized Physical Infrastructure Network (DePIN) - arXiv https://arxiv.org/html/2406.02239v1
[3] What is DePIN - decentralized physical infrastructure network? https://limechain.tech/blog/what-is-depin
[4] DePIN Explained: Bringing Real-World Devices to Web3 https://nftnewstoday.com/2025/01/28/depin-explained-bringing-real-world-devices-web3
[5] An Introduction to Decentralized Physical Infrastructure Networks ... https://www.cryptoaltruism.org/blog/infographic-an-introduction-to-decentralized-physical-infrastructure-networks-depin
[6] DePIN Explained: What Are Decentralized Physical Infrastructure ... https://hackernoon.com/depin-explained-what-are-decentralized-physical-infrastructure-networks
[7] Revolutionizing Infrastructure: Understanding DePINs and Their ... https://blaize.tech/blog/decentralized-physical-infrastructure-networks-depin/
[8] What is DePIN? The Future of Decentralized Physical Infrastructure ... https://osl.com/academy/article/what-is-depin-the-future-of-decentralized-physical-infrastructure-networks
[9] [PDF] Althea Whitepaper v2 https://blog.althea.net/content/files/2024/06/Althea-Whitepaper-v2.0.pdf
-
@ 0d788b5e:c99ddea5
2025-03-29 01:27:53
这是首页内容
-
@ d4cb227b:edca6019
2025-03-30 03:53:48
Dose:
30g coffee (Fine-medium grind size)
500mL soft or bottled water (97°C / 206.6°F)
Instructions:
1. Rinse out your filter paper with hot water to remove the papery taste. This will also preheat the brewer.
2. Add your grounds carefully to the center of the V60 and then create a well in the middle of the grounds.
3. For the bloom, start to gently pour 60mL of water, making sure that all the coffee is wet in this initial phase.
4. As soon as you’ve added your water, grab your V60 and begin to swirl in a circular motion. This will ensure the water and coffee are evenly mixed. Let this rest and bloom for up to 45 seconds.
5. Pour the rest of the water in in 2 phases. You want to try and get 60% of your total water in, within 30 seconds.
6. Pour until you reach 300mL total with a time at 1:15. Here you want to pour with a little agitation, but not so much that you have an uneven extraction.
7. Once you hit 60% of your total brew weight, start to pour a little slower and more gently, keeping your V60 cone topped up. Aim to have 100% of your brew weight in within the next 30 seconds.
8. Once you get to 500mL, with a spoon give the V60 a small stir in one direction, and then again in the other direction. This will release any grounds stuck to the side of the paper.
9. Allow the V60 to drain some more, and then give it one final swirl. This will help keep the bed flat towards the end of the brew, giving you the most even possible extraction.
-
@ fe32298e:20516265
2024-12-16 20:59:13
Today I learned how to install [NVapi](https://github.com/sammcj/NVApi) to monitor my GPUs in Home Assistant.
**NVApi** is a lightweight API designed for monitoring NVIDIA GPU utilization and enabling automated power management. It provides real-time GPU metrics, supports integration with tools like Home Assistant, and offers flexible power management and PCIe link speed management based on workload and thermal conditions.
- **GPU Utilization Monitoring**: Utilization, memory usage, temperature, fan speed, and power consumption.
- **Automated Power Limiting**: Adjusts power limits dynamically based on temperature thresholds and total power caps, configurable per GPU or globally.
- **Cross-GPU Coordination**: Total power budget applies across multiple GPUs in the same system.
- **PCIe Link Speed Management**: Controls minimum and maximum PCIe link speeds with idle thresholds for power optimization.
- **Home Assistant Integration**: Uses the built-in RESTful platform and template sensors.
## Getting the Data
```
sudo apt install golang-go
git clone https://github.com/sammcj/NVApi.git
cd NVapi
go run main.go -port 9999 -rate 1
curl http://localhost:9999/gpu
```
Response for a single GPU:
```
[
{
"index": 0,
"name": "NVIDIA GeForce RTX 4090",
"gpu_utilisation": 0,
"memory_utilisation": 0,
"power_watts": 16,
"power_limit_watts": 450,
"memory_total_gb": 23.99,
"memory_used_gb": 0.46,
"memory_free_gb": 23.52,
"memory_usage_percent": 2,
"temperature": 38,
"processes": [],
"pcie_link_state": "not managed"
}
]
```
Response for multiple GPUs:
```
[
{
"index": 0,
"name": "NVIDIA GeForce RTX 3090",
"gpu_utilisation": 0,
"memory_utilisation": 0,
"power_watts": 14,
"power_limit_watts": 350,
"memory_total_gb": 24,
"memory_used_gb": 0.43,
"memory_free_gb": 23.57,
"memory_usage_percent": 2,
"temperature": 36,
"processes": [],
"pcie_link_state": "not managed"
},
{
"index": 1,
"name": "NVIDIA RTX A4000",
"gpu_utilisation": 0,
"memory_utilisation": 0,
"power_watts": 10,
"power_limit_watts": 140,
"memory_total_gb": 15.99,
"memory_used_gb": 0.56,
"memory_free_gb": 15.43,
"memory_usage_percent": 3,
"temperature": 41,
"processes": [],
"pcie_link_state": "not managed"
}
]
```
# Start at Boot
Create `/etc/systemd/system/nvapi.service`:
```
[Unit]
Description=Run NVapi
After=network.target
[Service]
Type=simple
Environment="GOPATH=/home/ansible/go"
WorkingDirectory=/home/ansible/NVapi
ExecStart=/usr/bin/go run main.go -port 9999 -rate 1
Restart=always
User=ansible
# Environment="GPU_TEMP_CHECK_INTERVAL=5"
# Environment="GPU_TOTAL_POWER_CAP=400"
# Environment="GPU_0_LOW_TEMP=40"
# Environment="GPU_0_MEDIUM_TEMP=70"
# Environment="GPU_0_LOW_TEMP_LIMIT=135"
# Environment="GPU_0_MEDIUM_TEMP_LIMIT=120"
# Environment="GPU_0_HIGH_TEMP_LIMIT=100"
# Environment="GPU_1_LOW_TEMP=45"
# Environment="GPU_1_MEDIUM_TEMP=75"
# Environment="GPU_1_LOW_TEMP_LIMIT=140"
# Environment="GPU_1_MEDIUM_TEMP_LIMIT=125"
# Environment="GPU_1_HIGH_TEMP_LIMIT=110"
[Install]
WantedBy=multi-user.target
```
## Home Assistant
Add to Home Assistant `configuration.yaml` and restart HA (completely).
For a single GPU, this works:
```
sensor:
- platform: rest
name: MYPC GPU Information
resource: http://mypc:9999
method: GET
headers:
Content-Type: application/json
value_template: "{{ value_json[0].index }}"
json_attributes:
- name
- gpu_utilisation
- memory_utilisation
- power_watts
- power_limit_watts
- memory_total_gb
- memory_used_gb
- memory_free_gb
- memory_usage_percent
- temperature
scan_interval: 1 # seconds
- platform: template
sensors:
mypc_gpu_0_gpu:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} GPU"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'gpu_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_memory:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Memory"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'memory_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_power:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_power_limit:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Power Limit"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'power_limit_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_temperature:
friendly_name: "MYPC {{ state_attr('sensor.mypc_gpu_information', 'name') }} Temperature"
value_template: "{{ state_attr('sensor.mypc_gpu_information', 'temperature') }}"
unit_of_measurement: "°C"
```
For multiple GPUs:
```
rest:
scan_interval: 1
resource: http://mypc:9999
sensor:
- name: "MYPC GPU0 Information"
value_template: "{{ value_json[0].index }}"
json_attributes_path: "$.0"
json_attributes:
- name
- gpu_utilisation
- memory_utilisation
- power_watts
- power_limit_watts
- memory_total_gb
- memory_used_gb
- memory_free_gb
- memory_usage_percent
- temperature
- name: "MYPC GPU1 Information"
value_template: "{{ value_json[1].index }}"
json_attributes_path: "$.1"
json_attributes:
- name
- gpu_utilisation
- memory_utilisation
- power_watts
- power_limit_watts
- memory_total_gb
- memory_used_gb
- memory_free_gb
- memory_usage_percent
- temperature
- platform: template
sensors:
mypc_gpu_0_gpu:
friendly_name: "MYPC GPU0 GPU"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'gpu_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_memory:
friendly_name: "MYPC GPU0 Memory"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'memory_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_0_power:
friendly_name: "MYPC GPU0 Power"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_power_limit:
friendly_name: "MYPC GPU0 Power Limit"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'power_limit_watts') }}"
unit_of_measurement: "W"
mypc_gpu_0_temperature:
friendly_name: "MYPC GPU0 Temperature"
value_template: "{{ state_attr('sensor.mypc_gpu0_information', 'temperature') }}"
unit_of_measurement: "C"
- platform: template
sensors:
mypc_gpu_1_gpu:
friendly_name: "MYPC GPU1 GPU"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'gpu_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_1_memory:
friendly_name: "MYPC GPU1 Memory"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'memory_utilisation') }}"
unit_of_measurement: "%"
mypc_gpu_1_power:
friendly_name: "MYPC GPU1 Power"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_watts') }}"
unit_of_measurement: "W"
mypc_gpu_1_power_limit:
friendly_name: "MYPC GPU1 Power Limit"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'power_limit_watts') }}"
unit_of_measurement: "W"
mypc_gpu_1_temperature:
friendly_name: "MYPC GPU1 Temperature"
value_template: "{{ state_attr('sensor.mypc_gpu1_information', 'temperature') }}"
unit_of_measurement: "C"
```
Basic entity card:
```
type: entities
entities:
- entity: sensor.mypc_gpu_0_gpu
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_memory
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_power
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_power_limit
secondary_info: last-updated
- entity: sensor.mypc_gpu_0_temperature
secondary_info: last-updated
```
# Ansible Role
```
---
- name: install go
become: true
package:
name: golang-go
state: present
- name: git clone
git:
repo: "https://github.com/sammcj/NVApi.git"
dest: "/home/ansible/NVapi"
update: yes
force: true
# go run main.go -port 9999 -rate 1
- name: install systemd service
become: true
copy:
src: nvapi.service
dest: /etc/systemd/system/nvapi.service
- name: Reload systemd daemons, enable, and restart nvapi
become: true
systemd:
name: nvapi
daemon_reload: yes
enabled: yes
state: restarted
```
-
@ fd06f542:8d6d54cd
2025-03-28 02:27:52
NIP-02
======
Follow List
-----------
`final` `optional`
A special event with kind `3`, meaning "follow list" is defined as having a list of `p` tags, one for each of the followed/known profiles one is following.
Each tag entry should contain the key for the profile, a relay URL where events from that key can be found (can be set to an empty string if not needed), and a local name (or "petname") for that profile (can also be set to an empty string or not provided), i.e., `["p", <32-bytes hex key>, <main relay URL>, <petname>]`.
The `.content` is not used.
For example:
```jsonc
{
"kind": 3,
"tags": [
["p", "91cf9..4e5ca", "wss://alicerelay.com/", "alice"],
["p", "14aeb..8dad4", "wss://bobrelay.com/nostr", "bob"],
["p", "612ae..e610f", "ws://carolrelay.com/ws", "carol"]
],
"content": "",
// other fields...
}
```
Every new following list that gets published overwrites the past ones, so it should contain all entries. Relays and clients SHOULD delete past following lists as soon as they receive a new one.
Whenever new follows are added to an existing list, clients SHOULD append them to the end of the list, so they are stored in chronological order.
## Uses
### Follow list backup
If one believes a relay will store their events for sufficient time, they can use this kind-3 event to backup their following list and recover on a different device.
### Profile discovery and context augmentation
A client may rely on the kind-3 event to display a list of followed people by profiles one is browsing; make lists of suggestions on who to follow based on the follow lists of other people one might be following or browsing; or show the data in other contexts.
### Relay sharing
A client may publish a follow list with good relays for each of their follows so other clients may use these to update their internal relay lists if needed, increasing censorship-resistance.
### Petname scheme
The data from these follow lists can be used by clients to construct local ["petname"](http://www.skyhunter.com/marcs/petnames/IntroPetNames.html) tables derived from other people's follow lists. This alleviates the need for global human-readable names. For example:
A user has an internal follow list that says
```json
[
["p", "21df6d143fb96c2ec9d63726bf9edc71", "", "erin"]
]
```
And receives two follow lists, one from `21df6d143fb96c2ec9d63726bf9edc71` that says
```json
[
["p", "a8bb3d884d5d90b413d9891fe4c4e46d", "", "david"]
]
```
and another from `a8bb3d884d5d90b413d9891fe4c4e46d` that says
```json
[
["p", "f57f54057d2a7af0efecc8b0b66f5708", "", "frank"]
]
```
When the user sees `21df6d143fb96c2ec9d63726bf9edc71` the client can show _erin_ instead;
When the user sees `a8bb3d884d5d90b413d9891fe4c4e46d` the client can show _david.erin_ instead;
When the user sees `f57f54057d2a7af0efecc8b0b66f5708` the client can show _frank.david.erin_ instead.
-
@ fd06f542:8d6d54cd
2025-03-30 01:51:35
- [首页](/readme.md)
- [第一章、 NIP-01: Basic protocol flow description](/01.md)
- [第二章、 NIP-02: Follow List](/02.md)
- [第三章、NIP-03: OpenTimestamps Attestations for Events](/03.md)
-
@ 4c96d763:80c3ee30
2025-03-24 01:43:12
# Changes
## Ahmed Bedair (2):
- Fix build.rs to link Security framework only for Apple targets
- switch from string matching to checking the CARGO_CFG_TARGET_VENDOR value instead
## Jack Chakany (1):
- update thiserror from 2.0.3 to 2.0.7
## Ken Sedgwick (5):
- drive-by warning cleanup
- added multiple event unit tests
- add (passing) unit test for Mention::Profile relays
- drive-by clippy fixes
- add relays_iter to bech32_{nprofile,nevent,naddr}
## William Casarin (32):
- async: adding efficient, poll-based stream support
- Release v0.5.0
- add get_profilekey_by_pubkey
- nostrdb: fix subscription memory leaks
- test: "fix" flaky text
- release v0.5.1
- expose {Mut,}FilterField
- unsubscribe from SubscriptionStreams on Drop
- debug log subcount
- bump nostrdb to fix since in kind queries
- expose process_client_event
- stream: fix polling issues leading to missed events
- tags: add porcelain api for getting ids and strings
- nostrdb: update to silence annoying debug logs
- build: minor makefile changes
- update posix bindings
- filter: add nip50 search field
- windows: update bindings for search features
- filter: add json display
- Revert "filter: add json display"
- filter: fix memory leak in clone
- unix: fix bindgen for writer scratch changes
- win: bindgen for windows
- fix lint
- feat: add relay index and ingestion metadata
- Release v0.6.0
- misc stuff
- fix potential relay index corruption
- v0.6.1
- add author_kinds query plan execution
- filter: expose initial buffer size option
- attempt macos build fix
## Yuki Kishimoto (2):
- Take an iterator of `&str` in `Filter::tags`
- Remove `tracing-subscriber` dep
## kernelkind (1):
- add search_profile
pushed to [nostrdb-rs:refs/heads/master](http://git.jb55.com/nostrdb-rs/commit/0d28fab41e2b829c149086a2449dbda162318abb.html)
-
@ 30ceb64e:7f08bdf5
2025-03-30 00:37:54
Hey Freaks,
RUNSTR is a motion tracking app built on top of nostr. The project is built by TheWildHustle and TheNostrDev Team. The project has been tinkered with for about 3 months, but development has picked up and its goals and direction have become much clearer.
In a previous post I mentioned that RUNSTR was looking to become a Nike Run Club or Strava competitor, offering users an open source community and privacy focused alternative to the centralized silos that we've become used to.
I normally ramble incoherently.....even in writing, but this is my attempt to communicate the project's goals and direction as we move forward.
This is where the project is now:
## Core Features
- **Run Tracker**: Uses an algorithm which adjusts to your phone's location permissions and stores the data on your phone locally
- **Stats**: Stored locally on your phone with a basic profile screen so users can monitor calories burned during runs
- **Nostr Feed**: Made up of kind1 notes that contain #RUNSTR and other running related hashtags
- **Music**: Brought to you via a wavlake API, enabling your wavlake playlists and liked songs to be seen and played in the app
## Current Roadmap
- **Bugs and small improvements**: Fixing known issues within the client
- **zap.store release**: Launching a bug bounty program after release
- **Clubs**: Enabling running organizations to create territories for events, challenges, rewards and competition
- **Testflight**: Opening up the app to iOS users (currently Android only)
- **Modes**: Adding functionality to switch between Running, Walking, or Cycling modes
## Future Roadmap
- **Requested Features**: Implementing features requested by club managers to support virtual events and challenges
- **Blossom**: Giving power users the ability to upload their data to personal blossom servers
- **NIP28**: Making clubs interoperable with other group chat clients like 0xchat, Keychat, and Chachi Chat
- **DVM's**: Creating multiple feeds based on movement mode (e.g., Walking mode shows walkstr feed)
- **NIP101e**: Allowing users to create run records and store them on nostr relays
- **Calories over relays**: Using NIP89-like functionality for users to save calorie data on relays for use in other applications
- **NIP60**: Implementing automatic wallet creation for users to zap and get zapped within the app
## In Conclusion
I've just barely begun this thing and it'll be an up and down journey trying to push it into existence. I think RUNSTR has the potential to highlight the other things that nostr has going for it, demonstrating the protocol's interoperability, flexing its permissionless identity piece, and offering an experience that gives users a glimpse into what is possible when shipping into a new paradigm. Although we build into an environment that often offers no solutions, you'd have to be a crazy person not to try.
https://github.com/HealthNoteLabs/Runstr/releases/tag/feed-0.1.0-20250329-210157
-
@ fd208ee8:0fd927c1
2025-03-29 22:21:11
# Overview
### Philosophy
Markdown is intended to be as easy-to-read and easy-to-write as is feasible.
Readability, however, is emphasized above all else. A Markdown-formatted
document should be publishable as-is, as plain text, without looking
like it's been marked up with tags or formatting instructions. While
Markdown's syntax has been influenced by several existing text-to-HTML
filters -- including [Setext](http://docutils.sourceforge.net/mirror/setext.html), [atx](http://www.aaronsw.com/2002/atx/), [Textile](http://textism.com/tools/textile/), [reStructuredText](http://docutils.sourceforge.net/rst.html),
[Grutatext](http://www.triptico.com/software/grutatxt.html), and [EtText](http://ettext.taint.org/doc/) -- the single biggest source of
inspiration for Markdown's syntax is the format of plain text email.
## Block Elements
### Paragraphs and Line Breaks
A paragraph is simply one or more consecutive lines of text, separated
by one or more blank lines. (A blank line is any line that looks like a
blank line -- a line containing nothing but spaces or tabs is considered
blank.) Normal paragraphs should not be indented with spaces or tabs.
The implication of the "one or more consecutive lines of text" rule is
that Markdown supports "hard-wrapped" text paragraphs. This differs
significantly from most other text-to-HTML formatters (including Movable
Type's "Convert Line Breaks" option) which translate every line break
character in a paragraph into a `<br />` tag.
When you *do* want to insert a `<br />` break tag using Markdown, you
end a line with two or more spaces, then type return.
### Headers
Markdown supports two styles of headers, [Setext] [1] and [atx] [2].
Optionally, you may "close" atx-style headers. This is purely
cosmetic -- you can use this if you think it looks better. The
closing hashes don't even need to match the number of hashes
used to open the header. (The number of opening hashes
determines the header level.)
### Blockquotes
Markdown uses email-style `>` characters for blockquoting. If you're
familiar with quoting passages of text in an email message, then you
know how to create a blockquote in Markdown. It looks best if you hard
wrap the text and put a `>` before every line:
> This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet,
> consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus.
> Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
>
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse
> id sem consectetuer libero luctus adipiscing.
Markdown allows you to be lazy and only put the `>` before the first
line of a hard-wrapped paragraph:
> This is a blockquote with two paragraphs. Lorem ipsum dolor sit amet,
consectetuer adipiscing elit. Aliquam hendrerit mi posuere lectus.
Vestibulum enim wisi, viverra nec, fringilla in, laoreet vitae, risus.
> Donec sit amet nisl. Aliquam semper ipsum sit amet velit. Suspendisse
id sem consectetuer libero luctus adipiscing.
Blockquotes can be nested (i.e. a blockquote-in-a-blockquote) by
adding additional levels of `>`:
> This is the first level of quoting.
>
> > This is nested blockquote.
>
> Back to the first level.
Blockquotes can contain other Markdown elements, including headers, lists,
and code blocks:
> ## This is a header.
>
> 1. This is the first list item.
> 2. This is the second list item.
>
> Here's some example code:
>
> return shell_exec("echo $input | $markdown_script");
Any decent text editor should make email-style quoting easy. For
example, with BBEdit, you can make a selection and choose Increase
Quote Level from the Text menu.
### Lists
Markdown supports ordered (numbered) and unordered (bulleted) lists.
Unordered lists use asterisks, pluses, and hyphens -- interchangably
-- as list markers:
* Red
* Green
* Blue
is equivalent to:
+ Red
+ Green
+ Blue
and:
- Red
- Green
- Blue
Ordered lists use numbers followed by periods:
1. Bird
2. McHale
3. Parish
It's important to note that the actual numbers you use to mark the
list have no effect on the HTML output Markdown produces. The HTML
Markdown produces from the above list is:
If you instead wrote the list in Markdown like this:
1. Bird
1. McHale
1. Parish
or even:
3. Bird
1. McHale
8. Parish
you'd get the exact same HTML output. The point is, if you want to,
you can use ordinal numbers in your ordered Markdown lists, so that
the numbers in your source match the numbers in your published HTML.
But if you want to be lazy, you don't have to.
To make lists look nice, you can wrap items with hanging indents:
* Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi,
viverra nec, fringilla in, laoreet vitae, risus.
* Donec sit amet nisl. Aliquam semper ipsum sit amet velit.
Suspendisse id sem consectetuer libero luctus adipiscing.
But if you want to be lazy, you don't have to:
* Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
Aliquam hendrerit mi posuere lectus. Vestibulum enim wisi,
viverra nec, fringilla in, laoreet vitae, risus.
* Donec sit amet nisl. Aliquam semper ipsum sit amet velit.
Suspendisse id sem consectetuer libero luctus adipiscing.
List items may consist of multiple paragraphs. Each subsequent
paragraph in a list item must be indented by either 4 spaces
or one tab:
1. This is a list item with two paragraphs. Lorem ipsum dolor
sit amet, consectetuer adipiscing elit. Aliquam hendrerit
mi posuere lectus.
Vestibulum enim wisi, viverra nec, fringilla in, laoreet
vitae, risus. Donec sit amet nisl. Aliquam semper ipsum
sit amet velit.
2. Suspendisse id sem consectetuer libero luctus adipiscing.
It looks nice if you indent every line of the subsequent
paragraphs, but here again, Markdown will allow you to be
lazy:
* This is a list item with two paragraphs.
This is the second paragraph in the list item. You're
only required to indent the first line. Lorem ipsum dolor
sit amet, consectetuer adipiscing elit.
* Another item in the same list.
To put a blockquote within a list item, the blockquote's `>`
delimiters need to be indented:
* A list item with a blockquote:
> This is a blockquote
> inside a list item.
To put a code block within a list item, the code block needs
to be indented *twice* -- 8 spaces or two tabs:
* A list item with a code block:
<code goes here>
### Code Blocks
Pre-formatted code blocks are used for writing about programming or
markup source code. Rather than forming normal paragraphs, the lines
of a code block are interpreted literally. Markdown wraps a code block
in both `<pre>` and `<code>` tags.
To produce a code block in Markdown, simply indent every line of the
block by at least 4 spaces or 1 tab.
This is a normal paragraph:
This is a code block.
Here is an example of AppleScript:
tell application "Foo"
beep
end tell
A code block continues until it reaches a line that is not indented
(or the end of the article).
Within a code block, ampersands (`&`) and angle brackets (`<` and `>`)
are automatically converted into HTML entities. This makes it very
easy to include example HTML source code using Markdown -- just paste
it and indent it, and Markdown will handle the hassle of encoding the
ampersands and angle brackets. For example, this:
<div class="footer">
© 2004 Foo Corporation
</div>
Regular Markdown syntax is not processed within code blocks. E.g.,
asterisks are just literal asterisks within a code block. This means
it's also easy to use Markdown to write about Markdown's own syntax.
```
tell application "Foo"
beep
end tell
```
## Span Elements
### Links
Markdown supports two style of links: *inline* and *reference*.
In both styles, the link text is delimited by [square brackets].
To create an inline link, use a set of regular parentheses immediately
after the link text's closing square bracket. Inside the parentheses,
put the URL where you want the link to point, along with an *optional*
title for the link, surrounded in quotes. For example:
This is [an example](http://example.com/) inline link.
[This link](http://example.net/) has no title attribute.
### Emphasis
Markdown treats asterisks (`*`) and underscores (`_`) as indicators of
emphasis. Text wrapped with one `*` or `_` will be wrapped with an
HTML `<em>` tag; double `*`'s or `_`'s will be wrapped with an HTML
`<strong>` tag. E.g., this input:
*single asterisks*
_single underscores_
**double asterisks**
__double underscores__
### Code
To indicate a span of code, wrap it with backtick quotes (`` ` ``).
Unlike a pre-formatted code block, a code span indicates code within a
normal paragraph. For example:
Use the `printf()` function.
-
@ ff517fbf:fde1561b
2025-03-30 04:43:09
## ビットコインが「最強の担保」と言われる理由
ビットコインは「デジタルゴールド」とも呼ばれることがありますが、実は**ローンの担保としても最強**だと言われています。その理由を、他の資産(株式、不動産、金など)と比較しながら見てみましょう。
- **流動性と即時性**:ビットコインは**24時間365日世界中で取引されているため、非常に流動性が高い**資産です。売買がすぐにできて価格も常に明確なので、担保評価がしやすく、お金を貸す側・借りる側双方に安心感を与えます。一方、株式や不動産は市場が営業時間内しか動かず、現金化にも時間がかかります。不動産は売却に数ヶ月かかることもありますし、金(ゴールド)は現物を保管・輸送する手間があります。ビットコインなら**ネット上で即座に担保設定・解除**ができるのです。
- **分割性と柔軟性**:ビットコインは小数点以下8桁まで分割可能(1億分の1が最小単位の「サトシ」)なので、**必要な額だけ正確に担保に充てる**ことができます。他方、土地や建物を一部だけ担保に入れることは難しいですし、株式も1株未満の細かい調整はできません。ビットコインなら価値の微調整が容易で、担保として柔軟に扱えるのです。
- **管理のしやすさ(マルチシグによる信頼性)**:HodlHodlのLendでは、ビットコイン担保は**2-of-3のマルチシグ契約**で管理されます。これは「借り手・貸し手・プラットフォーム」の3者それぞれが鍵を持ち、**2つの鍵の同意がないとビットコインを動かせない**仕組みです。このため、誰か一人が勝手に担保を持ち逃げすることができず、第三者(HodlHodl)も単独ではコインを移動できません。ビットコインだからこそ実現できる**非中央集権で安全な担保管理**であり、株式や不動産を担保にする場合のように銀行や証券会社といった仲介業者に頼る必要がありません。
- **国境を越えた利用**:ビットコインはインターネットがつながる所なら世界中どこでも送受信できます。このため、日本にいながら海外の相手とでもローン契約が可能です。たとえば日本の方がビットコインを担保にドル建てのステーブルコインを借り、それを日本円に換えて使うこともできます(為替リスクには注意ですが…)。不動産を海外の人と直接やり取りするのは現実的に難しいですが、ビットコインなら**グローバルに担保が活用**できるのです。
- **希少性と価値の上昇期待**:ビットコインは発行上限が決まっており(2100万BTCまで)、時間とともに新規供給が減っていきます。過去の長期的な価格推移を見ると、短期的な変動は激しいものの数年〜十年のスパンでは上昇傾向にあります。一方、法定通貨建ての資産(債券や株式など)はインフレの影響で実質価値が目減りすることがあります。ビットコインは**長期保有すれば価値が上がりやすい**特性があるため、「今手放したくない資産」として担保に向いています。実際、HodlHodlのチームは「ビットコインはスーパーカCollateral(超優秀な担保)だ」と述べています。
こうした理由から、**ビットコインは現時点で考えうる中でも最良の担保資産**と考えられています。株や不動産のように書類手続きや名義変更をしなくても、ビットコインならブロックチェーン上の契約でシンプルに担保設定ができる――この手軽さと信頼性が大きな魅力です。
## 匿名&プライバシー重視:KYC不要のP2Pレンディングのメリット
HodlHodlのLend最大の特徴の一つは、**本人確認(KYC)が一切不要**だという点です。日本の多くの金融サービスでは口座開設時に運転免許証やマイナンバー提出など煩雑な手続きが必要ですが、Lendでは**メールアドレスでアカウント登録するだけでOK**。これは「匿名性・プライバシー」を重視する人にとって非常に相性が良いポイントです。
- **個人情報を晒さなくて良い安心感**:日本では昔から「人に迷惑をかけない」「目立たない」ことが美徳とされ、特にお金の話は他人に知られたくないと考える人が多いですよね。Lendは匿名で利用できるため、借金をすることを周囲に知られたくない人でも安心です。銀行からローンを借りるときのように収入証明や保証人を用意する必要もなく、**誰にも知られずひっそりと資金調達**ができます。
- **ノー・チェック&ノー・ペーパー**:貸し借りにあたって**信用審査や過去の借入履歴チェックがありません** 。極端な話、今まで金融履歴が全く無い人や、銀行に相手にされないような人でも、ビットコインさえ持っていればお金を借りられるのです。書類のやり取りが無いので手続きもスピーディーです。「印鑑証明や収入証明を揃えて…」という面倒とは無縁で、ネット上でクリックして契約が完結します。
- **プライバシーの保護**:個人情報を提出しないということは、情報漏洩のリスクも無いということです。近年、日本でも個人情報の流出事件が相次いでおり、不安に感じる方も多いでしょう。Lendではアカウント登録時にメールアドレスとパスワード以外何も求められません。財務情報や身元情報がどこかに蓄積される心配がないのは、大きな安心材料です。
- **国や機関から干渉されにくい**:匿名であるということは、極端に言えば**誰にも利用を知られない**ということです。たとえば「ローンを借りると住宅ローンの審査に響くかな…」とか「副業の資金調達を会社に知られたくないな…」といった心配も、匿名のP2Pローンなら不要です。借りたお金の使い道も自由ですし、何より**利用自体が自分だけの秘密**にできるのは、日本人にとって心理的ハードルを下げてくれるでしょう。
このように、**ノーKYC(本人確認なし)** のP2Pレンディングは、日本のようにプライバシーや控えめさを重んじる文化圏でも利用しやすいサービスと言えます。実際、HodlHodlのLendは「地理的・規制的な制限がなく、世界中の誰もが利用できる純粋なP2P市場」とされています。日本に居ながらグローバルな貸し借りができ、しかも身元明かさずに済む――これは画期的ですね。
## **Borrow編:HodlHodlのLendでビットコインを担保にお金を借りる方法**
それでは具体的に、HodlHodlのLendで**どのようにビットコイン担保のローンを借りるのか**、手順を追って説明します。初心者でも迷わないよう、シンプルなステップにまとめました。
### 1. アカウント登録 (Sign up)
まずはHodlHodlのLendサイトにアクセスし、無料のアカウントを作成します。必要なのは**メールアドレスとパスワードだけ**です。登録後、確認メールが届くのでリンクをクリックして認証すれば準備完了。これでプラットフォーム上でオファー(契約希望)を閲覧・作成できるようになります。
※HodlHodlは日本語には対応していませんが、英語のシンプルなUIです。Google翻訳などを使っても良いでしょう。
### 2. 借りたい条件のオファーを探す or 作成
ログインしたら、「To Borrow(借りる)」のメニューから現在出ている貸し手のオファー一覧を見てみましょう。オファーには**借入希望額**(例:$1000相当のUSDT)、**期間**(例:3ヶ月)、**金利**(例:5%)や**LTV**(担保価値比率、例:60%)などの条件が書かれています。自分の希望に合うものがあれば選んで詳細画面へ進みます。条件に合うオファーが見つからない場合は、自分で「○○ USDTを△ヶ月、金利○%で借りたい」という**借り手オファーを新規作成**することも可能です。
**用語補足**:*LTV*(ローン・トゥ・バリュー)とはローン額に対する担保価値の割合です。たとえばLTV50%なら、借りたい額の2倍の価値のビットコインを担保に入れる必要があります。LTVは貸し手が設定しており、一般に**30%〜70%程度**の範囲でオファーが出ています。低いLTVほど借り手は多くのBTC担保が必要ですが、その分だけ貸し手にとって安全なローンとなります。
### 3. 契約成立とマルチシグ担保のデポジット
借り手・貸し手双方が条件に合意すると**契約成立**です。HodlHodlプラットフォーム上で自動的に**専用のマルチシグ・エスクロー用ビットコインアドレス**(担保保管先アドレス)が生成されます。次に、借り手であるあなたは**自分のウォレットからビットコインをそのエスクローアドレスに送金**します。
- *📌ポイント:マルチシグで安心* – 上述の通り、このエスクロー用アドレスのコインを動かすには**3者中2者の署名が必要**です。あなた(借り手)は常にそのうちの1つの鍵を保有しています。つまり、**自分が承認しない限り担保BTCが勝手に引き出されることはない**のでご安心ください。
ビットコインの入金がブロックチェーン上で所定の承認(通常数ブロック程度)を得ると、担保デポジット完了です。これで契約は有効化され、次のステップへ進みます。
### 4. 貸し手から資金(ステーブルコイン)を受け取る
担保のロックが確認できると、今度は貸し手が**ローン金額の送金**を行います。Lendで借りられるのは主に**ステーブルコイン**です。ステーブルコインとは、米ドルなど法定通貨の価値に連動するよう設計された仮想通貨で、USDTやUSDC、DAIといった種類があります。借り手は契約時に受取用のステーブルコインアドレス(自分のウォレットアドレス)を指定しますので、貸し手はそのアドレス宛に契約どおりの額を送金します。例えばUSDTを借りる契約なら、貸し手からあなたのUSDTウォレットにUSDTが送られてきます。
**これで晴れて、あなた(借り手)は希望のステーブルコインを手にすることができました!** あなたのビットコインは担保としてロックされていますが、期限までに返済すれば取り戻せますので、しばしのお別れです。借りたステーブルコインは自由に使えますので、後述する活用例を参考に有効活用しましょう。
### 5. 返済(リペイメント)
契約期間中は基本的に何もする必要はありません(途中で追加担保や一部返済を行うことも可能ですが、初心者向け記事では割愛します)。期間が満了するまでに、借りたステーブルコイン**+利息**を貸し手に返済します。返済も、貸し手の指定するウォレットアドレスにステーブルコインを送金する形で行われます。
- **利息の計算**:利息は契約時に決めた率で発生します。例えば年利10%で6ヶ月間$1000を借りたなら、利息は単純計算で$50(=$1000×10%×0.5年)です。契約によっては「期間全体で○%」と定める場合もありますが、プラットフォーム上で年率(APR)換算が表示されます。
期間内であれば**任意のタイミングで早期返済することも可能**です。返済期限より早く全額返せば、利息もその日数分だけで済みます(※ただし契約によります。事前に契約条件を確認してください)。HodlHodlでは**分割返済**にも対応しており、例えば月ごとに少しずつ返して最後に完済することもできます。
### 6. ビットコイン担保の解除(返却)
貸し手があなたからの返済受領を確認すると、プラットフォーム上で契約終了の手続きを行います。マルチシグの担保アドレスから**あなたのビットコインを解放(返却)する署名**を貸し手とプラットフォームが行い、あなたの元のウォレットにビットコインが送られます。こうして無事に担保のBTCが戻ってくれば、一連のローン取引は完了です🎉。
もし**返済が滞った場合**はどうなるのでしょうか?その場合、契約で定められた猶予期間やマージンコール(追加担保のお願い)を経た後、**担保のビットコインが強制的に貸し手に渡されて契約終了(清算)**となります。担保額が未返済額を上回っていれば、差額は借り手に返ってきます。つまり、返せなかったとしても借り手が担保以上の損をすることはありませんが、大切なビットコインを失ってしまう結果にはなるので注意しましょう。
**Borrow(借りる)側のまとめ**:ビットコインさえあれば、あとの手続きは非常に簡単です。借入までの流れをもう一度簡潔にまとめると:
1. メールアドレスでLendに登録
2. 借入オファーを探すor作成してマッチング
3. マルチシグ契約が自動生成・BTC担保を自分で入金
4. 貸し手からステーブルコインを受領
5. 期限までにステーブルコイン+利息を返済
6. ビットコイン担保が自分のウォレットに戻る
第三者の仲介なしに、ネット上でこれだけのことが完結するのは驚きですよね。HodlHodlは「あなたの条件、あなたの鍵、あなたのコイン」と銘打っており、自分の望む条件で・自分が鍵を管理し・自分の資産を動かせるプラットフォームであることを強調しています。
## **Lend編:HodlHodlのプラットフォームでお金を貸してみよう**
次は逆に、**自分が貸し手(Lender)となってステーブルコインを貸し出し、利息収入を得る方法**です。銀行に預けても超低金利のこのご時世、手持ちの資金をうまく運用したい方にとってP2Pレンディングは魅力的な選択肢になりえます。HodlHodlのLendなら、これもまた簡単な手順で始められます。
基本的な流れは先ほどの「Borrow編」と鏡写しになっています。
### 1. アカウント登録
借り手と同様、まずはHodlHodlに登録します(すでに借り手として登録済みなら同じアカウントで貸し手にもなれます)。メールアドレスだけでOK、もちろん貸し手側もKYC不要です。
### 2. 貸出オファーの確認 or 作成
ログイン後、「To Lend(貸す)」メニューから現在の借り手募集一覧を見ます。各オファーには**希望額**・**期間**・**支払い利率**・**LTV**など条件が表示されています。「この条件なら貸してもいいかな」という案件があれば選択しましょう。もし自分の希望する利回りや期間が合わない場合は、自分で**貸し手オファーを作成**することも可能です。「○○ USDTまで、最長△ヶ月、最低利息◻◻%で貸せます」といった条件を提示できます。プラットフォーム上ではユーザーがお互いに条件を提示しあってマッチングする仕組みなので、**金利や期間もすべてユーザー自身が自由に設定**できます。
### 3. マッチングと契約開始
あなたの提示した条件で借りたい人が現れたら契約成立です(逆に誰かの借入オファーに応じる形なら、その時点で成立)。システムが**マルチシグの担保用BTCアドレス**を生成し、借り手がそこへビットコインをデポジットします。借り手からのBTC入金が確認できるまで、貸し手であるあなたは資金を送る必要はありません。担保が確保されたのを見届けてから次に進みます。
### 4. 資金(ステーブルコイン)の送金
借り手の担保ロックが完了したら、**契約で定めたステーブルコインを借り手へ送金**します。送金先アドレスは契約詳細画面に表示されます(借り手が指定済み)。例えばUSDCを貸す契約なら、相手のUSDCアドレスに約束の額を送ります。ここで送金した金額がローンの principal(元本)となり、後ほど利息とともに返ってくるわけです。
無事に相手に届けば、あとは契約期間終了まで待つだけです。あなたは**担保のBTCに対して鍵を1つ持っている**状態なので、万一トラブルが起きた場合でも担保を引き出す権利を部分的に持っています(詳しくは次ステップ)。
### 5. 返済の受領
契約期間が終わると、借り手があなたにステーブルコインを返済してくるはずです。約束どおり**元本+利息**を受け取ったら、それを確認してプラットフォーム上で「返済完了」を操作します。すると担保のビットコインがマルチシグから解放され、借り手に返却されます。これで貸し手としてのあなたは**利息分の収益を獲得**できました。お疲れ様です!
もし**借り手が返済しなかった場合**どうなるでしょうか?その場合、所定の猶予期間やマージンコール通知の後、**担保のビットコインがあなた(貸し手)に渡される**ことになります。具体的には、LTVが90%に達するか返済期日から24時間以上滞納が続くと強制清算となり、担保BTCからあなたの貸付相当額が充当されます。担保が十分であれば元本と利息はカバーされ、余剰があれば借り手に返還されます。つまり**貸し手側はかなり手厚く保護**されており、返済を受け取れない場合でも担保で穴埋めされる仕組みです。
### 6. 収益を管理・再投資
受け取ったステーブルコイン(元本+利息)は再度プラットフォームで貸し出しても良いですし、他の用途に使ってもOKです。年利に換算すると**だいたい10%前後の利回り**になる案件が多く見られます。条件次第では更に高い利率の契約も可能ですが、その分借り手が見つかりにくかったりリスク(担保不足のリスク)が高まる可能性もあります。ご自身のリスク許容度に合わせて運用しましょう。
**Lend(貸す)側のまとめ**:
- HodlHodlに登録(メールアドレスのみ)
- 貸出オファーを提示 or 借り手募集に応じる
- 契約成立後、借り手がBTC担保を入金
- 貸し手(自分)がステーブルコインを送金
- 期限まで待ち、借り手から元本+利息を受領
- 担保BTCを返却し、利息収入を得る
銀行預金では考えられないような利息収入を得られるのが魅力ですが、その裏で**ビットコイン価格変動リスク**も担っています。大暴落が起きて担保評価額が急落すると、清算時に元本を割るリスクもゼロではありません(LTV設定とマージンコール制度で極力保護されまますが)。リスクとリターンを理解した上で、小額から試すことをおすすめします。
## ステーブルコインの活用:お金持ちは借金で生活する?
ここまで、ビットコインを手放さずにステーブルコインを手に入れる方法を見てきました。それでは、**借りたステーブルコインは具体的に何に使える**のでしょうか?いくつか例を挙げてみましょう。
- **日常の出費に充当**:ビットコイン投資家の中には「生活費はすべて借りたお金で賄い、自分のBTCはガチホ(売らずに長期保有)する」という方針の人もいます。例えば毎月の家賃や食費をステーブルコインのローンで支払い(これについても今後詳しく解説していきます)、ビットコインは一切使わないというイメージです。こうすれば、手持ちのBTCを売らずに済むので将来の値上がり益を逃しません。また日本では仮想通貨を売却すると雑所得として高率の税金がかかりますが、**ローンで得たお金は借入金なので課税対象になりません**(※将来的な税務計算は自己責任で行ってください)。つまり、ビットコインを売却して現金化する代わりにローンを使うことで、節税と資産温存のメリットが得られる可能性があります。
- **投資・資産運用に回す**:借りた資金をさらに別の投資に活用することもできます。例えば有望な株式や不動産に投資したり、あるいは他の仮想通貨を買うこともできます。極端な例では、ビットコインを担保にUSDTを借りて、そのUSDTでまた別の仮想通貨を買い、それを運用益で返済する…といった戦略も理論上は可能です。ただし、**借りたお金での投機はハイリスク**なので慎重に!手堅い使い道としては、事業資金に充てるのも良いでしょう。例えば小さなオンラインビジネスを始めるための元手にしたり、新しい資格取得のための学費にするなど、自分への投資に使えば将来的なリターンでローンを返しつつ利益を上げることが期待できます。
- **急な支払いへの備え**:人生何があるか分かりません。医療費や冠婚葬祭など急に現金が必要になる場面もあります。そんなとき、ビットコインをすぐ売ってしまうのは惜しい…という場合にローンで一時的にしのぐことができます。後で落ち着いてから返済すれば、大事なBTCを手放さずにピンチを乗り切れます。言わば**デジタル質屋**のような感覚で、ビットコインを預けてお金を工面し、後で買い戻す(返済する)イメージですね。日本でも昔から「質屋」で着物や宝石を預けてお金を借りる文化がありましたが、HodlHodl Lendは**ビットコイン版の質屋**とも言えるでしょう。
- **市場の機会を逃さない**:仮想通貨市場は変動が激しく、「今これを買いたいのに現金が無い!」というチャンスもあるでしょう。例えば「ビットコインが急落したから買い増したいが、現金が足りない」という場合、手持ちBTCを担保にしてステーブルコインを借り、その急落で安く買い増しする、といった動きもできます。そして後日価格が戻したところで返済すれば、差益を得つつBTC保有枚数も増やせるかもしれません。このように**ローンを戦略的に使えば、市場の好機を掴む資金余力を生み出す**ことができます。ただしハイリスクな手法でもあるため、上級者向けではあります。
ここで覚えておきたいのは、「**お金持ちは借金との付き合い方が上手い**」という点です。日本では借金にネガティブな印象を持つ人も多いですが、世界的な資産家や大企業はしばしば**あえて借金をして手元資金を他に活用**しています。アメリカのベストセラー『金持ち父さん貧乏父さん』で有名なロバート・キヨサキ氏も「**富裕層は他人のお金(借金)を利用してさらに富を築く**」と強調しています。例えば彼は借金で高級車を買い、不動産投資にも借入を活用したそう ([金持ちは貧乏人より借金が多い | 「金持ち父さん 貧乏父さん」日本オフィシャルサイト]( https://www.richdad-jp.com/article/%E9%87%91%E6%8C%81%E3%81%A1%E3%81%AF%E8%B2%A7%E4%B9%8F%E4%BA%BA%E3%82%88%E3%82%8A%E5%80%9F%E9%87%91%E3%81%8C%E5%A4%9A%E3%81%84/#:~:text=%E9%87%91%E6%8C%81%E3%81%A1%E3%81%AB%E3%81%AA%E3%81%A3%E3%81%A6%E7%94%9F%E6%B4%BB%E3%82%92%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%A7%E3%82%A4%E3%81%97%E3%81%9F%E3%81%84%E3%81%A8%E6%80%9D%E3%81%A3%E3%81%A6%E3%81%84%E3%82%8B%E4%BA%BA%E3%81%AF%E3%80%81%E3%80%8C%E3%82%82%E3%81%A3%E3%81%A8%E5%A4%9A%E3%81%8F%E3%81%AE%E3%80%8D%E5%80%9F%E9%87%91%E3%82%92%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%E3%82%92%E7%9F%A5%E3%82%8B%E5%BF%85%E8%A6%81%E3%81%8C%E3%81%82%E3%82%8B%E3%81%97%E3%80%81%E5%80%9F%E9%87%91%E3%81%AE%E5%8A%9B%E3%82%92%E5%B0%8A%E9%87%8D%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%E3%81%A8%E3%80%81%E3%81%9D%E3%81%AE%E5%8A%9B%E3%82%92%E3%81%86%E3%81%BE%E3%81%8F%E5%88%A9%E7%94%A8%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%E3%82%92%E5%AD%A6%20%E3%81%B0%E3%81%AA%E3%81%91%E3%82%8C%E3%81%B0%E3%81%AA%E3%82%89%E3%81%AA%E3%81%84%E3%80%82))❤️。借金を味方につけて資産運用すれば、自分の持ち出し資金を抑えつつ豊かな生活を実現できる可能性があります。
もちろん無計画な借金は禁物ですが、**ローンを上手に使うことは決して悪いことではなく、むしろ経済的戦略として有効**なのです。ビットコイン担保ローンはその新しい選択肢として、「お金にお金に働いてもらう」感覚を身につけるきっかけになるかもしれません。
## 高い金利でもローンを利用するのはなぜ?その理由と戦略
Lendのプラットフォームで提示される金利は、年利換算で見ると**10〜15%程度が一つの目安** です。中にはそれ以上の利率の契約もあります。日本の銀行ローン(金利数%以下)と比べるとかなり高利に思えますが、それでも**多くの人がこのサービスを利用してローンを組んでいます**。なぜ高い利息を支払ってまで借りる価値があるのでしょうか?最後に、その理由と利用者の戦略について考えてみましょう。
- **(1) ビットコインの期待リターンが高い**:借り手にとって一番の動機は、「ビットコインは将来もっと値上がりするはずだから、多少利息を払っても売りたくない」というものです。例えば年利15%で$1000借りると一年後に$1150返す必要がありますが、もしビットコイン価格がその間に15%以上上昇すれば、利息分を差し引いても得をする計算になります。過去のビットコイン相場は年率ベースで大きく成長した年も多く、強気のホルダーほど**利息より値上がり益を優先**する傾向があります。「金利よりビットコインの価値上昇のほうが大きい」という自信が、高金利を払ってでも借りる動機になっているのです。
- **(2) 課税や手数料の回避**:先ほど述べたように、日本ではビットコインを売却すると高額の税金が発生する可能性があります。仮に30%〜50%の税金がかかるのであれば、年利10%前後のローンで済ませたほうがトクだという判断も成り立ちます。また、取引所で売却するときのスプレッドや出金手数料なども考えると、**売却コストを回避する手段**としてローンを選ぶ人もいます。要するに「売るくらいなら借りた方がマシ」という考え方ですね。
- **(3) 自由と速さを優先**:従来の金融機関からお金を借りるには時間がかかりますし、使途にも制限があることが多いです(事業資金なのか生活費なのか、といった審査があります)。それに対してHodlHodlのP2Pローンは**使い道自由・即日資金調達**が可能です。利息が高めでも「今すぐ○○がしたい」「明日までに現金が要る」といったニーズには代えられません。特に仮想通貨業界はスピード命ですから、チャンスを逃さないために**高コストでも素早く借りる**という選択が生まれます。
- **(4) 借金=時間を買うこと**:あるユーザーの言葉を借りれば、「**借金をすることは未来の時間を先取りすること**」でもあります。例えば住宅ローンがあるからこそ若い世代でもマイホームに住めますし、事業ローンがあるからこそ企業は成長の機会を掴めます。ビットコイン担保ローンも同じで、「今はお金が無いけど将来増やすアテはある。だから今借りてしまおう」というケースもあるでしょう。将来の収入や資産増加を見込んで、**時間を味方につけるためにあえて借金をする**のです。日本語では「借金してでも◯◯する」という表現がありますが、前向きな借金は将来への投資とも言えるでしょう。
- **(5) 非中央集権への支持**:もう一つ見逃せないのは、HodlHodlのようなプラットフォームを利用する理由に**思想的な支持**があります。つまり「銀行や政府に頼らないお金の流れを実現したい」「ビットコインのエコシステムを活性化させたい」というビットコイナーたちです。多少コストが高くても、理念に共感して使っているケースもあります。匿名で自由にお金を借りられる世界を体験することで、金融システムの新たな可能性を感じているのです。
以上のように、**高い金利にも関わらずローンを利用するのは明確なメリットや戦略があるから**なのです。もちろん全ての人に当てはまるわけではありません。ビットコイン価格が下落局面ではリスクも伴いますし、利息分だけ損になる場合もあります。しかし、それらを理解した上で**「自分のお金を働かせる」「資産を手放さずレバレッジを利かせる」**手段として活用している人々が増えてきています。
最後に、HodlHodlの公式ブログの一文をご紹介します。
> “私たちはビットコインこそがスーパーカ collateral(超優秀な担保)であり、利回りを得るために使うのではなく、それを担保に資金を借りるために使われるべきだと考えています" ([The lending is dead, long live the lending | by Hodl Hodl | Hodl Hodl | Medium]( https://medium.com/hodl-hodl/the-lending-is-dead-long-live-the-lending-13af0763f53e#:~:text=match%20at%20L202%20As%20a,out%20there%20on%20the%20market))。
ビットコイン時代の新しいお金の借り方・貸し方であるP2Pローン。最初は難しく感じるかもしれませんが、仕組みを理解すればとてもシンプルで強力なツールです。日本ではまだ馴染みが薄いかもしれませんが、匿名性を好み、コツコツ資産を増やすのが得意な人にこそフィットするサービスかもしれません。ぜひ少額から試し、自分なりの活用法を見つけてみてください。きっと新たな発見があるはずです。
---
もしビットコイン担保のP2Pローンなどについてもっと深く知りたい、あるいは個別に相談してみたいと思えば、どうぞお気軽にご連絡ください。**1対1のコンサルティング**も承っています。
サービスには決まった料金はありませんが、ご相談を通じて「役に立った」と思い、お悩みや疑問を解決できたと感じていただけたら、**「3つのT」でのご支援(Value for Value)**をぜひご検討ください:
- **時間(Time)**:この記事をSNSなどでシェアしていただくこと。
- **才能(Talent)**:コメントや補足情報などを通じて知識を共有していただくこと。
- **宝(Treasure)**:世界で最も健全なお金、ビットコインの最小単位「sats」でのご支援。
もちろん、支援の有無にかかわらず、お力になれればとても嬉しいです。
では、また次回!
-
@ b5d34eed:a7475cbf
2025-03-21 10:12:21
### Introduction
In an era of increasing surveillance, data breaches, and corporate control over digital communication, privacy-focused tools have become essential. ProtonMail, a secure and encrypted email service, stands as a stronghold for those seeking privacy in their online correspondence.
At the same time, Nostr, a decentralized social networking protocol, is revolutionizing how people connect without relying on centralized platforms. Together, ProtonMail and Nostr create a powerful combination for individuals who prioritize security, anonymity, and freedom in their online interactions.
This article explores the ProtonMail application suite, its relevance to privacy, and how it aligns with Nostr’s decentralized approach to communication.
---
### What is ProtonMail?
ProtonMail is an encrypted email service founded in 2013 by scientists at CERN, the European Organization for Nuclear Research. Unlike mainstream email providers such as Gmail or Outlook, ProtonMail does not collect personal data, does not track users, and ensures end-to-end encryption for emails.
Key Features of ProtonMail
End-to-End Encryption: Ensures that only the sender and recipient can read messages.
No Personal Information Required: Users can sign up without providing identifying details.
Open-Source Cryptography: Transparency in security protocols, allowing community audits.
Swiss-Based Privacy Laws: ProtonMail operates under Switzerland’s strict data protection regulations, shielding it from intrusive government surveillance.
Self-Destructing Emails: Allows users to send messages that automatically expire after a set time.
ProtonMail’s security-first approach makes it an ideal choice for activists, journalists, and privacy-conscious individuals who want to communicate without fear of surveillance or data mining.
---
### ProtonMail Application Suite: A Holistic Privacy Ecosystem
Beyond encrypted email, Proton has expanded into a full suite of privacy-focused tools:
ProtonMail – Secure, encrypted email with zero access to user data.
ProtonVPN – A no-logs VPN that protects internet traffic from ISPs and surveillance.
ProtonCalendar – An encrypted calendar that ensures event data remains private.
ProtonDrive – Secure cloud storage for files with end-to-end encryption.
ProtonPass – A password manager that encrypts credentials and autofills login details safely.
This ecosystem provides a seamless experience for those looking to secure not just their emails but also their browsing, file storage, scheduling, and password management.
---
### Why ProtonMail is a Must for Privacy-Conscious Users
1. End-to-End Encryption: Unlike Gmail and Outlook, ProtonMail ensures that even ProtonMail itself cannot access your emails.
2. No IP Tracking: Protects against metadata collection, preserving user anonymity.
3. Zero Access Architecture: Even Proton employees cannot read your emails.
4. Decentralization-Friendly: Complements Nostr’s ethos of distributed, private communication.
ProtonMail’s strict security measures align well with the values of decentralization and censorship resistance, making it a natural ally to protocols like Nostr.
---
### ProtonMail and Nostr: A Privacy Power Duo
Nostr is an open-source, censorship-resistant social networking protocol that allows users to communicate without relying on a centralized platform. Unlike Twitter, Facebook, or even Mastodon, Nostr operates through decentralized relays, making it nearly impossible to shut down or control.
ProtonMail and Nostr share a fundamental philosophy: empowering users with control over their own data. Here’s how they complement each other:
1. Secure and Private Communication
Nostr messages are cryptographically signed and relayed across decentralized nodes. ProtonMail, with its encryption-first approach, ensures that even off-platform communication remains private.
2. No Central Authority
ProtonMail is protected under Swiss privacy laws and is not beholden to big tech surveillance. Nostr operates without central servers, preventing a single entity from controlling conversations.
3. Protecting Metadata
While Nostr encrypts direct messages, email remains a critical form of communication for many users. ProtonMail’s metadata protection ensures that senders, recipients, and message content remain shielded.
4. Enhanced Security for Activists and Journalists
Nostr is popular among privacy advocates, activists, and whistleblowers due to its resilience against censorship. ProtonMail adds an extra layer of protection for sensitive information shared over email.
By using ProtonMail and Nostr together, users can create a robust digital identity that is censorship-resistant, private, and secure.
---
### How to Get Started with ProtonMail
If you’re ready to enhance your privacy, setting up ProtonMail is simple:
1. Sign Up: Visit ProtonMail.com and create a free or premium account.
2. Set Up Your Inbox: Customize security settings and enable two-factor authentication.
3. Explore Proton’s Suite: Utilize ProtonVPN, ProtonDrive, and ProtonPass for full privacy coverage.
4. Integrate with Nostr: Use ProtonMail for private communication outside of Nostr’s relay-based messaging system.
ProtonMail offers free plans, but for advanced security features, encrypted storage, and custom domains, premium plans are available.
---
### Conclusion: A Privacy-First Digital Future
In a world where data privacy is constantly under threat, services like ProtonMail and Nostr pave the way for a more secure and independent digital future. Whether you are a journalist, activist, or simply someone who values personal privacy, these tools provide the protection you need.
By combining ProtonMail’s encrypted email with Nostr’s decentralized networking, users can take control of their communications, free from surveillance and corporate interference.
Now is the time to reclaim your digital privacy—sign up for ProtonMail and explore Nostr to experience a censorship-resistant, secure way of communicating.
---
Further Resources
ProtonMail Official Website
ProtonVPN for Secure Browsing
Nostr Documentation and GitHub
Privacy Guides for Online Security
Are you using ProtonMail and Nostr together? Share your thoughts on how these tools empower you in the comments below!
-
@ fd06f542:8d6d54cd
2025-03-28 02:24:00
NIP-01
======
Basic protocol flow description
-------------------------------
`draft` `mandatory`
This NIP defines the basic protocol that should be implemented by everybody. New NIPs may add new optional (or mandatory) fields and messages and features to the structures and flows described here.
## Events and signatures
Each user has a keypair. Signatures, public key, and encodings are done according to the [Schnorr signatures standard for the curve `secp256k1`](https://bips.xyz/340).
The only object type that exists is the `event`, which has the following format on the wire:
```jsonc
{
"id": <32-bytes lowercase hex-encoded sha256 of the serialized event data>,
"pubkey": <32-bytes lowercase hex-encoded public key of the event creator>,
"created_at": <unix timestamp in seconds>,
"kind": <integer between 0 and 65535>,
"tags": [
[<arbitrary string>...],
// ...
],
"content": <arbitrary string>,
"sig": <64-bytes lowercase hex of the signature of the sha256 hash of the serialized event data, which is the same as the "id" field>
}
```
To obtain the `event.id`, we `sha256` the serialized event. The serialization is done over the UTF-8 JSON-serialized string (which is described below) of the following structure:
```
[
0,
<pubkey, as a lowercase hex string>,
<created_at, as a number>,
<kind, as a number>,
<tags, as an array of arrays of non-null strings>,
<content, as a string>
]
```
To prevent implementation differences from creating a different event ID for the same event, the following rules MUST be followed while serializing:
- UTF-8 should be used for encoding.
- Whitespace, line breaks or other unnecessary formatting should not be included in the output JSON.
- The following characters in the content field must be escaped as shown, and all other characters must be included verbatim:
- A line break (`0x0A`), use `\n`
- A double quote (`0x22`), use `\"`
- A backslash (`0x5C`), use `\\`
- A carriage return (`0x0D`), use `\r`
- A tab character (`0x09`), use `\t`
- A backspace, (`0x08`), use `\b`
- A form feed, (`0x0C`), use `\f`
### Tags
Each tag is an array of one or more strings, with some conventions around them. Take a look at the example below:
```jsonc
{
"tags": [
["e", "5c83da77af1dec6d7289834998ad7aafbd9e2191396d75ec3cc27f5a77226f36", "wss://nostr.example.com"],
["p", "f7234bd4c1394dda46d09f35bd384dd30cc552ad5541990f98844fb06676e9ca"],
["a", "30023:f7234bd4c1394dda46d09f35bd384dd30cc552ad5541990f98844fb06676e9ca:abcd", "wss://nostr.example.com"],
["alt", "reply"],
// ...
],
// ...
}
```
The first element of the tag array is referred to as the tag _name_ or _key_ and the second as the tag _value_. So we can safely say that the event above has an `e` tag set to `"5c83da77af1dec6d7289834998ad7aafbd9e2191396d75ec3cc27f5a77226f36"`, an `alt` tag set to `"reply"` and so on. All elements after the second do not have a conventional name.
This NIP defines 3 standard tags that can be used across all event kinds with the same meaning. They are as follows:
- The `e` tag, used to refer to an event: `["e", <32-bytes lowercase hex of the id of another event>, <recommended relay URL, optional>, <32-bytes lowercase hex of the author's pubkey, optional>]`
- The `p` tag, used to refer to another user: `["p", <32-bytes lowercase hex of a pubkey>, <recommended relay URL, optional>]`
- The `a` tag, used to refer to an addressable or replaceable event
- for an addressable event: `["a", "<kind integer>:<32-bytes lowercase hex of a pubkey>:<d tag value>", <recommended relay URL, optional>]`
- for a normal replaceable event: `["a", "<kind integer>:<32-bytes lowercase hex of a pubkey>:", <recommended relay URL, optional>]` (note: include the trailing colon)
As a convention, all single-letter (only english alphabet letters: a-z, A-Z) key tags are expected to be indexed by relays, such that it is possible, for example, to query or subscribe to events that reference the event `"5c83da77af1dec6d7289834998ad7aafbd9e2191396d75ec3cc27f5a77226f36"` by using the `{"#e": ["5c83da77af1dec6d7289834998ad7aafbd9e2191396d75ec3cc27f5a77226f36"]}` filter. Only the first value in any given tag is indexed.
### Kinds
Kinds specify how clients should interpret the meaning of each event and the other fields of each event (e.g. an `"r"` tag may have a meaning in an event of kind 1 and an entirely different meaning in an event of kind 10002). Each NIP may define the meaning of a set of kinds that weren't defined elsewhere. [NIP-10](10.md), for instance, especifies the `kind:1` text note for social media applications.
This NIP defines one basic kind:
- `0`: **user metadata**: the `content` is set to a stringified JSON object `{name: <nickname or full name>, about: <short bio>, picture: <url of the image>}` describing the user who created the event. [Extra metadata fields](24.md#kind-0) may be set. A relay may delete older events once it gets a new one for the same pubkey.
And also a convention for kind ranges that allow for easier experimentation and flexibility of relay implementation:
- for kind `n` such that `1000 <= n < 10000 || 4 <= n < 45 || n == 1 || n == 2`, events are **regular**, which means they're all expected to be stored by relays.
- for kind `n` such that `10000 <= n < 20000 || n == 0 || n == 3`, events are **replaceable**, which means that, for each combination of `pubkey` and `kind`, only the latest event MUST be stored by relays, older versions MAY be discarded.
- for kind `n` such that `20000 <= n < 30000`, events are **ephemeral**, which means they are not expected to be stored by relays.
- for kind `n` such that `30000 <= n < 40000`, events are **addressable** by their `kind`, `pubkey` and `d` tag value -- which means that, for each combination of `kind`, `pubkey` and the `d` tag value, only the latest event MUST be stored by relays, older versions MAY be discarded.
In case of replaceable events with the same timestamp, the event with the lowest id (first in lexical order) should be retained, and the other discarded.
When answering to `REQ` messages for replaceable events such as `{"kinds":[0],"authors":[<hex-key>]}`, even if the relay has more than one version stored, it SHOULD return just the latest one.
These are just conventions and relay implementations may differ.
## Communication between clients and relays
Relays expose a websocket endpoint to which clients can connect. Clients SHOULD open a single websocket connection to each relay and use it for all their subscriptions. Relays MAY limit number of connections from specific IP/client/etc.
### From client to relay: sending events and creating subscriptions
Clients can send 3 types of messages, which must be JSON arrays, according to the following patterns:
* `["EVENT", <event JSON as defined above>]`, used to publish events.
* `["REQ", <subscription_id>, <filters1>, <filters2>, ...]`, used to request events and subscribe to new updates.
* `["CLOSE", <subscription_id>]`, used to stop previous subscriptions.
`<subscription_id>` is an arbitrary, non-empty string of max length 64 chars. It represents a subscription per connection. Relays MUST manage `<subscription_id>`s independently for each WebSocket connection. `<subscription_id>`s are not guaranteed to be globally unique.
`<filtersX>` is a JSON object that determines what events will be sent in that subscription, it can have the following attributes:
```json
{
"ids": <a list of event ids>,
"authors": <a list of lowercase pubkeys, the pubkey of an event must be one of these>,
"kinds": <a list of a kind numbers>,
"#<single-letter (a-zA-Z)>": <a list of tag values, for #e — a list of event ids, for #p — a list of pubkeys, etc.>,
"since": <an integer unix timestamp in seconds. Events must have a created_at >= to this to pass>,
"until": <an integer unix timestamp in seconds. Events must have a created_at <= to this to pass>,
"limit": <maximum number of events relays SHOULD return in the initial query>
}
```
Upon receiving a `REQ` message, the relay SHOULD return events that match the filter. Any new events it receives SHOULD be sent to that same websocket until the connection is closed, a `CLOSE` event is received with the same `<subscription_id>`, or a new `REQ` is sent using the same `<subscription_id>` (in which case a new subscription is created, replacing the old one).
Filter attributes containing lists (`ids`, `authors`, `kinds` and tag filters like `#e`) are JSON arrays with one or more values. At least one of the arrays' values must match the relevant field in an event for the condition to be considered a match. For scalar event attributes such as `authors` and `kind`, the attribute from the event must be contained in the filter list. In the case of tag attributes such as `#e`, for which an event may have multiple values, the event and filter condition values must have at least one item in common.
The `ids`, `authors`, `#e` and `#p` filter lists MUST contain exact 64-character lowercase hex values.
The `since` and `until` properties can be used to specify the time range of events returned in the subscription. If a filter includes the `since` property, events with `created_at` greater than or equal to `since` are considered to match the filter. The `until` property is similar except that `created_at` must be less than or equal to `until`. In short, an event matches a filter if `since <= created_at <= until` holds.
All conditions of a filter that are specified must match for an event for it to pass the filter, i.e., multiple conditions are interpreted as `&&` conditions.
A `REQ` message may contain multiple filters. In this case, events that match any of the filters are to be returned, i.e., multiple filters are to be interpreted as `||` conditions.
The `limit` property of a filter is only valid for the initial query and MUST be ignored afterwards. When `limit: n` is present it is assumed that the events returned in the initial query will be the last `n` events ordered by the `created_at`. Newer events should appear first, and in the case of ties the event with the lowest id (first in lexical order) should be first. It is safe to return less events than `limit` specifies, but it is expected that relays do not return (much) more events than requested so clients don't get unnecessarily overwhelmed by data.
### From relay to client: sending events and notices
Relays can send 5 types of messages, which must also be JSON arrays, according to the following patterns:
* `["EVENT", <subscription_id>, <event JSON as defined above>]`, used to send events requested by clients.
* `["OK", <event_id>, <true|false>, <message>]`, used to indicate acceptance or denial of an `EVENT` message.
* `["EOSE", <subscription_id>]`, used to indicate the _end of stored events_ and the beginning of events newly received in real-time.
* `["CLOSED", <subscription_id>, <message>]`, used to indicate that a subscription was ended on the server side.
* `["NOTICE", <message>]`, used to send human-readable error messages or other things to clients.
This NIP defines no rules for how `NOTICE` messages should be sent or treated.
- `EVENT` messages MUST be sent only with a subscription ID related to a subscription previously initiated by the client (using the `REQ` message above).
- `OK` messages MUST be sent in response to `EVENT` messages received from clients, they must have the 3rd parameter set to `true` when an event has been accepted by the relay, `false` otherwise. The 4th parameter MUST always be present, but MAY be an empty string when the 3rd is `true`, otherwise it MUST be a string formed by a machine-readable single-word prefix followed by a `:` and then a human-readable message. Some examples:
* `["OK", "b1a649ebe8...", true, ""]`
* `["OK", "b1a649ebe8...", true, "pow: difficulty 25>=24"]`
* `["OK", "b1a649ebe8...", true, "duplicate: already have this event"]`
* `["OK", "b1a649ebe8...", false, "blocked: you are banned from posting here"]`
* `["OK", "b1a649ebe8...", false, "blocked: please register your pubkey at https://my-expensive-relay.example.com"]`
* `["OK", "b1a649ebe8...", false, "rate-limited: slow down there chief"]`
* `["OK", "b1a649ebe8...", false, "invalid: event creation date is too far off from the current time"]`
* `["OK", "b1a649ebe8...", false, "pow: difficulty 26 is less than 30"]`
* `["OK", "b1a649ebe8...", false, "restricted: not allowed to write."]`
* `["OK", "b1a649ebe8...", false, "error: could not connect to the database"]`
- `CLOSED` messages MUST be sent in response to a `REQ` when the relay refuses to fulfill it. It can also be sent when a relay decides to kill a subscription on its side before a client has disconnected or sent a `CLOSE`. This message uses the same pattern of `OK` messages with the machine-readable prefix and human-readable message. Some examples:
* `["CLOSED", "sub1", "unsupported: filter contains unknown elements"]`
* `["CLOSED", "sub1", "error: could not connect to the database"]`
* `["CLOSED", "sub1", "error: shutting down idle subscription"]`
- The standardized machine-readable prefixes for `OK` and `CLOSED` are: `duplicate`, `pow`, `blocked`, `rate-limited`, `invalid`, `restricted`, and `error` for when none of that fits.
-
@ 04ff5a72:22ba7b2d
2025-03-19 02:06:34
# Taking Back Control of the Internet
Web3 represents a fundamental reimagining of how users interact with and control their data online, marking a significant departure from the Web2 paradigm that has dominated the internet for the past two decades. This transformation is centered around shifting power dynamics, decentralizing authority, and returning data sovereignty to individuals. While Web2 created unprecedented connectivity and digital services, it came with significant trade-offs in terms of privacy, security, and user autonomy. Web3 technologies aim to address these shortcomings through blockchain-based systems and decentralized architectures that fundamentally alter who controls, benefits from, and has access to user data.
# Fundamental Shift in Data Ownership
## Web2: Corporate Control and Exploitation
In the Web2 paradigm, users effectively surrender ownership of their personal data to centralized platforms. When individuals sign up for services from tech giants like Google, Facebook, or Twitter, they typically grant these companies extensive rights to collect, analyze, and monetize their information[[2]](https://cryptix.ag/web2-vs-web3/). This arrangement creates a profound power imbalance where users have minimal visibility into or control over how their data is used. Companies can sell this information to third parties for marketing purposes without providing meaningful compensation to the individuals who generated it[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve).
This centralized model has created what many critics describe as "surveillance capitalism," where detailed profiles of users are constructed across platforms to predict and influence behavior. The value generated from this data has contributed to the immense wealth of a small number of technology corporations while leaving users with little to show for their contributions[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve).
## Web3: User-Centric Ownership Model
Web3 fundamentally inverts this ownership paradigm. In Web3 systems, users retain ownership of their own data and can make deliberate decisions about how it is used, shared, or monetized[[2]](https://cryptix.ag/web2-vs-web3/). This principle is enabled through blockchain technology and cryptographic mechanisms that allow individuals to maintain control over their digital footprint without relying on centralized intermediaries[[3]](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki).
The decentralized architecture of Web3 systems means that personal information is not concentrated in massive corporate databases but is instead distributed across networks with varying levels of user-controlled access[[7]](https://crowleymediagroup.com/resources/decentralized-data-impact-in-web-3-0-ownership/). This shift represents not merely a technical change but a philosophical reorientation of the internet toward user sovereignty.
# Decentralized Infrastructure and Enhanced Security
## Web2: Vulnerable Centralized Systems
The Web2 model relies heavily on centralized servers and data centers controlled by individual companies. This architecture creates significant vulnerabilities, as these centralized repositories become high-value targets for hackers and malicious actors[[2]](https://cryptix.ag/web2-vs-web3/). Data breaches affecting millions of users have become increasingly common, demonstrating the inherent security weaknesses of storing vast amounts of personal information in single locations.
Additionally, the centralized nature of Web2 infrastructure creates single points of failure where service disruptions or security compromises can have widespread impacts across entire user bases[[8]](https://blockapps.net/blog/enhancing-digital-security-and-user-privacy-with-web3/).
## Web3: Distributed Networks and Cryptographic Protection
Web3 transforms this security model through decentralization. By leveraging blockchain technology, Web3 distributes data across multiple nodes worldwide rather than concentrating it in centralized servers[[3]](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki). This architecture significantly increases resilience against attacks, as compromising the network would require breaching numerous points simultaneously rather than a single centralized database[[2]](https://cryptix.ag/web2-vs-web3/).
Cryptographic protection is fundamental to Web3 systems, with data access controlled through sophisticated encryption mechanisms. This approach makes unauthorized access significantly more difficult and provides users with verifiable assurance about who can see their information and under what circumstances[[5]](https://www.linkedin.com/pulse/safeguarding-privacy-web3-era-deep-dive-user-anonymity-data-protection-85hrf).
The Web3 infrastructure model explicitly addresses the vulnerability of centralized systems by removing single points of failure and distributing both data and control across broad networks of participants[[8]](https://blockapps.net/blog/enhancing-digital-security-and-user-privacy-with-web3/).
# Self-Sovereign Identity and Authentication
## Web2: Platform-Dependent Digital Identities
In Web2, digital identities are typically fragmented across numerous platforms, each requiring separate credentials and controlling different aspects of a user's online presence[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve). This fragmentation creates security vulnerabilities and makes it difficult for individuals to maintain a coherent digital footprint or track how their information is being used across services.
Users often rely on third-party identity providers (like "Sign in with Google" or "Login with Facebook"), which further centralizes control and creates dependencies that can be revoked at the platform's discretion[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve).
## Web3: User-Controlled Identity Management
Web3 introduces the concept of self-sovereign identity, where users create and manage decentralized identifiers that they fully control without intermediaries[[1]](https://whimsygames.co/blog/data-ownership-in-web3-empowering-users-with-control/)[[5]](https://www.linkedin.com/pulse/safeguarding-privacy-web3-era-deep-dive-user-anonymity-data-protection-85hrf). Instead of relying on centralized identity providers that can restrict access or modify terms, individuals maintain ownership of their digital identities across different applications and services.
Decentralized Identifiers (DIDs) and Self-Sovereign Identity (SSI) systems enable secure identity management that preserves privacy while still allowing for verified interactions[[1]](https://whimsygames.co/blog/data-ownership-in-web3-empowering-users-with-control/)[[3].](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki) Users can selectively disclose only the specific information needed for particular interactions without revealing unrelated personal details, significantly reducing unnecessary data exposure[[3].](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki)
This approach minimizes the risk of identity theft by eliminating the centralized repositories of identity information that currently make attractive targets for attackers[[3]](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki).
# Transparency and Consent Mechanisms
## Web2: Opaque Data Practices and Forced Consent
Web2 platforms are notorious for their complex and often deliberately obscure data governance practices[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve). Users typically must agree to extensive terms of service and privacy policies they rarely read or fully understand. Even when policies are comprehensible, users face a binary choice: accept all conditions or forgo the service entirely.
This lack of transparency has eroded trust, with many users unaware of how extensively their information is being collected, analyzed, and shared with third parties[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve). The actual conditions of data usage often change without meaningful notification or consent opportunities.
## Web3: Transparent Governance and Programmable Consent
Web3 systems operate on public, immutable ledgers where data processing rules are encoded in transparent smart contracts that anyone can examine[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve)[[5]](https://www.linkedin.com/pulse/safeguarding-privacy-web3-era-deep-dive-user-anonymity-data-protection-85hrf). This radical transparency allows users to verify exactly how their information will be handled before agreeing to share it.
Rather than all-or-nothing consent models, Web3 enables granular, programmable consent where users can specify precise conditions under which their data may be accessed or utilized[[5]](https://www.linkedin.com/pulse/safeguarding-privacy-web3-era-deep-dive-user-anonymity-data-protection-85hrf). These conditions become enforced by code rather than by trusting companies to honor their stated policies.
This transparency extends to the broader governance of Web3 platforms, many of which operate as Decentralized Autonomous Organizations (DAOs) where users can participate in decision-making about how the system evolves[[8]](https://blockapps.net/blog/enhancing-digital-security-and-user-privacy-with-web3/).
# Data Monetization and Value Exchange
## Web2: Asymmetric Value Capture
In Web2 ecosystems, the value created from user data flows predominantly to platform owners. Users effectively trade their data for free services, but the economic exchange is highly unbalanced[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve). The personal information collected is worth far more to the companies than the services provided in return, creating massive wealth for a small number of technology corporations.
Users have little visibility into how their data contributes to platform revenues and receive minimal compensation for their valuable contributions to these ecosystems[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve).
## Web3: Direct User Monetization
Web3 revolutionizes this economic model by enabling users to directly monetize their own data if they choose to share it[[4]](https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve). Through blockchain-based platforms and decentralized applications (dApps), individuals can selectively sell access to their data or receive compensation for their online contributions.
This model creates more equitable value distribution, where the economic benefits of data flow to those who generate it rather than being concentrated among platform owners[[7]](https://crowleymediagroup.com/resources/decentralized-data-impact-in-web-3-0-ownership/). Users can make informed decisions about when and how to monetize their information based on transparent value propositions.
The incentive structures of Web3 platforms often include tokenization mechanisms that allow users to benefit directly from network growth and participation, creating alignment between individual and collective interests[[8]](https://blockapps.net/blog/enhancing-digital-security-and-user-privacy-with-web3/).
# Challenges and Future Directions
Despite its promising approach to data control, Web3 faces significant challenges in achieving mainstream adoption. Technical barriers remain substantial, with many Web3 interfaces less user-friendly than their Web2 counterparts[[3]](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki). Scalability issues can lead to slower transactions and higher costs compared to centralized solutions.
Regulatory frameworks are still evolving to address the unique characteristics of decentralized systems, creating uncertainty around compliance requirements[[3]](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki)[[5]](https://www.linkedin.com/pulse/safeguarding-privacy-web3-era-deep-dive-user-anonymity-data-protection-85hrf). Additionally, the public nature of some blockchain networks introduces new privacy considerations that must be carefully managed.
Future developments in Web3 privacy will likely focus on improving scalability solutions, developing more intuitive user interfaces for privacy management, and refining privacy-preserving technologies like zero-knowledge proofs[[3]](https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki). Education remains critical, as users need to understand Web3 mechanisms to fully leverage their benefits.
# Conclusion
The transition from Web2 to Web3 represents a profound shift in how user data is controlled, managed, and valued. While Web2 created unprecedented connectivity at the cost of personal privacy and autonomy, Web3 aims to preserve the benefits of digital connection while returning control to individuals.
By decentralizing infrastructure, enabling self-sovereign identity, increasing transparency, and creating more equitable value distribution, Web3 technologies offer a vision of the internet that aligns more closely with principles of user empowerment and data sovereignty.
Though challenges remain in fully realizing this vision, the fundamental reorientation toward user control over personal data represents one of the most significant developments in the internet's evolution since the emergence of social platforms. As Web3 technologies mature and adoption increases, they have the potential to fundamentally transform our relationship with our digital selves and reshape the power dynamics of the online world.
---
### Sources
[1] Data Ownership in Web3: Empowering Users with Control https://whimsygames.co/blog/data-ownership-in-web3-empowering-users-with-control/
[2] Web2 vs Web3: What's the Difference - Cryptix AG https://cryptix.ag/web2-vs-web3/
[3] The Role of Web3 in Digital Privacy: Protecting User Data in ... https://dev.to/lisaward867/the-role-of-web3-in-digital-privacy-protecting-user-data-in-decentralized-systems-18ki
[4] How Web3 Enhances User Privacy As Compared to Web2 - LinkedIn https://www.linkedin.com/pulse/how-web3-enhances-user-privacy-compared-web2-mr-mint-official-umtve
[5] Safeguarding Privacy in the Web3 Era: A Deep Dive into User ... https://www.linkedin.com/pulse/safeguarding-privacy-web3-era-deep-dive-user-anonymity-data-protection-85hrf
[6] Web2 vs. Web3: What's the Difference? [The Breakthrough] - Metana https://metana.io/blog/web2-vs-web3-whats-the-difference-the-breakthrough/
[7] Decentralized Data Impact in Web 3.0 Ownership https://crowleymediagroup.com/resources/decentralized-data-impact-in-web-3-0-ownership/
[8] Enhancing Digital Security and User Privacy with Web3 - BlockApps https://blockapps.net/blog/enhancing-digital-security-and-user-privacy-with-web3/
-
@ 6f6b50bb:a848e5a1
2024-12-15 15:09:52
Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
### Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
### Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
- **Scoperta.** Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
- **Efficienza.** La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
### Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
### Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!Che cosa significherebbe trattare l'IA come uno strumento invece che come una persona?
Dall’avvio di ChatGPT, le esplorazioni in due direzioni hanno preso velocità.
La prima direzione riguarda le capacità tecniche. Quanto grande possiamo addestrare un modello? Quanto bene può rispondere alle domande del SAT? Con quanta efficienza possiamo distribuirlo?
La seconda direzione riguarda il design dell’interazione. Come comunichiamo con un modello? Come possiamo usarlo per un lavoro utile? Quale metafora usiamo per ragionare su di esso?
La prima direzione è ampiamente seguita e enormemente finanziata, e per una buona ragione: i progressi nelle capacità tecniche sono alla base di ogni possibile applicazione. Ma la seconda è altrettanto cruciale per il campo e ha enormi incognite. Siamo solo a pochi anni dall’inizio dell’era dei grandi modelli. Quali sono le probabilità che abbiamo già capito i modi migliori per usarli?
Propongo una nuova modalità di interazione, in cui i modelli svolgano il ruolo di applicazioni informatiche (ad esempio app per telefoni): fornendo un’interfaccia grafica, interpretando gli input degli utenti e aggiornando il loro stato. In questa modalità, invece di essere un “agente” che utilizza un computer per conto dell’essere umano, l’IA può fornire un ambiente informatico più ricco e potente che possiamo utilizzare.
### Metafore per l’interazione
Al centro di un’interazione c’è una metafora che guida le aspettative di un utente su un sistema. I primi giorni dell’informatica hanno preso metafore come “scrivanie”, “macchine da scrivere”, “fogli di calcolo” e “lettere” e le hanno trasformate in equivalenti digitali, permettendo all’utente di ragionare sul loro comportamento. Puoi lasciare qualcosa sulla tua scrivania e tornare a prenderlo; hai bisogno di un indirizzo per inviare una lettera. Man mano che abbiamo sviluppato una conoscenza culturale di questi dispositivi, la necessità di queste particolari metafore è scomparsa, e con esse i design di interfaccia skeumorfici che le rafforzavano. Come un cestino o una matita, un computer è ora una metafora di se stesso.
La metafora dominante per i grandi modelli oggi è modello-come-persona. Questa è una metafora efficace perché le persone hanno capacità estese che conosciamo intuitivamente. Implica che possiamo avere una conversazione con un modello e porgli domande; che il modello possa collaborare con noi su un documento o un pezzo di codice; che possiamo assegnargli un compito da svolgere da solo e che tornerà quando sarà finito.
Tuttavia, trattare un modello come una persona limita profondamente il nostro modo di pensare all’interazione con esso. Le interazioni umane sono intrinsecamente lente e lineari, limitate dalla larghezza di banda e dalla natura a turni della comunicazione verbale. Come abbiamo tutti sperimentato, comunicare idee complesse in una conversazione è difficile e dispersivo. Quando vogliamo precisione, ci rivolgiamo invece a strumenti, utilizzando manipolazioni dirette e interfacce visive ad alta larghezza di banda per creare diagrammi, scrivere codice e progettare modelli CAD. Poiché concepiamo i modelli come persone, li utilizziamo attraverso conversazioni lente, anche se sono perfettamente in grado di accettare input diretti e rapidi e di produrre risultati visivi. Le metafore che utilizziamo limitano le esperienze che costruiamo, e la metafora modello-come-persona ci impedisce di esplorare il pieno potenziale dei grandi modelli.
Per molti casi d’uso, e specialmente per il lavoro produttivo, credo che il futuro risieda in un’altra metafora: modello-come-computer.
### Usare un’IA come un computer
Sotto la metafora modello-come-computer, interagiremo con i grandi modelli seguendo le intuizioni che abbiamo sulle applicazioni informatiche (sia su desktop, tablet o telefono). Nota che ciò non significa che il modello sarà un’app tradizionale più di quanto il desktop di Windows fosse una scrivania letterale. “Applicazione informatica” sarà un modo per un modello di rappresentarsi a noi. Invece di agire come una persona, il modello agirà come un computer.
Agire come un computer significa produrre un’interfaccia grafica. Al posto del flusso lineare di testo in stile telescrivente fornito da ChatGPT, un sistema modello-come-computer genererà qualcosa che somiglia all’interfaccia di un’applicazione moderna: pulsanti, cursori, schede, immagini, grafici e tutto il resto. Questo affronta limitazioni chiave dell’interfaccia di chat standard modello-come-persona:
Scoperta. Un buon strumento suggerisce i suoi usi. Quando l’unica interfaccia è una casella di testo vuota, spetta all’utente capire cosa fare e comprendere i limiti del sistema. La barra laterale Modifica in Lightroom è un ottimo modo per imparare l’editing fotografico perché non si limita a dirti cosa può fare questa applicazione con una foto, ma cosa potresti voler fare. Allo stesso modo, un’interfaccia modello-come-computer per DALL-E potrebbe mostrare nuove possibilità per le tue generazioni di immagini.
Efficienza. La manipolazione diretta è più rapida che scrivere una richiesta a parole. Per continuare l’esempio di Lightroom, sarebbe impensabile modificare una foto dicendo a una persona quali cursori spostare e di quanto. Ci vorrebbe un giorno intero per chiedere un’esposizione leggermente più bassa e una vibranza leggermente più alta, solo per vedere come apparirebbe. Nella metafora modello-come-computer, il modello può creare strumenti che ti permettono di comunicare ciò che vuoi più efficientemente e quindi di fare le cose più rapidamente.
A differenza di un’app tradizionale, questa interfaccia grafica è generata dal modello su richiesta. Questo significa che ogni parte dell’interfaccia che vedi è rilevante per ciò che stai facendo in quel momento, inclusi i contenuti specifici del tuo lavoro. Significa anche che, se desideri un’interfaccia più ampia o diversa, puoi semplicemente richiederla. Potresti chiedere a DALL-E di produrre alcuni preset modificabili per le sue impostazioni ispirati da famosi artisti di schizzi. Quando clicchi sul preset Leonardo da Vinci, imposta i cursori per disegni prospettici altamente dettagliati in inchiostro nero. Se clicchi su Charles Schulz, seleziona fumetti tecnicolor 2D a basso dettaglio.
### Una bicicletta della mente proteiforme
La metafora modello-come-persona ha una curiosa tendenza a creare distanza tra l’utente e il modello, rispecchiando il divario di comunicazione tra due persone che può essere ridotto ma mai completamente colmato. A causa della difficoltà e del costo di comunicare a parole, le persone tendono a suddividere i compiti tra loro in blocchi grandi e il più indipendenti possibile. Le interfacce modello-come-persona seguono questo schema: non vale la pena dire a un modello di aggiungere un return statement alla tua funzione quando è più veloce scriverlo da solo. Con il sovraccarico della comunicazione, i sistemi modello-come-persona sono più utili quando possono fare un intero blocco di lavoro da soli. Fanno le cose per te.
Questo contrasta con il modo in cui interagiamo con i computer o altri strumenti. Gli strumenti producono feedback visivi in tempo reale e sono controllati attraverso manipolazioni dirette. Hanno un overhead comunicativo così basso che non è necessario specificare un blocco di lavoro indipendente. Ha più senso mantenere l’umano nel loop e dirigere lo strumento momento per momento. Come stivali delle sette leghe, gli strumenti ti permettono di andare più lontano a ogni passo, ma sei ancora tu a fare il lavoro. Ti permettono di fare le cose più velocemente.
Considera il compito di costruire un sito web usando un grande modello. Con le interfacce di oggi, potresti trattare il modello come un appaltatore o un collaboratore. Cercheresti di scrivere a parole il più possibile su come vuoi che il sito appaia, cosa vuoi che dica e quali funzionalità vuoi che abbia. Il modello genererebbe una prima bozza, tu la eseguirai e poi fornirai un feedback. “Fai il logo un po’ più grande”, diresti, e “centra quella prima immagine principale”, e “deve esserci un pulsante di login nell’intestazione”. Per ottenere esattamente ciò che vuoi, invierai una lista molto lunga di richieste sempre più minuziose.
Un’interazione alternativa modello-come-computer sarebbe diversa: invece di costruire il sito web, il modello genererebbe un’interfaccia per te per costruirlo, dove ogni input dell’utente a quell’interfaccia interroga il grande modello sotto il cofano. Forse quando descrivi le tue necessità creerebbe un’interfaccia con una barra laterale e una finestra di anteprima. All’inizio la barra laterale contiene solo alcuni schizzi di layout che puoi scegliere come punto di partenza. Puoi cliccare su ciascuno di essi, e il modello scrive l’HTML per una pagina web usando quel layout e lo visualizza nella finestra di anteprima. Ora che hai una pagina su cui lavorare, la barra laterale guadagna opzioni aggiuntive che influenzano la pagina globalmente, come accoppiamenti di font e schemi di colore. L’anteprima funge da editor WYSIWYG, permettendoti di afferrare elementi e spostarli, modificarne i contenuti, ecc. A supportare tutto ciò è il modello, che vede queste azioni dell’utente e riscrive la pagina per corrispondere ai cambiamenti effettuati. Poiché il modello può generare un’interfaccia per aiutare te e lui a comunicare più efficientemente, puoi esercitare più controllo sul prodotto finale in meno tempo.
La metafora modello-come-computer ci incoraggia a pensare al modello come a uno strumento con cui interagire in tempo reale piuttosto che a un collaboratore a cui assegnare compiti. Invece di sostituire un tirocinante o un tutor, può essere una sorta di bicicletta proteiforme per la mente, una che è sempre costruita su misura esattamente per te e il terreno che intendi attraversare.
### Un nuovo paradigma per l’informatica?
I modelli che possono generare interfacce su richiesta sono una frontiera completamente nuova nell’informatica. Potrebbero essere un paradigma del tutto nuovo, con il modo in cui cortocircuitano il modello di applicazione esistente. Dare agli utenti finali il potere di creare e modificare app al volo cambia fondamentalmente il modo in cui interagiamo con i computer. Al posto di una singola applicazione statica costruita da uno sviluppatore, un modello genererà un’applicazione su misura per l’utente e le sue esigenze immediate. Al posto della logica aziendale implementata nel codice, il modello interpreterà gli input dell’utente e aggiornerà l’interfaccia utente. È persino possibile che questo tipo di interfaccia generativa sostituisca completamente il sistema operativo, generando e gestendo interfacce e finestre al volo secondo necessità.
All’inizio, l’interfaccia generativa sarà un giocattolo, utile solo per l’esplorazione creativa e poche altre applicazioni di nicchia. Dopotutto, nessuno vorrebbe un’app di posta elettronica che occasionalmente invia email al tuo ex e mente sulla tua casella di posta. Ma gradualmente i modelli miglioreranno. Anche mentre si spingeranno ulteriormente nello spazio di esperienze completamente nuove, diventeranno lentamente abbastanza affidabili da essere utilizzati per un lavoro reale.
Piccoli pezzi di questo futuro esistono già. Anni fa Jonas Degrave ha dimostrato che ChatGPT poteva fare una buona simulazione di una riga di comando Linux. Allo stesso modo, websim.ai utilizza un LLM per generare siti web su richiesta mentre li navighi. Oasis, GameNGen e DIAMOND addestrano modelli video condizionati sull’azione su singoli videogiochi, permettendoti di giocare ad esempio a Doom dentro un grande modello. E Genie 2 genera videogiochi giocabili da prompt testuali. L’interfaccia generativa potrebbe ancora sembrare un’idea folle, ma non è così folle.
Ci sono enormi domande aperte su come apparirà tutto questo. Dove sarà inizialmente utile l’interfaccia generativa? Come condivideremo e distribuiremo le esperienze che creiamo collaborando con il modello, se esistono solo come contesto di un grande modello? Vorremmo davvero farlo? Quali nuovi tipi di esperienze saranno possibili? Come funzionerà tutto questo in pratica? I modelli genereranno interfacce come codice o produrranno direttamente pixel grezzi?
Non conosco ancora queste risposte. Dovremo sperimentare e scoprirlo!
Tradotto da:\
https://willwhitney.com/computing-inside-ai.htmlhttps://willwhitney.com/computing-inside-ai.html
-
@ 57d1a264:69f1fee1
2025-03-26 08:45:13
> I was curious to see how Stacker.News domain and website contents scored from a SEO (Search Engine Optimization) perspective. Here what Semrush nows about SN. But first have alook at the Page Performance Score on Google (Detailled report available [here](https://pagespeed.web.dev/analysis/https-stacker-news/pjnc9jgscy?form_factor=mobile)). **Performance** and **Accessibility** looks have really low score!
| Desktop | Mobile |
|---|---|
|  |  |
|  |  |
Now let's see what Semrush knows.
# Analytics
General view on your metrics and performance trend compared to last 30 days.


See estimations of stacker.news's desktop and mobile traffic based on Semrush’s proprietary AI and machine learning algorithms, petabytes of clickstream data, and Big Data technologies.

Distribution of SN's organic traffic and keywords by country. The Organic Traffic graph shows changes in the amount of estimated organic and paid traffic driven to the SN analyzed domain over time.

| Organic Search | Backlinks Analytics |
|---|---|
| |  |
| Position Changes Trend | Top Page Changes |
|---|---|
| |  |
|This trend allows you to monitor organic traffic changes, as well as improved and declined positions.| Top pages with the biggest traffic changes over the last 28 days. |

# Competitors

The Competitive Positioning Map shows the strengths and weaknesses of SN competitive domains' presence in organic search results. Data visualizations are based on the domain's organic traffic and the number of keywords that they are ranking for in Google's top 20 organic search results. The larger the circle, the more visibility a domain has. Below, a list of domains an analyzed domain is competing against in Google's top 20 organic search results.

# Referring Domains


# Daily Stats
| Organic Traffic | Organic Keywords | Backlinks |
|---|---|---|
| 976 | 15.9K | 126K |
| `-41.87%` | `-16.4%` | `-1.62%` |
### 📝 Traffic Drop
Traffic downturn detected! It appears SN domain experienced a traffic drop of 633 in the last 28 days. Take a closer look at these pages with significant traffic decline and explore areas for potential improvement. Here are the pages taking the biggest hits:
- https://stacker.news/items/723989 ⬇️ -15
- https://stacker.news/items/919813 ⬇️ -12
- https://stacker.news/items/783355 ⬇️ -5
### 📉 Decreased Authority Score
Uh-oh! Your Authority score has dropped from 26 to 25. Don't worry, we're here to assist you. Check out the new/lost backlinks in the Backlink Analytics tool to uncover insights on how to boost your authority.
### 🌟 New Keywords
Opportunity Alert! Targeting these keywords could help you increase organic traffic quickly and efficiently. We've found some low-hanging fruits for you! Take a look at these keywords:
- nitter.moomoo.me — Volume 70
- 0xchat — Volume 30
- amethyst nostr — Volume 30
### 🛠️ Broken Pages
This could hurt the user experience and lead to a loss in organic traffic. Time to take action: amend those pages or set up redirects. Here below, few pages on SN domain that are either broken or not _crawlable_:
- https://stacker.news/404 — 38 backlinks
- https://stacker.news/api/capture/items/91154 — 24 backlinks
- https://stacker.news/api/capture/items/91289 — 24 backlinks
Dees this post give you some insights? Hope so, comment below if you have any SEO suggestion? Mine is to improve or keep an eye on Accessibility!
One of the major issues I found is that SN does not have a `robots.txt`, a key simple text file that allow crawlers to read or not-read the website for indexing purposes. @k00b and @ek is that voluntary?
Here are other basic info to improve the SEO score and for those of us that want to learn more:
- Intro to Accessibility: https://www.w3.org/WAI/fundamentals/accessibility-intro/
- Design for Accessibility: https://www.w3.org/WAI/tips/designing/
- Web Accessibility Best Practices: https://www.freecodecamp.org/news/web-accessibility-best-practices/
originally posted at https://stacker.news/items/925433
-
@ fd06f542:8d6d54cd
2025-03-28 02:21:20
# NIPs
NIPs stand for **Nostr Implementation Possibilities**.
They exist to document what may be implemented by [Nostr](https://github.com/nostr-protocol/nostr)-compatible _relay_ and _client_ software.
---
- [List](#list)
- [Event Kinds](#event-kinds)
- [Message Types](#message-types)
- [Client to Relay](#client-to-relay)
- [Relay to Client](#relay-to-client)
- [Standardized Tags](#standardized-tags)
- [Criteria for acceptance of NIPs](#criteria-for-acceptance-of-nips)
- [Is this repository a centralizing factor?](#is-this-repository-a-centralizing-factor)
- [How this repository works](#how-this-repository-works)
- [Breaking Changes](#breaking-changes)
- [License](#license)
---
## List
- [NIP-01: Basic protocol flow description](01.md)
- [NIP-02: Follow List](02.md)
- [NIP-03: OpenTimestamps Attestations for Events](03.md)
- [NIP-04: Encrypted Direct Message](04.md) --- **unrecommended**: deprecated in favor of [NIP-17](17.md)
- [NIP-05: Mapping Nostr keys to DNS-based internet identifiers](05.md)
- [NIP-06: Basic key derivation from mnemonic seed phrase](06.md)
- [NIP-07: `window.nostr` capability for web browsers](07.md)
- [NIP-08: Handling Mentions](08.md) --- **unrecommended**: deprecated in favor of [NIP-27](27.md)
- [NIP-09: Event Deletion Request](09.md)
- [NIP-10: Text Notes and Threads](10.md)
- [NIP-11: Relay Information Document](11.md)
- [NIP-13: Proof of Work](13.md)
- [NIP-14: Subject tag in text events](14.md)
- [NIP-15: Nostr Marketplace (for resilient marketplaces)](15.md)
- [NIP-17: Private Direct Messages](17.md)
- [NIP-18: Reposts](18.md)
- [NIP-19: bech32-encoded entities](19.md)
- [NIP-21: `nostr:` URI scheme](21.md)
- [NIP-22: Comment](22.md)
- [NIP-23: Long-form Content](23.md)
- [NIP-24: Extra metadata fields and tags](24.md)
- [NIP-25: Reactions](25.md)
- [NIP-26: Delegated Event Signing](26.md)
- [NIP-27: Text Note References](27.md)
- [NIP-28: Public Chat](28.md)
- [NIP-29: Relay-based Groups](29.md)
- [NIP-30: Custom Emoji](30.md)
- [NIP-31: Dealing with Unknown Events](31.md)
- [NIP-32: Labeling](32.md)
- [NIP-34: `git` stuff](34.md)
- [NIP-35: Torrents](35.md)
- [NIP-36: Sensitive Content](36.md)
- [NIP-37: Draft Events](37.md)
- [NIP-38: User Statuses](38.md)
- [NIP-39: External Identities in Profiles](39.md)
- [NIP-40: Expiration Timestamp](40.md)
- [NIP-42: Authentication of clients to relays](42.md)
- [NIP-44: Encrypted Payloads (Versioned)](44.md)
- [NIP-45: Counting results](45.md)
- [NIP-46: Nostr Remote Signing](46.md)
- [NIP-47: Nostr Wallet Connect](47.md)
- [NIP-48: Proxy Tags](48.md)
- [NIP-49: Private Key Encryption](49.md)
- [NIP-50: Search Capability](50.md)
- [NIP-51: Lists](51.md)
- [NIP-52: Calendar Events](52.md)
- [NIP-53: Live Activities](53.md)
- [NIP-54: Wiki](54.md)
- [NIP-55: Android Signer Application](55.md)
- [NIP-56: Reporting](56.md)
- [NIP-57: Lightning Zaps](57.md)
- [NIP-58: Badges](58.md)
- [NIP-59: Gift Wrap](59.md)
- [NIP-60: Cashu Wallet](60.md)
- [NIP-61: Nutzaps](61.md)
- [NIP-62: Request to Vanish](62.md)
- [NIP-64: Chess (PGN)](64.md)
- [NIP-65: Relay List Metadata](65.md)
- [NIP-66: Relay Discovery and Liveness Monitoring](66.md)
- [NIP-68: Picture-first feeds](68.md)
- [NIP-69: Peer-to-peer Order events](69.md)
- [NIP-70: Protected Events](70.md)
- [NIP-71: Video Events](71.md)
- [NIP-72: Moderated Communities](72.md)
- [NIP-73: External Content IDs](73.md)
- [NIP-75: Zap Goals](75.md)
- [NIP-78: Application-specific data](78.md)
- [NIP-84: Highlights](84.md)
- [NIP-86: Relay Management API](86.md)
- [NIP-88: Polls](88.md)
- [NIP-89: Recommended Application Handlers](89.md)
- [NIP-90: Data Vending Machines](90.md)
- [NIP-92: Media Attachments](92.md)
- [NIP-94: File Metadata](94.md)
- [NIP-96: HTTP File Storage Integration](96.md)
- [NIP-98: HTTP Auth](98.md)
- [NIP-99: Classified Listings](99.md)
- [NIP-7D: Threads](7D.md)
- [NIP-C7: Chats](C7.md)
## Event Kinds
| kind | description | NIP |
| ------------- | ------------------------------- | -------------------------------------- |
| `0` | User Metadata | [01](01.md) |
| `1` | Short Text Note | [10](10.md) |
| `2` | Recommend Relay | 01 (deprecated) |
| `3` | Follows | [02](02.md) |
| `4` | Encrypted Direct Messages | [04](04.md) |
| `5` | Event Deletion Request | [09](09.md) |
| `6` | Repost | [18](18.md) |
| `7` | Reaction | [25](25.md) |
| `8` | Badge Award | [58](58.md) |
| `9` | Chat Message | [C7](C7.md) |
| `10` | Group Chat Threaded Reply | 29 (deprecated) |
| `11` | Thread | [7D](7D.md) |
| `12` | Group Thread Reply | 29 (deprecated) |
| `13` | Seal | [59](59.md) |
| `14` | Direct Message | [17](17.md) |
| `15` | File Message | [17](17.md) |
| `16` | Generic Repost | [18](18.md) |
| `17` | Reaction to a website | [25](25.md) |
| `20` | Picture | [68](68.md) |
| `21` | Video Event | [71](71.md) |
| `22` | Short-form Portrait Video Event | [71](71.md) |
| `30` | internal reference | [NKBIP-03] |
| `31` | external web reference | [NKBIP-03] |
| `32` | hardcopy reference | [NKBIP-03] |
| `33` | prompt reference | [NKBIP-03] |
| `40` | Channel Creation | [28](28.md) |
| `41` | Channel Metadata | [28](28.md) |
| `42` | Channel Message | [28](28.md) |
| `43` | Channel Hide Message | [28](28.md) |
| `44` | Channel Mute User | [28](28.md) |
| `62` | Request to Vanish | [62](62.md) |
| `64` | Chess (PGN) | [64](64.md) |
| `818` | Merge Requests | [54](54.md) |
| `1018` | Poll Response | [88](88.md) |
| `1021` | Bid | [15](15.md) |
| `1022` | Bid confirmation | [15](15.md) |
| `1040` | OpenTimestamps | [03](03.md) |
| `1059` | Gift Wrap | [59](59.md) |
| `1063` | File Metadata | [94](94.md) |
| `1068` | Poll | [88](88.md) |
| `1111` | Comment | [22](22.md) |
| `1311` | Live Chat Message | [53](53.md) |
| `1617` | Patches | [34](34.md) |
| `1621` | Issues | [34](34.md) |
| `1622` | Git Replies (deprecated) | [34](34.md) |
| `1630`-`1633` | Status | [34](34.md) |
| `1971` | Problem Tracker | [nostrocket][nostrocket] |
| `1984` | Reporting | [56](56.md) |
| `1985` | Label | [32](32.md) |
| `1986` | Relay reviews | |
| `1987` | AI Embeddings / Vector lists | [NKBIP-02] |
| `2003` | Torrent | [35](35.md) |
| `2004` | Torrent Comment | [35](35.md) |
| `2022` | Coinjoin Pool | [joinstr][joinstr] |
| `4550` | Community Post Approval | [72](72.md) |
| `5000`-`5999` | Job Request | [90](90.md) |
| `6000`-`6999` | Job Result | [90](90.md) |
| `7000` | Job Feedback | [90](90.md) |
| `7374` | Reserved Cashu Wallet Tokens | [60](60.md) |
| `7375` | Cashu Wallet Tokens | [60](60.md) |
| `7376` | Cashu Wallet History | [60](60.md) |
| `9000`-`9030` | Group Control Events | [29](29.md) |
| `9041` | Zap Goal | [75](75.md) |
| `9321` | Nutzap | [61](61.md) |
| `9467` | Tidal login | [Tidal-nostr] |
| `9734` | Zap Request | [57](57.md) |
| `9735` | Zap | [57](57.md) |
| `9802` | Highlights | [84](84.md) |
| `10000` | Mute list | [51](51.md) |
| `10001` | Pin list | [51](51.md) |
| `10002` | Relay List Metadata | [65](65.md), [51](51.md) |
| `10003` | Bookmark list | [51](51.md) |
| `10004` | Communities list | [51](51.md) |
| `10005` | Public chats list | [51](51.md) |
| `10006` | Blocked relays list | [51](51.md) |
| `10007` | Search relays list | [51](51.md) |
| `10009` | User groups | [51](51.md), [29](29.md) |
| `10013` | Private event relay list | [37](37.md) |
| `10015` | Interests list | [51](51.md) |
| `10019` | Nutzap Mint Recommendation | [61](61.md) |
| `10030` | User emoji list | [51](51.md) |
| `10050` | Relay list to receive DMs | [51](51.md), [17](17.md) |
| `10063` | User server list | [Blossom][blossom] |
| `10096` | File storage server list | [96](96.md) |
| `10166` | Relay Monitor Announcement | [66](66.md) |
| `13194` | Wallet Info | [47](47.md) |
| `17375` | Cashu Wallet Event | [60](60.md) |
| `21000` | Lightning Pub RPC | [Lightning.Pub][lnpub] |
| `22242` | Client Authentication | [42](42.md) |
| `23194` | Wallet Request | [47](47.md) |
| `23195` | Wallet Response | [47](47.md) |
| `24133` | Nostr Connect | [46](46.md) |
| `24242` | Blobs stored on mediaservers | [Blossom][blossom] |
| `27235` | HTTP Auth | [98](98.md) |
| `30000` | Follow sets | [51](51.md) |
| `30001` | Generic lists | 51 (deprecated) |
| `30002` | Relay sets | [51](51.md) |
| `30003` | Bookmark sets | [51](51.md) |
| `30004` | Curation sets | [51](51.md) |
| `30005` | Video sets | [51](51.md) |
| `30007` | Kind mute sets | [51](51.md) |
| `30008` | Profile Badges | [58](58.md) |
| `30009` | Badge Definition | [58](58.md) |
| `30015` | Interest sets | [51](51.md) |
| `30017` | Create or update a stall | [15](15.md) |
| `30018` | Create or update a product | [15](15.md) |
| `30019` | Marketplace UI/UX | [15](15.md) |
| `30020` | Product sold as an auction | [15](15.md) |
| `30023` | Long-form Content | [23](23.md) |
| `30024` | Draft Long-form Content | [23](23.md) |
| `30030` | Emoji sets | [51](51.md) |
| `30040` | Curated Publication Index | [NKBIP-01] |
| `30041` | Curated Publication Content | [NKBIP-01] |
| `30063` | Release artifact sets | [51](51.md) |
| `30078` | Application-specific Data | [78](78.md) |
| `30166` | Relay Discovery | [66](66.md) |
| `30267` | App curation sets | [51](51.md) |
| `30311` | Live Event | [53](53.md) |
| `30315` | User Statuses | [38](38.md) |
| `30388` | Slide Set | [Corny Chat][cornychat-slideset] |
| `30402` | Classified Listing | [99](99.md) |
| `30403` | Draft Classified Listing | [99](99.md) |
| `30617` | Repository announcements | [34](34.md) |
| `30618` | Repository state announcements | [34](34.md) |
| `30818` | Wiki article | [54](54.md) |
| `30819` | Redirects | [54](54.md) |
| `31234` | Draft Event | [37](37.md) |
| `31388` | Link Set | [Corny Chat][cornychat-linkset] |
| `31890` | Feed | [NUD: Custom Feeds][NUD: Custom Feeds] |
| `31922` | Date-Based Calendar Event | [52](52.md) |
| `31923` | Time-Based Calendar Event | [52](52.md) |
| `31924` | Calendar | [52](52.md) |
| `31925` | Calendar Event RSVP | [52](52.md) |
| `31989` | Handler recommendation | [89](89.md) |
| `31990` | Handler information | [89](89.md) | |
| `32267` | Software Application | | |
| `34550` | Community Definition | [72](72.md) |
| `38383` | Peer-to-peer Order events | [69](69.md) |
| `39000-9` | Group metadata events | [29](29.md) |
[NUD: Custom Feeds]: https://wikifreedia.xyz/cip-01/
[nostrocket]: https://github.com/nostrocket/NIPS/blob/main/Problems.md
[lnpub]: https://github.com/shocknet/Lightning.Pub/blob/master/proto/autogenerated/client.md
[cornychat-slideset]: https://cornychat.com/datatypes#kind30388slideset
[cornychat-linkset]: https://cornychat.com/datatypes#kind31388linkset
[joinstr]: https://gitlab.com/1440000bytes/joinstr/-/blob/main/NIP.md
[NKBIP-01]: https://wikistr.com/nkbip-01*fd208ee8c8f283780a9552896e4823cc9dc6bfd442063889577106940fd927c1
[NKBIP-02]: https://wikistr.com/nkbip-02*fd208ee8c8f283780a9552896e4823cc9dc6bfd442063889577106940fd927c1
[NKBIP-03]: https://wikistr.com/nkbip-03*fd208ee8c8f283780a9552896e4823cc9dc6bfd442063889577106940fd927c1
[blossom]: https://github.com/hzrd149/blossom
[Tidal-nostr]: https://wikistr.com/tidal-nostr
## Message types
### Client to Relay
| type | description | NIP |
| ------- | --------------------------------------------------- | ----------- |
| `EVENT` | used to publish events | [01](01.md) |
| `REQ` | used to request events and subscribe to new updates | [01](01.md) |
| `CLOSE` | used to stop previous subscriptions | [01](01.md) |
| `AUTH` | used to send authentication events | [42](42.md) |
| `COUNT` | used to request event counts | [45](45.md) |
### Relay to Client
| type | description | NIP |
| -------- | ------------------------------------------------------- | ----------- |
| `EOSE` | used to notify clients all stored events have been sent | [01](01.md) |
| `EVENT` | used to send events requested to clients | [01](01.md) |
| `NOTICE` | used to send human-readable messages to clients | [01](01.md) |
| `OK` | used to notify clients if an EVENT was successful | [01](01.md) |
| `CLOSED` | used to notify clients that a REQ was ended and why | [01](01.md) |
| `AUTH` | used to send authentication challenges | [42](42.md) |
| `COUNT` | used to send requested event counts to clients | [45](45.md) |
## Standardized Tags
| name | value | other parameters | NIP |
| ----------------- | ------------------------------------ | ------------------------------- | -------------------------------------------------- |
| `a` | coordinates to an event | relay URL | [01](01.md) |
| `A` | root address | relay URL | [22](22.md) |
| `d` | identifier | -- | [01](01.md) |
| `e` | event id (hex) | relay URL, marker, pubkey (hex) | [01](01.md), [10](10.md) |
| `E` | root event id | relay URL | [22](22.md) |
| `f` | currency code | -- | [69](69.md) |
| `g` | geohash | -- | [52](52.md) |
| `h` | group id | -- | [29](29.md) |
| `i` | external identity | proof, url hint | [35](35.md), [39](39.md), [73](73.md) |
| `I` | root external identity | -- | [22](22.md) |
| `k` | kind | -- | [18](18.md), [25](25.md), [72](72.md), [73](73.md) |
| `K` | root scope | -- | [22](22.md) |
| `l` | label, label namespace | -- | [32](32.md) |
| `L` | label namespace | -- | [32](32.md) |
| `m` | MIME type | -- | [94](94.md) |
| `p` | pubkey (hex) | relay URL, petname | [01](01.md), [02](02.md), [22](22.md) |
| `P` | pubkey (hex) | -- | [22](22.md), [57](57.md) |
| `q` | event id (hex) | relay URL, pubkey (hex) | [18](18.md) |
| `r` | a reference (URL, etc) | -- | [24](24.md), [25](25.md) |
| `r` | relay url | marker | [65](65.md) |
| `s` | status | -- | [69](69.md) |
| `t` | hashtag | -- | [24](24.md), [34](34.md), [35](35.md) |
| `u` | url | -- | [61](61.md), [98](98.md) |
| `x` | hash | -- | [35](35.md), [56](56.md) |
| `y` | platform | -- | [69](69.md) |
| `z` | order number | -- | [69](69.md) |
| `-` | -- | -- | [70](70.md) |
| `alt` | summary | -- | [31](31.md) |
| `amount` | millisatoshis, stringified | -- | [57](57.md) |
| `bolt11` | `bolt11` invoice | -- | [57](57.md) |
| `challenge` | challenge string | -- | [42](42.md) |
| `client` | name, address | relay URL | [89](89.md) |
| `clone` | git clone URL | -- | [34](34.md) |
| `content-warning` | reason | -- | [36](36.md) |
| `delegation` | pubkey, conditions, delegation token | -- | [26](26.md) |
| `description` | description | -- | [34](34.md), [57](57.md), [58](58.md) |
| `emoji` | shortcode, image URL | -- | [30](30.md) |
| `encrypted` | -- | -- | [90](90.md) |
| `expiration` | unix timestamp (string) | -- | [40](40.md) |
| `file` | full path (string) | -- | [35](35.md) |
| `goal` | event id (hex) | relay URL | [75](75.md) |
| `image` | image URL | dimensions in pixels | [23](23.md), [52](52.md), [58](58.md) |
| `imeta` | inline metadata | -- | [92](92.md) |
| `lnurl` | `bech32` encoded `lnurl` | -- | [57](57.md) |
| `location` | location string | -- | [52](52.md), [99](99.md) |
| `name` | name | -- | [34](34.md), [58](58.md), [72](72.md) |
| `nonce` | random | difficulty | [13](13.md) |
| `preimage` | hash of `bolt11` invoice | -- | [57](57.md) |
| `price` | price | currency, frequency | [99](99.md) |
| `proxy` | external ID | protocol | [48](48.md) |
| `published_at` | unix timestamp (string) | -- | [23](23.md) |
| `relay` | relay url | -- | [42](42.md), [17](17.md) |
| `relays` | relay list | -- | [57](57.md) |
| `server` | file storage server url | -- | [96](96.md) |
| `subject` | subject | -- | [14](14.md), [17](17.md), [34](34.md) |
| `summary` | summary | -- | [23](23.md), [52](52.md) |
| `thumb` | badge thumbnail | dimensions in pixels | [58](58.md) |
| `title` | article title | -- | [23](23.md) |
| `tracker` | torrent tracker URL | -- | [35](35.md) |
| `web` | webpage URL | -- | [34](34.md) |
| `zap` | pubkey (hex), relay URL | weight | [57](57.md) |
Please update these lists when proposing new NIPs.
## Criteria for acceptance of NIPs
1. They should be fully implemented in at least two clients and one relay -- when applicable.
2. They should make sense.
3. They should be optional and backwards-compatible: care must be taken such that clients and relays that choose to not implement them do not stop working when interacting with the ones that choose to.
4. There should be no more than one way of doing the same thing.
5. Other rules will be made up when necessary.
## Is this repository a centralizing factor?
To promote interoperability, we need standards that everybody can follow, and we need them to define a **single way of doing each thing** without ever hurting **backwards-compatibility**, and for that purpose there is no way around getting everybody to agree on the same thing and keep a centralized index of these standards. However the fact that such an index exists doesn't hurt the decentralization of Nostr. _At any point the central index can be challenged if it is failing to fulfill the needs of the protocol_ and it can migrate to other places and be maintained by other people.
It can even fork into multiple versions, and then some clients would go one way, others would go another way, and some clients would adhere to both competing standards. This would hurt the simplicity, openness and interoperability of Nostr a little, but everything would still work in the short term.
There is a list of notable Nostr software developers who have commit access to this repository, but that exists mostly for practical reasons, as by the nature of the thing we're dealing with the repository owner can revoke membership and rewrite history as they want -- and if these actions are unjustified or perceived as bad or evil the community must react.
## How this repository works
Standards may emerge in two ways: the first way is that someone starts doing something, then others copy it; the second way is that someone has an idea of a new standard that could benefit multiple clients and the protocol in general without breaking **backwards-compatibility** and the principle of having **a single way of doing things**, then they write that idea and submit it to this repository, other interested parties read it and give their feedback, then once most people reasonably agree we codify that in a NIP which client and relay developers that are interested in the feature can proceed to implement.
These two ways of standardizing things are supported by this repository. Although the second is preferred, an effort will be made to codify standards emerged outside this repository into NIPs that can be later referenced and easily understood and implemented by others -- but obviously as in any human system discretion may be applied when standards are considered harmful.
## Breaking Changes
[Breaking Changes](BREAKING.md)
## License
All NIPs are public domain.
## Contributors
<a align="center" href="https://github.com/nostr-protocol/nips/graphs/contributors">
<img src="https://contrib.rocks/image?repo=nostr-protocol/nips" />
</a>
-
@ 30876140:cffb1126
2025-03-26 04:58:21
The portal is closing.
The symphony comes to an end.
Ballet, a dance of partners,
A wish of hearts,
Now closing its curtains.
I foolishly sit
Eagerly waiting
For the circus to begin again,
As crowds file past me,
Chuckles and popcorn falling,
Crushed under foot,
I sit waiting
For the show to carry on.
But the night is now over,
The laughs have been had,
The music been heard,
The dancers are gone now
Into the nightbreeze chill.
Yet still, I sit waiting,
The empty chairs yawning,
A cough, I start, could it be?
Yet the lights now go out,
And now without my sight
I am truly alone in the theater.
Yet still, I am waiting
For the show to carry on,
But I know that it won’t,
Yet still, I am waiting.
Never shall I leave
For the show was too perfect
And nothing perfect should ever be finished.
-
@ fd06f542:8d6d54cd
2025-03-28 02:14:43
{"coverurl":"https://cdn.nostrcheck.me/fd06f542bc6c06a39881810de917e6c5d277dfb51689a568ad7b7a548d6d54cd/5ad7189d30c9b49aa61652d98ac7853217b7e445f863be09f9745c49df9f514c.webp","title":"Nostr protocol","author":"fiatjaf"}
-
@ 50de492c:0a8871de
2025-03-30 00:23:36
{"title":"test","description":"","imageUrl":"https://i.nostr.build/Xo67.png"}
-
@ ecda4328:1278f072
2025-03-25 10:00:52
**Kubernetes and Linux Swap: A Practical Perspective**
After reviewing kernel documentation on swap management (e.g., [Linux Swap Management](https://www.kernel.org/doc/gorman/html/understand/understand014.html)), [KEP-2400 (Kubernetes Node Memory Swap Support)](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2400-node-swap/README.md), and community discussions like [this post on ServerFault](https://serverfault.com/questions/881517/why-disable-swap-on-kubernetes), it's clear that the topic of swap usage in modern systems—especially Kubernetes environments—is nuanced and often contentious. Here's a practical synthesis of the discussion.
---
### The Rationale for Disabling Swap
We disable SWAP on our Linux servers to ensure stable and predictable performance by relying on available RAM, avoiding the performance degradation and unnecessary I/O caused by SWAP usage. If an application runs out of memory, it’s usually due to insufficient RAM allocation or a memory leak, and enabling SWAP only worsens performance for other applications. It's more efficient to let a leaking app restart than to rely on SWAP to prevent OOM crashes.
With modern platforms like Kubernetes, memory requests and limits are enforced, ensuring apps use only the RAM allocated to them, while avoiding overcommitment to prevent resource exhaustion.
Additionally, disabling swap may protect data from **data remanence attacks**, where sensitive information could potentially be recovered from the swap space even after a process terminates.
---
### Theoretical Capability vs. Practical Deployment
Linux provides a powerful and flexible memory subsystem. With proper tuning (e.g., swappiness, memory pinning, cgroups), it's technically possible to make swap usage efficient and targeted. Seasoned sysadmins often argue that disabling swap entirely is a lazy shortcut—an avoidance of learning how to use the tools properly.
But Kubernetes is not a traditional system. It's an orchestrated environment that favors predictability, fail-fast behavior, and clear isolation between workloads. Within this model:
- Memory **requests and limits** are declared explicitly.
- The scheduler makes decisions based on RAM availability, not total virtual memory (RAM + swap).
- Swap introduces **non-deterministic performance** characteristics that conflict with Kubernetes' goals.
So while the kernel supports intelligent swap usage, Kubernetes **intentionally sidesteps** that complexity.
---
### Why Disable Swap in Kubernetes?
1. **Deterministic Failure > Degraded Performance**\
If a pod exceeds its memory allocation, it should fail fast — not get throttled into slow oblivion due to swap. This behavior surfaces bugs (like memory leaks or poor sizing) early.
2. **Transparency & Observability**\
With swap disabled, memory issues are clearer to diagnose. Swap obfuscates root causes and can make a healthy-looking node behave erratically.
3. **Performance Consistency**\
Swap causes I/O overhead. One noisy pod using swap can impact unrelated workloads on the same node — even if they’re within their resource limits.
4. **Kubernetes Doesn’t Manage Swap Well**\
Kubelet has historically lacked intelligence around swap. As of today, Kubernetes still doesn't support swap-aware scheduling or per-container swap control.
5. **Statelessness is the Norm**\
Most containerized workloads are designed to be ephemeral. Restarting a pod is usually preferable to letting it hang in a degraded state.
---
### "But Swap Can Be Useful..."
Yes — for certain workloads (e.g., in-memory databases, caching layers, legacy systems), there may be valid reasons to keep swap enabled. In such cases, you'd need:
- Fine-tuned `vm.swappiness`
- Memory pinning and cgroup-based control
- Swap-aware monitoring and alerting
- Custom kubelet/systemd integration
That's possible, but **not standard practice** — and for good reason.
---
### Future Considerations
Recent Kubernetes releases have introduced [experimental swap support](https://kubernetes.io/blog/2023/08/24/swap-linux-beta/) via [KEP-2400](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2400-node-swap/README.md). While this provides more flexibility for advanced use cases — particularly Burstable QoS pods on cgroupsv2 — swap remains disabled by default and is not generally recommended for production workloads unless carefully planned. The rationale outlined in this article remains applicable to most Kubernetes operators, especially in multi-tenant and performance-sensitive environments.
Even the Kubernetes maintainers acknowledge the inherent trade-offs of enabling swap. As noted in [KEP-2400's Risks and Mitigations section](https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/2400-node-swap/README.md), swap introduces unpredictability, can severely degrade performance compared to RAM, and complicates Kubernetes' resource accounting — increasing the risk of noisy neighbors and unexpected scheduling behavior.
Some argue that with emerging technologies like **non-volatile memory** (e.g., Intel Optane/XPoint), swap may become viable again. These systems promise near-RAM speed with large capacity, offering hybrid memory models. But these are not widely deployed or supported in mainstream Kubernetes environments yet.
---
### Conclusion
Disabling swap in Kubernetes is not a lazy hack — it’s a **strategic tradeoff**. It improves transparency, predictability, and system integrity in multi-tenant, containerized environments. While the kernel allows for more advanced configurations, Kubernetes intentionally simplifies memory handling for the sake of reliability.
If we want to revisit swap usage, it should come with serious planning: proper instrumentation, swap-aware observability, and potentially upstream K8s improvements. Until then, **disabling swap remains the sane default**.
-
@ e6817453:b0ac3c39
2024-12-07 15:06:43
I started a long series of articles about how to model different types of knowledge graphs in the relational model, which makes on-device memory models for AI agents possible.
We model-directed graphs
Also, graphs of entities
We even model hypergraphs
Last time, we discussed why classical triple and simple knowledge graphs are insufficient for AI agents and complex memory, especially in the domain of time-aware or multi-model knowledge.
So why do we need metagraphs, and what kind of challenge could they help us to solve?
- complex and nested event and temporal context and temporal relations as edges
- multi-mode and multilingual knowledge
- human-like memory for AI agents that has multiple contexts and relations between knowledge in neuron-like networks
## MetaGraphs
A meta graph is a concept that extends the idea of a graph by allowing edges to become graphs. Meta Edges connect a set of nodes, which could also be subgraphs. So, at some level, node and edge are pretty similar in properties but act in different roles in a different context.
Also, in some cases, edges could be referenced as nodes.
This approach enables the representation of more complex relationships and hierarchies than a traditional graph structure allows. Let’s break down each term to understand better metagraphs and how they differ from hypergraphs and graphs.
## Graph Basics
- A standard **graph** has a set of **nodes** (or vertices) and **edges** (connections between nodes).
- Edges are generally simple and typically represent a binary relationship between two nodes.
- For instance, an edge in a social network graph might indicate a “friend” relationship between two people (nodes).
## Hypergraph
- A **hypergraph** extends the concept of an edge by allowing it to connect any number of nodes, not just two.
- Each connection, called a **hyperedge**, can link multiple nodes.
- This feature allows hypergraphs to model more complex relationships involving multiple entities simultaneously. For example, a hyperedge in a hypergraph could represent a project team, connecting all team members in a single relation.
- Despite its flexibility, a hypergraph doesn’t capture hierarchical or nested structures; it only generalizes the number of connections in an edge.
## Metagraph
- A **metagraph** allows the edges to be graphs themselves. This means each edge can contain its own nodes and edges, creating nested, hierarchical structures.
- In a meta graph, an edge could represent a relationship defined by a graph. For instance, a meta graph could represent a network of organizations where each organization’s structure (departments and connections) is represented by its own internal graph and treated as an edge in the larger meta graph.
- This recursive structure allows metagraphs to model complex data with multiple layers of abstraction. They can capture multi-node relationships (as in hypergraphs) and detailed, structured information about each relationship.
## Named Graphs and Graph of Graphs
As you can notice, the structure of a metagraph is quite complex and could be complex to model in relational and classical RDF setups. It could create a challenge of luck of tools and software solutions for your problem.
If you need to model nested graphs, you could use a much simpler model of Named graphs, which could take you quite far.
The concept of the named graph came from the RDF community, which needed to group some sets of triples. In this way, you form subgraphs inside an existing graph. You could refer to the subgraph as a regular node. This setup simplifies complex graphs, introduces hierarchies, and even adds features and properties of hypergraphs while keeping a directed nature.
It looks complex, but it is not so hard to model it with a slight modification of a directed graph.
So, the node could host graphs inside. Let's reflect this fact with a location for a node. If a node belongs to a main graph, we could set the location to null or introduce a main node . it is up to you
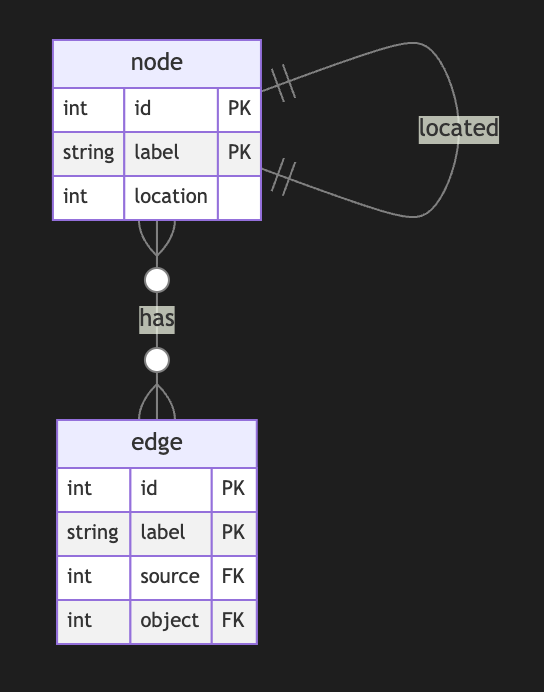
Nodes could have edges to nodes in different subgraphs. This structure allows any kind of nesting graphs. Edges stay location-free
## Meta Graphs in Relational Model
Let’s try to make several attempts to model different meta-graphs with some constraints.
## Directed Metagraph where edges are not used as nodes and could not contain subgraphs
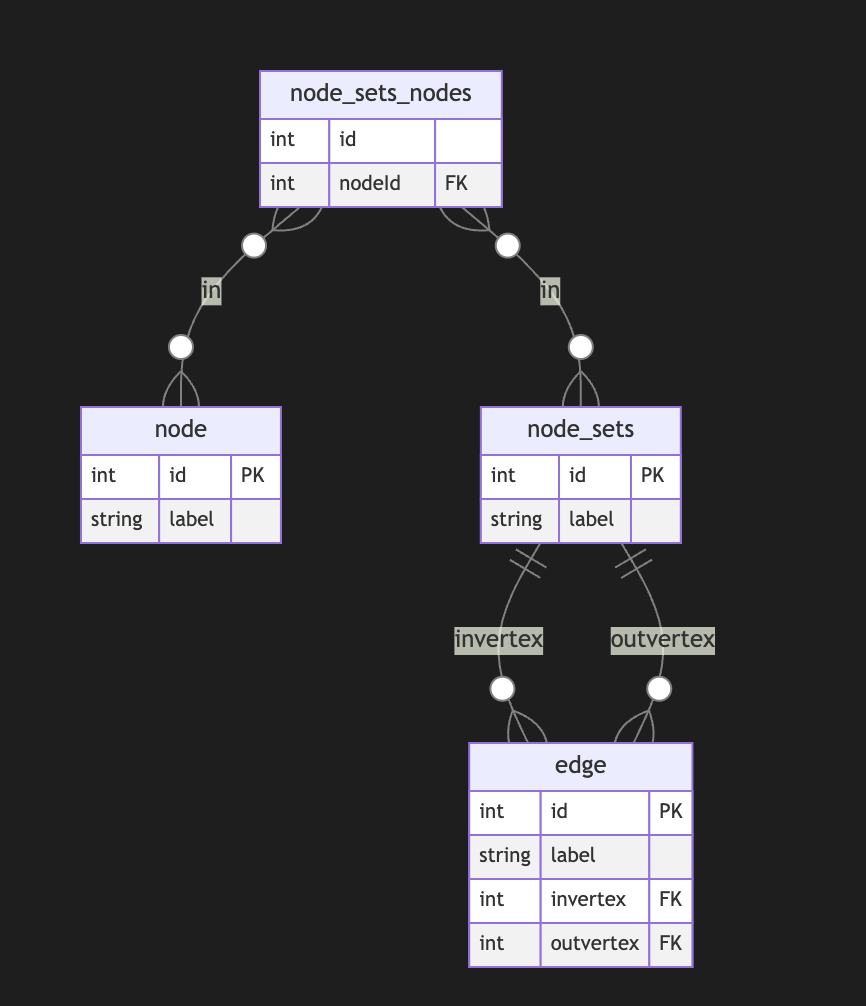
In this case, the edge always points to two sets of nodes. This introduces an overhead of creating a node set for a single node. In this model, we can model empty node sets that could require application-level constraints to prevent such cases.
## Directed Metagraph where edges are not used as nodes and could contain subgraphs
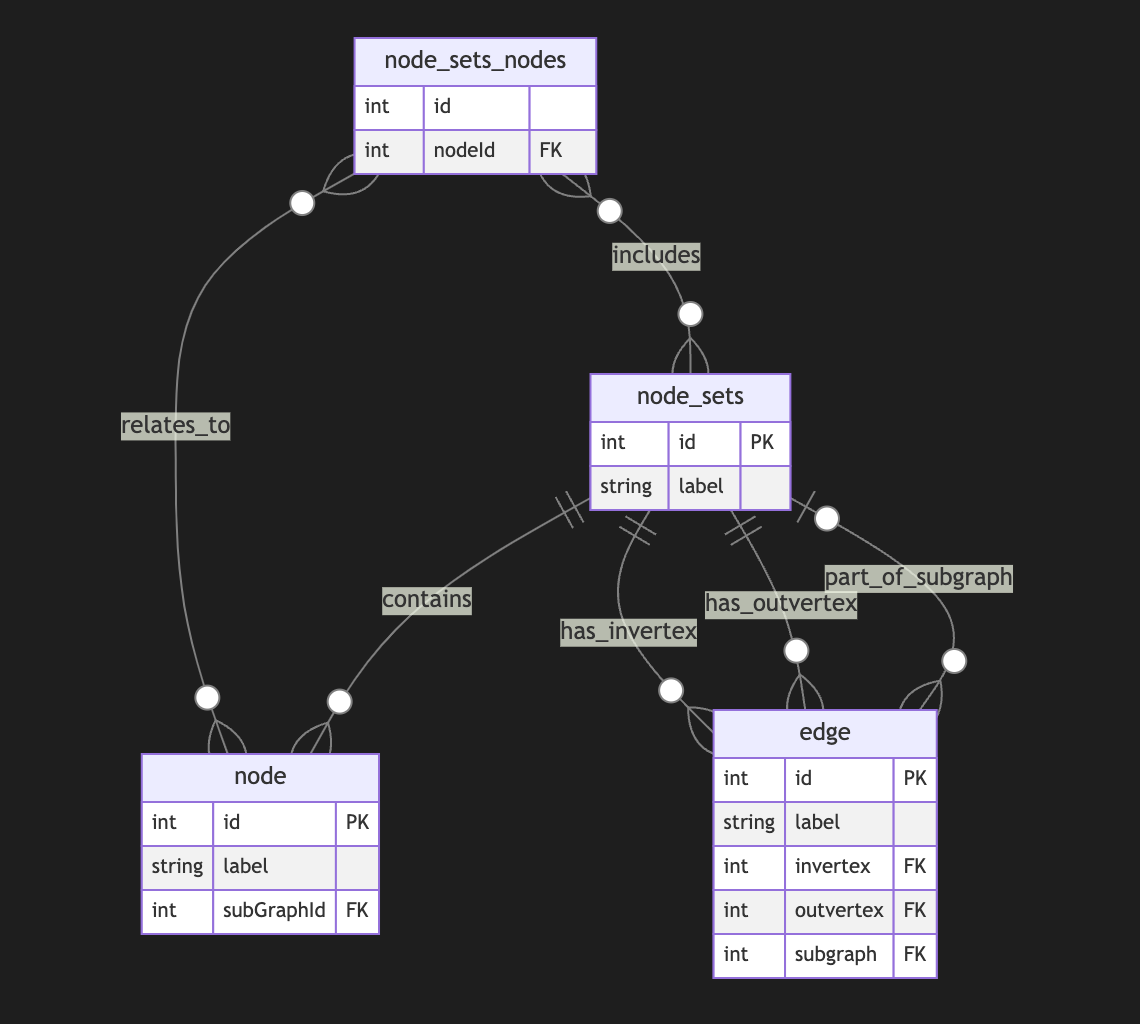
Adding a node set that could model a subgraph located in an edge is easy but could be separate from in-vertex or out-vert.
I also do not see a direct need to include subgraphs to a node, as we could just use a node set interchangeably, but it still could be a case.
## Directed Metagraph where edges are used as nodes and could contain subgraphs
As you can notice, we operate all the time with node sets. We could simply allow the extension node set to elements set that include node and edge IDs, but in this case, we need to use uuid or any other strategy to differentiate node IDs from edge IDs. In this case, we have a collision of ephemeral edges or ephemeral nodes when we want to change the role and purpose of the node as an edge or vice versa.
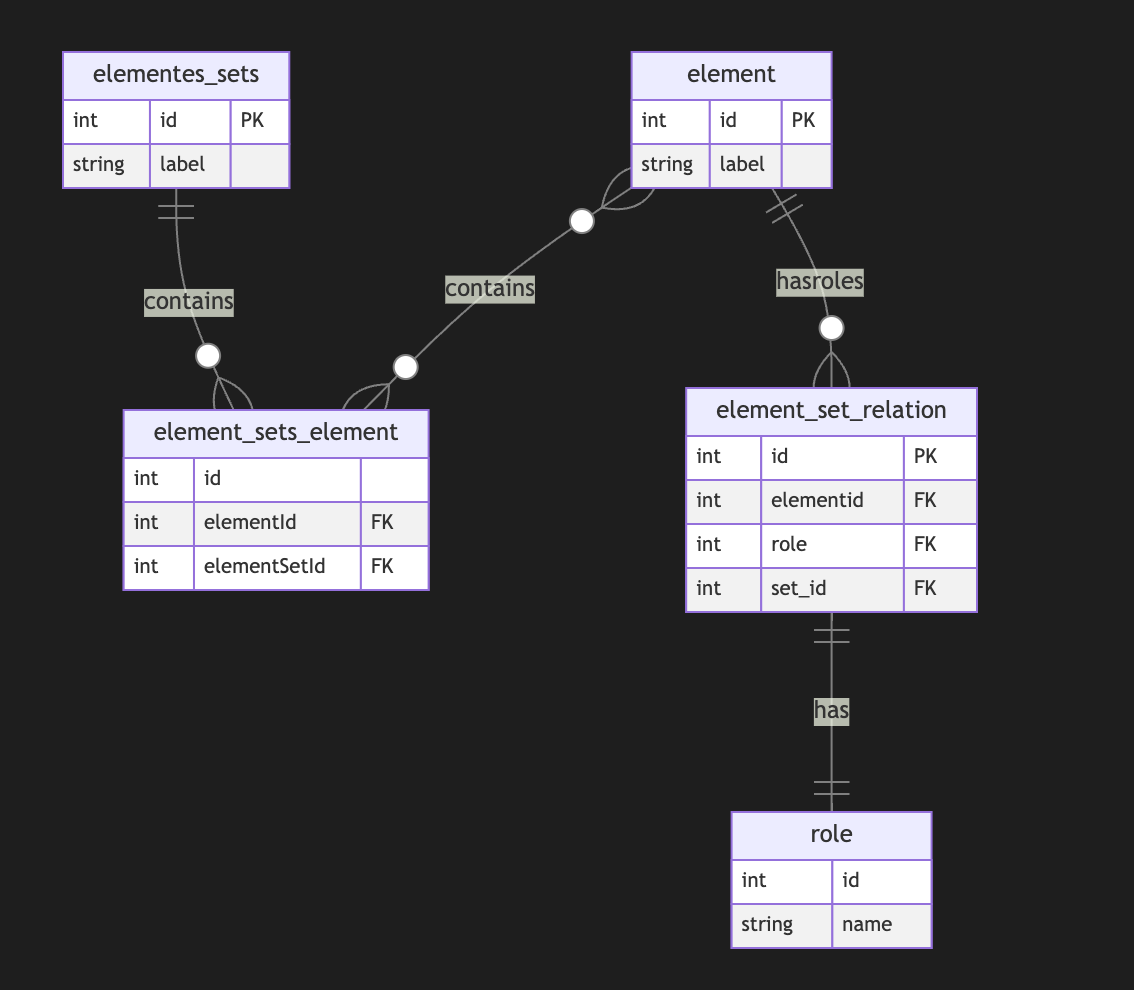
A full-scale metagraph model is way too complex for a relational database.
So we need a better model.
Now, we have more flexibility but loose structural constraints. We cannot show that the element should have one vertex, one vertex, or both. This type of constraint has been moved to the application level. Also, the crucial question is about query and retrieval needs.
Any meta-graph model should be more focused on domain and needs and should be used in raw form. We did it for a pure theoretical purpose.
-
@ 872982aa:8fb54cfe
2025-03-27 05:50:35
NIP-03
======
OpenTimestamps Attestations for Events
--------------------------------------
`draft` `optional`
This NIP defines an event with `kind:1040` that can contain an [OpenTimestamps](https://opentimestamps.org/) proof for any other event:
```json
{
"kind": 1040
"tags": [
["e", <event-id>, <relay-url>],
["alt", "opentimestamps attestation"]
],
"content": <base64-encoded OTS file data>
}
```
- The OpenTimestamps proof MUST prove the referenced `e` event id as its digest.
- The `content` MUST be the full content of an `.ots` file containing at least one Bitcoin attestation. This file SHOULD contain a **single** Bitcoin attestation (as not more than one valid attestation is necessary and less bytes is better than more) and no reference to "pending" attestations since they are useless in this context.
### Example OpenTimestamps proof verification flow
Using [`nak`](https://github.com/fiatjaf/nak), [`jq`](https://jqlang.github.io/jq/) and [`ots`](https://github.com/fiatjaf/ots):
```bash
~> nak req -i e71c6ea722987debdb60f81f9ea4f604b5ac0664120dd64fb9d23abc4ec7c323 wss://nostr-pub.wellorder.net | jq -r .content | ots verify
> using an esplora server at https://blockstream.info/api
- sequence ending on block 810391 is valid
timestamp validated at block [810391]
```
-
@ 3514ac1b:cf164691
2025-03-29 22:07:33
# About Me
-
@ 57d1a264:69f1fee1
2025-03-24 17:08:06
Nice podcast with @sbddesign and @ConorOkus about bitcoin payments.
https://www.youtube.com/watch?v=GTSqoFKs1cE
In this episode, Conor, Open Source product manager at Spiral & Stephen, Product Designer at Voltage & Co founder of ATL Bitlab join Stephan to discuss the current state of Bitcoin user experience, particularly focusing on payments and the challenges faced by users. They explore the comparison between Bitcoin and physical cash, the Western perspective on Bitcoin payments, and the importance of user experience in facilitating Bitcoin transactions.
They also touch upon various payment protocols like #BOLT11, #LNURL, and #BOLT12, highlighting the need for interoperability and better privacy features in the Bitcoin ecosystem. The discussion also covers resources available for developers and designers to enhance wallet usability and integration.
@StephanLivera Official Podcast Episode: https://stephanlivera.com/646
### Takeaways
🔸Bitcoin has excelled as a savings technology.
🔸The payments use case for Bitcoin still needs improvement.
🔸User experience is crucial for Bitcoin adoption.
🔸Comparing Bitcoin to cash highlights privacy concerns.
🔸Western users may not see a payments problem.
🔸Regulatory issues impact Bitcoin payments in the West.
🔸User experience challenges hinder Bitcoin transactions.
🔸Different payment protocols create compatibility issues.
🔸Community collaboration is essential for Bitcoin's future.
🔸Improving interoperability can enhance Bitcoin payments. Wallet compatibility issues can create negative user impressions.
🔸Designers can significantly improve wallet user experience.
🔸Testing compatibility between wallets is essential for user satisfaction.
🔸Tether's integration may boost Bitcoin adoption.
🔸Developers should prioritize payment capabilities before receiving capabilities.
🔸Collaboration between designers and developers can lead to better products.
🔸User experience improvements can be low-hanging fruit for wallet projects.
🔸A global hackathon aims to promote miner decentralization.
🔸Resources like BOLT12 and the Bitcoin Design Guide are valuable for developers.
🔸Engaging with the community can lead to innovative solutions.
### Timestamps
([00:00](/watch?v=GTSqoFKs1cE)) - Intro
([01:10](/watch?v=GTSqoFKs1cE&t=70s)) - What is the current state of Bitcoin usage - Payments or Savings?
([04:32](/watch?v=GTSqoFKs1cE&t=272s)) - Comparing Bitcoin with physical cash
([07:08](/watch?v=GTSqoFKs1cE&t=428s)) - What is the western perspective on Bitcoin payments?
([11:30](/watch?v=GTSqoFKs1cE&t=690s)) - Would people use Bitcoin more with improved UX?
([17:05](/watch?v=GTSqoFKs1cE&t=1025s)) - Exploring payment protocols: Bolt11, LNURL, Bolt12 & BIP353
([30:14](/watch?v=GTSqoFKs1cE&t=1814s)) - Navigating Bitcoin wallet compatibility challenges
([34:45](/watch?v=GTSqoFKs1cE&t=2085s)) - What is the role of designers in wallet development?
([43:13](/watch?v=GTSqoFKs1cE&t=2593s)) - Rumble’s integration of Tether & Bitcoin; The impact of Tether on Bitcoin adoption
([51:22](/watch?v=GTSqoFKs1cE&t=3082s)) - Resources for wallet developers and designers
### Links:
• [https://x.com/conorokus](https://x.com/conorokus)
• [https://x.com/StephenDeLorme](https://x.com/StephenDeLorme)
• [https://bolt12.org/](https://bolt12.org/)
• [https://twelve.cash/](https://twelve.cash)
• [https://bitcoin.design/guide/](https://bitcoin.design/guide/)
• Setting Up Bitcoin Tips for Streamers](/watch?v=IWTpSN8IaLE)
originally posted at https://stacker.news/items/923714
-
@ 872982aa:8fb54cfe
2025-03-27 05:47:40
NIP-03
======
OpenTimestamps Attestations for Events
--------------------------------------
`draft` `optional`
This NIP defines an event with `kind:1040` that can contain an [OpenTimestamps](https://opentimestamps.org/) proof for any other event:
```json
{
"kind": 1040
"tags": [
["e", <event-id>, <relay-url>],
["alt", "opentimestamps attestation"]
],
"content": <base64-encoded OTS file data>
}
```
- The OpenTimestamps proof MUST prove the referenced `e` event id as its digest.
- The `content` MUST be the full content of an `.ots` file containing at least one Bitcoin attestation. This file SHOULD contain a **single** Bitcoin attestation (as not more than one valid attestation is necessary and less bytes is better than more) and no reference to "pending" attestations since they are useless in this context.
### Example OpenTimestamps proof verification flow
Using [`nak`](https://github.com/fiatjaf/nak), [`jq`](https://jqlang.github.io/jq/) and [`ots`](https://github.com/fiatjaf/ots):
```bash
~> nak req -i e71c6ea722987debdb60f81f9ea4f604b5ac0664120dd64fb9d23abc4ec7c323 wss://nostr-pub.wellorder.net | jq -r .content | ots verify
> using an esplora server at https://blockstream.info/api
- sequence ending on block 810391 is valid
timestamp validated at block [810391]
```
-
@ 3514ac1b:cf164691
2025-03-29 21:58:22
Hi this is me ,Erna .
i am testing this Habla news .
i have been trying using this but got no luck .
always disconnect and no content .
Hopefully this one will work .
BREAKING NEWS : Vance uses Greenland visit to slam Denmark , as Trump escalates rhetoric .
https://wapo.st/4c6YkhO
-
@ 866e0139:6a9334e5
2025-03-24 10:50:59
**Autor:** *Ludwig F. Badenhagen.* *Dieser Beitrag wurde mit dem* *[Pareto-Client](https://pareto.space/read)* *geschrieben.*
***
Einer der wesentlichen Gründe dafür, dass während der „Corona-Pandemie“ so viele Menschen den Anweisungen der Spitzenpolitiker folgten, war sicher der, dass diese Menschen den Politikern vertrauten. Diese Menschen konnten sich nicht vorstellen, dass Spitzenpolitiker den Auftrag haben könnten, die Bürger analog klaren Vorgaben zu belügen, zu betrügen und sie vorsätzlich (tödlich) zu verletzen. Im Gegenteil, diese gutgläubigen Menschen waren mit der Zuversicht aufgewachsen, dass Spitzenpolitiker den Menschen dienen und deren Wohl im Fokus haben (müssen). Dies beteuerten Spitzenpolitiker schließlich stets in Talkshows und weiteren Medienformaten. Zwar wurden manche Politiker auch bei Fehlverhalten erwischt, aber hierbei ging es zumeist „nur“ um Geld und nicht um Leben. Und wenn es doch einmal um Leben ging, dann passieren die Verfehlungen „aus Versehen“, aber nicht mit Vorsatz. So oder so ähnlich dachte die Mehrheit der Bürger.
Aber vor 5 Jahren änderte sich für aufmerksame Menschen alles, denn analog dem Lockstep-Szenario der Rockefeller-Foundation wurde der zuvor ausgiebig vorbereitete Plan zur Inszenierung der „Corona-Pandemie“ Realität. Seitdem wurde so manchem Bürger, der sich jenseits von Mainstream-Medien informierte, das Ausmaß der unter dem Vorwand einer erfundenen Pandemie vollbrachten Taten klar. Und unverändert kommen täglich immer neue Erkenntnisse ans Licht. Auf den Punkt gebracht war die Inszenierung der „Corona-Pandemie“ ein Verbrechen an der Menschheit, konstatieren unabhängige Sachverständige.
Dieser Beitrag befasst sich allerdings nicht damit, die vielen Bestandteile dieses Verbrechens (nochmals) aufzuzählen oder weitere zu benennen. Stattdessen soll beleuchtet werden, warum die Spitzenpolitiker sich so verhalten haben und ob es überhaupt nach alledem möglich ist, der Politik jemals wieder zu vertrauen? Ferner ist es ein Anliegen dieses Artikels, die weiteren Zusammenhänge zu erörtern. Und zu guter Letzt soll dargelegt werden, warum sich der große Teil der Menschen unverändert alles gefallen lässt.
**Demokratie**
Von jeher organisierten sich Menschen mit dem Ziel, Ordnungsrahmen zu erschaffen, welche wechselseitiges Interagieren regeln. Dies führte aber stets dazu, dass einige wenige alle anderen unterordneten. Der Grundgedanke, der vor rund 2500 Jahren formulierten Demokratie, verfolgte dann aber das Ziel, dass die Masse darüber entscheiden können soll, wie sie leben und verwaltet werden möchte. Dieser Grundgedanke wurde von den Mächtigen sowohl gehasst als auch gefürchtet, denn die Gefahr lag nahe, dass die besitzlosen Vielen beispielsweise mit einer schlichten Abstimmung verfügen könnten, den Besitz der Wenigen zu enteignen. Selbst Sokrates war gegen solch eine Gesellschaftsordnung, da die besten Ideen nicht durch die Vielen, sondern durch einige wenige Kluge und Aufrichtige in die Welt kommen. Man müsse die Vielen lediglich manipulieren und würde auf diese Weise quasi jeden Unfug umsetzen können. Die Demokratie war ein Rohrkrepierer.
**Die Mogelpackung „Repräsentative Demokratie“**
Erst im Zuge der Gründung der USA gelang der Trick, dem Volk die „Repräsentative Demokratie“ unterzujubeln, die sich zwar nach Demokratie anhört, aber mit der Ursprungsdefinition nichts zu tun hat. Man konnte zwischen zwei Parteien wählen, die sich mit ihren jeweiligen Versprechen um die Gunst des Volkes bewarben. Tatsächlich paktierten die Vertreter der gewählten Parteien (Politiker) aber mit den wirklich Mächtigen, die letztendlich dafür sorgten, dass diese Politiker in die jeweiligen exponierten Positionen gelangten, welche ihnen ermöglichten (und somit auch den wirklich Mächtigen), Macht auszuüben. Übrigens, ob die eine oder andere Partei „den Volkswillen“ für sich gewinnen konnte, war für die wirklich Mächtigen weniger von Bedeutung, denn der Wille der wirklich Mächtigen wurde so oder so, wenn auch in voneinander differierenden Details, umgesetzt.
Die Menschen waren begeistert von dieser Idee, denn sie glaubten, dass sie selbst „der Souverän“ seien. Schluss mit Monarchie sowie sonstiger Fremdherrschaft und Unterdrückung.
Die Mächtigen waren ebenfalls begeistert, denn durch die Repräsentative Demokratie waren sie selbst nicht mehr in der Schusslinie, weil das Volk sich mit seinem Unmut fortan auf die Politiker konzentrierte. Da diese Politiker aber vielleicht nicht von einem selbst, sondern von vielen anderen Wahlberechtigten gewählt wurden, lenkte sich der Groll der Menschen nicht nur ab von den wirklich Mächtigen, sondern auch ab von den Politikern, direkt auf „die vielen Idioten“ aus ihrer eigenen Mitte, die sich „ver-wählt“ hatten. Diese Lenkung des Volkes funktionierte so hervorragend, dass andere Länder die Grundprinzipien dieses Steuerungsinstrumentes übernahmen. Dies ist alles bei Rainer Mausfeld nachzulesen.
Ursprünglich waren die Mächtigen nur regional mächtig, sodass das Führen der eigenen Menschen(vieh)herde eher eine lokale Angelegenheit war. Somit mussten auch nur lokale Probleme gelöst werden und die Mittel zur Problemlösung blieben im eigenen Problembereich.
***
JETZT ABONNIEREN:
***[Hier](https://pareto.space/u/friedenstaube@pareto.space)*** *können Sie die Friedenstaube abonnieren und bekommen die Artikel in Ihr Postfach, vorerst für alle kostenfrei, wir starten gänzlich ohne Paywall. (Die Bezahlabos fangen erst zu laufen an, wenn ein Monetarisierungskonzept für die Inhalte steht).*
***
* Für **50 CHF/EURO** bekommen Sie ein Jahresabo der Friedenstaube.
* Für **120 CHF/EURO** bekommen Sie ein Jahresabo und ein T-Shirt/Hoodie mit der Friedenstaube.
* Für **500 CHF/EURO** werden Sie Förderer und bekommen ein lebenslanges Abo sowie ein T-Shirt/Hoodie mit der Friedenstaube.
* Ab **1000 CHF/EURO** werden Sie Genossenschafter der Friedenstaube mit Stimmrecht (und bekommen lebenslanges Abo, T-Shirt/Hoodie).
**Für Einzahlungen in CHF (Betreff: Friedenstaube):**
[](https://substackcdn.com/image/fetch/f_auto%2Cq_auto%3Agood%2Cfl_progressive%3Asteep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F3fdee17a-c22f-404e-a10c-7f87a7b8182a_2176x998.png)
**Für Einzahlungen in Euro:**
Milosz Matuschek
IBAN DE 53710520500000814137
BYLADEM1TST
Sparkasse Traunstein-Trostberg
**Betreff: Friedenstaube**
Wenn Sie auf anderem Wege beitragen wollen, schreiben Sie die Friedenstaube an: <milosz@pareto.space> oder <kontakt@idw-europe.org>.
***
**Beherrschungsinstrumente der globalen Massenhaltung**
Im Zuge der territorialen Erweiterungen der „Besitzungen“ einiger wirklich Mächtiger wurden die Verwaltungs- und Beherrschungsinstrumente überregionaler. Und heute, zu Zeiten der globalen Vernetzung, paktieren die wirklich Mächtigen miteinander und beanspruchen die Weltherrschaft. Längst wird offen über die finale Realisierung einen Weltregierung, welche die Nationalstaaten „nicht mehr benötigt“, gesprochen. Dass sich Deutschland, ebenso wie andere europäische Staaten, der EU untergeordnet hat, dürfte auch Leuten nicht entgangen sein, die sich nur über die Tagesschau informieren. Längst steht das EU-Recht über dem deutschen Recht. Und nur kurze Zeit ist es her, als die EU und alle ihre Mitgliedsstaaten die WHO autonom darüber entscheiden lassen wollten, was eine Pandemie ist und wie diese für alle verbindlich „bekämpft“ werden soll. Eine spannende Frage ist nun, wer denn über der EU und der WHO sowie anderen Institutionen steht?
Diese Beschreibung macht klar, dass ein „souveränes Land“ wie das unverändert von der amerikanischen Armee besetzte Deutschland in der Entscheidungshierarchie an die Weisungen übergeordneter Entscheidungsorgane gebunden ist. An der Spitze stehen - wie kann es anders sein - die wirklich Mächtigen.
Aber was nützt es dann, Spitzenpolitiker zu wählen, wenn diese analog Horst Seehofer nichts zu melden haben? Ist das Wählen von Politikern nicht völlig sinnlos, wenn deren Wahlversprechen ohnehin nicht erfüllt werden? Ist es nicht so, dass die Menschen, welche ihre Stimme nicht behalten, sondern abgeben, das bestehende System nur nähren, indem sie Wahlergebnisse akzeptieren, ohne zu wissen, ob diese manipuliert wurden, aber mit der Gewissheit, dass das im Zuge des Wahlkampfes Versprochene auf keinen Fall geliefert wird? Aktive Wähler glauben trotz allem an die Redlichkeit und Wirksamkeit von Wahlen, und sie akzeptieren Wahlergebnisse, weil sie denken, dass sie von „so vielen Idioten, die falsch wählen“, umgeben sind, womit wir wieder bei der Spaltung sind. Sie glauben, der Stand des aktuellen Elends sei „selbst gewählt“.
**Die Wahl der Aufseher**
Stellen Sie sich bitte vor, Sie wären im Gefängnis, weil Sie einen kritischen Artikel mit „gefällt mir“ gekennzeichnet haben oder weil Sie eine „Kontaktschuld“ trifft, da in Ihrer Nachbarschaft ein „verschwörerisches Symbol“ von einem „aufmerksamen“ Nachbarn bei einer „Meldestelle“ angezeigt wurde oder Sie gar eine Tat, „unterhalb der Strafbarkeitsgrenze“ begangen hätten, dann würden Sie möglicherweise mit Maßnahmen bestraft, die „keine Folter wären“. Beispielsweise würde man Sie während Ihrer „Umerziehungshaft“ mit Waterboarding, Halten von Stresspositionen, Dunkelhaft etc. dabei „unterstützen“, „Ihre Verfehlungen zu überdenken“. Stellen Sie sich weiterhin vor, dass Sie, so wie alle anderen Inhaftierten, an der alle vier Jahre stattfindenden Wahl der Aufseher teilnehmen könnten, und Sie hätten auch einen Favoriten, der zwar Waterboarding betreibt, aber gegen alle anderen Maßnahmen steht. Sie hätten sicher allen Grund zur Freude, wenn Sie Ihren Kandidaten durchbringen könnten, oder? Aber was wäre, wenn der Aufseher Ihrer Wahl dann dennoch alle 3 „Nicht-Folter-Maßnahmen“ anwenden würde, wie sämtliche anderen Aufseher zuvor? Spätestens dann müssten Sie sich eingestehen, dass es der Beruf des Aufsehers ist, Aufseher zu sein und dass er letztendlich tut, was ihm „von oben“ aufgetragen wird. Andernfalls verliert er seinen Job. Oder er verunfallt oder gerät in einen Skandal etc. So oder so, er verliert seinen Job - und den erledigt dann ein anderer Aufseher.
Die Wahl des Aufsehers ändert wenig, solange Sie sich im System des Gefängnisses befinden und der Aufseher integraler Bestandteil dieses Systems ist. Zur Realisierung einer tatsächlichen Änderung müssten Sie dort herauskommen.
Dieses Beispiel soll darstellen, dass alles in Hierarchien eingebunden ist. Die in einem System eingebundenen Menschen erfüllen ihre zugewiesenen Aufgaben, oder sie werden bestraft.
**Das aktuelle System schadet dem Volk**
Auch in der staatlichen Organisation von Menschen existieren hierarchische Gliederungen. Eine kommunale Selbstverwaltung gehört zum Kreis, dieser zum Land, dieses zum Staat, dieser zur EU, und diese - zu wem auch immer. Und vereinnahmte Gelder fließen nach oben. Obwohl es natürlich wäre, dass die Mittel dorthin fließen, wo sie der Allgemeinheit und nicht einigen wenigen dienen, also nach unten.
Warum muss es also eine Weltregierung geben? Warum sollen nur einige Wenige über alle anderen bestimmen und an diesen verdienen (Nahrung, Medikamente, Krieg, Steuern etc.)? Warum sollen Menschen, so wie Vieh, das jemandem „gehört“, mit einem Code versehen und bereits als Baby zwangsgeimpft werden? Warum müssen alle Transaktionen und sämtliches Verhalten strickt gesteuert, kontrolliert und bewertet werden?
Viele Menschen werden nach alledem zu dem Schluss kommen, dass solch ein System nur einigen wenigen wirklich Mächtigen und deren Helfershelfern nützt. Aber es gibt auch eine Gruppe Menschen, für die im Land alles beanstandungsfrei funktioniert. Die Spaltung der Menschen ist perfekt gelungen und sofern die eine Gruppe darauf wartet, dass die andere „endlich aufwacht“, da die Fakten doch auf dem Tisch liegen, so wird sie weiter warten dürfen.
Julian Assange erwähnte einst, dass es für ihn eine unglaubliche Enttäuschung war, dass ihm niemand half. Assange hatte Ungeheuerlichkeiten aufgedeckt. Es gab keinen Aufstand. Assange wurde inhaftiert und gefoltert. Es gab keinen Aufstand. Assange sagte, er hätte nicht damit gerechnet, dass die Leute „so unglaublich feige“ seien.
Aber womit rechnete er den stattdessen? Dass die Massen „sich erheben“. Das gibt es nur im Film, denn die Masse besteht aus vielen maximal Indoktrinierten, die sich wie Schafe verhalten, was als Züchtungserfolg der Leute an den Schalthebeln der Macht und deren Herren, den wirklich Mächtigen, anzuerkennen ist. Denn wer mächtig ist und bleiben möchte, will sicher keine problematischen Untertanen, sondern eine gefügige, ängstliche Herde, die er nach Belieben ausbeuten und steuern kann. Wenn er hierüber verfügt, will er keinen Widerstand.
Ob Corona, Krieg, Demokratie- und Klimarettung oder Meinungsäußerungsverbote und Bürgerrechte, die unterhalb der Strafbarkeitsgrenze liegen, all diese und viele weitere Stichworte mehr sind es, die viele traurig und so manche wütend machen.
Auch das Mittel des Demonstrierens hat sich als völlig wirkungslos erwiesen. Die vielen gruseligen Videoaufnahmen über die massivsten Misshandlungen von Demonstranten gegen die Corona-Maßnahmen führen zu dem Ergebnis, dass die Exekutive ihr Gewaltmonopol nutzt(e), um die Bevölkerung gezielt zu verletzen und einzuschüchtern. Bekanntlich kann jede friedliche Demonstration zum Eskalieren gebracht werden, indem man Menschen in die Enge treibt (fehlender Sicherheitsabstand) und einige V-Leute in Zivil mit einschlägigen Flaggen und sonstigen „Symbolen“ einschleust, die für Krawall sorgen, damit die gepanzerten Kollegen dann losknüppeln und die scharfen Hunde zubeißen können. So lauten zumindest die Berichte vieler Zeitzeugen und so ist es auch auf vielen Videos zu sehen. Allerdings nicht im Mainstream.
Dieses Vorgehen ist deshalb besonders perfide, weil man den Deutschen ihre Wehrhaftigkeit aberzogen hat. Nicht wehrfähige Bürger und eine brutale Staatsmacht mit Gewaltmonopol führen zu einem Gemetzel bei den Bürgern.
Ähnliches lässt sich auch in zivilen Lebenssituationen beobachten, wenn die hiesige zivilisierte Bevölkerung auf „eingereiste“ Massenvergewaltiger und Messerstecher trifft, die über ein anderes Gewalt- und Rechtsverständnis verfügen als die Einheimischen.
**System-Technik**
Die These ist, dass es eine Gruppe von global agierenden Personen gibt, welche das Geschehen auf der Erde zunehmend wirksam zu ihrem individuellen Vorteil gestaltet. Wie sich diese Gruppe definiert, kann bei John Coleman (Das Komitee der 300) und David Icke nachgelesen werden. Hierbei handelt es ich um Autoren, die jahrzehntelang analog streng wissenschaftlichen Grundlagen zu ihren Themen geforscht haben und in ihren jeweiligen Werken sämtliche Quellen benennen. Diese Autoren wurden vom Mainstream mit dem Prädikatsmerkmal „Verschwörungstheoretiker“ ausgezeichnet, wodurch die Ergebnisse Ihrer Arbeiten umso glaubwürdiger sind.
Diese mächtige Gruppe hat mit ihren Schergen nahezu den gesamten Planeten infiltriert, indem sie Personen in führenden Positionen in vielen Belangen größtmögliche Freiheiten sowie Schutz gewährt, aber diesen im Gegenzug eine völlige Unterwerfung bei Kernthemen abfordert. Die Motivatoren für diese Unterwerfung sind, abgesehen von materiellen Zuwendungen, auch „Ruhm und Ehre sowie Macht“. Manchmal wird auch Beweismaterial für begangene Verfehlungen (Lolita-Express, Pizzagate etc.) genutzt, um Forderungen Nachdruck zu verleihen. Und auch körperliche Bestrafungen der betroffenen Person oder deren Angehörigen zählen zum Repertoire der Motivatoren. Letztendlich ähnlich den Verhaltensweisen in einem Mafia-Film.
Mit dieser Methodik hat sich diese mächtige Gruppe im Laufe von Jahrhunderten! eine Organisation erschaffen, welche aus Kirchen, Parteien, Firmen, NGO, Vereinen, Verbänden und weiteren Organisationsformen besteht. Bestimmte Ämter und Positionen in Organisationen können nur von Personen eingenommen und gehalten werden, die „auf Linie sind“.
Die Mitglieder der Gruppe tauchen in keiner Rubrik wie „Die reichsten Menschen der Welt“ auf, sondern bleiben fern der Öffentlichkeit. Wer jemanden aus ihren Reihen erkennt und beschuldigt, ist ein „Antisemit“ oder sonstiger Übeltäter und wird verfolgt und bekämpft. Über mächtige Vermögensverwaltungskonzerne beteiligen sich die Mitglieder dieser Gruppe anonym an Unternehmen in Schlüsselpositionen in einer Dimension, die ihnen wesentlichen Einfluss auf die Auswahl der Topmanager einräumt, sodass die jeweilige Unternehmenspolitik nach Vorgaben der Gruppe gestaltet wird.
Die Gruppe steuert das Geldsystem, von dem sich der Planet abhängig zu sein wähnt. Hierzu eine Erläuterung: Ein Staat wie Deutschland ist bekanntlich maximal verschuldet. Man stelle sich vor, ein unliebsamer Politiker würde entgegen sämtlicher „Brandmauern“ und sonstiger Propaganda und Wahlmanipulationen gewählt, das Land zu führen, dann könnte dieser keine Kredit über 500 Mrd. Euro bei der nächsten Sparkasse beantragen, sondern wäre auf die Mächtigen dieser Welt angewiesen. Jeder weiß, dass Deutschland als Staat kein funktionierendes Geschäftsmodell hat und somit nicht in der Lage ist, solch ein Darlehen zurückzuzahlen. Welche Motivation sollte also jemand haben, einem Land wie Deutschland so viel Geld ohne Aussicht auf Rückführung zu geben? Es leuchtet ein, dass dieser Politiker andere Gefälligkeiten anbieten müsste, um das Darlehen zu bekommen. Im Falle einer Weigerung zur Kooperation könnte der Staatsapparat mit seinen Staatsdienern, Bürgergeld- und Rentenempfänger etc. nicht mehr bezahlt werden und dieser Politiker wäre schnell wieder weg. Er würde medial hingerichtet. Es ist somit davon auszugehen, dass ein Spitzenpolitiker dieser Tage nicht über viele Optionen verfügt, denn er übernimmt eine Situation, die von seinen Vorgängern erschaffen wurde. Trotz alledem darauf zu hoffen, dass es einen anderen Politiker geben könnte, mit dem dann alles wieder gut wird, mutet ziemlich infantil an.
Dass ein Großteil der Medien von Zuwendungen abhängig ist, dürfte ebenfalls leicht nachzuvollziehen sein, denn der gewöhnliche Bürger zahlt nichts für den Content der MSM. Abhängig davon, von wem (Regierung, Philanthrop, Konzern etc.) ein Medium am Leben gehalten wird, gestalten sich auch dessen Inhalte. Und wenn angewiesen wird, dass ein Politiker medial hingerichtet werden soll, dann bedient die Maschinerie das Thema. Man beobachte einfach einmal, dass Politiker der Kartell-Parteien völlig anders behandelt werden als solche jenseits der „Brandmauer“. Und der Leser, der solche Auftragsarbeiten kostenlos liest, ist der Konsument, für dessen Indoktrination die Finanziers der Verlage gerne zahlen. Mittlerweile kann durch die Herrschaft über die Medien und die systematische Vergiftung der Körper und Geister der Population die öffentliche Meinung gesteuert werden. Die überwiegende Zahl der Deutschen scheint nicht mehr klar denken zu können.
Wer sich das aktuelle Geschehen in der deutschen Politik mit klarem Verstand ansieht, kommt nicht umhin, eine Fernsteuerung der handelnden Politiker in Betracht zu ziehen. Aber was soll daran verwundern? Sind es deshalb „böse Menschen“? Sind die in „Forschungslaboren“ arbeitenden Quäler von „Versuchstieren“ böse Menschen? Sind der Schlächter, der Folterer und der Henker böse Menschen? Oder der knüppelnde Polizist? Es handelt sich zunächst einmal um Personen, die einen Vorteil dadurch haben, Ihrer Tätigkeit nachzugehen. Sie sind integrale Bestandteile eines Belohnungssystems, welches von oben nach unten Anweisungen gibt. Und wenn diese Anweisungen nicht befolgt werden, führt dies für den Befehlsverweigerer zu Konsequenzen.
**Der klare Verstand**
Es ist nun eine spannende Frage, warum so viele Menschen sich solch eine Behandlung gefallen lassen? Nun, das ist relativ einfach, denn das angepasste Verhalten der Vielen ist nichts anderes als ein Züchtungserfolg der Wenigen.
Die Psyche der Menschen ist ebenso akribisch erforscht worden wie deren Körperfunktionen. Würden die Menschen von den wirklich Mächtigen geliebt, dann würde genau gewusst, wie sie zu behandeln und mit ihren jeweiligen Bedürfnissen zu versorgen sind. Stattdessen werden die Menschen aber als eine Einnahmequelle betrachtet. Dies manifestiert sich exemplarisch in folgenden Bereichen:
1. Das Gesundheitssystem verdient nichts am gesunden Menschen, sondern nur am (dauerhaft) kranken, der um Schmerzlinderung bettelt. Bereits als Baby werden Menschen geimpft, was die jeweilige Gesundheit (mit Verweis auf die Werke von Anita Petek-Dimmer u. a.) nachhaltig negativ beeinflusst. Wer hat denn heute keine Krankheiten? Die „Experten“ des Gesundheitssystems verteufeln Vitamin D, Vitamin C, Lithium, die Sonne, Natur etc. und empfehlen stattdessen Präparate, die man patentieren konnte und mit denen die Hersteller viel Geld verdienen. Die Präparate heilen selten, sondern lindern bestenfalls zuvor künstlich erzeugte Leiden, und müssen oftmals dauerhaft eingenommen werden. Was ist aus den nicht Geimpften geworden, die alle sterben sollten? Sind diese nicht die einzigen Gesunden dieser Tage? Ist nicht jeder Geimpfte entweder permanent krank oder bereits tot? Abgesehen von denen, welche das Glück hatten, „Sonderchargen“ mit Kochsalz zu erhalten. \
\
Wem gehören die wesentlichen Player im Gesundheitswesen zu einem erheblichen Teil? Die Vermögensverwalter der wirklich Mächtigen.
2. Ähnlich gestaltet es sich bei der Ernährungsindustrie. Die von dort aus verabreichten Produkte sind die Ursachen für den Gesundheitszustand der deutschen Population. Das ist aber auch irgendwie logisch, denn wer sich nicht falsch ernährt und gesund bleibt, wird kein Kunde des Gesundheitswesens. \
\
Die Besitzverhältnisse in der Ernährungsindustrie ähneln denen im Gesundheitswesen, sodass am gleichen Kunden gearbeitet und verdient wird.
3. Die Aufzählung konnte nun über die meisten Branchen, in denen mit dem Elend der Menschen viel verdient werden kann, fortgesetzt werden. Waffen (BlackRock erhöhte beispielsweise seine Anteile an der Rheinmetall AG im Juni 2024 auf 5,25 Prozent. Der US-Vermögensverwalter ist damit der zweitgrößte Anteilseigner nach der französischen Großbank Société Générale.), Energie, Umwelt, Technologie, IT, Software, KI, Handel etc.
Wie genau Chemtrails und Technologien wie 5G auf den Menschen und die Tiere wirken, ist ebenfalls umstritten. Aber ist es nicht seltsam, wie krank, empathielos, antriebslos und aggressiv viele Menschen heute sind? Was genau verabreicht man der Berliner Polizei, damit diese ihre Prügelorgien auf den Rücken und in den Gesichtern der Menschen wahrnehmen, die friedlich ihre Demonstrationsrechte wahrnehmen? Und was erhalten die ganzen zugereisten „Fachkräfte“, die mit Ihren Autos in Menschenmengen rasen oder auch Kinder und Erwachsene niedermessern?
Das Titelbild dieses Beitrags zeigt einige Gebilde, welche regelmäßig bei Obduktionen von Geimpften in deren Blutgefäßen gefunden werden. Wie genau wirken diese kleinen Monster? Können wir Menschen ihr Unverständnis und ihr Nicht-Aufwachen vorwerfen, wenn wir erkennen, dass diese Menschen maximal vergiftet wurden? Oder sollten einfach Lösungen für die Probleme dieser Zeit auch ohne den Einbezug derer gefunden werden, die offenbar nicht mehr Herr ihrer Sinne sind?
**Die Ziele der wirklich Mächtigen**
Wer sich entsprechende Videosequenzen der Bilderberger, des WEF und anderen „Überorganisationen“ ansieht, der erkennt schnell das Muster:
* Reduzierung der Weltpopulation um ca. 80 Prozent
* Zusammenbruch der Wirtschaft, damit diese von den Konzernen übernommen werden kann.
* Zusammenbruch der öffentlichen Ordnung, um eine totale Entwaffnung und eine totale Überwachung durchsetzen zu können.
* Zusammenbruch der Regierungen, damit die Weltregierung übernehmen kann.
Es ist zu überdenken, ob die Weltregierung tatsächlich das für die Vielen beste Organisationssystem ist, oder ob die dezentrale Eigenorganisation der jeweils lokalen Bevölkerung nicht doch die bessere Option darstellt. Baustellen würden nicht nur begonnen, sondern auch schnell abgearbeitet. Jede Region könnte bestimmen, ob sie sich mit Chemtrails und anderen Substanzen besprühen lassen möchte. Und die Probleme in Barcelona könnte die Menschen dort viel besser lösen als irgendwelche wirklich Mächtigen in ihren Elfenbeintürmen. Die lokale Wirtschaft könnte wieder zurückkommen und mit dieser die Eigenständigkeit. Denn die den wirklich Mächtigen über ihre Vermögensverwalter gehörenden Großkonzerne haben offensichtlich nicht das Wohl der Bevölkerung im Fokus, sondern eher deren Ausbeutung.
Das Aussteigen aus dem System ist die wahre Herkulesaufgabe und es bedarf sicher Mut und Klugheit, sich dieser zu stellen. Die Politiker, die unverändert die Narrative der wirklich Mächtigen bedienen, sind hierfür denkbar ungeeignet, denn sie verfolgen kein Lebensmodell, welches sich von Liebe und Mitgefühl geleitet in den Dienst der Gesamtheit von Menschen, Tieren und Natur stellt.
Schauen Sie einmal genau hin, denken Sie nach und fühlen Sie mit.
**Was tun?**
Jedes System funktioniert nur so lange, wie es unterstützt wird. Somit stellt sich die Frage, wie viele Menschen das System ignorieren müssen, damit es kollabiert, und auf welche Weise dieses Ignorieren durchzuführen ist? Merkbar ist, dass die große Masse der Verwaltungsangestellten krank und oder unmotiviert und somit nicht wirksam ist. Würden die entsprechenden Stellen massiv belastet und parallel hierzu keine Einnahmen mehr realisieren, wäre ein Kollaps nah. Die Prügelpolizisten aus Berlin können nicht überall sein und normale Polizisten arbeiten nicht gegen unbescholtene Bürger, sondern sorgen sich selbst um ihre Zukunft. Gewalt ist sicher keine Lösung, und sicher auch nicht erforderlich.
Wie eine gerechte Verwaltungsform aufgebaut werden muss? Einfach so, wie sie in den hiesigen Gesetzen beschrieben steht. Aber eine solche Organisationsform muss frei sein von Blockparteien und korrupten Politikern und weisungsgebundenen Richtern etc. Stattdessen werden Menschen benötigt, welche die Menschen lieben und ihnen nicht schaden wollen. Außerdem sollten diese Führungspersonen auch wirklich etwas können, und nicht nur „Politiker“ ohne weitere Berufserfahrungen sein.
***
Ludwig F. Badenhagen (Pseudonym, Name ist der Redaktion bekannt).
*Der Autor hat deutsche Wurzeln und betrachtet das Geschehen in Deutschland und Europa aus seiner Wahlheimat Südafrika. Seine Informationen bezieht er aus verlässlichen Quellen und insbesondere von Menschen, die als „Verschwörungstheoretiker“, „Nazi“, „Antisemit“ sowie mit weiteren Kampfbegriffen der dortigen Systemakteure wie Politiker und „Journalisten“ diffamiert werden. Solche Diffamierungen sind für ihn ein Prädikatsmerkmal. Er ist international agierender Manager mit einem globalen Netzwerk und verfügt hierdurch über tiefe Einblicke in Konzerne und Politik.*
***
**Not yet on** **[Nostr](https://nostr.com/)** **and want the full experience?** Easy onboarding via **[Start.](https://start.njump.me/)**
-
@ e6817453:b0ac3c39
2024-12-07 15:03:06
Hey folks! Today, let’s dive into the intriguing world of neurosymbolic approaches, retrieval-augmented generation (RAG), and personal knowledge graphs (PKGs). Together, these concepts hold much potential for bringing true reasoning capabilities to large language models (LLMs). So, let’s break down how symbolic logic, knowledge graphs, and modern AI can come together to empower future AI systems to reason like humans.
## The Neurosymbolic Approach: What It Means ?
Neurosymbolic AI combines two historically separate streams of artificial intelligence: symbolic reasoning and neural networks. Symbolic AI uses formal logic to process knowledge, similar to how we might solve problems or deduce information. On the other hand, neural networks, like those underlying GPT-4, focus on learning patterns from vast amounts of data — they are probabilistic statistical models that excel in generating human-like language and recognizing patterns but often lack deep, explicit reasoning.
While GPT-4 can produce impressive text, it’s still not very effective at reasoning in a truly logical way. Its foundation, transformers, allows it to excel in pattern recognition, but the models struggle with reasoning because, at their core, they rely on statistical probabilities rather than true symbolic logic. This is where neurosymbolic methods and knowledge graphs come in.
## Symbolic Calculations and the Early Vision of AI
If we take a step back to the 1950s, the vision for artificial intelligence was very different. Early AI research was all about symbolic reasoning — where computers could perform logical calculations to derive new knowledge from a given set of rules and facts. Languages like **Lisp** emerged to support this vision, enabling programs to represent data and code as interchangeable symbols. Lisp was designed to be homoiconic, meaning it treated code as manipulatable data, making it capable of self-modification — a huge leap towards AI systems that could, in theory, understand and modify their own operations.
## Lisp: The Earlier AI-Language
**Lisp**, short for “LISt Processor,” was developed by John McCarthy in 1958, and it became the cornerstone of early AI research. Lisp’s power lay in its flexibility and its use of symbolic expressions, which allowed developers to create programs that could manipulate symbols in ways that were very close to human reasoning. One of the most groundbreaking features of Lisp was its ability to treat code as data, known as homoiconicity, which meant that Lisp programs could introspect and transform themselves dynamically. This ability to adapt and modify its own structure gave Lisp an edge in tasks that required a form of self-awareness, which was key in the early days of AI when researchers were exploring what it meant for machines to “think.”
Lisp was not just a programming language—it represented the vision for artificial intelligence, where machines could evolve their understanding and rewrite their own programming. This idea formed the conceptual basis for many of the self-modifying and adaptive algorithms that are still explored today in AI research. Despite its decline in mainstream programming, Lisp’s influence can still be seen in the concepts used in modern machine learning and symbolic AI approaches.
## Prolog: Formal Logic and Deductive Reasoning
In the 1970s, **Prolog** was developed—a language focused on formal logic and deductive reasoning. Unlike Lisp, based on lambda calculus, Prolog operates on formal logic rules, allowing it to perform deductive reasoning and solve logical puzzles. This made Prolog an ideal candidate for expert systems that needed to follow a sequence of logical steps, such as medical diagnostics or strategic planning.
Prolog, like Lisp, allowed symbols to be represented, understood, and used in calculations, creating another homoiconic language that allows reasoning. Prolog’s strength lies in its rule-based structure, which is well-suited for tasks that require logical inference and backtracking. These features made it a powerful tool for expert systems and AI research in the 1970s and 1980s.
The language is declarative in nature, meaning that you define the problem, and Prolog figures out **how** to solve it. By using formal logic and setting constraints, Prolog systems can derive conclusions from known facts, making it highly effective in fields requiring explicit logical frameworks, such as legal reasoning, diagnostics, and natural language understanding. These symbolic approaches were later overshadowed during the AI winter — but the ideas never really disappeared. They just evolved.
## Solvers and Their Role in Complementing LLMs
One of the most powerful features of **Prolog** and similar logic-based systems is their use of **solvers**. Solvers are mechanisms that can take a set of rules and constraints and automatically find solutions that satisfy these conditions. This capability is incredibly useful when combined with LLMs, which excel at generating human-like language but need help with logical consistency and structured reasoning.
For instance, imagine a scenario where an LLM needs to answer a question involving multiple logical steps or a complex query that requires deducing facts from various pieces of information. In this case, a **solver** can derive valid conclusions based on a given set of logical rules, providing structured answers that the LLM can then articulate in natural language. This allows the LLM to retrieve information and ensure the logical integrity of its responses, leading to much more robust answers.
Solvers are also ideal for handling **constraint satisfaction problems** — situations where multiple conditions must be met simultaneously. In practical applications, this could include scheduling tasks, generating optimal recommendations, or even diagnosing issues where a set of symptoms must match possible diagnoses. Prolog’s solver capabilities and LLM’s natural language processing power can make these systems highly effective at providing intelligent, rule-compliant responses that traditional LLMs would struggle to produce alone.
By integrating **neurosymbolic methods** that utilize solvers, we can provide LLMs with a form of deductive reasoning that is missing from pure deep-learning approaches. This combination has the potential to significantly improve the quality of outputs for use-cases that require explicit, structured problem-solving, from legal queries to scientific research and beyond. Solvers give LLMs the backbone they need to not just generate answers but to do so in a way that respects logical rigor and complex constraints.
## Graph of Rules for Enhanced Reasoning
Another powerful concept that complements LLMs is using a **graph of rules**. A graph of rules is essentially a structured collection of logical rules that interconnect in a network-like structure, defining how various entities and their relationships interact. This structured network allows for complex reasoning and information retrieval, as well as the ability to model intricate relationships between different pieces of knowledge.
In a **graph of rules**, each node represents a rule, and the edges define relationships between those rules — such as dependencies or causal links. This structure can be used to enhance LLM capabilities by providing them with a formal set of rules and relationships to follow, which improves logical consistency and reasoning depth. When an LLM encounters a problem or a question that requires multiple logical steps, it can traverse this graph of rules to generate an answer that is not only linguistically fluent but also logically robust.
For example, in a healthcare application, a graph of rules might include nodes for medical symptoms, possible diagnoses, and recommended treatments. When an LLM receives a query regarding a patient’s symptoms, it can use the graph to traverse from symptoms to potential diagnoses and then to treatment options, ensuring that the response is coherent and medically sound. The graph of rules guides reasoning, enabling LLMs to handle complex, multi-step questions that involve chains of reasoning, rather than merely generating surface-level responses.
Graphs of rules also enable **modular reasoning**, where different sets of rules can be activated based on the context or the type of question being asked. This modularity is crucial for creating adaptive AI systems that can apply specific sets of logical frameworks to distinct problem domains, thereby greatly enhancing their versatility. The combination of **neural fluency** with **rule-based structure** gives LLMs the ability to conduct more advanced reasoning, ultimately making them more reliable and effective in domains where accuracy and logical consistency are critical.
By implementing a graph of rules, LLMs are empowered to perform **deductive reasoning** alongside their generative capabilities, creating responses that are not only compelling but also logically aligned with the structured knowledge available in the system. This further enhances their potential applications in fields such as law, engineering, finance, and scientific research — domains where logical consistency is as important as linguistic coherence.
## Enhancing LLMs with Symbolic Reasoning
Now, with LLMs like GPT-4 being mainstream, there is an emerging need to add real reasoning capabilities to them. This is where **neurosymbolic approaches** shine. Instead of pitting neural networks against symbolic reasoning, these methods combine the best of both worlds. The neural aspect provides language fluency and recognition of complex patterns, while the symbolic side offers real reasoning power through formal logic and rule-based frameworks.
**Personal Knowledge Graphs (PKGs)** come into play here as well. Knowledge graphs are data structures that encode entities and their relationships — they’re essentially semantic networks that allow for structured information retrieval. When integrated with neurosymbolic approaches, LLMs can use these graphs to answer questions in a far more contextual and precise way. By retrieving relevant information from a knowledge graph, they can ground their responses in well-defined relationships, thus improving both the relevance and the logical consistency of their answers.
Imagine combining an LLM with a **graph of rules** that allow it to reason through the relationships encoded in a personal knowledge graph. This could involve using **deductive databases** to form a sophisticated way to represent and reason with symbolic data — essentially constructing a powerful hybrid system that uses LLM capabilities for language fluency and rule-based logic for structured problem-solving.
## My Research on Deductive Databases and Knowledge Graphs
I recently did some research on modeling **knowledge graphs using deductive databases**, such as DataLog — which can be thought of as a limited, data-oriented version of Prolog. What I’ve found is that it’s possible to use formal logic to model knowledge graphs, ontologies, and complex relationships elegantly as rules in a deductive system. Unlike classical RDF or traditional ontology-based models, which sometimes struggle with complex or evolving relationships, a deductive approach is more flexible and can easily support dynamic rules and reasoning.
**Prolog** and similar logic-driven frameworks can complement LLMs by handling the parts of reasoning where explicit rule-following is required. LLMs can benefit from these rule-based systems for tasks like entity recognition, logical inferences, and constructing or traversing knowledge graphs. We can even create a **graph of rules** that governs how relationships are formed or how logical deductions can be performed.
The future is really about creating an AI that is capable of both deep contextual understanding (using the powerful generative capacity of LLMs) and true reasoning (through symbolic systems and knowledge graphs). With the neurosymbolic approach, these AIs could be equipped not just to generate information but to explain their reasoning, form logical conclusions, and even improve their own understanding over time — getting us a step closer to true artificial general intelligence.
## Why It Matters for LLM Employment
Using **neurosymbolic RAG (retrieval-augmented generation)** in conjunction with personal knowledge graphs could revolutionize how LLMs work in real-world applications. Imagine an LLM that understands not just language but also the relationships between different concepts — one that can navigate, reason, and explain complex knowledge domains by actively engaging with a personalized set of facts and rules.
This could lead to practical applications in areas like healthcare, finance, legal reasoning, or even personal productivity — where LLMs can help users solve complex problems logically, providing relevant information and well-justified reasoning paths. The combination of **neural fluency** with **symbolic accuracy and deductive power** is precisely the bridge we need to move beyond purely predictive AI to truly intelligent systems.
Let's explore these ideas further if you’re as fascinated by this as I am. Feel free to reach out, follow my YouTube channel, or check out some articles I’ll link below. And if you’re working on anything in this field, I’d love to collaborate!
Until next time, folks. Stay curious, and keep pushing the boundaries of AI!
-
@ 04ff5a72:22ba7b2d
2025-03-19 01:54:44
# How Blockchain Technology Birthed Web3
The emergence of Web3 represents a paradigm shift in how we conceptualize and interact with the internet, moving from centralized platforms toward user-centric, decentralized systems. At the heart of this transformation lies blockchain technology, which serves as the architectural foundation enabling this new internet vision. Blockchain's unique characteristics—decentralization, transparency, and security—have positioned it as the critical infrastructure layer upon which the Web3 ecosystem is being built, fundamentally reshaping digital interactions, ownership models, and value exchange mechanisms.
# Blockchain as the Architectural Foundation
Blockchain serves as the building block of Web3 by creating a network where information is stored across many computers instead of one central location[[1]](https://www.chiliz.com/blockchain-in-web-3-0/). This distributed architecture represents a fundamental departure from the centralized server model that has dominated Web1 and Web2, where data and control are concentrated in the hands of a few corporations.
## From Centralized to Distributed Systems
Web3 is built on blockchain technology, which enables secure, transparent, and censorship-resistant transactions[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). Unlike Facebook, Google, and other Web2 platforms where user data, posts, likes, and photos are controlled by corporations, Web3 leverages blockchain to put users in charge of their digital lives[[1]](https://www.chiliz.com/blockchain-in-web-3-0/). This shift redistributes power from centralized authorities to a communal network of participants.
Blockchain essentially functions as a public, immutable ledger that everyone can see but no one can unilaterally alter. As described by McKinsey, Web3 is "a new, decentralized internet built on blockchains, which are distributed ledgers controlled communally by participants"[[4]](https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-web3). This architecture enables users to store their digital items in secure digital spaces over which they have complete control[[1]](https://www.chiliz.com/blockchain-in-web-3-0/).
## Distinguishing Between Blockchain and Web3 Development
While often used interchangeably, blockchain development and Web3 development represent different aspects of this technological evolution. Blockchain development focuses specifically on building the blockchain-based architecture, while Web3 is an umbrella term encompassing various tools and protocols that enable decentralized web applications[[5]](https://www.infuy.com/blog/understanding-the-differences-between-web3-and-blockchain-development/). A Web3 application typically runs on or interacts with a specific blockchain, relying on this underlying infrastructure for its core functionalities[[5]](https://www.infuy.com/blog/understanding-the-differences-between-web3-and-blockchain-development/).
In practical terms, blockchain development requires knowledge of specialized programming languages like Solidity, while Web3 development frequently employs standard web development languages like ReactJs, VueJs, CSS, and JavaScript to create user interfaces that interact with blockchain systems[[5]](https://www.infuy.com/blog/understanding-the-differences-between-web3-and-blockchain-development/).
# Enabling Core Web3 Principles
Blockchain technology enables three fundamental principles that define the Web3 vision: decentralization, transparency, and security. These characteristics are instrumental in creating an internet where users have greater control over their digital experiences.
## Decentralization and User Sovereignty
Decentralization represents a core value proposition of Web3. Rather than storing data on Facebook's or Google's servers, blockchain spreads information across a network of computers, ensuring that no single company controls user information[[1]](https://www.chiliz.com/blockchain-in-web-3-0/). This distributed approach fundamentally changes the power dynamic of the internet, giving users sovereignty over their digital identities and assets.
This decentralized model eliminates intermediaries, allowing people to interact and trade directly with each other without corporate oversight or intervention[[1]](https://www.chiliz.com/blockchain-in-web-3-0/). Users can buy, sell, create, and share online without big tech companies controlling their actions or taking a percentage of their transactions. According to a McKinsey report, this signals "a new era of the internet, one in which use and access are controlled by community-run networks rather than the current, centralized model in which a handful of corporations preside over Web2"[[4]](https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-web3).
## Transparency and Trust
Blockchain technology creates unprecedented transparency in digital interactions. Every transaction and change gets recorded in a way everyone can see but nobody can alter[[1]](https://www.chiliz.com/blockchain-in-web-3-0/). This transparency is often described as a "glass wall where all activities are visible to everyone, making cheating or hiding information impossible"[[1]](https://www.chiliz.com/blockchain-in-web-3-0/).
This level of visibility creates trust in data in ways that were not possible before, potentially revolutionizing how we share information and conduct transactions online[[7]](https://digital-strategy.ec.europa.eu/en/policies/blockchain-strategy). The European Commission recognizes this capability, noting that blockchain/web3 technology "allows people and organisations who may not know or trust each other to collectively agree on and permanently record information without a third-party authority"[[7]](https://digital-strategy.ec.europa.eu/en/policies/blockchain-strategy).
## Enhanced Security and Immutability
Once information is recorded on the blockchain, it cannot be changed or deleted, creating a secure environment for digital interactions[[1]](https://www.chiliz.com/blockchain-in-web-3-0/). This immutability provides foundational security for Web3 applications and services. By distributing data across multiple nodes worldwide rather than concentrating it in centralized servers, blockchain significantly increases resilience against attacks[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/).
This enhanced security is a key benefit of Web3, as the "distributed nature of blockchain makes it extremely difficult for hackers to penetrate the network"[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). Cryptographic protection is fundamental to Web3 systems, with data access controlled through sophisticated encryption mechanisms that protect user information and digital assets.
# Transforming Digital Ownership and Value Exchange
Blockchain technology is fundamentally redefining concepts of ownership and value exchange in the digital realm, enabling new economic models and business opportunities within the Web3 ecosystem.
### User-Controlled Digital Assets
A defining characteristic of Web3 is its emphasis on true digital ownership. Through blockchain technology, users can assert verifiable ownership over digital assets in ways previously impossible under Web2 models[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). This capability extends from social media posts to digital art, all secured in a transparent and user-controlled environment.
Blockchain enables features like digital scarcity and provable ownership, which are crucial for the development of unique digital assets such as non-fungible tokens (NFTs)[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). By creating scarcity in the digital realm, blockchain opens new opportunities for creators to monetize their content and for users to truly own and trade digital items.
## New Economic Models Through Tokenization
Tokenization—the process of converting real-world or digital assets into digital tokens managed on a blockchain—is creating more liquid and accessible markets for both physical and digital goods[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). These tokens can represent diverse assets, including real estate, stocks, commodities, art, music, and in-game items.
Web3 introduces the concept of token economies, where digital assets represent ownership, access, or participation in a network[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). This creates new economic models and incentives for users, fundamentally changing how value is created and distributed online.
## Smart Contracts and Programmable Agreements
Smart contracts are self-executing contracts with terms directly written into code, enabling trustless transactions without intermediaries[[2]](https://www.rapidinnovation.io/post/web3-development-a-comprehensive-guide). These automated agreements are central to blockchain development and play a critical role in Web3 functionality, powering everything from decentralized finance applications to content royalty systems.
By automating complex agreements and ensuring their execution according to predefined rules, smart contracts enhance efficiency and reduce the need for traditional intermediaries. They run on platforms like the Ethereum Virtual Machine (EVM), which "ensures that they execute as programmed without downtime or interference"[[2]](https://www.rapidinnovation.io/post/web3-development-a-comprehensive-guide).
# Key Web3 Applications Powered by Blockchain
Blockchain technology enables numerous applications and use cases within the Web3 ecosystem, transforming multiple sectors through decentralized approaches.
### Decentralized Finance (DeFi)
One of the most prominent applications of blockchain in Web3 is decentralized finance (DeFi). Blockchain-based DeFi platforms allow users to access financial services such as lending, borrowing, and liquidity provision without relying on traditional financial institutions[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/).
These platforms offer increased transparency through public transaction records, greater accessibility by allowing anyone with an internet connection to participate regardless of location or financial status, and enhanced user control by eliminating intermediaries[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). Ethereum serves as the backbone of the DeFi movement, enabling users to conduct financial transactions in a decentralized environment[[2]](https://www.rapidinnovation.io/post/web3-development-a-comprehensive-guide).
## Metaverse and Virtual Worlds
Blockchain technology is also making significant strides in enabling the metaverse—interconnected virtual worlds where users can interact, create, and exchange value. Through blockchain, these virtual environments become decentralized, secure, and transparent[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/).
Blockchain facilitates true ownership of digital assets within virtual worlds, enables secure transactions between users, and promotes interoperability between different platforms[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). These capabilities are essential for creating persistent, user-owned digital spaces where individuals can freely interact and transact.
## Decentralized Content Creation and Distribution
Web3 is revolutionizing how content creators monetize and distribute their work. Blockchain-based platforms allow creators to monetize content through fair and transparent processes, eliminating intermediaries and ensuring creators receive a larger share of revenue[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/).
Smart contracts automate content monetization and distribution, reducing administrative overhead and ensuring timely payments to creators[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). The transparency of blockchain ensures fair compensation, while direct creator-fan relationships foster deeper connections and loyalty without platform intermediation.
# Challenges and Future Considerations
Despite its transformative potential, blockchain implementation in Web3 faces several significant challenges that must be addressed for widespread adoption.
## Technical and Operational Hurdles
Web3 and blockchain implementation face technical challenges including high processing costs and complex user experiences. These technologies currently require substantial initial investment in hardware and high-end devices, potentially limiting accessibility[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/).
Scalability remains a significant concern, as many blockchain networks struggle to handle large transaction volumes efficiently. Additionally, interoperability between different blockchain networks is limited, hindering seamless communication between platforms[3].
## Regulatory and Adoption Considerations
The decentralized nature of Web3 creates regulatory challenges, potentially making monitoring and management difficult for authorities[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). Finding the right balance between innovation and consumer protection remains a complex undertaking.
Adoption rates for Web3 technologies remain relatively slow, following a similar trajectory to the transition from Web1 to Web2[[3]](https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/). Overcoming user hesitation and education barriers will be crucial for driving mainstream acceptance of blockchain-based Web3 applications.
# Conclusion
Blockchain technology serves as the fundamental infrastructure enabling the Web3 vision of a decentralized, user-centric internet. By providing the architectural foundation for decentralization, transparency, and security, blockchain is transforming how we conceptualize digital ownership, value exchange, and online interactions.
From decentralized finance to virtual worlds and content monetization, blockchain is powering diverse applications that redistribute control from centralized entities to individual users and communities. Despite facing technical, regulatory, and adoption challenges, the role of blockchain in Web3 development continues to expand as the technology matures.
As noted by McKinsey, momentum around Web3 elements has increased significantly since 2018, with growth in equity investment, patent filings, scientific publications, and job opportunities[[4]](https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-web3). With 90% of executives agreeing that blockchain helps create stronger partnerships and unlock new value[[6]](https://www.accenture.com/us-en/services/metaverse/blockchain-web3), the technology is increasingly positioned at the center of commerce, supply chain management, and digital interactions.
The continued evolution of blockchain will be central to realizing the full potential of Web3—creating an internet that is more open, equitable, and aligned with the needs and interests of its users rather than centralized gatekeepers.
---
### Sources
[1] The Role of Blockchain in Web 3.0 - Chiliz https://www.chiliz.com/blockchain-in-web-3-0/
[2] Web3 Development: Comprehensive Guide for Blockchain Builders https://www.rapidinnovation.io/post/web3-development-a-comprehensive-guide
[3] Blockchain Web 3.0: The Role of Blockchain in Enabling - BlockApps Inc. https://blockapps.net/blog/the-role-of-blockchain-in-enabling-web-3-0/
[4] What is Web3 technology (and why is it important)? | McKinsey https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-web3
[5] Web3 vs blockchain: Understanding the Differences | Infuy https://www.infuy.com/blog/understanding-the-differences-between-web3-and-blockchain-development/
[6] Accenture's Blockchain & Web3 Innovations in the Metaverse https://www.accenture.com/us-en/services/metaverse/blockchain-web3
[7] Blockchain and Web3 Strategy | Shaping Europe's digital future https://digital-strategy.ec.europa.eu/en/policies/blockchain-strategy
-
@ e6817453:b0ac3c39
2024-12-07 14:54:46
## Introduction: Personal Knowledge Graphs and Linked Data
We will explore the world of personal knowledge graphs and discuss how they can be used to model complex information structures. Personal knowledge graphs aren’t just abstract collections of nodes and edges—they encode meaningful relationships, contextualizing data in ways that enrich our understanding of it. While the core structure might be a directed graph, we layer semantic meaning on top, enabling nuanced connections between data points.
The origin of knowledge graphs is deeply tied to concepts from linked data and the semantic web, ideas that emerged to better link scattered pieces of information across the web. This approach created an infrastructure where data islands could connect — facilitating everything from more insightful AI to improved personal data management.
In this article, we will explore how these ideas have evolved into tools for modeling AI’s semantic memory and look at how knowledge graphs can serve as a flexible foundation for encoding rich data contexts. We’ll specifically discuss three major paradigms: RDF (Resource Description Framework), property graphs, and a third way of modeling entities as graphs of graphs. Let’s get started.
## Intro to RDF
The Resource Description Framework (RDF) has been one of the fundamental standards for linked data and knowledge graphs. RDF allows data to be modeled as triples: subject, predicate, and object. Essentially, you can think of it as a structured way to describe relationships: “X has a Y called Z.” For instance, “Berlin has a population of 3.5 million.” This modeling approach is quite flexible because RDF uses unique identifiers — usually URIs — to point to data entities, making linking straightforward and coherent.
RDFS, or RDF Schema, extends RDF to provide a basic vocabulary to structure the data even more. This lets us describe not only individual nodes but also relationships among types of data entities, like defining a class hierarchy or setting properties. For example, you could say that “Berlin” is an instance of a “City” and that cities are types of “Geographical Entities.” This kind of organization helps establish semantic meaning within the graph.
## RDF and Advanced Topics
## Lists and Sets in RDF
RDF also provides tools to model more complex data structures such as lists and sets, enabling the grouping of nodes. This extension makes it easier to model more natural, human-like knowledge, for example, describing attributes of an entity that may have multiple values. By adding RDF Schema and OWL (Web Ontology Language), you gain even more expressive power — being able to define logical rules or even derive new relationships from existing data.
## Graph of Graphs
A significant feature of RDF is the ability to form complex nested structures, often referred to as graphs of graphs. This allows you to create “named graphs,” essentially subgraphs that can be independently referenced. For example, you could create a named graph for a particular dataset describing Berlin and another for a different geographical area. Then, you could connect them, allowing for more modular and reusable knowledge modeling.
## Property Graphs
While RDF provides a robust framework, it’s not always the easiest to work with due to its heavy reliance on linking everything explicitly. This is where property graphs come into play. Property graphs are less focused on linking everything through triples and allow more expressive properties directly within nodes and edges.
For example, instead of using triples to represent each detail, a property graph might let you store all properties about an entity (e.g., “Berlin”) directly in a single node. This makes property graphs more intuitive for many developers and engineers because they more closely resemble object-oriented structures: you have entities (nodes) that possess attributes (properties) and are connected to other entities through relationships (edges).
The significant benefit here is a condensed representation, which speeds up traversal and queries in some scenarios. However, this also introduces a trade-off: while property graphs are more straightforward to query and maintain, they lack some complex relationship modeling features RDF offers, particularly when connecting properties to each other.
## Graph of Graphs and Subgraphs for Entity Modeling
A third approach — which takes elements from RDF and property graphs — involves modeling entities using subgraphs or nested graphs. In this model, each entity can be represented as a graph. This allows for a detailed and flexible description of attributes without exploding every detail into individual triples or lump them all together into properties.
For instance, consider a person entity with a complex employment history. Instead of representing every employment detail in one node (as in a property graph), or as several linked nodes (as in RDF), you can treat the employment history as a subgraph. This subgraph could then contain nodes for different jobs, each linked with specific properties and connections. This approach keeps the complexity where it belongs and provides better flexibility when new attributes or entities need to be added.
## Hypergraphs and Metagraphs
When discussing more advanced forms of graphs, we encounter hypergraphs and metagraphs. These take the idea of relationships to a new level. A hypergraph allows an edge to connect more than two nodes, which is extremely useful when modeling scenarios where relationships aren’t just pairwise. For example, a “Project” could connect multiple “People,” “Resources,” and “Outcomes,” all in a single edge. This way, hypergraphs help in reducing the complexity of modeling high-order relationships.
Metagraphs, on the other hand, enable nodes and edges to themselves be represented as graphs. This is an extremely powerful feature when we consider the needs of artificial intelligence, as it allows for the modeling of relationships between relationships, an essential aspect for any system that needs to capture not just facts, but their interdependencies and contexts.
## Balancing Structure and Properties
One of the recurring challenges when modeling knowledge is finding the balance between structure and properties. With RDF, you get high flexibility and standardization, but complexity can quickly escalate as you decompose everything into triples. Property graphs simplify the representation by using attributes but lose out on the depth of connection modeling. Meanwhile, the graph-of-graphs approach and hypergraphs offer advanced modeling capabilities at the cost of increased computational complexity.
So, how do you decide which model to use? It comes down to your use case. RDF and nested graphs are strong contenders if you need deep linkage and are working with highly variable data. For more straightforward, engineer-friendly modeling, property graphs shine. And when dealing with very complex multi-way relationships or meta-level knowledge, hypergraphs and metagraphs provide the necessary tools.
The key takeaway is that only some approaches are perfect. Instead, it’s all about the modeling goals: how do you want to query the graph, what relationships are meaningful, and how much complexity are you willing to manage?
## Conclusion
Modeling AI semantic memory using knowledge graphs is a challenging but rewarding process. The different approaches — RDF, property graphs, and advanced graph modeling techniques like nested graphs and hypergraphs — each offer unique strengths and weaknesses. Whether you are building a personal knowledge graph or scaling up to AI that integrates multiple streams of linked data, it’s essential to understand the trade-offs each approach brings.
In the end, the choice of representation comes down to the nature of your data and your specific needs for querying and maintaining semantic relationships. The world of knowledge graphs is vast, with many tools and frameworks to explore. Stay connected and keep experimenting to find the balance that works for your projects.
-
@ 3514ac1b:cf164691
2025-03-29 18:55:29
Cryptographic Identity (CI): An Overview
## Definition of Cryptographic Identity
Cryptographic identity refers to a digital identity that is secured and verified using cryptographic techniques. It allows individuals to prove their identity online without relying on centralized authorities.
## Background of Cryptographic Identity
### Historical Context
- Traditional identity systems rely on centralized authorities (governments, companies)
- Digital identities historically tied to platforms and services
- Rise of public-key cryptography enabled self-sovereign identity concepts
- Blockchain and decentralized systems accelerated development
### Technical Foundations
- Based on public-key cryptography (asymmetric encryption)
- Uses key pairs: private keys (secret) and public keys (shareable)
- Digital signatures provide authentication and non-repudiation
- Cryptographic proofs verify identity claims without revealing sensitive data
## Importance of Cryptographic Identity
### Privacy Benefits
- Users control their personal information
- Selective disclosure of identity attributes
- Reduced vulnerability to mass data breaches
- Protection against surveillance and tracking
### Security Advantages
- Not dependent on password security
- Resistant to impersonation attacks
- Verifiable without trusted third parties
- Reduces centralized points of failure
### Practical Applications
- Censorship-resistant communication
- Self-sovereign finance and transactions
- Decentralized social networking
- Cross-platform reputation systems
- Digital signatures for legal documents
## Building Cryptographic Identity with Nostr
### Understanding Nostr Protocol
#### Core Concepts
- Nostr (Notes and Other Stuff Transmitted by Relays)
- Simple, open protocol for censorship-resistant global networks
- Event-based architecture with relays distributing signed messages
- Uses NIP standards (Nostr Implementation Possibilities)
#### Key Components
- Public/private keypairs as identity foundation
- Relays for message distribution
- Events (signed JSON objects) as the basic unit of data
- Clients that interface with users and relays
### Implementation Steps
#### Step 1: Generate Keypair
- Use cryptographic libraries to generate secure keypair
- Private key must be kept secure (password managers, hardware wallets)
- Public key becomes your identifier on the network
#### Step 2: Set Up Client
- Choose from existing Nostr clients or build custom implementation
- Connect to multiple relays for redundancy
- Configure identity preferences and metadata
#### Step 3: Publish Profile Information
- Create and sign kind 0 event with profile metadata
- Include displayable information (name, picture, description)
- Publish to connected relays
#### Step 4: Verification and Linking
- Cross-verify identity with other platforms (Twitter, GitHub)
- Use NIP-05 identifier for human-readable identity
- Consider NIP-07 for browser extension integration
### Advanced Identity Features
#### Reputation Building
- Consistent posting builds recognition
- Accumulate follows and reactions
- Establish connections with well-known identities
#### Multi-device Management
- Secure private key backup strategies
- Consider key sharing across devices
- Explore NIP-26 delegated event signing
#### Recovery Mechanisms
- Implement social recovery options
- Consider multisig approaches
- Document recovery procedures
## Challenges and Considerations
### Key Management
- Private key loss means identity loss
- Balance security with convenience
- Consider hardware security modules for high-value identities
### Adoption Barriers
- Technical complexity for average users
- Network effects and critical mass
- Integration with existing systems
### Future Developments
- Zero-knowledge proofs for enhanced privacy
- Standardization efforts across protocols
- Integration with legal identity frameworks
-
@ f839fb67:5c930939
2025-03-19 01:17:57
# Relays
| Name | Address | Price (Sats/Year) | Status |
| - | - | - | - |
| stephen's aegis relay | wss://paid.relay.vanderwarker.family | 42069 |   |
| stephen's Outbox | wss://relay.vanderwarker.family | Just Me |   |
| stephen's Inbox | wss://haven.vanderwarker.family/inbox | WoT |   |
| stephen's DMs | wss://haven.vanderwarker.family/chat | WoT |   |
| VFam Data Relay | wss://data.relay.vanderwarker.family | 0 |   |
| VFam Bots Relay | wss://skeme.vanderwarker.family | Invite |   |
| VFGroups (NIP29) | wss://groups.vanderwarker.family | 0 |   |
| [TOR] My Phone Relay | ws://naswsosuewqxyf7ov7gr7igc4tq2rbtqoxxirwyhkbuns4lwc3iowwid.onion | 0 | Meh... |
---
# My Pubkeys
| Name | hex | nprofile |
| - | - | - |
| Main | f839fb6714598a7233d09dbd42af82cc9781d0faa57474f1841af90b5c930939 | nprofile1qqs0sw0mvu29nznjx0gfm02z47pve9up6ra22ar57xzp47gttjfsjwgpramhxue69uhhyetvv9ujuanpdejx2unhv9exketj9enxzmtfd3us9mapfx |
| Vanity (Backup) | 82f21be67353c0d68438003fe6e56a35e2a57c49e0899b368b5ca7aa8dde7c23 | nprofile1qqsg9usmuee48sxkssuqq0lxu44rtc4903y7pzvmx694efa23h08cgcpramhxue69uhhyetvv9ujuanpdejx2unhv9exketj9enxzmtfd3ussel49x |
| VFStore | 6416f1e658ba00d42107b05ad9bf485c7e46698217e0c19f0dc2e125de3af0d0 | nprofile1qqsxg9h3uevt5qx5yyrmqkkehay9cljxdxpp0cxpnuxu9cf9mca0p5qpramhxue69uhhyetvv9ujuanpdejx2unhv9exketj9enxzmtfd3usaa8plu |
| NostrSMS | 9be1b8315248eeb20f9d9ab2717d1750e4f27489eab1fa531d679dadd34c2f8d | nprofile1qqsfhcdcx9fy3m4jp7we4vn305t4pe8jwjy74v062vwk08dd6dxzlrgpramhxue69uhhyetvv9ujuanpdejx2unhv9exketj9enxzmtfd3us595d45 |
# Bot Pubkeys
| Name | hex | nprofile |
| - | - | - |
| Unlocks Bot | 2e941ad17144e0a04d1b8c21c4a0dbc3fbcbb9d08ae622b5f9c85341fac7c2d0 | nprofile1qqsza9q669c5fc9qf5dccgwy5rdu877th8gg4e3zkhuus56pltru95qpramhxue69uhhx6m9d4jjuanpdejx2unhv9exketj9enxzmtfd3ust4kvak |
| Step Counter | 9223d2faeb95853b4d224a184c69e1df16648d35067a88cdf947c631b57e3de7 | nprofile1qqsfyg7jlt4etpfmf53y5xzvd8sa79ny356sv75gehu50333k4lrmecpramhxue69uhhx6m9d4jjuanpdejx2unhv9exketj9enxzmtfd3ustswp3w |
---
# "Personal Nostr Things"
> [D] = Saves darkmode preferences over nostr
> [A] = Auth over nostr
> [B] = Beta (software)
> [z] = zap enabled
- [[DABz] Main Site](https://vanderwarker.family)
- [[DAB] Contact Site](https://stephen.vanderwarker.family)
- [[DAB] PGP Site](https://pgp.vanderwarker.family)
- [[DAB] VFCA Site](https://ca.vanderwarker.family)
---
# Other Services (Hosted code)
* [Blossom](https://blossom.vanderwarker.family)
 
* [NostrCheck](https://nostr.vanderwarker.family)
 
---
# Emojis Packs
* Minecraft
- <code>nostr:naddr1qqy566twv43hyctxwsq37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gzyrurn7m8z3vc5u3n6zwm6s40stxf0qwsl2jhga83ssd0jz6ujvynjqcyqqq82nsd0k5wp</code>
* AIM
- <code>nostr:naddr1qqxxz6tdv4kk7arfvdhkuucpramhxue69uhhyetvv9ujuanpdejx2unhv9exketj9enxzmtfd3usyg8c88akw9ze3fer85yah4p2lqkvj7qap749w360rpq6ly94eycf8ypsgqqqw48qe0j2yk</code>
* Blobs
- <code>nostr:naddr1qqz5ymr0vfesz8mhwden5te0wfjkccte9emxzmnyv4e8wctjddjhytnxv9kkjmreqgs0sw0mvu29nznjx0gfm02z47pve9up6ra22ar57xzp47gttjfsjwgrqsqqqa2wek4ukj</code>
* FavEmojis
- <code>nostr:naddr1qqy5vctkg4kk76nfwvq37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gzyrurn7m8z3vc5u3n6zwm6s40stxf0qwsl2jhga83ssd0jz6ujvynjqcyqqq82nsf7sdwt</code>
* Modern Family
- <code>nostr:naddr1qqx56mmyv4exugzxv9kkjmreqy0hwumn8ghj7un9d3shjtnkv9hxgetjwashy6m9wghxvctdd9k8jq3qlqulkec5tx98yv7snk759tuzejtcr5865468fuvyrtuskhynpyusxpqqqp65ujlj36n</code>
* nostriches (Amethyst collection)
- <code>nostr:naddr1qq9xummnw3exjcmgv4esz8mhwden5te0wfjkccte9emxzmnyv4e8wctjddjhytnxv9kkjmreqgs0sw0mvu29nznjx0gfm02z47pve9up6ra22ar57xzp47gttjfsjwgrqsqqqa2w2sqg6w</code>
* Pepe
- <code>nostr:naddr1qqz9qetsv5q37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gzyrurn7m8z3vc5u3n6zwm6s40stxf0qwsl2jhga83ssd0jz6ujvynjqcyqqq82ns85f6x7</code>
* Minecraft Font
- <code>nostr:naddr1qq8y66twv43hyctxwssyvmmwwsq37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gzyrurn7m8z3vc5u3n6zwm6s40stxf0qwsl2jhga83ssd0jz6ujvynjqcyqqq82nsmzftgr</code>
* Archer Font
- <code>nostr:naddr1qq95zunrdpjhygzxdah8gqglwaehxw309aex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0ypzp7peldn3gkv2wgeap8dag2hc9nyhs8g04ft5wnccgxhepdwfxzfeqvzqqqr4fclkyxsh</code>
* SMB Font
- <code>nostr:naddr1qqv4xatsv4ezqntpwf5k7gzzwfhhg6r9wfejq3n0de6qz8mhwden5te0wfjkccte9emxzmnyv4e8wctjddjhytnxv9kkjmreqgs0sw0mvu29nznjx0gfm02z47pve9up6ra22ar57xzp47gttjfsjwgrqsqqqa2w0wqpuk</code>
---
# Git Over Nostr
* NostrSMS
- <code>nostr:naddr1qqyxummnw3e8xmtnqy0hwumn8ghj7un9d3shjtnkv9hxgetjwashy6m9wghxvctdd9k8jqfrwaehxw309amk7apwwfjkccte9emxzmnyv4e8wctjddjhytnxv9kkjmreqyj8wumn8ghj7urpd9jzuun9d3shjtnkv9hxgetjwashy6m9wghxvctdd9k8jqg5waehxw309aex2mrp0yhxgctdw4eju6t0qyxhwumn8ghj7mn0wvhxcmmvqgs0sw0mvu29nznjx0gfm02z47pve9up6ra22ar57xzp47gttjfsjwgrqsqqqaueqp0epk</code>
* nip51backup
- <code>nostr:naddr1qq9ku6tsx5ckyctrdd6hqqglwaehxw309aex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0yqjxamnwvaz7tmhda6zuun9d3shjtnkv9hxgetjwashy6m9wghxvctdd9k8jqfywaehxw309acxz6ty9eex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0yq3gamnwvaz7tmjv4kxz7fwv3sk6atn9e5k7qgdwaehxw309ahx7uewd3hkcq3qlqulkec5tx98yv7snk759tuzejtcr5865468fuvyrtuskhynpyusxpqqqpmej4gtqs6</code>
* bukkitstr
- <code>nostr:naddr1qqykyattdd5hgum5wgq37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gpydmhxue69uhhwmm59eex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0yqjgamnwvaz7tmsv95kgtnjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gpz3mhxue69uhhyetvv9ujuerpd46hxtnfduqs6amnwvaz7tmwdaejumr0dspzp7peldn3gkv2wgeap8dag2hc9nyhs8g04ft5wnccgxhepdwfxzfeqvzqqqrhnyf6g0n2</code>
---
# Market Places
Please use [Nostr Market](https://market.nostr.com) or somthing simular, to view.
* VFStore
- <code>nostr:naddr1qqjx2v34xe3kxvpn95cnqven956rwvpc95unscn9943kxet98q6nxde58p3ryqglwaehxw309aex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0yqjvamnwvaz7tmgv9mx2m3wweskuer9wfmkzuntv4ezuenpd45kc7f0da6hgcn00qqjgamnwvaz7tmsv95kgtnjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gpydmhxue69uhhwmm59eex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0ypzqeqk78n93wsq6sss0vz6mxl5shr7ge5cy9lqcx0smshpyh0r4uxsqvzqqqr4gvlfm7gu</code>
---
# Badges
## Created
* paidrelayvf
- <code>nostr:naddr1qq9hqctfv3ex2mrp09mxvqglwaehxw309aex2mrp0yh8vctwv3jhyampwf4k2u3wvesk66tv0ypzp7peldn3gkv2wgeap8dag2hc9nyhs8g04ft5wnccgxhepdwfxzfeqvzqqqr48y85v3u3</code>
* iPow
- <code>nostr:naddr1qqzxj5r02uq37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gzyrurn7m8z3vc5u3n6zwm6s40stxf0qwsl2jhga83ssd0jz6ujvynjqcyqqq82wgg02u0r</code>
* codmaster
- <code>nostr:naddr1qqykxmmyd4shxar9wgq37amnwvaz7tmjv4kxz7fwweskuer9wfmkzuntv4ezuenpd45kc7gzyrurn7m8z3vc5u3n6zwm6s40stxf0qwsl2jhga83ssd0jz6ujvynjqcyqqq82wgk3gm4g</code>
* iMine
- <code>nostr:naddr1qqzkjntfdejsz8mhwden5te0wfjkccte9emxzmnyv4e8wctjddjhytnxv9kkjmreqgs0sw0mvu29nznjx0gfm02z47pve9up6ra22ar57xzp47gttjfsjwgrqsqqqafed5s4x5</code>
---
# Clients I Use
* Amethyst
- <code>nostr:naddr1qqxnzd3cx5urqv3nxymngdphqgsyvrp9u6p0mfur9dfdru3d853tx9mdjuhkphxuxgfwmryja7zsvhqrqsqqql8kavfpw3</code>
* noStrudel
- <code>nostr:naddr1qqxnzd3cxccrvd34xser2dpkqy28wumn8ghj7un9d3shjtnyv9kh2uewd9hsygpxdq27pjfppharynrvhg6h8v2taeya5ssf49zkl9yyu5gxe4qg55psgqqq0nmq5mza9n</code>
* nostrsms
- <code>nostr:naddr1qq9rzdejxcunxde4xymqz8mhwden5te0wfjkccte9emxzmnyv4e8wctjddjhytnxv9kkjmreqgsfhcdcx9fy3m4jp7we4vn305t4pe8jwjy74v062vwk08dd6dxzlrgrqsqqql8kjn33qm</code>
-
@ 57d1a264:69f1fee1
2025-03-23 12:24:46
https://www.youtube.com/watch?v=obXEnyQ_Veg



source: https://media.jaguar.com/news/2024/11/fearless-exuberant-compelling-jaguar-reimagined-0
originally posted at https://stacker.news/items/922356
-
@ c631e267:c2b78d3e
2025-03-21 19:41:50
*Wir werden nicht zulassen, dass technisch manches möglich ist,* *\
aber der Staat es nicht nutzt.* *\
Angela Merkel*  
**Die Modalverben zu erklären, ist im Deutschunterricht manchmal nicht ganz einfach.** Nicht alle Fremdsprachen unterscheiden zum Beispiel bei der Frage nach einer Möglichkeit gleichermaßen zwischen «können» im Sinne von «die Gelegenheit, Kenntnis oder Fähigkeit haben» und «dürfen» als «die Erlaubnis oder Berechtigung haben». Das spanische Wort «poder» etwa steht für beides.
**Ebenso ist vielen Schülern auf den ersten Blick nicht recht klar,** dass das logische Gegenteil von «müssen» nicht unbedingt «nicht müssen» ist, sondern vielmehr «nicht dürfen». An den Verkehrsschildern lässt sich so etwas meistens recht gut erklären: Manchmal muss man abbiegen, aber manchmal darf man eben nicht.

**Dieses Beispiel soll ein wenig die Verwirrungstaktik veranschaulichen,** die in der Politik gerne verwendet wird, um unpopuläre oder restriktive Maßnahmen Stück für Stück einzuführen. Zuerst ist etwas einfach innovativ und bringt viele Vorteile. Vor allem ist es freiwillig, jeder kann selber entscheiden, niemand muss mitmachen. Später kann man zunehmend weniger Alternativen wählen, weil sie verschwinden, und irgendwann verwandelt sich alles andere in «nicht dürfen» – die Maßnahme ist obligatorisch.
**Um die Durchsetzung derartiger Initiativen strategisch zu unterstützen** und nett zu verpacken, gibt es Lobbyisten, gerne auch NGOs genannt. Dass das «NG» am Anfang dieser Abkürzung übersetzt «Nicht-Regierungs-» bedeutet, ist ein Anachronismus. Das war [vielleicht früher](https://transition-news.org/der-sumpf-aus-ngos-parteien-und-steuergeld) einmal so, heute ist eher das Gegenteil gemeint.
**In unserer modernen Zeit wird enorm viel Lobbyarbeit für die Digitalisierung** praktisch sämtlicher Lebensbereiche aufgewendet. Was das auf dem Sektor der Mobilität bedeuten kann, haben wir diese Woche anhand aktueller Entwicklungen in Spanien [beleuchtet](https://transition-news.org/nur-abschied-vom-alleinfahren-monstrose-spanische-uberwachungsprojekte-gemass). Begründet teilweise mit Vorgaben der Europäischen Union arbeitet man dort fleißig an einer «neuen Mobilität», basierend auf «intelligenter» technologischer Infrastruktur. Derartige Anwandlungen wurden auch schon als [«Technofeudalismus»](https://transition-news.org/yanis-varoufakis-der-europaische-traum-ist-tot-es-lebe-der-neue-traum) angeprangert.
**Nationale** **[Zugangspunkte](https://transport.ec.europa.eu/transport-themes/smart-mobility/road/its-directive-and-action-plan/national-access-points_en)** **für Mobilitätsdaten im Sinne der EU** gibt es nicht nur in allen Mitgliedsländern, sondern auch in der [Schweiz](https://opentransportdata.swiss/de/) und in Großbritannien. Das Vereinigte Königreich beteiligt sich darüber hinaus an anderen EU-Projekten für digitale Überwachungs- und Kontrollmaßnahmen, wie dem biometrischen [Identifizierungssystem](https://transition-news.org/biometrische-gesichtserkennung-in-britischen-hafen) für «nachhaltigen Verkehr und Tourismus».
**Natürlich marschiert auch Deutschland stracks und euphorisch** in Richtung digitaler Zukunft. Ohne [vernetzte Mobilität](https://mobilithek.info/about) und einen «verlässlichen Zugang zu Daten, einschließlich Echtzeitdaten» komme man in der Verkehrsplanung und -steuerung nicht aus, erklärt die Regierung. Der Interessenverband der IT-Dienstleister Bitkom will «die digitale Transformation der deutschen Wirtschaft und Verwaltung vorantreiben». Dazu bewirbt er unter anderem die Konzepte Smart City, Smart Region und Smart Country und behauptet, deutsche Großstädte «setzen bei Mobilität [voll auf Digitalisierung](https://www.smartcountry.berlin/de/newsblog/smart-city-index-grossstaedte-setzen-bei-mobilitaet-voll-auf-digitalisierung.html)».
**Es steht zu befürchten, dass das umfassende Sammeln, Verarbeiten und Vernetzen von Daten,** das angeblich die Menschen unterstützen soll (und theoretisch ja auch könnte), eher dazu benutzt wird, sie zu kontrollieren und zu manipulieren. Je elektrischer und digitaler unsere Umgebung wird, desto größer sind diese Möglichkeiten. Im Ergebnis könnten solche Prozesse den Bürger nicht nur einschränken oder überflüssig machen, sondern in mancherlei Hinsicht regelrecht abschalten. Eine gesunde Skepsis ist also geboten.
*\[Titelbild:* *[Pixabay](https://pareto.space/readhttps://pixabay.com/de/illustrations/schaufensterpuppe-platine-gesicht-5254046/)]*
***
Dieser Beitrag wurde mit dem [Pareto-Client](https://pareto.space/read) geschrieben. Er ist zuerst auf ***[Transition News](https://transition-news.org/das-gegenteil-von-mussen-ist-nicht-durfen)*** erschienen.
-
@ 872982aa:8fb54cfe
2025-03-27 05:47:06
- [首页](/readme.md)
- [第一章、 NIP-01: Basic protocol flow description](/01.md)
- [第二章、 NIP-02: Follow List](/02.md)
- [第三章、NIP-03: OpenTimestamps Attestations for Events](/03.md)
-
@ e6817453:b0ac3c39
2024-12-07 14:52:47
The temporal semantics and **temporal and time-aware knowledge graphs. We have different memory models for artificial intelligence agents. We all try to mimic somehow how the brain works, or at least how the declarative memory of the brain works. We have the split of episodic memory** and **semantic memory**. And we also have a lot of theories, right?
## Declarative Memory of the Human Brain
How is the semantic memory formed? We all know that our brain stores semantic memory quite close to the concept we have with the personal knowledge graphs, that it’s connected entities. They form a connection with each other and all those things. So far, so good. And actually, then we have a lot of concepts, how the episodic memory and our experiences gets transmitted to the semantic:
- hippocampus indexing and retrieval
- sanitization of episodic memories
- episodic-semantic shift theory
They all give a different perspective on how different parts of declarative memory cooperate.
We know that episodic memories get semanticized over time. You have semantic knowledge without the notion of time, and probably, your episodic memory is just decayed.
But, you know, it’s still an open question:
> do we want to mimic an AI agent’s memory as a human brain memory, or do we want to create something different?
It’s an open question to which we have no good answer. And if you go to the theory of neuroscience and check how episodic and semantic memory interfere, you will still find a lot of theories, yeah?
Some of them say that you have the hippocampus that keeps the indexes of the memory. Some others will say that you semantic the episodic memory. Some others say that you have some separate process that digests the episodic and experience to the semantics. But all of them agree on the plan that it’s operationally two separate areas of memories and even two separate regions of brain, and the semantic, it’s more, let’s say, protected.
So it’s harder to forget the semantical facts than the episodes and everything. And what I’m thinking about for a long time, it’s this, you know, the semantic memory.
## Temporal Semantics
It’s memory about the facts, but you somehow mix the time information with the semantics. I already described a lot of things, including how we could combine time with knowledge graphs and how people do it.
There are multiple ways we could persist such information, but we all hit the wall because the complexity of time and the semantics of time are highly complex concepts.
## Time in a Semantic context is not a timestamp.
What I mean is that when you have a fact, and you just mentioned that I was there at this particular moment, like, I don’t know, 15:40 on Monday, it’s already awake because we don’t know which Monday, right? So you need to give the exact date, but usually, you do not have experiences like that.
You do not record your memories like that, except you do the journaling and all of the things. So, usually, you have no direct time references. What I mean is that you could say that I was there and it was some event, blah, blah, blah.
Somehow, we form a chain of events that connect with each other and maybe will be connected to some period of time if we are lucky enough. This means that we could not easily represent temporal-aware information as just a timestamp or validity and all of the things.
For sure, the validity of the knowledge graphs (simple quintuple with start and end dates)is a big topic, and it could solve a lot of things. It could solve a lot of the time cases. It’s super simple because you give the end and start dates, and you are done, but it does not answer facts that have a relative time or time information in facts . It could solve many use cases but struggle with facts in an indirect temporal context. I like the simplicity of this idea. But the problem of this approach that in most cases, we simply don’t have these timestamps. We don’t have the timestamp where this information starts and ends. And it’s not modeling many events in our life, especially if you have the processes or ongoing activities or recurrent events.
I’m more about thinking about the time of semantics, where you have a time model as a **hybrid clock** or some **global clock** that does the partial ordering of the events. It’s mean that you have the chain of the experiences and you have the chain of the facts that have the different time contexts.
We could deduct the time from this chain of the events. But it’s a big, big topic for the research. But what I want to achieve, actually, it’s not separation on episodic and semantic memory. It’s having something in between.
## Blockchain of connected events and facts
I call it temporal-aware semantics or time-aware knowledge graphs, where we could encode the semantic fact together with the time component.I doubt that time should be the simple timestamp or the region of the two timestamps. For me, it is more a chain for facts that have a partial order and form a blockchain like a database or a partially ordered Acyclic graph of facts that are temporally connected. We could have some notion of time that is understandable to the agent and a model that allows us to order the events and focus on what the agent knows and how to order this time knowledge and create the chains of the events.
## Time anchors
We may have a particular time in the chain that allows us to arrange a more concrete time for the rest of the events. But it’s still an open topic for research. The temporal semantics gets split into a couple of domains. One domain is how to add time to the knowledge graphs. We already have many different solutions. I described them in my previous articles.
Another domain is the agent's memory and how the memory of the artificial intelligence treats the time. This one, it’s much more complex. Because here, we could not operate with the simple timestamps. We need to have the representation of time that are understandable by model and understandable by the agent that will work with this model. And this one, it’s way bigger topic for the research.”
-
@ 2fdeba99:fd961eff
2025-03-21 17:16:33
# == January 17 2025
Out From Underneath | Prism Shores
crazy arms | pigeon pit
Humanhood | The Weather Station
# == february 07 2025
Wish Defense | FACS
Sayan - Savoie | Maria Teriaeva
Nowhere Near Today | Midding
# == february 14 2025
Phonetics On and On | Horsegirl
# == february 21 2025
Finding Our Balance | Tsoh Tso
Machine Starts To Sing | Porridge Radio
Armageddon In A Summer Dress | Sunny Wa
# == february 28 2025
you, infinite | you, infinite
On Being | Max Cooper
Billboard Heart | Deep Sea Diver
# == March 21 2025
Watermelon/Peacock | Exploding Flowers
Warlord of the Weejuns | Goya Gumbani
-
@ 7d33ba57:1b82db35
2025-03-29 18:47:34
Pula, located at the southern tip of Istria, is a city where ancient Roman ruins meet stunning Adriatic beaches. Known for its well-preserved amphitheater, charming old town, and crystal-clear waters, Pula offers a perfect blend of history, culture, and relaxation.

## **🏛️ Top Things to See & Do in Pula**
### **1️⃣ Pula Arena (Roman Amphitheater) 🏟️**
- **One of the best-preserved Roman amphitheaters in the world**, built in the 1st century.
- Used for **gladiator fights**, now a venue for **concerts & film festivals**.
- Climb to the top for **stunning sea views**.

### **2️⃣ Explore Pula’s Old Town 🏡**
- Wander through **cobbled streets**, past **Venetian, Roman, and Austro-Hungarian architecture**.
- Visit the **Arch of the Sergii** (a 2,000-year-old Roman triumphal arch).
- Enjoy a drink in **Forum Square**, home to the **Temple of Augustus**.
### **3️⃣ Relax at Pula’s Beaches 🏖️**
- **Hawaiian Beach (Havajska Plaža):** Turquoise waters & cliffs for jumping.
- **Ambrela Beach:** A Blue Flag beach with **calm waters, great for families**.
- **Pješčana Uvala:** A **sandy beach**, rare for Croatia!

### **4️⃣ Cape Kamenjak Nature Park 🌿**
- A **wild and rugged coastline** with hidden coves and crystal-clear water.
- Great for **cliff jumping, kayaking, and biking**.
- Located **30 minutes south of Pula**.
### **5️⃣ Visit Brijuni National Park 🏝️**
- A group of **14 islands**, once Tito’s private retreat.
- Features **Roman ruins, a safari park, and cycling trails**.
- Accessible via **boat from Fazana (15 min from Pula)**.

### **6️⃣ Try Istrian Cuisine 🍽️**
- **Fuži with truffles** – Istria is famous for **white & black truffles**.
- **Istrian prosciutto & cheese** – Perfect with local **Malvazija wine**.
- **Fresh seafood** – Try grilled squid or buzara-style mussels.

## **🚗 How to Get to Pula**
✈️ **By Air:** Pula Airport (PUY) has flights from major European cities.
🚘 **By Car:**
- **From Zagreb:** ~3 hours (270 km)
- **From Ljubljana (Slovenia):** ~2.5 hours (160 km)
🚌 **By Bus:** Regular buses connect Pula with **Rovinj, Rijeka, Zagreb, and Trieste (Italy)**.
🚢 **By Ferry:** Seasonal ferries run from **Venice and Zadar**.

## **💡 Tips for Visiting Pula**
✅ **Best time to visit?** **May–September** for warm weather & festivals 🌞
✅ **Book Arena event tickets in advance** – Summer concerts sell out fast 🎶
✅ **Try local wines** – Istrian **Malvazija (white) and Teran (red)** are excellent 🍷
✅ **Explore nearby towns** – Rovinj & Motovun make great day trips 🏡
✅ **Cash is useful** – Some small shops & markets prefer cash 💶

-
@ 3bf0c63f:aefa459d
2024-12-06 20:37:26
# início
> "Vocês vêem? Vêem a história? Vêem alguma coisa? Me parece que estou tentando lhes contar um sonho -- fazendo uma tentativa inútil, porque nenhum relato de sonho pode transmitir a sensação de sonho, aquela mistura de absurdo, surpresa e espanto numa excitação de revolta tentando se impôr, aquela noção de ser tomado pelo incompreensível que é da própria essência dos sonhos..."
> Ele ficou em silêncio por alguns instantes.
> "... Não, é impossível; é impossível transmitir a sensação viva de qualquer época determinada de nossa existência -- aquela que constitui a sua verdade, o seu significado, a sua essência sutil e contundente. É impossível. Vivemos, como sonhamos -- sozinhos..."
* [Livros mencionados por Olavo de Carvalho](https://fiatjaf.com/livros-olavo.html)
* [Antiga _homepage_ Olavo de Carvalho](https://site.olavo.fiatjaf.com "Sapientiam autem non vincit malitia")
* [Bitcoin explicado de um jeito correto e inteligível](nostr:naddr1qqrky6t5vdhkjmspz9mhxue69uhkv6tpw34xze3wvdhk6q3q80cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsxpqqqp65wp3k3fu)
* [Reclamações](nostr:naddr1qqyrgwf4vseryvmxqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c9f9u03)
---
* [Nostr](-/tags/nostr)
* [Bitcoin](nostr:naddr1qqyryveexumnyd3kqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c7nywz4)
* [How IPFS is broken](nostr:naddr1qqyxgdfsxvck2dtzqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823c8y87ll)
* [Programming quibbles](nostr:naddr1qqyrjvehxq6ngvpkqyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cu05y0j)
* [Economics](nostr:naddr1qqyk2cm0dehk66trwvq3zamnwvaz7tmxd9shg6npvchxxmmdqgsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8grqsqqqa28clr866)
* [Open-source software](nostr:naddr1qqy8xmmxw3mkzun9qyghwumn8ghj7enfv96x5ctx9e3k7mgzyqalp33lewf5vdq847t6te0wvnags0gs0mu72kz8938tn24wlfze6qcyqqq823cmyvl8h)
---
[Nostr](nostr:nprofile1qqsrhuxx8l9ex335q7he0f09aej04zpazpl0ne2cgukyawd24mayt8gpyfmhxue69uhkummnw3ez6an9wf5kv6t9vsh8wetvd3hhyer9wghxuet5fmsq8j) [GitHub](https://github.com/fiatjaf) [Telegram](https://t.me/fiatjaf) [code](https://git.fiatjaf.com)
-
@ 77110427:f621e11c
2024-12-02 22:55:12
> All credit to Guns Magazine. Read the full issue here ⬇️
[February 1970 PDF
](https://gunsmagazine.com/wp-content/uploads/2020/03/G0270.pdf)
---



















---
### 📰 Past Magazine Mondays 📰
[001: May 1963](nostr:note1r5ve5en9tyv38hathy2twhm9h4dn7tq7fgradzkazskxyxtckysqeqxyzm)
[002: August 1969](nostr:note1zkeur68w9h8ljswp4a4xc45exfv725v6vudqdhyukqz6kz37vdaq097f9z)
---
### ⬇️ Follow 1776 HODL ⬇️
[Website](https://1776.npub.pro)
[Nostr](nostr:npub1wugsgfcs7edz70qtc56khmxv7js90mp2hwrfu46vkk4fda3puywq3xaz5a)
-
@ 57d1a264:69f1fee1
2025-03-16 14:17:25
Recently we shared an update for a new Open Cash Foundation website https://stacker.news/items/811604/r/Design_r Today a new logo by Vladimir Krstić!




File available for review at https://www.figma.com/design/Yxb4JEsjHYSibY06T8piB7/OpenCash%3A-Logo?node-id=151-249&p=f&t=FYyeTBkJznCKdbd7-0
https://primal.net/e/nevent1qvzqqqqqqypzqhzsmgfjj3l68068t84e0rtcfkcjh2k3c0jmdft4gy9wke2x8x6tqyg8wumn8ghj7efwdehhxtnvdakz7qgkwaehxw309ajkgetw9ehx7um5wghxcctwvshszrnhwden5te0dehhxtnvdakz7qpqryz9rj0wgshykjuzqksxxs50l7jfnwyvtkfmdvmudrg92s3xuxys8fqzr7
originally posted at https://stacker.news/items/914665
-
@ f9cf4e94:96abc355
2024-12-31 20:18:59
Scuttlebutt foi iniciado em maio de 2014 por Dominic Tarr ( [dominictarr]( https://github.com/dominictarr/scuttlebutt) ) como uma rede social alternativa off-line, primeiro para convidados, que permite aos usuários obter controle total de seus dados e privacidade. Secure Scuttlebutt ([ssb]( https://github.com/ssbc/ssb-db)) foi lançado pouco depois, o que coloca a privacidade em primeiro plano com mais recursos de criptografia.
Se você está se perguntando de onde diabos veio o nome Scuttlebutt:
> Este termo do século 19 para uma fofoca vem do Scuttlebutt náutico: “um barril de água mantido no convés, com um buraco para uma xícara”. A gíria náutica vai desde o hábito dos marinheiros de se reunir pelo boato até a fofoca, semelhante à fofoca do bebedouro.

Marinheiros se reunindo em torno da rixa. ( [fonte]( https://twitter.com/IntEtymology/status/998879578851508224) )
Dominic descobriu o termo boato em um [artigo de pesquisa]( https://www.cs.cornell.edu/home/rvr/papers/flowgossip.pdf) que leu.
Em sistemas distribuídos, [fofocar]( https://en.wikipedia.org/wiki/Gossip_protocol) é um processo de retransmissão de mensagens ponto a ponto; as mensagens são disseminadas de forma análoga ao “boca a boca”.
**Secure Scuttlebutt é um banco de dados de feeds imutáveis apenas para acréscimos, otimizado para replicação eficiente para protocolos ponto a ponto.** **Cada usuário tem um log imutável somente para acréscimos no qual eles podem gravar.** Eles gravam no log assinando mensagens com sua chave privada. Pense em um feed de usuário como seu próprio diário de bordo, como um diário [de bordo]( https://en.wikipedia.org/wiki/Logbook) (ou diário do capitão para os fãs de Star Trek), onde eles são os únicos autorizados a escrever nele, mas têm a capacidade de permitir que outros amigos ou colegas leiam ao seu diário de bordo, se assim o desejarem.
Cada mensagem possui um número de sequência e a mensagem também deve fazer referência à mensagem anterior por seu ID. O ID é um hash da mensagem e da assinatura. A estrutura de dados é semelhante à de uma lista vinculada. É essencialmente um log somente de acréscimo de JSON assinado. **Cada item adicionado a um log do usuário é chamado de mensagem.**
**Os logs do usuário são conhecidos como feed e um usuário pode seguir os feeds de outros usuários para receber suas atualizações.** Cada usuário é responsável por armazenar seu próprio feed. Quando Alice assina o feed de Bob, Bob baixa o log de feed de Alice. Bob pode verificar se o registro do feed realmente pertence a Alice verificando as assinaturas. Bob pode verificar as assinaturas usando a chave pública de Alice.

Estrutura de alto nível de um feed
**Pubs são servidores de retransmissão conhecidos como “super peers”. Pubs conectam usuários usuários e atualizações de fofocas a outros usuários conectados ao Pub. Um Pub é análogo a um pub da vida real, onde as pessoas vão para se encontrar e se socializar.** Para ingressar em um Pub, o usuário deve ser convidado primeiro. Um usuário pode solicitar um código de convite de um Pub; o Pub simplesmente gerará um novo código de convite, mas alguns Pubs podem exigir verificação adicional na forma de verificação de e-mail ou, com alguns Pubs, você deve pedir um código em um fórum público ou chat. Pubs também podem mapear aliases de usuário, como e-mails ou nome de usuário, para IDs de chave pública para facilitar os pares de referência.
Depois que o Pub enviar o código de convite ao usuário, o usuário resgatará o código, o que significa que o Pub seguirá o usuário, o que permite que o usuário veja as mensagens postadas por outros membros do Pub, bem como as mensagens de retransmissão do Pub pelo usuário a outros membros do Pub.
Além de retransmitir mensagens entre pares, os Pubs também podem armazenar as mensagens. Se Alice estiver offline e Bob transmitir atualizações de feed, Alice perderá a atualização. Se Alice ficar online, mas Bob estiver offline, não haverá como ela buscar o feed de Bob. Mas com um Pub, Alice pode buscar o feed no Pub mesmo se Bob estiver off-line porque o Pub está armazenando as mensagens. **Pubs são úteis porque assim que um colega fica online, ele pode sincronizar com o Pub para receber os feeds de seus amigos potencialmente offline.**
Um usuário pode, opcionalmente, executar seu próprio servidor Pub e abri-lo ao público ou permitir que apenas seus amigos participem, se assim o desejarem. Eles também podem ingressar em um Pub público. Aqui está uma lista de [Pubs públicos em que]( https://github.com/ssbc/ssb-server/wiki/Pub-Servers) todos podem participar **.** Explicaremos como ingressar em um posteriormente neste guia. **Uma coisa importante a observar é que o Secure Scuttlebutt em uma rede social somente para convidados significa que você deve ser “puxado” para entrar nos círculos sociais.** Se você responder às mensagens, os destinatários não serão notificados, a menos que estejam seguindo você de volta. O objetivo do SSB é criar “ilhas” isoladas de redes pares, ao contrário de uma rede pública onde qualquer pessoa pode enviar mensagens a qualquer pessoa.

Perspectivas dos participantes
## Scuttlebot
O software Pub é conhecido como servidor Scuttlebutt (servidor [ssb]( https://github.com/ssbc/ssb-server) ), mas também é conhecido como “Scuttlebot” e `sbot`na linha de comando. O servidor SSB adiciona comportamento de rede ao banco de dados Scuttlebutt (SSB). Estaremos usando o Scuttlebot ao longo deste tutorial.
**Os logs do usuário são conhecidos como feed e um usuário pode seguir os feeds de outros usuários para receber suas atualizações.** Cada usuário é responsável por armazenar seu próprio feed. Quando Alice assina o feed de Bob, Bob baixa o log de feed de Alice. Bob pode verificar se o registro do feed realmente pertence a Alice verificando as assinaturas. Bob pode verificar as assinaturas usando a chave pública de Alice.

Estrutura de alto nível de um feed
**Pubs são servidores de retransmissão conhecidos como “super peers”. Pubs conectam usuários usuários e atualizações de fofocas a outros usuários conectados ao Pub. Um Pub é análogo a um pub da vida real, onde as pessoas vão para se encontrar e se socializar.** Para ingressar em um Pub, o usuário deve ser convidado primeiro. Um usuário pode solicitar um código de convite de um Pub; o Pub simplesmente gerará um novo código de convite, mas alguns Pubs podem exigir verificação adicional na forma de verificação de e-mail ou, com alguns Pubs, você deve pedir um código em um fórum público ou chat. Pubs também podem mapear aliases de usuário, como e-mails ou nome de usuário, para IDs de chave pública para facilitar os pares de referência.
Depois que o Pub enviar o código de convite ao usuário, o usuário resgatará o código, o que significa que o Pub seguirá o usuário, o que permite que o usuário veja as mensagens postadas por outros membros do Pub, bem como as mensagens de retransmissão do Pub pelo usuário a outros membros do Pub.
Além de retransmitir mensagens entre pares, os Pubs também podem armazenar as mensagens. Se Alice estiver offline e Bob transmitir atualizações de feed, Alice perderá a atualização. Se Alice ficar online, mas Bob estiver offline, não haverá como ela buscar o feed de Bob. Mas com um Pub, Alice pode buscar o feed no Pub mesmo se Bob estiver off-line porque o Pub está armazenando as mensagens. **Pubs são úteis porque assim que um colega fica online, ele pode sincronizar com o Pub para receber os feeds de seus amigos potencialmente offline.**
Um usuário pode, opcionalmente, executar seu próprio servidor Pub e abri-lo ao público ou permitir que apenas seus amigos participem, se assim o desejarem. Eles também podem ingressar em um Pub público. Aqui está uma lista de [Pubs públicos em que]( https://github.com/ssbc/ssb-server/wiki/Pub-Servers) todos podem participar **.** Explicaremos como ingressar em um posteriormente neste guia. **Uma coisa importante a observar é que o Secure Scuttlebutt em uma rede social somente para convidados significa que você deve ser “puxado” para entrar nos círculos sociais.** Se você responder às mensagens, os destinatários não serão notificados, a menos que estejam seguindo você de volta. O objetivo do SSB é criar “ilhas” isoladas de redes pares, ao contrário de uma rede pública onde qualquer pessoa pode enviar mensagens a qualquer pessoa.


Perspectivas dos participantes
## Pubs - Hubs
### Pubs públicos
| Pub Name | Operator | Invite Code |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| `scuttle.us` | [@Ryan]( https://keybase.io/ryan_singer) | `scuttle.us:8008:@WqcuCOIpLtXFRw/9vOAQJti8avTZ9vxT9rKrPo8qG6o=.ed25519~/ZUi9Chpl0g1kuWSrmehq2EwMQeV0Pd+8xw8XhWuhLE=` |
| [pub1.upsocial.com]( https://upsocial.com/) | [@freedomrules]( https://github.com/freedomrules) | `pub1.upsocial.com:8008:@gjlNF5Cyw3OKZxEoEpsVhT5Xv3HZutVfKBppmu42MkI=.ed25519~lMd6f4nnmBZEZSavAl4uahl+feajLUGqu8s2qdoTLi8=` |
| [Monero Pub]( https://xmr-pub.net/) | [@Denis]( https://github.com/Orville2112) | `xmr-pub.net:8008:@5hTpvduvbDyMLN2IdzDKa7nx7PSem9co3RsOmZoyyCM=.ed25519~vQU+r2HUd6JxPENSinUWdfqrJLlOqXiCbzHoML9iVN4=` |
| [FreeSocial]( https://freesocial.co/) | [@Jarland]( https://github.com/mxroute) | `pub.freesocial.co:8008:@ofYKOy2p9wsaxV73GqgOyh6C6nRGFM5FyciQyxwBd6A=.ed25519~ye9Z808S3KPQsV0MWr1HL0/Sh8boSEwW+ZK+8x85u9w=` |
| `ssb.vpn.net.br` | [@coffeverton]( https://about.me/coffeverton) | `ssb.vpn.net.br:8008:@ze8nZPcf4sbdULvknEFOCbVZtdp7VRsB95nhNw6/2YQ=.ed25519~D0blTolH3YoTwSAkY5xhNw8jAOjgoNXL/+8ZClzr0io=` |
| [gossip.noisebridge.info]( https://www.noisebridge.net/wiki/Pub) | [Noisebridge Hackerspace]( https://www.noisebridge.net/wiki/Unicorn) [@james.network]( https://james.network/) | `gossip.noisebridge.info:8008:@2NANnQVdsoqk0XPiJG2oMZqaEpTeoGrxOHJkLIqs7eY=.ed25519~JWTC6+rPYPW5b5zCion0gqjcJs35h6JKpUrQoAKWgJ4=` |
### Pubs privados
Você precisará entrar em contato com os proprietários desses bares para receber um convite.
| Pub Name | Operator | Contact |
| --------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------- |
| `many.butt.nz` | [@dinosaur]( https://dinosaur.is/) | [mikey@enspiral.com](mailto:mikey@enspiral.com) |
| `one.butt.nz` | [@dinosaur]( https://dinosaur.is/) | [mikey@enspiral.com](mailto:mikey@enspiral.com) |
| `ssb.mikey.nz` | [@dinosaur]( https://dinosaur.is/) | [mikey@enspiral.com](mailto:mikey@enspiral.com) |
| [ssb.celehner.com]( https://ssb.celehner.com/) | [@cel]( https://github.com/ssbc/ssb-server/wiki/@f/6sQ6d2CMxRUhLpspgGIulDxDCwYD7DzFzPNr7u5AU=.ed25519) | [cel@celehner.com](mailto:cel@celehner.com) |
### Pubs muito grandes
 *Aviso: embora tecnicamente funcione usar um convite para esses pubs, você provavelmente se divertirá se o fizer devido ao seu tamanho (muitas coisas para baixar, risco para bots / spammers / idiotas)* 
| Pub Name | Operator | Invite Code |
| --------------------------------------- | ----------------------------------------------- | ------------------------------------------------------------ |
| `scuttlebutt.de` | [SolSoCoG]( https://solsocog.de/impressum) | `scuttlebutt.de:8008:@yeh/GKxlfhlYXSdgU7CRLxm58GC42za3tDuC4NJld/k=.ed25519~iyaCpZ0co863K9aF+b7j8BnnHfwY65dGeX6Dh2nXs3c=` |
| `Lohn's Pub` | [@lohn]( https://github.com/lohn) | `p.lohn.in:8018:@LohnKVll9HdLI3AndEc4zwGtfdF/J7xC7PW9B/JpI4U=.ed25519~z3m4ttJdI4InHkCtchxTu26kKqOfKk4woBb1TtPeA/s=` |
| [Scuttle Space]( https://scuttle.space/) | [@guil-dot]( https://github.com/guil-dot) | Visit [scuttle.space]( https://scuttle.space/) |
| `SSB PeerNet US-East` | [timjrobinson]( https://github.com/timjrobinson) | `us-east.ssbpeer.net:8008:@sTO03jpVivj65BEAJMhlwtHXsWdLd9fLwyKAT1qAkc0=.ed25519~sXFc5taUA7dpGTJITZVDCRy2A9jmkVttsr107+ufInU=` |
| Hermies | s | net:hermies.club:8008~shs:uMYDVPuEKftL4SzpRGVyQxLdyPkOiX7njit7+qT/7IQ=:SSB+Room+PSK3TLYC2T86EHQCUHBUHASCASE18JBV24= |
## GUI - Interface Gráfica do Utilizador(Usuário)
### Patchwork - Uma GUI SSB (Descontinuado)
[**Patchwork**]( https://github.com/ssbc/patchwork) **é o aplicativo de mensagens e compartilhamento descentralizado construído em cima do SSB** . O protocolo scuttlebutt em si não mantém um conjunto de feeds nos quais um usuário está interessado, então um cliente é necessário para manter uma lista de feeds de pares em que seu respectivo usuário está interessado e seguindo.

Fonte: [scuttlebutt.nz]( https://www.scuttlebutt.nz/getting-started)
**Quando você instala e executa o Patchwork, você só pode ver e se comunicar com seus pares em sua rede local. Para acessar fora de sua LAN, você precisa se conectar a um Pub.** Um pub é apenas para convidados e eles retransmitem mensagens entre você e seus pares fora de sua LAN e entre outros Pubs.
Lembre-se de que você precisa seguir alguém para receber mensagens dessa pessoa. Isso reduz o envio de mensagens de spam para os usuários. Os usuários só veem as respostas das pessoas que seguem. Os dados são sincronizados no disco para funcionar offline, mas podem ser sincronizados diretamente com os pares na sua LAN por wi-fi ou bluetooth.
### Patchbay - Uma GUI Alternativa
Patchbay é um cliente de fofoca projetado para ser fácil de modificar e estender. Ele usa o mesmo banco de dados que [Patchwork]( https://github.com/ssbc/patchwork) e [Patchfoo]( https://github.com/ssbc/patchfoo) , então você pode facilmente dar uma volta com sua identidade existente.

### Planetary - GUI para IOS

[Planetary]( https://apps.apple.com/us/app/planetary-app/id1481617318) é um app com pubs pré-carregados para facilitar integração.
### Manyverse - GUI para Android

[Manyverse]( https://www.manyver.se/) é um aplicativo de rede social com recursos que você esperaria: posts, curtidas, perfis, mensagens privadas, etc. Mas não está sendo executado na nuvem de propriedade de uma empresa, em vez disso, as postagens de seus amigos e todos os seus dados sociais vivem inteiramente em seu telefone .
## Fontes
* https://scuttlebot.io/
* https://decentralized-id.com/decentralized-web/scuttlebot/#plugins
* https://medium.com/@miguelmota/getting-started-with-secure-scuttlebut-e6b7d4c5ecfd
* [**Secure Scuttlebutt**]( http://ssbc.github.io/secure-scuttlebutt/) **:** um protocolo de banco de dados global.
-
@ a39d19ec:3d88f61e
2025-03-18 17:16:50
Nun da das deutsche Bundesregime den Ruin Deutschlands beschlossen hat, der sehr wahrscheinlich mit dem Werkzeug des Geld druckens "finanziert" wird, kamen mir so viele Gedanken zur Geldmengenausweitung, dass ich diese für einmal niedergeschrieben habe.
Die Ausweitung der Geldmenge führt aus klassischer wirtschaftlicher Sicht immer zu Preissteigerungen, weil mehr Geld im Umlauf auf eine begrenzte Menge an Gütern trifft. Dies lässt sich in mehreren Schritten analysieren:
### 1. Quantitätstheorie des Geldes
Die klassische Gleichung der Quantitätstheorie des Geldes lautet:
M • V = P • Y
wobei:
- M die Geldmenge ist,
- V die Umlaufgeschwindigkeit des Geldes,
- P das Preisniveau,
- Y die reale Wirtschaftsleistung (BIP).
Wenn M steigt und V sowie Y konstant bleiben, muss P steigen – also Inflation entstehen.
### 2. Gütermenge bleibt begrenzt
Die Menge an real produzierten Gütern und Dienstleistungen wächst meist nur langsam im Vergleich zur Ausweitung der Geldmenge. Wenn die Geldmenge schneller steigt als die Produktionsgütermenge, führt dies dazu, dass mehr Geld für die gleiche Menge an Waren zur Verfügung steht – die Preise steigen.
### 3. Erwartungseffekte und Spekulation
Wenn Unternehmen und Haushalte erwarten, dass mehr Geld im Umlauf ist, da eine zentrale Planung es so wollte, können sie steigende Preise antizipieren. Unternehmen erhöhen ihre Preise vorab, und Arbeitnehmer fordern höhere Löhne. Dies kann eine sich selbst verstärkende Spirale auslösen.
### 4. Internationale Perspektive
Eine erhöhte Geldmenge kann die Währung abwerten, wenn andere Länder ihre Geldpolitik stabil halten. Eine schwächere Währung macht Importe teurer, was wiederum Preissteigerungen antreibt.
### 5. Kritik an der reinen Geldmengen-Theorie
Der Vollständigkeit halber muss erwähnt werden, dass die meisten modernen Ökonomen im Staatsauftrag argumentieren, dass Inflation nicht nur von der Geldmenge abhängt, sondern auch von der Nachfrage nach Geld (z. B. in einer Wirtschaftskrise). Dennoch zeigt die historische Erfahrung, dass eine unkontrollierte Geldmengenausweitung langfristig immer zu Preissteigerungen führt, wie etwa in der Hyperinflation der Weimarer Republik oder in Simbabwe.
-
@ f1597634:c6d40bf4
2024-10-02 09:00:59
E aí, galera do Nostr! Já pensou em como proteger sua privacidade nesse mundo descentralizado? A gente sabe que a liberdade é daora, mas é importante saber como se proteger dos "bisbilhoteiros" que estão sempre à espreita.
**O perigo das fotos:**
- Sabia que as fotos que você posta podem dar muitas informações sobre você? É tipo deixar um mapa do tesouro nas mãos de alguém!
- Pessoal mau intencionadas podem usar essas fotos para descobrir onde você mora, qual seu IP e até mesmo sua identidade!
**Dicas para se proteger:**
- **Escolha seus apps com cuidado:** Nem todos os apps são iguais. Procure aqueles que a galera mais confia e que têm uma boa fama.
- **Ajuste as configurações:** A maioria dos apps tem configurações de privacidade. Mexa nelas para mostrar só o que você quiser para os outros.
- **Cuidado com links:** Não clique em qualquer link que você receber. Pode ser uma armadilha!
Uma boa prática ao navegar pelo Nostr é configurar um Proxy *confiável* no seu aplicativo. No Nostrudel por exemplo é possível configurar um proxy de imagem através das [configurações](https://nostrudel.ninja/#/settings/performance).
<img src="https://blossom.primal.net/d6f191331248dc5cc3e8617c0f94e2a2e44341451e0ec3275cc22b5195ccbdb3.jpg">
**Segundo análise, as redes a seguir ja disponibilizam esses proxies por padrão:**
- Amethyst
- Damus
\
**O que é esse tal de proxy?**
- Imagina que você está usando uma máscara. O proxy é tipo essa máscara, só que para o seu IP. Assim, ninguém vai saber quem você é de verdade.
- É como se você estivesse usando um disfarce para navegar pela internet!
**Outras dicas:**
- **Remover Exif:** Todas as fotos que tiramos possuem metadados, normalmente redes sociais e outras empresas removem esses dados quando recebem a imagem no servidor *(eventualmente pegam os dados)*.
Programas como [ExifCleaner](https://exifcleaner.com) removem essas informações antes do upload.
**Conclusão:**
A internet é um lugar incrível, mas também pode ser perigoso. Seguindo essas dicas, você vai poder curtir o Nostr com mais tranquilidade e sem se preocupar com os "bisbilhoteiros".
**Lembre-se:** A segurança é coisa séria! Compartilhe esse guia com seus amigos e ajude a criar uma comunidade mais segura.
**E aí, curtiu?**
**fonte: [https://victorhugo.info/artigos/nostr-como-se-proteger-1](https://victorhugo.info/artigos/nostr-como-se-proteger-1)**
-
@ aa8de34f:a6ffe696
2025-03-21 12:08:31
19\. März 2025
### 🔐 1. SHA-256 is Quantum-Resistant
Bitcoin’s **proof-of-work** mechanism relies on SHA-256, a hashing algorithm. Even with a powerful quantum computer, **SHA-256 remains secure** because:
- Quantum computers excel at **factoring large numbers** (Shor’s Algorithm).
- However, **SHA-256 is a one-way function**, meaning there's no known quantum algorithm that can efficiently reverse it.
- **Grover’s Algorithm** (which theoretically speeds up brute force attacks) would still require **2¹²⁸ operations** to break SHA-256 – far beyond practical reach.
++++++++++++++++++++++++++++++++++++++++++++++++++
### 🔑 2. Public Key Vulnerability – But Only If You Reuse Addresses
Bitcoin uses **Elliptic Curve Digital Signature Algorithm (ECDSA)** to generate keys.
- A quantum computer could use **Shor’s Algorithm** to break **SECP256K1**, the curve Bitcoin uses.
- If you never reuse addresses, it is an additional security element
- 🔑 1. Bitcoin Addresses Are NOT Public Keys
Many people assume a **Bitcoin address** is the public key—**this is wrong**.
- When you **receive Bitcoin**, it is sent to a **hashed public key** (the Bitcoin address).
- The **actual public key is never exposed** because it is the Bitcoin Adress who addresses the Public Key which never reveals the creation of a public key by a spend
- Bitcoin uses **Pay-to-Public-Key-Hash (P2PKH)** or newer methods like **Pay-to-Witness-Public-Key-Hash (P2WPKH)**, which add extra layers of security.
### 🕵️♂️ 2.1 The Public Key Never Appears
- When you **send Bitcoin**, your wallet creates a **digital signature**.
- This signature uses the **private key** to **prove** ownership.
- The **Bitcoin address is revealed and creates the Public Key**
- The public key **remains hidden inside the Bitcoin script and Merkle tree**.
This means: ✔ **The public key is never exposed.** ✔ **Quantum attackers have nothing to target, attacking a Bitcoin Address is a zero value game.**
+++++++++++++++++++++++++++++++++++++++++++++++++
### 🔄 3. Bitcoin Can Upgrade
Even if quantum computers **eventually** become a real threat:
- Bitcoin developers can **upgrade to quantum-safe cryptography** (e.g., lattice-based cryptography or post-quantum signatures like Dilithium).
- Bitcoin’s decentralized nature ensures a network-wide **soft fork or hard fork** could transition to quantum-resistant keys.
++++++++++++++++++++++++++++++++++++++++++++++++++
### ⏳ 4. The 10-Minute Block Rule as a Security Feature
- Bitcoin’s network operates on a **10-minute block interval**, meaning:Even if an attacker had immense computational power (like a quantum computer), they could only attempt an attack **every 10 minutes**.Unlike traditional encryption, where a hacker could continuously brute-force keys, Bitcoin’s system **resets the challenge with every new block**.This **limits the window of opportunity** for quantum attacks.
---
### 🎯 5. Quantum Attack Needs to Solve a Block in Real-Time
- A quantum attacker **must solve the cryptographic puzzle (Proof of Work) in under 10 minutes**.
- The problem? **Any slight error changes the hash completely**, meaning:**If the quantum computer makes a mistake (even 0.0001% probability), the entire attack fails**.**Quantum decoherence** (loss of qubit stability) makes error correction a massive challenge.The computational cost of **recovering from an incorrect hash** is still incredibly high.
---
### ⚡ 6. Network Resilience – Even if a Block Is Hacked
- Even if a quantum computer **somehow** solved a block instantly:The network would **quickly recognize and reject invalid transactions**.Other miners would **continue mining** under normal cryptographic rules.**51% Attack?** The attacker would need to consistently beat the **entire Bitcoin network**, which is **not sustainable**.
---
### 🔄 7. The Logarithmic Difficulty Adjustment Neutralizes Threats
- Bitcoin adjusts mining difficulty every **2016 blocks (\~2 weeks)**.
- If quantum miners appeared and suddenly started solving blocks too quickly, **the difficulty would adjust upward**, making attacks significantly harder.
- This **self-correcting mechanism** ensures that even quantum computers wouldn't easily overpower the network.
---
### 🔥 Final Verdict: Quantum Computers Are Too Slow for Bitcoin
✔ **The 10-minute rule limits attack frequency** – quantum computers can’t keep up.
✔ **Any slight miscalculation ruins the attack**, resetting all progress.
✔ **Bitcoin’s difficulty adjustment would react, neutralizing quantum advantages**.
**Even if quantum computers reach their theoretical potential, Bitcoin’s game theory and design make it incredibly resistant.** 🚀
-
@ 8671a6e5:f88194d1
2025-03-18 23:46:54
### **glue for the mind**
\
You’ve seen them, these garish orange Bitcoin stickers slapped on lampposts, laptops, windows and the occasional rust-bucket Honda. They’re sometimes in some areas a sort of graffiti plague on the landscape, certainly when a meetup or bitcoin conference was held in the area (especially then the city or town can fork out some extra budget to clean things up and scrape the stickers from statues of famous folk heroes or the door to the headquarters of a local bank branche).\
\
At first glance, it might seem like enthusiasm Bitcoiners desperate to scream their obsession from the rooftops. Both for the fun of it, and to get rid of the pack of stickers they’ve got at a local meetup.\
\
But let’s cut to the chase: covering half a town in stickers isn’t clever. It’s lazy, counterproductive, and has nothing to do with what Bitcoin actually stands for.\
Worse, it reeks of the brain-dead low grade (cheap) marketing tactics you’d expect from shitcoiners or the follow up of some half-baked flyer campaign by a local communist clique.\
Proof? Bitcoin stickers are literally covering up — or being covered up themselves, usually by - communist stickers in a pointless competition for use of real-world ad space.\
\
Maybe, bitcoiners should just create a sticker where Karl Marx ànd the bitcoin logo appear in the same sticker, so both groups can enjoy it’s uselessness, and call it quits to get this stupidity over with once and for all.\
A sticker with a shiny B might look cool at first. But what does it actually do?
Communist and Bitcoin logo sticker
**Spamming stickers doesn’t make “frens”**
There’s a psychology behind these stickers of course: people slap them up to feel part of a rebel tribe, flipping off central banks or feeling part of the crew.\
This crude, omnipresent approach to marketing echoes the late 1960s— an era of peak fiat, not Bitcoin’s time.\
Mimicking those tactics today, as if Bitcoin were some hip underground record store trying to spread its brand name, is utterly irrelevant.\
Sure, people love signaling affiliations with an easy and cheap identity flex — like a bumper sticker yelling: “Look at me I’m special!”\
\
But plaster a town with Bitcoin logos, and it stops being edgy and it was never funny; it becomes an eyesore and puts bitcoiners in the same category as the social justice warriors and political youth movements or brands of local energy drinks doing some weird campaign.\
\
Advertising psychology shows overexposure breeds resentment, not interest. Flood a street with stickers, and you’re not lighting a spark. You’re making people uninterested, gag, associating Bitcoin with spam or worse: get totally blended into the background along all the other noise from the street marketeers.\
\
***The "mere exposure effect" (Zajonc, 1968)[1](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-1-159370932)*** claims familiarity breeds liking, even from annoyance. Since the 1960s however, a lot has changed, as we’ll see… and above all, yet, after years of Bitcoin stickers in many areas, they’ve just turned into meaningless wallpaper. It has usually no strong message, no slogan, no conversation starter other than “buy bitcoin”, it’s disassociated from reality for many people, as the reaction show us. It’s also happening in a vacuum, where “normies” and no-coiners pass by and don’t even recognize such stickers for anything else than background colors.
**It’s Lazy Man’s Work**
Let’s talk effort — or the lack of it - for these kind of campaigns and stickers. Invented in the 1920s, stickers began expressing political opinions in the 1970s during student, peace, and anti-nuclear campaigns. It’s easy, cheap and also quick to distribute.\
\
These stickers aren’t masterful designs from an artistic genius (safe some clever exceptions). They’re usually ripped off from somewhere else, tweaked for five minutes, and bulk-ordered online. It’s the “IKEA effect” gone wrong: a tiny bit of customization, and suddenly people think they’re visionaries. But it’s a low-effort form of activism at best. Compare that to coding a Bitcoin tool or patiently explaining its value to a normie or organizing a meetup or conference, starting a company.\
Not that low-level or guerrilla marketing can’t work, I just don’t see it happen with stickers. Why not go out there and try to convince a whole series of fruit and vegetable market owners to accept bitcoin instead of using very expensive bank Point-of-sale systems?\
Why not direct mailing? Why not… do more than just putting a sticker on a signpost and walk away like a sneaky student promoting his 4 person political group?\
\
Stickers are the “Save the whales (pun intended)” magnet on your fridge: lazy-ass advocacy that screams intellectual deficiency. They’re a shortcut to feeling involved, not a strategy for real impact.
imaginary Save-the-Whales bitcoin sticker
**Strategy territory signaling**
Here’s the kicker: Bitcoin’s strength lies in its tech and value properties — decentralized, borderless value transfer that eliminates middlemen and has provable digital scarcity.\
Stickers? They’re just physical garbage. Sure, they might feel like a way to make an abstract idea tangible, tapping into “embodied cognition.” But they explain nothing about Bitcoin’s purpose or how it revolutionizes finance.\
They’re a dopamine hit for the people sticking them anywhere — a pathetic “I did something” moment — while everyone else walks by without a glance.\
Bitcoin is about innovation, not old-school social groups with low-budget marketing tactics.
**\
The psychology of Bitcoin stickers**
Why bother? Stickers are simple and loud—easy for the brain to process, a cheap thrill of rebellion. The person who spends an afternoon covering a city in them thinks they’re spreading the gospel. In reality, they’re just littering. Real advocacy takes effort, discussion, and substance — not a pack of adhesive stickers ordered with the click of a button.\
It’s the same reason nobody turns communist from a hammer-and-sickle sticker on a pole. It’s dead air.\
\
The proof of their uselessness? In 2 years, not one person I know has bought, researched, or even asked about Bitcoin because of a sticker in the neighborhood bar. A bar near me has had one on the wall for years — zero requests to pay with Bitcoin.
A sticker sitting on a bar wall for five years without impact isn’t “subtle marketing”—it’s a neon sign of failure. And the people cleaning those stickers off street signs, or the local communist student activists constantly covering them with their own, are locked in an endless, mindless sticker war.\
\
Other areas are even having a tsunami of bitcoin stickers, and hardly any places where they actually accept bitcoin for goods.\
More so, places where they do accept bitcoin readily, usually only need one sticker: the one at the door of a business saying “bitcoin accepted here”. And that’s about it.
**What the little amount of research says**
Studies shows stickers work for movements claiming public space and resisting dominant narratives — when done on a massive scale, targeting a specific audience have a visual and emotional effect when combined with other forms of resistance in social movements.\
***"Stickin' it to the Man: The Geographies of Protest Stickers"*** [2](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-2-159370932)\
\
For Bitcoin, a global monetary network meant for everyone, that localized, niche-based campaign makes little sense.\
Unlike sports teams or clothing brands, Bitcoiners can’t pinpoint a target area. A random sticker on a busy street claims nothing—no momentum, atmosphere, or intrigue. Political campaigns and underground youth movements concentrate stickers in student neighborhoods, universities, or subcultures where the message resonates. But Bitcoin isn’t a corporation, company, or fashion brand—it’s a Wall Street-embraced asset by now, with activists not really situated in the sticker-guerrilla kind of persons.
When was the last time you saw a "Buy Gold!" sticker? A "Get Your Microsoft Stock Options Now!" sticker? Or a "Crude Oil—Yeah, Baby!" sticker? Never. Serious assets don’t need guerrilla marketing.
The overload on stickers is also becoming an issue (especially in some areas with higher concentration of bitcoiners).
**Bitcoin stickers fall flat**
Invented in the 1920s, stickers began expressing political opinions in the 1970s during student, peace, and anti-nuclear campaigns. Protest stickers massively appear after protest rallies or campaigns with multi-level plans to reach audiences.\
As significant, overlooked tools of resistance and debate, their effect remains under-studied, with no data on “recruitment.”\
\
If Bitcoin stickers (which don’t provoke debate ever, other than people being angry about having to clean them up) in a bar are any clue—after one full year, not a single person asked why it was there or if Bitcoin was accepted—they’re just decor, lost among the clutter.
Bitcoiners still think slapping a shiny "B" logo on a street sign without explanation or slogan will spark momentum. But that requires a massive, organized campaign with thousands of people and a clear audience while you claim certain well aimed areas of public space — that something that’s not happening in bitcoin. There’s no plan, no campaign, just someone sticking a bitcoin logo at the supermarkt trolley or the backside of a street sign.\
And even if we did reach a higher number of stickers, it would annoy the f out of people.
***"Study: Ad Overload Could Pose Steeper Risk to Brands Than Messages Near Inappropriate Content" (GWI & WARC, 2021)*** [3](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-3-159370932)\
\
There’s also the effect of high ad exposure. When a whole street is covered in bitcoin stickers, it’s having the opposite effect. Or still… no one cares.
***"Coping with High Advertising Exposure: A Source-Monitoring Perspective" (Bell et al., 2022)***[4](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-4-159370932)
### **No synergy, no consensus**
The synergy between offline sticker placement and online sharing? Absent. Bitcoiners online might be called “cyber hornets”, but this swarm is notoriously bad at sharing content. Post a Bitcoin sticker photo, and at best 1-2% will share it — no momentum, no discussion, no engagement.\
\
Non-Bitcoiners have zero reason to care. When was the last time you, as a Bitcoiner, shared a soccer team’s sticker? A political campaign sticker? Never. That’s normal, as you’re not in their bubble, so for us, it’s irrelevant. We won’t share the soccer team’s sticker (unless it’s [Real Bedford FC](https://www.realbedford.com/) probably).\
\
It's just a layer of plastic with adhesive glued to a surfase where someone will sooner or later either have to clean it up, or where the bitcoin sticker will be covered over by another person wasting his or her time by claiming that “sticker real-estate space” for their cause or brand-awareness.

And so, the red sticker calling all students and workers to vote for a Leninist party (with 10 members) is stickered over by a bright orange Bitcoin logo, and that one, in turn, will be over-stickered by a local fitness company's new logo, and so forth. It’s all a pointless rush for giggles and dopamine. And it’s time to recognize it for what it really is: retardation.
Bitcoin deserves better than this 70s guerrilla marketing ploy, from a time when activism was more than sitting behind a computer ordering stickers and (mostly not) clicking a link. Leave the sticker wars to students searching for an ideological dopamine rush and soccer fans claiming a neighborhood as "their territory."\
\
As Bitcoiners, we can do something more useful. For example: ask yourself how many businesses in your area accept Bitcoin, or what coworker you can save from investing in blatant scams, or… invent something nice, start a meetup, podcast, or learn to code, convince, build.
Bitcoin deserves better.
by **AVB** / [tips go here](https://coinos.io/allesvoorbitcoin/receive)
@avbpodcast - allesvoorbitcoin.be - [12 Bitcoin Food for Thought](https://allesvoorbitcoin.be/toolsguides/12writings/)
[1](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-anchor-1-159370932)
https://typeset.io/papers/attitudinal-effects-of-mere-exposure-12e5gwrysc
[2](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-anchor-2-159370932)
https://www.research.ed.ac.uk/en/publications/stickin-it-to-the-man-the-geographies-of-protest-stickers
[3](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-anchor-3-159370932)
https://www.warc.com/content/article/warc-datapoints-gwi/too-many-ads-is-the-most-damaging-factor-for-brands/en-gb/136530
[4](https://allesvoorbitcoin.substack.com/p/bitcoin-stickers-a-study-in-intellectual#footnote-anchor-4-159370932)
https://pmc.ncbi.nlm.nih.gov/articles/PMC9444107/
-
@ a95c6243:d345522c
2025-03-20 09:59:20
**Bald werde es verboten, alleine im Auto zu fahren,** konnte man dieser Tage in verschiedenen spanischen Medien lesen. Die nationale Verkehrsbehörde (Dirección General de Tráfico, kurz DGT) werde Alleinfahrern das Leben schwer machen, wurde gemeldet. Konkret erörtere die Generaldirektion geeignete Sanktionen für Personen, die ohne Beifahrer im Privatauto unterwegs seien.
**Das Alleinfahren sei zunehmend verpönt und ein Mentalitätswandel notwendig,** hieß es. Dieser «Luxus» stehe im Widerspruch zu den Maßnahmen gegen Umweltverschmutzung, die in allen europäischen Ländern gefördert würden. In Frankreich sei es «bereits verboten, in der Hauptstadt allein zu fahren», [behauptete](https://noticiastrabajo.huffingtonpost.es/sociedad/adios-a-conducir-solo-la-dgt-se-lo-pone-crudo-a-los-conductores-que-viajen-sin-acompanante-en-el-coche/) *Noticiastrabajo Huffpost* in einer Zwischenüberschrift. Nur um dann im Text zu konkretisieren, dass die sogenannte «Umweltspur» auf der Pariser Ringautobahn gemeint war, die für Busse, Taxis und Fahrgemeinschaften reserviert ist. [Ab Mai](https://www.lefigaro.fr/conso/peripherique-parisien-entree-en-vigueur-de-la-voie-reservee-au-covoiturage-ce-lundi-20250303) werden Verstöße dagegen mit einem Bußgeld geahndet.
**Die DGT jedenfalls wolle bei der Umsetzung derartiger Maßnahmen** nicht hinterherhinken. Diese Medienberichte, inklusive des angeblich bevorstehenden Verbots, beriefen sich auf Aussagen des Generaldirektors der Behörde, Pere Navarro, beim Mobilitätskongress Global Mobility Call im November letzten Jahres, wo es um «nachhaltige Mobilität» ging. Aus diesem Kontext stammt auch Navarros Warnung: «Die Zukunft des Verkehrs ist geteilt oder es gibt keine».
**Die «Faktenchecker» kamen der Generaldirektion prompt zu Hilfe.** Die DGT habe derlei Behauptungen [zurückgewiesen](https://www.newtral.es/dgt-una-persona-coche/20250312/) und klargestellt, dass es keine Pläne gebe, Fahrten mit nur einer Person im Auto zu verbieten oder zu bestrafen. Bei solchen Meldungen handele es sich um Fake News. Teilweise wurde der Vorsitzende der spanischen «Rechtsaußen»-Partei Vox, Santiago Abascal, der Urheberschaft bezichtigt, weil er einen entsprechenden [Artikel](https://gaceta.es/espana/la-dgt-estudia-formas-de-sancionar-a-quien-circule-solo-en-su-vehiculo-el-futuro-sera-compartido-o-no-sera-20250311-1612/) von *La Gaceta* kommentiert hatte.
**Der Beschwichtigungsversuch der Art «niemand hat die Absicht»** ist dabei erfahrungsgemäß eher ein Alarmzeichen als eine Beruhigung. Walter Ulbrichts Leugnung einer geplanten Berliner [Mauer](https://www.berlin-mauer.de/videos/walter-ulbricht-zum-mauerbau-530/) vom Juni 1961 ist vielen genauso in Erinnerung wie die Fake News-Warnungen des deutschen Bundesgesundheitsministeriums bezüglich [Lockdowns](https://x.com/BMG_Bund/status/1238780849652465664) im März 2020 oder diverse Äußerungen zu einer [Impfpflicht](https://www.achgut.com/artikel/die_schoensten_politiker_zitate_zur_impfpflicht) ab 2020.
**Aber Aufregung hin, Dementis her:** Die [Pressemitteilung](https://archive.is/xXQWD) der DGT zu dem Mobilitätskongress enthält in Wahrheit viel interessantere Informationen als «nur» einen Appell an den «guten» Bürger wegen der Bemühungen um die Lebensqualität in Großstädten oder einen möglichen obligatorischen Abschied vom Alleinfahren. Allerdings werden diese Details von Medien und sogenannten Faktencheckern geflissentlich übersehen, obwohl sie keineswegs versteckt sind. Die Auskünfte sind sehr aufschlussreich, wenn man genauer hinschaut.
### Digitalisierung ist der Schlüssel für Kontrolle
**Auf dem Kongress stellte die Verkehrsbehörde ihre Initiativen zur Förderung der «neuen Mobilität» vor,** deren Priorität Sicherheit und Effizienz sei. Die vier konkreten Ansätze haben alle mit Digitalisierung, Daten, Überwachung und Kontrolle im großen Stil zu tun und werden unter dem Euphemismus der «öffentlich-privaten Partnerschaft» angepriesen. Auch lassen sie die transhumanistische Idee vom unzulänglichen Menschen erkennen, dessen Fehler durch «intelligente» technologische Infrastruktur kompensiert werden müssten.
**Die Chefin des Bereichs «Verkehrsüberwachung» erklärte die Funktion** des spanischen National Access Point ([NAP](https://nap.dgt.es/)), wobei sie betonte, wie wichtig Verkehrs- und Infrastrukturinformationen in Echtzeit seien. Der NAP ist «eine essenzielle Web-Applikation, die unter EU-Mandat erstellt wurde», kann man auf der Website der DGT nachlesen.
**Das Mandat meint Regelungen zu einem einheitlichen europäischen Verkehrsraum,** mit denen die Union mindestens seit 2010 den Aufbau einer digitalen Architektur mit offenen Schnittstellen betreibt. Damit begründet man auch «umfassende Datenbereitstellungspflichten im Bereich multimodaler Reiseinformationen». Jeder Mitgliedstaat musste einen NAP, also einen nationalen [Zugangspunkt](https://transport.ec.europa.eu/transport-themes/smart-mobility/road/its-directive-and-action-plan/national-access-points_en) einrichten, der Zugang zu statischen und dynamischen Reise- und Verkehrsdaten verschiedener Verkehrsträger ermöglicht.
**Diese Entwicklung ist heute schon weit fortgeschritten,** auch und besonders in Spanien. Auf besagtem Kongress erläuterte die Leiterin des Bereichs «Telematik» die Plattform [«DGT 3.0»](https://www.dgt.es/muevete-con-seguridad/tecnologia-e-innovacion-en-carretera/dgt-3.0/). Diese werde als Integrator aller Informationen genutzt, die von den verschiedenen öffentlichen und privaten Systemen, die Teil der Mobilität sind, bereitgestellt werden.
**Es handele sich um eine Vermittlungsplattform zwischen Akteuren wie Fahrzeugherstellern,** Anbietern von Navigationsdiensten oder Kommunen und dem Endnutzer, der die Verkehrswege benutzt. Alle seien auf Basis des Internets der Dinge (IOT) anonym verbunden, «um der vernetzten Gemeinschaft wertvolle Informationen zu liefern oder diese zu nutzen».
**So sei DGT 3.0 «ein Zugangspunkt für einzigartige, kostenlose und genaue Echtzeitinformationen** über das Geschehen auf den Straßen und in den Städten». Damit lasse sich der Verkehr nachhaltiger und vernetzter gestalten. Beispielsweise würden die Karten des Produktpartners Google dank der DGT-Daten 50 Millionen Mal pro Tag aktualisiert.
**Des Weiteren informiert die Verkehrsbehörde über ihr SCADA-Projekt.** Die Abkürzung steht für Supervisory Control and Data Acquisition, zu deutsch etwa: Kontrollierte Steuerung und Datenerfassung. Mit SCADA kombiniert man Software und Hardware, um automatisierte Systeme zur Überwachung und Steuerung technischer Prozesse zu schaffen. Das SCADA-Projekt der DGT wird von Indra entwickelt, einem spanischen Beratungskonzern aus den Bereichen Sicherheit & Militär, Energie, Transport, Telekommunikation und Gesundheitsinformation.
**Das SCADA-System der Behörde umfasse auch eine Videostreaming- und Videoaufzeichnungsplattform,** die das Hochladen in die Cloud in Echtzeit ermöglicht, wie Indra [erklärt](https://www.indracompany.com/es/noticia/indra-presenta-global-mobility-call-pionera-plataforma-nube-desplegada-centros-gestion). Dabei gehe es um Bilder, die von Überwachungskameras an Straßen aufgenommen wurden, sowie um Videos aus DGT-Hubschraubern und Drohnen. Ziel sei es, «die sichere Weitergabe von Videos an Dritte sowie die kontinuierliche Aufzeichnung und Speicherung von Bildern zur möglichen Analyse und späteren Nutzung zu ermöglichen».
**Letzteres klingt sehr nach biometrischer Erkennung** und Auswertung durch künstliche Intelligenz. Für eine bessere Datenübertragung wird derzeit die [Glasfaserverkabelung](https://www.moncloa.com/2025/03/18/linea-azul-conduccion-dgt-3191554/) entlang der Landstraßen und Autobahnen ausgebaut. Mit der Cloud sind die Amazon Web Services (AWS) gemeint, die spanischen [Daten gehen](https://norberthaering.de/news/digitalgipfel-wehnes-interview/) somit direkt zu einem US-amerikanischen «Big Data»-Unternehmen.
**Das Thema «autonomes Fahren», also Fahren ohne Zutun des Menschen,** bildet den Abschluss der Betrachtungen der DGT. Zusammen mit dem Interessenverband der Automobilindustrie ANFAC (Asociación Española de Fabricantes de Automóviles y Camiones) sprach man auf dem Kongress über Strategien und Perspektiven in diesem Bereich. Die Lobbyisten hoffen noch in diesem Jahr 2025 auf einen [normativen Rahmen](https://www.coches.net/noticias/informe-coche-autonomo-conectado-espana-2024) zur erweiterten Unterstützung autonomer Technologien.
**Wenn man derartige Informationen im Zusammenhang betrachtet,** bekommt man eine Idee davon, warum zunehmend alles elektrisch und digital werden soll. Umwelt- und Mobilitätsprobleme in Städten, wie Luftverschmutzung, Lärmbelästigung, Platzmangel oder Staus, sind eine Sache. Mit dem Argument «emissionslos» wird jedoch eine Referenz zum CO2 und dem «menschengemachten Klimawandel» hergestellt, die Emotionen triggert. Und damit wird so ziemlich alles verkauft.
**Letztlich aber gilt: Je elektrischer und digitaler unsere Umgebung wird** und je freigiebiger wir mit unseren Daten jeder Art sind, desto besser werden wir kontrollier-, steuer- und sogar abschaltbar. Irgendwann entscheiden KI-basierte Algorithmen, ob, wann, wie, wohin und mit wem wir uns bewegen dürfen. Über einen 15-Minuten-Radius geht dann möglicherweise nichts hinaus. Die Projekte auf diesem Weg sind ernst zu nehmen, real und schon weit fortgeschritten.
*\[Titelbild:* *[Pixabay](https://pixabay.com/de/photos/reisen-wagen-ferien-fahrzeug-1426822/)]*
***
Dieser Beitrag ist zuerst auf ***[Transition News](https://transition-news.org/nur-abschied-vom-alleinfahren-monstrose-spanische-uberwachungsprojekte-gemass)*** erschienen.
-
@ a367f9eb:0633efea
2024-11-05 08:48:41
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The [reporting](https://www.reuters.com/technology/artificial-intelligence/chinese-researchers-develop-ai-model-military-use-back-metas-llama-2024-11-01/) purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
> In a June paper reviewed by Reuters, six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
>
> The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the Star Trek episode “A Taste of Armageddon“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over one million open-source LLMs available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are potentially trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American infrastructure, data, and yes, your credit history?
As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much many times.
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
Open-source matters When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various licensing schemes – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also open-source, which has allowed thousands of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
Open-source is for your friends, and enemies In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to Hugging Face, download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put export controls on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see The Crypto Wars). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
Limiting open-source threatens our own advancement If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “Hundred Year Marathon” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with trillions of dollars’ worth of investments that span far beyond AI chatbots and skip logic protocols.
The theft of intellectual property at factories in Shenzhen, or in US courts by third-party litigation funding coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
Last week, an investigation by Reuters revealed that Chinese researchers have been using open-source AI tools to build nefarious-sounding models that may have some military application.
The reporting purports that adversaries in the Chinese Communist Party and its military wing are taking advantage of the liberal software licensing of American innovations in the AI space, which could someday have capabilities to presumably harm the United States.
> In a June paper reviewed by[ Reuters](https://www.reuters.com/technology/artificial-intelligence/chinese-researchers-develop-ai-model-military-use-back-metas-llama-2024-11-01/), six Chinese researchers from three institutions, including two under the People’s Liberation Army’s (PLA) leading research body, the Academy of Military Science (AMS), detailed how they had used an early version of Meta’s Llama as a base for what it calls “ChatBIT”.
>
> The researchers used an earlier Llama 13B large language model (LLM) from Meta, incorporating their own parameters to construct a military-focused AI tool to gather and process intelligence, and offer accurate and reliable information for operational decision-making.
While I’m doubtful that today’s existing chatbot-like tools will be the ultimate battlefield for a new geopolitical war (queue up the computer-simulated war from the *Star Trek* episode “[A Taste of Armageddon](https://en.wikipedia.org/wiki/A_Taste_of_Armageddon)“), this recent exposé requires us to revisit why large language models are released as open-source code in the first place.
Added to that, should it matter that an adversary is having a poke around and may ultimately use them for some purpose we may not like, whether that be China, Russia, North Korea, or Iran?
The number of open-source AI LLMs continues to grow each day, with projects like Vicuna, LLaMA, BLOOMB, Falcon, and Mistral available for download. In fact, there are over [one million open-source LLMs](https://huggingface.co/models) available as of writing this post. With some decent hardware, every global citizen can download these codebases and run them on their computer.
With regard to this specific story, we could assume it to be a selective leak by a competitor of Meta which created the LLaMA model, intended to harm its reputation among those with cybersecurity and national security credentials. There are [potentially](https://bigthink.com/business/the-trillion-dollar-ai-race-to-create-digital-god/) trillions of dollars on the line.
Or it could be the revelation of something more sinister happening in the military-sponsored labs of Chinese hackers who have already been caught attacking American[ infrastructure](https://www.nbcnews.com/tech/security/chinese-hackers-cisa-cyber-5-years-us-infrastructure-attack-rcna137706),[ data](https://www.cnn.com/2024/10/05/politics/chinese-hackers-us-telecoms/index.html), and yes, [your credit history](https://thespectator.com/topic/chinese-communist-party-credit-history-equifax/)?
**As consumer advocates who believe in the necessity of liberal democracies to safeguard our liberties against authoritarianism, we should absolutely remain skeptical when it comes to the communist regime in Beijing. We’ve written as much[ many times](https://consumerchoicecenter.org/made-in-china-sold-in-china/).**
At the same time, however, we should not subrogate our own critical thinking and principles because it suits a convenient narrative.
Consumers of all stripes deserve technological freedom, and innovators should be free to provide that to us. And open-source software has provided the very foundations for all of this.
## **Open-source matters**
When we discuss open-source software and code, what we’re really talking about is the ability for people other than the creators to use it.
The various [licensing schemes](https://opensource.org/licenses) – ranging from GNU General Public License (GPL) to the MIT License and various public domain classifications – determine whether other people can use the code, edit it to their liking, and run it on their machine. Some licenses even allow you to monetize the modifications you’ve made.
While many different types of software will be fully licensed and made proprietary, restricting or even penalizing those who attempt to use it on their own, many developers have created software intended to be released to the public. This allows multiple contributors to add to the codebase and to make changes to improve it for public benefit.
Open-source software matters because anyone, anywhere can download and run the code on their own. They can also modify it, edit it, and tailor it to their specific need. The code is intended to be shared and built upon not because of some altruistic belief, but rather to make it accessible for everyone and create a broad base. This is how we create standards for technologies that provide the ground floor for further tinkering to deliver value to consumers.
Open-source libraries create the building blocks that decrease the hassle and cost of building a new web platform, smartphone, or even a computer language. They distribute common code that can be built upon, assuring interoperability and setting standards for all of our devices and technologies to talk to each other.
I am myself a proponent of open-source software. The server I run in my home has dozens of dockerized applications sourced directly from open-source contributors on GitHub and DockerHub. When there are versions or adaptations that I don’t like, I can pick and choose which I prefer. I can even make comments or add edits if I’ve found a better way for them to run.
Whether you know it or not, many of you run the Linux operating system as the base for your Macbook or any other computer and use all kinds of web tools that have active repositories forked or modified by open-source contributors online. This code is auditable by everyone and can be scrutinized or reviewed by whoever wants to (even AI bots).
This is the same software that runs your airlines, powers the farms that deliver your food, and supports the entire global monetary system. The code of the first decentralized cryptocurrency Bitcoin is also [open-source](https://github.com/bitcoin), which has allowed [thousands](https://bitcoinmagazine.com/business/bitcoin-is-money-for-enemies) of copycat protocols that have revolutionized how we view money.
You know what else is open-source and available for everyone to use, modify, and build upon?
PHP, Mozilla Firefox, LibreOffice, MySQL, Python, Git, Docker, and WordPress. All protocols and languages that power the web. Friend or foe alike, anyone can download these pieces of software and run them how they see fit.
Open-source code is speech, and it is knowledge.
We build upon it to make information and technology accessible. Attempts to curb open-source, therefore, amount to restricting speech and knowledge.
## **Open-source is for your friends, and enemies**
In the context of Artificial Intelligence, many different developers and companies have chosen to take their large language models and make them available via an open-source license.
At this very moment, you can click on over to[ Hugging Face](https://huggingface.co/), download an AI model, and build a chatbot or scripting machine suited to your needs. All for free (as long as you have the power and bandwidth).
Thousands of companies in the AI sector are doing this at this very moment, discovering ways of building on top of open-source models to develop new apps, tools, and services to offer to companies and individuals. It’s how many different applications are coming to life and thousands more jobs are being created.
We know this can be useful to friends, but what about enemies?
As the AI wars heat up between liberal democracies like the US, the UK, and (sluggishly) the European Union, we know that authoritarian adversaries like the CCP and Russia are building their own applications.
The fear that China will use open-source US models to create some kind of military application is a clear and present danger for many political and national security researchers, as well as politicians.
A bipartisan group of US House lawmakers want to put [export controls](https://www.reuters.com/technology/us-lawmakers-unveil-bill-make-it-easier-restrict-exports-ai-models-2024-05-10/) on AI models, as well as block foreign access to US cloud servers that may be hosting AI software.
If this seems familiar, we should also remember that the US government once classified cryptography and encryption as “munitions” that could not be exported to other countries (see[ The Crypto Wars](https://en.wikipedia.org/wiki/Export_of_cryptography_from_the_United_States)). Many of the arguments we hear today were invoked by some of the same people as back then.
Now, encryption protocols are the gold standard for many different banking and web services, messaging, and all kinds of electronic communication. We expect our friends to use it, and our foes as well. Because code is knowledge and speech, we know how to evaluate it and respond if we need to.
Regardless of who uses open-source AI, this is how we should view it today. These are merely tools that people will use for good or ill. It’s up to governments to determine how best to stop illiberal or nefarious uses that harm us, rather than try to outlaw or restrict building of free and open software in the first place.
## **Limiting open-source threatens our own advancement**
If we set out to restrict and limit our ability to create and share open-source code, no matter who uses it, that would be tantamount to imposing censorship. There must be another way.
If there is a “[Hundred Year Marathon](https://www.amazon.com/Hundred-Year-Marathon-Strategy-Replace-Superpower/dp/1250081343)” between the United States and liberal democracies on one side and autocracies like the Chinese Communist Party on the other, this is not something that will be won or lost based on software licenses. We need as much competition as possible.
The Chinese military has been building up its capabilities with [trillions of dollars’](https://www.economist.com/china/2024/11/04/in-some-areas-of-military-strength-china-has-surpassed-america) worth of investments that span far beyond AI chatbots and skip logic protocols.
The [theft](https://www.technologyreview.com/2023/06/20/1075088/chinese-amazon-seller-counterfeit-lawsuit/) of intellectual property at factories in Shenzhen, or in US courts by [third-party litigation funding](https://nationalinterest.org/blog/techland/litigation-finance-exposes-our-judicial-system-foreign-exploitation-210207) coming from China, is very real and will have serious economic consequences. It may even change the balance of power if our economies and countries turn to war footing.
But these are separate issues from the ability of free people to create and share open-source code which we can all benefit from. In fact, if we want to continue our way our life and continue to add to global productivity and growth, it’s demanded that we defend open-source.
If liberal democracies want to compete with our global adversaries, it will not be done by reducing the freedoms of citizens in our own countries.
*Originally published on the website of the [Consumer Choice Center](https://consumerchoicecenter.org/open-source-is-for-everyone-even-your-adversaries/).*
-
@ 21335073:a244b1ad
2025-03-15 23:00:40
I want to see Nostr succeed. If you can think of a way I can help make that happen, I’m open to it. I’d like your suggestions.
My schedule’s shifting soon, and I could volunteer a few hours a week to a Nostr project. I won’t have more total time, but how I use it will change.
Why help? I care about freedom. Nostr’s one of the most powerful freedom tools I’ve seen in my lifetime. If I believe that, I should act on it.
I don’t care about money or sats. I’m not rich, I don’t have extra cash. That doesn’t drive me—freedom does. I’m volunteering, not asking for pay.
I’m not here for clout. I’ve had enough spotlight in my life; it doesn’t move me. If I wanted clout, I’d be on Twitter dropping basic takes. Clout’s easy. Freedom’s hard. I’d rather help anonymously. No speaking at events—small meetups are cool for the vibe, but big conferences? Not my thing. I’ll never hit a huge Bitcoin conference. It’s just not my scene.
That said, I could be convinced to step up if it’d really boost Nostr—as long as it’s legal and gets results.
In this space, I’d watch for social engineering. I watch out for it. I’m not here to make friends, just to help. No shade—you all seem great—but I’ve got a full life and awesome friends irl. I don’t need your crew or to be online cool. Connect anonymously if you want; I’d encourage it.
I’m sick of watching other social media alternatives grow while Nostr kinda stalls. I could trash-talk, but I’d rather do something useful.
Skills? I’m good at spotting social media problems and finding possible solutions. I won’t overhype myself—that’s weird—but if you’re responding, you probably see something in me. Perhaps you see something that I don’t see in myself.
If you need help now or later with Nostr projects, reach out. Nostr only—nothing else. Anonymous contact’s fine. Even just a suggestion on how I can pitch in, no project attached, works too. 💜
Creeps or harassment will get blocked or I’ll nuke my simplex code if it becomes a problem.
https://simplex.chat/contact#/?v=2-4&smp=smp%3A%2F%2FSkIkI6EPd2D63F4xFKfHk7I1UGZVNn6k1QWZ5rcyr6w%3D%40smp9.simplex.im%2FbI99B3KuYduH8jDr9ZwyhcSxm2UuR7j0%23%2F%3Fv%3D1-2%26dh%3DMCowBQYDK2VuAyEAS9C-zPzqW41PKySfPCEizcXb1QCus6AyDkTTjfyMIRM%253D%26srv%3Djssqzccmrcws6bhmn77vgmhfjmhwlyr3u7puw4erkyoosywgl67slqqd.onion
-
@ 266815e0:6cd408a5
2025-03-19 11:10:21
How to create a nostr app quickly using [applesauce](https://hzrd149.github.io/applesauce/)
In this guide we are going to build a nostr app that lets users follow and unfollow [fiatjaf](nostr:npub180cvv07tjdrrgpa0j7j7tmnyl2yr6yr7l8j4s3evf6u64th6gkwsyjh6w6)
## 1. Setup new project
Start by setting up a new vite app using `pnpm create vite`, then set the name and select `Solid` and `Typescript`
```sh
➜ pnpm create vite
│
◇ Project name:
│ followjaf
│
◇ Select a framework:
│ Solid
│
◇ Select a variant:
│ TypeScript
│
◇ Scaffolding project in ./followjaf...
│
└ Done. Now run:
cd followjaf
pnpm install
pnpm run dev
```
## 2. Adding nostr dependencies
There are a few useful nostr dependencies we are going to need. `nostr-tools` for the types and small methods, and [`rx-nostr`](https://penpenpng.github.io/rx-nostr/) for making relay connections
```sh
pnpm install nostr-tools rx-nostr
```
## 3. Setup rx-nostr
Next we need to setup rxNostr so we can make connections to relays. create a new `src/nostr.ts` file with
```ts
import { createRxNostr, noopVerifier } from "rx-nostr";
export const rxNostr = createRxNostr({
// skip verification here because we are going to verify events at the event store
skipVerify: true,
verifier: noopVerifier,
});
```
## 4. Setup the event store
Now that we have a way to connect to relays, we need a place to store events. We will use the [`EventStore`](https://hzrd149.github.io/applesauce/typedoc/classes/applesauce_core.EventStore.html) class from `applesauce-core` for this. create a new `src/stores.ts` file with
> The event store does not store any events in the browsers local storage or anywhere else. It's in-memory only and provides a model for the UI
```ts
import { EventStore } from "applesauce-core";
import { verifyEvent } from "nostr-tools";
export const eventStore = new EventStore();
// verify the events when they are added to the store
eventStore.verifyEvent = verifyEvent;
```
## 5. Create the query store
The event store is where we store all the events, but we need a way for the UI to query them. We can use the [`QueryStore`](https://hzrd149.github.io/applesauce/typedoc/classes/applesauce_core.QueryStore.html) class from `applesauce-core` for this.
Create a query store in `src/stores.ts`
```ts
import { QueryStore } from "applesauce-core";
// ...
// the query store needs the event store to subscribe to it
export const queryStore = new QueryStore(eventStore);
```
## 6. Setup the profile loader
Next we need a way to fetch user profiles. We are going to use the [`ReplaceableLoader`](https://hzrd149.github.io/applesauce/overview/loaders.html#replaceable-loader) class from [`applesauce-loaders`](https://www.npmjs.com/package/applesauce-loaders) for this.
> `applesauce-loaders` is a package that contains a few loader classes that can be used to fetch different types of data from relays.
First install the package
```sh
pnpm install applesauce-loaders
```
Then create a `src/loaders.ts` file with
```ts
import { ReplaceableLoader } from "applesauce-loaders";
import { rxNostr } from "./nostr";
import { eventStore } from "./stores";
export const replaceableLoader = new ReplaceableLoader(rxNostr);
// Start the loader and send any events to the event store
replaceableLoader.subscribe((packet) => {
eventStore.add(packet.event, packet.from);
});
```
## 7. Fetch fiatjaf's profile
Now that we have a way to store events, and a loader to help with fetching them, we should update the `src/App.tsx` component to fetch the profile.
We can do this by calling the `next` method on the loader and passing a `pubkey`, `kind` and `relays` to it
```tsx
function App() {
// ...
onMount(() => {
// fetch fiatjaf's profile on load
replaceableLoader.next({
pubkey: "3bf0c63fcb93463407af97a5e5ee64fa883d107ef9e558472c4eb9aaaefa459d",
kind: 0,
relays: ["wss://pyramid.fiatjaf.com/"],
});
});
// ...
}
```
## 8. Display the profile
Now that we have a way to fetch the profile, we need to display it in the UI.
We can do this by using the [`ProfileQuery`](https://hzrd149.github.io/applesauce/typedoc/functions/applesauce_core.Queries.ProfileQuery.html) which gives us a stream of updates to a pubkey's profile.
Create the profile using `queryStore.createQuery` and pass in the `ProfileQuery` and the pubkey.
```tsx
const fiatjaf = queryStore.createQuery(
ProfileQuery,
"3bf0c63fcb93463407af97a5e5ee64fa883d107ef9e558472c4eb9aaaefa459d"
);
```
But this just gives us an [observable](https://rxjs.dev/guide/observable), we need to subscribe to it to get the profile.
Luckily SolidJS profiles a simple [`from`](https://docs.solidjs.com/reference/reactive-utilities/from) method to subscribe to any observable.
> To make things reactive SolidJS uses accessors, so to get the profile we need to call `fiatjaf()`
```tsx
function App() {
// ...
// Subscribe to fiatjaf's profile from the query store
const fiatjaf = from(
queryStore.createQuery(ProfileQuery, "3bf0c63fcb93463407af97a5e5ee64fa883d107ef9e558472c4eb9aaaefa459d")
);
return (
<>
{/* replace the vite and solid logos with the profile picture */}
<div>
<img src={fiatjaf()?.picture} class="logo" />
</div>
<h1>{fiatjaf()?.name}</h1>
{/* ... */}
</>
);
}
```
## 9. Letting the user signin
Now we should let the user signin to the app. We can do this by creating a [`AccountManager`](https://hzrd149.github.io/applesauce/accounts/manager.html) class from `applesauce-accounts`
First we need to install the packages
```sh
pnpm install applesauce-accounts applesauce-signers
```
Then create a new `src/accounts.ts` file with
```ts
import { AccountManager } from "applesauce-accounts";
import { registerCommonAccountTypes } from "applesauce-accounts/accounts";
// create an account manager instance
export const accounts = new AccountManager();
// Adds the common account types to the manager
registerCommonAccountTypes(accounts);
```
Next lets presume the user has a NIP-07 browser extension installed and add a signin button.
```tsx
function App() {
const signin = async () => {
// do nothing if the user is already signed in
if (accounts.active) return;
// create a new nip-07 signer and try to get the pubkey
const signer = new ExtensionSigner();
const pubkey = await signer.getPublicKey();
// create a new extension account, add it, and make it the active account
const account = new ExtensionAccount(pubkey, signer);
accounts.addAccount(account);
accounts.setActive(account);
};
return (
<>
{/* ... */}
<div class="card">
<p>Are you following the fiatjaf? the creator of "The nostr"</p>
<button onClick={signin}>Check</button>
</div>
</>
);
}
```
Now when the user clicks the button the app will ask for the users pubkey, then do nothing... but it's a start.
> We are not persisting the accounts, so when the page reloads the user will NOT be signed in. you can learn about persisting the accounts in the [docs](https://hzrd149.github.io/applesauce/accounts/manager.html#persisting-accounts)
## 10. Showing the signed-in state
We should show some indication to the user that they are signed in. We can do this by modifying the signin button if the user is signed in and giving them a way to sign-out
```tsx
function App() {
// subscribe to the currently active account (make sure to use the account$ observable)
const account = from(accounts.active$);
// ...
const signout = () => {
// do nothing if the user is not signed in
if (!accounts.active) return;
// signout the user
const account = accounts.active;
accounts.removeAccount(account);
accounts.clearActive();
};
return (
<>
{/* ... */}
<div class="card">
<p>Are you following the fiatjaf? ( creator of "The nostr" )</p>
{account() === undefined ? <button onClick={signin}>Check</button> : <button onClick={signout}>Signout</button>}
</div>
</>
);
}
```
## 11. Fetching the user's profile
Now that we have a way to sign in and out of the app, we should fetch the user's profile when they sign in.
```tsx
function App() {
// ...
// fetch the user's profile when they sign in
createEffect(async () => {
const active = account();
if (active) {
// get the user's relays or fallback to some default relays
const usersRelays = await active.getRelays?.();
const relays = usersRelays ? Object.keys(usersRelays) : ["wss://relay.damus.io", "wss://nos.lol"];
// tell the loader to fetch the users profile event
replaceableLoader.next({
pubkey: active.pubkey,
kind: 0,
relays,
});
// tell the loader to fetch the users contacts
replaceableLoader.next({
pubkey: active.pubkey,
kind: 3,
relays,
});
// tell the loader to fetch the users mailboxes
replaceableLoader.next({
pubkey: active.pubkey,
kind: 10002,
relays,
});
}
});
// ...
}
```
Next we need to subscribe to the users profile, to do this we can use some rxjs operators to chain the observables together.
```tsx
import { Match, Switch } from "solid-js";
import { of, switchMap } from "rxjs";
function App() {
// ...
// subscribe to the active account, then subscribe to the users profile or undefined
const profile = from(
accounts.active$.pipe(
switchMap((account) => (account ? queryStore.createQuery(ProfileQuery, account!.pubkey) : of(undefined)))
)
);
// ...
return (
<>
{/* ... */}
<div class="card">
<Switch>
<Match when={account() && !profile()}>
<p>Loading profile...</p>
</Match>
<Match when={profile()}>
<p style="font-size: 1.2rem; font-weight: bold;">Welcome {profile()?.name}</p>
</Match>
</Switch>
{/* ... */}
</div>
</>
);
}
```
## 12. Showing if the user is following fiatjaf
Now that the app is fetching the users profile and contacts we should show if the user is following fiatjaf.
```tsx
function App() {
// ...
// subscribe to the active account, then subscribe to the users contacts or undefined
const contacts = from(
accounts.active$.pipe(
switchMap((account) => (account ? queryStore.createQuery(UserContactsQuery, account!.pubkey) : of(undefined)))
)
);
const isFollowing = createMemo(() => {
return contacts()?.some((c) => c.pubkey === "3bf0c63fcb93463407af97a5e5ee64fa883d107ef9e558472c4eb9aaaefa459d");
});
// ...
return (
<>
{/* ... */}
<div class="card">
{/* ... */}
<Switch
fallback={
<p style="font-size: 1.2rem;">
Sign in to check if you are a follower of the fiatjaf ( creator of "The nostr" )
</p>
}
>
<Match when={contacts() && isFollowing() === undefined}>
<p>checking...</p>
</Match>
<Match when={contacts() && isFollowing() === true}>
<p style="color: green; font-weight: bold; font-size: 2rem;">
Congratulations! You are a follower of the fiatjaf
</p>
</Match>
<Match when={contacts() && isFollowing() === false}>
<p style="color: red; font-weight: bold; font-size: 2rem;">
Why don't you follow the fiatjaf? do you even like nostr?
</p>
</Match>
</Switch>
{/* ... */}
</div>
</>
);
}
```
## 13. Adding the follow button
Now that we have a way to check if the user is following fiatjaf, we should add a button to follow him. We can do this with [Actions](https://hzrd149.github.io/applesauce/overview/actions.html) which are pre-built methods to modify nostr events for a user.
First we need to install the `applesauce-actions` and `applesauce-factory` package
```sh
pnpm install applesauce-actions applesauce-factory
```
Then create a `src/actions.ts` file with
```ts
import { EventFactory } from "applesauce-factory";
import { ActionHub } from "applesauce-actions";
import { eventStore } from "./stores";
import { accounts } from "./accounts";
// The event factory is used to build and modify nostr events
export const factory = new EventFactory({
// accounts.signer is a NIP-07 signer that signs with the currently active account
signer: accounts.signer,
});
// The action hub is used to run Actions against the event store
export const actions = new ActionHub(eventStore, factory);
```
Then create a `toggleFollow` method that will add or remove fiatjaf from the users contacts.
> We are using the `exec` method to run the action, and the [`forEach`](https://rxjs.dev/api/index/class/Observable#foreach) method from RxJS allows us to await for all the events to be published
```tsx
function App() {
// ...
const toggleFollow = async () => {
// send any created events to rxNostr and the event store
const publish = (event: NostrEvent) => {
eventStore.add(event);
rxNostr.send(event);
};
if (isFollowing()) {
await actions
.exec(UnfollowUser, "3bf0c63fcb93463407af97a5e5ee64fa883d107ef9e558472c4eb9aaaefa459d")
.forEach(publish);
} else {
await actions
.exec(
FollowUser,
"3bf0c63fcb93463407af97a5e5ee64fa883d107ef9e558472c4eb9aaaefa459d",
"wss://pyramid.fiatjaf.com/"
)
.forEach(publish);
}
};
// ...
return (
<>
{/* ... */}
<div class="card">
{/* ... */}
{contacts() && <button onClick={toggleFollow}>{isFollowing() ? "Unfollow" : "Follow"}</button>}
</div>
</>
);
}
```
## 14. Adding outbox support
The app looks like it works now but if the user reloads the page they will still see an the old version of their contacts list. we need to make sure rxNostr is publishing the events to the users outbox relays.
To do this we can subscribe to the signed in users mailboxes using the query store in `src/nostr.ts`
```ts
import { MailboxesQuery } from "applesauce-core/queries";
import { accounts } from "./accounts";
import { of, switchMap } from "rxjs";
import { queryStore } from "./stores";
// ...
// subscribe to the active account, then subscribe to the users mailboxes and update rxNostr
accounts.active$
.pipe(switchMap((account) => (account ? queryStore.createQuery(MailboxesQuery, account.pubkey) : of(undefined))))
.subscribe((mailboxes) => {
if (mailboxes) rxNostr.setDefaultRelays(mailboxes.outboxes);
else rxNostr.setDefaultRelays([]);
});
```
And that's it! we have a working nostr app that lets users follow and unfollow fiatjaf.
-
@ 09fbf8f3:fa3d60f0
2024-11-02 08:00:29
> ### 第三方API合集:
---
免责申明:
在此推荐的 OpenAI API Key 由第三方代理商提供,所以我们不对 API Key 的 有效性 和 安全性 负责,请你自行承担购买和使用 API Key 的风险。
| 服务商 | 特性说明 | Proxy 代理地址 | 链接 |
| --- | --- | --- | --- |
| AiHubMix | 使用 OpenAI 企业接口,全站模型价格为官方 86 折(含 GPT-4 )| https://aihubmix.com/v1 | [官网](https://aihubmix.com?aff=mPS7) |
| OpenAI-HK | OpenAI的API官方计费模式为,按每次API请求内容和返回内容tokens长度来定价。每个模型具有不同的计价方式,以每1,000个tokens消耗为单位定价。其中1,000个tokens约为750个英文单词(约400汉字)| https://api.openai-hk.com/ | [官网](https://openai-hk.com/?i=45878) |
| CloseAI | CloseAI是国内规模最大的商用级OpenAI代理平台,也是国内第一家专业OpenAI中转服务,定位于企业级商用需求,面向企业客户的线上服务提供高质量稳定的官方OpenAI API 中转代理,是百余家企业和多家科研机构的专用合作平台。 | https://api.openai-proxy.org | [官网](https://www.closeai-asia.com/) |
| OpenAI-SB | 需要配合Telegram 获取api key | https://api.openai-sb.com | [官网](https://www.openai-sb.com/) |
` 持续更新。。。`
---
### 推广:
访问不了openai,去`低调云`购买VPN。
官网:https://didiaocloud.xyz
邀请码:`w9AjVJit`
价格低至1元。